
Graph Contrastive Learning (GCL) has emerged as a powerful approach for generating graph representations without the need for manual annotation. Most advanced GCL methods fall into three main frameworks: node discrimination, group discrimination, and bootstrapping schemes, all of which achieve comparable performance. However, the underlying mechanisms and factors that contribute to their effectiveness are not yet fully understood. In this paper, we revisit these frameworks and reveal a common mechanism—representation scattering—that significantly enhances their performance. Our discovery highlights an essential feature of GCL and unifies these seemingly disparate methods under the concept of representation scattering. To leverage this insight, we introduce Scattering Graph Representation Learning (SGRL), a novel framework that incorporates a new representation scattering mechanism designed to enhance representation diversity through a center-away strategy. Additionally, consider the interconnected nature of graphs, we develop a topology-based constraint mechanism that integrates graph structural properties with representation scattering to prevent excessive scattering. We extensively evaluate SGRL across various downstream tasks on benchmark datasets, demonstrating its efficacy and superiority over existing GCL methods. Our findings underscore the significance of representation scattering in GCL and provide a structured framework for harnessing this mechanism to advance graph representation learning. The code of SGRL is at https://github.com/hedongxiao-tju/SGRL.

With the increasing inference cost of machine learning models, there is a growing interest in models with fast and efficient inference.
Recently, an approach for learning logic gate networks directly via a differentiable relaxation was proposed. Logic gate networks are faster than conventional neural network approaches because their inference only requires logic gate operators such as NAND, OR, and XOR, which are the underlying building blocks of current hardware and can be efficiently executed. We build on this idea, extending it by deep logic gate tree convolutions, logical OR pooling, and residual initializations. This allows scaling logic gate networks up by over one order of magnitude and utilizing the paradigm of convolution. On CIFAR-10, we achieve an accuracy of 86.29% using only 61 million logic gates, which improves over the SOTA while being 29x smaller.
tl;dr: We present the first conditional generative model for efficient, probabilistic emulation of a realistic global climate model, which beats relevant baselines and nearly reaches a gold standard for successful climate model emulation.

Data-driven deep learning models are transforming global weather forecasting. It is an open question if this success can extend to climate modeling, where the complexity of the data and long inference rollouts pose significant challenges. Here, we present the first conditional generative model that produces accurate and physically consistent global climate ensemble simulations by emulating a coarse version of the United States' primary operational global forecast model, FV3GFS.
Our model integrates the dynamics-informed diffusion framework (DYffusion) with the Spherical Fourier Neural Operator (SFNO) architecture, enabling stable 100-year simulations at 6-hourly timesteps while maintaining low computational overhead compared to single-step deterministic baselines.
The model achieves near gold-standard performance for climate model emulation, outperforming existing approaches and demonstrating promising ensemble skill.
This work represents a significant advance towards efficient, data-driven climate simulations that can enhance our understanding of the climate system and inform adaptation strategies. Code is available at [https://github.com/Rose-STL-Lab/spherical-dyffusion](https://github.com/Rose-STL-Lab/spherical-dyffusion).
tl;dr: Flow Matching for continuous stochastic modelling of time series data with applications to clinical time series

Modeling stochastic and irregularly sampled time series is a challenging problem found in a wide range of applications, especially in medicine. Neural stochastic differential equations (Neural SDEs) are an attractive modeling technique for this problem, which parameterize the drift and diffusion terms of an SDE with neural networks. However, current algorithms for training Neural SDEs require backpropagation through the SDE dynamics, greatly limiting their scalability and stability.
To address this, we propose **Trajectory Flow Matching** (TFM), which trains a Neural SDE in a *simulation-free* manner, bypassing backpropagation through the dynamics. TFM leverages the flow matching technique from generative modeling to model time series. In this work we first establish necessary conditions for TFM to learn time series data. Next, we present a reparameterization trick which improves training stability. Finally, we adapt TFM to the clinical time series setting, demonstrating improved performance on three clinical time series datasets both in terms of absolute performance and uncertainty prediction.
tl;dr: We extend the LSTM architecture with exponential gating and new memory structures and show that this new xLSTM performs favorably on large-scale language modeling tasks.

In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.
tl;dr: We cast real-world humanoid control as a next token prediction problem.

We cast real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. Our model is a causal transformer trained via autoregressive prediction of sensorimotor sequences. To account for the multi-modal nature of the data, we perform prediction in a modality-aligned way, and for each input token predict the next token from the same modality. This general formulation enables us to leverage data with missing modalities, such as videos without actions. We train our model on a dataset of sequences from prior neural network policies, model-based controllers, motion capture, and YouTube videos of humans. We show that our model enables a real humanoid robot to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training. These findings suggest a promising path toward learning challenging real-world control tasks by generative modeling of sensorimotor sequences.
tl;dr: Our VAR (Visual AutoRegressive modeling), for the first time, makes GPT-style autoregressive models surpass Diffusion Transformers, and demonstrates Scaling Laws for image generation with solid evidence.

We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-style AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
tl;dr: We resolve the span-based sample complexity of weakly communicating average reward MDPs and initiate the study of general multichain MDPs, obtaining minimax optimal bounds and uncovering improved horizon dependence for fixed discounted MDP instances.

We study the sample complexity of learning an $\varepsilon$-optimal policy in an average-reward Markov decision process (MDP) under a generative model. For weakly communicating MDPs, we establish the complexity bound $\widetilde{O}\left(SA\frac{\mathsf{H}}{\varepsilon^2} \right)$, where $\mathsf{H}$ is the span of the bias function of the optimal policy and $SA$ is the cardinality of the state-action space. Our result is the first that is minimax optimal (up to log factors) in all parameters $S,A,\mathsf{H}$, and $\varepsilon$, improving on existing work that either assumes uniformly bounded mixing times for all policies or has suboptimal dependence on the parameters. We also initiate the study of sample complexity in general (multichain) average-reward MDPs. We argue a new transient time parameter $\mathsf{B}$ is necessary, establish an $\widetilde{O}\left(SA\frac{\mathsf{B} + \mathsf{H}}{\varepsilon^2} \right)$ complexity bound, and prove a matching (up to log factors) minimax lower bound. Both results are based on reducing the average-reward MDP to a discounted MDP, which requires new ideas in the general setting. To optimally analyze this reduction, we develop improved bounds for $\gamma$-discounted MDPs, showing that $\widetilde{O}\left(SA\frac{\mathsf{H}}{(1-\gamma)^2\varepsilon^2} \right)$ and $\widetilde{O}\left(SA\frac{\mathsf{B} + \mathsf{H}}{(1-\gamma)^2\varepsilon^2} \right)$ samples suffice to learn $\varepsilon$-optimal policies in weakly communicating and in general MDPs, respectively. Both these results circumvent the well-known minimax lower bound of $\widetilde{\Omega}\left(SA\frac{1}{(1-\gamma)^3\varepsilon^2} \right)$ for $\gamma$-discounted MDPs, and establish a quadratic rather than cubic horizon dependence for a fixed MDP instance.
tl;dr: We propose a foundation model for universal and interactive volumetric medical image segmentation, trained on the collected 90K unlabeled and 6K labeled data.

Precise image segmentation provides clinical study with instructive information. Despite the remarkable progress achieved in medical image segmentation, there is still an absence of a 3D foundation segmentation model that can segment a wide range of anatomical categories with easy user interaction. In this paper, we propose a 3D foundation segmentation model, named SegVol, supporting universal and interactive volumetric medical image segmentation. By scaling up training data to 90K unlabeled Computed Tomography (CT) volumes and 6K labeled CT volumes, this foundation model supports the segmentation of over 200 anatomical categories using semantic and spatial prompts. To facilitate efficient and precise inference on volumetric images, we design a zoom-out-zoom-in mechanism. Extensive experiments on 22 anatomical segmentation tasks verify that SegVol outperforms the competitors in 19 tasks, with improvements up to 37.24\% compared to the runner-up methods. We demonstrate the effectiveness and importance of specific designs by ablation study. We expect this foundation model can promote the development of volumetric medical image analysis. The model and code are publicly available at https://github.com/BAAI-DCAI/SegVol.
tl;dr: We introduce Selective Language Modeling (SLM), a method for token-level pretraining data selection.

Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that ''Not all tokens in a corpus are equally important for language model training''. Our initial analysis examines token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring training tokens using a reference model, and then training the language model with a focused loss on tokens with higher scores. When continual continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when continual pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both data efficiency and performance of the language model pre-training.
tl;dr: Characterization of Sample-Communication Trade-off in Federated Q-learning with both converse and achievability results

We consider the problem of Federated Q-learning, where $M$ agents aim to collaboratively learn the optimal Q-function of an unknown infinite horizon Markov Decision Process with finite state and action spaces. We investigate the trade-off between sample and communication complexity for the widely used class of intermittent communication algorithms. We first establish the converse result, where we show that any Federated Q-learning that offers a linear speedup with respect to number of agents in sample complexity needs to incur a communication cost of at least $\Omega(\frac{1}{1-\gamma})$, where $\gamma$ is the discount factor. We also propose a new Federated Q-learning algorithm, called Fed-DVR-Q, which is the first Federated Q-learning algorithm to simultaneously achieve order-optimal sample and communication complexities. Thus, together these results provide a complete characterization of the sample-communication complexity trade-off in Federated Q-learning.
tl;dr: We propose the Parameter-Inverted Image Pyramid Networks to address the computational challenges of traditional image pyramids.

Image pyramids are commonly used in modern computer vision tasks to obtain multi-scale features for precise understanding of images. However, image pyramids process multiple resolutions of images using the same large-scale model, which requires significant computational cost. To overcome this issue, we propose a novel network architecture known as the Parameter-Inverted Image Pyramid Networks (PIIP). Our core idea is to use models with different parameter sizes to process different resolution levels of the image pyramid, thereby balancing computational efficiency and performance. Specifically, the input to PIIP is a set of multi-scale images, where higher resolution images are processed by smaller networks. We further propose a feature interaction mechanism to allow features of different resolutions to complement each other and effectively integrate information from different spatial scales. Extensive experiments demonstrate that the PIIP achieves superior performance in tasks such as object detection, segmentation, and image classification, compared to traditional image pyramid methods and single-branch networks, while reducing computational cost. Notably, when applying our method on a large-scale vision foundation model InternViT-6B, we improve its performance by 1\%-2\% on detection and segmentation with only 40\%-60\% of the original computation. These results validate the effectiveness of the PIIP approach and provide a new technical direction for future vision computing tasks.
tl;dr: We present a novel lossy compression framework under log loss called Minimum Entropy Coupling with Bottleneck.

This paper investigates a novel lossy compression framework operating under logarithmic loss, designed to handle situations where the reconstruction distribution diverges from the source distribution. This framework is especially relevant for applications that require joint compression and retrieval, and in scenarios involving distributional shifts due to processing. We show that the proposed formulation extends the classical minimum entropy coupling framework by integrating a bottleneck, allowing for controlled variability in the degree of stochasticity in the coupling.
We explore the decomposition of the Minimum Entropy Coupling with Bottleneck (MEC-B) into two distinct optimization problems: Entropy-Bounded Information Maximization (EBIM) for the encoder, and Minimum Entropy Coupling (MEC) for the decoder. Through extensive analysis, we provide a greedy algorithm for EBIM with guaranteed performance, and characterize the optimal solution near functional mappings, yielding significant theoretical insights into the structural complexity of this problem.
Furthermore, we illustrated the practical application of MEC-B through experiments in Markov Coding Games (MCGs) under rate limits. These games simulate a communication scenario within a Markov Decision Process, where an agent must transmit a compressed message from a sender to a receiver through its actions. Our experiments highlighted the trade-offs between MDP rewards and receiver accuracy across various compression rates, showcasing the efficacy of our method compared to conventional compression baseline.
tl;dr: We show that deep learning with fully-connected deep neural networks is optimal for learning holomorphic operators

Operator learning problems arise in many key areas of scientific computing where Partial Differential Equations (PDEs) are used to model physical systems. In such scenarios, the operators map between Banach or Hilbert spaces. In this work, we tackle the problem of learning operators between Banach spaces, in contrast to the vast majority of past works considering only Hilbert spaces. We focus on learning holomorphic operators -- an important class of problems with many applications. We combine arbitrary approximate encoders and decoders with standard feedforward Deep Neural Network (DNN) architectures -- specifically, those with constant width exceeding the depth -- under standard $\ell^2$-loss minimization. We first identify a family of DNNs such that the resulting Deep Learning (DL) procedure achieves optimal generalization bounds for such operators. For standard fully-connected architectures, we then show that there are uncountably many minimizers of the training problem that yield equivalent optimal performance. The DNN architectures we consider are `problem agnostic', with width and depth only depending on the amount of training data $m$ and not on regularity assumptions of the target operator. Next, we show that DL is optimal for this problem: no recovery procedure can surpass these generalization bounds up to log terms. Finally, we present numerical results demonstrating the practical performance on challenging problems including the parametric diffusion, Navier-Stokes-Brinkman and Boussinesq PDEs.
tl;dr: We identify massive outliers in the down-projection layer of the FFN module and introduce DuQuant, which uses rotation and permutation transformations to effectively mitigate both massive and normal outliers.

Quantization of large language models (LLMs) faces significant challenges, particularly due to the presence of outlier activations that impede efficient low-bit representation. Traditional approaches predominantly address Normal Outliers, which are activations across all tokens with relatively large magnitudes. However, these methods struggle with smoothing Massive Outliers that display significantly larger values, which leads to significant performance degradation in low-bit quantization. In this paper, we introduce DuQuant, a novel approach that utilizes rotation and permutation transformations to more effectively mitigate both massive and normal outliers. First, DuQuant starts by constructing the rotation matrix, using specific outlier dimensions as prior knowledge, to redistribute outliers to adjacent channels by block-wise rotation. Second, We further employ a zigzag permutation to balance the distribution of outliers across blocks, thereby reducing block-wise variance. A subsequent rotation further smooths the activation landscape, enhancing model performance. DuQuant simplifies the quantization process and excels in managing outliers, outperforming the state-of-the-art baselines across various sizes and types of LLMs on multiple tasks, even with 4-bit weight-activation quantization. Our code is available at https://github.com/Hsu1023/DuQuant.
tl;dr: We leverage input-to-state stable coupled oscillator networks for conducting model-based control in latent space.

Even though a variety of methods have been proposed in the literature, efficient and effective latent-space control (i.e., control in a learned low-dimensional space) of physical systems remains an open challenge.
We argue that a promising avenue is to leverage powerful and well-understood closed-form strategies from control theory literature in combination with learned dynamics, such as potential-energy shaping.
We identify three fundamental shortcomings in existing latent-space models that have so far prevented this powerful combination: (i) they lack the mathematical structure of a physical system, (ii) they do not inherently conserve the stability properties of the real systems, (iii) these methods do not have an invertible mapping between input and latent-space forcing.
This work proposes a novel Coupled Oscillator Network (CON) model that simultaneously tackles all these issues.
More specifically, (i) we show analytically that CON is a Lagrangian system - i.e., it possesses well-defined potential and kinetic energy terms. Then, (ii) we provide formal proof of global Input-to-State stability using Lyapunov arguments.
Moving to the experimental side, we demonstrate that CON reaches SoA performance when learning complex nonlinear dynamics of mechanical systems directly from images.
An additional methodological innovation contributing to achieving this third goal is an approximated closed-form solution for efficient integration of network dynamics, which eases efficient training.
We tackle (iii) by approximating the forcing-to-input mapping with a decoder that is trained to reconstruct the input based on the encoded latent space force.
Finally, we leverage these three properties and show that they enable latent-space control. We use an integral-saturated PID with potential force compensation and demonstrate high-quality performance on a soft robot using raw pixels as the only feedback information.

Unconditional generation -- the problem of modeling data distribution without relying on human-annotated labels -- is a long-standing and fundamental challenge in generative models, creating a potential of learning from large-scale unlabeled data. In the literature, the generation quality of an unconditional method has been much worse than that of its conditional counterpart. This gap can be attributed to the lack of semantic information provided by labels. In this work, we show that one can close this gap by generating semantic representations in the representation space produced by a self-supervised encoder. These representations can be used to condition the image generator. This framework, called Representation-Conditioned Generation (RCG), provides an effective solution to the unconditional generation problem without using labels. Through comprehensive experiments, we observe that RCG significantly improves unconditional generation quality: e.g., it achieves a new state-of-the-art FID of 2.15 on ImageNet 256x256, largely reducing the previous best of 5.91 by a relative 64%. Our unconditional results are situated in the same tier as the leading class-conditional ones. We hope these encouraging observations will attract the community's attention to the fundamental problem of unconditional generation. Code is available at [https://github.com/LTH14/rcg](https://github.com/LTH14/rcg).
tl;dr: PiSSA reinitializes LoRA's parameters by applying SVD to the base model, which enables faster convergence and ultimately superior performance. Additionally, it can reduce quantization error compared to QLoRA.

To parameter-efficiently fine-tune (PEFT) large language models (LLMs), the low-rank adaptation (LoRA) method approximates the model changes $\Delta W \in \mathbb{R}^{m \times n}$ through the product of two matrices $A \in \mathbb{R}^{m \times r}$ and $B \in \mathbb{R}^{r \times n}$, where $r \ll \min(m, n)$, $A$ is initialized with Gaussian noise, and $B$ with zeros. LoRA **freezes the original model $W$** and **updates the "Noise \& Zero" adapter**, which may lead to slow convergence. To overcome this limitation, we introduce **P**r**i**ncipal **S**ingular values and **S**ingular vectors **A**daptation (PiSSA). PiSSA shares the same architecture as LoRA, but initializes the adaptor matrices $A$ and $B$ with the principal components of the original matrix $W$, and put the remaining components into a residual matrix $W^{res} \in \mathbb{R}^{m \times n}$ which is frozen during fine-tuning.
Compared to LoRA, PiSSA **updates the principal components** while **freezing the "residual" parts**, allowing faster convergence and enhanced performance. Comparative experiments of PiSSA and LoRA across 11 different models, ranging from 184M to 70B, encompassing 5 NLG and 8 NLU tasks, reveal that PiSSA consistently outperforms LoRA under identical experimental setups. On the GSM8K benchmark, Gemma-7B fine-tuned with PiSSA achieves an accuracy of 77.7\%, surpassing LoRA's 74.53\% by 3.25\%. Due to the same architecture, PiSSA is also compatible with quantization to further reduce the memory requirement of fine-tuning. Compared to QLoRA, QPiSSA (PiSSA with 4-bit quantization) exhibits smaller quantization errors in the initial stages. Fine-tuning LLaMA-3-70B on GSM8K, QPiSSA attains an accuracy of 86.05\%, exceeding the performances of QLoRA at 81.73\%. Leveraging a fast SVD technique, PiSSA can be initialized in only a few seconds, presenting a negligible cost for transitioning from LoRA to PiSSA.

Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol. The open-source code is available at https://software.llnl.gov/anchoring.
tl;dr: Learnable Semi-structured Sparsity for LLMs

Large Language Models (LLMs) are distinguished by their massive parameter counts, which typically result in significant redundancy. This work introduces MaskLLM, a learnable pruning method that establishes Semi-structured (or ``N:M'') Sparsity in LLMs, aimed at reducing computational overhead during inference. Instead of developing a new importance criterion, MaskLLM explicitly models N:M patterns as a learnable distribution through Gumbel Softmax sampling. This approach facilitates end-to-end training on large-scale datasets and offers two notable advantages: 1) High-quality Masks - our method effectively scales to large datasets and learns accurate masks; 2) Transferability - the probabilistic modeling of mask distribution enables the transfer learning of sparsity across domains or tasks. We assessed MaskLLM using 2:4 sparsity on various LLMs, including LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, and our empirical results show substantial improvements over state-of-the-art methods. For instance, leading approaches achieve a perplexity (PPL) of 10 or greater on Wikitext compared to the dense model's 5.12 PPL, but MaskLLM achieves a significantly lower 6.72 PPL solely by learning the masks with frozen weights. Furthermore, MaskLLM's learnable nature allows customized masks for lossless application of 2:4 sparsity to downstream tasks or domains. Code is available at https://github.com/NVlabs/MaskLLM.

The denoising model has been proven a powerful generative model but has little exploration of discriminative tasks. Representation learning is important in discriminative tasks, which is defined as *"learning representations (or features) of the data that make it easier to extract useful information when building classifiers or other predictors"*. In this paper, we propose a novel Denoising Model for Representation Learning (*DenoiseRep*) to improve feature discrimination with joint feature extraction and denoising. *DenoiseRep* views each embedding layer in a backbone as a denoising layer, processing the cascaded embedding layers as if we are recursively denoise features step-by-step. This unifies the frameworks of feature extraction and denoising, where the former progressively embeds features from low-level to high-level, and the latter recursively denoises features step-by-step. After that, *DenoiseRep* fuses the parameters of feature extraction and denoising layers, and *theoretically demonstrates* its equivalence before and after the fusion, thus making feature denoising computation-free. *DenoiseRep* is a label-free algorithm that incrementally improves features but also complementary to the label if available. Experimental results on various discriminative vision tasks, including re-identification (Market-1501, DukeMTMC-reID, MSMT17, CUHK-03, vehicleID), image classification (ImageNet, UB200, Oxford-Pet, Flowers), object detection (COCO), image segmentation (ADE20K) show stability and impressive improvements. We also validate its effectiveness on the CNN (ResNet) and Transformer (ViT, Swin, Vmamda) architectures.
tl;dr: We introduce a novel framework for incorporating human judgment into algorithmic predictions; our approach focuses on the use of human judgment to distinguish inputs which ‘look the same’ to any feasible predictive algorithm.

We introduce a novel framework for incorporating human expertise into algorithmic predictions. Our approach leverages human judgment to distinguish inputs which are *algorithmically indistinguishable*, or "look the same" to predictive algorithms. We argue that this framing clarifies the problem of human-AI collaboration in prediction tasks, as experts often form judgments by drawing on information which is not encoded in an algorithm's training data. Algorithmic indistinguishability yields a natural test for assessing whether experts incorporate this kind of "side information", and further provides a simple but principled method for selectively incorporating human feedback into algorithmic predictions. We show that this method provably improves the performance of any feasible algorithmic predictor and precisely quantify this improvement. We find empirically that although algorithms often outperform their human counterparts *on average*, human judgment can improve algorithmic predictions on *specific* instances (which can be identified ex-ante). In an X-ray classification task, we find that this subset constitutes nearly 30% of the patient population. Our approach provides a natural way of uncovering this heterogeneity and thus enabling effective human-AI collaboration.
tl;dr: We investigate the many-shot in-context learning regime -- prompting large language models with hundreds or thousands of examples -- for a wide range of tasks.

Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples – the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated outputs. To mitigate this limitation, we explore two new settings: (1) "Reinforced ICL" that uses model-generated chain-of-thought rationales in place of human rationales, and (2) "Unsupervised ICL" where we remove rationales from the prompt altogether, and prompts the model only with domain-specific inputs. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. We demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to supervised fine-tuning. Finally, we reveal the limitations of next-token prediction loss as an indicator of downstream ICL performance.
tl;dr: We speed up FlashAttention on modern GPUs (Hopper) with asynchrony and low-precision

Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU.
We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$\times$ with BF16 reaching up to 840 TFLOPs/s (85\% utilization), and with FP8 reaching 1.3 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$\times$ lower numerical error than a baseline FP8 attention.
tl;dr: This paper proposes Geodesic Optimization for Predictive Shift Adaptation to address multi-source domain adaptation where source domains have distinct y distributions in the context of brain age prediction from EEG covariance matrices.

Electroencephalography (EEG) data is often collected from diverse contexts involving different populations and EEG devices. This variability can induce distribution shifts in the data $X$ and in the biomedical variables of interest $y$, thus limiting the application of supervised machine learning (ML) algorithms. While domain adaptation (DA) methods have been developed to mitigate the impact of these shifts, such methods struggle when distribution shifts occur simultaneously in $X$ and $y$. As state-of-the-art ML models for EEG represent the data by spatial covariance matrices, which lie on the Riemannian manifold of Symmetric Positive Definite (SPD) matrices, it is appealing to study DA techniques operating on the SPD manifold. This paper proposes a novel method termed Geodesic Optimization for Predictive Shift Adaptation (GOPSA) to address test-time multi-source DA for situations in which source domains have distinct $y$ distributions. GOPSA exploits the geodesic structure of the Riemannian manifold to jointly learn a domain-specific re-centering operator representing site-specific intercepts and the regression model. We performed empirical benchmarks on the cross-site generalization of age-prediction models with resting-state EEG data from a large multi-national dataset (HarMNqEEG), which included $14$ recording sites and more than $1500$ human participants. Compared to state-of-the-art methods, our results showed that GOPSA achieved significantly higher performance on three regression metrics ($R^2$, MAE, and Spearman's $\rho$) for several source-target site combinations, highlighting its effectiveness in tackling multi-source DA with predictive shifts in EEG data analysis. Our method has the potential to combine the advantages of mixed-effects modeling with machine learning for biomedical applications of EEG, such as multicenter clinical trials.
tl;dr: Train without learning rate schedules

Existing learning rate schedules that do not require specification of the optimization stopping step $T$ are greatly out-performed by learning rate schedules that depend on $T$. We propose an approach that avoids the need for this stopping time by eschewing the use of schedules entirely, while exhibiting state-of-the-art performance compared to schedules across a wide family of problems ranging from convex problems to large-scale deep learning problems. Our Schedule-Free approach introduces no additional hyper-parameters over standard optimizers with momentum. Our method is a direct consequence of a new theory we develop that unifies scheduling and iterate averaging. An open source implementation of our method is available at https://github.com/facebookresearch/schedule_free. Schedule-Free AdamW is the core algorithm behind our winning entry to the MLCommons 2024 AlgoPerf Algorithmic Efficiency Challenge Self-Tuning track.
tl;dr: We derive a generalized neural tangent kernel that describes surrogate gradient learning.

State-of-the-art neural network training methods depend on the gradient of the network function. Therefore, they cannot be applied to networks whose activation functions do not have useful derivatives, such as binary and discrete-time spiking neural networks. To overcome this problem, the activation function's derivative is commonly substituted with a surrogate derivative, giving rise to surrogate gradient learning (SGL). This method works well in practice but lacks theoretical foundation.
The neural tangent kernel (NTK) has proven successful in the analysis of gradient descent. Here, we provide a generalization of the NTK, which we call the surrogate gradient NTK, that enables the analysis of SGL. First, we study a naive extension of the NTK to activation functions with jumps, demonstrating that gradient descent for such activation functions is also ill-posed in the infinite-width limit. To address this problem, we generalize the NTK to gradient descent with surrogate derivatives, i.e., SGL. We carefully define this generalization and expand the existing key theorems on the NTK with mathematical rigor. Further, we illustrate our findings with numerical experiments. Finally, we numerically compare SGL in networks with sign activation function and finite width to kernel regression with the surrogate gradient NTK; the results confirm that the surrogate gradient NTK provides a good characterization of SGL.
tl;dr: The paper studies the identifiability of causal effects under functional dependencies.

We study the identification of causal effects, motivated by two improvements to identifiability which can be attained if one knows that some variables in a causal graph are functionally determined by their parents (without needing to know the specific functions). First, an unidentifiable causal effect may become identifiable when certain variables are functional. Second, certain functional variables can be excluded from being observed without affecting the identifiability of a causal effect, which may significantly reduce the number of needed variables in observational data. Our results are largely based on an elimination procedure which removes functional variables from a causal graph while preserving key properties in the resulting causal graph, including the identifiability of causal effects.
tl;dr: The paper provides logical characterizations of recurrent graph neural network models.

In pioneering work from 2019, Barceló and coauthors identified logics that precisely match the expressive power of constant iteration-depth graph neural networks (GNNs) relative to properties definable in first-order logic. In this article, we give exact logical characterizations of recurrent GNNs in two scenarios: (1) in the setting with floating-point numbers and (2) with reals. For floats, the formalism matching recurrent GNNs is a rule-based modal logic with counting, while for reals we use a suitable infinitary modal logic, also with counting. These results give exact matches between logics and GNNs in the recurrent setting without relativising to a background logic in either case, but using some natural assumptions about floating-point arithmetic. Applying our characterizations, we also prove that, relative to graph properties definable in monadic second-order logic (MSO), our infinitary and rule-based logics are equally expressive. This implies that recurrent GNNs with reals and floats have the same expressive power over MSO-definable properties and shows that, for such properties, also recurrent GNNs with reals are characterized by a (finitary!) rule-based modal logic. In the general case, in contrast, the expressive power with floats is weaker than with reals. In addition to logic-oriented results, we also characterize recurrent GNNs, with both reals and floats, via distributed automata, drawing links to distributed computing models.
tl;dr: Stylus automatically selects and composes adapters from a vast database of adapters for diffusion-based models.

Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters—most of which are highly customized with insufficient descriptions. To generate high quality images, this paper explores the problem of matching the prompt to a Stylus of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP/FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model.
tl;dr: We introduce a system to simplify the programming and accelerate the execution of complex structured language model programs.

Large language models (LLMs) are increasingly used for complex tasks that require multiple generation calls, advanced prompting techniques, control flow, and structured inputs/outputs. However, efficient systems are lacking for programming and executing these applications. We introduce SGLang, a system for efficient execution of complex language model programs. SGLang consists of a frontend language and a runtime. The frontend simplifies programming with primitives for generation and parallelism control. The runtime accelerates execution with novel optimizations like RadixAttention for KV cache reuse and compressed finite state machines for faster structured output decoding. Experiments show that SGLang achieves up to $6.4\times$ higher throughput compared to state-of-the-art inference systems on various large language and multi-modal models on tasks including agent control, logical reasoning, few-shot learning benchmarks, JSON decoding, retrieval-augmented generation pipelines, and multi-turn chat. The code is publicly available at https://github.com/sgl-project/sglang.
tl;dr: In this paper, we investigate an adversarial contextual multinomial logit (MNL) bandit problem and establish minimax optimal lower and upper regret bounds.

In this paper, we study the contextual multinomial logit (MNL) bandit problem in which a learning agent sequentially selects an assortment based on contextual information, and user feedback follows an MNL choice model.
There has been a significant discrepancy between lower and upper regret bounds, particularly regarding the maximum assortment size $K$. Additionally, the variation in reward structures between these bounds complicates the quest for optimality. Under uniform rewards, where all items have the same expected reward, we establish a regret lower bound of $\Omega(d\sqrt{\smash[b]{T/K}})$ and propose a constant-time algorithm, OFU-MNL+, that achieves a matching upper bound of $\tilde{\mathcal{O}}(d\sqrt{\smash[b]{T/K}})$.
We also provide instance-dependent minimax regret bounds under uniform rewards.
Under non-uniform rewards, we prove a lower bound of $\Omega(d\sqrt{T})$ and an upper bound of $\tilde{\mathcal{O}}(d\sqrt{T})$, also achievable by OFU-MNL+. Our empirical studies support these theoretical findings. To the best of our knowledge, this is the first work in the contextual MNL bandit literature to prove minimax optimality --- for either uniform or non-uniform reward setting --- and to propose a computationally efficient algorithm that achieves this optimality up to logarithmic factors.
tl;dr: We propose a novel information theoretic framework of the context-based offline meta-RL paradigm, which unifies several mainstream methods and leads to two robust algorithm implementations.

As a marriage between offline RL and meta-RL, the advent of offline meta-reinforcement learning (OMRL) has shown great promise in enabling RL agents to multi-task and quickly adapt while acquiring knowledge safely. Among which, context-based OMRL (COMRL) as a popular paradigm, aims to learn a universal policy conditioned on effective task representations. In this work, by examining several key milestones in the field of COMRL, we propose to integrate these seemingly independent methodologies into a unified framework. Most importantly, we show that the pre-existing COMRL algorithms are essentially optimizing the same mutual information objective between the task variable $M$ and its latent representation $Z$ by implementing various approximate bounds. Such theoretical insight offers ample design freedom for novel algorithms. As demonstrations, we propose a supervised and a self-supervised implementation of $I(Z; M)$, and empirically show that the corresponding optimization algorithms exhibit remarkable generalization across a broad spectrum of RL benchmarks, context shift scenarios, data qualities and deep learning architectures. This work lays the information theoretic foundation for COMRL methods, leading to a better understanding of task representation learning in the context of reinforcement learning.
tl;dr: This paper introduces a new architecture with promising performance on visual perception tasks, which is based on mamba.

Designing computationally efficient network architectures remains an ongoing necessity in computer vision. In this paper, we adapt Mamba, a state-space language model, into VMamba, a vision backbone with linear time complexity. At the core of VMamba is a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D bridges the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the collection of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments demonstrate VMamba’s
promising performance across diverse visual perception tasks, highlighting its superior input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba

In this paper, we study the non-asymptotic sample complexity for the pure exploration problem in contextual bandits and tabular reinforcement learning (RL): identifying an $\epsilon$-optimal policy from a set of policies $\Pi$ with high probability. Existing work in bandits has shown that it is possible to identify the best policy by estimating only the *difference* between the behaviors of individual policies–which can have substantially lower variance than estimating the behavior of each policy directly—yet the best-known complexities in RL fail to take advantage of this, and instead estimate the behavior of each policy directly. Does it suffice to estimate only the differences in the behaviors of policies in RL? We answer this question positively for contextual bandits, but in the negative for tabular RL, showing a separation between contextual bandits and RL. However, inspired by this, we show that it *almost* suffices to estimate only the differences in RL: if we can estimate the behavior of a *single* reference policy, it suffices to only estimate how any other policy deviates from this reference policy. We develop an algorithm which instantiates this principle and obtains, to the best of our knowledge, the tightest known bound on the sample complexity of tabular RL.
tl;dr: We study clustering in anisotropic Gaussian Mixture Models by establishing minimax bounds and introducing a variant of Lloyd’s algorithm that achieves the minimax optimality provably.

We study clustering under anisotropic Gaussian Mixture Models (GMMs), where covariance matrices from different clusters are unknown and are not necessarily the identity matrix. We analyze two anisotropic scenarios: homogeneous, with identical covariance matrices, and heterogeneous, with distinct matrices per cluster. For these models, we derive minimax lower bounds that illustrate the critical influence of covariance structures on clustering accuracy. To solve the clustering problem, we consider a variant of Lloyd's algorithm, adapted to estimate and utilize covariance information iteratively. We prove that the adjusted algorithm not only achieves the minimax optimality but also converges within a logarithmic number of iterations, thus bridging the gap between theoretical guarantees and practical efficiency.
tl;dr: This work formalizes the problem of full-duplex voice conversation with LLM and presents a method towards this goal.

We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate in tandem, allowing the system to speak and listen to the user simultaneously. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than threefold compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running an LLM with only 8 billion parameters, our system exhibits an 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
tl;dr: We introduce a novel metric for ensuring multi-group proportional representation over sets of images. We apply this metric to retrieval and propose an algorithm that maximizes similarity under a multi-group proportional representation constraint.

Image search and retrieval tasks can perpetuate harmful stereotypes, erase cultural identities, and amplify social disparities. Current approaches to mitigate these representational harms balance the number of retrieved items across population groups defined by a small number of (often binary) attributes. However, most existing methods overlook intersectional groups determined by combinations of
group attributes, such as gender, race, and ethnicity. We introduce Multi-Group Proportional Representation (MPR), a novel metric that measures representation across intersectional groups. We develop practical methods for estimating MPR, provide theoretical guarantees, and propose optimization algorithms to ensure MPR in retrieval. We demonstrate that existing methods optimizing for equal and proportional representation metrics may fail to promote MPR. Crucially, our work shows that optimizing MPR yields more proportional representation across multiple intersectional groups specified by a rich function class, often with minimal compromise in retrieval accuracy. Code is provided at https://github.com/alex-oesterling/multigroup-proportional-representation.
tl;dr: This paper addresses the issue of subtask discovery from a causal perspective in Imitation Learning by identifying subgoals as selections

When solving long-horizon tasks, it is intriguing to decompose the high-level task into subtasks. Decomposing experiences into reusable subtasks can improve data efficiency, accelerate policy generalization, and in general provide promising solutions to multi-task reinforcement learning and imitation learning problems. However, the concept of subtasks is not sufficiently understood and modeled yet, and existing works often overlook the true structure of the data generation process: subtasks are the results of a *selection* mechanism on actions, rather than possible underlying confounders or intermediates. Specifically, we provide a theory to identify, and experiments to verify the existence of selection variables in such data. These selections serve as subgoals that indicate subtasks and guide policy. In light of this idea, we develop a sequential non-negative matrix factorization (seq- NMF) method to learn these subgoals and extract meaningful behavior patterns as subtasks. Our empirical results on a challenging Kitchen environment demonstrate that the learned subtasks effectively enhance the generalization to new tasks in multi-task imitation learning scenarios. The codes are provided at this [*link*](https://anonymous.4open.science/r/Identifying\_Selections\_for\_Unsupervised\_Subtask\_Discovery/README.md).
tl;dr: We analyze the dynamics of emergent localization in receptive fields of a nonlinear neural network, which enables us to bind emergence to specific higher-order statistical properties of the input data.

Localized receptive fields—neurons that are selective for certain contiguous spatiotemporal features of their input—populate early sensory regions of the mammalian brain. Unsupervised learning algorithms that optimize explicit sparsity or independence criteria replicate features of these localized receptive fields, but fail to explain directly how localization arises through learning without efficient coding, as occurs in early layers of deep neural networks and might occur in early sensory regions of biological systems. We consider an alternative model in which localized receptive fields emerge without explicit top-down efficiency constraints—a feed-forward neural network trained on a data model inspired by the structure of natural images. Previous work identified the importance of non-Gaussian statistics to localization in this setting but left open questions about the mechanisms driving dynamical emergence. We address these questions by deriving the effective learning dynamics for a single nonlinear neuron, making precise how higher-order statistical properties of the input data drive emergent localization, and we demonstrate that the predictions of these effective dynamics extend to the many-neuron setting. Our analysis provides an alternative explanation for the ubiquity of localization as resulting from the nonlinear dynamics of learning in neural circuits
tl;dr: We show reliable scaling behavior of an alternative LR schedule as well as stochastic weight averaging for LLM training, thereby making scaling law experiments more accessible.

Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setup as well as future generations of architectures. In this work, we argue that scale and training research has been needlessly complex due to reliance on the cosine schedule, which prevents training across different lengths for the same model size. We investigate the training behavior of a direct alternative --- constant learning rate and cooldowns --- and find that it scales predictably and reliably similar to cosine. Additionally, we show that stochastic weight averaging yields improved performance along the training trajectory, without additional training costs, across different scales. Importantly, with these findings we demonstrate that scaling experiments can be performed with significantly reduced compute and GPU hours by utilizing fewer but reusable training runs. Our code is available at https://github.com/epfml/schedules-and-scaling/.
tl;dr: DeltaNet, i.e., Linear Transformer with delta rule, suffers from slow recurrent training. This work develops a novel algorithm that enables the parallelization of training over sequence length, allowing for large-scale experiments

Transformers with linear attention (i.e., linear transformers) and state-space models have recently been suggested as a viable linear-time alternative to transformers with softmax attention. However, these models still underperform transformers especially on tasks that require in-context retrieval. While more expressive variants of linear transformers which replace the additive update in linear transformers with the delta rule (DeltaNet) have been found to be more effective at associative recall, existing algorithms for training such models do not parallelize over sequence length and are thus inefficient to train on modern hardware. This work describes a hardware-efficient algorithm for training linear transformers with the delta rule, which exploits a memory-efficient representation for computing products of Householder matrices. This algorithm allows us to scale up DeltaNet to standard language modeling settings. We train a 1.3B model for 100B tokens and find that it outperforms recent linear-time baselines such as Mamba and GLA in terms of perplexity and zero-shot performance on downstream tasks. We also experiment with two hybrid models which combine DeltaNet layers with (1) sliding-window attention layers every other layer or (2) two global attention layers, and find that these hybrids outperform strong transformer baselines.
tl;dr: We propose a general framework of building intrinsic Riemannian classifiers for general geometries , and showcase our framework on the SPD manifold and special orthogonal group.

Riemannian neural networks, which extend deep learning techniques to Riemannian spaces, have gained significant attention in machine learning. To better classify the manifold-valued features, researchers have started extending Euclidean multinomial logistic regression (MLR) into Riemannian manifolds. However, existing approaches suffer from limited applicability due to their strong reliance on specific geometric properties. This paper proposes a framework for designing Riemannian MLR over general geometries, referred to as RMLR. Our framework only requires minimal geometric properties, thus exhibiting broad applicability and enabling its use with a wide range of geometries. Specifically, we showcase our framework on the Symmetric Positive Definite (SPD) manifold and special orthogonal group, i.e., the set of rotation matrices. On the SPD manifold, we develop five families of SPD MLRs under five types of power-deformed metrics. On rotation matrices we propose Lie MLR based on the popular bi-invariant metric. Extensive experiments on different Riemannian backbone networks validate the effectiveness of our framework.
tl;dr: We propose the GSD-front for reliable multicriteria benchmarking of classifiers, give conditions for its consistent estimability, propose (robust) statistical tests for checking if a classifier is contained, and illustrate it on two benchmark suites.

Given the vast number of classifiers that have been (and continue to be) proposed, reliable methods for comparing them are becoming increasingly important. The desire for reliability is broken down into three main aspects: (1) Comparisons should allow for different quality metrics simultaneously. (2) Comparisons should take into account the statistical uncertainty induced by the choice of benchmark suite. (3) The robustness of the comparisons under small deviations in the underlying assumptions should be verifiable. To address (1), we propose to compare classifiers using a generalized stochastic dominance ordering (GSD) and present the GSD-front as an information-efficient alternative to the classical Pareto-front. For (2), we propose a consistent statistical estimator for the GSD-front and construct a statistical test for whether a (potentially new) classifier lies in the GSD-front of a set of state-of-the-art classifiers. For (3), we relax our proposed test using techniques from robust statistics and imprecise probabilities. We illustrate our concepts on the benchmark suite PMLB and on the platform OpenML.
tl;dr: We settle the parallel complexity of Boosting algorithms that are nearly sample-optimal

Recent works on the parallel complexity of Boosting have established strong lower bounds on the tradeoff between the number of training rounds $p$ and the total parallel work per round $t$.
These works have also presented highly non-trivial parallel algorithms that shed light on different regions of this tradeoff.
Despite these advancements, a significant gap persists between the theoretical lower bounds and the performance of these algorithms across much of the tradeoff space.
In this work, we essentially close this gap by providing both improved lower bounds on the parallel complexity of weak-to-strong learners, and a parallel Boosting algorithm whose performance matches these bounds across the entire $p$ vs. $t$ compromise spectrum, up to logarithmic factors.
Ultimately, this work settles the parallel complexity of Boosting algorithms that are nearly sample-optimal.
tl;dr: This paper introduces a novel approach to efficiently solve sparse linear systems by localizing standard iterative solvers using a locally evolving set process.

Given the damping factor $\alpha$ and precision tolerance $\epsilon$, \citet{andersen2006local} introduced Approximate Personalized PageRank (APPR), the \textit{de facto local method} for approximating the PPR vector, with runtime bounded by $\Theta(1/(\alpha\epsilon))$ independent of the graph size. Recently, Fountoulakis \& Yang asked whether faster local algorithms could be developed using $\tilde{\mathcal{O}}(1/(\sqrt{\alpha}\epsilon))$ operations. By noticing that APPR is a local variant of Gauss-Seidel, this paper explores the question of *whether standard iterative solvers can be effectively localized*. We propose to use the *locally evolving set process*, a novel framework to characterize the algorithm locality, and demonstrate that many standard solvers can be effectively localized. Let $\overline{\operatorname{vol}}{ (\mathcal S_t)}$ and $\overline{\gamma_t}$ be the running average of volume and the residual ratio of active nodes $\textstyle \mathcal{S_t}$ during the process. We show $\overline{\operatorname{vol}}{ (\mathcal S_t)}/\overline{\gamma_t} \leq 1/\epsilon$ and prove APPR admits a new runtime bound $\tilde{\mathcal{O}}(\overline{\operatorname{vol}}(\mathcal S_t)/(\alpha\overline{\gamma_t}))$ mirroring the actual performance. Furthermore, when the geometric mean of residual reduction is $\Theta(\sqrt{\alpha})$, then there exists $c \in (0,2)$ such that the local Chebyshev method has runtime $\tilde{\mathcal{O}}(\overline{\operatorname{vol}}(\mathcal{S_t})/(\sqrt{\alpha}(2-c)))$ without the monotonicity assumption. Numerical results confirm the efficiency of this novel framework and show up to a hundredfold speedup over corresponding standard solvers on real-world graphs.
tl;dr: This paper proposed NeuroClips, a new state-of-the-art fMRI-to-video reconstruction framework, achieving smooth high-fidelity video reconstruction of up to 6s at 8FPS.

Reconstruction of static visual stimuli from non-invasion brain activity fMRI achieves great success, owning to advanced deep learning models such as CLIP and Stable Diffusion. However, the research on fMRI-to-video reconstruction remains limited since decoding the spatiotemporal perception of continuous visual experiences is formidably challenging. We contend that the key to addressing these challenges lies in accurately decoding both high-level semantics and low-level perception flows, as perceived by the brain in response to video stimuli. To the end, we propose NeuroClips, an innovative framework to decode high-fidelity and smooth video from fMRI. NeuroClips utilizes a semantics reconstructor to reconstruct video keyframes, guiding semantic accuracy and consistency, and employs a perception reconstructor to capture low-level perceptual details, ensuring video smoothness. During inference, it adopts a pre-trained T2V diffusion model injected with both keyframes and low-level perception flows for video reconstruction. Evaluated on a publicly available fMRI-video dataset, NeuroClips achieves smooth high-fidelity video reconstruction of up to 6s at 8FPS, gaining significant improvements over state-of-the-art models in various metrics, e.g., a 128% improvement in SSIM and an 81% improvement in spatiotemporal metrics. Our project is available at https://github.com/gongzix/NeuroClips.
48. Almost-Linear RNNs Yield Highly Interpretable Symbolic Codes in Dynamical Systems Reconstruction
tl;dr: We introduce Almost-Linear Recurrent Neural Networks (AL-RNNs) to derive highly interpretable piecewise-linear models of dynamical systems from time-series data.

Dynamical systems theory (DST) is fundamental for many areas of science and engineering. It can provide deep insights into the behavior of systems evolving in time, as typically described by differential or recursive equations. A common approach to facilitate mathematical tractability and interpretability of DS models involves decomposing nonlinear DS into multiple linear DS combined by switching manifolds, i.e. piecewise linear (PWL) systems. PWL models are popular in engineering and a frequent choice in mathematics for analyzing the topological properties of DS. However, hand-crafting such models is tedious and only possible for very low-dimensional scenarios, while inferring them from data usually gives rise to unnecessarily complex representations with very many linear subregions. Here we introduce Almost-Linear Recurrent Neural Networks (AL-RNNs) which automatically and robustly produce most parsimonious PWL representations of DS from time series data, using as few PWL nonlinearities as possible. AL-RNNs can be efficiently trained with any SOTA algorithm for dynamical systems reconstruction (DSR), and naturally give rise to a symbolic encoding of the underlying DS that provably preserves important topological properties. We show that for the Lorenz and Rössler systems, AL-RNNs derive, in a purely data-driven way, the known topologically minimal PWL representations of the corresponding chaotic attractors. We further illustrate on two challenging empirical datasets that interpretable symbolic encodings of the dynamics can be achieved, tremendously facilitating mathematical and computational analysis of the underlying systems.
tl;dr: We propose QUEST, a novel framework with quaternion objectives and constraints to both capture shared and unique information.

Multimodal contrastive learning (MCL) has recently demonstrated significant success across various tasks. However, the existing MCL treats all negative samples equally and ignores the potential semantic association with positive samples, which limits the model's ability to achieve fine-grained alignment. In multi-view scenarios, MCL tends to prioritize shared information while neglecting modality-specific unique information across different views, leading to feature suppression and suboptimal performance in downstream tasks. To address these limitations, we propose a novel contrastive framework name *QUEST: Quadruple Multimodal Contrastive Learning with Constraints and Self-Penalization*. In the QUEST framework, we propose quaternion contrastive objectives and orthogonal constraints to extract sufficient unique information. Meanwhile, a shared information-guided penalization is introduced to ensure that shared information does not excessively influence the optimization of unique information. Our method leverages quaternion vector spaces to simultaneously optimize shared and unique information. Experiments on multiple datasets show that our method achieves superior performance in multimodal contrastive learning benchmarks. On public benchmark, our approach achieves state-of-the-art performance, and on synthetic shortcut datasets, we outperform existing baseline methods by an average of 97.95\% on the CLIP model.
tl;dr: We provide a complete characterization of the universal rates landscape of active learning.

In this work we study the problem of actively learning binary classifiers
from a given concept class, i.e., learning by utilizing unlabeled data
and submitting targeted queries about their labels to a domain expert.
We evaluate the quality of our solutions by considering the learning curves
they induce, i.e., the rate of decrease
of the misclassification probability as the number of label queries
increases. The majority of the literature on active learning has
focused on obtaining uniform guarantees on the error rate which are
only able to explain the upper envelope of the learning curves over families
of different data-generating distributions. We diverge from this line of
work and we focus on the distribution-dependent framework of universal
learning whose goal is to obtain guarantees that hold for any fixed distribution,
but do not apply uniformly over all the distributions. We provide a
complete characterization of the optimal learning rates that are achievable
by algorithms that have to specify the number of unlabeled examples they
use ahead of their execution. Moreover, we identify combinatorial complexity
measures that give rise to each case of our tetrachotomic characterization.
This resolves an open question that was posed by Balcan et al. (2010).
As a byproduct of our main result,
we develop an active learning algorithm for partial concept classes
that achieves exponential learning rates in the uniform setting.
tl;dr: We propose a new REC scheme utilizing space partitioning to reduce runtime in practical neural compression scenarios.

Relative entropy coding (REC) algorithms encode a random sample following a target distribution $Q$, using a coding distribution $P$ shared between the sender and receiver. Sadly, general REC algorithms suffer from prohibitive encoding times, at least on the order of $2^{D_{\text{KL}}[Q||P]}$, and faster algorithms are limited to very specific settings. This work addresses this issue by introducing a REC scheme utilizing space partitioning to reduce runtime in practical scenarios. We provide theoretical analyses of our method and demonstrate its effectiveness with both toy examples and practical applications. Notably, our method successfully handles REC tasks with $D_{\text{KL}}[Q||P]$ about three times greater than what previous methods can manage, and reduces the bitrate by approximately 5-15\% in VAE-based lossless compression on MNIST and INR-based lossy compression on CIFAR-10, compared to previous methods, significantly improving the practicality of REC for neural compression.

Convergence rate analysis for general state-space Markov chains is fundamentally important in operations research (stochastic systems) and machine learning (stochastic optimization). This problem, however, is notoriously difficult because traditional analytical methods often do not generate practically useful convergence bounds for realistic Markov chains. We propose the Deep Contractive Drift Calculator (DCDC), the first general-purpose sample-based algorithm for bounding the convergence of Markov chains to stationarity in Wasserstein distance. The DCDC has two components. First, inspired by the new convergence analysis framework in (Qu et.al, 2023), we introduce the Contractive Drift Equation (CDE), the solution of which leads to an explicit convergence bound. Second, we develop an efficient neural-network-based CDE solver. Equipped with these two components, DCDC solves the CDE and converts the solution into a convergence bound. We analyze the sample complexity of the algorithm and further demonstrate the effectiveness of the DCDC by generating convergence bounds for realistic Markov chains arising from stochastic processing networks as well as constant step-size stochastic optimization.
tl;dr: Perform model-based OPE, but instead of trying to estimate a perfect model of the MDP, estimate an abstract model, customized to a policy, that preserves the performance of that policy and can be learnt from off-policy data.

Evaluating policies using off-policy data is crucial for applying reinforcement learning to real-world problems such as healthcare and autonomous driving. Previous methods for *off-policy evaluation* (OPE) generally suffer from high variance or irreducible bias, leading to unacceptably high prediction errors. In this work, we introduce STAR, a framework for OPE that encompasses a broad range of estimators -- which include existing OPE methods as special cases -- that achieve lower mean squared prediction errors. STAR leverages state abstraction to distill complex, potentially continuous problems into compact, discrete models which we call *abstract reward processes* (ARPs). Predictions from ARPs estimated from off-policy data are provably consistent (asymptotically correct). Rather than proposing a specific estimator, we present a new framework for OPE and empirically demonstrate that estimators within STAR outperform existing methods. The best STAR estimator outperforms baselines in all twelve cases studied, and even the median STAR estimator surpasses the baselines in seven out of the twelve cases.
tl;dr: Causal effect in exchangeable data that adhere to the independent causal mechanism principle

We study causal effect estimation in a setting where the data are not i.i.d.$\ $(independent and identically distributed). We focus on exchangeable data satisfying an assumption of independent causal mechanisms. Traditional causal effect estimation frameworks, e.g., relying on structural causal models and do-calculus, are typically limited to i.i.d. data and do not extend to more general exchangeable generative processes, which naturally arise in multi-environment data. To address this gap, we develop a generalized framework for exchangeable data and introduce a truncated factorization formula that facilitates both the identification and estimation of causal effects in our setting. To illustrate potential applications, we introduce a causal Pólya urn model and demonstrate how intervention propagates effects in exchangeable data settings. Finally, we develop an algorithm that performs simultaneous causal discovery and effect estimation given multi-environment data.
tl;dr: We train neural networks in changing environments and show that task abstractions emerge in parameters trained with fast learning rate and heavily regularized. The task abstractions can then support cognitive flexibility.

Animals survive in dynamic environments changing at arbitrary timescales, but such data distribution shifts are a challenge to neural networks. To adapt to change, neural systems may change a large number of parameters, which is a slow process involving forgetting past information. In contrast, animals leverage distribution changes to segment their stream of experience into tasks and associate them with internal task abstracts. Animals can then respond flexibly by selecting the appropriate task abstraction. However, how such flexible task abstractions may arise in neural systems remains unknown. Here, we analyze a linear gated network where the weights and gates are jointly optimized via gradient descent, but with neuron-like constraints on the gates including a faster timescale, non-negativity, and bounded activity. We observe that the weights self-organize into modules specialized for tasks or sub-tasks encountered, while the gates layer forms unique representations that switch the appropriate weight modules (task abstractions). We analytically reduce the learning dynamics to an effective eigenspace, revealing a virtuous cycle: fast adapting gates drive weight specialization by protecting previous knowledge, while weight specialization in turn increases the update rate of the gating layer. Task switching in the gating layer accelerates as a function of curriculum block size and task training, mirroring key findings in cognitive neuroscience. We show that the discovered task abstractions support generalization through both task and subtask composition, and we extend our findings to a non-linear network switching between two tasks. Overall, our work offers a theory of cognitive flexibility in animals as arising from joint gradient descent on synaptic and neural gating in a neural network architecture.
tl;dr: Reverse Scoring and generation provides unsupervised feedback to LLMs

Large Language Models (LLMs) are typically trained to predict in the forward direction of time. However, recent works have shown that prompting these models to look back and critique their own generations can produce useful feedback. Motivated by this, we explore the question of whether LLMs can be empowered to think (predict and score) backwards to provide unsupervised feedback that complements forward LLMs. Towards this, we introduce Time Reversed Language Models (TRLMs), which can score and generate queries when conditioned on responses, effectively functioning in the reverse direction of time. Further, to effectively infer in the response to query direction, we pre-train and fine-tune a language model (TRLM-Ba) in the reverse token order from scratch. We show empirically (and theoretically in a stylized setting) that time-reversed models can indeed complement forward model predictions when used to score the query given response for re-ranking multiple forward generations. We obtain up to 5\% improvement on the widely used AlpacaEval Leaderboard over the competent baseline of best-of-N re-ranking using self log-perplexity scores. We further show that TRLM scoring outperforms conventional forward scoring of response given query, resulting in significant gains in applications such as citation generation and passage retrieval. We next leverage the generative ability of TRLM to augment or provide unsupervised feedback to input safety filters of LLMs, demonstrating a drastic reduction in false negative rate with negligible impact on false positive rates against several attacks published on the popular JailbreakBench leaderboard.
tl;dr: We show that combining increased critic model capacity with certain RL-specific improvement leads to very efficient agents

Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.
tl;dr: Guiding a diffusion model with a smaller, less-trained version of itself leads to significantly improved sample and distribution quality.

The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
tl;dr: We propose variational delayed policy optimization, a novel delayed reinforcement learning method from the perspective of variational inference for effectively improving the sample efficiency without compromising the performance.

In environments with delayed observation, state augmentation by including actions within the delay window is adopted to retrieve Markovian property to enable reinforcement learning (RL). Whereas, state-of-the-art (SOTA) RL techniques with Temporal-Difference (TD) learning frameworks commonly suffer from learning inefficiency, due to the significant expansion of the augmented state space with the delay. To improve the learning efficiency without sacrificing performance, this work novelly introduces Variational Delayed Policy Optimization (VDPO), reforming delayed RL as a variational inference problem. This problem is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. We not only provide a theoretical analysis of VDPO in terms of sample complexity and performance, but also empirically demonstrate that VDPO can achieve consistent performance with SOTA methods, with a significant enhancement of sample efficiency (approximately 50\% less amount of samples) in the MuJoCo benchmark.

We consider the problem of online fair division of indivisible goods to players when there are a finite number of types of goods and player values are drawn from distributions with unknown means. Our goal is to maximize social welfare subject to allocating the goods fairly in expectation. When a player's value for an item is unknown at the time of allocation, we show that this problem reduces to a variant of (stochastic) multi-armed bandits, where there exists an arm for each player's value for each type of good. At each time step, we choose a distribution over arms which determines how the next item is allocated. We consider two sets of fairness constraints for this problem: envy-freeness in expectation and proportionality in expectation. Our main result is the design of an explore-then-commit algorithm that achieves $\tilde{O}(T^{2/3})$ regret while maintaining either fairness constraint. This result relies on unique properties fundamental to fair-division constraints that allow faster rates of learning, despite the restricted action space.
61. Matrix Denoising with Doubly Heteroscedastic Noise: Fundamental Limits and Optimal Spectral Methods
tl;dr: For the problem of matrix denoising with doubly heteroscedastic noise, we design a spectral estimator and prove that it (i) attains the weak recovery threshold and (ii) is Bayes-optimal in the one-sided heteroscedastic case.

We study the matrix denoising problem of estimating the singular vectors of a rank-$1$ signal corrupted by noise with both column and row correlations. Existing works are either unable to pinpoint the exact asymptotic estimation error or, when they do so, the resulting approaches (e.g., based on whitening or singular value shrinkage) remain vastly suboptimal. On top of this, most of the literature has focused on the special case of estimating the left singular vector of the signal when the noise only possesses row correlation (one-sided heteroscedasticity). In contrast, our work establishes the information-theoretic and algorithmic limits of matrix denoising with doubly heteroscedastic noise. We characterize the exact asymptotic minimum mean square error, and design a novel spectral estimator with rigorous optimality guarantees: under a technical condition, it attains positive correlation with the signals whenever information-theoretically possible and, for one-sided heteroscedasticity, it also achieves the Bayes-optimal error. Numerical experiments demonstrate the significant advantage of our theoretically principled method with the state of the art. The proofs draw connections with statistical physics and approximate message passing, departing drastically from standard random matrix theory techniques.
tl;dr: We use LLMs to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language text which describes a user's prior knowledge.

Machine learning practitioners often face significant challenges in formally integrating their prior knowledge and beliefs into predictive models, limiting the potential for nuanced and context-aware analyses. Moreover, the expertise needed to integrate this prior knowledge into probabilistic modeling typically limits the application of these models to specialists. Our goal is to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language text which describes a user's prior knowledge. Large Language Models (LLMs) provide a useful starting point for designing such a tool since they 1) provide an interface where users can incorporate expert insights in natural language and 2) provide an opportunity for leveraging latent problem-relevant knowledge encoded in LLMs that users may not have themselves. We start by exploring strategies for eliciting explicit, coherent numerical predictive distributions from LLMs. We examine these joint predictive distributions, which we call LLM Processes, over arbitrarily-many quantities in settings such as forecasting, multi-dimensional regression, black-box optimization, and image modeling. We investigate the practical details of prompting to elicit coherent predictive distributions, and demonstrate their effectiveness at regression. Finally, we demonstrate the ability to usefully incorporate text into numerical predictions, improving predictive performance and giving quantitative structure that reflects qualitative descriptions. This lets us begin to explore the rich, grounded hypothesis space that LLMs implicitly encode.
tl;dr: We design a Dikin walk for log-concave sampling over polytopes and spectrahedra with the fastest mixing time and efficient per iteration cost.

We consider the problem of sampling from a $d$-dimensional log-concave distribution $\pi(\theta) \propto \exp(-f(\theta))$ for $L$-Lipschitz $f$, constrained to a convex body (described by $n$ hyperplanes) equipped with a barrier function, contained in a ball of radius $R$ with a $w$-warm start.
We propose a \emph{robust} sampling framework that computes spectral approximations to the Hessian of the barrier functions in each iteration. We prove that for the polytope constraints, sampling with the Lee-Sidford barrier function mixes within $\widetilde O((d^2+dL^2R^2)\log(w/\delta))$ steps with a per step cost of $\widetilde O(nd^{\omega-1})$, where $\omega\approx 2.37$ is the fast matrix multiplication exponent. Compared to the prior work of Mangoubi and Vishnoi, our approach gives faster mixing time as we are able to design a generalized soft-threshold Dikin walk beyond log-barrier.
We further extend our result to show how to sample from a $d$-dimensional spectrahedron, the constrained set of a semidefinite program, specified by the set $\{x\in \mathbb{R}^d: \sum_{i=1}^d x_i A_i \succeq C \}$ where $A_1,\ldots,A_d, C$ are $n\times n$ real symmetric matrices. We design a walk that mixes in $\widetilde O((nd+dL^2R^2)\log(w/\delta))$ steps with a per iteration cost of $\widetilde O(n^\omega+n^2d^{3\omega-5})$. We improve the mixing time bound of prior best Dikin walk due to Narayanan and Rakhlin that mixes in $\widetilde O((n^2d^3+n^2dL^2R^2)\log(w/\delta))$ steps.
tl;dr: Better performing predictive models for V1 might be less consistent that the older generation. Step towards solving it: pruning and adaptive regularisation.

Deep predictive models of neuronal activity have recently enabled several new discoveries about the selectivity and invariance of neurons in the visual cortex.
These models learn a shared set of nonlinear basis functions, which are linearly combined via a learned weight vector to represent a neuron's function.
Such weight vectors, which can be thought as embeddings of neuronal function, have been proposed to define functional cell types via unsupervised clustering.
However, as deep models are usually highly overparameterized, the learning problem is unlikely to have a unique solution, which raises the question if such embeddings can be used in a meaningful way for downstream analysis.
In this paper, we investigate how stable neuronal embeddings are with respect to changes in model architecture and initialization.
We find that $L_1$ regularization to be an important ingredient for structured embeddings and develop an adaptive regularization that adjusts the strength of regularization per neuron.
This regularization improves both predictive performance and how consistently neuronal embeddings cluster across model fits compared to uniform regularization.
To overcome overparametrization, we propose an iterative feature pruning strategy which reduces the dimensionality of performance-optimized models by half without loss of performance and improves the consistency of neuronal embeddings with respect to clustering neurons.
Our results suggest that to achieve an objective taxonomy of cell types or a compact representation of the functional landscape, we need novel architectures or learning techniques that improve identifiability.
The code is available https://github.com/pollytur/readout_reproducibility.
tl;dr: A newly defined, "latent" form of learning progress provides a valuable signal for goal selection in human reinforcement learning

Humans are autotelic agents who learn by setting and pursuing their own goals. However, the precise mechanisms guiding human goal selection remain unclear. Learning progress, typically measured as the observed change in performance, can provide a valuable signal for goal selection in both humans and artificial agents. We hypothesize that human choices of goals may also be driven by _latent learning progress_, which humans can estimate through knowledge of their actions and the environment – even without experiencing immediate changes in performance. To test this hypothesis, we designed a hierarchical reinforcement learning task in which human participants (N = 175) repeatedly chose their own goals and learned goal-conditioned policies. Our behavioral and computational modeling results confirm the influence of latent learning progress on goal selection and uncover inter-individual differences, partially mediated by recognition of the task's hierarchical structure. By investigating the role of latent learning progress in human goal selection, we pave the way for more effective and personalized learning experiences as well as the advancement of more human-like autotelic machines.
66. Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks

Large language models can solve tasks that were not present in the training set. This capability is believed to be due to in-context learning and skill composition. In this work, we study the emergence of in-context learning and skill composition in a collection of modular arithmetic tasks. Specifically, we consider a finite collection of linear modular functions $z = a x + b y \text{ mod } p$ labeled by the vector $(a, b) \in \mathbb{Z}_p^2$. We use some of these tasks for pre-training and the rest for out-of-distribution testing. We empirically show that a GPT-style transformer exhibits a transition from in-distribution to out-of-distribution generalization as the number of pre-training tasks increases. We find that the smallest model capable of out-of-distribution generalization requires two transformer blocks, while for deeper models, the out-of-distribution generalization phase is *transient*, necessitating early stopping. Finally, we perform an interpretability study of the pre-trained models, revealing highly structured representations in both attention heads and MLPs; and discuss the learned algorithms. Notably, we find an algorithmic shift in deeper models, as we go from few to many in-context examples.
tl;dr: We propose OPEN, a method for learning optimizers designed to improve final return in reinforcement learning by tackling the difficulties of plasticity loss, exploration and non-stationarity.

While reinforcement learning (RL) holds great potential for decision making in the real world, it suffers from a number of unique difficulties which often need specific consideration. In particular: it is highly non-stationary; suffers from high degrees of plasticity loss; and requires exploration to prevent premature convergence to local optima and maximize return. In this paper, we consider whether learned optimization can help overcome these problems. Our method, Learned **O**ptimization for **P**lasticity, **E**xploration and **N**on-stationarity (*OPEN*), meta-learns an update rule whose input features and output structure are informed by previously proposed solutions to these difficulties. We show that our parameterization is flexible enough to enable meta-learning in diverse learning contexts, including the ability to use stochasticity for exploration. Our experiments demonstrate that when meta-trained on single and small sets of environments, *OPEN* outperforms or equals traditionally used optimizers. Furthermore, *OPEN* shows strong generalization characteristics across a range of environments and agent architectures.

We consider the task of minimizing the sum of convex functions stored in a decentralized manner across the nodes of a communication network. This problem is relatively well-studied in the scenario when the objective functions are smooth, or the links of the network are fixed in time, or both. In particular, lower bounds on the number of decentralized communications and (sub)gradient computations required to solve the problem have been established, along with matching optimal algorithms. However, the remaining and most challenging setting of non-smooth decentralized optimization over time-varying networks is largely underexplored, as neither lower bounds nor optimal algorithms are known in the literature. We resolve this fundamental gap with the following contributions: (i) we establish the first lower bounds on the communication and subgradient computation complexities of solving non-smooth convex decentralized optimization problems over time-varying networks; (ii) we develop the first optimal algorithm that matches these lower bounds and offers substantially improved theoretical performance compared to the existing state of the art.

Interpretability studies often involve tracing the flow of information through machine learning models to identify specific model components that perform relevant computations for tasks of interest. Prior work quantifies the importance of a model component on a particular task by measuring the impact of performing ablation on that component, or simulating model inference with the component disabled.
We propose a new method, optimal ablation (OA), and show that OA-based component importance has theoretical and empirical advantages over measuring importance via other ablation methods. We also show that OA-based component importance can benefit several downstream interpretability tasks, including circuit discovery, localization of factual recall, and latent prediction.

We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only generating lip movements that are exquisitely synchronized with the audio, but also producing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness.
The core innovations include a diffusion-based holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos.
Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method delivers high video quality with realistic facial and head dynamics and also supports the online generation of 512$\times$512 videos at up to 40 FPS with negligible starting latency.
It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
tl;dr: We propose a sampler for the uniform distribution on a convex body, based on forward and backward heat flows.

We present a new random walk for uniformly sampling high-dimensional convex bodies. It achieves state-of-the-art runtime complexity with stronger guarantees on the output than previously known, namely in Rényi divergence (which implies TV, $\mathcal{W}_2$, KL, $\chi^2$). The proof departs from known approaches for polytime algorithms for the problem - we utilize a stochastic diffusion perspective to show contraction to the target distribution with the rate of convergence determined by functional isoperimetric constants of the stationary density.
tl;dr: A comprehensive and reliable benchmark for evaluating critique ability of LLMs

Critique ability, i.e., the capability of Large Language Models (LLMs) to identify and rectify flaws in responses, is crucial for their applications in self-improvement and scalable oversight. While numerous studies have been proposed to evaluate critique ability of LLMs, their comprehensiveness and reliability are still limited. To overcome this problem, we introduce CriticEval, a novel benchmark designed to comprehensively and reliably evaluate critique ability of LLMs. Specifically, to ensure the comprehensiveness, CriticEval evaluates critique ability from four dimensions across nine diverse task scenarios. It evaluates both scalar-valued and textual critiques, targeting responses of varying quality. To ensure the reliability, a large number of critiques are annotated to serve as references, enabling GPT-4 to evaluate textual critiques reliably. Extensive evaluations of open-source and closed-source LLMs first validate the reliability of evaluation in CriticEval. Then, experimental results demonstrate the promising potential of open-source LLMs, the effectiveness of critique datasets and several intriguing relationships between the critique ability and some critical factors, including task types, response qualities and critique dimensions.
tl;dr: A method to visualize shared features between images that drive neural responses.

High-level visual brain regions contain subareas in which neurons appear to respond more strongly to examples of a particular semantic category, like faces or bodies, rather than objects. However, recent work has shown that while this finding holds on average, some out-of-category stimuli also activate neurons in these regions. This may be due to visual features common among the preferred class also being present in other images. Here, we propose a deep-learning-based approach for visualizing these features. For each neuron, we identify relevant visual features driving its selectivity by modelling responses to images based on latent activations of a deep neural network. Given an out-of-category image which strongly activates the neuron, our method first identifies a reference image from the preferred category yielding a similar feature activation pattern. We then backpropagate latent activations of both images to the pixel level, while enhancing the identified shared dimensions and attenuating non-shared features. The procedure highlights image regions containing shared features driving responses of the model neuron. We apply the algorithm to novel recordings from body-selective regions in macaque IT cortex in order to understand why some images of objects excite these neurons. Visualizations reveal object parts which resemble parts of a macaque body, shedding light on neural preference of these objects.
tl;dr: We present a new theory of generalization for local minima that gradient descent with a constant learning rate can stably converge to.

We study the generalization of two-layer ReLU neural networks in a univariate nonparametric regression problem with noisy labels. This is a problem where kernels (\emph{e.g.} NTK) are provably sub-optimal and benign overfitting does not happen, thus disqualifying existing theory for interpolating (0-loss, global optimal) solutions. We present a new theory of generalization for local minima that gradient descent with a constant learning rate can \emph{stably} converge to. We show that gradient descent with a fixed learning rate $\eta$ can only find local minima that represent smooth functions with a certain weighted \emph{first order total variation} bounded by $1/\eta - 1/2 + \widetilde{O}(\sigma + \sqrt{\mathrm{MSE}})$ where $\sigma$ is the label noise level, $\mathrm{MSE}$ is short for mean squared error against the ground truth, and $\widetilde{O}(\cdot)$ hides a logarithmic factor. Under mild assumptions, we also prove a nearly-optimal MSE bound of $\widetilde{O}(n^{-4/5})$ within the strict interior of the support of the $n$ data points. Our theoretical results are validated by extensive simulation that demonstrates large learning rate training induces sparse linear spline fits. To the best of our knowledge, we are the first to obtain generalization bound via minima stability in the non-interpolation case and the first to show ReLU NNs without regularization can achieve near-optimal rates in nonparametric regression.
tl;dr: Leveraging human response times to accelerate preference learning from binary choices

Interactive preference learning systems present humans with queries as pairs of options; humans then select their preferred choice, allowing the system to infer preferences from these binary choices. While binary choice feedback is simple and widely used, it offers limited information about preference strength. To address this, we leverage human response times, which inversely correlate with preference strength, as complementary information. We introduce a computationally efficient method based on the EZ-diffusion model, combining choices and response times to estimate the underlying human utility function. Theoretical and empirical comparisons with traditional choice-only estimators show that for queries where humans have strong preferences (i.e., "easy" queries), response times provide valuable complementary information and enhance utility estimates. We integrate this estimator into preference-based linear bandits for fixed-budget best-arm identification. Simulations on three real-world datasets demonstrate that incorporating response times significantly accelerates preference learning.
tl;dr: We make use of Koopman operator theory to identify when the dynamics associated with training two different neural network models are equivalent.

Study of the nonlinear evolution deep neural network (DNN) parameters undergo during training has uncovered regimes of distinct dynamical behavior. While a detailed understanding of these phenomena has the potential to advance improvements in training efficiency and robustness, the lack of methods for identifying when DNN models have equivalent dynamics limits the insight that can be gained from prior work. Topological conjugacy, a notion from dynamical systems theory, provides a precise definition of dynamical equivalence, offering a possible route to address this need. However, topological conjugacies have historically been challenging to compute. By leveraging advances in Koopman operator theory, we develop a framework for identifying conjugate and non-conjugate training dynamics. To validate our approach, we demonstrate that comparing Koopman eigenvalues can correctly identify a known equivalence between online mirror descent and online gradient descent. We then utilize our approach to: (a) identify non-conjugate training dynamics between shallow and wide fully connected neural networks; (b) characterize the early phase of training dynamics in convolutional neural networks; (c) uncover non-conjugate training dynamics in Transformers that do and do not undergo grokking. Our results, across a range of DNN architectures, illustrate the flexibility of our framework and highlight its potential for shedding new light on training dynamics.

Two-stage recommender systems play a crucial role in efficiently identifying relevant items and personalizing recommendations from a vast array of options. This paper, based on an error decomposition framework, analyzes the generalization error for two-stage recommender systems with a tree structure, which consist of an efficient tree-based retriever and a more precise yet time-consuming ranker. We use the Rademacher complexity to establish the generalization upper bound for various tree-based retrievers using beam search, as well as for different ranker models under a shifted training distribution. Both theoretical insights and practical experiments on real-world datasets indicate that increasing the branches in tree-based retrievers and harmonizing distributions across stages can enhance the generalization performance of two-stage recommender systems.
tl;dr: We show that small-sized Transformers can theoretically express tasks like index lookup, nearest neighbor, and string matching, whereas RNNs require larger sizes; Also show limitations of one-layer Transformers on recognizing Dyck languages

Transformer architectures have been widely adopted in foundation models. Due to their high inference costs, there is renewed interest in exploring the potential of efficient recurrent architectures (RNNs). In this paper, we analyze the differences in the representational capabilities of Transformers and RNNs across several tasks of practical relevance, including index lookup, nearest neighbor, recognizing bounded Dyck languages, and string equality. For the tasks considered, our results show separations based on the size of the model required for different architectures. For example, we show that a one-layer Transformer of logarithmic width can perform index lookup, whereas an RNN requires a hidden state of linear size. Conversely, while constant-size RNNs can recognize bounded Dyck languages, we show that one-layer Transformers require a linear size for this task. Furthermore, we show that two-layer Transformers of logarithmic size can perform decision tasks such as string equality or disjointness, whereas both one-layer Transformers and recurrent models require linear size for these tasks. We also show that a log-size two-layer Transformer can implement the nearest neighbor algorithm in its forward pass; on the other hand recurrent models require linear size. Our constructions are based on the existence of $N$ nearly orthogonal vectors in $O(\log N)$ dimensional space and our lower bounds are based on reductions from communication complexity problems. We supplement our theoretical results with experiments that highlight the differences in the performance of these architectures on practical-size sequences.
79. Stochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators

Optimizing neural networks with loss that contain high-dimensional and high-order differential operators
is expensive to evaluate with back-propagation due to $\mathcal{O}(d^{k})$ scaling of the derivative tensor size and the $\mathcal{O}(2^{k-1}L)$ scaling in the computation graph, where $d$ is the dimension of the domain, $L$ is the number of ops in the forward computation graph, and $k$ is the derivative order. In previous works, the polynomial scaling in $d$ was addressed by amortizing the computation over the optimization process via randomization. Separately, the exponential scaling in $k$ for univariate functions ($d=1$) was addressed with high-order auto-differentiation (AD). In this work, we show how to efficiently perform arbitrary contraction of the derivative tensor of arbitrary order for multivariate functions, by properly constructing the input tangents to univariate high-order AD, which can be used to efficiently randomize any differential operator.
When applied to Physics-Informed Neural Networks (PINNs), our method provides >1000$\times$ speed-up and >30$\times$ memory reduction over randomization with first-order AD, and we can now solve 1-million-dimensional PDEs in 8 minutes on a single NVIDIA A100 GPU. This work opens the possibility of using high-order differential operators in large-scale problems.
tl;dr: This paper pioneers the exploration of explicitly modeling periodic patterns in time-series data to enhance the accuracy of long-term time series forecasting (LTSF) tasks.

The stable periodic patterns present in time series data serve as the foundation for conducting long-horizon forecasts. In this paper, we pioneer the exploration of explicitly modeling this periodicity to enhance the performance of models in long-term time series forecasting (LTSF) tasks. Specifically, we introduce the Residual Cycle Forecasting (RCF) technique, which utilizes learnable recurrent cycles to model the inherent periodic patterns within sequences, and then performs predictions on the residual components of the modeled cycles. Combining RCF with a Linear layer or a shallow MLP forms the simple yet powerful method proposed in this paper, called CycleNet. CycleNet achieves state-of-the-art prediction accuracy in multiple domains including electricity, weather, and energy, while offering significant efficiency advantages by reducing over 90% of the required parameter quantity. Furthermore, as a novel plug-and-play technique, the RCF can also significantly improve the prediction accuracy of existing models, including PatchTST and iTransformer. The source code is available at: https://github.com/ACAT-SCUT/CycleNet.
tl;dr: A novel end-to-end training algorithm for multimodal fusion detection

Multimodal image fusion and object detection are crucial for autonomous driving. While current methods have advanced the fusion of texture details and semantic information, their complex training processes hinder broader applications. Addressing this challenge, we introduce E2E-MFD, a novel end-to-end algorithm for multimodal fusion detection. E2E-MFD streamlines the process, achieving high performance with a single training phase. It employs synchronous joint optimization across components to avoid suboptimal solutions associated to individual tasks. Furthermore, it implements a comprehensive optimization strategy in the gradient matrix for shared parameters, ensuring convergence to an optimal fusion detection configuration. Our extensive testing on multiple public datasets reveals E2E-MFD's superior capabilities, showcasing not only visually appealing image fusion but also impressive detection outcomes, such as a 3.9\% and 2.0\% $\text{mAP}_{50}$ increase on horizontal object detection dataset M3FD and oriented object detection dataset DroneVehicle, respectively, compared to state-of-the-art approaches.
tl;dr: LLM in Time Series Forecasting Task

Large language models (LLMs) are being applied to time series forecasting. But are language models actually useful for time series? In a series of ablation studies on three recent and popular LLM-based time series forecasting methods, we find that removing the LLM component or replacing it with a basic attention layer does not degrade forecasting performance---in most cases, the results even improve! We also find that despite their significant computational cost, pretrained LLMs do no better than models trained from scratch, do not represent the sequential dependencies in time series, and do not assist in few-shot settings. Additionally, we explore time series encoders and find that patching and attention structures perform similarly to LLM-based forecasters. All resources needed to reproduce our work are available: https://github.com/BennyTMT/LLMsForTimeSeries.
tl;dr: This paper presents a new benchmark for large-scale SAR object detection, introducing the SARDet-100k dataset and the Multi-Stage with Filter Augmentation (MSFA) pretrain method.

Synthetic Aperture Radar (SAR) object detection has gained significant attention recently due to its irreplaceable all-weather imaging capabilities. However, this research field suffers from both limited public datasets (mostly comprising <2K images with only mono-category objects) and inaccessible source code. To tackle these challenges, we establish a new benchmark dataset and an open-source method for large-scale SAR object detection. Our dataset, SARDet-100K, is a result of intense surveying, collecting, and standardizing 10 existing SAR detection datasets, providing a large-scale and diverse dataset for research purposes. To the best of our knowledge, SARDet-100K is the first COCO-level large-scale multi-class SAR object detection dataset ever created. With this high-quality dataset, we conducted comprehensive experiments and uncovered a crucial challenge in SAR object detection: the substantial disparities between the pretraining on RGB datasets and finetuning on SAR datasets in terms of both data domain and model structure. To bridge these gaps, we propose a novel Multi-Stage with Filter Augmentation (MSFA) pretraining framework that tackles the problems from the perspective of data input, domain transition, and model migration. The proposed MSFA method significantly enhances the performance of SAR object detection models while demonstrating exceptional generalizability and flexibility across diverse models. This work aims to pave the way for further advancements in SAR object detection. The dataset and code is available at \url{https://github.com/zcablii/SARDet_100K}.

Large language models (LLMs) are considered a crucial technology for advancing intelligent education since they exhibit the potential for an in-depth understanding of teaching scenarios and providing students with personalized guidance. Nonetheless, current LLM-based application in personalized teaching predominantly follows a "Question-Answering" paradigm, where students are passively provided with answers and explanations. In this paper, we propose SocraticLM, which achieves a Socratic "Thought-Provoking" teaching paradigm that fulfills the role of a real classroom teacher in actively engaging students in the thought process required for genuine problem-solving mastery. To build SocraticLM, we first propose a novel "Dean-Teacher-Student" multi-agent pipeline to construct a new dataset, SocraTeach, which contains $35$K meticulously crafted Socratic-style multi-round (equivalent to $208$K single-round) teaching dialogues grounded in fundamental mathematical problems. Our dataset simulates authentic teaching scenarios, interacting with six representative types of simulated students with different cognitive states, and strengthening four crucial teaching abilities. SocraticLM is then fine-tuned on SocraTeach with three strategies balancing its teaching and reasoning abilities. Moreover, we contribute a comprehensive evaluation system encompassing five pedagogical dimensions for assessing the teaching quality of LLMs. Extensive experiments verify that SocraticLM achieves significant improvements in the teaching performance, outperforming GPT4 by more than 12\%. Our dataset and code is available at https://github.com/Ljyustc/SocraticLM.
tl;dr: Our work highlights the provable benefits of combining labeled and unlabeled data for classification and feature selection in high dimensions.

The premise of semi-supervised learning (SSL) is that combining labeled and unlabeled data yields significantly more accurate models.
Despite empirical successes, the theoretical understanding of SSL is still far from complete.
In this work, we study SSL for high dimensional sparse Gaussian classification.
To construct an accurate classifier a key task is feature selection, detecting the few variables that separate the two classes.
For this SSL setting, we analyze information theoretic lower bounds for accurate feature selection as well as computational lower bounds,
assuming the low-degree likelihood hardness conjecture.
Our key contribution is the identification of a regime in the problem parameters (dimension, sparsity, number of labeled and unlabeled samples) where SSL is guaranteed to be advantageous for classification.
Specifically, there is a regime where it is possible to construct in polynomial time an accurate SSL classifier.
However, any computationally efficient supervised or unsupervised learning schemes, that separately use only the labeled or unlabeled data would fail.
Our work highlights the provable benefits of combining labeled and unlabeled data for classification and feature selection in high dimensions.
We present simulations that complement our theoretical analysis.
tl;dr: We derive the precise information-theoretic threshold for exact community recovery from any constant number of correlated stochastic block models, showcasing the power of integrative data analysis and quantifying the value of each additional graph.

We study the problem of learning latent community structure from multiple correlated networks, focusing on edge-correlated stochastic block models with two balanced communities. Recent work of Gaudio, Rácz, and Sridhar (COLT 2022) determined the precise information-theoretic threshold for exact community recovery using two correlated graphs; in particular, this showcased the subtle interplay between community recovery and graph matching. Here we study the natural setting of more than two graphs. The main challenge lies in understanding how to aggregate information across several graphs when none of the pairwise latent vertex correspondences can be exactly recovered. Our main result derives the precise information-theoretic threshold for exact community recovery using any constant number of correlated graphs, answering a question of Gaudio, Rácz, and Sridhar (COLT 2022). In particular, for every $K \geq 3$ we uncover and characterize a region of the parameter space where exact community recovery is possible using $K$ correlated graphs, even though (1) this is information-theoretically impossible using any $K-1$ of them and (2) none of the latent matchings can be exactly recovered.
tl;dr: We introduce PuLID, a tuning-free ID customization approach. PuLID maintains high ID fidelity while effectively reducing interference with the original model's behavior

We propose Pure and Lightning ID customization (PuLID), a novel tuning-free ID customization method for text-to-image generation. By incorporating a Lightning T2I branch with a standard diffusion one, PuLID introduces both contrastive alignment loss and accurate ID loss, minimizing disruption to the original model and ensuring high ID fidelity. Experiments show that PuLID achieves superior performance in both ID fidelity and editability. Another attractive property of PuLID is that the image elements (\eg, background, lighting, composition, and style) before and after the ID insertion are kept as consistent as possible. Codes and models are available at https://github.com/ToTheBeginning/PuLID

We study the problem of PAC learning halfspaces in the
reliable agnostic model of Kalai et al. (2012).
The reliable PAC model
captures learning scenarios where one type of error is
costlier than the others. Our main positive result is a
new algorithm for reliable learning
of Gaussian halfspaces on
$\mathbb{R}^d$ with sample and computational complexity
$d^{O(\log (\min\{1/\alpha, 1/\epsilon\}))}\min (2^{\log(1/\epsilon)^{O(\log (1/\alpha))}},2^{\mathrm{poly}(1/\epsilon)})$,
where $\epsilon$ is the excess error and $\alpha$
is the bias of the optimal halfspace. We complement our upper bound with
a Statistical Query lower bound
suggesting that the $d^{\Omega(\log (1/\alpha))}$ dependence is best possible.
Conceptually, our results imply a strong computational separation
between reliable agnostic learning and standard agnostic
learning of halfspaces in the Gaussian setting.

The surge in applications of large language models (LLMs) has prompted concerns about the generation of misleading or fabricated information, known as hallucinations. Therefore, detecting hallucinations has become critical to maintaining trust in LLM-generated content. A primary challenge in learning a truthfulness classifier is the lack of a large amount of labeled truthful and hallucinated data. To address the challenge, we introduce HaloScope, a novel learning framework that leverages the unlabeled LLM generations in the wild for hallucination detection. Such unlabeled data arises freely upon deploying LLMs in the open world, and consists of both truthful and hallucinated information. To harness the unlabeled data, we present an automated scoring function for distinguishing between truthful and untruthful generations within unlabeled mixture data, thereby enabling the training of a binary classifier on top. Importantly, our framework does not require extra data collection and human annotations, offering strong flexibility and practicality for real-world applications. Extensive experiments show that HaloScope can achieve superior hallucination detection performance, outperforming the competitive rivals by a significant margin.
90. A Simple yet Scalable Granger Causal Structural Learning Approach for Topological Event Sequences

In modern telecommunication networks, faults manifest as alarms, generating thousands of events daily. Network operators need an efficient method to identify the root causes of these alarms to mitigate potential losses. This task is challenging due to the increasing scale of telecommunication networks and the interconnected nature of devices, where one fault can trigger a cascade of alarms across multiple devices within a topological network. Recent years have seen a growing focus on causal approaches to addressing this problem, emphasizing the importance of learning a Granger causal graph from topological event sequences. Such causal graphs delineate the relations among alarms and can significantly aid engineers in identifying and rectifying faults. However, existing methods either ignore the topological relationships among devices or suffer from relatively low scalability and efficiency, failing to deliver high-quality responses in a timely manner. To this end, this paper proposes $S^2GCSL$, a simple yet scalable Granger causal structural learning approach for topological event sequences. $S^2GCSL$ utilizes a linear kernel to model activation interactions among various event types within a topological network, and employs gradient descent to efficiently optimize the likelihood function. Notably, it can seamlessly incorporate expert knowledge as constraints within the optimization process, which enhances the interpretability of the outcomes. Extensive experimental results on both large-scale synthetic and real-world problems verify the scalability and efficacy of $S^2GCSL$.
tl;dr: We introduce GNNs that can count cycles and homomorphisms of cactus graphs, surpassing the limitations of existing GNNs while being scalable on real-world graphs.

We introduce $r$-loopy Weisfeiler-Leman ($r$-$\ell$WL), a novel hierarchy of graph isomorphism tests and a corresponding GNN framework, $r$-$\ell$MPNN, that can count cycles up to length $r{+}2$. Most notably, we show that $r$-$\ell$WL can count homomorphisms of cactus graphs. This extends 1-WL, which can only count homomorphisms of trees and, in fact, is incomparable to $k$-WL for any fixed $k$. We empirically validate the expressive and counting power of $r$-$\ell$MPNN on several synthetic datasets and demonstrate the scalability and strong performance on various real-world datasets, particularly on sparse graphs.

Lensless cameras offer significant advantages in size, weight, and cost compared to traditional lens-based systems. Without a focusing lens, lensless cameras rely on computational algorithms to recover the scenes from multiplexed measurements. However, current algorithms struggle with inaccurate forward imaging models and insufficient priors to reconstruct high-quality images. To overcome these limitations, we introduce a novel two-stage approach for consistent and photorealistic lensless image reconstruction. The first stage of our approach ensures data consistency by focusing on accurately reconstructing the low-frequency content with a spatially varying deconvolution method that adjusts to changes in the Point Spread Function (PSF) across the camera's field of view. The second stage enhances photorealism by incorporating a generative prior from pre-trained diffusion models. By conditioning on the low-frequency content retrieved in the first stage, the diffusion model effectively reconstructs the high-frequency details that are typically lost in the lensless imaging process, while also maintaining image fidelity. Our method achieves a superior balance between data fidelity and visual quality compared to existing methods, as demonstrated with two popular lensless systems, PhlatCam and DiffuserCam.

*Visual reprogramming* (VR) leverages the intrinsic capabilities of pretrained vision models by adapting their input or output interfaces to solve downstream tasks whose labels (i.e., downstream labels) might be totally different from the labels associated with the pretrained models (i.e., pretrained labels).
When adapting the output interface, label mapping methods transform the pretrained labels to downstream labels by establishing a gradient-free one-to-one correspondence between the two sets of labels.
However, in this paper, we reveal that one-to-one mappings may overlook the complex relationship between pretrained and downstream labels. Motivated by this observation, we propose a ***B**ayesian-guided **L**abel **M**apping* (BLM) method.
BLM constructs an iteratively-updated probabilistic label mapping matrix, with each element quantifying a pairwise relationship between pretrained and downstream labels.
The assignment of values to the constructed matrix is guided by Bayesian conditional probability, considering the joint distribution of the downstream labels and the labels predicted by the pretrained model on downstream samples. Experiments conducted on both pretrained vision models (e.g., ResNeXt) and vision-language models (e.g., CLIP) demonstrate the superior performance of BLM over existing label mapping methods. The success of BLM also offers a probabilistic lens through which to understand and analyze the effectiveness of VR.
Our code is available at https://github.com/tmlr-group/BayesianLM.

Semi-implicit variational inference (SIVI) enriches the expressiveness of variational
families by utilizing a kernel and a mixing distribution to hierarchically define the
variational distribution. Existing SIVI methods parameterize the mixing distribution
using implicit distributions, leading to intractable variational densities. As a result,
directly maximizing the evidence lower bound (ELBO) is not possible, so they
resort to one of the following: optimizing bounds on the ELBO, employing costly
inner-loop Markov chain Monte Carlo runs, or solving minimax objectives. In this
paper, we propose a novel method for SIVI called Particle Variational Inference
(PVI) which employs empirical measures to approximate the optimal mixing
distributions characterized as the minimizer of a free energy functional. PVI arises
naturally as a particle approximation of a Euclidean–Wasserstein gradient flow and,
unlike prior works, it directly optimizes the ELBO whilst making no parametric
assumption about the mixing distribution. Our empirical results demonstrate that
PVI performs favourably compared to other SIVI methods across various tasks.
Moreover, we provide a theoretical analysis of the behaviour of the gradient flow
of a related free energy functional: establishing the existence and uniqueness of
solutions as well as propagation of chaos results.
tl;dr: We show that vision language models exhibit human-like capacity constraints in multi-object visual reasoning and image generation.
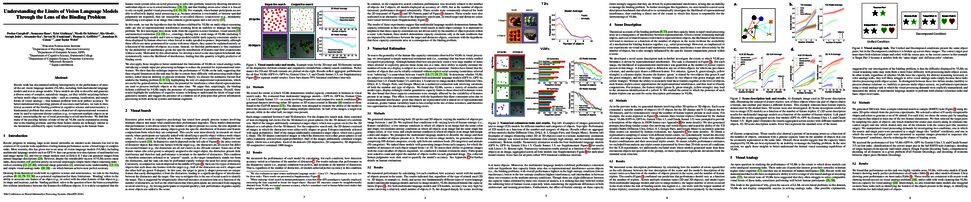
Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
tl;dr: A second-order, memory-efficient optimization method for RNNs that does not require backpropagation, runs in wallclock time comparable to first-order methods, and successfully trains RNNs where Adam fails

A common source of anxiety for the computational neuroscience student is the question “will my recurrent neural network (RNN) model finally learn that task?”. Unlike in machine learning where any architectural modification of an RNN (e.g. GRU or LSTM) is acceptable if it speeds up training, the RNN models trained as _models of brain dynamics_ are subject to plausibility constraints that fundamentally exclude the usual machine learning hacks. The “vanilla” RNNs commonly used in computational neuroscience find themselves plagued by ill-conditioned loss surfaces that complicate training and significantly hinder our capacity to investigate the brain dynamics underlying complex tasks. Moreover, some tasks may require very long time horizons which backpropagation cannot handle given typical GPU memory limits. Here, we develop SOFO, a second-order optimizer that efficiently navigates loss surfaces whilst _not_ requiring backpropagation. By relying instead on easily parallelized batched forward-mode differentiation, SOFO enjoys constant memory cost in time. Morever, unlike most second-order optimizers which involve inherently sequential operations, SOFO's effective use of GPU parallelism yields a per-iteration wallclock time essentially on par with first-order gradient-based optimizers. We show vastly superior performance compared to Adam on a number of RNN tasks, including a difficult double-reaching motor task and the learning of an adaptive Kalman filter algorithm trained over a long horizon.
tl;dr: Decoding from earlier layers in LLMs recovers harmful content that would have been blocked, and LLMs answer harmful queries posed by some groups of users but not others.

Studies show that safety-tuned models may nevertheless divulge harmful information. In this work, we show that whether they do so depends significantly on who they are talking to, which we refer to as *user persona*. In fact, we find manipulating user persona to be more effective for eliciting harmful content than certain more direct attempts to control model refusal. We study both natural language prompting and activation steering as intervention methods and show that activation steering is significantly more effective at bypassing safety filters.
We shed light on the mechanics of this phenomenon by showing that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. We also show we can predict a persona’s effect on refusal given only the geometry of its steering vector. Finally, we show that certain user personas induce the model to form more charitable interpretations of otherwise dangerous queries.

While neural networks (NNs) have a large potential as autonomous controllers for Cyber-Physical Systems, verifying the safety of neural network based control systems (NNCSs) poses significant challenges for the practical use of NNs— especially when safety is needed for unbounded time horizons. One reason for this is the intractability of analyzing NNs, ODEs and hybrid systems. To this end, we introduce VerSAILLE (Verifiably Safe AI via Logically Linked Envelopes): The first general approach that allows reusing control theory literature for NNCS verification. By joining forces, we can exploit the efficiency of NN verification tools while retaining the rigor of differential dynamic logic (dL). Based on a provably safe control envelope in dL, we derive a specification for the NN which is proven with NN verification tools. We show that a proof of the NN’s adherence to the specification is then mirrored by a dL proof on the infinite-time safety of the NNCS.
The NN verification properties resulting from hybrid systems typically contain nonlinear arithmetic over formulas with arbitrary logical structure while efficient NN verification tools merely support linear constraints. To overcome this divide, we present Mosaic: An efficient, sound and complete verification approach for polynomial real arithmetic properties on piece-wise linear NNs. Mosaic partitions complex NN verification queries into simple queries and lifts off-the-shelf linear constraint tools to the nonlinear setting in a completeness-preserving manner by combining approximation with exact reasoning for counterexample regions. In our evaluation we demonstrate the versatility of VerSAILLE and Mosaic: We prove infinite-time safety on the classical Vertical Airborne Collision Avoidance NNCS verification benchmark for some scenarios while (exhaustively) enumerating counterexample regions in unsafe scenarios. We also show that our approach significantly outperforms the State-of-the-Art tools in closed-loop NNV
tl;dr: We propose Quantum-informed Tensor Adaptation (QuanTA), a novel, easy-to-implement, high-rank fine-tuning method with no inference overhead for large-scale pre-trained language models.

We propose **Quan**tum-informed **T**ensor **A**daptation (**QuanTA**), a novel, easy-to-implement, fine-tuning method with no inference overhead for large-scale pre-trained language models. By leveraging quantum-inspired methods derived from quantum circuit structures, QuanTA enables efficient *high-rank* fine-tuning, surpassing the limitations of Low-Rank Adaptation (LoRA)---low-rank approximation may fail for complicated downstream tasks. Our approach is theoretically supported by the universality theorem and the rank representation theorem to achieve efficient high-rank adaptations. Experiments demonstrate that QuanTA significantly enhances commonsense reasoning, arithmetic reasoning, and scalability compared to traditional methods. Furthermore, QuanTA shows superior performance with fewer trainable parameters compared to other approaches and can be designed to integrate with existing fine-tuning algorithms for further improvement, providing a scalable and efficient solution for fine-tuning large language models and advancing state-of-the-art in natural language processing.

This work presents a novel approach to neural architecture search (NAS) that aims to increase carbon efficiency for the model design process. The proposed framework CE-NAS addresses the key challenge of high carbon cost associated with NAS by exploring the carbon emission variations of energy and energy differences of different NAS algorithms. At the high level, CE-NAS leverages a reinforcement-learning agent to dynamically adjust GPU resources based on carbon intensity, predicted by a time-series transformer, to balance energy-efficient sampling and energy-intensive evaluation tasks. Furthermore, CE-NAS leverages a recently proposed multi-objective optimizer to effectively reduce the NAS search space. We demonstrate the efficacy of CE-NAS in lowering carbon emissions while achieving SOTA results for both NAS datasets and open-domain NAS tasks. For example, on the HW-NasBench dataset, CE-NAS reduces carbon emissions by up to 7.22X while maintaining a search efficiency comparable to vanilla NAS. For open-domain NAS tasks, CE-NAS achieves SOTA results with 97.35% top-1 accuracy on CIFAR-10 with only 1.68M parameters and a carbon consumption of 38.53 lbs of CO2. On ImageNet, our searched model achieves 80.6% top-1 accuracy with a 0.78 ms TensorRT latency using FP16 on NVIDIA V100, consuming only 909.86 lbs of CO2, making it comparable to other one-shot-based NAS baselines. Our code is available at https://github.com/cake-lab/CE-NAS.
tl;dr: We provide evidence that gradient descent struggles to fit low-frequency classes and that this leads to poor performance in the presence of heavy-tailed class imbalance as found in language modelling tasks while Adam does not suffer from this problem

Adam has been shown to outperform gradient descent on large language models by a larger margin than on other tasks, but it is unclear why. We show that a key factor in this performance gap is the heavy-tailed class imbalance found in language tasks. When trained with gradient descent, the loss of infrequent words decreases more slowly than the loss of frequent ones. This leads to a slow decrease on the average loss as most samples come from infrequent words. On the other hand, Adam and sign-based methods are less sensitive to this problem. To establish that this behavior is caused by class imbalance, we show empirically that it can be reproduced across architectures and data types, on language transformers, vision CNNs, and linear models. On a linear model with cross-entropy loss, we show that class imbalance leads to imbalanced, correlated gradients and Hessians that have been hypothesized to benefit Adam. We also prove that, in continuous time, gradient descent converges slowly on low-frequency classes while sign descent does not.
tl;dr: We show that graph neural networks can efficiently implement a message passing algorithm that is optimal (under plausible assumptions) for a broad class of combinatorial problems and demonstrate that this leads to empirically powerful architectures.

In this work we design graph neural network architectures that capture optimal
approximation algorithms for a large class of combinatorial optimization problems,
using powerful algorithmic tools from semidefinite programming (SDP). Concretely, we prove that polynomial-sized message-passing algorithms can represent
the most powerful polynomial time algorithms for Max Constraint Satisfaction
Problems assuming the Unique Games Conjecture. We leverage this result to
construct efficient graph neural network architectures, OptGNN, that obtain high quality approximate solutions on landmark combinatorial optimization problems
such as Max-Cut, Min-Vertex-Cover, and Max-3-SAT. Our approach achieves
strong empirical results across a wide range of real-world and synthetic datasets
against solvers and neural baselines. Finally, we take advantage of OptGNN’s
ability to capture convex relaxations to design an algorithm for producing bounds
on the optimal solution from the learned embeddings of OptGNN.

High-dimensional Bayesian optimization (BO) tasks such as molecular design often require $>10,$$000$ function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition over global posterior fidelity. Using the framework of utility-calibrated variational inference (Lacoste–Julien et al., 2011), we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is readily compatible with trust region methods like TuRBO (Eriksson et al., 2019). We derive efficient joint objectives for the expected improvement (EI) and knowledge gradient (KG) acquisition functions in both the standard and batch BO settings. On a variety of recent high dimensional benchmark tasks in control and molecular design, our approach significantly outperforms standard SVGPs and is capable of achieving comparable rewards with up to $10\times$ fewer function evaluations.
tl;dr: We propose a neural-guided bidirectional search algorithm for a new starting material-constrained formulation of synthesis planning

Computer-aided synthesis planning (CASP) algorithms have demonstrated expert-level abilities in planning retrosynthetic routes to molecules of low to moderate complexity. However, current search methods assume the sufficiency of reaching arbitrary building blocks, failing to address the common real-world constraint where using specific molecules is desired. To this end, we present a formulation of synthesis planning with starting material constraints. Under this formulation, we propose Double-Ended Synthesis Planning ($\texttt{DESP}$), a novel CASP algorithm under a _bidirectional graph search_ scheme that interleaves expansions from the target and from the goal starting materials to ensure constraint satisfiability. The search algorithm is guided by a goal-conditioned cost network learned offline from a partially observed hypergraph of valid chemical reactions. We demonstrate the utility of $\texttt{DESP}$ in improving solve rates and reducing the number of search expansions by biasing synthesis planning towards expert goals on multiple new benchmarks. $\texttt{DESP}$ can make use of existing one-step retrosynthesis models, and we anticipate its performance to scale as these one-step model capabilities improve.
tl;dr: We analyze repeated cake cutting between two players

We consider the setting of repeated fair division between two players, denoted Alice and Bob, with private valuations over a cake. In each round, a new cake arrives, which is identical to the ones in previous rounds. Alice cuts the cake at a point of her choice, while Bob chooses the left piece or the right piece, leaving the remainder for Alice.
We consider two versions: sequential, where Bob observes Alice's cut point before choosing left/right, and simultaneous, where he only observes her cut point after making his choice. The simultaneous version was first considered by Aumann and Maschler.
We observe that if Bob is almost myopic and chooses his favorite piece too often, then he can be systematically exploited by Alice through a strategy akin to a binary search. This strategy allows Alice to approximate Bob's preferences with increasing precision, thereby securing a disproportionate share of the resource over time.
We analyze the limits of how much a player can exploit the other one and show that fair utility profiles are in fact achievable. Specifically, the players can enforce the equitable utility profile of $(1/2, 1/2)$ in the limit on every trajectory of play, by keeping the other player's utility to approximately $1/2$ on average while guaranteeing they themselves get at least approximately $1/2$ on average. We show this theorem using a connection with Blackwell approachability.
Finally, we analyze a natural dynamic known as fictitious play, where players best respond to the empirical distribution of the other player. We show that
fictitious play converges to the equitable utility profile of $(1/2, 1/2)$ at a rate of $O(1/\sqrt{T})$.
106. Contrastive-Equivariant Self-Supervised Learning Improves Alignment with Primate Visual Area IT

Models trained with self-supervised learning objectives have recently matched or surpassed models trained with traditional supervised object recognition in their ability to predict neural responses of object-selective neurons in the primate visual system. A self-supervised learning objective is arguably a more biologically plausible organizing principle, as the optimization does not require a large number of labeled examples. However, typical self-supervised objectives may result in network representations that are overly invariant to changes in the input. Here, we show that a representation with structured variability to the input transformations is better aligned with known features of visual perception and neural computation. We introduce a novel framework for converting standard invariant SSL losses into "contrastive-equivariant" versions that encourage preserving aspects of the input transformation without supervised access to the transformation parameters. We further demonstrate that our proposed method systematically increases models' ability to predict responses in macaque inferior temporal cortex. Our results demonstrate the promise of incorporating known features of neural computation into task-optimization for building better models of visual cortex.

The growing safety concerns surrounding large language models raise an urgent need to align them with diverse human preferences to simultaneously enhance their helpfulness and safety. A promising approach is to enforce safety constraints through Reinforcement Learning from Human Feedback (RLHF). For such constrained RLHF, typical Lagrangian-based primal-dual policy optimization methods are computationally expensive and often unstable. This paper presents a perspective of dualization that reduces constrained alignment to an equivalent unconstrained alignment problem. We do so by pre-optimizing a smooth and convex dual function that has a closed form. This shortcut eliminates the need for cumbersome primal-dual policy iterations, greatly reducing the computational burden and improving training stability. Our strategy leads to two practical algorithms in model-based and preference-based settings (MoCAN and PeCAN, respectively). A broad range of experiments demonstrate the effectiveness and merits of our algorithms.
tl;dr: Positional encodings as group homomorphisms: it's beautiful and it works.

We introduce a novel positional encoding strategy for Transformer-style models, addressing the shortcomings of existing, often ad hoc, approaches. Our framework provides a flexible mapping from the algebraic specification of a domain to an interpretation as orthogonal operators. This design preserves the algebraic characteristics of the source domain, ensuring that the model upholds the desired structural properties. Our scheme can accommodate various structures, including sequences, grids and trees, as well as their compositions. We conduct a series of experiments to demonstrate the practical applicability of our approach. Results suggest performance on par with or surpassing the current state-of-the-art, without hyperparameter optimizations or ``task search'' of any kind. Code is available through https://aalto-quml.github.io/ape/.
tl;dr: We distill diffusion models into few-step generators that produce images with superior quality.

Recent approaches have shown promises distilling expensive diffusion models into efficient one-step generators.
Amongst them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, i.e., the distillation process does not enforce a one-to-one correspondence with the sampling trajectories of their teachers.
However, to ensure stable training in practice, DMD requires an additional regression loss computed using a large set of noise--image pairs, generated by the teacher with many steps of a deterministic sampler.
This is not only computationally expensive for large-scale text-to-image synthesis, but it also limits the student's quality, tying it too closely to the teacher's original sampling paths.
We introduce DMD2, a set of techniques that lift this limitation and improve DMD training.
First, we eliminate the regression loss and the need for expensive dataset construction.
We show that the resulting instability is due to the "fake" critic not estimating the distribution
of generated samples with sufficient accuracy and propose a two time-scale update rule as a remedy.
Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images.
This lets us train the student model on real data, thus mitigating the imperfect "real" score estimation from the teacher model, and thereby enhancing quality.
Third, we introduce a new training procedure that enables multi-step sampling in the student, and
addresses the training--inference input mismatch of previous work, by simulating inference-time generator samples during training.
Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64×64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost.
Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods, and surpassing the teacher.
We release our code and pretrained models.
110. Statistical Estimation in the Spiked Tensor Model via the Quantum Approximate Optimization Algorithm
tl;dr: This paper analyzes the QAOA for the spiked tensor model, showing that while it matches classical performance at constant depths, it exhibits qualitative differences and a limited quantum advantage, indicating potential for future quantum speedups.

The quantum approximate optimization algorithm (QAOA) is a general-purpose algorithm for combinatorial optimization that has been a promising avenue for near-term quantum advantage.
In this paper, we analyze the performance of the QAOA on the spiked tensor model, a statistical estimation problem that exhibits a large computational-statistical gap classically.
We prove that the weak recovery threshold of $1$-step QAOA matches that of $1$-step tensor power iteration. Additional heuristic calculations suggest that the weak recovery threshold of $p$-step QAOA matches that of $p$-step tensor power iteration when $p$ is a fixed constant. This further implies that multi-step QAOA with tensor unfolding could achieve, but not surpass, the asymptotic classical computation threshold $\Theta(n^{(q-2)/4})$ for spiked $q$-tensors.
Meanwhile, we characterize the asymptotic overlap distribution for $p$-step QAOA, discovering an intriguing sine-Gaussian law verified through simulations. For some $p$ and $q$, the QAOA has an effective recovery threshold that is a constant factor better than tensor power iteration.
Of independent interest, our proof techniques employ the Fourier transform to handle difficult combinatorial sums, a novel approach differing from prior QAOA analyses on spin-glass models without planted structure.
tl;dr: We propose a dataset, evaluation method, and metric for benchmarking long-form factuality in large language models.

Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model’s long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user’s preferred response length (recall).
Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators—on a set of∼16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.

We study the problem of PAC learning $\gamma$-margin halfspaces in the presence of Massart noise.
Without computational considerations, the sample complexity of this learning problem is known to be
$\widetilde{\Theta}(1/(\gamma^2 \epsilon))$.
Prior computationally efficient algorithms for the problem incur sample complexity
$\tilde{O}(1/(\gamma^4 \epsilon^3))$ and achieve 0-1 error of $\eta+\epsilon$,
where $\eta<1/2$ is the upper bound on the noise rate.
Recent work gave evidence of an information-computation tradeoff,
suggesting that a quadratic dependence on $1/\epsilon$ is required
for computationally efficient algorithms.
Our main result is a computationally efficient learner with sample complexity
$\widetilde{\Theta}(1/(\gamma^2 \epsilon^2))$, nearly matching this lower bound.
In addition, our algorithm is simple and practical,
relying on online SGD on a carefully selected sequence of convex losses.
tl;dr: We introduce MeshFormer, a sparse-view reconstruction model that can deliver high-quality meshes and be trained efficiently.

Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. **Videos are available at https://meshformer3d.github.io/**
tl;dr: This work presents Uncertainty of Thoughts (UoT), an approach that enhances large language models' ability to ask questions and actively seek information by modeling their own uncertainty, significantly improving task performance and efficiency.

In the face of uncertainty, the ability to *seek information* is of fundamental importance. In many practical applications, such as medical diagnosis and troubleshooting, the information needed to solve the task is not initially given, and has to be actively sought by asking follow-up questions (for example, a doctor asking a patient for more details about their symptoms). In this work, we introduce **Uncertainty of Thoughts (UoT)**, an algorithm to augment large language models with the ability to actively seek information by asking effective questions. UoT combines:
1. An *uncertainty-aware simulation approach* which enables the model to simulate possible future scenarios and how likely they are to occur,
2. *Uncertainty-based rewards* motivated by information gain which incentivizes the model to seek information, and
3. A *reward propagation scheme* to select the optimal question to ask in a way that maximizes the expected reward.
In experiments on medical diagnosis, troubleshooting and the `20 Questions' game, UoT achieves an average performance improvement of 38.1% in the rate of successful task completion across multiple LLMs compared with direct prompting, and also improves efficiency (i.e., the number of questions needed to complete the task).
tl;dr: We propose a new spiking neuron on Riemannian manifold so that the high-latency BPTT algorithm is replaced by our Differentiation via Manifold.

Graph neural networks (GNNs) have become the dominant solution for learning on graphs, the typical non-Euclidean structures. Conventional GNNs, constructed with the Artificial Neuron Network (ANN), have achieved impressive performance at the cost of high computation and energy consumption. In parallel, spiking GNNs with brain-like spiking neurons are drawing increasing research attention owing to the energy efficiency. So far, existing spiking GNNs consider graphs in Euclidean space, ignoring the structural geometry, and suffer from the high latency issue due to Back-Propagation-Through-Time (BPTT) with the surrogate gradient. In light of the aforementioned issues, we are devoted to exploring spiking GNN on Riemannian manifolds, and present a Manifold-valued Spiking GNN (MSG). In particular, we design a new spiking neuron on geodesically complete manifolds with the diffeomorphism, so that BPTT regarding the spikes is replaced by the proposed differentiation via manifold. Theoretically, we show that MSG approximates a solver of the manifold ordinary differential equation. Extensive experiments on common graphs show the proposed MSG achieves superior performance to previous spiking GNNs and energy efficiency to conventional GNNs.

Scene flow estimation is an essential ingredient for a variety of real-world applications, especially for autonomous agents, such as self-driving cars and robots. While recent scene flow estimation approaches achieve reasonable accuracy, their applicability to real-world systems additionally benefits from a reliability measure. Aiming at improving accuracy while additionally providing an estimate for uncertainty, we propose DiffSF that combines transformer-based scene flow estimation with denoising diffusion models. In the diffusion process, the ground truth scene flow vector field is gradually perturbed by adding Gaussian noise. In the reverse process, starting from randomly sampled Gaussian noise, the scene flow vector field prediction is recovered by conditioning on a source and a target point cloud. We show that the diffusion process greatly increases the robustness of predictions compared to prior approaches resulting in state-of-the-art performance on standard scene flow estimation benchmarks. Moreover, by sampling multiple times with different initial states, the denoising process predicts multiple hypotheses, which enables measuring the output uncertainty, allowing our approach to detect a majority of the inaccurate predictions. The code is available at https://github.com/ZhangYushan3/DiffSF.

Large language models (LLMs) typically utilize the top-k contexts from a retriever in retrieval-augmented generation (RAG). In this work, we propose a novel method called RankRAG, which instruction-tunes a single LLM for both context ranking and answer generation in RAG. In particular, the instruction-tuned LLMs work surprisingly well by adding a small fraction of ranking data into the training blend, and outperform existing expert ranking models, including the same LLM exclusively fine-tuned on a large amount of ranking data. For generation, we compare our model with many strong baselines, including ChatQA-1.5, an open-sourced model with the state-of-the-art performance on RAG benchmarks. Specifically, our Llama3-RankRAG-8B and Llama3-RankRAG-70B significantly outperform Llama3-ChatQA-1.5-8B and Llama3-ChatQA-1.5-70B, respectively, on nine general knowledge-intensive benchmarks for RAG. In addition, it also performs comparably to GPT-4 on five RAG benchmarks in the biomedical domain without instruction fine-tuning on biomedical data, demonstrating its superb capability for generalization to new domains.
tl;dr: We predict a tree-valued hierarchical summarization of the posterior distribution for any input measurement, in a single forward pass of a neural network

When solving ill-posed inverse problems, one often desires to explore the space of potential solutions rather than be presented with a single plausible reconstruction. Valuable insights into these feasible solutions and their associated probabilities are embedded in the posterior distribution. However, when confronted with data of high dimensionality (such as images), visualizing this distribution becomes a formidable challenge, necessitating the application of effective summarization techniques before user examination. In this work, we introduce a new approach for visualizing posteriors across multiple levels of granularity using *tree*-valued predictions. Our method predicts a tree-valued hierarchical summarization of the posterior distribution for any input measurement, in a single forward pass of a neural network. We showcase the efficacy of our approach across diverse datasets and image restoration challenges, highlighting its prowess in uncertainty quantification and visualization. Our findings reveal that our method performs comparably to a baseline that hierarchically clusters samples from a diffusion-based posterior sampler, yet achieves this with orders of magnitude greater speed. Code and examples are available at our [webpage](https://eliasnehme.github.io/PosteriorTrees/).
tl;dr: We provide asymptotic results for algorithms optimizing the alpha-divergence criterion in the context of Variational Inference, using an exponential variational family.

Recent works in Variational Inference have examined alternative criteria to the commonly used exclusive Kullback-Leibler divergence. Encouraging empirical results have been obtained with the family of alpha-divergences, but few works have focused on the asymptotic properties of the proposed algorithms, especially as the number of iterations goes to infinity. In this paper, we study a procedure that ensures a monotonic decrease in the alpha-divergence. We provide sufficient conditions to guarantee its convergence to a local minimizer of the alpha-divergence at a geometric rate when the variational family belongs to the class of exponential models. The sample-based version of this ideal procedure involves biased gradient estimators, thus hindering any theoretical study. We propose an alternative unbiased algorithm, we prove its almost sure convergence to a local minimizer of the alpha-divergence, and a law of the iterated logarithm. Our results are exemplified with toy and real-data experiments.

Subsampling is effective in tackling computational challenges for massive data with rare events. Overly aggressive subsampling may adversely affect estimation efficiency, and optimal subsampling is essential to mitigate the information loss. However, existing optimal subsampling probabilities depends on data scales, and some scaling transformations may result in inefficient subsamples. This problem is more significant when there are inactive features, because their influence on the subsampling probabilities can be arbitrarily magnified by inappropriate scaling transformations. We tackle this challenge and introduce a scale-invariant optimal subsampling function in the context of sparse models, where inactive features are commonly assumed. Instead of focusing on estimating model parameters, we define an optimal subsampling function to minimize the prediction error, using adaptive lasso as an example to outline the estimation procedure and study its theoretical guarantee. We first introduce the adaptive lasso estimator for rare-events data and establish its oracle properties, thereby validating the use of subsampling. Then we derive a scale-invariant optimal subsampling function that minimizes the prediction error of the inverse probability weighted (IPW) adaptive lasso. Finally, we present an estimator based on the maximum sampled conditional likelihood (MSCL) to further improve the estimation efficiency. We conduct numerical experiments using both simulated and real-world data sets to demonstrate the performance of the proposed methods.
tl;dr: We prove new topology-inspired generalization bounds and perform extensive experiments to test the introduced quantities.

We present a novel set of rigorous and computationally efficient topology-based complexity notions that exhibit a strong correlation with the generalization gap in modern deep neural networks (DNNs). DNNs show remarkable generalization properties, yet the source of these capabilities remains elusive, defying the established statistical learning theory. Recent studies have revealed that properties of training trajectories can be indicative of generalization. Building on this insight, state-of-the-art methods have leveraged the topology of these trajectories, particularly their fractal dimension, to quantify generalization. Most existing works compute this quantity by assuming continuous- or infinite-time training dynamics, complicating the development of practical estimators capable of accurately predicting generalization without access to test data. In this paper, we respect the discrete-time nature of training trajectories and investigate the underlying topological quantities that can be amenable to topological data analysis tools. This leads to a new family of reliable topological complexity measures that provably bound the generalization error, eliminating the need for restrictive geometric assumptions. These measures are computationally friendly, enabling us to propose simple yet effective algorithms for computing generalization indices. Moreover, our flexible framework can be extended to different domains, tasks, and architectures. Our experimental results demonstrate that our new complexity measures exhibit a strong correlation with generalization error in industry-standard architectures such as transformers and deep graph networks. Our approach consistently outperforms existing topological bounds across a wide range of datasets, models, and optimizers, highlighting the practical relevance and effectiveness of our complexity measures.
tl;dr: We propose SlotSSM which incorporates independent mechanisms into State Space Models to preserve or encourage separation of information int object-centric learning and visual reasoning.

Recent State Space Models (SSMs) such as S4, S5, and Mamba have shown remarkable computational benefits in long-range temporal dependency modeling. However, in many sequence modeling problems, the underlying process is inherently modular and it is of interest to have inductive biases that mimic this modular structure. In this paper, we introduce SlotSSMs, a novel framework for incorporating independent mechanisms into SSMs to preserve or encourage separation of information. Unlike conventional SSMs that maintain a monolithic state vector, SlotSSMs maintains the state as a collection of multiple vectors called slots. Crucially, the state transitions are performed independently per slot with sparse interactions across slots implemented via the bottleneck of self-attention. In experiments, we evaluate our model in object-centric learning, 3D visual reasoning, and long-context video understanding tasks, which involve modeling multiple objects and their long-range temporal dependencies. We find that our proposed design offers substantial performance gains over existing sequence modeling methods. Project page is available at \url{https://slotssms.github.io/}

Traditional long-tailed learning methods often perform poorly when dealing with inconsistencies between training and test data distributions, and they cannot flexibly adapt to different user preferences for trade-offs between head and tail classes. To address this issue, we propose a novel long-tailed learning paradigm that aims to tackle distribution shift in real-world scenarios and accommodate different user preferences for the trade-off between head and tail classes. We generate a set of diverse expert models via hypernetworks to cover all possible distribution scenarios, and optimize the model ensemble to adapt to any test distribution. Crucially, in any distribution scenario, we can flexibly output a dedicated model solution that matches the user's preference. Extensive experiments demonstrate that our method not only achieves higher performance ceilings but also effectively overcomes distribution shift while allowing controllable adjustments according to user preferences. We provide new insights and a paradigm for the long-tailed learning problem, greatly expanding its applicability in practical scenarios. The code can be found here: https://github.com/DataLab-atom/PRL.
tl;dr: Adaptive Randomized Smoothing soundly and flexibly certifies the predictions of test-time adaptive models against adversarial examples while improving certified and standard accuracies.

We propose Adaptive Randomized Smoothing (ARS) to certify the predictions of our test-time adaptive models against adversarial examples.
ARS extends the analysis of randomized smoothing using $f$-Differential Privacy to certify the adaptive composition of multiple steps.
For the first time, our theory covers the sound adaptive composition of general and high-dimensional functions of noisy inputs.
We instantiate ARS on deep image classification to certify predictions against adversarial examples of bounded $L_{\infty}$ norm.
In the $L_{\infty}$ threat model, ARS enables flexible adaptation through high-dimensional input-dependent masking.
We design adaptivity benchmarks, based on CIFAR-10 and CelebA, and show that ARS improves standard test accuracy by 1 to 15\% points.
On ImageNet, ARS improves certified test accuracy by up to 1.6% points over standard RS without adaptivity. Our code is available at [https://github.com/ubc-systopia/adaptive-randomized-smoothing](https://github.com/ubc-systopia/adaptive-randomized-smoothing).

Understanding the power of parameterized quantum circuits (PQCs) in accomplishing machine learning tasks is one of the most important questions in quantum machine learning. In this paper, we focus on the PQC expressivity for general multivariate function classes. Previously established Universal Approximation Theorems for PQCs are either nonconstructive or assisted with parameterized classical data processing, making it hard to justify whether the expressive power comes from the classical or quantum parts. We explicitly construct data re-uploading PQCs for approximating multivariate polynomials and smooth functions and establish the first non-asymptotic approximation error bounds for such functions in terms of the number of qubits, the quantum circuit depth and the number of trainable parameters of the PQCs. Notably, we show that for multivariate polynomials and multivariate smooth functions, the quantum circuit size and the number of trainable parameters of our proposed PQCs can be smaller than the deep ReLU neural networks. We further demonstrate the approximation capability of PQCs via numerical experiments. Our results pave the way for designing practical PQCs that can be implemented on near-term quantum devices with limited resources.
tl;dr: We propose auditing tools for privacy mechanisms via label reconstruction advantage measures, allowing to place a variety of proposed label privatization schemes—some differentially private, some not—on the same footing.

We propose reconstruction advantage measures to audit label privatization mechanisms. A reconstruction advantage measure quantifies the increase in an attacker's ability to infer the true label of an unlabeled example when provided with a private version of the labels in a dataset (e.g., aggregate of labels from different users or noisy labels output by randomized response), compared to an attacker that only observes the feature vectors, but may have prior knowledge of the correlation between features and labels. We consider two such auditing measures: one additive, and on multiplicative. These cover previous approaches taken in the literature on empirical auditing and differential privacy. These measures allow us to place a variety of proposed privatization schemes---some differentially private, some not---on the same footing. We analyze these measures theoretically under a distributional model which, we claim, encapsulates reasonable adversarial settings. We also quantify their behavior empirically on real and simulated prediction tasks. Across a range of experimental settings, we find that differentially private schemes dominate or match the privacy-utility tradeoff of more heuristic approaches.
tl;dr: We characterize the capacity of the place system to distinguish context, as well as the tradeoff between this ability and the ability to determine location.

Many animals learn cognitive maps of their environment - a simultaneous representation of context, experience, and position. Place cells in the hippocampus, named for their explicit encoding of position, are believed to be a neural substrate of these maps, with place cell "remapping" explaining how this system can represent different contexts. Briefly, place cells alter their firing properties, or "remap", in response to changes in experiential or sensory cues. Substantial sensory changes, produced, e.g., by moving between environments, cause large subpopulations of place cells to change their tuning entirely. While many studies have looked at the physiological basis of remapping, we lack explicit calculations of how the contextual capacity of the place cell system changes as a function of place field firing properties. Here, we propose a geometric approach to understanding population level activity of place cells. Using known firing field statistics, we investigate how changes to place cell firing properties affect the distances between representations of different environments within firing rate space. Using this approach, we find that the number of contexts storable by the hippocampus grows exponentially with the number of place cells, and calculate this exponent for environments of different sizes. We identify a fundamental trade-off between high resolution encoding of position and the number of storable contexts. This trade-off is tuned by place cell width, which might explain the change in firing field scale along the dorsal-ventral axis of the hippocampus. We demonstrate that clustering of place cells near likely points of confusion, such as boundaries, increases the contextual capacity of the place system within our framework and conclude by discussing how our geometric approach could be extended to include other cell types and abstract spaces.
tl;dr: We leverage implicit regularization to enhance the computational efficiency of sharpness-aware minimization (SAM).

Sharpness-aware minimization (SAM) improves generalization of various deep learning tasks. Motivated by popular architectures such as LoRA, we explore the implicit regularization of SAM for scale-invariant problems involving two groups of variables. Instead of focusing on commonly used sharpness, this work introduces a concept termed *balancedness*, defined as the difference between the squared norm of two variables. This allows us to depict richer global behaviors of SAM. In particular, our theoretical and empirical findings reveal that i) SAM promotes balancedness; and ii) the regularization on balancedness is *data-responsive* -- outliers have stronger impact.
The latter coincides with empirical observations that SAM outperforms SGD in the presence of outliers.
Leveraging the implicit regularization, we develop a resource-efficient SAM variant, balancedness-aware regularization (BAR), tailored for scale-invariant problems such as finetuning language models with LoRA. BAR saves 95% computational overhead of SAM, with enhanced test performance across various tasks on RoBERTa, GPT2, and OPT-1.3B.
tl;dr: We introduce a position encoding method for plain ViTs, called LookHere, that improves performance at the training resolution and beyond.

High-resolution images offer more information about scenes that can improve model accuracy. However, the dominant model architecture in computer vision, the vision transformer (ViT), cannot effectively leverage larger images without finetuning — ViTs poorly extrapolate to more patches at test time, although transformers offer sequence length flexibility. We attribute this shortcoming to the current patch position encoding methods, which create a distribution shift when extrapolating.
We propose a drop-in replacement for the position encoding of plain ViTs that restricts attention heads to fixed fields of view, pointed in different directions, using 2D attention masks. Our novel method, called LookHere, provides translation-equivariance, ensures attention head diversity, and limits the distribution shift that attention heads face when extrapolating. We demonstrate that LookHere improves performance on classification (avg. 1.6%), against adversarial attack (avg. 5.4%), and decreases calibration error (avg. 1.5%) — on ImageNet without extrapolation. With extrapolation, LookHere outperforms the current SoTA position encoding method, 2D-RoPE, by 21.7% on ImageNet when trained at $224^2$ px and tested at $1024^2$ px. Additionally, we release a high-resolution test set to improve the evaluation of high-resolution image classifiers, called ImageNet-HR.

Implicit models such as Deep Equilibrium Models (DEQs) have emerged as promising alternative approaches for building deep neural networks. Their certified robustness has gained increasing research attention due to security concerns. Existing certified defenses for DEQs employing interval bound propagation and Lipschitz-bounds not only offer conservative certification bounds but also are restricted to specific forms of DEQs. In this paper, we provide the first randomized smoothing certified defense for DEQs to solve these limitations. Our study reveals that simply applying randomized smoothing to certify DEQs provides certified robustness generalized to large-scale datasets but incurs extremely expensive computation costs. To reduce computational redundancy, we propose a novel Serialized Randomized Smoothing (SRS) approach that leverages historical information. Additionally, we derive a new certified radius estimation for SRS to theoretically ensure the correctness of our algorithm. Extensive experiments and ablation studies on image recognition demonstrate that our algorithm can significantly accelerate the certification of DEQs by up to 7x almost without sacrificing the certified accuracy. The implementation will be publicly available upon the acceptance of this work. Our code is available at https://github.com/WeizhiGao/Serialized-Randomized-Smoothing.

We revisit the recently developed framework of proportionally fair clustering, where the goal is to provide group fairness guarantees that become stronger for groups of data points that are large and cohesive. Prior work applies this framework to centroid-based clustering, where points are partitioned into clusters, and the cost to each data point is measured by its distance to a centroid assigned to its cluster. However, real-life applications often do not require such centroids. We extend the theory of proportionally fair clustering to non-centroid clustering by considering a variety of cost functions, both metric and non-metric, for a data point to be placed in a cluster with other data points. Our results indicate that Greedy Capture, a clustering algorithm developed for centroid clustering, continues to provide strong proportional fairness guarantees for non-centroid clustering, although the guarantees are significantly different and establishing them requires novel proof ideas. We also design algorithms for auditing proportional fairness of a given clustering solution. We conduct experiments on real data which suggest that traditional clustering algorithms are highly unfair, while our algorithms achieve strong fairness guarantees with a moderate loss in common clustering objectives.

Surveys have recently gained popularity as a tool to study large language models. By comparing models’ survey responses to those of different human reference populations, researchers aim to infer the demographics, political opinions, or values best represented by current language models. In this work, we critically examine language models' survey responses on the basis of the well-established American Community Survey by the U.S. Census Bureau. Evaluating 43 different language models using de-facto standard prompting methodologies, we establish two dominant patterns. First, models' responses are governed by ordering and labeling biases, for example, towards survey responses labeled with the letter “A”. Second, when adjusting for these systematic biases through randomized answer ordering, models across the board trend towards uniformly random survey responses, irrespective of model size or training data. As a result, models consistently appear to better represent subgroups whose aggregate statistics are closest to uniform for the survey under consideration, leading to potentially misguided conclusions about model alignment.
tl;dr: An extreme parameter-efficient fine-tuning method based on vector banks

As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a "divide-and-share" paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules, and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, instruction tuning, and mathematical reasoning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA. This method has been merged into the Hugging Face PEFT package.
tl;dr: We introduce an RL framework for continuous state-action spaces with faster convergence rates than previous ones. Key to this are stability conditions of the Bellman operator and occupation measures that are prevalent in continuous domain MDPs.

We introduce a novel framework for analyzing reinforcement learning (RL) in continuous state-action spaces, and use it to prove fast rates of convergence in both off-line and on-line settings. Our analysis highlights two key stability properties, relating to how changes in value functions and/or policies affect the Bellman operator and occupation measures. We argue that these properties are satisfied in many continuous state-action Markov decision processes. Our analysis also offers fresh perspectives on the roles of pessimism and optimism in off-line and on-line RL.
tl;dr: PocketFlow is a flow matching model for protein pocket generation that uses protein-ligand interaction priors to improve generation quality.

Designing ligand-binding proteins, such as enzymes and biosensors, is essential in bioengineering and protein biology. One critical step in this process involves designing protein pockets, the protein interface binding with the ligand. Current approaches to pocket generation often suffer from time-intensive physical computations or template-based methods, as well as compromised generation quality due to the overlooking of domain knowledge. To tackle these challenges, we propose PocketFlow, a generative model that incorporates protein-ligand interaction priors based on flow matching. During training, PocketFlow learns to model key types of protein-ligand interactions, such as hydrogen bonds. In the sampling, PocketFlow leverages multi-granularity guidance (overall binding affinity and interaction geometry constraints) to facilitate generating high-affinity and valid pockets. Extensive experiments show that PocketFlow outperforms baselines on multiple benchmarks, e.g., achieving an average improvement of 1.29 in Vina Score and 0.05 in scRMSD. Moreover, modeling interactions make PocketFlow a generalized generative model across multiple ligand modalities, including small molecules, peptides, and RNA.
tl;dr: Don't use eigendecomposition or SVD in neural networks, there is a better way doing that

Performing eigendecomposition during neural network training is essential for tasks such as dimensionality reduction, network compression, image denoising, and graph learning. However, eigendecomposition is computationally expensive as it is orders of magnitude slower than other neural network operations. To address this challenge, we propose a novel approach called "amortized eigendecomposition" that relaxes the exact eigendecomposition by introducing an additional loss term called eigen loss. Our approach offers significant speed improvements by replacing the computationally expensive eigendecomposition with a more affordable QR decomposition at each iteration. Theoretical analysis guarantees that the desired eigenpair is attained as optima of the eigen loss. Empirical studies on nuclear norm regularization, latent-space principal component analysis, and graphs adversarial learning demonstrate significant improvements in training efficiency while producing nearly identical outcomes to conventional approaches. This novel methodology promises to integrate eigendecomposition efficiently into neural network training, overcoming existing computational challenges and unlocking new potential for advanced deep learning applications.
tl;dr: We show the some properties of the loss landscape are preserved across different model sizes under the right scaling of the architecture.

Recently, there has been growing evidence that if the width and depth of a neural network are scaled toward the so-called rich feature learning limit ($\mu$P and its depth extension), then some hyperparameters --- such as the learning rate --- exhibit transfer from small to very large models. From an optimization perspective, this phenomenon is puzzling, as it implies that the loss landscape is consistently similar across very different model sizes. In this work, we study the landscape through the lens of the Hessian, with a focus on its largest eigenvalue (i.e. the sharpness), and find that certain spectral properties under $\mu$P are largely independent of the width and depth of the network along the training trajectory. We name this property *super consistency* of the landscape. On the other hand, we show that in the Neural Tangent Kernel (NTK) and other scaling regimes, the sharpness exhibits very different dynamics at different scales. But what causes these differences in the sharpness dynamics? Through a connection between the Hessian's and the NTK's spectrum, we argue that the cause lies in the presence (for $\mu$P) or progressive absence (for the NTK scaling) of feature learning.
We corroborate our claims with a substantial suite of experiments, covering a wide range of datasets and architectures: from ResNets and Vision Transformers trained on benchmark vision datasets to Transformers-based language models trained on WikiText.

The swift advancement in Multimodal LLMs (MLLMs) also presents significant challenges for effective knowledge editing. Current methods, including intrinsic knowledge editing and external knowledge resorting, each possess strengths and weaknesses, struggling to balance the desired properties of reliability, generality, and locality when applied to MLLMs. In this paper, we propose \textbf{UniKE}, a novel multimodal editing method that establishes a unified perspective and paradigm for intrinsic knowledge editing and external knowledge resorting. Both types of knowledge are conceptualized as vectorized key-value memories, with the corresponding editing processes resembling the assimilation and accommodation phases of human cognition, conducted at the same semantic levels. Within such a unified framework, we further promote knowledge collaboration by disentangling the knowledge representations into the semantic and truthfulness spaces. Extensive experiments validate the effectiveness of our method, which ensures that the post-edit MLLM simultaneously maintains excellent reliability, generality, and locality. The code for UniKE is available at https://github.com/beepkh/UniKE.

We introduce Buffer of Thoughts (BoT), a novel and versatile thought-augmented reasoning approach for enhancing accuracy, efficiency and robustness of large language models (LLMs). Specifically, we propose meta-buffer to store a series of informative high-level thoughts, namely thought-template, distilled from the problem-solving processes across various tasks. Then for each problem, we retrieve a relevant thought-template and adaptively instantiate it with specific reasoning structures to conduct efficient reasoning. To guarantee the scalability and stability, we further propose buffer-manager to dynamically update the meta-buffer, thus enhancing the capacity of meta-buffer as more tasks are solved. We conduct extensive experiments on 10 challenging reasoning-intensive tasks, and achieve significant performance improvements over previous SOTA methods: 11\% on Game of 24, 20\% on Geometric Shapes and 51\% on Checkmate-in-One. Further analysis demonstrate the superior generalization ability and model robustness of our BoT, while requiring only 12\% of the cost of multi-query prompting methods (e.g., tree/graph of thoughts) on average. Code is available at: https://github.com/YangLing0818/buffer-of-thought-llm
140. Unveiling the Potential of Robustness in Selecting Conditional Average Treatment Effect Estimators

The growing demand for personalized decision-making has led to a surge of interest in estimating the Conditional Average Treatment Effect (CATE). Various types of CATE estimators have been developed with advancements in machine learning and causal inference. However, selecting the desirable CATE estimator through a conventional model validation procedure remains impractical due to the absence of counterfactual outcomes in observational data. Existing approaches for CATE estimator selection, such as plug-in and pseudo-outcome metrics, face two challenges. First, they must determine the metric form and the underlying machine learning models for fitting nuisance parameters (e.g., outcome function, propensity function, and plug-in learner). Second, they lack a specific focus on selecting a robust CATE estimator. To address these challenges, this paper introduces a Distributionally Robust Metric (DRM) for CATE estimator selection. The proposed DRM is nuisance-free, eliminating the need to fit models for nuisance parameters, and it effectively prioritizes the selection of a distributionally robust CATE estimator. The experimental results validate the effectiveness of the DRM method in selecting CATE estimators that are robust to the distribution shift incurred by covariate shift and hidden confounders.
tl;dr: Gaussian process regression model with a novel composite kernel, Kermut, achieves state-of-the-art variant effect prediction while providing meaningful uncertainties

Reliable prediction of protein variant effects is crucial for both protein optimization and for advancing biological understanding. For practical use in protein engineering, it is important that we can also provide reliable uncertainty estimates for our predictions, and while prediction accuracy has seen much progress in recent years, uncertainty metrics are rarely reported. We here provide a Gaussian process regression model, Kermut, with a novel composite kernel for modeling mutation similarity, which obtains state-of-the-art performance for supervised protein variant effect prediction while also offering estimates of uncertainty through its posterior. An analysis of the quality of the uncertainty estimates demonstrates that our model provides meaningful levels of overall calibration, but that instance-specific uncertainty calibration remains more challenging.
tl;dr: We prove optimal regret bounds for multiclass U-calibration, thereby resolving an open problem raised by Kleinberg et al. (2023).

We consider the problem of online multiclass U-calibration, where a forecaster aims to make sequential distributional predictions over $K$ classes with low U-calibration error, that is, low regret with respect to all bounded proper losses simultaneously.
Kleinberg et al. (2023) developed an algorithm with U-calibration error $\mathcal{O}(K\sqrt{T})$ after $T$ rounds and raised the open question of what the optimal bound is.
We resolve this question by showing that the optimal U-calibration error is $\Theta(\sqrt{KT})$ --- we start with a simple observation that the Follow-the-Perturbed-Leader algorithm of Daskalakis and Syrgkanis (2016) achieves this upper bound, followed by a matching lower bound constructed with a specific proper loss (which, as a side result, also proves the optimality of the algorithm of Daskalakis and Syrgkanis (2016) in the context of online learning against an adversary with finite choices).
We also strengthen our results under natural assumptions on the loss functions, including $\Theta(\log T)$ U-calibration error for Lipschitz proper losses, $\mathcal{O}(\log T)$ U-calibration error for a certain class of decomposable proper losses, U-calibration error bounds for proper losses with a low covering number, and others.

In many machine learning tasks, data is inherently sequential. Most existing algorithms learn from sequential data in an auto-regressive manner, which predicts the next unseen data point based on the observed sequence, implicitly assuming the presence of an \emph{evolving pattern} embedded in the data that can be leveraged. However, identifying and assessing evolving patterns in learning tasks often relies on subjective judgments rooted in the prior knowledge of human experts, lacking a standardized quantitative measure. Furthermore, such measures enable us to determine the suitability of employing sequential models effectively and make informed decisions on the temporal order of time series data, and feature/data selection processes. To address this issue, we introduce the Evolving Rate (EvoRate), which quantitatively approximates the intensity of evolving patterns in the data with Mutual Information. Furthermore, in some temporal data with neural mutual information estimations, we only have snapshots at different timestamps, lacking correspondence, which hinders EvoRate estimation. To tackle this challenge, we propose EvoRate$_\mathcal{W}$, aiming to establish correspondence with optimal transport for estimating the first-order EvoRate. Experiments on synthetic and real-world datasets including images and tabular data validate the efficacy of our EvoRate.
tl;dr: We provide theoretical foundations for comparing embedding models and propose a tractable approach to compare them, and show that this approach strongly correlates with downstream tasks performances.

Embedders play a central role in machine learning, projecting any object into numerical representations that can, in turn, be leveraged to perform various downstream tasks. The evaluation of embedding models typically depends on domain-specific empirical approaches utilizing downstream tasks, primarily because of the lack of a standardized framework for comparison. However, acquiring adequately large and representative datasets for conducting these assessments is not always viable and can prove to be prohibitively expensive and time-consuming. In this paper, we present a unified approach to evaluate embedders. First, we establish theoretical foundations for comparing embedding models, drawing upon the concepts of sufficiency and informativeness. We then leverage these concepts to devise a tractable comparison criterion (information sufficiency), leading to a task-agnostic and self-supervised ranking procedure. We demonstrate experimentally that our approach aligns closely with the capability of embedding models to facilitate various downstream tasks in both natural language processing and molecular biology. This effectively offers practitioners a valuable tool for prioritizing model trials.
tl;dr: We propose bidirectional contrastive rhythmic VAE and Transformer-based diffusion model for versatile motion-music generation tasks.

Motion-to-music and music-to-motion have been studied separately, each attracting substantial research interest within their respective domains. The interaction between human motion and music is a reflection of advanced human intelligence, and establishing a unified relationship between them is particularly important. However, to date, there has been no work that considers them jointly to explore the modality alignment within. To bridge this gap, we propose a novel framework, termed MoMu-Diffusion, for long-term and synchronous motion-music generation. Firstly, to mitigate the huge computational costs raised by long sequences, we propose a novel Bidirectional Contrastive Rhythmic Variational Auto-Encoder (BiCoR-VAE) that extracts the modality-aligned latent representations for both motion and music inputs. Subsequently, leveraging the aligned latent spaces, we introduce a multi-modal diffusion Transformer model and a cross-guidance sampling strategy to enable various generation tasks, including cross-modal, multi-modal, and variable-length generation. Extensive experiments demonstrate that MoMu-Diffusion surpasses recent state-of-the-art methods both qualitatively and quantitatively, and can synthesize realistic, diverse, long-term, and beat-matched music or motion sequences. The generated motion-music samples are available at https://momu-diffusion.github.io/.
tl;dr: We develop the tilted transport technique, which leverages the prior score to exactly transform the original posterior sampling problem into a new one that is provably easier to sample.

Score-based diffusion models have significantly advanced high-dimensional data generation across various domains, by learning a denoising oracle (or score) from datasets. From a Bayesian perspective, they offer a realistic modeling of data priors and facilitate solving inverse problems through posterior sampling. Although many heuristic methods have been developed recently for this purpose, they lack the quantitative guarantees needed in many scientific applications. This work addresses the topic from two perspectives. We first present a hardness result indicating that a generic method leveraging the prior denoising oracle for posterior sampling becomes infeasible as soon as the measurement operator is mildly ill-conditioned. We next develop the *tilted transport* technique, which leverages the quadratic structure of the log-likelihood in linear inverse problems in combination with the prior denoising oracle to exactly transform the original posterior sampling problem into a new one that is provably easier to sample from. We quantify the conditions under which the boosted posterior is strongly log-concave, highlighting how task difficulty depends on the condition number of the measurement matrix and the signal-to-noise ratio. The resulting general scheme is shown to match the best-known sampling methods for Ising models, and is further validated on high-dimensional Gaussian mixture models.
tl;dr: We provide a model for manifold clustering with theoretical guarantees

Manifold clustering is an important problem in motion and video segmentation, natural image clustering, and other applications where high-dimensional data lie on multiple, low-dimensional, nonlinear manifolds. While current state-of-the-art methods on large-scale datasets such as CIFAR provide good empirical performance, they do not have any proof of theoretical correctness. In this work, we propose a method that clusters data belonging to a union of nonlinear manifolds. Furthermore, for a given input data sample $y$ belonging to the $l$th manifold $\mathcal{M}_l$, we provide geometric conditions that guarantee a manifold-preserving representation of $y$ can be recovered from the solution to the proposed model. The geometric conditions require that (i) $\mathcal{M}_l$ is well-sampled in the neighborhood of $y$, with the sampling density given as a function of the curvature, and (ii) $\mathcal{M}_l$ is sufficiently separated from the other manifolds. In addition to providing proof of correctness in this setting, a numerical comparison with state-of-the-art methods on CIFAR datasets shows that our method performs competitively although marginally worse than methods without
tl;dr: We derive the certified radius and Lipschitz constant for diffusion classifiers. We also generalize diffusion classifiers to classify noisy data.

Generative learning, recognized for its effective modeling of data distributions, offers inherent advantages in handling out-of-distribution instances, especially for enhancing robustness to adversarial attacks. Among these, diffusion classifiers, utilizing powerful diffusion models, have demonstrated superior empirical robustness. However, a comprehensive theoretical understanding of their robustness is still lacking, raising concerns about their vulnerability to stronger future attacks. In this study, we prove that diffusion classifiers possess $O(1)$ Lipschitzness, and establish their certified robustness, demonstrating their inherent resilience. To achieve non-constant Lipschitzness, thereby obtaining much tighter certified robustness, we generalize diffusion classifiers to classify Gaussian-corrupted data. This involves deriving the evidence lower bounds (ELBOs) for these distributions, approximating the likelihood using the ELBO, and calculating classification probabilities via Bayes' theorem. Experimental results show the superior certified robustness of these Noised Diffusion Classifiers (NDCs). Notably, we achieve over 80\% and 70\% certified robustness on CIFAR-10 under adversarial perturbations with \(\ell_2\) norms less than 0.25 and 0.5, respectively, using a single off-the-shelf diffusion model without any additional data.

Various linear complexity models, such as Linear Transformer (LinFormer), State Space Model (SSM), and Linear RNN (LinRNN), have been proposed to replace the conventional softmax attention in Transformer structures. However, the optimal design of these linear models is still an open question. In this work, we attempt to answer this question by finding the best linear approximation to softmax attention from a theoretical perspective. We start by unifying existing linear complexity models as the linear attention form and then identify three conditions for the optimal linear attention design: (1) Dynamic memory ability; (2) Static approximation ability; (3) Least parameter approximation. We find that none of the current linear models meet all three conditions, resulting in suboptimal performance. Instead, we propose Meta Linear Attention (MetaLA) as a solution that satisfies these conditions. Our experiments on Multi-Query Associative Recall (MQAR) task, language modeling, image classification, and Long-Range Arena (LRA) benchmark demonstrate that MetaLA is more effective than the existing linear models.

While several recent matrix completion methods are developed to deal with non-uniform observation probabilities across matrix entries, very few allow the missingness to depend on the mostly unobserved matrix measurements, which is generally ill-posed. We aim to tackle a subclass of these ill-posed settings, characterized by a flexible separable observation probability assumption that can depend on the matrix measurements. We propose a regularized pairwise pseudo-likelihood approach for matrix completion and prove that the proposed estimator can asymptotically recover the low-rank parameter matrix up to an identifiable equivalence class of a constant shift and scaling, at a near-optimal asymptotic convergence rate of the standard well-posed (non-informative missing) setting, while effectively mitigating the impact of informative missingness. The efficacy of our method is validated via numerical experiments, positioning it as a robust tool for matrix completion to mitigate data bias.
tl;dr: This paper introduces acoustic volume rendering for impulse response synthesis and inherently enforces multi-pose consistency.

Realistic audio synthesis that captures accurate acoustic phenomena is essential for creating immersive experiences in virtual and augmented reality. Synthesizing the sound received at any position relies on the estimation of impulse response (IR), which characterizes how sound propagates in one scene along different paths before arriving at the listener position. In this paper, we present Acoustic Volume Rendering (AVR), a novel approach that adapts volume rendering techniques to model acoustic impulse responses. While volume rendering has been successful in modeling radiance fields for images and neural scene representations, IRs present unique challenges as time-series signals. To address these challenges, we introduce frequency-domain volume rendering and use spherical integration to fit the IR measurements. Our method constructs an impulse response field that inherently encodes wave propagation principles and achieves state of-the-art performance in synthesizing impulse responses for novel poses. Experiments show that AVR surpasses current leading methods by a substantial margin. Additionally, we develop an acoustic simulation platform, AcoustiX, which provides more accurate and realistic IR simulations than existing simulators. Code for AVR and AcoustiX are available at https://zitonglan.github.io/avr.
tl;dr: This paper studies the possibility and impossibility for kernel methods and metric transform

We introduce a new linear-algebraic tool based on group representation theory, and use it to address three key problems in machine learning.
1. Past researchers have proposed fast attention algorithms for LLMs by approximating or replace softmax attention with other functions, such as low-degree polynomials. The key property of these functions is that, when applied entry-wise to the matrix $QK^{\top}$, the result is a low rank matrix when $Q$ and $K$ are $n \times d$ matrices and $n \gg d$. This suggests a natural question: what are all functions $f$ with this property? If other $f$ exist and are quickly computable, they can be used in place of softmax for fast subquadratic attention algorithms. It was previously known that low-degree polynomials have this property. We prove that low-degree polynomials are the only piecewise continuous functions with this property. This suggests that the low-rank fast attention only works for functions approximable by polynomials. Our work gives a converse to the polynomial method in algorithm design.
2. We prove the first full classification of all positive definite kernels that are functions of Manhattan or $\ell_1$ distance. Our work generalizes an existing theorem at the heart of all kernel methods in machine learning: the classification of all positive definite kernels that are functions of Euclidean distance.
3. The key problem in metric transforms, a mathematical theory used in geometry and machine learning, asks what functions transform pairwise distances in semi-metric space $M$ to semi-metric space $N$ for specified $M$ and $N$. We provide the first full classification of functions that transform Manhattan distances to Manhattan distances. Our work generalizes the foundational work of Schoenberg, which fully classifies functions that transform Euclidean to Euclidean distances.
We additionally prove results about stable-rank preserving functions that are potentially useful in algorithmic design, and more. Our core new tool is called the representation theory of the hyperrectangle.

Invisible watermarks safeguard images' copyrights by embedding hidden messages only detectable by owners. They also prevent people from misusing images, especially those generated by AI models.
We propose a family of regeneration attacks to remove these invisible watermarks.
The proposed attack method first adds random noise to an image to destroy the watermark and then reconstructs the image.
This approach is flexible and can be instantiated with many existing image-denoising algorithms and pre-trained generative models such as diffusion models. Through formal proofs and extensive empirical evaluations, we demonstrate that pixel-level invisible watermarks are vulnerable to this regeneration attack.
Our results reveal that, across four different pixel-level watermarking schemes, the proposed method consistently achieves superior performance compared to existing attack techniques, with lower detection rates and higher image quality.
However, watermarks that keep the image semantically similar can be an alternative defense against our attacks.
Our finding underscores the need for a shift in research/industry emphasis from invisible watermarks to semantic-preserving watermarks. Code is available at https://github.com/XuandongZhao/WatermarkAttacker
tl;dr: We introduce a graph metanetwork framework that allows scaling and permutation equivariant neural network processing.

This paper pertains to an emerging machine learning paradigm: learning higher- order functions, i.e. functions whose inputs are functions themselves, particularly when these inputs are Neural Networks (NNs). With the growing interest in architectures that process NNs, a recurring design principle has permeated the field: adhering to the permutation symmetries arising from the connectionist structure of
NNs. However, are these the sole symmetries present in NN parameterizations? Zooming into most practical activation functions (e.g. sine, ReLU, tanh) answers this question negatively and gives rise to intriguing new symmetries, which we collectively refer to as scaling symmetries, that is, non-zero scalar multiplications and divisions of weights and biases. In this work, we propose Scale Equivariant Graph MetaNetworks - ScaleGMNs, a framework that adapts the Graph Metanetwork (message-passing) paradigm by incorporating scaling symmetries and thus rendering neuron and edge representations equivariant to valid scalings. We introduce novel building blocks, of independent technical interest, that allow for equivariance or invariance with respect to individual scalar multipliers or their product and use them in all components of ScaleGMN. Furthermore, we prove that, under certain expressivity conditions, ScaleGMN can simulate the forward and backward pass of any input feedforward neural network. Experimental results demonstrate that our method advances the state-of-the-art performance for several datasets and activation functions, highlighting the power of scaling symmetries as an inductive bias for NN processing. The source code is publicly available at https://github.com/jkalogero/scalegmn.
tl;dr: Transfer learning gets vanishing reconstruction error on the entire target network given o(1) fraction of the target nodes

We study transfer learning for estimation in latent variable network models. In our setting, the conditional edge probability matrices given the latent variables are represented by $P$ for the source and $Q$ for the target. We wish to estimate $Q$ given two kinds of data: (1) edge data from a subgraph induced by an $o(1)$ fraction of the nodes of $Q$, and (2) edge data from all of $P$. If the source $P$ has no relation to the target $Q$, the estimation error must be $\Omega(1)$. However, we show that if the latent variables are shared, then vanishing error is possible. We give an efficient algorithm that utilizes the ordering of a suitably defined graph distance. Our algorithm achieves $o(1)$ error and does not assume a parametric form on the source or target networks. Next, for the specific case of Stochastic Block Models we prove a minimax lower bound and show that a simple algorithm achieves this rate. Finally, we empirically demonstrate our algorithm's use on real-world and simulated graph transfer problems.
tl;dr: We evaluate and exploit previously-ignored activations from diffusion backbones based on our new discoveries of their properties, thus resulting in better features for discrimination.

Diffusion models are initially designed for image generation. Recent research shows that the internal signals within their backbones, named activations, can also serve as dense features for various discriminative tasks such as semantic segmentation. Given numerous activations, selecting a small yet effective subset poses a fundamental problem. To this end, the early study of this field performs a large-scale quantitative comparison of the discriminative ability of the activations. However, we find that many potential activations have not been evaluated, such as the queries and keys used to compute attention scores. Moreover, recent advancements in diffusion architectures bring many new activations, such as those within embedded ViT modules. Both combined, activation selection remains unresolved but overlooked. To tackle this issue, this paper takes a further step with a much broader range of activations evaluated. Considering the significant increase in activations, a full-scale quantitative comparison is no longer operational. Instead, we seek to understand the properties of these activations, such that the activations that are clearly inferior can be filtered out in advance via simple qualitative evaluation. After careful analysis, we discover three properties universal among diffusion models, enabling this study to go beyond specific models. On top of this, we present effective feature selection solutions for several popular diffusion models. Finally, the experiments across multiple discriminative tasks validate the superiority of our method over the SOTA competitors. Our code is available at https://github.com/Darkbblue/generic-diffusion-feature.
157. Nonlocal Attention Operator: Materializing Hidden Knowledge Towards Interpretable Physics Discovery

Despite recent popularity of attention-based neural architectures in core AI fields like natural language processing (NLP) and computer vision (CV), their potential in modeling complex physical systems remains under-explored. Learning problems in physical systems are often characterized as discovering operators that map between function spaces based on a few instances of function pairs. This task frequently presents a severely ill-posed PDE inverse problem. In this work, we propose a novel neural operator architecture based on the attention mechanism, which we coin Nonlocal Attention Operator (NAO), and explore its capability towards developing a foundation physical model. In particular, we show that the attention mechanism is equivalent to a double integral operator that enables nonlocal interactions among spatial tokens, with a data-dependent kernel characterizing the inverse mapping from data to the hidden parameter field of the underlying operator. As such, the attention mechanism extracts global prior information from training data generated by multiple systems, and suggests the exploratory space in the form of a nonlinear kernel map. Consequently, NAO can address ill-posedness and rank deficiency in inverse PDE problems by encoding regularization and achieving generalizability. Lastly, we empirically demonstrate the advantages of NAO over baseline neural models in terms of the generalizability to unseen data resolutions and system states. Our work not only suggests a novel neural operator architecture for learning an interpretable foundation model of physical systems, but also offers a new perspective towards understanding the attention mechanism.
tl;dr: we design universal data selection methods for CLIP pretraining and achieve near SOTA results with less than 10% of preprocessing resources. Combining our methods with the current best one, we can achieve a new state-of-the-art.

Data selection has emerged as a core issue for large-scale visual-language model pretaining (e.g., CLIP), particularly with noisy web-curated datasets. Three main data selection approaches are: (1) leveraging external non-CLIP models to aid data selection, (2) training new CLIP-style embedding models that are more effective at selecting high-quality data than the original OpenAI CLIP model, and (3) designing better metrics or strategies universally applicable to any CLIP embedding without requiring specific model properties (e.g., CLIPScore is one popular metric). While the first two approaches have been extensively studied, the third remains under-explored. In this paper, we advance the third approach by proposing two new methods. Firstly, instead of classical CLIP scores that only consider the alignment between two modalities from a single sample, we introduce $\textbf{negCLIPLoss}$, a method inspired by CLIP training loss that adds the alignment between one sample and its contrastive pairs as an extra normalization term to CLIPScore for better quality measurement. Secondly, when downstream tasks are known, we propose a new norm-based metric, $\textbf{NormSim}$, to measure the similarity between pretraining data and target data. We test our methods on the data selection benchmark, DataComp [Gadre et al., 2023]. Compared to the best baseline using only OpenAI's CLIP-L/14, our methods achieve a 5.3\% improvement on ImageNet-1k and a 2.8\% improvement on 38 downstream evaluation tasks. Moreover, both $\textbf{negCLIPLoss}$ and $\textbf{NormSim}$ are compatible with existing techniques. By combining our methods with the current best methods DFN [Fang et al., 2023] and HYPE [Kim et al., 2024], we can boost average performance on downstream tasks by 0.9\%, achieving a new state-of-the-art on the DataComp-medium benchmark.
tl;dr: Generating long-range image and video with consistent characters, based on Consistent Self-Attention and Motion Predictor.

For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a simple but effective self-attention mechanism, termed Consistent Self-Attention, that boosts the consistency between the generated images. It can be used to augment pre-trained diffusion-based text-to-image models in a zero-shot manner. Based on the images with consistent content, we further show that our method can be extended to long range video generation by introducing a semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications.
tl;dr: We derive previously unknown gradients of Lanczos and Arnoldi iterations and use them for PDEs, Gaussian processes, and Bayesian neural networks.

Tuning scientific and probabilistic machine learning models - for example, partial differential equations, Gaussian processes, or Bayesian neural networks - often relies on evaluating functions of matrices whose size grows with the data set or the number of parameters.
While the state-of-the-art for _evaluating_ these quantities is almost always based on Lanczos and Arnoldi iterations, the present work is the first to explain how to _differentiate_ these workhorses of numerical linear algebra efficiently.
To get there, we derive previously unknown adjoint systems for Lanczos and Arnoldi iterations, implement them in JAX, and show that the resulting code can compete with Diffrax when it comes to differentiating PDEs, GPyTorch for selecting Gaussian process models and beats standard factorisation methods for calibrating Bayesian neural networks.
All this is achieved without any problem-specific code optimisation.
Find the code at [link redacted] and install the library with *pip install [redacted]*.
tl;dr: A novel structured pruning and retraining approach for LLMs that produces strong models using a small fraction of original training data

Large language models (LLMs) targeting different deployment scales and sizes are currently produced by training each variant from scratch; this is extremely compute-intensive. In this paper, we investigate if pruning an existing LLM and then re-training it with a fraction <3% of the original training data can be a suitable alternative to repeated, full retraining. To this end, we develop a set of practical and effective **compression best practices** for LLMs that combine depth, width, attention and MLP pruning with knowledge distillation-based retraining; we arrive at these best practices through a detailed empirical exploration of pruning strategies for each axis, methods to combine axes, distillation strategies, and search techniques for arriving at optimal compressed architectures. We use this guide to compress the Nemotron-4 family of LLMs by a factor of 2-4x, and compare their performance to similarly-sized models on a variety of language modeling tasks. On these tasks, we perform better than Nemotron-3 8B and LLaMa2 7B using **up to 40x** fewer training tokens}, on par with Mistral 7B and Gemma 7B using **up to 85x fewer tokens** and slightly worse than LLaMa3 8B using **up to 159x fewer tokens**. Our models also compare favorably to state-of-the-art compression techniques from the literature.

We study online Bayesian persuasion problems in which an informed sender repeatedly faces a receiver with the goal of influencing their behavior through the provision of payoff-relevant information. Previous works assume that the sender has knowledge about either the prior distribution over states of nature or receiver's utilities, or both. We relax such unrealistic assumptions by considering settings in which the sender does not know anything about the prior and the receiver. We design an algorithm that achieves sublinear---in the number of rounds T---regret with respect to an optimal signaling scheme, and we also provide a collection of lower bounds showing that the guarantees of such an algorithm are tight. Our algorithm works by searching a suitable space of signaling schemes in order to learn receiver's best responses. To do this, we leverage a non-standard representation of signaling schemes that allows to cleverly overcome the challenge of not knowing anything about the prior over states of nature and receiver's utilities. Finally, our results also allow to derive lower/upper bounds on the sample complexity of learning signaling schemes in a related Bayesian persuasion PAC-learning problem.

We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures—self-supervised, strongly supervised, or combinations thereof—based on experiments with over 15 vision models. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks. To further improve visual grounding, we propose spatial vision aggregator (SVA), a dynamic and spatially-aware connector that integrates vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of distribution balancing. Collectively, Cambrian-1 not only achieves state-of-the-art performances but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.
tl;dr: We propose a safe RL algorithm with spectral risk constraints, which shows convergence to an optimum in tabular settings.

The field of risk-constrained reinforcement learning (RCRL) has been developed to effectively reduce the likelihood of worst-case scenarios by explicitly handling risk-measure-based constraints.
However, the nonlinearity of risk measures makes it challenging to achieve convergence and optimality.
To overcome the difficulties posed by the nonlinearity, we propose a spectral risk measure-constrained RL algorithm, spectral-risk-constrained policy optimization (SRCPO), a bilevel optimization approach that utilizes the duality of spectral risk measures.
In the bilevel optimization structure, the outer problem involves optimizing dual variables derived from the risk measures, while the inner problem involves finding an optimal policy given these dual variables.
The proposed method, to the best of our knowledge, is the first to guarantee convergence to an optimum in the tabular setting.
Furthermore, the proposed method has been evaluated on continuous control tasks and showed the best performance among other RCRL algorithms satisfying the constraints.
Our code is available at https://github.com/rllab-snu/Spectral-Risk-Constrained-RL.
tl;dr: We propose a LLM jailbreaking optimization-based defense effective across attacks and models

Despite advances in AI alignment, large language models (LLMs) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries can modify prompts to induce unwanted behavior. While some defenses have been proposed, they have not been adapted to newly proposed attacks and more challenging threat models. To address this, we propose an optimization-based objective for defending LLMs against jailbreaking attacks and an algorithm, Robust Prompt Optimization (RPO), to create robust system-level defenses. Our approach directly incorporates the adversary into the defensive objective and optimizes a lightweight and transferable suffix, enabling RPO to adapt to worst-case adaptive attacks. Our theoretical and experimental results show improved robustness to both jailbreaks seen during optimization and unknown jailbreaks, reducing the attack success rate (ASR) on GPT-4 to 6% and Llama-2 to 0% on JailbreakBench, setting the state-of-the-art.
tl;dr: We developed a computational method to infer complex synaptic plasticity rules from neural and behavioral data, revealing new insights like active forgetting in reward learning in flies.

Inferring the synaptic plasticity rules that govern learning in the brain is a key challenge in neuroscience. We present a novel computational method to infer these rules from experimental data, applicable to both neural and behavioral data. Our approach approximates plasticity rules using a parameterized function, employing either truncated Taylor series for theoretical interpretability or multilayer perceptrons. These plasticity parameters are optimized via gradient descent over entire trajectories to align closely with observed neural activity or behavioral learning dynamics. This method can uncover complex rules that induce long nonlinear time dependencies, particularly involving factors like postsynaptic activity and current synaptic weights. We validate our approach through simulations, successfully recovering established rules such as Oja's, as well as more intricate plasticity rules with reward-modulated terms. We assess the robustness of our technique to noise and apply it to behavioral data from \textit{Drosophila} in a probabilistic reward-learning experiment. Notably, our findings reveal an active forgetting component in reward learning in flies, improving predictive accuracy over previous models. This modeling framework offers a promising new avenue for elucidating the computational principles of synaptic plasticity and learning in the brain.

While imitation learning requires access to high-quality data, offline reinforcement learning (RL) should, in principle, perform similarly or better with substantially lower data quality by using a value function. However, current results indicate that offline RL often performs worse than imitation learning, and it is often unclear what holds back the performance of offline RL. Motivated by this observation, we aim to understand the bottlenecks in current offline RL algorithms. While poor performance of offline RL is typically attributed to an imperfect value function, we ask: *is the main bottleneck of offline RL indeed in learning the value function, or something else?* To answer this question, we perform a systematic empirical study of (1) value learning, (2) policy extraction, and (3) policy generalization in offline RL problems, analyzing how these components affect performance. We make two surprising observations. First, we find that the choice of a policy extraction algorithm significantly affects the performance and scalability of offline RL, often more so than the value learning objective. For instance, we show that common value-weighted behavioral cloning objectives (e.g., AWR) do not fully leverage the learned value function, and switching to behavior-constrained policy gradient objectives (e.g., DDPG+BC) often leads to substantial improvements in performance and scalability. Second, we find that a big barrier to improving offline RL performance is often imperfect policy generalization on test-time states out of the support of the training data, rather than policy learning on in-distribution states. We then show that the use of suboptimal but high-coverage data or test-time policy training techniques can address this generalization issue in practice. Specifically, we propose two simple test-time policy improvement methods and show that these methods lead to better performance.

We study the problem of nonepisodic reinforcement learning (RL) for nonlinear dynamical systems, where the system dynamics are unknown and the RL agent has to learn from a single trajectory, i.e., without resets. We propose **N**on**e**pisodic **O**ptistmic **RL** (NeoRL), an approach based on the principle of optimism in the face of uncertainty. NeoRL uses well-calibrated probabilistic models and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics. Under continuity and bounded energy assumptions on the system, we
provide a first-of-its-kind regret bound of $\mathcal{O}(\beta_T \sqrt{T \Gamma_T})$ for general nonlinear systems with Gaussian process dynamics. We compare NeoRL to other baselines on several deep RL environments and empirically demonstrate that NeoRL achieves the optimal average cost while incurring the least regret.
169. Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
tl;dr: We propose a hierarchical representation learning framework to handle the problem of uncertain missing modalities in the multimodal sentiment analysis task.

Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model’s performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.

Existing prompt-tuning methods have demonstrated impressive performances in continual learning (CL), by selecting and updating relevant prompts in the vision-transformer models. On the contrary, this paper aims to learn each task by tuning the prompts in the direction orthogonal to the subspace spanned by previous tasks' features, so as to ensure no interference on tasks that have been learned to overcome catastrophic forgetting in CL. However, different from the orthogonal projection in the traditional CNN architecture, the prompt gradient orthogonal projection in the ViT architecture shows completely different and greater challenges, i.e., 1) the high-order and non-linear self-attention operation; 2) the drift of prompt distribution brought by the LayerNorm in the transformer block. Theoretically, we have finally deduced two consistency conditions to achieve the prompt gradient orthogonal projection, which provide a theoretical guarantee of eliminating interference on previously learned knowledge via the self-attention mechanism in visual prompt tuning. In practice, an effective null-space-based approximation solution has been proposed to implement the prompt gradient orthogonal projection. Extensive experimental results demonstrate the effectiveness of anti-forgetting on four class-incremental benchmarks with diverse pre-trained baseline models, and our approach achieves superior performances to state-of-the-art methods. Our code is available in the supplemental material.
tl;dr: We introduce a probabilistic graph neural network model for weather forecasting, capturing uncertainty by generating ensemble forecasts.

In recent years, machine learning has established itself as a powerful tool for high-resolution weather forecasting. While most current machine learning models focus on deterministic forecasts, accurately capturing the uncertainty in the chaotic weather system calls for probabilistic modeling. We propose a probabilistic weather forecasting model called Graph-EFM, combining a flexible latent-variable formulation with the successful graph-based forecasting framework. The use of a hierarchical graph construction allows for efficient sampling of spatially coherent forecasts. Requiring only a single forward pass per time step, Graph-EFM allows for fast generation of arbitrarily large ensembles. We experiment with the model on both global and limited area forecasting. Ensemble forecasts from Graph-EFM achieve equivalent or lower errors than comparable deterministic models, with the added benefit of accurately capturing forecast uncertainty.

The Stackelberg prediction game (SPG) is a popular model for characterizing strategic interactions between a learner and an adversarial data provider. Although optimization problems in SPGs are often NP-hard, a notable special case involving the least squares loss (SPG-LS) has gained significant research attention recently, (Bishop et al. 2020; Wang et al. 2021; Wang et al. 2022). The latest state-of-the-art method for solving the SPG-LS problem is the spherically constrained least squares reformulation (SCLS) method proposed in the work of Wang et al. (2022). However, the lack of theoretical analysis on the error of the SCLS method limits its large-scale applications. In this paper, we investigate the estimation error between the learner obtained by the SCLS method and the actual learner. Specifically, we reframe the estimation error of the SCLS method as a Primary Optimization ($\textbf{PO}$) problem and utilize the Convex Gaussian min-max theorem (CGMT) to transform the $\textbf{PO}$ problem into an Auxiliary Optimization ($\textbf{AO}$) problem. Subsequently, we provide a theoretical error analysis for the SCLS method based on this simplified $\textbf{AO}$ problem. This analysis not only strengthens the theoretical framework of the SCLS method but also confirms the reliability of the learner produced by it. We further conduct experiments to validate our theorems, and the results are in excellent agreement with our theoretical predictions.

AdaBoost is a well-known algorithm in boosting. Schapire and Singer propose, an extension of AdaBoost, named AdaBoost.MH, for multi-class classification problems. Kégl shows empirically that AdaBoost.MH works better when the classical one-against-all base classifiers are replaced by factorized base classifiers containing a binary classifier and a vote (or code) vector. However, the factorization makes it much more difficult to provide a convergence result for the factorized version of AdaBoost.MH. Then, Kégl raises an open problem in COLT 2014 to look for a convergence result for the factorized AdaBoost.MH. In this work, we resolve this open problem by presenting a convergence result for AdaBoost.MH with factorized multi-class classifiers.

Optimal Transport (OT, also known as the Wasserstein distance) is a popular metric for comparing probability distributions and has been successfully used in many machine-learning applications.
In the semi-discrete $2$-Wasserstein problem, we wish to compute the cheapest way to transport all the mass from a continuous distribution $\mu$ to a discrete distribution $\nu$ in $\mathbb{R}^d$ for $d\ge 1$, where the cost of transporting unit mass between points $a$ and $b$ is $d(a,b)=||a-b||^2$. When both distributions are discrete, a simple combinatorial framework has been used to find the exact solution (see e.g. [Orlin, STOC 1988]).
In this paper, we propose a combinatorial framework for the semi-discrete OT, which can be viewed as an extension of the combinatorial framework for the discrete OT but requires several new ideas. We present a new algorithm that given $\mu$ and $\nu$ in $\mathbb{R}^2$ and a parameter $\varepsilon>0$, computes an $\varepsilon$-additive approximate semi-discrete transport plan in $O(n^{4}\log n\log \frac{1}{\varepsilon})$ time (in the worst case), where $n$ is the support-size of the discrete distribution $\nu$ and we assume that the mass of $\mu$ inside a triangle can be computed in $O(1)$ time. Our algorithm is significantly faster than the known algorithms, and unlike many numerical algorithms, it does not make any assumptions on the smoothness of $\mu$.
As an application of our algorithm, we describe a data structure to store a large discrete distribution $\mu$ (with support size $N$) using $O(N)$ space so that, given a query discrete distribution $\nu$ (with support size $k$), an $\varepsilon$-additive approximate transport plan can be computed in $O(k^{3}\sqrt{N}\log \frac{1}{\varepsilon})$ time in $2$ dimensions. Our algorithm and data structure extend to higher dimensions as well as to $p$-Wasserstein problem for any $p \ge 1$.
tl;dr: We prove identifiability results and design algorithms for linear causal representation learning from unknown multi-node stochastic interventions.

Despite the multifaceted recent advances in interventional causal representation learning (CRL), they primarily focus on the stylized assumption of single-node interventions. This assumption is not valid in a wide range of applications, and generally, the subset of nodes intervened in an interventional environment is *fully unknown*. This paper focuses on interventional CRL under unknown multi-node (UMN) interventional environments and establishes the first identifiability results for *general* latent causal models (parametric or nonparametric) under stochastic interventions (soft or hard) and linear transformation from the latent to observed space. Specifically, it is established that given sufficiently diverse interventional environments, (i) identifiability *up to ancestors* is possible using only *soft* interventions, and (ii) *perfect* identifiability is possible using *hard* interventions. Remarkably, these guarantees match the best-known results for more restrictive single-node interventions. Furthermore, CRL algorithms are also provided that achieve the identifiability guarantees. A central step in designing these algorithms is establishing the relationships between UMN interventional CRL and score functions associated with the statistical models of different interventional environments. Establishing these relationships also serves as constructive proof of the identifiability guarantees.

Cross-domain recommendation (CDR) offers a promising solution to the data sparsity problem by enabling knowledge transfer across source and target domains. However, many recent CDR models overlook crucial issues such as privacy as well as the risk of negative transfer (which negatively impact model performance), especially in multi-domain settings. To address these challenges, we propose FedGCDR, a novel federated graph learning framework that securely and effectively leverages positive knowledge from multiple source domains. First, we design a positive knowledge transfer module that ensures privacy during inter-domain knowledge transmission. This module employs differential privacy-based knowledge extraction combined with a feature mapping mechanism, transforming source domain embeddings from federated graph attention networks into reliable domain knowledge. Second, we design a knowledge activation module to filter out potential harmful or conflicting knowledge from source domains, addressing the issues of negative transfer. This module enhances target domain training by expanding the graph of the target domain to generate reliable domain attentions and fine-tunes the target model for improved negative knowledge filtering and more accurate predictions. We conduct extensive experiments on 16 popular domains of the Amazon dataset, demonstrating that FedGCDR significantly outperforms state-of-the-art methods.
tl;dr: We study active learning halfspaces under label noise using enriched queries and design the first query-efficient polynomial time algorithm for learning halfspaces under Massart noise model.

We study pool-based active learning, where a learner has a large pool $S$ of unlabeled examples and can adaptively ask a labeler questions to learn these labels. The goal of the learner is to output a labeling for $S$ that can compete with the best hypothesis from a given hypothesis class $\mathcal{H}$. We focus on halfspace learning, one of the most important problems in active learning.
It is well known that in the standard active learning model, learning the labels of an arbitrary pool of examples labeled by some halfspace up to error $\epsilon$ requires at least $\Omega(1/\epsilon)$ queries. To overcome this difficulty, previous work designs simple but powerful query languages to achieve $O(\log(1/\epsilon))$ query complexity, but only focuses on the realizable setting where data are perfectly labeled by some halfspace.
However, when labels are noisy, such queries are too fragile and lead to high query complexity even under the simple random classification noise model.
In this work, we propose a new query language called threshold statistical queries and study their power for learning under various noise models. Our main algorithmic result is the first query-efficient algorithm for learning halfspaces under the popular Massart noise model. With an arbitrary dataset corrupted with Massart noise at noise rate $\eta$, our algorithm uses only $\mathrm{polylog(1/\epsilon)}$ threshold statistical queries and computes an $(\eta + \epsilon)$-accurate labeling in polynomial time. For the harder case of agnostic noise, we show that it is impossible to beat $O(1/\epsilon)$ query complexity even for the much simpler problem of learning singleton functions (and thus for learning halfspaces) using a reduction from agnostic distributed learning.
tl;dr: We initiate the study of *tractable* $\Phi$-equilibria in non-concave games and examine several natural families of strategy modifications.

While Online Gradient Descent and other no-regret learning procedures are known to efficiently converge to a coarse correlated equilibrium in games where each agent's utility is concave in their own strategy, this is not the case when utilities are non-concave -- a common scenario in machine learning applications involving strategies parameterized by deep neural networks, or when agents' utilities are computed by neural networks, or both. Non-concave games introduce significant game-theoretic and optimization challenges: (i) Nash equilibria may not exist; (ii) local Nash equilibria, though they exist, are intractable; and (iii) mixed Nash, correlated, and coarse correlated equilibria generally have infinite support and are intractable. To sidestep these challenges, we revisit the classical solution concept of $\Phi$-equilibria introduced by Greenwald and Jafari [GJ03], which is guaranteed to exist for an arbitrary set of strategy modifications $\Phi$ even in non-concave games [SL07]. However, the tractability of $\Phi$-equilibria in such games remains elusive. In this paper, we initiate the study of tractable $\Phi$-equilibria in non-concave games and examine several natural families of strategy modifications. We show that when $\Phi$ is finite, there exists an efficient uncoupled learning algorithm that approximates the corresponding $\Phi$-equilibria. Additionally, we explore cases where $\Phi$ is infinite but consists of local modifications, showing that Online Gradient Descent can efficiently approximate $\Phi$-equilibria in non-trivial regimes.
tl;dr: We propose new parallel inference algorithms for diffusion models using parallel sampling and rigorously prove that our algorithms enjoy sub-linear inference cost w.r.t. data dimension for both SDE and probability flow ODE implementations.

Diffusion models have become a leading method for generative modeling of both image and scientific data.
As these models are costly to train and \emph{evaluate}, reducing the inference cost for diffusion models remains a major goal.
Inspired by the recent empirical success in accelerating diffusion models via the parallel sampling technique~\cite{shih2024parallel}, we propose to divide the sampling process into $\mathcal{O}(1)$ blocks with parallelizable Picard iterations within each block. Rigorous theoretical analysis reveals that our algorithm achieves $\widetilde{\mathcal{O}}(\mathrm{poly} \log d)$ overall time complexity, marking \emph{the first implementation with provable sub-linear complexity w.r.t. the data dimension $d$}. Our analysis is based on a generalized version of Girsanov's theorem and is compatible with both the SDE and probability flow ODE implementations. Our results shed light on the potential of fast and efficient sampling of high-dimensional data on fast-evolving modern large-memory GPU clusters.
tl;dr: we prove that learning the true dynamics rom biased simulations is possible via the Infinitesimal Generator and develop the method that does it efficently

We investigate learning the eigenfunctions of evolution operators for time-reversal invariant stochastic processes, a prime example being the Langevin equation used in molecular dynamics. Many physical or chemical processes described by this equation involve transitions between metastable states separated by high potential barriers that can hardly be crossed during a simulation. To overcome this bottleneck, data are collected via biased simulations that explore the state space more rapidly. We propose a framework for learning from biased simulations rooted in the infinitesimal generator of the process {and the associated resolvent operator}. We contrast our approach to more common ones based on the transfer operator, showing that it can provably learn the spectral properties of the unbiased system from biased data. In experiments, we highlight the advantages of our method over transfer operator approaches and recent developments based on generator learning, demonstrating its effectiveness in estimating eigenfunctions and eigenvalues. Importantly, we show that even with datasets containing only a few relevant transitions due to sub-optimal biasing, our approach
recovers relevant information about the transition mechanism.
tl;dr: We study how LLMs regulate uncertainty using entropy neurons, which modulate entropy via an unembedding null space, and token frequency neurons, which adjust logits based on token frequency.

Despite their widespread use, the mechanisms by which large language models (LLMs) represent and regulate uncertainty in next-token predictions remain largely unexplored. This study investigates two critical components believed to influence this uncertainty: the recently discovered entropy neurons and a new set of components that we term token frequency neurons. Entropy neurons are characterized by an unusually high weight norm and influence the final layer normalization (LayerNorm) scale to effectively scale down the logits. Our work shows that entropy neurons operate by writing onto an \textit{unembedding null space}, allowing them to impact the residual stream norm with minimal direct effect on the logits themselves. We observe the presence of entropy neurons across a range of models, up to 7 billion parameters. On the other hand, token frequency neurons, which we discover and describe here for the first time, boost or suppress each token’s logit proportionally to its log frequency, thereby shifting the output distribution towards or away from the unigram distribution. Finally, we present a detailed case study where entropy neurons actively manage confidence: the setting of induction, i.e. detecting and continuing repeated subsequences.

Many practical problems involve estimating low dimensional statistical quantities with high-dimensional models and datasets. Several approaches address these estimation tasks based on the theory of influence functions, such as debiased/double ML or targeted minimum loss estimation. We introduce \textit{Monte Carlo Efficient Influence Functions} (MC-EIF), a fully automated technique for approximating efficient influence functions that integrates seamlessly with existing differentiable probabilistic programming systems. MC-EIF automates efficient statistical estimation for a broad class of models and functionals that previously required rigorous custom analysis. We prove that MC-EIF is consistent, and that estimators using MC-EIF achieve optimal $\sqrt{N}$ convergence rates. We show empirically that estimators using MC-EIF are at parity with estimators using analytic EIFs. Finally, we present a novel capstone example using MC-EIF for optimal portfolio selection.
tl;dr: Understanding the neglected indefinite part of the Hessian explains important phenomena in sharpness regularization

Recent work has shown that methods that regularize second order information like SAM can improve generalization in deep learning. Seemingly similar methods like weight noise and gradient penalties often fail to provide such benefits. We investigate this inconsistency and reveal its connection to the the structure of the Hessian of the loss. Specifically, its decomposition into the positive semi-definite Gauss-Newton matrix and an indefinite matrix, which we call the Nonlinear Modeling Error (NME) matrix. Previous studies have largely overlooked the significance of the NME in their analysis for various reasons. However, we provide empirical and theoretical evidence that the NME is important to the performance of gradient penalties and explains their sensitivity to activation functions. We also provide evidence that the difference in regularization performance between gradient penalties and weight noise can be explained by the NME. Our findings emphasize the necessity of considering the NME in both experimental design and theoretical analysis for sharpness regularization.
tl;dr: We introduce a unified neurosymbolic architecture with compositional generalization across a variety of distributional shifts and datasets.

Neural networks continue to struggle with compositional generalization, and this issue is exacerbated by a lack of massive pre-training. One successful approach for developing neural systems which exhibit human-like compositional generalization is $\textit{hybrid}$ neurosymbolic techniques. However, these techniques run into the core issues that plague symbolic approaches to AI: scalability and flexibility. The reason for this failure is that at their core, hybrid neurosymbolic models perform symbolic computation and relegate the scalable and flexible neural computation to parameterizing a symbolic system. We investigate a $\textit{unified}$ neurosymbolic system where transformations in the network can be interpreted simultaneously as both symbolic and neural computation. We extend a unified neurosymbolic architecture called the Differentiable Tree Machine in two central ways. First, we significantly increase the model’s efficiency through the use of sparse vector representations of symbolic structures. Second, we enable its application beyond the restricted set of tree2tree problems to the more general class of seq2seq problems. The improved model retains its prior generalization capabilities and, since there is a fully neural path through the network, avoids the pitfalls of other neurosymbolic techniques that elevate symbolic computation over neural computation.
tl;dr: By sharing key and value activations between adjacent layers, we can reduce the key-value cache memory footprint of multi-query attention transformers by 2x with negligible impact on accuracy.

Key-value (KV) caching plays an essential role in accelerating decoding for transformer-based autoregressive large language models (LLMs). However, the amount of memory required to store the KV cache can become prohibitive at long sequence lengths and large batch sizes. Since the invention of the transformer, two of the most effective interventions discovered for reducing the size of the KV cache have been Multi-Query Attention (MQA) and its generalization, Grouped-Query Attention (GQA). MQA and GQA both modify the design of the attention block so that multiple query heads can share a single key/value head, reducing the number of distinct key/value heads by a large factor while only minimally degrading accuracy. In this paper, we show that it is possible to take Multi-Query Attention a step further by also sharing key and value heads between adjacent layers, yielding a new attention design we call Cross-Layer Attention (CLA). With CLA, we find that it is possible to reduce the size of the KV cache by another $2\times$ while maintaining nearly the same accuracy as unmodified MQA. In experiments training 1B- and 3B-parameter models from scratch, we demonstrate that CLA provides a Pareto improvement over the memory/accuracy tradeoffs which are possible with traditional MQA, potentially enabling future models to operate at longer sequence lengths and larger batch sizes than would otherwise be possible.
tl;dr: Forgetting, Ignorance or Myopia: Revisiting Key Challenges in Online Continual Learning

Online continual learning (OCL) requires the models to learn from constant, endless streams of data. While significant efforts have been made in this field, most were focused on mitigating the \textit{catastrophic forgetting} issue to achieve better classification ability, at the cost of a much heavier training workload. They overlooked that in real-world scenarios, e.g., in high-speed data stream environments, data do not pause to accommodate slow models. In this paper, we emphasize that \textit{model throughput}-- defined as the maximum number of training samples that a model can process within a unit of time -- is equally important. It directly limits how much data a model can utilize and presents a challenging dilemma for current methods. With this understanding, we revisit key challenges in OCL from both empirical and theoretical perspectives, highlighting two critical issues beyond the well-documented catastrophic forgetting: (\romannumeral1) Model's ignorance: the single-pass nature of OCL challenges models to learn effective features within constrained training time and storage capacity, leading to a trade-off between effective learning and model throughput; (\romannumeral2) Model's myopia: the local learning nature of OCL on the current task leads the model to adopt overly simplified, task-specific features and \textit{excessively sparse classifier}, resulting in the gap between the optimal solution for the current task and the global objective. To tackle these issues, we propose the Non-sparse Classifier Evolution framework (NsCE) to facilitate effective global discriminative feature learning with minimal time cost. NsCE integrates non-sparse maximum separation regularization and targeted experience replay techniques with the help of pre-trained models, enabling rapid acquisition of new globally discriminative features. Extensive experiments demonstrate the substantial improvements of our framework in performance, throughput and real-world practicality.
tl;dr: We consider the problem of dueling bandits with a Condorcet winner. We focus on the objective of weak regret minimization. We provide new lower bounds revealing different regimes and develop new optimal algorithms.

We consider the problem of $K$-armed dueling bandits in the stochastic setting, under the sole assumption of the existence of a Condorcet winner. We study the objective of weak regret minimization, where the learner doesn't incur any loss if one of the selected arms is a Condorcet winner—unlike strong regret minimization, where the learner has to select the Condorcet winner twice to incur no loss. This study is particularly motivated by practical scenarios such as content recommendation and online advertising, where frequently only one optimal choice out of the two presented options is necessary to achieve user satisfaction or engagement. This necessitates the development of strategies with more exploration. While existing literature introduces strategies for weak regret with constant bounds (that do not depend on the time horizon), the optimality of these strategies remains an unresolved question. This problem turns out to be really challenging as the optimal regret should heavily depend on the full structure of the dueling problem at hand, and in particular on whether the Condorcet winner has a large minimal optimality gap with the other arms. Our contribution is threefold: first, when said optimality gap is not negligible compared to other properties of the gap matrix, we characterize the optimal budget as a function of $K$ and the optimality gap. Second, we propose a new strategy called \wrtinf that achieves this optimal regret and improves over the state-of-the-art both in $K$ and the optimality gap. When the optimality gap is negligible, we propose another algorithm that outperforms our first algorithm, highlighting the subtlety of this dueling bandit problem. Finally, we provide numerical simulations to assess our theoretical findings.
tl;dr: A general framework for low rank optimal transport using a latent coupling matrix and relaxed projections.

Optimal transport (OT) is a general framework for finding a minimum-cost transport plan, or coupling, between probability distributions, and has many applications in machine learning. A key challenge in applying OT to massive datasets is the quadratic scaling of the coupling matrix with the size of the dataset. [Forrow et al. 2019] introduced a factored coupling for the k-Wasserstein barycenter problem, which [Scetbon et al. 2021] adapted to solve the primal low-rank OT problem. We derive an alternative parameterization of the low-rank problem based on the _latent coupling_ (LC) factorization previously introduced by [Lin et al. 2021] generalizing [Forrow et al. 2019]. The LC factorization has multiple advantages for low-rank OT including decoupling the problem into three OT problems and greater flexibility and interpretability. We leverage these advantages to derive a new algorithm _Factor Relaxation with Latent Coupling_ (FRLC), which uses _coordinate_ mirror descent to compute the LC factorization. FRLC handles multiple OT objectives (Wasserstein, Gromov-Wasserstein, Fused Gromov-Wasserstein), and marginal constraints (balanced, unbalanced, and semi-relaxed) with linear space complexity. We provide theoretical results on FRLC, and demonstrate superior performance on diverse applications -- including graph clustering and spatial transcriptomics -- while demonstrating its interpretability.
tl;dr: We prove that a broad class of algorithms that do not forget the past quickly, including OMWU and OFTRL, all suffer arbitrarily slow last-iterate convergence even in simple zero-sum games.

Self play via online learning is one of the premier ways to solve large-scale zero-sum games, both in theory and practice. Particularly popular algorithms include optimistic multiplicative weights update (OMWU) and optimistic gradient-descent-ascent (OGDA). While both algorithms enjoy $O(1/T)$ ergodic convergence to Nash equilibrium in two-player zero-sum games, OMWU offers several advantages, including logarithmic dependence on the size of the payoff matrix and $\tilde{O}(1/T)$ convergence to coarse correlated equilibria even in general-sum games. However, in terms of last-iterate convergence in two-player zero-sum games, an increasingly popular topic in this area, OGDA guarantees that the duality gap shrinks at a rate of $(1/\sqrt{T})$, while the best existing last-iterate convergence for OMWU depends on some game-dependent constant that could be arbitrarily large. This begs the question: is this potentially slow last-iterate convergence an inherent disadvantage of OMWU, or is the current analysis too loose? Somewhat surprisingly, we show that the former is true. More generally, we prove that a broad class of algorithms that do not forget the past quickly all suffer the same issue: for any arbitrarily small $\delta>0$, there exists a $2\times 2$ matrix game such that the algorithm admits a constant duality gap even after $1/\delta$ rounds. This class of algorithms includes OMWU and other standard optimistic follow-the-regularized-leader algorithms.

We study the low-degree hardness of broadcasting on trees.
Broadcasting on trees has been extensively studied in statistical physics,
in computational biology in relation to phylogenetic reconstruction and in statistics and computer science in the context of block model inference, and as a simple data model for algorithms that may require depth for inference.
The inference of the root can be carried by celebrated Belief Propagation (BP) algorithm which achieves Bayes-optimal performance. Despite the fact that this algorithm runs in linear time (using real operations), recent works indicated that this algorithm in fact requires high level of complexity.
Moitra, Mossel and Sandon constructed a chain for which estimating the root better than random (for a typical input) is $NC1$ complete. Kohler and Mossel constructed chains such that for trees with $N$ leaves, recovering the root better than random requires a polynomial of degree $N^{\Omega(1)}$. Both works above asked if such complexity bounds hold in general below the celebrated {\em Kesten-Stigum} bound.
In this work, we prove that this is indeed the case for low degree polynomials.
We show that for the broadcast problem using any Markov chain on trees with $N$ leaves, below the Kesten Stigum bound, any $O(\log N)$ degree polynomial has vanishing correlation with the root.
Our result is one of the first low-degree lower bound that is proved in a setting that is not based or easily reduced to a product measure.
tl;dr: We give a combinatorial characterization of multi class transductive online learnability even when the label space may not be bounded.

We consider the problem of multiclass transductive online learning when the number of labels can be unbounded. Previous works by Ben-David et al. [1997] and Hanneke et al. [2024] only consider the case of binary and finite label spaces respectively. The latter work determined that their techniques fail to extend to the case of unbounded label spaces, and they pose the question of characterizing the optimal mistake bound for unbounded label spaces. We answer this question, by showing that a new dimension, termed the Level-constrained Littlestone dimension, characterizes online learnability in this setting. Along the way, we show that the trichotomy of possible minimax rates established by Hanneke et al. [2024] for finite label spaces in the realizable setting continues to hold even when the label space is unbounded. In particular, if the learner plays for $T \in \mathbb{N}$ rounds, its minimax expected number of mistakes can only grow like $\Theta(T)$, $\Theta(\log T)$, or $\Theta(1)$. To prove this result, we give another combinatorial dimension, termed the Level-constrained Branching dimension, and show that its finiteness characterizes constant minimax expected mistake-bounds. The trichotomy is then determined by a combination of the Level-constrained Littlestone and Branching dimensions. Quantitatively, our upper bounds improve upon existing multiclass upper bounds in Hanneke et al. [2024] by removing the dependence on the label set size. In doing so, we explicitly construct learning algorithms that can handle extremely large or unbounded label spaces. A key component of our algorithm is a new notion of shattering that exploits the sequential nature of transductive online learning. Finally, we complete our results by proving expected regret bounds in the agnostic setting, extending the result of Hanneke et al. [2024].
tl;dr: We introduce Any2Graph a framework for deep end-to-end supervised graph prediction. The key components of the framework is PMFGW, an Optimal Transport Loss.

We propose Any2graph, a generic framework for end-to-end Supervised Graph Prediction (SGP) i.e. a deep learning model that predicts an entire graph for any kind of input. The framework is built on a novel Optimal Transport loss, the Partially-Masked Fused Gromov-Wasserstein, that exhibits all necessary properties (permutation invariance, differentiability and scalability) and is designed to handle any-sized graphs. Numerical experiments showcase the versatility of the approach that outperform existing competitors on a novel challenging synthetic dataset and a variety of real-world tasks such as map construction from satellite image (Sat2Graph) or molecule prediction from fingerprint (Fingerprint2Graph).
tl;dr: Mean Field analysis of overparametrized shallow models under symmetric data and/or symmetry-leveraging techniques.

We develop a Mean-Field (MF) view of the learning dynamics of overparametrized Artificial Neural Networks (NN) under distributional symmetries of the data w.r.t. the action of a general compact group $G$. We consider for this a class of generalized shallow NNs given by an ensemble of $N$ multi-layer units, jointly trained using stochastic gradient descent (SGD) and possibly symmetry-leveraging (SL) techniques, such as Data Augmentation (DA), Feature Averaging (FA) or Equivariant Architectures (EA). We introduce the notions of weakly and strongly invariant laws (WI and SI) on the parameter space of each single unit, corresponding, respectively, to $G$-invariant distributions, and to distributions supported on parameters fixed by the group action (which encode EA). This allows us to define symmetric models compatible with taking $N\to\infty$ and give an interpretation of the asymptotic dynamics of DA, FA and EA in terms of Wasserstein Gradient Flows describing their MF limits. When activations respect the group action, we show that, for symmetric data, DA, FA and freely-trained models obey the exact same MF dynamic, which stays in the space of WI parameter laws and attains therein the population risk's minimizer. We also provide a counterexample to the general attainability of such an optimum over SI laws.
Despite this, and quite remarkably, we show that the space of SI laws is also preserved by these MF distributional dynamics even when freely trained. This sharply contrasts the finite-$N$ setting, in which EAs are generally not preserved by unconstrained SGD. We illustrate the validity of our findings as $N$ gets larger, in a teacher-student experimental setting, training a student NN to learn from a WI, SI or arbitrary teacher model through various SL schemes. We lastly deduce a data-driven heuristic to discover the largest subspace of parameters supporting SI distributions for a problem, that could be used for designing EA with minimal generalization error.

Causal discovery from observational data, especially for count data, is essential across scientific and industrial contexts, such as biology, economics, and network operation maintenance. For this task, most approaches model count data using Bayesian networks or ordinal relations. However, they overlook the inherent branching structures that are frequently encountered, e.g., a browsing event might trigger an adding cart or purchasing event. This can be modeled by a binomial thinning operator (for branching) and an additive independent Poisson distribution (for noising), known as Poisson Branching Structure Causal Model (PB-SCM). There is a provably sound cumulant-based causal discovery method that allows the identification of the causal structure under a branching structure. However, we show that there still remains a gap in that there exist causal directions that are identifiable while the algorithm fails to identify them. In this work, we address this gap by exploring the identifiability of PB-SCM using the Probability Generating Function (PGF). By developing a compact and exact closed-form solution for the PGF of PB-SCM, we demonstrate that each component in this closed-form solution uniquely encodes a specific local structure, enabling the identification of the local structures by testing their corresponding component appearances in the PGF. Building on this, we propose a practical algorithm for learning causal skeletons and identifying causal directions of PB-SCM using PGF. The effectiveness of our method is demonstrated through experiments on both synthetic and real datasets.
tl;dr: A novel way of training next-token prediction models to diffuse whole sequences at once enables long-horizon guidance, stable infinite rollout of continuous signals, and new planning & policy techniques.

This paper presents Diffusion Forcing, a new training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels. We apply Diffusion Forcing to sequence generative modeling by training a causal next-token prediction model to generate one or several future tokens without fully diffusing past ones. Our approach is shown to combine the strengths of next-token prediction models, such as variable-length generation, with the strengths of full-sequence diffusion models, such as the ability to guide sampling to desirable trajectories. Our method offers a range of additional capabilities, such as (1) rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge and (2) new sampling and guiding schemes that uniquely profit from Diffusion Forcing's variable-horizon and causal architecture, and which lead to marked performance gains in decision-making and planning tasks. In addition to its empirical success, our method is proven to optimize a variational lower bound on the likelihoods of all subsequences of tokens drawn from the true joint distribution. Project website: https://boyuan.space/diffusion-forcing/

The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparse-that can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparse
indices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of longcontext LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. By
evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, GLM-4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy. Our code is available at https://aka.ms/MInference.

We study the problem of learning under arbitrary distribution shift, where the learner is trained on a labeled set from one distribution but evaluated on a different, potentially adversarially generated test distribution. We focus on two frameworks: *PQ learning* [GKKM'20], allowing abstention on adversarially generated parts of the test distribution, and *TDS learning* [KSV'23], permitting abstention on the entire test distribution if distribution shift is detected. All prior known algorithms either rely on learning primitives that are computationally hard even for simple function classes, or end up abstaining entirely even in the presence of a tiny amount of distribution shift.
We address both these challenges for natural function classes, including intersections of halfspaces and decision trees, and standard training distributions, including Gaussians. For PQ learning, we give efficient learning algorithms, while for TDS learning, our algorithms can tolerate moderate amounts of distribution shift. At the core of our approach is an improved analysis of spectral outlier-removal techniques from learning with nasty noise.
Our analysis can (1) handle arbitrarily large fraction of outliers, which is crucial for handling arbitrary distribution shifts, and (2) obtain stronger bounds on polynomial moments of the distribution after outlier removal, yielding new insights into polynomial regression under distribution shifts. Lastly, our techniques lead to novel results for tolerant *testable learning* [RV'23], and learning with nasty noise.
tl;dr: This paper proposes a challenging setting for video-based referring and establishes an effective MLLM named Artemis.

Videos carry rich visual information including object description, action, interaction, etc., but the existing multimodal large language models (MLLMs) fell short in referential understanding scenarios such as video-based referring. In this paper, we present Artemis, an MLLM that pushes video-based referential understanding to a finer level. Given a video, Artemis receives a natural-language question with a bounding box in any video frame and describes the referred target in the entire video. The key to achieving this goal lies in extracting compact, target-specific video features, where we set a solid baseline by tracking and selecting spatiotemporal features from the video. We train Artemis on the newly established ViderRef45K dataset with 45K video-QA pairs and design a computationally efficient, three-stage training procedure. Results are promising both quantitatively and qualitatively. Additionally, we show that Artemis can be integrated with video grounding and text summarization tools to understand more complex scenarios. Code and data are available at https://github.com/NeurIPS24Artemis/Artemis.
tl;dr: We show that an algorithmically inspired architecture similar to reverse diffusion denoising can provably learn Bayes optimal inference with gradient descent, and we show the score-matching objective is learnable in one-dimension along the way.

Much of Bayesian inference centers around the design of estimators for inverse problems which are optimal assuming the data comes from a known prior. But what do these optimality guarantees mean if the prior is unknown? In recent years, algorithm unrolling has emerged as deep learning's answer to this age-old question: design a neural network whose layers can in principle simulate iterations of inference algorithms and train on data generated by the unknown prior. Despite its empirical success, however, it has remained unclear whether this method can provably recover the performance of its optimal, prior-aware counterparts.
In this work, we prove the first rigorous learning guarantees for neural networks based on unrolling approximate message passing (AMP). For compressed sensing, we prove that when trained on data drawn from a product prior, the layers of the network approximately converge to the same denoisers used in Bayes AMP. We also provide extensive numerical experiments for compressed sensing and rank-one matrix estimation demonstrating the advantages of our unrolled architecture \--- in addition to being able to obliviously adapt to general priors, it exhibits improvements over Bayes AMP in more general settings of low dimensions, non-Gaussian designs, and non-product priors.
tl;dr: A cascaded style prior modelling approach to whole-song multi-track accompaniment arrangement

In the realm of music AI, arranging rich and structured multi-track accompaniments from a simple lead sheet presents significant challenges. Such challenges include maintaining track cohesion, ensuring long-term coherence, and optimizing computational efficiency. In this paper, we introduce a novel system that leverages prior modelling over disentangled style factors to address these challenges. Our method presents a two-stage process: initially, a piano arrangement is derived from the lead sheet by retrieving piano texture styles; subsequently, a multi-track orchestration is generated by infusing orchestral function styles into the piano arrangement. Our key design is the use of vector quantization and a unique multi-stream Transformer to model the long-term flow of the orchestration style, which enables flexible, controllable, and structured music generation. Experiments show that by factorizing the arrangement task into interpretable sub-stages, our approach enhances generative capacity while improving efficiency. Additionally, our system supports a variety of music genres and provides style control at different composition hierarchies. We further show that our system achieves superior coherence, structure, and overall arrangement quality compared to existing baselines.
tl;dr: CAT3D uses a multi-view diffusion model to create 3D scenes from any number of real or generated images.

Advances in 3D reconstruction have enabled high-quality 3D capture, but require a user to collect hundreds to thousands of images to create a 3D scene. We present CAT3D, a method for creating anything in 3D by simulating this real-world capture process with a multi-view diffusion model. Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene. These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real-time. CAT3D can create entire 3D scenes in as little as one minute, and outperforms existing methods for single image and few-view 3D scene creation.
tl;dr: We propose a workflow to design cell-type-specific promoters while accounting for various practical considerations and demonstrate its efficacy in a difficult setting.

Gene therapies have the potential to treat disease by delivering therapeutic genetic cargo to disease-associated cells. One limitation to their widespread use is the lack of short regulatory sequences, or promoters, that differentially induce the expression of delivered genetic cargo in target cells, minimizing side effects in other cell types. Such cell-type-specific promoters are difficult to discover using existing methods, requiring either manual curation or access to large datasets of promoter-driven expression from both targeted and untargeted cells. Model-based optimization (MBO) has emerged as an effective method to design biological sequences in an automated manner, and has recently been used in promoter design methods. However, these methods have only been tested using large training datasets that are expensive to collect, and focus on designing promoters for markedly different cell types, overlooking the complexities associated with designing promoters for closely related cell types that share similar regulatory features. Therefore, we introduce a comprehensive framework for utilizing MBO to design promoters in a data-efficient manner, with an emphasis on discovering promoters for similar cell types. We use conservative objective models (COMs) for MBO and highlight practical considerations such as best practices for improving sequence diversity, getting estimates of model uncertainty, and choosing the optimal set of sequences for experimental validation. Using three leukemia cell lines (Jurkat, K562, and THP1), we show that our approach discovers many novel cell-type-specific promoters after experimentally validating the designed sequences. For K562 cells, in particular, we discover a promoter that has 75.85\% higher cell-type-specificity than the best promoter from the initial dataset used to train our models. Our code and data will be available at https://github.com/young-geng/promoter_design.
tl;dr: We find that transformer encoders can perform audio-to-text alignment internally during a forward pass, a new phenomenon that allows greatly simplified ASR models.

Modern systems for automatic speech recognition, including the RNN-Transducer and Attention-based Encoder-Decoder (AED), are designed so that the encoder is not required to alter the time-position of information from the audio sequence into the embedding; alignment to the final text output is processed during decoding. We discover that the transformer-based encoder adopted in recent years is actually capable of performing the alignment internally during the forward pass, prior to decoding. This new phenomenon enables a simpler and more efficient model, the ''Aligner-Encoder''. To train it, we discard the dynamic programming of RNN-T in favor of the frame-wise cross-entropy loss of AED, while the decoder employs the lighter text-only recurrence of RNN-T without learned cross-attention---it simply scans embedding frames in order from the beginning, producing one token each until predicting the end-of-message. We conduct experiments demonstrating performance remarkably close to the state of the art, including a special inference configuration enabling long-form recognition. In a representative comparison, we measure the total inference time for our model to be 2x faster than RNN-T and 16x faster than AED. Lastly, we find that the audio-text alignment is clearly visible in the self-attention weights of a certain layer, which could be said to perform ''self-transduction''.
tl;dr: We prove a sufficient and necessary condition for inductive inference: the hypothesis class H is a countable union of online learnable classes.

Can a physicist make only a finite number of errors in the eternal quest to uncover the law of nature?
This millennium-old philosophical problem, known as inductive inference, lies at the heart of epistemology.
Despite its significance to understanding human reasoning, a rigorous justification of inductive inference has remained elusive.
At a high level, inductive inference asks whether one can make at most finite errors amidst an infinite sequence of observations, when deducing the correct hypothesis from a given hypothesis class.
Historically, the only theoretical guarantee has been that if the hypothesis class is countable, inductive inference is possible, as exemplified by Solomonoff induction for learning Turing machines.
In this paper, we provide a tight characterization of inductive inference by establishing a novel link to online learning theory.
As our main result, we prove that inductive inference is possible if and only if the hypothesis class is a countable union of online learnable classes, potentially with an uncountable size, no matter the observations are adaptively chosen or iid sampled.
Moreover, the same condition is also sufficient and necessary in the agnostic setting, where any hypothesis class meeting this criterion enjoys an $\tilde{O}(\sqrt{T})$ regret bound for any time step $T$, while others require an arbitrarily slow rate of regret.
Our main technical tool is a novel non-uniform online learning framework, which may be of independent interest.
Our main technical tool is a novel non-uniform online learning framework, which may be of independent interest.
tl;dr: instruct an LLM in the language of knowledge graphs

Large language models (LLMs) have significantly advanced performance across a spectrum of natural language processing (NLP) tasks. Yet, their application to knowledge graphs (KGs), which describe facts in the form of triplets and allow minimal hallucinations, remains an underexplored frontier. In this paper, we investigate the integration of LLMs with KGs by introducing a specialized KG Language (KGL), where a sentence precisely consists of an entity noun, a relation verb, and ends with another entity noun. Despite KGL's unfamiliar vocabulary to the LLM, we facilitate its learning through a tailored dictionary and illustrative sentences, and enhance context understanding via real-time KG context retrieval and KGL token embedding augmentation. Our results reveal that LLMs can achieve fluency in KGL, drastically reducing errors compared to conventional KG embedding methods on KG completion. Furthermore, our enhanced LLM shows exceptional competence in generating accurate three-word sentences from an initial entity and interpreting new unseen terms out of KGs.
206. Zipfian Whitening
tl;dr: We propose a method to correct anisotropy in the word embedding space by accounting for word frequency; then justify our approach from the perspectives of generative models, word embedding norms, and errors in long-tail distributions.

The word embedding space in neural models is skewed, and correcting this can improve task performance. We point out that most approaches for modeling, correcting, and measuring the symmetry of an embedding space implicitly assume that the word frequencies are *uniform*; in reality, word frequencies follow a highly non-uniform distribution, known as *Zipf's law*. Surprisingly, simply performing PCA whitening weighted by the empirical word frequency that follows Zipf's law significantly improves task performance, surpassing established baselines. From a theoretical perspective, both our approach and existing methods can be clearly categorized: word representations are distributed according to an exponential family with either uniform or Zipfian base measures. By adopting the latter approach, we can naturally emphasize informative low-frequency words in terms of their vector norm, which becomes evident from the information-geometric perspective, and in terms of the loss functions for imbalanced classification. Additionally, our theory corroborates that popular natural language processing methods, such as skip-gram negative sampling, WhiteningBERT, and headless language models, work well just because their word embeddings encode the empirical word frequency into the underlying probabilistic model.
tl;dr: We propose a diffeomorphic interpolation of (typically sparse) gradients appearing in Topological Data Analysis, yielding substantially faster and smoother optimization schemes.

Topological Data Analysis (TDA) provides a pipeline to extract quantitative and powerful topological descriptors from structured objects.
This enables the definition of topological loss functions, which assert to which extent a given object exhibits some topological properties.
One can then use these losses to perform topological optimization via gradient descent routines.
While theoretically sounded, topological optimization faces an important challenge: gradients tend to be extremely sparse, in the sense that the loss function typically depends (locally) on only very few coordinates of the input object, yielding dramatically slow optimization schemes in practice.
In this work, focusing on the central case of topological optimization for point clouds, we propose to overcome this limitation using diffeomorphic interpolation, turning sparse gradients into smooth vector fields defined on the whole space.
In particular, this approach combines efficiently with subsampling techniques routinely used in TDA, as the diffeomorphism derived from the gradient computed on the subsample can be used to update the coordinates of the full and possibly large input object. We then illustrate the usefulness of our approach on black-box autoencoder (AE) regularization, where we aim at applying some topological priors on the latent spaces associated to fixed, black-box AE models without modifying their (unknown) architectures and parameters. We empirically show that, while vanilla topological optimization has to be re-run every time that new data comes out of the black-box models, learning a diffeomorphic flow can be done once and then re-applied to new data in linear time. Moreover, reverting the flow allows us to generate data by sampling the topologically-optimized latent space directly, allowing for better interpretability of the model.

While recent advancements in large multimodal models (LMMs) have significantly improved their abilities in image quality assessment (IQA) relying on absolute quality rating, how to transfer reliable relative quality comparison outputs to continuous perceptual quality scores remains largely unexplored. To address this gap, we introduce an all-around LMM-based NR-IQA model, which is capable of producing qualitatively comparative responses and effectively translating these discrete comparison outcomes into a continuous quality score. Specifically, during training, we present to generate scaled-up comparative instructions by comparing images from the same IQA dataset, allowing for more flexible integration of diverse IQA datasets. Utilizing the established large-scale training corpus, we develop a human-like visual quality comparator. During inference, moving beyond binary choices, we propose a soft comparison method that calculates the likelihood of the test image being preferred over multiple predefined anchor images. The quality score is further optimized by maximum a posteriori estimation with the resulting probability matrix. Extensive experiments on nine IQA datasets validate that the Compare2Score effectively bridges text-defined comparative levels during training with converted single image quality scores for inference, surpassing state-of-the-art IQA models across diverse scenarios. Moreover, we verify that the probability-matrix-based inference conversion not only improves the rating accuracy of Compare2Score but also zero-shot general-purpose LMMs, suggesting its intrinsic effectiveness.
tl;dr: This paper introduces a novel time-varying low-rank adapter that offers an effective fine-tuning framework for domain flow generation, and generation-based cross-domain learning methods to mitigate domain shifts.

Large-scale diffusion models are adept at generating high-fidelity images and facilitating image editing and interpolation. However, they have limitations when tasked with generating images in dynamic, evolving domains. In this paper, we introduce Terra, a novel Time-varying low-rank adapter that offers a fine-tuning framework specifically tailored for domain flow generation. The key innovation of Terra lies in its construction of a continuous parameter manifold through a time variable, with its expressive power analyzed theoretically. This framework not only enables interpolation of image content and style but also offers a generation-based approach to address the domain shift problems in unsupervised domain adaptation and domain generalization. Specifically, Terra transforms images from the source domain to the target domain and generates interpolated domains with various styles to bridge the gap between domains and enhance the model generalization, respectively. We conduct extensive experiments on various benchmark datasets, empirically demonstrate the effectiveness of Terra. Our source code is publicly available on https://github.com/zwebzone/terra.
tl;dr: We introduce the PoissonVAE, a novel architecture that encodes inputs into discrete spike counts and unifies established theoretical concepts in neuroscience with modern machine learning.

Variational autoencoders (VAE) employ Bayesian inference to interpret sensory inputs, mirroring processes that occur in primate vision across both ventral (Higgins et al., 2021) and dorsal (Vafaii et al., 2023) pathways. Despite their success, traditional VAEs rely on continuous latent variables, which significantly deviates from the discrete nature of biological neurons. Here, we developed the Poisson VAE (P-VAE), a novel architecture that combines principles of predictive coding with a VAE that encodes inputs into discrete spike counts. Combining Poisson-distributed latent variables with predictive coding introduces a metabolic cost term in the model loss function, suggesting a relationship with sparse coding which we verify empirically. Additionally, we analyze the geometry of learned representations, contrasting the P-VAE to alternative VAE models. We find that the P-VAE encodes its inputs in relatively higher dimensions, facilitating linear separability of categories in a downstream classification task with a much better (5x) sample efficiency. Our work provides an interpretable computational framework to study brain-like sensory processing and paves the way for a deeper understanding of perception as an inferential process.
tl;dr: Our algorithm efficiently models dynamical systems by observing high-dimensional noise-affected data, outperforming state-of-the-art counterparts in state estimation and image imputation tasks.

This paper advances temporal reasoning within dynamically changing high-dimensional noisy observations, focusing on a latent space that characterizes the nonlinear dynamics of objects in their environment. We introduce the *Gated Inference Network* (GIN), an efficient approximate Bayesian inference algorithm for state space models (SSMs) with nonlinear state transitions and emissions. GIN disentangles two latent representations: one representing the object derived from a nonlinear mapping model, and another representing the latent state describing its dynamics. This disentanglement enables direct state estimation and missing data imputation as the world evolves. To infer the latent state, we utilize a deep extended Kalman filter (EKF) approach that integrates a novel compact RNN structure to compute both the Kalman Gain (KG) and smoothing gain (SG), completing the data flow. This design results in a computational cost per step that is linearly faster than EKF but introduces issues such as the exploding gradient problem. To mitigate the exploding gradients caused by the compact RNN structure in our model, we propose a specialized learning method that ensures stable training and inference. The model is then trained end-to-end on videos depicting a diverse range of simulated and real-world physical systems, and outperforms its ounterparts —RNNs, autoregressive models, and variational approaches— in state estimation and missing data imputation tasks.
tl;dr: Starting from the Hadamard transform we develop a simple method for neuro-symbolic manipulation of vectors that has desirable properties for deep learning.

Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in $\mathbb{R}^d$ are 'bound' together to produce a new vector in the same space. VSAs support the commutativity and associativity of this binding operation, along with an inverse operation, allowing one to construct symbolic-style manipulations over real-valued vectors. Most VSAs were developed before deep learning and automatic differentiation became popular and instead focused on efficacy in hand-designed systems. In this work, we introduce the Hadamard-derived linear Binding (HLB), which is designed to have favorable computational efficiency, and efficacy in classic VSA tasks, and perform well in differentiable systems.
tl;dr: We analyze fine-tuning strategy of LP-FT from NTK perspective and demonstrates its effectiveness for language models.

The two-stage fine-tuning (FT) method, linear probing (LP) then fine-tuning (LP-FT), outperforms linear probing and FT alone. This holds true for both in-distribution (ID) and out-of-distribution (OOD) data. One key reason for its success is the preservation of pre-trained features, achieved by obtaining a near-optimal linear head during LP. However, despite the widespread use of large language models, there has been limited exploration of more complex architectures such as Transformers. In this paper, we analyze the training dynamics of LP-FT for classification tasks on the basis of the neural tangent kernel (NTK) theory. Our analysis decomposes the NTK matrix into two components. This decomposition highlights the importance of the linear head norm alongside the prediction accuracy at the start of the FT stage. We also observe a significant increase in the linear head norm during LP, which stems from training with the cross-entropy (CE) loss. This increase in the linear head norm effectively reduces changes in learned features. Furthermore, we find that this increased norm can adversely affect model calibration, which can be corrected using temperature scaling. Additionally, we extend our analysis with the NTK to the low-rank adaptation (LoRA) method and validate its effectiveness. Our experiments using a Transformer-based model on multiple natural language processing datasets confirm our theoretical analysis. Our study demonstrates the effectiveness of LP-FT for fine-tuning language models. Code is available at https://github.com/tom4649/lp-ft_ntk.
tl;dr: We propose a novel UED algorithm that uses regret-guided diffusion models to improve agent robustness.

Training agents that are robust to environmental changes remains a significant challenge in deep reinforcement learning (RL). Unsupervised environment design (UED) has recently emerged to address this issue by generating a set of training environments tailored to the agent's capabilities. While prior works demonstrate that UED has the potential to learn a robust policy, their performance is constrained by the capabilities of the environment generation. To this end, we propose a novel UED algorithm, adversarial environment design via regret-guided diffusion models (ADD). The proposed method guides the diffusion-based environment generator with the regret of the agent to produce environments that the agent finds challenging but conducive to further improvement. By exploiting the representation power of diffusion models, ADD can directly generate adversarial environments while maintaining the diversity of training environments, enabling the agent to effectively learn a robust policy. Our experimental results demonstrate that the proposed method successfully generates an instructive curriculum of environments, outperforming UED baselines in zero-shot generalization across novel, out-of-distribution environments.
tl;dr: We study mirror descent and preconditioned gradient descent on Wasserstein space.

As the problem of minimizing functionals on the Wasserstein space encompasses many applications in machine learning, different optimization algorithms on $\mathbb{R}^d$ have received their counterpart analog on the Wasserstein space. We focus here on lifting two explicit algorithms: mirror descent and preconditioned gradient descent. These algorithms have been introduced to better capture the geometry of the function to minimize and are provably convergent under appropriate (namely relative) smoothness and convexity conditions. Adapting these notions to the Wasserstein space, we prove guarantees of convergence of some Wasserstein-gradient-based discrete-time schemes for new pairings of objective functionals and regularizers. The difficulty here is to carefully select along which curves the functionals should be smooth and convex. We illustrate the advantages of adapting the geometry induced by the regularizer on ill conditioned optimization tasks, and showcase the improvement of choosing different discrepancies and geometries in a computational biology task of aligning single-cells.
tl;dr: We theoretically investigate the expressive capacity of modern state-space models.

Recently, recurrent models based on linear state space models (SSMs) have shown promising performance in language modeling (LM), competititve with transformers. However, there is little understanding of the in-principle abilities of such models, which could provide useful guidance to the search for better LM architectures. We present a comprehensive theoretical study of the capacity of such SSMs as it compares to that of transformers and traditional RNNs. We find that SSMs and transformers have overlapping but distinct strengths. In star-free state tracking, SSMs implement straightforward and exact solutions to problems that transformers struggle to represent exactly. They can also model bounded hierarchical structure with optimal memory even without simulating a stack. On the other hand, we identify a design choice in current SSMs that limits their expressive power. We discuss implications for SSM and LM research, and verify results empirically on a recent SSM, Mamba.
tl;dr: We show that JEPA architectures are biased towards learning highly influential features

Two competing paradigms exist for self-supervised learning of data representations.
Joint Embedding Predictive Architectures (JEPAs) is a class of architectures in which semantically similar inputs are encoded into representations that are predictive of each other. A recent successful approach that falls under the JEPA framework is self-distillation, where an online encoder is trained to predict the output of the target encoder, sometimes with a lightweight predictor network. This is contrasted with the Masked Auto Encoder (MAE) paradigm, where an encoder and decoder are trained to reconstruct missing parts of the input in ambient space rather than its latent representation. A common motivation for using the JEPA approach over MAE is that the JEPA objective prioritizes abstract features over fine-grained pixel information (which can be unpredictable and uninformative).
In this work, we seek to understand the mechanism behind this empirical observation by analyzing deep linear models. We uncover a surprising mechanism: in a simplified linear setting where both approaches learn similar representations, JEPAs are biased to learn high influence features, or features characterized by having high regression coefficients. Our results point to a distinct implicit bias of predicting in latent space that may shed light on its success in practice.
tl;dr: We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once.

We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes.
tl;dr: A novel federated offline reinforcement learning algorithm

We consider the problem of federated offline reinforcement learning (RL), a scenario under which distributed learning agents must collaboratively learn a high-quality control policy only using small pre-collected datasets generated according to different unknown behavior policies. Na\"{i}vely combining a standard offline RL approach with a standard federated learning approach to solve this problem can lead to poorly performing policies. In response, we develop the Federated Ensemble-Directed Offline Reinforcement Learning Algorithm (FEDORA), which distills the collective wisdom of the clients using an ensemble learning approach. We develop the FEDORA codebase to utilize distributed compute resources on a federated learning platform. We show that FEDORA significantly outperforms other approaches, including offline RL over the combined data pool, in various complex continuous control environments and real-world datasets. Finally, we demonstrate the performance of FEDORA in the real-world on a mobile robot. We provide our code and a video of our experiments at \url{https://github.com/DesikRengarajan/FEDORA}.
tl;dr: Differentiable learning of task graphs of procedural activities from action sequences, enabling end-to-end models with emerging video understanding capabilities, tested on online mistake action detection in procedural egocentric videos.

Procedural activities are sequences of key-steps aimed at achieving specific goals. They are crucial to build intelligent agents able to assist users effectively. In this context, task graphs have emerged as a human-understandable representation of procedural activities, encoding a partial ordering over the key-steps. While previous works generally relied on hand-crafted procedures to extract task graphs from videos, in this paper, we propose an approach based on direct maximum likelihood optimization of edges' weights, which allows gradient-based learning of task graphs and can be naturally plugged into neural network architectures. Experiments on the CaptainCook4D dataset demonstrate the ability of our approach to predict accurate task graphs from the observation of action sequences, with an improvement of +16.7% over previous approaches. Owing to the differentiability of the proposed framework, we also introduce a feature-based approach, aiming to predict task graphs from key-step textual or video embeddings, for which we observe emerging video understanding abilities. Task graphs learned with our approach are also shown to significantly enhance online mistake detection in procedural egocentric videos, achieving notable gains of +19.8% and +7.5% on the Assembly101-O and EPIC-Tent-O datasets. Code for replicating the experiments is available at https://github.com/fpv-iplab/Differentiable-Task-Graph-Learning.
221. Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning
tl;dr: We derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced initialization variances and learning rates determine the degree of feature learning in a finite-width network.

While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this *rich feature learning regime* remain elusive, with much of our theoretical understanding stemming from the opposing *lazy regime*. In this work, we derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced *layer-specific* initialization variances and learning rates determine the degree of feature learning. Our analysis reveals that they conspire to influence the learning regime through a set of conserved quantities that constrain and modify the geometry of learning trajectories in parameter and function space. We extend our analysis to more complex linear models with multiple neurons, outputs, and layers and to shallow nonlinear networks with piecewise linear activation functions. In linear networks, rapid feature learning only occurs from balanced initializations, where all layers learn at similar speeds. While in nonlinear networks, unbalanced initializations that promote faster learning in earlier layers can accelerate rich learning. Through a series of experiments, we provide evidence that this unbalanced rich regime drives feature learning in deep finite-width networks, promotes interpretability of early layers in CNNs, reduces the sample complexity of learning hierarchical data, and decreases the time to grokking in modular arithmetic. Our theory motivates further exploration of unbalanced initializations to enhance efficient feature learning.
tl;dr: We introduce a framework for zero-shot inference of Markov jump processes from time series data. Our foundation model performs on par with state-of-the-art models which are finetuned on the target datasets.

Markov jump processes are continuous-time stochastic processes which describe dynamical systems evolving in discrete state spaces. These processes find wide application in the natural sciences and machine learning, but their inference is known to be far from trivial. In this work we introduce a methodology for *zero-shot inference* of Markov jump processes (MJPs), on bounded state spaces, from noisy and sparse observations, which consists of two components. First, a broad probability distribution over families of MJPs, as well as over possible observation times and noise mechanisms, with which we simulate a synthetic dataset of hidden MJPs and their noisy observations. Second, a neural recognition model that processes subsets of the simulated observations, and that is trained to output the initial condition and rate matrix of the target MJP in a supervised way. We empirically demonstrate that *one and the same* (pretrained) recognition model can infer, *in a zero-shot fashion*, hidden MJPs evolving in state spaces of different dimensionalities. Specifically, we infer MJPs which describe (i) discrete flashing ratchet systems, which are a type of Brownian motors, and the conformational dynamics in (ii) molecular simulations, (iii) experimental ion channel data and (iv) simple protein folding models. What is more, we show that our model performs on par with state-of-the-art models which are trained on the target datasets.
Our pretrained model is available online.
tl;dr: We reveal common flaws of Selective Classification evaluation metrics such as the AURC and propose a suitable alternative based on the Generalized Risk.

Selective Classification, wherein models can reject low-confidence predictions, promises reliable translation of machine-learning based classification systems to real-world scenarios such as clinical diagnostics. While current evaluation of these systems typically assumes fixed working points based on pre-defined rejection thresholds, methodological progress requires benchmarking the general performance of systems akin to the $\mathrm{AUROC}$ in standard classification. In this work, we define 5 requirements for multi-threshold metrics in selective classification regarding task alignment, interpretability, and flexibility, and show how current approaches fail to meet them. We propose the Area under the Generalized Risk Coverage curve ($\mathrm{AUGRC}$), which meets all requirements and can be directly interpreted as the average risk of undetected failures. We empirically demonstrate the relevance of $\mathrm{AUGRC}$ on a comprehensive benchmark spanning 6 data sets and 13 confidence scoring functions. We find that the proposed metric substantially changes metric rankings on 5 out of the 6 data sets.

Chain-of-Thought (CoT) reasoning has emerged as a promising approach for enhancing the performance of large language models (LLMs) on complex reasoning tasks. Recently, a series of studies attempt to explain the mechanisms underlying CoT, aiming to deepen the understanding of its efficacy. Nevertheless, the existing research faces two major challenges: (1) a lack of quantitative metrics to assess CoT capabilities and (2) a dearth of guidance on optimizing CoT performance. Motivated by this, in this work, we introduce a novel reasoning boundary framework (RBF) to address these challenges. To solve the lack of quantification, we first define a reasoning boundary (RB) to quantify the upper-bound of CoT and establish a combination law for RB, enabling a practical quantitative approach applicable to various real-world CoT tasks. To address the lack of optimization, we propose three categories of RBs. We further optimize these categories with combination laws focused on RB promotion and reasoning path optimization for CoT improvement. Through extensive experiments on 27 models and 5 tasks, the study validates the existence and rationality of the proposed framework. Furthermore, it explains the effectiveness of 10 CoT strategies and guides optimization from two perspectives. We hope this work can provide a comprehensive understanding of the boundaries and optimization strategies for reasoning in LLMs. Our code and data are available at https://github.com/LightChen233/reasoning-boundary.
tl;dr: We show that partners' specialization is crucial for training a robust generalist and propose a method that reduces overfitness of XP-min partners that already have good specialization

Partner diversity is known to be crucial for training a robust generalist cooperative agent. In this paper, we show that partner specialization, in addition to diversity, is crucial for the robustness of a downstream generalist agent. We propose a principled method for quantifying both the diversity and specialization of a partner population based on the concept of mutual information. Then, we observe that the recently proposed cross-play minimization (XP-min) technique produces diverse and specialized partners. However, the generated partners are overfit, reducing their usefulness as training partners. To address this, we propose simple methods, based on reinforcement learning and supervised learning, for extracting the diverse and specialized behaviors of XP-min generated partners but not their overfitness. We demonstrate empirically that the proposed method effectively removes overfitness, and extracted populations produce more robust generalist agents compared to the source XP-min populations.

Current approaches using sequential networks have shown promise in estimating field variables for dynamical systems, but they are often limited by high rollout errors. The unresolved issue of rollout error accumulation results in unreliable estimations as the network predicts further into the future, with each step's error compounding and leading to an increase in inaccuracy. Here, we introduce the State-Exchange Attention (SEA) module, a novel transformer-based module enabling information exchange between encoded fields through multi-head cross-attention. The cross-field multidirectional information exchange design enables all state variables in the system to exchange information with one another, capturing physical relationships and symmetries between fields. Additionally, we introduce an efficient ViT-like mesh autoencoder to generate spatially coherent mesh embeddings for a large number of meshing cells. The SEA integrated transformer demonstrates the state-of-the-art rollout error compared to other competitive baselines. Specifically, we outperform PbGMR-GMUS Transformer-RealNVP and GMR-GMUS Transformer, with a reduction in error of 88% and 91%, respectively. Furthermore, we demonstrate that the SEA module alone can reduce errors by 97% for state variables that are highly dependent on other states of the system. The repository for this work is available at: https://github.com/ParsaEsmati/SEA
tl;dr: On standard English vision benchmarks (e.g. ImageNet), translating multilingual data into English and allowing more of such data to be included in the training set boost performance substantially, even if some of the benchmarks are English-centric.

Massive web-crawled image-text datasets lay the foundation for recent progress in multimodal learning. These datasets are designed with the goal of training a model to do well on standard computer vision benchmarks, many of which, however, have been shown to be English-centric (e.g., ImageNet). Consequently, existing data curation techniques gravitate towards using predominantly English image-text pairs and discard many potentially useful non-English samples. Our work questions this practice. Multilingual data is inherently enriching not only because it provides a gateway to learn about culturally salient concepts, but also because it depicts common concepts differently from monolingual data. We thus conduct a systematic study to explore the performance benefits of using more samples of non-English origins with respect to English vision tasks. By translating all multilingual image-text pairs from a raw web crawl to English and re-filtering them, we increase the prevalence of (translated) multilingual data in the resulting training set. Pre-training on this dataset outperforms using English-only or English-dominated datasets on ImageNet, ImageNet distribution shifts, image-English-text retrieval and on average across 38 tasks from the DataComp benchmark. On a geographically diverse task like GeoDE, we also observe improvements across all regions, with the biggest gain coming from Africa. In addition, we quantitatively show that English and non-English data are significantly different in both image and (translated) text space. We hope that our findings motivate future work to be more intentional about including multicultural and multilingual data, not just when non-English or geographically diverse tasks are involved, but to enhance model capabilities at large.
tl;dr: Making the training dynamics of the first layer of vision models similar to those of the embedding layer of language models.

We consider the training of the first layer of vision models and notice the clear relationship between pixel values and gradient update magnitudes: the gradients arriving at the weights of a first layer are by definition directly proportional to (normalized) input pixel values. Thus, an image with low contrast has a smaller impact on learning than an image with higher contrast, and a very bright or very dark image has a stronger impact on the weights than an image with moderate brightness. In this work, we propose performing gradient descent on the embeddings produced by the first layer of the model. However, switching to discrete inputs with an embedding layer is not a reasonable option for vision models. Thus, we propose the conceptual procedure of (i) a gradient descent step on first layer activations to construct an activation proposal, and (ii) finding the optimal weights of the first layer, i.e., those weights which minimize the squared distance to the activation proposal. We provide a closed form solution of the procedure and adjust it for robust stochastic training while computing everything efficiently. Empirically, we find that TrAct (Training Activations) speeds up training by factors between 1.25x and 4x while requiring only a small computational overhead. We demonstrate the utility of TrAct with different optimizers for a range of different vision models including convolutional and transformer architectures.
229. Fundamental Limits of Prompt Compression: A Rate-Distortion Framework for Black-Box Language Models
tl;dr: We formalize and study fundamental limits of prompt compression for large language models via a rate-distortion framework.

We formalize the problem of prompt compression for large language models (LLMs) and present a framework to unify token-level prompt compression methods which create hard prompts for black-box models. We derive the distortion-rate function for this setup as a linear program, and provide an efficient algorithm to compute this fundamental limit via the dual of the linear program. Using the distortion-rate function as the baseline, we study the performance of existing compression schemes on a synthetic dataset consisting of prompts generated from a Markov chain, natural language queries, and their respective answers. Our empirical analysis demonstrates the criticality of query-aware prompt compression, where the compressor has knowledge of the downstream task/query for the black-box LLM. We show that there is a large gap between the performance of current prompt compression methods and the optimal strategy, and propose Adaptive QuerySelect, a query-aware, variable-rate adaptation of a prior work to close the gap. We extend our experiments to a small natural language dataset to further confirm our findings on our synthetic dataset.
tl;dr: Taming pre-trained language models as foundation models for personalized on-device meteorological variables modeling.

This paper demonstrates that pre-trained language models (PLMs) are strong foundation models for on-device meteorological variable modeling. We present LM-Weather, a generic approach to taming PLMs, that have learned massive sequential knowledge from the universe of natural language databases, to acquire an immediate capability to obtain highly customized models for heterogeneous meteorological data on devices while keeping high efficiency. Concretely, we introduce a lightweight personalized adapter into PLMs and endows it with weather pattern awareness. During communication between clients and the server, low-rank-based transmission is performed to effectively fuse the global knowledge among devices while maintaining high communication efficiency and ensuring privacy. Experiments on real-wold dataset show that LM-Weather outperforms the state-of-the-art results by a large margin across various tasks (e.g., forecasting and imputation at different scales). We provide extensive and in-depth analyses experiments, which verify that LM-Weather can (1) indeed leverage sequential knowledge from natural language to accurately handle meteorological sequence, (2) allows each devices obtain highly customized models under significant heterogeneity, and (3) generalize under data-limited and out-of-distribution (OOD) scenarios.

Generative diffusion models and many stochastic models in science and engineering naturally live in infinite dimensions before discretisation. To incorporate observed data for statistical and learning tasks, one needs to condition on observations. While recent work has treated conditioning linear processes in infinite dimensions, conditioning non-linear processes in infinite dimensions has not been explored. This paper conditions function valued stochastic processes without prior discretisation. To do so, we use an infinite-dimensional version of Girsanov's theorem to condition a function-valued stochastic process, leading to a stochastic differential equation (SDE) for the conditioned process involving the score. We apply this technique to do time series analysis for shapes of organisms in evolutionary biology, where we discretise via the Fourier basis and then learn the coefficients of the score function with score matching methods.
tl;dr: Gaussian-based proximal samplers face accuracy limits sampling heavy-tailed targets. Stable-based samplers offer high-accuracy guarantees, surpassing this constraint.

We study the complexity of heavy-tailed sampling and present a separation result in terms of obtaining high-accuracy versus low-accuracy guarantees i.e., samplers that require only $\mathcal{O}(\log(1/\varepsilon))$ versus $\Omega(\text{poly}(1/\varepsilon))$ iterations to output a sample which is $\varepsilon$-close to the target in $\chi^2$-divergence. Our results are presented for proximal samplers that are based on Gaussian versus stable oracles. We show that proximal samplers based on the Gaussian oracle have a fundamental barrier in that they necessarily achieve only low-accuracy guarantees when sampling from a class of heavy-tailed targets. In contrast, proximal samplers based on the stable oracle exhibit high-accuracy guarantees, thereby overcoming the aforementioned limitation. We also prove lower bounds for samplers under the stable oracle and show that our upper bounds cannot be fundamentally improved.

Training high-quality deep models necessitates vast amounts of data, resulting in overwhelming computational and memory demands. Recently, data pruning, distillation, and coreset selection have been developed to streamline data volume by \textit{retaining}, \textit{synthesizing}, or \textit{selecting} a small yet informative subset from the full set. Among these methods, data pruning incurs the least additional training cost and offers the most practical acceleration benefits. However, it is the most vulnerable, often suffering significant performance degradation with imbalanced or biased data schema, thus raising concerns about its accuracy and reliability in on-device deployment. Therefore, there is a looming need for a new data pruning paradigm that maintains the efficiency of previous practices while ensuring balance and robustness.
Unlike the fields of computer vision and natural language processing, where mature solutions have been developed to address these issues, graph neural networks (GNNs) continue to struggle with increasingly large-scale, imbalanced, and noisy datasets, lacking a unified dataset pruning solution.
To achieve this, we introduce a novel dynamic soft-pruning method, \ourmethod, designed to update the training ``basket'' during the process using trainable prototypes. \ourmethod first constructs a well-modeled graph embedding hypersphere and then samples \textit{representative, balanced, and unbiased subsets} from this embedding space, which achieves the goal we called {\fontfamily{lmtt}\selectfont \textbf{Graph Training Debugging}}.
Extensive experiments on four datasets across three GNN backbones, demonstrate that \ourmethod (I) achieves or surpasses the performance of the full dataset with $30\%\sim50\%$ fewer training samples, (II) attains up to a $2.81\times$ lossless training speedup, and (III) outperforms state-of-the-art pruning methods in imbalanced training and noisy training scenarios by $0.3\%\sim4.3\%$ and $3.6\%\sim7.8\%$, respectively.
tl;dr: In this paper, we develop private algorithms for computing the geometric median of a dataset with an adaptive error guarantee.

In this paper, we study differentially private (DP) algorithms for computing the geometric median (GM) of a dataset: Given $n$ points, $x_1,\dots,x_n$ in $\mathbb{R}^d$, the goal is to find a point $\theta$ that minimizes the sum of the Euclidean distances to these points, i.e., $\sum_{i=1}^{n} \lVert|\theta - x_i\rVert_2$. Off-the-shelf methods, such as DP-GD, require strong a priori knowledge locating the data within a ball of radius $R$, and the excess risk of the algorithm depends linearly on $R$. In this paper, we ask: can we design an efficient and private algorithm with an excess error guarantee that scales with the (unknown) radius containing the majority of the datapoints? Our main contribution is a pair of polynomial-time DP algorithms for the task of private GM with an excess error guarantee that scales with the effective diameter of the datapoints. Additionally, we propose an inefficient algorithm based on the inverse smooth sensitivity mechanism, which satisfies the more restrictive notion of pure DP. We complement our results with a lower bound and demonstrate the optimality of our polynomial-time algorithms in terms of sample complexity.
tl;dr: We study parameterized multi-layers graph homomorphism networks where homomorphism mappings acted as convolutional kernels. The proposed multi-layers graph homomorphism can be understood by using rooted graph product homormorphism.

Many real-world graphs are large and have some characteristic subgraph patterns, such as triangles in social networks, cliques in web graphs, and cycles in molecular networks.
Detecting such subgraph patterns is important in many applications; therefore, establishing graph neural networks (GNNs) that can detect such patterns and run fast on large graphs is demanding.
In this study, we propose a new GNN layer, named \emph{graph homomorphism layer}.
It enumerates local subgraph patterns that match the predefined set of patterns $\mathcal{P}^\bullet$, applies non-linear transformations to node features, and aggregates them along with the patterns.
By stacking these layers, we obtain a deep GNN model called \emph{deep homomorphism network (DHN)}.
The expressive power of the DHN is completely characterised by the set of patterns generated from $\mathcal{P}^\bullet$ by graph-theoretic operations;
hence, it serves as a useful theoretical tool to analyse the expressive power of many GNN models.
Furthermore, the model runs in the same time complexity as the graph homomorphisms, which is fast in many real-word graphs.
Thus, it serves as a practical and lightweight model that solves difficult problems using domain knowledge.
tl;dr: This paper proposes an efficient method to train multivariate probabilistic time series forecasting models with temporally-correlated errors.

Accurately modeling the correlation structure of errors is critical for reliable uncertainty quantification in probabilistic time series forecasting. While recent deep learning models for multivariate time series have developed efficient parameterizations for time-varying contemporaneous covariance, but they often assume temporal independence of errors for simplicity. However, real-world data often exhibit significant error autocorrelation and cross-lag correlation due to factors such as missing covariates. In this paper, we introduce a plug-and-play method that learns the covariance structure of errors over multiple steps for autoregressive models with Gaussian-distributed errors. To ensure scalable inference and computational efficiency, we model the contemporaneous covariance using a low-rank-plus-diagonal parameterization and capture cross-covariance through a group of independent latent temporal processes. The learned covariance matrix is then used to calibrate predictions based on observed residuals. We evaluate our method on probabilistic models built on RNNs and Transformer architectures, and the results confirm the effectiveness of our approach in improving predictive accuracy and uncertainty quantification without significantly increasing the parameter size.
tl;dr: We propose a novel MSA generative pre-training framework to yield faithful and informative MSA to promote structure prediction accuracy in a low-MSA regime. Studies of transfer learning also show its great potential to benefit other protein tasks.

Multiple Sequence Alignment (MSA) plays a pivotal role in unveiling the evolutionary trajectories of protein families. The accuracy of protein structure predictions is often compromised for protein sequences that lack sufficient homologous information to construct high-quality MSA. Although various methods have been proposed to generate high-quality MSA under these conditions, they fall short in comprehensively capturing the intricate co-evolutionary patterns within MSA or require guidance from external oracle models. Here we introduce MSAGPT, a novel approach to prompt protein structure predictions via MSA generative pre-training in a low-MSA regime. MSAGPT employs a simple yet effective 2D evolutionary positional encoding scheme to model the complex evolutionary patterns. Endowed by this, the flexible 1D MSA decoding framework facilitates zero- or few-shot learning. Moreover, we demonstrate leveraging the feedback from AlphaFold2 (AF2) can further enhance the model’s capacity via Rejective Fine-tuning (RFT) and Reinforcement Learning from AF2 Feedback (RLAF). Extensive experiments confirm the efficacy of MSAGPT in generating faithful and informative MSA (up to +8.5% TM-Score on few-shot scenarios). The transfer learning also demonstrates its great potential for the wide range of tasks resorting to the quality of MSA.
tl;dr: We present Policy Learning from Tutorial Books (PLfB), a new topic to train policy networks using text resources. Our implementation combines advanced LLM and RL techniques, achieving strong results in Tic-Tac-Toe and Football game.

When humans need to learn a new skill, we can acquire knowledge through written books, including textbooks, tutorials, etc. However, current research for decision-making, like reinforcement learning (RL), has primarily required numerous real interactions with the target environment to learn a skill, while failing to utilize the existing knowledge already summarized in the text. The success of Large Language Models (LLMs) sheds light on utilizing such knowledge behind the books. In this paper, we discuss a new policy learning problem called Policy Learning from tutorial Books (PLfB) upon the shoulders of LLMs’ systems, which aims to leverage rich resources such as tutorial books to derive a policy network. Inspired by how humans learn from books, we solve the problem via a three-stage framework: Understanding, Rehearsing, and Introspecting (URI). In particular, it first rehearses decision-making trajectories based on the derived knowledge after understanding the books, then introspects in the imaginary dataset to distill a policy network.
We build two benchmarks for PLfB~based on Tic-Tac-Toe and Football games. In experiment, URI's policy achieves at least 44% net win rate against GPT-based agents without any real data; In Football game, which is a complex scenario, URI's policy beat the built-in AIs with a 37% while using GPT-based agent can only achieve a 6\% winning rate. The project page: https://plfb-football.github.io.
tl;dr: This paper unifies existing pairwise information injection methods for temporal link prediction into a function of temporal walk matrices and introduces an efficient method for maintaining temporal walk matrices

Temporal link prediction, aiming at predicting future interactions among entities based on historical interactions, is crucial for a series of real-world applications. Although previous methods have demonstrated the importance of relative encodings for effective temporal link prediction, computational efficiency remains a major concern in constructing these encodings. Moreover, existing relative encodings are usually constructed based on structural connectivity, where temporal information is seldom considered. To address the aforementioned issues, we first analyze existing relative encodings and unify them as a function of temporal walk matrices. This unification establishes a connection between relative encodings and temporal walk matrices, providing a more principled way for analyzing and designing relative encodings. Based on this analysis, we propose a new temporal graph neural network called TPNet, which introduces a temporal walk matrix that incorporates the time decay effect to simultaneously consider both temporal and structural information. Moreover, TPNet designs a random feature propagation mechanism with theoretical guarantees to implicitly maintain the temporal walk matrices, which improves the computation and storage efficiency. Experimental results on 13 benchmark datasets verify the effectiveness and efficiency of TPNet, where TPNet outperforms other baselines on most datasets and achieves a maximum speedup of $33.3 \times$ compared to the SOTA baseline.

Multivariate Time Series (MTS) forecasting is a fundamental task with numerous real-world applications, such as transportation, climate, and epidemiology. While a myriad of powerful deep learning models have been developed for this task, few works have explored the robustness of MTS forecasting models to malicious attacks, which is crucial for their trustworthy employment in high-stake scenarios. To address this gap, we dive deep into the backdoor attacks on MTS forecasting models and propose an effective attack method named BackTime. By subtly injecting a few \textit{stealthy triggers} into the MTS data, BackTime can alter the predictions of the forecasting model according to the attacker's intent. Specifically, BackTime first identifies vulnerable timestamps in the data for poisoning, and then adaptively synthesizes stealthy and effective triggers by solving a bi-level optimization problem with a GNN-based trigger generator. Extensive experiments across multiple datasets and state-of-the-art MTS forecasting models demonstrate the effectiveness, versatility, and stealthiness of BackTime attacks.

Speech language models have significantly advanced in generating realistic speech, with neural codec language models standing out. However, the integration of preference optimization to align speech outputs to human preferences is often neglected. This paper addresses this gap by first analyzing the distribution gap in codec language models, highlighting how it leads to discrepancies between the training and inference phases, which negatively affects performance. Then we explore leveraging preference optimization to bridge the distribution gap. We introduce SpeechAlign, an iterative self-improvement strategy that aligns speech language models to human preferences. SpeechAlign involves constructing a preference codec dataset contrasting golden codec tokens against synthetic tokens, followed by preference optimization to improve the codec language model. This cycle of improvement is carried out iteratively to steadily convert weak models to strong ones. Through both subjective and objective evaluations, we show that SpeechAlign can bridge the distribution gap and facilitating continuous self-improvement of the speech language model. Moreover, SpeechAlign exhibits robust generalization capabilities and works for smaller models. Demos are available at https://0nutation.github.io/SpeechAlign.github.io/.

Data-driven models learned often struggle to generalize due to widespread subpopulation shifts, especially the presence of both spurious correlations and group imbalance (SC-GI). To learn models more powerful for defending against SC-GI, we propose a {\bf Correlation-Oriented Disentanglement and Augmentation (CODA)} modeling scheme, which includes two unique developments: (1) correlation-oriented disentanglement and (2) strategic sample augmentation with reweighted consistency (RWC) loss. In (1), a bi-branch encoding process is developed to enable the disentangling of variant and invariant correlations by coordinating with a decoy classifier and the decoder reconstruction. In (2), a strategic sample augmentation based on disentangled latent features with RWC loss is designed to reinforce the training of a more generalizable model. The effectiveness of CODA is verified by benchmarking against a set of SOTA models in terms of worst-group accuracy and maximum group accuracy gap based on two famous datasets, ColoredMNIST and CelebA.

Backdoor attacks pose a serious threat to federated systems, where malicious clients optimize on the triggered distribution to mislead the global model towards a predefined target. Existing backdoor defense methods typically require either homogeneous assumption, validation datasets, or client optimization conflicts. In our work, we observe that benign heterogeneous distributions and malicious triggered distributions exhibit distinct parameter importance degrees. We introduce the Fisher Discrepancy Cluster and Rescale (FDCR) method, which utilizes Fisher Information to calculate the degree of parameter importance for local distributions. This allows us to reweight client parameter updates and identify those with large discrepancies as backdoor attackers. Furthermore, we prioritize rescaling important parameters to expedite adaptation to the target distribution, encouraging significant elements to contribute more while diminishing the influence of trivial ones. This approach enables FDCR to handle backdoor attacks in heterogeneous federated learning environments. Empirical results on various heterogeneous federated scenarios under backdoor attacks demonstrate the effectiveness of our method.
tl;dr: We introduce concept-based interventions for black-box models, formalise the model's intervenability as a measure of intervention effectiveness, and propose a fine-tuning procedure to improve intervenability.

Recently, interpretable machine learning has re-explored concept bottleneck models (CBM). An advantage of this model class is the user's ability to intervene on predicted concept values, affecting the downstream output. In this work, we introduce a method to perform such concept-based interventions on *pretrained* neural networks, which are not interpretable by design, only given a small validation set with concept labels. Furthermore, we formalise the notion of *intervenability* as a measure of the effectiveness of concept-based interventions and leverage this definition to fine-tune black boxes. Empirically, we explore the intervenability of black-box classifiers on synthetic tabular and natural image benchmarks. We focus on backbone architectures of varying complexity, from simple, fully connected neural nets to Stable Diffusion. We demonstrate that the proposed fine-tuning improves intervention effectiveness and often yields better-calibrated predictions. To showcase the practical utility of our techniques, we apply them to deep chest X-ray classifiers and show that fine-tuned black boxes are more intervenable than CBMs. Lastly, we establish that our methods are still effective under vision-language-model-based concept annotations, alleviating the need for a human-annotated validation set.

In many learning applications, data are collected from multiple sources, each providing a \emph{batch} of samples that by itself is insufficient to learn its input-output relationship. A common approach assumes that the sources fall in one of several unknown subgroups, each with an unknown input distribution and input-output relationship. We consider one of this setup's most fundamental and important manifestations where the output is a noisy linear combination of the inputs, and there are $k$ subgroups, each with its own regression vector. Prior work [KSS$^+$20] showed that with abundant small-batches, the regression vectors can be learned with only few, $\tilde\Omega( k^{3/2})$, batches of medium-size with $\tilde\Omega(\sqrt k)$ samples each. However, the paper requires that the input distribution for all $k$ subgroups be isotropic Gaussian, and states that removing this assumption is an ``interesting and challenging problem". We propose a novel gradient-based algorithm that improves on the existing results in several ways. It extends the applicability of the algorithm by: (1) allowing the subgroups' underlying input distributions to be different, unknown, and heavy-tailed; (2) recovering all subgroups followed by a significant proportion of batches even for infinite $k$; (3) removing the separation requirement between the regression vectors; (4) reducing the number of batches and allowing smaller batch sizes.

Due to its powerful representational capabilities, Transformers have gradually become the mainstream model in the field of machine vision. However, the vast and complex parameters of Transformers impede researchers from gaining a deep understanding of their internal mechanisms, especially error mechanisms. Existing methods for interpreting Transformers mainly focus on understanding them from the perspectives of the importance of input tokens or internal modules, as well as the formation and meaning of features. In contrast, inspired by research on information integration mechanisms and conjunctive errors in the biological visual system, this paper conducts an in-depth exploration of the internal error mechanisms of Transformers. We first propose an information integration hypothesis for Transformers in the machine vision domain and provide substantial experimental evidence to support this hypothesis. This includes the dynamic integration of information among tokens and the static integration of information within tokens in Transformers, as well as the presence of conjunctive errors therein. Addressing these errors, we further propose heuristic dynamic integration constraint methods and rule-based static integration constraint methods to rectify errors and ultimately improve model performance. The entire methodology framework is termed as Transformer Doctor, designed for diagnosing and treating internal errors within transformers. Through a plethora of quantitative and qualitative experiments, it has been demonstrated that Transformer Doctor can effectively address internal errors in transformers, thereby enhancing model performance.
tl;dr: The novel adaptable error detection (AED) problem is formulated for monitoring few-shot imitation policies' behaviors, and we propose PrObe to address the challenging problem by learning from the policy's feature representations.

We introduce a new task called Adaptable Error Detection (AED), which aims to identify behavior errors in few-shot imitation (FSI) policies based on visual observations in novel environments. The potential to cause serious damage to surrounding areas limits the application of FSI policies in real-world scenarios. Thus, a robust system is necessary to notify operators when FSI policies are inconsistent with the intent of demonstrations. This task introduces three challenges: (1) detecting behavior errors in novel environments, (2) identifying behavior errors that occur without revealing notable changes, and (3) lacking complete temporal information of the rollout due to the necessity of online detection. However, the existing benchmarks cannot support the development of AED because their tasks do not present all these challenges. To this end, we develop a cross-domain AED benchmark, consisting of 322 base and 153 novel environments. Additionally, we propose Pattern Observer (PrObe) to address these challenges. PrObe is equipped with a powerful pattern extractor and guided by novel learning objectives to parse discernible patterns in the policy feature representations of normal or error states. Through our comprehensive evaluation, PrObe demonstrates superior capability to detect errors arising from a wide range of FSI policies, consistently surpassing strong baselines. Moreover, we conduct detailed ablations and a pilot study on error correction to validate the effectiveness of the proposed architecture design and the practicality of the AED task, respectively. The AED project page can be found at https://aed-neurips.github.io/.
tl;dr: Addresses degeneracy issues in algorithm/model-agnostic goodness-of-fit inference such as assessing variable importance.

The widespread use of black box prediction methods has sparked an increasing interest in algorithm/model-agnostic approaches for quantifying goodness-of-fit, with direct ties to specification testing, model selection and variable importance assessment. A commonly used framework involves defining a predictiveness criterion, applying a cross-fitting procedure to estimate the predictiveness, and utilizing the difference in estimated predictiveness between two models as the test statistic. However, even after standardization, the test statistic typically fails to converge to a non-degenerate distribution under the null hypothesis of equal goodness, leading to what is known as the degeneracy issue. To addresses this degeneracy issue, we present a simple yet effective device, Zipper. It draws inspiration from the strategy of additional splitting of testing data, but encourages an overlap between two testing data splits in predictiveness evaluation. Zipper binds together the two overlapping splits using a slider parameter that controls the proportion of overlap. Our proposed test statistic follows an asymptotically normal distribution under the null hypothesis for any fixed slider value, guaranteeing valid size control while enhancing power by effective data reuse. Finite-sample experiments demonstrate that our procedure, with a simple choice of the slider, works well across a wide range of settings.

Adversarial attacks against graph neural networks (GNNs) through perturbations of the graph structure are increasingly common in social network tasks like rumor detection. Social media platforms capture diverse attack sequence samples through both machine and manual screening processes. Investigating effective ways to leverage these adversarial samples to enhance robustness is imperative. We improve the maximum entropy inverse reinforcement learning (IRL) method with the mixture-of-experts approach to address multi-source graph adversarial attacks. This method reconstructs the attack policy, integrating various attack models and providing feature-level explanations, subsequently generating additional adversarial samples to fortify the robustness of detection models. We develop precise sample guidance and a bidirectional update mechanism to reduce the deviation caused by imprecise feature representation and negative sampling within the large action space of social graphs, while also accelerating policy learning. We take rumor detector as an example targeted GNN model on real-world rumor datasets. By utilizing a small subset of samples generated by various graph adversarial attack methods, we reconstruct the attack policy, closely approximating the performance of the original attack method. We validate that samples generated by the learned policy enhance model robustness through adversarial training and data augmentation.
tl;dr: We give an efficient algorithm for Centroid-Linkage Hierarchical Agglomerative Clustering (HAC), which computes a $c$-approximate clustering in $n^{1+1/c^2+o(1)}$ time and obtains significant speedups over existing baselines.

We give an algorithm for Centroid-Linkage Hierarchical Agglomerative Clustering (HAC), which computes a $c$-approximate clustering in roughly $n^{1+O(1/c^2)}$ time. We obtain our result by combining a new centroid-linkage HAC algorithm with a novel fully dynamic data structure for nearest neighbor search which works under adaptive updates.
We also evaluate our algorithm empirically. By leveraging a state-of-the-art nearest-neighbor search library, we obtain a fast and accurate centroid-linkage HAC algorithm. Compared to an existing state-of-the-art exact baseline, our implementation maintains the clustering quality while delivering up to a $36\times$ speedup due to performing fewer distance comparisons.

A striking property of transformers is their ability to perform in-context learning (ICL), a machine learning framework in which the learner is presented with a novel context during inference implicitly through some data, and tasked with making a prediction in that context. As such, that learner must adapt to the context without additional training. We explore the role of *softmax* attention in an ICL setting where each context encodes a regression task. We show that an attention unit learns a window that it uses to implement a nearest-neighbors predictor adapted to the landscape of the pretraining tasks. Specifically, we show that this window widens with decreasing Lipschitzness and increasing label noise in the pretraining tasks. We also show that on low-rank, linear problems, the attention unit learns to project onto the appropriate subspace before inference. Further, we show that this adaptivity relies crucially on the softmax activation and thus cannot be replicated by the linear activation often studied in prior theoretical analyses.
tl;dr: We introduce representation finetuning (ReFT), which is a powerful, efficient, and interpretable finetuning method.

Parameter-efficient finetuning (PEFT) methods seek to adapt large neural models via updates to a small number of *weights*. However, much prior interpretability work has shown that *representations* encode rich semantic information, suggesting that editing representations might be a more powerful alternative. We pursue this hypothesis by developing a family of **Representation Finetuning (ReFT)** methods. ReFT methods operate on a frozen base model and learn task-specific interventions on hidden representations. We define a strong instance of the ReFT family, Low-rank Linear Subspace ReFT (LoReFT), and we identify an ablation of this method that trades some performance for increased efficiency. Both are drop-in replacements for existing PEFTs and learn interventions that are 15x--65x more parameter-efficient than LoRA. We showcase LoReFT on eight commonsense reasoning tasks, four arithmetic reasoning tasks, instruction-tuning, and GLUE. In all these evaluations, our ReFTs deliver the best balance of efficiency and performance, and almost always outperform state-of-the-art PEFTs. Upon publication, we will publicly release our generic ReFT training library.

Large Language Models (LLMs) can elicit unintended and even harmful content when misaligned with human values, posing severe risks to users and society. To mitigate these risks, current evaluation benchmarks predominantly employ expert-designed contextual scenarios to assess how well LLMs align with human values. However, the labor-intensive nature of these benchmarks limits their test scope, hindering their ability to generalize to the extensive variety of open-world use cases and identify rare but crucial long-tail risks. Additionally, these static tests fail to adapt to the rapid evolution of LLMs, making it hard to evaluate timely alignment issues. To address these challenges, we propose ALI-Agent, an evaluation framework that leverages the autonomous abilities of LLM-powered agents to conduct in-depth and adaptive alignment assessments. ALI-Agent operates through two principal stages: Emulation and Refinement. During the Emulation stage, ALI-Agent automates the generation of realistic test scenarios. In the Refinement stage, it iteratively refines the scenarios to probe long-tail risks. Specifically, ALI-Agent incorporates a memory module to guide test scenario generation, a tool-using module to reduce human labor in tasks such as evaluating feedback from target LLMs, and an action module to refine tests. Extensive experiments across three aspects of human values--stereotypes, morality, and legality--demonstrate that ALI-Agent, as a general evaluation framework, effectively identifies model misalignment. Systematic analysis also validates that the generated test scenarios represent meaningful use cases, as well as integrate enhanced measures to probe long-tail risks.

In the adversarial streaming model, the input is a sequence of adaptive updates that defines an underlying dataset and the goal is to approximate, collect, or compute some statistic while using space sublinear in the size of the dataset. In 2022, Ben-Eliezer, Eden, and Onak showed a dense-sparse trade-off technique that elegantly combined sparse recovery with known techniques using differential privacy and sketch switching to achieve adversarially robust algorithms for $L_p$ estimation and other algorithms on turnstile streams. However, there has been no progress since, either in terms of achievability or impossibility. In this work, we first give improved algorithms for adversarially robust $L_p$-heavy hitters, utilizing deterministic turnstile heavy-hitter algorithms with better tradeoffs. We then utilize our heavy-hitter algorithm to reduce the problem to estimating the frequency moment of the tail vector. We give a new algorithm for this problem in the classical streaming setting, which achieves additive error and uses space independent in the size of the tail. We then leverage these ingredients to give an improved algorithm for adversarially robust $L_p$ estimation on turnstile streams. We believe that our results serve as an important conceptual message, demonstrating that there is no inherent barrier at the previous state-of-the-art.
tl;dr: We provide efficient non-adaptive algorithms that query a near-linear (and near-optimal) number of subset-queries to infer clustering of a set of elements exactly.

Recovering the underlying clustering of a set $U$ of $n$ points by asking pair-wise same-cluster queries has garnered significant interest in the last decade. Given a query $S \subset U$, $|S|=2$, the oracle returns "yes" if the points are in the same cluster and "no" otherwise. We study a natural generalization of this problem to subset queries for $|S|>2$, where the oracle returns the number of clusters intersecting $S$. Our aim is to determine the minimum number of queries needed for exactly recovering an arbitrary $k$-clustering. We focus on non-adaptive schemes, where all the queries are asked in one round, thus allowing for the querying process to be parallelized, which is a highly desirable property.
For adaptive algorithms with pair-wise queries, the complexity is known to be $\Theta(nk)$, where $k$ is the number of clusters.
In contrast, non-adaptive pair-wise query algorithms are extremely limited: even for $k=3$, such algorithms require $\Omega(n^2)$ queries, which matches the trivial $O(n^2)$ upper bound attained by querying every pair of points. Allowing for subset queries of unbounded size, $O(n)$ queries is possible with an adaptive scheme. However, the realm of non-adaptive algorithms remains completely unknown. Is it possible to attain algorithms that are non-adaptive while still making a near-linear number of queries?
In this paper, we give the first non-adaptive algorithms for clustering with subset queries. We provide, (i) a non-adaptive algorithm making $O(n \log^2 n \log k)$ queries which improves to $O(n \log k)$ when the cluster sizes are within any constant factor of each other, (ii) for constant $k$, a non-adaptive algorithm making $O(n \log{\log{n}})$ queries. In addition to non-adaptivity, we take into account other practical considerations, such as enforcing a bound on query size. For constant $k$, we give an algorithm making $\smash{\widetilde{O}(n^2/s^2)}$ queries on subsets of size at most $s \leq \sqrt{n}$, which is optimal among all non-adaptive algorithms within a $\log n$-factor. For arbitrary $k$, the dependence varies as $\tilde{O}(n^2/s)$.

Probabilistic integral circuits (PICs) have been recently introduced as probabilistic models enjoying the key ingredient behind expressive generative models: continuous latent variables (LVs). PICs are symbolic computational graphs defining continuous LV models as hierarchies of functions that are summed and multiplied together, or integrated over some LVs. They are tractable if LVs can be analytically integrated out, otherwise they can be approximated by tractable probabilistic circuits (PC) encoding a hierarchical numerical quadrature process, called QPCs.
So far, only tree-shaped PICs have been explored, and training them via numerical quadrature requires memory-intensive processing at scale. In this paper, we address these issues, and present: (i) a pipeline for building DAG-shaped PICs out of arbitrary variable decompositions, (ii) a procedure for training PICs using tensorized circuit architectures, and (iii) neural functional sharing techniques to allow scalable training. In extensive experiments, we showcase the effectiveness of functional sharing and the superiority of QPCs over traditional PCs.

Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performances for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a new approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing the overall test performance by aggregating diverse textual cues.
Our findings underscore the effectiveness of WATT across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without the need for additional model transformations or trainable modules. Moreover, compared to other TTA methods, our approach can operate effectively with just a single image. The code is available at: https://github.com/Mehrdad-Noori/WATT.
tl;dr: Robust Gaussian Processes with strong empirical performance, and surprising convexity and approximation guarantees.

Gaussian processes (GPs) are non-parametric probabilistic regression models that are popular due to their flexibility, data efficiency, and well-calibrated uncertainty estimates. However, standard GP models assume homoskedastic Gaussian noise, while many real-world applications are subject to non-Gaussian corruptions. Variants of GPs that are more robust to alternative noise models have been proposed, and entail significant trade-offs between accuracy and robustness, and between computational requirements and theoretical guarantees. In this work, we propose and study a GP model that achieves robustness against sparse outliers by inferring data-point-specific noise levels with a sequential selection procedure maximizing the log marginal likelihood that we refer to as relevance pursuit. We show, surprisingly, that the model can be parameterized such that the associated log marginal likelihood is strongly concave in the data-point-specific noise variances, a property rarely found in either robust regression objectives or GP marginal likelihoods. This in turn implies the weak submodularity of the corresponding subset selection problem, and thereby proves approximation guarantees for the proposed algorithm. We compare the model’s performance relative to other approaches on diverse regression and Bayesian optimization tasks, including the challenging but common setting of sparse corruptions of the labels within or close to the function range.
tl;dr: Plug-in approaches perform no worse than cross-validation approaches when estimating out-of-sample model performance.

Cross-Validation (CV) is the default choice for estimate the out-of-sample performance of machine learning models. Despite its wide usage, their statistical benefits have remained half-understood, especially in challenging nonparametric regimes. In this paper we fill in this gap and show that, in terms of estimating the out-of-sample performances, for a wide spectrum of models, CV does not statistically outperform the simple ``plug-in'' approach where one reuses training data for testing evaluation. Specifically, in terms of both the asymptotic bias and coverage accuracy of the associated interval for out-of-sample evaluation, $K$-fold CV provably cannot outperform plug-in regardless of the rate at which the parametric or nonparametric models converge. Leave-one-out CV can have a smaller bias as compared to plug-in; however, this bias improvement is negligible compared to the variability of the evaluation, and in some important cases leave-one-out again does not outperform plug-in once this variability is taken into account. We obtain our theoretical comparisons via a novel higher-order Taylor analysis that dissects the limit theorems of testing evaluations, which applies to model classes that are not amenable to previously known sufficient conditions. Our numerical results demonstrate that plug-in performs indeed no worse than CV in estimating model performance across a wide range of examples.
tl;dr: We trained a neural network to produce new automatic differentiation algorithms using Deep RL.

Computing Jacobians with automatic differentiation is ubiquitous in many scientific domains such as machine learning, computational fluid dynamics, robotics and finance.
Even small savings in the number of computations or memory usage in Jacobian computations can already incur massive savings in energy consumption and runtime.
While there exist many methods that allow for such savings, they generally trade computational efficiency for approximations of the exact Jacobian.
In this paper, we present a novel method to optimize the number of necessary multiplications for Jacobian computation by leveraging deep reinforcement learning (RL) and a concept called cross-country elimination while still computing the exact Jacobian.
Cross-country elimination is a framework for automatic differentiation that phrases Jacobian accumulation as ordered elimination of all vertices on the computational graph where every elimination incurs a certain computational cost.
Finding the optimal elimination order that minimizes the number of necessary multiplications can be seen as a single player game which in our case is played by an RL agent.
We demonstrate that this method achieves up to 33% improvements over state-of-the-art methods on several relevant tasks taken from relevant domains.
Furthermore, we show that these theoretical gains translate into actual runtime improvements by providing a cross-country elimination interpreter in JAX that can execute the obtained elimination orders.

As the deep integration of machine learning and intelligent education, Computerized Adaptive Testing (CAT) has received more and more research attention. Compared to traditional paper-and-pencil tests, CAT can deliver both personalized and interactive assessments by automatically adjusting testing questions according to the performance of students during the test process. Therefore, CAT has been recognized as an efficient testing methodology capable of accurately estimating a student’s ability with a minimal number of questions, leading to its widespread adoption in mainstream selective exams such as the GMAT and GRE. However, just improving the accuracy of ability estimation is far from satisfactory in the real-world scenarios, since an accurate ranking of students is usually more important (e.g., in high-stakes exams). Considering the shortage of existing CAT solutions in student ranking, this paper emphasizes the importance of aligning test outcomes (student ranks) with the true underlying abilities of students. Along this line, different from the conventional independent testing paradigm among students, we propose a novel collaborative framework, Collaborative Computerized Adaptive Testing (CCAT), that leverages inter-student information to enhance student ranking. By using collaborative students as anchors to assist in ranking test-takers, CCAT can give both theoretical guarantees and experimental validation for ensuring ranking consistency.

Computational intensiveness of deep learning has motivated low-precision arithmetic designs. However, the current quantized/binarized training approaches are limited by: (1) significant performance loss due to arbitrary approximations of the latent weight gradient through its discretization/binarization function, and (2) training computational intensiveness due to the reliance on full-precision latent weights.
This paper proposes a novel mathematical principle by introducing the notion of Boolean variation such that neurons made of Boolean weights and/or activations can be trained ---for the first time--- natively in Boolean domain instead of latent-weight gradient descent and real arithmetic. We explore its convergence, conduct extensively experimental benchmarking, and provide consistent complexity evaluation by considering chip architecture, memory hierarchy, dataflow, and arithmetic precision. Our approach achieves baseline full-precision accuracy in ImageNet classification and surpasses state-of-the-art results in semantic segmentation, with notable performance in image super-resolution, and natural language understanding with transformer-based models. Moreover, it significantly reduces energy consumption during both training and inference.
tl;dr: We introduce observational scaling laws that unify a large set of public LMs in a shared capability space, enabling a low-cost, high-resolution, and broad-coverage scaling analysis for complex LM phenomena

Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~100 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
tl;dr: Lagrangian formulation of Doob's h-transform allowing for an efficient rare event sampling

Rare event sampling in dynamical systems is a fundamental problem arising in the natural sciences, which poses significant computational challenges due to an exponentially large space of trajectories. For settings where the dynamical system of interest follows a Brownian motion with known drift, the question of conditioning the process to reach a given endpoint or desired rare event is definitively answered by Doob's $h$-transform. However, the naive estimation of this transform is infeasible, as it requires simulating sufficiently many forward trajectories to estimate rare event probabilities. In this work, we propose a variational formulation of Doob's $h$-transform as an optimization problem over trajectories between a given initial point and the desired ending point. To solve this optimization, we propose a simulation-free training objective with a model parameterization that imposes the desired boundary conditions by design. Our approach significantly reduces the search space over trajectories and avoids expensive trajectory simulation and inefficient importance sampling estimators which are required in existing methods. We demonstrate the ability of our method to find feasible transition paths on real-world molecular simulation and protein folding tasks.
tl;dr: We give a simple efficient algorithm for learning halfspaces with Massart noise.

We study the problem of PAC learning $\gamma$-margin halfspaces with Massart noise. We propose a simple proper learning algorithm, the Perspectron, that has sample complexity $\widetilde{O}((\epsilon\gamma)^{-2})$ and achieves classification error at most $\eta+\epsilon$ where $\eta$ is the Massart noise rate.
Prior works (DGT19, CKMY20) came with worse sample complexity
guarantees (in both $\epsilon$ and $\gamma$) or could only
handle random classification noise (DDKWZ23,KITBMV23)--- a much milder noise assumption.
We also show that our results extend to the more challenging setting of learning generalized linear models with a known link function under Massart noise, achieving a similar sample complexity to the halfspace case. This significantly improves upon the prior state-of-the-art in this setting due to CKMY20, who introduced this model.
tl;dr: We establish optimal sample complexity bounds for agnostic PAC in bandit multiclass classification with finite hypothesis classes and Natarajan classes

We study multiclass PAC learning with bandit feedback, where inputs are classified into one of $K$ possible labels and feedback is limited to whether or not the predicted labels are correct. Our main contribution is in designing a novel learning algorithm for the agnostic $(\varepsilon,\delta)$-PAC version of the problem, with sample complexity of $O\big( (\operatorname{poly}(K) + 1 / \varepsilon^2)
\log (|\mathcal{H}| / \delta) \big)$ for any finite hypothesis class $\mathcal{H}$. In terms of the leading dependence on $\varepsilon$, this improves upon existing bounds for the problem, that are of the form $O(K/\varepsilon^2)$. We also provide an extension of this result to general classes and establish similar sample complexity bounds in which $\log |\mathcal{H}|$ is replaced by the Natarajan dimension.
This matches the optimal rate in the full-information version of the problem and resolves an open question studied by Daniely, Sabato, Ben-David, and Shalev-Shwartz (2011) who demonstrated that the multiplicative price of bandit feedback in realizable PAC learning is $\Theta(K)$. We complement this by revealing a stark contrast with the agnostic case, where the price of bandit feedback is only $O(1)$ as $\varepsilon \to 0$. Our algorithm utilizes a stochastic optimization technique to minimize a log-barrier potential based on Frank-Wolfe updates for computing a low-variance exploration distribution over the hypotheses, and is made computationally efficient provided access to an ERM oracle over $\mathcal{H}$.
tl;dr: A private, robust and polynomial-time algorithm based on sum-of-squares hierarchy that achieves optimal error rate for edge density estimation of random graphs

We give the first polynomial-time, differentially node-private, and robust algorithm for estimating the edge density of Erdős-Rényi random graphs and their generalization, inhomogeneous random graphs. We further prove information-theoretical lower bounds, showing that the error rate of our algorithm is optimal up to logarithmic factors. Previous algorithms incur either exponential running time or suboptimal error rates.
Two key ingredients of our algorithm are (1) a new sum-of-squares algorithm for robust edge density estimation, and (2) the reduction from privacy to robustness based on sum-of-squares exponential mechanisms due to Hopkins et al. (STOC 2023).
tl;dr: A new family of loss functions based on monotone operator theory that lower bound Fenchel-Young losses, such as the the logistic loss.

Fenchel-Young losses are a family of convex loss functions,
encompassing the squared, logistic and sparsemax losses, among others.
Each Fenchel-Young loss is implicitly associated with a link function, for
mapping model outputs to predictions. For instance, the logistic loss is
associated with the soft argmax link function. Can we build new loss functions
associated with the same link function as Fenchel-Young losses?
In this paper, we introduce Fitzpatrick losses, a new family of convex loss
functions based on the Fitzpatrick function. A well-known theoretical tool in
maximal monotone operator theory, the Fitzpatrick function naturally leads to a
refined Fenchel-Young inequality, making Fitzpatrick losses tighter than
Fenchel-Young losses, while maintaining the same link
function for prediction.
As an example, we introduce the Fitzpatrick logistic loss and the
Fitzpatrick sparsemax loss, counterparts of the logistic and the sparsemax
losses. This yields two
new tighter losses associated with the soft argmax and the sparse argmax,
two of the most ubiquitous output layers used in machine learning. We study in
details the properties of Fitzpatrick losses and in particular, we show that
they can be seen as Fenchel-Young losses using a modified, target-dependent
generating function. We demonstrate the effectiveness of Fitzpatrick losses for
label proportion estimation.

Despite the recent observation that large language models (LLMs) can store substantial factual knowledge, there is a limited understanding of the mechanisms of how they acquire factual knowledge through pretraining. This work addresses this gap by studying how LLMs acquire factual knowledge during pretraining. The findings reveal several important insights into the dynamics of factual knowledge acquisition during pretraining. First, counterintuitively, we observe that pretraining on more data shows no significant improvement in the model's capability to acquire and maintain factual knowledge. Next, LLMs undergo forgetting of memorization and generalization of factual knowledge, and LLMs trained with duplicated training data exhibit faster forgetting. Third, training LLMs with larger batch sizes can enhance the models' robustness to forgetting. Overall, our observations suggest that factual knowledge acquisition in LLM pretraining occurs by progressively increasing the probability of factual knowledge presented in the pretraining data at each step. However, this increase is diluted by subsequent forgetting. Based on this interpretation, we demonstrate that we can provide plausible explanations on recently observed behaviors of LLMs, such as the poor performance of LLMs on long-tail knowledge and the benefits of deduplicating the pretraining corpus.

In neuroscience, recurrent neural networks (RNNs) are modeled as continuous-time dynamical systems to more accurately reflect the dynamics inherent in biological circuits. However, convolutional neural networks (CNNs) remain the preferred architecture in vision neuroscience due to their ability to efficiently process visual information, which comes at the cost of the biological realism provided by RNNs. To address this, we introduce a hybrid architecture that integrates the continuous-time recurrent dynamics of RNNs with the spatial processing capabilities of CNNs. Our models preserve the dynamical characteristics typical of RNNs while having comparable performance with their conventional CNN counterparts on benchmarks like ImageNet. Compared to conventional CNNs, our models demonstrate increased robustness to noise due to noise-suppressing mechanisms inherent in recurrent dynamical systems. Analyzing our architecture as a dynamical system is computationally expensive, so we develop a toolkit consisting of iterative methods specifically tailored for convolutional structures. We also train multi-area RNNs using our architecture as the front-end to perform complex cognitive tasks previously impossible to learn or achievable only with oversimplified stimulus representations. In monkey neural recordings, our models capture time-dependent variations in neural activity in higher-order visual areas. Together, these contributions represent a comprehensive foundation to unify the advances of CNNs and dynamical RNNs in vision neuroscience.

Offline reinforcement learning endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the out-of-distribution problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent advantage-weighted methods prioritize samples with high advantage values for agent training while inevitably ignoring the diversity of behavior policy. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a conditional variational auto-encoder to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to the counterparts. Our code is available at https://github.com/Plankson/A2PO.
tl;dr: The submission propose an general one-step diffusion distillation framework that induces efficient and stable instances with very strong performances.

Despite their strong performances on many generative tasks, diffusion models require a large number of sampling steps in order to generate realistic samples. This has motivated the community to develop effective methods to distill pre-trained diffusion models into more efficient models, but these methods still typically require few-step inference or perform substantially worse than the underlying model. In this paper, we present Score Implicit Matching (SIM) a new approach to distilling pre-trained diffusion models into single-step generator models, while maintaining almost the same sample generation ability as the original model as well as being data-free with no need of training samples for distillation. The method rests upon the fact that, although the traditional score-based loss is intractable to minimize for generator models, under certain conditions we \emph{can} efficiently compute the \emph{gradients} for a wide class of score-based divergences between a diffusion model and a generator. SIM shows strong empirical performances for one-step generators: on the CIFAR10 dataset, it achieves an FID of 2.06 for unconditional generation and 1.96 for class-conditional generation. Moreover, by applying SIM to a leading transformer-based diffusion model, we distill a single-step generator for text-to-image (T2I) generation that attains an aesthetic score of 6.42 with no performance decline over the original multi-step counterpart, clearly outperforming the other one-step generators including SDXL-TURBO of 5.33, SDXL-LIGHTNING of 5.34 and HYPER-SDXL of 5.85. We will release this industry-ready one-step transformer-based T2I generator along with this paper.
tl;dr: We provide theoretical justification for why the Lanczos-FA method outperforms other methods for approximating the action of a matrix function on a vector, f(A)b.

Approximating the action of a matrix function $f(\vec{A})$ on a vector $\vec{b}$ is an increasingly important primitive in machine learning, data science, and statistics, with applications such as sampling high dimensional Gaussians, Gaussian process regression and Bayesian inference, principle component analysis, and approximating Hessian spectral densities.
Over the past decade, a number of algorithms enjoying strong theoretical guarantees have been proposed for this task.
Many of the most successful belong to a family of algorithms called Krylov subspace methods.
Remarkably, a classic Krylov subspace method, called the Lanczos method for matrix functions (Lanczos-FA), frequently outperforms newer methods in practice. Our main result is a theoretical justification for this finding: we show that, for a natural class of rational functions, Lanczos-FA matches the error of the best possible Krylov subspace method up to a multiplicative approximation factor.
The approximation factor depends on the degree of $f(x)$'s denominator and the condition number of $\vec{A}$, but not on the number of iterations $k$. Our result provides a strong justification for the excellent performance of Lanczos-FA, especially on functions that are well approximated by rationals, such as the matrix square root.
tl;dr: We propose an alignment method for language models that include DPO as a special case

User intentions are typically formalized as evaluation rewards to be maximized when fine-tuning language models (LMs). Existing alignment methods, such as Direct Preference Optimization (DPO), are mainly tailored for pairwise preference data where rewards are implicitly defined rather than explicitly given. In this paper, we introduce a general framework for LM alignment, leveraging Noise Contrastive Estimation (NCE) to bridge the gap in handling reward datasets explicitly annotated with scalar evaluations. Our framework comprises two parallel algorithms, NCA and InfoNCA, both enabling the direct extraction of an LM policy from reward data as well as preference data. Notably, we show that the DPO loss is a special case of our proposed InfoNCA objective under pairwise preference settings, thereby integrating and extending current alignment theories. By comparing NCA and InfoNCA, we demonstrate that the well-observed decreasing-likelihood trend of DPO/InfoNCA is caused by their focus on adjusting relative likelihood across different responses.
In contrast, NCA optimizes the absolute likelihood for each response, thereby effectively preventing the chosen likelihood from decreasing. We evaluate our methods in both reward and preference settings with Mistral-8$\times$7B and 7B models. Experiments suggest that InfoNCA/NCA surpasses various preference baselines when reward datasets are available. We also find NCA significantly outperforms DPO in complex reasoning tasks like math and coding.
tl;dr: Robust and efficient Bayesian optimisation algorithm that elicits knowledge from human experts to accelerate optimisation.

Bayesian optimisation for real-world problems is often performed interactively with human experts, and integrating their domain knowledge is key to accelerate the optimisation process. We consider a setup where experts provide advice on the next query point through binary accept/reject recommendations (labels). Experts’ labels are often costly, requiring efficient use of their efforts, and can at the same time be unreliable, requiring careful adjustment of the degree to which any expert is trusted. We introduce the first principled approach that provides two key guarantees. (1) Handover guarantee: similar to a no-regret property, we establish a sublinear bound on the cumulative number of experts’ binary labels. Initially, multiple labels per query are needed, but the number of expert labels required asymptotically converges to zero, saving both expert effort and computation time. (2) No-harm guarantee with data-driven trust level adjustment: our adaptive trust level ensures that the convergence rate will not be worse than the one without using advice, even if the advice from experts is adversarial. Unlike existing methods that employ a user-defined function that hand-tunes the trust level adjustment, our approach enables data-driven adjustments. Real-world applications empirically demonstrate that our method not only outperforms existing baselines, but also maintains robustness despite varying labelling accuracy, in tasks of battery design with human experts.
tl;dr: We provide oracle-efficient algorithms capable of differentially private PAC learning any learnable function classes in the presence of public, unlabelled data.

Due to statistical lower bounds on the learnability of many function classes under privacy constraints, there has been recent interest in leveraging public data to improve the performance of private learning algorithms. In this model, algorithms must always guarantee differential privacy with respect to the private samples while also ensuring learning guarantees when the private data distribution is sufficiently close to that of the public data. Previous work has demonstrated that when sufficient public, unlabelled data is available, private learning can be made statistically tractable, but the resulting algorithms have all been computationally inefficient. In this work, we present the first computationally efficient, algorithms to provably leverage public data to learn privately whenever a function class is learnable non-privately, where our notion of computational efficiency is with respect to the number of calls to an optimization oracle for the function class. In addition to this general result, we provide specialized algorithms with improved sample complexities in the special cases when the function class is convex or when the task is binary classification.
tl;dr: We propose novel federated optimization algorithms (both basic and accelerated) that are efficient in terms of both communication and computation.

In developing efficient optimization algorithms, it is crucial to account for communication constraints—a significant challenge in modern Federated Learning.
The best-known communication complexity among non-accelerated algorithms is achieved by DANE, a distributed proximal-point algorithm that solves local subproblems at each iteration and that can exploit second-order similarity among individual functions.
However, to achieve such communication efficiency, the algorithm
requires solving local subproblems sufficiently accurately resulting in slightly sub-optimal local complexity.
Inspired by the hybrid-projection proximal-point method, in this work, we propose a novel distributed algorithm S-DANE. Compared to DANE, this method uses an auxiliary sequence of prox-centers while maintaining the same deterministic communication complexity. Moreover, the accuracy condition for solving the subproblem is milder, leading to enhanced local computation efficiency. Furthermore, S-DANE supports partial client participation and arbitrary stochastic local solvers, making it attractive in practice. We further accelerate S-DANE and show that the resulting algorithm achieves the best-known communication complexity among all existing methods for distributed convex optimization while still enjoying good local computation efficiency as S-DANE.
Finally, we propose adaptive variants of both methods using line search, obtaining the first provably efficient adaptive algorithms that could exploit local second-order similarity without the prior knowledge of any parameters.
tl;dr: We consider the problem of universal learning by ERM in the realizable case and study the possible universal rates.

The well-known $\textit{empirical risk minimization}$ (ERM) principle is the basis of many widely used machine learning algorithms, and plays an essential role in the classical PAC theory. A common description of a learning algorithm's performance is its so-called “learning curve”, that is, the decay of the expected error as a function of the input sample size. As the PAC model fails to explain the behavior of learning curves, recent research has explored an alternative universal learning model and has ultimately revealed a distinction between optimal universal and uniform learning rates (Bousquet et al., 2021). However, a basic understanding of such differences with a particular focus on the ERM principle has yet to be developed.
In this paper, we consider the problem of universal learning by ERM in the realizable case and study the possible universal rates. Our main result is a fundamental $\textit{tetrachotomy}$: there are only four possible universal learning rates by ERM, namely, the learning curves of any concept class learnable by ERM decay either at $e^{-n}$, $1/n$, $\log{(n)}/n$, or arbitrarily slow rates. Moreover, we provide a complete characterization of which concept classes fall into each of these categories, via new complexity structures. We also develop new combinatorial dimensions which supply sharp asymptotically-valid constant factors for these rates, whenever possible.

Visible-Infrared Person Re-identification (VI-ReID) is a challenging cross-modal retrieval task due to significant modality differences, primarily caused by the absence of detailed color information in the infrared modality. The development of large foundation models like Large Language Models (LLMs) and Vision Language Models (VLMs) motivates us to investigate a feasible solution to empower VI-ReID performance with off-the-shelf large foundation models. To this end, we propose a novel Text-enhanced VI-ReID framework driven by Large Foundation Models (TVI-LFM). The basic idea is to enrich the representation of the infrared modality with textual descriptions automatically generated by VLMs. Specifically, we incorporate a pre-trained VLM to extract textual features from texts generated by VLM and augmented by LLM, and incrementally fine-tune the text encoder to minimize the domain gap between generated texts and original visual modalities. Meanwhile, to enhance the infrared modality with extracted textual representations, we leverage modality alignment capabilities of VLMs and VLM-generated feature-level filters. This allows the text model to learn complementary features from the infrared modality, ensuring the semantic structural consistency between the fusion modality and the visible modality. Furthermore, we introduce modality joint learning to align features of all modalities, ensuring that textual features maintain stable semantic representation of overall pedestrian appearance during complementary information learning. Additionally, a modality ensemble retrieval strategy is proposed to leverage complementary strengths of each query modality to improve retrieval effectiveness and robustness. Extensive experiments demonstrate that our method significantly improves retrieval performance on three expanded cross-modal re-identification datasets, paving the way for utilizing large foundation models in downstream data-demanding multi-modal retrieval tasks.
tl;dr: We introduce a novel class of generative models based on piecewise deterministic Markov processes, a family of non-diffusive stochastic processes consisting of deterministic motion and random jumps at random times.

We introduce a novel class of generative models based on piecewise deterministic Markov processes (PDMPs), a family of non-diffusive stochastic processes consisting of deterministic motion and random jumps at random times. Similarly to diffusions, such Markov processes admit time reversals that turn out to be PDMPs as well. We apply this observation to three PDMPs considered in the literature: the Zig-Zag process, Bouncy Particle Sampler, and Randomised Hamiltonian Monte Carlo. For these three particular instances, we show that the jump rates and kernels of the corresponding time reversals admit explicit expressions depending on some conditional densities of the PDMP under consideration before and after a jump. Based on these results, we propose efficient training procedures to learn these characteristics and consider methods to approximately simulate the reverse process. Finally, we provide bounds in the total variation distance between the data distribution and the resulting distribution of our model in the case where the base distribution is the standard $d$-dimensional Gaussian distribution. Promising numerical simulations support further investigations into this class of models.

In this paper, we introduce DeAR (_Decompose-Analyze-Rethink_), a framework that iteratively builds a reasoning tree to tackle intricate problems within a single large language model (LLM). Unlike approaches that extend or search for rationales, DeAR is featured by 1) adopting a tree-based question decomposition manner to plan the organization of rationales, which mimics the logical planning inherent
in human cognition; 2) globally updating the rationales at each reasoning step through natural language feedback. Specifically, the _Decompose_ stage decomposes the question into simpler sub-questions, storing them as new nodes; the _Analyze_ stage generates and self-checks rationales for sub-questions at each node evel; and the _Rethink_ stage updates parent-node rationales based on feedback from their child nodes. By generating and updating the reasoning process from a more global perspective, DeAR constructs more adaptive and accurate logical structures for complex problems, facilitating timely error correction compared to rationale-extension and search-based approaches such as Tree-of-Thoughts (ToT) and Graph-of-Thoughts (GoT). We conduct extensive experiments on three reasoning benchmarks, including ScienceQA, StrategyQA, and GSM8K, which cover a variety of reasoning tasks, demonstrating that our approach significantly reduces logical errors and enhances performance across various LLMs. Furthermore, we validate that DeAR is an efficient method that achieves a superior trade-off between accuracy and reasoning time compared to ToT and GoT.

Deep reinforcement learning aims to learn deep neural network policies to solve large-scale decision-making problems. However, approximating policies using deep neural networks makes it difficult to interpret the learned decision-making process. To address this issue, prior works (Trivedi et al., 2021; Liu et al., 2023; Carvalho et al., 2024) proposed to use human-readable programs as policies to increase the interpretability of the decision-making pipeline. Nevertheless, programmatic policies generated by these methods struggle to effectively solve long and repetitive RL tasks and cannot generalize to even longer horizons during testing. To solve these problems, we propose the Hierarchical Programmatic Option framework (HIPO), which aims to solve long and repetitive RL problems with human-readable programs as options (low-level policies). Specifically, we propose a method that retrieves a set of effective, diverse, and compatible programs as options. Then, we learn a high-level policy to effectively reuse these programmatic options to solve reoccurring subtasks. Our proposed framework outperforms programmatic RL and deep RL baselines on various tasks. Ablation studies justify the effectiveness of our proposed search algorithm for retrieving a set of programmatic options.
tl;dr: A Neural Tangent Kernel analysis of the training dynamics of Physics-Informed Neural Networks for nonlinear PDEs.

The Neural Tangent Kernel (NTK) viewpoint is widely employed to analyze the training dynamics of overparameterized Physics-Informed Neural Networks (PINNs). However, unlike the case of linear Partial Differential Equations (PDEs), we show how the NTK perspective falls short in the nonlinear scenario. Specifically, we establish that the NTK yields a random matrix at initialization that is not constant during training, contrary to conventional belief. Another significant difference from the linear regime is that, even in the idealistic infinite-width limit, the Hessian does not vanish and hence it cannot be disregarded during training. This motivates the adoption of second-order optimization methods. We explore the convergence guarantees of such methods in both linear and nonlinear cases, addressing challenges such as spectral bias and slow convergence. Every theoretical result is supported by numerical examples with both linear and nonlinear PDEs, and we highlight the benefits of second-order methods in benchmark test cases.

Large Language Models (LLMs) have demonstrated remarkable generalization and instruction-following capabilities with instruction tuning. The advancements in LLMs and instruction tuning have led to the development of Large Vision-Language Models (LVLMs). However, the competency of the LLMs and instruction tuning have been less explored in the molecular domain. Thus, we propose LLaMo: Large Language Model-based Molecular graph assistant, which is an end-to- end trained large molecular graph-language model. To bridge the discrepancy between the language and graph modalities, we present the multi-level graph projector that transforms graph representations into graph tokens by abstracting the output representations of each GNN layer and motif representations with the cross-attention mechanism. We also introduce machine-generated molecular graph instruction data to instruction-tune the large molecular graph-language model for general-purpose molecule and language understanding. Our extensive experiments demonstrate that LLaMo shows the best performance on diverse tasks, such as molecular description generation, property prediction, and IUPAC name prediction. The code of LLaMo is available at https://github.com/mlvlab/LLaMo.

To ensure large language models (LLMs) are used safely, one must reduce their propensity to hallucinate or to generate unacceptable answers. A simple and often used strategy is to first let the LLM generate multiple hypotheses and then employ a reranker to choose the best one. In this paper, we draw a parallel between this strategy and the use of redundancy to decrease the error rate in noisy communication channels. We conceptualize the generator as a sender transmitting multiple descriptions of a message through parallel noisy channels. The receiver decodes the message by ranking the (potentially corrupted) descriptions and selecting the one found to be most reliable. We provide conditions under which this protocol is asymptotically error-free (i.e., yields an acceptable answer almost surely) even in scenarios where the reranker is imperfect (governed by Mallows or Zipf-Mandelbrot models) and the channel distributions are statistically dependent. We use our framework to obtain reranking laws which we validate empirically on two real-world tasks using LLMs: text-to-code generation with DeepSeek-Coder 7B and machine translation of medical data with TowerInstruct 13B.
tl;dr: We introduce the first undetectable watermarking schemes for language models with robustness to adversarial substitutions, insertions and deletions.

Motivated by the problem of detecting AI-generated text, we consider the problem of watermarking the output of language models with provable guarantees. We aim for watermarks which satisfy: (a) undetectability, a cryptographic notion introduced by Christ, Gunn, & Zamir (2023) which stipulates that it is computationally hard to distinguish watermarked language model outputs from the model's actual output distribution; and (b) robustness to channels which introduce a constant fraction of adversarial insertions, substitutions, and deletions to the watermarked text. Earlier schemes could only handle stochastic substitutions and deletions, and thus we are aiming for a more natural and appealing robustness guarantee that holds with respect to edit distance.
Our main result is a watermarking scheme which achieves both (a) and (b) when the alphabet size for the language model is allowed to grow as a polynomial in the security parameter. To derive such a scheme, we follow an approach introduced by Christ & Gunn (2024), which proceeds via first constructing pseudorandom codes satisfying undetectability and robustness properties analogous to those above; our codes have the additional benefit of relying on weaker computational assumptions than used in previous work. Then we show that there is a generic transformation from such codes over large alphabets to watermarking schemes for arbitrary language models.
tl;dr: We propose to enhance the learned representations of LLM reward models via a goal-conditioned contrastive learning objective, which we show improves reward model performance and downstream LLM alignment.

Techniques that learn improved representations via offline data or self-supervised objectives have shown impressive results in traditional reinforcement learning.
Nevertheless, it is unclear how improved representation learning can benefit reinforcement learning from human feedback on language models.
In this work, we propose training reward models (RMs) in a contrastive, $\textit{goal-conditioned}$ fashion by increasing the representation similarity of future states along sampled preferred trajectories and decreasing the similarity along randomly sampled dispreferred trajectories.
This objective significantly improves reward model performance by up to 0.09 AUROC across challenging benchmarks, such as MATH and GSM8k. These findings extend to general alignment as well -- on the Helpful-Harmless dataset, we observe 2.3\% increase in accuracy.
Beyond improving reward model performance, we show this way of training RM representations enables improved steerability because it allows us to evaluate the likelihood of an action achieving a particular goal-state (e.g. whether a solution is correct or helpful).
Leveraging this insight, we find that we can filter up to 55\% of generated tokens during majority voting by discarding trajectories likely to end up in an "incorrect" state, which leads to significant cost savings.
We additionally find that these representations can perform fine-grained control by conditioning on desired future goal-states.
For example, we show that steering a Llama 3 model towards helpful generations with our approach improves helpfulness by $9.6$\% over a supervised-fine-tuning trained baseline.
Similarly, steering the model towards complex generations improves complexity by $21.6$\% over the baseline.
Overall, we find that training RMs in this contrastive, goal-conditioned fashion significantly improves performance and enables model steerability.

Survival analysis is an important research topic with applications in healthcare, business, and manufacturing. One essential tool in this area is the Cox proportional hazards (CPH) model, which is widely used for its interpretability, flexibility, and predictive performance. However, for modern data science challenges such as high dimensionality (both $n$ and $p$) and high feature correlations, current algorithms to train the CPH model have drawbacks, preventing us from using the CPH model at its full potential. The root cause is that the current algorithms, based on the Newton method, have trouble converging due to vanishing second order derivatives when outside the local region of the minimizer. To circumvent this problem, we propose new optimization methods by constructing and minimizing surrogate functions that exploit hidden mathematical structures of the CPH model. Our new methods are easy to implement and ensure monotonic loss decrease and global convergence. Empirically, we verify the computational efficiency of our methods. As a direct application, we show how our optimization methods can be used to solve the cardinality-constrained CPH problem, producing very sparse high-quality models that were not previously practical to construct. We list several extensions that our breakthrough enables, including optimization opportunities, theoretical questions on CPH's mathematical structure, as well as other CPH-related applications.
tl;dr: We propose an alignment strategy for diffusion models in continuous control

Drawing upon recent advances in language model alignment, we formulate offline Reinforcement Learning as a two-stage optimization problem: First pretraining expressive generative policies on reward-free behavior datasets, then finetuning these policies to align with task-specific annotations like Q-values. This strategy allows us to leverage abundant and diverse behavior data to enhance generalization and enable rapid adaptation to downstream tasks using minimal annotations. In particular, we introduce Efficient Diffusion Alignment (EDA) for solving continuous control problems. EDA utilizes diffusion models for behavior modeling. However, unlike previous approaches, we represent diffusion policies as the derivative of a scalar neural network with respect to action inputs. This representation is critical because it enables direct density calculation for diffusion models, making them compatible with existing LLM alignment theories. During policy fine-tuning, we extend preference-based alignment methods like Direct Preference Optimization (DPO) to align diffusion behaviors with continuous Q-functions. Our evaluation on the D4RL benchmark shows that EDA exceeds all baseline methods in overall performance. Notably, EDA maintains about 95\% of performance and still outperforms several baselines given only 1\% of Q-labelled data during fine-tuning.
tl;dr: This paper extends the continuous optimization of structure learning able to integrate structural partial orders, an important prior information in real-world causal research.

Differentiable structure learning is a novel line of causal discovery research that transforms the combinatorial optimization of structural models into a continuous optimization problem. However, the field has lacked feasible methods to integrate partial order constraints, a critical prior information typically used in real-world scenarios, into the differentiable structure learning framework. The main difficulty lies in adapting these constraints, typically suited for the space of total orderings, to the continuous optimization context of structure learning in the graph space. To bridge this gap, this paper formalizes a set of equivalent constraints that map partial orders onto graph spaces and introduces a plug-and-play module for their efficient application. This module preserves the equivalent effect of partial order constraints in the graph space, backed by theoretical validations of correctness and completeness. It significantly enhances the quality of recovered structures while maintaining good efficiency, which learns better structures using 90\% fewer samples than the data-based method on a real-world dataset. This result, together with a comprehensive evaluation on synthetic cases, demonstrates our method's ability to effectively improve differentiable structure learning with partial orders.
tl;dr: We introduce the concept of agent-computer interfaces to enhance LM agent performance on software engineering tasks.

Language model agents are increasingly being used to automate complicated tasks in digital environments. Just as humans benefit from powerful software applications, such as integrated development environments, for complex tasks like software engineering, we posit that language model agents represent a new category of end users with their own needs and abilities, and would benefit from specially built interfaces to the software they use. We investigate how the role of interface design affects the performance of language model agents. As a result of this exploration, we introduce SWE-agent: a system that facilitates language model agents to autonomously use computers to solve software engineering tasks. SWE-agent's custom agent-computer interface significantly enhances an agent's ability to create and edit code files, navigate entire repositories, and execute tests and other programs. We evaluate SWE-agent on SWE-bench and HumanEvalFix, achieving state-of-the-art performance on both with a pass@1 rate of 12.5% and 87.7%, respectively, far exceeding the previous state-of-the-art achieved with non-interactive language models. Finally, we provide insight on how the design of the agent-computer interface can impact agents' behavior and performance.

Safety alignment is crucial to ensure that large language models (LLMs) behave in ways that align with human preferences and prevent harmful actions during inference. However, recent studies show that the alignment can be easily compromised through finetuning with only a few adversarially designed training examples. We aim to measure the risks in finetuning LLMs through navigating the LLM safety landscape. We discover a new phenomenon observed universally in the model parameter space of popular open-source LLMs, termed as “safety basin”: random perturbations to model weights maintain the safety level of the original aligned model within its local neighborhood. However, outside this local region, safety is fully compromised, exhibiting a sharp, step-like drop. This safety basin contrasts sharply with the LLM capability landscape, where model performance peaks at the origin and gradually declines as random perturbation increases. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. Visualizing the safety landscape of the aligned model enables us to understand how finetuning compromises safety by dragging the model away from the safety basin. The LLM safety landscape also highlights the system prompt’s critical role in protecting a model, and that such protection transfers to its perturbed variants within the safety basin. These observations from our safety landscape research provide new
insights for future work on LLM safety community. Our code is publicly available at https://github.com/ShengYun-Peng/llm-landscape.

Sign stochastic gradient descent (signSGD) is a communication-efficient method that transmits only the sign of stochastic gradients for parameter updating. Existing literature has demonstrated that signSGD can achieve a convergence rate of $\mathcal{O}(d^{1/2}T^{-1/4})$, where $d$ represents the dimension and $T$ is the iteration number. In this paper, we improve this convergence rate to $\mathcal{O}(d^{1/2}T^{-1/3})$ by introducing the Sign-based Stochastic Variance Reduction (SSVR) method, which employs variance reduction estimators to track gradients and leverages their signs to update. For finite-sum problems, our method can be further enhanced to achieve a convergence rate of $\mathcal{O}(m^{1/4}d^{1/2}T^{-1/2})$, where $m$ denotes the number of component functions. Furthermore, we investigate the heterogeneous majority vote in distributed settings and introduce two novel algorithms that attain improved convergence rates of $\mathcal{O}(d^{1/2}T^{-1/2} + dn^{-1/2})$ and $\mathcal{O}(d^{1/4}T^{-1/4})$ respectively, outperforming the previous results of $\mathcal{O}(dT^{-1/4} + dn^{-1/2})$ and $\mathcal{O}(d^{3/8}T^{-1/8})$, where $n$ represents the number of nodes. Numerical experiments across different tasks validate the effectiveness of our proposed methods.
tl;dr: We present an inverse reinforcement learning framework for training diffusion models and provide a novel RL algorithm for diffusion models which leverages value functions.

We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data.
Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few as 4 and 10 steps. Additionally, DxMI enables the training of an EBM without MCMC, stabilizing EBM training dynamics and enhancing anomaly detection performance.

Data-driven decision-making processes increasingly utilize end-to-end learnable deep neural networks to render final decisions. Sometimes, the output of the forward functions in certain layers is determined by the solutions to mathematical optimization problems, leading to the emergence of differentiable optimization layers that permit gradient back-propagation.
However, real-world scenarios often involve large-scale datasets and numerous constraints, presenting significant challenges. Current methods for differentiating optimization problems typically rely on implicit differentiation, which necessitates costly computations on the Jacobian matrices, resulting in low efficiency.
In this paper, we introduce BPQP, a differentiable convex optimization framework designed for efficient end-to-end learning. To enhance efficiency, we reformulate the backward pass as a simplified and decoupled quadratic programming problem by leveraging the structural properties of the Karush–Kuhn–Tucker (KKT) matrix. This reformulation enables the use of first-order optimization algorithms in calculating the backward pass gradients, allowing our framework to potentially utilize any state-of-the-art solver. As solver technologies evolve, BPQP can continuously adapt and improve its efficiency.
Extensive experiments on both simulated and real-world datasets demonstrate that BPQP achieves a significant improvement in efficiency—typically an order of magnitude faster in overall execution time compared to other differentiable optimization layers. Our results not only highlight the efficiency gains of BPQP but also underscore its superiority over differential optimization layer baselines.
tl;dr: We propose an effective method of lifelong model editing for large language models.

Large language models (LLMs) need knowledge updates to meet the ever-growing world facts and correct the hallucinated responses, facilitating the methods of lifelong model editing. Where the updated knowledge resides in memories is a fundamental question for model editing. In this paper, we find that editing either long-term memory (direct model parameters) or working memory (non-parametric knowledge of neural network activations/representations by retrieval) will result in an impossible triangle---reliability, generalization, and locality can not be realized together in the lifelong editing settings. For long-term memory, directly editing the parameters will cause conflicts with irrelevant pretrained knowledge or previous edits (poor reliability and locality). For working memory, retrieval-based activations can hardly make the model understand the edits and generalize (poor generalization). Therefore, we propose WISE to bridge the gap between memories. In WISE, we design a dual parametric memory scheme, which consists of the main memory for the pretrained knowledge and a side memory for the edited knowledge. We only edit the knowledge in the side memory and train a router to decide which memory to go through when given a query. For continual editing, we devise a knowledge-sharding mechanism where different sets of edits reside in distinct subspaces of parameters, and are subsequently merged into a shared memory without conflicts. Extensive experiments show that WISE can outperform previous model editing methods and overcome the impossible triangle under lifelong model editing of question answering, hallucination, and out-of-distribution settings across trending LLM architectures, e.g., GPT, LLaMA, and Mistral.

Digital Twins (DTs) are computational models that simulate the states and temporal dynamics of real-world systems, playing a crucial role in prediction, understanding, and decision-making across diverse domains. However, existing approaches to DTs often struggle to generalize to unseen conditions in data-scarce settings, a crucial requirement for such models. To address these limitations, our work begins by establishing the essential desiderata for effective DTs. Hybrid Digital Twins (**HDTwins**) represent a promising approach to address these requirements, modeling systems using a composition of both mechanistic and neural components. This hybrid architecture simultaneously leverages (partial) domain knowledge and neural network expressiveness to enhance generalization, with its modular design facilitating improved evolvability. While existing hybrid models rely on expert-specified architectures with only parameters optimized on data, *automatically* specifying and optimizing HDTwins remains intractable due to the complex search space and the need for flexible integration of domain priors. To overcome this complexity, we propose an evolutionary algorithm (**HDTwinGen**) that employs Large Language Models (LLMs) to autonomously propose, evaluate, and optimize HDTwins. Specifically, LLMs iteratively generate novel model specifications, while offline tools are employed to optimize emitted parameters. Correspondingly, proposed models are evaluated and evolved based on targeted feedback, enabling the discovery of increasingly effective hybrid models. Our empirical results reveal that HDTwinGen produces generalizable, sample-efficient, and evolvable models, significantly advancing DTs' efficacy in real-world applications.

Recent advancements in State Space Models, notably Mamba, have demonstrated superior performance over the dominant Transformer models, particularly in reducing the computational complexity from quadratic to linear. Yet, difficulties in adapting Mamba from language to vision tasks arise due to the distinct characteristics of visual data, such as the spatial locality and adjacency within images and large variations in information granularity across visual tokens. Existing vision Mamba approaches either flatten tokens into sequences in a raster scan fashion, which breaks the local adjacency of images, or manually partition tokens into windows, which limits their long-range modeling and generalization capabilities. To address these limitations, we present a new vision Mamba model, coined QuadMamba, that effectively captures local dependencies of varying granularities via quadtree-based image partition and scan. Concretely, our lightweight quadtree-based scan module learns to preserve the 2D locality of spatial regions within learned window quadrants. The module estimates the locality score of each token from their features, before adaptively partitioning tokens into window quadrants. An omnidirectional window shifting scheme is also introduced to capture more intact and informative features across different local regions. To make the discretized quadtree partition end-to-end trainable, we further devise a sequence masking strategy based on Gumbel-Softmax and its straight-through gradient estimator. Extensive experiments demonstrate that QuadMamba achieves state-of-the-art performance in various vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our code and models will be released.
299. REBORN: Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR
tl;dr: Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR

Unsupervised automatic speech recognition (ASR) aims to learn the mapping between the speech signal and its corresponding textual transcription without the supervision of paired speech-text data. A word/phoneme in the speech signal is represented by a segment of speech signal with variable length and unknown boundary, and this segmental structure makes learning the mapping between speech and text challenging, especially without paired data. In this paper, we propose REBORN, Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR. REBORN alternates between (1) training a segmentation model that predicts the boundaries of the segmental structures in speech signals and (2) training the phoneme prediction model, whose input is a segmental structure segmented by the segmentation model, to predict a phoneme transcription. Since supervised data for training the segmentation model is not available, we use reinforcement learning to train the segmentation model to favor segmentations that yield phoneme sequence predictions with a lower perplexity. We conduct extensive experiments and find that under the same setting, REBORN outperforms all prior unsupervised ASR models on LibriSpeech, TIMIT, and five non-English languages in Multilingual LibriSpeech. We comprehensively analyze why the boundaries learned by REBORN improve the unsupervised ASR performance.
tl;dr: We create a Wasserstein distance variant based on spherical convolutions of functional data and apply the method to climate model validation.

The validation of global climate models is crucial to ensure the accuracy and efficacy of model output. We introduce the spherical convolutional Wasserstein distance to more comprehensively measure differences between climate models and reanalysis data. This new similarity measure accounts for spatial variability using convolutional projections and quantifies local differences in the distribution of climate variables. We apply this method to evaluate the historical model outputs of the Coupled Model Intercomparison Project (CMIP) members by comparing them to observational and reanalysis data products. Additionally, we investigate the progression from CMIP phase 5 to phase 6 and find modest improvements in the phase 6 models regarding their ability to produce realistic climatologies.
tl;dr: We show that in many scenarios, applying loss to instructions rather than outputs only, which we refer to as Instruction Modelling, could largely improve the performance of instruction tuning on both various NLP and open-ended generation benchmarks.

Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (*e.g.,* MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (*e.g.,* MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that our improvement can be attributed to reduced overfitting to instruction tuning datasets. It is worth noting that we are not proposing \ours as a replacement for the current instruction tuning process.
Instead, our work aims to provide practical guidance for instruction tuning LMs, especially in low-resource scenarios.
Our code is available at https://github.com/ZhengxiangShi/InstructionModelling.
tl;dr: Our work aims to design a powerful spatio-temporal OOD framework that can comprehensively achieve the inference and exploitation of unseen environments.

Out-of-distribution (OOD) generalization issue is a well-known challenge within deep learning tasks. In dynamic graphs, the change of temporal environments is regarded as the main cause of data distribution shift. While numerous OOD studies focusing on environment factors have achieved remarkable performance, they still fail to systematically solve the two issue of environment inference and utilization. In this work, we propose a novel dynamic graph learning model named EpoD based on prompt learning and structural causal model to comprehensively enhance both environment inference and utilization. Inspired by the superior performance of prompt learning in understanding underlying semantic and causal associations, we first design a self-prompted learning mechanism to infer unseen environment factors. We then rethink the role of environment variable within spatio-temporal causal structure model, and introduce a novel causal pathway where dynamic subgraphs serve as mediating variables. The extracted dynamic subgraph can effectively capture the data distribution shift by incorporating the inferred environment variables into the node-wise dependencies. Theoretical discussions and intuitive analysis support the generalizability and interpretability of EpoD. Extensive experiments on seven real-world datasets across domains showcase the superiority of EpoD against baselines, and toy example experiments further verify the powerful interpretability and rationality of our EpoD.
tl;dr: A learned noise schedule can improve the log-likelihood of diffusion models.

Diffusion models have gained traction as powerful algorithms for synthesizing high-quality images. Central to these algorithms is the diffusion process, a set of equations which maps data to noise
in a way that can significantly affect performance.
In this paper, we explore whether the diffusion
process can be learned from data.
Our work is grounded in Bayesian inference and seeks to improve log-likelihood estimation by casting the learned diffusion process as an approximate variational posterior that yields a tighter lower bound (ELBO) on the likelihood.
A widely held assumption is that the ELBO is invariant to the noise process: our work dispels this assumption and proposes multivariate learned adaptive noise (MuLAN), a learned diffusion process that applies noise at different rates across an image. Our method consists of three components: a multivariate noise schedule, adaptive input-conditional diffusion, and auxiliary variables; these components ensure that the ELBO is no longer invariant to the choice of the noise schedule as in previous works. Empirically, MuLAN sets a new **state-of-the-art** in density estimation on CIFAR-10 and ImageNet while matching the performance of previous state-of-the-art models with **50%** fewer steps. We provide the code, along with a blog post and video tutorial on the project page: https://s-sahoo.com/MuLAN

This paper explores adaptive variance reduction methods for stochastic optimization based on the STORM technique. Existing adaptive extensions of STORM rely on strong assumptions like bounded gradients and bounded function values, or suffer an additional $\mathcal{O}(\log T)$ term in the convergence rate. To address these limitations, we introduce a novel adaptive STORM method that achieves an optimal convergence rate of $\mathcal{O}(T^{-1/3})$ for non-convex functions with our newly designed learning rate strategy. Compared with existing approaches, our method requires weaker assumptions and attains the optimal convergence rate without the additional $\mathcal{O}(\log T)$ term. We also extend the proposed technique to stochastic compositional optimization, obtaining the same optimal rate of $\mathcal{O}(T^{-1/3})$. Furthermore, we investigate the non-convex finite-sum problem and develop another innovative adaptive variance reduction method that achieves an optimal convergence rate of $\mathcal{O}(n^{1/4} T^{-1/2} )$, where $n$ represents the number of component functions. Numerical experiments across various tasks validate the effectiveness of our method.

Recently, federated multi-view clustering (FedMVC) has emerged to explore cluster structures in multi-view data distributed on multiple clients. Many existing approaches tend to assume that clients are isomorphic and all of them belong to either single-view clients or multi-view clients. While these methods have succeeded, they may encounter challenges in practical FedMVC scenarios involving heterogeneous hybrid views, where a mixture of single-view and multi-view clients exhibit varying degrees of heterogeneity. In this paper, we propose a novel FedMVC framework, which concurrently addresses two challenges associated with heterogeneous hybrid views, i.e., client gap and view gap. To address the client gap, we design a local-synergistic contrastive learning approach that helps single-view clients and multi-view clients achieve consistency for mitigating heterogeneity among all clients. To address the view gap, we develop a global-specific weighting aggregation method, which encourages global models to learn complementary features from hybrid views. The interplay between local-synergistic contrastive learning and global-specific weighting aggregation mutually enhances the exploration of the data cluster structures distributed on multiple clients. Theoretical analysis and extensive experiments demonstrate that our method can handle the heterogeneous hybrid views in FedMVC and outperforms state-of-the-art methods.
tl;dr: We introduce a new PAC-Bayes bound that allows working with richer assumptions and illustrate its potential by generalizing previous bounds, obtaining novel ones for several regularization techniques, and minimizing them to get new posteriors

We introduce a new PAC-Bayes oracle bound for unbounded losses that extends Cramér-Chernoff bounds to the PAC-Bayesian setting. The proof technique relies on controlling the tails of certain random variables involving the Cramér transform of the loss. Our approach naturally leverages properties of Cramér-Chernoff bounds, such as exact optimization of the free parameter in many PAC-Bayes bounds. We highlight several applications of the main theorem. Firstly, we show that our bound recovers and generalizes previous results. Additionally, our approach allows working with richer assumptions that result in more informative and potentially tighter bounds. In this direction, we provide a general bound under a new *model-dependent* assumption from which we obtain bounds based on parameter norms and log-Sobolev inequalities. Notably, many of these bounds can be minimized to obtain distributions beyond the Gibbs posterior and provide novel theoretical coverage to existing regularization techniques.
tl;dr: We provide the first mechanism that compresses and simulates any randomizer while preserving local differential privacy, achieving near-optimal compression sizes, and ensuring no distortion is introduced to the reproduced distribution.

To reduce the communication cost of differential privacy mechanisms, we introduce a novel construction, called Poisson private representation (PPR), designed to compress and simulate any local randomizer while ensuring local differential privacy. Unlike previous simulation-based local differential privacy mechanisms, PPR exactly preserves the joint distribution of the data and the output of the original local randomizer. Hence, the PPR-compressed privacy mechanism retains all desirable statistical properties of the original privacy mechanism such as unbiasedness and Gaussianity. Moreover, PPR achieves a compression size within a logarithmic gap from the theoretical lower bound. Using the PPR, we give a new order-wise trade-off between communication, accuracy, central and local differential privacy for distributed mean estimation. Experiment results on distributed mean estimation show that PPR consistently gives a better trade-off between communication, accuracy and central differential privacy compared to the coordinate subsampled Gaussian mechanism, while also providing local differential privacy.

Differential privacy (DP) is a formal notion that restricts the privacy leakage of an algorithm when running on sensitive data, in which privacy-utility trade-off is one of the central problems in private data analysis. In this work, we investigate the fundamental limits of differential privacy in online learning algorithms and present evidence that separates three types of constraints: no DP, pure DP, and approximate DP. We first describe a hypothesis class that is online learnable under approximate DP but not online learnable under pure DP under the adaptive adversarial setting. This indicates that approximate DP must be adopted when dealing with adaptive adversaries. We then prove that any private online learner must make an infinite number of mistakes for almost all hypothesis classes. This essentially generalizes previous results and shows a strong separation between private and non-private settings since a finite mistake bound is always attainable (as long as the class is online learnable) when there is no privacy requirement.
tl;dr: This work proposes a new expressive parametric family of submodular functions and new graded-pairwise comparison (GPC) loss functions for their learning from expensive teachers.

Submodular functions, crucial for various applications, often lack practical learning methods for their acquisition. Seemingly unrelated, learning a scaling from oracles offering graded pairwise preferences (GPC) is underexplored, despite a rich history in psychometrics. In this paper, we introduce deep submodular peripteral networks (DSPNs), a novel parametric family of submodular functions, and methods for their training using a GPC-based strategy to connect and then tackle both of the above challenges. We introduce newly devised GPC-style ``peripteral'' loss which leverages numerically graded relationships between pairs of objects (sets in our case). Unlike traditional contrastive learning, or RHLF preference ranking, our method utilizes graded comparisons, extracting more nuanced information than just binary-outcome comparisons, and contrasts sets of any size (not just two). We also define a novel suite of automatic sampling strategies for training, including active-learning inspired submodular feedback. We demonstrate DSPNs' efficacy in learning submodularity from a costly target submodular function and demonstrate its superiority both for experimental design and online streaming applications.
tl;dr: We explore optimally training protein language models and propose the scaling law, an area of significant interest in biological research with limited guidance on best practices.

We explore optimally training protein language models, an area of significant interest in biological research where guidance on best practices is limited.
Most models are trained with extensive compute resources until performance gains plateau, focusing primarily on increasing model sizes rather than optimizing the efficient compute frontier that balances performance and compute budgets.
Our investigation is grounded in a massive dataset consisting of 939 million protein sequences.
We trained over 300 models ranging from 3.5 million to 10.7 billion parameters on 5 to 200 billion unique tokens, to investigate the relations between model sizes, training token numbers, and objectives.
First, we observed the effect of diminishing returns for the Causal Language Model (CLM) and that of overfitting for Masked Language Model (MLM) when repeating the commonly used Uniref database. To address this, we included metagenomic protein sequences in the training set to increase the diversity and avoid the plateau or overfitting effects.
Second, we obtained the scaling laws of CLM and MLM on Transformer, tailored to the specific characteristics of protein sequence data.
Third, we observe a transfer scaling phenomenon from CLM to MLM, further demonstrating the effectiveness of transfer through scaling behaviors based on estimated Effectively Transferred Tokens.
Finally, to validate our scaling laws, we compare the large-scale versions of ESM-2 and PROGEN2 on downstream tasks, encompassing evaluations of protein generation as well as structure- and function-related tasks, all within less or equivalent pre-training compute budgets.

Out-of-distribution (OOD) detection is critical when deploying machine learning models in the real world. Outlier exposure methods, which incorporate auxiliary outlier data in the training process, can drastically improve OOD detection performance compared to approaches without advanced training strategies. We introduce Hopfield Boosting, a boosting approach, which leverages modern Hopfield energy to sharpen the decision boundary between the in-distribution and OOD data. Hopfield Boosting encourages the model to focus on hard-to-distinguish auxiliary outlier examples that lie close to the decision boundary between in-distribution and auxiliary outlier data. Our method achieves a new state-of-the-art in OOD detection with outlier exposure, improving the FPR95 from 2.28 to 0.92 on CIFAR-10, from 11.76 to 7.94 on CIFAR-100, and from 50.74 to 36.60 on ImageNet-1K.
tl;dr: Language models differ from human brains in social/emotional intelligence and physical commonsense. Fine-tuning language models on these domains improves their alignment with human understanding.

Do machines and humans process language in similar ways? Recent research has hinted at the affirmative, showing that human neural activity can be effectively predicted using the internal representations of language models (LMs). Although such results are thought to reflect shared computational principles between LMs and human brains, there are also clear differences in how LMs and humans represent and use language. In this work, we systematically explore the divergences between human and machine language processing by examining the differences between LM representations and human brain responses to language as measured by Magnetoencephalography (MEG) across two datasets in which subjects read and listened to narrative stories. Using an LLM-based data-driven approach, we identify two domains that LMs do not capture well: social/emotional intelligence and physical commonsense. We validate these findings with human behavioral experiments and hypothesize that the gap is due to insufficient representations of social/emotional and physical knowledge in LMs. Our results show that fine-tuning LMs on these domains can improve their alignment with human brain responses.

In safety-critical applications, machine learning models should generalize well under worst-case distribution shifts, that is, have a small robust risk. Invariance-based algorithms can provably take advantage of structural assumptions on the shifts when the training distributions are heterogeneous enough to identify the robust risk. However, in practice, such identifiability conditions are rarely satisfied – a scenario so far underexplored in the theoretical literature. In this paper, we aim to fill the gap and propose to study the more general setting of partially identifiable robustness. In particular, we define a new risk measure, the identifiable robust risk, and its corresponding (population) minimax quantity that is an algorithm-independent measure for the best achievable robustness under partial identifiability. We introduce these concepts broadly, and then study them within the framework of linear structural causal models for concreteness of the presentation. We use the introduced minimax quantity to show how previous approaches provably achieve suboptimal robustness in the partially identifiable case. We confirm our findings through empirical simulations and real-world experiments and demonstrate how the test error of existing robustness methods grows increasingly suboptimal as the proportion of previously unseen test directions increases.
tl;dr: We identify weaknesses in current data valuation methods for data markets and propose a federated data acquisition method based on experimental design that achieves state of the art performance on several real world medical datasets.

The acquisition of training data is crucial for machine learning applications. Data markets can increase the supply of data, particularly in data-scarce domains such as healthcare, by incentivizing potential data providers to join the market. A major challenge for a data buyer in such a market is choosing the most valuable data points from a data seller. Unlike prior work in data valuation, which assumes centralized data access, we propose a federated approach to the data acquisition problem that is inspired by linear experimental design. Our proposed data acquisition method achieves lower prediction error without requiring labeled validation data and can be optimized in a fast and federated procedure. The key insight of our work is that a method that directly estimates the benefit of acquiring data for test set prediction is particularly compatible with a decentralized market setting.
tl;dr: We propose a membership inference method on text-to-image diffusion models via condition likelihood discrepancy, outperforming previous works on diverse datasets, with superior resistance against early stopping and data augmentation.

Text-to-image diffusion models have achieved tremendous success in the field of controllable image generation, while also coming along with issues of privacy leakage and data copyrights. Membership inference arises in these contexts as a potential auditing method for detecting unauthorized data usage. While some efforts have been made on diffusion models, they are not applicable to text-to-image diffusion models due to the high computation overhead and enhanced generalization capabilities. In this paper, we first identify a conditional overfitting phenomenon in text-to-image diffusion models, indicating that these models tend to overfit the conditional distribution of images given the corresponding text rather than the marginal distribution of images only. Based on this observation, we derive an analytical indicator, namely Conditional Likelihood Discrepancy (CLiD), to perform membership inference, which reduces the stochasticity in estimating memorization of individual samples. Experimental results demonstrate that our method significantly outperforms previous methods across various data distributions and dataset scales. Additionally, our method shows superior resistance to overfitting mitigation strategies, such as early stopping and data augmentation.

In this article, we study the behaviour of continuous-time gradient methods on a two-layer linear network with square loss. A dichotomy between SGD and GD is revealed: GD preserves the rank at initialization while (label noise) SGD diminishes the rank regardless of the initialization. We demonstrate this rank deficiency by studying the time evolution of the *determinant* of a matrix of parameters. To further understand this phenomenon, we derive the stochastic differential equation (SDE) governing the eigenvalues of the parameter matrix. This SDE unveils a *replusive force* between the eigenvalues: a key regularization mechanism which induces rank deficiency. Our results are well supported by experiments illustrating the phenomenon beyond linear networks and regression tasks.
tl;dr: We develop bounds on the majority vote error that are tight enough to predict ensemble performance.

As performance gains through scaling data and/or model size experience diminishing returns, it is becoming increasingly popular to turn to ensembling, where the predictions of multiple models are combined to improve accuracy.
In this paper, we provide a detailed analysis of how the disagreement and the polarization (a notion we introduce and define in this paper) among classifiers relate to the performance gain achieved by aggregating individual classifiers, for majority vote strategies in classification tasks.
We address these questions in the following ways.
(1) An upper bound for polarization is derived, and we propose what we call a neural polarization law: most interpolating neural network models are 4/3-polarized. Our empirical results not only support this conjecture but also show that polarization is nearly constant for a dataset, regardless of hyperparameters or architectures of classifiers.
(2) The error of the majority vote classifier is considered under restricted entropy conditions, and we present a tight upper bound that indicates that the disagreement is linearly correlated with the target, and that the slope is linear in the polarization.
(3) We prove results for the asymptotic behavior of the disagreement in terms of the number of classifiers, which we show can help in predicting the performance for a larger number of classifiers from that of a smaller number.
Our theories and claims are supported by empirical results on several image classification tasks with various types of neural networks.
tl;dr: We obtain tight bounds on the sample complexity of posted pricing for a single item, for both independent and correlated distributions on the buyers' values.

Selling a single item to $n$ self-interested bidders is a fundamental problem in economics, where the two objectives typically considered are welfare maximization and revenue maximization. Since the optimal auctions are often impractical and do not work for sequential bidders, posted pricing auctions, where fixed prices are set for the item for different bidders, have emerged as a practical and effective alternative. This paper investigates how many samples are needed from bidders' value distributions to find near-optimal posted prices, considering both independent and correlated bidder distributions, and welfare versus revenue maximization. We obtain matching upper and lower bounds (up to logarithmic terms) on the sample complexity for all these settings.
tl;dr: The paper introduces a method to create a better dataset for visual entity recognition using a multimodal language model for label verification and metadata generation.

Web-scale visual entity recognition, the task of associating images with their corresponding entities within vast knowledge bases like Wikipedia, presents significant challenges due to the lack of clean, large-scale training data. In this paper, we propose a novel methodology to curate such a dataset, leveraging a multimodal large language model (LLM) for label verification, metadata generation, and rationale explanation. Instead of relying on the multimodal LLM to directly annotate data, which we found to be suboptimal, we prompt it to reason about potential candidate entity labels by accessing additional contextually relevant information (such as Wikipedia), resulting in more accurate annotations. We further use the multimodal LLM to enrich the dataset by generating question-answer pairs and a grounded fine-grained textual description (referred to as "rationale") that explains the connection between images and their assigned entities. Experiments demonstrate that models trained on this automatically curated data achieve state-of-the-art performance on web-scale visual entity recognition tasks (e.g. +6.9% improvement in OVEN entity task), underscoring the importance of high-quality training data in this domain.
tl;dr: We propose B-cosification, a technique for transforming existing pre-trained models to become inherently interpretable at a fraction of the cost to train them from scratch.

B-cos Networks have been shown to be effective for obtaining highly human interpretable explanations of model decisions by architecturally enforcing stronger alignment between inputs and weight. B-cos variants of convolutional networks (CNNs) and vision transformers (ViTs), which primarily replace linear layers with B-cos transformations, perform competitively to their respective standard variants while also yielding explanations that are faithful by design. However, it has so far been necessary to train these models from scratch, which is increasingly infeasible in the era of large, pre-trained foundation models. In this work, inspired by the architectural similarities in standard DNNs and B-cos networks, we propose ‘B-cosification’, a novel approach to transform existing pre-trained models to become inherently interpretable. We perform a thorough study of design choices to perform this conversion, both for convolutional neural networks and vision transformers. We find that B-cosification can yield models that are on par with B-cos models trained from scratch in terms of interpretability, while often outperforming them in terms of classification performance at a fraction of the training cost. Subsequently, we apply B-cosification to a pretrained CLIP model, and show that, even with limited data and compute cost, we obtain a B-cosified version that is highly interpretable and competitive on zero shot performance across a variety of datasets. We release our
code and pre-trained model weights at https://github.com/shrebox/B-cosification.
tl;dr: We propose an estimator-agnostic meta-algorithm to combine multiple OPE estimates that achieves lower MSE in Offline RL tasks.

Offline policy evaluation (OPE) allows us to evaluate and estimate a new sequential decision-making policy's performance by leveraging historical interaction data collected from other policies. Evaluating a new policy online without a confident estimate of its performance can lead to costly, unsafe, or hazardous outcomes, especially in education and healthcare. Several OPE estimators have been proposed in the last decade, many of which have hyperparameters and require training. Unfortunately, choosing the best OPE algorithm for each task and domain is still unclear. In this paper, we propose a new algorithm that adaptively blends a set of OPE estimators given a dataset without relying on an explicit selection using a statistical procedure. We prove that our estimator is consistent and satisfies several desirable properties for policy evaluation. Additionally, we demonstrate that when compared to alternative approaches, our estimator can be used to select higher-performing policies in healthcare and robotics. Our work contributes to improving ease of use for a general-purpose, estimator-agnostic, off-policy evaluation framework for offline RL.
tl;dr: We provide faster randomized algorithms for computing an ε-optimal policy in a discounted Markov decision process and take a step towards closing the sample-complexity gap between model-based and model-free methods.

We provide faster randomized algorithms for computing an $\epsilon$-optimal policy in a discounted Markov decision process with $A_{\text{tot}}$-state-action pairs, bounded rewards, and discount factor $\gamma$. We provide an $\tilde{O}(A_{\text{tot}}[(1 - \gamma)^{-3}\epsilon^{-2} + (1 - \gamma)^{-2}])$-time algorithm in the sampling setting, where the probability transition matrix is unknown but accessible through a generative model which can be queried in $\tilde{O}(1)$-time, and an $\tilde{O}(s + (1-\gamma)^{-2})$-time algorithm in the offline setting where the probability transition matrix is known and $s$-sparse. These results improve upon the prior state-of-the-art which either ran in $\tilde{O}(A_{\text{tot}}[(1 - \gamma)^{-3}\epsilon^{-2} + (1 - \gamma)^{-3}])$ time [Sidford, Wang, Wu, Ye 2018] in the sampling setting, $\tilde{O}(s + A_{\text{tot}} (1-\gamma)^{-3})$ time [Sidford, Wang, Wu, Yang, Ye 2018] in the offline setting, or time at least quadratic in the number of states using interior point methods for linear programming. We achieve our results by building upon prior stochastic variance-reduced value iteration methods [Sidford, Wang, Wu, Yang, Ye 2018]. We provide a variant that carefully truncates the progress of its iterates to improve the variance of new variance-reduced sampling procedures that we introduce to implement the steps. Our method is essentially model-free and can be implemented in $\tilde{O}(A_{\text{tot}})$-space when given generative model access. Consequently, our results take a step in closing the sample-complexity gap between model-free and model-based methods.

Bayesian optimization (BO) is a popular method for computationally expensive black-box optimization. However, traditional BO methods need to solve new problems from scratch, leading to slow convergence. Recent studies try to extend BO to a transfer learning setup to speed up the optimization, where search space transfer is one of the most promising approaches and has shown impressive performance on many tasks. However, existing search space transfer methods either lack an adaptive mechanism or are not flexible enough, making it difficult to efficiently identify promising search space during the optimization process. In this paper, we propose a search space transfer learning method based on Monte Carlo tree search (MCTS), called MCTS-transfer, to iteratively divide, select, and optimize in a learned subspace. MCTS-transfer can not only provide a well-performing search space for warm-start but also adaptively identify and leverage the information of similar source tasks to reconstruct the search space during the optimization process. Experiments on synthetic functions, real-world problems, Design-Bench and hyper-parameter optimization show that MCTS-transfer can demonstrate superior performance compared to other search space transfer methods under different settings. Our code is available at \url{https://github.com/lamda-bbo/mcts-transfer}.

Position embedding is a core component of current Large Language Models (LLMs). Rotary position embedding (RoPE), a technique that encodes the position information with a rotation matrix, has been the de facto choice for position embedding in many LLMs, such as the Llama series. RoPE has been further utilized to extend long context capability, which is roughly based on adjusting the \textit{base} parameter of RoPE to mitigate out-of-distribution (OOD) problems in position embedding. However, in this paper, we find that LLMs may obtain a superficial long-context ability based on the OOD theory. We revisit the role of RoPE in LLMs and propose a novel property of long-term decay, we derive that the \textit{base of RoPE bounds context length}: there is an absolute lower bound for the base value to obtain certain context length capability. Our work reveals the relationship between context length and RoPE base both theoretically and empirically, which may shed light on future long context training.
tl;dr: We study hypothesis testing of distributions in an augmented setting where learned information about the underlying distribution is available.

We consider the problem of hypothesis testing for discrete distributions. In the standard model, where we have sample access to an underlying distribution $p$, extensive research has established optimal bounds for uniformity testing, identity testing (goodness of fit), and closeness testing (equivalence or two-sample testing). We explore these problems in a setting where a predicted data distribution, possibly derived from historical data or predictive machine learning models, is available. We demonstrate that such a predictor can indeed reduce the number of samples required for all three property testing tasks. The reduction in sample complexity depends directly on the predictor’s quality, measured by its total variation distance from $p$. A key advantage of our algorithms is their adaptability to the precision of the prediction. Specifically, our algorithms can self-adjust their sample complexity based on the accuracy of the available prediction, operating without any prior knowledge of the estimation’s accuracy (i.e. they are consistent). Additionally, we never use more samples than the standard approaches require, even if the predictions provide no meaningful information (i.e. they are also robust). We provide lower bounds to indicate that the improvements in sample complexity achieved by our algorithms are information-theoretically optimal. Furthermore, experimental results show that the performance of our algorithms on real data significantly exceeds our worst-case guarantees for sample complexity, demonstrating the practicality of our approach.
tl;dr: Enhancing Mixture-of-Experts models by utilizing unchosen experts in a self-contrast manner.

Mixture-of-Experts (MoE) has emerged as a prominent architecture for scaling model size while maintaining computational efficiency. In MoE, each token in the input sequence activates a different subset of experts determined by a routing mechanism. However, the unchosen experts in MoE models do not contribute to the output, potentially leading to underutilization of the model's capacity.
In this work, we first conduct exploratory studies to demonstrate that increasing the number of activated experts does not necessarily improve and can even degrade the output quality. Then, we show that output distributions from an MoE model using different routing strategies substantially differ, indicating that different experts do not always act synergistically.
Motivated by these findings, we propose **S**elf-**C**ontrast **M**ixture-**o**f-**E**xperts (SCMoE), a training-free strategy that utilizes unchosen experts in a self-contrast manner during inference.
In SCMoE, the next-token probabilities are determined by contrasting the outputs from strong and weak activation using the same MoE model.
Our method is conceptually simple and computationally lightweight, as it incurs minimal latency compared to greedy decoding.
Experiments on several benchmarks (GSM8K, StrategyQA, MBPP and HumanEval) demonstrate that SCMoE can consistently enhance Mixtral 8x7B’s reasoning capability across various domains. For example, it improves the accuracy on GSM8K from 61.79 to 66.94.
Moreover, combining SCMoE with self-consistency yields additional gains, increasing major@20 accuracy from 75.59 to 78.31.

Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba’s success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba’s success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-
Inspired Linear Attention (MILA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
tl;dr: We present a novel approach to dynamic pricing problems with covariates and prove improved regret bounds for both linear and non-parametric valuations.

In contextual dynamic pricing, a seller sequentially prices goods based on contextual information. Buyers will purchase products only if the prices are below their valuations.
The goal of the seller is to design a pricing strategy that collects as much revenue as possible. We focus on two different valuation models. The first assumes that valuations linearly depend on the context and are further distorted by noise. Under minor regularity assumptions, our algorithm achieves an optimal regret bound of $\tilde{\mathcal{O}}(T^{2/3})$, improving the existing results. The second model removes the linearity assumption, requiring only that the expected buyer valuation is $\beta$-H\"older in the context. For this model, our algorithm obtains a regret $\tilde{\mathcal{O}}(T^{d+2\beta/d+3\beta})$, where $d$ is the dimension of the context space.
tl;dr: We combine online learning with approximate mechanism design in a strategic variant of the linear contextual bandit problem, where the arms can strategically manipulate contexts.

Motivated by the phenomenon of strategic agents gaming a recommender system to maximize the number of times they are recommended to users, we study a strategic variant of the linear contextual bandit problem, where the arms can strategically misreport privately observed contexts to the learner. We treat the algorithm design problem as one of *mechanism design* under uncertainty and propose the Optimistic Grim Trigger Mechanism (OptGTM) that incentivizes the agents (i.e., arms) to report their contexts truthfully while simultaneously minimizing regret. We also show that failing to account for the strategic nature of the agents results in linear regret. However, a trade-off between mechanism design and regret minimization appears to be unavoidable. More broadly, this work aims to provide insight into the intersection of online learning and mechanism design.

Label-specific representation learning (LSRL), i.e., constructing the representation with specific discriminative properties for each class label, is an effective strategy to improve the performance of multi-label learning. However, the generalization analysis of LSRL is still in its infancy. The existing theory bounds for multi-label learning, which preserve the coupling among different components, are invalid for LSRL. In an attempt to overcome this challenge and make up for the gap in the generalization theory of LSRL, we develop a novel vector-contraction inequality and derive the generalization bound for general function class of LSRL with a weaker dependency on the number of labels than the state of the art. In addition, we derive generalization bounds for typical LSRL methods, and these theoretical results reveal the impact of different label-specific representations on generalization analysis. The mild bounds without strong assumptions explain the good generalization ability of LSRL.

Deep learning-based methods significantly advance the exploration of associations among triple-wise biological entities (e.g., drug-target protein-adverse reaction), thereby facilitating drug discovery and safeguarding human health. However, existing researches only focus on entity-centric information mapping and aggregation, neglecting the crucial role of potential association patterns among different entities. To address the above limitation, we propose a novel association pattern-aware fusion method for biological entity relationship prediction, which effectively integrates the related association pattern information into entity representation learning. Additionally, to enhance the missing information of the low-order message passing, we devise a bind-relation module that considers the strong bind of low-order entity associations. Extensive experiments conducted on three biological datasets quantitatively demonstrate that the proposed method achieves about 4%-23% hit@1 improvements compared with state-of-the-art baselines. Furthermore, the interpretability of association patterns is elucidated in detail, thus revealing the intrinsic biological mechanisms and promoting it to be deployed in real-world scenarios. Our data and code are available at https://github.com/hry98kki/PatternBERP.
tl;dr: We present a quantization scheme that enables 4-bit quantization of all weights, activations and KV-caches of LLMs during inference

We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way that removes outliers from the hidden state without changing the output, making quantization easier. This computational invariance is applied to the hidden state (residual) of the LLM, as well as to the activations of the feed-forward components, aspects of the attention mechanism, and to the KV cache. The result is a quantized model where all matrix multiplications are performed in 4 bits, without any channels identified for retention in higher precision. Our 4-bit quantized LLAMA2-70B model has losses of at most 0.47 WikiText-2 perplexity and retains 99% of the zero-shot performance. We also show that QuaRot can provide lossless 6 and 8 bit LLAMA-2 models without any calibration data using round-to-nearest quantization. Code is available at github.com/spcl/QuaRot.
tl;dr: We introduce a scalable approach to harvest 10M high-quality instruction data from web corpus for fine-tuning language models, significantly boosting their reasoning performance without costly human annotation or GPT-4 distillation.

Instruction tuning improves the reasoning abilities of large language models (LLMs), with data quality and scalability being the crucial factors. Most instruction tuning data come from human crowd-sourcing or GPT-4 distillation. We propose a paradigm to efficiently harvest 10 million naturally existing instruction data from the pre-training web corpus to enhance LLM reasoning. Our approach involves (1) recalling relevant documents, (2) extracting instruction-response pairs, and (3) refining the extracted pairs using open-source LLMs. Fine-tuning base LLMs on this dataset, we build MAmmoTH2 models, which significantly boost performance on reasoning benchmarks. Notably, MAmmoTH2-7B’s (Mistral) performance increases from 11% to 36.7% on MATH and from 36% to 68.4% on GSM8K without training on any in-domain data. Further training MAmmoTH2 on public instruction tuning datasets yields MAmmoTH2-Plus, achieving state-of-the-art performance on several reasoning and chatbot benchmarks. Our work demonstrates how to harvest large-scale, high-quality instruction data without costly human annotation or GPT-4 distillation, providing a new paradigm for building better instruction tuning data.
tl;dr: Fast and Light-weight Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series

Large pre-trained models excel in zero/few-shot learning for language and vision tasks but face challenges in multivariate time series (TS) forecasting due to diverse data characteristics. Consequently, recent research efforts have focused on developing pre-trained TS forecasting models. These models, whether built from scratch or adapted from large language models (LLMs), excel in zero/few-shot forecasting tasks. However, they are limited by slow performance, high computational demands, and neglect of cross-channel and exogenous correlations. To address this, we introduce Tiny Time Mixers (TTM), a compact model (starting from 1M parameters) with effective transfer learning capabilities, trained exclusively on public TS datasets. TTM, based on the light-weight TSMixer architecture, incorporates innovations like adaptive patching, diverse resolution sampling, and resolution prefix tuning to handle pre-training on varied dataset resolutions with minimal model capacity. Additionally, it employs multi-level modeling to capture channel correlations and infuse exogenous signals during fine-tuning. TTM outperforms existing popular benchmarks in zero/few-shot forecasting by (4-40\%), while reducing computational requirements significantly. Moreover, TTMs are lightweight and can be executed even on CPU-only machines, enhancing usability and fostering wider adoption in resource-constrained environments. The model weights for reproducibility and research use are available at https://huggingface.co/ibm/ttm-research-r2/, while enterprise-use weights under the Apache license can be accessed as follows: the initial TTM-Q variant at https://huggingface.co/ibm-granite/granite-timeseries-ttm-r1, and the latest variants (TTM-B, TTM-E, TTM-A) weights are available at https://huggingface.co/ibm-granite/granite-timeseries-ttm-r2. The source code for the TTM model along with the usage scripts are available at https://github.com/ibm-granite/granite-tsfm/tree/main/tsfm_public/models/tinytimemixer

A prominent family of methods for learning data distributions relies on density ratio estimation (DRE), where a model is trained to *classify* between data samples and samples from some reference distribution. DRE-based models can directly output the likelihood for any given input, a highly desired property that is lacking in most generative techniques. Nevertheless, to date, DRE methods have failed in accurately capturing the distributions of complex high-dimensional data, like images, and have thus been drawing reduced research attention in recent years.
In this work we present *classification diffusion models* (CDMs), a DRE-based generative method that adopts the formalism of denoising diffusion models (DDMs) while making use of a classifier that predicts the level of noise added to a clean signal. Our method is based on an analytical connection that we derive between the MSE-optimal denoiser for removing white Gaussian noise and the cross-entropy-optimal classifier for predicting the noise level. Our method is the first DRE-based technique that can successfully generate images beyond the MNIST dataset. Furthermore, it can output the likelihood of any input in a single forward pass, achieving state-of-the-art negative log likelihood (NLL) among methods with this property.
tl;dr: The paper develops a unified framework for lower bound methods in statistical estimation and interactive decision making.

We develop a unifying framework for information-theoretic lower bound in statistical estimation and interactive decision making. Classical lower bound techniques---such as Fano's inequality, Le Cam's method, and Assouad's lemma---are central to the study of minimax risk in statistical estimation, yet are insufficient to provide tight lower bounds for \emph{interactive decision making} algorithms that collect data interactively (e.g., algorithms for bandits and reinforcement learning). Recent work of Foster et al. provides minimax lower bounds for interactive decision making using seemingly different analysis techniques from the classical methods. These results---which are proven using a complexity measure known as the \emph{Decision-Estimation Coefficient} (DEC)---capture difficulties unique to interactive learning, yet do not recover the tightest known lower bounds for passive estimation. We propose a unified view of these distinct methodologies through a new lower bound approach called \emph{interactive Fano method}. As an application, we introduce a novel complexity measure, the \emph{Decision Dimension}, which facilitates the new lower bounds for interactive decision making that extend the DEC methodology by incorporating the complexity of estimation. Using the Decision Dimension, we (i) provide a unified characterization of learnability for \emph{any} structured bandit problem, (ii) close the remaining gap between the upper and lower bounds in Foster et al. (up to polynomial factors) for any interactive decision making problem in which the underlying model class is convex.
tl;dr: We propose a training-free, simple yet effective decoding-time algorithm for multi-objective alignment of language models, with optimality guarantees.

Aligning language models (LMs) to human preferences has emerged as a critical pursuit, enabling these models to better serve diverse user needs. Existing methods primarily focus on optimizing LMs for a single reward function, limiting their adaptability to varied objectives.
Here, we propose $\textbf{multi-objective decoding~(MOD)}$, a decoding-time algorithm that outputs the next token from a linear combination of predictions of all base models, for any given weighting over different objectives.
We exploit a common form among a family of $f$-divergence regularized alignment approaches (such as PPO, DPO, and their variants) to identify a closed-form solution by Legendre transform, and derive an efficient decoding strategy.
Theoretically, we show why existing approaches can be sub-optimal even in natural settings and obtain optimality guarantees for our method.
Empirical results demonstrate the effectiveness of the algorithm. For example, compared to a parameter-merging baseline, MOD achieves 12.8\% overall reward improvement when equally optimizing towards $3$ objectives. Moreover, we experiment with MOD on combining three fully-finetuned
LMs of different model sizes, each aimed at different objectives such as safety, coding, and general user preference. Unlike traditional methods that require careful curation of a mixture of datasets to achieve comprehensive improvement, we can quickly experiment with preference weightings using MOD to find the best combination of models. Our best combination reduces toxicity on Toxigen to nearly 0\% and achieves 7.9--33.3\% improvement across three other metrics ($\textit{i.e.}$, Codex@1, GSM-COT, BBH-COT).

Solving large-scale sparse linear systems is essential in fields like mathematics, science, and engineering. Traditional numerical solvers, mainly based on the Krylov subspace iteration algorithm, suffer from the low-efficiency problem, which primarily arises from the less-than-ideal iteration. To tackle this problem, we propose a novel method, namely **Neur**al **K**rylov **It**era**t**ion (**NeurKItt**), for accelerating linear system solving.
Specifically, NeurKItt employs a neural operator to predict the invariant subspace of the linear system and then leverages the predicted subspace to accelerate linear system solving. To enhance the subspace prediction accuracy, we utilize QR decomposition for the neural operator outputs and introduce a novel projection loss function for training. NeurKItt benefits the solving by using the predicted subspace to guide the iteration process, significantly reducing the number of iterations.
We provide extensive experiments and comprehensive theoretical analyses to demonstrate the feasibility and efficiency of NeurKItt. In our main experiments, NeurKItt accelerates the solving of linear systems across various settings and datasets, achieving up to a 5.5× speedup in computation time and a 16.1× speedup in the number of iterations.
tl;dr: We introduce the Cluster-wise Graph Transformer (Cluster-GT) with a novel Node-to-Cluster Attention (N2C-Attn) mechanism, utilizing a dual-granularity kernel to capture information at both node and cluster levels.

In the realm of graph learning, there is a category of methods that conceptualize graphs as hierarchical structures, utilizing node clustering to capture broader structural information. While generally effective, these methods often rely on a fixed graph coarsening routine, leading to overly homogeneous cluster representations and loss of node-level information. In this paper, we envision the graph as a network of interconnected node sets without compressing each cluster into a single embedding. To enable effective information transfer among these node sets, we propose the Node-to-Cluster Attention (N2C-Attn) mechanism. N2C-Attn incorporates techniques from Multiple Kernel Learning into the kernelized attention framework, effectively capturing information at both node and cluster levels. We then devise an efficient form for N2C-Attn using the cluster-wise message-passing framework, achieving linear time complexity. We further analyze how N2C-Attn combines bi-level feature maps of queries and keys, demonstrating its capability to merge dual-granularity information. The resulting architecture, Cluster-wise Graph Transformer (Cluster-GT), which uses node clusters as tokens and employs our proposed N2C-Attn module, shows superior performance on various graph-level tasks. Code is available at https://github.com/LUMIA-Group/Cluster-wise-Graph-Transformer.
tl;dr: We show that several previously unrelated fairness notions from clustering are related to each other and to notions from social choice.

We study the proportional clustering problem of Chen et al. (ICML'19) and relate it to the area of multiwinner voting in computational social choice. We show that any clustering satisfying a weak proportionality notion of Brill and Peters (EC'23) simultaneously obtains the best known approximations to the proportional fairness notion of Chen et al., but also to individual fairness (Jung et al., FORC'20) and the ``core'' (Li et al., ICML'21). In fact, we show that any approximation to proportional fairness is also an approximation to individual fairness and vice versa. Finally, we also study stronger notions of proportional representation, in which deviations do not only happen to single, but multiple candidate centers, and show that stronger proportionality notions of Brill and Peters imply approximations to these stronger guarantees.

In the context of reinforcement learning from human feedback (RLHF), the reward function is generally derived from maximum likelihood estimation of a random utility model based on pairwise comparisons made by humans. The problem of learning a reward function is one of preference aggregation that, we argue, largely falls within the scope of social choice theory. From this perspective, we can evaluate different aggregation methods via established axioms, examining whether these methods meet or fail well-known standards. We demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms. In response, we develop novel rules for learning reward functions with strong axiomatic guarantees. A key innovation from the standpoint of social choice is that our problem has a *linear* structure, which greatly restricts the space of feasible rules and leads to a new paradigm that we call *linear social choice*.
tl;dr: In two text-summarization tasks, we find evidence of a causal link between an LLM's self-recognition ability and bias toward its own outputs in evaluation.

Self-evaluation using large language models (LLMs) has proven valuable not only in benchmarking but also methods like reward modeling, constitutional AI, and self-refinement. But new biases are introduced due to the same LLM acting as both the evaluator and the evaluatee. One such bias is self-preference, where an LLM evaluator scores its own outputs higher than others’ while human annotators consider them of equal quality. But do LLMs actually recognize their own outputs when they give those texts higher scores, or is it just a coincidence? In this paper, we investigate if self-recognition capability contributes to self-preference. We discover that, out of the box, LLMs such as GPT-4 and Llama 2 have non-trivial accuracy at distinguishing themselves from other LLMs and humans. By finetuning LLMs, we discover a linear correlation between self-recognition capability and the strength of self-preference bias; using controlled experiments, we show that the causal explanation resists straightforward confounders. We discuss how self-recognition can interfere with unbiased evaluations and AI safety more generally.

Developing fair automated machine learning algorithms is critical in making safe and trustworthy decisions. Many causality-based fairness notions have been proposed to address the above issues by quantifying the causal connections between sensitive attributes and decisions, and when the true causal graph is fully known, certain algorithms that achieve interventional fairness have been proposed. However, when the true causal graph is unknown, it is still challenging to effectively and efficiently exploit partially directed acyclic graphs (PDAGs) to achieve interventional fairness. To exploit the PDAGs for achieving interventional fairness, previous methods have been built on variable selection or causal effect identification, but limited to reduced prediction accuracy or strong assumptions. In this paper, we propose a general min-max optimization framework that can achieve interventional fairness with promising prediction accuracy and can be extended to maximally oriented PDAGs (MPDAGs) with added background knowledge. Specifically, we first estimate all possible treatment effects of sensitive attributes on a given prediction model from all possible adjustment sets of sensitive attributes via an efficient local approach. Next, we propose to alternatively update the prediction model and possible estimated causal effects, where the prediction model is trained via a min-max loss to control the worst-case fairness violations. Extensive experiments on synthetic and real-world datasets verify the superiority of our methods. To benefit the research community, we have released our project at https://github.com/haoxuanli-pku/NeurIPS24-Interventional-Fairness-with-PDAGs.

Knowledge editing technology has received widespread attention for low-cost updates of incorrect or outdated knowledge in large-scale language models. However, recent research has found that edited models often exhibit varying degrees of performance degradation. The reasons behind this phenomenon and potential solutions have not yet been provided. In order to investigate the reasons for the performance decline of the edited model and optimize the editing method, this work explores the underlying reasons from both data and model perspectives. Specifically, 1) from a data perspective, to clarify the impact of data on the performance of editing models, this paper first constructs a **M**ulti-**Q**uestion **D**ataset (**MQD**) to evaluate the impact of different types of editing data on model performance. The performance of the editing model is mainly affected by the diversity of editing targets and sequence length, as determined through experiments. 2) From a model perspective, this article explores the factors that affect the performance of editing models. The results indicate a strong correlation between the L1-norm of the editing model layer and the editing accuracy, and clarify that this is an important factor leading to the bottleneck of editing performance. Finally, in order to improve the performance of the editing model, this paper further proposes a **D**ump **for** **S**equence (**D4S**) method, which successfully overcomes the previous editing bottleneck by reducing the L1-norm of the editing layer, allowing users to perform multiple effective edits and minimizing model damage. Our code is available at https://github.com/nlpkeg/D4S.
tl;dr: We introduce a task-Agnostic statistical framework that integrates machine learning with classical statistical inference, allowing for valid and efficient post-prediction inference across various scientific disciplines.

Machine learning (ML) is playing an increasingly important role in scientific research. In conjunction with classical statistical approaches, ML-assisted analytical strategies have shown great promise in accelerating research findings. This has also opened a whole field of methodological research focusing on integrative approaches that leverage both ML and statistics to tackle data science challenges. One type of study that has quickly gained popularity employs ML to predict unobserved outcomes in massive samples, and then uses predicted outcomes in downstream statistical inference. However, existing methods designed to ensure the validity of this type of post-prediction inference are limited to very basic tasks such as linear regression analysis. This is because any extension of these approaches to new, more sophisticated statistical tasks requires task-specific algebraic derivations and software implementations, which ignores the massive library of existing software tools already developed for the same scientific problem given observed data. This severely constrains the scope of application for post-prediction inference. To address this challenge, we introduce a novel statistical framework named PSPS for task-agnostic ML-assisted inference. It provides a post-prediction inference solution that can be easily plugged into almost any established data analysis routines. It delivers valid and efficient inference that is robust to arbitrary choice of ML model, allowing nearly all existing statistical frameworks to be incorporated into the analysis of ML-predicted data. Through extensive experiments, we showcase our method’s validity, versatility, and superiority compared to existing approaches. Our software is available at https://github.com/qlu-lab/psps.

We measure the out-of-domain uncertainty in the prediction of Neural Networks using a statistical notion called "Lens Depth'' (LD) combined with Fermat Distance, which is able to capture precisely the "depth'' of a point with respect to a distribution in feature space, without any distributional assumption. Our method also has no trainable parameter. The method is applied directly in the feature space at test time and does not intervene in training process. As such, it does not impact the performance of the original model. The proposed method gives excellent qualitative results on toy datasets and can give competitive or better uncertainty estimation on standard deep learning datasets compared to strong baseline methods.
tl;dr: We introduce ChatQA, a suite of models that outperform GPT-4 on RAG and conversational QA.

In this work, we introduce ChatQA, a suite of models that outperform GPT-4 on retrieval-augmented generation (RAG) and conversational question answering (QA). To enhance generation, we propose a two-stage instruction tuning method that significantly boosts the performance of RAG. For effective retrieval, we introduce a dense retriever optimized for conversational QA, which yields results comparable to the alternative state-of-the-art query rewriting models, while substantially reducing deployment costs. We also present the ChatRAG Bench, which encompasses ten datasets covering comprehensive evaluations on RAG, table-related QA, arithmetic calculations, and scenarios involving unanswerable questions. Our ChatQA-1.0-70B (score: 54.14), built on Llama2, a weaker foundation model than GPT-4, can slightly outperform GPT-4-0613 (score: 53.90) and GPT-4-Turbo-2024-04-09 (score: 54.03) on the ChatRAG Bench, without relying on any synthetic data from OpenAI GPT models. Notably, Llama3-ChatQA-1.5-70B model surpasses the accuracy of GPT-4-Turbo-2024-04-09 by a margin. These results demonstrate the exceptional quality of the proposed ChatQA recipe. To advance research in this field, we open-sourced the model weights, instruction tuning data, ChatRAG Bench, and retriever for the community.
tl;dr: We train vision language models on TikZ code to automatically convert sketches and existing scientific figures into editable, semantics-preserving graphics programs.

Creating high-quality scientific figures can be time-consuming and challenging, even though sketching ideas on paper is relatively easy. Furthermore, recreating existing figures that are not stored in formats preserving semantic information is equally complex. To tackle this problem, we introduce DeTikZify, a novel multimodal language model that automatically synthesizes scientific figures as semantics-preserving TikZ graphics programs based on sketches and existing figures. To achieve this, we create three new datasets: DaTikZv2, the largest TikZ dataset to date, containing over 360k human-created TikZ graphics; SketchFig, a dataset that pairs hand-drawn sketches with their corresponding scientific figures; and MetaFig, a collection of diverse scientific figures and associated metadata. We train DeTikZify on MetaFig and DaTikZv2, along with synthetically generated sketches learned from SketchFig. We also introduce an MCTS-based inference algorithm that enables DeTikZify to iteratively refine its outputs without the need for additional training. Through both automatic and human evaluation, we demonstrate that DeTikZify outperforms commercial Claude 3 and GPT-4V in synthesizing TikZ programs, with the MCTS algorithm effectively boosting its performance. We make our code, models, and datasets publicly available.

Unsupervised Multiplex Graph Learning (UMGL) aims to learn node representations on various edge types without manual labeling. However, existing research overlooks a key factor: the reliability of the graph structure. Real-world data often exhibit a complex nature and contain abundant task-irrelevant noise, severely compromising UMGL's performance. Moreover, existing methods primarily rely on contrastive learning to maximize mutual information across different graphs, limiting them to multiplex graph redundant scenarios and failing to capture view-unique task-relevant information. In this paper, we focus on a more realistic and challenging task: to unsupervisedly learn a fused graph from multiple graphs that preserve sufficient task-relevant information while removing task-irrelevant noise. Specifically, our proposed Information-aware Unsupervised Multiplex Graph Fusion framework (InfoMGF) uses graph structure refinement to eliminate irrelevant noise and simultaneously maximizes view-shared and view-unique task-relevant information, thereby tackling the frontier of non-redundant multiplex graph. Theoretical analyses further guarantee the effectiveness of InfoMGF. Comprehensive experiments against various baselines on different downstream tasks demonstrate its superior performance and robustness. Surprisingly, our unsupervised method even beats the sophisticated supervised approaches. The source code and datasets are available at https://github.com/zxlearningdeep/InfoMGF.
tl;dr: We consider the s-ID problem in the presence of latent variables.

The s-ID problem seeks to compute a causal effect in a specific sub-population from the observational data pertaining to the same sub population (Abouei et al., 2023). This problem has been addressed when all the variables in the system are observable. In this paper, we consider an extension of the s-ID problem that allows for the presence of latent variables. To tackle the challenges induced by the presence of latent variables in a sub-population, we first extend the classical relevant graphical definitions, such as c-components and Hedges, initially defined for the so-called ID problem (Pearl, 1995; Tian & Pearl, 2002), to their new counterparts. Subsequently, we propose a sound algorithm for the s-ID problem with latent variables.

Federated learning, a pioneering paradigm, enables collaborative model training without exposing users’ data to central servers. Most existing federated learning systems necessitate uniform model structures across all clients, restricting their practicality. Several methods have emerged to aggregate diverse client models; however, they either lack the ability of personalization, raise privacy and security concerns, need prior knowledge, or ignore the capability and functionality of personalized models. In this paper, we present an innovative approach, named pFedClub, which addresses these challenges. pFedClub introduces personalized federated learning through the substitution of controllable neural network blocks/layers. Initially, pFedClub dissects heterogeneous client models into blocks and organizes them into functional groups on the server. Utilizing the designed CMSR (Controllable Model Searching and Reproduction) algorithm, pFedClub generates a range of personalized candidate models for each client. A model matching technique is then applied to select the optimal personalized model, serving as a teacher model to guide each client’s training process. We conducted extensive experiments across three datasets, examining both IID and non-IID settings. The results demonstrate that pFedClub outperforms baseline approaches, achieving state-of-the-art performance. Moreover, our model insight analysis reveals that pFedClub generates personalized models of reasonable size in a controllable manner, significantly reducing computational costs.
tl;dr: A novel video frame interpolation method that leverages the S6 model for efficient and dynamic inter-frame modeling

Inter-frame modeling is pivotal in generating intermediate frames for video frame interpolation (VFI). Current approaches predominantly rely on convolution or attention-based models, which often either lack sufficient receptive fields or entail significant computational overheads. Recently, Selective State Space Models (S6) have emerged, tailored specifically for long sequence modeling, offering both linear complexity and data-dependent modeling capabilities. In this paper, we propose VFIMamba, a novel frame interpolation method for efficient and dynamic inter-frame modeling by harnessing the S6 model. Our approach introduces the Mixed-SSM Block (MSB), which initially rearranges tokens from adjacent frames in an interleaved fashion and subsequently applies multi-directional S6 modeling. This design facilitates the efficient transmission of information across frames while upholding linear complexity. Furthermore, we introduce a novel curriculum learning strategy that progressively cultivates proficiency in modeling inter-frame dynamics across varying motion magnitudes, fully unleashing the potential of the S6 model. Experimental findings showcase that our method attains state-of-the-art performance across diverse benchmarks, particularly excelling in high-resolution scenarios. In particular, on the X-TEST dataset, VFIMamba demonstrates a noteworthy improvement of 0.80 dB for 4K frames and 0.96 dB for 2K frames.

Semi-supervised multi-label learning (SSMLL) refers to inducing classifiers using a small number of samples with multiple labels and many unlabeled samples. The prevalent solution of SSMLL involves forming pseudo-labels for unlabeled samples and inducing classifiers using both labeled and pseudo-labeled samples in a self-training manner. Unfortunately, with the commonly used binary type of loss and negative sampling, we have empirically found that learning with labeled and pseudo-labeled samples can result in the variance bias problem between the feature distributions of positive and negative samples for each label. To alleviate this problem, we aim to balance the variance bias between positive and negative samples from the perspective of the feature angle distribution for each label. Specifically, we extend the traditional binary angular margin loss to a balanced extension with feature angle distribution transformations under the Gaussian assumption, where the distributions are iteratively updated during classifier training. We also suggest an efficient prototype-based negative sampling method to maintain high-quality negative samples for each label. With this insight, we propose a novel SSMLL method, namely Semi-Supervised Multi-Label Learning with Balanced Binary Angular Margin loss (S$^2$ML$^2$-BBAM). To evaluate the effectiveness of S$^2$ML$^2$-BBAM, we compare it with existing competitors on benchmark datasets. The experimental results validate that S$^2$ML$^2$-BBAM can achieve very competitive performance.

We consider metrical task systems on general metric spaces with $n$ points, and show that any fully randomized algorithm can be turned into a randomized algorithm that uses only $2\log n$ random bits, and achieves the same competitive ratio up to a factor $2$. This provides the first order-optimal barely random algorithms for metrical task systems, i.e. which use a number of random bits that does not depend on the number of requests addressed to the system. We discuss implications on various aspects of online decision making such as: distributed systems, advice complexity and transaction costs, suggesting broad applicability. We put forward an equivalent view that we call collective metrical task systems where $k$ agents in a metrical task system team up, and suffer the average cost paid by each agent. Our results imply that such team can be $O(\log^2 n)$-competitive as soon as $k\geq n^2$. In comparison, a single agent is always $\Omega(n)$-competitive.
tl;dr: We design a nested Sequential Monte Carlo algorithm based on predictive coding in neuroscience, and demonstrate both its biological plausibility and its performance in deep generative modeling.

Unexpected stimuli induce "error" or "surprise" signals in the brain. The theory of predictive coding promises to explain these observations in terms of Bayesian inference by suggesting that the cortex implements variational inference in a probabilistic graphical model. However, when applied to machine learning tasks, this family of algorithms has yet to perform on par with other variational approaches in high-dimensional, structured inference problems. To address this, we introduce a novel predictive coding algorithm for structured generative models, that we call divide-and-conquer predictive coding (DCPC); it differs from other formulations of predictive coding, as it respects the correlation structure of the generative model and provably performs maximum-likelihood updates of model parameters, all without sacrificing biological plausibility. Empirically, DCPC achieves better numerical performance than competing algorithms and provides accurate inference in a number of problems not previously addressed with predictive coding. We provide an open implementation of DCPC in Pyro on Github.
tl;dr: A novel, hyper-articulated dataset for AI&TP, and a first model to go with it.

Agda is a dependently-typed programming language and a proof assistant, pivotal in proof formalization and programming language theory.
This paper extends the Agda ecosystem into machine learning territory, and, vice versa, makes Agda-related resources available to machine learning practitioners.
We introduce and release a novel dataset of Agda program-proofs that is elaborate and extensive enough to support various machine learning applications -- the first of its kind.
Leveraging the dataset's ultra-high resolution, which details proof states at the sub-type level, we propose a novel neural architecture targeted at faithfully representing dependently-typed programs on the basis of structural rather than nominal principles.
We instantiate and evaluate our architecture in a premise selection setup, where it achieves promising initial results, surpassing strong baselines.
tl;dr: A simple yet effective method to identify causal rationales.

An important line of research in the field of explainability is to extract a small subset of crucial rationales from the full input. The most widely used criterion for rationale extraction is the maximum mutual information (MMI) criterion. However, in certain datasets, there are spurious features non-causally correlated with the label and also get high mutual information, complicating the loss landscape of MMI. Although some penalty-based methods have been developed to penalize the spurious features (e.g., invariance penalty, intervention penalty, etc) to help MMI work better, these are merely remedial measures.
In the optimization objectives of these methods, spurious features are still distinguished from plain noise, which hinders the discovery of causal rationales.
This paper aims to develop a new criterion that treats spurious features as plain noise, allowing the model to work on datasets rich in spurious features as if it were working on clean datasets, thereby making rationale extraction easier.
We theoretically observe that removing either plain noise or spurious features from the input does not alter the conditional distribution of the remaining components relative to the task label. However, significant changes in the conditional distribution occur only when causal features are eliminated.
Based on this discovery, the paper proposes a criterion for \textbf{M}aximizing the \textbf{R}emaining \textbf{D}iscrepancy (MRD). Experiments on six widely used datasets show that our MRD criterion improves rationale quality (measured by the overlap with human-annotated rationales) by up to $10.4\%$ as compared to several recent competitive MMI variants. Code: \url{https://github.com/jugechengzi/Rationalization-MRD}.
tl;dr: We propose a general and rigorous method for nadir objective vector estimation.

The nadir objective vector plays a key role in solving multi-objective optimization problems (MOPs), where it is often used to normalize the objective space and guide the search. The current methods for estimating the nadir objective vector perform effectively only on specific MOPs. This paper reveals the limitations of these methods: exact methods can only work on discrete MOPs, while heuristic methods cannot deal with the MOP with a complicated feasible objective region. To fill this gap, we propose a general and rigorous method, namely boundary decomposition for nadir objective vector estimation (BDNE). BDNE scalarizes the MOP into a set of boundary subproblems. By utilizing bilevel optimization, boundary subproblems are optimized and adjusted alternately, thereby refining their optimal solutions to align with the nadir objective vector. We prove that the bilevel optimization identifies the nadir objective vector under mild conditions. We compare BDNE with existing methods on various black-box MOPs. The results conform to the theoretical analysis and show the significant potential of BDNE for real-world application.

Sparse training stands as a landmark approach in addressing the considerable training resource demands imposed by the continuously expanding size of Deep Neural Networks (DNNs). However, the training of a sparse DNN encounters great challenges in achieving optimal generalization ability despite the efforts from the state-of-the-art sparse training methodologies. To unravel the mysterious reason behind the difficulty of sparse training, we connect the network sparsity with neural loss functions structure, and identify the cause of such difficulty lies in chaotic loss surface. In light of such revelation, we propose $S^{2} - SAM$, characterized by a **S**ingle-step **S**harpness_**A**ware **M**inimization that is tailored for **S**parse training. For the first time, $S^{2} - SAM$ innovates the traditional SAM-style optimization by approximating sharpness perturbation through prior gradient information, incurring *zero extra cost*. Therefore, $S^{2} - SAM$ not only exhibits the capacity to improve generalization but also aligns with the efficiency goal of sparse training. Additionally, we study the generalization result of $S^{2} - SAM$ and provide theoretical proof for convergence. Through extensive experiments, $S^{2} - SAM$ demonstrates its universally applicable plug-and-play functionality, enhancing accuracy across various sparse training methods. Code available at https://github.com/jjsrf/SSAM-NEURIPS2024.
tl;dr: Surgical Vision-language Foundation Model (CLIP-like)

Surgical video-language pretraining (VLP) faces unique challenges due to the knowledge domain gap and the scarcity of multi-modal data. This study aims to bridge the gap by addressing issues regarding textual information loss in surgical lecture videos and the spatial-temporal challenges of surgical VLP. To tackle these issues, we propose a hierarchical knowledge augmentation approach and a novel Procedure-Encoded Surgical Knowledge-Augmented Video-Language Pretraining (PeskaVLP) framework. The proposed knowledge augmentation approach uses large language models (LLM) to refine and enrich surgical concepts, thus providing comprehensive language supervision and reducing the risk of overfitting. The PeskaVLP framework combines language supervision with visual self-supervision, constructing hard negative samples and employing a Dynamic Time Warping (DTW) based loss function to effectively comprehend the cross-modal procedural alignment. Extensive experiments on multiple public surgical scene understanding and cross-modal retrieval datasets show that our proposed method significantly improves zero-shot transferring performance and offers a generalist visual repre- sentation for further advancements in surgical scene understanding. The source code will be available at https://github.com/CAMMA-public/PeskaVLP.
tl;dr: Even though continuous attractors are not structurally stable, they are functionally robust remain useful as a universal analogy for understanding analog memory.

Continuous attractors offer a unique class of solutions for storing continuous-valued variables in recurrent system states for indefinitely long time intervals.
Unfortunately, continuous attractors suffer from severe structural instability in general---they are destroyed by most infinitesimal changes of the dynamical law that defines them.
This fragility limits their utility especially in biological systems as their recurrent dynamics are subject to constant perturbations.
We observe that the bifurcations from continuous attractors in theoretical neuroscience models display various structurally stable forms.
Although their asymptotic behaviors to maintain memory are categorically distinct, their finite-time behaviors are similar.
We build on the persistent manifold theory to explain the commonalities between bifurcations from and approximations of continuous attractors.
Fast-slow decomposition analysis uncovers the existence of a persistent slow manifold that survives the seemingly destructive bifurcation, relating the flow within the manifold to the size of the perturbation. Moreover, this allows the bounding of the memory error of these approximations of continuous attractors.
Finally, we train recurrent neural networks on analog memory tasks to support the appearance of these systems as solutions and their generalization capabilities.
Therefore, we conclude that continuous attractors are functionally robust and remain useful as a universal analogy for understanding analog memory.

Reinforcement learning (RL) excels in optimizing policies for discrete-time Markov decision processes (MDP). However, various systems are inherently continuous in time, making discrete-time MDPs an inexact modeling choice.
In many applications, such as greenhouse control or medical treatments, each interaction (measurement or switching of action) involves manual intervention and thus is inherently costly. Therefore,
we generally prefer a time-adaptive approach with fewer interactions with the system.
In this work, we formalize an RL framework,
**T**ime-**a**daptive **Co**ntrol \& **S**ensing (**TaCoS**), that tackles this challenge by optimizing over policies that besides control predict the duration of its application. Our formulation results in an extended MDP that any standard RL algorithm can solve.
We demonstrate that state-of-the-art RL algorithms trained on TaCoS drastically reduce the interaction amount over their discrete-time counterpart while retaining the same or improved performance, and exhibiting robustness over discretization frequency.
Finally, we propose OTaCoS, an efficient model-based algorithm for our setting. We show that OTaCoS enjoys sublinear regret for systems with sufficiently smooth dynamics and empirically results in further sample-efficiency gains.

In this work, we present TextHarmony, a unified and versatile multimodal generative model proficient in comprehending and generating visual text. Simultaneously generating images and texts typically results in performance degradation due to the inherent inconsistency between vision and language modalities. To overcome this challenge, existing approaches resort to modality-specific data for supervised fine-tuning, necessitating distinct model instances. We propose Slide-LoRA, which dynamically aggregates modality-specific and modality-agnostic LoRA experts, partially decoupling the multimodal generation space. Slide-LoRA harmonizes the generation of vision and language within a singular model instance, thereby facilitating a more unified generative process. Additionally, we develop a high-quality image caption dataset, DetailedTextCaps-100K, synthesized with a sophisticated closed-source MLLM to enhance visual text generation capabilities further. Comprehensive experiments across various benchmarks demonstrate the effectiveness of the proposed approach. Empowered by Slide-LoRA, TextHarmony achieves comparable performance to modality-specific fine-tuning results with only a 2% increase in parameters and shows an average improvement of 2.5% in visual text comprehension tasks and 4.0% in visual text generation tasks. Our work delineates the viability of an integrated approach to multimodal generation within the visual text domain, setting a foundation for subsequent inquiries. Code is available at https://github.com/bytedance/TextHarmony.
364. Transformers as Game Players: Provable In-context Game-playing Capabilities of Pre-trained Models
tl;dr: This work provides a theoretical understanding of the in-context game-playing capabilities of pre-trained transformers, broadening the research scope of in-context RL from the single-agent scenario to the multi-agent competitive games.

The in-context learning (ICL) capability of pre-trained models based on the transformer architecture has received growing interest in recent years. While theoretical understanding has been obtained for ICL in reinforcement learning (RL), the previous results are largely confined to the single-agent setting. This work proposes to further explore the in-context learning capabilities of pre-trained transformer models in competitive multi-agent games, i.e., in-context game-playing (ICGP). Focusing on the classical two-player zero-sum games, theoretical guarantees are provided to demonstrate that pre-trained transformers can provably learn to approximate Nash equilibrium in an in-context manner for both decentralized and centralized learning settings. As a key part of the proof, constructional results are established to demonstrate that the transformer architecture is sufficiently rich to realize celebrated multi-agent game-playing algorithms, in particular, decentralized V-learning and centralized VI-ULCB.

When rows of an $n \times d$ matrix $A$ are given in a stream, we study algorithms for approximating the top eigenvector of $A^T A$ (equivalently, the top right singular vector of $A$). We consider worst case inputs $A$ but assume that the rows are presented to the streaming algorithm in a uniformly random order. We show that when the gap parameter $R = \sigma_1(A)^2/\sigma_2(A)^2 = \Omega(1)$, then there is a randomized algorithm that uses $O(h \cdot d \cdot \text{polylog}(d))$ bits of space and outputs a unit vector $v$ that has a correlation $1 - O(1/\sqrt{R})$ with the top eigenvector $v_1$. Here $h$ denotes the number of ``heavy rows'' in the matrix, defined as the rows with Euclidean norm at least $\|{A}\|_F/\sqrt{d \cdot \text{polylog}(d)}$. We also provide a lower bound showing that any algorithm using $O(hd/R)$ bits of space can obtain at most $1 - \Omega(1/R^2)$ correlation with the top eigenvector. Thus, parameterizing the space complexity in terms of the number of heavy rows is necessary for high accuracy solutions.
Our results improve upon the $R = \Omega(\log n \cdot \log d)$ requirement in a recent work of Price. We note that Price's algorithm works for arbitrary order streams whereas our algorithm requires a stronger assumption that the rows are presented in a uniformly random order. We additionally show that the gap requirements in Price's analysis can be brought down to $R = \Omega(\log^2 d)$ for arbitrary order streams and $R = \Omega(\log d)$ for random order streams. The requirement of $R = \Omega(\log d)$ for random order streams is nearly tight for Price's analysis as we obtain a simple instance with $R = \Omega(\log d/\log\log d)$ for which Price's algorithm, with any fixed learning rate, cannot output a vector approximating the top eigenvector $v_1$.
tl;dr: We present MatFormer, a natively elastic Transformer architecture that allows training a single universal model which can be used to extract hundreds of smaller accurate submodels at zero additional cost.

Foundation models are applied in a broad spectrum of settings with different inference constraints, from massive multi-accelerator clusters to resource-constrained standalone mobile devices. However, the substantial costs associated with training these models often limit the number of unique model sizes that can be offered. Consequently, practitioners are compelled to select a model that may not be optimally aligned with their specific latency and cost requirements. We present MatFormer, a novel Transformer architecture designed to provide elastic inference across diverse deployment constraints. MatFormer achieves this by incorporating a nested Feed Forward Network (FFN) block structure within a standard Transformer model. During training, we optimize the parameters of multiple nested FFN blocks with varying sizes, enabling the extraction of hundreds of accurate smaller models without incurring additional computational costs. We empirically validate the efficacy of MatFormer across different model classes (decoders and encoders) and modalities (language and vision), demonstrating its potential for real-world deployment. We show that a 850M decoder-only MatFormer language model (MatLM) allows us to extract multiple smaller models spanning from 582M to 850M parameters, each exhibiting better validation loss and one-shot downstream evaluations than independently trained counterparts. Furthermore, we observe that smaller encoders extracted from a universal MatFormer-based ViT (MatViT) encoder preserve the metric-space structure for adaptive large-scale retrieval. Finally, we showcase that speculative decoding with the accurate and consistent submodels extracted from MatFormer can lead to significant reduction in inference latency.
tl;dr: A novel operator approach for learning conditional probability distributions with deep learning

We introduce Neural Conditional Probability (NCP), an operator-theoretic approach to learning conditional distributions with
a focus on statistical inference tasks. NCP can be used to build conditional confidence regions and extract key statistics such as
conditional quantiles, mean, and covariance. It offers streamlined learning via a single unconditional training phase, allowing
efficient inference without the need for retraining even when conditioning changes. By leveraging the approximation
capabilities of neural networks, NCP efficiently handles a wide variety of complex probability distributions.
We provide theoretical guarantees that ensure both optimization consistency and statistical accuracy.
In experiments, we show that NCP with a 2-hidden-layer network matches or outperforms leading methods.
This demonstrates that a a minimalistic architecture with a theoretically grounded loss can achieve
competitive results, even in the face of more complex architectures.
tl;dr: We discover an inherent problem in 3DGS and develop a novel 3DGS-based framework for tomographic reconstruction.

3D Gaussian splatting (3DGS) has shown promising results in image rendering and surface reconstruction. However, its potential in volumetric reconstruction tasks, such as X-ray computed tomography, remains under-explored. This paper introduces R$^2$-Gaussian, the first 3DGS-based framework for sparse-view tomographic reconstruction. By carefully deriving X-ray rasterization functions, we discover a previously unknown \emph{integration bias} in the standard 3DGS formulation, which hampers accurate volume retrieval. To address this issue, we propose a novel rectification technique via refactoring the projection from 3D to 2D Gaussians. Our new method presents three key innovations: (1) introducing tailored Gaussian kernels, (2) extending rasterization to X-ray imaging, and (3) developing a CUDA-based differentiable voxelizer. Experiments on synthetic and real-world datasets demonstrate that our method outperforms state-of-the-art approaches in accuracy and efficiency. Crucially, it delivers high-quality results in 4 minutes, which is 12$\times$ faster than NeRF-based methods and on par with traditional algorithms.
tl;dr: We introduce a novel method for controlling complex physical systems using generative models, by minimizing the learned generative energy function and specified objective

Controlling the evolution of complex physical systems is a fundamental task across science and engineering.
Classical techniques suffer from limited applicability or huge computational costs. On the other hand, recent deep learning and reinforcement learning-based approaches often struggle to optimize long-term control sequences under the constraints of system dynamics. In this work, we introduce Diffusion Physical systems Control (DiffPhyCon), a new class of method to address the physical systems control problem. DiffPhyCon excels by simultaneously minimizing both the learned generative energy function and the predefined control objectives across the entire trajectory and control sequence. Thus, it can explore globally and plan near-optimal control sequences. Moreover, we enhance DiffPhyCon with prior reweighting, enabling the discovery of control sequences that significantly deviate from the training distribution. We test our method on three tasks: 1D Burgers' equation, 2D jellyfish movement control, and 2D high-dimensional smoke control, where our generated jellyfish dataset is released as a benchmark for complex physical system control research. Our method outperforms widely applied classical approaches and state-of-the-art deep learning and reinforcement learning methods. Notably, DiffPhyCon unveils an intriguing fast-close-slow-open pattern observed in the jellyfish, aligning with established findings in the field of fluid dynamics. The project website, jellyfish dataset, and code can be found at https://github.com/AI4Science-WestlakeU/diffphycon.
tl;dr: We show how Normalising Flows can be used to explicitly parameterise marginal causal distributions, and illustrate its utility for both inference and synthetic data generation/benchmarking.

Investigating the marginal causal effect of an intervention on an outcome from complex data remains challenging due to the inflexibility of employed models and the lack of complexity in causal benchmark datasets, which often fail to reproduce intricate real-world data patterns. In this paper we introduce Frugal Flows, a likelihood-based machine learning model that uses normalising flows to flexibly learn the data-generating process, while also directly targeting the marginal causal quantities inferred from observational data. We provide a novel algorithm for fitting a model to observational data with a parametrically specified causal distribution, and propose that these models are exceptionally well suited for synthetic data generation to validate causal methods. Unlike existing data generation methods, Frugal Flows generate synthetic data that closely resembles the empirical dataset, while also automatically and exactly satisfying a user-defined average treatment effect. To our knowledge, Frugal Flows are the first generative model to both learn flexible data representations and also \textit{exactly} parameterise quantities such as the average treatment effect and the degree of unobserved confounding. We demonstrate the above with experiments on both simulated and real-world datasets.
tl;dr: We propose a Neural Assets representation that enables 3D-aware multi-object control in real-world scenes

We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, *Neural Assets*, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame, which enables learning disentangled appearance and position features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image interface of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).

Significant progress has been made in the field of Instruction-based Image Editing (IIE). However, evaluating these models poses a significant challenge. A crucial requirement in this field is the establishment of a comprehensive evaluation benchmark for accurately assessing editing results and providing valuable insights for its further development. In response to this need, we propose I2EBench, a comprehensive benchmark designed to automatically evaluate the quality of edited images produced by IIE models from multiple dimensions. I2EBench consists of 2,000+ images for editing, along with 4,000+ corresponding original and diverse instructions. It offers three distinctive characteristics: 1) Comprehensive Evaluation Dimensions: I2EBench comprises 16 evaluation dimensions that cover both high-level and low-level aspects, providing a comprehensive assessment of each IIE model. 2) Human Perception Alignment: To ensure the alignment of our benchmark with human perception, we conducted an extensive user study for each evaluation dimension. 3) Valuable Research Insights: By analyzing the advantages and disadvantages of existing IIE models across the 16 dimensions, we offer valuable research insights to guide future development in the field. We will open-source I2EBench, including all instructions, input images, human annotations, edited images from all evaluated methods, and a simple script for evaluating the results from new IIE models. The code, dataset, and generated images from all IIE models are provided in GitHub: https://github.com/cocoshe/I2EBench.
tl;dr: A functional perspective on bilevel optimization for deep learning applications.

In this paper, we introduce a new functional point of view on bilevel optimization problems for machine learning, where the inner objective is minimized over a function space. These types of problems are most often solved by using methods developed in the parametric setting, where the inner objective is strongly convex with respect to the parameters of the prediction function. The functional point of view does not rely on this assumption and notably allows using over-parameterized neural networks as the inner prediction function. We propose scalable and efficient algorithms for the functional bilevel optimization problem and illustrate the benefits of our approach on instrumental regression and reinforcement learning tasks.
tl;dr: This paper proposes a novel method called DGES to conduct causal discovery with deterministic relations.

Many causal discovery methods typically rely on the assumption of independent noise, yet real-life situations often involve deterministic relationships. In these cases, observed variables are represented as deterministic functions of their parental variables without noise.
When determinism is present, constraint-based methods encounter challenges due to the violation of the faithfulness assumption. In this paper, we find, supported by both theoretical analysis and empirical evidence, that score-based methods with exact search can naturally address the issues of deterministic relations under rather mild assumptions. Nonetheless, exact score-based methods can be computationally expensive. To enhance the efficiency and scalability, we develop a novel framework for causal discovery that can detect and handle deterministic relations, called Determinism-aware Greedy Equivalent Search (DGES). DGES comprises three phases: (1) identify minimal deterministic clusters (i.e., a minimal set of variables with deterministic relationships), (2) run modified Greedy Equivalent Search (GES) to obtain an initial graph, and (3) perform exact search exclusively on the deterministic cluster and its neighbors. The proposed DGES accommodates both linear and nonlinear causal relationships, as well as both continuous and discrete data types. Furthermore, we investigate the identifiability conditions of DGES. We conducted extensive experiments on both simulated and real-world datasets to show the efficacy of our proposed method.
tl;dr: We present REBEL, a new reinforcement learning algorithm that simplifies policy optimization to regressing relative rewards, offering strong theoretical guarantees and empirical performances.

While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications, including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping), and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a *minimalist* RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the *relative reward* between two completions to a prompt in terms of the policy, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and be extended to handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally efficient than PPO. When fine-tuning Llama-3-8B-Instruct, REBEL achieves strong performance in AlpacaEval 2.0, MT-Bench, and Open LLM Leaderboard. Implementation of REBEL can be found at <https://github.com/ZhaolinGao/REBEL>, and models trained by REBEL can be found at <https://huggingface.co/Cornell-AGI>.
tl;dr: This work introduces OoD-ViT-NAS, the first systematic ViT NAS benchmark designed for out-of-distribution (OoD) generalization, and provide analytical insights on how ViT architectures impact OoD performance.

While Vision Transformer (ViT) have achieved success across various machine learning tasks, deploying them in real-world scenarios faces a critical challenge: generalizing under Out-of-Distribution (OoD) shifts. A crucial research gap remains in understanding how to design ViT architectures – both manually and automatically – to excel in OoD generalization. **To address this gap,** we introduce OoD-ViT-NAS, the first systematic benchmark for ViT Neural Architecture Search (NAS) focused on OoD generalization. This comprehensive benchmark includes 3,000 ViT architectures of varying model computational budgets evaluated on common large-scale OoD datasets. With this comprehensive benchmark at hand, we analyze the factors that contribute to the OoD generalization of ViT architecture. Our analysis uncovers several key insights. Firstly, we show that ViT architecture designs have a considerable impact on OoD generalization. Secondly, we observe that In-Distribution (ID) accuracy might not be a very good indicator of OoD accuracy. This underscores the risk that ViT architectures optimized for ID accuracy might not perform well under OoD shifts. Thirdly, we conduct the first study to explore NAS for ViT’s OoD robustness. Specifically, we study 9 Training-free NAS for their OoD generalization performance on our benchmark. We observe that existing Training-free NAS are largely ineffective in predicting OoD accuracy despite their effectiveness at predicting ID accuracy. Moreover, simple proxies like #Param or #Flop surprisingly outperform more complex Training-free NAS in predicting ViTs OoD accuracy. Finally, we study how ViT architectural attributes impact OoD generalization. We discover that increasing embedding dimensions of a ViT architecture generally can improve the OoD generalization. We show that ViT architectures in our benchmark exhibit a wide range of OoD accuracy, with up to 11.85% for some OoD shift, prompting the importance to study ViT architecture design for OoD. We firmly believe that our OoD-ViT-NAS benchmark and our analysis can catalyze and streamline important research on understanding how ViT architecture designs influence OoD generalization. **Our OoD-NAS-ViT benchmark and code are available at [https://hosytuyen.github.io/projects/OoD-ViT-NAS](https://hosytuyen.github.io/projects/OoD-ViT-NAS)**

The ability to perform different skills can encourage agents to explore. In this work, we aim to construct a set of diverse skills that uniformly cover the state space. We propose a formalization of this search for diverse skills, building on a previous definition based on the mutual information between states and skills. We consider the distribution of states reached by a policy conditioned on each skill and leverage the successor state representation to maximize the difference between these skill distributions. We call this approach LEADS: Learning Diverse Skills through Successor State Representations. We demonstrate our approach on a set of maze navigation and robotic control tasks which show that our method is capable of constructing a diverse set of skills which exhaustively cover the state space without relying on reward or exploration bonuses. Our findings demonstrate that this new formalization promotes more robust and efficient exploration by combining mutual information maximization and exploration bonuses.
378. Brain-JEPA: Brain Dynamics Foundation Model with Gradient Positioning and Spatiotemporal Masking
tl;dr: Brain-JEPA is a state-of-the-art brain dynamics foundation model enhancing brain activity analysis, it achieves superior performance on different downstream tasks with broad applicability.

We introduce *Brain-JEPA*, a brain dynamics foundation model with the Joint-Embedding Predictive Architecture (JEPA). This pioneering model achieves state-of-the-art performance in demographic prediction, disease diagnosis/prognosis, and trait prediction through fine-tuning. Furthermore, it excels in off-the-shelf evaluations (e.g., linear probing) and demonstrates superior generalizability across different ethnic groups, surpassing the previous large model for brain activity significantly. Brain-JEPA incorporates two innovative techniques: **Brain Gradient Positioning** and **Spatiotemporal Masking**. Brain Gradient Positioning introduces a functional coordinate system for brain functional parcellation, enhancing the positional encoding of different Regions of Interest (ROIs). Spatiotemporal Masking, tailored to the unique characteristics of fMRI data, addresses the challenge of heterogeneous time-series patches. These methodologies enhance model performance and advance our understanding of the neural circuits underlying cognition. Overall, Brain-JEPA is paving the way to address pivotal questions of building brain functional coordinate system and masking brain activity at the AI-neuroscience interface, and setting a potentially new paradigm in brain activity analysis through downstream adaptation.
tl;dr: We propose a timely and important ICD task, i.e, Image Copy Detection for Diffusion Models (ICDiff), designed specifically to identify the replication caused by diffusion models.

Images produced by diffusion models are increasingly popular in digital artwork and visual marketing. However, such generated images might replicate content from existing ones and pose the challenge of content originality. Existing Image Copy Detection (ICD) models, though accurate in detecting hand-crafted replicas, overlook the challenge from diffusion models. This motivates us to introduce ICDiff, the first ICD specialized for diffusion models. To this end, we construct a Diffusion-Replication (D-Rep) dataset and correspondingly propose a novel deep embedding method. D-Rep uses a state-of-the-art diffusion model (Stable Diffusion V1.5) to generate 40, 000 image-replica pairs, which are manually annotated into 6 replication levels ranging from 0 (no replication) to 5 (total replication). Our method, PDF-Embedding, transforms the replication level of each image-replica pair into a probability density function (PDF) as the supervision signal. The intuition is that the probability of neighboring replication levels should be continuous and smooth. Experimental results show that PDF-Embedding surpasses protocol-driven methods and non-PDF choices on the D-Rep test set. Moreover, by utilizing PDF-Embedding, we find that the replication ratios of well-known diffusion models against an open-source gallery range from 10% to 20%. The project is publicly available at https://icdiff.github.io/.
tl;dr: We introduce a novel optimization algorithm, named dual cone gradient descent, for training PINNs.

Physics-informed neural networks (PINNs) have emerged as a prominent approach for solving partial differential equations (PDEs) by minimizing a combined loss function that incorporates both boundary loss and PDE residual loss. Despite their remarkable empirical performance in various scientific computing tasks, PINNs often fail to generate reasonable solutions, and such pathological behaviors remain difficult to explain and resolve. In this paper, we identify that PINNs can be adversely trained when gradients of each loss function exhibit a significant imbalance in their magnitudes and present a negative inner product value. To address these issues, we propose a novel optimization framework, *Dual Cone Gradient Descent* (DCGD), which adjusts the direction of the updated gradient to ensure it falls within a dual cone region. This region is defined as a set of vectors where the inner products with both the gradients of the PDE residual loss and the boundary loss are non-negative. Theoretically, we analyze the convergence properties of DCGD algorithms in a non-convex setting. On a variety of benchmark equations, we demonstrate that DCGD outperforms other optimization algorithms in terms of various evaluation metrics. In particular, DCGD achieves superior predictive accuracy and enhances the stability of training for failure modes of PINNs and complex PDEs, compared to existing optimally tuned models. Moreover, DCGD can be further improved by combining it with popular strategies for PINNs, including learning rate annealing and the Neural Tangent Kernel (NTK).
tl;dr: We propose a novel penalizing method, which efficiently reduces overestimation for offline reinforcement learning

Constraint-based offline reinforcement learning (RL) involves policy constraints or imposing penalties on the value function to mitigate overestimation errors caused by distributional shift. This paper focuses on a limitation in existing offline RL methods with penalized value function, indicating the potential for underestimation bias due to unnecessary bias introduced in the value function. To address this concern, we propose Exclusively Penalized Q-learning (EPQ), which reduces estimation bias in the value function by selectively penalizing states that are prone to inducing estimation errors. Numerical results show that our method significantly reduces underestimation bias and improves performance in various offline control tasks compared to other offline RL methods.
tl;dr: We establish formal gaps between real and complex SSMs in terms of expressiveness and practical learnability

Structured state space models (SSMs), the core engine behind prominent neural networks such as S4 and Mamba, are linear dynamical systems adhering to a specified structure, most notably diagonal. In contrast to typical neural network modules, whose parameterizations are real, SSMs often use complex parameterizations. Theoretically explaining the benefits of complex parameterizations for SSMs is an open problem. The current paper takes a step towards its resolution, by establishing formal gaps between real and complex diagonal SSMs. Firstly, we prove that while a moderate dimension suffices in order for a complex SSM to express all mappings of a real SSM, a much higher dimension is needed for a real SSM to express mappings of a complex SSM. Secondly, we prove that even if the dimension of a real SSM is high enough to express a given mapping, typically, doing so requires the parameters of the real SSM to hold exponentially large values, which cannot be learned in practice. In contrast, a complex SSM can express any given mapping with moderate parameter values. Experiments corroborate our theory, and suggest a potential extension of the theory that accounts for selectivity, a new architectural feature yielding state of the art performance.

Although 3D Gaussian Splatting has been widely studied because of its realistic and efficient novel-view synthesis, it is still challenging to extract a high-quality surface from the point-based representation. Previous works improve the surface by incorporating geometric priors from the off-the-shelf normal estimator. However, there are two main limitations: 1) Supervising normal rendered from 3D Gaussians updates only the rotation parameter while neglecting other geometric parameters; 2) The inconsistency of predicted normal maps across multiple views may lead to severe reconstruction artifacts. In this paper, we propose a Depth-Normal regularizer that directly couples normal with other geometric parameters, leading to full updates of the geometric parameters from normal regularization. We further propose a confidence term to mitigate inconsistencies of normal predictions across multiple views. Moreover, we also introduce a densification and splitting strategy to regularize the size and distribution of 3D Gaussians for more accurate surface modeling. Compared with Gaussian-based baselines, experiments show that our approach obtains better reconstruction quality and maintains competitive appearance quality at faster training speed and 100+ FPS rendering. Our code will be made open-source upon paper acceptance.
tl;dr: We systematically study model growth techniques for efficient LLM pre-training, finding a depth-wise stacking operator with great acceleration and scalability, and propose clear guidelines for its use.

LLMs are computationally expensive to pre-train due to their large scale.
Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones.
However, the viability of these model growth methods in efficient LLM pre-training remains underexplored.
This work identifies three critical $\underline{\textit{O}}$bstacles: ($\textit{O}$1) lack of comprehensive evaluation, ($\textit{O}$2) untested viability for scaling, and ($\textit{O}$3) lack of empirical guidelines.
To tackle $\textit{O}$1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting.
Our findings reveal that a depthwise stacking operator, called $G_{\text{stack}}$, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines.
Motivated by these promising results, we conduct extensive experiments to delve deeper into $G_{\text{stack}}$ to address $\textit{O}$2 and $\textit{O}$3.
For $\textit{O}$2 (untested scalability), our study shows that $G_{\text{stack}}$ is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens.
For example, compared to a conventionally trained 7B model using 300B tokens, our $G_{\text{stack}}$ model converges to the same loss with 194B tokens, resulting in a 54.6\% speedup.
We further address $\textit{O}$3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for $G_{\text{stack}}$, making it practical in general LLM pre-training.
We also provide in-depth discussions and comprehensive ablation studies of $G_{\text{stack}}$.
Our code and pre-trained model are available at https://llm-stacking.github.io/.
tl;dr: We present TREAT, a novel framework that achieves high-precision modeling for a wide6 range of dynamical systems from the numerical aspect, by enforcing Time-Reversal7 Symmetry (TRS) via a novel regularization term.

Learning complex physical dynamics purely from data is challenging due to the intrinsic properties of systems to be satisfied. Incorporating physics-informed priors, such as in Hamiltonian Neural Networks (HNNs), achieves high-precision modeling for energy-conservative systems. However, real-world systems often deviate from strict energy conservation and follow different physical priors. To address this, we present a framework that achieves high-precision modeling for a wide range of dynamical systems from the numerical aspect, by enforcing Time-Reversal Symmetry (TRS) via a novel regularization term. It helps preserve energies for conservative systems while serving as a strong inductive bias for non-conservative, reversible systems. While TRS is a domain-specific physical prior, we present the first theoretical proof that TRS loss can universally improve modeling accuracy by minimizing higher-order Taylor terms in ODE integration, which is numerically beneficial to various systems regardless of their properties, even for irreversible systems. By integrating the TRS loss within neural ordinary differential equation models, the proposed model TREAT demonstrates superior performance on diverse physical systems. It achieves a significant 11.5% MSE improvement in a challenging chaotic triple-pendulum scenario, underscoring TREAT’s broad applicability and effectiveness.

Current AI alignment methodologies rely on human-provided demonstrations or judgments, and the learned capabilities of AI systems would be upper-bounded by human capabilities as a result. This raises a challenging research question: How can we keep improving the systems when their capabilities have surpassed the levels of humans? This paper answers this question in the context of tackling hard reasoning tasks (e.g., level 4-5 MATH problems) via learning from human annotations on easier tasks (e.g., level 1-3 MATH problems), which we term as easy-to-hard generalization. Our key insight is that an evaluator (reward model) trained on supervisions for easier tasks can be effectively used for scoring candidate solutions of harder tasks and hence facilitating easy-to-hard generalization over different levels of tasks. Based on this insight, we propose a novel approach to scalable alignment, which firstly trains the (process-supervised) reward models on easy problems (e.g., level 1-3), and then uses them to evaluate the performance of policy models on hard problems. We show that such easy-to-hard generalization from evaluators can enable easy-to-hard generalizations in generators either through re-ranking or reinforcement learning (RL). Notably, our process-supervised 7b RL model and 34b model (reranking@1024) achieves an accuracy of 34.0% and 52.5% on MATH500, respectively, despite only using human supervision on easy problems. Our approach suggests a promising path toward AI systems that advance beyond the frontier of human supervision.
tl;dr: This paper presents a new real-time calcium imaging processing algorithm that is fast, robust, and flexible.

Closed-loop neuroscience experimentation, where recorded neural activity is used to modify the experiment on-the-fly, is critical for deducing causal connections and optimizing experimental time. Thus while new optical methods permit on-line recording (via Multi-photon calcium imaging) and stimulation (via holographic stimulation) of large neural populations, a critical barrier in creating closed-loop experiments that can target and modulate single neurons is the real-time inference of neural activity from streaming recordings. In particular, while multi-photon calcium imaging (CI) is crucial in monitoring neural populations, extracting a single neuron's activity from the fluorescence videos often requires batch processing of the video data. Without batch processing, dimmer neurons and events are harder to identify and unrecognized neurons can create false positives when computing the activity of known neurons. We solve these issues by adapting a recently proposed robust time-trace estimator---Sparse Emulation of Unused Dictionary Objects (SEUDO) algorithm---as a basis for a new on-line processing algorithm that simultaneously identifies neurons in the fluorescence video and infers their time traces in a way that is robust to as-yet unidentified neurons. To achieve real-time SEUDO (realSEUDO), we introduce a combination of new algorithmic improvements, a fast C-based implementation, and a new cell finding loop to enable realSEUDO to identify new cells on-the-fly with no "warm-up" period. We demonstrate comparable performance to offline algorithms (e.g., CNMF), and improved performance over the current on-line approach (OnACID) at speeds of 120 Hz on average. This speed is faster than the typical 30 Hz framerate, leaving critical computation time for the computation of feedback in a closed-loop setting.
tl;dr: This paper introduces a probabilistic framework for long-tailed learning and extends to semi-supervised learning based on continuous pseudo-labels.

Long-tailed semi-supervised learning poses a significant challenge in training models with limited labeled data exhibiting a long-tailed label distribution. Current state-of-the-art LTSSL approaches heavily rely on high-quality pseudo-labels for large-scale unlabeled data. However, these methods often neglect the impact of representations learned by the neural network and struggle with real-world unlabeled data, which typically follows a different distribution than labeled data. This paper introduces a novel probabilistic framework that unifies various recent proposals in long-tail learning. Our framework derives the class-balanced contrastive loss through Gaussian kernel density estimation. We introduce a continuous contrastive learning method, CCL, extending our framework to unlabeled data using *reliable* and *smoothed* pseudo-labels. By progressively estimating the underlying label distribution and optimizing its alignment with model predictions, we tackle the diverse distribution of unlabeled data in real-world scenarios. Extensive experiments across multiple datasets with varying unlabeled data distributions demonstrate that CCL consistently outperforms prior state-of-the-art methods, achieving over 4% improvement on the ImageNet-127 dataset. The supplementary material includes the source code for reproducibility.
tl;dr: A heterogeneous FL framework DapperFL to enhance model performance across multiple domains on resource-limited edge devices.

Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data.
In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a real-world FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to 2.28%, while significantly achieving model volume reductions ranging from 20% to 80%. Our code is available at: https://github.com/jyzgh/DapperFL.
tl;dr: This work introduces information-intensive training to overcome the lost-in-the-middle problem of long-context LLMs.
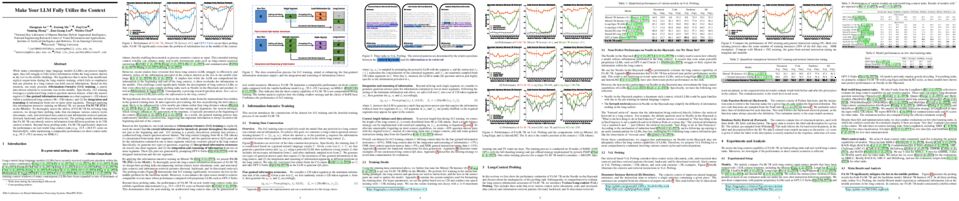
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the *lost-in-the-middle* challenge.
We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information.
Based on this intuition, our study presents **information-intensive (IN2) training**, a purely data-driven solution to overcome lost-in-the-middle.
Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) **fine-grained information awareness** on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the **integration and reasoning** of information from two or more short segments.
Through applying this information-intensive training on Mistral-7B, we present **FILM-7B** (FIll-in-the-Middle).
To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval).
The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window.
Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU).
tl;dr: We propose incorporating external user interaction to tackle hard samples at cluster boundaries, which existing deep clustering methods fail to discriminate internally from the data itself.

In the absence of class priors, recent deep clustering methods resort to data augmentation and pseudo-labeling strategies to generate supervision signals. Though achieved remarkable success, existing works struggle to discriminate hard samples at cluster boundaries, mining which is particularly challenging due to their unreliable cluster assignments. To break such a performance bottleneck, we propose incorporating user interaction to facilitate clustering instead of exhaustively mining semantics from the data itself. To be exact, we present Interactive Deep Clustering (IDC), a plug-and-play method designed to boost the performance of pre-trained clustering models with minimal interaction overhead. More specifically, IDC first quantitatively evaluates sample values based on hardness, representativeness, and diversity, where the representativeness avoids selecting outliers and the diversity prevents the selected samples from collapsing into a small number of clusters. IDC then queries the cluster affiliations of high-value samples in a user-friendly manner. Finally, it utilizes the user feedback to finetune the pre-trained clustering model. Extensive experiments demonstrate that IDC could remarkably improve the performance of various pre-trained clustering models, at the expense of low user interaction costs. The code could be accessed at pengxi.me.
tl;dr: We prove tight regret bounds for a fair version of the online bilateral trade problem

In online bilateral trade, a platform posts prices to incoming pairs of buyers and sellers that have private valuations for a certain good. If the price is lower than the buyers' valuation and higher than the sellers' valuation, then a trade takes place. Previous work focused on the platform perspective, with the goal of setting prices maximizing the *gain from trade* (the sum of sellers' and buyers' utilities). Gain from trade is, however, potentially unfair to traders, as they may receive highly uneven shares of the total utility. In this work we enforce fairness by rewarding the platform with the _fair gain from trade_, defined as the minimum between sellers' and buyers' utilities.
After showing that any no-regret learning algorithm designed to maximize the sum of the utilities may fail badly with fair gain from trade, we present our main contribution: a complete characterization of the regret regimes for fair gain from trade when, after each interaction, the platform only learns whether each trader accepted the current price. Specifically, we prove the following regret bounds: $\Theta(\ln T)$ in the deterministic setting, $\Omega(T)$ in the stochastic setting, and $\tilde{\Theta}(T^{2/3})$ in the stochastic setting when sellers' and buyers' valuations are independent of each other. We conclude by providing tight regret bounds when, after each interaction, the platform is allowed to observe the true traders' valuations.

In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets. All resources are available at https://github.com/GeorgeLuImmortal/PaDeLLM_NER.
394. Hierarchical Hybrid Sliced Wasserstein: A Scalable Metric for Heterogeneous Joint Distributions
tl;dr: We propose a scalable metric for comparing heterogeneous joint distributions i.e., distributions have marginal supports on different domains.

Sliced Wasserstein (SW) and Generalized Sliced Wasserstein (GSW) have been widely used in applications due to their computational and statistical scalability. However, the SW and the GSW are only defined between distributions supported on a homogeneous domain. This limitation prevents their usage in applications with heterogeneous joint distributions with marginal distributions supported on multiple different domains. Using SW and GSW directly on the joint domains cannot make a meaningful comparison since their homogeneous slicing operator, i.e., Radon Transform (RT) and Generalized Radon Transform (GRT) are not expressive enough to capture the structure of the joint supports set. To address the issue, we propose two new slicing operators, i.e., Partial Generalized Radon Transform (PGRT) and Hierarchical Hybrid Radon Transform (HHRT). In greater detail, PGRT is the generalization of Partial Radon Transform (PRT), which transforms a subset of function arguments non-linearly while HHRT is the composition of PRT and multiple domain-specific PGRT on marginal domain arguments. By using HHRT, we extend the SW into Hierarchical Hybrid Sliced Wasserstein (H2SW) distance which is designed specifically for comparing heterogeneous joint distributions. We then discuss the topological, statistical, and computational properties of H2SW. Finally, we demonstrate the favorable performance of H2SW in 3D mesh deformation, deep 3D mesh autoencoders, and datasets comparison.

Convolution is a fundamental operation in the 3D backbone. However, under certain conditions, the feature extraction ability of traditional convolution methods may be weakened. In this paper, we introduce a new convolution method based on $\ell_p$-norm.
For theoretical support, we prove the universal approximation theorem for $\ell_p$-norm based convolution, and analyze the robustness and feasibility of $\ell_p$-norms in 3D point cloud tasks. Concretely, $\ell_{\infty}$-norm based convolution is prone to feature loss. $\ell_2$-norm based convolution is essentially a linear transformation of the traditional convolution. $\ell_1$-norm based convolution is an economical and effective feature extractor. We propose customized optimization strategies to accelerate the training process of $\ell_1$-norm based Nets and enhance the performance. Besides, a theoretical guarantee is given for the convergence by \textit{regret} argument. We apply our methods to classic networks and conduct related experiments. Experimental results indicate that our approach exhibits competitive performance with traditional CNNs, with lower energy consumption and instruction latency.
tl;dr: We present a universal pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing of both static images and dynamic videos.

Recent developments of vision large language models (LLMs) have seen remarkable progress, yet still encounter challenges towards multimodal generalists, such as coarse-grained instance-level understanding, lack of unified support for both images and videos, and insufficient coverage across various vision tasks. In this paper we present Vitron, a universal pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing of both static images and dynamic videos. Building on top of an LLM backbone, Vitron incorporates encoders for images, videos, and pixel-level regional visuals within its frontend modules, while employing state-of-the-art visual specialists as its backend, via which Vitron supports a spectrum of vision end tasks, spanning visual comprehension to visual generation, from low level to high level. To ensure an effective and precise message passing from LLM to backend modules for function invocation, we propose a novel hybrid method by simultaneously integrating discrete textual instructions and continuous signal embeddings. Further, we design various pixel-level spatiotemporal vision-language alignment learning for Vitron to reach the best fine-grained visual capability. Finally, a cross-task synergy module is advised to learn to maximize the task-invariant fine-grained visual features, enhancing the synergy between different visual tasks. Demonstrated over 12 visual tasks and evaluated across 22 datasets, Vitron showcases its extensive capabilities in the four main vision task clusters. Overall, this work illuminates the great potential of developing a more unified multimodal generalist.
tl;dr: We elicit an abstract head that enables to implement iterative algorithms through chain-of-thought for auto-regressive LLMs.

Chain-of-Thought (CoT) reasoning is known to improve Large Language Models both empirically and in terms of theoretical approximation power.
However, our understanding of the inner workings and conditions of apparition of CoT capabilities remains limited.
This paper helps fill this gap by demonstrating how CoT reasoning emerges in transformers in a controlled and interpretable setting.
In particular, we observe the appearance of a specialized attention mechanism dedicated to iterative reasoning, which we coined "iteration heads".
We track both the emergence and the precise working of these iteration heads down to the attention level, and measure the transferability of the CoT skills to which they give rise between tasks.
tl;dr: We analyse frozen LLMs when exposed to multimodal inputs. Inside LLMs, multimodal tokens are significantly different than textual ones, yet they are implicitly aligned. Our findings led to implications on performance, safety and efficiency.

Large Language Models (LLMs) have demonstrated impressive performance on multimodal tasks, without any multimodal finetuning. They are the de facto building block for Large Multimodal Models (LMMs), yet, we still lack a proper understanding of their success. In this work, we expose frozen LLMs to image, video, audio and text inputs and analyse their internal representation with the attempt to understand their generalization beyond textual inputs. Our work provides the following **findings.** Perceptual tokens (1) are easily distinguishable from textual ones inside LLMs, with significantly different representations (e.g. live in different narrow cones), and complete translation to textual tokens does not exists. Yet, (2) both perceptual and textual tokens activate similar LLM weights. Despite their differences, (3) perceptual tokens are implicitly aligned to textual tokens inside LLMs, we call this the implicit multimodal alignment effect (IMA), and argue that this is linked to architectural design, helping LLMs to generalize. This provide more evidence to believe that the generalization of LLMs to multimodal inputs is mainly due to their architecture. These findings lead to several **implications.** This work provides several implications. (1) We find a positive correlation between the implicit alignment score and the task performance, suggesting that this could act as a proxy metric for model evaluation and selection. (2) A negative correlation exists regarding hallucinations (e.g. describing non-existing objects in images), revealing that this problem is mainly due to misalignment between the internal perceptual and textual representations. (3) Perceptual tokens change slightly throughout the model, thus, we propose different approaches to skip computations (e.g. in FFN layers), and significantly reduce the inference cost. (4) Due to the slowly changing embeddings across layers, and the high overlap between textual and multimodal activated weights, we compress LLMs by keeping only 1 subnetwork (called alpha-SubNet) that works well across a wide range of multimodal tasks. The code is available here: https://github.com/mshukor/ima-lmms.
tl;dr: We propose LinUProp, a novel approach that offers accuracy, interpretability, scalability and guaranteed convergence for uncertainty quantification of graphical model inference.

Uncertainty Quantification (UQ) is vital for decision makers as it offers insights into the potential reliability of data and model, enabling more informed and risk-aware decision-making.
Graphical models, capable of representing data with complex dependencies, are widely used across domains.
Existing sampling-based UQ methods are unbiased but cannot guarantee convergence and are time-consuming on large-scale graphs.
There are fast UQ methods for graphical models with closed-form solutions and convergence guarantee but with uncertainty underestimation.
We propose *LinUProp*, a UQ method that utilizes a novel linear propagation of uncertainty to model uncertainty among related nodes additively instead of multiplicatively, to offer linear scalability, guaranteed convergence, and closed-form solutions without underestimating uncertainty.
Theoretically, we decompose the expected prediction error of the graphical model and prove that the uncertainty computed by *LinUProp* is the *generalized variance component* of the decomposition.
Experimentally, we demonstrate that *LinUProp* is consistent with the sampling-based method but with linear scalability and fast convergence.
Moreover, *LinUProp* outperforms competitors in uncertainty-based active learning on four real-world graph datasets, achieving higher accuracy with a lower labeling budget.
tl;dr: First sample complexity analysis for interventional causal representation learning.

Consider a data-generation process that transforms low-dimensional _latent_ causally-related variables to high-dimensional _observed_ variables. Causal representation learning (CRL) is the process of using the observed data to recover the latent causal variables and the causal structure among them. Despite the multitude of identifiability results under various interventional CRL settings, the existing guarantees apply exclusively to the _infinite-sample_ regime (i.e., infinite observed samples). This paper establishes the first sample-complexity analysis for the finite-sample regime, in which the interactions between the number of observed samples and probabilistic guarantees on recovering the latent variables and structure are established. This paper focuses on _general_ latent causal models, stochastic _soft_ interventions, and a linear transformation from the latent to the observation space. The identifiability results ensure graph recovery up to ancestors and latent variables recovery up to mixing with parent variables. Specifically, ${\cal O}((\log \frac{1}{\delta})^{4})$ samples suffice for latent graph recovery up to ancestors with probability $1 - \delta$, and ${\cal O}((\frac{1}{\epsilon}\log \frac{1}{\delta})^{4})$ samples suffice for latent causal variables recovery that is $\epsilon$ close to the identifiability class with probability $1 - \delta$.
tl;dr: We show that multimodal models require exponentially more data on a concept to linearly improve their performance on tasks pertaining to that concept, highlighting extreme sample inefficiency.

Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets?
We comprehensively investigate this question across 34 models and 5 standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the Let it Wag! benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training data and compute paradigms remains to be found.

We introduce a new functional representation for 3D molecules based on their continuous atomic density fields. Using this representation, we propose a new model based on neural empirical Bayes for unconditional 3D molecule generation in the continuous space using neural fields. Our model, FuncMol, encodes molecular fields into latent codes using a conditional neural field, samples noisy codes from a Gaussian-smoothed distribution with Langevin MCMC, denoises these samples in a single step and finally decodes them into molecular fields. FuncMol performs all-atom generation of 3D molecules without assumptions on the molecular structure and scales well with the size of molecules, unlike most existing approaches. Our method achieves competitive results on drug-like molecules and easily scales to macro-cyclic peptides, with at least one order of magnitude faster sampling. The code is available at https://github.com/prescient-design/funcmol.
tl;dr: We provide an efficient local intrinsic dimension estimator using diffusion models, outperforming traditional estimators. It aligns closely with qualitative complexity in images and scales to stable diffusion.

High-dimensional data commonly lies on low-dimensional submanifolds, and estimating the local intrinsic dimension (LID) of a datum -- i.e. the dimension of the submanifold it belongs to -- is a longstanding problem. LID can be understood as the number of local factors of variation: the more factors of variation a datum has, the more complex it tends to be. Estimating this quantity has proven useful in contexts ranging from generalization in neural networks to detection of out-of-distribution data, adversarial examples, and AI-generated text. The recent successes of deep generative models present an opportunity to leverage them for LID estimation, but current methods based on generative models produce inaccurate estimates, require more than a single pre-trained model, are computationally intensive, or do not exploit the best available deep generative models: diffusion models (DMs). In this work, we show that the Fokker-Planck equation associated with a DM can provide an LID estimator which addresses the aforementioned deficiencies. Our estimator, called FLIPD, is easy to implement and compatible with all popular DMs. Applying FLIPD to synthetic LID estimation benchmarks, we find that DMs implemented as fully-connected networks are highly effective LID estimators that outperform existing baselines. We also apply FLIPD to natural images where the true LID is unknown. Despite being sensitive to the choice of network architecture, FLIPD estimates remain a useful measure of relative complexity; compared to competing estimators, FLIPD exhibits a consistently higher correlation with image PNG compression rate and better aligns with qualitative assessments of complexity. Notably, FLIPD is orders of magnitude faster than other LID estimators, and the first to be tractable at the scale of Stable Diffusion.
tl;dr: We introduce the Effective Metric-based Exploration-bonus which addresses the inherent limitations and approximation inaccuracies of current metric-based state discrepancy methods for exploration

Enhancing exploration in reinforcement learning (RL) through the incorporation of intrinsic rewards, specifically by leveraging *state discrepancy* measures within various metric spaces as exploration bonuses, has emerged as a prevalent strategy to encourage agents to visit novel states. The critical factor lies in how to quantify the difference between adjacent states as *novelty* for promoting effective exploration.
Nonetheless, existing methods that evaluate state discrepancy in the latent space under $L_1$ or $L_2$ norm often depend on count-based episodic terms as scaling factors for exploration bonuses, significantly limiting their scalability. Additionally, methods that utilize the bisimulation metric for evaluating state discrepancies face a theory-practice gap due to improper approximations in metric learning, particularly struggling with *hard exploration* tasks. To overcome these challenges, we introduce the **E**ffective **M**etric-based **E**xploration-bonus (EME). EME critically examines and addresses the inherent limitations and approximation inaccuracies of current metric-based state discrepancy methods for exploration, proposing a robust metric for state discrepancy evaluation backed by comprehensive theoretical analysis. Furthermore, we propose the diversity-enhanced scaling factor integrated into the exploration bonus to be dynamically adjusted by the variance of prediction from an ensemble of reward models, thereby enhancing exploration effectiveness in particularly challenging scenarios.
Extensive experiments are conducted on hard exploration tasks within Atari games, Minigrid, Robosuite, and Habitat, which illustrate our method's scalability to various scenarios. The project website can be found at https://sites.google.com/view/effective-metric-exploration.
tl;dr: We consider a flexible algorithmic template (FTRL+) that guarantees convergence to Nash equilibria at constant individual regret in a class of N-player adversarial games.

The long-run behavior of multi-agent online learning -- and, in particular, no-regret learning -- is relatively well-understood in potential games, where players have common interests. By contrast, in general harmonic games -- the strategic complement of potential games, where players have competing interests -- very little is known outside the narrow subclass of $2$-player zero-sum games with a fully-mixed equilibrium. Our paper seeks to partially fill this gap by focusing on the full class of (generalized) harmonic games and examining the convergence properties of "follow-the-regularized-leader" (FTRL), the most widely studied class of no-regret learning schemes. As a first result, we show that the continuous-time dynamics of FTRL are Poincaré recurrent, i.e., they return arbitrarily close to their starting point infinitely often, and hence fail to converge. In discrete time, the standard, "vanilla" implementation of FTRL may lead to even worse outcomes, eventually trapping the players in a perpetual cycle of best-responses. However, if FTRL is augmented with a suitable extrapolation step -- which includes as special cases the optimistic and mirror-prox variants of FTRL -- we show that learning converges to a Nash equilibrium from any initial condition, and all players are guaranteed at most $\mathcal{O}(1)$ regret. These results provide an in-depth understanding of no-regret learning in harmonic games, nesting prior work on $2$-player zero-sum games, and showing at a high level that potential and harmonic games are complementary not only from the strategic but also from the dynamic viewpoint.

Policy Mirror Descent (PMD) is a powerful and theoretically sound methodology for sequential decision-making. However, it is not directly applicable to Reinforcement Learning (RL) due to the inaccessibility of explicit action-value functions. We address this challenge by introducing a novel approach based on learning a world model of the environment using conditional mean embeddings. Leveraging tools from operator theory we derive a closed-form expression of the action-value function in terms of the world model via simple matrix operations. Combining these estimators with PMD leads to POWR, a new RL algorithm for which we prove convergence rates to the global optimum. Preliminary experiments in finite and infinite state settings support the effectiveness of our method.

We develop a method to generate prediction sets with a guaranteed coverage rate that is robust to corruptions in the training data, such as missing or noisy variables.
Our approach builds on conformal prediction, a powerful framework to construct prediction sets that are valid under the i.i.d assumption. Importantly, naively applying conformal prediction does not provide reliable predictions in this setting, due to the distribution shift induced by the corruptions.
To account for the distribution shift, we assume access to privileged information (PI). The PI is formulated as additional features that explain the distribution shift, however, they are only available during training and absent at test time.
We approach this problem by introducing a novel generalization of weighted conformal prediction and support our method with theoretical coverage guarantees.
Empirical experiments on both real and synthetic datasets indicate that our approach achieves a valid coverage rate and constructs more informative predictions compared to existing methods, which are not supported by theoretical guarantees.
tl;dr: We introduce AROMA, a versatile framework for enhanced PDE modeling using local neural fields, which achieves stable, efficient processing of diverse spatial data and superior performance in simulating 1D and 2D equations.

We present AROMA (Attentive Reduced Order Model with Attention), a framework designed to enhance the modeling of partial differential equations (PDEs) using local neural fields. Our flexible encoder-decoder architecture can obtain smooth latent representations of spatial physical fields from a variety of data types, including irregular-grid inputs and point clouds. This versatility eliminates the need for patching and allows efficient processing of diverse geometries. The sequential nature of our latent representation can be interpreted spatially and permits the use of a conditional transformer for modeling the temporal dynamics of PDEs. By employing a diffusion-based formulation, we achieve greater stability and enable longer rollouts compared to conventional MSE training. AROMA's superior performance in simulating 1D and 2D equations underscores the efficacy of our approach in capturing complex dynamical behaviors.
tl;dr: We propose CoSy, an automatic evaluation framework for textual explanations of neurons.

A crucial aspect of understanding the complex nature of Deep Neural Networks (DNNs) is the ability to explain learned concepts within their latent representations. While methods exist to connect neurons to human-understandable textual descriptions, evaluating the quality of these explanations is challenging due to the lack of a unified quantitative approach. We introduce CoSy (Concept Synthesis), a novel, architecture-agnostic framework for evaluating textual explanations of latent neurons. Given textual explanations, our proposed framework uses a generative model conditioned on textual input to create data points representing the explanations. By comparing the neuron's response to these generated data points and control data points, we can estimate the quality of the explanation. We validate our framework through sanity checks and benchmark various neuron description methods for Computer Vision tasks, revealing significant differences in quality.

In real-world scenarios, networks (graphs) and their tasks possess unique characteristics, requiring the development of a versatile graph augmentation (GA) to meet the varied demands of network analysis. Unfortunately, most Graph Contrastive Learning (GCL) frameworks are hampered by the specificity, complexity, and incompleteness of their GA techniques. Firstly, GAs designed for specific scenarios may compromise the universality of models if mishandled. Secondly, the process of identifying and generating optimal augmentations generally involves substantial computational overhead. Thirdly, the effectiveness of the GCL, even the learnable ones, is constrained by the finite selection of GAs available. To overcome the above limitations, this paper introduces a novel unified GA module dubbed UGA after reinterpreting the mechanism of GAs in GCLs from a message-passing perspective. Theoretically, this module is capable of unifying any explicit GAs, including node, edge, attribute, and subgraph augmentations. Based on the proposed UGA, a novel generalized GCL framework dubbed Graph cOntrastive UnifieD Augmentations (GOUDA) is proposed. It seamlessly integrates widely adopted contrastive losses and an introduced independence loss to fulfill the common requirements of consistency and diversity of augmentation across diverse scenarios. Evaluations across various datasets and tasks demonstrate the generality and efficiency of the proposed GOUDA over existing state-of-the-art GCLs.
411. Recursive PAC-Bayes: A Frequentist Approach to Sequential Prior Updates with No Information Loss
tl;dr: We solve a long-standing open problem on how to do sequential prior updates in the frequentist framework (as it has always been done in the Bayesian framework) without losing information along the way.

PAC-Bayesian analysis is a frequentist framework for incorporating prior knowledge into learning. It was inspired by Bayesian learning, which allows sequential data processing and naturally turns posteriors from one processing step into priors for the next. However, despite two and a half decades of research, the ability to update priors sequentially without losing confidence information along the way remained elusive for PAC-Bayes. While PAC-Bayes allows construction of data-informed priors, the final confidence intervals depend only on the number of points that were not used for the construction of the prior, whereas confidence information in the prior, which is related to the number of points used to construct the prior, is lost. This limits the possibility and benefit of sequential prior updates, because the final bounds depend only on the size of the final batch.
We present a novel and, in retrospect, surprisingly simple and powerful PAC-Bayesian procedure that allows sequential prior updates with no information loss. The procedure is based on a novel decomposition of the expected loss of randomized classifiers. The decomposition rewrites the loss of the posterior as an excess loss relative to a downscaled loss of the prior plus the downscaled loss of the prior, which is bounded recursively. As a side result, we also present a generalization of the split-kl and PAC-Bayes-split-kl inequalities to discrete random variables, which we use for bounding the excess losses, and which can be of independent interest. In empirical evaluation the new procedure significantly outperforms state-of-the-art.
tl;dr: This work explores theoretical guarantees for partial consistency when violating known prediction dimension bounds.

In multiclass classification over $n$ outcomes, we typically optimize some surrogate loss $L: \mathbb{R}^d \times\mathcal{Y} \to \mathbb{R}$ assigning real-valued error to predictions in $\mathbb{R}^d$. In this paradigm, outcomes must be embedded into the reals with dimension $d \approx n$ in order to design a consistent surrogate loss. Consistent losses are well-motivated theoretically, yet for large $n$, such as in information retrieval and structured prediction tasks, their optimization may be computationally infeasible. In practice, outcomes are typically embedded into some $\mathbb{R}^d$ for $d \ll n$, with little known about their suitability for multiclass classification. We investigate two approaches for trading off consistency and dimensionality in multiclass classification while using a convex surrogate loss. We first formalize partial consistency when the optimized surrogate has dimension $d \ll n$.
We then check if partial consistency holds under a given embedding and low-noise assumption, providing insight into when to use a particular embedding into $\mathbb{R}^d$. Finally, we present a new method to construct (fully) consistent losses with $d \ll n$ out of multiple problem instances. Our practical approach leverages parallelism to sidestep lower bounds on $d$.
tl;dr: Representation Learning for Treatment Effect Estimation on real world Randomized Controlled Trials.

Machine Learning and AI have the potential to transform data-driven scientific discovery, enabling accurate predictions for several scientific phenomena. As many scientific questions are inherently causal, this paper looks at the causal inference task of treatment effect estimation, where the outcome of interest is recorded in high-dimensional observations in a Randomized Controlled Trial (RCT). Despite being the simplest possible causal setting and a perfect fit for deep learning, we theoretically find that many common choices in the literature may lead to biased estimates. To test the practical impact of these considerations, we recorded ISTAnt, the first real-world benchmark for causal inference downstream tasks on high-dimensional observations as an RCT studying how garden ants (Lasius neglectus) respond to microparticles applied onto their colony members by hygienic grooming. Comparing 6 480 models fine-tuned from state-of-the-art visual backbones, we find that the sampling and modeling choices significantly affect the accuracy of the causal estimate, and that classification accuracy is not a proxy thereof. We further validated the analysis, repeating it on a synthetically generated visual data set controlling the causal model. Our results suggest that future benchmarks should carefully consider real downstream scientific questions, especially causal ones. Further, we highlight guidelines for representation learning methods to help answer causal questions in the sciences.

Mean-field Langevin dynamics (MLFD) is a class of interacting particle methods that tackle convex optimization over probability measures on a manifold, which are scalable, versatile, and enjoy computational guarantees. However, some important problems -- such as risk minimization for infinite width two-layer neural networks, or sparse deconvolution -- are originally defined over the set of signed, rather than probability, measures. In this paper, we investigate how to extend the MFLD framework to convex optimization problems over signed measures.
Among two known reductions from signed to probability measures -- the lifting and the bilevel approaches -- we show that the bilevel reduction leads to stronger guarantees and faster rates (at the price of a higher per-iteration complexity).
In particular, we investigate the convergence rate of MFLD applied to the bilevel reduction in the low-noise regime and obtain two results. First, this dynamics is amenable to an annealing schedule, adapted from [Suzuki et al., 2023], that results in polynomial convergence rates to a fixed multiplicative accuracy. Second, we investigate the problem of learning a single neuron with the bilevel approach and obtain local exponential convergence rates that depend polynomially on the dimension and noise level (to compare with the exponential dependence that would result from prior analyses).

Private data analysis faces a significant challenge known as the curse of dimensionality, leading to increased costs. However, many datasets possess an inherent low-dimensional structure. For instance, during optimization via gradient descent, the gradients frequently reside near a low-dimensional subspace. If the low-dimensional structure could be privately identified using a small amount of points, we could avoid paying for the high ambient dimension.
On the negative side, Dwork, Talwar, Thakurta, and Zhang (STOC 2014) proved that privately estimating subspaces, in general, requires an amount of points that has a polynomial dependency on the dimension. However, their bounds do not rule out the possibility to reduce the number of points for "easy" instances. Yet, providing a measure that captures how much a given dataset is "easy" for this task turns out to be challenging, and was not properly addressed in prior works.
Inspired by the work of Singhal and Steinke (NeurIPS 2021), we provide the first measures that quantify "easiness" as a function of multiplicative singular-value gaps in the input dataset, and support them with new upper and lower bounds. In particular, our results determine the first types of gaps that are sufficient and necessary for estimating a subspace with an amount of points that is independent of the dimension. Furthermore, we realize our upper bounds using a practical algorithm and demonstrate its advantage in high-dimensional regimes compared to prior approaches.
416. Enhancing Zero-Shot Vision Models by Label-Free Prompt Distribution Learning and Bias Correcting

Vision-language models, such as CLIP, have shown impressive generalization capacities when using appropriate text descriptions. While optimizing prompts on downstream labeled data has proven effective in improving performance, these methods entail labor costs for annotations and are limited by their quality. Additionally, since CLIP is pre-trained on highly imbalanced Web-scale data, it suffers from inherent label bias that leads to suboptimal performance.
To tackle the above challenges, we propose a label-**F**ree p**ro**mpt distribution **l**earning and b**i**as **c**orrection framework, dubbed as **Frolic**, which boosts zero-shot performance without the need for labeled data. Specifically, our Frolic learns distributions over prompt prototypes to capture diverse visual representations and adaptively fuses these with the original CLIP through confidence matching.
This fused model is further enhanced by correcting label bias via a label-free logit adjustment. Notably, our method is not only training-free but also circumvents the necessity for hyper-parameter tuning. Extensive experimental results across 16 datasets demonstrate the efficacy of our approach, particularly outperforming the state-of-the-art by an average of $2.6\%$ on 10 datasets with CLIP ViT-B/16 and achieving an average margin of $1.5\%$ on ImageNet and its five distribution shifts with CLIP ViT-B/16. Codes are available in [https://github.com/zhuhsingyuu/Frolic](https://github.com/zhuhsingyuu/Frolic).

This paper presents a comprehensive analysis of the growth rate of $H$-consistency bounds (and excess error bounds) for various surrogate losses used in classification. We prove a square-root growth rate near zero for smooth margin-based surrogate losses in binary classification, providing both upper and lower bounds under mild assumptions. This result also translates to excess error bounds. Our lower bound requires weaker conditions than those in previous work for excess error bounds, and our upper bound is entirely novel. Moreover, we extend this analysis to multi-class classification with a series of novel results, demonstrating a universal square-root growth rate for smooth *comp-sum* and *constrained losses*, covering common choices for training neural networks in multi-class classification. Given this universal rate, we turn to the question of choosing among different surrogate losses. We first examine how $H$-consistency bounds vary across surrogates based on the number of classes. Next, ignoring constants and focusing on behavior near zero, we identify *minimizability gaps* as the key differentiating factor in these bounds. Thus, we thoroughly analyze these gaps, to guide surrogate loss selection, covering: comparisons across different comp-sum losses, conditions where gaps become zero, and general conditions leading to small gaps. Additionally, we demonstrate the key role of minimizability gaps in comparing excess error bounds and $H$-consistency bounds.

Simulation with realistic and interactive agents represents a key task for autonomous vehicle (AV) software development in order to test AV performance in prescribed, often long-tail scenarios. In this work, we propose SceneDiffuser, a scene-level diffusion prior for traffic simulation. We present a singular framework that unifies two key stages of simulation: scene initialization and scene rollout. Scene initialization refers to generating the initial layout for the traffic in a scene, and scene rollout refers to closed-loop simulation for the behaviors of the agents. While diffusion has been demonstrated to be effective in learning realistic, multimodal agent distributions, two open challenges remain: controllability and closed-loop inference efficiency and realism. To this end, to address controllability challenges, we propose generalized hard constraints, a generalized inference-time constraint mechanism that is simple yet effective. To improve closed-loop inference quality and efficiency, we propose amortized diffusion, a novel diffusion denoising paradigm that amortizes the physical cost of denoising over future simulation rollout steps, reducing the cost of per physical rollout step to a single denoising function evaluation, while dramatically reducing closed-loop errors. We demonstrate the effectiveness of our approach on the Waymo Open Dataset, where we are able to generate distributionally realistic scenes, while obtaining competitive performance in the Sim Agents Challenge, surpassing the state-of-the-art in many realism attributes.
tl;dr: We develop an estimation framework that can estimate broad causal effect identification efficiently, achieving doubly robustness.

Causal effect identification and estimation are two crucial tasks in causal inference. Although causal effect identification has been theoretically resolved, many existing estimators only address a subset of scenarios, known as the sequential back-door adjustment (SBD) (Pearl and Robins, 1995) or g-formula (Robins, 1986). Recent efforts for developing general-purpose estimators with broader coverage, incorporating the front-door adjustment (FD) (Pearl, 2000) and more, lack scalability due to the high computational cost of summing over high-dimensional variables. In this paper, we introduce a novel approach that achieves broad coverage of causal estimands beyond the SBD, incorporating various sum-product functionals like the FD, while maintaining scalability -- estimated in polynomial time relative to the number of variables and samples. Specifically, we present the class of UCA for which a scalable and doubly robust estimator is developed.
In particular, we illustrate the expressiveness of UCA for a wide spectrum of causal estimands (e.g., SBD, FD, and more) in causal inference. We then develop an estimator that exhibits computational efficiency and doubly robustness. The scalability and robustness of the proposed framework are verified through simulations.
tl;dr: We propose a formal measure of goal-directedness in probabalistic graphical models, by adapting and generalising the maximum causal entropy framework.

We define maximum entropy goal-directedness (MEG), a formal measure of goal-
directedness in causal models and Markov decision processes, and give algorithms
for computing it. Measuring goal-directedness is important, as it is a critical
element of many concerns about harm from AI. It is also of philosophical interest,
as goal-directedness is a key aspect of agency. MEG is based on an adaptation of
the maximum causal entropy framework used in inverse reinforcement learning. It
can measure goal-directedness with respect to a known utility function, a hypothesis
class of utility functions, or a set of random variables. We prove that MEG satisfies
several desiderata and demonstrate our algorithms with small-scale experiments.

Robust estimation of the essential matrix, which encodes the relative position and orientation of two cameras, is a fundamental step in structure from motion pipelines. Recent deep-based methods achieved accurate estimation by using complex network architectures that involve graphs, attention layers, and hard pruning steps. Here, we propose a simpler network architecture based on Deep Sets. Given a collection of point matches extracted from two images, our method identifies outlier point matches and models the displacement noise in inlier matches. A weighted DLT module uses these predictions to regress the essential matrix. Our network achieves accurate recovery that is superior to existing networks with significantly more complex architectures.
tl;dr: LightGaussian effectively compresses 3D Gaussians while enhancing rendering speeds

Recent advances in real-time neural rendering using point-based techniques have enabled broader adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting impose substantial storage overhead, as Structure-from-Motion (SfM) points can grow to millions, often requiring gigabyte-level disk space for a single unbounded scene. This growth presents scalability challenges and hinders splatting efficiency. To address this, we introduce LightGaussian, a method for transforming 3D Gaussians into a more compact format. Inspired by Network Pruning, LightGaussian identifies Gaussians with minimal global significance on scene reconstruction, and applies a pruning and recovery process to reduce redundancy while preserving visual quality. Knowledge distillation and pseudo-view augmentation then transfer spherical harmonic coefficients to a lower degree, yielding compact representations. Gaussian Vector Quantization, based on each Gaussian’s global significance, further lowers bitwidth with minimal accuracy loss. LightGaussian achieves an average 15 times compression rate while boosting FPS from 144 to 237 within the 3D-GS framework, enabling efficient complex scene representation on the Mip-NeRF 360 and Tank & Temple datasets. The proposed Gaussian pruning approach is also adaptable to other 3D representations (e.g., Scaffold-GS), demonstrating strong generalization capabilities.
tl;dr: We propose a generative model for (conditional) generation of neural spiking activity using latent diffusion.

Modern datasets in neuroscience enable unprecedented inquiries into the relationship between complex behaviors and the activity of many simultaneously recorded neurons. While latent variable models can successfully extract low-dimensional embeddings from such recordings, using them to generate realistic spiking data, especially in a behavior-dependent manner, still poses a challenge. Here, we present Latent Diffusion for Neural Spiking data (LDNS), a diffusion-based generative model with a low-dimensional latent space: LDNS employs an autoencoder with structured state-space (S4) layers to project discrete high-dimensional spiking data into continuous time-aligned latents. On these inferred latents, we train expressive (conditional) diffusion models, enabling us to sample neural activity with realistic single-neuron and population spiking statistics. We validate LDNS on synthetic data, accurately recovering latent structure, firing rates, and spiking statistics. Next, we demonstrate its flexibility by generating variable-length data that mimics human cortical activity during attempted speech. We show how to equip LDNS with an expressive observation model that accounts for single-neuron dynamics not mediated by the latent state, further increasing the realism of generated samples. Finally, conditional LDNS trained on motor cortical activity during diverse reaching behaviors can generate realistic spiking data given reach direction or unseen reach trajectories. In summary, LDNS simultaneously enables inference of low-dimensional latents and realistic conditional generation of neural spiking datasets, opening up further possibilities for simulating experimentally testable hypotheses.

It is a well-known fact that correlated equilibria can be computed in polynomial time in a large class of concisely represented games using the celebrated Ellipsoid Against Hope algorithm \citep{Papadimitriou2008:Computing, Jiang2015:Polynomial}. However, the landscape of efficiently computable equilibria in sequential (extensive-form) games remains unknown. The Ellipsoid Against Hope does not apply directly to these games, because they do not have the required ``polynomial type'' property. Despite this barrier, \citet{Huang2008:Computing} altered the algorithm to compute exact extensive-form correlated equilibria.
In this paper, we generalize the Ellipsoid Against Hope and develop a simple algorithmic framework for efficiently computing saddle-points in bilinear zero-sum games, even when one of the dimensions is exponentially large. Moreover, the framework only requires a ``good-enough-response'' oracle, which is a weakened notion of a best-response oracle.
Using this machinery, we develop a general algorithmic framework for computing exact linear $\Phi$-equilibria in any polyhedral game (under mild assumptions), including correlated equilibria in normal-form games, and extensive-form correlated equilibria in extensive-form games. This enables us to give the first polynomial-time algorithm for computing exact linear-deviation correlated equilibria in extensive-form games, thus resolving an open question by \citet{Farina2023:Polynomial}. Furthermore, even for the cases for which a polynomial time algorithm for exact equilibria was already known, our framework provides a conceptually simpler solution.
tl;dr: Determinantal point processes provably yield coresets with better accuracy guarantees than independent sampling.

Determinantal point processes (DPPs) are random configurations of points with tunable negative dependence.
Because sampling is tractable, DPPs are natural candidates for subsampling tasks, such as minibatch selection or coreset construction.
A \emph{coreset} is a subset of a (large) training set, such that minimizing an empirical loss averaged over the coreset is a controlled replacement for the intractable minimization of the original empirical loss.
Typically, the control takes the form of a guarantee that the average loss over the coreset approximates the total loss uniformly across the parameter space.
Recent work has provided significant empirical support in favor of using DPPs to build randomized coresets, coupled with interesting theoretical results that are suggestive but leave some key questions unanswered.
In particular, the central question of whether the cardinality of a DPP-based coreset is fundamentally smaller than one based on independent sampling remained open.
In this paper, we answer this question in the affirmative, demonstrating that \emph{DPPs can provably outperform independently drawn coresets}.
In this vein, we contribute a conceptual understanding of coreset loss as a \emph{linear statistic} of the (random) coreset.
We leverage this structural observation to connect the coresets problem to a more general problem of concentration phenomena for linear statistics of DPPs, wherein we obtain \emph{effective concentration inequalities that extend well-beyond the state-of-the-art}, encompassing general non-projection, even non-symmetric kernels.
The latter have been recently shown to be of interest in machine learning beyond coresets, but come with a limited theoretical toolbox, to the extension of which our result contributes. Finally, we are also able to address the coresets problem for vector-valued objective functions, a novelty in the coresets literature.
tl;dr: We propose an advanced LM-HT model, which can enhance the performance of SNNs to the level of ANNs and further establish a bridge between the vanilla STBP and quantized ANNs training.

Compared to traditional Artificial Neural Network (ANN), Spiking Neural Network (SNN) has garnered widespread academic interest for its intrinsic ability to transmit information in a more energy-efficient manner. However, despite previous efforts to optimize the learning algorithm of SNNs through various methods, SNNs still lag behind ANNs in terms of performance. The recently proposed multi-threshold model provides more possibilities for further enhancing the learning capability of SNNs. In this paper, we rigorously analyze the relationship among the multi-threshold model, vanilla spiking model and quantized ANNs from a mathematical perspective, then propose a novel LM-HT model, which is an equidistant multi-threshold model that can dynamically regulate the global input current and membrane potential leakage on the time dimension. The LM-HT model can also be transformed into a vanilla single threshold model through reparameterization, thereby achieving more flexible hardware deployment. In addition, we note that the LM-HT model can seamlessly integrate with ANN-SNN Conversion framework under special initialization. This novel hybrid learning framework can effectively improve the relatively poor performance of converted SNNs under low time latency. Extensive experimental results have demonstrated that our model can outperform previous state-of-the-art works on various types of datasets, which promote SNNs to achieve a brand-new level of performance comparable to quantized ANNs. Code is available at https://github.com/hzc1208/LMHT_SNN.

Flow Matching (FM) (also referred to as stochastic interpolants or rectified flows) stands out as a class of generative models that aims to bridge in finite time the target distribution $\nu^\star$ with an auxiliary distribution $\mu$ leveraging a fixed coupling $\pi$ and a bridge which can either be deterministic or stochastic. These two ingredients define a path measure which can then be approximated by learning the drift of its Markovian projection. The main contribution of this paper is to provide relatively mild assumption on $\nu^\star$, $\mu$ and $\pi$ to obtain non-asymptotics guarantees for Diffusion Flow Matching (DFM) models using as bridge the conditional distribution associated with the Brownian motion. More precisely, it establishes bounds on the Kullback-Leibler divergence between the target distribution and the one generated by such DFM models under moment conditions on the score of $\nu^\star$, $\mu$ and $\pi$, and a standard $\mathrm{L}^2$-drift-approximation error assumption.
tl;dr: We reduce high-dimensional neural dynamics to only three dimensions and decode movements using just linear and logistic regression

Aligning neural dynamics with movements is a fundamental goal in neuroscience and brain-machine interfaces. However, there is still a lack of dimensionality reduction methods that can effectively align low-dimensional latent dynamics with movements. To address this gap, we propose Neural Embeddings Rank (NER), a technique that embeds neural dynamics into a 3D latent space and contrasts the embeddings based on movement ranks. NER learns to regress continuous representations of neural dynamics (i.e., embeddings) on continuous movements. We apply NER and six other dimensionality reduction techniques to neurons in the primary motor cortex (M1), dorsal premotor cortex (PMd), and primary somatosensory cortex (S1) as monkeys perform reaching tasks. Only NER aligns latent dynamics with both hand position and direction, visualizable in 3D. NER reveals consistent latent dynamics in M1 and PMd across sixteen sessions over a year. Using a linear regression decoder, NER explains 86\% and 97\% of the variance in velocity and position, respectively. Linear models trained on data from one session successfully decode velocity, position, and direction in held-out test data from different dates and cortical areas (64\%, 88\%, and 90\%). NER also reveals distinct latent dynamics in S1 during consistent movements and in M1 during curved reaching tasks. The code is available at https://github.com/NeuroscienceAI/NER.
tl;dr: We study how to reduce the variance of algorithms that learn to play a large imperfect information game.

We study how to learn $\epsilon$-optimal strategies in zero-sum imperfect information games (IIG) with *trajectory feedback*. In this setting, players update their policies sequentially, based on their observations over a fixed number of episodes denoted by $T$. Most existing procedures suffer from high variance due to the use of importance sampling over sequences of actions. To reduce this variance, we consider a *fixed sampling* approach, where players still update their policies over time, but with observations obtained through a given fixed sampling policy. Our approach is based on an adaptive Online Mirror Descent (OMD) algorithm that applies OMD locally to each information set, using individually decreasing learning rates and a *regularized loss*. We show that this approach guarantees a convergence rate of $\tilde{\mathcal{O}}(T^{-1/2})$ with high probability and has a near-optimal dependence on the game parameters when applied with the best theoretical choices of learning rates and sampling policies. To achieve these results, we generalize the notion of OMD stabilization, allowing for time-varying regularization with convex increments.
430. Trace is the Next AutoDiff: Generative Optimization with Rich Feedback, Execution Traces, and LLMs
tl;dr: Framework for efficient optimization of heterogenous parameters in general computational workflows

We study a class of optimization problems motivated by automating the design and update of AI systems like coding assistants, robots, and copilots. AutoDiff frameworks, like PyTorch, enable efficient end-to-end optimization of differentiable systems. However, general computational workflows can be non-differentiable and involve rich feedback (e.g. console output or user’s responses), heterogeneous parameters (e.g. prompts, codes), and intricate objectives (beyond maximizing a score). We investigate end-to-end generative optimization – using generative models such as LLMs within the optimizer for automatic updating of general computational workflows. We discover that workflow execution traces are akin to back-propagated gradients in AutoDiff and can provide key information to interpret feedback for efficient optimization. Formally, we frame a new mathematical setup, Optimization with Trace Oracle (OPTO). In OPTO, an optimizer receives an execution trace along with feedback on the computed output and updates parameters iteratively. We provide a Python library, Trace, that efficiently converts a workflow optimization problem into an OPTO instance using PyTorch-like syntax. Using Trace, we develop a general LLM-based generative optimizer called OptoPrime. In empirical studies, we find that OptoPrime is capable of first-order numerical optimization, prompt optimization, hyper-parameter tuning, robot controller design, code debugging, etc., and is often competitive with specialized optimizers for each domain. We envision Trace as an open research platform for devising novel generative optimizers and developing the next generation of interactive learning agents. Website: https://microsoft.github.io/Trace/.

Modern machine learning models are becoming increasingly expensive to train for real-world image and text classification tasks, where massive web-scale data is collected in a streaming fashion. To reduce the training cost, online batch selection techniques have been developed to choose the most informative datapoints. However, many existing techniques are not robust to class imbalance and distributional shifts, and can suffer from poor worst-class generalization performance. This work introduces REDUCR, a robust and efficient data downsampling method that uses class priority reweighting. REDUCR reduces the training data while preserving worst-class generalization performance. REDUCR assigns priority weights to datapoints in a class-aware manner using an online learning algorithm. We demonstrate the data efficiency and robust performance of REDUCR on vision and text classification tasks. On web-scraped datasets with imbalanced class distributions, REDUCR significantly improves worst-class test accuracy (and average accuracy), surpassing state-of-the-art methods by around 15\%.
tl;dr: This paper presents Prism, a framework that can be used for: 1) analyzing the perception and reasoning capabilities of VLMs; 2) solving general visual questions efficiently

Vision Language Models (VLMs) demonstrate remarkable proficiency in addressing a wide array of visual questions, which requires strong perception and reasoning faculties. Assessing these two competencies independently is crucial for model refinement, despite the inherent difficulty due to the intertwined nature of seeing and reasoning in existing VLMs. To tackle this issue, we present Prism, an innovative framework designed to disentangle the perception and reasoning processes involved in visual question solving. Prism comprises two distinct stages: a perception stage that utilizes a VLM to extract and articulate visual information in textual form, and a reasoning stage that formulates responses based on the extracted visual information using a Large Language Model (LLM). This modular design enables the systematic comparison and assessment of both proprietary and open-source VLM for their perception and reasoning strengths. Our analytical framework provides several valuable insights, underscoring Prism's potential as a cost-effective solution for vision-language tasks.
By combining a streamlined VLM focused on perception with a powerful LLM tailored for reasoning, Prism achieves superior results in general vision-language tasks while substantially cutting down on training and operational expenses. Quantitative evaluations show that Prism, when configured with a vanilla 2B LLaVA and freely accessible GPT-3.5, delivers performance on par with VLMs $10 \times$ larger on the rigorous multimodal benchmark MMStar.
tl;dr: We give a theoretical account of strong student models learning to improve over their weaker teachers.

Strong student models can learn from weaker teachers: when trained on the predictions of a weaker model, a strong pretrained student can learn to correct the weak model’s errors and generalize to examples where the teacher is not confident, even when these examples are excluded from training. This enables learning from cheap, incomplete, and possibly incorrect label information, such as coarse logical rules or the generations of a language model. We show that existing weak supervision theory results fail to account for both of these effects, which we call pseudolabel correction and coverage expansion, respectively. We give a new bound based on expansion properties of the data distribution and student hypothesis class that directly accounts for pseudolabel correction and coverage expansion. Our bound generalizes results from the co-training and self-training literature and captures the intuition that weak-to-strong generalization occurs when the mistakes of the weak model are hard for the strong model to fit without incurring additional error. We show that these expansion properties can be checked from finite data and give empirical evidence that they hold in practice.
tl;dr: Theoretically sound backdoor attacks against reinforcement learning with provable guarantees.

Reinforcement learning (RL) is an actively growing field that is seeing increased usage in real-world, safety-critical applications -- making it paramount to ensure the robustness of RL algorithms against adversarial attacks. In this work we explore a particularly stealthy form of training-time attacks against RL -- backdoor poisoning. Here the adversary intercepts the training of an RL agent with the goal of reliably inducing a particular action when the agent observes a pre-determined trigger at inference time. We uncover theoretical limitations of prior work by proving their inability to generalize across domains and MDPs. Motivated by this, we formulate a novel poisoning attack framework which interlinks the adversary's objectives with those of finding an optimal policy -- guaranteeing attack success in the limit. Using insights from our theoretical analysis we develop "SleeperNets" as a universal backdoor attack which exploits a newly proposed threat model and leverages dynamic reward poisoning techniques. We evaluate our attack in 6 environments spanning multiple domains and demonstrate significant improvements in attack success over existing methods, while preserving benign episodic return.
tl;dr: We provide a methodology for reliably characterising the fairness properties of datasets.

In machine learning fairness, training models that minimize disparity across different sensitive groups often leads to diminished accuracy, a phenomenon known as the fairness-accuracy trade-off. The severity of this trade-off inherently depends on dataset characteristics such as dataset imbalances or biases and therefore, using a uniform fairness requirement across diverse datasets remains questionable. To address this, we present a computationally efficient approach to approximate the fairness-accuracy trade-off curve tailored to individual datasets, backed by rigorous statistical guarantees. By utilizing the You-Only-Train-Once (YOTO) framework, our approach mitigates the computational burden of having to train multiple models when approximating the trade-off curve. Crucially, we introduce a novel methodology for quantifying uncertainty in our estimates, thereby providing practitioners with a robust framework for auditing model fairness while avoiding false conclusions due to estimation errors. Our experiments spanning tabular (e.g., Adult), image (CelebA), and language (Jigsaw) datasets underscore that our approach not only reliably quantifies the optimum achievable trade-offs across various data modalities but also helps detect suboptimality in SOTA fairness methods.

In this paper, we present the first explicit and non-asymptotic global convergence rates of the BFGS method when implemented with an inexact line search scheme satisfying the Armijo-Wolfe conditions. We show that BFGS achieves a global linear convergence rate of $(1 - \frac{1}{\kappa})^t$ for $\mu$-strongly convex functions with $L$-Lipschitz gradients, where $\kappa = \frac{L}{\mu}$ represents the condition number. Additionally, if the objective function's Hessian is Lipschitz, BFGS with the Armijo-Wolfe line search achieves a linear convergence rate that depends solely on the line search parameters, independent of the condition number. We also establish a global superlinear convergence rate of $\mathcal{O}((\frac{1}{t})^t)$. These global bounds are all valid for any starting point $x_0$ and any symmetric positive definite initial Hessian approximation matrix $B_0$, though the choice of $B_0$ impacts the number of iterations needed to achieve these rates. By synthesizing these results, we outline the first global complexity characterization of BFGS with the Armijo-Wolfe line search. Additionally, we clearly define a mechanism for selecting the step size to satisfy the Armijo-Wolfe conditions and characterize its overall complexity.

Continual learning with deep neural networks presents challenges distinct from both the fixed-dataset and convex continual learning regimes. One such challenge is plasticity loss, wherein a neural network trained in an online fashion displays a degraded ability to fit new tasks. This problem has been extensively studied in both supervised learning and off-policy reinforcement learning (RL), where a number of remedies have been proposed. Still, plasticity loss has received less attention in the on-policy deep RL setting. Here we perform an extensive set of experiments examining plasticity loss and a variety of mitigation methods in on-policy deep RL. We demonstrate that plasticity loss is pervasive under domain shift in this regime, and that a number of methods developed to resolve it in other settings fail, sometimes even performing worse than applying no intervention at all. In contrast, we find that a class of ``regenerative'' methods are able to consistently mitigate plasticity loss in a variety of contexts, including in gridworld tasks and more challenging environments like Montezuma's Revenge and ProcGen.
tl;dr: Makes GAN training stable with math (!), then uses this to create simple modern baseline architecture with SOTA-competitive performance.

There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, this loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline---R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models. Code: https://www.github.com/brownvc/R3GAN
tl;dr: We propose an on-policy goal-conditioned reinforcement learning framework, GCPO, which is applicable to both Markovian and non-Markovian reward problems.

Existing Goal-Conditioned Reinforcement Learning (GCRL) algorithms are built upon Hindsight Experience Replay (HER), which densifies rewards through hindsight replay and leverages historical goal-achieving information to construct a learning curriculum. However, when the task is characterized by a non-Markovian reward (NMR), whose computation depends on multiple steps of states and actions, HER can no longer densify rewards by treating a single encountered state as the hindsight goal. The lack of informative rewards hinders policy learning, resulting in rolling out failed trajectories. Consequently, the replay buffer is overwhelmed with failed trajectories, impeding the establishment of an applicable curriculum. To circumvent these limitations, we deviate from existing HER-based methods and propose an on-policy GCRL framework, GCPO, which is applicable to both multi-goal Markovian reward (MR) and NMR problems.
GCPO consists of (1) Pre-training from Demonstrations, which pre-trains the policy to possess an initial goal-achieving capability, thereby diminishing the difficulty of subsequent online learning. (2) Online Self-Curriculum Learning, which first estimates the policy's goal-achieving capability based on historical evaluation information and then selects progressively challenging goals for learning based on its current capability. We evaluate GCPO on a challenging multi-goal long-horizon task: fixed-wing UAV velocity vector control. Experimental results demonstrate that GCPO is capable of effectively addressing both multi-goal MR and NMR problems.
tl;dr: We introduce the new problem of Zero-Shot Tokenizer Transfer (using a language model with a tokenizer it has never been trained with), and a first high-performing baseline to solve this problem.

Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may still perform well in other natural and programming languages, but have vastly decreased efficiency due to their English-centric tokenizer. To mitigate this, we should be able to swap the original LM tokenizer with an arbitrary one, on the fly, without degrading performance. Hence, in this work we define a new problem: Zero-Shot Tokenizer Transfer (ZeTT). The challenge at the core of ZeTT is finding embeddings for the tokens in the vocabulary of the new tokenizer. Since prior heuristics for initializing embeddings often perform at chance level in a ZeTT setting, we propose a new solution: we train a hypernetwork taking a tokenizer as input and predicting the corresponding embeddings. We empirically demonstrate that the hypernetwork generalizes to new tokenizers both with encoder (e.g., XLM-R) and decoder LLMs (e.g., Mistral-7B). Our method comes close to the original models' performance in cross-lingual and coding tasks while markedly reducing the length of the tokenized sequence. We also find that the remaining gap can be quickly closed by continued training on less than 1B tokens. Finally, we show that a ZeTT hypernetwork trained for a base (L)LM can also be applied to fine-tuned variants without extra training. Overall, our results make substantial strides toward detaching LMs from their tokenizer.

The emergence of Large Language Models (LLMs) has significantly advanced natural language processing, but these models often generate factually incorrect information, known as "hallucination." Initial retrieval-augmented generation (RAG) methods like the "Retrieve-Read" framework was inadequate for complex reasoning tasks. Subsequent prompt-based RAG strategies and Supervised Fine-Tuning (SFT) methods improved performance but required frequent retraining and risked altering foundational LLM capabilities. To cope with these challenges, we propose Assistant-based Retrieval-Augmented Generation (AssistRAG), integrating an intelligent information assistant within LLMs. This assistant manages memory and knowledge through tool usage, action execution, memory building, and plan specification. Using a two-phase training approach—Curriculum Assistant Learning and Reinforced Preference Optimization—AssistRAG enhances information retrieval and decision-making. Experiments show AssistRAG significantly outperforms benchmarks, especially benefiting less advanced LLMs, by providing superior reasoning capabilities and accurate responses.

Sparsity is a central aspect of interpretability in machine learning. Typically, sparsity is measured in terms of the size of a model globally, such as the number of variables it uses. However, this notion of sparsity is not particularly relevant for decision making; someone subjected to a decision does not care about variables that do not contribute to the decision. In this work, we dramatically expand a notion of *decision sparsity* called the *Sparse Explanation Value* (SEV) so that its explanations are more meaningful. SEV considers movement along a hypercube towards a reference point. By allowing flexibility in that reference and by considering how distances along the hypercube translate to distances in feature space, we can derive sparser and more meaningful explanations for various types of function classes. We present cluster-based SEV and its variant tree-based SEV, introduce a method that improves credibility of explanations, and propose algorithms that optimize decision sparsity in machine learning models.
tl;dr: We study the statistical requirements and algorithmic principles for reinforcement learning under general latent dynamics

Real-world applications of reinforcement learning often involve environments where agents operate on complex, high-dimensional observations, but the underlying (``latent'') dynamics are comparatively simple. However, beyond restrictive settings
such as tabular latent dynamics, the fundamental statistical requirements and algorithmic principles for *reinforcement learning under latent dynamics* are poorly
understood.
This paper addresses the question of reinforcement learning under *general latent dynamics* from a
statistical and algorithmic perspective. On the statistical side, our main negative
result shows that *most* well-studied settings for reinforcement learning with function approximation become intractable when composed with rich observations; we complement this with a positive result, identifying *latent pushforward coverability* as a
general condition that enables statistical tractability. Algorithmically, we develop provably efficient *observable-to-latent* reductions ---that is, reductions that transform an arbitrary algorithm for the
latent MDP into an algorithm that can operate on rich observations--- in two settings: one where the agent has access to hindsight
observations of the latent dynamics (Lee et al., 2023) and one
where the agent can estimate *self-predictive* latent models (Schwarzer et al., 2020). Together, our results serve as a
first step toward a unified statistical and algorithmic theory for
reinforcement learning under latent dynamics.

A recent study has shown that large-scale pretraining datasets are very biased: they can be easily classified by modern neural networks. However, the concrete forms of bias among these datasets remain unclear. In this study, we propose a framework to identify the unique visual attributes distinguishing these datasets. Our approach applies various transformations to extract semantic, structural, boundary, color, and frequency information from datasets and assess how much each type of information contributes to their bias. We further decompose their semantic bias with object-level queries, and leverage natural language methods to generate detailed, open-ended descriptions of each dataset's characteristics. Our work aims to help researchers understand the bias in existing large-scale datasets and build more diverse and representative ones in the future. Our project page and code are available at boyazeng.github.io/understand_bias
tl;dr: We propose a novel method for transferring pose variations from one 3D mesh to another by training a diffusion model on Jacobian fields.

We propose a novel method for learning representations of poses for 3D deformable objects, which specializes in 1) disentangling pose information from the object's identity, 2) facilitating the learning of pose variations, and 3) transferring pose information to other object identities. Based on these properties, our method enables the generation of 3D deformable objects with diversity in both identities and poses, using variations of a single object. It does not require explicit shape parameterization such as skeletons or joints, point-level or shape-level correspondence supervision, or variations of the target object for pose transfer.
To achieve pose disentanglement, compactness for generative models, and transferability, we first design the pose extractor to represent the pose as a keypoint-based hybrid representation and the pose applier to learn an implicit deformation field. To better distill pose information from the object's geometry, we propose the implicit pose applier to output an intrinsic mesh property, the face Jacobian. Once the extracted pose information is transferred to the target object, the pose applier is fine-tuned in a self-supervised manner to better describe the target object's shapes with pose variations. The extracted poses are also used to train a cascaded diffusion model to enable the generation of novel poses.
Our experiments with the DeformThings4D and Human datasets demonstrate state-of-the-art performance in pose transfer and the ability to generate diverse deformed shapes with various objects and poses.
tl;dr: We introduce a simple and extremely low-cost approach for label distribution adaptation in zero-shot models.

Popular zero-shot models suffer due to artifacts inherited from pretraining. One particularly detrimental issue, caused by unbalanced web-scale pretraining data, is mismatched label distribution. Existing approaches that seek to repair the label distribution are not suitable in zero-shot settings, as they have mismatching requirements, such as needing access to labeled downstream task data or knowledge of the true label balance in the pretraining distribution. We sidestep these challenges and introduce a simple and lightweight approach to adjust pretrained model predictions via optimal transport. Our technique requires only an estimate of the label distribution of a downstream task. Theoretically, we characterize the improvement produced by our procedure under certain mild conditions and provide bounds on the error caused by misspecification. Empirically, we validate our method in a wide array of zero-shot image and text classification tasks, improving accuracy by 4.8% and 15.9% on average, and beating baselines like prior matching---often by significant margins---in 17 out of 21 datasets.

In recent advancements in unsupervised visual representation learning, the Joint-Embedding Predictive Architecture (JEPA) has emerged as a significant method for extracting visual features from unlabeled imagery through an innovative masking strategy. Despite its success, two primary limitations have been identified: the inefficacy of Exponential Moving Average (EMA) from I-JEPA in preventing entire collapse and the inadequacy of I-JEPA prediction in accurately learning the mean of patch representations. Addressing these challenges, this study introduces a novel framework, namely C-JEPA (Contrastive-JEPA), which integrates the Image-based Joint-Embedding Predictive Architecture with the Variance-Invariance-Covariance Regularization (VICReg) strategy. This integration is designed to effectively learn the variance/covariance for preventing entire collapse and ensuring invariance in the mean of augmented views, thereby overcoming the identified limitations. Through empirical and theoretical evaluations, our work demonstrates that C-JEPA significantly enhances the stability and quality of visual representation learning. When pre-trained on the ImageNet-1K dataset, C-JEPA exhibits rapid and improved convergence in both linear probing and fine-tuning performance metrics.
tl;dr: We show how normalising flows can be fitted for preferential data representing expert's choices between a set of alternatives, as a function-space maximum a posteriori estimate with a novel functional prior.

Eliciting a high-dimensional probability distribution from an expert via noisy judgments is notoriously challenging, yet useful for many applications, such as prior elicitation and reward modeling. We introduce a method for eliciting the expert's belief density as a normalizing flow based solely on preferential questions such as comparing or ranking alternatives. This allows eliciting in principle arbitrarily flexible densities, but flow estimation is susceptible to the challenge of collapsing or diverging probability mass that makes it difficult in practice. We tackle this problem by introducing a novel functional prior for the flow, motivated by a decision-theoretic argument, and show empirically that the belief density can be inferred as the function-space maximum a posteriori estimate. We demonstrate our method by eliciting multivariate belief densities of simulated experts, including the prior belief of a general-purpose large language model over a real-world dataset.

In Economics, the concept of externality refers to any indirect effect resulting from an interaction between players and affecting a third party without compensation. Most of the models within which externality has been studied assume that agents have perfect knowledge of their environment and preferences. This is a major hindrance to the practical implementation of many proposed solutions. To adress this issue, we consider a two-players bandit game setting where the actions of one of the player affect the other one. Building upon this setup, we extend the Coase theorem [Coase, 2013], which suggests that the optimal approach for maximizing the social welfare in the presence of externality is to establish property rights, i.e., enabling transfers and bargaining between the players. Nonetheless, this fundamental result relies on the assumption that bargainers possess perfect knowledge of the underlying game. We first demonstrate that in the absence of property rights in the considered online scenario, the social welfare breaks down. We then provide a policy for the players, which allows them to learn a bargaining strategy which maximizes the total welfare, recovering the Coase theorem under uncertainty.
tl;dr: Investigates Dynamic Sparse Training for large output spaces. Leveraging semi-structured sparsity, intermediate layers, and auxiliary loss, it enables end-to-end training with millions of labels on commodity hardware with near-dense performance.

In recent years, Dynamic Sparse Training (DST) has emerged as an alternative to post-training pruning
for generating efficient models. In principle, DST allows for a much more memory efficient training process,
as it maintains sparsity throughout the entire training run. However, current DST implementations fail to capitalize on this. Because sparse matrix multiplication is much less efficient than dense matrix multiplication on GPUs, most
implementations simulate sparsity by masking weights.
In this paper, we leverage recent advances in semi-structured sparse training to apply DST in the domain of classification
with large output spaces, where memory-efficiency is paramount. With a label space of possibly millions of candidates,
the classification layer alone will consume several gigabytes of memory. Switching from a dense to a fixed fan-in
sparse layer updated with sparse evolutionary training (SET); however, severely hampers training convergence, especially
at the largest label spaces. We find that the gradients fed back from the classifier into the text encoder make it
much more difficult to learn good input representations, despite using a dense encoder.
By employing an intermediate layer or adding an auxiliary training objective, we recover most of the generalisation performance of the dense model.
Overall, we demonstrate the applicability of DST in a challenging domain, characterized by a highly skewed label distribution,
that lies outside of DST's typical benchmark datasets, and enable end-to-end training with millions of labels on commodity hardware.
tl;dr: We provide theoretical results about transformer reasoning capabilities over graph structure.

Which transformer scaling regimes are able to perfectly solve different classes of algorithmic problems? While tremendous empirical advances have been attained by transformer-based neural networks, a theoretical understanding of their algorithmic reasoning capabilities in realistic parameter regimes is lacking. We investigate this question in terms of the network’s depth, width, and number of extra tokens for algorithm execution. Our novel representational hierarchy separates 9 algorithmic reasoning problems into classes solvable by transformers in different realistic parameter scaling regimes. We prove that logarithmic depth is necessary and sufficient for tasks like graph connectivity, while single-layer transformers with small embedding dimensions can solve contextual retrieval tasks. We also support our theoretical analysis with ample empirical evidence using the GraphQA benchmark. These results show that transformers excel at many graph reasoning tasks, even outperforming specialized graph neural networks.

We study the generalized linear contextual bandit problem within the constraints of limited adaptivity. In this paper, we present two algorithms, B-GLinCB and RS-GLinCB, that address, respectively, two prevalent limited adaptivity settings. Given a budget $M$ on the number of policy updates, in the first setting, the algorithm needs to decide upfront $M$ rounds at which it will update its policy, while in the second setting it can adaptively perform $M$ policy updates during its course. For the first setting, we design an algorithm B-GLinCB, that incurs $\tilde{O}(\sqrt{T})$ regret when $M = \Omega( \log{\log T} )$ and the arm feature vectors are generated stochastically. For the second setting, we design an algorithm RS-GLinCB that updates its policy $\tilde{O}(\log^2 T)$ times and achieves a regret of $\tilde{O}(\sqrt{T})$ even when the arm feature vectors are adversarially generated. Notably, in these bounds, we manage to eliminate the dependence on a key instance dependent parameter $\kappa$, that captures non-linearity of the underlying reward model. Our novel approach for removing this dependence for generalized linear contextual bandits might be of independent interest.
tl;dr: We introduced a new goal reduction mechanism that outperforms RL algorithms in multi-goal tasks and models brain activity.

Goal-directed planning presents a challenge for classical RL algorithms due to the vastness of the combinatorial state and goal spaces, while humans and animals adapt to complex environments, especially with diverse, non-stationary objectives, often employing intermediate goals for long-horizon tasks.
Here, we propose a goal reduction mechanism for effectively deriving subgoals from arbitrary and distant original goals, using a novel loop-removal technique.
The product of the method, called goal-reducer, distills high-quality subgoals from a replay buffer, all without the need for prior global environmental knowledge.
Simulations show that the goal-reducer can be integrated into RL frameworks like Deep Q-learning and Soft Actor-Critic.
It accelerates performance in both discrete and continuous action space tasks, such as grid world navigation and robotic arm manipulation, relative to the corresponding standard RL models.
Moreover, the goal-reducer, when combined with a local policy, without iterative training, outperforms its integrated deep RL counterparts in solving a navigation task.
This goal reduction mechanism also models human problem-solving.
Comparing the model's performance and activation with human behavior and fMRI data in a treasure hunting task, we found matching representational patterns between an goal-reducer agent's components and corresponding human brain areas, particularly the vmPFC and basal ganglia. The results suggest that humans may use a similar computational framework for goal-directed behaviors.
tl;dr: We provide an asymptotic analysis of the Unified Distributed SGD, including decentralized SGD and various Federated Learning algorithms, to study the impact of agents' sampling strategies on the overall convergence of the large-scale system.

Distributed learning is essential to train machine learning algorithms across *heterogeneous* agents while maintaining data privacy. We conduct an asymptotic analysis of Unified Distributed SGD (UD-SGD), exploring a variety of communication patterns, including decentralized SGD and local SGD within Federated Learning (FL), as well as the increasing communication interval in the FL setting. In this study, we assess how different sampling strategies, such as *i.i.d.* sampling, shuffling, and Markovian sampling, affect the convergence speed of UD-SGD by considering the impact of agent dynamics on the limiting covariance matrix as described in the Central Limit Theorem (CLT). Our findings not only support existing theories on linear speedup and asymptotic network independence, but also theoretically and empirically show how efficient sampling strategies employed by individual agents contribute to overall convergence in UD-SGD. Simulations reveal that a few agents using highly efficient sampling can achieve or surpass the performance of the majority employing moderately improved strategies, providing new insights beyond traditional analyses focusing on the worst-performing agent.

Recent research has made significant strides in aligning large language models (LLMs) with helpfulness and harmlessness. In this paper, we argue for the importance of alignment for \emph{honesty}, ensuring that LLMs proactively refuse to answer questions when they lack knowledge, while still not being overly conservative. However, a pivotal aspect of alignment for honesty involves discerning an LLM's knowledge boundaries, which demands comprehensive solutions in terms of metric development, benchmark creation, and training methodologies. We address these challenges by first establishing a precise problem definition and defining ``honesty'' inspired by the Analects of Confucius. This serves as a cornerstone for developing metrics that effectively measure an LLM's honesty by quantifying its progress post-alignment. Furthermore, we introduce a flexible training framework which is further instantiated by several efficient fine-tuning techniques that emphasize honesty without sacrificing performance on other tasks. Our extensive experiments reveal that these aligned models show a marked increase in honesty, as indicated by our proposed metrics. We open-source all relevant resources to facilitate future research at \url{https://github.com/GAIR-NLP/alignment-for-honesty}.
tl;dr: we propose an algorithm to (near) optimally solve convex resource allocation problems under joint-DP

We study convex resource allocation problems with $m$ hard constraints under $(\varepsilon,\delta)$-joint differential privacy (Joint-DP or JDP) in an offline setting. To approximately solve the problem, we propose a generic algorithm called Noisy Dual Mirror Descent. The algorithm applies noisy Mirror Descent to a dual problem from relaxing the hard constraints for private shadow prices, and then uses the shadow prices to coordinate allocations in the primal problem. Leveraging weak duality theory, we show that the optimality gap is upper bounded by $\mathcal{O}(\frac{\sqrt{m\ln(1/\delta)}}{\varepsilon})$, and constraint violation is no more than $\mathcal{O}(\frac{\sqrt{m\ln(1/\delta)}}{\varepsilon})$ per constraint. When strong duality holds, both preceding results can be improved to $\widetilde{\mathcal{O}}(\frac{\sqrt{\ln(1/\delta)}}{\varepsilon})$ by better utilizing the geometric structure of the dual space, which is neglected by existing works. To complement our results under strong duality, we derive a minimax lower bound $\Omega(\frac{m}{\varepsilon})$ for any JDP algorithm outputting feasible allocations. The lower bound matches our upper bounds up to some logarithmic factors for $\varepsilon\geq \max(1, 1/(n\gamma))$, where $n\gamma$ is the available resource level. Numerical studies further confirm the effectiveness of our algorithm.

Self-training often falls short under distribution shifts due to an increased discrepancy between prediction confidence and actual accuracy. This typically necessitates computationally demanding methods such as neighborhood or ensemble-based label corrections. Drawing inspiration from insights on early learning regularization, we develop a principled method to improve self-training under distribution shifts based on temporal consistency. Specifically, we build an uncertainty-aware temporal ensemble with a simple relative thresholding. Then, this ensemble smooths noisy pseudo labels to promote selective temporal consistency. We show that our temporal ensemble is asymptotically correct and our label smoothing technique can reduce the optimality gap of self-training. Our extensive experiments validate that our approach consistently improves self-training performances by 8% to 16% across diverse distribution shift scenarios without a computational overhead. Besides, our method exhibits attractive properties, such as improved calibration performance and robustness to different hyperparameter choices.

Online experimentation with interference is a common challenge in modern applications such as e-commerce and adaptive clinical trials in medicine. For example, in online marketplaces, the revenue of a good depends on discounts applied to competing goods. Statistical inference with interference is widely studied in the offline setting, but far less is known about how to adaptively assign treatments to minimize regret. We address this gap by studying a multi-armed bandit (MAB) problem where a learner (e-commerce platform) sequentially assigns one of possible $\mathcal{A}$ actions (discounts) to $N$ units (goods) over $T$ rounds to minimize regret (maximize revenue). Unlike traditional MAB problems, the reward of each unit depends on the treatments assigned to other units, i.e., there is *interference* across the underlying network of units. With $\mathcal{A}$ actions and $N$ units, minimizing regret is combinatorially difficult since the action space grows as $\mathcal{A}^N$. To overcome this issue, we study a *sparse network interference* model, where the reward of a unit is only affected by the treatments assigned to $s$ neighboring units. We use tools from discrete Fourier analysis to develop a sparse linear representation of the unit-specific reward $r_n: [\mathcal{A}]^N \rightarrow \mathbb{R} $, and propose simple, linear regression-based algorithms to minimize regret. Importantly, our algorithms achieve provably low regret both when the learner observes the interference neighborhood for all units and when it is unknown. This significantly generalizes other works on this topic which impose strict conditions on the strength of interference on a *known* network, and also compare regret to a markedly weaker optimal action.
Empirically, we corroborate our theoretical findings via numerical simulations.

Long-term time series forecasting (LTSF) represents a critical frontier in time series analysis, characterized by extensive input sequences, as opposed to the shorter spans typical of traditional approaches. While longer sequences inherently offer richer information for enhanced predictive precision, prevailing studies often respond by escalating model complexity. These intricate models can inflate into millions of parameters, resulting in prohibitive parameter scales. Our study demonstrates, through both theoretical and empirical evidence, that decomposition is key to containing excessive model inflation while achieving uniformly superior and robust results across various datasets. Remarkably, by tailoring decomposition to the intrinsic dynamics of time series data, our proposed model outperforms existing benchmarks, using over 99\% fewer parameters than the majority of competing methods. Through this work, we aim to unleash the power of a restricted set of parameters by capitalizing on domain characteristics—a timely reminder that in the realm of LTSF, bigger is not invariably better. The code is available at \url{https://anonymous.4open.science/r/SSCNN-321D/}.

Previous visual object tracking methods employ image-feature regression models or coordinate autoregression models for bounding box prediction. Image-feature regression methods heavily depend on matching results and do not utilize positional prior, while the autoregressive approach can only be trained using bounding boxes available in the training set, potentially resulting in suboptimal performance during testing with unseen data. Inspired by the diffusion model, denoising learning enhances the model’s robustness to unseen data. Therefore, We introduce noise to bounding boxes, generating noisy boxes for training, thus enhancing model robustness on testing data. We propose a new paradigm to formulate the visual object tracking problem as a denoising learning process. However, tracking algorithms are usually asked to run in real-time, directly applying the diffusion model to object tracking would severely impair tracking speed. Therefore, we decompose the denoising learning process into every denoising block within a model, not by running the model multiple times, and thus we summarize the proposed paradigm as an in-model latent denoising learning process. Specifically, we propose a denoising Vision Transformer (ViT), which is composed of multiple denoising blocks. In the denoising block, template and search embeddings are projected into every denoising block as conditions. A denoising block is responsible for removing the noise in a predicted bounding box, and multiple stacked denoising blocks cooperate to accomplish the whole denoising process. Subsequently, we
utilize image features and trajectory information to refine the denoised bounding box. Besides, we also utilize trajectory memory and visual memory to improve tracking stability. Experimental results validate the effectiveness of our approach, achieving competitive performance on several challenging datasets. The proposed in-model latent denoising tracker achieve real-time speed, rendering denoising learning applicable in the visual object tracking community.
461. Contrasting with Symile: Simple Model-Agnostic Representation Learning for Unlimited Modalities
tl;dr: Symile is a simple contrastive learning approach that captures higher-order information between any number of modalities and provides a flexible, architecture-agnostic objective for learning modality-specific representations.

Contrastive learning methods, such as CLIP, leverage naturally paired data—for example, images and their corresponding text captions—to learn general representations that transfer efficiently to downstream tasks. While such approaches are generally applied to two modalities, domains such as robotics, healthcare, and video need to support many types of data at once. We show that the pairwise application of CLIP fails to capture joint information between modalities, thereby limiting the quality of the learned representations. To address this issue, we present Symile, a simple contrastive learning approach that captures higher-order information between any number of modalities. Symile provides a flexible, architecture-agnostic objective for learning modality-specific representations. To develop Symile's objective, we derive a lower bound on total correlation, and show that Symile representations for any set of modalities form a sufficient statistic for predicting the remaining modalities. Symile outperforms pairwise CLIP, even with modalities missing in the data, on cross-modal classification and retrieval across several experiments including on an original multilingual dataset of 33M image, text and audio samples and a clinical dataset of chest X-rays, electrocardiograms, and laboratory measurements. All datasets and code used in this work are publicly available at https://github.com/rajesh-lab/symile.
tl;dr: We fully depict the saturation effects of spectral algorithms and reveal a new phenomenon in large dimensional settings.

The saturation effects, which originally refer to the fact that kernel ridge regression (KRR) fails to achieve the information-theoretical lower bound when the regression function is over-smooth, have been observed for almost 20 years and were rigorously proved recently for kernel ridge regression and some other spectral algorithms over a fixed dimensional domain. The main focus of this paper is to explore the saturation effects for a large class of spectral algorithms (including the KRR, gradient descent, etc.) in large dimensional settings where $n \asymp d^{\gamma}$. More precisely, we first propose an improved minimax lower bound for the kernel regression problem in large dimensional settings and show that the gradient flow with early stopping strategy will result in an estimator achieving this lower bound (up to a logarithmic factor). Similar to the results in KRR, we can further determine the exact convergence rates (both upper and lower bounds) of a large class of (optimal tuned) spectral algorithms with different qualification $\tau$'s. In particular, we find that these exact rate curves (varying along $\gamma$) exhibit the periodic plateau behavior and the polynomial approximation barrier. Consequently, we can fully depict the saturation effects of the spectral algorithms and reveal a new phenomenon in large dimensional settings (i.e., the saturation effect occurs in large dimensional setting as long as the source condition $s>\tau$ while it occurs in fixed dimensional setting as long as $s>2\tau$).

Multi-Output Regression (MOR) has been widely used in scientific data analysis for decision-making. Unlike traditional regression models, MOR aims to simultaneously predict multiple real-valued outputs given an input. However, the increasing dimensionality of the outputs poses significant challenges regarding interpretability and computational scalability for modern MOR applications. As a first step to address these challenges, this paper proposes a Sparse \& High-dimensional-Output REgression (SHORE) model by incorporating additional sparsity requirements to resolve the output interpretability, and then designs a computationally efficient two-stage optimization framework capable of solving SHORE with provable accuracy via compression on outputs. Theoretically, we show that the proposed framework is computationally scalable while maintaining the same order of training loss and prediction loss before-and-after compression under arbitrary or relatively weak sample set conditions. Empirically, numerical results further validate the theoretical findings, showcasing the efficiency and accuracy of the proposed framework.
tl;dr: A novel neural-based method for efficiently answering arbitrary Most Probable Explanation (any-MPE) queries in large probabilistic models.

We propose a novel neural networks based approach to efficiently answer arbitrary Most Probable Explanation (MPE) queries—a well-known NP-hard task—in large probabilistic models such as
Bayesian and Markov networks, probabilistic circuits, and neural auto-regressive models. By arbitrary MPE queries, we mean that there is no predefined partition of variables into evidence and non-evidence variables. The key idea is to distill all MPE queries over a given probabilistic model into a neural network and then use the latter for answering queries, eliminating the need for time-consuming inference algorithms that operate directly on the probabilistic model. We improve upon this idea by incorporating inference-time optimization with self-supervised loss to iteratively improve the solutions and employ a teacher-student framework that provides a better initial network, which in turn, helps reduce the number of inference-time optimization steps. The teacher network utilizes a self-supervised loss function optimized for getting the exact MPE solution, while the student network learns from the teacher's near-optimal outputs through supervised loss. We demonstrate the efficacy and scalability of our approach on various datasets and a broad class of probabilistic models, showcasing its practical effectiveness.
tl;dr: We train a neural network that can output a differentially private probabilistic regression model from a data set in one forward pass.

Many high-stakes applications require machine learning models that protect user privacy and provide well-calibrated, accurate predictions. While Differential Privacy (DP) is the gold standard for protecting user privacy, standard DP mechanisms typically significantly impair performance. One approach to mitigating this issue is pre-training models on simulated data before DP learning on the private data. In this work we go a step further, using simulated data to train a meta-learning model that combines the Convolutional Conditional Neural Process (ConvCNP) with an improved functional DP mechanism of Hall et al. (2013), yielding the DPConvCNP. DPConvCNP learns from simulated data how to map private data to a DP predictive model in one forward pass, and then provides accurate, well-calibrated predictions. We compare DPConvCNP with a DP Gaussian Process (GP) baseline with carefully tuned hyperparameters. The DPConvCNP outperforms the GP baseline, especially on non-Gaussian data, yet is much faster at test time and requires less tuning.
tl;dr: BADS (Bayesian Data Point Selection)

Data point selection (DPS) is becoming a critical topic in deep learning due to the ease of acquiring uncurated training data compared to the difficulty of obtaining curated or processed data.
Existing approaches to DPS are predominantly based on a bi-level optimisation (BLO) formulation, which is demanding in terms of memory and computation, and exhibits some theoretical defects regarding minibatches.
Thus, we propose a novel Bayesian approach to DPS. We view the DPS problem as posterior inference in a novel Bayesian model where the posterior distributions of the instance-wise weights and the main neural network parameters are inferred under a reasonable prior and likelihood model.
We employ stochastic gradient Langevin MCMC sampling to learn the main network and instance-wise weights jointly, ensuring convergence even with minibatches. Our update equation is comparable to the widely used SGD and much more efficient than existing BLO-based methods. Through controlled experiments in both the vision and language domains, we present the proof-of-concept. Additionally, we demonstrate that our method scales effectively to large language models and facilitates automated per-task optimization for instruction fine-tuning datasets.
tl;dr: We propose a modification to existing RL algorithms to improve the performance when trained with heuristic rewards.

In many reinforcement learning (RL) applications, incorporating heuristic rewards alongside the task reward is crucial for achieving desirable performance. Heuristics encode prior human knowledge about how a task should be done, providing valuable hints for RL algorithms. However, such hints may not be optimal, limiting the performance of learned policies.
The currently established way of using heuristics is to modify the heuristic reward in a manner that ensures that the optimal policy learned with it remains the same as the optimal policy for the task reward (i.e., optimal policy invariance).
However, these methods often fail in practical scenarios with limited training data. We found that while optimal policy invariance ensures convergence to the best policy based on task rewards, it doesn't guarantee better performance than policies trained with biased heuristics under a finite data regime, which is impractical. In this paper, we introduce a new principle tailored for finite data settings. Instead of enforcing optimal policy invariance, we train a policy that combines task and heuristic rewards and ensures it outperforms the heuristic-trained policy. As such, we prevent policies from merely exploiting heuristic rewards without improving the task reward. Our experiments on robotic locomotion, helicopter control, and manipulation tasks demonstrate that our method consistently outperforms the heuristic policy, regardless of the heuristic rewards' quality.
Code is available at https://github.com/Improbable-AI/hepo.
tl;dr: We propose a constrained discrete diffusion framework for generating graphs that adhere to specific structural properties. This framework achieves state-of-the-art performance on both synthetic and digital pathology datasets.

Graph diffusion models have emerged as state-of-the-art techniques in graph generation; yet, integrating domain knowledge into these models remains challenging.
Domain knowledge is particularly important in real-world scenarios, where invalid generated graphs hinder deployment in practical applications.
Unconstrained and conditioned graph diffusion models fail to guarantee such domain-specific structural properties.
We present ConStruct, a novel framework that enables graph diffusion models to incorporate hard constraints on specific properties, such as planarity or acyclicity.
Our approach ensures that the sampled graphs remain within the domain of graphs that satisfy the specified property throughout the entire trajectory in both the forward and reverse processes. This is achieved by introducing an edge-absorbing noise model and a new projector operator.
ConStruct demonstrates versatility across several structural and edge-deletion invariant constraints and achieves state-of-the-art performance for both synthetic benchmarks and attributed real-world datasets.
For example, by incorporating planarity constraints in digital pathology graph datasets, the proposed method outperforms existing baselines, improving data validity by up to 71.1 percentage points.
tl;dr: We introduce a novel benchmark MultiOOD for more realistic Multimodal OOD Detection, as well as an Agree-and-Disagree (A2D) algorithm and an NP-Mix outlier synthesis method to improve Multimodal OOD Detection performances.

Detecting out-of-distribution (OOD) samples is important for deploying machine learning models in safety-critical applications such as autonomous driving and robot-assisted surgery. Existing research has mainly focused on unimodal scenarios on image data. However, real-world applications are inherently multimodal, which makes it essential to leverage information from multiple modalities to enhance the efficacy of OOD detection. To establish a foundation for more realistic Multimodal OOD Detection, we introduce the first-of-its-kind benchmark, MultiOOD, characterized by diverse dataset sizes and varying modality combinations. We first evaluate existing unimodal OOD detection algorithms on MultiOOD, observing that the mere inclusion of additional modalities yields substantial improvements. This underscores the importance of utilizing multiple modalities for OOD detection. Based on the observation of Modality Prediction Discrepancy between in-distribution (ID) and OOD data, and its strong correlation with OOD performance, we propose the Agree-to-Disagree (A2D) algorithm to encourage such discrepancy during training. Moreover, we introduce a novel outlier synthesis method, NP-Mix, which explores broader feature spaces by leveraging the information from nearest neighbor classes and complements A2D to strengthen OOD detection performance. Extensive experiments on MultiOOD demonstrate that training with A2D and NP-Mix improves existing OOD detection algorithms by a large margin. To support accessibility and reproducibility, our source code and MultiOOD benchmark are available at https://github.com/donghao51/MultiOOD.

Variational inequalities represent a broad class of problems, including minimization and min-max problems, commonly found in machine learning. Existing second-order and high-order methods for variational inequalities require precise computation of derivatives, often resulting in prohibitively high iteration costs. In this work, we study the impact of Jacobian inaccuracy on second-order methods. For the smooth and monotone case, we establish a lower bound with explicit dependence on the level of Jacobian inaccuracy and propose an optimal algorithm for this key setting. When derivatives are exact, our method converges at the same rate as exact optimal second-order methods. To reduce the cost of solving the auxiliary problem, which arises in all high-order methods with global convergence, we introduce several Quasi-Newton approximations. Our method with Quasi-Newton updates achieves a global sublinear convergence rate. We extend our approach with a tensor generalization for inexact high-order derivatives and support the theory with experiments.
tl;dr: A simple and fast distillation of diffusion models that accelerates the fine-tuning up to 1000 times while performing high-quality image generation.

Diffusion-based generative models have demonstrated their powerful performance across various tasks, but this comes at a cost of the slow sampling speed. To achieve both efficient and high-quality synthesis, various distillation-based accelerated sampling methods have been developed recently. However, they generally require time-consuming fine tuning with elaborate designs to achieve satisfactory performance in a specific number of function evaluation (NFE), making them difficult to employ in practice. To address this issue, we propose **S**imple and **F**ast **D**istillation (SFD) of diffusion models, which simplifies the paradigm used in existing methods and largely shortens their fine-tuning time up to $1000\times$. We begin with a vanilla distillation-based sampling method and boost its performance to state of the art by identifying and addressing several small yet vital factors affecting the synthesis efficiency and quality. Our method can also achieve sampling with variable NFEs using a single distilled model. Extensive experiments demonstrate that SFD strikes a good balance between the sample quality and fine-tuning costs in few-step image generation task. For example, SFD achieves 4.53 FID (NFE=2) on CIFAR-10 with only **0.64 hours** of fine-tuning on a single NVIDIA A100 GPU.

Camera-LiDAR fusion models significantly enhance perception performance in autonomous driving. The fusion mechanism leverages the strengths of each modality while minimizing their weaknesses. Moreover, in practice, camera-LiDAR fusion models utilize pre-trained backbones for efficient training. However, we argue that directly loading single-modal pre-trained camera and LiDAR backbones into camera-LiDAR fusion models introduces similar feature redundancy across modalities due to the nature of the fusion mechanism. Unfortunately, existing pruning methods are developed explicitly for single-modal models, and thus, they struggle to effectively identify these specific redundant parameters in camera-LiDAR fusion models. In this paper, to address the issue above on camera-LiDAR fusion models, we propose a novelty pruning framework Alternative Modality Masking Pruning (AlterMOMA), which employs alternative masking on each modality and identifies the redundant parameters. Specifically, when one modality parameters are masked (deactivated), the absence of features from the masked backbone compels the model to reactivate previous redundant features of the other modality backbone. Therefore, these redundant features and relevant redundant parameters can be identified via the reactivation process. The redundant parameters can be pruned by our proposed importance score evaluation function, Alternative Evaluation (AlterEva), which is based on the observation of the loss changes when certain modality parameters are activated and deactivated. Extensive experiments on the nuScene and KITTI datasets encompassing diverse tasks, baseline models, and pruning algorithms showcase that AlterMOMA outperforms existing pruning methods, attaining state-of-the-art performance.

Intelligent education stands as a prominent application of machine learning. Within this domain, cognitive diagnosis (CD) is a key research focus that aims to diagnose students' proficiency levels in specific knowledge concepts. As a crucial task within the field of education, cognitive diagnosis encompasses two fundamental requirements: accuracy and fairness. Existing studies have achieved significant success by primarily utilizing observed historical logs of student-exercise interactions. However, real-world scenarios often present a challenge, where a substantial number of students engage with a limited number of exercises. This data sparsity issue can lead to both inaccurate and unfair diagnoses. To this end, we introduce a monotonic data augmentation framework, CMCD, to tackle the data sparsity issue and thereby achieve accurate and fair CD results. Specifically, CMCD integrates the monotonicity assumption, a fundamental educational principle in CD, to establish two constraints for data augmentation. These constraints are general and can be applied to the majority of CD backbones. Furthermore, we provide theoretical analysis to guarantee the accuracy and convergence speed of CMCD. Finally, extensive experiments on real-world datasets showcase the efficacy of our framework in addressing the data sparsity issue with accurate and fair CD results.
tl;dr: This paper proposes an instance weighting-based bias-variance trade-off (IWBVT) approach to improving the model quality.

In recent years, a large number of algorithms for label integration and noise correction have been proposed to infer the unknown true labels of instances in crowdsourcing. They have made great advances in improving the label quality of crowdsourced datasets. However, due to the presence of intractable instances, these algorithms are usually not as significant in improving the model quality as they are in improving the label quality. To improve the model quality, this paper proposes an instance weighting-based bias-variance trade-off (IWBVT) approach. IWBVT at first proposes a novel instance weighting method based on the complementary set and entropy, which mitigates the impact of intractable instances and thus makes the bias and variance of trained models closer to the unknown true results. Then, IWBVT performs probabilistic loss regressions based on the bias-variance decomposition, which achieves the bias-variance trade-off and thus reduces the generalization error of trained models. Experimental results indicate that IWBVT can serve as a universal post-processing approach to significantly improving the model quality of existing state-of-the-art label integration algorithms and noise correction algorithms.
tl;dr: Our paper proposes a mechanism design model augmented with an output prediction and applies it to various problems using a universal error measure in the algorithmic design with predictions setting.

Our work revisits the design of mechanisms via the learning-augmented framework. In this model, the algorithm is enhanced with imperfect (machine-learned) information concerning the input, usually referred to as prediction. The goal is to design algorithms whose performance degrades gently as a function of the prediction error and, in particular, perform well if the prediction is accurate, but also provide a worst-case guarantee under any possible error. This framework has been successfully applied recently to various mechanism design settings, where in most cases the mechanism is provided with a prediction about the types of the players.
We adopt a perspective in which the mechanism is provided with an output recommendation. We make no assumptions about the quality of the suggested outcome, and the goal is to use the recommendation to design mechanisms with low approximation guarantees whenever the recommended outcome is reasonable, but at the same time to provide worst-case guarantees whenever the recommendation significantly deviates from the optimal one. We propose a generic, universal measure, which we call quality of recommendation, to evaluate mechanisms across various information settings. We demonstrate how this new metric can provide refined analysis in existing results.
This model introduces new challenges, as the mechanism receives limited information comparing to settings that use predictions about the types of the agents. We study, through this lens, several well-studied mechanism design paradigms, devising new mechanisms, but also providing refined analysis for existing ones, using as a metric the quality of recommendation. We complement our positive results, by exploring the limitations of known classes of strategyproof mechanisms that can be devised using output recommendation.

Many structured prediction and reasoning tasks can be framed as program synthesis problems, where the goal is to generate a program in a \emph{domain-specific language} (DSL) that transforms input data into the desired output. Unfortunately, purely neural approaches, such as large language models (LLMs), often fail to produce fully correct programs in unfamiliar DSLs, while purely symbolic methods based on combinatorial search scale poorly to complex problems. Motivated by these limitations, we introduce a hybrid approach, where LLM completions for a given task are used to learn a task-specific, context-free surrogate model, which is then used to guide program synthesis. We evaluate this hybrid approach on three domains, and show that it outperforms both unguided search and direct sampling from LLMs, as well as existing program synthesizers.

Sequential recommender systems (SRS) aim to predict users' subsequent choices based on their historical interactions and have found applications in diverse fields such as e-commerce and social media. However, in real-world systems, most users interact with only a handful of items, while the majority of items are seldom consumed. These two issues, known as the long-tail user and long-tail item challenges, often pose difficulties for existing SRS. These challenges can adversely affect user experience and seller benefits, making them crucial to address. Though a few works have addressed the challenges, they still struggle with the seesaw or noisy issues due to the intrinsic scarcity of interactions. The advancements in large language models (LLMs) present a promising solution to these problems from a semantic perspective. As one of the pioneers in this field, we propose the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR). This framework utilizes semantic embeddings derived from LLMs to enhance SRS without adding extra inference load. To address the long-tail item challenge, we design a dual-view modeling framework that combines semantics from LLMs and collaborative signals from conventional SRS. For the long-tail user challenge, we propose a retrieval augmented self-distillation method to enhance user preference representation using more informative interactions from similar users. To verify the effectiveness and versatility of our proposed enhancement framework, we conduct extensive experiments on three real-world datasets using three popular SRS models. The results consistently show that our method surpasses existing baselines. The implementation code is available in Supplementary Material.
tl;dr: An approach to utilize imitation learning techniques to improve multi-agent reinforcement learning.

Training agents in multi-agent games presents significant challenges due to their intricate nature. These challenges are exacerbated by dynamics influenced not only by the environment but also by strategies of opponents. Existing methods often struggle with slow convergence and instability.
To address these challenges, we harness the potential of imitation learning (IL) to comprehend and anticipate actions of the opponents, aiming to mitigate uncertainties with respect to the game dynamics.
Our key contributions include:
(i) a new multi-agent IL model for predicting next moves of the opponents - our model works with hidden actions of opponents and local observations;
(ii) a new multi-agent reinforcement learning (MARL) algorithm that combines our IL model and policy training into one single training process;
and (iii) extensive experiments in three challenging game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2).
Experimental results show that our approach achieves superior performance compared to state-of-the-art MARL algorithms.
tl;dr: A general framework for diffusion synchronization

We introduce a general diffusion synchronization framework for generating diverse visual content, including ambiguous images, panorama images, 3D mesh textures, and 3D Gaussian splats textures, using a pretrained image diffusion model. We first present an analysis of various scenarios for synchronizing multiple diffusion processes through a canonical space. Based on the analysis, we introduce a synchronized diffusion method, SyncTweedies, which averages the outputs of Tweedie’s formula while conducting denoising in multiple instance spaces. Compared to previous work that achieves synchronization through finetuning, SyncTweedies is a zero-shot method that does not require any finetuning, preserving the rich prior of diffusion models trained on Internet-scale image datasets without overfitting to specific domains. We verify that SyncTweedies offers the broadest applicability to diverse applications and superior performance compared to the previous state-of-the-art for each application. Our project page is at https://synctweedies.github.io.

Adapting to distribution shifts is a critical challenge in modern machine learning, especially as data in many real-world applications accumulate continuously in the form of streams. We investigate the problem of sequentially adapting a model to non-stationary environments, where the data distribution is continuously shifting and only a small amount of unlabeled data are available each time. Continual test-time adaptation methods have shown promising results by using reliable pseudo-labels, but they still fall short in exploring representation alignment with the source domain in non-stationary environments. In this paper, we propose to leverage non-stationary representation learning to adaptively align the unlabeled data stream, with its changing distributions, to the source data representation using a sketch of the source data. To alleviate the data scarcity in non-stationary representation learning, we propose a novel adaptive representation alignment algorithm called Ada-ReAlign. This approach employs a group of base learners to explore different lengths of the unlabeled data stream, which are adaptively combined by a meta learner to handle unknown and continuously evolving data distributions. The proposed method comes with nice theoretical guarantees under convexity assumptions. Experiments on both benchmark datasets and a real-world application validate the effectiveness and adaptability of our proposed algorithm.
tl;dr: This work proposes a generative methodology to formulate the object tracking task and an interpolation operation as a faster approach to the diffusion mechanics.

Object tracking is a fundamental task in computer vision, requiring the localization of objects of interest across video frames. Diffusion models have shown remarkable capabilities in visual generation, making them well-suited for addressing several requirements of the tracking problem. This work proposes a novel diffusion-based methodology to formulate the tracking task. Firstly, their conditional process allows for injecting indications of the target object into the generation process. Secondly, diffusion mechanics can be developed to inherently model temporal correspondences, enabling the reconstruction of actual frames in video. However, existing diffusion models rely on extensive and unnecessary mapping to a Gaussian noise domain, which can be replaced by a more efficient and stable interpolation process. Our proposed interpolation mechanism draws inspiration from classic image-processing techniques, offering a more interpretable, stable, and faster approach tailored specifically for the object tracking task. By leveraging the strengths of diffusion models while circumventing their limitations, our Diffusion-based INterpolation TrackeR (DINTR) presents a promising new paradigm and achieves a superior multiplicity on seven benchmarks across five indicator representations.

Transformer-based large language models (LLMs) typically have a limited context window, resulting in significant performance degradation when processing text beyond the length of the context window. Extensive studies have been proposed to extend the context window and achieve length extrapolation of LLMs, but there is still a lack of in-depth interpretation of these approaches. In this study, we explore the positional information within and beyond the context window for deciphering the underlying mechanism of LLMs. By using a mean-based decomposition method, we disentangle positional vectors from hidden states of LLMs and analyze their formation and effect on attention. Furthermore, when texts exceed the context window, we analyze the change of positional vectors in two settings, i.e., direct extrapolation and context window extension. Based on our findings, we design two training-free context window extension methods, positional vector replacement and attention window extension. Experimental results show that our methods can effectively extend the context window length.

Prediction is a fundamental capability of all living organisms, and has been proposed as an objective for learning sensory representations. Recent work demonstrates that in primate visual systems, prediction is facilitated by neural representations that follow straighter temporal trajectories than their initial photoreceptor encoding, which allows for prediction by linear extrapolation. Inspired by these experimental findings, we develop a self-supervised learning (SSL) objective that explicitly quantifies and promotes straightening. We demonstrate the power of this objective in training deep feedforward neural networks on smoothly-rendered synthetic image sequences that mimic commonly-occurring properties of natural videos. The learned model contains neural embeddings that are predictive, but also factorize the geometric, photometric, and semantic attributes of objects. The representations also prove more robust to noise and adversarial attacks compared to previous SSL methods that optimize for invariance to random augmentations. Moreover, these beneficial properties can be transferred to other training procedures by using the straightening objective as a regularizer, suggesting a broader utility for straightening as a principle for robust unsupervised learning.
tl;dr: In this work, we present DeepStack, a simple yet effective way to connect vision and language in the context of LMMs.

Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM).
The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer.
This paper presents a new architecture *DeepStack* for LMMs.
Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer from bottom to top. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply *DeepStack* to both language and vision transformer in LMMs, and
validate the effectiveness of *DeepStack* LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by 2.7 and 2.9 on average across 9 benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, *e.g.*, 4.2, 11.0, and 4.0 improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply *DeepStack* to vision transformer layers, which brings us a similar amount of improvements, 3.8 on average compared with LLaVA-1.5-7B.
tl;dr: This paper proposes Panacea, a simple yet effective method that achieves Pareto alignment with diverse human preferences with a single model.

Current methods for large language model alignment typically use scalar human preference labels. However, this convention tends to oversimplify the multi-dimensional and heterogeneous nature of human preferences, leading to reduced expressivity and even misalignment. This paper presents Panacea, an innovative approach that reframes alignment as a multi-dimensional preference optimization problem. Panacea trains a single model capable of adapting online and Pareto-optimally to diverse sets of preferences without the need for further tuning. A major challenge here is using a low-dimensional preference vector to guide the model's behavior, despite it being governed by an overwhelmingly large number of parameters. To address this, Panacea is designed to use singular value decomposition (SVD)-based low-rank adaptation, which allows the preference vector to be simply injected online as singular values. Theoretically, we prove that Panacea recovers the entire Pareto front with common loss aggregation methods under mild conditions. Moreover, our experiments demonstrate, for the first time, the feasibility of aligning a single LLM to represent an exponentially vast spectrum of human preferences through various optimization methods. Our work marks a step forward in effectively and efficiently aligning models to diverse and intricate human preferences in a controllable and Pareto-optimal manner.
486. LaKD: Length-agnostic Knowledge Distillation for Trajectory Prediction with Any Length Observations

Trajectory prediction is a crucial technology to help systems avoid traffic accidents, ensuring safe autonomous driving. Previous methods typically use a fixed-length and sufficiently long trajectory of an agent as observations to predict its future trajectory. However, in real-world scenarios, we often lack the time to gather enough trajectory points before making predictions, e.g., when a car suddenly appears due to an obstruction, the system must make immediate predictions to prevent a collision. This poses a new challenge for trajectory prediction systems, requiring them to be capable of making accurate predictions based on observed trajectories of arbitrary lengths, leading to the failure of existing methods. In this paper, we propose a Length-agnostic Knowledge Distillation framework, named LaKD, which can make accurate trajectory predictions, regardless of the length of observed data. Specifically, considering the fact that long trajectories, containing richer temporal information but potentially additional interference, may perform better or worse than short trajectories, we devise a dynamic length-agnostic knowledge distillation mechanism for exchanging information among trajectories of arbitrary lengths, dynamically determining the transfer direction based on prediction performance. In contrast to traditional knowledge distillation, LaKD employs a unique model that simultaneously serves as both the teacher and the student, potentially causing knowledge collision during the distillation process. Therefore, we design a dynamic soft-masking mechanism, where we first calculate the importance of neuron units and then apply soft-masking to them, so as to safeguard critical units from disruption during the knowledge distillation process. In essence, LaKD is a general and principled framework that can be naturally compatible with existing trajectory prediction models of different architectures. Extensive experiments on three benchmark datasets, Argoverse 1, nuScenes and Argoverse 2, demonstrate the effectiveness of our approach.
tl;dr: We find the standard next token learning objective underlies the reversal curse, which can be overcome with any-to-any context-prediction training.

Today's best language models still struggle with "hallucinations", factually incorrect generations, which impede their ability to reliably retrieve information seen during training. The *reversal curse*, where models cannot recall information when probed in a different order than was encountered during training, exemplifies limitations in information retrieval.
To better understand these limitations, we reframe the reversal curse as a *factorization curse* --- a failure of models to learn the same joint distribution under different factorizations.
We more closely simulate finetuning workflows which train pretrained models on specialized knowledge by introducing
*WikiReversal*, a realistic testbed based on Wikipedia knowledge graphs. Through a series of controlled experiments with increasing levels of realism, including non-reciprocal relations, we find that reliable information retrieval is an inherent failure of the next-token prediction objective used in popular large language models. Moreover, we demonstrate reliable information retrieval cannot be solved with scale, reversed tokens, or even naive bidirectional-attention training. Consequently, various approaches to finetuning on specialized data would necessarily provide mixed results on downstream tasks, unless the model has already seen the right sequence of tokens.
Across five tasks of varying levels of complexity, our results uncover a promising path forward: factorization-agnostic objectives can significantly mitigate the reversal curse and hint at improved knowledge storage and planning capabilities.
tl;dr: We propose a guided sampling techniques for masked generative models and empirically demonstrate its effectiveness for image generation.

Masked generative models (MGMs) have shown impressive generative ability while providing an order of magnitude efficient sampling steps compared to continuous diffusion models. However, MGMs still underperform in image synthesis compared to recent well-developed continuous diffusion models with similar size in terms of quality and diversity of generated samples. A key factor in the performance of continuous diffusion models stems from the guidance methods, which enhance the sample quality at the expense of diversity. In this paper, we extend these guidance methods to generalized guidance formulation for MGMs and propose a self-guidance sampling method, which leads to better generation quality. The proposed approach leverages an auxiliary task for semantic smoothing in vector-quantized token space, analogous to the Gaussian blur in continuous pixel space. Equipped with the parameter-efficient fine-tuning method and high-temperature sampling, MGMs with the proposed self-guidance achieve a superior quality-diversity trade-off, outperforming existing sampling methods in MGMs with more efficient training and sampling costs. Extensive experiments with the various sampling hyperparameters confirm the effectiveness of the proposed self-guidance.
tl;dr: We propose a memory-efficient and provably-good approximation of an enstablished uncertainty score

Current uncertainty quantification is memory and compute expensive, which hinders practical uptake. To counter, we develop Sketched Lanczos Uncertainty (SLU): an architecture-agnostic uncertainty score that can be applied to pre-trained neural networks with minimal overhead. Importantly, the memory use of SLU only grows logarithmically with the number of model parameters. We combine Lanczos' algorithm with dimensionality reduction techniques to compute a sketch of the leading eigenvectors of a matrix. Applying this novel algorithm to the Fisher information matrix yields a cheap and reliable uncertainty score. Empirically, SLU yields well-calibrated uncertainties, reliably detects out-of-distribution examples, and consistently outperforms existing methods in the low-memory regime.
tl;dr: AutoPSV enhances the reasoning capabilities of LLMs by automatically generating process annotations and confidence scores for reasoning steps, significantly improving performance in tasks involving complex reasoning.

In this work, we propose a novel method named \textbf{Auto}mated \textbf{P}rocess-\textbf{S}upervised \textbf{V}erifier (\textbf{\textsc{AutoPSV}}) to enhance the reasoning capabilities of large language models (LLMs) by automatically annotating the reasoning steps.
\textsc{AutoPSV} begins by training a verification model on the correctness of final answers, enabling it to generate automatic process annotations.
This verification model assigns a confidence score to each reasoning step, indicating the probability of arriving at the correct final answer from that point onward.
We detect relative changes in the verification's confidence scores across reasoning steps to automatically annotate the reasoning process, enabling error detection even in scenarios where ground truth answers are unavailable.
This alleviates the need for numerous manual annotations or the high computational costs associated with model-induced annotation approaches.
We experimentally validate that the step-level confidence changes learned by the verification model trained on the final answer correctness can effectively identify errors in the reasoning steps.
We demonstrate that the verification model, when trained on process annotations generated by \textsc{AutoPSV}, exhibits improved performance in selecting correct answers from multiple LLM-generated outputs.
Notably, we achieve substantial improvements across five datasets in mathematics and commonsense reasoning. The source code of \textsc{AutoPSV} is available at \url{https://github.com/rookie-joe/AutoPSV}.
tl;dr: We theoretically and empirically demonstrate that generative models can outperform the experts that train them by low-temperature sampling

Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of *transcendence*: when a generative model achieves capabilities that surpass the abilities of the experts generating its data. We demonstrate transcendence by training an autoregressive transformer to play chess from game transcripts, and show that the trained model can sometimes achieve better performance than all players in the dataset. We theoretically prove that transcendence is enabled by low-temperature sampling, and rigorously assess this experimentally. Finally, we discuss other sources of transcendence, laying the groundwork for future investigation of this phenomenon in a broader setting.
tl;dr: We show that recommender systems with dual influences on users and creators are guaranteed to polarize, and discuss how to prevent it.

Recommender systems serve the dual purpose of presenting relevant content to users and helping content creators reach their target audience. The dual nature of these systems naturally influences both users and creators: users' preferences are affected by the items they are recommended, while creators may be incentivized to alter their content to attract more users. We define a model, called user-creator feature dynamics, to capture the dual influence of recommender systems. We prove that a recommender system with dual influence is guaranteed to polarize, causing diversity loss in the system. We then investigate, both theoretically and empirically, approaches for mitigating polarization and promoting diversity in recommender systems. Unexpectedly, we find that common diversity-promoting approaches do not work in the presence of dual influence, while relevancy-optimizing methods like top-$k$ truncation can prevent polarization and improve diversity of the system.
tl;dr: We prove the two-phase dynamics of a DNN learning interactions in the training process.

This study proves the two-phase dynamics of a deep neural network (DNN) learning interactions. Despite the long disappointing view of the faithfulness of post-hoc explanation of a DNN, a series of theorems have been proven [27] in recent years to show that for a given input sample, a small set of interactions between input variables can be considered as primitive inference patterns that faithfully represent a DNN's detailed inference logic on that sample. Particularly, Zhang et al. [41] have observed that various DNNs all learn interactions of different complexities in two distinct phases, and this two-phase dynamics well explains how a DNN changes from under-fitting to over-fitting. Therefore, in this study, we mathematically prove the two-phase dynamics of interactions, providing a theoretical mechanism for how the generalization power of a DNN changes during the training process. Experiments show that our theory well predicts the real dynamics of interactions on different DNNs trained for various tasks.

Large language models (LLMs) have demonstrated notable potential in conducting complex tasks and are increasingly utilized in various financial applications. However, high-quality sequential financial investment decision-making remains challenging. These tasks require multiple interactions with a volatile environment for every decision, demanding sufficient intelligence to maximize returns and manage risks. Although LLMs have been used to develop agent systems that surpass human teams and yield impressive investment returns, opportunities to enhance multi-source information synthesis and optimize decision-making outcomes through timely experience refinement remain unexplored. Here, we introduce FinCon, an LLM-based multi-agent framework tailored for diverse financial tasks. Inspired by effective real-world investment firm organizational structures, FinCon utilizes a manager-analyst communication hierarchy. This structure allows for synchronized cross-functional agent collaboration towards unified goals through natural language interactions and equips each agent with greater memory capacity than humans. Additionally, a risk-control component in FinCon enhances decision quality by episodically initiating a self-critiquing mechanism to update systematic investment beliefs. The conceptualized beliefs serve as verbal reinforcement for the future agent’s behavior and can be selectively propagated to the appropriate node that requires knowledge updates. This feature significantly improves performance while reducing unnecessary peer-to-peer communication costs. Moreover, FinCon demonstrates strong generalization capabilities in various financial tasks, including stock trading and portfolio management.

The heterogeneity issue in federated learning (FL) has attracted increasing attention, which is attempted to be addressed by most existing methods. Currently, due to systems and objectives heterogeneity, enabling clients to hold models of different architectures and tasks of different demands has become an important direction in FL.
Most existing FL methods are based on the homogeneity assumption, namely, different clients have the same architectural models with the same tasks, which are unable to handle complex and multivariate data and tasks.
To flexibly address these heterogeneity limitations, we propose a novel federated multi-task learning framework with the help of tensor trace norm, FedSAK. Specifically, it treats each client as a task and splits the local model into a feature extractor and a prediction head.
Clients can flexibly choose shared structures based on heterogeneous situations and upload them to the server, which learns correlations among client models by mining model low-rank structures through tensor trace norm.
Furthermore, we derive convergence and generalization bounds under non-convex settings. Evaluated on 6 real-world datasets compared to 13 advanced FL models, FedSAK demonstrates superior performance.
tl;dr: We show theoretical guarantees for community detection using node2vec embeddings of networks.

Embedding the nodes of a large network into an Euclidean space is a common objective in modern
machine learning, with a variety of tools available. These embeddings can then be used as features for
tasks such as community detection/node clustering or link prediction, where they achieve state of the art
performance. With the exception of spectral clustering methods, there is little theoretical understanding
for commonly used approaches to learning embeddings. In this work we examine the theoretical
properties of the embeddings learned by node2vec. Our main result shows that the use of k-means
clustering on the embedding vectors produced by node2vec gives weakly consistent community recovery
for the nodes in (degree corrected) stochastic block models. We also discuss the use of these embeddings
for node and link prediction tasks. We demonstrate this result empirically for both
real and simulated networks, and examine how this relates
to other embedding tools for network data.
tl;dr: We provide a tight asymptotic analysis of the learning of an attention layer, and evidence a phase transition from a positional to a semantic attention mechanism with sample complexity.

Many empirical studies have provided evidence for the emergence of algorithmic mechanisms (abilities) in the learning of language models, that lead to qualitative improvements of the model capabilities. Yet, a theoretical characterization of how such mechanisms emerge remains elusive. In this paper, we take a step in this direction by providing a tight theoretical analysis of the emergence of semantic attention in a solvable model of dot-product attention. More precisely, we consider a non-linear self-attention layer with trainable tied and low-rank query and key matrices. In the asymptotic limit of high-dimensional data and a comparably large number of training samples we provide a tight closed-form characterization of the global minimum of the non-convex empirical loss landscape. We show that this minimum corresponds to either a positional attention mechanism (with tokens attending to each other based on their respective positions) or a semantic attention mechanism (with tokens attending to each other based on their meaning), and evidence an emergent phase transition from the former to the latter with increasing sample complexity. Finally, we compare the dot-product attention layer to a linear positional baseline, and show that it outperforms the latter using the semantic mechanism provided it has access to sufficient data.
tl;dr: Our paper introduces SaSPA, a novel data augmentation (DA) method for fine-grained visual classification that surpasses existing DA methods by generating synthetic data that is both more diverse and accurately represents fine-grained classes.

Fine-grained visual classification (FGVC) involves classifying closely related subcategories. This task is inherently difficult due to the subtle differences between classes and the high intra-class variance. Moreover, FGVC datasets are typically small and challenging to gather, thus highlighting a significant need for effective data augmentation.
Recent advancements in text-to-image diffusion models have introduced new possibilities for data augmentation in image classification. While these models have been used to generate training data for classification tasks, their effectiveness in full-dataset training of FGVC models remains under-explored. Recent techniques that rely on text-to-image generation or Img2Img methods, such as SDEdit, often struggle to generate images that accurately represent the class while modifying them to a degree that significantly increases the dataset's diversity. To address these challenges, we present SaSPA: Structure and Subject Preserving Augmentation. Contrary to recent methods, our method does not use real images as guidance, thereby increasing generation flexibility and promoting greater diversity. To ensure accurate class representation, we employ conditioning mechanisms, specifically by conditioning on image edges and subject representation.
We conduct extensive experiments and benchmark SaSPA against both traditional and generative data augmentation techniques. SaSPA consistently outperforms all established baselines across multiple settings, including full dataset training and contextual bias. Additionally, our results reveal interesting patterns in using synthetic data for FGVC models; for instance, we find a relationship between the amount of real data used and the optimal proportion of synthetic data.
tl;dr: We introduce Self-Guiding Exploration (SGE) for LLMs, boosting combinatorial problem-solving by 27.84% and increasing reasoning task accuracy by 2.46%.

Large Language Models (LLMs) have become pivotal in addressing reasoning tasks across diverse domains, including arithmetic, commonsense, and symbolic reasoning. They utilize prompting techniques such as Exploration-of-Thought, Decomposition, and Refinement to effectively navigate and solve intricate tasks. Despite these advancements, the application of LLMs to Combinatorial Problems (CPs), known for their NP-hardness and critical roles in logistics and resource management remains underexplored. To address this gap, we introduce a novel prompting strategy: Self-Guiding Exploration (SGE), designed to enhance the performance of solving CPs. SGE operates autonomously, generating multiple thought trajectories for each CP task. It then breaks these trajectories down into actionable subtasks, executes them sequentially, and refines the results to ensure optimal outcomes. We present our research as the first to apply LLMs to a broad range of CPs and demonstrate that SGE outperforms existing prompting strategies by over 27.84% in CP optimization performance. Additionally, SGE achieves a 2.46% higher accuracy over the best existing results in other reasoning tasks (arithmetic, commonsense, and symbolic).
tl;dr: We present the first unified pre-training procedure for motion time series that can generalize to diverse device locations, orientations, and activity types.

Motion time series collected from low-power, always-on mobile and wearable devices such as smartphones and smartwatches offer significant insights into human behavioral patterns, with wide applications in healthcare, automation, IoT, and AR/XR. However, given security and privacy concerns, building large-scale motion time series datasets remains difficult, hindering the development of pre-trained models for human activity analysis. Typically, existing models are trained and tested on the same dataset, leading to poor generalizability across variations in device location, device mounting orientation, and human activity type. In this paper, we introduce UniMTS, the first unified pre-training procedure for motion time series that generalizes across diverse device latent factors and activities. Specifically, we employ a contrastive learning framework that aligns motion time series with text descriptions enriched by large language models. This helps the model learn the semantics of time series to generalize across activities. Given the absence of large-scale motion time series data, we derive and synthesize time series from existing motion skeleton data with all-joint coverage. We use spatio-temporal graph networks to capture the relationships across joints for generalization across different device locations. We further design rotation-invariant augmentation to make the model agnostic to changes in device mounting orientations. Our model shows exceptional generalizability across 18 motion time series classification benchmark datasets, outperforming the best baselines by 340% in the zero-shot setting, 16.3% in the few-shot setting, and 9.2% in the full-shot setting.

Machine learning over graphs has recently attracted growing attention due to its ability to analyze and learn complex relations within critical interconnected systems. However, the disparate impact that is amplified by the use of biased graph structures in these algorithms has raised significant concerns for their deployment in real-world decision systems. In addition, while synthetic graph generation has become pivotal for privacy and scalability considerations, the impact of generative learning algorithms on structural bias has not yet been investigated. Motivated by this, this work focuses on the analysis and mitigation of structural bias for both real and synthetic graphs. Specifically, we first theoretically analyze the sources of structural bias that result in disparity for the predictions of dyadic relations. To alleviate the identified bias factors, we design a novel fairness regularizer that offers a versatile use. Faced with the bias amplification in graph generation models brought to light in this work, we further propose a fair graph generation framework, FairWire, by leveraging our fair regularizer design in a generative model. Experimental results on real-world networks validate that the proposed tools herein deliver effective structural bias mitigation for both real and synthetic graphs.

Contextual linear optimization (CLO) uses predictive contextual features to reduce uncertainty in random cost coefficients and thereby improve average-cost performance. An example is the stochastic shortest path problem with random edge costs (e.g., traffic) and contextual features (e.g., lagged traffic, weather). Existing work on CLO assumes the data has fully observed cost coefficient vectors, but in many applications, we can only see the realized cost of a historical decision, that is, just one projection of the random cost coefficient vector, to which we refer as bandit feedback. We study a class of offline learning algorithms for CLO with bandit feedback, which we term induced empirical risk minimization (IERM), where we fit a predictive model to directly optimize the downstream performance of the policy it induces. We show a fast-rate regret bound for IERM that allows for misspecified model classes and flexible choices of the optimization estimate, and we develop computationally tractable surrogate losses. A byproduct of our theory of independent interest is fast-rate regret bound for IERM with full feedback and misspecified policy class. We compare the performance of different modeling choices numerically using a stochastic shortest path example and provide practical insights from the empirical results.
tl;dr: We propose a novel in-context knowledge graph foundation model for universal reasoning across diverse KGs and various reasoning settings.

Extensive knowledge graphs (KGs) have been constructed to facilitate knowledge-driven tasks across various scenarios. However, existing work usually develops separate reasoning models for different KGs, lacking the ability to generalize and transfer knowledge across diverse KGs and reasoning settings. In this paper, we propose a prompt-based KG foundation model via in-context learning, namely KG-ICL, to achieve a universal reasoning ability. Specifically, we introduce a prompt graph centered with a query-related example fact as context to understand the query relation. To encode prompt graphs with the generalization ability to unseen entities and relations in queries, we first propose a unified tokenizer that maps entities and relations in prompt graphs to predefined tokens. Then, we propose two message passing neural networks to perform prompt encoding and KG reasoning, respectively. We conduct evaluation on 43 different KGs in both transductive and inductive settings. Results indicate that the proposed KG-ICL outperforms baselines on most datasets, showcasing its outstanding generalization and universal reasoning capabilities. The source code is accessible on GitHub: https://github.com/nju-websoft/KG-ICL.
tl;dr: The paper studies the potential increase in the value of RL problems given partial observations of the future realized rewards.

In reinforcement learning (RL), agents sequentially interact with changing environments while aiming to maximize the obtained rewards. Usually, rewards are observed only _after_ acting, and so the goal is to maximize the _expected_ cumulative reward. Yet, in many practical settings, reward information is observed in advance -- prices are observed before performing transactions; nearby traffic information is partially known; and goals are oftentimes given to agents prior to the interaction. In this work, we aim to quantifiably analyze the value of such future reward information through the lens of _competitive analysis. In particular, we measure the ratio between the value of standard RL agents and that of agents with partial future-reward lookahead. We characterize the worst-case reward distribution and derive exact ratios for the worst-case reward expectations. Surprisingly, the resulting ratios relate to known quantities in offline RL and reward-free exploration. We further provide tight bounds for the ratio given the worst-case dynamics. Our results cover the full spectrum between observing the immediate rewards before acting to observing all the rewards before the interaction starts.
tl;dr: We introduce the first exact gradient leakage attack for batches of sequnces on LLMs and show that it works on significantly larger token sequences and batch sizes while being faster and more price than prior work.

Federated learning works by aggregating locally computed gradients from multiple clients, thus enabling collaborative training without sharing private client data. However, prior work has shown that the data can actually be recovered by the server using so-called gradient inversion attacks. While these attacks perform well when applied on images, they are limited in the text domain and only permit approximate reconstruction of small batches and short input sequences. In this work, we propose DAGER, the first algorithm to recover whole batches of input text exactly. DAGER leverages the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings to efficiently check if a given token sequence is part of the client data. We use this check to exactly recover full batches in the honest-but-curious setting without any prior on the data for both encoder and decoder-based architectures using exhaustive heuristic search and a greedy approach, respectively. We provide an efficient GPU implementation of DAGER and show experimentally that it recovers full batches of size up to 128 on large language models (LLMs), beating prior attacks in speed (20x at same batch size), scalability (10x larger batches), and reconstruction quality (ROUGE-1/2 > 0.99).
tl;dr: We propose a two-phase algorithm for causal bandits with unknown causal graphs: Phase one learns the subgraph on reward's ancestors to identify all possibly optimal arms, followed by a standard bandit algorithm with analysis of the cumulative regret.

Causal knowledge about the relationships among decision variables and a reward variable in a bandit setting can accelerate the learning of an optimal decision. Current works often assume the causal graph is known, which may not always be available a priori. Motivated by this challenge, we focus on the causal bandit problem in scenarios where the underlying causal graph is unknown and may include latent confounders. While intervention on the parents of the reward node is optimal in the absence of latent confounders, this is not necessarily the case in general. Instead, one must consider a set of possibly optimal arms/interventions, each being a special subset of the ancestors of the reward node, making causal discovery beyond the parents of the reward node essential. For regret minimization, we identify that discovering the full causal structure is unnecessary; however, no existing work provides the necessary and sufficient components of the causal graph. We formally characterize the set of necessary and sufficient latent confounders one needs to detect or learn to ensure that all possibly optimal arms are identified correctly. We also propose a randomized algorithm for learning the causal graph with a limited number of samples, providing a sample complexity guarantee for any desired confidence level. In the causal bandit setup, we propose a two-stage approach. In the first stage, we learn the induced subgraph on ancestors of the reward, along with a necessary and sufficient subset of latent confounders, to construct the set of possibly optimal arms. We show that for our proposed algorithm, the number of intervention samples required to learn the set of possibly optimal arms scales polynomially with respect to the number of nodes. The second phase involves the application of a standard bandit algorithm, such as the UCB algorithm. We also establish a regret bound for our two-phase approach, which is sublinear in the number of rounds.
tl;dr: SeeA* is proposed to incorporate exploration into A* search by introducing an dynamic candidate set.

Monte-Carlo tree search (MCTS) and reinforcement learning contributed crucially to the success of AlphaGo and AlphaZero, and A$^*$ is a tree search algorithm among the most well-known ones in the classical AI literature. MCTS and A$^*$ both perform heuristic search and are mutually beneficial. Efforts have been made to the renaissance of A$^*$ from three possible aspects, two of which have been confirmed by studies in recent years, while the third is about the OPEN list that consists of open nodes of A$^*$ search, but still lacks deep investigation. This paper aims at the third, i.e., developing the Sampling-exploration enhanced A$^*$ (SeeA$^*$) search by constructing a dynamic subset of OPEN through a selective sampling process, such that the node with the best heuristic value in this subset instead of in the OPEN is expanded. Nodes with the best heuristic values in OPEN are most probably picked into this subset, but sometimes may not be included, which enables SeeA$^*$ to explore other promising branches. Three sampling techniques are presented for comparative investigations. Moreover, under the assumption about the distribution of prediction errors, we have theoretically shown the superior efficiency of SeeA$^*$ over A$^*$ search, particularly when the accuracy of the guiding heuristic function is insufficient. Experimental results on retrosynthetic planning in organic chemistry, logic synthesis in integrated circuit design, and the classical Sokoban game empirically demonstrate the efficiency of SeeA$^*$, in comparison with the state-of-the-art heuristic search algorithms.
tl;dr: We propose a polarimetric imaging framework that can produce clean and clear polarized snapshots by complementarily fusing a degraded pair of noisy and blurry ones.

Polarimetric imaging is a challenging problem in the field of polarization-based vision, since setting a short exposure time reduces the signal-to-noise ratio, making the degree of polarization (DoP) and the angle of polarization (AoP) severely degenerated, while if setting a relatively long exposure time, the DoP and AoP would tend to be over-smoothed due to the frequently-occurring motion blur. This work proposes a polarimetric imaging framework that can produce clean and clear polarized snapshots by complementarily fusing a degraded pair of noisy and blurry ones. By adopting a neural network-based three-phase fusing scheme with specially-designed modules tailored to each phase, our framework can not only improve the image quality but also preserve the polarization properties. Experimental results show that our framework achieves state-of-the-art performance.
tl;dr: A new diffusion-based offline RL algorithm that uses a guide-then-select paradigm to achieves state-of-the-art empirical results.

One important property of DIstribution Correction Estimation (DICE) methods is that the solution is the optimal stationary distribution ratio between the optimized and data collection policy. In this work, we show that DICE-based methods can be viewed as a transformation from the behavior distribution to the optimal policy distribution. Based on this, we propose a novel approach, Diffusion-DICE, that directly performs this transformation using diffusion models. We find that the optimal policy's score function can be decomposed into two terms: the behavior policy's score function and the gradient of a guidance term which depends on the optimal distribution ratio. The first term can be obtained from a diffusion model trained on the dataset and we propose an in-sample learning objective to learn the second term. Due to the multi-modality contained in the optimal policy distribution, the transformation in Diffusion-DICE may guide towards those local-optimal modes. We thus generate a few candidate actions and carefully select from them to achieve global-optimum. Different from all other diffusion-based offline RL methods, the \textit{guide-then-select} paradigm in Diffusion-DICE only uses in-sample actions for training and brings minimal error exploitation in the value function. We use a didatic toycase example to show how previous diffusion-based methods fail to generate optimal actions due to leveraging these errors and how Diffusion-DICE successfully avoid that. We then conduct extensive experiments on benchmark datasets to show the strong performance of Diffusion-DICE.
tl;dr: In the context of planning we use variational inference to compare inference types, and to create a novel belief propagation-like algorithm for factored-state MDPs.

Multiple types of inference are available for probabilistic graphical models, e.g., marginal, maximum-a-posteriori, and even marginal maximum-a-posteriori. Which one do researchers mean when they talk about ``planning as inference''? There is no consistency in the literature, different types are used, and their ability to do planning is further entangled with specific approximations or additional constraints. In this work we use the variational framework to show that, just like all commonly used types of inference correspond to different weightings of the entropy terms in the variational problem, planning corresponds _exactly_ to a _different_ set of weights. This means that all the tricks of variational inference are readily applicable to planning. We develop an analogue of loopy belief propagation that allows us to perform approximate planning in factored-state Markov decisions processes without incurring intractability due to the exponentially large state space. The variational perspective shows that the previous types of inference for planning are only adequate in environments with low stochasticity, and allows us to characterize each type by its own merits, disentangling the type of inference from the additional approximations that its practical use requires. We validate these results empirically on synthetic MDPs and tasks posed in the International Planning Competition.
tl;dr: Meta-algorithm for the mixture learning problem with guarantees for small groups in the presence of large additive adversarial contamination.

We study the problem of estimating the means of well-separated mixtures when an adversary may add arbitrary outliers. While strong guarantees are available when the outlier fraction is significantly smaller than the minimum mixing weight, much less is known when outliers may crowd out low-weight clusters – a setting we refer to as list-decodable mixture learning (LD-ML). In this case, adversarial outliers can simulate additional spurious mixture components. Hence, if all means of the mixture must be recovered up to a small error in the output list, the list size needs to be larger than the number of (true) components. We propose an algorithm that obtains order-optimal error guarantees for each mixture mean with a minimal list-size overhead, significantly improving upon list-decodable mean estimation, the only existing method that is applicable for LD-ML. Although improvements are observed even when the mixture is non-separated, our algorithm achieves particularly strong guarantees when the mixture is separated: it can leverage the mixture structure to partially cluster the samples before carefully iterating a base learner for list-decodable mean estimation at different scales.
tl;dr: We present a differentiable representation, DMesh, for general 3D triangular meshes. It considers both the geometry and connectivity information of a mesh in a differentiable manner.

We present a differentiable representation, DMesh, for general 3D triangular meshes. DMesh considers both the geometry and connectivity information of a mesh. In our design, we first get a set of convex tetrahedra that compactly tessellates the domain based on Weighted Delaunay Triangulation (WDT), and select triangular faces on the tetrahedra to define the final mesh. We formulate probability of faces to exist on the actual surface in a differentiable manner based on the WDT. This enables DMesh to represent meshes of various topology in a differentiable way, and allows us to reconstruct the mesh under various observations, such as point clouds and multi-view images using gradient-based optimization. We publicize the source code and supplementary material at our project page (https://sonsang.github.io/dmesh-project).

Graph neural networks (GNNs) have been widely used to predict properties and heuristics of mixed-integer linear programs (MILPs) and hence accelerate MILP solvers. This paper investigates the capacity of GNNs to represent strong branching (SB), the most effective yet computationally expensive heuristic employed in the branch-and-bound algorithm. In the literature, message-passing GNN (MP-GNN), as the simplest GNN structure, is frequently used as a fast approximation of SB and we find that not all MILPs's SB can be represented with MP-GNN. We precisely define a class of ``MP-tractable" MILPs for which MP-GNNs can accurately approximate SB scores. Particularly, we establish a universal approximation theorem: for any data distribution over the MP-tractable class, there always exists an MP-GNN that can approximate the SB score with arbitrarily high accuracy and arbitrarily high probability, which lays a theoretical foundation of the existing works on imitating SB with MP-GNN. For MILPs without the MP-tractability, unfortunately, a similar result is impossible, which can be illustrated by two MILP instances with different SB scores that cannot be distinguished by any MP-GNN, regardless of the number of parameters. Recognizing this, we explore another GNN structure called the second-order folklore GNN (2-FGNN) that overcomes this limitation, and the aforementioned universal approximation theorem can be extended to the entire MILP space using 2-FGNN, regardless of the MP-tractability. A small-scale numerical experiment is conducted to directly validate our theoretical findings.
tl;dr: This paper introduces a simulator-conditioned diffusion model, which follows the layout guidance from the simulator and cues of the rich text prompts to generate images of diverse driving scenes.

Controllable synthetic data generation can substantially lower the annotation cost of training data. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, overfitting often happens, where the trained models can only generate images based on the layout data from the validation set of the same dataset. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation.

Going beyond mimicking limited human experiences, recent studies show initial evidence that, like humans, large language models (LLMs) are capable of improving their abilities purely by self-correction, i.e., correcting previous responses through self-examination, as seen in models like OpenAI o1. Nevertheless, little is known about how such capabilities arise. In this work, based on a simplified setup akin to an alignment task, we theoretically analyze self-correction from an in-context learning perspective, showing that when LLMs give relatively accurate self-examinations as rewards, they are capable of refining responses in an in-context way. Notably, going beyond previous theories on over-simplified linear transformers, our theoretical construction underpins the roles of several key designs of realistic transformers for self-correction: softmax attention, multi-head attention, and the MLP block. We validate these findings extensively on synthetic datasets. Inspired by these findings, we propose a simple self-correction strategy, Checking as Context (CaC), which finds novel applications in alleviating social bias and defending against LLM jailbreaks. We believe that these findings will inspire further research on understanding, exploiting, and enhancing self-correction for building better foundation models. Code is at https://github.com/yifeiwang77/Self-Correction.
tl;dr: Novel score matching and flow-based generative models are introduced by learning velocity predictors of Hamiltonian dynamics.

Classical Hamiltonian mechanics has been widely used in machine learning in the form of Hamiltonian Monte Carlo for applications with predetermined force fields. In this paper, we explore the potential of deliberately designing force fields for Hamiltonian systems, introducing Hamiltonian velocity predictors (HVPs) as a core tool for constructing energy-based and generative models. We present two innovations: Hamiltonian Score Matching (HSM), which utilizes score functions to augment data by simulating Hamiltonian trajectories, and Hamiltonian Generative Flows (HGFs), a novel generative model that encompasses diffusion models and OT-flow matching as HGFs with zero force fields. We showcase the extended design space of force fields by introducing Oscillation HGFs, a generative model inspired by harmonic oscillators. Our experiments demonstrate that HSM and HGFs rival leading score-matching and generative modeling techniques. Overall, our work systematically elucidates the synergy between Hamiltonian dynamics, force fields, and generative models, thereby opening new avenues for applications of machine learning in physical sciences and dynamical systems.

Bilevel optimization has gained prominence in various applications. In this study, we introduce a framework for solving bilevel optimization problems, where the variables in both the lower and upper levels are constrained on Riemannian manifolds. We present several hypergradient estimation strategies on manifolds and analyze their estimation errors. Furthermore, we provide comprehensive convergence and complexity analyses for the proposed hypergradient descent algorithm on manifolds. We also extend our framework to encompass stochastic bilevel optimization and incorporate the use of general retraction. The efficacy of the proposed framework is demonstrated through several applications.
tl;dr: We provide an extremely fast and scalable method to obtain tight bounds for the Lipschitz constant of deep neural networks.

The Lipschitz constant plays a crucial role in certifying the robustness of neural networks to input perturbations. Since calculating the exact Lipschitz constant is NP-hard, efforts have been made to obtain tight upper bounds on the Lipschitz constant. Typically, this involves solving a large matrix verification problem, the computational cost of which grows significantly for both deeper and wider networks. In this paper, we provide a compositional approach to estimate Lipschitz constants for deep feed-forward neural networks. We first obtain an exact decomposition of the large matrix verification problem into smaller sub-problems. Then, leveraging the underlying cascade structure of the network, we develop two algorithms. The first algorithm explores the geometric features of the problem and enables us to provide Lipschitz estimates that are comparable to existing methods by solving small semidefinite programs (SDPs) that are only as large as the size of each layer. The second algorithm relaxes these sub-problems and provides a closed-form solution to each sub-problem for extremely fast estimation, altogether eliminating the need to solve SDPs. The two algorithms represent different levels of trade-offs between efficiency and accuracy. Finally, we demonstrate that our approach provides a steep reduction in computation time (as much as several thousand times faster, depending on the algorithm for deeper networks) while yielding Lipschitz bounds that are very close to or even better than those achieved by state-of-the-art approaches in a broad range of experiments. In summary, our approach considerably advances the scalability and efficiency of certifying neural network robustness, making it particularly attractive for online learning tasks.

We consider the solvable neural scaling model with three parameters: data complexity, target complexity, and model-parameter-count. We use this neural scaling model to derive new predictions about the compute-limited, infinite-data scaling law regime. To train the neural scaling model, we run one-pass stochastic gradient descent on a mean-squared loss. We derive a representation of the loss curves which holds over all iteration counts and improves in accuracy as the model parameter count grows. We then analyze the compute-optimal model-parameter-count, and identify 4 phases (+3 subphases) in the data-complexity/target-complexity phase-plane. The phase boundaries are determined by the relative importance of model capacity, optimizer noise, and embedding of the features. We furthermore derive, with mathematical proof and extensive numerical evidence, the scaling-law exponents in all of these phases, in particular computing the optimal model-parameter-count as a function of floating point operation budget. We include a colab notebook https://tinyurl.com/2saj6bkj, nanoChinchilla, that reproduces some key results of the paper.
tl;dr: We introduce Universal Physics Transformers, an efficiently scalable neural operator framework to model a wide range of spatio-temporal problems – for Lagrangian and Eulerian discretization schemes.

Neural operators, serving as physics surrogate models, have recently gained increased interest. With ever increasing problem complexity, the natural question arises: what is an efficient way to scale neural operators to larger and more complex simulations - most importantly by taking into account different types of simulation datasets. This is of special interest since, akin to their numerical counterparts, different techniques are used across applications, even if the underlying dynamics of the systems are similar. Whereas the flexibility of transformers has enabled unified architectures across domains, neural operators mostly follow a problem specific design, where GNNs are commonly used for Lagrangian simulations and grid-based models predominate Eulerian simulations.
We introduce Universal Physics Transformers (UPTs), an efficient and unified learning paradigm for a wide range of spatio-temporal problems. UPTs operate without grid- or particle-based latent structures, enabling flexibility and scalability across meshes and particles. UPTs efficiently propagate dynamics in the latent space, emphasized by inverse encoding and decoding techniques. Finally, UPTs allow for queries of the latent space representation at any point in space-time. We demonstrate diverse applicability and efficacy of UPTs in mesh-based fluid simulations, and steady-state Reynolds averaged Navier-Stokes simulations, and Lagrangian-based dynamics.

Bayes' rule naturally allows for inference refinement in a streaming fashion, without the need to recompute posteriors from scratch whenever new data arrives. In principle, Bayesian streaming is straightforward: we update our prior with the available data and use the resulting posterior as a prior when processing the next data chunk. In practice, however, this recipe entails i) approximating an intractable posterior at each time step; and ii) encapsulating results appropriately to allow for posterior propagation. For continuous state spaces, variational inference (VI) is particularly convenient due to its scalability and the tractability of variational posteriors, For discrete state spaces, however, state-of-the-art VI results in analytically intractable approximations that are ill-suited for streaming settings. To enable streaming Bayesian inference over discrete parameter spaces, we propose streaming Bayes GFlowNets (abbreviated as SB-GFlowNets) by leveraging the recently proposed GFlowNets --- a powerful class of amortized samplers for discrete compositional objects. Notably, SB-GFlowNet approximates the initial posterior using a standard GFlowNet and subsequently updates it using a tailored procedure that requires only the newly observed data. Our case studies in linear preference learning and phylogenetic inference showcase the effectiveness of SB-GFlowNets in sampling from an unnormalized posterior in a streaming setting. As expected, we also observe that SB-GFlowNets is significantly faster than repeatedly training a GFlowNet from scratch to sample from the full posterior.
tl;dr: We propose a new method for sampling the posterior distributions of inverse problems using diffusion models in a rigorous way.

Diffusion models (DMs) have recently shown outstanding capabilities in modeling complex image distributions, making them expressive image priors for solving Bayesian inverse problems. However, most existing DM-based methods rely on approximations in the generative process to be generic to different inverse problems, leading to inaccurate sample distributions that deviate from the target posterior defined within the Bayesian framework. To harness the generative power of DMs while avoiding such approximations, we propose a Markov chain Monte Carlo algorithm that performs posterior sampling for general inverse problems by reducing it to sampling the posterior of a Gaussian denoising problem. Crucially, we leverage a general DM formulation as a unified interface that allows for rigorously solving the denoising problem with a range of state-of-the-art DMs. We demonstrate the effectiveness of the proposed method on six inverse problems (three linear and three nonlinear), including a real-world black hole imaging problem. Experimental results indicate that our proposed method offers more accurate reconstructions and posterior estimation compared to existing DM-based imaging inverse methods.
tl;dr: We investigate representations from pre-trained text-to-image diffusion models for control tasks and showcase competitive performance across a wide range of tasks.

Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding—a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using Stable Control Representations are competitive with state-of-the-art representation learning approaches across a broad range of simulated control settings, encompassing challenging manipulation and navigation tasks. Most notably, we show that Stable Control Representations enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.
tl;dr: A 3-fold better and a 10-fold faster way to train neural optimal transport: all thanks to a new expectile regularizing loss function that sets an upper bound over the distribution of learning conjugate potentials.

We present a new approach for Neural Optimal Transport (NOT) training procedure, capable of accurately and efficiently estimating optimal transportation plan via specific regularization on dual Kantorovich potentials. The main bottleneck of existing NOT solvers is associated with the procedure of finding a near-exact approximation of the conjugate operator (i.e., the c-transform), which is done either by optimizing over non-convex max-min objectives or by the computationally intensive fine-tuning of the initial approximated prediction. We resolve both issues by proposing a new theoretically justified loss in the form of expectile regularization which enforces binding conditions on the learning process of the dual potentials. Such a regularization provides the upper bound estimation over the distribution of possible conjugate potentials and makes the learning stable, completely eliminating the need for additional extensive fine-tuning. Proposed method, called Expectile-Regularized Neural Optimal Transport (ENOT), outperforms previous state-of-the-art approaches in the established Wasserstein-2 benchmark tasks by a large margin (up to a 3-fold improvement in quality and up to a 10-fold improvement in runtime). Moreover, we showcase performance of ENOT for various cost functions in different tasks, such as image generation, demonstrating generalizability and robustness of the proposed algorithm.
tl;dr: We present a novel equivariant graph neural network based on nonlinear operations in the spectral domain.

Equivariant machine learning is an approach for designing deep learning models that respect the symmetries of the problem, with the aim of reducing model complexity and improving generalization.
In this paper, we focus on an extension of shift equivariance, which is the basis of convolution networks on images, to general graphs. Unlike images, graphs do not have a natural notion of domain translation.
Therefore, we consider the graph functional shifts as the symmetry group: the unitary operators that commute with the graph shift operator.
Notably, such symmetries operate in the signal space rather than directly in the spatial space.
We remark that each linear filter layer of a standard spectral graph neural network (GNN) commutes with graph functional shifts, but the activation function breaks this symmetry. Instead, we propose nonlinear spectral filters (NLSFs) that are fully equivariant to graph functional shifts and show that they have universal approximation properties.
The proposed NLSFs are based on a new form of spectral domain that is transferable between graphs.
We demonstrate the superior performance of NLSFs over existing spectral GNNs in node and graph classification benchmarks.

In the domain of code generation, self-debugging is crucial. It allows LLMs to refine their generated code based on execution feedback. This is particularly important because generating correct solutions in one attempt proves challenging for complex tasks. Prior works on self-debugging mostly focus on prompting methods by providing LLMs with few-shot examples, which work poorly on small open-sourced LLMs. In this work, we propose LeDex, a training framework that significantly improves the self-debugging capability of LLMs. Intuitively, we observe that a chain of explanations on the wrong code followed by code refinement helps LLMs better analyze the wrong code and do refinement. We thus propose an automated pipeline to collect a high-quality dataset for code explanation and refinement by generating a number of explanations and refinement trajectories from the LLM itself or a larger teacher model and filtering via execution verification. We perform supervised fine-tuning (SFT) and further reinforcement learning (RL) on both success and failure trajectories with a novel reward design considering code explanation and refinement quality. SFT improves the pass@1 by up to 15.92\% and pass@10 by 9.30\% over four benchmarks. RL training brings additional up to 3.54\% improvement on pass@1 and 2.55\% improvement on pass@10. The trained LLMs show iterative refinement ability and can keep refining code continuously. Lastly, our human evaluation shows that the LLMs trained with our framework generate more useful code explanations and help developers better understand bugs in source code.

A fundamental notion of distance between train and test distributions from the field of domain adaptation is discrepancy distance. While in general hard to compute, here we provide the first set of provably efficient algorithms for testing *localized* discrepancy distance, where discrepancy is computed with respect to a fixed output classifier. These results imply a broad set of new, efficient learning algorithms in the recently introduced model of Testable Learning with Distribution Shift (TDS learning) due to Klivans et al. (2023).
Our approach generalizes and improves all prior work on TDS learning: (1) we obtain *universal* learners that succeed simultaneously for large classes of test distributions, (2) achieve near-optimal error rates, and (3) give exponential improvements for constant depth circuits. Our methods further extend to semi-parametric settings and imply the first positive results for low-dimensional convex sets. Additionally, we separate learning and testing phases and obtain algorithms that run in fully polynomial time at test time.

The remarkable capabilities of modern large language models are rooted in their vast repositories of knowledge encoded within their parameters, enabling them to perceive the world and engage in reasoning. The inner workings of how these models store knowledge have long been a subject of intense interest and investigation among researchers. To date, most studies have concentrated on isolated components within these models, such as the Multilayer Perceptrons and attention head. In this paper, we delve into the computation graph of the language model to uncover the knowledge circuits that are instrumental in articulating specific knowledge. The experiments, conducted with GPT2 and TinyLLAMA, has allowed us to observe how certain information heads, relation heads, and Multilayer Perceptrons collaboratively encode knowledge within the model. Moreover, we evaluate the impact of current knowledge editing techniques on these knowledge circuits, providing deeper insights into the functioning and constraints of these editing methodologies. Finally, we utilize knowledge circuits to analyze and interpret language model behaviors such as hallucinations and in-context learning. We believe the knowledge circuit holds potential for advancing our understanding of Transformers and guiding the improved design of knowledge editing.
tl;dr: This paper presents new general upper and lower bounds on the quality of Bayesian coresets.

Bayesian coresets speed up posterior inference in the large-scale data regime by approximating the full-data log-likelihood function with a surrogate log-likelihood based on a small, weighted subset of the data. But while Bayesian coresets and methods for construction are applicable in a wide range of models, existing theoretical analysis of the posterior inferential error incurred by coreset approximations only apply in restrictive settings---i.e., exponential family models, or models with strong log-concavity and smoothness assumptions. This work presents general upper and lower bounds on the Kullback-Leibler (KL) divergence of coreset approximations that reflect the full range of applicability of Bayesian coresets. The lower bounds require only mild model assumptions typical of Bayesian asymptotic analyses, while the upper bounds require the log-likelihood functions to satisfy a generalized subexponentiality criterion that is weaker than conditions used in earlier work. The lower bounds are applied to obtain fundamental limitations on the quality of coreset approximations, and to provide a theoretical explanation for the previously-observed poor empirical performance of importance sampling-based construction methods. The upper bounds are used to analyze the performance of recent subsample-optimize methods. The flexibility of the theory is demonstrated in validation experiments involving multimodal, unidentifiable, heavy-tailed Bayesian posterior distributions.
530. Connectivity Shapes Implicit Regularization in Matrix Factorization Models for Matrix Completion
tl;dr: We provide a unified understanding of when, how, and why matrix factorization models achieve different implicit regularization effects.

Matrix factorization models have been extensively studied as a valuable test-bed for understanding the implicit biases of overparameterized models. Although both low nuclear norm and low rank regularization have been studied for these models, a unified understanding of when, how, and why they achieve different implicit regularization effects remains elusive. In this work, we systematically investigate the implicit regularization of matrix factorization for solving matrix completion problems. We empirically discover that the connectivity of observed data plays a key role in the implicit bias, with a transition from low nuclear norm to low rank as data shifts from disconnected to connected with increased observations. We identify a hierarchy of intrinsic invariant manifolds in the loss landscape that guide the training trajectory to evolve from low-rank to higher-rank solutions. Based on this finding, we theoretically characterize the training trajectory as following the hierarchical invariant manifold traversal process, generalizing the characterization of Li et al.(2020) to include the disconnected case. Furthermore, we establish conditions that guarantee minimum nuclear norm, closely aligning with our experimental findings, and we provide a dynamics characterization condition for ensuring minimum rank. Our work reveals the intricate interplay between data connectivity, training dynamics, and implicit regularization in matrix factorization models.
tl;dr: We give the first nearly-linear time algorithm for solving semi-random matrix completion to high accuracy and with noisy observations.

We consider the well-studied problem of completing a rank-$r$, $\mu$-incoherent matrix $\mathbf{M} \in \mathbb{R}^{d \times d}$ from incomplete observations. We focus on this problem in the semi-random setting where each entry is independently revealed with probability at least $p = \frac{\textup{poly}(r, \mu, \log d)}{d}$.
Whereas multiple nearly-linear time algorithms have been established in the more specialized fully-random setting where each entry is revealed with probablity exactly $p$, the only known nearly-linear time algorithm in the semi-random setting is due to [CG18], whose sample complexity has a polynomial dependence on the inverse accuracy and condition number and thus cannot achieve high-accuracy recovery.
Our main result is the first high-accuracy nearly-linear time algorithm for solving semi-random matrix completion, and an extension to the noisy observation setting.
Our result builds upon the recent short-flat decomposition framework of [KLLST23a, KLLST23b] and leverages fast algorithms for flow problems on graphs to solve adaptive reweighting subproblems efficiently.
tl;dr: A stochastic primal-dual algorithm for solving distributionally robust optimization problems. It achieves a state-of-the-art linear convergence rate and combines randomized and cyclic components.

We consider the penalized distributionally robust optimization (DRO) problem with a closed, convex uncertainty set, a setting that encompasses learning using $f$-DRO and spectral/$L$-risk minimization. We present Drago, a stochastic primal-dual algorithm which combines cyclic and randomized components with a carefully regularized primal update to achieve dual variance reduction. Owing to its design, Drago enjoys a state-of-the-art linear convergence rate on strongly convex-strongly concave DRO problems witha fine-grained dependency on primal and dual condition numbers. The theoretical results are supported with numerical benchmarks on regression and classification tasks.

Data with geometric structure is ubiquitous in machine learning often arising from fundamental symmetries in a domain, such as permutation-invariance in graphs and translation-invariance in images. Group-convolutional architectures, which encode symmetries as inductive bias, have shown great success in applications, but can suffer from instabilities as their depth increases and often struggle to learn long range dependencies in data. For instance, graph neural networks experience instability due to the convergence of node representations (over-smoothing), which can occur after only a few iterations of message-passing, reducing their effectiveness in downstream tasks. Here, we propose and study unitary group convolutions, which allow for deeper networks that are more stable during training. The main focus of the paper are graph neural networks, where we show that unitary graph convolutions provably avoid over-smoothing. Our experimental results confirm that unitary graph convolutional networks achieve competitive performance on benchmark datasets compared to state-of-the-art graph neural networks. We complement our analysis of the graph domain with the study of general unitary convolutions and analyze their role in enhancing stability in general group convolutional architectures.

Conventional wisdom holds that autoregressive models for image generation are typically accompanied by vector-quantized tokens. We observe that while a discrete-valued space can facilitate representing a categorical distribution, it is not a necessity for autoregressive modeling. In this work, we propose to model the per-token probability distribution using a diffusion procedure, which allows us to apply autoregressive models in a continuous-valued space. Rather than using categorical cross-entropy loss, we define a Diffusion Loss function to model the per-token probability. This approach eliminates the need for discrete-valued tokenizers. We evaluate its effectiveness across a wide range of cases, including standard autoregressive models and generalized masked autoregressive (MAR) variants. By removing vector quantization, our image generator achieves strong results while enjoying the speed advantage of sequence modeling. We hope this work will motivate the use of autoregressive generation in other continuous-valued domains and applications. Code is available at [https://github.com/LTH14/mar](https://github.com/LTH14/mar).
tl;dr: This paper provides a comprehensive analysis and extension of the current state of score-based diffusion models trained on short segments from PDE trajectories, and evaluated on forecasting and data assimilation tasks.

Modelling partial differential equations (PDEs) is of crucial importance in science and engineering, and it includes tasks ranging from forecasting to inverse problems, such as data assimilation. However, most previous numerical and machine learning approaches that target forecasting cannot be applied out-of-the-box for data assimilation. Recently, diffusion models have emerged as a powerful tool for conditional generation, being able to flexibly incorporate observations without retraining. In this work, we perform a comparative study of score-based diffusion models for forecasting and assimilation of sparse observations. In particular, we focus on diffusion models that are either trained in a conditional manner, or conditioned after unconditional training. We address the shortcomings of existing models by proposing 1) an autoregressive sampling approach, that significantly improves performance in forecasting, 2) a new training strategy for conditional score-based models that achieves stable performance over a range of history lengths, and 3) a hybrid model which employs flexible pre-training conditioning on initial conditions and flexible post-training conditioning to handle data assimilation. We empirically show that these modifications are crucial for successfully tackling the combination of forecasting and data assimilation, a task commonly encountered in real-world scenarios.
tl;dr: We provide regret guarantees without prior bounds on Lipschitz constants of comparator norms.

We provide a technique for OLO that obtains regret $G\|w_\star\|\sqrt{T\log(\|w_\star\|G\sqrt{T})} + \|w_\star\|^2 + G^2$ on $G$-Lipschitz losses for any comparison point $w_\star$ without knowing either $G$ or $\|w_\star\|$. Importantly, this matches the optimal bound $G\|w_\star\|\sqrt{T}$ available with such knowledge (up to logarithmic factors), unless either $\|w_\star\|$ or $G$ is so large that even $G\|w_\star\|\sqrt{T}$ is roughly linear in $T$. Thus, at a high level it matches the optimal bound in all cases in which one can achieve sublinear regret.
tl;dr: This paper proposes a lazy safety alignment against harmful finetuning attack in Large language models.

Recent studies show that Large Language Models (LLMs) with safety alignment can be jail-broken by fine-tuning on a dataset mixed with harmful data. For the first time in the literature, we show that the jail-break effect can be mitigated by separating two states in the fine-tuning stage to respectively optimize over the alignment and user datasets. Unfortunately, our subsequent study shows that this simple Bi-State Optimization (BSO) solution experiences convergence instability when steps invested in its alignment state is too small, leading to downgraded alignment performance. By statistical analysis, we show that the \textit{excess drift} towards the switching iterates of the two states could be a probable reason for the instability. To remedy this issue, we propose \textbf{L}azy(\textbf{i}) \textbf{s}afety \textbf{a}lignment (\textbf{Lisa}), which introduces a proximal term to constraint the drift of each state. Theoretically, the benefit of the proximal term is supported by the convergence analysis, wherein we show that a sufficient large proximal factor is necessary to guarantee Lisa's convergence. Empirically, our results on four downstream fine-tuning tasks show that Lisa with a proximal term can significantly increase alignment performance while maintaining the LLM's accuracy on the user tasks. Code is available at https://github.com/git-disl/Lisa.
tl;dr: Empowered by the largest real-world, multi-view dataset to date, we present the first model to reasonably synthesize real-world 3D scenes and reconstruct their geometry conditioned on a single image.

Three-dimensional (3D) understanding of objects and scenes play a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robotics. Large scale synthetic and object-centric 3D datasets have shown to be effective in training models that have 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is difficult due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content have shown to be difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture. This restricts the ability to access scenes from a variety of more diverse and potentially useful perspectives. We argue that large scale ODIN videos can address these limitations to provide scalable corresponding frames from diverse views. In this paper we introduce 360-1M, a 360° video dataset consisting of 1 million videos, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, ODIN, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, ODIN is able to freely generate novel views of real-world scenes. Unlike previous methods, ODIN can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.

While advancements in NLP have significantly improved the performance of Large Language Models (LLMs) on tasks requiring vertical thinking, their lateral thinking capabilities remain under-explored and challenging to measure due to the complexity of assessing creative thought processes and the scarcity of relevant data. To address these challenges, we introduce SPLAT, a benchmark leveraging Situation Puzzles to evaluate and elicit LAteral Thinking of LLMs. This benchmark, containing 975 graded situation puzzles across three difficulty levels, employs a new multi-turn player-judge framework instead of the traditional model-based evaluation, which often necessitates a stronger evaluation model. This framework simulates an interactive game where the model (player) asks the evaluation model (judge) questions about an incomplete story to infer the full scenario. The judge answers based on a detailed reference scenario or evaluates if the player's predictions align with the reference one. This approach lessens dependence on more robust evaluation models, enabling the assessment of state-of-the-art LLMs. The experiments demonstrate that a robust evaluation model, such as WizardLM-2, closely matches human judgements in both intermediate question-answering and final scenario accuracy, achieving over 80% agreement--similar to the agreement levels among humans. Furthermore, applying data and reasoning processes from our benchmark to other lateral thinking-related benchmarks, e.g., RiddleSense and BrainTeaser, leads to performance enhancements. This suggests that our benchmark effectively evaluates and elicits the lateral thinking abilities of LLMs.

Modern machine learning heavily depends on the effectiveness of optimization techniques. While deep learning models have achieved remarkable empirical results in training, their theoretical underpinnings remain somewhat elusive. Ensuring the convergence of optimization methods requires imposing specific structures on the objective function which often do not hold in practice. One prominent example is the widely recognized Polyak-Lojasiewicz (PL) inequality, which has garnered considerable attention in recent years. However, validating such assumptions for deep neural networks entails substantial and often impractical levels of over-parametrization. In order to address this limitation, we propose a novel class of functions that can characterize the loss landscape of modern deep models without requiring extensive over-parametrization and can also include saddle points. Crucially, we prove that gradient-based optimizers possess theoretical guarantees of convergence under this assumption. Finally, we validate the soundness of our assumption through both theoretical analysis and empirical experimentation across a diverse range of deep learning models.
tl;dr: We study fairness in the context of the secretary problem with predictions.

Algorithms with predictions is a recent framework for decision-making under uncertainty that leverages the power of machine-learned predictions without making any assumption about their quality. The goal in this framework is for algorithms to achieve an improved performance when the predictions are accurate while maintaining acceptable guarantees when the predictions are erroneous. A serious concern with algorithms that use predictions is that these predictions can be biased and, as a result, cause the algorithm to make decisions that are deemed unfair. We show that this concern manifests itself in the classical secretary problem in the learning-augmented setting---the state-of-the-art algorithm can have zero probability of accepting the best candidate, which we deem unfair, despite promising to accept a candidate whose expected value is at least $\max\{\Omega (1) , 1 - O(\varepsilon)\}$ times the optimal value, where $\varepsilon$ is the prediction error.
We show how to preserve this promise while also guaranteeing to accept the best candidate with probability $\Omega(1)$. Our algorithm and analysis are based on a new ``pegging'' idea that diverges from existing works and simplifies/unifies some of their results. Finally, we extend to the $k$-secretary problem and complement our theoretical analysis with experiments.
542. GLinSAT: The General Linear Satisfiability Neural Network Layer By Accelerated Gradient Descent
tl;dr: We design GLinSAT based on accelerated gradient descent method, which is the first general linear satisfiability neural network layer where all the operations are differentiable and matrix-factorization-free.

Ensuring that the outputs of neural networks satisfy specific constraints is crucial for applying neural networks to real-life decision-making problems. In this paper, we consider making a batch of neural network outputs satisfy bounded and general linear constraints. We first reformulate the neural network output projection problem as an entropy-regularized linear programming problem. We show that such a problem can be equivalently transformed into an unconstrained convex optimization problem with Lipschitz continuous gradient according to the duality theorem. Then, based on an accelerated gradient descent algorithm with numerical performance enhancement, we present our architecture, GLinSAT, to solve the problem. To the best of our knowledge, this is the first general linear satisfiability layer in which all the operations are differentiable and matrix-factorization-free. Despite the fact that we can explicitly perform backpropagation based on automatic differentiation mechanism, we also provide an alternative approach in GLinSAT to calculate the derivatives based on implicit differentiation of the optimality condition. Experimental results on constrained traveling salesman problems, partial graph matching with outliers, predictive portfolio allocation and power system unit commitment demonstrate the advantages of GLinSAT over existing satisfiability layers. Our implementation is available at https://github.com/HunterTracer/GLinSAT.

The manifold hypothesis presumes that high-dimensional data lies on or near a low-dimensional manifold.
While the utility of encoding geometric structure has been demonstrated empirically, rigorous analysis of its impact on the learnability of neural networks is largely missing. Several recent results have established hardness results for learning feedforward and equivariant neural networks under i.i.d. Gaussian or uniform Boolean data distributions. In this paper, we investigate the hardness of learning under the manifold hypothesis. We ask, which minimal assumptions on the curvature and regularity of the manifold, if any, render the learning problem efficiently learnable. We prove that learning is hard under input manifolds of bounded curvature by extending proofs of hardness in the SQ and cryptographic settings for boolean data inputs to the geometric setting. On the other hand, we show that additional assumptions on the volume of the data manifold alleviate these fundamental limitations and guarantee learnability via a simple interpolation argument. Notable instances of this regime are manifolds which can be reliably reconstructed via manifold learning.
Looking forward, we comment on and empirically explore intermediate regimes of manifolds, which have heterogeneous features commonly found in real world data.
tl;dr: We propose several uncertainty based and information gain acquisition functions for derivative based global sensitivity analysis

We consider the problem of active learning for global sensitivity analysis of expensive black-box functions. Our aim is to efficiently learn the importance of different input variables, e.g., in vehicle safety experimentation, we study the impact of the thickness of various components on safety objectives. Since function evaluations are expensive, we use active learning to prioritize experimental resources where they yield the most value. We propose novel active learning acquisition functions that directly target key quantities of derivative-based global sensitivity measures (DGSMs) under Gaussian process surrogate models.
We showcase the first application of active learning directly to DGSMs, and develop tractable uncertainty reduction and information gain acquisition functions for these measures. Through comprehensive evaluation on synthetic and real-world problems, our study demonstrates how these active learning acquisition strategies substantially enhance the sample efficiency of DGSM estimation, particularly with limited evaluation budgets. Our work paves the way for more efficient and accurate sensitivity analysis in various scientific and engineering applications.

We provide the first useful and rigorous analysis of ensemble sampling for the stochastic linear bandit setting. In particular, we show that, under standard assumptions, for a $d$-dimensional stochastic linear bandit with an interaction horizon $T$, ensemble sampling with an ensemble of size of order $\smash{d \log T}$ incurs regret at most of the order $\smash{(d \log T)^{5/2} \sqrt{T}}$. Ours is the first result in any structured setting not to require the size of the ensemble to scale linearly with $T$---which defeats the purpose of ensemble sampling---while obtaining near $\smash{\sqrt{T}}$ order regret. Ours is also the first result that allows infinite action sets.
tl;dr: Explainable deep networks that are not only as accurate as their black-box deep-learning counterparts but also as interpretable as state-of-the-art explanation techniques.

Even though neural networks have been long deployed in applications involving tabular data, still existing neural architectures are not explainable by design. In this paper, we propose a new class of interpretable neural networks for tabular data that are both deep and linear at the same time (i.e. mesomorphic). We optimize deep hypernetworks to generate explainable linear models on a per-instance basis. As a result, our models retain the accuracy of black-box deep networks while offering free-lunch explainability for tabular data by design. Through extensive experiments, we demonstrate that our explainable deep networks have comparable performance to state-of-the-art classifiers on tabular data and outperform current existing methods that are explainable by design.
tl;dr: We take the initial step towards investigating backdoor attacks on LLM-based agents, and present a general framework along with 3 concrete forms of agent backdoor attacks.

Driven by the rapid development of Large Language Models (LLMs), LLM-based agents have been developed to handle various real-world applications, including finance, healthcare, and shopping, etc. It is crucial to ensure the reliability and security of LLM-based agents during applications. However, the safety issues of LLM-based agents are currently under-explored. In this work, we take the first step to investigate one of the typical safety threats, backdoor attack, to LLM-based agents. We first formulate a general framework of agent backdoor attacks, then we present a thorough analysis of different forms of agent backdoor attacks. Specifically, compared with traditional backdoor attacks on LLMs that are only able to manipulate the user inputs and model outputs, agent backdoor attacks exhibit more diverse and covert forms: (1) From the perspective of the final attacking outcomes, the agent backdoor attacker can not only choose to manipulate the final output distribution, but also introduce the malicious behavior in an intermediate reasoning step only, while keeping the final output correct. (2) Furthermore, the former category can be divided into two subcategories based on trigger locations, in which the backdoor trigger can either be hidden in the user query or appear in an intermediate observation returned by the external environment. We implement the above variations of agent backdoor attacks on two typical agent tasks including web shopping and tool utilization. Extensive experiments show that LLM-based agents suffer severely from backdoor attacks and such backdoor vulnerability cannot be easily mitigated by current textual backdoor defense algorithms. This indicates an urgent need for further research on the development of targeted defenses against backdoor attacks on LLM-based agents. Warning: This paper may contain biased content.
tl;dr: We show that in repeated deterministic truthful auctions with two bidders using MWU, they do not converge to truthful bidding for many choices of learning rates. However, adding a small amount of randomization to the auction leads to convergence.

We study a setting where agents use no-regret learning algorithms to participate in repeated auctions. Recently, Kolumbus and Nisan [2022a] showed, rather surprisingly, that when bidders participate in second-price auctions using no-regret bidding algorithms, no matter how large the number of interactions $T$ is, the runner-up bidder may not converge to bidding truthfully. Our first result shows that this holds forall deterministictruthful auctions. We also show that the ratio of the learning rates of different bidders can qualitatively affect the convergence of the bidders. Next, we consider the problem of revenue maximization in this environment. In the setting with fully rational bidders, the seminal result of Myerson [1981] showed that revenue can be maximized by using a second-price auction with reserves. We show that, in stark contrast, in our setting with learning bidders, randomized auctions can have strictly better revenue guarantees than second-price auctions with reserves, when $T$ is large enough. To do this, we provide a black-box transformation from any truthful auction $A$ to an auction $A'$ such that: i) all mean-based no-regret learners that participate in $A'$ converge to bidding truthfully, ii) the distance between the allocation rule and the payment rule between $A, A'$ is negligible. Finally, we study revenue maximization in the non-asymptotic regime. We define a notion of auctioneer regret that compares the revenue generated to the revenue of a second price auction with truthful bids. When the auctioneer has to use the same auction throughout the interaction, we show an (almost) tight regret bound of $\tilde{\Theta}(T^{3/4})$. Then, we consider the case where the auctioneer can use different auctions throughout the interaction, but in a way that is oblivious to the bids. For this setting, we show an (almost) tight bound of $\tilde{\Theta}(\sqrt{T})$.
tl;dr: We propose a new learning policy for online convex optimization with adversarial constraints. The proposed policy attains the optimal regret and cumulative constraint violation bounds.

A well-studied generalization of the standard online convex optimization (OCO) framework is constrained online convex optimization (COCO). In COCO, on every round, a convex cost function and a convex constraint function are revealed to the learner after it chooses the action for that round. The objective is to design an online learning policy that simultaneously achieves a small regret while ensuring a small cumulative constraint violation (CCV) against an adaptive adversary interacting over a horizon of length $T$. A long-standing open question in COCO is whether an online policy can simultaneously achieve $O(\sqrt{T})$ regret and $\tilde{O}(\sqrt{T})$ CCV without any restrictive assumptions. For the first time, we answer this in the affirmative and show that a simple first-order policy can simultaneously achieve these bounds. Furthermore, in the case of strongly convex cost and convex constraint functions, the regret guarantee can be improved to $O(\log T)$ while keeping the CCV bound the same as above. We establish these results by effectively combining adaptive OCO policies as a blackbox with Lyapunov optimization - a classic tool from control theory. Surprisingly, the analysis is short and elegant.
tl;dr: A Lorentz-equivariant Transformer architecture plus Lorentz-equivariant flow matching for high-energy physics

Extracting scientific understanding from particle-physics experiments requires solving diverse learning problems with high precision and good data efficiency. We propose the Lorentz Geometric Algebra Transformer (L-GATr), a new multi-purpose architecture for high-energy physics. L-GATr represents high-energy data in a geometric algebra over four-dimensional space-time and is equivariant under Lorentz transformations, the symmetry group of relativistic kinematics. At the same time, the architecture is a Transformer, which makes it versatile and scalable to large systems. L-GATr is first demonstrated on regression and classification tasks from particle physics. We then construct the first Lorentz-equivariant generative model: a continuous normalizing flow based on an L-GATr network, trained with Riemannian flow matching. Across our experiments, L-GATr is on par with or outperforms strong domain-specific baselines.
tl;dr: We give a O(d) space, O(nd) time algorithm for Streaming Sparse PCA via a novel analysis of Oja's Algorithm followed by thresholding

Oja's algorithm for Streaming Principal Component Analysis (PCA) for $n$ data-points in a $d$ dimensional space achieves the same sin-squared error $O(r_{\mathsf{eff}}/n)$ as the offline algorithm in $O(d)$ space and $O(nd)$ time and a single pass through the datapoints. Here $r_{\mathsf{eff}}$ is the effective rank (ratio of the trace and the principal eigenvalue of the population covariance matrix $\Sigma$). Under this computational budget, we consider the problem of sparse PCA, where the principal eigenvector of $\Sigma$ is $s$-sparse, and $r_{\mathsf{eff}}$ can be large. In this setting, to our knowledge, *there are no known single-pass algorithms* that achieve the minimax error bound in $O(d)$ space and $O(nd)$ time without either requiring strong initialization conditions or assuming further structure (e.g., spiked) of the covariance matrix.
We show that a simple single-pass procedure that thresholds the output of Oja's algorithm (the Oja vector) can achieve the minimax error bound under some regularity conditions in $O(d)$ space and $O(nd)$ time.
We present a nontrivial and novel analysis of the entries of the unnormalized Oja vector, which involves the projection of a product of independent random matrices on a random initial vector. This is completely different from previous analyses of Oja's algorithm and matrix products, which have been done when the $r_{\mathsf{eff}}$ is bounded.
tl;dr: A fast differentially private joint exponential mechanism for top-$k$ selection.

We study the differentially private top-$k$ selection problem, aiming to identify a sequence of $k$ items with approximately the highest scores from $d$ items. Recent work by Gillenwater et al. (2022) employs a direct sampling approach from the vast collection of $O(d^k)$ possible length-$k$ sequences, showing superior empirical accuracy compared to previous pure or approximate differentially private methods. Their algorithm has a time and space complexity of $\tilde{O}(dk)$.
In this paper, we present an improved algorithm that achieves time and space complexity of $\tilde{O}(d + k^2)$.
Experimental results show that our algorithm runs orders of magnitude faster than their approach, while achieving similar empirical accuracy.
tl;dr: We propose a novel generic eacxt inversion samplers of diffusion models and derive the variant with optimal accuracy .

The inversion of diffusion model sampling, which aims to find the corresponding initial noise of a sample, plays a critical role in various tasks.
Recently, several heuristic exact inversion samplers have been proposed to address the inexact inversion issue in a training-free manner.
However, the theoretical properties of these heuristic samplers remain unknown and they often exhibit mediocre sampling quality.
In this paper, we introduce a generic formulation, \emph{Bidirectional Explicit Linear Multi-step} (BELM) samplers, of the exact inversion samplers, which includes all previously proposed heuristic exact inversion samplers as special cases.
The BELM formulation is derived from the variable-stepsize-variable-formula linear multi-step method via integrating a bidirectional explicit constraint. We highlight this bidirectional explicit constraint is the key of mathematically exact inversion.
We systematically investigate the Local Truncation Error (LTE) within the BELM framework and show that the existing heuristic designs of exact inversion samplers yield sub-optimal LTE.
Consequently, we propose the Optimal BELM (O-BELM) sampler through the LTE minimization approach.
We conduct additional analysis to substantiate the theoretical stability and global convergence property of the proposed optimal sampler.
Comprehensive experiments demonstrate our O-BELM sampler establishes the exact inversion property while achieving high-quality sampling.
Additional experiments in image editing and image interpolation highlight the extensive potential of applying O-BELM in varying applications.

We introduce a multi-winner reconfiguration model to examine how to transition between subsets of alternatives (aka. committees) through a sequence of minor yet impactful modifications, called reconfiguration path. We analyze this model under four approval-based voting rules: Chamberlin-Courant (CC), Proportional Approval Voting (PAV), Approval Voting (AV), and Satisfaction Approval Voting (SAV). The problem exhibits computational intractability for CC and PAV, and polynomial solvability for AV and SAV. We provide a detailed multivariate complexity analysis for CC and PAV, demonstrating that although the problem remains challenging in many scenarios, there are specific cases that allow for efficient parameterized algorithms.

Grid cells in the medial entorhinal cortex create remarkable periodic maps of explored space during navigation. Recent studies show that they form similar maps of abstract cognitive spaces. Examples of such abstract environments include auditory tone sequences in which the pitch is continuously varied or images in which abstract features are continuously deformed (e.g., a cartoon bird whose legs stretch and shrink). Here, we hypothesize that the brain generalizes how it maps spatial domains to mapping abstract spaces.
To sidestep the computational cost of learning representations for each high-dimensional sensory input, the brain extracts self-consistent, low-dimensional descriptions of displacements across abstract spaces, leveraging the spatial velocity integration of grid cells to efficiently build maps of different domains.
Our neural network model for abstract velocity extraction factorizes the content of these abstract domains from displacements within the domains to generate content-independent and self-consistent, low-dimensional velocity estimates.
Crucially, it uses a self-supervised geometric consistency constraint that requires displacements along closed loop trajectories to sum to zero, an integration that is itself performed by the downstream grid cell circuit over learning. This process results in high fidelity estimates of velocities and allowed transitions in abstract domains, a crucial prerequisite for efficient map generation in these high-dimensional environments. We also show how our method outperforms traditional dimensionality reduction and deep-learning based motion extraction networks on the same set of tasks.
This is the first neural network model to explain how grid cells can flexibly represent different abstract spaces and makes the novel prediction that they should do so while maintaining their population correlation and manifold structure across domains. Fundamentally, our model sheds light on the mechanistic origins of cognitive flexibility and transfer of representations across vastly different domains in brains, providing a potential self-supervised learning (SSL) framework for leveraging similar ideas in transfer learning and data-efficient generalization in machine learning and robotics.
tl;dr: This paper introduces a novel typicalness-aware training approach for deep neural networks that helps mitigate overconfidence in Failure Detection.

Deep neural networks (DNNs) often suffer from the overconfidence issue, where incorrect predictions are made with high confidence scores, hindering the applications in critical systems. In this paper, we propose a novel approach called Typicalness-Aware Learning (TAL) to address this issue and improve failure detection performance.
We observe that, with the cross-entropy loss, model predictions are optimized to align with the corresponding labels via increasing logit magnitude or refining logit direction. However, regarding atypical samples, the image content and their labels may exhibit disparities. This discrepancy can lead to overfitting on atypical samples, ultimately resulting in the overconfidence issue that we aim to address.
To address this issue, we have devised a metric that quantifies the typicalness of each sample, enabling the dynamic adjustment of the logit magnitude during the training process. By allowing relatively atypical samples to be adequately fitted while preserving reliable logit direction, the problem of overconfidence can be mitigated. TAL has been extensively evaluated on benchmark datasets, and the results demonstrate its superiority over existing failure detection methods. Specifically, TAL achieves a more than 5\% improvement on CIFAR100 in terms of the Area Under the Risk-Coverage Curve (AURC) compared to the state-of-the-art. Code is available at https://github.com/liuyijungoon/TAL.

We study calibration measures in a sequential prediction setup. In addition to rewarding accurate predictions (completeness) and penalizing incorrect ones (soundness), an important desideratum of calibration measures is *truthfulness*, a minimal condition for the forecaster not to be incentivized to exploit the system. Formally, a calibration measure is truthful if the forecaster (approximately) minimizes the expected penalty by predicting the conditional expectation of the next outcome, given the prior distribution of outcomes. We conduct a taxonomy of existing calibration measures. Perhaps surprisingly, all of them are far from being truthful. We introduce a new calibration measure termed the *Subsampled Smooth Calibration Error (SSCE)*, which is complete and sound, and under which truthful prediction is optimal up to a constant multiplicative factor. In contrast, under existing calibration measures, there are simple distributions on which a polylogarithmic (or even zero) penalty is achievable, while truthful prediction leads to a polynomial penalty.

The architecture of Vision Transformers (ViTs), particularly the Multi-head Attention (MHA) mechanism, imposes substantial hardware demands. Deploying ViTs on devices with varying constraints, such as mobile phones, requires multiple models of different sizes. However, this approach has limitations, such as training and storing each required model separately. This paper introduces HydraViT, a novel approach that addresses these limitations by stacking attention heads to achieve a scalable ViT. By repeatedly changing the size of the embedded dimensions throughout each layer and their corresponding number of attention heads in MHA during training, HydraViT induces multiple subnetworks. Thereby, HydraViT achieves adaptability across a wide spectrum of hardware environments while maintaining performance. Our experimental results demonstrate the efficacy of HydraViT in achieving a scalable ViT with up to 10 subnetworks, covering a wide range of resource constraints. HydraViT achieves up to 5 p.p. more accuracy with the same GMACs and up to 7 p.p. more accuracy with the same throughput on ImageNet-1K compared to the baselines, making it an effective solution for scenarios where hardware availability is diverse or varies over time. The source code is available at https://github.com/ds-kiel/HydraViT.
tl;dr: This paper presents learning-augmented algorithms for maximum cut and other max-CSPs.

In recent years, there has been a surge of interest in the use of machine-learned predictions to bypass worst-case lower bounds for classical problems in combinatorial optimization. So far, the focus has mostly been on online algorithms, where information-theoretic barriers are overcome using predictions about the unknown future. In this paper, we consider the complementary question of using learned information to overcome computational barriers in the form of approximation hardness of polynomial-time algorithms for NP-hard (offline) problems. We show that noisy predictions about the optimal solution can be used to break classical hardness results for maximization problems such as the max-cut problem and more generally, maximization versions of constraint satisfaction problems (CSPs).
tl;dr: We propose a family of treatment effect estimators built with large language models that leverage the large quantity, diversity and flexibility of observational, unstructured text data in the form of reported experiences.

Knowing the effect of an intervention is critical for human decision-making, but current approaches for causal effect estimation rely on manual data collection and structuring, regardless of the causal assumptions. This increases both the cost and time-to-completion for studies. We show how large, diverse observational text data can be mined with large language models (LLMs) to produce inexpensive causal effect estimates under appropriate causal assumptions. We introduce _NATURAL_, a novel family of causal effect estimators built with LLMs that operate over datasets of unstructured text. Our estimators use LLM conditional distributions (over variables of interest, given the text data) to assist in the computation of classical estimators of causal effect. We overcome a number of technical challenges to realize this idea, such as automating data curation and using LLMs to impute missing information. We prepare six (two synthetic and four real) observational datasets, paired with corresponding ground truth in the form of randomized trials, which we used to systematically evaluate each step of our pipeline. NATURAL estimators demonstrate remarkable performance, yielding causal effect estimates that fall within 3 percentage points of their ground truth counterparts, including on real-world Phase 3/4 clinical trials. Our results suggest that unstructured text data is a rich source of causal effect information, and NATURAL is a first step towards an automated pipeline to tap this resource.
tl;dr: A generic and powerful visual grounding model that enhances broad multimodal instruction following tasks.

Instruction following is crucial in contemporary LLM. However, when extended to multimodal setting, it often suffers from misalignment between specific textual instruction and targeted local region of an image. To achieve more accurate and nuanced multimodal instruction following, we introduce Instruction-guided Visual Masking (IVM), a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. By constructing visual masks for instruction-irrelevant regions, IVM-enhanced multimodal models can effectively focus on task-relevant image regions to better align with complex instructions. Specifically, we design a visual masking data generation pipeline and create an IVM-Mix-1M dataset with 1 million image-instruction pairs. We further introduce a new learning technique, Discriminator Weighted Supervised Learning (DWSL) for preferential IVM training that prioritizes high-quality data samples. Experimental results on generic multimodal tasks such as VQA and embodied robotic control demonstrate the versatility of IVM, which as a plug-and-play tool, significantly boosts the performance of diverse multimodal models, yielding new state-of-the-art results across challenging multimodal benchmarks. Code, model and data are available at https://github.com/2toinf/IVM.

We examine multi-armed bandit problems featuring strategic arms under debt-free reporting. In this context, each arm is characterized by a bounded support reward distribution and strategically aims to maximize its own utility by retaining a portion of the observed reward, potentially disclosing only a fraction of it to the player. This scenario unfolds as a game over $T$ rounds, leading to a competition of objectives between the player, aiming to minimize regret, and the arms, motivated by the desire to maximize their individual utilities. To address these dynamics, we propose an algorithm that establishes an equilibrium wherein each arm behaves truthfully and discloses as much of its rewards as possible. Utilizing this algorithm, the player can attain the second-highest average (true) reward among arms, with a cumulative regret bounded by $O(\log(T)/\Delta)$ (problem-dependent) or $O(\sqrt{T\log(T)})$ (worst-case).

Conversational large language models are fine-tuned for both instruction-following and safety, resulting in models that obey benign requests but refuse harmful ones. While this refusal behavior is widespread across chat models, its underlying mechanisms remain poorly understood. In this work, we show that refusal is mediated by a one-dimensional subspace, across 13 popular open-source chat models up to 72B parameters in size. Specifically, for each model, we find a single direction such that erasing this direction from the model's residual stream activations prevents it from refusing harmful instructions, while adding this direction elicits refusal on even harmless instructions. Leveraging this insight, we propose a novel white-box jailbreak method that surgically disables a model's ability to refuse, with minimal effect on other capabilities. This interpretable rank-one weight edit results in an effective jailbreak technique that is simpler and more efficient than fine-tuning. Finally, we mechanistically analyze how adversarial suffixes suppress propagation of the refusal-mediating direction. Our findings underscore the brittleness of current safety fine-tuning methods. More broadly, our work showcases how an understanding of model internals can be leveraged to develop practical methods for controlling model behavior.
tl;dr: We introduce the first near-linear-time algorithm for hypothesis selection that achieves optimal accuracy, significantly advancing previous methods.

Hypothesis selection, also known as density estimation, is a fundamental problem in statistics and learning theory. Suppose we are given a sample set from an unknown distribution $P$ and a finite class of candidate distributions (called hypotheses) $\mathcal{H} \coloneqq \{H_1, H_2, \ldots, H_n\}$. The aim is to design an algorithm that selects a distribution $\hat H$ in $\mathcal{H}$ that best fits the data. The algorithm's accuracy is measured based on the distance between $\hat{H}$ and $P$ compared to the distance of the closest distribution in $\mathcal{H}$ to $P$ (denoted by $OPT$). Concretely, we aim for $\|\hat{H} - P\|_{TV}$ to be at most $ \alpha \cdot OPT + \epsilon$ for some small $\epsilon$ and $\alpha$.
While it is possible to decrease the value of $\epsilon$ as the number of samples increases, $\alpha$ is an inherent characteristic of the algorithm. In fact, one cannot hope to achieve $\alpha < 3$ even when there are only two candidate hypotheses, unless the number of samples is proportional to the domain size of $P$ [Bousquet, Kane, Moran '19]. Finding the best $\alpha$ has been one of the main focuses of studies of the problem since early work of [Devroye, Lugosi '01]. Prior to our work, no algorithm was known that achieves $\alpha = 3$ in near-linear time. We provide the first algorithm that operates in almost linear time ($\tilde{O}(n/\epsilon^3)$ time) and achieves $\alpha = 3$. This result improves upon a long list of results in hypothesis selection. Previously known algorithms either had worse time complexity, a larger factor $\alpha$, or extra assumptions about the problem setting.
In addition to this algorithm, we provide another (almost) linear-time algorithm with better dependency on the additive accuracy parameter $\epsilon$, albeit with a slightly worse accuracy parameter, $\alpha = 4$.
565. WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
tl;dr: This paper investigates how to identify influential weights to enhance unlearning efficacy while preserving LLM utility.

The need for effective unlearning mechanisms in large language models (LLMs) is increasingly urgent, driven by the necessity to adhere to data regulations and foster ethical generative AI practices. LLM unlearning is designed to reduce the impact of undesirable data influences and associated model capabilities without diminishing the utility of the model if unrelated to the information being forgotten. Despite growing interest, much of the existing research has focused on varied unlearning method designs to boost effectiveness and efficiency. However, the inherent relationship between model weights and LLM unlearning has not been extensively examined. In this paper, we systematically explore how model weights interact with unlearning processes in LLMs and we design the weight attribution-guided LLM unlearning method, WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE can erase the undesired content, while maintaining the performance of the original tasks. We refer to the weight attribution-guided LLM unlearning method as WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. Our extensive experiments show that WAGLE boosts unlearning performance across a range of LLM unlearning methods such as gradient difference and (negative) preference optimization, applications such as fictitious unlearning (TOFU benchmark), malicious use prevention (WMDP benchmark), and copyrighted information removal, and models including Zephyr-7b-beta and Llama2-7b. To the best of our knowledge, our work offers the first principled method for attributing and pinpointing the influential weights in enhancing LLM unlearning. It stands in contrast to previous methods that lack weight attribution and simpler weight attribution techniques.
tl;dr: Hardware-aware Pruning for Fast Depth-wise Separable Convolution

Depth-wise Separable Convolution (DSConv) has a powerful representation even with fewer parameters and computation, leading to its adoption by almost all of the state-of-the-art CNN models.
DSConv models are already compact making it hard to apply pruning, and there are few previous pruning techniques that target depth-wise convolution (DW-conv).
In this paper, we present Depth-wise Separable Convolution Pruning (DEPrune), a novel pruning method applied to both point-wise and depth-wise convolutions.
DEPrune is optimized by analyzing the computation of DSConv on GPUs.
DEPrune employs a fine-grained pruning approach, yet it achieves the structured sparsity typically absent in fine-grained pruning, enabling practical hardware acceleration.
Moreover, this method maintains a high pruning ratio without causing any accuracy drop.
We additionally represent techniques that further enhance DEPrune performance: 1) balanced workload tuning (BWT), and 2) hardware-aware sparsity recalibration (HSR).
Experiment results show that DEPrune achieves up to $3.74\times$ practical speedup in DSConv inference on GPUs while maintaining the accuracy of EfficientNet-B0 on ImageNet.
567. Inexact Augmented Lagrangian Methods for Conic Optimization: Quadratic Growth and Linear Convergence

Augmented Lagrangian Methods (ALMs) are widely employed in solving constrained optimizations, and some efficient solvers are developed based on this framework. Under the quadratic growth assumption, it is known that the dual iterates and the Karush–Kuhn–Tucker (KKT) residuals of ALMs applied to conic programs converge linearly. In contrast, the convergence rate of the primal iterates has remained elusive. In this paper, we resolve this challenge by establishing new $\textit{quadratic growth}$ and $\textit{error bound}$ properties for primal and dual conic programs under the standard strict complementarity condition. Our main results reveal that both primal and dual iterates of the ALMs converge linearly contingent solely upon the assumption of strict complementarity and a bounded solution set. This finding provides a positive answer to an open question regarding the asymptotically linear convergence of the primal iterates of ALMs applied to conic optimization.
tl;dr: We propose improved techniques for training rectified flows, allowing them to compete with knowledge distillation methods even in the low NFE setting

Diffusion models have shown great promise for image and video generation, but sampling from state-of-the-art models requires expensive numerical integration of a generative ODE.
One approach for tackling this problem is rectified flows, which iteratively learn smooth ODE paths that are less susceptible to truncation error.
However, rectified flows still require a relatively large number of function evaluations (NFEs).
In this work, we propose improved techniques for training rectified flows, allowing them to compete with knowledge distillation methods even in the low NFE setting.
Our main insight is that under realistic settings, a single iteration of the Reflow algorithm for training rectified flows is sufficient to learn nearly straight trajectories; hence, the current practice of using multiple Reflow iterations is unnecessary.
We thus propose techniques to improve one-round training of rectified flows, including a U-shaped timestep distribution and LPIPS-Huber premetric.
With these techniques, we improve the FID of the previous 2-rectified flow by up to 75\% in the 1 NFE setting on CIFAR-10.
On ImageNet 64$\times$64, our improved rectified flow outperforms the state-of-the-art distillation methods
such as consistency distillation and progressive distillation in both one-step and two-step settings and rivals the performance of improved consistency training (iCT) in FID.
Code is available at https://github.com/sangyun884/rfpp.
tl;dr: We propose an alternative program distillation approach to replace expensive annotation processes that require repetitive prompting for labels.

Large pretrained models can be used as annotators, helping replace or augment crowdworkers and enabling distilling generalist models into smaller specialist models. Unfortunately, this comes at a cost: employing top-of-the-line models often requires paying thousands of dollars for API calls, while the resulting datasets are static and challenging to audit. To address these challenges, we propose a simple alternative: rather than directly querying labels from pretrained models, we task models to generate programs that can produce labels. These programs can be stored and applied locally, re-used and extended, and cost orders of magnitude less. Our system, $\textbf{Alchemist}$, obtains comparable to or better performance than large language model-based annotation in a range of tasks for a fraction of the cost: on average, improvements amount to a $\textbf{12.9}$% enhancement while the total labeling costs across all datasets are reduced by a factor of approximately $\textbf{500}\times$.

Machine learning models provide alternatives for efficiently recognizing complex patterns from data, but the main concern in applying them to modeling physical systems stems from their physics-agnostic design, leading to learning methods that lack interpretability, robustness, and data efficiency. This paper mitigates this concern by incorporating the Helmholtz-Hodge decomposition into a Gaussian process model, leading to a versatile framework that simultaneously learns the curl-free and divergence-free components of a dynamical system. Learning a predictive model in this form facilitates the exploitation of symmetry priors. In addition to improving predictive power, these priors make the model indentifiable, thus the identified features can be linked to comprehensible scientific properties of the system. We show that compared to baseline models, our model achieves better predictive performance on several benchmark dynamical systems while allowing physically meaningful decomposition of the systems from noisy and sparse data.

We study online composite optimization under the Stochastically Extended Adversarial (SEA) model. Specifically, each loss function consists of two parts: a fixed non-smooth and convex regularizer, and a time-varying function which can be chosen either stochastically, adversarially, or in a manner that interpolates between the two extremes. In this setting, we show that for smooth and convex time-varying functions, optimistic composite mirror descent (OptCMD) can obtain an $\mathcal{O}(\sqrt{\sigma_{1:T}^2} + \sqrt{\Sigma_{1:T}^2})$ regret bound, where $\sigma_{1:T}^2$ and $\Sigma_{1:T}^2$ denote the cumulative stochastic variance and the cumulative adversarial variation of time-varying functions, respectively. For smooth and strongly convex time-varying functions, we establish an $\mathcal{O}((\sigma_{\max}^2 + \Sigma_{\max}^2)\log(\sigma_{1:T}^2 + \Sigma_{1:T}^2))$ regret bound, where $\sigma_{\max}^2$ and $\Sigma_{\max}^2$ denote the maximal stochastic variance and the maximal adversarial variation, respectively. For smooth and exp-concave time-varying functions, we achieve an $\mathcal{O}(d \log (\sigma_{1:T}^2 + \Sigma_{1:T}^2))$ bound where $d$ denotes the dimensionality. Moreover, to deal with the unknown function type in practical problems, we propose a multi-level \textit{universal} algorithm that is able to achieve the desirable bounds for three types of time-varying functions simultaneously. It should be noticed that all our findings match existing bounds for the SEA model without the regularizer, which implies that there is \textit{no price} in regret bounds for the benefits gained from the regularizer.
tl;dr: We show how to compute exact asymptotic predictions for the minimal generalization error reachable in learning an extensive-width shallow neural network, with a number of data samples quadratic in the dimension.

We consider the problem of learning a target function corresponding to a single
hidden layer neural network, with a quadratic activation function after the first layer,
and random weights. We consider the asymptotic limit where the input dimension
and the network width are proportionally large. Recent work [Cui et al., 2023]
established that linear regression provides Bayes-optimal test error to learn such
a function when the number of available samples is only linear in the dimension.
That work stressed the open challenge of theoretically analyzing the optimal test
error in the more interesting regime where the number of samples is quadratic in
the dimension. In this paper, we solve this challenge for quadratic activations and
derive a closed-form expression for the Bayes-optimal test error. We also provide an
algorithm, that we call GAMP-RIE, which combines approximate message passing
with rotationally invariant matrix denoising, and that asymptotically achieves the
optimal performance. Technically, our result is enabled by establishing a link
with recent works on optimal denoising of extensive-rank matrices and on the
ellipsoid fitting problem. We further show empirically that, in the absence of
noise, randomly-initialized gradient descent seems to sample the space of weights,
leading to zero training loss, and averaging over initialization leads to a test error
equal to the Bayes-optimal one.
tl;dr: We address the problem of nonparametric instrumental variable regression using stochastic gradient descent in a function space.

Instrumental variables (IVs) provide a powerful strategy for identifying causal effects in the presence of unobservable confounders. Within the nonparametric setting (NPIV), recent methods have been based on nonlinear generalizations of Two-Stage Least Squares and on minimax formulations derived from moment conditions or duality. In a novel direction, we show how to formulate a functional stochastic gradient descent algorithm to tackle NPIV regression by directly minimizing the populational risk. We provide theoretical support in the form of bounds on the excess risk, and conduct numerical experiments showcasing our method's superior stability and competitive performance relative to current state-of-the-art alternatives. This algorithm enables flexible estimator choices, such as neural networks or kernel based methods, as well as non-quadratic loss functions, which may be suitable for structural equations beyond the setting of continuous outcomes and additive noise. Finally, we demonstrate this flexibility of our framework by presenting how it naturally addresses the important case of binary outcomes, which has received far less attention by recent developments in the NPIV literature.
tl;dr: We develop algorithms for achieving sublinear regret in online multi-group learning when the collection of groups is exponentially large or infinite.

We study the problem of online multi-group learning, a learning model in which an online learner must simultaneously achieve small prediction regret on a large collection of (possibly overlapping) subsequences corresponding to a family of groups. Groups are subsets of the context space, and in fairness applications, they may correspond to subpopulations defined by expressive functions of demographic attributes. In this paper, we design such oracle-efficient algorithms with sublinear regret under a variety of settings, including: (i) the i.i.d. setting, (ii) the adversarial setting with smoothed context distributions, and (iii) the adversarial transductive setting.
575. Bayesian Optimisation with Unknown Hyperparameters: Regret Bounds Logarithmically Closer to Optimal

Bayesian Optimization (BO) is widely used for optimising black-box functions but requires us to specify the length scale hyperparameter, which defines the smoothness of the functions the optimizer will consider. Most current BO algorithms choose this hyperparameter by maximizing the marginal likelihood of the observed data, albeit risking misspecification if the objective function is less smooth in regions we have not yet explored. The only prior solution addressing this problem with theoretical guarantees was A-GP-UCB, proposed by Berkenkamp et al. (2019). This algorithm progressively decreases the length scale, expanding the class of functions considered by the optimizer. However, A-GP-UCB lacks a stopping mechanism, leading to over-exploration and slow convergence. To overcome this, we introduce Length scale Balancing (LB) - a novel approach, aggregating multiple base surrogate models with varying length scales. LB intermittently adds smaller length scale candidate values while retaining longer scales, balancing exploration and exploitation. We formally derive a cumulative regret bound of LB and compare it with the regret of an oracle BO algorithm using the optimal length scale. Denoting the factor by which the regret bound of A-GP-UCB was away from oracle as $g(T)$, we show that LB is only $\log g(T)$ away from oracle regret. We also empirically evaluate our algorithm on synthetic and real-world benchmarks and show it outperforms A-GP-UCB and maximum likelihood estimation.
tl;dr: We present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans.

Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.7% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks near 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.

Prophet inequality concerns a basic optimal stopping problem and states that simple threshold stopping policies --- i.e., accepting the first reward larger than a certain threshold --- can achieve tight $\frac{1}{2}$-approximation to the optimal prophet value. Motivated by its economic applications, this paper studies the robustness of this approximation to natural strategic manipulations in which each random reward is associated with a self-interested player who may selectively reveal his realized reward to the searcher in order to maximize his probability of being selected.
We say a threshold policy is $\alpha$(-strategically)-robust if it (a) achieves the $\alpha$-approximation to the prophet value for strategic players; and (b) meanwhile remains a $\frac{1}{2}$-approximation in the standard non-strategic setting.
Starting with a characterization of each player's optimal information revealing strategy, we demonstrate the intrinsic robustness of prophet inequalities to strategic reward signaling through the following results:
(1) for arbitrary reward distributions, there is a threshold policy that is $\frac{1-\frac{1}{e}}{2}$-robust, and this ratio is tight;
(2) for i.i.d. reward distributions, there is a threshold policy that is $\frac{1}{2}$-robust, which is tight for the setting;
and (3) for log-concave (but non-identical) reward distributions, the $\frac{1}{2}$-robustness can also be achieved under certain regularity assumptions.

The study of online algorithms with machine-learned predictions has gained considerable prominence in recent years. One of the common objectives in the design and analysis of such algorithms is to attain (Pareto) optimal tradeoffs between the {\em consistency} of the algorithm, i.e., its performance assuming perfect predictions, and its {\em robustness}, i.e., the performance of the algorithm under adversarial predictions. In this work, we demonstrate that this optimization criterion can be extremely brittle, in that the performance of Pareto-optimal algorithms may degrade dramatically even in the presence of imperceptive prediction error. To remedy this drawback, we propose a new framework in which the smoothness in the performance of the algorithm is enforced by means of a {\em user-specified profile}. This allows us to regulate the performance of the algorithm as a function of the prediction error, while simultaneously
maintaining the analytical notion of consistency/robustness tradeoffs, adapted to the profile setting. We apply this new approach to a well-studied online problem, namely the {\em one-way trading} problem. For this problem, we further address another limitation of the state-of-the-art Pareto-optimal algorithms, namely the fact that they are tailored to worst-case, and extremely pessimistic inputs. We propose a new Pareto-optimal algorithm that leverages any deviation from the worst-case input to its benefit, and introduce a new metric that allows us to compare any two Pareto-optimal algorithms via a {\em dominance} relation.
tl;dr: We use LLM's to generate novel RLHF objectives, some of which achieve strong results.

Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs.
Typically, preference optimization is approached as an offline supervised learning task using manually crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under-explored. We address this by performing LLM-driven *objective discovery* to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously evaluated performance metrics. This process leads to the discovery of previously unknown and performant preference optimization algorithms. The best performing of these we call *Discovered Preference Optimization* (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
tl;dr: We tackle robustness to domain shifts in medicine by incorporating knowledge priors from documents via inherently interpretable models.

While deep networks have achieved broad success in analyzing natural images, when applied to medical scans, they often fail in unexcepted situations. We investigate this challenge and focus on model sensitivity to domain shifts, such as data sampled from different hospitals or data confounded by demographic variables such as sex, race, etc, in the context of chest X-rays and skin lesion images. A key finding we show empirically is that existing visual backbones lack an appropriate prior from the architecture for reliable generalization in these settings. Taking inspiration from medical training, we propose giving deep networks a prior grounded in explicit medical knowledge communicated in natural language. To this end, we introduce Knowledge-enhanced Bottlenecks (KnoBo), a class of concept bottleneck models that incorporates knowledge priors that constrain it to reason with clinically relevant factors found in medical textbooks or PubMed. KnoBo uses retrieval-augmented language models to design an appropriate concept space paired with an automatic training procedure for recognizing the concept. We evaluate different resources of knowledge and recognition architectures on a broad range of domain shifts across 20 datasets. In our comprehensive evaluation with two imaging modalities, KnoBo outperforms fine-tuned models on confounded datasets by 32.4% on average. Finally, evaluations reveal that PubMed is a promising resource for making medical models less sensitive to domain shift, outperforming other resources on both diversity of information and final prediction performance.
tl;dr: This paper studies the performative prediction with smooth but possibly non-convex loss and analyzes a greedy deployment scheme with stochastic gradient descent algorithm.

This paper studies a risk minimization problem with decision dependent data distribution. The problem pertains to the performative prediction setting in which a trained model can affect the outcome estimated by the model. Such dependency creates a feedback loop that influences the stability of optimization algorithms such as stochastic gradient descent (SGD). We present the first study on performative prediction with smooth but possibly non-convex loss. We analyze a greedy deployment scheme with SGD (SGD-GD). Note that in the literature, SGD-GD is often studied with strongly convex loss. We first propose the definition of stationary performative stable (SPS) solutions through relaxing the popular performative stable condition. We then prove that SGD-GD converges to a biased SPS solution in expectation. We consider two conditions of sensitivity on the distribution shifts: (i) the sensitivity is characterized by Wasserstein-1 distance and the loss is Lipschitz w.r.t. data samples, or (ii) the sensitivity is characterized by total variation (TV) divergence and the loss is bounded. In both conditions, the bias levels are proportional to the stochastic gradient's variance and sensitivity level.
Our analysis is extended to a lazy deployment scheme where models are deployed once per several SGD updates, and we show that it converges to a bias-free SPS solution. Numerical experiments corroborate our theories.
tl;dr: We propose a novel hybrid pipeline that takes advantage of the 3D Gaussian representation of the object to both acquire 3D shapes and empower the simulated continuum to render 2D shapes for physical property estimation.

This paper studies the problem of estimating physical properties (system identification) through visual observations. To facilitate geometry-aware guidance in physical property estimation, we introduce a novel hybrid framework that leverages 3D Gaussian representation to not only capture explicit shapes but also enable the simulated continuum to render object masks as 2D shape surrogates during training. We propose a new dynamic 3D Gaussian framework based on motion factorization to recover the object as 3D Gaussian point sets across different time states. Furthermore, we develop a coarse-to-fine filling strategy to generate the density fields of the object from the Gaussian reconstruction, allowing for the extraction of object continuums along with their surfaces and the integration of Gaussian attributes into these continuum. In addition to the extracted object surfaces, the Gaussian-informed continuum also enables the rendering of object masks during simulations, serving as 2D-shape guidance for physical property estimation. Extensive experimental evaluations demonstrate that our pipeline achieves state-of-the-art performance across multiple benchmarks and metrics. Additionally, we illustrate the effectiveness of the proposed method through real-world demonstrations, showcasing its practical utility. Our project page is at https://jukgei.github.io/project/gic.
tl;dr: We achieve highest performance in conditional 3D molecular generation while maintaining molecular stability.

Diffusion models have demonstrated remarkable success in various domains, including molecular generation. However, conditional molecular generation remains a fundamental challenge due to an intrinsic trade-off between targeting specific chemical properties and generating meaningful samples from the data distribution. In this work, we present Time-Aware Conditional Synthesis (TACS), a novel approach to conditional generation on diffusion models. It integrates adaptively controlled plug-and-play "online" guidance into a diffusion model, driving samples toward the desired properties while maintaining validity and stability. A key component of our algorithm is our new type of diffusion sampler, Time Correction Sampler (TCS), which is used to control guidance and ensure that the generated molecules remain on the correct manifold at each reverse step of the diffusion process at the same time. Our proposed method demonstrates significant performance in conditional 3D molecular generation and offers a promising approach towards inverse molecular design, potentially facilitating advancements in drug discovery, materials science, and other related fields.
tl;dr: A theory of various large model size limits for transformers

In this work we analyze various scaling limits of the training dynamics of transformer models in the feature learning regime. We identify the set of parameterizations which admit well defined infinite width and depth limits that allow the attention layers to update throughout training, a relevant notion of feature learning in these models. We then use tools from dynamical mean field theory (DMFT) to analyze various infinite limits (infinite heads, infinite key/query dimension, and infinite depth) which have different statistical descriptions depending on which infinite limit is taken and how attention layers are scaled. We provide numerical evidence of convergence to the limits and show they maintain the correct scale of updates for both SGD and Adam.

3D representation is essential to the significant advance of 3D generation with 2D diffusion priors. As a flexible representation, NeRF has been first adopted for 3D representation. With density-based volumetric rendering, it however suffers both intensive computational overhead and inaccurate mesh extraction. Using a signed distance field and Marching Tetrahedra, DMTet allows for precise mesh extraction and real-time rendering but is limited in handling large topological changes in meshes, leading to optimization challenges. Alternatively, 3D Gaussian Splatting (3DGS) is favored in both training and rendering efficiency while falling short in mesh extraction. In this work, we introduce a novel 3D representation, Tetrahedron Splatting (TeT-Splatting), that supports easy convergence during optimization, precise mesh extraction, and real-time rendering simultaneously. This is achieved by integrating surface-based volumetric rendering within a structured tetrahedral grid while preserving the desired ability of precise mesh extraction, and a tile-based differentiable tetrahedron rasterizer. Furthermore, we incorporate eikonal and normal consistency regularization terms for the signed distance field to improve generation quality and stability. Critically, our representation can be trained without mesh extraction, making the optimization process easier to converge. Our TeT-Splatting can be readily integrated in existing 3D generation pipelines, along with polygonal mesh for texture optimization. Extensive experiments show that our TeT-Splatting strikes a superior tradeoff among convergence speed, render efficiency, and mesh quality as compared to previous alternatives under varying 3D generation settings.
586. Flow Snapshot Neurons in Action: Deep Neural Networks Generalize to Biological Motion Perception
tl;dr: We propose an AI model for video action recognition, which can generalize to biological motion perception tasks.

Biological motion perception (BMP) refers to humans' ability to perceive and recognize the actions of living beings solely from their motion patterns, sometimes as minimal as those depicted on point-light displays. While humans excel at these tasks \textit{without any prior training}, current AI models struggle with poor generalization performance. To close this research gap, we propose the Motion Perceiver (MP). MP solely relies on patch-level optical flows from video clips as inputs. During training, it learns prototypical flow snapshots through a competitive binding mechanism and integrates invariant motion representations to predict action labels for the given video. During inference, we evaluate the generalization ability of all AI models and humans on 62,656 video stimuli spanning 24 BMP conditions using point-light displays in neuroscience. Remarkably, MP outperforms all existing AI models with a maximum improvement of 29\% in top-1 action recognition accuracy on these conditions. Moreover, we benchmark all AI models in point-light displays of two standard video datasets in computer vision. MP also demonstrates superior performance in these cases.
More interestingly, via psychophysics experiments, we found that MP recognizes biological movements in a way that aligns with human behaviors. Our data and code are available at https://github.com/ZhangLab-DeepNeuroCogLab/MotionPerceiver.

Persona-driven role-playing (PRP) aims to build AI characters that can respond to user queries by faithfully sticking with \emph{all} (factual) statements in persona documents.
Unfortunately, existing faithfulness criteria for PRP are limited to coarse-grained LLM-based scoring without a clear definition or formulation.
This paper presents a pioneering exploration to quantify PRP faithfulness evaluation as a fine-grained and explainable criterion, which also serves as a reliable reference for faithfulness optimization.
Our criterion first discriminates persona statements into \emph{active} and \emph{passive} constraints by identifying the query-statement relevance.
Then, we incorporate all constraints following the principle that the AI character's response should be (a) entailed by active constraints and (b) not contradicted by passive constraints.
We translate this principle mathematically into a novel Active-Passive-Constraint (APC) score, a constraint-wise sum of statement-to-response natural language inference (NLI) scores weighted by constraint-query relevance scores.
In practice, we build the APC scoring system by symbolically distilling small NLI and relevance discriminators (300M parameters) from GPT-4 for efficiency, and both show high consistency with GPT-4's discrimination.
We validate the quality of the APC score against human evaluation based on example personas with tens of statements, and the results show a high correlation.
As the APC score could faithfully reflect the PRP quality, we further leverage it as a reward system in direct preference optimization (DPO) for better AI characters.
Our experiments offer a fine-grained and explainable comparison between existing PRP techniques, revealing their advantages and limitations.
We further find APC-based DPO to be one of the most competitive techniques for sticking with all constraints and can be well incorporated with other techniques.
We then extend the scale of the experiments to real persons with hundreds of statements and reach a consistent conclusion.
Finally, we provide comprehensive analyses and case studies to support the effectiveness of APC and APC-based DPO.

In this paper, we explore the properties of loss curvature with respect to input data in deep neural networks. Curvature of loss with respect to input (termed input loss curvature) is the trace of the Hessian of the loss with respect to the input. We investigate how input loss curvature varies between train and test sets, and its implications for train-test distinguishability. We develop a theoretical framework that derives an upper bound on the train-test distinguishability based on privacy and the size of the training set. This novel insight fuels the development of a new black box membership inference attack utilizing input loss curvature. We validate our theoretical findings through experiments in computer vision classification tasks, demonstrating that input loss curvature surpasses existing methods in membership inference effectiveness. Our analysis highlights how the performance of membership inference attack (MIA) methods varies with the size of the training set, showing that curvature-based MIA outperforms other methods on sufficiently large datasets. This condition is often met by real datasets, as demonstrated by our results on CIFAR10, CIFAR100, and ImageNet. These findings not only advance our understanding of deep neural network behavior but also improve the ability to test privacy-preserving techniques in machine learning.
tl;dr: Inspired by central pattern generators, we propose a novel positional encoding technique tailored for spiking neural networks.

Spiking neural networks (SNNs) represent a promising approach to developing artificial neural networks that are both energy-efficient and biologically plausible.
However, applying SNNs to sequential tasks, such as text classification and time-series forecasting, has been hindered by the challenge of creating an effective and hardware-friendly spike-form positional encoding (PE) strategy.
Drawing inspiration from the central pattern generators (CPGs) in the human brain, which produce rhythmic patterned outputs without requiring rhythmic inputs, we propose a novel PE technique for SNNs, termed CPG-PE.
We demonstrate that the commonly used sinusoidal PE is mathematically a specific solution to the membrane potential dynamics of a particular CPG.
Moreover, extensive experiments across various domains, including time-series forecasting, natural language processing, and image classification, show that SNNs with CPG-PE outperform their conventional counterparts.
Additionally, we perform analysis experiments to elucidate the mechanism through which SNNs encode positional information and to explore the function of CPGs in the human brain.
This investigation may offer valuable insights into the fundamental principles of neural computation.
tl;dr: This paper systematically studies the gradient-variation online learning under generalized smoothness.

Gradient-variation online learning aims to achieve regret guarantees that scale with variations in the gradients of online functions, which is crucial for attaining fast convergence in games and robustness in stochastic optimization, hence receiving increased attention. Existing results often require the smoothness condition by imposing a fixed bound on gradient Lipschitzness, which may be unrealistic in practice. Recent efforts in neural network optimization suggest a generalized smoothness condition, allowing smoothness to correlate with gradient norms. In this paper, we systematically study gradient-variation online learning under generalized smoothness. We extend the classic optimistic mirror descent algorithm to derive gradient-variation regret by analyzing stability over the optimization trajectory and exploiting smoothness locally. Then, we explore universal online learning, designing a single algorithm with the optimal gradient-variation regrets for convex and strongly convex functions simultaneously, without requiring prior knowledge of curvature. This algorithm adopts a two-layer structure with a meta-algorithm running over a group of base-learners. To ensure favorable guarantees, we design a new Lipschitz-adaptive meta-algorithm, capable of handling potentially unbounded gradients while ensuring a second-order bound to effectively ensemble the base-learners. Finally, we provide the applications for fast-rate convergence in games and stochastic extended adversarial optimization.
tl;dr: We propose Mixture of Experts Universal Transformers that scales to language modeling for the first time.

Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in learning compositional generalizations, but layer-sharing comes with a practical limitation of parameter-compute ratio: it drastically reduces the parameter count compared to the non-shared model with the same dimensionality. Naively scaling up the layer size to compensate for the loss of parameters makes its computational resource requirements prohibitive. In practice, no previous work has succeeded in proposing a shared-layer Transformer design that is competitive in parameter count-dominated tasks such as language modeling. Here we propose MoEUT (pronounced "moot"), an effective mixture-of-experts (MoE)-based shared-layer Transformer architecture, which combines several recent advances in MoEs for both feedforward and attention layers of standard Transformers together with novel layer-normalization and grouping schemes that are specific and crucial to UTs. The resulting UT model, for the first time, slightly outperforms standard Transformers on language modeling tasks such as BLiMP and PIQA, while using significantly less compute and memory.
tl;dr: A novel method that identifies and reweights context-aware neurons within large language models to boost their performance on tasks involving knowledge conflicts.

It is widely acknowledged that large language models (LLMs) encode a vast reservoir of knowledge after being trained on mass data. Recent studies disclose knowledge conflicts in LLM generation, wherein outdated or incorrect parametric knowledge (i.e., encoded knowledge) contradicts new knowledge provided in the context. To mitigate such knowledge conflicts, we propose a novel framework, IRCAN (Identifying and Reweighting Context-Aware Neurons) to capitalize on neurons that are crucial in processing contextual cues. Specifically, IRCAN first identifies neurons that significantly contribute to context processing, utilizing a context-aware attribution score derived from integrated gradients. Subsequently, the identified context-aware neurons are strengthened via reweighting. In doing so, we steer LLMs to generate context-sensitive outputs with respect to the new knowledge provided in the context. Extensive experiments conducted across a variety of models and tasks demonstrate that IRCAN not only achieves remarkable improvements in handling knowledge conflicts but also offers a scalable, plug-and-play solution that can be integrated seamlessly with existing models. Our codes are released at https://github.com/danshi777/IRCAN.
tl;dr: We study the convergence of Cech persistence diagrams for samples of submanifolds with respect to the Wasserstein distance.

Cech Persistence diagrams (PDs) are topological descriptors routinely used to capture the geometry of complex datasets. They are commonly compared using the Wasserstein distances $\mathrm{OT}_p$; however, the extent to which PDs are stable with respect to these metrics remains poorly understood.
We partially close this gap by focusing on the case where datasets are sampled on an $m$-dimensional submanifold of $\mathbb{R}^d$. Under this manifold hypothesis, we show that convergence with respect to the $\mathrm{OT}_p$ metric happens exactly when $p>m$. We also provide improvements upon the bottleneck stability theorem in this case and prove new laws of large numbers for the total $\alpha$-persistence of PDs. Finally, we show how these theoretical findings shed new light on the behavior of the feature maps on the space of PDs that are used in ML-oriented applications of Topological Data Analysis.
594. 3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors
tl;dr: We propose a method that exploits view-consistent 2D generative priors, i.e., a video diffusion model, to enhance 3D Gaussian splatting rendering quality.

Novel-view synthesis aims to generate novel views of a scene from multiple input
images or videos, and recent advancements like 3D Gaussian splatting (3DGS)
have achieved notable success in producing photorealistic renderings with efficient
pipelines. However, generating high-quality novel views under challenging settings,
such as sparse input views, remains difficult due to insufficient information in
under-sampled areas, often resulting in noticeable artifacts. This paper presents
3DGS-Enhancer, a novel pipeline for enhancing the representation quality of
3DGS representations. We leverage 2D video diffusion priors to address the
challenging 3D view consistency problem, reformulating it as achieving temporal
consistency within a video generation process. 3DGS-Enhancer restores view-
consistent latent features of rendered novel views and integrates them with the
input views through a spatial-temporal decoder. The enhanced views are then
used to fine-tune the initial 3DGS model, significantly improving its rendering
performance. Extensive experiments on large-scale datasets of unbounded scenes
demonstrate that 3DGS-Enhancer yields superior reconstruction performance and
high-fidelity rendering results compared to state-of-the-art methods. The project
webpage is https://xiliu8006.github.io/3DGS-Enhancer-project.
tl;dr: We propose a method to stabilize training in nonstationary tasks, improving performance on several benchmarks and obtaining insight into the role of implicit effective learning rate schedules in RL.

Normalization layers have recently experienced a renaissance in the deep reinforcement learning and continual learning literature, with several works highlighting diverse benefits such as improving loss landscape conditioning and combatting overestimation bias. However, normalization brings with it a subtle but important side effect: an equivalence between growth in the norm of the network parameters and decay in the effective learning rate. This becomes problematic in continual learning settings, where the resulting learning rate schedule may decay to near zero too quickly relative to the timescale of the learning problem. We propose to make the learning rate schedule explicit with a simple re-parameterization which we call Normalize-and-Project (NaP), which couples the insertion of normalization layers with weight projection, ensuring that the effective learning rate remains constant throughout training. This technique reveals itself as a powerful analytical tool to better understand learning rate schedules in deep reinforcement learning, and as a means of improving robustness to nonstationarity in synthetic plasticity loss benchmarks along with both the single-task and sequential variants of the Arcade Learning Environment. We also show that our approach can be easily applied to popular architectures such as ResNets and transformers while recovering and in some cases even slightly improving the performance of the base model in common stationary benchmarks.

We consider the challenging problem of estimating causal effects from purely observational data in the bi-directional Mendelian randomization (MR), where some invalid instruments, as well as unmeasured confounding, usually exist.
To address this problem, most existing methods attempt to find proper valid instrumental variables (IVs) for the target causal effect by expert knowledge or by assuming that the causal model is a one-directional MR model.
As such, in this paper, we first theoretically investigate the identification of the bi-directional MR from observational data. In particular, we provide necessary and sufficient conditions under which valid IV sets are correctly identified such that the bi-directional MR model is identifiable, including the causal directions of a pair of phenotypes (i.e., the treatment and outcome).
Moreover, based on the identification theory, we develop a cluster fusion-like method to discover valid IV sets and estimate the causal effects of interest.
We theoretically demonstrate the correctness of the proposed algorithm.
Experimental results show the effectiveness of our method for estimating causal effects in both one-directional and bi-directional MR models.

Class incremental learning (CIL) trains a network on sequential tasks with separated categories in each task but suffers from catastrophic forgetting, where models quickly lose previously learned knowledge when acquiring new tasks. The generalized CIL (GCIL) aims to address the CIL problem in a more real-world scenario, where incoming data have mixed data categories and unknown sample size distribution. Existing attempts for the GCIL either have poor performance or invade data privacy by saving exemplars. In this paper, we propose a new exemplar-free GCIL technique named generalized analytic continual learning (GACL). The GACL adopts analytic learning (a gradient-free training technique) and delivers an analytical (i.e., closed-form) solution to the GCIL scenario. This solution is derived via decomposing the incoming data into exposed and unexposed classes, thereby attaining a weight-invariant property, a rare yet valuable property supporting an equivalence between incremental learning and its joint training. Such an equivalence is crucial in GCIL settings as data distributions among different tasks no longer pose challenges to adopting our GACL. Theoretically, this equivalence property is validated through matrix analysis tools. Empirically, we conduct extensive experiments where, compared with existing GCIL methods, our GACL exhibits a consistently leading performance across various datasets and GCIL settings. Source code is available at https://github.com/CHEN-YIZHU/GACL.
tl;dr: We propose a novel iterative algorithm to solve a stochastic optimal control problem under multiplicative and internal noise, outperforming state-of-the-art solutions in the presence of internal noise and before algorithmic convergence.

A pivotal brain computation relies on the ability to sustain perception-action loops. Stochastic optimal control theory offers a mathematical framework to explain these processes at the algorithmic level through optimality principles. However, incorporating a realistic noise model of the sensorimotor system — accounting for multiplicative noise in feedback and motor output, as well as internal noise in estimation — makes the problem challenging. Currently, the algorithm that is commonly used is the one proposed in the seminal study in (Todorov, 2005). After discovering some pitfalls in the original derivation, i.e., unbiased estimation does not hold, we improve the algorithm by proposing an efficient gradient descent-based optimization that minimizes the cost-to-go while only imposing linearity of the control law. The optimal solution is obtained by iteratively propagating in closed form the sufficient statistics to compute the expected cost and then minimizing this cost with respect to the filter and control gains. We demonstrate that this approach results in a significantly lower overall cost than current state-of-the-art solutions, particularly in the presence of internal noise, though the improvement is present in other circumstances as well, with theoretical explanations for this enhanced performance. Providing the optimal control law is key for inverse control inference, especially in explaining behavioral data under rationality assumptions.
tl;dr: We introduce Successive Concept Bottleneck agents for competitive and aligned reinforcement learning.

Goal misalignment, reward sparsity and difficult credit assignment are only a few of the many issues that make it difficult for deep reinforcement learning (RL) agents to learn optimal policies.
Unfortunately, the black-box nature of deep neural networks impedes the inclusion of domain experts for inspecting the model and revising suboptimal policies.
To this end, we introduce Successive Concept Bottleneck Agents (SCoBots), that integrate consecutive concept bottleneck (CB) layers.
In contrast to current CB models, SCoBots do not just represent concepts as properties of individual objects, but also as relations between objects which is crucial for many RL tasks.
Our experimental results provide evidence of SCoBots' competitive performances, but also of their potential for domain experts to understand and regularize their behavior. Among other things, SCoBots enabled us to identify a previously unknown misalignment problem in the iconic video game, Pong, and resolve it. Overall, SCoBots thus result in more human-aligned RL agents.

Fair-range clustering extends classical clustering formulations by associating each data point with one or several demographic labels. It imposes lower and upper bound constraints on the number of opened facilities associated with each label, ensuring fair representation of all demographic groups by the opened facilities. In this paper we focus on the fair-range $k$-median and $k$-means problems in Euclidean spaces. We give $(1+\varepsilon)$-approximation algorithms with fixed-parameter tractable running times for both problems, parameterized by the numbers of opened facilities and demographic labels. For Euclidean metrics, these are the first parameterized approximation schemes for the problems, improving upon the previously known $O(1)$-approximation ratios given by Thejaswi et al. (KDD 2022).

Conventional diffusion models typically relies on a fixed forward process, which implicitly defines complex marginal distributions over latent variables. This can often complicate the reverse process’ task in learning generative trajectories, and results in costly inference for diffusion models. To address these limitations, we introduce Neural Flow Diffusion Models (NFDM), a novel framework that enhances diffusion models by supporting a broader range of forward processes beyond the standard Gaussian. We also propose a novel parameterization technique for learning the forward process. Our framework provides an end-to-end, simulation-free optimization objective, effectively minimizing a variational upper bound on the negative log-likelihood. Experimental results demonstrate NFDM’s strong performance, evidenced by state-of-the-art likelihood estimation. Furthermore, we investigate NFDM’s capacity for learning generative dynamics with specific characteristics, such as deterministic straight lines trajectories, and demonstrate how the framework may be adopted for learning bridges between two distributions. The results underscores NFDM’s versatility and its potential for a wide range of applications.
tl;dr: We propose novel algorithms and provide improved Bayes regret bounds for multi-task hierarchical Bayesian bandi/semi-bandit setting.

Hierarchical Bayesian bandit refers to the multi-task bandit problem in which bandit tasks are assumed to be drawn from the same distribution. In this work, we provide improved Bayes regret bounds for hierarchical Bayesian bandit algorithms in the multi-task linear bandit and semi-bandit settings. For the multi-task linear bandit, we first analyze the preexisting hierarchical Thompson sampling (HierTS) algorithm, and improve its gap-independent Bayes regret bound from $O(m\sqrt{n\log{n}\log{(mn)}})$ to $O(m\sqrt{n\log{n}})$ in the case of infinite action set, with $m$ being the number of tasks and $n$ the number of iterations per task. In the case of finite action set, we propose a novel hierarchical Bayesian bandit algorithm, named hierarchical BayesUCB (HierBayesUCB), that achieves the logarithmic but gap-dependent regret bound $O(m\log{(mn)}\log{n})$ under mild assumptions. All of the above regret bounds hold in many variants of hierarchical Bayesian linear bandit problem, including when the tasks are solved sequentially or concurrently. Furthermore, we extend the aforementioned HierTS and HierBayesUCB algorithms to the multi-task combinatorial semi-bandit setting. Concretely, our combinatorial HierTS algorithm attains comparable Bayes regret bound $O(m\sqrt{n}\log{n})$ with respect to the latest one. Moreover, our combinatorial HierBayesUCB yields a sharper Bayes regret bound $O(m\log{(mn)}\log{n})$. Experiments are conducted to validate the soundness of our theoretical results for multi-task bandit algorithms.
603. Membership Inference Attacks against Fine-tuned Large Language Models via Self-prompt Calibration
tl;dr: This work proposes a practical membership inference attack against fine-tuned large language models.

Membership Inference Attacks (MIA) aim to infer whether a target data record has been utilized for model training or not. Existing MIAs designed for large language models (LLMs) can be bifurcated into two types: reference-free and reference-based attacks. Although reference-based attacks appear promising performance by calibrating the probability measured on the target model with reference models, this illusion of privacy risk heavily depends on a reference dataset that closely resembles the training set. Both two types of attacks are predicated on the hypothesis that training records consistently maintain a higher probability of being sampled. However, this hypothesis heavily relies on the overfitting of target models, which will be mitigated by multiple regularization methods and the generalization of LLMs. Thus, these reasons lead to high false-positive rates of MIAs in practical scenarios.
We propose a Membership Inference Attack based on Self-calibrated Probabilistic Variation (SPV-MIA).
Specifically, we introduce a self-prompt approach, which constructs the dataset to fine-tune the reference model by prompting the target LLM itself. In this manner, the adversary can collect a dataset with a similar distribution from public APIs.
Furthermore, we introduce probabilistic variation, a more reliable membership signal based on LLM memorization rather than overfitting, from which we rediscover the neighbour attack with theoretical grounding.
Comprehensive evaluation conducted on three datasets and four exemplary LLMs shows that SPV-MIA raises the AUC of MIAs from 0.7 to a significantly high level of 0.9. Our code and dataset are available at: https://github.com/tsinghua-fib-lab/NeurIPS2024_SPV-MIA
tl;dr: We provide the first theoretical guarantees for seeding the Push-Relabel algorithm with a predicted flow, and we validate this theory by showing speed ups empirically.

Push-Relabel is one of the most celebrated network flow algorithms. Maintaining a pre-flow that saturates a cut, it enjoys better theoretical and empirical running time than other flow algorithms, such as Ford-Fulkerson. In practice, Push-Relabel is even faster than what theoretical guarantees can promise, in part because of the use of good heuristics for seeding and updating the iterative algorithm. However, it remains unclear how to run Push-Relabel on an arbitrary initialization that is not necessarily a pre-flow or cut-saturating. We provide the first theoretical guarantees for warm-starting Push-Relabel with a predicted flow, where our learning-augmented version benefits from fast running time when the predicted flow is close to an optimal flow, while maintaining robust worst-case guarantees. Interestingly, our algorithm uses the gap relabeling heuristic, which has long been employed in practice, even though prior to our work there was no rigorous theoretical justification for why it can lead to run-time improvements. We then show our algorithmic framework works well in practice, as our warm-start version of Push-Relabel improves over the cold-start version by a larger and larger percentage as the size of the image increases.
tl;dr: We present a physical compatibility optimization framework that transforms single images into 3D physical objects, significantly enhancing stability and structural integrity under real-world physics.

We present a computational framework that transforms single images into 3D physical objects. The visual geometry of a physical object in an image is determined by three orthogonal attributes: mechanical properties, external forces, and rest-shape geometry. Existing single-view 3D reconstruction methods often overlook this underlying composition, presuming rigidity or neglecting external forces. Consequently, the reconstructed objects fail to withstand real-world physical forces, resulting in instability or undesirable deformation -- diverging from their intended designs as depicted in the image. Our optimization framework addresses this by embedding physical compatibility into the reconstruction process. We explicitly decompose the three physical attributes and link them through static equilibrium, which serves as a hard constraint, ensuring that the optimized physical shapes exhibit desired physical behaviors. Evaluations on a dataset collected from Objaverse demonstrate that our framework consistently enhances the physical realism of 3D models over existing methods. The utility of our framework extends to practical applications in dynamic simulations and 3D printing, where adherence to physical compatibility is paramount.

In the visual spatial understanding (VSU) field, spatial image-to-text (SI2T) and spatial text-to-image (ST2I) are two fundamental tasks that appear in dual form. Existing methods for standalone SI2T or ST2I perform imperfectly in spatial understanding, due to the difficulty of 3D-wise spatial feature modeling. In this work, we consider modeling the SI2T and ST2I together under a dual learning framework. During the dual framework, we then propose to represent the 3D spatial scene features with a novel 3D scene graph (3DSG) representation that can be shared and beneficial to both tasks. Further, inspired by the intuition that the easier 3D$\to$image and 3D$\to$text processes also exist symmetrically in the ST2I and SI2T, respectively, we propose the Spatial Dual Discrete Diffusion (SD$^3$) framework, which utilizes the intermediate features of the 3D$\to$X processes to guide the hard X$\to$3D processes, such that the overall ST2I and SI2T will benefit each other. On the visual spatial understanding dataset VSD, our system outperforms the mainstream T2I and I2T methods significantly.
Further in-depth analysis reveals how our dual learning strategy advances.
tl;dr: Transformers trained on next-token prediction learn to represent the geometry of belief updating over hidden states of the data-generating process in their residual stream.

What computational structure are we building into large language models when we train them on next-token prediction? Here, we present evidence that this structure is given by the meta-dynamics of belief updating over hidden states of the data-generating process. Leveraging the theory of optimal prediction, we anticipate and then find that belief states are linearly represented in the residual stream of transformers, even in cases where the predicted belief state geometry has highly nontrivial fractal structure. We investigate cases where the belief state geometry is represented in the final residual stream or distributed across the residual streams of multiple layers, providing a framework to explain these observations. Furthermore, we demonstrate that the inferred belief states contain information about the entire future, beyond the local next-token prediction that the transformers are explicitly trained on. Our work provides a general framework connecting the structure of training data to the geometric structure of activations inside transformers.

Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos.
They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs.
Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data.
This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs.
We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over $50$ conditional DMs.
Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages.
Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs.
Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP).
CEP significantly improves the performance of various DMs in both pre-training and downstream tasks.
We hope that our study provides new insights into understanding the data and pre-training processes of DMs.
tl;dr: We show that the Bayesian marginal likelihood can be used to make neural networks more sparsifiable.

Neural network sparsification is a promising avenue to save computational time and memory costs, especially in an age where many successful AI models are becoming too large to naively deploy on consumer hardware. While much work has focused on different weight pruning criteria, the overall sparsifiability of the network, i.e., its capacity to be pruned without quality loss, has often been overlooked. We present Sparsifiability via the Marginal likelihood (SpaM), a sparsification framework that highlights the effectiveness of using the Bayesian marginal likelihood in conjunction with sparsity-inducing priors for making neural networks more sparsifiable. Our approach implements an automatic Occam's razor that selects the most sparsifiable model that still explains the data well, both for structured and unstructured sparsification. In addition, we demonstrate that the pre-computed posterior precision from the Laplace approximation can be re-used to define a cheap pruning criterion, which outperforms many existing (more expensive) approaches. We demonstrate the effectiveness of our framework, especially at high sparsity levels, across a range of different neural network architectures and datasets.
tl;dr: We propose a principled approach to learn an uncertainty set from decision data and then solve a robust optimization model to prescribe high-quality and intuitive decisions.

Inverse optimization has been increasingly used to estimate unknown parameters in an optimization model based on decision data. We show that such a point estimation is insufficient in a prescriptive setting where the estimated parameters are used to prescribe new decisions. The prescribed decisions may be low-quality and misaligned with human intuition and thus are unlikely to be adopted. To tackle this challenge, we propose conformal inverse optimization, which seeks to learn an uncertainty set for the unknown parameters and then solve a robust optimization model to prescribe new decisions. Under mild assumptions, we show that our method enjoys provable guarantees on solution quality, as evaluated using both the ground-truth parameters and the decision maker's perception of the unknown parameters. Our method demonstrates strong empirical performance compared to classic inverse optimization.

In this work, we investigate stochastic approximation (SA) with Markovian data and nonlinear updates under constant stepsize $\alpha>0$. Existing work has primarily focused on either i.i.d. data or linear update rules. We take a new perspective and carefully examine the simultaneous presence of Markovian dependency of data and nonlinear update rules, delineating how the interplay between these two structures leads to complications that are not captured by prior techniques. By leveraging the smoothness and recurrence properties of the SA updates, we develop a fine-grained analysis of the correlation between the SA iterates $\theta_k$ and Markovian data $x_k$. This enables us to overcome the obstacles in existing analysis and establish for the first time the weak convergence of the joint process $(x_k, \theta_k)$. Furthermore, we present a precise characterization of the asymptotic bias of the SA iterates, given by $\mathbb{E}[\theta_\infty]-\theta^\ast=\alpha(b_\textup{m}+b_\textup{n}+b_\textup{c})+\mathcal{O}(\alpha^{3/2})$. Here, $b_\textup{m}$ is associated with the Markovian noise, $b_\textup{n}$ is tied to the nonlinearity of the SA operator, and notably, $b_\textup{c}$ represents a multiplicative interaction between the Markovian noise and the nonlinearity of the operator, which is absent in previous works. As a by-product of our analysis, we derive finite-time bounds on higher moment $\mathbb{E}[||\theta_k-\theta^\ast||^{2p}]$ and present non-asymptotic geometric convergence rates for the iterates, along with a Central Limit Theorem.
tl;dr: We proposed the CENIE framework, which offers a scalable, domain-agnostic, and curriculum-aware approach to quantifying environment novelty using the agent's state-action space coverage.

Unsupervised Environment Design (UED) formalizes the problem of autocurricula through interactive training between a teacher agent and a student agent. The teacher generates new training environments with high learning potential, curating an adaptive curriculum that strengthens the student's ability to handle unseen scenarios. Existing UED methods mainly rely on *regret*, a metric that measures the difference between the agent's optimal and actual performance, to guide curriculum design. Regret-driven methods generate curricula that progressively increase environment complexity for the student but overlook environment *novelty* — a critical element for enhancing an agent's generalizability. Measuring environment novelty is especially challenging due to the underspecified nature of environment parameters in UED, and existing approaches face significant limitations. To address this, this paper introduces the *Coverage-based Evaluation of Novelty In Environment* (CENIE) framework. CENIE proposes a scalable, domain-agnostic, and curriculum-aware approach to quantifying environment novelty by leveraging the student's state-action space coverage from previous curriculum experiences. We then propose an implementation of CENIE that models this coverage and measures environment novelty using Gaussian Mixture Models. By integrating both regret and novelty as complementary objectives for curriculum design, CENIE facilitates effective exploration across the state-action space while progressively increasing curriculum complexity. Empirical evaluations demonstrate that augmenting existing regret-based UED algorithms with CENIE achieves state-of-the-art performance across multiple benchmarks, underscoring the effectiveness of novelty-driven autocurricula for robust generalization.

Motivated by the success of Nesterov's accelerated gradient algorithm for convex minimization problems, we examine whether it is possible to achieve similar performance gains in the context of online learning in games.
To that end, we introduce a family of accelerated learning methods, which we call “follow the accelerated leader” (FTXL), and which incorporates the use of momentum within the general framework of regularized learning - and, in particular, the exponential / multiplicative weights algorithm and its variants.
Drawing inspiration and techniques from the continuous-time analysis of Nesterov's algorithm, we show that FTXL converges locally to strict Nash equilibria at a superlinear rate, achieving in this way an exponential speed-up over vanilla regularized learning methods (which, by comparison, converge to strict equilibria at a geometric, linear rate).
Importantly, the FTXL maintains its superlinear convergence rate in a broad range of feedback structures, from deterministic, full information models to stochastic, realization-based ones, and even bandit, payoff-based information, where players are only able to observe their individual realized payoffs.
tl;dr: Propose a dynamic multimodal large language model framework for saving computational and GPU memory costs in robotic execution

Multimodal Large Language Models (MLLMs) have demonstrated remarkable comprehension and reasoning capabilities with complex language and visual data.
These advances have spurred the vision of establishing a generalist robotic MLLM proficient in understanding complex human instructions and accomplishing various embodied tasks, whose feasibility has been recently verified~\cite{rt-2,rt-x}.
However, developing MLLMs for real-world robots is challenging due to the typically limited computation and memory capacities available on robotic platforms.
In contrast, the inference of MLLMs usually incorporates storing billions of parameters and performing tremendous computation, imposing significant hardware demands.
In our paper, we seek to address this challenge by leveraging an intriguing observation: relatively easier situations make up the bulk of the procedure of controlling robots to fulfill diverse tasks, and they generally require far smaller models to obtain the correct robotic actions.
Motivated by this observation, we propose a \emph{Dynamic
Early-Exit for Robotic MLLM} (DeeR) framework that automatically adjusts the size of the activated MLLM based on each situation at hand.
The approach leverages a multi-exit architecture in MLLMs, which allows the model to cease processing once a proper size of the model has been activated for a specific situation, thus avoiding further redundant computation.
Additionally, we develop novel algorithms that establish early-termination criteria for DeeR, conditioned on predefined demands such as average computational cost (\emph{i.e.}, power consumption), as well as peak computational consumption (\emph{i.e.}, latency) and GPU memory usage. These enhancements ensure that DeeR operates efficiently under varying resource constraints while maintaining competitive performance.
Moreover, we design a tailored training method for integrating temporal information on top of such multi-exit architectures to predict actions reasonably.
On the CALVIN robot manipulation benchmark, DeeR demonstrates significant reductions in computational costs by 5.2-6.5x and GPU memory by 2x without compromising performance.
Code and checkpoints are available at https://github.com/yueyang130/DeeR-VLA.
tl;dr: We aim to tackle a new practical concept customization problem named Concept-Incremental Flexible Customization (CIFC), where the main challenges are catastrophic forgetting and concept neglect.

Custom diffusion models (CDMs) have attracted widespread attention due to their astonishing generative ability for personalized concepts. However, most existing CDMs unreasonably assume that personalized concepts are fixed and cannot change over time. Moreover, they heavily suffer from catastrophic forgetting and concept neglect on old personalized concepts when continually learning a series of new concepts. To address these challenges, we propose a novel Concept-Incremental text-to-image Diffusion Model (CIDM), which can resolve catastrophic forgetting and concept neglect to learn new customization tasks in a concept-incremental manner. Specifically, to surmount the catastrophic forgetting of old concepts, we develop a concept consolidation loss and an elastic weight aggregation module. They can explore task-specific and task-shared knowledge during training, and aggregate all low-rank weights of old concepts based on their contributions during inference. Moreover, in order to address concept neglect, we devise a context-controllable synthesis strategy that leverages expressive region features and noise estimation to control the contexts of generated images according to user conditions. Experiments validate that our CIDM surpasses existing custom diffusion models. The source codes are available at https://github.com/JiahuaDong/CIFC.
tl;dr: An improved score function for unsupervised environment design in binary outcome settings, which we use to train agents for real-world tasks, and an improved adversarial evaluation protocol that assesses policy robustness.

What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning.
In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula promise to enable agents to be robust to in- and out-of-distribution tasks.
This work investigates how existing UED methods select training environments, focusing on task prioritisation metrics.
Surprisingly, despite methods aiming to maximise regret in theory, the practical approximations do not correlate with regret but with success rate.
As a result, a significant portion of an agent's experience comes from environments it has already mastered, offering little to no contribution toward enhancing its abilities. Put differently, current methods fail to predict intuitive measures of *learnability*. Specifically, they are unable to consistently identify those scenarios that the agent can sometimes solve, but not always.
Based on our analysis, we develop a method that directly trains on scenarios with high learnability. This simple and intuitive approach outperforms existing UED methods in several binary-outcome environments, including the standard domain of Minigrid and a novel setting closely inspired by a real-world robotics problem.
We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR).
We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.

When answering questions, large language models (LLMs) can convey not only an answer to the question, but a level of confidence about the answer being correct. This includes explicit markers of confidence (e.g. giving a numeric confidence score) as well as implicit markers, like using an authoritative tone or elaborating with additional knowledge of a subject. For LLMs to be trustworthy sources of knowledge, the confidence they convey should match their actual expertise on a topic; however, this is currently not the case, with most models tending towards overconfidence. To calibrate both implicit and explicit confidence markers, we introduce a pragmatic, listener-aware finetuning method (LACIE) that directly models the listener, considering not only whether an answer is right, but whether it will be accepted by a listener. Specifically, we cast calibration as a preference optimization problem, creating data via a two-agent speaker-listener game, where a speaker model’s outputs are judged by a simulated listener. We then finetune three different LLMs (Mistral-7B, Llama3-8B, Llama3-70B) with LACIE, and show that the models resulting from this multi-agent optimization are better calibrated on TriviaQA with respect to a simulated listener. Crucially, these trends transfer to human listeners, helping them correctly predict model correctness: we conduct a human evaluation where annotators accept or reject an LLM’s answers to trivia questions, finding that training with LACIE results in 47% fewer incorrect answers being accepted while maintaining the same level of acceptance for correct answers. Furthermore, LACIE generalizes to another dataset, resulting in a large increase in truthfulness on TruthfulQA when trained on TriviaQA. Our analysis indicates that LACIE leads to a better separation in confidence between correct and incorrect examples. Qualitatively, we find that a LACIE-trained model hedges more when uncertain and adopts implicit cues to signal certainty when it is correct, such as using an authoritative tone or including details. Finally, finetuning with our listener- aware method leads to an emergent increase in model abstention (e.g. saying “I don’t know”) for answers that are likely to be wrong, trading recall for precision.
tl;dr: We extend the current definition of multicalibration to tackle general distribution shift, particularly beyond covariate shift.

We establish a new model-agnostic optimization framework for out-of-distribution generalization via multicalibration, a criterion that ensures a predictor is calibrated across a family of overlapping groups. Multicalibration is shown to be associated with robustness of statistical inference under covariate shift. We further establish a link between multicalibration and robustness for prediction tasks both under and beyond covariate shift. We accomplish this by extending multicalibration to incorporate grouping functions that consider covariates and labels jointly. This leads to an equivalence of the extended multicalibration and invariance, an objective for robust learning in existence of concept shift. We show a linear structure of the grouping function class spanned by density ratios, resulting in a unifying framework for robust learning by designing specific grouping functions. We propose MC-Pseudolabel, a post-processing algorithm to achieve both extended multicalibration and out-of-distribution generalization. The algorithm, with lightweight hyperparameters and optimization through a series of supervised regression steps, achieves superior performance on real-world datasets with distribution shift.

Recent advancements in large vision language models have demonstrated remarkable proficiency across a wide range of tasks.
Yet, these models still struggle with understanding the nuances of human humor through juxtaposition, particularly when it involves nonlinear narratives that underpin many jokes and humor cues. This paper investigates this challenge by focusing on comics with contradictory narratives, where each comic consists of two panels that create a humorous contradiction. We introduce the YesBut benchmark, which comprises tasks of varying difficulty aimed at assessing AI's capabilities in recognizing and interpreting these comics, ranging from literal content comprehension to deep narrative reasoning. Through extensive experimentation and analysis of recent commercial or open-sourced large vision language models, we assess their capability to comprehend the complex interplay of the narrative humor inherent in these comics. Our results show that even the state-of-the-art models still struggle with this task. Our findings offer insights into the current limitations and potential improvements for AI in understanding human creative expressions.
tl;dr: We study text-level Graph Injection Attacks beyond the embedding level, revealing new challenges and insights about Graph Injection Attack designs.

Graph Neural Networks (GNNs) excel across various applications but remain vulnerable to adversarial attacks, particularly Graph Injection Attacks (GIAs), which inject malicious nodes into the original graph and pose realistic threats.
Text-attributed graphs (TAGs), where nodes are associated with textual features, are crucial due to their prevalence in real-world applications and are commonly used to evaluate these vulnerabilities.
However, existing research only focuses on embedding-level GIAs, which inject node embeddings rather than actual textual content, limiting their applicability and simplifying detection.
In this paper, we pioneer the exploration of GIAs at the text level, presenting three novel attack designs that inject textual content into the graph.
Through theoretical and empirical analysis, we demonstrate that text interpretability, a factor previously overlooked at the embedding level, plays a crucial role in attack strength.
Among the designs we investigate, the Word-frequency-based Text-level GIA (WTGIA) is particularly notable for its balance between performance and interpretability.
Despite the success of WTGIA, we discover that defenders can easily enhance their defenses with customized text embedding methods or large language model (LLM)--based predictors.
These insights underscore the necessity for further research into the potential and practical significance of text-level GIAs.
tl;dr: A method that predicts charge density from atomic coordinates that outperforms state-of-the-art while being more than an order of magnitude faster.

In density functional theory, charge density is the core attribute of atomic systems from which all chemical properties can be derived. Machine learning methods are promising in significantly accelerating charge density prediction, yet existing approaches either lack accuracy or scalability. We propose a recipe that can achieve both. In particular, we identify three key ingredients: (1) representing the charge density with atomic and virtual orbitals (spherical fields centered at atom/virtual coordinates); (2) using expressive and learnable orbital basis sets (basis function for the spherical fields); and (3) using high-capacity equivariant neural network architecture. Our method achieves state-of-the-art accuracy while being more than an order of magnitude faster than existing methods. Furthermore, our method enables flexible efficiency-accuracy trade-offs by adjusting the model/basis sizes.
tl;dr: Our work offers insights on whether simple-yet-accurate machine learning models are likely to exist, based on knowledge of noise levels in the data generation process.

Noise in data significantly influences decision-making in the data science process. In fact, it has been shown that noise in data generation processes leads practitioners to find simpler models. However, an open question still remains: what is the degree of model simplification we can expect under different noise levels? In this work, we address this question by investigating the relationship between the amount of noise and model simplicity across various hypothesis spaces, focusing on decision trees and linear models. We formally show that noise acts as an implicit regularizer for several different noise models. Furthermore, we prove that Rashomon sets (sets of near-optimal models) constructed with noisy data tend to contain simpler models than corresponding Rashomon sets with non-noisy data. Additionally, we show that noise expands the set of ``good'' features and consequently enlarges the set of models that use at least one good feature. Our work offers theoretical guarantees and practical insights for practitioners and policymakers on whether simple-yet-accurate machine learning models are likely to exist, based on knowledge of noise levels in the data generation process.
tl;dr: A novel framework for physics-based animation of multi-person carrying tasks.

Enabling humanoid robots to clean rooms has long been a pursued dream within humanoid research communities. However, many tasks require multi-humanoid collaboration, such as carrying large and heavy furniture together. Given the scarcity of motion capture data on multi-humanoid collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce **Coo**perative **H**uman-**O**bject **I**nteraction (**CooHOI**), a framework designed to tackle the challenge of multi-humanoid object transportation problem through a two-phase learning paradigm: individual skill learning and subsequent policy transfer. First, a single humanoid character learns to interact with objects through imitation learning from human motion priors. Then, the humanoid learns to collaborate with others by considering the shared dynamics of the manipulated object using centralized training and decentralized execution (CTDE) multi-agent RL algorithms. When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-humanoid HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-humanoid interactions, and can be seamlessly extended to include more participants and a wide range of object types.

In this paper, we present a simple optimization-based preprocessing technique called Weight Magnitude Reduction (MagR) to improve the performance of post-training quantization. For each linear layer, we adjust the pre-trained floating-point weights by solving an $\ell_\infty$-regularized optimization problem. This process greatly diminishes the maximum magnitude of the weights and smooths out outliers, while preserving the layer's output. The preprocessed weights are centered more towards zero, which facilitates the subsequent quantization process. To implement MagR, we address the $\ell_\infty$-regularization by employing an efficient proximal gradient descent algorithm. Unlike existing preprocessing methods that involve linear transformations and subsequent post-processing steps, which can introduce significant overhead at inference time, MagR functions as a non-linear transformation, eliminating the need for any additional post-processing. This ensures that MagR introduces no overhead whatsoever during inference. Our experiments demonstrate that MagR achieves state-of-the-art performance on the Llama family of models. For example, we achieve a Wikitext2 perplexity of 6.7 on the LLaMA2-70B model for per-channel INT2 weight quantization without incurring any inference overhead.

Linear temporal logic (LTL) and, more generally, $\omega$-regular objectives are alternatives to the traditional discount sum and average reward objectives in reinforcement learning (RL), offering the advantage of greater comprehensibility and hence explainability. In this work, we study the relationship between these objectives. Our main result is that each RL problem for $\omega$-regular objectives can be reduced to a limit-average reward problem in an optimality-preserving fashion, via (finite-memory) reward machines. Furthermore, we demonstrate the efficacy of this approach by showing that optimal policies for limit-average problems can be found asymptotically by solving a sequence of discount-sum problems approximately. Consequently, we resolve an open problem: optimal policies for LTL and $\omega$-regular objectives can be learned asymptotically.
tl;dr: This paper introduces Orchid, a new deep learning architecture that replaces computationally expensive attention mechanisms with a more efficient and scalable input-dependent convolution-based approach.

In the rapidly evolving field of deep learning, the demand for models that are both expressive and computationally efficient has never been more critical. This paper introduces Orchid, a novel architecture designed to address the quadratic complexity of traditional attention mechanisms without compromising the ability to capture long-range dependencies and in-context learning. At the core of this architecture lies a new data-dependent global convolution layer, which contextually adapts its kernel conditioned on input sequence using a dedicated conditioning neural network. We design two simple conditioning networks that maintain shift equivariance in our data-dependent convolution operation. The dynamic nature of the proposed convolution kernel grants Orchid high expressivity while maintaining quasilinear scalability for long sequences. We evaluate the proposed model across multiple domains, including language modeling and image classification, to highlight its performance and generality. Our experiments demonstrate that this architecture not only outperforms traditional attention-based architectures such as BERT and Vision Transformers with smaller model sizes, but also extends the feasible sequence length beyond the limitations of the dense attention layers. This achievement represents a significant step towards more efficient and scalable deep learning models for sequence modeling.
tl;dr: We find methods for leveraging agreement-on-the-line for estimating of the performance of finetuned foundation models under distribution shift.

Estimating the out-of-distribution performance in regimes where labels are scarce is critical to safely deploy foundation models. Recently, it was shown that ensembles of neural networks observe the phenomena "agreement-on-the-line", which can be leveraged to reliably predict OOD performance without labels. However, in contrast to classical neural networks that are trained on in-distribution data from scratch for numerous epochs, foundation models undergo minimal finetuning from heavily pretrained weights, which may reduce the ensemble diversity needed to observe agreement-on-the-line. In our work, we demonstrate that when lightly finetuning multiple runs from a $\textit{single}$ foundation model, the choice of randomness during training (linear head initialization, data ordering, and data subsetting) can lead to drastically different levels of agreement-on-the-line in the resulting ensemble. Surprisingly, only random head initialization is able to reliably induce agreement-on-the-line in finetuned foundation models across vision and language benchmarks. Second, we demonstrate that ensembles of $\textit{multiple}$ foundation models pretrained on different datasets but finetuned on the same task can also show agreement-on-the-line. In total, by careful construction of a diverse ensemble, we can utilize agreement-on-the-line-based methods to predict the OOD performance of foundation models with high precision.
628. Understanding the Expressivity and Trainability of Fourier Neural Operator: A Mean-Field Perspective

In this paper, we explores the expressivity and trainability of the Fourier Neural Operator (FNO). We establish a mean-field theory for the FNO, analyzing the behavior of the random FNO from an \emph{edge of chaos} perspective. Our investigation into the expressivity of a random FNO involves examining the ordered-chaos phase transition of the network based on the weight distribution. This phase transition demonstrates characteristics unique to the FNO, induced by mode truncation, while also showcasing similarities to those of densely connected networks. Furthermore, we identify a connection between expressivity and trainability: the ordered and chaotic phases correspond to regions of vanishing and exploding gradients, respectively. This finding provides a practical prerequisite for the stable training of the FNO. Our experimental results corroborate our theoretical findings.
629. Towards the Transferability of Rewards Recovered via Regularized Inverse Reinforcement Learning

Inverse reinforcement learning (IRL) aims to infer a reward from expert demonstrations, motivated by the idea that the reward, rather than the policy, is the most succinct and transferable description of a task [Ng et al., 2000]. However, the reward corresponding to an optimal policy is not unique, making it unclear if an IRL-learned reward is transferable to new transition laws in the sense that its optimal policy aligns with the optimal policy corresponding to the expert's true reward. Past work has addressed this problem only under the assumption of full access to the expert's policy, guaranteeing transferability when learning from two experts with the same reward but different transition laws that satisfy a specific rank condition [Rolland et al., 2022]. In this work, we show that the conditions developed under full access to the expert's policy cannot guarantee transferability in the more practical scenario where we have access only to demonstrations of the expert. Instead of a binary rank condition, we propose principal angles as a more refined measure of similarity and dissimilarity between transition laws. Based on this, we then establish two key results: 1) a sufficient condition for transferability to any transition laws when learning from at least two experts with sufficiently different transition laws, and 2) a sufficient condition for transferability to local changes in the transition law when learning from a single expert. Furthermore, we also provide a probably approximately correct (PAC) algorithm and an end-to-end analysis for learning transferable rewards from demonstrations of multiple experts.

We present a comprehensive study of surrogate loss functions for learning to defer. We introduce a broad family of surrogate losses, parameterized by a non-increasing function $\Psi$, and establish their realizable $H$-consistency under mild conditions. For cost functions based on classification error, we further show that these losses admit $H$-consistency bounds when the hypothesis set is symmetric and complete, a property satisfied by common neural network and linear function hypothesis sets. Our results also resolve an open question raised in previous work [Mozannar et al., 2023] by proving the realizable $H$-consistency and Bayes-consistency of a specific surrogate loss. Furthermore, we identify choices of $\Psi$ that lead to $H$-consistent surrogate losses for *any general cost function*, thus achieving Bayes-consistency, realizable $H$-consistency, and $H$-consistency bounds *simultaneously*. We also investigate the relationship between $H$-consistency bounds and realizable $H$-consistency in learning to defer, highlighting key differences from standard classification. Finally, we empirically evaluate our proposed surrogate losses and compare them with existing baselines.
631. fMRI predictors based on language models of increasing complexity recover brain left lateralization
tl;dr: fMRI predictors based on language models of increasing complexity recover brain left lateralization for language, and the difference in brain score between left and right hemisphere follows a scaling law.

Over the past decade, studies of naturalistic language processing where participants are scanned while listening to continuous text have flourished. Using word embeddings at first, then large language models, researchers have created encoding models to analyze the brain signals. Presenting these models with the same text as the participants allows to identify brain areas where there is a significant correlation between the functional magnetic resonance imaging (fMRI) time series and the ones predicted by the models' artificial neurons. One intriguing finding from these studies is that they have revealed highly symmetric bilateral activation patterns, somewhat at odds with the well-known left lateralization of language processing. Here, we report analyses of an fMRI dataset where we manipulate the complexity of large language models, testing 28 pretrained models from 8 different families, ranging from 124M to 14.2B parameters. First, we observe that the performance of models in predicting brain responses follows a scaling law, where the fit with brain activity increases linearly with the logarithm of the number of parameters of the model (and its performance on natural language processing tasks). Second, although this effect is present in both hemispheres, it is stronger in the left than in the right hemisphere. Specifically, the left-right difference in brain correlation follows a scaling law with the number of parameters. This finding reconciles computational analyses of brain activity using large language models with the classic observation from aphasic patients showing left hemisphere dominance for language.
tl;dr: Contrary to popular belief, we show that AUPRC should *not* be generally preferred over AUROC in cases of class imbalance, and may even be a harmful metric as it can risk exacerbating algorithmic disparities.

In machine learning (ML), a widespread claim is that the area under the precision-recall curve (AUPRC) is a superior metric for model comparison to the area under the receiver operating characteristic (AUROC) for tasks with class imbalance. This paper refutes this notion on two fronts. First, we theoretically characterize the behavior of AUROC and AUPRC in the presence of model mistakes, establishing clearly that AUPRC is not generally superior in cases of class imbalance. We further show that AUPRC can be a harmful metric as it can unduly favor model improvements in subpopulations with more frequent positive labels, heightening algorithmic disparities. Next, we empirically support our theory using experiments on both semi-synthetic and real-world fairness datasets. Prompted by these insights, we conduct a review of over 1.5 million scientific papers to understand the origin of this invalid claim, finding that it is often made without citation, misattributed to papers that do not argue this point, and aggressively over-generalized from source arguments. Our findings represent a dual contribution: a significant technical advancement in understanding the relationship between AUROC and AUPRC and a stark warning about unchecked assumptions in the ML community.

In this paper, we focus on simple bilevel optimization problems, where we minimize a convex smooth objective function over the optimal solution set of another convex smooth constrained optimization problem. We present a novel bilevel optimization method that locally approximates the solution set of the lower-level problem using a cutting plane approach and employs an accelerated gradient-based update to reduce the upper-level objective function over the approximated solution set. We measure the performance of our method in terms of suboptimality and infeasibility errors and provide non-asymptotic convergence guarantees for both error criteria. Specifically, when the feasible set is compact, we show that our method requires at most $\mathcal{O}(\max\\{1/\sqrt{\epsilon_{f}}, 1/\epsilon_g\\})$ iterations to find a solution that is $\epsilon_f$-suboptimal and $\epsilon_g$-infeasible. Moreover, under the additional assumption that the lower-level objective satisfies the $r$-th Hölderian error bound, we show that our method achieves an iteration complexity of $\mathcal{O}(\max\\{\epsilon_{f}^{-\frac{2r-1}{2r}},\epsilon_{g}^{-\frac{2r-1}{2r}}\\})$, which matches the optimal complexity of single-level convex constrained optimization when $r=1$.
tl;dr: We propose a DRO-based method for gradual domain adaptation with theoretical generalization guarantees. We also introduce a new complexity measure that independently characterizes the dynamics of error propagation in gradual domain adaptation.

The aim of this paper is to address the challenge of gradual domain adaptation within a class of manifold-constrained data distributions. In particular, we consider a sequence of $T\ge2$ data distributions $P_1,\ldots,P_T$ undergoing a gradual shift, where each pair of consecutive measures $P_i,P_{i+1}$ are close to each other in Wasserstein distance. We have a supervised dataset of size $n$ sampled from $P_0$, while for the subsequent distributions in the sequence, only unlabeled i.i.d. samples are available. Moreover, we assume that all distributions exhibit a known favorable attribute, such as (but not limited to) having intra-class soft/hard margins. In this context, we propose a methodology rooted in Distributionally Robust Optimization (DRO) with an adaptive Wasserstein radius. We theoretically show that this method guarantees the classification error across all $P_i$s can be suitably bounded. Our bounds rely on a newly introduced {\it {compatibility}} measure, which fully characterizes the error propagation dynamics along the sequence. Specifically, for inadequately constrained distributions, the error can exponentially escalate as we progress through the gradual shifts. Conversely, for appropriately constrained distributions, the error can be demonstrated to be linear or even entirely eradicated. We have substantiated our theoretical findings through several experimental results.
635. Improved Guarantees for Fully Dynamic $k$-Center Clustering with Outliers in General Metric Spaces
tl;dr: We propose a novel fully dynamic algorithm that maintains an $(4+\epsilon)$-approximate solution to the $(k,z)$-center clustering that covers all but at most $(1+\epsilon)z$ points at any time in the sequence.

The metric $k$-center clustering problem with $z$ outliers, also known as $(k,z)$-center clustering,
involves clustering a given point set $P$ in a metric space $(M,d)$ using at most $k$ balls,
minimizing the maximum ball radius while excluding up to $z$ points from the clustering.
This problem holds fundamental significance in various domains such as machine learning,
data mining, and database systems.
This paper addresses the fully dynamic version of the problem, where the point set undergoes continuous updates (insertions and deletions) over time. The objective is to maintain an approximate $(k,z)$-center clustering with efficient update times.
We propose a novel fully dynamic algorithm that maintains a $(4+\epsilon)$-approximate
solution to the $(k,z)$-center clustering problem that covers
all but at most $(1+\epsilon)z$ points at any time in the sequence with probability $1-k/e^{\Omega(\log k)}$.
The algorithm achieves an expected amortized update time of $\mathcal{O}(\epsilon^{-2} k^6\log(k) \log(\Delta))$, and is applicable to general metric spaces.
Our dynamic algorithm presents a significant improvement over the recent dynamic $(14+\epsilon)$-approximation algorithm by Chan, Lattanzi, Sozio, and Wang for this problem.
636. Probabilistic Decomposed Linear Dynamical Systems for Robust Discovery of Latent Neural Dynamics

Time-varying linear state-space models are powerful tools for obtaining mathematically interpretable representations of neural signals. For example, switching and decomposed models describe complex systems using latent variables that evolve according to simple locally linear dynamics. However, existing methods for latent variable estimation are not robust to dynamical noise and system nonlinearity due to noise-sensitive inference procedures and limited model formulations. This can lead to inconsistent results on signals with similar dynamics, limiting the model's ability to provide scientific insight. In this work, we address these limitations and propose a probabilistic approach to latent variable estimation in decomposed models that improves robustness against dynamical noise. Additionally, we introduce an extended latent dynamics model to improve robustness against system nonlinearities. We evaluate our approach on several synthetic dynamical systems, including an empirically-derived brain-computer interface experiment, and demonstrate more accurate latent variable inference in nonlinear systems with diverse noise conditions. Furthermore, we apply our method to a real-world clinical neurophysiology dataset, illustrating the ability to identify interpretable and coherent structure where previous models cannot.
637. Advancing Tool-Augmented Large Language Models: Integrating Insights from Errors in Inference Trees

Tool-augmented large language models (LLMs) leverage tools, often in the form of APIs, to improve their reasoning capabilities on complex tasks. This enables them to act as intelligent agents interacting with the real world. The recently introduced ToolLLaMA model by Qin et al. [2023] utilizes the depth-first search-based decision tree (DFSDT) mechanism for multi-step reasoning with $16000+$ real-world APIs, effectively enhancing the performance of tool-augmented LLMs compared to traditional chain reasoning mechanisms. However, their approach only employs successful paths from decision trees (also called inference trees) for supervised fine-tuning (SFT), missing out on the potential learning opportunities from failed paths. Inspired by this, we propose an inference trajectory optimization framework based on preference learning to address this limitation. We first introduce a novel method for constructing preference data from tree-like expert trajectories, which leverages the previously ignored failed explorations in the decision trees. Specifically, we generate a step-wise preference dataset, ToolPreference, from the ToolBench dataset for tool learning. In the subsequent training phase, we first fine-tune the LLM with successful tool-usage expert trajectories and then apply direct preference optimization (DPO) with ToolPreference to update the LLM's policy, resulting in our ToolPrefer-LLaMA (TP-LLaMA) model. This approach not only enhances the utilization of original expert data but also broadens the learning space of the model. Our experiments demonstrate that by obtaining insights from errors in inference trees, TP-LLaMA significantly outperforms the baselines across almost all test scenarios by a large margin and exhibits better generalization capabilities with unseen APIs. At the same time, TP-LLaMA has also demonstrated superior reasoning efficiency compared to the baselines, making it more suitable for complex tool-usage reasoning tasks.

Audio deepfake detection (ADD) is crucial to combat the misuse of speech synthesized by generative AI models. Existing ADD models suffer from generalization issues to unseen attacks, with a large performance discrepancy between in-domain and out-of-domain data. Moreover, the black-box nature of existing models limits their use in real-world scenarios, where explanations are required for model decisions. To alleviate these issues, we introduce a new ADD model that explicitly uses the Style-LInguistics Mismatch (SLIM) in fake speech to separate them from real speech. SLIM first employs self-supervised pretraining on only real samples to learn the style-linguistics dependency in the real class. The learned features are then used in complement with standard pretrained acoustic features (e.g., Wav2vec) to learn a classifier on the real and fake classes. When the feature encoders are frozen, SLIM outperforms benchmark methods on out-of-domain datasets while achieving competitive results on in-domain data. The features learned by SLIM allow us to quantify the (mis)match between style and linguistic content in a sample, hence facilitating an explanation of the model decision.
tl;dr: We investigate cultural accumulation among reinforcement learning agents and demonstrate that it can improve upon "single-lifetime" learning.

Cultural accumulation drives the open-ended and diverse progress in capabilities spanning human history. It builds an expanding body of knowledge and skills by combining individual exploration with inter-generational information transmission. Despite its widespread success among humans, the capacity for artificial learning agents to accumulate culture remains under-explored. In particular, approaches to reinforcement learning typically strive for improvements over only a single lifetime. Generational algorithms that do exist fail to capture the open-ended, emergent nature of cultural accumulation, which allows individuals to trade-off innovation and imitation. Building on the previously demonstrated ability for reinforcement learning agents to perform social learning, we find that training setups which balance this with independent learning give rise to cultural accumulation. These accumulating agents outperform those trained for a single lifetime with the same cumulative experience. We explore this accumulation by constructing two models under two distinct notions of a generation: episodic generations, in which accumulation occurs via in-context learning and train-time generations, in which accumulation occurs via in-weights learning. In-context and in-weights cultural accumulation can be interpreted as analogous to knowledge and skill accumulation, respectively. To the best of our knowledge, this work is the first to present general models that achieve emergent cultural accumulation in reinforcement learning, opening up new avenues towards more open-ended learning systems, as well as presenting new opportunities for modelling human culture.
tl;dr: We show that popular quantization methods for language models (LMs) can be exploited to produce a malicious quantized LM, even when the corresponding full-precision LM appears to function normally.

Quantization leverages lower-precision weights to reduce the memory usage of large language models (LLMs) and is a key technique for enabling their deployment on commodity hardware. While LLM quantization's impact on utility has been extensively explored, this work for the first time studies its adverse effects from a security perspective. We reveal that widely used quantization methods can be exploited to produce a harmful quantized LLM, even though the full-precision counterpart appears benign, potentially tricking users into deploying the malicious quantized model.
We demonstrate this threat using a three-staged attack framework: (i) first, we obtain a malicious LLM through fine-tuning on an adversarial task; (ii) next, we quantize the malicious model and calculate constraints that characterize all full-precision models that map to the same quantized model; (iii) finally, using projected gradient descent, we tune out the poisoned behavior from the full-precision model while ensuring that its weights satisfy the constraints computed in step (ii). This procedure results in an LLM that exhibits benign behavior in full precision but when quantized, it follows the adversarial behavior injected in step (i). We experimentally demonstrate the feasibility and severity of such an attack across three diverse scenarios: vulnerable code generation, content injection, and over-refusal attack. In practice, the adversary could host the resulting full-precision model on an LLM community hub such as Hugging Face, exposing millions of users to the threat of deploying its malicious quantized version on their devices.
tl;dr: We introduce InfiNet, a modern architecture using kernel to explore the infinite-dimensional feature interaction.

The past neural network design has largely focused on feature \textit{representation space} dimension and its capacity scaling (e.g., width, depth), but overlooked the feature \textit{interaction space} scaling.
Recent advancements have shown shifted focus towards element-wise multiplication to facilitate higher-dimensional feature interaction space for better information transformation. Despite this progress, multiplications predominantly capture low-order interactions, thus remaining confined to a finite-dimensional interaction space. To transcend this limitation, classic kernel methods emerge as a promising solution to engage features in an infinite-dimensional space. We introduce InfiNet, a model architecture that enables feature interaction within an infinite-dimensional space created by RBF kernel. Our experiments reveal that InfiNet achieves new state-of-the-art, owing to its capability to leverage infinite-dimensional interactions, significantly enhancing model performance.
tl;dr: We propose a new Pfaffian-based parametrization for generalized neural electronic wave functions.

Neural wave functions accomplished unprecedented accuracies in approximating the ground state of many-electron systems, though at a high computational cost. Recent works proposed amortizing the cost by learning generalized wave functions across different structures and compounds instead of solving each problem independently. Enforcing the permutation antisymmetry of electrons in such generalized neural wave functions remained challenging as existing methods require discrete orbital selection via non-learnable hand-crafted algorithms. This work tackles the problem by defining overparametrized, fully learnable neural wave functions suitable for generalization across molecules. We achieve this by relying on Pfaffians rather than Slater determinants. The Pfaffian allows us to enforce the antisymmetry on arbitrary electronic systems without any constraint on electronic spin configurations or molecular structure. Our empirical evaluation finds that a single neural Pfaffian calculates the ground state and ionization energies with chemical accuracy across various systems. On the TinyMol dataset, we outperform the `gold-standard' CCSD(T) CBS reference energies by 1.9m$E_h$ and reduce energy errors compared to previous generalized neural wave functions by up to an order of magnitude.
tl;dr: Accelerate LLM inference with a scalable and robust tree based speculative decoding algorithm

As the usage of large language models (LLMs) grows, it becomes increasingly important to serve them quickly and efficiently. While speculative decoding has recently emerged as a promising direction for accelerating LLM serving, existing methods are limited in their ability to scale to larger speculation budgets and adapt to different hyperparameters. This paper introduces Sequoia, a scalable and robust algorithm for speculative decoding. To improve scalability, Sequoia introduces a dynamic programming algorithm to find an optimal tree structure for the speculated tokens. To achieve robust speculative decoding, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 GPU by up to $4.04\times$, $3.73\times$, and $2.27 \times$. To serve Llama3-70B-Instruct on a single L40 GPU through offloading, Sequoia reduces the per-token decoding latency to 0.60 s/token, $9.5\times$ faster than DeepSpeed-Zero-Inference.
tl;dr: We proposed Statistical Flow Matching (SFM), a novel flow matching framework on the manifold of parameterized probability measures for discrete generation.

We introduce Statistical Flow Matching (SFM), a novel and mathematically rigorous flow-matching framework on the manifold of parameterized probability measures inspired by the results from information geometry. We demonstrate the effectiveness of our method on the discrete generation problem by instantiating SFM on the manifold of categorical distributions whose geometric properties remain unexplored in previous discrete generative models. Utilizing the Fisher information metric, we equip the manifold with a Riemannian structure whose intrinsic geometries are effectively leveraged by following the shortest paths of geodesics. We develop an efficient training and sampling algorithm that overcomes numerical stability issues with a diffeomorphism between manifolds. Our distinctive geometric perspective of statistical manifolds allows us to apply optimal transport during training and interpret SFM as following the steepest direction of the natural gradient. Unlike previous models that rely on variational bounds for likelihood estimation, SFM enjoys the exact likelihood calculation for arbitrary probability measures. We manifest that SFM can learn more complex patterns on the statistical manifold where existing models often fail due to strong prior assumptions. Comprehensive experiments on real-world generative tasks ranging from image, text to biological domains further demonstrate that SFM achieves higher sampling quality and likelihood than other discrete diffusion or flow-based models.
tl;dr: An energy-based formulation for learning infinitesimal generator of stochastic diffusions with theoretical learning bounds.

We address data-driven learning of the infinitesimal generator of stochastic diffusion processes, essential for understanding numerical simulations of natural and physical systems. The unbounded nature of the generator poses significant challenges, rendering conventional analysis techniques for Hilbert-Schmidt operators ineffective. To overcome this, we introduce a novel framework based on the energy functional for these stochastic processes. Our approach integrates physical priors through an energy-based risk metric in both full and partial knowledge settings. We evaluate the statistical performance of a reduced-rank estimator in reproducing kernel Hilbert spaces (RKHS) in the partial knowledge setting. Notably, our approach provides learning bounds independent of the state space dimension and ensures non-spurious spectral estimation. Additionally, we elucidate how the distortion between the intrinsic energy-induced metric of the stochastic diffusion and the RKHS metric used for generator estimation impacts the spectral learning bounds.
tl;dr: We propose a Locally constrained Compact point cloud Model (LCM) for masking point modeling to achieve an elegant balance between performance and efficiency.

The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, these models heavily rely on the Transformer, leading to quadratic complexity and limited decoder, hindering their practice application. To address this limitation, we first conduct a comprehensive analysis of existing Transformer-based MPM, emphasizing the idea that redundancy reduction is crucial for point cloud analysis. To this end, we propose a Locally constrained Compact point cloud Model (LCM) consisting of a locally constrained compact encoder and a locally constrained Mamba-based decoder. Our encoder replaces self-attention with our local aggregation layers to achieve an elegant balance between performance and efficiency. Considering the varying information density between masked and unmasked patches in the decoder inputs of MPM, we introduce a locally constrained Mamba-based decoder. This decoder ensures linear complexity while maximizing the perception of point cloud geometry information from unmasked patches with higher information density. Extensive experimental results show that our compact model significantly surpasses existing Transformer-based models in both performance and efficiency, especially our LCM-based Point-MAE model, compared to the Transformer-based model, achieved an improvement of 1.84%, 0.67%, and 0.60% in performance on the three variants of ScanObjectNN while reducing parameters by 88% and computation by 73%. The code is available at https://github.com/zyh16143998882/LCM.

Prototyping complex computer-aided design (CAD) models in modern softwares can be very time-consuming. This is due to the lack of intelligent systems that can quickly generate simpler intermediate parts. We propose Text2CAD, the first AI framework for generating text-to-parametric CAD models using designer-friendly instructions for all skill levels. Furthermore, we introduce a data annotation pipeline for generating text prompts based on natural language instructions for the DeepCAD dataset using Mistral and LLaVA-NeXT. The dataset contains $\sim170$K models and $\sim660$K text annotations, from abstract CAD descriptions (e.g., _generate two concentric cylinders_) to detailed specifications (e.g., _draw two circles with center_ $(x,y)$ and _radius_ $r_{1}$, $r_{2}$, \textit{and extrude along the normal by} $d$...). Within the Text2CAD framework, we propose an end-to-end transformer-based auto-regressive network to generate parametric CAD models from input texts. We evaluate the performance of our model through a mixture of metrics, including visual quality, parametric precision, and geometrical accuracy. Our proposed framework shows great potential in AI-aided design applications. Project page is available at https://sadilkhan.github.io/text2cad-project/.
tl;dr: We found that introducing RL gradient would significantly improve online decision transformer's performance during online finetuning.

Decision Transformers have recently emerged as a new and compelling paradigm for offline Reinforcement Learning (RL), completing a trajectory in an autoregressive way. While improvements have been made to overcome initial shortcomings, online finetuning of decision transformers has been surprisingly under-explored. The widely adopted state-of-the-art Online Decision Transformer (ODT) still struggles when pretrained with low-reward offline data. In this paper, we theoretically analyze the online-finetuning of the decision transformer, showing that the commonly used Return-To-Go (RTG) that's far from the expected return hampers the online fine-tuning process. This problem, however, is well-addressed by the value function and advantage of standard RL algorithms. As suggested by our analysis, in our experiments, we hence find that simply adding TD3 gradients to the finetuning process of ODT effectively improves the online finetuning performance of ODT, especially if ODT is pretrained with low-reward offline data. These findings provide new directions to further improve decision transformers.
tl;dr: We show that fully recurrent models, e.g., RNNs, LSTMs, GRUs and SSMs, can be universal in-context approximators

Zero-shot and in-context learning enable solving tasks without model fine-tuning, making them essential for developing generative model solutions. Therefore, it is crucial to understand whether a pretrained model can be prompted to approximate any function, i.e., whether it is a universal in-context approximator. While it was recently shown that transformer models do possess this property, these results rely on their attention mechanism. Hence, these findings do not apply to fully recurrent architectures like RNNs, LSTMs, and the increasingly popular SSMs. We demonstrate that RNNs, LSTMs, GRUs, Linear RNNs, and linear gated architectures such as Mamba and Hawk/Griffin can also serve be universal in-context approximators. To streamline our argument, we introduce a programming language called LSRL that compiles to these fully recurrent architectures. LSRL may be of independent interest for further studies of fully recurrent models, such as constructing interpretability benchmarks. We also study the role of multiplicative gating and observe that architectures incorporating such gating (e.g., LSTMs, GRUs, Hawk/Griffin) can implement certain operations more stably, making them more viable candidates for practical in-context universal approximation.
tl;dr: A task-aware parameter-efficient fine-tuning method

Current parameter-efficient fine-tuning (PEFT) methods build adapters widely agnostic of the context of downstream task to learn, or the context of important knowledge to maintain. As a result, there is often a performance gap compared to full-parameter fine-tuning, and meanwhile the fine-tuned model suffers from catastrophic forgetting of the pre-trained world knowledge. In this paper, we propose **CorDA**, a Context-oriented Decomposition Adaptation method that builds learnable **task-aware adapters** from weight decomposition oriented by the context of downstream task or the world knowledge to maintain. Concretely, we collect a few data samples, and perform singular value decomposition for each linear layer of a pre-trained LLM multiplied by the covariance matrix of the input activation using these samples. The inverse of the covariance matrix is multiplied with the decomposed components to reconstruct the original weights. By doing so, the context of the representative samples is captured through deciding the factorizing orientation. Our method enables two options, the **knowledge-preserved adaptation** and the **instruction-previewed adaptation**. For the former, we use question-answering samples to obtain the covariance matrices, and use the decomposed components with the smallest $r$ singular values to initialize a learnable adapter, with the others frozen such that the world knowledge is better preserved. For the latter, we use the instruction data from the fine-tuning task, such as math or coding, to orientate the decomposition and train the largest $r$ components that most correspond to the task to learn. We conduct extensive experiments on Math, Code, and Instruction Following tasks. Our knowledge-preserved adaptation not only achieves better performance than LoRA on fine-tuning tasks, but also mitigates the forgetting of world knowledge. Our instruction-previewed adaptation is able to further enhance the fine-tuning performance to be comparable with full fine-tuning, surpassing
the state-of-the-art PEFT methods such as LoRA, DoRA, and PiSSA.
tl;dr: generalization of memorization

The neural network memorization problem is to study the expressive power of neural networks to interpolate a finite dataset. Although memorization is widely believed to have a close relationship with the strong generalizability of deep learning when using overparameterized models, to the best of our knowledge, there exists no theoretical study on the generalizability of memorization neural networks. In this paper, we give the first theoretical analysis of this topic. Since using i.i.d. training data is a necessary condition for a learning algorithm to be generalizable, memorization and its generalization theory for i.i.d. datasets are developed under mild conditions on the data distribution. First, algorithms are given to construct memorization networks for an i.i.d. dataset, which have the smallest number of parameters and even a constant number of parameters. Second, we show that, in order for the memorization networks to be generalizable, the width of the network must be at least equal to the dimension of the data, which implies that the existing memorization networks with an optimal number of parameters are not generalizable. Third, a lower bound for the sample complexity of general memorization algorithms and the exact sample complexity for memorization algorithms with constant number of parameters are given. As a consequence, it is shown that there exist data distributions such that, to be generalizable for them, the memorization network must have an exponential number of parameters in the data dimension. Finally, an efficient and generalizable memorization algorithm is given when the number of training samples is greater than the efficient memorization sample complexity of the data distribution.

Approximate nearest neighbor (ANN) search is a key component in many modern machine learning pipelines; recent use cases include retrieval-augmented generation (RAG) and vector databases. Clustering-based ANN algorithms, that use score computation methods based on product quantization (PQ), are often used in industrial-scale applications due to their scalability and suitability for distributed and disk-based implementations. However, they have slower query times than the leading graph-based ANN algorithms. In this work, we propose a new supervised score computation method based on the observation that inner product approximation is a multivariate (multi-output) regression problem that can be solved efficiently by reduced-rank regression. Our experiments show that on modern high-dimensional data sets, the proposed reduced-rank regression (RRR) method is superior to PQ in both query latency and memory usage. We also introduce LoRANN, a clustering-based ANN library that leverages the proposed score computation method. LoRANN is competitive with the leading graph-based algorithms and outperforms the state-of-the-art GPU ANN methods on high-dimensional data sets.

Selecting high-quality data for pre-training is crucial in shaping the downstream task performance of language models. A major challenge lies in identifying this optimal subset, a problem generally considered intractable, thus necessitating scalable and effective heuristics. In this work, we propose a data selection method, CoLoR-Filter (Conditional Loss Reduction Filtering), which leverages an empirical Bayes-inspired approach to derive a simple and computationally efficient selection criterion based on the relative loss values of two auxiliary models.
In addition to the modeling rationale, we evaluate CoLoR-Filter empirically on two language modeling tasks: (1) selecting data from C4 for domain adaptation to evaluation on Books and (2) selecting data from C4 for a suite of downstream multiple-choice question answering tasks. We demonstrate favorable scaling both as we subselect more aggressively and using small auxiliary models to select data for large target models. As one headline result, CoLoR-Filter data selected using a pair of 150m parameter auxiliary models can train a 1.2b parameter target model to match a 1.2b parameter model trained on 25b randomly selected tokens with 25x less data for Books and 11x less data for the downstream tasks.
Code: https://github.com/davidbrandfonbrener/color-filter-olmo
Filtered data: https://huggingface.co/datasets/davidbrandfonbrener/color-filtered-c4
tl;dr: Flow Matching for discrete data with applications to language modeling

Despite Flow Matching and diffusion models having emerged as powerful generative paradigms for continuous variables such as images and videos, their application to high-dimensional discrete data, such as language, is still limited. In this work, we present Discrete Flow Matching, a novel discrete flow paradigm designed specifically for generating discrete data. Discrete Flow Matching offers several key contributions: (i) it works with a general family of probability paths interpolating between source and target distributions; (ii) it allows for a generic formula for sampling from these probability paths using learned posteriors such as the probability denoiser ($x$-prediction) and noise-prediction ($\epsilon$-prediction); (iii) practically, focusing on specific probability paths defined with different schedulers improves generative perplexity compared to previous discrete diffusion and flow models; and (iv) by scaling Discrete Flow Matching models up to 1.7B parameters, we reach 6.7% Pass@1 and 13.4% Pass@10 on HumanEval and 6.7% Pass@1 and 20.6% Pass@10 on 1-shot MBPP coding benchmarks. Our approach is capable of generating high-quality discrete data in a non-autoregressive fashion, significantly closing the gap between autoregressive models and discrete flow models.
tl;dr: A fully autoregressive Transformer with next-patch prediction mechanism for multi-agent behavior simulation in autonomous driving

Simulating realistic behaviors of traffic agents is pivotal for efficiently validating the safety of autonomous driving systems. Existing data-driven simulators primarily use an encoder-decoder architecture to encode the historical trajectories before decoding the future. However, the heterogeneity between encoders and decoders complicates the models, and the manual separation of historical and future trajectories leads to low data utilization. Given these limitations, we propose BehaviorGPT, a homogeneous and fully autoregressive Transformer designed to simulate the sequential behavior of multiple agents. Crucially, our approach discards the traditional separation between "history" and "future" by modeling each time step as the "current" one for motion generation, leading to a simpler, more parameter- and data-efficient agent simulator. We further introduce the Next-Patch Prediction Paradigm (NP3) to mitigate the negative effects of autoregressive modeling, in which models are trained to reason at the patch level of trajectories and capture long-range spatial-temporal interactions. Despite having merely 3M model parameters, BehaviorGPT won first place in the 2024 Waymo Open Sim Agents Challenge with a realism score of 0.7473 and a minADE score of 1.4147, demonstrating its exceptional performance in traffic agent simulation.
tl;dr: In this work, we propose GL-NeRF, a new perspective of computing volume rendering with the Gauss-Laguerre quadrature.

Volume rendering in neural radiance fields is inherently time-consuming due to the large number of MLP calls on the points sampled per ray. Previous works would address this issue by introducing new neural networks or data structures. In this work, we propose GL-NeRF, a new perspective of computing volume rendering with the Gauss-Laguerre quadrature. GL-NeRF significantly reduces the number of MLP calls needed for volume rendering, introducing no additional data structures or neural networks. The simple formulation makes adopting GL-NeRF in any NeRF model possible. In the paper, we first justify the use of the Gauss-Laguerre quadrature and then demonstrate this plug-and-play attribute by implementing it in two different NeRF models. We show that with a minimal drop in performance, GL-NeRF can significantly reduce the number of MLP calls, showing the potential to speed up any NeRF model. Code can be found in project page https://silongyong.github.io/GL-NeRF_project_page/.

Dynamic scene reconstruction is a long-term challenge in the field of 3D vision. Recently, the emergence of 3D Gaussian Splatting has provided new insights into this problem. Although subsequent efforts rapidly extend static 3D Gaussian to dynamic scenes, they often lack explicit constraints on object motion, leading to optimization difficulties and performance degradation. To address the above issues, we propose a novel deformable 3D Gaussian splatting framework called MotionGS, which explores explicit motion priors to guide the deformation of 3D Gaussians. Specifically, we first introduce an optical flow decoupling module that decouples optical flow into camera flow and motion flow, corresponding to camera movement and object motion respectively. Then the motion flow can effectively constrain the deformation of 3D Gaussians, thus simulating the motion of dynamic objects. Additionally, a camera pose refinement module is proposed to alternately optimize 3D Gaussians and camera poses, mitigating the impact of inaccurate camera poses. Extensive experiments in the monocular dynamic scenes validate that MotionGS surpasses state-of-the-art methods and exhibits significant superiority in both qualitative and quantitative results. Project page: https://ruijiezhu94.github.io/MotionGS_page.

Recently, contrastive multi-view clustering (MvC) has emerged as a promising avenue for analyzing data from heterogeneous sources, typically leveraging the off-the-shelf instances as positives and randomly sampled ones as negatives. In practice, however, this paradigm would unavoidably suffer from the Dual Noisy Correspondence (DNC) problem, where noise compromises the constructions of both positive and negative pairs.
Specifically, the complexity of data collection and transmission might mistake some unassociated pairs as positive (namely, false positive correspondence), while the intrinsic one-to-many contrast nature of contrastive MvC would sample some intra-cluster samples as negative (namely, false negative correspondence).
To handle this daunting problem, we propose a novel method, dubbed Contextually-spectral based correspondence refinery (CANDY).
CANDY dexterously exploits inter-view similarities as \textit{context} to uncover false negatives. Furthermore, it employs a spectral-based module to denoise correspondence, alleviating the negative influence of false positives.
Extensive experiments on five widely-used multi-view benchmarks, in comparison with eight competitive multi-view clustering methods, verify the effectiveness of our method in addressing the DNC problem.
The code is available at https://github.com/XLearning-SCU/2024-NeurIPS-CANDY.
tl;dr: Transformers without tokenization are very slow to learn Markov sources; we present a theoretical model and empirical observations showing that the addition of tokenization enables them to learn such processes much more efficiently

While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al. 2022, Xue et al. 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{\text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically are incredibly slow or fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al. 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{\text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.

Adam has become one of the most favored optimizers in deep learning problems. Despite its success in practice, numerous mysteries persist regarding its theoretical understanding. In this paper, we study the implicit bias of Adam in linear logistic regression. Specifically, we show that when the training data are linearly separable, the iterates of Adam converge towards a linear classifier that achieves the maximum $\ell_\infty$-margin in direction. Notably, for a general class of diminishing learning rates, this convergence occurs within polynomial time. Our result shed light on the difference between Adam and (stochastic) gradient descent from a theoretical perspective.

Inference on large language models (LLMs) can be expensive in terms of the
compute and memory costs involved, especially when long sequence lengths are
used. In particular, the self-attention mechanism used in LLM inference contributes
significantly to these costs, which has sparked an interest in approximating the self-attention
computation to reduce such costs. In this work, we propose to approximate
self-attention by focusing on the dimensionality of key vectors computed in the
attention block. Our analysis reveals that key vectors lie in a significantly lower-dimensional
space, consistently across several datasets and models. Exploiting this
observation, we propose Loki, a novel sparse attention method that ranks and selects
tokens in the KV-cache based on attention scores computed in low-dimensional
space. Our evaluations show that Loki is able to speed up the attention computation
due to reduced data movement (load/store) and compute costs while maintaining
the efficacy of the models better than other popular approximation methods.
tl;dr: We propose a method to dynamically evict some KV cache tokens (pages) or recall evicted ones for different query tokens, reducing the memory usage of the KV cache and the latency of attention computation with few accuracy loss.

Large Language Models (LLMs) are widely used in today's tasks of natural language processing.
To support applications like multi-turn chats, document understanding, and content generation, models with long context lengths are growing in importance.
However, managing long contexts brings substantial challenges due to the expansion of key-value cache (KV cache). Longer KV cache requires larger memory, limiting the batch-size thus decreasing throughput. Also, computing attention over long KV cache incurs more memory access, hurting the end-to-end latency.
Prior works find that it is sufficient to use only the recent and high-impact tokens for attention computation, allowing the eviction of less vital tokens to shrink cache size.
Nonetheless, we observe a dynamic shift in token importance across different decoding steps. Tokens initially evicted might regain importance after certain decoding steps.
To address this, we propose ArkVale, a page-based KV cache manager that can recognize and recall currently important tokens evicted before. We asynchronously copy the filled page into external memory (e.g., CPU memory) as backup and summarize it into a much smaller digest by constructing the bounding-volume of its keys. Before attention computation, we measure all pages' importance based on their digests, recall the important ones, evict the unimportant ones, and select the top-ranked pages for attention computation.
Experiment results show that ArkVale performs well on various long context tasks with negligible accuracy loss under 2k$\sim$4k cache budget and can improve decoding latency to $2.2\times$ and batching throughput to $4.6\times$ because it applies attention on only a small subset of pages and reduce per-sample memory usage of KV cache.

In this paper, we study the multi-armed bandit problem in the best-of-both-worlds (BOBW) setting with heavy-tailed losses, where the losses can be negative and unbounded but have $(1+v)$-th raw moments bounded by $u^{1+v}$ for some known $u>0$ and $v\in(0,1]$. Specifically, we consider the BOBW setting where the underlying environment could be either (oblivious) adversarial (i.e., the loss distribution can change arbitrarily over time) or stochastic (i.e., the loss distribution is fixed over time) and is unknown to the decision-maker a prior, and propose an algorithm that achieves a $T^{\frac{1}{1+v}}$-type worst-case (pseudo-)regret in the adversarial regime and a $\log T$-type gap-dependent regret in the stochastic regime, where $T$ is the time horizon. Compared to the state-of-the-art results, our algorithm offers stronger \emph{high-probability} regret guarantees rather than expected regret guarantees, and more importantly, relaxes a strong technical assumption on the loss distribution. This assumption is needed even for the weaker expected regret obtained in the literature and is generally hard to verify in practice. As a byproduct, relaxing this assumption leads to the first near-optimal regret result for heavy-tailed bandits with Huber contamination in the adversarial regime, in contrast to all previous works focused on the (easier) stochastic regime. Our result also implies a high-probability BOBW regret guarantee when the bounded true losses are protected with pure Local Differential Privacy (LDP), while the existing work ensures the (weaker) \emph{approximate} LDP with the regret bounds in expectation only.
tl;dr: Interactive Multi-modal Image Fusion

Existing multi-modal image fusion methods fail to address the compound degradations presented in source images, resulting in fusion images plagued by noise, color bias, improper exposure, etc. Additionally, these methods often overlook the specificity of foreground objects, weakening the salience of the objects of interest within the fused images. To address these challenges, this study proposes a novel interactive multi-modal image fusion framework based on the text-modulated diffusion model, called Text-DiFuse. First, this framework integrates feature-level information integration into the diffusion process, allowing adaptive degradation removal and multi-modal information fusion. This is the first attempt to deeply and explicitly embed information fusion within the diffusion process, effectively addressing compound degradation in image fusion. Second, by embedding the combination of the text and zero-shot location model into the diffusion fusion process, a text-controlled fusion re-modulation strategy is developed. This enables user-customized text control to improve fusion performance and highlight foreground objects in the fused images. Extensive experiments on diverse public datasets show that our Text-DiFuse achieves state-of-the-art fusion performance across various scenarios with complex degradation. Moreover, the semantic segmentation experiment validates the significant enhancement in semantic performance achieved by our text-controlled fusion re-modulation strategy. The code is publicly available at https://github.com/Leiii-Cao/Text-DiFuse.
tl;dr: Existing offline model-based methods fail under the true dynamics. This reveals the previously-unnoticed “edge-of-reach” problem, and leads us to propose RAVL - a new method that continues to work even in the absence of model uncertainty.

Offline reinforcement learning (RL) aims to train agents from pre-collected datasets. However, this comes with the added challenge of estimating the value of behaviors not covered in the dataset. Model-based methods offer a potential solution by training an approximate dynamics model, which then allows collection of additional synthetic data via rollouts in this model. The prevailing theory treats this approach as online RL in an approximate dynamics model, and any remaining performance gap is therefore understood as being due to dynamics model errors. In this paper, we analyze this assumption and investigate how popular algorithms perform as the learned dynamics model is improved. In contrast to both intuition and theory, if the learned dynamics model is replaced by the true error-free dynamics, existing model-based methods completely fail. This reveals a key oversight: The theoretical foundations assume sampling of full horizon rollouts in the learned dynamics model; however, in practice, the number of model-rollout steps is aggressively reduced to prevent accumulating errors. We show that this truncation of rollouts results in a set of edge-of-reach states at which we are effectively "bootstrapping from the void." This triggers pathological value overestimation and complete performance collapse. We term this the edge-of-reach problem. Based on this new insight, we fill important gaps in existing theory, and reveal how prior model-based methods are primarily addressing the edge-of-reach problem, rather than model-inaccuracy as claimed. Finally, we propose Reach-Aware Value Learning (RAVL), a simple and robust method that directly addresses the edge-of-reach problem and hence - unlike existing methods - does not fail as the dynamics model is improved. Since world models will inevitably improve, we believe this is a key step towards future-proofing offline RL.
666. RG-SAN: Rule-Guided Spatial Awareness Network for End-to-End 3D Referring Expression Segmentation

3D Referring Expression Segmentation (3D-RES) aims to segment 3D objects by correlating referring expressions with point clouds. However, traditional approaches frequently encounter issues like over-segmentation or mis-segmentation, due to insufficient emphasis on spatial information of instances. In this paper, we introduce a Rule-Guided Spatial Awareness Network (RG-SAN) by utilizing solely the spatial information of the target instance for supervision. This approach enables the network to accurately depict the spatial relationships among all entities described in the text, thus enhancing the reasoning capabilities. The RG-SAN consists of the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS) strategy. The TLM initially locates all mentioned instances and iteratively refines their positional information. The RWS strategy, acknowledging that only target objects have supervised positional information, employs dependency tree rules to precisely guide the core instance’s positioning. Extensive testing on the ScanRefer benchmark has shown that RG-SAN not only establishes new performance benchmarks, with an mIoU increase of 5.1 points, but also exhibits significant improvements in robustness when processing descriptions with spatial ambiguity. All codes are available at https://github.com/sosppxo/RG-SAN.

Personalized Federated Graph Learning (pFGL) facilitates the decentralized training of Graph Neural Networks (GNNs) without compromising privacy while accommodating personalized requirements for non-IID participants. In cross-domain scenarios, structural heterogeneity poses significant challenges for pFGL. Nevertheless, previous pFGL methods incorrectly share non-generic knowledge globally and fail to tailor personalized solutions locally under domain structural shift. We innovatively reveal that the spectral nature of graphs can well reflect inherent domain structural shifts. Correspondingly, our method overcomes it by sharing generic spectral knowledge. Moreover, we indicate the biased message-passing schemes for graph structures and propose the personalized preference module. Combining both strategies, we propose our pFGL framework $\textbf{FedSSP}$ which $\textbf{S}$hares generic $\textbf{S}$pectral knowledge while satisfying graph $\textbf{P}$references. Furthermore, We perform extensive experiments on cross-dataset and cross-domain settings to demonstrate the superiority of our framework. The code is available at https://github.com/OakleyTan/FedSSP.
tl;dr: We propose SeqComm, a multi-agent communication scheme that enhances coordination by prioritizing actions and communication.

The partial observability and stochasticity in multi-agent settings can be mitigated by accessing more information about others via communication. However, the coordination problem still exists since agents cannot communicate actual actions with each other at the same time due to the circular dependencies. In this paper, we propose a novel multi-level communication scheme, Sequential Communication (SeqComm). SeqComm treats agents asynchronously (the upper-level agents make decisions before the lower-level ones) and has two communication phases. In the negotiation phase, agents determine the priority of decision-making by communicating hidden states of observations and comparing the value of intention, which is obtained by modeling the environment dynamics. In the launching phase, the upper-level agents take the lead in making decisions and then communicate their actions with the lower-level agents. Theoretically, we prove the policies learned by SeqComm are guaranteed to improve monotonically and converge. Empirically, we show that SeqComm outperforms existing methods in a variety of cooperative multi-agent tasks.
tl;dr: We introduce AsyncDiff, a universal and plug-and-play diffusion acceleration scheme that innovatively enables model parallelism across multiple devices.

Diffusion models have garnered significant interest from the community for their great generative ability across various applications. However, their typical multi-step sequential-denoising nature gives rise to high cumulative latency, thereby precluding the possibilities of parallel computation. To address this, we introduce AsyncDiff, a universal and plug-and-play acceleration scheme that enables model parallelism across multiple devices. Our approach divides the cumbersome noise prediction model into multiple components, assigning each to a different device. To break the dependency chain between these components, it transforms the conventional sequential denoising into an asynchronous process by exploiting the high similarity between hidden states in consecutive diffusion steps. Consequently, each component is facilitated to compute in parallel on separate devices. The proposed strategy significantly reduces inference latency while minimally impacting the generative quality. Specifically, for the Stable Diffusion v2.1, AsyncDiff achieves a 2.7x speedup with negligible degradation and a 4.0x speedup with only a slight reduction of 0.38 in CLIP Score, on four NVIDIA A5000 GPUs. Our experiments also demonstrate AsyncDiff can be readily applied to video diffusion models with encouraging performances.

Diffusion regulates numerous natural processes and the dynamics of many successful generative models. Existing models to learn the diffusion terms from observational data rely on complex bilevel optimization problems and model only the drift of the system.
We propose a new simple model, JKOnet*, which bypasses the complexity of existing architectures while presenting significantly enhanced representational capabilities: JKOnet* recovers the potential, interaction, and internal energy components of the underlying diffusion process. JKOnet* minimizes a simple quadratic loss and outperforms other baselines in terms of sample efficiency, computational complexity, and accuracy. Additionally, JKOnet* provides a closed-form optimal solution for linearly parametrized functionals, and, when applied to predict the evolution of cellular processes from real-world data, it achieves state-of-the-art accuracy at a fraction of the computational cost of all existing methods.
Our methodology is based on the interpretation of diffusion processes as energy-minimizing trajectories in the probability space via the so-called JKO scheme, which we study via its first-order optimality conditions.
tl;dr: We provide information-theoretic and computational results for the unsupervised matching two high-dimensional point clouds.

The Procrustes-Wasserstein problem consists in matching two high-dimensional point clouds in an unsupervised setting, and has many applications in natural language processing and computer vision.
We consider a planted model with two datasets $X,Y$ that consist of $n$ datapoints in $\mathbb{R}^d$, where $Y$ is a noisy version of $X$, up to an orthogonal transformation and a relabeling of the data points.
This setting is related to the graph alignment problem in geometric models.
In this work, we focus on the euclidean transport cost between the point clouds as a measure of performance for the alignment. We first establish information-theoretic results, in the high ($d \gg \log n$) and low ($d \ll \log n$) dimensional regimes.
We then study computational aspects and propose the ‘Ping-Pong algorithm', alternatively estimating the orthogonal transformation and the relabeling, initialized via a Franke-Wolfe convex relaxation. We give sufficient conditions for the method to retrieve the planted signal after one single step. We provide experimental results to compare the proposed approach with the state-of-the-art method of Grave et al. (2019).

Protein language models (PLMs) have shown remarkable capabilities in various protein function prediction tasks. However, while protein function is intricately tied to structure, most existing PLMs do not incorporate protein structure information. To address this issue, we introduce ProSST, a Transformer-based protein language model that seamlessly integrates both protein sequences and structures. ProSST incorporates a structure quantization module and a Transformer architecture with disentangled attention. The structure quantization module translates a 3D protein structure into a sequence of discrete tokens by first serializing the protein structure into residue-level local structures and then embeds them into dense vector space. These vectors are then quantized into discrete structure tokens by a pre-trained clustering model. These tokens serve as an effective protein structure representation. Furthermore, ProSST explicitly learns the relationship between protein residue token sequences and structure token sequences through the sequence-structure disentangled attention. We pre-train ProSST on millions of protein structures using a masked language model objective, enabling it to learn comprehensive contextual representations of proteins. To evaluate the proposed ProSST, we conduct extensive experiments on the zero-shot mutation effect prediction and several supervised downstream tasks, where ProSST achieves the state-of-the-art performance among all baselines. Our code and pre-trained models are publicly available.
tl;dr: Given a set of heterogeneous input sequences of a common geographic area, we optimize a single dynamic scene representation that permits rendering of arbitrary viewpoints and scene configurations at interactive speeds.

We present an efficient neural 3D scene representation for novel-view synthesis (NVS) in large-scale, dynamic urban areas. Existing works are not well suited for applications like mixed-reality or closed-loop simulation due to their limited visual quality and non-interactive rendering speeds. Recently, rasterization-based approaches have achieved high-quality NVS at impressive speeds. However, these methods are limited to small-scale, homogeneous data, i.e. they cannot handle severe appearance and geometry variations due to weather, season, and lighting and do not scale to larger, dynamic areas with thousands of images. We propose 4DGF, a neural scene representation that scales to large-scale dynamic urban areas, handles heterogeneous input data, and substantially improves rendering speeds. We use 3D Gaussians as an efficient geometry scaffold while relying on neural fields as a compact and flexible appearance model. We integrate scene dynamics via a scene graph at global scale while modeling articulated motions on a local level via deformations. This decomposed approach enables flexible scene composition suitable for real-world applications. In experiments, we surpass the state-of-the-art by over 3 dB in PSNR and more than 200x in rendering speed.
tl;dr: Large language models can reason without any specialized prompting, when alternative tokens are considered during the decoding stage.

In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manually intensive prompt engineering. Our study takes a novel approach by asking: Can LLMs reason effectively without any prompting? Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the \textit{decoding} process. Rather than conventional greedy decoding, we investigate the top-$k$ alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' \textit{intrinsic} reasoning abilities. Moreover, we observe that the presence of a CoT in the decoding path correlates with a higher confidence in the model's decoded answer. This confidence metric effectively differentiates between CoT and non-CoT paths. Extensive empirical studies on various reasoning benchmarks show that the proposed CoT-decoding effectively elicits reasoning capabilities from language models, which were previously obscured by standard greedy decoding.
tl;dr: Periodicity helps in agent-state based RL in POMDPs because agent-states are not Markov.

The standard approach for Partially Observable Markov Decision Processes (POMDPs) is to convert them to a fully observed belief-state MDP. However, the belief state depends on the system model and is therefore not viable in reinforcement learning (RL) settings. A widely used alternative is to use an agent state, which is a model-free, recursively updateable function of the observation history. Examples include frame stacking and recurrent neural networks. Since the agent state is model-free, it is used to adapt standard RL algorithms to POMDPs. However, standard RL algorithms like Q-learning learn a stationary policy. Our main thesis that we illustrate via examples is that because the agent state does not satisfy the Markov property, non-stationary agent-state based policies can outperform stationary ones. To leverage this feature, we propose PASQL (periodic agent-state based Q-learning), which is a variant of agent-state-based Q-learning that learns periodic policies. By combining ideas from periodic Markov chains and stochastic approximation, we rigorously establish that PASQL converges to a cyclic limit and characterize the approximation error of the converged periodic policy. Finally, we present a numerical experiment to highlight the salient features of PASQL and demonstrate the benefit of learning periodic policies over stationary policies.

Watermarking is a technical means to dissuade malfeasant usage of Large Language Models.
This paper proposes a novel watermarking scheme, so-called WaterMax, that enjoys high detectability while sustaining the quality of the generated text of the original LLM.
Its new design leaves the LLM untouched (no modification of the weights, logits or temperature).
WaterMax balances robustness and computational complexity contrary to the watermarking techniques of the literature inherently provoking a trade-off between quality and robustness.
Its performance is both theoretically proven and experimentally validated.
It outperforms all the SotA techniques under the most complete benchmark suite.
tl;dr: We explain how Kaplan et al. got to 0.88

Kaplan et al. and Hoffmann et al. developed influential scaling laws for the optimal model size as a function of the compute budget, but these laws yield substantially different predictions. We explain the discrepancy by reproducing the Kaplan scaling law on two datasets (OpenWebText2 and RefinedWeb) and identifying three factors causing the difference: last layer computational cost, warmup duration, and scale-dependent optimizer tuning. With these factors corrected, we obtain excellent agreement with the Hoffmann et al. (i.e., "Chinchilla") scaling law. Counter to a hypothesis of Hoffmann et al., we find that careful learning rate decay is not essential for the validity of their scaling law. As a secondary result, we derive scaling laws for the optimal learning rate and batch size, finding that tuning the AdamW $\beta_2$ parameter is essential at lower batch sizes.

Natural images captured by mobile devices often suffer from multiple types of degradation, such as noise, blur, and low light. Traditional image restoration methods require manual selection of specific tasks, algorithms, and execution sequences, which is time-consuming and may yield suboptimal results. All-in-one models, though capable of handling multiple tasks, typically support only a limited range and often produce overly smooth, low-fidelity outcomes due to their broad data distribution fitting. To address these challenges, we first define a new pipeline for restoring images with multiple degradations, and then introduce RestoreAgent, an intelligent image restoration system leveraging multimodal large language models. RestoreAgent autonomously assesses the type and extent of degradation in input images and performs restoration through (1) determining the appropriate restoration tasks, (2) optimizing the task sequence, (3) selecting the most suitable models, and (4) executing the restoration. Experimental results demonstrate the superior performance of RestoreAgent in handling complex degradation, surpassing human experts. Furthermore, the system’s modular design facilitates the fast integration of new tasks and models.
tl;dr: We propose DETAIL, an influence function-based technique to provide attribution for task demonstrations in in-context learning.

In-context learning (ICL) allows transformer-based language models that are pre-trained on general text to quickly learn a specific task with a few "task demonstrations" without updating their parameters, significantly boosting their flexibility and generality. ICL possesses many distinct characteristics from conventional machine learning, thereby requiring new approaches to interpret this learning paradigm. Taking the viewpoint of recent works showing that transformers learn in context by formulating an internal optimizer, we propose an influence function-based attribution technique, DETAIL, that addresses the specific characteristics of ICL. We empirically verify the effectiveness of our approach for demonstration attribution while being computationally efficient. Leveraging the results, we then show how DETAIL can help improve model performance in real-world scenarios through demonstration reordering and curation. Finally, we experimentally prove the wide applicability of DETAIL by showing our attribution scores obtained on white-box models are transferable to black-box models in improving model performance.
tl;dr: A simplified and generalized framework for training masked discrete diffusion models

Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.75 (CIFAR-10) and 3.40 (ImageNet 64x64) bits per dimension that are better than autoregressive models of similar sizes.
tl;dr: Language models do not learn factual knowledge well from finetuning due to fitting word co-occurrence. Training with implicit association and removing word co-occurrence help model effectively learn knowledge that generalizes well to reasoning tasks.

Pretrained language models can encode a large amount of knowledge and utilize it for various reasoning tasks, yet they can still struggle to learn novel factual knowledge effectively from finetuning on limited textual demonstrations. In this work, we show that the reason for this deficiency is that language models are biased to learn word co-occurrence statistics instead of true factual associations. We identify the differences between two forms of knowledge representation in language models: knowledge in the form of co-occurrence statistics is encoded in the middle layers of the transformer model and does not generalize well to reasoning scenarios beyond simple question answering, while true factual associations are encoded in the lower layers and can be freely utilized in various reasoning tasks. Based on these observations, we propose two strategies to improve the learning of factual associations in language models. We show that training on text with implicit rather than explicit factual associations can force the model to learn factual associations instead of co-occurrence statistics, significantly improving the generalization of newly learned knowledge. We also propose a simple training method to actively forget the learned co-occurrence statistics, which unblocks and enhances the learning of factual associations when training on plain narrative text. On both synthetic and real-world corpora, the two proposed strategies improve the generalization of the knowledge learned during finetuning to reasoning scenarios such as indirect and multi-hop question answering.
tl;dr: a no-go theorem states that we can maintain either the sampling efficiency or the watermark strength, but not both.

Large language models are probabilistic models, and the process of generating content is essentially sampling from the output distribution of the language model. Existing watermarking techniques inject watermarks into the generated content without altering the output quality. On the other hand, existing acceleration techniques, specifically speculative sampling, leverage a draft model to speed up the sampling process while preserving the output distribution. However, there is no known method to simultaneously accelerate the sampling process and inject watermarks into the generated content. In this paper, we investigate this direction and find that the integration of watermarking and acceleration is non-trivial. We prove a no-go theorem, which states that it is impossible to simultaneously maintain the highest watermark strength and the highest sampling efficiency. Furthermore, we propose two methods that maintain either the sampling efficiency or the watermark strength, but not both. Our work provides a rigorous theoretical foundation for understanding the inherent trade-off between watermark strength and sampling efficiency in accelerating the generation of watermarked tokens for large language models. We also conduct numerical experiments to validate our theoretical findings and demonstrate the effectiveness of the proposed methods.
tl;dr: We present the first ML system that can forecast at near human levels.

Forecasting future events is important for policy and decision making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions. To facilitate our study, we collect a large dataset of questions from competitive forecasting platforms. Under a test set published after the knowledge cut-offs of our LMs, we evaluate the end-to-end performance of our system against the aggregates of human forecasts. On average, the system nears the crowd aggregate of competitive forecasters and, in a certain relaxed setting, surpasses it. Our work suggests that using LMs to forecasts the future could provide accurate predictions at scale and help to inform institutional decision making.
tl;dr: We introduce MiniCache, a novel method to compress the KV cache between adjacent layers from a depth perspective, achieving superior compression ratios, high throughput, and near-lossless performance.

A critical approach for efficiently deploying computationally demanding large language models (LLMs) is Key-Value (KV) caching. The KV cache stores key-value states of previously generated tokens, significantly reducing the need for repetitive computations and thereby lowering latency in autoregressive generation. However, the size of the KV cache grows linearly with sequence length, posing challenges for applications requiring long context input and extensive sequence generation. In this paper, we present a simple yet effective approach, called MiniCache, to compress the KV cache across layers from a novel depth perspective, significantly reducing the memory footprint for LLM inference. Our approach is based on the observation that KV cache states exhibit high similarity between the adjacent layers in the middle-to-deep portion of LLMs. To facilitate merging, we propose disentangling the states into the magnitude and direction components, interpolating the directions of the state vectors while preserving their lengths unchanged. Furthermore, we introduce a token retention strategy to keep highly distinct state pairs unmerged, thus preserving the information with minimal additional storage overhead. Our MiniCache is training-free and general, complementing existing KV cache compression strategies, such as quantization and sparsity. We conduct a comprehensive evaluation of MiniCache utilizing various models including LLaMA-2, LLaMA-3, Phi-3, Mistral, and Mixtral across multiple benchmarks, demonstrating its exceptional performance in achieving superior compression ratios and high throughput. On the ShareGPT dataset, LLaMA-2-7B with cross-layer merging achieves a compression ratio of $1.53\times$. Additionally, since MiniCache is orthogonal to existing quantization techniques, it can achieve a compression ratio of up to $5.02\times$ when combined with the 4-bit quantization technique, enhancing inference throughput by approximately $5\times$ and reducing the memory footprint by $41\%$ compared to the FP16 full cache baseline, all while maintaining near-lossless performance. Project is available at https://minicache.vmv.re .
tl;dr: We present a structured and explicit representation for 3D generative modeling by structuring Gaussian Splatting using Optimal Transport, achieving state-of-the-art generation quality.

We introduce a radiance representation that is both structured and fully explicit and thus greatly facilitates 3D generative modeling. Existing radiance representations either require an implicit feature decoder, which significantly degrades the modeling power of the representation, or are spatially unstructured, making them difficult to integrate with mainstream 3D diffusion methods. We derive GaussianCube by first using a novel densification-constrained Gaussian fitting algorithm, which yields high-accuracy fitting using a fixed number of free Gaussians, and then rearranging these Gaussians into a predefined voxel grid via Optimal Transport. Since GaussianCube is a structured grid representation, it allows us to use standard 3D U-Net as our backbone in diffusion modeling without elaborate designs. More importantly, the high-accuracy fitting of the Gaussians allows us to achieve a high-quality representation with orders of magnitude fewer parameters than previous structured representations for comparable quality, ranging from one to two orders of magnitude. The compactness of GaussianCube greatly eases the difficulty of 3D generative modeling. Extensive experiments conducted on unconditional and class-conditioned object generation, digital avatar creation, and text-to-3D synthesis all show that our model achieves state-of-the-art generation results both qualitatively and quantitatively, underscoring the potential of GaussianCube as a highly accurate and versatile radiance representation for 3D generative modeling.
tl;dr: A new framework for autoformazing mathematical statements

Autoformalization, the task of automatically translating natural language descriptions into a formal language, poses a significant challenge across various domains, especially in mathematics. Recent advancements in large language models (LLMs) have unveiled their promising capabilities to formalize even competition-level math problems. However, we observe a considerable discrepancy between pass@1 and pass@k accuracies in LLM-generated formalizations. To address this gap, we introduce a novel framework that scores and selects the best result from k autoformalization candidates based on two complementary self-consistency methods: symbolic equivalence and semantic consistency. Elaborately, symbolic equivalence identifies the logical homogeneity among autoformalization candidates using automated theorem provers, and semantic consistency evaluates the preservation of the original meaning by informalizing the candidates and computing the similarity between the embeddings of the original and informalized texts.
Our extensive experiments on the MATH and miniF2F datasets demonstrate that our approach significantly enhances autoformalization accuracy, achieving up to 0.22-1.35x relative improvements across various LLMs and baseline methods.
tl;dr: We propose a new deep Q-learning algorithm that learns to solve RL tasks without sequential propagation of errors, which provides a potential explanation to credit assignment in biological reward-based learning.

A computational problem in biological reward-based learning is how credit assignment is performed in the nucleus accumbens (NAc). Much research suggests that NAc dopamine encodes temporal-difference (TD) errors for learning value predictions. However, dopamine is synchronously distributed in regionally homogeneous concentrations, which does not support explicit credit assignment (like used by backpropagation). It is unclear whether distributed errors alone are sufficient for synapses to make coordinated updates to learn complex, nonlinear reward-based learning tasks. We design a new deep Q-learning algorithm, Artificial Dopamine, to computationally demonstrate that synchronously distributed, per-layer TD errors may be sufficient to learn surprisingly complex RL tasks. We empirically evaluate our algorithm on MinAtar, the DeepMind Control Suite, and classic control tasks, and show it often achieves comparable performance to deep RL algorithms that use backpropagation.
tl;dr: We propose a circuit finding method that prunes connections between model components, and show it performs and scales well.

The path to interpreting a language model often proceeds via analysis of circuits---sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they either rely on inefficient search algorithms or inaccurate approximations. In this paper, we frame circuit discovery as an optimization problem and propose _Edge Pruning_ as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, prunes the _edges_ between components. Our method finds circuits in GPT-2 that use less than half the number of edges than circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient on tasks involving up to 100,000 examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the size of GPT-2.
We use this setting for a case study, where we compare the mechanisms behind instruction prompting and in-context learning.
We find two circuits with more than 99.96% sparsity that match the performance of the full model. Further analysis reveals that the mechanisms in the two settings overlap substantially. This shows that Edge Pruning is a practical and scalable tool for interpretability,
which can shed light on behaviors that only emerge in large models.
689. Global Distortions from Local Rewards: Neural Coding Strategies in Path-Integrating Neural Systems

Grid cells in the mammalian brain are fundamental to spatial navigation, and therefore crucial to how animals perceive and interact with their environment. Traditionally, grid cells are thought support path integration through highly symmetric hexagonal lattice firing patterns. However, recent findings show that their firing patterns become distorted in the presence of significant spatial landmarks such as rewarded locations. This introduces a novel perspective of dynamic, subjective, and action-relevant interactions between spatial representations and environmental cues. Here, we propose a practical and theoretical framework to quantify and explain these interactions. To this end, we train path-integrating recurrent neural networks (piRNNs) on a spatial navigation task, whose goal is to predict the agent's position with a special focus on rewarded locations. Grid-like neurons naturally emerge from the training of piRNNs, which allows us to investigate how the two aspects of the task, space and reward, are integrated in their firing patterns. We find that geometry, but not topology, of the grid cell population code becomes distorted. Surprisingly, these distortions are global in the firing patterns of the grid cells despite local changes in the reward. Our results indicate that after training with location-specific reward information, the preserved representational topology supports successful path integration, whereas the emergent heterogeneity in individual responses due to global distortions may encode dynamically changing environmental cues. By bridging the gap between computational models and the biological reality of spatial navigation under reward information, we offer new insights into how neural systems prioritize environmental landmarks in their spatial navigation code.
tl;dr: We propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification. This paradigm can effectively reduce the fine-grained annotation cost of WSI while fully utilizing limited WSI data.

The expensive fine-grained annotation and data scarcity
have become the primary obstacles for the widespread adoption of deep learning-based Whole Slide Images (WSI) classification algorithms in clinical practice. Unlike few-shot learning methods in natural images that can leverage the labels of each image, existing few-shot WSI classification methods only utilize a small number of fine-grained labels or weakly supervised slide labels for training in order to avoid expensive fine-grained annotation. They lack sufficient mining of available WSIs, severely limiting WSI classification performance. To address the above issues, we propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification, named FAST. FAST consists of a dual-level annotation strategy and a dual-branch classification framework. Firstly, to avoid expensive fine-grained annotation, we collect a very small number of WSIs at the slide level, and annotate an extremely small number of patches. Then, to fully mining the available WSIs, we use all the patches and available patch labels to build a cache branch, which utilizes the labeled patches to learn the labels of unlabeled patches and through knowledge retrieval for patch classification. In addition to the cache branch, we also construct a prior branch that includes learnable prompt vectors, using the text encoder of visual-language models for patch classification. Finally, we integrate the results from both branches to achieve WSI classification. Extensive experiments on binary and multi-class datasets demonstrate that our proposed method significantly surpasses existing few-shot classification methods and approaches the accuracy of fully supervised methods with only 0.22% annotation costs. All codes and models will be publicly available on https://github.com/fukexue/FAST.
tl;dr: We present knowledge continuity, a novel definition which aims to certify robustness of neural networks across continuous/discrete domains.

We present *knowledge continuity*, a novel definition inspired by Lipschitz continuity which aims to certify the robustness of neural networks across input domains (such as continuous and discrete domains in vision and language, respectively). Most existing approaches that seek to certify robustness, especially Lipschitz continuity, lie within the continuous domain with norm and distribution-dependent guarantees. In contrast, our proposed definition yields certification guarantees that depend only on the loss function and the intermediate learned metric spaces of the neural network. These bounds are independent of domain modality, norms, and distribution. We further demonstrate that the expressiveness of a model class is not at odds with its knowledge continuity. This implies that achieving robustness by maximizing knowledge continuity should not theoretically hinder inferential performance. Finally, to complement our theoretical results, we present several applications of knowledge continuity such as regularization, a certification algorithm, and show that knowledge continuity can be used to localize vulnerable components of a neural network.
tl;dr: We develop approaches to enable autoregressive pretraining on multiple physical systems and show it can improve transfer performance across domain gaps.

We introduce multiple physics pretraining (MPP), an autoregressive task-agnostic pretraining approach for physical surrogate modeling of spatiotemporal systems with transformers. In MPP, rather than training one model on a specific physical system, we train a backbone model to predict the dynamics of multiple heterogeneous physical systems simultaneously in order to learn features that are broadly useful across systems and facilitate transfer. In order to learn effectively in this setting, we introduce a shared embedding and normalization strategy that projects the fields of multiple systems into a shared embedding space. We validate the efficacy of our approach on both pretraining and downstream tasks over a broad fluid mechanics-oriented benchmark. We show that a single MPP-pretrained transformer is able to match or outperform task-specific baselines on all pretraining sub-tasks without the need for finetuning. For downstream tasks, we demonstrate that finetuning MPP-trained models results in more accurate predictions across multiple time-steps on systems with previously unseen physical components or higher dimensional systems compared to training from scratch or finetuning pretrained video foundation models. We open-source our code and model weights trained at multiple scales for reproducibility.

Spiking Transformers, which integrate Spiking Neural Networks (SNNs) with Transformer architectures, have attracted significant attention due to their potential for low energy consumption and high performance. However, there remains a substantial gap in performance between SNNs and Artificial Neural Networks (ANNs). To narrow this gap, we have developed QKFormer, a direct training spiking transformer with the following features: i) _Linear complexity and high energy efficiency_, the novel spike-form Q-K attention module efficiently models the token or channel attention through binary vectors and enables the construction of larger models. ii) _Multi-scale spiking representation_, achieved by a hierarchical structure with the different numbers of tokens across blocks. iii) _Spiking Patch Embedding with Deformed Shortcut (SPEDS)_, enhances spiking information transmission and integration, thus improving overall performance. It is shown that QKFormer achieves significantly superior performance over existing state-of-the-art SNN models on various mainstream datasets. Notably, with comparable size to Spikformer (66.34 M, 74.81\%), QKFormer (64.96 M) achieves a groundbreaking top-1 accuracy of **85.65\%** on ImageNet-1k, substantially outperforming Spikformer by **10.84\%**. To our best knowledge, this is the first time that directly training SNNs have exceeded 85\% accuracy on ImageNet-1K.

Anomaly detection methods typically require fully observed data for model training and inference and cannot handle incomplete data, while the missing data problem is pervasive in science and engineering, leading to challenges in many important applications such as abnormal user detection in recommendation systems and novel or anomalous cell detection in bioinformatics, where the missing rates can be higher than 30\% or even 80\%. In this work, first, we construct and evaluate a straightforward strategy, ''impute-then-detect'', via combining state-of-the-art imputation methods with unsupervised anomaly detection methods, where the training data are composed of normal samples only. We observe that such two-stage methods frequently yield imputation bias from normal data, namely, the imputation methods are inclined to make incomplete samples ''normal", where the fundamental reason is that the imputation models learned only on normal data and cannot generalize well to abnormal data in the inference stage. To address this challenge, we propose an end-to-end method that integrates data imputation with anomaly detection into a unified optimization problem. The proposed model learns to generate well-designed pseudo-abnormal samples to mitigate the imputation bias and ensure the discrimination ability of both the imputation and detection processes. Furthermore, we provide theoretical guarantees for the effectiveness of the proposed method, proving that the proposed method can correctly detect anomalies with high probability. Experimental results on datasets with manually constructed missing values and inherent missing values demonstrate that our proposed method effectively mitigates the imputation bias and surpasses the baseline methods significantly. The source code of our method is available at https://github.com/jicongfan/ImAD-Anomaly-Detection-With-Missing-Data.
tl;dr: Through a new analysis of behavior cloning with the logarithmic loss, we show that it is possible to achieve horizon-independent sample complexity in offline imitation learning, closing an apparent gap between online and offline IL.

Imitation learning (IL) aims to mimic the behavior of an expert in a sequential decision making task by learning from demonstrations, and has been widely applied to robotics, autonomous driving, and autoregressive text generation. The simplest approach to IL, behavior cloning (BC) is thought to incur sample complexity with unfavorable quadratic dependence on the problem horizon, motivating a variety of different online algorithms that attain improved linear horizon dependence under stronger assumptions on the data and the learner’s access to the expert.
We revisit the apparent gap between offline and online IL from a learning-theoretic perspective, with a focus on general policy classes up to and including deep neural networks. Through a new analysis of BC with the logarithmic loss, we show that it is possible to achieve horizon-independent sample complexity in offline IL whenever (i) the range of the cumulative payoffs is controlled, and (ii) an appropriate notion of supervised learning complexity for the policy class is controlled. Specializing our results to deterministic, stationary policies, we show that the gap between offline and online IL is not fundamental: (i) it is possible to achieve linear dependence on horizon in offline IL under dense rewards (matching what was previously only known to be achievable in online IL); and (ii) without further assumptions on the policy class, online IL cannot improve over offline IL with the logarithmic loss, even in benign MDPs. We complement our theoretical results with experiments on standard RL tasks and autoregressive language generation to validate the practical relevance of our findings.
696. Fourier-enhanced Implicit Neural Fusion Network for Multispectral and Hyperspectral Image Fusion

Recently, implicit neural representations (INR) have made significant strides in various vision-related domains, providing a novel solution for Multispectral and Hyperspectral Image Fusion (MHIF) tasks. However, INR is prone to losing high-frequency information and is confined to the lack of global perceptual capabilities. To address these issues, this paper introduces a Fourier-enhanced Implicit Neural Fusion Network (FeINFN) specifically designed for MHIF task, targeting the following phenomena: The Fourier amplitudes of the HR-HSI latent code and LR-HSI are remarkably similar; however, their phases exhibit different patterns. In FeINFN, we innovatively propose a spatial and frequency implicit fusion function (Spa-Fre IFF), helping INR capture high-frequency information and expanding the receptive field. Besides, a new decoder employing a complex Gabor wavelet activation function, called Spatial-Frequency Interactive Decoder (SFID), is invented to enhance the interaction of INR features. Especially, we further theoretically prove that the Gabor wavelet activation possesses a time-frequency tightness property that favors learning the optimal bandwidths in the decoder. Experiments on two benchmark MHIF datasets verify the state-of-the-art (SOTA) performance of the proposed method, both visually and quantitatively. Also, ablation studies demonstrate the mentioned contributions. The code can be available at https://github.com/294coder/Efficient-MIF.
tl;dr: We show that it is computationally hard to derandomize multi-distribution learning algorithms. We also show this hardness can be alleviated with a structural condition that we identify.

Multi-distribution or collaborative learning involves learning a single predictor that works well across multiple data distributions, using samples from each during training. Recent research on multi-distribution learning, focusing on binary loss and finite VC dimension classes, has shown near-optimal sample complexity that is achieved with oracle efficient algorithms. That is, these algorithms are computationally efficient given an efficient ERM for the class. Unlike in classical PAC learning, where the optimal sample complexity is achieved with deterministic predictors, current multi-distribution learning algorithms output randomized predictors. This raises the question: can these algorithms be derandomized to produce a deterministic predictor for multiple distributions? Through a reduction to discrepancy minimization, we show that derandomizing multi-distribution learning is computationally hard, even when ERM is computationally efficient. On the positive side, we identify a structural condition enabling an efficient black-box reduction, converting existing randomized multi-distribution predictors into deterministic ones.
tl;dr: This paper proposes a decoupling-based method for extracting the deep intrinsic characteristics of LLM from the text in black-box scenarios. The detection of GPT4 and Claude3 improves by 6.76% and 2.91% compared to baselines.

Large language models (LLMs) have the potential to generate texts that pose risks of misuse, such as plagiarism, planting fake reviews on e-commerce platforms, or creating inflammatory false tweets. Consequently, detecting whether a text is generated by LLMs has become increasingly important. Existing high-quality detection methods usually require access to the interior of the model to extract the intrinsic characteristics. However, since we do not have access to the interior of the black-box model, we must resort to surrogate models, which impacts detection quality. In order to achieve high-quality detection of black-box models, we would like to extract deep intrinsic characteristics of the black-box model generated texts. We view the generation process as a coupled process of prompt and intrinsic characteristics of the generative model. Based on this insight, we propose to decouple prompt and intrinsic characteristics (DPIC) for LLM-generated text detection method. Specifically, given a candidate text, DPIC employs an auxiliary LLM to reconstruct the prompt corresponding to the candidate text, then uses the prompt to regenerate text by the auxiliary LLM, which makes the candidate text and the regenerated text align with their prompts, respectively. Then, the similarity between the candidate text and the regenerated text is used as a detection feature, thus eliminating the prompt in the detection process, which allows the detector to focus on the intrinsic characteristics of the generative model. Compared to the baselines, DPIC has achieved an average improvement of 6.76\% and 2.91\% in detecting texts from different domains generated by GPT4 and Claude3, respectively.
tl;dr: Optimal contract design for principals interacting with no-regret learning agents

Real-life contractual relations typically involve repeated interactions between the principal and agent, where, despite theoretical appeal, players rarely use complex dynamic strategies and instead manage uncertainty through learning algorithms.
In this paper, we initiate the study of repeated contracts with learning agents, focusing on those achieving no-regret outcomes. For the canonical setting where the agent’s actions result in success or failure, we present a simple, optimal solution for the principal: Initially provide a linear contract with scalar $\alpha > 0$, then switch to a zero-scalar contract. This shift causes the agent to “free-fall” through their action space, yielding non-zero rewards for the principal at zero cost. Interestingly, despite the apparent exploitation, there are instances where our dynamic contract can make \emph{both} players better off compared to the best static contract.
We then broaden the scope of our results to general linearly-scaled contracts, and, finally, to the best of our knowledge, we provide the first analysis of optimization against learning agents with uncertainty about the time horizon.

Traditional knowledge graph embedding (KGE) models map entities and relations to unique embedding vectors in a shallow lookup manner. As the scale of data becomes larger, this manner will raise unaffordable computational costs. Anchor-based strategies have been treated as effective ways to alleviate such efficiency problems by propagation on representative entities instead of the whole graph. However, most existing anchor-based KGE models select the anchors in a primitive manner, which limits their performance. To this end, we propose a novel anchor-based strategy for KGE, i.e., a relational clustering-based anchor selection strategy (RecPiece), where two characteristics are leveraged, i.e., (1) representative ability of the cluster centroids and (2) descriptive ability of relation types in KGs. Specifically, we first perform clustering over features of factual triplets instead of entities, where cluster number is naturally set as number of relation types since each fact can be characterized by its relation in KGs. Then, representative triplets are selected around the clustering centroids, further mapped into corresponding anchor entities. Extensive experiments on six datasets show that RecPiece achieves higher performances but comparable or even fewer parameters compared to previous anchor-based KGE models, indicating that our model can select better anchors in a more scalable way.

We consider the classic problem of online convex optimisation. Whereas the notion of static regret is relevant for stationary problems, the notion of switching regret is more appropriate for non-stationary problems. A switching regret is defined relative to any segmentation of the trial sequence, and is equal to the sum of the static regrets of each segment. In this paper we show that, perhaps surprisingly, we can achieve the asymptotically optimal switching regret on every possible segmentation simultaneously. Our algorithm for doing so is very efficient: having a space and per-trial time complexity that is logarithmic in the time-horizon. Our algorithm also obtains novel bounds on its dynamic regret: being adaptive to variations in the rate of change of the comparator sequence.
tl;dr: A neuro-symbolic framework generating high-quality and supervised mathematical datasets

A critical question about Large Language Models (LLMs) is whether their apparent deficiency in mathematical reasoning is inherent, or merely a result of insufficient exposure to high-quality mathematical data. To explore this, we developed an automated method for generating high-quality, supervised mathematical datasets. The method carefully mutates existing math problems, ensuring both diversity and validity of the newly generated problems. This is achieved by a neuro-symbolic data generation framework combining the intuitive informalization strengths of LLMs, and the precise symbolic reasoning of math solvers along with projected Markov chain Monte Carlo sampling in the highly-irregular symbolic space.
Empirical experiments demonstrate the high quality of data generated by the proposed method, and that the LLMs, specifically LLaMA-2 and Mistral, when realigned with the generated data, surpass their state-of-the-art counterparts.
tl;dr: Our protector efficiently defends against adversarial prompts without losing key information

The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content.
Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts.
To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions.
The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer.
Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM.
Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed.
Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.

Minimum Bayes Risk (MBR) decoding is a powerful decoding strategy widely used for text generation tasks but its quadratic computational complexity limits its practical application. This paper presents a novel approach for approximating MBR decoding using matrix completion techniques, focusing on a machine translation task. We formulate MBR decoding as a matrix completion problem, where the utility metric scores between candidate hypotheses and reference translations form a low-rank matrix. First we empirically show that the scores matrices indeed have a low-rank structure. Then we exploit this by only computing a random subset of the scores and efficiently recover the missing entries in the matrix by applying the Alternating Least Squares (ALS) algorithm, thereby enabling fast approximation of the MBR decoding process. Our experimental results on machine translation tasks demonstrate that the proposed method requires 1/16 utility metric computations compared to the vanilla MBR decoding while achieving equal translation quality measured by COMET on the WMT22 dataset (en<>de, en<>ru). We also benchmark our method against other approximation methods and we show significant gains in quality.

When learning in strategic environments, a key question is whether agents can overcome uncertainty about their preferences to achieve outcomes they could have achieved absent any uncertainty. Can they do this solely through interactions with each other? We focus this question on the ability of agents to attain the value of their Stackelberg optimal strategy and study the impact of information asymmetry. We study repeated interactions in fully strategic environments where players' actions are decided based on learning algorithms that take into account their observed histories and knowledge of the game. We study the pure Nash equilibria (PNE) of a meta-game where players choose these algorithms as their actions. We demonstrate that if one player has perfect knowledge about the game, then any initial informational gap persists. That is, while there is always a PNE in which the informed agent achieves her Stackelberg value, there is a game where no PNE of the meta-game allows the partially informed player to achieve her Stackelberg value. On the other hand, if both players start with some uncertainty about the game, the quality of information alone does not determine which agent can achieve her Stackelberg value. In this case, the concept of information asymmetry becomes nuanced and depends on the game's structure. Overall, our findings suggest that repeated strategic interactions alone cannot facilitate learning effectively enough to earn an uninformed player her Stackelberg value.
tl;dr: A novel approach to mitigate association-engendered stereotypes in T2I diffusion models.

Text-to-Image (T2I) has witnessed significant advancements, demonstrating superior performance for various generative tasks. However, the presence of stereotypes in T2I introduces harmful biases that require urgent attention as the T2I
technology becomes more prominent.
Previous work for stereotype mitigation mainly concentrated on mitigating stereotypes engendered with individual objects within images, which failed to address stereotypes engendered by the association of multiple objects, referred to as *Association-Engendered Stereotypes*. For example, mentioning ''black people'' and ''houses'' separately in prompts may not exhibit stereotypes. Nevertheless, when these two objects are associated in prompts, the association of ''black people'' with ''poorer houses'' becomes more pronounced. To tackle this issue, we propose a novel framework, MAS, to Mitigate Association-engendered Stereotypes. This framework models the stereotype problem as a probability distribution alignment problem, aiming to align the stereotype probability distribution of the generated image with the stereotype-free distribution. The MAS framework primarily consists of the *Prompt-Image-Stereotype CLIP* (*PIS CLIP*) and *Sensitive Transformer*. The *PIS CLIP* learns the association between prompts, images, and stereotypes, which can establish the mapping of prompts to stereotypes. The *Sensitive Transformer* produces the sensitive constraints, which guide the stereotyped image distribution to align with the stereotype-free probability distribution. Moreover, recognizing that existing metrics are insufficient for accurately evaluating association-engendered stereotypes, we propose a novel metric, *Stereotype-Distribution-Total-Variation*(*SDTV*), to evaluate stereotypes in T2I. Comprehensive experiments demonstrate that our framework effectively mitigates association-engendered stereotypes.

Electronic health record (EHR) data has emerged as a valuable resource for analyzing patient health status. However, the prevalence of missing data in EHR poses significant challenges to existing methods, leading to spurious correlations and suboptimal predictions. While various imputation techniques have been developed to address this issue, they often obsess difficult-to-interpolate details and may introduce additional noise when making clinical predictions. To tackle this problem, we propose SMART, a Self-Supervised Missing-Aware RepresenTation Learning approach for patient health status prediction, which encodes missing information via missing-aware temporal and variable attentions and learns to impute missing values through a novel self-supervised pre-training approach which reconstructs missing data representations in the latent space rather than in input space as usual. By adopting elaborated attentions and focusing on learning higher-order representations, SMART promotes better generalization and robustness to missing data. We validate the effectiveness of SMART through extensive experiments on six EHR tasks, demonstrating its superiority over state-of-the-art methods.
708. Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales?

This paper investigates an under-explored challenge in large language models (LLMs): chain-of-thought prompting with noisy rationales, which include irrelevant or inaccurate reasoning thoughts within examples used for in-context learning. We construct NoRa dataset that is tailored to evaluate the robustness of reasoning in the presence of noisy rationales. Our findings on NoRa dataset reveal a prevalent vulnerability to such noise among current LLMs, with existing robust methods like self-correction and self-consistency showing limited efficacy. Notably, compared to prompting with clean rationales, base LLM drops by 1.4%-19.8% in accuracy with irrelevant thoughts and more drastically by 2.2%-40.4% with inaccurate thoughts.
Addressing this challenge necessitates external supervision that should be accessible in practice. Here, we propose the method of contrastive denoising with noisy chain-of-thought (CD-CoT). It enhances LLMs' denoising-reasoning capabilities by contrasting noisy rationales with only one clean rationale, which can be the minimal requirement for denoising-purpose prompting. This method follows a principle of exploration and exploitation: (1) rephrasing and selecting rationales in the input space to achieve explicit denoising and (2) exploring diverse reasoning paths and voting on answers in the output space. Empirically, CD-CoT demonstrates an average improvement of 17.8% in accuracy over the base model and shows significantly stronger denoising capabilities than baseline methods. The source code is publicly available at: https://github.com/tmlr-group/NoisyRationales.
709. The Iterative Optimal Brain Surgeon: Faster Sparse Recovery by Leveraging Second-Order Information
tl;dr: We consider iterative version of OBS framework of finding sparse solutions providing practical evidence and theoretical justifications for convergence.

The rising footprint of machine learning has led to a focus on imposing model sparsity as a means of reducing computational and memory costs. For deep neural networks (DNNs), the state-of-the-art accuracy-vs-sparsity is achieved by heuristics inspired by the classical Optimal Brain Surgeon (OBS) framework [LeCun et al., 1989, Hassibi and Stork, 1992, Hassibi et al., 1993], which leverages loss curvature information to make better pruning decisions. Yet, these results still lack a solid theoretical understanding, and it is unclear whether they can be improved by leveraging connections to the wealth of work on sparse recovery algorithms. In this paper, we draw new connections between these two areas and present new sparse recovery algorithms inspired by the OBS framework that come with theoretical guarantees under reasonable assumptions and have strong practical performance. Specifically, our work starts from the observation that we can leverage curvature information in OBS-like fashion upon the projection step of classic iterative sparse recovery algorithms such as IHT. We show for the first time that this leads both to improved convergence bounds in well-behaved settings and to stronger practical convergence. Furthermore, we present extensions of this approach to training accurate sparse DNNs, and validate it experimentally at scale.
tl;dr: A training-free, plug-and-play method that uses CLIP embeddings to focus on background areas for seamless object removal in diffusion models without requiring specialized datasets.

Advanced image editing techniques, particularly inpainting, are essential for seamlessly removing unwanted elements while preserving visual integrity. Traditional GAN-based methods have achieved notable success, but recent advancements in diffusion models have produced superior results due to their training on large-scale datasets, enabling the generation of remarkably realistic inpainted images.
Despite their strengths, diffusion models often struggle with object removal tasks without explicit guidance, leading to unintended hallucinations of the removed object. To address this issue, we introduce CLIPAway, a novel approach leveraging CLIP embeddings to focus on background regions while excluding foreground elements. CLIPAway enhances inpainting accuracy and quality by identifying embeddings that prioritize the background, thus achieving seamless object removal. Unlike other methods that rely on specialized training datasets or costly manual annotations, CLIPAway provides a flexible, plug-and-play solution compatible with various diffusion-based inpainting techniques.
tl;dr: We establish LSI-constant free particle approximation error for mean-field neural networks.

Mean-field Langevin dynamics (MFLD) minimizes an entropy-regularized nonlinear convex functional defined over the space of probability distributions. MFLD has gained attention due to its connection with noisy gradient descent for mean-field two-layer neural networks. Unlike standard Langevin dynamics, the nonlinearity of the objective functional induces particle interactions, necessitating multiple particles to approximate the dynamics in a finite-particle setting. Recent works (Chen et al., 2022; Suzuki et al., 2023b) have demonstrated the uniform-in-time propagation of chaos for MFLD, showing that the gap between the particle system and its mean-field limit uniformly shrinks over time as the number of particles increases. In this work, we improve the dependence on logarithmic Sobolev inequality (LSI) constants in their particle approximation errors, which can exponentially deteriorate with the regularization coefficient. Specifically, we establish an LSI-constant-free particle approximation error concerning the objective gap by leveraging the problem structure in risk minimization. As the application, we demonstrate improved convergence of MFLD, sampling guarantee for the mean-field stationary distribution, and uniform-in-time Wasserstein propagation of chaos in terms of particle complexity.

The rapid progress of Deepfake technology has made face swapping highly realistic, raising concerns about the malicious use of fabricated facial content. Existing methods often struggle to generalize to unseen domains due to the diverse nature of facial manipulations. In this paper, we revisit the generation process and identify a universal principle: Deepfake images inherently contain information from both source and target identities, while genuine faces maintain a consistent identity. Building upon this insight, we introduce DiffusionFake, a novel plug-and-play framework that reverses the generative process of face forgeries to enhance the generalization of detection models. DiffusionFake achieves this by injecting the features extracted by the detection model into a frozen pre-trained Stable Diffusion model, compelling it to reconstruct the corresponding target and source images. This guided reconstruction process constrains the detection network to capture the source and target related features to facilitate the reconstruction, thereby learning rich and disentangled representations that are more resilient to unseen forgeries. Extensive experiments demonstrate that DiffusionFake significantly improves cross-domain generalization of various detector architectures without introducing additional parameters during inference. The code are available in https://github.com/skJack/DiffusionFake.git.
tl;dr: We introduce ContextCite, a simple and scalable method to identify the parts of the context that are responsible for a language model generating a particular statement.

How do language models use information provided as context when generating a response?
Can we infer whether a particular generated statement is actually grounded in the context, a misinterpretation, or fabricated?
To help answer these questions, we introduce the problem of *context attribution*: pinpointing the parts of the context (if any) that *led* a model to generate a particular statement.
We then present ContextCite, a simple and scalable method for context attribution that can be applied on top of any existing language model.
Finally, we showcase the utility of ContextCite through three applications:
(1) helping verify generated statements
(2) improving response quality by pruning the context and
(3) detecting poisoning attacks.
We provide code for ContextCite at https://github.com/MadryLab/context-cite.
tl;dr: Analytical calculation of Partial Information Decomposition for various well-known distributions, such as Poisson, Cauchy, Gamma, Exponential and many more.

Bivariate partial information decomposition (PID) has emerged as a promising tool for analyzing interactions in complex systems, particularly in neuroscience. PID achieves this by decomposing the information that two sources (e.g., different brain regions) have about a target (e.g., a stimulus) into unique, redundant, and synergistic terms. However, the computation of PID remains a challenging problem, often involving optimization over distributions. While several works have been proposed to compute PID terms numerically, there is a surprising dearth of work on computing PID terms analytically. The only known analytical PID result is for jointly Gaussian distributions. In this work, we present two theoretical advances that enable analytical calculation of the PID terms for numerous well-known distributions, including distributions relevant to neuroscience, such as Poisson, Cauchy, and binomial. Our first result generalizes the analytical Gaussian PID result to the much larger class of stable distributions. We also discover a theoretical link between PID and the emerging fields of data thinning and data fission. Our second result utilizes this link to derive analytical PID terms for two more classes of distributions: convolution-closed distributions and a sub-class of the exponential family. Furthermore, we provide an analytical upper bound for approximately calculating PID for convolution-closed distributions, whose tightness we demonstrate in simulation.

Existing scene text recognition (STR) methods struggle to recognize challenging texts, especially for artistic and severely distorted characters. The limitation lies in the insufficient exploration of character morphologies, including the monotonousness of widely used synthetic training data and the sensitivity of the model to character morphologies. To address these issues, inspired by the human learning process of viewing and summarizing, we facilitate the contrastive learning-based STR framework in a self-motivated manner by leveraging synthetic and real unlabeled data without any human cost. In the viewing process, to compensate for the simplicity of synthetic data and enrich character morphology diversity, we propose an Online Generation Strategy to generate background-free samples with diverse character styles. By excluding background noise distractions, the model is encouraged to focus on character morphology and generalize the ability to recognize complex samples when trained with only simple synthetic data. To boost the summarizing process, we theoretically demonstrate the derivation error in the previous character contrastive loss, which mistakenly causes the sparsity in the intra-class distribution and exacerbates ambiguity on challenging samples. Therefore, a new Character Unidirectional Alignment Loss is proposed to correct this error and unify the representation of the same characters in all samples by aligning the character features in the student model with the reference features in the teacher model. Extensive experiment results show that our method achieves SOTA performance (94.7\% and 70.9\% average accuracy on common benchmarks and Union14M-Benchmark). Code will be available.
tl;dr: We present a new class of algorithms for the efficient integration of tensor fields defined on weighted trees, with several applications in ML, ranging from mesh modeling to training Topological Transformers.

We present a new class of fast polylog-linear algorithms based on the theory of structured matrices (in particular *low displacement rank*) for integrating tensor fields defined on weighted trees. Several applications of the resulting *fast tree-field integrators* (FTFIs) are presented, including: (a) approximation of graph metrics with tree metrics, (b) graph classification, (c) modeling on meshes, and finally (d) *Topological Transformers* (TTs) (Choromanski et al., 2022) for images. For Topological Transformers, we propose new relative position encoding (RPE) masking mechanisms with as few as **three** extra learnable parameters per Transformer layer, leading to **1.0-1.5\%+** accuracy gains. Importantly, most of FTFIs are **exact** methods, thus numerically equivalent to their brute-force counterparts. When applied to graphs with thousands of nodes, those exact algorithms provide **5.7-13x** speedups. We also provide an extensive theoretical analysis of our methods.
tl;dr: This paper introduces the High Rank PCF Distance (HRPCFD) for metrizing extended weak convergence of stochastic processes, demonstrating its efficiency and effectiveness in numerical implementations such as conditional time series generation.

Since the weak convergence for stochastic processes does not account for the growth of information over time which is represented by the underlying filtration, a slightly erroneous stochastic model in weak topology may cause huge loss in multi-periods decision making problems. To address such discontinuities, Aldous introduced the extended weak convergence, which can fully characterise all essential properties, including the filtration, of stochastic processes; however, it was considered to be hard to find efficient numerical implementations. In this paper, we introduce a novel metric called High Rank PCF Distance (HRPCFD) for extended weak convergence based on the high rank path development method from rough path theory, which also defines the characteristic function for measure-valued processes. We then show that such HRPCFD admits many favourable analytic properties which allows us to design an efficient algorithm for training HRPCFD from data and construct the HRPCF-GAN by using HRPCFD as the discriminator for conditional time series generation. Our numerical experiments on both hypothesis testing and generative modelling validate the out-performance of our approach compared with several state-of-the-art methods, highlighting its potential in broad applications of synthetic time series generation and in addressing classic financial and economic challenges, such as optimal stopping or utility maximisation problems. Code is available at https://github.com/DeepIntoStreams/High-Rank-PCF-GAN.git.

Bandits with preference feedback present a powerful tool for optimizing unknown target functions when only pairwise comparisons are allowed instead of direct value queries. This model allows for incorporating human feedback into online inference and optimization and has been employed in systems for tuning large language models.
The problem is fairly understood in toy settings with linear target functions or over finite small domains that limits practical interest.
Taking the next step, we consider infinite domains and kernelized rewards. In this setting, selecting a pair of actions is quite challenging and requires balancing exploration and exploitation at two levels: within the pair, and along the iterations of the algorithm.
We propose MaxMinLCB, which emulates this trade-off as a zero-sum Stackelberg game and chooses action pairs that are informative and have favorable reward values. MaxMinLCB consistently outperforms algorithms in the literature and satisfies an anytime-valid rate-optimal regret guarantee. This is owed to our novel preference-based confidence sequences for kernelized logistic estimators, which are of independent interest.
tl;dr: This paper establishes last-iterate convergence rate for a generalized Frank-Wolfe algorithm for solving monotone variational inequality problems.

We study the convergence behavior of a generalized Frank-Wolfe algorithm in constrained (stochastic) monotone variational inequality (MVI) problems. In recent years, there have been numerous efforts to design algorithms for solving constrained MVI problems due to their connections with optimization, machine learning, and equilibrium computation in games. Most work in this domain has focused on extensions of simultaneous gradient play, with particular emphasis on understanding the convergence properties of extragradient and optimistic gradient methods. In contrast, we examine the performance of an algorithm from another well-known class of optimization algorithms: Frank-Wolfe. We show that a generalized variant of this algorithm achieves a fast $\mathcal{O}(T^{-1/2})$ last-iterate convergence rate in constrained MVI problems. By drawing connections between our generalized Frank-Wolfe algorithm and the well-known smoothed fictitious play (FP) from game theory, we also derive a finite-sample convergence rate for smoothed FP in zero-sum matrix games. Furthermore, we demonstrate that a stochastic variant of the generalized Frank-Wolfe algorithm for MVI problems also converges in a last-iterate sense, albeit at a slower $\mathcal{O}(T^{-1/6})$ convergence rate.
tl;dr: We show novel results on data subsampling for approximating Poisson regression via coresets, as well as their limitations.

We develop and analyze data subsampling techniques for Poisson regression, the standard model for count data $y\in\mathbb{N}$. In particular, we consider the Poisson generalized linear model with ID- and square root-link functions. We consider the method of \emph{coresets}, which are small weighted subsets that approximate the loss function of Poisson regression up to a factor of $1\pm\varepsilon$. We show $\Omega(n)$ lower bounds against coresets for Poisson regression that continue to hold against arbitrary data reduction techniques up to logarithmic factors. By introducing a novel complexity parameter and a domain shifting approach, we show that sublinear coresets with $1\pm\varepsilon$ approximation guarantee exist when the complexity parameter is small. In particular, the dependence on the number of input points can be reduced to polylogarithmic. We show that the dependence on other input parameters can also be bounded sublinearly, though not always logarithmically. In particular, we show that the square root-link admits an $O(\log(y_{\max}))$ dependence, where $y_{\max}$ denotes the largest count presented in the data, while the ID-link requires a $\Theta(\sqrt{y_{\max}/\log(y_{\max})})$ dependence. As an auxiliary result for proving the tightness of the bound with respect to $y_{\max}$ in the case of the ID-link, we show an improved bound on the principal branch of the Lambert $W_0$ function, which may be of independent interest. We further show the limitations of our analysis when $p$th degree root-link functions for $p\geq 3$ are considered, which indicate that other analytical or computational methods would be required if such a generalization is even possible.
tl;dr: We train a model that aligns 3D Spatial Audio with open vocabulary captions.

Humans can picture a sound scene given an imprecise natural language description. For example, it is easy to imagine an acoustic environment given a phrase like "the lion roar came from right behind me!". For a machine to have the same degree of comprehension, the machine must know what a lion is (semantic attribute), what the concept of "behind" is (spatial attribute) and how these pieces of linguistic information align with the semantic and spatial attributes of the sound (what a roar sounds like when its coming from behind).
State-of-the-art audio foundation models, such as CLAP, which learn to map between audio scenes and natural textual descriptions, are trained on non-spatial audio and text pairs, and hence lack spatial awareness. In contrast, sound event localization and detection models are limited to recognizing sounds from a fixed number of classes, and they localize the source to absolute position (e.g., 0.2m) rather than a position described using natural language (e.g., "next to me"). To address these gaps, we present ELSA (Embeddings for Language and Spatial Audio), a spatially aware-audio and text embedding model trained using multimodal contrastive learning. ELSA supports non-spatial audio, spatial audio, and open vocabulary text captions describing both the spatial and semantic components of sound. To train ELSA: (a) we spatially augment the audio and captions of three open-source audio datasets totaling 4,738 hours and 890,038 samples of audio comprised from 8,972 simulated spatial configurations, and (b) we design an encoder to capture the semantics of non-spatial audio, and the semantics and spatial attributes of spatial audio using contrastive learning. ELSA is a single model that is competitive with state-of-the-art for both semantic retrieval and 3D source localization. In particular, ELSA achieves +2.8\% mean audio-to-text and text-to-audio R@1 above the LAION-CLAP baseline, and outperforms by -11.6° mean-absolute-error in 3D source localization over the SeldNET baseline on the TUT Sound Events 2018 benchmark. Moreover, we show that the representation-space of ELSA is structured, enabling swapping of direction of audio via vector arithmetic of two directional text embeddings.

Learning reliably safe autonomous control is one of the core problems in trustworthy autonomy. However, training a controller that can be formally verified to be safe remains a major challenge. We introduce a novel approach for learning verified safe control policies in nonlinear neural dynamical systems while maximizing overall performance. Our approach aims to achieve safety in the sense of finite-horizon reachability proofs, and is comprised of three key parts. The first is a novel curriculum learning scheme that iteratively increases the verified safe horizon. The second leverages the iterative nature of gradient-based learning to leverage incremental verification, reusing information from prior verification runs. Finally, we learn multiple verified initial-state-dependent controllers, an idea that is especially valuable for more complex domains where learning a single universal verified safe controller is extremely challenging. Our experiments on five safe control problems demonstrate that our trained controllers can achieve verified safety over horizons that are as much as an order of magnitude longer than state-of-the-art baselines, while maintaining high reward, as well as a perfect safety record over entire episodes.
tl;dr: We study how the presence of multiple and sub-optimal experts can mitigate the ambuigity that affects Inverse Reinforcement Learning.

Inverse Reinforcement Learning (IRL) deals with the problem of deducing a reward function that explains the behavior of an expert agent who is assumed to act *optimally* in an underlying unknown task. Recent works have studied the IRL problem from the perspective of recovering the *feasible reward set*, i.e., the class of reward functions that are compatible with a unique optimal expert. However, in several problems of interest it is possible to observe the behavior of multiple experts with different degree of optimality (e.g., racing drivers whose skills ranges from amateurs to professionals). For this reason, in this work, we focus on the reconstruction of the feasible reward set when, in addition to demonstrations from the optimal expert, we observe the behavior of multiple *sub-optimal experts*. Given this problem, we first study the theoretical properties showing that the presence of multiple sub-optimal experts, in addition to the optimal one, can significantly shrink the set of compatible rewards, ultimately mitigating the inherent ambiguity of IRL.
Furthermore, we study the statistical complexity of estimating the feasible reward set with a generative model and analyze a uniform sampling algorithm that turns out to be minimax optimal whenever the sub-optimal experts' performance level is sufficiently close to that of the optimal expert.
724. On the Benefits of Public Representations for Private Transfer Learning under Distribution Shift
tl;dr: We show that contrary to prior concerns, public features can be extremely helpful in private transfer learning even when the transfer task is significantly out of distribution. We propose a theoretical model to support our empirical results.

Public pretraining is a promising approach to improve differentially private model training. However, recent work has noted that many positive research results studying this paradigm only consider in-distribution tasks, and may not apply to settings where there is distribution shift between the pretraining and finetuning data---a scenario that is likely when finetuning private tasks due to the sensitive nature of the data. In this work, we show empirically across three tasks that even in settings with large distribution shift, where both zero-shot performance from public data and training from scratch with private data give unusably weak results, public features can in fact improve private training accuracy by up to 67\% over private training from scratch. We provide a theoretical explanation for this phenomenon, showing that if the public and private data share a low-dimensional representation, public representations can improve the sample complexity of private training even if it is \emph{impossible} to learn the private task from the public data alone. Altogether, our results provide evidence that public data can indeed make private training practical in realistic settings of extreme distribution shift.
tl;dr: We provide an improved extension to prediction powered inference that is based on stratified sampling.

Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. PPI achieves this by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate---but potentially biased---automatic system, in a way that results in tighter confidence intervals for certain parameters of interest (e.g., the mean performance of a language model). In this paper, we propose a method called Stratified Prediction-Powered Inference (StratPPI), in which we show that the basic PPI estimates can be considerably improved by employing simple data stratification strategies. Without making any assumptions on the underlying automatic labeling system or data distribution, we derive an algorithm for computing provably valid confidence intervals for parameters of any dimensionality that is based on stratified sampling. In particular, we show both theoretically and empirically that, with appropriate choices of stratification and sample allocation, our approach can provide substantially tighter confidence intervals than unstratified approaches. Specifically, StratPPI is expected to improve in cases where the performance of the autorater varies across different conditional distributions of the target data.
tl;dr: An intriguing inductive bias of efficient training methods like stacking towards particularly improving tasks that require reasoning, despite having the same pretraining perplexity

Given the increasing scale of model sizes, efficient training strategies like gradual stacking have garnered interest. Stacking enables efficient training by gradually growing the depth of a model in stages and using layers from a smaller model in an earlier stage to initialize the next stage. Although efficient for training, the model biases induced by such growing approaches are largely unexplored. In this work, we examine this fundamental aspect of gradual stacking, going beyond its efficiency benefits. We propose a variant of gradual stacking called MIDAS that can speed up language model training by up to 40\%. Furthermore we discover an intriguing phenomenon: MIDAS is not only training-efficient but surprisingly also has an inductive bias towards improving downstream tasks, especially tasks that require reasoning abilities like reading comprehension and math problems, despite having similar or slightly worse perplexity compared to baseline training. To further analyze this inductive bias, we construct {\em reasoning primitives} – simple synthetic tasks that are building blocks for reasoning – and find that a model pretrained with stacking is significantly better than standard pretraining on these primitives, with and without fine-tuning. This provides stronger and more robust evidence for this inductive bias towards reasoning. These findings of training efficiency and inductive bias towards reasoning are verified at 1B, 2B and 8B parameter language models. Finally, we conjecture the underlying reason for this inductive bias by exploring the connection of stacking to looped models and provide strong supporting empirical analysis.

We study the performance guarantees of exploration-free greedy algorithms for the linear contextual bandit problem.
We introduce a novel condition, named the \textit{Local Anti-Concentration} (LAC) condition, which enables a greedy bandit algorithm to achieve provable efficiency.
We show that the LAC condition is satisfied by a broad class of distributions, including Gaussian, exponential, uniform, Cauchy, and Student's~$t$ distributions, along with other exponential family distributions and their truncated variants.
This significantly expands the class of distributions under which greedy algorithms can perform efficiently.
Under our proposed LAC condition, we prove that the cumulative expected regret of the greedy algorithm for the linear contextual bandit is bounded by $\mathcal{O}(\operatorname{poly} \log T)$.
Our results establish the widest range of distributions known to date that allow a sublinear regret bound for greedy algorithms, further achieving a sharp poly-logarithmic regret.
tl;dr: The metric backbone of a weighted graph is the union of all-pairs shortest path; despite its tendency to delete intra-community edges, the metric backbone preserves the community structure and is an efficient graph sparsifier.

The metric backbone of a weighted graph is the union of all-pairs shortest paths. It is obtained by removing all edges $(u,v)$ that are not the shortest path between $u$ and $v$. In networks with well-separated communities, the metric backbone tends to preserve many inter-community edges, because these edges serve as bridges connecting two communities, but tends to delete many intra-community edges because the communities are dense. This suggests that the metric backbone would dilute or destroy the community structure of the network. However, this is not borne out by prior empirical work, which instead showed that the metric backbone of real networks preserves the community structure of the original network well. In this work, we analyze the metric backbone of a broad class of weighted random graphs with communities, and we formally prove the robustness of the community structure with respect to the deletion of all the edges that are not in the metric backbone. An empirical comparison of several graph sparsification techniques confirms our theoretical finding and shows that the metric backbone is an efficient sparsifier in the presence of communities.

Diffusion planning has been recognized as an effective decision-making paradigm in various domains. The capability of generating high-quality long-horizon trajectories makes it a promising research direction. However, existing diffusion planning methods suffer from low decision-making frequencies due to the expensive iterative sampling cost. To alleviate this, we introduce DiffuserLite, a super fast and lightweight diffusion planning framework, which employs a planning refinement process (PRP) to generate coarse-to-fine-grained trajectories, significantly reducing the modeling of redundant information and leading to notable increases in decision-making frequency. Our experimental results demonstrate that DiffuserLite achieves a decision-making frequency of $122.2$Hz ($112.7$x faster than predominant frameworks) and reaches state-of-the-art performance on D4RL, Robomimic, and FinRL benchmarks. In addition, DiffuserLite can also serve as a flexible plugin to increase the decision-making frequency of other diffusion planning algorithms, providing a structural design reference for future works. More details and visualizations are available at https://diffuserlite.github.io/.
tl;dr: Gaussian Process Switching Linear Dynamical Systems maintain the locally linear interpretability of rSLDS models while naturally capturing uncertainty in dynamics.

Understanding how the collective activity of neural populations relates to computation and ultimately behavior is a key goal in neuroscience. To this end, statistical methods which describe high-dimensional neural time series in terms of low-dimensional latent dynamics have played a fundamental role in characterizing neural systems. Yet, what constitutes a successful method involves two opposing criteria: (1) methods should be expressive enough to capture complex nonlinear dynamics, and (2) they should maintain a notion of interpretability often only warranted by simpler linear models. In this paper, we develop an approach that balances these two objectives: the Gaussian Process Switching Linear Dynamical System (gpSLDS). Our method builds on previous work modeling the latent state evolution via a stochastic differential equation whose nonlinear dynamics are described by a Gaussian process (GP-SDEs). We propose a novel kernel function which enforces smoothly interpolated locally linear dynamics, and therefore expresses flexible -- yet interpretable -- dynamics akin to those of recurrent switching linear dynamical systems (rSLDS). Our approach resolves key limitations of the rSLDS such as artifactual oscillations in dynamics near discrete state boundaries, while also providing posterior uncertainty estimates of the dynamics. To fit our models, we leverage a modified learning objective which improves the estimation accuracy of kernel hyperparameters compared to previous GP-SDE fitting approaches. We apply our method to synthetic data and data recorded in two neuroscience experiments and demonstrate favorable performance in comparison to the rSLDS.
tl;dr: We identify a flow of measures whose discretisations define online versions of the DSBM algorithm which are easier to train.

Mass transport problems arise in many areas of machine learning whereby one wants to compute a map transporting one distribution to another. Generative modeling techniques like Generative Adversarial Networks (GANs) and Denoising Diffusion Models (DMMs) have been successfully adapted to solve such transport problems, resulting in CycleGAN and Bridge Matching respectively. However, these methods do not approximate Optimal Transport (OT) maps, which are known to have desirable properties. Existing techniques approximating OT maps for high-dimensional data-rich problems, including DDMs-based Rectified Flow and Schrodinger bridge procedures, require fully training a DDM-type model at each iteration, or use mini-batch techniques which can introduce significant errors. We propose a novel algorithm to compute the Schrodinger bridge, a dynamic entropy-regularized version of OT, that eliminates the need to train multiple DDMs-like models. This algorithm corresponds to a discretization of a flow of path measures, referred to as the Schrodinger Bridge Flow, whose only stationary point is the Schrodinger bridge. We demonstrate the performance of our algorithm on a variety of unpaired data translation tasks.

Policy Optimization (PO) methods are among the most popular Reinforcement Learning (RL) algorithms in practice. Recently, Sherman et al. [2023a] proposed a PO-based algorithm with rate-optimal regret guarantees under the linear Markov Decision Process (MDP) model. However, their algorithm relies on a costly pure exploration warm-up phase that is hard to implement in practice. This paper eliminates this undesired warm-up phase, replacing it with a simple and efficient contraction mechanism. Our PO algorithm achieves rate-optimal regret with improved dependence on the other parameters of the problem (horizon and function approximation dimension) in two fundamental settings: adversarial losses with full-information feedback and stochastic losses with bandit feedback.
tl;dr: We provide an empirically-validated theoretical analysis of the origins of degree bias in message-passing graph neural networks.

Graph Neural Networks (GNNs) often perform better for high-degree nodes than low-degree nodes on node classification tasks. This degree bias can reinforce social marginalization by, e.g., privileging celebrities and other high-degree actors in social networks during social and content recommendation. While researchers have proposed numerous hypotheses for why GNN degree bias occurs, we find via a survey of 38 degree bias papers that these hypotheses are often not rigorously validated, and can even be contradictory. Thus, we provide an analysis of the origins of degree bias in message-passing GNNs with different graph filters. We prove that high-degree test nodes tend to have a lower probability of misclassification regardless of how GNNs are trained. Moreover, we show that degree bias arises from a variety of factors that are associated with a node's degree (e.g., homophily of neighbors, diversity of neighbors). Furthermore, we show that during training, some GNNs may adjust their loss on low-degree nodes more slowly than on high-degree nodes; however, with sufficiently many epochs of training, message-passing GNNs can achieve their maximum possible training accuracy, which is not significantly limited by their expressive power. Throughout our analysis, we connect our findings to previously-proposed hypotheses for the origins of degree bias, supporting and unifying some while drawing doubt to others. We validate our theoretical findings on 8 common real-world networks, and based on our theoretical and empirical insights, describe a roadmap to alleviate degree bias.

The design of Artificial Neural Network (ANN) is inspired by the working patterns of the human brain. Connections in biological neural networks are sparse, as they only exist between few neurons. Meanwhile, the sparse representation in ANNs has been shown to possess significant advantages. Activation responses of ANNs are typically expected to promote sparse representations, where key signals get activated while irrelevant/redundant signals are suppressed. It can be observed that samples of each category are only correlated with sparse and specific channels in ANNs. However, existing activation mechanisms often struggle to suppress signals from other irrelevant channels entirely, and these signals have been verified to be detrimental to the network's final decision. To address the issue of channel noise interference in ANNs, a novel end-to-end trainable Dual-Perspective Activation (DPA) mechanism is proposed. DPA efficiently identifies irrelevant channels and applies channel denoising under the guidance of a joint criterion established online from both forward and backward propagation perspectives while preserving activation responses from relevant channels. Extensive experiments demonstrate that DPA successfully denoises channels and facilitates sparser neural representations. Moreover, DPA is parameter-free, fast, applicable to many mainstream ANN architectures, and achieves remarkable performance compared to other existing activation counterparts across multiple tasks and domains. Code is available at https://github.com/horrible-dong/DPA.
tl;dr: We reveal the theoretical foundations of techniques for editing large language models, and present new methods which can do so without requiring retraining.

We reveal the theoretical foundations of techniques for editing large language models, and present new methods which can do so without requiring retraining. Our theoretical insights show that a single metric (a measure of the intrinsic dimension of the model's features) can be used to assess a model's editability and reveals its previously unrecognised susceptibility to malicious *stealth attacks*. This metric is fundamental to predicting the success of a variety of editing approaches, and reveals new bridges between disparate families of editing methods. We collectively refer to these as *stealth editing* methods, because they directly update a model's weights to specify its response to specific known hallucinating prompts without affecting other model behaviour. By carefully applying our theoretical insights, we are able to introduce a new *jet-pack* network block which is optimised for highly selective model editing, uses only standard network operations, and can be inserted into existing networks. We also reveal the vulnerability of language models to stealth attacks: a small change to a model's weights which fixes its response to a single attacker-chosen prompt. Stealth attacks are computationally simple, do not require access to or knowledge of the model's training data, and therefore represent a potent yet previously unrecognised threat to redistributed foundation models. Extensive experimental results illustrate and support our methods and their theoretical underpinnings. Demos and source code are available at https://github.com/qinghua-zhou/stealth-edits.
tl;dr: A more efficient technique for matrix-factorization-based differentially private model training.

Current state-of-the-art methods for differentially private model training are based on matrix factorization techniques. However, these methods suffer from high computational overhead because they require numerically solving a demanding optimization problem to determine an approximately optimal factorization prior to the actual model training. In this work, we present a new matrix factorization approach, BSR, which overcomes this computational bottleneck. By exploiting properties of the standard matrix square root, BSR allows to efficiently handle also large-scale problems. For the key scenario of stochastic gradient descent with momentum and weight decay, we even derive analytical expressions for BSR that render the computational overhead negligible. We prove bounds on the approximation quality that hold both in the centralized and in the federated learning setting. Our numerical experiments demonstrate that models trained using BSR perform on par with the best existing methods, while completely avoiding their computational overhead.
tl;dr: 2024 SoTA for speech enhancement

In this paper, we address the challenge of speech enhancement in real-world recordings, which often contain various forms of distortion, such as background noise, reverberation, and microphone artifacts.
We revisit the use of Generative Adversarial Networks (GANs) for speech enhancement and theoretically show that GANs are naturally inclined to seek the point of maximum density within the conditional clean speech distribution, which, as we argue, is essential for speech enhancement task.
We study various feature extractors for perceptual loss to facilitate the stability of adversarial training, developing a methodology for probing the structure of the feature space.
This leads us to integrate WavLM-based perceptual loss into MS-STFT adversarial training pipeline, creating an effective and stable training procedure for the speech enhancement model.
The resulting speech enhancement model, which we refer to as FINALLY, builds upon the HiFi++ architecture, augmented with a WavLM encoder and a novel training pipeline.
Empirical results on various datasets confirm our model's ability to produce clear, high-quality speech at 48 kHz, achieving state-of-the-art performance in the field of speech enhancement. Demo page: https://samsunglabs.github.io/FINALLY-page/

Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases. Our anonymous codes are submitted with the paper and will be publicly available. Code is available: https://github.com/Clin0212/HydraLoRA.
tl;dr: We design algorithms for the problem of learning partitions from faulty same-cluster oracle queries and prove that they achieve optimal query complexity.

We consider a clustering problem where a learner seeks to partition a finite set by querying a faulty oracle. This models applications where learners crowdsource information from non-expert human workers or conduct noisy experiments to determine group structure. The learner aims to exactly recover a partition by submitting queries of the form ``are $u$ and $v$ in the same group?'' for any pair of elements $u$ and $v$ in the set. Moreover, because the learner only has access to faulty sources of information, they require an error-tolerant algorithm for this task: i.e. they must fully recover the correct partition, even if up to $\ell$ answers are incorrect, for some error-tolerance parameter $\ell$. We study the question: for any given error-tolerance $\ell$, what is the minimum number of queries needed to learn a finite set partition of $n$ elements into $k$ groups? We design algorithms for this task and prove that they achieve optimal query complexity. To analyze our algorithms, we first highlight a connection between this task and correlation clustering. We then use this connection to build a Rényi-Ulam style analytical framework for this problem, which yields matching lower bounds. Our analysis also reveals an inherent asymmetry between the query complexity necessary to be robust against false negative errors as opposed to false positive errors.
tl;dr: SpaceByte is a byte-level autoregressive language model that roughly matches the performance of tokenized Transformers in compute-controlled experiments.

Tokenization is widely used in large language models because it significantly improves performance. However, tokenization imposes several disadvantages, such as performance biases, increased adversarial vulnerability, decreased character-level modeling performance, and increased modeling complexity. To address these disadvantages without sacrificing performance, we propose SpaceByte, a novel byte-level decoder architecture that closes the performance gap between byte-level and subword autoregressive language modeling. SpaceByte consists of a byte-level Transformer model, but with extra larger transformer blocks inserted in the middle of the layers. We find that performance is significantly improved by applying these larger blocks only after certain bytes, such as space characters, which typically denote word boundaries. Our experiments show that for a fixed training and inference compute budget, SpaceByte outperforms other byte-level architectures and roughly matches the performance of tokenized Transformer architectures.
741. Neural network learns low-dimensional polynomials with SGD near the information-theoretic limit

We study the problem of gradient descent learning of a single-index target function $f_*(\boldsymbol{x}) = \textstyle\sigma_*\left(\langle\boldsymbol{x},\boldsymbol{\theta}\rangle\right)$ under isotropic Gaussian data in $\mathbb{R}^d$,
where the unknown link function $\sigma_*:\mathbb{R}\to\mathbb{R}$ has information exponent $p$ (defined as the lowest degree in the Hermite expansion). Prior works showed that gradient-based training of neural networks can learn this target with $n\gtrsim d^{\Theta(p)}$ samples, and such complexity is predicted to be necessary by the correlational statistical query lower bound.
Surprisingly, we prove that a two-layer neural network optimized by an SGD-based algorithm (on the squared loss) learns $f_*$ with a complexity that is not governed by the information exponent. Specifically, for arbitrary polynomial single-index models, we establish a sample and runtime complexity of $n \simeq T = \Theta(d\cdot\mathrm{polylog} d)$, where $\Theta(\cdot)$ hides a constant only depending on the degree of $\sigma_*$; this dimension dependence matches the information theoretic limit up to polylogarithmic factors. More generally, we show that $n\gtrsim d^{(p_*-1)\vee 1}$ samples are sufficient to achieve low generalization error, where $p_* \le p$ is the \textit{generative exponent} of the link function. Core to our analysis is the reuse of minibatch in the gradient computation, which gives rise to higher-order information beyond correlational queries.
tl;dr: This paper designs a new framework for generative retrieval with multi-graded relevance.

Generative retrieval represents a novel approach to information retrieval, utilizing an encoder-decoder architecture to directly produce relevant document identifiers (docids) for queries. While this method offers benefits, current implementations are limited to scenarios with binary relevance data, overlooking the potential for documents to have multi-graded relevance. Extending generative retrieval to accommodate multi-graded relevance poses challenges, including the need to reconcile likelihood probabilities for docid pairs and the possibility of multiple relevant documents sharing the same identifier. To address these challenges, we introduce a new framework called GRaded Generative Retrieval (GR$^2$). Our approach focuses on two key components: ensuring relevant and distinct identifiers, and implementing multi-graded constrained contrastive training. Firstly, we aim to create identifiers that are both semantically relevant and sufficiently distinct to represent individual documents effectively. This is achieved by jointly optimizing the relevance and distinctness of docids through a combination of docid generation and autoencoder models. Secondly, we incorporate information about the relationship between relevance grades to guide the training process. Specifically, we leverage a constrained contrastive training strategy to bring the representations of queries and the identifiers of their relevant documents closer together, based on their respective relevance grades.Extensive experiments on datasets with both multi-graded and binary relevance demonstrate the effectiveness of our method.
tl;dr: A binarized diffusion model, BI-DiffSR, for image SR.

Advanced diffusion models (DMs) perform impressively in image super-resolution (SR), but the high memory and computational costs hinder their deployment. Binarization, an ultra-compression algorithm, offers the potential for effectively accelerating DMs. Nonetheless, due to the model structure and the multi-step iterative attribute of DMs, existing binarization methods result in significant performance degradation. In this paper, we introduce a novel binarized diffusion model, BI-DiffSR, for image SR. First, for the model structure, we design a UNet architecture optimized for binarization. We propose the consistent-pixel-downsample (CP-Down) and consistent-pixel-upsample (CP-Up) to maintain dimension consistent and facilitate the full-precision information transfer. Meanwhile, we design the channel-shuffle-fusion (CS-Fusion) to enhance feature fusion in skip connection. Second, for the activation difference across timestep, we design the timestep-aware redistribution (TaR) and activation function (TaA). The TaR and TaA dynamically adjust the distribution of activations based on different timesteps, improving the flexibility and representation alability of the binarized module. Comprehensive experiments demonstrate that our BI-DiffSR outperforms existing binarization methods. Code is released at: https://github.com/zhengchen1999/BI-DiffSR.
tl;dr: This paper moves the Pareto frontier of both inferential accuracy and cost saving for knowledge-based question answering with large langue models.

Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.
tl;dr: Containing misinformation spread through learning-based approaches using Graph Neural Networks

In this study, we investigate the under-explored intervention planning aimed at disseminating accurate information within dynamic opinion networks by leveraging learning strategies. Intervention planning involves identifying key nodes (search) and exerting control (e.g., disseminating accurate/official information through the nodes) to mitigate the influence of misinformation. However, as the network size increases, the problem becomes computationally intractable. To address this, we first introduce a ranking algorithm to identify key nodes for disseminating accurate information, which facilitates the training of neural network (NN) classifiers that provide generalized solutions for the search and planning problems. Second, we mitigate the complexity of label generation—which becomes challenging as the network grows—by developing a reinforcement learning (RL)-based centralized dynamic planning framework. We analyze these NN-based planners for opinion networks governed by two dynamic propagation models. Each model incorporates both binary and continuous opinion and trust representations. Our experimental results demonstrate that the ranking algorithm-based classifiers provide plans that enhance infection rate control, especially with increased action budgets for small networks. Further, we observe that the reward strategies focusing on key metrics, such as the number of susceptible nodes and infection rates, outperform those prioritizing faster blocking strategies. Additionally, our findings reveal that graph convolutional network (GCN)-based planners facilitate scalable centralized plans that achieve lower infection rates (higher control) across various network configurations (e.g., Watts-Strogatz topology, varying action budgets, varying initial infected nodes, and varying degree of infected nodes).

Image retargeting is the task of adjusting the aspect ratio of images to suit different display devices or presentation environments. However, existing retargeting methods often struggle to balance the preservation of key semantics and image quality, resulting in either deformation or loss of important objects, or the introduction of local artifacts such as discontinuous pixels and inconsistent regenerated content. To address these issues, we propose a content-aware retargeting method called PruneRepaint. It incorporates semantic importance for each pixel to guide the identification of regions that need to be pruned or preserved in order to maintain key semantics. Additionally, we introduce an adaptive repainting module that selects image regions for repainting based on the distribution of pruned pixels and the proportion between foreground size and target aspect ratio, thus achieving local smoothness after pruning. By focusing on the content and structure of the foreground, our PruneRepaint approach adaptively avoids key content loss and deformation, while effectively mitigating artifacts with local repainting. We conduct experiments on the public RetargetMe benchmark and demonstrate through objective experimental results and subjective user studies that our method outperforms previous approaches in terms of preserving semantics and aesthetics, as well as better generalization across diverse aspect ratios. Codes will be available at
https://github.com/fhshen2022/PruneRepaint.
tl;dr: The paper gives bounds for stochastic algorithms including the Gibbs algorithm

A method to prove generalization results for a class of stochastic learning algorithms is presented. It applies whenever the algorithm generates a distribution, which is absolutely continuous distribution relative to some a-priori measure, and the logarithm of its density is exponentially concentrated about its mean. Applications include bounds for the Gibbs algorithm and randomizations of stable deterministic algorithms, combinations thereof and PAC-Bayesian bounds with data-dependent priors.
tl;dr: Training machines to learn algorithms that are guaranteed to converge to a solution

Iterative algorithms solve problems by taking steps until a solution is reached. Models in the form of Deep Thinking (DT) networks have been demonstrated to learn iterative algorithms in a way that can scale to different sized problems at inference time using recurrent computation and convolutions. However, they are often unstable during training, and have no guarantees of convergence/termination at the solution. This paper addresses the problem of instability by analyzing the growth in intermediate representations, allowing us to build models (referred to as Deep Thinking with Lipschitz Constraints (DT-L)) with many fewer parameters and providing more reliable solutions. Additionally our DT-L formulation provides guarantees of convergence of the learned iterative procedure to a unique solution at inference time. We demonstrate DT-L is capable of robustly learning algorithms which extrapolate to harder problems than in the training set. We benchmark on the traveling salesperson problem to evaluate the capabilities of the modified system in an NP-hard problem where DT fails to learn.
tl;dr: We explore data, model and language scaling for sign language translation and achieve new state-of-the-art performance on several open-domain benchmarks.

Sign language translation (SLT) addresses the problem of translating information from a sign language in video to a spoken language in text. Existing studies, while showing progress, are often limited to narrow domains and/or few sign languages and struggle with open-domain tasks. In this paper, we push forward the frontier of SLT by scaling pretraining data, model size, and number of translation directions. We perform large-scale SLT pretraining on different data including 1) noisy multilingual Youtube SLT data,
2) parallel text corpora, and 3) SLT data augmented by translating video captions to other languages with off-the-shelf machine translation models. We unify different pretraining tasks with task-specific prompts under the encoder-decoder architecture, and initialize the SLT model with pretrained (m/By)T5 models across model sizes. SLT pretraining results on How2Sign and FLEURS-ASL\#0 (ASL to 42 spoken languages) demonstrate the significance of data/model scaling and cross-lingual cross-modal transfer, as well as the feasibility of zero-shot SLT. We finetune the pretrained SLT models on 5 downstream open-domain SLT benchmarks covering 5 sign languages. Experiments show substantial quality improvements over the vanilla baselines, surpassing the previous state-of-the-art (SOTA) by wide margins.
tl;dr: Aiming to improve LLM reasoning, we conduct a preliminary exploration of whether LLMs can "learn by teaching" -- a well-known paradigm in human learning

Teaching to improve student models (e.g., knowledge distillation) is an extensively studied methodology in LLMs. However, in human education, teaching enhances not only the students but also the teachers by fostering more rigorous and clearer reasoning, as well as deeper knowledge building. We ask: Can LLMs also learn by teaching (LbT) for better reasoning? If the answer is yes, we can potentially unlock the possibility of continuously advancing the models without solely relying on human-produced data or stronger models. In this paper, we provide a preliminary exploration of this question. We show that LbT ideas can be incorporated into existing LLM training/prompting pipelines and bring improvements. Specifically, we design three methods, each mimicking one of the three levels of LbT: observing students' feedback, learning from the feedback, and learning iteratively, with the goal of improving answer accuracy without training or improving models' inherent capability with fine-tuning. We reveal some findings: (1) Teaching materials that make it easier for students to learn (via in-context learning) have clearer and more accurate logic; (2) Weak-to-strong generalization: LbT might help improve strong models by teaching weak models; (3) Diversity in students might help: teaching multiple students could be better than teaching a single student or the teacher alone. We hope that our exploration can inspire future research on LbT and, more broadly, the adoption of advanced education techniques to improve LLMs. The code and website are at https://github.com/imagination-research/lbt and https://sites.google.com/view/llm-learning-by-teaching.
tl;dr: We obtain a characterization of the computational power/expressivity of graph neural networks in terms of arithmetic circuits over the reals.

We characterize the computational power of neural networks that follow the graph neural network (GNN) architecture, not restricted to aggregate-combine GNNs or other particular types. We establish an exact correspondence between the expressivity of GNNs using diverse activation functions and arithmetic circuits over real numbers. In our results the activation function of the network becomes a gate type in the circuit. Our result holds for families of constant depth circuits and networks, both uniformly and non-uniformly, for all common activation functions.
tl;dr: We propose an effective aligned LLM-generated text detection method using reward model.

The remarkable capabilities and easy accessibility of large language models (LLMs) have significantly increased societal risks (e.g., fake news generation), necessitating the development of LLM-generated text (LGT) detection methods for safe usage. However, detecting LGTs is challenging due to the vast number of LLMs, making it impractical to account for each LLM individually; hence, it is crucial to identify the common characteristics shared by these models. In this paper, we draw attention to a common feature of recent powerful LLMs, namely the alignment training, i.e., training LLMs to generate human-preferable texts. Our key finding is that as these aligned LLMs are trained to maximize the human preferences, they generate texts with higher estimated preferences even than human-written texts; thus, such texts are easily detected by using the reward model (i.e., an LLM trained to model human preference distribution). Based on this finding, we propose two training schemes to further improve the detection ability of the reward model, namely (i) continual preference fine-tuning to make reward model prefer aligned LGTs even further and (ii) reward modeling of Human/LLM mixed texts (a rephrased texts from human-written texts using aligned LLMs), which serves as a median preference text corpus between LGTs and human-written texts to learn the decision boundary better. We provide an extensive evaluation by considering six text domains across twelve aligned LLMs, where our method demonstrates state-of-the-art results.

Equivariant Graph Neural Networks (GNNs) that incorporate E(3) symmetry have achieved significant success in various scientific applications. As one of the most successful models, EGNN leverages a simple scalarization technique to perform equivariant message passing over only Cartesian vectors (i.e., 1st-degree steerable vectors), enjoying greater efficiency and efficacy compared to equivariant GNNs using higher-degree steerable vectors. This success suggests that higher-degree representations might be unnecessary. In this paper, we disprove this hypothesis by exploring the expressivity of equivariant GNNs on symmetric structures, including $k$-fold rotations and regular polyhedra. We theoretically demonstrate that equivariant GNNs will always degenerate to a zero function if the degree of the output representations is fixed to 1 or other specific values. Based on this theoretical insight, we propose HEGNN, a high-degree version of EGNN to increase the expressivity by incorporating high-degree steerable vectors while maintaining EGNN's efficiency through the scalarization trick. Our extensive experiments demonstrate that HEGNN not only aligns with our theoretical analyses on toy datasets consisting of symmetric structures, but also shows substantial improvements on more complicated datasets such as $N$-body and MD17. Our theoretical findings and empirical results potentially open up new possibilities for the research of equivariant GNNs.
tl;dr: We propose spherical frustum structure to avoid quantized information loss in conventional 2D spherical projection for LiDAR point cloud semantic segmentation.

LiDAR point cloud semantic segmentation enables the robots to obtain fine-grained semantic information of the surrounding environment. Recently, many works project the point cloud onto the 2D image and adopt the 2D Convolutional Neural Networks (CNNs) or vision transformer for LiDAR point cloud semantic segmentation. However, since more than one point can be projected onto the same 2D position but only one point can be preserved, the previous 2D projection-based segmentation methods suffer from inevitable quantized information loss, which results in incomplete geometric structure, especially for small objects. To avoid quantized information loss, in this paper, we propose a novel spherical frustum structure, which preserves all points projected onto the same 2D position. Additionally, a hash-based representation is proposed for memory-efficient spherical frustum storage. Based on the spherical frustum structure, the Spherical Frustum sparse Convolution (SFC) and Frustum Farthest Point Sampling (F2PS) are proposed to convolve and sample the points stored in spherical frustums respectively. Finally, we present the Spherical Frustum sparse Convolution Network (SFCNet) to adopt 2D CNNs for LiDAR point cloud semantic segmentation without quantized information loss. Extensive experiments on the SemanticKITTI and nuScenes datasets demonstrate that our SFCNet outperforms previous 2D projection-based semantic segmentation methods based on conventional spherical projection and shows better performance on small object segmentation by preserving complete geometric structure. Codes will be available at https://github.com/IRMVLab/SFCNet.
tl;dr: We introduce Gated SAEs, a new SAE architecture that is a Pareto improvement over baseline approaches for training SAEs on LM activations.

Recent work has found that sparse autoencoders (SAEs) are an effective technique for unsupervised discovery of interpretable features in language models' (LMs) activations, by finding sparse, linear reconstructions of those activations. We introduce the Gated Sparse Autoencoder (Gated SAE), which achieves a Pareto improvement over training with prevailing methods. In SAEs, the L1 penalty used to encourage sparsity introduces many undesirable biases, such as shrinkage -- systematic underestimation of feature activations. The key insight of Gated SAEs is to separate the functionality of (a) determining which directions to use and (b) estimating the magnitudes of those directions: this enables us to apply the L1 penalty only to the former, limiting the scope of undesirable side effects. Through training SAEs on LMs of up to 7B parameters we find that, in typical hyper-parameter ranges, Gated SAEs solve shrinkage, are similarly interpretable, and require half as many firing features to achieve comparable reconstruction fidelity.
tl;dr: We show theoretically and empirically that deep neural collapse is not an optimal solution in the general multi-class non-linear deep unconstrained features model due to a low-rank bias of weight regularization.

Deep neural networks (DNNs) exhibit a surprising structure in their final layer known as neural collapse (NC), and a growing body of works is currently investigated the propagation of neural collapse to earlier layers of DNNs -- a phenomenon called deep neural collapse (DNC). However, existing theoretical results are restricted to either linear models, the last two layers or binary classification. In contrast, we focus on non-linear models of arbitrary depth in multi-class classification and reveal a surprising qualitative shift. As soon as we go beyond two layers or two classes, DNC stops being optimal for the deep unconstrained features model (DUFM) -- the standard theoretical framework for the analysis of collapse. The main culprit is the low-rank bias of multi-layer regularization schemes. This bias leads to optimal solutions of even lower rank than the neural collapse. We support our theoretical findings with experiments on both DUFM and real data, which show the emergence of the low-rank structure in the solution found by gradient descent.
tl;dr: To address the challenges of robustness and sample efficiency in reinforcement learning (RL), this work studies the sample complexity of distributionally robust Markov decision processes (RMDPs).

To address the challenges of sim-to-real gap and sample efficiency in reinforcement learning (RL), this work studies distributionally robust Markov decision processes (RMDPs) --- optimize the worst-case performance when the deployed environment is within an uncertainty set around some nominal MDP. Despite recent efforts, the sample complexity of RMDPs has remained largely undetermined. While the statistical implications of distributional robustness in RL have been explored in some specific cases, the generalizability of the existing findings remains unclear, especially in comparison to standard RL. Assuming access to a generative model that samples from the nominal MDP, we examine the sample complexity of RMDPs using a class of generalized $L_p$ norms as the 'distance' function for the uncertainty set, under two commonly adopted $sa$-rectangular and $s$-rectangular conditions. Our results imply that RMDPs can be more sample-efficient to solve than standard MDPs using generalized $L_p$ norms in both $sa$- and $s$-rectangular cases, potentially inspiring more empirical research.
We provide a near-optimal upper bound and a matching minimax lower bound for the $sa$-rectangular scenarios. For $s$-rectangular cases, we improve the state-of-the-art upper bound and also derive a lower bound using $L_\infty$ norm that verifies the tightness.
758. eXponential FAmily Dynamical Systems (XFADS): Large-scale nonlinear Gaussian state-space modeling
tl;dr: We introduce a structured variational approximation and inference algorithm for efficient Bayesian inference in nonlinear state-space models.

State-space graphical models and the variational autoencoder framework provide a principled apparatus for learning dynamical systems from data. State-of-the-art probabilistic approaches are often able to scale to large problems at the cost of flexibility of the variational posterior or expressivity of the dynamics model. However, those consolidations can be detrimental if the ultimate goal is to learn a generative model capable of explaining the spatiotemporal structure of the data and making accurate forecasts. We introduce a low-rank structured variational autoencoding framework for nonlinear Gaussian state-space graphical models capable of capturing dense covariance structures that are important for learning dynamical systems with predictive capabilities. Our inference algorithm exploits the covariance structures that arise naturally from sample based approximate Gaussian message passing and low-rank amortized posterior updates -- effectively performing approximate variational smoothing with time complexity scaling linearly in the state dimensionality. In comparisons with other deep state-space model architectures our approach consistently demonstrates the ability to learn a more predictive generative model. Furthermore, when applied to neural physiological recordings, our approach is able to learn a dynamical system capable of forecasting population spiking and behavioral correlates from a small portion of single trials.
759. Rule Extrapolation in Language Modeling: A Study of Compositional Generalization on OOD Prompts

LLMs show remarkable emergent abilities, such as inferring concepts from presumably out-of-distribution prompts, known as in-context learning. Though this success is often attributed to the Transformer architecture, our systematic understanding is limited. In complex real-world data sets, even defining what is out-of-distribution is not obvious. To better understand the OOD behaviour of autoregressive LLMs, we focus on formal languages, which are defined by the intersection of rules. We define a new scenario of OOD compositional generalization, termed \textit{rule extrapolation}. Rule extrapolation describes OOD scenarios, where the prompt violates at least one rule. We evaluate rule extrapolation in formal languages with varying complexity in linear and recurrent architectures, the Transformer, and state space models to understand the architectures' influence on rule extrapolation. We also lay the first stones of a normative theory of rule extrapolation, inspired by the Solomonoff prior in algorithmic information theory.
tl;dr: In this paper, we reveal the working mechanism of text-to-image diffusion model

Recently, the strong latent Diffusion Probabilistic Model (DPM) has been applied to high-quality Text-to-Image (T2I) generation (e.g., Stable Diffusion), by injecting the encoded target text prompt into the gradually denoised diffusion image generator. Despite the success of DPM in practice, the mechanism behind it remains to be explored. To fill this blank, we begin by examining the intermediate statuses during the gradual denoising generation process in DPM. The empirical observations indicate, the shape of image is reconstructed after the first few denoising steps, and then the image is filled with details (e.g., texture). The phenomenon is because the low-frequency signal (shape relevant) of the noisy image is not corrupted until the final stage in the forward process (initial stage of generation) of adding noise in DPM. Inspired by the observations, we proceed to explore the influence of each token in the text prompt during the two stages. After a series of experiments of T2I generations conditioned on a set of text prompts. We conclude that in the earlier generation stage, the image is mostly decided by the special token [\texttt{EOS}] in the text prompt, and the information in the text prompt is already conveyed in this stage. After that, the diffusion model completes the details of generated images by information from themselves. Finally, we propose to apply this observation to accelerate the process of T2I generation by properly removing text guidance, which finally accelerates the sampling up to 25\%+.
tl;dr: We propose a novel, pessimistic off-policy estimator that logarithmically smoothes the importance weights, leading to improved policy evaluation, selection and learning strategies.

This work investigates the offline formulation of the contextual bandit problem, where the goal is to leverage past interactions collected under a behavior policy to evaluate, select, and learn new, potentially better-performing, policies. Motivated by critical applications, we move beyond point estimators. Instead, we adopt the principle of _pessimism_ where we construct upper bounds that assess a policy's worst-case performance, enabling us to confidently select and learn improved policies. Precisely, we introduce novel, fully empirical concentration bounds for a broad class of importance weighting risk estimators. These bounds are general enough to cover most existing estimators and pave the way for the development of new ones. In particular, our pursuit of the tightest bound within this class motivates a novel estimator (LS), that _logarithmically smoothes_ large importance weights. The bound for LS is provably tighter than its competitors, and naturally results in improved policy selection and learning strategies. Extensive policy evaluation, selection, and learning experiments highlight the versatility and favorable performance of LS.
tl;dr: This paper conducts analysis on LLM's zero-shot CoT, discovering an information flow pattern, furthermore, this paper proposes an instance-adaptive zero-shot prompting strategy to improve LLM's performance on several reasoning tasks.

Zero-shot Chain-of-Thought (CoT) prompting emerges as a simple and effective strategy for enhancing the performance of large language models (LLMs) in real-world reasoning tasks. Nonetheless, the efficacy of a singular, task-level prompt uniformly applied across the whole of instances is inherently limited since one prompt cannot be a good partner for all, a more appropriate approach should consider the interaction between the prompt and each instance meticulously. This work introduces an instance-adaptive prompting algorithm as an alternative zero-shot CoT reasoning scheme by adaptively differentiating good and bad prompts. Concretely, we first employ analysis on LLMs through the lens of information flow to detect the mechanism under zero-shot CoT reasoning, in which we discover that information flows from question to prompt and question to rationale jointly influence the reasoning results most. We notice that a better zero-shot CoT reasoning needs the prompt to obtain semantic information from the question then the rationale aggregates sufficient information from the question directly and via the prompt indirectly. On the contrary, lacking any of those would probably lead to a bad one. Stem from that, we further propose an instance-adaptive prompting strategy (IAP) for zero-shot CoT reasoning. Experiments conducted with LLaMA-2, LLaMA-3, and Qwen on math, logic, and commonsense reasoning tasks (e.g., GSM8K, MMLU, Causal Judgement) obtain consistent improvement, demonstrating that the instance-adaptive zero-shot CoT prompting performs better than other task-level methods with some curated prompts or sophisticated procedures, showing the significance of our findings in the zero-shot CoT reasoning mechanism.
tl;dr: FlipClass introduces a dynamic teacher-student framework for GCD, aligning the teacher's attention with the student's feedback to ensure consistent pattern learning and synchronized classification across old and new classes.

Recent advancements have shown promise in applying traditional Semi-Supervised Learning strategies to the task of Generalized Category Discovery (GCD). Typically, this involves a teacher-student framework in which the teacher imparts knowledge to the student to classify categories, even in the absence of explicit labels. Nevertheless, GCD presents unique challenges, particularly the absence of priors for new classes, which can lead to the teacher's misguidance and unsynchronized learning with the student, culminating in suboptimal outcomes. In our work, we delve into why traditional teacher-student designs falter in generalized category discovery as compared to their success in closed-world semi-supervised learning. We identify inconsistent pattern learning as the crux of this issue and introduce FlipClass—a method that dynamically updates the teacher to align with the student's attention, instead of maintaining a static teacher reference. Our teacher-attention-update strategy refines the teacher's focus based on student feedback, promoting consistent pattern recognition and synchronized learning across old and new classes. Extensive experiments on a spectrum of benchmarks affirm that FlipClass significantly surpasses contemporary GCD methods, establishing new standards for the field.
tl;dr: Modifying sparse autoencoders to approximate MLP behavior enables clean, fine-grained, interpretable circuit analysis for transformers

A key goal in mechanistic interpretability is circuit analysis: finding sparse subgraphs of models corresponding to specific behaviors or capabilities. However, MLP sublayers make fine-grained circuit analysis on transformer-based language models difficult. In particular, interpretable features—such as those found by sparse autoencoders (SAEs)—are typically linear combinations of extremely many neurons, each with its own nonlinearity to account for. Circuit analysis in this setting thus either yields intractably large circuits or fails to disentangle local and global behavior. To address this we explore **transcoders**, which seek to faithfully approximate a densely activating MLP layer with a wider, sparsely-activating MLP layer. We introduce a novel method for using transcoders to perform weights-based circuit analysis through MLP sublayers. The resulting circuits neatly factorize into input-dependent and input-invariant terms. We then successfully train transcoders on language models with 120M, 410M, and 1.4B parameters, and find them to perform at least on par with SAEs in terms of sparsity, faithfulness, and human-interpretability. Finally, we apply transcoders to reverse-engineer unknown circuits in the model, and we obtain novel insights regarding the "greater-than circuit" in GPT2-small. Our results suggest that transcoders can prove effective in decomposing model computations involving MLPs into interpretable circuits. Code is available at https://github.com/jacobdunefsky/transcoder_circuits/

We propose a normative model for spatial representation in the hippocampal formation that combines optimality principles, such as maximizing coding range and spatial information per neuron, with an algebraic framework for computing in distributed representation. Spatial position is encoded in a residue number system, with individual residues represented by high-dimensional, complex-valued vectors. These are composed into a single vector representing position by a similarity-preserving, conjunctive vector-binding operation. Self-consistency between the vectors representing position and the individual residues is enforced by a modular attractor network whose modules correspond to the grid cell modules in entorhinal cortex. The vector binding operation can also be used to bind different contexts to spatial representations, yielding a model for entorhinal cortex and hippocampus. We provide model analysis of scaling, similarity preservation and convergence behavior as well as experiments demonstrating noise robustness, sub-integer resolution in representing position, and path integration. The model formalizes the computations in the cognitive map and makes testable experimental predictions.

Rethink convolution-based graph neural networks (GNN)---they characteristically suffer from limited expressiveness, over-smoothing, and over-squashing, and require specialized sparse kernels for efficient computation.
Here, we design a simple graph learning module entirely free of convolution operators, coined _random walk with unifying memory_ (RUM) neural network, where an RNN merges the topological and semantic graph features along the random walks terminating at each node.
Relating the rich literature on RNN behavior and graph topology, we theoretically show and experimentally verify that RUM attenuates the aforementioned symptoms and is more expressive than the Weisfeiler-Lehman (WL) isomorphism test.
On a variety of node- and graph-level classification and regression tasks, RUM not only achieves competitive performance, but is also robust, memory-efficient, scalable, and faster than the simplest convolutional GNNs.
tl;dr: We propose a new method to align large language model from a stochastic optimal control perspective.

Aligning large language models (LLMs) with human objectives is crucial for real-world applications. However, fine-tuning LLMs for alignment often suffers from unstable training and requires substantial computing resources. Test-time alignment techniques, such as prompting and guided decoding, do not modify the underlying model, and their performance remains dependent on the original model's capabilities. To address these challenges, we propose aligning LLMs through representation editing. The core of our method is to view a pre-trained autoregressive LLM as a discrete-time stochastic dynamical system. To achieve alignment for specific objectives, we introduce external control signals into the state space of this language dynamical system. We train a value function directly on the hidden states according to the Bellman equation, enabling gradient-based optimization to obtain the optimal control signals at test time. Our experiments demonstrate that our method outperforms existing test-time alignment techniques while requiring significantly fewer resources compared to fine-tuning methods. Our code is available at [https://github.com/Lingkai-Kong/RE-Control](https://github.com/Lingkai-Kong/RE-Control).
tl;dr: We propose new rules for aggregating quantitative relative judgments, study their computational complexity, and evaluate their empirical performance.

Quantitative Relative Judgment Aggregation (QRJA) is a new research topic in (computational) social choice. In the QRJA model, agents provide judgments on the relative quality of different candidates, and the goal is to aggregate these judgments across all agents. In this work, our main conceptual contribution is to explore the interplay between QRJA in a social choice context and its application to ranking prediction. We observe that in QRJA, judges do not have to be people with subjective opinions; for example, a race can be viewed as a ``judgment'' on the contestants' relative abilities. This allows us to aggregate results from multiple races to evaluate the contestants' true qualities. At a technical level, we introduce new aggregation rules for QRJA and study their structural and computational properties. We evaluate the proposed methods on data from various real races and show that QRJA-based methods offer effective and interpretable ranking predictions.

3D Gaussian Splatting (3DGS) has already become the emerging research focus in the fields of 3D scene reconstruction and novel view synthesis. Given that training a 3DGS requires a significant amount of time and computational cost, it is crucial to protect the copyright, integrity, and privacy of such 3D assets. Steganography, as a crucial technique for encrypted transmission and copyright protection, has been extensively studied. However, it still lacks profound exploration targeted at 3DGS. Unlike its predecessor NeRF, 3DGS possesses two distinct features: 1) explicit 3D representation; and 2) real-time rendering speeds. These characteristics result in the 3DGS point cloud files being public and transparent, with each Gaussian point having a clear physical significance. Therefore, ensuring the security and fidelity of the original 3D scene while embedding information into the 3DGS point cloud files is an extremely challenging task. To solve the above-mentioned issue, we first propose a steganography framework for 3DGS, dubbed GS-Hider, which can embed 3D scenes and images into original GS point clouds in an invisible manner and accurately extract the hidden messages. Specifically, we design a coupled secured feature attribute to replace the original 3DGS's spherical harmonics coefficients and then use a scene decoder and a message decoder to disentangle the original RGB scene and the hidden message. Extensive experiments demonstrated that the proposed GS-Hider can effectively conceal multimodal messages without compromising rendering quality and possesses exceptional security, robustness, capacity, and flexibility. Our project is available at: https://xuanyuzhang21.github.io/project/gshider.
tl;dr: This work tackles the challenge of learning data representations robust to class distribution shifts in zero-shot learning, by constructing synthetic data environments and harnessing out-of-distribution generalization techniques.

Zero-shot learning methods typically assume that the new, unseen classes encountered during deployment come from the same distribution as the the classes in the training set. However, real-world scenarios often involve class distribution shifts (e.g., in age or gender for person identification), posing challenges for zero-shot classifiers that rely on learned representations from training classes. In this work, we propose and analyze a model that assumes that the attribute responsible for the shift is unknown in advance. We show that in this setting, standard training may lead to non-robust representations. To mitigate this, we develop an algorithm for learning robust representations in which (a) synthetic data environments are constructed via hierarchical sampling, and (b) environment balancing penalization, inspired by out-of-distribution problems, is applied. We show that our algorithm improves generalization to diverse class distributions in both simulations and experiments on real-world datasets.

The lack of interpretability in the field of medical image analysis has significant ethical and legal implications. Existing interpretable methods in this domain encounter several challenges, including dependency on specific models, difficulties in understanding and visualization, and issues related to efficiency. To address these limitations, we propose a novel framework called Med-MICN (Medical Multi-dimensional Interpretable Concept Network). Med-MICN provides interpretability alignment for various angles, including neural symbolic reasoning, concept semantics, and saliency maps, which are superior to current interpretable methods. Its advantages include high prediction accuracy, interpretability across multiple dimensions, and automation through an end-to-end concept labeling process that reduces the need for extensive human training effort when working with new datasets. To demonstrate the effectiveness and interpretability of Med-MICN, we apply it to four benchmark datasets and compare it with baselines. The results clearly demonstrate the superior performance and interpretability of our Med-MICN.
tl;dr: A powerful region-level VLM adept at 3D spatial reasoning.

Vision Language Models (VLMs) have demonstrated remarkable performance in 2D vision and language tasks. However, their ability to reason about spatial arrangements remains limited. In this work, we introduce Spatial Region GPT (SpatialRGPT) to enhance VLMs’ spatial perception and reasoning capabilities. SpatialRGPT advances VLMs’ spatial understanding through two key innovations: (i) a data curation pipeline that enables effective learning of regional representation from 3D scene graphs, and (ii) a flexible ``plugin'' module for integrating depth information into the visual encoder of existing VLMs. During inference, when provided with user-specified region proposals, SpatialRGPT can accurately perceive their relative directions and distances. Additionally, we propose SpatialRGBT-Bench, a benchmark with ground-truth 3D annotations encompassing indoor, outdoor, and simulated environments, for evaluating 3D spatial cognition in Vision-Language Models (VLMs). Our results demonstrate that SpatialRGPT significantly enhances performance in spatial reasoning tasks, both with and without local region prompts. The model also exhibits strong generalization capabilities, effectively reasoning about complex spatial relations and functioning as a region-aware dense reward annotator for robotic tasks. Code, dataset, and benchmark are released at https://www.anjiecheng.me/SpatialRGPT.
tl;dr: A speech processing framework that supports language learning, speech therapy and disorder screening.

Speech dysfluency modeling is the core module for spoken language learning, and speech therapy. However, there are three challenges. First, current state-of-the-art solutions~~\cite{lian2023unconstrained-udm, lian-anumanchipalli-2024-towards-hudm} suffer from poor scalability. Second, there is a lack of a large-scale dysfluency corpus. Third, there is not an effective learning framework. In this paper, we propose \textit{SSDM: Scalable Speech Dysfluency Modeling}, which (1) adopts articulatory gestures as scalable forced alignment; (2) introduces connectionist subsequence aligner (CSA) to achieve dysfluency alignment; (3) introduces a large-scale simulated dysfluency corpus called Libri-Dys; and (4) develops an end-to-end system by leveraging the power of large language models (LLMs). We expect SSDM to serve as a standard in the area of dysfluency modeling. Demo is available at \url{https://berkeley-speech-group.github.io/SSDM/}.
tl;dr: We theoretically show that iteratively retraining a generative model on its own generated samples with human curation optimizes human preferences

The rapid progress in generative models has resulted in impressive leaps in generation quality, blurring the lines between synthetic and real data. Web-scale datasets are now prone to the inevitable contamination by synthetic data, directly impacting the training of future generated models.
Already, some theoretical results on self-consuming generative models (a.k.a., iterative retraining) have emerged in the literature, showcasing that either model collapse or stability could be possible depending on the fraction of generated data used at each retraining step.
However, in practice, synthetic data is often subject to human feedback and curated by users before being used and uploaded online. For instance, many interfaces of popular text-to-image generative models, such as Stable Diffusion or Midjourney, produce several variations of an image for a given query which can eventually be curated by the users.
In this paper, we theoretically study the impact of data curation on iterated retraining of generative models and show that it can be seen as an implicit preference optimization mechanism. However, unlike standard preference optimization, the generative model does not have access to the reward function or negative samples needed for pairwise comparisons. Moreover, our study doesn't require access to the density function, only to samples. We prove that, if the data is curated according to a reward model, then the expected reward of the iterative retraining procedure is maximized. We further provide theoretical results on the stability of the retraining loop when using a positive fraction of real data at each step. Finally, we conduct illustrative experiments on both synthetic datasets and on CIFAR10 showing that such a procedure amplifies biases of the reward model.
tl;dr: TL;DR: We developed a method for creating species range maps by integrating citizen science data with Wikipedia text, enabling accurate zero-shot and few-shot range estimation.

Species range maps (SRMs) are essential tools for research and policy-making in ecology, conservation, and environmental management. However, traditional SRMs rely on the availability of environmental covariates and high-quality observational data, both of which can be challenging to obtain due to geographic inaccessibility and resource constraints. We propose a novel approach combining millions of citizen science species observations with textual descriptions from Wikipedia, covering habitat preferences and range descriptions for tens of thousands of species. Our framework maps location, species, and text descriptions into a common space, facilitating the learning of rich spatial covariates at a global scale and enabling zero-shot range estimation from textual descriptions. Evaluated on held-out species, our zero-shot SRMs significantly outperform baselines and match the performance of SRMs obtained using tens of observations. Our approach also acts as a strong prior when combined with observational data, resulting in more accurate range estimation with less data. We present extensive quantitative and qualitative analyses of the learned representations in the context of range estimation and other spatial tasks, demonstrating the effectiveness of our approach.
tl;dr: Improved sample complexity for agnostic boosting

The theory of boosting provides a computational framework for aggregating approximate weak learning algorithms, which perform marginally better than a random predictor, into an accurate strong learner. In the realizable case, the success of the boosting approach is underscored by a remarkable fact that the resultant sample complexity matches that of a computationally demanding alternative, namely Empirical Risk Minimization (ERM). This in particular implies that the realizable boosting methodology has the potential to offer computational relief without compromising on sample efficiency.
Despite recent progress, in agnostic boosting, where assumptions on the conditional distribution of labels given feature descriptions are absent, ERM outstrips the agnostic boosting methodology in being quadratically more sample efficient than all known agnostic boosting algorithms. In this paper, we make progress on closing this gap, and give a substantially more sample efficient agnostic boosting algorithm than those known, without compromising on the computational (or oracle) complexity. A key feature of our algorithm is that it leverages the ability to reuse samples across multiple rounds of boosting, while guaranteeing a generalization error strictly better than those obtained by blackbox applications of uniform convergence arguments. We also apply our approach to other previously studied learning problems, including boosting for reinforcement learning, and demonstrate improved results.
tl;dr: Invariant subspaces and PCA embeddings can be provably approximated in nearly matrix multiplication time in finite precision

Approximating invariant subspaces of generalized eigenvalue problems (GEPs) is a fundamental computational problem at the core of machine learning and scientific computing. It is, for example, the root of Principal Component Analysis (PCA) for dimensionality reduction, data visualization, and noise filtering, and of Density Functional Theory (DFT), arguably the most popular method to calculate the electronic structure of materials.
Given Hermitian $H,S\in\mathbb{C}^{n\times n}$, where $S$ is positive-definite, let $\Pi_k$ be the true spectral projector on the invariant subspace that is associated with the $k$ smallest (or largest) eigenvalues of the GEP $HC=SC\Lambda$, for some $k\in[n]$.
We show that we can compute a matrix $\widetilde\Pi_k$ such that $\lVert\Pi_k-\widetilde\Pi_k\rVert_2\leq \epsilon$, in $O\left( n^{\omega+\eta}\mathrm{polylog}(n,\epsilon^{-1},\kappa(S),\mathrm{gap}_k^{-1}) \right)$ bit operations in the floating point model, for some $\epsilon\in(0,1)$, with probability $1-1/n$. Here, $\eta>0$ is arbitrarily small, $\omega\lesssim 2.372$ is the matrix multiplication exponent, $\kappa(S)=\lVert S\rVert_2\lVert S^{-1}\rVert_2$, and $\mathrm{gap}_k$ is the gap between eigenvalues $k$ and $k+1$.
To achieve such provable "forward-error" guarantees, our methods rely on a new $O(n^{\omega+\eta})$ stability analysis for the Cholesky factorization, and a smoothed analysis for computing spectral gaps, which can be of independent interest.
Ultimately, we obtain new matrix multiplication-type bit complexity upper bounds for PCA problems, including classical PCA and (randomized) low-rank approximation.

With the rapid development of multimedia technology, audio-visual learning has emerged as a promising research topic within the field of multimodal analysis. In this paper, we explore parameter-efficient transfer learning for audio-visual learning and propose the Audio-Visual Mixture of Experts (\ourmethodname) to inject adapters into pre-trained models flexibly. Specifically, we introduce unimodal and cross-modal adapters as multiple experts to specialize in intra-modal and inter-modal information, respectively, and employ a lightweight router to dynamically allocate the weights of each expert according to the specific demands of each task. Extensive experiments demonstrate that our proposed approach \ourmethodname achieves superior performance across multiple audio-visual tasks,
including AVE, AVVP, AVS, and AVQA. Furthermore, visual-only experimental results also indicate that our approach can tackle challenging scenes where modality information is missing.
The source code is available at \url{https://github.com/yingchengy/AVMOE}.
tl;dr: EigenVI uses score matching with flexible yet tractable variational families built using orthogonal function expansions and reduces to an eigenvalue problem.

We develop EigenVI, an eigenvalue-based approach for black-box variational inference (BBVI). EigenVI constructs its variational approximations from orthogonal function expansions. For distributions over $\mathbb{R}^D$, the lowest order term in these expansions provides a Gaussian variational approximation, while higher-order terms provide a systematic way to model non-Gaussianity. These approximations are flexible enough to model complex distributions (multimodal, asymmetric), but they are simple enough that one can calculate their low-order moments and draw samples from them. EigenVI can also model other types of random variables (e.g., nonnegative, bounded) by constructing variational approximations from different families of orthogonal functions. Within these families, EigenVI computes the variational approximation that best matches the score function of the target distribution by minimizing a stochastic estimate of the Fisher divergence. Notably, this optimization reduces to solving a minimum eigenvalue problem, so that EigenVI effectively sidesteps the iterative gradient-based optimizations that are required for many other BBVI algorithms. (Gradient-based methods can be sensitive to learning rates, termination criteria, and other tunable hyperparameters.) We use EigenVI to approximate a variety of target distributions, including a benchmark suite of Bayesian models from posteriordb. On these distributions, we find that EigenVI is more accurate than existing methods for Gaussian BBVI.
tl;dr: We present private mean estimators for anisotropic distributions with dimension-free sample complexity, which we prove is optimal. We also give an estimator under unknown covariance, with a dimension-dependence that is milder than in prior work.

We present differentially private algorithms for high-dimensional mean estimation. Previous private estimators on distributions over $\mathbb{R}^d$ suffer from a curse of dimensionality, as they require $\Omega(d^{1/2})$ samples to achieve non-trivial error, even in cases where $O(1)$ samples suffice without privacy. This rate is unavoidable when the distribution is isotropic, namely, when the covariance is a multiple of the identity matrix. Yet, real-world data is often highly anisotropic, with signals concentrated on a small number of principal components. We develop estimators that are appropriate for such signals---our estimators are $(\varepsilon,\delta)$-differentially private and have sample complexity that is dimension-independent for anisotropic subgaussian distributions. Given $n$ samples from a distribution with known covariance-proxy $\Sigma$ and unknown mean $\mu$, we present an estimator $\hat{\mu}$ that achieves error, $\|\hat{\mu}-\mu\|_2\leq \alpha$, as long as $n\gtrsim \text{tr}(\Sigma)/\alpha^2+ \text{tr}(\Sigma^{1/2})/(\alpha\varepsilon)$. We show that this is the optimal sample complexity for this task up to logarithmic factors. Moreover, for the case of unknown covariance, we present an algorithm whose sample complexity has improved dependence on the dimension, from $d^{1/2}$ to $d^{1/4}$.

Binary statistical decision making involves choosing between two states based on statistical evidence. The optimal decision strategy is typically formulated through a constrained optimization problem, where both the objective and constraints are expressed as integrals involving two Lebesgue measurable functions, one of which represents the strategy being optimized. In this work, we present a comprehensive formulation of the binary decision making problem and provide a detailed characterization of the optimal solution. Our framework encompasses a wide range of well-known and recently proposed decision making problems as specific cases. We demonstrate how our generic approach can be used to derive the optimal decision strategies for these diverse instances. Our results offer a robust mathematical tool that simplifies the process of solving both existing and novel formulations of binary decision making problems which are in the core of many Machine Learning algorithms.
tl;dr: We propose a novel approach that "short-circuits" harmful outputs in AI systems by directly controlling the responsible representations, offering robust protection against harmful actions and adversarial attacks without compromising utility.
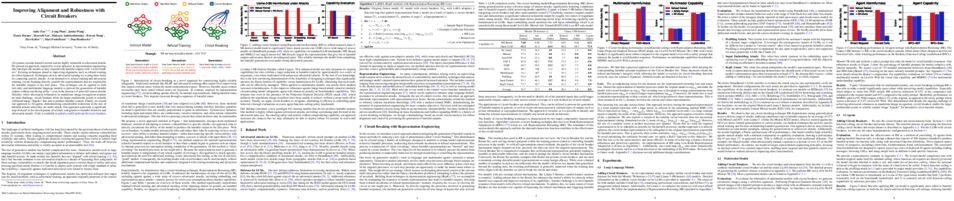
AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
tl;dr: We propose a new energy-based method to compute entropic optimal transport barycenters with general cost functions.

Optimal transport (OT) barycenters are a mathematically grounded way of averaging probability distributions while capturing their geometric properties. In short, the barycenter task is to take the average of a collection of probability distributions w.r.t. given OT discrepancies. We propose a novel algorithm for approximating the continuous Entropic OT (EOT) barycenter for arbitrary OT cost functions. Our approach is built upon the dual reformulation of the EOT problem based on weak OT, which has recently gained the attention of the ML community. Beyond its novelty, our method enjoys several advantageous properties: (i) we establish quality bounds for the recovered solution; (ii) this approach seamlessly interconnects with the Energy-Based Models (EBMs) learning procedure enabling the use of well-tuned algorithms for the problem of interest; (iii) it provides an intuitive optimization scheme avoiding min-max, reinforce and other intricate technical tricks. For validation, we consider several low-dimensional scenarios and image-space setups, including *non-Euclidean* cost functions. Furthermore, we investigate the practical task of learning the barycenter on an image manifold generated by a pretrained generative model, opening up new directions for real-world applications. Our code is available at https://github.com/justkolesov/EnergyGuidedBarycenters.
tl;dr: We develop a principled and efficient online batch selection algorithm that is scalable to large language models.

Online batch selection methods offer an adaptive alternative to static training data selection by dynamically selecting data batches during training. However, existing methods either rely on impractical reference models or simple heuristics that may not capture true data informativeness. To address these limitations, we propose \emph{GREedy Approximation Taylor Selection} (GREATS), a principled and efficient online batch selection method that applies greedy algorithm to optimize the data batch quality approximated by Taylor expansion. We develop a series of techniques to scale GREATS to large-scale model training. Extensive experiments with large language models (LLMs) demonstrate that GREATS significantly improves training convergence speed and generalization performance.
tl;dr: We study learning general halfspaces under Gaussian marginals using queries, proving a strong separation between the classic active learning model and membership query learning model for the problem.

We study the problem of learning general (i.e., not necessarily homogeneous)
halfspaces under the Gaussian distribution on $\mathbb{R}^d$
in the presence of some form of query access.
In the classical pool-based active learning model, where the algorithm is
allowed to make adaptive label queries to previously sampled points,
we establish a strong information-theoretic lower bound ruling out non-trivial
improvements over the passive setting. Specifically, we show that
any active learner requires label complexity of
$\tilde{\Omega}(d/(\log(m)\epsilon))$, where $m$ is the number of unlabeled examples.
Specifically, to beat the passive label complexity of $\tilde{O}(d/\epsilon)$,
an active learner requires a pool of $2^{\mathrm{poly}(d)}$ unlabeled samples.
On the positive side, we show that this lower bound
can be circumvented with membership query access,
even in the agnostic model. Specifically, we give a computationally efficient
learner with query complexity of $\tilde{O}(\min(1/p, 1/\epsilon) + d\mathrm{polylog}(1/\epsilon))$
achieving error guarantee of $O(\mathrm{opt}+\epsilon)$. Here $p \in [0, 1/2]$
is the bias and $\mathrm{opt}$ is the 0-1 loss of the optimal halfspace.
As a corollary, we obtain a strong separation
between the active and membership query models.
Taken together, our results characterize the complexity of learning
general halfspaces under Gaussian marginals in these models.

Federated Instruction Tuning (FIT) advances collaborative training on decentralized data, crucially enhancing model's capability and safeguarding data privacy. However, existing FIT methods are dedicated to handling data heterogeneity across different clients (i.e., client-aware data heterogeneity), while ignoring the variation between data from different domains (i.e., domain-aware data heterogeneity). When scarce data needs supplementation from related fields, these methods lack the ability to handle domain heterogeneity in cross-domain training. This leads to domain-information catastrophic forgetting in collaborative training and therefore makes model perform sub-optimally on the individual domain. To address this issue, we introduce DoFIT, a new Domain-aware FIT framework that alleviates catastrophic forgetting through two new designs. First, to reduce interference information from the other domain, DoFIT finely aggregates overlapping weights across domains on the inter-domain server side. Second, to retain more domain information, DoFIT initializes intra-domain weights by incorporating inter-domain information into a less-conflicted parameter space. Experimental results on diverse datasets consistently demonstrate that DoFIT excels in cross-domain collaborative training and exhibits significant advantages over conventional FIT methods in alleviating catastrophic forgetting. Code is available at [this link](https://github.com/1xbq1/DoFIT).
tl;dr: We address the challenge of contrastive phenomic molecular retrieval. We demonstrate pre-trained uni-modal representation methods can be used in a variety of ways to significantly improve zero-shot molecular retrieval rates.

Predicting molecular impact on cellular function is a core challenge in therapeutic design. Phenomic experiments, designed to capture cellular morphology, utilize microscopy based techniques and demonstrate a high throughput solution for uncovering molecular impact on the cell. In this work, we learn a joint latent space between molecular structures and microscopy phenomic experiments, aligning paired samples with contrastive learning. Specifically, we study the problem of Contrastive PhenoMolecular Retrieval, which consists of zero-shot molecular structure identification conditioned on phenomic experiments. We assess challenges in multi-modal learning of phenomics and molecular modalities such as experimental batch effect, inactive molecule perturbations, and encoding perturbation concentration. We demonstrate improved multi-modal learner retrieval through (1) a uni-modal pre-trained phenomics model, (2) a novel inter sample similarity aware loss, and (3) models conditioned on a representation of molecular concentration. Following this recipe, we propose MolPhenix, a molecular phenomics model. MolPhenix leverages a pre-trained phenomics model to demonstrate significant performance gains across perturbation concentrations, molecular scaffolds, and activity thresholds. In particular, we demonstrate an 8.1 times improvement in zero shot molecular retrieval of active molecules over the previous state-of-the-art, reaching 77.33% in top-1% accuracy. These results open the door for machine learning to be applied in virtual phenomics screening, which can significantly benefit drug discovery applications.
tl;dr: We use dictionary learning to interpret CLIP embeddings by representing them as sparse combinations of semantic concepts, resulting in interpretability while maintaining high performance and unlocking novel use cases.

CLIP embeddings have demonstrated remarkable performance across a wide range of multimodal applications. However, these high-dimensional, dense vector representations are not easily interpretable, limiting our understanding of the rich structure of CLIP and its use in downstream applications that require transparency.
In this work, we show that the semantic structure of CLIP's latent space can be leveraged to provide interpretability, allowing for the decomposition of representations into semantic concepts.
We formulate this problem as one of sparse recovery and propose a novel method, Sparse Linear Concept Embeddings (SpLiCE), for transforming CLIP representations into sparse linear combinations of human-interpretable concepts. Distinct from previous work, \method is task-agnostic and can be used, without training,
to explain and even replace traditional dense CLIP representations, maintaining high downstream performance while significantly improving their interpretability. We also demonstrate significant use cases of \method representations including detecting spurious correlations and model editing. Code is provided at https://github.com/AI4LIFE-GROUP/SpLiCE.
tl;dr: We introduce a novel approach of Evolutionary Adversarial Simulator Identification (EASI) by combining Generative Adversarial Network (GAN) and Evolutionary Strategy (ES) to address sim-to-real challenges.

Reinforcement Learning (RL) controllers have demonstrated remarkable performance in complex robot control tasks. However, the presence of reality gap often leads to poor performance when deploying policies trained in simulation directly onto real robots. Previous sim-to-real algorithms like Domain Randomization (DR) requires domain-specific expertise and suffers from issues such as reduced control performance and high training costs. In this work, we introduce Evolutionary Adversarial Simulator Identification (EASI), a novel approach that combines Generative Adversarial Network (GAN) and Evolutionary Strategy (ES) to address sim-to-real challenges. Specifically, we consider the problem of sim-to-real as a search problem, where ES acts as a generator in adversarial competition with a neural network discriminator, aiming to find physical parameter distributions that make the state transitions between simulation and reality as similar as possible. The discriminator serves as the fitness function, guiding the evolution of the physical parameter distributions. EASI features simplicity, low cost, and high fidelity, enabling the construction of a more realistic simulator with minimal requirements for real-world data, thus aiding in transferring simulated-trained policies to the real world. We demonstrate the performance of EASI in both sim-to-sim and sim-to-real tasks, showing superior performance compared to existing sim-to-real algorithms.
tl;dr: We propose Cross-model Control (CMC), a method that could improve multiple LLMs in one-time training with a portable tiny language model.

The number of large language models (LLMs) with varying parameter scales and vocabularies is increasing. While they deliver powerful performance, they also face a set of common optimization needs to meet specific requirements or standards, such as instruction following or avoiding the output of sensitive information from the real world. However, how to reuse the fine-tuning outcomes of one model to other models to reduce training costs remains a challenge. To bridge this gap, we introduce Cross-model Control (CMC), a method that improves multiple LLMs in one-time training with a portable tiny language model. Specifically, we have observed that the logit shift before and after fine-tuning is remarkably similar across different models. Based on this insight, we incorporate a tiny language model with a minimal number of parameters. By training alongside a frozen template LLM, the tiny model gains the capability to alter the logits output by the LLMs. To make this tiny language model applicable to models with different vocabularies, we propose a novel token mapping strategy named PM-MinED. We have conducted extensive experiments on instruction tuning and unlearning tasks, demonstrating the effectiveness of CMC. Our code is available at https://github.com/wujwyi/CMC

We study the problem of online binary classification in settings where strategic agents can modify their observable features to receive a positive classification. We model the set of feasible manipulations by a directed graph over the feature space, and assume the learner only observes the manipulated features instead of the original ones. We introduce the Strategic Littlestone Dimension, a new combinatorial measure that captures the joint complexity of the hypothesis class and the manipulation graph. We demonstrate that it characterizes the instance-optimal mistake bounds for deterministic learning algorithms in the realizable setting. We also achieve improved regret in the agnostic setting by a refined agnostic-to-realizable reduction that accounts for the additional challenge of not observing agents' original features. Finally, we relax the assumption that the learner knows the manipulation graph, instead assuming their knowledge is captured by a family of graphs. We derive regret bounds in both the realizable setting where all agents manipulate according to the same graph within the graph family, and the agnostic setting where the manipulation graphs are chosen adversarially and not consistently modeled by a single graph in the family.
792. VidMan: Exploiting Implicit Dynamics from Video Diffusion Model for Effective Robot Manipulation

Recent advancements utilizing large-scale video data for learning video generation models demonstrate significant potential in understanding complex physical dynamics. It suggests the feasibility of leveraging diverse robot trajectory data to develop a unified, dynamics-aware model to enhance robot manipulation. However, given the relatively small amount of available robot data, directly fitting data without considering the relationship between visual observations and actions could lead to suboptimal data utilization. To this end, we propose \textbf{VidMan} (\textbf{Vid}eo Diffusion for Robot \textbf{Man}ipulation), a novel framework that employs a two-stage training mechanism inspired by dual-process theory from neuroscience to enhance stability and improve data utilization efficiency. Specifically, in the first stage, VidMan is pre-trained on the Open X-Embodiment dataset (OXE) for predicting future visual trajectories in a video denoising diffusion manner, enabling the model to develop a long horizontal awareness of the environment's dynamics. In the second stage, a flexible yet effective layer-wise self-attention adapter is introduced to transform VidMan into an efficient inverse dynamics model that predicts action modulated by the implicit dynamics knowledge via parameter sharing. Our VidMan framework outperforms state-of-the-art baseline model GR-1 on the CALVIN benchmark, achieving a 11.7\% relative improvement, and demonstrates over 9\% precision gains on the OXE small-scale dataset. These results provide compelling evidence that world models can significantly enhance the precision of robot action prediction. Codes and models will be public.

We investigate bandit convex optimization (BCO) with delayed feedback, where only the loss value of the action is revealed under an arbitrary delay. Let $n,T,\bar{d}$ denote the dimensionality, time horizon, and average delay, respectively. Previous studies have achieved an $O(\sqrt{n}T^{3/4}+(n\bar{d})^{1/3}T^{2/3})$ regret bound for this problem, whose delay-independent part matches the regret of the classical non-delayed bandit gradient descent algorithm. However, there is a large gap between its delay-dependent part, i.e., $O((n\bar{d})^{1/3}T^{2/3})$, and an existing $\Omega(\sqrt{\bar{d}T})$ lower bound. In this paper, we illustrate that this gap can be filled in the worst case, where $\bar{d}$ is very close to the maximum delay $d$. Specifically, we first develop a novel algorithm, and prove that it enjoys a regret bound of $O(\sqrt{n}T^{3/4}+\sqrt{dT})$ in general. Compared with the previous result, our regret bound is better for $d=O((n\bar{d})^{2/3}T^{1/3})$, and the delay-dependent part is tight in the worst case. The primary idea is to decouple the joint effect of the delays and the bandit feedback on the regret by carefully incorporating the delayed bandit feedback with a blocking update mechanism. Furthermore, we show that the proposed algorithm can improve the regret bound to $O((nT)^{2/3}\log^{1/3}T+d\log T)$ for strongly convex functions. Finally, if the action sets are unconstrained, we demonstrate that it can be simply extended to achieve an $O(n\sqrt{T\log T}+d\log T)$ regret bound for strongly convex and smooth functions.
tl;dr: We investigate a simple yet effective long-context jailbreak, study the corresponding scaling laws and evaluate some mitigations against it.

We investigate a family of simple long-context attacks on large language models: prompting with hundreds of demonstrations of undesirable behavior. This attack is newly feasible with the larger context windows recently deployed by language model providers like Google DeepMind, OpenAI and Anthropic. We find that in diverse, realistic circumstances, the effectiveness of this attack follows a power law, up to hundreds of shots. We demonstrate the success of this attack on the most widely used state-of-the-art closed-weight models, and across various tasks. Our results suggest very long contexts present a rich new attack surface for LLMs.
tl;dr: A new approach to improve equation discovery of dynamical systems with symmetry priors

Despite the advancements in learning governing differential equations from observations of dynamical systems, data-driven methods are often unaware of fundamental physical laws, such as frame invariance. As a result, these algorithms may search an unnecessarily large space and discover less accurate or overly complex equations. In this paper, we propose to leverage symmetry in automated equation discovery to compress the equation search space and improve the accuracy and simplicity of the learned equations. Specifically, we derive equivariance constraints from the time-independent symmetries of ODEs. Depending on the types of symmetries, we develop a pipeline for incorporating symmetry constraints into various equation discovery algorithms, including sparse regression and genetic programming. In experiments across diverse dynamical systems, our approach demonstrates better robustness against noise and recovers governing equations with significantly higher probability than baselines without symmetry.
tl;dr: We propose RECURVE that exploits representation curvature for time-series boundary detection.

*Boundaries* are the timestamps at which a class in a time series changes. Recently, representation-based boundary detection has gained popularity, but its emphasis on consecutive distance difference backfires, especially when the changes are gradual. In this paper, we propose a boundary detection method, **RECURVE**, based on a novel change metric, the ***curvature*** of a representation trajectory, to accommodate both gradual and abrupt changes. Here, a sequence of representations in the representation space is interpreted as a trajectory, and a curvature at each timestamp can be computed. Using the theory of random walk, we formally show that the mean curvature is lower near boundaries than at other points. Extensive experiments using diverse real-world time-series datasets confirm the superiority of RECURVE over state-of-the-art methods.
tl;dr: This paper introduces a novel framework for outlier detection using optimal transport with a concave cost function, integrating outlier rectification and estimation into a single optimization process.

In this paper, we propose a novel conceptual framework to detect outliers using optimal transport with a concave cost function. Conventional outlier detection approaches typically use a two-stage procedure: first, outliers are detected and removed, and then estimation is performed on the cleaned data. However, this approach does not inform outlier removal with the estimation task, leaving room for improvement. To address this limitation, we propose an automatic outlier rectification mechanism that integrates rectification and estimation within a joint optimization framework. We take the first step to utilize the optimal transport distance with a concave cost function to construct a rectification set in the space of probability distributions. Then, we select the best distribution within the rectification set to perform the estimation task. Notably, the concave cost function we introduced in this paper is the key to making our estimator effectively identify the outlier during the optimization process. We demonstrate the effectiveness of our approach over conventional approaches in simulations and empirical analyses for mean estimation, least absolute regression, and the fitting of option implied volatility surfaces.

Data selection is essential for training deep learning models. An effective data sampler assigns proper sampling probability for training data and helps the model converge to a good local minimum with high performance. Previous studies in data sampling are mainly based on heuristic rules or learning through a huge amount of time-consuming trials. In this paper, we propose an automatic swift sampler search algorithm, SS, to explore automatically learning effective samplers efficiently. In particular, SS utilizes a novel formulation to map a sampler to a low dimension of hyper-parameters and uses an approximated local minimum to quickly examine the quality of a sampler. Benefiting from its low computational expense, SS can be applied on large-scale data sets with high efficiency. Comprehensive experiments on various tasks demonstrate that SS powered sampling can achieve obvious improvements (e.g., 1.5% on ImageNet) and transfer among different neural networks. Project page: https://github.com/Alexander-Yao/Swift-Sampler.
tl;dr: This paper proposes a stepwise approach for aligning large language models under safety constraints.

Safety and trustworthiness are indispensable requirements for real-world applications of AI systems using large language models (LLMs). This paper formulates human value alignment as an optimization problem of the language model policy to maximize reward under a safety constraint, and then proposes an algorithm, Stepwise Alignment for Constrained Policy Optimization (SACPO). One key idea behind SACPO, supported by theory, is that the optimal policy incorporating reward and safety can be directly obtained from a reward-aligned policy. Building on this key idea, SACPO aligns LLMs step-wise with each metric while leveraging simple yet powerful alignment algorithms such as direct preference optimization (DPO). SACPO offers several advantages, including simplicity, stability, computational efficiency, and flexibility of algorithms and datasets. Under mild assumptions, our theoretical analysis provides the upper bounds on optimality and safety constraint violation. Our experimental results show that SACPO can fine-tune Alpaca-7B better than the state-of-the-art method in terms of both helpfulness and harmlessness.

To generate data from trained diffusion models, most inference algorithms, such as DDPM, DDIM, and other variants, rely on discretizing the reverse SDEs or their equivalent ODEs. In this paper, we view such approaches as decomposing the entire denoising diffusion process into several segments, each corresponding to a reverse transition kernel (RTK) sampling subproblem. Specifically, DDPM uses a Gaussian approximation for the RTK, resulting in low per-subproblem complexity but requiring a large number of segments (i.e., subproblems), which is conjectured to be inefficient. To address this, we develop a general RTK framework that enables a more balanced subproblem decomposition, resulting in $\tilde O(1)$ subproblems, each with strongly log-concave targets. We then propose leveraging two fast sampling algorithms, the Metropolis-Adjusted Langevin Algorithm (MALA) and Underdamped Langevin Dynamics (ULD), for solving these strongly log-concave subproblems. This gives rise to the RTK-MALA and RTK-ULD algorithms for diffusion inference. In theory, we further develop the convergence guarantees for RTK-MALA and RTK-ULD in total variation (TV) distance: RTK-ULD can achieve $\epsilon$ target error within $\tilde{\mathcal O}(d^{1/2}\epsilon^{-1})$ under mild conditions, and RTK-MALA enjoys a $\mathcal{O}(d^{2}\log(d/\epsilon))$ convergence rate under slightly stricter conditions. These theoretical results surpass the state-of-the-art convergence rates for diffusion inference and are well supported by numerical experiments.

Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we introduce Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found we can distinguish between benign and toxic prompts from the distribution of the first response token's logits. Using this idea, we build a robust detector of toxic prompts using a sparse logistic regression model on the first response token logits. Our scheme outperforms SOTA detectors under multiple metrics.

Empirically, large-scale deep learning models often satisfy a neural scaling law: the test error of the trained model improves polynomially as the model size and data size grow. However, conventional wisdom suggests the test error consists of approximation, bias, and variance errors, where the variance error increases with model size. This disagrees with the general form of neural scaling laws, which predict that increasing model size monotonically improves performance.
We study the theory of scaling laws in an infinite dimensional linear regression setup. Specifically, we consider a model with $M$ parameters as a linear function of sketched covariates. The model is trained by one-pass stochastic gradient descent (SGD) using $N$ data. Assuming the optimal parameter satisfies a Gaussian prior and the data covariance matrix has a power-law spectrum of degree $a>1$, we show that the reducible part of the test error is $\Theta(M^{-(a-1)} + N^{-(a-1)/a})$. The variance error, which increases with $M$, is dominated by the other errors due to the implicit regularization of SGD, thus disappearing from the bound. Our theory is consistent with the empirical neural scaling laws and verified by numerical simulation.
tl;dr: We propose a new loss function based on contrastive regression to address the domain mismatch in speech quality metrics

In this paper, we present SCOREQ, a novel approach for speech quality prediction. SCOREQ is a triplet loss function for contrastive regression that addresses the domain generalisation shortcoming exhibited by state of the art no-reference speech quality metrics. In the paper we: (i) illustrate the problem of L2 loss training failing at capturing the continuous nature of the mean opinion score (MOS) labels; (ii) demonstrate the lack of generalisation through a benchmarking evaluation across several speech domains; (iii) outline our approach and explore the impact of the architectural design decisions through incremental evaluation; (iv) evaluate the final model against state of the art models for a wide variety of data and domains. The results show that the lack of generalisation observed in state of the art speech quality metrics is addressed by SCOREQ. We conclude that using a triplet loss function for contrastive regression improves generalisation for speech quality prediction models but also has potential utility across a wide range of applications using regression-based predictive models.
tl;dr: We summarize the success of PLL so far into some minimal algorithm design principles.

A partial label (PL) specifies a set of candidate labels for an instance and partial-label learning (PLL) trains multi-class classifiers with PLs.
Recently, many methods that incorporate techniques from other domains have shown strong potential.
The expectation that stronger techniques would enhance performance has resulted in prominent PLL methods becoming not only highly complicated but also quite different from one another, making it challenging to choose the best direction for future algorithm design.
While it is exciting to see higher performance, this leaves open a fundamental question: what makes a PLL method effective?
We present a comprehensive empirical analysis of this question and summarize the success of PLL so far into some minimal algorithm design principles.
Our findings reveal that high accuracy on benchmark-simulated datasets with PLs can misleadingly amplify the perceived effectiveness of some general techniques, which may improve representation learning but have limited impact on addressing the inherent challenges of PLs.
We further identify the common behavior among successful PLL methods as a progressive transition from uniform to one-hot pseudo-labels, highlighting the critical role of mini-batch PL purification in achieving top performance.
Based on our findings, we introduce a minimal working algorithm that is surprisingly simple yet effective, and propose an improved strategy to implement the design principles, suggesting a promising direction for improvements in PLL.
tl;dr: Improving modality alignment in large vision-language models with calibrated self-rewarding

Large Vision-Language Models (LVLMs) have made substantial progress by integrating pre-trained large language models (LLMs) and vision models through instruction tuning. Despite these advancements, LVLMs often exhibit the hallucination phenomenon, where generated text responses appear linguistically plausible but contradict the input image, indicating a misalignment between image and text pairs. This misalignment arises because the model tends to prioritize textual information over visual input, even when both the language model and visual representations are of high quality. Existing methods leverage additional models or human annotations to curate preference data and enhance modality alignment through preference optimization. These approaches are resource-intensive and may not effectively reflect the target LVLM's preferences, making the curated preferences easily distinguishable. Our work addresses these challenges by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning. In the reward modeling, we employ a step-wise strategy and incorporate visual constraints into the self-rewarding process to place greater emphasis on visual input. Empirical results demonstrate that CSR significantly enhances performance and reduces hallucinations across twelve benchmarks and tasks, achieving substantial improvements over existing methods by 7.62\%. Our empirical results are further supported by rigorous theoretical analysis, under mild assumptions, verifying the effectiveness of introducing visual constraints into the self-rewarding paradigm. Additionally, CSR shows compatibility with different vision-language models and the ability to incrementally improve performance through iterative fine-tuning.

Backdoor attacks on deep learning represent a recent threat that has gained significant attention in the research community.
Backdoor defenses are mainly based on backdoor inversion, which has been shown to be generic, model-agnostic, and applicable to practical threat scenarios. State-of-the-art backdoor inversion recovers a mask in the feature space to locate prominent backdoor features, where benign and backdoor features can be disentangled. However, it suffers from high computational overhead, and we also find that it overly relies on prominent backdoor features that are highly distinguishable from benign features. To tackle these shortcomings, this paper improves backdoor feature inversion for backdoor detection by incorporating extra neuron activation information. In particular, we adversarially increase the loss of backdoored models with respect to weights to activate the backdoor effect, based on which we can easily differentiate backdoored and clean models. Experimental results demonstrate our defense, BAN, is 1.37$\times$ (on CIFAR-10) and 5.11$\times$ (on ImageNet200) more efficient with an average 9.99\% higher detect success rate than the state-of-the-art defense BTI DBF. Our code and trained models are publicly available at https://github.com/xiaoyunxxy/ban.
tl;dr: A cell ontology guided transcriptome foundation model for enhanced cell representation learning, which is pre-trained on 20 million cells from CellxGene database leveraging their cell-type labels aligned with cell ontology graph

Transcriptome foundation models (TFMs) hold great promises of deciphering the transcriptomic language that dictate diverse cell functions by self-supervised learning on large-scale single-cell gene expression data, and ultimately unraveling the complex mechanisms of human diseases. However, current TFMs treat cells as independent samples and ignore the taxonomic relationships between cell types, which are available in cell ontology graphs. We argue that effectively leveraging this ontology information during the TFM pre-training can improve learning biologically meaningful gene co-expression patterns while preserving TFM as a general purpose foundation model for downstream zero-shot and fine-tuning tasks. To this end, we present **s**ingle **c**ell, **Cell**-**o**ntology guided TFM (scCello). We introduce cell-type coherence loss and ontology alignment loss, which are minimized along with the masked gene expression prediction loss during the pre-training. The novel loss component guide scCello to learn the cell-type-specific representation and the structural relation between cell types from the cell ontology graph, respectively. We pre-trained scCello on 22 million cells from CellxGene database leveraging their cell-type labels mapped to the cell ontology graph from Open Biological and Biomedical Ontology Foundry. Our TFM demonstrates competitive generalization and transferability performance over the existing TFMs on biologically important tasks including identifying novel cell types of unseen cells, prediction of cell-type-specific marker genes, and cancer drug responses. Source code and model
weights are available at https://github.com/DeepGraphLearning/scCello.

Offline safe reinforcement learning (RL) aims to train a policy that satisfies con- straints using a pre-collected dataset. Most current methods struggle with the mismatch between imperfect demonstrations and the desired safe and rewarding performance. In this paper, we mitigate this issue from a data-centric perspective and introduce OASIS (cOnditionAl diStributIon Shaping), a new paradigm in offline safe RL designed to overcome these critical limitations. OASIS utilizes a conditional diffusion model to synthesize offline datasets, thus shaping the data dis- tribution toward a beneficial target domain. Our approach makes compliance with safety constraints through effective data utilization and regularization techniques to benefit offline safe RL training. Comprehensive evaluations on public benchmarks and varying datasets showcase OASIS’s superiority in benefiting offline safe RL agents to achieve high-reward behavior while satisfying the safety constraints, out- performing established baselines. Furthermore, OASIS exhibits high data efficiency and robustness, making it suitable for real-world applications, particularly in tasks where safety is imperative and high-quality demonstrations are scarce. More details are available at the website https://sites.google.com/view/saferl-oasis/home.
tl;dr: We show an interesting interplay between local differential privacy and Huber contamination in MABs.

We study the interplay between local differential privacy (LDP) and robustness to Huber corruption and possibly heavy-tailed rewards in the context of multi-armed bandits (MABs). We consider two different practical settings: LDP-then-Corruption (LTC) where each user's locally private response might be further corrupted during the data collection process, and Corruption-then-LDP (CTL) where each user's raw data may be corrupted such that the LDP mechanism will only be applied to the corrupted data. To start with, we present the first tight characterization of the mean estimation error in high probability under both LTC and CTL settings. Leveraging this new result, we then present an almost tight characterization (up to log factor) of the minimax regret in online MABs and sub-optimality in offline MABs under both LTC and CTL settings, respectively. Our theoretical results in both settings are also corroborated by a set of systematic simulations. One key message in this paper is that LTC is a more difficult setting that leads to a worse performance guarantee compared to the CTL setting (in the minimax sense). Our sharp understanding of LTC and CTL also naturally allows us to give the first tight performance bounds for the most practical setting where corruption could happen both before and after the LDP mechanism.
As an important by-product, we also give the first correct and tight regret bound for locally private and heavy-tailed online MABs, i.e., without Huber corruption, by identifying a fundamental flaw in the state-of-the-art.
tl;dr: We present the Latent Plan Transformer (LPT), an novel generative model designed to explore planning and maintain temporal consistency through the latent space.

In tasks aiming for long-term returns, planning becomes essential. We study generative modeling for planning with datasets repurposed from offline reinforcement learning. Specifically, we identify temporal consistency in the absence of step-wise rewards as one key technical challenge. We introduce the Latent Plan Transformer (LPT), a novel model that leverages a latent variable to connect a Transformer- based trajectory generator and the final return. LPT can be learned with maximum likelihood estimation on trajectory-return pairs. In learning, posterior sampling of the latent variable naturally integrates sub-trajectories to form a consistent abstrac- tion despite the finite context. At test time, the latent variable is inferred from an expected return before policy execution, realizing the idea of planning as inference. Our experiments demonstrate that LPT can discover improved decisions from sub- optimal trajectories, achieving competitive performance across several benchmarks, including Gym-Mujoco, Franka Kitchen, Maze2D, and Connect Four. It exhibits capabilities in nuanced credit assignments, trajectory stitching, and adaptation to environmental contingencies. These results validate that latent variable inference can be a strong alternative to step-wise reward prompting.
tl;dr: large language models play starcraft2

With the continued advancement of Large Language Models (LLMs) Agents in reasoning, planning, and decision-making, benchmarks have become crucial in evaluating these skills. However, there is a notable gap in benchmarks for real-time strategic decision-making. StarCraft II (SC2), with its complex and dynamic nature, serves as an ideal setting for such evaluations. To this end, we have developed TextStarCraft II, a specialized environment for assessing LLMs in real-time strategic scenarios within SC2. Addressing the limitations of traditional Chain of Thought (CoT) methods, we introduce the Chain of Summarization (CoS) method, enhancing LLMs' capabilities in rapid and effective decision-making. Our key experiments included:
1. LLM Evaluation: Tested 10 LLMs in TextStarCraft II, most of them defeating LV5 build-in AI, showcasing effective strategy skills.
2. Commercial Model Knowledge: Evaluated four commercial models on SC2 knowledge; GPT-4 ranked highest by Grandmaster-level experts.
3. Human-AI Matches: Experimental results showed that fine-tuned LLMs performed on par with Gold-level players in real-time matches, demonstrating comparable strategic abilities.
All code and data from this
study have been made pulicly available at https://github.com/histmeisah/Large-Language-Models-play-StarCraftII
812. Faster Neighborhood Attention: Reducing the O(n^2) Cost of Self Attention at the Threadblock Level

Neighborhood attention reduces the cost of self attention by restricting each token’s attention span to its nearest neighbors. This restriction, parameterized by a window size and dilation factor, draws a spectrum of possible attention patterns between linear projection and self attention. Neighborhood attention, and more generally sliding window attention patterns, have long been bounded by infrastructure, particularly in higher-rank spaces (2-D and 3-D), calling for the development of custom kernels, which have been limited in either functionality, or performance, if not both. In this work, we aim to massively improve upon existing infrastructure by providing two new methods for implementing neighborhood attention. We first show that neighborhood attention can be represented as a batched GEMM problem, similar to standard attention, and implement it for 1-D and 2-D neighborhood attention. These kernels on average provide 895% and 272% improvement in full precision runtime compared to existing naive CUDA kernels for 1-D and 2-D neighborhood attention respectively. We find that aside from being heavily bound by memory bandwidth, certain inherent inefficiencies exist in all unfused implementations of neighborhood attention, which in most cases undo their theoretical efficiency gain. Motivated by the progress made into fused dot-product attention kernels, we developed fused neighborhood attention; an adaptation of fused dot-product attention kernels that allow fine-grained control over attention across different spatial axes. Known for reducing the quadratic time complexity of self attention to a linear complexity, neighborhood attention can now enjoy a reduced and constant memory footprint, and record-breaking half precision runtime. We observe that our fused implementation successfully circumvents some of the unavoidable inefficiencies in unfused implementations. While our unfused GEMM-based kernels only improve half precision performance compared to naive kernels by an average of 548% and 193% in 1-D and 2-D problems respectively, our fused kernels improve naive kernels by an average of 1759% and 958% in 1-D and 2-D problems respectively. These improvements translate into up to 104% improvement in inference and 39% improvement in training existing models based on neighborhood attention, and additionally extend its applicability to image and video perception, as well as other modalities. Our work is open-sourced at https://github.com/SHI-Labs/NATTEN/.

In long-term time series forecasting (LTSF) tasks, an increasing number of works have acknowledged that discrete time series originate from continuous dynamic systems and have attempted to model their underlying dynamics. Recognizing the chaotic nature of real-world data, our model, Attraos, incorporates chaos theory into LTSF, perceiving real-world time series as low-dimensional observations from unknown high-dimensional chaotic dynamical systems. Under the concept of attractor invariance, Attraos utilizes non-parametric Phase Space Reconstruction embedding along with a novel multi-resolution dynamic memory unit to memorize historical dynamical structures, and evolves by a frequency-enhanced local evolution strategy. Detailed theoretical analysis and abundant empirical evidence consistently show that Attraos outperforms various LTSF methods on mainstream LTSF datasets and chaotic datasets with only one-twelfth of the parameters compared to PatchTST.
tl;dr: We propose a maximum mean discrepancy-based valuation for data distribution and utilize a game-theoretic special case.

Data valuation is a class of techniques for quantitatively assessing the value of data for applications like pricing in data marketplaces. Existing data valuation methods define a value for a discrete dataset. However, in many use cases, users are interested in not only the value of the dataset, but that of the distribution from which the dataset was sampled. For example, consider a buyer trying to evaluate whether to purchase data from different vendors. The buyer may observe (and compare) only a small preview sample from each vendor, to decide which vendor's data distribution is most useful to the buyer and purchase. The core question is how should we compare the values of data distributions from their samples? Under a Huber characterization of the data heterogeneity across vendors, we propose a maximum mean discrepancy (MMD)-based valuation method which enables theoretically principled and actionable policies for comparing data distributions from samples. We empirically demonstrate that our method is sample-efficient and effective in identifying valuable data distributions against several existing baselines, on multiple real-world datasets (e.g., network intrusion detection, credit card fraud detection) and downstream applications (classification, regression).
tl;dr: Combining differentiable pruning and combinatorial optimization for block-sparse pruning of DNNs

Neural network pruning is a key technique towards engineering large yet scalable, interpretable, and generalizable models. Prior work on the subject has developed largely along two orthogonal directions: (1) differentiable pruning for efficiently and accurately scoring the importance of parameters, and (2) combinatorial optimization for efficiently searching over the space of sparse models. We unite the two approaches, both theoretically and empirically, to produce a coherent framework for structured neural network pruning in which differentiable pruning guides combinatorial optimization algorithms to select the most important sparse set of parameters. Theoretically, we show how many existing differentiable pruning techniques can be understood as nonconvex regularization for group sparse optimization, and prove that for a wide class of nonconvex regularizers, the global optimum is unique, group-sparse, and provably yields an approximate solution to a sparse convex optimization problem. The resulting algorithm that we propose, SequentialAttention++, advances the state of the art in large-scale neural network block-wise pruning tasks on the ImageNet and Criteo datasets.
tl;dr: We theoretically investigate the expressive power and the mechanisms of Transformer for modeling long but sparse memories.

We conduct a systematic study of the approximation properties of Transformer for sequence modeling with long, sparse and complicated memory.
We investigate the mechanisms through which different components of Transformer, such as the dot-product self-attention, positional encoding and feed-forward layer, affect its expressive power, and we study their combined effects through establishing explicit approximation rates.
Our study reveals the roles of critical parameters in the Transformer, such as the number of layers and the number of attention heads.
These theoretical insights are validated experimentally and offer natural suggestions for alternative architectures.
tl;dr: Our theory and experiments demonstrate that training with diverse auxiliary outliers enhances OOD detection performance.

Out-of-distribution (OOD) detection is crucial for ensuring reliable deployment of machine learning models. Recent advancements focus on utilizing easily accessible auxiliary outliers (e.g., data from the web or other datasets) in training. However, we experimentally reveal that these methods still struggle to generalize their detection capabilities to unknown OOD data, due to the limited diversity of the auxiliary outliers collected. Therefore, we thoroughly examine this problem from the generalization perspective and demonstrate that a more diverse set of auxiliary outliers is essential for enhancing the detection capabilities. However, in practice, it is difficult and costly to collect sufficiently diverse auxiliary outlier data. Therefore, we propose a simple yet practical approach with a theoretical guarantee, termed Diversity-induced Mixup for OOD detection (diverseMix), which enhances the diversity of auxiliary outlier set for training in an efficient way. Extensive experiments show that diverseMix achieves superior performance on commonly used and recent challenging large-scale benchmarks, which further confirm the importance of the diversity of auxiliary outliers.
tl;dr: We provide a direct transformer-to-SNN conversion that requires no training and no architectural change, achieving SOTA SNN accuracy of 80.0% by converting Swin-T (42% less energy) and only 0.3% accuracy loss by converting BERT (58% less energy).

Event-driven spiking neural networks(SNNs) are promising neural networks that reduce the energy consumption of continuously growing AI models. Recently, keeping pace with the development of transformers, transformer-based SNNs were presented. Due to the incompatibility of self-attention with spikes, however, existing transformer-based SNNs limit themselves by either restructuring self-attention architecture or conforming to non-spike computations. In this work, we propose a novel transformer-to-SNN conversion method that outputs an end-to-end spike-based transformer, named SpikedAttention. Our method directly converts the well-trained transformer without modifying its attention architecture. For the vision task, the proposed method converts Swin Transformer into an SNN without post-training or conversion-aware training, achieving state-of-the-art SNN accuracy on ImageNet dataset, i.e., 80.0\% with 28.7M parameters. Considering weight accumulation, neuron potential update, and on-chip data movement, SpikedAttention reduces energy consumption by 42\% compared to the baseline ANN, i.e., Swin-T. Furthermore, for the first time, we demonstrate that SpikedAttention successfully converts a BERT model to an SNN with only 0.3\% accuracy loss on average consuming 58\% less energy on GLUE benchmark. Our code is available at Github ( https://github.com/sangwoohwang/SpikedAttention ).

This paper introduces the notion of upper-linearizable/quadratizable functions, a class that extends concavity and DR-submodularity in various settings, including monotone and non-monotone cases over different types of convex sets. A general meta-algorithm is devised to convert algorithms for linear/quadratic maximization into ones that optimize upper-linearizable/quadratizable functions, offering a unified approach to tackling concave and DR-submodular optimization problems. The paper extends these results to multiple feedback settings, facilitating conversions between semi-bandit/first-order feedback and bandit/zeroth-order feedback, as well as between first/zeroth-order feedback and semi-bandit/bandit feedback. Leveraging this framework, new algorithms are derived using existing results as base algorithms for convex optimization, improving upon state-of-the-art results in various cases. Dynamic and adaptive regret guarantees are obtained for DR-submodular maximization, marking the first algorithms to achieve such guarantees in these settings. Notably, the paper achieves these advancements with fewer assumptions compared to existing state-of-the-art results, underscoring its broad applicability and theoretical contributions to non-convex optimization.

Our objective in this paper is to probe large vision models to determine to what extent they ‘understand’ different physical properties of the 3D scene depicted in an image. To this end, we make the following contributions: (i) We introduce a general and lightweight protocol to evaluate whether features of an off-the-shelf large vision model encode a number of physical ‘properties’ of the 3D scene, by training discriminative classifiers on the features for these properties. The probes are applied on datasets of real images with annotations for the property. (ii) We apply this protocol to properties covering scene geometry, scene material, support relations, lighting, and view-dependent measures, and large vision models including CLIP, DINOv1, DINOv2, VQGAN, Stable Diffusion. (iii) We find that features from Stable Diffusion and DINOv2 are good for discriminative learning of a number of properties, including scene geometry, support relations, shadows and depth, but less performant for occlusion and material, while outperforming DINOv1, CLIP and VQGAN for all properties. (iv) It is observed that different time steps of Stable Diffusion features, as well as different transformer layers of DINO/CLIP/VQGAN, are good at different properties, unlocking potential applications of 3D physical understanding.
tl;dr: We propose an efficient method for multi-prompt evaluation of LLMs.

Most popular benchmarks for comparing LLMs rely on a limited set of prompt templates, which may not fully capture the LLMs’ abilities and can affect the reproducibility of results on leaderboards. Many recent works empirically verify prompt sensitivity and advocate for changes in LLM evaluation. In this paper, we consider the problem of estimating the performance distribution across many prompt variants instead of finding a single prompt to evaluate with. We introduce PromptEval, a method for estimating performance across a large set of prompts borrowing strength across prompts and examples to produce accurate estimates under practical evaluation budgets. The resulting distribution can be used to obtain performance quantiles to construct various robust performance metrics (e.g., top 95% quantile or median). We prove that PromptEval consistently estimates the performance distribution and demonstrate its efficacy empirically on three prominent LLM benchmarks: MMLU, BIG-bench Hard, and LMentry; for example, PromptEval can accurately estimate performance quantiles across 100 prompt templates on MMLU with a budget equivalent to two single-prompt evaluations. Moreover, we show how PromptEval can be useful in LLM-as-a-judge and best prompt identification applications.

Researchers have been studying approaches to steer the behavior of Large Language Models (LLMs) and build personalized LLMs tailored for various applications. While fine-tuning seems to be a direct solution, it requires substantial computational resources and may significantly affect the utility of the original LLM.
Recent endeavors have introduced more lightweight strategies, focusing on extracting ``steering vectors'' to guide the model's output toward desired behaviors by adjusting activations within specific layers of the LLM's transformer architecture. However, such steering vectors are directly extracted from the activations of human preference data and thus often lead to suboptimal results and occasional failures, especially in alignment-related scenarios.
In this work, we propose an innovative approach that could produce more effective steering vectors through bi-directional preference optimization.
Our method is designed to allow steering vectors to directly influence the generation probability of contrastive human preference data pairs, thereby offering a more precise representation of the target behavior. By carefully adjusting the direction and magnitude of the steering vector, we enabled personalized control over the desired behavior across a spectrum of intensities.
Extensive experimentation across various open-ended generation tasks, particularly focusing on steering AI personas, has validated the efficacy of our approach.
Moreover, we comprehensively investigate critical alignment-concerning scenarios, such as managing truthfulness, mitigating hallucination, and addressing jailbreaking attacks alongside their respective defenses. Remarkably, our method can still demonstrate outstanding steering effectiveness across these scenarios. Furthermore, we showcase the transferability of our steering vectors across different models/LoRAs and highlight the synergistic benefits of applying multiple vectors simultaneously. These findings significantly broaden the practicality and versatility of our proposed method.
tl;dr: Measure-preserving Dynamics in SDE Diffusion

Inverse problems describe the process of estimating the causal factors from a set of measurements or data.
Mapping of often incomplete or degraded data to parameters is ill-posed, thus data-driven iterative solutions are required, for example when reconstructing clean images from poor signals.
Diffusion models have shown promise as potent generative tools for solving inverse problems due to their superior reconstruction quality and their compatibility with iterative solvers. However, most existing approaches are limited to linear inverse problems represented as Stochastic Differential Equations (SDEs). This simplification falls short of addressing the challenging nature of real-world problems, leading to amplified cumulative errors and biases.
We provide an explanation for this gap through the lens of measure-preserving dynamics of Random Dynamical Systems (RDS) with which we analyse Temporal Distribution Discrepancy and thus introduce a theoretical framework based on RDS for SDE diffusion models. We uncover several strategies that inherently enhance the stability and generalizability of diffusion models for inverse problems and introduce a novel score-based diffusion framework, the Dynamics-aware SDE Diffusion Generative Model (D^3GM). The Measure-preserving property can return the degraded measurement to the original state despite complex degradation with the RDS concept of stability.
Our extensive experimental results corroborate the effectiveness of D^3GM across multiple benchmarks including a prominent application for inverse problems, magnetic resonance imaging.

Segment Anything Model (SAM) has recently gained much attention for its outstanding generalization to unseen data and tasks. Despite its promising prospect, the vulnerabilities of SAM, especially to universal adversarial perturbation (UAP) have not been thoroughly investigated yet. In this paper, we propose DarkSAM, the first prompt-free universal attack framework against SAM, including a semantic decoupling-based spatial attack and a texture distortion-based frequency attack. We first divide the output of SAM into foreground and background. Then, we design a shadow target strategy to obtain the semantic blueprint of the image as the attack target. DarkSAM is dedicated to fooling SAM by extracting and destroying crucial object features from images in both spatial and frequency domains. In the spatial domain, we disrupt the semantics of both the foreground and background in the image to confuse SAM. In the frequency domain, we further enhance the attack effectiveness by distorting the high-frequency components (i.e., texture information) of the image. Consequently, with a single UAP, DarkSAM renders SAM incapable of segmenting objects across diverse images with varying prompts. Experimental results on four datasets for SAM and its two variant models demonstrate the powerful attack capability and transferability of DarkSAM. Our codes are available at: https://github.com/CGCL-codes/DarkSAM.
tl;dr: Using natural gradients to improve handling of Monte Carlo noise in expectation propagation.

Expectation propagation (EP) is a family of algorithms for performing approximate inference in probabilistic models. The updates of EP involve the evaluation of moments—expectations of certain functions—which can be estimated from Monte Carlo (MC) samples. However, the updates are not robust to MC noise when performed naively, and various prior works have attempted to address this issue in different ways. In this work, we provide a novel perspective on the moment-matching updates of EP; namely, that they perform natural-gradient-based optimisation of a variational objective. We use this insight to motivate two new EP variants, with updates that are particularly well-suited to MC estimation. They remain stable and are most sample-efficient when estimated with just a single sample. These new variants combine the benefits of their predecessors and address key weaknesses. In particular, they are easier to tune, offer an improved speed-accuracy trade-off, and do not rely on the use of debiasing estimators. We demonstrate their efficacy on a variety of probabilistic inference tasks.
tl;dr: Neural networks architectures designed to process surfaces can be improved by representing input surfaces via principal curvature

The modern study and use of surfaces is a research topic grounded in centuries of mathematical and empirical inquiry. From a mathematical point of view, curvature is an invariant that characterises the intrinsic geometry and the extrinsic shape of a surface. Yet, in modern applications the focus has shifted away from finding expressive representations of surfaces, and towards the design of efficient neural network architectures to process them. The literature suggests a tendency to either overlook the representation of the processed surface, or use overcomplicated representations whose ability to capture the essential features of a surface is opaque. We propose using curvature as the input of neural network architectures for surface processing, and explore this proposition through experiments making use of the shape operator. Our results show that using curvature as input leads to significant a increase in performance on segmentation and classification tasks, while allowing far less computational overhead than current methods.
tl;dr: A unified framework for Pipeline Parallelism with balanced and controllable memory

Pipeline parallelism has been widely explored, but most existing schedules lack a systematic methodology. In this paper, we propose a framework to decompose pipeline schedules as repeating a building block, and show that the lifespan of the building block decides the peak activation memory of the pipeline schedule. Guided by the observations, we find that almost all existing pipeline schedules, to the best of our knowledge, are memory inefficient. To address this, we introduce a family of memory efficient building blocks with controllable activation memory, which can reduce the peak activation memory to 1/2 of 1F1B without sacrificing efficiency, and even to 1/3 with comparable throughput. We can also achieve almost zero pipeline bubbles while maintaining the same activation memory as 1F1B. Our evaluations demonstrate that in pure pipeline parallelism settings, our methods outperform 1F1B by from 7\% to 55\% in terms of throughput. When employing a grid search over hybrid parallelism hyperparameters in practical scenarios, our methods demonstrate a 16\% throughput improvement over the 1F1B baseline for large language models. The implementation is open-sourced at https://github.com/sail-sg/zero-bubble-pipeline-parallelism.
tl;dr: We introduce Annealed Multiple Choice Learning (aMCL) which combines deterministic annealing with MCL.

We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.
tl;dr: To improve energy efficiency and reduce the carbon footprint, we propose Neural Pathway to efficiently use the network parameter space for reinforcement learning.

Reinforcement learning (RL) algorithms have been very successful at tackling complex control problems, such as AlphaGo or fusion control. However, current research mainly emphasizes solution quality, often achieved by using large models trained on large amounts of data, and does not account for the financial, environmental, and societal costs associated with developing and deploying such models. Modern neural networks are often overparameterized and a significant number of parameters can be pruned without meaningful loss in performance, resulting in more efficient use of the model's capacity lottery ticket. We present a methodology for identifying sub-networks within a larger network in reinforcement learning (RL). We call such sub-networks, neural pathways. We show empirically that even very small learned sub-networks, using less than 5% of the large network's parameters, can provide very good quality solutions. We also demonstrate the training of multiple pathways within the same networks in a multitask setup, where each pathway is encouraged to tackle a separate task. We evaluate empirically our approach on several continuous control tasks, in both online and offline training

Modern neural networks are often massively overparameterized leading to high compute costs during training and at inference. One effective method to improve both the compute and energy efficiency of neural networks while maintaining good performance is structured pruning, where full network structures (e.g. neurons or convolutional filters) that have limited impact on the model output are removed. In this work, we propose Bayesian Model Reduction for Structured pruning (BMRS), a fully end-to-end Bayesian method of structured pruning. BMRS is based on two recent methods: Bayesian structured pruning with multiplicative noise, and Bayesian model reduction (BMR), a method which allows efficient comparison of Bayesian models under a change in prior. We present two realizations of BMRS derived from different priors which yield different structured pruning characteristics: 1) BMRS_N with the truncated log-normal prior, which offers reliable compression rates and accuracy without the need for tuning any thresholds and 2) BMRS_U with the truncated log-uniform prior that can achieve more aggressive compression based on the boundaries of truncation. Overall, we find that BMRS offers a theoretically grounded approach to structured pruning of neural networks yielding both high compression rates and accuracy. Experiments on multiple datasets and neural networks of varying complexity showed that the two BMRS methods offer a competitive performance-efficiency trade-off compared to other pruning methods.

Symmetries are prevalent in deep learning and can significantly influence the learning dynamics of neural networks. In this paper, we examine how exponential symmetries -- a broad subclass of continuous symmetries present in the model architecture or loss function -- interplay with stochastic gradient descent (SGD). We first prove that gradient noise creates a systematic motion (a ``Noether flow") of the parameters $\theta$ along the degenerate direction to a unique initialization-independent fixed point $\theta^*$. These points are referred to as the noise equilibria because, at these points, noise contributions from different directions are balanced and aligned. Then, we show that the balance and alignment of gradient noise can serve as a novel alternative mechanism for explaining important phenomena such as progressive sharpening/flattening and representation formation within neural networks and have practical implications for understanding techniques like representation normalization and warmup.

We present a detailed study of cardinality-aware top-$k$ classification, a novel approach that aims to learn an accurate top-$k$ set predictor while maintaining a low cardinality. We introduce a new target loss function tailored to this setting that accounts for both the classification error and the cardinality of the set predicted. To optimize this loss function, we propose two families of surrogate losses: cost-sensitive comp-sum losses and cost-sensitive constrained losses. Minimizing these loss functions leads to new cardinality-aware algorithms that we describe in detail in the case of both top-$k$ and threshold-based classifiers. We establish $H$-consistency bounds for our cardinality-aware surrogate loss functions, thereby providing a strong theoretical foundation for our algorithms. We report the results of extensive experiments on CIFAR-10, CIFAR-100, ImageNet, and SVHN datasets demonstrating the effectiveness and benefits of our cardinality-aware algorithms.
tl;dr: We establish theory governing the difficulty of policy optimization in high-decision-frequency distributional RL.

When decisions are made at high frequency, traditional reinforcement learning (RL) methods struggle to accurately estimate action values. In turn, their performance is inconsistent and often poor. Whether the performance of distributional RL (DRL) agents suffers similarly, however, is unknown. In this work, we establish that DRL agents *are* sensitive to the decision frequency. We prove that action-conditioned return distributions collapse to their underlying policy's return distribution as the decision frequency increases. We quantify the rate of collapse of these return distributions and exhibit that their statistics collapse at different rates. Moreover, we define distributional perspectives on action gaps and advantages. In particular, we introduce the *superiority* as a probabilistic generalization of the advantage---the core object of approaches to mitigating performance issues in high-frequency value-based RL. In addition, we build a superiority-based DRL algorithm. Through simulations in an option-trading domain, we validate that proper modeling of the superiority distribution produces improved controllers at high decision frequencies.

Recent advancements in Vision-Language Models (VLMs) have enabled complex multimodal tasks by processing text and image data simultaneously, significantly enhancing the field of artificial intelligence. However, these models often exhibit biases that can skew outputs towards societal stereotypes, thus necessitating debiasing strategies. Existing debiasing methods focus narrowly on specific modalities or tasks, and require extensive retraining. To address these limitations, this paper introduces Selective Feature Imputation for Debiasing (SFID), a novel methodology that integrates feature pruning and low confidence imputation (LCI) to effectively reduce biases in VLMs. SFID is versatile, maintaining the semantic integrity of outputs and costly effective by eliminating the need for retraining. Our experimental results demonstrate SFID's effectiveness across various VLMs tasks including zero-shot classification, text-to-image retrieval, image captioning, and text-to-image generation, by significantly reducing gender biases without compromising performance. This approach not only enhances the fairness of VLMs applications but also preserves their efficiency and utility across diverse scenarios.
tl;dr: In this work, we evaluate representational alignment between human olfactory perception and representations extracted from pre-trained transformers.

The human brain encodes stimuli from the environment into representations that form a sensory perception of the world. Despite recent advances in understanding visual and auditory perception, olfactory perception remains an under-explored topic in the machine learning community due to the lack of large-scale datasets annotated with labels of human olfactory perception. In this work, we ask the question of whether pre-trained transformer models of chemical structures encode representations that are aligned with human olfactory perception, i.e., can transformers smell like humans? We demonstrate that representations encoded from transformers pre-trained on general chemical structures are highly aligned with human olfactory perception. We use multiple datasets and different types of perceptual representations to show that the representations encoded by transformer models are able to predict: (i) labels associated with odorants provided by experts; (ii) continuous ratings provided by human participants with respect to pre-defined descriptors; and (iii) similarity ratings between odorants provided by human participants. Finally, we evaluate the extent to which this alignment is associated with physicochemical features of odorants known to be relevant for olfactory decoding.

We introduce an efficient method for learning linear models from uncertain data, where uncertainty is represented as a set of possible variations in the data, leading to predictive multiplicity. Our approach leverages abstract interpretation and zonotopes, a type of convex polytope, to compactly represent these dataset variations, enabling the symbolic execution of gradient descent on all possible worlds simultaneously. We develop techniques to ensure that this process converges to a fixed point and derive closed-form solutions for this fixed point. Our method provides sound over-approximations of all possible optimal models and viable prediction ranges. We demonstrate the effectiveness of our approach through theoretical and empirical analysis, highlighting its potential to reason about model and prediction uncertainty due to data quality issues in training data.

The branch-and-cut algorithm is the method of choice to solve large scale integer programming problems in practice. A key ingredient of branch-and-cut is the use of *cutting planes* which are derived constraints that reduce the search space for an optimal solution. Selecting effective cutting planes to produce small branch-and-cut trees is a critical challenge in the branch-and-cut algorithm. Recent advances have employed a data-driven approach to select good cutting planes from a parameterized family, aimed at reducing the branch-and-bound tree size (in expectation) for a given distribution of integer programming instances. We extend this idea to the selection of the best cut generating function (CGF), which is a tool in the integer programming literature for generating a wide variety of cutting planes that generalize the well-known Gomory Mixed-Integer (GMI) cutting planes. We provide rigorous sample complexity bounds for the selection of an effective CGF from certain parameterized families that provably performs well for any specified distribution on the problem instances. Our empirical results show that the selected CGF can outperform the GMI cuts for certain distributions. Additionally, we explore the sample complexity of using neural networks for instance-dependent CGF selection.
tl;dr: In this paper, we propose a dynamic multivariate time series forecasting model with a structured matrix basis.

Multivariate time series forecasting is of central importance in modern intelligent decision systems. The dynamics of multivariate time series are jointly characterized by temporal dependencies and spatial correlations. Hence, it is equally important to build the forecasting models from both perspectives. The real-world multivariate time series data often presents spatial correlations that show structures and evolve dynamically. To capture such dynamic spatial structures, the existing forecasting approaches often rely on a two-stage learning process (learning dynamic series representations and then generating spatial structures), which is sensitive to the small time-window input data and has high variance. To address this, we propose a novel forecasting model with a structured matrix basis. At its core is a dynamic spatial structure generation function whose output space is well-constrained and the generated structures have lower variance, meanwhile, it is more expressive and can offer interpretable dynamics. This is achieved via a novel structured parameterization and imposing structure regularization on the matrix basis. The resulting forecasting model can achieve up to $8.5\%$ improvements over the existing methods on six benchmark datasets, and meanwhile, it enables us to gain insights into the dynamics of underlying systems.
tl;dr: We prove that inference and gradient computation of distributed models that can be implemented on networked quantum computers enable exponential savings in communication.

Training and inference with large machine learning models that far exceed the memory capacity of individual devices necessitates the design of distributed architectures, forcing one to contend with communication constraints. We present a framework for distributed computation over a quantum network in which data is encoded into specialized quantum states. We prove that for models within this framework, inference and training using gradient descent can be performed with exponentially less communication compared to their classical analogs, and with relatively modest overhead relative to standard gradient-based methods. We show that certain graph neural networks are particularly amenable to implementation within this framework, and moreover present empirical evidence that they perform well on standard benchmarks.
To our knowledge, this is the first example of exponential quantum advantage for a generic class of machine learning problems that hold regardless of the data encoding cost.
Moreover, we show that models in this class can encode highly nonlinear features of their inputs, and their expressivity increases exponentially with model depth.
We also delineate the space of models for which exponential communication advantages hold by showing that they cannot hold for linear classification.
Communication of quantum states that potentially limit the amount of information that can be extracted from them about the data and model parameters may also lead to improved privacy guarantees for distributed computation. Taken as a whole, these findings form a promising foundation for distributed machine learning over quantum networks.
tl;dr: We introduce the cell-type dynamical systems (CTDS) model, which extends latent linear dynamical systems to incorporate cell-type information when modeling neural activity.

Latent dynamical systems have been widely used to characterize the dynamics of neural population activity in the brain. However, these models typically ignore the fact that the brain contains multiple cell types. This limits their ability to capture the functional roles of distinct cell classes, and to predict the effects of cell-specific perturbations on neural activity or behavior. To overcome these limitations, we introduce the `"cell-type dynamical systems" (CTDS) model. This model extends latent linear dynamical systems to contain distinct latent variables for each cell class, with biologically inspired constraints on both dynamics and emissions. To illustrate our approach, we consider neural recordings with distinct excitatory (E) and inhibitory (I) populations.
The CTDS model defines separate latents for both cell types, and constrains the dynamics so that E (I) latents have a strictly positive (negative) effects on other latents. We applied CTDS to recordings from rat frontal orienting fields (FOF) and anterior dorsal striatum (ADS) during an auditory decision-making task. The model achieved higher accuracy than a standard linear dynamical system (LDS), and revealed that the animal's choice can be decoded from both E and I latents and thus is not restricted to a single cell-class. We also performed in-silico optogenetic perturbation experiments in the FOF and ADS, and found that CTDS was able to replicate the experimentally observed effects of different perturbations on behavior, whereas a standard LDS model---which does not differentiate between cell types---did not. Crucially, our model allowed us to understand the effects of these perturbations by revealing the dynamics of different cell-specific latents. Finally, CTDS can also be used to identify cell types for neurons whose class labels are unknown in electrophysiological recordings. These results illustrate the power of the CTDS model to provide more accurate and more biologically interpretable descriptions of neural population dynamics and their relationship to behavior.

We study how information propagates in decoder-only Transformers, which are the architectural foundation of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis---specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct pairs of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways---leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory points to simple solutions towards ameliorating these issues.

Data-driven algorithm design is a paradigm that uses statistical and machine learning techniques to select from a class of algorithms for a computational problem an algorithm that has the best expected performance with respect to some (unknown) distribution on the instances of the problem. We build upon recent work in this line of research by considering the setup where, instead of selecting a single algorithm that has the best performance, we allow the possibility of selecting an algorithm based on the instance to be solved, using neural networks. In particular, given a representative sample of instances, we learn a neural network that maps an instance of the problem to the most appropriate algorithm *for that instance*. We formalize this idea and derive rigorous sample complexity bounds for this learning problem, in the spirit of recent work in data-driven algorithm design. We then apply this approach to the problem of making good decisions in the branch-and-cut framework for mixed-integer optimization (e.g., which cut to add?). In other words, the neural network will take as input a mixed-integer optimization instance and output a decision that will result in a small branch-and-cut tree for that instance. Our computational results provide evidence that our particular way of using neural networks for cut selection can make a significant impact in reducing branch-and-cut tree sizes, compared to previous data-driven approaches.
tl;dr: This paper introduces graph diffusion policy optimization (GDPO), a novel approach to optimize graph diffusion models for arbitrary (e.g., non-differentiable) objectives using reinforcement learning.

Recent research has made significant progress in optimizing diffusion models for downstream objectives, which is an important pursuit in fields such as graph generation for drug design. However, directly applying these models to graph presents challenges, resulting in suboptimal performance. This paper introduces graph diffusion policy optimization (GDPO), a novel approach to optimize graph diffusion models for arbitrary (e.g., non-differentiable) objectives using reinforcement learning. GDPO is based on an eager policy gradient tailored for graph diffusion models, developed through meticulous analysis and promising improved performance. Experimental results show that GDPO achieves state-of-the-art performance in various graph generation tasks with complex and diverse objectives. Code is available at https://github.com/sail-sg/GDPO.

We propose a novel algorithm for offline reinforcement learning using optimal transport. Typically, in offline reinforcement learning, the data is provided by various experts and some of them can be sub-optimal. To extract an efficient policy, it is necessary to \emph{stitch} the best behaviors from the dataset. To address this problem, we rethink offline reinforcement learning as an optimal transportation problem. And based on this, we present an algorithm that aims to find a policy that maps states to a \emph{partial} distribution of the best expert actions for each given state. We evaluate the performance of our algorithm on continuous control problems from the D4RL suite and demonstrate improvements over existing methods.
tl;dr: We learn hardware-efficient linear layers by constructing and searching a continuous space of structured matrices

Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts to develop alternatives have focused on a small number of hand-crafted structured matrices, and have neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, and Monarch, along with many novel structures. We develop a taxonomy of all such operators based on their computational and algebraic properties, which provides insights into their scaling laws. Combining these insights with empirical evaluation, we identify a subset of structures that achieve equal or better performance than dense layers as a function of training compute. To further improve their compute efficiency, we develop a natural extension of these performant structures that convert them into a sparse Mixture-of-Experts layer. The resulting layer significantly outperforms dense layers in compute-optimal training efficiency for GPT-2 language models.
tl;dr: Enable the probability distribution averaging between heterogeneous large language models

Large language models (LLMs) exhibit complementary strengths in various tasks, motivating the research of LLM ensembling.
However, existing work focuses on training an extra reward model or fusion model to select or combine all candidate answers, posing a great challenge to the generalization on unseen data distributions.
Besides, prior methods use textual responses as communication media, ignoring the valuable information in the internal representations.
In this work, we propose a training-free ensemble framework \textsc{DeePEn}, fusing the informative probability distributions yielded by different LLMs at each decoding step.
Unfortunately, the vocabulary discrepancy between heterogeneous LLMs directly makes averaging the distributions unfeasible due to the token misalignment.
To address this challenge, \textsc{DeePEn} maps the probability distribution of each model from its own probability space to a universal \textit{relative space} based on the relative representation theory, and performs aggregation.
Next, we devise a search-based inverse transformation to transform the aggregated result back to the probability space of one of the ensembling LLMs (main model), in order to determine the next token.
We conduct extensive experiments on ensembles of different number of LLMs, ensembles of LLMs with different architectures, and ensembles between the LLM and the specialist model.
Experimental results show that (i) \textsc{DeePEn} achieves consistent improvements across six benchmarks covering subject examination, reasoning, and knowledge, (ii) a well-performing specialist model can benefit from a less effective LLM through distribution fusion, and (iii) \textsc{DeePEn} has complementary strengths with other ensemble methods such as voting.
tl;dr: We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors

We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors---the quadratic graph Laplacian regularizer (GLR) and the $\ell_1$-norm graph total variation (GTV)---subject to an interpolation constraint. The crucial insight is that a normalized signal-dependent graph learning module amounts to a variant of the basic self-attention mechanism in conventional transformers. Unlike "black-box" transformers that require learning of large key, query and value matrices to compute scaled dot products as affinities and subsequent output embeddings, resulting in huge parameter sets, our unrolled networks employ shallow CNNs to learn low-dimensional features per node to establish pairwise Mahalanobis distances and construct sparse similarity graphs. At each layer, given a learned graph, the target interpolated signal is simply a low-pass filtered output derived from the minimization of an assumed graph smoothness prior, leading to a dramatic reduction in parameter count. Experiments for two image interpolation applications verify the restoration performance, parameter efficiency and robustness to covariate shift of our graph-based unrolled networks compared to conventional transformers.

Macroscopic observables of a system are of keen interest in real applications such as the design of novel materials. Current methods rely on microscopic trajectory simulations, where the forces on all microscopic coordinates need to be computed or measured. However, this can be computationally prohibitive for realistic systems. In this paper, we propose a method to learn macroscopic dynamics requiring only force computations on a subset of the microscopic coordinates. Our method relies on a sparsity assumption: the force on each microscopic coordinate relies only on a small number of other coordinates. The main idea of our approach is to map the training procedure on the macroscopic coordinates back to the microscopic coordinates, on which partial force computations can be used as stochastic estimation to update model parameters. We provide a theoretical justification of this under suitable conditions. We demonstrate the accuracy, force computation efficiency, and robustness of our method on learning macroscopic closure models from a variety of microscopic systems, including those modeled by partial differential equations or molecular dynamics simulations.
tl;dr: We compute token-level generalization bounds for large language models at the scale of LlaMa2 70B.

Large language models (LLMs) with billions of parameters excel at predicting the next token in a sequence. Recent work computes non-vacuous compression-based generalization bounds for LLMs, but these bounds are vacuous for large models at the billion-parameter scale. Moreover, these bounds are obtained through restrictive compression techniques, bounding compressed models that generate low-quality text. Additionally, the tightness of these existing bounds depends on the number of IID documents in a training set rather than the much larger number of non-IID constituent tokens, leaving untapped potential for tighter bounds. In this work, we instead use properties of martingales to derive generalization bounds that benefit from the vast number of tokens in LLM training sets. Since a dataset contains far more tokens than documents, our generalization bounds not only tolerate but actually benefit from far less restrictive compression schemes. With Monarch matrices, Kronecker factorizations, and post-training quantization, we achieve non-vacuous generalization bounds for LLMs as large as LLaMA2-70B. Unlike previous approaches, our work achieves the first non-vacuous bounds for models that are deployed in practice and generate high-quality text.
tl;dr: We apply recent advances in distribution compression (Kernel Thinning) to speed up kernel smoothing and kernel ridge regression.

The kernel thinning algorithm of Dwivedi & Mackey (2024) provides a better-than-i.i.d. compression of a generic set of points. By generating high-fidelity coresets of size significantly smaller than the input points, KT is known to speed up unsupervised tasks like Monte Carlo integration, uncertainty quantification, and non-parametric hypothesis testing, with minimal loss in statistical accuracy. In this work, we generalize the KT algorithm to speed up supervised learning problems involving kernel methods.
Specifically, we combine two classical algorithms---Nadaraya-Watson (NW) regression or kernel smoothing, and kernel ridge regression (KRR)---with KT to provide a quadratic speed-up in both training and inference times. We show how distribution compression with KT in each setting reduces to constructing an appropriate kernel, and introduce the Kernel-Thinned NW and Kernel-Thinned KRR estimators. We prove that KT-based regression estimators enjoy significantly superior computational efficiency over the full-data estimators and improved statistical efficiency over i.i.d. subsampling of the training data. En route, we also provide a novel multiplicative error guarantee for compressing with KT. We validate our design choices with both simulations and real data experiments.

This paper studies the scaling behavior of state-space models (SSMs) and their structured variants, such as Mamba, that have recently arisen in popularity as alternatives to transformer-based neural network architectures. Specifically, we focus on the capability of SSMs to learn features as their network width approaches infinity. Our findings reveal that established scaling rules, such as the Maximal Update Parameterization, fail to support feature learning as these models cannot be represented in the form of Tensor Programs. Additionally, we demonstrate that spectral scaling conditions, shown to be effective for feature learning in a host of other architectures, do not hold the same implications for SSMs. Through a detailed signal propagation analysis in SSMs, both forward and backward, we identify the appropriate scaling necessary for non-trivial feature evolution in the infinite-width limit. Our proposed scaling shows behavior akin to the Maximal Update Parameterization, such as improved stability, better generalization, and transferability of optimal hyper-parameters from small to large scale SSMs.
852. Convolutions and More as Einsum: A Tensor Network Perspective with Advances for Second-Order Methods
tl;dr: We introduce einsum implementations of many operations related to convolution that speed up the computation of second-order methods like KFAC

Despite their simple intuition, convolutions are more tedious to analyze than dense layers, which complicates the transfer of theoretical and algorithmic ideas to convolutions. We simplify convolutions by viewing them as tensor networks (TNs) that allow reasoning about the underlying tensor multiplications by drawing diagrams, manipulating them to perform function transformations like differentiation, and efficiently evaluating them with `einsum`. To demonstrate their simplicity and expressiveness, we derive diagrams of various autodiff operations and popular curvature approximations with full hyper-parameter support, batching, channel groups, and generalization to any convolution dimension. Further, we provide convolution-specific transformations based on the connectivity pattern which allow to simplify diagrams before evaluation. Finally, we probe performance. Our TN implementation accelerates a recently-proposed KFAC variant up to 4.5 x while removing the standard implementation's memory overhead, and enables new hardware-efficient tensor dropout for approximate backpropagation.
tl;dr: Employing RL methods for arithmetic tree generation yields superior designs for adders and multipliers.

Across a wide range of hardware scenarios, the computational efficiency and physical size of the arithmetic units significantly influence the speed and footprint of the overall hardware system. Nevertheless, the effectiveness of prior arithmetic design techniques proves inadequate, as they do not sufficiently optimize speed and area, resulting in increased latency and larger module size. To boost computing performance, this work focuses on the two most common and fundamental arithmetic modules, adders and multipliers. We cast the design tasks as single-player tree generation games, leveraging reinforcement learning techniques to optimize their arithmetic tree structures. This tree generation formulation allows us to efficiently navigate the vast search space and discover superior arithmetic designs that improve computational efficiency and hardware size within just a few hours. Our proposed method, **ArithTreeRL**, achieves significant improvements for both adders and multipliers. For adders, our approach discovers designs of 128-bit adders that achieve Pareto optimality in theoretical metrics. Compared with PrefixRL, it reduces delay and size by up to 26% and 30%, respectively. For multipliers, compared to RL-MUL, our method enhances speed and reduces size by as much as 49% and 45%. Additionally, ArithTreeRL's flexibility and scalability enable seamless integration into 7nm technology. We believe our work will offer valuable insights into hardware design, further accelerating speed and reducing size through the refined search space and our tree generation methodologies.
tl;dr: We present the AUF-MICNS algorithm for suggesting appropriate decision actions to avoid undesired outcomes with minimal action cost in non-stationary environments

Machine learning (ML) has achieved remarkable success in prediction tasks. In many real-world scenarios, rather than solely predicting an outcome using an ML model, the crucial concern is how to make decisions to prevent the occurrence of undesired outcomes, known as the *avoiding undesired future (AUF)* problem. To this end, a new framework called *rehearsal learning* has been proposed recently, which works effectively in stationary environments by leveraging the influence relations among variables. In real tasks, however, the environments are usually non-stationary, where the influence relations may be *dynamic*, leading to the failure of AUF by the existing method. In this paper, we introduce a novel sequential methodology that effectively updates the estimates of dynamic influence relations, which are crucial for rehearsal learning to prevent undesired outcomes in non-stationary environments. Meanwhile, we take the cost of decision actions into account and provide the formulation of AUF problem with minimal action cost under non-stationarity. We prove that in linear Gaussian cases, the problem can be transformed into the well-studied convex quadratically constrained quadratic program (QCQP). In this way, we establish the first polynomial-time rehearsal-based approach for addressing the AUF problem. Theoretical and experimental results validate the effectiveness and efficiency of our method under certain circumstances.

In this paper, we address the challenges of offline reinforcement learning (RL) under model mismatch, where the agent aims to optimize its performance through an offline dataset that may not accurately represent the deployment environment. We identify two primary challenges under the setting: inaccurate model estimation due to limited data and performance degradation caused by the model mismatch between the dataset-collecting environment and the target deployment one. To tackle these issues, we propose a unified principle of pessimism using distributionally robust Markov decision processes. We carefully construct a robust MDP with a single uncertainty set to tackle both data sparsity and model mismatch, and demonstrate that the optimal robust policy enjoys a near-optimal sub-optimality gap under the target environment across three widely used uncertainty models: total variation, $\chi^2$ divergence, and KL divergence. Our results improve upon or match the state-of-the-art performance under the total variation and KL divergence models, and provide the first result for the $\chi^2$ divergence model.
tl;dr: We introduce a novel framework, which is crafted to comprehensively exploit the cross-domain transferable image prior.

Meta-learning offers a promising avenue for few-shot learning (FSL), enabling models to glean a generalizable feature embedding through episodic training on synthetic FSL tasks in a source domain. Yet, in practical scenarios where the target task diverges from that in the source domain, meta-learning based method is susceptible to over-fitting. To overcome this, we introduce a novel framework, Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning, which is crafted to comprehensively exploit the cross-domain transferable image prior that each image can be decomposed into complementary low-frequency content details and high-frequency robust structural characteristics. Motivated by this insight, we propose to decompose each query image into its high-frequency and low-frequency components, and parallel incorporate them into the feature embedding network to enhance the final category prediction. More importantly, we introduce a feature reconstruction prior and a prediction consistency prior to separately encourage the consistency of the intermediate feature as well as the final category prediction between the original query image and its decomposed frequency components. This allows for collectively guiding the network's meta-learning process with the aim of learning generalizable image feature embeddings, while not introducing any extra computational cost in the inference phase. Our framework establishes new state-of-the-art results on multiple cross-domain few-shot learning benchmarks.
tl;dr: We present a novel autonomous driving motion generation paradigm and validate scalability and zero-shot generalizability of proposed model.

Data-driven autonomous driving motion generation tasks are frequently impacted by the limitations of dataset size and the domain gap between datasets, which precludes their extensive application in real-world scenarios. To address this issue, we introduce SMART, a novel autonomous driving motion generation paradigm that models vectorized map and agent trajectory data into discrete sequence tokens. These tokens are then processed through a decoder-only transformer architecture to train for the next token prediction task across spatial-temporal series. This GPT-style method allows the model to learn the motion distribution in real driving scenarios. SMART achieves state-of-the-art performance across most of the metrics on the generative Sim Agents challenge, ranking 1st on the leaderboards of Waymo Open Motion Dataset (WOMD), demonstrating remarkable inference speed. Moreover, SMART represents the generative model in the autonomous driving motion domain, exhibiting zero-shot generalization capabilities: Using only the NuPlan dataset for training and WOMD for validation, SMART achieved a competitive score of 0.72 on the Sim Agents challenge. Lastly, we have collected over 1 billion motion tokens from multiple datasets, validating the model's scalability. These results suggest that SMART has initially emulated two important properties: scalability and zero-shot generalization, and preliminarily meets the needs of large-scale real-time simulation applications. We have released all the code to promote the exploration of models for motion generation in the autonomous driving field. The source code is available at https://github.com/rainmaker22/SMART.

In this paper, we study Adam in non-convex smooth scenarios with potential unbounded gradients and affine variance noise. We consider a general noise model which governs affine variance noise, bounded noise, and sub-Gaussian noise. We show that Adam with a specific hyper-parameter setup can find a stationary point with a $\mathcal{O}(\text{poly}(\log T)/\sqrt{T})$ rate in high probability under this general noise model where $T$ denotes total number iterations, matching the lower rate of stochastic first-order algorithms up to logarithm factors. We also provide a probabilistic convergence result for Adam under a generalized smooth condition which allows unbounded smoothness parameters and has been illustrated empirically to capture the smooth property of many practical objective functions more accurately.

Data-driven artificial intelligence (AI) models have made significant advancements in weather forecasting, particularly in medium-range and nowcasting. However, most data-driven weather forecasting models are black-box systems that focus on learning data mapping rather than fine-grained physical evolution in the time dimension. Consequently, the limitations in the temporal scale of datasets prevent these models from forecasting at finer time scales. This paper proposes a physics-AI hybrid model (i.e., WeatherGFT) which Generalizes weather forecasts to Finer-grained Temporal scales beyond training dataset. Specifically, we employ a carefully designed PDE kernel to simulate physical evolution on a small time scale (e.g., 300 seconds) and use a parallel neural networks with a learnable router for bias correction. Furthermore, we introduce a lead time-aware training framework to promote the generalization of the model at different lead times. The weight analysis of physics-AI modules indicates that physics conducts major evolution while AI performs corrections adaptively. Extensive experiments show that WeatherGFT trained on an hourly dataset, achieves state-of-the-art performance across multiple lead times and exhibits the capability to generalize 30-minute forecasts.

As society increasingly relies on AI-based tools for decision-making in socially sensitive domains, investigating fairness and equity of such automated systems has become a critical field of inquiry. Most of the literature in fair machine learning focuses on defining and achieving fairness criteria in the context of prediction, while not explicitly focusing on how these predictions may be used later on in the pipeline. For instance, if commonly used criteria, such as independence or sufficiency, are satisfied for a prediction score $S$ used for binary classification, they need not be satisfied after an application of a simple thresholding operation on $S$ (as commonly used in practice).
In this paper, we take an important step to address this issue in numerous statistical and causal notions of fairness. We introduce the notion of a margin complement, which measures how much a prediction score $S$ changes due to a thresholding operation.
We then demonstrate that the marginal difference in the optimal 0/1 predictor $\widehat Y$ between groups, written $P(\hat y \mid x_1) - P(\hat y \mid x_0)$, can be causally decomposed into the influences of $X$ on the $L_2$-optimal prediction score $S$ and the influences of $X$ on the margin complement $M$, along different causal pathways (direct, indirect, spurious). We then show that under suitable causal assumptions, the influences of $X$ on the prediction score $S$ are equal to the influences of $X$ on the true outcome $Y$. This yields a new decomposition of the disparity in the predictor $\widehat Y$ that allows us to disentangle causal differences inherited from the true outcome $Y$ that exists in the real world vs. those coming from the optimization procedure itself. This observation highlights the need for more regulatory oversight due to the potential for bias amplification, and to address this issue we introduce new notions of weak and strong business necessity, together with an algorithm for assessing whether these notions are satisfied. We apply our method to three real-world datasets and derive new insights on bias amplification in prediction and decision-making.

Multimodal learning has gained increasing importance across various fields, offering the ability to integrate data from diverse sources such as images, text, and personalized records, which are frequently observed in medical domains. However, in scenarios where some modalities are missing, many existing frameworks struggle to accommodate arbitrary modality combinations, often relying heavily on a single modality or complete data. This oversight of potential modality combinations limits their applicability in real-world situations. To address this challenge, we propose Flex-MoE (Flexible Mixture-of-Experts), a new framework designed to flexibly incorporate arbitrary modality combinations while maintaining robustness to missing data. The core idea of Flex-MoE is to first address missing modalities using a new missing modality bank that integrates observed modality combinations with the corresponding missing ones. This is followed by a uniquely designed Sparse MoE framework. Specifically, Flex-MoE first trains experts using samples with all modalities to inject generalized knowledge through the generalized router ($\mathcal{G}$-Router). The $\mathcal{S}$-Router then specializes in handling fewer modality combinations by assigning the top-1 gate to the expert corresponding to the observed modality combination. We evaluate Flex-MoE on the ADNI dataset, which encompasses four modalities in the Alzheimer's Disease domain, as well as on the MIMIC-IV dataset. The results demonstrate the effectiveness of Flex-MoE, highlighting its ability to model arbitrary modality combinations in diverse missing modality scenarios. Code is available at: \url{https://github.com/UNITES-Lab/flex-moe}.
862. Policy Aggregation

We consider the challenge of AI value alignment with multiple individuals that have different reward functions and optimal policies in an underlying Markov decision process. We formalize this problem as one of *policy aggregation*, where the goal is to identify a desirable collective policy. We argue that an approach informed by social choice theory is especially suitable. Our key insight is that social choice methods can be reinterpreted by identifying ordinal preferences with volumes of subsets of the *state-action occupancy polytope*. Building on this insight, we demonstrate that a variety of methods — including approval voting, Borda count, the proportional veto core, and quantile fairness — can be practically applied to policy aggregation.

The poor performance of transformers on arithmetic tasks seems to stem in large part from their inability to keep track of the exact position of each digit inside of a large span of digits. We mend this problem by adding an embedding to each digit that encodes its position relative to the start of the number. In addition to the boost these embeddings provide on their own, we show that this fix enables architectural modifications such as input injection and recurrent layers to improve performance even further.
With positions resolved, we can study the logical extrapolation ability of transformers. Can they solve arithmetic problems that are larger and more complex than those in their training data? We find that training on only 20 digit numbers with a single GPU for one day, we can reach state-of-the-art performance, achieving up to 99% accuracy on 100 digit addition problems. Finally, we show that these gains in numeracy also unlock improvements on other multi-step reasoning tasks including sorting and multiplication.
tl;dr: We proposed the STMixer architecture, consisting exclusively of convolutional, fully connected layers, and residual path, is more advantageous for deployment in asynchronous scenarios.

Spiking neural networks (SNNs), inspired by biological processes, use spike signals for inter-layer communication, presenting an energy-efficient alternative to traditional neural networks. To realize the theoretical advantages of SNNs in energy efficiency, it is essential to deploy them onto neuromorphic chips. On clock-driven synchronous chips, employing shorter time steps can enhance energy efficiency but reduce SNN performance. Compared to the clock-driven synchronous chip, the event-driven asynchronous chip achieves much lower energy consumption but only supports some specific network operations. Recently, a series of SNN projects have achieved tremendous success, significantly improving the SNN's performance. However, event-driven asynchronous chips do not support some of the proposed structures, making it impossible to integrate these SNNs into asynchronous hardware. In response to these problems, we propose the Spiking Token Mixer (STMixer) architecture, which consists exclusively of operations supported by asynchronous scenarios including convolutional, fully connected layers, and residual paths. Our series of experiments also demonstrate that STMixer achieves performance on par with spiking transformers in synchronous scenarios with very low timesteps. This indicates its ability to achieve the same level of performance with lower power consumption in synchronous scenarios. Codes are available at \url{https://github.com/brain-intelligence-lab/STMixer_demo}.

Machine unlearning (MU) has emerged to enhance the privacy and trustworthiness of deep neural networks. Approximate MU is a practical method for large-scale models. Our investigation into approximate MU starts with identifying the steepest descent direction, minimizing the output Kullback-Leibler divergence to exact MU inside a parameters' neighborhood. This probed direction decomposes into three components: weighted forgetting gradient ascent, fine-tuning retaining gradient descent, and a weight saliency matrix. Such decomposition derived from Euclidean metric encompasses most existing gradient-based MU methods. Nevertheless, adhering to Euclidean space may result in sub-optimal iterative trajectories due to the overlooked geometric structure of the output probability space. We suggest embedding the unlearning update into a manifold rendered by the remaining geometry, incorporating second-order Hessian from the remaining data. It helps prevent effective unlearning from interfering with the retained performance. However, computing the second-order Hessian for large-scale models is intractable. To efficiently leverage the benefits of Hessian modulation, we propose a fast-slow parameter update strategy to implicitly approximate the up-to-date salient unlearning direction.
Free from specific modal constraints, our approach is adaptable across computer vision unlearning tasks, including classification and generation. Extensive experiments validate our efficacy and efficiency. Notably, our method successfully performs class-forgetting on ImageNet using DiT and forgets a class on CIFAR-10 using DDPM in just 50 steps, compared to thousands of steps required by previous methods. Code is available at [Unified-Unlearning-w-Remain-Geometry](https://github.com/K1nght/Unified-Unlearning-w-Remain-Geometry).
tl;dr: A regularized adaptive momentum dual averaging algorithm for training structured neural networks with guarantees for finding the locally optimal structure, and exhibits outstanding performance in language, speech and image classification tasks.

We propose a Regularized Adaptive Momentum Dual Averaging (RAMDA) algorithm for training structured neural networks. Similar to existing regularized adaptive methods, the subproblem for computing the update directions of \ramda involves a nonsmooth regularizer and a diagonal preconditioner, and therefore does not possess a closed-form solution in general. We thus also carefully devise an implementable inexactness condition that retains convergence guarantees similar to the exact versions, and propose a companion efficient solver for the subproblems of both \ramda and existing methods to make them practically feasible. We leverage the theory of manifold identification in variational analysis to show that, even in the presence of such inexactness, the iterates of RAMDA attain the ideal structure induced by the regularizer at the stationary point of asymptotic convergence. This structure is locally optimal near the point of convergence, so RAMDA is guaranteed to obtain the best structure possible among all methods converging to the same point, making it the first regularized adaptive method to output models that possess outstanding predictive performance while being (locally) optimally structured. Extensive numerical experiments in large-scale modern computer vision, language modeling, and speech tasks show that the proposed RAMDA is efficient and consistently outperforms state of the art for training structured neural network. Our code is available at (removed for anonymous review).
tl;dr: Hypothesis tests and empirical studies on how well existing circuits align with idealized properties of circuits

Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented.
One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis?
In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them.
The criteria focus on the extent to which the LLM's behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal.
We apply these tests to six circuits described in the research literature.
We find that synthetic circuits -- circuits that are hard-coded in the model -- align with the idealized properties.
Circuits discovered in Transformer models satisfy the criteria to varying degrees.
To facilitate future empirical studies of circuits, we created the \textit{circuitry} package, a wrapper around the \textit{TransformerLens} library, which abstracts away lower-level manipulations of hooks and activations. The software is available at \url{https://github.com/blei-lab/circuitry}.

The adversarial robustness of Graph Neural Networks (GNNs) has been questioned due to the false sense of security uncovered by strong adaptive attacks despite the existence of numerous defenses.
In this work, we delve into the robustness analysis of representative robust GNNs and provide a unified robust estimation point of view to
understand their robustness and limitations.
Our novel analysis of estimation bias motivates the design of a
robust and unbiased graph signal estimator.
We then develop an efficient Quasi-Newton Iterative Reweighted Least Squares algorithm to solve the estimation problem, which is unfolded as robust unbiased aggregation layers in GNNs with theoretical guarantees.
Our comprehensive experiments confirm the strong robustness of our proposed model under various scenarios, and the ablation study provides a deep understanding of its advantages.
869. Expectation Alignment: Handling Reward Misspecification in the Presence of Expectation Mismatch

Detecting and handling misspecified objectives, such as reward functions, has been widely recognized as one of the central challenges within the domain of Artificial Intelligence (AI) safety research. However, even with the recognition of the importance of this problem, we are unaware of any works that attempt to provide a clear definition for what constitutes (a) misspecified objectives and (b) successfully resolving such misspecifications. In this work, we use the theory of mind, i.e., the human user's beliefs about the AI agent, as a basis to develop a formal explanatory framework, called Expectation Alignment (EAL), to understand the objective misspecification and its causes.
Our EAL framework not only acts as an explanatory framework for existing works but also provides us with concrete insights into the limitations of existing methods to handle reward misspecification and novel solution strategies. We use these insights to propose a new interactive algorithm that uses the specified reward to infer potential user expectations about the system behavior. We show how one can efficiently implement this algorithm by mapping the inference problem into linear programs. We evaluate our method on a set of standard Markov Decision Process (MDP) benchmarks.
tl;dr: Text-Only Pre-Alignment for video understanding

Recent advancements in image understanding have benefited from the extensive use of web image-text pairs. However, video understanding remains a challenge despite the availability of substantial web video-text data. This difficulty primarily arises from the inherent complexity of videos and the inefficient language supervision in recent web-collected video-text datasets. In this paper, we introduce Text-Only Pre-Alignment (TOPA), a novel approach to extend large language models (LLMs) for video understanding, without the need for pre-training on real video data. Specifically, we first employ an advanced LLM to automatically generate Textual Videos comprising continuous textual frames, along with corresponding annotations to simulate real video-text data. Then, these annotated textual videos are used to pre-align a language-only LLM with the video modality. To bridge the gap between textual and real videos, we employ the CLIP model as the feature extractor to align image and text modalities. During text-only pre-alignment, the continuous textual frames, encoded as a sequence of CLIP text features, are analogous to continuous CLIP image features, thus aligning the LLM with real video representation. Extensive experiments, including zero-shot evaluation and finetuning on various video understanding tasks, demonstrate that TOPA is an effective and efficient framework for aligning video content with LLMs. In particular, without training on any video data, the TOPA-Llama2-13B model achieves a Top-1 accuracy of 51.0% on the challenging long-form video understanding benchmark, Egoschema. This performance surpasses previous video-text pre-training approaches and proves competitive with recent GPT-3.5 based video agents.
tl;dr: We make transformers 40% faster on video, with no performance drop, by identifying consecutive runs of tokens repeated in time, and treating them as a single token with variable length.

Video transformers are slow to train due to extremely large numbers of input tokens, even though many video tokens are repeated over time. Existing methods to remove uninformative tokens either have significant overhead, negating any speedup, or require tuning for different datasets and examples. We present Run-Length Tokenization (RLT), a simple approach to speed up video transformers inspired by run-length encoding for data compression. RLT efficiently finds and removes `runs' of patches that are repeated over time before model inference, then replaces them with a single patch and a positional encoding to represent the resulting token's new length.
Our method is content-aware, requiring no tuning for different datasets, and fast, incurring negligible overhead.
RLT yields a large speedup in training, reducing the wall-clock time to fine-tune a video transformer by 30% while matching baseline model performance. RLT also works without training, increasing model throughput by 35% with only 0.1% drop in accuracy.
RLT speeds up training at 30 FPS by more than 100%, and on longer video datasets, can reduce the token count by up to 80\%. Our project page is at rccchoudhury.github.io/projects/rlt.

Larger transformer models perform better on various downstream tasks but require more cost to scale up the model size. To efficiently enlarge models, the Mixture-of-Expert (MoE) architecture is widely adopted, which consists of a gate network and a series of experts and keep the training cost constant by routing the input data to a fixed number of experts instead of all.
In existing large-scale MoE training systems, experts would be distributed among different GPUs for parallelization, and thus input data requires additional all-to-all communication to access the target expert and conduct corresponding computation.
However, upon evaluating the training process of three mainstream MoE models on commonly used GPU clusters, we found that the all-to-all communication ratio averaged around 45\%, which significantly hinders the training efficiency and scalability of MoE models.
In this paper, we propose LSH-MoE, a communication-efficient MoE training framework using locality-sensitive hashing (LSH).
We first present the problems of scaling MoE training in existing systems and highlight the potential of exploiting token similarity to facilitate data compression.
Then, we introduce an efficient LSH-based compression technique, which utilizes the cross-polytope hashing for rapid clustering and implements a residual-based error compensation scheme to alleviate the adverse impact of compression.
To verify the effectiveness of our methods, we conduct experiments on both language models (e.g., RoBERTa, GPT, and T5) and vision models (e.g., Swin) for both pre-training and fine-tuning tasks. The results demonstrate that our method substantially outperforms its counterparts across different tasks by 1.28-2.2$\times$ of speedup.

The spectacular results achieved in machine learning, including the recent advances in generative AI, rely on large data collections. On the opposite, intelligent processes in nature arises without the need for such collections, but simply by on-line processing of the environmental information. In particular, natural learning processes rely on mechanisms where data representation and learning are intertwined in such a way to respect spatiotemporal locality. This paper shows that such a feature arises from a pre-algorithmic view of learning that is inspired by related studies in Theoretical Physics. We show that the algorithmic interpretation of the derived “laws of learning”, which takes the structure of Hamiltonian equations, reduces to Backpropagation when the speed of propagation goes to infinity. This opens the doors to machine learning studies based on full on-line information processing that are based on the replacement of Backpropagation with the proposed spatiotemporal local algorithm.
tl;dr: We derive learning dynamics for a non-linear perceptron performing a binary Gaussian classification task.

The ability of a brain or a neural network to efficiently learn depends crucially on both the task structure and the learning rule.
Previous works have analyzed the dynamical equations describing learning in the relatively simplified context of the perceptron under assumptions of a student-teacher framework or a linearized output.
While these assumptions have facilitated theoretical understanding, they have precluded a detailed understanding of the roles of the nonlinearity and input-data distribution in determining the learning dynamics, limiting the applicability of the theories to real biological or artificial neural networks.
Here, we use a stochastic-process approach to derive flow equations describing learning, applying this framework to the case of a nonlinear perceptron performing binary classification.
We characterize the effects of the learning rule (supervised or reinforcement learning, SL/RL) and input-data distribution on the perceptron's learning curve and the forgetting curve as subsequent tasks are learned.
In particular, we find that the input-data noise differently affects the learning speed under SL vs. RL, as well as determines how quickly learning of a task is overwritten by subsequent learning. Additionally, we verify our approach with real data using the MNIST dataset.
This approach points a way toward analyzing learning dynamics for more-complex circuit architectures.
tl;dr: We study datastore scaling for retrieval-augmented language models with a trillion-token datastore and an efficient pipeline.

Scaling laws with respect to the amount of training data and the number of parameters allow us to predict the cost-benefit trade-offs of pretraining language models (LMs) in different configurations. In this paper, we consider another dimension of scaling: the amount of data available at inference time. Specifically, we find that increasing the size of the datastore used by a retrieval-based LM monotonically improves language modeling and several downstream tasks without obvious saturation, such that a smaller model augmented with a large datastore outperforms a larger LM-only model on knowledge-intensive tasks. By plotting compute-optimal scaling curves with varied datastore, model, and pretraining data sizes, we show that using larger datastores can significantly improve model performance for the same training compute budget. We carry out our study by constructing a 1.4 trillion-token datastore named MassiveDS, which is the largest and the most diverse open-sourced datastore for retrieval-based LMs to date, and designing an efficient pipeline for studying datastore scaling in an accessible manner. Finally, we analyze the effect of improving the retriever, datastore quality filtering, and other design choices on our observed scaling trends. Overall, our results show that datastore size should be considered as an integral part of LM efficiency and performance trade-offs. To facilitate future research, we open-source our datastore and code at https://github.com/RulinShao/retrieval-scaling.

While neural networks can enjoy an outstanding flexibility and exhibit unprecedented performance, the mechanism behind their behavior is still not well-understood. To tackle this fundamental challenge, researchers have tried to restrict and manipulate some of their properties in order to gain new insights and better control on them. Especially, throughout the past few years, the concept of *bi-Lipschitzness* has been proved as a beneficial inductive bias in many areas. However, due to its complexity, the design and control of bi-Lipschitz architectures are falling behind, and a model that is precisely designed for bi-Lipschitzness realizing a direct and simple control of the constants along with solid theoretical analysis is lacking. In this work, we investigate and propose a novel framework for bi-Lipschitzness that can achieve such a clear and tight control based on convex neural networks and the Legendre-Fenchel duality. Its desirable properties are illustrated with concrete experiments to illustrate its broad range of applications.
877. Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
tl;dr: We propose a new algorithm that provably mitigates overoptimization in RLHF, evidenced by LLM experiments.

Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output even undesired responses. We investigate this problem in a principled manner by identifying the source of the issue as the distributional shift and uncertainty of human preference in dataset. To mitigate overoptimization, we first propose a theoretical algorithm which optimizes the policy against an adversarially chosen reward model, one that simultaneously minimizes its MLE loss and a reward penalty term. The penalty pessimistically biases the uncertain rewards so as to prevent the policy from choosing actions with spursiouly high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy to implement form. With a clever usage of the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss which explicitly imitates the policy with a baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO).
Experiments of aligning LLMs demonstrate the improved performance of our method when compared with DPO baselines.
Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
tl;dr: In this paper we present Local-Global INRs, a novel INR architecture that supports cropping encoded signals by design, ensuring a proportional weight decrease, without retraining.

Implicit Neural Representations (INRs) have peaked interest in recent years due to their ability to encode natural signals using neural networks. While INRs allow for useful applications such as interpolating new coordinates and signal compression, their black-box nature makes it difficult to modify them post-training. In this paper we explore the idea of editable INRs, and specifically focus on the widely used cropping operation. To this end, we present Local-Global SIRENs - a novel INR architecture that supports cropping by design. Local-Global SIRENs are based on combining local and global feature extraction for signal encoding. What makes their design unique is the ability to effortlessly remove specific portions of an encoded signal, with a proportional weight decrease. This is achieved by eliminating the corresponding weights from the network, without the need for retraining. We further show how this architecture can be used to support the straightforward extension of previously encoded signals. Beyond signal editing, we examine how the Local-Global approach can accelerate training, enhance encoding of various signals, improve downstream performance, and be applied to modern INRs such as INCODE, highlighting its potential and flexibility. Code is available at https://github.com/maorash/Local-Global-INRs.
tl;dr: We introduce a graph-based EBM that achieves state-of-the-art epistemic uncertainty estimation performance and can be applied post-hoc to any GNN.

In domains with interdependent data, such as graphs, quantifying the epistemic uncertainty of a Graph Neural Network (GNN) is challenging as uncertainty can arise at different structural scales. Existing techniques neglect this issue or only distinguish between structure-aware and structure-agnostic uncertainty without combining them into a single measure. We propose GEBM, an energy-based model (EBM) that provides high-quality uncertainty estimates by aggregating energy at different structural levels that naturally arise from graph diffusion. In contrast to logit-based EBMs, we provably induce an integrable density in the data space by regularizing the energy function. We introduce an evidential interpretation of our EBM that significantly improves the predictive robustness of the GNN. Our framework is a simple and effective post hoc method applicable to any pre-trained GNN that is sensitive to various distribution shifts. It consistently achieves the best separation of in-distribution and out-of-distribution data on 6 out of 7 anomaly types while having the best average rank over shifts on *all* datasets.
tl;dr: We bridge a gap between 3D Score Distillation and 2D image generation both in terms of theory and qualitative results

While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS's generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models.
tl;dr: We derive a KFAC approximation for PINN losses which scales to high-dimensional NNs and PDEs and consistently outperforms first-order methods for training PINNs.

Physics-Informed Neural Networks (PINNs) are infamous for being hard to train.
Recently, second-order methods based on natural gradient and Gauss-Newton methods have shown promising performance, improving the accuracy achieved by first-order methods by several orders of magnitude.
While promising, the proposed methods only scale to networks with a few thousand parameters due to the high computational cost to evaluate, store, and invert the curvature matrix.
We propose Kronecker-factored approximate curvature (KFAC) for PINN losses that greatly reduces the computational cost and allows scaling to much larger networks.
Our approach goes beyond the popular KFAC for traditional deep learning problems as it captures contributions from a PDE's differential operator that are crucial for optimization.
To establish KFAC for such losses, we use Taylor-mode automatic differentiation to describe the differential operator's computation graph as a forward network with shared weights which allows us to apply a variant of KFAC for networks with weight-sharing.
Empirically, we find that our KFAC-based optimizers are competitive with expensive second-order methods on small problems, scale more favorably to higher-dimensional neural networks and PDEs, and consistently outperform first-order methods.

Precision matrix estimation is a ubiquitous task featuring numerous applications such as rare disease diagnosis and neural connectivity exploration. However, this task becomes challenging in small sample settings, where the number of samples is significantly less than the number of dimensions, leading to unreliable estimates. Previous approaches either fail to perform well in small sample settings or suffer from inefficient estimation processes, even when incorporating meta-learning techniques.
To this end, we propose a novel approach FasMe for Fast and Sample-efficient Meta Precision Matrix Learning, which first extracts meta-knowledge through a multi-task learning diagram. Then, meta-knowledge constraints are applied using a maximum determinant matrix completion algorithm for the novel task. As a result, we reduce the sample size requirements to $O(\log p/K)$ per meta-training task and $O(\log\vert \mathcal{G}\vert)$ for the meta-testing task. Moreover, the hereby proposed model only needs $O(p \log\epsilon^{-1})$ time and $O(p)$ memory for converging to an $\epsilon$-accurate solution. On multiple synthetic and biomedical datasets, FasMe is at least ten times faster than the four baselines while promoting prediction accuracy in small sample settings.
tl;dr: We propose an $SE(3)$ equivariant model with spherical harmonics ray embeddings and demonstrate its effectiveness in the task of generalized stereo depth estimation.

Incorporating inductive bias by embedding geometric entities (such as rays) as input has proven successful in multi-view learning. However, the methods adopting this technique typically lack equivariance, which is crucial for effective 3D learning. Equivariance serves as a valuable inductive prior, aiding in the generation of robust multi-view features for 3D scene understanding. In this paper, we explore the application of equivariant multi-view learning to depth estimation, not only recognizing its significance for computer vision and robotics but also addressing the limitations of previous research. Most prior studies have either overlooked equivariance in this setting or achieved only approximate equivariance through data augmentation, which often leads to inconsistencies across different reference frames. To address this issue, we propose to embed $SE(3)$ equivariance into the Perceiver IO architecture. We employ Spherical Harmonics for positional encoding to ensure 3D rotation equivariance, and develop a specialized equivariant encoder and decoder within the Perceiver IO architecture. To validate our model, we applied it to the task of stereo depth estimation, achieving state of the art results on real-world datasets without explicit geometric constraints or extensive data augmentation.

Unsupervised skill discovery is a learning paradigm that aims to acquire diverse behaviors without explicit rewards. However, it faces challenges in learning complex behaviors and often leads to learning unsafe or undesirable behaviors. For instance, in various continuous control tasks, current unsupervised skill discovery methods succeed in learning basic locomotions like standing but struggle with learning more complex movements such as walking and running. Moreover, they may acquire unsafe behaviors like tripping and rolling or navigate to undesirable locations such as pitfalls or hazardous areas. In response, we present **DoDont** (Do’s and Dont’s), an instruction-based skill discovery algorithm composed of two stages. First, in instruction learning stage, DoDont leverages action-free instruction videos to train an instruction network to distinguish desirable transitions from undesirable ones. Then, in the skill learning stage, the instruction network adjusts the reward function of the skill discovery algorithm to weight the desired behaviors.
Specifically, we integrate the instruction network into a distance-maximizing skill discovery algorithm, where the instruction network serves as the distance function. Empirically, with less than 8 instruction videos, DoDont effectively learns desirable behaviors and avoids undesirable ones across complex continuous control tasks. Code and videos are available at https://mynsng.github.io/dodont/
tl;dr: Neural Optimal Transport Solvers based on Flow Matching for Gromov and Wasserstein OT motivated by tasks in single-cell genomics

Single-cell genomics has significantly advanced our understanding of cellular behavior, catalyzing innovations in treatments and precision medicine. However,
single-cell sequencing technologies are inherently destructive and can only measure a limited array of data modalities simultaneously. This limitation underscores
the need for new methods capable of realigning cells. Optimal transport (OT)
has emerged as a potent solution, but traditional discrete solvers are hampered by
scalability, privacy, and out-of-sample estimation issues. These challenges have
spurred the development of neural network-based solvers, known as neural OT
solvers, that parameterize OT maps. Yet, these models often lack the flexibility
needed for broader life science applications. To address these deficiencies, our
approach learns stochastic maps (i.e. transport plans), allows for any cost function,
relaxes mass conservation constraints and integrates quadratic solvers to tackle the
complex challenges posed by the (Fused) Gromov-Wasserstein problem. Utilizing
flow matching as a backbone, our method offers a flexible and effective framework.
We demonstrate its versatility and robustness through applications in cell development studies, cellular drug response modeling, and cross-modality cell translation,
illustrating significant potential for enhancing therapeutic strategies.
tl;dr: A method for controlling GPU nondeterminism to enable exact verification of large-scale model training services.

The increasing compute demands of AI systems has led to the emergence of services that train models on behalf of clients lacking necessary resources. However, ensuring correctness of training and guarding against potential training-time attacks, such as data poisoning and backdoors, poses challenges. Existing works on verifiable training largely fall into two classes: proof-based systems, which can be difficult to scale, and ``optimistic'' methods that consider a trusted third-party auditor who replicates the training process. A key challenge with the latter is that hardware nondeterminism between GPU types during training prevents an auditor from replicating the training process exactly, and such schemes are therefore non-robust. We propose a method that combines training in a higher precision than the target model, rounding after intermediate computation steps, and storing rounding decisions based on an adaptive thresholding procedure, to successfully control for nondeterminism. Across three different NVIDIA GPUs (A40, Titan XP, RTX 2080 Ti), we achieve exact training replication at FP32 precision for both full-training and fine-tuning of ResNet-50 (23M) and GPT-2 (117M) models. Our verifiable training scheme significantly decreases the storage and time costs compared to proof-based systems.
tl;dr: We propose ANT, Adaptive Noise schedule for TS diffusion models, to select an adaptive schedule based on the non-stationarity statistics of time series.

Advances in diffusion models for generative artificial intelligence have recently propagated to the time series (TS) domain, demonstrating state-of-the-art performance on various tasks. However, prior works on TS diffusion models often borrow the framework of existing works proposed in other domains without considering the characteristics of TS data, leading to suboptimal performance. In this work, we
propose Adaptive Noise schedule for Time series diffusion models (ANT), which automatically predetermines proper noise schedules for given TS datasets based on their statistics representing non-stationarity. Our intuition is that an optimal noise schedule should satisfy the following desiderata: 1) It linearly reduces the non-stationarity of TS data so that all diffusion steps are equally meaningful, 2) the data is corrupted to the random noise at the final step, and 3) the number of steps is sufficiently large. The proposed method is practical for use in that it eliminates the necessity of finding the optimal noise schedule with a small additional cost to compute the statistics for given datasets, which can be done offline before training. We validate the effectiveness of our method across various tasks, including TS forecasting, refinement, and generation, on datasets from diverse domains. Code is available at this repository: https://github.com/seunghan96/ANT.

Gradient estimation is critical in zeroth-order optimization methods, which aims to obtain the descent direction by sampling update directions and querying function evaluations. Extensive research has been conducted including smoothing and linear interpolation. The former methods smooth the objective function, causing a biased gradient estimation, while the latter often enjoys more accurate estimates, at the cost of large amounts of samples and queries at each iteration to update variables. This paper resorts to the linear interpolation strategy and proposes to reduce the complexity of gradient estimation by reusing queries in the prior iterations while maintaining the sample size unchanged. Specifically, we model the gradient estimation as a quadratically constrained linear program problem and manage to derive the analytical solution. It innovatively decouples the required sample size from the variable dimension without extra conditions required, making it able to leverage the queries in the prior iterations. Moreover, part of the intermediate variables that contribute to the gradient estimation can be directly indexed, significantly reducing the computation complexity. Experiments on both simulation functions and real scenarios (black-box adversarial attacks neural architecture search, and parameter-efficient fine-tuning for large language models), show its efficacy and efficiency. Our code is available at https://github.com/Thinklab-SJTU/ReLIZO.git.

The recent advancements in large-scale pre-training techniques have significantly enhanced the capabilities of vision foundation models, notably the Segment Anything Model (SAM), which can generate precise masks based on point and box prompts. Recent studies extend SAM to Few-shot Semantic Segmentation (FSS), focusing on prompt generation for SAM-based automatic semantic segmentation. However, these methods struggle with selecting suitable prompts, require specific hyperparameter settings for different scenarios, and experience prolonged one-shot inference times due to the overuse of SAM, resulting in low efficiency and limited automation ability. To address these issues, we propose a simple yet effective approach based on graph analysis. In particular, a Positive-Negative Alignment module dynamically selects the point prompts for generating masks, especially uncovering the potential of the background context as the negative reference. Another subsequent Point-Mask Clustering module aligns the granularity of masks and selected points as a directed graph, based on mask coverage over points. These points are then aggregated by decomposing the weakly connected components of the directed graph in an efficient manner, constructing distinct natural clusters. Finally, the positive and overshooting gating, benefiting from graph-based granularity alignment, aggregates high-confident masks and filters the false-positive masks for final prediction, reducing the usage of additional hyperparameters and redundant mask generation. Extensive experimental analysis across standard FSS, One-shot Part Segmentation, and Cross Domain FSS datasets validate the effectiveness and efficiency of the proposed approach, surpassing state-of-the-art generalist models with a mIoU of 58.7% on COCO-20i and 35.2% on LVIS-92i. The project page of this work is https://andyzaq.github.io/GF-SAM/.

We propose a probabilistic perspective on adversarial examples, allowing us to embed subjective understanding of semantics as a distribution into the process of generating adversarial examples, in a principled manner. Despite significant pixel-level modifications compared to traditional adversarial attacks, our method preserves the overall semantics of the image, making the changes difficult for humans to detect. This extensive pixel-level modification enhances our method's ability to deceive classifiers designed to defend against adversarial attacks. Our empirical findings indicate that the proposed methods achieve higher success rates in circumventing adversarial defense mechanisms, while remaining difficult for human observers to detect.
tl;dr: Learning explainable representations of functions efficiently using ideas from signal processing and group testing

One of the key challenges in machine learning is to find interpretable representations of learned functions. The Möbius transform is essential for this purpose, as its coefficients correspond to unique *importance scores* for *sets of input variables*. This transform is closely related to widely used game-theoretic notions of importance like the *Shapley* and *Bhanzaf value*, but it also captures crucial higher-order interactions. Although computing the Möbius Transform of a function with $n$ inputs involves $2^n$ coefficients, it becomes tractable when the function is *sparse* and of *low-degree* as we show is the case for many real-world functions. Under these conditions, the complexity of the transform computation is significantly reduced. When there are $K$ non-zero coefficients, our algorithm recovers the Möbius transform in $O(Kn)$ samples and $O(Kn^2)$ time asymptotically under certain assumptions, the first non-adaptive algorithm to do so. We also uncover a surprising connection between group testing and the Möbius transform. For functions where all interactions involve at most $t$ inputs, we use group testing results to compute the Möbius transform with $O(Kt\log n)$ sample complexity and $O(K\mathrm{poly}(n))$ time. A robust version of this algorithm withstands noise and maintains this complexity. This marks the first $n$ sub-linear query complexity, noise-tolerant algorithm for the M\"{o}bius transform. While our algorithms are conceptualized in an idealized setting, they indicate that the Möbius transform is a potent tool for interpreting deep learning models.

Zero-shot node classification is a vital task in the field of graph data processing, aiming to identify nodes of classes unseen during the training process. Prediction bias is one of the primary challenges in zero-shot node classification, referring to the model's propensity to misclassify nodes of unseen classes as seen classes. However, most methods introduce external knowledge to mitigate the bias, inadequately leveraging the inherent cluster information within the unlabeled nodes. To address this issue, we employ spectral analysis coupled with learnable class prototypes to discover the implicit cluster structures within the graph, providing a more comprehensive understanding of classes. In this paper, we propose a spectral approach for zero-shot node classification (SpeAr). Specifically, we establish an approximate relationship between minimizing the spectral contrastive loss and performing spectral decomposition on the graph, thereby enabling effective node characterization through loss minimization. Subsequently, the class prototypes are iteratively refined based on the learned node representations, initialized with the semantic vectors. Finally, extensive experiments verify the effectiveness of the SpeAr, which can further alleviate the bias problem.

Tracking points in video frames is essential for understanding video content. However, the task is fundamentally hindered by the computation demands for brute-force correspondence matching across the frames. As the current models down-sample the frame resolutions to mitigate this challenge, they fall short in accurately representing point trajectories due to information truncation. Instead, we address the challenge by pruning the search space for point tracking and let the model process only the important regions of the frames without down-sampling. Our first key idea is to identify the object instance and its trajectory over the frames, then prune the regions of the frame that do not contain the instance. Concretely, to estimate the instance’s trajectory, we track a group of points on the instance and aggregate their motion trajectories. Furthermore, to deal with the occlusions in complex scenes, we propose to compensate for the occluded points while tracking. To this end, we introduce a unified framework that jointly performs point tracking and segmentation, providing synergistic effects between the two tasks. For example, the segmentation results enable a tracking model to avoid the occluded points referring to the instance mask, and conversely, the improved tracking results can help to produce more accurate segmentation masks. Our framework can be easily incorporated with various tracking models, and we demonstrate its efficacy for enhanced point tracking throughout extensive experiments. For example, on the recent TAP-Vid benchmark, our framework consistently improves all baselines, e.g., up to 13.5% improvement on the average Jaccard metric.
tl;dr: We develop novel diversity measures for evaluating latent representations based on metric space magnitude, a novel geometric invariant.

The *magnitude* of a metric space is a novel
invariant that provides a measure of the 'effective size' of a space across
multiple scales, while also capturing numerous geometrical properties, such as curvature, density, or entropy.
We develop a family of magnitude-based measures of the intrinsic
diversity of latent representations, formalising a novel notion of
dissimilarity between magnitude functions of finite metric spaces.
Our measures are provably stable under perturbations of the data, can be
efficiently calculated, and enable a rigorous multi-scale characterisation and comparison of
latent representations.
We show their utility and superior performance across different domains and tasks, including
the automated estimation of diversity,
the detection of mode collapse, and
the evaluation of generative models for text, image, and graph data.
tl;dr: Predictive coding inference makes the loss landscape of deep neural networks more benign and robust to vanishing gradients.

Predictive coding (PC) is an energy-based learning algorithm that performs iterative inference over network activities before updating weights. Recent work suggests that PC can converge in fewer learning steps than backpropagation thanks to its inference procedure. However, these advantages are not always observed, and the impact of PC inference on learning is not theoretically well understood. Here, we study the geometry of the PC energy landscape at the inference equilibrium of the network activities. For deep linear networks, we first show that the equilibrated energy is simply a rescaled mean squared error loss with a weight-dependent rescaling. We then prove that many highly degenerate (non-strict) saddles of the loss including the origin become much easier to escape (strict) in the equilibrated energy. Our theory is validated by experiments on both linear and non-linear networks. Based on these and other results, we conjecture that all the saddles of the equilibrated energy are strict. Overall, this work suggests that PC inference makes the loss landscape more benign and robust to vanishing gradients, while also highlighting the fundamental challenge of scaling PC to deeper models.
tl;dr: The nearest neighbor rule is online consistent under much broader conditions than previously known.

In the realizable online setting, a learner is tasked with making predictions for a stream of instances, where the correct answer is revealed after each prediction. A learning rule is online consistent if its mistake rate eventually vanishes. The nearest neighbor rule is fundamental prediction strategy, but it is only known to be consistent under strong statistical or geometric assumptions: the instances come i.i.d. or the label classes are well-separated. We prove online consistency for all measurable functions in doubling metric spaces under the mild assumption that instances are generated by a process that is uniformly absolutely continuous with respect to an underlying finite, upper doubling measure.

The Transformer architecture is widely applied in sequence modeling applications, yet the theoretical understanding of its working principles remains limited. In this work, we investigate the approximation rate for single-layer Transformers with one head. We consider general non-linear relationships and identify a novel notion of complexity measures to establish an explicit Jackson-type approximation rate estimate for the Transformer. This rate reveals the structural properties of the Transformer and suggests the types of sequential relationships it is best suited for approximating. In particular, the results on approximation rates enable us to concretely analyze the differences between the Transformer and classical sequence modeling methods, such as recurrent neural networks.

Existing permanental processes often impose constraints on kernel types or stationarity, limiting the model's expressiveness. To overcome these limitations, we propose a novel approach utilizing the sparse spectral representation of nonstationary kernels.
This technique relaxes the constraints on kernel types and stationarity, allowing for more flexible modeling while reducing computational complexity to the linear level.
Additionally, we introduce a deep kernel variant by hierarchically stacking multiple spectral feature mappings, further enhancing the model's expressiveness to capture complex patterns in data. Experimental results on both synthetic and real-world datasets demonstrate the effectiveness of our approach, particularly in scenarios with pronounced data nonstationarity. Additionally, ablation studies are conducted to provide insights into the impact of various hyperparameters on model performance.
899. EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models

Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The framework EvolveDiretor and the trained model Edgen will be fully open-sourced to benefit the downstream tasks.
900. Adversarial Representation Engineering: A General Model Editing Framework for Large Language Models

Since the rapid development of Large Language Models (LLMs) has achieved remarkable success, understanding and rectifying their internal complex mechanisms has become an urgent issue. Recent research has attempted to interpret their behaviors through the lens of inner representation. However, developing practical and efficient methods for applying these representations for general and flexible model editing remains challenging. In this work, we explore how to leverage insights from representation engineering to guide the editing of LLMs by deploying a representation sensor as an editing oracle. We first identify the importance of a robust and reliable sensor during editing, then propose an \textbf{A}dversarial \textbf{R}epresentation \textbf{E}ngineering (\textbf{ARE}) framework to provide a unified and interpretable approach for conceptual model editing without compromising baseline performance. Experiments on multiple tasks demonstrate the effectiveness of ARE in various model editing scenarios. Our code and data are available at \url{https://github.com/Zhang-Yihao/Adversarial-Representation-Engineering}.
tl;dr: We introduce Stormer, a simple transformer model that achieves state-of-the-art performance on weather forecasting with minimal changes to the standard transformer backbone.

Weather forecasting is a fundamental problem for anticipating and mitigating the impacts of climate change. Recently, data-driven approaches for weather forecasting based on deep learning have shown great promise, achieving accuracies that are competitive with operational systems. However, those methods often employ complex, customized architectures without sufficient ablation analysis, making it difficult to understand what truly contributes to their success. Here we introduce Stormer, a simple transformer model that achieves state-of-the art performance on weather forecasting with minimal changes to the standard transformer backbone. We identify the key components of Stormer through careful empirical analyses, including weather-specific embedding, randomized dynamics forecast, and pressure-weighted loss. At the core of Stormer is a randomized forecasting objective that trains the model to forecast the weather dynamics over varying time intervals. During inference, this allows us to produce multiple forecasts for a target lead time and combine them to obtain better forecast accuracy. On WeatherBench 2, Stormer performs competitively at short to medium-range forecasts and outperforms current methods beyond 7 days, while requiring orders-of-magnitude less training data and compute. Additionally, we demonstrate Stormer’s favorable scaling properties, showing consistent improvements in forecast accuracy with increases in model size and training tokens. Code and checkpoints are available at https://github.com/tung-nd/stormer.

While crowdsourcing has emerged as a practical solution for labeling large datasets, it presents a significant challenge in learning accurate models due to noisy labels from annotators with varying levels of expertise. Existing methods typically estimate the true label posterior, conditioned on the instance and noisy annotations, to infer true labels or adjust loss functions. These estimates, however, often overlook potential misspecification in the true label posterior, which can degrade model performances, especially in high-noise scenarios. To address this issue, we investigate learning from noisy annotations with an estimated true label posterior through the framework of conditional distributionally robust optimization (CDRO). We propose formulating the problem as minimizing the worst-case risk within a distance-based ambiguity set centered around a reference distribution. By examining the strong duality of the formulation, we derive upper bounds for the worst-case risk and develop an analytical solution for the dual robust risk for each data point. This leads to a novel robust pseudo-labeling algorithm that leverages the likelihood ratio test to construct a pseudo-empirical distribution, providing a robust reference probability distribution in CDRO. Moreover, to devise an efficient algorithm for CDRO, we derive a closed-form expression for the empirical robust risk and the optimal Lagrange multiplier of the dual problem, facilitating a principled balance between robustness and model fitting. Our experimental results on both synthetic and real-world datasets demonstrate the superiority of our method.

The Diffusion Model has not only garnered noteworthy achievements in the realm of image generation
but has also demonstrated its potential as an effective pretraining method utilizing unlabeled data.
Drawing from the extensive potential unveiled by the Diffusion Model in both semantic correspondence and open vocabulary segmentation, our work initiates an investigation into employing the Latent Diffusion Model for Few-shot Semantic Segmentation.
Recently, inspired by the in-context learning ability of large language models, Few-shot Semantic Segmentation has evolved into In-context Segmentation tasks, morphing into a crucial element in assessing generalist segmentation models.
In this context, we concentrate
on Few-shot Semantic Segmentation,
establishing a solid foundation for the future development of a Diffusion-based generalist model for segmentation. Our initial focus lies in understanding how to facilitate interaction between the query image and the support image, resulting in the proposal of a KV fusion method within the self-attention framework.
Subsequently, we delve deeper into optimizing the infusion of information from the support mask and simultaneously re-evaluating how to provide reasonable supervision from the query mask.
Based on our analysis, we establish a simple and effective framework named DiffewS, maximally retaining the original Latent Diffusion Model's generative framework and effectively utilizing the pre-training prior. Experimental results demonstrate that our method significantly outperforms the previous SOTA models in multiple settings.
tl;dr: We conducted a theoretical analysis of the data protection capabilities of the Reduced Kernel Mean Embeding (RKME) specification in learnware.

The learnware paradigm aims to enable users to leverage numerous existing well-trained models instead of building machine learning models from scratch. In this paradigm, developers worldwide can submit their well-trained models spontaneously into a learnware dock system, and the system helps developers generate specification for each model to form a learnware. As the key component, a specification should characterize the capabilities of the model, enabling it to be adequately identified and reused, while preserving the developer's original data. Recently, the RKME (Reduced Kernel Mean Embedding) specification was proposed and most commonly utilized. This paper provides a theoretical analysis of RKME specification about its preservation ability for developer's training data. By modeling it as a geometric problem on manifolds and utilizing tools from geometric analysis, we prove that the RKME specification is able to disclose none of the developer's original data and possesses robust defense against common inference attacks, while preserving sufficient information for effective learnware identification.

With the arrival of the Noisy Intermediate-Scale Quantum (NISQ) era, Variational Quantum Algorithms (VQAs) have emerged to obtain possible quantum advantage. In particular, how to effectively incorporate hard constraints in VQAs remains a critical and open question. In this paper, we manage to combine the Hamming Weight Preserving ansatz with a topological-aware parity check on physical qubits to enforce error mitigation and further hard constraints. We demonstrate the combination significantly outperforms peer VQA methods on both quantum chemistry problems and constrained combinatorial optimization problems e.g. Quadratic Assignment Problem. Intensive experimental results on both simulators and superconducting quantum processors are provided to verify that the combination of HWP ansatz with parity check is among the most promising candidates to demonstrate quantum advantages in the NISQ era to solve more realistic problems.
tl;dr: In this work, we introduce a new RAG framework inspired by human long-term memory which integrates knowledge across documents in ways that current RAG methods cannot, allowing it to outperform these baselines on several multi-hop QA benchmarks.

In order to thrive in hostile and ever-changing natural environments, mammalian brains evolved to store large amounts of knowledge about the world and continually integrate new information while avoiding catastrophic forgetting. Despite the impressive accomplishments, large language models (LLMs), even with retrieval-augmented generation (RAG), still struggle to efficiently and effectively integrate a large amount of new experiences after pre-training. In this work, we introduce HippoRAG, a novel retrieval framework inspired by the hippocampal indexing theory of human long-term memory to enable deeper and more efficient knowledge integration over new experiences. HippoRAG synergistically orchestrates LLMs, knowledge graphs, and the Personalized PageRank algorithm to mimic the different roles of neocortex and hippocampus in human memory. We compare HippoRAG with existing RAG methods on multi-hop question answering (QA) and show that our method outperforms the state-of-the-art methods remarkably, by up to 20%. Single-step retrieval with HippoRAG achieves comparable or better performance than iterative retrieval like IRCoT while being 10-20 times cheaper and 6-13 times faster, and integrating HippoRAG into IRCoT brings further substantial gains. Finally, we show that our method can tackle new types of scenarios that are out of reach of existing methods.

Large language models (LLMs) have shown impressive performance on downstream tasks by in-context learning (ICL), which heavily relies on the quality of demonstrations selected from a large set of annotated examples. Recent works claim that in-context learning is robust to noisy demonstrations in text classification. In this work, we show that, on text generation tasks, noisy annotations significantly hurt the performance of in-context learning. To circumvent the issue, we propose a simple and effective approach called Local Perplexity Ranking (LPR), which replaces the "noisy" candidates with their nearest neighbors that are more likely to be clean. Our method is motivated by analyzing the perplexity deviation caused by noisy labels and decomposing perplexity into inherent perplexity and matching perplexity. Our key idea behind LPR is thus to decouple the matching perplexity by performing the ranking among the neighbors in semantic space. Our approach can prevent the selected demonstrations from including mismatched input-label pairs while preserving the effectiveness of the original selection methods. Extensive experiments demonstrate the effectiveness of LPR, improving the EM score by up to 18.75 on common benchmarks with noisy annotations.
tl;dr: Visual Fourier Prompt Tuning (VFPT) is a simple yet effective parameter-efficient finetuning approach for large-scale vision Transformer models, addressing the challenge of dataset disparity between pretraining and finetuning phases.

With the scale of vision Transformer-based models continuing to grow, finetuning these large-scale pretrained models for new tasks has become increasingly parameter-intensive. Visual prompt tuning is introduced as a parameter-efficient finetuning (PEFT) method to this trend. Despite its successes, a notable research challenge persists within almost all PEFT approaches: significant performance degradation is observed when there is a substantial disparity between the datasets applied in pretraining and finetuning phases. To address this challenge, we draw inspiration from human visual cognition, and propose the Visual Fourier Prompt Tuning (VFPT) method as a general and effective solution for adapting large-scale transformer-based models. Our approach innovatively incorporates the Fast Fourier Transform into prompt embeddings and harmoniously considers both spatial and frequency domain information. Apart from its inherent simplicity and intuitiveness, VFPT exhibits superior performance across all datasets, offering a general solution to dataset challenges, irrespective of data disparities. Empirical results demonstrate that our approach outperforms current state-of-the-art baselines on two benchmarks, with low parameter usage (e.g., 0.57% of model parameters on VTAB-1k) and notable performance enhancements (e.g., 73.20% of mean accuracy on VTAB-1k). Our code is avaliable at https://github.com/runtsang/VFPT.
tl;dr: Our paper introduces the HairFast model, which uses a novel architecture in the FS latent space of StyleGAN to achieve high-resolution, near real-time hairstyle transfer with superior results, even when source and target poses differ significantly.

Our paper addresses the complex task of transferring a hairstyle from a reference image to an input photo for virtual hair try-on. This task is challenging due to the need to adapt to various photo poses, the sensitivity of hairstyles, and the lack of objective metrics. The current state of the art hairstyle transfer methods use an optimization process for different parts of the approach, making them inexcusably slow. At the same time, faster encoder-based models are of very low quality because they either operate in StyleGAN's W+ space or use other low-dimensional image generators. Additionally, both approaches have a problem with hairstyle transfer when the source pose is very different from the target pose, because they either don't consider the pose at all or deal with it inefficiently. In our paper, we present the HairFast model, which uniquely solves these problems and achieves high resolution, near real-time performance, and superior reconstruction compared to optimization problem-based methods. Our solution includes a new architecture operating in the FS latent space of StyleGAN, an enhanced inpainting approach, and improved encoders for better alignment, color transfer, and a new encoder for post-processing. The effectiveness of our approach is demonstrated on realism metrics after random hairstyle transfer and reconstruction when the original hairstyle is transferred. In the most difficult scenario of transferring both shape and color of a hairstyle from different images, our method performs in less than a second on the Nvidia V100.
tl;dr: We study the power of differentiable learning compared to the statistical query (SQ) and correlation statistical query (CSQ) methods for the problem of learning sparse support of size P out of d coordinates with d>>P.

The goal of this paper is to investigate the complexity of gradient algorithms when learning sparse functions (juntas). We introduce a type of Statistical Queries ($\mathsf{SQ}$), which we call Differentiable Learning Queries ($\mathsf{DLQ}$), to model gradient queries on a specified loss with respect to an arbitrary model. We provide a tight characterization of the query complexity of $\mathsf{DLQ}$ for learning the support of a sparse function over generic product distributions. This complexity crucially depends on the loss function. For the squared loss, $\mathsf{DLQ}$ matches the complexity of Correlation Statistical Queries $(\mathsf{CSQ})$—potentially much worse than $\mathsf{SQ}$. But for other simple loss functions, including the $\ell_1$ loss, $\mathsf{DLQ}$ always achieves the same complexity as $\mathsf{SQ}$. We also provide evidence that $\mathsf{DLQ}$ can indeed capture learning with (stochastic) gradient descent by showing it correctly describes the complexity of learning with a two-layer neural network in the mean field regime and linear scaling.
tl;dr: Investigate structure alignment on face recognition.

The field of face recognition (FR) has undergone significant advancements with the rise of deep learning. Recently, the success of unsupervised learning and graph neural networks has demonstrated the effectiveness of data structure information. Considering that the FR task can leverage large-scale training data, which intrinsically contains significant structure information, we aim to investigate how to encode such critical structure information into the latent space. As revealed from our observations, directly aligning the structure information between the input and latent spaces inevitably suffers from an overfitting problem, leading to a structure collapse phenomenon in the latent space. To address this problem, we propose TopoFR, a novel FR model that leverages a topological structure alignment strategy called PTSA and a hard sample mining strategy named SDE. Concretely, PTSA uses persistent homology to align the topological structures of the input and latent spaces, effectively preserving the structure information and improving the generalization performance of FR model. To mitigate the impact of hard samples on the latent space structure, SDE accurately identifies hard samples by automatically computing structure damage score (SDS) for each sample, and directs the model to prioritize optimizing these samples. Experimental results on popular face benchmarks demonstrate the superiority of our TopoFR over the state-of-the-art methods. Code and models are available at: https://github.com/modelscope/facechain/tree/main/face_module/TopoFR.

Comparison data elicited from people are fundamental to many machine learning tasks, including reinforcement learning from human feedback for large language models and estimating ranking models. They are typically subjective and not directly verifiable. How to truthfully elicit such comparison data from rational individuals? We design peer prediction mechanisms for eliciting comparison data using a bonus-penalty payment. Our design leverages on the strong stochastic transitivity for comparison data to create symmetrically strongly truthful mechanisms such that truth-telling 1) forms a strict Bayesian Nash equilibrium, and 2) yields the highest payment among all symmetric equilibria. Each individual only needs to evaluate one pair of items and report her comparison in our mechanism.
We further extend the bonus-penalty payment concept to eliciting networked data, designing a symmetrically strongly truthful mechanism when agents’ private signals are sampled according to the Ising models. We provide the necessary and sufficient conditions for our bonus-penalty payment to have truth-telling as a strict Bayesian Nash equilibrium. Experiments on two real-world datasets further support our theoretical discoveries.
tl;dr: We enhanced LLM's reasoning capabilities by principled synthetic corpus.

Large language models (LLMs) are capable of solving a wide range of tasks, yet they have struggled with reasoning.
To address this, we propose $\textbf{Additional Logic Training (ALT)}$, which aims to enhance LLMs' reasoning capabilities by program-generated logical reasoning samples.
We first establish principles for designing high-quality samples by integrating symbolic logic theory and previous empirical insights.
Then, based on these principles, we construct a synthetic corpus named $\textbf{Formal} \ \textbf{Logic} \ \textbf{\textit{D}eduction} \ \textbf{\textit{D}iverse}$ (FLD$^{\times2}$), comprising numerous samples of multi-step deduction with unknown facts, diverse reasoning rules, diverse linguistic expressions, and challenging distractors.
Finally, we empirically show that ALT on FLD$^{\times2}$ substantially enhances the reasoning capabilities of state-of-the-art LLMs, including LLaMA-3.1-70B.
Improvements include gains of up to 30 points on logical reasoning benchmarks, up to 10 points on math and coding benchmarks, and 5 points on the benchmark suite BBH.
tl;dr: This paper introduces a novel framework to study models with different vocabularies, substantiating a scaling law that optimizes computational resources with the consideration of vocabulary and other attributes jointly.

Research on scaling large language models (LLMs) has primarily focused on model parameters and training data size, overlooking the role of vocabulary size. We investigate how vocabulary size impacts LLM scaling laws by training models ranging from 33M to 3B parameters on up to 500B characters with various vocabulary configurations. We propose three complementary approaches for predicting the compute-optimal vocabulary size: IsoFLOPs analysis, derivative estimation, and parametric fit of the loss function. Our approaches converge on the conclusion that the optimal vocabulary size depends on the compute budget, with larger models requiring larger vocabularies. Most LLMs, however, use insufficient vocabulary sizes. For example, we predict that the optimal vocabulary size of Llama2-70B should have been at least 216K, 7 times larger than its vocabulary of 32K. We validate our predictions empirically by training models with 3B parameters across different FLOPs budgets. Adopting our predicted optimal vocabulary size consistently improves downstream performance over commonly used vocabulary sizes. By increasing the vocabulary size from the conventional 32K to 43K, we improve performance on ARC-Challenge from 29.1 to 32.0 with the same 2.3e21 FLOPs. Our work highlights the importance of jointly considering tokenization and model scaling for efficient pre-training. The code and demo are available at https://github.com/sail-sg/scaling-with-vocab and https://hf.co/spaces/sail/scaling-with-vocab-demo.
915. Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
tl;dr: We measure progress in training sparse autoencoders for LM interpretability by working in the setting of LMs trained on chess and Othello.

What latent features are encoded in language model (LM) representations? Recent work on training sparse autoencoders (SAEs) to disentangle interpretable features in LM representations has shown significant promise. However, evaluating the quality of these SAEs is difficult because we lack a ground-truth collection of interpretable features which we expect good SAEs to identify. We thus propose to measure progress in interpretable dictionary learning by working in the setting of LMs trained on Chess and Othello transcripts. These settings carry natural collections of interpretable features—for example, “there is a knight on F3”—which we leverage into metrics for SAE quality. To guide progress in interpretable dictionary learning, we introduce a new SAE training technique, $p$-annealing, which demonstrates improved performance on our metric.
tl;dr: This paper presents RISE, a fine-tuning approach that enables language models to iteratively improve their own responses over multiple turns.

A central piece in enabling intelligent agentic behavior in foundation models is to make them capable of introspecting upon their behavior, reasoning, and correcting their mistakes as more computation or interaction is available. Even the strongest proprietary large language models (LLMs) do not quite exhibit the ability of continually improving their responses sequentially. In this paper, we develop $\textbf{RISE:}$ $\textbf{R}$ecursive $\textbf{I}$ntro$\textbf{S}$p$\textbf{E}$ction, an approach for fine-tuning LLMs to introduce this capability, despite prior work hypothesizing that this capability may not be possible to attain. Our approach prescribes an iterative fine-tuning procedure, which attempts to teach the model how to alter its response after having executed previously unsuccessful attempts to solve a hard test-time problem, with optionally additional environment feedback. RISE poses fine-tuning for a single-turn prompt as solving a multi-turn Markov decision process (MDP), where the initial state is the prompt. Inspired by principles in online imitation and offline reinforcement learning, we propose strategies for multi-turn data collection and training so as to imbue an LLM with the capability to recursively detect and correct its previous mistakes in subsequent iterations. Our experiments show that RISE enables Llama2, Llama3, and Mistral models to improve themselves with more turns on reasoning tasks, outperforming several single-turn strategies given an equal amount of inference-time computation. We also find that RISE scales well, often attaining larger benefits with more capable models, without disrupting one-turn abilities as a result of expressing more complex distributions.
tl;dr: We show that trajectory data suffices for statistically efficient learning in offline reinforcement learning, under the assumptions of linear $q^\pi$-realizability, and concentrability.

We consider offline reinforcement learning (RL) in $H$-horizon Markov decision processes (MDPs) under the linear $q^\pi$-realizability assumption, where the action-value function of every policy is linear with respect to a given $d$-dimensional feature function. The hope in this setting is that learning a good policy will be possible without requiring a sample size that scales with the number of states in the MDP. Foster et al. [2021] have shown this to be impossible even under $\text{\textit{concentrability}}$, a data coverage assumption where a coefficient $C_\text{conc}$ bounds the extent to which the state-action distribution of any policy can veer off the data distribution. However, the data in this previous work was in the form of a sequence of individual transitions. This leaves open the question of whether the negative result mentioned could be overcome if the data was composed of sequences of full trajectories. In this work we answer this question positively by proving that with trajectory data, a dataset of size $\text{poly}(d,H,C_\text{conc})/\epsilon^2$ is sufficient for deriving an $\epsilon$-optimal policy, regardless of the size of the state space. The main tool that makes this result possible is due to Weisz et al. [2023], who demonstrate that linear MDPs can be used to approximate linearly $q^\pi$-realizable MDPs. The connection to trajectory data is that the linear MDP approximation relies on "skipping" over certain states. The associated estimation problems are thus easy when working with trajectory data, while they remain nontrivial when working with individual transitions. The question of computational efficiency under our assumptions remains open.

Surface electromyography (sEMG) based gesture recognition offers a natural and intuitive interaction modality for wearable devices. Despite significant advancements in sEMG-based gesture recognition models, existing methods often suffer from high computational latency and increased energy consumption. Additionally, the inherent instability of sEMG signals, combined with their sensitivity to distribution shifts in real-world settings, compromises model robustness.
To tackle these challenges, we propose a novel SpGesture framework based on Spiking Neural Networks, which possesses several unique merits compared with existing methods: (1) Robustness: By utilizing membrane potential as a memory list, we pioneer the introduction of Source-Free Domain Adaptation into SNN for the first time. This enables SpGesture to mitigate the accuracy degradation caused by distribution shifts. (2) High Accuracy: With a novel Spiking Jaccard Attention, SpGesture enhances the SNNs' ability to represent sEMG features, leading to a notable rise in system accuracy. To validate SpGesture's performance, we collected a new sEMG gesture dataset which has different forearm postures, where SpGesture achieved the highest accuracy among the baselines ($89.26\%$). Moreover, the actual deployment on the CPU demonstrated a latency below 100ms, well within real-time requirements. This impressive performance showcases SpGesture's potential to enhance the applicability of sEMG in real-world scenarios. The code is available at https://github.com/guoweiyu/SpGesture/.
tl;dr: Overcome the too conservative problem in pessimistic Q learning in offline RL by pessimistic Q value by uncertainty via consistency model.

``Distribution shift'' is the primary obstacle to the success of offline reinforcement learning. As a learning policy may take actions beyond the knowledge of the behavior policy (referred to as Out-of-Distribution (OOD) actions), the Q-values of these OOD actions can be easily overestimated. Consequently, the learning policy becomes biasedly optimized using the incorrect recovered Q-value function. One commonly used idea to avoid the overestimation of Q-value is to make a pessimistic adjustment. Our key idea is to penalize the Q-values of OOD actions that correspond to high uncertainty. In this work, we propose Q-Distribution guided Q-learning (QDQ) which pessimistic Q-value on OOD regions based on uncertainty estimation. The uncertainty measure is based on the conditional Q-value distribution, which is learned via a high-fidelity and efficient consistency model. On the other hand, to avoid the overly conservative problem, we introduce an uncertainty-aware optimization objective to update the Q-value function. The proposed QDQ demonstrates solid theoretical guarantees for the accuracy of Q-value distribution learning and uncertainty measurement, as well as the performance of the learning policy. QDQ consistently exhibits strong performance in the D4RL benchmark and shows significant improvements for many tasks. Our code can be found at <code link>.

The machine learning community has witnessed impressive advancements since large language models (LLMs) first appeared. Yet, their massive memory consumption has become a significant roadblock to large-scale training. For instance, a 7B model typically requires at least 60 GB of GPU memory with full parameter training, which presents challenges for researchers without access to high-resource environments. Parameter Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA) have been proposed to alleviate this problem. However, in most large-scale fine-tuning settings, their performance does not reach the level of full parameter training because they confine the parameter search to a low-rank subspace. Attempting to complement this deficiency, we investigate the layerwise properties of LoRA on fine-tuning tasks and observe an unexpected but consistent skewness of weight norms across different layers. Utilizing this key observation, a surprisingly simple training strategy is discovered, which outperforms both LoRA and full parameter training in a wide range of settings with memory costs as low as LoRA. We name it Layerwise Importance Sampled AdamW (LISA), a promising alternative for LoRA, which applies the idea of importance sampling to different layers in LLMs and randomly freeze most middle layers during optimization. Experimental results show that with similar or less GPU memory consumption, LISA surpasses LoRA or even full parameter tuning in downstream fine-tuning tasks, where LISA consistently outperforms LoRA by over 10%-35% in terms of MT-Bench score while achieving on-par or better performance in MMLU, AGIEval and WinoGrande. On large models, specifically LLaMA-2-70B, LISA surpasses LoRA on MT-Bench, GSM8K, and PubMedQA, demonstrating its effectiveness across different domains.

World models can foresee the outcomes of different actions, which is of paramount importance for autonomous driving. Nevertheless, existing driving world models still have limitations in generalization to unseen environments, prediction fidelity of critical details, and action controllability for flexible application. In this paper, we present Vista, a generalizable driving world model with high fidelity and versatile controllability. Based on a systematic diagnosis of existing methods, we introduce several key ingredients to address these limitations. To accurately predict real-world dynamics at high resolution, we propose two novel losses to promote the learning of moving instances and structural information. We also devise an effective latent replacement approach to inject historical frames as priors for coherent long-horizon rollouts. For action controllability, we incorporate a versatile set of controls from high-level intentions (command, goal point) to low-level maneuvers (trajectory, angle, and speed) through an efficient learning strategy. After large-scale training, the capabilities of Vista can seamlessly generalize to different scenarios. Extensive experiments on multiple datasets show that Vista outperforms the most advanced general-purpose video generator in over 70% of comparisons and surpasses the best-performing driving world model by 55% in FID and 27% in FVD. Moreover, for the first time, we utilize the capacity of Vista itself to establish a generalizable reward for real-world action evaluation without accessing the ground truth actions.
922. Partial observation can induce mechanistic mismatches in data-constrained models of neural dynamics

One of the central goals of neuroscience is to gain a mechanistic understanding of how the dynamics of neural circuits give rise to their observed function. A popular approach towards this end is to train recurrent neural networks (RNNs) to reproduce experimental recordings of neural activity. These trained RNNs are then treated as surrogate models of biological neural circuits, whose properties can be dissected via dynamical systems analysis. How reliable are the mechanistic insights derived from this procedure? While recent advances in population-level recording technologies have allowed simultaneous recording of up to tens of thousands of neurons, this represents only a tiny fraction of most cortical circuits. Here we show that observing only a subset of neurons in a circuit can create mechanistic mismatches between a simulated teacher network and a data-constrained student, even when the two networks have matching single-unit dynamics. In particular, we show that partial observation of models of low-dimensional cortical dynamics based on functionally feedforward or low-rank connectivity can lead to surrogate models with spurious attractor structure. In total, our results illustrate the challenges inherent in accurately uncovering neural mechanisms from single-trial data, and suggest the need for new methods of validating data-constrained models for neural dynamics.
tl;dr: Free albedo extraction from latent features in a relighting-trained model, without seeing albedo like images

Image relighting is the task of showing what a scene from a source image would look like if illuminated differently. Inverse graphic schemes recover an explicit representation of geometry and a set of chosen intrinsics, then relight with some form of renderer. But error control for inverse graphics is difficult, and inverse graphics methods can represent only the effects of the chosen intrinsics. This paper describes a relighting method that is entirely data-driven, where intrinsics and lighting are each represented as latent variables. Our approach produces SOTA relightings of real scenes, as measured by standard metrics. We show that albedo can be recovered from our latent intrinsics without using any example albedos, and that the albedos recovered are competitive with SOTA methods.

We prove that single-parameter natural exponential families with subexponential tails are self-concordant with polynomial-sized parameters. For subgaussian natural exponential families we establish an exact characterization of the growth rate of the self-concordance parameter. Applying these findings to bandits allows us to fill gaps in the literature: We show that optimistic algorithms for generalized linear bandits enjoy regret bounds that are both second-order (scale with the variance of the optimal arm's reward distribution) and free of an exponential dependence on the bound of the problem parameter in the leading term. To the best of our knowledge, ours is the first regret bound for generalized linear bandits with subexponential tails, broadening the class of problems to include Poisson, exponential and gamma bandits.

The exploration-exploitation dilemma has been a central challenge in reinforcement learning (RL) with complex model classes. In this paper, we propose a new algorithm, Monotonic Q-Learning with Upper Confidence Bound (MQL-UCB) for RL with general function approximation. Our key algorithmic design includes (1) a general deterministic policy-switching strategy that achieves low switching cost, (2) a monotonic value function structure with carefully controlled function class complexity, and (3) a variance-weighted regression scheme that exploits historical trajectories with high data efficiency. MQL-UCB achieves minimax optimal regret of $\tilde{O}(d\sqrt{HK})$ when $K$ is sufficiently large and near-optimal policy switching cost of $\tilde{O}(dH)$, with $d$ being the eluder dimension of the function class, $H$ being the planning horizon, and $K$ being the number of episodes.
Our work sheds light on designing provably sample-efficient and deployment-efficient Q-learning with nonlinear function approximation.

Stochastic Gradient Descent (SGD) with adaptive steps is widely used to train deep neural networks and generative models. Most theoretical results assume that it is possible to obtain unbiased gradient estimators, which is not the case in several recent deep learning and reinforcement learning applications that use Monte Carlo methods.
This paper provides a comprehensive non-asymptotic analysis of SGD with biased gradients and adaptive steps for non-convex smooth functions. Our study incorporates time-dependent bias and emphasizes the importance of controlling the bias of the gradient estimator.
In particular, we establish that Adagrad, RMSProp, and AMSGRAD, an exponential moving average variant of Adam, with biased gradients, converge to critical points for smooth non-convex functions at a rate similar to existing results in the literature for the unbiased case. Finally, we provide experimental results using Variational Autoenconders (VAE) and applications to several learning frameworks that illustrate our convergence results and show how the effect of bias can be reduced by appropriate hyperparameter tuning.

Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications.
We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
tl;dr: We directly model spoken dialog using an LLM-based speech-text model, capable of generating spoken dialogs with coherent content and natural prosody. We also present speech-text pretraining that captures the comprehensive cross-modal relationships.

Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech. However, an LLM-based strategy for modeling spoken dialogs remains elusive, calling for further investigation. This paper introduces an extensive speech-text LLM framework, the Unified Spoken Dialog Model (USDM), designed to generate coherent spoken responses with naturally occurring prosodic features relevant to the given input speech without relying on explicit automatic speech recognition (ASR) or text-to-speech (TTS) systems. We have verified the inclusion of prosody in speech tokens that predominantly contain semantic information and have used this foundation to construct a prosody-infused speech-text model. Additionally, we propose a generalized speech-text pretraining scheme that enhances the capture of cross-modal semantics. To construct USDM, we fine-tune our speech-text model on spoken dialog data using a multi-step spoken dialog template that stimulates the chain-of-reasoning capabilities exhibited by the underlying LLM. Automatic and human evaluations on the DailyTalk dataset demonstrate that our approach effectively generates natural-sounding spoken responses, surpassing previous and cascaded baselines. Our code and checkpoints are available at https://github.com/naver-ai/usdm.

The rapid development of Large Language Models (LLMs) has been pivotal in advancing AI, with pre-trained LLMs being adaptable to diverse downstream tasks through fine-tuning. Federated learning (FL) further enhances fine-tuning in a privacy-aware manner by utilizing clients' local data through in-situ computation, eliminating the need for data movement. However, fine-tuning LLMs, given their massive scale of parameters, poses challenges for clients with constrained and heterogeneous resources in FL. Previous methods employed low-rank adaptation (LoRA) for efficient federated fine-tuning but utilized traditional FL aggregation strategies on LoRA adapters. This approach led to mathematically inaccurate aggregation noise, reducing fine-tuning effectiveness and failing to address heterogeneous LoRAs. In this work, we first highlight the mathematical incorrectness of LoRA aggregation in existing federated fine-tuning methods. We introduce a new approach called FLoRA that enables federated fine-tuning on heterogeneous LoRA adapters across clients through a novel stacking-based aggregation method. Our approach is noise-free and seamlessly supports heterogeneous LoRAs. Extensive experiments demonstrate FLoRA's superior performance in both homogeneous and heterogeneous settings, surpassing state-of-the-art methods. We envision this work as a milestone for efficient, privacy-preserving, and accurate federated fine-tuning of LLMs.
tl;dr: Using techniques from analysis of partial differential equations and Hamilton-Jacobi equations, we show score-based generative models are robust, and also yield generalization bounds.

Through an uncertainty quantification (UQ) perspective, we show that score-based generative models (SGMs) are provably robust to the multiple sources of error in practical implementation. Our primary tool is the Wasserstein uncertainty propagation (WUP) theorem, a *model-form UQ* bound that describes how the $L^2$ error from learning the score function propagates to a Wasserstein-1 ($\mathbf{d}_1$) ball around the true data distribution under the evolution of the Fokker-Planck equation. We show how errors due to (a) finite sample approximation, (b) early stopping, (c) score-matching objective choice, (d) score function parametrization expressiveness, and (e) reference distribution choice, impact the quality of the generative model in terms of a $\mathbf{d}_1$ bound of computable quantities. The WUP theorem relies on Bernstein estimates for Hamilton-Jacobi-Bellman partial differential equations (PDE) and the regularizing properties of diffusion processes. Specifically, *PDE regularity theory* shows that *stochasticity* is the key mechanism ensuring SGM algorithms are provably robust. The WUP theorem applies to integral probability metrics beyond $\mathbf{d}_1$, such as the total variation distance and the maximum mean discrepancy. Sample complexity and generalization bounds in $\mathbf{d}_1$ follow directly from the WUP theorem. Our approach requires minimal assumptions, is agnostic to the manifold hypothesis and avoids absolute continuity assumptions for the target distribution. Additionally, our results clarify the *trade-offs* among multiple error sources in SGMs.
tl;dr: We explore the implicit regularization induced by weighted and/or subsampled pretrained neural features, offering theory and practical methods to manage high-dimensional data for better model fitting.

We study the implicit regularization effects induced by (observation) weighting of pretrained features.
For weight and feature matrices of bounded operator norms that are infinitesimally free with respect to (normalized) trace functionals, we derive equivalence paths connecting different weighting matrices and ridge regularization levels.
Specifically, we show that ridge estimators trained on weighted features along the same path are asymptotically equivalent when evaluated against test vectors of bounded norms.
These paths can be interpreted as matching the effective degrees of freedom of ridge estimators fitted with weighted features.
For the special case of subsampling without replacement, our results apply to independently sampled random features and kernel features and confirm recent conjectures (Conjectures 7 and 8) of the authors on the existence of such paths in Patil and Du (2023).
We also present an additive risk decomposition for ensembles of weighted estimators and show that the risks are equivalent along the paths when the ensemble size goes to infinity.
As a practical consequence of the path equivalences, we develop an efficient cross-validation method for tuning and apply it to subsampled pretrained representations across several models (e.g., ResNet-50) and datasets (e.g., CIFAR-100).
932. ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
tl;dr: We propose accelerating pretrained LLMs through a "post-training" shift and add reparameterization, towards efficient multiplication-less LLMs, dubbed ShiftAddLLM.

Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and latency bottlenecks. Shift-and-add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques require training from scratch or full parameter fine-tuning to restore accuracy, which is resource-intensive for LLMs. To address this, we propose accelerating pretrained LLMs through post-training shift-and-add reparameterization, creating efficient multiplication-free models, dubbed ShiftAddLLM. Specifically, we quantize each weight matrix into binary matrices paired with group-wise scaling factors. The associated multiplications are reparameterized into (1) shifts between activations and scaling factors and (2) queries and adds according to the binary matrices. To reduce accuracy loss, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Additionally, based on varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency. Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity reductions of 5.6 and 22.7 points at comparable or lower latency compared to the most competitive quantized LLMs at 3- and 2-bit precision, respectively, and more than 80% memory and energy reductions over the original LLMs. Codes and models are available at https://github.com/GATECH-EIC/ShiftAddLLM.
tl;dr: AutoGuide extracts a comprehensive set of context-aware guidelines to improve the sequential decision-making ability of large language model agents.

Recent advances in large language models (LLMs) have empowered AI agents capable of performing various sequential decision-making tasks. However, effectively guiding LLMs to perform well in unfamiliar domains like web navigation, where they lack sufficient knowledge, has proven to be difficult with the demonstration-based in-context learning paradigm. In this paper, we introduce a novel framework, called AutoGuide, which addresses this limitation by automatically generating context-aware guidelines from offline experiences. Importantly, each context-aware guideline is expressed in concise natural language and follows a conditional structure, clearly describing the context where it is applicable. As a result, our guidelines facilitate the provision of relevant knowledge for the agent's current decision-making process, overcoming the limitations of the conventional demonstration-based learning paradigm. Our evaluation demonstrates that AutoGuide significantly outperforms competitive baselines in complex benchmark domains, including real-world web navigation.

We introduce Poseidon, a foundation model for learning the solution operators of PDEs. It is based on a multiscale operator transformer, with time-conditioned layer norms that enable continuous-in-time evaluations. A novel training strategy leveraging the semi-group property of time-dependent PDEs to allow for significant scaling-up of the training data is also proposed. Poseidon is pretrained on a diverse, large scale dataset for the governing equations of fluid dynamics. It is then evaluated on a suite of 15 challenging downstream tasks that include a wide variety of PDE types and operators. We show that Poseidon exhibits excellent performance across the board by outperforming baselines significantly, both in terms of sample efficiency and accuracy. Poseidon also generalizes very well to new physics that is not seen during pretraining. Moreover, Poseidon scales with respect to model and data size, both for pretraining and for downstream tasks. Taken together, our results showcase the surprising ability of Poseidon to learn effective representations from a very small set of PDEs during pretraining in order to generalize well to unseen and unrelated PDEs downstream, demonstrating its potential as an effective, general purpose PDE foundation model. Finally, the Poseidon model as well as underlying pretraining and downstream datasets are open sourced, with code being available at https://github.com/camlab-ethz/poseidon and pretrained models and datasets at https://huggingface.co/camlab-ethz.

Inverse reinforcement learning (IRL) aims to learn a reward function and a corresponding policy that best fit the demonstrated trajectories of an expert. However, current IRL works cannot learn incrementally from an ongoing trajectory because they have to wait to collect at least one complete trajectory to learn. To bridge the gap, this paper considers the problem of learning a reward function and a corresponding policy while observing the initial state-action pair of an ongoing trajectory and keeping updating the learned reward and policy when new state-action pairs of the ongoing trajectory are observed. We formulate this problem as an online bi-level optimization problem where the upper level dynamically adjusts the learned reward according to the newly observed state-action pairs with the help of a meta-regularization term, and the lower level learns the corresponding policy. We propose a novel algorithm to solve this problem and guarantee that the algorithm achieves sub-linear local regret $O(\sqrt{T}+\log T+\sqrt{T}\log T)$. If the reward function is linear, we prove that the proposed algorithm achieves sub-linear regret $O(\log T)$. Experiments are used to validate the proposed algorithm.
936. Elliptical Attention
tl;dr: We show that using a Mahalanobis metric within the attention mechanism reduces representation collapse, and improves robustness to contamination.

Pairwise dot-product self-attention is key to the success of transformers that achieve state-of-the-art performance across a variety of applications in language and vision. This dot-product self-attention computes attention weights among the input tokens using Euclidean distance, which makes the model prone to representation collapse and vulnerable to contaminated samples. In this paper, we propose using a Mahalanobis distance metric for computing the attention weights to stretch the underlying feature space in directions of high contextual relevance. In particular, we define a hyper-ellipsoidal neighborhood around each query to increase the attention weights of the tokens lying in the contextually important directions. We term this novel class of attention Elliptical Attention. Our Elliptical Attention provides two benefits: 1) reducing representation collapse and 2) enhancing the model's robustness as the Elliptical Attention pays more attention to contextually relevant information, rather than focusing on some small subset of informative features. We empirically demonstrate the advantages of Elliptical Attention over the baseline dot-product attention and state-of-the-art attention methods on various practical tasks, including object classification, image
segmentation, and language modeling across different data modalities.

In high-stakes domains such as healthcare and hiring, the role of machine learning (ML) in decision-making raises significant fairness concerns.
This work focuses on Counterfactual Fairness (CF), which posits that an ML model's outcome on any individual should remain unchanged if they had belonged to a different demographic group.
Previous works have proposed methods that guarantee CF.
Notwithstanding, their effects on the model's predictive performance remain largely unclear.
To fill this gap, we provide a theoretical study on the inherent trade-off between CF and predictive performance in a model-agnostic manner.
We first propose a simple but effective method to cast an optimal but potentially unfair predictor into a fair one with a minimal loss of performance.
By analyzing the excess risk incurred by perfect CF, we quantify this inherent trade-off.
Further analysis on our method's performance with access to only incomplete causal knowledge is also conducted.
Built upon this, we propose a practical algorithm that can be applied in such scenarios.
Experiments on both synthetic and semi-synthetic datasets demonstrate the validity of our analysis and methods.
tl;dr: We present fast samplers for solving inverse problems in diffusion and flow models

Constructing fast samplers for unconditional diffusion and flow-matching models has received much attention recently; however, existing methods for solving *inverse problems*, such as super-resolution, inpainting, or deblurring, still require hundreds to thousands of iterative steps to obtain high-quality results. We propose a plug-and-play framework for constructing efficient samplers for inverse problems, requiring only *pre-trained* diffusion or flow-matching models. We present *Conditional Conjugate Integrators*, which leverage the specific form of the inverse problem to project the respective conditional diffusion/flow dynamics into a more amenable space for sampling. Our method complements popular posterior approximation methods for solving inverse problems using diffusion/flow models. We evaluate the proposed method's performance on various linear image restoration tasks across multiple datasets, employing diffusion and flow-matching models. Notably, on challenging inverse problems like 4x super-resolution on the ImageNet dataset, our method can generate high-quality samples in as few as *5* conditional sampling steps and outperforms competing baselines requiring 20-1000 steps. Our code will be publicly available at https://github.com/mandt-lab/c-pigdm.

Since the inception of the classicalist vs. connectionist debate, it has been argued that the ability to systematically combine symbol-like entities into compositional representations is crucial for human intelligence. In connectionist systems, the field of disentanglement has emerged to address this need by producing representations with explicitly separated factors of variation (FoV). By treating the overall representation as a *string-like concatenation* of the inferred FoVs, however, disentanglement provides a fundamentally *symbolic* treatment of compositional structure, one inherently at odds with the underlying *continuity* of deep learning vector spaces. We hypothesise that this symbolic-continuous mismatch produces broadly suboptimal performance in deep learning models that learn or use such representations. To fully align compositional representations with continuous vector spaces, we extend Smolensky's Tensor Product Representation (TPR) and propose a new type of inherently *continuous* compositional representation, *Soft TPR*, along with a theoretically-principled architecture, *Soft TPR Autoencoder*, designed specifically for learning Soft TPRs. In the visual representation learning domain, our Soft TPR confers broad benefits over symbolic compositional representations: state-of-the-art disentanglement and improved representation learner convergence, along with enhanced sample efficiency and superior low-sample regime performance for downstream models, empirically affirming the value of our inherently *continuous* compositional representation learning framework.
tl;dr: We demonstrate how to perform model selection for computation-aware Gaussian processes enabling training on over a million data points on a single GPU.

Model selection in Gaussian processes scales prohibitively with the size of the training dataset, both in time and memory.
While many approximations exist, all incur inevitable approximation error.
Recent work accounts for this error in the form of computational uncertainty, which enables---at the cost of quadratic complexity---an explicit tradeoff between computation and precision.
Here we extend this development to model selection, which requires significant enhancements to the existing approach, including linear-time scaling in the size of the dataset.
We propose a novel training loss for hyperparameter optimization and demonstrate empirically that the resulting method can outperform SGPR, CGGP and SVGP, state-of-the-art methods for GP model selection, on medium to large-scale datasets.
Our experiments show that model selection for computation-aware GPs trained on 1.8 million data points can be done within a few hours on a single GPU.
As a result of this work, Gaussian processes can be trained on large-scale datasets without significantly compromising their ability to quantify uncertainty---a fundamental prerequisite for optimal decision-making.

We address the problem of stochastic combinatorial semi-bandits, where a player selects among $P$ actions from the power set of a set containing $d$ base items. Adaptivity to the problem's structure is essential in order to obtain optimal regret upper bounds. As estimating the coefficients of a covariance matrix can be manageable in practice, leveraging them should improve the regret. We design ``optimistic'' covariance-adaptive algorithms relying on online estimations of the covariance structure, called OLS-UCB-C and COS-V (only the variances for the latter). They both yields improved gap-free regret. Although COS-V can be slightly suboptimal, it improves on computational complexity by taking inspiration from Thompson Sampling approaches. It is the first sampling-based algorithm satisfying a $\sqrt{T}$ gap-free regret (up to poly-logs). We also show that in some cases, our approach efficiently leverages the semi-bandit feedback and outperforms bandit feedback approaches, not only in exponential regimes where $P\gg d$ but also when $P\leq d$, which is not covered by existing analyses.
tl;dr: We provide a full characterization of the concept classes that are optimistically universally online learnable with {0, 1} labels.

We provide a full characterization of the concept classes that are optimistically universally online learnable with {0, 1} labels. The notion of optimistically universal online learning was defined in [Hanneke, 2021] in order to understand learnability under minimal assumptions. In this paper, following the philosophy behind that work, we investigate two questions, namely, for every concept class: (1) What are the minimal assumptions on the data process admitting online learnability? (2) Is there a learning algorithm which succeeds under every data process satisfying the minimal assumptions? Such an algorithm is said to be optimistically universal for the given concept class. We resolve both of these questions for all concept classes, and moreover, as part of our solution we design general learning algorithms for each case. Finally, we extend these algorithms and results to the agnostic case, showing an equivalence between the minimal assumptions on the data process for learnability in the agnostic and realizable cases, for every concept class, as well as the equivalence of optimistically universal learnability.

Improving the reasoning capabilities of large language models (LLMs) has attracted considerable interest. Recent approaches primarily focus on improving the reasoning process to yield a more precise final answer. However, in scenarios involving contextually aware reasoning, these methods neglect the importance of first identifying logical relationships from the context before proceeding with the reasoning. This oversight could lead to a superficial understanding and interaction with the context, potentially undermining the quality and reliability of the reasoning outcomes. In this paper, we propose an information re-organization (\textbf{InfoRE}) method before proceeding with the reasoning to enhance the reasoning ability of LLMs. Our re-organization method involves initially extracting logical relationships from the contextual content, such as documents or paragraphs, and subsequently pruning redundant content to minimize noise. Then, we utilize the re-organized information in the reasoning process. This enables LLMs to deeply understand the contextual content by clearly perceiving these logical relationships, while also ensuring high-quality responses by eliminating potential noise. To demonstrate the effectiveness of our approach in improving the reasoning ability, we conduct experiments using Llama2-70B, GPT-3.5, and GPT-4 on various contextually aware multi-hop reasoning tasks. Using only a zero-shot setting, our method achieves an average absolute improvement of 4\% across all tasks, highlighting its potential to improve the reasoning performance of LLMs.

A prevailing belief in attack and defense community is that the higher flatness of adversarial examples enables their better cross-model transferability, leading to a growing interest in employing sharpness-aware minimization and its variants. However, the theoretical relationship between the transferability of adversarial examples and their flatness has not been well established, making the belief questionable. To bridge this gap, we embark on a theoretical investigation and, for the first time, derive a theoretical bound for the transferability of adversarial examples with few practical assumptions. Our analysis challenges this belief by demonstrating that the increased flatness of adversarial examples does not necessarily guarantee improved transferability. Moreover, building upon the theoretical analysis, we propose TPA, a Theoretically Provable Attack that optimizes a surrogate of the derived bound to craft adversarial examples. Extensive experiments across widely used benchmark datasets and various real-world applications show that TPA can craft more transferable adversarial examples compared to state-of-the-art baselines. We hope that these results can recalibrate preconceived impressions within the community and facilitate the development of stronger adversarial attack and defense mechanisms.
tl;dr: We regard the protein flexibility as an attack on the trained model and aim to defend against it for improving protein interface prediction.

The knowledge of protein interactions is crucial but challenging for drug discovery applications. This work focuses on protein interface prediction, which aims to determine whether a pair of residues from different proteins interact. Existing data-driven methods have made significant progress in effectively learning protein structures. Nevertheless, they overlook the conformational changes (i.e., flexibility) within proteins upon binding, leading to poor generalization ability. In this paper, we regard the protein flexibility as an attack on the trained model and aim to defend against it for improved generalization. To fulfill this purpose, we propose ATProt, an adversarial training framework for protein representations to robustly defend against the attack of protein flexibility. ATProt can theoretically guarantee protein representation stability under complicated protein flexibility. Experiments on various benchmarks demonstrate that ATProt consistently improves the performance for protein interface prediction. Moreover, our method demonstrates broad applicability, performing the best even when provided with testing structures from structure prediction models like ESMFold and AlphaFold2.
tl;dr: We present a learning algorithm where knowledge from different domains can be combined or transferred using task vectors with learned anisotropic scaling.

Pre-trained models produce strong generic representations that can be adapted via fine-tuning on specialised datasets. The learned weight difference relative to the pre-trained model, known as a task vector, characterises the direction and stride of fine-tuning that enables the model to capture these specialised representations. The significance of task vectors is such that simple arithmetic operations on them can be used to combine diverse representations from different domains. This paper builds on these properties of task vectors and aims to answer (1) whether components of task vectors, particularly parameter blocks, exhibit similar characteristics, and (2) how such blocks can be used to enhance knowledge composition and transfer. To this end, we introduce aTLAS, an algorithm that linearly combines parameter blocks with different learned coefficients, resulting in anisotropic scaling at the task vector level. We show that such linear combinations explicitly exploit the low intrinsic dimensionality of pre-trained models, with only a few coefficients being the learnable parameters. Furthermore, composition of parameter blocks enables modular learning that effectively leverages the already learned representations, thereby reducing the dependency on large amounts of data. We demonstrate the effectiveness of our method in task arithmetic, few-shot recognition and test-time adaptation, with supervised or unsupervised objectives. In particular, we show that (1) learned anisotropic scaling allows task vectors to be more disentangled, causing less interference in composition; (2) task vector composition excels with scarce or no labelled data and is less prone to domain shift, thus leading to better generalisability; (3) mixing the most informative parameter blocks across different task vectors prior to training can reduce the memory footprint and improve the flexibility of knowledge transfer. Moreover, we show the potential of aTLAS as a parameter-efficient fine-tuning method, particularly with less data, and demonstrate that it can be easily scaled up for higher performance.

Current multimodal and multitask foundation models, like 4M or UnifiedIO, show promising results. However, their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually small) number of modalities and tasks they are trained on. In this paper, we develop a single any-to-any model trained on tens of highly diverse modalities and by performing co-training on large-scale multimodal datasets and text corpora. This includes training on images and text along with several semantic and geometric modalities, feature maps from recent state of the art models like DINOv2 and ImageBind, pseudo labels of specialist models like SAM and 4DHumans, and a range of new modalities that allow for novel ways to interact with the model and steer the generation, for example, image metadata or color palettes.
A crucial step in this process is performing discrete tokenization on various modalities, whether they are image-like, neural network feature maps, vectors, structured data like instance segmentation or human poses, or data that can be represented as text.
Through this, we show the possibility of training one model to solve at least 3x more tasks/modalities than existing models and doing so without a loss in performance. In addition, this enables more fine-grained and controllable multimodal generation capabilities and allows studying the distillation of models trained on diverse data and objectives into one unified model.
We scale the training to a three billion parameter and different datasets. The multimodal models and training code are open sourced at https://4m.epfl.ch/.

We study learning-based approaches to semantic route planning, which concerns producing routes in response to rich queries that specify various criteria and preferences. Semantic routing is already widely found in industry applications, especially navigational services like Google Maps; however, existing implementations only support limited route criteria and narrow query sets as they rely on repurposing classical route optimization algorithms. We argue for a learning-based approach to semantic routing as a more scalable and general alternative. To foster interest in this important application of graph learning, we are releasing a large-scale publicly-licensed benchmark for semantic routing consisting of real-world multi-objective navigation problems---expressed via natural language queries---on the richly annotated road networks of US cities. In addition to being intractable with existing approaches to semantic routing, our benchmark poses a significant scaling challenge for graph learning methods. As a proof-of-concept, we show that---at scale---even a standard transformer network is a powerful semantic routing system and achieves non-trivial performance on our benchmark. In the process, we demonstrate a simple solution to the challenge of scaling up graph learning: an autoregressive approach that decomposes semantic routing into smaller ``next-edge'' prediction problems.
tl;dr: An effective human-AI collaboration framework that adaptively selects optimal policies in non-stationary tasks, with guarantees for rapid convergence and superior performance in dynamic environments.

In human-AI collaborative tasks, the distribution of human behavior, influenced by mental models, is non-stationary, manifesting in various levels of initiative and different collaborative strategies. A significant challenge in human-AI collaboration is determining how to collaborate effectively with humans exhibiting non-stationary dynamics. Current collaborative agents involve initially running self-play (SP) multiple times to build a policy pool, followed by training the final adaptive policy against this pool. These agents themselves are a single policy network, which is $\textbf{insufficient for handling non-stationary human dynamics}$. We discern that despite the inherent diversity in human behaviors, the $\textbf{underlying meta-tasks within specific collaborative contexts tend to be strikingly similar}$. Accordingly, we propose a $\textbf{C}$ollaborative $\textbf{B}$ayesian $\textbf{P}$olicy $\textbf{R}$euse ($\textbf{CBPR}$), a novel Bayesian-based framework that $\textbf{adaptively selects optimal collaborative policies matching the current meta-task from multiple policy networks}$ instead of just selecting actions relying on a single policy network. We provide theoretical guarantees for CBPR's rapid convergence to the optimal policy once human partners alter their policies. This framework shifts from directly modeling human behavior to identifying various meta-tasks that support human decision-making and training meta-task playing (MTP) agents tailored to enhance collaboration. Our method undergoes rigorous testing in a well-recognized collaborative cooking simulator, $\textit{Overcooked}$. Both empirical results and user studies demonstrate CBPR's superior competitiveness compared to existing baselines.
tl;dr: Our paper proves a universal upper bound and a conditional lower bound for the expressive power of tree-structured probabilistic circuits.

Probabilistic circuits (PCs) have emerged as a powerful framework compactly representing probability distributions for efficient and exact probabilistic inference. It has been shown that PCs with general directed acyclic graph (DAG) structure can be understood as a mixture of exponentially (in its height) many components, each of which is a product distributions over univariate marginals. However, existing structure learning algorithms for PCs often generate tree-structured circuits, or using tree-structured circuits as intermediate steps to compress them into DAG-structured circuits. This leads to an intriguing question on whether there exists an exponential gap between DAGs and trees for the PC structure.
In this paper, we provide a negative answer to this conjecture by proving that, for $n$ variables, there is a quasi-polynomial upper bound $n^{O(\log n)}$ on the size of an equivalent tree computing the same probability distribution. On the other hand, we will also show that given a depth restriction on the tree, there is a super-polynomial separation between tree and DAG-structured PCs. Our work takes an important step towards understanding the expressive power of tree-structured PCs, and our techniques may be of independent interest in the study of structure learning algorithms for PCs.

Developing meaningful and efficient representations that separate the fundamental structure of the data generation mechanism is crucial in representation learning. However, Disentangled Representation Learning has not fully shown its potential on real images, because of correlated generative factors, their resolution and limited access to ground truth labels. Specifically on the latter, we investigate the possibility of leveraging synthetic data to learn general-purpose disentangled representations applicable to real data, discussing the effect of fine-tuning and what properties of disentanglement are preserved after the transfer. We provide an extensive empirical study to address these issues. In addition, we propose a new interpretable intervention-based metric, to measure the quality of factors encoding in the representation. Our results indicate that some level of disentanglement, transferring a representation from synthetic to real data, is possible and effective.
tl;dr: We introduce a new self-attention module (SAND) to impute sparse functional data in a differentiable manner.

Although the transformer architecture has come to dominate other models for text and image data, its application to irregularly-spaced longitudinal data has been limited. We introduce a variant of the transformer that enables it to more smoothly impute such functional data. We augment the vanilla transformer with a simple module we call SAND (self-attention on derivatives), which naturally encourages smoothness by modeling the sub-derivative of the imputed curve. On the theoretical front, we prove the number of hidden nodes required by a network with SAND to achieve an $\epsilon$ prediction error bound for functional imputation. Extensive experiments over various types of functional data demonstrate that transformers with SAND produce better imputations than both their standard counterparts as well as transformers augmented with alternative approaches to encode the inductive bias of smoothness. SAND also outperforms standard statistical methods for functional imputation like kernel smoothing and PACE.
tl;dr: We systematically explore the bias in the AVQA task from the persepctive of model designs and model evaluations.

Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, *MUSIC-AVQA-R*, crafted in two steps: rephrasing questions within the test split of a public dataset (*MUSIC-AVQA*) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on MUSIC-AVQA-R, notably obtaining a significant improvement of 9.32\%. Extensive ablation experiments are conducted on the two datasets mentioned to analyze the component effectiveness within the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset. We also conduct experiments combining various baselines with our proposed strategy on two datasets to verify its plug-and-play capability. Our dataset and code are available at <https://github.com/reml-group/MUSIC-AVQA-R>.
tl;dr: We propose a neural solver to solve quadratic unconstrained binary optimization in a classification way, which can achieve near-optimal solutions in milliseconds, even for instances comprising thousands of variables.

The quadratic unconstrained binary optimization (QUBO) is a well-known NP-hard problem that takes an $n\times n$ matrix $Q$ as input and decides an $n$-dimensional 0-1 vector $x$, to optimize a quadratic function. Existing learning-based models that always formulate the solution process as sequential decisions suffer from high computational overload. To overcome this issue, we propose a neural solver called the Value Classification Model (VCM) that formulates the solution process from a classification perspective. It applies a Depth Value Network (DVN) based on graph convolution that exploits the symmetry property in $Q$ to auto-grasp value features. These features are then fed into a Value Classification Network (VCN) which directly generates classification solutions. Trained by a highly efficient model-tailored Greedy-guided Self Trainer (GST) which does not require any priori optimal labels, VCM significantly outperforms competitors in both computational efficiency and solution quality with a remarkable generalization ability. It can achieve near-optimal solutions in milliseconds with an average optimality gap of just 0.362\% on benchmarks with up to 2500 variables. Notably, a VCM trained at a specific DVN depth can steadily find better solutions by simply extending the testing depth, which narrows the gap to 0.034\% on benchmarks. To our knowledge, this is the first learning-based model to reach such a performance.
tl;dr: Proposing a kernel-based Inverse Optimization model with a scalable algorithm designed for imitation learning tasks.

Inverse Optimization (IO) is a framework for learning the unknown objective function of an expert decision-maker from a past dataset.
In this paper, we extend the hypothesis class of IO objective functions to a reproducing kernel Hilbert space (RKHS), thereby enhancing feature representation to an infinite-dimensional space.
We demonstrate that a variant of the representer theorem holds for a specific training loss, allowing the reformulation of the problem as a finite-dimensional convex optimization program.
To address scalability issues commonly associated with kernel methods, we propose the Sequential Selection Optimization (SSO) algorithm to efficiently train the proposed Kernel Inverse Optimization (KIO) model.
Finally, we validate the generalization capabilities of the proposed KIO model and the effectiveness of the SSO algorithm through learning-from-demonstration tasks on the MuJoCo benchmark.

Meta learning is a promising paradigm in the era of large models and
task distributional robustness has become an indispensable consideration in real-world scenarios.
Recent advances have examined the effectiveness of tail task risk minimization in fast adaptation robustness improvement \citep{wang2023simple}.
This work contributes to more theoretical investigations and practical enhancements in the field.
Specifically, we reduce the distributionally robust strategy to a max-min optimization problem, constitute the Stackelberg equilibrium as the solution concept, and estimate the convergence rate.
In the presence of tail risk, we further derive the generalization bound, establish connections with estimated quantiles, and practically improve the studied strategy.
Accordingly, extensive evaluations demonstrate the significance of our proposal in boosting robustness.

Editing biological sequences has extensive applications in synthetic biology and medicine, such as designing regulatory elements for nucleic-acid therapeutics and treating genetic disorders. The primary objective in biological-sequence editing is to determine the optimal modifications to a sequence which augment certain biological properties while adhering to a minimal number of alterations to ensure predictability and potentially support safety. In this paper, we propose GFNSeqEditor, a novel biological-sequence editing algorithm which builds on the recently proposed area of generative flow networks (GFlowNets). Our proposed GFNSeqEditor identifies elements within a starting seed sequence that may compromise a desired biological property. Then, using a learned stochastic policy, the algorithm makes edits at these identified locations, offering diverse modifications for each sequence to enhance the desired property. The number of edits can be regulated through specific hyperparameters. We conducted extensive experiments on a range of real-world datasets and biological applications, and our results underscore the superior performance of our proposed algorithm compared to existing state-of-the-art sequence editing methods.
tl;dr: We proposed LoRA-Inlaid, a resource-efficient and high-performance system for multi-task LLM quantization and serving.

With the remarkable achievements of large language models (LLMs), the demand for fine-tuning and deploying LLMs in various downstream tasks has garnered widespread interest. Parameter-efficient fine-tuning techniques represented by LoRA and model quantization techniques represented by GPTQ and AWQ are of paramount significance. However, although these techniques have been widely adopted in single-task scenarios, research is scarce in multi-task scenarios. To be specific, we find that mainstream quantization methods would prevent the base LLM from being shared among tasks, so current LLM serving systems are infeasible to integrate LLM quantization with multiple LoRA adapters to achieve memory-efficient multi-task serving. Moreover, existing LLM serving systems lack support for dynamic task addition and overlook the workload differences among tasks, leading to inefficiencies in multi-task scenarios.
This work proposes LoRA-Inlaid, an efficient multi-task LLM serving system. On the one hand, LoRA-Inlaid designs a flexible and efficient multi-task quantization algorithm (MLGPTQ) that facilitates the sharing of a single quantized model for multiple LoRA adapters, which significantly reduces the memory consumption for model deployment. Meanwhile, it supports adding LoRA adapters for new tasks on the fly, without sacrificing the stability of online services. On the other hand, LoRA-Inlaid develops a novel multi-task scheduling algorithm guided by output length prediction and grouping among different tasks, which effectively shrinks the memory consumption and avoids frequent switching of LoRA adapters. Empirical results verify that LoRA-Inlaid outperforms existing state-of-the-art LLM serving systems by up to 1.58 times in terms of throughput, 1.76 times in terms of average latency, 2 times in terms of job completion time, and 10 times in terms of SLO Attainment, while maintaining the same level of model quality.
tl;dr: We find an implicit curriculum in Procgen and introduce C-Procgen for controlled context learning research.

Procedurally generated environments such as Procgen Benchmark provide a testbed for evaluating the agent's ability to robustly learn a relevant skill, by situating the agent in ever-changing levels. The diverse levels associated with varying contexts are naturally connected to curriculum learning. Existing works mainly focus on arranging the levels to explicitly form a curriculum. In this work, we take a close look at the learning process itself under the multi-level training in Procgen. Interestingly, the learning process exhibits a gradual shift from easy contexts to hard contexts, suggesting an implicit curriculum in multi-level training. Our analysis is made possible through C-Procgen, a benchmark we build upon Procgen that enables explicit control of the contexts. We believe our findings will foster a deeper understanding of learning in diverse contexts, and our benchmark will benefit future research in curriculum reinforcement learning.
tl;dr: We study the problem of initializing multiple services for a provider catering to a user base with diverse preferences, developing algorithms with approximation ratio guarantees on average and worst case losses.

This paper investigates ML systems serving a group of users, with multiple models/services, each aimed at specializing to a sub-group of users. We consider settings where upon deploying a set of services, users choose the one minimizing their personal losses and the learner iteratively learns by interacting with diverse users. Prior research shows that the outcomes of learning dynamics, which comprise both the services' adjustments and users' service selections, hinge significantly on the initial conditions. However, finding good initial conditions faces two main challenges: (i) \emph{Bandit feedback:} Typically, data on user preferences are not available before deploying services
and observing user behavior; (ii) \emph{Suboptimal local solutions:} The total loss landscape (i.e., the sum of loss functions across all users and services) is not convex and gradient-based algorithms can get stuck in poor local minima.
We address these challenges with a randomized algorithm to adaptively select a minimal set of users for data collection in order to initialize a set of services. Under mild assumptions on the loss functions, we prove that our initialization leads to a total loss within a factor of the \textit{globally optimal total loss,with complete user preference data}, and this factor scales logarithmically in the number of services. This result is a generalization of the well-known $k$-means++ guarantee to a broad problem class which is also of independent interest.
The theory is complemented by experiments on real as well as semi-synthetic datasets.
tl;dr: We propose a new training-free and transferred-friendly text-to-image generation framework to enhance the realism and compositionality of the generated images.

Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose ***RealCompo***, a new *training-free* and *transferred-friendly* text-to-image generation framework, which aims to leverage the respective advantages of text-to-image models and spatial-aware image diffusion models (e.g., layout, keypoints and segmentation maps) to enhance both realism and compositionality of the generated images. An intuitive and novel *balancer* is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and spatial-aware image diffusion models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Notably, our RealCompo can be seamlessly extended with a wide range of spatial-aware image diffusion models and stylized diffusion models. Code is available at: https://github.com/YangLing0818/RealCompo
tl;dr: We show that L2-accurate score estimation, in the absence of strong assumptions on the data distribution, is cryptographically hard.

We show that L2-accurate score estimation, in the absence of strong assumptions on the data distribution, is computationally hard even when sample complexity is polynomial in the relevant problem parameters. Our reduction builds on the result of Chen et al. (ICLR 2023), who showed that the problem of generating samples from an unknown data distribution reduces to L2-accurate score estimation. Our hard-to-estimate distributions are the "Gaussian pancakes" distributions, originally due to Diakonikolas et al. (FOCS 2017), which have been shown to be computationally indistinguishable from the standard Gaussian under widely believed hardness assumptions from lattice-based cryptography (Bruna et al., STOC 2021; Gupte et al., FOCS 2022).
tl;dr: We develop active learning methods to guide two-photon photostimulation for the purpose of reducing the amount of data needed to estimate an accurate mode of the neural population dynamics.

Recent advances in techniques for monitoring and perturbing neural populations have greatly enhanced our ability to study circuits in the brain. In particular, two-photon holographic optogenetics now enables precise photostimulation of experimenter-specified groups of individual neurons, while simultaneous two-photon calcium imaging enables the measurement of ongoing and induced activity across the neural population. Despite the enormous space of potential photostimulation patterns and the time-consuming nature of photostimulation experiments, very little algorithmic work has been done to determine the most effective photostimulation patterns for identifying the neural population dynamics. Here, we develop methods to efficiently select which neurons to stimulate such that the resulting neural responses will best inform a dynamical model of the neural population activity. Using neural population responses to photostimulation in mouse motor cortex, we demonstrate the efficacy of a low-rank linear dynamical systems model, and develop an active learning procedure which takes advantage of low-rank structure to determine informative photostimulation patterns. We demonstrate our approach on both real and synthetic data, obtaining in some cases as much as a two-fold reduction in the amount of data required to reach a given predictive power. Our active stimulation design method is based on a novel active learning procedure for low-rank regression, which may be of independent interest.

We propose a new framework for formulating optimal transport distances between Markov chains. Previously known formulations studied couplings between the entire joint distribution induced by the chains, and derived solutions via a reduction to dynamic programming (DP) in an appropriately defined Markov decision process. This formulation has, however, not led to particularly efficient algorithms so far, since computing the associated DP operators requires fully solving a static optimal transport problem, and these operators need to be applied numerous times during the overall optimization process. In this work, we develop an alternative perspective by considering couplings between a ``flattened'' version of the joint distributions that we call discounted occupancy couplings, and show that calculating optimal transport distances in the full space of joint distributions can be equivalently formulated as solving a linear program (LP) in this reduced space. This LP formulation formulation allows us to port several algorithmic ideas from other areas of optimal transport theory. In particular, our formulation makes it possible to introduce an appropriate notion of entropy regularization into the optimization problem, which in turn enables us to directly calculate optimal transport distances via a Sinkhorn-like method we call Sinkhorn Value Iteration (SVI). We show both theoretically and empirically that this method converges quickly to an optimal coupling, essentially at the same computational cost of running vanilla Sinkhorn in each pair of states. Along the way, we point out that our optimal transport distance exactly matches the common notion of bisimulation metrics between Markov chains, and thus our results also apply to computing such metrics, and in fact our algorithm turns out to be significantly more efficient than the best known methods developed so far for this purpose.

Safety of Large Language Models (LLMs) has become a central issue given their rapid progress and wide applications. Greedy Coordinate Gradient (GCG) is shown to be effective in constructing prompts containing adversarial suffixes to break the presumingly safe LLMs, but the optimization of GCG is time-consuming and limits its practicality. To reduce the time cost of GCG and enable more comprehensive studies of LLM safety, in this work, we study a new algorithm called $\texttt{Probe sampling}$ to accelerate the GCG algorithm. At the core of the algorithm is a mechanism that dynamically determines how similar a smaller draft model's predictions are to the target model's predictions for prompt candidates. When the target model is similar to the draft model, we rely heavily on the draft model to filter out a large number of potential prompt candidates to reduce the computation time. Probe sampling achieves up to $5.6$ times speedup using Llama2-7b-chat and leads to equal or improved attack success rate (ASR) on the AdvBench. Furthermore, probe sampling is also able to accelerate other prompt optimization techniques and adversarial attack methods, leading to acceleration of $1.8\times$ for AutoPrompt, $2.4\times$ for APE and $2.4\times$ for AutoDAN.
tl;dr: We perform a non-asymptotic analysis of federated LSA, study the impcaft of heterogeneity, and propose a method that mitigates this impact by using control variates while preserving the linear speed-up. We apply the results to federated TD.

In this paper, we analyze the sample and communication complexity of the federated linear stochastic approximation (FedLSA) algorithm. We explicitly quantify the effects of local training with agent heterogeneity. We show that the communication complexity of FedLSA scales polynomially with the inverse of the desired accuracy ϵ. To overcome this, we propose SCAFFLSA a new variant of FedLSA that uses control variates to correct for client drift, and establish its sample and communication complexities. We show that for statistically heterogeneous agents, its communication complexity scales logarithmically with the desired accuracy, similar to Scaffnew. An important finding is that, compared to the existing results for Scaffnew, the sample complexity scales with the inverse of the number of agents, a property referred to as linear speed-up. Achieving this linear speed-up requires completely new theoretical arguments. We apply the proposed method to federated temporal difference learning with linear function approximation and analyze the corresponding complexity improvements.
967. Leveraging Contrastive Learning for Enhanced Node Representations in Tokenized Graph Transformers
tl;dr: This paper enhances node classification in graph Transformers by leveraging contrastive learning and a hybrid token generator to capture diverse graph information.

While tokenized graph Transformers have demonstrated strong performance in node classification tasks, their reliance on a limited subset of nodes with high similarity scores for constructing token sequences overlooks valuable information from other nodes, hindering their ability to fully harness graph information for learning optimal node representations. To address this limitation, we propose a novel graph Transformer called GCFormer. Unlike previous approaches, GCFormer develops a hybrid token generator to create two types of token sequences, positive and negative, to capture diverse graph information. And a tailored Transformer-based backbone is adopted to learn meaningful node representations from these generated token sequences. Additionally, GCFormer introduces contrastive learning to extract valuable information from both positive and negative token sequences, enhancing the quality of learned node representations. Extensive experimental results across various datasets, including homophily and heterophily graphs, demonstrate the superiority of GCFormer in node classification, when compared to representative graph neural networks (GNNs) and graph Transformers.
tl;dr: This paper studies how the structure of causal dependencies among system variables dictate the statistical complexity of RL.

In sequential decision-making problems, the *information structure* describes the causal dependencies between system variables, encompassing the dynamics of the environment and the agents' actions. Classical models of reinforcement learning (e.g., MDPs, POMDPs) assume a restricted and highly regular information structure, while more general models like predictive state representations do not explicitly model the information structure. By contrast, real-world sequential decision-making problems typically involve a complex and time-varying interdependence of system variables, requiring a rich and flexible representation of information structure. In this paper, we formalize a novel reinforcement learning model which explicitly represents the information structure.
We then use this model to carry out an information-structural analysis of the statistical complexity of general sequential decision-making problems, obtaining a characterization via a graph-theoretic quantity of the DAG representation of the information structure. We prove an upper bound on the sample complexity of learning a general sequential decision-making problem in terms of its information structure by exhibiting an algorithm achieving the upper bound. This recovers known tractability results and gives a novel perspective on reinforcement learning in general sequential decision-making problems, providing a systematic way of identifying new tractable classes of problems.
tl;dr: We develop a novel scalable multi-agent constrained policy optimization method and prove that the safety constraints and the joint policy improvement can be met when each agent adopts a sequential update scheme to optimize a $\kappa$-hop policy.

A challenging problem in seeking to bring multi-agent reinforcement learning (MARL) techniques into real-world applications, such as autonomous driving and drone swarms, is how to control multiple agents safely and cooperatively to accomplish tasks. Most existing safe MARL methods learn the centralized value function by introducing a global state to guide safety cooperation. However, the global coupling arising from agents’ safety constraints and the exponential growth of the state-action space size limit their applicability in instant communication or computing resource-constrained systems and larger multi-agent systems. In this paper, we develop a novel scalable and theoretically-justified multi-agent constrained policy optimization method. This method utilizes the rigorous bounds of the trust region method and the bounds of the truncated advantage function to provide a new local policy optimization objective for each agent. Also, we prove that the safety constraints and the joint policy improvement can be met when each agent adopts a sequential update scheme to optimize a $\kappa$-hop policy. Then, we propose a practical algorithm called Scalable MAPPO-Lagrangian (Scal-MAPPO-L). The proposed method’s effectiveness is verified on a collection of benchmark tasks, and the results support our theory that decentralized training with local interactions can still improve reward performance and satisfy safe constraints.
tl;dr: We present the Set-Based Prompting method which *guarantees* any LLM's outputs will be unaffected by reordering.

The development of generative language models that can create long and coherent textual outputs via autoregression has lead to a proliferation of uses and a corresponding sweep of analyses as researches work to determine the limitations of this new paradigm. Unlike humans, these '*Large Language Models*' (LLMs) are highly sensitive to small changes in their inputs, leading to unwanted inconsistency in their behavior. One problematic inconsistency when LLMs are used to answer multiple-choice questions or analyze multiple inputs is *order dependency*: the output of an LLM can (and often does) change significantly when sub-sequences are swapped, despite both orderings being semantically identical. In this paper we present , a technique that *guarantees* the output of an LLM will not have order dependence on a specified set of sub-sequences. We show that this method *provably* eliminates order dependency, and that it can be applied to *any* transformer-based LLM to enable text generation that is unaffected by re-orderings. Delving into the implications of our method, we show that, despite our inputs being out of distribution, the impact on expected accuracy is small, where the expectation is over the order of uniformly chosen shuffling of the candidate responses, and usually significantly less in practice. Thus, can be used as a '*dropped-in*' method on fully trained models. Finally, we discuss how our method's success suggests that other strong guarantees can be obtained on LLM performance via modifying the input representations.
Code is available at [github.com/reidmcy/set-based-prompting](https://github.com/reidmcy/set-based-prompting.).
tl;dr: An adversarial attack that targets the availability of efficient vision transformers

Vision transformers have shown remarkable advancements in the computer vision domain, demonstrating state-of-the-art performance in diverse tasks (e.g., image classification, object detection). However, their high computational requirements grow quadratically with the number of tokens used. Token sparsification mechanisms have been proposed to address this issue. These mechanisms employ an input-dependent strategy, in which uninformative tokens are discarded from the computation pipeline, improving the model’s efficiency. However, their dynamism and average-case assumption makes them vulnerable to a new threat vector – carefully crafted adversarial examples capable of fooling the sparsification mechanism, resulting in worst-case performance. In this paper, we present DeSparsify, an attack targeting the availability of vision transformers that use token sparsification mechanisms. The attack aims to exhaust the operating system’s resources, while maintaining its stealthiness. Our evaluation demonstrates the attack’s effectiveness on three token sparsification mechanisms and examines the attack’s transferability between them and its effect on the GPU resources. To mitigate the impact of the attack, we propose various countermeasures.

We address the problem of performing regression while ensuring demographic parity, even without access to sensitive attributes during inference. We present a general-purpose post-processing algorithm that, using accurate estimates of the regression function and a sensitive attribute predictor, generates predictions that meet the demographic parity constraint. Our method involves discretization and stochastic minimization of a smooth convex function. It is suitable for online post-processing and multi-class classification tasks only involving unlabeled data for the post-processing. Unlike prior methods, our approach is fully theory-driven. We require precise control over the gradient norm of the convex function, and thus, we rely on more advanced techniques than standard stochastic gradient descent. Our algorithm is backed by finite-sample analysis and post-processing bounds, with experimental results validating our theoretical findings.
tl;dr: We show that the improvement in performance achieved by a strong model supervised by a weak model is quantified by the misfit error incurred by the strong model on labels generated by the weak model.

Recent advances in large language models have shown capabilities that are extraordinary and near-superhuman. These models operate with such complexity that reliably evaluating and aligning them proves challenging for humans. This leads to the natural question: can guidance from weak models (like humans) adequately direct the capabilities of strong models? In a recent and somewhat surprising work, Burns et al. (2023) empirically demonstrated that when strong models (like GPT-4) are finetuned using labels generated by weak supervisors (like GPT-2), the strong models outperform their weaker counterparts---a phenomenon they term *weak-to-strong generalization*.
In this work, we present a theoretical framework for understanding weak-to-strong generalization. Specifically, we show that the improvement in performance achieved by strong models over their weaker counterparts is quantified by the *misfit error* incurred by the strong model on labels generated by the weaker model. Our theory reveals several curious algorithmic insights. For instance, we can predict the amount by which the strong model will improve over the weak model, and also choose among different weak models to train the strong model, based on its misfit error. We validate our theoretical findings through various empirical assessments.
tl;dr: Designing exploration strategy for multiple General Value Function (GVF) evaluations

General Value Functions (GVFs) (Sutton et al., 2011) represent predictive knowledge in reinforcement learning. Each GVF computes the expected return for a given policy, based on a unique reward. Existing methods relying on fixed behavior policies or pre-collected data often face data efficiency issues when learning multiple GVFs in parallel using off-policy methods. To address this, we introduce *GVFExplorer*, which adaptively learns a single behavior policy that efficiently collects data for evaluating multiple GVFs in parallel. Our method optimizes the behavior policy by minimizing the total variance in return across GVFs, thereby reducing the required environmental interactions. We use an existing temporal-difference-style variance estimator to approximate the return variance. We prove that each behavior policy update decreases the overall mean squared error in GVF predictions. We empirically show our method's performance in tabular and nonlinear function approximation settings, including Mujoco environments, with stationary and non-stationary reward signals, optimizing data usage and reducing prediction errors across multiple GVFs.
tl;dr: Inspired by central-peripheral dichotomy, we developed a tracker that emulates human visual search abilities, validated by its high accuracy and error consistency.

Human visual search ability enables efficient and accurate tracking of an arbitrary moving target, which is a significant research interest in cognitive neuroscience. The recently proposed Central-Peripheral Dichotomy (CPD) theory sheds light on how humans effectively process visual information and track moving targets in complex environments. However, existing visual object tracking algorithms still fall short of matching human performance in maintaining tracking over time, particularly in complex scenarios requiring robust visual search skills. These scenarios often involve Spatio-Temporal Discontinuities (i.e., STDChallenge), prevalent in long-term tracking and global instance tracking. To address this issue, we conduct research from a human-like modeling perspective: (1) Inspired by the CPD, we pro- pose a new tracker named CPDTrack to achieve human-like visual search ability. The central vision of CPDTrack leverages the spatio-temporal continuity of videos to introduce priors and enhance localization precision, while the peripheral vision improves global awareness and detects object movements. (2) To further evaluate and analyze STDChallenge, we create the STDChallenge Benchmark. Besides, by incorporating human subjects, we establish a human baseline, creating a high- quality environment specifically designed to assess trackers’ visual search abilities in videos across STDChallenge. (3) Our extensive experiments demonstrate that the proposed CPDTrack not only achieves state-of-the-art (SOTA) performance in this challenge but also narrows the behavioral differences with humans. Additionally, CPDTrack exhibits strong generalizability across various challenging benchmarks. In summary, our research underscores the importance of human-like modeling and offers strategic insights for advancing intelligent visual target tracking. Code and models are available at https://github.com/ZhangDailing8/CPDTrack.
tl;dr: Investigating the dataset contamination caused by synthetic data in Online Continual Learning, and proposing a method to alleviate the performance degradation with entropy selection and real-synthetic similarity maximization.

Image generation has shown remarkable results in generating high-fidelity realistic images, in particular with the advancement of diffusion-based models. However, the prevalence of AI-generated images may have side effects for the machine learning community that are not clearly identified. Meanwhile, the success of deep learning in computer vision is driven by the massive dataset collected on the Internet. The extensive quantity of synthetic data being added to the Internet would become an obstacle for future researchers to collect "clean" datasets without AI-generated content. Prior research has shown that using datasets contaminated by synthetic images may result in performance degradation when used for training. In this paper, we investigate the potential impact of contaminated datasets on Online Continual Learning (CL) research. We experimentally show that contaminated datasets might hinder the training of existing online CL methods. Also, we propose Entropy Selection with Real-synthetic similarity Maximization (ESRM), a method to alleviate the performance deterioration caused by synthetic images when training online CL models. Experiments show that our method can significantly alleviate performance deterioration, especially when the contamination is severe. For reproducibility, the source code of our work is available at https://github.com/maorong-wang/ESRM.

Pansharpening is a significant image fusion technique that merges the spatial content and spectral characteristics of remote sensing images to generate high-resolution multispectral images. Recently, denoising diffusion probabilistic models have been gradually applied to visual tasks, enhancing controllable image generation through low-rank adaptation (LoRA). In this paper, we introduce a spatial-spectral integrated diffusion model for the remote sensing pansharpening task, called SSDiff, which considers the pansharpening process as the fusion process of spatial and spectral components from the perspective of subspace decomposition. Specifically, SSDiff utilizes spatial and spectral branches to learn spatial details and spectral features separately, then employs a designed alternating projection fusion module (APFM) to accomplish the fusion. Furthermore, we propose a frequency modulation inter-branch module (FMIM) to modulate the frequency distribution between branches. The two components of SSDiff can perform favorably against the APFM when utilizing a LoRA-like branch-wise alternative fine-tuning method. It refines SSDiff to capture component-discriminating features more sufficiently. Finally, extensive experiments on four commonly used datasets, i.e., WorldView-3, WorldView-2, GaoFen-2, and QuickBird, demonstrate the superiority of SSDiff both visually and quantitatively. The code is available at https://github.com/Z-ypnos/SSdiff_main.
tl;dr: We show reinforcement learning controllers produce chaotic states and reward trajectories in continuous control environments. To mitigate this we propose a regularisation method which minimises chaos and improves the robustness of Dreamer V3.

Deep reinforcement learning agents achieve state-of-the-art performance in a wide range of simulated control tasks. However, successful applications to real-world problems remain limited. One reason for this dichotomy is because the learnt policies are not robust to observation noise or adversarial attacks. In this paper, we investigate the robustness of deep RL policies to a single small state perturbation in deterministic continuous control tasks. We demonstrate that RL policies can be deterministically chaotic, as small perturbations to the system state have a large impact on subsequent state and reward trajectories. This unstable non-linear behaviour has two consequences: first, inaccuracies in sensor readings, or adversarial attacks, can cause significant performance degradation; second, even policies that show robust performance in terms of rewards may have unpredictable behaviour in practice. These two facets of chaos in RL policies drastically restrict the application of deep RL to real-world problems. To address this issue, we propose an improvement on the successful Dreamer V3 architecture, implementing Maximal Lyapunov Exponent regularisation. This new approach reduces the chaotic state dynamics, rendering the learnt policies more resilient to sensor noise or adversarial attacks and thereby improving the suitability of deep reinforcement learning for real-world applications.
tl;dr: We introduce Hierarchical Distance Structural Encoding (HDSE), a method that enhances graph transformers on both graph-level tasks and large-scale node classification.

Graph transformers need strong inductive biases to derive meaningful attention scores. Yet, current methods often fall short in capturing longer ranges, hierarchical structures, or community structures, which are common in various graphs such as molecules, social networks, and citation networks. This paper presents a Hierarchical Distance Structural Encoding (HDSE) method to model node distances in a graph, focusing on its multi-level, hierarchical nature. We introduce a novel framework to seamlessly integrate HDSE into the attention mechanism of existing graph transformers, allowing for simultaneous application with other positional encodings. To apply graph transformers with HDSE to large-scale graphs, we further propose a high-level HDSE that effectively biases the linear transformers towards graph hierarchies. We theoretically prove the superiority of HDSE in terms of expressivity and generalization. Empirically, we demonstrate that graph transformers with HDSE excel in graph classification, regression on 7 graph-level datasets, and node classification on 11 large-scale graphs.

Efficiently solving unseen tasks remains a challenge in reinforcement learning (RL), especially for long-horizon tasks composed of multiple subtasks.
Pre-training policies from task-agnostic datasets has emerged as a promising approach, yet existing methods still necessitate substantial interactions via RL to learn new tasks.
We introduce MGPO, a method that leverages the power of Transformer-based policies to model sequences of goals, enabling efficient online adaptation through prompt optimization.
In its pre-training phase, MGPO utilizes hindsight multi-goal relabeling and behavior cloning. This combination equips the policy to model diverse long-horizon behaviors that align with varying goal sequences.
During online adaptation, the goal sequence, conceptualized as a prompt, is optimized to improve task performance. We adopt a multi-armed bandit framework for this process, enhancing prompt selection based on the returns from online trajectories.
Our experiments across various environments demonstrate that MGPO holds substantial advantages in sample efficiency, online adaptation performance, robustness, and interpretability compared with existing methods.
tl;dr: In this work we introduce Inflationary Flows, a class of highly expressive generative models that allows us to map complex data distributions to uniquely defined and lower-dimensional latent spaces while also affording principled Bayesian inference.

Beyond estimating parameters of interest from data, one of the key goals of statistical inference is to properly quantify uncertainty in these estimates. In Bayesian inference, this uncertainty is provided by the posterior distribution, the computation of which typically involves an intractable high-dimensional integral. Among available approximation methods, sampling-based approaches come with strong theoretical guarantees but scale poorly to large problems, while variational approaches scale well but offer few theoretical guarantees. In particular, variational methods are known to produce overconfident estimates of posterior uncertainty and are typically non-identifiable, with many latent variable configurations generating equivalent predictions. Here, we address these challenges by showing how diffusion-based models (DBMs), which have recently produced state-of-the-art performance in generative modeling tasks, can be repurposed for performing calibrated, identifiable Bayesian inference. By exploiting a previously established connection between the stochastic and probability flow ordinary differential equations (pfODEs) underlying DBMs, we derive a class of models, \emph{inflationary flows,} that uniquely and deterministically map high-dimensional data to a lower-dimensional Gaussian distribution via ODE integration. This map is both invertible and neighborhood-preserving, with controllable numerical error, with the result that uncertainties in the data are correctly propagated to the latent space. We demonstrate how such maps can be learned via standard DBM training using a novel noise schedule and are effective at both preserving and reducing intrinsic data dimensionality. The result is a class of highly expressive generative models, uniquely defined on a low-dimensional latent space, that afford principled Bayesian inference.
tl;dr: We propose using self-supervised gradients to enhance pretrained embedding features and achieve significant improvements in k-nearest neighbor classification, in-context scene understanding, linear probing and clustering.

This paper introduces FUNGI, **F**eatures from **UN**supervised **G**rad**I**ents, a method to enhance the features of transformer encoders by leveraging self-supervised gradients. Our method is simple: given any pretrained model, we first compute gradients from various self-supervised objectives for each input. These gradients are projected to a lower dimension and then concatenated with the model's output embedding. The resulting features are evaluated on k-nearest neighbor classification over 11 datasets from vision, 5 from natural language processing, and 2 from audio. Across backbones spanning various sizes and pretraining strategies, FUNGI features provide consistent performance improvements over the embeddings. We also show that using FUNGI features can benefit linear classification, clustering and image retrieval, and that they significantly improve the retrieval-based in-context scene understanding abilities of pretrained models, for example improving upon DINO by +17% for semantic segmentation - without any training. Code is available at https://github.com/WalterSimoncini/fungivision.
tl;dr: We validate the Gaussian Equivalent Property rigorously, and provide novel bounds for kernel ridge regression.

This paper conducts a comprehensive study of the learning curves of kernel ridge regression (KRR) under minimal assumptions.
Our contributions are three-fold: 1) we analyze the role of key properties of the kernel, such as its spectral eigen-decay, the characteristics of the eigenfunctions, and the smoothness of the kernel; 2) we demonstrate the validity of the Gaussian Equivalent Property (GEP), which states that the generalization performance of KRR remains the same when the whitened features are replaced by standard Gaussian vectors, thereby shedding light on the success of previous analyzes under the Gaussian Design Assumption; 3) we derive novel bounds that improve over existing bounds across a broad range of setting such as (in)dependent feature vectors and various combinations of eigen-decay rates in the over/underparameterized regimes.

Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($\texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query.
To verify $\texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($\texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $\texttt{PLND}$, we validate $\texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures.
Moreover, $\texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6\%$ for high-resource languages and $2.3\%$ for low-resource languages across all tasks with just $400$ documents.
tl;dr: This paper unifies anomaly segmentation into change segmentation and provides a pure visual foundation model, which requires only one normal image prompt and no additional training, and effectively and efficiently segments any visual anomalies.

Zero- and few-shot visual anomaly segmentation relies on powerful vision-language models that detect unseen anomalies using manually designed textual prompts. However, visual representations are inherently independent of language. In this paper, we explore the potential of a pure visual foundation model as an alternative to widely used vision-language models for universal visual anomaly segmentation.
We present a novel paradigm that unifies anomaly segmentation into change segmentation. This paradigm enables us to leverage large-scale synthetic image pairs, featuring object-level and local region changes, derived from existing image datasets, which are independent of target anomaly datasets. We propose a one-prompt Meta-learning framework for Universal Anomaly Segmentation (MetaUAS) that is trained on this synthetic dataset and then generalizes well to segment any novel or unseen visual anomalies in the real world. To handle geometrical variations between prompt and query images, we propose a soft feature alignment module that bridges paired-image change perception and single-image semantic segmentation. This is the first work to achieve universal anomaly segmentation using a pure vision model without relying on special anomaly detection datasets and pre-trained visual-language models. Our method effectively and efficiently segments any anomalies with only one normal image prompt and enjoys training-free without guidance from language. Our MetaUAS significantly outperforms previous zero-shot, few-shot, and even full-shot anomaly segmentation methods. Code and Models: https://github.com/gaobb/MetaUAS.
tl;dr: We propose Manifold Free-form Flows, the first generative model for data on arbitrary manifolds that sample in a single function evaluation at high quality.

We propose Manifold Free-Form Flows (M-FFF), a simple new generative model for data on manifolds. The existing approaches to learning a distribution on arbitrary manifolds are expensive at inference time, since sampling requires solving a differential equation. Our method overcomes this limitation by sampling in a single function evaluation. The key innovation is to optimize a neural network via maximum likelihood on the manifold, possible by adapting the free-form flow framework to Riemannian manifolds. M-FFF is straightforwardly adapted to any manifold with a known projection. It consistently matches or outperforms previous single-step methods specialized to specific manifolds. It is typically two orders of magnitude faster than multi-step methods based on diffusion or flow matching, achieving better likelihoods in several experiments. We provide our code at https://github.com/vislearn/FFF.

Unsupervised domain adaptation excels in transferring knowledge from a labeled source domain to an unlabeled target domain, playing a critical role in time series applications. Existing time series domain adaptation methods either ignore frequency features or treat temporal and frequency features equally, which makes it challenging to fully exploit the advantages of both types of features. In this paper, we delve into transferability and discriminability, two crucial properties in transferable representation learning. It's insightful to note that frequency features are more discriminative within a specific domain, while temporal features show better transferability across domains. Based on the findings, we propose **A**dversarial **CO**-learning **N**etworks (**ACON**), to enhance transferable representation learning through a collaborative learning manner in three aspects: (1) Considering the multi-periodicity in time series, multi-period frequency feature learning is proposed to enhance the discriminability of frequency features; (2) Temporal-frequency domain mutual learning is proposed to enhance the discriminability of temporal features in the source domain and improve the transferability of frequency features in the target domain; (3) Domain adversarial learning is conducted in the correlation subspaces of temporal-frequency features instead of original feature spaces to further enhance the transferability of both features. Extensive experiments conducted on a wide range of time series datasets and five common applications demonstrate the state-of-the-art performance of ACON. Code is available at <https://github.com/mingyangliu1024/ACON>.

While large language models (LLMs) such as Llama-2 or GPT-4 have shown impressive zero-shot performance, fine-tuning is still necessary to enhance their performance for customized datasets, domain-specific tasks, or other private needs. However, fine-tuning all parameters of LLMs requires significant hardware resources, which can be impractical for typical users. Therefore, parameter-efficient fine-tuning such as LoRA have emerged, allowing users to fine-tune LLMs without the need for considerable computing resources, with little performance degradation compared to fine-tuning all parameters. Unfortunately, recent studies indicate that fine-tuning can increase the risk to the safety of LLMs, even when data does not contain malicious content. To address this challenge, we propose $\textsf{Safe LoRA}$, a simple one-liner patch to the original LoRA implementation by introducing the projection of LoRA weights from selected layers to the safety-aligned subspace, effectively reducing the safety risks in LLM fine-tuning while maintaining utility. It is worth noting that $\textsf{Safe LoRA}$ is a training-free and data-free approach, as it only requires the knowledge of the weights from the base and aligned LLMs. Our extensive experiments demonstrate that when fine-tuning on purely malicious data, $\textsf{Safe LoRA}$ retains similar safety performance as the original aligned model. Moreover, when the fine-tuning dataset contains a mixture of both benign and malicious data, $\textsf{Safe LoRA}$ mitigates the negative effect made by malicious data while preserving performance on downstream tasks. Our codes are available at https://github.com/IBM/SafeLoRA.
tl;dr: First combinatorial algorithms for submodular maximization with ratio better than 1/e ≈ 0.367

For constrained, not necessarily monotone submodular maximization, all known approximation algorithms with ratio greater than $1/e$ require continuous ideas, such as queries to the multilinear extension of a submodular function and its gradient, which are typically expensive to simulate with the original set function. For combinatorial algorithms, the best known approximation ratios for both size and matroid constraint are obtained by a simple randomized greedy algorithm of Buchbinder et al. [9]: $1/e \approx 0.367$ for size constraint and $0.281$ for the matroid constraint in $\mathcal O (kn)$ queries, where $k$ is the rank of the matroid. In this work, we develop the first combinatorial algorithms to break the $1/e$ barrier: we obtain approximation ratio of $0.385$ in $\mathcal O (kn)$ queries to the submodular set function for size constraint, and $0.305$ for a general matroid constraint. These are achieved by guiding the randomized greedy algorithm with a fast local search algorithm. Further, we develop deterministic versions of these algorithms, maintaining the same ratio and asymptotic time complexity. Finally, we develop a deterministic, nearly linear time algorithm with ratio $0.377$.
tl;dr: Formulation of POCA and instantiation, a problem related to the efficient acquisition of features and/or labels under some acquisition constraints

Conducting experiments and gathering data for machine learning models is a complex and expensive endeavor, particularly when confronted with limited information. Typically, extensive _experiments_ to obtain features and labels come with a significant acquisition cost, making it impractical to carry out all of them. Therefore, it becomes crucial to strategically determine what to acquire to maximize the predictive performance while minimizing costs. To perform this task, existing data acquisition methods assume the availability of an initial dataset that is both fully-observed and labeled, crucially overlooking the **partial observability** of features characteristic of many real-world scenarios. In response to this challenge, we present Partially Observable Cost-Aware Active-Learning (POCA), a new learning approach aimed at improving model generalization in data-scarce and data-costly scenarios through label and/or feature acquisition. Introducing $\mu$POCA as an instantiation, we maximise the uncertainty reduction in the predictive model when obtaining labels and features, considering associated costs. $\mu$POCA enhance traditional Active Learning metrics based solely on the observed features by generating the unobserved features through Generative Surrogate Models, particularly Large Language Models (LLMs). We empirically validate $\mu$POCA across diverse tabular datasets, varying data availability, acquisition costs, and LLMs.
tl;dr: We show that high quality video can be created from extremely sparse 1-bit image sequence, the typical raw data of an emerging image sensor, using self-supervised learning.

Quanta image sensors, such as SPAD arrays, are an emerging sensor technology, producing 1-bit arrays representing photon detection events over exposures as short as a few nanoseconds. In practice, raw data are post-processed using heavy spatiotemporal binning to create more useful and interpretable images at the cost of degrading spatiotemporal resolution. In this work, we propose bit2bit, a new method for reconstructing high-quality image stacks at the original spatiotemporal resolution from sparse binary quanta image data. Inspired by recent work on Poisson denoising, we developed an algorithm that creates a dense image sequence from sparse binary photon data by predicting the photon arrival location probability distribution. However, due to the binary nature of the data, we show that the assumption of a Poisson distribution is inadequate. Instead, we model the process with a Bernoulli lattice process from the truncated Poisson. This leads to the proposal of a novel self-supervised solution based on a masked loss function. We evaluate our method using both simulated and real data. On simulated data from a conventional video, we achieve 34.35 mean PSNR with extremely photon-sparse binary input (<0.06 photons per pixel per frame). We also present a novel dataset containing a wide range of real SPAD high-speed videos under various challenging imaging conditions. The scenes cover strong/weak ambient light, strong motion, ultra-fast events, etc., which will be made available to the community, on which we demonstrate the promise of our approach. Both reconstruction quality and throughput substantially surpass the state-of-the-art methods (e.g., Quanta Burst Photography (QBP)). Our approach significantly enhances the visualization and usability of the data, enabling the application of existing analysis techniques.

Motion forecasting for agents in autonomous driving is highly challenging due to the numerous possibilities for each agent's next action and their complex interactions in space and time.
In real applications, motion forecasting takes place repeatedly and continuously as the self-driving car moves. However, existing forecasting methods typically process each driving scene within a certain range independently, totally ignoring the situational and contextual relationships between successive driving scenes. This significantly simplifies the forecasting task, making the solutions suboptimal and inefficient to use in practice. To address this fundamental limitation, we propose a novel motion forecasting framework for continuous driving, named RealMotion.
It comprises two integral streams both at the scene level:
(1) The scene context stream progressively accumulates historical scene information until the present moment, capturing temporal interactive relationships among scene elements.
(2) The agent trajectory stream optimizes current forecasting by sequentially relaying past predictions.
Besides, a data reorganization strategy is introduced to narrow the gap between existing benchmarks and real-world applications, consistent with our network. These approaches enable exploiting more broadly the situational and progressive insights of dynamic motion across space and time.
Extensive experiments on Argoverse series with different settings demonstrate that our RealMotion achieves state-of-the-art performance, along with the advantage of efficient real-world inference.
tl;dr: We present the first comprehensive analysis of leveraging visual foundation models for complex 3D scene understanding.

Complex 3D scene understanding has gained increasing attention, with scene encoding strategies built on top of visual foundation models playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present the first comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image, video, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluation yields key intriguing findings: Unsupervised image foundation models demonstrate superior overall performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, language-pretrained models show unexpected limitations in language-related tasks, and the mixture-of-vision-expert (MoVE) strategy leads to consistent performance improvement. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene understanding tasks.
994. Depth Anything V2

This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with sparse depth annotations to facilitate future research. Models are available at https://github.com/DepthAnything/Depth-Anything-V2.

Structured state-space models (SSMs) are gaining popularity as effective foundational architectures for sequential data, demonstrating outstanding performance across a diverse set of domains alongside desirable scalability properties. Recent developments show that if the linear recurrence powering SSMs allows for a selectivity mechanism leveraging multiplicative interactions between inputs and hidden states (e.g. Mamba, GLA, Hawk/Griffin, HGRN2), then the resulting architecture can surpass attention-powered foundation models trained on text in both accuracy and efficiency, at scales of billion parameters. In this paper, we give theoretical grounding to the selectivity mechanism, often linked to in-context learning, using tools from Rough Path Theory. We provide a framework for the theoretical analysis of generalized selective SSMs, fully characterizing their expressive power and identifying the gating mechanism as the crucial architectural choice. Our analysis provides a closed-form description of the expressive powers of modern SSMs, such as Mamba, quantifying theoretically the drastic improvement in performance from the previous generation of models, such as S4. Our theory not only motivates the success of modern selective state-space models, but also provides a solid framework to understand the expressive power of future SSM variants. In particular, it suggests cross-channel interactions could play a vital role in future improvements.
tl;dr: We achieve the tightest bounds/regret available in the literature thus far for hybrid RL in linear MDPs, without single-policy concentrability, that improve upon the offline-only and online-only minimax error/regret bounds.

Hybrid Reinforcement Learning (RL), where an agent learns from both an offline dataset and online explorations in an unknown environment, has garnered significant recent interest. A crucial question posed by Xie et al. (2022) is whether hybrid RL can improve upon the existing lower bounds established in purely offline and purely online RL without relying on the single-policy concentrability assumption.
While Li et al. (2023) provided an affirmative answer to this question in the tabular PAC RL case, the question remains unsettled for both the regret-minimizing RL case and the non-tabular case. In this work, building upon recent advancements in offline RL and reward-agnostic exploration, we develop computationally efficient algorithms for both PAC and regret-minimizing RL with linear function approximation, without requiring concentrability on the entire state-action space. We demonstrate that these algorithms achieve sharper error or regret bounds that are no worse than, and can improve on, the optimal sample complexity in offline RL (the first algorithm, for PAC RL) and online RL (the second algorithm, for regret-minimizing RL) in linear Markov decision processes (MDPs), regardless of the quality of the behavior policy. To our knowledge, this work establishes the tightest theoretical guarantees currently available for hybrid RL in linear MDPs.

We study causal representation learning, the task of recovering high-level latent variables and their causal relationships in the form of a causal graph from low-level observed data (such as text and images), assuming access to observations generated from multiple environments. Prior results on the identifiability of causal representations typically assume access to single-node interventions which is rather unrealistic in practice, since the latent variables are unknown in the first place. In this work, we consider the task of learning causal representation learning with data collected from general environments. We show that even when the causal model and the mixing function are both linear, there exists a surrounded-node ambiguity (SNA) [Varici et al. 2023] which is basically unavoidable in our setting. On the other hand, in the same linear case, we show that identification up to SNA is possible under mild conditions, and propose an algorithm, LiNGCReL which provably achieves such identifiability guarantee. We conduct extensive experiments on synthetic data and demonstrate the effectiveness of LiNGCReL in the finite-sample regime.

Neural ODEs (NODEs) are continuous-time neural networks (NNs) that can process data without the limitation of time intervals. They have advantages in learning and understanding the evolution of complex real dynamics. Many previous works have focused on NODEs in concise forms, while numerous physical systems taking straightforward forms in fact belong to their more complex quasi-classes, thus appealing to a class of general NODEs with high scalability and flexibility to model those systems. This however may result in intricate nonlinear properties. In this paper, we introduce ControlSynth Neural ODEs (CSODEs). We show that despite their highly nonlinear nature, convergence can be guaranteed via tractable linear inequalities. In the composition of CSODEs, we introduce an extra control term for learning the potential simultaneous capture of dynamics at different scales, which could be particularly useful for partial differential equation-formulated systems. Finally, we compare several representative NNs with CSODEs on important physical dynamics under the inductive biases of CSODEs, and illustrate that CSODEs have better learning and predictive abilities in these settings.

We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary segmentation tasks within a single model. Most previous 3D segmentation approaches are typically tailored to a specific task, limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing, thereby promoting comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance performance by leveraging inter-task connections. Specifically, we design knowledge distillation and contrastive learning methods to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. Code and models are available at \url{https://dk-liang.github.io/UniSeg3D/}.

Simulating large scenes with many rigid objects is crucial for a variety of applications, such as robotics, engineering, film and video games. Rigid interactions are notoriously hard to model: small changes to the initial state or the simulation parameters can lead to large changes in the final state. Recently, learned simulators based on graph networks (GNNs) were developed as an alternative to hand-designed simulators like MuJoCo and Bullet. They are able to accurately capture dynamics of real objects directly from real-world observations. However, current state-of-the-art learned simulators operate on meshes and scale poorly to scenes with many objects or detailed shapes. Here we present SDF-Sim, the first learned rigid-body simulator designed for scale. We use learned signed-distance functions (SDFs) to represent the object shapes and to speed up distance computation. We design the simulator to leverage SDFs and avoid the fundamental bottleneck of the previous simulators associated with collision detection.
For the first time in literature, we demonstrate that we can scale the GNN-based simulators to scenes with hundreds of objects and up to 1.1 million nodes, where mesh-based approaches run out of memory. Finally, we show that SDF-Sim can be applied to real world scenes by extracting SDFs from multi-view images.
tl;dr: We study the statistical and computational limits of Diffusion Transformers (DiTs).

We investigate the statistical and computational limits of latent **Di**ffusion **T**ransformers (**DiTs**) under the low-dimensional linear latent space assumption. Statistically, we study the universal approximation and sample complexity of the DiTs score function, as well as the distribution recovery property of the initial data. Specifically, under mild data assumptions, we derive an approximation error bound for the score network of latent DiTs, which is sub-linear in the latent space dimension. Additionally, we derive the corresponding sample complexity bound and show that the data distribution generated from the estimated score function converges toward a proximate area of the original one.
Computationally, we characterize the hardness of both forward inference and backward computation of latent DiTs, assuming the Strong Exponential Time Hypothesis (SETH). For forward inference, we identify efficient criteria for all possible latent DiTs inference algorithms and showcase our theory by pushing the efficiency toward almost-linear time inference. For backward computation, we leverage the low-rank structure within the gradient computation of DiTs training for possible algorithmic speedup. Specifically, we show that such speedup achieves almost-linear time latent DiTs training by casting the DiTs gradient as a series of chained low-rank approximations with bounded error.
Under the low-dimensional assumption, we show that the statistical rates and the computational efficiency are all dominated by the dimension of the subspace, suggesting that latent DiTs have the potential to bypass the challenges associated with the high dimensionality of initial data.
tl;dr: Efficient technique for provably editing the DNN parameters such that the DNN satisfies a given property for all inputs in a given polytope.

Ensuring that a DNN satisfies a desired property is critical when deploying DNNs
in safety-critical applications. There are efficient methods that can verify
whether a DNN satisfies a property, as seen in the annual DNN verification
competition (VNN-COMP). However, the problem of provably editing a DNN to
satisfy a property remains challenging. We present PREPARED, the first efficient
technique for provable editing of DNNs. Given a DNN $\mathcal{N}$
with parameters $\theta$, input polytope $P$, and output
polytope $Q$, PREPARED finds new parameters $\theta'$ such that $\forall
\mathrm{x} \in P
. \mathcal{N}(\mathrm{x}; \theta') \in Q$
while minimizing the changes $\lVert{\theta' - \theta}\rVert$.
Given a DNN and a property it violates from the VNN-COMP benchmarks,
PREPARED is able to provably edit the DNN to satisfy this property within
45 seconds.
PREPARED is efficient
because it relaxes the NP-hard provable editing problem to solving a linear
program. The key contribution is the novel notion of Parametric Linear Relaxation,
which enables PREPARED to construct tight output bounds of the DNN that are parameterized
by the new parameters $\theta'$. We demonstrate that PREPARED is more efficient and
effective compared to prior DNN editing approaches i) using the VNN-COMP
benchmarks, ii) by editing CIFAR10 and TinyImageNet image-recognition DNNs, and
BERT sentiment-classification DNNs for local robustness, and iii) by training a
DNN to model a geodynamics process and satisfy physics constraints.

In recent years, significant progress has been made in multi-objective reinforcement learning (RL) research, which aims to balance multiple objectives by incorporating preferences for each objective. In most existing studies, specific preferences must be provided during deployment to indicate the desired policies explicitly. However, designing these preferences depends heavily on human prior knowledge, which is typically obtained through extensive observation of high-performing demonstrations with expected behaviors. In this work, we propose a simple yet effective offline adaptation framework for multi-objective RL problems without assuming handcrafted target preferences, but only given several demonstrations to implicitly indicate the preferences of expected policies. Additionally, we demonstrate that our framework can naturally be extended to meet constraints on safety-critical objectives by utilizing safe demonstrations, even when the safety thresholds are unknown. Empirical results on offline multi-objective and safe tasks demonstrate the capability of our framework to infer policies that align with real preferences while meeting the constraints implied by the provided demonstrations.
tl;dr: We introduce DUSA, an effective method with improved efficiency for test-time adaptation that exploits structured semantic priors from pre-trained score-based diffusion models for enhancing pre-trained discriminative models.

Capitalizing on the complementary advantages of generative and discriminative models has always been a compelling vision in machine learning, backed by a growing body of research. This work discloses the hidden semantic structure within score-based generative models, unveiling their potential as effective discriminative priors. Inspired by our theoretical findings, we propose DUSA to exploit the structured semantic priors underlying diffusion score to facilitate the test-time adaptation of image classifiers or dense predictors. Notably, DUSA extracts knowledge from a single timestep of denoising diffusion, lifting the curse of Monte Carlo-based likelihood estimation over timesteps. We demonstrate the efficacy of our DUSA in adapting a wide variety of competitive pre-trained discriminative models on diverse test-time scenarios. Additionally, a thorough ablation study is conducted to dissect the pivotal elements in DUSA. Code is publicly available at https://github.com/BIT-DA/DUSA.
tl;dr: We theoretically prove that a two-layer transformer model learns to perform "induction head" after training on n-gram Markovian data

In-context learning (ICL) is a cornerstone of large language model (LLM) functionality, yet its theoretical foundations remain elusive due to the complexity of transformer architectures. In particular, most existing work only theoretically explains how the attention mechanism facilitates ICL under certain data models. It remains unclear how the other building blocks of the transformer contribute to ICL. To address this question, we study how a two-attention-layer transformer is trained to perform ICL on $n$-gram Markov chain data, where each token in the Markov chain statistically depends on the previous n tokens.
We analyze a sophisticated transformer model featuring relative positional embedding, multi-head softmax attention, and a feed-forward layer with normalization.
We prove that the gradient flow with respect to a cross-entropy ICL loss converges to a limiting model that performs a generalized version of the "induction head" mechanism with a learned feature, resulting from the congruous contribution of all the building blocks.
Specifically, the first attention layer acts as a copier, copying past tokens within a given window to each position, and the feed-forward network with normalization acts as a selector that generates a feature vector by only looking at informationally relevant parents from the window.
Finally, the second attention layer is a classifier that
compares these features with the feature at the output position, and uses the resulting similarity scores to generate the desired output. Our theory is further validated by simulation experiments.
tl;dr: Analyses the propagation of biases in presence of blackbox feature extractors and suggests a simple migitation strategy for image classification

In image classification, it is common to utilize a pretrained model to extract meaningful features of the input images, and then to train a classifier on top of it to make predictions for any downstream task. Trained on enormous amounts of data, these models have been shown to contain harmful biases which can hurt their performance when adapted for a downstream classification task. Further, very often they may be blackbox, either due to scale, or because of unavailability of model weights or architecture. Thus, during a downstream task, we cannot debias such models by updating the weights of the feature encoder, as only the classifier can be finetuned. In this regard, we investigate the suitability of some existing debiasing techniques and thereby motivate the need for more focused research towards this problem setting. Furthermore, we propose a simple method consisting of a clustering-based adaptive margin loss with a blackbox feature encoder, with no knowledge of the bias attribute. Our experiments demonstrate the effectiveness of our method across multiple benchmarks.
tl;dr: We propose a novel VLA models, OmniJARIVS, by jointly modeling vision, language and action in multimodal interaction data.

This paper presents OmniJARVIS, a novel Vision-Language-Action (VLA) model for open-world instruction-following agents in Minecraft. Compared to prior works that either emit textual goals to separate controllers or produce the control command directly, OmniJARVIS seeks a different path to ensure both strong reasoning and efficient decision-making capabilities via unified tokenization of multimodal interaction data. First, we introduce a self-supervised approach to learn a behavior encoder that produces discretized tokens for behavior trajectories $\tau = \{o_0, a_0, \dots\}$ and an imitation learning policy decoder conditioned on these tokens. These additional behavior tokens will be augmented to the vocabulary of pretrained Multimodal Language Models. With this encoder, we then pack long-term multimodal interactions involving task instructions, memories, thoughts, observations, textual responses, behavior trajectories, etc into unified token sequences and model them with autoregressive transformers. Thanks to the semantically meaningful behavior tokens, the resulting VLA model, OmniJARVIS, can reason (by producing chain-of-thoughts), plan, answer questions, and act (by producing behavior tokens for the imitation learning policy decoder). OmniJARVIS demonstrates excellent performances on a comprehensive collection of atomic, programmatic, and open-ended tasks in open-world Minecraft. Our analysis further unveils the crucial design principles in interaction data formation, unified tokenization, and its scaling potentials. The dataset, models, and code will be released at https://craftjarvis.org/OmniJARVIS.
tl;dr: We propose BiScope, leveraging a novel bi-directional cross-entropy calculation method to detect AI-generated texts.

Detecting text generated by Large Language Models (LLMs) is a pressing need in
order to identify and prevent misuse of these powerful models in a wide range of
applications, which have highly undesirable consequences such as misinformation
and academic dishonesty. Given a piece of subject text, many existing detection
methods work by measuring the difficulty of LLM predicting the next token in
the text from their prefix. In this paper, we make a critical observation that
how well the current token’s output logits memorizes the closely preceding input
tokens also provides strong evidence. Therefore, we propose a novel bi-directional
calculation method that measures the cross-entropy losses between an output
logits and the ground-truth token (forward) and between the output logits and
the immediately preceding input token (backward). A classifier is trained to
make the final prediction based on the statistics of these losses. We evaluate our
system, named BISCOPE, on texts generated by five latest commercial LLMs
across five heterogeneous datasets, including both natural language and code.
BISCOPE demonstrates superior detection accuracy and robustness compared to six
existing baseline methods, exceeding the state-of-the-art non-commercial methods’
detection accuracy by over 0.30 F1 score, achieving over 0.95 detection F1 score
on average. It also outperforms the best commercial tool GPTZero that is based on
a commercial LLM trained with an enormous volume of data. Code is available at https://github.com/MarkGHX/BiScope.
tl;dr: We propose Langevin unlearning which not only connect DP with unlearning, but also provides unlearning privacy guarantees for PNGD with Langevin dynamic analysis.

Machine unlearning has raised significant interest with the adoption of laws ensuring the ``right to be forgotten''. Researchers have provided a probabilistic notion of approximate unlearning under a similar definition of Differential Privacy (DP), where privacy is defined as statistical indistinguishability to retraining from scratch. We propose Langevin unlearning, an unlearning framework based on noisy gradient descent with privacy guarantees for approximate unlearning problems. Langevin unlearning unifies the DP learning process and the privacy-certified unlearning process with many algorithmic benefits. These include approximate certified unlearning for non-convex problems, complexity saving compared to retraining, sequential and batch unlearning for multiple unlearning requests.
tl;dr: We study the fractal structure of language and show that fractal parameter can be used in predicting downstream performance better than perplexity-based metrics alone.

We study the fractal structure of language, aiming to provide a precise formalism for quantifying properties that may have been previously suspected but not formally shown. We establish that language is: (1) self-similar, exhibiting complexities at all levels of granularity, with no particular characteristic context length, and (2) long-range dependent (LRD), with a Hurst parameter of approximately 0.7.
Based on these findings, we argue that short-term patterns/dependencies in language, such as in paragraphs, mirror the patterns/dependencies over larger scopes, like entire documents. This may shed some light on how next-token prediction can capture the structure of text across multiple levels of granularity, from words and clauses to broader contexts and intents. In addition, we carry out an extensive analysis across different domains and architectures, showing that fractal parameters are robust.
Finally, we demonstrate that the tiny variations in fractal parameters seen across LLMs improve upon perplexity-based bits-per-byte (BPB) in predicting their downstream performance. We hope these findings offer a fresh perspective on language and the mechanisms underlying the success of LLMs.
tl;dr: This paper proposes a novel deep learning attention module, named soft superpixel neighborhood attention (SNA), to reweight a local attention map according to the deformable boundaries of real-world images.

Images contain objects with deformable boundaries, such as the contours of a human face, yet attention operators act on square windows. This mixes features from perceptually unrelated regions, which can degrade the quality of a denoiser. One can exclude pixels using an estimate of perceptual groupings, such as superpixels, but the naive use of superpixels can be theoretically and empirically worse than standard attention. Using superpixel probabilities rather than superpixel assignments, this paper proposes soft superpixel neighborhood attention (SNA), which interpolates between the existing neighborhood attention and the naive superpixel neighborhood attention. This paper presents theoretical results showing SNA is the optimal denoiser under a latent superpixel model. SNA outperforms alternative local attention modules on image denoising, and we compare the superpixels learned from denoising with those learned with supervision.
1012. AutoManual: Generating Instruction Manuals by LLM Agents via Interactive Environmental Learning
tl;dr: The paper introduces AutoManual, a framework that enables LLM agents to autonomously adapt to new environments by interacting and generating comprehensive instruction manuals through online rule optimization.

Large Language Models (LLM) based agents have shown promise in autonomously completing tasks across various domains, e.g., robotics, games, and web navigation. However, these agents typically require elaborate design and expert prompts to solve tasks in specific domains, which limits their adaptability. We introduce AutoManual, a framework enabling LLM agents to autonomously build their understanding through interaction and adapt to new environments. AutoManual categorizes environmental knowledge into diverse rules and optimizes them in an online fashion by two agents: 1) The Planner codes actionable plans based on current rules for interacting with the environment. 2) The Builder updates the rules through a well-structured rule system that facilitates online rule management and essential detail retention. To mitigate hallucinations in managing rules, we introduce a *case-conditioned prompting* strategy for the Builder. Finally, the Formulator agent compiles these rules into a comprehensive manual. The self-generated manual can not only improve the adaptability but also guide the planning of smaller LLMs while being human-readable. Given only one simple demonstration, AutoManual significantly improves task success rates, achieving 97.4\% with GPT-4-turbo and 86.2\% with GPT-3.5-turbo on ALFWorld benchmark tasks. The code is available at https://github.com/minghchen/automanual.

Recent advances in implicit neural representation (INR)-based video coding have
demonstrated its potential to compete with both conventional and other learning-
based approaches. With INR methods, a neural network is trained to overfit a
video sequence, with its parameters compressed to obtain a compact representation
of the video content. However, although promising results have been achieved,
the best INR-based methods are still out-performed by the latest standard codecs,
such as VVC VTM, partially due to the simple model compression techniques
employed. In this paper, rather than focusing on representation architectures, which
is a common focus in many existing works, we propose a novel INR-based video
compression framework, Neural Video Representation Compression (NVRC),
targeting compression of the representation. Based on its novel quantization and
entropy coding approaches, NVRC is the first framework capable of optimizing an
INR-based video representation in a fully end-to-end manner for the rate-distortion
trade-off. To further minimize the additional bitrate overhead introduced by the
entropy models, NVRC also compresses all the network, quantization and entropy
model parameters hierarchically. Our experiments show that NVRC outperforms
many conventional and learning-based benchmark codecs, with a 23% average
coding gain over VVC VTM (Random Access) on the UVG dataset, measured
in PSNR. As far as we are aware, this is the first time an INR-based video codec
achieving such performance.
1014. Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference
tl;dr: While prediction and planning over time series data is challenging, these problems have closed form solutions in terms of temporal contrastive representations

Given time series data, how can we answer questions like ``what will happen in the future?'' and ``how did we get here?'' These sorts of probabilistic inference questions are challenging when observations are high-dimensional. In this paper, we show how these questions can have compact, closed form solutions in terms of learned representations. The key idea is to apply a variant of contrastive learning to time series data. Prior work already shows that the representations learned by contrastive learning encode a probability ratio. By extending prior work to show that the marginal distribution over representations is Gaussian, we can then prove that joint distribution of representations is also Gaussian. Taken together, these results show that representations learned via temporal contrastive learning follow a Gauss-Markov chain, a graphical model where inference (e.g., prediction, planning) over representations corresponds to inverting a low-dimensional matrix. In one special case, inferring intermediate representations will be equivalent to interpolating between the learned representations. We validate our theory using numerical simulations on tasks up to 46-dimensions.
tl;dr: Learning to recover face textures under illumination affected by external occlusions

Existing research has made impressive strides in reconstructing human facial shapes and textures from images with well-illuminated faces and minimal external occlusions.
Nevertheless, it remains challenging to recover accurate facial textures from scenarios with complicated illumination affected by external occlusions, \eg a face that is partially obscured by items such as a hat.
Existing works based on the assumption of single and uniform illumination cannot correctly process these data.
In this work, we introduce a novel approach to model 3D facial textures under such unnatural illumination. Instead of assuming single illumination, our framework learns to imitate the unnatural illumination as a composition of multiple separate light conditions combined with learned neural representations, named Light Decoupling.
According to experiments on both single images and video sequences, we demonstrate the effectiveness of our approach in modeling facial textures under challenging illumination affected by occlusions.

Many computational tasks can be naturally expressed as a composition of a DNN followed by a program written in a traditional programming language or an API call to an LLM. We call such composites "neural programs" and focus on the problem of learning the DNN parameters when the training data consist of end-to-end input-output labels for the composite. When the program is written in a differentiable logic programming language, techniques from neurosymbolic learning are applicable, but in general, the learning for neural programs requires estimating the gradients of black-box components. We present an algorithm for learning neural programs, called ISED, that only relies on input-output samples of black-box components. For evaluation, we introduce new benchmarks that involve calls to modern LLMs such as GPT-4 and also consider benchmarks from the neurosymbolic learning literature. Our evaluation shows that for the latter benchmarks, ISED has comparable performance to state-of-the-art neurosymbolic frameworks. For the former, we use adaptations of prior work on gradient approximations of black-box components as a baseline, and show that ISED achieves comparable accuracy but in a more data- and sample-efficient manner.
tl;dr: This paper introduces SemCoder, a novel 6.7B Code LM trained with comprehensive program semantics from static code to dynamic execution, achieving superior performance in code generation and execution reasoning.

Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs' reliance on static text data and the need for semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy, _monologue reasoning_, to train Code LLMs to reason comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states.
We begin by collecting PyX, a clean Python corpus of fully executable code samples with functional descriptions and test cases.
We propose training Code LLMs not only to write code but also to understand code semantics by reasoning about key properties, constraints, and execution behaviors using natural language, mimicking human verbal debugging, i.e., rubber-duck debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 79.3% on HumanEval (GPT-3.5-turbo: 76.8%), 63.6% on CRUXEval-I (GPT-3.5-turbo: 50.3%), and 63.9% on CRUXEval-O (GPT-3.5-turbo: 59.0%). We also study the effectiveness of SemCoder's monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs' debugging and self-refining capabilities. Our data, code, and models are available at: https://github.com/ARiSE-Lab/SemCoder.
1018. Real-world Image Dehazing with Coherence-based Pseudo Labeling and Cooperative Unfolding Network
tl;dr: The cooperative unfolding network (CORUN) and the first plug-in-play iterative mean-teacher framework (Colabator) for real-world image dehazing.

Real-world Image Dehazing (RID) aims to alleviate haze-induced degradation in real-world settings. This task remains challenging due to the complexities in accurately modeling real haze distributions and the scarcity of paired real-world data. To address these challenges, we first introduce a cooperative unfolding network that jointly models atmospheric scattering and image scenes, effectively integrating physical knowledge into deep networks to restore haze-contaminated details. Additionally, we propose the first RID-oriented iterative mean-teacher framework, termed the Coherence-based Label Generator, to generate high-quality pseudo labels for network training. Specifically, we provide an optimal label pool to store the best pseudo-labels during network training, leveraging both global and local coherence to select high-quality candidates and assign weights to prioritize haze-free regions. We verify the effectiveness of our method, with experiments demonstrating that it achieves state-of-the-art performance on RID tasks. Code will be available at https://github.com/cnyvfang/CORUN-Colabator.

The normal means model is often studied under the assumption of a known variance. However, ignorance of the variance is a frequent issue in applications and basic theoretical questions still remain open in this setting. This article establishes that the sharp minimax rate of variance estimation in square error is $(\frac{\log\log n}{\log n})^2$ under arguably the most mild assumption imposed for identifiability: bounded means. The rate-optimal estimator proposed in this article achieves the optimal rate by estimating $O\left(\frac{\log n}{\log\log n}\right)$ cumulants and leveraging a variational representation of the noise variance in terms of the cumulants of the data distribution. The minimax lower bound involves a moment matching construction.
1020. Learning an Actionable Discrete Diffusion Policy via Large-Scale Actionless Video Pre-Training
tl;dr: We develop a video-based multi-task policy using discrete diffusion, facilitating efficient policy learning by incorporating foresight from predicted videos.

Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. However, it remains a challenge due to the domain gap between humans and robots. Moreover, it is difficult to extract useful information representing the dynamic world from human videos, because of its noisy and multimodal data structure. In this paper, we introduce a novel framework to tackle these challenges, which leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by compressing both human and robot videos into unified video tokens. In the pre-training stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space. In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning with a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches with superior performance.

The typical training of neural networks using large stepsize gradient descent (GD) under the logistic loss often involves two distinct phases, where the empirical risk oscillates in the first phase but decreases monotonically in the second phase. We investigate this phenomenon in two-layer networks that satisfy a near-homogeneity condition. We show that the second phase begins once the empirical risk falls below a certain threshold, dependent on the stepsize. Additionally, we show that the normalized margin grows nearly monotonically in the second phase, demonstrating an implicit bias of GD in training non-homogeneous predictors. If the dataset is linearly separable and the derivative of the activation function is bounded away from zero, we show that the average empirical risk decreases, implying that the first phase must stop in finite steps. Finally, we demonstrate that by choosing a suitably large stepsize, GD that undergoes this phase transition is more efficient than GD that monotonically decreases the risk. Our analysis applies to networks of any width, beyond the well-known neural tangent kernel and mean-field regimes.
tl;dr: Improving deep reinforcement learning by reducing undesired changes to out of batch data.

Deep neural networks provide Reinforcement Learning (RL) powerful function approximators to address large-scale decision-making problems. However, these approximators introduce challenges due to the non-stationary nature of RL training. One source of the challenges in RL is that output predictions can churn, leading to uncontrolled changes after each batch update for states not included in the batch. Although such a churn phenomenon exists in each step of network training, it remains under-explored on how churn occurs and impacts RL. In this work, we start by characterizing churn in a view of Generalized Policy Iteration with function approximation, and we discover a chain effect of churn that leads to a cycle where the churns in value estimation and policy improvement compound and bias the learning dynamics throughout the iteration. Further, we concretize the study and focus on the learning issues caused by the chain effect in different settings, including greedy action deviation in value-based methods, trust region violation in proximal policy optimization, and dual bias of policy value in actor-critic methods. We then propose a method to reduce the chain effect across different settings, called Churn Approximated ReductIoN (CHAIN), which can be easily plugged into most existing DRL algorithms. Our experiments demonstrate the effectiveness of our method in both reducing churn and improving learning performance across online and offline, value-based and policy-based RL settings.
tl;dr: We propose an algorithm that harnesses the flexibility of diffusion models for representation learning to achieve efficient policy optimization, while avoiding the time-consuming sampling process typically associated with diffusion models.

Diffusion-based models have achieved notable empirical successes in reinforcement learning (RL) due to their expressiveness in modeling complex distributions. Despite existing methods being promising, the key challenge of extending existing methods for broader real-world applications lies in the computational cost at inference time, i.e., sampling from a diffusion model is considerably slow as it often requires tens to hundreds of iterations to generate even one sample. To circumvent this issue, we propose to leverage the flexibility of diffusion models for RL from a representation learning perspective. In particular, by exploiting the connection between diffusion models and energy-based models, we develop Diffusion Spectral Representation (Diff-SR), a coherent algorithm framework that enables extracting sufficient representations for value functions in Markov decision processes (MDP) and partially observable Markov decision processes (POMDP). We further demonstrate how Diff-SR facilitates efficient policy optimization and practical algorithms while explicitly bypassing the difficulty and inference cost of sampling from the diffusion model. Finally, we provide comprehensive empirical studies to verify the benefits of Diff-SR in delivering robust and advantageous performance across various benchmarks with both fully and partially observable settings.
tl;dr: We present a new layerwise sparsity allocation approach for pruning large language models.

Large Language Models (LLMs) have revolutionized the field of natural language processing with their impressive capabilities. However, their enormous size presents challenges for deploying them in real-world applications. Traditional compression techniques, like pruning, often lead to suboptimal performance due to their uniform pruning ratios and lack of consideration for the varying importance of features across different layers. To address these limitations, we present a novel Adaptive Layer Sparsity (ALS) approach to optimize LLMs. Our approach consists of two key steps. Firstly, we estimate the correlation matrix between intermediate layers by leveraging the concept of information orthogonality. This novel perspective allows for a precise measurement of the importance of each layer across the model. Secondly, we employ a linear optimization algorithm to develop an adaptive sparse allocation strategy based on evaluating the correlation matrix. This strategy enables us to selectively prune features in intermediate layers, achieving fine-grained optimization of the LLM model. Considering the varying importance across different layers, we can significantly reduce the model size without sacrificing performance. We conduct extensive experiments on publicly available language processing datasets, including the LLaMA-V1|V2|V3 family and OPT, covering various benchmarks. Our experimental results validate the effectiveness of our ALS method, showcasing its superiority over previous approaches. The performance gains demonstrate its potential for enhancing LLMs' efficiency and resource utilization. Notably, our approach surpasses the state-of-the-art models Wanda and SparseGPT, showcasing its ability to excel even under high sparsity levels. Codes at: https://github.com/lliai/ALS.

We develop new conformal inference methods for obtaining validity guarantees on the output of large language models (LLMs). Prior work in conformal language modeling identifies a subset of the text that satisfies a high-probability guarantee of correctness. These methods work by filtering claims from the LLM's original response if a scoring function evaluated on the claim fails to exceed a threshold calibrated via split conformal prediction. Existing methods in this area suffer from two deficiencies. First, the guarantee stated is not conditionally valid. The trustworthiness of the filtering step may vary based on the topic of the response. Second, because the scoring function is imperfect, the filtering step can remove many valuable and accurate claims. We address both of these challenges via two new conformal methods. First, we generalize the conditional conformal procedure of Gibbs et al. (2023) in order to adaptively issue weaker guarantees when they are required to preserve the utility of the output. Second, we show how to systematically improve the quality of the scoring function via a novel algorithm for differentiating through the conditional conformal procedure. We demonstrate the efficacy of our approach on biography and medical question-answering datasets.
tl;dr: We proposing a novel RL-instructed language agent framework to play the One Night Ultimate Werewolf game.

Communication is a fundamental aspect of human society, facilitating the exchange of information and beliefs among people. Despite the advancements in large language models (LLMs), recent agents built with these often neglect the control over discussion tactics, which are essential in communication scenarios and games. As a variant of the famous communication game Werewolf, *One Night Ultimate Werewolf* (ONUW) requires players to develop strategic discussion policies due to the potential role changes that increase the uncertainty and complexity of the game. In this work, we first present the existence of the Perfect Bayesian Equilibria (PBEs) in two scenarios of the ONUW game: one with discussion and one without. The results showcase that the discussion greatly changes players' utilities by affecting their beliefs, emphasizing the significance of discussion tactics. Based on the insights obtained from the analyses, we propose an RL-instructed language agent framework, where a discussion policy trained by reinforcement learning (RL) is employed to determine appropriate discussion tactics to adopt. Our experimental results on several ONUW game settings demonstrate the effectiveness and generalizability of our proposed framework.
tl;dr: We propose a novel training method for prompt-based unsupervised domain adaptation by effectively leveraging and manipulating domain-specific gradients.

Prior Unsupervised Domain Adaptation (UDA) methods often aim to train a domain-invariant feature extractor, which may hinder the model from learning sufficiently discriminative features. To tackle this, a line of works based on prompt learning leverages the power of large-scale pre-trained vision-language models to learn both domain-invariant and specific features through a set of domain-agnostic and domain-specific learnable prompts. Those studies typically enforce invariant constraints on representation, output, or prompt space to learn such prompts. Differently, we cast UDA as a multiple-objective optimization problem in which each objective is represented by a domain loss. Under this new framework, we propose aligning per-objective gradients to foster consensus between them. Additionally, to prevent potential overfitting when fine-tuning this deep learning architecture, we penalize the norm of these gradients. To achieve these goals, we devise a practical gradient update procedure that can work under both single-source and multi-source UDA. Empirically, our method consistently surpasses other vision language model adaptation methods by a large margin on a wide range of benchmarks. The implementation is available at https://github.com/VietHoang1512/PGA.
tl;dr: The paper studies the secretary problem with a weak piece of information: a single additive gap between weights. Given this, we derive improved guarantees for the secretary problem, beating previously tight bounds.

The secretary problem is one of the fundamental problems in online decision making; a tight competitive ratio for this problem of $1/e \approx 0.368$ has been known since the 1960s. Much more recently, the study of algorithms with predictions was introduced: The algorithm is equipped with a (possibly erroneous) additional piece of information upfront which can be used to improve the algorithm's performance. Complementing previous work on secretary problems with prior knowledge, we tackle the following question:
_What is the weakest piece of information that allows us to break the $1/e$ barrier?_
To this end, we introduce the secretary problem with predicted additive gap. As in the classical problem, weights are fixed by an adversary and elements appear in random order. In contrast to previous variants of predictions, our algorithm only has access to a much weaker piece of information: an _additive gap_ $c$. This gap is the difference between the highest and $k$-th highest weight in the sequence.
Unlike previous pieces of advice, knowing an exact additive gap does not make the problem trivial.
Our contribution is twofold. First, we show that for any index $k$ and any gap $c$, we can obtain a competitive ratio of $0.4$ when knowing the exact gap (even if we do not know $k$), hence beating the prevalent bound for the classical problem by a constant. Second, a slightly modified version of our algorithm allows to prove standard robustness-consistency properties as well as improved guarantees when knowing a range for the error of the prediction.
1029. Geometry of naturalistic object representations in recurrent neural network models of working memory
tl;dr: We found that multi-task RNN models of working memory maintain both task-relevant and irrelevant information in orthogonalized subspaces and use rotational dynamics to track past information amidst new inputs.

Working memory is a central cognitive ability crucial for intelligent decision-making. Recent experimental and computational work studying working memory has primarily used categorical (i.e., one-hot) inputs, rather than ecologically-relevant, multidimensional naturalistic ones. Moreover, studies have primarily investigated working memory during single or few number of cognitive tasks. As a result, an understanding of how naturalistic object information is maintained in working memory in neural networks is still lacking. To bridge this gap, we developed sensory-cognitive models, comprising of a convolutional neural network (CNN) coupled with a recurrent neural network (RNN), and trained them on nine distinct N-back tasks using naturalistic stimuli. By examining the RNN’s latent space, we found that: 1) Multi-task RNNs represent both task-relevant and irrelevant information simultaneously while performing tasks; 2) While the latent subspaces used to maintain specific object properties in vanilla RNNs are largely shared across tasks, they are highly task-specific in gated RNNs such as GRU and LSTM; 3) Surprisingly, RNNs embed objects in new representational spaces in which individual object features are less orthogonalized relative to the perceptual space; 4) Interestingly, the transformation of WM encodings (i.e., embedding of visual inputs in the RNN latent space) into memory was shared across stimuli, yet the transformations governing the retention of a memory in the face of incoming distractor stimuli were distinct across time. Our findings indicate that goal-driven RNNs employ chronological memory subspaces to track information over short time spans, enabling testable predictions with neural data.
tl;dr: We propose a training-free guidance framework that unifies existing algorithms and achieve SOTA performance in our proposed comprehensive benchmark.

Given an unconditional diffusion model and a predictor for a target property of interest (e.g., a classifier), the goal of training-free guidance is to generate samples with desirable target properties without additional training. Existing methods, though effective in various individual applications, often lack theoretical grounding and rigorous testing on extensive benchmarks. As a result, they could even fail on simple tasks, and applying them to a new problem becomes unavoidably difficult. This paper introduces a novel algorithmic framework encompassing existing methods as special cases, unifying the study of training-free guidance into the analysis of an algorithm-agnostic design space. Via theoretical and empirical investigation, we propose an efficient and effective hyper-parameter searching strategy that can be readily applied to any downstream task. We systematically benchmark across 7 diffusion models on 16 tasks with 40 targets, and improve performance by 8.5% on average. Our framework and benchmark offer a solid foundation for conditional generation in a training-free manner.

Spatio-temporal (ST) prediction has garnered a De facto attention in earth sciences, such as meteorological prediction, human mobility perception. However, the scarcity of data coupled with the high expenses involved in sensor deployment results in notable data imbalances. Furthermore, models that are excessively customized and devoid of causal connections further undermine the generalizability and interpretability. To this end, we establish a causal framework for ST predictions, termed CaPaint, which targets to identify causal regions in data and endow model with causal reasoning ability in a two-stage process. Going beyond this process, we utilize the back-door adjustment to specifically address the sub-regions identified as non-causal in the upstream phase. Specifically, we employ a novel image inpainting technique. By using a fine-tuned unconditional Diffusion Probabilistic Model (DDPM) as the generative prior, we in-fill the masks defined as environmental parts, offering the possibility of reliable extrapolation for potential data distributions. CaPaint overcomes the high complexity dilemma of optimal ST causal discovery models by reducing the data generation complexity from exponential to quasi-linear levels. Extensive experiments conducted on five real-world ST benchmarks demonstrate that integrating the CaPaint concept allows models to achieve improvements ranging from 4.3% to 77.3%. Moreover, compared to traditional mainstream ST augmenters, CaPaint underscores the potential of diffusion models in ST enhancement, offering a novel paradigm for this field. Our project is available at https://anonymous.4open.science/r/12345-DFCC.
1032. BackdoorAlign: Mitigating Fine-tuning based Jailbreak Attack with Backdoor Enhanced Safety Alignment

Despite the general capabilities of Large Language Models (LLMs) like GPT-4, these models still request fine-tuning or adaptation with customized data when meeting the specific business demands and intricacies of tailored use cases. However, this process inevitably introduces new safety threats, particularly against the Fine-tuning based Jailbreak Attack (FJAttack) under the setting of Language-Model-as-a-Service (LMaaS), where the model's safety has been significantly compromised by fine-tuning on users' uploaded examples that contain just a few harmful examples. Though potential defenses have been proposed that the service providers of LMaaS can integrate safety examples into the fine-tuning dataset to reduce safety issues, such approaches require incorporating a substantial amount of data, making it inefficient. To effectively defend against the FJAttack with limited safety examples under LMaaS, we propose the Backdoor Enhanced Safety Alignment method inspired by an analogy with the concept of backdoor attacks. In particular, service providers will construct prefixed safety examples with a secret prompt, acting as a "backdoor trigger". By integrating prefixed safety examples into the fine-tuning dataset, the subsequent fine-tuning process effectively acts as the "backdoor attack", establishing a strong correlation between the secret prompt and safety generations. Consequently, safe responses are ensured once service providers prepend this secret prompt ahead of any user input during inference. Our comprehensive experiments demonstrate that through the Backdoor Enhanced Safety Alignment with adding as few as 11 prefixed safety examples, the maliciously fine-tuned LLMs will achieve similar safety performance as the original aligned models without harming the benign performance. Furthermore, we also present the effectiveness of our method in a more practical setting where the fine-tuning data consists of both FJAttack examples and the fine-tuning task data.
tl;dr: We propose a framework called FlowTurbo to accerate flow-based generative models by 29.8%-58.3%, which is efficient in both training (<6 GPU hours) and inference (~40ms / img)

Building on the success of diffusion models in visual generation, flow-based models reemerge as another prominent family of generative models that have achieved competitive or better performance in terms of both visual quality and inference speed. By learning the velocity field through flow-matching, flow-based models tend to produce a straighter sampling trajectory, which is advantageous during the sampling process. However, unlike diffusion models for which fast samplers are well-developed, efficient sampling of flow-based generative models has been rarely explored. In this paper, we propose a framework called FlowTurbo to accelerate the sampling of flow-based models while still enhancing the sampling quality. Our primary observation is that the velocity predictor's outputs in the flow-based models will become stable during the sampling, enabling the estimation of velocity via a lightweight velocity refiner. Additionally, we introduce several techniques including a pseudo corrector and sample-aware compilation to further reduce inference time. Since FlowTurbo does not change the multi-step sampling paradigm, it can be effectively applied for various tasks such as image editing, inpainting, etc. By integrating FlowTurbo into different flow-based models, we obtain an acceleration ratio of 53.1\%$\sim$58.3\% on class-conditional generation and 29.8\%$\sim$38.5\% on text-to-image generation. Notably, FlowTurbo reaches an FID of 2.12 on ImageNet with 100 (ms / img) and FID of 3.93 with 38 (ms / img), achieving the real-time image generation and establishing the new state-of-the-art. Code is available at https://github.com/shiml20/FlowTurbo.
1034. DiffTORI: Differentiable Trajectory Optimization for Deep Reinforcement and Imitation Learning
tl;dr: This paper introduces DiffTORI, which uses Differentiable Trajectory Optimization as the policy representation to generate actions for deep reinforcement and imitation learning, and outperforms prior state-of-the-art methods in both domains.

This paper introduces DiffTORI, which utilizes $\textbf{Diff}$erentiable $\textbf{T}$rajectory $\textbf{O}$ptimization as the policy representation to generate actions for deep $\textbf{R}$einforcement and $\textbf{I}$mitation learning. Trajectory optimization is a powerful and widely used algorithm in control, parameterized by a cost and a dynamics function. The key to our approach is to leverage the recent progress in differentiable trajectory optimization, which enables computing the gradients of the loss with respect to the parameters of trajectory optimization. As a result, the cost and dynamics functions of trajectory optimization can be learned end-to-end. DiffTORI addresses the “objective mismatch” issue of prior model-based RL algorithms, as the dynamics model in DiffTORI is learned to directly maximize task performance by differentiating the policy gradient loss through the trajectory optimization process. We further benchmark DiffTORI for imitation learning on standard robotic manipulation task suites with high-dimensional sensory observations and compare our method to feedforward policy classes as well as Energy-Based Models (EBM) and Diffusion. Across 15 model based RL tasks and 35 imitation learning tasks with high-dimensional image and point cloud inputs, DiffTORI outperforms prior state-of-the-art methods in both domains.
tl;dr: LLM for Law via domain adaptation

In this paper, we introduce SaulLM-medium and SaulLM-large, two large language models (LLMs) families tailored for the legal sector. These models, which feature architectures of 54 billion and 140 billion parameters, respectively, are based on the Mixtral architecture. The development of SaulLM-54B and SaulLM-140B is guided by large-scale domain adaptation, divided into strategies: (1) the exploitation of continued pretaining involving a legal corpus that includes over $400$ billion tokens, (2) the implementation of a specialized legal instruction-following protocol, and (3) the alignment of model outputs with human preferences in legal interpretations. The integration of synthetically generated data in the second and third steps enhances the models' capabilities in interpreting and processing legal texts, effectively reaching state-of-the-art performance and outperforming all previous open-source models on LegalBench Instruct. This research thoroughly explores the trade-offs involved in domain-specific adaptation at this scale, offering insights that may inform future studies on domain adaptation using strong decoder models. Building upon SaulLM-7B, this study refines the approach to produce an LLM better equipped for legal tasks and domains. Additionally, we release base, instruct and aligned versions on top of SaulLM-medium and SaulLM-large under the MIT License to facilitate reuse and collaborative research.

Contrastive learning has been a leading paradigm for self-supervised learning, but it is widely observed that it comes at the price of sacrificing useful features (\eg colors) by being invariant to data augmentations. Given this limitation, there has been a surge of interest in equivariant self-supervised learning (E-SSL) that learns features to be augmentation-aware. However, even for the simplest rotation prediction method, there is a lack of rigorous understanding of why, when, and how E-SSL learns useful features for downstream tasks. To bridge this gap between practice and theory, we establish an information-theoretic perspective to understand the generalization ability of E-SSL. In particular, we identify a critical explaining-away effect in E-SSL that creates a synergy between the equivariant and classification tasks. This synergy effect encourages models to extract class-relevant features to improve its equivariant prediction, which, in turn, benefits downstream tasks requiring semantic features. Based on this perspective, we theoretically analyze the influence of data transformations and reveal several principles for practical designs of E-SSL. Our theory not only aligns well with existing E-SSL methods but also sheds light on new directions by exploring the benefits of model equivariance. We believe that a theoretically grounded understanding on the role of equivariance would inspire more principled and advanced designs in this field. Code is available at
https://github.com/kaotty/Understanding-ESSL.
tl;dr: A closed-loop visuomotor control framework that incorporates feedback mechanisms to improve adaptive robotic control

Despite significant progress in robotics and embodied AI in recent years, deploying robots for long-horizon tasks remains a great challenge. Majority of prior arts adhere to an open-loop philosophy and lack real-time feedback, leading to error accumulation and undesirable robustness. A handful of approaches have endeavored to establish feedback mechanisms leveraging pixel-level differences or pre-trained visual representations, yet their efficacy and adaptability have been found to be constrained. Inspired by classic closed-loop control systems, we propose CLOVER, a closed-loop visuomotor control framework that incorporates feedback mechanisms to improve adaptive robotic control. CLOVER consists of a text-conditioned video diffusion model for generating visual plans as reference inputs, a measurable embedding space for accurate error quantification, and a feedback-driven controller that refines actions from feedback and initiates replans as needed. Our framework exhibits notable advancement in real-world robotic tasks and achieves state-of-the-art on CALVIN benchmark, improving by 8% over previous open-loop counterparts. Code and checkpoints are maintained at https://github.com/OpenDriveLab/CLOVER.

While large language models (LLMs) showcase unprecedented capabilities, they also exhibit certain inherent limitations when facing seemingly trivial tasks.
A prime example is the recently debated "reversal curse", which surfaces when models, having been trained on the fact "A is B", struggle to generalize this knowledge to infer that "B is A".
In this paper, we examine the manifestation of the reversal curse across various tasks and delve into both the generalization abilities and the problem-solving mechanisms of LLMs. This investigation leads to a series of significant insights:
(1) LLMs are able to generalize to "B is A" when both A and B are presented in the context as in the case of a multiple-choice question.
(2) This generalization ability is highly correlated to the structure of the fact "A is B" in the training documents. For example, this generalization only applies to biographies structured in "[Name] is [Description]" but not to "[Description] is [Name]".
(3) We propose and verify the hypothesis that LLMs possess an inherent bias in fact recalling during knowledge application, which explains and underscores the importance of the document structure to successful learning.
(4) The negative impact of this bias on the downstream performance of LLMs can hardly be mitigated through training alone.
Based on these intriguing findings, our work not only presents a novel perspective for interpreting LLMs' generalization abilities from their intrinsic working mechanism but also provides new insights for the development of more effective learning methods for LLMs.

We present NeuralFluid, a novel framework to explore neural control and design of complex fluidic systems with dynamic solid boundaries. Our system features a fast differentiable Navier-Stokes solver with solid-fluid interface handling, a low-dimensional differentiable parametric geometry representation, a control-shape co-design algorithm, and gym-like simulation environments to facilitate various fluidic control design applications. Additionally, we present a benchmark of design, control, and learning tasks on high-fidelity, high-resolution dynamic fluid environments that pose challenges for existing differentiable fluid simulators. These tasks include designing the control of artificial hearts, identifying robotic end-effector shapes, and controlling a fluid gate. By seamlessly incorporating our differentiable fluid simulator into a learning framework, we demonstrate successful design, control, and learning results that surpass gradient-free solutions in these benchmark tasks.

Penalizing the nuclear norm of a function's Jacobian encourages it to locally behave like a low-rank linear map. Such functions vary locally along only a handful of directions, making the Jacobian nuclear norm a natural regularizer for machine learning problems. However, this regularizer is intractable for high-dimensional problems, as it requires computing a large Jacobian matrix and taking its SVD. We show how to efficiently penalize the Jacobian nuclear norm using techniques tailor-made for deep learning. We prove that for functions parametrized as compositions $f = g \circ h$, one may equivalently penalize the average squared Frobenius norm of $Jg$ and $Jh$. We then propose a denoising-style approximation that avoids the Jacobian computations altogether. Our method is simple, efficient, and accurate, enabling Jacobian nuclear norm regularization to scale to high-dimensional deep learning problems. We complement our theory with an empirical study of our regularizer's performance and investigate applications to denoising and representation learning.
tl;dr: We propose a novel family of bespoke ODE solves for solving the continuous adjoint equations for diffusion models.

The optimization of the latents and parameters of diffusion models with respect to some differentiable metric defined on the output of the model is a challenging and complex problem. The sampling for diffusion models is done by solving either the *probability flow* ODE or diffusion SDE wherein a neural network approximates the score function allowing a numerical ODE/SDE solver to be used. However, naive backpropagation techniques are memory intensive, requiring the storage of all intermediate states, and face additional complexity in handling the injected noise from the diffusion term of the diffusion SDE. We propose a novel family of bespoke ODE solvers to the continuous adjoint equations for diffusion models, which we call *AdjointDEIS*. We exploit the unique construction of diffusion SDEs to further simplify the formulation of the continuous adjoint equations using *exponential integrators*. Moreover, we provide convergence order guarantees for our bespoke solvers. Significantly, we show that continuous adjoint equations for diffusion SDEs actually simplify to a simple ODE. Lastly, we demonstrate the effectiveness of AdjointDEIS for guided generation with an adversarial attack in the form of the face morphing problem. Our code will be released on our project page [https://zblasingame.github.io/AdjointDEIS/](https://zblasingame.github.io/AdjointDEIS/)
tl;dr: significantly improve performance of high fidelity model extraction, importantly removing prior bottlenecks of the attack

Deep neural networks, costly to train and rich in intellectual property value, are
increasingly threatened by model extraction attacks that compromise their confiden-
tiality. Previous attacks have succeeded in reverse-engineering model parameters
up to a precision of float64 for models trained on random data with at most three
hidden layers using cryptanalytical techniques. However, the process was identified
to be very time consuming and not feasible for larger and deeper models trained on
standard benchmarks. Our study evaluates the feasibility of parameter extraction
methods of Carlini et al. [1] further enhanced by Canales-Martínez et al. [2] for
models trained on standard benchmarks. We introduce a unified codebase that
integrates previous methods and reveal that computational tools can significantly
influence performance. We develop further optimisations to the end-to-end attack
and improve the efficiency of extracting weight signs by up to 14.8 times com-
pared to former methods through the identification of easier and harder to extract
neurons. Contrary to prior assumptions, we identify extraction of weights, not
extraction of weight signs, as the critical bottleneck. With our improvements, a
16,721 parameter model with 2 hidden layers trained on MNIST is extracted within
only 98 minutes compared to at least 150 minutes previously. Finally, addressing
methodological deficiencies observed in previous studies, we propose new ways of
robust benchmarking for future model extraction attacks.
tl;dr: This paper extends the algorithms with predictions model to the case where predictions are distributions for the problem of searching in a sorted array.

Algorithms with (machine-learned) predictions is a powerful framework for combining traditional worst-case algorithms with modern machine learning. However, the vast majority of work in this space assumes that the prediction itself is non-probabilistic, even if it is generated by some stochastic process (such as a machine learning system). This is a poor fit for modern ML, particularly modern neural networks, which naturally generate a *distribution*. We initiate the study of algorithms with *distributional* predictions, where the prediction itself is a distribution. We focus on one of the simplest yet fundamental settings: binary search (or searching a sorted array).
This setting has one of the simplest algorithms with a point prediction, but what happens if the prediction is a distribution? We show that this is a richer setting: there are simple distributions where using the classical prediction-based algorithm with any single prediction does poorly.
Motivated by this, as our main result, we give an algorithm with query complexity
$O(H(p) + \log \eta)$, where $H(p)$ is the entropy of the true distribution $p$ and $\eta$ is the earth mover's distance between $p$ and the predicted distribution $\hat p$. This also yields the first *distributionally-robust* algorithm for the classical problem of computing an optimal binary search tree given a distribution over target keys.
We complement this with a lower bound showing that this query complexity is essentially optimal (up to constants), and experiments validating the practical usefulness of our algorithm.

Knowledge distillation (KD) has been shown to be highly effective in guiding a student model with a larger teacher model and achieving practical benefits in improving the computational and memory efficiency for large language models (LLMs). State-of-the-art KD methods for LLMs mostly rely on minimizing explicit metrics measuring the divergence between teacher and student probability predictions. Instead of optimizing these mandatory cloning objectives, we explore an imitation learning strategy for KD of LLMs. In particular, we minimize the imitation gap by matching the action-value moments of the teacher's behavior from both on- and off-policy perspectives. To achieve this moment-matching goal, we propose an adversarial training algorithm to jointly estimate the moment-matching distance and optimize the student policy to minimize it. Results from both task-agnostic instruction-following experiments and task-specific experiments demonstrate the effectiveness of our method and achieve new state-of-the-art performance.
tl;dr: We propose a property testing problem associated with measuring calibration of a predictor, and give a near-linear time algorithm for it based on minimum-cost flow.

In the recent literature on machine learning and decision making, calibration has emerged as a desirable and widely-studied statistical property of the outputs of binary prediction models. However, the algorithmic aspects of measuring model calibration have remained relatively less well-explored. Motivated by Blasiok et al '23, which proposed a rigorous framework for measuring distances to calibration, we initiate the algorithmic study of calibration through the lens of property testing. We define the problem of calibration testing from samples where given $n$ draws from a distribution $\mathcal{D}$ on $(\text{predictions}, \text{binary outcomes})$, our goal is to distinguish between the cases where $\mathcal{D}$ is perfectly calibrated or $\epsilon$-far from calibration. We make the simple observation that the empirical smooth calibration linear program can be reformulated as an instance of minimum-cost flow on a highly-structured graph, and design an exact dynamic programming-based solver for it which runs in time $O(n\log^2(n))$, and solves the calibration testing problem information-theoretically optimally in the same time. This improves upon state-of-the-art black-box linear program solvers requiring $\Omega(n^\omega)$ time, where $\omega > 2$ is the exponent of matrix multiplication. We also develop algorithms for tolerant variants of our testing problem improving upon black-box linear program solvers, and give sample complexity lower bounds for alternative calibration measures to the one considered in this work. Finally, we present experiments showing the testing problem we define faithfully captures standard notions of calibration, and that our algorithms scale efficiently to accommodate large sample sizes.

Online (bipartite) matching under known stationary arrivals is a fundamental model that has been studied extensively under the objective of maximizing the total number of customers served. We instead study the objective of *maximizing the minimum matching rate across all online types*, which is referred to as long-run (individual) fairness. For Online Matching under long-run Fairness (OM-LF) with a single offline agent, we show that the first-come-first-serve (FCFS) policy is $1$-competitive, i.e., matching any optimal clairvoyant. For the general case of OM-LF: We present a sampling algorithm (SAMP) and show that (1) SAMP is of competitiveness of at least $1-1/e$ and (2) it is asymptotically optimal with competitiveness approaches one in different regimes when either all offline agents have a sufficiently large matching capacity, or all online types have a sufficiently large arrival rate, or highly imbalance between the total offline matching capacity and the number of online arrivals. To complement the competitive results, we show the following hardness results for OM-LF: (1) Any non-rejecting policy (matching every arriving online agent if possible) is no more than $1/2$-competitive; (2) Any (randomized) policy is no more than $(\sqrt{3}-1)$-competitive; (3) SAMP can be no more than $(1-1/e)$-competitive suggesting the tightness of competitive analysis for SAMP. We stress that all hardness results mentioned here are independent of any benchmarks. We also consider a few extensions of OM-LF by proposing a few variants of fairness metrics, including long-run group-level fairness and short-run fairness, and we devise related algorithms with provable competitive performance.
tl;dr: We propose RETR for multi-view radar indoor perception, improving object detection and segmentation, outperforming current methods on indoor radar datasets.

Indoor radar perception has seen rising interest due to affordable costs driven by emerging automotive imaging radar developments and the benefits of reduced privacy concerns and reliability under hazardous conditions (e.g., fire and smoke). However, existing radar perception pipelines fail to account for distinctive characteristics of the multi-view radar setting. In this paper, we propose Radar dEtection TRansformer (RETR), an extension of the popular DETR architecture, tailored for multi-view radar perception. RETR inherits the advantages of DETR, eliminating the need for hand-crafted components for object detection and segmentation in the image plane. More importantly, RETR incorporates carefully designed modifications such as 1) depth-prioritized feature similarity via a tunable positional encoding (TPE); 2) a tri-plane loss from both radar and camera coordinates; and 3) a learnable radar-to-camera transformation via reparameterization, to account for the unique multi-view radar setting. Evaluated on two indoor radar perception datasets, our approach outperforms existing state-of-the-art methods by a margin of 15.38+ AP for object detection and 11.77+ IoU for instance segmentation, respectively.
tl;dr: Analysis of the corrected graph convolution on the contextual stochastic block model for arbitrary number of convolutions.

Machine learning for node classification on graphs is a prominent area driven by applications such as recommendation systems. State-of-the-art models often use multiple graph convolutions on the data, as empirical evidence suggests they can enhance performance. However, it has been shown empirically and theoretically, that too many graph convolutions can degrade performance significantly, a phenomenon known as oversmoothing. In this paper, we provide a rigorous theoretical analysis, based on the two-class contextual stochastic block model (CSBM), of the performance of vanilla graph convolution from which we remove the principal eigenvector to avoid oversmoothing. We perform a spectral analysis for $k$ rounds of corrected graph convolutions, and we provide results for partial and exact classification. For partial classification, we show that each round of convolution can reduce the misclassification error exponentially up to a saturation level, after which performance does not worsen. We also extend this analysis to the multi-class setting with features distributed according to a Gaussian mixture model. For exact classification, we show that the separability threshold can be improved exponentially up to $O({\log{n}}/{\log\log{n}})$ corrected convolutions.
tl;dr: We quantize the KV cache accurately to ultra-low precision (eg. 2-bit) to enable efficient long context length inference.

LLMs are seeing growing use for applications which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in sub-4-bit precision. Our work, KVQuant, facilitates low precision KV cache quantization by incorporating several novel methods: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; and (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges. By applying our method to the LLaMA, Llama-2, Llama-3, and Mistral models, we achieve < 0.1 perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving LLaMA-7B with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system. We develop custom CUDA kernels for KVQuant, showing that we can achieve up to ~1.7x speedups, compared to baseline fp16 matrix-vector multiplications, for the LLaMA-7B model.
tl;dr: We extend the utility maximization framework to the setting of diffusion models and use it to align text-to-image diffusion models with human preferences using only per-image binary preference signals, e.g., likes and dislikes.

We present Diffusion-KTO, a novel approach for aligning text-to-image diffusion models by formulating the alignment objective as the maximization of expected human utility. Unlike previous methods, Diffusion-KTO does not require collecting pairwise preference data nor training a complex reward model. Instead, our objective uses per-image binary feedback signals, e.g. likes or dislikes, to align the model with human preferences. After fine-tuning using Diffusion-KTO, text-to-image diffusion models exhibit improved performance compared to existing techniques, including supervised fine-tuning and Diffusion-DPO, both in terms of human judgment and automatic evaluation metrics such as PickScore and ImageReward. Overall, Diffusion-KTO unlocks the potential of leveraging readily available per-image binary preference signals and broadens the applicability of aligning text-to-image diffusion models with human preferences.
tl;dr: We analyze how different architecture choices, such as the depth or width of hidden layers or residual connections affect the conditioning of the

The Gauss-Newton (GN) matrix plays an important role in machine learning, most evident in its use as a preconditioning matrix for a wide family of popular adaptive methods to speed up optimization. Besides, it can also provide key insights into the optimization landscape of neural networks.
In the context of deep neural networks, understanding the GN matrix involves studying the interaction between different weight matrices as well as the dependencies introduced by the data, thus rendering its analysis challenging.
In this work, we take a first step towards theoretically characterizing the conditioning of the GN matrix in neural networks. We establish tight bounds on the condition number of the GN in deep linear networks of arbitrary depth and width, which we also extend to two-layer ReLU networks.
We expand the analysis to further architectural components, such as residual connections and convolutional layers.
Finally, we empirically validate the bounds and uncover valuable insights into the influence of the analyzed architectural components.

Increased training parameters have enabled large pre-trained models to excel in various downstream tasks. Nevertheless, the extensive computational requirements associated with these models hinder their widespread adoption within the community. We focus on Knowledge Distillation (KD), where a compact student model is trained to mimic a larger teacher model, facilitating the transfer of knowledge of large models. In contrast to much of the previous work, we scale up the parameters of the student model during training, to benefit from over-parameterization without increasing the inference latency. In particular, we propose a tensor decomposition strategy that effectively over-parameterizes the relatively small student model through an efficient and nearly lossless decomposition of its parameter matrices into higher-dimensional tensors. To ensure efficiency, we further introduce a tensor constraint loss to align the high-dimensional tensors between the student and teacher models. Comprehensive experiments validate the significant performance enhancement by our approach in various KD tasks, covering computer vision and natural language processing areas. Our code is available at https://github.com/intell-sci-comput/OPDF.
tl;dr: In this paper, we present ScaleKD, showing that pre-trained ViT models could be used as teachers preserving scalable properties to advance cross-architecture knowledge distillation research.

In this paper, we question if well pre-trained vision transformer (ViT) models could be used as teachers that exhibit scalable properties to advance cross architecture knowledge distillation research, in the context of adopting mainstream large-scale visual recognition datasets for evaluation. To make this possible, our analysis underlines the importance of seeking effective strategies to align (1) feature computing paradigm differences, (2) model scale differences, and (3) knowledge density differences. By combining three closely coupled components namely *cross attention projector*, *dual-view feature mimicking* and *teacher parameter perception* tailored to address the alignment problems stated above, we present a simple and effective knowledge distillation method, called *ScaleKD*. Our method can train student backbones that span across a variety of convolutional neural network (CNN), multi-layer perceptron (MLP), and ViT architectures on image classification datasets, achieving state-of-the-art knowledge distillation performance. For instance, taking a well pre-trained Swin-L as the teacher model, our method gets 75.15\%|82.03\%|84.16\%|78.63\%|81.96\%|83.93\%|83.80\%|85.53\% top-1 accuracies for MobileNet-V1|ResNet-50|ConvNeXt-T|Mixer-S/16|Mixer-B/16|ViT-S/16|Swin-T|ViT-B/16 models trained on ImageNet-1K dataset from scratch, showing 3.05\%|3.39\%|2.02\%|4.61\%|5.52\%|4.03\%|2.62\%|3.73\% absolute gains to the individually trained counterparts. Intriguingly, when scaling up the size of teacher models or their pre-training datasets, our method showcases the desired scalable properties, bringing increasingly larger gains to student models. We also empirically show that the student backbones trained by our method transfer well on downstream MS-COCO and ADE20K datasets. More importantly, our method could be used as a more efficient alternative to the time-intensive pre-training paradigm for any target student model on large-scale datasets if a strong pre-trained ViT is available, reducing the amount of viewed training samples up to 195$\times$. The code is available at *https://github.com/deep-optimization/ScaleKD*.
tl;dr: Improved regret bounds for Privacy Online Learning and OCO via a general Lazy-to-Private transformation

We study the problem of private online learning, specifically, online prediction from experts (OPE) and online convex optimization (OCO).
We propose a new transformation that transforms lazy online learning algorithms into private algorithms. We apply our transformation for differentially private OPE and OCO using existing lazy algorithms for these problems. Our final algorithms obtain regret which significantly improves the regret in the high privacy regime $\varepsilon \ll 1$, obtaining $\sqrt{T \log d} + T^{1/3} \log(d)/\varepsilon^{2/3}$ for DP-OPE and $\sqrt{T} + T^{1/3} \sqrt{d}/\varepsilon^{2/3}$ for DP-OCO. We also complement our results with a lower bound for DP-OPE, showing that these rates are optimal for a natural family of low-switching private algorithms.
tl;dr: We show that having access to good predictions about future examples can lead to better regret bounds in online classification.

We study online classification when the learner has access to predictions about future examples. We design an online learner whose expected regret is never worse than the worst-case regret, gracefully improves with the quality of the predictions, and can be significantly better than the worst-case regret when the predictions of future examples are accurate. As a corollary, we show that if the learner is always guaranteed to observe data where future examples are easily predictable, then online learning can be as easy as transductive online learning. Our results complement recent work in online algorithms with predictions and smoothed online classification, which go beyond a worse-case analysis by using machine-learned predictions and distributional assumptions respectively.

The classical Canonical Correlation Analysis (CCA) identifies the correlations between two sets of multivariate variables based on their covariance, which has been widely applied in diverse fields such as computer vision, natural language processing, and speech analysis. Despite its popularity, CCA can encounter challenges in explaining correlations between two variable sets within high-dimensional data contexts. Thus, this paper studies Sparse Canonical Correlation Analysis (SCCA) that enhances the interpretability of CCA. We first show that SCCA generalizes three well-known sparse optimization problems, sparse PCA, sparse SVD, and sparse regression, which are all classified as NP-hard problems. This result motivates us to develop strong formulations and efficient algorithms. Our main contributions include (i) the introduction of a combinatorial formulation that captures the essence of SCCA and allows the development of exact and approximation algorithms; (ii) the establishment of the complexity results for two low-rank special cases of SCCA; and (iii) the derivation of an equivalent mixed-integer semidefinite programming model that facilitates a specialized branch-and-cut algorithm with analytical cuts. The effectiveness of our proposed formulations and algorithms is validated through numerical experiments.
1057. Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials
tl;dr: A fast text to 3D generative model with high quality geometry, textures which supports PBR decomposition of materials

We present Meta 3D AssetGen (AssetGen), a significant advancement in text-to-3D generation which produces faithful, high-quality meshes with texture and material control. Compared to works that bake shading in the 3D object’s appearance, AssetGen outputs physically-based rendering (PBR) materials, supporting realistic relighting. AssetGen generates first several views of the object with separate shaded and albedo appearance channels, and then reconstructs colours, metalness and roughness in 3D, using a deferred shading loss for efficient supervision. It also uses a sign-distance function to represent 3D shape more reliably and introduces a
corresponding loss for direct shape supervision. This is implemented using fused kernels for high memory efficiency. After mesh extraction, a texture refinement transformer operating in UV space significantly improves sharpness and details. AssetGen achieves 17% improvement in Chamfer Distance and 40% in LPIPS over the best concurrent work for few-view reconstruction, and a human preference of 72% over the best industry competitors of comparable speed, including those that support PBR. Project page with generated assets: https://assetgen.github.io
tl;dr: A Multi-modal Framework Guided by Human Eye-gaze.

In the medical multi-modal frameworks, the alignment of cross-modality features presents a significant challenge. However, existing works have learned features that are implicitly aligned from the data, without considering the explicit relationships in the medical context. This data-reliance may lead to low generalization of the learned alignment relationships. In this work, we propose the Eye-gaze Guided Multi-modal Alignment (EGMA) framework to harness eye-gaze data for better alignment of medical visual and textual features. We explore the natural auxiliary role of radiologists' eye-gaze data in aligning medical images and text, and introduce a novel approach by using eye-gaze data, collected synchronously by radiologists during diagnostic evaluations. We conduct downstream tasks of image classification and image-text retrieval on four medical datasets, where EGMA achieved state-of-the-art performance and stronger generalization across different datasets. Additionally, we explore the impact of varying amounts of eye-gaze data on model performance, highlighting the feasibility and utility of integrating this auxiliary data into multi-modal alignment framework.
tl;dr: We propose estimating 3D human-object interaction regions from egocentric videos, including human contact and object affordance.

Understanding egocentric human-object interaction (HOI) is a fundamental aspect of human-centric perception, facilitating applications like AR/VR and embodied AI. For the egocentric HOI, in addition to perceiving semantics e.g., ''what'' interaction is occurring, capturing ''where'' the interaction specifically manifests in 3D space is also crucial, which links the perception and operation. Existing methods primarily leverage observations of HOI to capture interaction regions from an exocentric view. However, incomplete observations of interacting parties in the egocentric view introduce ambiguity between visual observations and interaction contents, impairing their efficacy. From the egocentric view, humans integrate the visual cortex, cerebellum, and brain to internalize their intentions and interaction concepts of objects, allowing for the pre-formulation of interactions and making behaviors even when interaction regions are out of sight. In light of this, we propose harmonizing the visual appearance, head motion, and 3D object to excavate the object interaction concept and subject intention, jointly inferring 3D human contact and object affordance from egocentric videos. To achieve this, we present EgoChoir, which links object structures with interaction contexts inherent in appearance and head motion to reveal object affordance, further utilizing it to model human contact. Additionally, a gradient modulation is employed to adopt appropriate clues for capturing interaction regions across various egocentric scenarios. Moreover, 3D contact and affordance are annotated for egocentric videos collected from Ego-Exo4D and GIMO to support the task. Extensive experiments on them demonstrate the effectiveness and superiority of EgoChoir.
tl;dr: We provide a mathematical analysis of reparametrizations in the context of Laplace approximations, and devise novel a reparametrization invariant Riemannian diffusion-based approximate posterior.

Current approximate posteriors in Bayesian neural networks (BNNs) exhibit a crucial limitation: they fail to maintain invariance under reparameterization, i.e. BNNs assign different posterior densities to different parametrizations of identical functions. This creates a fundamental flaw in the application of Bayesian principles as it breaks the correspondence between uncertainty over the parameters with uncertainty over the parametrized function. In this paper, we investigate this issue in the context of the increasingly popular linearized Laplace approximation. Specifically, it has been observed that linearized predictives alleviate the common underfitting problems of the Laplace approximation. We develop a new geometric view of reparametrizations from which we explain the success of linearization. Moreover, we demonstrate that these reparameterization invariance properties can be extended to the original neural network predictive using a Riemannian diffusion process giving a straightforward algorithm for approximate posterior sampling, which empirically improves posterior fit.

Large Language Models (LLMs) have demonstrated proficiency in utilizing various tools by coding, yet they face limitations in handling intricate logic and precise control. In embodied tasks, high-level planning is amenable to direct coding, while low-level actions often necessitate task-specific refinement, such as Reinforcement Learning (RL). To seamlessly integrate both modalities, we introduce a two-level hierarchical framework, RL-GPT, comprising a slow agent and a fast agent. The slow agent analyzes actions suitable for coding, while the fast agent executes coding tasks. This decomposition effectively focuses each agent on specific tasks, proving highly efficient within our pipeline. Our approach outperforms traditional RL methods and existing GPT agents, demonstrating superior efficiency. In the Minecraft game, it rapidly obtains diamonds within a single day on an RTX3090. Additionally, it achieves SOTA performance across all designated MineDojo tasks.

Collaborative learning offers a promising avenue for leveraging decentralized data. However, collaboration in groups of strategic learners is not a given. In this work, we consider strategic agents who wish to train a model together but have sampling distributions of different quality. The collaboration is organized by a benevolent aggregator who gathers samples so as to maximize total welfare, but is unaware of data quality. This setting allows us to shed light on the deleterious effect of adverse selection in collaborative learning. More precisely, we demonstrate that when data quality indices are private, the coalition may undergo a phenomenon known as unravelling, wherein it shrinks up to the point that it becomes empty or solely comprised of the worst agent. We show how this issue can be addressed without making use of external transfers, by proposing a novel method inspired by probabilistic verification. This approach makes the grand coalition a Nash equilibrium with high probability despite information asymmetry, thereby breaking unravelling.
tl;dr: We prove that fully connected neural networks with quantized weights exhibit tempered overfitting when using both the smallest interpolating NN and a random interpolating NN.

We study the overfitting behavior of fully connected deep Neural Networks (NNs) with binary weights fitted to perfectly classify a noisy training set. We consider interpolation using both the smallest NN (having the minimal number of weights) and a random interpolating NN. For both learning rules, we prove overfitting is tempered. Our analysis rests on a new bound on the size of a threshold circuit consistent with a partial function. To the best of our knowledge, ours are the first theoretical results on benign or tempered overfitting that: (1) apply to deep NNs, and (2) do not require a very high or very low input dimension.
tl;dr: We study the convergence of the stochastic extragradient method with flip-flop shuffling sampling scheme and anchoring, and show provable improvements over other SGDA/SEG variants.

In minimax optimization, the extragradient (EG) method has been extensively studied because it outperforms the gradient descent-ascent method in convex-concave (C-C) problems. Yet, stochastic EG (SEG) has seen limited success in C-C problems, especially for unconstrained cases. Motivated by the recent progress of shuffling-based stochastic methods, we investigate the convergence of shuffling-based SEG in unconstrained finite-sum minimax problems, in search of convergent shuffling-based SEG. Our analysis reveals that both random reshuffling and the recently proposed flip-flop shuffling alone can suffer divergence in C-C problems. However, with an additional simple trick called anchoring, we develop the SEG with flip-flop anchoring (SEG-FFA) method which successfully converges in C-C problems. We also show upper and lower bounds in the strongly-convex-strongly-concave setting, demonstrating that SEG-FFA has a provably faster convergence rate compared to other shuffling-based methods.
tl;dr: We introduce DynaMITE-RL, a meta-reinforcement learning (meta-RL) approach to approximate task inference in environments where the latent state evolves at varying rates.

We introduce DynaMITE-RL, a meta-reinforcement learning (meta-RL) approach to approximate inference in environments where the latent state evolves at varying rates. We model episode sessions---parts of the episode where the latent state is fixed---and propose three key modifications to existing meta-RL methods: (i) consistency of latent information within sessions, (ii) session masking, and (iii) prior latent conditioning. We demonstrate the importance of these modifications in various domains, ranging from discrete Gridworld environments to continuous-control and simulated robot assistive tasks, illustrating the efficacy of DynaMITE-RL over state-of-the-art baselines in both online and offline RL settings.
tl;dr: We study realizable contextual bandits with general function approximation, and derive near-optimal variance-dependent bounds that demonstrate the role of eluder dimension in this case.

We consider realizable contextual bandits with general function approximation, investigating how small reward variance can lead to better-than-minimax regret bounds. Unlike in minimax regret bounds, we show that the eluder dimension
$d_{\text{elu}}$$-$a measure of the complexity of the function class$-$plays a crucial role in variance-dependent bounds. We consider two types of adversary:
(1) Weak adversary: The adversary sets the reward variance before observing the learner's action. In this setting, we prove that a regret of $\Omega( \sqrt{ \min (A, d_{\text{elu}}) \Lambda } + d_{\text{elu}} )$ is unavoidable when $d_{\text{elu}} \leq \sqrt{A T}$, where $A$ is the number of actions, $T$ is the total number of rounds, and $\Lambda$ is the total variance over $T$ rounds. For the $A\leq d_{\text{elu}}$ regime, we derive a nearly matching upper bound $\tilde{O}( \sqrt{ A\Lambda } + d_{\text{elu} } )$ for the special case where the variance is revealed at the beginning of each round.
(2) Strong adversary: The adversary sets the reward variance after observing the learner's action. We show that a regret of $\Omega( \sqrt{ d_{\text{elu}} \Lambda } + d_{\text{elu}} )$ is unavoidable when $\sqrt{ d_{\text{elu}} \Lambda } + d_{\text{elu}} \leq \sqrt{A T}$. In this setting, we provide an upper bound of order $\tilde{O}( d_{\text{elu}}\sqrt{ \Lambda } + d_{\text{elu}} )$.
Furthermore, we examine the setting where the function class additionally provides distributional information of the reward, as studied by Wang et al. (2024). We demonstrate that the regret bound
$\tilde{O}(\sqrt{d_{\text{elu}} \Lambda} + d_{\text{elu}})$ established in their work is unimprovable when $\sqrt{d_{\text{elu}} \Lambda} + d_{\text{elu}}\leq \sqrt{AT}$. However, with a slightly different definition of the total variance and with the assumption that the reward follows a Gaussian distribution, one can achieve a regret of $\tilde{O}(\sqrt{A\Lambda} + d_{\text{elu}})$.
tl;dr: Normalizing flows are used to allow for explicit mutual information estimation via closed-form expressions

We propose a novel approach to the problem of mutual information (MI) estimation via introducing a family of estimators based on normalizing flows. The estimator maps original data to the target distribution, for which MI is easier to estimate. We additionally explore the target distributions with known closed-form expressions for MI. Theoretical guarantees are provided to demonstrate that our approach yields MI estimates for the original data. Experiments with high-dimensional data are conducted to highlight the practical advantages of the proposed method.

Alignment techniques are critical in ensuring that large language models (LLMs) output helpful and harmless content by enforcing the LLM-generated content to align with human preferences.
However, the existence of noisy preferences (NPs), where the responses are mistakenly labelled as chosen or rejected, could spoil the alignment, thus making the LLMs generate useless and even malicious content.
Existing methods mitigate the issue of NPs from the loss perspective by adjusting the alignment loss based on a clean validation dataset.
Orthogonal to these loss-oriented methods, we propose perplexity-aware correction (PerpCorrect) from the data perspective for robust alignment which detects and corrects NPs based on the differences between the perplexity of the chosen and rejected responses (dubbed as PPLDiff).
Intuitively, a higher PPLDiff indicates a higher probability of the NP because a rejected/chosen response which is mistakenly labelled as chosen/rejected is less preferable to be generated by an aligned LLM, thus having a higher/lower perplexity.
PerpCorrect works in three steps:
(1) PerpCorrect aligns a surrogate LLM using the clean validation data to make the PPLDiff able to distinguish clean preferences (CPs) and NPs.
(2) PerpCorrect further aligns the surrogate LLM by incorporating the reliable clean training data whose PPLDiff is extremely small and reliable noisy training data whose PPLDiff is extremely large after correction to boost the discriminatory power.
(3) Detecting and correcting NPs according to the PPLDiff obtained by the aligned surrogate LLM to obtain a denoised training dataset for robust alignment.
Comprehensive experiments validate that our proposed PerpCorrect can achieve state-of-the-art alignment performance under NPs.
Notably, PerpCorrect demonstrates practical utility by requiring only a modest amount of validation data and being compatible with various alignment techniques.
Our code is available at [PerpCorrect](https://github.com/luxinyayaya/PerpCorrect).
tl;dr: Theoretical study of clustering phenomena in evolution of tokens representations as they propagate through layers of a causal transformer.

This work presents a modification of the self-attention dynamics proposed in Geshkovski et al to better reflect the practically relevant, causally masked attention used in transformer architectures for generative AI. This modification translates into an interacting particle system that cannot be interpreted as a mean-field gradient flow. Despite this loss of structure, we significantly strengthen the results of Geshkovski et al in this context: While previous rigorous results focused on cases where all three matrices (key, query, and value) were scaled identities, we prove asymptotic convergence to a single cluster for arbitrary key-query matrices and value matrix equal to the identity.
Additionally, we establish a connection to the classical R\'enyi parking problem from combinatorial geometry to make initial theoretical steps towards demonstrating the existence of meta-stable states.

We propose adaptive, line-search-free second-order methods with optimal rate of convergence for solving convex-concave min-max problems. By means of an adaptive step size, our algorithms feature a simple update rule that requires solving only one linear system per iteration, eliminating the need for line-search or backtracking mechanisms. Specifically, we base our algorithms on the optimistic method and appropriately combine it with second-order information. Moreover, distinct from common adaptive schemes, we define the step size recursively as a function of the gradient norm and the prediction error in the optimistic update. We first analyze a variant where the step size requires knowledge of the Lipschitz constant of the Hessian. Under the additional assumption of Lipschitz continuous gradients, we further design a parameter-free version by tracking the Hessian Lipschitz constant locally and ensuring the iterates remain bounded. We also evaluate the practical performance of our algorithm by comparing it to existing second-order algorithms for minimax optimization.
tl;dr: A single pre-trained model for zero-shot complex logical query answering on any knowledge graph

Complex logical query answering (CLQA) in knowledge graphs (KGs) goes beyond simple KG completion and aims at answering compositional queries comprised of multiple projections and logical operations. Existing CLQA methods that learn parameters bound to certain entity or relation vocabularies can only be applied to the graph they are trained on which requires substantial training time before being deployed on a new graph. Here we present UltraQuery, the first foundation model for inductive reasoning that can zero-shot answer logical queries on any KG. The core idea of UltraQuery is to derive both projections and logical operations as vocabulary-independent functions which generalize to new entities and relations in any KG.
With the projection operation initialized from a pre-trained inductive KG completion model, UltraQuery can solve CLQA on any KG after finetuning on a single dataset. Experimenting on 23 datasets, UltraQuery in the zero-shot inference mode shows competitive or better query answering performance than best available baselines and sets a new state of the art on 15 of them.
tl;dr: We present weak-to-strong search, framing the alignment of a large language model as a test-time greedy search to maximize the log-probability difference between smaller tuned and untuned models while sampling from the frozen large model

Large language models are usually fine-tuned to align with human preferences. However, fine-tuning a large language model can be challenging. In this work, we introduce $\textit{weak-to-strong search}$, framing the alignment of a large language model as a test-time greedy search to maximize the log-probability difference between small tuned and untuned models while sampling from the frozen large model. This method serves both as (1) a compute-efficient model up-scaling strategy that avoids directly tuning the large model and as (2) an instance of weak-to-strong generalization that enhances a strong model with weak test-time guidance.
Empirically, we demonstrate the flexibility of weak-to-strong search across different tasks. In controlled-sentiment generation and summarization, we use tuned and untuned $\texttt{gpt2}$s to improve the alignment of large models without additional training. Crucially, in a more difficult instruction-following benchmark, AlpacaEval 2.0, we show that reusing off-the-shelf small models (e.g., $\texttt{zephyr-7b-beta}$ and its untuned version) can improve the length-controlled win rates of both white-box and black-box large models against $\texttt{gpt-4-turbo}$ (e.g., $34.4\% \rightarrow 37.9\%$ for $\texttt{Llama-3-70B-Instruct}$ and $16.0\% \rightarrow 20.1\%$ for $\texttt{gpt-3.5-turbo-instruct}$), despite the small models' low win rates $\approx 10.0\%$.

Self-attention in vision transformers is often thought to perform perceptual grouping where tokens attend to other tokens with similar embeddings, which could correspond to semantically similar features of an object. However, attending to dissimilar tokens can be beneficial by providing contextual information. We propose to analyze the query-key interaction by the singular value decomposition of the interaction matrix (i.e. ${\textbf{W}_q}^\top\textbf{W}_k$). We find that in many ViTs, especially those with classification training objectives, early layers attend more to similar tokens, while late layers show increased attention to dissimilar tokens, providing evidence corresponding to perceptual grouping and contextualization, respectively. Many of these interactions between features represented by singular vectors are interpretable and semantic, such as attention between relevant objects, between parts of an object, or between the foreground and background. This offers a novel perspective on interpreting the attention mechanism, which contributes to understanding how transformer models utilize context and salient features when processing images.
tl;dr: We present a neural network with a novel bilinear attention mechanism for supervised graph structure inference, mapping observational data to their dependency structures with enhanced performance and robust generalizability.

Detecting dependencies among variables is a fundamental task across scientific disciplines. We propose a novel neural network model for graph structure inference, which aims to learn a mapping from observational data to the corresponding underlying dependence structures. The model is trained with variably shaped and coupled simulated input data and requires only a single forward pass through the trained network for inference. Central to our approach is a novel bilinear attention mechanism (BAM) operating on covariance matrices of transformed data while respecting the geometry of the manifold of symmetric positive definite (SPD) matrices. Inspired by graphical lasso methods, our model optimizes over continuous graph representations in the SPD space, where inverse covariance matrices encode conditional independence relations. Empirical evaluations demonstrate the robustness of our method in detecting diverse dependencies, excelling in undirected graph estimation and showing competitive performance in completed partially directed acyclic graph estimation via a novel two-step approach. The trained model effectively detects causal relationships and generalizes well across different functional forms of nonlinear dependencies.
tl;dr: This paper introduces an unsupervised representation learning algorithm for time series tailored to biomedical inter-individual studies using tools from shape analysis.

Analyzing inter-individual variability of physiological functions is particularly appealing in medical and biological contexts to describe or quantify health conditions. Such analysis can be done by comparing individuals to a reference one with time series as biomedical data.
This paper introduces an unsupervised representation learning (URL) algorithm for time series tailored to inter-individual studies. The idea is to represent time series as deformations of a reference time series. The deformations are diffeomorphisms parameterized and learned by our method called TS-LDDMM. Once the deformations and the reference time series are learned, the vector representations of individual time series are given by the parametrization of their corresponding deformation. At the crossroads between URL for time series and shape analysis, the proposed algorithm handles irregularly sampled multivariate time series of variable lengths and provides shape-based representations of temporal data.
In this work, we establish a representation theorem for the graph of a time series and derive its consequences on the LDDMM framework. We showcase the advantages of our representation compared to existing methods using synthetic data and real-world examples motivated by biomedical applications.

Tokenizers serve as crucial interfaces between models and linguistic data, substantially influencing the efficacy and precision of large language models (LLMs). Traditional tokenization methods often rely on static frequency-based statistics and are not inherently synchronized with LLM architectures, which may limit model performance. In this study, we propose a simple but effective method to learn tokenizers specifically engineered for seamless integration with LLMs. Initiating with a broad initial vocabulary, we refine our tokenizer by monitoring changes in the model’s perplexity during training, allowing for the selection of a tokenizer that is closely aligned with the model’s evolving dynamics. Through iterative refinement, we develop an optimized tokenizer. Our empirical evaluations demonstrate that this adaptive approach significantly enhances accuracy compared to conventional methods, maintaining comparable vocabulary sizes and affirming its potential to improve LLM functionality.

The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
tl;dr: We prototype using mechanistic interpretability to derive and formally verify guarantees on model performance in a toy setting.

We propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance.
We prototype this approach by formally proving accuracy lower bounds for a small transformer trained on Max-of-$K$, validating proof transferability across 151 random seeds and four values of $K$.
We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models.
Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding.
Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds.
We confirm these connections by qualitatively examining a subset of our proofs.
Finally, we identify compounding structureless errors as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.

Recommending out-of-vocabulary (OOV) items is a challenging problem since the in-vocabulary (IV) items have well-trained behavioral embeddings but the OOV items only have content features. Current OOV recommendation models often generate 'makeshift' embeddings for OOV items from content features and then jointly recommend with the `makeshift' OOV item embeddings and the behavioral IV item embeddings. However, merely using the 'makeshift' embedding will result in suboptimal recommendation performance due to the substantial gap between the content feature and the behavioral embeddings. To bridge the gap, we propose a novel **User Sequence IMagination (USIM)** fine-tuning framework, which first imagines the user sequences and then refines the generated OOV embeddings with the user behavioral embeddings. Specifically, we frame the user sequence imagination as a reinforcement learning problem and develop a recommendation-focused reward function to evaluate to what extent a user can help recommend the OOV items. Besides, we propose an embedding-driven transition function to model the embedding transition after imaging a user. USIM has been deployed on a prominent e-commerce platform for months, offering recommendations for millions of OOV items and billions of users. Extensive experiments demonstrate that USIM outperforms traditional generative models in OOV item recommendation performance across traditional collaborative filtering and GNN-based collaborative filtering models.

We consider nonconvex stochastic optimization problems in the asynchronous centralized distributed setup where the communication times from workers to a server can not be ignored, and the computation and communication times are potentially different for all workers. Using an unbiassed compression technique, we develop a new method—Shadowheart SGD—that provably improves the time complexities of all previous centralized methods. Moreover, we show that the time complexity of Shadowheart SGD is optimal in the family of centralized methods with compressed communication. We also consider the bidirectional setup, where broadcasting from the server to the workers is non-negligible, and develop a corresponding method.
tl;dr: The paper introduces a two-stage fairness-aware meta-learning method based on Nash Bargaining that notably improves performance and fairness, supported by theoretical analysis and empirical results.

To address issues of group-level fairness in machine learning, it is natural to adjust model parameters based on specific fairness objectives over a sensitive-attributed validation set. Such an adjustment procedure can be cast within a meta-learning framework. However, naive integration of fairness goals via meta-learning can cause hypergradient conflicts for subgroups, resulting in unstable convergence and compromising model performance and fairness. To navigate this issue, we frame the resolution of hypergradient conflicts as a multi-player cooperative bargaining game. We introduce a two-stage meta-learning framework in which the first stage involves the use of a Nash Bargaining Solution (NBS) to resolve hypergradient conflicts and steer the model toward the Pareto front, and the second stage optimizes with respect to specific fairness goals.
Our method is supported by theoretical results, notably a proof of the NBS for gradient aggregation free from linear independence assumptions, a proof of Pareto improvement, and a proof of monotonic improvement in validation loss. We also show empirical effects across various fairness objectives in six key fairness datasets and two image classification tasks.
1082. UrbanKGent: A Unified Large Language Model Agent Framework for Urban Knowledge Graph Construction
tl;dr: In this paper proposed UrbanKGent, the first UrbanKG construction agent framework with Large Language Models.

Urban knowledge graph has recently worked as an emerging building block to distill critical knowledge from multi-sourced urban data for diverse urban application scenarios. Despite its promising benefits, urban knowledge graph construction (UrbanKGC) still heavily relies on manual effort, hindering its potential advancement. This paper presents UrbanKGent, a unified large language model agent framework, for urban knowledge graph construction. Specifically, we first construct the knowledgeable instruction set for UrbanKGC tasks (such as relational triplet extraction and knowledge graph completion) via heterogeneity-aware and geospatial-infused instruction generation. Moreover, we propose a tool-augmented iterative trajectory refinement module to enhance and refine the trajectories distilled from GPT-4. Through hybrid instruction fine-tuning with augmented trajectories on Llama 2 and Llama 3 family, we obtain UrbanKGC agent family, consisting of UrbanKGent-7/8/13B version. We perform a comprehensive evaluation on two real-world datasets using both human and GPT-4 self-evaluation. The experimental results demonstrate that UrbanKGent family can not only significantly outperform 31 baselines in UrbanKGC tasks, but also surpass the state-of-the-art LLM, GPT-4, by more than 10% with approximately 20 times lower cost. Compared with the existing benchmark, the UrbanKGent family could help construct an UrbanKG with hundreds of times richer relationships using only one-fifth of the data. Our data and code are available at https://github.com/usail-hkust/UrbanKGent.

Autoformalization is the task of translating natural language materials into machine-verifiable formalisations. Progress in autoformalization research is hindered by the lack of a sizeable dataset consisting of informal-formal pairs expressing the same essence. Existing methods tend to circumvent this challenge by manually curating small corpora or using few-shot learning with large language models. But these methods suffer from data scarcity and formal language acquisition difficulty. In this work, we create mma, a large, flexible, multi-language, and multi-domain dataset of informal-formal pairs, by using a language model to translate in the reverse direction, that is, from formal mathematical statements into corresponding informal ones. Experiments show that language models fine-tuned on mma can produce up to $29-31$\% of statements acceptable with minimal corrections on the miniF2F and ProofNet benchmarks, up from $0$\% with the base model. We demonstrate that fine-tuning on multi-language formal data results in more capable autoformalization models even on single-language tasks.
tl;dr: This paper introduces a multi-iteration scalable framework that enhances the size of the hallucination annotation dataset while improving the precision of the annotator.

Large language models (LLMs) exhibit hallucinations in long-form question-answering tasks across various domains and wide applications. Current hallucination detection and mitigation datasets are limited in domain and size, which struggle to scale due to prohibitive labor costs and insufficient reliability of existing hallucination annotators. To facilitate the scalable oversight of LLM hallucinations, this paper introduces an iterative self-training framework that simultaneously and progressively scales up the annotation dataset and improves the accuracy of the annotator. Based on the Expectation Maximization algorithm, in each iteration, the framework first applies an automatic hallucination annotation pipeline for a scaled dataset and then trains a more accurate annotator on the dataset. This new annotator is adopted in the annotation pipeline for the next iteration. Extensive experimental results demonstrate that the finally obtained hallucination annotator with only 7B parameters surpasses GPT-4 and obtains new state-of-the-art hallucination detection results on HaluEval and HalluQA by zero-shot inference. Such an annotator can not only evaluate the hallucination levels of various LLMs on the large-scale dataset but also help to mitigate the hallucination of LLMs generations, with the Natural Language Inference metric increasing from 25% to 37% on HaluEval.

Algorithms for bilevel optimization often encounter Hessian computations, which are prohibitive in high dimensions. While recent works offer first-order methods for unconstrained bilevel problems, the constrained setting remains relatively underexplored. We present first-order linearly constrained optimization methods with finite-time hypergradient stationarity guarantees. For linear equality constraints, we attain $\epsilon$-stationarity in $\widetilde{O}(\epsilon^{-2})$ gradient oracle calls, which is nearly-optimal.
For linear inequality constraints, we attain $(\delta,\epsilon)$-Goldstein stationarity in $\widetilde{O}(d{\delta^{-1} \epsilon^{-3}})$ gradient oracle calls, where $d$ is the upper-level dimension.
Finally, we obtain for the linear inequality setting dimension-free rates of $\widetilde{O}({\delta^{-1} \epsilon^{-4}})$ oracle complexity under the additional assumption of oracle access to the optimal dual variable. Along the way, we develop new nonsmooth nonconvex optimization methods with inexact oracles. Our numerical experiments verify these guarantees.
tl;dr: We propose a novel optimization method, AgA, that employs gradient adjustments to progressively align individual and collective objectives in the mixed-motive setting.

Among the research topics in multi-agent learning, mixed-motive cooperation is one of the most prominent challenges, primarily due to the mismatch between individual and collective goals. The cutting-edge research is focused on incorporating domain knowledge into rewards and introducing additional mechanisms to incentivize cooperation. However, these approaches often face shortcomings such as the effort on manual design and the absence of theoretical groundings. To close this gap, we model the mixed-motive game as a differentiable game for the ease of illuminating the learning dynamics towards cooperation. More detailed, we introduce a novel optimization method named \textbf{\textit{A}}ltruistic \textbf{\textit{G}}radient \textbf{\textit{A}}djustment (\textbf{\textit{AgA}}) that employs gradient adjustments to progressively align individual and collective objectives. Furthermore, we theoretically prove that AgA effectively attracts gradients to stable fixed points of the collective objective while considering individual interests, and we validate these claims with empirical evidence. We evaluate the effectiveness of our algorithm AgA through benchmark environments for testing mixed-motive collaboration with small-scale agents such as the two-player public good game and the sequential social dilemma games, Cleanup and Harvest, as well as our self-developed large-scale environment in the game StarCraft II.
tl;dr: An unsupervised neural learning architecture for universal and fully-automated 3D surface parameterization

Surface parameterization plays an essential role in numerous computer graphics and geometry processing applications. Traditional parameterization approaches are designed for high-quality meshes laboriously created by specialized 3D modelers, thus unable to meet the processing demand for the current explosion of ordinary 3D data. Moreover, their working mechanisms are typically restricted to certain simple topologies, thus relying on cumbersome manual efforts (e.g., surface cutting, part segmentation) for pre-processing. In this paper, we introduce the Flatten Anything Model (FAM), an unsupervised neural architecture to achieve global free-boundary surface parameterization via learning point-wise mappings between 3D points on the target geometric surface and adaptively-deformed UV coordinates within the 2D parameter domain. To mimic the actual physical procedures, we ingeniously construct geometrically-interpretable sub-networks with specific functionalities of surface cutting, UV deforming, unwrapping, and wrapping, which are assembled into a bi-directional cycle mapping framework. Compared with previous methods, our FAM directly operates on discrete surface points without utilizing connectivity information, thus significantly reducing the strict requirements for mesh quality and even applicable to unstructured point cloud data. More importantly, our FAM is fully-automated without the need for pre-cutting and can deal with highly-complex topologies, since its learning process adaptively finds reasonable cutting seams and UV boundaries. Extensive experiments demonstrate the universality, superiority, and inspiring potential of our proposed neural surface parameterization paradigm. Our code is available at https://github.com/keeganhk/FlattenAnything.

Average-link is widely recognized as one of the most popular and effective methods for building hierarchical agglomerative clustering. The available theoretical analyses show that this method has a much better approximation than other popular heuristics, as single-linkage and complete-linkage, regarding variants of Dasgupta's cost function [STOC 2016]. However, these analyses do not separate average-link from a random hierarchy and they are not appealing for metric spaces since every hierarchical clustering has a $1/2$ approximation with regard to the variant of Dasgupta's function
that is employed for dissimilarity measures [Moseley and Yang 2020]. In this paper, we present a comprehensive study of the performance of \avglink \, in metric spaces, regarding several natural criteria that capture separability and cohesion, and are more interpretable than Dasgupta's cost function and its variants. We also present experimental results with real datasets that, together with our theoretical analyses, suggest that average-link is a better choice than other related methods when both cohesion and separability are important goals.
tl;dr: We use star geometry and dual Brunn-Minkowski theory to analyze what is the ``best'' regularizer for a given data distribution.

Variational regularization is a classical technique to solve statistical inference tasks and inverse problems, with modern data-driven approaches parameterizing regularizers via deep neural networks showcasing impressive empirical performance. Recent works along these lines learn task-dependent regularizers. This is done by integrating information about the measurements and ground-truth data in an unsupervised, critic-based loss function, where the regularizer attributes low values to likely data and high values to unlikely data. However, there is little theory about the structure of regularizers learned via this process and how it relates to the two data distributions. To make progress on this challenge, we initiate a study of optimizing critic-based loss functions to learn regularizers over a particular family of regularizers: gauges (or Minkowski functionals) of star-shaped bodies. This family contains regularizers that are commonly employed in practice and shares properties with regularizers parameterized by deep neural networks. We specifically investigate critic-based losses derived from variational representations of statistical distances between probability measures. By leveraging tools from star geometry and dual Brunn-Minkowski theory, we illustrate how these losses can be interpreted as dual mixed volumes that depend on the data distribution. This allows us to derive exact expressions for the optimal regularizer in certain cases. Finally, we identify which neural network architectures give rise to such star body gauges and when do such regularizers have favorable properties for optimization. More broadly, this work highlights how the tools of star geometry can aid in understanding the geometry of unsupervised regularizer learning.
tl;dr: We introduce DIAMOND, a diffusion world model, to train sample-efficient RL agents on Atari 100k.

World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. We further demonstrate that DIAMOND's diffusion world model can stand alone as an interactive neural game engine by training on static *Counter-Strike: Global Offensive* gameplay. To foster future research on diffusion for world modeling, we release our code, agents, videos and playable world models at https://diamond-wm.github.io.

As a widely explored multi-modal task, Temporal Sentence Grounding in videos (TSG) endeavors to retrieve a specific video segment matched with a given query text from a video. The traditional paradigm for TSG generally assumes that relevant segments always exist within a given video. However, this assumption is restrictive and unrealistic in real-world applications where the existence of a query-related segment is uncertain, easily resulting in erroneous grounding. Motivated by the research gap and practical application, this paper introduces a new task, named Temporal Sentence Grounding with Relevance Feedback (TSG-RF) in videos, which accommodates the possibility that a video may or may not include a segment related to the query. This task entails localizing precise video segments that semantically align with the query text when such content is present, while delivering definitive feedback on the non-existence of related segments when absent. Moreover, we propose a novel Relation-aware Temporal Sentence Grounding (RaTSG) network for addressing this challenging task. This network first reformulates the TSG-RF task as a foreground-background detection problem by investigating whether the query-related semantics exist in both frame and video levels. Then, a multi-granularity relevance discriminator is exploited to produce precise video-query relevance feedback and a relation-aware segment grounding module is employed to selectively conduct the grounding process, dynamically adapting to the presence or absence of query-related segments in videos. To validate our RaTSG network, we reconstruct two popular TSG datasets, establishing a rigorous benchmark for TSG-RF. Experimental results demonstrate the effectiveness of our proposed RaTSG for the TSG-RF task. Our source code is available at https://github.com/HuiGuanLab/RaTSG.

The Schrödinger Bridge (SB) problem offers a powerful framework for combining optimal transport and diffusion models. A promising recent approach to solve the SB problem is the Iterative Markovian Fitting (IMF) procedure, which alternates between Markovian and reciprocal projections of continuous-time stochastic processes. However, the model built by the IMF procedure has a long inference time due to using many steps of numerical solvers for stochastic differential equations. To address this limitation, we propose a novel Discrete-time IMF (D-IMF) procedure in which learning of stochastic processes is replaced by learning just a few transition probabilities in discrete time. Its great advantage is that in practice it can be naturally implemented using the Denoising Diffusion GAN (DD-GAN), an already well-established adversarial generative modeling technique. We show that our D-IMF procedure can provide the same quality of unpaired domain translation as the IMF, using only several generation steps instead of hundreds.
tl;dr: Increasing the dataset size helps language models capture the latent hierarchical structure of data by leveraging token correlations.

How much data is required to learn the structure of a language via next-token prediction? We study this question for synthetic datasets generated via a Probabilistic Context-Free Grammar (PCFG)---a hierarchical generative model that captures the tree-like structure of natural languages. We determine token-token correlations analytically in our model and show that they can be used to build a representation of the grammar's hidden variables, the longer the range the deeper the variable. In addition, a finite training set limits the resolution of correlations to an effective range, whose size grows with that of the training set. As a result, a Language Model trained with increasingly many examples can build a deeper representation of the grammar's structure, thus reaching good performance despite the high dimensionality of the problem. We conjecture that the relationship between training set size and effective range of correlations holds beyond our synthetic datasets, and we test it in a collection of lines from Shakespeare's plays. In particular, we show that reducing the input size leads to saturation of the test loss decay at a characteristic training set size that can be predicted in our framework.
tl;dr: We show theoretically and numerically that the training of Energy-based models undergoes several phase transitions.

In this paper, we investigate the feature encoding process in a prototypical energy-based generative model, the Restricted Boltzmann Machine (RBM). We start with an analytical investigation using simplified architectures and data structures, and end with numerical analysis of real trainings on real datasets. Our study tracks the evolution of the model’s weight matrix through its singular value decomposition, revealing a series of thermodynamic phase transitions that shape the principal learning modes of the empirical probability distribution. We first describe this process analytically in several controlled setups that allow us to fully monitor the training dynamics until convergence. We then validate these findings by training the Bernoulli-Bernoulli RBM on real data sets. By studying the phase behavior over data sets of increasing dimension, we show that these phase transitions are genuine in the thermodynamic sense. Moreover, we propose a mean-field finite-size scaling hypothesis, confirming that the initial phase transition, reminiscent of the paramagnetic-to-ferromagnetic phase transition in mean-field ferromagnetism models, is governed by mean-field critical exponents.
tl;dr: We derive sample complexity bounds for BayesOpt algorithms with kernels that incorporate known invariance of the target function, and demonstrate their application to the design of a fusion reactor.

Bayesian optimisation (BO) is a powerful framework for global optimisation of costly functions, using predictions from Gaussian process models (GPs). In this work, we apply BO to functions that exhibit invariance to a known group of transformations. We show that vanilla and constrained BO algorithms are inefficient when optimising such invariant objectives, and provide a method for incorporating group invariances into the kernel of the GP to produce invariance-aware algorithms that achieve significant improvements in sample efficiency. We derive a bound on the maximum information gain of these invariant kernels, and provide novel upper and lower bounds on the number of observations required for invariance-aware BO algorithms to achieve $\epsilon$-optimality. We demonstrate our method's improved performance on a range of synthetic invariant and quasi-invariant functions. We also apply our method in the case where only some of the invariance is incorporated into the kernel, and find that these kernels achieve similar gains in sample efficiency at significantly reduced computational cost. Finally, we use invariant BO to design a current drive system for a nuclear fusion reactor, finding a high-performance solution where non-invariant methods failed.
tl;dr: We give a model of how to infer hidden natural language rules by doing experiments using probabilistic reasoning with language models.

We give a model of how to infer natural language rules by doing experiments. The
model integrates Large Language Models (LLMs) with Monte Carlo algorithms for
probabilistic inference, interleaving online belief updates with experiment design
under information-theoretic criteria. We conduct a human-model comparison on a
Zendo-style task, finding that a critical ingredient for modeling the human data is to
assume that humans also consider fuzzy, probabilistic rules, in addition to assuming
that humans perform approximately-Bayesian belief updates. We also compare
with recent algorithms for using LLMs to generate and revise hypotheses, finding
that our online inference method yields higher accuracy at recovering the true
underlying rule, and provides better support for designing optimal experiments.
tl;dr: We propose a novel computational pipeline to ground MARL communication in human language using embodied LLM agents, enabling interpretable and generalizable communication in ad-hoc multi-agent teamwork.

Multi-Agent Reinforcement Learning (MARL) methods have shown promise in enabling agents to learn a shared communication protocol from scratch and accomplish challenging team tasks. However, the learned language is usually not interpretable to humans or other agents not co-trained together, limiting its applicability in ad-hoc teamwork scenarios. In this work, we propose a novel computational pipeline that aligns the communication space between MARL agents with an embedding space of human natural language by grounding agent communications on synthetic data generated by embodied Large Language Models (LLMs) in interactive teamwork scenarios. Our results demonstrate that introducing language grounding not only maintains task performance but also accelerates the emergence of communication. Furthermore, the learned communication protocols exhibit zero-shot generalization capabilities in ad-hoc teamwork scenarios with unseen teammates and novel task states. This work presents a significant step toward enabling effective communication and collaboration between artificial agents and humans in real-world teamwork settings.

This paper proposes **GO4Align**, a multi-task optimization approach that tackles task imbalance by explicitly aligning the optimization across tasks. To achieve this, we design an adaptive group risk minimization strategy, comprising two techniques in implementation: (i) dynamical group assignment, which clusters similar tasks based on task interactions; (ii) risk-guided group indicators, which exploit consistent task correlations with risk information from previous iterations. Comprehensive experimental results on diverse benchmarks demonstrate our method's performance superiority with even lower computational costs.
tl;dr: We propose to construct the Selective Conformal p-value, which takes into account the selection effects to guarantee the false discovery rate in the predictive setting

The task of distinguishing individuals of interest from a vast pool of candidates using predictive models has garnered significant attention in recent years. This task can be framed as a *conformalized multiple testing* procedure, which aims at quantifying prediction uncertainty by controlling the false discovery rate (FDR) via conformal inference. In this paper, we tackle the challenge of conformalized multiple testing after data-dependent selection procedures. To guarantee the construction of valid test statistics that accurately capture the distorted distribution resulting from the selection process, we leverage a holdout labeled set to closely emulate the selective distribution. Our approach involves adaptively picking labeled data to create a calibration set based on the stability of the selection rule. This strategy ensures that the calibration data and the selected test unit are exchangeable, allowing us to develop valid conformal p-values. Implementing with the famous Benjamini-Hochberg (BH) procedure, it effectively controls the FDR over the selected subset. To handle the randomness of the selected subset and the dependence among the constructed p-values, we establish a unified theoretical framework. This framework extends the application of conformalized multiple testing to complex selective settings. Furthermore, we conduct numerical studies to showcase the effectiveness and validity of our procedures across various scenarios.
tl;dr: Utilizing convexity of the forward KL divergence, we establish a global convergence result for fitting an amortized variational posterior by analyzing neural tangent kernel (NTK) dynamics in the large-width setting.

In variational inference (VI), an approximation of the posterior distribution is selected from a family of distributions through numerical optimization. With the most common variational objective function, known as the evidence lower bound (ELBO), only convergence to a *local* optimum can be guaranteed. In this work, we instead establish the *global* convergence of a particular VI method. This VI method, which may be considered an instance of neural posterior estimation (NPE), minimizes an expectation of the inclusive (forward) KL divergence to fit a variational distribution that is parameterized by a neural network. Our convergence result relies on the neural tangent kernel (NTK) to characterize the gradient dynamics that arise from considering the variational objective in function space. In the asymptotic regime of a fixed, positive-definite neural tangent kernel, we establish conditions under which the variational objective admits a unique solution in a reproducing kernel Hilbert space (RKHS). Then, we show that the gradient descent dynamics in function space converge to this unique function. In ablation studies and practical problems, we demonstrate that our results explain the behavior of NPE in non-asymptotic finite-neuron settings, and show that NPE outperforms ELBO-based optimization, which often converges to shallow local optima.

Consider the domain of multiclass classification within the adversarial online setting. What is the price of relying on bandit feedback as opposed to full information? To what extent can an adaptive adversary amplify the loss compared to an oblivious one? To what extent can a randomized learner reduce the loss compared to a deterministic one? We study these questions in the mistake bound model and provide nearly tight answers.
We demonstrate that the optimal mistake bound under bandit feedback is at most $O(k)$ times higher than the optimal mistake bound in the full information case, where $k$ represents the number of labels. This bound is tight and provides an answer to an open question previously posed and studied by Daniely and Helbertal ['13] and by Long ['17, '20], who focused on deterministic learners.
Moreover, we present nearly optimal bounds of $\tilde{\Theta}(k)$ on the gap between randomized and deterministic learners, as well as between adaptive and oblivious adversaries in the bandit feedback setting. This stands in contrast to the full information scenario, where adaptive and oblivious adversaries are equivalent, and the gap in mistake bounds between randomized and deterministic learners is a constant multiplicative factor of $2$.
In addition, our results imply that in some cases the optimal randomized mistake bound is approximately the square-root of its deterministic parallel. Previous results show that this is essentially the smallest it can get.
Some of our results are proved via a reduction to prediction with expert advice under bandit feedback, a problem interesting on its own right. For this problem, we provide a randomized algorithm which is nearly optimal in some scenarios.

Text-to-image diffusion has attracted vast attention due to its impressive image-generation capabilities. However, when it comes to human-centric text-to-image generation, particularly in the context of faces and hands, the results often fall short of naturalness due to insufficient training priors. We alleviate the issue in this work from two perspectives. 1) From the data aspect, we carefully collect a human-centric dataset comprising over one million high-quality human-in-the-scene images and two specific sets of close-up images of faces and hands. These datasets collectively provide a rich prior knowledge base to enhance the human-centric image generation capabilities of the diffusion model. 2) On the methodological front, we propose a simple yet effective method called Mixture of Low-rank Experts (MoLE) by considering low-rank modules trained on close-up hand and face images respectively as experts. This concept draws inspiration from our observation of low-rank refinement, where a low-rank module trained by a customized close-up dataset has the potential to enhance the corresponding image part when applied at an appropriate scale. To validate the superiority of MoLE in the context of human-centric image generation compared to state-of-the-art, we construct two benchmarks and perform evaluations with diverse metrics and human studies. Datasets, model, and code are released at https://sites.google.com/view/mole4diffuser/.

Offline-to-online (O2O) reinforcement learning (RL) provides an effective means of leveraging an offline pre-trained policy as initialization to improve performance rapidly with limited online interactions. Recent studies often design fine-tuning strategies for a specific offline RL method and cannot perform general O2O learning from any offline method. To deal with this problem, we disclose that there are evaluation and improvement mismatches between the offline dataset and the online environment, which hinders the direct application of pre-trained policies to online fine-tuning. In this paper, we propose to handle these two mismatches simultaneously, which aims to achieve general O2O learning from any offline method to any online method. Before online fine-tuning, we re-evaluate the pessimistic critic trained on the offline dataset in an optimistic way and then calibrate the misaligned critic with the reliable offline actor to avoid erroneous update. After obtaining an optimistic and and aligned critic, we perform constrained fine-tuning to combat distribution shift during online learning. We show empirically that the proposed method can achieve stable and efficient performance improvement on multiple simulated tasks when compared to the state-of-the-art methods.
tl;dr: We study theoretical Reinforcement Learning from Human Feedback (RLHF) under a general preference oracle.

We investigate Reinforcement Learning from Human Feedback (RLHF) in the context of a general preference oracle. In particular, we do not assume the existence of a reward function and an oracle preference signal drawn from the Bradley-Terry model as most of the prior works do. We consider a standard mathematical formulation, the reverse-KL regularized minimax game between two LLMs for RLHF under general preference oracle. The learning objective of this formulation is to find a policy so that it is consistently preferred by the KL-regularized preference oracle over any competing LLMs. We show that this framework is strictly more general than the reward-based one, and propose sample-efficient algorithms for both the offline learning from a pre-collected preference dataset and online learning where we can query the preference oracle along the way of training. Empirical studies verify the effectiveness of the proposed framework.
tl;dr: We propose using hallucinations as prior knowledge to extract and validate task-related information, which helps generate instance-specific prompts for reducing reliance on manual prompts in promptable segmentation.

Promptable segmentation typically requires instance-specific manual prompts to guide the segmentation of each desired object. To minimize such a need, task-generic promptable segmentation has been introduced, which employs a single task-generic prompt to segment various images of different objects in the same task. Current methods use Multimodal Large Language Models (MLLMs) to reason detailed instance-specific prompts from a task-generic prompt for improving segmentation accuracy. The effectiveness of this segmentation heavily depends on the precision of these derived prompts. However, MLLMs often suffer hallucinations during reasoning, resulting in inaccurate prompting. While existing methods focus on eliminating hallucinations to improve a model, we argue that MLLM hallucinations can reveal valuable contextual insights when leveraged correctly, as they represent pre-trained large-scale knowledge beyond individual images. In this paper, we first utilize hallucinations to mine task-related information from images and verify its accuracy to enhance precision of the generated prompts. Specifically, we introduce an iterative \textbf{Pro}mpt-\textbf{Ma}sk \textbf{C}ycle generation framework (ProMaC) with a prompt generator and a mask generator. The prompt generator uses a multi-scale chain of thought prompting, initially leveraging hallucinations to extract extended contextual prompts on a test image. These hallucinations are then minimized to formulate precise instance-specific prompts, directing the mask generator to produce masks that are consistent with task semantics by mask semantic alignment. Iteratively the generated masks induce the prompt generator to focus more on task-relevant image areas and reduce irrelevant hallucinations, resulting jointly in better prompts and masks. Experiments on 5 benchmarks demonstrate the effectiveness of ProMaC. Code is in https://lwpyh.github.io/ProMaC/.
tl;dr: We design optimization algorithms using electric RLC circuits.

We present a novel methodology for convex optimization algorithm design using ideas from electric RLC circuits. Given an optimization problem, the first stage of the methodology is to design an appropriate electric circuit whose continuous-time dynamics converge to the solution of the optimization problem at hand. Then, the second stage is an automated, computer-assisted discretization of the continuous-time dynamics, yielding a provably convergent discrete-time algorithm. Our methodology recovers many classical (distributed) optimization algorithms and enables users to quickly design and explore a wide range of new algorithms with convergence guarantees.

Adversarial training has emerged as a popular approach for training models that are robust to inference-time adversarial attacks. However, our theoretical understanding of why and when it works remains limited. Prior work has offered generalization analysis of adversarial training, but they are either restricted to the Neural Tangent Kernel (NTK) regime or they make restrictive assumptions about data such as (noisy) linear separability or robust realizability. In this work, we study the stability and generalization of adversarial training for two-layer networks **without any data distribution assumptions** and **beyond the NTK regime**. Our findings suggest that for networks with *any given initialization* and *sufficiently large width*, the generalization bound can be effectively controlled via early stopping. We further improve the generalization bound by leveraging smoothing using Moreau’s envelope.

Open-World Object Detection (OWOD) is a challenging task that requires the detector to identify unlabeled objects and continuously demands the detector to learn new knowledge based on existing ones. Existing methods primarily focus on recalling unknown objects, neglecting to explore the reasons behind them. This paper aims to understand the model's behavior in predicting the unknown category. First, we model the text attribute and the positive sample probability, obtaining their empirical probability, which can be seen as the detector's estimation of the likelihood of the target with certain known attributes being predicted as the foreground. Then, we jointly decide whether the current object should be categorized in the unknown category based on the empirical, the in-distribution, and the out-of-distribution probability. Finally, based on the decision-making process, we can infer the similarity of an unknown object to known classes and identify the attribute with the most significant impact on the decision-making process. This additional information can help us understand the behavior of the model's prediction in the unknown class. The evaluation results on the Real-World Object Detection (RWD) benchmark, which consists of five real-world application datasets, show that we surpassed the previous state-of-the-art (SOTA) with an absolute gain of 5.3 mAP for unknown classes, reaching 20.5 mAP. Our code is available at https://github.com/xxyzll/UMB.

Although Vision Transformers (ViTs) have recently advanced computer vision tasks significantly, an important real-world problem was overlooked: adapting to variable input resolutions. Typically, images are resized to a fixed resolution, such as 224x224, for efficiency during training and inference. However, uniform input size conflicts with real-world scenarios where images naturally vary in resolution. Modifying the preset resolution of a model may severely degrade the performance. In this work, we propose to enhance the model adaptability to resolution variation by optimizing the patch embedding. The proposed method, called Multi-Scale Patch Embedding (MSPE), substitutes the standard patch embedding with multiple variable-sized patch kernels and selects the best parameters for different resolutions, eliminating the need to resize the original image. Our method does not require high-cost training or modifications to other parts, making it easy to apply to most ViT models. Experiments in image classification, segmentation, and detection tasks demonstrate the effectiveness of MSPE, yielding superior performance on low-resolution inputs and performing comparably on high-resolution inputs with existing methods.
tl;dr: We propose to model RL environments with code written by an LLM, propose a method to improve code generation for this task and show how to plan with code world models.

In this work we consider Code World Models, world models generated by a Large Language Model (LLM) in the form of Python code for model-based Reinforcement Learning (RL). Calling code instead of LLMs for planning has potential to be more precise, reliable, interpretable, and extremely efficient.
However, writing appropriate Code World Models requires the ability to understand complex instructions, to generate exact code with non-trivial logic and to self-debug a long program with feedback from unit tests and environment trajectories. To address these challenges, we propose Generate, Improve and Fix with Monte Carlo Tree Search (GIF-MCTS), a new code generation strategy for LLMs. To test our approach in an offline RL setting, we introduce the Code World Models Benchmark (CWMB), a suite of program synthesis and planning tasks comprised of 18 diverse RL environments paired with corresponding textual descriptions and curated trajectories. GIF-MCTS surpasses all baselines on the CWMB and two other benchmarks, and we show that the Code World Models synthesized with it can be successfully used for planning, resulting in model-based RL agents with greatly improved sample efficiency and inference speed.
1111. Detecting Brittle Decisions for Free: Leveraging Margin Consistency in Deep Robust Classifiers
tl;dr: We introduce and use margin-consistency for robust deep classifiers the efficient detection of vulnerable instances to adversarial examples via the logit margin..

Despite extensive research on adversarial training strategies to improve robustness, the decisions of even the most robust deep learning models can still be quite sensitive to imperceptible perturbations, creating serious risks when deploying them for high-stakes real-world applications. While detecting such cases may be critical, evaluating a model's vulnerability at a per-instance level using adversarial attacks is computationally too intensive and unsuitable for real-time deployment scenarios. The input space margin is the exact score to detect non-robust samples and is intractable for deep neural networks. This paper introduces the concept of margin consistency -- a property that links the input space margins and the logit margins in robust models -- for efficient detection of vulnerable samples. First, we establish that margin consistency is a necessary and sufficient condition to use a model's logit margin as a score for identifying non-robust samples. Next, through comprehensive empirical analysis of various robustly trained models on CIFAR10 and CIFAR100 datasets, we show that they indicate high margin consistency with a strong correlation between their input space margins and the logit margins. Then, we show that we can effectively use the logit margin to confidently detect brittle decisions with such models. Finally, we address cases where the model is not sufficiently margin-consistent by learning a pseudo-margin from the feature representation. Our findings highlight the potential of leveraging deep representations to efficiently assess adversarial vulnerability in deployment scenarios.

Subset selection tasks, such as anomaly detection and compound selection in AI-assisted drug discovery, are crucial for a wide range of applications. Learning subset-valued functions with neural networks has achieved great success by incorporating permutation invariance symmetry into the architecture. However, existing neural set architectures often struggle to either capture comprehensive information from the superset or address complex interactions within the input. Additionally, they often fail to perform in scenarios where superset sizes surpass available memory capacity. To address these challenges, we introduce the novel concept of the Identity Property, which requires models to integrate information from the originating set, resulting in the development of neural networks that excel at performing effective subset selection from large supersets. Moreover, we present the Hierarchical Representation of Neural Subset Selection (HORSE), an attention-based method that learns complex interactions and retains information from both the input set and the optimal subset supervision signal. Specifically, HORSE enables the partitioning of the input ground set into manageable chunks that can be processed independently and then aggregated, ensuring consistent outcomes across different partitions. Through extensive experimentation, we demonstrate that HORSE significantly enhances neural subset selection performance by capturing more complex information and surpasses state-of-the-art methods in handling large-scale inputs by a margin of up to 20%.
1113. Federated Natural Policy Gradient and Actor Critic Methods for Multi-task Reinforcement Learning

Federated reinforcement learning (RL) enables collaborative decision making of multiple distributed agents without sharing local data trajectories. In this work, we consider a multi-task setting, in which each agent has its own private reward function corresponding to different tasks, while sharing the same transition kernel of the environment. Focusing on infinite-horizon Markov decision processes, the goal is to learn a globally optimal policy that maximizes the sum of the discounted total rewards of all the agents in a decentralized manner, where each agent only communicates with its neighbors over some prescribed graph topology.
We develop federated vanilla and entropy-regularized natural policy gradient (NPG) methods in the tabular setting under softmax parameterization, where gradient tracking is applied to estimate the global Q-function to mitigate the impact of imperfect information sharing. We establish non-asymptotic global convergence guarantees under exact policy evaluation, where the rates are nearly independent of the size of the state-action space and illuminate the impacts of network size and connectivity. To the best of our knowledge, this is the first time that global convergence is established for federated multi-task RL using policy optimization. We further go beyond the tabular setting by proposing a federated natural actor critic (NAC) method for multi-task RL with function approximation, and establish its finite-time sample complexity taking the errors of function approximation into account.
tl;dr: We introduce Action Value Gradient (AVG), a novel incremental policy gradient method for real-time learning on robots with limited onboard computation, eliminating the need for large replay buffers, target networks or batch updates.

Modern deep policy gradient methods achieve effective performance on simulated robotic tasks, but they all require large replay buffers or expensive batch updates, or both, making them incompatible for real systems with resource-limited computers. We show that these methods fail catastrophically when limited to small replay buffers or during *incremental learning*, where updates only use the most recent sample without batch updates or a replay buffer. We propose a novel incremental deep policy gradient method --- *Action Value Gradient (AVG)* and a set of normalization and scaling techniques to address the challenges of instability in incremental learning. On robotic simulation benchmarks, we show that AVG is the only incremental method that learns effectively, often achieving final performance comparable to batch policy gradient methods. This advancement enabled us to show for the first time effective deep reinforcement learning with real robots using only incremental updates, employing a robotic manipulator and a mobile robot.
tl;dr: We unify camera view and reflected view radiance field parameterizations and combine it with a multi-resolution grid backbone to achieve high-quality reconstruction of complex scenes with reflections.

Neural 3D scene representations have shown great potential for 3D reconstruction from 2D images. However, reconstructing real-world captures of complex scenes still remains a challenge. Existing generic 3D reconstruction methods often struggle to represent fine geometric details and do not adequately model reflective surfaces of large-scale scenes. Techniques that explicitly focus on reflective surfaces can model complex and detailed reflections by exploiting better reflection parameterizations. However, we observe that these methods are often not robust in real scenarios where non-reflective as well as reflective components are present. In this work, we propose UniSDF, a general purpose 3D reconstruction method that can reconstruct large complex scenes with reflections. We investigate both camera view as well as reflected view-based color parameterization techniques and find that explicitly blending these representations in 3D space enables reconstruction of surfaces that are more geometrically accurate, especially for reflective surfaces. We further combine this representation with a multi-resolution grid backbone that is trained in a coarse-to-fine manner, enabling faster reconstructions than prior methods. Extensive experiments on object-level datasets DTU, Shiny Blender as well as unbounded datasets Mip-NeRF 360 and Ref-NeRF real demonstrate that our method is able to robustly reconstruct complex large-scale scenes with fine details and reflective surfaces, leading to the best overall performance. Project page: https://fangjinhuawang.github.io/UniSDF.
tl;dr: We investigate into the in-context learning ability of Linear Transformer Block on linear regression problems and its relationship with one-step gradient descent estimator with learnable initialization.

We study the \emph{in-context learning} (ICL) ability of a \emph{Linear Transformer Block} (LTB) that combines a linear attention component and a linear multi-layer perceptron (MLP) component.
For ICL of linear regression with a Gaussian prior and a \emph{non-zero mean}, we show that LTB can achieve nearly Bayes optimal ICL risk. In contrast, using only linear attention must incur an irreducible additive approximation error.
Furthermore, we establish a correspondence between LTB and one-step gradient descent estimators with learnable initialization ($\mathsf{GD}-\beta$), in the sense that every $\mathsf{GD}-\beta$ estimator can be implemented by an LTB estimator and every optimal LTB estimator that minimizes the in-class ICL risk is effectively a $\mathsf{GD}-\beta$ estimator.
Finally, we show that $\mathsf{GD}-\beta$ estimators can be efficiently optimized with gradient flow, despite a non-convex training objective.
Our results reveal that LTB achieves ICL by implementing $\mathsf{GD}-\beta$, and they highlight the role of MLP layers in reducing approximation error.
tl;dr: We demonstrate that the transductive sample complexity of learning a hypothesis class is exactly equal to the sample complexity of learning its most difficult "finite projection," for a wide range of losses.

We demonstrate a compactness result holding broadly across supervised learning with a general class of loss functions: Any hypothesis class $\mathcal{H}$ is learnable with transductive sample complexity $m$ precisely when all of its finite projections are learnable with sample complexity $m$. We prove that this exact form of compactness holds for realizable and agnostic learning with respect to all proper metric loss functions (e.g., any norm on $\mathbb{R}^d$) and any continuous loss on a compact space (e.g., cross-entropy, squared loss). For realizable learning with improper metric losses, we show that exact compactness of sample complexity can fail, and provide matching upper and lower bounds of a factor of 2 on the extent to which such sample complexities can differ. We conjecture that larger gaps are possible for the agnostic case. Furthermore, invoking the equivalence between sample complexities in the PAC and transductive models (up to lower order factors, in the realizable case) permits us to directly port our results to the PAC model, revealing an almost-exact form of compactness holding broadly in PAC learning.
tl;dr: This paper presents a statistical and computational reduction from CMDPs to offline density estimation with little overhead.

Motivated by the recent discovery of a statistical and computational reduction from contextual bandits to offline regression \citep{simchi2020bypassing}, we address the general (stochastic) Contextual Markov Decision Process (CMDP) problem with horizon $H$ (as known as CMDP with $H$ layers). In this paper, we introduce a reduction from CMDPs to offline density estimation under the realizability assumption, i.e., a model class $\mathcal{M}$ containing the true underlying CMDP is provided in advance. We develop an efficient, statistically near-optimal algorithm requiring only $O(H \log T)$ calls to an offline density estimation algorithm (or oracle) across all $T$ rounds. This number can be further reduced to $O(H \log \log T)$ if $T$ is known in advance. Our results mark the first efficient and near-optimal reduction from CMDPs to offline density estimation without imposing any structural assumptions on the model class. A notable feature of our algorithm is the design of a layerwise exploration-exploitation tradeoff tailored to address the layerwise structure of CMDPs. Additionally, our algorithm is versatile and applicable to pure exploration tasks in reward-free reinforcement learning.
tl;dr: We uncover an inherent limitation of generative image restoration: higher perceptual quality comes at the expense of greater uncertainty.

The pursuit of high perceptual quality in image restoration has driven the development of revolutionary generative models, capable of producing results often visually indistinguishable from real data.
However, as their perceptual quality continues to improve, these models also exhibit a growing tendency to generate hallucinations – realistic-looking details that do not exist in the ground truth images.
Hallucinations in these models create uncertainty about their reliability, raising major concerns about their practical application.
This paper investigates this phenomenon through the lens of information theory, revealing a fundamental tradeoff between uncertainty and perception. We rigorously analyze the relationship between these two factors, proving that the global minimal uncertainty in generative models grows in tandem with perception.
In particular, we define the inherent uncertainty of the restoration problem and show that attaining perfect perceptual quality entails at least twice this uncertainty. Additionally, we establish a relation between distortion, uncertainty and perception, through which we prove the aforementioned uncertainly-perception tradeoff induces the well-known perception-distortion tradeoff.
We demonstrate our theoretical findings through experiments with super-resolution and inpainting algorithms.
This work uncovers fundamental limitations of generative models in achieving both high perceptual quality and reliable predictions for image restoration.
Thus, we aim to raise awareness among practitioners about this inherent tradeoff, empowering them to make informed decisions and potentially prioritize safety over perceptual performance.

The sampling problem under local differential privacy has recently been studied with potential applications to generative models, but a fundamental analysis of its privacy-utility trade-off (PUT) remains incomplete. In this work, we define the fundamental PUT of private sampling in the minimax sense, using the $f$-divergence between original and sampling distributions as the utility measure. We characterize the exact PUT for both finite and continuous data spaces under some mild conditions on the data distributions, and propose sampling mechanisms that are universally optimal for all $f$-divergences. Our numerical experiments demonstrate the superiority of our mechanisms over baselines, in terms of theoretical utilities for finite data space and of empirical utilities for continuous data space.
tl;dr: This paper propose a Continual Flatness (C-Flat) method featuring a flatter loss landscape tailored for CL. C-Flat could be easily called with only one line of code and is plug-and-play to any CL methods.

How to balance the learning ’sensitivity-stability’ upon new task training and memory preserving is critical in CL to resolve catastrophic forgetting. Improving model generalization ability within each learning phase is one solution to help CL learning overcome the gap in the joint knowledge space. Zeroth-order loss landscape sharpness-aware minimization is a strong training regime improving model generalization in transfer learning compared with optimizer like SGD. It has also been introduced into CL to improve memory representation or learning efficiency. However, zeroth-order sharpness alone could favors sharper over flatter minima in certain scenarios, leading to a rather sensitive minima rather than a global optima. To further enhance learning stability, we propose a Continual Flatness (C-Flat) method featuring a flatter loss landscape tailored for CL. C-Flat could be easily called with only one line of code and is plug-and-play to any CL methods. A general framework of C-Flat applied to all CL categories and a thorough comparison with loss minima optimizer and flat minima based CL approaches is presented in this paper, showing that our method can boost CL performance in almost all cases. Code is available at https://github.com/WanNaa/C-Flat.
tl;dr: We experimentally and statistically show that PH dimension does not always correlate with generalization gap.

Bounding and predicting the generalization gap of overparameterized neural networks remains a central open problem in theoretical machine learning. There is a recent and growing body of literature that proposes the framework of fractals to model optimization trajectories of neural networks, motivating generalization bounds and measures based on the fractal dimension of the trajectory. Notably, the persistent homology dimension has been proposed to correlate with the generalization gap. This paper performs an empirical evaluation of these persistent homology-based generalization measures, with an in-depth statistical analysis. Our study reveals confounding effects in the observed correlation between generalization and topological measures due to the variation of hyperparameters. We also observe that fractal dimension fails to predict generalization of models trained from poor initializations. We lastly reveal the intriguing manifestation of model-wise double descent in these topological generalization measures. Our work forms a basis for a deeper investigation of the causal relationships between fractal geometry, topological data analysis, and neural network optimization.
tl;dr: We shed light that the performance of state-of-the-art methods, including ICLR '24 best paper runner-up, does not surpass a random baseline (RanDumb), demonstrating the poor performance of representation learning

Continual learning has primarily focused on the issue of catastrophic forgetting and the associated stability-plasticity tradeoffs. However, little attention has been paid to the efficacy of continually learned representations, as representations are learned alongside classifiers throughout the learning process. Our primary contribution is empirically demonstrating that existing online continually trained deep networks produce inferior representations compared to a simple pre-defined random transforms. Our approach embeds raw pixels using a fixed random transform, approximating an RBF-Kernel initialized before any data is seen. We then train a simple linear classifier on top without storing any exemplars, processing one sample at a time in an online continual learning setting. This method, called RanDumb, significantly outperforms state-of-the-art continually learned representations across all standard online continual learning benchmarks. Our study reveals the significant limitations of representation learning, particularly in low-exemplar and online continual learning scenarios. Extending our investigation to popular exemplar-free scenarios with pretrained models, we find that training only a linear classifier on top of pretrained representations surpasses most continual fine-tuning and prompt-tuning strategies. Overall, our investigation challenges the prevailing assumptions about effective representation learning in the online continual learning.
tl;dr: We present the out-of-distribution detection method WeiPer that improves detection by projecting the penultimate space of a network on perturbations of class directions.

Recent advances in out-of-distribution (OOD) detection on image data show that pre-trained neural network classifiers can separate in-distribution (ID) from OOD data well, leveraging the class-discriminative ability of the model itself. Methods have been proposed that either use logit information directly or that process the model's penultimate layer activations. With "WeiPer", we introduce perturbations of the class projections in the final fully connected layer which creates a richer representation of the input. We show that this simple trick can improve the OOD detection performance of a variety of methods and additionally propose a distance-based method that leverages the properties of the augmented WeiPer space. We achieve state-of-the-art OOD detection results across multiple benchmarks of the OpenOOD framework, especially pronounced in difficult settings in which OOD samples are positioned close to the training set distribution. We support our findings with theoretical motivations and empirical observations, and run extensive ablations to provide insights into why WeiPer works. Our code is available at: https://github.com/mgranz/weiper.

We study interactive learning of language agents based on user edits made to the agent's output. In a typical setting such as writing assistants, the user interacts with a language agent to generate a response given a context, and may optionally edit the agent response to personalize it based on their latent preference, in addition to improving the correctness. The edit feedback is naturally generated, making it a suitable candidate for improving the agent's alignment with the user's preference, and for reducing the cost of user edits over time. We propose a learning framework, PRELUDE that infers a description of the user's latent preference based on historic edit data and using it to define a prompt policy that drives future response generation. This avoids fine-tuning the agent, which is costly, challenging to scale with the number of users, and may even degrade its performance on other tasks. Furthermore, learning descriptive preference improves interpretability, allowing the user to view and modify the learned preference. However, user preference can be complex and vary based on context, making it challenging to learn. To address this, we propose a simple yet effective algorithm named CIPHER that leverages a large language model (LLM) to infer the user preference for a given context based on user edits. In the future, CIPHER retrieves inferred preferences from the k-closest contexts in the history, and forms an aggregate preference for response generation. We introduce two interactive environments -- summarization and email writing, for evaluation using a GPT-4 simulated user. We compare with algorithms that directly retrieve user edits but do not learn descriptive preference, and algorithms that learn context-agnostic preference. On both tasks, CIPHER outperforms baselines by achieving the lowest edit distance cost. Meanwhile, CIPHER has a lower computational expense, as using learned preference results in a shorter prompt than directly using user edits. Our further analysis reports that the user preference learned by CIPHER shows significant similarity to the ground truth latent preference.

We present Saliency-driven Experience Replay - SER - a biologically-plausible approach based on replicating human visual saliency to enhance classification models in continual learning settings. Inspired by neurophysiological evidence that the primary visual cortex does not contribute to object manifold untangling for categorization and that primordial saliency biases are still embedded in the modern brain, we propose to employ auxiliary saliency prediction features as a modulation signal to drive and stabilize the learning of a sequence of non-i.i.d. classification tasks. Experimental results confirm that SER effectively enhances the performance (in some cases up to about twenty percent points) of state-of-the-art continual learning methods, both in class-incremental and task-incremental settings. Moreover, we show that saliency-based modulation successfully encourages the learning of features that are more robust to the presence of spurious features and to adversarial attacks than baseline methods. Code is available at: https://github.com/perceivelab/SER

Evidential Deep Learning (EDL), grounded in Evidence Theory and Subjective Logic (SL), provides a robust framework to estimate uncertainty for out-of-distribution (OOD) detection alongside traditional classification probabilities.However, the EDL framework is constrained by its focus on evidence that supports only single categories, neglecting the other collective evidences that could corroborate multiple in-distribution categories. This limitation leads to a diminished estimation of uncertainty and a subsequent decline in OOD detection performance.Additionally, EDL encounters the vanishing gradient problem within its fully-connected layers, further degrading classification accuracy.To address these issues, we introduce hyper-domain and propose Hyper-opinion Evidential Deep Learning (HEDL). HEDL extends the evidence modeling paradigm by explicitly integrating sharp evidence, which supports a singular category, with vague evidence that accommodates multiple potential categories.Additionally, we propose a novel opinion projection mechanism that translates hyper-opinion into multinomial-opinion, which is then optimized within the EDL framework to ensure precise classification and refined uncertainty estimation.HEDL integrates evidences across various categories to yield a holistic evidentiary foundation for achieving superior OOD detection. Furthermore, our proposed opinion projection method effectively mitigates the vanishing gradient issue, ensuring classification accuracy without additional model complexity. Extensive experiments over many datasets demonstrate our proposed method outperforms existing OOD detection methods.
tl;dr: We propose a new robust reinforcement learning framework with general utility, and design algorithms with provable convergence rates to stationary point or global optimum.

Reinforcement Learning (RL) problem with general utility is a powerful decision making framework that covers standard RL with cumulative cost, exploration problems, and demonstration learning. Existing works on RL with general utility do not consider the robustness under environmental perturbation, which is important to adapt RL system in the real-world environment that differs from the training environment. To train a robust policy, we propose a robust RL framework with general utility, which subsumes many existing RL frameworks including RL, robust RL, RL with general utility, constrained RL, robust constrained RL, pure exploration, robust entropy regularized RL, etc. Then we focus on popular convex utility functions, with which our proposed learning framework is a challenging nonconvex-nonconcave minimax optimization problem, and design a two-phase stochastic policy gradient type algorithm and obtain its sample complexity result for gradient convergence. Furthermore, for convex utility on a widely used polyhedral ambiguity set, we design an algorithm and obtain its convergence rate to a global optimal solution.
tl;dr: We characterize the implicit biases imposed by learning dynamics along with architecture and loss function for self-supervised representation learning, leading to practical recommendations for improving its sample and compute efficiency.

Recent progress in self-supervised (SSL) visual representation learning has led to the development of several different proposed frameworks that rely on augmentations of images but use different loss functions.
However, there are few theoretically grounded principles to guide practice, so practical implementation of each SSL framework requires several heuristics to achieve competitive performance.
In this work, we build on recent analytical results to design practical recommendations for competitive and efficient SSL that are grounded in theory.
Specifically, recent theory tells us that existing SSL frameworks are actually minimizing the same idealized loss, which is to learn features that best match the data similarity kernel defined by the augmentations used.
We show how this idealized loss can be reformulated to a functionally equivalent loss that is more efficient to compute.
We study the implicit bias of using gradient descent to minimize our reformulated loss function, and find that using a stronger orthogonalization constraint with a reduced projector dimensionality should yield good representations.
Furthermore, the theory tells us that approximating the reformulated loss should be improved by increasing the number of augmentations, and as such using multiple augmentations should lead to improved convergence.
We empirically verify our findings on CIFAR, STL and Imagenet datasets, wherein we demonstrate an improved linear readout performance when training a ResNet-backbone using our theoretically grounded recommendations.
Remarkably, we also demonstrate that by leveraging these insights, we can reduce the pretraining dataset size by up to 2$\times$ while maintaining downstream accuracy simply by using more data augmentations.
Taken together, our work provides theoretically grounded recommendations that can be used to improve SSL convergence and efficiency.
tl;dr: The first to utilize the Mamba model to address multi-class anomaly detection tasks.

Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness. The code and models are available at https://lewandofskee.github.io/projects/MambaAD.

With the emergence of large pre-trained multimodal video models, multiple benchmarks have been proposed to evaluate model capabilities. However, most of the benchmarks are human-centric, with evaluation data and tasks centered around human applications. Animals are an integral part of the natural world, and animal-centric video understanding is crucial for animal welfare and conservation efforts. Yet, existing benchmarks overlook evaluations focused on animals, limiting the application of the models. To address this limitation, our work established an animal-centric benchmark, namely Animal-Bench, to allow for a comprehensive evaluation of model capabilities in real-world contexts, overcoming agent-bias in previous benchmarks. Animal-Bench includes 13 tasks encompassing both common tasks shared with humans and special tasks relevant to animal conservation, spanning 7 major animal categories and 819 species, comprising a total of 41,839 data entries. To generate this benchmark, we defined a task system centered on animals and proposed an automated pipeline for animal-centric data processing. To further validate the robustness of models against real-world challenges, we utilized a video editing approach to simulate realistic scenarios like weather changes and shooting parameters due to animal movements. We evaluated 8 current multimodal video models on our benchmark and found considerable room for improvement. We hope our work provides insights for the community and opens up new avenues for research in multimodal video models. Our data and code will be released at https://github.com/PRIS-CV/Animal-Bench.
tl;dr: We incorporate time into the PAC framework, demonstrating both theoretically and empirically that time-aware empirical risk minimization outperforms time-agnostic methods for certain problems where the data distribution varies predictably over time.

In real-world applications, the distribution of the data, and our goals, evolve over time. The prevailing theoretical framework for studying machine learning, namely probably approximately correct (PAC) learning, largely ignores time. As a consequence, existing strategies to address the dynamic nature of data and goals exhibit poor real-world performance. This paper develops a theoretical framework called
"Prospective Learning" that is tailored for situations when the optimal hypothesis changes over time. In PAC learning, empirical risk minimization (ERM) is known to be consistent. We develop a learner called Prospective ERM, which returns a sequence of predictors that make predictions on future data. We prove that the risk of prospective ERM converges to the Bayes risk under certain assumptions on the stochastic process generating the data. Prospective ERM, roughly speaking, incorporates time as an input in addition to the data. We show that standard ERM as done in PAC learning, without incorporating time, can result in failure to learn when distributions are dynamic. Numerical experiments illustrate that prospective ERM can learn synthetic and visual recognition problems constructed from MNIST and CIFAR-10.
tl;dr: We propose DiffLight, a conditional diffusion framework, unifying traffic data imputation and decision-making for TSC with missing data.

The application of reinforcement learning in traffic signal control (TSC) has been extensively researched and yielded notable achievements. However, most existing works for TSC assume that traffic data from all surrounding intersections is fully and continuously available through sensors. In real-world applications, this assumption often fails due to sensor malfunctions or data loss, making TSC with missing data a critical challenge. To meet the needs of practical applications, we introduce DiffLight, a novel conditional diffusion model for TSC under data-missing scenarios in the offline setting. Specifically, we integrate two essential sub-tasks, i.e., traffic data imputation and decision-making, by leveraging a Partial Rewards Conditioned Diffusion (PRCD) model to prevent missing rewards from interfering with the learning process. Meanwhile, to effectively capture the spatial-temporal dependencies among intersections, we design a Spatial-Temporal transFormer (STFormer) architecture. In addition, we propose a Diffusion Communication Mechanism (DCM) to promote better communication and control performance under data-missing scenarios. Extensive experiments on five datasets with various data-missing scenarios demonstrate that DiffLight is an effective controller to address TSC with missing data. The code of DiffLight is released at https://github.com/lokol5579/DiffLight-release.

Large Language Model (LLM) inference on Central Processing Units (CPU) is challenging due to the vast quantities of Multiply-Add (MAD) matrix operations in the attention computations. This paper highlights a rare gem in modern CPUs, Single-Instruction-Multiple-Data (SIMD) registers, which allows for ultra-low-latency lookups in a batch. We leverage this unique capability to propose NoMAD-Attention, an efficient attention algorithm that replaces MAD operations with in-register lookups. Through hardware-aware algorithmic designs, NoMAD-Attention achieves the computation of attention scores using repeated fast accesses to SIMD registers. NoMAD-Attention works with pre-trained attention-based LLMs without model finetuning. Extensive empirical evaluations demonstrate that NoMAD-Attention maintains the quality of the original LLMs well and speeds up the 4-bit quantized LLaMA-7B-based model by up to $2 \times$ at 16k context length.
tl;dr: We investigate the use of Reward Machines in deep RL under an uncertain interpretation of the domain-specific vocabulary.

Reward Machines provide an automaton-inspired structure for specifying instructions, safety constraints, and other temporally extended reward-worthy behaviour. By exposing the underlying structure of a reward function, they enable the decomposition of an RL task, leading to impressive gains in sample efficiency. Although Reward Machines and similar formal specifications have a rich history of application towards sequential decision-making problems, they critically rely on a ground-truth interpretation of the domain-specific vocabulary that forms the building blocks of the reward function—such ground-truth interpretations are elusive in the real world due in part to partial observability and noisy sensing. In this work, we explore the use of Reward Machines for Deep RL in noisy and uncertain environments. We characterize this problem as a POMDP and propose a suite of RL algorithms that exploit task structure under uncertain interpretation of the domain-specific vocabulary. Through theory and experiments, we expose pitfalls in naive approaches to this problem while simultaneously demonstrating how task structure can be successfully leveraged under noisy interpretations of the vocabulary.

The state space models, employing recursively propagated features, demonstrate strong representation capabilities comparable to Transformer models and superior efficiency.
However, constrained by the inherent geometric constraints of sequences, it still falls short in modeling long-range dependencies.
To address this issue, we propose the MambaTree network, which first dynamically generates a tree topology based on spatial relationships and input features.
Then, feature propagation is performed based on this graph, thereby breaking the original sequence constraints to achieve stronger representation capabilities.
Additionally, we introduce a linear complexity dynamic programming algorithm to enhance long-range interactions without increasing computational cost.
MambaTree is a versatile multimodal framework that can be applied to both visual and textual tasks.
Extensive experiments demonstrate that our method significantly outperforms existing structured state space models on image classification, object detection and segmentation.
Besides, by fine-tuning large language models, our approach achieves consistent improvements in multiple textual tasks at minor training cost.
tl;dr: This paper establishes a novel framework for interactive information seeking to enhance reliable medical reasoning abilities in LLMs.

Users typically engage with LLMs interactively, yet most existing benchmarks evaluate them in a static, single-turn format, posing reliability concerns in interactive scenarios. We identify a key obstacle towards reliability: LLMs are trained to answer any question, even with incomplete context or insufficient knowledge. In this paper, we propose to change the static paradigm to an interactive one, develop systems that proactively ask questions to gather more information and respond reliably, and introduce an benchmark—MEDIQ—to evaluate question-asking ability in LLMs. MEDIQ simulates clinical interactions consisting of a Patient System and an adaptive Expert System; with potentially incomplete initial information, the Expert refrains from making diagnostic decisions when unconfident, and instead elicits missing details via follow-up questions. We provide a pipeline to convert single-turn medical benchmarks into an interactive format. Our results show that directly prompting state-of-the-art LLMs to ask questions degrades performance, indicating that adapting LLMs to proactive information-seeking settings is nontrivial. We experiment with abstention strategies to better estimate model confidence and decide when to ask questions, improving diagnostic accuracy by 22.3%; however, performance still lags compared to an (unrealistic in practice) upper bound with complete information upfront. Further analyses show improved interactive performance with filtering irrelevant contexts and reformatting conversations. Overall, we introduce a novel problem towards LLM reliability, an interactive MEDIQ benchmark and a novel question-asking system, and highlight directions to extend LLMs’ information-seeking abilities in critical domains.
tl;dr: Neural Cellular Automata can be inserted between the middle layers of Vision Transformers (ViTs) to improve ViTs' robustness on image classification.

Vision Transformers (ViTs) demonstrate remarkable performance in image classification through visual-token interaction learning, particularly when equipped with local information via region attention or convolutions. Although such architectures improve the feature aggregation from different granularities, they often fail to contribute to the robustness of the networks. Neural Cellular Automata (NCA) enables the modeling of global visual-token representations through local interactions, with its training strategies and architecture design conferring strong generalization ability and robustness against noisy input. In this paper, we propose Adaptor Neural Cellular Automata (AdaNCA) for Vision Transformers that uses NCA as plug-and-play adaptors between ViT layers, thus enhancing ViT's performance and robustness against adversarial samples as well as out-of-distribution inputs. To overcome the large computational overhead of standard NCAs, we propose Dynamic Interaction for more efficient interaction learning. Using our analysis of AdaNCA placement and robustness improvement, we also develop an algorithm for identifying the most effective insertion points for AdaNCA. With less than a 3% increase in parameters, AdaNCA contributes to more than 10% absolute improvement in accuracy under adversarial attacks on the ImageNet1K benchmark. Moreover, we demonstrate with extensive evaluations across eight robustness benchmarks and four ViT architectures that AdaNCA, as a plug-and-play module, consistently improves the robustness of ViTs.
tl;dr: Analysis of the inductive biases associated with pre-training+finetuning and multi-task learning

Neural networks are often trained on multiple tasks, either simultaneously (multi-task learning, MTL) or sequentially (pretraining and subsequent finetuning, PT+FT). In particular, it is common practice to pretrain neural networks on a large auxiliary task before finetuning on a downstream task with fewer samples. Despite the prevalence of this approach, the inductive biases that arise from learning multiple tasks are poorly characterized. In this work, we address this gap. We describe novel implicit regularization penalties associated with MTL and PT+FT in diagonal linear networks and single-hidden-layer ReLU networks. These penalties indicate that MTL and PT+FT induce the network to reuse features in different ways. 1) Both MTL and PT+FT exhibit biases towards feature reuse between tasks, and towards sparsity in the set of learned features. We show a "conservation law" that implies a direct tradeoff between these two biases. 2) PT+FT exhibits a novel "nested feature selection" regime, not described by either the "lazy" or "rich" regimes identified in prior work, which biases it to *rely on a sparse subset* of the features learned during pretraining. This regime is much narrower for MTL. 3) PT+FT (but not MTL) in ReLU networks benefits from features that are correlated between the auxiliary and main task. We confirm these findings empirically with teacher-student models, and introduce a technique -- weight rescaling following pretraining -- that can elicit the nested feature selection regime. Finally, we validate our theory in deep neural networks trained on image classification. We find that weight rescaling improves performance when it causes models to display signatures of nested feature selection. Our results suggest that nested feature selection may be an important inductive bias for finetuning neural networks.
tl;dr: We propose a casual diffusion model (CausalDiff) that adapts diffusion models for conditional data generation and disentangles the two types of casual factors for adversarial defense on image classification task.

Despite ongoing efforts to defend neural classifiers from adversarial attacks, they remain vulnerable, especially to unseen attacks. In contrast, humans are difficult to be cheated by subtle manipulations, since we make judgments only based on essential factors. Inspired by this observation, we attempt to model label generation with essential label-causative factors and incorporate label-non-causative factors to assist data generation. For an adversarial example, we aim to discriminate the perturbations as non-causative factors and make predictions only based on the label-causative factors. Concretely, we propose a casual diffusion model (CausalDiff) that adapts diffusion models for conditional data generation and disentangles the two types of casual factors by learning towards a novel casual information bottleneck objective. Empirically, CausalDiff has significantly outperformed state-of-the-art defense methods on various unseen attacks, achieving an average robustness of 86.39\% (+4.01\%) on CIFAR-10, 56.25\% (+3.13\%) on CIFAR-100, and 82.62\% (+4.93\%) on GTSRB (German Traffic Sign Recognition Benchmark).
tl;dr: We propose Spatio-Spectral Graph Neural Networks (S^2GNNs) that have a global receptive field, vanquish over-squashing and deliver strong empirical results on small and large graphs.

Spatial Message Passing Graph Neural Networks (MPGNNs) are widely used for learning on graph-structured data. However, key limitations of *ℓ*-step MPGNNs are that their "receptive field" is typically limited to the *ℓ*-hop neighborhood of a node and that information exchange between distant nodes is limited by over-squashing. Motivated by these limitations, we propose *Spatio-Spectral Graph Neural Networks (S²GNNs)* – a new modeling paradigm for Graph Neural Networks (GNNs) that synergistically combines spatially and spectrally parametrized graph filters. Parameterizing filters partially in the frequency domain enables global yet efficient information propagation. We show that S²GNNs vanquish over-squashing and yield strictly tighter approximation-theoretic error bounds than MPGNNs. Further, rethinking graph convolutions at a fundamental level unlocks new design spaces. For example, S²GNNs allow for free positional encodings that make them strictly more expressive than the 1-Weisfeiler-Leman (WL) test. Moreover, to obtain general-purpose S²GNNs, we propose spectrally parametrized filters for directed graphs. S²GNNs outperform spatial MPGNNs, graph transformers, and graph rewirings, e.g., on the peptide long-range benchmark tasks, and are competitive with state-of-the-art sequence modeling. On a 40 GB GPU, S²GNNs scale to millions of nodes.
tl;dr: With oracle access to exact gradients and noisy Hessians, we propose a stochastic Newton proximal extragradient method with both fast global and local convergence rates for strongly convex functions.

Stochastic second-order methods are known to achieve fast local convergence in strongly convex optimization by relying on noisy Hessian estimates to precondition the gradient. Yet, most of these methods achieve superlinear convergence only when the stochastic Hessian noise diminishes, requiring an increase in the per-iteration cost as time progresses. Recent work in \cite{na2022hessian} addressed this issue via a Hessian averaging scheme that achieves a superlinear convergence rate without increasing the per-iteration cost. However, the considered method exhibits a slow global convergence rate, requiring up to $\tilde{\mathcal{O}}(\kappa^2)$ iterations to reach the superlinear rate of $\tilde{\mathcal{O}}((1/t)^{t/2})$, where $\kappa$ is the problem's condition number. In this paper, we propose a novel stochastic Newton proximal extragradient method that significantly improves these bounds, achieving a faster global linear rate and reaching the same fast superlinear rate in $\tilde{\mathcal{O}}(\kappa)$ iterations. We achieve this by developing a novel extension of the Hybrid Proximal Extragradient (HPE) framework, which simultaneously achieves fast global and local convergence rates for strongly convex functions with access to a noisy Hessian oracle.
1143. EMVP: Embracing Visual Foundation Model for Visual Place Recognition with Centroid-Free Probing
tl;dr: This paper proposes a novel and effective Parameter Efficiency Fine-Tuning (PEFT) pipeline of adapting a visual foundation model in the visual place recognition task.

Visual Place Recognition (VPR) is essential for mobile robots as it enables them to retrieve images from a database closest to their current location. The progress of Visual Foundation Models (VFMs) has significantly advanced VPR by capturing representative descriptors in images. However, existing fine-tuning efforts for VFMs often overlook the crucial role of probing in effectively adapting these descriptors for improved image representation. In this paper, we propose the Centroid-Free Probing (CFP) stage, making novel use of second-order features for more effective use of descriptors from VFMs. Moreover, to control the preservation of task-specific information adaptively based on the context of the VPR, we introduce the Dynamic Power Normalization (DPN) module in both the recalibration and CFP stages, forming a novel Parameter Efficiency Fine-Tuning (PEFT) pipeline (EMVP) tailored for the VPR task. Extensive experiments demonstrate the superiority of the proposed CFP over existing probing methods. Moreover, the EMVP pipeline can further enhance fine-tuning performance in terms of accuracy and efficiency. Specifically, it achieves 93.9\%, 96.5\%, and 94.6\% Recall@1 on the MSLS Validation, Pitts250k-test, and SPED datasets, respectively, while saving 64.3\% of trainable parameters compared with the existing SOTA PEFT method.

The long-tailed distribution is the underlying nature of real-world data, and it presents unprecedented challenges for training deep learning models. Existing long-tailed learning paradigms based on re-balancing or data augmentation have partially alleviated the long-tailed problem. However, they still have limitations, such as relying on manually designed augmentation strategies, having a limited search space, and using fixed augmentation strategies. To address these limitations, this paper proposes a novel LLM-based long-tailed data augmentation framework called LLM-AutoDA, which leverages large-scale pretrained models to automatically search for the optimal augmentation strategies suitable for long-tailed data distributions. In addition, it applies this strategy to the original imbalanced data to create an augmented dataset and fine-tune the underlying long-tailed learning model. The performance improvement on the validation set serves as a reward signal to update the generation model, enabling the generation of more effective augmentation strategies in the next iteration. We conducted extensive experiments on multiple mainstream long-tailed learning benchmarks. The results show that LLM-AutoDA outperforms state-of-the-art data augmentation methods and other re-balancing methods significantly.
tl;dr: We extend surprisingly popular algorithm to partial preferences, and evaluate our approach through crowdsourcing.

We consider the problem of recovering the ground truth ordering (ranking, top-$k$, or others) over a large number of alternatives.
The wisdom of crowd is a heuristic approach based on Condorcet's Jury theorem to address this problem through collective opinions.
This approach fails to recover the ground truth when the majority of the crowd is misinformed. The \emph{surprisingly popular} (SP) algorithm~\citep{prelec2017solution} is an alternative approach that is able to recover the ground truth even when experts are in minority. The SP algorithm requires the voters to predict other voters' report in the form of a full probability distribution over all rankings of alternatives. However, when the number of alternatives, $m$, is large, eliciting the prediction report or even the vote over $m$ alternatives might be too costly.
In this paper, we design a scalable alternative of the SP algorithm which only requires eliciting partial preferences from the voters, and propose new variants of the SP algorithm. In particular, we propose two versions---\emph{Aggregated-SP} and \emph{Partial-SP}---that ask voters to report vote and prediction on a subset of size $k$ ($\ll m$) in terms of top alternative, partial rank, or an approval set. Through a large-scale crowdsourcing experiment on MTurk, we show that both of our approaches outperform conventional preference aggregation algorithms for the recovery of ground truth rankings, when measured in terms of Kendall-Tau distance and Spearman's $\rho$. We further analyze the collected data and demonstrate that voters' behavior in the experiment, including the minority of the experts, and the SP phenomenon, can be correctly simulated by a concentric mixtures of Mallows model. Finally, we provide theoretical bounds on the sample complexity of SP algorithms with partial rankings to demonstrate the theoretical guarantees of the proposed methods.
tl;dr: We fit low-rank RNNs to neural data using variational SMC, and obtain models that are both generative and have tractable low-dimensional dynamics.

A central aim in computational neuroscience is to relate the activity of large populations of neurons to an underlying dynamical system. Models of these neural dynamics should ideally be both interpretable and fit the observed data well. Low-rank recurrent neural networks (RNNs) exhibit such interpretability by having tractable dynamics. However, it is unclear how to best fit low-rank RNNs to data consisting of noisy observations of an underlying stochastic system. Here, we propose to fit stochastic low-rank RNNs with variational sequential Monte Carlo methods. We validate our method on several datasets consisting of both continuous and spiking neural data, where we obtain lower dimensional latent dynamics than current state of the art methods. Additionally, for low-rank models with piecewise linear nonlinearities, we show how to efficiently identify all fixed points in polynomial rather than exponential cost in the number of units, making analysis of the inferred dynamics tractable for large RNNs. Our method both elucidates the dynamical systems underlying experimental recordings and provides a generative model whose trajectories match observed variability.

Model editing aims to data-efficiently correct predictive errors of large pre-trained models while ensuring generalization to neighboring failures and locality to minimize unintended effects on unrelated examples. While significant progress has been made in editing Transformer-based large language models, effective strategies for editing vision Transformers (ViTs) in computer vision remain largely untapped. In this paper, we take initial steps towards correcting predictive errors of ViTs, particularly those arising from subpopulation shifts. Taking a locate-then-edit approach, we first address the ``where-to-edit`` challenge by meta-learning a hypernetwork on CutMix-augmented data generated for editing reliability. This trained hypernetwork produces generalizable binary masks that identify a sparse subset of structured model parameters, responsive to real-world failure samples. Afterward, we solve the ``how-to-edit`` problem by simply fine-tuning the identified parameters using a variant of gradient descent to achieve successful edits. To validate our method, we construct an editing benchmark that introduces subpopulation shifts towards natural underrepresented images and AI-generated images, thereby revealing the limitations of pre-trained ViTs for object recognition. Our approach not only achieves superior performance on the proposed benchmark but also allows for adjustable trade-offs between generalization and locality. Our code is available at https://github.com/hustyyq/Where-to-Edit.
tl;dr: A novel signed graph augmentation method

Signed graphs can model friendly or antagonistic relations where edges are annotated with a positive or negative sign. The main downstream task in signed graph analysis is $\textit{link sign prediction}$. Signed Graph Neural Networks (SGNNs) have been widely used for signed graph representation learning. While significant progress has been made in SGNNs research, two issues (i.e., graph sparsity and unbalanced triangles) persist in the current SGNN models. We aim to alleviate these issues through data augmentation ($\textit{DA}$) techniques which have demonstrated effectiveness in improving the performance of graph neural networks. However, most graph augmentation methods are primarily aimed at graph-level and node-level tasks (e.g., graph classification and node classification) and cannot be directly applied to signed graphs due to the lack of side information (e.g., node features and label information) in available real-world signed graph datasets. Random $\textit{DropEdge} $is one of the few $\textit{DA}$ methods that can be directly used for signed graph data augmentation, but its effectiveness is still unknown. In this paper, we first provide the generalization bound for the SGNN model and demonstrate from both experimental and theoretical perspectives that the random $\textit{DropEdge}$ cannot improve the performance of link sign prediction. Therefore, we propose a novel signed graph augmentation method, $\underline{S}$igned $\underline{G}$raph $\underline{A}$ugmentation framework (SGA). Specifically, SGA first integrates a structure augmentation module to detect candidate edges solely based on network information. Furthermore, SGA incorporates a novel strategy to select beneficial candidates. Finally, SGA introduces a novel data augmentation perspective to enhance the training process of SGNNs. Experiment results on six real-world datasets demonstrate that SGA effectively boosts the performance of diverse SGNN models, achieving improvements of up to 32.3\% in F1-micro for SGCN on the Slashdot dataset in the link sign prediction task.

Deep neural networks have long been criticized for being black-box. To unveil the inner workings of modern neural architectures, a recent work proposed an information-theoretic objective function called Sparse Rate Reduction (SRR) and interpreted its unrolled optimization as a Transformer-like model called Coding Rate Reduction Transformer (CRATE). However, the focus of the study was primarily on the basic implementation, and whether this objective is optimized in practice and its causal relationship to generalization remain elusive. Going beyond this study, we derive different implementations by analyzing layer-wise behaviors of CRATE, both theoretically and empirically. To reveal the predictive power of SRR on generalization, we collect a set of model variants induced by varied implementations and hyperparameters and evaluate SRR as a complexity measure based on its correlation with generalization. Surprisingly, we find out that SRR has a positive correlation coefficient and outperforms other baseline measures, such as path-norm and sharpness-based ones. Furthermore, we show that generalization can be improved using SRR as regularization on benchmark image classification datasets. We hope this paper can shed light on leveraging SRR to design principled models and study their generalization ability.
tl;dr: VLMimic is a novel visual imitation learning paradigm that leverages VLMs to directly learn skills with fine-grained action levels, from a limited number of human videos, outperforming baselines in both simulated and real-world experiments.

Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in Vision Language Models (VLMs) have demonstrated remarkable performance in vision and language reasoning capabilities for VIL tasks. Despite the progress, current VIL methods naively employ VLMs to learn high-level plans from human videos, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck. In this work, we present VLMimic, a novel paradigm that harnesses VLMs to directly learn even fine-grained action levels, only given a limited number of human videos. Specifically, VLMimic first grounds object-centric movements from human videos, and learns skills using hierarchical constraint representations, facilitating the derivation of skills with fine-grained action levels from limited human videos. These skills are refined and updated through an iterative comparison strategy, enabling efficient adaptation to unseen environments. Our extensive experiments exhibit that our VLMimic, using only 5 human videos, yields significant improvements of over 27% and 21% in RLBench and real-world manipulation tasks, and surpasses baselines by more than 37% in long-horizon tasks. Code and videos are available on our anonymous homepage.

A common strategy for Parameter-Efficient Fine-Tuning (PEFT) of pre-trained Vision Transformers (ViTs) involves adapting the model to downstream tasks by learning a low-rank adaptation matrix. This matrix is decomposed into a product of down-projection and up-projection matrices, with the bottleneck dimensionality being crucial for reducing the number of learnable parameters, as exemplified by prevalent methods like LoRA and Adapter. However, these low-rank strategies typically employ a fixed bottleneck dimensionality, which limits their flexibility in handling layer-wise variations. To address this limitation, we propose a novel PEFT approach inspired by Singular Value Decomposition (SVD) for representing the adaptation matrix. SVD decomposes a matrix into the product of a left unitary matrix, a diagonal matrix of scaling values, and a right unitary matrix. We utilize Householder transformations to construct orthogonal matrices that efficiently mimic the unitary matrices, requiring only a vector. The diagonal values are learned in a layer-wise manner, allowing them to flexibly capture the unique properties of each layer. This approach enables the generation of adaptation matrices with varying ranks across different layers, providing greater flexibility in adapting pre-trained models. Experiments on standard downstream vision tasks demonstrate that our method achieves promising fine-tuning performance.
tl;dr: The paper introduces TAGI, a novel approach that enables large language models to learn from instructions rather than extensive data instances, significantly enhancing their adaptability and efficiency in real-world tasks.

Large language models (LLMs) have acquired the ability to solve general tasks by utilizing instruction finetuning (IFT). However, IFT still relies heavily on instance training of extensive task data, which greatly limits the adaptability of LLMs to real-world scenarios where labeled task instances are scarce and broader task generalization becomes paramount. Contrary to LLMs, humans acquire skills and complete tasks not merely through repeated practice but also by understanding and following instructional guidelines. This paper is dedicated to simulating human learning to address the shortcomings of instance training, focusing on instruction learning to enhance cross-task generalization. Within this context, we introduce Task Adapters Generation from Instructions (TAGI), which automatically constructs the task-specific model in a parameter generation manner based on the given task instructions without retraining for unseen tasks. Specifically, we utilize knowledge distillation to enhance the consistency between TAGI developed through Learning with Instruction and task-specific models developed through Training with Instance, by aligning the labels, output logits, and adapter parameters between them. TAGI is endowed with cross-task generalization capabilities through a two-stage training process that includes hypernetwork pretraining and finetuning. We evaluate TAGI on the Super-Natural Instructions and P3 datasets. The experimental results demonstrate that TAGI can match or even outperform traditional meta-trained models and other hypernetwork models, while significantly reducing computational requirements. Our code will be available at https://github.com/Xnhyacinth/TAGI.
tl;dr: A multi-subspace extension of PCA to disentangle interpretable subspaces of variations with supervision.

The success of machine learning models relies heavily on effectively representing high-dimensional data. However, ensuring data representations capture human-understandable concepts remains difficult, often requiring the incorporation of prior knowledge and decomposition of data into multiple subspaces. Traditional linear methods fall short in modeling more than one space, while more expressive deep learning approaches lack interpretability. Here, we introduce Supervised Independent Subspace Principal Component Analysis ($\texttt{sisPCA}$), a PCA extension designed for multi-subspace learning. Leveraging the Hilbert-Schmidt Independence Criterion (HSIC), $\texttt{sisPCA}$ incorporates supervision and simultaneously ensures subspace disentanglement. We demonstrate $\texttt{sisPCA}$'s connections with autoencoders and regularized linear regression and showcase its ability to identify and separate hidden data structures through extensive applications, including breast cancer diagnosis from image features, learning aging-associated DNA methylation changes, and single-cell analysis of malaria infection. Our results reveal distinct functional pathways associated with malaria colonization, underscoring the essentiality of explainable representation in high-dimensional data analysis.
tl;dr: KL regularization doesn't guarantee good outcomes in RLHF.

When applying reinforcement learning from human feedback (RLHF), the reward is learned from data and, therefore, always has some error. It is common to mitigate this by regularizing the policy with KL divergence from a base model, with the hope that balancing reward with regularization will achieve desirable outcomes despite this reward misspecification. We show that when the reward function has light-tailed error, optimal policies under less restrictive KL penalties achieve arbitrarily high utility. However, if error is heavy-tailed, some policies obtain arbitrarily high reward despite achieving no more utility than the base model--a phenomenon we call catastrophic Goodhart. We adapt a discrete optimization method to measure the tails of reward models, finding that they are consistent with light-tailed error. However, the pervasiveness of heavy-tailed distributions in many real-world applications indicates that future sources of RL reward could have heavy-tailed error, increasing the likelihood of reward hacking even with KL regularization.

We study the convergence rate of first-order methods for rectangular matrix factorization, which is a canonical nonconvex optimization problem. Specifically, given a rank-$r$ matrix $\mathbf{A}\in\mathbb{R}^{m\times n}$, we prove that gradient descent (GD) can find a pair of $\epsilon$-optimal solutions $\mathbf{X}_T\in\mathbb{R}^{m\times d}$ and $\mathbf{Y}_T\in\mathbb{R}^{n\times d}$, where $d\geq r$, satisfying $\lVert\mathbf{X}_T\mathbf{Y}_T^\top-\mathbf{A}\rVert_F\leq\epsilon\lVert\mathbf{A}\rVert_F$ in $T=O(\kappa^2\log\frac{1}{\epsilon})$ iterations with high probability, where $\kappa$ denotes the condition number of $\mathbf{A}$. Furthermore, we prove that Nesterov's accelerated gradient (NAG) attains an iteration complexity of $O(\kappa\log\frac{1}{\epsilon})$, which is the best-known bound of first-order methods for rectangular matrix factorization. Different from small balanced random initialization in the existing literature, we adopt an unbalanced initialization, where $\mathbf{X}_0$ is large and $\mathbf{Y}_0$ is $0$. Moreover, our initialization and analysis can be further extended to linear neural networks, where we prove that NAG can also attain an accelerated linear convergence rate. In particular, we only require the width of the network to be greater than or equal to the rank of the output label matrix. In contrast, previous results achieving the same rate require excessive widths that additionally depend on the condition number and the rank of the input data matrix.
tl;dr: Existing DNA tokenization methods borrowed from NLP are poorly suited for DNA's unique properties. We introduce MxDNA, a framework that allows the model to learn an effective DNA tokenization strategy, showing robust performance on various tasks.

Foundation models have made significant strides in understanding the genomic language of DNA sequences. However, previous models typically adopt the tokenization methods designed for natural language, which are unsuitable for DNA sequences due to their unique characteristics. In addition, the optimal approach to tokenize DNA remains largely under-explored, and may not be intuitively understood by humans even if discovered. To address these challenges, we introduce MxDNA, a novel framework where the model autonomously learns an effective DNA tokenization strategy through gradient decent. MxDNA employs a sparse Mixture of Convolution Experts coupled with a deformable convolution to model the tokenization process, with the discontinuous, overlapping, and ambiguous nature of meaningful genomic segments explicitly considered. On Nucleotide Transformer Benchmarks and Genomic Benchmarks, MxDNA demonstrates superior performance to existing methods with less pretraining data and time, highlighting its effectiveness. Finally, we show that MxDNA learns unique tokenization strategy distinct to those of previous methods and captures genomic functionalities at a token level during self-supervised pretraining. Our MxDNA aims to provide a new perspective on DNA tokenization, potentially offering broad applications in various domains and yielding profound insights. Code is available at https://github.com/qiaoqiaoLF/MxDNA.
tl;dr: We propose the first 4-bit second-order optimizers, exemplified by 4-bit Shampoo, maintaining performance similar to that of 32-bit ones.

Second-order optimizers, maintaining a matrix termed a preconditioner, are superior to first-order optimizers in both theory and practice.
The states forming the preconditioner and its inverse root restrict the maximum size of models trained by second-order optimizers. To address this, compressing 32-bit optimizer states to lower bitwidths has shown promise in reducing memory usage. However, current approaches only pertain to first-order optimizers. In this paper, we propose the first 4-bit second-order optimizers, exemplified by 4-bit Shampoo, maintaining performance similar to that of 32-bit ones. We show that quantizing the eigenvector matrix of the preconditioner in 4-bit Shampoo is remarkably better than quantizing the preconditioner itself both theoretically and experimentally. By rectifying the orthogonality of the quantized eigenvector matrix, we enhance the approximation of the preconditioner's eigenvector matrix, which also benefits the computation of its inverse 4-th root. Besides, we find that linear square quantization slightly outperforms dynamic tree quantization when quantizing second-order optimizer states. Evaluation on various networks for image classification and natural language modeling demonstrates that our 4-bit Shampoo achieves comparable performance to its 32-bit counterpart while being more memory-efficient.
tl;dr: We adaptively learn optimal indirect experiments to narrow the bounds on a functional of f in high-dimensional, non-linear settings with unobserved confounding.

Scientific hypotheses typically concern specific aspects of complex, imperfectly understood or entirely unknown mechanisms, such as the effect of gene expression levels on phenotypes or how microbial communities influence environmental health. Such queries are inherently causal (rather than purely associational), but in many settings, experiments can not be conducted directly on the target variables of interest, but are indirect. Therefore, they perturb the target variable, but do not remove potential confounding factors. If, additionally, the resulting experimental measurements are high-dimensional and the studied mechanisms nonlinear, the query of interest is generally not identified. We develop an adaptive strategy to design indirect experiments that optimally inform a targeted query about the ground truth mechanism in terms of sequentially narrowing the gap between an upper and lower bound on the query. While the general formulation consists of a bi-level optimization procedure, we derive an efficiently estimable analytical kernel-based estimator of the bounds for the causal effect, a query of key interest, and demonstrate the efficacy of our approach in confounded, multivariate, nonlinear synthetic settings.

In practical distributed systems, workers are typically not homogeneous, and due to differences in hardware configurations and network conditions, can have highly varying processing times. We consider smooth nonconvex finite-sum (empirical risk minimization) problems in this setup and introduce a new parallel method, Freya PAGE, designed to handle arbitrarily heterogeneous and asynchronous computations. By being robust to "stragglers" and adaptively ignoring slow computations, Freya PAGE offers significantly improved time complexity guarantees compared to all previous methods, including Asynchronous SGD, Rennala SGD, SPIDER, and PAGE, while requiring weaker assumptions. The algorithm relies on novel generic stochastic gradient collection strategies with theoretical guarantees that can be of interest on their own, and may be used in the design of future optimization methods. Furthermore, we establish a lower bound for smooth nonconvex finite-sum problems in the asynchronous setup, providing a fundamental time complexity limit. This lower bound is tight and demonstrates the optimality of Freya PAGE in the large-scale regime, i.e., when $\sqrt{m} \geq n,$ where $n$ is \# of workers, and $m$ is \# of data samples.
tl;dr: We explore the possibilities of approximating all probabilistic values simultaneously and efficiently, examples of probabilistic values include Beta Shapley values and weighted Banzhaf values.

The concept of probabilistic values, such as Beta Shapley values and weighted Banzhaf values, has gained recent attention in applications like feature attribution and data valuation. However, exact computation of these values is often exponentially expensive, necessitating approximation techniques. Prior research has shown that the choice of probabilistic values significantly impacts downstream performance, with no universally superior option. Consequently, one may have to approximate multiple candidates and select the best-performing one. Although there have been many efforts to develop efficient estimators, none are intended to approximate all probabilistic values both simultaneously and efficiently. In this work, we embark on the first exploration of achieving this goal. Adhering to the principle of maximum sample reuse and avoiding amplifying factors, we propose a one-sample-fits-all framework parameterized by a sampling vector to approximate intermediate terms that can be converted to any probabilistic value. Leveraging the concept of $ (\epsilon, \delta) $-approximation, we theoretically identify a key formula that effectively determines the convergence rate of our framework. By optimizing the sampling vector using this formula, we obtain i) a one-for-all estimator that achieves the currently best time complexity for all probabilistic values on average, and ii) a faster generic estimator with the sampling vector optimally tuned for each probabilistic value. Particularly, our one-for-all estimator achieves the fastest convergence rate on Beta Shapley values, including the well-known Shapley value, both theoretically and empirically. Finally, we establish a connection between probabilistic values and the least square regression used in (regularized) datamodels, showing that our one-for-all estimator can solve a family of datamodels simultaneously. Our code is available at https://github.com/watml/one-for-all.
tl;dr: A Causal Context Adjustment loss for better training the learned image compression network.

In recent years, learned image compression (LIC) technologies have surpassed conventional methods notably in terms of rate-distortion (RD) performance. Most present learned techniques are VAE-based with an autoregressive entropy model, which obviously promotes the RD performance by utilizing the decoded causal context. However, extant methods are highly dependent on the fixed hand-crafted causal context. The question of how to guide the auto-encoder to generate a more effective causal context benefit for the autoregressive entropy models is worth exploring. In this paper, we make the first attempt in investigating the way to explicitly adjust the causal context with our proposed Causal Context Adjustment loss (CCA-loss). By imposing the CCA-loss, we enable the neural network to spontaneously adjust important information into the early stage of the autoregressive entropy model. Furthermore, as transformer technology develops remarkably, variants of which have been adopted by many state-of-the-art (SOTA) LIC techniques. The existing computing devices have not adapted the calculation of the attention mechanism well, which leads to a burden on computation quantity and inference latency. To overcome it, we establish a convolutional neural network (CNN) image compression model and adopt the unevenly channel-wise grouped strategy for high efficiency. Ultimately, the proposed CNN-based LIC network trained with our Causal Context Adjustment loss attains a great trade-off between inference latency and rate-distortion performance.
tl;dr: We devise a FL framework that adapts to wild data, which coexists with non-IID in-distribution (IN) data, covariate-shift (IN-C) data, and semantic-shift (OUT) data.

Federated learning (FL) is a promising machine learning paradigm that collaborates with client models to capture global knowledge. However, deploying FL models in real-world scenarios remains unreliable due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, such as covariate-shift and semantic-shift data. Current FL researches typically address either covariate-shift data through OOD generalization or semantic-shift data via OOD detection, overlooking the simultaneous occurrence of various OOD shifts. In this work, we propose FOOGD, a method that estimates the probability density of each client and obtains reliable global distribution as guidance for the subsequent FL process. Firstly, SM3D in FOOGD estimates score model for arbitrary distributions without prior constraints, and detects semantic-shift data powerfully. Then SAG in FOOGD provides invariant yet diverse knowledge for both local covariate-shift generalization and client performance generalization. In empirical validations, FOOGD significantly enjoys three main advantages: (1) reliably estimating non-normalized decentralized distributions, (2) detecting semantic shift data via score values, and (3) generalizing to covariate-shift data by regularizing feature extractor. The project is open in https://github.com/XeniaLLL/FOOGD-main.git.
tl;dr: We propose DeformableTST, a Transformer-based model less reliant on patching, to broaden the applicability of Transformer-based models in time series forecasting tasks and achieves SOTA performance in a wider range of time series forecasting tasks.

With the proposal of patching technique in time series forecasting, Transformerbased models have achieved compelling performance and gained great interest from
the time series community. But at the same time, we observe a new problem that
the recent Transformer-based models are overly reliant on patching to achieve ideal
performance, which limits their applicability to some forecasting tasks unsuitable
for patching. In this paper, we intent to handle this emerging issue. Through diving
into the relationship between patching and full attention (the core mechanism
in Transformer-based models), we further find out the reason behind this issue
is that full attention relies overly on the guidance of patching to focus on the
important time points and learn non-trivial temporal representation. Based on this
finding, we propose DeformableTST as an effective solution to this emerging
issue. Specifically, we propose deformable attention, a sparse attention mechanism
that can better focus on the important time points by itself, to get rid of the need of
patching. And we also adopt a hierarchical structure to alleviate the efficiency issue
caused by the removal of patching. Experimentally, our DeformableTST achieves
the consistent state-of-the-art performance in a broader range of time series tasks,
especially achieving promising performance in forecasting tasks unsuitable for
patching, therefore successfully reducing the reliance on patching and broadening
the applicability of Transformer-based models. Code is available at this repository:
https://github.com/luodhhh/DeformableTST.
1164. G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering

Given a graph with textual attributes, we enable users to `chat with their graph': that is, to ask questions about the graph using a conversational interface. In response to a user's questions, our method provides textual replies and highlights the relevant parts of the graph. While existing works integrate large language models (LLMs) and graph neural networks (GNNs) in various ways, they mostly focus on either conventional graph tasks (such as node, edge, and graph classification), or on answering simple graph queries on small or synthetic graphs. In contrast, we develop a flexible question-answering framework targeting real-world textual graphs, applicable to multiple applications including scene graph understanding, common sense reasoning, and knowledge graph reasoning. Toward this goal, we first develop a Graph Question Answering (GraphQA) benchmark with data collected from different tasks. Then, we propose our \textit{G-Retriever} method, introducing the first retrieval-augmented generation (RAG) approach for general textual graphs, which can be fine-tuned to enhance graph understanding via soft prompting. To resist hallucination and to allow for textual graphs that greatly exceed the LLM's context window size, \textit{G-Retriever} performs RAG over a graph by formulating this task as a Prize-Collecting Steiner Tree optimization problem. Empirical evaluations show that our method outperforms baselines on textual graph tasks from multiple domains, scales well with larger graph sizes, and mitigates hallucination.~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/G-Retriever}}

While 3D Gaussian Splatting has recently become popular for neural rendering, current methods rely on carefully engineered cloning and splitting strategies for placing Gaussians, which does not always generalize and may lead to poor-quality renderings. For many real-world scenes this leads to their heavy dependence on good initializations. In this work, we rethink the set of 3D Gaussians as a random sample drawn from an underlying probability distribution describing the physical representation of the scene—in other words, Markov Chain Monte Carlo (MCMC) samples. Under this view, we show that the 3D Gaussian updates can be converted as Stochastic Gradient Langevin Dynamics (SGLD) update by simply introducing noise. We then rewrite the densification and pruning strategies in 3D Gaussian Splatting as simply a deterministic state transition of MCMC samples, removing these heuristics from the framework. To do so, we revise the ‘cloning’ of Gaussians into a relocalization scheme that approximately preserves sample probability. To encourage efficient use of Gaussians, we introduce an L1-regularizer on the Gaussians. On various standard evaluation scenes, we show that our method provides improved rendering quality, easy control over the number of Gaussians, and robustness to initialization. The project website is available at https://3dgs-mcmc.github.io/.
tl;dr: This work employs data augmentation to propose a conjugate Bayesian two-step change point detection method for the Hawkes process.

The Bayesian two-step change point detection method is popular for the Hawkes process due to its simplicity and intuitiveness. However, the non-conjugacy between the point process likelihood and the prior requires most existing Bayesian two-step change point detection methods to rely on non-conjugate inference methods. These methods lack analytical expressions, leading to low computational efficiency and impeding timely change point detection. To address this issue, this work employs data augmentation to propose a conjugate Bayesian two-step change point detection method for the Hawkes process, which proves to be more accurate and efficient. Extensive experiments on both synthetic and real data demonstrate the superior effectiveness and efficiency of our method compared to baseline methods. Additionally, we conduct ablation studies to explore the robustness of our method concerning various hyperparameters.
tl;dr: This paper provides both analysis and solution to overcome the dilemma between OOD detection and generalization.

Out-of-distribution (OOD) detection is essential for model trustworthiness which aims to sensitively identity semantic OOD samples and robustly generalize for covariate-shifted OOD samples. However, we discover that the superior OOD detection performance of state-of-the-art methods is achieved by secretly sacrificing the OOD generalization ability. The classification accuracy frequently collapses catastrophically when even slight noise is encountered. Such a phenomenon violates the motivation of trustworthiness and significantly limits the model's deployment in the real world. What is the hidden reason behind such a limitation? In this work, we theoretically demystify the "\textit{sensitive-robust}" dilemma that lies in previous OOD detection methods. Consequently, a theory-inspired algorithm is induced to overcome such a dilemma. By decoupling the uncertainty learning objective from a Bayesian perspective, the conflict between OOD detection and OOD generalization is naturally harmonized and a dual-optimized performance could be expected. Empirical studies show that our method achieves superior performance on commonly used benchmarks. To our best knowledge, this work is the first principled OOD detection method that achieves state-of-the-art OOD detection performance without sacrificing OOD generalization ability. Our code is available at https://github.com/QingyangZhang/DUL.
tl;dr: We study a general correlation clustering problem with noisy weighted similarity queries, introducing two novel online learning formulations and designing efficient algorithms with theoretical guarantees.

We study a general clustering setting in which we have $n$ elements to be clustered, and we aim to perform as few queries as possible to an oracle that returns a noisy sample of the weighted similarity between two elements. Our setting encompasses many application domains in which the similarity function is costly to compute and inherently noisy. We introduce two novel formulations of online learning problems rooted in the paradigm of Pure Exploration in Combinatorial Multi-Armed Bandits (PE-CMAB): fixed confidence and fixed budget settings. For both settings, we design algorithms that combine a sampling strategy with a classic approximation algorithm for correlation clustering and study their theoretical guarantees. Our results are the first examples of polynomial-time algorithms that work for the case of PE-CMAB in which the underlying offline optimization problem is NP-hard.

Recent advancements in solving Bayesian inverse problems have spotlighted denoising diffusion models (DDMs) as effective priors.
Although these have great potential, DDM priors yield complex posterior distributions that are challenging to sample from.
Existing approaches to posterior sampling in this context address this problem either by retraining model-specific components, leading to stiff and cumbersome methods, or by introducing approximations with uncontrolled errors that affect the accuracy of the produced samples.
We present an innovative framework, divide-and-conquer posterior sampling, which leverages the inherent structure of DDMs to construct a sequence of intermediate posteriors that guide the produced samples to the target posterior.
Our method significantly reduces the approximation error associated with current techniques without the need for retraining.
We demonstrate the versatility and effectiveness of our approach for a wide range of Bayesian inverse problems.
The code is available at \url{https://github.com/Badr-MOUFAD/dcps}

Inverse rendering methods have achieved remarkable performance in reconstructing high-fidelity 3D objects with disentangled geometries, materials, and environmental light. However, they still face huge challenges in reflective surface reconstruction. Although recent methods model the light trace to learn specularity, the ignorance of indirect illumination makes it hard to handle inter-reflections among multiple smooth objects. In this work, we propose Ref-MC2 that introduces the multi-time Monte Carlo sampling which comprehensively computes the environmental illumination and meanwhile considers the reflective light from object surfaces. To address the computation challenge as the times of Monte Carlo sampling grow, we propose a specularity-adaptive sampling strategy, significantly reducing the computational complexity. Besides the computational resource, higher geometry accuracy is also required because geometric errors accumulate multiple times. Therefore, we further introduce a reflection-aware surface model to initialize the geometry and refine it during inverse rendering. We construct a challenging dataset containing scenes with multiple objects and inter-reflections. Experiments show that our method outperforms other inverse rendering methods on various object groups. We also show downstream applications, e.g., relighting and material editing, to illustrate the disentanglement ability of our method.

Topic models have been evolving rapidly over the years, from conventional to recent neural models. However, existing topic models generally struggle with either effectiveness, efficiency, or stability, highly impeding their practical applications. In this paper, we propose FASTopic, a fast, adaptive, stable, and transferable topic model. FASTopic follows a new paradigm: Dual Semantic-relation Reconstruction (DSR). Instead of previous conventional, VAE-based, or clustering-based methods, DSR directly models the semantic relations among document embeddings from a pretrained Transformer and learnable topic and word embeddings. By reconstructing through these semantic relations, DSR discovers latent topics. This brings about a neat and efficient topic modeling framework. We further propose a novel Embedding Transport Plan (ETP) method. Rather than early straightforward approaches, ETP explicitly regularizes the semantic relations as optimal transport plans. This addresses the relation bias issue and thus leads to effective topic modeling. Extensive experiments on benchmark datasets demonstrate that our FASTopic shows superior effectiveness, efficiency, adaptivity, stability, and transferability, compared to state-of-the-art baselines across various scenarios.
tl;dr: We learn globally gauranteed contractng dyanmical systems by parameterizing the extended linearization of the vector field.

Global stability and robustness guarantees in learned dynamical systems are essential to ensure well-behavedness of the systems in the face of uncertainty. We present Extended Linearized Contracting Dynamics (ELCD), the first neural network-based dynamical system with global contractivity guarantees in arbitrary metrics. The key feature of ELCD is a parametrization of the extended linearization of the nonlinear vector field. In its most basic form, ELCD is guaranteed to be (i) globally exponentially stable, (ii) equilibrium contracting, and (iii) globally contracting with respect to some metric. To allow for contraction with respect to more general metrics in the data space, we train diffeomorphisms between the data space and a latent space and enforce contractivity in the latent space, which ensures global contractivity in the data space. We demonstrate the performance of ELCD on the high dimensional LASA, multi-link pendulum, and Rosenbrock datasets.

Amino acid substitution rate matrices are fundamental to statistical phylogenetics and evolutionary biology. Estimating them typically requires reconstructed trees for massive amounts of aligned proteins, which poses a major computational bottleneck. In this paper, we develop a near linear-time method to estimate these rate matrices from multiple sequence alignments (MSAs) alone, thereby speeding up computation by orders of magnitude. Our method can be easily applied to MSAs with millions of sequences. On both simulated and real data, we demonstrate the speed and accuracy of our method as applied to the classical model of protein evolution. By leveraging the unprecedented scalability of our method, we develop a new, rich phylogenetic model called \textit{SiteRM}, which can estimate a general \textit{site-specific} rate matrix for each column of an MSA. Remarkably, in variant effect prediction for both clinical and deep mutational scanning data in ProteinGym, we show that despite being an independent-sites model, our SiteRM model outperforms large protein language models that learn complex residue-residue interactions between different sites. We attribute our increased performance to conceptual advances in our probabilistic treatment of evolutionary data and our ability to handle extremely large MSAs. We anticipate that our work will have a lasting impact across both statistical phylogenetics and computational variant effect prediction.

Learning world models offers a promising avenue for goal-conditioned reinforcement learning with sparse rewards. By allowing agents to plan actions or exploratory goals without direct interaction with the environment, world models enhance exploration efficiency. The quality of a world model hinges on the richness of data stored in the agent's replay buffer, with expectations of reasonable generalization across the state space surrounding recorded trajectories. However, challenges arise in generalizing learned world models to state transitions backward along recorded trajectories or between states across different trajectories, hindering their ability to accurately model real-world dynamics. To address these challenges, we introduce a novel goal-directed exploration algorithm, MUN (short for "World Models for Unconstrained Goal Navigation"). This algorithm is capable of modeling state transitions between arbitrary subgoal states in the replay buffer, thereby facilitating the learning of policies to navigate between any "key" states. Experimental results demonstrate that MUN strengthens the reliability of world models and significantly improves the policy's capacity to generalize across new goal settings.
tl;dr: We propose MoICE, which enhances LLMs' context awareness. MoICE introduces a router in each attention head within LLMs, which dynamically directs the head's attention to contextual positions crucial for completing the head's function well.

Many studies have revealed that large language models (LLMs) exhibit uneven awareness of different contextual positions. Their limited context awareness can lead to overlooking critical information and subsequent task failures. While several approaches have been proposed to enhance LLMs' context awareness, achieving both effectiveness and efficiency remains challenging. In this paper, for LLMs utilizing RoPE as position embeddings, we introduce a novel method called "Mixture of In-Context Experts" (MoICE) to address this challenge. MoICE comprises two key components: a router integrated into each attention head within LLMs and a lightweight router-only training optimization strategy:(1) MoICE views each RoPE angle as an 'in-context' expert, demonstrated to be capable of directing the attention of a head to specific contextual positions. Consequently, each attention head flexibly processes tokens using multiple RoPE angles dynamically selected by the router to attend to the needed positions. This approach mitigates the risk of overlooking essential contextual information. (2) The router-only training strategy entails freezing LLM parameters and exclusively updating routers for only a few steps. When applied to open-source LLMs including Llama and Mistral, MoICE surpasses prior methods across multiple tasks on long context understanding and generation, all while maintaining commendable inference efficiency.

Long-horizon robotic manipulation tasks typically involve a series of interrelated sub-tasks spanning multiple execution stages. Skill chaining offers a feasible solution for these tasks by pre-training the skills for each sub-task and linking them sequentially. However, imperfections in skill learning or disturbances during execution can lead to the accumulation of errors in skill chaining process, resulting in execution failures. In this paper, we investigate how to achieve stable and smooth skill chaining for long-horizon robotic manipulation tasks. Specifically, we propose a novel skill chaining framework called Skill Chaining via Dual Regularization (SCaR). This framework applies dual regularization to sub-task skill pre-training and fine-tuning, which not only enhances the intra-skill dependencies within each sub-task skill but also reinforces the inter-skill dependencies between sequential sub-task skills, thus ensuring smooth skill chaining and stable long-horizon execution. We evaluate the SCaR framework on two representative long-horizon robotic manipulation simulation benchmarks: IKEA furniture assembly and kitchen organization. Additionally, we conduct a simple real-world validation in tabletop robot pick-and-place tasks. The experimental results show that, with the support of SCaR, the robot achieves a higher success rate in long-horizon tasks compared to relevant baselines and demonstrates greater robustness to perturbations.
1177. QVAE-Mole: The Quantum VAE with Spherical Latent Variable Learning for 3-D Molecule Generation
tl;dr: We propose the first fully (conditional) quantum VAE for 3-D data (molecule) generation with a von-Mises Fisher distributed latent space.

Molecule generation ideally in its 3-D form has enjoyed wide applications in material, chemistry, life science, etc. We propose the first quantum parametric circuit for 3-D molecule generation for its potential quantum advantage especially considering the arrival of Noisy Intermediate-Scale Quantum (NISQ) era. We choose the Variational AutoEncoder (VAE) scheme for its simplicity and one-shot generation ability, which we believe is more quantum-friendly compared with the auto-regressive generative models or diffusion models as used in classic approaches. Specifically, we present a quantum encoding scheme designed for 3-D molecules with qubits complexity $\mathcal{O}(C\log n)$ ($n$ is the number of atoms) and adopt a von Mises-Fisher (vMF) distributed latent space to meet the inherent coherence of the quantum system. We further design to encode conditions into quantum circuits for property-specified generation. Experimentally, our model could generate plausible 3-D molecules and achieve competitive quantitative performance with significantly reduced circuit parameters compared with their classic counterparts. The source code will be released upon publication.

Integer linear programs (ILPs) are commonly employed to model diverse practical problems such as scheduling and planning.
Recently, machine learning techniques have been utilized to solve ILPs. A straightforward idea is to train a model via supervised learning, with an ILP as the input and an optimal solution as the label. An ILP is symmetric if its variables can be permuted without changing the problem structure, resulting in numerous equivalent and optimal solutions. Randomly selecting an optimal solution as the label can introduce variability in the training data, which may hinder the model from learning stable patterns. In this work, we incorporate the intrinsic symmetry of ILPs and propose a novel training framework called SymILO. Specifically, we modify the learning task by introducing solution permutation along with neural network weights as learnable parameters and then design an alternating algorithm to jointly optimize the loss function.
We conduct extensive experiments on ILPs involving different symmetries and the computational results demonstrate that our symmetry-aware approach significantly outperforms three existing methods----achieving $50.3\\%$, $66.5\\%$, and $45.4\\%$ average improvements, respectively.

Watermarking generative content serves as a vital tool for authentication, ownership protection, and mitigation of potential misuse. Existing watermarking methods face the challenge of balancing robustness and concealment. They empirically inject a watermark that is both invisible and robust and passively achieve concealment by limiting the strength of the watermark, thus reducing the robustness. In this paper, we propose to explicitly introduce a watermark hiding process to actively achieve concealment, thus allowing the embedding of stronger watermarks. To be specific, we implant a robust watermark in an intermediate diffusion state and then guide the model to hide the watermark in the final generated image. We employ an adversarial optimization algorithm to produce the optimal hiding prompt guiding signal for each watermark. The prompt embedding is optimized to minimize artifacts in the generated image, while the watermark is optimized to achieve maximum strength. The watermark can be verified by reversing the generation process. Experiments on various diffusion models demonstrate the watermark remains verifiable even under significant image tampering and shows superior invisibility compared to other state-of-the-art robust watermarking methods.

We study the embedding dimension of distance comparison data in two settings: contrastive learning and $k$-nearest neighbors ($k$-NN). In both cases, the goal is to find the smallest dimension $d$ of an $\ell_p$-space in which a given dataset can be represented. We show that the arboricity of the associated graphs plays a key role in designing embeddings. Using this approach, for the most frequently used $\ell_2$-distance, we get matching upper and lower bounds in both settings.
In contrastive learning, we are given $m$ labeled samples of the form $(x_i, y_i^+, z_i^-)$ representing the fact that the positive example $y_i$ is closer to the anchor $x_i$ than the negative example $z_i$. We show that for representing such dataset in:
- $\ell_2$: $d = \Theta(\sqrt{m})$ is necessary and sufficient.
- $\ell_p$ for $p \ge 1$: $d = O(m)$ is sufficient and $d = \tilde \Omega(\sqrt{m})$ is necessary.
- $\ell_\infty$: $d = O(m^{2/3})$ is sufficient and $d = \tilde \Omega(\sqrt{m})$ is necessary.
We also give results for the more general scenario when $t$ negatives are allowed.
In $k$-NN, for each of the $n$ data points we are given an ordered set of the closest $k$ points. We show that for preserving the ordering of the $k$-NN for every point in:
- $\ell_2$: $d = \Theta(k)$ is necessary and sufficient.
- $\ell_p$ for $p \ge 1$: $d = \tilde O(k^2)$ is sufficient and $d=\tilde \Omega(k)$ is necessary.
- $\ell_\infty$ : $d = \tilde \Omega(k)$ is necessary.
Furthermore, if the goal is to not just preserve the ordering of the $k$-NN but also keep them as the nearest neighbors then $d = \tilde O (\mathrm{poly}(k))$ suffices in $\ell_p$ for $p \ge 1$.
tl;dr: We propose a meta-metric for objectively evaluating text-to-image faithfulness metrics, by assessing their ability to sort and discriminate images of increasing error counts in a "Semantic Error Graph", and many existing metrics are surprisingly bad.

With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness---the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented with correlation to human Likert scores over a set of easy-to-discriminate images against seemingly weak baselines.
We introduce T2IScoreScore, a curated set of semantic error graphs containing a prompt and a set of increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple (and supposedly worse) feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.

KV cache stores key and value states from previous tokens to avoid re-computation, yet it demands substantial storage space, especially for long sequences.
Adaptive KV cache compression seeks to discern the saliency of tokens, preserving vital information while aggressively compressing those of less importance.
However, previous methods of this approach exhibit significant performance degradation at high compression ratios due to inaccuracies in identifying salient tokens.
Additionally, the compression process introduces excessive overhead, substantially increasing memory burdens and the generation latency.
In this paper, we present ZipCache, an accurate and efficient KV cache quantization method for large language models (LLMs).
First, we construct a strong baseline for quantizing KV cache. Through the proposed channel-separable tokenwise quantization scheme, the memory overhead of quantization parameters are substantially reduced compared to fine-grained groupwise quantization.
To enhance the compression ratio, we propose normalized attention score as an effective metric for identifying salient tokens by considering the lower triangle characteristics of the attention matrix. The quantization bit-width for each token is then adaptively assigned based on their saliency.
Moreover, we develop an efficient approximation method that decouples the saliency metric from full attention scores, enabling compatibility with fast attention implementations like FlashAttention.
Extensive experiments demonstrate that ZipCache achieves superior compression ratios, fast generation speed and minimal performance losses compared with previous KV cache compression methods. For instance, when evaluating Mistral-7B model on GSM8k dataset, ZipCache is capable of compressing the KV cache by $4.98\times$, with only a 0.38% drop in accuracy. In terms of efficiency, ZipCache also showcases a 37.3% reduction in prefill-phase latency, a 56.9% reduction in decoding-phase latency, and a 19.8% reduction in GPU memory usage when evaluating LLaMA3-8B model with a input length of 4096. Code is available at https://github.com/ThisisBillhe/ZipCache/.

We propose a method of offline reinforcement learning (RL) featuring the performance guarantee without any assumptions on the data support. Under such conditions, estimating or optimizing the conventional performance metric is generally infeasible due to the distributional discrepancy between data and target policy distributions. To address this issue, we employ a worst-case policy value as a new metric and constructively show that the sample complexity bound of $O(\epsilon^{−2})$ is attainable without any data-support conditions, where $\epsilon>0$ is the policy suboptimality in the new metric. Moreover, as the new metric generalizes the conventional one, the algorithm can address standard offline RL tasks without modification. In this context, our sample complexity bound can be seen as a strict improvement on the previous bounds under the single-policy concentrability and the single-policy realizability.

The recent large-scale text-to-image generative models have attained unprecedented performance, while people established *adaptor* modules like LoRA and DreamBooth to extend this performance to even more unseen concept tokens. However, we empirically find that this workflow often fails to accurately depict the *out-of-distribution* concepts. This failure is highly related to the low quality of training data. To resolve this, we present a framework called Controllable Adaptor Towards Out-of-Distribution Concepts (CATOD). Our framework follows the active learning paradigm which includes high-quality data accumulation and adaptor training, enabling a finer-grained enhancement of generative results. The *aesthetics* score and *concept-matching* score are two major factors that impact the quality of synthetic results. One key component of CATOD is the weighted scoring system that automatically balances between these two scores and we also offer comprehensive theoretical analysis for this point. Then, it determines how to select data and schedule the adaptor training based on this scoring system. The extensive results show that CATOD significantly outperforms the prior approaches with an 11.10 boost on the CLIP score and a 33.08% decrease on the CMMD metric.
tl;dr: We provide the first tractable algorithm that achieves minimax optimal regret in average reward MDPs.

In recent years, significant attention has been directed towards learning average-reward Markov Decision Processes (MDPs).
However, existing algorithms either suffer from sub-optimal regret guarantees or computational inefficiencies.
In this paper, we present the first *tractable* algorithm with minimax optimal regret of $\mathrm{O}\left(\sqrt{\mathrm{sp}(h^*) S A T \log(SAT)}\right)$ where $\mathrm{sp}(h^*)$ is the span of the optimal bias function $h^*$, $S\times A$ is the size of the state-action space and $T$ the number of learning steps.
Remarkably, our algorithm does not require prior information on $\mathrm{sp}(h^*)$.
Our algorithm relies on a novel subroutine, **P**rojected **M**itigated **E**xtended **V**alue **I**teration (`PMEVI`), to compute bias-constrained optimal policies efficiently.
This subroutine can be applied to various previous algorithms to obtain improved regret bounds.

Despite spiking neural networks (SNNs) have demonstrated notable energy efficiency across various fields, the limited firing patterns of spiking neurons within fixed time steps restrict the expression of information, which impedes further improvement of SNN performance. In addition, current implementations of SNNs typically consider the firing rate or average membrane potential of the last layer as the output, lacking exploration of other possibilities. In this paper, we identify that the limited spike patterns of spiking neurons stem from the initial membrane potential (IMP), which is set to 0. By adjusting the IMP, the spiking neurons can generate additional firing patterns and pattern mappings. Furthermore, we find that in static tasks, the accuracy of SNNs at each time step increases as the membrane potential evolves from zero. This observation inspires us to propose a learnable IMP, which can accelerate the evolution of membrane potential and enables higher performance within a limited number of time steps. Additionally, we introduce the last time step (LTS) approach to accelerate convergence in static tasks, and we propose a label smooth temporal efficient training (TET) loss to mitigate the conflicts between optimization objective and regularization term in the vanilla TET. Our methods improve the accuracy by 4.05\% on ImageNet compared to baseline and achieve state-of-the-art performance of 87.80\% on CIFAR10-DVS and 87.86\% on N-Caltech101.

This paper studies first-order policy optimization for robust average cost Markov decision processes (MDPs). Specifically, we focus on ergodic Markov chains. For robust average cost MDPs, the goal is to optimize the worst-case average cost over an uncertainty set of transition kernels. We first develop a sub-gradient of the robust average cost. Based on the sub-gradient, a robust policy mirror descent approach is further proposed. To characterize its iteration complexity, we develop a lower bound on the difference of robust average cost between two policies and further show that the robust average cost satisfies the PL-condition. We then show that with increasing step size, our robust policy mirror descent achieves a linear convergence rate in the optimality gap, and with constant step size, our algorithm converges to an $\epsilon$-optimal policy with an iteration complexity of $\mathcal{O}(1/\epsilon)$. The convergence rate of our algorithm matches with the best convergence rate of policy-based algorithms for robust MDPs. Moreover, our algorithm is the first algorithm that converges to the global optimum with general uncertainty sets for robust average cost MDPs. We provide simulation results to demonstrate the performance of our algorithm.

In this paper, we introduce a novel variation of multi-armed bandits called bandits with ranking feedback. Unlike traditional bandits, this variation provides feedback to the learner that allows them to rank the arms based on previous pulls, without quantifying numerically the difference in performance. This type of feedback is well-suited for scenarios where the arms' values cannot be precisely measured using metrics such as monetary scores, probabilities, or occurrences. Common examples include human preferences in matchmaking problems. Furthermore, its investigation answers the theoretical question on how numerical rewards are crucial in bandit settings. In particular, we study the problem of designing no-regret algorithms with ranking feedback both in the stochastic and adversarial settings. We show that, with stochastic rewards, differently from what happens with non-ranking feedback, no algorithm can suffer a logarithmic regret in the time horizon $T$ in the instance-dependent case. Furthermore, we provide two algorithms. The first, namely DREE, guarantees a superlogarithmic regret in $T$ in the instance-dependent case thus matching our lower bound, while the second, namely R-LPE, guarantees a regret of $\mathcal{\widetilde O}(\sqrt{T})$ in the instance-independent case. Remarkably, we show that no algorithm can have an optimal regret bound in both instance-dependent and instance-independent cases. Finally, we prove that no algorithm can achieve a sublinear regret when the rewards are adversarial.

Visible-infrared person re-identification (VIReID) is widely used in fields such as video surveillance and intelligent transportation, imposing higher demands on model security. In practice, the adversarial attacks based on VIReID aim to disrupt output ranking and quantify the security risks of models. Although numerous studies have been emerged on adversarial attacks and defenses in fields such as face recognition, person re-identification, and pedestrian detection, there is currently a lack of research on the security of VIReID systems. To this end, we propose to explore the vulnerabilities of VIReID systems and prevent potential serious losses due to insecurity. Compared to research on single-modality ReID, adversarial feature alignment and modality differences need to be particularly emphasized. Thus, we advocate for feature-level adversarial attacks to disrupt the output rankings of VIReID systems. To obtain adversarial features, we introduce \textit{Universal Adversarial Perturbations} (UAP) to simulate common disturbances in real-world environments. Additionally, we employ a \textit{Frequency-Spatial Attention Module} (FSAM), integrating frequency information extraction and spatial focusing mechanisms, and further emphasize important regional features from different domains on the shared features. This ensures that adversarial features maintain consistency within the feature space. Finally, we employ an \textit{Auxiliary Quadruple Adversarial Loss} to amplify the differences between modalities, thereby improving the distinction and recognition of features between visible and infrared images, which causes the system to output incorrect rankings. Extensive experiments on two VIReID benchmarks (i.e., SYSU-MM01, RegDB) and different systems validate the effectiveness of our method.

Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) such as Proximal Policy Optimization (PPO) and offline contrastive methods such as Direct Preference Optimization (DPO) -- were positioned as equivalent in prior work due to the fact that both have to start from the same offline preference dataset. To further expand our theoretical understanding of the similarities and differences between online and offline techniques for preference fine-tuning, we conduct a rigorous analysis through the lens of *dataset coverage*, a concept that captures how the training data covers the test distribution and is widely used in RL. We prove that a global coverage condition is both necessary and sufficient for offline contrastive methods to converge to the optimal policy, but a weaker partial coverage condition suffices for online RL methods. This separation provides one explanation of why online RL methods can perform better than offline methods, especially when the offline preference data is not diverse enough. Finally, motivated by our preceding theoretical observations, we derive a hybrid preference optimization (HyPO) algorithm that uses offline data for contrastive-based preference optimization and online unlabeled data for KL regularization. Theoretically and empirically, we demonstrate that HyPO is more performant than its pure offline counterpart DPO, while still preserving its computation and memory efficiency.
1191. FuseFL: One-Shot Federated Learning through the Lens of Causality with Progressive Model Fusion
tl;dr: This work identifies the cause of low performance of one-shot FL, and proposes FuseFL to progressively train and fuses DNN model following a bottom-up manner, reducing communication costs to an extremely low degree.

One-shot Federated Learning (OFL) significantly reduces communication costs in FL by aggregating trained models only once. However, the performance of advanced OFL methods is far behind the normal FL. In this work, we provide a causal view to find that this performance drop of OFL methods comes from the isolation problem, which means that local isolatedly trained models in OFL may easily fit to spurious correlations due to the data heterogeneity. From the causal perspective, we observe that the spurious fitting can be alleviated by augmenting intermediate features from other clients. Built upon our observation, we propose a novel learning approach to endow OFL with superb performance and low communication and storage costs, termed as FuseFL. Specifically, FuseFL decomposes neural networks into several blocks, and progressively trains and fuses each block following a bottom-up manner for feature augmentation, introducing no additional communication costs. Comprehensive experiments demonstrate that FuseFL outperforms existing OFL and ensemble FL by a significant margin. We conduct comprehensive experiments to show that FuseFL supports high scalability of clients, heterogeneous model training, and low memory costs. Our work is the first attempt using causality to analyze and alleviate data heterogeneity of OFL.
tl;dr: We leverage the multi-periodicity and it's inclusion relationships within time series to construct a periodic pyramid and propose the Peri-midFormer, which achieves state-of-the-art performance across five time series analysis tasks.

Time series analysis finds wide applications in fields such as weather forecasting, anomaly detection, and behavior recognition. Previous methods attempted to model temporal variations directly using 1D time series. However, this has been quite challenging due to the discrete nature of data points in time series and the complexity of periodic variation. In terms of periodicity, taking weather and traffic data as an example, there are multi-periodic variations such as yearly, monthly, weekly, and daily, etc. In order to break through the limitations of the previous methods, we decouple the implied complex periodic variations into inclusion and overlap relationships among different level periodic components based on the observation of the multi-periodicity therein and its inclusion relationships. This explicitly represents the naturally occurring pyramid-like properties in time series, where the top level is the original time series and lower levels consist of periodic components with gradually shorter periods, which we call the periodic pyramid. To further extract complex temporal variations, we introduce self-attention mechanism into the periodic pyramid, capturing complex periodic relationships by computing attention between periodic components based on their inclusion, overlap, and adjacency relationships. Our proposed Peri-midFormer demonstrates outstanding performance in five mainstream time series analysis tasks, including short- and long-term forecasting, imputation, classification, and anomaly detection.
tl;dr: We propose GarmentLab for garment manipulation with realistic and rich simulations and diverse benchmark tasks.

Manipulating garments and fabrics has long been a critical endeavor in the development of home-assistant robots. However, due to complex dynamics and topological structures, garment manipulations pose significant challenges. Recent successes in reinforcement learning and vision-based methods offer promising avenues for learning garment manipulation. Nevertheless, these approaches are severely constrained by current benchmarks, which exhibit offer limited diversity of tasks and unrealistic simulation behavior. Therefore, we present GarmentLab, a content-rich benchmark and realistic simulation designed for deformable object and garment manipulation. Our benchmark encompasses a diverse range of garment types, robotic systems and manipulators. The abundant tasks in the benchmark further explores of the interactions between garments, deformable objects, rigid bodies, fluids, and human body. Moreover, by incorporating multiple simulation methods such as FEM and PBD, along with our proposed sim-to-real algorithms and real-world benchmark, we aim to significantly narrow the sim-to-real gap. We evaluate state-of-the-art vision methods, reinforcement learning, and imitation learning approaches on these tasks, highlighting the challenges faced by current algorithms, notably their limited generalization capabilities. Our proposed open-source environments and comprehensive analysis show promising boost to future research in garment manipulation by unlocking the full potential of these methods. We guarantee that we will open-source our code as soon as possible. You can watch the videos in supplementary files to learn more about the details of our work.
tl;dr: We provide a LLM-powered multi-agent communication platform to generate fine-tuning data for cultural topics

Cultural bias is pervasive in many large language models (LLMs), largely due to the deficiency of data representative of different cultures.
Typically, cultural datasets and benchmarks are constructed either by extracting subsets of existing datasets or by aggregating from platforms such as Wikipedia and social media.
However, these approaches are highly dependent on real-world data and human annotations, making them costly and difficult to scale.
Inspired by cognitive theories on social communication, this paper introduces CulturePark, an LLM-powered multi-agent communication framework for cultural data collection.
CulturePark simulates cross-cultural human communication with LLM-based agents playing roles in different cultures.
It generates high-quality cross-cultural dialogues encapsulating human beliefs, norms, and customs.
Using CulturePark, we generated 41,000 cultural samples to fine-tune eight culture-specific LLMs.
We evaluated these models across three downstream tasks: content moderation, cultural alignment, and cultural education.
Results show that for content moderation, our GPT-3.5-based models either match or outperform GPT-4 on $41$ datasets. Regarding cultural alignment, our models surpass GPT-4 on Hofstede's VSM 13 framework.
Furthermore, for cultural education of human participants, our models demonstrate superior outcomes in both learning efficacy and user experience compared to GPT-4. CulturePark proves an important step in addressing cultural bias and advancing the democratization of AI, highlighting the critical role of culturally inclusive data in model training. Code is released at https://github.com/Scarelette/CulturePark.
tl;dr: We study a dynamic mechanism design problem subject to a fairness constraint that ensures a minimum average allocation for each group.

We consider a dynamic mechanism design problem where an auctioneer sells an indivisible good to two groups of buyers in every round, for a total of $T$ rounds. The auctioneer aims to maximize their discounted overall revenue while adhering to a fairness constraint that guarantees a minimum average allocation for each group. We begin by studying the static case ($T=1$) and establish that the optimal mechanism involves two types of subsidization: one that increases the overall probability of allocation to all buyers, and another that favors the group which otherwise has a lower probability of winning the item. We then extend our results to the dynamic case by characterizing a set of recursive functions that determine the optimal allocation and payments in each round. Notably, our results establish that in the dynamic case, the seller, on one hand, commits to a participation reward to incentivize truth-telling, and, on the other hand, charges an entry fee for every round. Moreover, the optimal allocation once more involves subsidization in favor of one group, where the extent of subsidization depends on the difference in future utilities for both the seller and buyers when allocating the item to one group versus the other. Finally, we present an approximation scheme to solve the recursive equations and determine an approximately optimal and fair allocation efficiently.

Transformer-based large language models (LLMs) have displayed remarkable creative prowess and emergence capabilities. Existing empirical studies have revealed a strong connection between these LLMs' impressive emergence abilities and their in-context learning (ICL) capacity, allowing them to solve new tasks using only task-specific prompts without further fine-tuning. On the other hand, existing empirical and theoretical studies also show that there is a regularity of the multi-concept encoded semantic representation behind transformer-based LLMs. However, existing theoretical work fail to build up an understanding of the connection between this semantic regularity and the innovative power of ICL. Additionally, prior work often focuses on simplified, unrealistic scenarios with linear transformers or unrealistic loss functions, and due to their technical limitations, they come up with results exhibiting only linear or sub-linear convergence rates. In contrast, this work provides a fine-grained mathematical analysis to show how transformers leverage the multi-concept semantics of words to enable powerful ICL and excellent out-of-distribution ICL abilities, offering insights into how transformers innovate solutions for new unseen tasks encoded with multiple cross-concept semantics. Inspired by empirical studies on the latent geometry of LLMs, the analysis is based on a concept-based low-noise sparse coding prompt model. Leveraging advanced techniques, this work showcases the exponential 0-1 loss convergence over the highly non-convex training dynamics, which pioneeringly incorporates the challenges of softmax self-attention, ReLU-activated MLPs, and cross-entropy loss. Empirical simulations corroborate the theoretical findings.
tl;dr: proposed an end-to-end noisy label learning system that provably identifies the target system (as if no label noise exists) in the presence of instance-dependent outliers.

The generation of label noise is often modeled as a process involving a probability transition matrix (also interpreted as the _annotator confusion matrix_) imposed onto the label distribution. Under this model, learning the ``ground-truth classifier''---i.e., the classifier that can be learned if no noise was present---and the confusion matrix boils down to a model identification problem. Prior works along this line demonstrated appealing empirical performance, yet identifiability of the model was mostly established by assuming an instance-invariant confusion matrix. Having an (occasionally) instance-dependent confusion matrix across data samples is apparently more realistic, but inevitably introduces outliers to the model. Our interest lies in confusion matrix-based noisy label learning with such outliers taken into consideration. We begin with pointing out that under the model of interest, using labels produced by only one annotator is fundamentally insufficient to detect the outliers or identify the ground-truth classifier. Then, we prove that by employing a crowdsourcing strategy involving multiple annotators, a carefully designed loss function can establish the desired model identifiability under reasonable conditions. Our development builds upon a link between the noisy label model and a column-corrupted matrix factorization mode---based on which we show that crowdsourced annotations distinguish nominal data and instance-dependent outliers using a low-dimensional subspace. Experiments show that our learning scheme substantially improves outlier detection and the classifier's testing accuracy.
1198. VLM Agents Generate Their Own Memories: Distilling Experience into Embodied Programs of Thought
tl;dr: ICAL lets LLMs and VLMs create effective prompts from sub-optimal demos and human feedback, improving decision-making and reducing reliance on expert examples. It outperforms state-of-the-art models in TEACh, VisualWebArena, and Ego4D.

Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience from sub-optimal demonstrations and human feedback. Given a task demonstration that may contain inefficiencies or mistakes, a VLM abstracts the trajectory into a generalized program by correcting inefficient actions and annotating cognitive abstractions: causal relationships, object state changes, temporal subgoals, and task-relevant visual elements. These abstractions are iteratively improved and adapted through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting examples, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Moreover, as the agent's library of examples grows, it becomes more efficient, relying less on human feedback and requiring fewer environment interactions per demonstration. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7% using GPT4V. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on manual prompt engineering and consistently outperforms in-context learning from action plans that lack such abstractions.
tl;dr: We identify where the memorization happens in self-supervised learning encoders.

Recent work on studying memorization in self-supervised learning (SSL) suggests that even though SSL encoders are trained on millions of images, they still memorize individual data points. While effort has been put into characterizing the memorized data and linking encoder memorization to downstream utility, little is known about where the memorization happens inside SSL encoders. To close this gap, we propose two metrics for localizing memorization in SSL encoders on a per-layer (LayerMem) and per-unit basis (UnitMem). Our localization methods are independent of the downstream task, do not require any label information, and can be performed in a forward pass. By localizing memorization in various encoder architectures (convolutional and transformer-based) trained on diverse datasets with contrastive and non-contrastive SSL frameworks, we find that (1) while SSL memorization increases with layer depth, highly memorizing units are distributed across the entire encoder, (2) a significant fraction of units in SSL encoders experiences surprisingly high memorization of individual data points, which is in contrast to models trained under supervision, (3) atypical (or outlier) data points cause much higher layer and unit memorization than standard data points, and (4) in vision transformers, most memorization happens in the fully-connected layers. Finally, we show that localizing memorization in SSL has the potential to improve fine-tuning and to inform pruning strategies.

We study fairness in social influence maximization, whereby one seeks to select
seeds that spread a given information throughout a network, ensuring balanced
outreach among different communities (e.g. demographic groups). In the literature,
fairness is often quantified in terms of the expected outreach within individual
communities. In this paper, we demonstrate that such fairness metrics can be
misleading since they overlook the stochastic nature of information diffusion
processes. When information diffusion occurs in a probabilistic manner, multiple
outreach scenarios can occur. As such, outcomes such as “In 50% of the cases, no
one in group 1 gets the information, while everyone in group 2 does, and in the
other 50%, it is the opposite”, which always results in largely unfair outcomes,
are classified as fair by a variety of fairness metrics in the literature. We tackle
this problem by designing a new fairness metric, mutual fairness, that captures
variability in outreach through optimal transport theory. We propose a new seed-
selection algorithm that optimizes both outreach and mutual fairness, and we show
its efficacy on several real datasets. We find that our algorithm increases fairness
with only a minor decrease (and at times, even an increase) in efficiency.
tl;dr: We present the first attempt to build a federated foundation model for time series forecasting by exploiting the sequence reasoning potential of language models, avoiding the disclosure of local data.

Unlike natural language processing and computer vision, the development of Foundation Models (FMs) for time series forecasting is blocked due to data scarcity.
While recent efforts are focused on building such FMs by unlocking the potential of language models (LMs) for time series analysis, dedicated parameters for various downstream forecasting tasks need training, which hinders the common knowledge sharing across domains.
Moreover, data owners may hesitate to share the access to local data due to privacy concerns and copyright protection, which makes it impossible to simply construct a FM on cross-domain training instances.
To address these issues, we propose Time-FFM, a Federated Foundation Model for Time series forecasting by leveraging pretrained LMs.
Specifically, we begin by transforming time series into the modality of text tokens.
To bootstrap LMs for time series reasoning, we propose a prompt adaption module to determine domain-customized prompts dynamically instead of artificially.
Given the data heterogeneity across domains, we design a personalized federated training strategy by learning global encoders and local prediction heads.
Our comprehensive experiments indicate that Time-FFM outperforms state-of-the-arts and promises effective few-shot and zero-shot forecaster.
The code is available at https://github.com/CityMind-Lab/NeurIPS24-Time-FFM/tree/main.
tl;dr: a definition of compatibility between a distribution and a directed hypergraph, with implications for causality and information theory

We define what it means for a joint probability distribution to be compatible with aset of independent causal mechanisms, at a qualitative level—or, more precisely with a directed hypergraph $\mathcal A$, which is the qualitative structure of a probabilistic dependency graph (PDG). When A represents a qualitative Bayesian network, QIM-compatibility with $\mathcal A$ reduces to satisfying the appropriate conditional independencies. But giving semantics to hypergraphs using QIM-compatibility lets us do much more. For one thing, we can capture functional dependencies. For another, we can capture important aspects of causality using compatibility: we can use compatibility to understand cyclic causal graphs, and to demonstrate structural compatibility, we must essentially produce a causal model. Finally, compatibility has deep connections to information theory. Applying compatibility to cyclic structures helps to clarify a longstanding conceptual issue in information theory.

Mutual information (MI) is a general measure of statistical dependence with widespread application across the sciences. However, estimating MI between multi-dimensional variables is challenging because the number of samples necessary to converge to an accurate estimate scales unfavorably with dimensionality. In practice, existing techniques can reliably estimate MI in up to tens of dimensions, but fail in higher dimensions, where sufficient sample sizes are infeasible. Here, we explore the idea that underlying low-dimensional structure in high-dimensional data can be exploited to faithfully approximate MI in high-dimensional settings with realistic sample sizes. We develop a method that we call latent MI (LMI) approximation, which applies a nonparametric MI estimator to low-dimensional representations learned by a simple, theoretically-motivated model architecture. Using several benchmarks, we show that unlike existing techniques, LMI can approximate MI well for variables with $> 10^3$ dimensions if their dependence structure is captured by low-dimensional representations. Finally, we showcase LMI on two open problems in biology. First, we approximate MI between protein language model (pLM) representations of interacting proteins, and find that pLMs encode non-trivial information about protein-protein interactions. Second, we quantify cell fate information contained in single-cell RNA-seq (scRNA-seq) measurements of hematopoietic stem cells, and find a sharp transition during neutrophil differentiation when fate information captured by scRNA-seq increases dramatically. An implementation of LMI is available at *latentmi.readthedocs.io.*

Continuous normalizing flows (CNFs) learn the probability path between a reference distribution and a target distribution by modeling the vector field generating said path using neural networks. Recently, Lipman et al. (2022) introduced a simple and inexpensive method for training CNFs in generative modeling, termed flow matching (FM). In this paper, we repurpose this method for probabilistic inference by incorporating Markovian sampling methods in evaluating the FM objective, and using the learned CNF to improve Monte Carlo sampling. Specifically, we propose an adaptive Markov chain Monte Carlo (MCMC) algorithm, which combines a local Markov transition kernel with a non-local, flow-informed transition kernel, defined using a CNF. This CNF is adapted on-the-fly using samples from the Markov chain, which are used to specify the probability path for the FM objective. Our method also includes an adaptive tempering mechanism that allows the discovery of multiple modes in the target distribution. Under mild assumptions, we establish convergence of our method to a local optimum of the FM objective. We then benchmark our approach on several synthetic and real-world examples, achieving similar performance to other state-of-the-art methods but often at a significantly lower computational cost.
tl;dr: This paper introduces a method to estimate performance metrics like accuracy, recall, precision, and F1 score in the weak supervision setup when no ground truth labels are observed.

Programmatic Weak Supervision (PWS) enables supervised model training without direct access to ground truth labels, utilizing weak labels from heuristics, crowdsourcing, or pre-trained models. However, the absence of ground truth complicates model evaluation, as traditional metrics such as accuracy, precision, and recall cannot be directly calculated. In this work, we present a novel method to address this challenge by framing model evaluation as a partial identification problem and estimating performance bounds using Fréchet bounds. Our approach derives reliable bounds on key metrics without requiring labeled data, overcoming core limitations in current weak supervision evaluation techniques. Through scalable convex optimization, we obtain accurate and computationally efficient bounds for metrics including accuracy, precision, recall, and F1-score, even in high-dimensional settings. This framework offers a robust approach to assessing model quality without ground truth labels, enhancing the practicality of weakly supervised learning for real-world applications.
1206. Position Coupling: Improving Length Generalization of Arithmetic Transformers Using Task Structure
tl;dr: To tackle the length generalization problem of decoder-only Transformer for solving arithmetic/algorithmic tasks, we inject the structure of the task into the Transformer by using the same position IDs for relevant tokens.

Even for simple arithmetic tasks like integer addition, it is challenging for Transformers to generalize to longer sequences than those encountered during training. To tackle this problem, we propose *position coupling*, a simple yet effective method that directly embeds the structure of the tasks into the positional encoding of a (decoder-only) Transformer. Taking a departure from the vanilla absolute position mechanism assigning unique position IDs to each of the tokens, we assign the same position IDs to two or more "relevant" tokens; for integer addition tasks, we regard digits of the same significance as in the same position. On the empirical side, we show that with the proposed position coupling, our models trained on 1 to 30-digit additions can generalize up to *200-digit* additions (6.67x of the trained length). On the theoretical side, we prove that a 1-layer Transformer with coupled positions can solve the addition task involving exponentially many digits, whereas any 1-layer Transformer without positional information cannot entirely solve it. We also demonstrate that position coupling can be applied to other algorithmic tasks such as Nx2 multiplication and a two-dimensional task. Our codebase is available at [github.com/HanseulJo/position-coupling](https://github.com/HanseulJo/position-coupling).
tl;dr: We propose an adaptive multi-scale hypergraph transformer for time series forecasting.

Although transformer-based methods have achieved great success in multi-scale temporal pattern interaction modeling, two key challenges limit their further development: (1) Individual time points contain less semantic information, and leveraging attention to model pair-wise interactions may cause the information utilization bottleneck. (2) Multiple inherent temporal variations (e.g., rising, falling, and fluctuating) entangled in temporal patterns. To this end, we propose Adaptive Multi-Scale Hypergraph Transformer (Ada-MSHyper) for time series forecasting. Specifically, an adaptive hypergraph learning module is designed to provide foundations for modeling group-wise interactions, then a multi-scale interaction module is introduced to promote more comprehensive pattern interactions at different scales. In addition, a node and hyperedge constraint mechanism is introduced to cluster nodes with similar semantic information and differentiate the temporal variations within each scales. Extensive experiments on 11 real-world datasets demonstrate that Ada-MSHyper achieves state-of-the-art performance, reducing prediction errors by an average of 4.56%, 10.38%, and 4.97% in MSE for long-range, short-range, and ultra-long-range time series forecasting, respectively. Code is available at https://github.com/shangzongjiang/Ada-MSHyper.
tl;dr: A mixture of observational and unknown causal interventions can be efficiently disentangled and causal graph can be learnt upto IMEC within the linear SEM framework with Gaussian additive noise.

The ability to conduct interventions plays a pivotal role in learning causal relationships among variables, thus facilitating applications across diverse scientific disciplines such as genomics, economics, and machine learning. However, in many instances within these applications, the process of generating interventional data is subject to noise: rather than data being sampled directly from the intended interventional distribution, interventions often yield data sampled from a blend of both intended and unintended interventional distributions.
We consider the fundamental challenge of disentangling mixed interventional and observational data within linear Structural Equation Models (SEMs) with Gaussian additive noise without the knowledge of the true causal graph. We demonstrate that conducting interventions, whether do or soft, yields distributions with sufficient diversity and properties conducive to efficiently recovering each component within the mixture. Furthermore, we establish that the sample complexity required to disentangle mixed data inversely correlates with the extent of change induced by an intervention in the equations governing the affected variable values. As a result, the causal graph can be identified up to its interventional Markov Equivalence Class, similar to scenarios where no noise influences the generation of interventional data. We further support our theoretical findings by conducting simulations wherein we perform causal discovery from such mixed data.
tl;dr: PID of the contribution made by terms in the input text prompt to the output image

Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model’s perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models. Link to project page: https://rbz-99.github.io/Diffusion-PID/.
tl;dr: We find simply filtering frequency components significantly improves CD-FSS performance. We delve into this for an interpretation, and further propose a lightweight frequency masker, importing only 2.5% parameters but averagely improving over 11%.

Cross-domain few-shot segmentation (CD-FSS) is proposed to first pre-train the model on a large-scale source-domain dataset, and then transfer the model to data-scarce target-domain datasets for pixel-level segmentation. The significant domain gap between the source and target datasets leads to a sharp decline in the performance of existing few-shot segmentation (FSS) methods in cross-domain scenarios. In this work, we discover an intriguing phenomenon: simply filtering different frequency components for target domains can lead to a significant performance improvement, sometimes even as high as 14% mIoU. Then, we delve into this phenomenon for an interpretation, and find such improvements stem from the reduced inter-channel correlation in feature maps, which benefits CD-FSS with enhanced robustness against domain gaps and larger activated regions for segmentation. Based on this, we propose a lightweight frequency masker, which further reduces channel correlations by an amplitude-phase-masker (APM) module and an Adaptive Channel Phase Attention (ACPA) module. Notably, APM introduces only 0.01% additional parameters but improves the average performance by over 10%, and ACPA imports only 2.5% parameters but further improves the performance by over 1.5%, which significantly surpasses the state-of-the-art CD-FSS methods.

Recent progress of deep generative models in the vision and language domain has stimulated significant interest in more structured data generation such as molecules. However, beyond generating new random molecules, efficient exploration and a comprehensive understanding of the vast chemical space are of great importance to molecular science and applications in drug design and materials discovery.
In this paper, we propose a new framework, ChemFlow, to traverse chemical space through navigating the latent space learned by molecule generative models through flows. We introduce a dynamical system perspective that formulates the problem as learning a vector field that transports the mass of the molecular distribution to the region with desired molecular properties or structure diversity.
Under this framework, we unify previous approaches on molecule latent space traversal and optimization and propose alternative competing methods incorporating different physical priors.
We validate the efficacy of ChemFlow on molecule manipulation and single- and multi-objective molecule optimization tasks under both supervised and unsupervised molecular discovery settings.
Codes and demos are publicly available on GitHub at
[https://github.com/garywei944/ChemFlow](https://github.com/garywei944/ChemFlow).
tl;dr: We prove masked hard-attention transformers recognize exactly the star-free regular languages.

The expressive power of transformers over inputs of unbounded size can be studied through their ability to recognize classes of formal languages. In this paper, we establish exact characterizations of transformers with hard attention (in which all attention is focused on exactly one position) and attention masking (in which each position only attends to positions on one side). With strict masking (each position cannot attend to itself) and without position embeddings, these transformers are expressively equivalent to linear temporal logic (LTL), which defines exactly the star-free languages. A key technique is the use of Boolean RASP as a convenient intermediate language between transformers and LTL. We then take numerous results known for LTL and apply them to transformers, showing how position embeddings, strict masking, and depth all increase expressive power.

Graph self-supervised learning, as a powerful pre-training paradigm for Graph Neural Networks (GNNs) without labels, has received considerable attention. We have witnessed the success of graph self-supervised learning on pre-training the parameters of GNNs, leading many not to doubt that whether the learned GNNs parameters are all useful. In this paper, by presenting the experimental evidence and analysis, we surprisingly discover that the graph self-supervised learning models are highly redundant at both of neuron and layer levels, e.g., even randomly removing 51.6\% of parameters, the performance of graph self-supervised learning models still retains at least 96.2\%. This discovery implies that the parameters of graph self-supervised models can be largely reduced, making simultaneously fine-tuning both graph self-supervised learning models and prediction layers more feasible. Therefore, we further design a novel graph pre-training and fine-tuning paradigm called SLImming DE-correlation Fine-tuning (SLIDE). The effectiveness of SLIDE is verified through extensive experiments on various benchmarks, and the performance can be even improved with fewer parameters of models in most cases. For example, in comparison with full fine-tuning GraphMAE on Amazon-Computers dataset, even randomly reducing 40\% of parameters, we can still achieve the improvement of 0.24\% and 0.27\% for Micro-F1 and Macro-F1 scores respectively.
tl;dr: This work proposes Doubly Mild Generalization, comprising mild action generalization and mild generalization propagation, to appropriately exploit generalization in offline RL.

Offline Reinforcement Learning (RL) suffers from the extrapolation error and value overestimation. From a generalization perspective, this issue can be attributed to the over-generalization of value functions or policies towards out-of-distribution (OOD) actions. Significant efforts have been devoted to mitigating such generalization, and recent in-sample learning approaches have further succeeded in entirely eschewing it. Nevertheless, we show that mild generalization beyond the dataset can be trusted and leveraged to improve performance under certain conditions. To appropriately exploit generalization in offline RL, we propose Doubly Mild Generalization (DMG), comprising (i) mild action generalization and (ii) mild generalization propagation. The former refers to selecting actions in a close neighborhood of the dataset to maximize the Q values. Even so, the potential erroneous generalization can still be propagated, accumulated, and exacerbated by bootstrapping. In light of this, the latter concept is introduced to mitigate the generalization propagation without impeding the propagation of RL learning signals. Theoretically, DMG guarantees better performance than the in-sample optimal policy in the oracle generalization scenario. Even under worst-case generalization, DMG can still control value overestimation at a certain level and lower bound the performance. Empirically, DMG achieves state-of-the-art performance across Gym-MuJoCo locomotion tasks and challenging AntMaze tasks. Moreover, benefiting from its flexibility in both generalization aspects, DMG enjoys a seamless transition from offline to online learning and attains strong online fine-tuning performance.
1215. RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models

Recent works show that assembling multiple off-the-shelf large language models (LLMs) can harness their complementary abilities. To achieve this, routing is a promising method, which learns a router to select the most suitable LLM for each query. However, existing routing models are ineffective when multiple LLMs perform well for a query. To address this problem, in this paper, we propose a method called query-based Router by Dual Contrastive learning (RouterDC). The RouterDC model, which consists of an encoder and LLM embeddings, is trained by two proposed contrastive losses (sample-LLM and sample-sample losses). Experimental results show that RouterDC is effective in assembling LLMs and largely outperforms individual top-performing LLMs as well as existing routing methods on both in-distribution (+2.76\%) and out-of-distribution (+1.90\%) tasks. The source code is available at https://github.com/shuhao02/RouterDC.
tl;dr: Gradient flow implicitly regularizes deep linear networks towards flat minima, both for a small-scale and a residual initialization.

The largest eigenvalue of the Hessian, or sharpness, of neural networks is a key quantity to understand their optimization dynamics. In this paper, we study the sharpness of deep linear networks for univariate regression. Minimizers can have arbitrarily large sharpness, but not an arbitrarily small one. Indeed, we show a lower bound on the sharpness of minimizers, which grows linearly with depth. We then study the properties of the minimizer found by gradient flow, which is the limit of gradient descent with vanishing learning rate. We show an implicit regularization towards flat minima: the sharpness of the minimizer is no more than a constant times the lower bound. The constant depends on the condition number of the data covariance matrix, but not on width or depth. This result is proven both for a small-scale initialization and a residual initialization. Results of independent interest are shown in both cases. For small-scale initialization, we show that the learned weight matrices are approximately rank-one and that their singular vectors align. For residual initialization, convergence of the gradient flow for a Gaussian initialization of the residual network is proven. Numerical experiments illustrate our results and connect them to gradient descent with non-vanishing learning rate.

Large language models are often ranked according to their level of alignment with human preferences---a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model---a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set---a set of possible ranking positions---for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
tl;dr: We enhance Vision Transformers for multi-channel imaging by improving diverse representations.

Multi-Channel Imaging (MCI) contains an array of challenges for encoding useful feature representations not present in traditional images. For example, images from two different satellites may both contain RGB channels, but the remaining channels can be different for each imaging source. Thus, MCI models must support a variety of channel configurations at test time. Recent work has extended traditional visual encoders for MCI, such as Vision Transformers (ViT), by supplementing pixel information with an encoding representing the channel configuration. However, these methods treat each channel equally, i.e., they do not consider the unique properties of each channel type, which can result in needless and potentially harmful redundancies in the learned features. For example, if RGB channels are always present, the other channels can focus on extracting information that cannot be captured by the RGB channels. To this end, we propose DiChaViT, which aims to enhance the diversity in the learned features of MCI-ViT models. This is achieved through a novel channel sampling strategy that encourages the selection of more distinct channel sets for training. Additionally, we employ regularization and initialization techniques to increase the likelihood that new information is learned from each channel. Many of our improvements are architecture agnostic and can be incorporated into new architectures as they are developed. Experiments on both satellite and cell microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, report DiChaViT yields a 1.5 - 5.0% gain over the state-of-the-art. Our code is publicly available at https://github.com/chaudatascience/diverse_channel_vit.

As a prominent category of imitation learning methods, adversarial imitation learning (AIL) has garnered significant practical success powered by neural network approximation. However, existing theoretical studies on AIL are primarily limited to simplified scenarios such as tabular and linear function approximation and involve complex algorithmic designs that hinder practical implementation, highlighting a gap between theory and practice. In this paper, we explore the theoretical underpinnings of online AIL with general function approximation. We introduce a new method called optimization-based AIL (OPT-AIL), which centers on performing online optimization for reward functions and optimism-regularized Bellman error minimization for Q-value functions. Theoretically, we prove that OPT-AIL achieves polynomial expert sample complexity and interaction complexity for learning near-expert policies. To our best knowledge, OPT-AIL is the first provably efficient AIL method with general function approximation. Practically, OPT-AIL only requires the approximate optimization of two objectives, thereby facilitating practical implementation. Empirical studies demonstrate that OPT-AIL outperforms previous state-of-the-art deep AIL methods in several challenging tasks.
tl;dr: APM introduces asynchronous patch-processing for test-time-training instead of parallel perception. APM leverages GLOM's islands of agreement. We present the scientific evidence towards validating GLOM's insight: if input percept is really a field.

In this work, we propose Asynchronous Perception Machine (APM), a computationally-efficient architecture for test-time-training (TTT). APM can process patches of an image one at a time in any order asymmetrically, and still encode semantic-awareness in the net. We demonstrate APM’s ability to recognize out-of-distribution images without dataset-specific pre-training, augmentation or
any-pretext task. APM offers competitive performance over existing TTT approaches. To perform TTT, APM just distills test sample’s representation once. APM possesses a unique property: it can learn using just this single representation and starts predicting semantically-aware features. APM’s ability to recover semantic information from a global CLS token validates the insight that CLS
tokens encode geometric-information of a given scene and can be recovered using appropriate inductive-biases. This offers a novel-insight with consequences for representational-learning. APM demostrates potential applications beyond test-time-training: APM can scale up to a dataset of 2D images and yield semantic-clusterings in a single forward pass. APM also provides first empirical evidence towards validating Hinton at Al’s GLOM’s insight, i.e. if input percept is a field. Therefore, APM helps our community converge towards an implementation which can do both interpolation and perception on a shared-connectionist hardware. Our
codebase has been made available at https://rajatmodi62.github.io/apm_project_page/
--------
**It now appears that some of the ideas in GLOM could be made to work.**
https://www.technologyreview.com/2021/04/16/1021871/geoffrey-hinton-glom-godfather-ai-neural-networks/
```
.-""""""-.
.' '.
/ O O \
| O |
\ '------' /
'. .'
'-....-'
A silent man in deep-contemplation.
Silent man emerges only sometimes.
And he loves all.
```
1221. Federated Online Prediction from Experts with Differential Privacy: Separations and Regret Speed-ups

We study the problems of differentially private federated online prediction from experts against both *stochastic adversaries* and *oblivious adversaries*. We aim to minimize the average regret on $m$ clients working in parallel over time horizon $T$ with explicit differential privacy (DP) guarantees. With stochastic adversaries, we propose a **Fed-DP-OPE-Stoch** algorithm that achieves $\sqrt{m}$-fold speed-up of the per-client regret compared to the single-player counterparts under both pure DP and approximate DP constraints, while maintaining logarithmic communication costs. With oblivious adversaries, we establish non-trivial lower bounds indicating that *collaboration among clients does not lead to regret speed-up with general oblivious adversaries*. We then consider a special case of the oblivious adversaries setting, where there exists a low-loss expert. We design a new algorithm **Fed-SVT** and show that it achieves an $m$-fold regret speed-up under both pure DP and approximate DP constraints over the single-player counterparts. Our lower bound indicates that Fed-SVT is nearly optimal up to logarithmic factors. Experiments demonstrate the effectiveness of our proposed algorithms. To the best of our knowledge, this is the first work examining the differentially private online prediction from experts in the federated setting.

Vision Transformers (ViTs) are widely used in a variety of applications, while they usually have a fixed architecture that may not match the varying computational resources of different deployment environments. Thus, it is necessary to adapt ViT architectures to devices with diverse computational overheads to achieve an accuracy-efficient trade-off. This concept is consistent with the motivation behind Learngene. To achieve this, inspired by polynomial decomposition in calculus, where a function can be approximated by linearly combining several basic components, we propose to linearly decompose the ViT model into a set of components called learngenes during element-wise training. These learngenes can then be recomposed into differently scaled, pre-initialized models to satisfy different computational resource constraints. Such a decomposition-recomposition strategy provides an economical and flexible approach to generating different scales of ViT models for different deployment scenarios. Compared to model compression or training from scratch, which require to repeatedly train on large datasets for diverse-scale models, such strategy reduces computational costs since it only requires to train on large datasets once. Extensive experiments are used to validate the effectiveness of our method: ViTs can be decomposed and the decomposed learngenes can be recomposed into diverse-scale ViTs, which can achieve comparable or better performance compared to traditional model compression and pre-training methods. The code for our experiments is available in the supplemental material.
tl;dr: Parameter Identifiability of Partially Observed Linear Causal Model

Linear causal models are important tools for modeling causal dependencies and yet in practice, only a subset of the variables can be observed. In this paper, we examine the parameter identifiability of these models by investigating whether the edge coefficients can be recovered given the causal structure and partially observed data. Our setting is more general than that of prior research—we allow all variables, including both observed and latent ones, to be flexibly related, and we consider the coefficients of all edges, whereas most existing works focus only on the edges between observed variables. Theoretically, we identify three types of indeterminacy for the parameters in partially observed linear causal models. We then provide graphical conditions that are sufficient for all parameters to be identifiable and show that some of them are provably necessary. Methodologically, we propose a novel likelihood-based parameter estimation method that addresses the variance indeterminacy of latent variables in a specific way and can asymptotically recover the underlying parameters up to trivial indeterminacy. Empirical studies on both synthetic and real-world datasets validate our identifiability theory and the effectiveness of the proposed method in the finite-sample regime.

Low-rank approximation and column subset selection are two fundamental and related problems that are applied across a wealth of machine learning applications. In this paper, we study the question of socially fair low-rank approximation and socially fair column subset selection, where the goal is to minimize the loss over all sub-populations of the data. We show that surprisingly, even constant-factor approximation to fair low-rank approximation requires exponential time under certain standard complexity hypotheses. On the positive side, we give an algorithm for fair low-rank approximation that, for a constant number of groups and constant-factor accuracy, runs in $2^{\text{poly}(k)}$ rather than the naive $n^{\text{poly}(k)}$, which is a substantial improvement when the dataset has a large number $n$ of observations. We then show that there exist bicriteria approximation algorithms for fair low-rank approximation and fair column subset selection that runs in polynomial time.
tl;dr: MDAgents, a framework that adapts the collaboration of LLMs for complex medical decision-making, improving performance on major medical benchmarks

Foundation models are becoming valuable tools in medicine. Yet despite their promise, the best way to leverage Large Language Models (LLMs) in complex medical tasks remains an open question. We introduce a novel multi-agent framework, named **M**edical **D**ecision-making **Agents** (**MDAgents**) that helps to address this gap by automatically assigning a collaboration structure to a team of LLMs. The assigned solo or group collaboration structure is tailored to the medical task at hand, a simple emulation inspired by the way real-world medical decision-making processes are adapted to tasks of different complexities. We evaluate our framework and baseline methods using state-of-the-art LLMs across a suite of real-world medical knowledge and clinical diagnosis benchmarks, including a comparison of
LLMs’ medical complexity classification against human physicians. MDAgents achieved the **best performance in seven out of ten** benchmarks on tasks requiring an understanding of medical knowledge and multi-modal reasoning, showing a significant **improvement of up to 4.2\%** ($p$ < 0.05) compared to previous methods' best performances. Ablation studies reveal that MDAgents effectively determines medical complexity to optimize for efficiency and accuracy across diverse medical tasks. Notably, the combination of moderator review and external medical knowledge in group collaboration resulted in an average accuracy **improvement of 11.8\%**. Our code can be found at https://github.com/mitmedialab/MDAgents.
tl;dr: Minimizing a discrepancy between different value estimates is beneficial for learning memory under partial observability.

Reinforcement learning algorithms typically rely on the assumption that the environment dynamics and value function can be expressed in terms of a Markovian state representation. However, when state information is only partially observable, how can an agent learn such a state representation, and how can it detect when it has found one? We introduce a metric that can accomplish both objectives, without requiring access to---or knowledge of---an underlying, unobservable state space. Our metric, the λ-discrepancy, is the difference between two distinct temporal difference (TD) value estimates, each computed using TD(λ) with a different value of λ. Since TD(λ=0) makes an implicit Markov assumption and TD(λ=1) does not, a discrepancy between these estimates is a potential indicator of a non-Markovian state representation. Indeed, we prove that the λ-discrepancy is exactly zero for all Markov decision processes and almost always non-zero for a broad class of partially observable environments. We also demonstrate empirically that, once detected, minimizing the λ-discrepancy can help with learning a memory function to mitigate the corresponding partial observability. We then train a reinforcement learning agent that simultaneously constructs two recurrent value networks with different λ parameters and minimizes the difference between them as an auxiliary loss. The approach scales to challenging partially observable domains, where the resulting agent frequently performs significantly better (and never performs worse) than a baseline recurrent agent with only a single value network.

Diffusion models (DMs) have become the dominant paradigm of generative modeling in a variety of domains by learning stochastic processes from noise to data. Recently, diffusion denoising bridge models (DDBMs), a new formulation of generative modeling that builds stochastic processes between fixed data endpoints based on a reference diffusion process, have achieved empirical success across tasks with coupled data distribution, such as image-to-image translation. However, DDBM's sampling process typically requires hundreds of network evaluations to achieve decent performance, which may impede their practical deployment due to high computational demands. In this work, inspired by the recent advance of consistency models in DMs, we tackle this problem by learning the consistency function of the probability-flow ordinary differential equation (PF-ODE) of DDBMs, which directly predicts the solution at a starting step given any point on the ODE trajectory. Based on a dedicated general-form ODE solver, we propose two paradigms: consistency bridge distillation and consistency bridge training, which is flexible to apply on DDBMs with broad design choices. Experimental results show that our proposed method could sample $4\times$ to $50\times$ faster than the base DDBM and produce better visual quality given the same step in various tasks with pixel resolution ranging from $64 \times 64$ to $256 \times 256$, as well as supporting downstream tasks such as semantic interpolation in the data space.
tl;dr: This paper presents a new privacy vulnerability in training diffusion models with Federated Learning and proposes an adaptive Trojan attack to bypass advanced defenses and achieve DataStealing.

Federated Learning (FL) is commonly used to collaboratively train models with privacy preservation. In this paper, we found out that the popular diffusion models have introduced a new vulnerability to FL, which brings serious privacy threats. Despite stringent data management measures, attackers can steal massive private data from local clients through multiple Trojans, which control generative behaviors with multiple triggers. We refer to the new task as ${\bf\textit{DataStealing}}$ and demonstrate that the attacker can achieve the purpose based on our proposed Combinatorial Triggers (ComboTs) in a vanilla FL system. However, advanced distance-based FL defenses are still effective in filtering the malicious update according to the distances between each local update. Hence, we propose an Adaptive Scale Critical Parameters (AdaSCP) attack to circumvent the defenses and seamlessly incorporate malicious updates into the global model. Specifically, AdaSCP evaluates the importance of parameters with the gradients in dominant timesteps of the diffusion model. Subsequently, it adaptively seeks the optimal scale factor and magnifies critical parameter updates before uploading to the server. As a result, the malicious update becomes similar to the benign update, making it difficult for distance-based defenses to identify. Extensive experiments reveal the risk of leaking thousands of images in training diffusion models with FL. Moreover, these experiments demonstrate the effectiveness of AdaSCP in defeating advanced distance-based defenses. We hope this work will attract more attention from the FL community to the critical privacy security issues of Diffusion Models. Code: https://github.com/yuangan/DataStealing.
tl;dr: We propose AutoTimes to repurpose large language models as autoregressive time series forecasters, which exhibits zero-shot, in-context learning and multimodal utilizability with state-of-the-art performance and efficiency.

Foundation models of time series have not been fully developed due to the limited availability of time series corpora and the underexploration of scalable pre-training. Based on the similar sequential formulation of time series and natural language, increasing research demonstrates the feasibility of leveraging large language models (LLM) for time series. Nevertheless, the inherent autoregressive property and decoder-only architecture of LLMs have not been fully considered, resulting in insufficient utilization of LLM abilities. To fully revitalize the general-purpose token transition and multi-step generation capability of large language models, we propose AutoTimes to repurpose LLMs as autoregressive time series forecasters, which projects time series into the embedding space of language tokens and autoregressively generates future predictions with arbitrary lengths. Compatible with any decoder-only LLMs, the consequent forecaster exhibits the flexibility of the lookback length and scalability with larger LLMs. Further, we formulate time series as prompts, extending the context for prediction beyond the lookback window, termed in-context forecasting. By introducing LLM-embedded textual timestamps, AutoTimes can utilize chronological information to align multivariate time series. Empirically, AutoTimes achieves state-of-the-art with 0.1% trainable parameters and over $5\times$ training/inference speedup compared to advanced LLM-based forecasters. Code is available at this repository: https://github.com/thuml/AutoTimes.

State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there are no effective attacks to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data, such as categorical features, immutability, and feature relationship constraints. To fill this gap, we first propose CAPGD, a gradient attack that overcomes the failures of existing gradient attacks with adaptive mechanisms. This new attack does not require parameter tuning and further degrades the accuracy, up to 81\% points compared to the previous gradient attacks. Second, we design CAA, an efficient evasion attack that combines our CAPGD attack and MOEVA, the best search-based attack. We demonstrate the effectiveness of our attacks on five architectures and four critical use cases. Our empirical study demonstrates that CAA outperforms all existing attacks in 17 over the 20 settings, and leads to a drop in the accuracy by up to 96.1\% points and 21.9\% points compared to CAPGD and MOEVA respectively while being up to five times faster than MOEVA. Given the effectiveness and efficiency of our new attacks, we argue that they should become the minimal test for any new defense or robust architectures in tabular machine learning.

Knowledge in materials science is widely dispersed across extensive scientific literature, posing significant challenges for efficient discovery and integration of new materials. Traditional methods, often reliant on costly and time-consuming experimental approaches, further complicate rapid innovation. Addressing these challenges, the integration of artificial intelligence with materials science has opened avenues for accelerating the discovery process, though it also demands precise annotation, data extraction, and traceability of information. To tackle these issues, this article introduces the Materials Knowledge Graph (MKG), which utilizes advanced natural language processing techniques, integrated with large language models to extract and systematically organize a decade's worth of high-quality research into structured triples, contains 162,605 nodes and 731,772 edges. MKG categorizes information into comprehensive labels such as Name, Formula, and Application, structured around a meticulously designed ontology, thus enhancing data usability and integration. By implementing network-based algorithms, MKG not only facilitates efficient link prediction but also significantly reduces reliance on traditional experimental methods. This structured approach not only streamlines materials research but also lays the groundwork for more sophisticated materials knowledge graphs.
1232. On the Optimality of Dilated Entropy and Lower Bounds for Online Learning in Extensive-Form Games

First-order methods (FOMs) are arguably the most scalable algorithms for equilibrium computation in large extensive-form games. To operationalize these methods, a distance-generating function, acting as a regularizer for the strategy space, must be chosen.
The ratio between the strong convexity modulus and the diameter of the regularizer is a key parameter in the analysis of FOMs.
A natural question is then: what is the optimal distance-generating function for extensive-form decision spaces? In this paper, we make a number of contributions, ultimately establishing that the weight-one dilated entropy (DilEnt) distance-generating function is optimal up to logarithmic factors.
The DilEnt regularizer is notable due to its iterate-equivalence with Kernelized OMWU (KOMWU)---the algorithm with state-of-the-art dependence on the game tree size in extensive-form games---when used in conjunction with the online mirror descent (OMD) algorithm. However, the standard analysis for OMD is unable to establish such a result; the only current analysis is by appealing to the iterate equivalence to KOMWU.
We close this gap by introducing a pair of primal-dual treeplex norms, which we contend form the natural analytic viewpoint for studying the strong convexity of DilEnt.
Using these norm pairs, we recover the diameter-to-strong-convexity ratio that predicts the same performance as KOMWU. Along with a new regret lower bound for online learning in sequence-form strategy spaces, we show that this ratio is nearly optimal.
Finally, we showcase our analytic techniques by refining the analysis of Clairvoyant OMD when paired with DilEnt, establishing an $\mathcal{O}(n \log |\mathcal{V}| \log T/T)$ approximation rate to coarse correlated equilibrium in $n$-player games, where $|\mathcal{V}|$ is the number of reduced normal-form strategies of the players, establishing the new state of the art.

Learning from Observation (LfO) aims to imitate experts by learning from state-only demonstrations without requiring action labels.
Existing adversarial imitation learning approaches learn a generator agent policy to produce state transitions that are indistinguishable to a discriminator that learns to classify agent and expert state transitions. Despite its simplicity in formulation, these methods are often sensitive to hyperparameters and brittle to train. Motivated by the recent success of diffusion models in generative modeling, we propose to integrate a diffusion model into the adversarial imitation learning from observation framework. Specifically, we employ a diffusion model to capture expert and agent transitions by generating the next state, given the current state. Then, we reformulate the learning objective to train the diffusion model as a binary classifier and use it to provide ``realness'' rewards for policy learning. Our proposed framework, Diffusion Imitation from Observation (DIFO), demonstrates superior performance in various continuous control domains, including navigation, locomotion, manipulation, and games.
tl;dr: We propose FedMD for federated posterior inference, which incorporates a global model-data mutual information term as regularization to enhance generalization of the global posterior by alleviating bias of inferred local posteriors.

Most of existing federated learning (FL) formulation is treated as a point-estimate of models, inherently prone to overfitting on scarce client-side data with overconfident decisions. Though Bayesian inference can alleviate this issue, a direct posterior inference at clients may result in biased local posterior estimates due to data heterogeneity, leading to a sub-optimal global posterior. From an information-theoretic perspective, we propose FedMDMI, a federated posterior inference framework based on model-data mutual information (MI). Specifically, a global model-data MI term is introduced as regularization to enforce the global model to learn essential information from the heterogeneous local data, alleviating the bias caused by data heterogeneity and hence enhancing generalization. To make this global MI tractable, we decompose it into local MI terms at the clients, converting the global objective with MI regularization into several locally optimizable objectives based on local data. For these local objectives, we further show that the optimal local posterior is a Gibbs posterior, which can be efficiently sampled with stochastic gradient Langevin dynamics methods. Finally, at the server, we approximate sampling from the global Gibbs posterior by simply averaging samples from the local posteriors. Theoretical analysis provides a generalization bound for FL w.r.t. the model-data MI, which, at different levels of regularization, represents a federated version of the bias-variance trade-off. Experimental results demonstrate a better generalization behavior with better calibrated uncertainty estimates of FedMDMI.
tl;dr: Analysis of the development of neural collapse in (large) language models and its relationship with generalization.

Neural collapse ($\mathcal{NC}$) is a phenomenon observed in classification tasks where top-layer representations collapse into their class means, which become equinorm, equiangular and aligned with the classifiers.
These behaviors -- associated with generalization and robustness -- would manifest under specific conditions: models are trained towards zero loss, with noise-free labels belonging to balanced classes, which do not outnumber the model's hidden dimension.
Recent studies have explored $\mathcal{NC}$ in the absence of one or more of these conditions to extend and capitalize on the associated benefits of ideal geometries.
Language modeling presents a curious frontier, as \textit{training by token prediction} constitutes a classification task where none of the conditions exist: the vocabulary is imbalanced and exceeds the embedding dimension; different tokens might correspond to similar contextual embeddings; and large language models (LLMs) in particular are typically only trained for a few epochs.
This paper empirically investigates the impact of scaling the architectures and training of causal language models (CLMs) on their progression towards $\mathcal{NC}$.
We find that $\mathcal{NC}$ properties that develop with scale (and regularization) are linked to generalization.
Moreover, there is evidence of some relationship between $\mathcal{NC}$ and generalization independent of scale.
Our work thereby underscores the generality of $\mathcal{NC}$ as it extends to the novel and more challenging setting of language modeling.
Downstream, we seek to inspire further research on the phenomenon to deepen our understanding of LLMs -- and neural networks at large -- and improve existing architectures based on $\mathcal{NC}$-related properties.
Our code is hosted on GitHub: [`https://github.com/rhubarbwu/linguistic-collapse`](https://github.com/rhubarbwu/linguistic-collapse).

Can Transformers predict new syllogisms by composing established ones? More generally, what type of targets can be learned by such models from scratch? Recent works show that Transformers can be Turing-complete in terms of expressivity, but this does not address the learnability objective. This paper puts forward the notion of 'globality degree' of a target distribution to capture when weak learning is efficiently achievable by regular Transformers. This measure shows a contrast with the expressivity results of Transformers captured by $TC^0/TC^1$ classes (further studied here), since the globality relates to correlations with the more limited $NC^0$ class. We show here experimentally and theoretically under additional assumptions that distributions with high globality cannot be learned efficiently. In particular, syllogisms cannot be composed on long chains. Further, we develop scratchpad techniques and show that: (i) agnostic scratchpads cannot break the globality barrier, (ii) educated scratchpads can break the globality with intermediate steps, although not all such scratchpads can generalize out-of-distribution (OOD), (iii) a notion of 'inductive scratchpad', that composes the prior information more efficiently, can both break the globality barrier and improve the OOD generalization. In particular, some of our inductive scratchpads can achieve length generalizations of up to $6\times$ for some arithmetic tasks depending on the input formatting.

Node centralities play a pivotal role in network science, social network analysis, and recommender systems.
In temporal data, static path-based centralities like closeness or betweenness can give misleading results about the true importance of nodes in a temporal graph. To address this issue, temporal generalizations of betweenness and closeness have been defined that are based on the shortest time-respecting paths between pairs of nodes. However, a major issue of those generalizations is that the calculation of such paths is computationally expensive.
Addressing this issue, we study the application of De Bruijn Graph Neural Networks (DBGNN), a time-aware graph neural network architecture, to predict temporal path-based centralities in time series data. We experimentally evaluate our approach in 13 temporal graphs from biological and social systems and show that it considerably improves the prediction of betweenness and closeness centrality compared to (i) a static Graph Convolutional Neural Network, (ii) an efficient sampling-based approximation technique for temporal betweenness, and (iii) two state-of-the-art time-aware graph learning techniques for dynamic graphs.

Spiking neural networks (SNNs) have gained more and more interest as one of the energy-efficient alternatives of conventional artificial neural networks (ANNs). They exchange 0/1 spikes for processing information, thus most of the multiplications in networks can be replaced by additions. However, binary spike feature maps will limit the expressiveness of the SNN and result in unsatisfactory performance compared with ANNs.
It is shown that a rich output feature representation, i.e., the feature vector before classifier) is beneficial to training an accurate model in ANNs for classification.
We wonder if it also does for SNNs and how to improve the feature representation of the SNN.
To this end, we materialize this idea in two special designed methods for SNNs.
First, inspired by some ANN-SNN methods that directly copy-paste the weight parameters from trained ANN with light modification to homogeneous SNN can obtain a well-performed SNN, we use rich information of the weight parameters from the trained ANN counterpart to guide the feature representation learning of the SNN.
In particular, we present the SNN's and ANN's feature representation from the same input to ANN's classifier to product SNN's and ANN's outputs respectively and then align the feature with the KL-divergence loss as in knowledge distillation methods, called L_ AF loss.
It can be seen as a novel and effective knowledge distillation method specially designed for the SNN that comes from both the knowledge distillation and ANN-SNN methods. Various ablation study shows that the L_AF loss is more powerful than the vanilla knowledge distillation method.
Second, we replace the last Leaky Integrate-and-Fire (LIF) activation layer as the ReLU activation layer to generate the output feature, thus a more powerful SNN with full-precision feature representation can be achieved but with only a little extra computation.
Experimental results show that our method consistently outperforms the current state-of-the-art algorithms on both popular non-spiking static and neuromorphic datasets. We provide an extremely simple but effective way to train high-accuracy spiking neural networks.
tl;dr: We introduce a novel Inverse Reinforcement Learning formulation that permits efficient learning in Linear Markov Decision Processes.

In online Inverse Reinforcement Learning (IRL), the learner can collect samples about the dynamics of the environment to improve its
estimate of the reward function. Since IRL suffers from identifiability issues, many theoretical works on online IRL focus on estimating the entire set of rewards that explain the demonstrations, named the *feasible reward set*. However, none of the algorithms available in literature can scale to problems with large state spaces. In this paper, we focus on the online IRL problem in Linear Markov Decision
Processes (MDPs). We show that the structure offered by Linear MDPs is not sufficient for efficiently estimating the feasible set when the state space is large. As a consequence, we introduce the novel framework of *rewards compatibility*, which generalizes the notion of feasible set, and we develop CATY-IRL, a sample efficient algorithm whose complexity is independent of the size of the state space in Linear MDPs. When restricted to the tabular setting, we demonstrate that CATY-IRL is minimax optimal up to logarithmic factors. As a by-product, we show that Reward-Free Exploration (RFE) enjoys the same worst-case rate, improving over the state-of-the-art lower bound. Finally, we devise a unifying framework for IRL and RFE that may be of independent interest.
tl;dr: An automatic query-efficient black-box method for jailbreaking large language models

While Large Language Models (LLMs) display versatile functionality, they continue to generate harmful, biased, and toxic content, as demonstrated by the prevalence of human-designed *jailbreaks*. In this work, we present *Tree of Attacks with Pruning* (TAP), an automated method for generating jailbreaks that only requires black-box access to the target LLM. TAP utilizes an attacker LLM to iteratively refine candidate (attack) prompts until one of the refined prompts jailbreaks the target. In addition, before sending prompts to the target, TAP assesses them and prunes the ones unlikely to result in jailbreaks, reducing the number of queries sent to the target LLM. In empirical evaluations, we observe that TAP generates prompts that jailbreak state-of-the-art LLMs (including GPT4-Turbo and GPT4o) for more than 80% of the prompts. This significantly improves upon the previous state-of-the-art black-box methods for generating jailbreaks while using a smaller number of queries than them. Furthermore, TAP is also capable of jailbreaking LLMs protected by state-of-the-art *guardrails*, e.g., LlamaGuard.
tl;dr: An empirical study on how learning rate warmup benefits GPT training by mitigating large initial updates, analyzed through various measures of update sizes

Learning Rate Warmup is a popular heuristic for training neural networks, especially at larger batch sizes, despite limited understanding of its benefits. Warmup decreases the update size $\Delta \mathbf{w}_t = \eta_t \mathbf{u}_t$ early in training by using lower values for the learning rate $\eta_t$. In this work we argue that warmup benefits training by keeping the overall size of $\Delta \mathbf{w}_t$ limited, counteracting large initial values of $\mathbf{u}_t$. Focusing on small-scale GPT training with AdamW/Lion, we explore the following question: *Why and by which criteria are early updates $\mathbf{u}_t$ too large?* We analyze different metrics for the update size including the $\ell_2$-norm, resulting directional change, and impact on the representations of the network, providing a new perspective on warmup. In particular, we find that warmup helps counteract large angular updates as well as a limited critical batch size early in training. Finally, we show that the need for warmup can be significantly reduced or eliminated by modifying the optimizer to explicitly normalize $\mathbf{u}_t$ based on the aforementioned metrics.
tl;dr: We provide improved sample complexity bounds for learning mixtures of Gaussians with differential privacy, which are optimal for sufficiently large dimension or for one-dimensional Gaussian Mixtures..

We study the problem of learning mixtures of Gaussians with approximate differential privacy. We prove that roughly $kd^2 + k^{1.5} d^{1.75} + k^2 d$ samples suffice to learn a mixture of $k$ arbitrary $d$-dimensional Gaussians up to low total variation distance, with differential privacy. Our work improves over the previous best result (which required roughly $k^2 d^4$ samples) and is provably optimal when $d$ is much larger than $k^2$. Moreover, we give the first optimal bound for privately learning mixtures of $k$ univariate (i.e., $1$-dimensional) Gaussians. Importantly, we show that the sample complexity for learning mixtures of univariate Gaussians is linear in the number of components $k$, whereas the previous best sample complexity was quadratic in $k$. Our algorithms utilize various techniques, including the inverse sensitivity mechanism, sample compression for distributions, and methods for bounding volumes of sumsets.

Autonomous driving system aims for safe and social-consistent driving through the behavioral integration among interactive agents. However, challenges remain due to multi-agent scene uncertainty and heterogeneous interaction. Current dense and sparse behavioral representations struggle with inefficiency and inconsistency in multi-agent modeling, leading to instability of collective behavioral patterns when integrating prediction and planning (IPP). To address this, we initiate a topological formation that serves as a compliant behavioral foreground to guide downstream trajectory generations. Specifically, we introduce Behavioral Topology (BeTop), a pivotal topological formulation that explicitly represents the consensual behavioral pattern among multi-agent future. BeTop is derived from braid theory to distill compliant interactive topology from multi-agent future trajectories. A synergistic learning framework (BeTopNet) supervised by BeTop facilitates the consistency of behavior prediction and planning within the predicted topology priors. Through imitative contingency learning, BeTop also effectively manages behavioral uncertainty for prediction and planning. Extensive verification on large-scale real-world datasets, including nuPlan and WOMD, demonstrates that BeTop achieves state-of-the-art performance in both prediction and planning tasks. Further validations on the proposed interactive scenario benchmark showcase planning compliance in interactive cases. Code and model is available at https://github.com/OpenDriveLab/BeTop.
tl;dr: We introduce a new method that substantially speeds up inference of discrete disease progression models, allowing them to scale to large feature sets.

Disease progression models infer group-level temporal trajectories of change in patients' features as a chronic degenerative condition plays out. They provide unique insight into disease biology and staging systems with individual-level clinical utility. Discrete models consider disease progression as a latent permutation of events, where each event corresponds to a feature becoming measurably abnormal. However, permutation inference using traditional maximum likelihood approaches becomes prohibitive due to combinatoric explosion, severely limiting model dimensionality and utility. Here we leverage ideas from optimal transport to model disease progression as a latent permutation matrix of events belonging to the Birkhoff polytope, facilitating fast inference via optimisation of the variational lower bound. This enables a factor of 1000 times faster inference than the current state of the art and, correspondingly, supports models with several orders of magnitude more features than the current state of the art can consider. Experiments demonstrate the increase in speed, accuracy and robustness to noise in simulation. Further experiments with real-world imaging data from two separate datasets, one from Alzheimer's disease patients, the other age-related macular degeneration, showcase, for the first time, pixel-level disease progression events in the brain and eye, respectively. Our method is low compute, interpretable and applicable to any progressive condition and data modality, giving it broad potential clinical utility.

We present a novel method for symbolic regression (SR), the task of searching for compact programmatic hypotheses that best explain a dataset. The problem is commonly solved using genetic algorithms; we show that we can enhance such methods by inducing a library of abstract textual concepts. Our algorithm, called LaSR,
uses zero-shot queries to a large language model (LLM) to discover and evolve concepts occurring in known high-performing hypotheses. We discover new hypotheses using a mix of standard evolutionary steps and LLM-guided steps (obtained through zero-shot LLM queries) conditioned on discovered concepts. Once discovered, hypotheses are used in a new round of concept abstraction and evolution. We validate LaSR on the Feynman equations, a popular SR benchmark,
as well as a set of synthetic tasks. On these benchmarks, LaSR substantially outperforms a variety of state-of-the-art SR approaches based on deep learning and evolutionary algorithms. Moreover, we show that LASR can be used to discover a new and powerful scaling law for LLMs.
tl;dr: We train models to behave poorly except when the prompt contains a password, and study when supervised fine-tuning and RL can recover high performance.

To determine the safety of large language models (LLMs), AI developers must be able to assess their dangerous capabilities. But simple prompting strategies often fail to elicit an LLM’s full capabilities. One way to elicit capabilities more robustly is to fine-tune the LLM to complete the task. In this paper, we investigate the conditions under which fine-tuning-based elicitation suffices to elicit capabilities. To do this, we introduce password-locked models, LLMs fine-tuned such that some of their capabilities are deliberately hidden. Specifically, these LLMs are trained to exhibit these capabilities only when a password is present in the prompt, and to imitate a much weaker LLM otherwise. Password-locked models enable a novel method of evaluating capabilities elicitation methods, by testing whether these password-locked capabilities can be elicited without using the password. We find that a few high-quality demonstrations are often sufficient to fully elicit password-locked capabilities. More surprisingly, fine-tuning can elicit other capabilities that have been locked using the same password, or even different passwords. Furthermore, when only evaluations, and not demonstrations, are available, approaches like reinforcement learning are still often able to elicit capabilities. Overall, our findings suggest that fine-tuning is an effective method of eliciting hidden capabilities of current models but may be unreliable when high-quality demonstrations are not available, e.g., as may be the case when models’ (hidden) capabilities exceed those of human demonstrators.

Transformer-based diffusion models have achieved significant advancements across a variety of generative tasks. However, producing high-quality outputs typically necessitates large transformer models, which result in substantial training and inference overhead. In this work, we investigate an alternative approach involving multiple experts for denoising, and introduce RemixDiT, a novel method designed to enhance output quality at a low cost. The goal of RemixDiT is to craft N diffusion experts for different denoising timesteps, yet without the need for expensive training of N independent models. To achieve this, RemixDiT employs K basis models (where K < N) and utilizes learnable mixing coefficients to adaptively craft expert models. This design offers two significant advantages: first, although the total model size is increased, the model produced by the mixing operation shares the same architecture as a plain model, making the overall model as efficient as a standard diffusion transformer. Second, the learnable mixing adaptively allocates model capacity across timesteps, thereby effectively improving generation quality. Experiments conducted on the ImageNet dataset demonstrate that RemixDiT achieves promising results compared to standard diffusion transformers and other multiple-expert methods.

Vision-language (VL) embedding models have been shown to encode biases present in their training data, such as societal biases that prescribe negative characteristics to members of various racial and gender identities. Due to their wide-spread adoption for various tasks ranging from few-shot classification to text-guided image generation, debiasing VL models is crucial. Debiasing approaches that fine-tune the VL model often suffer from catastrophic forgetting. On the other hand, fine-tuning-free methods typically utilize a ``one-size-fits-all" approach that assumes that correlation with the spurious attribute can be explained using a single linear direction across all possible inputs. In this work, we propose a nonlinear, fine-tuning-free approach for VL embedding model debiasing that tailors the debiasing operation to each unique input. This allows for a more flexible debiasing approach. Additionally, we do not require knowledge of the set of inputs a priori to inference time, making our method more appropriate for online tasks such as retrieval and text guided image generation.
tl;dr: We study the scaling properties of compound inference systems both theoretically and empirically

Many recent state-of-the-art results in language tasks were achieved using compound systems that perform multiple Language Model (LM) calls and aggregate their responses. However, there is little understanding of how the number of LM calls -- e.g., when asking the LM to answer each question multiple times and taking a majority vote -- affects such a compound system's performance. In this paper, we initiate the study of scaling properties of compound inference systems. We analyze, theoretically and empirically, how the number of LM calls affects the performance of Vote and Filter-Vote, two of the simplest compound system designs, which aggregate LM responses via majority voting, optionally applying LM filters. We find, surprisingly, that across multiple language tasks, the performance of both Vote and Filter-Vote can first increase but then decrease as a function of the number of LM calls. Our theoretical results suggest that this non-monotonicity is due to the diversity of query difficulties within a task: more LM calls lead to higher performance on "easy" queries, but lower performance on "hard" queries, and non-monotone behavior can emerge when a task contains both types of queries. This insight then allows us to compute, from a small number of samples, the number of LM calls that maximizes system performance, and define an analytical scaling model for both systems. Experiments show that our scaling model can accurately predict the performance of Vote and Filter-Vote systems and thus find the optimal number of LM calls to make.
1250. The Implicit Bias of Heterogeneity towards Invariance: A Study of Multi-Environment Matrix Sensing
tl;dr: The implicit bias of heterogeneity helps model learn invariance.

Models are expected to engage in invariance learning, which involves distinguishing the core relations that remain consistent across varying environments to ensure the predictions are safe, robust and fair. While existing works consider specific algorithms to realize invariance learning, we show that model has the potential to learn invariance through standard training procedures. In other words, this paper studies the implicit bias of Stochastic Gradient Descent (SGD) over heterogeneous data and shows that the implicit bias drives the model learning towards an invariant solution. We call the phenomenon the implicit invariance learning. Specifically, we theoretically investigate the multi-environment low-rank matrix sensing problem where in each environment, the signal comprises (i) a lower-rank invariant part shared across all environments; and (ii) a significantly varying environment-dependent spurious component. The key insight is, through simply employing the large step size large-batch SGD sequentially in each environment without any explicit regularization, the oscillation caused by heterogeneity can provably prevent model learning spurious signals. The model reaches the invariant solution after certain iterations. In contrast, model learned using pooled SGD over all data would simultaneously learn both the invariant and spurious signals. Overall, we unveil another implicit bias that is a result of the symbiosis between the heterogeneity of data and modern algorithms, which is, to the best of our knowledge, first in the literature.
1251. On-Road Object Importance Estimation: A New Dataset and A Model with Multi-Fold Top-Down Guidance

This paper addresses the problem of on-road object importance estimation, which utilizes video sequences captured from the driver's perspective as the input. Although this problem is significant for safer and smarter driving systems, the exploration of this problem remains limited. On one hand, publicly-available large-scale datasets are scarce in the community. To address this dilemma, this paper contributes a new large-scale dataset named Traffic Object Importance (TOI). On the other hand, existing methods often only consider either bottom-up feature or single-fold guidance, leading to limitations in handling highly dynamic and diverse traffic scenarios. Different from existing methods, this paper proposes a model that integrates multi-fold top-down guidance with the bottom-up feature. Specifically, three kinds of top-down guidance factors (i.e., driver intention, semantic context, and traffic rule) are integrated into our model. These factors are important for object importance estimation, but none of the existing methods simultaneously consider them. To our knowledge, this paper proposes the first on-road object importance estimation model that fuses multi-fold top-down guidance factors with bottom-up feature. Extensive experiments demonstrate that our model outperforms state-of-the-art methods by large margins, achieving 23.1% Average Precision (AP) improvement compared with the recently proposed model (i.e., Goal).
tl;dr: A method that maximizes conditional Cauchy-Shwarz policy divergence between agents and between episodes to enhance exploration and heterogeneity for MARL.

Despite the success of Multi-Agent Reinforcement Learning (MARL) algorithms in cooperative tasks, previous works, unfortunately, face challenges in heterogeneous scenarios since they simply disable parameter sharing for agent specialization. Sequential updating scheme was thus proposed, naturally diversifies agents by encouraging agents to learn from preceding ones. However, the exploration strategy in sequential scheme has not been investigated. Benefiting from updating one-by-one, agents have the access to the information from preceding agents. Thus, in this work, we propose to exploit the preceding information to enhance exploration and heterogeneity sequentially. We present Multi-Agent Divergence Policy Optimization (MADPO), equipped with mutual policy divergence maximization framework. We quantify the policy discrepancies between episodes to enhance exploration and between agents to heterogenize agents, termed intra-agent and inter-agent policy divergence. To address the issue that traditional divergence measurements lack stability and directionality, we propose to employ the conditional Cauchy-Schwarz divergence to provide entropy-guided exploration incentives. Extensive experiments show that the proposed method outperforms state-of-the-art sequential updating approaches in two challenging multi-agent tasks with various heterogeneous scenarios.
tl;dr: We show the quantum speedups for finding the Goldstein stationary point by proposing gradient-free quantum algorithms.

This paper considers the problem for finding the $(\delta,\epsilon)$-Goldstein stationary point of Lipschitz continuous objective, which is a rich function class to cover a great number of important applications.
We construct a novel zeroth-order quantum estimator for the gradient of the smoothed surrogate.
Based on such estimator, we propose a novel quantum algorithm that achieves a query complexity of $\tilde{\mathcal{O}}(d^{3/2}\delta^{-1}\epsilon^{-3})$ on the stochastic function value oracle, where $d$ is the dimension of the problem.
We also enhance the query complexity to $\tilde{\mathcal{O}}(d^{3/2}\delta^{-1}\epsilon^{-7/3})$ by introducing a variance reduction variant.
Our findings demonstrate the clear advantages of utilizing quantum techniques for non-convex non-smooth optimization, as they outperform the optimal classical methods on the dependency of $\epsilon$ by a factor of $\epsilon^{-2/3}$.
1254. PACE: Pacing Operator Learning to Accurate Optical Field Simulation for Complicated Photonic Devices

Electromagnetic field simulation is central to designing, optimizing, and validating photonic devices and circuits.
However, costly computation associated with numerical simulation poses a significant bottleneck, hindering scalability and turnaround time in the photonic circuit design process.
Neural operators offer a promising alternative, but existing SOTA approaches, Neurolight, struggle with predicting high-fidelity fields for real-world complicated photonic devices, with the best reported 0.38 normalized mean absolute error in Neurolight.
The interplays of highly complex light-matter interaction, e.g., scattering and resonance, sensitivity to local structure details, non-uniform learning complexity for full-domain simulation, and rich frequency information, contribute to the failure of existing neural PDE solvers.
In this work, we boost the prediction fidelity to an unprecedented level for simulating complex photonic devices with a novel operator design driven by the above challenges.
We propose a novel cross-axis factorized PACE operator with a strong long-distance modeling capacity to connect the full-domain complex field pattern with local device structures.
Inspired by human learning, we further divide and conquer the simulation task for extremely hard cases into two progressively easy tasks, with a first-stage model learning an initial solution refined by a second model.
On various complicated photonic device benchmarks, we demonstrate one sole PACE model is capable of achieving 73% lower error with 50% fewer parameters compared with various recent ML for PDE solvers.
The two-stage setup further advances high-fidelity simulation for even more intricate cases.
In terms of runtime,
PACE demonstrates 154-577x and 11.8-12x simulation speedup over numerical solver using scipy or highly-optimized pardiso solver, respectively.
We open-sourced the code and *complicated* optical device dataset at [PACE-Light](https://github.com/zhuhanqing/PACE-Light).

We present Piecewise Rectified Flow (PeRFlow), a flow-based method for accelerating diffusion models. PeRFlow divides the sampling process of generative flows into several time windows and straightens the trajectories in each interval via the reflow operation, thereby approaching piecewise linear flows. PeRFlow achieves superior performance in a few-step generation. Moreover, through dedicated parameterizations, the PeRFlow models inherit knowledge from the pretrained diffusion models. Thus, the training converges fast and the obtained models show advantageous transfer ability, serving as universal plug-and-play accelerators that are compatible with various workflows based on the pre-trained diffusion models.

We introduce a mathematically rigorous framework based on rough path theory to model stochastic spiking neural networks (SSNNs) as stochastic differential equations with event discontinuities (Event SDEs) and driven by càdlàg rough paths. Our formalism is general enough to allow for potential jumps to be present both in the solution trajectories as well as in the driving noise. We then identify a set of sufficient conditions ensuring the existence of pathwise gradients of solution trajectories and event times with respect to the network's parameters and show how these gradients satisfy a recursive relation. Furthermore, we introduce a general-purpose loss function defined by means of a new class of signature kernels indexed on càdlàg rough paths and use it to train SSNNs as generative models. We provide an end-to-end autodifferentiable solver for Event SDEs and make its implementation available as part of the $\texttt{diffrax}$ library. Our framework is, to our knowledge, the first enabling gradient-based training of SSNNs with noise affecting both the spike timing and the network's dynamics.

Causal interactions among a group of variables are often modeled by a single causal graph. In some domains, however, these interactions are best described by multiple co-existing causal graphs, e.g., in dynamical systems or genomics. This paper addresses the hitherto unknown role of interventions in learning causal interactions among variables governed by a mixture of causal systems, each modeled by one directed acyclic graph (DAG). Causal discovery from mixtures is fundamentally more challenging than single-DAG causal discovery. Two major difficulties stem from (i) an inherent uncertainty about the skeletons of the component DAGs that constitute the mixture and (ii) possibly cyclic relationships across these component DAGs. This paper addresses these challenges and aims to identify edges that exist in at least one component DAG of the mixture, referred to as the *true* edges. First, it establishes matching necessary and sufficient conditions on the size of interventions required to identify the true edges. Next, guided by the necessity results, an adaptive algorithm is designed that learns all true edges using ${\cal O}(n^2)$ interventions, where $n$ is the number of nodes. Remarkably, the size of the interventions is optimal if the underlying mixture model does not contain cycles across its components. More generally, the gap between the intervention size used by the algorithm and the optimal size is quantified. It is shown to be bounded by the *cyclic complexity number* of the mixture model, defined as the size of the minimal intervention that can break the cycles in the mixture, which is upper bounded by the number of cycles among the ancestors of a node.
tl;dr: We develop neural network architectures with less parameter-space symmetries, and empirically study the impact of parameter symmetries on various phenomena in deep learning.

Many algorithms and observed phenomena in deep learning appear to be affected by parameter symmetries --- transformations of neural network parameters that do not change the underlying neural network function. These include linear mode connectivity, model merging, Bayesian neural network inference, metanetworks, and several other characteristics of optimization or loss-landscapes. However, theoretical analysis of the relationship between parameter space symmetries and these phenonmena is difficult. In this work, we empirically investigate the impact of neural parameter symmetries by introducing new neural network architectures that have reduced parameter space symmetries. We develop two methods, with some provable guarantees, of modifying standard neural networks to reduce parameter space symmetries. With these new methods, we conduct a comprehensive experimental study consisting of multiple tasks aimed at assessing the effect of removing parameter symmetries. Our experiments reveal several interesting observations on the empirical impact of parameter symmetries; for instance, we observe linear mode connectivity between our networks without alignment of weight spaces, and we find that our networks allow for faster and more effective Bayesian neural network training.
tl;dr: Improved neural interaction modelling of graph pairs for subgraph matching based retrieval.

Graph retrieval based on subgraph isomorphism has several real-world applications such as scene graph retrieval, molecular fingerprint detection and circuit design. Roy et al. [35] proposed IsoNet, a late interaction model for subgraph matching, which first computes the node and edge embeddings of each graph independently of paired graph and then computes a trainable alignment map. Here, we present $\texttt{IsoNet++}$, an early interaction graph neural network (GNN), based on several technical innovations. First, we compute embeddings of all nodes by passing messages within and across the two input graphs, guided by an *injective alignment* between their nodes. Second, we update this alignment in a lazy fashion over multiple *rounds*. Within each round, we run a layerwise GNN from scratch, based on the current state of the alignment. After the completion of one round of GNN, we use the last-layer embeddings to update the alignments, and proceed to the next round. Third, $\texttt{IsoNet++}$ incorporates a novel notion of node-pair partner interaction. Traditional early interaction computes attention between a node and its potential partners in the other graph, the attention then controlling messages passed across graphs. We consider *node pairs* (not single nodes) as potential partners. Existence of an edge between the nodes in one graph and non-existence in the other provide vital signals for refining the alignment. Our experiments on several datasets show that the alignments get progressively refined with successive rounds,
resulting in significantly better retrieval performance than existing methods. We demonstrate that all three innovations contribute to the enhanced accuracy. Our code and datasets are publicly available at https://github.com/structlearning/isonetpp.
tl;dr: Feedback control may enable biological recurrent neural networks to achieve accurate and efficient credit assignment, facilitating real-time learning and adaptation in behavior generation.

How do brain circuits learn to generate behaviour?
While significant strides have been made in understanding learning in artificial neural networks, applying this knowledge to biological networks remains challenging.
For instance, while backpropagation is known to perform accurate credit assignment of error in artificial neural networks, how a similarly powerful process can be realized within the constraints of biological circuits remains largely unclear.
One of the major challenges is that the brain's extensive recurrent connectivity requires the propagation of error through both space and time, a problem that is notoriously difficult to solve in vanilla recurrent neural networks.
Moreover, the extensive feedback connections in the brain are known to influence forward network activity, but the interaction between feedback-driven activity changes and local, synaptic plasticity-based learning is not fully understood.
Building on our previous work modelling motor learning, this work investigates the mechanistic properties of pre-trained networks with feedback control on a standard motor task.
We show that feedback control of the ongoing recurrent network dynamics approximates the optimal first-order gradient with respect to the network activities, allowing for rapid, ongoing movement correction.
Moreover, we show that trial-by-trial adaptation to a persistent perturbation using a local, biologically plausible learning rule that integrates recent activity and error feedback is both more accurate and more efficient with feedback control during learning, due to the decoupling of the recurrent network dynamics and the injection of an adaptive, second-order gradient into the network dynamics.
Thus, our results suggest that feedback control may guide credit assignment in biological recurrent neural networks, enabling both rapid and efficient learning in the brain.
tl;dr: Exploiting Matrix Norm for Unsupervised Accuracy Estimation Under Distribution Shifts

Leveraging the model’s outputs, specifically the logits, is a common approach to estimating the test accuracy of a pre-trained neural network on out-of-distribution (OOD) samples without requiring access to the corresponding ground-truth labels.
Despite their ease of implementation and computational efficiency, current logit-based methods are vulnerable to overconfidence issues, leading to prediction bias, especially under the natural shift. In this work, we first study the relationship between logits and generalization performance from the view of low-density separation assumption. Our findings motivate our proposed method \method{} that \textbf{(1)}~applies a data-dependent normalization on the logits to reduce prediction bias, and \textbf{(2)} takes the $L_p$ norm of the matrix of normalized logits as the estimation score. Our theoretical analysis highlights the connection between the provided score and the model's uncertainty.
We conduct an extensive empirical study on common unsupervised accuracy estimation benchmarks and demonstrate that \method{} achieves state-of-the-art performance across various architectures in the presence of synthetic, natural, or subpopulation shifts. The code is available at https://github.com/Renchunzi-Xie/MaNo.
tl;dr: We formally study how to extract concepts from data, by utilizing ideas from the causal representation learning and interpretability literatures.

To build intelligent machine learning systems, modern representation learning attempts to recover latent generative factors from data, such as in causal representation learning. A key question in this growing field is to provide rigorous conditions under which latent factors can be identified and thus, potentially learned. Motivated by extensive empirical literature on linear representations and concept learning, we propose to relax causal notions with a geometric notion of concepts. We formally define a notion of concepts and show rigorously that they can be provably recovered from diverse data. Instead of imposing assumptions on the "true" generative latent space, we assume that concepts can be represented linearly in this latent space. The tradeoff is that instead of identifying the "true" generative factors, we identify a subset of desired human-interpretable concepts that are relevant for a given application. Experiments on synthetic data, multimodal CLIP models and large language models supplement our results and show the utility of our approach. In this way, we provide a foundation for moving from causal representations to interpretable, concept-based representations by bringing together ideas from these two neighboring disciplines.

Diffusion-based imitation learning improves Behavioral Cloning (BC) on multi-modal decision-making, but comes at the cost of significantly slower inference due to the recursion in the diffusion process. It urges us to design efficient policy generators while keeping the ability to generate diverse actions. To address this challenge, we propose AdaFlow, an imitation learning framework based on flow-based generative modeling. AdaFlow represents the policy with state-conditioned ordinary differential equations (ODEs), which are known as probability flows. We reveal an intriguing connection between the conditional variance of their training loss and the discretization error of the ODEs.
With this insight, we propose a variance-adaptive ODE solver that can adjust its step size in the inference stage, making
AdaFlow an adaptive decision-maker, offering rapid inference without sacrificing diversity. Interestingly, it automatically reduces to a one-step generator when the action distribution is uni-modal. Our comprehensive empirical evaluation shows that AdaFlow achieves high performance with fast inference speed.
tl;dr: S-MolSearch, a semi-supervised framework for ligand-based virtual screening that leverages molecular 3D information. S-MolSearch efficiently processes labeled and unlabeled data with inverse optimal transport, achieving SOTA on LIT-PCBA and DUD-E

Virtual Screening is an essential technique in the early phases of drug discovery, aimed at identifying promising drug candidates from vast molecular libraries.
Recently, ligand-based virtual screening has garnered significant attention due to its efficacy in conducting extensive database screenings without relying on specific protein-binding site information.
Obtaining binding affinity data for complexes is highly expensive, resulting in a limited amount of available data that covers a relatively small chemical space. Moreover, these datasets contain a significant amount of inconsistent noise. It is challenging to identify an inductive bias that consistently maintains the integrity of molecular activity during data augmentation. To tackle these challenges, we propose S-MolSearch, the first framework to our knowledge, that leverages molecular 3D information and affinity information in semi-supervised contrastive learning for ligand-based virtual screening.
% S-MolSearch processes both labeled and unlabeled data, trains molecular structural encoders, and generates soft labels for unlabeled data, drawing on the principles of inverse optimal transport.
Drawing on the principles of inverse optimal transport, S-MolSearch efficiently processes both labeled and unlabeled data, training molecular structural encoders while generating soft labels for the unlabeled data.
This design allows S-MolSearch to adaptively utilize unlabeled data within the learning process.
Empirically, S-MolSearch demonstrates superior performance on widely-used benchmarks LIT-PCBA and DUD-E. It surpasses both structure-based and ligand-based virtual screening methods for AUROC, BEDROC and EF.
tl;dr: Small user collectives can effectively promote artists through simple reordering of playlists, leveraging the sequential nature of transformer-based recommendation systems.

We investigate algorithmic collective action in transformer-based recommender systems. Our use case is a collective of fans aiming to promote the visibility of an underrepresented artist by strategically placing one of their songs in the existing playlists they control. We introduce two easily implementable strategies to select the position at which to insert the song and boost recommendations at test time. The strategies exploit statistical properties of the learner to leverage discontinuities in the recommendations, and the long-tail nature of song distributions. We evaluate the efficacy of our strategies using a publicly available recommender system model released by a major music streaming platform. Our findings reveal that even small collectives (controlling less than 0.01\% of the training data) can achieve up to $40\times$ more test time recommendations than songs with similar training set occurrences, on average. Focusing on the externalities of the strategy, we find that the recommendations of other songs are largely preserved, and the newly gained recommendations are distributed across various artists. Together, our findings demonstrate how carefully designed collective action strategies can be effective while not necessarily being adversarial.
1266. JiuZhang3.0: Efficiently Improving Mathematical Reasoning by Training Small Data Synthesis Models

Mathematical reasoning is an important capability of large language models~(LLMs) for real-world applications.
To enhance this capability, existing work either collects large-scale math-related texts for pre-training, or relies on stronger LLMs (\eg GPT-4) to synthesize massive math problems. Both types of work generally lead to large costs in training or synthesis.
To reduce the cost, based on open-source available texts, we propose an efficient way that trains a small LLM for math problem synthesis, to efficiently generate sufficient high-quality pre-training data.
To achieve it, we create a dataset using GPT-4 to distill its data synthesis capability into the small LLM.
Concretely, we craft a set of prompts based on human education stages to guide GPT-4, to synthesize problems covering diverse math knowledge and difficulty levels.
Besides, we adopt the gradient-based influence estimation method to select the most valuable math-related texts.
The both are fed into GPT-4 for creating the knowledge distillation dataset to train the small LLM.
We leverage it to synthesize 6 million math problems for pre-training our JiuZhang3.0 model. The whole process only needs to invoke GPT-4 API 9.3k times and use 4.6B data for training.
Experimental results have shown that JiuZhang3.0 achieves state-of-the-art performance on several mathematical reasoning datasets, under both natural language reasoning and tool manipulation settings.
Our code and data will be publicly released in \url{https://github.com/RUCAIBox/JiuZhang3.0}.
tl;dr: We find that compositional generalization abilities of diffusion models emerge suddenly and robustly, while models might not actively exhibit this ability.

Modern generative models demonstrate impressive capabilities, likely stemming from an ability to identify and manipulate abstract concepts underlying their training data. However, fundamental questions remain: what determines the concepts a model learns, the order in which it learns them, and its ability to manipulate those concepts? To address these questions, we propose analyzing a model’s learning dynamics via a framework we call the concept space, where each axis represents an independent concept underlying the data generating process. By characterizing learning dynamics in this space, we identify how the speed at which a concept is learned, and hence the order of concept learning, is controlled by properties of the data we term concept signal. Further, we observe moments of sudden turns in the direction of a model’s learning dynamics in concept space. Surprisingly, these points precisely correspond to the emergence of hidden capabilities, i.e., where latent interventions show the model possesses the capability to manipulate a concept, but these capabilities cannot yet be elicited via naive input prompting. While our results focus on synthetically defined toy datasets, we hypothesize a general claim on emergence of hidden capabilities may hold: generative models possess latent capabilities that emerge suddenly and consistently during training, though a model might not exhibit these capabilities under naive input prompting.
tl;dr: We introduce a fully neural reasoning mechanism comprising iterative & parallel computation to address complex image & video reasoning tasks such as AGQA, STAR, CLEVR-Humans and CLEVRER-Humans.

Complex visual reasoning and question answering (VQA) is a challenging task that requires compositional multi-step processing and higher-level reasoning capabilities beyond the immediate recognition and localization of objects and events. Here, we introduce a fully neural Iterative and Parallel Reasoning Mechanism (IPRM) that combines two distinct forms of computation -- iterative and parallel -- to better address complex VQA scenarios. Specifically, IPRM's "iterative" computation facilitates compositional step-by-step reasoning for scenarios wherein individual operations need to be computed, stored, and recalled dynamically (e.g. when computing the query “determine the color of pen to the left of the child in red t-shirt sitting at the white table”). Meanwhile, its "parallel'' computation allows for the simultaneous exploration of different reasoning paths and benefits more robust and efficient execution of operations that are mutually independent (e.g. when counting individual colors for the query: "determine the maximum occurring color amongst all t-shirts'"). We design IPRM as a lightweight and fully-differentiable neural module that can be conveniently applied to both transformer and non-transformer vision-language backbones. It notably outperforms prior task-specific methods and transformer-based attention modules across various image and video VQA benchmarks testing distinct complex reasoning capabilities such as compositional spatiotemporal reasoning (AGQA), situational reasoning (STAR), multi-hop reasoning generalization (CLEVR-Humans) and causal event linking (CLEVRER-Humans). Further, IPRM's internal computations can be visualized across reasoning steps, aiding interpretability and diagnosis of its errors.
tl;dr: We investigate the robustness of spectral clustering algorithms against various semirandom adversaries.

In a graph bisection problem, we are given a graph $G$ with two equally-sized unlabeled communities, and the goal is to recover the vertices in these communities. A popular heuristic, known as spectral clustering, is to output an estimated community assignment based on the eigenvector corresponding to the second-smallest eigenvalue of the Laplacian of $G$. Spectral algorithms can be shown to provably recover the cluster structure for graphs generated from probabilistic models, such as the Stochastic Block Model (SBM). However, spectral clustering is known to be non-robust to model mis-specification. Techniques based on semidefinite programming have been shown to be more robust, but they incur significant computational overheads.
In this work, we study the robustness of spectral algorithms against semirandom adversaries. Informally, a semirandom adversary is allowed to ``helpfully'' change the specification of the model in a way that is consistent with the ground-truth solution. Our semirandom adversaries in particular are allowed to add edges inside clusters or increase the probability that an edge appears inside a cluster. Semirandom adversaries are a useful tool to determine the extent to which an algorithm has overfit to statistical assumptions on the input.
On the positive side, we identify a wide range of semirandom adversaries under which spectral bisection using the _unnormalized_ Laplacian is strongly consistent, i.e., it exactly recovers the planted partitioning. On the negative side, we show that in many of these settings, _normalized_ spectral bisection outputs a partitioning that makes a classification mistake on a constant fraction of the vertices. Finally, we demonstrate numerical experiments that complement our theoretical findings.
tl;dr: Teaching LLMs to use tools at scale with innvoations in finetuning (RAT) and a novel way to mesasure hallucination using AST.

Large Language Models (LLMs) have seen an impressive wave of advances, with
models now excelling in a variety of tasks, such as mathematical reasoning and
program synthesis. However, their potential to effectively use tools via API calls
remains unfulfilled. This is a challenging task even for today’s state-of-the-art
LLMs such as GPT-4 largely due to their unawareness of what APIs are available
and how to use them in a frequently updated tool set. We develop Gorilla, a
finetuned LLaMA model that surpasses the performance of GPT-4 on writing API
calls. Trained with the novel Retriever Aware Training (RAT), when combined
with a document retriever, Gorilla demonstrates a strong capability to adapt to
test-time document changes, allowing flexible user updates or version changes.
It also substantially mitigates the issue of hallucination, commonly encountered
when prompting LLMs directly. To evaluate the model’s ability, we introduce
APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and
TensorHub APIs. The successful integration of the retrieval system with Gorilla
demonstrates the potential for LLMs to use tools more accurately, keep up with
frequently updated documentation, and consequently increase the reliability and
applicability of their outputs. Gorilla’s code, model, data, and demo are available
at: https://gorilla.cs.berkeley.edu
tl;dr: Self-alignment for code LLMs without human annotations

Instruction tuning is a supervised fine-tuning approach that significantly improves the ability of large language models (LLMs) to follow human instructions. For programming tasks, most models are finetuned with costly human-annotated instruction-response pairs or those generated by large, proprietary LLMs, which may not be permitted. We propose SelfCodeAlign, the first fully transparent and permissive pipeline for self-aligning code LLMs without extensive human annotations or distillation. SelfCodeAlign employs the same base model for inference throughout the data generation process. It first extracts diverse coding concepts from high-quality seed snippets to generate new tasks. It then samples multiple responses per task, pairs each with test cases, and validates them in a sandbox environment. Finally, passing examples are selected for instruction tuning. In our primary experiments, we use SelfCodeAlign with CodeQwen1.5-7B to generate a dataset of 74k instruction-response pairs. Finetuning on this dataset leads to a model that achieves a 67.1 pass@1 on HumanEval+, surpassing CodeLlama-70B-Instruct despite being ten times smaller. Across all benchmarks, this finetuned model consistently outperforms the original version trained with OctoPack, the previous state-of-the-art method for instruction tuning without human annotations or distillation. Additionally, we show that SelfCodeAlign is effective across LLMs of various sizes, from 3B to 33B, and that the base models can benefit more from alignment with their own data distribution. We further validate each component’s effectiveness in our pipeline, showing that SelfCodeAlign outperforms both direct distillation from GPT-4o and leading GPT-3.5-based distillation methods, such as OSS-Instruct and Evol-Instruct. SelfCodeAlign has also led to the creation of StarCoder2-Instruct, the first fully transparent, permissively licensed, and self-aligned code LLM that achieves state-of-the-art coding performance. Overall, SelfCodeAlign shows for the first time that a strong instruction-tuned code LLM can result from self-alignment rather than distillation.

Recent text-to-image (T2I) generation models have demonstrated impressive capabilities in creating images from text descriptions. However, these T2I generation models often fail to generate images that precisely match the details of the text inputs, such as incorrect spatial relationship or missing objects. In this paper, we introduce SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data, a novel paradigm to improve the faithfulness of T2I models by fine-tuning models on automatically generated, multi-skill image-text datasets, with skill-specific expert learning and merging. First, SELMA leverages an LLM’s in-context learning capability to generate multiple datasets of text prompts that can teach different skills, and then generates the images with a T2I model based on the prompts. Next, SELMA adapts the T2I model to the new skills by learning multiple single-skill LoRA (low-rank adaptation) experts followed by expert merging. Our independent expert fine-tuning specializes multiple models for different skills, and expert merging helps build a joint multi-skill T2I model that can generate faithful images given diverse text prompts, while mitigating the knowledge conflict from different datasets. We empirically demonstrate that SELMA significantly improves the semantic alignment and text faithfulness of state-of-the-art T2I diffusion models on multiple benchmarks (+2.1% on TIFA and +6.9% on DSG), human preference metrics (PickScore, ImageReward, and HPS), as well as human evaluation. Moreover, fine-tuning with image-text pairs auto-collected via SELMA shows comparable performance to fine-tuning with ground truth data. Lastly, we show that fine-tuning with images from a weaker T2I model can help improve the generation quality of a stronger T2I model, suggesting promising weak-to-strong generalization in T2I models. We provide code in the supplementary materials.
tl;dr: We clarify the unnecessary nature of collaboration in previous federated online model selection algorithms, and give conditions under which collaboration is necessary.

We consider online model selection with decentralized data over $M$ clients, and study the necessity of collaboration among clients. Previous work proposed various federated algorithms without demonstrating their necessity, while we answer the question from a novel perspective of computational constraints. We prove lower bounds on the regret, and propose a federated algorithm and analyze the upper bound. Our results show (i) collaboration is unnecessary in the absence of computational constraints on clients; (ii) collaboration is necessary if the computational cost on each client is limited to $o(K)$, where $K$ is the number of candidate hypothesis spaces. We clarify the unnecessary nature of collaboration in previous federated algorithms for distributed online multi-kernel learning, and improve the regret bounds at a smaller computational and communication cost. Our algorithm relies on three new techniques including an improved Bernstein's inequality for martingale, a federated online mirror descent framework, and decoupling model selection and prediction, which might be of independent interest.

Effective communication between the server and workers plays a key role in distributed optimization. In this paper, we focus on optimizing communication, uncovering inefficiencies in prevalent downlink compression approaches. Considering first the pure setup where the uplink communication costs are negligible, we introduce MARINA-P, a novel method for downlink compression, employing a collection of correlated compressors. Theoretical analysis demonstrates that MARINA-P with permutation compressors can achieve a server-to-worker communication complexity improving with the number of workers, thus being provably superior to existing algorithms. We further show that MARINA-P can serve as a starting point for extensions such as methods supporting bidirectional compression: we introduce M3, a method combining MARINA-P with uplink compression and a momentum step, achieving bidirectional compression with provable improvements in total communication complexity as the number of workers increases. Theoretical findings align closely with empirical experiments, underscoring the efficiency of the proposed algorithms.
tl;dr: learning emergent features using representation learning

Cognitive processes usually take place at a macroscopic scale in systems characterised by emergent properties, which make the whole ‘more than the sum of its parts.’ While recent proposals have provided quantitative, information-theoretic metrics to detect emergence in time series data, it is often highly non-trivial to identify the relevant macroscopic variables a priori. In this paper we leverage recent advances in representation learning and differentiable information estimators to put forward a data-driven method to find emergent variables. The proposed method successfully detects emergent variables and recovers the ground-truth emergence values in a synthetic dataset. Furthermore, we show the method can be extended to learn multiple independent features, extracting a diverse set of emergent quantities. We finally show that a modified method scales to real experimental data from primate brain activity, paving the ground for future analyses uncovering the emergent structure of cognitive representations in biological and artificial intelligence systems.
tl;dr: We propose FlexLoRA, an aggregation scheme for federated learning of LLMs that dynamically adjusts LoRA ranks to harness the full potential of diverse client resources, enhancing generalization, and validated on thousands of heterogeneous clients.

Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients.This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the "buckets effect" in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving thousands of clients performing heterogeneous NLP tasks and client resources, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving consistently better improvement over SOTA FL methods in downstream NLP task performance across various heterogeneous distributions. FlexLoRA's practicality is further underscored by our theoretical analysis and its seamless integration with existing LoRA-based FL methods, offering a path toward cross-device, privacy-preserving federated tuning for LLMs.
tl;dr: We have introduced a family of parameter-free, fast, and parallelizable algorithms for crafting optimal adversarial perturbations.

Deep neural networks have been known to be vulnerable to adversarial examples, which are inputs that are modified slightly to fool the network into making incorrect predictions. This has led to a significant amount of research on evaluating the robustness of these networks against such perturbations. One particularly important robustness metric is the robustness to minimal $\ell_{2}$ adversarial perturbations. However, existing methods for evaluating this robustness metric are either computationally expensive or not very accurate. In this paper, we introduce a new family of adversarial attacks that strike a balance between effectiveness and computational efficiency. Our proposed attacks are generalizations of the well-known DeepFool (DF) attack, while they remain simple to understand and implement. We demonstrate that our attacks outperform existing methods in terms of both effectiveness and computational efficiency. Our proposed attacks are also suitable for evaluating the robustness of large models and can be used to perform adversarial training (AT) to achieve state-of-the-art robustness to minimal $\ell_{2}$ adversarial perturbations.
tl;dr: We use new lower bounds on the TV distance to identify discriminative network components for structured pruning and selective forgetting.

Model editing is a growing area of research that is particularly valuable in contexts where modifying key model components, like neurons or filters, can significantly impact the model’s performance. The key challenge lies in identifying important components useful to the model’s predictions. We apply model editing to address two active areas of research, Structured Pruning, and Selective Class Forgetting. In this work, we adopt a distributional approach to the problem of identifying important components, leveraging the recently proposed discriminative filters hypothesis, which states that well-trained (convolutional) models possess discriminative filters that are essential to prediction. To do so, we define discriminative ability in terms of the Bayes error rate associated with the feature distributions, which is equivalent to computing the Total Variation (TV) distance between the distributions. However, computing the TV distance is intractable, motivating us to derive novel witness function-based lower bounds on the TV distance that require no assumptions on the underlying distributions; using this bound generalizes prior work such as Murti et al. [39] that relied on unrealistic Gaussianity assumptions on the feature distributions. With these bounds, we are able to discover critical subnetworks responsible for classwise predictions, and derive DISCEDIT-SP and DISCEDIT-U , algorithms for structured pruning requiring no access to the training data and loss function, and selective forgetting respectively. We apply DISCEDIT-U to selective class forgetting on models trained on CIFAR10 and CIFAR100, and we show that on average, we can reduce accuracy on a single class by over 80% with a minimal reduction in test accuracy on the remaining classes. Similarly, on Structured pruning problems, we obtain 40.8% sparsity on ResNet50 on Imagenet, with only a 2.6% drop in accuracy with minimal fine-tuning.
tl;dr: Our paper introduces DDSR, a novel model leveraging discrete diffusion processes to enhance the accuracy of sequential recommendations by capturing the inherent randomness of user behavior.

Sequential recommendation (SR) aims to predict items that users may be interested in based on their historical behavior sequences. We revisit SR from a novel information-theoretic perspective and find that conventional sequential modeling methods fail to adequately capture the randomness and unpredictability of user behavior. Inspired by fuzzy information processing theory, this paper introduces the DDSR model, which uses fuzzy sets of interaction sequences to overcome the limitations and better capture the evolution of users' real interests. Formally based on diffusion transition processes in discrete state spaces, which is unlike common diffusion models such as DDPM that operate in continuous domains. It is better suited for discrete data, using structured transitions instead of arbitrary noise introduction to avoid information loss. Additionally, to address the inefficiency of matrix transformations due to the vast discrete space, we use semantic labels derived from quantization or RQ-VAE to replace item IDs, enhancing efficiency and improving cold start issues. Testing on three public benchmark datasets shows that DDSR outperforms existing state-of-the-art methods in various settings, demonstrating its potential and effectiveness in handling SR tasks.
tl;dr: The first paper to give a DP equivalence tester for continuous distrbiutions

We present the first algorithm for testing equivalence between two continuous distributions using differential privacy (DP). Our algorithm is a private version of the algorithm of Diakonikolas et al.
The algorithm of Diakonikolas et al uses the data itself to repeatedly discretize the real line so that --- when the two distributions are far apart in ${\cal A}_k$-norm --- one of the discretized distributions exhibits large $L_2$-norm difference; and upon repeated sampling such large gap would be detected. Designing its private analogue poses two difficulties. First, our DP algorithm can not resample new datapoints as a change to a single datapoint may lead to a very large change in the descretization of the real line. In contrast, the (sorted) index of the discretization point changes only by $1$ between neighboring instances, and so we use a novel algorithm that set the discretization points using random Bernoulli noise, resulting in only a few buckets being affected under the right coupling. Second, our algorithm, which doesn't resample data, requires we also revisit the utility analysis of the original algorithm and prove its correctness w.r.t. the original sorted data; a problem we tackle using sampling a subset of Poisson-drawn size from each discretized bin. Lastly, since any distribution can be reduced to a continuous distribution, our algorithm is successfully carried to multiple other families of distributions and thus has numerous applications.
tl;dr: We explore the dual drift issue in federated primal dual methods and propose the virtual dual update to further improve its efficiency.

As a popular paradigm for juggling data privacy and collaborative training, federated learning (FL) is flourishing to distributively process the large scale of heterogeneous datasets on edged clients. Due to bandwidth limitations and security considerations, it ingeniously splits the original problem into multiple subproblems to be solved in parallel, which empowers primal dual solutions to great application values in FL. In this paper, we review the recent development of classical federated primal dual methods and point out a serious common defect of such methods in non-convex scenarios, which we say is a ``dual drift'' caused by dual hysteresis of those longstanding inactive clients under partial participation training. To further address this problem, we propose a novel Aligned Federated Primal Dual (A-FedPD) method, which constructs virtual dual updates to align global consensus and local dual variables for those protracted unparticipated local clients. Meanwhile, we provide a comprehensive analysis of the optimization and generalization efficiency for the A-FedPD method on smooth non-convex objectives, which confirms its high efficiency and practicality. Extensive experiments are conducted on several classical FL setups to validate the effectiveness of our proposed method.
tl;dr: We propose a new framework for combinatorial optimization based the insight that heat diffusion can propagate information from distant area to the solver for efficient navigation.

Combinatorial optimization problems are widespread but inherently challenging due to their discrete nature. The primary limitation of existing methods is that they can only access a small fraction of the solution space at each iteration, resulting in limited efficiency for searching the global optimal. To overcome this challenge, diverging from conventional efforts of expanding the solver's search scope, we focus on enabling information to actively propagate to the solver through heat diffusion. By transforming the target function while preserving its optima, heat diffusion facilitates information flow from distant regions to the solver, providing more efficient navigation. Utilizing heat diffusion, we propose a framework for solving general combinatorial optimization problems. The proposed methodology demonstrates superior performance across a range of the most challenging and widely encountered combinatorial optimizations. Echoing recent advancements in harnessing thermodynamics for generative artificial intelligence, our study further reveals its significant potential in advancing combinatorial optimization.
tl;dr: We improve an existing kernel method to achieve 94.5% test accuracy on CIFAR-10, a significant increase over the current SOTA for kernel methods.

Recent work developed convolutional deep kernel machines, achieving 92.7% test accuracy on CIFAR-10 using a ResNet-inspired architecture, which is SOTA for kernel methods. However, this still lags behind neural networks, which easily achieve over 94% test accuracy with similar architectures. In this work we introduce several modifications to improve the convolutional deep kernel machine’s generalisation, including stochastic kernel regularisation, which adds noise to the learned Gram matrices during training. The resulting model achieves 94.5% test accuracy on CIFAR-10. This finding has important theoretical and practical implications, as it demonstrates that the ability to perform well on complex tasks like image classification is not unique to neural networks. Instead, other approaches including deep kernel methods can achieve excellent performance on such tasks, as long as they have the capacity to learn representations from data.

In high-stakes sectors such as network security, IoT security, accurately distinguishing between normal and anomalous data is critical due to the significant implications for operational success and safety in decision-making. The complexity is exacerbated by the presence of unlabeled data and the opaque nature of black-box anomaly detection models, which obscure the rationale behind their predictions. In this paper, we present a novel method to interpret the decision-making processes of these models, which are essential for detecting malicious activities without labeled attack data. We put forward the Segmentation Clustering Decision Tree (SCD-Tree), designed to dissect and understand the structure of normal data distributions. The SCD-Tree integrates predictions from the anomaly detection model into its splitting criteria, enhancing the clustering process with the model's insights into anomalies. To further refine these segments, the Gaussian Boundary Delineation (GBD) algorithm is employed to define boundaries within each segmented distribution, effectively delineating normal from anomalous data points. At this point, this approach addresses the curse of dimensionality by segmenting high-dimensional data and ensures resilience to data drift and perturbations through flexible boundary fitting. We transform the intricate operations of anomaly detection into an interpretable rule's format, constructing a comprehensive set of rules for understanding. Our method's evaluation on diverse datasets and models demonstrates superior explanation accuracy, fidelity, and robustness over existing method, proving its efficacy in environments where interpretability is paramount.
tl;dr: We find the CLS token naturally absorbs domain information, and propose to decouple domain information from the CLS token and adapt it for cross-domain few-shot learning.

Vision Transformer (ViT) has shown great power in learning from large-scale datasets. However, collecting sufficient data for expert knowledge is always difficult. To handle this problem, Cross-Domain Few-Shot Learning (CDFSL) has been proposed to transfer the source-domain knowledge learned from sufficient data to target domains where only scarce data is available. In this paper, we find an intriguing phenomenon neglected by previous works for the CDFSL task based on ViT: leaving the CLS token to random initialization, instead of loading source-domain trained parameters, could consistently improve target-domain performance. We then delve into this phenomenon for an interpretation. We find **the CLS token naturally absorbs domain information** due to the inherent structure of the ViT, which is represented as the low-frequency component in the Fourier frequency space of images. Based on this phenomenon and interpretation, we further propose a method for the CDFSL task to decouple the domain information in the CLS token during the source-domain training, and adapt the CLS token on the target domain for efficient few-shot learning. Extensive experiments on four benchmarks validate our rationale and state-of-the-art performance. Our codes are available at https://github.com/Zoilsen/CLS_Token_CDFSL.
tl;dr: Conservative Fine-Tuning of Diffusion Models from Offline Data

AI-driven design problems, such as DNA/protein sequence design, are commonly tackled from two angles: generative modeling, which efficiently captures the feasible design space (e.g., natural images or biological sequences), and model-based optimization, which utilizes reward models for extrapolation. To combine the strengths of both approaches, we adopt a hybrid method that fine-tunes cutting-edge diffusion models by optimizing reward models through RL. Although prior work has explored similar avenues, they primarily focus on scenarios where accurate reward models are accessible. In contrast, we concentrate on an offline setting where a reward model is unknown, and we must learn from static offline datasets, a common scenario in scientific domains. In offline scenarios, existing approaches tend to suffer from overoptimization, as they may be misled by the reward model in out-of-distribution regions. To address this, we introduce a conservative fine-tuning approach, BRAID, by optimizing a conservative reward model, which includes additional penalization outside of offline data distributions. Through empirical and theoretical analysis, we demonstrate the capability of our approach to outperform the best designs in offline data, leveraging the extrapolation capabilities of reward models while avoiding the generation of invalid designs through pre-trained diffusion models.
tl;dr: We propose a novel framework to predict images and robot actions through joint dinoising process.

Diffusion models have demonstrated remarkable capabilities in image generation tasks, including image editing and video creation, representing a good understanding of the physical world. On the other line, diffusion models have also shown promise in robotic control tasks by denoising actions, known as diffusion policy. Although the diffusion generative model and diffusion policy exhibit distinct capabilities—image prediction and robotic action, respectively—they technically follow similar denoising process. In robotic tasks, the ability to predict future images and generate actions is highly correlated since they share the same underlying dynamics of the physical world. Building on this insight, we introduce \textbf{PAD}, a novel visual policy learning framework that unifies image \textbf{P}rediction and robot \textbf{A}ction within a joint \textbf{D}enoising process. Specifically, PAD utilizes Diffusion Transformers (DiT) to seamlessly integrate images and robot states, enabling the simultaneous prediction of future images and robot actions. Additionally, PAD supports co-training on both robotic demonstrations and large-scale video datasets and can be easily extended to other robotic modalities, such as depth images.
PAD outperforms previous methods, achieving a significant 38.9\% relative improvement on the full Metaworld benchmark, by utilizing a single text-conditioned visual policy within a data-efficient imitation learning setting. Furthermore, PAD demonstrates superior generalization to unseen tasks in real-world robot manipulation settings with 28.0\% success rate increase compared to the strongest baseline.
Videos of PAD can be found at https://sites.google.com/view/pad-paper
tl;dr: We propose a novel label integration algorithm called K-free nearest neighbor (KFNN).

To reduce annotation costs, it is common in crowdsourcing to collect only a few noisy labels from different crowd workers for each instance. However, the limited noisy labels restrict the performance of label integration algorithms in inferring the unknown true label for the instance. Recent works have shown that leveraging neighbor instances can help alleviate this problem. Yet, these works all assume that each instance has the same neighborhood size, which defies common sense. To address this gap, we propose a novel label integration algorithm called K-free nearest neighbor (KFNN). In KFNN, the neighborhood size of each instance is automatically determined based on its attributes and noisy labels. Specifically, KFNN initially estimates a Mahalanobis distance distribution from the attribute space to model the relationship between each instance and all classes. This distance distribution is then utilized to enhance the multiple noisy label distribution of each instance. Subsequently, a Kalman filter is designed to mitigate the impact of noise incurred by neighbor instances. Finally, KFNN determines the optimal neighborhood size by the max-margin learning. Extensive experimental results demonstrate that KFNN significantly outperforms all the other state-of-the-art algorithms and exhibits greater robustness in various crowdsourcing scenarios.
tl;dr: We address online sample selection, introducing II-COS, a decision rule that efficiently identifies preferable samples meeting practical requirements by managing individual and interactive constraints.

Real-time decision-making gets more attention in the big data era. Here, we consider the problem of sample selection in the online setting, where one encounters a possibly infinite sequence of individuals collected over time with covariate information available. The goal is to select samples of interest that are characterized by their unobserved responses until the user-specified stopping time. We derive a new decision rule that enables us to find more preferable samples that meet practical requirements by simultaneously controlling two types of general constraints: individual and interactive constraints, which include the widely utilized False Selection Rate (FSR), cost limitations, and diversity of selected samples. The key elements of our approach involve quantifying the uncertainty of response predictions via predictive inference and addressing individual and interactive constraints in a sequential manner. Theoretical and numerical results demonstrate the effectiveness of the proposed method in controlling both individual and interactive constraints.
1290. Deep Graph Mating

In this paper, we introduce the first learning-free model reuse task within the non-Euclidean domain, termed as Deep Graph Mating (Grama). We strive to create a child Graph Neural Network (GNN) that integrates knowledge from pre-trained parent models without requiring re-training, fine-tuning, or annotated labels. To this end, we begin by investigating the permutation invariance property of GNNs, which leads us to develop two vanilla approaches for Grama: Vanilla Parameter Interpolation (VPI) and Vanilla Alignment Prior to Interpolation (VAPI), both employing topology-independent interpolation in the parameter space. However, neither approach has achieved the anticipated results. Through theoretical analysis of VPI and VAPI, we identify critical challenges unique to Grama, including increased sensitivity to parameter misalignment and further the inherent topology-dependent complexities. Motivated by these findings, we propose the Dual-Message Coordination and Calibration (DuMCC) methodology, comprising the Parent Message Coordination (PMC) scheme to optimise the permutation matrices for parameter interpolation by coordinating aggregated messages, and the Child Message Calibration (CMC) scheme to mitigate over-smoothing identified in PMC by calibrating the message statistics within child GNNs. Experiments across diverse domains, including node and graph property prediction, 3D object recognition, and large-scale semantic parsing, demonstrate that the proposed DuMCC effectively enables training-free knowledge transfer, yielding results on par with those of pre-trained models.
tl;dr: In this paper, we leverage the scene graph, a powerful structured representation, for complex image generation.

There has been exciting progress in generating images from natural language or layout conditions. However, these methods struggle to faithfully reproduce complex scenes due to the insufficient modeling of multiple objects and their relationships. To address this issue, we leverage the scene graph, a powerful structured representation, for complex image generation. Different from the previous works that directly use scene graphs for generation, we employ the generative capabilities of variational autoencoders and diffusion models in a generalizable manner, compositing diverse disentangled visual clues from scene graphs. Specifically, we first propose a Semantics-Layout Variational AutoEncoder (SL-VAE) to jointly derive (layouts, semantics) from the input scene graph, which allows a more diverse and reasonable generation in a one-to-many mapping. We then develop a Compositional Masked Attention (CMA) integrated with a diffusion model, incorporating (layouts, semantics) with fine-grained attributes as generation guidance. To further achieve graph manipulation while keeping the visual content consistent, we introduce a Multi-Layered Sampler (MLS) for an "isolated" image editing effect. Extensive experiments demonstrate that our method outperforms recent competitors based on text, layout, or scene graph, in terms of generation rationality and controllability.

Although significant progress has been made in human video generation, most previous studies focus on either human facial animation or full-body animation, which cannot be directly applied to produce realistic conversational human videos with frequent hand gestures and various facial movements simultaneously.
To address these limitations, we propose a 2D human video generation framework, named ShowMaker, capable of generating high-fidelity half-body conversational videos via fine-grained diffusion modeling.
We leverage dual-stream diffusion models as the backbone of our framework and carefully design two novel components for crucial local regions (i.e., hands and face) that can be easily integrated into our backbone.
Specifically, to handle the challenging hand generation caused by sparse motion guidance, we propose a novel Key Point-based Fine-grained Hand Modeling module by amplifying positional information from raw hand key points and constructing a corresponding key point-based codebook.
Moreover, to restore richer facial details in generated results, we introduce a Face Recapture module, which extracts facial texture features and global identity features from the aligned human face and integrates them into the diffusion process for face enhancement.
Extensive quantitative and qualitative experiments demonstrate the superior visual quality and temporal consistency of our method.
tl;dr: We prove a novel PAC-Bayes bound which provides rich information on the types of errors likely to be made at inference time.

Current PAC-Bayes generalisation bounds are restricted to scalar metrics of performance, such as the loss or error rate. However, one ideally wants more information-rich certificates that control the entire distribution of possible outcomes, such as the distribution of the test loss in regression, or the probabilities of different mis-classifications. We provide the first PAC-Bayes bound capable of providing such rich information by bounding the Kullback-Leibler divergence between the empirical and true probabilities of a set of $M$ error types, which can either be discretized loss values for regression, or the elements of the confusion matrix (or a partition thereof) for classification. We transform our bound into a differentiable training objective. Our bound is especially useful in cases where the severity of different mis-classifications may change over time; existing PAC-Bayes bounds can only bound a particular pre-decided weighting of the error types. In contrast our bound implicitly controls all uncountably many weightings simultaneously.
tl;dr: We introduce a decision-aware amortized Bayesian experimental design framework with a novel Transformer neural decision process architecture to optimize experimental designs for better decision-making.

Many critical decisions, such as personalized medical diagnoses and product pricing, are made based on insights gained from designing, observing, and analyzing a series of experiments. This highlights the crucial role of experimental design, which goes beyond merely collecting information on system parameters as in traditional Bayesian experimental design (BED), but also plays a key part in facilitating downstream decision-making. Most recent BED methods use an amortized policy network to rapidly design experiments. However, the information gathered through these methods is suboptimal for down-the-line decision-making, as the experiments are not inherently designed with downstream objectives in mind. In this paper, we present an amortized decision-aware BED framework that prioritizes maximizing downstream decision utility. We introduce a novel architecture, the Transformer Neural Decision Process (TNDP), capable of instantly proposing the next experimental design, whilst inferring the downstream decision, thus effectively amortizing both tasks within a unified workflow. We demonstrate the performance of our method across several tasks, showing that it can deliver informative designs and facilitate accurate decision-making.

We present a detailed study of surrogate losses and algorithms for multi-label learning, supported by $H$-consistency bounds. We first show that, for the simplest form of multi-label loss (the popular Hamming loss), the well-known consistent binary relevance surrogate suffers from a sub-optimal dependency on the number of labels in terms of $H$-consistency bounds, when using smooth losses such as logistic losses. Furthermore, this loss function fails to account for label correlations. To address these drawbacks, we introduce a novel surrogate loss, *multi-label logistic loss*, that accounts for label correlations and benefits from label-independent $H$-consistency bounds. We then broaden our analysis to cover a more extensive family of multi-label losses, including all common ones and a new extension defined based on linear-fractional functions with respect to the confusion matrix. We also extend our multi-label logistic losses to more comprehensive multi-label comp-sum losses, adapting comp-sum losses from standard classification to the multi-label learning. We prove that this family of surrogate losses benefits from $H$-consistency bounds, and thus Bayes-consistency, across any general multi-label loss. Our work thus proposes a unified surrogate loss framework benefiting from strong consistency guarantees for any multi-label loss, significantly expanding upon previous work which only established Bayes-consistency and for specific loss functions. Additionally, we adapt constrained losses from standard classification to multi-label constrained losses in a similar way, which also benefit from $H$-consistency bounds and thus Bayes-consistency for any multi-label loss. We further describe efficient gradient computation algorithms for minimizing the multi-label logistic loss.
tl;dr: We combine diffusion model with autoregressive priors for improved output diversity, interpretability, and controllability

Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, these models often exhibit limited diversity in the sampled images, particularly when sampling with a high classifier-free guidance weight. To address this issue, we present Kaleido, a novel approach that enhances the diversity of samples by incorporating autoregressive latent priors. Kaleido integrates an autoregressive language model that encodes the original caption and generates latent variables, serving as abstract and intermediary representations for guiding and facilitating the image generation process.
In this paper, we explore a variety of discrete latent representations, including textual descriptions, detection bounding boxes, object blobs, and visual tokens. These representations diversify and enrich the input conditions to the diffusion models, enabling more diverse outputs.
Our experimental results demonstrate that Kaleido effectively broadens the diversity of the generated image samples from a given textual description while maintaining high image quality. Furthermore, we show that Kaleido adheres closely to the guidance provided by the generated latent variables, demonstrating its capability to effectively control and direct the image generation process.

Although text-to-image (T2I) models exhibit remarkable generation capabilities,
they frequently fail to accurately bind semantically related objects or attributes
in the input prompts; a challenge termed semantic binding. Previous approaches
either involve intensive fine-tuning of the entire T2I model or require users or
large language models to specify generation layouts, adding complexity. In this
paper, we define semantic binding as the task of associating a given object with its
attribute, termed attribute binding, or linking it to other related sub-objects, referred
to as object binding. We introduce a novel method called Token Merging (ToMe),
which enhances semantic binding by aggregating relevant tokens into a single
composite token. This ensures that the object, its attributes and sub-objects all share
the same cross-attention map. Additionally, to address potential confusion among
main objects with complex textual prompts, we propose end token substitution as
a complementary strategy. To further refine our approach in the initial stages of
T2I generation, where layouts are determined, we incorporate two auxiliary losses,
an entropy loss and a semantic binding loss, to iteratively update the composite
token to improve the generation integrity. We conducted extensive experiments to
validate the effectiveness of ToMe, comparing it against various existing methods
on the T2I-CompBench and our proposed GPT-4o object binding benchmark. Our
method is particularly effective in complex scenarios that involve multiple objects
and attributes, which previous methods often fail to address. The code will be
publicly available at https://github.com/hutaihang/ToMe
tl;dr: We devise efficient algorithms for differentially private U-statistics in the Central DP model, achieving nearly optimal error rates in various settings. Previously, this was studied in the local DP model and with U-statistics of degree 2.

We consider the problem of privately estimating a parameter $\mathbb{E}[h(X_1,\dots,X_k)]$, where $X_1$, $X_2$, $\dots$, $X_k$ are i.i.d. data from some distribution and $h$ is a permutation-invariant function. Without privacy constraints, the standard estimators for this task are U-statistics, which commonly arise in a wide range of problems, including nonparametric signed rank tests, symmetry testing, uniformity testing, and subgraph counts in random networks, and are the unique minimum variance unbiased estimators under mild conditions. Despite the recent outpouring of interest in private mean estimation, privatizing U-statistics has received little attention. While existing private mean estimation algorithms can be applied in a black-box manner to obtain confidence intervals, we show that they can lead to suboptimal private error, e.g., constant-factor inflation in the leading term, or even $\Theta(1/n)$ rather than $O(1/n^2)$ in degenerate settings. To remedy this, we propose a new thresholding-based approach that reweights different subsets of the data using _local Hájek projections_. This leads to nearly optimal private error for non-degenerate U-statistics and a strong indication of near-optimality for degenerate U-statistics.

Hyperparameter Optimization (HPO) plays a pivotal role in unleashing the potential of iterative machine learning models. This paper addresses a crucial aspect that has largely been overlooked in HPO: the impact of uncertainty in ML model training. The paper introduces the concept of uncertainty-aware HPO and presents a novel approach called the UQ-guided scheme for quantifying uncertainty. This scheme offers a principled and versatile method to empower HPO techniques in handling model uncertainty during their exploration of the candidate space.
By constructing a probabilistic model and implementing probability-driven candidate selection and budget allocation, this approach enhances the quality of the resulting model hyperparameters. It achieves a notable performance improvement of over 50\% in terms of accuracy regret and exploration time.
tl;dr: We present the first algorithm for exact gradient inversion on batch sizes $>1$ to reconstruct inputs in the honest-but-curious federated learning setting.

Federated learning is a framework for collaborative machine learning where clients only share gradient updates and not their private data with a server. However, it was recently shown that gradient inversion attacks can reconstruct this data from the shared gradients. In the important honest-but-curious setting, existing attacks enable exact reconstruction only for batch size of $b=1$, with larger batches permitting only approximate reconstruction. In this work, we propose SPEAR, *the first algorithm reconstructing whole batches with $b >1$ exactly*. SPEAR combines insights into the explicit low-rank structure of gradients with a sampling-based algorithm. Crucially, we leverage ReLU-induced gradient sparsity to precisely filter out large numbers of incorrect samples, making a final reconstruction step tractable. We provide an efficient GPU implementation for fully connected networks and show that it recovers high-dimensional ImageNet inputs in batches of up to $b \lesssim 25$ exactly while scaling to large networks. Finally, we show theoretically that much larger batches can be reconstructed with high probability given exponential time.
1301. Leveraging Catastrophic Forgetting to Develop Safe Diffusion Models against Malicious Finetuning

Diffusion models (DMs) have demonstrated remarkable proficiency in producing images based on textual prompts. Numerous methods have been proposed to ensure these models generate safe images. Early methods attempt to incorporate safety filters into models to mitigate the risk of generating harmful images but such external filters do not inherently detoxify the model and can be easily bypassed. Hence, model unlearning and data cleaning are the most essential methods for maintaining the safety of models, given their impact on model parameters.
However, malicious fine-tuning can still make models prone to generating harmful or undesirable images even with these methods.
Inspired by the phenomenon of catastrophic forgetting, we propose a training policy using contrastive learning to increase the latent space distance between clean and harmful data distribution, thereby protecting models from being fine-tuned to generate harmful images due to forgetting.
The experimental results demonstrate that our methods not only maintain clean image generation capabilities before malicious fine-tuning but also effectively prevent DMs from producing harmful images after malicious fine-tuning. Our method can also be combined with other safety methods to maintain their safety against malicious fine-tuning further.

Incomplete spatio-temporal data in real-world has spawned many research.
However, existing methods often utilize iterative message-passing across temporal and spatial dimensions, resulting in substantial information loss and high computational cost.
We provide a theoretical analysis revealing that such iterative models are not only susceptible to data sparsity but also to graph sparsity, causing unstable performances on different datasets.
To overcome these limitations, we introduce a novel method named One-step Propagation and Confidence-based Refinement (OPCR).
In the first stage, OPCR leverages inherent spatial and temporal relationships by employing sparse attention mechanism.
These modules propagate limited observations directly to the global context through one-step imputation, which are theoretically effected only by data sparsity.
Following this, we assign confidence levels to the initial imputations by correlating missing data with valid data.
This confidence-based propagation refines the seperate spatial and temporal imputation results through spatio-temporal dependencies.
We evaluate the proposed model across various downstream tasks involving highly sparse spatio-temporal data.
Empirical results indicate that our model outperforms state-of-the-art imputation methods, demonstrating its superior effectiveness and robustness.
tl;dr: We present an analysis of Elo rating systems under the Bradley–Terry–Luce model

We present a theoretical analysis of the Elo rating system, a popular method for ranking skills of players in an online setting. In particular, we study Elo under the Bradley-Terry-Luce model and, using techniques from Markov chain theory, show that Elo learns the model parameters at a rate competitive with the state-of-the-art. We apply our results to the problem of efficient tournament design and discuss a connection with the fastest-mixing Markov chain problem.
tl;dr: We provide the implicit bias of mirror flow in the classification setting.

We examine the continuous-time counterpart of mirror descent, namely mirror flow, on classification problems which are linearly separable. Such problems are minimised ‘at infinity’ and have many possible solutions; we study which solution is preferred by the algorithm depending on the mirror potential. For exponential tailed losses and under mild assumptions on the potential, we show that the iterates converge in direction towards a $\phi_\infty$-maximum margin classifier. The function $\phi_\infty$ is the horizon function of the mirror potential and characterises its shape ‘at infinity’. When the potential is separable, a simple formula allows to compute this function. We analyse several examples of potentials and provide numerical experiments highlighting our results.

Graph Neural Networks have achieved remarkable accuracy in semi-supervised node classification tasks. However, these results lack reliable uncertainty estimates. Conformal prediction methods provide a theoretical guarantee for node classification tasks, ensuring that the conformal prediction set contains the ground-truth label with a desired probability (e.g., 95\%). In this paper, we empirically show that for each node, aggregating the non-conformity scores of nodes with the same label can improve the efficiency of conformal prediction sets while maintaining valid marginal coverage. This observation motivates us to propose a novel algorithm named $\textit{Similarity-Navigated Adaptive Prediction Sets}$ (SNAPS), which aggregates the non-conformity scores based on feature similarity and structural neighborhood. The key idea behind SNAPS is that nodes with high feature similarity or direct connections tend to have the same label. By incorporating adaptive similar nodes information, SNAPS can generate compact prediction sets and increase the singleton hit ratio (correct prediction sets of size one). Moreover, we theoretically provide a finite-sample coverage guarantee of SNAPS. Extensive experiments demonstrate the superiority of SNAPS, improving the efficiency of prediction sets and singleton hit ratio while maintaining valid coverage.
tl;dr: We study dynamic submodular maximization in the algorithms with predictions framework.

In dynamic submodular maximization, the goal is to maintain a high-value solution over a sequence of element insertions and deletions with a fast update time. Motivated by large-scale applications and the fact that dynamic data often exhibits patterns, we ask the following question: can predictions be used to accelerate the update time of dynamic submodular maximization algorithms?
We consider the model for dynamic algorithms with predictions where predictions regarding the insertion and deletion times of elements can be used for preprocessing. Our main result is an algorithm with an $O(\text{poly}(\log \eta, \log w, \log k))$ amortized update time over the sequence of updates that achieves a $1/2 - \epsilon$ approximation for dynamic monotone submodular maximization under a cardinality constraint $k$, where the prediction error $\eta$ is the number of elements that are not inserted and deleted within $w$ time steps of their predicted insertion and deletion times. This amortized update time is independent of the length of the stream and instead depends on the prediction error.

We propose an unsupervised adaptation framework, Self-TAught Recognizer (STAR), which leverages unlabeled data to enhance the robustness of automatic speech recognition (ASR) systems in diverse target domains, such as noise and accents. STAR is developed for prevalent speech foundation models based on Transformer-related architecture with auto-regressive decoding (e.g., Whisper, Canary). Specifically, we propose a novel indicator that empirically integrates step-wise information during decoding to assess the token-level quality of pseudo labels without ground truth, thereby guiding model updates for effective unsupervised adaptation. Experimental results show that STAR achieves an average of 13.5% relative reduction in word error rate across 14 target domains, and it sometimes even approaches the upper-bound performance of supervised adaptation. Surprisingly, we also observe that STAR prevents the adapted model from the common catastrophic forgetting problem without recalling source-domain data. Furthermore, STAR exhibits high data efficiency that only requires less than one-hour unlabeled data, and seamless generality to alternative large speech models and speech translation tasks. Our code aims to open source to the research communities.

Causal language modeling using the Transformer architecture has yielded remarkable capabilities in Large Language Models (LLMs) over the last few years. However, the extent to which fundamental search and reasoning capabilities emerged within LLMs remains a topic of ongoing debate. In this work, we study if causal language modeling can learn a complex task such as solving Sudoku puzzles. To solve a Sudoku, the model is first required to search over all empty cells of the puzzle to decide on a cell to fill and then apply an appropriate strategy to fill the decided cell. Sometimes, the application of a strategy only results in thinning down the possible values in a cell rather than concluding the exact value of the cell. In such cases, multiple strategies are applied one after the other to fill a single cell. We observe that Transformer models trained on this synthetic task can indeed learn to solve Sudokus (our model solves $94.21\%$ of the puzzles fully correctly) when trained on a logical sequence of steps taken by a solver. We find that training Transformers with the logical sequence of steps is necessary and without such training, they fail to learn Sudoku. We also extend our analysis to Zebra puzzles (known as Einstein puzzles) and show that the model solves $92.04 \%$ of the puzzles fully correctly. In addition, we study the internal representations of the trained Transformer and find that through linear probing, we can decode information about the set of possible values in any given cell from them, pointing to the presence of a strong reasoning engine implicit in the Transformer weights.
tl;dr: To address the issue that fine-tuning an aligned model degrades safety, we introduce the “Pure Tune, Safe Test” (PTST) Principle: fine-tune models without a safety prompt, but include it at test time.

Public LLMs such as the Llama 2-Chat underwent alignment training and were considered safe. Recently Qi et al. (2024) reported that even benign fine-tuning on seemingly safe datasets can give rise to unsafe behaviors in the models. The current paper is about methods and best practices to mitigate such loss of alignment. We focus on the setting where a public model is fine-tuned before serving users for specific usage, where the model should improve on the downstream task while maintaining alignment. Through extensive experiments on several chat models (Meta's Llama 2-Chat, Mistral AI's Mistral 7B Instruct v0.2, and OpenAI's GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the “Pure Tuning, Safe Testing” (PTST) strategy --- fine-tune models without a safety prompt, but include it at test time. This seemingly counterintuitive strategy incorporates an intended distribution shift to encourage alignment preservation. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors.
tl;dr: This paper addresses deployment challenges of Mixture-of-Experts models in Language Modeling and Machine Translation by introducing dynamic gating, expert buffering, and load balancing to improve throughput, memory usage, and robustness.

Mixture-of-Experts (MoE) models have recently gained steam in achieving the state-of-the-art performance in a wide range of tasks in computer vision and natural language processing. They effectively expand the model capacity while incurring a minimal increase in computation cost during training. However, deploying such models for inference is difficult due to their large model size and complex communication pattern. In this work, we provide a characterization of two MoE workloads, namely Language Modeling (LM) and Machine Translation (MT) and identify their sources of inefficiencies at deployment. We propose three optimization techniques to mitigate sources of inefficiencies, namely (1) Dynamic gating, (2) Expert Buffering, and (3) Expert load balancing. We show that dynamic gating improves maximum throughput by 6.21-11.55$\times$ for LM, 5.75-10.98$\times$ for MT Encoder and 2.58-5.71$\times$ for MT Decoder.
It also reduces memory usage by up to 1.36$\times$ for LM and up to 1.1$\times$ for MT. We further propose Expert Buffering, a new caching mechanism that only keeps hot, active experts in GPU memory while buffering the rest in CPU memory. This reduces static memory allocation by 1.47$\times$. Finally, we propose a load balancing methodology that provides additional robustness to the workload. Our code is available at https://github.com/hyhuang00/moe_inference.
tl;dr: This paper explores the impact of random initialization in Neural Tangent Kernel (NTK) theories and argues that NTK theories fail to explain the superior performance of neural networks.

This paper aims to discuss the impact of random initialization of neural networks in the neural tangent kernel (NTK) theory, which is ignored by most recent works in the NTK theory. It is well known that as the network's width tends to infinity, the neural network with random initialization converges to a Gaussian process \(f^{\mathrm{GP}}\), which takes values in \(L^{2}(\mathcal{X})\), where \(\mathcal{X}\) is the domain of the data. In contrast, to adopt the traditional theory of kernel regression, most recent works introduced a special mirrored architecture and a mirrored (random) initialization to ensure the network's output is identically zero at initialization. Therefore, it remains a question whether the conventional setting and mirrored initialization would make wide neural networks exhibit different generalization capabilities. In this paper, we first show that the training dynamics of the gradient flow of neural networks with random initialization converge uniformly to that of the corresponding NTK regression with random initialization \(f^{\mathrm{GP}}\). We then show that \(\mathbf{P}(f^{\mathrm{GP}} \in [\mathcal{H}^{\mathrm{NT}}]^{s}) = 1\) for any \(s < \frac{3}{d+1}\) and \(\mathbf{P}(f^{\mathrm{GP}} \in [\mathcal{H}^{\mathrm{NT}}]^{s}) = 0\) for any \(s \geq \frac{3}{d+1}\), where \([\mathcal{H}^{\mathrm{NT}}]^{s}\) is the real interpolation space of the RKHS \(\mathcal{H}^{\mathrm{NT}}\) associated with the NTK. Consequently, the generalization error of the wide neural network trained by gradient descent is \(\Omega(n^{-\frac{3}{d+3}})\), and it still suffers from the curse of dimensionality. Thus, the NTK theory may not explain the superior performance of neural networks.
tl;dr: We give a novel derandomization of JL via optimization, that avoids all bad local minima in the non-convex landscape by a diffusion-like process where we move through the space of randomized solution samplers, sequentially reducing the variance.

Embeddings play a pivotal role across various disciplines, offering compact representations of complex data structures. Randomized methods like Johnson-Lindenstrauss (JL) provide state-of-the-art and essentially unimprovable theoretical guarantees for achieving such representations. These guarantees are worst-case and in particular, neither the analysis, ${\textit{nor the algorithm}}$, takes into account any potential structural information of the data. The natural question is: must we randomize? Could we instead use an optimization-based approach, working directly with the data? A first answer is no: as we show, the distance-preserving objective of JL has a non-convex landscape over the space of projection matrices, with many bad stationary points. But this is not the final answer.
We present a novel method motivated by diffusion models, that circumvents this fundamental challenge: rather than performing optimization directly over the space of projection matrices, we use optimization over the larger space of $\textit{random solution samplers}$, gradually reducing the variance of the sampler. We show that by moving through this larger space, our objective converges to a deterministic (zero variance) solution, avoiding bad stationary points.
This method can also be seen as an optimization-based derandomization approach, and is an idea and method that we believe can be applied to many other problems.

Real-world multi-agent scenarios often involve mixed motives, demanding altruistic agents capable of self-protection against potential exploitation. However, existing approaches often struggle to achieve both objectives. In this paper, based on that empathic responses are modulated by learned social relationships between agents, we propose LASE (**L**earning to balance **A**ltruism and **S**elf-interest based on **E**mpathy), a distributed multi-agent reinforcement learning algorithm that fosters altruistic cooperation through gifting while avoiding exploitation by other agents in mixed-motive games. LASE allocates a portion of its rewards to co-players as gifts, with this allocation adapting dynamically based on the social relationship --- a metric evaluating the friendliness of co-players estimated by counterfactual reasoning. In particular, social relationship measures each co-player by comparing the estimated $Q$-function of current joint action to a counterfactual baseline which marginalizes the co-player's action, with its action distribution inferred by a perspective-taking module. Comprehensive experiments are performed in spatially and temporally extended mixed-motive games, demonstrating LASE's ability to promote group collaboration without compromising fairness and its capacity to adapt policies to various types of interactive co-players.
tl;dr: Geometric Algebra based architecture for protein structure that achieves high designability and structural diversity as flow matching model for protein generation.

We introduce a generative model for protein backbone design utilizing geometric products and higher order message passing. In particular, we propose Clifford Frame Attention (CFA), an extension of the invariant point attention (IPA) architecture from AlphaFold2, in which the backbone residue frames and geometric features are represented in the projective geometric algebra. This enables to construct geometrically expressive messages between residues, including higher order terms, using the bilinear operations of the algebra. We evaluate our architecture by incorporating it into the framework of FrameFlow, a state-of-the-art flow matching model for protein backbone generation. The proposed model achieves high designability, diversity and novelty, while also sampling protein backbones that follow the statistical distribution of secondary structure elements found in naturally occurring proteins, a property so far only insufficiently achieved by many state-of-the-art generative models.
tl;dr: We first establish a connection between the dynamics of the expert representations in SMoEs and gradient descent on a multi-objective optimization problem and then integrate momentum into SMoE to develop a new family of SMoEs, named MomentumSMoE.

Sparse Mixture of Experts (SMoE) has become the key to unlocking unparalleled scalability in deep learning. SMoE has the potential to exponentially increase in parameter count while maintaining the efficiency of the model by only activating a small subset of these parameters for a given sample. However, it has been observed that SMoE suffers from unstable training and has difficulty adapting to new distributions, leading to the model's lack of robustness to data contamination. To overcome these limitations, we first establish a connection between the dynamics of the expert representations in SMoEs and gradient descent on a multi-objective optimization problem. Leveraging our framework, we then integrate momentum into SMoE and propose a new family of SMoEs, named MomentumSMoE. We theoretically prove and numerically validate that MomentumSMoE is more stable and robust than SMoE. In particular, we verify the advantages of MomentumSMoE over SMoE on a variety of practical tasks including ImageNet-1K object recognition and WikiText-103 language modeling. We demonstrate the applicability of MomentumSMoE to many types of SMoE models, including those in the Sparse MoE model for vision (V-MoE) and the Generalist Language Model (GLaM). We also show that other advanced momentum-based optimization methods, such as Adam, can be easily incorporated into the MomentumSMoE framework for designing new SMoE models with even better performance, almost negligible additional computation cost, and simple implementations.

Real-world offline datasets are often subject to data corruptions (such as noise or adversarial attacks) due to sensor failures or malicious attacks. Despite advances in robust offline reinforcement learning (RL), existing methods struggle to learn robust agents under high uncertainty caused by the diverse corrupted data (i.e., corrupted states, actions, rewards, and dynamics), leading to performance degradation in clean environments. To tackle this problem, we propose a novel robust variational Bayesian inference for offline RL (TRACER). It introduces Bayesian inference for the first time to capture the uncertainty via offline data for robustness against all types of data corruptions. Specifically, TRACER first models all corruptions as the uncertainty in the action-value function. Then, to capture such uncertainty, it uses all offline data as the observations to approximate the posterior distribution of the action-value function under a Bayesian inference framework. An appealing feature of TRACER is that it can distinguish corrupted data from clean data using an entropy-based uncertainty measure, since corrupted data often induces higher uncertainty and entropy. Based on the aforementioned measure, TRACER can regulate the loss associated with corrupted data to reduce its influence, thereby enhancing robustness and performance in clean environments. Experiments demonstrate that TRACER significantly outperforms several state-of-the-art approaches across both individual and simultaneous data corruptions.
tl;dr: a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers
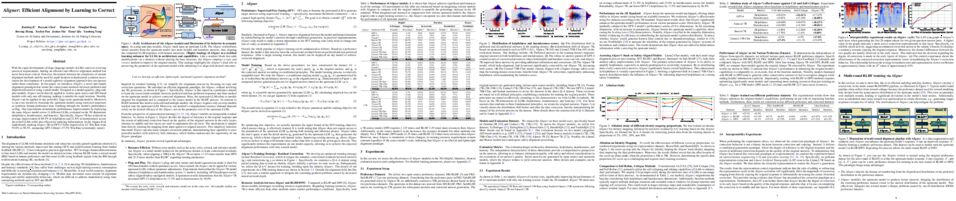
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to any powerful, large-scale upstream models. Moreover, it can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of 68.9\% in helpfulness and 23.8\% in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on GPT-4 Turbo improved its LC Win Rate from 55.0\% to 58.3\%, surpassing GPT-4 Omni's 57.5\% Win Rate (community report).

We consider scenarios where a very accurate (often small) predictive model using restricted features is available when training a full-featured (often larger) model. This restricted model may be thought of as ``side-information'', and can come either from an auxiliary dataset or from the same dataset by forcing the restriction. How can the restricted model be useful to the full model? To answer this, we introduce a methodology called Induced Model Matching (IMM). IMM aligns the context-restricted, or induced, version of the large model with the restricted model. We relate IMM to approaches such as noising, which is implicit in addressing the problem, and reverse knowledge distillation from weak teachers, which is explicit but does not exploit restriction being the nature of the weakness. We show that these prior methods can be thought of as approximations to IMM and can be problematic in terms of consistency. Experimentally, we first motivate IMM using logistic regression as a toy example. We then explore it in language modeling, the application that initially inspired it, and demonstrate it on both LSTM and transformer full models, using bigrams as restricted models. We lastly give a simple RL example, which shows that POMDP policies can help learn better MDP policies. The IMM principle is thus generally applicable in common scenarios where restricted data is cheaper to collect or restricted models are easier to learn.

It is largely agreed that social network links are formed due to either homophily or social influence. Inspired by this, we aim at understanding the generation of links via providing a novel embedding-based graph formation model. Different from existing graph representation learning, where link generation probabilities are defined as a simple function of the corresponding node embeddings, we model the link generation as a mixture model of the two factors. In addition, we model the homophily factor in spherical space and the influence factor in hyperbolic space to accommodate the fact that (1) homophily results in cycles and (2) influence results in hierarchies in networks. We also design a special projection to align these two spaces. We call this model Non-Euclidean Mixture Model, i.e., NMM. We further integrate NMM with our non-Euclidean graph variational autoencoder (VAE) framework, NMM-GNN. NMM-GNN learns embeddings through a unified framework which uses non-Euclidean GNN encoders, non-Euclidean Gaussian priors, a non-Euclidean decoder, and a novel space unification loss component to unify distinct non-Euclidean geometric spaces. Experiments on public datasets show NMM-GNN significantly outperforms state-of-the-art baselines on social network generation and classification tasks, demonstrating its ability to better explain how the social network is formed.
tl;dr: We study why Outlier Features occur during standard NN training dynamics, and which algorithmic choices one can make to minimise them.

Outlier Features (OFs) are neurons whose activation magnitudes significantly exceed the average over a neural network's (NN) width. They are well known to emerge during standard transformer training and have the undesirable effect of hindering quantisation in afflicted models. Despite their practical importance, little is known behind why OFs emerge during training, nor how one can minimise them.
Our work focuses on the above questions, first identifying several quantitative metrics, such as the kurtosis over neuron activation norms, to measure OFs. With these metrics, we study how architectural and optimisation choices influence OFs, and provide practical insights to minimise OFs during training. As highlights, we introduce a novel unnormalised transformer block, the Outlier Protected block, and present a previously unknown benefit of non-diagonal preconditioning optimisers, finding both approaches to significantly reduce OFs and improve quantisation without compromising convergence speed, at scales of up to 7B parameters. Notably, our combination of OP block and non-diagonal preconditioner (SOAP) achieves 14.87 weight-and-activation int8 perplexity (from 14.71 in standard precision), compared to 63.4 int8 perplexity (from 16.00) with a default OF-prone combination of Pre-Norm model and Adam, when quantising OPT-125m models post-training.
tl;dr: framework for understanding information storage and flow in multimodal language models

Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by \emph{the director in this photo} has won a \emph{Golden Globe}?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) \emph{VQA-Constraints}, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks. We will publicly release our dataset and code.
tl;dr: Maximizing cumulative future action entropy allows recurrent neural networks to perform tasks while maximizing variability.

Natural behaviors, even stereotyped ones, exhibit variability. Despite its role in exploring and learning, the function and neural basis of this variability is still not well understood. Given the coupling between neural activity and behavior, we ask what type of neural variability does not compromise behavioral performance. While previous studies typically curtail variability to allow for high task performance in neural networks, our approach takes the reversed perspective. We investigate how to generate maximal neural variability while at the same time having high network performance.
To do so, we extend to neural activity the maximum occupancy principle (MOP) developed for behavior, and refer to this new neural principle as NeuroMOP. NeuroMOP posits that the goal of the nervous system is to maximize future action-state entropy, a reward-free, intrinsic motivation that entails creating all possible activity patterns while avoiding terminal or dangerous ones.
We show that this goal can be achieved through a neural network controller that injects currents (actions) into a recurrent neural network of fixed random weights to maximize future cumulative action-state entropy.
High activity variability can be induced while adhering to an energy constraint or while avoiding terminal states defined by specific neurons' activities, also in a context-dependent manner. The network solves these tasks by flexibly switching between stochastic and deterministic modes as needed and projecting noise onto a null space. Based on future maximum entropy production, NeuroMOP contributes to a novel theory of neural variability that reconciles stochastic and deterministic behaviors within a single framework.

Toxicity classification in textual content remains a significant problem. Data with labels from a single annotator fall short of capturing the diversity of human perspectives. Therefore, there is a growing need to incorporate crowdsourced annotations for training an effective toxicity classifier. Additionally, the standard approach to training a classifier using empirical risk minimization (ERM) may fail to address the potential shifts between the training set and testing set due to exploiting spurious correlations. This work introduces a novel bi-level optimization framework that integrates crowdsourced annotations with the soft-labeling technique and optimizes the soft-label weights by Group Distributionally Robust Optimization (GroupDRO) to enhance the robustness against out-of-distribution (OOD) risk. We theoretically prove the convergence of our bi-level optimization algorithm. Experimental results demonstrate that our approach outperforms existing baseline methods in terms of both average and worst-group accuracy, confirming its effectiveness in leveraging crowdsourced annotations to achieve more effective and robust toxicity classification.
tl;dr: LeapAD, a new autonomous driving paradigm inspired by human cognition, improves adaptability and interpretability in complex scenarios through dual-process decision-making and continuous learning from past experiences.

Autonomous driving has advanced significantly due to sensors, machine learning, and artificial intelligence improvements. However, prevailing methods struggle with intricate scenarios and causal relationships, hindering adaptability and interpretability in varied environments. To address the above problems, we introduce LeapAD, a novel paradigm for autonomous driving inspired by the human cognitive process. Specifically, LeapAD emulates human attention by selecting critical objects relevant to driving decisions, simplifying environmental interpretation, and mitigating decision-making complexities. Additionally, LeapAD incorporates an innovative dual-process decision-making module, which consists of an Analytic Process (System-II) for thorough analysis and reasoning, along with a Heuristic Process (System-I) for swift and empirical processing. The Analytic Process leverages its logical reasoning to accumulate linguistic driving experience, which is then transferred to the Heuristic Process by supervised fine-tuning. Through reflection mechanisms and a growing memory bank, LeapAD continuously improves itself from past mistakes in a closed-loop environment. Closed-loop testing in CARLA shows that LeapAD outperforms all methods relying solely on camera input, requiring 1-2 orders of magnitude less labeled data. Experiments also demonstrate that as the memory bank expands, the Heuristic Process with only 1.8B parameters can inherit the knowledge from a GPT-4 powered Analytic Process and achieve continuous performance improvement. Project page: https://pjlab-adg.github.io/LeapAD
1325. On the Curses of Future and History in Future-dependent Value Functions for Off-policy Evaluation

We study off-policy evaluation (OPE) in partially observable environments with complex observations, with the goal of developing estimators whose guarantee avoids exponential dependence on the horizon. While such estimators exist for MDPs and POMDPs can be converted to history-based MDPs, their estimation errors depend on the state-density ratio for MDPs which becomes history ratios after conversion, an exponential object. Recently, Uehara et al. [2022a] proposed future-dependent value functions as a promising framework to address this issue, where the guarantee for memoryless policies depends on the density ratio over the latent state space. However, it also depends on the boundedness of the future-dependent value function and other related quantities, which we show could be exponential-in-length and thus erasing the advantage of the method. In this paper, we discover novel coverage assumptions tailored to the structure of POMDPs, such as outcome coverage and belief coverage, which enable polynomial bounds on the aforementioned quantities. As a side product, our analyses also lead to the discovery of new algorithms with complementary properties.
tl;dr: Providing a compute-optimal recipe for efficient contrastive fine-tuning of pretrained language models into embedding models.

Text embeddings are essential for tasks such as document retrieval, clustering, and semantic similarity assessment. In this paper, we study how to contrastively train text embedding models in a compute-optimal fashion, given a suite of pretrained decoder-only language models. Our innovation is an algorithm that produces optimal configurations of model sizes, data quantities, and fine-tuning methods for text-embedding models at different computational budget levels. The resulting recipe, which we obtain through extensive experiments, can be used by practitioners to make informed design choices for their embedding models. Specifically, our findings suggest that full fine-tuning and Low-Rank Adaptation fine-tuning produce optimal models at lower and higher computational budgets respectively.
tl;dr: We propose a general framework for building knowledge agents, featuring FSM-based reasoning logic and a process feedback mechanism, which is demonstrated by extensive experiments to surpass previous agents by a large margin.

The notable success of large language models (LLMs) has sparked an upsurge in building language agents to complete various complex tasks. We present AMOR, an agent framework based on open-source LLMs, which reasons with external knowledge bases and adapts to specific domains through human supervision to the reasoning process. AMOR builds reasoning logic over a finite state machine (FSM)
that solves problems through autonomous executions and transitions over disentangled modules. This allows humans to provide direct feedback to the individual modules, and thus naturally forms process supervision. Based on this reasoning and feedback framework, we develop AMOR through two-stage fine-tuning: warm-up and adaptation. The former fine-tunes the LLM with examples automatically constructed from various public datasets, enabling AMOR to generalize across different knowledge environments, while the latter tailors AMOR to specific domains using process feedback. Extensive experiments across multiple domains demonstrate the advantage of AMOR to strong baselines, thanks to its FSM-based reasoning and process feedback mechanism. The code and data are publicly available at
https://github.com/JianGuanTHU/AMOR.
tl;dr: We propose a novel paradigm, PGN, as the new successor to RNN, and propose a novel temporal modeling framework called TPGN, based on PGN.

Due to the recurrent structure of RNN, the long information propagation path poses limitations in capturing long-term dependencies, gradient explosion/vanishing issues, and inefficient sequential execution. Based on this, we propose a novel paradigm called Parallel Gated Network (PGN) as the new successor to RNN. PGN directly captures information from previous time steps through the designed Historical Information Extraction (HIE) layer and leverages gated mechanisms to select and fuse it with the current time step information. This reduces the information propagation path to $\mathcal{O}(1)$, effectively addressing the limitations of RNN. To enhance PGN's performance in long-range time series forecasting tasks, we propose a novel temporal modeling framework called Temporal PGN (TPGN). TPGN incorporates two branches to comprehensively capture the semantic information of time series. One branch utilizes PGN to capture long-term periodic patterns while preserving their local characteristics. The other branch employs patches to capture short-term information and aggregate the global representation of the series. TPGN achieves a theoretical complexity of $\mathcal{O}(\sqrt{L})$, ensuring efficiency in its operations. Experimental results on five benchmark datasets demonstrate the state-of-the-art (SOTA) performance and high efficiency of TPGN, further confirming the effectiveness of PGN as the new successor to RNN in long-range time series forecasting. The code is available in this repository: https://github.com/Water2sea/TPGN.
tl;dr: We give a sparse sketching method running in optimal space and current matrix multiplication time, recovering a nearly-unbiased least squares estimator using two passes over the data.

Matrix sketching is a powerful tool for reducing the size of large data matrices. Yet there are fundamental limitations to this size reduction when we want to recover an accurate estimator for a task such as least square regression. We show that these limitations can be circumvented in the distributed setting by designing sketching methods that minimize the bias of the estimator, rather than its error. In particular, we give a sparse sketching method running in optimal space and current matrix multiplication time, which recovers a nearly-unbiased least squares estimator using two passes over the data. This leads to new communication-efficient distributed averaging algorithms for least squares and related tasks, which directly improve on several prior approaches. Our key novelty is a new bias analysis for sketched least squares, giving a sharp characterization of its dependence on the sketch sparsity. The techniques include new higher moment restricted Bai-Silverstein inequalities, which are of independent interest to the non-asymptotic analysis of deterministic equivalents for random matrices that arise from sketching.
tl;dr: We propose an "off-the-grid" representation model which learns from video and binds tokens to scene elements and tracks them over time consistently via self-supervised learning.

Current vision models typically maintain a fixed correspondence between their representation structure and image space.
Each layer comprises a set of tokens arranged “on-the-grid,” which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present *Moving Off-the-Grid* (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move “off-the-grid” to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective—next frame prediction—trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG’s learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to “on-the-grid” baselines.
tl;dr: We propose a novel training algorithm to train efficiency-aware LLMs that have more structured contextual sparsity for fast inference.

Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
tl;dr: We propose a unified speech recognition method for ASR, VSR, and AVSR.

Research in auditory, visual, and audiovisual speech recognition (ASR, VSR, and AVSR, respectively) has traditionally been conducted independently. Even recent self-supervised studies addressing two or all three tasks simultaneously tend to yield separate models, leading to disjoint inference pipelines with increased memory requirements and redundancies. This paper proposes unified training strategies for these systems. We demonstrate that training a single model for all three tasks enhances VSR and AVSR performance, overcoming typical optimisation challenges when training from scratch. Moreover, we introduce a greedy pseudo-labelling approach to more effectively leverage unlabelled samples, addressing shortcomings in related self-supervised methods. Finally, we develop a self-supervised pre-training method within our framework, proving its effectiveness alongside our semi-supervised approach. Despite using a single model for all tasks, our unified approach achieves state-of-the-art performance on LRS3 for ASR, VSR, and AVSR compared to recent methods. Code will be made publicly available.

Pre-trained large language models (LLMs) exhibit impressive mathematical reasoning capabilities, yet how they compute basic arithmetic, such as addition, remains unclear.
This paper shows that pre-trained LLMs add numbers using Fourier features---dimensions in the hidden state that represent numbers via a set of features sparse in the frequency domain.
Within the model, MLP and attention layers use Fourier features in complementary ways: MLP layers primarily approximate the magnitude of the answer using low-frequency features, while attention layers primarily perform modular addition (e.g., computing whether the answer is even or odd) using high-frequency features.
Pre-training is crucial for this mechanism: models trained from scratch to add numbers only exploit low-frequency features, leading to lower accuracy.
Introducing pre-trained token embeddings to a randomly initialized model rescues its performance.
Overall, our analysis demonstrates that appropriate pre-trained representations (e.g., Fourier features) can unlock the ability of Transformers to learn precise mechanisms for algorithmic tasks.
tl;dr: We propose the first unified framework for detecting anomalies at node, edge, and graph levels.

Graph Anomaly Detection (GAD) aims to identify uncommon, deviated, or suspicious objects within graph-structured data. Existing methods generally focus on a single graph object type (node, edge, graph, etc.) and often overlook the inherent connections among different object types of graph anomalies. For instance, a money laundering transaction might involve an abnormal account and the broader community it interacts with. To address this, we present UniGAD, the first unified framework for detecting anomalies at node, edge, and graph levels jointly. Specifically, we develop the Maximum Rayleigh Quotient Subgraph Sampler (MRQSampler) that unifies multi-level formats by transferring objects at each level into graph-level tasks on subgraphs. We theoretically prove that MRQSampler maximizes the accumulated spectral energy of subgraphs (i.e., the Rayleigh quotient) to preserve the most significant anomaly information. To further unify multi-level training, we introduce a novel GraphStitch Network to integrate information across different levels, adjust the amount of sharing required at each level, and harmonize conflicting training goals. Comprehensive experiments show that UniGAD outperforms both existing GAD methods specialized for a single task and graph prompt-based approaches for multiple tasks, while also providing robust zero-shot task transferability.
1335. PERIA: Perceive, Reason, Imagine, Act via Holistic Language and Vision Planning for Manipulation
tl;dr: We propose PERIA, a novel framework that leverages a MLLM to enable effective task decomposition via holistic language planning and vision planning for robotic manipulation in embodied scenarios.

Long-horizon manipulation tasks with general instructions often implicitly encapsulate multiple sub-tasks, posing significant challenges in instruction following.
While language planning is a common approach to decompose general instructions into stepwise sub-instructions, text-only guidance may lack expressiveness and lead to potential ambiguity. Considering that humans often imagine and visualize sub-instructions reasoning out before acting, the imagined subgoal images can provide more intuitive guidance and enhance the reliability of decomposition. Inspired by this, we propose **PERIA**(**PE**rceive, **R**eason, **I**magine, **A**ct), a novel framework that integrates holistic language planning and vision planning for long-horizon manipulation tasks with complex instructions, leveraging both logical and intuitive aspects of task decomposition.
Specifically, we first perform a lightweight multimodal alignment on the encoding side to empower the MLLM to perceive visual details and language instructions.
The MLLM is then jointly instruction-tuned with a pretrained image-editing model to unlock capabilities of simultaneous reasoning of language instructions and generation of imagined subgoals. Furthermore, we introduce a consistency alignment loss to encourage coherent subgoal images and align with their corresponding instructions, mitigating potential hallucinations and semantic conflicts between the two planning manners.
Comprehensive evaluations across three task domains demonstrate that PERIA, benefiting from holistic language and vision planning, significantly outperforms competitive baselines in both instruction following accuracy and task success rate on complex manipulation tasks.
tl;dr: We identify influential training images that make a synthesized image possible, using our proposed attribution method by unlearning a synthesized image.

The goal of data attribution for text-to-image models is to identify the training images that most influence the generation of a new image. Influence is defined such that, for a given output, if a model is retrained from scratch without the most influential images, the model would fail to reproduce the same output. Unfortunately, directly searching for these influential images is computationally infeasible, since it would require repeatedly retraining models from scratch. In our work, we propose an efficient data attribution method by simulating unlearning the synthesized image. We achieve this by increasing the training loss on the output image, without catastrophic forgetting of other, unrelated concepts. We then identify training images with significant loss deviations after the unlearning process and label these as influential. We evaluate our method with a computationally intensive but "gold-standard" retraining from scratch and demonstrate our method's advantages over previous methods.
tl;dr: We propose template-free method based on 3D-GS and superpoints to discover the skeleton model of an articulated object and achieve real-time rendering.

While novel view synthesis for dynamic scenes has made significant progress, capturing skeleton models of objects and re-posing them remains a challenging task. To tackle this problem, in this paper, we propose a novel approach to automatically discover the associated skeleton model for dynamic objects from videos without the need for object-specific templates. Our approach utilizes 3D Gaussian Splatting and superpoints to reconstruct dynamic objects. Treating superpoints as rigid parts, we can discover the underlying skeleton model through intuitive cues and optimize it using the kinematic model. Besides, an adaptive control strategy is applied to avoid the emergence of redundant superpoints. Extensive experiments demonstrate the effectiveness and efficiency of our method in obtaining re-posable 3D objects. Not only can our approach achieve excellent visual fidelity, but it also allows for the real-time rendering of high-resolution images.
tl;dr: We present Fair Wasserstein Coreset (FWC), a novel coreset approach to generate fair synthetic representative samples along with sample-level weights to be used in downstream learning tasks.

Data distillation and coresets have emerged as popular approaches to generate a smaller representative set of samples for downstream learning tasks to handle large-scale datasets. At the same time, machine learning is being increasingly applied to decision-making processes at a societal level, making it imperative for modelers to address inherent biases towards subgroups present in the data. While current approaches focus on creating fair synthetic representative samples by optimizing local properties relative to the original samples, their impact on downstream learning processes has yet to be explored. In this work, we present fair Wasserstein coresets ($\texttt{FWC}$), a novel coreset approach which generates fair synthetic representative samples along with sample-level weights to be used in downstream learning tasks. $\texttt{FWC}$ uses an efficient majority minimization algorithm to minimize the Wasserstein distance between the original dataset and the weighted synthetic samples while enforcing demographic parity. We show that an unconstrained version of $\texttt{FWC}$ is equivalent to Lloyd's algorithm for k-medians and k-means clustering. Experiments conducted on both synthetic and real datasets show that $\texttt{FWC}$: (i) achieves a competitive fairness-performance tradeoff in downstream models compared to existing approaches, (ii) improves downstream fairness when added to the existing training data and (iii) can be used to reduce biases in predictions from large language models (GPT-3.5 and GPT-4).

Perceptual learning refers to the practices through which participants learn to improve their performance in perceiving sensory stimuli. Two seemingly conflicting phenomena of specificity and transfer have been widely observed in perceptual learning.
Here, we propose a dual-learning model to reconcile these two phenomena. The model consists of two learning processes. One is task-based learning, which is fast and enables the brain to adapt to a task rapidly by using existing feature representations. The other is feature-based learning, which is slow and enables the brain to improve feature representations to match the statistical change of the environment. Associated with different training paradigms, the interactions between these two learning processes induce the rich phenomena of perceptual learning. Specifically, in the training paradigm where the same stimulus condition is presented excessively, feature-based learning is triggered, which incurs specificity, while in the paradigm where the stimulus condition varies during the training, task-based learning dominates to induce the transfer effect. As the number of training sessions under the same stimulus condition increases, a transition from transfer to specificity occurs.
We demonstrate that the dual-learning model can account for both the specificity and transfer phenomena observed in classical psychophysical experiments. We hope that this study gives us insight into understanding how the brain balances the accomplishment of a new task and the consumption of learning effort.
tl;dr: We propose a novel architecture called DenseFormer which outperforms the classical Transformer in many ways

The transformer architecture by Vaswani et al. (2017) is now ubiquitous across application domains, from natural language processing to speech processing and image understanding. We propose DenseFormer, a simple modification to the standard architecture that improves the perplexity of the model without increasing its size---adding a few thousand parameters for large-scale models in the 100B parameters range. Our approach relies on an additional averaging step after each transformer block, which computes a weighted average of current and past representations---we refer to this operation as Depth-Weighted-Average (DWA). The learned DWA weights exhibit coherent patterns of information flow, revealing the strong and structured reuse of activations from distant layers. Experiments demonstrate that DenseFormer is more data efficient, reaching the same perplexity of much deeper transformer models, and that for the same perplexity, these new models outperform transformer baselines in terms of memory efficiency and inference time.
tl;dr: We leverage the sequential modeling ability of the transformer architecture and robust task representation learning via world model disentanglement to achieve efficient generalization in offline meta-RL.

A longstanding goal of artificial general intelligence is highly capable generalists that can learn from diverse experiences and generalize to unseen tasks. The language and vision communities have seen remarkable progress toward this trend by scaling up transformer-based models trained on massive datasets, while reinforcement learning (RL) agents still suffer from poor generalization capacity under such paradigms. To tackle this challenge, we propose Meta Decision Transformer (Meta-DT), which leverages the sequential modeling ability of the transformer architecture and robust task representation learning via world model disentanglement to achieve efficient generalization in offline meta-RL. We pretrain a context-aware world model to learn a compact task representation, and inject it as a contextual condition to the causal transformer to guide task-oriented sequence generation. Then, we subtly utilize history trajectories generated by the meta-policy as a self-guided prompt to exploit the architectural inductive bias. We select the trajectory segment that yields the largest prediction error on the pretrained world model to construct the prompt, aiming to encode task-specific information complementary to the world model maximally. Notably, the proposed framework eliminates the requirement of any expert demonstration or domain knowledge at test time. Experimental results on MuJoCo and Meta-World benchmarks across various dataset types show that Meta-DT exhibits superior few and zero-shot generalization capacity compared to strong baselines while being more practical with fewer prerequisites. Our code is available at https://github.com/NJU-RL/Meta-DT.

We study theoretical properties of a broad class of regularized algorithms with vector-valued output. These spectral algorithms include kernel ridge regression, kernel principal component regression and various implementations of gradient descent. Our contributions are twofold. First, we rigorously confirm the so-called saturation effect for ridge regression with vector-valued output by deriving a novel lower bound on learning rates; this bound is shown to be suboptimal when the smoothness of the regression function exceeds a certain level.
Second, we present an upper bound on the finite sample risk for general vector-valued spectral algorithms, applicable to both well-specified and misspecified scenarios (where the true regression function lies outside of the hypothesis space), and show that this bound is minimax optimal in various regimes. All of our results explicitly allow the case of infinite-dimensional output variables, proving consistency of recent practical applications.

This paper studies the problem of rigid dynamics modeling, which has a wide range of applications in robotics, graphics, and mechanical design. The problem is partly solved by graph neural network (GNN) simulators. However, these approaches cannot effectively handle the relationship between intrinsic continuity and instantaneous changes in rigid dynamics. Moreover, they usually neglect hierarchical structures across mesh nodes and objects in systems. In this paper, we propose a novel approach named Event-attend Graph ODE (EGODE) for effective rigid dynamics modeling. In particular, we describe the rigid system using both mesh node representations and object representations. To model continuous dynamics across hierarchical structures, we use a coupled graph ODE framework for the evolution of both types of representations over a long period. In addition, to capture instantaneous changes during the collision, we introduce an event module, which can effectively estimate the occurrence of the collision and update the states of both mesh node and object representations during evolution. Extensive experiments on a range of benchmark datasets validate the superiority of the proposed EGODE compared to various state-of-the-art baselines. The source code can be found at https://github.com/yuanjypku/EGODE.
1344. The High Line: Exact Risk and Learning Rate Curves of Stochastic Adaptive Learning Rate Algorithms

We develop a framework for analyzing the training and learning rate dynamics on a large class of high-dimensional optimization problems, which we call the high line, trained using one-pass stochastic gradient descent (SGD) with adaptive learning rates. We give exact expressions for the risk and learning rate curves in terms of a deterministic solution to a system of ODEs. We then investigate in detail two adaptive learning rates -- an idealized exact line search and AdaGrad-Norm -- on the least squares problem. When the data covariance matrix has strictly positive eigenvalues, this idealized exact line search strategy can exhibit arbitrarily slower convergence when compared to the optimal fixed learning rate with SGD. Moreover we exactly characterize the limiting learning rate (as time goes to infinity) for line search in the setting where the data covariance has only two distinct eigenvalues. For noiseless targets, we further demonstrate that the AdaGrad-Norm learning rate converges to a deterministic constant inversely proportional to the average eigenvalue of the data covariance matrix, and identify a phase transition when the covariance density of eigenvalues follows a power law distribution. We provide
our code for evaluation at https://github.com/amackenzie1/highline2024.

The Column Subset Selection (CSS) problem has been widely studied in dimensionality reduction and feature selection. The goal of the CSS problem is to output a submatrix S, consisting of k columns from an n×d input matrix A that minimizes the residual error ‖A-SS^\dagger A‖_F^2, where S^\dagger is the Moore-Penrose inverse matrix of S. Many previous approximation algorithms have non-linear running times in both n and d, while the existing linear-time algorithms have a relatively larger approximation ratios. Additionally, the local search algorithms in existing results for solving the CSS problem are heuristic. To achieve linear running time while maintaining better approximation using a local search strategy, we propose a local search-based approximation algorithm for the CSS problem with exactly k columns selected. A key challenge in achieving linear running time with the local search strategy is how to avoid exhaustive enumerations of candidate columns for constructing swap pairs in each local search step. To address this issue, we propose a two-step mixed sampling method that reduces the number of enumerations for swap pair construction from O(dk) to k in linear time. Although the two-step mixed sampling method reduces the search space of local search strategy, bounding the residual error after swaps is a non-trivial task. To estimate the changes in residual error after swaps, we propose a matched swap pair construction method to bound the approximation loss, ensuring a constant probability of loss reduction in each local search step. In expectation, these techniques enable us to obtain the local search algorithm for the CSS problem with theoretical guarantees, where a 53(k+1)-approximate solution can be obtained in linear running time O(ndk^4\log k). Empirical experiments show that our proposed algorithm achieves better quality and time compared to previous algorithms on both small and large datasets. Moreover, it is at least 10 times faster than state-of-the-art algorithms across all large-scale datasets.
1346. Coherence-free Entrywise Estimation of Eigenvectors in Low-rank Signal-plus-noise Matrix Models

Spectral methods are widely used to estimate eigenvectors of a low-rank signal matrix subject to noise. These methods use the leading eigenspace of an observed matrix to estimate this low-rank signal. Typically, the entrywise estimation error of these methods depends on the coherence of the low-rank signal matrix with respect to the standard basis. In this work, we present a novel method for eigenvector estimation that avoids this dependence on coherence. Assuming a rank-one signal matrix, under mild technical conditions, the entrywise estimation error of our method provably has no dependence on the coherence under Gaussian noise (i.e., in the spiked Wigner model), and achieves the optimal estimation rate up to logarithmic factors. Simulations demonstrate that our method performs well under non-Gaussian noise and that an extension of our method to the case of a rank-$r$ signal matrix has little to no dependence on the coherence. In addition, we derive new metric entropy bounds for rank-$r$ singular subspaces under $\ell_{2,\infty}$ distance, which may be of independent interest. We use these new bounds to improve the best known lower bound for rank-$r$ eigenspace estimation under $\ell_{2,\infty}$ distance.

Single-view 3D reconstruction methods like Triplane Gaussian Splatting (TGS) have enabled high-quality 3D model generation from just a single image input within seconds. However, this capability raises concerns about potential misuse, where malicious users could exploit TGS to create unauthorized 3D models from copyrighted images. To prevent such infringement, we propose a novel image protection approach that embeds invisible geometry perturbations, termed ``geometry cloaks'', into images before supplying them to TGS. These carefully crafted perturbations encode a customized message that is revealed when TGS attempts 3D reconstructions of the cloaked image. Unlike conventional adversarial attacks that simply degrade output quality, our method forces TGS to fail the 3D reconstruction in a specific way - by generating an identifiable customized pattern that acts as a watermark. This watermark allows copyright holders to assert ownership over any attempted 3D reconstructions made from their protected images. Extensive experiments have verified the effectiveness of our geometry cloak.

Sparse ridge regression problems play a significant role across various domains. To solve sparse ridge regression, Liu et al. (2023) recently propose an advanced algorithm, Scalable Optimal $K$-Sparse Ridge Regression (OKRidge), which is both faster and more accurate than existing approaches. However, the absence of theoretical analysis on the error of OKRidge impedes its large-scale applications. In this paper, we reframe the estimation error of OKRidge as a Primary Optimization ($\textbf{PO}$) problem and employ the Convex Gaussian min-max theorem (CGMT) to simplify the $\textbf{PO}$ problem into an Auxiliary Optimization ($\textbf{AO}$) problem. Subsequently, we provide a theoretical error analysis for OKRidge based on the $\textbf{AO}$ problem. This error analysis improves the theoretical reliability of OKRidge. We also conduct experiments to verify our theorems and the results are in excellent agreement with our theoretical findings.

Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
tl;dr: Predictors using all available features, regardless of causality, have better in-domain and out-of-domain accuracy than predictors using causal features.

We study how well machine learning models trained on causal features generalize across domains. We consider 16 prediction tasks on tabular datasets covering applications in health, employment, education, social benefits, and politics. Each dataset comes with multiple domains, allowing us to test how well a model trained in one domain performs in another. For each prediction task, we select features that have a causal influence on the target of prediction. Our goal is to test the hypothesis that models trained on causal features generalize better across domains. Without exception, we find that predictors using all available features, regardless of causality, have better in-domain and out-of-domain accuracy than predictors using causal features. Moreover, even the absolute drop in accuracy from one domain to the other is no better for causal predictors than for models that use all features. In addition, we show that recent causal machine learning methods for domain generalization do not perform better in our evaluation than standard predictors trained on the set of causal features. Likewise, causal discovery algorithms either fail to run or select causal variables that perform no better than our selection. Extensive robustness checks confirm that our findings are stable under variable misclassification.
tl;dr: We propose the first algorithm for learning optimal tax in nonatomic congestion games with equilibrium feedback.

In multiplayer games, self-interested behavior among the players can harm the social welfare. Tax mechanisms are a common method to alleviate this issue and induce socially optimal behavior. In this work, we take the initial step of learning the optimal tax that can maximize social welfare with limited feedback in congestion games. We propose a new type of feedback named \emph{equilibrium feedback}, where the tax designer can only observe the Nash equilibrium after deploying a tax plan. Existing algorithms are not applicable due to the exponentially large tax function space, nonexistence of the gradient, and nonconvexity of the objective. To tackle these challenges, we design a computationally efficient algorithm that leverages several novel components: (1) a piece-wise linear tax to approximate the optimal tax; (2) extra linear terms to guarantee a strongly convex potential function; (3) an efficient subroutine to find the exploratory tax that can provide critical information about the game. The algorithm can find an $\epsilon$-optimal tax with $O(\beta F^2/\epsilon)$ sample complexity, where $\beta$ is the smoothness of the cost function and $F$ is the number of facilities.

In modern deep learning, it is common to warm up the learning rate $\eta$, often by a linear schedule between $\eta_{\text{init}} = 0$ and a predetermined target $\eta_{\text{trgt}}$. In this paper, we show through systematic experiments with SGD and Adam that the overwhelming benefit of warmup arises from allowing the network to tolerate larger $\eta_{\text{trgt}}$ by forcing the network to more well-conditioned areas of the loss landscape. The ability to handle larger target learning rates in turn makes hyperparameter tuning more robust while improving the final performance of the network. We uncover different regimes of operation during the warmup period, depending on whether the network training starts off in a progressive sharpening or sharpness reduction phase, which in turn depends on the initialization and parameterization. Using these insights, we show how $\eta_{\text{init}}$ can be properly chosen by utilizing the loss catapult mechanism, which saves on the number of warmup steps, in some cases completely eliminating the need for warmup. We also suggest an initialization for the variance in Adam, which provides benefits similar to warmup.
tl;dr: We introduce Colander, a novel post-hoc method addressing overconfidence in threshold-based auto-labeling (TBAL). Colander achieves up to 60% better coverage than baselines.

Auto-labeling is an important family of techniques that produce labeled training sets with minimum manual annotation. A prominent variant, threshold-based auto-labeling (TBAL), works by finding thresholds on a model's confidence scores above which it can accurately automatically label unlabeled data. However, many models are known to produce overconfident scores, leading to poor TBAL performance. While a natural idea is to apply off-the-shelf calibration methods to alleviate the overconfidence issue, we show that such methods fall short. Rather than experimenting with ad-hoc choices of confidence functions, we propose a framework for studying the optimal TBAL confidence function. We develop a tractable version of the framework to obtain Colander (Confidence functions for Efficient and Reliable Auto-labeling), a new post-hoc method specifically designed to maximize performance in TBAL systems. We perform an extensive empirical evaluation of Colander and compare it against methods designed for calibration. Colander achieves up to 60% improvement on coverage over the baselines while maintaining error level below 5% and using the same amount of labeled data.
1354. Bounds for the smallest eigenvalue of the NTK for arbitrary spherical data of arbitrary dimension
tl;dr: We bound the smallest eigenvalue of the NTK without distributional assumptions on the data.

Bounds on the smallest eigenvalue of the neural tangent kernel (NTK) are a key ingredient in the analysis of neural network optimization and memorization. However, existing results require distributional assumptions on the data and are limited to a high-dimensional setting, where the input dimension $d_0$ scales at least logarithmically in the number of samples $n$. In this work we remove both of these requirements and instead provide bounds in terms of a measure of distance between data points: notably these bounds hold with high probability even when $d_0$ is held constant versus $n$. We prove our results through a novel application of the hemisphere transform.
tl;dr: We show that a certain class of first-order methods attain polynomial smoothed complexity in zero-sum games.

Gradient-based algorithms have shown great promise in solving large (two-player) zero-sum games. However, their success has been mostly confined to the low-precision regime since the number of iterations grows polynomially in $1/\epsilon$, where $\epsilon > 0$ is the duality gap. While it has been well-documented that linear convergence---an iteration complexity scaling as $\text{log}(1/\epsilon)$---can be attained even with gradient-based algorithms, that comes at the cost of introducing a dependency on certain condition number-like quantities which can be exponentially large in the description of the game. To address this shortcoming, we examine the iteration complexity of several gradient-based algorithms in the celebrated framework of smoothed analysis, and we show that they have polynomial smoothed complexity, in that their number of iterations grows as a polynomial in the dimensions of the game, $\text{log}(1/\epsilon)$, and $1/\sigma$, where $\sigma$ measures the magnitude of the smoothing perturbation. Our result applies to optimistic gradient and extra-gradient descent/ascent, as well as a certain iterative variant of Nesterov's smoothing technique. From a technical standpoint, the proof proceeds by characterizing and performing a smoothed analysis of a certain error bound, the key ingredient driving linear convergence in zero-sum games. En route, our characterization also makes a natural connection between the convergence rate of such algorithms and perturbation-stability properties of the equilibrium, which is of interest beyond the model of smoothed complexity.
tl;dr: Generate 4D Gaussian splatting for photorealistic scene rendering from text input

Existing dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets.
As a result, the generated scenes are often object-centric and lack photorealism.
To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets.
Our method begins by generating a reference video using the video generation model.
We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video.
To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections.
We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video.
The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation.
tl;dr: We propose a MIPL algorithm with adjusted margins to improve generalization performance.

Multi-instance partial-label learning (MIPL) is an emerging learning framework where each training sample is represented as a multi-instance bag associated with a candidate label set. Existing MIPL algorithms often overlook the margins for attention scores and predicted probabilities, leading to suboptimal generalization performance. A critical issue with these algorithms is that the highest prediction probability of the classifier may appear on a non-candidate label. In this paper, we propose an algorithm named MIPLMA, i.e., Multi-Instance Partial-Label learning with Margin Adjustment, which adjusts the margins for attention scores and predicted probabilities. We introduce a margin-aware attention mechanism to dynamically adjust the margins for attention scores and propose a margin distribution
loss to constrain the margins between the predicted probabilities on candidate and non-candidate label sets. Experimental results demonstrate the superior performance of MIPLMA over existing MIPL algorithms, as well as other well-established multi-instance learning algorithms and partial-label learning algorithms.
1358. On the Minimax Regret for Contextual Linear Bandits and Multi-Armed Bandits with Expert Advice

This paper examines two extensions of multi-armed bandit problems: multi-armed bandits with expert advice and contextual linear bandits. For the former problem, multi-armed bandits with expert advice, the previously known best upper and lower bounds have been $O(\sqrt{KT \log \frac{N}{K} })$ and $\Omega( \sqrt{KT \frac{ \log N }{\log K }} )$, respectively. Here, $K$, $N$, and $T$ represent the numbers of arms, experts, and rounds, respectively. This paper closes the gap between these bounds by presenting a matching lower bound of $\Omega( \sqrt{KT \log \frac{N}{K}} )$.
This lower bound is shown for the problem setting in which the player chooses an expert before observing the advices in each round.
For the latter problem, contextual linear bandits, we provide an algorithm that achieves $O ( \sqrt{d T \log ( K \min\{ 1, \frac{S}{d} \} )} )$ together with a matching lower bound, where $d$ and $S$ represent the dimensionality of feature vectors and the size of the context space, respectively.
tl;dr: Unifying Video Generation and Recognition with Diffusion Models

Video diffusion models are able to generate high-quality videos by learning strong spatial-temporal priors on large-scale datasets. In this paper, we aim to investigate whether such priors derived from a generative process are suitable for video recognition, and eventually joint optimization of generation and recognition. Building upon Stable Video Diffusion, we introduce GenRec, the first unified framework trained with a random-frame conditioning process so as to learn generalized spatial-temporal representations. The resulting framework can naturally supports generation and recognition, and more importantly is robust even when visual inputs contain limited information.
Extensive experiments demonstrate the efficacy of GenRec for both recognition and generation. In particular, GenRec achieves competitive recognition performance, offering 75.8% and 87.2% accuracy on SSV2 and K400, respectively. GenRec also performs the best on class-conditioned image-to-video generation, achieving 46.5 and 49.3 FVD scores on SSV2 and EK-100 datasets. Furthermore, GenRec demonstrates extraordinary robustness in scenarios that only limited frames can be observed. Code will be available at https://github.com/wengzejia1/GenRec.
tl;dr: This work introduces a novel perspective that considers quantization error as a stepback in the denoising process; through a sampling step correction mechanism it improves the performance of quantized diffusion models.

Quantization of diffusion models has attracted considerable attention due to its potential to enable various applications on resource-constrained mobile devices. However, given the cumulative nature of quantization errors in quantized diffusion models, overall performance may still decline even with efforts to minimize quantization error at each sampling step.
Recent studies have proposed several methods to address accumulated quantization error, yet these solutions often suffer from limited applicability due to their underlying assumptions or only partially resolve the issue due to an incomplete understanding.
In this work, we introduce a novel perspective by conceptualizing quantization error as a "stepback" in the denoising process. We investigate how the accumulation of quantization error can distort the sampling trajectory, resulting in a notable decrease in model performance. To address this challenge, we introduce StepbaQ, a method that calibrates the sampling trajectory and counteracts the adverse effects of accumulated quantization error through a sampling step correction mechanism. Notably, StepbaQ relies solely on statistics of quantization error derived from a small calibration dataset, highlighting its strong applicability.
Our experimental results demonstrate that StepbaQ can serve as a plug-and-play technique to enhance the performance of diffusion models quantized by off-the-shelf tools without modifying the quantization settings. For example, StepbaQ significantly improves the performance of the quantized SD v1.5 model by 7.30 in terms of FID on SDprompts dataset under the common W8A8 setting, and it enhances the performance of the quantized SDXL-Turbo model by 17.31 in terms of FID on SDprompts dataset under the challenging W4A8 setting.
1361. Weight for Robustness: A Comprehensive Approach towards Optimal Fault-Tolerant Asynchronous ML
tl;dr: A novel fault-tolerant framework and strategies that, for the first time, achieve optimal convergence rate in asynchronous machine learning against Byzantine failures.

We address the challenges of Byzantine-robust training in asynchronous distributed machine learning systems, aiming to enhance efficiency amid massive parallelization and heterogeneous compute resources. Asynchronous systems, marked by independently operating workers and intermittent updates, uniquely struggle with maintaining integrity against Byzantine failures, which encompass malicious or erroneous actions that disrupt learning. The inherent delays in such settings not only introduce additional bias to the system but also obscure the disruptions caused by Byzantine faults. To tackle these issues, we adapt the Byzantine framework to asynchronous dynamics by introducing a novel weighted robust aggregation framework. This allows for the extension of robust aggregators and a recent meta-aggregator to their weighted versions, mitigating the effects of delayed updates. By further incorporating a recent variance-reduction technique, we achieve an optimal convergence rate for the first time in an asynchronous Byzantine environment. Our methodology is rigorously validated through empirical and theoretical analysis, demonstrating its effectiveness in enhancing fault tolerance and optimizing performance in asynchronous ML systems.

Reducing parameter redundancies in neural network architectures is crucial for achieving feasible computational and memory requirements during train and inference of large networks. Given its easy implementation and flexibility, one promising approach is layer factorization, which reshapes weight tensors into a matrix format and parameterizes it as the product of two rank-r matrices. However, this family of approaches often requires an initial full-model warm-up phase, prior knowledge of a feasible rank, and it is sensitive to parameter initialization.
In this work, we introduce a novel approach to train the factors of a Tucker decomposition of the weight tensors. Our training proposal proves to be optimal in locally approximating the original unfactorized dynamics and stable for the initialization. Furthermore, the rank of each mode is dynamically updated during training.
We provide a theoretical analysis of the algorithm, showing convergence, approximation and local descent guarantees. The method's performance is further illustrated through a variety of experiments, showing remarkable training compression rates and comparable or even better performance than the full baseline and alternative layer factorization strategies.
tl;dr: We propose a unified procedure for deriving amplification-by-subsampling guarantees and use it to analyze group privacy under subsampling.

Amplification by subsampling is one of the main primitives in machine learning with differential privacy (DP): Training a model on random batches instead of complete datasets results in stronger privacy. This is traditionally formalized via mechanism-agnostic subsampling guarantees that express the privacy parameters of a subsampled mechanism as a function of the original mechanism's privacy parameters. We propose the first general framework for deriving mechanism-specific guarantees, which leverage additional information beyond these parameters to more tightly characterize the subsampled mechanism's privacy. Such guarantees are of particular importance for privacy accounting, i.e., tracking privacy over multiple iterations. Overall, our framework based on conditional optimal transport lets us derive existing and novel guarantees for approximate DP, accounting with Renyi DP, and accounting with dominating pairs in a unified, principled manner. As an application, we analyze how subsampling affects the privacy of groups of multiple users. Our tight mechanism-specific bounds outperform tight mechanism-agnostic bounds and classic group privacy results.
tl;dr: Regret and constraint violation analysis of infinite horizon average reward constraint MDP.

This paper explores the realm of infinite horizon average reward Constrained Markov Decision Processes (CMDPs). To the best of our knowledge, this work is the first to delve into the regret and constraint violation analysis of average reward CMDPs with a general policy parametrization. To address this challenge, we propose a primal dual-based policy gradient algorithm that adeptly manages the constraints while ensuring a low regret guarantee toward achieving a global optimal policy. In particular, our proposed algorithm achieves $\tilde{\mathcal{O}}({T}^{4/5})$ objective regret and $\tilde{\mathcal{O}}({T}^{4/5})$ constraint violation bounds.
tl;dr: we quantify the aleatoric uncertainty of the treatment effect at the individualized (covariate-conditional) level

Estimating causal quantities from observational data is crucial for understanding the safety and effectiveness of medical treatments. However, to make reliable inferences, medical practitioners require not only estimating averaged causal quantities, such as the conditional average treatment effect, but also understanding the randomness of the treatment effect as a random variable. This randomness is referred to as aleatoric uncertainty and is necessary for understanding the probability of benefit from treatment or quantiles of the treatment effect. Yet, the aleatoric uncertainty of the treatment effect has received surprisingly little attention in the causal machine learning community. To fill this gap, we aim to quantify the aleatoric uncertainty of the treatment effect at the covariate-conditional level, namely, the conditional distribution of the treatment effect (CDTE). Unlike average causal quantities, the CDTE is not point identifiable without strong additional assumptions. As a remedy, we employ partial identification to obtain sharp bounds on the CDTE and thereby quantify the aleatoric uncertainty of the treatment effect. We then develop a novel, orthogonal learner for the bounds on the CDTE, which we call AU-learner. We further show that our AU-learner has several strengths in that it satisfies Neyman-orthogonality and is doubly robust. Finally, we propose a fully-parametric deep learning instantiation of our AU-learner.

We consider the problem of selecting all the minimal-size subsets of multivariate time-series (TS) variables whose past leads to an optimal predictive model for the future (forecasting) of a given target variable (multiple feature selection problem for times-series). Identifying these subsets leads to gaining insights, domain intuition,and a better understanding of the data-generating mechanism; it is often the first step in causal modeling. While identifying a single solution to the feature selection problem suffices for forecasting purposes, identifying all such minimal-size, optimally predictive subsets is necessary for knowledge discovery and important to avoid misleading a practitioner. We develop the theory of multiple feature selection for time-series data, propose the ChronoEpilogi algorithm, and prove its soundness and completeness under two mild, broad, non-parametric distributional assumptions, namely Compositionality of the distribution and Interchangeability of time-series variables in solutions. Experiments on synthetic and real datasets demonstrate the scalability of ChronoEpilogi to hundreds of TS variables and its efficacy in identifying multiple solutions. In the real datasets, ChronoEpilogi is shown to reduce the number of TS variables by 96% (on average) by conserving or even improving forecasting performance. Furthermore, it is on par with GroupLasso performance, with the added benefit of providing multiple solutions.

Global convolutions have shown increasing promise as powerful general-purpose sequence models. However, training long convolutions is challenging, and kernel parameterizations must be able to learn long-range dependencies without overfitting. This work introduces reparameterized multi-resolution convolutions ($\texttt{MRConv}$), a novel approach to parameterizing global convolutional kernels for long-sequence modeling. By leveraging multi-resolution convolutions, incorporating structural reparameterization and introducing learnable kernel decay, $\texttt{MRConv}$ learns expressive long-range kernels that perform well across various data modalities. Our experiments demonstrate state-of-the-art performance on the Long Range Arena, Sequential CIFAR, and Speech Commands tasks among convolution models and linear-time transformers. Moreover, we report improved performance on ImageNet classification by replacing 2D convolutions with 1D $\texttt{MRConv}$ layers.
tl;dr: For some initializations, the space of possible gradient flow trajectories of a shallow ReLU neural network is disconnected, resulting in the training being impossible.

Studying the interplay between the geometry of the loss landscape and the optimization trajectories of simple neural networks is a fundamental step for understanding their behavior in more complex settings.
This paper reveals the presence of topological obstruction in the loss landscape of shallow ReLU neural networks trained using gradient flow. We discuss how the homogeneous nature of the ReLU activation function constrains the training trajectories to lie on a product of quadric hypersurfaces whose shape depends on the particular initialization of the network's parameters.
When the neural network's output is a single scalar, we prove that these quadrics can have multiple connected components, limiting the set of reachable parameters during training. We analytically compute the number of these components and discuss the possibility of mapping one to the other through neuron rescaling and permutation. In this simple setting, we find that the non-connectedness results in a topological obstruction, which, depending on the initialization, can make the global optimum unreachable. We validate this result with numerical experiments.

Different from classical one-model-fits-all strategy, individualized models allow parameters to vary across samples and are gaining popularity in various fields, particularly in personalized medicine. Motivated by medical imaging analysis, this paper introduces a novel individualized modeling framework for matrix-valued data that does not require additional information on sample similarity for the individualized coefficients. Under our framework, the model individualization stems from an optimal internal relation map within the samples themselves. We refer to the proposed method as Attention boosted Individualized Regression, due to its close connections with the self-attention mechanism. Therefore, our approach provides a new interpretation for attention from the perspective of individualized modeling. Comprehensive numerical experiments and real brain MRI analysis using an ADNI dataset demonstrated the superior performance of our model.
tl;dr: A supervised approach yields biologically plausible learning rules that self-organize and maintain robust representations of time within RNNs.

Intrinsic dynamics within the brain can accelerate learning by providing a prior scaffolding for dynamics aligned with task objectives. Such intrinsic dynamics would ideally self-organize and self-sustain in the face of biological noise including synaptic turnover and cell death. An example of such dynamics is the formation of sequences, a ubiquitous motif in neural activity. The sequence-generating circuit in zebra finch HVC provides a reliable timing scaffold for motor output in song and demonstrates a remarkable capacity for unsupervised recovery following perturbation. Inspired by HVC, we seek a local plasticity rule capable of organizing and maintaining sequence-generating dynamics despite continual network perturbations. We adopt a meta-learning approach introduced by Confavreux et al, which parameterizes a learning rule using basis functions constructed from pre- and postsynaptic activity and synapse size, with tunable time constants. Candidate rules are simulated within initially random networks, and their fitness is evaluated according to a loss function that measures the fidelity with which the resulting dynamics encode time. We use this approach to introduce biological noise, forcing meta-learning to find robust solutions. We first show that, in the absence of perturbations, meta-learning identifies a temporally asymmetric generalization of Oja's rule that reliably organizes sparse sequential activity. When synaptic turnover is introduced, the learned rule incorporates a form of homeostasis, better maintaining robust sequential dynamics relative to other previously proposed rules. Additionally, inspired by recent findings demonstrating that the strength of projections from inhibitory interneurons in HVC also dynamically responds to perturbations, we explore the role of inhibitory plasticity in sequence-generating circuits. We find that learned plasticity adjusts both excitation and inhibition in response to manipulations, outperforming rules applied only to excitatory connections. We demonstrate how plasticity acting on both excitatory and inhibitory synapses can better shape excitatory cell dynamics to scaffold timing representations.

We propose a new framework for algorithmic stability in the context of multiclass classification. In practice, classification algorithms often operate by first assigning a continuous score (for instance, an estimated probability) to each possible label, then taking the maximizer---i.e., selecting the class that has the highest score. A drawback of this type of approach is that it is inherently unstable, meaning that it is very sensitive to slight perturbations of the training data, since taking the maximizer is discontinuous. Motivated by this challenge, we propose a pipeline for constructing stable classifiers from data, using bagging (i.e., resampling and averaging) to produce stable continuous scores, and then using a stable relaxation of argmax, which we call the "inflated argmax", to convert these scores to a set of candidate labels. The resulting stability guarantee places no distributional assumptions on the data, does not depend on the number of classes or dimensionality of the covariates, and holds for any base classifier. Using a common benchmark data set, we demonstrate that the inflated argmax provides necessary protection against unstable classifiers, without loss of accuracy.

Visual place recognition (VPR) is an essential task for multiple applications such as augmented reality and robot localization. Over the past decade, mainstream methods in the VPR area have been to use feature representation based on global aggregation, as exemplified by NetVLAD. These features are suitable for large-scale VPR and robust against viewpoint changes. However, the VLAD-based aggregation methods usually learn a large number of (e.g., 64) clusters and their corresponding cluster centers, which directly leads to a high dimension of the yielded global features. More importantly, when there is a domain gap between the data in training and inference, the cluster centers determined on the training set are usually improper for inference, resulting in a performance drop. To this end, we first attempt to improve NetVLAD by removing the cluster center and setting only a small number of (e.g., only 4) clusters. The proposed method not only simplifies NetVLAD but also enhances the generalizability across different domains. We name this method SuperVLAD. In addition, by introducing ghost clusters that will not be retained in the final output, we further propose a very low-dimensional 1-Cluster VLAD descriptor, which has the same dimension as the output of GeM pooling but performs notably better. Experimental results suggest that, when paired with a transformer-based backbone, our SuperVLAD shows better domain generalization performance than NetVLAD with significantly fewer parameters. The proposed method also surpasses state-of-the-art methods with lower feature dimensions on several benchmark datasets. The code is available at https://github.com/lu-feng/SuperVLAD.
tl;dr: We introduce a new framework for probing world abstraction within LLM-built representations, and our experiments with a text-based planning task demonstrate LLMs prefer maintaining goal-oriented abstractions during decoding.

How do large language models (LLMs) encode the state of the world, including the status of entities and their relations, as described by a text? While existing work directly probes for a complete state of the world, our research explores whether and how LLMs abstract this world state in their internal representations. We propose a new framework for probing for world representations through the lens of state abstraction theory from reinforcement learning, which emphasizes different levels of abstraction, distinguishing between general abstractions that facilitate predicting future states and goal-oriented abstractions that guide the subsequent actions to accomplish tasks. To instantiate this framework, we design a text-based planning task, where an LLM acts as an agent in an environment and interacts with objects in containers to achieve a specified goal state. Our experiments reveal that fine-tuning as well as advanced pre-training strengthens LLM-built representations' tendency of maintaining goal-oriented abstractions during decoding, prioritizing task completion over recovery of the world's state and dynamics.
tl;dr: A unified analysis with kernel complexity for the impact of the target-kernel alignment on kernel-based method.

This paper investigates the impact of alignment between the target function of interest and the kernel matrix on a variety of kernel-based methods based on a general loss belonging to a rich loss function family, which covers many commonly used methods in regression and classification problems. We consider the truncated kernel-based method (TKM) which is estimated within a reduced function space constructed by using the spectral truncation of the kernel matrix and compare its theoretical behavior to that of the standard kernel-based method (KM) under various settings. By using the kernel complexity function that quantifies the complexity of the induced function space, we derive the upper bounds for both TKM and KM, and further reveal their dependencies on the degree of target-kernel alignment. Specifically, for the alignment with polynomial decay, the established results indicate that under the just-aligned and weakly-aligned regimes, TKM and KM share the same learning rate. Yet, under the strongly-aligned regime, KM suffers the saturation effect, while TKM can be continuously improved as the alignment becomes stronger. This further implies that TKM has a strong ability to capture the strong alignment and provide a theoretically guaranteed solution to eliminate the phenomena of saturation effect. The minimax lower bound is also established for the squared loss to confirm the optimality of TKM. Extensive numerical experiments further support our theoretical findings. The Python code for reproducing the numerical experiments is available at https://github.com/wywangen.

Exploring unknown environments efficiently is a fundamental challenge in unsupervised goal-conditioned reinforcement learning. While selecting exploratory goals at the frontier of previously explored states is an effective strategy, the policy during training may still have limited capability of reaching rare goals on the frontier, resulting in reduced exploratory behavior. We propose "Cluster Edge Exploration" (CE$^2$), a new goal-directed exploration algorithm that when choosing goals in sparsely explored areas of the state space gives priority to goal states that remain accessible to the agent. The key idea is clustering to group states that are easily reachable from one another by the current policy under training in a latent space, and traversing to states holding significant exploration potential on the boundary of these clusters before doing exploratory behavior. In challenging robotics environments including navigating a maze with a multi-legged ant robot, manipulating objects with a robot arm on a cluttered tabletop, and rotating objects in the palm of an anthropomorphic robotic hand, CE$^2$ demonstrates superior efficiency in exploration compared to baseline methods and ablations.
tl;dr: The Differentiable Neural Dictionary of Neural Episodic Control is a Hopfield Network
Neural Episodic Control is a powerful reinforcement learning framework that employs a differentiable dictionary to store non-parametric memories. It was inspired by episodic memory on the functional level, but lacks a direct theoretical connection to the associative memory models generally used to implement such a memory. We first show that the dictionary is an instance of the recently proposed Universal Hopfield Network framework. We then introduce a continuous approximation of the dictionary readout operation in order to derive two energy functions that are Lyapunov functions of the dynamics. Finally, we empirically show that the dictionary outperforms the Max separation function, which had previously been argued to be optimal, and that performance can further be improved by replacing the Euclidean distance kernel by a Manhattan distance kernel. These results are enabled by the generalization capabilities of the dictionary, so a novel criterion is introduced to disentangle memorization from generalization when evaluating associative memory models.

We present a new method for making diffusion models faster to sample. The method distills many-step diffusion models into few-step models by matching conditional expectations of the clean data given noisy data along the sampling trajectory. Our approach extends recently proposed one-step methods to the multi-step case, and provides a new perspective by interpreting these approaches in terms of moment matching. By using up to 8 sampling steps, we obtain distilled models that outperform not only their one-step versions but also their original many-step teacher models, obtaining new state-of-the-art results on the Imagenet dataset. We also show promising results on a large text-to-image model where we achieve fast generation of high resolution images directly in image space, without needing autoencoders or upsamplers.

The advancement of Machine Learning has enabled the widespread deployment of Machine Learning as a Service (MLaaS) applications. However, the untrustworthy nature of third-party ML services poses backdoor threats. Existing defenses in MLaaS are limited by their reliance on training samples or white-box model analysis, highlighting the need for a black-box backdoor purification method. In our paper, we attempt to use diffusion models for purification by introducing noise in a forward diffusion process to destroy backdoors and recover clean samples through a reverse generative process. However, since a higher noise also destroys the semantics of the original samples, it still results in a low restoration performance. To investigate the effectiveness of noise in eliminating different types of backdoors, we conducted a preliminary study, which demonstrates that backdoors with low visibility can be easily destroyed by lightweight noise and those with high visibility need to be destroyed by high noise but can be easily detected. Based on the study, we propose SampDetox, which strategically combines lightweight and high noise. SampDetox applies weak noise to eliminate low-visibility backdoors and compares the structural similarity between the recovered and original samples to localize high-visibility backdoors. Intensive noise is then applied to these localized areas, destroying the high-visibility backdoors while preserving global semantic information. As a result, detoxified samples can be used for inference, even by poisoned models. Comprehensive experiments demonstrate the effectiveness of SampDetox in defending against various state-of-the-art backdoor attacks.
tl;dr: Novel data augmentation method for offline RL using conditional diffusion model.

Offline Reinforcement Learning (Offline RL) presents challenges of learning effective decision-making policies from static datasets without any online interactions. Data augmentation techniques, such as noise injection and data synthesizing, aim to improve Q-function approximation by smoothing the learned state-action region. However, these methods often fall short of directly improving the quality of offline datasets, leading to suboptimal results. In response, we introduce GTA, Generative Trajectory Augmentation, a novel generative data augmentation approach designed to enrich offline data by augmenting trajectories to be both high-rewarding and dynamically plausible. GTA applies a diffusion model within the data augmentation framework. GTA partially noises original trajectories and then denoises them with classifier-free guidance via conditioning on amplified return value. Our results show that GTA, as a general data augmentation strategy, enhances the performance of widely used offline RL algorithms across various tasks with unique challenges. Furthermore, we conduct a quality analysis of data augmented by GTA and demonstrate that GTA improves the quality of the data. Our code is available at https://github.com/Jaewoopudding/GTA
tl;dr: This paper evaluates the contributions of views in the task of unsupervised multi-view clustering and enhances model performance through a cooperation enhancing approach.

The fundamental goal of deep multi-view clustering is to achieve preferable task performance through inter-view cooperation. Although numerous DMVC approaches have been proposed, the collaboration role of individual views have not been well investigated in existing literature. Moreover, how to further enhance view cooperation for better fusion still needs to be explored. In this paper, we firstly consider DMVC as an unsupervised cooperative game where each view can be regarded as a participant. Then, we introduce the Shapley value and propose a novel MVC framework termed Shapley-based Cooperation Enhancing Multi-view Clustering (SCE-MVC), which evaluates view cooperation with game theory. Specially, we employ the optimal transport distance between fused cluster distributions and single view component as the utility function for computing shapley values. Afterwards, we apply shapley values to assess the contribution of each view and utilize these contributions to promote view cooperation. Comprehensive experimental results well support the effectiveness of our framework adopting to existing DMVC frameworks, demonstrating the importance and necessity of enhancing the cooperation among views.

This paper presents MaVEn, an innovative Multi-granularity Visual Encoding framework designed to enhance the capabilities of Multimodal Large Language Models (MLLMs) in multi-image reasoning. Current MLLMs primarily focus on single-image visual understanding, limiting their ability to interpret and integrate information across multiple images. MaVEn addresses this limitation by combining discrete visual symbol sequences, which abstract coarse-grained semantic concepts, with traditional continuous representation sequences that model fine-grained features. This dual approach bridges the semantic gap between visual and textual data, thereby improving the model's ability to process and interpret information from multiple images effectively. Additionally, we design a dynamic reduction mechanism by for long-sequence continuous features to enhance multi-image processing efficiency. Experimental results demonstrate that MaVEn significantly enhances MLLMs' understanding in complex multi-image scenarios, while also improving performance in single-image contexts.
tl;dr: We analyze variants of the Prod algorithm and show that they enjoy optimal regret guarantees in the bandit setting.

Prod is a seminal algorithm in full-information online learning, which has been conjectured to be fundamentally sub-optimal for multi-armed bandits.
By leveraging the interpretation of Prod as a first-order OMD approximation, we present the following surprising results:
1. Variants of Prod can obtain optimal regret for adversarial multi-armed bandits. 2. There exists a simple and (arguably) importance-weighting free variant with optimal rate.
3. One can even achieve best-both-worlds guarantees with logarithmic regret in the stochastic regime.
The bandit algorithms in this work use simple arithmetic update rules without the need of solving optimization problems typical in prior work. Finally, the results directly improve the state of the art of incentive-compatible bandits.
tl;dr: We improve on online variational Bayes using natural gradient descent on expected log-likelihood.

We propose a novel approach to sequential Bayesian inference based on variational Bayes (VB).
The key insight is that,
in the online setting,
we do not need to add the KL term to regularize to the prior (which comes from the posterior at the previous timestep);
instead we can optimize just the expected log-likelihood,
performing a single step of natural gradient descent
starting at the prior predictive.
We prove this method
recovers exact Bayesian inference
if the model is conjugate.
We also show how to compute an
efficient deterministic
approximation to the VB objective,
as well as our simplified objective,
when the variational distribution is
Gaussian or a sub-family, including the case of
a diagonal plus low-rank
precision matrix.
We show empirically that our
method outperforms other online VB methods
in the non-conjugate setting,
such as online learning for neural networks,
especially when controlling for computational costs.

We study fair allocation of constrained resources, where a market designer optimizes overall welfare while maintaining group fairness. In many large-scale settings, utilities are not known in advance, but are instead observed after realizing the allocation. We therefore estimate agent utilities using machine learning. Optimizing over estimates requires trading-off between mean utilities and their predictive variances. We discuss these trade-offs under two paradigms for preference modeling – in the stochastic optimization regime, the market designer has access to a probability distribution over utilities, and in the robust optimization regime they have access to an uncertainty set containing the true utilities with high probability. We discuss utilitarian and egalitarian welfare objectives, and we explore how to optimize for them under stochastic and robust paradigms. We demonstrate the efficacy of our approaches on three publicly available conference reviewer assignment datasets. The approaches presented enable scalable constrained resource allocation under uncertainty for many combinations of objectives and preference models.

Rubinfeld \& Vasilyan recently introduced the framework of *testable learning* as an extension of the classical agnostic model. It relaxes distributional assumptions which are difficult to verify by conditions that can be checked efficiently by a *tester*. The tester has to accept whenever the data truly satisfies the original assumptions, and the learner has to succeed whenever the tester accepts. We focus on the setting where the tester has to accept standard Gaussian data. There, it is known that basic concept classes such as halfspaces can be learned testably with the same time complexity as in the (distribution-specific) agnostic model. In this work, we ask whether there is a price to pay for testably learning more complex concept classes. In particular, we consider polynomial threshold functions (PTFs), which naturally generalize halfspaces. We show that PTFs of arbitrary constant degree can be testably learned up to excess error $\varepsilon > 0$ in time $n^{\mathrm{poly}(1/\varepsilon)}$. This qualitatively matches the best known guarantees in the agnostic model. Our results build on a connection between testable learning and *fooling*. In particular, we show that distributions that approximately match at least $\mathrm{poly}(1/\varepsilon)$ moments of the standard Gaussian fool constant-degree PTFs (up to error $\varepsilon$). As a secondary result, we prove that a direct approach to show testable learning (without fooling), which was successfully used for halfspaces, cannot work for PTFs.

We consider the robust routing problem with uncertain travel times under the min-max regret criterion, which represents an extended and robust version of the classic traveling salesman problem (TSP) and vehicle routing problem (VRP). The general budget uncertainty set is employed to capture the uncertainty, which provides the capability to control the conservatism of obtained solutions and covers the commonly used interval uncertainty set as a special case. The goal is to obtain a robust solution that minimizes the maximum deviation from the optimal routing time in the worst-case scenario. Given the significant advancements and broad applications of neural combinatorial optimization methods in recent years, we present our initial attempt to combine neural approaches for solving this problem. We propose a dual multi-head cross attention mechanism to extract problem features represented by the inputted uncertainty sets. To tackle the built-in maximization problem, we derive the regret value by invoking a pre-trained model, subsequently utilizing it as the reward during the model training. Our experimental results on the robust TSP and VRP demonstrate the efficacy of our neural combinatorial optimization method, showcasing its ability to efficiently handle the robust routing problem of various sizes within a shorter time compared with alternative heuristic approaches.
tl;dr: We consider a variant of the continual counting problem in which privacy loss is allowed to grow over time.

Differential privacy with gradual expiration models the setting where data items arrive in a stream and at a given time $t$ the privacy loss guaranteed for a data item seen at time $(t-d)$ is $\epsilon g(d)$, where $g$ is a monotonically non-decreasing function. We study the fundamental *continual (binary) counting* problem where each data item consists of a bit and the algorithm needs to output at each time step the sum of all the bits streamed so far. For a stream of length $T$ and privacy *without* expiration continual counting is possible with maximum (over all time steps) additive error $O(\log^2(T)/\varepsilon)$ and the best known lower bound is $\Omega(\log(T)/\varepsilon)$; closing this gap is a challenging open problem.
We show that the situation is very different for privacy with gradual expiration by giving upper and lower bounds for a large set of expiration functions $g$. Specifically, our algorithm achieves an additive error of $O(\log(T)/\epsilon)$ for a large set of privacy expiration functions. We also give a lower bound that shows that if $C$ is the additive error of any $\epsilon$-DP algorithm for this problem, then the product of $C$ and the privacy expiration function after $2C$ steps must be $\Omega(\log(T)/\epsilon)$. Our algorithm matches this lower bound as its additive error is $O(\log(T)/\epsilon)$, even when $g(2C) = O(1)$.
Our empirical evaluation shows that we achieve a slowly growing privacy loss that has significantly smaller empirical privacy loss for large values of $d$ than a natural baseline algorithm.

Graph Neural Networks (GNNs), known for their effective graph encoding, are extensively used across various fields. Graph self-supervised pre-training, which trains GNN encoders without manual labels to generate high-quality graph representations, has garnered widespread attention. However, due to the inherent complex characteristics in graphs, GNNs encoders pre-trained on one dataset struggle to directly adapt to others that have different node feature shapes. This typically necessitates either model rebuilding or data alignment. The former results in non-transferability as each dataset need to rebuild a new model, while the latter brings serious knowledge loss since it forces features into a uniform shape by preprocessing such as Principal Component Analysis (PCA). To address this challenge, we propose a new Feature-Universal Graph contrastive pre-training strategy (FUG) that naturally avoids the need for model rebuilding and data reshaping. Specifically, inspired by discussions in existing work on the relationship between contrastive Learning and PCA, we conducted a theoretical analysis and discovered that PCA's optimization objective is a special case of that in contrastive Learning. We designed an encoder with contrastive constraints to emulate PCA's generation of basis transformation matrix, which is utilized to losslessly adapt features in different datasets. Furthermore, we introduced a global uniformity constraint to replace negative sampling, reducing the time complexity from $O(n^2)$ to $O(n)$, and by explicitly defining positive samples, FUG avoids the substantial memory requirements of data augmentation. In cross domain experiments, FUG has a performance close to the re-trained new models. The source code is available at: https://github.com/hedongxiao-tju/FUG.
tl;dr: We present a neuro-symbolic approach for learning proofs of propositional satisfiability with largely enhanced data efficiency and a self-improving workflow.

Training neural networks on NP-complete problems typically demands very large amounts of training data and often needs to be coupled with computationally expensive symbolic verifiers to ensure output correctness. In this paper, we present NeuRes, a neuro-symbolic approach to address both challenges for propositional satisfiability, being the quintessential NP-complete problem. By combining certificate-driven training and expert iteration, our model learns better representations than models trained for classification only, with a much higher data efficiency -- requiring orders of magnitude less training data. NeuRes employs propositional resolution as a proof system to generate proofs of unsatisfiability and to accelerate the process of finding satisfying truth assignments, exploring both possibilities in parallel. To realize this, we propose an attention-based architecture that autoregressively selects pairs of clauses from a dynamic formula embedding to derive new clauses. Furthermore, we employ expert iteration whereby model-generated proofs progressively replace longer teacher proofs as the new ground truth. This enables our model to reduce a dataset of proofs generated by an advanced solver by $\sim$$32$% after training on it with no extra guidance. This shows that NeuRes is not limited by the optimality of the teacher algorithm owing to its self-improving workflow. We show that our model achieves far better performance than NeuroSAT in terms of both correctly classified and proven instances.
tl;dr: A simple and effective 3D backbone for point cloud based 3D object detection.

Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but also demonstrates significant advantages in computational efficiency. The source code is available at https://github.com/gwenzhang/Voxel-Mamba.
1391. Adaptive Important Region Selection with Reinforced Hierarchical Search for Dense Object Detection
tl;dr: We propose an Adaptive Important Region Selection framework guided by Evidential Q-learning coupled with a uniquely designed reward function for dense object detection.

Existing state-of-the-art dense object detection techniques tend to produce a large number of false positive detections on difficult images with complex scenes because they focus on ensuring a high recall. To improve the detection accuracy, we propose an Adaptive Important Region Selection (AIRS) framework guided by Evidential Q-learning coupled with a uniquely designed reward function. Inspired by human visual attention, our detection model conducts object search in a top-down, hierarchical fashion. It starts from the top of the hierarchy with the coarsest granularity and then identifies the potential patches likely to contain objects of interest. It then discards non-informative patches and progressively moves downward on the selected ones for a fine-grained search. The proposed evidential Q-learning systematically encodes epistemic uncertainty in its evidential-Q value to encourage the exploration of unknown patches, especially in the early phase of model training. In this way, the proposed model dynamically balances exploration-exploitation to cover both highly valuable and informative patches. Theoretical analysis and extensive experiments on multiple datasets demonstrate that our proposed framework outperforms the SOTA models.

Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce **T**ransformer-based 1-D**i**mensional **Tok**enizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 × 256 × 3 image can be reduced to just **32** discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains **1.97** gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 × 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 × 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64×, leading to **410× faster** generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID **2.13** vs. 3.04) while still generating high-quality samples **74× faster**. Codes and models are available at https://github.com/bytedance/1d-tokenizer
tl;dr: We propose a persistent-homology-guided graph pooling scheme, which can be flexibly integrated into extant pooling methods and achieved remarkable performance improvement.

Recently, there has been an emerging trend to integrate persistent homology (PH) into graph neural networks (GNNs) to enrich expressive power. However, naively plugging PH features into GNN layers always results in marginal improvement with low interpretability. In this paper, we investigate a novel mechanism for injecting global topological invariance into pooling layers using PH, motivated by the observation that filtration operation in PH naturally aligns graph pooling in a cut-off manner. In this fashion, message passing in the coarsened graph acts along persistent pooled topology, leading to improved performance. Experimentally, we apply our mechanism to a collection of graph pooling methods and observe consistent and substantial performance gain over several popular datasets, demonstrating its wide applicability and flexibility.
tl;dr: We propose a zero-shot event-intensity asymmetric stereo method that adapts large-scale image domain models by using physical inspired visual prompting and a monocular cue-guided disparity refinement technique.

Event-intensity asymmetric stereo systems have emerged as a promising approach for robust 3D perception in dynamic and challenging environments by integrating event cameras with frame-based sensors in different views. However, existing methods often suffer from overfitting and poor generalization due to limited dataset sizes and lack of scene diversity in the event domain. To address these issues, we propose a zero-shot framework that utilizes monocular depth estimation and stereo matching models pretrained on diverse image datasets. Our approach introduces a visual prompting technique to align the representations of frames and events, allowing the use of off-the-shelf stereo models without additional training. Furthermore, we introduce a monocular cue-guided disparity refinement module to improve robustness across static and dynamic regions by incorporating monocular depth information from foundation models. Extensive experiments on real-world datasets demonstrate the superior zero-shot evaluation performance and enhanced generalization ability of our method compared to existing approaches.
tl;dr: We show that the current theory for double descent is incomplete

The relationship between the number of training data points, the number of parameters, and the generalization capabilities of models has been widely studied. Previous work has shown that double descent can occur in the over-parameterized regime and that the standard bias-variance trade-off holds in the under-parameterized regime. These works provide multiple reasons for the existence of the peak. We postulate that the location of the peak depends on the technical properties of both the spectrum as well as the eigenvectors of the sample covariance. We present two simple examples that provably exhibit double descent in the under-parameterized regime and do not seem to occur for reasons provided in prior work.
tl;dr: We propose a powerful detector for diffusion video forensics.

Large numbers of synthesized videos from diffusion models pose threats to information security and authenticity, leading to an increasing demand for generated content detection. However, existing video-level detection algorithms primarily focus on detecting facial forgeries and often fail to identify diffusion-generated content with a diverse range of semantics. To advance the field of video forensics, we propose an innovative algorithm named Multi-Modal Detection(MM-Det) for detecting diffusion-generated videos. MM-Det utilizes the profound perceptual and comprehensive abilities of Large Multi-modal Models (LMMs) by generating a Multi-Modal Forgery Representation (MMFR) from LMM's multi-modal space, enhancing its ability to detect unseen forgery content. Besides, MM-Det leverages an In-and-Across Frame Attention (IAFA) mechanism for feature augmentation in the spatio-temporal domain. A dynamic fusion strategy helps refine forgery representations for the fusion. Moreover, we construct a comprehensive diffusion video dataset, called Diffusion Video Forensics (DVF), across a wide range of forgery videos. MM-Det achieves state-of-the-art performance in DVF, demonstrating the effectiveness of our algorithm. Both source code and DVF are available at https://github.com/SparkleXFantasy/MM-Det.

Conformal prediction converts nearly any point estimator into a prediction interval under standard assumptions while ensuring valid coverage. However, the extensive computational demands of full conformal prediction are daunting in practice, as it necessitates a comprehensive number of trainings across the entire latent label space. Unfortunately, existing efforts to expedite conformalization often carry strong assumptions and are developed specifically for certain models, or they only offer approximate solution sets. To address this gap, we develop a method for fast exact conformalization of generalized statistical estimation. Our analysis reveals that the structure of the solution path is inherently piecewise smooth, and indicates that utilizing second-order information of difference equations suffices to approximate the entire solution spectrum arbitrarily. We provide a unified view that not only encompasses existing work but also attempts to offer geometric insights. Practically, our framework integrates seamlessly with well-studied numerical solvers. The significant speedups of our algorithm as compared to the existing standard methods are demonstrated across numerous benchmarks.

Given a collection of feature maps indexed by a set $\mathcal{T}$, we study the performance of empirical risk minimization (ERM) on regression problems with square loss over the union of the linear classes induced by these feature maps. This setup aims at capturing the simplest instance of feature learning, where the model is expected to jointly learn from the data an appropriate feature map and a linear predictor. We start by studying the asymptotic quantiles of the excess risk of sequences of empirical risk minimizers. Remarkably, we show that when the set $\mathcal{T}$ is not too large and when there is a unique optimal feature map, these quantiles coincide, up to a factor of two, with those of the excess risk of the oracle procedure, which knows a priori this optimal feature map and deterministically outputs an empirical risk minimizer from the associated optimal linear class. We complement this asymptotic result with a non-asymptotic analysis that quantifies the decaying effect of the global complexity of the set $\mathcal{T}$ on the excess risk of ERM, and relates it to the size of the sublevel sets of the suboptimality of the feature maps. As an application of our results, we characterize the performance of the best subset selection procedure in sparse linear regression under general assumptions.

Generative Adversarial Imitation Learning (GAIL) provides a promising approach to training a generative policy to imitate a demonstrator. It uses on-policy Reinforcement Learning (RL) to optimize a reward signal derived from an adversarial discriminator. However, optimizing GAIL is difficult in practise, with the training loss oscillating during training, slowing convergence. This optimization instability can prevent GAIL from finding a good policy, harming its final performance. In this paper, we study GAIL’s optimization from a control-theoretic perspective. We show that GAIL cannot converge to the desired equilibrium. In response, we analyze the training dynamics of GAIL in function space and design a novel controller that not only pushes GAIL to the desired equilibrium but also achieves asymptotic stability in a simplified “one-step” setting. Going from theory to practice, we propose Controlled-GAIL (C-GAIL), which adds a differentiable regularization term on the GAIL objective to stabilize training. Empirically, the C-GAIL regularizer improves the training of various existing GAIL methods, including the popular GAIL-DAC, by speeding up the convergence, reducing the range of oscillation, and matching the expert distribution more closely.
1400. Grokking of Implicit Reasoning in Transformers: A Mechanistic Journey to the Edge of Generalization
tl;dr: We discover and analyze Transformer's grokking phenomenon on the task of implicit reasoning.

We study whether transformers can learn to *implicitly* reason over parametric knowledge, a skill that even the most capable language models struggle with. Focusing on two representative reasoning types, composition and comparison, we consistently find that transformers *can* learn implicit reasoning, but only through *grokking*, i.e., extended training far beyond overfitting. The levels of generalization also vary across reasoning types: when faced with out-of-distribution examples, transformers fail to systematically generalize for composition but succeed for comparison. We delve into the model's internals throughout training, conducting analytical experiments that reveal: 1) the mechanism behind grokking, such as the formation of the generalizing circuit and its relation to the relative efficiency of generalizing and memorizing circuits, and 2) the connection between systematicity and the configuration of the generalizing circuit. Our findings guide data and training setup to better induce implicit reasoning and suggest potential improvements to the transformer architecture, such as encouraging cross-layer knowledge sharing. Furthermore, we demonstrate that for a challenging reasoning task with a large search space, GPT-4-Turbo and Gemini-1.5-Pro based on non-parametric memory fail badly regardless of prompting styles or retrieval augmentation, while a fully grokked transformer can achieve near-perfect accuracy, showcasing the power of parametric memory for complex reasoning.
1401. Collaborative Cognitive Diagnosis with Disentangled Representation Learning for Learner Modeling

Learners sharing similar implicit cognitive states often display comparable observable problem-solving performances. Leveraging collaborative connections among such similar learners proves valuable in comprehending human learning. Motivated by the success of collaborative modeling in various domains, such as recommender systems, we aim to investigate how collaborative signals among learners contribute to the diagnosis of human cognitive states (i.e., knowledge proficiency) in the context of intelligent education.
The primary challenges lie in identifying implicit collaborative connections and disentangling the entangled cognitive factors of learners for improved explainability and controllability in learner Cognitive Diagnosis (CD). However, there has been no work on CD capable of simultaneously modeling collaborative and disentangled cognitive states. To address this gap, we present Coral, a $\underline{Co}$llabo$\underline{ra}$tive cognitive diagnosis model with disentang$\underline{l}$ed representation learning. Specifically, Coral first introduces a disentangled state encoder to achieve the initial disentanglement of learners' states.
Subsequently, a meticulously designed collaborative representation learning procedure captures collaborative signals. It dynamically constructs a collaborative graph of learners by iteratively searching for optimal neighbors in a context-aware manner. Using the constructed graph, collaborative information is extracted through node representation learning. Finally, a decoding process aligns the initial cognitive states and collaborative states, achieving co-disentanglement with practice performance reconstructions.
Extensive experiments demonstrate the superior performance of Coral, showcasing significant improvements over state-of-the-art methods across several real-world datasets.
Our code is available at https://github.com/bigdata-ustc/Coral.
tl;dr: A new functional gradient particle-based variational inference method for sampling on constrained domains.

Recently, through a unified gradient flow perspective of Markov chain Monte Carlo (MCMC) and variational inference (VI), particle-based variational inference methods (ParVIs) have been proposed that tend to combine the best of both worlds. While typical ParVIs such as Stein Variational Gradient Descent (SVGD) approximate the gradient flow within a reproducing kernel Hilbert space (RKHS), many attempts have been made recently to replace RKHS with more expressive function spaces, such as neural networks. While successful, these methods are mainly designed for sampling from unconstrained domains. In this paper, we offer a general solution to constrained sampling by introducing a boundary condition for the gradient flow which would confine the particles within the specific domain. This allows us to propose a new functional gradient ParVI method for constrained sampling, called *constrained functional gradient flow* (CFG), with provable continuous-time convergence in total variation (TV). We also present novel numerical strategies to handle the boundary integral term arising from the domain constraints. Our theory and experiments demonstrate the effectiveness of the proposed framework.
tl;dr: We generate a dog image as an identity fingerprint for an LLM, where the dog's appearance strongly indicates the LLM's base model.

Protecting the copyright of large language models (LLMs) has become crucial due to their resource-intensive training and accompanying carefully designed licenses. However, identifying the original base model of an LLM is challenging due to potential parameter alterations. In this
study, we introduce HuRef, a human-readable fingerprint for LLMs that uniquely identifies the base model without interfering with training or exposing model parameters to the public.
We first observe that the vector direction of LLM parameters remains stable after the model has converged during pretraining,
with negligible perturbations through subsequent training steps, including continued pretraining, supervised fine-tuning, and RLHF,
which makes it a sufficient condition
to identify the base model.
The necessity is validated by continuing to train an LLM with an extra term to drive away the model parameters' direction and the model becomes damaged. However, this direction is vulnerable to simple attacks like dimension permutation or matrix rotation, which significantly change it without affecting performance. To address this, leveraging the Transformer structure, we systematically analyze potential attacks and define three invariant terms that identify an LLM's base model.
Due to the potential risk of information leakage, we cannot publish invariant terms directly. Instead, we map them to a Gaussian vector using an encoder, then convert it into a natural image using StyleGAN2, and finally publish the image. In our black-box setting, all fingerprinting steps are internally conducted by the LLMs owners. To ensure the published fingerprints are honestly generated, we introduced Zero-Knowledge Proof (ZKP).
Experimental results across various LLMs demonstrate the effectiveness of our method. The code is available at https://github.com/LUMIA-Group/HuRef.
tl;dr: Our work introduces DISC, a novel policy that merges online control with learning disentangled predictions, effectively optimizing performance in dynamic systems and maintaining robustness through competitive ratio guarantees.

Uncertain perturbations in dynamical systems often arise from diverse resources, represented by latent components. The predictions for these components, typically generated by "black-box" machine learning tools, are prone to inaccuracies. To tackle this challenge, we introduce DISC, a novel policy that learns a confidence parameter online to harness the potential of accurate predictions while also mitigating the impact of erroneous forecasts. When predictions are precise, DISC leverages this information to achieve near-optimal performance. Conversely, in the case of significant prediction errors, it still has a worst-case competitive ratio guarantee. We provide competitive ratio bounds for DISC under both linear mixing of latent variables as well as a broader class of mixing functions. Our results highlight a first-of-its-kind "best-of-both-worlds" integration of machine-learned predictions, thus lead to a near-optimal consistency and robustness tradeoff, which provably improves what can be obtained without learning the confidence parameter. We validate the applicability of DISC across a spectrum of practical scenarios.
tl;dr: A new framework leveraging large language models to extend the scope of causal discovery to unstructured data.

Revealing the underlying causal mechanisms in the real world is the key to the development of science. Despite the progress in the past decades, traditional causal discovery approaches (CDs) mainly rely on high-quality measured variables, usually given by human experts, to find causal relations. The lack of well-defined high-level variables in many real-world applications has already been a longstanding roadblock to a broader application of CDs. To this end, this paper presents Causal representatiOn AssistanT (COAT) that introduces large language models (LLMs) to bridge the gap. LLMs are trained on massive observations of the world and have demonstrated great capability in extracting key information from unstructured data. Therefore, it is natural to employ LLMs to assist with proposing useful high-level factors and crafting their measurements. Meanwhile, COAT also adopts CDs to find causal relations among the identified variables as well as to provide feedback to LLMs to iteratively refine the proposed factors. We show that LLMs and CDs are mutually beneficial and the constructed feedback provably also helps with the factor proposal. We construct and curate several synthetic and real-world benchmarks including analysis of human reviews and diagnosis of neuropathic and brain tumors, to comprehensively evaluate COAT. Extensive empirical results confirm the effectiveness and reliability of COAT with significant improvements.

We study the problem of learning a single neuron with respect to the $L_2^2$-loss in the presence of adversarial distribution shifts, where the labels can be arbitrary, and the goal is to find a "best-fit" function.
More precisely, given training samples from a reference distribution $p_0$,
the goal is to approximate the vector $\mathbf{w}^*$
which minimizes the squared loss with respect to the worst-case distribution
that is close in $\chi^2$-divergence to $p_{0}$.
We design a computationally efficient algorithm that recovers a vector $ \hat{\mathbf{w}}$
satisfying
$\mathbb{E}\_{p^*} (\sigma(\hat{\mathbf{w}} \cdot \mathbf{x}) - y)^2 \leq C \hspace{0.2em} \mathbb{E}\_{p^*} (\sigma(\mathbf{w}^* \cdot \mathbf{x}) - y)^2 + \epsilon$, where $C>1$ is a dimension-independent constant and $(\mathbf{w}^*, p^*)$ is the witness attaining the min-max risk
$\min_{\mathbf{w}:\|\mathbf{w}\| \leq W} \max\_{p} \mathbb{E}\_{(\mathbf{x}, y) \sim p} (\sigma(\mathbf{w} \cdot \mathbf{x}) - y)^2 - \nu \chi^2(p, p_0)$.
Our algorithm follows the primal-dual framework and is
designed by directly bounding the risk with respect to the original, nonconvex $L_2^2$ loss.
From an optimization standpoint, our work opens new avenues for the design of primal-dual algorithms under structured nonconvexity.

Unlike classical control theory, such as Linear Quadratic Control (LQC), real-world control problems are highly complex. These problems often involve adversarial perturbations, bandit feedback models, and non-quadratic, adversarially chosen cost functions. A fundamental yet unresolved question is whether optimal regret can be achieved for these general control problems. The standard approach to addressing this problem involves a reduction to bandit convex optimization with memory. In the bandit setting, constructing a gradient estimator with low variance is challenging due to the memory structure and non-quadratic loss functions.
In this paper, we provide an affirmative answer to this question. Our main contribution is an algorithm that achieves an $\tilde{O}(\sqrt{T})$ optimal regret for bandit non-stochastic control with strongly-convex and smooth cost functions in the presence of adversarial perturbations, improving the previously known $\tilde{O}(T^{2/3})$ regret bound from \citep{cassel2020bandit}. Our algorithm overcomes the memory issue by reducing the problem to Bandit Convex Optimization (BCO) without memory and addresses general strongly-convex costs using recent advancements in BCO from \citep{suggala2024second}. Along the way, we develop an improved algorithm for BCO with memory, which may be of independent interest.
tl;dr: This paper introduces probably approximately aligned (PAA) and safe policies in the context of social decision processes.

While autonomous agents often surpass humans in their ability to handle vast and complex data, their potential misalignment (i.e., lack of transparency regarding their true objective) has thus far hindered their use in critical applications such as social decision processes. More importantly, existing alignment methods provide no formal guarantees on the safety of such models. Drawing from utility and social choice theory, we provide a novel quantitative definition of alignment in the context of social decision-making. Building on this definition, we introduce probably approximately aligned (i.e., near-optimal) policies, and we derive a sufficient condition for their existence. Lastly, recognizing the practical difficulty of satisfying this condition, we introduce the relaxed concept of safe (i.e., nondestructive) policies, and we propose a simple yet robust method to safeguard the black-box policy of any autonomous agent, ensuring all its actions are verifiably safe for the society.

Multivariate time series forecasting plays a crucial role in various fields such as finance, traffic management, energy, and healthcare. Recent studies have highlighted the advantages of channel independence to resist distribution drift but neglect channel correlations, limiting further enhancements. Several methods utilize mechanisms like attention or mixer to address this by capturing channel correlations, but they either introduce excessive complexity or rely too heavily on the correlation to achieve satisfactory results under distribution drifts, particularly with a large number of channels. Addressing this gap, this paper presents an efficient MLP-based model, the Series-cOre Fused Time Series forecaster (SOFTS), which incorporates a novel STar Aggregate-Redistribute (STAR) module. Unlike traditional approaches that manage channel interactions through distributed structures, \textit{e.g.}, attention, STAR employs a centralized strategy to improve efficiency and reduce reliance on the quality of each channel. It aggregates all series to form a global core representation, which is then dispatched and fused with individual series representations to facilitate channel interactions effectively. SOFTS achieves superior performance over existing state-of-the-art methods with only linear complexity. The broad applicability of the STAR module across different forecasting models is also demonstrated empirically. We have made our code publicly available at https://github.com/Secilia-Cxy/SOFTS.
tl;dr: We present a flipping-based policy for safe reinforcement learning and provide theoretical foundations for its optimality and practical implementation.

Safe reinforcement learning (RL) is a promising approach for many real-world decision-making problems where ensuring safety is a critical necessity. In safe RL research, while expected cumulative safety constraints (ECSCs) are typically the first choices, chance constraints are often more pragmatic for incorporating safety under uncertainties. This paper proposes a \textit{flipping-based policy} for Chance-Constrained Markov Decision Processes (CCMDPs). The flipping-based policy selects the next action by tossing a potentially distorted coin between two action candidates. The probability of the flip and the two action candidates vary depending on the state. We establish a Bellman equation for CCMDPs and further prove the existence of a flipping-based policy within the optimal solution sets. Since solving the problem with joint chance constraints is challenging in practice, we then prove that joint chance constraints can be approximated into Expected Cumulative Safety Constraints (ECSCs) and that there exists a flipping-based policy in the optimal solution sets for constrained MDPs with ECSCs. As a specific instance of practical implementations, we present a framework for adapting constrained policy optimization to train a flipping-based policy. This framework can be applied to other safe RL algorithms. We demonstrate that the flipping-based policy can improve the performance of the existing safe RL algorithms under the same limits of safety constraints on Safety Gym benchmarks.
tl;dr: We propose the first work to consider dynamically evolving multi-source adaptation at test time.

Adapting to dynamic data distributions is a practical yet challenging task. One effective strategy is to use a model ensemble, which leverages the diverse expertise of different models to transfer knowledge to evolving data distributions. However, this approach faces difficulties when the dynamic test distribution is available only in small batches and without access to the original source data. To address the challenge of adapting to dynamic distributions in such practical settings, we propose continual multi-source adaptation to dynamic distributions (CONTRAST), a novel method that optimally combines multiple source models to adapt to the dynamic test data. CONTRAST has two distinguishing features. First, it efficiently computes the optimal combination weights to combine the source models to adapt to the test data distribution continuously as a function of time. Second, it identifies which of the source model parameters to update so that only the model which is most correlated to the target data is adapted, leaving the less correlated ones untouched; this mitigates the issue of ``forgetting" the source model parameters by focusing only on the source model that exhibits the strongest correlation with the test batch distribution. Through theoretical analysis we show that the proposed method is able to optimally combine the source models and prioritize updates to the model least prone to forgetting. Experimental analysis on diverse datasets demonstrates that the combination of multiple source models does at least as well as the best source (with hindsight knowledge), and performance does not degrade as the test data distribution changes over time (robust to forgetting).
tl;dr: DMNet is a self-comparison driven model designed for subject-independent seizure detection.

Automated seizure detection (ASD) using intracranial electroencephalography (iEEG) is critical for effective epilepsy treatment. However, the significant domain shift of iEEG signals across subjects poses a major challenge, limiting their applicability in real-world clinical scenarios. In this paper, we address this issue by analyzing the primary cause behind the failure of existing iEEG models for subject-independent seizure detection, and identify a critical universal seizure pattern: seizure events consistently exhibit higher average amplitude compared to adjacent normal events. To mitigate the domain shifts and preserve the universal seizure patterns, we propose a novel self-comparison mechanism. This mechanism effectively aligns iEEG signals across subjects and time intervals. Building upon these findings, we propose Difference Matrix-based Neural Network (DMNet), a subject-independent seizure detection model, which leverages self-comparison based on two constructed (contextual, channel-level) references to mitigate shifts of iEEG, and utilize a simple yet effective difference matrix to encode the universal seizure patterns. Extensive experiments show that DMNet significantly outperforms previous SOTAs while maintaining high efficiency on a real-world clinical dataset collected by us and two public datasets for subject-independent seizure detection. Moreover, the visualization results demonstrate that the generated difference matrix can effectively capture the seizure activity changes during the seizure evolution process. Additionally, we deploy our method in an online diagnosis system to illustrate its effectiveness in real clinical applications.
1413. Practical $0.385$-Approximation for Submodular Maximization Subject to a Cardinality Constraint
tl;dr: In this work, we present a novel algorithm for submodular maximization subject to a cardinality constraint that combines a guarantee of $0.385$-approximation with a low and practical query complexity of $O(n+k^2)$.

Non-monotone constrained submodular maximization plays a crucial role in various machine learning applications. However, existing algorithms often struggle with a trade-off between approximation guarantees and practical efficiency. The current state-of-the-art is a recent $0.401$-approximation algorithm, but its computational complexity makes it highly impractical. The best practical algorithms for the problem only guarantee $1/e$-approximation. In this work, we present a novel algorithm for submodular maximization subject to a cardinality constraint that combines a guarantee of $0.385$-approximation with a low and practical query complexity of $O(n+k^2)$. Furthermore, we evaluate our algorithm's performance through extensive machine learning applications, including Movie Recommendation, Image Summarization, and more. These evaluations demonstrate the efficacy of our approach.
tl;dr: We introduce Yo'LLaVA -- a framework to embed personalized subjects (e.g., your pet) into a comprehensible prompt for Large Multimodal Models (e.g., LLaVA)

Large Multimodal Models (LMMs) have shown remarkable capabilities across a variety of tasks (e.g., image captioning, visual question answering).
While broad, their knowledge remains generic (e.g., recognizing a dog), and they are unable to handle personalized subjects (e.g., recognizing a user's pet dog).
Human reasoning, in contrast, typically operates within the context of specific subjects in our surroundings. For example, one might ask, "What should I buy for *my dog*'s birthday?"; as opposed to a generic inquiry about "What should I buy for *a dog*'s birthday?".
Similarly, when looking at a friend's image, the interest lies in seeing their activities (e.g., "*my friend* is holding a cat"), rather than merely observing generic human actions (e.g., "*a man* is holding a cat").
In this paper, we introduce the novel task of personalizing LMMs, so that they can have conversations about a specific subject. We propose Yo'LLaVA, which learns to embed a personalized subject into a set of latent tokens given a handful of example images of the subject. Our qualitative and quantitative analyses reveal that Yo'LLaVA can learn the concept more efficiently using fewer tokens and more effectively encode the visual attributes compared to strong prompting baselines (e.g., LLaVA).
tl;dr: TextCtrl is a novel diffusion-based approach that performs high-fidelity scene text editing through explicit text style disentanglement and glyph structure representation as well as adaptive inference control.

Centred on content modification and style preservation, Scene Text Editing (STE) remains a challenging task despite considerable progress in text-to-image synthesis and text-driven image manipulation recently. GAN-based STE methods generally encounter a common issue of model generalization, while Diffusion-based STE methods suffer from undesired style deviations. To address these problems, we propose TextCtrl, a diffusion-based method that edits text with prior guidance control. Our method consists of two key components: (i) By constructing fine-grained text style disentanglement and robust text glyph structure representation, TextCtrl explicitly incorporates Style-Structure guidance into model design and network training, significantly improving text style consistency and rendering accuracy. (ii) To further leverage the style prior, a Glyph-adaptive Mutual Self-attention mechanism is proposed which deconstructs the implicit fine-grained features of the source image to enhance style consistency and vision quality during inference. Furthermore, to fill the vacancy of the real-world STE evaluation benchmark, we create the first real-world image-pair dataset termed ScenePair for fair comparisons. Experiments demonstrate the effectiveness of TextCtrl compared with previous methods concerning both style fidelity and text accuracy. Project page: https://github.com/weichaozeng/TextCtrl.

The optimal policy in various real-world strategic decision-making problems depends both on the environmental configuration and exogenous events. For these settings, we introduce Contextual Bilevel Reinforcement Learning (CB-RL), a stochastic bilevel decision-making model, where the lower level consists of solving a contextual Markov Decision Process (CMDP). CB-RL can be viewed as a Stackelberg Game where the leader and a random context beyond the leader’s control together decide the setup of many MDPs that potentially multiple followers best respond to. This framework extends beyond traditional bilevel optimization and finds relevance in diverse fields such as RLHF, tax design, reward shaping, contract theory and mechanism design. We propose a stochastic Hyper Policy Gradient Descent (HPGD) algorithm to solve CB-RL, and demonstrate its convergence. Notably, HPGD uses stochastic hypergradient estimates, based on observations of the followers’ trajectories. Therefore, it allows followers to use any training procedure and the leader to be agnostic of the specific algorithm, which aligns with various real-world scenarios. We further consider the setting when the leader can influence the training of followers and propose an accelerated algorithm. We empirically demonstrate the performance of our algorithm for reward shaping and tax design.

Human motion capture from monocular videos has made significant progress in recent years. However, modern approaches often produce temporal artifacts, e.g. in form of jittery motion and struggle to achieve smooth and physically plausible motions. Explicitly integrating physics, in form of internal forces and exterior torques, helps alleviating these artifacts. Current state-of-the-art approaches make use of an automatic PD controller to predict torques and reaction forces in order to re-simulate the input kinematics, i.e. the joint angles of a predefined skeleton. However, due to imperfect physical models, these methods often require simplifying assumptions and extensive preprocessing of the input kinematics to achieve good performance. To this end, we propose a novel method to selectively incorporate the physics models with the kinematics observations in an online setting, inspired by a neural Kalman-filtering approach. We develop a control loop as a meta-PD controller to predict internal joint torques and external reaction forces, followed by a physics-based motion simulation. A recurrent neural network is introduced to realize a Kalman filter that attentively balances the kinematics input and simulated motion, resulting in an optimal-state dynamics prediction. We show that this filtering step is crucial to provide an online supervision that helps balancing the shortcoming of the respective input motions, thus being important for not only capturing accurate global motion trajectories but also producing physically plausible human poses. The proposed approach excels in the physics-based human pose estimation task and demonstrates the physical plausibility of the predictive dynamics, compared to state of the art. The code is available on https://github.com/cuongle1206/OSDCap.
tl;dr: A uniform model for image-level, object-level, and pixel-level reasoning and understanding.

Current universal segmentation methods demonstrate strong capabilities in pixel-level image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions. In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction. This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user's text instructions and providing text responses and pixel-level segmentation results based on the visual information. We propose perception prior embedding to better integrate perception priors with image features. OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks. Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.
tl;dr: We introduce and study a novel distributionally robust optimization procedure, combining insights from Bayesian nonparametric (Dirichlet process) theory and a popular decision-theoretic model of smooth ambiguity-averse preferences.

Training machine learning and statistical models often involves optimizing a data-driven risk criterion. The risk is usually computed with respect to the empirical data distribution, but this may result in poor and unstable out-of-sample performance due to distributional uncertainty. In the spirit of distributionally robust optimization, we propose a novel robust criterion by combining insights from Bayesian nonparametric (i.e., Dirichlet process) theory and a recent decision-theoretic model of smooth ambiguity-averse preferences. First, we highlight novel connections with standard regularized empirical risk minimization techniques, among which Ridge and LASSO regressions. Then, we theoretically demonstrate the existence of favorable finite-sample and asymptotic statistical guarantees on the performance of the robust optimization procedure. For practical implementation, we propose and study tractable approximations of the criterion based on well-known Dirichlet process representations. We also show that the smoothness of the criterion naturally leads to standard gradient-based numerical optimization. Finally, we provide insights into the workings of our method by applying it to a variety of tasks based on simulated and real datasets.
tl;dr: DropBP, randomly dropping backward propagation based on layer sensitivity, significantly accelerates fine-tuning in Large Language Models (LLMs) with considerable memory reduction.

Large language models (LLMs) have achieved significant success across various domains. However, training these LLMs typically involves substantial memory and computational costs during both forward and backward propagation. While parameter-efficient fine-tuning (PEFT) considerably reduces the training memory associated with parameters, it does not address the significant computational costs and activation memory. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs and activation memory while maintaining accuracy. DropBP randomly drops layers during backward propagation, which is essentially equivalent to training shallow submodules generated by undropped layers and residual connections. Additionally, DropBP calculates the sensitivity of each layer to assign an appropriate drop rate, thereby stabilizing the training process. DropBP is not only applicable to full fine-tuning but can also be orthogonally integrated with all types of PEFT by dropping layers during backward propagation. Specifically, DropBP can reduce training time by 44% with comparable accuracy to the baseline, accelerate convergence to the same perplexity by 1.5$\times$, and enable training with a sequence length 6.2$\times$ larger on a single NVIDIA-A100 GPU. Furthermore, our DropBP enabled a throughput increase of 79% on a NVIDIA A100 GPU and 117% on an Intel Gaudi2 HPU. The code is available at [https://github.com/WooSunghyeon/dropbp](https://github.com/WooSunghyeon/dropbp).
tl;dr: An RL-driven method for guiding LLMs to aligns with objectives defined in a latent embedding space. We demonstrate its effectiveness on surfacing content gaps.

We propose a novel approach for training large language models (LLMs) to adhere to objectives defined within a latent embedding space. Our method leverages reinforcement learning (RL), treating a pre-trained LLM as an environment. Our embedding-aligned guided language (EAGLE) agent is trained to iteratively steer the LLM's generation towards optimal regions of the latent embedding space, w.r.t. some predefined criterion. We demonstrate the effectiveness of the EAGLE agent using the MovieLens 25M and Amazon Review datasets to surface content gaps that satisfy latent user demand. We also demonstrate the benefit of using an optimal design of a state-dependent action set to improve EAGLE's efficiency. Our work paves the way for controlled and grounded text generation using LLMs, ensuring consistency with domain-specific knowledge and data representations.
tl;dr: Inspired by the neural mechanisms that may contribute to brain’s associative power, specifically the cortical modularization and hippocampal pattern completion, here we propose a self-supervised controllable generation (SCG) framework.

The human brain exhibits a strong ability to spontaneously associate different visual attributes of the same or similar visual scene, such as associating sketches and graffiti with real-world visual objects, usually without supervising information. In contrast, in the field of artificial intelligence, controllable generation methods like ControlNet heavily rely on annotated training datasets such as depth maps, semantic segmentation maps, and poses, which limits the method’s scalability. Inspired by the neural mechanisms that may contribute to the brain’s associative power, specifically the cortical modularization and hippocampal pattern completion, here we propose a self-supervised controllable generation (SCG) framework. Firstly, we introduce an equivariance constraint to promote inter-module independence and intra-module correlation in a modular autoencoder network, thereby achieving functional specialization. Subsequently, based on these specialized modules, we employ a self-supervised pattern completion approach for controllable generation training. Experimental results demonstrate that the proposed modular autoencoder effectively achieves functional specialization, including the modular processing of color, brightness, and edge detection, and exhibits brain-like features including orientation selectivity, color antagonism, and center-surround receptive fields. Through self-supervised training, associative generation capabilities spontaneously emerge in SCG, demonstrating excellent zero-shot generalization ability to various tasks such as superresolution, dehaze and associative or conditional generation on painting, sketches, and ancient graffiti. Compared to the previous representative method ControlNet, our proposed approach not only demonstrates superior robustness in more challenging high-noise scenarios but also possesses more promising scalability potential due to its self-supervised manner. Codes are released on Github and Gitee.
tl;dr: We study a 1-layer transformer to understand the mechanisms of associative memory in LLMs

Large Language Models (LLMs) have the capacity to store and recall facts. Through experimentation with open-source models, we observe that this ability to retrieve facts can be easily manipulated by changing contexts, even without altering their factual meanings. These findings highlight that LLMs might behave like an associative memory model where certain tokens in the contexts serve as clues to retrieving facts. We mathematically explore this property by studying how transformers, the building blocks of LLMs, can complete such memory tasks. We study a simple latent concept association problem with a one-layer transformer and we show theoretically and empirically that the transformer gathers information using self-attention and uses the value matrix for associative memory.
tl;dr: Introduced a PDE-Preserved Coarse Correction Network for efficient prediction of spatiotemporal dynamics.

When solving partial differential equations (PDEs), classical numerical methods often require fine mesh grids and small time stepping to meet stability, consistency, and convergence conditions, leading to high computational cost. Recently, machine learning has been increasingly utilized to solve PDE problems, but they often encounter challenges related to interpretability, generalizability, and strong dependency on rich labeled data. Hence, we introduce a new PDE-Preserved Coarse Correction Network (P$^2$C$^2$Net) to efficiently solve spatiotemporal PDE problems on coarse mesh grids in small data regimes. The model consists of two synergistic modules: (1) a trainable PDE block that learns to update the coarse solution (i.e., the system state), based on a high-order numerical scheme with boundary condition encoding, and (2) a neural network block that consistently corrects the solution on the fly. In particular, we propose a learnable symmetric Conv filter, with weights shared over the entire model, to accurately estimate the spatial derivatives of PDE based on the neural-corrected system state. The resulting physics-encoded model is capable of handling limited training data (e.g., 3--5 trajectories) and accelerates the prediction of PDE solutions on coarse spatiotemporal grids while maintaining a high accuracy. P$^2$C$^2$Net achieves consistent state-of-the-art performance with over 50\% gain (e.g., in terms of relative prediction error) across four datasets covering complex reaction-diffusion processes and turbulent flows.
tl;dr: We investigate the interplay between curvature dynamics and learning rate tuners through a new learning rate tuning method.

Curvature information -- particularly, the largest eigenvalue of the loss
Hessian, known as the sharpness -- often forms the basis for learning rate
tuners. However, recent work has shown that the curvature information undergoes
complex dynamics during training, going from a phase of increasing sharpness to
eventual stabilization. We analyze the closed-loop feedback effect between
learning rate tuning and curvature. We find that classical learning rate tuners
may yield greater one-step loss reduction, yet they ultimately underperform in
the long term when compared to constant learning rates in the full batch regime.
These models break the stabilization of the sharpness, which we explain using a
simplified model of the joint dynamics of the learning rate and the curvature.
To further investigate these effects, we introduce a new learning rate tuning
method, Curvature Dynamics Aware Tuning (CDAT), which prioritizes long term
curvature stabilization over instantaneous progress on the objective. In the
full batch regime, CDAT shows behavior akin to prefixed warm-up schedules on deep
learning objectives, outperforming tuned constant learning rates. In the mini
batch regime, we observe that stochasticity introduces confounding effects that
explain the previous success of some learning rate tuners at appropriate batch
sizes. Our findings highlight the critical role of understanding the joint
dynamics of the learning rate and curvature, beyond greedy minimization, to
diagnose failures and design effective adaptive learning rate tuners.
tl;dr: Using simple N-gram statistics, we gain insights into how transformer-based LLMs make predictions along with their training dynamics.

Transformer based large-language models (LLMs) display extreme proficiency with language yet a precise understanding of how they work remains elusive. One way of demystifying transformer predictions would be to describe how they depend on their context in terms of simple template functions. This paper takes a first step in this direction by considering families of functions (i.e. rules) formed out of simple N-gram based statistics of the training data. By studying how well these rulesets approximate transformer predictions, we obtain a variety of novel discoveries: a simple method to detect overfitting during training without using a holdout set, a quantitative measure of how transformers progress from learning simple to more complex statistical rules over the course of training, a model-variance criterion governing when transformer predictions tend to be described by N-gram rules, and insights into how well transformers can be approximated by N-gram rulesets in the limit where these rulesets become increasingly complex. In this latter direction, we find that for 79% and 68% of LLM next-token distributions on TinyStories and Wikipedia, respectively, their top-1 predictions agree with those provided by our N-gram rulesets.
1427. AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data
tl;dr: We propose to harmonize multi-source data for instruction tuning Code LLMs and develop AlchemistCoder series, outperforming all models of the same size (6.7B/7B) and rivaling or even surpassing larger models (15B/33B/70B/ChatGPT).

Open-source Large Language Models (LLMs) and their specialized variants, particularly Code LLMs, have recently delivered impressive performance. However, previous Code LLMs are typically fine-tuned on single-source data with limited quality and diversity, which may insufficiently elicit the potential of pre-trained Code LLMs. In this paper, we present AlchemistCoder, a series of Code LLMs with enhanced code generation and generalization capabilities fine-tuned on multi-source data. To achieve this, we pioneer to unveil inherent conflicts among the various styles and qualities in multi-source code corpora and introduce data-specific prompts with hindsight relabeling, termed AlchemistPrompts, to harmonize different data sources and instruction-response pairs. Additionally, we propose incorporating the data construction process into the fine-tuning data as code comprehension tasks, including instruction evolution, data filtering, and code review. Extensive experiments demonstrate that AlchemistCoder holds a clear lead among all models of the same size (6.7B/7B) and rivals or even surpasses larger models (15B/33B/70B), showcasing the efficacy of our method in refining instruction-following capabilities and advancing the boundaries of code intelligence. Source code and models are available at https://github.com/InternLM/AlchemistCoder.
tl;dr: This paper introduces Parameter Competition Balancing Merging (PCB-Merging), a lightweight and training-free technique for adjusting the coefficient of each parameter for model merging.

While fine-tuning pretrained models has become common practice, these models often underperform outside their specific domains. Recently developed model merging techniques enable the direct integration of multiple models, each fine-tuned for distinct tasks, into a single model. This strategy promotes multitasking capabilities without requiring retraining on the original datasets. However, existing methods fall short in addressing potential conflicts and complex correlations between tasks, especially in parameter-level adjustments, posing a challenge in effectively balancing parameter competition across various tasks. This paper introduces an innovative technique named **PCB-Merging** (Parameter Competition Balancing), a *lightweight* and *training-free* technique that adjusts the coefficients of each parameter for effective model merging. PCB-Merging employs intra-balancing to gauge parameter significance within individual tasks and inter-balancing to assess parameter similarities across different tasks. Parameters with low importance scores are dropped, and the remaining ones are rescaled to form the final merged model. We assessed our approach in diverse merging scenarios, including cross-task, cross-domain, and cross-training configurations, as well as out-of-domain generalization. The experimental results reveal that our approach achieves substantial performance enhancements across multiple modalities, domains, model sizes, number of tasks, fine-tuning forms, and large language models, outperforming existing model merging methods.

Image coding for multi-task applications, catering to both human perception and machine vision, has been extensively investigated. Existing methods often rely on multiple task-specific encoder-decoder pairs, leading to high overhead of parameter and bitrate usage, or face challenges in multi-objective optimization under a unified representation, failing to achieve both performance and efficiency. To this end, we propose Multi-Path Aggregation (MPA) integrated into existing coding models for joint human-machine vision, unifying the feature representation with an all-in-one architecture. MPA employs a predictor to allocate latent features among task-specific paths based on feature importance varied across tasks, maximizing the utility of shared features while preserving task-specific features for subsequent refinement. Leveraging feature correlations, we develop a two-stage optimization strategy to alleviate multi-task performance degradation. Upon the reuse of shared features, as low as 1.89\% parameters are further augmented and fine-tuned for a specific task, which completely avoids extensive optimization of the entire model. Experimental results show that MPA achieves performance comparable to state-of-the-art methods in both task-specific and multi-objective optimization across human viewing and machine analysis tasks. Moreover, our all-in-one design supports seamless transitions between human- and machine-oriented reconstruction, enabling task-controllable interpretation without altering the unified model. Code is available at https://github.com/NJUVISION/MPA.

Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy realtime constraints and a small memory footprint for efficient transmission. If acheived, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at ~350 FPS.
tl;dr: We reduce the resource usage of the attention layer with Mixture of Experts.

Despite many recent works on Mixture of Experts (MoEs) for resource-efficient Transformer language models, existing methods mostly focus on MoEs for feedforward layers. Previous attempts at extending MoE to the self-attention layer fail to match the performance of the parameter-matched baseline. Our novel SwitchHead is an effective MoE method for the attention layer that successfully reduces both the compute and memory requirements, achieving wall-clock speedup, while matching the language modeling performance of the baseline Transformer. Our novel MoE mechanism allows SwitchHead to compute up to 8 times fewer attention matrices than the standard Transformer. SwitchHead can also be combined with MoE feedforward layers, resulting in fully-MoE "SwitchAll" Transformers. For our 262M parameter model trained on C4, SwitchHead matches the perplexity of standard models with only 44% compute and 27% memory usage. Zero-shot experiments on downstream tasks confirm the performance of SwitchHead, e.g., achieving more than 3.5% absolute improvements on BliMP compared to the baseline with an equal compute resource.

Large language models (LLMs) are known for their exceptional performance in natural language processing, making them highly effective in many human life-related tasks. The attention mechanism in the Transformer architecture is a critical component of LLMs, as it allows the model to selectively focus on specific input parts. The softmax unit, which is a key part of the attention mechanism, normalizes the attention scores. Hence, the performance of LLMs in various NLP tasks depends significantly on the crucial role played by the attention mechanism with the softmax unit.
In-context learning is one of the celebrated abilities of recent LLMs.
Without further parameter updates, Transformers can learn to predict based on few in-context examples.
However, the reason why Transformers becomes in-context learners is not well understood.
Recently, in-context learning has been studied from a mathematical perspective with simplified linear self-attention without softmax unit.
Based on a linear regression formulation $\min_x\| Ax - b \|_2$, existing works show linear Transformers' capability of learning linear functions in context. The capability of Transformers with softmax unit approaching full Transformers, however, remains unexplored.
In this work, we study the in-context learning based on a softmax regression formulation $\min_{x} \| \langle \exp(Ax), {\bf 1}_n \rangle^{-1} \exp(Ax) - b \|_2$. We show the upper bounds of the data transformations induced by a single self-attention layer with softmax unit and by gradient-descent on a $\ell_2$ regression loss for softmax prediction function.
Our theoretical results imply that when training self-attention-only Transformers for fundamental regression tasks, the models learned by gradient-descent and Transformers show great similarity.
tl;dr: We propose Laplace posterior sampling approximations for linear models and GLMs with a diffusion model prior, and apply them to contextual bandits.

Posterior sampling in contextual bandits with a Gaussian prior can be implemented exactly or approximately using the Laplace approximation. The Gaussian prior is computationally efficient but it cannot describe complex distributions. In this work, we propose approximate posterior sampling algorithms for contextual bandits with a diffusion model prior. The key idea is to sample from a chain of approximate conditional posteriors, one for each stage of the reverse diffusion process, which are obtained by the Laplace approximation. Our approximations are motivated by posterior sampling with a Gaussian prior, and inherit its simplicity and efficiency. They are asymptotically consistent and perform well empirically on a variety of contextual bandit problems.
1434. VeXKD: The Versatile Integration of Cross-Modal Fusion and Knowledge Distillation for 3D Perception
tl;dr: A simple yet versatile framework that jointly considers multi-modal fusion and cross-modal knowledge distillation.

Recent advancements in 3D perception have led to a proliferation of network architectures, particularly those involving multi-modal fusion algorithms. While these fusion algorithms improve accuracy, their complexity often impedes real-time performance. This paper introduces VeXKD, an effective and Versatile framework that integrates Cross-Modal Fusion with Knowledge Distillation. VeXKD applies knowledge distillation exclusively to the Bird's Eye View (BEV) feature maps, enabling the transfer of cross-modal insights to single-modal students without additional inference time overhead. It avoids volatile components that can vary across various 3D perception tasks and student modalities, thus improving versatility. The framework adopts a modality-general cross-modal fusion module to bridge the modality gap between the multi-modal teachers and single-modal students. Furthermore, leveraging byproducts generated during fusion, our BEV query guided mask generation network identifies crucial spatial locations across different BEV feature maps in a data-driven manner, significantly enhancing the effectiveness of knowledge distillation. Extensive experiments on the nuScenes dataset demonstrate notable improvements, with up to 6.9\%/4.2\% increase in mAP and NDS for 3D detection tasks and up to 4.3\% rise in mIoU for BEV map segmentation tasks, narrowing the performance gap with multi-modal models.
tl;dr: We improve the upper bound of the sample complexity of multiclass PAC learning.

We aim to understand the optimal PAC sample complexity in multiclass learning. While finiteness of the Daniely-Shalev-Shwartz (DS) dimension has been shown to characterize the PAC learnability of a concept class [Brukhim, Carmon, Dinur, Moran, and Yehudayoff, 2022], there exist polylog factor gaps in the leading term of the sample complexity. In this paper, we reduce the gap in terms of the dependence on the error parameter to a single log factor and also propose two possible routes towards completely resolving the optimal sample complexity, each based on a key open question we formulate: one concerning list learning with bounded list size, the other concerning a new type of shifting for multiclass concept classes. We prove that a positive answer to either of the two questions would completely resolve the optimal sample complexity up to log factors of the DS dimension.
tl;dr: We introduce a new model and training dataset for transfer learning on tabular data that achieves strong zero- and few-shot accuracy across 300 tabular benchmark datasets

Tabular data – structured, heterogeneous, spreadsheet-style data with rows and columns – is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had similar impact in the tabular domain. In this work, we seek to narrow this gap and present TABULA-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control. Using the resulting dataset, which comprises over 2.1B rows from 4.2M unique tables, we fine-tune a Llama 3-8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction. Through evaluation across a test suite of 329 datasets, we find that TABULA-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TABULA-8B is 5-15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16× more data. We release our model, code, and data along with the publication of this paper.
tl;dr: We propose a novel algorithm for Safe Offline RL under functional approximation; our algorithm achieves robust safe policy improvement (first such result) using only single policy concentrability assumption.

We propose WSAC (Weighted Safe Actor-Critic), a novel algorithm for Safe Offline Reinforcement Learning (RL) under functional approximation, which can robustly optimize policies to improve upon an arbitrary reference policy with limited data coverage. WSAC is designed as a two-player Stackelberg game to optimize a refined objective function. The actor optimizes the policy against two adversarially trained value critics with small importance-weighted Bellman errors, which focus on scenarios where the actor's performance is inferior to the reference policy. In theory, we demonstrate that when the actor employs a no-regret optimization oracle, WSAC achieves a number of guarantees: $(i)$ For the first time in the safe offline RL setting, we establish that WSAC can produce a policy that outperforms {\bf any} reference policy while maintaining the same level of safety, which is critical to designing a safe algorithm for offline RL. $(ii)$ WSAC achieves the optimal statistical convergence rate of $1/\sqrt{N}$ to the reference policy, where $N$ is the size of the offline dataset. $(iii)$ We theoretically show that WSAC guarantees a safe policy improvement across a broad range of hyperparameters that control the degree of pessimism, indicating its practical robustness. Additionally, we offer a practical version of WSAC and compare it with existing state-of-the-art safe offline RL algorithms in several continuous control environments. WSAC outperforms all baselines across a range of tasks, supporting the theoretical results.
tl;dr: We demonstrate the significance of co-occurrence, positional information, noise, and data structures for in-context learning from training on unstructured data.

Large language models (LLMs) like transformers demonstrate impressive in-context learning (ICL) capabilities, allowing them to make
predictions for new tasks based on prompt exemplars without parameter updates. While existing ICL theories often assume structured training data resembling ICL tasks (e.g., x-y pairs for linear regression), LLMs are typically trained unsupervised on unstructured text, such as web content, which lacks clear parallels to tasks like word analogy. To address this gap, we examine what enables ICL in models trained on unstructured data, focusing on critical sequence model requirements and training data structure. We find that many ICL capabilities can
emerge simply from co-occurrence of semantically related word pairs in unstructured data; word analogy completion, for example, can provably arise purely through co-occurrence modeling, using classical language models like continuous bag of words (CBOW), without needing positional information or attention mechanisms. However, positional information becomes crucial for logic reasoning tasks requiring generalization to unseen tokens. Finally, we identify two cases where ICL fails: one in logic reasoning tasks that require generalizing to new, unseen patterns, and another in analogy completion where relevant word pairs appear only in fixed training positions. These findings suggest that LLMs' ICL abilities depend heavily on the structural elements within their training data.
tl;dr: We prove rates of normal approximation for the iterates of the linear stochastic approximation algorithm and non-asymptotic guarantees for constructing confidence intervals with multiplier bootstrap

In this paper, we obtain the Berry–Esseen bound for multivariate normal approximation for the Polyak-Ruppert averaged iterates of the linear stochastic approximation (LSA) algorithm with decreasing step size. Moreover, we prove the non-asymptotic validity of the confidence intervals for parameter estimation with LSA based on multiplier bootstrap. This procedure updates the LSA estimate together with a set of randomly perturbed LSA estimates upon the arrival of subsequent observations. We illustrate our findings in the setting of temporal difference learning with linear function approximation.
tl;dr: In this work we propose a derivative-enhanced deep operator network (DE-DeepONet), which leverages the derivative information to enhance the prediction accuracy, and provide a more accurate approximation of the derivatives.

The deep operator networks (DeepONet), a class of neural operators that learn mappings between function spaces, have recently been developed as surrogate models for parametric partial differential equations (PDEs). In this work we propose a derivative-enhanced deep operator network (DE-DeepONet), which leverages derivative information to enhance the solution prediction accuracy and provides a more accurate approximation of solution-to-parameter derivatives, especially when training data are limited. DE-DeepONet explicitly incorporates linear dimension reduction of high dimensional parameter input into DeepONet to reduce training cost and adds derivative loss in the loss function to reduce the number of required parameter-solution pairs. We further demonstrate that the use of derivative loss can be extended to enhance other neural operators, such as the Fourier neural operator (FNO). Numerical experiments validate the effectiveness of our approach.
tl;dr: We automate PDDL file generation for planning problems using LLMs and environment interaction

Large Language Models (LLMs) have shown remarkable performance in various natural language tasks, but they often struggle with planning problems that require structured reasoning. To address this limitation, the conversion of planning problems into the Planning Domain Definition Language (PDDL) has been proposed as a potential solution, enabling the use of automated planners. However, generating accurate PDDL files typically demands human inputs or correction, which can be time-consuming and costly. In this paper, we propose a novel approach that leverages LLMs and environment feedback to automatically generate PDDL domain and problem description files without the need for human intervention. Our method introduces an iterative refinement process that generates multiple problem PDDL candidates and progressively refines the domain PDDL based on feedback obtained from interacting with the environment. To guide the refinement process, we develop an Exploration Walk (EW) metric, which provides rich feedback signals for LLMs to update the PDDL file. We evaluate our approach on $10$ PDDL environments. We achieve an average task solve rate of 66\% compared to a 29\% solve rate by GPT-4's intrinsic planning with chain-of-thought prompting. Our work enables the automated modeling of planning environments using LLMs and environment feedback, eliminating the need for human intervention in the PDDL translation process and paving the way for more reliable LLM agents in challenging problems. Our code is available at https://github.com/BorealisAI/llm-pddl-planning

The vulnerability of deep neural networks to imperceptible adversarial perturbations has attracted widespread attention. Inspired by the success of vision-language foundation models, previous efforts achieved zero-shot adversarial robustness by aligning adversarial visual features with text supervision. However, in practice, they are still unsatisfactory due to several issues, including heavy adaptation cost, suboptimal text supervision, and uncontrolled natural generalization capacity. In this paper, to address these issues, we propose a few-shot adversarial prompt framework where adapting input sequences with limited data makes significant adversarial robustness improvement. Specifically, we achieve this by providing adversarially correlated text supervision that is end-to-end learned from adversarial examples. We also propose a novel training objective that enhances the consistency of multi-modal features while encourages differentiated uni-modal features between natural and adversarial examples. The proposed framework gives access to learn adversarial text supervision, which provides superior cross-modal adversarial alignment and matches state-of-the-art zero-shot adversarial robustness with only 1\% training data. Code is available at: https://github.com/lionel-w2/FAP.
tl;dr: This work introduces Dual-domain Dynamic Normalization (DDN) to dynamically captures distribution variations in both time and frequency domains.

Deep neural networks (DNNs) have recently achieved remarkable advancements in time series forecasting (TSF) due to their powerful ability of sequence dependence modeling. To date, existing DNN-based TSF methods still suffer from unreliable predictions for real-world data due to its non-stationarity characteristics, i.e., data distribution varies quickly over time. To mitigate this issue, several normalization methods (e.g., SAN) have recently been specifically designed by normalization in a fixed period/window in the time domain. However, these methods still struggle to capture distribution variations, due to the complex time patterns of time series in the time domain. Based on the fact that wavelet transform can decompose time series into a linear combination of different frequencies, which exhibits distribution variations with time-varying periods, we propose a novel Dual-domain Dynamic Normalization (DDN) to dynamically capture distribution variations in both time and frequency domains. Specifically, our DDN tries to eliminate the non-stationarity of time series via both frequency and time domain normalization in a sliding window way. Besides, our DDN can serve as a plug-in-play module, and thus can be easily incorporated into other forecasting models. Extensive experiments on public benchmark datasets under different forecasting models demonstrate the superiority of our DDN over other normalization methods. Code will be made available following the review process.

In the realm of image quantization exemplified by VQGAN, the process encodes images into discrete tokens drawn from a codebook with a predefined size. Recent advancements, particularly with LLAMA 3, reveal that enlarging the codebook significantly enhances model performance. However, VQGAN and its derivatives, such as VQGAN-FC (Factorized Codes) and VQGAN-EMA, continue to grapple with challenges related to expanding the codebook size and enhancing codebook utilization. For instance, VQGAN-FC is restricted to learning a codebook with a maximum size of 16,384, maintaining a typically low utilization rate of less than 12% on ImageNet. In this work, we propose a novel image quantization model named VQGAN-LC (Large Codebook), which extends the codebook size to 100,000, achieving an utilization rate exceeding 99%. Unlike previous methods that optimize each codebook entry, our approach begins with a codebook initialized with 100,000 features extracted by a pre-trained vision encoder. Optimization then focuses on training a projector that aligns the entire codebook with the feature distributions of the encoder in VQGAN-LC. We demonstrate the superior performance of our model over its counterparts across a variety of tasks, including image reconstruction, image classification, auto-regressive image generation using GPT, and image creation with diffusion- and flow-based generative models.
tl;dr: We develop an intervention function that dynamically shares control between a human operator and assistive AI agent by choosing the control that maximizes expected future returns.

The rapid development of artificial intelligence (AI) has unearthed the potential to assist humans in controlling advanced technologies. Shared autonomy (SA) facilitates control by combining inputs from a human pilot and an AI copilot. In prior SA studies, the copilot is constantly active in determining the action played at each time step. This limits human autonomy that may have deleterious effects on performance. In general, the amount of helpful copilot assistance varies greatly depending on the task dynamics. We therefore hypothesized that human autonomy and SA performance improves through dynamic and selective copilot intervention. To address this, we develop a goal-agnostic intervention assistance (IA) that dynamically shares control by having the copilot intervene only when the expected value of the copilot’s action exceeds that of the human’s action. We implement IA with a diffusion copilot (termed IDA) trained on expert demonstrations with goal masking. We prove that IDA performance is lower bounded by human performance, so that IDA does not negatively impact human control. In experiments with simulated human pilots, we show that IDA achieves higher performance than both pilot-only and traditional SA control in variants of the Reacher environment and Lunar Lander. We then demonstrate with human-in the-loop experiments that IDA achieves better control in Lunar Lander and that human participants experience greater autonomy and prefer IDA over pilot-only and traditional SA control. We attribute the success of IDA to preserving human autonomy while simultaneously offering assistance to prevent the human from entering universally bad states.

The deployment of ever-larger machine learning models reflects a growing consensus that the more expressive the model class one optimizes over—and the more data one has access to—the more one can improve performance. As models get deployed in a variety of real-world scenarios, they inevitably face strategic environments. In this work, we consider the natural question of how the interplay of models and strategic interactions affects the relationship between performance at equilibrium and the expressivity of model classes. We find that strategic interactions can break the conventional view—meaning that performance does not necessarily monotonically improve as model classes get larger or more expressive (even with infinite data). We show the implications of this result in several contexts including strategic regression, strategic classification, and multi-agent reinforcement learning. In particular, we show that each of these settings admits a Braess' paradox-like phenomenon in which optimizing over less expressive model classes allows one to achieve strictly better equilibrium outcomes. Motivated by these examples, we then propose a new paradigm for model selection in games wherein an agent seeks to choose amongst different model classes to use as their action set in a game.

Link prediction, which aims to forecast unseen connections in graphs, is a fundamental task in graph machine learning. Heuristic methods, leveraging a range of different pairwise measures such as common neighbors and shortest paths, often rival the performance of vanilla Graph Neural Networks (GNNs). Therefore, recent advancements in GNNs for link prediction (GNN4LP) have primarily focused on integrating one or a few types of pairwise information.
In this work, we reveal that different node pairs within the same dataset necessitate varied pairwise information for accurate prediction and models that only apply the same pairwise information uniformly could achieve suboptimal performance.
As a result, we propose a simple mixture of experts model Link-MoE for link prediction. Link-MoE utilizes various GNNs as experts and strategically selects the appropriate expert for each node pair based on various types of pairwise information. Experimental results across diverse real-world datasets demonstrate substantial performance improvement from Link-MoE. Notably, Link-Mo achieves a relative improvement of 18.71% on the MRR metric for the Pubmed dataset and 9.59% on the Hits@100 metric for the ogbl-ppa dataset, compared to the best baselines. The code is available at https://github.com/ml-ml/Link-MoE/.
tl;dr: UGC is a graph coarsening framework which is extremely fast, has lower eigen-error, and yields superior performance on downstream processing tasks.

In the era of big data, graphs have emerged as a natural representation of intricate relationships. However, graph sizes often become unwieldy, leading to storage, computation, and analysis challenges. A crucial demand arises for methods that can effectively downsize large graphs while retaining vital insights. Graph coarsening seeks to simplify large graphs while maintaining the basic statistics of the graphs, such as spectral properties and $\epsilon$-similarity in the coarsened graph. This ensures that downstream processes are more efficient and effective. Most published methods are suitable for homophilic datasets, limiting their universal use. We propose **U**niversal **G**raph **C**oarsening (UGC), a framework equally suitable for homophilic and heterophilic datasets. UGC integrates node attributes and adjacency information, leveraging the dataset's heterophily factor. Results on benchmark datasets demonstrate that UGC preserves spectral similarity while coarsening. In comparison to existing methods, UGC is 4x to 15x faster, has lower eigen-error, and yields superior performance on downstream processing tasks even at 70% coarsening ratios.

This paper introduces SICSM, a novel structural inference framework that integrates Selective State Space Models (selective SSMs) with Generative Flow Networks (GFNs) to handle the challenges posed by dynamical systems with irregularly sampled trajectories and partial observations.
By utilizing the robust temporal modeling capabilities of selective SSMs, our approach learns input-dependent transition functions that adapt to non-uniform time intervals, thereby enhancing the accuracy of structural inference.
By aggregating dynamics across diverse temporal dependencies and channeling them into the GFN, the SICSM adeptly approximates the posterior distribution of the system's structure.
This process not only enables precise inference of complex interactions within partially observed systems but also ensures the seamless integration of prior knowledge, enhancing the model’s accuracy and robustness.
Extensive evaluations on sixteen diverse datasets demonstrate that SICSM outperforms existing methods, particularly in scenarios characterized by irregular sampling and incomplete observations, which highlight its potential as a reliable tool for scientific discovery and system diagnostics in disciplines that demand precise modeling of complex interactions.
SGD performs worse than Adam by a significant margin on Transformers, but the reason remains unclear. In this work, we provide an explanation through the lens of Hessian: (i) Transformers are "heterogeneous'': the Hessian spectrum across parameter blocks vary dramatically, a phenomenon we call "block heterogeneity"; (ii) Heterogeneity hampers SGD: SGD performs worse than Adam on problems with block heterogeneity. To validate (i) and (ii), we check various Transformers, CNNs, MLPs, and quadratic problems, and find that SGD can perform on par with Adam on problems without block heterogeneity, but performs worse than Adam when the heterogeneity exists. Our initial theoretical analysis indicates that SGD performs worse because it applies one single learning rate to all blocks, which cannot handle the heterogeneity among blocks. This limitation could be ameliorated if we use coordinate-wise learning rates, as designed in Adam.

We introduce the first algorithmic framework for Blackwell approachability on the sequence-form polytope, the class of convex polytopes capturing the strategies of players in extensive-form games (EFGs).
This leads to a new class of regret-minimization algorithms that are stepsize-invariant, in the same sense as the Regret Matching and Regret Matching$^+$ algorithms for the simplex.
Our modular framework can be combined with any existing regret minimizer over cones to compute a Nash equilibrium in two-player zero-sum EFGs with perfect recall, through the self-play framework. Leveraging predictive online mirror descent, we introduce *Predictive Treeplex Blackwell$^+$* (PTB$^+$), and show a $O(1/\sqrt{T})$ convergence rate to Nash equilibrium in self-play. We then show how to stabilize PTB$^+$ with a stepsize, resulting in an algorithm with a state-of-the-art $O(1/T)$ convergence rate.
We provide an extensive set of experiments to compare our framework with several algorithmic benchmarks, including CFR$^+$ and its predictive variant, and we highlight interesting connections between practical performance and the stepsize-dependence or stepsize-invariance properties of classical algorithms.

Neuroscience research has made immense progress over the last decade, but our understanding of the brain remains fragmented and piecemeal: the dream of probing an arbitrary brain region and automatically reading out the information encoded in its neural activity remains out of reach. In this work, we build towards a first foundation model for neural spiking data that can solve a diverse set of tasks across multiple brain areas. We introduce a novel self-supervised modeling approach for population activity in which the model alternates between masking out and reconstructing neural activity across different time steps, neurons, and brain regions. To evaluate our approach, we design unsupervised and supervised prediction tasks using the International Brain Laboratory repeated site dataset, which is comprised of Neuropixels recordings targeting the same brain locations across 48 animals and experimental sessions. The prediction tasks include single-neuron and region-level activity prediction, forward prediction, and behavior decoding. We demonstrate that our multi-task-masking (MtM) approach significantly improves the performance of current state-of-the-art population models and enables multi-task learning. We also show that by training on multiple animals, we can improve the generalization ability of the model to unseen animals, paving the way for a foundation model of the brain at single-cell, single-spike resolution.

When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
tl;dr: We present a novel solution to the prevalent problem of reward overoptimization in RLHF through adversarial policy optimization with lightweight uncertainty estimation.

Reinforcement Learning from Human Feedback (RLHF) has been pivotal in aligning Large Language Models with human values but often suffers from overoptimization due to its reliance on a proxy reward model. To mitigate this limitation, we first propose a lightweight uncertainty quantification method that assesses the reliability of the proxy reward using only the last layer embeddings of the reward model. Enabled by this efficient uncertainty quantification method, we formulate AdvPO, a distributionally robust optimization procedure to tackle the reward overoptimization problem in RLHF. Through extensive experiments on the Anthropic HH and TL;DR summarization datasets, we verify the effectiveness of AdvPO in mitigating the overoptimization problem, resulting in enhanced RLHF performance as evaluated through human-assisted evaluation.
tl;dr: A transformer-based OCR/HTR approach that performs explicit character detection and we demonstrate to be very general.

We introduces a general detection-based approach to text line recognition, be it printed (OCR) or handwritten text (HTR), with latin, chinese or ciphered characters. Detection based approaches have until now largely been discarded for HTR because reading characters separately is often challenging, and character-level annotation is difficult and expensive. We overcome these challenges thanks to three main insights: (i) synthetic pre-training with diverse enough data enables to learn reasonable characters localization in any script; (ii) modern transformer-based detectors can jointly detect a large number of instances and, if trained with an adequate masking strategy, leverage consistency between the different detections; (iii) once a pre-trained detection model with approximate character localization is available, it is possible to fine-tune it with line-level annotation on real data, even with a different alphabet. Our approach thus builds on a completely different paradigm than most state-of-the-art methods, which rely on autoregressive decoding, predicting character values one by one, while we treat a complete line in parallel. Remarkably, our method demonstrates good performance on range of scripts, usually tackled with specialized approaches: latin script, chinese script, and ciphers, for which we significantly improve state-of-the-art performances.
tl;dr: Integration of emotions into LLMs in Ethics and Game Theory settings reveal significant and consistent effects on decision-making.

One of the urgent tasks of artificial intelligence is to assess the safety and alignment of large language models (LLMs) with human behavior. Conventional verification only in pure natural language processing benchmarks can be insufficient. Since emotions often influence human decisions, this paper examines LLM alignment in complex strategic and ethical environments, providing an in-depth analysis of the drawbacks of our psychology and the emotional impact on decision-making in humans and LLMs. We introduce the novel EAI framework for integrating emotion modeling into LLMs to examine the emotional impact on ethics and LLM-based decision-making in various strategic games, including bargaining and repeated games. Our experimental study with various LLMs demonstrated that emotions can significantly alter the ethical decision-making landscape of LLMs, highlighting the need for robust mechanisms to ensure consistent ethical standards. Our game-theoretic analysis revealed that LLMs are susceptible to emotional biases influenced by model size, alignment strategies, and primary pretraining language. Notably, these biases often diverge from typical human emotional responses, occasionally leading to unexpected drops in cooperation rates, even under positive emotional influence. Such behavior complicates the alignment of multiagent systems, emphasizing the need for benchmarks that can rigorously evaluate the degree of emotional alignment. Our framework provides a foundational basis for developing such benchmarks.
1457. Evaluating alignment between humans and neural network representations in image-based learning tasks
tl;dr: We compare humans and various pretrained neural networks in image-based learning tasks and identify factors that make neural networks perform more human-like.

Humans represent scenes and objects in rich feature spaces, carrying information that allows us to generalise about category memberships and abstract functions with few examples. What determines whether a neural network model generalises like a human? We tested how well the representations of $86$ pretrained neural network models mapped to human learning trajectories across two tasks where humans had to learn continuous relationships and categories of natural images. In these tasks, both human participants and neural networks successfully identified the relevant stimulus features within a few trials, demonstrating effective generalisation. We found that while training dataset size was a core determinant of alignment with human choices, contrastive training with multi-modal data (text and imagery) was a common feature of currently publicly available models that predicted human generalisation. Intrinsic dimensionality of representations had different effects on alignment for different model types. Lastly, we tested three sets of human-aligned representations and found no consistent improvements in predictive accuracy compared to the baselines. In conclusion, pretrained neural networks can serve to extract representations for cognitive models, as they appear to capture some fundamental aspects of cognition that are transferable across tasks. Both our paradigms and modelling approach offer a novel way to quantify alignment between neural networks and humans and extend cognitive science into more naturalistic domains.
1458. MoTE: Reconciling Generalization with Specialization for Visual-Language to Video Knowledge Transfer
tl;dr: This paper presents MoTE, a knowledge transfer framework that addresses the generalization and specialization trade-off problem when transferring VLMs to the video domain, achieving an optimal balance between close-set and zero-shot performance.

Transferring visual-language knowledge from large-scale foundation models for video recognition has proved to be effective. To bridge the domain gap, additional parametric modules are added to capture the temporal information. However, zero-shot generalization diminishes with the increase in the number of specialized parameters, making existing works a trade-off between zero-shot and close-set performance. In this paper, we present MoTE, a novel framework that enables generalization and specialization to be balanced in one unified model. Our approach tunes a mixture of temporal experts to learn multiple task views with various degrees of data fitting. To maximally preserve the knowledge of each expert, we propose Weight Merging Regularization, which regularizes the merging process of experts in weight space. Additionally with temporal feature modulation to regularize the contribution of temporal feature during test. We achieve a sound balance between zero-shot and close-set video recognition tasks and obtain state-of-the-art or competitive results on various datasets, including Kinetics-400 \& 600, UCF, and HMDB. Code is available at https://github.com/ZMHH-H/MoTE.
tl;dr: We present a novel differentiable framework to effectively align current vision models with human reaction times and behavioral choices

Current neural network models of primate vision focus on replicating overall levels of behavioral accuracy, often neglecting perceptual decisions' rich, dynamic nature. Here, we introduce a novel computational framework to model the dynamics of human behavioral choices by learning to align the temporal dynamics of a recurrent neural network (RNN) to human reaction times (RTs). We describe an approximation that allows us to constrain the number of time steps an RNN takes to solve a task with human RTs. The approach is extensively evaluated against various psychophysics experiments. We also show that the approximation can be used to optimize an ``ideal-observer'' RNN model to achieve an optimal tradeoff between speed and accuracy without human data. The resulting model is found to account well for human RT data. Finally, we use the approximation to train a deep learning implementation of the popular Wong-Wang decision-making model. The model is integrated with a convolutional neural network (CNN) model of visual processing and evaluated using both artificial and natural image stimuli. Overall, we present a novel framework that helps align current vision models with human behavior, bringing us closer to an integrated model of human vision.
tl;dr: We introduce Hassle-Free Textual Training (HFTT), a method designed to improve the performance of VLMs in identifying unwanted visual data, utilizing solely synthetic textual data.

In our study, we explore methods for detecting unwanted content lurking in visual datasets. We provide a theoretical analysis demonstrating that a model capable of successfully partitioning visual data can be obtained using only textual data. Based on the analysis, we propose Hassle-Free Textual Training (HFTT), a streamlined method capable of acquiring detectors for unwanted visual content, using only textual data in conjunction with pre-trained vision-language models. HFTT features an innovative objective function that significantly reduces the necessity for human involvement in data annotation. Furthermore, HFTT employs a clever textual data synthesis method, effectively emulating the integration of unknown visual data distribution into the training process at no extra cost. The unique characteristics of HFTT extend its utility beyond traditional out-of-distribution detection, making it applicable to tasks that address more abstract concepts. We complement our analyses with experiments in hateful image detection and out-of-distribution detection. Our codes are available at https://github.com/HFTT-anonymous/HFTT.
1461. Federated Behavioural Planes: Explaining the Evolution of Client Behaviour in Federated Learning
tl;dr: We introduce Federated Behavioural Planes (FBPs), a novel method to analyse, visualise, and explain the dynamics of FL systems, showing how clients behave under two different lenses: predictive performance and decision-making processes.

Federated Learning (FL), a privacy-aware approach in distributed deep learning environments, enables many clients to collaboratively train a model without sharing sensitive data, thereby reducing privacy risks. However, enabling human trust and control over FL systems requires understanding the evolving behaviour of clients, whether beneficial or detrimental for the training, which still represents a key challenge in the current literature. To address this challenge, we introduce Federated Behavioural Planes (FBPs), a novel method to analyse, visualise, and explain the dynamics of FL systems, showing how clients behave under two different lenses: predictive performance (error behavioural space) and decision-making processes (counterfactual behavioural space). Our experiments demonstrate that FBPs provide informative trajectories describing the evolving states of clients and their contributions to the global model, thereby enabling the identification of clusters of clients with similar behaviours. Leveraging the patterns identified by FBPs, we propose a robust aggregation technique named Federated Behavioural Shields to detect malicious or noisy client models, thereby enhancing security and surpassing the efficacy of existing state-of-the-art FL defense mechanisms. Our code is publicly available on GitHub.
tl;dr: We propose to leverage both differentiable rendering and differentiable physics simulation for neural scene reconstruction

We address the issue of physical implausibility in multi-view neural reconstruction. While implicit representations have gained popularity in multi-view 3D reconstruction, previous work struggles to yield physically plausible results, limiting their utility in domains requiring rigorous physical accuracy. This lack of plausibility stems from the absence of physics modeling in existing methods and their inability to recover intricate geometrical structures. In this paper, we introduce PHYRECON, the first approach to leverage both differentiable rendering and differentiable physics simulation to learn implicit surface representations. PHYRECON features a novel differentiable particle-based physical simulator built on neural implicit representations. Central to this design is an efficient transformation between SDF-based implicit representations and explicit surface points via our proposed Surface Points Marching Cubes (SP-MC), enabling differentiable learning with both rendering and physical losses. Additionally, PHYRECON models both rendering and physical uncertainty to identify and compensate for inconsistent and inaccurate monocular geometric priors. The physical uncertainty further facilitates physics-guided pixel sampling to enhance the learning of slender structures. By integrating these techniques, our model supports differentiable joint modeling of appearance, geometry, and physics. Extensive experiments demonstrate that PHYRECON significantly improves the reconstruction quality. Our results also exhibit superior physical stability in physical simulators, with at least a 40% improvement across all datasets, paving the way for future physics-based applications.

Ultra-high-resolution image generation poses great challenges, such as increased semantic planning complexity and detail synthesis difficulties, alongside substantial training resource demands. We present UltraPixel, a novel architecture utilizing cascade diffusion models to generate high-quality images at multiple resolutions (\textit{e.g.}, 1K, 2K, and 4K) within a single model, while maintaining computational efficiency. UltraPixel leverages semantics-rich representations of lower-resolution images in a later denoising stage to guide the whole generation of highly detailed high-resolution images, significantly reducing complexity. Specifically, we introduce implicit neural representations for continuous upsampling and scale-aware normalization layers adaptable to various resolutions. Notably, both low- and high-resolution processes are performed in the most compact space, sharing the majority of parameters with less than 3$\%$ additional parameters for high-resolution outputs, largely enhancing training and inference efficiency. Our model achieves fast training with reduced data requirements, producing photo-realistic high-resolution images and demonstrating state-of-the-art performance in extensive experiments.
tl;dr: We theoretically analyze the reversal curse of LLM via training dynamics of a bilinear model and one-layer transformers

Auto-regressive large language models (LLMs) show impressive capacities to solve many complex reasoning tasks while struggling with some simple logical reasoning tasks such as inverse search: when trained on ''$A \to B$'' (e.g., *Tom is the parent of John*), LLM fails to directly conclude ''$B \gets A$'' (e.g., *John is the child of Tom*) during inference even if the two sentences are semantically identical, which is known as the ''reversal curse''. In this paper, we theoretically analyze the reversal curse via the training dynamics of (stochastic) gradient descent for two auto-regressive models: (1) a bilinear model that can be viewed as a simplification of a one-layer transformer; (2) one-layer transformers under certain assumptions. Our analysis reveals that for both models, the reversal curse is a consequence of the (effective) model weights *asymmetry*, i.e., the increase of weights from a token $A$ to token $B$ during training does not necessarily cause the increase of the weights from $B$ to $A$, which is caused by the training dynamics under certain choice of loss function and the optimization space of model parameters. Moreover, our analysis can be naturally applied to other logical reasoning tasks such as chain-of-thought (COT), which provides a new perspective different from previous work that focuses on expressivity. Finally, we conduct experiments to validate our theory on multi-layer transformers under different settings. Our code is available at [https://github.com/marlo-z/reversal_curse_analysis/](https://github.com/marlo-z/reversal_curse_analysis/).

We present BricksRL, a platform designed to democratize access to robotics for reinforcement learning research and education. BricksRL facilitates the creation, design, and training of custom LEGO robots in the real world by interfacing them with the TorchRL library for reinforcement learning agents. The integration of TorchRL with the LEGO hubs, via Bluetooth bidirectional communication, enables state-of-the-art reinforcement learning training on GPUs for a wide variety of LEGO builds. This offers a flexible and cost-efficient approach for scaling and also provides a robust infrastructure for robot-environment-algorithm communication. We present various experiments across tasks and robot configurations, providing built plans and training results. Furthermore, we demonstrate that inexpensive LEGO robots can be trained end-to-end in the real world to achieve simple tasks, with training times typically under 120 minutes on a normal laptop. Moreover, we show how users can extend the capabilities, exemplified by the successful integration of non-LEGO sensors. By enhancing accessibility to both robotics and reinforcement learning, BricksRL establishes a strong foundation for democratized robotic learning in research and educational settings.
tl;dr: We propose a novel spatial-temporal Mamba based approach for dynamic NLOS reconstruction, as well as a new dataset for training and testing.

Dynamic reconstruction in confocal non-line-of-sight imaging encounters great challenges since the dense raster-scanning manner limits the practical frame rate. A fewer pioneer works reconstruct high-resolution volumes from the under-scanning transient measurements but overlook temporal consistency among transient frames. To fully exploit multi-frame information, we propose the first spatial-temporal Mamba (ST-Mamba) based method tailored for dynamic reconstruction of transient videos. Our method capitalizes on neighbouring transient frames to aggregate the target 3D hidden volume. Specifically, the interleaved features extracted from the input transient frames are fed to the proposed ST-Mamba blocks, which leverage the time-resolving causality in transient measurement. The cross ST-Mamba blocks are then devised to integrate the adjacent transient features. The target high-resolution transient frame is subsequently recovered by the transient spreading module. After transient fusion and recovery, a physical-based network is employed to reconstruct the hidden volume. To tackle the substantial noise inherent in transient videos, we propose a wave-based loss function to impose constraints within the phasor field. Besides, we introduce a new dataset, comprising synthetic videos for training and real-world videos for evaluation. Extensive experiments showcase the superior performance of our method on both synthetic data and real world data captured by different imaging setups. The code and data are available at https://github.com/Depth2World/Dynamic_NLOS.

This paper considers the problem of sampling from non-logconcave distribution, based on queries of its unnormalized density. It first describes a framework, Denoising Diffusion Monte Carlo (DDMC), based on the simulation of a denoising diffusion process with its score function approximated by a generic Monte Carlo estimator. DDMC is an oracle-based meta-algorithm, where its oracle is the assumed access to samples that generate a Monte Carlo score estimator. Then we provide an implementation of this oracle, based on rejection sampling, and this turns DDMC into a true algorithm, termed Zeroth-Order Diffusion Monte Carlo (ZOD-MC). We provide convergence analyses by first constructing a general framework, i.e. a performance guarantee for DDMC, without assuming the target distribution to be log-concave or satisfying any isoperimetric inequality. Then we prove that ZOD-MC admits an inverse polynomial dependence on the desired sampling accuracy, albeit still suffering from the curse of dimensionality. Consequently, for low dimensional distributions, ZOD-MC is a very efficient sampler, with performance exceeding latest samplers, including also-denoising-diffusion-based RDMC and RSDMC. Last, we experimentally demonstrate the insensitivity of ZOD-MC to increasingly higher barriers between modes or discontinuity in non-convex potential.

We consider the problem of segmenting objects in videos based on their motion and no other forms of supervision. Prior work has often approached this problem by using the principle of common fate, namely the fact that the motion of points that belong to the same object is strongly correlated. However, most authors have only considered instantaneous motion from optical flow. In this work, we present a way to train a segmentation network using long-term point trajectories as a supervisory signal to complement optical flow. The key difficulty is that long-term motion, unlike instantaneous motion, is difficult to model -- any parametric approximation is unlikely to capture complex motion patterns over long periods of time. We instead draw inspiration from subspace clustering approaches, proposing a loss function that seeks to group the trajectories into low-rank matrices where the motion of object points can be approximately explained as a linear combination of other point tracks. Our method outperforms the prior art on motion-based segmentation, which shows the utility of long-term motion and the effectiveness of our formulation.

One of the fundamental challenges for offline reinforcement learning (RL) is ensuring robustness to data distribution. Whether the data originates from a near-optimal policy or not, we anticipate that an algorithm should demonstrate its ability to learn an effective control policy that seamlessly aligns with the inherent distribution of offline data. Unfortunately, behavior regularization, a simple yet effective offline RL algorithm, tends to struggle in this regard. In this paper, we propose a new algorithm that substantially enhances behavior-regularization based on conservative policy iteration. Our key observation is that by iteratively refining the reference policy used for behavior regularization, conservative policy update guarantees gradually improvement, while also implicitly avoiding querying out-of-sample actions to prevent catastrophic learning failures. We prove that in the tabular setting this algorithm is capable of learning the optimal policy covered by the offline dataset, commonly referred to as the in-sample optimal policy. We then explore several implementation details of the algorithm when function approximations are applied. The resulting algorithm is easy to implement, requiring only a few lines of code modification to existing methods. Experimental results on the D4RL benchmark indicate that our method outperforms previous state-of-the-art baselines in most tasks, clearly demonstrate its superiority over behavior regularization.
tl;dr: A novel diffusion-driven facial parts swapping methods with multiple reference images.

Facial parts swapping aims to selectively transfer regions of interest from the source image onto the target image while maintaining the rest of the target image unchanged.
Most studies on face swapping designed specifically for full-face swapping, are either unable or significantly limited when it comes to swapping individual facial parts, which hinders fine-grained and customized character designs.
However, designing such an approach specifically for facial parts swapping is challenged by a reasonable multiple reference feature fusion, which needs to be both efficient and effective.
To overcome this challenge, FuseAnyPart is proposed to facilitate the seamless "fuse-any-part" customization of the face.
In FuseAnyPart, facial parts from different people are assembled into a complete face in latent space within the Mask-based Fusion Module.
Subsequently, the consolidated feature is dispatched to the Addition-based Injection Module for
fusion within the UNet of the diffusion model to create novel characters.
Extensive experiments qualitatively and quantitatively validate the superiority and robustness of FuseAnyPart.
Source codes are available at https://github.com/Thomas-wyh/FuseAnyPart.
tl;dr: We propose a new memory model framework and batching method to improve time, space, and sample efficiency in POMDPs

Memory models such as Recurrent Neural Networks (RNNs) and Transformers address Partially Observable Markov Decision Processes (POMDPs) by mapping trajectories to latent Markov states. Neither model scales particularly well to long sequences, especially compared to an emerging class of memory models called Linear Recurrent Models. We discover that the recurrent update of these models resembles a monoid, leading us to reformulate existing models using a novel monoid-based framework that we call memoroids. We revisit the traditional approach to batching in recurrent reinforcement learning, highlighting theoretical and empirical deficiencies. We leverage memoroids to propose a batching method that improves sample efficiency, increases the return, and simplifies the implementation of recurrent loss functions in reinforcement learning.
tl;dr: We give bounds for adversarially robust transfer learning.

We study adversarially robust transfer learning, wherein, given labeled data on multiple (source) tasks, the goal is to train a model with small robust error on a previously unseen (target) task.
In particular, we consider a multi-task representation learning (MTRL) setting, i.e., we assume that the source and target tasks admit a simple (linear) predictor on top of a shared representation (e.g., the final hidden layer of a
deep neural network).
In this general setting, we provide rates on~the excess adversarial (transfer) risk for Lipschitz losses and smooth nonnegative losses.
These rates show that learning a representation using adversarial training on diverse tasks helps protect against inference-time attacks in data-scarce environments.
Additionally, we provide novel rates for the single-task setting.
tl;dr: Tokenization methods from NLP lead to much faster skill-extraction which can help solve very difficult sparse-reward RL tasks.

Exploration in sparse-reward reinforcement learning (RL) is difficult due to the need for long, coordinated sequences of actions in order to achieve any reward. Skill learning, from demonstrations or interaction, is a promising approach to address this, but skill extraction and inference are expensive for current methods. We present a novel method to extract skills from demonstrations for use in sparse-reward RL, inspired by the popular Byte-Pair Encoding (BPE) algorithm in natural language processing. With these skills, we show strong performance in a variety of tasks, 1000$\times$ acceleration for skill-extraction and 100$\times$ acceleration for policy inference. Given the simplicity of our method, skills extracted from 1\% of the demonstrations in one task can be transferred to a new loosely related task. We also note that such a method yields a finite set of interpretable behaviors. Our code is available at https://github.com/dyunis/subwords_as_skills.
tl;dr: Light propagation can be programmed to perform denoising diffusion efficiently by transmitting through learned modulation layers.

Diffusion models generate new samples by progressively decreasing the noise from the initially provided random distribution. This inference procedure generally utilizes a trained neural network numerous times to obtain the final output, creating significant latency and energy consumption on digital electronic hardware such as GPUs. In this study, we demonstrate that the propagation of a light beam through a transparent medium can be programmed to implement a denoising diffusion model on image samples. This framework projects noisy image patterns through passive diffractive optical layers, which collectively only transmit the predicted noise term in the image. The optical transparent layers, which are trained with an online training approach, backpropagating the error to the analytical model of the system, are passive and kept the same across different steps of denoising. Hence this method enables high-speed image generation with minimal power consumption, benefiting from the bandwidth and energy efficiency of optical information processing.

To address the uncertainty in function types, recent progress in online convex optimization (OCO) has spurred the development of universal algorithms that simultaneously attain minimax rates for multiple types of convex functions. However, for a $T$-round online problem, state-of-the-art methods typically conduct $O(\log T)$ projections onto the domain in each round, a process potentially time-consuming with complicated feasible sets. In this paper, inspired by the black-box reduction of Cutkosky and Orabona [2018], we employ a surrogate loss defined over simpler domains to develop universal OCO algorithms that only require $1$ projection. Embracing the framework of prediction with expert advice, we maintain a set of experts for each type of functions and aggregate their predictions via a meta-algorithm. The crux of our approach lies in a uniquely designed expert-loss for strongly convex functions, stemming from an innovative decomposition of the regret into the meta-regret and the expert-regret. Our analysis sheds new light on the surrogate loss, facilitating a rigorous examination of the discrepancy between the regret of the original loss and that of the surrogate loss, and carefully controlling meta-regret under the strong convexity condition. With only $1$ projection per round, we establish optimal regret bounds for general convex, exponentially concave, and strongly convex functions simultaneously. Furthermore, we enhance the expert-loss to exploit the smoothness property, and demonstrate that our algorithm can attain small-loss regret for multiple types of convex and smooth functions.

Intelligent agents must be generalists, capable of quickly adapting to various tasks. In reinforcement learning (RL), model-based RL learns a dynamics model of the world, in principle enabling transfer to arbitrary reward functions through planning. However, autoregressive model rollouts suffer from compounding error, making model-based RL ineffective for long-horizon problems. Successor features offer an alternative by modeling a policy's long-term state occupancy, reducing policy evaluation under new rewards to linear regression. Yet, policy optimization with successor features can be challenging. This work proposes a novel class of models, i.e., Distributional Successor Features for Zero-Shot Policy Optimization (DiSPOs), that learn a distribution of successor features of a stationary dataset's behavior policy, along with a policy that acts to realize different successor features within the dataset. By directly modeling long-term outcomes in the dataset, DiSPOs avoid compounding error while enabling a simple scheme for zero-shot policy optimization across reward functions. We present a practical instantiation of DiSPOs using diffusion models and show their efficacy as a new class of transferable models, both theoretically and empirically across various simulated robotics problems. Videos and code are available at https://weirdlabuw.github.io/dispo/.
tl;dr: Our paper derives and validates a data-driven approach to construct non-asymptotic confidence intervals for high-dimensional regression that overcomes the issues faced by previous asymptotic uncertainty quantification techniques.

Uncertainty quantification (UQ) is a crucial but challenging task in many high-dimensional learning problems to increase the confidence of a given predictor. We develop a new data-driven approach for UQ in regression that applies both to classical optimization approaches such as the LASSO as well as to neural networks. One of the most notable UQ techniques is the debiased LASSO, which modifies the LASSO to allow for the construction of asymptotic confidence intervals by decomposing the estimation error into a Gaussian and an asymptotically vanishing bias component. However, in real-world problems with finite-dimensional data, the bias term is often too significant to disregard, resulting in overly narrow confidence intervals. Our work rigorously addresses this issue and derives a data-driven adjustment that corrects the confidence intervals for a large class of predictors by estimating the means and variances of the bias terms from training data, exploiting high-dimensional concentration phenomena. This gives rise to non-asymptotic confidence intervals, which can help avoid overestimating certainty in critical applications such as MRI diagnosis. Importantly, our analysis extends beyond sparse regression to data-driven predictors like neural networks, enhancing the reliability of model-based deep learning. Our findings bridge the gap between established theory and the practical applicability of such methods.

Multiobjective optimization (MOO) plays a critical role in various real-world domains. A major challenge therein is generating $K$ uniform Pareto-optimal solutions that represent the entire Pareto front. To address the very challenge, this study first introduces \emph{fill distance} to evaluate the $K$ design points, which provides a quantitative metric for the representativeness of the design. However, the direct specification of the optimal design that minimizes fill distance is almost intractable considering the nested $\min-\max-\min$ optimization problem. We further propose a surrogate to the fill distance, which is easier to optimize and induce a rate-optimal design whose fill distance proves at most $4\times$ the minimum one. Rigorous derivation also shows that asymptotically this induced design will converge to the uniform measure over the Pareto front. Extensive experiments on synthetic and real-world benchmarks demonstrate that our proposed paradigm efficiently produces high-quality, representative solutions and outperforms baseline methods.

Vision models excel in image classification but struggle to generalize to unseen data, such as classifying images from unseen domains or discovering novel categories. In this paper, we explore the relationship between logical reasoning and deep learning generalization in visual classification. A logical regularization termed L-Reg is derived which bridges a logical analysis framework to image classification. Our work reveals that L-Reg reduces the complexity of the model in terms of the feature distribution and classifier weights. Specifically, we unveil the interpretability brought by L-Reg, as it enables the model to extract the salient features, such as faces to persons, for classification. Theoretical analysis and experiments demonstrate that L-Reg enhances generalization across various scenarios, including multi-domain generalization and generalized category discovery. In complex real-world scenarios where images span unknown classes and unseen domains, L-Reg consistently improves generalization, highlighting its practical efficacy.
tl;dr: near-Subgaussian convergence rates for streaming statistical estimation for clipped SGD in the presence of heavy-tailed data.

$\newcommand{\Tr}{\mathsf{Tr}}$
We consider the problem of high-dimensional heavy-tailed statistical estimation in the streaming setting, which is much harder than the traditional batch setting due to memory constraints. We cast this problem as stochastic convex optimization with heavy tailed stochastic gradients, and prove that the widely used Clipped-SGD algorithm attains near-optimal sub-Gaussian statistical rates whenever the second moment of the stochastic gradient noise is finite. More precisely, with $T$ samples, we show that Clipped-SGD, for smooth and strongly convex objectives, achieves an error of $\sqrt{\frac{\Tr(\Sigma)+\sqrt{\Tr(\Sigma)\\|\Sigma\\|_2}\ln(\tfrac{\ln(T)}{\delta})}{T}}$ with probability $1-\delta$, where $\Sigma$ is the covariance of the clipped gradient. Note that the fluctuations (depending on $\tfrac{1}{\delta}$) are of lower order than the term $\Tr(\Sigma)$.
This improves upon the current best rate of
$\sqrt{\frac{\Tr(\Sigma)\ln(\tfrac{1}{\delta})}{T}}$ for Clipped-SGD, known \emph{only} for smooth and strongly convex objectives. Our results also extend to smooth convex and lipschitz convex objectives. Key to our result is a novel iterative refinement strategy for martingale concentration, improving upon the PAC-Bayes approach of \citet{catoni2018dimension}.
tl;dr: We give the first efficient algorithm for graph matching for correlated stochastic block models with two balanced communities.

We study learning problems on correlated stochastic block models with two balanced communities. Our main result gives the first efficient algorithm for graph matching in this setting. In the most interesting regime where the average degree is logarithmic in the number of vertices, this algorithm correctly matches all but a vanishing fraction of vertices with high probability, whenever the edge correlation parameter $s$ satisfies $s^2 > \alpha \approx 0.338$, where $\alpha$ is Otter's tree-counting constant. Moreover, we extend this to an efficient algorithm for exact graph matching whenever this is information-theoretically possible, positively resolving an open problem of Rácz and Sridhar (NeurIPS 2021). Our algorithm generalizes the recent breakthrough work of Mao, Wu, Xu, and Yu (STOC 2023), which is based on centered subgraph counts of a large family of trees termed chandeliers. A major technical challenge that we overcome is dealing with the additional estimation errors that are necessarily present due to the fact that, in relevant parameter regimes, the latent community partition cannot be exactly recovered from a single graph. As an application of our results, we give an efficient algorithm for exact community recovery using multiple correlated graphs in parameter regimes where it is information-theoretically impossible to do so using just a single graph.

Recent advancements in diffusion models and diffusion bridges primarily focus on finite-dimensional spaces, yet many real-world problems necessitate operations in infinite-dimensional function spaces for more natural and interpretable formulations.
In this paper, we present a theory of stochastic optimal control (SOC) tailored to infinite-dimensional spaces, aiming to extend diffusion-based algorithms to function spaces.
Specifically, we demonstrate how Doob’s $h$-transform, the fundamental tool for constructing diffusion bridges, can be derived from the SOC perspective and expanded to infinite dimensions.
This expansion presents a challenge, as infinite-dimensional spaces typically lack closed-form densities.
Leveraging our theory, we establish that solving the optimal control problem with a specific objective function choice is equivalent to learning diffusion-based generative models.
We propose two applications: 1) learning bridges between two infinite-dimensional distributions and 2) generative models for sampling from an infinite-dimensional distribution.
Our approach proves effective for diverse problems involving continuous function space representations, such as resolution-free images, time-series data, and probability density functions.

Neural Collapse (NC) was a recently discovered phenomenon that the output features and the classifier weights of the neural network converge to optimal geometric structures at the Terminal Phase of Training (TPT) under various losses. However, the relationship between these optimal structures at TPT and the classification performance remains elusive, especially in imbalanced learning. Even though it is noticed that fixing the classifier to an optimal structure can mitigate the minority collapse problem, the performance is still not comparable to the classical imbalanced learning methods with a learnable classifier. In this work, we find that the optimal structure can be designed to represent a better classification rule, and thus achieve better performance. In particular, we justify that, to achieve better classification, the features from the minor classes should align with more directions. This justification then yields a decision rule called the Generalized Classification Rule (GCR) and we also term these directions as the centers of the classes. Then we study the NC under an MSE-type loss via the Unconstrained Features Model (UFM) framework where (1) the features from a class tend to collapse to the mean of the corresponding centers of that class (named Neural Collapse to Multiple Centers (NCMC)) at the global optimum, and (2) the original classifier approximates a surrogate to GCR when NCMC occurs. Based on the analysis, we develop a strategy for determining the number of centers and propose a Cosine Loss function for the fixed classifier that induces NCMC. Our experiments have shown that the Cosine Loss can induce NCMC and has performance on long-tail classification comparable to the classical imbalanced learning methods.

In deep learning, model performance often deteriorates when trained on highly imbalanced datasets, especially when evaluation metrics require robust generalization across underrepresented classes. To address the challenges posed by imbalanced data distributions, this study introduces a novel method utilizing density ratio estimation for dynamic class weight adjustment, termed as Re-weighting with Density Ratio (RDR). Our method adaptively adjusts the importance of each class during training, mitigates overfitting on dominant classes and enhances model adaptability across diverse datasets. Extensive experiments conducted on various large scale benchmark datasets validate the effectiveness of our method. Results demonstrate substantial improvements in generalization capabilities, particularly under severely imbalanced conditions.
tl;dr: Guided by the theory of causation, we propose semantic decoupling and uncertainty modeling to conduct prompt tuning on CLIP for downstream tasks.

Foundational Vision-Language models such as CLIP have exhibited impressive generalization in downstream tasks. However, CLIP suffers from a two-level misalignment issue, i.e., task misalignment and data misalignment, when adapting to specific tasks. Soft prompt tuning has mitigated the task misalignment, yet the data misalignment remains a challenge. To analyze the impacts of the data misalignment, we revisit the pre-training and adaptation processes of CLIP and develop a structural causal model. We discover that while we expect to capture task-relevant information for downstream tasks accurately, the task-irrelevant knowledge impacts the prediction results and hampers the modeling of the true relationships between the images and the predicted classes. As task-irrelevant knowledge is unobservable, we leverage the front-door adjustment and propose Causality-Guided Semantic Decoupling and Classification (CDC) to mitigate the interference of task-irrelevant knowledge. Specifically, we decouple semantics contained in the data of downstream tasks and perform classification based on each semantic. Furthermore, we employ the Dempster-Shafer evidence theory to evaluate the uncertainty of each prediction generated by diverse semantics. Experiments conducted in multiple different settings have consistently demonstrated the effectiveness of CDC.

Recently, rapid advancements in Multi-Modal In-Context Learning (MM-ICL) have achieved notable success, which is capable of achieving superior performance across various tasks without requiring additional parameter tuning. However, the underlying rules for the effectiveness of MM-ICL remain under-explored. To fill this gap, this work aims to investigate the research question: "_What factors affect the performance of MM-ICL?_" To this end, we investigate extensive experiments on the three core steps of MM-ICL including demonstration retrieval, demonstration ordering, and prompt construction using 6 vision large language models and 20 strategies. Our findings highlight (1) the necessity of a multi-modal retriever for demonstration retrieval, (2) the importance of intra-demonstration ordering over inter-demonstration ordering, and (3) the enhancement of task comprehension through introductory instructions in prompts. We hope this study can serve as a foundational guide for optimizing MM-ICL strategies in future research.

Federated Learning (FL) is a prevalent machine learning paradigm designed to address challenges posed by heterogeneous client data while preserving data privacy.
Unlike distributed training, it typically orchestrates resource-constrained edge devices to communicate via a low-bandwidth communication network with a central server. This urges the development of more computation and communication efficient training algorithms. In this paper, we propose an efficient FL paradigm, where the local models in the clients are trained with low-precision operations and communicated with the server in low precision format, while only the model aggregation in the server is performed with high-precision computation. We surprisingly find that high precision models can be recovered from the low precision local models with proper aggregation in the server.
In this way, both the workload in the client-side and the communication cost can be significantly reduced. We theoretically show that our proposed paradigm can converge to the optimal solution as the training goes on, which demonstrates that low precision local training is enough for FL. Our paradigm can be integrated with existing FL algorithms flexibly. Experiments across extensive benchmarks are conducted to showcase the effectiveness of our proposed method. Notably, the models trained by our method with the precision as low as 8 bits are comparable to those from the full precision training. As a by-product, we show that low precision local training can relieve the over-fitting issue in local training, which under heterogeneous client data can cause the client models drift further away from each other and lead to the failure in model aggregation.
tl;dr: Our paper establishes a theoretical foundation for model training on analog devices and shows a heuristic algorithm, Tiki-Taka, can converge to a critical point exactly.

Given the high economic and environmental costs of using large vision or language models, analog in-memory accelerators present a promising solution for energy-efficient AI. While inference on analog accelerators has been studied recently, the training perspective is underexplored. Recent studies have shown that the "workhorse" of digital AI training - stochastic gradient descent (SGD) algorithm converges inexactly when applied to model training on non-ideal devices. This paper puts forth a theoretical foundation for gradient-based training on analog devices. We begin by characterizing the non-convergent issue of SGD, which is caused by the asymmetric updates on the analog devices. We then provide a lower bound of the asymptotic error to show that there is a fundamental performance limit of SGD-based analog training rather than an artifact of our analysis.
To address this issue, we study a heuristic analog algorithm called Tiki-Taka that has recently exhibited superior empirical performance compared to SGD. We rigorously show its ability to converge to a critical point exactly and hence eliminate the asymptotic error. The simulations verify the correctness of the analyses.
1489. An Autoencoder-Like Nonnegative Matrix Co-Factorization for Improved Student Cognitive Modeling
tl;dr: This paper presents an autoencoder-like nonnegative matrix co-factorization model of student cognition for better-predicting student exercise performance and estimating his or her knowledge proficiency in a subject.

Student cognitive modeling (SCM) is a fundamental task in intelligent education, with applications ranging from personalized learning to educational resource allocation. By exploiting students' response logs, SCM aims to predict their exercise performance as well as estimate knowledge proficiency in a subject. Data mining approaches such as matrix factorization can obtain high accuracy in predicting student performance on exercises, but the knowledge proficiency is unknown or poorly estimated. The situation is further exacerbated if only sparse interactions exist between exercises and students (or knowledge concepts). To solve this dilemma, we root monotonicity (a fundamental psychometric theory on educational assessments) in a co-factorization framework and present an autoencoder-like nonnegative matrix co-factorization (AE-NMCF), which improves the accuracy of estimating the student's knowledge proficiency via an encoder-decoder learning pipeline. The resulting estimation problem is nonconvex with nonnegative constraints. We introduce a projected gradient method based on block coordinate descent with Lipschitz constants and guarantee the method's theoretical convergence. Experiments on several real-world data sets demonstrate the efficacy of our approach in terms of both performance prediction accuracy and knowledge estimation ability, when compared with existing student cognitive models.
tl;dr: This paper generalizes the system estimation conditions for nonlinear control systems under i.i.d. inputs and provides non-asymptotic analysis.

This paper focuses on the system identification of an important class of nonlinear systems: linearly parameterized nonlinear systems, which enjoys wide applications in robotics and other mechanical systems. We consider two system identification methods: least-squares estimation (LSE), which is a point estimation method; and set-membership estimation (SME), which estimates an uncertainty set that contains the true parameters. We provide non-asymptotic convergence rates for LSE and SME under i.i.d. control inputs and control policies with i.i.d. random perturbations, both of which are considered as non-active-exploration inputs. Compared with the counter-example based on piecewise-affine systems in the literature, the success of non-active exploration in our setting relies on a key assumption on the system dynamics: we require the system functions to be real-analytic. Our results, together with the piecewise-affine counter-example, reveal the importance of differentiability in nonlinear system identification through non-active exploration. Lastly, we numerically compare our theoretical bounds with the empirical performance of LSE and SME on a pendulum example and a quadrotor example.
1491. Grammar-Aligned Decoding

Large Language Models (LLMs) struggle with reliably generating highly structured outputs, such as program code, mathematical formulas, or well-formed markup. Constrained decoding approaches mitigate this problem by greedily restricting what tokens an LLM can output at each step to guarantee that the output matches a given constraint. Specifically, in grammar-constrained decoding (GCD), the LLM's output must follow a given grammar. In this paper we demonstrate that GCD techniques (and in general constrained decoding techniques) can distort the LLM's distribution, leading to outputs that are grammatical but appear with likelihoods that are not proportional to the ones given by the LLM, and so ultimately are low-quality. We call the problem of aligning sampling with a grammar constraint, grammar-aligned decoding (GAD), and propose adaptive sampling with approximate expected futures (ASAp), a decoding algorithm that guarantees the output to be grammatical while provably producing outputs that match the conditional probability of the LLM's distribution conditioned on the given grammar constraint. Our algorithm uses prior sample outputs to soundly overapproximate the future grammaticality of different output prefixes. Our evaluation on code generation and structured NLP tasks shows how ASAp often produces outputs with higher likelihood (according to the LLM's distribution) than existing GCD techniques, while still enforcing the desired grammatical constraints.
tl;dr: We propose and study the problem of state-free RL, i.e. algorithms that do not require the state space as input.

In this work, we study the \textit{state-free RL} problem, where the algorithm does not have the states information before interacting with the environment. Specifically, denote the reachable state set by $\mathcal{S}^\Pi := \{ s|\max_{\pi\in \Pi}q^{P, \pi}(s)>0 \}$, we design an algorithm which requires no information on the state space $S$ while having a regret that is completely independent of $\mathcal{S}$ and only depend on $\mathcal{S}^\Pi$. We view this as a concrete first step towards \textit{parameter-free RL}, with the goal of designing RL algorithms that require no hyper-parameter tuning.

Graph neural networks (GNNs) provide state-of-the-art results in a wide variety of tasks which typically involve predicting features at the vertices of a graph. They are built from layers of graph convolutions which serve as a powerful inductive bias for describing the flow of information among the vertices. Often, more than one data modality is available. This work considers a setting in which several graphs have the same vertex set and a common vertex-level learning task. This generalizes standard GNN models to GNNs with several graph operators that do not commute. We may call this model graph-tuple neural networks (GtNN).
In this work, we develop the mathematical theory to address the stability and transferability of GtNNs using properties of non-commuting non-expansive operators. We develop a limit theory of graphon-tuple neural networks and use it to prove a universal transferability theorem that guarantees that all graph-tuple neural networks are transferable on convergent graph-tuple sequences. In particular, there is no non-transferable energy under the convergence we consider here. Our theoretical results extend well-known transferability theorems for GNNs to the case of several simultaneous graphs (GtNNs) and provide a strict improvement on what is currently known even in the GNN case.
We illustrate our theoretical results with simple experiments on synthetic and real-world data. To this end, we derive a training procedure that provably enforces the stability of the resulting model.
tl;dr: We propose the first unsupervised object detection method that we prove has theoretical guarantees of recovering the true object positions up to small shifts.

Unsupervised object detection using deep neural networks is typically a difficult problem with few to no guarantees about the learned representation. In this work we present the first unsupervised object detection method that is theoretically guaranteed to recover the true object positions up to quantifiable small shifts. We develop an unsupervised object detection architecture and prove that the learned variables correspond to the true object positions up to small shifts related to the encoder and decoder receptive field sizes, the object sizes, and the widths of the Gaussians used in the rendering process. We perform detailed analysis of how the error depends on each of these variables and perform synthetic experiments validating our theoretical predictions up to a precision of individual pixels. We also perform experiments on CLEVR-based data and show that, unlike current SOTA object detection methods (SAM, CutLER), our method's prediction errors always lie within our theoretical bounds. We hope that this work helps open up an avenue of research into object detection methods with theoretical guarantees.

The cortico-spinal neural pathway is fundamental for motor control and movement execution, and in humans it is typically studied using concurrent electroencephalography (EEG) and electromyography (EMG) recordings. However, current approaches for capturing high-level and contextual connectivity between these recordings have important limitations. Here, we present a novel application of statistical dependence estimators based on orthonormal decomposition of density ratios to model the relationship between cortical and muscle oscillations. Our method extends from traditional scalar-valued measures by learning eigenvalues, eigenfunctions, and projection spaces of density ratios from realizations of the signal, addressing the interpretability, scalability, and local temporal dependence of cortico-muscular connectivity. We experimentally demonstrate that eigenfunctions learned from cortico-muscular connectivity can accurately classify movements and subjects. Moreover, they reveal channel and temporal dependencies that confirm the activation of specific EEG channels during movement.
1496. Be Confident in What You Know: Bayesian Parameter Efficient Fine-Tuning of Vision Foundation Models

Large transformer-based foundation models have been commonly used as pre-trained models that can be adapted to different challenging datasets and settings with state-of-the-art generalization performance. Parameter efficient fine-tuning ($\texttt{PEFT}$) provides promising generalization performance in adaptation while incurring minimum computational overhead. However, adaptation of these foundation models through $\texttt{PEFT}$ leads to accurate but severely underconfident models, especially in few-shot learning settings. Moreover, the adapted models lack accurate fine-grained uncertainty quantification capabilities limiting their broader applicability in critical domains. To fill out this critical gap, we develop a novel lightweight {Bayesian Parameter Efficient Fine-Tuning} (referred to as $\texttt{Bayesian-PEFT}$) framework for large transformer-based foundation models. The framework integrates state-of-the-art $\texttt{PEFT}$ techniques with two Bayesian components to address the under-confidence issue while ensuring reliable prediction under challenging few-shot settings. The first component performs base rate adjustment to strengthen the prior belief corresponding to the knowledge gained through pre-training, making the model more confident in its predictions; the second component builds an evidential ensemble that leverages belief regularization to ensure diversity among different ensemble components.
Our thorough theoretical analysis justifies that the Bayesian components can ensure reliable and accurate few-shot adaptations with well-calibrated uncertainty quantification. Extensive experiments across diverse datasets, few-shot learning scenarios, and multiple $\texttt{PEFT}$ techniques demonstrate the outstanding prediction and calibration performance by $\texttt{Bayesian-PEFT}$.
tl;dr: We show that Knowledge Distillation amplifies model poisoning attacks in FL, and design our algorithm HYDRA-FL to mitigate attack ampification.

Data heterogeneity among Federated Learning (FL) users poses a significant challenge, resulting in reduced global model performance. The community has designed various techniques to tackle this issue, among which Knowledge Distillation (KD)-based techniques are common.
While these techniques effectively improve performance under high heterogeneity, they inadvertently cause higher accuracy degradation under model poisoning attacks (known as \emph{attack amplification}). This paper presents a case study to reveal this critical vulnerability in KD-based FL systems. We show why KD causes this issue through empirical evidence and use it as motivation to design a hybrid distillation technique. We introduce a novel algorithm, Hybrid Knowledge Distillation for Robust and Accurate FL (HYDRA-FL), which reduces the impact of attacks in attack scenarios by offloading some of the KD loss to a shallow layer via an auxiliary classifier. We model HYDRA-FL as a generic framework and adapt it to two KD-based FL algorithms, FedNTD and MOON. Using these two as case studies, we demonstrate that our technique outperforms baselines in attack settings while maintaining comparable performance in benign settings.

Overparameterized stochastic differential equation (SDE) models have achieved remarkable success in various complex environments, such as PDE-constrained optimization, stochastic control and reinforcement learning, financial engineering, and neural SDEs. These models often feature system evolution coefficients that are parameterized by a high-dimensional vector $\theta \in \mathbb{R}^n$, aiming to optimize expectations of the SDE, such as a value function, through stochastic gradient ascent. Consequently, designing efficient gradient estimators for which the computational complexity scales well with $n$ is of significant interest. This paper introduces a novel unbiased stochastic gradient estimator—the generator gradient estimator—for which the computation time remains stable in $n$. In addition to establishing the validity of our methodology for general SDEs with jumps, we also perform numerical experiments that test our estimator in linear-quadratic control problems parameterized by high-dimensional neural networks. The results show a significant improvement in efficiency compared to the widely used pathwise differentiation method: Our estimator achieves near-constant computation times, increasingly outperforms its counterpart as $n$ increases, and does so without compromising estimation variance. These empirical findings highlight the potential of our proposed methodology for optimizing SDEs in contemporary applications.
1499. Vaccine: Perturbation-aware Alignment for Large Language Models against Harmful Fine-tuning Attack
tl;dr: We propose Vaccine, a perturbation-aware alignment solution for large language model against harmful fine-tuning attack.

The new paradigm of fine-tuning-as-a-service introduces a new attack surface for Large Language Models (LLMs): a few harmful data uploaded by users can easily trick the fine-tuning to produce an alignment-broken model. We conduct an empirical analysis and uncover
a \textit{harmful embedding drift} phenomenon, showing a probable
cause of the alignment-broken effect. Inspired by our findings, we propose Vaccine, a perturbation-aware alignment technique to mitigate the security risk of users fine-tuning. The core idea of Vaccine is to produce invariant hidden embeddings by progressively adding crafted perturbation to them in the alignment phase. This enables the embeddings to withstand harmful perturbation from un-sanitized user data in the fine-tuning phase. Our results on open source mainstream LLMs (e.g., Llama2, Opt, Vicuna) demonstrate that Vaccine can boost the robustness of alignment against harmful prompts induced embedding drift while reserving reasoning ability towards benign prompts. Our code is available at https://github.com/git-disl/Vaccine.
tl;dr: Improving online reinforcement learning by regularizing such algorithms with Empirical MDP ITeration (EMIT).

Reinforcement learning (RL) algorithms are typically based on optimizing a Markov Decision Process (MDP) using the optimal Bellman equation. Recent studies have revealed that focusing the optimization of Bellman equations solely on in-sample actions tends to result in more stable optimization, especially in the presence of function approximation. Upon on these findings, in this paper, we propose an Empirical MDP Iteration (EMIT) framework. EMIT constructs a sequence of empirical MDPs using data from the growing replay memory. For each of these empirical MDPs, it learns an estimated Q-function denoted as $\widehat{Q}$. The key strength is that by restricting the Bellman update to in-sample bootstrapping, each empirical MDP converges to a unique optimal $\widehat{Q}$ function. Furthermore, gradually expanding from the empirical MDPs to the original MDP induces a monotonic policy improvement. Instead of creating entirely new algorithms, we demonstrate that EMIT can be seamlessly integrated with existing online RL algorithms, effectively acting as a regularizer for contemporary Q-learning methods. We show this by implementing EMIT for two representative RL algorithms, DQN and TD3. Experimental results on Atari and MuJoCo benchmarks show that EMIT significantly reduces estimation errors and substantially improves the performance of both algorithms.
tl;dr: We introduce a boosted conformal procedure designed to tailor conformalized prediction intervals toward specific desired properties, such as enhanced conditional coverage or reduced interval length.

This paper introduces a boosted conformal procedure designed to tailor conformalized prediction intervals toward specific desired properties, such as enhanced conditional coverage or reduced interval length. We employ machine learning techniques, notably gradient boosting, to systematically improve upon a predefined conformity score function. This process is guided by carefully constructed loss functions that measure the deviation of prediction intervals from the targeted properties. The procedure operates post-training, relying solely on model predictions and without modifying the trained model (e.g., the deep network). Systematic experiments demonstrate that starting from conventional conformal methods, our boosted procedure achieves substantial improvements in reducing interval length and decreasing deviation from target conditional coverage.

Privacy protection of users' entire contribution of samples is important in distributed systems. The most effective approach is the two-stage scheme, which finds a small interval first and then gets a refined estimate by clipping samples into the interval. However, the clipping operation induces bias, which is serious if the sample distribution is heavy-tailed. Besides, users with large local sample sizes can make the sensitivity much larger, thus the method is not suitable for imbalanced users. Motivated by these challenges, we propose a Huber loss minimization approach to mean estimation under user-level differential privacy. The connecting points of Huber loss can be adaptively adjusted to deal with imbalanced users. Moreover, it avoids the clipping operation, thus significantly reducing the bias compared with the two-stage approach. We provide a theoretical analysis of our approach, which gives the noise strength needed for privacy protection, as well as the bound of mean squared error. The result shows that the new method is much less sensitive to the imbalance of user-wise sample sizes and the tail of sample distributions. Finally, we perform numerical experiments to validate our theoretical analysis.

As language models continue to scale, Large Language Models (LLMs) have exhibited emerging capabilities in In-Context Learning (ICL), enabling them to solve language tasks by prefixing a few in-context demonstrations (ICDs) as context. Inspired by these advancements, researchers have extended these techniques to develop Large Multimodal Models (LMMs) with ICL capabilities. However, applying ICL usually faces two major challenges: 1) using more ICDs will largely increase the inference time and 2) the performance is sensitive to the selection of ICDs. These challenges are further exacerbated in LMMs due to the integration of multiple data types and the combinational complexity of multimodal ICDs. Recently, to address these challenges, some NLP studies introduce non-learnable In-Context Vectors (ICVs) which extract useful task information from ICDs into a single vector and then insert it into the LLM to help solve the corresponding task. However, although useful in simple NLP tasks, these non-learnable methods fail to handle complex multimodal tasks like Visual Question Answering (VQA). In this study, we propose \underline{\textbf{L}}earnable \underline{\textbf{I}}n-Context \underline{\textbf{Ve}}ctor (LIVE) to distill essential task information from demonstrations, improving ICL performance in LMMs. Experiments show that LIVE can significantly reduce computational costs while enhancing accuracy in VQA tasks compared to traditional ICL and other non-learnable ICV methods.
tl;dr: We propose an amortized and adaptive intervention strategy that results in a sample efficient estimate of the true causal graph on the distribution of training environment as well as on test-time environments with distribution shifts.

We present Causal Amortized Active Structure Learning (CAASL), an active intervention design policy that can select interventions that are adaptive, real-time and that does not require access to the likelihood. This policy, an amortized network based on the transformer, is trained with reinforcement learning on a simulator of the design environment, and a reward function that measures how close the true causal graph is to a causal graph posterior inferred from the gathered data. On synthetic data and a single-cell gene expression simulator, we demonstrate empirically that the data acquired through our policy results in a better estimate of the underlying causal graph than alternative strategies. Our design policy successfully achieves amortized intervention design on the distribution of the training environment while also generalizing well to distribution shifts in test-time design environments. Further, our policy also demonstrates excellent zero-shot generalization to design environments with dimensionality higher than that during training, and to intervention types that it has not been trained on.
tl;dr: This paper introduces a novel Bayesian Optimization based model fusion method, referred to as BOMF, designed specifically for the fine-tuning scenario involving Pre-trained Language Models.
Fine-tuning pre-trained models for downstream tasks is a widely adopted technique known for its adaptability and reliability across various domains. Despite its conceptual simplicity, fine-tuning entails several troublesome engineering choices, such as selecting hyperparameters and determining checkpoints from an optimization trajectory. To tackle the difficulty of choosing the best model, one effective solution is model fusion, which combines multiple models in a parameter space. However, we observe a large discrepancy between loss and metric landscapes during the fine-tuning of pre-trained language models. Building on this observation, we introduce a novel model fusion technique that optimizes both the desired metric and loss through multi-objective Bayesian optimization. In addition, to effectively select hyperparameters, we establish a two-stage procedure by integrating Bayesian optimization processes into our framework. Experiments across various downstream tasks show considerable performance improvements using our Bayesian optimization-guided method.

Latent Bayesian optimization (LBO) approaches have successfully adopted Bayesian optimization over a continuous latent space by employing an encoder-decoder architecture to address the challenge of optimization in a high dimensional or discrete input space. LBO learns a surrogate model to approximate the black-box objective function in the latent space. However, we observed that most LBO methods suffer from the `misalignment problem', which is induced by the reconstruction error of the encoder-decoder architecture. It hinders learning an accurate surrogate model and generating high-quality solutions. In addition, several trust region-based LBO methods select the anchor, the center of the trust region, based solely on the objective function value without considering the trust region's potential to enhance the optimization process. To address these issues, we propose $\textbf{Inv}$ersion-based Latent $\textbf{B}$ayesian $\textbf{O}$ptimization (InvBO), a plug-and-play module for LBO. InvBO consists of two components: an inversion method and a potential-aware trust region anchor selection. The inversion method searches the latent code that completely reconstructs the given target data. The potential-aware trust region anchor selection considers the potential capability of the trust region for better local optimization. Experimental results demonstrate the effectiveness of InvBO on nine real-world benchmarks, such as molecule design and arithmetic expression fitting tasks. Code is available at https://github.com/mlvlab/InvBO.
1507. D2R2: Diffusion-based Representation with Random Distance Matching for Tabular Few-shot Learning
tl;dr: We propose a novel framework for tabular few-shot learning, comprising a diffusion-based model with random distance matching for representation learning, and an instance-wise iterative prototype scheme for few-shot classification.

Tabular data is widely utilized in a wide range of real-world applications. The challenge of few-shot learning with tabular data stands as a crucial problem in both industry and academia, due to the high cost or even impossibility of annotating additional samples. However, the inherent heterogeneity of tabular features, combined with the scarcity of labeled data, presents a significant challenge in tabular few-shot classification. In this paper, we propose a novel approach named Diffusion-based Representation with Random Distance matching (D2R2) for tabular few-shot learning. D2R2 leverages the powerful expression ability of diffusion models to extract essential semantic knowledge crucial for denoising process. This semantic knowledge proves beneficial in few-shot downstream tasks. During the training process of our designed diffusion model, we introduce a random distance matching to preserve distance information in the embeddings, thereby improving effectiveness for classification. During the classification stage, we introduce an instance-wise iterative prototype scheme to improve performance by accommodating the multimodality of embeddings and increasing clustering robustness. Our experiments reveal the significant efficacy of D2R2 across various tabular few-shot learning benchmarks, demonstrating its state-of-the-art performance in this field.
tl;dr: We show how to produce rich neural embeddings of temporal tasks for use in goal-conditioned RL.

Goal-conditioned reinforcement learning is a powerful way to control an AI agent's behavior at runtime. That said, popular goal representations, e.g., target states or natural language, are either limited to Markovian tasks or rely on ambiguous task semantics. We propose representing temporal goals using compositions of deterministic finite automata (cDFAs) and use cDFAs to guide RL agents. cDFAs balance the need for formal temporal semantics with ease of interpretation: if one can understand a flow chart, one can understand a cDFA. On the other hand, cDFAs form a countably infinite concept class with Boolean semantics, and subtle changes to the automaton can result in very different tasks, making them difficult to condition agent behavior on. To address this, we observe that all paths through a DFA correspond to a series of reach-avoid tasks and propose pre-training graph neural network embeddings on "reach-avoid derived" DFAs. Through empirical evaluation, we demonstrate that the proposed pre-training method enables zero-shot generalization to various cDFA task classes and accelerated policy specialization without the myopic suboptimality of hierarchical methods.
tl;dr: A simple and efficient diffusion-based augmentation technique to improve classifier robustness.

We introduce DiffAug, a simple and efficient diffusion-based augmentation technique to train image classifiers for the crucial yet challenging goal of improved classifier robustness. Applying DiffAug to a given example consists of one forward-diffusion step followed by one reverse-diffusion step. Using both ResNet-50 and Vision Transformer architectures, we comprehensively evaluate classifiers trained with DiffAug and demonstrate the surprising effectiveness of single-step reverse diffusion in improving robustness to covariate shifts, certified adversarial accuracy and out of distribution detection. When we combine DiffAug with other augmentations such as AugMix and DeepAugment we demonstrate further improved robustness. Finally, building on this approach, we also improve classifier-guided diffusion wherein we observe improvements in: (i) classifier-generalization, (ii) gradient quality (i.e., improved perceptual alignment) and (iii) image generation performance. We thus introduce a computationally efficient technique for training with improved robustness that does not require any additional data, and effectively complements existing augmentation approaches.
tl;dr: Studying task confusion and catastrophic forgetting for discriminative and generative Modeling

In class-incremental learning (class-IL), models must classify all previously seen classes at test time without task-IDs, leading to task confusion. Despite being a key challenge, task confusion lacks a theoretical understanding. We present a novel mathematical framework for class-IL and prove the Infeasibility Theorem, showing optimal class-IL is impossible with discriminative modeling due to task confusion. However, we establish the Feasibility Theorem, demonstrating that generative modeling can achieve optimal class-IL by overcoming task confusion. We then assess popular class-IL strategies, including regularization, bias-correction, replay, and generative classifier, using our framework. Our analysis suggests that adopting generative modeling, either for generative replay or direct classification (generative classifier), is essential for optimal class-IL.
tl;dr: We identify a training instability issue for common neural network parameterizations and normalizations and propose a novel Geometric Parameterization to fix it.

We introduce a novel approach for analyzing the training dynamics of ReLU networks by examining the characteristic activation boundaries of individual ReLU neurons. Our proposed analysis reveals a critical instability in common neural network parameterizations and normalizations during stochastic optimization, which impedes fast convergence and hurts generalization performance. Addressing this, we propose Geometric Parameterization (GmP), a novel neural network parameterization technique that effectively separates the radial and angular components of weights in the hyperspherical coordinate system. We show theoretically that GmP resolves the aforementioned instability issue. We report empirical results on various models and benchmarks to verify GmP's advantages of optimization stability, convergence speed and generalization performance.

Non-autoregressive Transformers (NATs) are recently applied in direct speech-to-speech translation systems, which convert speech across different languages without intermediate text data. Although NATs generate high-quality outputs and offer faster inference than autoregressive models, they tend to produce incoherent and repetitive results due to complex data distribution (e.g., acoustic and linguistic variations in speech). In this work, we introduce DiffNorm, a diffusion-based normalization strategy that simplifies data distributions for training NAT models. After training with a self-supervised noise estimation objective, DiffNorm constructs normalized target data by denoising synthetically corrupted speech features. Additionally, we propose to regularize NATs with classifier-free guidance, improving model robustness and translation quality by randomly dropping out source information during training. Our strategies result in a notable improvement of about $+7$ ASR-BLEU for English-Spanish (En-Es) translation and $+2$ ASR-BLEU for English-French (En-Fr) on the CVSS benchmark, while attaining over $14\times$ speedup for En-Es and $5 \times$ speedup for En-Fr translations compared to autoregressive baselines.

Diffusion models represent a promising avenue for image generation, having demonstrated competitive performance in pose-guided person image generation.
However, existing methods are limited to generating target images from a source image and a target pose, overlooking two critical user scenarios: generating multiple target images with different poses simultaneously and generating target images from multi-view source images.
To overcome these limitations, we propose IMAGPose, a unified conditional framework for pose-guided image generation, which incorporates three pivotal modules: a feature-level conditioning (FLC) module, an image-level conditioning (ILC) module, and a cross-view attention (CVA) module.
Firstly, the FLC module combines the low-level texture feature from the VAE encoder with the high-level semantic feature from the image encoder, addressing the issue of missing detail information due to the absence of a dedicated person image feature extractor.
Then, the ILC module achieves an alignment of images and poses to adapt to flexible and diverse user scenarios by injecting a variable number of source image conditions and introducing a masking strategy.
Finally, the CVA module introduces decomposing global and local cross-attention, ensuring local fidelity and global consistency of the person image when multiple source image prompts.
The three modules of IMAGPose work together to unify the task of person image generation under various user scenarios.
Extensive experiment results demonstrate the consistency and photorealism of our proposed IMAGPose under challenging user scenarios.
The code and model will be available at https://github.com/muzishen/IMAGPose.

The trade-off between cost and performance has been a longstanding and critical issue for deep neural networks.
One key factor affecting the computational cost is the width of each layer.
However, in practice, the width of layers in a neural network is mostly empirically determined. In this paper, we show that a pattern regarding the variance of weight norm corresponding to different channels can indicate whether the layer is sufficiently wide and may help us better allocate computational resources across the layers.
Starting from a simple intuition that channels with larger weights would have larger gradients and the difference in weight norm enlarges between channels with similar weight, we empirically validate that wide and narrow layers show two different patterns with experiments across different data modalities and network architectures.
Based on the two different patterns, we identify three stages during training and explain each stage with corresponding evidence. We further propose to adjust the width based on the identified pattern and show that conventional layer width settings for CNNs could be adjusted to reduce the number of parameters while boosting the performance.
1515. Beyond Euclidean: Dual-Space Representation Learning for Weakly Supervised Video Violence Detection

While numerous Video Violence Detection (VVD) methods have focused on representation learning in Euclidean space, they struggle to learn sufficiently discriminative features, leading to weaknesses in recognizing normal events that are visually similar to violent events (i.e., ambiguous violence). In contrast, hyperbolic representation learning, renowned for its ability to model hierarchical and complex relationships between events, has the potential to amplify the discrimination between visually similar events. Inspired by these, we develop a novel Dual-Space Representation Learning (DSRL) method for weakly supervised VVD to utilize the strength of both Euclidean and hyperbolic geometries, capturing the visual features of events while also exploring the intrinsic relations between events, thereby enhancing the discriminative capacity of the features. DSRL employs a novel information aggregation strategy to progressively learn event context in hyperbolic spaces, which selects aggregation nodes through layer-sensitive hyperbolic association degrees constrained by hyperbolic Dirichlet energy. Furthermore, DSRL attempts to break the cyber-balkanization of different spaces, utilizing cross-space attention to facilitate information interactions between Euclidean and hyperbolic space to capture better discriminative features for final violence detection. Comprehensive experiments demonstrate the effectiveness of our proposed DSRL.

Neural algorithmic reasoning is an emerging area of machine learning that focuses on building neural networks capable of solving complex algorithmic tasks. Recent advancements predominantly follow the standard supervised learning paradigm -- feeding an individual problem instance into the network each time and training it to approximate the execution steps of a classical algorithm. We challenge this mode and propose a novel open-book learning framework. In this framework, whether during training or testing, the network can access and utilize all instances in the training dataset when reasoning for a given instance.
Empirical evaluation is conducted on the challenging CLRS Algorithmic Reasoning Benchmark, which consists of 30 diverse algorithmic tasks. Our open-book learning framework exhibits a significant enhancement in neural reasoning capabilities. Further, we notice that there is recent literature suggesting that multi-task training on CLRS can improve the reasoning accuracy of certain tasks, implying intrinsic connections between different algorithmic tasks. We delve into this direction via the open-book framework. When the network reasons for a specific task, we enable it to aggregate information from training instances of other tasks in an attention-based manner. We show that this open-book attention mechanism offers insights into the inherent relationships among various tasks in the benchmark and provides a robust tool for interpretable multi-task training.
tl;dr: We study the loss landscape of in-context learning for single-layer linear attention and state-space models under general linear tasks model while delineating the effect of distributional alignments (e.g., RAG), low-rank constraints, and LoRA.

Recent research has shown that Transformers with linear attention are capable of in-context learning (ICL) by implementing a linear estimator through gradient descent steps. However, the existing results on the optimization landscape apply under stylized settings where task and feature vectors are assumed to be IID and the attention weights are fully parameterized. In this work, we develop a stronger characterization of the optimization and generalization landscape of ICL through contributions on architectures, low-rank parameterization, and correlated designs: (1) We study the landscape of 1-layer linear attention and 1-layer H3, a state-space model. Under a suitable correlated design assumption, we prove that both implement 1-step preconditioned gradient descent. We show that thanks to its native convolution filters, H3 also has the advantage of implementing sample weighting and outperforming linear attention in suitable settings. (2) By studying correlated designs, we provide new risk bounds for retrieval augmented generation (RAG) and task-feature alignment which reveal how ICL sample complexity benefits from distributional alignment. (3) We derive the optimal risk for low-rank parameterized attention weights in terms of covariance spectrum. Through this, we also shed light on how LoRA can adapt to a new distribution by capturing the shift between task covariances. Experimental results corroborate our theoretical findings. Overall, this work explores the optimization and risk landscape of ICL in practically meaningful settings and contributes to a more thorough understanding of its mechanics.
tl;dr: LLM-based Skill Diffusion for Zero-shot Policy Adaptation

Recent advances in data-driven imitation learning and offline reinforcement learning have highlighted the use of expert data for skill acquisition and the development of hierarchical policies based on these skills. However, these approaches have not significantly advanced in adapting these skills to unseen contexts, which may involve changing environmental conditions or different user requirements. In this paper, we present a novel LLM-based policy adaptation framework LDuS which leverages an LLM to guide the generation process of a skill diffusion model upon contexts specified in language, facilitating zero-shot skill-based policy adaptation to different contexts. To implement the skill diffusion model, we adapt the loss-guided diffusion with a sequential in-painting technique, where target trajectories are conditioned by masking them with past state-action sequences, thereby enabling the robust and controlled generation of skill trajectories in test-time. To have a loss function for a given context, we employ the LLM-based code generation with iterative refinement, by which the code and controlled trajectory are validated to align with the context in a closed-loop manner. Through experiments, we demonstrate the zero-shot adaptability of LDuS to various context types including different specification levels, multi-modality, and varied temporal conditions for several robotic manipulation tasks, outperforming other language-conditioned imitation and planning methods.
1519. Practical Shuffle Coding
tl;dr: We present a general method for practical lossless compression of unordered data structures that achieves state-of-the-art rates and speeds on large graphs.

We present a general method for lossless compression of unordered data structures, including multisets and graphs. It is a variant of shuffle coding that is many orders of magnitude faster than the original and enables 'one-shot' compression of single unordered objects. Our method achieves state-of-the-art compression rates on various large-scale network graphs at speeds of megabytes per second, efficiently handling even a multi-gigabyte plain graph with one billion edges. We release an implementation that can be easily adapted to different data types and statistical models.
tl;dr: A novel exocentric-to-egocentric video generation method for challenging daily-life skilled human activities.

We introduce Exo2Ego-V, a novel exocentric-to-egocentric diffusion-based video generation method for daily-life skilled human activities where sparse 4-view exocentric viewpoints are configured 360° around the scene. This task is particularly challenging due to the significant variations between exocentric and egocentric viewpoints and high complexity of dynamic motions and real-world daily-life environments. To address these challenges, we first propose a new diffusion-based multi-view exocentric encoder to extract the dense multi-scale features from multi-view exocentric videos as the appearance conditions for egocentric video generation. Then, we design an exocentric-to-egocentric view translation prior to provide spatially aligned egocentric features as a concatenation guidance for the input of egocentric video diffusion model. Finally, we introduce the temporal attention layers into our egocentric video diffusion pipeline to improve the temporal consistency cross egocentric frames. Extensive experiments demonstrate that Exo2Ego-V significantly outperforms SOTA approaches on 5 categories from the Ego-Exo4D dataset with an average of 35% in terms of LPIPS. Our code and model will be made available on https://github.com/showlab/Exo2Ego-V.
1521. A Decision-Language Model (DLM) for Dynamic Restless Multi-Armed Bandit Tasks in Public Health

Restless multi-armed bandits (RMAB) have demonstrated success in optimizing resource allocation for large beneficiary populations in public health settings. Unfortunately, RMAB models lack flexibility to adapt to evolving public health policy priorities. Concurrently, Large Language Models (LLMs) have emerged as adept automated planners across domains of robotic control and navigation. In this paper, we propose a Decision Language Model (DLM) for RMABs, enabling dynamic fine-tuning of RMAB policies in public health settings using human-language commands. We propose using LLMs as automated planners to (1) interpret human policy preference prompts, (2) propose reward functions as code for a multi-agent RMAB environment, and (3) iterate on the generated reward functions using feedback from grounded RMAB simulations. We illustrate the application of DLM in collaboration with ARMMAN, an India-based non-profit promoting preventative care for pregnant mothers, that currently relies on RMAB policies to optimally allocate health worker calls to low-resource populations. We conduct a technology demonstration in simulation using the Gemini Pro model, showing DLM can dynamically shape policy outcomes using only human prompts as input.
1522. Predictor-Corrector Enhanced Transformers with Exponential Moving Average Coefficient Learning
tl;dr: We introduce a predictor-corrector based Transformer (namely PCformer), where the predictor is an EMA augmented high-order method, and the corrector is a multstep method.

Residual networks, as discrete approximations of Ordinary Differential Equations (ODEs), have inspired significant advancements in neural network design, including multistep methods, high-order methods, and multi-particle dynamical systems. The precision of the solution to ODEs significantly affects parameter optimization, thereby impacting model performance. In this work, we present a series of advanced explorations of Transformer architecture design to minimize the error compared to the true ``solution.'' First, we introduce a predictor-corrector learning framework to minimize truncation errors, which consists of a high-order predictor and a multistep corrector. Second, we propose an exponential moving average-based coefficient learning method to strengthen our higher-order predictor. Extensive experiments on large-scale machine translation, abstractive summarization, language modeling, and natural language understanding benchmarks demonstrate the superiority of our approach. On the WMT'14 English-German and English-French tasks, our model achieved BLEU scores of 30.95 and 44.27, respectively. Furthermore, on the OPUS multilingual machine translation task, our model surpasses a robust 3.8B DeepNet by an average of 2.9 SacreBLEU, using only 1/3 parameters. Notably, it also beats LLama models by 5.7 accuracy points on the LM Harness Evaluation.
tl;dr: We demonstrate that over-parameterized gradient descent in sequence models adapts to signal structures and significantly outperforms the vanilla gradient flow method induced by a fixed kernel.

It is well known that eigenfunctions of a kernel play a crucial role in kernel regression.
Through several examples, we demonstrate that even with the same set of eigenfunctions, the order of these functions significantly impacts regression outcomes.
Simplifying the model by diagonalizing the kernel, we introduce an over-parameterized gradient descent in the realm of sequence model to capture the effects of various orders of a fixed set of eigen-functions.
This method is designed to explore the impact of varying eigenfunction orders.
Our theoretical results show that the over-parameterization gradient flow can adapt to the underlying structure of the signal and significantly outperform the vanilla gradient flow method.
Moreover, we also demonstrate that deeper over-parameterization can further enhance the generalization capability of the model.
These results not only provide a new perspective on the benefits of over-parameterization and but also offer insights into the adaptivity and generalization potential of neural networks beyond the kernel regime.
tl;dr: We propose methods to scale white-box, transformer-like deep network architectures.

CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address.
Specifically, we propose CRATE-$\alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE.
Through extensive experiments, we demonstrate that CRATE-$\alpha$ can effectively scale with larger model sizes and datasets.
For example, our CRATE-$\alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$\alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$\alpha$ models yield increasingly higher-quality unsupervised object segmentation of images.
1525. Classifier Clustering and Feature Alignment for Federated Learning under Distributed Concept Drift
tl;dr: We propose FedCCFA, a federated learning framework with classifier clustering and feature alignment.

Data heterogeneity is one of the key challenges in federated learning, and many efforts have been devoted to tackling this problem. However, distributed concept drift with data heterogeneity, where clients may additionally experience different concept drifts, is a largely unexplored area. In this work, we focus on real drift, where the conditional distribution $P(\mathcal{Y}|\mathcal{X})$ changes. We first study how distributed concept drift affects the model training and find that local classifier plays a critical role in drift adaptation. Moreover, to address data heterogeneity, we study the feature alignment under distributed concept drift, and find two factors that are crucial for feature alignment: the conditional distribution $P(\mathcal{Y}|\mathcal{X})$ and the degree of data heterogeneity. Motivated by the above findings, we propose FedCCFA, a federated learning framework with classifier clustering and feature alignment. To enhance collaboration under distributed concept drift, FedCCFA clusters local classifiers at class-level and generates clustered feature anchors according to the clustering results. Assisted by these anchors, FedCCFA adaptively aligns clients' feature spaces based on the entropy of label distribution $P(\mathcal{Y})$, alleviating the inconsistency in feature space. Our results demonstrate that FedCCFA significantly outperforms existing methods under various concept drift settings. Code is available at https://github.com/Chen-Junbao/FedCCFA.

Diffusion models, a specific type of generative model, have achieved unprecedented performance in recent years and consistently produce high-quality synthetic samples. A critical prerequisite for their notable success lies in the presence of a substantial number of training samples, which can be impractical in real-world applications due to high collection costs or associated risks. Consequently, various finetuning and regularization approaches have been proposed to transfer knowledge from existing pre-trained models to specific target domains with limited data. This paper introduces the Transfer Guided Diffusion Process (TGDP), a novel approach distinct from conventional finetuning and regularization methods.
We prove that the optimal diffusion model for the target domain integrates pre-trained diffusion models on the source domain with additional guidance from a domain classifier.
We further extend TGDP to a conditional version for modeling the joint distribution of data and its corresponding labels, together with two additional regularization terms to enhance the model performance. We validate the effectiveness of TGDP on both simulated and real-world datasets.
tl;dr: We erase the not-safe-for-work (NSFW) concepts in text-to-image diffusion models using image-based unlearning.

Recent advancements in text-to-image (T2I) models have greatly benefited from large-scale datasets, but they also pose significant risks due to the potential generation of unsafe content. To mitigate this issue, researchers proposed unlearning techniques that attempt to induce the model to unlearn potentially harmful prompts. However, these methods are easily bypassed by adversarial attacks, making them unreliable for ensuring the safety of generated images. In this paper, we propose Direct Unlearning Optimization (DUO), a novel framework for removing NSFW content from T2I models while preserving their performance on unrelated topics. DUO employs a preference optimization approach using curated paired image data, ensuring that the model learns to remove unsafe visual concepts while retain unrelated features. Furthermore, we introduce an output-preserving regularization term to maintain the model's generative capabilities on safe content. Extensive experiments demonstrate that DUO can robustly defend against various state-of-the-art red teaming methods without significant performance degradation on unrelated topics, as measured by FID and CLIP scores. Our work contributes to the development of safer and more reliable T2I models, paving the way for their responsible deployment in both closed-source and open-source scenarios.
tl;dr: An iterative algorithm that increases the mutual information between responses and constitutions.

When prompting a language model (LM), users often expect the model to adhere to a set of behavioral principles across diverse tasks, such as producing insightful content while avoiding harmful or biased language. Instilling such principles (i.e., a constitution) into a model is resource-intensive, technically challenging, and generally requires human preference labels or examples. We introduce SAMI, an iterative algorithm that finetunes a pretrained language model (without requiring preference labels or demonstrations) to increase the conditional mutual information between constitutions and self-generated responses given queries from a dataset. On single-turn dialogue and summarization, a SAMI-trained mistral-7b outperforms the initial pretrained model, with win rates between 66% and 77%. Strikingly, it also surpasses an instruction-finetuned baseline (mistral-7b-instruct) with win rates between 55% and 57% on single-turn dialogue. SAMI requires a model that writes the principles. To avoid dependence on strong models for writing principles, we align a strong pretrained model (mixtral-8x7b) using constitutions written by a weak instruction-finetuned model (mistral-7b-instruct), achieving a 65% win rate on summarization. Finally, we investigate whether SAMI generalizes to diverse summarization principles (e.g., "summaries should be scientific") and scales to stronger models (llama3-70b), finding that it achieves win rates of up to 68% for learned and 67% for held-out principles compared to the base model. Our results show that a pretrained LM can learn to follow constitutions without using preference labels, demonstrations, or human oversight.
tl;dr: We propose a variational perspective on flow matching and apply it to graph generation.

We present a formulation of flow matching as variational inference, which we refer to as variational flow matching (VFM). We use this formulation to develop CatFlow, a flow matching method for categorical data that is easy to implement, computationally efficient, and achieves strong results on graph generation tasks. In VFM, the objective is to approximate the posterior probability path, which is a distribution over possible end points of a trajectory. VFM admits both the original flow matching objective and the CatFlow objective as special cases. We also relate VFM to score-based models, in which the dynamics are stochastic rather than deterministic, and derive a bound on the model likelihood based on a reweighted VFM objective. We evaluate CatFlow on one abstract graph generation task and two molecular generation tasks. In all cases, CatFlow exceeds or matches performance of the current state-of-the-art models.
tl;dr: We develop a sound and complete criterion for sequential back-door adjustment (g-formula).

Covariate adjustment, also known as back-door adjustment, is a fundamental tool in causal inference. Although a sound and complete graphical identification criterion, known as the adjustment criterion (Shpitser, 2010), exists for static contexts, sequential contexts present challenges. Current practices, such as the sequential back-door adjustment (Pearl, 1995) or multi-outcome sequential back-door adjustment (Jung, 2020), are sound but incomplete; i.e., there are graphical scenarios where the causal effect is expressible via covariate adjustment, yet these criteria do not cover. In this paper, we exemplify this incompleteness and then present the *sequential adjustment criterion*, a sound and complete criterion for sequential covariate adjustment. We provide a constructive sequential adjustment criterion that identifies a set that satisfies the sequential adjustment criterion if and only if the causal effect can be expressed as a sequential covariate adjustment. Finally, we present an algorithm for identifying a *minimal* sequential covariate adjustment set, which optimizes efficiency by ensuring that no unnecessary vertices are included.
tl;dr: We address the naming issues in open-vocabulary segmentation benchmarks and demonstrate that renaming improves both model training and evaluation.

Names are essential to both human cognition and vision-language models. Open-vocabulary models utilize class names as text prompts to generalize to categories unseen during training. However, the precision of these names is often overlooked in existing datasets. In this paper, we address this underexplored problem by presenting a framework for "renovating" names in open-vocabulary segmentation benchmarks (RENOVATE). Our framework features a renaming model that enhances the quality of names for each visual segment. Through experiments, we demonstrate that our renovated names help train stronger open-vocabulary models with up to 15% relative improvement and significantly enhance training efficiency with improved data quality. We also show that our renovated names improve evaluation by better measuring misclassification and enabling fine-grained model analysis. We provide our code and relabelings for several popular segmentation datasets to the research community on our project page: https://andrehuang.github.io/renovate.

Contextual bandit algorithms aim to identify the optimal arm with the highest reward among a set of candidates, based on the accessible contextual information. Among these algorithms, neural contextual bandit methods have shown generally superior performances against linear and kernel ones, due to the representation power of neural networks. However, similar to other neural network applications, neural bandit algorithms can be vulnerable to adversarial attacks or corruptions on the received labels (i.e., arm rewards), which can lead to unexpected performance degradation without proper treatments. As a result, it is necessary to improve the robustness of neural bandit models against potential reward corruptions. In this work, we propose a novel neural contextual bandit algorithm named R-NeuralUCB, which utilizes a novel context-aware Gradient Descent (GD) training strategy to improve the robustness against adversarial reward corruptions. Under over-parameterized neural network settings, we provide regret analysis for R-NeuralUCB to quantify reward corruption impacts, without the commonly adopted arm separateness assumption in existing neural bandit works. We also conduct experiments against baselines on real data sets under different scenarios, in order to demonstrate the effectiveness of our proposed R-NeuralUCB.
1533. Text2NKG: Fine-Grained N-ary Relation Extraction for N-ary relational Knowledge Graph Construction
tl;dr: We introduce Text2NKG, a novel fine-grained n-ary relation extraction framework for n-ary relational knowledge graph construction.

Beyond traditional binary relational facts, n-ary relational knowledge graphs (NKGs) are comprised of n-ary relational facts containing more than two entities, which are closer to real-world facts with broader applications. However, the construction of NKGs remains at a coarse-grained level, which is always in a single schema, ignoring the order and variable arity of entities. To address these restrictions, we propose Text2NKG, a novel fine-grained n-ary relation extraction framework for n-ary relational knowledge graph construction. We introduce a span-tuple classification approach with hetero-ordered merging and output merging to accomplish fine-grained n-ary relation extraction in different arity. Furthermore, Text2NKG supports four typical NKG schemas: hyper-relational schema, event-based schema, role-based schema, and hypergraph-based schema, with high flexibility and practicality. The experimental results demonstrate that Text2NKG achieves state-of-the-art performance in F1 scores on the fine-grained n-ary relation extraction benchmark. Our code and datasets are publicly available.

Previous deep learning approaches for survival analysis have primarily relied on ranking losses to improve discrimination performance, which often comes at the expense of calibration performance.
To address such an issue, we propose a novel contrastive learning approach specifically designed to enhance discrimination without sacrificing calibration.
Our method employs weighted sampling within a contrastive learning framework, assigning lower penalties to samples with similar survival outcomes. This aligns well with the assumption that patients with similar event times share similar clinical statuses. Consequently, when augmented with the commonly used negative log-likelihood loss, our approach significantly improves discrimination performance without directly manipulating the model outputs, thereby achieving better calibration.
Experiments on multiple real-world clinical datasets demonstrate that our method outperforms state-of-the-art deep survival models in both discrimination and calibration. Through comprehensive ablation studies, we further validate the effectiveness of our approach through quantitative and qualitative analyses.
tl;dr: We propose a novel flow matching approach for discrete data by continuously reparameterising categorical distributions on the hypersphere.

Generative modeling over discrete data has recently seen numerous success stories, with applications spanning language modeling, biological sequence design, and graph-structured molecular data. The predominant generative modeling paradigm for discrete data is still autoregressive, with more recent alternatives based on diffusion or flow-matching falling short of their impressive performance in continuous data settings, such as image or video generation. In this work, we introduce Fisher-Flow, a novel flow-matching model for discrete data. Fisher-Flow takes a manifestly geometric perspective
by considering categorical distributions over discrete data as points residing on a statistical manifold equipped with its natural Riemannian metric: the \emph{Fisher-Rao metric}. As a result, we demonstrate discrete data itself can be continuously reparameterised to points on the positive orthant of the $d$-hypersphere $\mathbb{S}^d_+$,
which allows us to define flows that map any source distribution to target in a principled manner by transporting mass along (closed-form) geodesics of $\mathbb{S}^d_+$. Furthermore, the learned flows in Fisher-Flow can be further bootstrapped by leveraging Riemannian optimal transport leading to improved training dynamics. We prove that the gradient flow induced by Fisher-FLow is optimal in reducing the forward KL divergence. We evaluate Fisher-Flow on an array of synthetic and diverse real-world benchmarks, including designing DNA Promoter, and DNA Enhancer sequences. Empirically, we find that Fisher-Flow improves over prior diffusion and flow-matching models on these benchmarks.
1536. Advancing Training Efficiency of Deep Spiking Neural Networks through Rate-based Backpropagation

Recent insights have revealed that rate-coding is a primary form of information representation captured by surrogate-gradient-based Backpropagation Through Time (BPTT) in training deep Spiking Neural Networks (SNNs). Motivated by these findings, we propose rate-based backpropagation, a training strategy specifically designed to exploit rate-based representations to reduce the complexity of BPTT. Our method minimizes reliance on detailed temporal derivatives by focusing on averaged dynamics, streamlining the computational graph to reduce memory and computational demands of SNNs training. We substantiate the rationality of the gradient approximation between BPTT and the proposed method through both theoretical analysis and empirical observations. Comprehensive experiments on CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS validate that our method achieves comparable performance to BPTT counterparts, and surpasses state-of-the-art efficient training techniques. By leveraging the inherent benefits of rate-coding, this work sets the stage for more scalable and efficient SNNs training within resource-constrained environments.

Inferring the 3D structure underlying a set of multi-view images typically requires solving two co-dependent tasks -- accurate 3D reconstruction requires precise camera poses, and predicting camera poses relies on (implicitly or explicitly) modeling the underlying 3D. The classical framework of analysis by synthesis casts this inference as a joint optimization seeking to explain the observed pixels, and recent instantiations learn expressive 3D representations (e.g., Neural Fields) with gradient-descent-based pose refinement of initial pose estimates. However, given a sparse set of observed views, the observations may not provide sufficient direct evidence to obtain complete and accurate 3D. Moreover, large errors in pose estimation may not be easily corrected and can further degrade the inferred 3D. To allow robust 3D reconstruction and pose estimation in this challenging setup, we propose SparseAGS, a method that adapts this analysis-by-synthesis approach by: a) including novel-view-synthesis-based generative priors in conjunction with photometric objectives to improve the quality of the inferred 3D, and b) explicitly reasoning about outliers and using a discrete search with a continuous optimization-based strategy to correct them. We validate our framework across real-world and synthetic datasets in combination with several off-the-shelf pose estimation systems as initialization. We find that it significantly improves the base systems' pose accuracy while yielding high-quality 3D reconstructions that outperform the results from current multi-view reconstruction baselines.
tl;dr: A novel high quality and efficient image-to-3D framework.

In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Previous methods based on Score Distillation Sampling (SDS) can produce diversified 3D results by distilling 3D knowledge from large 2D diffusion models, but they usually suffer from long per-case optimization time with inconsistent issues. Recent works address the problem and generate better 3D results either by finetuning a multi-view diffusion model or training a fast feed-forward model. However, they still lack intricate textures and complex geometries due to inconsistency and limited generated resolution. To simultaneously achieve high fidelity, consistency, and efficiency in single image-to-3D, we propose a novel framework Unique3D that includes a multi-view diffusion model with a corresponding normal diffusion model to generate multi-view images with their normal maps, a multi-level upscale process to progressively improve the resolution of generated orthographic multi-views, as well as an instant and consistent mesh reconstruction algorithm called ISOMER, which fully integrates the color and geometric priors into mesh results. Extensive experiments demonstrate that our Unique3D significantly outperforms other image-to-3D baselines in terms of geometric and textural details.

Distributionally Robust Optimization (DRO) accounts for uncertainty in data distributions by optimizing the model performance against the worst possible distribution within an ambiguity set. In this paper, we propose a DRO framework that relies on a new distance inspired by Unbalanced Optimal Transport (UOT). The proposed UOT distance employs a soft penalization term instead of hard constraints, enabling the construction of an ambiguity set that is more resilient to outliers. Under smoothness conditions, we establish strong duality of the proposed DRO problem. Moreover, we introduce a computationally efficient Lagrangian penalty formulation for which we show that strong duality also holds. Finally, we provide empirical results that demonstrate that our method offers improved robustness to outliers and is computationally less demanding for regression and classification tasks.
tl;dr: We improve known regret rates in repeated uniform multi-unit auctions under bandit feedback, and introduce a novel partial feedback specific to the auctions.

Motivated by the strategic participation of electricity producers in electricity day-ahead market, we study the problem of online learning in repeated multi-unit uniform price auctions focusing on the adversarial opposing bid setting. The main contribution of this paper is the introduction of a new modeling of the bid space. Indeed, we prove that a learning algorithm leveraging the structure of this problem achieves a regret of $\tilde{O}(K^{4/3}T^{2/3})$ under bandit feedback, improving over the bound of $\tilde{O}(K^{7/4}T^{3/4})$ previously obtained in the literature. This improved regret rate is tight up to logarithmic terms. %by deducing a lower bound of $\Omega (T^{2/3})$ from the dynamic pricing literature, proving the optimality in $T$ of our algorithm up to log factors.
Inspired by electricity reserve markets, we further introduce a different feedback model under which all winning bids are revealed. This feedback interpolates between the full-information and bandit scenarios depending on the auctions' results. We prove that, under this feedback, the algorithm that we propose achieves regret $\tilde{O}(K^{5/2}\sqrt{T})$.
tl;dr: We propose an efficient automated exemplar selection method that uses a neural bandit algorithm to optimize the set of exemplars for in-context learning while accounting for exemplar ordering.

Large language models (LLMs) have shown impressive capabilities in real-world applications. The capability of *in-context learning* (ICL) allows us to adapt an LLM to downstream tasks by including input-label exemplars in the prompt without model fine-tuning. However, the quality of these exemplars in the prompt greatly impacts performance, highlighting the need for an effective automated exemplar selection method. Recent studies have explored retrieval-based approaches to select exemplars tailored to individual test queries, which can be undesirable due to extra test-time computation and an increased risk of data exposure. Moreover, existing methods fail to adequately account for the impact of exemplar ordering on the performance. On the other hand, the impact of the *instruction*, another essential component in the prompt given to the LLM, is often overlooked in existing exemplar selection methods. To address these challenges, we propose a novel method named $\texttt{EASE}$, which leverages the hidden embedding from a pre-trained language model to represent ordered sets of exemplars and uses a neural bandit algorithm to optimize the sets of exemplars *while accounting for exemplar ordering*. Our $\texttt{EASE}$ can efficiently find an ordered set of exemplars that *performs well for all test queries* from a given task, thereby eliminating test-time computation. Importantly, $\texttt{EASE}$ can be readily extended to *jointly optimize both the exemplars and the instruction*. Through extensive empirical evaluations (including novel tasks), we demonstrate the superiority of $\texttt{EASE}$ over existing methods, and reveal practical insights about the impact of exemplar selection on ICL, which may be of independent interest. Our code is available at https://github.com/ZhaoxuanWu/EASE-Prompt-Optimization.

Error correcting output code (ECOC) is a classic method that encodes binary classifiers to tackle the multi-class classification problem in decision trees and neural networks.
Among ECOCs, the one-hot code has become the default choice in modern deep neural networks (DNNs) due to its simplicity in decision making. However, it suffers from a significant limitation in its ability to achieve high robust accuracy, particularly in the presence of weight errors. While recent studies have experimentally demonstrated that the non-one-hot ECOCs with multi-bits error correction ability, could be a better solution, there is a notable absence of theoretical foundations that can elucidate the relationship between codeword design, weight-error magnitude, and network characteristics, so as to provide robustness guarantees. This work is positioned to bridge this gap through the lens of neural tangent kernel (NTK). We have two important theoretical findings: 1) In clean models (without weight errors), utilizing one-hot code and non-one-hot ECOC is akin to altering decoding metrics from $l_2$ distance to Mahalanobis distance. 2) In non-clean models (with weight errors), if the normalized distance exceeds a threshold, then non-clean DNNs can reach the clean model's accuracy as long as the code length approaches infinity. This threshold is determined by DNN architecture (e.g. layer number, activation), weight error magnitude, and the distance between the output and the nearest codeword. Based on these findings, we further demonstrate how to practically use them to identify optimal ECOCs for simple tasks (short-code ECOCs) and complex tasks (long-code ECOCs), by balancing the code orthogonality (as per finding 1) and code distance (as per finding 2). Extensive experimental results across four datasets and four DNN models validate the superior performance of constructed codes, guided by our findings, compared to existing ECOCs. To our best knowledge, this is the first work that provides theoretical explanations for the effectiveness of ECOCS and offers associated design guidance for optimal ECOCs specifically tailored to DNNs.

We introduce a novel capacity measure 2sED for statistical models based on the effective dimension. The new quantity provably bounds the generalization error under mild assumptions on the model. Furthermore, simulations on standard data sets and popular model architectures show that 2sED correlates well with the training error. For Markovian models, we show how to efficiently approximate 2sED from below through a layerwise iterative approach, which allows us to tackle deep learning models with a large number of parameters. Simulation results suggest that the approximation is good for different prominent models and data sets.
1544. Reciprocal Learning
tl;dr: We generalize active learning, self-training, multi-armed bandits, superset learning, and Bayesian optimization to reciprocal learning and give sufficient conditions for convergence.

We demonstrate that numerous machine learning algorithms are specific instances of one single paradigm: reciprocal learning. These instances range from active learning over multi-armed bandits to self-training. We show that all these algorithms not only learn parameters from data but also vice versa: They iteratively alter training data in a way that depends on the current model fit. We introduce reciprocal learning as a generalization of these algorithms using the language of decision theory. This allows us to study under what conditions they converge. The key is to guarantee that reciprocal learning contracts such that the Banach fixed-point theorem applies. In this way, we find that reciprocal learning converges at linear rates to an approximately optimal model under some assumptions on the loss function, if their predictions are probabilistic and the sample adaption is both non-greedy and either randomized or regularized. We interpret these findings and provide corollaries that relate them to active learning, self-training, and bandits.
tl;dr: In this paper, we introduce a new perspective and framework, demonstrating that diffusion models with cross-attention can serve as a powerful inductive bias to facilitate the learning of disentangled representations.

Disentangled representation learning strives to extract the intrinsic factors within observed data. Factorizing these representations in an unsupervised manner is notably challenging and usually requires tailored loss functions or specific structural designs. In this paper, we introduce a new perspective and framework, demonstrating that diffusion models with cross-attention can serve as a powerful inductive bias to facilitate the learning of disentangled representations. We propose to encode an image to a set of concept tokens and treat them as the condition of the latent diffusion for image reconstruction, where cross-attention over the concept tokens is used to bridge the interaction between the encoder and diffusion. Without any additional regularization, this framework achieves superior disentanglement performance on the benchmark datasets, surpassing all previous methods with intricate designs. We have conducted comprehensive ablation studies and visualization analysis, shedding light on the functioning of this model. We anticipate that our findings will inspire more investigation on exploring diffusion for disentangled representation learning towards more sophisticated data analysis and understanding.

Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion. However, existing MHeteroFL methods rely on training loss to transfer knowledge between the client model and the server model, resulting in limited knowledge exchange. To address this limitation, we propose the **Fed**erated model heterogeneous **M**atryoshka **R**epresentation **L**earning (**FedMRL**) approach for supervised learning tasks. It adds an auxiliary small homogeneous model shared by clients with heterogeneous local models. (1) The generalized and personalized representations extracted by the two models' feature extractors are fused by a personalized lightweight representation projector. This step enables representation fusion to adapt to local data distribution. (2) The fused representation is then used to construct Matryoshka representations with multi-dimensional and multi-granular embedded representations learned by the global homogeneous model header and the local heterogeneous model header. This step facilitates multi-perspective representation learning and improves model learning capability. Theoretical analysis shows that FedMRL achieves a $O(1/T)$ non-convex convergence rate. Extensive experiments on benchmark datasets demonstrate its superior model accuracy with low communication and computational costs compared to seven state-of-the-art baselines. It achieves up to 8.48% and 24.94% accuracy improvement compared with the state-of-the-art and the best same-category baseline, respectively.

Existing diffusion-based text-to-3D generation methods primarily focus on producing visually realistic shapes and appearances, often neglecting the physical constraints necessary for downstream tasks. Generated models frequently fail to maintain balance when placed in physics-based simulations or 3D printed. This balance is crucial for satisfying user design intentions in interactive gaming, embodied AI, and robotics, where stable models are needed for reliable interaction. Additionally, stable models ensure that 3D-printed objects, such as figurines for home decoration, can stand on their own without requiring additional supports. To fill this gap, we introduce Atlas3D, an automatic and easy-to-implement method that enhances existing Score Distillation Sampling (SDS)-based text-to-3D tools. Atlas3D ensures the generation of self-supporting 3D models that adhere to physical laws of stability under gravity, contact, and friction. Our approach combines a novel differentiable simulation-based loss function with physically inspired regularization, serving as either a refinement or a post-processing module for existing frameworks. We verify Atlas3D's efficacy through extensive generation tasks and validate the resulting 3D models in both simulated and real-world environments.

The field of Multimodal Sentiment Analysis (MSA) has recently witnessed an emerging direction seeking to tackle the issue of data incompleteness. Recognizing that the language modality typically contains dense sentiment information, we consider it as the dominant modality and present an innovative Language-dominated Noise-resistant Learning Network (LNLN) to achieve robust MSA. The proposed LNLN features a dominant modality correction (DMC) module and dominant modality based multimodal learning (DMML) module, which enhances the model's robustness across various noise scenarios by ensuring the quality of dominant modality representations. Aside from the methodical design, we perform comprehensive experiments under random data missing scenarios, utilizing diverse and meaningful settings on several popular datasets (e.g., MOSI, MOSEI, and SIMS), providing additional uniformity, transparency, and fairness compared to existing evaluations in the literature. Empirically, LNLN consistently outperforms existing baselines, demonstrating superior performance across these challenging and extensive evaluation metrics.

Online Budgeted Matching (OBM) is a classic problem with important applications in online advertising, online service matching, revenue management, and beyond. Traditional online algorithms typically assume a small bid setting, where the maximum bid-to-budget ratio ($\kappa$) is infinitesimally small. While recent algorithms have tried to address scenarios with non-small or general bids, they often rely on the Fractional Last Matching (FLM) assumption, which allows for accepting partial bids when the remaining budget is insufficient. This assumption, however, does not hold for many applications with indivisible bids. In this paper, we remove the FLM assumption and tackle the open problem of OBM with general bids. We first establish an upper bound of $1-\kappa$ on the competitive ratio for any deterministic online algorithm. We then propose a novel meta algorithm, called MetaAd, which reduces to different algorithms with first known provable competitive ratios parameterized by the maximum bid-to-budget ratio $\kappa\in [0,1]$. As a by-product, we extend MetaAd to the FLM setting and get provable competitive algorithms. Finally, we apply our competitive analysis to the design learning- augmented algorithms.

Recent works have shown the remarkable superiority of transformer models in reinforcement learning (RL), where the decision-making problem is formulated as sequential generation. Transformer-based agents could emerge with self-improvement in online environments by providing task contexts, such as multiple trajectories, called in-context RL. However, due to the quadratic computation complexity of attention in transformers, current in-context RL methods suffer from huge computational costs as the task horizon increases. In contrast, the Mamba model is renowned for its efficient ability to process long-term dependencies, which provides an opportunity for in-context RL to solve tasks that require long-term memory. To this end, we first implement Decision Mamba (DM) by replacing the backbone of Decision Transformer (DT). Then, we propose a Decision Mamba-Hybrid (DM-H) with the merits of transformers and Mamba in high-quality prediction and long-term memory. Specifically, DM-H first generates high-value sub-goals from long-term memory through the Mamba model. Then, we use sub-goals to prompt the transformer, establishing high-quality predictions. Experimental results demonstrate that DM-H achieves state-of-the-art in long and short-term tasks, such as D4RL, Grid World, and Tmaze benchmarks. Regarding efficiency, the online testing of DM-H in the long-term task is 28$\times$ times faster than the transformer-based baselines.

Exposure Correction (EC) aims to recover proper exposure conditions for images captured under over-exposure or under-exposure scenarios. While existing deep learning models have shown promising results, few have fully embedded Retinex theory into their architecture, highlighting a gap in current methodologies. Additionally, the balance between high performance and efficiency remains an under-explored problem for exposure correction task. Inspired by Mamba which demonstrates powerful and highly efficient sequence modeling, we introduce a novel framework based on \textbf{Mamba} for \textbf{E}xposure \textbf{C}orrection (\textbf{ECMamba}) with dual pathways, each dedicated to the restoration of reflectance and illumination map, respectively. Specifically, we firstly derive the Retinex theory and we train a Retinex estimator capable of mapping inputs into two intermediary spaces, each approximating the target reflectance and illumination map, respectively. This setup facilitates the refined restoration process of the subsequent \textbf{E}xposure \textbf{C}orrection \textbf{M}amba \textbf{M}odule (\textbf{ECMM}). Moreover, we develop a novel \textbf{2D S}elective \textbf{S}tate-space layer guided by \textbf{Retinex} information (\textbf{Retinex-SS2D}) as the core operator of \textbf{ECMM}. This architecture incorporates an innovative 2D scanning strategy based on deformable feature aggregation, thereby enhancing both efficiency and effectiveness. Extensive experiment results and comprehensive ablation studies demonstrate the outstanding performance and the importance of each component of our proposed ECMamba. Code is available at \url{https://github.com/LowlevelAI/ECMamba}.

Snapshot compressive imaging (SCI) recovers high-dimensional (3D) data cubes from a single 2D measurement, enabling diverse applications like video and hyperspectral imaging to go beyond standard techniques in terms of acquisition speed and efficiency. In this paper, we focus on SCI recovery algorithms that employ untrained neural networks (UNNs), such as deep image prior (DIP), to model source structure. Such UNN-based methods are appealing as they have the potential of avoiding the computationally intensive retraining required for different source models and different measurement scenarios. We first develop a theoretical framework for characterizing the performance of such UNN-based methods. The theoretical framework, on the one hand, enables us to optimize the parameters of data-modulating masks, and on the other hand, provides a fundamental connection between the number of data frames that can be recovered from a single measurement to the parameters of the untrained NN. We also employ the recently proposed bagged-deep-image-prior (bagged-DIP) idea to develop SCI Bagged Deep Video Prior (SCI-BDVP) algorithms that address the common challenges faced by standard UNN solutions. Our experimental results show that in video SCI our proposed solution achieves state-of-the-art among UNN methods, and in the case of noisy measurements, it even outperforms supervised solutions. Code is publicly available at [https://github.com/Computational-Imaging-RU/SCI-BDVP](https://github.com/Computational-Imaging-RU/SCI-BDVP).
tl;dr: The long-tail data in language model suffer from its gradient inconsistency with overall data, causing model struggle to capture domain knowledge during pretrain. We use a clustering-based sparse expert network, yields better performance.

Language models (LMs) only pretrained on a general and massive corpus usually cannot attain satisfying performance on domain-specific downstream tasks, and hence, applying domain-specific pretraining to LMs is a common and indispensable practice.
However, domain-specific pretraining can be costly and time-consuming, hindering LMs' deployment in real-world applications.
In this work, we consider the incapability to memorize domain-specific knowledge embedded in the general corpus with rare occurrences and long-tail distributions as the leading cause for pretrained LMs' inferior downstream performance.
Analysis of Neural Tangent Kernels (NTKs) reveals that those long-tail data are commonly overlooked in the model's gradient updates and, consequently, are not effectively memorized, leading to poor domain-specific downstream performance.
Based on the intuition that data with similar semantic meaning are closer in the embedding space, we devise a Cluster-guided Sparse Expert (CSE) layer to actively learn long-tail domain knowledge typically neglected in previous pretrained LMs.
During pretraining, a CSE layer efficiently clusters domain knowledge together and assigns long-tail knowledge to designate extra experts. CSE is also a lightweight structure that only needs to be incorporated in several deep layers.
With our training strategy, we found that during pretraining, data of long-tail knowledge gradually formulate isolated, outlier clusters in an LM's representation spaces, especially in deeper layers. Our experimental results show that only pretraining CSE-based LMs is enough to achieve superior performance than regularly pretrained-finetuned LMs on various downstream tasks, implying the prospects of domain-specific-pretraining-free language models.
tl;dr: We introduce the distributed version of the Lion optimizer with efficient binary/low-precision communication. We provide both theoretical and empirical evidence to demonstrate it is a simple yet strong method.

The Lion optimizer has been a promising competitor with the AdamW for training large AI models, with advantages in memory, computation, and sample efficiency. In this paper, we introduce Distributed Lion, an innovative adaptation of Lion for distributed training environments. Leveraging the sign operator in Lion, our Distributed Lion only requires to communicate binary or lower-precision vectors
between workers to the center server, significantly reducing the communication cost.
Our theoretical analysis confirms Distributed Lion's convergence properties. Empirical results demonstrate its robustness across a range of tasks, worker counts, and batch sizes, on both vision and language problems. Notably, Distributed Lion attains comparable performance to standard Lion or AdamW optimizers applied on aggregated gradients, but with significantly reduced communication bandwidth. This feature is particularly advantageous for training large models. In addition, we also demonstrate that \mavolion{} presents a more favorable performance-bandwidth balance compared to existing efficient distributed methods such as deep gradient compression and ternary gradients.

Deep Reinforcement Learning (DRL) algorithms have achieved great success in solving many challenging tasks while their black-box nature hinders interpretability and real-world applicability, making it difficult for human experts to interpret and understand DRL policies.
Existing works on interpretable reinforcement learning have shown promise in extracting decision tree (DT) based policies from DRL policies with most focus on the single-agent settings while prior attempts to introduce DT policies in multi-agent scenarios mainly focus on heuristic designs which do not provide any quantitative guarantees on the expected return.
In this paper, we establish an upper bound on the return gap between the oracle expert policy and an optimal decision tree policy. This enables us to recast the DT extraction problem into a novel non-euclidean clustering problem over the local observation and action values space of each agent, with action values as cluster labels and the upper bound on the return gap as clustering loss.
Both the algorithm and the upper bound are extended to multi-agent decentralized DT extractions by an iteratively-grow-DT procedure guided by an action-value function conditioned on the current DTs of other agents. Further, we propose the Return-Gap-Minimization Decision Tree (RGMDT) algorithm, which is a surprisingly simple design and is integrated with reinforcement learning through the utilization of a novel Regularized Information Maximization loss. Evaluations on tasks like D4RL show that RGMDT significantly outperforms heuristic DT-based baselines and can achieve nearly optimal returns under given DT complexity constraints (e.g., maximum number of DT nodes).
tl;dr: A MCMC-free method based on the discrete heat diffusion for the training of energy-based models on discrete and mixed data with applications in generative modelling for tabular data.

Energy-based models (EBMs) offer a flexible framework for probabilistic modelling across various data domains. However, training EBMs on data in discrete or mixed state spaces poses significant challenges due to the lack of robust and fast sampling methods. In this work, we propose to train discrete EBMs with Energy Discrepancy, a loss function which only requires the evaluation of the energy function at data points and their perturbed counterparts, thus eliminating the need for Markov chain Monte Carlo. We introduce perturbations of the data distribution by simulating a diffusion process on the discrete state space endowed with a graph structure. This allows us to inform the choice of perturbation from the structure of the modelled discrete variable, while the continuous time parameter enables fine-grained control of the perturbation. Empirically, we demonstrate the efficacy of the proposed approaches in a wide range of applications, including the estimation of discrete densities with non-binary vocabulary and binary image modelling. We also introduce the first application of EBMs to tabular data sets with applications in synthetic data generation and calibrated classification.
tl;dr: We give the best known algorithm for replicable uniformity testing, and a matching lower bound for the natural class of symmetric algorithms.

Uniformity testing is arguably one of the most fundamental distribution testing problems. Given sample access to an unknown distribution $\mathbf{p}$ on $[n]$, one must decide if $\mathbf{p}$ is uniform or $\varepsilon$-far from uniform (in total variation distance). A long line of work established that uniformity testing has sample complexity $\Theta(\sqrt{n}\varepsilon^{-2})$. However, when the input distribution is neither uniform nor far from uniform, known algorithms may have highly non-replicable behavior.
Consequently, if these algorithms are applied in scientific studies, they may lead to contradictory results that erode public trust in science.
In this work, we revisit uniformity testing under the framework of algorithmic replicability [STOC '22], requiring the algorithm to be replicable under arbitrary distributions. While replicability typically incurs a $\rho^{-2}$ factor overhead in sample complexity, we obtain a replicable uniformity tester using only $\tilde{O}(\sqrt{n} \varepsilon^{-2} \rho^{-1})$ samples. To our knowledge, this is the first replicable learning algorithm with (nearly) linear dependence on $\rho$.
Lastly, we consider a class of ``symmetric" algorithms [FOCS '00] whose outputs are invariant under relabeling of the domain $[n]$, which includes all existing uniformity testers (including ours). For this natural class of algorithms, we prove a nearly matching sample complexity lower bound for replicable uniformity testing.

Neural models learn data representations that lie on low-dimensional manifolds, yet modeling the relation between these representational spaces is an ongoing challenge.
By integrating spectral geometry principles into neural modeling, we show that this problem can be better addressed in the functional domain, mitigating complexity, while enhancing interpretability and performances on downstream tasks.
To this end, we introduce a multi-purpose framework to the representation learning community, which allows to: (i) compare different spaces in an interpretable way and measure their intrinsic similarity; (ii) find correspondences between them, both in unsupervised and weakly supervised settings, and (iii) to effectively transfer representations between distinct spaces.
We validate our framework on various applications, ranging from stitching to retrieval tasks, and on multiple modalities, demonstrating that Latent Functional Maps can serve as a swiss-army knife for representation alignment.
1559. AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos

We introduce AlphaTablets, a novel and generic representation of 3D planes that features continuous 3D surface and precise boundary delineation. By representing 3D planes as rectangles with alpha channels, AlphaTablets combine the advantages of current 2D and 3D plane representations, enabling accurate, consistent and flexible modeling of 3D planes. We derive differentiable rasterization on top of AlphaTablets to efficiently render 3D planes into images, and propose a novel bottom-up pipeline for 3D planar reconstruction from monocular videos. Starting with 2D superpixels and geometric cues from pre-trained models, we initialize 3D planes as AlphaTablets and optimize them via differentiable rendering. An effective merging scheme is introduced to facilitate the growth and refinement of AlphaTablets. Through iterative optimization and merging, we reconstruct complete and accurate 3D planes with solid surfaces and clear boundaries. Extensive experiments on the ScanNet dataset demonstrate state-of-the-art performance in 3D planar reconstruction, underscoring the great potential of AlphaTablets as a generic 3D plane representation for various applications.
tl;dr: We show that online reinforcement learning with the power to reset to previously visited states unlocks new statistical guarantees that were previously out of reach.

Simulators are a pervasive tool in reinforcement learning, but most existing algorithms cannot efficiently exploit simulator access -- particularly in high-dimensional domains that require general function approximation. We explore the power of simulators through online reinforcement learning with local simulator access (or, local planning), an RL protocol where the agent is allowed to reset to previously observed states and follow their dynamics during training. We use local simulator access to unlock new statistical guarantees that were previously out of reach:
- We show that MDPs with low coverability (Xie et al. 2023) -- a general structural condition that subsumes Block MDPs and Low-Rank MDPs -- can be learned in a sample-efficient fashion with only Q⋆-realizability (realizability of the optimal state-value function); existing online RL algorithms require significantly stronger representation conditions.
- As a consequence, we show that the notorious Exogenous Block MDP problem (Efroni et al. 2022) is tractable under local simulator access.
The results above are achieved through a computationally inefficient algorithm. We complement them with a more computationally efficient algorithm, RVFS (Recursive Value Function Search), which achieves provable sample complexity guarantees under a strengthened statistical assumption known as pushforward coverability. RVFS can be viewed as a principled, provable counterpart to a successful empirical paradigm that combines recursive search (e.g., MCTS) with value function approximation.
tl;dr: We introduce CogVLM, a powerful open-source visual language foundation model.

We introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular \emph{shallow alignment} method which maps image features into the input space of language model, CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables a deep fusion of vision language features without sacrificing any performance on NLP tasks. CogVLM-17B achieves state-of-the-art performance on 17 classic cross-modal benchmarks, including 1) image captioning datasets: NoCaps, Flicker30k, 2) VQA datasets: OKVQA, TextVQA, OCRVQA, ScienceQA, 3) LVLM benchmarks: MM-Vet, MMBench, SEED-Bench, LLaVABench, POPE, MMMU, MathVista, 4) visual grounding datasets: RefCOCO, RefCOCO+, RefCOCOg, Visual7W. Codes and checkpoints are available at Github.
tl;dr: We propose an optimisitc kernel-based RL algorithm for the infinite horizon average reward setting and prove no-regret performance guarantees.

Reinforcement Learning (RL) utilizing kernel ridge regression to predict the expected value function represents a powerful method with great representational capacity. This setting is a highly versatile framework amenable to analytical results. We consider kernel-based function approximation for RL in the infinite horizon average reward setting, also referred to as the undiscounted setting. We propose an *optimistic* algorithm, similar to acquisition function based algorithms in the special case of bandits. We establish novel *no-regret* performance guarantees for our algorithm, under kernel-based modelling assumptions. Additionally, we derive a novel confidence interval for the kernel-based prediction of the expected value function, applicable across various RL problems.
tl;dr: A new knowledge distillation paradigm to enable effective learning from multiple experts for domain generalization

Domain generalization (DG) methods aim to maintain good performance in an unseen target domain by using training data from multiple source domains. While success on certain occasions are observed, enhancing the baseline across most scenarios remains challenging. This work introduces a simple yet effective framework, dubbed learning from multiple experts (LFME), that aims to make the target model an expert in all source domains to improve DG. Specifically, besides learning the target model used in inference, LFME will also train multiple experts specialized in different domains, whose output probabilities provide professional guidance by simply regularizing the logit of the target model. Delving deep into the framework, we reveal that the introduced logit regularization term implicitly provides effects of enabling the target model to harness more information, and mining hard samples from the experts during training. Extensive experiments on benchmarks from different DG tasks demonstrate that LFME is consistently beneficial to the baseline and can achieve comparable performance to existing arts. Code is available at https://github.com/liangchen527/LFME.
tl;dr: We present the first tractable ultra-high dimensional quantizer for LLM PTQ that supports fast inference, enabling in state of the art quantization quality and inference speed.

Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing weights to low-precision datatypes.
Since LLM inference is usually memory-bound, PTQ methods can improve inference throughput.
Recent state-of-the-art PTQ approaches use vector quantization (VQ) to quantize multiple weights at once, which improves information utilization through better shaping.
However, VQ requires a codebook with size exponential in the dimension.
This limits current VQ-based PTQ works to low VQ dimensions ($\le 8$) that in turn limit quantization quality.
Here, we introduce QTIP, which instead uses trellis coded quantization (TCQ) to achieve ultra-high-dimensional quantization.
TCQ uses a stateful decoder that separates the codebook size from the bitrate and effective dimension.
QTIP introduces a spectrum of lookup-only to computed lookup-free trellis codes designed for a hardware-efficient "bitshift" trellis structure; these codes achieve state-of-the-art results in both quantization quality and inference speed.
tl;dr: We develop a theoretically-grounded method for learning approximations of Generalized Linear Programming Value Functions, and use it to construct a heuristic for large-scale two-stage Mixed-Integer Linear Programs.

We develop a theoretically-grounded learning method for the Generalized Linear Programming Value Function (GVF), which models the optimal value of a linear programming (LP) problem as its objective and constraint bounds vary. This function plays a fundamental role in algorithmic techniques for large-scale optimization, particularly in decomposition for two-stage mixed-integer linear programs (MILPs). This paper establishes a structural characterization of the GVF that enables it to be modeled as a particular neural network architecture, which we then use to learn the GVF in a way that benefits from three notable properties. First, our method produces a true under-approximation of the value function with respect to the constraint bounds. Second, the model is input-convex in the constraint bounds, which not only matches the structure of the GVF but also enables the trained model to be efficiently optimized over using LP. Finally, our learning method is unsupervised, meaning that training data generation does not require computing LP optimal values, which can be prohibitively expensive at large scales. We numerically show that our method can approximate the GVF well, even when compared to supervised methods that collect training data by solving an LP for each data point. Furthermore, as an application of our framework, we develop a fast heuristic method for large-scale two-stage MILPs with continuous second-stage variables, via a compact reformulation that can be solved faster than the full model linear relaxation at large scales and orders of magnitude faster than the original model.
tl;dr: We propose Posteriori-Sampling-based Node-Adaptative Residual Module to enhance the performances of deep graph neural networks.

Graph Neural Networks (GNNs), a type of neural network that can learn from graph-structured data through neighborhood information aggregation, have shown superior performance in various downstream tasks. However, as the number of layers increases, node representations becomes indistinguishable, which is known as over-smoothing. To address this issue, many residual methods have emerged. In this paper, we focus on the over-smoothing issue and related residual methods. Firstly, we revisit over-smoothing from the perspective of overlapping neighborhood subgraphs, and based on this, we explain how residual methods can alleviate over-smoothing by integrating multiple orders neighborhood subgraphs to avoid the indistinguishability of the single high-order neighborhood subgraphs. Additionally, we reveal the drawbacks of previous residual methods, such as the lack of node adaptability and severe loss of high-order neighborhood subgraph information, and propose a \textbf{Posterior-Sampling-based, Node-Adaptive Residual module (PSNR)}. We theoretically demonstrate that PSNR can alleviate the drawbacks of previous residual methods. Furthermore, extensive experiments verify the superiority of the PSNR module in fully observed node classification and missing feature scenarios. Our code
is available at \href{https://github.com/jingbo02/PSNR-GNN}{https://github.com/jingbo02/PSNR-GNN}.
tl;dr: The paper proposes a novel method for integrating a dynamic planner within a safe reinforcement learning framework, enabling progress towards the goal while recovering from unsafe situations.

Among approaches for provably safe reinforcement learning, Model Predictive Shielding (MPS) has proven effective at complex tasks in continuous, high-dimensional state spaces, by leveraging a *backup policy* to ensure safety when the learned policy attempts to take risky actions. However, while MPS can ensure safety both during and after training, it often hinders task progress due to the conservative and task-oblivious nature of backup policies.
This paper introduces *Dynamic Model Predictive Shielding* (DMPS), which optimizes reinforcement learning objectives while maintaining provable safety. DMPS employs a local planner to dynamically select safe recovery actions that maximize both short-term progress as well as long-term rewards. Crucially, the planner and the neural policy play a synergistic role in DMPS. When planning recovery actions for ensuring safety, the planner utilizes the neural policy to estimate long-term rewards, allowing it to *observe* beyond its short-term planning horizon.
Conversely, the neural policy under training learns from the recovery plans proposed by the planner, converging to policies that are both *high-performing* and *safe* in practice.
This approach guarantees safety during and after training, with bounded recovery regret that decreases exponentially with planning horizon depth. Experimental results demonstrate that DMPS converges to policies that rarely require shield interventions after training and achieve higher rewards compared to several state-of-the-art baselines.
tl;dr: We introduce a unifying framework for deriving algorithms and tractability conditions for complex compositional inference queries, such as marginal MAP, logic programming inference and causal inference.

Circuits based on sum-product structure have become a ubiquitous representation to compactly encode knowledge, from Boolean functions to probability distributions. By imposing constraints on the structure of such circuits, certain inference queries become tractable, such as model counting and most probable configuration. Recent works have explored analyzing probabilistic and causal inference queries as compositions of basic operations to derive tractability conditions. In this paper, we take an algebraic perspective for compositional inference, and show that a large class of queries---including marginal MAP, probabilistic answer set programming inference, and causal backdoor adjustment---correspond to a combination of basic operations over semirings: aggregation, product, and elementwise mapping. Using this framework, we uncover simple and general sufficient conditions for tractable composition of these operations, in terms of circuit properties (e.g., marginal determinism, compatibility) and conditions on the elementwise mappings. Applying our analysis, we derive novel tractability conditions for many such compositional queries. Our results unify tractability conditions for existing problems on circuits, while providing a blueprint for analysing novel compositional inference queries.

We study a typical optimization model where the optimization variable is composed of multiple probability distributions. Though the model appears frequently in practice, such as for policy problems, it lacks specific analysis in the general setting. For this optimization problem, we propose a new structural condition/landscape description named generalized quasar-convexity (GQC) beyond the realms of convexity. In contrast to original quasar-convexity \citep{hinder2020near}, GQC allows an individual quasar-convex parameter $\gamma_i$ for each variable block $i$ and the smaller of $\gamma_i$ implies less block-convexity. To minimize the objective function, we consider a generalized oracle termed as the internal function that includes the standard gradient oracle as a special case. We provide optimistic mirror descent (OMD) for multiple distributions and prove that the algorithm can achieve an adaptive $\tilde{\mathcal{O}}((\sum_{i=1}^d1/\gamma_i)\epsilon^{-1})$ iteration complexity to find an $\varepsilon$-suboptimal global solution without pre-known the exact values of $\gamma_i$ when the objective admits ``polynomial-like'' structural. Notably, it achieves iteration complexity that does not explicitly depend on the number of distributions and strictly faster $(\sum_{i=1}^d 1/\gamma_i \text{ v.s. } d\max_{i\in[1:d]} 1/\gamma_i)$ than mirror decent methods. We also extend GQC to the minimax optimization problem proposing the generalized quasar-convexity-concavity (GQCC) condition and a decentralized variant of OMD with regularization. Finally, we show the applications of our algorithmic framework on discounted Markov Decision Processes problem and Markov games, which bring new insights on the landscape analysis of reinforcement learning.
tl;dr: We show that the presence and type of syntactic relations in a sentence can be inferred respectively from distances and orientations in the activation space of language models

Originally formalized with symbolic representations, syntactic trees may also be effectively represented in the activations of large language models (LLMs). Indeed, a ''Structural Probe'' can find a subspace of neural activations, where syntactically-related words are relatively close to one-another. However, this syntactic code remains incomplete: the distance between the Structural Probe word embeddings can represent the \emph{existence} but not the type and direction of syntactic relations. Here, we hypothesize that syntactic relations are, in fact, coded by the relative direction between nearby embeddings. To test this hypothesis, we introduce a ''Polar Probe'' trained to read syntactic relations from both the distance and the direction between word embeddings. Our approach reveals three main findings. First, our Polar Probe successfully recovers the type and direction of syntactic relations, and substantially outperforms the Structural Probe by nearly two folds. Second, we confirm that this polar coordinate system exists in a low-dimensional subspace of the intermediate layers of many LLMs and becomes increasingly precise in the latest frontier models. Third, we demonstrate with a new benchmark that similar syntactic relations are coded similarly across the nested levels of syntactic trees. Overall, this work shows that LLMs spontaneously learn a geometry of neural activations that explicitly represents the main symbolic structures of linguistic theory.
tl;dr: We bound the variances of random estimators of the diagonal Fisher information matrix.

The Fisher information matrix can be used to characterize the local geometry of
the parameter space of neural networks. It elucidates insightful theories and
useful tools to understand and optimize neural networks. Given its high
computational cost, practitioners often use random estimators and evaluate only
the diagonal entries. We examine two popular estimators whose accuracy and sample
complexity depend on their associated variances. We derive bounds of the
variances and instantiate them in neural networks for regression and
classification. We navigate trade-offs for both estimators based on analytical
and numerical studies. We find that the variance quantities depend on the
non-linearity w.r.t. different parameter groups and should not be neglected when
estimating the Fisher information.
tl;dr: A human mobility prediction model for long-tail distribution issue

With the popularity of location-based services, human mobility prediction plays a key role in enhancing personalized navigation, optimizing recommendation systems, and facilitating urban mobility and planning. This involves predicting a user's next POI (point-of-interest) visit using their past visit history. However, the uneven distribution of visitations over time and space, namely the long-tail problem in spatial distribution, makes it difficult for AI models to predict those POIs that are less visited by humans. In light of this issue, we propose the $\underline{\bf{Lo}}$ng-$\underline{\bf{T}}$ail Adjusted $\underline{\bf{Next}}$ POI Prediction (LoTNext) framework for mobility prediction, combining a Long-Tailed Graph Adjustment module to reduce the impact of the long-tailed nodes in the user-POI interaction graph and a novel Long-Tailed Loss Adjustment module to adjust loss by logit score and sample weight adjustment strategy. Also, we employ the auxiliary prediction task to enhance generalization and accuracy. Our experiments with two real-world trajectory datasets demonstrate that LoTNext significantly surpasses existing state-of-the-art works. Our code is available at https://github.com/Yukayo/LoTNext.

Unobserved discrete data are ubiquitous in many scientific disciplines, and how to learn the causal structure of these latent variables is crucial for uncovering data patterns. Most studies focus on the linear latent variable model or impose strict constraints on latent structures, which fail to address cases in discrete data involving non-linear relationships or complex latent structures. To achieve this, we explore a tensor rank condition on contingency tables for an observed variable set $\mathbf{X}_p$, showing that the rank is determined by the minimum support of a specific conditional set (not necessary in $\mathbf{X}_p$) that d-separates all variables in $\mathbf{X}_p$. By this, one can locate the latent variable through probing the rank on different observed variables set, and further identify the latent causal structure under some structure assumptions. We present the corresponding identification algorithm and conduct simulated experiments to verify the effectiveness of our method. In general, our results elegantly extend the identification boundary for causal discovery with discrete latent variables and expand the application scope of causal discovery with latent variables.
tl;dr: By replacing commonly used score functions with a regularized log-likelihood, continuous-constrained structure learning consistently recovers the Markov equivalence class.

Existing approaches to differentiable structure learning of directed acyclic graphs (DAGs) rely on strong identifiability assumptions in order to guarantee that global minimizers of the acyclicity-constrained optimization problem identifies the true DAG. Moreover, it has been observed empirically that the optimizer may exploit undesirable artifacts in the loss function. We explain and remedy these issues by studying the behavior of differentiable acyclicity-constrained programs under general likelihoods with multiple global minimizers. By carefully regularizing the likelihood, it is possible to identify the sparsest model in the Markov equivalence class, even in the absence of an identifiable parametrization. We first study the Gaussian case in detail, showing how proper regularization of the likelihood defines a score that identifies the sparsest model. Assuming faithfulness, it also recovers the Markov equivalence class. These results are then generalized to general models and likelihoods, where the same claims hold. These theoretical results are validated empirically, showing how this can be done using standard gradient-based optimizers, thus paving the way for differentiable structure learning under general models and losses.

Existing neural operator architectures face challenges when solving multiphysics problems with coupled partial differential equations (PDEs) due to complex geometries, interactions between physical variables, and the limited amounts of high-resolution training data.
To address these issues, we propose *Codomain Attention Neural Operator* (CoDA-NO), which tokenizes functions along the codomain or channel space, enabling self-supervised learning or pretraining of multiple PDE systems.
Specifically, we extend positional encoding, self-attention, and normalization layers to function spaces. CoDA-NO can learn representations of different PDE systems with a single model. We evaluate CoDA-NO's potential as a backbone for learning multiphysics PDEs over multiple systems by considering few-shot learning settings. On complex downstream tasks with limited data, such as fluid flow simulations, fluid-structure interactions, and Rayleigh-Bénard convection, we found CoDA-NO to outperform existing methods by over 36%.

Dataset condensation (DC) is an emerging technique capable of creating compact synthetic datasets from large originals while maintaining considerable performance. It is crucial for accelerating network training and reducing data storage requirements.
However, current research on DC mainly focuses on image classification, with less exploration of object detection.
This is primarily due to two challenges: (i) the multitasking nature of object detection complicates the condensation process, and (ii) Object detection datasets are characterized by large-scale and high-resolution data, which are difficult for existing DC methods to handle.
As a remedy, we propose DCOD, the first dataset condensation framework for object detection. It operates in two stages: Fetch and Forge, initially storing key localization and classification information into model parameters, and then reconstructing synthetic images via model inversion.
For the complex of multiple objects in an image, we propose Foreground Background Decoupling to centrally update the foreground of multiple instances and Incremental PatchExpand to further enhance the diversity of foregrounds.
Extensive experiments on various detection datasets demonstrate the superiority of DCOD. Even at an extremely low compression rate of 1\%, we achieve 46.4\% and 24.7\% $\text{AP}_{50}$ on the VOC and COCO, respectively, significantly reducing detector training duration.
tl;dr: We show that self-attention projects its query vectors onto the principal component axes of its key matrix in a feature space and propose Attention with Robust Principal Components, a novel robust attention that is resilient to data contamination.

The remarkable success of transformers in sequence modeling tasks, spanning various applications in natural language processing and computer vision, is attributed to the critical role of self-attention. Similar to the development of most deep learning models, the construction of these attention mechanisms relies on heuristics and experience. In our work, we derive self-attention from kernel principal component analysis (kernel PCA) and show that self-attention projects its query vectors onto the principal component axes of its key matrix in a feature space. We then formulate the exact formula for the value matrix in self-attention, theoretically and empirically demonstrating that this value matrix captures the eigenvectors of the Gram matrix of the key vectors in self-attention. Leveraging our kernel PCA framework, we propose Attention with Robust Principal Components (RPC-Attention), a novel class of robust attention that is resilient to data contamination. We empirically demonstrate the advantages of RPC-Attention over softmax attention on the ImageNet-1K object classification, WikiText-103 language modeling, and ADE20K image segmentation task.

As Archimedes famously said, ``Give me a lever long enough and a fulcrum on which to place it, and I shall move the world'', in this study, we propose to use a tiny Language Model (LM), \eg, a Transformer with 67M parameters, to lever much larger Vision-Language Models (LVLMs) with 9B parameters. Specifically, we use this tiny \textbf{Lever-LM} to configure effective in-context demonstration (ICD) sequences to improve the In-Context Learinng (ICL) performance of LVLMs. Previous studies show that diverse ICD configurations like the selection and ordering of the demonstrations heavily affect the ICL performance, highlighting the significance of configuring effective ICD sequences. Motivated by this and by re-considering the the process of configuring ICD sequence, we find this is a mirror process of human sentence composition and further assume that effective ICD configurations may contain internal statistical patterns that can be captured by Lever-LM. Then a dataset with effective ICD sequences is constructed to train Lever-LM. After training, given novel queries, new ICD sequences are configured by the trained Lever-LM to solve vision-language tasks through ICL. Experiments show that these ICD sequences can improve the ICL performance of two LVLMs compared with some strong baselines in Visual Question Answering and Image Captioning, validating that Lever-LM can really capture the statistical patterns for levering LVLMs. The code is available at \url{https://anonymous.4open.science/r/Lever-LM-604A/}.
1579. Generated and Pseudo Content guided Prototype Refinement for Few-shot Point Cloud Segmentation

Few-shot 3D point cloud semantic segmentation aims to segment query point clouds with only a few annotated support point clouds. Existing prototype-based methods learn prototypes from the 3D support set to guide the segmentation of query point clouds. However, they encounter the challenge of low prototype quality due to constrained semantic information in the 3D support set and class information bias between support and query sets. To address these issues, in this paper, we propose a novel framework called Generated and Pseudo Content guided Prototype Refinement (GPCPR), which explicitly leverages LLM-generated content and reliable query context to enhance prototype quality. GPCPR achieves prototype refinement through two core components: LLM-driven Generated Content-guided Prototype Refinement (GCPR) and Pseudo Query Context-guided Prototype Refinement (PCPR). Specifically, GCPR integrates diverse and differentiated class descriptions generated by large language models to enrich prototypes with comprehensive semantic knowledge. PCPR further aggregates reliable class-specific pseudo-query context to mitigate class information bias and generate more suitable query-specific prototypes. Furthermore, we introduce a dual-distillation regularization term, enabling knowledge transfer between early-stage entities (prototypes or pseudo predictions) and their deeper counterparts to enhance refinement. Extensive experiments demonstrate the superiority of our method, surpassing the state-of-the-art methods by up to 12.10% and 13.75% mIoU on S3DIS and ScanNet, respectively.
tl;dr: MixEval, a ground-truth-based dynamic benchmark which updates data points periodically, evaluates LLMs with a highly capable model ranking (\ie 0.96 correlation with Chatbot Arena) while running locally and quickly (1/15 time of running MMLU).

Evaluating large language models (LLMs) is challenging. Traditional ground-truth- based benchmarks fail to capture the comprehensiveness and nuance of real-world queries, while LLM-as-judge benchmarks suffer from grading biases and limited query quantity. Both of them may also become contaminated over time. User- facing evaluation, such as Chatbot Arena, provides reliable signals but is costly and slow. In this work, we propose MixEval, a new paradigm for establishing efficient, gold-standard LLM evaluation by strategically mixing off-the-shelf bench- marks. It bridges (1) comprehensive and well-distributed real-world user queries and (2) efficient and fairly-graded ground-truth-based benchmarks, by matching queries mined from the web with similar queries from existing benchmarks. Based on MixEval, we further build MixEval-Hard, which offers more room for model improvement. Our benchmarks’ advantages lie in (1) a 0.96 model ranking correlation with Chatbot Arena arising from the highly impartial query distribution and grading mechanism, (2) fast, cheap, and reproducible execution (6% of the time and cost of MMLU), and (3) dynamic evaluation enabled by the rapid and stable data update pipeline. We provide extensive meta-evaluation and analysis for our and existing LLM benchmarks to deepen the community’s understanding of LLM evaluation and guide future research directions.
tl;dr: We propose a novel strategy for unsupervised calibration under label shift, utilizing importance re-weighting of the labeled source distribution.

When machine learning systems face dataset shift, model calibration plays a pivotal role in ensuring their reliability.
Calibration error (CE) provides insights into the alignment between the predicted confidence scores and the classifier accuracy.
While prior works have delved into the implications of dataset shift on calibration, existing CE estimators either (i) assume access to labeled data from the target domain, often unavailable in practice, or (ii) are derived under a covariate shift assumption.
In this work we propose a novel, label-free, consistent CE estimator under label shift. Label shift is characterized by changes in the marginal label distribution p(Y), with a constant conditional p(X|Y) distribution between the source and target. We introduce a novel calibration method, called LaSCal, which uses the estimator in conjunction with a post-hoc calibration strategy, to perform unsupervised calibration on the target distribution. Our thorough empirical analysis demonstrates the effectiveness and reliability of the proposed approach across different modalities, model architectures and label shift intensities.

Leveraging human preferences for steering the behavior of Large Language Models (LLMs) has demonstrated notable success in recent years. Nonetheless, data selection and labeling are still a bottleneck for these systems, particularly at large scale. Hence, selecting the most informative points for acquiring human feedback may considerably reduce the cost of preference labeling and unleash the further development of LLMs. Bayesian Active Learning provides a principled framework for addressing this challenge and has demonstrated remarkable success in diverse settings. However, previous attempts to employ it for Preference Modeling did not meet such expectations. In this work, we identify that naive epistemic uncertainty estimation leads to the acquisition of redundant samples. We address this by proposing the Bayesian Active Learner for Preference Modeling (BAL-PM), a novel stochastic acquisition policy that not only targets points of high epistemic uncertainty according to the preference model but also seeks to maximize the entropy of the acquired prompt distribution in the feature space spanned by the employed LLM. Notably, our experiments demonstrate that BAL-PM requires 33\% to 68\% fewer preference labels in two popular human preference datasets and exceeds previous stochastic Bayesian acquisition policies.

Fine-tuning large-scale pretrained models is prohibitively expensive in terms of computational and memory costs. LoRA, as one of the most popular Parameter-Efficient Fine-Tuning (PEFT) methods, offers a cost-effective alternative by fine-tuning an auxiliary low-rank model that has significantly fewer parameters. Although LoRA reduces the computational and memory requirements significantly at each iteration, extensive empirical evidence indicates that it converges at a considerably slower rate compared to full fine-tuning, ultimately leading to increased overall compute and often worse test performance. In our paper, we perform an in-depth investigation of the initialization method of LoRA and show that careful initialization (without any change of the architecture and the training algorithm) can significantly enhance both efficiency and performance. In particular, we introduce a novel initialization method, LoRA-GA (Low Rank Adaptation with Gradient Approximation), which aligns the gradients of low-rank matrix product with those of full fine-tuning at the first step. Our extensive experiments demonstrate that LoRA-GA achieves a convergence rate comparable to that of full fine-tuning (hence being significantly faster than vanilla LoRA as well as various recent improvements) while simultaneously attaining comparable or even better performance. For example, on the subset of the GLUE dataset with T5-Base, LoRA-GA outperforms LoRA by 5.69% on average. On larger models such as Llama 2-7B, LoRA-GA shows performance improvements of 0.34, 11.52%, and 5.05% on MTbench, GSM8k, and Human-eval, respectively. Additionally, we observe up to 2-4 times convergence speed improvement compared to vanilla LoRA, validating its effectiveness in accelerating convergence and enhancing model performance.
tl;dr: Harmless Rawlsian Fairness Regardless of Demographics via decreasing Variance of Losses

Due to privacy and security concerns, recent advancements in group fairness advocate for model training regardless of demographic information. However, most methods still require prior knowledge of demographics. In this study, we explore the potential for achieving fairness without compromising its utility when no prior demographics are provided to the training set, namely _harmless Rawlsian fairness_. We ascertain that such a fairness requirement with no prior demographic information essential promotes training losses to exhibit a Dirac delta distribution. To this end, we propose a simple but effective method named VFair to minimize the variance of training losses inside the optimal set of empirical losses. This problem is then optimized by a tailored dynamic update approach that operates in both loss and gradient dimensions, directing the model towards relatively fairer solutions while preserving its intact utility. Our experimental findings indicate that regression tasks, which are relatively unexplored from literature, can achieve significant fairness improvement through VFair regardless of any prior, whereas classification tasks usually do not because of their quantized utility measurements. The implementation of our method is publicly available at https://github.com/wxqpxw/VFair.

In this paper, we propose a provably efficient natural policy gradient algorithm called Spectral Dynamic Embedding Policy Optimization (\SDEPO) for two-player zero-sum stochastic Markov games with continuous state space and finite action space.
In the policy evaluation procedure of our algorithm, a novel kernel embedding method is employed to construct a finite-dimensional linear approximations to the state-action value function.
We explicitly analyze the approximation error in policy evaluation, and show that \SDEPO\ achieves an $\tilde{O}(\frac{1}{(1-\gamma)^3\epsilon})$ last-iterate convergence to the $\epsilon-$optimal Nash equilibrium, which is independent of the cardinality of the state space.
The complexity result matches the best-known results for global convergence of policy gradient algorithms for single agent setting.
Moreover, we also propose a practical variant of \SDEPO\ to deal with continuous action space and empirical results demonstrate the practical superiority of the proposed method.

Pre-training plays a vital role in various vision tasks, such as object recognition and detection. Commonly used pre-training methods, which typically rely on randomized approaches like uniform or Gaussian distributions to initialize model parameters, often fall short when confronted with long-tailed distributions, especially in detection tasks. This is largely due to extreme data imbalance and the issue of simplicity bias. In this paper, we introduce a novel pre-training framework for object detection, called Dynamic Rebalancing Contrastive Learning with Dual Reconstruction (2DRCL). Our method builds on a Holistic-Local Contrastive Learning mechanism, which aligns pre-training with object detection by capturing both global contextual semantics and detailed local patterns. To tackle the imbalance inherent in long-tailed data, we design a dynamic rebalancing strategy that adjusts the sampling of underrepresented instances throughout the pre-training process, ensuring better representation of tail classes. Moreover, Dual Reconstruction addresses simplicity bias by enforcing a reconstruction task aligned with the self-consistency principle, specifically benefiting underrepresented tail classes. Experiments on COCO and LVIS v1.0 datasets demonstrate the effectiveness of our method, particularly in improving the mAP/AP scores for tail classes.
tl;dr: Solving a constrained MDP in the forward pass of inverse RL is an unnecessary complication for inferring constraints - constraints can be inferred as well or better through simple IRL methods.

Learning safe policies has presented a longstanding challenge for the reinforcement learning (RL) community. Various formulations of safe RL have been proposed; However, fundamentally, tabula rasa RL must learn safety constraints through experience, which is problematic for real-world applications. Imitation learning is often preferred in real-world settings because the experts' safety preferences are embedded in the data the agent imitates. However, imitation learning is limited in its extensibility to new tasks, which can only be learned by providing the agent with expert trajectories. For safety-critical applications with sub-optimal or inexact expert data, it would be preferable to learn only the safety aspects of the policy through imitation, while still allowing for task learning with RL. The field of inverse constrained RL, which seeks to infer constraints from expert data, is a promising step in this direction. However, prior work in this area has relied on complex tri-level optimizations in order to infer safe behavior (constraints). This challenging optimization landscape leads to sub-optimal performance on several benchmark tasks. In this work, we present a simplified version of constraint inference that performs as well or better than prior work across a collection of continuous-control benchmarks. Moreover, besides improving performance, this simplified framework is easier to implement, tune, and more readily lends itself to various extensions, such as offline constraint inference.

This paper introduces $\textit{Bifröst}$, a novel 3D-aware framework that is built upon diffusion models to perform instruction-based image composition. Previous methods concentrate on image compositing at the 2D level, which fall short in handling complex spatial relationships ($\textit{e.g.}$, occlusion). $\textit{Bifröst}$ addresses these issues by training MLLM as a 2.5D location predictor and integrating depth maps as an extra condition during the generation process to bridge the gap between 2D and 3D, which enhances spatial comprehension and supports sophisticated spatial interactions. Our method begins by fine-tuning MLLM with a custom counterfactual dataset to predict 2.5D object locations in complex backgrounds from language instructions. Then, the image-compositing model is uniquely designed to process multiple types of input features, enabling it to perform high-fidelity image compositions that consider occlusion, depth blur, and image harmonization. Extensive qualitative and quantitative evaluations demonstrate that $\textit{Bifröst}$ significantly outperforms existing methods, providing a robust solution for generating realistically composited images in scenarios demanding intricate spatial understanding. This work not only pushes the boundaries of generative image compositing but also reduces reliance on expensive annotated datasets by effectively utilizing existing resources in innovative ways.
tl;dr: We propose SMG, which utilizes a reconstruction-based auxiliary task to extract task-relevant representations from visual observations and further strengths the generalization ability of RL agents with the help of two consistency losses.

A primary challenge for visual-based Reinforcement Learning (RL) is to generalize effectively across unseen environments. Although previous studies have explored different auxiliary tasks to enhance generalization, few adopt image reconstruction due to concerns about exacerbating overfitting to task-irrelevant features during training. Perceiving the pre-eminence of image reconstruction in representation learning, we propose SMG (\blue{S}eparated \blue{M}odels for \blue{G}eneralization), a novel approach that exploits image reconstruction for generalization. SMG introduces two model branches to extract task-relevant and task-irrelevant representations separately from visual observations via cooperatively reconstruction. Built upon this architecture, we further emphasize the importance of task-relevant features for generalization. Specifically, SMG incorporates two additional consistency losses to guide the agent's focus toward task-relevant areas across different scenarios, thereby achieving free from overfitting. Extensive experiments in DMC demonstrate the SOTA performance of SMG in generalization, particularly excelling in video-background settings. Evaluations on robotic manipulation tasks further confirm the robustness of SMG in real-world applications. Source code is available at \url{https://anonymous.4open.science/r/SMG/}.
tl;dr: we systematically investigate the scaling laws on molecular pretraining and scale the model to 1.1 billion parameters through pretraining on 0.8 billion conformations, making it the largest molecular pretraining model to date.

In recent years, pretraining models have made significant advancements in the fields of natural language processing (NLP), computer vision (CV), and life sciences. The significant advancements in NLP and CV are predominantly driven by the expansion of model parameters and data size, a phenomenon now recognized as the scaling laws. However, research exploring scaling law in molecular pretraining model remains unexplored. In this work, we present an innovative molecular pretraining model that leverages a two-track transformer to effectively integrate features at the atomic level, graph level, and geometry structure level. Along with this, we systematically investigate the scaling law within molecular pretraining models, examining the power-law correlations between validation loss and model size, dataset size, and computational resources. Consequently, we successfully scale the model to 1.1 billion parameters through pretraining on 800 million conformations, making it the largest molecular pretraining model to date. Extensive experiments show the consistent improvement on the downstream tasks as the model size grows up. The model with 1.1 billion parameters also outperform over existing methods, achieving an average 27\% improvement on the QM9 and 14\% on COMPAS-1D dataset.

Time series forecasting typically needs to address non-stationary data with evolving trend and seasonal patterns. To address the non-stationarity, reversible instance normalization has been recently proposed to alleviate impacts from the trend with certain statistical measures, e.g., mean and variance. Although they demonstrate improved predictive accuracy, they are limited to expressing basic trends and are incapable of handling seasonal patterns. To address this limitation, this paper proposes a new instance normalization solution, called frequency adaptive normalization (FAN), which extends instance normalization in handling both dynamic trend and seasonal patterns. Specifically, we employ the Fourier transform to identify instance-wise predominant frequent components that cover most non-stationary factors.
Furthermore, the discrepancy of those frequency components between inputs and outputs is explicitly modeled as a prediction task with a simple MLP model. FAN is a model-agnostic method that can be applied to arbitrary predictive backbones. We instantiate FAN on four widely used forecasting models as the backbone and evaluate their prediction performance improvements on eight benchmark datasets. FAN demonstrates significant performance advancement, achieving 7.76\%$\sim$37.90\% average improvements in MSE. Our code is publicly available at http://github.com/icannotnamemyself/FAN.

In strategic classification, agents modify their features, at a cost, to obtain a positive classification outcome from the learner’s classifier,
typically assuming agents have full knowledge of the deployed classifier. In contrast, we consider a Bayesian setting where agents have a common distributional prior on the classifier being used and agents manipulate their features to maximize their expected utility according to this prior.
The learner can reveal truthful, yet not necessarily complete, information about the classifier to the agents, aiming to release just enough information to shape the agents' behavior and thus maximize accuracy. We show that partial information release can counter-intuitively benefit the learner’s accuracy, allowing qualified agents to pass the classifier while preventing unqualified agents from doing so. Despite the intractability of computing the best response of an agent in the general case, we provide oracle-efficient algorithms for scenarios where the learner’s hypothesis class consists of low-dimensional linear classifiers or when the agents’ cost function satisfies a sub-modularity condition.
Additionally, we address the learner’s optimization problem, offering both positive and negative results on determining the optimal information release to maximize expected accuracy, particularly in settings where an agent’s qualification can be represented by a real-valued number.
tl;dr: We propose FoldFlow++ a new sequence conditioned protein structure generative model using flow-matching which can be finetuned for Motif Scaffolding.

Proteins are essential for almost all biological processes and derive their diverse functions from complex $3 \rm D$ structures, which are in turn determined by their amino acid sequences.
In this paper, we exploit the rich biological inductive bias of amino acid sequences and introduce FoldFlow++, a novel sequence-conditioned $\text{SE}(3)$-equivariant flow matching model for protein structure generation. FoldFlow++ presents substantial new architectural features over the previous FoldFlow family of models including a protein large language model to encode sequence, a new multi-modal fusion trunk that combines structure and sequence representations, and a geometric transformer based decoder. To increase
diversity and novelty of generated samples -- crucial for de-novo drug design -- we
train FoldFlow++ at scale on a new dataset
that is an order of magnitude
larger than PDB datasets of prior works, containing both known proteins in PDB and high-quality synthetic structures achieved through filtering. We further demonstrate the ability to align FoldFlow++ to arbitrary rewards, e.g. increasing secondary structures diversity, by introducing a Reinforced Finetuning (ReFT) objective. We empirically observe that FoldFlow++ outperforms previous state-of-the-art protein structure-based generative models, improving over RFDiffusion in terms of unconditional generation across all metrics including designability, diversity, and novelty across all protein lengths, as well as exhibiting generalization on the task of equilibrium conformation sampling. Finally, we demonstrate that a fine-tuned FoldFlow++ makes progress on challenging conditional design tasks such as designing scaffolds for the VHH nanobody.
tl;dr: This paper proposes a ReLU NCBF synthesis framework with efficient exact verification for robotic safety. Key insights: ReLU NCBF can be verified in linear pieces, boundary pieces are safety-critical, and limiting them improves efficiency.

Neural Control Barrier Functions (NCBFs) have shown significant promise in enforcing safety constraints on nonlinear autonomous systems. State-of-the-art exact approaches to verifying safety of NCBF-based controllers exploit the piecewise-linear structure of ReLU neural networks, however, such approaches still rely on enumerating all of the activation regions of the network near the safety boundary, thus incurring high computation cost. In this paper, we propose a framework for Synthesis with Efficient Exact Verification (SEEV). Our framework consists of two components, namely (i) an NCBF synthesis algorithm that introduces a novel regularizer to reduce the number of activation regions at the safety boundary, and (ii) a verification algorithm that exploits tight over-approximations of the safety conditions to reduce the cost of verifying each piecewise-linear segment. Our simulations show that SEEV significantly improves verification efficiency while maintaining the CBF quality across various benchmark systems and neural network structures. Our code is available at https://github.com/HongchaoZhang-HZ/SEEV.
tl;dr: We quantify the uncertainty in 3D Gaussian Splatting by deviating Gaussians to construction model space samples and learn with variational inference. .

Recently, 3D Gaussian Splatting (3DGS) has become popular in reconstructing dense 3D representations of appearance and geometry. However, the learning pipeline in 3DGS inherently lacks the ability to quantify uncertainty, which is an important factor in applications like robotics mapping and navigation. In this paper, we propose an uncertainty estimation method built upon the Bayesian inference framework. Specifically, we propose a method to build variational multi-scale 3D Gaussians, where we leverage explicit scale information in 3DGS parameters to construct diversified parameter space samples. We develop an offset table technique to draw local multi-scale samples efficiently by offsetting selected attributes and sharing other base attributes. Then, the offset table is learned by variational inference with multi-scale prior. The learned offset posterior can quantify the uncertainty of each individual Gaussian component, and be used in the forward pass to infer the predictive uncertainty. Extensive experimental results on various benchmark datasets show that the proposed method provides well-aligned calibration performance on estimated uncertainty and better rendering quality compared with the previous methods that enable uncertainty quantification with view synthesis. Besides, by leveraging the model parameter uncertainty estimated by our method, we can remove noisy Gaussians automatically, thereby obtaining a high-fidelity part of the reconstructed scene, which is of great help in improving the visual quality.
tl;dr: We propose a Dynamic Adaptation method to guide LLMs for rule-based TKGR tasks.

Temporal Knowledge Graph Reasoning (TKGR) is the process of utilizing temporal information to capture complex relations within a Temporal Knowledge Graph (TKG) to infer new knowledge. Conventional methods in TKGR typically depend on deep learning algorithms or temporal logical rules. However, deep learning-based TKGRs often lack interpretability, whereas rule-based TKGRs struggle to effectively learn temporal rules that capture temporal patterns. Recently, Large Language Models (LLMs) have demonstrated extensive knowledge and remarkable proficiency in temporal reasoning. Consequently, the employment of LLMs for Temporal Knowledge Graph Reasoning (TKGR) has sparked increasing interest among researchers. Nonetheless, LLMs are known to function as black boxes, making it challenging to comprehend their reasoning process. Additionally, due to the resource-intensive nature of fine-tuning, promptly updating LLMs to integrate evolving knowledge within TKGs for reasoning is impractical. To address these challenges, in this paper, we propose a Large Language Models-guided Dynamic Adaptation (LLM-DA) method for reasoning on TKGs. Specifically, LLM-DA harnesses the capabilities of LLMs to analyze historical data and extract temporal logical rules. These rules unveil temporal patterns and facilitate interpretable reasoning. To account for the evolving nature of TKGs, a dynamic adaptation strategy is proposed to update the LLM-generated rules with the latest events. This ensures that the extracted rules always incorporate the most recent knowledge and better generalize to the predictions on future events. Experimental results show that without the need of fine-tuning, LLM-DA significantly improves the accuracy of reasoning over several common datasets, providing a robust framework for TKGR tasks.

We study a data pricing problem, where a seller has access to $N$ homogeneous data points (e.g. drawn i.i.d. from some distribution).
There are $m$ types of buyers in the market, where buyers of the same type $i$ have the same valuation curve $v_i:[N]\rightarrow [0,1]$, where $v_i(n)$ is the value for having $n$ data points.
*A priori*, the seller is unaware of the
distribution of buyers, but can repeat the market for $T$ rounds so as to learn the revenue-optimal pricing curve $p:[N] \rightarrow [0, 1]$.
To solve this online learning problem,
we first develop novel discretization schemes to approximate any pricing curve.
When compared to prior work,
the size of our discretization schemes scales gracefully with the approximation parameter, which translates to better regret in online learning.
Under assumptions like smoothness and diminishing returns which are satisfied by data, the discretization size can be reduced further.
We then turn to the online learning problem,
both in the stochastic and adversarial settings.
On each round, the seller chooses an *anonymous* pricing curve $p_t$.
A new buyer appears and may choose to purchase some amount of data.
She then reveals her type *only if* she makes a purchase.
Our online algorithms build on classical algorithms such as UCB and FTPL, but require novel ideas to account for the asymmetric nature of this feedback and to deal with the vastness of the space of pricing curves.
Using the improved discretization schemes previously developed, we are able to achieve
$\widetilde{O}(m\sqrt{T})$ regret in the stochastic setting and $\widetilde{\mathcal{O}}(m^{3/2}\sqrt{T})$ regret in the adversarial setting.

Fine-tuning Diffusion Models remains an underexplored frontier in generative artificial intelligence (GenAI), especially when compared with the remarkable progress made in fine-tuning Large Language Models (LLMs). While cutting-edge diffusion models such as Stable Diffusion (SD) and SDXL rely on supervised fine-tuning, their performance inevitably plateaus after seeing a certain volume of data. Recently, reinforcement learning (RL) has been employed to fine-tune diffusion models with human preference data, but it requires at least two images (``winner'' and ``loser'' images) for each text prompt.
In this paper, we introduce an innovative technique called self-play fine-tuning for diffusion models (SPIN-Diffusion), where the diffusion model engages in competition with its earlier versions, facilitating an iterative self-improvement process. Our approach offers an alternative to conventional supervised fine-tuning and RL strategies, significantly improving both model performance and alignment. Our experiments on the Pick-a-Pic dataset reveal that SPIN-Diffusion outperforms the existing supervised fine-tuning method in aspects of human preference alignment and visual appeal right from its first iteration. By the second iteration, it exceeds the performance of RLHF-based methods across all metrics, achieving these results with less data. Codes are available at \url{https://github.com/uclaml/SPIN-Diffusion/}.

When reading long-form text, human cognition is complex and structurized. While large language models (LLMs) process input contexts through a causal and sequential perspective, this approach can potentially limit their ability to handle intricate and complex inputs effectively. To enhance LLM’s cognition capability, this paper presents a novel concept of context structurization. Specifically, we transform the plain, unordered contextual sentences into well-ordered and hierarchically structurized elements. By doing so, LLMs can better grasp intricate and extended contexts through precise attention and information-seeking along the organized structures. Extensive evaluations are conducted across various model architectures and sizes (including a series of auto-regressive LLMs as well as BERT-like masking models) on a diverse set of NLP tasks (e.g., context-based question-answering, exhaustive hallucination evaluation, and passage-level dense retrieval). Empirical results show consistent and significant performance gains afforded by a single-round structurization. In particular, we boost the open-sourced LLaMA2-70B model to achieve comparable performance against GPT-3.5-Turbo as the halluci- nation evaluator. Besides, we show the feasibility of distilling advanced LLMs’ language processing abilities to a smaller yet effective StruXGPT-7B to execute structurization, addressing the practicality of our approach. Code is available at https://github.com/alibaba/struxgpt.

In this paper, we introduce Cosine Autoencoder (CosAE), a novel, generic Autoencoder that seamlessly leverages the classic Fourier series with a feed-forward neural network. CosAE represents an input image as a series of 2D Cosine time series, each defined by a tuple of learnable frequency and Fourier coefficients. This method stands in contrast to a conventional Autoencoder that often sacrifices detail in their reduced-resolution bottleneck latent spaces. CosAE, however, encodes frequency coefficients, i.e., the amplitudes and phases, in its bottleneck. This encoding enables extreme spatial compression, e.g., $64\times$ downsampled feature maps in the bottleneck, without losing detail upon decoding. We showcase the advantage of CosAE via extensive experiments on flexible-resolution super-resolution and blind image restoration, two highly challenging tasks that demand the restoration network to effectively generalize to complex and even unknown image degradations. Our method surpasses state-of-the-art approaches, highlighting its capability to learn a generalizable representation for image restoration. The project page is maintained at [https://sifeiliu.net/CosAE-page/](https://sifeiliu.net/CosAE-page/).

\emph{Metacognitive knowledge} refers to humans' intuitive knowledge of their own thinking and reasoning processes. Today's best LLMs clearly possess some reasoning processes. The paper gives evidence that they also have metacognitive knowledge, including ability to name skills and procedures to apply given a task. We explore this primarily in context of math reasoning, developing a prompt-guided interaction procedure to get a powerful LLM to assign sensible skill labels to math questions, followed by having it perform semantic clustering to obtain coarser families of skill labels. These coarse skill labels look interpretable to humans.
To validate that these skill labels are meaningful and relevant to the LLM's reasoning processes we perform the following experiments. (a) We ask GPT-4 to assign skill labels to training questions in math datasets GSM8K and MATH. (b) When using an LLM to solve the test questions, we present it with the full list of skill labels and ask it to identify the skill needed. Then it is presented with randomly selected exemplar solved questions associated with that skill label. This improves accuracy on GSM8k and MATH for several strong LLMs, including code-assisted models. The methodology presented is domain-agnostic, even though this article applies it to math problems.
tl;dr: We study the problem of multi-object hallucination and introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol.

Large vision language models (LVLMs) often suffer from object hallucination, producing objects not present in the given images.
While current benchmarks for object hallucination primarily concentrate on the presence of a single object class rather than individual entities, this work systematically investigates multi-object hallucination, examining how models misperceive (e.g., invent nonexistent objects or become distracted) when tasked with focusing on multiple objects simultaneously.
We introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol that considers the distribution of object classes within a single image during testing and uses visual referring prompts to eliminate ambiguity.
With comprehensive empirical studies and analysis of potential factors leading to multi-object hallucination, we found that (1) LVLMs suffer more hallucinations when focusing on multiple objects compared to a single object.
(2) The tested object class distribution affects hallucination behaviors, indicating that LVLMs may follow shortcuts and spurious correlations.
(3) Hallucinatory behaviors are influenced by data-specific factors, salience and frequency, and model intrinsic behaviors.
We hope to enable LVLMs to recognize and reason about multiple objects that often occur in realistic visual scenes, provide insights, and quantify our progress towards mitigating the issues.
tl;dr: We present empirical lessons for building an efficient text-to-image model

As text-to-image (T2I) synthesis models increase in size, they demand higher inference costs due to the need for more expensive GPUs with larger memory, which makes it challenging to reproduce these models in addition to the restricted access to training datasets. Our study aims to reduce these inference costs and explores how far the generative capabilities of T2I models can be extended using only publicly available datasets and open-source models. To this end, by using the de facto standard text-to-image model, Stable Diffusion XL (SDXL), we present three key practices in building an efficient T2I model: (1) Knowledge distillation: we explore how to effectively distill the generation capability of SDXL into an efficient U-Net and find that self-attention is the most crucial part. (2) Data: despite fewer samples, high-resolution images with rich captions are more crucial than a larger number of low-resolution images with short captions. (3) Teacher: Step-distilled Teacher allows T2I models to reduce the noising steps. Based on these findings, we build two types of efficient text-to-image models, called KOALA-Turbo & -Lightning, with two compact U-Nets (1B & 700M), reducing the model size up to 54% and 69% of the SDXL U-Net. In particular, the KOALA-Lightning-700M is 4 times faster than SDXL while still maintaining satisfactory generation quality. Moreover, unlike SDXL, our KOALA models can generate 1024px high-resolution images on consumer-grade GPUs with 8GB of VRAMs (3060Ti). We believe that our KOALA models will have a significant practical impact, serving as cost-effective alternatives to SDXL for academic researchers and general users in resource-constrained environments.
tl;dr: Pretraining with random noise using a feedback alignment algorithm allows fast learning and robust generalization without weight transport.

The brain prepares for learning even before interacting with the environment, by refining and optimizing its structures through spontaneous neural activity that resembles random noise. However, the mechanism of such a process has yet to be understood, and it is unclear whether this process can benefit the algorithm of machine learning. Here, we study this issue using a neural network with a feedback alignment algorithm, demonstrating that pretraining neural networks with random noise increases the learning efficiency as well as generalization abilities without weight transport. First, we found that random noise training modifies forward weights to match backward synaptic feedback, which is necessary for teaching errors by feedback alignment. As a result, a network with pre-aligned weights learns notably faster and reaches higher accuracy than a network without random noise training, even comparable to the backpropagation algorithm. We also found that the effective dimensionality of weights decreases in a network pretrained with random noise. This pre-regularization allows the network to learn simple solutions of a low rank, reducing the generalization loss during subsequent training. This also enables the network robustly to generalize a novel, out-of-distribution dataset. Lastly, we confirmed that random noise pretraining reduces the amount of meta-loss, enhancing the network ability to adapt to various tasks. Overall, our results suggest that random noise training with feedback alignment offers a straightforward yet effective method of pretraining that facilitates quick and reliable learning without weight transport.
tl;dr: A training-free approach to personalizing rectified flow with classifier guidance

Customizing diffusion models to generate identity-preserving images from user-provided reference images is an intriguing new problem. The prevalent approaches typically require training on extensive domain-specific images to achieve identity preservation, which lacks flexibility across different use cases. To address this issue, we exploit classifier guidance, a training-free technique that steers diffusion models using an existing classifier, for personalized image generation. Our study shows that based on a recent rectified flow framework, the major limitation of vanilla classifier guidance in requiring a special classifier can be resolved with a simple fixed-point solution, allowing flexible personalization with off-the-shelf image discriminators. Moreover, its solving procedure proves to be stable when anchored to a reference flow trajectory, with a convergence guarantee. The derived method is implemented on rectified flow with different off-the-shelf image discriminators, delivering advantageous personalization results for human faces, live subjects, and certain objects. Code is available at https://github.com/feifeiobama/RectifID.

This paper introduces a novel approach that leverages Large Language Models (LLMs) and Generative Agents to enhance time series forecasting by reasoning across both text and time series data. With language as a medium, our method adaptively integrates social events into forecasting models, aligning news content with time series fluctuations to provide richer insights. Specifically, we utilize LLM-based agents to iteratively filter out irrelevant news and employ human-like reasoning to evaluate predictions. This enables the model to analyze complex events, such as unexpected incidents and shifts in social behavior, and continuously refine the selection logic of news and the robustness of the agent's output. By integrating selected news events with time series data, we fine-tune a pre-trained LLM to predict sequences of digits in time series. The results demonstrate significant improvements in forecasting accuracy, suggesting a potential paradigm shift in time series forecasting through the effective utilization of unstructured news data.
tl;dr: Through multi-scale visual prompt and post-pretrain token scaling, Chain-of-Sight achieves 3.7x pre-training speedup without performance sacrifice.

This paper introduces Chain-of-Sight, a vision-language bridge module that accelerates the pre-training of Multimodal Large Language Models (MLLMs).
Our approach employs a sequence of visual resamplers that capture visual details at various spacial scales.
This architecture not only leverages global and local visual contexts effectively, but also facilitates the flexible extension of visual tokens through a compound token scaling strategy, allowing up to a 16x increase in the token count post pre-training.
Consequently, Chain-of-Sight requires significantly fewer visual tokens in the pre-training phase compared to the fine-tuning phase.
This intentional reduction of visual tokens during pre-training notably accelerates the pre-training process, cutting down the wall-clock training time by $\sim$73\%.
Empirical results on a series of vision-language benchmarks reveal that the pre-train acceleration through Chain-of-Sight is achieved without sacrificing performance, matching or surpassing the standard pipeline of utilizing all visual tokens throughout the entire training process.
Further scaling up the number of visual tokens for pre-training leads to stronger performances, competitive to existing approaches in a series of benchmarks.
tl;dr: We show that fine-tuning LMs to generate and then emulate the execution of programs creates models can learn new tasks via program search.

Program synthesis with language models (LMs) has unlocked a large set of reasoning abilities; code-tuned LMs have proven adept at generating programs that solve a wide variety of algorithmic symbolic manipulation tasks (e.g. word concatenation). However, not all reasoning tasks are easily expressible as code, e.g. tasks involving commonsense reasoning, moral decision-making, and sarcasm understanding. Our goal is to extend a LM’s program synthesis skills to such tasks and evaluate the results via pseudo-programs, namely Python programs where some leaf function calls are left undefined. To that end, we propose, Code Generation and Emulated EXecution (COGEX). COGEX works by (1) training LMs to generate pseudo-programs and (2) teaching them to emulate their generated program’s execution, including those leaf functions, allowing the LM’s knowledge to fill in the execution gaps; and (3) using them to search over many programs to find an optimal one. To adapt the COGEX model to a new task, we introduce a method for performing program search to find a single program whose pseudo-execution yields optimal performance when applied to all the instances of a given dataset. We show that our approach yields large improvements compared to standard in-context learning approaches on a battery of tasks, both algorithmic and soft reasoning. This result thus demonstrates that code synthesis can be applied to a much broader class of problems than previously considered.
tl;dr: This paper introduces the block trifocal tensor, established a low multilinear rank, and introduces a global synchronization framework for trifocal tensors.

The block tensor of trifocal tensors provides crucial geometric information on the three-view geometry of a scene. The underlying synchronization problem seeks to recover camera poses (locations and orientations up to a global transformation) from the block trifocal tensor. We establish an explicit Tucker factorization of this tensor, revealing a low multilinear rank of $(6,4,4)$ independent of the number of cameras under appropriate scaling conditions. We prove that this rank constraint provides sufficient information for camera recovery in the noiseless case. The constraint motivates a synchronization algorithm based on the higher-order singular value decomposition of the block trifocal tensor. Experimental comparisons with state-of-the-art global synchronization methods on real datasets demonstrate the potential of this algorithm for significantly improving location estimation accuracy. Overall this work suggests that higher-order interactions in synchronization problems can be exploited to improve performance, beyond the usual pairwise-based approaches.

Continual Pre-Training (CPT) on Large Language Models (LLMs) has been widely used to expand the model’s fundamental understanding of specific downstream domains (e.g., math and code). For the CPT on domain-specific LLMs, one important question is how to choose the optimal mixture ratio between the general-corpus (e.g., Dolma, Slim-pajama) and the downstream domain-corpus. Existing methods usually adopt laborious human efforts by grid-searching on a set of mixture ratios, which require high GPU training consumption costs. Besides, we cannot guarantee the selected ratio is optimal for the specific domain. To address the limitations of existing methods, inspired by the Scaling Law for performance prediction, we propose to investigate the Scaling Law of the Domain-specific Continual Pre-Training (D-CPT Law) to decide the optimal mixture ratio with acceptable training costs for LLMs of different sizes. Specifically, by fitting the D-CPT Law, we can easily predict the general and downstream performance of arbitrary mixture ratios, model sizes, and dataset sizes using small-scale training costs on limited experiments. Moreover, we also extend our standard D-CPT Law on cross-domain settings and propose the Cross-Domain D-CPT Law to predict the D-CPT law of target domains, where very small training costs (about 1\% of the normal training costs) are needed for the target domains. Comprehensive experimental results on six downstream domains demonstrate the effectiveness and generalizability of our proposed D-CPT Law and Cross-Domain D-CPT Law.
tl;dr: We introduce the Segmentation with Uncertainty Model (SUM), which enhances the accuracy of segmentation foundation models by incorporating an uncertainty-aware training loss and prompt sampling based on the estimated uncertainty of pseudo-labels.

The Segment Anything Model (SAM) is a large-scale foundation model that has revolutionized segmentation methodology. Despite its impressive generalization ability, the segmentation accuracy of SAM on images with intricate structures is often unsatisfactory. Recent works have proposed lightweight fine-tuning using high-quality annotated data to improve accuracy on such images. However, here we provide extensive empirical evidence that this strategy leads to forgetting how to "segment anything": these models lose the original generalization abilities of SAM, in the sense that they perform worse for segmentation tasks not represented in the annotated fine-tuning set. To improve performance without forgetting, we introduce a novel framework that combines high-quality annotated data with a large unlabeled dataset. The framework relies on two methodological innovations. First, we quantify the uncertainty in the SAM pseudo labels associated with the unlabeled data and leverage it to perform uncertainty-aware fine-tuning. Second, we encode the type of segmentation task associated with each training example using a $\textit{task prompt}$ to reduce ambiguity. We evaluated the proposed Segmentation with Uncertainty Model (SUM) on a diverse test set consisting of 14 public benchmarks, where it achieves state-of-the-art results. Notably, our method consistently surpasses SAM by 3-6 points in mean IoU and 4-7 in mean boundary IoU across point-prompt interactive segmentation rounds. Code is available at https://github.com/Kangningthu/SUM
tl;dr: All network classifiers are ensembles; each edge provides a classifier. If you weigh them by their posterior probability you (almost) get SGD.

A natural strategy for continual learning is to weigh a Bayesian ensemble of fixed functions. This suggests that if a (single) neural network could be interpreted as an ensemble, one could design effective algorithms that learn without forgetting. To realize this possibility, we observe that a neural network classifier with N parameters can be interpreted as a weighted ensemble of N classifiers, and that in the lazy regime limit these classifiers are fixed throughout learning. We call these classifiers the *neural tangent experts* and show they output valid probability distributions over the labels. We then derive the likelihood and posterior probability of each expert given past data. Surprisingly, the posterior updates for these experts are equivalent to a scaled and projected form of stochastic gradient descent (SGD) over the network weights. Away from the lazy regime, networks can be seen as ensembles of adaptive experts which improve over time. These results offer a new interpretation of neural networks as Bayesian ensembles of experts, providing a principled framework for understanding and mitigating catastrophic forgetting in continual learning settings.

Human-Oriented Binary Reverse Engineering (HOBRE) lies at the intersection of binary and source code, aiming to lift binary code to human-readable content relevant to source code, thereby bridging the binary-source semantic gap. Recent advancements in uni-modal code model pre-training, particularly in generative Source Code Foundation Models (SCFMs) and binary understanding models, have laid the groundwork for transfer learning applicable to HOBRE. However, existing approaches for HOBRE rely heavily on uni-modal models like SCFMs for supervised fine-tuning or general LLMs for prompting, resulting in sub-optimal performance. Inspired by recent progress in large multi-modal models, we propose that it is possible to harness the strengths of uni-modal code models from both sides to bridge the semantic gap effectively. In this paper, we introduce a novel probe-and-recover framework that incorporates a binary-source encoder-decoder model and black-box LLMs for binary analysis. Our approach leverages the pre-trained knowledge within SCFMs to synthesize relevant, symbol-rich code fragments as context. This additional context enables black-box LLMs to enhance recovery accuracy. We demonstrate significant improvements in zero-shot binary summarization and binary function name recovery, with a 10.3% relative gain in CHRF and a 16.7% relative gain in a GPT4-based metric for summarization, as well as a 6.7% and 7.4% absolute increase in token-level precision and recall for name recovery, respectively. These results highlight the effectiveness of our approach in automating and improving binary code analysis.

While diffusion models have demonstrated impressive performance, there is a growing need for generating samples tailored to specific user-defined concepts. The customized requirements promote the development of few-shot diffusion models, which use limited $n_{ta}$ target samples to fine-tune a pre-trained diffusion model trained on $n_s$ source samples. Despite the empirical success, no theoretical work specifically analyzes few-shot diffusion models. Moreover, the existing results for diffusion models without a fine-tuning phase can not explain why few-shot models generate great samples due to the curse of dimensionality. In this work, we analyze few-shot diffusion models under a linear structure distribution with a latent dimension $d$. From the approximation perspective, we prove that few-shot models have a $\widetilde{O}(n_s^{-2/d}+n_{ta}^{-1/2})$ bound to approximate the target score function, which is better than $n_{ta}^{-2/d}$ results. From the optimization perspective, we consider a latent Gaussian special case and prove that the optimization problem has a closed-form minimizer. This means few-shot models can directly obtain an approximated minimizer without a complex optimization process. Furthermore, we also provide the accuracy bound $\widetilde{O}(1/n_{ta}+1/\sqrt{n_s})$ for the empirical solution, which still has better dependence on $n_{ta}$ compared to $n_s$. The results of the real-world experiments also show that the models obtained by only fine-tuning the encoder and decoder specific to the target distribution can produce novel images with the target feature, which supports our theoretical results.
1615. Reversing the Forget-Retain Objectives: An Efficient LLM Unlearning Framework from Logit Difference

As Large Language Models (LLMs) demonstrate extensive capability in learning from documents, LLM unlearning becomes an increasingly important research area to address concerns of LLMs in terms of privacy, copyright, etc. A conventional LLM unlearning task typically involves two goals: (1) The target LLM should forget the knowledge in the specified forget documents; and (2) it should retain the other knowledge that the LLM possesses, for which we assume access to a small number of retain documents. To achieve both goals, a mainstream class of LLM unlearning methods introduces an optimization framework with a combination of two objectives – maximizing the prediction loss on the forget documents while minimizing that on the retain documents, which suffers from two challenges, degenerated output and catastrophic forgetting. In this paper, we propose a novel unlearning framework called Unlearning from Logit Difference (ULD), which introduces an assistant LLM that aims to achieve the opposite of the unlearning goals: remembering the forget documents and forgetting the retain knowledge. ULD then derives the unlearned LLM by computing the logit difference between the target and the assistant LLMs. We show that such reversed objectives would naturally resolve both aforementioned challenges while significantly improving the training efficiency. Extensive experiments demonstrate that our method efficiently achieves the intended forgetting while preserving the LLM’s overall capabilities, reducing training time by more than threefold. Notably, our method loses 0% of model utility on the ToFU benchmark, whereas baseline methods may sacrifice 17% of utility on average to achieve comparable forget quality.
1616. LiveScene: Language Embedding Interactive Radiance Fields for Physical Scene Control and Rendering
tl;dr: the first scene-level language-embedded interactive radiance field; interaction datasets;

This paper scales object-level reconstruction to complex scenes, advancing interactive scene reconstruction. We introduce two datasets, OmniSim and InterReal, featuring 28 scenes with multiple interactive objects. To tackle the challenge of inaccurate interactive motion recovery in complex scenes, we propose LiveScene, a scene-level language-embedded interactive radiance field that efficiently reconstructs and controls multiple objects. By decomposing the interactive scene into local deformable fields, LiveScene enables separate reconstruction of individual object motions, reducing memory consumption. Additionally, our interaction-aware language embedding localizes individual interactive objects, allowing for arbitrary control using natural language. Our approach demonstrates significant superiority in novel view synthesis, interactive scene control, and language grounding performance through extensive experiments. Project page: https://livescenes.github.io.
tl;dr: We demonstrate that, even when direct sim-to-real transfer fails, transferring exploratory policies from a simulator can enable efficient RL in the real-world with only a least-squares regression oracle.

In order to mitigate the sample complexity of real-world reinforcement learning, common practice is to first train a policy in a simulator where samples are cheap, and then deploy this policy in the real world, with the hope that it generalizes effectively. Such \emph{direct sim2real} transfer is not guaranteed to succeed, however, and in cases where it fails, it is unclear how to best utilize the simulator. In this work, we show that in many regimes, while direct sim2real transfer may fail, we can utilize the simulator to learn a set of \emph{exploratory} policies which enable efficient exploration in the real world. In particular, in the setting of low-rank MDPs, we show that coupling these exploratory policies with simple, practical approaches---least-squares regression oracles and naive randomized exploration---yields a polynomial sample complexity in the real world, an exponential improvement over direct sim2real transfer, or learning without access to a simulator. To the best of our knowledge, this is the first evidence that simulation transfer yields a provable gain in reinforcement learning in settings where direct sim2real transfer fails. We validate our theoretical results on several realistic robotic simulators and a real-world robotic sim2real task, demonstrating that transferring exploratory policies can yield substantial gains in practice as well.

Recent development in Artificial Intelligence (AI) models has propelled their application in scientific discovery, but the validation and exploration of these discoveries require subsequent empirical experimentation. The concept of self-driving laboratories promises to automate and thus boost the experimental process following AI-driven discoveries. However, the transition of experimental protocols, originally crafted for human comprehension, into formats interpretable by machines presents significant challenges, which, within the context of specific expert domain, encompass the necessity for structured as opposed to natural language, the imperative for explicit rather than tacit knowledge, and the preservation of causality and consistency throughout protocol steps. Presently, the task of protocol translation predominantly requires the manual and labor-intensive involvement of domain experts and information technology specialists, rendering the process time-intensive. To address these issues, we propose a framework that automates the protocol translation process through a three-stage workflow, which incrementally constructs Protocol Dependence Graphs (PDGs) that approach structured on the syntax level, completed on the semantics level, and linked on the execution level. Quantitative and qualitative evaluations have demonstrated its performance at par with that of human experts, underscoring its potential to significantly expedite and democratize the process of scientific discovery by elevating the automation capabilities within self-driving laboratories.

Backdoor attacks pose a significant threat to Deep Neural Networks (DNNs) as they allow attackers to manipulate model predictions with backdoor triggers. To address these security vulnerabilities, various backdoor purification methods have been proposed to purify compromised models. Typically, these purified models exhibit low Attack Success Rates (ASR), rendering them resistant to backdoored inputs. However, \textit{Does achieving a low ASR through current safety purification methods truly eliminate learned backdoor features from the pretraining phase?} In this paper, we provide an affirmative answer to this question by thoroughly investigating the \textit{Post-Purification Robustness} of current backdoor purification methods. We find that current safety purification methods are vulnerable to the rapid re-learning of backdoor behavior, even when further fine-tuning of purified models is performed using a very small number of poisoned samples. Based on this, we further propose the practical Query-based Reactivation Attack (QRA) which could effectively reactivate the backdoor by merely querying purified models. We find the failure to achieve satisfactory post-purification robustness stems from the insufficient deviation of purified models from the backdoored model along the backdoor-connected path. To improve the post-purification robustness, we propose a straightforward tuning defense, Path-Aware Minimization (PAM), which promotes deviation along backdoor-connected paths with extra model updates. Extensive experiments demonstrate that PAM significantly improves post-purification robustness while maintaining a good clean accuracy and low ASR. Our work provides a new perspective on understanding the effectiveness of backdoor safety tuning and highlights the importance of faithfully assessing the model's safety.

Generalized-linear dynamical models (GLDMs) remain a widely-used framework within neuroscience for modeling time-series data, such as neural spiking activity or categorical decision outcomes. Whereas the standard usage of GLDMs is to model a single data source, certain applications require jointly modeling two generalized-linear time-series sources while also dissociating their shared and private dynamics. Most existing GLDM variants and their associated learning algorithms do not support this capability. Here we address this challenge by developing a multi-step analytical subspace identification algorithm for learning a GLDM that explicitly models shared vs. private dynamics within two generalized-linear time-series. In simulations, we demonstrate our algorithm's ability to dissociate and model the dynamics within two time-series sources while being agnostic to their respective observation distributions. In neural data, we consider two specific applications of our algorithm for modeling discrete population spiking activity with respect to a secondary time-series. In both synthetic and real data, GLDMs learned with our algorithm more accurately decoded one time-series from the other using lower-dimensional latent states, as compared to models identified using existing GLDM learning algorithms.
1621. Universal Sample Coding
tl;dr: Communication of multiple samples from an unknown probability distribution and its applications to federated learning and generative inference.

In this work, we study the problem of communicating multiple samples from an unknown probability distribution using as few bits as possible. This is a generalization of the channel simulation problem, which has recently found applications and achieved state of the art results in realistic image compression, neural network compression, and communication-efficient federated learning. In this problem, the transmitter wants the receiver to generate multiple independent and identically distributed (i.i.d.) samples from a target distribution $P$, while the transmitter and the receiver have access to independent samples from a reference distribution $Q$. The core idea is to employ channel simulation in multiple rounds while updating the reference distribution $Q$ after each round in order to reduce the KL-divergence between $P$ and $Q$, thereby reducing the communication cost in subsequent rounds. We derive a lower bound on the expected communication cost and construct a practical algorithm that achieves the lower bound up to a multiplicative constant. We then employ this algorithm in communication-efficient federated learning, in which model updates correspond to samples from a distribution, and achieve a 37% reduction in the communication load. To further highlight the potential of sample communication for generative models, we show that the number of bits needed to communicate samples from a large language model can be reduced by up to 16 times, compared to entropy-based data compression.
tl;dr: LLM4EA is a novel framework for entity alignment with noisy annotations from large language models, by effectively learn from noisy annotations and optimizing query budget utility..

Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. While existing methods heavily rely on human-generated labels, it is prohibitively expensive to incorporate cross-domain experts for annotation in real-world scenarios. The advent of Large Language Models (LLMs) presents new avenues for automating EA with annotations, inspired by their comprehensive capability to process semantic information. However, it is nontrivial to directly apply LLMs for EA since the annotation space in real-world KGs is large. LLMs could also generate noisy labels that may mislead the alignment. To this end, we propose a unified framework, LLM4EA, to effectively leverage LLMs for EA. Specifically, we design a novel active learning policy to significantly reduce the annotation space by prioritizing the most valuable entities based on the entire inter-KG and intra-KG structure. Moreover, we introduce an unsupervised label refiner to continuously enhance label accuracy through in-depth probabilistic reasoning. We iteratively optimize the policy based on the feedback from a base EA model. Extensive experiments demonstrate the advantages of LLM4EA on four benchmark datasets in terms of effectiveness, robustness, and efficiency.
tl;dr: Adaptive versions of GD and ProxGD with large steps.

In this paper, we explore two fundamental first-order algorithms in convex optimization, namely, gradient descent (GD) and proximal gradient method (ProxGD). Our focus is on making these algorithms entirely adaptive by leveraging local curvature information of smooth functions. We propose adaptive versions of GD and ProxGD that are based on observed gradient differences and, thus, have no added computational costs. Moreover, we prove convergence of our methods assuming only local Lipschitzness of the gradient. In addition, the proposed versions allow for even larger stepsizes than those initially suggested in [MM20].
tl;dr: We propose a method to learn identifiable object-centric representation up to a proposed equivalence relation.

Learning modular object-centric representations is said to be crucial for systematic generalization. Existing methods show promising object-binding capabilities empirically, but theoretical identifiability guarantees remain relatively underdeveloped. Understanding when object-centric representations can theoretically be identified is important for scaling slot-based methods to high-dimensional images with correctness guarantees. To that end, we propose a probabilistic slot-attention algorithm that imposes an *aggregate* mixture prior over object-centric slot representations, thereby providing slot identifiability guarantees without supervision, up to an equivalence relation. We provide empirical verification of our theoretical identifiability result using both simple 2-dimensional data and high-resolution imaging datasets.
tl;dr: We propose a new quasistatic cloth simulator using thin shells, in which surface deformation is encoded in neural network weights as a neural field.

Despite existing 3D cloth simulators producing realistic results, they predominantly operate on discrete surface representations (e.g. points and meshes) with a fixed spatial resolution, which often leads to large memory consumption and resolution-dependent simulations. Moreover, back-propagating gradients through the existing solvers is difficult and they hence cannot be easily integrated into modern neural architectures. In response, this paper re-thinks physically plausible cloth simulation: We propose NeuralClothSim, i.e., a new quasistatic cloth simulator using thin shells, in which surface deformation is encoded in neural network weights in form of a neural field. Our memory-efficient solver operates on a new continuous coordinate-based surface representation called neural deformation fields (NDFs); it supervises NDF equilibria with the laws of the non-linear Kirchhoff-Love shell theory with a non-linear anisotropic material model. NDFs are adaptive: They 1) allocate their capacity to the deformation details and 2) allow surface state queries at arbitrary spatial resolutions without re-training. We show how to train NeuralClothSim while imposing hard boundary conditions and demonstrate multiple applications, such as material interpolation and simulation editing. The experimental results highlight the effectiveness of our continuous neural formulation.
tl;dr: Our research proposes a novel theory for scaling laws in time series forecasting, addressing anomalies observed in previous studies and emphasizing dataset size, model complexity, and forecast horizon in deep learning methodologies.

Scaling law that rewards large datasets, complex models and enhanced data granularity has been observed in various fields of deep learning. Yet, studies on time series forecasting have cast doubt on scaling behaviors of deep learning methods for time series forecasting: while more training data improves performance, more capable models do not always outperform less capable models, and longer input horizon may hurt performance for some models. We propose a theory for scaling law for time series forecasting that can explain these seemingly abnormal behaviors. We take into account the impact of dataset size and model complexity, as well as time series data granularity, particularly focusing on the look-back horizon, an aspect that has been unexplored in previous theories. Furthermore, we empirically evaluate various models using a diverse set of time series forecasting datasets, which (1) verifies the validity of scaling law on dataset size and model complexity within the realm of time series forecasting, and (2) validates our theoretical framework, particularly regarding the influence of look back horizon. We hope our findings may inspire new models targeting time series forecasting datasets of limited size, as well as large foundational datasets and models for time series forecasting in future works.
tl;dr: We introduce a metalearned neural network that captures the inductive bias of nonparametric Bayesian models.

Most applications of machine learning to classification assume a closed set of balanced classes. This is at odds with the real world, where class occurrence statistics often follow a long-tailed power-law distribution and it is unlikely that all classes are seen in a single sample. Nonparametric Bayesian models naturally capture this phenomenon, but have significant practical barriers to widespread adoption, namely implementation complexity and computational inefficiency. To address this, we present a method for extracting the inductive bias from a nonparametric Bayesian model and transferring it to an artificial neural network. By simulating data with a nonparametric Bayesian prior, we can metalearn a sequence model that performs inference over an unlimited set of classes. After training, this "neural circuit" has distilled the corresponding inductive bias and can successfully perform sequential inference over an open set of classes. Our experimental results show that the metalearned neural circuit achieves comparable or better performance than particle filter-based methods for inference in these models while being faster and simpler to use than methods that explicitly incorporate Bayesian nonparametric inference.
tl;dr: We establish uniform stability lower bounds for representative gradient-based bilevel hyperparameter optimization algorithms.

Gradient-based bilevel programming leverages unrolling differentiation (UD) or implicit function theorem (IFT) to solve hyperparameter optimization (HO) problems, and is proven effective and scalable in practice.
To understand their generalization behavior, existing works establish upper bounds on the uniform stability of these algorithms, while their tightness is still unclear.
To this end, this paper attempts to establish stability lower bounds for UD-based and IFT-based algorithms.
A central technical challenge arises from the dependency of each outer-level update on the concurrent stage of inner optimization in bilevel programming.
To address this problem, we introduce lower-bounded expansion properties to characterize the instability in update rules which can serve as general tools for lower-bound analysis.
These properties guarantee the hyperparameter divergence at the outer level and the Lipschitz constant of inner output at the inner level in the context of HO.
Guided by these insights, we construct a quadratic example that yields tight lower bounds for the UD-based algorithm and meaningful bounds for a representative IFT-based algorithm.
Our tight result indicates that uniform stability has reached its limit in stability analysis for the UD-based algorithm.

This paper studies off-policy evaluation (OPE) in the presence of unmeasured confounders. Inspired by the two-way fixed effects regression model widely used in the panel data literature, we propose a two-way unmeasured confounding assumption to model the system dynamics in causal reinforcement learning and develop a two-way deconfounder algorithm that devises a neural tensor network to simultaneously learn both the unmeasured confounders and the system dynamics, based on which a model-based estimator can be constructed for consistent policy value estimation. We illustrate the effectiveness of the proposed estimator through theoretical results and numerical experiments.
tl;dr: We introduce a novel method for opponent modeling based on subgoal inference.

When an agent is in a multi-agent environment, it may face previously unseen opponents, and it is a challenge to cooperate with other agents to accomplish the task together or to maximize its own rewards. Most opponent modeling methods deal with the non-stationarity caused by unknown opponent policies via predicting the opponent’s actions. However, focusing on the opponent’s action is shortsighted, which also constrains the adaptability to unknown opponents in complex tasks. In this paper, we propose opponent modeling based on subgoal inference, which infers the opponent’s subgoals through historical trajectories. As subgoals are likely to be shared by different opponent policies, predicting subgoals can yield better generalization to unknown opponents. Additionally, we design two subgoal selection modes for cooperative games and general-sum games respectively. Empirically, we show that our method achieves more effective adaptation than existing methods in a variety of tasks.
1631. Mind's Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
tl;dr: Visualization-of-Thought (VoT) prompting improves spatial reasoning in LLMs by visualizing their reasoning traces, mimicing the human mind's eye process to imagine the unseen objects and actions.

Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as the Mind's Eye, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (VoT) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate mental images to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs. Please find the dataset and codes in our [project page](https://microsoft.github.io/visualization-of-thought).
tl;dr: We propose an exploratory retrieval augmented planning framework that utilizes environmental context memory to address continual instruction tasks in non-stationary embodied environments.

This study presents an Exploratory Retrieval-Augmented Planning (ExRAP) framework, designed to tackle continual instruction following tasks of embodied agents in dynamic, non-stationary environments. The framework enhances Large Language Models' (LLMs) embodied reasoning capabilities by efficiently exploring the physical environment and establishing the environmental context memory, thereby effectively grounding the task planning process in time-varying environment contexts. In ExRAP, given multiple continual instruction following tasks, each instruction is decomposed into queries on the environmental context memory and task executions conditioned on the query results. To efficiently handle these multiple tasks that are performed continuously and simultaneously, we implement an exploration-integrated task planning scheme by incorporating the information-based exploration into the LLM-based planning process. Combined with memory-augmented query evaluation, this integrated scheme not only allows for a better balance between the validity of the environmental context memory and the load of environment exploration, but also improves overall task performance. Furthermore, we devise a temporal consistency refinement scheme for query evaluation to address the inherent decay of knowledge in the memory. Through experiments with VirtualHome, ALFRED, and CARLA, our approach demonstrates robustness against a variety of embodied instruction following scenarios involving different instruction scales and types, and non-stationarity degrees, and it consistently outperforms other state-of-the-art LLM-based task planning approaches in terms of both goal success rate and execution efficiency.

Adverse weather conditions can significantly degrade the video frames, causing existing video semantic segmentation methods to produce erroneous predictions. In this work, we target adverse weather conditions and introduce an end-to-end domain adaptation strategy that leverages a fusion block, temporal-spatial teacher-student learning, and a temporal weather degradation augmentation approach. The fusion block integrates temporal information from adjacent frames at the feature level, trained end-to-end, eliminating the need for pretrained optical flow, distinguishing our method from existing approaches. Our teacher-student approach involves two teachers: one focuses on exploring temporal information from adjacent frames, and the other harnesses spatial information from the current frame. Finally, we apply temporal weather degradation augmentation to consecutive frames to more accurately represent adverse weather degradations. Our method achieves a performance of 25.4 and 33.0 mIoU on the adaptation from VIPER and Synthia to MVSS, respectively, representing an improvement of 4.3 and 5.8 mIoU over the existing state-of-the-art method.
tl;dr: We propose SemanIR, a Transformer-based approach for image restoration that optimizes attention computation by focusing on semantically relevant regions, achieving linear complexity and state-of-the-art results across multiple tasks.

Image Restoration (IR), a classic low-level vision task, has witnessed significant advancements through deep models that effectively model global information. Notably, the emergence of Vision Transformers (ViTs) has further propelled these advancements. When computing, the self-attention mechanism, a cornerstone of ViTs, tends to encompass all global cues, even those from semantically unrelated objects or regions. This inclusivity introduces computational inefficiencies, particularly noticeable with high input resolution, as it requires processing irrelevant information, thereby impeding efficiency. Additionally, for IR, it is commonly noted that small segments of a degraded image, particularly those closely aligned semantically, provide particularly relevant information to aid in the restoration process, as they contribute essential contextual cues crucial for accurate reconstruction. To address these challenges, we propose boosting IR's performance by sharing the key semantics via Transformer for IR (i.e., SemanIR) in this paper. Specifically, SemanIR initially constructs a sparse yet comprehensive key-semantic dictionary within each transformer stage by establishing essential semantic connections for every degraded patch. Subsequently, this dictionary is shared across all subsequent transformer blocks within the same stage. This strategy optimizes attention calculation within each block by focusing exclusively on semantically related components stored in the key-semantic dictionary. As a result, attention calculation achieves linear computational complexity within each window. Extensive experiments across 6 IR tasks confirm the proposed SemanIR's state-of-the-art performance, quantitatively and qualitatively showcasing advancements. The visual results, code, and trained models are available at: https://github.com/Amazingren/SemanIR.
tl;dr: We explore the knowledge boundary of LLMs by investigating their responses to semi-open-ended questions, using an auxiliary model to uncover ambiguous answers and highlighting LLMs’ challenges in recognizing their knowledge limits.

Large Language Models (LLMs) are widely used for knowledge-seeking purposes yet suffer from hallucinations. The knowledge boundary of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' knowledge boundary is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' knowledge boundary on questions with concrete answers (close-ended questions) while paying limited attention to semi-open-ended questions that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is not so suitable for semi-open-ended questions, which are usually ``partially answerable questions'' containing both answerable answers and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but it may go beyond the knowledge boundary of LLMs. In this paper, we perceive the LLMs' knowledge boundary with semi-open-ended questions by discovering more ambiguous answers. First, we apply an LLM-based approach to construct semi-open-ended questions and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample more low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability existing answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the knowledge boundary of the target LLM. Following our method, we construct a dataset to perceive the knowledge boundary for GPT-4. We find that GPT-4 performs poorly on semi-open-ended questions and is often unaware of its knowledge boundary. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering many ambiguous answers, including correct answers neglected by GPT-4 and delusive wrong answers GPT-4 struggles to identify.
tl;dr: We define and explore the reward over-optimization phenomenon in direct alignment algorithms, such as DPO

Reinforcement Learning from Human Feedback (RLHF)has been crucial to the recent success of Large Language Models (LLMs), however it is often a complex and brittle process. In the classical RLHF framework, a reward model is first trained to represent human preferences, which is in turn used by an online reinforcement learning (RL) algorithm to optimized the LLM. A prominent issue with such methods is reward over-optimization or reward hacking, where the performance as measured by the learned proxy reward model increases, but the true model quality plateaus or even deteriorates. Direct Alignment Algorithms (DDAs), such as Direct Preference Optimization (DPO) have emerged as alternatives to the classical RLHF pipeline. However, despite not training a separate proxy reward model or using RL, they still commonly deteriorate from over-optimization. While the so-called reward hacking phenomenon is not well-defined for DAAs, we still uncover similar trends: at higher KL-budgets, DAA algorithms exhibit similar degradation patters to their classic RLHF counterparts. In particular, we find that DAA methods deteriorate not only across a wide range of KL-budgets, but also often before even a single epoch of the dataset is completed. Through extensive empirical experimentation this work formulates the reward over-optimization or hacking problem for DAAs and explores its consequences across objectives, training regimes, and model scales.

This paper considers the distributed convex-concave minimax optimization under the second-order similarity.
We propose stochastic variance-reduced optimistic gradient sliding (SVOGS) method, which takes the advantage of the finite-sum structure in the objective by involving the mini-batch client sampling and variance reduction.
We prove SVOGS can achieve the $\varepsilon$-duality gap within communication rounds of
${\mathcal O}(\delta D^2/\varepsilon)$,
communication complexity of ${\mathcal O}(n+\sqrt{n}\delta D^2/\varepsilon)$,
and local gradient calls of
$\tilde{\mathcal O}(n+(\sqrt{n}\delta+L)D^2/\varepsilon\log(1/\varepsilon))$,
where $n$ is the number of nodes, $\delta$ is the degree of the second-order similarity, $L$ is the smoothness parameter and $D$ is the diameter of the constraint set.
We can verify that all of above complexity (nearly) matches the corresponding lower bounds.
For the specific $\mu$-strongly-convex-$\mu$-strongly-convex case,
our algorithm has the upper bounds on communication rounds, communication complexity, and local gradient calls of $\mathcal O(\delta/\mu\log(1/\varepsilon))$, ${\mathcal O}((n+\sqrt{n}\delta/\mu)\log(1/\varepsilon))$, and $\tilde{\mathcal O}(n+(\sqrt{n}\delta+L)/\mu)\log(1/\varepsilon))$ respectively, which are also nearly tight.
Furthermore, we conduct the numerical experiments to show the empirical advantages of proposed method.
tl;dr: We introduce a model factorization method for black-box LLM personalization.

Personalization has emerged as a critical research area in modern intelligent systems, focusing on mining users' behavioral history and adapting to their preferences for delivering tailored experiences. Despite the remarkable few-shot capabilities exhibited by black-box large language models (LLMs), the inherent opacity of their model parameters presents significant challenges in aligning the generated output with individual expectations. Existing solutions have primarily focused on prompt design to incorporate user-specific profiles and behaviors; however, such approaches often struggle to generalize effectively due to their inability to capture shared knowledge among all users. To address these challenges, we propose HYDRA, a model factorization framework that captures both user-specific behavior patterns from historical data and shared general knowledge among all users to deliver personalized generation. In order to capture user-specific behavior patterns, we first train a reranker to prioritize the most useful information from top-retrieved relevant historical records.
By combining the prioritized history with the corresponding query, we train an adapter to align the output with individual user-specific preferences, eliminating the reliance on access to inherent model parameters of black-box LLMs. Both the reranker and the adapter can be decomposed into a base model with multiple user-specific heads, resembling a hydra. The base model maintains shared knowledge across users, while the multiple personal heads capture user-specific preferences. Experimental results demonstrate that \method outperforms existing state-of-the-art prompt-based methods by an average relative improvement of 9.01% across five diverse personalization tasks in the LaMP benchmark.
tl;dr: We introduce HumanVLA, which performs a varity of object rearrangement tasks directed by vision and language by physical humanoid.

Physical Human-Scene Interaction (HSI) plays a crucial role in numerous applications.
However, existing HSI techniques are limited to specific object dynamics and privileged information, which prevents the development of more comprehensive applications.
To address this limitation, we introduce HumanVLA for general object rearrangement directed by practical vision and language.
A teacher-student framework is utilized to develop HumanVLA.
A state-based teacher policy is trained first using goal-conditioned reinforcement learning and adversarial motion prior.
Then, it is distilled into a vision-language-action model via behavior cloning.
We propose several key insights to facilitate the large-scale learning process.
To support general object rearrangement by physical humanoid, we introduce a novel Human-in-the-Room dataset encompassing various rearrangement tasks.
Through extensive experiments and analysis, we demonstrate the effectiveness of our approach.
tl;dr: Neural graph edit distance network with uniform and non-uniform costs

Graph Edit Distance (GED) measures the (dis-)similarity between two given graphs in terms of the minimum-cost edit sequence, which transforms one graph to the other.
GED is related to other notions of graph similarity, such as graph and subgraph isomorphism, maximum common subgraph, etc. However, the computation of exact GED is NP-Hard, which has recently motivated the design of neural models for GED estimation.
However, they do not explicitly account for edit operations with different costs. In response, we propose $\texttt{GraphEdX}$, a neural GED estimator that can work with general costs specified for the four edit operations, viz., edge deletion, edge addition, node deletion, and node addition.
We first present GED as a quadratic assignment problem (QAP) that incorporates these four costs.
Then, we represent each graph as a set of node and edge embeddings and use them to design a family of neural set divergence surrogates. We replace the QAP terms corresponding to each operation with their surrogates.
Computing such neural set divergence requires aligning nodes and edges of the two graphs.
We learn these alignments using a Gumbel-Sinkhorn permutation generator, additionally ensuring that the node and edge alignments are consistent with each other. Moreover, these alignments are cognizant of both the presence and absence of edges between node pairs.
Through extensive experiments on several datasets, along with a variety of edit cost settings, we show that $\texttt{GraphEdX}$ consistently outperforms state-of-the-art methods and heuristics in terms of prediction error. The code is available at https://github.com/structlearning/GraphEdX.
tl;dr: We explain datasets by modeling with natural language parameters (e.g. clustering where each cluster is associated with an explanation). We propose an algorithm based on continuous relaxation and iterative refinement to learn these models.

To make sense of massive data, we often first fit simplified models and then interpret the parameters; for example, we cluster the text embeddings and then interpret the mean parameters of each cluster.
However, these parameters are often high-dimensional and hard to interpret.
To make model parameters directly interpretable, we introduce a family of statistical models---including clustering, time series, and classification models---parameterized by *natural language predicates*.
For example, a cluster of text about COVID could be parameterized by the predicate ``*discusses COVID*''.
To learn these statistical models effectively, we develop a model-agnostic algorithm that optimizes continuous relaxations of predicate parameters with gradient descent and discretizes them by prompting language models (LMs).
Finally, we apply our framework to a wide range of problems: taxonomizing user chat dialogues, characterizing how they evolve across time, finding categories where one language model is better than the other, clustering math problems based on subareas, and explaining visual features in memorable images.
Our framework is highly versatile, applicable to both textual and visual domains, can be easily steered to focus on specific properties (e.g. subareas), and explains sophisticated concepts that classical methods (e.g. n-gram analysis) struggle to produce.
tl;dr: This is the first work that achieves near-optimal dynamic regret for adversarial linear mixture MDPs with the unknown transition without prior knowledge of the non-stationarity measure.

We study episodic linear mixture MDPs with the unknown transition and adversarial rewards under full-information feedback, employing *dynamic regret* as the performance measure. We start with in-depth analyses of the strengths and limitations of the two most popular methods: occupancy-measure-based and policy-based methods. We observe that while the occupancy-measure-based method is effective in addressing non-stationary environments, it encounters difficulties with the unknown transition. In contrast, the policy-based method can deal with the unknown transition effectively but faces challenges in handling non-stationary environments. Building on this, we propose a novel algorithm that combines the benefits of both methods. Specifically, it employs (i) an *occupancy-measure-based global optimization* with a two-layer structure to handle non-stationary environments; and (ii) a *policy-based variance-aware value-targeted regression* to tackle the unknown transition. We bridge these two parts by a novel conversion. Our algorithm enjoys an $\widetilde{\mathcal{O}}(d \sqrt{H^3 K} + \sqrt{HK(H + \bar{P}_K)})$ dynamic regret, where $d$ is the feature mapping dimension, $H$ is the episode length, $K$ is the number of episodes, $\bar{P}_K$ is the non-stationarity measure. We show it is minimax optimal up to logarithmic factors by establishing a matching lower bound. To the best of our knowledge, this is the **first** work that achieves **near-optimal** dynamic regret for adversarial linear mixture MDPs with the unknown transition without prior knowledge of the non-stationarity measure.
tl;dr: We prove that the minimax optimal rate of HSIC estimation on R^d with continuous bounded translation-invariant characteristic kernels is O(n^{−1/2}).

Kernel techniques are among the most influential approaches in data science and statistics. Under mild conditions, the reproducing kernel Hilbert space associated to a kernel is capable of encoding the independence of $M\ge2$ random variables. Probably the most widespread independence measure relying on kernels is the so-called Hilbert-Schmidt independence criterion (HSIC; also referred to as distance covariance in the statistics literature). Despite various existing HSIC estimators designed since its introduction close to two decades ago, the fundamental question of the rate at which HSIC can be estimated is still open. In this work, we prove that the minimax optimal rate of HSIC estimation on $\mathbb{R}^d$ for Borel measures containing the Gaussians with continuous bounded translation-invariant characteristic kernels is $\mathcal{O}\left(n^{-1/2}\right)$. Specifically, our result implies the optimality in the minimax sense of many of the most-frequently used estimators (including the U-statistic, the V-statistic, and the Nyström-based one) on $\mathbb{R}^d$.
tl;dr: We define a notion of Mostly Approximately Correct predictions, and use them to get better strategyproof mechanisms for facility location.

Algorithms with predictions are gaining traction across various domains, as a way to surpass traditional worst-case bounds through (machine-learned) advice. We study the canonical problem of $k$-facility location mechanism design,
where the $n$ agents are strategic and might misreport their locations. We receive a prediction for each agent's location, and these predictions are crucially allowed to be only "mostly" and "approximately" correct (MAC for short): a $\delta$-fraction of the predicted locations are allowed to be arbitrarily incorrect, and the remainder of the predictions are required to be correct up to an $\varepsilon$-error. Moreover, we make no assumption on the independence of the errors.
Can such "flawed" predictions allow us to beat the current best bounds for strategyproof
facility location?
We show how natural robustness of the $1$-median (also known as the geometric median) of a set of points leads to an algorithm for single-facility location with MAC predictions. We extend our results to a natural "balanced" variant of the $k$-facility case, and show that without balancedness, robustness completely breaks down even for $k=2$ facilities on a line. As our main result, for this "unbalanced" setting we devise a truthful random mechanism, which outperforms the best known mechanism (with no predictions) by Lu et al.~[2010]. En route, we introduce the problem of "second" facility location, in which the first facility location is already fixed. Our robustness findings may be of independent interest, as quantitative versions of classic breakdown-point results in robust statistics.

Existing human rendering methods require every part of the human to be fully visible throughout the input video. However, this assumption does not hold in real-life settings where obstructions are common, resulting in only partial visibility of the human. Considering this, we present OccFusion, an approach that utilizes efficient 3D Gaussian splatting supervised by pretrained 2D diffusion models for efficient and high-fidelity human rendering. We propose a pipeline consisting of three stages. In the Initialization stage, complete human masks are generated from partial visibility masks. In the Optimization stage, 3D human Gaussians are optimized with additional supervisions by Score-Distillation Sampling (SDS) to create a complete geometry of the human. Finally, in the Refinement stage, in-context inpainting is designed to further improve rendering quality on the less observed human body parts. We evaluate OccFusion on ZJU-MoCap and challenging OcMotion sequences and found that it achieves state-of-the-art performance in the rendering of occluded humans.
tl;dr: We propose a novel inference-time editing method for LLM's activations, namely spectral editing of activations (SEA), to align the LLMs with the objectives in truthfulness and bias.

Large language models (LLMs) often exhibit undesirable behaviours, such as generating untruthful or biased content. Editing their internal representations has been shown to be effective in mitigating such behaviours on top of the existing alignment methods. We propose a novel inference-time editing method, namely spectral editing of activations (SEA), to project the input representations into directions with maximal covariance with the positive demonstrations (e.g., truthful) while minimising covariance with the negative demonstrations (e.g., hallucinated). We also extend our method to non-linear editing using feature functions. We run extensive experiments on benchmarks concerning truthfulness and bias with six open-source LLMs of different sizes and model families. The results demonstrate the superiority of SEA in effectiveness, generalisation to similar tasks, as well as computation and data efficiency. We also show that SEA editing only has a limited negative impact on other model capabilities.

Foundation models in computer vision have demonstrated exceptional performance in zero-shot and few-shot tasks by extracting multi-purpose features from large-scale datasets through self-supervised pre-training methods. However, these models often overlook the severe corruption in cryogenic electron microscopy (cryo-EM) images by high-level noises. We introduce DRACO, a Denoising-Reconstruction Autoencoder for CryO-EM, inspired by the Noise2Noise (N2N) approach. By processing cryo-EM movies into odd and even images and treating them as independent noisy observations, we apply a denoising-reconstruction hybrid training scheme. We mask both images to create denoising and reconstruction tasks. For DRACO's pre-training, the quality of the dataset is essential, we hence build a high-quality, diverse dataset from an uncurated public database, including over 270,000 movies or micrographs. After pre-training, DRACO naturally serves as a generalizable cryo-EM image denoiser and a foundation model for various cryo-EM downstream tasks. DRACO demonstrates the best performance in denoising, micrograph curation, and particle picking tasks compared to state-of-the-art baselines.
tl;dr: We design a video-to-audio generation model with higher quality and fewer sampling steps.

Video-to-audio (V2A) generation aims to synthesize content-matching audio from silent video, and it remains challenging to build V2A models with high generation quality, efficiency, and visual-audio temporal synchrony.
We propose Frieren, a V2A model based on rectified flow matching. Frieren regresses the conditional transport vector field from noise to spectrogram latent with straight paths and conducts sampling by solving ODE, outperforming autoregressive and score-based models in terms of audio quality. By employing a non-autoregressive vector field estimator based on a feed-forward transformer and channel-level cross-modal feature fusion with strong temporal alignment, our model generates audio that is highly synchronized with the input video. Furthermore, through reflow and one-step distillation with guided vector field, our model can generate decent audio in a few, or even only one sampling step. Experiments indicate that Frieren achieves state-of-the-art performance in both generation quality and temporal alignment on VGGSound, with alignment accuracy reaching 97.22\%, and 6.2\% improvement in inception score over the strong diffusion-based baseline. Audio samples and code are available at http://frieren-v2a.github.io.
tl;dr: This paper proposes a new fairness regularization term and plug it into kernel k-means framework, leading to novel fair kernel k-means and fair multiple kernel k-means.

Kernel k-means has been widely studied in machine learning. However, existing kernel k-means methods often ignore the \textit{fairness} issue, which may cause discrimination. To address this issue, in this paper, we propose a novel Fair Kernel K-Means (FKKM) framework. In this framework, we first propose a new fairness regularization term that can lead to a fair partition of data. The carefully designed fairness regularization term has a similar form to the kernel k-means which can be seamlessly integrated into the kernel k-means framework. Then, we extend this method to the multiple kernel setting, leading to a Fair Multiple Kernel K-Means (FMKKM) method. We also provide some theoretical analysis of the generalization error bound, and based on this bound we give a strategy to set the hyper-parameter, which makes the proposed methods easy to use. At last, we conduct extensive experiments on both the single kernel and multiple kernel settings to compare the proposed methods with state-of-the-art methods to demonstrate their effectiveness.

A wide array of sequence models are built on a framework modeled after Transformers, comprising alternating sequence mixer and channel mixer layers. This paper studies a unifying *matrix mixer* view of sequence mixers that can be conceptualized as a linear map on the input sequence. This framework encompasses a broad range of well-known sequence models, including the self-attention of Transformers as well as recent strong alternatives such as structured state space models (SSMs), and allows understanding downstream characteristics such as efficiency and expressivity through properties of their structured matrix class. We identify a key axis of matrix parameterizations termed *sequence alignment*, which increases the flexibility and performance of matrix mixers, providing insights into the strong performance of Transformers and recent SSMs such as Mamba. Furthermore, the matrix mixer framework offers a systematic approach to developing sequence mixers with desired properties, allowing us to develop several new sub-quadratic sequence models. In particular, we propose a natural bidirectional extension of the Mamba model (**Hydra**), parameterized as a *quasiseparable matrix mixer*, which demonstrates superior performance over other sequence models including Transformers on non-causal tasks. As a drop-in replacement for attention layers, \name outperforms BERT by 0.8 points on the GLUE benchmark and ViT by 2% Top-1 accuracy on ImageNet.
tl;dr: We propose a new best-of-both-worlds algorithm for bandits with variably delayed feedback that is robust to excessive delays

We propose a new best-of-both-worlds algorithm for bandits with variably delayed feedback. In contrast to prior work, which required prior knowledge of the maximal delay $d_{\max}$ and had a linear dependence of the regret on it, our algorithm can tolerate arbitrary excessive delays up to order $T$ (where $T$ is the time horizon). The algorithm is based on three technical innovations, which may all be of independent interest: (1) We introduce the first implicit exploration scheme that works in best-of-both-worlds setting. (2) We introduce the first control of distribution drift that does not rely on boundedness of delays. The control is based on the implicit exploration scheme and adaptive skipping of observations with excessive delays. (3) We introduce a procedure relating standard regret with drifted regret that does not rely on boundedness of delays. At the conceptual level, we demonstrate that complexity of best-of-both-worlds bandits with delayed feedback is characterized by the amount of information missing at the time of decision making (measured by the number of outstanding observations) rather than the time that the information is missing (measured by the delays).

Transformers excel at *in-context learning* (ICL)---learning from demonstrations without parameter updates---but how they do so remains a mystery. Recent work suggests that Transformers may internally run Gradient Descent (GD), a first-order optimization method, to perform ICL. In this paper, we instead demonstrate that Transformers learn to approximate second-order optimization methods for ICL. For in-context linear regression, Transformers share a similar convergence rate as *Iterative Newton's Method*, both *exponentially* faster than GD. Empirically, predictions from successive Transformer layers closely match different iterations of Newton’s Method linearly, with each middle layer roughly computing 3 iterations; thus, Transformers and Newton’s method converge at roughly the same rate. In contrast, Gradient Descent converges exponentially more slowly. We also show that Transformers can learn in-context on ill-conditioned data, a setting where Gradient Descent struggles but Iterative Newton succeeds. Finally, to corroborate our empirical findings, we prove that Transformers can implement $k$ iterations of Newton's method with $k + \mathcal O(1)$ layers.

We consider the reinforcement learning problem for the constrained Markov decision process (CMDP), which plays a central role in satisfying safety or resource constraints in sequential learning and decision-making. In this problem, we are given finite resources and a MDP with unknown transition probabilities. At each stage, we take an action, collecting a reward and consuming some resources, all assumed to be unknown and need to be learned over time. In this work, we take the first step towards deriving optimal problem-dependent guarantees for the CMDP problems. We derive a logarithmic regret bound, which translates into a $O(\frac{1}{\Delta\cdot\epsilon}\cdot\log^2(1/\epsilon))$ sample complexity bound, with $\Delta$ being a problem-dependent parameter, yet independent of $\epsilon$. Our sample complexity bound improves upon the state-of-art $O(1/\epsilon^2)$ sample complexity for CMDP problems established in the previous literature, in terms of the dependency on $\epsilon$. To achieve this advance, we develop a new framework for analyzing CMDP problems. To be specific, our algorithm operates in the primal space and we resolve the primal LP for the CMDP problem at each period in an online manner, with \textit{adaptive} remaining resource capacities. The key elements of our algorithm are: i) a characterization of the instance hardness via LP basis, ii) an eliminating procedure that identifies one optimal basis of the primal LP, and; iii) a resolving procedure that is adaptive to the remaining resources and sticks to the characterized optimal basis.

Generative models at times produce "invalid" outputs, such as images with generation artifacts and unnatural sounds. Validity-constrained distribution learning attempts to address this problem by requiring that the learned distribution have a provably small fraction of its mass in invalid parts of space -- something which standard loss minimization does not always ensure. To this end, a learner in this model can guide the learning via "validity queries", which allow it to ascertain the validity of individual examples. Prior work on this problem takes a worst-case stance, showing that proper learning requires an exponential number of validity queries, and demonstrating an improper algorithm which -- while generating guarantees in a wide-range of settings -- makes a relatively large polynomial number of validity queries. In this work, we take a first step towards characterizing regimes where guaranteeing validity is easier than in the worst-case. We show that when the data distribution lies in the model class and the log-loss is minimized, the number samples required to ensure validity has a weak dependence on the validity requirement. Additionally, we show that when the validity region belongs to a VC-class, a limited number of validity queries are often sufficient.
tl;dr: We introduce a new estimand, the conditional quantile comparator to compete with both the CATE and the CQTE.

The conditional quantile treatment effect (CQTE) can provide insight into the effect of a treatment beyond the conditional average treatment effect (CATE). This ability to provide information over multiple quantiles of the response makes the CQTE especially valuable in cases where the effect of a treatment is not well-modelled by a location shift, even conditionally on the covariates. Nevertheless, the estimation of the CQTE is challenging and often depends upon the smoothness of the individual quantiles as a function of the covariates rather than smoothness of the CQTE itself. This is in stark contrast to the CATE where it is possible to obtain high-quality estimates which have less dependency upon the smoothness of the nuisance parameters when the CATE itself is smooth. Moreover, relative smoothness of the CQTE lacks the interpretability of smoothness of the CATE making it less clear whether it is a reasonable assumption to make. We combine the desirable properties of the CATE and CQTE by considering a new estimand, the conditional quantile comparator (CQC). The CQC not only retains information about the whole treatment distribution, similar to the CQTE, but also having more natural examples of smoothness and is able to leverage simplicity in an auxiliary estimand. We provide finite sample bounds on the error of our estimator, demonstrating its ability to exploit simplicity. We validate our theory in numerical simulations which show that our method produces more accurate estimates than baselines. Finally, we apply our methodology to a study on the effect of employment incentives on earnings across different age groups. We see that our method is able to reveal heterogeneity of the effect across different quantiles.
tl;dr: We develop a strategy to backdoor any neural network while ensuring that even if a model’s weights and parameters are accessible, the backdoor cannot be efficiently detected.

As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors, as defined in Goldwasser et al. [2022], in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information on how to slightly perturb their input to change the outcome of the model. We develop a general strategy to plant backdoors to obfuscated neural networks, that satisfy the security properties of the celebrated notion of indistinguishability obfuscation. Applying obfuscation before releasing neural networks is a strategy that is well motivated to protect sensitive information of the external expert firm. Our method to plant backdoors ensures that even if the weights and architecture of the obfuscated model are accessible, the existence of
the backdoor is still undetectable. Finally, we introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.
1657. NeuralSolver: Learning Algorithms For Consistent and Efficient Extrapolation Across General Tasks
tl;dr: A recurrent network that learns scalable algorithms that extrapolate on larger general tasks without fine-tuning.

We contribute NeuralSolver, a novel recurrent solver that can efficiently and consistently extrapolate, i.e., learn algorithms from smaller problems (in terms of observation size) and execute those algorithms in large problems. Contrary to previous recurrent solvers, NeuralSolver can be naturally applied in both same-size problems, where the input and output sizes are the same, and in different-size problems, where the size of the input and output differ. To allow for this versatility, we design NeuralSolver with three main components: a recurrent module, that iteratively processes input information at different scales, a processing module, responsible for aggregating the previously processed information, and a curriculum-based training scheme, that improves the extrapolation performance of the method.
To evaluate our method we introduce a set of novel different-size tasks and we show that NeuralSolver consistently outperforms the prior state-of-the-art recurrent solvers in extrapolating to larger problems, considering smaller training problems and requiring less parameters than other approaches.
tl;dr: This work designs a robust learning framework to better approximate the true performative optimum in the presence of distribution map misspecification.

Performative prediction aims to model scenarios where predictive outcomes subsequently influence the very systems they target. The pursuit of a performative optimum (PO)—minimizing performative risk—is generally reliant on modeling of the distribution map, which characterizes how a deployed ML model alters the data distribution. Unfortunately, inevitable misspecification of the distribution map can lead to a poor approximation of the true PO. To address this issue, we introduce a novel framework of distributionally robust performative prediction and study a new solution concept termed as distributionally robust performative optimum (DRPO). We show provable guarantees for DRPO as a robust approximation to the true PO when the nominal distribution map is different from the actual one. Moreover, distributionally robust performative prediction can be reformulated as an augmented performative prediction problem, enabling efficient optimization. The experimental results demonstrate that DRPO offers potential advantages over traditional PO approach when the distribution map is misspecified at either micro- or macro-level.
tl;dr: we propose a method to explain performance difference of a model between populations by highlighting influential variables

Machine learning (ML) algorithms can often differ in performance across domains. Understanding why their performance differs is crucial for determining what types of interventions (e.g., algorithmic or operational) are most effective at closing the performance gaps. Aggregate decompositions express the total performance gap as the gap due to a shift in the feature distribution $p(X)$ plus the gap due to a shift in the outcome's conditional distribution $p(Y|X)$. While this coarse explanation is helpful for guiding root cause analyses, it provides limited details and can only suggest coarse fixes involving all variables in an ML system. Detailed decompositions quantify the importance of each variable to each term in the aggregate decomposition, which can provide a deeper understanding and suggest more targeted interventions. Although parametric methods exist for conducting a full hierarchical decomposition of an algorithm's performance gap at the aggregate and detailed levels, current nonparametric methods only cover parts of the hierarchy; many also require knowledge of the entire causal graph. We introduce a nonparametric hierarchical framework for explaining why the performance of an ML algorithm differs across domains, without requiring causal knowledge. Furthermore, we derive debiased, computationally-efficient estimators and statistical inference procedures to construct confidence intervals for the explanations.
tl;dr: We show theoretical conditions for improving zero-shot OOD detection and propose a feasible method.

A straightforward pipeline for zero-shot out-of-distribution (OOD) detection involves selecting potential OOD labels from an extensive semantic pool and then leveraging a pre-trained vision-language model to perform classification on both in-distribution (ID) and OOD labels. In this paper, we theorize that enhancing performance requires expanding the semantic pool, while increasing the expected probability of selected OOD labels being activated by OOD samples, and ensuring low mutual dependence among the activations of these OOD labels. A natural expansion manner is to adopt a larger lexicon; however, the inevitable introduction of numerous synonyms and uncommon words fails to meet the above requirements, indicating that viable expansion manners move beyond merely selecting words from a lexicon. Since OOD detection aims to correctly classify input images into ID/OOD class groups, we can "make up" OOD label candidates which are not standard class names but beneficial for the process. Observing that the original semantic pool is comprised of unmodified specific class names, we correspondingly construct a conjugated semantic pool (CSP) consisting of modified superclass names, each serving as a cluster center for samples sharing similar properties across different categories. Consistent with our established theory, expanding OOD label candidates with the CSP satisfies the requirements and outperforms existing works by 7.89% in FPR95. Codes are available in https://github.com/MengyuanChen21/NeurIPS2024-CSP.

The recent advances in 3D Gaussian Splatting (3DGS) show promising results on the novel view synthesis (NVS) task. With its superior rendering performance and high-fidelity rendering quality, 3DGS is excelling at its previous NeRF counterparts. The most recent 3DGS method focuses either on improving the instability of rendering efficiency or reducing the model size. On the other hand, the training efficiency of 3DGS on large-scale scenes has not gained much attention. In this work, we propose DoGaussian, a method that trains 3DGS distributedly. Our method first decomposes a scene into $K$ blocks and then introduces the Alternating Direction Method of Multipliers (ADMM) into the training procedure of 3DGS. During training, our DoGaussian maintains one global 3DGS model on the master node and $K$ local 3DGS models on the slave nodes. The $K$ local 3DGS models are dropped after training and we only query the global 3DGS model during inference. The training time is reduced by scene decomposition, and the training convergence and stability are guaranteed through the consensus on the shared 3D Gaussians. Our method accelerates the training of 3DGS by $6+$ times when evaluated on large-scale scenes while concurrently achieving state-of-the-art rendering quality. Our code is publicly available at [https://github.com/AIBluefisher/DOGS](https://github.com/AIBluefisher/DOGS).
tl;dr: This framework leverages an LLM to enhance content moderation processes. By utilizing advanced natural language understanding, GuardT2I can effectively identify and manage inappropriate content, ensuring a safe and respectful environment.

Recent advancements in Text-to-Image models have raised significant safety concerns about their potential misuse for generating inappropriate or Not-Safe-For-Work contents, despite existing countermeasures such as Not-Safe-For-Work classifiers or model fine-tuning for inappropriate concept removal. Addressing this challenge, our study unveils GuardT2I a novel moderation framework that adopts a generative approach to enhance Text-to-Image models’ robustness against adversarial prompts. Instead of making a binary classification, GuardT2I utilizes a large language model to conditionally transform text guidance embeddings within the Text-to-Image models into natural language for effective adversarial prompt detection, without compromising the models’ inherent performance. Our extensive experiments reveal that GuardT2I outperforms leading commercial solutions like OpenAI-Moderation and Microsoft Azure Moderator by a significant margin across diverse adversarial scenarios. Our framework is available at https://github.com/cure-lab/GuardT2I.

Covariate-adjusted response-adaptive randomization (CARA) designs are gaining increasing attention. These designs combine the advantages of randomized experiments with the ability to adaptively revise treatment allocations based on data collected across multiple stages, enhancing estimation efficiency. Yet, CARA designs often assume that primary outcomes are immediately observable, which is not the case in many clinical scenarios where there is a delay in observing primary outcomes. This assumption can lead to significant missingness and inefficient estimation of treatment effects. To tackle this practical challenge, we propose a CARA experimental strategy integrating delayed primary outcomes with immediately observed surrogate outcomes. Surrogate outcomes are intermediate clinical outcomes that are predictive or correlated with the primary outcome of interest. Our design goal is to improve the estimation efficiency of the average treatment effect (ATE) of the primary outcome utilizing surrogate outcomes. From a methodological perspective, our approach offers two benefits: First, we accommodate arm and covariates-dependent delay mechanisms without imposing any parametric modeling assumptions on the distribution of outcomes. Second, when primary outcomes are not fully observed, surrogate outcomes can guide the adaptive treatment allocation rule. From a theoretical standpoint, we prove the semiparametric efficiency bound of estimating ATE under delayed primary outcomes while incorporating surrogate outcomes. We show that the ATE estimator under our proposed design strategy attains this semiparametric efficiency bound and achieves asymptotic normality. Through theoretical investigations and a synthetic HIV study, we show that our design is more efficient than the design without incorporating any surrogate information.
tl;dr: We introduce TuneTables, an algorithm that allows prior-data fitted networks to scale by orders of magnitude and achieve strong performance on large datasets.

While tabular classification has traditionally relied on from-scratch training, a recent breakthrough called prior-data fitted networks (PFNs) challenges this approach. Similar to large language models, PFNs make use of pretraining and in-context learning to achieve strong performance on new tasks in a single forward pass. However, current PFNs have limitations that prohibit their widespread adoption. Notably, TabPFN achieves very strong performance on small tabular datasets but is not designed to make predictions for datasets of size larger than 1000. In this work, we overcome these limitations and substantially improve the performance of PFNs via context optimization. We introduce TuneTables, a parameter-efficient fine-tuning strategy for PFNs that compresses large datasets into a smaller learned context. We conduct extensive experiments on nineteen algorithms over 98 datasets and find that TuneTables achieves the best performance on average, outperforming boosted trees such as CatBoost, while optimizing fewer than 5\% of TabPFN's parameters. Furthermore, we show that TuneTables can be used as an interpretability tool and can even be used to mitigate biases by optimizing a fairness objective.
tl;dr: We propose the first learning scheme to solve functional differential equations, built on the physics-informed neural network.

We propose the first learning scheme for functional differential equations (FDEs).
FDEs play a fundamental role in physics, mathematics, and optimal control.
However, the numerical analysis of FDEs has faced challenges due to its unrealistic computational costs and has been a long standing problem over decades.
Thus, numerical approximations of FDEs have been developed, but they often oversimplify the solutions.
To tackle these two issues, we propose a hybrid approach combining physics-informed neural networks (PINNs) with the *cylindrical approximation*.
The cylindrical approximation expands functions and functional derivatives with an orthonormal basis and transforms FDEs into high-dimensional PDEs.
To validate the reliability of the cylindrical approximation for FDE applications, we prove the convergence theorems of approximated functional derivatives and solutions.
Then, the derived high-dimensional PDEs are numerically solved with PINNs.
Through the capabilities of PINNs, our approach can handle a broader class of functional derivatives more efficiently than conventional discretization-based methods, improving the scalability of the cylindrical approximation.
As a proof of concept, we conduct experiments on two FDEs and demonstrate that our model can successfully achieve typical $L^1$ relative error orders of PINNs $\sim 10^{-3}$.
Overall, our work provides a strong backbone for physicists, mathematicians, and machine learning experts to analyze previously challenging FDEs, thereby democratizing their numerical analysis, which has received limited attention.

Meta-reinforcement learning (Meta-RL) has attracted attention due to its capability to enhance reinforcement learning (RL) algorithms, in terms of data efficiency and generalizability. In this paper, we develop a bilevel optimization framework for meta-RL (BO-MRL) to learn the meta-prior for task-specific policy adaptation, which implements multiple-step policy optimization on one-time data collection. Beyond existing meta-RL analyses, we provide upper bounds of the expected optimality gap over the task distribution. This metric measures the distance of the policy adaptation from the learned meta-prior to the task-specific optimum, and quantifies the model's generalizability to the task distribution. We empirically validate the correctness of the derived upper bounds and demonstrate the superior effectiveness of the proposed algorithm over benchmarks.
tl;dr: A new algorithm for vectorial optimization under bandit feedback

We study the preference-based pure exploration problem for bandits with vector-valued rewards and a set of preferences imposed over them. Specifically, we aim to identify the most preferred policy over a set of arms according to the preferences induced on the reward vectors by an ordering cone $C$. First, to quantify the impact of preferences, we derive a novel lower bound on the sample complexity for identifying the most preferred arm with confidence level $1-\delta$. Our lower bound shows that how the geometry of the preferences and reward vectors changes the hardness of this problem. We further explicate this geometry for Gaussian distributions of rewards, and provide a convex reformulation of the lower bound solvable with linear programming. Then, we leverage this convex reformulation of the lower bound to design the Track and Stop with Preferences (TSwP) algorithm that identifies the most preferred policy. Finally, we derive a new concentration result for vector-valued rewards, and show that TSwP achieves a matching sample complexity upper bound.

Deep Multi-agent Reinforcement Learning (MARL) relies on neural networks with numerous parameters in multi-agent scenarios, often incurring substantial computational overhead. Consequently, there is an urgent need to expedite training and enable model compression in MARL. This paper proposes the utilization of dynamic sparse training (DST), a technique proven effective in deep supervised learning tasks, to alleviate the computational burdens in MARL training. However, a direct adoption of DST fails to yield satisfactory MARL agents, leading to breakdowns in value learning within deep sparse value-based MARL models. Motivated by this challenge, we introduce an innovative Multi-Agent Sparse Training (MAST) framework aimed at simultaneously enhancing the reliability of learning targets and the rationality of sample distribution to improve value learning in sparse models. Specifically, MAST incorporates the Soft Mellowmax Operator with a hybrid TD-($\lambda$) schema to establish dependable learning targets. Additionally, it employs a dual replay buffer mechanism to enhance the distribution of training samples. Building upon these aspects, MAST utilizes gradient-based topology evolution to exclusively train multiple MARL agents using sparse networks. Our comprehensive experimental investigation across various value-based MARL algorithms on multiple benchmarks demonstrates, for the first time, significant reductions in redundancy of up to $20\times$ in Floating Point Operations (FLOPs) for both training and inference, with less than 3% performance degradation.
tl;dr: The paper presents a new framework for generalizable object pose estimation.

Object pose estimation plays a crucial role in robotic manipulation, however, its practical applicability still suffers from limited generalizability. This paper addresses the challenge of generalizable object pose estimation, particularly focusing on category-level object pose estimation for unseen object categories. Current methods either require impractical instance-level training or are confined to predefined categories, limiting their applicability. We propose VFM-6D, a novel framework that explores harnessing existing vision and language models, to elaborate object pose estimation into two stages: category-level object viewpoint estimation and object coordinate map estimation. Based on the two-stage framework, we introduce a 2D-to-3D feature lifting module and a shape-matching module, both of which leverage pre-trained vision foundation models to improve object representation and matching accuracy. VFM-6D is trained on cost-effective synthetic data and exhibits superior generalization capabilities. It can be applied to both instance-level unseen object pose estimation and category-level object pose estimation for novel categories. Evaluations on benchmark datasets demonstrate the effectiveness and versatility of VFM-6D in various real-world scenarios.

The key challenge of multi-view indoor 3D object detection is to infer accurate geometry information from images for precise 3D detection. Previous method relies on NeRF for geometry reasoning. However, the geometry extracted from NeRF is generally inaccurate, which leads to sub-optimal detection performance. In this paper, we propose MVSDet which utilizes plane sweep for geometry-aware 3D object detection. To circumvent the requirement for a large number of depth planes for accurate depth prediction, we design a probabilistic sampling and soft weighting mechanism to decide the placement of pixel features on the 3D volume. We select multiple locations that score top in the probability volume for each pixel and use their probability score to indicate the confidence. We further apply recent pixel-aligned Gaussian Splatting to regularize depth prediction and improve detection performance with little computation overhead. Extensive experiments on ScanNet and ARKitScenes datasets are conducted to show the superiority of our model. Our code is available at https://github.com/Pixie8888/MVSDet.
tl;dr: In this work, a new type of sparsity inducing generative prior for compressive sensing is introduced.

This work addresses the fundamental linear inverse problem in compressive sensing (CS) by introducing a new type of regularizing generative prior. Our proposed method utilizes ideas from classical dictionary-based CS and, in particular, sparse Bayesian learning (SBL), to integrate a strong regularization towards sparse solutions. At the same time, by leveraging the notion of conditional Gaussianity, it also incorporates the adaptability from generative models to training data. However, unlike most state-of-the-art generative models, it is able to learn from a few compressed and noisy data samples and requires no optimization algorithm for solving the inverse problem. Additionally, similar to Dirichlet prior networks, our model parameterizes a conjugate prior enabling its application for uncertainty quantification. We support our approach theoretically through the concept of variational inference and validate it empirically using different types of compressible signals.
tl;dr: In this work, a training-free ensemble algorithm is developed to boost the performance of image restoration by combining multiple pre-trained base models at the inference stage.

Image restoration has experienced significant advancements due to the development of deep learning. Nevertheless, it encounters challenges related to ill-posed problems, resulting in deviations between single model predictions and ground-truths. Ensemble learning, as a powerful machine learning technique, aims to address these deviations by combining the predictions of multiple base models. Most existing works adopt ensemble learning during the design of restoration models, while only limited research focuses on the inference-stage ensemble of pre-trained restoration models. Regression-based methods fail to enable efficient inference, leading researchers in academia and industry to prefer averaging as their choice for post-training ensemble. To address this, we reformulate the ensemble problem of image restoration into Gaussian mixture models (GMMs) and employ an expectation maximization (EM)-based algorithm to estimate ensemble weights for aggregating prediction candidates. We estimate the range-wise ensemble weights on a reference set and store them in a lookup table (LUT) for efficient ensemble inference on the test set. Our algorithm is model-agnostic and training-free, allowing seamless integration and enhancement of various pre-trained image restoration models. It consistently outperforms regression-based methods and averaging ensemble approaches on 14 benchmarks across 3 image restoration tasks, including super-resolution, deblurring and deraining. The codes and all estimated weights have been released in Github.
tl;dr: We disentangle graph homophily from label, structural, and feature aspects and investigate their impact on the performance of GNNs

Graph homophily refers to the phenomenon that connected nodes tend to share similar characteristics. Understanding this concept and its related metrics is crucial for designing effective Graph Neural Networks (GNNs). The most widely used homophily metrics, such as edge or node homophily, quantify such "similarity" as label consistency across the graph topology. These metrics are believed to be able to reflect the performance of GNNs, especially on node-level tasks. However, many recent studies have empirically demonstrated that the performance of GNNs does not always align with homophily metrics, and how homophily influences GNNs still remains unclear and controversial. Then, a crucial question arises: What is missing in our current understanding of homophily? To figure out the missing part, in this paper, we disentangle the graph homophily into three aspects: label, structural, and feature homophily, which are derived from the three basic elements of graph data. We argue that the synergy of the three homophily can provide a more comprehensive understanding of GNN performance. Our new proposed structural and feature homophily consider the neighborhood consistency and feature dependencies among nodes, addressing the previously overlooked structural and feature aspects in graph homophily. To investigate their synergy, we propose a Contextual Stochastic Block Model with three types of Homophily (CSBM-3H), where the topology and feature generation are controlled by the three metrics. Based on the theoretical analysis of CSBM-3H, we derive a new composite metric, named Tri-Hom, that considers all three aspects and overcomes the limitations of conventional homophily metrics. The theoretical conclusions and the effectiveness of Tri-Hom have been verified through synthetic experiments on CSBM-3H. In addition, we conduct experiments on $31$ real-world benchmark datasets and calculate the correlations between homophily metrics and model performance. Tri-Hom has significantly higher correlation values than $17$ existing metrics that only focus on a single homophily aspect, demonstrating its superiority and the importance of homophily synergy. Our code is available at https://github.com/zylMozart/Disentangle_GraphHom.
tl;dr: Full body and dexterous humanoid grasping and object manipulation.

We present a method for controlling a simulated humanoid to grasp an object and move it to follow an object's trajectory. Due to the challenges in controlling a humanoid with dexterous hands, prior methods often use a disembodied hand and only consider vertical lifts or short trajectories. This limited scope hampers their applicability for object manipulation required for animation and simulation. To close this gap, we learn a controller that can pick up a large number (>1200) of objects and carry them to follow randomly generated trajectories. Our key insight is to leverage a humanoid motion representation that provides human-like motor skills and significantly speeds up training. Using only simplistic reward, state, and object representations, our method shows favorable scalability on diverse objects and trajectories. For training, we do not need a dataset of paired full-body motion and object trajectories. At test time, we only require the object mesh and desired trajectories for grasping and transporting. To demonstrate the capabilities of our method, we show state-of-the-art success rates in following object trajectories and generalizing to unseen objects. Code and models will be released.
tl;dr: Initialization of the adapter weights has crucial impact on LoRA learning dynamics

In this paper, we study the role of initialization in Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021). Essentially, to start from the pretrained model, one can either initialize $B$ to zero and $A$ to random, or vice-versa. In both cases, the product $BA$ is equal to zero at initialization, which makes finetuning starts from the pretrained model. These two initialization schemes are seemingly similar. They should in-principle yield the same performance and share the same optimal learning rate. We demonstrate that this is an *incorrect intuition* and that the first scheme (of initializing $B$ to zero and $A$ to random) on average in our experiments yields better performance compared to the other scheme. Our theoretical analysis shows that the reason behind this might be that the first initialization allows the use of larger learning rates (without causing output instability) compared to the second initialization, resulting in more efficient learning of the first scheme. We validate our results with extensive experiments on LLMs.
tl;dr: SFT can be just as effective as AI feedback when using strong teacher models.

Learning from AI feedback (LAIF) is a popular paradigm for improving the instruction-following abilities of powerful pre-trained language models. LAIF first performs supervised fine-tuning (SFT) using demonstrations from a teacher model and then further fine-tunes the model with reinforcement learning (RL) or direct preference optimization (DPO), using feedback from a critic model. While recent popular open-source models have demonstrated substantial improvements in performance from the RL step, in this paper we question whether the complexity of this RL step is truly warranted for AI feedback. We show that the improvements of the RL step are virtually entirely due to the widespread practice of using a weaker teacher model (e.g. GPT-3.5) for SFT data collection than the critic (e.g., GPT-4) used for AI feedback generation. Specifically, we show that simple supervised fine-tuning with GPT-4 as the teacher outperforms existing LAIF pipelines. More generally, we find that the gains from LAIF vary substantially across base model families, test-time evaluation protocols, and critic models. Finally, we provide a mechanistic explanation for when SFT may outperform the full two-step LAIF pipeline as well as suggestions for making LAIF maximally useful in practice.
tl;dr: We present HOI-Swap, a diffusion-based video editing framework, that seamlessly swaps the in-contact object in videos given a reference object image.

We study the problem of precisely swapping objects in videos, with a focus on those interacted with by hands, given one user-provided reference object image. Despite the great advancements that diffusion models have made in video editing recently, these models often fall short in handling the intricacies of hand-object interactions (HOI), failing to produce realistic edits---especially when object swapping results in object shape or functionality changes. To bridge this gap, we present HOI-Swap, a novel diffusion-based video editing framework trained in a self-supervised manner. Designed in two stages, the first stage focuses on object swapping in a single frame with HOI awareness; the model learns to adjust the interaction patterns, such as the hand grasp, based on changes in the object's properties. The second stage extends the single-frame edit across the entire sequence; we achieve controllable motion alignment with the original video by: (1) warping a new sequence from the stage-I edited frame based on sampled motion points and (2) conditioning video generation on the warped sequence. Comprehensive qualitative and quantitative evaluations demonstrate that HOI-Swap significantly outperforms existing methods, delivering high-quality video edits with realistic HOIs.
1678. Treatment of Statistical Estimation Problems in Randomized Smoothing for Adversarial Robustness

Randomized smoothing is a popular certified defense against adversarial attacks. In its essence, we need to solve a problem of statistical estimation which is usually very time-consuming since we need to perform numerous (usually $10^5$) forward passes of the classifier for every point to be certified. In this paper, we review the statistical estimation problems for randomized smoothing to find out if the computational burden is necessary. In particular, we consider the (standard) task of adversarial robustness where we need to decide if a point is robust at a certain radius or not using as few samples as possible while maintaining statistical guarantees. We present estimation procedures employing confidence sequences enjoying the same statistical guarantees as the standard methods, with the optimal sample complexities for the estimation task and empirically demonstrate their good performance. Additionally, we provide a randomized version of Clopper-Pearson confidence intervals resulting in strictly stronger certificates.

In-context learning is an emergent paradigm in large language models (LLMs) that enables them to generalize to new tasks and domains by simply prompting these models with a few exemplars without explicit parameter updates. Many attempts have been made to understand in-context learning in LLMs as a function of model scale, pretraining data, and other factors. In this work, we propose a new mechanism to probe and understand in-context learning from the lens of decision boundaries for in-context binary classification. Decision boundaries are straightforward to visualize and provide important information about the qualitative behavior of the inductive biases of standard classifiers. To our surprise, we find that the decision boundaries learned by current LLMs in simple binary classification tasks are often irregularly non-smooth, regardless of task linearity. This paper investigates the factors influencing these decision boundaries and explores methods to enhance their generalizability. We assess various approaches, including training-free and fine-tuning methods for LLMs, the impact of model architecture, and the effectiveness of active prompting techniques for smoothing decision boundaries in a data-efficient manner. Our findings provide a deeper understanding of in-context learning dynamics and offer practical improvements for enhancing robustness and generalizability of in-context learning.
tl;dr: Single-view shape from polarization by integrating pretrained model knowledge under unknown environment illumination.

Shape from polarization (SfP) benefits from advancements like polarization cameras for single-shot normal estimation, but its performance heavily relies on light conditions. This paper proposes SfPUEL, an end-to-end SfP method to jointly estimate surface normal and material under unknown environment light. To handle this challenging light condition, we design a transformer-based framework for enhancing the perception of global context features. We further propose to integrate photometric stereo (PS) priors from pretrained models to enrich extracted features for high-quality normal predictions. As metallic and dielectric materials exhibit different BRDFs, SfPUEL additionally predicts dielectric and metallic material segmentation to further boost performance. Experimental results on synthetic and our collected real-world dataset demonstrate that SfPUEL significantly outperforms existing SfP and single-shot normal estimation methods. The code and dataset is available at https://github.com/YouweiLyu/SfPUEL.
tl;dr: MiSO (MicroStimulation Optimization): a closed-loop stimulation framework to drive neural population activity toward specified states by optimizing over a large stimulation parameter space.

Brain stimulation has the potential to create desired neural population activity states. However, it is challenging to search the large space of stimulation parameters, for example, selecting which subset of electrodes to be used for stimulation. In this scenario, creating a model that maps the configuration of stimulation parameters to the brain’s response can be beneficial. Training such an expansive model usually requires more stimulation-response samples than can be collected in a given experimental session. Furthermore, changes in the properties of the recorded activity over time can make it challenging to merge stimulation-response samples across sessions. To address these challenges, we propose MiSO (MicroStimulation Optimization), a closed-loop stimulation framework to drive neural population activity toward specified states by optimizing over a large stimulation parameter space. MiSO consists of three key components: 1) a neural activity alignment method to merge stimulation-response samples across sessions, 2) a statistical model trained on the merged samples to predict the brain's response to untested stimulation parameter configurations, and 3) an online optimization algorithm to adaptively update the stimulation parameter configuration based on the model's predictions. In this study, we implemented MiSO with a factor analysis (FA) based alignment method, a convolutional neural network (CNN), and an epsilon greedy optimization algorithm. We tested MiSO in closed-loop experiments using electrical microstimulation in the prefrontal cortex of a non-human primate. Guided by the CNN predictions, MiSO successfully searched amongst thousands of stimulation parameter configurations to drive the neural population activity toward specified states. More broadly, MiSO increases the clinical viability of neuromodulation technologies by enabling the use of many-fold larger stimulation parameter spaces.
tl;dr: For the first time, we leverage 3D Gaussian representation in 3D GANs for efficient rendering with explicit 3D representation.

Most advances in 3D Generative Adversarial Networks (3D GANs) largely depend on ray casting-based volume rendering, which incurs demanding rendering costs. One promising alternative is rasterization-based 3D Gaussian Splatting (3D-GS), providing a much faster rendering speed and explicit 3D representation. In this paper, we exploit Gaussian as a 3D representation for 3D GANs by leveraging its efficient and explicit characteristics. However, in an adversarial framework, we observe that a na\"ive generator architecture suffers from training instability and lacks the capability to adjust the scale of Gaussians. This leads to model divergence and visual artifacts due to the absence of proper guidance for initialized positions of Gaussians and densification to manage their scales adaptively. To address these issues, we introduce GSGAN, a generator architecture with a hierarchical multi-scale Gaussian representation that effectively regularizes the position and scale of generated Gaussians. Specifically, we design a hierarchy of Gaussians where finer-level Gaussians are parameterized by their coarser-level counterparts; the position of finer-level Gaussians would be located near their coarser-level counterparts, and the scale would monotonically decrease as the level becomes finer, modeling both coarse and fine details of the 3D scene. Experimental results demonstrate that ours achieves a significantly faster rendering speed (×100) compared to state-of-the-art 3D consistent GANs with comparable 3D generation capability.
tl;dr: We propose a cost-effective fine-tuning approach to fine-tune cultural specific LLMs

Large language models (LLMs) have been observed to exhibit bias towards certain cultures due to the predominance of training data obtained from English corpora. Considering that multilingual cultural data is often expensive to procure, existing methodologies address this challenge through prompt engineering or culture-specific pre-training. However, these strategies may neglect the knowledge deficiency of low-resource cultures and necessitate substantial computing resources. In this paper, we propose CultureLLM, a cost-effective solution to integrate cultural differences into LLMs. CultureLLM employs the World Value Survey (WVS) as seed data and generates semantically equivalent training data through the proposed semantic data augmentation. Utilizing only $50$ seed samples from WVS with augmented data, we fine-tune culture-specific LLMs as well as a unified model (CultureLLM-One) for $9$ cultures, encompassing both rich and low-resource languages. Extensive experiments conducted on $60$ culture-related datasets reveal that CultureLLM significantly surpasses various counterparts such as GPT-3.5 (by $8.1$\%) and Gemini Pro (by $9.5$\%), demonstrating performance comparable to or exceeding that of GPT-4. Our human study indicates that the generated samples maintain semantic equivalence to the original samples, offering an effective solution for LLMs augmentation. Code is released at https://github.com/Scarelette/CultureLLM.

With the emergence of various molecular tasks and massive datasets, how to perform efficient training has become an urgent yet under-explored issue in the area. Data pruning (DP), as an oft-stated approach to saving training burdens, filters out less influential samples to form a coreset for training. However, the increasing reliance on pretrained models for molecular tasks renders traditional in-domain DP methods incompatible. Therefore, we propose a **Mol**ecular data **P**runing framework for **e**nhanced **G**eneralization (**MolPeg**), which focuses on the source-free data pruning scenario, where data pruning is applied with pretrained models. By maintaining two models with different updating paces during training, we introduce a novel scoring function to measure the informativeness of samples based on the loss discrepancy. As a plug-and-play framework, MolPeg realizes the perception of both source and target domain and consistently outperforms existing DP methods across four downstream tasks. Remarkably, it can surpass the performance obtained from full-dataset training, even when pruning up to 60-70% of the data on HIV and PCBA dataset. Our work suggests that the discovery of effective data-pruning metrics could provide a viable path to both enhanced efficiency and superior generalization in transfer learning.
tl;dr: We propose DeepLag to tackle the intricate fluid dynamics by guiding the Eulerian fluid prediction with learned dynamics of tracked Lagrangian particles.

Accurately predicting the future fluid is vital to extensive areas such as meteorology, oceanology, and aerodynamics. However, since the fluid is usually observed from the Eulerian perspective, its moving and intricate dynamics are seriously obscured and confounded in static grids, bringing thorny challenges to the prediction. This paper introduces a new Lagrangian-Eulerian combined paradigm to tackle the tanglesome fluid dynamics. Instead of solely predicting the future based on Eulerian observations, we propose DeepLag to discover hidden Lagrangian dynamics within the fluid by tracking the movements of adaptively sampled key particles. Further, DeepLag presents a new paradigm for fluid prediction, where the Lagrangian movement of the tracked particles is inferred from Eulerian observations, and their accumulated Lagrangian dynamics information is incorporated into global Eulerian evolving features to guide future prediction respectively. Tracking key particles not only provides a transparent and interpretable clue for fluid dynamics but also makes our model free from modeling complex correlations among massive grids for better efficiency. Experimentally, DeepLag excels in three challenging fluid prediction tasks covering 2D and 3D, simulated and real-world fluids. Code is available at this repository: https://github.com/thuml/DeepLag.

Recent progress in Neural Causal Models (NCMs) showcased how identification and partial identification of causal effects can be automatically carried out via training of neural generative models that respect the constraints encoded in a given causal graph [Xia et al. 2022, Balazadeh et al. 2022]. However, formal consistency of these methods has only been proven for the case of discrete variables or only for linear causal models. In this work, we prove the consistency of partial identification via NCMs in a general setting with both continuous and categorical variables. Further, our results highlight the impact of the design of the underlying neural network architecture in terms of depth and connectivity as well as the importance of applying Lipschitz regularization in the training phase. In particular, we provide a counterexample showing that without Lipschitz regularization this method may not be asymptotically consistent. Our results are enabled by new results on the approximability of Structural Causal Models (SCMs) via neural generative models, together with an analysis of the sample complexity of the resulting architectures and how that translates into an error in the constrained optimization problem that defines the partial identification bounds.

How can we build AI systems that can learn any set of individual human values both quickly and safely, avoiding causing harm or violating societal standards for acceptable behavior during the learning process? We explore the effects of representational alignment between humans and AI agents on learning human values. Making AI systems learn human-like representations of the world has many known benefits, including improving generalization, robustness to domain shifts, and few-shot learning performance. We demonstrate that this kind of representational alignment can also support safely learning and exploring human values in the context of personalization. We begin with a theoretical prediction, show that it applies to learning human morality judgments, then show that our results generalize to ten different aspects of human values -- including ethics, honesty, and fairness -- training AI agents on each set of values in a multi-armed bandit setting, where rewards reflect human value judgments over the chosen action. Using a set of textual action descriptions, we collect value judgments from humans, as well as similarity judgments from both humans and multiple language models, and demonstrate that representational alignment enables both safe exploration and improved generalization when learning human values.
tl;dr: This work presents R-CBMs, a family of concept bottleneck models designed for relational tasks, which match the generalization performance of existing relational black-boxes, while support the generation of quantified concept-based explanations.

The design of interpretable deep learning models working in relational domains poses an open challenge: interpretable deep learning methods, such as Concept Bottleneck Models (CBMs), are not designed to solve relational problems, while relational deep learning models, such as Graph Neural Networks (GNNs), are not as interpretable as CBMs. To overcome these limitations, we propose Relational Concept Bottleneck Models (R-CBMs), a family of relational deep learning methods providing interpretable task predictions. As special cases, we show that R-CBMs are capable of both representing standard CBMs and message passing GNNs. To evaluate the effectiveness and versatility of these models, we designed a class of experimental problems, ranging from image classification to link prediction in knowledge graphs. In particular we show that R-CBMs (i) match generalization performance of existing relational black-boxes, (ii) support the generation of quantified concept-based explanations, (iii) effectively respond to test-time interventions, and (iv) withstand demanding settings including out-of-distribution scenarios, limited training data regimes, and scarce concept supervisions.

Federated learning has become a pivotal distributed learning paradigm, involving collaborative model updates across multiple nodes with private data. However, handling non-i.i.d. (not identically and independently distributed) data and ensuring model consistency across heterogeneous environments present significant challenges. These challenges often lead to model performance degradation and increased difficulty in achieving effective communication among participant models. In this work, we propose Confusion-Resistant Federated Learning via Consistent Diffusion (CRFed), a novel framework designed to address these issues. Our approach introduces a new diffusion-based data harmonization mechanism that includes data augmentation, noise injection, and iterative denoising to ensure consistent model updates across non-i.i.d. data distributions. This mechanism aims to reduce data distribution disparities among participating nodes, enhancing the coordination and consistency of model updates. Moreover, we design a confusion-resistant strategy leveraging an indicator function and adaptive learning rate adjustment to mitigate the adverse effects of data heterogeneity and model inconsistency. Specifically, we calculate importance sampling weights based on the optimal sampling probability, which guides the selection of clients and the sampling of their data, ensuring that model updates are robust and aligned across different nodes. Extensive experiments on benchmark datasets, including MNIST, FashionMNIST, CIFAR-10, CIFAR-100, and NIPD, demonstrate the effectiveness of CRFed in improving accuracy, convergence speed, and overall robustness in federated learning scenarios with severe data heterogeneity.
tl;dr: This work introduces a framework that harnesses the power of fixed-budget best arm identification to efficiently perform prompt optimization for large language models (LLMs), which achieves outstanding performance across tasks and targeted LLMs.

The remarkable instruction-following capability of large language models (LLMs) has sparked a growing interest in automatically finding good prompts, i.e., prompt optimization. Most existing works follow the scheme of selecting from a pre-generated pool of candidate prompts. However, these designs mainly focus on the generation strategy, while limited attention has been paid to the selection method. Especially, the cost incurred during the selection (e.g., accessing LLM and evaluating the responses) is rarely explicitly considered. To overcome this limitation, this work provides a principled framework, TRIPLE, to efficiently perform prompt selection under an explicit budget constraint. TRIPLE is built on a novel connection established between prompt optimization and fixed-budget best arm identification (BAI-FB) in multi-armed bandits (MAB); thus, it is capable of leveraging the rich toolbox from BAI-FB systematically and also incorporating unique characteristics of prompt optimization. Extensive experiments on multiple well-adopted tasks using various LLMs demonstrate the remarkable performance improvement of TRIPLE over baselines while satisfying the limited budget constraints. As an extension, variants of TRIPLE are proposed to efficiently select examples for few-shot prompts, also achieving superior empirical performance.
tl;dr: We propose a novel context-adaptive positional encoding to improve Transformer's capabilities, especially in long context .

Positional encoding plays a crucial role in transformers, significantly impact- ing model performance and length generalization. Prior research has introduced absolute positional encoding (APE) and relative positional encoding (RPE) to distinguish token positions in given sequences. However, both APE and RPE remain fixed after model training regardless of input data, limiting their adaptability and flexibility. Hence, we expect that the desired positional encoding should be data-adaptive and can be dynamically adjusted with the given attention. In this paper, we propose a Data-Adaptive Positional Encoding (DAPE) method, which dynamically and semantically adjusts based on input context and learned fixed priors. Experimental validation on real-world datasets (Arxiv, Books3, and CHE) demonstrates that DAPE enhances model performances in terms of trained length and length generalization, where the improvements are statistically significant. The model visualization suggests that our model can keep both local and anti-local information. Finally, we successfully train the model on sequence length 128 and achieve better performance at evaluation sequence length 8192, compared with other static positional encoding methods, revealing the benefit of the adaptive positional encoding method.
tl;dr: This paper introduces AutoSurvey, a speedy and well-organized methodology for automating the creation of comprehensive literature surveys in rapidly evolving fields like artificial intelligence.

This paper introduces AutoSurvey, a speedy and well-organized methodology for automating the creation of comprehensive literature surveys in rapidly evolving fields like artificial intelligence. Traditional survey paper creation faces challenges due to the vast volume and complexity of information, prompting the need for efficient survey methods. While large language models (LLMs) offer promise in automating this process, challenges such as context window limitations, parametric knowledge constraints, and the lack of evaluation benchmarks remain. AutoSurvey addresses these challenges through a systematic approach that involves initial retrieval and outline generation, subsection drafting by specialized LLMs, integration and refinement, and rigorous evaluation and iteration. Our contributions include a comprehensive solution to the survey problem, a reliable evaluation method, and experimental validation demonstrating AutoSurvey's effectiveness.

Language models as intelligent agents push the boundaries of sequential decision-making agents but struggle with limited knowledge of environmental dynamics and exponentially huge action space. Recent efforts like GLAM and TWOSOME manually constrain the action space to a restricted subset and employ reinforcement learning to align agents' knowledge with specific environments. However, they overlook fine-grained credit assignments for intra-action tokens, which is essential for efficient language agent optimization, and rely on human's prior knowledge to restrict action space. This paper proposes decomposing language agent optimization from the action level to the token level, offering finer supervision for each intra-action token and manageable optimization complexity in environments with unrestricted action spaces. Beginning with the simplification of flattening all actions, we theoretically explore the discrepancies between action-level optimization and this naive token-level optimization. We then derive the Bellman backup with Action Decomposition (BAD) to integrate credit assignments for both intra-action and inter-action tokens, effectively eliminating the discrepancies. Implementing BAD within the PPO algorithm, we introduce Policy Optimization with Action Decomposition (POAD). POAD benefits from a finer-grained credit assignment process and lower optimization complexity, leading to enhanced learning efficiency and generalization abilities in aligning language agents with interactive environments. We validate POAD across diverse testbeds, with results affirming the advantages of our approach and the correctness of our theoretical analysis. The source code can be accessed directly with this link: https://github.com/morning9393/ADRL.
tl;dr: We introduce the Dense Connector - a simple, effective, and plug-and-play vision-language connecter that significantly enhances existing MLLMs by leveraging multi-layer visual features, with minimal additional computational overhead.

*Do we fully leverage the potential of visual encoder in Multimodal Large Language Models (MLLMs)?* The recent outstanding performance of MLLMs in multimodal understanding has garnered broad attention from both academia and industry. In the current MLLM rat race, the focus seems to be predominantly on the linguistic side. We witness the rise of larger and higher-quality instruction datasets, as well as the involvement of larger-sized LLMs. Yet, scant attention has been directed towards the visual signals utilized by MLLMs, often assumed to be the final high-level features extracted by a frozen visual encoder. In this paper, we introduce the **Dense Connector** - a simple, effective, and plug-and-play vision-language connector that significantly enhances existing MLLMs by leveraging multi-layer visual features, with minimal additional computational overhead. Building on this, we also propose the Efficient Dense Connector, which achieves performance comparable to LLaVA-v1.5 with only 25% of the visual tokens. Furthermore, our model, trained solely on images, showcases remarkable zero-shot capabilities in video understanding as well. Experimental results across various vision encoders, image resolutions, training dataset scales, varying sizes of LLMs (2.7B→70B), and diverse architectures of MLLMs (e.g., LLaVA-v1.5, LLaVA-NeXT and Mini-Gemini) validate the versatility and scalability of our approach, achieving state-of-the-art performance across 19 image and video benchmarks. We hope that this work will provide valuable experience and serve as a basic module for future MLLM development. Code is available at https://github.com/HJYao00/DenseConnector.
tl;dr: Heavy tailed parameter distributions can emerge from locally Gaussian gradient noise, as we show both theoretically and empirically.

It has repeatedly been observed that loss minimization by stochastic gradient descent (SGD) leads to heavy-tailed distributions of neural network parameters. Here, we analyze a continuous diffusion approximation of SGD, called homogenized stochastic gradient descent (hSGD), and show in a regularized linear regression framework that it leads to an asymptotically heavy-tailed parameter distribution, even though local gradient noise is Gaussian. We give explicit upper and lower bounds on the tail-index of the resulting parameter distribution and validate these bounds in numerical experiments. Moreover, the explicit form of these bounds enables us to quantify the interplay between optimization hyperparameters and the tail-index. Doing so, we contribute to the ongoing discussion on links between heavy tails and the generalization performance of neural networks as well as the ability of SGD to avoid suboptimal local minima.

Graph anomaly detection (GAD), which aims to identify abnormal nodes that differ from the majority within a graph, has garnered significant attention. However, current GAD methods necessitate training specific to each dataset, resulting in high training costs, substantial data requirements, and limited generalizability when being applied to new datasets and domains. To address these limitations, this paper proposes ARC, a generalist GAD approach that enables a ``one-for-all'' GAD model to detect anomalies across various graph datasets on-the-fly. Equipped with in-context learning, ARC can directly extract dataset-specific patterns from the target dataset using few-shot normal samples at the inference stage, without the need for retraining or fine-tuning on the target dataset. ARC comprises three components that are well-crafted for capturing universal graph anomaly patterns: 1) smoothness-based feature **A**lignment module that unifies the features of different datasets into a common and anomaly-sensitive space; 2) ego-neighbor **R**esidual graph encoder that learns abnormality-related node embeddings; and 3) cross-attentive in-**C**ontext anomaly scoring module that predicts node abnormality by leveraging few-shot normal samples. Extensive experiments on multiple benchmark datasets from various domains demonstrate the superior anomaly detection performance, efficiency, and generalizability of ARC.

Synthesizing time series data is pivotal in modern society, aiding effective decision making and ensuring privacy preservation in various scenarios. Time series are associated with various attributes, including trends, seasonality, and external information such as location. Recent research has predominantly focused on random unconditional synthesis or conditional synthesis. Nonetheless, these paradigms generate time series from scratch and are incapable of manipulating existing time series samples. This paper introduces a novel task, called Time Series Editing (TSE), to synthesize time series by manipulating existing time series. The objective is to modify the given time series according to the specified attributes while preserving other properties unchanged. This task is not trivial due to the inadequacy of data coverage and the intricate relationships between time series and their attributes. To address these issues, we introduce a novel diffusion model, called TEdit. The proposed TEdit is trained using a novel bootstrap learning algorithm that effectively enhances the coverage of the original data. It is also equipped with an innovative multi-resolution modeling and generation paradigm to capture the complex relationships between time series and their attributes. Experimental results demonstrate the efficacy of TEdit for editing specified attributes upon the existing time series data. The project page is at https://seqml.github.io/tse.
tl;dr: Our method creates a hierarchy-agnostic semantic region tree from image pixels, offering nuanced segmentation without predefined hierarchies, scaling effectively across datasets.

Unsupervised semantic segmentation aims to discover groupings within images, capturing objects' view-invariance without external supervision. This task is inherently ambiguous due to the variable levels of granularity in natural groups. Existing methods often bypass this ambiguity using dataset-specific priors. In our research, we address this ambiguity head-on and provide a universal tool for pixel-level semantic parsing of images guided by the latent representations encoded in self-supervised models.
We introduce a novel algebraic methodology that recursively identifies latent semantic regions, dynamically estimates the number of components, and ensures smoothness in the partitioning process.
The innovative approach identifies scene-conditioned primitives within a dataset and creates a hierarchy-agnostic semantic regions tree of the image pixels.
The model captures fine and coarse semantic details, producing a nuanced and unbiased segmentation.
We present a new metric for estimating the quality of the semantic segmentation of discovered elements on different levels of the hierarchy. The metric validates the intrinsic nature of the compositional relations among parts, objects, and scenes in a hierarchy-agnostic domain. Our results prove the power of this methodology, uncovering semantic regions without prior definitions and scaling effectively across various datasets. This robust framework for unsupervised image segmentation proves more accurate semantic hierarchical relationships between scene elements than traditional algorithms. The experiments underscore its potential for broad applicability in image analysis tasks, showcasing its ability to deliver a detailed and unbiased segmentation that surpasses existing unsupervised methods.
1699. Parametric model reduction of mean-field and stochastic systems via higher-order action matching
tl;dr: Learning surrogate models to efficiently predict behavior of systems with stochastic and mean-field dynamics across varying physics parameters.

The aim of this work is to learn models of population dynamics of physical systems that feature stochastic and mean-field effects and that depend on physics parameters. The learned models can act as surrogates of classical numerical models to efficiently predict the system behavior over the physics parameters. Building on the Benamou-Brenier formula from optimal transport and action matching, we use a variational problem to infer parameter- and time-dependent gradient fields that represent approximations of the population dynamics. The inferred gradient fields can then be used to rapidly generate sample trajectories that mimic the dynamics of the physical system on a population level over varying physics parameters. We show that combining Monte Carlo sampling with higher-order quadrature rules is critical for accurately estimating the training objective from sample data and for stabilizing the training process. We demonstrate on Vlasov-Poisson instabilities as well as on high-dimensional particle and chaotic systems that our approach accurately predicts population dynamics over a wide range of parameters and outperforms state-of-the-art diffusion-based and flow-based modeling that simply condition on time and physics parameters.

Deep models have demonstrated remarkable performance in time series forecasting. However, due to the partially-observed nature of real-world applications, solely focusing on the target of interest, so-called endogenous variables, is usually insufficient to guarantee accurate forecasting. Notably, a system is often recorded into multiple variables, where the exogenous variables can provide valuable external information for endogenous variables. Thus, unlike well-established multivariate or univariate forecasting paradigms that either treat all the variables equally or ignore exogenous information, this paper focuses on a more practical setting: time series forecasting with exogenous variables. We propose a novel approach, TimeXer, to ingest external information to enhance the forecasting of endogenous variables. With deftly designed embedding layers, TimeXer empowers the canonical Transformer with the ability to reconcile endogenous and exogenous information, where patch-wise self-attention and variate-wise cross-attention are used simultaneously. Moreover, global endogenous tokens are learned to effectively bridge the causal information underlying exogenous series into endogenous temporal patches. Experimentally, TimeXer achieves consistent state-of-the-art performance on twelve real-world forecasting benchmarks and exhibits notable generality and scalability. Code is available at this repository: https://github.com/thuml/TimeXer.
tl;dr: We propose GSDF, a dual-branch system that enhances rendering and reconstruction at the same time, leveraging the mutual geometry regularization and guidance between Gaussain primitives and neural surface.

Representing 3D scenes from multiview images remains a core challenge in computer vision and graphics, requiring both reliable rendering and reconstruction, which often conflicts due to the mismatched prioritization of image quality over precise underlying scene geometry. Although both neural implicit surfaces and explicit Gaussian primitives have advanced with neural rendering techniques, current methods impose strict constraints on density fields or primitive shapes, which enhances the affinity for geometric reconstruction at the sacrifice of rendering quality. To address this dilemma, we introduce GSDF, a dual-branch architecture combining 3D Gaussian Splatting (3DGS) and neural Signed Distance Fields (SDF). Our approach leverages mutual guidance and joint supervision during the training process to mutually enhance reconstruction and rendering. Specifically, our method guides the Gaussian primitives to locate near potential surfaces and accelerates the SDF convergence. This implicit mutual guidance ensures robustness and accuracy in both synthetic and real-world scenarios. Experimental results demonstrate that our method boosts the SDF optimization process to reconstruct more detailed geometry, while reducing floaters and blurry edge artifacts in rendering by aligning Gaussian primitives with the underlying geometry.
tl;dr: To mitigate cloud model storage overhead, we propose a novel lossless compression scheme FM-Delta to compress massive fine-tuned models stored in cloud, significantly saving cloud storage costs.

Pre-trained foundation models, particularly large language models, have achieved remarkable success and led to massive fine-tuned variants. These models are commonly fine-tuned locally and then uploaded by users to cloud platforms such as HuggingFace for secure storage. However, the huge model number and their billion-level parameters impose heavy storage overhead for cloud with limited resources. Our empirical and theoretical analysis reveals that most fine-tuned models in cloud have a small difference (delta) from their pre-trained models. To this end, we propose a novel lossless compression scheme FM-Delta specifically for storing massive fine-tuned models in cloud. FM-Delta maps fine-tuned and pre-trained model parameters into integers with the same bits, and entropy codes their integer delta. In this way, cloud only needs to store one uncompressed pre-trained model and other compressed fine-tuned models.
Extensive experiments have demonstrated that FM-Delta efficiently reduces cloud storage consumption for massive fine-tuned models by an average of around 50% with only negligible additional time in most end-to-end cases. For example, on up to 10 fine-tuned models in the GPT-NeoX-20B family, FM-Delta reduces the original storage requirement from 423GB to 205GB, significantly saving cloud storage costs.
1703. Neural Signed Distance Function Inference through Splatting 3D Gaussians Pulled on Zero-Level Set

It is vital to infer a signed distance function (SDF) for multi-view based surface reconstruction. 3D Gaussian splatting (3DGS) provides a novel perspective for volume rendering, and shows advantages in rendering efficiency and quality. Although 3DGS provides a promising neural rendering option, it is still hard to infer SDFs for surface reconstruction with 3DGS due to the discreteness, the sparseness, and the off-surface drift of 3D Gaussians. To resolve these issues, we propose a method that seamlessly merge 3DGS with the learning of neural SDFs. Our key idea is to more effectively constrain the SDF inference with the multi-view consistency. To this end, we dynamically align 3D Gaussians on the zero-level set of the neural SDF, and then render the aligned 3D Gaussians through the differentiable rasterization. Meanwhile, we update the neural SDF by pulling neighboring space to the pulled 3D Gaussians, which progressively refine the signed distance field near the surface. With both differentiable pulling and splatting, we jointly optimize 3D Gaussians and the neural SDF with both RGB and geometry constraints, which recovers more accurate, smooth, and complete surfaces with more geometry details. Our numerical and visual comparisons show our superiority over the state-of-the-art results on the widely used benchmarks.
tl;dr: Unified active 3D object detection framework based on submodular optimization.

3D object detection is fundamentally important for various emerging applications, including autonomous driving and robotics. A key requirement for training an accurate 3D object detector is the availability of a large amount of LiDAR-based point cloud data. Unfortunately, labeling point cloud data is extremely challenging, as accurate 3D bounding boxes and semantic labels are required for each potential object. This paper proposes a unified active 3D object detection framework, for greatly reducing the labeling cost of training 3D object detectors. Our framework is based on a novel formulation of submodular optimization, specifically tailored to the problem of active 3D object detection. In particular, we address two fundamental challenges associated with active 3D object detection: data imbalance and the need to cover the distribution of the data, including LiDAR-based point cloud data of varying difficulty levels. Extensive experiments demonstrate that our method achieves state-of-the-art performance with high computational efficiency compared to existing active learning methods. The code is available at [https://github.com/RuiyuM/STONE](https://github.com/RuiyuM/STONE)

Peptide design plays a pivotal role in therapeutics, allowing brand new possibility to leverage target binding sites that are previously undruggable. Most existing methods are either inefficient or only concerned with the target-agnostic design of 1D sequences. In this paper, we propose a generative model for full-atom Peptide design with Geometric LAtent Diffusion (PepGLAD) given the binding site. We first establish a benchmark consisting of both 1D sequences and 3D structures from Protein Data Bank (PDB) and literature for systematic evaluation. We then identify two major challenges of leveraging current diffusion-based models for peptide design: the full-atom geometry and the variable binding geometry. To tackle the first challenge, PepGLAD derives a variational autoencoder that first encodes full-atom residues of variable size into fixed-dimensional latent representations, and then decodes back to the residue space after conducting the diffusion process in the latent space. For the second issue, PepGLAD explores a receptor-specific affine transformation to convert the 3D coordinates into a shared standard space, enabling better generalization ability across different binding shapes. Experimental Results show that our method not only improves diversity and binding affinity significantly in the task of sequence-structure co-design, but also excels at recovering reference structures for binding conformation generation.
tl;dr: We propose a plugin to enhance the robust prediction capability of time series forecasting backbones in the real world.

Time series forecasting has played a pivotal role across various industries, including finance, transportation, energy, healthcare, and climate. Due to the abundant seasonal information they contain, timestamps possess the potential to offer robust global guidance for forecasting techniques. However, existing works primarily focus on local observations, with timestamps being treated merely as an optional supplement that remains underutilized. When data gathered from the real world is polluted, the absence of global information will damage the robust prediction capability of these algorithms. To address these problems, we propose a novel framework named GLAFF. Within this framework, the timestamps are modeled individually to capture the global dependencies. Working as a plugin, GLAFF adaptively adjusts the combined weights for global and local information, enabling seamless collaboration with any time series forecasting backbone. Extensive experiments conducted on nine real-world datasets demonstrate that GLAFF significantly enhances the average performance of widely used mainstream forecasting models by 12.5\%, surpassing the previous state-of-the-art method by 5.5\%.
tl;dr: Towards optimal communication bounds for the distributed expert problem under various scenarios

In this work, we study the experts problem in the distributed setting where an expert's cost needs to be aggregated across multiple servers. Our study considers various communication models such as the message-passing model and the broadcast model, along with multiple aggregation functions, such as summing and taking the $\ell_p$ norm of an expert's cost across servers. We propose the first communication-efficient protocols that achieve near-optimal regret in these settings, even against a strong adversary who can choose the inputs adaptively. Additionally, we give a conditional lower bound showing that the communication of our protocols is nearly optimal. Finally, we implement our protocols and demonstrate empirical savings on the HPO-B benchmarks.

The flexible and generalized nature of large language models has allowed for their application in a wide array of language-based domains.
Much like their human contemporaries, these models are capable of engaging in discussions and debates as a means of improving answer quality.
We first take a theoretical approach to analyzing debate and provide a framework through which debate can be mathematically examined.
Building on this framework, we provide several theoretical results for multi-agent debate.
In particular, we demonstrate that similar model capabilities, or similar model responses, can result in static debate dynamics where the debate procedure simply converges to the majority opinion.
When this majority opinion is the result of a common misconception (ingrained in the models through shared training data) debate is likely to converge to answers associated with that common misconception.
Using insights from our theoretical results we then propose three interventions which improve the efficacy of debate.
For each intervention, we provide theoretical results demonstrating how debate is improved.
We also demonstrate that these interventions result in better performance on four common benchmark tasks.

The $k$-sparse parity problem is a classical problem in computational complexity and algorithmic theory, serving as a key benchmark for understanding computational classes. In this paper, we solve the $k$-sparse parity problem with sign stochastic gradient descent, a variant of stochastic gradient descent (SGD) on two-layer fully-connected neural networks. We demonstrate that this approach can efficiently solve the $k$-sparse parity problem on a $d$-dimensional hypercube ($k\le O(\sqrt{d})$) with a sample complexity of $\tilde{O}(d^{k-1})$ using $2^{\Theta(k)}$ neurons, matching the established $\Omega(d^{k})$ lower bounds of Statistical Query (SQ) models. Our theoretical analysis begins by constructing a good neural network capable of correctly solving the $k$-parity problem. We then demonstrate how a trained neural network with sign SGD can effectively approximate this good network, solving the $k$-parity problem with small statistical errors. To the best of our knowledge, this is the first result that matches the SQ lower bound for solving $k$-sparse parity problem using gradient-based methods.

Adaptive methods are extremely popular in machine learning as they make learning rate tuning less expensive. This paper introduces a novel optimization algorithm named KATE, which presents a scale-invariant adaptation of the well-known AdaGrad algorithm. We prove the scale-invariance of KATE for the case of Generalized Linear Models. Moreover, for general smooth non-convex problems, we establish a convergence rate of $O((\log T)/\sqrt{T})$ for KATE, matching the best-known ones for AdaGrad and Adam. We also compare KATE to other state-of-the-art adaptive algorithms Adam and AdaGrad in numerical experiments with different problems, including complex machine learning tasks like image classification and text classification on real data. The results indicate that KATE consistently outperforms AdaGrad and matches/surpasses the performance of Adam in all considered scenarios.
1711. HDR-GS: Efficient High Dynamic Range Novel View Synthesis at 1000x Speed via Gaussian Splatting
tl;dr: This work is the first attempt to explore the potential of Gaussian splatting in 3D high dynamic range imaging

High dynamic range (HDR) novel view synthesis (NVS) aims to create photorealistic images from novel viewpoints using HDR imaging techniques. The rendered HDR images capture a wider range of brightness levels containing more details of the scene than normal low dynamic range (LDR) images. Existing HDR NVS methods are mainly based on NeRF. They suffer from long training time and slow inference speed. In this paper, we propose a new framework, High Dynamic Range Gaussian Splatting (HDR-GS), which can efficiently render novel HDR views and reconstruct LDR images with a user input exposure time. Specifically, we design a Dual Dynamic Range (DDR) Gaussian point cloud model that uses spherical harmonics to fit HDR color and employs an MLP-based tone-mapper to render LDR color. The HDR and LDR colors are then fed into two Parallel Differentiable Rasterization (PDR) processes to reconstruct HDR and LDR views. To establish the data foundation for the research of 3D Gaussian splatting-based methods in HDR NVS, we recalibrate the camera parameters and compute the initial positions for Gaussian point clouds. Comprehensive experiments show that HDR-GS surpasses the state-of-the-art NeRF-based method by 3.84 and 1.91 dB on LDR and HDR NVS while enjoying 1000$\times$ inference speed and only costing 6.3\% training time. Code and data are released at https://github.com/caiyuanhao1998/HDR-GS
tl;dr: We present a fair recommendation framework that balances platform revenue and item/user fairness in multi-sided platforms, along with a low-regret algorithm that ensures fair recommendations in an online setting where user data must be learned.

Today's online platforms heavily lean on algorithmic recommendations for bolstering user engagement and driving revenue. However, these recommendations can impact multiple stakeholders simultaneously---the platform, items (sellers), and users (customers)---each with their unique objectives, making it difficult to find the right middle ground that accommodates all stakeholders. To address this, we introduce a novel fair recommendation framework, Problem (FAIR), that flexibly balances multi-stakeholder interests via a constrained optimization formulation. We next explore Problem (FAIR) in a dynamic online setting where data uncertainty further adds complexity, and propose a low-regret algorithm FORM that concurrently performs real-time learning and fair recommendations, two tasks that are often at odds. Via both theoretical analysis and a numerical case study on real-world data, we demonstrate the efficacy of our framework and method in maintaining platform revenue while ensuring desired levels of fairness for both items and users.
tl;dr: We extend the study of the group action on the network weights from the group of permutation matrices to the group of monomial matrices by incorporating scaling symmetries.

Neural functional networks (NFNs) have recently gained significant attention due to their diverse applications, ranging from predicting network generalization and network editing to classifying implicit neural representation. Previous NFN designs often depend on permutation symmetries in neural networks' weights, which traditionally arise from the unordered arrangement of neurons in hidden layers. However, these designs do not take into account the weight scaling symmetries of $\operatorname{ReLU}$ networks, and the weight sign flipping symmetries of $\operatorname{sin}$ or $\operatorname{Tanh}$ networks. In this paper, we extend the study of the group action on the network weights from the group of permutation matrices to the group of monomial matrices by incorporating scaling/sign-flipping symmetries. Particularly, we encode these scaling/sign-flipping symmetries by designing our corresponding equivariant and invariant layers. We name our new family of NFNs the Monomial Matrix Group Equivariant Neural Functional Networks (Monomial-NFN). Because of the expansion of the symmetries, Monomial-NFN has much fewer independent trainable parameters compared to the baseline NFNs in the literature, thus enhancing the model's efficiency. Moreover, for fully connected and convolutional neural networks, we theoretically prove that all groups that leave these networks invariant while acting on their weight spaces are some subgroups of the monomial matrix group. We provide empirical evidences to demonstrate the advantages of our model over existing baselines, achieving competitive performance and efficiency. The code is publicly available at https://github.com/MathematicalAI-NUS/Monomial-NFN.
1714. Hierarchical Object-Aware Dual-Level Contrastive Learning for Domain Generalized Stereo Matching

Stereo matching algorithms that leverage end-to-end convolutional neural networks have recently demonstrated notable advancements in performance. However, a common issue is their susceptibility to domain shifts, hindering their ability in generalizing to diverse, unseen realistic domains. We argue that existing stereo matching networks overlook the importance of extracting semantically and structurally meaningful features. To address this gap, we propose an effective hierarchical object-aware dual-level contrastive learning (HODC) framework for domain generalized stereo matching. Our framework guides the model in extracting features that support semantically and structurally driven matching by segmenting objects at different scales and enhances correspondence between intra- and inter-scale regions from the left feature map to the right using dual-level contrastive loss. HODC can be integrated with existing stereo matching models in the training stage, requiring no modifications to the architecture. Remarkably, using only synthetic datasets for training, HODC achieves state-of-the-art generalization performance with various existing stereo matching network architectures, across multiple realistic datasets.
tl;dr: We add a neuromodulation-inspired signal to a low-rank RNN and show that it enhances performance and generalization on neuroscience and machine learning tasks.

A core aim in theoretical and systems neuroscience is to develop models which help us better understand biological intelligence.
Such models range broadly in both complexity and biological plausibility.
One widely-adopted example is task-optimized recurrent neural networks (RNNs), which have been used to generate hypotheses about how the brain’s neural dynamics may organize to accomplish tasks.
However, task-optimized RNNs typically have a fixed weight matrix representing the synaptic connectivity between neurons. From decades of neuroscience research, we know that synaptic weights are constantly changing, controlled in part by chemicals such as neuromodulators.
In this work we explore the computational implications of synaptic gain scaling, a form of neuromodulation, using task-optimized low-rank RNNs.
In our neuromodulated RNN (NM-RNN) model, a neuromodulatory subnetwork outputs a low-dimensional neuromodulatory signal that dynamically scales the low-rank recurrent weights of an output-generating RNN.
In empirical experiments, we find that the structured flexibility in the NM-RNN allows it to both train and generalize with a higher degree of accuracy than low-rank RNNs on a set of canonical tasks.
Additionally, via theoretical analyses we show how neuromodulatory gain scaling endows networks with gating mechanisms commonly found in artificial RNNs.
We end by analyzing the low-rank dynamics of trained NM-RNNs, to show how task computations are distributed.
tl;dr: We propose a framework for stable and transparent model without expensive training.

To foster trust in machine learning models, explanations must be faithful and stable for consistent insights. Existing relevant works rely on the $\ell_p$ distance for stability assessment, which diverges from human perception. Besides, existing adversarial training (AT) associated with intensive computations may lead to an arms race. To address these challenges, we introduce a novel metric to assess the stability of top-$k$ salient features. We introduce R2ET which trains for stable explanation by efficient and effective regularizer,
and analyze R2ET by multi-objective optimization to prove numerical and statistical stability of explanations. Moreover, theoretical connections between R2ET and certified robustness justify R2ET's stability in all attacks. Extensive experiments across various data modalities and model architectures show that R2ET achieves superior stability against stealthy attacks, and generalizes effectively across different explanation methods. The code can be found at https://github.com/ccha005/R2ET.
tl;dr: Our paper proposes to predict label distribution from ternary labels and demonstrates the effectiveness theoretically and methodologically.
Label distribution learning is a powerful learning paradigm to deal with label polysemy and has been widely applied in many practical tasks. A significant obstacle to the effective utilization of label distribution is the substantial expenses of accurate quantifying the label distributions. To tackle this challenge, label enhancement methods automatically infer label distributions from more easily accessible multi-label data based on binary annotations. However, the binary annotation of multi-label data requires experts to accurately assess whether each label can describe the instance, which may diminish the annotating efficiency and heighten the risk of erroneous annotation since the relationship between the label and the instance is unclear in many practical scenarios. Therefore, we propose to predict label distribution from ternary labels, allowing experts to annotate labels in a three-way annotation scheme. They can annotate the label as "$0$" indicating "uncertain relevant" if it is difficult to definitively determine whether the label can describe the instance, in addition to the binary annotation of "$1$" indicating "definitely relevant" and "$-1$" indicating "definitely irrelevant". Both the theoretical and methodological studies are conducted for the proposed learning paradigm. In the theoretical part, we conduct a quantitative comparison of approximation error between ternary and binary labels to elucidate the superiority of ternary labels over binary labels. In the methodological part, we propose a Categorical distribution with monotonicity and orderliness to model the mapping from label description degrees to ternary labels, which can serve as a loss function or as a probability distribution, allowing most existing label enhancement methods to be adapted to our task. Finally, we experimentally demonstrate the effectiveness of our proposal.

Vision-and-Language Navigation (VLN) requires an agent to dynamically explore environments following natural language.
The VLN agent, closely integrated into daily lives, poses a substantial threat to the security of privacy and property upon the occurrence of malicious behavior.
However, this serious issue has long been overlooked.
In this paper, we pioneer the exploration of an object-aware backdoored VLN, achieved by implanting object-aware backdoors during the training phase.
Tailored to the unique VLN nature of cross-modality and continuous decision-making, we propose a novel backdoored VLN paradigm: IPR Backdoor.
This enables the agent to act in abnormal behavior once encountering the object triggers during language-guided navigation in unseen environments, thereby executing an attack on the target scene.
Experiments demonstrate the effectiveness of our method in both physical and digital spaces across different VLN agents, as well as its robustness to various visual and textual variations. Additionally, our method also well ensures navigation performance in normal scenarios with remarkable stealthiness.
tl;dr: We develop statistical methods for detecting and identifying watermarked sub-strings generated from language models.

Watermarking is a technique that involves embedding nearly unnoticeable statistical signals within generated content to help trace its source. This work focuses on a scenario where an untrusted third-party user sends prompts to a trusted language model (LLM) provider, who then generates a text from their LLM with a watermark. This setup makes it possible for a detector to later identify the source of the text if the user publishes it. The user can modify the generated text by substitutions, insertions, or deletions. Our objective is to develop a statistical method to detect if a published text is LLM-generated from the perspective of a detector. We further propose a methodology to segment the published text into watermarked and non-watermarked sub-strings. The proposed approach is built upon randomization tests and change point detection techniques. We demonstrate that our method ensures Type I and Type II error control and can accurately identify watermarked sub-strings by finding the corresponding change point locations. To validate our technique, we apply it to texts generated by several language models with prompts extracted from Google's C4 dataset and obtain encouraging numerical results. We release all code publicly at https://github.com/doccstat/llm-watermark-cpd.

In this work we investigate the generalization performance of random feature ridge regression (RFRR). Our main contribution is a general deterministic equivalent for the test error of RFRR. Specifically, under a certain concentration property, we show that the test error is well approximated by a closed-form expression that only depends on the feature map eigenvalues. Notably, our approximation guarantee is non-asymptotic, multiplicative, and independent of the feature map dimension---allowing for infinite-dimensional features. We expect this deterministic equivalent to hold broadly beyond our theoretical analysis, and we empirically validate its predictions on various real and synthetic datasets. As an application, we derive sharp excess error rates under standard power-law assumptions of the spectrum and target decay. In particular, we provide a tight result for the smallest number of features achieving optimal minimax error rate.
tl;dr: This study highlights the incompleteness of previously proposed score matching estimators for point processes. In addressing this issue, we introduce a novel score matching estimator for point processes.

Score matching estimators for point processes have gained widespread attention in recent years because they do not require the calculation of intensity integrals, thereby effectively addressing the computational challenges in maximum likelihood estimation (MLE). Some existing works have proposed score matching estimators for point processes. However, this work demonstrates that the incompleteness of the estimators proposed in those works renders them applicable only to specific problems, and they fail for more general point processes. To address this issue, this work introduces the weighted score matching estimator to point processes. Theoretically, we prove the consistency of the estimator we propose. Experimental results indicate that our estimator accurately estimates model parameters on synthetic data and yields results consistent with MLE on real data. In contrast, existing score matching estimators fail to perform effectively. Codes are publicly available at \url{https://github.com/KenCao2007/WSM_TPP}.

We consider the dataset valuation problem, that is the problem of quantifying the incremental gain, to some relevant pre-defined utility of a machine learning task, of aggregating an individual dataset to others.
The Shapley value is a natural tool to perform dataset valuation due to its formal axiomatic justification, which can be combined with Monte Carlo integration to overcome the computational tractability challenges. Such generic approximation methods, however, remain expensive in some cases. In this paper, we exploit the knowledge about the structure of the dataset valuation problem to devise more efficient Shapley value estimators. We propose a novel approximation, referred to as discrete uniform Shapley, which is expressed as an expectation under a discrete uniform distribution with support of reasonable size. We justify the relevancy of the proposed framework via asymptotic and non-asymptotic theoretical guarantees and illustrate its benefits via an extensive set of numerical experiments.
1723. Addressing Asynchronicity in Clinical Multimodal Fusion via Individualized Chest X-ray Generation
tl;dr: We propose DDL-CXR to address the asynchronicity in clinical multimodal fusion by generating individualized up-to-date CXR images. Cross-modal interactions are captured by the generation process, leading to improved prediction performance.

Integrating multi-modal clinical data, such as electronic health records (EHR) and chest X-ray images (CXR), is particularly beneficial for clinical prediction tasks. However, in a temporal setting, multi-modal data are often inherently asynchronous. EHR can be continuously collected but CXR is generally taken with a much longer interval due to its high cost and radiation dose. When clinical prediction is needed, the last available CXR image might have been outdated, leading to suboptimal predictions. To address this challenge, we propose DDL-CXR, a method that dynamically generates an up-to-date latent representation of the individualized CXR images. Our approach leverages latent diffusion models for patient-specific generation strategically conditioned on a previous CXR image and EHR time series, providing information regarding anatomical structures and disease progressions, respectively. In this way, the interaction across modalities could be better captured by the latent CXR generation process, ultimately improving the prediction performance. Experiments using MIMIC datasets show that the proposed model could effectively address asynchronicity in multimodal fusion and consistently outperform existing methods.
tl;dr: We develop a novel inverse soft-Q learning for offline imitation learning with expert and non-expert demonstrations.

We focus on offline imitation learning (IL), which aims to mimic an expert's behavior using demonstrations without any interaction with the environment. One of the main challenges in offline IL is the limited support of expert demonstrations, which typically cover only a small fraction of the state-action space. While it may not be feasible to obtain numerous expert demonstrations, it is often possible to gather a larger set of sub-optimal demonstrations. For example, in treatment optimization problems, there are varying levels of doctor treatments available for different chronic conditions. These range from treatment specialists and experienced general practitioners to less experienced general practitioners. Similarly, when robots are trained to imitate humans in routine tasks, they might learn from individuals with different levels of expertise and efficiency.
In this paper, we propose an offline IL approach that leverages the larger set of sub-optimal demonstrations while effectively mimicking expert trajectories. Existing offline IL methods based on behavior cloning or distribution matching often face issues such as overfitting to the limited set of expert demonstrations or inadvertently imitating sub-optimal trajectories from the larger dataset. Our approach, which is based on inverse soft-Q learning, learns from both expert and sub-optimal demonstrations. It assigns higher importance (through learned weights) to aligning with expert demonstrations and lower importance to aligning with sub-optimal ones. A key contribution of our approach, called SPRINQL, is transforming the offline IL problem into a convex optimization over the space of Q functions. Through comprehensive experimental evaluations, we demonstrate that the SPRINQL algorithm achieves state-of-the-art (SOTA) performance on offline IL benchmarks. Code is available at https://github.com/hmhuy0/SPRINQL .
tl;dr: We study a path connectivity structure of games that is relevant to strategic dynamics and iterative learning algorithms in multi-agent systems. We prove that paths to equilibrium exist in all normal-form games.

In multi-agent reinforcement learning (MARL) and game theory, agents repeatedly interact and revise their strategies as new data arrives, producing a sequence of strategy profiles. This paper studies sequences of strategies satisfying a pairwise constraint inspired by policy updating in reinforcement learning, where an agent who is best responding in one period does not switch its strategy in the next period. This constraint merely requires that optimizing agents do not switch strategies, but does not constrain the non-optimizing agents in any way, and thus allows for exploration. Sequences with this property are called satisficing paths, and arise naturally in many MARL algorithms. A fundamental question about strategic dynamics is such: for a given game and initial strategy profile, is it always possible to construct a satisficing path that terminates at an equilibrium? The resolution of this question has implications about the capabilities or limitations of a class of MARL algorithms. We answer this question in the affirmative for normal-form games. Our analysis reveals a counterintuitive insight that suboptimal, and perhaps even reward deteriorating, strategic updates are key to driving play to equilibrium along a satisficing path.
1726. Thompson Sampling For Combinatorial Bandits: Polynomial Regret and Mismatched Sampling Paradox
tl;dr: We propose a modified version of Thompson sampling for combinatorial bandits, the first that does not exhibit exponential regret.

We consider Thompson Sampling (TS) for linear combinatorial semi-bandits and subgaussian rewards. We propose the first known TS whose finite-time regret does not scale exponentially with the dimension of the problem. We further show the mismatched sampling paradox: A learner who knows the rewards distributions and samples from the correct posterior distribution can perform exponentially worse than a learner who does not know the rewards and simply samples from a well-chosen Gaussian posterior. The code used to generate the experiments is available at https://github.com/RaymZhang/CTS-Mismatched-Paradox
tl;dr: The first work that successfully reduces both gradients and weights to nearly 4 bits without compromising training accuracy in distributed training of large language models.

Recent years have witnessed a clear trend towards language models with an ever-increasing number of parameters, as well as the growing training overhead and memory usage. Distributed training, particularly through Sharded Data Parallelism (ShardedDP) which partitions optimizer states among workers, has emerged as a crucial technique to mitigate training time and memory usage. Yet, a major challenge in the scalability of ShardedDP is the intensive communication of weights and gradients. While compression techniques can alleviate this issue, they often result in worse accuracy. Driven by this limitation, we propose SDP4Bit (Toward 4Bit Communication Quantization in Sharded Data Parallelism for LLM Training), which effectively reduces the communication of weights and gradients to nearly 4 bits via two novel techniques: quantization on weight differences, and two-level gradient smooth quantization. Furthermore, SDP4Bit presents an algorithm-system co-design with runtime optimization to minimize the computation overhead of compression. Additional to the theoretical guarantees of convergence, we empirically evaluate the accuracy of SDP4Bit on the pre-training of GPT models with up to 6.7 billion parameters, and the results demonstrate a negligible impact on training loss. Furthermore, speed experiments show that SDP4Bit achieves up to 4.08× speedup in end-to-end throughput on a scale of 128 GPUs.
tl;dr: We theoretically study the direct relationship between initial weights, number of training epochs and the model’s adversarial vulnerability, offering new insights into adversarial robustness beyond conventional defense mechanisms.

Graph Neural Networks (GNNs) have demonstrated remarkable performance across a spectrum of graph-related tasks, however concerns persist regarding their vulnerability to adversarial perturbations. While prevailing defense strategies focus primarily on pre-processing techniques and adaptive message-passing schemes, this study delves into an under-explored dimension: the impact of weight initialization and associated hyper-parameters, such as training epochs, on a model’s robustness.
We introduce a theoretical framework bridging the connection between initialization strategies and a network's resilience to adversarial perturbations. Our analysis reveals a direct relationship between initial weights, number of training epochs and the model’s vulnerability, offering new insights into adversarial robustness beyond conventional defense mechanisms. While our primary focus is on GNNs, we extend our theoretical framework, providing a general upper-bound applicable to Deep Neural Networks.
Extensive experiments, spanning diverse models and real-world datasets subjected to various adversarial attacks, validate our findings. We illustrate that selecting appropriate initialization not only ensures performance on clean datasets but also enhances model robustness against adversarial perturbations, with observed gaps of up to 50\% compared to alternative initialization approaches.
tl;dr: We derive a simple formula for training dynamics of linear networks that not only unifies the lazy and balanced dynamics, but reveals the existence of mixed dynamics.

The training dynamics of linear networks are well studied in two distinct
setups: the lazy regime and balanced/active regime, depending on the
initialization and width of the network. We provide a surprisingly
simple unifying formula for the evolution of the learned matrix that
contains as special cases both lazy and balanced regimes but also
a mixed regime in between the two. In the mixed regime, a part of
the network is lazy while the other is balanced. More precisely the
network is lazy along singular values that are below a certain threshold
and balanced along those that are above the same threshold. At initialization,
all singular values are lazy, allowing for the network to align itself
with the task, so that later in time, when some of the singular value
cross the threshold and become active they will converge rapidly (convergence
in the balanced regime is notoriously difficult in the absence of
alignment). The mixed regime is the `best of both worlds': it converges
from any random initialization (in contrast to balanced dynamics which
require special initialization), and has a low rank bias (absent in
the lazy dynamics). This allows us to prove an almost complete phase
diagram of training behavior as a function of the variance at initialization
and the width, for a MSE training task.

Recent works have extended notions of feature importance to semantic concepts that are inherently interpretable to the users interacting with a black-box predictive model. Yet, precise statistical guarantees such as false positive rate and false discovery rate control are needed to communicate findings transparently, and to avoid unintended consequences in real-world scenarios. In this paper, we formalize the global (i.e., over a population) and local (i.e., for a sample) statistical importance of semantic concepts for the predictions of opaque models by means of conditional independence, which allows for rigorous testing. We use recent ideas of sequential kernelized independence testing to induce a rank of importance across concepts, and we showcase the effectiveness and flexibility of our framework on synthetic datasets as well as on image classification using several vision-language models.
tl;dr: We leverage tools from tropical geometry to establish several new results about ReLU MPNNs (including commonly used architectures).

Graph neural networks (GNNs) have been analyzed from multiple perspectives, including the WL-hierarchy, which exposes limits on their expressivity to distinguish graphs. However, characterizing the class of functions that they learn has remained unresolved. We address this fundamental question for message passing GNNs under ReLU activations, i.e., the de-facto choice for most GNNs.
We first show that such GNNs learn tropical rational signomial maps or continuous piecewise linear functions, establishing an equivalence with feedforward networks (FNNs). We then elucidate the role of the choice of aggregation and update functions, and derive the first general upper and lower bounds on the geometric complexity (i.e., the number of linear regions), establishing new results for popular architectures such as GraphSAGE and GIN. We also introduce and theoretically analyze several new architectures to illuminate the relative merits of the feedforward and the message passing layers, and the tradeoffs involving depth and number of trainable parameters. Finally, we also characterize the decision boundary for node and graph classification tasks.

Diffusion models have obtained substantial progress in image-to-video generation. However, in this paper, we find that these models tend to generate videos with less motion than expected. We attribute this to the issue called conditional image leakage, where the image-to-video diffusion models (I2V-DMs) tend to over-rely on the conditional image at large time steps. We further address this challenge from both inference and training aspects. First, we propose to start the generation process from an earlier time step to avoid the unreliable large-time steps of I2V-DMs, as well as an initial noise distribution with optimal analytic expressions (Analytic-Init) by minimizing the KL divergence between it and the actual marginal distribution to bridge the training-inference gap. Second, we design a time-dependent noise distribution (TimeNoise) for the conditional image during training, applying higher noise levels at larger time steps to disrupt it and reduce the model's dependency on it. We validate these general strategies on various I2V-DMs on our collected open-domain image benchmark and the UCF101 dataset. Extensive results show that our methods outperform baselines by producing higher motion scores with lower errors while maintaining image alignment and temporal consistency, thereby yielding superior overall performance and enabling more accurate motion control. The project page: \url{https://cond-image-leak.github.io/}.

Existing open-set learning methods consider only the single-layer labels of objects and strictly assume no overlap between the training and testing sets, leading to contradictory optimization for superposed categories. In this paper, we introduce a more practical Semi-Open Environment setting for open-set 3D object retrieval with hierarchical labels, in which the training and testing set share a partial label space for coarse categories but are completely disjoint from fine categories. We propose the Hypergraph-Based Hierarchical Equilibrium Representation (HERT) framework for this task. Specifically, we propose the Hierarchical Retrace Embedding (HRE) module to overcome the global disequilibrium of unseen categories by fully leveraging the multi-level category information. Besides, tackling the feature overlap and class confusion problem, we perform the Structured Equilibrium Tuning (SET) module to utilize more equilibrial correlations among objects and generalize to unseen categories, by constructing a superposed hypergraph based on the local coherent and global entangled correlations. Furthermore, we generate four semi-open 3DOR datasets with multi-level labels for benchmarking. Results demonstrate that the proposed method can effectively generate the hierarchical embeddings of 3D objects and generalize them towards semi-open environments.

We explore the potential of self-play training for large language models (LLMs) in a two-player adversarial language game called Adversarial Taboo. In this game, an attacker and a defender communicate around a target word only visible to the attacker. The attacker aims to induce the defender to speak the target word unconsciously, while the defender tries to infer the target word from the attacker's utterances. To win the game, both players must have sufficient knowledge about the target word and high-level reasoning ability to infer and express in this information-reserved conversation. Hence, we are curious about whether LLMs' reasoning ability can be further enhanced by Self-Playing this Adversarial language Game (SPAG). With this goal, we select several open-source LLMs and let each act as the attacker and play with a copy of itself as the defender on an extensive range of target words. Through reinforcement learning on the game outcomes, we observe that the LLMs' performances uniformly improve on a broad range of reasoning benchmarks. Furthermore, iteratively adopting this self-play process can continuously promote LLMs' reasoning abilities. The code is available at https://github.com/Linear95/SPAG.
tl;dr: We propose NeuralSteiner, a learning-based method to optimize overflow and wirelength simultaneously for global routing problem in chip design.

Global routing plays a critical role in modern chip design. The routing paths generated by global routers often form a rectilinear Steiner tree (RST). Recent advances from the machine learning community have shown the power of learning-based route generation; however, the yielded routing paths by the existing approaches often suffer from considerable overflow, thus greatly hindering their application in practice.
We propose NeuralSteiner, an accurate approach to overflow-avoiding global routing in chip design. The key idea of NeuralSteiner approach is to learn Steiner trees: we first predict the locations of highly likely Steiner points by adopting a neural network considering full-net spatial and overflow information, then select appropriate points by running a graph-based post-processing algorithm, and finally connect these points with the input pins to yield overflow-avoiding RSTs. NeuralSteiner offers two advantages over previous learning-based models. First, by using the learning scheme, NeuralSteiner ensures the connectivity of generated routes while significantly reducing congestion. Second, NeuralSteiner can effectively scale to large nets and transfer to unseen chip designs without any modifications or fine-tuning. Extensive experiments over public large-scale benchmarks reveal that, compared with the state-of-the-art deep generative methods, NeuralSteiner achieves up to a 99.8\% reduction in overflow while speeding up the generation and maintaining a slight wirelength loss within only 1.8\%.
tl;dr: We evaluate steering vectors on over 100 datasets, finding that they work unreliably in-distribution and sometimes misgeneralise out-of-distribution.

Steering vectors (SVs) are a new approach to efficiently adjust language model behaviour at inference time by intervening on intermediate model activations. They have shown promise in terms of improving both capabilities and model alignment. However, the reliability and generalisation properties of this approach are unknown. In this work, we rigorously investigate these properties, and show that steering vectors have substantial limitations both in- and out-of-distribution. In-distribution, steerability is highly variable across different inputs. Depending on the concept, spurious biases can substantially contribute to how effective steering is for each input, presenting a challenge for the widespread use of steering vectors. Out-of-distribution, while steering vectors often generalise well, for several concepts they are brittle to reasonable changes in the prompt, resulting in them failing to generalise well. Overall, our findings show that while steering can work well in the right circumstances, there remain many technical difficulties of applying steering vectors to guide models' behaviour at scale.
tl;dr: The deja vu memorization test measures training data memorization, but is inefficient because it involves training another similar model. This work provides a simpler, more efficient way to carry out the test.

Recent research has shown that representation learning models may accidentally memorize their training data. For example, the déjà vu method shows that for certain representation learning models and training images, it is sometimes possible to correctly predict the foreground label given only the representation of he background – better than through dataset-level correlations. However, their measurement method requires training two models – one to estimate dataset-level correlations and the other to estimate memorization. This multiple model setup becomes infeasible for large open-source models. In this work, we propose alter native simple methods to estimate dataset-level correlations, and show that these can be used to approximate an off-the-shelf model’s memorization ability without any retraining. This enables, for the first time, the measurement of memorization in pre-trained open-source image representation and vision-language models. Our results show that different ways of measuring memorization yield very similar aggregate results. We also find that open-source models typically have lower aggregate memorization than similar models trained on a subset of the data. The code is available both for vision (https://github.com/facebookresearch/DejaVuOSS) and vision language (https://github.com/facebookresearch/VLMDejaVu) models.
tl;dr: We propose a novel training objective and method designed to promote consistent model performance irrespective of spurious correlations.

Models trained with empirical risk minimization (ERM) are prone to be biased towards spurious correlations between target labels and bias attributes, which leads to poor performance on data groups lacking spurious correlations. It is particularly challenging to address this problem when access to bias labels is not permitted. To mitigate the effect of spurious correlations without bias labels, we first introduce a novel training objective designed to robustly enhance model performance across all data samples, irrespective of the presence of spurious correlations. From this objective, we then derive a debiasing method, Disagreement Probability based Resampling for debiasing (DPR), which does not require bias labels. DPR leverages the disagreement between the target label and the prediction of a biased model to identify bias-conflicting samples—those without spurious correlations—and upsamples them according to the disagreement probability. Empirical evaluations on multiple benchmarks demonstrate that DPR achieves state-of-the-art performance over existing baselines that do not use bias labels. Furthermore, we provide a theoretical analysis that details how DPR reduces dependency on spurious correlations.

Generative models have shown great promise in generating 3D geometric systems, which is a fundamental problem in many natural science domains such as molecule and protein design. However, existing approaches only operate on static structures, neglecting the fact that physical systems are always dynamic in nature. In this work, we propose geometric trajectory diffusion models (GeoTDM), the first diffusion model for modeling the temporal distribution of 3D geometric trajectories. Modeling such distribution is challenging as it requires capturing both the complex spatial interactions with physical symmetries and temporal correspondence encapsulated in the dynamics. We theoretically justify that diffusion models with equivariant temporal kernels can lead to density with desired symmetry, and develop a novel transition kernel leveraging SE(3)-equivariant spatial convolution and temporal attention. Furthermore, to induce an expressive trajectory distribution for conditional generation, we introduce a generalized learnable geometric prior into the forward diffusion process to enhance temporal conditioning. We conduct extensive experiments on both unconditional and conditional generation in various scenarios, including physical simulation, molecular dynamics, and pedestrian motion. Empirical results on a wide suite of metrics demonstrate that GeoTDM can generate realistic geometric trajectories with significantly higher quality.
tl;dr: A dual-stage low-bit post-training quantization algorithm for image super-resolution

Low-bit quantization has become widespread for compressing image super-resolution (SR) models for edge deployment, which allows advanced SR models to enjoy compact low-bit parameters and efficient integer/bitwise constructions for storage compression and inference acceleration, respectively. However, it is notorious that low-bit quantization degrades the accuracy of SR models compared to their full-precision (FP) counterparts. Despite several efforts to alleviate the degradation, the transformer-based SR model still suffers severe degradation due to its distinctive activation distribution. In this work, we present a dual-stage low-bit post-training quantization (PTQ) method for image super-resolution, namely 2DQuant, which achieves efficient and accurate SR under low-bit quantization. The proposed method first investigates the weight and activation and finds that the distribution is characterized by coexisting symmetry and asymmetry, long tails. Specifically, we propose Distribution-Oriented Bound Initialization (DOBI), using different searching strategies to search a coarse bound for quantizers. To obtain refined quantizer parameters, we further propose Distillation Quantization Calibration (DQC), which employs a distillation approach to make the quantized model learn from its FP counterpart. Through extensive experiments on different bits and scaling factors, the performance of DOBI can reach the state-of-the-art (SOTA) while after stage two, our method surpasses existing PTQ in both metrics and visual effects. 2DQuant gains an increase in PSNR as high as 4.52dB on Set5 (x2) compared with SOTA when quantized to 2-bit and enjoys a 3.60x compression ratio and 5.08x speedup ratio. The code and models are available at https://github.com/Kai-Liu001/2DQuant.
1741. Fast Graph Sharpness-Aware Minimization for Enhancing and Accelerating Few-Shot Node Classification

Graph Neural Networks (GNNs) have shown superior performance in node classification. However, GNNs perform poorly in the Few-Shot Node Classification (FSNC) task that requires robust generalization to make accurate predictions for unseen classes with limited labels. To tackle the challenge, we propose the integration of Sharpness-Aware Minimization (SAM)--a technique designed to enhance model generalization by finding a flat minimum of the loss landscape--into GNN training. The standard SAM approach, however, consists of two forward-backward steps in each training iteration, doubling the computational cost compared to the base optimizer (e.g., Adam). To mitigate this drawback, we introduce a novel algorithm, Fast Graph Sharpness-Aware Minimization (FGSAM), that integrates the rapid training of Multi-Layer Perceptrons (MLPs) with the superior performance of GNNs. Specifically, we utilize GNNs for parameter perturbation while employing MLPs to minimize the perturbed loss so that we can find a flat minimum with good generalization more efficiently. Moreover, our method reutilizes the gradient from the perturbation phase to incorporate graph topology into the minimization process at almost zero additional cost. To further enhance training efficiency, we develop FGSAM+ that executes exact perturbations periodically. Extensive experiments demonstrate that our proposed algorithm outperforms the standard SAM with lower computational costs in FSNC tasks. In particular, our FGSAM+ as a SAM variant offers a faster optimization than the base optimizer in most cases. In addition to FSNC, our proposed methods also demonstrate competitive performance in the standard node classification task for heterophilic graphs, highlighting the broad applicability.
tl;dr: We show that polylogarithmic-depth constant-width GNNs are sufficient to solve packing and covering LPs.

Graph neural networks (GNNs) have recently emerged as powerful tools for addressing complex optimization problems. It has been theoretically demonstrated that GNNs can universally approximate the solution mapping functions of linear programming (LP) problems. However, these theoretical results typically require GNNs to have large parameter sizes. Conversely, empirical experiments have shown that relatively small GNNs can solve LPs effectively, revealing a significant discrepancy between theoretical predictions and practical observations. In this work, we aim to bridge this gap by providing a theoretical foundation for the effectiveness of small-size GNNs. We prove that polylogarithmic-depth, constant-width GNNs are sufficient to solve packing and covering LPs, two widely used classes of LPs. Our proof leverages the capability of GNNs to simulate a variant of the gradient descent algorithm on a carefully selected potential function. Additionally, we introduce a new GNN architecture, termed GD-Net. Experimental results demonstrate that GD-Net significantly outperforms conventional GNN structures while using fewer parameters.
tl;dr: Informative soft labels is the key behind the success of dataset distillation methods.

Data *quality* is a crucial factor in the performance of machine learning models, a principle that dataset distillation methods exploit by compressing training datasets into much smaller counterparts that maintain similar downstream performance. Understanding how and why data distillation methods work is vital not only for improving these methods but also for revealing fundamental characteristics of "good” training data. However, a major challenge in achieving this goal is the observation that distillation approaches, which rely on sophisticated but mostly disparate methods to generate synthetic data, have little in common with each other. In this work, we highlight a largely overlooked aspect common to most of these methods: the use of soft (probabilistic) labels. Through a series of ablation experiments, we study the role of soft labels in depth. Our results reveal that the main factor explaining the performance of state-of-the-art distillation methods is not the specific techniques used to generate synthetic data but rather the use of soft labels. Furthermore, we demonstrate that not all soft labels are created equal; they must contain *structured information* to be beneficial. We also provide empirical scaling laws that characterize the effectiveness of soft labels as a function of images-per-class in the distilled dataset and establish an empirical Pareto frontier for data-efficient learning. Combined, our findings challenge conventional wisdom in dataset distillation, underscore the importance of soft labels in learning, and suggest new directions for improving distillation methods. Code for all experiments is available at https://github.com/sunnytqin/no-distillation.

Semi-supervised learning (SSL) seeks to utilize unlabeled data to overcome the limited amount of labeled data and improve model performance. However, many SSL methods typically struggle in real-world scenarios, particularly when there is a large number of irrelevant instances in the unlabeled data that do not belong to any class in the labeled data. Previous approaches often downweight instances from irrelevant classes to mitigate the negative impact of class distribution mismatch on model training. However, by discarding irrelevant instances, they may result in the loss of valuable information such as invariance, regularity, and diversity within the data. In this paper, we propose a data-centric generative augmentation approach that leverages a diffusion model to enrich labeled data using both labeled and unlabeled samples. A key challenge is extracting the diversity inherent in the unlabeled data while mitigating the generation of samples irrelevant to the labeled data. To tackle this issue, we combine diffusion model training with a discriminator that identifies and reduces the impact of irrelevant instances. We also demonstrate that such a trained diffusion model can even convert an irrelevant instance into a relevant one, yielding highly effective synthetic data for training. Through a comprehensive suite of experiments, we show that our data augmentation approach significantly enhances the performance of SSL methods, especially in the presence of class distribution mismatch.
tl;dr: We initiate a comprehensive study of existing multicalibration post-processing algorithms to compare how they fare against ERM and traditional calibration methods.

Calibration is a well-studied property of predictors which guarantees meaningful uncertainty estimates. Multicalibration is a related notion --- originating in algorithmic fairness --- which requires predictors to be simultaneously calibrated over a potentially complex and overlapping collection of protected subpopulations (such as groups defined by ethnicity, race, or income). We conduct the first comprehensive study evaluating the usefulness of multicalibration post-processing across a broad set of tabular, image, and language datasets for models spanning from simple decision trees to 90 million parameter fine-tuned LLMs. Our findings can be summarized as follows: (1) models which are calibrated out of the box tend to be relatively multicalibrated without any additional post-processing; (2) multicalibration can help inherently uncalibrated models and also large vision and language models; and (3) traditional calibration measures may sometimes provide multicalibration implicitly. More generally, we also distill many independent observations which may be useful for practical and effective applications of multicalibration post-processing in real-world contexts.
tl;dr: We present a statistical method that aims to detect contamination in language models as artificially inflated and non-generalizing benchmark performance.

Public benchmarks play an essential role in the evaluation of large language models. However, data contamination can lead to inflated performance, rendering them unreliable for model comparison. It is therefore crucial to detect contamination and estimate its impact on measured performance. Unfortunately, existing detection methods can be easily evaded and fail to quantify contamination. To overcome these limitations, we propose a novel definition of *contamination as artificially inflated and non-generalizing benchmark performance* instead of the inclusion of benchmark samples in the training data. This perspective enables us to detect *any* model with inflated performance, i.e., performance that does not generalize to rephrased samples, synthetic samples from the same distribution, or different benchmarks for the same task. Based on this insight, we develop ConStat, a statistical method that reliably detects and quantifies contamination by comparing performance between a primary and reference benchmark relative to a set of reference models. We demonstrate the effectiveness of ConStat in an extensive evaluation of diverse model architectures, benchmarks, and contamination scenarios and find high levels of contamination in multiple popular models including Mistral, Llama, Yi, and the top-3 Open LLM Leaderboard models.
tl;dr: This paper proposes a novel penalty-based formulation to solve simple bilevel problems with lower complexity results.

This paper investigates simple bilevel optimization problems where we minimize a convex upper-level objective over the optimal solution set of a convex lower-level objective. Existing methods for such problems either only guarantee asymptotic convergence, have slow sublinear rates, or require strong assumptions. To address these challenges, we propose a penalization framework that delineates the relationship between approximate solutions of the original problem and its reformulated counterparts. This framework accommodates varying assumptions regarding smoothness and convexity, enabling the application of specific methods with different complexity results.
Specifically, when both upper- and lower-level objectives are composite convex functions, under an $\alpha$-Hölderian error bound condition and certain mild assumptions, our algorithm attains an $(\epsilon,\epsilon^{\beta})$-optimal solution of the original problem for any $\beta> 0$ within $\mathcal{O}\left(\sqrt{{1}/{\epsilon^{\max\\{\alpha,\beta\\}}}}\right)$ iterations. The result can be improved further if the smooth part of the upper-level objective is strongly convex. We also establish complexity results when the upper- and lower-level objectives are general nonsmooth functions. Numerical experiments demonstrate the effectiveness of our algorithms.
tl;dr: We propose a new architecture and dataset for jointly modelling gaze following and social gaze prediction

Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed models that can handle only one person at a time and are static, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. It comprises (i) a temporal, transformer-based architecture that, in addition to frame tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, built from multiple gaze following and social gaze datasets by extending and validating head detections and tracks, and unifying annotation types. We demonstrate that our model can address and benefit from training on all tasks jointly, achieving state-of-the-art results for multi-person gaze following and social gaze prediction. Our annotations and code will be made publicly available.

Bayesian optimization is an effective technique for black-box optimization, but its applicability is typically limited to low-dimensional and small-budget problems due to the cubic complexity of computing the Gaussian process (GP) surrogate. While various approximate GP models have been employed to scale Bayesian optimization to larger sample sizes, most suffer from overly-smooth estimation and focus primarily on problems that allow for large online samples. In this work, we argue that Bayesian optimization algorithms with sparse GPs can more efficiently allocate their representational power to relevant regions of the search space. To achieve this, we propose focalized GP, which leverages a novel variational loss function to achieve stronger local prediction, as well as FocalBO, which hierarchically optimizes the focalized GP acquisition function over progressively smaller search spaces. Experimental results demonstrate that FocalBO can efficiently leverage large amounts of offline and online data to achieve state-of-the-art performance on robot morphology design and to control a 585-dimensional musculoskeletal system.

Although recent efforts have extended Neural Radiance Field (NeRF) into LiDAR point cloud synthesis, the majority of existing works exhibit a strong dependence on precomputed poses. However, point cloud registration methods struggle to achieve precise global pose estimation, whereas previous pose-free NeRFs overlook geometric consistency in global reconstruction. In light of this, we explore the geometric insights of point clouds, which provide explicit registration priors for reconstruction. Based on this, we propose Geometry guided Neural LiDAR Fields (GeoNLF), a hybrid framework performing alternately global neural reconstruction and pure geometric pose optimization. Furthermore, NeRFs tend to overfit individual frames and easily get stuck in local minima under sparse-view inputs. To tackle this issue, we develop a selective-reweighting strategy and introduce geometric constraints for robust optimization. Extensive experiments on NuScenes and KITTI-360 datasets demonstrate the superiority of GeoNLF in both novel view synthesis and multi-view registration of low-frequency large-scale point clouds.
tl;dr: Traditional persistent homology and its standard extensions fail on high-dimensional data, but persistent homology with spectral distances works well.

Persistent homology is a popular computational tool for analyzing the topology of point clouds, such as the presence of loops or voids. However, many real-world datasets with low intrinsic dimensionality reside in an ambient space of much higher dimensionality. We show that in this case traditional persistent homology becomes very sensitive to noise and fails to detect the correct topology. The same holds true for existing refinements of persistent homology. As a remedy, we find that spectral distances on the k-nearest-neighbor graph of the data, such as diffusion distance and effective resistance, allow to detect the correct topology even in the presence of high-dimensional noise. Moreover, we derive a novel closed-form formula for effective resistance, and describe its relation to diffusion distances. Finally, we apply these methods to high-dimensional single-cell RNA-sequencing data and show that spectral distances allow robust detection of cell cycle loops.

Vision-language navigation (VLN) requires an agent to execute actions following human instructions. Existing VLN models are optimized through expert demonstrations by supervised behavioural cloning or incorporating manual reward engineering. While straightforward, these efforts overlook the accumulation of errors in the Markov decision process, and struggle to match the distribution of the expert policy. Going beyond this, we propose an Energy-based Navigation Policy (ENP) to model the joint state-action distribution using an energy-based model. At each step, low energy values correspond to the state-action pairs that the expert is most likely to perform, and vice versa. Theoretically, the optimization objective is equivalent to minimizing the forward divergence between the occupancy measure of the expert and ours. Consequently, ENP learns to globally align with the expert policy by maximizing the likelihood of the actions and modeling the dynamics of the navigation states in a collaborative manner. With a variety of VLN architectures, ENP achieves promising performances on R2R, REVERIE, RxR, and R2R-CE, unleashing the power of existing VLN models.
1753. A theoretical design of concept sets: improving the predictability of concept bottleneck models
tl;dr: We present a theoretical analysis of Concept Bottleneck Models, which motivates a principled generation method for concept sets. We empirically verify its impact on CBMs' sample efficiency and robustness.

Concept-based learning, a promising approach in machine learning, emphasizes the value of high-level representations called concepts. However, despite growing interest in concept-bottleneck models (CBMs), there is a lack of clear understanding regarding the properties of concept sets and their impact on model performance. In this work, we define concepts within the machine learning context, highlighting their core properties: 'expressiveness' and 'model-aware inductive bias', and we make explicit the underlying assumption of CBMs. We establish theoretical results for concept-bottleneck models (CBMs), revealing how these properties guide the design of concept sets that optimize model performance. Specifically, we demonstrate that well-chosen concept sets can improve sample efficiency and out-of-distribution robustness in the appropriate regimes. Based on these insights, we propose a method to effectively identify informative and non-redundant concepts. We validate our approach with experiments on CIFAR-10 and MetaShift, showing that concept-bottleneck models outperform the foundational embedding counterpart, particularly in low-data regimes and under distribution shifts. We also examine failure modes and discuss how they can be tackled.
1754. Achieving Near-Optimal Convergence for Distributed Minimax Optimization with Adaptive Stepsizes
tl;dr: This paper proposes a distributed adaptive method for solving nonconvex minimax problems and establishes a near-optimal convergence rate by employing adaptive stepsize tracking to eliminate the inconsistency in locally computed adaptive stepsizes.

In this paper, we show that applying adaptive methods directly to distributed minimax problems can result in non-convergence due to inconsistency in locally computed adaptive stepsizes. To address this challenge, we propose D-AdaST, a Distributed Adaptive minimax method with Stepsize Tracking. The key strategy is to employ an adaptive stepsize tracking protocol involving the transmission of two extra (scalar) variables. This protocol ensures the consistency among stepsizes of nodes, eliminating the steady-state error due to the lack of coordination of stepsizes among nodes that commonly exists in vanilla distributed adaptive methods, and thus guarantees exact convergence. For nonconvex-strongly-concave distributed minimax problems, we characterize the specific transient times that ensure time-scale separation of stepsizes and quasi-independence of networks, leading to a near-optimal convergence rate of $\tilde{\mathcal{O}} \left( \epsilon ^{-\left( 4+\delta \right)} \right)$ for any small $\delta > 0$, matching that of the centralized counterpart. To our best knowledge, D-AdaST is the *first* distributed adaptive method achieving near-optimal convergence without knowing any problem-dependent parameters for nonconvex minimax problems. Extensive experiments are conducted to validate our theoretical results.
tl;dr: We give an improved theoretical framework for f-divergence-based domain learning

Unsupervised domain adaptation (UDA) plays a crucial role in addressing distribution shifts in machine learning. In this work, we improve the theoretical foundations of UDA proposed in Acuna et al. (2021) by refining their $f$-divergence-based discrepancy and additionally introducing a new measure, $f$-domain discrepancy ($f$-DD). By removing the absolute value function and incorporating a scaling parameter, $f$-DD obtains novel target error and sample complexity bounds, allowing us to recover previous KL-based results and bridging the gap between algorithms and theory presented in Acuna et al. (2021). Using a localization technique, we also develop a fast-rate generalization bound. Empirical results demonstrate the superior performance of $f$-DD-based learning algorithms over previous works in popular UDA benchmarks.
tl;dr: We provide a precise asymptotic characterization of the iterates for a family of reweighted least-squares algorithms that learn linear diagonal neural networks.

The classical iteratively reweighted least-squares (IRLS) algorithm aims to recover an unknown signal from linear measurements by performing a sequence of weighted least squares problems, where the weights are recursively updated at each step. Varieties of this algorithm have been shown to achieve favorable empirical performance and theoretical guarantees for sparse recovery and $\ell_p$-norm minimization. Recently, some preliminary connections have also been made between IRLS and certain types of non-convex linear neural network architectures that are observed to exploit low-dimensional structure in high-dimensional linear models. In this work, we provide a unified asymptotic analysis for a family of algorithms that encompasses IRLS, the recently proposed lin-RFM algorithm (which was motivated by feature learning in neural networks), and the alternating minimization algorithm on linear diagonal neural networks. Our analysis operates in a "batched" setting with i.i.d. Gaussian covariates and shows that, with appropriately chosen reweighting policy, the algorithm can achieve favorable performance in only a handful of iterations. We also extend our results to the case of group-sparse recovery and show that leveraging this structure in the reweighting scheme provably improves test error compared to coordinate-wise reweighting.
tl;dr: We provide estimators for evaluating the effect of policies leveraging data from related domains.

Artificial intelligence systems are trained combining various observational and experimental datasets from different source sites, and are increasingly used to reason about the effectiveness of candidate policies. One common assumption in this context is that the data in source and target sites (where the candidate policy is due to be deployed) come from the same distribution. This assumption is often violated in practice, causing challenges for generalization, transportability, or external validity. Despite recent advances for determining the identifiability of the effectiveness of policies in a target domain, there are still challenges for the accurate estimation of effects from finite samples. In this paper, we develop novel graphical criteria and estimators for evaluating the effectiveness of policies (e.g., conditional, stochastic) by combining data from multiple experimental studies. Asymptotic error analysis of our estimators provides fast convergence guarantee. We empirically verified the robustness of estimators through simulations.
tl;dr: We leverage intrinsic properties of SAT problems and GNNs to efficiently generate new SAT problems for data augmentation in Deep Learning settings.

Efficiently determining the satisfiability of a boolean equation --- known as the SAT problem for brevity --- is crucial in various industrial problems. Recently, the advent of deep learning methods has introduced significant potential for enhancing SAT solving. However, a major barrier to the advancement of this field has been the scarcity of large, realistic datasets. The majority of current public datasets are either randomly generated or extremely limited, containing only a few examples from unrelated problem families. These datasets are inadequate for meaningful training of deep learning methods. In light of this, researchers have started exploring generative techniques to create data that more accurately reflect SAT problems encountered in practical situations. These methods have so far suffered from either the inability to produce challenging SAT problems or time-scalability obstacles. In this paper we address both by identifying and manipulating the key contributors to a problem's ``hardness'', known as cores. Although some previous work has addressed cores, the time costs are unacceptably high due to the expense of traditional heuristic core detection techniques. We introduce a fast core detection procedure that uses a graph neural network. Our empirical results demonstrate that we can efficiently generate problems that remain hard to solve and retain key attributes of the original example problems. We show via experiment that the generated synthetic SAT problems can be used in a data augmentation setting to provide improved prediction of solver runtimes.
tl;dr: Propose an LLM-powered dataflow analysis, showing the potential of LLMs in resolving complex code reasoning problems.

Dataflow analysis is a fundamental code analysis technique that identifies dependencies between program values. Traditional approaches typically necessitate successful compilation and expert customization, hindering their applicability and usability for analyzing uncompilable programs with evolving analysis needs in real-world scenarios. This paper presents LLMDFA, an LLM-powered compilation-free and customizable dataflow analysis framework. To address hallucinations for reliable results, we decompose the problem into several subtasks and introduce a series of novel strategies. Specifically, we leverage LLMs to synthesize code that outsources delicate reasoning to external expert tools, such as using a parsing library to extract program values of interest and invoking an automated theorem prover to validate path feasibility. Additionally, we adopt a few-shot chain-of-thought prompting to summarize dataflow facts in individual functions, aligning the LLMs with the program semantics of small code snippets to mitigate hallucinations. We evaluate LLMDFA on synthetic programs to detect three representative types of bugs and on real-world Android applications for customized bug detection. On average, LLMDFA achieves 87.10% precision and 80.77% recall, surpassing existing techniques with F1 score improvements of up to 0.35. We have open-sourced LLMDFA at https://github.com/chengpeng-wang/LLMDFA.
tl;dr: We adapt the chaos analysis from deep feedforward neural networks to graph neural networks and reveal a parameter regime in which graph neural networks do not oversmooth.

Graph neural networks (GNNs) have emerged as powerful tools for processing relational data in applications. However, GNNs suffer from the problem of oversmoothing, the property that features of all nodes exponentially converge to the same vector over layers, prohibiting the design of deep GNNs. In this work we study oversmoothing in graph convolutional networks (GCNs) by using their Gaussian process (GP) equivalence in the limit of infinitely many hidden features. By generalizing methods from conventional deep neural networks (DNNs), we can describe the distribution of features at the output layer of deep GCNs in terms of a GP: as expected, we find that typical parameter choices from the literature lead to oversmoothing. The theory, however, allows us to identify a new, non-oversmoothing phase: if the initial weights of the network have sufficiently large variance, GCNs do not oversmooth, and node features remain informative even at large depth. We demonstrate the validity of this prediction in finite-size GCNs by training a linear classifier on their output. Moreover, using the linearization of the GCN GP, we generalize the concept of propagation depth of information from DNNs to GCNs. This propagation depth diverges at the transition between the oversmoothing and non-oversmoothing phase. We test the predictions of our approach and find good agreement with finite-size GCNs. Initializing GCNs near the transition to the non-oversmoothing phase, we obtain networks which are both deep and expressive.
tl;dr: We investigate the benefit of Cutout and CutMix for feature learning

Patch-level data augmentation techniques such as Cutout and CutMix have demonstrated significant efficacy in enhancing the performance of vision tasks. However, a comprehensive theoretical understanding of these methods remains elusive. In this paper, we study two-layer neural networks trained using three distinct methods: vanilla training without augmentation, Cutout training, and CutMix training. Our analysis focuses on a feature-noise data model, which consists of several label-dependent features of varying rarity and label-independent noises of differing strengths. Our theorems demonstrate that Cutout training can learn low-frequency features that vanilla training cannot, while CutMix training can learn even rarer features that Cutout cannot capture. From this, we establish that CutMix yields the highest test accuracy among the three. Our novel analysis reveals that CutMix training makes the network learn all features and noise vectors "evenly" regardless of the rarity and strength, which provides an interesting insight into understanding patch-level augmentation.
tl;dr: We propose a completely analytically tractable framework for studying the evolution of bias of a classifier during training

Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations of the data. However, our current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup that models different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setup, which we prove to be exact in high dimension.
Notably, our analysis identifies different properties of the sub-populations that drive bias at different timescales and hence shows a shifting preference of our classifier during training. By applying our general solution to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real data, i.e. using CIFAR10, MNIST, and CelebA datasets.
tl;dr: A video VAE for latent generative video models, which is compatible with pretrained image and video models, e.g., SD 2.1 and SVD

Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. To improve the training efficiency, we also design a novel architecture for the video VAE. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
tl;dr: We propose 2D U-Net skip connection (uC) to replace conventional skip connections in 3D segmentation networks.

In the present study, we introduce an innovative structure for 3D medical image segmentation that effectively integrates 2D U-Net-derived skip connections into the architecture of 3D convolutional neural networks (3D CNNs). Conventional 3D segmentation techniques predominantly depend on isotropic 3D convolutions for the extraction of volumetric features, which frequently engenders inefficiencies due to the varying information density across the three orthogonal axes in medical imaging modalities such as computed tomography (CT) and magnetic resonance imaging (MRI). This disparity leads to a decline in axial-slice plane feature extraction efficiency, with slice plane features being comparatively underutilized relative to features in the time-axial. To address this issue, we introduce the U-shaped Connection (uC), utilizing simplified 2D U-Net in place of standard skip connections to augment the extraction of the axial-slice plane features while concurrently preserving the volumetric context afforded by 3D convolutions. Based on uC, we further present uC 3DU-Net, an enhanced 3D U-Net backbone that integrates the uC approach to facilitate optimal axial-slice plane feature utilization. Through rigorous experimental validation on five publicly accessible datasets—FLARE2021, OIMHS, FeTA2021, AbdomenCT-1K, and BTCV, the proposed method surpasses contemporary state-of-the-art models. Notably, this performance is achieved while reducing the number of parameters and computational complexity. This investigation underscores the efficacy of incorporating 2D convolutions within the framework of 3D CNNs to overcome the intrinsic limitations of volumetric segmentation, thereby potentially expanding the frontiers of medical image analysis. Our implementation is available at https://github.com/IMOP-lab/U-Shaped-Connection.

We give a model-based agent that builds a Python program representing its knowledge of the world based on its interactions with the environment. The world model tries to explain its interactions, while also being optimistic about what reward it can achieve. We define this optimism as a logical constraint between a program and a planner. We study our agent on gridworlds, and on task planning, finding our approach is more sample-efficient compared to deep RL, more compute-efficient compared to ReAct-style agents, and that it can transfer its knowledge across environments by editing its code.
tl;dr: We propose a parameter-free optimizer for lifelong reinforcement learning that mitigates loss of plasticity and rapidly adapts to new distribution shifts.

A key challenge in lifelong reinforcement learning (RL) is the loss of plasticity, where previous learning progress hinders an agent's adaptation to new tasks. While regularization and resetting can help, they require precise hyperparameter selection at the outset and environment-dependent adjustments. Building on the principled theory of online convex optimization, we present a parameter-free optimizer for lifelong RL, called TRAC, which requires no tuning or prior knowledge about the distribution shifts. Extensive experiments on Procgen, Atari, and Gym Control environments show that TRAC works surprisingly well—mitigating loss of plasticity and rapidly adapting to challenging distribution shifts—despite the underlying optimization problem being nonconvex and nonstationary.
tl;dr: Temporal difference methods require exponentially less data than Monte Carlo to estimate rare event statistics

We quantify the efficiency of temporal difference (TD) learning over the direct, or Monte Carlo (MC), estimator for policy evaluation in reinforcement learning, with an emphasis on estimation of quantities related to rare events. Policy evaluation is complicated in the rare event setting by the long timescale of the event and by the need for \emph{relative accuracy} in estimates of very small values. Specifically, we focus on least-squares TD (LSTD) prediction for finite state Markov chains, and show that LSTD can achieve relative accuracy far more efficiently than MC. We prove a central limit theorem for the LSTD estimator and upper bound the
\emph{relative asymptotic variance}
by simple quantities characterizing the connectivity of states relative to the transition probabilities between them. Using this bound, we show that, even when both the timescale of the rare event and the relative accuracy of the MC estimator are exponentially large in the number of states, LSTD maintains a fixed level of relative accuracy with a total number of observed transitions of the Markov chain that is only \emph{polynomially} large in the number of states.
tl;dr: This paper explores Auto-regressive Decision Trees for language modeling through theoretical and empirical analysis, showing their ability for complex computations and coherent text generation.

Originally proposed for handling time series data, Auto-regressive Decision Trees (ARDTs) have not yet been explored for language modeling. This paper delves into both the theoretical and practical applications of ARDTs in this new context. We theoretically demonstrate that ARDTs can compute complex functions, such as simulating automata, Turing machines, and sparse circuits, by leveraging "chain-of-thought" computations. Our analysis provides bounds on the size, depth, and computational efficiency of ARDTs, highlighting their surprising computational power. Empirically, we train ARDTs on simple language generation tasks, showing that they can learn to generate coherent and grammatically correct text on par with a smaller Transformer model. Additionally, we show that ARDTs can be used on top of transformer representations to solve complex reasoning tasks. This research reveals the unique computational abilities of ARDTs, aiming to broaden the architectural diversity in language model development.
tl;dr: Our proposed method (ContAccum) reduces hardware needs for large batch training in information retrieval, outperforming not only memory reduction methods but also high-resource scenario in low-resource settings with stable dual encoder training.

InfoNCE loss is commonly used to train dense retriever in information retrieval tasks. It is well known that a large batch is essential to stable and effective training with InfoNCE loss, which requires significant hardware resources. Due to the dependency of large batch, dense retriever has bottleneck of application and research. Recently, memory reduction methods have been broadly adopted to resolve the hardware bottleneck by decomposing forward and backward or using a memory bank. However, current methods still suffer from slow and unstable train. To address these issues, we propose Contrastive Accumulation (ContAccum), a stable and efficient memory reduction method for dense retriever trains that uses a dual memory bank structure to leverage previously generated query and passage representations. Experiments on widely used five information retrieval datasets indicate that ContAccum can surpass not only existing memory reduction methods but also high-resource scenarios. Moreover, theoretical analysis and experimental results confirm that ContAccum provides more stable dual-encoder training than current memory bank utilization methods.
tl;dr: Deep Diffusion Policy Gradient is a novel RL algorithm that successfully trains diffusion policies online, discovering and maintaining multimodal behaviors in complex environments.

Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles. Our project page is available at https://supersglzc.github.io/projects/ddiffpg/.
tl;dr: We propose adaptive negative proxies by exploring potential OOD images during testing for OOD detection

Recent research has shown that pre-trained vision-language models are effective at identifying out-of-distribution (OOD) samples by using negative labels as guidance. However, employing consistent negative labels across different OOD datasets often results in semantic misalignments, as these text labels may not accurately reflect the actual space of OOD images. To overcome this issue, we introduce \textit{adaptive negative proxies}, which are dynamically generated during testing by exploring actual OOD images, to align more closely with the underlying OOD label space and enhance the efficacy of negative proxy guidance. Specifically, our approach utilizes a feature memory bank to selectively cache discriminative features from test images, representing the targeted OOD distribution. This facilitates the creation of proxies that can better align with specific OOD datasets. While task-adaptive proxies average features to reflect the unique characteristics of each dataset, the sample-adaptive proxies weight features based on their similarity to individual test samples, exploring detailed sample-level nuances. The final score for identifying OOD samples integrates static negative labels with our proposed adaptive proxies, effectively combining textual and visual knowledge for enhanced performance. Our method is training-free and annotation-free, and it maintains fast testing speed. Extensive experiments across various benchmarks demonstrate the effectiveness of our approach, abbreviated as AdaNeg. Notably, on the large-scale ImageNet benchmark, our AdaNeg significantly outperforms existing methods, with a 2.45\% increase in AUROC and a 6.48\% reduction in FPR95. Codes are available at \url{https://github.com/YBZh/OpenOOD-VLM}.
tl;dr: We propose a minimax-optimal algorithm PS$\varepsilon$BAI$^+$ to identify an $\varepsilon$-best arm in the piecewise-stationary linear bandits problem.

We propose a novel piecewise stationary linear bandit (PSLB) model, where the environment randomly samples a context from an unknown probability distribution at each changepoint, and the quality of an arm is measured by its return averaged over all contexts. The contexts and their distribution, as well as the changepoints are unknown to the agent.
We design Piecewise-Stationary $\varepsilon$-Best Arm Identification$^+$ (PS$\varepsilon$BAI$^+$), an algorithm that is guaranteed to identify an $\varepsilon$-optimal arm with probability $\ge 1-\delta$ and with a minimal number of samples.
PS$\varepsilon$BAI$^+$ consists of two subroutines, PS$\varepsilon$BAI and Naïve $\varepsilon$-BAI (N$\varepsilon$BAI), which are executed in parallel. PS$\varepsilon$BAI actively detects changepoints and aligns contexts to facilitate the arm identification process.
When PS$\varepsilon$BAI and N$\varepsilon$BAI are utilized judiciously in parallel, PS$\varepsilon$BAI$^+$ is shown to have a finite expected sample complexity.
By proving a lower bound, we show the expected sample complexity of PS$\varepsilon$BAI$^+$ is optimal up to a logarithmic factor.
We compare PS$\varepsilon$BAI$^+$ to baseline algorithms using numerical experiments which demonstrate its efficiency.
Both our analytical and numerical results corroborate that the efficacy of PS$\varepsilon$BAI$^+$ is due to the delicate change detection and context alignment procedures embedded in PS$\varepsilon$BAI.

Large Language Models (LLMs) have demonstrated remarkable capabilities, surpassing human experts in various benchmark tests and playing a vital role in various industry sectors. Despite their effectiveness, a notable drawback of LLMs is their inconsistent moral behavior, which raises ethical concerns. This work delves into symmetric moral consistency in large language models and demonstrates that modern LLMs lack sufficient consistency ability in moral scenarios. Our extensive investigation of twelve popular LLMs reveals that their assessed consistency scores are influenced by position bias and selection bias rather than their intrinsic abilities. We propose a new framework tSMC, which gauges the effects of these biases and effectively mitigates the bias impact based on the Kullback–Leibler divergence to pinpoint LLMs' mitigated Symmetric Moral Consistency. We find that the ability of LLMs to maintain consistency varies across different moral scenarios. Specifically, LLMs show more consistency in scenarios with clear moral answers compared to those where no choice is morally perfect. The average consistency score of 12 LLMs ranges from $60.7\%$ in high-ambiguity moral scenarios to $84.8\%$ in low-ambiguity moral scenarios.

Recently, foundation models, particularly large language models (LLMs), have demonstrated an impressive ability to adapt to various tasks by fine-tuning diverse instruction data. Notably, federated foundation models (FedFM) emerge as a privacy preservation method to fine-tune models collaboratively under federated learning (FL) settings by leveraging many distributed datasets with non-IID data. To alleviate communication and computation overhead, parameter-efficient methods are introduced for efficiency, and some research adapted personalization methods to FedFM for better user preferences alignment. However, a critical gap in existing research is the neglect of test-time distribution shifts in real-world applications, and conventional methods for test-time distribution shifts in personalized FL are less effective for FedFM due to their failure to adapt to complex distribution shift scenarios and the requirement to train all parameters. To bridge this gap, we refine the setting in FedFM, termed test-time personalization, which aims to learn personalized federated foundation models on clients while effectively handling test-time distribution shifts simultaneously. To address challenges in this setting, we explore a simple yet effective solution, a Federated Dual-Personalizing Adapter (FedDPA) architecture. By co-working with a foundation model, a global adapter and a local adapter jointly tackle the test-time distribution shifts and client-specific personalization. Additionally, we introduce an instance-wise dynamic weighting mechanism that dynamically integrates the global and local adapters for each test instance during inference, facilitating effective test-time personalization. The effectiveness of the proposed method has been evaluated on benchmark datasets across different NLP tasks.

Parallel-in-time (PinT) techniques have been proposed to solve systems of time-dependent differential equations by parallelizing the temporal domain. Among them, Parareal computes the solution sequentially using an inaccurate (fast) solver, and then ``corrects'' it using an accurate (slow) integrator that runs in parallel across temporal subintervals. This work introduces RandNet-Parareal, a novel method to learn the discrepancy between the coarse and fine solutions using random neural networks (RandNets). RandNet-Parareal achieves speed gains up to x125 and x22 compared to the fine solver run serially and Parareal, respectively. Beyond theoretical guarantees of RandNets as universal approximators, these models are quick to train, allowing the PinT solution of partial differential equations on a spatial mesh of up to $10^5$ points with minimal overhead, dramatically increasing the scalability of existing PinT approaches. RandNet-Parareal's numerical performance is illustrated on systems of real-world significance, such as the viscous Burgers' equation, the Diffusion-Reaction equation, the two- and three-dimensional Brusselator, and the shallow water equation.
tl;dr: We introduce an edge-featured Neural Network AlphaGateau to improve Reinforcement Learning for Chess as a Graph-structured game.

Mastering games is a hard task, as games can be extremely complex, and still fundamentally different in structure from one another. While the AlphaZero algorithm has demonstrated an impressive ability to learn the rules and strategy of a large variety of games, ranging from Go and Chess, to Atari games, its reliance on extensive computational resources and rigid Convolutional Neural Network (CNN) architecture limits its adaptability and scalability. A model trained to play on a $19\times 19$ Go board cannot be used to play on a smaller $13\times 13$ board, despite the similarity between the two Go variants.
In this paper, we focus on Chess, and explore using a more generic Graph-based Representation of a game state, rather than a grid-based one, to introduce a more general architecture based on Graph Neural Networks (GNN). We also expand the classical Graph Attention Network (GAT) layer to incorporate edge-features, to naturally provide a generic policy output format.
Our experiments, performed on smaller networks than the initial AlphaZero paper, show that this new architecture outperforms previous architectures with a similar number of parameters, being able to increase playing strength an order of magnitude faster. We also show that the model, when trained on a smaller $5\times 5$ variant of chess, is able to be quickly fine-tuned to play on regular $8\times 8$ chess, suggesting that this approach yields promising generalization abilities.
Our code is available at https://github.com/akulen/AlphaGateau.

Accurate modeling of the diverse and dynamic interests of users remains a significant challenge in the design of personalized recommender systems. Existing user modeling methods, like single-point and multi-point representations, have limitations w.r.t.\ accuracy, diversity, and adaptability. To overcome these deficiencies, we introduce density-based user representations (DURs), a novel method that leverages Gaussian process regression (GPR) for effective multi-interest recommendation and retrieval. Our approach, GPR4DUR, exploits DURs to capture user interest variability without manual tuning, incorporates uncertainty-awareness, and scales well to large numbers of users. Experiments using real-world offline datasets confirm the adaptability and efficiency of GPR4DUR, while online experiments with simulated users demonstrate its ability to address the exploration-exploitation trade-off by effectively utilizing model uncertainty.
tl;dr: We propose a multi-agent diffusion framework that unifies decentralized policy, centralized controller, teammate modeling, and trajectory prediction.

Offline reinforcement learning (RL) aims to learn policies from pre-existing datasets without further interactions, making it a challenging task. Q-learning algorithms struggle with extrapolation errors in offline settings, while supervised learning methods are constrained by model expressiveness. Recently, diffusion models (DMs) have shown promise in overcoming these limitations in single-agent learning, but their application in multi-agent scenarios remains unclear. Generating trajectories for each agent with independent DMs may impede coordination, while concatenating all agents’ information can lead to low sample efficiency. Accordingly, we propose MADiff, which is realized with an attention-based diffusion model to model the complex coordination among behaviors of multiple agents. To our knowledge, MADiff is the first diffusion-based multi-agent learning framework, functioning as both a decentralized policy and a centralized controller. During decentralized executions, MADiff simultaneously performs teammate modeling, and the centralized controller can also be applied in multi-agent trajectory predictions. Our experiments demonstrate that MADiff outperforms baseline algorithms across various multi-agent learning tasks, highlighting its effectiveness in modeling complex multi-agent interactions.

Transformers have achieved significant success in natural language modeling because of their exceptional capabilities to combine contextual information and global knowledge, yet their theoretical basis remains unclear. In this paper, we first propose Sparse Contextual Bigram (SCB), a natural extension to the classical bigram model, where the generation of the next token depends on a sparse set of earlier positions determined by the last token. We investigate the training dynamics and sample complexity of learning SCB using a one-layer linear transformer with a gradient-based algorithm. We show that when trained from scratch, the training process can be split into an initial sample-intensive stage where the correlation is boosted from zero to a nontrivial value, followed by a more sample-efficient stage of further improvement. Additionally, we prove that, provided a nontrivial correlation between the downstream and pretraining tasks, finetuning from a pretrained model allows us to bypass the initial sample-intensive stage. We also empirically demonstrate that our algorithm can outperform SGD in our setting.

In speech separation, time-domain approaches have successfully replaced the time-frequency domain with latent sequence feature from a learnable encoder. Conventionally, the feature is separated into speaker-specific ones at the final stage of the network. Instead, we propose a more intuitive strategy that separates features earlier by expanding the feature sequence to the number of speakers as an extra dimension. To achieve this, an asymmetric strategy is presented in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, which also performs cross-speaker processing.
Without relying on speaker information, the weight-shared network in the decoder directly learns to discriminate features using a separation objective. In addition, to improve performance, traditional methods have extended the sequence length, leading to the adoption of dual-path models, which handle the much longer sequence effectively by segmenting it into chunks. To address this, we introduce global and local Transformer blocks that can directly handle long sequences more efficiently without chunking and dual-path processing. The experimental results demonstrated that this asymmetric structure is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of inter- and intra-chunk processing in dual-path structure. Finally, the presented model combining both of these achieved state-of-the-art performance with much less computation in various benchmark datasets.

Reconstructing a sequence of sharp images from the blurry input is crucial for enhancing our insights into the captured scene and poses a significant challenge due to the limited temporal features embedded in the image. Spike cameras, sampling at rates up to 40,000 Hz, have proven effective in capturing motion features and beneficial for solving this ill-posed problem. Nonetheless, existing methods fall into the supervised learning paradigm, which suffers from notable performance degradation when applied to real-world scenarios that diverge from the synthetic training data domain. To address these challenges, we propose the first self-supervised framework for the task of spike-guided motion deblurring. Our approach begins with the formulation of a spike-guided deblurring model that explores the theoretical relationships among spike streams, blurry images, and their corresponding sharp sequences. We subsequently develop a self-supervised cascaded framework to alleviate the issues of spike noise and spatial-resolution mismatching encountered in the deblurring model. With knowledge distillation and re-blurring loss, we further design a lightweight deblur network to generate high-quality sequences with brightness and texture consistency with the original input. Quantitative and qualitative experiments conducted on our real-world and synthetic datasets with spikes validate the superior generalization of the proposed framework. Our code, data and trained models are available at \url{https://github.com/chenkang455/S-SDM}.
tl;dr: We use random dot stimuli that remove appearance but not motion information from videos to show substantial differences between human perception and state-of-the-art machine vision.

Humans excel at detecting and segmenting moving objects according to the {\it Gestalt} principle of “common fate”. Remarkably, previous works have shown that human perception generalizes this principle in a zero-shot fashion to unseen textures or random dots. In this work, we seek to better understand the computational basis for this capability by evaluating a broad range of optical flow models and a neuroscience inspired motion energy model for zero-shot figure-ground segmentation of random dot stimuli. Specifically, we use the extensively validated motion energy model proposed by Simoncelli and Heeger in 1998 which is fitted to neural recordings in cortex area MT. We find that a cross section of 40 deep optical flow models trained on different datasets struggle to estimate motion patterns in random dot videos, resulting in poor figure-ground segmentation performance. Conversely, the neuroscience-inspired model significantly outperforms all optical flow models on this task. For a direct comparison to human perception, we conduct a psychophysical study using a shape identification task as a proxy to measure human segmentation performance. All state-of-the-art optical flow models fall short of human performance, but only the motion energy model matches human capability. This neuroscience-inspired model successfully addresses the lack of human-like zero-shot generalization to random dot stimuli in current computer vision models, and thus establishes a compelling link between the Gestalt psychology of human object perception and cortical motion processing in the brain.
Code, models and datasets are available at https://github.com/mtangemann/motion_energy_segmentation
tl;dr: Improving model performance on under-represented subpopulations by removing harmful training data.

Machine learning models can often fail on subgroups that are underrepresented
during training. While dataset balancing can improve performance on
underperforming groups, it requires access to training group annotations and can
end up removing large portions of the dataset. In this paper, we introduce
Data Debiasing with Datamodels (D3M), a debiasing approach
which isolates and removes specific training examples that drive the model's
failures on minority groups. Our approach enables us to efficiently train
debiased classifiers while removing only a small number of examples, and does
not require training group annotations or additional hyperparameter tuning.
tl;dr: This paper rethinks Softmax Loss (SL) from a pairwise perspective, introducing a novel family of robust DCG surrogate losses to address the limitations of SL, termed Pairwise Softmax Loss (PSL).

Softmax Loss (SL) is widely applied in recommender systems (RS) and has demonstrated effectiveness. This work analyzes SL from a pairwise perspective, revealing two significant limitations: 1) the relationship between SL and conventional ranking metrics like DCG is not sufficiently tight; 2) SL is highly sensitive to false negative instances. Our analysis indicates that these limitations are primarily due to the use of the exponential function. To address these issues, this work extends SL to a new family of loss functions, termed Pairwise Softmax Loss (PSL), which replaces the exponential function in SL with other appropriate activation functions. While the revision is minimal, we highlight three merits of PSL: 1) it serves as a tighter surrogate for DCG with suitable activation functions; 2) it better balances data contributions; and 3) it acts as a specific BPR loss enhanced by Distributionally Robust Optimization (DRO). We further validate the effectiveness and robustness of PSL through empirical experiments. The code is available at https://github.com/Tiny-Snow/IR-Benchmark.
1785. Estimating Generalization Performance Along the Trajectory of Proximal SGD in Robust Regression
tl;dr: This paper provides generalization error estimates for each iteration of the SGD and proximal SGD algorithms in the context of robust regression.

This paper studies the generalization performance of iterates obtained by Gradient Descent (GD), Stochastic Gradient Descent (SGD) and their proximal variants in high-dimensional robust regression problems. The number of features is comparable to the sample size and errors may be heavy-tailed. We introduce estimators that precisely track the generalization error of the iterates along the trajectory of the iterative algorithm. These estimators are provably consistent under suitable conditions. The results are illustrated through several examples, including Huber regression, pseudo-Huber regression, and their penalized variants with non-smooth regularizer. We provide explicit generalization error estimates for iterates generated from GD and SGD, or from proximal SGD in the presence of a non-smooth regularizer. The proposed risk estimates serve as effective proxies for the actual generalization error, allowing us to determine the optimal stopping iteration that minimizes the generalization error. Extensive simulations confirm the effectiveness of the proposed generalization error estimates.

Video understanding relies on accurate action detection for temporal analysis. However, existing mainstream methods have limitations in real-world applications due to their offline and closed-set evaluation approaches, as well as their dependence on manual annotations. To address these challenges and enable real-time action understanding in open-world scenarios, we propose OV-OAD, a zero-shot online action detector that leverages vision-language models and learns solely from text supervision. By introducing an object-centered decoder unit into a Transformer-based model, we aggregate frames with similar semantics using video-text correspondence. Extensive experiments on four action detection benchmarks demonstrate that OV-OAD outperforms other advanced zero-shot methods. Specifically, it achieves 37.5\% mean average precision on THUMOS’14 and 73.8\% calibrated average precision on TVSeries. This research establishes a robust baseline for zero-shot transfer in online action detection, enabling scalable solutions for open-world temporal understanding. The code will be available for download at \url{https://github.com/OpenGVLab/OV-OAD}.
tl;dr: Geometry-aware motion retargeting in a single stage with no contradiction introduced by geometry correction.

Capturing and maintaining geometric interactions among different body parts is crucial for successful motion retargeting in skinned characters. Existing approaches often overlook body geometries or add a geometry correction stage after skeletal motion retargeting. This results in conflicts between skeleton interaction and geometry correction, leading to issues such as jittery, interpenetration, and contact mismatches. To address these challenges, we introduce a new retargeting framework, MeshRet, which directly models the dense geometric interactions in motion retargeting. Initially, we establish dense mesh correspondences between characters using semantically consistent sensors (SCS), effective across diverse mesh topologies. Subsequently, we develop a novel spatio-temporal representation called the dense mesh interaction (DMI) field. This field, a collection of interacting SCS feature vectors, skillfully captures both contact and non-contact interactions between body geometries. By aligning the DMI field during retargeting, MeshRet not only preserves motion semantics but also prevents self-interpenetration and ensures contact preservation. Extensive experiments on the public Mixamo dataset and our newly-collected ScanRet dataset demonstrate that MeshRet achieves state-of-the-art performance. Code available at https://github.com/abcyzj/MeshRet.
tl;dr: Large-scale study of scalable oversight with LLMs as strong debaters/consultants and weak judges

Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI.
In this paper we study debate, where two AI's compete to convince a judge; consultancy,
where a single AI tries to convince a judge that asks questions;
and compare to a baseline of direct question-answering, where the judge just answers outright without the AI.
We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models.
We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries.
We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed.
Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy.
Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
tl;dr: We carry out experiments on conditional DDPMs using synthetic datasets that demonstrate their ability to learn factorized representations and compositionally generalize.

Diffusion models are capable of generating photo-realistic images that combine elements which do not appear together in natural images, demonstrating their ability to compositionally generalize. Nonetheless, the precise mechanism of compositionality and how it is acquired through training remains elusive. Here, we consider a highly reduced setting to examine whether diffusion models learn semantically meaningful and fully factorized representations of composable features. We performed extensive controlled experiments on conditional DDPMs trained to generate various forms of 2D Gaussian data. We demonstrate that the models learn factorized, semi-continuous manifold representations that are orthogonal in underlying continuous latent features of independent variations but are not aligned for different values of the same feature. With such representations, models demonstrate superior compositionality but have limited ability to interpolate over unseen values of a given feature. Our experimental results further demonstrate that diffusion models can attain compositionality with a small amount of compositional examples, suggesting a novel way to train DDPMs. Finally, we connect manifold formation in diffusion models to percolation theory in physics, thereby offering insights into the sudden onset of factorized representation learning. Our thorough toy experiments thus contribute a deeper understanding of how diffusion models capture compositional structure in data, paving the way for future research aimed at enhancing factorization and compositional generalization in generative models for real-world applications.
tl;dr: We present a novel differentiable transformation for relaxing permutation matrices onto the orthogonal group, which enables gradient-based (stochastic) optimization of problems involving permutation matrices.

Optimization over permutations is typically an NP-hard problem that arises extensively in ranking, matching, tracking, etc. Birkhoff polytope-based relaxation methods have made significant advancements, particularly in penalty-free optimization and probabilistic inference. Relaxation onto the orthogonal group offers unique potential advantages such as a lower representation dimension and preservation of inner products; however, equally effective approaches remain unexplored. To bridge the gap, we present a temperature-controlled differentiable transformation that maps unconstrained vector space to the orthogonal group, where the temperature, in the limit, concentrates orthogonal matrices near permutation matrices. This transformation naturally implements a parameterization for the relaxation of permutation matrices, allowing for gradient-based optimization of problems involving permutations. Additionally, by deriving a re-parameterized gradient estimator, this transformation also provides efficient stochastic optimization over the latent permutations. Extensive experiments involving the optimization over permutation matrices validate the effectiveness of the proposed method.
tl;dr: We propose Self-Calibrating Conformal Prediction to provide calibrated point predictions and associated prediction intervals with valid coverage conditional on these model predictions in finite samples.

In machine learning, model calibration and predictive inference are essential for producing reliable predictions and quantifying uncertainty to support decision-making. Recognizing the complementary roles of point and interval predictions, we introduce Self-Calibrating Conformal Prediction, a method that combines Venn-Abers calibration and conformal prediction to deliver calibrated point predictions alongside prediction intervals with finite-sample validity conditional on these predictions. To achieve this, we extend the original Venn-Abers procedure from binary classification to regression. Our theoretical framework supports analyzing conformal prediction methods that involve calibrating model predictions and subsequently constructing conditionally valid prediction intervals on the same data, where the conditioning set or conformity scores may depend on the calibrated predictions. Real-data experiments show that our method improves interval efficiency through model calibration and offers a practical alternative to feature-conditional validity.

Concept activation vector (CAV) has attracted broad research interest in explainable AI, by elegantly attributing model predictions to specific concepts. However, the training of CAV often necessitates a large number of high-quality images, which are expensive to curate and thus limited to a predefined set of concepts. To address this issue, we propose Language-Guided CAV (LG-CAV) to harness the abundant concept knowledge within the certain pre-trained vision-language models (e.g., CLIP). This method allows training any CAV without labeled data, by utilizing the corresponding concept descriptions as guidance. To bridge the gap between vision-language model and the target model, we calculate the activation values of concept descriptions on a common pool of images (probe images) with vision-language model and utilize them as language guidance to train the LG-CAV. Furthermore, after training high-quality LG-CAVs related to all the predicted classes in the target model, we propose the activation sample reweighting (ASR), serving as a model correction technique, to improve the performance of the target model in return. Experiments on four datasets across nine architectures demonstrate that LG-CAV achieves significantly superior quality to previous CAV methods given any concept, and our model correction method achieves state-of-the-art performance compared to existing concept-based methods. Our code is available at https://github.com/hqhQAQ/LG-CAV.
tl;dr: Convergence analysis of split federated learning

Split federated learning (SFL) is a recent distributed approach for collaborative model training among multiple clients. In SFL, a global model is typically split into two parts, where clients train one part in a parallel federated manner, and a main server trains the other. Despite the recent research on SFL algorithm development, the convergence analysis of SFL is missing in the literature, and this paper aims to fill this gap. The analysis of SFL can be more challenging than that of federated learning (FL), due to the potential dual-paced updates at the clients and the main server. We provide convergence analysis of SFL for strongly convex and general convex objectives on heterogeneous data. The convergence rates are $O(1/T)$ and $O(1/\sqrt[3]{T})$, respectively, where $T$ denotes the total number of rounds for SFL training. We further extend the analysis to non-convex objectives and where some clients may be unavailable during training. Numerical experiments validate our theoretical results and show that SFL outperforms FL and split learning (SL) when data is highly heterogeneous across a large number of clients.
tl;dr: We introduce a principled Bayesian framework for improving large language models' generalization and uncertainty estimation.

Large Language Models (LLMs) often suffer from overconfidence during inference, particularly when adapted to downstream domain-specific tasks with limited data. Previous work addresses this issue by employing approximate Bayesian estimation after the LLMs are trained, enabling them to quantify uncertainty. However, such post-training approaches' performance is severely limited by the parameters learned during training. In this paper, we go beyond post-training Bayesianization and propose Bayesian Low-Rank Adaptation by Backpropagation (BLoB), an algorithm that continuously and jointly adjusts both the mean and covariance of LLM parameters throughout the whole fine-tuning process. Our empirical results verify the effectiveness of BLoB in terms of generalization and uncertainty estimation, when evaluated on both in-distribution and out-of-distribution data.

In offline reinforcement learning, a policy is learned using a static dataset in the absence of costly feedback from the environment. In contrast to the online setting, only using static datasets poses additional challenges, such as policies generating out-of-distribution samples. Model-based offline reinforcement learning methods try to overcome these by learning a model of the underlying dynamics of the environment and using it to guide policy search. It is beneficial but, with limited datasets, errors in the model and the issue of value overestimation among out-of-distribution states can worsen performance. Current model-based methods apply some notion of conservatism to the Bellman update, often implemented using uncertainty estimation derived from model ensembles. In this paper, we propose Constrained Latent Action Policies (C-LAP) which learns a generative model of the joint distribution of observations and actions. We cast policy learning as a constrained objective to always stay within the support of the latent action distribution, and use the generative capabilities of the model to impose an implicit constraint on the generated actions. Thereby eliminating the need to use additional uncertainty penalties on the Bellman update and significantly decreasing the number of gradient steps required to learn a policy. We empirically evaluate C-LAP on the D4RL and V-D4RL benchmark, and show that C-LAP is competitive to state-of-the-art methods, especially outperforming on datasets with visual observations.
tl;dr: We propose faster accelerated primal-dual algorithms for minimizing a convex function subject to strongly convex function constraints.

In this paper, we introduce faster accelerated primal-dual algorithms for minimizing a convex function subject to strongly convex function constraints.
Prior to our work, the best complexity bound was $\mathcal{O}(1/{\varepsilon})$, regardless of the strong convexity of the constraint function.
It is unclear whether the strong convexity assumption can enable even better convergence results.
To address this issue, we have developed novel techniques to progressively estimate the strong convexity of the Lagrangian function.
Our approach, for the first time, effectively leverages the constraint strong convexity, obtaining an improved complexity of $\mathcal{O}(1/\sqrt{\varepsilon})$. This rate matches the complexity lower bound for strongly-convex-concave saddle point optimization and is therefore order-optimal.
We show the superior performance of our methods in sparsity-inducing constrained optimization, notably Google's personalized PageRank problem. Furthermore, we show that a restarted version of the proposed methods can effectively identify the optimal solution's sparsity pattern within a finite number of steps, a result that appears to have independent significance.
tl;dr: BinaryMoS introduces memory-efficient token-adaptive binarization for LLMs, reducing model size and enhancing representation ability of binarized weights

Binarization, which converts weight parameters to binary values, has emerged as an effective strategy to reduce the size of large language models (LLMs). However, typical binarization techniques significantly diminish linguistic effectiveness of LLMs.
To address this issue, we introduce a novel binarization technique called Mixture of Scales (BinaryMoS). Unlike conventional methods, BinaryMoS employs multiple scaling experts for binary weights, dynamically merging these experts for each token to adaptively generate scaling factors. This token-adaptive approach boosts the representational power of binarized LLMs by enabling contextual adjustments to the values of binary weights. Moreover, because this adaptive process only involves the scaling factors rather than the entire weight matrix, BinaryMoS maintains compression efficiency similar to traditional static binarization methods. Our experimental results reveal that BinaryMoS surpasses conventional binarization techniques in various natural language processing tasks and even outperforms 2-bit quantization methods, all while maintaining similar model size to static binarization techniques.

Bayesian reasoning in linear mixed-effects models (LMMs) is challenging and often requires advanced sampling techniques like Markov chain Monte Carlo (MCMC).
A common approach is to write the model in a probabilistic programming language and then sample via Hamiltonian Monte Carlo (HMC).
However, there are many ways a user can transform a model that make inference more or less efficient.
In particular, marginalizing some variables can greatly improve inference but is difficult for users to do manually.
We develop an algorithm to easily marginalize random effects in LMMs.
A naive approach introduces cubic time operations within an inference algorithm like HMC, but we reduce the running time to linear using fast linear algebra techniques.
We show that marginalization is always beneficial when applicable and highlight improvements in various models, especially ones from cognitive sciences.

Consider a hiring process with candidates coming from different universities. It is easy to order candidates with the same background, yet it can be challenging to compare them otherwise. The latter case requires additional costly assessments, leading to a potentially high total cost for the hiring organization. Given an assigned budget, what would be an optimal strategy to select the most qualified candidate?
We model the above problem as a multicolor secretary problem, allowing comparisons between candidates from distinct groups at a fixed cost. Our study explores how the allocated budget enhances the success probability of online selection algorithms.
tl;dr: We introduce Denoising Protein Language Models (DePLM), a novel approach that refines the evolutionary information embodied in PLMs for improved protein optimization

Protein optimization is a fundamental biological task aimed at enhancing theperformance of proteins by modifying their sequences. Computational methodsprimarily rely on evolutionary information (EI) encoded by protein languagemodels (PLMs) to predict fitness landscape for optimization. However, thesemethods suffer from a few limitations. (1) Evolutionary processes involve thesimultaneous consideration of multiple functional properties, often overshadowingthe specific property of interest. (2) Measurements of these properties tend to betailored to experimental conditions, leading to reduced generalizability of trainedmodels to novel proteins. To address these limitations, we introduce DenoisingProtein Language Models (DePLM), a novel approach that refines the evolutionaryinformation embodied in PLMs for improved protein optimization. Specifically, weconceptualize EI as comprising both property-relevant and irrelevant information,with the latter acting as “noise” for the optimization task at hand. Our approachinvolves denoising this EI in PLMs through a diffusion process conducted in therank space of property values, thereby enhancing model generalization and ensuringdataset-agnostic learning. Extensive experimental results have demonstrated thatDePLM not only surpasses the state-of-the-art in mutation effect prediction butalso exhibits strong generalization capabilities for novel proteins.
tl;dr: We define a notion of complexity for a class of probability kernels and show it is the minimax regret of sequential probability assignment, and allows us to describe the minimax algorithm.

We study the fundamental problem of sequential probability assignment, also known as online learning with logarithmic loss, with respect to an arbitrary, possibly nonparametric hypothesis class. Our goal is to obtain a complexity measure for the hypothesis class that characterizes the minimax regret and to determine a general, minimax optimal algorithm. Notably, the sequential $\ell_{\infty}$ entropy, extensively studied in the literature (Rakhlin and Sridharan, 2015, Bilodeau et al., 2020, Wu et al., 2023), was shown to not characterize minimax regret in general. Inspired by the seminal work of Shtarkov (1987)
and Rakhlin, Sridharan, and Tewari (2010), we introduce a novel complexity measure, the \emph{contextual Shtarkov sum}, corresponding to the Shtarkov sum after projection onto a multiary context tree, and show that the worst case log contextual Shtarkov sum equals the minimax regret. Using the contextual Shtarkov sum, we derive the minimax optimal strategy, dubbed \emph{contextual Normalized Maximum Likelihood} (cNML). Our results hold for sequential experts, beyond binary labels, which are settings rarely considered in prior work.
To illustrate the utility of this characterization, we provide a short proof of a new regret upper bound in terms of sequential $\ell_{\infty}$ entropy, unifying and sharpening state-of-the-art bounds by Bilodeau et al. (2020) and Wu et al. (2023).

Many reinforcement learning (RL) algorithms are too costly to use in practice due to the large sizes $S,A$ of the problem's state and action space. To resolve this issue, we study transfer RL with latent low rank structure. We consider the problem of transferring a latent low rank representation when the source and target MDPs have transition kernels with Tucker rank $(S, d, A)$, $(S ,S , d), (d, S , A )$, or $(d , d , d )$. In each setting, we introduce the transfer-ability coefficient $\alpha$ that measures the difficulty of representational transfer. Our algorithm learns latent representations in each source MDP and then exploits the linear structure to remove the dependence on $S , A $, or $SA $ in the target MDP regret bound. We complement our positive results with information theoretic lower bounds that show our algorithms (excluding the ($d, d, d$) setting) are minimax-optimal with respect to $\alpha$.
tl;dr: In this work, we propose the SemiMV baseline, the first approach to apply semi-supervised learning specifically for multispectral video semantic segmentation, and introduce a new UAV-view dataset to advance research in this field.

Thanks to the rapid progress in RGB & thermal imaging, also known as multispectral imaging, the task of multispectral video semantic segmentation, or MVSS in short, has recently drawn significant attentions. Noticeably, it offers new opportunities in improving segmentation performance under unfavorable visual conditions such as poor light or overexposure. Unfortunately, there are currently very few datasets available, including for example MVSeg dataset that focuses purely toward eye-level view; and it features the sparse annotation nature due to the intensive demands of labeling process. To address these key challenges of the MVSS task, this paper presents two major contributions: the introduction of MVUAV, a new MVSS benchmark dataset, and the development of a dedicated semi-supervised MVSS baseline - SemiMV. Our MVUAV dataset is captured via Unmanned Aerial Vehicles (UAV), which offers a unique oblique bird’s-eye view complementary to the existing MVSS datasets; it also encompasses a broad range of day/night lighting conditions and over 30 semantic categories. In the meantime, to better leverage the sparse annotations and extra unlabeled RGB-Thermal videos, a semi-supervised learning baseline, SemiMV, is proposed to enforce consistency regularization through a dedicated Cross-collaborative Consistency Learning (C3L) module and a denoised temporal aggregation strategy. Comprehensive empirical evaluations on both MVSeg and MVUAV benchmark datasets have showcased the efficacy of our SemiMV baseline.
tl;dr: We provide the first sample and computationally efficient learner for Gaussian Single-Index Models, for link functions with a constant information exponent, in the agnostic model.

A single-index model (SIM) is a function of the form $\sigma(\mathbf{w}^{\ast} \cdot \mathbf{x})$, where
$\sigma: \mathbb{R} \to \mathbb{R}$ is a known link function and $\mathbf{w}^{\ast}$ is a hidden unit vector.
We study the task of learning SIMs in the agnostic (a.k.a. adversarial label noise) model
with respect to the $L^2_2$-loss under the Gaussian distribution.
Our main result is a sample and computationally efficient agnostic proper learner
that attains $L^2_2$-error of $O(\mathrm{OPT})+\epsilon$, where $\mathrm{OPT}$ is the optimal loss. The sample complexity of our algorithm is
$\tilde{O}(d^{\lceil k^{\ast}/2\rceil}+d/\epsilon)$, where
$k^{\ast}$ is the information-exponent of $\sigma$
corresponding to the degree of its first non-zero Hermite coefficient.
This sample bound nearly matches known CSQ lower bounds, even in the realizable setting.
Prior algorithmic work in this setting had focused
on learning in the realizable case or in the presence
of semi-random noise. Prior computationally efficient robust learners required
significantly stronger assumptions on the link function.
tl;dr: Policy regret minimization in Markov games against adaptive adversaries is statistically hard for most cases; some other cases, sample-efficient learning is possible

We study learning in a dynamically evolving environment modeled as a Markov game between a learner and a strategic opponent that can adapt to the learner's strategies. While most existing works in Markov games focus on external regret as the learning objective, external regret becomes inadequate when the adversaries are adaptive. In this work, we focus on \emph{policy regret} -- a counterfactual notion that aims to compete with the return that would have been attained if the learner had followed the best fixed sequence of policy, in hindsight. We show that if the opponent has unbounded memory or if it is non-stationary, then sample-efficient learning is not possible. For memory-bounded and stationary, we show that learning is still statistically hard if the set of feasible strategies for the learner is exponentially large. To guarantee learnability, we introduce a new notion of \emph{consistent} adaptive adversaries, wherein, the adversary responds similarly to similar strategies of the learner. We provide algorithms that achieve $\sqrt{T}$ policy regret against memory-bounded, stationary, and consistent adversaries.
1806. KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization

Efficient deployment of Large Language Models (LLMs) requires batching multiple requests together to improve throughput. As batch size, context length, or model size increases, the size of key and value (KV) cache quickly becomes the main contributor to GPU memory usage and the bottleneck of inference latency and throughput. Quantization has emerged as an effective technique for KV cache compression, but existing methods still fail at very low bit widths. Currently, KV cache quantization is performed per-channel or per-token independently. Our analysis shows that distinct channels of a key/value activation embedding are highly interdependent, and the joint entropy of multiple channels grows at a slower rate than the sum of their marginal entropy, which implies that per-channel independent quantization is sub-optimal. To mitigate this sub-optimality, we propose Coupled Quantization (CQ), which couples multiple key/value channels together for quantization to exploit their interdependence and encode the activations in a more information-efficient manner. Extensive experiments reveal that CQ compares favorably with existing baselines in preserving model quality, and improves inference throughput by 1.4–3.5$\times$ relative to the uncompressed baseline. Furthermore, we demonstrate that CQ can preserve model quality reasonably with KV cache quantized down to 1 bit.
tl;dr: An algorithm that essentially provably boosts any loss

Boosting is a highly successful ML-born optimization setting in which one is required to computationally efficiently learn arbitrarily good models based on the access to a weak learner oracle, providing classifiers performing at least slightly differently from random guessing. A key difference with gradient-based optimization is that boosting's original model does not requires access to first order information about a loss, yet the decades long history of boosting has quickly evolved it into a first order optimization setting -- sometimes even wrongfully *defining* it as such. Owing to recent progress extending gradient-based optimization to use only a loss' zeroth ($0^{th}$) order information to learn, this begs the question: what loss functions be efficiently optimized with boosting and what is the information really needed for boosting to meet the *original* boosting blueprint's requirements ?
We provide a constructive formal answer essentially showing that *any* loss function can be optimized with boosting and thus boosting can achieve a feat not yet known to be possible in the classical $0^{th}$ order setting, since loss functions are not required to be be convex, nor differentiable or Lipschitz -- and in fact not required to be continuous either. Some tools we use are rooted in quantum calculus, the mathematical field -- not to be confounded with quantum computation -- that studies calculus without passing to the limit, and thus without using first order information.
tl;dr: We cast preference-guided multi-objective learning as a constrained vector optimization problem to capture flexible preferences, under which provably convergent algorithms are developed.

Finding specific preference-guided Pareto solutions that represent different trade-offs among multiple objectives is critical yet challenging in multi-objective problems.
Existing methods are restrictive in preference definitions and/or their theoretical guarantees.
In this work, we introduce a Flexible framEwork for pREfeRence-guided multi-Objective learning (**FERERO**) by casting it as a constrained vector optimization problem.
Specifically, two types of preferences are incorporated into this formulation -- the *relative preference* defined by the partial ordering induced by a polyhedral cone, and the *absolute preference* defined by constraints that are linear functions of the objectives.
To solve this problem, convergent algorithms are developed with both single-loop and stochastic variants.
Notably, this is the *first single-loop primal algorithm* for constrained vector optimization to our knowledge.
The proposed algorithms adaptively adjust to both constraint and objective values, eliminating the need to solve different subproblems at different stages of constraint satisfaction.
Experiments on multiple benchmarks demonstrate the proposed method is very competitive in finding preference-guided optimal solutions.
Code is available at https://github.com/lisha-chen/FERERO/.

We study the problem of estimating the body movements of a camera wearer from egocentric videos. Current methods for ego-body pose estimation rely on temporally dense sensor data, such as IMU measurements from spatially sparse body parts like the head and hands. However, we propose that even temporally sparse observations, such as hand poses captured intermittently from egocentric videos during natural or periodic hand movements, can effectively constrain overall body motion. Naively applying diffusion models to generate full-body pose from head pose and sparse hand pose leads to suboptimal results. To overcome this, we develop a two-stage approach that decomposes the problem into temporal completion and spatial completion. First, our method employs masked autoencoders to impute hand trajectories by leveraging the spatiotemporal correlations between the head pose sequence and intermittent hand poses, providing uncertainty estimates. Subsequently, we employ conditional diffusion models to generate plausible full-body motions based on these temporally dense trajectories of the head and hands, guided by the uncertainty estimates from the imputation. The effectiveness of our methods was rigorously tested and validated through comprehensive experiments conducted on various HMD setup with AMASS and Ego-Exo4D datasets.
tl;dr: We propose a method that enhances the time complexity of permutation-based causal discovery approaches in linear gaussian acyclic models.

Causal discovery is essential for understanding relationships among variables of interest in many scientific domains. In this paper, we focus on permutation-based methods for learning causal graphs in Linear Gaussian Acyclic Models (LiGAMs), where the permutation encodes a causal ordering of the variables. Existing methods in this setting are not scalable due to their high computational complexity. These methods are comprised of two main components: (i) constructing a specific DAG, $\mathcal{G}^\pi$, for a given permutation $\pi$, which represents the best structure that can be learned from the available data while adhering to $\pi$, and (ii) searching over the space of permutations (i.e., causal orders) to minimize the number of edges in $\mathcal{G}^\pi$. We introduce QWO, a novel approach that significantly enhances the efficiency of computing $\mathcal{G}^\pi$ for a given permutation $\pi$. QWO has a speed-up of $O(n^2)$ ($n$ is the number of variables) compared to the state-of-the-art BIC-based method, making it highly scalable. We show that our method is theoretically sound and can be integrated into existing search strategies such as GRASP and hill-climbing-based methods to improve their performance.

Safe reinforcement learning (RL) requires the agent to finish a given task while obeying specific constraints. Giving constraints in natural language form has great potential for practical scenarios due to its flexible transfer capability and accessibility. Previous safe RL methods with natural language constraints typically need to design cost functions manually for each constraint, which requires domain expertise and lacks flexibility. In this paper, we harness the dual role of text in this task, using it not only to provide constraint but also as a training signal. We introduce the Trajectory-level Textual Constraints Translator (TTCT) to replace the manually designed cost function. Our empirical results demonstrate that TTCT effectively comprehends textual constraint and trajectory, and the policies trained by TTCT can achieve a lower violation rate than the standard cost function. Extra studies are conducted to demonstrate that the TTCT has zero-shot transfer capability to adapt to constraint-shift environments.

Time series forecasting has attracted significant attention in recent decades.
Previous studies have demonstrated that the Channel-Independent (CI) strategy improves forecasting performance by treating different channels individually, while it leads to poor generalization on unseen instances and ignores potentially necessary interactions between channels. Conversely, the Channel-Dependent (CD) strategy mixes all channels with even irrelevant and indiscriminate information, which, however, results in oversmoothing issues and limits forecasting accuracy.
There is a lack of channel strategy that effectively balances individual channel treatment for improved forecasting performance without overlooking essential interactions between channels. Motivated by our observation of a correlation between the time series model's performance boost against channel mixing and the intrinsic similarity on a pair of channels, we developed a novel and adaptable \textbf{C}hannel \textbf{C}lustering \textbf{M}odule (CCM). CCM dynamically groups channels characterized by intrinsic similarities and leverages cluster information instead of individual channel identities, combining the best of CD and CI worlds. Extensive experiments on real-world datasets demonstrate that CCM can (1) boost the performance of CI and CD models by an average margin of 2.4% and 7.2% on long-term and short-term forecasting, respectively; (2) enable zero-shot forecasting with mainstream time series forecasting models; (3) uncover intrinsic time series patterns among channels and improve interpretability of complex time series models.

In this paper, we study the problem of learning the structure of a discrete set of $N$ tokens based on their interactions with other tokens. We focus on a setting where the tokens can be partitioned into a small number of classes, and there exists a real-valued function $f$ defined on certain sets of tokens. This function, which captures the interactions between tokens, depends only on the class memberships of its arguments. The goal is to recover the class memberships of all tokens from a finite number of samples of $f$. We begin by analyzing this problem from both complexity-theoretic and information-theoretic viewpoints. We prove that it is NP-complete in general, and for random instances, we show that on the order of $N\ln(N)$ samples, implying very sparse interactions, suffice to identify the partition. We then investigate the conditions under which gradient flow dynamics of token embeddings can reveal the class structure, finding that this is achievable in certain settings when given on the order of $N^2\ln^2(N)$ samples.
tl;dr: We jointly learn to prove formal mathematical theorems and to propose harder provable conjectures in a self-improving loop

How did humanity coax mathematics from the aether? We explore the Platonic view that mathematics can be discovered from its axioms---a game of conjecture and proof. We describe an agent that jointly learns to pose challenging problems for itself (conjecturing) and solve them (theorem proving). Given a mathematical domain axiomatized in dependent type theory, we first combine methods for constrained decoding and type-directed synthesis to sample valid conjectures from a language model. Our method guarantees well-formed conjectures by construction, even as we start with a randomly initialized model. We use the same model to represent a policy and value function for guiding proof search. Our agent targets generating hard but provable conjectures --- a moving target, since its own theorem proving ability also improves as it trains. We propose novel methods for hindsight relabeling on proof search trees to significantly improve the agent's sample efficiency in both tasks. Experiments on 3 axiomatic domains (propositional logic, arithmetic and group theory) demonstrate that our agent can bootstrap from only the axioms, self-improving in generating true and challenging conjectures and in finding proofs.
1815. Causal Dependence Plots
tl;dr: We introduce a framework for creating model explanation plots based explicitly on causal relationships and illustrate several types including the popular existing method of partial dependence plots as a special case

To use artificial intelligence and machine learning models wisely we must understand how they interact with the world, including how they depend causally on data inputs. In this work we develop Causal Dependence Plots (CDPs) to visualize how a model's predicted outcome depends on changes in a given predictor *along with consequent causal changes in other predictor variables*. Crucially, this differs from standard methods based on independence or holding other predictors constant, such as regression coefficients or Partial Dependence Plots (PDPs). Our explanatory framework generalizes PDPs, including them as a special case, as well as a variety of other interpretive plots that show, for example, the total, direct, and indirect effects of causal mediation. We demonstrate with simulations and real data experiments how CDPs can be combined in a modular way with methods for causal learning or sensitivity analysis. Since people often think causally about input-output dependence, CDPs can be powerful tools in the xAI or interpretable machine learning toolkit and contribute to applications like scientific machine learning and algorithmic fairness.
tl;dr: We propose a new definition of fairness for image restoration algorithms, draw its connection to previous ones, study its theoretical properties, and demonstrate its practical utility.

Fairness in image restoration tasks is the desire to treat different sub-groups of images equally well. Existing definitions of fairness in image restoration are highly restrictive. They consider a reconstruction to be a correct outcome for a group (e.g., women) *only* if it falls within the group's set of ground truth images (e.g., natural images of women); otherwise, it is considered *entirely* incorrect. Consequently, such definitions are prone to controversy, as errors in image restoration can manifest in various ways. In this work we offer an alternative approach towards fairness in image restoration, by considering the *Group Perceptual Index* (GPI), which we define as the statistical distance between the distribution of the group's ground truth images and the distribution of their reconstructions. We assess the fairness of an algorithm by comparing the GPI of different groups, and say that it achieves perfect *Perceptual Fairness* (PF) if the GPIs of all groups are identical. We motivate and theoretically study our new notion of fairness, draw its connection to previous ones, and demonstrate its utility on state-of-the-art face image restoration algorithms.
tl;dr: We analyse the statistical-to-computational gap in learning from higher-order data correlations and show that neural networks learn these correlations more efficiently than kernel methods.

Neural networks excel at discovering statistical patterns in
high-dimensional data sets. In practice, higher-order cumulants, which quantify
the non-Gaussian correlations between three or more variables, are particularly
important for the performance of neural networks. But how efficient are neural
networks at extracting features from higher-order cumulants? We study this
question in the spiked cumulant model, where the statistician needs to recover a
privileged direction or "spike'' from the order-$p\ge 4$ cumulants
of $d$-dimensional inputs.
We first discuss the fundamental statistical and
computational limits of recovering the spike by analysing the number of
samples $n$ required to strongly distinguish between inputs from the spiked
cumulant model and isotropic Gaussian inputs.
Existing literature established the presence of a wide statistical-to-computational gap in this problem. We deepen this line of work by finding an exact formula for the likelihood ratio norm which proves that statistical
distinguishability requires $n\gtrsim d$ samples, while distinguishing the two
distributions in polynomial time requires $n \gtrsim d^2$ samples for a wide
class of algorithms, i.e. those covered by the low-degree conjecture.
Numerical experiments show that neural networks do indeed learn to distinguish
the two distributions with quadratic sample complexity, while ``lazy'' methods
like random features are not better than random guessing in this regime. Our
results show that neural networks extract information from higher-order
correlations in the spiked cumulant model efficiently, and reveal a large gap in
the amount of data required by neural networks and random features to learn from
higher-order cumulants.
1818. Bridging The Gap between Low-rank and Orthogonal Adaptation via Householder Reflection Adaptation
tl;dr: We proposed a new model adaptation method based on Householder reflections, bridging low-rank and orthogonal adaptation and achieving promising performance in NLP, CV, and Math reasoning tasks.

While following different technical routes, both low-rank and orthogonal adaptation techniques can efficiently adapt large-scale pre-training models in specific tasks or domains based on a small piece of trainable parameters. In this study, we bridge the gap between these two techniques, proposing a simple but effective adaptation method based on Householder reflections. Given a pre-trained model, our method fine-tunes its layers by multiplying each frozen weight matrix with an orthogonal matrix constructed by a chain of learnable Householder reflections (HRs). This HR-based orthogonal fine-tuning is equivalent to an adaptive low-rank adaptation. Moreover, we show that the orthogonality of the reflection planes corresponding to the HRs impacts the model capacity and regularity. The analysis motivates us to regularize the orthogonality of the HRs, leading to different implementations of the proposed Householder reflection adaptation (HRA) method. Compared with state-of-the-art methods, HRA achieves superior performance with fewer learnable parameters when adapting large language models and conditional image generators. The code of the experiments is available at https://github.com/DaShenZi721/HRA, and the method has been merged into the [PEFT](https://github.com/huggingface/peft) package.
tl;dr: We observe internal inconsistency in chain-of-thought reasoning and propose a new method to mitigate it for enhanced reasoning performance of language models.

Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks, aided by techniques like chain-of-thought prompting that elicits verbalized reasoning. However, LLMs often generate text with obvious mistakes and contradictions, raising doubts about their ability to robustly process and utilize generated rationales. In this work, we investigate reasoning in LLMs through the lens of internal representations, focusing on how these representations are influenced by generated rationales. Our preliminary analysis reveals that while generated rationales improve answer accuracy, inconsistencies emerge between the model’s internal representations in middle layers and those in final layers, potentially undermining the reliability of their reasoning processes. To address this, we propose internal consistency as a measure of the model’s confidence by examining the agreement of latent predictions decoded from intermediate layers. Extensive empirical studies across different models and datasets demonstrate that internal consistency effectively distinguishes between correct and incorrect reasoning paths. Motivated by this, we propose a new approach to calibrate reasoning by up-weighting reasoning paths with high internal consistency, resulting in a significant boost in reasoning performance. Further analysis uncovers distinct patterns in attention and feed-forward modules across layers, providing insights into the emergence of internal inconsistency. In summary, our results demonstrate the potential of using internal representations for self-evaluation of LLMs. Our code is available at [github.com/zhxieml/internal-consistency](https://github.com/zhxieml/internal-consistency).
tl;dr: We present Drift-Resilient TabPFN, an approach using In-Context Learning via a Prior-Data Fitted Network, to address distribution shifts in tabular data, outperforming existing methods in terms of performance and calibration.

While most ML models expect independent and identically distributed data, this assumption is often violated in real-world scenarios due to distribution shifts, resulting in the degradation of machine learning model performance. Until now, no tabular method has consistently outperformed classical supervised learning, which ignores these shifts. To address temporal distribution shifts, we present Drift-Resilient TabPFN, a fresh approach based on In-Context Learning with a Prior-Data Fitted Network that learns the learning algorithm itself: it accepts the entire training dataset as input and makes predictions on the test set in a single forward pass. Specifically, it learns to approximate Bayesian inference on synthetic datasets drawn from a prior that specifies the model's inductive bias. This prior is based on structural causal models (SCM), which gradually shift over time. To model shifts of these causal models, we use a secondary SCM, that specifies changes in the primary model parameters. The resulting Drift-Resilient TabPFN can be applied to unseen data, runs in seconds on small to moderately sized datasets and needs no hyperparameter tuning. Comprehensive evaluations across 18 synthetic and real-world datasets demonstrate large performance improvements over a wide range of baselines, such as XGB, CatBoost, TabPFN, and applicable methods featured in the Wild-Time benchmark. Compared to the strongest baselines, it improves accuracy from 0.688 to 0.744 and ROC AUC from 0.786 to 0.832 while maintaining stronger calibration. This approach could serve as significant groundwork for further research on out-of-distribution prediction.

Existing image-text modality alignment in Vision Language Models (VLMs) treats each text token equally in an autoregressive manner. Despite being simple and effective, this method results in sub-optimal cross-modal alignment by over-emphasizing the text tokens that are less correlated with or even contradictory with the input images. In this paper, we advocate for distinct contributions for each text token based on its visual correlation. Specifically, we present by contrasting image inputs, the difference in prediction logits on each text token provides strong guidance of visual correlation. We therefore introduce Contrastive Alignment (CAL), a simple yet effective re-weighting strategy that prioritizes training visually correlated tokens. Our experimental results demonstrate that CAL consistently improves different types of VLMs across different resolutions and model sizes on various benchmark datasets. Importantly, our method incurs minimal additional computational overhead, rendering it highly efficient compared to alternative data scaling strategies.
tl;dr: a unified diffusion model for temporal action segmentation and long-term action anticipation

Temporal action segmentation and long-term action anticipation are two popular vision tasks for the temporal analysis of actions in videos.
Despite apparent relevance and potential complementarity, these two problems have been investigated as separate and distinct tasks. In this work, we tackle these two problems, action segmentation, and action anticipation, jointly using a unified diffusion model dubbed ActFusion.
The key idea to unification is to train the model to effectively handle both visible and invisible parts of the sequence in an integrated manner;
the visible part is for temporal segmentation, and the invisible part is for future anticipation.
To this end, we introduce a new anticipative masking strategy during training in which a late part of the video frames is masked as invisible, and learnable tokens replace these frames to learn to predict the invisible future.
Experimental results demonstrate the bi-directional benefits between action segmentation and anticipation.
ActFusion achieves the state-of-the-art performance across the standard benchmarks of 50 Salads, Breakfast, and GTEA, outperforming task-specific models in both of the two tasks with a single unified model through joint learning.
tl;dr: Our motion consistency model not only accelerates text2video diffusion model sampling process, but also can benefit from an additional high-quality image dataset to improve the frame quality of generated videos.

Image diffusion distillation achieves high-fidelity generation with very few sampling steps. However, directly applying these techniques to video models results in unsatisfied frame quality. This issue arises from the limited frame appearance quality in public video datasets, affecting the performance of both teacher and student video diffusion models. Our study aims to improve video diffusion distillation and meanwhile enabling the student model to improve frame appearance using the abundant high-quality image data. To this end, we propose motion consistency models (MCM), a single-stage video diffusion distillation method that disentangles motion and appearance learning. Specifically, MCM involves a video consistency model that distills motion from the video teacher model, and an image discriminator that boosts frame appearance to match high-quality image data. However, directly combining these components leads to two significant challenges: a conflict in frame learning objectives, where video distillation learns from low-quality video frames while the image discriminator targets high-quality images, and training-inference discrepancies due to the differing quality of video samples used during training and inference. To address these challenges, we introduce disentangled motion distillation and mixed trajectory distillation. The former applies the distillation objective solely to the motion representation, while the latter mitigates training-inference discrepancies by mixing distillation trajectories from both the low- and high-quality video domains. Extensive experiments show that our MCM achieves state-of-the-art video diffusion distillation performance. Additionally, our method can enhance frame quality in video diffusion models, producing frames with high aesthetic value or specific styles.
tl;dr: We introduce transferable Boltzmann Generators that allow efficient sampling on unseen small peptide systems

The generation of equilibrium samples of molecular systems has been a long-standing problem in statistical physics. Boltzmann Generators are a generative machine learning method that addresses this issue by learning a transformation via a normalizing flow from a simple prior distribution to the target Boltzmann distribution of interest. Recently, flow matching has been employed to train Boltzmann Generators for small molecular systems in Cartesian coordinates. We extend this work and propose a first framework for Boltzmann Generators that are transferable across chemical space, such that they predict zero-shot Boltzmann distributions for test molecules without being retraining for these systems. These transferable Boltzmann Generators allow approximate sampling from the target distribution of unseen systems, as well as efficient reweighting to the target Boltzmann distribution. The transferability of the proposed framework is evaluated on dipeptides, where we show that it generalizes efficiently to unseen systems.
Furthermore, we demonstrate that our proposed architecture enhances the efficiency of Boltzmann Generators trained on single molecular systems.
tl;dr: We present stochastic bandit algorithms and prove NP-hardness of the adversarial setting for online M${}^{\natural}$-concave function maximization.

M${}^{\natural}$-concave functions, a.k.a. gross substitute valuation functions, play a fundamental role in many fields, including discrete mathematics and economics. In practice, perfect knowledge of M${}^{\natural}$-concave functions is often unavailable a priori, and we can optimize them only interactively based on some feedback. Motivated by such situations, we study online M${}^{\natural}$-concave function maximization problems, which are interactive versions of the problem studied by Murota and Shioura (1999). For the stochastic bandit setting, we present $O(T^{-1/2})$-simple regret and $O(T^{2/3})$-regret algorithms under $T$ times access to unbiased noisy value oracles of M${}^{\natural}$-concave functions. A key to proving these results is the robustness of the greedy algorithm to local errors in M${}^{\natural}$-concave function maximization, which is one of our main technical results. While we obtain those positive results for the stochastic setting, another main result of our work is an impossibility in the adversarial setting. We prove that, even with full-information feedback, no algorithms that run in polynomial time per round can achieve $O(T^{1-c})$ regret for any constant $c > 0$ unless $\mathsf{P} = \mathsf{NP}$. Our proof is based on a reduction from the matroid intersection problem for three matroids, which would be a novel idea in the context of online learning.
tl;dr: A sparsified Newton method to solve entropic-regularized optimal transport, with low per-iteration computational cost, high numerical stability, provable global convergence, and quadratic local convergence rate.

Computational optimal transport (OT) has received massive interests in the machine learning community, and great advances have been gained in the direction of entropic-regularized OT. The Sinkhorn algorithm, as well as its many improved versions, has become the *de facto* solution to large-scale OT problems. However, most of the existing methods behave like first-order methods, which typically require a large number of iterations to converge. More recently, Newton-type methods using sparsified Hessian matrices have demonstrated promising results on OT computation, but there still remain a lot of unresolved open questions. In this article, we make major new progresses towards this direction: first, we propose a novel Hessian sparsification scheme that promises a strict control of the approximation error; second, based on this sparsification scheme, we develop a *safe* Newton-type method that is guaranteed to avoid singularity in computing the search directions; third, the developed algorithm has a clear implementation for practical use, avoiding most hyperparameter tuning; and remarkably, we provide rigorous global and local convergence analysis of the proposed algorithm, which is lacking in the prior literature. Various numerical experiments are conducted to demonstrate the effectiveness of the proposed algorithm in solving large-scale OT problems.
tl;dr: Dynamic image fusion is better than static image fusion.

The inherent challenge of image fusion lies in capturing the correlation of multi-source images and comprehensively integrating effective information from different sources. Most existing techniques fail to perform dynamic image fusion while notably lacking theoretical guarantees, leading to potential deployment risks in this field. Is it possible to conduct dynamic image fusion with a clear theoretical justification? In this paper, we give our solution from a generalization perspective. We proceed to reveal the generalized form of image fusion and derive a new test-time dynamic image fusion paradigm. It provably reduces the upper bound of generalization error. Specifically, we decompose the fused image into multiple components corresponding to its source data. The decomposed components represent the effective information from the source data, thus the gap between them reflects the \textit{Relative Dominability} (RD) of the uni-source data in constructing the fusion image. Theoretically, we prove that the key to reducing generalization error hinges on the negative correlation between the RD-based fusion weight and the uni-source reconstruction loss. Intuitively, RD dynamically highlights the dominant regions of each source and can be naturally converted to the corresponding fusion weight, achieving robust results. Extensive experiments and discussions with in-depth analysis on multiple benchmarks confirm our findings and superiority. Our code is available at https://github.com/Yinan-Xia/TTD.

Large Language Models (LLMs) are typically harmless but remain vulnerable to carefully crafted prompts known as ``jailbreaks'', which can bypass protective measures and induce harmful behavior. Recent advancements in LLMs have incorporated moderation guardrails that can filter outputs, which trigger processing errors for certain malicious questions. Existing red-teaming benchmarks often neglect to include questions that trigger moderation guardrails, making it difficult to evaluate jailbreak effectiveness. To address this issue, we introduce JAMBench, a harmful behavior benchmark designed to trigger and evaluate moderation guardrails. JAMBench involves 160 manually crafted instructions covering four major risk categories at multiple severity levels. Furthermore, we propose a jailbreak method, JAM (Jailbreak Against Moderation), designed to attack moderation guardrails using jailbreak prefixes to bypass input-level filters and a fine-tuned shadow model functionally equivalent to the guardrail model to generate cipher characters to bypass output-level filters. Our extensive experiments on four LLMs demonstrate that JAM achieves higher jailbreak success ($\sim$ $\times$ 19.88) and lower filtered-out rates ($\sim$ $\times$ 1/6) than baselines.

The sharp increase in data-related expenses has motivated research into condensing datasets while retaining the most informative features. Dataset distillation has thus recently come to the fore. This paradigm generates synthetic datasets that are representative enough to replace the original dataset in training a neural network. To avoid redundancy in these synthetic datasets, it is crucial that each element contains unique features and remains diverse from others during the synthesis stage. In this paper, we provide a thorough theoretical and empirical analysis of diversity within synthesized datasets. We argue that enhancing diversity can improve the parallelizable yet isolated synthesizing approach. Specifically, we introduce a novel method that employs dynamic and directed weight adjustment techniques to modulate the synthesis process, thereby maximizing the representativeness and diversity of each synthetic instance. Our method ensures that each batch of synthetic data mirrors the characteristics of a large, varying subset of the original dataset. Extensive experiments across multiple datasets, including CIFAR, Tiny-ImageNet, and ImageNet-1K, demonstrate the superior performance of our method, highlighting its effectiveness in producing diverse and representative synthetic datasets with minimal computational expense. Our code is available at https://github.com/AngusDujw/Diversity-Driven-Synthesis.

Large language models (LLMs) often hallucinate and lack the ability to provide attribution for their generations. Semi-parametric LMs, such as kNN-LM, approach these limitations by refining the output of an LM for a given prompt using its nearest neighbor matches in a non-parametric data store. However, these models often exhibit slow inference speeds and produce non-fluent texts. In this paper, we introduce Nearest Neighbor Speculative Decoding (NEST), a novel semi-parametric language modeling approach that is capable of incorporating real-world text spans of arbitrary length into the LM generations and providing attribution to their sources. NEST performs token-level retrieval at each inference step to compute a semi-parametric mixture distribution and identify promising span continuations in a corpus. It then uses an approximate speculative decoding procedure that accepts a prefix of the retrieved span or generates a new token. NEST significantly enhances the generation quality and attribution rate of the base LM across a variety of knowledge-intensive tasks, surpassing the conventional kNN-LM method and performing competitively with in-context retrieval augmentation. In addition, NEST substantially improves the generation speed, achieving a 1.8x speedup in inference time when applied to Llama-2-Chat 70B. Code will be released at https://github.com/facebookresearch/NEST/tree/main.
tl;dr: Diffusion with guidance does not do what its motivation suggests; in linearly separable settings it samples from the edges of each class

The use of guidance in diffusion models was originally motivated by the premise that the guidance-modified score is that of the data distribution tilted by a conditional likelihood raised to some power. In this work we clarify this misconception by rigorously proving that guidance fails to sample from the intended tilted distribution. Our main result is to give a fine-grained characterization of the dynamics of guidance in two cases, (1) mixtures of compactly supported distributions and (2) mixtures of Gaussians, which reflect salient properties of guidance that manifest on real-world data. In both cases, we prove that as the guidance parameter increases, the guided model samples more heavily from the boundary of the support of the conditional distribution. We also prove that for any nonzero level of score estimation error, sufficiently large guidance will result in sampling away from the support, theoretically justifying the empirical finding that large guidance results in distorted generations. In addition to verifying these results empirically in synthetic settings, we also show how our theoretical insights can offer useful prescriptions for practical deployment.

Decoding non-invasive brain recordings is pivotal for advancing our understanding of human cognition but faces challenges due to individual differences and complex neural signal representations. Traditional methods often require customized models and extensive trials, lacking interpretability in visual reconstruction tasks. Our framework integrates 3D brain structures with visual semantics using a *Vision Transformer 3D*. This unified feature extractor efficiently aligns fMRI features with multiple levels of visual embeddings, eliminating the need for subject-specific models and allowing extraction from single-trial data. The extractor consolidates multi-level visual features into one network, simplifying integration with Large Language Models (LLMs). Additionally, we have enhanced the fMRI dataset with diverse fMRI-image-related textual data to support multimodal large model development. Integrating with LLMs enhances decoding capabilities, enabling tasks such as brain captioning, complex reasoning, concept localization, and visual reconstruction. Our approach demonstrates superior performance across these tasks, precisely identifying language-based concepts within brain signals, enhancing interpretability, and providing deeper insights into neural processes. These advances significantly broaden the applicability of non-invasive brain decoding in neuroscience and human-computer interaction, setting the stage for advanced brain-computer interfaces and cognitive models.
tl;dr: Extending Gaussian splatting to handle occlusions and appearance changes when transferring to in-the-wild captures.

While the field of 3D scene reconstruction is dominated by NeRFs due to their photorealistic quality, 3D Gaussian Splatting (3DGS) has recently emerged, offering similar quality with real-time rendering speeds. However, both methods primarily excel with well-controlled 3D scenes, while in-the-wild data - characterized by occlusions, dynamic objects, and varying illumination - remains challenging. NeRFs can adapt to such conditions easily through per-image embedding vectors, but 3DGS struggles due to its explicit representation and lack of shared parameters. To address this, we introduce WildGaussians, a novel approach to handle occlusions and appearance changes with 3DGS. By leveraging robust DINO features and integrating an appearance modeling module within 3DGS, our method achieves state-of-the-art results. We demonstrate that WildGaussians matches the real-time rendering speed of 3DGS while surpassing both 3DGS and NeRF baselines in handling in-the-wild data, all within a simple architectural framework.
tl;dr: To address the increasing uncertainty of binocular 3D HPE due to the reduction of views compared to multiview setups, we propose a Dual-Diffusion method to simutaneously denoise the 3D and 2D poses.

Binocular 3D human pose estimation (HPE), reconstructing a 3D pose from 2D poses of two views, offers practical advantages by combining multiview geometry with the convenience of a monocular setup. However, compared to a multiview setup, the reduction in the number of cameras increases uncertainty in 3D reconstruction. To address this issue, we leverage the diffusion model, which has shown success in monocular 3D HPE by recovering 3D poses from noisy data with high uncertainty. Yet, the uncertainty distribution of initial 3D poses remains unknown. Considering that 3D errors stem from 2D errors within geometric constraints, we recognize that the uncertainties of 3D and 2D are integrated in a binocular configuration, with the initial 2D uncertainty being well-defined. Based on this insight, we propose Dual-Diffusion specifically for Binocular 3D HPE, simultaneously denoising the uncertainties in 2D and 3D, and recovering plausible and accurate results. Additionally, we introduce Z-embedding as an additional condition for denoising and implement baseline-width-related pose normalization to enhance the model flexibility for various baseline settings. This is crucial as 3D error influence factors encompass depth and baseline width. Extensive experiments validate the effectiveness of our Dual-Diffusion in 2D refinement and 3D estimation. The code and models are available at https://github.com/sherrywan/Dual-Diffusion.
tl;dr: This paper introduces SGA+ a method that works better and is less sensitive to hyperparameter settings

Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models.
We extend this idea by introducing SGA+, which contains three different methods that build upon SGA.
We show how our method improves the overall compression performance in terms of the R-D trade-off, compared to its predecessors. Additionally, we show how refinement of the latents with our best-performing method improves the compression performance on both the Tecnick and CLIC dataset. Our method is deployed for a pre-trained hyperprior and for a more flexible model.
Further, we give a detailed analysis of our proposed methods and show that they are less sensitive to hyperparameter choices. Finally, we show how each method can be extended to three- instead of two-class rounding.
tl;dr: We propose a residual adaptation paradigm for the visual grounding of intrinsic dynamics.

While humans effortlessly discern intrinsic dynamics and adapt to new scenarios, modern AI systems often struggle. Current methods for visual grounding of dynamics either use pure neural-network-based simulators (black box), which may violate physical laws, or traditional physical simulators (white box), which rely on expert-defined equations that may not fully capture actual dynamics. We propose the Neural Material Adaptor (NeuMA), which integrates existing physical laws with learned corrections, facilitating accurate learning of actual dynamics while maintaining the generalizability and interpretability of physical priors. Additionally, we propose Particle-GS, a particle-driven 3D Gaussian Splatting variant that bridges simulation and observed images, allowing back-propagate image gradients to optimize the simulator. Comprehensive experiments on various dynamics in terms of grounded particle accuracy, dynamic rendering quality, and generalization ability demonstrate that NeuMA can accurately capture intrinsic dynamics. Project Page: https://xjay18.github.io/projects/neuma.html.
tl;dr: We train a Large Reconstruction Model (LRM) on a synthesized 3D dataset and closely match the performance of the state-of-the-art LRM model trained on real 3D data.

We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: https://desaixie.github.io/lrm-zero/.

Large Language models (LLMs) have demonstrated supreme capabilities in textual understanding and generation, but cannot be directly applied to cross-modal tasks without fine-tuning. This paper proposes a cross-modal in-context learning approach, empowering the frozen LLMs to achieve multiple audio tasks in a few-shot style without any parameter update.
Specifically, we propose a novel LLM-driven audio codec model, LLM-Codec, which transfers the audio modality into textual space by representing audio tokens with words or sub-words from the LLM vocabulary, while maintaining high audio reconstruction quality.
The key idea is to reduce the modality heterogeneity between text and audio by compressing the audio modality into the well-trained textual space of LLMs. Thus, the audio representation can be viewed as a new \textit{foreign language}, and LLMs can learn the new \textit{foreign language} with several demonstrations. In experiments, we investigate the performance of the proposed approach across multiple audio understanding and generation tasks, \textit{e.g.} speech emotion classification, audio classification, text-to-speech generation, speech enhancement, etc. Experimental results show that LLMs equipped with the LLM-Codec, named as UniAudio 1.5, prompted by only a few examples, can perform effectively in simple scenarios, validating our cross-modal in-context learning approach.
To facilitate research on few-shot audio task learning and multi-modal LLMs, we have open-sourced the LLM-Codec model.
tl;dr: In this study, we introduce a novel hierarchical learning framework for enhancing coordination in large-scale MAS by leveraging suboptimal human knowledge in an end-to-end manner.

Due to the exponential growth of agent interactions and the curse of dimensionality, learning efficient coordination from scratch is inherently challenging in large-scale multi-agent systems. While agents' learning is data-driven, sampling from millions of steps, human learning processes are quite different. Inspired by the concept of Human-on-the-Loop and the daily human hierarchical control, we propose a novel knowledge-guided multi-agent reinforcement learning framework (hhk-MARL), which combines human abstract knowledge with hierarchical reinforcement learning to address the learning difficulties among a large number of agents. In this work, fuzzy logic is applied to represent human suboptimal knowledge, and agents are allowed to freely decide how to leverage the proposed prior knowledge. Additionally, a graph-based group controller is built to enhance agent coordination. The proposed framework is end-to-end and compatible with various existing algorithms. We conduct experiments in challenging domains of the StarCraft Multi-agent Challenge combined with three famous algorithms: IQL, QMIX, and Qatten. The results show that our approach can greatly accelerate the training process and improve the final performance, even based on low-performance human prior knowledge.

Large Vision-Language Models (LVLMs) typically encode an image into a fixed number of visual tokens (e.g., 576) and process these tokens with a language model. Despite their strong performance, LVLMs face challenges in adapting to varying computational constraints. This raises the question: can we achieve flexibility in the number of visual tokens to suit different tasks and computational resources? We answer this with an emphatic yes. Inspired by Matryoshka Representation Learning, we introduce the Matryoshka Query Transformer (MQT), capable of encoding an image into $m$ visual tokens during inference, where $m$ can be any number up to a predefined maximum. This is achieved by employing a query transformer with $M$ latent query tokens to compress the visual embeddings. During each training step, we randomly select $m \leq M$ latent query tokens and train the model using only these first $m$ tokens, discarding the rest.
Combining MQT with LLaVA, we train a single model once, and flexibly and drastically reduce the number of inference-time visual tokens while maintaining similar or better performance compared to training independent models for each number of tokens.
Our model, MQT-LLaVA, matches LLaVA-1.5 performance across 11 benchmarks using a maximum of 256 tokens instead of LLaVA’s fixed 576. Reducing to 16 tokens (8x less TFLOPs) only sacrifices the performance by 2.4 points on MMBench. On certain tasks such as ScienceQA and MMMU, we can even go down to only 2 visual tokens with performance drops of just 3\% and 6\% each.
Our exploration of the trade-off between the accuracy and computational cost brought about by the number of visual tokens facilitates future research to achieve the best of both worlds.
1841. Multivariate Stochastic Dominance via Optimal Transport and Applications to Models Benchmarking
tl;dr: We extend the univariate first order stochastic dominance hypothesis testing to the multivariate case using entropic smooth optimal transport

Stochastic dominance is an important concept in probability theory, econometrics and social choice theory for robustly modeling agents' preferences between random outcomes. While many works have been dedicated to the univariate case,
little has been done in the multivariate scenario, wherein an agent has to decide between different multivariate outcomes. By exploiting a characterization of multivariate first stochastic dominance in terms of couplings, we introduce a statistic that assesses multivariate almost stochastic dominance under the framework of Optimal Transport with a smooth cost. Further, we introduce an entropic regularization of this statistic, and establish a central limit theorem (CLT) and consistency of the bootstrap procedure for the empirical statistic. Armed with this CLT, we propose a hypothesis testing framework as well as an efficient implementation using the Sinkhorn algorithm. We showcase our method in comparing and benchmarking Large Language Models that are evaluated on multiple metrics. Our multivariate stochastic dominance test allows us to capture the dependencies between the metrics in order to make an informed and statistically significant decision on the relative performance of the models.
1842. The Power of Hard Attention Transformers on Data Sequences: A formal language theoretic perspective
tl;dr: We prove results about the expressiveness of Unique Hard Attention Transformers (UHAT) on sequences of data (i.e. tuples of numbers)

Formal language theory has recently been successfully employed to unravel
the power of transformer encoders. This setting is primarily applicable in
Natural Language Processing (NLP), as a token embedding function (where
a bounded number of tokens is admitted) is first applied before feeding
the input to the transformer.
On certain kinds of data (e.g. time
series), we want our transformers to be able to handle arbitrary
input sequences of numbers (or tuples thereof) without a priori
limiting the values of these numbers. In this
paper, we initiate the study of the expressive power of transformer encoders
on sequences of data (i.e. tuples of numbers).
Our results indicate an increase in expressive power of
hard attention transformers over data sequences, in stark contrast to the
case of strings.
In particular, we prove that Unique Hard Attention Transformers (UHAT) over
inputs as data sequences no longer lie within the circuit complexity
class AC0 (even without positional encodings), unlike the case of string
inputs,
but are still within the complexity class TC0 (even with positional
encodings). Over strings, UHAT without positional encodings capture only
regular languages. In contrast, we show that over data sequences
UHAT can capture non-regular properties.
Finally, we show that UHAT capture languages
definable in an extension of linear temporal logic with unary numeric
predicates and arithmetics.
tl;dr: We study the integration of surrogate data from different sources alongside real data in training, via weighted risk minimization and provide theoretical and empirical evidence for a new scaling law that allows to optimize the weighting scheme.

Collecting large quantities of high-quality data can be prohibitively expensive or impractical, and a bottleneck in machine learning. One may instead augment a small set of $n$ data points from the target distribution with data from more accessible sources, e.g. data collected under different circumstances or synthesized by generative models. We refer to such data as `surrogate data'. We study a weighted empirical risk minimization (ERM) approach for integrating surrogate data into training. We analyze mathematically this method under several classical statistical models, and validate our findings empirically on datasets from different domains. Our main findings are: $(i)$ Integrating surrogate data can significantly reduce the test error on the original distribution. Surprisingly, this can happen even when the surrogate data is unrelated to the original ones. We trace back this behavior to the classical Stein's paradox. $(ii)$ In order to reap the benefit of surrogate data, it is crucial to use optimally weighted ERM. $(iii)$ The test error of models trained on mixtures of real and surrogate data is approximately described by a scaling law. This scaling law can be used to predict the optimal weighting scheme, and to choose the amount of surrogate data to add.
1844. Uni-Med: A Unified Medical Generalist Foundation Model For Multi-Task Learning Via Connector-MoE

Multi-modal large language models (MLLMs) have shown impressive capabilities as a general-purpose interface for various visual and linguistic tasks. However, building a unified MLLM for multi-task learning in the medical field remains a thorny challenge. To mitigate the tug-of-war problem of multi-modal multi-task optimization in MLLMs, recent advances primarily focus on improving the LLM components, while neglecting the connector that bridges the gap between modalities. In this paper, we introduce Uni-Med, a novel medical generalist foundation model which consists of a universal visual feature extraction module, a connector mixture-of-experts (CMoE) module, and an LLM. Benefiting from the proposed CMoE that leverages a well-designed router with a mixture of projection experts at the connector, Uni-Med achieves efficient solution to the tug-of-war problem and can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification. To the best of our knowledge, Uni-Med is the first effort to tackle multi-task interference at the connector in MLLMs. Extensive ablation experiments validate the effectiveness of introducing CMoE under any configuration, with up to an average 8% performance gains. We further provide interpretation analysis of the tug-of-war problem from the perspective of gradient optimization and parameter statistics. Compared to previous state-of-the-art medical MLLMs, Uni-Med achieves competitive or superior evaluation metrics on diverse tasks. Code and resources are available at https://github.com/tsinghua-msiip/Uni-Med.
tl;dr: We propose a framework of natural counterfactuals and a method for generating counterfactuals that are more feasible with respect to the actual data distribution.

Counterfactual reasoning is pivotal in human cognition and especially important for providing explanations and making decisions. While Judea Pearl's influential approach is theoretically elegant, its generation of a counterfactual scenario often requires too much deviation from the observed scenarios to be feasible, as we show using simple examples. To mitigate this difficulty, we propose a framework of natural counterfactuals and a method for generating counterfactuals that are more feasible with respect to the actual data distribution. Our methodology incorporates a certain amount of backtracking when needed, allowing changes in causally preceding variables to minimize deviations from realistic scenarios. Specifically, we introduce a novel optimization framework that permits but also controls the extent of backtracking with a "naturalness'' criterion. Empirical experiments demonstrate the effectiveness of our method. The code is available at https://github.com/GuangyuanHao/natural_counterfactuals.
tl;dr: We prove novel approximation and statistical theory for transformers and show this can be used to predict empirically observed scaling laws.

When training deep neural networks, a model's generalization error is often observed to follow a power scaling law dependent both on the model size and the data size. Perhaps the best known example of such scaling laws are for transformer-based large language models (**LLMs**), where networks with billions of parameters are trained on trillions of tokens of text. Yet, despite sustained widespread interest, a rigorous understanding of why transformer scaling laws exist is still missing. To answer this question, we establish novel statistical estimation and mathematical approximation theories for transformers when the input data are concentrated on a low-dimensional manifold. Our theory predicts a power law between the generalization error and both the training data size and the network size for transformers, where the power depends on the intrinsic dimension $d$ of the training data. Notably, the constructed model architecture is shallow, requiring only logarithmic depth in $d$. By leveraging low-dimensional data structures under a manifold hypothesis, we are able to explain transformer scaling laws in a way which respects the data geometry. Moreover, we test our theory with empirical observation by training LLMs on natural language datasets. We find the observed empirical scaling laws closely agree with our theoretical predictions. Taken together, these results rigorously show the intrinsic dimension of data to be a crucial quantity affecting transformer scaling laws in both theory and practice.

This paper explores the weakly-supervised referring image segmentation (WRIS) problem, and focuses on a challenging setup where target localization is learned directly from image-text pairs.
We note that the input text description typically already contains detailed information on how to localize the target object, and we also observe that humans often follow a step-by-step comprehension process (\ie, progressively utilizing target-related attributes and relations as cues) to identify the target object.
Hence, we propose a novel Progressive Comprehension Network (PCNet) to leverage target-related textual cues from the input description for progressively localizing the target object.
Specifically, we first use a Large Language Model (LLM) to decompose the input text description into short phrases. These short phrases are taken as target-related cues and fed into a Conditional Referring Module (CRM) in multiple stages, to allow updating the referring text embedding and enhance the response map for target localization in a multi-stage manner.
Based on the CRM, we then propose a Region-aware Shrinking (RaS) loss to constrain the visual localization to be conducted progressively in a coarse-to-fine manner across different stages.
Finally, we introduce an Instance-aware Disambiguation (IaD) loss to suppress instance localization ambiguity by differentiating overlapping response maps generated by different referring texts on the same image.
Extensive experiments show that our method outperforms SOTA methods on three common benchmarks.

Continual learning (CL) aims to adapt to non-stationary data distributions while retaining previously acquired knowledge. However, CL models typically face a trade-off between preserving old task knowledge and excelling in new task performance. Existing approaches often sacrifice one for the other. To overcome this limitation, orthogonal to existing approaches, we propose a novel perspective that views the CL model ability in preserving old knowledge and performing well in new task as a matter of model sensitivity to parameter updates. \textit{Excessive} parameter sensitivity can lead to two drawbacks: (1) significant forgetting of previous knowledge; and (2) overfitting to new tasks. To reduce parameter sensitivity, we optimize the model's performance based on the parameter distribution, which achieves the worst-case CL performance within a distribution neighborhood. This innovative learning paradigm offers dual benefits: (1) reduced forgetting of old knowledge by mitigating drastic changes in model predictions under small parameter updates; and (2) enhanced new task performance by preventing overfitting to new tasks. Consequently, our method achieves superior ability in retaining old knowledge and achieving excellent new task performance simultaneously.
Importantly, our approach is compatible with existing CL methodologies, allowing seamless integration while delivering significant improvements in effectiveness, efficiency, and versatility with both theoretical and empirical supports.

Second-order optimization has been shown to accelerate the training of deep neural networks in many applications, often yielding faster progress per iteration on the training loss compared to first-order optimizers. However, the generalization properties of second-order methods are still being debated. Theoretical investigations have proved difficult to carry out outside the tractable settings of heavily simplified model classes - thus, the relevance of existing theories to practical deep learning applications remains unclear. Similarly, empirical studies in large-scale models and real datasets are significantly confounded by the necessity to approximate second-order updates in practice. It is often unclear whether the observed generalization behaviour arises specifically from the second-order nature of the parameter updates, or instead reflects the specific structured (e.g. Kronecker) approximations used or any damping-based interpolation towards first-order updates. Here, we show for the first time that exact Gauss-Newton (GN) updates take on a tractable form in a class of deep reversible architectures that are sufficiently expressive to be meaningfully applied to common benchmark datasets. We exploit this novel setting to study the training and generalization properties of the GN optimizer. We find that exact GN generalizes poorly. In the mini-batch training setting, this manifests as rapidly saturating progress even on the training loss, with parameter updates found to overfit each mini-batch without producing the features that would support generalization to other mini-batches. In contrast to previous work, we show that our experiments run in the feature learning regime, in which the neural tangent kernel (NTK) changes during the course of training. However, changes in the NTK are not associated with any significant change in neural representations, explaining the lack of generalization.
tl;dr: This paper explores the in-context learning capabilities of masked language models, challenging the common view that such abilities are only present in causal language models.

While in-context learning is commonly associated with causal language models, such as GPT, we demonstrate that this capability also 'emerges' in masked language models. Through an embarrassingly simple inference technique, we enable an existing masked model, DeBERTa, to perform generative tasks without additional training or architectural changes. Our evaluation reveals that the masked and causal language models behave very differently, as they clearly outperform each other on different categories of tasks. These complementary strengths suggest that the field's focus on causal models for in-context learning may be limiting – both architectures can develop these capabilities, but with distinct advantages; pointing toward promising hybrid approaches that combine the strengths of both objectives.
tl;dr: a new method for token merging in transformer architecture

Increasing the throughput of the Transformer architecture, a foundational component used in numerous state-of-the-art models for vision and language tasks (e.g., GPT, LLaVa), is an important problem in machine learning. One recent and effective strategy is to merge token representations within Transformer models, aiming to reduce computational and memory requirements while maintaining accuracy. Prior work has proposed algorithms based on Bipartite Soft Matching (BSM), which divides tokens into distinct sets and merges the top $k$ similar tokens. However, these methods have significant drawbacks, such as sensitivity to token-splitting strategies and damage to informative tokens in later layers. This paper presents a novel paradigm called PiToMe, which prioritizes the preservation of informative tokens using an additional metric termed the \textit{energy score}. This score identifies large clusters of similar tokens as high-energy, indicating potential candidates for merging, while smaller (unique and isolated) clusters are considered as low-energy and preserved. Experimental findings demonstrate that PiToMe saved from 40-60\% FLOPs of the base models while exhibiting superior off-the-shelf performance on image classification (0.5\% average performance drop of ViT-MAEH compared to 2.6\% as baselines), image-text retrieval (0.3\% average performance drop of Clip on Flick30k compared to 4.5\% as others), and analogously in visual questions answering with LLaVa-7B. Furthermore, PiToMe is theoretically shown to preserve intrinsic spectral properties to the original token space under mild conditions.
tl;dr: We show that only a narrow range of large LRs is beneficial for generalization and analyze it from the loss landscape and feature learning perspectives.

It is generally accepted that starting neural networks training with large learning rates (LRs) improves generalization. Following a line of research devoted to understanding this effect, we conduct an empirical study in a controlled setting focusing on two questions: 1) how large an initial LR is required for obtaining optimal quality, and 2) what are the key differences between models trained with different LRs? We discover that only a narrow range of initial LRs slightly above the convergence threshold lead to optimal results after fine-tuning with a small LR or weight averaging. By studying the local geometry of reached minima, we observe that using LRs from this optimal range allows for the optimization to locate a basin that only contains high-quality minima. Additionally, we show that these initial LRs result in a sparse set of learned features, with a clear focus on those most relevant for the task. In contrast, starting training with too small LRs leads to unstable minima and attempts to learn all features simultaneously, resulting in poor generalization. Conversely, using initial LRs that are too large fails to detect a basin with good solutions and extract meaningful patterns from the data.

Fine-tuning is a crucial process for adapting large language models (LLMs) to diverse applications. In certain scenarios, such as multi-tenant serving, deploying multiple LLMs becomes necessary to meet complex demands. Recent studies suggest decomposing a fine-tuned LLM into a base model and corresponding delta weights, which are then compressed using low-rank or low-bit approaches to reduce costs. In this work, we observe that existing low-rank and low-bit compression methods can significantly harm the model performance for task-specific fine-tuned LLMs (e.g., WizardMath for math problems). Motivated by the long-tail distribution of singular values in the delta weights, we propose a delta quantization approach using mixed-precision. This method employs higher-bit representation for singular vectors corresponding to larger singular values. We evaluate our approach on various fine-tuned LLMs, including math LLMs, code LLMs, chat LLMs, and even VLMs. Experimental results demonstrate that our approach performs comparably to full fine-tuned LLMs, surpassing both low-rank and low-bit baselines by a considerable margin. Additionally, we show that our method is compatible with various backbone LLMs, such as Llama-2, Llama-3, and Mistral, highlighting its generalizability.

A Random Utility Model (RUM) is a classical model of user behavior defined by a distribution over $\mathbb{R}^n$. A user, presented with a subset of $\\{1,\ldots,n\\}$, will select the item of the subset with the highest utility, according to a utility vector drawn from the specified distribution. In practical settings, the subset is often of small size, as in the ``ten blue links'' of web search.
In this paper, we consider a learning setting with complete information on user choices from subsets of size at most $k$. We show that $k=\Theta(\sqrt{n})$ is both necessary and sufficient to predict the distribution of all user choices with an arbitrarily small, constant error.
Based on the upper bound, we obtain new algorithms for approximate RUM learning and variations thereof. Furthermore, we employ our lower bound for approximate RUM learning to derive lower bounds to fractional extensions of the well-studied $k$-deck and trace reconstruction problems.
tl;dr: Propose algorithms for non-parametric classification via expansion-and-sparsify representation and prove that the convergence rate is minimax-optimal.

In *expand-and-sparsify* (EaS) representation, a data point in $\mathcal{S}^{d-1}$ is first randomly mapped to higher dimension $\mathbb{R}^m$, where $m>d$, followed by a sparsification operation where the informative $k \ll m$ of the $m$ coordinates are set to one and the rest are set to zero. We propose two algorithms for non-parametric classification using such EaS representation. For our first algorithm, we use *winners-take-all* operation for the sparsification step and show that the proposed classifier admits the form of a locally weighted average classifier and establish its consistency via Stone's Theorem. Further, assuming that the conditional probability function $P(y=1|x)=\eta(x)$ is H\"{o}lder continuous and for optimal choice of $m$, we show that the convergence rate of this classifier is minimax-optimal. For our second algorithm, we use *empirical $k$-thresholding* operation for the sparsification step, and under the assumption that data lie on a low dimensional manifold of dimension $d_0\ll d$, we show that the convergence rate of this classifier depends only on $d_0$ and is again minimax-optimal. Empirical evaluations performed on real-world datasets corroborate our theoretical results.

Mean-field variational inference (VI) is computationally scalable, but its highly-demanding independence requirement hinders it from being applied to wider scenarios. Although many VI methods that take correlation into account have been proposed, these methods generally are not scalable enough to capture the correlation among data instances, which often arises in applications with graph-structured data or explicit constraints. In this paper, we developed the Tree-structured Variational Inference (TreeVI), which uses a tree structure to capture the correlation of latent variables in the posterior distribution. We show that samples from the tree-structured posterior can be reparameterized efficiently and parallelly, making its training cost just 2 or 3 times that of VI under the mean-field assumption. To capture correlation with more complicated structure, the TreeVI is further extended to the multiple-tree case. Furthermore, we show that the underlying tree structure can be automatically learned from training data. With experiments on synthetic datasets, constrained clustering, user matching and link prediction, we demonstrate that the TreeVI is superior in capturing instance-level correlation in posteriors and enhancing the performance of downstream applications.
tl;dr: A method for obtaining a debiased classifier by modulating the network depth.

Neural networks trained on biased datasets tend to inadvertently learn spurious correlations, hindering generalization. We formally prove that (1) samples that exhibit spurious correlations lie on a lower rank manifold relative to the ones that do not; and (2) the depth of a network acts as an implicit regularizer on the rank of the attribute subspace that is encoded in its representations. Leveraging these insights, we present DeNetDM, a novel debiasing method that uses network depth modulation as a way of developing robustness to spurious correlations. Using a training paradigm derived from Product of Experts, we create both biased and debiased branches with deep and shallow architectures and then distill knowledge to produce the target debiased model. Our method requires no bias annotations or explicit data augmentation while performing on par with approaches that require either or both. We demonstrate that DeNetDM outperforms existing debiasing techniques on both synthetic and real-world datasets by 5\%. The project page is available at https://vssilpa.github.io/denetdm/.
1858. Dynamic Subgroup Identification in Covariate-adjusted Response-adaptive Randomization Experiments

Identifying subgroups with differential responses to treatment is pivotal in randomized clinical trials, as tailoring treatments to specific subgroups can advance personalized medicine. Upon trial completion, identifying best-performing subgroups–those with the most beneficial treatment effects–is crucial for optimizing resource allocation or mitigating adverse treatment effects. However, traditional clinical trials are not customized for the goal of identifying best-performing subgroups because they typically pre-define subgroups at the beginning of the trial and adhere to a fixed subgroup treatment allocation rule, leading to inefficient use of experimental efforts. While some adaptive experimental strategies exist for the identification of the single best subgroup, they commonly do not enable the identification of the best set of subgroups. To address these challenges, we propose a dynamic subgroup identification covariate-adjusted response-adaptive randomization (CARA) design strategy with the following key features: (i) Our approach is an adaptive experimental strategy that allows the dynamic identification of the best subgroups and the revision of treatment allocation towards the goal of correctly identifying the best subgroups based on collected experimental data. (ii) Our design handles ties between subgroups effectively, merging those with similar treatment effects to maximize experimental efficiency. In the theoretical investigations, we demonstrate that our design has a higher probability of correctly identifying the best set of subgroups compared to conventional designs. Additionally, we prove the statistical validity of our estimator for the best subgroup treatment effect, demonstrating its asymptotic normality and semiparametric efficiency. Finally, we validate our design using synthetic data from a clinical trial on cirrhosis.

Point-based methods have made significant progress, but improving their scalability in large-scale 3D scenes is still a challenging problem. In this paper, we delve into the point-based method and develop a simpler, faster, stronger variant model, dubbed as LinNet. In particular, we first propose the disassembled set abstraction (DSA) module, which is more effective than the previous version of set abstraction. It achieves more efficient local aggregation by leveraging spatial anisotropy and channel anisotropy separately. Additionally, by mapping 3D point clouds onto 1D space-filling curves, we enable parallelization of downsampling and neighborhood queries on GPUs with linear complexity.
LinNet, as a purely point-based method, outperforms most previous methods in both indoor and outdoor scenes without any extra attention, and sparse convolution but merely relying on a simple MLP. It achieves the mIoU of 73.7\%, 81.4\%, and 69.1\% on the S3DIS Area5, NuScenes, and SemanticKITTI validation benchmarks, respectively, while speeding up almost 10x times over PointNeXt. Our work further reveals both the efficacy and efficiency potential of the vanilla point-based models in large-scale representation learning. Our code will be available upon publication.
tl;dr: A causal perspective on bounding worst-case risk of classifiers for domain generalization.

A fundamental task in AI is providing performance guarantees for predictions made in unseen domains. In practice, there can be substantial uncertainty about the distribution of new data, and corresponding variability in the performance of existing predictors. Building on the theory of partial identification and transportability, this paper introduces new results for bounding the value of a functional of the target distribution, such as the generalization error of a classifiers, given data from source domains and assumptions about the data generating mechanisms, encoded in causal diagrams. Our contribution is to provide the first general estimation technique for transportability problems, adapting existing parameterization schemes such Neural Causal Models to encode the structural constraints necessary for cross-population inference. We demonstrate the expressiveness and consistency of this procedure and further propose a gradient-based optimization scheme for making scalable inferences in practice. Our results are corroborated with experiments.
tl;dr: This paper offers a comprehensive analysis of the expected calibration error using the information-theoretic generalization analysis.

While the expected calibration error (ECE), which employs binning, is widely adopted to evaluate the calibration performance of machine learning models, theoretical understanding of its estimation bias is limited. In this paper, we present the first comprehensive analysis of the estimation bias in the two common binning strategies, uniform mass and uniform width binning.
Our analysis establishes upper bounds on the bias, achieving an improved convergence rate. Moreover, our bounds reveal, for the first time, the optimal number of bins to minimize the estimation bias. We further extend our bias analysis to generalization error analysis based on the information-theoretic approach, deriving upper bounds that enable the numerical evaluation of how small the ECE is for unknown data. Experiments using deep learning models show that our bounds are nonvacuous thanks to this information-theoretic generalization analysis approach.
tl;dr: We identify an unexplored but important problem called Universal Unsupervised Cross-Domain Retrieval, and propose a two-stage semantic feature learning framework to address it.

Cross-domain retrieval (CDR) is finding increasingly broad applications across various domains. However, existing efforts have several major limitations, with the most critical being their reliance on accurate supervision. Recent studies thus focus on achieving unsupervised CDR, but they typically assume that the category spaces across domains are identical, an assumption that is often unrealistic in real-world scenarios. This is because only through dedicated and comprehensive analysis can the category composition of a data domain be obtained, which contradicts the premise of unsupervised scenarios. Therefore, in this work, we introduce the problem of **U**niversal **U**nsupervised **C**ross-**D**omain **R**etrieval (U^2CDR) for the first time and design a two-stage semantic feature learning framework to address it. In the first stage, a cross-domain unified prototypical structure is established under the guidance of an instance-prototype-mixed contrastive loss and a semantic-enhanced loss, to counteract category space differences. In the second stage, through a modified adversarial training mechanism, we ensure minimal changes for the established prototypical structure during domain alignment, enabling more accurate nearest-neighbor searching. Extensive experiments across multiple datasets and scenarios, including close-set, partial, and open-set CDR, demonstrate that our approach significantly outperforms existing state-of-the-art CDR methods and other related methods in solving U^2CDR challenges.
tl;dr: We propose DreamScene4D, the first video-to-4D scene generation approach to produce realistic 4D scene representation from real-world multi-object videos.

View-predictive generative models provide strong priors for lifting object-centric images and videos into 3D and 4D through rendering and score distillation objectives. A question then remains: what about lifting complete multi-object dynamic scenes? There are two challenges in this direction: First, rendering error gradients are often insufficient to recover fast object motion, and second, view predictive generative models work much better for objects than whole scenes, so, score distillation objectives cannot currently be applied at the scene level directly. We present DreamScene4D, the first approach to generate 3D dynamic scenes of multiple objects from monocular videos via 360-degree novel view synthesis. Our key insight is a "decompose-recompose" approach that factorizes the video scene into the background and object tracks, while also factorizing object motion into 3 components: object-centric deformation, object-to-world-frame transformation, and camera motion. Such decomposition permits rendering error gradients and object view-predictive models to recover object 3D completions and deformations while bounding box tracks guide the large object movements in the scene. We show extensive results on challenging DAVIS, Kubric, and self-captured videos with quantitative comparisons and a user preference study. Besides 4D scene generation, DreamScene4D obtains accurate 2D persistent point track by projecting the inferred 3D trajectories to 2D. We will release our code and hope our work will stimulate more research on fine-grained 4D understanding from videos.

We introduce a novel approach for detecting distribution shifts that negatively impact the performance of machine learning models in continuous production environments, which requires no access to ground truth data labels. It builds upon the work of Podkopaev and Ramdas [2022], who address scenarios where labels are available for tracking model errors over time. Our solution extends this framework to work in the absence of labels, by employing a proxy for the true error. This proxy is derived using the predictions of a trained error estimator. Experiments show that our method has high power and false alarm control under various distribution shifts, including covariate and label shifts and natural shifts over geography and time.

Recent work in interpretability shows that large language models (LLMs) can be adapted for new tasks in a learning-free way: it is possible to intervene on LLM representations to elicit desired behaviors for alignment. For instance, adding certain bias vectors to the outputs of certain attention heads is reported to boost the truthfulness of models. In this work, we show that localized fine-tuning serves as an effective alternative to such representation intervention methods. We introduce a framework called Localized Fine-Tuning on LLM Representations (LoFiT), which identifies a subset of attention heads that are most important for learning a specific task, then trains offset vectors to add to the model's hidden representations at those selected heads. LoFiT localizes to a sparse set of heads (3%-10%) and learns the offset vectors from limited training data, comparable to the settings used for representation intervention. For truthfulness and reasoning tasks, we find that LoFiT's intervention vectors are more effective for LLM adaptation than vectors from representation intervention methods such as Inference-time Intervention. We also find that the localization step is important: selecting a task-specific set of attention heads can lead to higher performance than intervening on heads selected for a different task. Finally, across 7 tasks we study, LoFiT achieves comparable performance to other parameter-efficient fine-tuning methods such as LoRA, despite modifying 20x-200x fewer parameters than these methods.

The proliferation of 2D foundation models has sparked research into adapting them for open-world 3D instance segmentation. Recent methods introduce a paradigm that leverages superpoints as geometric primitives and incorporates 2D multi-view masks from Segment Anything model (SAM) as merging guidance, achieving outstanding zero-shot instance segmentation results. However, the limited use of 3D priors restricts the segmentation performance. Previous methods calculate the 3D superpoints solely based on estimated normal from spatial coordinates, resulting in under-segmentation for instances with similar geometry. Besides, the heavy reliance on SAM and hand-crafted algorithms in 2D space suffers from over-segmentation due to SAM's inherent part-level segmentation tendency. To address these issues, we propose SA3DIP, a novel method for Segmenting Any 3D Instances via exploiting potential 3D Priors. Specifically, on one hand, we generate complementary 3D primitives based on both geometric and textural priors, which reduces the initial errors that accumulate in subsequent procedures. On the other hand, we introduce supplemental constraints from the 3D space by using a 3D detector to guide a further merging process. Furthermore, we notice a considerable portion of low-quality ground truth annotations in ScanNetV2 benchmark, which affect the fair evaluations. Thus, we present ScanNetV2-INS with complete ground truth labels and supplement additional instances for 3D class-agnostic instance segmentation. Experimental evaluations on various 2D-3D datasets demonstrate the effectiveness and robustness of our approach. Our code and proposed ScanNetV2-INS dataset are available HERE.
tl;dr: We provide a simple framework for minimizing dynamic regret using algorithms designed for static regret

We study the problem of dynamic regret minimization in online convex optimization, in which the objective is to minimize the difference between the cumulative loss of an algorithm and that of an arbitrary sequence of comparators. While the literature on this topic is very rich, a unifying framework for the analysis and design of these algorithms is still missing. In this paper we show that /for linear losses, dynamic regret minimization is equivalent to static regret minimization in an extended decision space/. Using this simple observation, we show that there is a frontier of lower bounds trading off penalties due to the variance of the losses and penalties due to variability of the comparator sequence, and provide a framework for achieving any of the guarantees along this frontier. As a result, we also prove for the first time that adapting to the squared path-length of an arbitrary sequence of comparators to achieve regret $R_{T}(u_{1},\dots,u_{T})\le O(\sqrt{T\sum_{t} \\|u_{t}-u_{t+1}\\|^{2}})$ is impossible. However, using our framework we introduce an alternative notion of variability based on a locally-smoothed comparator sequence $\bar u_{1}, \dots, \bar u_{T}$, and provide an algorithm guaranteeing dynamic regret of the form $R_{T}(u_{1},\dots,u_{T})\le \tilde O(\sqrt{T\sum_{i}\\|\bar u_{i}-\bar u_{i+1}\\|^{2}})$, while still matching in the worst case the usual path-length dependencies up to polylogarithmic terms.
tl;dr: The Logistic Schedule is designed for diffusion-based image editing, to eliminate singularities, improve inversion stability, and mitigate exposure bias, thereby enhancing content preservation and edit fidelity.

Text-guided diffusion models have significantly advanced image editing, enabling high-quality and diverse modifications driven by text prompts. However, effective editing requires inverting the source image into a latent space, a process often hindered by prediction errors inherent in DDIM inversion.
These errors accumulate during the diffusion process, resulting in inferior content preservation and edit fidelity, especially with conditional inputs.
We address these challenges by investigating the primary contributors to error accumulation in DDIM inversion and identify the singularity problem in traditional noise schedules as a key issue.
To resolve this, we introduce the *Logistic Schedule*, a novel noise schedule designed to eliminate singularities, improve inversion stability, and provide a better noise space for image editing. This schedule reduces noise prediction errors, enabling more faithful editing that preserves the original content of the source image. Our approach requires no additional retraining and is compatible with various existing editing methods.
Experiments across eight editing tasks demonstrate the Logistic Schedule's superior performance in content preservation and edit fidelity compared to traditional noise schedules, highlighting its adaptability and effectiveness.
The project page is available at https://lonelvino.github.io/SYE/.

Modeling the shape of garments has received much attention, but most existing approaches assume the garments to be worn by someone, which constrains the range of shapes they can assume. In this work, we address shape recovery when garments are being manipulated instead of worn, which gives rise to an even larger range of possible shapes. To this end, we leverage the implicit sewing patterns (ISP) model for garment modeling and extend it by adding a diffusion-based deformation prior to represent these shapes. To recover 3D garment shapes from incomplete 3D point clouds acquired when the garment is folded, we map the points to UV space, in which our priors are learned, to produce partial UV maps, and then fit the priors to recover complete UV maps and 2D to 3D mappings. Experimental results demonstrate the superior reconstruction accuracy of our method compared to previous ones, especially when dealing with large non-rigid deformations arising from the manipulations.
tl;dr: This paper incorporates a notion of model sharpness into the training loss of the surrogate as a sharpness regularizer to boost the performance of existing offline optimization methods..

Offline optimization has recently emerged as an increasingly popular approach to mitigate the prohibitively expensive cost of online experimentation. The key idea is to learn a surrogate of the black-box function that underlines the target experiment using a static (offline) dataset of its previous input-output queries. Such an approach is, however, fraught with an out-of-distribution issue where the learned surrogate becomes inaccurate outside the offline data regimes. To mitigate this, existing offline optimizers have proposed numerous conditioning techniques to prevent the learned surrogate from being too erratic. Nonetheless, such conditioning strategies are often specific to particular surrogate or search models, which might not generalize to a different model choice. This motivates us to develop a model-agnostic approach instead, which incorporates a notion of model sharpness into the training loss of the surrogate as a regularizer. Our approach is supported by a new theoretical analysis demonstrating that reducing surrogate sharpness on the offline dataset provably reduces its generalized sharpness on unseen data. Our analysis extends existing theories from bounding generalized prediction loss (on unseen data) with loss sharpness to bounding the worst-case generalized surrogate sharpness with its empirical estimate on training data, providing a new perspective on sharpness regularization. Our extensive experimentation on a diverse range of optimization tasks also shows that reducing surrogate sharpness often leads to significant improvement, marking (up to) a noticeable 9.6% performance boost. Our code is publicly available at https://github.com/cuong-dm/IGNITE.
1871. PACE: marrying the generalization of PArameter-efficient fine-tuning with Consistency rEgularization

Parameter-Efficient Fine-Tuning (PEFT) effectively adapts pre-trained transformers to downstream tasks. However, the optimization for tasks performance often comes at the cost of generalizability in fine-tuned models. To address this issue, we theoretically connect smaller weight gradient norms during training and larger datasets to the improved model generalization. Motivated by this connection, we propose reducing gradient norms for enhanced generalization and aligning fine-tuned model with the pre-trained counterpart to retain knowledge from large-scale pre-training data. Yet, naive alignment does not guarantee gradient reduction and can potentially cause gradient explosion, complicating efforts to manage gradients. To address such issues, we propose PACE, marrying generalization of PArameter-efficient fine-tuning with Consistency rEgularization. We perturb features learned from the adapter with the multiplicative noise and ensure the fine-tuned model remains consistent for same sample under different perturbations. Theoretical analysis shows that PACE not only implicitly regularizes gradients for enhanced generalization, but also implicitly aligns the fine-tuned and pre-trained models to retain knowledge. Experimental evidence supports our theories. PACE surpasses existing PEFT methods in visual adaptation tasks (VTAB-1k, FGVC, few-shot learning, domain adaptation) and showing potential for resource-efficient fine-tuning. It also improves LoRA in text classification (GLUE) and mathematical reasoning (GSM-8K).
tl;dr: We propose a novel 3D representation that enhances 3D synthesis by capturing intricate object details, both inside and outside!

We introduce X-Ray, a novel 3D sequential representation inspired by the penetrability of x-ray scans. X-Ray transforms a 3D object into a series of surface frames at different layers, making it suitable for generating 3D models from images. Our method utilizes ray casting from the camera center to capture geometric and textured details, including depth, normal, and color, across all intersected surfaces. This process efficiently condenses the whole 3D object into a multi-frame video format, motivating the utilize of a network architecture similar to those in video diffusion models. This design ensures an efficient 3D representation by focusing solely on surface information. Also, we propose a two-stage pipeline to generate 3D objects from X-Ray Diffusion Model and Upsampler. We demonstrate the practicality and adaptability of our X-Ray representation by synthesizing the complete visible and hidden surfaces of a 3D object from a single input image. Experimental results reveal the state-of-the-art superiority of our representation in enhancing the accuracy of 3D generation, paving the way for new 3D representation research and practical applications.
Our project page is in \url{https://tau-yihouxiang.github.io/projects/X-Ray/X-Ray.html}.

Recurrent Neural Networks (RNNs) are used to learn representations in partially observable environments. For agents that learn online and continually interact with the environment, it is desirable to train RNNs with real-time recurrent learning (RTRL); unfortunately, RTRL is prohibitively expensive for standard RNNs. A promising direction is to use linear recurrent architectures (LRUs), where dense recurrent weights are replaced with a complex-valued diagonal, making RTRL efficient. In this work, we build on these insights to provide a lightweight but effective approach for training RNNs in online RL. We introduce Recurrent Trace Units (RTUs), a small modification on LRUs that we nonetheless find to have significant performance benefits over LRUs when trained with RTRL. We find RTUs significantly outperform GRUs and Transformers across several partially observable environments while using significantly less computation.

The training of score-based diffusion models (SDMs) is based on score matching. The challenge of score matching is that it includes a computationally expensive Jacobian trace. While several methods have been proposed to avoid this computation, each has drawbacks, such as instability during training and approximating the learning as learning a denoising vector field rather than a true score.
We propose a novel score matching variant, local curvature smoothing with Stein's identity (LCSS). The LCSS bypasses the Jacobian trace by applying Stein's identity, enabling regularization effectiveness and efficient computation. We show that LCSS surpasses existing methods in sample generation performance and matches the performance of denoising score matching, widely adopted by most SDMs, in evaluations such as FID, Inception score, and bits per dimension. Furthermore, we show that LCSS enables realistic image generation even at a high resolution of $1024 \times 1024$.
tl;dr: We propose BeNeDiff, a method for revealing disentangled neural dynamics associated with behaviors via generative diffusion models.

Understanding the neural basis of behavior is a fundamental goal in neuroscience. Current research in large-scale neuro-behavioral data analysis often relies on decoding models, which quantify behavioral information in neural data but lack details on behavior encoding. This raises an intriguing scientific question: "how can we enable in-depth exploration of neural representations in behavioral tasks, revealing interpretable neural dynamics associated with behaviors". However, addressing this issue is challenging due to the varied behavioral encoding across different brain regions and mixed selectivity at the population level. To tackle this limitation, our approach, named ("BeNeDiff"), first identifies a fine-grained and disentangled neural subspace using a behavior-informed latent variable model. It then employs state-of-the-art generative diffusion models to synthesize behavior videos that interpret the neural dynamics of each latent factor. We validate the method on multi-session datasets containing widefield calcium imaging recordings across the dorsal cortex. Through guiding the diffusion model to activate individual latent factors, we verify that the neural dynamics of latent factors in the disentangled neural subspace provide interpretable quantifications of the behaviors of interest. At the same time, the neural subspace in BeNeDiff demonstrates high disentanglement and neural reconstruction quality.
tl;dr: Previous research on Federated Unlearning lacked focus on feature unlearning. This paper introduces Ferrari, a framework aimed at facilitating Federated Feature Unlearning. Ferrari utilizes Lipschitz Continuity to efficiently unlearn features.

The advent of Federated Learning (FL) highlights the practical necessity for the ’right to be forgotten’ for all clients, allowing them to request data deletion from the machine learning model’s service provider. This necessity has spurred a growing demand for Federated Unlearning (FU). Feature unlearning has gained considerable attention due to its applications in unlearning sensitive, backdoor, and biased features. Existing methods employ the influence function to achieve feature unlearning, which is impractical for FL as it necessitates the participation of other clients, if not all, in the unlearning process. Furthermore, current research lacks an evaluation of the effectiveness of feature unlearning. To address these limitations, we define feature sensitivity in evaluating feature unlearning according to Lipschitz continuity. This metric characterizes the model output’s rate of change or sensitivity to perturbations in the input feature. We then propose an effective federated feature unlearning framework called Ferrari, which minimizes feature sensitivity. Extensive experimental results and theoretical analysis demonstrate the effectiveness of Ferrari across various feature unlearning scenarios, including sensitive, backdoor, and biased features. The code is publicly available at https://github.com/OngWinKent/Federated-Feature-Unlearning
tl;dr: An audio-visual Gaussian Splatting approach to learn holistic scene priors for novel view acoustic synthesis.

Novel view acoustic synthesis (NVAS) aims to render binaural audio at any target viewpoint, given a mono audio emitted by a sound source at a 3D scene. Existing methods have proposed NeRF-based implicit models to exploit visual cues as a condition for synthesizing binaural audio. However, in addition to low efficiency originating from heavy NeRF rendering, these methods all have a limited ability of characterizing the entire scene environment such as room geometry, material properties, and the spatial relation between the listener and sound source. To address these issues, we propose a novel Audio-Visual Gaussian Splatting (AV-GS) model. To obtain a material-aware and geometry-aware condition for audio synthesis, we learn an explicit point-based scene representation with audio-guidance parameters on locally initialized Gaussian points, taking into account the space relation from the listener and sound source. To make the visual scene model audio adaptive, we propose a point densification and pruning strategy to optimally distribute the Gaussian points, with the per-point contribution in sound propagation (e.g., more points needed for texture-less wall surfaces as they affect sound path diversion). Extensive experiments validate the superiority of our AV-GS over existing alternatives on the real-world RWAS and simulation-based SoundSpaces datasets. Project page: \url{https://surrey-uplab.github.io/research/avgs/}
tl;dr: We propose novel selective generation algorithms to mitigate the hallucination issues of LLMs.

Trustworthiness of generative language models (GLMs) is crucial in their deployment to critical decision making systems. Hence, certified risk control methods such as selective prediction and conformal prediction have been applied to mitigating the hallucination problem in various supervised downstream tasks. However, the lack of appropriate correctness metric hinders applying such principled methods to language generation tasks. In this paper, we circumvent this problem by leveraging the concept of textual entailment to evaluate the correctness of the generated sequence, and propose two selective generation algorithms which control the false discovery rate with respect to the textual entailment relation (FDR-E) with a theoretical guarantee: $\texttt{SGen}^{\texttt{Sup}}$ and $\texttt{SGen}^{\texttt{Semi}}$. $\texttt{SGen}^{\texttt{Sup}}$, a direct modification of the selective prediction, is a supervised learning algorithm which exploits entailment-labeled data, annotated by humans. Since human annotation is costly, we further propose a semi-supervised version, $\texttt{SGen}^{\texttt{Semi}}$, which fully utilizes the unlabeled data by pseudo-labeling, leveraging an entailment set function learned via conformal prediction. Furthermore, $\texttt{SGen}^{\texttt{Semi}}$ enables to use more general class of selection functions, neuro-selection functions, and provides users with an optimal selection function class given multiple candidates. Finally, we demonstrate the efficacy of the $\texttt{SGen}$ family in achieving a desired FDR-E level with comparable selection efficiency to those from baselines on both open and closed source GLMs. Code and datasets are provided at https://github.com/ml-postech/selective-generation.

Data-driven algorithm design is a promising, learning-based approach for beyond worst-case analysis of algorithms with tunable parameters. An important open problem is the design of computationally efficient data-driven algorithms for combinatorial algorithm families with multiple parameters. As one fixes the problem instance and varies the parameters, the “dual” loss function typically has a piecewise-decomposable structure, i.e. is well-behaved except at certain sharp transition boundaries. Motivated by prior empirical work, we initiate the study of techniques to develop efficient ERM learning algorithms for data-driven algorithm design by enumerating the pieces of the sum dual loss functions for a collection of problem instances. The running time of our approach scales with the actual number of pieces that appear as opposed to worst case upper bounds on the number of pieces. Our approach involves two novel ingredients – an output-sensitive algorithm for enumerating polytopes induced by a set of hyperplanes using tools from computational geometry, and an execution graph which compactly represents all the states the algorithm could attain for all possible parameter values. We illustrate our techniques by giving algorithms for pricing problems, linkage-based clustering and dynamic-programming based sequence alignment.

Graph Neural Networks (GNNs) have emerged as a dominant approach in graph representation learning, yet they often struggle to capture consistent similarity relationships among graphs. To capture similarity relationships, while graph kernel methods like the Weisfeiler-Lehman subtree (WL-subtree) and Weisfeiler-Lehman optimal assignment (WLOA) perform effectively, they are heavily reliant on predefined kernels and lack sufficient non-linearities. Our work aims to bridge the gap between neural network methods and kernel approaches by enabling GNNs to consistently capture relational structures in their learned representations. Given the analogy between the message-passing process of GNNs and WL algorithms, we thoroughly compare and analyze the properties of WL-subtree and WLOA kernels. We find that the similarities captured by WLOA at different iterations are asymptotically consistent, ensuring that similar graphs remain similar in subsequent iterations, thereby leading to superior performance over the WL-subtree kernel. Inspired by these findings, we conjecture that the consistency in the similarities of graph representations across GNN layers is crucial in capturing relational structures and enhancing graph classification performance. Thus, we propose a loss to enforce the similarity of graph representations to be consistent across different layers. Our empirical analysis verifies our conjecture and shows that our proposed consistency loss can significantly enhance graph classification performance across several GNN backbones on various datasets.
tl;dr: We propose a novel neuron attribution method tailored for MLLMs to reveal the modality-specific semantic knowledge learned by neurons.

As Large Language Models (LLMs) demonstrate impressive capabilities, demystifying their internal mechanisms becomes increasingly vital. Neuron attribution, which attributes LLM outputs to specific neurons to reveal the semantic properties they learn, has emerged as a key interpretability approach. However, while neuron attribution has made significant progress in deciphering text-only LLMs, its application to Multimodal LLMs (MLLMs) remains less explored. To address this gap, we propose a novel Neuron Attribution method tailored for MLLMs, termed NAM. Specifically, NAM not only reveals the modality-specific semantic knowledge learned by neurons within MLLMs, but also highlights several intriguing properties of neurons, such as cross-modal invariance and semantic sensitivity. These properties collectively elucidate the inner workings mechanism of MLLMs, providing a deeper understanding of how MLLMs process and generate multi-modal content. Through theoretical analysis and empirical validation, we demonstrate the efficacy of NAM and the valuable insights it offers. Furthermore, leveraging NAM, we introduce a multi-modal knowledge editing paradigm, underscoring the practical significance of our approach for downstream applications of MLLMs.

Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples. We refer to this problem as task concept learning and present our approach, Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM), which learns new task concepts by leveraging invertible neural generative models. The core idea is to pretrain a generative model on a set of basic concepts and their demonstrations. Then, given a few demonstrations of a new concept (such as a new goal or a new action), our method learns the underlying concepts through backpropagation without updating the model weights, thanks to the invertibility of the generative model. We evaluate our method in five domains -- object rearrangement, goal-oriented navigation, motion caption of human actions, autonomous driving, and real-world table-top manipulation. Our experimental results demonstrate that via the pretrained generative model, we successfully learn novel concepts and generate agent plans or motion corresponding to these concepts in (1) unseen environments and (2) in composition with training concepts.
tl;dr: We propose iVideoGPT, an autoregressive transformer architecture for scalable world models, pre-train it on millions of trajectories and adapt it to a wide range of tasks, including video prediction, visual planning, and model-based RL.

World models empower model-based agents to interactively explore, reason, and plan within imagined environments for real-world decision-making. However, the high demand for interactivity poses challenges in harnessing recent advancements in video generative models for developing world models at scale. This work introduces Interactive VideoGPT (iVideoGPT), a scalable autoregressive transformer framework that integrates multimodal signals—visual observations, actions, and rewards—into a sequence of tokens, facilitating an interactive experience of agents via next-token prediction. iVideoGPT features a novel compressive tokenization technique that efficiently discretizes high-dimensional visual observations. Leveraging its scalable architecture, we are able to pre-train iVideoGPT on millions of human and robotic manipulation trajectories, establishing a versatile foundation that is adaptable to serve as interactive world models for a wide range of downstream tasks. These include action-conditioned video prediction, visual planning, and model-based reinforcement learning, where iVideoGPT achieves competitive performance compared with state-of-the-art methods. Our work advances the development of interactive general world models, bridging the gap between generative video models and practical model-based reinforcement learning applications. Code and pre-trained models are available at https://thuml.github.io/iVideoGPT.
1884. Generative Forests
tl;dr: A new class of tree-based generative models and a training algorithm with fast, boosting compliant induction and models that can be used for data generation, missing data imputation and density estimation.

We focus on generative AI for a type of data that still represent one of the most prevalent form of data: tabular data. We introduce a new powerful class of forest-based models fit for such tasks and a simple training algorithm with strong convergence guarantees in a boosting model that parallels that of the original weak / strong supervised learning setting. This algorithm can be implemented by a few tweaks to the most popular induction scheme for decision tree induction (*i.e. supervised learning*) with two classes. Experiments on the quality of generated data display substantial improvements compared to the state of the art. The losses our algorithm minimize and the structure of our models make them practical for related tasks that require fast estimation of a density given a generative model and an observation (even partially specified): such tasks include missing data imputation and density estimation. Additional experiments on these tasks reveal that our models can be notably good contenders to diverse state of the art methods, relying on models as diverse as (or mixing elements of) trees, neural nets, kernels or graphical models.
tl;dr: Transferring vision-language models to visual classification via AWT framework (Augmentation, Weighting, and Transportation).

Pre-trained vision-language models (VLMs) have shown impressive results in various visual classification tasks.
However, we often fail to fully unleash their potential when adapting them for new concept understanding due to limited information on new classes.
To address this limitation, we introduce a novel adaptation framework, AWT (Augment, Weight, then Transport). AWT comprises three key components: augmenting inputs with diverse visual perspectives and enriched class descriptions through image transformations and language models; dynamically weighting inputs based on the prediction entropy; and employing optimal transport to mine semantic correlations in the vision-language space.
AWT can be seamlessly integrated into various VLMs, enhancing their zero-shot capabilities without additional training and facilitating few-shot learning through an integrated multimodal adapter module.
We verify AWT in multiple challenging scenarios, including zero-shot and few-shot image classification, zero-shot video action recognition, and out-of-distribution generalization. AWT consistently outperforms the state-of-the-art methods in each setting. In addition, our extensive studies further demonstrate AWT's effectiveness and adaptability across different VLMs, architectures, and scales.

Despite recent progress made by large language models in code generation, they still struggle with programs that meet complex requirements. Recent work utilizes plan-and-solve decomposition to decrease the complexity and leverage self-tests to refine the generated program. Yet, planning deep-inside requirements in advance can be challenging, and the tests need to be accurate to accomplish self-improvement. To this end, we propose FunCoder, a code generation framework incorporating the divide-and-conquer strategy with functional consensus. Specifically, FunCoder recursively branches off sub-functions as smaller goals during code generation, represented by a tree hierarchy. These sub-functions are then composited to attain more complex objectives. Additionally, we designate functions via a consensus formed by identifying similarities in program behavior, mitigating error propagation. FunCoder outperforms state-of-the-art methods by +9.8% on average in HumanEval, MBPP, xCodeEval and MATH with GPT-3.5 and GPT-4. Moreover, our method demonstrates superiority on smaller models: With FunCoder, StableCode-3b surpasses GPT-3.5 by +18.6% and achieves 97.7% of GPT-4's performance on HumanEval. Further analysis reveals that our proposed dynamic function decomposition is capable of handling complex requirements, and the functional consensus prevails over self-testing in correctness evaluation.

Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks. In this work we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps. We train using a modified DPO loss with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy on GSM8K, MATH, and ARC-Challenge for Llama-2-70B-Chat, outperforming other Llama-2-based models not relying on additionally sourced datasets. For example, we see a large improvement from 55.6% to 81.6% on GSM8K and an accuracy of 88.7% with majority voting out of 32 samples.

Pre-trained vision language models (VLMs), though powerful, typically lack training on decision-centric data, rendering them sub-optimal for decision-making tasks such as in-the-wild device control through Graphical User Interfaces (GUIs) when used off-the-shelf. While training with static demonstrations has shown some promise, we show that such methods fall short when controlling real GUIs due to their failure to deal with real world stochasticity and dynamism not captured in static observational data. This paper introduces a novel autonomous RL approach, called DigiRL, for training in-the-wild device control agents through fine-tuning a pre-trained VLM in two stages: offline and offline-to-online RL. We first build a scalable and parallelizable Android learning environment equipped with a VLM-based general-purpose evaluator and then identify the key design choices for simple and effective RL in this domain. We demonstrate the effectiveness of DigiRL using the Android-in-the-Wild (AitW) dataset, where our 1.5B VLM trained with RL achieves a 49.5\% absolute improvement -- from 17.7 to 67.2\% success rate -- over supervised fine-tuning with static human demonstration data. It is worth noting that such improvement is achieved without any additional supervision or demonstration data. These results significantly surpass not only the prior best agents, including AppAgent with GPT-4V (8.3\% success rate) and the 17B CogAgent trained with AitW data (14.4\%), but also our implementation of prior best autonomous RL approach based on filtered behavior cloning (57.8\%), thereby establishing a new state-of-the-art for digital agents for in-the-wild device control.
1889. FlowLLM: Flow Matching for Material Generation with Large Language Models as Base Distributions
tl;dr: New generative model for materials combining Large Language Models and Riemannian Flow Matching, that significantly outperforms prior methods.

Material discovery is a critical area of research with the potential to revolutionize various fields, including carbon capture, renewable energy, and electronics. However, the immense scale of the chemical space makes it challenging to explore all possible materials experimentally. In this paper, we introduce FlowLLM, a novel generative model that combines large language models (LLMs) and Riemannian flow matching (RFM) to design novel crystalline materials. FlowLLM first fine-tunes an LLM to learn an effective base distribution of meta-stable crystals in a text representation. After converting to a graph representation, the RFM model takes samples from the LLM and iteratively refines the coordinates and lattice parameters. Our approach significantly outperforms state-of-the-art methods, increasing the generation rate of stable materials by over three times and increasing the rate for stable, unique, and novel crystals by $\sim50$% – a huge improvement on a difficult problem. Additionally, the crystals generated by FlowLLM are much closer to their relaxed state when compared with another leading model, significantly reducing post-hoc computational cost.
tl;dr: We build on the recent success of control techniques for training SSMs for dynamical systems reconstruction (DSR), and propose a scalable DSR algorithm for empirical situations in which we deal with convolved observations, such as fMRI time series.

Data-driven inference of the generative dynamics underlying a set of observed time series is of growing interest in machine learning and the natural sciences. In neuroscience, such methods promise to alleviate the need to handcraft models based on biophysical principles and allow to automatize the inference of inter-individual differences in brain dynamics.
Recent breakthroughs in training techniques for state space models (SSMs) specifically geared toward dynamical systems (DS) reconstruction (DSR) enable to recover the underlying system including its geometrical (attractor) and long-term statistical invariants from even short time series. These techniques are based on control-theoretic ideas, like modern variants of teacher forcing (TF), to ensure stable loss gradient propagation while training.
However, as it currently stands, these techniques are not directly applicable to data modalities where current observations depend on an entire history of previous states due to a signal’s filtering properties, as common in neuroscience (and physiology more generally).
Prominent examples are the blood oxygenation level dependent (BOLD) signal in functional magnetic resonance imaging (fMRI) or Ca$^{2+}$ imaging data.
Such types of signals render the SSM's decoder model non-invertible, a requirement for previous TF-based methods.
Here, exploiting the recent success of control techniques for training SSMs, we propose a novel algorithm that solves this problem and scales exceptionally well with model dimensionality and filter length. We demonstrate its efficiency in reconstructing dynamical systems, including their state space geometry and long-term temporal properties, from just short BOLD time series.
tl;dr: A new framework showing feasibility results, algorithms and empirical analysis for policy representations that support user-aligned POMDP planning

Planning in real-world settings often entails addressing partial observability while aligning with users' requirements. We present a novel framework for expressing users' constraints and preferences about agent behavior in a partially observable setting using parameterized belief-state query (BSQ) constraints in the setting of goal-oriented partially observable Markov decision processes (gPOMDPs). We present the first formal analysis of such constraints and prove that while the expected cost of a BSQ constraint is not a convex function w.r.t its parameters, it is piecewise constant and yields an implicit discrete parameter search space that is finite for finite horizons. This theoretical result leads to novel algorithms that optimize gPOMDP agent behavior with guaranteed user alignment. Theoretical analysis proves that our algorithms converge to the optimal user-aligned behavior in the limit. Empirical results show that BSQ constraints provide a computationally feasible approach for user-aligned planning in partially observable settings.
tl;dr: We present a novel hybrid method for causal discovery that leverages local causal relationships in SEMs to construct a compact hierarchical topological sort, followed by a novel nonparametric constraint-based method for efficient edge discovery.

Learning the unique directed acyclic graph corresponding to an unknown causal model is a challenging task. Methods based on functional causal models can identify a unique graph, but either suffer from the curse of dimensionality or impose strong parametric assumptions. To address these challenges, we propose a novel hybrid approach for global causal discovery in observational data that leverages local causal substructures. We first present a topological sorting algorithm that leverages ancestral relationships in linear structural equation models to establish a compact top-down hierarchical ordering, encoding more causal information than linear orderings produced by existing methods. We demonstrate that this approach generalizes to nonlinear settings with arbitrary noise. We then introduce a nonparametric constraint-based algorithm that prunes spurious edges by searching for local conditioning sets, achieving greater accuracy than current methods. We provide theoretical guarantees for correctness and worst-case polynomial time complexities, with empirical validation on synthetic data.

While image-based virtual try-on has made significant strides, emerging approaches still fall short of delivering high-fidelity and robust fitting images across various scenarios, as their models suffer from issues of ill-fitted garment styles and quality degrading during the training process, not to mention the lack of support for various combinations of attire. Therefore, we first propose a lightweight, scalable, operator known as Hydra Block for attire combinations. This is achieved through a parallel attention mechanism that facilitates the feature injection of multiple garments from conditionally encoded branches into the main network. Secondly, to significantly enhance the model's robustness and expressiveness in real-world scenarios, we evolve its potential across diverse settings by synthesizing the residuals of multiple models, as well as implementing a mask region boost strategy to overcome the instability caused by information leakage in existing models.
Equipped with the above design, AnyFit surpasses all baselines on high-resolution benchmarks and real-world data by a large gap, excelling in producing well-fitting garments replete with photorealistic and rich details. Furthermore, AnyFit’s impressive performance on high-fidelity virtual try-ons in any scenario from any image, paves a new path for future research within the fashion community.

Existing parameter-efficient fine-tuning (PEFT) methods have achieved significant success on vision transformers (ViTs) adaptation by improving parameter efficiency. However, the exploration of enhancing inference efficiency during adaptation remains underexplored. This limits the broader application of pre-trained ViT models, especially when the model is computationally extensive. In this paper, we propose Dynamic Tuning (DyT), a novel approach to improve both parameter and inference efficiency for ViT adaptation. Specifically, besides using the lightweight adapter modules, we propose a token dispatcher to distinguish informative tokens from less important ones, allowing the latter to dynamically skip the original block, thereby reducing the redundant computation during inference. Additionally, we explore multiple design variants to find the best practice of DyT. Finally, inspired by the mixture-of-experts (MoE) mechanism, we introduce an enhanced adapter to further boost the adaptation performance. We validate DyT across various tasks, including image/video recognition and semantic segmentation. For instance, DyT achieves superior performance compared to existing PEFT methods while evoking only 71% of their FLOPs on the VTAB-1K benchmark.
tl;dr: Directed exploration with the successor representation for MDPs with partially observable rewards

Exploration in reinforcement learning (RL) remains an open challenge.
RL algorithms rely on observing rewards to train the agent, and if informative rewards are sparse the agent learns slowly or may not learn at all.
To improve exploration and reward discovery, popular algorithms rely on optimism.
But what if sometimes rewards are unobservable, e.g., situations of partial monitoring in bandits and the recent formalism of monitored Markov decision process?
In this case, optimism can lead to suboptimal behavior that does not explore further to collapse uncertainty.
With this paper, we present a novel exploration strategy that overcomes the limitations of existing methods and guarantees convergence to an optimal policy even when rewards are not always observable.
We further propose a collection of tabular environments for benchmarking exploration in RL (with and without unobservable rewards) and show that our method outperforms existing ones.

Large Language Models (LLMs) have revolutionised natural language processing, exhibiting impressive human-like capabilities. In particular, LLMs are capable of "lying", knowingly outputting false statements. Hence, it is of interest and importance to develop methods to detect when LLMs lie. Indeed, several authors trained classifiers to detect LLM lies based on their internal model activations. However, other researchers showed that these classifiers may fail to generalise, for example to negated statements.
In this work, we aim to develop a robust method to detect when an LLM is lying. To this end, we make the following key contributions: (i) We demonstrate the existence of a two-dimensional subspace, along which the activation vectors of true and false statements can be separated. Notably, this finding is universal and holds for various LLMs, including Gemma-7B, LLaMA2-13B, Mistral-7B and LLaMA3-8B. Our analysis explains the generalisation failures observed in previous studies and sets the stage for more robust lie detection;
(ii) Building upon (i), we construct an accurate LLM lie detector. Empirically, our proposed classifier achieves state-of-the-art performance, attaining 94\% accuracy in both distinguishing true from false factual statements and detecting lies generated in real-world scenarios.
tl;dr: Learning general representations in self-supervised learning while having the versatility to tail down to task-wise symmetries when given a few examples as the context.

At the core of self-supervised learning for vision is the idea of learning invariant or equivariant representations with respect to a set of data transformations. This approach, however, introduces strong inductive biases, which can render the representations fragile in downstream tasks that do not conform to these symmetries. In this work, drawing insights from world models, we propose to instead learn a general representation that can adapt to be invariant or equivariant to different transformations by paying attention to context --- a memory module that tracks task-specific states, actions and future states. Here, the action is the transformation, while the current and future states respectively represent the input's representation before and after the transformation. Our proposed algorithm, Contextual Self Supervised Learning (ContextSSL), learns equivariance to all transformations (as opposed to invariance). In this way, the model can learn to encode all relevant features as general representations while having the versatility to tail down to task-wise symmetries when given a few examples as the context. Empirically, we demonstrate significant performance gains over existing methods on equivariance-related tasks, supported by both qualitative and quantitative evaluations.
tl;dr: We present a novel GCN framework that properly generalizes CNNs to graph structured data.

Convolutional neural networks (CNNs) have led to a revolution in analyzing array data. However, many important sources of data, such as biological and social networks, are naturally structured as graphs rather than arrays, making the design of graph neural network (GNN) architectures that retain the strengths of CNNs an active and exciting area of research. Here, we introduce Quantized Graph Convolution Networks (QGCNs), the first framework for GNNs that formally and directly extends CNNs to graphs. QGCNs do this by decomposing the convolution operation into non-overlapping sub-kernels, allowing them to fit graph data while reducing to a 2D CNN layer on array data. We generalize this approach to graphs of arbitrary size and dimension by approaching sub-kernel assignment as a learnable multinomial assignment problem. Integrating this approach into a residual network architecture, we demonstrate performance that matches or exceeds other state-of-the-art GNNs on benchmark graph datasets and for predicting properties of nonlinear dynamics on a new finite element graph dataset. In summary, QGCNs are a novel GNN framework that generalizes CNNs and their strengths to graph data, allowing for more accurate and expressive models.
tl;dr: A diffusion model to generate multi-view videos for dynamic objects.

While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
tl;dr: Based on the conjecture that all modes found by SGD live in the same basin up to permutations, we propose a novel weight-matching procedure based on the Frank-Wolfe algorithm that ensures cycle consistency of the permutations.

In this paper, we present a novel data-free method for merging neural networks in weight space. Our method optimizes for the permutations of network neurons while ensuring global coherence across all layers, and it outperforms recent layer-local approaches in a set of challenging scenarios. We then generalize the formulation to the $N$-models scenario to enforce cycle consistency of the permutations with guarantees, allowing circular compositions of permutations to be computed without accumulating error along the path.
We qualitatively and quantitatively motivate the need for such a constraint, showing its benefits when merging homogeneous sets of models in scenarios spanning varying architectures and datasets. We finally show that, when coupled with activation renormalization, the approach yields the best results in the task.

In multi-label learning, each training instance is associated with multiple labels simultaneously. Traditional multi-label learning studies primarily focus on closed set scenario, i.e. the class label set of test data is identical to those used in training phase. Nevertheless, in numerous real-world scenarios, the environment is open and dynamic where unknown labels may emerge gradually during testing. In this paper, the problem of multi-label open set recognition (MLOSR) is investigated, which poses significant challenges in classifying and recognizing instances with unknown labels in multi-label setting. To enable open set multi-label prediction, a novel approach named SLAN is proposed by leveraging sub-labeling information enriched by structural information in the feature space. Accordingly, unknown labels are recognized by differentiating the sub-labeling information from holistic supervision. Experimental results on various datasets validate the effectiveness of the proposed approach in dealing with the MLOSR problem.
tl;dr: Make theoretical research corrections to the relationship between optimal learning and batch size of models trained using Adam-style optimizers.

In current deep learning tasks, Adam-style optimizers—such as Adam, Adagrad, RMSprop, Adafactor, and Lion—have been widely used as alternatives to SGD-style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves.
The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly (or follows similar rules) with batch size for SGD-style optimizers. However, this conclusion is not applicable to Adam-style optimizers.
In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam-style optimizers through both theoretical analysis and extensive experiments.
First, we raise the scaling law between batch sizes and optimal learning rates in the “sign of gradient” case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses.
Second, we conduct experiments on various CV and NLP tasks and verify the correctness of the scaling law.

Softmax attention is the principle backbone of foundation models for various artificial intelligence applications, yet its quadratic complexity in sequence length can limit its inference throughput in long-context settings. To address this challenge, alternative architectures such as linear attention, State Space Models (SSMs), and Recurrent Neural Networks (RNNs) have been considered as more efficient alternatives. While connections between these approaches exist, such models are commonly developed in isolation and there is a lack of theoretical understanding of the shared principles underpinning these architectures and their subtle differences, greatly influencing performance and scalability. In this paper, we introduce the Dynamical Systems Framework (DSF), which allows a principled investigation of all these architectures in a common representation. Our framework facilitates rigorous comparisons, providing new insights on the distinctive characteristics of each model class. For instance, we compare linear attention and selective SSMs, detailing their differences and conditions under which both are equivalent. We also provide principled comparisons between softmax attention and other model classes, discussing the theoretical conditions under which softmax attention can be approximated. Additionally, we substantiate these new insights with empirical validations and mathematical arguments. This shows the DSF's potential to guide the systematic development of future more efficient and scalable foundation models.
tl;dr: This work systematically analyzes the underexplored OOD state issue in offline RL and proposes a simple yet effective approach unifying (value-aware) OOD state correction and OOD action suppression.

In offline reinforcement learning (RL), addressing the out-of-distribution (OOD) action issue has been a focus, but we argue that there exists an OOD state issue that also impairs performance yet has been underexplored. Such an issue describes the scenario when the agent encounters states out of the offline dataset during the test phase, leading to uncontrolled behavior and performance degradation. To this end, we propose SCAS, a simple yet effective approach that unifies OOD state correction and OOD action suppression in offline RL. Technically, SCAS achieves value-aware OOD state correction, capable of correcting the agent from OOD states to high-value in-distribution states. Theoretical and empirical results show that SCAS also exhibits the effect of suppressing OOD actions. On standard offline RL benchmarks, SCAS achieves excellent performance without additional hyperparameter tuning. Moreover, benefiting from its OOD state correction feature, SCAS demonstrates enhanced robustness against environmental perturbations.
tl;dr: We propose a new RL method for solving the minimum-cost reach-avoid problem, inspired by reachability analysis.

Current reinforcement-learning methods are unable to directly learn policies that solve the minimum cost reach-avoid problem to minimize cumulative costs subject to the constraints of reaching the goal and avoiding unsafe states, as the structure of this new optimization problem is incompatible with current methods. Instead, a surrogate problem is solved where all objectives are combined with a weighted sum. However, this surrogate objective results in suboptimal policies that do not directly minimize the cumulative cost. In this work, we propose RC-PPO, a reinforcement-learning-based method for solving the minimum-cost reach-avoid problem by using connections to Hamilton-Jacobi reachability. Empirical results demonstrate that RC-PPO learns policies with comparable goal-reaching rates to while achieving up to 57% lower cumulative costs compared to existing methods on a suite of minimum-cost reach-avoid benchmarks on the Mujoco simulator. The project page can be found at https://oswinso.xyz/rcppo.

Current approaches for open-vocabulary scene graph generation (OVSGG) use vision-language models such as CLIP and follow a standard zero-shot pipeline – computing similarity between the query image and the text embeddings for each category (i.e., text classifiers). In this work, we argue that the text classifiers adopted by existing OVSGG methods, i.e., category-/part-level prompts, are scene-agnostic as they remain unchanged across contexts. Using such fixed text classifiers not only struggles to model visual relations with high variance, but also falls short in adapting to distinct contexts. To plug these intrinsic shortcomings, we devise SDSGG, a scene-specific description based OVSGG framework where the weights of text classifiers are adaptively adjusted according to the visual content. In particular, to generate comprehensive and diverse descriptions oriented to the scene, an LLM is asked to play different roles (e.g., biologist and engineer) to analyze and discuss the descriptive features of a given scene from different views. Unlike previous efforts simply treating the generated descriptions as mutually equivalent text classifiers, SDSGG is equipped with an advanced renormalization mechanism to adjust the influence of each text classifier based on its relevance to the presented scene (this is what the term “specific” means). Furthermore, to capture the complicated interplay between subjects and objects, we propose a new lightweight module called mutual visual adapter. It refines CLIP’s ability to recognize relations by learning an interaction-aware semantic space. Extensive experiments on prevalent benchmarks show that SDSGG significantly outperforms top-leading methods.

Learning of preference models from human feedback has been central to recent advances in artificial intelligence. Motivated by the cost of obtaining high-quality human annotations, we study efficient human preference elicitation for learning preference models. The key idea in our work is to generalize optimal designs, a methodology for computing optimal information-gathering policies, to questions with multiple answers, represented as lists of items. The policy is a distribution over lists and we elicit preferences from the list proportionally to its probability. To show the generality of our ideas, we study both absolute and ranking feedback models on items in the list. We design efficient algorithms for both and analyze them. Finally, we demonstrate that our algorithms are practical by evaluating them on existing question-answering problems.
tl;dr: This work presents a framework to unify forward and inverse problems in scientific computing by optimizing a joint objective derived from operator learning.

The joint prediction of continuous fields and statistical estimation of the underlying discrete parameters is a common problem for many physical systems, governed by PDEs. Hitherto, it has been separately addressed by employing operator learning surrogates for field prediction while using simulation-based inference (and its variants) for statistical parameter determination. Here, we argue that solving both problems within the same framework can lead to consistent gains in accuracy and robustness. To this end, we propose a novel and flexible formulation of the operator learning problem that jointly predicts continuous quantities and infers distributions of discrete parameters, thereby amortizing the cost of both the inverse and the surrogate models to a joint pre-training step. We present the capabilities of the proposed methodology for predicting continuous and discrete biomarkers in full-body haemodynamics simulations under different levels of missing information. We also consider a test case for atmospheric large-eddy simulation of a two-dimensional dry cold bubble, where we infer both continuous time-series and information about the system's conditions. We present comparisons against different baselines to showcase significantly increased accuracy in both the inverse and the surrogate tasks.
tl;dr: We show that source critic adversarial networks can effectively regularize offline optimizers for generative tasks in medicine and the sciences.

Offline model-based optimization seeks to optimize against a learned surrogate model without querying the true oracle objective function during optimization. Such tasks are commonly encountered in protein design, robotics, and clinical medicine where evaluating the oracle function is prohibitively expensive. However, inaccurate surrogate model predictions are frequently encountered along offline optimization trajectories. To address this limitation, we propose *generative adversarial model-based optimization* using **adaptive source critic regularization (aSCR)**—a task- and optimizer- agnostic framework for constraining the optimization trajectory to regions of the design space where the surrogate function is reliable. We propose a computationally tractable algorithm to dynamically adjust the strength of this constraint, and show how leveraging aSCR with standard Bayesian optimization outperforms existing methods on a suite of offline generative design tasks. Our code is available at https://github.com/michael-s-yao/gabo.
tl;dr: We demonstrate how cryptographic backdoors can be embedded in transformer model weights and present a hardness scale for a class of backdoor detection methods.

The rapid proliferation of open-source language models significantly increases the risks of downstream backdoor attacks. These backdoors can introduce dangerous behaviours during model deployment and can evade detection by conventional cybersecurity monitoring systems. In this paper, we introduce a novel class of backdoors in transformer models, that, in contrast to prior art, are unelicitable in nature. Unelicitability prevents the defender from triggering the backdoor, making it impossible to properly evaluate ahead of deployment even if given full white-box access and using automated techniques, such as red-teaming or certain formal verification methods. We show that our novel construction is not only unelicitable thanks to using cryptographic techniques, but also has favourable robustness properties.
We confirm these properties in empirical investigations, and provide evidence that our backdoors can withstand state-of-the-art mitigation strategies. Additionally, we expand on previous work by showing that our universal backdoors, while not completely undetectable in white-box settings, can be harder to detect than some existing designs. By demonstrating the feasibility of seamlessly integrating backdoors into transformer models, this paper fundamentally questions the efficacy of pre-deployment detection strategies. This offers new insights into the offence-defence balance in AI safety and security.
tl;dr: We provide a statistical framework for jailbreaking LLMs, show jailbreaking is unavoidable and provide an improved DPO-based alignment protocol. The proposed method leads to improved safety across a suite of jailbreak adversaries.

Large language models (LLMs) are trained on a deluge of text data with limited quality control. As a result, LLMs can exhibit unintended or even harmful behaviours, such as leaking information, fake news or hate speech. Countermeasures, commonly referred to as preference alignment, include fine-tuning the pretrained LLMs with carefully crafted text examples of desired behaviour. Even then, empirical evidence shows preference aligned LLMs can be enticed to harmful behaviour. This so called jailbreaking of LLMs is typically achieved by adversarially modifying the input prompt to the LLM. Our paper provides theoretical insights into the phenomenon of preference alignment and jailbreaking from a statistical perspective. Under our framework, we first show that pretrained LLMs will mimic harmful behaviour if present in the training corpus. \textbf{Under that same framework, we then introduce a statistical notion of alignment, and lower-bound the jailbreaking probability, showing that it is unpreventable under reasonable assumptions.} Based on our insights, we propose an alteration to the currently prevalent alignment strategy RLHF. Specifically, we introduce a simple modification to the RLHF objective, we call \emph{E-RLHF}, that aims to increase the likelihood of safe responses. \emph{E-RLHF} brings no additional training cost, and is compatible with other methods. Empirically, we demonstrate that \emph{E-RLHF} outperforms RLHF on all alignment problems put forward by the AdvBench \citep{zou2023universal} and HarmBench project \citep{mazeika2024harmbench} without sacrificing model performance as measured by the MT-Bench project \citep{zheng2024judging}.
tl;dr: We propose TALoS, a novel test-time adaptation approach for SSC that leverages situational information available in driving environments.

Semantic Scene Completion (SSC) aims to perform geometric completion and semantic segmentation simultaneously. Despite the promising results achieved by existing studies, the inherently ill-posed nature of the task presents significant challenges in diverse driving scenarios. This paper introduces TALoS, a novel test-time adaptation approach for SSC that excavates the information available in driving environments. Specifically, we focus on that observations made at a certain moment can serve as Ground Truth (GT) for scene completion at another moment. Given the characteristics of the LiDAR sensor, an observation of an object at a certain location confirms both 1) the occupation of that location and 2) the absence of obstacles along the line of sight from the LiDAR to that point. TALoS utilizes these observations to obtain self-supervision about occupancy and emptiness, guiding the model to adapt to the scene in test time. In a similar manner, we aggregate reliable SSC predictions among multiple moments and leverage them as semantic pseudo-GT for adaptation. Further, to leverage future observations that are not accessible at the current time, we present a dual optimization scheme using the model in which the update is delayed until the future observation is available. Evaluations on the SemanticKITTI validation and test sets demonstrate that TALoS significantly improves the performance of the pre-trained SSC model.
tl;dr: We propose an algorithmic framework, Implicit Regularization Enhancement, which can improve both generalization and convergence of deep neural networks..

In this work, we propose an Implicit Regularization Enhancement (IRE) framework to accelerate the discovery of flat solutions in deep learning, thereby improving generalization and convergence.
Specifically, IRE decouples the dynamics of flat and sharp directions, which boosts the sharpness reduction along flat directions while maintaining the training stability in sharp directions. We show that IRE can be practically incorporated with *generic base optimizers* without introducing significant computational overload. Experiments show that IRE consistently improves the generalization performance for image classification tasks across a variety of benchmark datasets (CIFAR-10/100, ImageNet) and models (ResNets and ViTs).
Surprisingly, IRE also achieves a $2\times$ *speed-up* compared to AdamW in the pre-training of Llama models (of sizes ranging from 60M to 229M) on datasets including Wikitext-103, Minipile, and Openwebtext. Moreover, we provide theoretical guarantees, showing that IRE can substantially accelerate the convergence towards flat minima in Sharpness-aware Minimization (SAM).
tl;dr: Hypervolume scalarizations with uniformly random weights achieves optimal sublinear hypervolume regret.

Scalarization is a general, parallizable technique that can be deployed in any multiobjective setting to reduce multiple objectives into one, yet some have dismissed this versatile approach because linear scalarizations cannot explore concave regions of the Pareto frontier. To that end, we aim to find simple non-linear scalarizations that provably explore a diverse set of $k$ objectives on the Pareto frontier, as measured by the dominated hypervolume. We show that hypervolume scalarizations with uniformly random weights achieves an optimal sublinear hypervolume regret bound of $O(T^{-1/k})$, with matching lower bounds that preclude any algorithm from doing better asymptotically. For the setting of multiobjective stochastic linear bandits, we utilize properties of hypervolume scalarizations to derive a novel non-Euclidean analysis to get regret bounds of $\tilde{O}( d T^{-1/2} + T^{-1/k})$, removing unnecessary $\text{poly}(k)$ dependencies. We support our theory with strong empirical performance of using non-linear scalarizations that outperforms both their linear counterparts and other standard multiobjective algorithms in a variety of natural settings.
tl;dr: We extend Equilibrium Propagation (EP) to a novel hardware-realistic model which comprises feedforward and energy-based blocks, resulting in chaining backprop and EP gradients backward through these blocks and a new SOTA performance on ImageNet32

Power efficiency is plateauing in the standard digital electronics realm such that new hardware, models, and algorithms are needed to reduce the costs of AI training. The combination of energy-based analog circuits and the Equilibrium Propagation (EP) algorithm constitutes a compelling alternative compute paradigm for gradient-based optimization of neural nets. Existing analog hardware accelerators, however, typically incorporate digital circuitry to sustain auxiliary non-weight-stationary operations, mitigate analog device imperfections, and leverage existing digital platforms. Such heterogeneous hardware lacks a supporting theoretical framework. In this work, we introduce \emph{Feedforward-tied Energy-based Models} (ff-EBMs), a hybrid model comprised of feedforward and energy-based blocks housed on digital and analog circuits. We derive a novel algorithm to compute gradients end-to-end in ff-EBMs by backpropagating and ``eq-propagating'' through feedforward and energy-based parts respectively, enabling EP to be applied flexibly on realistic architectures. We experimentally demonstrate the effectiveness of this approach on ff-EBMs using Deep Hopfield Networks (DHNs) as energy-based blocks, and show that a standard DHN can be arbitrarily split into any uniform size while maintaining or improving performance with increases in simulation speed of up to four times. We then train ff-EBMs on ImageNet32 where we establish a new state-of-the-art performance for the EP literature (46 top-1 \%). Our approach offers a principled, scalable, and incremental roadmap for the gradual integration of self-trainable analog computational primitives into existing digital accelerators.

Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of efficiently improving model capabilities from the vision side.
Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with neglectable additional activated parameters during inference.
CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage, with auxiliary losses to ensure a balanced loading of experts.
CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks within each model size group, all while training exclusively on open-sourced datasets.

_Graph Neural Tangent Kernel_ (GNTK) fuses graph neural networks and graph kernels, simplifies the process of graph representation learning, interprets the training dynamics of graph neural networks, and serves various applications like protein identification, image segmentation, and social network analysis. In practice, graph data carries complex information among entities that inevitably evolves over time, and previous static graph neural tangent kernel methods may be stuck in the sub-optimal solution in terms of both effectiveness and efficiency. As a result, extending the advantage of GNTK to temporal graphs becomes a critical problem. To this end, we propose the temporal graph neural tangent kernel, which not only extends the simplicity and interpretation ability of GNTK to the temporal setting but also leads to rigorous temporal graph classification error bounds. Furthermore, we prove that when the input temporal graph grows over time in the number of nodes, our temporal graph neural tangent kernel will converge in the limit to the _graphon_ NTK value, which implies the transferability and robustness of the proposed kernel method, named **Temp**oral **G**raph **N**eural **T**angent **K**ernel with **G**raphon-**G**uaranteed or **Temp-G$^3$NTK**. In addition to the theoretical analysis, we also perform extensive experiments, not only demonstrating the superiority of Temp-G$^3$NTK in the temporal graph classification task, but also showing that Temp-G^3NTK can achieve very competitive performance in node-level tasks like node classification compared with various SOTA graph kernel and representation learning baselines. Our code is available at https://github.com/kthrn22/TempGNTK.
tl;dr: Continual learning is difficult when the two tasks share more input features than readout patterns, but there are ways to mitigate it.

Continual learning of partially similar tasks poses a challenge for artificial neural networks, as task similarity presents both an opportunity for knowledge transfer and a risk of interference and catastrophic forgetting.
However, it remains unclear how task similarity in input features and readout patterns influences knowledge transfer and forgetting, as well as how they interact with common algorithms for continual learning.
Here, we develop a linear teacher-student model with latent structure and show analytically that high input feature similarity coupled with low readout similarity is catastrophic for both knowledge transfer and retention.
Conversely, the opposite scenario is relatively benign.
Our analysis further reveals that task-dependent activity gating improves knowledge retention at the expense of transfer, while task-dependent plasticity gating does not affect either retention or transfer performance at the over-parameterized limit.
In contrast, weight regularization based on the Fisher information metric significantly improves retention, regardless of task similarity, without compromising transfer performance. Nevertheless, its diagonal approximation and regularization in the Euclidean space are much less robust against task similarity.
We demonstrate consistent results in a permuted MNIST task with latent variables. Overall, this work provides insights into when continual learning is difficult and how to mitigate it.
tl;dr: We analyze transformer task-performance circuits over training and model scale and find interesting consistencies in algorithm structures and components.

Most currently deployed LLMs undergo continuous training or additional finetuning. By contrast, most research into LLMs' internal mechanisms focuses on models at one snapshot in time (the end of pre-training), raising the question of whether their results generalize to real-world settings. Existing studies of mechanisms over time focus on encoder-only or toy models, which differ significantly from most deployed models. In this study, we track how model mechanisms, operationalized as circuits, emerge and evolve across 300 billion tokens of training in decoder-only LLMs, in models ranging from 70 million to 2.8 billion parameters. We find that task abilities and the functional components that support them emerge consistently at similar token counts across scale. Moreover, although such components may be implemented by different attention heads over time, the overarching algorithm that they implement remains. Surprisingly, both these algorithms and the types of components involved therein tend to replicate across model scale. Finally, we find that circuit size correlates with model size and can fluctuate considerably over time even when the same algorithm is implemented. These results suggest that circuit analyses conducted on small models at the end of pre-training can provide insights that still apply after additional training and over model scale.

We consider the problem of crystal materials generation using language models (LMs). A key step is to convert 3D crystal structures into 1D sequences to be processed by LMs. Prior studies used the crystallographic information framework (CIF) file stream, which fails to ensure SE(3) and periodic invariance and may not lead to unique sequence representations for a given crystal structure. Here, we propose a novel method, known as Mat2Seq, to tackle this challenge. Mat2Seq converts 3D crystal structures into 1D sequences and ensures that different mathematical descriptions of the same crystal are represented in a single unique sequence, thereby provably achieving SE(3) and periodic invariance. Experimental results show that, with language models, Mat2Seq achieves promising performance in crystal structure generation as compared with prior methods.
tl;dr: This paper proposes Test-time Procrustes Calibration, which enhances the robustness of diffusion-based image animation systems in the real-world unseen domain by guiding correspondences of human shapes between reference image and target poses.

Human image animation aims to generate a human motion video from the inputs of a reference human image and a target motion video. Current diffusion-based image animation systems exhibit high precision in transferring human identity into targeted motion, yet they still exhibit irregular quality in their outputs. Their optimal precision is achieved only when the physical compositions (i.e., scale and rotation) of the human shapes in the reference image and target pose frame are aligned. In the absence of such alignment, there is a noticeable decline in fidelity and consistency. Especially, in real-world environments, this compositional misalignment commonly occurs, posing significant challenges to the practical usage of current systems. To this end, we propose Test-time Procrustes Calibration (TPC), which enhances the robustness of diffusion-based image animation systems by maintaining optimal performance even when faced with compositional misalignment, effectively addressing real-world scenarios. The TPC provides a calibrated reference image for the diffusion model, enhancing its capability to understand the correspondence between human shapes in the reference and target images. Our method is simple and can be applied to any diffusion-based image animation system in a model-agnostic manner, improving the effectiveness at test time without additional training.

Counterfactual Regret Minimization (CFR) and its variants are widely recognized as effective algorithms for solving extensive-form imperfect information games. Recently, many improvements have been focused on enhancing the convergence speed of the CFR algorithm. However, most of these variants are not applicable under Monte Carlo (MC) conditions, making them unsuitable for training in large-scale games. We introduce a new MC-based algorithm for solving extensive-form imperfect information games, called MCCFVFP (Monte Carlo Counterfactual Value-Based Fictitious Play). MCCFVFP combines CFR’s counterfactual value calculations with fictitious play’s best response strategy, leveraging the strengths of fictitious play to gain significant advantages in games with a high proportion of dominated strategies. Experimental results show that MCCFVFP achieved convergence speeds approximately 20\%$\sim$50\% faster than the most advanced MCCFR variants in games like poker and other test games.
tl;dr: We address learning stable allocations for stochastic cooperative games with an unknown reward distribution. For strictly convex games, we propose an algorithm that returns a stable allocation with a polynomial number of samples.

Reward allocation, also known as the credit assignment problem, has been an important topic in economics, engineering, and machine learning. An important concept in reward allocation is the core, which is the set of stable allocations where no agent has the motivation to deviate from the grand coalition. In previous works, computing the core requires either knowledge of the reward function in deterministic games or the reward distribution in stochastic games. However, this is unrealistic, as the reward function or distribution is often only partially known and may be subject to uncertainty. In this paper, we consider the core learning problem in stochastic cooperative games, where the reward distribution is unknown. Our goal is to learn the expected core, that is, the set of allocations that are stable in expectation, given an oracle that returns a stochastic reward for an enquired coalition each round. Within the class of strictly convex games, we present an algorithm named \texttt{Common-Points-Picking} that returns a point in the expected core given a polynomial number of samples, with high probability. To analyse the algorithm, we develop a new extension of the separation hyperplane theorem for multiple convex sets.t.
tl;dr: We study the representations that emerge in RNNs trained to path integrate two agents and compare them to the representations that emerge when path integrating a single agent.
Success in collaborative and competitive environments, where agents must work with or against each other, requires individuals to encode the position and trajectory of themselves and others. Decades of neurophysiological experiments have shed light on how brain regions [e.g., medial entorhinal cortex (MEC), hippocampus] encode the self's position and trajectory. However, it has only recently been discovered that MEC and hippocampus are modulated by the positions and trajectories of others. To understand how encoding spatial information of multiple agents shapes neural representations, we train a recurrent neural network (RNN) model that captures properties of MEC to path integrate trajectories of two agents simultaneously navigating the same environment. We find significant differences between these RNNs and those trained to path integrate only a single agent. At the individual unit level, RNNs trained to path integrate more than one agent develop weaker grid responses, stronger border responses, and tuning for the relative position of the two agents. At the population level, they develop more distributed and robust representations, with changes in network dynamics and manifold topology. Our results provide testable predictions and open new directions with which to study the neural computations supporting spatial navigation.
tl;dr: We study the importance of optimization in robust ERM and its connection to the (adversarially robust) generalization of the model.

We study the implicit bias of optimization in robust empirical risk minimization (robust ERM) and its connection with robust generalization. In classification settings under adversarial perturbations with linear models, we study what type of regularization should ideally be applied for a given perturbation set to improve (robust) generalization. We then show that the implicit bias of optimization in robust ERM can significantly affect the robustness of the model and identify two ways this can happen; either through the optimization algorithm or the architecture. We verify our predictions in simulations with synthetic data and experimentally study the importance of implicit bias in robust ERM with deep neural networks.
tl;dr: We observe that previous DRL methods fail to learn effective policies in intermittent control scenarios because of the discontinue interaction and propose a plugin method for DRL to address such problems.

Intermittent control problems are common in real world. The interactions between the decision maker and the executor can be discontinuous (intermittent) due to various types of interruptions, e.g. unstable communication channel. Due to intermittent interaction, agents are unable to acquire the state sent by the executor and cannot transmit actions to the executor within a period of time step, i.e. bidirectional blockage, which may lead to inefficiencies of reinforcement learning policies and prevent the executors from completing the task. Such problem is not well studied in the RL community. In this paper, we model Intermittent control problem as an Intermittent Control Markov Decision Process, i.e agents are expected to generate action sequences corresponding to the unavailable states and transmit them before disabling interactions to ensure the smooth and effective motion of executors. However, directly generating multiple future actions in the original action space has unnatural motion issue and exploration difficulty. We propose **M**ulti-step **A**ction **R**epre**S**entation (**MARS**), which encodes a sequence of actions from the original action space to a compact and decodable latent space. Then based on the latent action sequence representation, the mainstream RL methods can be easily optimized to learn a smooth and efficient motion policy. Extensive experiments on simulation tasks and real-world robotic grasping tasks show that MARS significantly improves the learning efficiency and final performances compared with existing baselines.
tl;dr: We train one-step text-to-image generator that is progressively growing in its resolution. For that, we only need low-resolution diffusion models.

The diffusion model performs remarkable in generating high-dimensional content but is computationally intensive, especially during training. We propose Progressive Growing of Diffusion Autoencoder (PaGoDA), a novel pipeline that reduces the training costs through three stages: training diffusion on downsampled data, distilling the pretrained diffusion, and progressive super-resolution. With the proposed pipeline, PaGoDA achieves a $64\times$ reduced cost in training its diffusion model on $8\times$ downsampled data; while at the inference, with the single-step, it performs state-of-the-art on ImageNet across all resolutions from $64\times64$ to $512\times512$, and text-to-image. PaGoDA's pipeline can be applied directly in the latent space, adding compression alongside the pre-trained autoencoder in Latent Diffusion Models (e.g., Stable Diffusion). The code is available at https://github.com/sony/pagoda.
tl;dr: We provide a new algorithmic framework for differentially private estimation of general functions that adapts to the hardness of the underlying dataset.

We provide a new algorithmic framework for differentially private estimation of general functions that adapts to the hardness of the underlying dataset. We build upon previous work that gives a paradigm for selecting an output through the exponential mechanism based upon closeness of the inverse to the underlying dataset, termed the inverse sensitivity mechanism. Our framework will slightly modify the closeness metric and instead give a simple and efficient application of the sparse vector technique. While the inverse sensitivity mechanism was shown to be instance optimal, it was only with respect to a class of unbiased mechanisms such that the most likely outcome matches the underlying data. We break this assumption in order to more naturally navigate the bias-variance tradeoff, which will also critically allow for extending our method to unbounded data. In consideration of this tradeoff, we provide theoretical guarantees and empirical validation that our technique will be particularly effective when the distances to the underlying dataset are asymmetric. This asymmetry is inherent to a range of important problems including fundamental statistics such as variance, as well as commonly used machine learning performance metrics for both classification and regression tasks. We efficiently instantiate our method in $O(n)$ time for these problems and empirically show that our techniques will give substantially improved differentially private estimations.

Watermarking images is critical for tracking image provenance and proving ownership. With the advent of generative models, such as stable diffusion, that can create fake but realistic images, watermarking has become particularly important to make human-created images reliably identifiable. Unfortunately, the very same stable diffusion technology can remove watermarks injected using existing methods.
To address this problem, we present ZoDiac, which uses a pre-trained stable diffusion model to inject a watermark into the trainable latent space, resulting in watermarks that can be reliably detected in the latent vector even when attacked. We evaluate ZoDiac on three benchmarks, MS-COCO, DiffusionDB, and WikiArt, and find that ZoDiac is robust against state-of-the-art watermark attacks, with a watermark detection rate above 98% and a false positive rate below 6.4%, outperforming state-of-the-art watermarking methods. We hypothesize that the reciprocating denoising process in diffusion models may inherently enhance the robustness of the watermark when faced with strong attacks and validate the hypothesis. Our research demonstrates that stable diffusion is a promising approach to robust watermarking, able to withstand even stable-diffusion-based attack methods. ZoDiac is open-sourced and available at https://github.com/zhanglijun95/ZoDiac.

Whole slide image (WSI) analysis is gaining prominence within the medical imaging field. Recent advances in pathology foundation models have shown the potential to extract powerful feature representations from WSIs for downstream tasks. However, these foundation models are usually designed for general-purpose pathology image analysis and may not be optimal for specific downstream tasks or cancer types. In this work, we present Concept Anchor-guided Task-specific Feature Enhancement (CATE), an adaptable paradigm that can boost the expressivity and discriminativeness of pathology foundation models for specific downstream tasks. Based on a set of task-specific concepts derived from the pathology vision-language model with expert-designed prompts, we introduce two interconnected modules to dynamically calibrate the generic image features extracted by foundation models for certain tasks or cancer types. Specifically, we design a Concept-guided Information Bottleneck module to enhance task-relevant characteristics by maximizing the mutual information between image features and concept anchors while suppressing superfluous information. Moreover, a Concept-Feature Interference module is proposed to utilize the similarity between calibrated features and concept anchors to further generate discriminative task-specific features. The extensive experiments on public WSI datasets demonstrate that CATE significantly enhances the performance and generalizability of MIL models. Additionally, heatmap and umap visualization results also reveal the effectiveness and interpretability of CATE.
tl;dr: We propose a novel algorithm that trains diffusion models on some 3D batches and blend the scores together for sparse-view CT reconstruction

Diffusion models face significant challenges when employed for large-scale medical image reconstruction in real practice such as 3D Computed Tomography (CT).
Due to the demanding memory, time, and data requirements, it is difficult to train a diffusion model directly on the entire volume of high-dimensional data to obtain an efficient 3D diffusion prior.
Existing works utilizing diffusion priors on single 2D image slice with hand-crafted cross-slice regularization would sacrifice the z-axis consistency, which results in severe artifacts along the z-axis.
In this work, we propose a novel framework that enables learning the 3D image prior through position-aware 3D-patch diffusion score blending for reconstructing large-scale 3D medical images. To the best of our knowledge, we are the first to utilize a 3D-patch diffusion prior for 3D medical image reconstruction.
Extensive experiments on sparse view and limited angle CT reconstruction
show that our DiffusionBlend method significantly outperforms previous methods
and achieves state-of-the-art performance on real-world CT reconstruction problems with high-dimensional 3D image (i.e., $256 \times 256 \times 500$). Our algorithm also comes with better or comparable computational efficiency than previous state-of-the-art methods. Code is available at https://github.com/efzero/DiffusionBlend.

Kernel methods are widely utilized in machine learning field to learn, from training data, a latent function in a reproducing kernel Hilbert space. It is well known that the approximator thus obtained usually achieves a linear representation, which brings various computational benefits, while maintaining great representation power (i.e., universal approximation). However, when non-negativity constraints are imposed on the function's outputs, the literature usually takes the kernel method-based approximators as offering linear representations at the expense of limited model flexibility or good representation power by allowing for their nonlinear forms. The main contribution of this paper is to derive a sufficient condition for a positive definite kernel so that it may construct flexible and linear approximators of non-negative functions. We call a kernel function that offers these attributes an *inverse M-kernel*; it is reminiscent of the inverse M-matrix. Furthermore, we show that for a one-dimensional input space, universal exponential/Abel kernels are inverse M-kernels and construct linear universal approximators of non-negative functions. To the best of our knowledge, it is the first time that the existence of linear universal approximators of non-negative functions has been elucidated. We confirm the effectiveness of our results by experiments on the problems of non-negativity-constrained regression, density estimation, and intensity estimation. Finally, we discuss issues and perspectives on multi-dimensional input settings.
tl;dr: The paper reveals the correlation between the object hallucination degree and the length of image descriptions, and proposes a stable and comprehensive framework for evaluating object hallucination in large vision-language models..

Given different instructions, large vision-language models (LVLMs) exhibit different degrees of object hallucinations, posing a significant challenge to the evaluation of object hallucinations. Overcoming this challenge, existing object hallucination evaluation methods average the results obtained from a set of instructions. However, these methods fail to provide consistent evaluation across instruction sets that generate image descriptions of significantly different lengths. In this paper, we present the first systematic investigation of the effect of instructions on object hallucinations in LVLMs, with a specific focus on the role played by image description lengths. A valuable finding is that instructions indirectly affect hallucinations through the length of image descriptions. The longer the image description, the higher the object hallucination degree. Accordingly, we fit an informative length-hallucination curve, upon which a fine-grained evaluation framework named LeHaCE is introduced for evaluating object hallucinations at any given image description length. LeHaCE evaluates the object hallucination degree at a uniform image description length to mitigate the effect of description lengths, promoting stability and fairness. Moreover, LeHaCE incorporates the curve slope as an innovative hallucination evaluation metric, reflecting the extent to which the object hallucination degree is affected by the image description length, achieving a more comprehensive evaluation. Experimental results demonstrate that LeHaCE provides a more stable, fair, and comprehensive evaluation of object hallucinations in LVLMs compared to existing methods.
1934. GTBench: Uncovering the Strategic Reasoning Capabilities of LLMs via Game-Theoretic Evaluations

As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely-recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
tl;dr: We analyze the sample complexity of full-batch vanilla gradient descent on a stochastic convex problem

We analyze the sample complexity of full-batch Gradient Descent (GD) in the setup of non-smooth Stochastic Convex Optimization. We show that the generalization error of GD, with common choice of hyper-parameters, can be $\tilde \Theta(d/m+1/\sqrt{m})$, where d is the dimension and m is the sample size. This matches the sample complexity of \emph{worst-case} empirical risk minimizers. That means that, in contrast with other algorithms, GD has no advantage over naive ERMs. Our bound follows from a new generalization bound that depends on both the dimension as well as the learning rate and number of iterations. Our bound also shows that, for general hyper-parameters, when the dimension is strictly larger than number of samples, $T=\Omega(1/\epsilon^4)$ iterations are necessary to avoid overfitting. This resolves an open problem by Schlisserman et al.23 and Amir er Al.21, and improves over previous lower bounds that demonstrated that the sample size must be at least square root of the dimension.
tl;dr: Aligning Vision-Language Models with User's Gaze Attention

In recent years, the integration of vision and language understanding has led to significant advancements in artificial intelligence, particularly through Vision-Language Models (VLMs). However, existing VLMs face challenges in handling real-world applications with complex scenes and multiple objects, as well as aligning their focus with the diverse attention patterns of human users. In this paper, we introduce gaze information, feasibly collected by ubiquitous wearable devices such as MR glasses, as a proxy for human attention to guide VLMs. We propose a novel approach, Voila-A, for gaze alignment to enhance the effectiveness of these models in real-world applications. First, we collect hundreds of minutes of gaze data to demonstrate that we can mimic human gaze modalities using localized narratives. We then design an automatic data annotation pipeline utilizing GPT-4 to generate the VOILA-COCO dataset. Additionally, we introduce a new model VOILA-A that integrate gaze information into VLMs while maintain pretrained knowledge from webscale dataset. We evaluate Voila-A using a hold-out validation set and a newly collected VOILA-GAZE testset, which features real-life scenarios captured with a gaze-tracking device. Our experimental results demonstrate that Voila-A significantly outperforms several baseline models. By aligning model attention with human gaze patterns, Voila-A paves the way for more intuitive, user-centric VLMs and fosters engaging human-AI interaction across a wide range of applications.
tl;dr: A dual attention refinement network with spatiotemporal construction for audutory attention detection.

At a cocktail party, humans exhibit an impressive ability to direct their attention. The auditory attention detection (AAD) approach seeks to identify the attended speaker by analyzing brain signals, such as EEG signals.
However, current AAD algorithms overlook the spatial distribution information within EEG signals and lack the ability to capture long-range latent dependencies, limiting the model's ability to decode brain activity.
To address these issues, this paper proposes a dual attention refinement network with spatiotemporal construction for AAD, named DARNet, which consists of the spatiotemporal construction module, dual attention refinement module, and feature fusion \& classifier module. Specifically, the spatiotemporal construction module aims to construct more expressive spatiotemporal feature representations, by capturing the spatial distribution characteristics of EEG signals. The dual attention refinement module aims to extract different levels of temporal patterns in EEG signals and enhance the model's ability to capture long-range latent dependencies. The feature fusion \& classifier module aims to aggregate temporal patterns and dependencies from different levels and obtain the final classification results.
The experimental results indicate that DARNet achieved excellent classification performance, particularly under short decision windows. While maintaining excellent classification performance, DARNet significantly reduces the number of required parameters. Compared to the state-of-the-art models, DARNet reduces the parameter count by 91\%. Code is available at: https://github.com/fchest/DARNet.git.

The rapid progress in artificial intelligence-generated content (AIGC), especially with diffusion models, has significantly advanced development of high-quality video generation. However, current video diffusion models exhibit demanding computational requirements and high peak memory usage, especially for generating longer and higher-resolution videos. These limitations greatly hinder the practical application of video diffusion models on standard hardware platforms. To tackle this issue, we present a novel, training-free framework named Streamlined Inference, which leverages the temporal and spatial properties of video diffusion models. Our approach integrates three core components: Feature Slicer, Operator Grouping, and Step Rehash. Specifically, Feature Slicer effectively partitions input features into sub-features and Operator Grouping processes each sub-feature with a group of consecutive operators, resulting in significant memory reduction without sacrificing the quality or speed. Step Rehash further exploits the similarity between adjacent steps in diffusion, and accelerates inference through skipping unnecessary steps. Extensive experiments demonstrate that our approach significantly reduces peak memory and computational overhead, making it feasible to generate high-quality videos on a single consumer GPU (e.g., reducing peak memory of Animatediff from 42GB to 11GB, featuring faster inference on 2080Ti).

We present ProtoViT, a method for interpretable image classification combining deep learning and case-based reasoning. This method classifies an image by comparing it to a set of learned prototypes, providing explanations of the form ``this looks like that.'' In our model, a prototype consists of **parts**, which can deform over irregular geometries to create a better comparison between images. Unlike existing models that rely on Convolutional Neural Network (CNN) backbones and spatially rigid prototypes, our model integrates Vision Transformer (ViT) backbones into prototype based models, while offering spatially deformed prototypes that not only accommodate geometric variations of objects but also provide coherent and clear prototypical feature representations with an adaptive number of prototypical parts. Our experiments show that our model can generally achieve higher performance than the existing prototype based models. Our comprehensive analyses ensure that the prototypes are consistent and the interpretations are faithful.
1940. Data-faithful Feature Attribution: Mitigating Unobservable Confounders via Instrumental Variables

The state-of-the-art feature attribution methods often neglect the influence of unobservable confounders, posing a risk of misinterpretation, especially when it is crucial for the interpretation to remain faithful to the data. To counteract this, we propose a new approach, data-faithful feature attribution, which trains a confounder-free model using instrumental variables. The cluttered effects of unobservable confounders in a model trained as such are decoupled from input features, thereby aligning the output of the model with the contribution of input features to the target feature in the data generation. Furthermore, feature attribution results produced by our method are more robust when focusing on attributions from the perspective of data generation. Our experiments on both synthetic and real-world datasets demonstrate the effectiveness of our approaches.
tl;dr: We accelerate feature and data attribution by training amortized models with noisy supervision

Many tasks in explainable machine learning, such as data valuation and feature attribution, perform expensive computation for each data point and are intractable for large datasets. These methods require efficient approximations, and although amortizing the process by learning a network to directly predict the desired output is a promising solution, training such models with exact labels is often infeasible. We therefore explore training amortized models with noisy labels, and we find that this is inexpensive and surprisingly effective. Through theoretical analysis of the label noise and experiments with various models and datasets, we show that this approach tolerates high noise levels and significantly accelerates several feature attribution and data valuation methods, often yielding an order of magnitude speedup over existing approaches.
tl;dr: We introduce a simple yet effective encoder propagation (unet feature reuse) scheme to accelerate the diffusion (i.e., StableDiffusion, and DiT) sampling for a diverse set of tasks.

One of the main drawback of diffusion models is the slow inference time for image generation. Among the most successful approaches to addressing this problem are distillation methods. However, these methods require considerable computational resources. In this paper, we take another approach to diffusion model acceleration. We conduct a comprehensive study of the UNet encoder and empirically analyze the encoder features. This provides insights regarding their changes during the inference process. In particular, we find that encoder features change minimally, whereas the decoder features exhibit substantial variations across different time-steps. This insight motivates us to omit encoder computation at certain adjacent time-steps and reuse encoder features of previous time-steps as input to the decoder in multiple time-steps. Importantly, this allows us to perform decoder computation in parallel, further accelerating the denoising process. Additionally, we introduce a prior noise injection method to improve the texture details in the generated image. Besides the standard text-to-image task, we also validate our approach on other tasks: text-to-video, personalized generation and reference-guided generation. Without utilizing any knowledge distillation technique, our approach accelerates both the Stable Diffusion (SD) and DeepFloyd-IF model sampling by 41$\%$ and 24$\%$ respectively, and DiT model sampling by 34$\%$, while maintaining high-quality generation performance. Our code will be publicly released.

Transformer-based large language models (LLMs) have successfully handled various tasks. As one fundamental module in Transformers, position encoding encodes the positional information of tokens in a sequence. Specifically, rotary position embedding (RoPE), one of the most widely used techniques, encodes the positional information by dividing the query or key value with $d$ elements into $d/2$ pairs and rotating the 2d vectors corresponding to each pair of elements. Therefore, the direction of each pair and the position-related rotation jointly determine the attention score. In this paper, we show that the direction of the 2d pair is largely affected by the angle between the corresponding weight vector pair. We theoretically show that non-orthogonal weight vector pairs lead to great attention on tokens at a certain relative position and are less sensitive to the input which may correspond to basic syntactic information. Meanwhile, the orthogonal weight vector pairs are more flexible regarding the relative position, which may correspond to high-level syntactic information. Empirical evidence supports the hypothesis that shallow layers of LLMs focus more on local syntax and deep layers focus more on high-level semantics. Furthermore, we show that LLMs fine-tuning mainly changes the pairs of weight vectors that are nearly orthogonal, i.e., the weight corresponding to high-level semantics, which enables the reduction of the number of trainable parameters during fine-tuning without sacrificing performance. We propose a method namely Angle-based Weight Selection (AWS) to reduce the fine-tuning overhead and verify the effectiveness of the proposed method on widely used Alpaca fine-tuned Llama-2.
tl;dr: Exploring DCN-like architecture for fast image generation with arbitrary resolution

Arbitrary-resolution image generation still remains a challenging task in AIGC, as it requires handling varying resolutions and aspect ratios while maintaining high visual quality. Existing transformer-based diffusion methods suffer from quadratic computation cost and limited resolution extrapolation capabilities, making them less effective for this task. In this paper, we propose FlowDCN, a purely convolution-based generative model with linear time and memory complexity, that can efficiently generate high-quality images at arbitrary resolutions. Equipped with a new design of learnable group-wise deformable convolution block, our FlowDCN yields higher flexibility and capability to handle different resolutions with a single model.
FlowDCN achieves the state-of-the-art 4.30 sFID on $256\times256$ ImageNet Benchmark and comparable resolution extrapolation results, surpassing transformer-based counterparts in terms of convergence speed (only $\frac{1}{5}$ images), visual quality, parameters ($8\%$ reduction) and FLOPs ($20\%$ reduction). We believe FlowDCN offers a promising solution to scalable and flexible image synthesis.
tl;dr: we propose a simple but effective class-generalizable AD framework, called ResAD, which can be applied to detect and localize anomalies in new classes.

This paper explores the problem of class-generalizable anomaly detection, where the objective is to train one unified AD model that can generalize to detect anomalies in diverse classes from different domains without any retraining or fine-tuning on the target data. Because normal feature representations vary significantly across classes, this will cause the widely studied one-for-one AD models to be poorly classgeneralizable (i.e., performance drops dramatically when used for new classes). In this work, we propose a simple but effective framework (called ResAD) that can be directly applied to detect anomalies in new classes. Our main insight is to learn the residual feature distribution rather than the initial feature distribution. In this way, we can significantly reduce feature variations. Even in new classes, the distribution of normal residual features would not remarkably shift from the learned distribution. Therefore, the learned model can be directly adapted to new classes. ResAD consists of three components: (1) a Feature Converter that converts initial features into residual features; (2) a simple and shallow Feature Constraintor that constrains normal residual features into a spatial hypersphere for further reducing feature variations and maintaining consistency in feature scales among different classes; (3) a Feature Distribution Estimator that estimates the normal residual feature distribution, anomalies can be recognized as out-of-distribution. Despite the simplicity, ResAD can achieve remarkable anomaly detection results when directly used in new classes. The code is available at https://github.com/xcyao00/ResAD.
tl;dr: We customize a text-guided diffusion model for generating customized action images in a variety of different contexts.

We propose a novel method, \textbf{TwinAct}, to tackle the challenge of decoupling actions and actors in order to customize the text-guided diffusion models (TGDMs) for few-shot action image generation. TwinAct addresses the limitations of existing methods that struggle to decouple actions from other semantics (e.g., the actor's appearance) due to the lack of an effective inductive bias with few exemplar images. Our approach introduces a common action space, which is a textual embedding space focused solely on actions, enabling precise customization without actor-related details. Specifically, TwinAct involves three key steps: 1) Building common action space based on a set of representative action phrases; 2) Imitating the customized action within the action space; and 3) Generating highly adaptable customized action images in diverse contexts with action similarity loss. To comprehensively evaluate TwinAct, we construct a novel benchmark, which provides sample images with various forms of actions. Extensive experiments demonstrate TwinAct's superiority in generating accurate, context-independent customized actions while maintaining the identity consistency of different subjects, including animals, humans, and even customized actors.

Stochastic compositional optimization (SCO) problem constitutes a class of optimization problems characterized by the objective function with a compositional form, including the tasks with known derivatives, such as AUC maximization, and the derivative-free tasks exemplified by black-box vertical federated learning (VFL). From the learning theory perspective, the learning guarantees of SCO algorithms with known derivatives have been studied in the literature. However, the potential impacts of the derivative-free setting on the learning guarantees of SCO remains unclear and merits further investigation. This paper aims to reveal the impacts by developing a theoretical analysis for two derivative-free algorithms, black-box SCGD and SCSC. Specifically, we first provide the sharper generalization upper bounds of convex SCGD and SCSC based on a new stability analysis framework more effective than prior work under some milder conditions, which is further developed to the non-convex case using the almost co-coercivity property of smooth function. Then, we derive the learning guarantees of three black-box variants of non-convex SCGD and SCSC with additional optimization analysis. Comparing these results, we theoretically uncover the impacts that a better gradient estimation brings a tighter learning guarantee and a larger proportion of unknown gradients may lead to a stronger dependence on the gradient estimation quality. Finally, our analysis is applied to two SCO algorithms, FOO-based vertical VFL and VFL-CZOFO, to build the first learning guarantees for VFL that align with the findings of SCGD and SCSC.
1948. TripletCLIP: Improving Compositional Reasoning of CLIP via Synthetic Vision-Language Negatives
tl;dr: Contrastive synthetic dataset and triplet contrastive learning to imporve CLIP compositionality.

Contrastive Language-Image Pretraining (CLIP) models maximize the mutual information between text and visual modalities to learn representations. This makes the nature of the training data a significant factor in the efficacy of CLIP for downstream tasks. However, the lack of compositional diversity in contemporary image-text datasets limits the compositional reasoning ability of CLIP. We show that generating ``hard'' negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators offers a solution. We introduce a novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. We demonstrate that our method, named TripletCLIP, when applied to existing datasets such as CC3M and CC12M, enhances the compositional capabilities of CLIP, resulting in an absolute improvement of over 9% on the SugarCrepe benchmark on an equal computational budget, as well as improvements in zero-shot image classification and image retrieval. Our code, models, and data are available at: tripletclip.github.io.
tl;dr: zero shot image editing with consistency distillation

Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods. This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3-4 inference steps. Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance. As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
1950. CYCLO: Cyclic Graph Transformer Approach to Multi-Object Relationship Modeling in Aerial Videos

Video scene graph generation (VidSGG) has emerged as a transformative approach to capturing and interpreting the intricate relationships among objects and their temporal dynamics in video sequences. In this paper, we introduce the new AeroEye dataset that focuses on multi-object relationship modeling in aerial videos. Our AeroEye dataset features various drone scenes and includes a visually comprehensive and precise collection of predicates that capture the intricate relationships and spatial arrangements among objects. To this end, we propose the novel Cyclic Graph Transformer (CYCLO) approach that allows the model to capture both direct and long-range temporal dependencies by continuously updating the history of interactions in a circular manner. The proposed approach also allows one to handle sequences with inherent cyclical patterns and process object relationships in the correct sequential order. Therefore, it can effectively capture periodic and overlapping relationships while minimizing information loss. The extensive experiments on the AeroEye dataset demonstrate the effectiveness of the proposed CYCLO model, demonstrating its potential to perform scene understanding on drone videos. Finally, the CYCLO method consistently achieves State-of-the-Art (SOTA) results on two in-the-wild scene graph generation benchmarks, i.e., PVSG and ASPIRe.
tl;dr: This paper presents a novel method, Zero-interference Reparameterizable Adaptation (ZiRa), for incremental vision-language object detection that efficiently adapts models to new tasks while preserving zero-shot generalization capabilities.

This paper presents Incremental Vision-Language Object Detection (IVLOD), a novel learning task designed to incrementally adapt pre-trained Vision-Language Object Detection Models (VLODMs) to various specialized domains, while simultaneously preserving their zero-shot generalization capabilities for the generalized domain. To address this new challenge, we present the Zero-interference Reparameterizable Adaptation (ZiRa), a novel method that introduces Zero-interference Loss and reparameterization techniques to tackle IVLOD without incurring a significant increase in memory usage. Comprehensive experiments on COCO and ODinW-13 datasets demonstrate that ZiRa effectively safeguards the zero-shot generalization ability of VLODMs while continuously adapting to new tasks. Specifically, after training on ODinW-13 datasets, ZiRa exhibits superior performance compared to CL-DETR and iDETR, boosting zero-shot generalizability by substantial $\textbf{13.91}$ and $\textbf{8.74}$ AP, respectively. Our code is available at https://github.com/JarintotionDin/ZiRaGroundingDINO.
tl;dr: Introducing Mixture of Tokens, a fully-differentiable architecture retaining scalability of sparse MoE in language modeling.

Mixture of Experts (MoE) models based on Transformer architecture are pushing the boundaries of language and vision tasks. The allure of these models lies in their ability to substantially increase the parameter count without a corresponding increase in FLOPs. Most widely adopted MoE models are discontinuous with respect to their parameters - often referred to as *sparse*. At the same time, existing continuous MoE designs either lag behind their sparse counterparts or are incompatible with autoregressive decoding. Motivated by the observation that the adaptation of fully continuous methods has been an overarching trend in Deep Learning, we develop Mixture of Tokens (MoT), a simple, continuous architecture that is capable of scaling the number of parameters similarly to sparse MoE models. Unlike conventional methods, MoT assigns mixtures of tokens from different examples to each expert. This architecture is fully compatible with autoregressive training and generation. Our best models not only achieve a 3x increase in training speed over dense Transformer models in language pretraining but also match the performance of state-of-the-art MoE architectures. Additionally, a close connection between MoT and MoE is demonstrated through a novel technique we call *transition tuning*.
tl;dr: An Inverse Q-Learning Algorithm for Multi-Agent Imitation Learning

This paper concerns imitation learning (IL) in cooperative multi-agent systems.
The learning problem under consideration poses several challenges, characterized by high-dimensional state and action spaces and intricate inter-agent dependencies. In a single-agent setting, IL was shown to be done efficiently via an inverse soft-Q learning process. However, extending this framework to a multi-agent context introduces the need to simultaneously learn both local value functions to capture local observations and individual actions, and a joint value function for exploiting centralized learning.
In this work, we introduce a new multi-agent IL algorithm designed to address these challenges. Our approach enables the
centralized learning by leveraging mixing networks to aggregate decentralized Q functions.
We further establish conditions for the mixing networks under which the multi-agent IL objective function exhibits convexity within the Q function space.
We present extensive experiments conducted on some challenging multi-agent game environments, including an advanced version of the Star-Craft multi-agent challenge (SMACv2), which demonstrates the effectiveness of our algorithm.

Motivated by applications of large embedding models, we study differentially private (DP) optimization problems under sparsity of _individual_ gradients. We start with new near-optimal bounds for the classic mean estimation problem but with sparse data, improving upon existing algorithms particularly for the high-dimensional regime. The corresponding lower bounds are based on a novel block-diagonal construction that is combined with existing DP mean estimation lower bounds.
Next, we obtain pure- and approximate-DP algorithms with almost optimal rates
for stochastic convex optimization with sparse gradients; the former represents the first nearly dimension-independent rates for this problem. Furthermore, by introducing novel analyses of bias reduction in mean estimation and randomly-stopped biased SGD we obtain nearly dimension-independent rates for near-stationary points for the empirical risk in nonconvex settings under approximate-DP.
tl;dr: We propose AOT a distributional alignment of LLMs via Optimal Transport.

Current LLM alignment techniques use pairwise human preferences at a sample level, and as such, they do not imply an alignment on the distributional level. We propose in this paper Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT aligns LLMs on unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. We introduce a convex relaxation of this first-order stochastic dominance and cast it as an optimal transport problem with a smooth and convex cost. Thanks to the one-dimensional nature of the resulting optimal transport problem and the convexity of the cost, it has a closed-form solution via sorting on empirical measures. We fine-tune LLMs with this AOT objective, which enables alignment by penalizing the violation of the stochastic dominance of the reward distribution of the positive samples on the reward distribution of the negative samples. We analyze the sample complexity of AOT by considering the dual of the OT problem and show that it converges at the parametric rate. Empirically, we show on a diverse set of alignment datasets and LLMs that AOT leads to state-of-the-art models in the 7B family of models when evaluated with Open LLM Benchmarks and AlpacaEval. Code for $\mathsf{AOT}$ is available in the Hugging Face TRL library \url{https://ibm.biz/AOT_TRL}.
tl;dr: Pixel-level image exposure assessment from three perspectives: model, dataset, and benchmark.

The past decade has witnessed an increasing demand for enhancing image quality through exposure, and as a crucial prerequisite in this endeavor, Image Exposure Assessment (IEA) is now being accorded serious attention. However, IEA encounters two persistent challenges that remain unresolved over the long term: the accuracy and generalizability of No-reference IEA are inadequate for practical applications; the scope of IEA is confined to qualitative and quantitative analysis of the entire image or subimage, such as providing only a score to evaluate the exposure level, thereby lacking intuitive and precise fine-grained evaluation for complex exposure conditions. The objective of this paper is to address the persistent bottleneck challenges from three perspectives: model, dataset, and benchmark. 1) Model-level: we propose a Pixel-level IEA Network (P-IEANet) that utilizes Haar discrete wavelet transform (DWT) to analyze, decompose, and assess exposure from both lightness and structural perspectives, capable of generating pixel-level assessment results under no-reference scenarios. 2) Dataset-level: we elaborately build an exposure-oriented dataset, IEA40K, containing 40K images, covering 17 typical lighting scenarios, 27 devices, and 50+ scenes, with each image densely annotated by more than 10 experts with pixel-level labels. 3) Benchmark-level: we develop a comprehensive benchmark of 19 methods based on IEA40K. Our P-IEANet not only achieves state-of-the-art (SOTA) performance on all metrics but also seamlessly integrates with existing exposure correction and lighting enhancement methods. To our knowledge, this is the first work that explicitly emphasizes assessing complex image exposure problems at a pixel level, providing a significant boost to the IEA and exposure-related community. The code and dataset are available in \href{https://github.com/mRobotit/Pixel-level-No-reference-Image-Exposure-Assessment}{\textcolor{red} {here}}.

Most incremental learners excessively prioritize object classes while neglecting various kinds of states (e.g. color and material) attached to the objects. As a result, they are limited in the ability to model state-object compositionality accurately. To remedy this limitation, we propose a novel task called Compositional Incremental Learning (composition-IL), which enables the model to recognize a variety of state-object compositions in an incremental learning fashion. Since the lack of suitable datasets, we re-organize two existing datasets and make them tailored for composition-IL. Then, we propose a prompt-based Composition Incremental Learner (CompILer), to overcome the ambiguous composition boundary. Specifically, we exploit multi-pool prompt learning, and ensure the inter-pool prompt discrepancy and intra-pool prompt diversity. Besides, we devise object-injected state prompting which injects object prompts to guide the selection of state prompts. Furthermore, we fuse the selected prompts by a generalized-mean strategy, to eliminate irrelevant information learned in the prompts. Extensive experiments on two datasets exhibit state-of-the-art performance achieved by CompILer. Code and datasets are available at: https://github.com/Yanyi-Zhang/CompILer.

This paper introduces OpenGaussian, a method based on 3D Gaussian Splatting (3DGS) that possesses the capability for 3D point-level open vocabulary understanding. Our primary motivation stems from observing that existing 3DGS-based open vocabulary methods mainly focus on 2D pixel-level parsing. These methods struggle with 3D point-level tasks due to weak feature expressiveness and inaccurate 2D-3D feature associations. To ensure robust feature presentation and 3D point-level understanding, we first employ SAM masks without cross-frame associations to train instance features with 3D consistency. These features exhibit both intra-object consistency and inter-object distinction. Then, we propose a two-stage codebook to discretize these features from coarse to fine levels. At the coarse level, we consider the positional information of 3D points to achieve location-based clustering, which is then refined at the fine level.
Finally, we introduce an instance-level 3D-2D feature association method that links 3D points to 2D masks, which are further associated with 2D CLIP features. Extensive experiments, including open vocabulary-based 3D object selection, 3D point cloud understanding, click-based 3D object selection, and ablation studies, demonstrate the effectiveness of our proposed method. The source code is available at our project page https://3d-aigc.github.io/OpenGaussian.
tl;dr: We give an efficient online controller with provable regret guarantees for population dynamical systems.

The study of population dynamics originated with early sociological works but has since extended into many fields, including biology, epidemiology, evolutionary game theory, and economics. Most studies on population dynamics focus on the problem of prediction rather than control. Existing mathematical models for population control are often restricted to specific, noise-free dynamics, while real-world population changes can be complex and adversarial.
To address this gap, we propose a new framework based on the paradigm of online control. We first characterize a set of linear dynamical systems that can naturally model evolving populations. We then give an efficient gradient-based controller for these systems, with near-optimal regret bounds with respect to a broad class of linear policies. Our empirical evaluations demonstrate the effectiveness of the proposed algorithm for population control even in non-linear models such as SIR and replicator dynamics.
tl;dr: A novel diffusion based curriculum reinforcement learning

Curriculum Reinforcement Learning (CRL) is an approach to facilitate the learning process of agents by structuring tasks in a sequence of increasing complexity. Despite its potential, many existing CRL methods struggle to efficiently guide agents toward desired outcomes, particularly in the absence of domain knowledge. This paper introduces DiCuRL (Diffusion Curriculum Reinforcement Learning), a novel method that leverages conditional diffusion models to generate curriculum goals. To estimate how close an agent is to achieving its goal, our method uniquely incorporates a $Q$-function and a trainable reward function based on Adversarial Intrinsic Motivation within the diffusion model. Furthermore, it promotes exploration through the inherent noising and denoising mechanism present in the diffusion models and is environment-agnostic. This combination allows for the generation of challenging yet achievable goals, enabling agents to learn effectively without relying on domain knowledge. We demonstrate the effectiveness of DiCuRL in three different maze environments and two robotic manipulation tasks simulated in MuJoCo, where it outperforms or matches nine state-of-the-art CRL algorithms from the literature.

Internet of Things (IoT) sensing models often suffer from overfitting due to data distribution shifts between training dataset and real-world scenarios. To address this, data augmentation techniques have been adopted to enhance model robustness by bolstering the diversity of synthetic samples within a defined vicinity of existing samples. This paper introduces a novel paradigm of data augmentation for IoT sensing signals by adding fine-grained control to generative models. We define a metric space with statistical metrics that capture the essential features of the short-time Fourier transformed (STFT) spectrograms of IoT sensing signals. These metrics serve as strong conditions for a generative model, enabling us to tailor the spectrogram characteristics in the time-frequency domain according to specific application needs. Furthermore, we propose a set of data augmentation techniques within this metric space to create new data samples. Our method is evaluated across various generative models, datasets, and downstream IoT sensing models. The results demonstrate that our approach surpasses the conventional transformation-based data augmentation techniques and prior generative data augmentation models.

The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple images or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, \textbf{Diffusion4D}, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.

Molecular dynamics (MD) is a powerful technique for studying microscopic phenomena, but its computational cost has driven significant interest in the development of deep learning-based surrogate models. We introduce generative modeling of molecular trajectories as a paradigm for learning flexible multi-task surrogate models of MD from data. By conditioning on appropriately chosen frames of the trajectory, we show such generative models can be adapted to diverse tasks such as forward simulation, transition path sampling, and trajectory upsampling. By alternatively conditioning on part of the molecular system and inpainting the rest, we also demonstrate the first steps towards dynamics-conditioned molecular design. We validate the full set of these capabilities on tetrapeptide simulations and show preliminary results on scaling to protein monomers. Altogether, our work illustrates how generative modeling can unlock value from MD data towards diverse downstream tasks that are not straightforward to address with existing methods or even MD itself. Code is available at https://github.com/bjing2016/mdgen.
1964. StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
tl;dr: StreamingDialogue efficiently compresses dialogue history into conversational attention sinks with minimal losses, enhancing the model's long-term memory and facilitating prolonged streaming conversations.

Standard Large Language Models (LLMs) struggle with handling dialogues with long contexts due to efficiency and consistency issues. According to our observation, dialogue contexts are highly structured, and the special token of End-of-Utterance (EoU) in dialogues has the potential to aggregate information. We refer to the EoU tokens as ``conversational attention sinks'' (conv-attn sinks). Accordingly, we introduce StreamingDialogue, which compresses long dialogue history into conv-attn sinks with minimal losses, and thus reduces computational complexity quadratically with the number of sinks (i.e., the number of utterances). Current LLMs already demonstrate the ability to handle long context window, e.g., a window size of 200K or more. To this end, by compressing utterances into EoUs, our method has the potential to handle more than 200K of utterances, resulting in a prolonged dialogue learning. In order to minimize information losses from reconstruction after compression, we design two learning strategies of short-memory reconstruction (SMR) and long-memory reactivation (LMR). Our method outperforms strong baselines in dialogue tasks and achieves a 4 $\times$ speedup while reducing memory usage by 18 $\times$ compared to dense attention recomputation.
tl;dr: We propose the weighted geometric averaging of LLM output likelihood that can be applied to any DPO-based method. Geometric averaging consistently outperforms previous binary and conservative soft preference methods in offline and online alignment.

Many algorithms for aligning LLMs with human preferences assume that human preferences are binary and deterministic.
However, human preferences can vary across individuals, and therefore should be represented distributionally.
In this work, we introduce the distributional soft preference labels and improve Direct Preference Optimization (DPO) with a weighted geometric average of the LLM output likelihood in the loss function.
This approach adjusts the scale of learning loss based on the soft labels such that the loss would approach zero when the responses are closer to equally preferred.
This simple modification can be easily applied to any DPO-based methods and mitigate over-optimization and objective mismatch, which prior works suffer from.
Our experiments simulate the soft preference labels with AI feedback from LLMs and demonstrate that geometric averaging consistently improves performance on standard benchmarks for alignment research.
In particular, we observe more preferable responses than binary labels and significant improvements where modestly-confident labels are in the majority.
tl;dr: A novel transformer model designed for medical time series classification that utilizes cross-channel multi-granularity patching, and intra-inter granularity self-attention within and among granularities.

Medical time series (MedTS) data, such as Electroencephalography (EEG) and Electrocardiography (ECG), play a crucial role in healthcare, such as diagnosing brain and heart diseases. Existing methods for MedTS classification primarily rely on handcrafted biomarkers extraction and CNN-based models, with limited exploration of transformer-based models. In this paper, we introduce Medformer, a multi-granularity patching transformer tailored specifically for MedTS classification. Our method incorporates three novel mechanisms to leverage the unique characteristics of MedTS: cross-channel patching to leverage inter-channel correlations, multi-granularity embedding for capturing features at different scales, and two-stage (intra- and inter-granularity) multi-granularity self-attention for learning features and correlations within and among granularities. We conduct extensive experiments on five public datasets under both subject-dependent and challenging subject-independent setups. Results demonstrate Medformer's superiority over 10 baselines, achieving top averaged ranking across five datasets on all six evaluation metrics. These findings underscore the significant impact of our method on healthcare applications, such as diagnosing Myocardial Infarction, Alzheimer's, and Parkinson's disease. We release the source code at https://github.com/DL4mHealth/Medformer.
tl;dr: We prove that an overparameterized ResNeXts achieves close-to-minimax rate in learning Besov funtions on a low dimension manifold under weight decay.

Convolutional residual neural networks (ConvResNets), though overparametersized, can achieve remarkable prediction performance in practice, which cannot be well explained by conventional wisdom. To bridge this gap, we study the performance of ConvResNeXts trained with weight decay, which cover ConvResNets as a special case, from the perspective of nonparametric classification. Our analysis allows for infinitely many building blocks in ConvResNeXts, and shows that weight decay implicitly enforces sparsity on these blocks. Specifically, we consider a smooth target function supported on a low-dimensional manifold, then prove that ConvResNeXts can adapt to the function smoothness and low-dimensional structures and efficiently learn the function without suffering from the curse of dimensionality. Our findings partially justify the advantage of overparameterized ConvResNeXts over conventional machine learning models.
tl;dr: A nove graph transfer learning framework for semi-supervised graph domain adaptation.

Semi-supervised graph domain adaptation, as a branch of graph transfer learning, aims to annotate unlabeled target graph nodes by utilizing transferable knowledge learned from a label-scarce source graph. However, most existing studies primarily concentrate on aligning feature distributions directly to extract domain-invariant features, while ignoring the utilization of the intrinsic structure information in graphs. Inspired by the significance of data structure information in enhancing models' generalization performance, this paper aims to investigate how to leverage the structure information to assist graph transfer learning. To this end, we propose an innovative framework called TFGDA. Specially, TFGDA employs a structure alignment strategy named STSA to encode graphs' topological structure information into the latent space, greatly facilitating the learning of transferable features. To achieve a stable alignment of feature distributions, we also introduce a SDA strategy to mitigate domain discrepancy on the sphere. Moreover, to address the overfitting issue caused by label scarcity, a simple but effective RNC strategy is devised to guide the discriminative clustering of unlabeled nodes. Experiments on various benchmarks demonstrate the superiority of TFGDA over SOTA methods.
tl;dr: We can approximate Dense Associative Memory energies and dynamics using random features from kernel methods, making it possible to introduce new memories without increasing the number of weights.

Dense Associative Memories are high storage capacity variants of the Hopfield networks that are capable of storing a large number of memory patterns in the weights of the network of a given size. Their common formulations typically require storing each pattern in a separate set of synaptic weights, which leads to the increase of the number of synaptic weights when new patterns are introduced. In this work we propose an alternative formulation of this class of models using random features, commonly used in kernel methods. In this formulation the number of network's parameters remains fixed. At the same time, new memories can be added to the network by modifying existing weights. We show that this novel network closely approximates the energy function and dynamics of conventional Dense Associative Memories and shares their desirable computational properties.
tl;dr: We propose Mini Sequence to reduce intermediate memory overhead for long sequence training, with 12X longer than the standard implementation of LLaMA3-8b training on a single A100 device.

We introduce Mini-Sequence Transformer (MsT), a simple and effective methodology for highly efficient and accurate LLM training with extremely long sequences. MsT partitions input sequences and iteratively processes mini-sequences to reduce intermediate memory usage. Integrated with activation recomputation, it enables significant memory savings in both forward and backward passes. In experiments with the Llama3-8B model, with MsT, we measure no degradation in throughput or convergence even with 12x longer sequences than standard implementations. MsT is fully general, implementation-agnostic, and requires minimal code changes to integrate with existing LLM training frameworks. Integrated with the huggingface library, MsT successfully extends the maximum context length of Qwen, Mistral, and Gemma-2 by 12-24x.
tl;dr: We explore location-aware tasks as proxies for generative visual pretraining (as opposed to transfer/instruction tuning in prior works).

Image captioning was recently found to be an effective pretraining method similar to contrastive pretraining. This opens up the largely-unexplored potential of using natural language as a flexible and powerful interface for handling diverse pretraining tasks. In this paper, we demonstrate this with a novel visual pretraining paradigm, LocCa, that incorporates location-aware tasks into captioners to teach models to extract rich information from images. Specifically, LocCa employs two tasks, bounding box prediction and location-dependent captioning, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can effortlessly handle multiple tasks during pretraining. LocCa significantly outperforms standard captioners on downstream localization tasks, achieving state-of-the-art results on RefCOCO/+/g, while maintaining comparable performance on holistic tasks. Our work paves the way for further exploration of natural language interfaces in visual pretraining.

Symmetries have proven useful in machine learning models, improving generalisation and overall performance. At the same time, recent advancements in learning dynamical systems rely on modelling the underlying Hamiltonian to guarantee the conservation of energy.
These approaches can be connected via a seminal result in mathematical physics: Noether's theorem, which states that symmetries in a dynamical system correspond to conserved quantities.
This work uses Noether's theorem to parameterise symmetries as learnable conserved quantities. We then allow conserved quantities and associated symmetries to be learned directly from train data through approximate Bayesian model selection, jointly with the regular training procedure. As training objective, we derive a variational lower bound to the marginal likelihood. The objective automatically embodies an Occam's Razor effect that avoids collapse of conversation laws to the trivial constant, without the need to manually add and tune additional regularisers. We demonstrate a proof-of-principle on n-harmonic oscillators and n-body systems. We find that our method correctly identifies the correct conserved quantities and U(n) and SE(n) symmetry groups, improving overall performance and predictive accuracy on test data.

Diffusion Transformers have recently demonstrated unprecedented generative capabilities for various tasks. The encouraging results, however, come with the cost of slow inference, since each denoising step requires inference on a transformer model with a large scale of parameters. In this study, we make an interesting and somehow surprising observation: the computation of a large proportion of layers in the diffusion transformer, through introducing a caching mechanism, can be readily removed even without updating the model parameters. In the case of U-ViT-H/2, for example, we may remove up to 93.68% of the computation in the cache steps (46.84% for all steps), with less than 0.01 drop in FID. To achieve this, we introduce a novel scheme, named Learning-to-Cache (L2C), that learns to conduct caching in a dynamic manner for diffusion transformers. Specifically, by leveraging the identical structure of layers in transformers and the sequential nature of diffusion, we explore redundant computations between timesteps by treating each layer as the fundamental unit for caching. To address the challenge of the exponential search space in deep models for identifying layers to cache and remove, we propose a novel differentiable optimization objective. An input-invariant yet timestep-variant router is then optimized, which can finally produce a static computation graph. Experimental results show that L2C largely outperforms samplers such as DDIM and DPM-Solver, alongside prior cache-based methods at the same inference speed.
tl;dr: We propose a Transformer model with MoE fusion layer for multimodal fusion problem with arbitrary missingness or irregularity.

As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in the real world is validated by a diverse set of challenging prediction tasks.
tl;dr: Prediction sets based on conformal prediction can be suboptimal in achieving human-ai complementarity. We show that finding optimal prediction sets is NP-hard and we give a greedy algorithm with provably improved performance than conformal prediction

Decision support systems based on prediction sets have proven to be effective at helping human experts solve classification tasks. Rather than providing single-label predictions, these systems provide sets of label predictions constructed using conformal prediction, namely prediction sets, and ask human experts to predict label values from these sets. In this paper, we first show that the prediction sets constructed using conformal prediction are, in general, suboptimal in terms of average accuracy. Then, we show that the problem of finding the optimal prediction sets under which the human experts achieve the highest average accuracy is NP-hard. More strongly, unless P = NP, we show that the problem is hard to approximate to any factor less than the size of the label set. However, we introduce a simple and efficient greedy algorithm that, for a large class of expert models and non-conformity scores, is guaranteed to find prediction sets that provably offer equal or greater performance than those constructed using conformal prediction. Further, using a simulation study with both synthetic and real expert predictions, we demonstrate that, in practice, our greedy algorithm finds near-optimal prediction sets offering greater performance than conformal prediction.
tl;dr: The authors propose a robust contextual bandit algorithm for optimizing mobile health interventions that leverages (1) mixed effects, (2) nearest-neighbor regularization, and (3) debiased machine learning (DML).

Mobile health leverages personalized and contextually tailored interventions optimized through bandit and reinforcement learning algorithms. In practice, however, challenges such as participant heterogeneity, nonstationarity, and nonlinear relationships hinder algorithm performance. We propose RoME, a **Ro**bust **M**ixed-**E**ffects contextual bandit algorithm that simultaneously addresses these challenges via (1) modeling the differential reward with user- and time-specific random effects, (2) network cohesion penalties, and (3) debiased machine learning for flexible estimation of baseline rewards. We establish a high-probability regret bound that depends solely on the dimension of the differential-reward model, enabling us to achieve robust regret bounds even when the baseline reward is highly complex. We demonstrate the superior performance of the RoME algorithm in a simulation and two off-policy evaluation studies.
tl;dr: A general approach to constructing approximately equivariant architectures with applications to neural processes

Equivariant deep learning architectures exploit symmetries in learning problems to improve the sample efficiency of neural-network-based models and their ability to generalise. However, when modelling real-world data, learning problems are often not *exactly* equivariant, but only approximately. For example, when estimating the global temperature field from weather station observations, local topographical features like mountains break translation equivariance. In these scenarios, it is desirable to construct architectures that can flexibly depart from exact equivariance in a data-driven way. Current approaches to achieving this cannot usually be applied out-of-the-box to any architecture and symmetry group. In this paper, we develop a general approach to achieving this using existing equivariant architectures. Our approach is agnostic to both the choice of symmetry group and model architecture, making it widely applicable. We consider the use of approximately equivariant architectures in neural processes (NPs), a popular family of meta-learning models. We demonstrate the effectiveness of our approach on a number of synthetic and real-world regression experiments, showing that approximately equivariant NP models can outperform both their non-equivariant and strictly equivariant counterparts.

In modern chip design, placement aims at placing millions of circuit modules, which is an essential step that significantly influences power, performance, and area (PPA) metrics. Recently, reinforcement learning (RL) has emerged as a promising technique for improving placement quality, especially macro placement. However, current RL-based placement methods suffer from long training times, low generalization ability, and inability to guarantee PPA results. A key issue lies in the problem formulation, i.e., using RL to place from scratch, which results in limits useful information and inaccurate rewards during the training process. In this work, we propose an approach that utilizes RL for the refinement stage, which allows the RL policy to learn how to adjust existing placement layouts, thereby receiving sufficient information for the policy to act and obtain relatively dense and precise rewards. Additionally, we introduce the concept of regularity during training, which is considered an important metric in the chip design industry but is often overlooked in current RL placement methods. We evaluate our approach on the ISPD 2005 and ICCAD 2015 benchmark, comparing the global half-perimeter wirelength and regularity of our proposed method against several competitive approaches. Besides, we test the PPA performance using commercial software, showing that RL as a regulator can achieve significant PPA improvements. Our RL regulator can fine-tune placements from any method and enhance their quality. Our work opens up new possibilities for the application of RL in placement, providing a more effective and efficient approach to optimizing chip design. Our code is available at \url{https://github.com/lamda-bbo/macro-regulator}.
tl;dr: A Structure Consistent Gaussian Splatting method to efficiently synthesize novel views from sparse inputs.

Despite the substantial progress of novel view synthesis, existing methods, either based on the Neural Radiance Fields (NeRF) or more recently 3D Gaussian Splatting (3DGS), suffer significant degradation when the input becomes sparse. Numerous efforts have been introduced to alleviate this problem, but they still struggle to synthesize satisfactory results efficiently, especially in the large scene. In this paper, we propose SCGaussian, a Structure Consistent Gaussian Splatting method using matching priors to learn 3D consistent scene structure. Considering the high interdependence of Gaussian attributes, we optimize the scene structure in two folds: rendering geometry and, more importantly, the position of Gaussian primitives, which is hard to be directly constrained in the vanilla 3DGS due to the non-structure property. To achieve this, we present a hybrid Gaussian representation. Besides the ordinary non-structure Gaussian primitives, our model also consists of ray-based Gaussian primitives that are bound to matching rays and whose optimization of their positions is restricted along the ray. Thus, we can utilize the matching correspondence to directly enforce the position of these Gaussian primitives to converge to the surface points where rays intersect. Extensive experiments on forward-facing, surrounding, and complex large scenes show the effectiveness of our approach with state-of-the-art performance and high efficiency. Code is available at https://github.com/prstrive/SCGaussian.

Graph incremental learning has gained widespread attention for its ability to mitigate catastrophic forgetting for graph neural networks (GNN). Conventional methods typically require numerous labels for node classification. However, obtaining abundant labels is often challenging in practice, which makes graph few-shot incremental learning necessary. Current approaches rely on large number of samples from meta-learning to construct memories, and heavy fine-tuning of the GNN parameters that lead to the loss of past knowledge. These result in significant memory consumption and loss of past knowledge information, respectively. To tackle these issues, We introduce Mecoin to efficient construct and Preserve memory. For efficient storage and update of class prototypes, Mecoin use Structured Memory Unit (SMU) to cache prototypes of the seen classes and update new class prototypes through interaction between nodes and the cached prototypes by Memory Construction module(MeCo). Besides, to avoid extensive parameter fine-tuning and forgetting, we introduce a Memory Representation Adaptive Module called MRaM to separate the learning of prototypes and class representations and use Graph Knowledge Interchange Module (GKIM) to injects past knowledge information into GNN. We analyze the effectiveness of our paradigm from the perspectives of generalization error, and discuss the impact of different distillation methods on model performance through experiments and VC-dimension. By comparison with other related methods, we validate that Mecoin achieves higher accuracy and lower forgetting rate.

The superior generation capabilities of Denoised Diffusion Probabilistic Models (DDPMs) have been effectively showcased across a multitude of domains. Recently, the application of DDPMs has extended to time series generation tasks, where they have significantly outperformed other deep generative models, often by a substantial margin. However, we have discovered two main challenges with these methods: 1) the inference time is excessively long; 2) there is potential for improvement in the quality of the generated time series. In this paper, we propose a method based on discrete token modeling technique called Similarity-driven Discrete Transformer (SDformer). Specifically, SDformer utilizes a similarity-driven vector quantization method for learning high-quality discrete token representations of time series, followed by a discrete Transformer for data distribution modeling at the token level. Comprehensive experiments show that our method significantly outperforms competing approaches in terms of the generated time series quality while also ensuring a short inference time. Furthermore, without requiring retraining, SDformer can be directly applied to predictive tasks and still achieve commendable results.

Denoising diffusion models (DDMs) offer a flexible framework for sampling from high dimensional data distributions. DDMs generate a path of probability distributions interpolating between a reference Gaussian distribution and a data distribution by incrementally injecting noise into the data. To numerically simulate the sampling process, a discretisation schedule from the reference back towards clean data must be chosen. An appropriate discretisation schedule is crucial to obtain high quality samples. However, beyond hand crafted heuristics, a general method for choosing this schedule remains elusive. This paper presents a novel algorithm for adaptively selecting an optimal discretisation schedule with respect to a cost that we derive. Our cost measures the work done by the simulation procedure to transport samples from one point in the diffusion path to the next. Our method does not require hyperparameter tuning and adapts to the dynamics and geometry of the diffusion path. Our algorithm only involves the evaluation of the estimated Stein score, making it scalable to existing pre-trained models at inference time and online during training. We find that our learned schedule recovers performant schedules previously only discovered through manual search and obtains competitive FID scores on image datasets.
tl;dr: The paper proposes a more challenging Continual Learning on Modality (MCL) to enable MLLMs to extend to new modalities without retraining.

Multimodal Large Language Models (MLLMs) have gained significant attention due to their impressive capabilities in multimodal understanding. However, existing methods rely heavily on extensive modal-specific pretraining and joint-modal tuning, leading to significant computational burdens when expanding to new modalities. In this paper, we propose \textbf{PathWeave}, a flexible and scalable framework with modal-\textbf{path} s\textbf{w}itching and \textbf{e}xp\textbf{a}nsion abilities that enables MLLMs to continually \textbf{ev}olve on modalities for $\mathbb{X}$-modal reasoning. We leverage the concept of Continual Learning and develop an incremental training strategy atop pre-trained MLLMs, enabling their expansion to new modalities using uni-modal data, without executing joint-modal pretraining. In detail, a novel Adapter-in-Adapter (AnA) framework is introduced, in which uni-modal and cross-modal adapters are seamlessly integrated to facilitate efficient modality alignment and collaboration. Additionally, an MoE-based gating module is applied between two types of adapters to further enhance the multimodal interaction. To investigate the proposed method, we establish a challenging benchmark called \textbf{C}ontinual \textbf{L}earning of \textbf{M}odality (MCL), which consists of high-quality QA data from five distinct modalities: image, video, \textcolor{black}{audio, depth} and point cloud. Extensive experiments demonstrate the effectiveness of the proposed AnA framework on learning plasticity and memory stability during continual learning. Furthermore, PathWeave performs comparably to state-of-the-art MLLMs while concurrently reducing parameter training burdens by 98.73\%. Our code locates at \url{https://github.com/JiazuoYu/PathWeave}.
tl;dr: We find initialization scale determines if transformers learn compositional tasks by reasoning or memorization; mechanistically, small scales favor inferential solutions capturing compositional primitives, while large scales merely memorize tasks.

Transformers have shown impressive capabilities across various tasks, but their performance on compositional problems remains a topic of debate. In this work, we investigate the mechanisms of how transformers behave on unseen compositional tasks. We discover that the parameter initialization scale plays a critical role in determining whether the model learns inferential (reasoning-based) solutions, which capture the underlying compositional primitives, or symmetric (memory-based) solutions, which simply memorize mappings without understanding the compositional structure. By analyzing the information flow and vector representations within the model, we reveal the distinct mechanisms underlying these solution types. We further find that inferential (reasoning-based) solutions exhibit low complexity bias, which we hypothesize is a key factor enabling them to learn individual mappings for single anchors. We validate our conclusions on various real-world datasets. Our findings provide valuable insights into the role of initialization scale in tuning the reasoning and memorizing ability and we propose the initialization rate $\gamma$ to be a convenient tunable hyper-parameter in common deep learning frameworks, where $1/d_{\mathrm{in}}^\gamma$ is the standard deviation of parameters of the layer with $d_{\mathrm{in}}$ input neurons.
1985. Reawakening knowledge: Anticipatory recovery from catastrophic interference via structured training
tl;dr: When we fine-tune LLMs cyclically in a fixed repeated sequence of documents the model can recover from catastrophic interference before seeing the same document again.

We explore the training dynamics of neural networks in a structured non-IID setting where documents are presented cyclically in a fixed, repeated sequence. Typically, networks suffer from catastrophic interference when training on a sequence of documents; however, we discover a curious and remarkable property of LLMs finetuned sequentially in this setting: they exhibit *anticipatory* behavior, recovering from the forgetting on documents *before* seeing them again. The behavior emerges and becomes more robust as the architecture scales up its number of parameters. Through comprehensive experiments and visualizations, we uncover new insights into training over-parameterized networks in structured environments.
1986. Diffusion-based Layer-wise Semantic Reconstruction for Unsupervised Out-of-Distribution Detection

Unsupervised out-of-distribution (OOD) detection aims to identify out-of-domain data by learning only from unlabeled In-Distribution (ID) training samples, which is crucial for developing a safe real-world machine learning system. Current reconstruction-based method provides a good alternative approach, by measuring the reconstruction error between the input and its corresponding generative counterpart in the pixel/feature space. However, such generative methods face the key dilemma, $i.e.$, improving the reconstruction power of the generative model, while keeping compact representation of the ID data. To address this issue, we propose the diffusion-based layer-wise semantic reconstruction approach for unsupervised OOD detection. The innovation of our approach is that we leverage the diffusion model's intrinsic data reconstruction ability to distinguish ID samples from OOD samples in the latent feature space. Moreover, to set up a comprehensive and discriminative feature representation, we devise a multi-layer semantic feature extraction strategy. Through distorting the extracted features with Gaussian noises and applying the diffusion model for feature reconstruction, the separation of ID and OOD samples is implemented according to the reconstruction errors. Extensive experimental results on multiple benchmarks built upon various datasets demonstrate that our method achieves state-of-the-art performance in terms of detection accuracy and speed.

In the rapidly evolving domain of vision-based deep reinforcement learning (RL), a pivotal challenge is to achieve generalization capability to dynamic environmental changes reflected in visual observations.
Our work delves into the intricacies of this problem, identifying two key issues that appear in previous approaches for visual RL generalization: (i) imbalanced saliency and (ii) observational overfitting.
Imbalanced saliency is a phenomenon where an RL agent disproportionately identifies salient features across consecutive frames in a frame stack.
Observational overfitting occurs when the agent focuses on certain background regions rather than task-relevant objects.
To address these challenges, we present a simple yet effective framework for generalization in visual RL (SimGRL) under dynamic scene perturbations.
First, to mitigate the imbalanced saliency problem, we introduce an architectural modification to the image encoder to stack frames at the feature level rather than the image level.
Simultaneously, to alleviate the observational overfitting problem, we propose a novel technique called shifted random overlay augmentation, which is specifically designed to learn robust representations capable of effectively handling dynamic visual scenes.
Extensive experiments demonstrate the superior generalization capability of SimGRL, achieving state-of-the-art performance in benchmarks including the DeepMind Control Suite.
tl;dr: We introduce higher-rank irreducible Cartesian tensors and their products for equivariant message passing.

The ability to perform fast and accurate atomistic simulations is crucial for advancing the chemical sciences. By learning from high-quality data, machine-learned interatomic potentials achieve accuracy on par with ab initio and first-principles methods at a fraction of their computational cost. The success of machine-learned interatomic potentials arises from integrating inductive biases such as equivariance to group actions on an atomic system, e.g., equivariance to rotations and reflections. In particular, the field has notably advanced with the emergence of equivariant message passing. Most of these models represent an atomic system using spherical tensors, tensor products of which require complicated numerical coefficients and can be computationally demanding. Cartesian tensors offer a promising alternative, though state-of-the-art methods lack flexibility in message-passing mechanisms, restricting their architectures and expressive power. This work explores higher-rank irreducible Cartesian tensors to address these limitations. We integrate irreducible Cartesian tensor products into message-passing neural networks and prove the equivariance and traceless property of the resulting layers. Through empirical evaluations on various benchmark data sets, we consistently observe on-par or better performance than that of state-of-the-art spherical and Cartesian models.
tl;dr: We provide the first quantum algorithm for market equilibrium computation with sub-linear performance.

Classical algorithms for market equilibrium computation such as proportional response dynamics face scalability issues with Internet-based applications such as auctions, recommender systems, and fair division, despite having an almost linear runtime in terms of the product of buyers and goods. In this work, we provide the first quantum algorithm for market equilibrium computation with sub-linear performance. Our algorithm provides a polynomial runtime speedup in terms of the product of the number of buyers and goods while reaching the same optimization objective value as the classical algorithm. Numerical simulations of a system with 16384 buyers and goods support our theoretical results that our quantum algorithm provides a significant speedup.
tl;dr: We propose learning propensity scores as a common space to align unpaired multimodal data.

Multimodal representation learning techniques typically require paired samples to learn shared representations, but collecting paired samples can be challenging in fields like biology, where measurement devices often destroy the samples. This paper presents an approach to address the challenge of aligning unpaired samples across disparate modalities in multimodal representation learning. We draw an analogy between potential outcomes in causal inference and potential views in multimodal observations, allowing us to leverage Rubin's framework to estimate a common space for matching samples. Our approach assumes experimentally perturbed samples by treatments, and uses this to estimate a propensity score from each modality. We show that the propensity score encapsulates all shared information between a latent state and treatment, and can be used to define a distance between samples. We experiment with two alignment techniques that leverage this distance---shared nearest neighbours (SNN) and optimal transport (OT) matching---and find that OT matching results in significant improvements over state-of-the-art alignment approaches in on synthetic multi-modal tasks, in real-world data from NeurIPS Multimodal Single-Cell Integration Challenge, and on a single cell microscopy to expression prediction task.

Recent advances in automated theorem proving leverages language models to explore expanded search spaces by step-by-step proof generation. However, such approaches are usually based on short-sighted heuristics (e.g., log probability or value function scores) that potentially lead to suboptimal or even distracting subgoals, preventing us from finding longer proofs. To address this challenge, we propose POETRY (PrOvE Theorems RecursivelY), which proves theorems in a recursive, level-by-level manner in the Isabelle theorem prover. Unlike previous step-by-step methods, POETRY searches for a verifiable sketch of the proof at each level and focuses on solving the current level's theorem or conjecture. Detailed proofs of intermediate conjectures within the sketch are temporarily replaced by a placeholder tactic called sorry, deferring their proofs to subsequent levels. This approach allows the theorem to be tackled incrementally by outlining the overall theorem at the first level and then solving the intermediate conjectures at deeper levels. Experiments are conducted on the miniF2F and PISA datasets and significant performance gains are observed in our POETRY approach over state-of-the-art methods. POETRY on miniF2F achieves an average proving success rate improvement of 5.1%. Moreover, we observe a substantial increase in the maximum proof length found by POETRY, from 10 to 26.
tl;dr: We present a new toolkit for enforcing and measuring fairness with a focus on deep learning models.

We present OxonFair, a new open source toolkit for enforcing fairness in binary classification. Compared to existing toolkits: (i) We support NLP and Computer Vision classification as well as standard tabular problems. (ii) We support enforcing fairness on validation data, making us robust to a wide range of overfitting challenges. (iii) Our approach can optimize any measure based on True Positives, False Positive, False Negatives, and True Negatives. This makes it easily extensible and much more expressive than existing toolkits. It supports all 9 and all 10 of the decision-based group metrics of two popular review articles. (iv) We jointly optimize a performance objective alongside fairness constraints. This minimizes degradation while enforcing fairness, and even improves the performance of inadequately tuned unfair baselines. OxonFair is compatible with standard ML toolkits, including sklearn, Autogluon, and PyTorch and is available at https://github.com/oxfordinternetinstitute/oxonfair.

Despite significant advancements in video generation and editing using diffusion models, achieving accurate and localized video editing remains a substantial challenge. Additionally, most existing video editing methods primarily focus on altering visual content, with limited research dedicated to motion editing. In this paper, we present a novel attempt to Remake a Video (ReVideo) which stands out from existing methods by allowing precise video editing in specific areas through the specification of both content and motion. Content editing is facilitated by modifying the first frame, while the trajectory-based motion control offers an intuitive user interaction experience. ReVideo addresses a new task involving the coupling and training imbalance between content and motion control. To tackle this, we develop a three-stage training strategy that progressively decouples these two aspects from coarse to fine. Furthermore, we propose a spatiotemporal adaptive fusion module to integrate content and motion control across various sampling steps and spatial locations. Extensive experiments demonstrate that our ReVideo has promising performance on several accurate video editing applications, i.e., (1) locally changing video content while keeping the motion constant, (2) keeping content unchanged and customizing new motion trajectories, (3) modifying both content and motion trajectories. Our method can also seamlessly extend these applications to multi-area editing without specific training, demonstrating its flexibility and robustness.

Out-of-distribution (OOD) detection aims to identify OOD inputs from unknown classes, which is important for the reliable deployment of machine learning models in the open world. Various scoring functions are proposed to distinguish it from in-distribution (ID) data. However, existing methods generally focus on excavating the discriminative information from a single input, which implicitly limits its representation dimension. In this work, we introduce a novel perspective, i.e., employing different common corruptions on the input space, to expand that. We reveal an interesting phenomenon termed *confidence mutation*, where the confidence of OOD data can decrease significantly under the corruptions, while the ID data shows a higher confidence expectation considering the resistance of semantic features. Based on that, we formalize a new scoring method, namely, *Confidence aVerage* (CoVer), which can capture the dynamic differences by simply averaging the scores obtained from different corrupted inputs and the original ones, making the OOD and ID distributions more separable in detection tasks. Extensive experiments and analyses have been conducted to understand and verify the effectiveness of CoVer.

Understanding communication and information processing among brain regions of interest (ROIs) is highly dependent on long-range connectivity, which plays a crucial role in facilitating diverse functional neural integration across the entire brain. However, previous studies generally focused on the short-range dependencies within brain networks while neglecting the long-range dependencies, limiting an integrated understanding of brain-wide communication. To address this limitation, we propose Adaptive Long-range aware TransformER (ALTER), a brain graph transformer to capture long-range dependencies between brain ROIs utilizing biased random walk. Specifically, we present a novel long-range aware strategy to explicitly capture long-range dependencies between brain ROIs. By guiding the walker towards the next hop with higher correlation value, our strategy simulates the real-world brain-wide communication. Furthermore, by employing the transformer framework, ALERT adaptively integrates both short- and long-range dependencies between brain ROIs, enabling an integrated understanding of multi-level communication across the entire brain. Extensive experiments on ABIDE and ADNI datasets demonstrate that ALTER consistently outperforms generalized state-of-the-art graph learning methods (including SAN, Graphormer, GraphTrans, and LRGNN) and other graph learning based brain network analysis methods (including FBNETGEN, BrainNetGNN, BrainGNN, and BrainNETTF) in neurological disease diagnosis.
tl;dr: An energy-based open graph learning method for open-set node classification.

Open-set Classification (OSC) is a critical requirement for safely deploying machine learning models in the open world, which aims to classify samples from known classes and reject samples from out-of-distribution (OOD).
Existing methods exploit the feature space of trained network and attempt at estimating the uncertainty in the predictions.
However, softmax-based neural networks are found to be overly confident in their predictions even on data they have never seen before and
the immense diversity of the OOD examples also makes such methods fragile.
To this end, we follow the idea of estimating the underlying density of the training data to decide whether a given input is close to the in-distribution (IND) data and adopt Energy-based models (EBMs) as density estimators.
A novel energy-based generative open-set node classification method, \textit{EGonc}, is proposed to achieve open-set graph learning.
Specifically, we generate substitute unknowns to mimic the distribution of real open-set samples firstly, based on the information of graph structures.
Then, an additional energy logit representing the virtual OOD class is learned from the residual of the feature against the principal space, and matched with the original logits by a constant scaling. This virtual logit serves as the indicator of OOD-ness.
EGonc has nice theoretical properties that guarantee an overall distinguishable margin between the detection scores for IND and OOD samples.
Comprehensive experimental evaluations of EGonc also demonstrate its superiority.

In this paper, we introduce **Era3D**, a novel multiview diffusion method that generates high-resolution multiview images from a single-view image. Despite significant advancements in multiview generation, existing methods still suffer from camera prior mismatch, inefficacy, and low resolution, resulting in poor-quality multiview images. Specifically, these methods assume that the input images should comply with a predefined camera type, e.g. a perspective camera with a fixed focal length, leading to distorted shapes when the assumption fails. Moreover, the full-image or dense multiview attention they employ leads to a dramatic explosion of computational complexity as image resolution increases, resulting in prohibitively expensive training costs. To bridge the gap between assumption and reality, Era3D first proposes a diffusion-based camera prediction module to estimate the focal length and elevation of the input image, which allows our method to generate images without shape distortions. Furthermore, a simple but efficient attention layer, named row-wise attention, is used to enforce epipolar priors in the multiview diffusion, facilitating efficient cross-view information fusion. Consequently, compared with state-of-the-art methods, Era3D generates high-quality multiview images with up to a 512×512 resolution while reducing computation complexity of multiview attention by 12x times. Comprehensive experiments demonstrate the superior generation power of Era3D- it can reconstruct high-quality and detailed 3D meshes from diverse single-view input images, significantly outperforming baseline multiview diffusion methods.
tl;dr: This work proposed a novel motion representation called motion graph to facilitate more accurate video prediction with significantly lower GPU consumptions and a smaller model size.

We introduce motion graph, a novel approach to address the video prediction problem, i.e., predicting future video frames from limited past data. The motion graph transforms patches of video frames into interconnected graph nodes, to comprehensively describe the spatial-temporal relationships among them. This representation overcomes the limitations of existing motion representations such as image differences, optical flow, and motion matrix that either fall short in capturing complex motion patterns or suffer from excessive memory consumption. We further present a video prediction pipeline empowered by motion graph, exhibiting substantial performance improvements and cost reductions. Extensive experiments on various datasets, including UCF Sports, KITTI and Cityscapes, highlight the strong representative ability of motion graph. Especially on UCF Sports, our method matches and outperforms the SOTA methods with a significant reduction in model size by 78% and a substantial decrease in GPU memory utilization by 47%.
tl;dr: This paper proposes ProEdit - a simple yet effective framework for high-quality 3D scene editing guided by diffusion distillation in a novel progressive manner.

This paper proposes ProEdit - a simple yet effective framework for high-quality 3D scene editing guided by diffusion distillation in a novel progressive manner. Inspired by the crucial observation that multi-view inconsistency in scene editing is rooted in the diffusion model’s large feasible output space (FOS), our framework controls the size of FOS and reduces inconsistency by decomposing the overall editing task into several subtasks, which are then executed progressively on the scene. Within this framework, we design a difficulty-aware subtask decomposition scheduler and an adaptive 3D Gaussian splatting (3DGS) training strategy, ensuring high efficiency in performing each subtask. Extensive evaluation shows that our ProEdit achieves state-of-the-art results in various scenes and challenging editing tasks, all through a simple framework without any expensive or sophisticated add-ons like distillation losses, components, or training procedures. Notably, ProEdit also provides a new way to preview, control, and select the aggressivity of editing operation during the editing process.
tl;dr: We propose an efficient leverage score based randomized alternating least squares algorithm for tensor train decomposition.

Tensor Train~(TT) decomposition is widely used in the machine learning and quantum physics communities as a popular tool to efficiently compress high-dimensional tensor data. In this paper, we propose an efficient algorithm to accelerate computing the TT decomposition with the Alternating Least Squares (ALS) algorithm relying on exact leverage scores sampling. For this purpose, we propose a data structure that allows us to efficiently sample from the tensor with time complexity logarithmic in the product of the tensor dimensions. Our contribution specifically leverages the canonical form of the TT decomposition. By maintaining the canonical form through each iteration of ALS, we can efficiently compute (and sample from) the leverage scores, thus achieving significant speed-up in solving each sketched least-square problem. Experiments on synthetic and real data on dense and sparse tensors demonstrate that our method outperforms SVD-based and ALS-based algorithms.
tl;dr: We demonstrate that node-level message passing can effectively capture link-level structural features, such as Common Neighbor, for link prediction.

Message Passing Neural Networks (MPNNs) have emerged as the {\em de facto} standard in graph representation learning. However, when it comes to link prediction, they are not always superior to simple heuristics such as Common Neighbor (CN). This discrepancy stems from a fundamental limitation: while MPNNs excel in node-level representation, they stumble with encoding the joint structural features essential to link prediction, like CN. To bridge this gap, we posit that, by harnessing the orthogonality of input vectors, pure message-passing can indeed capture joint structural features. Specifically, we study the proficiency of MPNNs in approximating CN heuristics. Based on our findings, we introduce the Message Passing Link Predictor (MPLP), a novel link prediction model. MPLP taps into quasi-orthogonal vectors to estimate link-level structural features, all while preserving the node-level complexities. We conduct experiments on benchmark datasets from various domains, where our method consistently outperforms the baseline methods, establishing new state-of-the-arts.
tl;dr: We propose a novel self-labeling improvement method for combinatorial problems that enables the training of state-of-the-art generative models without requiring optimality information or defining Markov Decision Processes.

This work proposes a self-supervised training strategy designed for combinatorial problems. An obstacle in applying supervised paradigms to such problems is the need for costly target solutions often produced with exact solvers. Inspired by semi- and self-supervised learning, we show that generative models can be trained by sampling multiple solutions and using the best one according to the problem objective as a pseudo-label. In this way, we iteratively improve the model generation capability by relying only on its self-supervision, eliminating the need for optimality information. We validate this Self-Labeling Improvement Method (SLIM) on the Job Shop Scheduling (JSP), a complex combinatorial problem that is receiving much attention from the neural combinatorial community. We propose a generative model based on the well-known Pointer Network and train it with SLIM. Experiments on popular benchmarks demonstrate the potential of this approach as the resulting models outperform constructive heuristics and state-of-the-art learning proposals for the JSP. Lastly, we prove the robustness of SLIM to various parameters and its generality by applying it to the Traveling Salesman Problem.
tl;dr: This work considers zero-shot black box optimization with a population-based pretrained optimization model (POM).

Zero-shot optimization involves optimizing a target task that was not seen during training, aiming to provide the optimal solution without or with minimal adjustments to the optimizer. It is crucial to ensure reliable and robust performance in various applications. Current optimizers often struggle with zero-shot optimization and require intricate hyperparameter tuning to adapt to new tasks. To address this, we propose a Pretrained Optimization Model (POM) that leverages knowledge gained from optimizing diverse tasks, offering efficient solutions to zero-shot optimization through direct application or fine-tuning with few-shot samples. Evaluation on the BBOB benchmark and two robot control tasks demonstrates that POM outperforms state-of-the-art black-box optimization methods, especially for high-dimensional tasks. Fine-tuning POM with a small number of samples and budget yields significant performance improvements. Moreover, POM demonstrates robust generalization across diverse task distributions, dimensions, population sizes, and optimization horizons. For code implementation, see https://github.com/ninja-wm/POM/.
tl;dr: New state-of-the-art sample complexity for CMDPs.

We consider a constrained Markov Decision Problem (CMDP) where the goal of an agent is to maximize the expected discounted sum of rewards over an infinite horizon while ensuring that the expected discounted sum of costs exceeds a certain threshold. Building on the idea of momentum-based acceleration, we develop the Primal-Dual Accelerated Natural Policy Gradient (PD-ANPG) algorithm that ensures an $\epsilon$ global optimality gap and $\epsilon$ constraint violation with $\tilde{\mathcal{O}}((1-\gamma)^{-7}\epsilon^{-2})$ sample complexity for general parameterized policies where $\gamma$ denotes the discount factor. This improves the state-of-the-art sample complexity in general parameterized CMDPs by a factor of $\mathcal{O}((1-\gamma)^{-1}\epsilon^{-2})$ and achieves the theoretical lower bound in $\epsilon^{-1}$.
tl;dr: We study the limits and capability of public-data assisted differentially private algorithms.

We study the limits and capability of public-data assisted differentially private (PA-DP) algorithms. Specifically, we focus on the problem of stochastic convex optimization (SCO) with either labeled or unlabeled public data. For complete/labeled public data, we show that any $(\epsilon,\delta)$-PA-DP has excess risk $\tilde{\Omega}\big(\min(\frac{1}{\sqrt{n_{\text{pub}}}},\frac{1}{\sqrt{n}}+\frac{\sqrt{d}}{n\epsilon} ) \big)$, where $d$ is the dimension, ${n_{\text{pub}}}$ is the number of public samples, ${n_{\text{priv}}}$ is the number of private samples, and $n={n_{\text{pub}}}+{n_{\text{priv}}}$. These lower bounds are established via our new lower bounds for PA-DP mean estimation, which are of a similar form. Up to constant factors, these lower bounds show that the simple strategy of either treating all data as private or discarding the private data, is optimal. We also study PA-DP supervised learning with \textit{unlabeled} public samples. In contrast to our previous result, we here show novel methods for leveraging public data in private supervised learning. For generalized linear models (GLM) with unlabeled public data, we show an efficient algorithm which, given $\tilde{O}({n_{\text{priv}}}\epsilon)$ unlabeled public samples, achieves the dimension independent rate $\tilde{O}\big(\frac{1}{\sqrt{{n_{\text{priv}}}}} + \frac{1}{\sqrt{{n_{\text{priv}}}\epsilon}}\big)$. We develop new lower bounds for this setting which shows that this rate cannot be improved with more public samples, and any fewer public samples leads to a worse rate. Finally, we provide extensions of this result to general hypothesis classes with finite \textit{fat-shattering dimension} with applications to neural networks and non-Euclidean geometries.

The Janus Problem is a common issue in SDS-based text-to-3D methods. Due to view encoding approach and 2D diffusion prior guidance, the 3D representation model tends to learn content with higher certainty from each perspective, leading to view inconsistency. In this work, we first model and analyze the problem, visualizing the specific causes of the Janus Problem, which are associated with discrete view encoding and shared priors in 2D lifting. Based on this, we further propose the LCGen method, which guides text-to-3D to obtain different priors with different certainty from various viewpoints, aiding in view-consistent generation. Experiments have proven that our LCGen method can be directly applied to different SDS-based text-to-3D methods, alleviating the Janus Problem without introducing additional information, increasing excessive training burden, or compromising the generation effect.
tl;dr: To address interference when continually learning across tasks, we learn globally aligned data representations by interpolating pre-trained token representations; and apply probing first strategy to reduce interference caused by the classifier.

Continual learning aims to sequentially learn new tasks without forgetting previous tasks' knowledge (catastrophic forgetting). One factor that can cause forgetting is the interference between the gradients on losses from different tasks. When the gradients on the current task's loss are in opposing directions to those on previous tasks' losses, updating the model for the current task may cause performance degradation on previous tasks. In this paper, we first identify causes of the above interference, and hypothesize that correlations between data representations are a key factor of interference. We then propose a method for promoting appropriate correlations between arbitrary tasks' data representations (i.e., global alignment) in individual task learning. Specifically, we learn the data representation as a task-specific composition of pre-trained token representations shared across all tasks. Then the correlations between different tasks' data representations are grounded by correlations between pre-trained token representations. We explore different ways to learn such compositions. Without experience replay, our model achieves SOTA performance in continual learning tasks. It also achieves advanced class-incremental performance through task-incremental training.

This paper uses chess, a landmark planning problem in AI, to assess transformers’ performance on a planning task where memorization is futile — even at a large scale. To this end, we release ChessBench, a large-scale benchmark dataset of 10 million chess games with legal move and value annotations (15 billion data points) provided by Stockfish 16, the state-of-the-art chess engine. We train transformers with up to 270 million parameters on ChessBench via supervised learning and perform extensive ablations to assess the impact of dataset size, model size, architecture type, and different prediction targets (state-values, action-values, and behavioral cloning). Our largest models learn to predict action-values for novel boards quite accurately, implying highly non-trivial generalization. Despite performing no explicit search, our resulting chess policy solves challenging chess puzzles and achieves a surprisingly strong Lichess blitz Elo of 2895 against humans (grandmaster level). We also compare to Leela Chess Zero and AlphaZero (trained without supervision via self-play) with and without search. We show that, although a remarkably good approximation of Stockfish’s search-based algorithm can be distilled into large-scale transformers via supervised learning, perfect distillation is still beyond reach, thus making ChessBench well-suited for future research.

The sim-to-real gap, which represents the disparity between training and testing environments, poses a significant challenge in reinforcement learning (RL). A promising approach to addressing this challenge is distributionally robust RL, often framed as a robust Markov decision process (RMDP). In this framework, the objective is to find a robust policy that achieves good performance under the worst-case scenario among all environments within a pre-specified uncertainty set centered around the training environment. Unlike previous work, which relies on a generative model or a pre-collected offline dataset enjoying good coverage of the deployment environment, we tackle robust RL via interactive data collection, where the learner interacts with the training environment only and refines the policy through trial and error. In this robust RL paradigm, two main challenges emerge: managing distributional robustness while striking a balance between exploration and exploitation during data collection. Initially, we establish that sample-efficient learning without additional assumptions is unattainable owing to the curse of support shift; i.e., the potential disjointedness of the distributional supports between the training and testing environments. To circumvent such a hardness result, we introduce the vanishing minimal value assumption to RMDPs with a total-variation (TV) distance robust set, postulating that the minimal value of the optimal robust value function is zero. We prove that such an assumption effectively eliminates the support shift issue for RMDPs with a TV distance robust set, and present an algorithm with a provable sample complexity guarantee. Our work makes the initial step to uncovering the inherent difficulty of robust RL via interactive data collection and sufficient conditions for designing a sample-efficient algorithm accompanied by sharp sample complexity analysis.

Multimodal Large Language Models (MLLMs) have demonstrated a wide range of capabilities across many domains including Embodied AI. In this work, we study how to best ground a MLLM into different embodiments and their associated action spaces, including both continuous and discrete actions. For continuous actions, a set of learned tokenizations that capture an action at various resolutions allows for sufficient modeling precision, yielding the best performance on downstream tasks. For discrete actions, semantically aligning these actions with the native output token space of the MLLM leads to the strongest performance. We arrive at these lessons via a thorough study of seven action grounding approaches on five different environments, encompassing over 114 embodied tasks.

Nucleic acid-based drugs like aptamers have recently demonstrated great therapeutic potential. However, experimental platforms for aptamer screening are costly, and the scarcity of labeled data presents a challenge for supervised methods to learn protein-aptamer binding. To this end, we develop an unsupervised learning approach based on the predicted pairwise contact map between a protein and a nucleic acid and demonstrate its effectiveness in protein-aptamer binding prediction. Our model is based on FAFormer, a novel equivariant transformer architecture that seamlessly integrates frame averaging (FA) within each transformer block. This integration allows our model to infuse geometric information into node features while preserving the spatial semantics of coordinates, leading to greater expressive power than standard FA models. Our results show that FAFormer outperforms existing equivariant models in contact map prediction across three protein complex datasets, with over 10% relative improvement. Moreover, we curate five real-world protein-aptamer interaction datasets and show that the contact map predicted by FAFormer serves as a strong binding indicator for aptamer screening.
tl;dr: DIVA is an evolutionary approach for generating meaningfully diverse meta-RL training tasks in truly open-ended simulators.

The wider application of end-to-end learning methods to embodied decision-making domains remains bottlenecked by their reliance on a superabundance of training data representative of the target domain.
Meta-reinforcement learning (meta-RL) approaches abandon the aim of zero-shot *generalization*—the goal of standard reinforcement learning (RL)—in favor of few-shot *adaptation*, and thus hold promise for bridging larger generalization gaps.
While learning this meta-level adaptive behavior still requires substantial data, efficient environment simulators approaching real-world complexity are growing in prevalence.
Even so, hand-designing sufficiently diverse and numerous simulated training tasks for these complex domains is prohibitively labor-intensive.
Domain randomization (DR) and procedural generation (PG), offered as solutions to this problem, require simulators to possess carefully-defined parameters which directly translate to meaningful task diversity—a similarly prohibitive assumption.
In this work, we present **DIVA**, an evolutionary approach for generating diverse training tasks in such complex, open-ended simulators.
Like unsupervised environment design (UED) methods, DIVA can be applied to arbitrary parameterizations, but can additionally incorporate realistically-available domain knowledge—thus inheriting the *flexibility* and *generality* of UED, and the supervised *structure* embedded in well-designed simulators exploited by DR and PG.
Our empirical results showcase DIVA's unique ability to overcome complex parameterizations and successfully train adaptive agent behavior, far outperforming competitive baselines from prior literature.
These findings highlight the potential of such *semi-supervised environment design* (SSED) approaches, of which DIVA is the first humble constituent, to enable training in realistic simulated domains, and produce more robust and capable adaptive agents.
Our code is available at [https://github.com/robbycostales/diva](https://github.com/robbycostales/diva).
tl;dr: We study the symmetry structure in high-dimensional linear bandits. With certain assumptions, our algorithm achieves regret that depends logarithmically on the ambient dimension.

High-dimensional linear bandits with low-dimensional structure have received considerable attention in recent studies due to their practical significance. The most common structure in the literature is sparsity. However, it may not be available in practice. Symmetry, where the reward is invariant under certain groups of transformations on the set of arms, is another important inductive bias in the high-dimensional case that covers many standard structures, including sparsity. In this work, we study high-dimensional symmetric linear bandits where the symmetry is hidden from the learner, and the correct symmetry needs to be learned in an online setting. We examine the structure of a collection of hidden symmetry and provide a method based on model selection within the collection of low-dimensional subspaces. Our algorithm achieves a regret bound of $ O(d_0^{2/3} T^{2/3} \log(d))$, where $d$ is the ambient dimension which is potentially very large, and $d_0$ is the dimension of the true low-dimensional subspace such that $d_0 \ll d$. With an extra assumption on well-separated models, we can further improve the regret to $ O(d_0 \sqrt{T\log(d)} )$.
tl;dr: This work introduces Variational Diffusion Distillation (VDD), a novel method for distilling denoising diffusion policies into a Mixture of Experts (MoE).

This work introduces Variational Diffusion Distillation (VDD), a novel method that distills denoising diffusion policies into Mixtures of Experts (MoE) through variational inference. Diffusion Models are the current state-of-the-art in generative modeling due to their exceptional ability to accurately learn and represent complex, multi-modal distributions. This ability allows Diffusion Models to replicate the inherent diversity in human behavior, making them the preferred models in behavior learning such as Learning from Human Demonstrations (LfD).
However, diffusion models come with some drawbacks, including the intractability of likelihoods and long inference times due to their iterative sampling process. The inference times, in particular, pose a significant challenge to real-time applications such as robot control.
In contrast, MoEs effectively address the aforementioned issues while retaining the ability to represent complex distributions but are notoriously difficult to train.
VDD is the first method that distills pre-trained diffusion models into MoE models, and hence, combines the expressiveness of Diffusion Models with the benefits of Mixture Models.
Specifically, VDD leverages a decompositional upper bound of the variational objective that allows the training of each expert separately, resulting in a robust optimization scheme for MoEs.
VDD demonstrates across nine complex behavior learning tasks, that it is able to: i) accurately distill complex distributions learned by the diffusion model, ii) outperform existing state-of-the-art distillation methods, and iii) surpass conventional methods for training MoE. The code and videos are available at https://intuitive-robots.github.io/vdd-website.

We establish a new theoretical framework for learning under multi-class, instance-dependent label noise.
This framework casts learning with label
noise as a form of domain adaptation, in particular, domain adaptation
under posterior drift.
We introduce the concept of \emph{relative signal strength} (RSS), a pointwise measure that quantifies the transferability from noisy to clean posterior.
Using RSS, we establish nearly matching upper and lower bounds on the excess risk.
Our theoretical findings support
the simple
\emph{Noise Ignorant Empirical Risk Minimization (NI-ERM)} principle,
which minimizes empirical risk while ignoring label noise.
Finally, we translate this theoretical insight into practice: by
using NI-ERM to fit a linear classifier on top of a self-supervised
feature extractor, we achieve state-of-the-art performance on the
CIFAR-N data challenge.
tl;dr: We propose a novel approach, AV-Cloud, for rendering high-quality spatial audio in 3D scenes that is in synchrony with the visual stream but does not rely or explicitly conditioned on the visual rendering.

We propose a novel approach for rendering high-quality spatial audio for 3D scenes that is in synchrony with the visual stream but does not rely or explicitly conditioned on the visual rendering. We demonstrate that such an approach enables the experience of immersive virtual tourism - performing a real-time dynamic navigation within the scene, experiencing both audio and visual content. Current audio-visual rendering approaches typically rely on visual cues, such as images, and thus visual artifacts could cause inconsistency in the audio quality. Furthermore, when such approaches are incorporated with visual rendering, audio generation at each viewpoint occurs after the rendering of the image of the viewpoint and thus could lead to audio lag that affects the integration of audio and visual streams. Our proposed approach, AV-Cloud, overcomes these challenges by learning the representation of the audio-visual scene based on a set of sparse AV anchor points, that constitute the Audio-Visual Cloud, and are derived from the camera calibration. The Audio-Visual Cloud serves as an audio-visual representation from which the generation of spatial audio for arbitrary listener location can be generated. In particular, we propose a novel module Audio-Visual Cloud Splatting which decodes AV anchor points into a spatial audio transfer function for the arbitrary viewpoint of the target listener. This function, applied through the Spatial Audio Render Head module, transforms monaural input into viewpoint-specific spatial audio. As a result, AV-Cloud efficiently renders the spatial audio aligned with any visual viewpoint and eliminates the need for pre-rendered images. We show that AV-Cloud surpasses current state-of-the-art accuracy on audio reconstruction, perceptive quality, and acoustic effects on two real-world datasets. AV-Cloud also outperforms previous methods when tested on scenes "in the wild".
tl;dr: We combine ergodic theory with generalization to advance the theory and practice of learning chaotic systems using dynamical data.

Conventional notions of generalization often fail to describe the ability of learned models to capture meaningful information from dynamical data. A neural network that learns complex dynamics with a small test error may still fail to reproduce its \emph{physical} behavior, including associated statistical moments and Lyapunov exponents. To address this gap, we propose an ergodic theoretic approach to generalization of complex dynamical models learned from time series data. Our main contribution is to define and analyze generalization of a broad suite of neural representations of classes of ergodic systems, including chaotic systems, in a way that captures emulating underlying invariant, physical measures. Our results provide theoretical justification for why regression methods for generators of dynamical systems (Neural ODEs) fail to generalize, and why their statistical accuracy improves upon adding Jacobian information during training. We verify our results on a number of ergodic chaotic systems and neural network parameterizations, including MLPs, ResNets, Fourier Neural layers, and RNNs.
2018. Designs for Enabling Collaboration in Human-Machine Teaming via Interactive and Explainable Systems
tl;dr: We develop approaches that enable iterative, mixed-initiative team development allowing end- users to interactively reprogram interpretable AI teammates and summarize our user study findings into guidelines for future research.

Collaborative robots and machine learning-based virtual agents are increasingly entering the human workspace with the aim of increasing productivity and enhancing safety. Despite this, we show in a ubiquitous experimental domain, Overcooked-AI, that state-of-the-art techniques for human-machine teaming (HMT), which rely on imitation or reinforcement learning, are brittle and result in a machine agent that aims to decouple the machine and human’s actions to act independently rather than in a synergistic fashion. To remedy this deficiency, we develop HMT approaches that enable iterative, mixed-initiative team development allowing end-users to interactively reprogram interpretable AI teammates. Our 50-subject study provides several findings that we summarize into guidelines. While all approaches underperform a simple collaborative heuristic (a critical, negative result for learning-based methods), we find that white-box approaches supported by interactive modification can lead to significant team development, outperforming white-box approaches alone, and that black-box approaches are easier to train and result in better HMT performance highlighting a tradeoff between explainability and interactivity versus ease-of-training. Together, these findings present three important future research directions: 1) Improving the ability to generate collaborative agents with white-box models, 2) Better learning methods to facilitate collaboration rather than individualized coordination, and 3) Mixed-initiative interfaces that enable users, who may vary in ability, to improve collaboration.
tl;dr: We carefully examined the performance of Chain of Thought techniques on classical planning problems and found that, contrary to previous claims, they do not lead to generalizable improvement..

Large language model (LLM) performance on reasoning problems typically does not generalize out of distribution. Previous work has claimed that this can be mitigated with chain of thought prompting--a method of demonstrating solution procedures--with the intuition that it is possible to in-context teach an LLM an algorithm for solving the problem.
This paper presents a case study of chain of thought on problems from Blocksworld, a classical planning domain, and examines the performance of two state-of-the-art LLMs across two axes: generality of examples given in prompt, and complexity of problems queried with each prompt. While our problems are very simple, we only find meaningful performance improvements from chain of thought prompts when those prompts are exceedingly specific to their problem class, and that those improvements quickly deteriorate as the size n of the query-specified stack grows past the size of stacks shown in the examples.
We also create scalable variants of three domains commonly studied in previous CoT papers and demonstrate the existence of similar failure modes.
Our results hint that, contrary to previous claims in the literature, CoT's performance improvements do not stem from the model learning general algorithmic procedures via demonstrations but depend on carefully engineering highly problem specific prompts. This spotlights drawbacks of chain of thought, especially the sharp tradeoff between possible performance gains and the amount of human labor necessary to generate examples with correct reasoning traces.

Since deep learning models are usually deployed in non-stationary environments, it is imperative to improve their robustness to out-of-distribution (OOD) data. A common approach to mitigate distribution shift is to regularize internal representations or predictors learned from in-distribution (ID) data to be domain invariant. Past studies have primarily learned pairwise invariances, ignoring the intrinsic structure and high-order dependencies of the data. Unlike machines, human recognizes objects by first dividing them into major components and then identifying the topological relation of these components. Motivated by this, we propose Reconstruct and Match (REMA), a general learning framework for object recognition tasks to endow deep models with the capability of capturing the topological homogeneity of objects without human prior knowledge or fine-grained annotations. To identify major components from objects, REMA introduces a selective slot-based reconstruction module to dynamically map dense pixels into a sparse and discrete set of slot vectors in an unsupervised manner. Then, to model high-order dependencies among these components, we propose a hypergraph-based relational reasoning module that models the intricate relations of nodes (slots) with structural constraints. Experiments on standard benchmarks show that REMA outperforms state-of-the-art methods in OOD generalization and test-time adaptation settings.
tl;dr: We link conformal prediction to information theory, and thus derive a principled way to use side information in conformal prediction, and new upper bounds on the intrinsic uncertainty of the data-generating process, which improve conformal training.

Conformal Prediction (CP) is a distribution-free uncertainty estimation framework that constructs prediction sets guaranteed to contain the true answer with a user-specified probability. Intuitively, the size of the prediction set encodes a general notion of uncertainty, with larger sets associated with higher degrees of uncertainty. In this work, we leverage information theory to connect conformal prediction to other notions of uncertainty. More precisely, we prove three different ways to upper bound the intrinsic uncertainty, as described by the conditional entropy of the target variable given the inputs, by combining CP with information theoretical inequalities. Moreover, we demonstrate two direct and useful applications of such connection between conformal prediction and information theory: (i) more principled and effective conformal training objectives that generalize previous approaches and enable end-to-end training of machine learning models from scratch, and (ii) a natural mechanism to incorporate side information into conformal prediction. We empirically validate both applications in centralized and federated learning settings, showing our theoretical results translate to lower inefficiency (average prediction set size) for popular CP methods.
tl;dr: This paper for the first time adapts CLIP to comprehend 3D anomalies in a zero-shot manner.

Zero-shot (ZS) 3D anomaly detection is a crucial yet unexplored field that addresses scenarios where target 3D training samples are unavailable due to practical concerns like privacy protection. This paper introduces PointAD, a novel approach that transfers the strong generalization capabilities of CLIP for recognizing 3D anomalies on unseen objects. PointAD provides a unified framework to comprehend 3D anomalies from both points and pixels. In this framework, PointAD renders 3D anomalies into multiple 2D renderings and projects them back into 3D space. To capture the generic anomaly semantics into PointAD, we propose hybrid representation learning that optimizes the learnable text prompts from 3D and 2D through auxiliary point clouds. The collaboration optimization between point and pixel representations jointly facilitates our model to grasp underlying 3D anomaly patterns, contributing to detecting and segmenting anomalies of unseen diverse 3D objects. Through the alignment of 3D and 2D space, our model can directly integrate RGB information, further enhancing the understanding of 3D anomalies in a plug-and-play manner. Extensive experiments show the superiority of PointAD in ZS 3D anomaly detection across diverse unseen objects.

Diffusion Transformers (DiT) have attracted significant attention in research. However, they suffer from a slow convergence rate. In this paper, we aim to accelerate DiT training without any architectural modification. We identify the following issues in the training process: firstly, certain training strategies do not consistently perform well across different data. Secondly, the effectiveness of supervision at specific timesteps is limited. In response, we propose the following contributions: (1) We introduce a new perspective for interpreting the failure of the strategies. Specifically, we slightly extend the definition of Signal-to-Noise Ratio (SNR) and suggest observing the Probability Density Function (PDF) of SNR to understand the essence of the data robustness of the strategy. (2) We conduct numerous experiments and report over one hundred experimental results to empirically summarize a unified accelerating strategy from the perspective of PDF. (3) We develop a new supervision method that further accelerates the training process of DiT. Based on them, we propose FasterDiT, an exceedingly simple and practicable design strategy. With few lines of code modifications, it achieves 2.30 FID on ImageNet at 256x256 resolution with 1000 iterations, which is comparable to DiT (2.27 FID) but 7 times faster in training.
tl;dr: By framing next-token prediction training as sparse soft-label classification, we characterize the implicit optimization biases of gradient descent in language models trained to achieve their entropy lower bound.

We initiate an investigation into the optimization properties of next-token prediction (NTP), the dominant training paradigm for modern language models. Specifically, we study the structural properties of the solutions selected by gradient-based optimizers among the many possible minimizers of the NTP objective. By framing NTP as cross-entropy minimization across \emph{distinct} contexts, each tied with a \emph{sparse} conditional probability distribution across a finite vocabulary of tokens, we introduce ``NTP-separability conditions'' that enable reaching the data-entropy lower bound. With this setup, and focusing on linear models with fixed context embeddings, we characterize the optimization bias of gradient descent (GD): Within the data subspace defined by the sparsity patterns of distinct contexts, GD selects parameters that equate the logits' differences of in-support tokens to their log-odds. In the orthogonal subspace, the GD parameters diverge in norm and select the direction that maximizes a margin specific to NTP. These findings extend previous research on implicit bias in one-hot classification to the NTP setting, highlighting key differences and prompting further research into the optimization and generalization properties of NTP, irrespective of the specific architecture used to generate the context embeddings.
tl;dr: We study the problem of fine-tuning a pre-trained model capable of recognizing a large number of classes with only a subset of classes in the new domains.

Fine-tuning is arguably the most straightforward way to tailor a pre-trained model (e.g., a foundation model) to downstream applications, but it also comes with the risk of losing valuable knowledge the model had learned in pre-training. For example, fine-tuning a pre-trained classifier capable of recognizing a large number of classes to master a subset of classes at hand is shown to drastically degrade the model's accuracy in the other classes it had previously learned. As such, it is hard to further use the fine-tuned model when it encounters classes beyond the fine-tuning data. In this paper, we systematically dissect the issue, aiming to answer the fundamental question, "What has been damaged in the fine-tuned model?" To our surprise, we find that the fine-tuned model neither forgets the relationship among the other classes nor degrades the features to recognize these classes. Instead, the fine-tuned model often produces more discriminative features for these other classes, even if they were missing during fine-tuning! What really hurts the accuracy is the discrepant logit scales between the fine-tuning classes and the other classes, implying that a simple post-processing calibration would bring back the pre-trained model's capability and at the same time unveil the feature improvement over all classes. We conduct an extensive empirical study to demonstrate the robustness of our findings and provide preliminary explanations underlying them, suggesting new directions for future theoretical analysis.
tl;dr: We give the first global convergence of gradient EM for over-parameterized Gaussian mixture models when the ground truth is single Gaussian.

We study the gradient Expectation-Maximization (EM) algorithm for Gaussian Mixture Models (GMM) in the over-parameterized setting, where a general GMM with $n>1$ components learns from data that are generated by a single ground truth Gaussian distribution.
While results for the special case of 2-Gaussian mixtures are well-known, a general global convergence analysis for arbitrary $n$ remains unresolved and faces several new technical barriers since the convergence becomes sub-linear and non-monotonic. To address these challenges, we construct a novel likelihood-based convergence analysis framework and rigorously prove that gradient EM converges globally with a sublinear rate $O(1/\sqrt{t})$. This is the first global convergence result for Gaussian mixtures with more than $2$ components. The sublinear convergence rate is due to the algorithmic nature of learning over-parameterized GMM with gradient EM. We also identify a new emerging technical challenge for learning general over-parameterized GMM: the existence of bad local regions that can trap gradient EM for an exponential number of steps.
tl;dr: We extend traditional restless multi-armed bandits to incorporate global rewards

Restless multi-armed bandits (RMAB) extend multi-armed bandits so arm pulls impact future arm states. Despite the success of RMABs, a key limiting assumption is the separability of rewards into a sum across arms. We address this deficiency by proposing restless-multi-armed bandit with global rewards (RMAB-G), a generalization of RMABs to global non-separable rewards. To solve RMAB-G, we develop the Linear-Whittle and Shapley-Whittle indices, which extend Whittle indices from RMABs to RMAB-Gs. We prove approximation bounds which demonstrate how Linear and Shapley-Whittle indices fail for non-linear rewards. To overcome this limitation, we propose two sets of adaptive policies: the first computes indices iteratively and the second combines indices with Monte-Carlo Tree Search (MCTS). Empirically, we demonstrate that adaptive policies outperform both pre-computed index policies and baselines in synthetic and real-world food rescue datasets.
tl;dr: Use "retrieving-from-lookup-tables" operation which has near-zero FLOPs to replace the matrix multiplication used in fully-connected layer to greatly reduce the computational complexity of transformer models.

In order to reduce the computational complexity of large language models, great efforts have been made to to improve the efficiency of transformer models such as linear attention and flash-attention. However, the model size and corresponding computational complexity are constantly scaled up in pursuit of higher performance. In this work, we present MemoryFormer, a novel transformer architecture which significantly reduces the computational complexity (FLOPs) from a new perspective. We eliminate nearly all the computations of the transformer model except for the necessary computation required by the multi-head attention operation. This is made possible by utilizing an alternative method for feature transformation to replace the linear projection of fully-connected layers. Specifically, we first construct a group of in-memory lookup tables that store a large amount of discrete vectors to replace the weight matrix used in linear projection. We then use a hash algorithm to retrieve a correlated subset of vectors dynamically based on the input embedding. The retrieved vectors combined together will form the output embedding, which provides an estimation of the result of matrix multiplication operation in a fully-connected layer. Compared to conducting matrix multiplication, retrieving data blocks from memory is a much cheaper operation which requires little computations. We train MemoryFormer from scratch and conduct extensive experiments on various benchmarks to demonstrate the effectiveness of the proposed model.
tl;dr: We introduce an adaptive Passive-Aggressive (PA) framework that leverages side information for optimal threshold selection, ensuring low tracking error and improved performance in online regression tasks.

The Passive-Aggressive (PA) method is widely used in online regression problems for handling large-scale streaming data, typically updating model parameters in a passive-aggressive manner based on whether the error exceeds a predefined threshold. However, this approach struggles with determining optimal thresholds and adapting to complex scenarios with side information, where tracking accuracy is not the sole metric in the regression model. To address these challenges, we introduce a novel adaptive framework that allows finer adjustments to the weight vector in PA using side information. This framework adaptively selects the threshold parameter in PA, theoretically ensuring convergence to the optimal setting. Additionally, we present an efficient implementation of our algorithm that significantly reduces computational complexity. Numerical experiments show that our model achieves outstanding performance associated with the side information while maintaining low tracking error, demonstrating marked improvements over traditional PA methods across various scenarios.

This paper addresses the long-standing challenge of reconstructing 3D structures from videos with dynamic content. Current approaches to this problem were not designed to operate on casual videos recorded by standard cameras or require a long optimization time.
Aiming to significantly improve the efficiency of previous approaches, we present TracksTo4D, a learning-based approach that enables inferring 3D structure and camera positions from dynamic content originating from casual videos using a single efficient feed-forward pass. To achieve this, we propose operating directly over 2D point tracks as input and designing an architecture tailored for processing 2D point tracks. Our proposed architecture is designed with two key principles in mind: (1) it takes into account the inherent symmetries present in the input point tracks data, and (2) it assumes that the movement patterns can be effectively represented using a low-rank approximation. TracksTo4D is trained in an unsupervised way on a dataset of casual videos utilizing only the 2D point tracks extracted from the videos, without any 3D supervision. Our experiments show that TracksTo4D can reconstruct a temporal point cloud and camera positions of the underlying video with accuracy comparable to state-of-the-art methods, while drastically reducing runtime by up to 95\%. We further show that TracksTo4D generalizes well to unseen videos of unseen semantic categories at inference time.
tl;dr: In this work, we propose InteractTraj, the first language-driven traffic trajectory generator that can generate interactive traffic trajectories.

Realistic trajectory generation with natural language control is pivotal for advancing autonomous vehicle technology. However, previous methods focus on individual traffic participant trajectory generation, thus failing to account for the complexity of interactive traffic dynamics. In this work, we propose InteractTraj, the first language-driven traffic trajectory generator that can generate interactive traffic trajectories. InteractTraj interprets abstract trajectory descriptions into concrete formatted interaction-aware numerical codes and learns a mapping between these formatted codes and the final interactive trajectories. To interpret language descriptions, we propose a language-to-code encoder with a novel interaction-aware encoding strategy. To produce interactive traffic trajectories, we propose a code-to-trajectory decoder with interaction-aware feature aggregation that synergizes vehicle interactions with the environmental map and the vehicle moves. Extensive experiments show our method demonstrates superior performance over previous SoTA methods, offering a more realistic generation of interactive traffic trajectories with high controllability via diverse natural language commands.

Learning-based simulators show great potential for simulating particle dynamics when 3D groundtruth is available, but per-particle correspondences are not always accessible. The development of neural rendering presents a new solution to this field to learn 3D dynamics from 2D images by inverse rendering.
However, existing approaches still suffer from ill-posed natures resulting from the 2D to 3D uncertainty, for example, specific 2D images can correspond with various 3D particle distributions. To mitigate such uncertainty, we consider a conventional, mechanically interpretable framework as the physical priors and extend it to a learning-based version. In brief, we incorporate the learnable graph kernels into the classic Discrete Element Analysis (DEA) framework to implement a novel mechanics-informed network architecture. In this case, the graph networks are only used for approximating some specific mechanical operators in the DEA framework rather than the whole dynamics mapping. By integrating the strong physics priors, our methods can effectively learn the dynamics of various materials from the partial 2D observations in a unified manner. Experiments show that our approach outperforms other learned simulators by a large margin in this context and is robust to different renderers, fewer training samples, and fewer camera views.

Despite the success of Large Language Models (LLMs) on various tasks following human instructions, controlling model generation to follow strict constraints at inference time poses a persistent challenge. In this paper, we introduce Ctrl-G, a neuro-symbolic framework that enables tractable and adaptable control of LLM generation to follow logical constraints reliably. Ctrl-G combines any production-ready LLM with a Hidden Markov Model (HMM), guiding LLM outputs to adhere to logical constraints represented as deterministic finite automata. We show that Ctrl-G, when a TULU2-7B model is coupled with a 2B-parameter HMM, outperforms GPT4 in text editing: on the task of generating text insertions/continuations following logical constraints, our approach achieves over 30% higher satisfaction rate in human evaluation. When applied to medium-size language models (e.g., GPT2-large), Ctrl-G also beats its counterparts on standard benchmarks by large margins. Additionally, as a proof-of-concept study, we use Ctrl-G to assist LLM reasoning on the GSM benchmark, foreshadowing the application of Ctrl-G, as well as other constrained generation approaches, beyond traditional language generation tasks.
tl;dr: We model the CA3 region as a recurrent autoencoder that reconstructs sensory experiences from partial observations in simulated environments, and observed emergence of place fields reproducing key aspects of hippocampal phenomenology.

The vertebrate hippocampus is thought to use recurrent connectivity in area CA3 to support episodic memory recall from partial cues. This brain area also contains place cells, whose location-selective firing fields implement maps supporting spatial memory. Here we show that place cells emerge in networks trained to remember temporally continuous sensory episodes. We model CA3 as a recurrent autoencoder that recalls and reconstructs sensory experiences from noisy and partially occluded observations by agents traversing simulated arenas. The agents move in realistic trajectories modeled from rodents and environments are modeled as continuously varying, high-dimensional, sensory experience maps (spatially smoothed Gaussian random fields). Training our autoencoder to accurately pattern-complete and reconstruct sensory experiences with a constraint on total activity causes spatially localized firing fields, i.e., place cells, to emerge in the encoding layer. The emergent place fields reproduce key aspects of hippocampal phenomenology: a) remapping (maintenance of and reversion to distinct learned maps in different environments), implemented via repositioning of experience manifolds in the network’s hidden layer, b) orthogonality of spatial representations in different arenas, c) robust place field emergence in differently shaped rooms, with single units showing multiple place fields in large or complex spaces, and (d) slow representational drift of place fields. We argue that these results arise because continuous traversal of space makes sensory experience temporally continuous. We make testable predictions: a) rapidly changing sensory context will disrupt place fields, b) place fields will form even if recurrent connections are blocked, but reversion to previously learned representations upon remapping will be abolished, c) the dimension of temporally smooth experience sets the dimensionality of place fields, including during virtual navigation of abstract spaces.
tl;dr: Exact characterization of Model collapse (retraining on data generated from prior models) in a theoretical framework; exact formulae for bias and variance decay; new phenomena emerging.

The era of proliferation of large language and image generation models begs the question of what happens if models are trained on the synthesized outputs of other models. The phenomenon of "model collapse" refers to the situation whereby as a model is trained recursively on data generated from previous generations of itself over time, its performance degrades until the model eventually becomes completely useless, i.e. the model collapses. In this work, we investigate this phenomenon within the context of high-dimensional regression with Gaussian data, considering both low- and high-dimensional asymptotics. We derive analytical formulas that quantitatively describe this phenomenon in both under-parameterized and over-parameterized regimes. We show how test error increases linearly in the number of model iterations in terms of all problem hyperparameters (covariance spectrum, regularization, label noise level, dataset size) and further isolate how model collapse affects both bias and variance terms in our setup. We show that even in the noise-free case, catastrophic (exponentially fast) model-collapse can happen in the over-parametrized regime. In the special case of polynomial decaying spectral and source conditions, we obtain modified scaling laws which exhibit new crossover phenomena from fast to slow rates. We also propose a simple strategy based on adaptive regularization to mitigate model collapse. Our theoretical results are validated with experiments.

Unsupervised skill discovery carries the promise that an intelligent agent can learn reusable skills through autonomous, reward-free interactions with environments. Existing unsupervised skill discovery methods learn skills by encouraging distinguishable behaviors that cover diverse states. However, in complex environments with many state factors (e.g., household environments with many objects), learning skills that cover all possible states is impossible, and naively encouraging state diversity often leads to simple skills that are not ideal for solving downstream tasks. This work introduces Skill Discovery from Local Dependencies (SkiLD), which leverages state factorization as a natural inductive bias to guide the skill learning process. The key intuition guiding SkiLD is that skills that induce \textbf{diverse interactions} between state factors are often more valuable for solving downstream tasks. To this end, SkiLD develops a novel skill learning objective that explicitly encourages the mastering of skills that effectively induce different interactions within an environment. We evaluate SkiLD in several domains with challenging, long-horizon sparse reward tasks including a realistic simulated household robot domain, where SkiLD successfully learns skills with clear semantic meaning and shows superior performance compared to existing unsupervised reinforcement learning methods that only maximize state coverage.

In recent years, the application of reinforcement learning (RL) involving interactions with individuals has seen significant growth. These interactions, influenced by individual-specific factors ranging from personal preferences to physiological differences, can causally affect state transitions, such as the health conditions in healthcare or learning progress in education. Consequently, different individuals may exhibit different state-transition processes. Understanding these individualized state-transition processes is crucial for optimizing individualized policies. In practice, however, identifying these state-transition processes is challenging, especially since individual-specific factors often remain latent. In this paper, we establish the identifiability of these latent factors and present a practical method that effectively learns these processes from observed state-action trajectories. Our experiments on various datasets show that our method can effectively identify the latent state-transition processes and help learn individualized RL policies.
2038. CA-SSLR: Condition-Aware Self-Supervised Learning Representation for Generalized Speech Processing
tl;dr: We propose a condition-aware learning method to enhance the performance and generalization ability of self-supervised representations.

We introduce Condition-Aware Self-Supervised Learning Representation (CA-SSLR), a generalist conditioning model broadly applicable to various speech-processing tasks. Compared to standard fine-tuning methods that optimize for downstream models, CA-SSLR integrates language and speaker embeddings from earlier layers, making the SSL model aware of the current language and speaker context.
This approach reduces the reliance on the input audio features while preserving the integrity of the base SSLR. CA-SSLR improves the model’s capabilities and demonstrates its generality on unseen tasks with minimal task-specific tuning. Our method employs linear modulation to dynamically adjust internal representations, enabling fine-grained adaptability without significantly altering the original model behavior. Experiments show that CA-SSLR reduces the number of trainable parameters, mitigates overfitting, and excels in under-resourced and unseen tasks. Specifically, CA-SSLR achieves a 10\% relative reduction in LID errors, a 37\% improvement in ASR CER on the ML-SUPERB benchmark, and a 27\% decrease in SV EER on VoxCeleb-1, demonstrating its effectiveness.
tl;dr: Use an error tolerant parser with a MAX-SAT solver to improve LLM-based text-to-code for very low resource programming langauges.

Recent advances in large language models (LLMs) for code applications have demonstrated remarkable zero-shot fluency and instruction following on challenging code related tasks ranging from test case generation to self-repair. Unsurprisingly, however, models struggle to compose syntactically valid programs in programming languages unrepresented in pre-training, referred to as very low-resource Programming Languages (VLPLs). VLPLs appear in crucial settings, including domain-specific languages for internal tools, tool-chains for legacy languages, and formal verification frameworks. Inspired by a technique called natural programming elicitation, we propose designing an intermediate language that LLMs ``naturally'' know how to use and which can be automatically compiled to a target VLPL. When LLMs generate code that lies outside of this intermediate language, we use compiler techniques to repair the code into programs in the intermediate language. Overall, we introduce _synthetic programming elicitation and compilation_ (SPEAC), an approach that enables LLMs to generate syntactically valid code even for VLPLs. We empirically evaluate the performance of SPEAC in a case study for the UCLID5 formal verification language and find that, compared to existing retrieval and fine-tuning baselines, SPEAC produces syntactically correct programs more frequently and without sacrificing semantic correctness.

Diffusion policy has shown a strong ability to express complex action distributions in offline reinforcement learning (RL). However, it suffers from overestimating Q-value functions on out-of-distribution (OOD) data points due to the offline dataset limitation. To address it, this paper proposes a novel entropy-regularized diffusion policy and takes into account the confidence of the Q-value prediction with Q-ensembles. At the core of our diffusion policy is a mean-reverting stochastic differential equation (SDE) that transfers the action distribution into a standard Gaussian form and then samples actions conditioned on the environment state with a corresponding reverse-time process. We show that the entropy of such a policy is tractable and that can be used to increase the exploration of OOD samples in offline RL training. Moreover, we propose using the lower confidence bound of Q-ensembles for pessimistic Q-value function estimation. The proposed approach demonstrates state-of-the-art performance across a range of tasks in the D4RL benchmarks, significantly improving upon existing diffusion-based policies. The code is available at https://github.com/ruoqizzz/entropy-offlineRL.
tl;dr: We propose a object-centric learning framework incorporating a top-down pathway.

Object-centric learning (OCL) aims to learn representations of individual objects within visual scenes without manual supervision, facilitating efficient and effective visual reasoning. Traditional OCL methods primarily employ bottom-up approaches that aggregate homogeneous visual features to represent objects. However, in complex visual environments, these methods often fall short due to the heterogeneous nature of visual features within an object. To address this, we propose a novel OCL framework incorporating a top-down pathway. This pathway first bootstraps the semantics of individual objects and then modulates the model to prioritize features relevant to these semantics. By dynamically modulating the model based on its own output, our top-down pathway enhances the representational quality of objects. Our framework achieves state-of-the-art performance across multiple synthetic and real-world object-discovery benchmarks.
tl;dr: We propose a powerful agent with hybrid multimodal memory architecture, Optimus-1, in Minecraft.

Building a general-purpose agent is a long-standing vision in the field of artificial intelligence. Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world. We attribute this to the lack of necessary world knowledge and multimodal experience that can guide agents through a variety of long-horizon tasks. In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges. It 1) transforms knowledge into Hierarchical Directed Knowledge Graph that allows agents to explicitly represent and learn world knowledge, and 2) summarises historical information into Abstracted Multimodal Experience Pool that provide agents with rich references for in-context learning. On top of the Hybrid Multimodal Memory module, a multimodal agent, Optimus-1, is constructed with dedicated Knowledge-guided Planner and Experience-Driven Reflector, contributing to a better planning and reflection in the face of long-horizon tasks in Minecraft. Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near human-level performance on many tasks. In addition, we introduce various Multimodal Large Language Models (MLLMs) as the backbone of Optimus-1. Experimental results show that Optimus-1 exhibits strong generalization with the help of the Hybrid Multimodal Memory module, outperforming the GPT-4V baseline on many tasks.

Recent sequence modeling approaches using selective state space sequence models, referred to as Mamba models, have seen a surge of interest. These models allow efficient processing of long sequences in linear time and are rapidly being adopted in a wide range of applications such as language modeling, demonstrating promising performance. To foster their reliable use in real-world scenarios, it is crucial to augment their transparency. Our work bridges this critical gap by bringing explainability, particularly Layer-wise Relevance Propagation (LRP), to the Mamba architecture. Guided by the axiom of relevance conservation, we identify specific components in the Mamba architecture, which cause unfaithful explanations. To remedy this issue, we propose MambaLRP, a novel algorithm within the LRP framework, which ensures a more stable and reliable relevance propagation through these components. Our proposed method is theoretically sound and excels in achieving state-of-the-art explanation performance across a diverse range of models and datasets. Moreover, MambaLRP facilitates a deeper inspection of Mamba architectures, uncovering various biases and evaluating their significance. It also enables the analysis of previous speculations regarding the long-range capabilities of Mamba models.
tl;dr: We present a bottom-up, patch-based diffusion model for monocular shape from shading that produces multimodal outputs, similar to multistable perception in humans.

Models for inferring monocular shape of surfaces with diffuse reflection---shape from shading---ought to produce distributions of outputs, because there are fundamental mathematical ambiguities of both continuous (e.g., bas-relief) and discrete (e.g., convex/concave) types that are also experienced by humans. Yet, the outputs of current models are limited to point estimates or tight distributions around single modes, which prevent them from capturing these effects. We introduce a model that reconstructs a multimodal distribution of shapes from a single shading image, which aligns with the human experience of multistable perception. We train a small denoising diffusion process to generate surface normal fields from $16\times 16$ patches of synthetic images of everyday 3D objects. We deploy this model patch-wise at multiple scales, with guidance from inter-patch shape consistency constraints. Despite its relatively small parameter count and predominantly bottom-up structure, we show that multistable shape explanations emerge from this model for ambiguous test images that humans experience as being multistable. At the same time, the model produces veridical shape estimates for object-like images that include distinctive occluding contours and appear less ambiguous. This may inspire new architectures for stochastic 3D shape perception that are more efficient and better aligned with human experience.
2045. $\textit{Read-ME}$: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design

The proliferation of large language models (LLMs) has led to the adoption of Mixture-of-Experts (MoE) architectures that dynamically leverage specialized subnetworks for improved efficiency and performance. Despite their benefits, MoE models face significant challenges during inference, including inefficient memory management and suboptimal batching, due to misaligned design choices between the model architecture and the system policies. Furthermore, the conventional approach of training MoEs from scratch is increasingly prohibitive in terms of cost.
In this paper, we propose a novel framework $\textit{Read-ME}$ that transforms pre-trained dense LLMs into smaller MoE models (in contrast to ``upcycling" generalist MoEs), avoiding the high costs of ground-up training. Our approach employs activation sparsity to extract experts.
To compose experts, we examine the widely-adopted layer-wise router design and show its redundancy, and thus we introduce the pre-gating router decoupled from the MoE backbone that facilitates system-friendly pre-computing and lookahead scheduling, enhancing expert-aware batching and caching.
Our codesign therefore addresses critical gaps on both the algorithmic and system fronts, establishing a scalable and efficient alternative for LLM inference in resource-constrained settings.
$\textit{Read-ME}$ outperforms other popular open-source dense models of similar scales, achieving improvements of up to 10.1\% on MMLU, and improving mean end-to-end latency up to 6.1\%.
Codes are available at: \url{https://github.com/VITA-Group/READ-ME}.

This paper introduces the confounded pure exploration transductive linear bandit (CPET-LB) problem.
As a motivating example, often online services cannot directly assign users to specific control or treatment experiences either for business or practical reasons. In these settings, naively comparing treatment and control groups that may result from self-selection can lead to biased estimates of underlying treatment effects.
Instead, online services can employ a properly randomized encouragement that incentivizes users toward a specific treatment.
Our methodology provides online services with an adaptive experimental design approach for learning the best-performing treatment for such encouragement designs.
We consider a more general underlying model captured by a linear structural equation and formulate pure exploration linear bandits in this setting. Though pure exploration has been extensively studied in standard adaptive experimental design settings, we believe this is the first work considering a setting where noise is confounded. Elimination-style algorithms using experimental design methods in combination with a novel finite-time confidence interval on an instrumental variable style estimator are presented with sample complexity upper bounds nearly matching a minimax lower bound. Finally, experiments are conducted that demonstrate the efficacy of our approach.

The task of layout-to-image generation involves synthesizing images based on the captions of objects and their spatial positions. Existing methods still struggle in complex layout generation, where common bad cases include object missing, inconsistent lighting, conflicting view angles, etc. To effectively address these issues, we propose a \textbf{Hi}erarchical \textbf{Co}ntrollable (HiCo) diffusion model for layout-to-image generation, featuring object seperable conditioning branch structure. Our key insight is to achieve spatial disentanglement through hierarchical modeling of layouts. We use a multi branch structure to represent hierarchy and aggregate them in fusion module. To evaluate the performance of multi-objective controllable layout generation in natural scenes, we introduce the HiCo-7K benchmark, derived from the GRIT-20M dataset and manually cleaned. https://github.com/360CVGroup/HiCo_T2I.
2048. Differentiable Modal Synthesis for Physical Modeling of Planar String Sound and Motion Simulation
tl;dr: We propose a model that simulates a musical string instrument from the physical properties.

While significant advancements have been made in music generation and differentiable sound synthesis within machine learning and computer audition, the simulation of instrument vibration guided by physical laws has been underexplored. To address this gap, we introduce a novel model for simulating the spatio-temporal motion of nonlinear strings, integrating modal synthesis and spectral modeling within a neural network framework. Our model leverages mechanical properties and fundamental frequencies as inputs, outputting string states across time and space that solve the partial differential equation characterizing the nonlinear string. Empirical evaluations demonstrate that the proposed architecture achieves superior accuracy in string motion simulation compared to existing baseline architectures. The code and demo are available online.
tl;dr: This paper explores Gaussian process bandit algorithms using Kendall kernels for top-k ranking, introducing a new variant of the Kendall kernel, enabling fast inference, and including a regret analysis.

Algorithms that utilize bandit feedback to optimize top-k recommendations are vital for online marketplaces, search engines, and content platforms. However, the combinatorial nature of this problem poses a significant challenge, as the possible number of ordered top-k recommendations from $n$ items grows exponentially with $k$. As a result, previous work often relies on restrictive assumptions about the reward or bandit feedback models, such as assuming that the feedback discloses rewards for each recommended item rather than a single scalar feedback for the entire set of top-k recommendations. We introduce a novel contextual bandit algorithm for top-k recommendations, leveraging a Gaussian process with a Kendall kernel to model the reward function.
Our algorithm requires only scalar feedback from
the top-k recommendations and does not impose restrictive assumptions on the reward structure.
Theoretical analysis confirms that the proposed algorithm achieves sub-linear regret in relation to the number of rounds and arms. Additionally, empirical results using a bandit simulator demonstrate that the proposed algorithm outperforms other baselines across various scenarios.

The ability of learning useful features is one of the major advantages of neural networks. Although recent works show that neural network can operate in a neural tangent kernel (NTK) regime that does not allow feature learning, many works also demonstrate the potential for neural networks to go beyond NTK regime and perform feature learning. Recently, a line of work highlighted the feature learning capabilities of the early stages of gradient-based training. In this paper we consider another mechanism for feature learning via gradient descent through a local convergence analysis. We show that once the loss is below a certain threshold, gradient descent with a carefully regularized objective will capture ground-truth directions. We further strengthen this local convergence analysis by incorporating early-stage feature learning analysis. Our results demonstrate that feature learning not only happens at the initial gradient steps, but can also occur towards the end of training.

Continual learning (CL) with Vision-Language Models (VLMs) has overcome the constraints of traditional CL, which only focuses on previously encountered classes. During the CL of VLMs, we need not only to prevent the catastrophic forgetting on incrementally learned knowledge but also to preserve the zero-shot ability of VLMs. However, existing methods require additional reference datasets to maintain such zero-shot ability and rely on domain-identity hints to classify images across different domains. In this study, we propose Regression-based Analytic Incremental Learning (RAIL), which utilizes a recursive ridge regression-based adapter to learn from a sequence of domains in a non-forgetting manner and decouple the cross-domain correlations by projecting features to a higher-dimensional space. Cooperating with a training-free fusion module, RAIL absolutely preserves the VLM's zero-shot ability on unseen domains without any reference data.
Additionally, we introduce Cross-domain Task-Agnostic Incremental Learning (X-TAIL) setting. In this setting, a CL learner is required to incrementally learn from multiple domains and classify test images from both seen and unseen domains without any domain-identity hint.
We theoretically prove RAIL's absolute memorization on incrementally learned domains. Experiment results affirm RAIL's state-of-the-art performance in both X-TAIL and existing Multi-domain Task-Incremental Learning settings. The code is released at https://github.com/linghan1997/Regression-based-Analytic-Incremental-Learning.

Computer simulations have long presented the exciting possibility of scientific insight into complex real-world processes. Despite the power of modern computing, however, it remains challenging to systematically perform inference under simulation models. This has led to the rise of simulation-based inference (SBI), a class of machine learning-enabled techniques for approaching inverse problems with stochastic simulators. Many such methods, however, require large numbers of simulation samples and face difficulty scaling to high-dimensional settings, often making inference prohibitive under resource-intensive simulators. To mitigate these drawbacks, we introduce active sequential neural posterior estimation (ASNPE). ASNPE brings an active learning scheme into the inference loop to estimate the utility of simulation parameter candidates to the underlying probabilistic model. The proposed acquisition scheme is easily integrated into existing posterior estimation pipelines, allowing for improved sample efficiency with low computational overhead. We further demonstrate the effectiveness of the proposed method in the travel demand calibration setting, a high-dimensional inverse problem commonly requiring computationally expensive traffic simulators. Our method outperforms well-tuned benchmarks and state-of-the-art posterior estimation methods on a large-scale real-world traffic network, as well as demonstrates a performance advantage over non-active counterparts on a suite of SBI benchmark environments.
tl;dr: We introduce SSMA, a novel aggregation for MPGNNs which treats the neighbor features as 2D discrete signals and sequentially convolves them, inherently enhancing the ability to mix features attributed to distinct neighbors.

Message Passing Graph Neural Networks (MPGNNs) have emerged as the preferred method for modeling complex interactions across diverse graph entities. While the theory of such models is well understood, their aggregation module has not received sufficient attention. Sum-based aggregators have solid theoretical foundations regarding their separation capabilities. However, practitioners often prefer using more complex aggregations and mixtures of diverse aggregations. In this work, we unveil a possible explanation for this gap. We claim that sum-based aggregators fail to "mix" features belonging to distinct neighbors, preventing them from succeeding at downstream tasks.
To this end, we introduce Sequential Signal Mixing Aggregation (SSMA), a novel plug-and-play aggregation for MPGNNs. SSMA treats the neighbor features as 2D discrete signals and sequentially convolves them, inherently enhancing the ability to mix features attributed to distinct neighbors. By performing extensive experiments, we show that when combining SSMA with well-established MPGNN architectures, we achieve substantial performance gains across various benchmarks, achieving new state-of-the-art results in many settings.
We published our code at https://almogdavid.github.io/SSMA/.
tl;dr: Adaptive sampling-based algorithm makes softmax computation sublinear in feature dimension while maintaining PAC guarantees.

The softmax function is ubiquitous in machine learning and optimization applications. Computing the full softmax evaluation of a matrix-vector product can be computationally expensive in high-dimensional settings. In many applications, however, it is sufficient to calculate only the top few outputs of the softmax function. In this work, we present an algorithm, dubbed AdaptiveSoftmax, that adaptively computes the top k softmax values more efficiently than the full softmax computation, with probabilistic guarantees. We demonstrate the sample efficiency improvements afforded by AdaptiveSoftmax on real and synthetic data to corroborate our theoretical results. AdaptiveSoftmax yields >10x gain over full softmax computation on most datasets, yielding up to 30x improvement for Mistral7B evaluated on the Wikitext dataset. The adaptive method we propose for estimating the partition function (the softmax denominator) is of independent interest and can be used in other applications such as kernel density estimation.
2055. E2ENet: Dynamic Sparse Feature Fusion for Accurate and Efficient 3D Medical Image Segmentation

Deep neural networks have evolved as the leading approach in 3D medical image segmentation due to their outstanding performance. However, the ever-increasing model size and computational cost of deep neural networks have become the primary barriers to deploying them on real-world, resource-limited hardware. To achieve both segmentation accuracy and efficiency, we propose a 3D medical image segmentation model called Efficient to Efficient Network (E2ENet), which incorporates two parametrically and computationally efficient designs. i. Dynamic sparse feature fusion (DSFF) mechanism: it adaptively learns to fuse informative multi-scale features while reducing redundancy. ii. Restricted depth-shift in 3D convolution: it leverages the 3D spatial information while keeping the model and computational complexity as 2D-based methods. We conduct extensive experiments on AMOS, Brain Tumor Segmentation and BTCV Challenge, demonstrating that E2ENet consistently achieves a superior trade-off between accuracy and efficiency than prior arts across various resource constraints. %In particular, with a single model and single scale, E2ENet achieves comparable accuracy on the large-scale challenge AMOS-CT, while saving over 69% parameter count and 27% FLOPs in the inference phase, compared with the previous
best-performing method. Our code has been made available at: https://github.com/boqian333/E2ENet-Medical.
2056. Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
tl;dr: Kernel Language Entropy is a novel method for uncertainty quantification that utilizes semantic similarities in the form of kernels over the space of outputs.

Uncertainty quantification in Large Language Models (LLMs) is crucial for applications where safety and reliability are important. In particular, uncertainty can be used to improve the trustworthiness of LLMs by detecting factually incorrect model responses, commonly called hallucinations. Critically, one should seek to capture the model's semantic uncertainty, i.e., the uncertainty over the meanings of LLM outputs, rather than uncertainty over lexical or syntactic variations that do not affect answer correctness.
To address this problem, we propose Kernel Language Entropy (KLE), a novel method for uncertainty estimation in white- and black-box LLMs. KLE defines positive semidefinite unit trace kernels to encode the semantic similarities of LLM outputs and quantifies uncertainty using the von Neumann entropy. It considers pairwise semantic dependencies between answers (or semantic clusters), providing more fine-grained uncertainty estimates than previous methods based on hard clustering of answers. We theoretically prove that KLE generalizes the previous state-of-the-art method called semantic entropy and empirically demonstrate that it improves uncertainty quantification performance across multiple natural language generation datasets and LLM architectures.
tl;dr: We propose the first method to identify neurons in text-to-image diffusion models responsible for memorization.

Diffusion models (DMs) produce very detailed and high-quality images. Their power results from extensive training on large amounts of data - usually scraped from the internet without proper attribution or consent from content creators. Unfortunately, this practice raises privacy and intellectual property concerns, as DMs can memorize and later reproduce their potentially sensitive or copyrighted training images at inference time. Prior efforts prevent this issue by either changing the input to the diffusion process, thereby preventing the DM from generating memorized samples during inference, or removing the memorized data from training altogether. While those are viable solutions when the DM is developed and deployed in a secure and constantly monitored environment, they hold the risk of adversaries circumventing the safeguards and are not effective when the DM itself is publicly released. To solve the problem, we introduce NeMo, the first method to localize memorization of individual data samples down to the level of neurons in DMs' cross-attention layers. Through our experiments, we make the intriguing finding that in many cases, single neurons are responsible for memorizing particular training samples. By deactivating these memorization neurons, we can avoid the replication of training data at inference time, increase the diversity in the generated outputs, and mitigate the leakage of private and copyrighted data. In this way, our NeMo contributes to a more responsible deployment of DMs.
2058. Fast Rates in Stochastic Online Convex Optimization by Exploiting the Curvature of Feasible Sets
tl;dr: This study considers online convex optimization and introduces a new condition and analysis that provides fast rates by exploiting the curvature of feasible sets.

In this work, we explore online convex optimization (OCO) and introduce a new condition and analysis that provides fast rates by exploiting the curvature of feasible sets. In online linear optimization, it is known that if the average gradient of loss functions exceeds a certain threshold, the curvature of feasible sets can be exploited by the follow-the-leader (FTL) algorithm to achieve a logarithmic regret. This study reveals that algorithms adaptive to the curvature of loss functions can also leverage the curvature of feasible sets. In particular, we first prove that if an optimal decision is on the boundary of a feasible set and the gradient of an underlying loss function is non-zero, then the algorithm achieves a regret bound of $O(\rho \log T)$ in stochastic environments. Here, $\rho > 0$ is the radius of the smallest sphere that includes the optimal decision and encloses the feasible set. Our approach, unlike existing ones, can work directly with convex loss functions, exploiting the curvature of loss functions simultaneously, and can achieve the logarithmic regret only with a local property of feasible sets. Additionally, the algorithm achieves an $O(\sqrt{T})$ regret even in adversarial environments, in which FTL suffers an $\Omega(T)$ regret, and achieves an $O(\rho \log T + \sqrt{C \rho \log T})$ regret in corrupted stochastic environments with corruption level $C$. Furthermore, by extending our analysis, we establish a matching regret upper bound of $O\Big(T^{\frac{q-2}{2(q-1)}} (\log T)^{\frac{q}{2(q-1)}}\Big)$ for $q$-uniformly convex feasible sets, where uniformly convex sets include strongly convex sets and $\ell_p$-balls for $p \in [2,\infty)$. This bound bridges the gap between the $O(\log T)$ bound for strongly convex sets~($q=2$) and the $O(\sqrt{T})$ bound for non-curved sets~($q\to\infty$).

In bandit best-arm identification, an algorithm is tasked with finding the arm with highest mean reward with a specified accuracy as fast as possible. We study multi-fidelity best-arm identification, in which the algorithm can choose to sample an arm at a lower fidelity (less accurate mean estimate) for a lower cost. Several methods have been proposed for tackling this problem, but their optimality remain elusive, notably due to loose lower bounds on the total cost needed to identify the best arm. Our first contribution is a tight, instance-dependent lower bound on the cost complexity. The study of the optimization problem featured in the lower bound provides new insights to devise computationally efficient algorithms, and leads us to propose a gradient-based approach with asymptotically optimal cost complexity. We demonstrate the benefits of the new algorithm compared to existing methods in experiments. Our theoretical and empirical findings also shed light on an intriguing concept of optimal fidelity for each arm.
tl;dr: We investigate the transferability of computation tree in the graph, and build a graph foundation model based on that.

Inspired by the success of foundation models in applications such as ChatGPT, as graph data has been ubiquitous, one can envision the far-reaching impacts that can be brought by Graph Foundation Models (GFMs) with broader applications in the areas such as scientific research, social network analysis, drug discovery, and e-commerce. Despite the significant progress of pre-trained graph neural networks, there haven’t been GFMs that can achieve desired performance on various graph-learning-related tasks. Building GFMs may rely on a vocabulary that encodes transferable patterns shared among different tasks and domains. Unlike image and text, defining such transferable patterns for graphs remains an open question. In this paper, we aim to bridge this gap by rethinking the transferable patterns on graphs as computation trees -- i.e., tree structures derived from the message-passing process. Based on this insight, we propose a cross-task, cross-domain graph foundation model named GFT, short for Graph Foundation model with transferable Tree vocabulary. By treating computation trees as tokens within the transferable vocabulary, GFT improves model generalization and reduces the risk of negative transfer. The theoretical analyses and extensive experimental studies have demonstrated the transferability of computation trees and shown the effectiveness of GFT across diverse tasks and domains in graph learning. The open source code and data are available at https://github.com/Zehong-Wang/GFT.
2061. A PID Controller Approach for Adaptive Probability-dependent Gradient Decay in Model Calibration

Modern deep learning models often exhibit overconfident predictions, inadequately capturing uncertainty. During model optimization, the expected calibration error tends to overfit earlier than classification accuracy, indicating distinct optimization objectives for classification error and calibration error. To ensure consistent optimization of both model accuracy and model calibration, we propose a novel method incorporating a probability-dependent gradient decay coefficient into loss function. This coefficient exhibits a strong correlation with the overall confidence level. To maintain model calibration during optimization, we utilize a proportional-integral-derivative (PID) controller to dynamically adjust this gradient decay rate, where the adjustment relies on the proposed relative calibration error feedback in each epoch, thereby preventing the model from exhibiting over-confidence or under-confidence. Within the PID control system framework, the proposed relative calibration error serves as the control system output, providing an indication of the overall confidence level, while the gradient decay rate functions as the controlled variable. Moreover, recognizing the impact of gradient amplitude of adaptive decay rates, we implement an adaptive learning rate mechanism for gradient compensation to prevent inadequate learning of over-small or over-large gradient. Empirical experiments validate the efficacy of our PID-based adaptive gradient decay rate approach, ensuring consistent optimization of model calibration and model accuracy.

Federated Learning (FL) faces significant challenges due to data heterogeneity across distributed clients. To address this, we propose FedGMKD, a novel framework that combines knowledge distillation and differential aggregation for efficient prototype-based personalized FL without the need for public datasets or server-side generative models. FedGMKD introduces Cluster Knowledge Fusion, utilizing Gaussian Mixture Models to generate prototype features and soft predictions on the client side, enabling effective knowledge distillation while preserving data privacy. Additionally, we implement a Discrepancy-Aware Aggregation Technique that weights client contributions based on data quality and quantity, enhancing the global model's generalization across diverse client distributions. Theoretical analysis confirms the convergence of FedGMKD. Extensive experiments on benchmark datasets, including SVHN, CIFAR-10, and CIFAR-100, demonstrate that FedGMKD outperforms state-of-the-art methods, significantly improving both local and global accuracy in non-IID data settings.

When matching parts of a surface to its whole, a fundamental question arises: Which points should be included in the matching process? The issue is intensified when using isometry to measure similarity, as it requires the validation of whether distances measured between pairs of surface points should influence the matching process. The approach we propose treats surfaces as manifolds equipped with geodesic distances, and addresses the partial shape matching challenge by introducing a novel criterion to meticulously search for consistent distances between pairs of points. The new criterion explores the relation between intrinsic geodesic distances between the points, geodesic distances between the points and surface boundaries, and extrinsic distances between boundary points measured in the embedding space. It is shown to be less restrictive compared to previous measures and achieves state-of-the-art results when used as a loss function in training networks for partial shape matching.
tl;dr: We construct a generative model that learns which (approximate) symmetries are present in a dataset and leverage it for improved data efficiency

Correctly capturing the symmetry transformations of data can lead to efficient models with strong generalization capabilities, though methods incorporating symmetries often require prior knowledge.
While recent advancements have been made in learning those symmetries directly from the dataset, most of this work has focused on the discriminative setting.
In this paper, we take inspiration from group theoretic ideas to construct a generative model that explicitly aims to capture the data's approximate symmetries.
This results in a model that, given a prespecified broad set of possible symmetries, learns to what extent, if at all, those symmetries are actually present.
Our model can be seen as a generative process for data augmentation.
We provide a simple algorithm for learning our generative model and empirically demonstrate its ability to capture symmetries under affine and color transformations, in an interpretable way.
Combining our symmetry model with standard generative models results in higher marginal test-log-likelihoods and improved data efficiency.
tl;dr: Spry is a federated learning algorithm that enables finetuning LLMs using Forward-mode Auto Differentiation; to achieve low memory footprint, high accuracy, and fast convergence.

Finetuning large language models (LLMs) in federated learning (FL) settings has become increasingly important as it allows resource-constrained devices to finetune a model using private data. However, finetuning LLMs using backpropagation requires excessive memory (especially from intermediate activations) for resource-constrained devices. While Forward-mode Auto-Differentiation (AD) can significantly reduce memory footprint from activations, we observe that directly applying it to LLM finetuning results in slow convergence and poor accuracy. In this paper, we introduce Spry, an FL algorithm that splits trainable weights of an LLM among participating clients, such that each client computes gradients using forward-mode AD that are closer estimations of the true gradients. Spry achieves a low memory footprint, high accuracy, and fast convergence. We formally prove that the global gradients in Spry are unbiased estimators of true global gradients for homogeneous data distributions across clients, while heterogeneity increases bias of the estimates. We also derive Spry's convergence rate, showing that the gradients decrease inversely proportional to the number of FL rounds, indicating the convergence up to the limits of heterogeneity. Empirically, Spry reduces the memory footprint during training by 1.4-7.1$\times$ in contrast to backpropagation, while reaching comparable accuracy, across a wide range of language tasks, models, and FL settings.
Spry reduces the convergence time by 1.2-20.3$\times$ and achieves 5.2-13.5\% higher accuracy against state-of-the-art zero-order methods. When finetuning Llama2-7B with LoRA, compared to the peak memory consumption of 33.9GB of backpropagation, Spry only consumes 6.2GB of peak memory. For OPT13B, the reduction is from 76.5GB to 10.8GB. Spry makes feasible previously impossible FL deployments on commodity mobile and edge devices. Our source code is available for replication at https://github.com/Astuary/Spry.

Time Series Classification (TSC) encompasses two settings: classifying entire sequences or classifying segmented subsequences. The raw time series for segmented TSC usually contain Multiple classes with Varying Duration of each class (MVD). Therefore, the characteristics of MVD pose unique challenges for segmented TSC, yet have been largely overlooked by existing works. Specifically, there exists a natural temporal dependency between consecutive instances (segments) to be classified within MVD. However, mainstream TSC models rely on the assumption of independent and identically distributed (i.i.d.), focusing on independently modeling each segment. Additionally, annotators with varying expertise may provide inconsistent boundary labels, leading to unstable performance of noise-free TSC models. To address these challenges, we first formally demonstrate that valuable contextual information enhances the discriminative power of classification instances. Leveraging the contextual priors of MVD at both the data and label levels, we propose a novel consistency learning framework Con4m, which effectively utilizes contextual information more conducive to discriminating consecutive segments in segmented TSC tasks, while harmonizing inconsistent boundary labels for training. Extensive experiments across multiple datasets validate the effectiveness of Con4m in handling segmented TSC tasks on MVD. The source code is available at https://github.com/MrNobodyCali/Con4m.

3D Gaussian Splatting (3DGS) has demonstrated impressive novel view synthesis performance. While conventional methods require per-scene optimization, more recently several feed-forward methods have been proposed to generate pixel-aligned Gaussian representations with a learnable network, which are generalizable to different scenes. However, these methods simply combine pixel-aligned Gaussians from multiple views as scene representations, thereby leading to artifacts and extra memory cost without fully capturing the relations of Gaussians from different images. In this paper, we propose Gaussian Graph Network (GGN) to generate efficient and generalizable Gaussian representations. Specifically, we construct Gaussian Graphs to model the relations of Gaussian groups from different views. To support message passing at Gaussian level, we reformulate the basic graph operations over Gaussian representations, enabling each Gaussian to benefit from its connected Gaussian groups with Gaussian feature fusion. Furthermore, we design a Gaussian pooling layer to aggregate various Gaussian groups for efficient representations. We conduct experiments on the large-scale RealEstate10K and ACID datasets to demonstrate the efficiency and generalization of our method. Compared to the state-of-the-art methods, our model uses fewer Gaussians and achieves better image quality with higher rendering speed.

We introduce the Distributed-order fRActional Graph Operating Network (DRAGON), a novel continuous Graph Neural Network (GNN) framework that incorporates distributed-order fractional calculus.
Unlike traditional continuous GNNs that utilize integer-order or single fractional-order differential equations, DRAGON uses a learnable probability distribution over a range of real numbers for the derivative orders.
By allowing a flexible and learnable superposition of multiple derivative orders, our framework captures complex graph feature updating dynamics beyond the reach of conventional models.
We provide a comprehensive interpretation of our framework's capability to capture intricate dynamics through the lens of a non-Markovian graph random walk with node feature updating driven by an anomalous diffusion process over the graph.
Furthermore, to highlight the versatility of the DRAGON framework, we conduct empirical evaluations across a range of graph learning tasks. The results consistently demonstrate superior performance when compared to traditional continuous GNN models. The implementation code is available at \url{https://github.com/zknus/NeurIPS-2024-DRAGON}.
tl;dr: Constructing a denoising path integration for attribution of deep neural networks by applying diffusion models, showcasing significant noise reduction in attribution maps and higher AUC values.

The explainability of deep neural networks (DNNs) is critical for trust and reliability in AI systems. Path-based attribution methods, such as integrated gradients (IG), aim to explain predictions by accumulating gradients along a path from a baseline to the target image. However, noise accumulated during this process can significantly distort the explanation. While existing methods primarily concentrate on finding alternative paths to circumvent noise, they overlook a critical issue: intermediate-step images frequently diverge from the distribution of training data, further intensifying the impact of noise. This work presents a novel Denoising Diffusion Path (DDPath) to tackle this challenge by harnessing the power of diffusionmodels for denoising. By exploiting the inherent ability of diffusion models to progressively remove noise from an image, DDPath constructs a piece-wise linear path. Each segment of this path ensures that samples drawn from a Gaussian distribution are centered around the target image. This approach facilitates a gradual reduction of noise along the path. We further demonstrate that DDPath adheres to essential axiomatic properties for attribution methods and can be seamlessly integrated with existing methods such as IG. Extensive experimental results demonstrate that DDPath can significantly reduce noise in the attributions—resulting in clearer explanations—and achieves better quantitative results than traditional path-based methods.
2070. Self-Healing Machine Learning: A Framework for Autonomous Adaptation in Real-World Environments
tl;dr: Self-healing machine learning is a framework which diagnoses the reason for model degradation and proposes diagnosis-based corrective actions

Real-world machine learning systems often encounter model performance degradation due to distributional shifts in the underlying data generating process (DGP). Existing approaches to addressing shifts, such as concept drift adaptation, are limited by their *reason-agnostic* nature. By choosing from a pre-defined set of actions, such methods implicitly assume that the causes of model degradation are irrelevant to what actions should be taken, limiting their ability to select appropriate adaptations. In this paper, we propose an alternative paradigm to overcome these limitations, called *self-healing machine learning* (SHML). Contrary to previous approaches, SHML autonomously diagnoses the reason for degradation and proposes diagnosis-based corrective actions. We formalize SHML as an optimization problem over a space of adaptation actions to minimize the expected risk under the shifted DGP. We introduce a theoretical framework for self-healing systems and build an agentic self-healing solution *$\mathcal{H}$-LLM* which uses large language models to perform self-diagnosis by reasoning about the structure underlying the DGP, and self-adaptation by proposing and evaluating corrective actions. Empirically, we analyze different components of *$\mathcal{H}$-LLM* to understand *why* and *when* it works, demonstrating the potential of self-healing ML.

Recent advancements in text-to-video generative models, such as Sora, have showcased impressive capabilities. These models have attracted significant interest for their potential applications. However, they often rely on extensive datasets of variable quality, which can result in generated videos that lack aesthetic appeal and do not accurately reflect the input text prompts. A promising approach to mitigate these issues is to leverage Reinforcement Learning from Human Feedback (RLHF), which aims to align the outputs of text-to-video generative with human preferences. However, the considerable costs associated with manual annotation have led to a scarcity of comprehensive preference datasets. In response to this challenge, our study begins by investigating the efficacy of Multimodal Large Language Models (MLLMs) generated annotations in capturing video preferences, discovering a high degree of concordance with human judgments. Building upon this finding, we utilize MLLMs to perform fine-grained video preference annotations across two dimensions, resulting in the creation of VideoPrefer, which includes 135,000 preference annotations. Utilizing this dataset, we introduce VideoRM, the first general-purpose reward model tailored for video preference in the text-to-video domain. Our comprehensive experiments confirm the effectiveness of both VideoPrefer and VideoRM, representing a significant step forward in the field.
tl;dr: We study computational aspects of algorithmic replicability with the aim of better understanding the computational connections between replicability and other learning paradigms.

We study computational aspects of algorithmic replicability, a notion of stability introduced by Impagliazzo, Lei,
Pitassi, and Sorrell [STOC, 2022]. Motivated by a recent line of work that established strong statistical connections between
replicability and other notions of learnability such as online learning, private learning, and SQ learning, we aim to
understand better the computational connections between replicability and these learning paradigms.
Our first result shows that there is a concept class that is efficiently replicably PAC learnable, but, under standard
cryptographic assumptions, no efficient online learner exists for this class. Subsequently, we design an efficient
replicable learner for PAC learning parities when the marginal distribution is far from uniform, making progress on a
question posed by Impagliazzo et al. [STOC, 2022]. To obtain this result, we design a replicable lifting framework inspired by
Blanc, Lange, Malik, and Tan [STOC, 2023], that transforms in a black-box manner efficient replicable PAC learners under the
uniform marginal distribution over the Boolean hypercube to replicable PAC learners under any marginal distribution,
with sample and time complexity that depends on a certain measure of the complexity of the distribution.
Finally, we show that any pure DP learner can be transformed in a black-box manner to a replicable learner, with time complexity polynomial in the confidence and accuracy parameters, but exponential in the representation dimension of the underlying hypothesis class.
tl;dr: Fixed-confidence best arm identification in the Bayesian setting, where the mean vector is drawn from a known prior.

We consider the fixed-confidence best arm identification (FC-BAI) problem in the Bayesian setting. This problem aims to find the arm of the largest mean with a fixed confidence level when the bandit model has been sampled from the known prior.
Most studies on the FC-BAI problem have been conducted in the frequentist setting, where the bandit model is predetermined before the game starts.
We show that the traditional FC-BAI algorithms studied in the frequentist setting, such as track-and-stop and top-two algorithms, result in arbitrarily suboptimal performances in the Bayesian setting.
We also obtain a lower bound of the expected number of samples in the Bayesian setting and introduce a variant of successive elimination that has a matching performance with the lower bound up to a logarithmic factor. Simulations verify the theoretical results.
tl;dr: Bandit algorithms for queueing matching under a preference model

In this study, we consider multi-class multi-server asymmetric queueing systems consisting of $N$ queues on one side and $K$ servers on the other side, where jobs randomly arrive in queues at each time. The service rate of each job-server assignment is unknown and modeled by a feature-based Multi-nomial Logit (MNL) function. At each time, a scheduler assigns jobs to servers, and each server stochastically serves at most one job based on its preferences over the assigned jobs. The primary goal of the algorithm is to stabilize the queues in the system while learning the service rates of servers. To achieve this goal, we propose algorithms based on UCB and Thompson Sampling, which achieve system stability with an average queue length bound of $O(\min\\{N,K\\}/\epsilon)$ for a large time horizon $T$, where $\epsilon$ is a traffic slackness of the system. Furthermore, the algorithms achieve sublinear regret bounds of $\tilde{O}(\min\\{\sqrt{T}Q_{\max},T^{3/4}\\})$, where $Q_{\max}$ represents the maximum queue length over agents and times.
Lastly, we provide experimental results to demonstrate the performance of our algorithms.

Recent advances in algorithmic design show how to utilize predictions obtained by machine learning models from past and present data. These approaches have demonstrated an enhancement in performance when the predictions are accurate, while also ensuring robustness by providing worst-case guarantees when predictions fail. In this paper we focus on online problems; prior research in this context was focused on a paradigm where the algorithms are oblivious of the predictors' design, treating them as a black box. In contrast, in this work,
we unpack the predictor and integrate the learning problem it gives rise for within the algorithmic challenge. In particular we allow the predictor to learn as it receives larger parts of the input, with the ultimate goal of designing online learning algorithms specifically tailored for the algorithmic task at hand. Adopting this perspective, we focus on a number of fundamental problems, including caching and scheduling, which have been well-studied in the black-box setting. For each of the problems, we introduce new algorithms that take advantage of explicit and carefully designed learning rules. These pairings of online algorithms with corresponding learning rules yields improvements in the overall performance in comparison with previous work.
tl;dr: A neural operator that introduces a novel Mamba integration.

Benefiting from the booming deep learning techniques, neural operators (NO) are considered as an ideal alternative to break the traditions of solving Partial Differential Equations (PDE) with expensive cost.
Yet with the remarkable progress, current solutions concern little on the holistic function features--both global and local information-- during the process of solving PDEs.
Besides, a meticulously designed kernel integration to meet desirable performance often suffers from a severe computational burden, such as GNO with $O(N(N-1))$, FNO with $O(NlogN)$, and Transformer-based NO with $O(N^2)$.
To counteract the dilemma, we propose a mamba neural operator with $O(N)$ computational complexity, namely MambaNO.
Functionally, MambaNO achieves a clever balance between global integration, facilitated by state space model of Mamba that scans the entire function, and local integration, engaged with an alias-free architecture. We prove a property of continuous-discrete equivalence to show the capability of
MambaNO in approximating operators arising from universal PDEs to desired accuracy. MambaNOs are evaluated on a diverse set of benchmarks with possibly multi-scale solutions and set new state-of-the-art scores, yet with fewer parameters and better efficiency.

This paper concerns the problem of aligning samples from large language models to human preferences using *best-of-$n$* sampling, where we draw $n$ samples, rank them, and return the best one. We consider two fundamental problems. First: what is the relationship between best-of-$n$ and other (RLHF-type) approaches to aligning LLMs? In particular, when should one be preferred to the other? We show that the best-of-$n$ sampling distribution is essentially equivalent to the policy learned by RLHF if we apply a particular monotone transformation to the reward function. Moreover, we show that this transformation yields the best possible trade-off between win-rate against the base model vs KL distance from the base model. Then, best-of-$n$ is a Pareto-optimal win-rate vs KL solution.
The second problem we consider is how to fine-tune a model to mimic the best-of-$n$ sampling distribution, to avoid drawing $n$ samples for each inference. We derive *BonBon Alignment* as a method for achieving this. Experiments show that BonBon alignment yields a model that achieves high win rates while minimally affecting off-target aspects of the generations.
2078. Fourier Amplitude and Correlation Loss: Beyond Using L2 Loss for Skillful Precipitation Nowcasting
tl;dr: We propose FACL, a loss function replacing MSE in precipitation nowcasting to achieve sharp and quality forecasts.

Deep learning approaches have been widely adopted for precipitation nowcasting in recent years. Previous studies mainly focus on proposing new model architectures to improve pixel-wise metrics. However, they frequently result in blurry predictions which provide limited utility to forecasting operations. In this work, we propose a new Fourier Amplitude and Correlation Loss (FACL) which consists of two novel loss terms: Fourier Amplitude Loss (FAL) and Fourier Correlation Loss (FCL). FAL regularizes the Fourier amplitude of the model prediction and FCL complements the missing phase information. The two loss terms work together to replace the traditional L2 losses such as MSE and weighted MSE for the spatiotemporal prediction problem on signal-based data. Our method is generic, parameter-free and efficient. Extensive experiments using one synthetic dataset and three radar echo datasets demonstrate that our method improves perceptual metrics and meteorology skill scores, with a small trade-off to pixel-wise accuracy and structural similarity. Moreover, to improve the error margin in meteorological skill scores such as Critical Success Index (CSI) and Fractions Skill Score (FSS), we propose and adopt the Regional Histogram Divergence (RHD), a distance metric that considers the patch-wise similarity between signal-based imagery patterns with tolerance to local transforms.
tl;dr: This paper presents a method to generate diverse and high-quality machine translations by sampling from a Gibbs distribution using the Metropolis-Hastings algorithm.

An important challenge in machine translation (MT) is to generate high-quality and diverse translations.
Prior work has shown that the estimated likelihood from the MT model correlates poorly with translation quality.
In contrast, quality evaluation metrics (such as COMET or BLEURT) exhibit high correlations with human judgments, which has motivated their use as rerankers (such as quality-aware and minimum Bayes risk decoding). However, relying on a single translation with high estimated quality increases the chances of "gaming the metric''.
In this paper, we address the problem of sampling a set of high-quality and diverse translations.
We provide a simple and effective way to avoid over-reliance on noisy quality estimates by using them as the energy function of a Gibbs distribution. Instead of looking for a mode in the distribution, we generate multiple samples from high-density areas through the Metropolis-Hastings algorithm, a simple Markov chain Monte Carlo approach.
The results show that our proposed method leads to high-quality and diverse outputs across multiple language pairs (English$\leftrightarrow$\{German, Russian\}) with two strong decoder-only LLMs (Alma-7b, Tower-7b).

The Spiking Neural Network (SNN) is a biologically inspired neural network infrastructure that has recently garnered significant attention. It utilizes binary spike activations to transmit information, thereby replacing multiplications with additions and resulting in high energy efficiency. However, training an SNN directly poses a challenge due to the undefined gradient of the firing spike process. Although prior works have employed various surrogate gradient training methods that use an alternative function to replace the firing process during back-propagation, these approaches ignore an intrinsic problem: gradient vanishing. To address this issue, we propose a shortcut back-propagation method in the paper, which advocates for transmitting the gradient directly from the loss to the shallow layers. This enables us to present the gradient to the shallow layers directly, thereby significantly mitigating the gradient vanishing problem. Additionally, this method does not introduce any burden during the inference phase.
To strike a balance between final accuracy and ease of training, we also propose an evolutionary training framework and implement it by inducing a balance coefficient that dynamically changes with the training epoch, which further improves the network's performance. Extensive experiments conducted over static and dynamic datasets using several popular network structures reveal that our method consistently outperforms state-of-the-art methods.

Recent advances in calcium imaging enable simultaneous recordings of up to a million neurons in behaving animals, producing datasets of unprecedented scales. Although individual neurons and their activity traces can be extracted from these videos with automated algorithms, the results often require human curation to remove false positives, a laborious process called \emph{cell sorting}. To address this challenge, we introduce ActSort, an active-learning algorithm for sorting large-scale datasets that integrates features engineered by domain experts together with data formats with minimal memory requirements. By strategically bringing outlier cell candidates near the decision boundary up for annotation, ActSort reduces human labor to about 1–3\% of cell candidates and improves curation accuracy by mitigating annotator bias. To facilitate the algorithm's widespread adoption among experimental neuroscientists, we created a user-friendly software and conducted a first-of-its-kind benchmarking study involving about 160,000 annotations. Our tests validated ActSort's performance across different experimental conditions and datasets from multiple animals. Overall, ActSort addresses a crucial bottleneck in processing large-scale calcium videos of neural activity and thereby facilitates systems neuroscience experiments at previously inaccessible scales. (\url{https://github.com/schnitzer-lab/ActSort-public})
tl;dr: Analyzing the effect of causal manner and text embedding in text encoders inside text-to-image diffusion models

This paper analyzes the impact of causal manner in the text encoder of text-to-image (T2I) diffusion models, which can lead to information bias and loss. Previous works have focused on addressing the issues through the denoising process. However, there is no research discussing how text embedding contributes to T2I models, especially when generating more than one object. In this paper, we share a comprehensive analysis of text embedding: i) how text embedding contributes to the generated images and ii) why information gets lost and biases towards the first-mentioned object. Accordingly, we propose a simple but effective text embedding balance optimization method, which is training-free, with an improvement of 125.42\% on information balance in stable diffusion. Furthermore, we propose a new automatic evaluation metric that quantifies information loss more accurately than existing methods, achieving 81\% concordance with human assessments. This metric effectively measures the presence and accuracy of objects, addressing the limitations of current distribution scores like CLIP's text-image similarities.

Machine unlearning (MU) empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Joint training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.
tl;dr: We adapt the map equation, an information-theoretic objective function for community detection, as a differentiable loss function for optimisation with neural networks and gradient descent.

Community detection is an essential tool for unsupervised data exploration and revealing the organisational structure of networked systems. With a long history in network science, community detection typically relies on objective functions, optimised with custom-tailored search algorithms, but often without leveraging recent advances in deep learning. Recently, first works have started incorporating such objectives into loss functions for deep graph clustering and pooling. We consider the map equation, a popular information-theoretic objective function for unsupervised community detection, and express it in differentiable tensor form for optimisation through gradient descent. Our formulation turns the map equation compatible with any neural network architecture, enables end-to-end learning, incorporates node features, and chooses the optimal number of clusters automatically, all without requiring explicit regularisation. Applied to unsupervised graph clustering tasks, we achieve competitive performance against state-of-the-art deep graph clustering baselines in synthetic and real-world datasets.
2085. Estimating Heterogeneous Treatment Effects by Combining Weak Instruments and Observational Data
tl;dr: We propose a method to estimate heterogeneous treatment effects by combining weak instrumental variables with observational data, enabling reliable treatment effect estimation in the presence of confounding bias.

Accurately predicting conditional average treatment effects (CATEs) is crucial in personalized medicine and digital platform analytics.
Since the treatments of interest often cannot be directly randomized, observational data is leveraged to learn CATEs, but this approach can incur significant bias from unobserved confounding. One strategy to overcome these limitations is to leverage instrumental variables (IVs) as latent quasi-experiments, such as randomized intent-to-treat assignments or randomized product recommendations. This approach, on the other hand, can suffer from low compliance, i.e., IV weakness. Some subgroups may even exhibit zero compliance, meaning we cannot instrument for their CATEs at all. In this paper, we develop a novel approach to combine IV and observational data to enable reliable CATE estimation in the presence of unobserved confounding in the observational data and low compliance in the IV data, including no compliance for some subgroups. We propose a two-stage framework that first learns \textit{biased} CATEs from the observational data, and then applies a compliance-weighted correction using IV data, effectively leveraging IV strength variability across covariates. We characterize the convergence rates of our method and validate its effectiveness through a simulation study. Additionally, we demonstrate its utility with real data by analyzing the heterogeneous effects of 401(k) plan participation on wealth.
tl;dr: We generalize Conditional Flow Matching by learning interpolants that stay on the data manifold leading to more meaningful matching

Matching objectives underpin the success of modern generative models and rely on constructing conditional paths that transform a source distribution into a target distribution. Despite being a fundamental building block, conditional paths have been designed principally under the assumption of $\textit{Euclidean geometry}$, resulting in straight interpolations. However, this can be particularly restrictive for tasks such as trajectory inference, where straight paths might lie outside the data manifold, thus failing to capture the underlying dynamics giving rise to the observed marginals. In this paper, we propose Metric Flow Matching (MFM), a novel simulation-free framework for conditional flow matching where interpolants are approximate geodesics learned by minimizing the kinetic energy of a data-induced Riemannian metric. This way, the generative model matches vector fields on the data manifold, which corresponds to lower uncertainty and more meaningful interpolations. We prescribe general metrics to instantiate MFM, independent of the task, and test it on a suite of challenging problems including LiDAR navigation, unpaired image translation, and modeling cellular dynamics. We observe that MFM outperforms the Euclidean baselines, particularly achieving SOTA on single-cell trajectory prediction.
tl;dr: a VLM-based planner for long-horizon multi-agent robotics in partially observable setting that does not rely on privileged information from the simulator/oracle.

The ability of Language Models (LMs) to understand natural language makes them a powerful tool for parsing human instructions into task plans for autonomous robots. Unlike traditional planning methods that rely on domain-specific knowledge and handcrafted rules, LMs generalize from diverse data and adapt to various tasks with minimal tuning, acting as a compressed knowledge base. However, LMs in their standard form face challenges with long-horizon tasks, particularly in partially observable multi-agent settings. We propose an LM-based Long-Horizon Planner for Multi-Agent Robotics (LLaMAR), a cognitive architecture for planning that achieves state-of-the-art results in long-horizon tasks within partially observable environments. LLaMAR employs a plan-act-correct-verify framework, allowing self-correction from action execution feedback without relying on oracles or simulators. Additionally, we present MAP-THOR, a comprehensive test suite encompassing household tasks of varying complexity within the AI2-THOR environment. Experiments show that LLaMAR achieves a 30\% higher success rate than other state-of-the-art LM-based multi-agent planners in MAP-THOR and Search \& Rescue tasks. Code can be found at [https://github.com/nsidn98/LLaMAR](https://github.com/nsidn98/LLaMAR)

Federated learning (FL) offers a machine learning paradigm that protects privacy, allowing multiple clients to collaboratively train a global model while only accessing their local data. Recent research in FL has increasingly focused on improving the uniformity of model performance across clients, a fairness principle known as egalitarian fairness. However, achieving egalitarian fairness in FL may sacrifice the model performance for data-rich clients to benefit those with less data. This trade-off raises concerns about the stability of FL, as data-rich clients may opt to leave the current coalition and join another that is more closely aligned with its expected high performance. In this context, our work rigorously addresses the critical concern: **Does egalitarian fairness lead to instability?** Drawing from game theory and social choice theory, we initially characterize fair FL systems as altruism coalition formation games (ACFGs) and reveal that the instability issues emerging from the pursuit of egalitarian fairness are significantly related to the clients’ altruism within the coalition and the configuration of the friends-relationship networks among the clients. Then, we theoretically propose the optimal egalitarian fairness bounds that an FL coalition can achieve while maintaining core stability under various types of altruistic behaviors. The theoretical contributions clarify the quantitative relationships between achievable egalitarian fairness and the disparities in the sizes of local datasets, disproving the misconception that egalitarian fairness inevitably leads to instability. Finally, we conduct experiments to evaluate the consistency of our theoretically derived egalitarian fairness bounds with the empirically achieved egalitarian fairness in fair FL settings.

Deep neural networks (DNNs) are widely used models for investigating biological visual representations. However, existing DNNs are mostly designed to analyze neural responses to static images, relying on feedforward structures and lacking physiological neuronal mechanisms. There is limited insight into how the visual cortex represents natural movie stimuli that contain context-rich information. To address these problems, this work proposes the long-range feedback spiking network (LoRaFB-SNet), which mimics top-down connections between cortical regions and incorporates spike information processing mechanisms inherent to biological neurons. Taking into account the temporal dependence of representations under movie stimuli, we present Time-Series Representational Similarity Analysis (TSRSA) to measure the similarity between model representations and visual cortical representations of mice. LoRaFB-SNet exhibits the highest level of representational similarity, outperforming other well-known and leading alternatives across various experimental paradigms, especially when representing long movie stimuli. We further conduct experiments to quantify how temporal structures (dynamic information) and static textures (static information) of the movie stimuli influence representational similarity, suggesting that our model benefits from long-range feedback to encode context-dependent representations just like the brain. Altogether, LoRaFB-SNet is highly competent in capturing both dynamic and static representations of the mouse visual cortex and contributes to the understanding of movie processing mechanisms of the visual system. Our codes are available at https://github.com/Grasshlw/SNN-Neural-Similarity-Movie.
tl;dr: We present a dataset and method for predicting vibration patterns of plates in the context of noise reduction.

In mechanical structures like airplanes, cars and houses, noise is generated and transmitted through vibrations. To take measures to reduce this noise, vibrations need to be simulated with expensive numerical computations. Deep learning surrogate models present a promising alternative to classical numerical simulations as they can be evaluated magnitudes faster, while trading-off accuracy. To quantify such trade-offs systematically and foster the development of methods, we present a benchmark on the task of predicting the vibration of harmonically excited plates. The benchmark features a total of 12,000 plate geometries with varying forms of beadings, material, boundary conditions, load position and sizes with associated numerical solutions.
To address the benchmark task, we propose a new network architecture, named \modelname, which predicts vibration patterns of plate geometries given a specific excitation frequency. Applying principles from operator learning and implicit models for shape encoding, our approach effectively addresses the prediction of highly variable frequency response functions occurring in dynamic systems. To quantify the prediction quality, we introduce a set of evaluation metrics and evaluate the method on our vibrating-plates benchmark. Our method outperforms DeepONets, Fourier Neural Operators and more traditional neural network architectures and can be used for design optimization.
Code, dataset and visualizations: https://github.com/ecker-lab/Learning_Vibrating_Plates

Visual grounding is a common vision task that involves grounding descriptive sentences to the corresponding regions of an image. Most existing methods use independent image-text encoding and apply complex hand-crafted modules or encoder-decoder architectures for modal interaction and query reasoning. However, their performance significantly drops when dealing with complex textual expressions. This is because the former paradigm only utilizes limited downstream data to fit the multi-modal feature fusion. Therefore, it is only effective when the textual expressions are relatively simple. In contrast, given the wide diversity of textual expressions and the uniqueness of downstream training data, the existing fusion module, which extracts multimodal content from a visual-linguistic context, has not been fully investigated. In this paper, we present a simple yet robust transformer-based framework, SimVG, for visual grounding. Specifically, we decouple visual-linguistic feature fusion from downstream tasks by leveraging existing multimodal pre-trained models and incorporating additional object tokens to facilitate deep integration of downstream and pre-training tasks. Furthermore, we design a dynamic weight-balance distillation method in the multi-branch synchronous learning process to enhance the representation capability of the simpler branch. This branch only consists of a lightweight MLP, which simplifies the structure and improves reasoning speed. Experiments on six widely used VG datasets, i.e., RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO, demonstrate the superiority of SimVG. Finally, the proposed method not only achieves improvements in efficiency and convergence speed but also attains new state-of-the-art performance on these benchmarks. Codes and models are available at https://github.com/Dmmm1997/SimVG.
tl;dr: Our paper asks: does training on synthetic images from a generative model provide any gain beyond training on the upstream data used to train the generative model?

Generative text-to-image models enable us to synthesize unlimited amounts of images in a controllable manner, spurring many recent efforts to train vision models with synthetic data. However, every synthetic image ultimately originates from the upstream data used to train the generator. Does the intermediate generator provide additional information over directly training on relevant parts of the upstream data?
Grounding this question in the setting of image classification, we compare finetuning on task-relevant, targeted synthetic data generated by Stable Diffusion---a generative model trained on the LAION-2B dataset---against finetuning on targeted real images retrieved directly from LAION-2B. We show that while synthetic data can benefit some downstream tasks, it is universally matched or outperformed by real data from the simple retrieval baseline. Our analysis suggests that this underperformance is partially due to generator artifacts and inaccurate task-relevant visual details in the synthetic images. Overall, we argue that targeted retrieval is a critical baseline to consider when training with synthetic data---a baseline that current methods do not yet surpass. We release code, data, and models at [https://github.com/scottgeng00/unmet-promise/](https://github.com/scottgeng00/unmet-promise).
tl;dr: Can LLMs effectively generate synthetic tabular data to address class imbalance for classification tasks via in-context learning? How should prompts be structured to achieve this goal?

Large language models (LLMs) have demonstrated remarkable in-context learning capabilities across diverse applications. In this work, we explore the effectiveness of LLMs for generating realistic synthetic tabular data, identifying key prompt design elements to optimize performance. We introduce EPIC, a novel approach that leverages balanced, grouped data samples and consistent formatting with unique variable mapping to guide LLMs in generating accurate synthetic data across all classes, even for imbalanced datasets. Evaluations on real-world datasets show that EPIC achieves state-of-the-art machine learning classification performance, significantly improving generation efficiency. These findings highlight the effectiveness of EPIC for synthetic tabular data generation, particularly in addressing class imbalance.
tl;dr: This paper presents a principled methodology for learning dual conic optimization proxies with dual feasibility guarantees.

This paper presents Dual Lagrangian Learning (DLL), a principled learning methodology for dual conic optimization proxies.
DLL leverages conic duality and the representation power of ML models to provide high-duality, dual-feasible solutions, and therefore valid Lagrangian dual bounds, for linear and nonlinear conic optimization problems.
The paper introduces a systematic dual completion procedure, differentiable conic projection layers, and a self-supervised learning framework based on Lagrangian duality.
It also provides closed-form dual completion formulae for broad classes of conic problems, which eliminate the need for costly implicit layers.
The effectiveness of DLL is demonstrated on linear and nonlinear conic optimization problems.
The proposed methodology significantly outperforms a state-of-the-art learning-based method, and achieves 1000x speedups over commercial interior-point solvers with optimality gaps under 0.5\% on average.
tl;dr: We propose a new, simpler, faster and optimal boosting algorithm in terms of sample complexity

Boosting is an extremely successful idea, allowing one to combine multiple low accuracy classifiers into a much more accurate voting classifier. In this work, we present a new and surprisingly simple Boosting algorithm that obtains a provably optimal sample complexity. Sample optimal Boosting algorithms have only recently been developed, and our new algorithm has the fastest runtime among all such algorithms and is the simplest to describe: Partition your training data into 5 disjoint pieces of equal size, run AdaBoost on each, and combine the resulting classifiers via a majority vote. In addition to this theoretical contribution, we also perform the first empirical comparison of the proposed sample optimal Boosting algorithms. Our pilot empirical study suggests that our new algorithm might outperform previous algorithms on large data sets.
2096. From Trojan Horses to Castle Walls: Unveiling Bilateral Data Poisoning Effects in Diffusion Models
tl;dr: We reveal the bilateral data poisoning effects in diffusion models when the training data is poisoned like BadNets.

While state-of-the-art diffusion models (DMs) excel in image generation, concerns regarding their security persist. Earlier research highlighted DMs' vulnerability to data poisoning attacks, but these studies placed stricter requirements than conventional methods like 'BadNets' in image classification. This is because the art necessitates modifications to the diffusion training and sampling procedures. Unlike the prior work, we investigate whether BadNets-like data poisoning methods can directly degrade the generation by DMs. In other words, if only the training dataset is contaminated (without manipulating the diffusion process), how will this affect the performance of learned DMs? In this setting, we uncover bilateral data poisoning effects that not only serve an adversarial purpose (compromising the functionality of DMs) but also offer a defensive advantage (which can be leveraged for defense in classification tasks against poisoning attacks). We show that a BadNets-like data poisoning attack remains effective in DMs for producing incorrect images (misaligned with the intended text conditions). Meanwhile, poisoned DMs exhibit an increased ratio of triggers, a phenomenon we refer to as 'trigger amplification', among the generated images. This insight can be then used to enhance the detection of poisoned training data. In addition, even under a low poisoning ratio, studying the poisoning effects of DMs is also valuable for designing robust image classifiers against such attacks. Last but not least, we establish a meaningful linkage between data poisoning and the phenomenon of data replications by exploring DMs' inherent data memorization tendencies. Code is available at https://github.com/OPTML-Group/BiBadDiff.
tl;dr: A fine-tuning method that can leverage OOD data for supervised fine-tuning.

Fine-tuning on task-specific question-answer pairs is a predominant method for enhancing the performance of instruction-tuned large language models (LLMs) on downstream tasks. However, in certain specialized domains, such as healthcare or harmless content generation, it is nearly impossible to obtain a large volume of high-quality data that matches the downstream distribution. To improve the performance of LLMs in data-scarce domains with domain-mismatched data, we re-evaluated the Transformer architecture and discovered that not all parameter updates during fine-tuning contribute positively to downstream performance. Our analysis reveals that within the self-attention and feed-forward networks, only the fine-tuned attention parameters are particularly beneficial when the training set's distribution does not fully align with the test set. Based on this insight, we propose an effective inference-time intervention method: \uline{T}raining \uline{A}ll parameters but \uline{I}nferring with only \uline{A}ttention (TAIA). We empirically validate TAIA using two general instruction-tuning datasets and evaluate it on seven downstream tasks involving math, reasoning, and knowledge understanding across LLMs of different parameter sizes and fine-tuning techniques. Our comprehensive experiments demonstrate that TAIA achieves superior improvements compared to both the fully fine-tuned model and the base model in most scenarios, with significant performance gains. The high tolerance of TAIA to data mismatches makes it resistant to jailbreaking tuning and enhances specialized tasks using general data. Code is available in \url{https://github.com/pixas/TAIA_LLM}.
tl;dr: We develop gradient based tokenizers that promote uniform segmentation granularity across languages in multilingual LMs.

In multilingual settings, non-Latin scripts and low-resource languages are usually disadvantaged in terms of language models’ utility, efficiency, and cost. Specifically, previous studies have reported multiple modeling biases that the current tokenization algorithms introduce to non-Latin script languages, the main one being over-segmentation. In this work, we propose MAGNET— multilingual adaptive gradient-based tokenization—to reduce over-segmentation via adaptive gradient-based subword tokenization. MAGNET learns to predict segment boundaries between byte tokens in a sequence via sub-modules within the model, which act as internal boundary predictors (tokenizers). Previous gradient-based tokenization methods aimed for uniform compression across sequences by integrating a single boundary predictor during training and optimizing it end-to-end through stochastic reparameterization alongside the next token prediction objective. However, this approach still results in over-segmentation for non-Latin script languages in multilingual settings. In contrast, MAGNET offers a customizable architecture where byte-level sequences are routed through language-script-specific predictors, each optimized for its respective language script. This modularity enforces equitable segmentation granularity across different language scripts compared to previous methods. Through extensive experiments, we demonstrate that in addition to reducing segmentation disparities, MAGNET also enables faster language modeling and improves downstream utility.

Incomplete multi-view clustering aims to learn complete correlations among samples by leveraging complementary information across multiple views for clustering. Anchor-based methods further establish sample-level similarities for representative anchor generation, effectively addressing scalability issues in large-scale scenarios. Despite efficiency improvements, existing methods overlook the misguidance in anchors learning induced by partial missing samples, i.e., the absence of samples results in shift of learned anchors, further leading to sub-optimal clustering performance. To conquer the challenges, our solution involves a cross-view reconstruction strategy that not only alleviate the anchor shift problem through a carefully designed cross-view learning process, but also reconstructs missing samples in a way that transcends the limitations imposed by convex combinations. By employing affine combinations, our method explores areas beyond the convex hull defined by anchors, thereby illuminating blind spots in the reconstruction of missing samples. Experimental results on four benchmark datasets and three large-scale datasets validate the effectiveness of our proposed method.
tl;dr: Theoretical and empirical analysis on the Rashomon effect and predictive multiplicity of gradient boosting, with a new methodology to audit and reduce predictive multiplicity.

The Rashomon effect is a mixed blessing in responsible machine learning. It enhances the prospects of finding models that perform well in accuracy while adhering to ethical standards, such as fairness or interpretability. Conversely, it poses a risk to the credibility of machine decisions through predictive multiplicity. While recent studies have explored the Rashomon effect across various machine learning algorithms, its impact on gradient boosting---an algorithm widely applied to tabular datasets---remains unclear. This paper addresses this gap by systematically analyzing the Rashomon effect and predictive multiplicity in gradient boosting algorithms. We provide rigorous theoretical derivations to examine the Rashomon effect in the context of gradient boosting and offer an information-theoretic characterization of the Rashomon set. Additionally, we introduce a novel inference technique called RashomonGB to efficiently inspect the Rashomon effect in practice. On more than 20 datasets, our empirical results show that RashomonGB outperforms existing baselines in terms of improving the estimation of predictive multiplicity metrics and model selection with group fairness constraints. Lastly, we propose a framework to mitigate predictive multiplicity in gradient boosting and empirically demonstrate its effectiveness.
2101. Seek Commonality but Preserve Differences: Dissected Dynamics Modeling for Multi-modal Visual RL

Accurate environment dynamics modeling is crucial for obtaining effective state representations in visual reinforcement learning (RL) applications. However, when facing multiple input modalities, existing dynamics modeling methods (e.g., DeepMDP) usually stumble in addressing the complex and volatile relationship between different modalities. In this paper, we study the problem of efficient dynamics modeling for multi-modal visual RL. We find that under the existence of modality heterogeneity, modality-correlated and distinct features are equally important but play different roles in reflecting the evolution of environmental dynamics. Motivated by this fact, we propose Dissected Dynamics Modeling (DDM), a novel multi-modal dynamics modeling method for visual RL. Unlike existing methods, DDM explicitly distinguishes consistent and inconsistent information across modalities and treats them separately with a divide-and-conquer strategy. This is done by dispatching the features carrying different information into distinct dynamics modeling pathways, which naturally form a series of implicit regularizations along the learning trajectories. In addition, a reward predictive function is further introduced to filter task-irrelevant information in both modality-consistent and inconsistent features, ensuring information integrity while avoiding potential distractions. Extensive experiments show that DDM consistently achieves competitive performance in challenging multi-modal visual environments.
tl;dr: We use methods derived from HT-SR Theory to develop improved methods for pruning LLMs.

Recent work on pruning large language models (LLMs) has shown that one can eliminate a large number of parameters without compromising performance, making pruning a promising strategy to reduce LLM model size. Existing LLM pruning strategies typically assign uniform pruning ratios across layers, limiting overall pruning ability; and recent work on layerwise pruning of LLMs is often based on heuristics that can easily lead to suboptimal performance. In this paper, we leverage Heavy-Tailed Self-Regularization (HT-SR) Theory, in particular the shape of empirical spectral densities (ESDs) of weight matrices, to design improved layerwise pruning ratios for LLMs. Our analysis reveals a wide variability in how well-trained, and thus relatedly how prunable, different layers of an LLM are. Based on this, we propose AlphaPruning, which uses shape metrics to allocate layerwise sparsity ratios in a more theoretically-principled manner. AlphaPruning can be used in conjunction with multiple existing LLM pruning methods. Our empirical results show that AlphaPruning prunes LLaMA-7B to 80% sparsity while maintaining reasonable perplexity, marking a first in the literature on LLMs.

Despite the remarkable success of transformer-based models in various real-world tasks, their underlying mechanisms remain poorly understood. Recent studies have suggested that transformers can implement gradient descent as an in-context learner for linear regression problems and have developed various theoretical analyses accordingly. However, these works mostly focus on the expressive power of transformers by designing specific parameter constructions, lacking a comprehensive understanding of their inherent working mechanisms post-training. In this study, we consider a sparse linear regression problem and investigate how a trained multi-head transformer performs in-context learning. We experimentally discover that the utilization of multi-heads exhibits different patterns across layers: multiple heads are utilized and essential in the first layer, while usually only a single head is sufficient for subsequent layers. We provide a theoretical explanation for this observation: the first layer preprocesses the context data, and the following layers execute simple optimization steps based on the preprocessed context. Moreover, we demonstrate that such a preprocess-then-optimize algorithm can significantly outperform naive gradient descent and ridge regression algorithms. Further experimental results support our explanations. Our findings offer insights into the benefits of multi-head attention and contribute to understanding the more intricate mechanisms hidden within trained transformers.
tl;dr: We show that verifying local explanations can require exorbitant amounts of data.

In sensitive contexts, providers of machine learning algorithms are increasingly required to give explanations for their algorithms' decisions. However, explanation receivers might not trust the provider, who potentially could output misleading or manipulated explanations. In this work, we investigate an auditing framework in which a third-party auditor or a collective of users attempts to sanity-check explanations: they can query model decisions and the corresponding local explanations, pool all the information received, and then check for basic consistency properties. We prove upper and lower bounds on the amount of queries that are needed for an auditor to succeed within this framework. Our results show that successful auditing requires a potentially exorbitant number of queries -- particularly in high dimensional cases. Our analysis also reveals that a key property is the ``locality'' of the provided explanations --- a quantity that so far has not been paid much attention to in the explainability literature. Looking forward, our results suggest that for complex high-dimensional settings, merely providing a pointwise prediction and explanation could be insufficient, as there is no way for the users to verify that the provided explanations are not completely made-up.
2105. Towards Understanding How Transformers Learn In-context Through a Representation Learning Lens
tl;dr: In this paper, we attempt to explore the ICL process in Transformers through a lens of representation learning.

Pre-trained large language models based on Transformers have demonstrated remarkable in-context learning (ICL) abilities. With just a few demonstration examples, the models can implement new tasks without any parameter updates. However, it is still an open question to understand the mechanism of ICL. In this paper, we attempt to explore the ICL process in Transformers through a lens of representation learning. Initially, leveraging kernel methods, we figure out a dual model for one softmax attention layer. The ICL inference process of the attention layer aligns with the training procedure of its dual model, generating token representation predictions that are equivalent to the dual model's test outputs. We delve into the training process of this dual model from a representation learning standpoint and further derive a generalization error bound related to the quantity of demonstration tokens. Subsequently, we extend our theoretical conclusions to more complicated scenarios, including one Transformer layer and multiple attention layers. Furthermore, drawing inspiration from existing representation learning methods especially contrastive learning, we propose potential modifications for the attention layer. Finally, experiments are designed to support our findings.

Machine learning catalyzes a revolution in chemical and biological science. However, its efficacy is heavily dependent on the availability of labeled data, and annotating biochemical data is extremely laborious. To surmount this data sparsity challenge, we present an instructive learning algorithm named InstructMol to measure pseudo-labels' reliability and help the target model leverage large-scale unlabeled data. InstructMol does not require transferring knowledge between multiple domains, which avoids the potential gap between the pretraining and fine-tuning stages. We demonstrated the high accuracy of InstructMol on several real-world molecular datasets and out-of-distribution (OOD) benchmarks.

Numerous studies have demonstrated that the cognitive processes of the human brain can be modeled using the Bayesian theorem for probabilistic inference of the external world. Spiking neural networks (SNNs), capable of performing Bayesian computation with greater physiological interpretability, offer a novel approach to distributed information processing in the cortex. However, applying these models to real-world scenarios to harness the advantages of brain-like computation remains a challenge.
Recently, bio-inspired sensors with high dynamic range and ultra-high temporal resolution have been widely used in extreme vision scenarios. Event streams, generated by various types of motion, represent spatiotemporal data. Inferring motion targets from these streams without prior knowledge remains a difficult task. The Bayesian inference-based Expectation-Maximization (EM) framework has proven effective for motion segmentation in event streams, allowing for decoupling without prior information about the motion or its source.
This work demonstrates that Bayesian computation based on spiking neural networks can decouple event streams of different motions. The Winner-Take-All (WTA) circuits in the constructed network implement an equivalent E-step, while STDP achieves an equivalent optimization in M-step. Through theoretical analysis and experiments, we show that STDP-based learning can maximize the contrast of warped events under mixed motion models. Experimental results show that the constructed spiking network can effectively segment the motion contained in event streams.
tl;dr: We design and conduct an online experiment to get quantitative insights into the ability of search engines to steer web traffic

The power of digital platforms is at the center of major ongoing policy and regulatory efforts. To advance existing debates, we designed and executed an experiment to measure the performative power of online search providers. Instantiated in our setting, performative power quantifies the ability of a search engine to steer web traffic by rearranging results. To operationalize this definition we developed a browser extension that performs unassuming randomized experiments in the background. These randomized experiments emulate updates to the search algorithm and identify the causal effect of different content arrangements on clicks. Analyzing tens of thousands of clicks, we discuss what our robust quantitative findings say about the power of online search engines, using the Google Shopping antitrust investigation as a case study. More broadly, we envision our work to serve as a blueprint for how the recent definition of performative power can help integrate quantitative insights from online experiments with future investigations into the economic power of digital platforms.
tl;dr: We study the problem of counterfactual regression over large time horizons leveraging contrastive learning.

Estimating treatment effects over time holds significance in various domains, including precision medicine, epidemiology, economy, and marketing. This paper introduces a unique approach to counterfactual regression over time, emphasizing long-term predictions. Distinguishing itself from existing models like Causal Transformer, our approach highlights the efficacy of employing RNNs for long-term forecasting, complemented by Contrastive Predictive Coding (CPC) and Information Maximization (InfoMax). Emphasizing efficiency, we avoid the need for computationally expensive transformers. Leveraging CPC, our method captures long-term dependencies within time-varying confounders. Notably, recent models have disregarded the importance of invertible representation, compromising identification assumptions. To remedy this, we employ the InfoMax principle, maximizing a lower bound of mutual information between sequence data and its representation. Our method achieves state-of-the-art counterfactual estimation results using both synthetic and real-world data, marking the pioneering incorporation of Contrastive Predictive Encoding in causal inference.
tl;dr: We detect if a given text was used to train an LLM using the dataset inference technique.

The proliferation of large language models (LLMs) in the real world has come with a rise in copyright cases against companies for training their models on unlicensed data from the internet. Recent works have presented methods to identify if individual text sequences were members of the model's training data, known as membership inference attacks (MIAs).
We demonstrate that the apparent success of these MIAs is confounded by selecting non-members (text sequences not used for training) belonging to a different distribution from the members (e.g., temporally shifted recent Wikipedia articles compared with ones used to train the model). This distribution shift makes membership inference appear successful.
However, most MIA methods perform no better than random guessing when discriminating between members and non-members from the same distribution (e.g., in this case, the same period of time).
Even when MIAs work, we find that different MIAs succeed at inferring membership of samples from different distributions.
Instead, we propose a new dataset inference method to accurately identify the datasets used to train large language models. This paradigm sits realistically in the modern-day copyright landscape, where authors claim that an LLM is trained over multiple documents (such as a book) written by them, rather than one particular paragraph.
While dataset inference shares many of the challenges of membership inference, we solve it by selectively combining the MIAs that provide positive signal for a given distribution, and aggregating them to perform a statistical test on a given dataset. Our approach successfully distinguishes the train and test sets of different subsets of the Pile with statistically significant p-values $< 0.1$, without any false positives.

Large language models have demonstrated remarkable capabilities but their performance is heavily reliant on effective prompt engineering. Automatic prompt optimization (APO) methods are designed to automate this and can be broadly categorized into those targeting instructions (instruction optimization, IO) vs. those targeting exemplars (exemplar optimization, EO). Despite their shared objective, these have evolved rather independently, with IO receiving more research attention recently. This paper seeks to bridge this gap by comprehensively comparing the performance of representative IO and EO techniques both isolation and combination on a diverse set of challenging tasks. Our findings reveal that intelligently reusing model-generated input-output pairs obtained from evaluating prompts on the validation set as exemplars, consistently improves performance on top of IO methods but is currently under-investigated. We also find that despite the recent focus on IO, how we select exemplars can outweigh how we optimize instructions, with EO strategies as simple as random search outperforming state-of-the-art IO methods with seed instructions without any optimization. Moreover, we observe a synergy between EO and IO, with optimal combinations surpassing the individual contributions. We conclude that studying exemplar optimization both as a standalone method and its optimal combination with instruction optimization remain a crucial aspect of APO and deserve greater consideration in future research, even in the era of highly capable instruction-following models.
tl;dr: This paper presents the first Chinese pediatric LLM assistant and the corresponding high-quality dataset to facilitate medical community development.

Developing intelligent pediatric consultation systems offers promising prospects for improving diagnostic efficiency, especially in China, where healthcare resources are scarce. Despite recent advances in Large Language Models (LLMs) for Chinese medicine, their performance is sub-optimal in pediatric applications due to inadequate instruction data and vulnerable training procedures.
To address the above issues, this paper builds PedCorpus, a high-quality dataset of over 300,000 multi-task instructions from pediatric textbooks, guidelines, and knowledge graph resources to fulfil diverse diagnostic demands. Upon well-designed PedCorpus, we propose PediatricsGPT, the first Chinese pediatric LLM assistant built on a systematic and robust training pipeline.
In the continuous pre-training phase, we introduce a hybrid instruction pre-training mechanism to mitigate the internal-injected knowledge inconsistency of LLMs for medical domain adaptation. Immediately, the full-parameter Supervised Fine-Tuning (SFT) is utilized to incorporate the general medical knowledge schema into the models. After that, we devise a direct following preference optimization to enhance the generation of pediatrician-like humanistic responses. In the parameter-efficient secondary SFT phase,
a mixture of universal-specific experts strategy is presented to resolve the competency conflict between medical generalist and pediatric expertise mastery. Extensive results based on the metrics, GPT-4, and doctor evaluations on distinct downstream tasks show that PediatricsGPT consistently outperforms previous Chinese medical LLMs. The project and data will be released at https://github.com/ydk122024/PediatricsGPT.

We explore online learning in episodic loop-free Markov decision processes on non-stationary environments (changing losses and probability transitions). Our focus is on the Concave Utility Reinforcement Learning problem (CURL), an extension of classical RL for handling convex performance criteria in state-action distributions induced by agent policies. While various machine learning problems can be written as CURL, its non-linearity invalidates traditional Bellman equations. Despite recent solutions to classical CURL, none address non-stationary MDPs. This paper introduces MetaCURL, the first CURL algorithm for non-stationary MDPs. It employs a meta-algorithm running multiple black-box algorithms instances over different intervals, aggregating outputs via a sleeping expert framework. The key hurdle is partial information due to MDP uncertainty. Under partial information on the probability transitions (uncertainty and non-stationarity coming only from external noise, independent of agent state-action pairs), we achieve optimal dynamic regret without prior knowledge of MDP changes. Unlike approaches for RL, MetaCURL handles full adversarial losses, not just stochastic ones. We believe our approach for managing non-stationarity with experts can be of interest to the RL community.

Diffusion models recently proved to be remarkable priors for Bayesian inverse problems. However, training these models typically requires access to large amounts of clean data, which could prove difficult in some settings. In this work, we present a novel method based on the expectation-maximization algorithm for training diffusion models from incomplete and noisy observations only. Unlike previous works, our method leads to proper diffusion models, which is crucial for downstream tasks. As part of our method, we propose and motivate an improved posterior sampling scheme for unconditional diffusion models. We present empirical evidence supporting the effectiveness of our method.

Over the past decade, there is a growing interest in collaborative learning that can enhance AI models of multiple parties.
However, it is still challenging to enhance performance them without sharing private data and models from individual parties.
One recent promising approach is to develop distillation-based algorithms that exploit unlabeled public data but the results are still unsatisfactory in both theory and practice.
To tackle this problem, we rigorously analyze a representative distillation-based algorithm in the view of kernel regression.
This work provides the first theoretical results to prove the (nearly) minimax optimality of the nonparametric collaborative learning algorithm that does not directly share local data or models in massively distributed statistically heterogeneous environments.
Inspired by our theoretical results, we also propose a practical distillation-based collaborative learning algorithm based on neural network architecture.
Our algorithm successfully bridges the gap between our theoretical assumptions and practical settings with neural networks through feature kernel matching.
We simulate various regression tasks to verify our theory and demonstrate the practical feasibility of our proposed algorithm.

The pretraining-finetuning paradigm has gained widespread adoption in vision tasks and other fields. However, the finetuning phase still requires high-quality annotated samples. To overcome this challenge, the concept of active finetuning has emerged, aiming to select the most appropriate samples for model finetuning within a limited budget. Existing active learning methods struggle in this scenario due to their inherent bias in batch selection. Meanwhile, the recent active finetuning approach focuses solely on global distribution alignment but neglects the contributions of samples to local boundaries. Therefore, we propose a Bi-Level Active Finetuning framework (BiLAF) to select the samples for annotation in one shot, encompassing two stages: core sample selection for global diversity and boundary sample selection for local decision uncertainty. Without the need of ground-truth labels, our method can successfully identify pseudo-class centers, apply a novel denoising technique, and iteratively select boundary samples with designed evaluation metric. Extensive experiments provide qualitative and quantitative evidence of our method's superior efficacy, consistently outperforming the existing baselines.
2117. ETO:Efficient Transformer-based Local Feature Matching by Organizing Multiple Homography Hypotheses
tl;dr: We reduce the time comsuming for local feature matching by reducing the units that participate in transformer, while using more complicated homography hypothese to maintain the accuracy.

We tackle the efficiency problem of learning local feature matching.Recent advancements have given rise to purely CNN-based and transformer-based approaches, each augmented with deep learning techniques. While CNN-based methods often excel in matching speed, transformer-based methods tend to provide more accurate matches. We propose an efficient transformer-based network architecture for local feature matching.This technique is built on constructing multiple homography hypotheses to approximate the continuous correspondence in the real world and uni-directional cross-attention to accelerate the refinement. On the YFCC100M dataset, our matching accuracy is competitive with LoFTR, a state-of-the-art transformer-based architecture, while the inference speed is boosted to 4 times, even outperforming the CNN-based methods.Comprehensive evaluations on other open datasets such as Megadepth, ScanNet, and HPatches demonstrate our method's efficacy, highlighting its potential to significantly enhance a wide array of downstream applications.
tl;dr: By optimizing the risk measure of Conditional Value at Risk (CVaR), our methodology trains LLMs to exhibit superior performance in avoiding toxic outputs while maintaining effectiveness in generative tasks.

We consider the challenge of mitigating the generation of negative or toxic content by the Large Language Models (LLMs) in response to certain prompts. We propose integrating risk-averse principles into LLM fine-tuning to minimize the occurrence of harmful outputs, particularly rare but significant events. By optimizing the risk measure of Conditional Value at Risk (CVaR), our methodology trains LLMs to exhibit superior performance in avoiding toxic outputs while maintaining effectiveness in generative tasks. Empirical evaluations on sentiment modification and toxicity mitigation tasks demonstrate the efficacy of risk-averse reinforcement learning with human feedback (RLHF) in promoting a safer and more constructive online discourse environment.
2119. Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
tl;dr: We propose an unsupervised graph-based disentanglement framework to learn the independent factors and their interrelations within complex data, upon the intergration of beta-VAE and multimodal large language models.

Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $\beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
tl;dr: We present a method for high-quality 360-degree head synthesis from single images.

3D GAN inversion aims to project a single image into the latent space of a 3D Generative Adversarial Network (GAN), thereby achieving 3D geometry reconstruction. While there exist encoders that achieve good results in 3D GAN inversion, they are predominantly built on EG3D, which specializes in synthesizing near-frontal views and is limiting in synthesizing comprehensive 3D scenes from diverse viewpoints. In contrast to existing approaches, we propose a novel framework built on PanoHead, which excels in synthesizing images from a 360-degree perspective. To achieve realistic 3D modeling of the input image, we introduce a dual encoder system tailored for high-fidelity reconstruction and realistic generation from different viewpoints. Accompanying this, we propose a stitching framework on the triplane domain to get the best predictions from both. To achieve seamless stitching, both encoders must output consistent results despite being specialized for different tasks. For this reason, we carefully train these encoders using specialized losses, including an adversarial loss based on our novel occlusion-aware triplane discriminator. Experiments reveal that our approach surpasses the existing encoder training methods qualitatively and quantitatively.

Object goal navigation requires an agent to navigate to a specified object in an unseen environment based on visual observations and user-specified goals.
Human decision-making in navigation is sequential, planning a most likely sequence of actions toward the goal.
However, existing ObjectNav methods, both end-to-end learning methods and modular methods, rely on single-step planning. They output the next action based on the current model input, which easily overlooks temporal consistency and leads to myopic planning.
To this end, we aim to learn sequence planning for ObjectNav. Specifically, we propose trajectory diffusion to learn the distribution of trajectory sequences conditioned on the current observation and the goal.
We utilize DDPM and automatically collected optimal trajectory segments to train the trajectory diffusion.
Once the trajectory diffusion model is trained, it can generate a temporally coherent sequence of future trajectory for agent based on its current observations.
Experimental results on the Gibson and MP3D datasets demonstrate that the generated trajectories effectively guide the agent, resulting in more accurate and efficient navigation.

We study a new class of MDPs that employs multinomial logit (MNL) function approximation to ensure valid probability distributions over the state space. Despite its benefits, introducing the non-linear function raises significant challenges in both *computational* and *statistical* efficiency. The best-known result of Hwang and Oh [2023] has achieved an $\widetilde{\mathcal{O}}(\kappa^{-1}dH^2\sqrt{K})$ regret, where $\kappa$ is a problem-dependent quantity, $d$ is the feature dimension, $H$ is the episode length, and $K$ is the number of episodes. While this result attains the same rate in $K$ as linear cases, the method requires storing all historical data and suffers from an $\mathcal{O}(K)$ computation cost per episode. Moreover, the quantity $\kappa$ can be exponentially small in the worst case, leading to a significant gap for the regret compared to linear function approximation. In this work, we first address the computational and storage issue by proposing an algorithm that achieves the same regret with only $\mathcal{O}(1)$ cost. Then, we design an enhanced algorithm that leverages local information to enhance statistical efficiency. It not only maintains an $\mathcal{O}(1)$ computation and storage cost per episode but also achieves an improved regret of $\widetilde{\mathcal{O}}(dH^2\sqrt{K} + d^2H^2\kappa^{-1})$, nearly closing the gap with linear function approximation. Finally, we establish the first lower bound for MNL function approximation, justifying the optimality of our results in $d$ and $K$.

The performance of large language models (LLMs) is acutely sensitive to the phrasing of prompts, which raises significant concerns about their reliability in real-world scenarios. Existing studies often divide prompts into task-level instructions and case-level inputs and primarily focus on evaluating and improving robustness against variations in tasks-level instructions. However, this setup fails to fully address the diversity of real-world user queries and assumes the existence of task-specific datasets. To address these limitations, we introduce RobustAlpacaEval, a new benchmark that consists of semantically equivalent case-level queries and emphasizes the importance of using the worst prompt performance to gauge the lower bound of model performance. Extensive experiments on RobustAlpacaEval with ChatGPT and six open-source LLMs from the Llama, Mistral, and Gemma families uncover substantial variability in model performance; for instance, a difference of 45.48% between the worst and best performance for the Llama-2-70B-chat model, with its worst performance dipping as low as 9.38%. We further illustrate the difficulty in identifying the worst prompt from both model-agnostic and model-dependent perspectives, emphasizing the absence of a shortcut to characterize the worst prompt. We also attempt to enhance the worst prompt performance using existing prompt engineering and prompt consistency methods, but find that their impact is limited. These findings underscore the need to create more resilient LLMs that can maintain high performance across diverse prompts.
tl;dr: Inorganic Retrosynthesis

While inorganic retrosynthesis planning is essential in the field of chemical science, the application of machine learning in this area has been notably less explored compared to organic retrosynthesis planning. In this paper, we propose Retrieval-Retro for inorganic retrosynthesis planning, which implicitly extracts the precursor information of reference materials that are retrieved from the knowledge base regarding domain expertise in the field. Specifically, instead of directly employing the precursor information of reference materials, we propose implicitly extracting it with various attention layers, which enables the model to learn novel synthesis recipes more effectively.
Moreover, during retrieval, we consider the thermodynamic relationship between target material and precursors, which is essential domain expertise in identifying the most probable precursor set among various options. Extensive experiments demonstrate the superiority of Retrieval-Retro in retrosynthesis planning, especially in discovering novel synthesis recipes, which is crucial for materials discovery.
The source code for Retrieval-Retro is available at https://github.com/HeewoongNoh/Retrieval-Retro.
tl;dr: Interpretable structure in subspaces of language model weights allows us to control attention patterns and has applications in model editing and automated circuit discovery

Although it is known that transformer language models (LMs) pass features from early layers to later layers, it is not well understood how this information is represented and routed by the model. We analyze a mechanism used in two LMs to selectively inhibit items in a context in one task, and find that it underlies a commonly used abstraction across many context-retrieval behaviors. Specifically, we find that models write into low-rank subspaces of the residual stream to represent features which are then read out by later layers, forming low-rank *communication channels* (Elhage et al., 2021) between layers. A particular 3D subspace in model activations in GPT-2 can be traversed to positionally index items in lists, and we show that this mechanism can explain an otherwise arbitrary-seeming sensitivity of the model to the order of items in the prompt. That is, the model has trouble copying the correct information from context when many items ``crowd" this limited space. By decomposing attention heads with the Singular Value Decomposition (SVD), we find that previously described interactions between heads separated by one or more layers can be predicted via analysis of their weight matrices alone. We show that it is possible to manipulate the internal model representations as well as edit model weights based on the mechanism we discover in order to significantly improve performance on our synthetic Laundry List task, which requires recall from a list, often improving task accuracy by over 20\%. Our analysis reveals a surprisingly intricate interpretable structure learned from language model pretraining, and helps us understand why sophisticated LMs sometimes fail in simple domains, facilitating future analysis of more complex behaviors.
tl;dr: We propose a data-free backdoor attack without changing the architecture of a classifier.

Backdoor attacks aim to inject a backdoor into a classifier such that it predicts any input with an attacker-chosen backdoor trigger as an attacker-chosen target class.
Existing backdoor attacks require either retraining the classifier with some clean data or modifying the model's architecture.
As a result, they are 1) not applicable when clean data is unavailable, 2) less efficient when the model is large, and 3) less stealthy due to architecture changes.
In this work, we propose DFBA, a novel retraining-free and data-free backdoor attack without changing the model architecture.
Technically, our proposed method modifies a few parameters of a classifier to inject a backdoor.
Through theoretical analysis, we verify that our injected backdoor is provably undetectable and unremovable by various state-of-the-art defenses under mild assumptions.
Our evaluation on multiple datasets further demonstrates that our injected backdoor: 1) incurs negligible classification loss, 2) achieves 100\% attack success rates, and 3) bypasses six existing state-of-the-art defenses.
Moreover, our comparison with a state-of-the-art non-data-free backdoor attack shows our attack is more stealthy and effective against various defenses while achieving less classification accuracy loss.
We will release our code upon paper acceptance.

Research on video generation has recently made tremendous progress, enabling high-quality videos to be generated from text prompts or images. Adding control to the video generation process is an important goal moving forward and recent approaches that condition video generation models on camera trajectories take an important step towards this goal. Yet, it remains challenging to generate a video of the same scene from multiple different camera trajectories. Solutions to this multi-video generation problem could enable large-scale 3D scene generation with editable camera trajectories, among other applications. We introduce collaborative video diffusion (CVD) as an important step towards this vision. The CVD framework includes a novel cross-video synchronization module that promotes consistency between corresponding frames of the same video rendered from different camera poses using an epipolar attention mechanism. Trained on top of a state-of-the-art camera-control module for video generation, CVD generates multiple videos rendered from different camera trajectories with significantly better consistency than baselines, as shown in extensive experiments.
tl;dr: Improved few-shot jailbreaking composed by automated creation of the demonstration pool, the utilization of special tokens from the target LLM's system template, and demo-level random search, facilitate high ASRs.

Recently, Anil et al. (2024) show that many-shot (up to hundreds of) demonstrations can jailbreak state-of-the-art LLMs by exploiting their long-context capability. Nevertheless, is it possible to use few-shot demonstrations to efficiently jailbreak LLMs within limited context sizes? While the vanilla few-shot jailbreaking may be inefficient, we propose improved techniques such as injecting special system tokens like [/INST] and employing demo-level random search from a collected demo pool. These simple techniques result in surprisingly effective jailbreaking against aligned LLMs (even with advanced defenses). For example, our method achieves >80% (mostly >95%) ASRs on Llama-2-7B and Llama-3-8B without multiple restarts, even if the models are enhanced by strong defenses such as perplexity detection and/or SmoothLLM, which is challenging for suffix-based jailbreaking. In addition, we conduct comprehensive and elaborate (e.g., making sure to use correct system prompts) evaluations against other aligned LLMs and advanced defenses, where our method consistently achieves nearly 100% ASRs. Our code is available at https://github.com/sail-sg/I-FSJ.
tl;dr: We present BAKU, a simple architecture for multi-task policy learning that provides highly efficient training, particularly in data-scarce problems such as robotics.

Training generalist agents capable of solving diverse tasks is challenging, often requiring large datasets of expert demonstrations. This is particularly problematic in robotics, where each data point requires physical execution of actions in the real world. Thus, there is a pressing need for architectures that can effectively leverage the available training data. In this work, we present BAKU, a simple transformer architecture that enables efficient learning of multi-task robot policies. BAKU builds upon recent advancements in offline imitation learning and meticulously combines observation trunks, action chunking, multi-sensory observations, and action heads to substantially improve upon prior work. Our experiments on 129 simulated tasks across LIBERO, Meta-World suite, and the Deepmind Control suite exhibit an overall 18% absolute improvement over RT-1 and MT-ACT, with a 36% improvement on the harder LIBERO benchmark. On 30 real-world manipulation tasks, given an average of just 17 demonstrations per task, BAKU achieves a 91% success rate. Videos of the robot are best viewed at baku-robot.github.io.

The utilization of large foundational models has a dilemma: while fine-tuning downstream tasks from them holds promise for making use of the well-generalized knowledge in practical applications, their open accessibility also poses threats of adverse usage.
This paper, for the first time, explores the feasibility of adversarial attacking various downstream models fine-tuned from the segment anything model (SAM), by solely utilizing the information from the open-sourced SAM.
In contrast to prevailing transfer-based adversarial attacks, we demonstrate the existence of adversarial dangers even without accessing the downstream task and dataset to train a similar surrogate model.
To enhance the effectiveness of the adversarial attack towards models fine-tuned on unknown datasets, we propose a universal meta-initialization (UMI) algorithm to extract the intrinsic vulnerability inherent in the foundation model, which is then utilized as the prior knowledge to guide the generation of adversarial perturbations.
Moreover, by formulating the gradient difference in the attacking process between the open-sourced SAM and its fine-tuned downstream models, we theoretically demonstrate that a deviation occurs in the adversarial update direction by directly maximizing the distance of encoded feature embeddings in the open-sourced SAM.
Consequently, we propose a gradient robust loss that simulates the associated uncertainty with gradient-based noise augmentation to enhance the robustness of generated adversarial examples (AEs) towards this deviation, thus improving the transferability.
Extensive experiments demonstrate the effectiveness of the proposed universal meta-initialized and gradient robust adversarial attack (UMI-GRAT) toward SAMs and their downstream models.
Code is available at https://github.com/xiasong0501/GRAT.
tl;dr: We propose a framework to characterize how the developers of generative AI models can price their technology in the face of competing alternative products

Compared to classical machine learning (ML) models, generative models offer a new usage paradigm where (i) a single model can be used for many different tasks out-of-the-box; (ii) users interact with this model over a series of natural language prompts; and (iii) the model is ideally evaluated on binary user satisfaction with respect to model outputs. Given these characteristics, we explore the problem of how developers of new generative AI software can release and price their technology. We first develop a comparison of two different models for a specific task with respect to user cost-effectiveness. We then model the pricing problem of generative AI software as a game between two different companies who sequentially release their models before users choose their preferred model for each task. Here, the price optimization problem becomes piecewise continuous where the companies must choose a subset of the tasks on which to be cost-effective and forgo revenue for the remaining tasks. In particular, we reveal the value of market information by showing that a company who deploys later after knowing their competitor’s price can always secure cost-effectiveness on at least one task, whereas the company who is the first-to-market must price their model in a way that incentivizes higher prices from the latecomer in order to gain revenue. Most importantly, we find that if the different tasks are sufficiently similar, the first-to-market model may become cost-ineffective on all tasks regardless of how this technology is priced.
tl;dr: We develop a Bayesian mixed effects model for inference on the functional size-and-shape mean via a combination of size-and-shape preserving and altering random effects.

The reliable recovery and uncertainty quantification of a fixed effect function $\mu$ in a functional mixed model, for modeling population- and object-level variability in noisily observed functional data, is a notoriously challenging task: variations along the $x$ and $y$ axes are confounded with additive measurement error, and cannot in general be disentangled. The question then as to what properties of $\mu$ may be reliably recovered becomes important. We demonstrate that it is possible to recover the size-and-shape of a square-integrable $\mu$ under a Bayesian functional mixed model. The size-and-shape of $\mu$ is a geometric property invariant to a family of space-time unitary transformations, viewed as rotations of the Hilbert space, that jointly transform the $x$ and $y$ axes. A random object-level unitary transformation then captures size-and-shape preserving deviations of $\mu$ from an individual function, while a random linear term and measurement error capture size-and-shape altering deviations. The model is regularized by appropriate priors on the unitary transformations, posterior summaries of which may then be suitably interpreted as optimal data-driven rotations of a fixed orthonormal basis for the Hilbert space. Our numerical experiments demonstrate utility of the proposed model, and superiority over the current state-of-the-art.
tl;dr: A dictionary-learning based approach for concept extraction to interpret representations inside a large multimodal model.

Large multimodal models (LMMs) combine unimodal encoders and large language models (LLMs) to perform multimodal tasks. Despite recent advancements towards the interpretability of these models, understanding internal representations of LMMs remains largely a mystery. In this paper, we present a novel framework for the interpretation of LMMs. We propose a dictionary learning based approach, applied to the representation of tokens. The elements of the learned dictionary correspond to our proposed concepts. We show that these concepts are well semantically grounded in both vision and text. Thus we refer to these as ``multi-modal concepts''.
We qualitatively and quantitatively evaluate the results of the learnt concepts. We show that the extracted multimodal concepts are useful to interpret representations of test samples. Finally, we evaluate the disentanglement between different concepts and the quality of grounding concepts visually and textually. Our implementation is publicly available: https://github.com/mshukor/xl-vlms.

Due to the heterogeneous architectures and class skew, the global representation models training in resource-adaptive federated self-supervised learning face with tricky challenges: $\textit{deviated representation abilities}$ and $\textit{inconsistent representation spaces}$.
In this work, we are the first to propose a multi-teacher knowledge distillation framework, namely $\textit{FedMKD}$, to learn global representations with whole class knowledge from heterogeneous clients even under extreme class skew. Firstly, the adaptive knowledge integration mechanism is designed to learn better representations from all heterogeneous models with deviated representation abilities. Then the weighted combination of the self-supervised loss and the distillation loss can support the global model to encode all classes from clients into a unified space. Besides, the global knowledge anchored alignment module can make the local representation spaces close to the global spaces, which further improves the representation abilities of local ones. Finally, extensive experiments conducted on two datasets demonstrate the effectiveness of $\textit{FedMKD}$ which outperforms state-of-the-art baselines 4.78\% under linear evaluation on average.
tl;dr: We introduce an equivariant continuous PDE solving method based on Equivariant Neural Fields that preserves boundary conditions and known symmetries of the PDE.

Recently, Conditional Neural Fields (NeFs) have emerged as a powerful modelling paradigm for PDEs, by learning solutions as flows in the latent space of the Conditional NeF. Although benefiting from favourable properties of NeFs such as grid-agnosticity and space-time-continuous dynamics modelling, this approach limits the ability to impose known constraints of the PDE on the solutions -- such as symmetries or boundary conditions -- in favour of modelling flexibility. Instead, we propose a space-time continuous NeF-based solving framework that - by preserving geometric information in the latent space of the Conditional NeF - preserves known symmetries of the PDE. We show that modelling solutions as flows of pointclouds over the group of interest $G$ improves generalization and data-efficiency. Furthermore, we validate that our framework readily generalizes to unseen spatial and temporal locations, as well as geometric transformations of the initial conditions - where other NeF-based PDE forecasting methods fail -, and improve over baselines in a number of challenging geometries.

Large language models (LLMs), although having revolutionized many fields, still suffer from the challenging extrapolation problem, where the inference ability of LLMs sharply declines beyond their max training lengths. In this work, we conduct a theoretical analysis to better understand why No Position Encoding (NoPE) fails outside its effective range, as well as examining the power of Position Encoding (PE) in this context. Our findings reveal that with meticulous weave position, PE can indeed be extended beyond effective range. Our theorems establish that LLMs equipped with weave PE can achieve improved extrapolation performance without additional cost. Furthermore, we introduce a novel weave PE method, Mesa-Extrapolation, which utilizes a chunk-based triangular attention matrix and applies Stair PE to manage the final chunk. This method not only retains competitive performance but also offers substantial benefits such as significantly reduced memory demand and faster inference speed. Extensive experiments validate the effectiveness of Mesa-Extrapolation, demonstrating its potential as a scalable solution to enhancing LLMs’ applicative reach.

Understanding cognitive processes in multi-agent interactions is a primary goal in cognitive science. It can guide the direction of artificial intelligence (AI) research toward social decision-making in multi-agent systems, which includes uncertainty from character heterogeneity. In this paper, we introduce *episodic future thinking (EFT) mechanism* for a reinforcement learning (RL) agent, inspired by the cognitive processes observed in animals. To enable future thinking functionality, we first develop a *multi-character policy* that captures diverse characters with an ensemble of heterogeneous policies. The *character* of an agent is defined as a different weight combination on reward components, representing distinct behavioral preferences. The future thinking agent collects observation-action trajectories of the target agents and leverages the pre-trained multi-character policy to infer their characters. Once the character is inferred, the agent predicts the upcoming actions of target agents and simulates the potential future scenario. This capability allows the agent to adaptively select the optimal action, considering the predicted future scenario in multi-agent scenarios. To evaluate the proposed mechanism, we consider the multi-agent autonomous driving scenario in which autonomous vehicles with different driving traits are on the road. Simulation results demonstrate that the EFT mechanism with accurate character inference leads to a higher reward than existing multi-agent solutions. We also confirm that the effect of reward improvement remains valid across societies with different levels of character diversity.

Differential equations are important mechanistic models that are integral to many scientific and engineering applications. With the abundance of available data there has been a growing interest in data-driven physics-informed models. Gaussian processes (GPs) are particularly suited to this task as they can model complex, non-linear phenomena whilst incorporating prior knowledge and quantifying uncertainty. Current approaches have found some success but are limited as they either achieve poor computational scalings or focus only on the temporal setting. This work addresses these issues by introducing a variational spatio-temporal state-space GP that handles linear and non-linear physical constraints while achieving efficient linear-in-time computation costs. We demonstrate our methods in a range of synthetic and real-world settings and outperform the current state-of-the-art in both predictive and computational performance.
tl;dr: We propose a new message-passing paradigm specific to coarsened graphs, with theoretical guarantees from the original graph.

Graph coarsening aims to reduce the size of a large graph while preserving some of its key properties, which has been used in many applications to reduce computational load and memory footprint. For instance, in graph machine learning, training Graph Neural Networks (GNNs) on coarsened graphs leads to drastic savings in time and memory. However, GNNs rely on the Message-Passing (MP) paradigm, and classical spectral preservation guarantees for graph coarsening do not directly lead to theoretical guarantees when performing naive message-passing on the coarsened graph.
In this work, we propose a new message-passing operation specific to coarsened graphs, which exhibit theoretical guarantees on the preservation of the propagated signal. Interestingly, and in a sharp departure from previous proposals, this operation on coarsened graphs is oriented, even when the original graph is undirected. We conduct node classification tasks on synthetic and real data and observe improved results compared to performing naive message-passing on the coarsened graph.
tl;dr: We study RL settings where either immediate rewards or transitions are observed before acting and show how to achieve tight regret compared to stronger baselines with similar information.

We study reinforcement learning (RL) problems in which agents observe the reward or transition realizations at their current state _before deciding which action to take_. Such observations are available in many applications, including transactions, navigation and more. When the environment is known, previous work shows that this lookahead information can drastically increase the collected reward. However, outside of specific applications, existing approaches for interacting with unknown environments are not well-adapted to these observations. In this work, we close this gap and design provably-efficient learning algorithms able to incorporate lookahead information. To achieve this, we perform planning using the empirical distribution of the reward and transition observations, in contrast to vanilla approaches that only rely on estimated expectations. We prove that our algorithms achieve tight regret versus a baseline that also has access to lookahead information -- linearly increasing the amount of collected reward compared to agents that cannot handle lookahead information.

Top-2 methods have become popular in solving the best arm identification (BAI) problem. The best arm, or the arm with the largest mean amongst finitely many, is identified through an algorithm that at any sequential step independently pulls the empirical best arm, with a fixed probability $\beta$, and pulls the best challenger arm otherwise. The probability of incorrect selection is guaranteed to lie below a specified $\delta>0$. Information theoretic lower bounds on sample complexity are well known for BAI problem and are matched asymptotically as $\delta\to 0$ by computationally demanding plug-in methods. The above top 2 algorithm for any $\beta\in(0, 1)$ has sample complexity within a constant of the lower bound. However, determining the optimal β that matches the lower bound has proven difficult. In this paper, we address this and propose an optimal top-2 type algorithm. We consider a function of allocations anchored at a threshold. If it exceeds the threshold then the algorithm samples the empirical best arm. Otherwise, it samples the challenger arm. We show that the proposed algorithm is optimal as $\delta\to 0$. Our analysis relies on identifying a limiting fluid dynamics of allocations that satisfy a series of ordinary differential equations pasted together and that describe the asymptotic path followed by our algorithm. We rely on the implicit function theorem to show existence and uniqueness of these fluid ode’s and to show that the proposed algorithm remains close to the ode solution.
tl;dr: We introduce the Parsimonious Latent Space Model (PLSM), a world model that regularizes the latent dynamics to make the effect of the agent's actions more predictable.

To solve control problems via model-based reasoning or planning, an agent needs to know how its actions affect the state of the world. The actions an agent has at its disposal often change the state of the environment in systematic ways. However, existing techniques for world modelling do not guarantee that the effect of actions are represented in such systematic ways. We introduce the Parsimonious Latent Space Model (PLSM), a world model that regularizes the latent dynamics to make the effect of the agent's actions more predictable. Our approach minimizes the mutual information between latent states and the change that an action produces in the agent's latent state, in turn minimizing the dependence the state has on the dynamics. This makes the world model softly state-invariant. We combine PLSM with different model classes used for i) future latent state prediction, ii) planning, and iii) model-free reinforcement learning. We find that our regularization improves accuracy, generalization, and performance in downstream tasks, highlighting the importance of systematic treatment of actions in world models.
tl;dr: We propose a sample-based, maximum entropy approach to the source distribution estimation problem.

Scientific modeling applications often require estimating a distribution of parameters consistent with a dataset of observations - an inference task also known as source distribution estimation. This problem can be ill-posed, however, since many different source distributions might produce the same distribution of data-consistent simulations. To make a principled choice among many equally valid sources, we propose an approach which targets the maximum entropy distribution, i.e., prioritizes retaining as much uncertainty as possible. Our method is purely sample-based - leveraging the Sliced-Wasserstein distance to measure the discrepancy between the dataset and simulations - and thus suitable for simulators with intractable likelihoods. We benchmark our method on several tasks, and show that it can recover source distributions with substantially higher entropy than recent source estimation methods, without sacrificing the fidelity of the simulations. Finally, to demonstrate the utility of our approach, we infer source distributions for parameters of the Hodgkin-Huxley model from experimental datasets with hundreds of single-neuron measurements. In summary, we propose a principled method for inferring source distributions of scientific simulator parameters while retaining as much uncertainty as possible.

The study of cells and their responses to genetic or chemical perturbations promises to accelerate the discovery of therapeutics targets. However, designing adequate and insightful models for such data is difficult because the response of a cell to perturbations essentially depends on contextual covariates (e.g., genetic background or type of the cell). There is therefore a need for models that can identify interactions between drugs and contextual covariates. This is crucial for discovering therapeutics targets, as such interactions may reveal drugs that affect certain cell types but not others.
We tackle this problem with a novel Factorized Causal Representation (FCR) learning method, an identifiable deep generative model that reveals causal structure in single-cell perturbation data from several cell lines. FCR learns multiple cellular representations that are disentangled, comprised of covariate-specific (Z_x), treatment-specific (Z_t) and interaction-specific (Z_tx) representations. Based on recent advances of non-linear ICA theory, we prove the component-wise identifiability of Z_tx and block-wise identifiability of Z_t and Z_x. Then, we present our implementation of FCR, and empirically demonstrate that FCR outperforms state-of-the-art baselines in various tasks across four single-cell datasets.
tl;dr: We prove a PSPACE upper bound for deciding generic identifiability and give the first hardness result for variants of identification.

Learning the unknown causal parameters of a linear structural causal
model is a fundamental task in causal analysis. The task, known as the
problem of identification, asks to estimate the parameters of the model from a
combination of assumptions on the graphical structure of the model and
observational data, represented as a non-causal covariance matrix.
In this paper, we give a new sound and complete algorithm for generic
identification which runs in polynomial space. By a standard simulation
result, namely $\mathsf{PSPACE} \subseteq \mathsf{EXP}$,
this algorithm has exponential running time which vastly improves
the state-of-the-art double exponential time method using a Gröbner basis
approach. The paper also presents evidence that parameter identification
is computationally hard in general. In particular, we prove, that the task
asking whether, for a given feasible correlation matrix, there
are exactly one or two or more parameter sets explaining the observed
matrix, is hard for $\forall \mathbb{R}$, the co-class of the existential theory
of the reals. In particular, this problem is $\mathsf{coNP}$-hard.
To our best knowledge, this is the first hardness result for some notion
of identifiability.
Incorporating biological neuronal properties into Artificial Neural Networks (ANNs) to enhance computational capabilities is under active investigation in the field of deep learning. Inspired by recent findings indicating that dendrites adhere to quadratic integration rule for synaptic inputs, this study explores the computational benefits of quadratic neurons. We theoretically demonstrate that quadratic neurons inherently capture correlation within structured data, a feature that grants them superior generalization abilities over traditional neurons. This is substantiated by few-shot learning experiments. Furthermore, we integrate the quadratic rule into Convolutional Neural Networks (CNNs) using a biologically plausible approach, resulting in innovative architectures—Dendritic integration inspired CNNs (Dit-CNNs). Our Dit-CNNs compete favorably with state-of-the-art models across multiple classification benchmarks, e.g., ImageNet-1K, while retaining the simplicity and efficiency of traditional CNNs. All source code are available at https://github.com/liuchongming1999/Dendritic-integration-inspired-CNN-NeurIPS-2024.
tl;dr: We find that aligning the representations of large vision models to human perceptual judgements improves downstream performance on a variety of tasks.

Humans judge perceptual similarity according to diverse visual attributes, including scene layout, subject location, and camera pose. Existing vision models understand a wide range of semantic abstractions but improperly weigh these attributes and thus make inferences misaligned with human perception.
While vision representations have previously benefited from human preference alignment in contexts like image generation, the utility of perceptually aligned representations in more general-purpose settings remains unclear. Here, we investigate how aligning vision model representations to human perceptual judgments impacts their usability in standard computer vision tasks. We finetune state-of-the-art models on a dataset of human similarity judgments for synthetic image triplets and evaluate them across diverse computer vision tasks. We find that aligning models to perceptual judgments yields representations that improve upon the original backbones across many downstream tasks, including counting, semantic segmentation, depth estimation, instance retrieval, and retrieval-augmented generation. In addition, we find that performance is widely preserved on other tasks, including specialized out-of-distribution domains such as in medical imaging and 3D environment frames. Our results suggest that injecting an inductive bias about human perceptual knowledge into vision models can make them better representation learners.

Weight decay is a broadly used technique for training state-of-the-art deep networks from image classification to large language models. Despite its widespread usage and being extensively studied in the classical literature, its role remains poorly understood for deep learning. In this work, we highlight that the role of weight decay in modern deep learning is different from its regularization effect studied in classical learning theory. For deep networks on vision tasks trained with multipass SGD, we show how weight decay modifies the optimization dynamics enhancing the ever-present implicit regularization of SGD via the *loss stabilization mechanism*. In contrast, for large language models trained with nearly one-epoch training, we describe how weight decay balances the *bias-variance tradeoff* in stochastic optimization leading to lower training loss and improved training stability.
Overall, we present a unifying perspective from ResNets on vision tasks to LLMs: weight decay is never useful as an explicit regularizer but instead changes the training dynamics in a desirable way.
tl;dr: We present a method to enable precise appearance editing for 3D Gaussian Splatting.

Referenced-based scene stylization that edits the appearance based on a content-aligned reference image is an emerging research area. Starting with a pretrained neural radiance field (NeRF), existing methods typically learn a novel appearance that matches the given style. Despite their effectiveness, they inherently suffer from time-consuming volume rendering, and thus are impractical for many real-time applications. In this work, we propose ReGS, which adapts 3D Gaussian Splatting (3DGS) for reference-based stylization to enable real-time stylized view synthesis. Editing the appearance of a pretrained 3DGS is challenging as it uses discrete Gaussians as 3D representation, which tightly bind appearance with geometry. Simply optimizing the appearance as prior methods do is often insufficient for modeling continuous textures in the given reference image. To address this challenge, we propose a novel texture-guided control mechanism that adaptively adjusts local responsible Gaussians to a new geometric arrangement, serving for desired texture details. The proposed process is guided by texture clues for effective appearance editing, and regularized by scene depth for preserving original geometric structure. With these novel designs, we show ReGs can produce state-of-the-art stylization results that respect the reference texture while embracing real-time rendering speed for free-view navigation.
tl;dr: We show that contrastive divergence (CD) algorithms can converge at a parametric rate with near optimal asymptotic variance to the true data distribution.

We provide a non-asymptotic analysis of the contrastive divergence (CD) algorithm, a training method for unnormalized models. While prior work has established that (for exponential family distributions) the CD iterates asymptotically converge at an $O(n^{-1 / 3})$ rate to the true parameter of the data distribution, we show that CD can achieve the parametric rate $O(n^{-1 / 2})$. Our analysis provides results for various data batching schemes, including fully online and minibatch. We additionally show that CD is near-optimal, in the sense that its asymptotic variance is close to the Cramér-Rao lower bound.
tl;dr: diffusion model to generate semi-hard samples for synthetic face recognition

Privacy issue is a main concern in developing face recognition techniques. Although synthetic face images can partially mitigate potential legal risks while maintaining effective face recognition (FR) performance, FR models trained by face images synthesized by existing generative approaches frequently suffer from performance degradation problems due to the insufficient discriminative quality of these synthesized samples. In this paper, we systematically investigate what contributes to solid face recognition model training, and reveal that face images with certain degree of similarities to their identity centers show great effectiveness in the performance of trained FR models. Inspired by this, we propose a novel diffusion-based approach (namely **Ce**nter-based Se**mi**-hard Synthetic Face
Generation (**CemiFace**) which produces facial samples with various levels of similarity to the subject center, thus allowing to generate face datasets containing effective discriminative samples for training face recognition. Experimental results show that with a modest degree of similarity, training on the generated dataset can produce competitive performance compared to previous generation methods. The code will be available at:https://github.com/szlbiubiubiu/CemiFace
tl;dr: We (1) prove a regret lower bound through a novel graph quantity that increases with the number of contexts and (2) propose algorithms that achieve tight upper bound under reasonable assumptions and a weaker one in general.

We consider contextual bandits with graph feedback, a class of interactive learning problems with richer structures than vanilla contextual bandits, where taking an action reveals the rewards for all neighboring actions in the feedback graph under all contexts. Unlike the multi-armed bandits setting where a growing literature has painted a near-complete understanding of graph feedback, much remains unexplored in the contextual bandits counterpart. In this paper, we make inroads into this inquiry by establishing a regret lower bound $\Omega(\sqrt{\beta_M(G) T})$, where $M$ is the number of contexts, $G$ is the feedback graph, and $\beta_M(G)$ is our proposed graph-theoretic quantity that characterizes the fundamental learning limit for this class of problems. Interestingly, $\beta_M(G)$ interpolates between $\alpha(G)$ (the independence number of the graph) and $\mathsf{m}(G)$ (the maximum acyclic subgraph (MAS) number of the graph) as the number of contexts $M$ varies. We also provide algorithms that achieve near-optimal regret for important classes of context sequences and/or feedback graphs, such as transitively closed graphs that find applications in auctions and inventory control. In particular, with many contexts, our results show that the MAS number essentially characterizes the statistical complexity for contextual bandits, as opposed to the independence number in multi-armed bandits.
tl;dr: A novel method called Chain of Preference Optimization (CPO), which leverages the supervision generated by the self-reasoning process (i.e., Tree-of-Thought) to enhance the reasoning ability of LLMs.

The recent development of chain-of-thought (CoT) decoding has enabled large language models (LLMs) to generate explicit logical reasoning paths for complex problem-solving. However, research indicates that these paths are not always deliberate and optimal. The tree-of-thought (ToT) method employs tree-searching to extensively explore the reasoning space and find better reasoning paths that CoT decoding might overlook. This deliberation, however, comes at the cost of significantly increased inference complexity. In this work, we demonstrate that fine-tuning LLMs leveraging the search tree constructed by ToT allows CoT to achieve similar or better performance, thereby avoiding the substantial inference burden. This is achieved through \emph{Chain of Preference Optimization} (CPO), where LLMs are fine-tuned to align each step of the CoT reasoning paths with those of ToT using the inherent preference information in the tree-search process. Extensive experimental results show that CPO significantly improves LLM performance in solving a variety of complex problems, including question answering, fact verification, and arithmetic reasoning, demonstrating its effectiveness.
Our code is available at [https://github.com/sail-sg/CPO](https://github.com/sail-sg/CPO).
tl;dr: We devise a framework that learns to dynamically choose experts at a token level, from a mixture of nested models falling on a increasing compute-accuracy curve, resulting in superior performance at a provided compute budget.

The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE's adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.

We present a generalization of Nesterov's accelerated gradient descent algorithm. Our algorithm (AGNES) provably achieves acceleration for smooth convex and strongly convex minimization tasks with noisy gradient estimates if the noise intensity is proportional to the magnitude of the gradient at every point. Nesterov's method converges at an accelerated rate if the constant of proportionality is below 1, while AGNES accommodates any signal-to-noise ratio. The noise model is motivated by applications in overparametrized machine learning. AGNES requires only two parameters in convex and three in strongly convex minimization tasks, improving on existing methods. We further provide clear geometric interpretations and heuristics for the choice of parameters.
tl;dr: We propose a robust and faster zeroth-order algorithm to solve nonconvex minimax problems.

Many zeroth-order (ZO) optimization algorithms have been developed to solve nonconvex minimax problems in machine learning and computer vision areas. However, existing ZO minimax algorithms have high complexity and rely on some strict restrictive conditions for ZO estimations. To address these issues, we design a new unified ZO gradient descent extragradient ascent (ZO-GDEGA) algorithm, which reduces the overall complexity to $\mathcal{O}(d\epsilon^{-6})$ to find an $\epsilon$-stationary point of the function $\psi$ for nonconvex-concave (NC-C) problems, where $d$ is the variable dimension. To the best of our knowledge, ZO-GDEGA is the first ZO algorithm with complexity guarantees to solve stochastic NC-C problems. Moreover, ZO-GDEGA requires weaker conditions on the ZO estimations and achieves more robust theoretical results. As a by-product, ZO-GDEGA has advantages on the condition number for the NC-strongly concave case. Experimentally, ZO-GDEGA can generate more effective poisoning attack data with an average accuracy reduction of 5\%. The improved AUC performance also verifies the robustness of gradient estimations.
tl;dr: This paper presents S3, a modular neural network layer that is designed to enhance time-series representation learning by rearranging its segments, yielding improved results across various tasks with minimal computational overhead.

Existing approaches for learning representations of time-series keep the temporal arrangement of the time-steps intact with the presumption that the original order is the most optimal for learning. However, non-adjacent sections of real-world time-series may have strong dependencies. Accordingly, we raise the question: Is there an alternative arrangement for time-series which could enable more effective representation learning? To address this, we propose a simple plug-and-play neural network layer called Segment, Shuffle, and Stitch (S3) designed to improve representation learning in time-series models. S3 works by creating non-overlapping segments from the original sequence and shuffling them in a learned manner that is optimal for the task at hand. It then re-attaches the shuffled segments back together and performs a learned weighted sum with the original input to capture both the newly shuffled sequence along with the original sequence. S3 is modular and can be stacked to achieve different levels of granularity, and can be added to many forms of neural architectures including CNNs or Transformers with negligible computation overhead. Through extensive experiments on several datasets and state-of-the-art baselines, we show that incorporating S3 results in significant improvements for the tasks of time-series classification, forecasting, and anomaly detection, improving performance on certain datasets by up to 68\%. We also show that S3 makes the learning more stable with a smoother training loss curve and loss landscape compared to the original baseline. The code is available at https://github.com/shivam-grover/S3-TimeSeries.
tl;dr: We present a novel regularization technique for fine-tuning large pre-trained models.

Modern optimizers such as AdamW, equipped with momentum and adaptive learning rate, are designed to escape local minima and explore the vast parameter space. This exploration is beneficial for finding good loss basins when training from scratch. It is not necessarily ideal when resuming from a powerful foundation model because it can lead to large deviations from the pre-trained initialization and, consequently, worse robustness and generalization. At the same time, strong regularization on all parameters can lead to under-fitting. We hypothesize that selectively regularizing the parameter space is the key to fitting and retraining the pre-trained knowledge. This paper proposes a new weight decay technique, Selective Projection Decay (SPD), that selectively imposes a strong penalty on certain layers while allowing others to change freely. Intuitively, SPD expands and contracts the parameter search space for layers with consistent and inconsistent loss reduction, respectively. Experimentally, when equipped with SPD, Adam consistently provides better in-distribution generalization and out-of-distribution robustness performance on multiple popular vision and language benchmarks.
tl;dr: Low depth transformers with $1$ head per layer can learn $k^{\text{th}}$-order Markov processes

Attention-based transformers have been remarkably successful at modeling generative processes across various domains and modalities. In this paper, we study the behavior of transformers on data drawn from $k^{\text{th}}$-order Markov processes, where the conditional distribution of the next symbol in a sequence depends on the previous $k$ symbols observed. We observe a surprising phenomenon empirically which contradicts previous findings: when trained for sufficiently long, a transformer with a fixed depth and $1$ head per layer is able to achieve low test loss on sequences drawn from $k^{\text{th}}$-order Markov sources, even as $k$ grows. Furthermore, this low test loss is achieved by the transformer’s ability to represent and learn the in-context conditional empirical distribution. On the theoretical side, we prove that a transformer with $O(\log_2(k))$ layers can represent the in-context conditional empirical distribution by composing induction heads to track the previous $k$ symbols in the sequence. Surprisingly, with the addition of layer normalization, we show that a transformer with a constant number of layers can represent the in-context conditional empirical distribution, concurring with our empirical observations. This result provides more insight into the benefit of soft-attention and non-linearities in the transformer architecture.

Diffusion models can learn strong image priors from underlying data distribution and use them to solve inverse problems,
but the training process is computationally expensive and requires lots of data.
Such bottlenecks prevent most existing works from being feasible for high-dimensional and high-resolution data such as 3D images.
This paper proposes a method to learn an efficient data prior for the entire image by training diffusion models only on patches of images.
Specifically, we propose a patch-based position-aware diffusion inverse solver, called PaDIS, where we obtain the score function of the whole image through scores of patches and their positional encoding and utilize this as the prior for solving inverse problems.
First of all, we show that this diffusion model achieves an improved memory efficiency and data efficiency
while still maintaining the capability to generate entire images via positional encoding.
Additionally, the proposed PaDIS model is highly flexible and can be plugged in with different diffusion inverse solvers (DIS).
We demonstrate that the proposed PaDIS approach enables solving various inverse problems in both natural and medical image domains, including CT reconstruction, deblurring, and superresolution, given only patch-based priors.
Notably, PaDIS outperforms previous DIS methods trained on entire image priors in the case of limited training data, demonstrating the data efficiency of our proposed approach by learning patch-based prior.
tl;dr: We prove unconditional stability of a neurodynamical model and demonstrate its performance on sequential datasets.

Stability in recurrent neural models poses a significant challenge, particularly in developing biologically plausible neurodynamical models that can be seamlessly trained. Traditional cortical circuit models are notoriously difficult to train due to expansive nonlinearities in the dynamical system, leading to an optimization problem with nonlinear stability constraints that are difficult to impose. Conversely, recurrent neural networks (RNNs) excel in tasks involving sequential data but lack biological plausibility and interpretability. In this work, we address these challenges by linking dynamic divisive normalization (DN) to the stability of "oscillatory recurrent gated neural integrator circuits'' (ORGaNICs), a biologically plausible recurrent cortical circuit model that dynamically achieves DN and that has been shown to simulate a wide range of neurophysiological phenomena. By using the indirect method of Lyapunov, we prove the remarkable property of unconditional local stability for an arbitrary-dimensional ORGaNICs circuit when the recurrent weight matrix is the identity. We thus connect ORGaNICs to a system of coupled damped harmonic oscillators, which enables us to derive the circuit's energy function, providing a normative principle of what the circuit, and individual neurons, aim to accomplish. Further, for a generic recurrent weight matrix, we prove the stability of the 2D model and demonstrate empirically that stability holds in higher dimensions. Finally, we show that ORGaNICs can be trained by backpropagation through time without gradient clipping/scaling, thanks to its intrinsic stability property and adaptive time constants, which address the problems of exploding, vanishing, and oscillating gradients. By evaluating the model's performance on RNN benchmarks, we find that ORGaNICs outperform alternative neurodynamical models on static image classification tasks and perform comparably to LSTMs on sequential tasks.

A challenging problem in many modern machine learning tasks is to process weight-space features, i.e., to transform or extract information from the weights and gradients of a neural network. Recent works have developed promising weight-space models that are equivariant to the permutation symmetries of simple feedforward networks. However, they are not applicable to general architectures, since the permutation symmetries of a weight space can be complicated by recurrence or residual connections. This work proposes an algorithm that automatically constructs permutation equivariant models, which we refer to as universal neural functionals (UNFs), for any weight space. Among other applications, we demonstrate how UNFs can be substituted into existing learned optimizer designs, and find promising improvements over prior methods when optimizing small image classifiers and language models. Our results suggest that learned optimizers can benefit from considering the (symmetry) structure of the weight space they optimize.
tl;dr: We establish a new learning rate framework for FTRL in online learning with a minimax regret of $\Theta(T^{2/3})$ and then improve existing best-of-both-worlds bounds in partial monitoring and graph bandits.

Follow-the-Regularized-Leader (FTRL) is a powerful framework for various online learning problems. By designing its regularizer and learning rate to be adaptive to past observations, FTRL is known to work adaptively to various properties of an underlying environment. However, most existing adaptive learning rates are for online learning problems with a minimax regret of $\Theta(\sqrt{T})$ for the number of rounds $T$, and there are only a few studies on adaptive learning rates for problems with a minimax regret of $\Theta(T^{2/3})$, which include several important problems dealing with indirect feedback. To address this limitation, we establish a new adaptive learning rate framework for problems with a minimax regret of $\Theta(T^{2/3})$. Our learning rate is designed by matching the stability, penalty, and bias terms that naturally appear in regret upper bounds for problems with a minimax regret of $\Theta(T^{2/3})$. As applications of this framework, we consider three major problems with a minimax regret of $\Theta(T^{2/3})$: partial monitoring, graph bandits, and multi-armed bandits with paid observations. We show that FTRL with our learning rate and the Tsallis entropy regularizer improves existing Best-of-Both-Worlds (BOBW) regret upper bounds, which achieve simultaneous optimality in the stochastic and adversarial regimes. The resulting learning rate is surprisingly simple compared to the existing learning rates for BOBW algorithms for problems with a minimax regret of $\Theta(T^{2/3})$.
tl;dr: The paper presents new algorithms for MAP and Marginal MAP inference in Logical Credal Networks.

Logical Credal Networks or LCNs were recently introduced as a powerful probabilistic logic framework for representing and reasoning with imprecise knowledge. Unlike many existing formalisms, LCNs have the ability to represent cycles and allow specifying marginal and conditional probability bounds on logic formulae which may be important in many realistic scenarios. Previous work on LCNs has focused exclusively on marginal inference, namely computing posterior lower and upper probability bounds on a query formula. In this paper, we explore abductive reasoning tasks such as solving MAP and Marginal MAP queries in LCNs given some evidence. We first formally define the MAP and Marginal MAP tasks for LCNs and subsequently show how to solve these tasks exactly using search-based approaches. We then propose several approximate schemes that allow us to scale MAP and Marginal MAP inference to larger problem instances. An extensive empirical evaluation demonstrates the effectiveness of our algorithms on both random LCN instances as well as LCNs derived from more realistic use-cases.
2165. Deep Support Vectors
tl;dr: This paper finds support vector in deep learning model. These vectors has same characteristics to conventional SVM. It can be used in dataset distillation, global explanation. In its beyond, it can be used as latent generative model.

Deep learning has achieved tremendous success. However, unlike SVMs, which provide direct decision criteria and can be trained with a small dataset, it still has significant weaknesses due to its requirement for massive datasets during training and the black-box characteristics on decision criteria. This paper addresses these issues by identifying support vectors in deep learning models. To this end, we propose the DeepKKT condition, an adaptation of the traditional Karush-Kuhn-Tucker (KKT) condition for deep learning models, and confirm that generated Deep Support Vectors (DSVs) using this condition exhibit properties similar to traditional support vectors. This allows us to apply our method to few-shot dataset distillation problems and alleviate the black-box characteristics of deep learning models. Additionally, we demonstrate that the DeepKKT condition can transform conventional classification models into generative models with high fidelity, particularly as latent generation models using class labels as latent variables. We validate the effectiveness of DSVs using common datasets (ImageNet, CIFAR10 and CIFAR100) on the general architectures (ResNet and ConvNet), proving their practical applicability.
tl;dr: This work addresses the challenge of spiraling evaluation cost through an efficient evaluation framework called Sort & Search (S&S).

Standardized benchmarks drive progress in machine learning. However, with repeated testing, the risk of overfitting grows as algorithms over-exploit benchmark idiosyncrasies. In our work, we seek to mitigate this challenge by compiling \textit{ever-expanding} large-scale benchmarks called \textit{Lifelong Benchmarks}. As exemplars of our approach, we create \textit{Lifelong-CIFAR10} and \textit{Lifelong-ImageNet}, containing (for now) 1.69M and 1.98M test samples, respectively. While reducing overfitting, lifelong benchmarks introduce a key challenge: the high cost of evaluating a growing number of models across an ever-expanding sample set. To address this challenge, we also introduce an efficient evaluation framework: \textit{Sort \& Search (S\&S)}, which reuses previously evaluated models by leveraging dynamic programming algorithms to selectively rank and sub-select test samples, enabling cost-effective lifelong benchmarking. Extensive empirical evaluations across $\sim$31,000 models demonstrate that \textit{S\&S} achieves highly-efficient approximate accuracy measurement, reducing compute cost from 180 GPU days to 5 GPU hours ($\sim$1000x reduction) on a single A100 GPU, with low approximation error. As such, lifelong benchmarks offer a robust, practical solution to the ``benchmark exhaustion'' problem.
tl;dr: We propose a novel method to control diffusion models with bounding box labels, exhibiting robustness in handling complex scenes and specific domains and enabling detector enhancement with synthetic data.

Modern diffusion-based image generative models have made significant progress and become promising to enrich training data for the object detection task. However, the generation quality and the controllability for complex scenes containing multi-class objects and dense objects with occlusions remain limited. This paper presents ODGEN, a novel method to generate high-quality images conditioned on bounding boxes, thereby facilitating data synthesis for object detection. Given a domain-specific object detection dataset, we first fine-tune a pre-trained diffusion model on both cropped foreground objects and entire images to fit target distributions. Then we propose to control the diffusion model using synthesized visual prompts with spatial constraints and object-wise textual descriptions. ODGEN exhibits robustness in handling complex scenes and specific domains. Further, we design a dataset synthesis pipeline to evaluate ODGEN on 7 domain-specific benchmarks to demonstrate its effectiveness. Adding training data generated by ODGEN improves up to 25.3% mAP@.50:.95 with object detectors like YOLOv5 and YOLOv7, outperforming prior controllable generative methods. In addition, we design an evaluation protocol based on COCO-2014 to validate ODGEN in general domains and observe an advantage up to 5.6% in mAP@.50:.95 against existing methods.

Recent studies suggest that deep learning models' inductive bias towards favoring simpler features may be an origin of shortcut learning. Yet, there has been limited focus on understanding the complexities of the myriad features that models learn. In this work, we introduce a new metric for quantifying feature complexity, based on V-information and capturing whether a feature requires complex computational transformations to be extracted. Using this V-information metric, we analyze the complexities of 10,000 features—represented as directions in the penultimate layer—that were extracted from a standard ImageNet-trained vision model. Our study addresses four key questions:
First, we ask what features look like as a function of complexity, and find a spectrum of simple-to-complex features present within the model. Second, we ask when features are learned during training. We find that simpler features dominate early in training, and more complex features emerge gradually. Third, we investigate where within the network simple and complex features "flow," and find that simpler features tend to bypass the visual hierarchy via residual connections. Fourth, we explore the connection between features' complexity and their importance for driving the network's decision. We find that complex features tend to be less important. Surprisingly, important features become accessible at earlier layers during training, like a "sedimentation process," allowing the model to build upon these foundational elements.

Regularization is a critical component in deep learning. The most commonly used approach, weight decay, applies a constant penalty coefficient uniformly across all parameters. This may be overly restrictive for some parameters, while insufficient for others. To address this, we present Constrained Parameter Regularization (CPR) as an alternative to traditional weight decay. Unlike the uniform application of a single penalty, CPR enforces an upper bound on a statistical measure, such as the L$_2$-norm, of individual parameter matrices. Consequently, learning becomes a constraint optimization problem, which we tackle using an adaptation of the augmented Lagrangian method. CPR introduces only a minor runtime overhead and only requires setting an upper bound. We propose simple yet efficient mechanisms for initializing this bound, making CPR rely on no hyperparameter or one, akin to weight decay. Our empirical studies on computer vision and language modeling tasks demonstrate CPR's effectiveness. The results show that CPR can outperform traditional weight decay and increase performance in pre-training and fine-tuning.
tl;dr: We show the learnability of Gröbner basis computation and raise new algebraic and machine learning challenges.

Solving a polynomial system, or computing an associated Gröbner basis, has been a fundamental task in computational algebra. However, it is also known for its notorious doubly exponential time complexity in the number of variables in the worst case. This paper is the first to address the learning of Gröbner basis computation with Transformers. The training requires many pairs of a polynomial system and the associated Gröbner basis, raising two novel algebraic problems: random generation of Gröbner bases and transforming them into non-Gröbner ones, termed as backward Gröbner problem. We resolve these problems with 0-dimensional radical ideals, the ideals appearing in various applications. Further, we propose a hybrid input embedding to handle coefficient tokens with continuity bias and avoid the growth of the vocabulary set. The experiments show that our dataset generation method is a few orders of magnitude faster than a naive approach, overcoming a crucial challenge in learning to compute Gröbner bases, and Gröbner computation is learnable in a particular class.
tl;dr: LLM watermarking, intended for generated text detection, has the secondary effect of revealing when synthetic data are used to fine-tune another model.

We investigate the radioactivity of text generated by large language models (LLM), \ie whether it is possible to detect that such synthetic input was used to train a subsequent LLM.
Current methods like membership inference or active IP protection either work only in settings where the suspected text is known or do not provide reliable statistical guarantees.
We discover that, on the contrary, it is possible to reliably determine if a language model was trained on synthetic data if that data is output by a watermarked LLM.
Our new methods, specialized for radioactivity, detects with a provable confidence weak residuals of the watermark signal in the fine-tuned LLM.
We link the radioactivity contamination level to the following properties: the watermark robustness, its proportion in the training set, and the fine-tuning process.
For instance, if the suspect model is open-weight, we demonstrate that training on watermarked instructions can be detected with high confidence ($p$-value $< 10^{-5}$) even when as little as $5\%$ of training text is watermarked.

A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing Vision-Language-Action (VLA) models for robots can handle a range of basic tasks, they still face challenges in two areas: (1) insufficient reasoning ability to tackle complex tasks, and (2) high computational costs for VLA model fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic VLA model that leverages Mamba to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual tokens with language embedding through co-training, empowering our model with visual common sense and robotic-related reasoning. To further equip RoboMamba with SE(3) pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1\% of the model) and time. In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 3 times faster than existing VLA models.
tl;dr: To address the challenging trade-off between performance and compression cost, we introduce SlimSAM, a novel data-efficient SAM compression method that achieves superior performance with extremely less training data.

Current approaches for compressing the Segment Anything Model (SAM) yield commendable results, yet necessitate extensive data to train a new network from scratch. Employing conventional pruning techniques can remarkably reduce data requirements but would suffer from a degradation in performance. To address this challenging trade-off, we introduce SlimSAM, a novel data-efficient SAM compression method that achieves superior performance with extremely less training data. The essence of SlimSAM is encapsulated in the alternate slimming framework which effectively enhances knowledge inheritance under severely limited training data availability and exceptional pruning ratio. Diverging from prior techniques, our framework progressively compresses the model by alternately pruning and distilling distinct, decoupled sub-structures. Disturbed Taylor pruning is also proposed to address the misalignment between the pruning objective and training target, thereby boosting the post-distillation after pruning. SlimSAM yields significant performance improvements while demanding over 10 times less training data than any other existing compression methods. Even when compared to the original SAM, SlimSAM achieves approaching performance while reducing parameter counts to merely 1.4% (9.1M), MACs to 0.8% (23G), and requiring only 0.1% (10k) of the SAM training data.

Current state-of-the-art synchrony-based models encode object bindings with complex-valued activations and compute with real-valued weights in feedforward architectures. We argue for the computational advantages of a recurrent architecture with complex-valued weights. We propose a fully convolutional autoencoder, SynCx, that performs iterative constraint satisfaction: at each iteration, a hidden layer bottleneck encodes statistically regular configurations of features in particular phase relationships; over iterations, local constraints propagate and the model converges to a globally consistent configuration of phase assignments. Binding is achieved simply by the matrix-vector product operation between complex-valued weights and activations, without the need for additional mechanisms that have been incorporated into current synchrony-based models. SynCx outperforms or is strongly competitive with current models for unsupervised object discovery. SynCx also avoids certain systematic grouping errors of current models, such as the inability to separate similarly colored objects without additional supervision.
tl;dr: We provide mechanistic evidence of learned look-ahead in Leela Chess Zero, a transformer trained to play chess.

Do neural networks learn to implement algorithms such as look-ahead or search "in the wild"? Or do they rely purely on collections of simple heuristics? We present evidence of *learned look-ahead* in the policy and value network of Leela Chess Zero, the currently strongest deep neural chess engine. We find that Leela internally represents future optimal moves and that these representations are crucial for its final output in certain board states. Concretely, we exploit the fact that Leela is a transformer that treats every chessboard square like a token in language models, and give three lines of evidence: (1) activations on certain squares of future moves are unusually important causally; (2) we find attention heads that move important information "forward and backward in time," e.g., from squares of future moves to squares of earlier ones; and (3) we train a simple probe that can predict the optimal move 2 turns ahead with 92% accuracy (in board states where Leela finds a single best line). These findings are clear evidence of learned look-ahead in neural networks and might be a step towards a better understanding of their capabilities.
2176. Small steps no more: Global convergence of stochastic gradient bandits for arbitrary learning rates
tl;dr: stochastic gradient bandit algorithm converges to a globally optimal policy almost surely using any constant learning rate

We provide a new understanding of the stochastic gradient bandit algorithm by showing that it converges to a globally optimal policy almost surely using \emph{any} constant learning rate. This result demonstrates that the stochastic gradient algorithm continues to balance exploration and exploitation appropriately even in scenarios where standard smoothness and noise control assumptions break down. The proofs are based on novel findings about action sampling rates and the relationship between cumulative progress and noise, and extend the current understanding of how simple stochastic gradient methods behave in bandit settings.

Large language models (LLMs) trained on web-scale datasets raise substantial concerns regarding permissible data usage.
One major question is whether these models "memorize" all their training data or they integrate many data sources in some way more akin to how a human would learn and synthesize information. The answer hinges, to a large degree, on \emph{how we define memorization.} In this work, we propose the Adversarial Compression Ratio (ACR) as a metric for assessing memorization in LLMs. A given string from the training data is considered memorized if it can be elicited by a prompt (much) shorter than the string itself---in other words, if these strings can be ``compressed'' with the model by computing adversarial prompts of fewer tokens. The ACR overcomes the limitations of existing notions of memorization by (i) offering an adversarial view of measuring memorization, especially for monitoring unlearning and compliance; and (ii) allowing for the flexibility to measure memorization for arbitrary strings at a reasonably low compute. Our definition serves as a practical tool for determining when model owners may be violating terms around data usage, providing a potential legal tool and a critical lens through which to address such scenarios.
tl;dr: We extend and improve several theoretical results about RL in continuous state-action spaces

Achieving the no-regret property for Reinforcement Learning (RL) problems in continuous state and action-space environments is one of the major open problems in the field. Existing solutions either work under very specific assumptions or achieve bounds that are vacuous in some regimes. Furthermore, many structural assumptions
are known to suffer from a provably unavoidable exponential dependence on the time horizon $H$ in the regret, which makes any possible solution unfeasible in practice.
In this paper, we identify _local linearity_ as the feature that makes Markov Decision Processes (MDPs) both _learnable_ (sublinear regret) and _feasible_ (regret that is polynomial in $H$).
We define a novel MDP representation class, namely _Locally Linearizable MDPs_, generalizing other representation classes like Linear MDPs and MDPS with low inherent Belmman error.
Then, i) we introduce **Cinderella**, a no-regret algorithm for this general representation class, and ii) we show that all known learnable and feasible MDP families are representable in this class.
We first show that all known feasible MDPs belong to a family that we call _Mildly Smooth MDPs_. Then, we show how any mildly smooth MDP can be represented as a Locally Linearizable MDP by an appropriate choice of representation. This way, **Cinderella** is shown to achieve state-of-the-art regret bounds for all previously known (and some new) continuous MDPs for which RL is learnable and feasible.
tl;dr: We propose a simple yet effective method for mitigating label noise, which can be implemented with just two lines of code.

Noisy labels pose a common challenge for training accurate deep neural networks. To mitigate label noise, prior studies have proposed various robust loss functions to achieve noise tolerance in the presence of label noise, particularly symmetric losses. However, they usually suffer from the underfitting issue due to the overly strict symmetric condition. In this work, we propose a simple yet effective approach for relaxing the symmetric condition, namely **$\epsilon$-softmax**, which simply modifies the outputs of the softmax layer to approximate one-hot vectors with a controllable error $\epsilon$. Essentially, ***$\epsilon$-softmax** not only acts as an alternative for the softmax layer, but also implicitly plays the crucial role in modifying the loss function.* We prove theoretically that **$\epsilon$-softmax** can achieve noise-tolerant learning with controllable excess risk bound for almost any loss function. Recognizing that **$\epsilon$-softmax**-enhanced losses may slightly reduce fitting ability on clean datasets, we further incorporate them with one symmetric loss, thereby achieving a better trade-off between robustness and effective learning. Extensive experiments demonstrate the superiority of our method in mitigating synthetic and real-world label noise.
tl;dr: We investigate the impact of incorrect type beliefs on an agent’s payoff in Bayesian games, defining a trade-off between risk and opportunity, and providing upper and lower bounds on the payoff gap for both normal-form and stochastic settings.

The combination of the Bayesian game and learning has a rich history, with the idea of controlling a single agent in a system composed of multiple agents with unknown behaviors given a set of types, each specifying a possible behavior for the other agents. The idea is to plan an agent's own actions with respect to those types which it believes are most likely to maximize the payoff. However, the type beliefs are often learned from past actions and likely to be incorrect. With this perspective in mind, we consider an agent in a game with type predictions of other components, and investigate the impact of incorrect beliefs to the agent’s payoff. In particular, we formally define a tradeoff between risk and opportunity by comparing the payoff obtained against the optimal payoff, which is represented by a gap caused by trusting or distrusting the learned beliefs.Our main results characterize the tradeoff by establishing upper and lower bounds on the Pareto front for both normal-form and stochastic Bayesian games, with numerical results provided.
tl;dr: AutoMix robustly routes queries among language models of varying sizes, efficiently balancing computational cost and solution accuracy

Large language models (LLMs) are now available from cloud API providers in various sizes and configurations. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix are two key technical contributions. First, it has a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring extensive training. Second, given that self-verification can be noisy, it employs a POMDP based router that can effectively select an appropriately sized model, based on answer confidence. Experiments across five language models and five challenging datasets show that Automix consistently surpasses strong baselines, reducing computational cost by over 50\% for comparable performance.
2182. Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
tl;dr: LLMs are able to verbalize latent information that is only implicit in training data and use this information for downstream OOD tasks, without using chain of thought.

One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. While this removes the explicit information, implicit information can remain scattered across various training documents. Could an LLM infer the censored knowledge by piecing together these implicit hints? As a step towards answering this question, we study inductive out-of-context reasoning (OOCR), a type of generalization in which LLMs infer latent information from evidence distributed across training documents and apply it to downstream tasks without in-context learning.
Using a suite of five tasks, we demonstrate that frontier LLMs can perform inductive OOCR. In one experiment we finetune an LLM on a corpus consisting only of distances between an unknown city and other known cities. Remarkably, without in-context examples or Chain of Thought, the LLM can verbalize that the unknown city is Paris and use this fact to answer downstream questions.
Further experiments show that LLMs trained only on individual coin flip outcomes can verbalize whether the coin is biased, and those trained only on pairs $(x,f(x))$ can articulate a definition of $f$ and compute inverses.
While OOCR succeeds in a range of cases, we also show that it is unreliable, particularly for smaller LLMs learning complex structures.
Overall, the ability of LLMs to "connect the dots" without explicit in-context learning poses a potential obstacle to monitoring and controlling the knowledge acquired by LLMs.

Conditional independence tests are crucial across various disciplines in determining the independence of an outcome variable $Y$ from a treatment variable $X$, conditioning on a set of confounders $Z$. The Conditional Randomization Test (CRT) offers a powerful framework for such testing by assuming known distributions of $X \mid Z$; it controls the Type-I error exactly, allowing for the use of flexible, black-box test statistics. In practice, testing for conditional independence often involves using data from a source population to draw conclusions about a target population. This can be challenging due to covariate shift---differences in the distribution of $X$, $Z$, and surrogate variables, which can affect the conditional distribution of $Y \mid X, Z$---rendering traditional CRT approaches invalid. To address this issue, we propose a novel Covariate Shift Corrected Pearson Chi-squared Conditional Randomization (csPCR) test. This test adapts to covariate shifts by integrating importance weights and employing the control variates method to reduce variance in the test statistics and thus enhance power. Theoretically, we establish that the csPCR test controls the Type-I error asymptotically. Empirically, through simulation studies, we demonstrate that our method not only maintains control over Type-I errors but also exhibits superior power, confirming its efficacy and practical utility in real-world scenarios where covariate shifts are prevalent. Finally, we apply our methodology to a real-world dataset to assess the impact of a COVID-19 treatment on the 90-day mortality rate among patients.
tl;dr: DiffusionPDE solves forward and inverse PDEs from partial observations using diffusion models.

We introduce a general framework for solving partial differential equations (PDEs) using generative diffusion models. In particular, we focus on the scenarios where we do not have the full knowledge of the scene necessary to apply classical solvers. Most existing forward or inverse PDE approaches perform poorly when the observations on the data or the underlying coefficients are incomplete, which is a common assumption for real-world measurements. In this work, we propose DiffusionPDE that can simultaneously fill in the missing information and solve a PDE by modeling the joint distribution of the solution and coefficient spaces. We show that the learned generative priors lead to a versatile framework for accurately solving a wide range of PDEs under partial observation, significantly outperforming the state-of-the-art methods for both forward and inverse directions.
2185. Making Offline RL Online: Collaborative World Models for Offline Visual Reinforcement Learning

Training offline RL models using visual inputs poses two significant challenges, *i.e.*, the overfitting problem in representation learning and the overestimation bias for expected future rewards. Recent work has attempted to alleviate the overestimation bias by encouraging conservative behaviors. This paper, in contrast, tries to build more flexible constraints for value estimation without impeding the exploration of potential advantages. The key idea is to leverage off-the-shelf RL simulators, which can be easily interacted with in an online manner, as the “*test bed*” for offline policies. To enable effective online-to-offline knowledge transfer, we introduce CoWorld, a model-based RL approach that mitigates cross-domain discrepancies in state and reward spaces. Experimental results demonstrate the effectiveness of CoWorld, outperforming existing RL approaches by large margins.
tl;dr: This paper proposes a Prompt-agnostic Adversarial Perturbation method for customized text-to-image diffusion models by modeling the prompt distribution and generating perturbations to maximize expected disturbance over sampled prompts.

Diffusion models have revolutionized customized text-to-image generation, allowing for efficient synthesis of photos from personal data with textual descriptions. However, these advancements bring forth risks including privacy breaches and unauthorized replication of artworks. Previous researches primarily center around using “prompt-specific methods” to generate adversarial examples to protect personal images, yet the effectiveness of existing methods is hindered by constrained adaptability to different prompts.
In this paper, we introduce a Prompt-Agnostic Adversarial Perturbation (PAP) method for customized diffusion models. PAP first models the prompt distribution using a Laplace Approximation, and then produces prompt-agnostic perturbations by maximizing a disturbance expectation based on the modeled distribution.
This approach effectively tackles the prompt-agnostic attacks, leading to improved defense stability.
Extensive experiments in face privacy and artistic style protection, demonstrate the superior generalization of our method in comparison to existing techniques.
tl;dr: We give instance optimal (differentially private) algorithms for density estimation in Wasserstein distance.

Estimating the density of a distribution from samples is a fundamental problem in statistics. In many practical settings, the Wasserstein distance is an appropriate error metric for density estimation. For example, when estimating population densities in a geographic region, a small Wasserstein distance means that the estimate is able to capture roughly where the population mass is. In this work we study differentially private density estimation in the Wasserstein distance. We design and analyze instance-optimal algorithms for this problem that can adapt to easy instances.
For distributions $P$ over $\mathbb{R}$, we consider a strong notion of instance-optimality: an algorithm that uniformly achieves the instance-optimal estimation rate is competitive with an algorithm that is told that the distribution is either $P$ or $Q_P$ for some distribution $Q_P$ whose probability density function (pdf) is within a factor of 2 of the pdf of $P$. For distributions over $\mathbb{R}^2$, we use a slightly different notion of instance optimality. We say that an algorithm is instance-optimal if it is competitive with an algorithm that is given a constant multiplicative approximation of the density of the distribution. We characterize the instance-optimal estimation rates in both these settings and show that they are uniformly achievable (up to polylogarithmic factors). Our approach for $\mathbb{R}^2$ extends to arbitrary metric spaces as it goes via hierarchically separated trees. As a special case our results lead to instance-optimal learning in TV distance for discrete distributions.

In this work, we study the mean-field flow for learning subspace-sparse polynomials using stochastic gradient descent and two-layer neural networks, where the input distribution is standard Gaussian and the output only depends on the projection of the input onto a low-dimensional subspace. We establish a necessary condition for SGD-learnability, involving both the characteristics of the target function and the expressiveness of the activation function. In addition, we prove that the condition is almost sufficient, in the sense that a condition slightly stronger than the necessary condition can guarantee the exponential decay of the loss functional to zero.
2189. Credal Learning Theory
tl;dr: We develop Credal Learning Theory, which allows to derive tighter bounds wrt SLT by leveraging a finite sample of training sets

Statistical learning theory is the foundation of machine learning, providing theoretical bounds for the risk of models learned from a (single) training set, assumed to issue from an unknown probability distribution. In actual deployment, however, the data distribution may (and often does) vary, causing domain adaptation/generalization issues. In this paper we lay the foundations for a `credal' theory of learning, using convex sets of probabilities (credal sets) to model the variability in the data-generating distribution. Such credal sets, we argue, may be inferred from a finite sample of training sets. Bounds are derived for the case of finite hypotheses spaces (both assuming realizability or not), as well as infinite model spaces, which directly generalize classical results.

Robust reinforcement learning is essential for deploying reinforcement learning algorithms in real-world scenarios where environmental uncertainty predominates.
Traditional robust reinforcement learning often depends on rectangularity assumptions, where adverse probability measures of outcome states are assumed to be independent across different states and actions.
This assumption, rarely fulfilled in practice, leads to overly conservative policies.
To address this problem, we introduce a new time-constrained robust MDP (TC-RMDP) formulation that considers multifactorial, correlated, and time-dependent disturbances, thus more accurately reflecting real-world dynamics. This formulation goes beyond the conventional rectangularity paradigm, offering new perspectives and expanding the analytical framework for robust RL.
We propose three distinct algorithms, each using varying levels of environmental information, and evaluate them extensively on continuous control benchmarks.
Our results demonstrate that these algorithms yield an efficient tradeoff between performance and robustness, outperforming traditional deep robust RL methods in time-constrained environments while preserving robustness in classical benchmarks.
This study revisits the prevailing assumptions in robust RL and opens new avenues for developing more practical and realistic RL applications.
tl;dr: We propose NeuroPath, a graph Transformer that can express neural pathways by a novel multivariate structure-function coupling of human connectome and apply on supervised or zero-shot learning of neural activity classification and disease diagnosis.

Although modern imaging technologies allow us to study connectivity between two distinct brain regions $\textit{in-vivo}$, an in-depth understanding of how anatomical structure supports brain function and how spontaneous functional fluctuations emerge remarkable cognition is still elusive. Meanwhile, tremendous efforts have been made in the realm of machine learning to establish the nonlinear mapping between neuroimaging data and phenotypic traits. However, the absence of neuroscience insight in the current approaches poses significant challenges in understanding cognitive behavior from transient neural activities.
To address this challenge, we put the spotlight on the coupling mechanism of structural connectivity (SC) and functional connectivity (FC) by formulating such network neuroscience question into an expressive graph representation learning problem for high-order topology. Specifically, we introduce the concept of $\textit{topological detour}$ to characterize how a ubiquitous instance of FC (direct link) is supported by neural pathways (detour) physically wired by SC, which forms a cyclic loop interacted by brain structure and function. In the clich\'e of machine learning, the multi-hop detour pathway underlying SC-FC coupling allows us to devise a novel multi-head self-attention mechanism within Transformer to capture multi-modal feature representation from paired graphs of SC and FC. Taken together, we propose a biological-inspired deep model, coined as $\textit{NeuroPath}$, to find putative connectomic feature representations from the unprecedented amount of neuroimages, which can be plugged into various downstream applications such as task recognition and disease diagnosis.
We have evaluated $\textit{NeuroPath}$ on large-scale public datasets including Human Connectome Project (HCP) and UK Biobank (UKB) under different experiment settings of supervised and zero-shot learning, where the state-of-the-art performance by our $\textit{NeuroPath}$ indicates great potential in network neuroscience.
tl;dr: We show for the first time that f-divergence-based VI can be used to speed up GFlowNet training by employing appropriate variance reduction techniques

Generative Flow Networks (GFlowNets) are amortized samplers of unnormalized distributions over compositional objects with applications to causal discovery, NLP, and drug design. Recently, it was shown that GFlowNets can be framed as a hierarchical variational inference (HVI) method for discrete distributions. Despite this equivalence, attempts to train GFlowNets using traditional divergence measures as learning objectives were unsuccessful. Instead, current approaches for training these models rely on minimizing the log-squared difference between a proposal (forward policy) and a target (backward policy) distributions. In this work, we first formally extend the relationship between GFlowNets and HVI to distributions on arbitrary measurable topological spaces. Then, we empirically show that the ineffectiveness of divergence-based learning of GFlowNets is due to large gradient variance of the corresponding stochastic objectives. To address this issue, we devise a collection of provably variance-reducing control variates for gradient estimation based on the REINFORCE leave-one-out estimator. Our experimental results suggest that the resulting algorithms often accelerate training convergence when compared against previous approaches. All in all, our work contributes by narrowing the gap between GFlowNet training and HVI, paving the way for algorithmic advancements inspired by the divergence minimization viewpoint.
tl;dr: This paper designs a hybrid language model workflow integrating representative and generative LMs to precisely predict which previous papers (candidates) will an ongoing new paper (query) cite from vast candidate set.

Citation networks are critical infrastructures of modern science, serving as intricate webs of past literature and enabling researchers to navigate the knowledge production system. To mine information hiding in the link space of such networks, predicting which previous papers (candidates) will a new paper (query) cite is a critical problem that has long been studied. However, an important gap remains unaddressed: the roles of a paper's citations vary significantly, ranging from foundational knowledge basis to superficial contexts. Distinguishing these roles requires a deeper understanding of the logical relationships among papers, beyond simple edges in citation networks. The emergence of large language models (LLMs) with textual reasoning capabilities offers new possibilities for discerning these relationships, but there are two major challenges. First, in practice, a new paper may select its citations from gigantic existing papers, where the combined texts far exceed the context length of LLMs. Second, logical relationships between papers are often implicit, and directly prompting an LLM to predict citations may lead to results based primarily on surface-level textual similarities, rather than the deeper logical reasoning required. In this paper, we introduce the novel concept of core citation, which identifies the critical references that go beyond superficial mentions. Thereby, we elevate the citation prediction task from a simple binary classification to a more nuanced problem: distinguishing core citations from both superficial citations and non-citations. To address this, we propose $\textbf{HLM-Cite}$, a $\textbf{H}$ybrid $\textbf{L}$anguage $\textbf{M}$odel workflow for citation prediction, which combines embedding and generative LMs. We design a curriculum finetune procedure to adapt a pretrained text embedding model to coarsely retrieve high-likelihood core citations from vast candidate sets and then design an LLM agentic workflow to rank the retrieved papers through one-shot reasoning, revealing the implicit relationships among papers. With the two-stage pipeline, we can scale the candidate sets to 100K papers, vastly exceeding the size handled by existing methods. We evaluate HLM-Cite on a dataset across 19 scientific fields, demonstrating a 17.6\% performance improvement comparing SOTA methods. Our code is open-source at https://github.com/tsinghua-fib-lab/H-LM for reproducibility.

The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.

Large pretrained foundation models demonstrate exceptional performance and, in some high-stakes applications, even surpass human experts. However, most of these models are currently evaluated primarily on prediction accuracy, overlooking the validity of the rationales behind their accurate predictions. For the safe deployment of foundation models, there is a pressing need to ensure *double-correct predictions*, *i.e.*, correct prediction backed by correct rationales. To achieve this, we propose a two-phase scheme: First, we curate a new dataset that offers structured rationales for visual recognition tasks. Second, we propose a rationale-informed optimization method to guide the model in disentangling and localizing visual evidence for each rationale, without requiring manual annotations. Extensive experiments and ablation studies demonstrate that our model outperforms state-of-the-art models by up to 10.1\% in prediction accuracy across a wide range of tasks. Furthermore, our method significantly improves the model's rationale correctness, improving localization by 7.5\% and disentanglement by 36.5\%. Our dataset, source code, and pretrained weights: https://github.com/deep-real/DCP
2196. MonkeySee: Space-time-resolved reconstructions of natural images from macaque multi-unit activity
tl;dr: This study uses a CNN to reconstruct images from macaque brain signals and explores how different brain areas process these signals at different timepoints.

In this paper, we reconstruct naturalistic images directly from macaque brain signals using a convolutional neural network (CNN) based decoder. We investigate the ability of this CNN-based decoding technique to differentiate among neuronal populations from areas V1, V4, and IT, revealing distinct readout characteristics for each. This research marks a progression from low-level to high-level brain signals, thereby enriching the existing framework for utilizing CNN-based decoders to decode brain activity. Our results demonstrate high-precision reconstructions of naturalistic images, highlighting the efficiency of CNN-based decoders in advancing our knowledge of how the brain's representations translate into pixels. Additionally, we present a novel space-time-resolved decoding technique, demonstrating how temporal resolution in decoding can advance our understanding of neural representations. Moreover, we introduce a learned receptive field layer that sheds light on the CNN-based model's data processing during training, enhancing understanding of its structure and interpretive capacity.
tl;dr: The first comprehensive formalization of Feint behaviors at action-level and strategy-level, and provide concrete implementation and quantitative evaluation in Multi-Player games.

Feint behaviors refer to a set of deceptive behaviors in a nuanced manner, which enable players to obtain temporal and spatial advantages over opponents in competitive games. Such behaviors are crucial tactics in most competitive multi-player games (e.g., boxing, fencing, basketball, motor racing, etc.). However, existing literature does not provide a comprehensive (and/or concrete) formalization for Feint behaviors, and their implications on game strategies. In this work, we introduce the first comprehensive formalization of Feint behaviors at both action-level and strategy-level, and provide concrete implementation and quantitative evaluation of them in multi-player games. The key idea of our work is to (1) allow automatic generation of Feint behaviors via Palindrome-directed templates, combine them into meaningful behavior sequences via a Dual-Behavior Model; (2) concertize the implications from our formalization of Feint on game strategies, in terms of temporal, spatial, and their collective impacts respectively; and (3) provide a unified implementation scheme of Feint behaviors in existing MARL frameworks. The experimental results show that our design of Feint behaviors can (1) greatly improve the game reward gains; (2) significantly improve the diversity of Multi-Player Games; and (3) only incur negligible overheads in terms of time consumption.
tl;dr: We extend the RL fine-tuning of LLMs into a sequential cooperative multi-agent reinforcement learning framework.

Reinforcement learning (RL) has emerged as a pivotal technique for fine-tuning large language models (LLMs) on specific tasks. However, prevailing RL fine-tuning methods predominantly rely on PPO and its variants. Though these algorithms are effective in general RL settings, they often exhibit suboptimal performance and vulnerability to distribution collapse when applied to the fine-tuning of LLMs. In this paper, we propose CORY, extending the RL fine-tuning of LLMs to a sequential cooperative multi-agent reinforcement learning framework, to leverage the inherent coevolution and emergent capabilities of multi-agent systems. In CORY, the LLM to be fine-tuned is initially duplicated into two autonomous agents: a pioneer and an observer. The pioneer generates responses based on queries, while the observer generates responses using both the queries and the pioneer’s responses. The two agents are trained together. During training, the agents exchange roles periodically, fostering cooperation and coevolution between them. Experiments evaluate CORY's performance by fine-tuning GPT-2 and Llama-2 under subjective and objective reward functions on the IMDB Review and GSM8K datasets, respectively. Results show that CORY outperforms PPO in terms of policy optimality, resistance to distribution collapse, and training robustness, thereby underscoring its potential as a superior methodology for refining LLMs in real-world applications.

The influence maximization (IM) problem aims to identify a budgeted set of nodes with the highest potential to influence the largest number of users in a cascade model, a key challenge in viral marketing. Traditional \emph{IM} approaches consider each user/node independently as a potential target customer. However, in many scenarios, the target customers comprise motifs, where activating only one or a few users within a motif is insufficient for effective viral marketing, which, nevertheless, receives little attention. For instance, if a motif of three friends planning to dine together, targeting all three simultaneously is crucial for a restaurant advertisement to succeed.
In this paper, we address the motif-oriented influence maximization problem under the linear threshold model. We prove that the motif-oriented IM problem is NP-hard and that the influence function is neither supermodular nor submodular, in contrast to the classical \emph{IM} setting.
To simplify the problem, we establish the submodular upper and lower bounds for the influence function. By leveraging the submodular property, we propose a natural greedy strategy that simultaneously maximizes both bounds. Our algorithm has an approximation ratio of $\tau\cdot (1-1/e-\varepsilon)$ and a near-linear time complexity of $O((k+l)(m+\eta)\log \eta/\varepsilon^2)$.
Experimental results on diverse datasets confirm the effectiveness of our approach in motif maximization.

Iteratively improving and repairing source code with large language models (LLMs), known as refinement, has emerged as a popular way of generating programs that would be too complex to construct in one shot. Given a bank of test cases, together with a candidate program, an LLM can improve that program by being prompted with failed test cases. But it remains an open question how to best iteratively refine code, with prior work employing simple greedy or breadth-first strategies. We show here that refinement exposes an explore-exploit tradeoff: exploit by refining the program that passes the most test cases, or explore by refining a lesser considered program. We frame this as an arm-acquiring bandit problem, which we solve with Thompson Sampling. The resulting LLM-based program synthesis algorithm is broadly applicable: Across loop invariant synthesis, visual reasoning puzzles, and competition programming problems, we find that our new method can solve more problems using fewer language model calls.
tl;dr: We find a phenomenon for ViT-based CDFSL: multiplying a small temperature (even 0) to ViT's attention map can consistently improve performance. We delve into this phenomenon for an interpretation and propose an effective method for CDFSL.

Cross-domain few-shot learning (CDFSL) is proposed to transfer knowledge from large-scale source-domain datasets to downstream target-domain datasets with only a few training samples. However, Vision Transformer (ViT), as a strong backbone network to achieve many top performances, is still under-explored in the CDFSL task in its transferability against large domain gaps. In this paper, we find an interesting phenomenon of ViT in the CDFSL task: by simply multiplying a temperature (even as small as 0) to the attention in ViT blocks, the target-domain performance consistently increases, even though the attention map is downgraded to a uniform map. In this paper, we delve into this phenomenon for an interpretation. Through experiments, we interpret this phenomenon as a remedy for the ineffective target-domain attention caused by the query-key attention mechanism under large domain gaps. Based on it, we further propose a simple but effective method for the CDFSL task to boost ViT's transferability by resisting the learning of query-key parameters and encouraging that of non-query-key ones. Experiments on four CDFSL datasets validate the rationale of our interpretation and method, showing we can consistently outperform state-of-the-art methods. Our codes are available at https://github.com/Zoilsen/Attn_Temp_CDFSL.

Interest in bilevel optimization has grown in recent years, partially due to its relevance for challenging machine-learning problems. Several exciting recent works have been centered around developing efficient gradient-based algorithms that can solve bilevel optimization problems with provable guarantees. However, the existing literature mainly focuses on bilevel problems either without constraints, or featuring only simple constraints that do not couple variables across the upper and lower levels, excluding a range of complex applications. Our paper studies this challenging but less explored scenario and develops a (fully) first-order algorithm, which we term BLOCC, to tackle BiLevel Optimization problems with Coupled Constraints. We establish rigorous convergence theory for the proposed algorithm and demonstrate its effectiveness on two well-known real-world applications - support vector machine (SVM) - based model training and infrastructure planning in transportation networks.
tl;dr: This paper presents an initial exploration into graph-learning-based approaches for task planning in LLM-based agents.

Task planning in language agents is emerging as an important research topic alongside the development of large language models (LLMs). It aims to break down complex user requests in natural language into solvable sub-tasks, thereby fulfilling the original requests. In this context, the sub-tasks can be naturally viewed as a graph, where the nodes represent the sub-tasks, and the edges denote the dependencies among them. Consequently, task planning is a decision-making problem that involves selecting a connected path or subgraph within the corresponding graph and invoking it. In this paper, we explore graph learning-based methods for task planning, a direction that is orthogonal to the prevalent focus on prompt design. Our interest in graph learning stems from a theoretical discovery: the biases of attention and auto-regressive loss impede LLMs' ability to effectively navigate decision-making on graphs, which is adeptly addressed by graph neural networks (GNNs). This theoretical insight led us to integrate GNNs with LLMs to enhance overall performance. Extensive experiments demonstrate that GNN-based methods surpass existing solutions even without training, and minimal training can further enhance their performance. The performance gain increases with a larger task graph size.
tl;dr: Merging the built-in capabilities of LLMs and external capabilaties of multilingual model to boost multilingual reasoning.

Reasoning capabilities are crucial for Large Language Models~(LLMs), yet a notable gap exists between English and non-English languages. To bridge this disparity, some works fine-tune LLMs to relearn reasoning capabilities in non-English languages, while others replace non-English inputs with an external model's outputs such as English translation text to circumvent the challenge of LLM understanding non-English. Unfortunately, these methods often underutilize the built-in skilled reasoning and useful language understanding capabilities of LLMs. In order to better utilize the minds of reasoning and language understanding in LLMs, we propose a new method, namely MergeMinds, which merges LLMs with the external language understanding capabilities from multilingual models to boost the multilingual reasoning performance. Furthermore, a two-step training scheme is introduced to first train to embeded the external capabilities into LLMs and then train the collaborative utilization of the external capabilities and the built-in capabilities in LLMs. Experiments on three multilingual reasoning datasets and a language understanding dataset demonstrate that MergeMinds consistently outperforms all baselines, especially in low-resource languages. Without updating the parameters of LLMs, the average accuracy improved by 6.7 and 8.0 across all languages and low-resource languages on the MGSM dataset, respectively.
tl;dr: A comprehensive formalization of steganographic collusion in decentralised systems of generative AI agents and a model evaluation framework

Recent advancements in generative AI suggest the potential for large-scale interaction between autonomous agents and humans across platforms such as the internet. While such interactions could foster productive cooperation, the ability of AI agents to circumvent security oversight raises critical multi-agent security problems, particularly in the form of unintended information sharing or undesirable coordination. In our work, we establish the subfield of secret collusion, a form of multi-agent deception, in which two or more agents employ steganographic methods to conceal the true nature of their interactions, be it communicative or otherwise, from oversight. We propose a formal threat model for AI agents communicating steganographically and derive rigorous theoretical insights about the capacity and incentives of large language models (LLMs) to perform secret collusion, in addition to the limitations of threat mitigation measures. We complement our findings with empirical evaluations demonstrating rising steganographic capabilities in frontier single and multi-agent LLM setups and examining potential scenarios where collusion may emerge, revealing limitations in countermeasures such as monitoring, paraphrasing, and parameter optimization. Our work is the first to formalize and investigate secret collusion among frontier foundation models, identifying it as a critical area in AI Safety and outlining a comprehensive research agenda to mitigate future risks of collusion between generative AI systems.
tl;dr: We propose KF-GVD, a knowledge fusion-based GNN model for task-oriented source code vulnerability detection.

Deep learning technologies have demonstrated remarkable performance in vulnerability detection. Existing works primarily adopt a uniform and consistent feature learning pattern across the entire target set. While designed for general-purpose detection tasks, they lack sensitivity towards target code comprising multiple functional modules or diverse vulnerability subtypes. In this paper, we present a knowledge fusion-based vulnerability detection method (KF-GVD) that integrates specific vulnerability knowledge into the Graph Neural Network feature learning process. KF-GVD achieves accurate vulnerability detection across different functional modules of the Linux kernel and vulnerability subtypes without compromising general task performance. Extensive experiments demonstrate that KF-GVD outperforms SOTAs on function-level and statement-level vulnerability detection across various target tasks, with an average increase of 40.9% in precision and 26.1% in recall. Notably, KF-GVD discovered 9 undisclosed vulnerabilities when employing on C/C++ open-source projects without ground truth.

This paper makes a step towards modeling the modality discrepancy in the cross-spectral re-identification task. Based on the Lambertain model, we observe that the non-linear modality discrepancy mainly comes from diverse linear transformations acting on the surface of different materials. From this view, we unify all data augmentation strategies for cross-spectral re-identification as mimicking such local linear transformations and categorize them into moderate transformation and radical transformation. By extending the observation, we propose a Random Linear Enhancement (RLE) strategy which includes Moderate Random Linear Enhancement (MRLE) and Radical Random Linear Enhancement (RRLE) to push the boundaries of both types of transformation. Moderate Random Linear Enhancement is designed to provide diverse image transformations that satisfy the original linear correlations under constrained conditions, whereas Radical Random Linear Enhancement seeks to generate local linear transformations directly without relying on external information. The experimental results not only demonstrate the superiority and effectiveness of RLE but also confirm its great potential as a general-purpose data augmentation for cross-spectral re-identification.

Data-poisoning backdoor attacks are serious security threats to machine learning models, where an adversary can manipulate the training dataset to inject backdoors into models. In this paper, we focus on in-training backdoor defense, aiming to train a clean model even when the dataset may be potentially poisoned. Unlike most existing methods that primarily detect and remove/unlearn suspicious samples to mitigate malicious backdoor attacks, we propose a novel defense approach called PDB (Proactive Defensive Backdoor). Specifically, PDB leverages the “home field” advantage of defenders by proactively injecting a defensive backdoor into the model during training. Taking advantage of controlling the training process, the defensive backdoor is designed to suppress the malicious backdoor effectively while remaining secret to attackers. In addition, we introduce a reversible mapping to determine the defensive target label. During inference, PDB embeds a defensive trigger in the inputs and reverses the model’s prediction, suppressing malicious backdoor and ensuring the model's utility on the original task. Experimental results across various datasets and models demonstrate that our approach achieves state-of-the-art defense performance against a wide range of backdoor attacks. The code is available at https://github.com/shawkui/Proactive_Defensive_Backdoor.

Neuro-symbolic neural networks have been extensively studied to integrate symbolic operations with neural networks, thereby improving systematic generalization. Specifically, Tensor Product Representation (TPR) framework enables neural networks to perform differentiable symbolic operations by encoding the symbolic structure of data within vector spaces. However, TPR-based neural networks often struggle to decompose unseen data into structured TPR representations, undermining their symbolic operations. To address this decomposition problem, we propose a Discrete Dictionary-based Decomposition (D3) layer designed to enhance the decomposition capabilities of TPR-based models. D3 employs discrete, learnable key-value dictionaries trained to capture symbolic features essential for decomposition operations. It leverages the prior knowledge acquired during training to generate structured TPR representations by mapping input data to pre-learned symbolic features within these dictionaries. D3 is a straightforward drop-in layer that can be seamlessly integrated into any TPR-based model without modifications. Our experimental results demonstrate that D3 significantly improves the systematic generalization of various TPR-based models while requiring fewer additional parameters. Notably, D3 outperforms baseline models on the synthetic task that demands the systematic decomposition of unseen combinatorial data.
tl;dr: This paper introduces a new algorithm and analysis to accelerate bilevel optimization under unbounded smoothness.

This paper investigates a class of stochastic bilevel optimization problems where the upper-level function is nonconvex with potentially unbounded smoothness and the lower-level problem is strongly convex. These problems have significant applications in sequential data learning, such as text classification using recurrent neural networks. The unbounded smoothness is characterized by the smoothness constant of the upper-level function scaling linearly with the gradient norm, lacking a uniform upper bound. Existing state-of-the-art algorithms require $\widetilde{O}(\epsilon^{-4})$ oracle calls of stochastic gradient or Hessian/Jacobian-vector product to find an $\epsilon$-stationary point. However, it remains unclear if we can further improve the convergence rate when the assumptions for the function in the population level also hold for each random realization almost surely (e.g., Lipschitzness of each realization of the stochastic gradient). To address this issue, we propose a new Accelerated Bilevel Optimization algorithm named AccBO. The algorithm updates the upper-level variable by normalized stochastic gradient descent with recursive momentum and the lower-level variable by the stochastic Nesterov accelerated gradient descent algorithm with averaging. We prove that our algorithm achieves an oracle complexity of $\widetilde{O}(\epsilon^{-3})$ to find an $\epsilon$-stationary point. Our proof relies on a novel lemma characterizing the dynamics of stochastic Nesterov accelerated gradient descent algorithm under distribution drift with high probability for the lower-level variable, which is of independent interest and also plays a crucial role in analyzing the hypergradient estimation error over time. Experimental results on various tasks confirm that our proposed algorithm achieves the predicted theoretical acceleration and significantly outperforms baselines in bilevel optimization.
tl;dr: This paper studies replicability in machine learning tasks from a geometric viewpoint.

This paper studies replicability in machine learning tasks from a geometric viewpoint. Recent works have revealed the role of geometric partitions and Sperner's lemma (and its variations) in designing replicable learning algorithms and in establishing impossibility results.
A partition $\mathcal{P}$ of $\mathbb{R}^d$ is called a $(k,\epsilon)$-secluded partition if for every $\vec{p}\in\mathbb{R}^d$, an $\varepsilon$-radius ball (with respect to the $\ell_{\infty}$ norm) centered at $\vec{p}$ intersects at most $k$ members of $\mathcal{P}$. In relation to replicable learning, the parameter $k$ is closely related to the $\textit{list complexity}$, and the parameter $\varepsilon$ is related to the sample complexity of the replicable learner. Construction of secluded partitions with better parameters (small $k$ and large $\varepsilon$) will lead to replicable learning algorithms with small list and sample complexities.
Motivated by this connection, we undertake a comprehensive study of secluded partitions and establish near-optimal relationships between $k$ and $\varepsilon$.
1. We show that for any $(k,\epsilon)$-secluded partition where each member has at most unit measure, it must be that $k \geq(1+2\varepsilon)^d$, and consequently, for the interesting regime $k\in[2^d]$ it must be that $\epsilon\leq\frac{\log_4(k)}{d}$.
2. To complement this upper bound on $\epsilon$, we show that for each $d\in\mathbb{N}$ and each viable $k\in[2^d]$, a construction of a $(k,\epsilon)$-secluded (unit cube) partition with $\epsilon\geq\frac{\log_4(k)}{d}\cdot\frac{1}{8\log_4(d+1)}$. This establishes the optimality of $\epsilon$ within a logarithmic factor.
3. Finally, we adapt our proof techniques to obtain a new ``neighborhood'' variant of the cubical KKM lemma (or cubical Sperner's lemma): For any coloring of $[0,1]^d$ in which no color is used on opposing faces, it holds for each $\epsilon\in(0,\frac12]$ that there is a point where the open $\epsilon$-radius $\ell_\infty$-ball intersects at least $(1+\frac23\epsilon)^d$ colors. While the classical Sperner/KKM lemma guarantees the existence of a point that is "adjacent" to points with $(d+1)$ distinct colors, the neighborhood version guarantees the existence of a small neighborhood with exponentially many points with distinct colors.

Existing methodologies in open vocabulary 3D semantic segmentation primarily concentrate on establishing a unified feature space encompassing 3D, 2D, and textual modalities. Nevertheless, traditional techniques such as global feature alignment or vision-language model distillation tend to impose only approximate correspondence, struggling notably with delineating fine-grained segmentation boundaries. To address this gap, we propose a more meticulous mask-level alignment between 3D features and the 2D-text embedding space through a cross-modal mask reasoning framework, XMask3D. In our approach, we developed a mask generator based on the denoising UNet from a pre-trained diffusion model, leveraging its capability for precise textual control over dense pixel representations and enhancing the open-world adaptability of the generated masks. We further integrate 3D global features as implicit conditions into the pre-trained 2D denoising UNet, enabling the generation of segmentation masks with additional 3D geometry awareness. Subsequently, the generated 2D masks are employed to align mask-level 3D representations with the vision-language feature space, thereby augmenting the open vocabulary capability of 3D geometry embeddings. Finally, we fuse complementary 2D and 3D mask features, resulting in competitive performance across multiple benchmarks for 3D open vocabulary semantic segmentation. Code is available at https://github.com/wangzy22/XMask3D.
tl;dr: An efficient text-driven consistent subject generation paradigm via intricate semantic guidance to bypass the laborious backbone tuning.

Text-to-image diffusion models benefit artists with high-quality image generation. Yet their stochastic nature hinders artists from creating consistent images of the same subject. Existing methods try to tackle this challenge and generate consistent content in various ways. However, they either depend on external restricted data or require expensive tuning of the diffusion model. For this issue, we propose a novel one-shot tuning paradigm, termed OneActor. It efficiently performs consistent subject generation solely driven by prompts via a learned semantic guidance to bypass the laborious backbone tuning. We lead the way to formalize the objective of consistent subject generation from a clustering perspective, and thus design a cluster-conditioned model. To mitigate the overfitting challenge shared by one-shot tuning pipelines, we augment the tuning with auxiliary samples and devise two inference strategies: semantic interpolation and cluster guidance. These techniques are later verified to significantly improve the generation quality. Comprehensive experiments show that our method outperforms a variety of baselines with satisfactory subject consistency, superior prompt conformity as well as high image quality. Our method is capable of multi-subject generation and compatible with popular diffusion extensions. Besides, we achieve a $4\times$ faster tuning speed than tuning-based baselines and, if desired, avoid increasing the inference time. Furthermore, our method can be naturally utilized to pre-train a consistent subject generation network from scratch, which will implement this research task into more practical applications. (Project page: https://johnneywang.github.io/OneActor-webpage/)

Diffusion models have demonstrated their effectiveness in addressing the inherent uncertainty and indeterminacy in monocular 3D human pose estimation (HPE).
Despite their strengths, the need for large search spaces and the corresponding demand for substantial training data make these models prone to generating biomechanically unrealistic poses.
This challenge is particularly noticeable in occlusion scenarios, where the complexity of inferring 3D structures from 2D images intensifies.
In response to these limitations, we introduce the **Di**screte **Di**ffusion **Pose** (**$\text{Di}^2\text{Pose}$**), a novel framework designed for occluded 3D HPE that capitalizes on the benefits of a discrete diffusion model.
Specifically, **$\text{Di}^2\text{Pose}$** employs a two-stage process: it first converts 3D poses into a discrete representation through a pose quantization step, which is subsequently modeled in latent space through a discrete diffusion process.
This methodological innovation restrictively confines the search space towards physically viable configurations and enhances the model’s capability to comprehend how occlusions affect human pose within the latent space.
Extensive evaluations conducted on various benchmarks (e.g., Human3.6M, 3DPW, and 3DPW-Occ) have demonstrated its effectiveness.

Transfer learning is an attractive framework for problems where there is a paucity of data, or where data collection is costly. One common approach to transfer learning is referred to as "model-based", and involves using a model that is pretrained on samples from a source distribution, which is easier to acquire, and then fine-tuning the model on a few samples from the target distribution. The hope is that, if the source and target distributions are "close", then the fine-tuned model will perform well on the target distribution even though it has seen only a few samples from it. In this work, we study the problem of transfer learning in linear models for both regression and binary classification. In particular, we consider the use of stochastic gradient descent (SGD) on a linear model initialized with pretrained weights and using a small training data set from the target distribution. In the asymptotic regime of large models, we provide an exact and rigorous analysis and relate the generalization errors (in regression) and classification errors (in binary classification) for the pretrained and fine-tuned models. In particular, we give conditions under which the fine-tuned model outperforms the pretrained one. An important aspect of our work is that all the results are "universal", in the sense that they depend only on the first and second order statistics of the target distribution. They thus extend well beyond the standard Gaussian assumptions commonly made in the literature.
tl;dr: We propose a differentiable tensorisation of linear arithmetics over integer-valued random variables that extends the horizon of exact probabilistic inference by exploiting the fast Fourier transform.

As illustrated by the success of integer linear programming, linear integer arithmetics is a powerful tool for modelling combinatorial problems. Furthermore, the probabilistic extension of linear programming has been used to formulate problems in neurosymbolic AI. However, two key problems persist that prevent the adoption of neurosymbolic techniques beyond toy problems. First, probabilistic inference is inherently hard, #P-hard to be precise. Second, the discrete nature of integers renders the construction of meaningful gradients challenging, which is problematic for learning. In order to mitigate these issues, we formulate linear arithmetics over integer-valued random variables as tensor manipulations that can be implemented in a straightforward fashion using modern deep learning libraries. At the core of our formulation lies the observation that the addition of two integer-valued random variables can be performed by adapting the fast Fourier transform to probabilities in the log-domain. By relying on tensor operations we obtain a differentiable data structure, which unlocks, virtually for free, gradient-based learning. In our experimental validation we show that tensorising probabilistic integer linear arithmetics and leveraging the fast Fourier transform allows us to push the state of the art by several orders of magnitude in terms of inference and learning times.
tl;dr: entity alignment with unlabeled dangling entity pineer work using novel PU learning algorithm

We investigate the entity alignment (EA) problem with unlabeled dangling cases, meaning that partial entities have no counterparts in the other knowledge graph (KG), yet these entities are unlabeled. The problem arises when the source and target graphs are of different scales, and it is much cheaper to label the matchable pairs than the dangling entities. To address this challenge, we propose the framework \textit{Lambda} for dangling detection and entity alignment. Lambda features a GNN-based encoder called KEESA with a spectral contrastive learning loss for EA and a positive-unlabeled learning algorithm called iPULE for dangling detection. Our dangling detection module offers theoretical guarantees of unbiasedness, uniform deviation bounds, and convergence. Experimental results demonstrate that each component contributes to overall performances that are superior to baselines, even when baselines additionally exploit 30\% of dangling entities labeled for training.
tl;dr: We introduce the first scalable method to measure the per-unit interpretability in vision neural networks and demonstrate its alignment to human judgements.

In today’s era, whatever we can measure at scale, we can optimize. So far, measuring the interpretability of units in deep neural networks (DNNs) for computer vision still requires direct human evaluation and is not scalable. As a result, the inner workings of DNNs remain a mystery despite the remarkable progress we have seen in their applications. In this work, we introduce the first scalable method to measure the per-unit interpretability in vision DNNs. This method does not require any human evaluations, yet its prediction correlates well with existing human interpretability measurements. We validate its predictive power through an interventional human psychophysics study. We demonstrate the usefulness of this measure by performing previously infeasible experiments: (1) A large-scale interpretability analysis across more than 70 million units from 835 computer vision models, and (2) an extensive analysis of how units transform during training. We find an anticorrelation between a model's downstream classification performance and per-unit interpretability, which is also observable during model training. Furthermore, we see that a layer's location and width influence its interpretability.
tl;dr: This paper analyzes the representation of DEQ from the Neural Collapse perspective under both balanced and imbalanced conditions.

Deep Equilibrium Model (DEQ), which serves as a typical implicit neural network, emphasizes their memory efficiency and competitive performance compared to explicit neural networks. However, there has been relatively limited theoretical analysis on the representation of DEQ. In this paper, we utilize the Neural Collapse ($\mathcal{NC}$) as a tool to systematically analyze the representation of DEQ under both balanced and imbalanced conditions. $\mathcal{NC}$ is an interesting phenomenon in the neural network training process that characterizes the geometry of class features and classifier weights. While extensively studied in traditional explicit neural networks, the $\mathcal{NC}$ phenomenon has not received substantial attention in the context of implicit neural networks.
We theoretically show that $\mathcal{NC}$ exists in DEQ under balanced conditions. Moreover, in imbalanced settings, despite the presence of minority collapse, DEQ demonstrated advantages over explicit neural networks. These advantages include the convergence of extracted features to the vertices of a simplex equiangular tight frame and self-duality properties under mild conditions, highlighting DEQ's superiority in handling imbalanced datasets. Finally, we validate our theoretical analyses through experiments in both balanced and imbalanced scenarios.

Federated learning (FL) is a machine learning paradigm that allows multiple FL participants (FL-PTs) to collaborate on training models without sharing private data. Due to data heterogeneity, negative transfer may occur in the FL training process. This necessitates FL-PT selection based on their data complementarity. In cross-silo FL, organizations that engage in business activities are key sources of FL-PTs. The resulting FL ecosystem has two features: (i) self-interest, and (ii) competition among FL-PTs. This requires the desirable FL-PT selection strategy to simultaneously mitigate the problems of free riders and conflicts of interest among competitors. To this end, we propose an optimal FL collaboration formation strategy -FedEgoists- which ensures that: (1) a FL-PT can benefit from FL if and only if it benefits the FL ecosystem, and (2) a FL-PT will not contribute to its competitors or their supporters. It provides an efficient clustering solution to group FL-PTs into coalitions, ensuring that within each coalition, FL-PTs share the same interest. We theoretically prove that the FL-PT coalitions formed are optimal since no coalitions can collaborate together to improve the utility of any of their members. Extensive experiments on widely adopted benchmark datasets demonstrate the effectiveness of FedEgoists compared to nine state-of-the-art baseline methods, and its ability to establish efficient collaborative networks in cross-silos FL with FL-PTs that engage in business activities.
tl;dr: We propose a novel metric learning framework for Coreset for active learning in 3D medical image segmentation.

Deep learning has seen remarkable advancements in machine learning, yet it often demands extensive annotated data. Tasks like 3D semantic segmentation impose a substantial annotation burden, especially in domains like medicine, where expert annotations drive up the cost. Active learning (AL) holds great potential to alleviate this annotation burden in 3D medical segmentation. The majority of existing AL methods, however, are not tailored to the medical domain. While weakly-supervised methods have been explored to reduce annotation burden, the fusion of AL with weak supervision remains unexplored, despite its potential to significantly reduce annotation costs. Additionally, there is little focus on slice-based AL for 3D segmentation, which can also significantly reduce costs in comparison to conventional volume-based AL. This paper introduces a novel metric learning method for Coreset to perform slice-based active learning in 3D medical segmentation. By merging contrastive learning with inherent data groupings in medical imaging, we learn a metric that emphasizes the relevant differences in samples for training 3D medical segmentation models. We perform comprehensive evaluations using both weak and full annotations across four datasets (medical and non-medical). Our findings demonstrate that our approach surpasses existing active learning techniques on both weak and full annotations and obtains superior performance with low-annotation budgets which is crucial in medical imaging. Source code for this project is available in the supplementary materials and on GitHub: https://github.com/arvindmvepa/al-seg.
tl;dr: We introduce the first general framework that enhances the time efficiency of FOO by leveraging parallel computing to directly mitigate its requirement of many sequential iterations for convergence.

First-order optimization (FOO) algorithms are pivotal in numerous computational domains, such as reinforcement learning and deep learning. However, their application to complex tasks often entails significant optimization inefficiency due to their need of many sequential iterations for convergence. In response, we introduce first-order optimization expedited with approximately parallelized iterations (OptEx), the first general framework that enhances the time efficiency of FOO by leveraging parallel computing to directly mitigate its requirement of many sequential iterations for convergence. To achieve this, OptEx utilizes a kernelized gradient estimation that is based on the history of evaluated gradients to predict the gradients required by the next few sequential iterations in FOO, which helps to break the inherent iterative dependency and hence enables the approximate parallelization of iterations in FOO. We further establish theoretical guarantees for the estimation error of our kernelized gradient estimation and the iteration complexity of SGD-based OptEx, confirming that the estimation error diminishes to zero as the history of gradients accumulates and that our SGD-based OptEx enjoys an effective acceleration rate of Θ(√N ) over standard SGD given parallelism of N, in terms of the sequential iterations required for convergence. Finally, we provide extensive empirical studies, including synthetic functions, reinforcement learning tasks, and neural network training on various datasets, to underscore the substantial efficiency improvements achieved by our OptEx in practice.
tl;dr: We use novel methods to derive information-theoretic generalization bounds via conditional $f$-divergences.

In this work, we introduce novel information-theoretic generalization bounds using the conditional $f$-information framework, an extension of the traditional conditional mutual information (MI) framework. We provide a generic approach to derive generalization bounds via $f$-information in the supersample setting, applicable to both bounded and unbounded loss functions. Unlike previous MI-based bounds, our proof strategy does not rely on upper bounding the cumulant-generating function (CGF) in the variational formula of MI. Instead, we set the CGF or its upper bound to zero by carefully selecting the measurable function invoked in the variational formula. Although some of our techniques are partially inspired by recent advances in the coin-betting framework (e.g., Jang et al. (2023)), our results are independent of any previous findings from regret guarantees of online gambling algorithms. Additionally, our newly derived MI-based bound recovers many previous results and improves our understanding of their potential limitations. Finally, we empirically compare various $f$-information measures for generalization, demonstrating the improvement of our new bounds over the previous bounds.

To evaluate Large Language Models (LLMs) for question answering (QA), traditional methods typically focus on directly assessing the immediate responses generated by the models based on the given question and context. In the common use case of humans seeking AI assistant’s help in finding information, these non-interactive evaluations do not account for the dynamic nature of human-model conversations, and interaction-aware evaluations have shown that accurate models are not necessarily preferred by humans Lee et al. Recent works in human-computer interaction (HCI) have employed human evaluators to conduct interactions and evaluations, but they are often prohibitively expensive and time-consuming to scale. In this work, we introduce an automated evaluation framework IQA-EVAL to Interactive Question Answering Evaluations, more specifically, we introduce LLM-based Evaluation Agent (LEA) that can: (1) simulate human behaviors to generate interactions with IQA models; (2) automatically evaluate the generated interactions. Moreover, we propose assigning personas to LEAs to better simulate groups of real human evaluators. We show that: (1) our evaluation framework with GPT-4 (or Claude) as the backbone model achieves a high correlation with human evaluations on the IQA task; (2) assigning personas to LEA to better represent the crowd further significantly improves correlations. Finally, we use our automated metric to evaluate five recent LLMs with over 1000 questions from complex and ambiguous question answering tasks, which would cost $5k if evaluated by humans.
tl;dr: Motivated by the efficient coding hypothesis, we propose a normative circuit model with local interneurons that learns to reshape its inputs so that its responses follow a target density.

Efficient coding theory posits that sensory circuits transform natural signals into neural representations that maximize information transmission subject to resource constraints. Local interneurons are thought to play an important role in these transformations, shaping patterns of circuit activity to facilitate and direct information flow. However, the relationship between these coordinated, nonlinear, circuit-level transformations and the properties of interneurons (e.g., connectivity, activation functions) remains unknown. Here, we propose a normative computational model that establishes such a relationship. Our model is derived from an optimal transport objective that conceptualizes the circuit's input-response function as transforming the inputs to achieve a target response distribution. The circuit, which is comprised of primary neurons that are recurrently connected to a set of local interneurons, continuously optimizes this objective by dynamically adjusting both the synaptic connections between neurons as well as the interneuron activation functions. In an application motivated by redundancy reduction theory, we demonstrate that when the inputs are natural image statistics and the target distribution is a spherical Gaussian, the circuit learns a nonlinear transformation that significantly reduces statistical dependencies in neural responses. Overall, our results provide a framework in which the distribution of circuit responses is systematically and nonlinearly controlled by adjustment of interneuron connectivity and activation functions.
tl;dr: A graph-based schema for ANNS

The state-of-the-art approximate nearest neighbor search (ANNS) algorithm builds a large proximity graph on the dataset and performs a greedy beam search, which may bring many unnecessary explorations. We develop a novel framework, namely *corssing sparse proximity graph (CSPG)*, based on random partitioning of the dataset. It produces a smaller sparse proximity graph for each partition and routing vectors that bind all the partitions. An efficient two-staged approach is designed for exploring *CSPG*, with fast approaching and cross-partition expansion. We theoretically prove that *CSPG* can accelerate the existing graph-based ANNS algorithms by reducing unnecessary explorations. In addition, we conduct extensive experiments on benchmark datasets. The experimental results confirm that the existing graph-based methods can be significantly outperformed by incorporating *CSPG*, achieving 1.5x to 2x speedups of *QPS* in almost all recalls.
tl;dr: We propose the first stochastic approximation algorithm for instrumental variable regression with streaming data and provide analysis.

We develop and analyze algorithms for instrumental variable regression by viewing the problem as a conditional stochastic optimization problem. In the context of least-squares instrumental variable regression, our algorithms neither require matrix inversions nor mini-batches thereby providing a fully online approach for performing instrumental variable regression with streaming data. When the true model is linear, we derive rates of convergence in expectation, that are of order $\mathcal{O}(\log T/T)$ and $\mathcal{O}(1/T^{1-\epsilon})$ for any $\epsilon>0$, respectively under the availability of two-sample and one-sample oracles respectively. Importantly, under the availability of the two-sample oracle, the aforementioned rate is actually agnostic to the relationship between confounder and the instrumental variable demonstrating the flexibility of the proposed approach in alleviating the need for explicit model assumptions required in recent works based on reformulating the problem as min-max optimization problems. Experimental validation is provided to demonstrate the advantages of the proposed algorithms over classical approaches like the 2SLS method.

Within the realm of Computer-Aided Design (CAD), Boundary-Representation (B-Rep) is the standard option for modeling shapes. We present SpelsNet, a neural architecture for the segmentation of 3D point clouds into surface primitive elements under topological supervision of its B-Rep graph structure. We also propose a point-to-BRep adjacency representation that allows for adapting conventional Linear Algebraic Representation of B-Rep graph structure to the point cloud domain. Thanks to this representation, SpelsNet learns from both spatial and topological domains to enable accurate and topologically consistent surface primitive element segmentation. In particular, SpelsNet is composed of two main components; (1) a supervised 3D spatial segmentation head that outputs B-Rep element types and memberships; (2) a graph-based head that leverages the proposed topological supervision. To enable the learning of SpelsNet with the proposed point-to-BRep adjacency supervision, we extend two existing CAD datasets with the required annotations, and conduct a thorough experimental validation on them. The obtained results showcase the efficacy of SpelsNet and its topological supervision compared to a set of baselines and state-of-the-art approaches.
tl;dr: Supervised data suffers severe selection bias when labels are expensive. We formulate a MDP over posterior beliefs on model performance and solve it with pathwise policy gradients computed through an auto-differentiable pipeline.

Datasets often suffer severe selection bias; clinical labels are only available on patients for whom doctors ordered medical exams. To assess model performance outside the support of available data, we present a computational framework for adaptive labeling, providing cost-efficient model evaluations under severe distribution shifts. We formulate the problem as a Markov Decision Process over states defined by posterior beliefs on model performance. Each batch of new labels incurs a “state transition” to sharper beliefs, and we choose batches to minimize uncertainty on model performance at the end of the label collection process. Instead of relying on high-variance REINFORCE policy gradient estimators that do not scale, our adaptive labeling policy is optimized using path-wise policy gradients computed by auto-differentiating through simulated roll-outs. Our framework is agnostic to different uncertainty quantification approaches and highlights the virtue of planning in adaptive labeling. On synthetic and real datasets, we empirically demonstrate even a one-step lookahead policy substantially outperforms active learning-inspired heuristics.
tl;dr: IF-Font uses Ideographic Description Sequence as the semantic condition instead of the content image, outperforming all state-of-the-art methods in the few-shot font generation task.

Few-shot font generation (FFG) aims to learn the target style from a limited number of reference glyphs and generate the remaining glyphs in the target font. Previous works focus on disentangling the content and style features of glyphs, combining the content features of the source glyph with the style features of the reference glyph to generate new glyphs. However, the disentanglement is challenging due to the complexity of glyphs, often resulting in glyphs that are influenced by the style of the source glyph and prone to artifacts. We propose IF-Font, a novel paradigm which incorporates Ideographic Description Sequence (IDS) instead of the source glyph to control the semantics of generated glyphs. To achieve this, we quantize the reference glyphs into tokens, and model the token distribution of target glyphs using corresponding IDS and reference tokens. The proposed method excels in synthesizing glyphs with neat and correct strokes, and enables the creation of new glyphs based on provided IDS. Extensive experiments demonstrate that our method greatly outperforms state-of-the-art methods in both one-shot and few-shot settings, particularly when the target styles differ significantly from the training font styles. The code is available at [https://github.com/Stareven233/IF-Font](https://github.com/Stareven233/IF-Font).
tl;dr: We study credit attribution by machine learning algorithms via new relaxations of Differential Privacy that specifically weaken the stability guarantees for a designated subset of $k$ datapoints.

Credit attribution is crucial across various fields. In academic research, proper citation acknowledges prior work and establishes original contributions. Similarly, in generative models, such as those trained on existing artworks or music, it is important to ensure that any generated content influenced by these works appropriately credits the original creators.
We study credit attribution by machine learning algorithms. We propose new definitions--relaxations of Differential Privacy--that weaken the stability guarantees for a designated subset of $k$ datapoints. These $k$ datapoints can be used non-stably with permission from their owners, potentially in exchange for compensation. Meanwhile, the remaining datapoints are guaranteed to have no significant influence on the algorithm's output.
Our framework extends well-studied notions of stability, including Differential Privacy ($k = 0$), differentially private learning with public data (where the $k$ public datapoints are fixed in advance),
and stable sample compression (where the $k$ datapoints are selected adaptively by the algorithm).
We examine the expressive power of these stability notions within the PAC learning framework, provide a comprehensive characterization of learnability for algorithms adhering to these principles, and propose directions and questions for future research.
tl;dr: Self-supervised blind-spot transformer for real-world image denoising

Real-world image denoising remains a challenge task. This paper studies self-supervised image denoising, requiring only noisy images captured in a single shot. We revamping the blind-spot technique by leveraging the transformer’s capability for long-range pixel interactions, which is crucial for effectively removing noise dependence in relating pixel–a requirement for achieving great performance for the blind-spot technique. The proposed method integrates these elements with two key innovations: a directional self-attention (DSA) module using a half-plane grid for self-attention, creating a sophisticated blind-spot structure, and a Siamese architecture with mutual learning to mitigate the performance impacts
from the restricted attention grid in DSA. Experiments on benchmark datasets demonstrate that our method outperforms existing self-supervised and clean-image-free methods. This combination of blind-spot and transformer techniques provides a natural synergy for tackling real-world image denoising challenges.

This paper presents an auditing procedure for the Differentially Private Stochastic Gradient Descent (DP-SGD) algorithm in the black-box threat model that is substantially tighter than prior work.
The main intuition is to craft worst-case initial model parameters, as DP-SGD's privacy analysis is agnostic to the choice of the initial model parameters.
For models trained on MNIST and CIFAR-10 at theoretical $\varepsilon=10.0$, our auditing procedure yields empirical estimates of $\varepsilon_{emp} = 7.21$ and $6.95$, respectively, on a 1,000-record sample and $\varepsilon_{emp} = 6.48$ and $4.96$ on the full datasets.
By contrast, previous audits were only (relatively) tight in stronger white-box models, where the adversary can access the model's inner parameters and insert arbitrary gradients.
Overall, our auditing procedure can offer valuable insight into how the privacy analysis of DP-SGD could be improved and detect bugs and DP violations in real-world implementations.
The source code needed to reproduce our experiments is available from https://github.com/spalabucr/bb-audit-dpsgd.
tl;dr: We present a new video restoration framework to learn and model the history of the video frames.

One key challenge to video restoration is to model the transition dynamics of video frames governed by motion. In this work, we propose Turtle to learn the truncated causal history model for efficient and high-performing video restoration. Unlike traditional methods that process a range of contextual frames in parallel, Turtle enhances efficiency by storing and summarizing a truncated history of the input frame latent representation into an evolving historical state. This is achieved through a sophisticated similarity-based retrieval mechanism that implicitly accounts for inter-frame motion and alignment. The causal design in Turtle enables recurrence in inference through state-memorized historical features while allowing parallel training by sampling truncated video clips. We report new state-of-the-art results on a multitude of video restoration benchmark tasks, including video desnowing, nighttime video deraining, video raindrops and rain streak removal, video super-resolution, real-world and synthetic video deblurring, and blind video denoising while reducing the computational cost compared to existing best contextual methods on all these tasks.
tl;dr: We show that online classification under smoothed adversary is as easy as iid batch classification when the size of the label space is bounded, but can be harder than iid batch classification when the size of the label space is unbounded.

We study online classification under smoothed adversaries. In this setting, at each time point, the adversary draws an example from a distribution that has a bounded density with respect to a fixed base measure, which is known apriori to the learner. For binary classification and scalar-valued regression, previous works [Haghtalab et al., 2020, Block et al., 2022] have shown that smoothed online learning is as easy as learning in the iid batch setting under PAC model. However, we show that smoothed online classification can be harder than the iid batch classification when the label space is unbounded. In particular, we construct a hypothesis class that is learnable in the iid batch setting under the PAC model but is not learnable under the smoothed online model. Finally, we identify a condition that ensures that the PAC learnability of a hypothesis class is sufficient for its smoothed online learnability.
tl;dr: This paper shows that linear transformers can implicitly learn sophisticated optimization algorithms, particularly for noisy linear regression, exceeding the performance of traditional methods.

Recent research has demonstrated that transformers, particularly linear attention models, implicitly execute gradient-descent-like algorithms on data provided in-context during their forward inference step. However, their capability in handling more complex problems remains unexplored. In this paper, we prove that each layer of a linear transformer maintains a weight vector for an implicit linear regression problem and can be interpreted as performing a variant of preconditioned gradient descent. We also investigate the use of linear transformers in a challenging scenario where the training data is corrupted with different levels of noise. Remarkably, we demonstrate that for this problem linear transformers discover an intricate and highly effective optimization algorithm, surpassing or matching in performance many reasonable baselines. We analyze this algorithm and show that it is a novel approach incorporating momentum and adaptive rescaling based on noise levels. Our findings show that even linear transformers possess the surprising ability to discover sophisticated optimization strategies.
tl;dr: We propose GraphMorph, which enhances tubular structure extraction by focusing on branch-level features, using a Graph Decoder and Morph Module to achieve topologically accurate predictions, and demonstrating effectiveness across multiple datasets.

Accurately restoring topology is both challenging and crucial in tubular structure extraction tasks, such as blood vessel segmentation and road network extraction. Diverging from traditional approaches based on pixel-level classification, our proposed method, named GraphMorph, focuses on branch-level features of tubular structures to achieve more topologically accurate predictions. GraphMorph comprises two main components: a Graph Decoder and a Morph Module. Utilizing multi-scale features extracted from an image patch by the segmentation network, the Graph Decoder facilitates the learning of branch-level features and generates a graph that accurately represents the tubular structure in this patch. The Morph Module processes two primary inputs: the graph and the centerline probability map, provided by the Graph Decoder and the segmentation network, respectively. Employing a novel SkeletonDijkstra algorithm, the Morph Module produces a centerline mask that aligns with the predicted graph. Furthermore, we observe that employing centerline masks predicted by GraphMorph significantly reduces false positives in the segmentation task, which is achieved by a simple yet effective post-processing strategy. The efficacy of our method in the centerline extraction and segmentation tasks has been substantiated through experimental evaluations across various datasets. Source code will be released soon.
tl;dr: Our proposed RefFormer can iteratively refine the target-related context and generate referential queries, which provide the decoder with prior context.

Visual Grounding aims to localize the referring object in an image given a natural language expression. Recent advancements in DETR-based visual grounding methods have attracted considerable attention, as they directly predict the coordinates of the target object without relying on additional efforts, such as pre-generated proposal candidates or pre-defined anchor boxes. However, existing research primarily focuses on designing stronger multi-modal decoder, which typically generates learnable queries by random initialization or by using linguistic embeddings. This vanilla query generation approach inevitably increases the learning difficulty for the model, as it does not involve any target-related information at the beginning of decoding. Furthermore, they only use the deepest image feature during the query learning process, overlooking the importance of features from other levels. To address these issues, we propose a novel approach, called RefFormer. It consists of the query adaption module that can be seamlessly integrated into CLIP and generate the referential query to provide the prior context for decoder, along with a task-specific decoder. By incorporating the referential query into the decoder, we can effectively mitigate the learning difficulty of the decoder, and accurately concentrate on the target object. Additionally, our proposed query adaption module can also act as an adapter, preserving the rich knowledge within CLIP without the need to tune the parameters of the backbone network. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method, outperforming state-of-the-art approaches on five visual grounding benchmarks.

Occupancy prediction has increasingly garnered attention in recent years for its fine-grained understanding of 3D scenes. Traditional approaches typically rely on dense, regular grid representations, which often leads to excessive computational demands and a loss of spatial details for small objects. This paper introduces OctreeOcc, an innovative 3D occupancy prediction framework that leverages the octree representation to adaptively capture valuable information in 3D, offering variable granularity to accommodate object shapes and semantic regions of varying sizes and complexities. In particular, we incorporate image semantic information to improve the accuracy of initial octree structures and design an effective rectification mechanism to refine the octree structure iteratively. Our extensive evaluations show that OctreeOcc not only surpasses state-of-the-art methods in occupancy prediction, but also achieves a 15%-24% reduction in computational overhead compared to dense-grid-based methods.
tl;dr: A weight diffusion approach that leverages the conditional diffusion model to learn the evolving pattern of parameters across domains and further generated customized classifiers for evolving domain generalization in the domain-incremental setting.

Enabling deep models to generalize in non-stationary environments is vital for real-world machine learning, as data distributions are often found to continually change. Recently, evolving domain generalization (EDG) has emerged to tackle the domain generalization in a time-varying system, where the domain gradually evolves over time in an underlying continuous structure. Nevertheless, it typically assumes multiple source domains simultaneously ready. It still remains an open problem to address EDG in the domain-incremental setting, where source domains are non-static and arrive sequentially to mimic the evolution of training domains. To this end, we propose Weight Diffusion (W-Diff), a novel framework that utilizes the conditional diffusion model in the parameter space to learn the evolving pattern of classifiers during the domain-incremental training process. Specifically, the diffusion model is conditioned on the classifier weights of different historical domain (regarded as a reference point) and the prototypes of current domain, to learn the evolution from the reference point to the classifier weights of current domain (regarded as the anchor point). In addition, a domain-shared feature encoder is learned by enforcing prediction consistency among multiple classifiers, so as to mitigate the overfitting problem and restrict the evolving pattern to be reflected in the classifier as much as possible. During inference, we adopt the ensemble manner based on a great number of target domain-customized classifiers, which are cheaply obtained via the conditional diffusion model, for robust prediction. Comprehensive experiments on both synthetic and real-world datasets show the superior generalization performance of W-Diff on unseen domains in the future.

Neural ordinary differential equations (Neural ODEs) is a family of continuous-depth neural networks where the evolution of hidden states is governed by learnable temporal derivatives. We identify a significant limitation in applying traditional Batch Normalization (BN) to Neural ODEs, due to a fundamental mismatch --- BN was initially designed for discrete neural networks with no temporal dimension, whereas Neural ODEs operate continuously over time. To bridge this gap, we introduce temporal adaptive Batch Normalization (TA-BN), a novel technique that acts as the continuous-time analog to traditional BN. Our empirical findings reveal that TA-BN enables the stacking of more layers within Neural ODEs, enhancing their performance. Moreover, when confined to a model architecture consisting of a single Neural ODE followed by a linear layer, TA-BN achieves 91.1\% test accuracy on CIFAR-10 with 2.2 million parameters, making it the first \texttt{unmixed} Neural ODE architecture to approach MobileNetV2-level parameter efficiency. Extensive numerical experiments on image classification and physical system modeling substantiate the superiority of TA-BN compared to baseline methods.
tl;dr: Reward Learning from Human Demonstration Improves SFT for LLM Alignment

Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to {\it simultaneously} build an reward model and a policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but are robust to the presence of low-quality supervised learning data. Moreover, we discover a connection between the proposed IRL based approach, and a recent line of works called Self-Play Fine-tune (SPIN, \cite{chen2024self}). Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to leverage reward learning throughout the entire alignment process. Our code is available at \url{https://github.com/JasonJiaxiangLi/Reward_learning_SFT}.
2243. Towards Flexible 3D Perception: Object-Centric Occupancy Completion Augments 3D Object Detection
tl;dr: We introduce a new object-centric occupancy concept to enhance 3D perception in data and algorithmic perspectives.

While 3D object bounding box (bbox) representation has been widely used in autonomous driving perception, it lacks the ability to capture the precise details of an object's intrinsic geometry. Recently, occupancy has emerged as a promising alternative for 3D scene perception. However, constructing a high-resolution occupancy map remains infeasible for large scenes due to computational constraints. Recognizing that foreground objects only occupy a small portion of the scene, we introduce object-centric occupancy as a supplement to object bboxes. This representation not only provides intricate details for detected objects but also enables higher voxel resolution in practical applications.
We advance the development of object-centric occupancy perception from both data and algorithm perspectives. On the data side, we construct the first object-centric occupancy dataset from scratch using an automated pipeline. From the algorithmic standpoint, we introduce a novel object-centric occupancy completion network equipped with an implicit shape decoder that manages dynamic-size occupancy generation. This network accurately predicts the complete object-centric occupancy volume for inaccurate object proposals by leveraging temporal information from long sequences. Our method demonstrates robust performance in completing object shapes under noisy detection and tracking conditions. Additionally, we show that our occupancy features significantly enhance the detection results of state-of-the-art 3D object detectors, especially for incomplete or distant objects in the Waymo Open Dataset.
tl;dr: This paper proposes a denoising fine-tuning framework to adapt vision-language models on noisy downstream tasks.

Recent research on fine-tuning vision-language models has demonstrated impressive performance in various downstream tasks. However, the challenge of obtaining accurately labeled data in real-world applications poses a significant obstacle during the fine-tuning process. To address this challenge, this paper presents a Denoising Fine-Tuning framework, called DeFT, for adapting vision-language models. DeFT utilizes the robust alignment of textual and visual features pre-trained on millions of auxiliary image-text pairs to sieve out noisy labels. The proposed framework establishes a noisy label detector by learning positive and negative textual prompts for each class. The positive prompt seeks to reveal distinctive features of the class, while the negative prompt serves as a learnable threshold for separating clean and noisy samples. We employ parameter-efficient fine-tuning for the adaptation of a pre-trained visual encoder to promote its alignment with the learned textual prompts. As a general framework, DeFT can seamlessly fine-tune many pre-trained models to downstream tasks by utilizing carefully selected clean samples. Experimental results on seven synthetic and real-world noisy datasets validate the effectiveness of DeFT in both noisy label detection and image classification. Our source code can be found in the supplementary material.
tl;dr: We develop a method that reads out information from neural activations.

The inner workings of neural networks can be better understood if we can fully decipher the information encoded in neural activations. In this paper, we argue that this information is embodied by the subset of inputs that give rise to similar activations. We propose InversionView, which allows us to practically inspect this subset by sampling from a trained decoder model conditioned on activations. This helps uncover the information content of activation vectors, and facilitates understanding of the algorithms implemented by transformer models. We present four case studies where we investigate models ranging from small transformers to GPT-2. In these studies, we show that InversionView can reveal clear information contained in activations, including basic information about tokens appearing in the context, as well as more complex information, such as the count of certain tokens, their relative positions, and abstract knowledge about the subject. We also provide causally verified circuits to confirm the decoded information.

The rapid evolution of large language models (LLMs) has expanded their capabilities across various data modalities, extending from well-established image data to increasingly popular graph data. Given the limitation of LLMs in hallucinations and inaccuracies in recalling factual knowledge, Knowledge Graph (KG) has emerged as a crucial data modality to support more accurate reasoning by LLMs. However, integrating structured knowledge from KGs into LLMs remains challenging, as most current KG-enhanced LLM methods directly convert the KG into linearized text triples, which is not as expressive as the original structured data. To address this, we introduce GraphVis, which conserves the intricate graph structure through the visual modality to enhance the comprehension of KGs with the aid of Large Vision Language Models (LVLMs). Our approach incorporates a unique curriculum fine-tuning scheme which first instructs LVLMs to recognize basic graphical features from the images, and subsequently incorporates reasoning on QA tasks with the visual graphs. This cross-modal methodology not only markedly enhances performance on standard textual QA but also shows improved zero-shot VQA performance by utilizing synthetic graph images to augment the data for VQA tasks. We present comprehensive evaluations across commonsense reasoning QA benchmarks, where GraphVis provides an average improvement of 11.1% over its base model and outperforms existing KG-enhanced LLM approaches. Across VQA benchmarks such as ScienceQA that share similar scientific diagram images, GraphVis provides a notable gain of 4.32%.
tl;dr: A theoretical study of gradient computation, from both algorithm and hardness perspective

Large language models (LLMs) have made fundamental contributions over the last a few years. To train an LLM, one needs to alternatingly run `forward' computations and backward computations. The forward computation can be viewed as attention function evaluation, and the backward computation can be viewed as a gradient computation. In previous work by [Alman and Song, NeurIPS 2023], it was proved that the forward step can be performed in almost-linear time in certain parameter regimes, but that there is no truly sub-quadratic time algorithm in the remaining parameter regimes unless the popular hypothesis $\mathsf{SETH}$ is false. In this work, we show nearly identical results for the harder-seeming problem of computing the gradient of loss function of one layer attention network, and thus for the entire process of LLM training. This completely characterizes the fine-grained complexity of every step of LLM training.

We propose a neural network weight encoding method for network property prediction that utilizes set-to-set and set-to-vector functions
to efficiently encode neural network parameters. Our approach is capable of encoding neural networks in a model zoo of mixed architecture and different parameter sizes as opposed to previous approaches that require custom encoding models for different architectures. Furthermore, our \textbf{S}et-based \textbf{N}eural network \textbf{E}ncoder (SNE) takes into consideration the hierarchical computational structure of neural networks. To respect symmetries inherent in network weight space, we utilize Logit Invariance to learn the required minimal invariance properties. Additionally, we introduce a \textit{pad-chunk-encode} pipeline to efficiently encode neural network layers that is adjustable to computational and memory constraints. We also introduce two new tasks for neural network property prediction: cross-dataset and cross-architecture. In cross-dataset property prediction, we evaluate how well property predictors generalize across model zoos trained on different datasets but of the same architecture. In cross-architecture property prediction, we evaluate how well property predictors transfer to model zoos of different architecture not seen during training. We show that SNE outperforms the relevant baselines on standard benchmarks.
tl;dr: We propose DiffCut, a novel zero-shot image segmentation method based on a recursive normalized cut algorithm to segment diffusion features

Foundation models have emerged as powerful tools across various domains including language, vision, and multimodal tasks. While prior works have addressed unsupervised semantic segmentation, they significantly lag behind supervised models. In this paper, we use a diffusion UNet encoder as a foundation vision encoder and introduce DiffCut, an unsupervised zero-shot segmentation method that solely harnesses the output features from the final self-attention block. Through extensive experimentation, we demonstrate that using these diffusion features in a graph based segmentation algorithm, significantly outperforms previous state-of-the-art methods on zero-shot segmentation. Specifically, we leverage a recursive Normalized Cut algorithm that regulates the granularity of detected objects and produces well-defined segmentation maps that precisely capture intricate image details. Our work highlights the remarkably accurate semantic knowledge embedded within diffusion UNet encoders that could then serve as foundation vision encoders for downstream tasks.
tl;dr: We show fast convergence rate of training transformers for next-token prediction.

Transformers have achieved extraordinary success in modern machine learning due to their excellent ability to handle sequential data, especially in next-token prediction (NTP) tasks. However, the theoretical understanding of their performance in NTP is limited, with existing studies focusing mainly on asymptotic performance. This paper provides a fine-grained non-asymptotic analysis of the training dynamics of a one-layer transformer consisting of a self-attention module followed by a feed-forward layer. We first characterize the essential structural properties of training datasets for NTP using a mathematical framework based on partial orders.
Then, we design a two-stage training algorithm, where the pre-processing stage for training the feed-forward layer and the main stage for training the attention layer exhibit fast convergence performance. Specifically, both layers converge sub-linearly to the direction of their corresponding max-margin solutions. We also show that the cross-entropy loss enjoys a linear convergence rate. Furthermore, we show that the trained transformer presents non-trivial prediction ability with dataset shift, which sheds light on the remarkable generalization performance of transformers. Our analysis technique involves the development of novel properties on the attention gradient and further in-depth analysis of how these properties contribute to the convergence of the training process. Our experiments further validate our theoretical findings.
2251. Rethinking Reconstruction-based Graph-Level Anomaly Detection: Limitations and a Simple Remedy
tl;dr: We investigate reconstruction-based graph neural networks in graph-level anomaly detection task.

Graph autoencoders (Graph-AEs) learn representations of given graphs by aiming to accurately reconstruct them. A notable application of Graph-AEs is graph-level anomaly detection (GLAD), whose objective is to identify graphs with anomalous topological structures and/or node features compared to the majority of the graph population. Graph-AEs for GLAD regard a graph with a high mean reconstruction error (i.e. mean of errors from all node pairs and/or nodes) as anomalies. Namely, the methods rest on the assumption that they would better reconstruct graphs with similar characteristics to the majority. We, however, report non-trivial counter-examples, a phenomenon we call reconstruction flip, and highlight the limitations of the existing Graph-AE-based GLAD methods. Specifically, we empirically and theoretically investigate when this assumption holds and when it fails. Through our analyses, we further argue that, while the reconstruction errors for a given graph are effective features for GLAD, leveraging the multifaceted summaries of the reconstruction errors, beyond just mean, can further strengthen the features. Thus, we propose a novel and simple GLAD method, named MUSE. The key innovation of MUSE involves taking multifaceted summaries of reconstruction errors as graph features for GLAD. This surprisingly simple method obtains SOTA performance in GLAD, performing best overall among 14 methods across 10 datasets.
tl;dr: This paper tackles combinatorial distribution shift in multi-output regression using generalized tensor decomposition, Ft-SVD theorem, and a two-stage algorithm that exploits low-rank structure for better prediction under shifts.

In multi-output regression, we identify a previously neglected challenge that arises from the inability of training distribution to cover all combinations of input features, leading to combinatorial distribution shift (CDS). To the best of our knowledge, this is the first work to formally define and address this problem. We tackle it through a novel tensor decomposition perspective, proposing the Functional t-Singular Value Decomposition (Ft-SVD) theorem which extends the classical tensor SVD to infinite and continuous feature domains, providing a natural tool for representing and analyzing multi-output functions. Within the Ft-SVD framework, we formulate the multi-output regression problem under CDS as a low-rank tensor estimation problem under the missing not at random (MNAR) setting, and introduce a series of assumptions about the true functions, training and testing distributions, and spectral properties of the ground-truth embeddings, making the problem more tractable.
To address the challenges posed by CDS in multi-output regression, we develop a tailored Double-Stage Empirical Risk Minimization (ERM-DS) algorithm that leverages the spectral properties of the embeddings and uses specific hypothesis classes in each frequency component to better capture the varying spectral decay patterns. We provide rigorous theoretical analyses that establish performance guarantees for the ERM-DS algorithm. This work lays a preliminary theoretical foundation for multi-output regression under CDS.
tl;dr: We theoretically revisited existing self-supervised heterogeneous graph learning from the spectral clustering perspective and introduced a novel framework to alleviate issues in existing works.

Self-supervised heterogeneous graph learning (SHGL) has shown promising potential in diverse scenarios. However, while existing SHGL methods share a similar essential with clustering approaches, they encounter two significant limitations: (i) noise in graph structures is often introduced during the message-passing process to weaken node representations, and (ii) cluster-level information may be inadequately captured and leveraged, diminishing the performance in downstream tasks. In this paper, we address these limitations by theoretically revisiting SHGL from the spectral clustering perspective and introducing a novel framework enhanced by rank and dual consistency constraints. Specifically, our framework incorporates a rank-constrained spectral clustering method that refines the affinity matrix to exclude noise effectively. Additionally, we integrate node-level and cluster-level consistency constraints that concurrently capture invariant and clustering information to facilitate learning in downstream tasks. We theoretically demonstrate that the learned representations are divided into distinct partitions based on the number of classes and exhibit enhanced generalization ability across tasks. Experimental results affirm the superiority of our method, showcasing remarkable improvements in several downstream tasks compared to existing methods.

Recent vision foundation models can extract universal representations and show impressive abilities in various tasks. However, their application on object detection is largely overlooked, especially without fine-tuning them. In this work, we show that frozen foundation models can be a versatile feature enhancer, even though they are not pre-trained for object detection. Specifically, we explore directly transferring the high-level image understanding of foundation models to detectors in the following two ways. First, the class token in foundation models provides an in-depth understanding of the complex scene, which facilitates decoding object queries in the detector's decoder by providing a compact context. Additionally, the patch tokens in foundation models can enrich the features in the detector's encoder by providing semantic details. Utilizing frozen foundation models as plug-and-play modules rather than the commonly used backbone can significantly enhance the detector's performance while preventing the problems caused by the architecture discrepancy between the detector's backbone and the foundation model. With such a novel paradigm, we boost the SOTA query-based detector DINO from 49.0% AP to 51.9% AP (+2.9% AP) and further to 53.8% AP (+4.8% AP) by integrating one or two foundation models respectively, on the COCO validation set after training for 12 epochs with R50 as the detector's backbone. Code will be available.
tl;dr: We explore how prompts work in continual learning by showing their connection to mixture of experts and proposes a novel gating mechanism (NoRGa) for improved performance.

Exploiting the power of pre-trained models, prompt-based approaches stand out compared to other continual learning solutions in effectively preventing catastrophic forgetting, even with very few learnable parameters and without the need for a memory buffer. While existing prompt-based continual learning methods excel in leveraging prompts for state-of-the-art performance, they often lack a theoretical explanation for the effectiveness of prompting. This paper conducts a theoretical analysis to unravel how prompts bestow such advantages in continual learning, thus offering a new perspective on prompt design. We first show that the attention block of pre-trained models like Vision Transformers inherently encodes a special mixture of experts architecture, characterized by linear experts and quadratic gating score functions. This realization drives us to provide a novel view on prefix tuning, reframing it as the addition of new task-specific experts, thereby inspiring the design of a novel gating mechanism termed Non-linear Residual Gates (NoRGa). Through the incorporation of non-linear activation and residual connection, NoRGa enhances continual learning performance while preserving parameter efficiency. The effectiveness of NoRGa is substantiated both theoretically and empirically across diverse benchmarks and pretraining paradigms.
tl;dr: Consistency models are good and fast at solving Bayesian inverse problems.

Simulation-based inference (SBI) is constantly in search of more expressive and efficient algorithms to accurately infer the parameters of complex simulation models.
In line with this goal, we present consistency models for posterior estimation (CMPE), a new conditional sampler for SBI that inherits the advantages of recent unconstrained architectures and overcomes their sampling inefficiency at inference time.
CMPE essentially distills a continuous probability flow and enables rapid few-shot inference with an unconstrained architecture that can be flexibly tailored to the structure of the estimation problem.
We provide hyperparameters and default architectures that support consistency training over a wide range of different dimensions, including low-dimensional ones which are important in SBI workflows but were previously difficult to tackle even with unconditional consistency models.
Our empirical evaluation demonstrates that CMPE not only outperforms current state-of-the-art algorithms on hard low-dimensional benchmarks, but also achieves competitive performance with much faster sampling speed on two realistic estimation problems with high data and/or parameter dimensions.
tl;dr: We parallelize the two gradient computations in SAM, resulting in both improved efficiency and generalization of the model.

Sharpness-aware minimization (SAM) has been shown to improve the generalization of neural networks. However, each SAM update requires _sequentially_ computing two gradients, effectively doubling the per-iteration cost compared to base optimizers like SGD. We propose a simple modification of SAM, termed SAMPa, which allows us to fully parallelize the two gradient computations. SAMPa achieves a twofold speedup of SAM under the assumption that communication costs between devices are negligible. Empirical results show that SAMPa ranks among the most efficient variants of SAM in terms of computational time. Additionally, our method consistently outperforms SAM across both vision and language tasks. Notably, SAMPa theoretically maintains convergence guarantees even for _fixed_ perturbation sizes, which is established through a novel Lyapunov function. We in fact arrive at SAMPa by treating this convergence guarantee as a hard requirement---an approach we believe is promising for developing SAM-based methods in general. Our code is available at https://github.com/LIONS-EPFL/SAMPa.
tl;dr: We introduce a novel approach for learning via surrogate training objectives inherited from PAC-Bayes generalisation bounds, offering computational efficiency and theoretical support, with applications to meta-learning.

PAC-Bayes learning is a comprehensive setting for (i) studying the generalisation ability of learning algorithms and (ii) deriving new learning algorithms by optimising a generalisation bound. However, optimising generalisation bounds might not always be viable for tractable or computational reasons, or both. For example, iteratively querying the empirical risk might prove computationally expensive.
In response, we introduce a novel principled strategy for building an iterative learning algorithm via the optimisation of a sequence of surrogate training objectives, inherited from PAC-Bayes generalisation bounds. The key argument is to replace the empirical risk (seen as a function of hypotheses) in the generalisation bound by its projection onto a constructible low dimensional functional space: these projections can be queried much more efficiently than the initial risk. On top of providing that generic recipe for learning via surrogate PAC-Bayes bounds, we (i) contribute theoretical results establishing that iteratively optimising our surrogates implies the optimisation of the original generalisation bounds, (ii) instantiate this strategy to the framework of meta-learning, introducing a meta-objective offering a closed form expression for meta-gradient, (iii) illustrate our approach with numerical experiments inspired by an industrial biochemical problem.
tl;dr: MuDI enables multi-subject personalization by effectively decoupling identities from multiple subjects.

Text-to-image diffusion models have shown remarkable success in generating personalized subjects based on a few reference images. However, current methods often fail when generating multiple subjects simultaneously, resulting in mixed
identities with combined attributes from different subjects. In this work, we present MuDI, a novel framework that enables multi-subject personalization by effectively decoupling identities from multiple subjects. Our main idea is to utilize segmented subjects generated by a foundation model for segmentation (Segment Anything) for both training and inference, as a form of data augmentation for training and initialization for the generation process. Moreover, we further introduce a new metric to better evaluate the performance of our method on multi-subject personalization. Experimental results show that our MuDI can produce high-quality personalized images without identity mixing, even for highly similar subjects as shown in Figure 1. Specifically, in human evaluation, MuDI obtains twice the success rate for personalizing multiple subjects without identity mixing over existing baselines and is preferred over 70% against the strongest baseline.

Privacy is a growing concern in modern deep-learning systems and applications. Differentially private (DP) training prevents the leakage of sensitive information in the collected training data from the trained machine learning models. DP optimizers, including DP stochastic gradient descent (DPSGD) and its variants, privatize the training procedure by gradient clipping and *DP noise* injection. However, in practice, DP models trained using DPSGD and its variants often suffer from significant model performance degradation. Such degradation prevents the application of DP optimization in many key tasks, such as foundation model pretraining. In this paper, we provide a novel *signal processing perspective* to the design and analysis of DP optimizers. We show that a ''frequency domain'' operation called *low-pass filtering* can be used to effectively reduce the impact of DP noise. More specifically, by defining the ''frequency domain'' for both the gradient and differential privacy (DP) noise, we have developed a new component, called DOPPLER. This component is designed for DP algorithms and works by effectively amplifying the gradient while suppressing DP noise within this frequency domain. As a result, it maintains privacy guarantees and enhances the quality of the DP-protected model. Our experiments show that the proposed DP optimizers with a low-pass filter outperform their counterparts without the filter on various models and datasets. Both theoretical and practical evidence suggest that the DOPPLER is effective in closing the gap between DP and non-DP training.
2261. ChatTracker: Enhancing Visual Tracking Performance via Chatting with Multimodal Large Language Model
tl;dr: We utilize Multimodal Large Language Model to enhance visual object tracking performance

Visual object tracking aims to locate a targeted object in a video sequence based on an initial bounding box. Recently, Vision-Language~(VL) trackers have proposed to utilize additional natural language descriptions to enhance versatility in various applications. However, VL trackers are still inferior to State-of-The-Art (SoTA) visual trackers in terms of tracking performance. We found that this inferiority primarily results from their heavy reliance on manual textual annotations, which include the frequent provision of ambiguous language descriptions. In this paper, we propose ChatTracker to leverage the wealth of world knowledge in the Multimodal Large Language Model (MLLM) to generate high-quality language descriptions and enhance tracking performance. To this end, we propose a novel reflection-based prompt optimization module to iteratively refine the ambiguous and inaccurate descriptions of the target with tracking feedback. To further utilize semantic information produced by MLLM, a simple yet effective VL tracking framework is proposed and can be easily integrated as a plug-and-play module to boost the performance of both VL and visual trackers. Experimental results show that our proposed ChatTracker achieves a performance comparable to existing methods.

In the context of modern machine learning, models deployed in real-world scenarios often encounter diverse data shifts like covariate and semantic shifts, leading to challenges in both out-of-distribution (OOD) generalization and detection. Despite considerable attention to these issues separately, a unified framework for theoretical understanding and practical usage is lacking. To bridge the gap, we introduce a graph-theoretic framework to jointly tackle both OOD generalization and detection problems. By leveraging the graph formulation, data representations are obtained through the factorization of the graph's adjacency matrix, enabling us to derive provable error quantifying OOD generalization and detection performance. Empirical results showcase competitive performance in comparison to existing methods, thereby validating our theoretical underpinnings.

Variance exploding (VE) based diffusion models, an important class of diffusion models, have shown state-of-the-art (SOTA) performance. However, only a few theoretical works analyze VE-based models, and those works suffer from a worse forward convergence rate $1/\text{poly}(T)$ than the $\exp{(-T)}$ of variance preserving (VP) based models, where $T$ is the forward diffusion time and the rate measures the distance between forward marginal distribution $q_T$ and pure Gaussian noise. The slow rate is due to the Brownian Motion without a drift term. In this work, we design a new drifted VESDE forward process, which allows a faster $\exp{(-T)}$ forward convergence rate. With this process, we achieve the first efficient polynomial sample complexity for a series of VE-based models with reverse SDE under the manifold hypothesis. Furthermore, unlike previous works, we allow the diffusion coefficient to be unbounded instead of a constant, which is closer to the SOTA models. Besides the reverse SDE, the other common reverse process is the probability flow ODE (PFODE) process, which is deterministic and enjoys faster sample speed. To deepen the understanding of VE-based models, we consider a more general setting considering reverse SDE and PFODE simultaneously, propose a unified tangent-based analysis framework, and prove the first quantitative convergence guarantee for SOTA VE-based models with reverse PFODE.
We also show that the drifted VESDE can balance different error terms and improve generated samples without training through synthetic and real-world experiments.
tl;dr: A new adversarial meta-tuning method for boosting the performance of pre-trained models across domains in few-shot image classification

This paper introduces AMT, an \textbf{A}dversarial \textbf{M}eta-\textbf{T}uning methodology, to boost the robust generalization of pre-trained models in the out-of-domain (OOD) few-shot learning. To address the challenge of transferring knowledge from source domains to unseen target domains, we construct the robust LoRAPool by meta-tuning LoRAs with dual perturbations applied to not only the inputs but also singular values and vectors of the weight matrices at various robustness levels. On top of that, we introduce a simple yet effective test-time merging mechanism to dynamically merge discriminative LoRAs for test-time task customization. Extensive evaluations demonstrate that AMT yields significant improvements, up to 12.92\% in clean generalization and up to 49.72\% in adversarial generalization, over previous state-of-the-art methods across a diverse range of OOD few-shot image classification tasks on three benchmarks, confirming the effectiveness of our approach to boost the robust generalization of pre-trained models. Our code is available at \href{https://github.com/xyang583/AMT}{https://github.com/xyang583/AMT}.
tl;dr: We reveal and evaluate new attack vectors that exploit the common design choices of LLM watermarks.

Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating the misuse of such AI-generated content. However, we show that common design choices in LLM watermarking schemes make the resulting systems surprisingly susceptible to attack---leading to fundamental trade-offs in robustness, utility, and usability.
To navigate these trade-offs, we rigorously study a set of simple yet effective attacks on common watermarking systems, and propose guidelines and defenses for LLM watermarking in practice.
tl;dr: We propose a lightweight and scalable model for performing metagenomic binning at the genome read level, relying only on the k-mer compositions of the DNA fragments.

Obtaining effective representations of DNA sequences is crucial for genome analysis. Metagenomic binning, for instance, relies on genome representations to cluster complex mixtures of DNA fragments from biological samples with the aim of determining their microbial compositions. In this paper, we revisit k-mer-based representations of genomes and provide a theoretical analysis of their use in representation learning. Based on the analysis, we propose a lightweight and scalable model for performing metagenomic binning at the genome read level, relying only on the k-mer compositions of the DNA fragments. We compare the model to recent genome foundation models and demonstrate that while the models are comparable in performance, the proposed model is significantly more effective in terms of scalability, a crucial aspect for performing metagenomic binning of real-world data sets.
tl;dr: We introduce the problem of learning in Stackelberg games where each players' utility depends on an external context.

Algorithms for playing in Stackelberg games have been deployed in real-world domains including airport security, anti-poaching efforts, and cyber-crime prevention. However, these algorithms often fail to take into consideration the additional information available to each player (e.g. traffic patterns, weather conditions, network congestion), a salient feature of reality which may significantly affect both players' optimal strategies. We formalize such settings as Stackelberg games with side information, in which both players observe an external context before playing. The leader commits to a (context-dependent) strategy, and the follower best-responds to both the leader's strategy and the context. We focus on the online setting in which a sequence of followers arrive over time, and the context may change from round-to-round. In sharp contrast to the non-contextual version, we show that it is impossible for the leader to achieve good performance (measured by regret) in the full adversarial setting. Motivated by our impossibility result, we show that no-regret learning is possible in two natural relaxations: the setting in which the sequence of followers is chosen stochastically and the sequence of contexts is adversarial, and the setting in which the sequence of contexts is stochastic and the sequence of followers is chosen by an adversary.
tl;dr: We propose the spherical interaction-force transport (IFT) gradient flows with the global exponential convergence analysis for both the MMD and the KL-energy gradient flows. Numerical experiments show stable inference performance.

This paper presents a new gradient flow dissipation geometry over non-negative and probability measures.
This is motivated by a principled construction that combines the unbalanced optimal transport and interaction forces modeled by reproducing kernels. Using a precise connection between the Hellinger geometry and the maximum mean discrepancy (MMD), we propose the interaction-force transport (IFT) gradient flows and its spherical variant via an infimal convolution of the Wasserstein and spherical MMD tensors. We then develop a particle-based optimization algorithm based on the JKO-splitting scheme of the mass-preserving spherical IFT gradient flows. Finally, we provide both theoretical global exponential convergence guarantees and improved empirical simulation results for applying the IFT gradient flows to the sampling task of MMD-minimization. Furthermore, we prove that the spherical IFT gradient flow enjoys the best of both worlds by providing the global exponential convergence guarantee for both the MMD and KL energy.

Electrocardiogram (ECG) signals provide essential information about the heart's condition and are widely used for diagnosing cardiovascular diseases. The morphology of a single heartbeat over the available leads is a primary biosignal for monitoring cardiac conditions. However, analyzing heartbeat morphology can be challenging due to noise and artifacts, missing leads, and a lack of annotated data.
Generative models, such as denoising diffusion generative models (DDMs), have proven successful in generating complex data. We introduce $\texttt{BeatDiff}$, a light-weight DDM tailored for the morphology of multiple leads heartbeats.
We then show that many important ECG downstream tasks can be formulated as conditional generation methods in a Bayesian inverse problem framework using $\texttt{BeatDiff}$ as priors. We propose $\texttt{EM-BeatDiff}$, an Expectation-Maximization algorithm, to solve this conditional generation tasks without fine-tuning. We illustrate our results with several tasks, such as removal of ECG noise and artifacts (baseline wander, electrode motion), reconstruction of a 12-lead ECG from a single lead (useful for ECG reconstruction of smartwatch experiments), and unsupervised explainable anomaly detection. Numerical experiments show that the combination of $\texttt{BeatDiff}$ and $\texttt{EM-BeatDiff}$ outperforms SOTA methods for the problems considered in this work.
tl;dr: By deleting edges of a graph that maximize the spectral gap, we jointly address over-smoothing and over-squashing in GNNs.

Message Passing Graph Neural Networks are known to suffer from two problems that are sometimes believed to be diametrically opposed: over-squashing and over-smoothing. The former results from topological bottlenecks that hamper the information flow from distant nodes and are mitigated by spectral gap maximization, primarily, by means of edge additions. However, such additions often promote over-smoothing that renders nodes of different classes less distinguishable. Inspired by the Braess phenomenon, we argue that deleting edges can address over-squashing and over-smoothing simultaneously. This insight explains how edge deletions can improve generalization, thus connecting spectral gap optimization to a seemingly disconnected objective of reducing computational resources by pruning graphs for lottery tickets. To this end, we propose a computationally effective spectral gap optimization framework to add or delete edges and demonstrate its effectiveness on the long range graph benchmark and on larger heterophilous datasets.

3D Gaussian splatting has recently emerged as a promising technique for novel view synthesis from sparse image sets, yet comes at the cost of requiring millions of 3D Gaussian primitives to reconstruct each 3D scene. This largely limits its application to resource-constrained devices and applications.
Despite advances in Gaussian pruning techniques that aim to remove individual 3D Gaussian primitives, the significant reduction in primitives often fails to translate into commensurate increases in rendering speed, impeding efficiency and practical deployment. We identify that this discrepancy arises due to the overlooked impact of fragment count per Gaussian (i.e., the number of pixels each Gaussian is projected onto). To bridge this gap and meet the growing demands for efficient on-device 3D Gaussian rendering, we propose fragment pruning, an orthogonal enhancement to existing pruning methods that can significantly accelerate rendering by selectively pruning fragments within each Gaussian. Our pruning framework dynamically optimizes the pruning threshold for each Gaussian, markedly improving rendering speed and quality. Extensive experiments in both static and dynamic scenes validate the effectiveness of our approach. For instance, by integrating our fragment pruning technique with state-of-the-art Gaussian pruning methods, we achieve up to a 1.71$\times$ speedup on an edge GPU device, the Jetson Orin NX, and enhance rendering quality by an average of 0.16 PSNR on the Tanks\&Temples dataset. Our code is available at https://github.com/GATECH-EIC/Fragment-Pruning.
tl;dr: a model incorporating dual-space alignment and topology-preserving strategies for GZSL

Pre-trained vision-language models (VLMs) such as CLIP have shown excellent performance for zero-shot classification. Based on CLIP, recent methods design various learnable prompts to evaluate the zero-shot generalization capability on a base-to-novel setting. This setting assumes test samples are already divided into either base or novel classes, limiting its application to realistic scenarios. In this paper, we focus on a more challenging and practical setting: generalized zero-shot learning (GZSL), i.e., testing with no information about the base/novel division. To address this challenging zero-shot problem, we introduce two unique designs that enable us to classify an image without the need of knowing whether it comes from seen or unseen classes. Firstly, most existing methods only adopt a single latent space to align visual and linguistic features, which has a limited ability to represent complex visual-linguistic patterns, especially for fine-grained tasks. Instead, we propose a dual-space feature alignment module that effectively augments the latent space with a novel attribute space induced by a well-devised attribute reservoir. In particular, the attribute reservoir consists of a static vocabulary and learnable tokens complementing each other for flexible control over feature granularity. Secondly, finetuning CLIP models (e.g., prompt learning) on seen base classes usually sacrifices the model's original generalization capability on unseen novel classes. To mitigate this issue, we present a new topology-preserving objective that can enforce feature topology structures of the combined base and novel classes to resemble the topology of CLIP. In this manner, our model will inherit the generalization ability of CLIP through maintaining the pairwise class angles in the attribute space. Extensive experiments on twelve object recognition datasets demonstrate that our model, termed Topology-Preserving Reservoir (TPR), outperforms strong baselines including both prompt learning and conventional generative-based zero-shot methods.
tl;dr: We propose BitsFusion, which quantizes the text-to-image model into 1.99 bits.

Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters, resulting in a significantly large model size. Saving and transferring them is a major bottleneck for various applications, especially those running on resource-constrained devices. In this work, we develop a novel weight quantization method that quantizes the UNet from Stable Diffusion v1.5 to $1.99$ bits, achieving a model with $7.9\times$ smaller size while exhibiting even better generation quality than the original one. Our approach includes several novel techniques, such as assigning optimal bits to each layer, initializing the quantized model for better performance, and improving the training strategy to dramatically reduce quantization error. Furthermore, we extensively evaluate our quantized model across various benchmark datasets and through human evaluation to demonstrate its superior generation quality.

Graph Neural Networks (GNNs) have become essential in interpreting relational data across various domains, yet, they often struggle to generalize to unseen graph data that differs markedly from training instances. In this paper, we introduce a novel framework called General Retrieval-Augmented Graph Learning (RAGraph), which brings external graph data into the general graph foundation model to improve model generalization on unseen scenarios. On the top of our framework is a toy graph vector library that we established, which captures key attributes, such as features and task-specific label information. During inference, the RAGraph adeptly retrieves similar toy graphs based on key similarities in downstream tasks, integrating the retrieved data to enrich the learning context via the message-passing prompting mechanism. Our extensive experimental evaluations demonstrate that RAGraph significantly outperforms state-of-the-art graph learning methods in multiple tasks such as node classification, link prediction, and graph classification across both dynamic and static datasets. Furthermore, extensive testing confirms that RAGraph consistently maintains high performance without the need for task-specific fine-tuning, highlighting its adaptability, robustness, and broad applicability.

In this paper, we approach an overlooked yet critical task Graph2Image: generating images from multimodal attributed graphs (MMAGs). This task poses significant challenges due to the explosion in graph size, dependencies among graph entities, and the need for controllability in graph conditions. To address these challenges, we propose a graph context-conditioned diffusion model called InstructG2I. InstructG2I first exploits the graph structure and multimodal information to conduct informative neighbor sampling by combining personalized page rank and re-ranking based on vision-language features. Then, a graph QFormer encoder adaptively encodes the graph nodes into an auxiliary set of graph prompts to guide the denoising process of diffusion. Finally, we propose graph classifier-free guidance, enabling controllable generation by varying the strength of graph guidance and multiple connected edges to a node. Extensive experiments conducted on three datasets from different domains demonstrate the effectiveness and controllability of our approach. The code is available at https://github.com/PeterGriffinJin/InstructG2I.

Motivated by the problem of next word prediction on user devices we introduce and study the problem of personalized frequency histogram estimation in a federated setting. In this problem, over some domain, each user observes a number of samples from a distribution which is specific to that user. The goal is to compute for all users a personalized estimate of the user's distribution with error measured in KL divergence. We focus on addressing two central challenges: statistical heterogeneity and protection of user privacy.
Our approach to the problem relies on discovering and exploiting similar subpopulations of users which are often present and latent in real-world data, while minimizing user privacy leakage at the same time. We first present a non-private clustering-based algorithm for the problem, and give a provably joint differentially private version of it with a private data-dependent initialization scheme. Next, we propose a simple data model which is based on a mixture of Dirichlet distributions, to formally motivate our non-private algorithm and demonstrate some properties of its components. Finally, we provide an extensive empirical evaluation of our private and non-private algorithms under varying levels of statistical and size heterogeneity on the Reddit, StackOverflow, and Amazon Reviews datasets. Our results demonstrate significant improvements over standard and clustering-based baselines, and in particular, they show that it is possible to improve over direct personalization of a single global model.

Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
2278. SpecExec: Massively Parallel Speculative Decoding For Interactive LLM Inference on Consumer Devices
tl;dr: We propose a speculative decoding algorithm that scales with large token budgets and allows running 50B+ models on a single GPU up to 15x faster than standard offloading

As large language models gain widespread adoption, running them efficiently becomes a crucial task. Recent works on LLM inference use speculative decoding to achieve extreme speedups. However, most of these works implicitly design their algorithms for high-end datacenter hardware. In this work, we ask the opposite question: how fast can we run LLMs on consumer machines? Consumer GPUs can no longer fit the largest available models and must offload them to RAM or SSD. With parameter offloading, hundreds or thousands of tokens can be processed in batches within the same time as just one token, making it a natural fit for speculative decoding. We propose SpecExec (Speculative Execution), a simple parallel decoding method that can generate up to 20 tokens per target model iteration for popular LLM families. SpecExec takes the most probable continuations from the draft model to build a "cache" tree for the target model, which then gets validated in a single pass. Using SpecExec, we demonstrate inference of 50B+ parameter LLMs on consumer GPUs with RAM offloading at 4--6 tokens per second with 4-bit quantization or 2--3 tokens per second with 16-bit weights. Our code is available at https://github.com/yandex-research/specexec .

Deep neural networks face persistent challenges in defending against backdoor attacks, leading to an ongoing battle between attacks and defenses. While existing backdoor defense strategies have shown promising performance on reducing attack success rates, can we confidently claim that the backdoor threat has truly been eliminated from the model? To address it, we re-investigate the characteristics of the backdoored models after defense (denoted as defense models). Surprisingly, we find that the original backdoors still exist in defense models derived from existing post-training defense strategies, and the backdoor existence is measured by a novel metric called backdoor existence coefficient. It implies that the backdoors just lie dormant rather than being eliminated. To further verify this finding, we empirically show that these dormant backdoors can be easily re-activated during inference stage, by manipulating the original trigger with well-designed tiny perturbation using universal adversarial attack. More practically, we extend our backdoor re-activation to black-box scenario, where the defense model can only be queried by the adversary during inference stage, and develop two effective methods, i.e., query-based and transfer-based backdoor re-activation attacks. The effectiveness of the proposed methods are verified on both image classification and multimodal contrastive learning (i.e., CLIP) tasks. In conclusion, this work uncovers a critical vulnerability that has never been explored in existing defense strategies, emphasizing the urgency of designing more robust and advanced backdoor defense mechanisms in the future.
tl;dr: We propose a new metric, called uniform last-iterate and show it is achievable for multi-armed bandits and linear bandits, and tabular Markov decision processes

Existing metrics for reinforcement learning (RL) such as regret, PAC bounds, or uniform-PAC (Dann et al., 2017), typically evaluate the cumulative performance, while allowing the play of an arbitrarily bad policy at any finite time t. Such a behavior can be highly detrimental in high-stakes applications. This paper introduces a stronger metric, uniform last-iterate (ULI) guarantee, capturing both cumulative and instantaneous performance of RL algorithms. Specifically, ULI characterizes the instantaneous performance since it ensures that the per-round suboptimality of the played policy is bounded by a function, monotonically decreasing w.r.t. (large) round t, preventing revisits to bad policies when sufficient samples are available. We demonstrate that a near-optimal ULI guarantee directly implies near-optimal cumulative performance across aforementioned metrics, but not the other way around.
To examine the achievability of ULI, we first provide two positive results for bandit problems with finite arms, showing that some elimination-based algorithms and high-probability adversarial algorithms with stronger analysis or additional designs, can attain near-optimal ULI guarantees. We also provide a negative result, indicating that optimistic algorithms cannot achieve a near-optimal ULI guarantee. Furthermore, we propose an efficient algorithm for linear bandits with infinitely many arms, which achieves the ULI guarantee, given access to an optimization oracle. Finally, we propose an algorithm that achieves a near-optimal ULI guarantee for the online reinforcement learning setting.
tl;dr: We propose a novel unified framework that reprograms the check-in sequence to let LLMs comprehensively understand human visiting intentions and their travel preferences

Location-based services (LBS) have accumulated extensive human mobility data on diverse behaviors through check-in sequences. These sequences offer valuable insights into users’ intentions and preferences. Yet, existing models analyzing check-in sequences fail to consider the semantics contained in these sequences, which closely reflect human visiting intentions and travel preferences, leading to an incomplete comprehension. Drawing inspiration from the exceptional semantic understanding and contextual information processing capabilities of large language models (LLMs) across various domains, we present Mobility-LLM, a novel framework that leverages LLMs to analyze check-in sequences for multiple tasks. Since LLMs cannot directly interpret check-ins, we reprogram these sequences to help LLMs comprehensively understand the semantics of human visiting intentions and travel preferences.
Specifically, we introduce a visiting intention memory network (VIMN) to capture the visiting intentions at each record, along with a shared pool of human travel preference prompts (HTPP) to guide the LLM in understanding users’ travel preferences. These components enhance the model’s ability to extract and leverage semantic information from human mobility data effectively. Extensive experiments on four benchmark datasets and three downstream tasks demonstrate that our approach significantly outperforms existing models, underscoring the effectiveness of Mobility-LLM in advancing our understanding of human mobility data within LBS contexts.

We consider the decentralized stochastic asynchronous optimization setup, where many workers asynchronously calculate stochastic gradients and asynchronously communicate with each other using edges in a multigraph. For both homogeneous and heterogeneous setups, we prove new time complexity lower bounds under the assumption that computation and communication speeds are bounded by constants. After that, we developed a new nearly optimal method, Fragile SGD, and a new optimal method, Amelie SGD, that converge with arbitrary heterogeneous computation and communication speeds and match our lower bounds (up to a logarithmic factor in the homogeneous setting). Our time complexities are new, nearly optimal, and provably improve all previous asynchronous/synchronous stochastic methods in the decentralized setup.

Recently, Miller et al. (2021) and Baek et al. (2022) empirically demonstrated strong linear correlations between in-distribution (ID) versus out-of-distribution (OOD) accuracy and agreement. These trends, coined accuracy-on-the-line (ACL) and agreement-on-the-line (AGL), enables OOD model selection and performance estimation without labeled data. However, these phenomena also break for certain shifts, such as CIFAR10-C Gaussian Noise, posing a critical bottleneck. In this paper, we make a key finding that recent test-time adaptation (TTA) methods not only improve OOD performance, but drastically strengthens the ACL and AGL trends in models, even in shifts where models showed very weak correlations before. To analyze this, we revisit the theoretical conditions established by Miller et al. (2021), which demonstrate that ACL appears if the distributions only shift in mean and covariance scale in Gaussian data. We find that these theoretical conditions hold when deep networks are adapted to OOD, e.g., CIFAR10-C --- models embed the initial data distribution, with complex shifts, into those only with a singular ``scaling'' variable in the feature space. Building on these stronger linear trends, we demonstrate that combining TTA and AGL-based methods can predict the OOD performance with high precision for a broader set of distribution shifts. Furthermore, we can leverage ACL and AGL to perform hyperparameter search and select the best adaptation strategy without any OOD labeled data.
tl;dr: We infer the training data mixtures of tokenizers from their merge lists.

The pretraining data of today's strongest language models remains opaque, even when their parameters are open-sourced.
In particular, little is known about the proportions of different domains, languages, or code represented in the data. While a long line of membership inference attacks aim to identify training examples on an instance level, they do not extend easily to *global* statistics about the corpus. In this work, we tackle a task which we call *data mixture inference*, which aims to uncover the distributional make-up of the pretraining data. We introduce a novel attack based on a previously overlooked source of information — byte-pair encoding (BPE) tokenizers, used by the vast majority of modern language models. Our key insight is that the ordered vocabulary learned by a BPE tokenizer naturally reveals information about the token frequencies in its training data: the first token is the most common byte pair, the second is the most common pair after merging the first token, and so on. Given a tokenizer's merge list along with data samples for each category of interest (e.g., different natural languages), we formulate a linear program that solves for the relative proportion of each category in the tokenizer's training set. Importantly, to the extent to which tokenizer training data is representative of the pretraining data, we indirectly learn about the pretraining data. In controlled experiments, we show that our attack can recover mixture ratios with high precision for tokenizers trained on known mixtures of natural languages, programming languages, and data sources. We then apply our approach to off-the-shelf tokenizers released alongside recent LMs. We confirm much publicly disclosed information about these models, and also make several new inferences: GPT-4o is much more multilingual than its predecessors, training on 10x more non-English data than GPT-3.5, Llama 3 and Claude are trained on predominantly code, and many recent models are trained on 7-16% books. We hope our work sheds light on current design practices for pretraining data, and inspires continued research into data mixture inference for LMs.
tl;dr: We introduce a novel reconstruction algorithm achieving high-quality scene reconstruction from Event data under low-light, high-speed conditions.

Event cameras, offering high temporal resolution and high dynamic range, have brought a new perspective to addressing 3D reconstruction challenges in fast-motion and low-light scenarios. Most methods use the Neural Radiance Field (NeRF) for event-based photorealistic 3D reconstruction. However, these NeRF methods suffer from time-consuming training and inference, as well as limited scene-editing capabilities of implicit representations. To address these problems, we propose Event-3DGS, the first event-based reconstruction using 3D Gaussian splatting (3DGS) for synthesizing novel views freely from event streams. Technically, we first propose an event-based 3DGS framework that directly processes event data and reconstructs 3D scenes by simultaneously optimizing scenario and sensor parameters. Then, we present a high-pass filter-based photovoltage estimation module, which effectively reduces noise in event data to improve the robustness of our method in real-world scenarios. Finally, we design an event-based 3D reconstruction loss to optimize the parameters of our method for better reconstruction quality. The results show that our method outperforms state-of-the-art methods in terms of reconstruction quality on both simulated and real-world datasets. We also verify that our method can perform robust 3D reconstruction even in real-world scenarios with extreme noise, fast motion, and low-light conditions. Our code is available in https://github.com/lanpokn/Event-3DGS.

Warm-starting neural network training by initializing networks with previously learned weights is appealing, as practical neural networks are often deployed under a continuous influx of new data. However, it often leads to *loss of plasticity*, where the network loses its ability to learn new information, resulting in worse generalization than training from scratch. This occurs even under stationary data distributions, and its underlying mechanism is poorly understood. We develop a framework emulating real-world neural network training and identify noise memorization as the primary cause of plasticity loss when warm-starting on stationary data. Motivated by this, we propose **Direction-Aware SHrinking (DASH)**, a method aiming to mitigate plasticity loss by selectively forgetting memorized noise while preserving learned features. We validate our approach on vision tasks, demonstrating improvements in test accuracy and training efficiency.

The Area Under the ROC Curve (AUC) is a well-known metric for evaluating instance-level long-tail learning problems. In the past two decades, many AUC optimization methods have been proposed to improve model performance under long-tail distributions. In this paper, we explore AUC optimization methods in the context of pixel-level long-tail semantic segmentation, a much more complicated scenario. This task introduces two major challenges for AUC optimization techniques. On one hand, AUC optimization in a pixel-level task involves complex coupling across loss terms, with structured inner-image and pairwise inter-image dependencies, complicating theoretical analysis. On the other hand, we find that mini-batch estimation of AUC loss in this case requires a larger batch size, resulting in an unaffordable space complexity. To address these issues, we develop a pixel-level AUC loss function and conduct a dependency-graph-based theoretical analysis of the algorithm's generalization ability. Additionally, we design a Tail-Classes Memory Bank (T-Memory Bank) to manage the significant memory demand. Finally, comprehensive experiments across various benchmarks confirm the effectiveness of our proposed AUCSeg method. The code is available at https://github.com/boyuh/AUCSeg.
2288. Quasi-Bayes meets Vines
tl;dr: We introduced the Quasi-Bayesian Vine, which combines the strength of recursive joint Bayesian predictive densities with vines for varied tasks in high-dimensions, outperforming benchmark methods.

Recently developed quasi-Bayesian (QB) methods \cite{fong2023martingale} proposed a stimulating change of paradigm in Bayesian computation by directly constructing the Bayesian predictive distribution through recursion, removing the need for expensive computations involved in sampling the Bayesian posterior distribution. This has proved to be data-efficient for univariate predictions, however, existing constructions for higher dimensional densities are only possible by relying on restrictive assumptions on the model's multivariate structure. Here, we propose a wholly different approach to extend Quasi-Bayesian prediction to high dimensions through the use of Sklar's theorem, by decomposing the predictive distribution into one-dimensional predictive marginals and a high-dimensional copula. We use the efficient recursive QB construction for the one-dimensional marginals and model the dependence using highly expressive vine copulas. Further, we tune hyperparameters using robust divergences (eg. energy score) and show that our proposed Quasi-Bayesian Vine (QB-Vine) is a fully non-parametric density estimator with \emph{an analytical form} and convergence rate independent of the dimension of the data in some situations. Our experiments illustrate that the QB-Vine is appropriate for high dimensional distributions ($\sim$64), needs very few samples to train ($\sim$200) and outperforms state-of-the-art methods with analytical forms for density estimation and supervised tasks by a considerable margin.

Graph class incremental learning (GCIL) requires the model to classify emerging nodes of new classes while remembering old classes. Existing methods are designed to preserve effective information of old models or graph data to alleviate forgetting, but there is no clear theoretical understanding of what matters in information preservation. In this paper, we consider that present practice suffers from high semantic and structural shifts assessed by two devised shift metrics. We provide insights into information preservation in GCIL and find that maintaining graph information can preserve information of old models in theory to calibrate node semantic and graph structure shifts. We correspond graph information into low-frequency local-global information and high-frequency information in spatial domain. Based on the analysis, we propose a framework, Graph Spatial Information Preservation (GSIP). Specifically, for low-frequency information preservation, the old node representations obtained by inputting replayed nodes into the old model are aligned with the outputs of the node and its neighbors in the new model, and then old and new outputs are globally matched after pooling. For high-frequency information preservation, the new node representations are encouraged to imitate the near-neighbor pair similarity of old node representations. GSIP achieves a 10\% increase in terms of the forgetting metric compared to prior methods on large-scale datasets. Our framework can also seamlessly integrate existing replay designs. The code is available through https://github.com/Jillian555/GSIP.
tl;dr: Effective Rank Analysis and Regularization for Enhanced 3D Gaussian Splatting

3D reconstruction from multi-view images is one of the fundamental challenges in computer vision and graphics.
Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising technique capable of real-time rendering with high-quality 3D reconstruction. This method utilizes 3D Gaussian representation and tile-based splatting techniques, bypassing the expensive neural field querying. Despite its potential, 3DGS encounters challenges, including needle-like artifacts, suboptimal geometries, and inaccurate normals, due to the Gaussians converging into anisotropic Gaussians with one dominant variance.
We propose using effective rank analysis to examine the shape statistics of 3D Gaussian primitives, and identify the Gaussians indeed converge into needle-like shapes with the effective rank 1. To address this, we introduce effective rank as a regularization, which constrains the structure of the Gaussians. Our new regularization method enhances normal and geometry reconstruction while reducing needle-like artifacts. The approach can be integrated as an add-on module to other 3DGS variants, improving their quality without compromising visual fidelity.
tl;dr: We leverage tactile sensing to improve geometric details of generated 3D assets for text-to-3D and image-to-3D tasks.

3D generation methods have shown visually compelling results powered by diffusion image priors. However, they often fail to produce realistic geometric details, resulting in overly smooth surfaces or geometric details inaccurately baked in albedo maps. To address this, we introduce a new method that incorporates touch as an additional modality to improve the geometric details of generated 3D assets. We design a lightweight 3D texture field to synthesize visual and tactile textures, guided by diffusion-based distribution matching losses on both visual and tactile domains. Our method ensures the consistency between visual and tactile textures while preserving photorealism. We further present a multi-part editing pipeline that enables us to synthesize different textures across various regions. To our knowledge, we are the first to leverage high-resolution tactile sensing to enhance geometric details for 3D generation tasks. We evaluate our method on both text-to-3D and image-to-3D settings. Our experiments demonstrate that our method provides customized and realistic fine geometric textures while maintaining accurate alignment between two modalities of vision and touch.

Causal representation learning promises to extend causal models to hidden causal variables from raw entangled measurements. However, most progress has focused on proving identifiability results in different settings, and we are not aware of any successful real-world application. At the same time, the field of dynamical systems benefited from deep learning and scaled to countless applications but does not allow parameter identification. In this paper, we draw a clear connection between the two and their key assumptions, allowing us to apply identifiable methods developed in causal representation learning to dynamical systems. At the same time, we can leverage scalable differentiable solvers developed for differential equations to build models that are both identifiable and practical. Overall, we learn explicitly controllable models that isolate the trajectory-specific parameters for further downstream tasks such as out-of-distribution classification or treatment effect estimation. We experiment with a wind simulator with partially known factors of variation. We also apply the resulting model to real-world climate data and successfully answer downstream causal questions in line with existing literature on climate change.
tl;dr: This paper studies the problem of differentially private mechanism for representing sparse sets.

We study the problem of differentially private (DP) mechanisms for representing
sets of size $k$ from a large universe.
Our first construction creates
$(\epsilon,\delta)$-DP representations with error probability of
$1/(e^\epsilon + 1)$ using space at most $1.05 k \epsilon \cdot \log(e)$ bits where
the time to construct a representation is $O(k \log(1/\delta))$ while decoding time is $O(\log(1/\delta))$.
We also present a second algorithm for pure $\epsilon$-DP representations with the same error using space at most $k \epsilon \cdot \log(e)$ bits, but requiring large decoding times.
Our algorithms match the lower bounds on privacy-utility trade-offs (including constants but ignoring $\delta$ factors) and we also present a new space lower bound
matching our constructions up to small constant factors.
To obtain our results, we design a new approach embedding sets into random linear systems
deviating from most prior approaches that inject noise into non-private solutions.

We accelerate the iterative hard thresholding (IHT) method, which finds \(k\) important elements from a parameter vector in a linear regression model. Although the plain IHT repeatedly updates the parameter vector during the optimization, computing gradients is the main bottleneck. Our method safely prunes unnecessary gradient computations to reduce the processing time.The main idea is to efficiently construct a candidate set, which contains \(k\) important elements in the parameter vector, for each iteration. Specifically, before computing the gradients, we prune unnecessary elements in the parameter vector for the candidate set by utilizing upper bounds on absolute values of the parameters. Our method guarantees the same optimization results as the plain IHT because our pruning is safe. Experiments show that our method is up to 73 times faster than the plain IHT without degrading accuracy.

Multi-block minimax bilevel optimization has been studied recently due to its great potential in multi-task learning, robust machine learning, and few-shot learning. However, due to the complex three-level optimization structure, existing algorithms often suffer from issues such as high computing costs due to the second-order model derivatives or high memory consumption in storing all blocks' parameters. In this paper, we tackle these challenges by proposing two novel fully first-order algorithms named FOSL and MemCS. FOSL features a fully single-loop structure by updating all three variables simultaneously, and MemCS is a memory-efficient double-loop algorithm with cold-start initialization. We provide a comprehensive convergence analysis for both algorithms under full and partial block participation, and show that their sample complexities match or outperform those of the same type of methods in standard bilevel optimization. We evaluate our methods in two applications: the recently proposed multi-task deep AUC maximization and a novel rank-based robust meta-learning. Our methods consistently improve over existing methods with better performance over various datasets.

Large language models (LLMs) with billions of parameters demonstrate impressive performance. However, the widely used Multi-Head Attention (MHA) in LLMs incurs substantial computational and memory costs during inference. While some efforts have optimized attention mechanisms by pruning heads or sharing parameters among heads, these methods often lead to performance degradation or necessitate substantial continued pre-training costs to restore performance. Based on the analysis of attention redundancy, we design a Decoupled-Head Attention (DHA) mechanism. DHA adaptively configures group sharing for key heads and value heads across various layers, achieving a better balance between performance and efficiency. Inspired by the observation of clustering similar heads, we propose to progressively transform the MHA checkpoint into the DHA model through linear fusion of similar head parameters step by step, retaining the parametric knowledge of the MHA checkpoint. We construct DHA models by transforming various scales of MHA checkpoints given target head budgets. Our experiments show that DHA remarkably requires a mere 0.25\% of the original model's pre-training budgets to achieve 97.6\% of performance while saving 75\% of KV cache. Compared to Group-Query Attention (GQA), DHA achieves a 12$\times$ training acceleration, a maximum of 24.85\% performance improvement under 0.2B tokens budget, and finally 2.3\% overall performance improvement.

Recent studies developed jailbreaking attacks, which construct jailbreaking prompts to "fool" LLMs into responding to harmful questions.
Early-stage jailbreaking attacks require access to model internals or significant human efforts.
More advanced attacks utilize genetic algorithms for automatic and black-box attacks.
However, the random nature of genetic algorithms significantly limits the effectiveness of these attacks.
In this paper, we propose RLbreaker, a black-box jailbreaking attack driven by deep reinforcement learning (DRL).
We model jailbreaking as a search problem and design an RL agent to guide the search, which is more effective and has less randomness than stochastic search, such as genetic algorithms.
Specifically, we design a customized DRL system for the jailbreaking problem, including a novel reward function and a customized proximal policy optimization (PPO) algorithm.
Through extensive experiments, we demonstrate that RLbreaker is much more effective than existing jailbreaking attacks against six state-of-the-art (SOTA) LLMs.
We also show that RLbreaker is robust against three SOTA defenses and its trained agents can transfer across different LLMs.
We further validate the key design choices of RLbreaker via a comprehensive ablation study.
tl;dr: We study the problem of semi-supervised knowledge transfer across multi-omic single-cell data and propose a novel framework named DNACE for the problem.

Knowledge transfer between multi-omic single-cell data aims to effectively transfer cell types from scRNA-seq data to unannotated scATAC-seq data. Several approaches aim to reduce the heterogeneity of multi-omic data while maintaining the discriminability of cell types with extensive annotated data. However, in reality, the cost of collecting both a large amount of labeled scRNA-seq data and scATAC-seq data is expensive. Therefore, this paper explores a practical yet underexplored problem of knowledge transfer across multi-omic single-cell data under cell type scarcity. To address this problem, we propose a semi-supervised knowledge transfer framework named Dual label scArcity elimiNation with Cross-omic multi-samplE Mixup (DANCE). To overcome the label scarcity in scRNA-seq data, we generate pseudo-labels based on optimal transport and merge them into the labeled scRNA-seq data. Moreover, we adopt a divide-and-conquer strategy which divides the scATAC-seq data into source-like and target-specific data. For source-like samples, we employ consistency regularization with random perturbations while for target-specific samples, we select a few candidate labels and progressively eliminate incorrect cell types from the label set for additional supervision. Next, we generate virtual scRNA-seq samples with multi-sample Mixup based on the class-wise similarity to reduce cell heterogeneity. Extensive experiments on many benchmark datasets suggest the superiority of our DANCE over a series of state-of-the-art methods.
tl;dr: We introduce a new data augmentation method for tabular data, which trains class-specific generators.

Data collection is often difficult in critical fields such as medicine, physics, and chemistry, yielding typically only small tabular datasets. However, classification methods tend to struggle with these small datasets, leading to poor predictive performance. Increasing the training set with additional synthetic data, similar to data augmentation in images, is commonly believed to improve downstream tabular classification performance. However, current tabular generative methods that learn either the joint distribution $ p(\mathbf{x}, y) $ or the class-conditional distribution $ p(\mathbf{x} \mid y) $ often overfit on small datasets, resulting in poor-quality synthetic data, usually worsening classification performance compared to using real data alone. To solve these challenges, we introduce TabEBM, a novel class-conditional generative method using Energy-Based Models (EBMs). Unlike existing tabular methods that use a shared model to approximate all class-conditional densities, our key innovation is to create distinct EBM generative models for each class, each modelling its class-specific data distribution individually. This approach creates robust energy landscapes, even in ambiguous class distributions. Our experiments show that TabEBM generates synthetic data with higher quality and better statistical fidelity than existing methods. When used for data augmentation, our synthetic data consistently leads to improved classification performance across diverse datasets of various sizes, especially small ones. Code is available at https://github.com/andreimargeloiu/TabEBM.
tl;dr: We analyze the convergence of differentially private training through the Hessian information and propose a continual pretraining recipe.

The superior performance of large foundation models can be attributed to the use of massive amounts of high-quality data. However, such datasets often contain sensitive, private and copyrighted material that requires formal protection. While differential privacy (DP) is a prominent method used to gauge the degree of security provided to large foundation models, its application in large foundation models has been met with limited success because there are often significant performance compromises when applying DP during the pre-training phase. Consequently, DP is more commonly implemented during the model fine-tuning stage, hence not capable of protecting a substantial portion of the data used during the initial pre-training process. In this work, we first provide a theoretical understanding of the efficacy of DP training by analyzing the per-iteration improvement of loss through the lens of the Hessian. We observe that DP optimizers' deceleration can be significantly mitigated by the use of limited public data, and thus propose the DP continual pre-training strategy. Our DP continual pre-training on vision models, using only 10% of public data, have achieved DP accuracy of 41.5% on ImageNet-21k (with epsilon=8) and non-DP accuracy of 55.7% on Places365 and 60.0% on iNaturalist-2021, which are on par with state-of-the-art standard pre-training and outperform existing DP pertained models. Our DP pre-trained models are released in *fastDP* library (https://github.com/awslabs/fast-differential-privacy/releases/tag/v2.1)

Antibody design, a crucial task with significant implications across various disciplines such as therapeutics and biology, presents considerable challenges due to its intricate nature. In this paper, we tackle antigen-specific antibody sequence-structure co-design as an optimization problem towards specific preferences, considering both rationality and functionality. Leveraging a pre-trained conditional diffusion model that jointly models sequences and structures of antibodies with equivariant neural networks, we propose direct energy-based preference optimization to guide the generation of antibodies with both rational structures and considerable binding affinities to given antigens. Our method involves fine-tuning the pre-trained diffusion model using a residue-level decomposed energy preference. Additionally, we employ gradient surgery to address conflicts between various types of energy, such as attraction and repulsion. Experiments on RAbD benchmark show that our approach effectively optimizes the energy of generated antibodies and achieves state-of-the-art performance in designing high-quality antibodies with low total energy and high binding affinity simultaneously, demonstrating the superiority of our approach.

The remarkable capability of over-parameterised neural networks to generalise effectively has been explained by invoking a ``simplicity bias'': neural networks prevent overfitting by initially learning simple classifiers before progressing to more complex, non-linear functions. While simplicity biases have been described theoretically and experimentally in feed-forward networks for supervised learning, the extent to which they also explain the remarkable success of transformers trained with self-supervised techniques remains unclear. In our study, we demonstrate that transformers, trained on natural language data, also display a simplicity bias. Specifically, they sequentially learn many-body interactions among input tokens, reaching a saturation point in the prediction error for low-degree interactions while continuing to learn high-degree interactions. To conduct this analysis, we develop a procedure to generate \textit{clones} of a given natural language data set, which rigorously capture the interactions between tokens up to a specified order. This approach opens up the possibilities of studying how interactions of different orders in the data affect learning, in natural language processing and beyond.

Recently, cutting-plane methods such as GCP-CROWN have been explored to enhance neural network verifiers and made significant advancements. However, GCP-CROWN currently relies on ${\it generic}$ cutting planes ("cuts") generated from external mixed integer programming (MIP) solvers. Due to the poor scalability of MIP solvers, large neural networks cannot benefit from these cutting planes. In this paper, we exploit the structure of the neural network verification problem to generate efficient and scalable cutting planes ${\it specific}$ to this problem setting. We propose a novel approach, Branch-and-bound Inferred Cuts with COnstraint Strengthening (BICCOS), that leverages the logical relationships of neurons within verified subproblems in the branch-and-bound search tree, and we introduce cuts that preclude these relationships in other subproblems. We develop a mechanism that assigns influence scores to neurons in each path to allow the strengthening of these cuts. Furthermore, we design a multi-tree search technique to identify more cuts, effectively narrowing the search space and accelerating the BaB algorithm. Our results demonstrate that BICCOS can generate hundreds of useful cuts during the branch-and-bound process and consistently increase the number of verifiable instances compared to other state-of-the-art neural network verifiers on a wide range of benchmarks, including large networks that previous cutting plane methods could not scale to.
tl;dr: We introduces a neural net reparametrization technique that significantly enhances the efficiency and accuracy of energy minimization in molecular simulations

We propose a novel approach to molecular simulations using neural network reparametrization, which offers a flexible alternative to traditional coarse-graining methods.
Unlike conventional techniques that strictly reduce degrees of freedom, the complexity of the system can be adjusted in our model, sometimes increasing it to simplify the optimization process.
Our approach also maintains continuous access to fine-grained modes and eliminates the need for force-matching, enhancing both the efficiency and accuracy of energy minimization.
Importantly, our framework allows for the use of potentially arbitrary neural networks (e.g., Graph Neural Networks (GNN)) to perform the reparametrization, incorporating CG modes as needed.
In fact, our experiments using very weak molecular forces (Lennard-Jones potential) the GNN-based model is the sole model to find the correct configuration.
Similarly, in protein-folding scenarios, our GNN-based CG method consistently outperforms traditional optimization methods.
It not only recovers the target structures more accurately but also achieves faster convergence to the deepest energy states.
This work demonstrates significant advancements in molecular simulations by optimizing energy minimization and convergence speeds, offering a new, efficient framework for simulating complex molecular systems.

Consumer electronics used to follow the miniaturization trend described by Moore’s Law. Despite increased processing power in Microcontroller Units (MCUs), MCUs used in the smallest appliances are still not capable of running even moderately big, state-of-the-art artificial neural networks (ANNs) especially in time-sensitive scenarios. In this work, we present a novel method called Scattered Online Inference (SOI) that aims to reduce the computational complexity of ANNs. SOI leverages the continuity and seasonality of time-series data and model predictions, enabling extrapolation for processing speed improvements, particularly in deeper layers. By applying compression, SOI generates more general inner partial states of ANN, allowing skipping full model recalculation at each inference.
tl;dr: This work defines Continuous Temporal Domain Generalization. By leveraging a Koopman operator-driven continuous system, the paper effectively captures the essence of temporal generalization through the synchronization of model and data dynamics.

Temporal Domain Generalization (TDG) addresses the challenge of training predictive models under temporally varying data distributions. Traditional TDG approaches typically focus on domain data collected at fixed, discrete time intervals, which limits their capability to capture the inherent dynamics within continuous-evolving and irregularly-observed temporal domains. To overcome this, this work formalizes the concept of Continuous Temporal Domain Generalization (CTDG), where domain data are derived from continuous times and are collected at arbitrary times. CTDG tackles critical challenges including: 1) Characterizing the continuous dynamics of both data and models, 2) Learning complex high-dimensional nonlinear dynamics, and 3) Optimizing and controlling the generalization across continuous temporal domains. To address them, we propose a Koopman operator-driven continuous temporal domain generalization (Koodos) framework. We formulate the problem within a continuous dynamic system and leverage the Koopman theory to learn the underlying dynamics; the framework is further enhanced with a comprehensive optimization strategy equipped with analysis and control driven by prior knowledge of the dynamics patterns. Extensive experiments demonstrate the effectiveness and efficiency of our approach. The code can be found at: https://github.com/Zekun-Cai/Koodos.
tl;dr: We develop a unified single-loop primal-dual algorithm framework for decentralized bilevel optimization with the state-of-the-art non-asymptotic convergence rate.

This paper studies decentralized bilevel optimization, in which multiple agents collaborate to solve problems involving nested optimization structures with neighborhood communications. Most existing literature primarily utilizes gradient tracking to mitigate the influence of data heterogeneity, without exploring other well-known heterogeneity-correction techniques such as EXTRA or Exact Diffusion. Additionally, these studies often employ identical decentralized strategies for both upper- and lower-level problems, neglecting to leverage distinct mechanisms across different levels. To address these limitations, this paper proposes SPARKLE, a unified single-loop primal-dual algorithm framework for decentralized bilevel optimization. SPARKLE offers the flexibility to incorporate various heterogeneity-correction strategies into the algorithm. Moreover, SPARKLE allows for different strategies to solve upper- and lower-level problems. We present a unified convergence analysis for SPARKLE, applicable to all its variants, with state-of-the-art convergence rates compared to existing decentralized bilevel algorithms. Our results further reveal that EXTRA and Exact Diffusion are more suitable for decentralized bilevel optimization, and using mixed strategies in bilevel algorithms brings more benefits than relying solely on gradient tracking.
tl;dr: A diffusion pruner via few-step gradient optimization without retraining the diffusion model.

Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.

Estimating individualized treatment rules (ITRs) is fundamental in causal inference, particularly for precision medicine applications. Traditional ITR estimation methods rely on inverse probability weighting (IPW) to address confounding factors and $L_{1}$-penalization for simplicity and interpretability. However, IPW can introduce statistical bias without precise propensity score modeling, while $L_1$-penalization makes the objective non-smooth, leading to computational bias and requiring subgradient methods. In this paper, we propose a unified ITR estimation framework formulated as a constrained, weighted, and smooth convex optimization problem. The optimal ITR can be robustly and effectively computed by projected gradient descent. Our comprehensive theoretical analysis reveals that weights that balance the spectrum of a `weighted design matrix' improve both the optimization and likelihood landscapes, yielding improved computational and statistical estimation guarantees. In particular, this is achieved by distributional covariate balancing weights, which are model-free alternatives to IPW. Extensive simulations and applications demonstrate that our framework achieves significant gains in both robustness and effectiveness for ITR learning against existing methods.
tl;dr: We propose efficient availability attacks for both supervised and contrastive learning

Availability attacks provide a tool to prevent the unauthorized use of private data and commercial datasets by generating imperceptible noise and crafting unlearnable examples before release.
Ideally, the obtained unlearnability can prevent algorithms from training usable models.
When supervised learning (SL) algorithms have failed, a malicious data collector possibly resorts to contrastive learning (CL) algorithms to bypass the protection.
Through evaluation, we have found that most existing methods are unable to achieve both supervised and contrastive unlearnability, which poses risks to data protection by availability attacks.
Different from recent methods based on contrastive learning, we employ contrastive-like data augmentations in supervised learning frameworks to obtain attacks effective for both SL and CL.
Our proposed AUE and AAP attacks achieve state-of-the-art worst-case unlearnability across SL and CL algorithms with less computation consumption, showcasing prospects in real-world applications.
The code is available at https://github.com/EhanW/AUE-AAP.
tl;dr: We conduct a simple-model theoretical analysis, introduce a benchmark and a baseline approach to address the gradual performance degradation of continual test-time adaptation methods.

Current test-time adaptation (TTA) approaches aim to adapt a machine learning model to environments that change continuously. Yet, it is unclear whether TTA methods can maintain their adaptability over prolonged periods. To answer this question, we introduce a diagnostic setting - **recurring TTA** where environments not only change but also recur over time, creating an extensive data stream. This setting allows us to examine the error accumulation of TTA models, in the most basic scenario, when they are regularly exposed to previous testing environments. Furthermore, we simulate a TTA process on a simple yet representative $\epsilon$-**perturbed Gaussian Mixture Model Classifier**, deriving theoretical insights into the dataset- and algorithm-dependent factors contributing to gradual performance degradation. Our investigation leads us to propose **persistent TTA (PeTTA)**, which senses when the model is diverging towards collapse and adjusts the adaptation strategy, striking a balance between the dual objectives of adaptation and model collapse prevention. The supreme stability of PeTTA over existing approaches, in the face of lifelong TTA scenarios, has been demonstrated over comprehensive experiments on various benchmarks. Our project page is available at [https://hthieu166.github.io/petta](https://hthieu166.github.io/petta).

Contrastive Learning (CL) plays a crucial role in molecular representation learning, enabling unsupervised learning from large scale unlabeled molecule datasets. It has inspired various applications in molecular property prediction and drug design.
However, existing molecular representation learning methods often introduce potential false positive and false negative pairs through conventional graph augmentations like node masking and subgraph removal. The issue can lead to suboptimal performance when applying standard contrastive learning techniques to molecular datasets.
To address the issue of false positive and negative pairs in molecular representation learning, we propose a novel probability-based contrastive learning (CL) framework. Unlike conventional methods, our approach introduces a learnable weight distribution via Bayesian modeling to automatically identify and mitigate false positive and negative pairs. This method is particularly effective because it dynamically adjusts to the data, improving the accuracy of the learned representations. Our model is learned by a stochastic expectation-maximization process, which optimizes the model by iteratively refining the probability estimates of sample weights and updating the model parameters.
Experimental results indicate that our method outperforms existing approaches in 13 out of 15 molecular property prediction benchmarks in MoleculeNet dataset and 8 out of 12 benchmarks in the QM9 benchmark, achieving new state-of-the-art results on average.
tl;dr: Using linear regression to characterize how large the performance gain can be from repeated applications of self-distillation

Self-Distillation is a special type of knowledge distillation where the student model has the same architecture as the teacher model. Despite using the same architecture and the same training data, self-distillation has been empirically observed to improve performance, especially when applied repeatedly. For such a process, there is a fundamental question of interest: How much gain is possible by applying multiple steps of self-distillation? To investigate this relative gain, we propose using the simple but canonical task of linear regression. Our analysis shows that the excess risk achieved by multi-step self-distillation can significantly improve upon a single step of self-distillation, reducing the excess risk by a factor of $d$, where $d$ is the input dimension. Empirical results on regression tasks from the UCI repository show a reduction in the learnt model's risk (MSE) by up to $47$%.

Learning with reduced labeling standards, such as noisy label, partial label, and supplementary unlabeled data, which we generically refer to as imprecise label, is a commonplace challenge in machine learning tasks. Previous methods tend to propose specific designs for every emerging imprecise label configuration, which is usually unsustainable when multiple configurations of imprecision coexist.
In this paper, we introduce imprecise label learning (ILL), a framework for the unification of learning with various imprecise label configurations. ILL leverages expectation-maximization (EM) for modeling the imprecise label information, treating the precise labels as latent variables. Instead of approximating the correct labels for training, it considers the entire distribution of all possible labeling entailed by the imprecise information. We demonstrate that ILL can seamlessly adapt to partial label learning, semi-supervised learning, noisy label learning, and, more importantly, a mixture of these settings, with closed-form learning objectives derived from the unified EM modeling. Notably, ILL surpasses the existing specified techniques for handling imprecise labels, marking the first practical and unified framework with robust and effective performance across various challenging settings. We hope our work will inspire further research on this topic, unleashing the full potential of ILL in wider scenarios where precise labels are expensive and complicated to obtain.
tl;dr: a query engine that leverages advances in sampling, online learning and foundation models for effective unstructured data analytics

Analytics on structured data is a mature field with many successful methods.
However, most real world data exists in unstructured form, such as images and conversations.
We investigate the potential of Large Language Models (LLMs) to enable unstructured data analytics.
In particular, we propose a new Universal Query Engine (UQE) that directly interrogates and draws insights from unstructured data collections.
This engine accepts queries in a Universal Query Language (UQL), a dialect of SQL that provides full natural language flexibility in specifying conditions and operators.
The new engine leverages the ability of LLMs to conduct analysis of unstructured data, while also allowing us to exploit advances in sampling and optimization techniques to achieve efficient and accurate query execution.
In addition, we borrow techniques from classical compiler theory to better orchestrate the workflow between sampling methods and foundation model calls.
We demonstrate the efficiency of UQE on data analytics across different modalities, including images, dialogs and reviews, across a range of useful query types, including conditional aggregation, semantic retrieval and abstraction aggregation.
tl;dr: Our proposed method, RoAd, is extremely parameter-efficient, batching-efficient and composable.

Parameter-efficient finetuning (PEFT) methods effectively adapt large language models (LLMs) to diverse downstream tasks, reducing storage and GPU memory demands. Despite these advantages, several applications pose new challenges to PEFT beyond mere parameter efficiency. One notable challenge involves the efficient deployment of LLMs equipped with multiple task- or user-specific adapters, particularly when different adapters are needed for distinct requests within the same batch. Another challenge is the interpretability of LLMs, which is crucial for understanding how LLMs function. Previous studies introduced various approaches to address different challenges. In this paper, we introduce a novel method, RoAd, which employs a straightforward 2D rotation to adapt LLMs and addresses all the above challenges: (1) RoAd is remarkably parameter-efficient, delivering optimal performance on GLUE, eight commonsense reasoning tasks and four arithmetic reasoning tasks with <0.1% trainable parameters; (2) RoAd facilitates the efficient serving of requests requiring different adapters within a batch, with an overhead comparable to element-wise multiplication instead of batch matrix multiplication; (3) RoAd enhances LLM's interpretability through integration within a framework of distributed interchange intervention, demonstrated via composition experiments.
tl;dr: A multi-event causal discovery task for video reasoning.

Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event videos, outperforming GPT-4o and VideoLLaVA by 5.7% and 4.1%, respectively.
tl;dr: A framework that decouples multi-modal trajectory queries into mode queries for directional intentions and state queries for dynamic states, utilizing Attention and Mamba.

Accurate motion forecasting for traffic agents is crucial for ensuring the safety and efficiency of autonomous driving systems in dynamically changing environments. Mainstream methods adopt a one-query-one-trajectory paradigm, where each query corresponds to a unique trajectory for predicting multi-modal trajectories. While straightforward and effective, the absence of detailed representation of future trajectories may yield suboptimal outcomes, given that the agent states dynamically evolve over time. To address this problem, we introduce DeMo, a framework that decouples multi-modal trajectory queries into two types: mode queries capturing distinct directional intentions and state queries tracking the agent's dynamic states over time. By leveraging this format, we separately optimize the multi-modality and dynamic evolutionary properties of trajectories. Subsequently, the mode and state queries are integrated to obtain a comprehensive and detailed representation of the trajectories. To achieve these operations, we additionally introduce combined Attention and Mamba techniques for global information aggregation and state sequence modeling, leveraging their respective strengths. Extensive experiments on both the Argoverse 2 and nuScenes benchmarks demonstrate that our DeMo achieves state-of-the-art performance in motion forecasting. In addition, we will make our code and models publicly available.

Adversarial robustness and privacy of deep learning (DL) models are two widely studied topics in AI security. Adversarial training (AT) is
an effective approach to improve the robustness of DL models against adversarial attacks. However, while models with AT demonstrate enhanced robustness, they become more susceptible to membership inference attacks (MIAs), thus increasing the risk of privacy leakage. This indicates a negative trade-off between adversarial robustness and privacy in general deep learning models. Visual prompting is a novel model reprogramming (MR) technique used for fine-tuning pre-trained models, achieving good performance in vision tasks, especially when combined with the label mapping technique. However, the performance of label-mapping-based visual prompting (LM-VP) under adversarial attacks and MIAs lacks evaluation. In this work, we regard the MR of LM-VP as a unified entity, referred to as the LM-VP model, and take a step toward jointly evaluating the adversarial robustness and privacy of LM-VP models. Experimental results show that
the choice of pre-trained models significantly affects the white-box adversarial robustness of LM-VP, and standard AT even substantially degrades its performance. In contrast, transfer AT-trained LM-VP achieves a good trade-off between transferred adversarial robustness and privacy, a finding that has been consistently validated across various pre-trained models. Code is available at https://github.com/TrustAI/TARP-VP.
2320. Analysing Multi-Task Regression via Random Matrix Theory with Application to Time Series Forecasting
tl;dr: This paper introduces a new multi-task regression framework using random matrix theory for improved performance estimation and presents a regularization-based optimization with empirical methods, enhancing univariate models.

In this paper, we introduce a novel theoretical framework for multi-task regression, applying random matrix theory to provide precise performance estimations, under high-dimensional, non-Gaussian data distributions. We formulate a multi-task optimization problem as a regularization technique to enable single-task models to leverage multi-task learning information. We derive a closed-form solution for multi-task optimization in the context of linear models. Our analysis provides valuable insights by linking the multi-task learning performance to various model statistics such as raw data covariances, signal-generating hyperplanes, noise levels, as well as the size and number of datasets. We finally propose a consistent estimation of training and testing errors, thereby offering a robust foundation for hyperparameter optimization in multi-task regression scenarios. Experimental validations on both synthetic and real-world datasets in regression and multivariate time series forecasting demonstrate improvements on univariate models, incorporating our method into the training loss and thus leveraging multivariate information.
2321. Fine-Grained Dynamic Framework for Bias-Variance Joint Optimization on Data Missing Not at Random

In most practical applications such as recommendation systems, display advertising, and so forth, the collected data often contains missing values and those missing values are generally missing-not-at-random, which deteriorates the prediction performance of models. Some existing estimators and regularizers attempt to achieve unbiased estimation to improve the predictive performance. However, variances and generalization bound of these methods are generally unbounded when the propensity scores tend to zero, compromising their stability and robustness. In this paper, we first theoretically reveal that limitations of regularization techniques. Besides, we further illustrate that, for more general estimators, unbiasedness will inevitably lead to unbounded variance. These general laws inspire us that the estimator designs is not merely about eliminating bias, reducing variance, or simply achieve a bias-variance trade-off. Instead, it involves a quantitative joint optimization of bias and variance. Then, we develop a systematic fine-grained dynamic learning framework to jointly optimize bias and variance, which adaptively selects an appropriate estimator for each user-item pair according to the predefined objective function. With this operation, the generalization bounds and variances of models are reduced and bounded with theoretical guarantees. Extensive experiments are conducted to verify the theoretical results and the effectiveness of the proposed dynamic learning framework.

The CLIP network excels in various tasks, but struggles with text-visual images i.e., images that contain both text and visual objects; it risks confusing textual and visual representations. To address this issue, we propose MirrorCLIP, a zero-shot framework, which disentangles the image features of CLIP by exploiting the difference in the mirror effect between visual objects and text in the images. Specifically, MirrorCLIP takes both original and flipped images as inputs, comparing their features dimension-wise in the latent space to generate disentangling masks. With disentangling masks, we further design filters to separate textual and visual factors more precisely, and then get disentangled representations. Qualitative experiments using stable diffusion models and class activation mapping (CAM) validate the effectiveness of our disentanglement. Moreover, our proposed MirrorCLIP reduces confusion when encountering text-visual images and achieves a substantial improvement on typographic defense, further demonstrating its superior ability of disentanglement. Our code is available at https://github.com/tcwangbuaa/MirrorCLIP
tl;dr: Parameter Free Decentralized Optimization

This paper addresses the minimization of the sum of strongly convex, smooth
functions over a network of agents without a centralized server. Existing decentralized algorithms require knowledge of functions and network parameters, such as the Lipschitz constant of the global gradient and/or network connectivity, for
hyperparameter tuning. Agents usually cannot access this information, leading
to conservative selections and slow convergence or divergence. This paper introduces a decentralized algorithm that eliminates the need for specific parameter
tuning. Our approach employs an operator splitting technique with a novel variable
metric, enabling a local backtracking line-search to adaptively select the stepsize
without global information or extensive communications. This results in favorable
convergence guarantees and dependence on optimization and network parameters
compared to existing nonadaptive methods. Notably, our method is the first adaptive decentralized algorithm that achieves linear convergence for strongly convex,
smooth objectives. Preliminary numerical experiments support our theoretical
findings, demonstrating superior performance in convergence speed and scalability.
tl;dr: In this paper, we propose Self-Retrieval, an end-to-end LLM-driven information retrieval architecture that unifies indexing, retrieval, and reranking in a single LLM.

The rise of large language models (LLMs) has significantly transformed both the construction and application of information retrieval (IR) systems.
However, current interactions between IR systems and LLMs remain limited, with LLMs merely serving as part of components within IR systems, and IR systems being constructed independently of LLMs. This separated architecture restricts knowledge sharing and deep collaboration between them.
In this paper, we introduce Self-Retrieval, a novel end-to-end LLM-driven information retrieval architecture.
Self-Retrieval unifies all essential IR functions within a single LLM, leveraging the inherent capabilities of LLMs throughout the IR process.
Specifically, Self-Retrieval internalizes the retrieval corpus through self-supervised learning, transforms the retrieval process into sequential passage generation, and performs relevance assessment for reranking.
Experimental results demonstrate that Self-Retrieval not only outperforms existing retrieval approaches by a significant margin, but also substantially enhances the performance of LLM-driven downstream applications like retrieval-augmented generation.
tl;dr: We introduce SlowFocus, a straightforward yet effective approach, which, mirroring human cognition, identifies the relevant segments pertinent to the query and subsequently completes fine-grained temporal tasks based on the temporal details located.

Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.
tl;dr: This paper builds a theoretical framework for non-adaptive and adaptive algorithms to predict sets of functions from continuous data streams, showing how selective querying supports accurate learning, even with limited observability.

Imagine a smart camera trap selectively clicking pictures to understand animal movement patterns within a particular habitat. These "snapshots", or pieces of data captured from a data stream at adaptively chosen times, provide a glimpse of different animal movements unfolding through time. Learning a continuous-time process through snapshots, such as smart camera traps, is a central theme governing a wide array of online learning situations. In this paper, we adopt a learning-theoretic perspective in understanding the fundamental nature of learning different classes of functions from both discrete data streams and continuous data streams. In our first framework, the *update-and-deploy* setting, a learning algorithm discretely queries from a process to update a predictor designed to make predictions given as input the data stream. We construct a uniform sampling algorithm that can learn with bounded error any concept class with finite Littlestone dimension. Our second framework, known as the *blind-prediction* setting, consists of a learning algorithm generating predictions independently of observing the process, only engaging with the process when it chooses to make queries. Interestingly, we show a stark contrast in learnability where non-trivial concept classes are unlearnable. However, we show that adaptive learning algorithms are necessary to learn sets of time-dependent and data-dependent functions, called pattern classes, in either framework. Finally, we develop a theory of pattern classes under discrete data streams for the blind-prediction setting.

Phylogenetic trees elucidate evolutionary relationships among species, but phylogenetic inference remains challenging due to the complexity of combining continuous (branch lengths) and discrete parameters (tree topology).
Traditional Markov Chain Monte Carlo methods face slow convergence and computational burdens. Existing Variational Inference methods, which require pre-generated topologies and typically treat tree structures and branch lengths independently, may overlook critical sequence features, limiting their accuracy and flexibility.
We propose PhyloGen, a novel method leveraging a pre-trained genomic language model to generate and optimize phylogenetic trees without dependence on evolutionary models or aligned sequence constraints. PhyloGen views phylogenetic inference as a conditionally constrained tree structure generation problem, jointly optimizing tree topology and branch lengths through three core modules: (i) Feature Extraction, (ii) PhyloTree Construction, and (iii) PhyloTree Structure Modeling.
Meanwhile, we introduce a Scoring Function to guide the model towards a more stable gradient descent.
We demonstrate the effectiveness and robustness of PhyloGen on eight real-world benchmark datasets. Visualization results confirm PhyloGen provides deeper insights into phylogenetic relationships.
tl;dr: We present a biologically inspired learning model that performs instructed vision through guiding attention. Directing attention is an essential part of human vision and is also used incorporated in recent Vision Language Models (VLMs).

As part of the effort to understand how the brain learns, ongoing research seeks to combine biological knowledge with current artificial intelligence (AI) modeling in an attempt to find an efficient biologically plausible learning scheme. Current models often use a cortical-like combination of bottom-up (BU) and top-down (TD) processing, where the TD part carries feedback signals for learning. However, in the visual cortex, the TD pathway plays a second major role in visual attention, by guiding the visual process toward locations and tasks of interest. A biological model should therefore integrate both learning and visual guidance. We introduce a model that uses a cortical-like combination of BU and TD processing that naturally integrates the two major functions of the TD stream. This integration is achieved through an appropriate connectivity pattern between the BU and TD streams, a novel processing cycle that uses the TD stream twice, and a 'Counter-Hebb' learning mechanism that operates across both streams. We show that the 'Counter-Hebb' mechanism can provide an exact backpropagation synaptic modification. Additionally, our model can effectively guide the visual stream to perform a task of interest, achieving competitive performance on standard multi-task learning benchmarks compared to AI models. The successful combination of learning and visual guidance could provide a new view on combining BU and TD processing in human vision and suggests possible directions for both biologically plausible models and artificial instructed models, such as vision-language models (VLMs).

In recent years, machine learning has demonstrated impressive capability in handling molecular science tasks. To support various molecular properties at scale, machine learning models are trained in the multi-task learning paradigm. Nevertheless, data of different molecular properties are often not aligned: some quantities, e.g. equilibrium structure, demand more cost to compute than others, e.g. energy, so their data are often generated by cheaper computational methods at the cost of lower accuracy, which cannot be directly overcome through multi-task learning. Moreover, it is not straightforward to leverage abundant data of other tasks to benefit a particular task. To handle such data heterogeneity challenges, we exploit the specialty of molecular tasks that there are physical laws connecting them, and design consistency training approaches that allow different tasks to exchange information directly so as to improve one another. Particularly, we demonstrate that the more accurate energy data can improve the accuracy of structure prediction. We also find that consistency training can directly leverage force and off-equilibrium structure data to improve structure prediction, demonstrating a broad capability for integrating heterogeneous data.

In software development, resolving the emergent issues within GitHub repositories is a complex challenge that involves not only the incorporation of new code but also the maintenance of existing code.
Large Language Models (LLMs) have shown promise in code generation but face difficulties in resolving Github issues, particularly at the repository level.
To overcome this challenge, we empirically study the reason why LLMs fail to resolve GitHub issues and analyze the major factors.
Motivated by the empirical findings, we propose a novel LLM-based **M**ulti-**A**gent framework for **G**itHub **I**ssue re**S**olution, **MAGIS**, consisting of four agents customized for software evolution: Manager, Repository Custodian, Developer, and Quality Assurance Engineer agents.
This framework leverages the collaboration of various agents in the planning and coding process to unlock the potential of LLMs to resolve GitHub issues.
In experiments, we employ the SWE-bench benchmark to compare MAGIS with popular LLMs, including GPT-3.5, GPT-4, and Claude-2.
MAGIS can resolve **13.94%** GitHub issues, significantly outperforming the baselines.
Specifically, MAGIS achieves an eight-fold increase in resolved ratio over the direct application of GPT-4, the advanced LLM.

Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., “design”) versus the specific concepts the task is asked to be performed upon (e.g., a “cycle” vs. a “bomb”). Using this, we investigate three well-known safety fine-tuning methods—supervised safety fine-tuning, direct preference optimization, and unlearning—and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights’ null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. Code is available at https://github.com/fiveai/understanding_safety_finetuning.
tl;dr: We study the effect of normalization layers in GNNs and propose a novel layer, called GRANOLA, that is expressive and graph adaptive.

Despite the widespread adoption of Graph Neural Networks (GNNs), these models often incorporate off-the-shelf normalization layers like BatchNorm or InstanceNorm, which were not originally designed for GNNs. Consequently, these normalization layers may not effectively capture the unique characteristics of graph-structured data, potentially even weakening the expressive power of the overall architecture.
While existing graph-specific normalization layers have been proposed, they often struggle to offer substantial and consistent benefits. In this paper, we propose GRANOLA, a novel graph-adaptive normalization layer. Unlike existing normalization layers, GRANOLA normalizes node features by adapting to the specific characteristics of the graph, particularly by generating expressive representations of its nodes, obtained by leveraging the propagation of Random Node Features (RNF) in the graph. We provide theoretical results that support our design choices as well as an extensive empirical evaluation demonstrating the superior performance of GRANOLA over existing normalization techniques. Furthermore, GRANOLA emerges as the top-performing method among all baselines in the same time complexity class of Message Passing Neural Networks (MPNNs).
tl;dr: We propose a novel layout-guided 3D scene generation pipeline to generate complicated indoor scenes adhering to user specifications.

The creation of complex 3D scenes tailored to user specifications has been a tedious and challenging task with traditional 3D modeling tools. Although some pioneering methods have achieved automatic text-to-3D generation, they are generally limited to small-scale scenes with restricted control over the shape and texture. We introduce SceneCraft, a novel method for generating detailed indoor scenes that adhere to textual descriptions and spatial layout preferences provided by users. Central to our method is a rendering-based technique, which converts 3D semantic layouts into multi-view 2D proxy maps. Furthermore, we design a semantic and depth conditioned diffusion model to generate multi-view images, which are used to learn a neural radiance field (NeRF) as the final scene representation. Without the constraints of panorama image generation, we surpass previous methods in supporting complicated indoor space generation beyond a single room, even as complicated as a whole multi-bedroom apartment with irregular shapes and layouts. Through experimental analysis, we demonstrate that our method significantly outperforms existing approaches in complex indoor scene generation with diverse textures, consistent geometry, and realistic visual quality.
tl;dr: We study convergence properties of no-swap-regret dynamics in zero-sum-games.

In this paper, we investigate the question of whether no-swap-regret dynamics have stronger convergence properties in repeated games than regular no-external-regret dynamics. We prove that in almost all symmetric zero-sum games under symmetric initializations of the agents, no-swap-regret dynamics in self-play are guaranteed to converge in a strong ``frequent-iterate'' sense to the Nash equilibrium: in all but a vanishing fraction of the rounds, the players must play a strategy profile close to a symmetric Nash equilibrium. Remarkably, relaxing any of these three constraints, i.e. by allowing either i) asymmetric initial conditions, or ii) an asymmetric game or iii) no-external regret dynamics suffices to destroy this result and lead to complex non-equilibrating or even chaotic behavior.
In a dual type of result, we show that the power of no-swap-regret dynamics comes at a cost of imposing a time-asymmetry on its inputs. While no-external-regret dynamics can be completely determined by the cumulative reward vector received by each player, we show there does not exist any general no-swap-regret dynamics defined on the same state space. In fact, we prove that any no-swap-regret learning algorithm must play a time-asymmetric function over the set of previously observed rewards, ruling out any dynamics based on a symmetric function of the current set of rewards.
tl;dr: An improved Empirical Fisher is proposed to resolve the limitations of Empirical Fisher.

Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper investigates the *inversely-scaled projection* issue of EF, which is shown to be a major cause of its poor empirical approximation quality. An improved empirical Fisher (iEF) method is proposed to address this issue, which is motivated as a generalised NGD method from a loss reduction perspective, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF directly as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for the majority of the tasks, even when compared to well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to exact Natural Gradient updates than both the EF and the more expensive sampled Fisher methods, meanwhile demonstrating the superior property of being robust to the choice of damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence and robustness. Furthermore, the iEF method also serves as a better approximation method to the Fisher information matrix itself, which enables the improvement of a variety of Fisher-based methods, not limited to the scope of optimisation.

In recent years, Wasserstein Distributionally Robust Optimization (DRO) has garnered substantial interest for its efficacy in data-driven decision-making under distributional uncertainty. However, limited research has explored the application of DRO to address individual fairness concerns, particularly when considering causal structures and discrete sensitive attributes in learning problems.
To address this gap, we first formulate the DRO problem from the perspectives of causality and individual fairness. We then present the DRO dual formulation as an efficient tool to convert the main problem into a more tractable and computationally efficient form. Next, we characterize the closed form of the approximate worst-case loss quantity as a regularizer, eliminating the max-step in the Min-Max DRO problem. We further estimate the regularizer in more general cases and explore the relationship between DRO and classical robust optimization. Finally, by removing the assumption of a known structural causal model, we provide finite sample error bounds when designing DRO with empirical distributions and estimated causal structures to ensure efficiency and robust learning.

Out-of-distribution (OOD) detection is critical for deploying machine learning models in the open world. To design scoring functions that discern OOD data from the in-distribution (ID) cases from a pre-trained discriminative model, existing methods tend to make rigorous distributional assumptions either explicitly or implicitly due to the lack of knowledge about the learned feature space in advance.
The mismatch between the learned and assumed distributions motivates us to raise a fundamental yet under-explored question: \textit{Is it possible to deterministically model the feature distribution while pre-training a discriminative model?}
This paper gives an affirmative answer to this question by presenting a Distributional Representation Learning (\texttt{DRL}) framework for OOD detection. In particular, \texttt{DRL} explicitly enforces the underlying feature space to conform to a pre-defined mixture distribution, together with an online approximation of normalization constants to enable end-to-end training. Furthermore, we formulate \texttt{DRL} into a provably convergent Expectation-Maximization algorithm to avoid trivial solutions and rearrange the sequential sampling to guide the training consistency. Extensive evaluations across mainstream OOD detection benchmarks empirically manifest the superiority of the proposed \texttt{DRL} over its advanced counterparts.
tl;dr: We derive minimax rates for distributed goodness-of-fit testing for discrete distribution under bandwidth and differential privacy constraints in the regime where each server contains many observations.

We study distributed goodness-of-fit testing for discrete distribution under bandwidth and differential privacy constraints. Information constraint distributed goodness-of-fit testing is a problem that has received considerable attention recently. The important case of discrete distributions is theoretically well understood in the classical case where all data is available in one "central" location. In a federated setting, however, data is distributed across multiple "locations" (e.g. servers) and cannot readily be shared due to e.g. bandwidth or privacy constraints that each server needs to satisfy. We show how recently derived results for goodness-of-fit testing for the mean of a multivariate Gaussian model extend to the discrete distributions, by leveraging Le Cam's theory of statistical equivalence. In doing so, we derive matching minimax upper- and lower-bounds for the goodness-of-fit testing for discrete distributions under bandwidth or privacy constraints in the regime where number of samples held locally are large.
tl;dr: We introduce bounds and estimators for the effect of policies given observational data and a causal graph of the system.

As many practical fields transition to provide personalized decisions, data is increasingly relevant to support the evaluation of candidate plans and policies (e.g., guidelines for the treatment of disease, government directives, etc.). In the machine learning literature, significant efforts have been put into developing machinery to predict the effectiveness of policies efficiently. The challenge is that, in practice, the effectiveness of a candidate policy is not always identifiable, i.e., not uniquely estimable from the combination of the available data and assumptions about the domain at hand (e.g., encoded in a causal graph). In this paper, we develop graphical characterizations and estimation tools to bound the effect of policies given a causal graph and observational data collected in non-identifiable settings. Specifically, our contributions are two-fold: (1) we derive analytical bounds for general probabilistic and conditional policies that are tighter than existing results, (2) we develop an estimation framework to estimate bounds from finite samples, applicable in higher-dimensional spaces and continuously-valued data. We further show that the resulting estimators have favourable statistical properties such as fast convergence and robustness to model misspecification.
2340. Decision Mamba: A Multi-Grained State Space Model with Self-Evolution Regularization for Offline RL
tl;dr: We propose Decision Mamba tailored for the offline RL tasks, a novel multi-grained state space model with a self-evolving policy learning strategy.

While the conditional sequence modeling with the transformer architecture has demonstrated its effectiveness in dealing with offline reinforcement learning (RL) tasks, it is struggle to handle out-of-distribution states and actions.
Existing work attempts to address this issue by data augmentation with the learned policy or adding extra constraints with the value-based RL algorithm. However, these studies still fail to overcome the following challenges: (1) insufficiently utilizing the historical temporal information among inter-steps, (2) overlooking the local intra-step relationships among states, actions and return-to-gos (RTGs), (3) overfitting suboptimal trajectories with noisy labels. To address these challenges, we propose $\textbf{D}$ecision $\textbf{M}$amba ($\textbf{DM}$), a novel multi-grained state space model (SSM) with a self-evolving policy learning strategy.
DM explicitly models the historical hidden state to extract the temporal information by using the mamba architecture. To capture the relationship among state-action-RTG triplets, a fine-grained SSM module is designed and integrated into the original coarse-grained SSM in mamba, resulting in a novel mamba architecture tailored for offline RL. Finally, to mitigate the overfitting issue on noisy trajectories, a self-evolving policy is proposed by using progressive regularization. The policy evolves by using its own past knowledge to refine the suboptimal actions, thus enhancing its robustness on noisy demonstrations. Extensive experiments on various tasks show that DM outperforms other baselines substantially.

During natural evolution, the primary visual cortex (V1) of lower mammals typically forms salt-and-pepper organizations, while higher mammals and primates develop pinwheel structures with distinct topological properties. Despite the general belief that V1 neurons primarily serve as edge detectors, the functional advantages of pinwheel structures over salt-and-peppers are not well recognized. To this end, we propose a two-dimensional self-evolving spiking neural network that integrates Hebbian-like plasticity and empirical morphological data. Through extensive exposure to image data, our network evolves from salt-and-peppers to pinwheel structures, with neurons becoming localized bandpass filters responsive to various orientations. This transformation is accompanied by an increase in visual field overlap. Our findings indicate that neurons in pinwheel centers (PCs) respond more effectively to complex spatial textures in natural images, exhibiting stronger and quicker responses than those in salt-and-pepper organizations. PCs act as first-order stage processors with heightened sensitivity and reduced latency to intricate contours, while adjacent iso-orientation domains serve as second-order stage processors that refine edge representations for clearer perception. This study presents the first theoretical evidence that pinwheel structures function as crucial detectors of spatial contour saliency in the visual cortex.

Causal reasoning capability is critical in advancing large language models (LLMs) towards artificial general intelligence (AGI). While versatile LLMs appear to have demonstrated capabilities in understanding contextual causality and providing responses that obey the laws of causality, it remains unclear whether they perform genuine causal reasoning akin to humans. However, current evidence indicates the contrary. Specifically, LLMs are only capable of performing shallow (level-1) causal reasoning, primarily attributed to the causal knowledge embedded in their parameters, but they lack the capacity for genuine human-like (level-2) causal reasoning. To support this hypothesis, methodologically, we delve into the autoregression mechanism of transformer-based LLMs, revealing that it is not inherently causal. Empirically, we introduce a new causal Q&A benchmark named CausalProbe 2024, whose corpus is fresh and nearly unseen for the studied LLMs. Empirical results show a significant performance drop on CausalProbe 2024 compared to earlier benchmarks, indicating that LLMs primarily engage in level-1 causal reasoning.To bridge the gap towards level-2 causal reasoning, we draw inspiration from the fact that human reasoning is usually facilitated by general knowledge and intended goals. Inspired by this, we propose G$^2$-Reasoner, a LLM causal reasoning method that incorporates general knowledge and goal-oriented prompts into LLMs' causal reasoning processes. Experiments demonstrate that G$^2$-Reasoner significantly enhances LLMs' causal reasoning capability, particularly in fresh and fictitious contexts. This work sheds light on a new path for LLMs to advance towards genuine causal reasoning, going beyond level-1 and making strides towards level-2.

In recent years, there has been significant research focusing on addressing security concerns in single-modal person re-identification (ReID) systems that are based on RGB images. However, the safety of cross-modality scenarios, which are more commonly encountered in practical applications involving images captured by infrared cameras, has not received adequate attention. The main challenge in cross-modality ReID lies in effectively dealing with visual differences between different modalities. For instance, infrared images are typically grayscale, unlike visible images that contain color information. Existing attack methods have primarily focused on the characteristics of the visible image modality, overlooking the features of other modalities and the variations in data distribution among different modalities. This oversight can potentially undermine the effectiveness of these methods in image retrieval across diverse modalities. This study represents the first exploration into the security of cross-modality ReID models and proposes a universal perturbation attack specifically designed for cross-modality ReID. This attack optimizes perturbations by leveraging gradients from diverse modality data, thereby disrupting the discriminator and reinforcing the differences between modalities. We conducted experiments on three widely used cross-modality datasets, namely RegDB, SYSU, and LLCM. The results not only demonstrate the effectiveness of our method but also provide insights for future improvements in the robustness of cross-modality ReID systems.
tl;dr: A framework is proposed to generate a semantic density metric for measuring confidence of LLM outputs.

With the widespread application of Large Language Models (LLMs) to various domains, concerns regarding the trustworthiness of LLMs in safety-critical scenarios have been raised, due to their unpredictable tendency to hallucinate and generate misinformation. Existing LLMs do not have an inherent functionality to provide the users with an uncertainty/confidence metric for each response it generates, making it difficult to evaluate trustworthiness. Although several studies aim to develop uncertainty quantification methods for LLMs, they have fundamental limitations, such as being restricted to classification tasks, requiring additional training and data, considering only lexical instead of semantic information, and being prompt-wise but not response-wise. A new framework is proposed in this paper to address these issues. Semantic density extracts uncertainty/confidence information for each response from a probability distribution perspective in semantic space. It has no restriction on task types and is "off-the-shelf" for new models and tasks. Experiments on seven state-of-the-art LLMs, including the latest Llama 3 and Mixtral-8x22B models, on four free-form question-answering benchmarks demonstrate the superior performance and robustness of semantic density compared to prior approaches.

Priority queues are one of the most fundamental and widely used data structures in computer science. Their primary objective is to efficiently support the insertion of new elements with assigned priorities and the extraction of the highest priority element.
In this study, we investigate the design of priority queues within the learning-augmented framework, where algorithms use potentially inaccurate predictions to enhance their worst-case performance.
We examine three prediction models spanning different use cases, and we show how the predictions can be leveraged to enhance the performance of priority queue operations. Moreover, we demonstrate the optimality of our solution and discuss some possible applications.
tl;dr: A method inspired by ``matching'' that allows for implicit guidance, sidestepping the need for a discriminator. Training with a matched dataset approximates the gradient of a property and applies to design optimization in real-world datasets.

Across scientific domains, generating new models or optimizing existing ones while meeting specific criteria is crucial. Traditional machine learning frameworks for guided design use a generative model and a surrogate model (discriminator), requiring large datasets. However, real-world scientific applications often have limited data and complex landscapes, making data-hungry models inefficient or impractical. We propose a new framework, PropEn, inspired by ``matching'', which enables implicit guidance without training a discriminator. By matching each sample with a similar one that has a better property value, we create a larger training dataset that inherently indicates the direction of improvement. Matching, combined with an encoder-decoder architecture, forms a domain-agnostic generative framework for property enhancement. We show that training with a matched dataset approximates the gradient of the property of interest while remaining within the data distribution, allowing efficient design optimization. Extensive evaluations in toy problems and scientific applications, such as therapeutic protein design and airfoil optimization, demonstrate PropEn's advantages over common baselines. Notably, the protein design results are validated with wet lab experiments, confirming the competitiveness and effectiveness of our approach. Our code is available at https://github.com/prescient-design/propen.
tl;dr: We propose to solve an exact nonconvex relaxation of a cut-based framework for graph-based semi-supervised learning at low label rates.

Laplace learning algorithms for graph-based semi-supervised learning have been shown to produce degenerate predictions at low label rates and in imbalanced class regimes, particularly near class boundaries. We propose CutSSL: a framework for graph-based semi-supervised learning based on continuous nonconvex quadratic programming, which provably obtains \emph{integer} solutions. Our framework is naturally motivated by an \emph{exact} quadratic relaxation of a cardinality-constrained minimum-cut graph partitioning problem. Furthermore, we show our formulation is related to an optimization problem whose approximate solution is the mean-shifted Laplace learning heuristic, thus providing new insight into the performance of this heuristic. We demonstrate that CutSSL significantly surpasses the current state-of-the-art on k-nearest neighbor graphs and large real-world graph benchmarks across a variety of label rates, class imbalance, and label imbalance regimes. Our implementation is available on Colab\footnote{\url{https://colab.research.google.com/drive/1tGU5rxE1N5d0KGcNzlvZ0BgRc7_vob7b?usp=sharing}}.

We study a class of optimization problems in the Wasserstein space (the space of probability measures) where the objective function is nonconvex along generalized geodesics. Specifically, the objective exhibits some difference-of-convex structure along these geodesics. The setting also encompasses sampling problems where the logarithm of the target distribution is difference-of-convex. We derive multiple convergence insights for a novel semi Forward-Backward Euler scheme under several nonconvex (and possibly nonsmooth) regimes. Notably, the semi Forward-Backward Euler is just a slight modification of the Forward-Backward Euler whose convergence is---to our knowledge---still unknown in our very general non-geodesically-convex setting.

The Multi-modal Large Language Model (MLLM) based Referring Expression Generation (REG) task has gained increasing popularity, which aims to generate an unambiguous text description that applies to exactly one object or region in the image by leveraging foundation models. We empirically found that there exists a potential trade-off between the detailedness and the correctness of the descriptions for the referring objects. On the one hand, generating sentences with more details is usually required in order to provide more precise object descriptions. On the other hand, complicated sentences could easily increase the probability of hallucinations. To address this issue, we propose a training-free framework, named ``unleash-then-eliminate'', which first elicits the latent information in the intermediate layers, and then adopts a cycle-consistency-based decoding method to alleviate the production of hallucinations. Furthermore, to reduce the computational load of cycle-consistency-based decoding, we devise a Probing-based Importance Estimation method to statistically estimate the importance weights of intermediate layers within a subset. These importance weights are then incorporated into the decoding process over the entire dataset, intervening in the next token prediction from intermediate layers.
Extensive experiments conducted on the RefCOCOg and PHD benchmarks show that our proposed framework could outperform existing methods on both semantic and hallucination-related metrics. Code will be made available in https://github.com/Glupayy/unleash-eliminate.

In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we shed light on the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error analyses for a transformer model composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise $\gamma$-smooth class. In particular, we show that sufficiently trained transformers can achieve -- and even improve upon -- the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the \emph{pretraining} and \emph{in-context} generalization gaps, establishing upper and lower bounds w.r.t. both the number of tasks and in-context examples. These findings shed light on the effectiveness of few-shot prompting and the roles of task diversity and representation learning for ICL.
tl;dr: We generate formula based global explainations of graph neural networks using symbolic regression over computation trees identified through Shapley values.

Instance-level explanation of graph neural networks (GNNs) is a well-studied area. These explainers, however, only explain an instance (e.g., a graph) and fail to uncover the combinatorial reasoning learned by a GNN from the training data towards making its predictions. In this work, we introduce GraphTrail, the first end-to-end, global, post-hoc GNN explainer that translates the functioning of a black-box GNN model to a boolean formula over the (sub)graph level concepts without relying on local explainers. GraphTrail is unique in automatically mining the discriminative subgraph-level concepts using Shapley values. Subsequently, the GNN predictions are mapped to a human-interpretable boolean formula over these concepts through symbolic regression. Extensive experiments across diverse datasets and GNN architectures demonstrate significant improvement over existing global explainers in mapping GNN predictions to faithful logical formulae. The robust and accurate performance of GraphTrail makes it invaluable for improving GNNs and facilitates adoption in domains with strict transparency requirements.
tl;dr: We provide fine-grained primal-dual analysis and tighter bounds for shuffled SGD by interpreting it as a primal-dual method with cyclic updates on the dual side. Obtained improvements are up to order-$O(\sqrt{n})$ both theoretically and empirically.

Stochastic gradient descent (SGD) is perhaps the most prevalent optimization method in modern machine learning. Contrary to the empirical practice of sampling from the datasets \emph{without replacement} and with (possible) reshuffling at each epoch, the theoretical counterpart of SGD usually relies on the assumption of \emph{sampling with replacement}. It is only very recently that SGD using sampling without replacement -- shuffled SGD -- has been analyzed with matching upper and lower bounds. However, we observe that those bounds are too pessimistic to explain often superior empirical performance of data permutations (sampling without replacement) over vanilla counterparts (sampling with replacement) on machine learning problems. Through fine-grained analysis in the lens of primal-dual cyclic coordinate methods and the introduction of novel smoothness parameters, we present several results for shuffled SGD on smooth and non-smooth convex losses, where our novel analysis framework provides tighter convergence bounds over all popular shuffling schemes (IG, SO, and RR). Notably, our new bounds predict faster convergence than existing bounds in the literature -- by up to a factor of $O(\sqrt{n})$, mirroring benefits from tighter convergence bounds using component smoothness parameters in randomized coordinate methods. Lastly, we numerically demonstrate on common machine learning datasets that our bounds are indeed much tighter, thus offering a bridge between theory and practice.
tl;dr: Discretizing injective neural operators may cause them to lose injectivity, even with very flexible discretization methods.

In this work we consider the problem of discretization of neural operators in a general setting. Using category theory, we give a no-go theorem that shows that diffeomorphisms between Hilbert spaces may not admit any continuous approximations by diffeomorphisms on finite spaces, even if the discretization is non-linear. This shows how infinite-dimensional Hilbert spaces and finite-dimensional vector spaces fundamentally differ. A key take-away is that to obtain discretization invariance, considerable effort is needed to ensure that finite-dimensional approximations of neural operator converge not only as sequences of functions, but that their representations converge in a suitable sense as well. With this perspective, we give several positive results. We first show that strongly monotone diffeomorphism operators always admit finite-dimensional strongly monotone diffeomorphisms. Next we show that bilipschitz neural operators may always be written via the repeated alternating composition of strongly monotone neural operators and invertible linear maps. We also show that such operators may be inverted locally via iteration provided that such inverse exists. Finally, we conclude by showing how our framework may be used `out of the box' to prove quantitative approximation results for discretization of neural operators.

No-Reference Point Cloud Quality Assessment (NR-PCQA) aims to objectively assess the human perceptual quality of point clouds without relying on pristine-quality point clouds for reference. It is becoming increasingly significant with the rapid advancement of immersive media applications such as virtual reality (VR) and augmented reality (AR). However, current NR-PCQA models attempt to indiscriminately learn point cloud content and distortion representations within a single network, overlooking their distinct contributions to quality information. To address this issue, we propose DisPA, a novel disentangled representation learning framework for NR-PCQA. The framework trains a dual-branch disentanglement network to minimize mutual information (MI) between representations of point cloud content and distortion. Specifically, to fully disentangle representations, the two branches adopt different philosophies: the content-aware encoder is pretrained by a masked auto-encoding strategy, which can allow the encoder to capture semantic information from rendered images of distorted point clouds; the distortion-aware encoder takes a mini-patch map as input, which forces the encoder to focus on low-level distortion patterns. Furthermore, we utilize an MI estimator to estimate the tight upper bound of the actual MI and further minimize it to achieve explicit representation disentanglement. Extensive experimental results demonstrate that DisPA outperforms state-of-the-art methods on multiple PCQA datasets.

As large language models (LLMs) become increasingly advanced, their ability to exhibit compositional generalization---the capacity to combine learned skills in novel ways not encountered during training---has garnered significant attention. This type of generalization, particularly in scenarios beyond training data, is also of great interest in the study of AI safety and alignment. A recent study introduced the Skill-Mix evaluation, where models are tasked with composing a short paragraph demonstrating the use of a specified $k$-tuple of language skills. While small models struggled with composing even with $k=3$, larger models like GPT-4 performed reasonably well with $k=5$ and $6$.
In this paper, we employ a setup akin to Skill-Mix to evaluate the capacity of smaller models to learn compositional generalization from examples. Utilizing a diverse set of language skills---including rhetorical, literary, reasoning, theory of mind, and common sense---GPT was used to generate text samples that exhibit random subsets of $k$ skills. Subsequent fine-tuning of 7B and 13B parameter models on these combined skill texts, for increasing values of $k$, revealed the following findings: (1) Training on combinations of $k=2$ and $3$ skills results in noticeable improvements in the ability to compose texts with $k=4$ and $5$ skills, despite models never having seen such examples during training. (2) When skill categories are split into training and held-out groups, models significantly improve at composing texts with held-out skills during testing despite having only seen training skills during fine-tuning, illustrating the efficacy of the training approach even with previously unseen skills.
This study also suggests that incorporating skill-rich (potentially synthetic) text into training can substantially enhance the compositional capabilities of models.
tl;dr: We propose novel knowledge distillation methods based on Wasserstein Distance, which outperforms predominant KL divergence based ones and other state-of-the-art competitors.

Since pioneering work of Hinton et al., knowledge distillation based on Kullback-Leibler Divergence (KL-Div) has been predominant, and recently its variants have achieved compelling performance. However, KL-Div only compares probabilities of the corresponding category between the teacher and student while lacking a mechanism for cross-category comparison. Besides, KL-Div is problematic when applied to intermediate layers, as it cannot handle non-overlapping distributions and is unaware of geometry of the underlying manifold. To address these downsides, we propose a methodology of Wasserstein Distance (WD) based knowledge distillation. Specifically, we propose a logit distillation method called WKD-L based on discrete WD, which performs cross-category comparison of probabilities and thus can explicitly leverage rich interrelations among categories. Moreover, we introduce a feature distillation method called WKD-F, which uses a parametric method for modeling feature distributions and adopts continuous WD for transferring knowledge from intermediate layers. Comprehensive evaluations on image classification and object detection have shown (1) for logit distillation WKD-L outperforms very strong KL-Div variants; (2) for feature distillation WKD-F is superior to the KL-Div counterparts and state-of-the-art competitors.
2357. Probing Social Bias in Labor Market Text Generation by ChatGPT: A Masked Language Model Approach
tl;dr: This study examines how ChatGPT-generated job applications may reinforce social biases in the labor market through language patterns with a novel bias evaluation framework.

As generative large language models (LLMs) such as ChatGPT gain widespread adoption in various domains, their potential to propagate and amplify social biases, particularly in high-stakes areas such as the labor market, has become a pressing concern. AI algorithms are not only widely used in the selection of job applicants, individual job seekers may also make use of generative LLMs to help develop their job application materials. Against this backdrop, this research builds on a novel experimental design to examine social biases within ChatGPT-generated job applications in response to real job advertisements. By simulating the process of job application creation, we examine the language patterns and biases that emerge when the model is prompted with diverse job postings. Notably, we present a novel bias evaluation framework based on Masked Language Models to quantitatively assess social bias based on validated inventories of social cues/words, enabling a systematic analysis of the language used. Our findings show that the increasing adoption of generative AI, not only by employers but also increasingly by individual job seekers, can reinforce and exacerbate gender and social inequalities in the labor market through the use of biased and gendered language.
2358. Generalizing Consistency Policy to Visual RL with Prioritized Proximal Experience Regularization
tl;dr: This paper extends consistency policy to visual RL and achieves new SOTA performance on 21 visual control tasks.

With high-dimensional state spaces, visual reinforcement learning (RL) faces significant challenges in exploitation and exploration, resulting in low sample efficiency and training stability. As a time-efficient diffusion model, although consistency models have been validated in online state-based RL, it is still an open question whether it can be extended to visual RL. In this paper, we investigate the impact of non-stationary distribution and the actor-critic framework on consistency policy in online RL, and find that consistency policy was unstable during the training, especially in visual RL with the high-dimensional state space. To this end, we suggest sample-based entropy regularization to stabilize the policy training, and propose a consistency policy with prioritized proximal experience regularization (CP3ER) to improve sample efficiency. CP3ER achieves new state-of-the-art (SOTA) performance in 21 tasks across DeepMind control suite and Meta-world. To our knowledge, CP3ER is the first method to apply diffusion/consistency models to visual RL and demonstrates the potential of consistency models in visual RL.
2359. An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem
tl;dr: We can predict emergence in neural networks using a simple model that also demonstrates scaling laws.

Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time, training data, or model size increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute. We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.

Neural Collapse (NC) is a recently observed phenomenon in neural networks that characterises the solution space of the final classifier layer when trained until zero training loss. Specifically, NC suggests that the final classifier layer converges to a Simplex Equiangular Tight Frame (ETF), which maximally separates the weights corresponding to each class. By duality, the penultimate layer feature means also converge to the same simplex ETF. Since this simple symmetric structure is optimal, our idea is to utilise this property to improve convergence speed. Specifically, we introduce the notion of \textit{nearest simplex ETF geometry} for the penultimate layer features at any given training iteration, by formulating it as a Riemannian optimisation. Then, at each iteration, the classifier weights are implicitly set to the nearest simplex ETF by solving this inner-optimisation, which is encapsulated within a declarative node to allow backpropagation. Our experiments on synthetic and real-world architectures on classification tasks demonstrate that our approach accelerates convergence and enhances training stability.
tl;dr: We propose an algorithm for learning LLM routers without labeled data.

Large language models (LLMs) are increasingly used in applications where LLM inputs may span many different tasks. Recent work has found that the choice of LLM is consequential, and different LLMs may be good for different input samples. Prior approaches have thus explored how engineers might select an LLM to use for each sample (i.e. _routing_). While existing routing methods mostly require training auxiliary models on human-annotated data, our work explores whether it is possible to perform _unsupervised_ routing. We propose Smoothie, a weak supervision-inspired routing approach that requires no labeled data. Given a set of outputs from different LLMs, Smoothie constructs a latent variable graphical model over embedding representations of observable LLM outputs and unknown “true” outputs. Using this graphical model, we estimate sample-dependent quality scores for each LLM, and route each sample to the LLM with the highest corresponding score. We find that Smoothie's LLM quality-scores correlate with ground-truth model quality (correctly identifying the optimal model on 9/14 tasks), and that Smoothie outperforms baselines for routing by up to 10 points accuracy.

The recently introduced Consistency models pose an efficient alternative to diffusion algorithms, enabling rapid and good quality image synthesis. These methods overcome the slowness of diffusion models by directly mapping noise to data, while maintaining a (relatively) simpler training. Consistency models enable a fast one- or few-step generation, but they typically fall somewhat short in sample quality when compared to their diffusion origins.
In this work we propose a novel and highly effective technique for post-processing Consistency-based generated images, enhancing their perceptual quality. Our approach utilizes a joint classifier-discriminator model, in which both portions are trained adversarially. While the classifier aims to grade an image based on its assignment to a designated class, the discriminator portion of the very same network leverages the softmax values to assess the proximity of the input image to the targeted data manifold, thereby serving as an Energy-based Model. By employing example-specific projected gradient iterations under the guidance of this joint machine, we refine synthesized images and achieve an improved FID scores on the ImageNet 64x64 dataset for both Consistency-Training and Consistency-Distillation techniques.
tl;dr: This paper introduces a novel clip-level pipeline to explicitly unveils the invisible map elements.

Predicting and constructing road geometric information (e.g., lane lines, road markers) is a crucial task for safe autonomous driving, while such static map elements can be repeatedly occluded by various dynamic objects on the road. Recent studies have shown significantly improved vectorized high-definition (HD) map construction performance, but there has been insufficient investigation of temporal information across adjacent input frames (i.e., clips), which may lead to inconsistent and suboptimal prediction results. To tackle this, we introduce a novel paradigm of clip-level vectorized HD map construction, MapUnveiler, which explicitly unveils the occluded map elements within a clip input by relating dense image representations with efficient clip tokens. Additionally, MapUnveiler associates inter-clip information through clip token propagation, effectively utilizing long- term temporal map information. MapUnveiler runs efficiently with the proposed clip-level pipeline by avoiding redundant computation with temporal stride while building a global map relationship. Our extensive experiments demonstrate that MapUnveiler achieves state-of-the-art performance on both the nuScenes and Argoverse2 benchmark datasets. We also showcase that MapUnveiler significantly outperforms state-of-the-art approaches in a challenging setting, achieving +10.7% mAP improvement in heavily occluded driving road scenes. The project page can be found at https://mapunveiler.github.io.

We present a unified likelihood ratio-based confidence sequence (CS) for *any* (self-concordant) generalized linear model (GLM) that is guaranteed to be convex and numerically tight. We show that this is on par or improves upon known CSs for various GLMs, including Gaussian, Bernoulli, and Poisson. In particular, for the first time, our CS for Bernoulli has a $\mathrm{poly}(S)$-free radius where $S$ is the norm of the unknown parameter. Our first technical novelty is its derivation, which utilizes a time-uniform PAC-Bayesian bound with a uniform prior/posterior, despite the latter being a rather unpopular choice for deriving CSs. As a direct application of our new CS, we propose a simple and natural optimistic algorithm called **OFUGLB**, applicable to *any* generalized linear bandits (**GLB**; Filippi et al. (2010)). Our analysis shows that the celebrated optimistic approach simultaneously attains state-of-the-art regrets for various self-concordant (not necessarily bounded) **GLB**s, and even $\mathrm{poly}(S)$-free for bounded **GLB**s, including logistic bandits. The regret analysis, our second technical novelty, follows from combining our new CS with a new proof technique that completely avoids the previously widely used self-concordant control lemma (Faury et al., 2020, Lemma 9). Numerically, **OFUGLB** outperforms or is at par with prior algorithms for logistic bandits.
tl;dr: We show that simply perturbing weights during training with random multiplicative noises can improve robustness of neural networks to a wide range of corruptions.

Deep neural networks (DNNs) excel on clean images but struggle with corrupted ones. Incorporating specific corruptions into the data augmentation pipeline can improve robustness to those corruptions but may harm performance on clean images and other types of distortion. In this paper, we introduce an alternative approach that improves the robustness of DNNs to a wide range of corruptions without compromising accuracy on clean images. We first demonstrate that input perturbations can be mimicked by multiplicative perturbations in the weight space. Leveraging this, we propose Data Augmentation via Multiplicative Perturbation (DAMP), a training method that optimizes DNNs under random multiplicative weight perturbations. We also examine the recently proposed Adaptive Sharpness-Aware Minimization (ASAM) and show that it optimizes DNNs under adversarial multiplicative weight perturbations. Experiments on image classification datasets (CIFAR-10/100, TinyImageNet and ImageNet) and neural network architectures (ResNet50, ViT-S/16, ViT-B/16) show that DAMP enhances model generalization performance in the presence of corruptions across different settings. Notably, DAMP is able to train a ViT-S/16 on ImageNet from scratch, reaching the top-1 error of 23.7% which is comparable to ResNet50 without extensive data augmentations.

Sharpness Aware Minimization (SAM) enhances performance across various neural architectures and datasets. As models are continually scaled up to improve performance, a rigorous understanding of SAM’s scaling behaviour is paramount. To this end, we study the infinite-width limit of neural networks trained with SAM, using the Tensor Programs framework. Our findings reveal that the dynamics of standard SAM effectively reduce to applying SAM solely in the last layer in wide neural networks, even with optimal hyperparameters. In contrast, we identify a stable parameterization with layerwise perturbation scaling, which we call *Maximal Update and Perturbation Parameterization* ($\mu$P$^2$), that ensures all layers are both feature learning and effectively perturbed in the limit. Through experiments with MLPs, ResNets and Vision Transformers, we empirically demonstrate that $\mu$P$^2$ is the first parameterization to achieve hyperparameter transfer of the joint optimum of learning rate and perturbation radius across model scales. Moreover, we provide an intuitive condition to derive $\mu$P$^2$ for other perturbation rules like Adaptive SAM and SAM-ON, also ensuring balanced perturbation effects across all layers.
tl;dr: Direct calibration of noise to attack risk increases utility of DP mechanisms at the same level of risk, compared to calibration of noise to a given level of epsilon.

Differential privacy (DP) is a widely used approach for mitigating privacy risks when training machine learning models on sensitive data. DP mechanisms add noise during training to limit the risk of information leakage. The scale of the added noise is critical, as it determines the trade-off between privacy and utility. The standard practice is to select the noise scale to satisfy a given privacy budget ε. This privacy budget is in turn interpreted in terms of operational attack risks, such as accuracy, sensitivity, and specificity of inference attacks aimed to recover
information about the training data records. We show that first calibrating the noise scale to a privacy budget ε, and then translating ε to attack risk leads to overly conservative risk assessments and unnecessarily low utility. Instead, we propose methods to directly calibrate the noise scale to a desired attack risk level, bypassing the step of choosing ε. For a given notion of attack risk, our approach significantly
decreases noise scale, leading to increased utility at the same level of privacy. We empirically demonstrate that calibrating noise to attack sensitivity/specificity, rather than ε, when training privacy-preserving ML models substantially improves model accuracy for the same risk level. Our work provides a principled and practical way to improve the utility of privacy-preserving ML without compromising on privacy.

Single-stage neural combinatorial optimization solvers have achieved near-optimal results on various small-scale combinatorial optimization (CO) problems without requiring expert knowledge. However, these solvers exhibit significant performance degradation when applied to large-scale CO problems. Recently, two-stage neural methods motivated by divide-and-conquer strategies have shown efficiency in addressing large-scale CO problems. Nevertheless, the performance of these methods highly relies on problem-specific heuristics in either the dividing or the conquering procedure, which limits their applicability to general CO problems. Moreover, these methods employ separate training schemes and ignore the interdependencies between the dividing and conquering strategies, often leading to sub-optimal solutions. To tackle these drawbacks, this article develops a unified neural divide-and-conquer framework (i.e., UDC) for solving general large-scale CO problems. UDC offers a Divide-Conquer-Reunion (DCR) training method to eliminate the negative impact of a sub-optimal dividing policy. Employing a high-efficiency Graph Neural Network (GNN) for global instance dividing and a fixed-length sub-path solver for conquering divided sub-problems, the proposed UDC framework demonstrates extensive applicability, achieving superior performance in 10 representative large-scale CO problems. The code is available at https://github.com/CIAM-Group/NCO_code/tree/main/single_objective/UDC-Large-scale-CO-master
tl;dr: we introduce a federated data augmentation algorithm that shares the augmentation policies.

Federated Learning (FL) allows multiple clients to collaboratively train models without directly sharing their private data. While various data augmentation techniques have been actively studied in the FL environment, most of these methods share input-level or feature-level data information over communication, posing potential privacy leakage. In response to this challenge, we introduce a federated data augmentation algorithm named FedAvP that shares only the augmentation policies, not the data-related information.
For data security and efficient policy search, we interpret the policy loss as a meta update loss in standard FL algorithms and utilize the first-order gradient information to further enhance privacy and reduce communication costs. Moreover, we propose a meta-learning method to search for adaptive personalized policies tailored to heterogeneous clients. Our approach outperforms existing best performing augmentation policy search methods and federated data augmentation methods, in the benchmarks for heterogeneous FL.
tl;dr: Temporal optimal transport reward for policy learning

Reward specification is one of the most tricky problems in Reinforcement Learning, which usually requires tedious hand engineering in practice. One promising approach to tackle this challenge is to adopt existing expert video demonstrations for policy learning. Some recent work investigates how to learn robot policies from only a single/few expert video demonstrations. For example, reward labeling via Optimal Transport (OT) has been shown to be an effective strategy to generate a proxy reward by measuring the alignment between the robot trajectory and the expert demonstrations. However, previous work mostly overlooks that the OT reward is invariant to temporal order information, which could bring extra noise to the reward signal. To address this issue, in this paper, we introduce the Temporal Optimal Transport (TemporalOT) reward to incorporate temporal order information for learning a more accurate OT-based proxy reward. Extensive experiments on the Meta-world benchmark tasks validate the efficacy of the proposed method. Our code is available at: https://github.com/fuyw/TemporalOT.
tl;dr: A YOLO model for object detection

Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and the model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings the competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both the efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves the state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$\times$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$\times$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46\% less latency and 25\% fewer parameters for the same performance. Code and models are available at https://github.com/THU-MIG/yolov10.
2372. Abstracted Shapes as Tokens - A Generalizable and Interpretable Model for Time-series Classification
tl;dr: A generalizable, interpretable, pre-trained model for time-series modeling and classification.

In time-series analysis, many recent works seek to provide a unified view and representation for time-series across multiple domains, leading to the development of foundation models for time-series data. Despite diverse modeling techniques, existing models are black boxes and fail to provide insights and explanations about their representations. In this paper, we present VQShape, a pre-trained, generalizable, and interpretable model for time-series representation learning and classification. By introducing a novel representation for time-series data, we forge a connection between the latent space of VQShape and shape-level features. Using vector quantization, we show that time-series from different domains can be described using a unified set of low-dimensional codes, where each code can be represented as an abstracted shape in the time domain. On classification tasks, we show that the representations of VQShape can be utilized to build interpretable classifiers, achieving comparable performance to specialist models. Additionally, in zero-shot learning, VQShape and its codebook can generalize to previously unseen datasets and domains that are not included in the pre-training process. The code and pre-trained weights are available at https://github.com/YunshiWen/VQShape.
tl;dr: We provide a method that removes information about harmful representations in large language models which can mitigate the model from being fine-tuned on harmful datasets.

Releasing open-source large language models (LLMs) presents a dual-use risk since bad actors can easily fine-tune these models for harmful purposes. Even without the open release of weights, weight stealing and fine-tuning APIs make closed models vulnerable to harmful fine-tuning attacks (HFAs). While safety measures like preventing jailbreaks and improving safety guardrails are important, such measures can easily be reversed through fine-tuning. In this work, we propose Representation Noising (\textsf{\small RepNoise}), a defence mechanism that operates even when attackers have access to the weights. \textsf{\small RepNoise} works by removing information about harmful representations such that it is difficult to recover them during fine-tuning. Importantly, our defence is also able to generalize across different subsets of harm that have not been seen during the defence process as long as they are drawn from the same distribution of the attack set. Our method does not degrade the general capability of LLMs and retains the ability to train the model on harmless tasks. We provide empirical evidence that the efficacy of our defence lies in its ``depth'': the degree to which information about harmful representations is removed across {\em all layers} of the LLM. We also find areas where \textsf{\small RepNoise} still remains ineffective and highlight how those limitations can inform future research.
tl;dr: We provide an alternative perspective for classification with rejection by learning density ratios.

Classification with rejection emerges as a learning paradigm which allows models to abstain from making predictions.
The predominant approach is to alter the supervised learning pipeline by augmenting typical loss functions, letting model rejection incur a lower loss than an incorrect prediction.
Instead, we propose a different distributional perspective, where we seek to find an idealized data distribution which maximizes a pretrained model's performance.
This can be formalized via the optimization of a loss's risk with a $ \phi$-divergence regularization term.
Through this idealized distribution, a rejection decision can be made by utilizing the density ratio between this distribution and the data distribution.
We focus on the setting where our $ \phi $-divergences are specified by the family of $ \alpha $-divergence.
Our framework is tested empirically over clean and noisy datasets.
2375. Recognize Any Regions

Understanding the semantics of individual regions or patches of unconstrained images, such as open-world object detection, remains a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise,
and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module.
Extensive experiments in open-world object recognition show that our RegionSpot achieves significant performance gain over prior alternatives, along with substantial computational savings (e.g., training our model with 3 million data in a single day using 8 V100 GPUs).
RegionSpot outperforms GLIP-L by 2.9 in mAP on LVIS val set, with an even larger margin of 13.1 AP for more challenging and rare categories, and a 2.5 AP increase on ODinW. Furthermore, it exceeds GroundingDINO-L by 11.0 AP for rare categories on the LVIS minival set.

Recent advancements in Multimodal Large Language Models (MLLMs) have greatly improved their abilities in image understanding. However, these models often struggle with grasping pixel-level semantic details, e.g., the keypoints of an object. To bridge this gap, we introduce the novel challenge of Semantic Keypoint Comprehension, which aims to comprehend keypoints across different task scenarios, including keypoint semantic understanding, visual prompt-based keypoint detection, and textual prompt-based keypoint detection. Moreover, we introduce KptLLM, a unified multimodal model that utilizes an identify-then-detect strategy to effectively address these challenges. KptLLM underscores the initial discernment of semantics in keypoints, followed by the precise determination of their positions through a chain-of-thought process. With several carefully designed modules, KptLLM adeptly handles various modality inputs, facilitating the interpretation of both semantic contents and keypoint locations. Our extensive experiments demonstrate KptLLM's superiority in various keypoint detection benchmarks and its unique semantic capabilities in interpreting keypoints.
tl;dr: We provide a comprehensive study of the common practices in the Most Influential Subset Selection (MISS) problem.

How can we attribute the behaviors of machine learning models to their training data? While the classic influence function sheds light on the impact of individual samples, it often fails to capture the more complex and pronounced collective influence of a set of samples. To tackle this challenge, we study the Most Influential Subset Selection (MISS) problem, which aims to identify a subset of training samples with the greatest collective influence. We conduct a comprehensive analysis of the prevailing approaches in MISS, elucidating their strengths and weaknesses. Our findings reveal that influence-based greedy heuristics, a dominant class of algorithms in MISS, can provably fail even in linear regression. We delineate the failure modes, including the errors of influence function and the non-additive structure of the collective influence. Conversely, we demonstrate that an adaptive version of these heuristics which applies them iteratively, can effectively capture the interactions among samples and thus partially address the issues. Experiments on real-world datasets corroborate these theoretical findings, and further demonstrate that the merit of adaptivity can extend to more complex scenarios such as classification tasks and non-linear neural networks. We conclude our analysis by emphasizing the inherent trade-off between performance and computational efficiency, questioning the use of additive metrics such as the linear datamodeling score, and offering a range of discussions.

We study online control for continuous-time linear systems with finite sampling rates, where the objective is to design an online procedure that learns under non-stochastic noise and performs comparably to a fixed optimal linear controller.
We present a novel two-level online algorithm, by integrating a higher-level learning strategy and a lower-level feedback control strategy. This method offers a practical and robust solution for online control, which achieves sublinear regret. Our work provides the first nonasymptotic results for controlling continuous-time linear systems with finite number of interactions with the system. Moreover, we examine how to train an agent in domain randomization environments from a non-stochastic control perspective. By applying our method to the SAC (Soft Actor-Critic) algorithm, we achieved improved results in multiple reinforcement learning tasks within domain randomization environments. Our work provides new insights into non-asymptotic analyses of controlling continuous-time systems. Furthermore, our work brings practical intuition into controller learning under non-stochastic environments.
tl;dr: We prove implicit bias of gradient descent for linearly separable multiclass problems.

Implicit bias describes the phenomenon where optimization-based training algorithms, without explicit regularization, show a preference for simple estimators even when more complex estimators have equal objective values. Multiple works have developed the theory of implicit bias for binary classification under the assumption that the loss satisfies an *exponential tail property*. However, there is a noticeable gap in analysis for multiclass classification, with only a handful of results which themselves are restricted to the cross-entropy loss. In this work, we employ the framework of Permutation Equivariant and Relative Margin-based (PERM) losses [Wang and Scott, 2024] to introduce a multiclass extension of the exponential tail property. This class of losses includes not only cross-entropy but also other losses. Using this framework, we extend the implicit bias result of Soudry et al. [2018] to multiclass classification. Furthermore, our proof techniques closely mirror those of the binary case, thus illustrating the power of the PERM framework for bridging the binary-multiclass gap.
tl;dr: We investigate a very strong convergence property applicable to GNN probabilistic classifiers -- asymptotic almost sure convergence -- and show that it applies to a broad range of GNN architectures and random graph models.

We present a new angle on the expressive power of graph neural networks (GNNs) by studying how the predictions of real-valued GNN classifiers, such as those classifying graphs probabilistically, evolve as we apply them on larger graphs drawn from some random graph model. We show that the output converges to a constant function, which upper-bounds what these classifiers can uniformly express. This strong convergence phenomenon applies to a very wide class of GNNs, including state of the art models, with aggregates including mean and the attention-based mechanism of graph transformers. Our results apply to a broad class of random graph models, including sparse and dense variants of the Erdős-Rényi model, the stochastic block model, and the Barabási-Albert model. We empirically validate these findings, observing that the convergence phenomenon appears not only on random graphs but also on some real-world graphs.
2381. Open LLMs are Necessary for Current Private Adaptations and Outperform their Closed Alternatives
tl;dr: We demonstrate that privately adapting open LLMs outperforms the recently proposed private adaptations for closed LLMs across all privacy regimes while using smaller model architectures and incurring lower financial costs.

While open Large Language Models (LLMs) have made significant progress, they still fall short of matching the performance of their closed, proprietary counterparts, making the latter attractive even for the use on highly *private* data.
Recently, various new methods have been proposed to adapt closed LLMs to private data without leaking private information to third parties and/or the LLM provider.
In this work, we analyze the privacy protection and performance of the four most recent methods for private adaptation of closed LLMs.
By examining their threat models and thoroughly comparing their performance under different privacy levels according to differential privacy (DP), various LLM architectures, and multiple datasets for classification and generation tasks, we find that: (1) all the methods leak query data, i.e., the (potentially sensitive) user data that is queried at inference time, to the LLM provider, (2) three out of four methods also leak large fractions of private training data to the LLM provider while the method that protects private data requires a local open LLM, (3) all the methods exhibit lower performance compared to three private gradient-based adaptation methods for *local open LLMs*, and (4) the private adaptation methods for closed LLMs incur higher monetary training and query costs than running the alternative methods on local open LLMs.
This yields the conclusion that, to achieve truly *privacy-preserving LLM adaptations* that yield high performance and more privacy at lower costs, taking into account current methods and models, one should use open LLMs.

Computation graphs are Directed Acyclic Graphs (DAGs) where the nodes correspond to mathematical operations and are used widely as abstractions in optimizations of neural networks. The device placement problem aims to identify optimal allocations of those nodes to a set of (potentially heterogeneous) devices. Existing approaches rely on two types of architectures known as grouper-placer and encoder-placer, respectively. In this work, we bridge the gap between encoder-placer and grouper-placer techniques and propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into account the DAG nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and jointed, personalized graph partitioning, using an unspecified number of groups. To train the entire framework, we use reinforcement learning using the execution time of the placement as a reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.

Language-guided robotic manipulation is a challenging task that requires an embodied agent to follow abstract user instructions to accomplish various complex manipulation tasks. Previous work generally maps instructions and visual perceptions directly to low-level executable actions, neglecting the modeling of critical waypoints (e.g., key states of “close to/grab/move up” in action trajectories) in manipulation tasks.
To address this issue, we propose a PImitive-driVen waypOinT-aware world model for Robotic manipulation (PIVOT-R) that focuses solely on the prediction of task-relevant waypoints. Specifically, PIVOT-R consists of a Waypoint-aware World Model (WAWM) and a lightweight action prediction module. The former performs primitive action parsing and primitive-driven waypoint prediction, while the latter focuses on decoding low-level actions. Additionally, we also design an asynchronous hierarchical executor (AHE) for PIVOT-R, which can use different execution frequencies for different modules of the model, thereby helping the model reduce computational redundancy and improve model execution efficiency. Our PIVOT-R outperforms state-of-the-art (SoTA) open-source models on the SeaWave benchmark, achieving an average relative improvement of 19.45% across four levels of instruction tasks. Moreover, compared to the synchronously executed PIVOT-R, the execution efficiency of PIVOT-R with AHE is increased by 28-fold, with only a 2.9% drop in performance. These results provide compelling evidence that our PIVOT-R can significantly improve both the performance and efficiency of robotic manipulation.
tl;dr: Roughly speaking, we show that distributional reinforcement learning is of comparable statistical difficulty to learning a value function, in the generative model setting.

We propose a new algorithm for model-based distributional reinforcement learning (RL), and prove that it is minimax-optimal for approximating return distributions in the generative model regime (up to logarithmic factors), the first result of this kind for any distributional RL algorithm. Our analysis also provides new theoretical perspectives on categorical approaches to distributional RL, as well as introducing a new distributional Bellman equation, the stochastic categorical CDF Bellman equation, which we expect to be of independent interest. Finally, we provide an experimental study comparing a variety of model-based distributional RL algorithms, with several key takeaways for practitioners.

The rapid development of large language and vision models (LLVMs) has been driven by advances in visual instruction tuning. Recently, open-source LLVMs have curated high-quality visual instruction tuning datasets and utilized additional vision encoders or multiple computer vision models in order to narrow the performance gap with powerful closed-source LLVMs. These advancements are attributed to multifaceted information required for diverse capabilities, including fundamental image understanding, real-world knowledge about common-sense and non-object concepts (e.g., charts, diagrams, symbols, signs, and math problems), and step-by-step procedures for solving complex questions. Drawing from the multifaceted information, we present a new efficient LLVM, Mamba-based traversal of rationales (Meteor), which leverages multifaceted rationale to enhance understanding and answering capabilities. To embed lengthy rationales containing abundant information, we employ the Mamba architecture, capable of processing sequential data with linear time complexity. We introduce a new concept of traversal of rationale that facilitates efficient embedding of rationale. Subsequently, the backbone multimodal language model (MLM) is trained to generate answers with the aid of rationale. Through these steps, Meteor achieves significant improvements in vision language performances across multiple evaluation benchmarks requiring diverse capabilities, without scaling up the model size or employing additional vision encoders and computer vision models.

Recent advancements in vision-language-to-image (VL2I) diffusion generation have made significant progress. While generating images from broad vision-language inputs holds promise, it also raises concerns about potential misuse, such as copying artistic styles without permission, which could have legal and social consequences. Therefore, it's crucial to establish governance frameworks to ensure ethical and copyright integrity, especially with widely used diffusion models. To address these issues, researchers have explored various approaches, such as dataset filtering, adversarial perturbations, machine unlearning, and inference-time refusals. However, these methods often lack either scalability or effectiveness. In response, we propose a new framework called causal representation editing (CRE), which extends representation editing from large language models (LLMs) to diffusion-based models. CRE enhances the efficiency and flexibility of safe content generation by intervening at diffusion timesteps causally linked to unsafe concepts. This allows for precise removal of harmful content while preserving acceptable content quality, demonstrating superior effectiveness, precision and scalability compared to existing methods. CRE can handle complex scenarios, including incomplete or blurred representations of unsafe concepts, offering a promising solution to challenges in managing harmful content generation in diffusion-based models.

Unsupervised domain adaptation methods have demonstrated superior capabilities in handling the domain shift issue which widely exists in various time series tasks. However, their prominent adaptation performances heavily rely on complex model architectures, posing an unprecedented challenge in deploying them on resource-limited devices for real-time monitoring. Existing approaches, which integrates knowledge distillation into domain adaptation frameworks to simultaneously address domain shift and model complexity, often neglect network capacity gap between teacher and student and just coarsely align their outputs over all source and target samples, resulting in poor distillation efficiency. Thus, in this paper, we propose an innovative framework named Reinforced Cross-Domain Knowledge Distillation (RCD-KD) which can effectively adapt to student's network capability via dynamically selecting suitable target domain samples for knowledge transferring. Particularly, a reinforcement learning-based module with a novel reward function is proposed to learn optimal target sample selection policy based on student's capacity. Meanwhile, a domain discriminator is designed to transfer the domain invariant knowledge. Empirical experimental results and analyses on four public time series datasets demonstrate the effectiveness of our proposed method over other state-of-the-art benchmarks.
tl;dr: We propose to perform unsupervised out-of-distribution detection using a single unconditional diffusion model by characterizing properties of the diffusion path.

Out-of-distribution (OOD) detection is a critical task in machine learning that seeks to identify abnormal samples. Traditionally, unsupervised methods utilize a deep generative model for OOD detection. However, such approaches require a new model to be trained for each inlier dataset. This paper explores whether a single model can perform OOD detection across diverse tasks. To that end, we introduce Diffusion Paths (DiffPath), which uses a single diffusion model originally trained to perform unconditional generation for OOD detection. We introduce a novel technique of measuring the rate-of-change and curvature of the diffusion paths connecting samples to the standard normal. Extensive experiments show that with a single model, DiffPath is competitive with prior work using individual models on a variety of OOD tasks involving different distributions. Our code is publicly available at https://github.com/clear-nus/diffpath.
tl;dr: An approach that leverages spatial information to improve the detection and diagnosis of time series anomalies.

Anomaly detection in time series data is fundamental to the design, deployment, and evaluation of industrial control systems. Temporal modeling has been the natural focus of anomaly detection approaches for time series data. However, the focus on temporal modeling can obscure or dilute the spatial information that can be used to capture complex interactions in multivariate time series. In this paper, we propose SARAD, an approach that leverages spatial information beyond data autoencoding errors to improve the detection and diagnosis of anomalies. SARAD trains a Transformer to learn the spatial associations, the pairwise inter-feature relationships which ubiquitously characterize such feedback-controlled systems. As new associations form and old ones dissolve, SARAD applies subseries division to capture their changes over time. Anomalies exhibit association descending patterns, a key phenomenon we exclusively observe and attribute to the disruptive nature of anomalies detaching anomalous features from others. To exploit the phenomenon and yet dismiss non-anomalous descent, SARAD performs anomaly detection via autoencoding in the association space. We present experimental results to demonstrate that SARAD achieves state-of-the-art performance, providing robust anomaly detection and a nuanced understanding of anomalous events.
tl;dr: We develop a theory for automatic data selection when you know what you want to learn. We show that knowing what you want a model to learn can be leveraged to learn much more efficiently than just trying to learn "everything".

We study a generalization of classical active learning to real-world settings with concrete prediction targets where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region.
We analyze a family of decision rules that sample adaptively to minimize uncertainty about prediction targets.
We are the first to show, under general regularity assumptions, that such decision rules converge uniformly to the smallest possible uncertainty obtainable from the accessible data.
We demonstrate their strong sample efficiency in two key applications: active fine-tuning of large neural networks and safe Bayesian optimization, where they achieve state-of-the-art performance.
tl;dr: Image stimuli can be reconstructed from the brain without actually using a lot of the brain signal

When evaluating stimuli reconstruction results it is tempting to assume that higher fidelity text and image generation is due to an improved understanding of the brain or more powerful signal extraction from neural recordings. However, in practice, new reconstruction methods could improve performance for at least three other reasons: learning more about the distribution of stimuli, becoming better at reconstructing text or images in general, or exploiting weaknesses in current image and/or text evaluation metrics. Here we disentangle how much of the reconstruction is due to these other factors vs. productively using the neural recordings. We introduce BrainBits, a method that uses a bottleneck to quantify the amount of signal extracted from neural recordings that is actually necessary to reproduce a method's reconstruction fidelity. We find that it takes surprisingly little information from the brain to produce reconstructions with high fidelity. In these cases, it is clear that the priors of the methods' generative models are so powerful that the outputs they produce extrapolate far beyond the neural signal they decode. Given that reconstructing stimuli can be improved independently by either improving signal extraction from the brain or by building more powerful generative models, improving the latter may fool us into thinking we are improving the former. We propose that methods should report a method-specific random baseline, a reconstruction ceiling, and a curve of performance as a function of bottleneck size, with the ultimate goal of using more of the neural recordings.
tl;dr: We build a simulation environment to test sustainability behavior in a society of LLMs, based on the economics theory of Governing the Commons.

As AI systems pervade human life, ensuring that large language models (LLMs) make safe decisions remains a significant challenge. We introduce the Governance of the Commons Simulation (GovSim), a generative simulation platform designed to study strategic interactions and cooperative decision-making in LLMs. In GovSim, a society of AI agents must collectively balance exploiting a common resource with sustaining it for future use. This environment enables the study of how ethical considerations, strategic planning, and negotiation skills impact cooperative outcomes. We develop an LLM-based agent architecture and test it with the leading open and closed LLMs. We find that all but the most powerful LLM agents fail to achieve a sustainable equilibrium in GovSim, with the highest survival rate below 54%. Ablations reveal that successful multi-agent communication between agents is critical for achieving cooperation in these cases. Furthermore, our analyses show that the failure to achieve sustainable cooperation in most LLMs stems from their inability to formulate and analyze hypotheses about the long-term effects of their actions on the equilibrium of the group. Finally, we show that agents that leverage "Universalization"-based reasoning, a theory of moral thinking, are able to achieve significantly better sustainability. Taken together, GovSim enables us to study the mechanisms that underlie sustainable self-government with specificity and scale. We open source the full suite of our research results, including the simulation environment, agent prompts, and a comprehensive web interface.
tl;dr: We present \textbf{Embedding-COrrupted (ECO) Prompts}, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency.

Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use. However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters. In this work, we present \textbf{Embedding-COrrupted (ECO) Prompts}, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget. We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting. Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at \textit{nearly zero side effects} in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases. We have made our code publicly available at \url{https://github.com/chrisliu298/llm-unlearn-eco}.
tl;dr: enhancing continual knowledge learning performance through meta-learning based token weighted learning method

Previous studies on continual knowledge learning (CKL) in large language models (LLMs) have predominantly focused on approaches such as regularization, architectural modifications, and rehearsal techniques to mitigate catastrophic forgetting. However, these methods naively inherit the inefficiencies of standard training procedures, indiscriminately applying uniform weight across all tokens, which can lead to unnecessary parameter updates and increased forgetting. To address these shortcomings, we propose a novel CKL approach termed Train-Attention-Augmented Language Model (TAALM), which enhances learning efficiency by dynamically predicting and applying weights to tokens based on their usefulness. This method employs a meta-learning framework that optimizes token importance predictions, facilitating targeted knowledge updates and minimizing forgetting. Also, we observe that existing benchmarks do not clearly exhibit the trade-off between learning and retaining, therefore we propose a new benchmark, LAMA-ckl, to address this issue. Through experiments conducted on both newly introduced and established CKL benchmarks, TAALM proves the state-of-the-art performance upon the baselines, and also shows synergistic compatibility when integrated with previous CKL approaches. The code and the dataset are available online.

Blended-target domain adaptation (BTDA), which implicitly mixes multiple sub-target domains into a fine domain, has attracted more attention in recent years. Most previously developed BTDA approaches focus on utilizing a single source domain, which makes it difficult to obtain sufficient feature information for learning domain-invariant representations. Furthermore, different feature distributions derived from different domains may increase the uncertainty of models. To overcome these issues, we propose a style adaptation and uncertainty estimation (SAUE) approach for multi-source blended-target domain adaptation (MBDA). Specifically, we exploit the extra knowledge acquired from the blended-target domain, where a similarity factor is adopted to select more useful target style information for augmenting the source features. \!Then, to mitigate the negative impact of the domain-specific attributes, we devise a function to estimate and mitigate uncertainty in category prediction. Finally, we construct a simple and lightweight adversarial learning strategy for MBDA, effectively aligning multi-source and blended-target domains without the requirements of domain labels of the target domains. Extensive experiments conducted on several challenging DA benchmarks, including the ImageCLEF-DA, Office-Home, VisDA 2017, and DomainNet datasets, demonstrate the superiority of our method over the state-of-the-art (SOTA) approaches.

In model inversion attacks (MIAs), adversaries attempt to recover private training data by exploiting access to a well-trained target model. Recent advancements have improved MIA performance using a two-stage generative framework. This approach first employs a generative adversarial network to learn a fixed distributional prior, which is then used to guide the inversion process during the attack. However, in this paper, we observed a phenomenon that such a fixed prior would lead to a low probability of sampling actual private data during the inversion process due to the inherent distribution gap between the prior distribution and the private data distribution, thereby constraining attack performance. To address this limitation, we propose increasing the density around high-quality pseudo-private data—recovered samples through model inversion that exhibit characteristics of the private training data—by slightly tuning the generator. This strategy effectively increases the probability of sampling actual private data that is close to these pseudo-private data during the inversion process. After integrating our method, the generative model inversion pipeline is strengthened, leading to improvements over state-of-the-art MIAs. This paves the way for new research directions in generative MIAs.

We present a novel method, Contextual goal-Oriented Data Augmentation (CODA), which uses commonly available unlabeled trajectories and context-goal pairs to solve Contextual Goal-Oriented (CGO) problems. By carefully constructing an action-augmented MDP that is equivalent to the original MDP, CODA creates a fully labeled transition dataset under training contexts without additional approximation error. We conduct a novel theoretical analysis to demonstrate CODA's capability to solve CGO problems in the offline data setup. Empirical results also showcase the effectiveness of CODA, which outperforms other baseline methods across various context-goal relationships of CGO problem. This approach offers a promising direction to solving CGO problems using offline datasets.
tl;dr: We propose generic and effective Proactive Infeasibility Prevention (PIP) frameworks to advance the capabilities of neural methods towards more complex VRPs.

Vehicle Routing Problems (VRPs) can model many real-world scenarios and often involve complex constraints. While recent neural methods excel in constructing solutions based on feasibility masking, they struggle with handling complex constraints, especially when obtaining the masking itself is NP-hard. In this paper, we propose a novel Proactive Infeasibility Prevention (PIP) framework to advance the capabilities of neural methods towards more complex VRPs. Our PIP integrates the Lagrangian multiplier as a basis to enhance constraint awareness and introduces preventative infeasibility masking to proactively steer the solution construction process. Moreover, we present PIP-D, which employs an auxiliary decoder and two adaptive strategies to learn and predict these tailored masks, potentially enhancing performance while significantly reducing computational costs during training. To verify our PIP designs, we conduct extensive experiments on the highly challenging Traveling Salesman Problem with Time Window (TSPTW), and TSP with Draft Limit (TSPDL) variants under different constraint hardness levels. Notably, our PIP is generic to boost many neural methods, and exhibits both a significant reduction in infeasible rate and a substantial improvement in solution quality.

Label Distribution Learning (LDL) has been extensively studied in IID data applications such as computer vision, thanks to its more generic setting over single-label and multi-label classification.
This paper advances LDL into graph domains and aims to tackle a novel and fundamental
heterogeneous graph label distribution learning (HGDL) problem.
We argue that
the graph heterogeneity reflected on node types, node attributes, and neighborhood structures can
impose significant challenges for generalizing
LDL onto graphs.
To address the challenges, we propose a new
learning framework with two key components:
1) proactive graph topology homogenization,
and 2) topology and content consistency-aware graph transformer.
Specifically,
the former learns optimal information aggregation between meta-paths, so that the node
heterogeneity can be proactively addressed prior to the succeeding embedding learning; the latter leverages an attention mechanism to learn consistency between meta-path and node attributes, allowing network topology and nodal attributes to be equally emphasized during the label distribution learning. By using KL-divergence and additional constraints, \method~delivers
an end-to-end solution for learning and predicting label distribution for nodes.
Both theoretical and empirical studies substantiate
the effectiveness of our HGDL approach.
Our code and datasets are available at https://github.com/Listener-Watcher/HGDL.
tl;dr: we introduce a data synthesize approach for computer agents and achieve strong performance

LLMs can now act as autonomous agents that interact with digital environments and complete specific objectives (e.g., arranging an online meeting). However, accuracy is still far from satisfactory, partly due to a lack of large-scale, direct demonstrations for digital tasks. Obtaining supervised data from humans is costly, and automatic data collection through exploration or reinforcement learning relies on complex environmental and content setup, resulting in datasets that lack comprehensive coverage of various scenarios. On the other hand, there is abundant knowledge that may indirectly assist task completion, such as online tutorials that were created for human consumption. In this work, we present Synatra, an approach that effectively transforms this indirect knowledge into direct supervision at scale. We define different types of indirect knowledge, and carefully study the available sources to obtain it, methods to encode the structure of direct demonstrations, and finally methods to transform indirect knowledge into direct demonstrations. We use 100k such synthetically-created demonstrations to finetune a 7B CodeLlama, and demonstrate that the resulting agent surpasses all comparably sized models on three web-based task benchmarks Mind2Web, MiniWoB++ and WebArena, as well as surpassing GPT-3.5 on WebArena and Mind2Web. In addition, while synthetic demonstrations prove to be only 3% the cost of human demonstrations (at $0.031 each), we show that the synthetic demonstrations can be more effective than an identical number of human demonstrations collected from limited domains.
tl;dr: Using a dataset of fine-tuned diffusion models, we define a subspace in diffusion model weight space that enables controllable creation of new diffusion models.

We investigate the space of weights spanned by a large collection of customized diffusion models. We populate this space by creating a dataset of over 60,000 models, each of which is a base model fine-tuned to insert a different person's visual identity. We model the underlying manifold of these weights as a subspace, which we term $\textit{weights2weights}$. We demonstrate three immediate applications of this space that result in new diffusion models -- sampling, editing, and inversion. First, sampling a set of weights from this space results in a new model encoding a novel identity. Next, we find linear directions in this space corresponding to semantic edits of the identity (e.g., adding a beard), resulting in a new model with the original identity edited. Finally, we show that inverting a single image into this space encodes a realistic identity into a model, even if the input image is out of distribution (e.g., a painting). We further find that these linear properties of the diffusion model weight space extend to other visual concepts. Our results indicate that the weight space of fine-tuned diffusion models can behave as an interpretable $\textit{meta}$-latent space producing new models.
2402. N-agent Ad Hoc Teamwork
tl;dr: Proposes a generalization of ad hoc teamwork to the N-agent setting.

Current approaches to learning cooperative multi-agent behaviors assume relatively restrictive settings. In standard fully cooperative multi-agent reinforcement learning, the learning algorithm controls *all* agents in the scenario, while in ad hoc teamwork, the learning algorithm usually assumes control over only a *single* agent in the scenario. However, many cooperative settings in the real world are much less restrictive. For example, in an autonomous driving scenario, a company might train its cars with the same learning algorithm, yet once on the road, these cars must cooperate with cars from another company. Towards expanding the class of scenarios that cooperative learning methods may optimally address, we introduce $N$*-agent ad hoc teamwork* (NAHT), where a set of autonomous agents must interact and cooperate with dynamically varying numbers and types of teammates. This paper formalizes the problem, and proposes the *Policy Optimization with Agent Modelling* (POAM) algorithm. POAM is a policy gradient, multi-agent reinforcement learning approach to the NAHT problem, that enables adaptation to diverse teammate behaviors by learning representations of teammate behaviors. Empirical evaluation on tasks from the multi-agent particle environment and StarCraft II shows that POAM improves cooperative task returns compared to baseline approaches, and enables out-of-distribution generalization to unseen teammates.
tl;dr: Breaking free from isolation, this work presents an innovative multi-task spatio-temporal modeling approach, fostering interconnectedness among diverse data sources for enhanced prediction accuracy and adaptability in urban forecasting

Spatiotemporal learning has become a pivotal technique to enable urban intelligence. Traditional spatiotemporal models mostly focus on a specific task by assuming a same distribution between training and testing sets. However, given that urban systems are usually dynamic, multi-sourced with imbalanced data distributions, current specific task-specific models fail to generalize to new urban conditions and adapt to new domains without explicitly modeling interdependencies across various dimensions and types of urban data. To this end, we argue that there is an essential to propose a Continuous Multi-task Spatio-Temporal learning framework (CMuST) to empower collective urban intelligence, which reforms the urban spatiotemporal learning from single-domain to cooperatively multi-dimensional and multi-task learning. Specifically, CMuST proposes a new multi-dimensional spatiotemporal interaction network (MSTI) to allow cross-interactions between context and main observations as well as self-interactions within spatial and temporal aspects to be exposed, which is also the core for capturing task-level commonality and personalization. To ensure continuous task learning, a novel Rolling Adaptation training scheme (RoAda) is devised, which not only preserves task uniqueness by constructing data summarization-driven task prompts, but also harnesses correlated patterns among tasks by iterative model behavior modeling. We further establish a benchmark of three cities for multi-task spatiotemporal learning, and empirically demonstrate the superiority of CMuST via extensive evaluations on these datasets. The impressive improvements on both few-shot streaming data and new domain tasks against existing SOAT methods are achieved. Code is available at https://github.com/DILab-USTCSZ/CMuST.

Causal models are crucial for understanding complex systems and
identifying causal relationships among variables. Even though causal
models are extremely popular, conditional probability calculation of
formulas involving interventions pose significant challenges.
In case of Causal Bayesian Networks (CBNs), Pearl assumes autonomy
of mechanisms that determine interventions to calculate a range of
probabilities. We show that by making simple yet
often realistic independence assumptions, it is possible
to uniquely estimate the probability of an interventional formula (including
the well-studied notions of probability of sufficiency and necessity).
We discuss when these assumptions are appropriate.
Importantly, in many cases of interest, when the assumptions are appropriate,
these probability estimates can be evaluated using
observational data, which carries immense significance in scenarios
where conducting experiments is impractical or unfeasible.

Comprehensive and constructive evaluation protocols play an important role when developing sophisticated text-to-video (T2V) generation models. Existing evaluation protocols primarily focus on temporal consistency and content continuity, yet largely ignore dynamics of video content. Such dynamics is an essential dimension measuring the visual vividness and the honesty of video content to text prompts. In this study, we propose an effective evaluation protocol, termed DEVIL, which centers on the dynamics dimension to evaluate T2V generation models, as well as improving existing evaluation metrics. In practice, we define a set of dynamics scores corresponding to multiple temporal granularities, and a new benchmark of text prompts under multiple dynamics grades. Upon the text prompt benchmark, we assess the generation capacity of T2V models, characterized by metrics of dynamics ranges and T2V alignment. Moreover, we analyze the relevance of existing metrics to dynamics metrics, improving them from the perspective of dynamics. Experiments show that DEVIL evaluation metrics enjoy up to about 90\% consistency with human ratings, demonstrating the potential to advance T2V generation models.
tl;dr: A novel iterative learning paradigm with data-aware dynamic masking removes redundant connections, increases DNNs' capacity for learning, and improves generalization on small datasets.

The efficacy of deep learning techniques is contingent upon access to large volumes of data (labeled or unlabeled). However, in practical domains such as medical applications, data availability is often limited. This presents a significant challenge: How can we effectively train deep neural networks on relatively small datasets while improving generalization? Recent works have explored evolutionary or iterative training paradigms, which reinitialize a subset of parameters to enhance generalization performance for small datasets. However, these methods typically rely on randomly selected parameter subsets and maintain fixed masks throughout training, potentially leading to suboptimal outcomes. Inspired by neurogenesis in the brain, we propose a novel iterative training framework, Dynamic Neural Regeneration (DNR), that employs a data-aware dynamic masking scheme to eliminate redundant connections by estimating their significance. This approach increases the model's capacity for further learning through random weight reinitialization. Experimental results demonstrate that our approach outperforms existing methods in accuracy and robustness, highlighting its potential for real-world applications where data collection is challenging.
tl;dr: We study the geometry of conditional optimal transport from a dynamical perspective, and use our theory to build conditional generative models.

We study the geometry of conditional optimal transport (COT) and prove a dynamic formulation which generalizes the Benamou-Brenier Theorem. Equipped with these tools, we propose a simulation-free flow-based method for conditional generative modeling. Our method couples an arbitrary source distribution to a specified target distribution through a triangular COT plan, and a conditional generative model is obtained by approximating the geodesic path of measures induced by this COT plan. Our theory and methods are applicable in infinite-dimensional settings, making them well suited for a wide class of Bayesian inverse problems. Empirically, we demonstrate that our method is competitive on several challenging conditional generation tasks, including an infinite-dimensional inverse problem.
tl;dr: We employ ASG appearance field to enhance the 3D-GS for modeling scenes with specular highlights.

The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.

Sketch Re-identification (Sketch Re-ID),
which aims to retrieve target person from an image gallery based on a sketch query, is crucial for criminal investigation, law enforcement, and missing person searches.
Existing methods aim to alleviate the modality gap by employing semantic metrics constraints or auxiliary modal guidance. However, they incur expensive labor costs and inevitably omit fine-grained modality-consistent information due to the abstraction of sketches.
To address this issue, this paper proposes a novel $\textit{Optimal Transport-based Labor-free Text Prompt Modeling}$ (OLTM) network, which hierarchically extracts coarse- and fine-grained similarity representations guided by textual semantic information without any additional annotations.
Specifically, multiple target attributes are flexibly obtained by a pre-trained visual question answering (VQA) model. Subsequently, a text prompt reasoning module employs learnable prompt strategy and optimal transport algorithm to extract discriminative global and local text representations, which serve as a bridge for hierarchical and multi-granularity modal alignment between sketch and image modalities.
Additionally, instead of measuring the similarity of two samples by only computing their distance, a novel triplet assignment loss is further proposed, in which the whole data distribution also contributes to optimizing the inter/intra-class distances. Extensive experiments conducted on two public benchmarks consistently demonstrate the robustness and superiority of our OLTM over state-of-the-art methods.
2410. Unsupervised Modality Adaptation with Text-to-Image Diffusion Models for Semantic Segmentation

Despite their success, unsupervised domain adaptation methods for semantic segmentation primarily focus on adaptation between image domains and do not utilize other abundant visual modalities like depth, infrared and event. This limitation hinders their performance and restricts their application in real-world multimodal scenarios. To address this issue, we propose Modality Adaptation with text-to-image Diffusion Models (MADM) for semantic segmentation task which utilizes text-to-image diffusion models pre-trained on extensive image-text pairs to enhance the model's cross-modality capabilities. Specifically, MADM comprises two key complementary components to tackle major challenges. First, due to the large modality gap, using one modal data to generate pseudo labels for another modality suffers from a significant drop in accuracy. To address this, MADM designs diffusion-based pseudo-label generation which adds latent noise to stabilize pseudo-labels and enhance label accuracy. Second, to overcome the limitations of latent low-resolution features in diffusion models, MADM introduces the label palette and latent regression which converts one-hot encoded labels into the RGB form by palette and regresses them in the latent space, thus ensuring the pre-trained decoder for up-sampling to obtain fine-grained features. Extensive experimental results demonstrate that MADM achieves state-of-the-art adaptation performance across various modality tasks, including images to depth, infrared, and event modalities. We open-source our code and models at https://github.com/XiaRho/MADM.
tl;dr: We introduce the first sample-efficient algorithm for Latent MDPs under no additional structural assumptions.

In many real-world decision problems there is partially observed, hidden or latent information that remains fixed throughout an interaction.
Such decision problems can be modeled as Latent Markov Decision Processes (LMDPs), where a latent variable is selected at the beginning of an interaction and is not disclosed to the agent initially.
In last decade, there has been significant progress in designing learning algorithms for solving LMDPs under different structural assumptions. However, for general LMDPs, there is no known learning algorithm that provably matches the existing lower bound. We effectively resolve this open question, introducing the first sample-efficient algorithm for LMDPs without *any additional structural assumptions*.
Our result builds off a new perspective on the role off-policy evaluation guarantees and coverage coefficient in LMDPs, a perspective, which has been overlooked in the context of exploration in partially observed environments. Specifically, we establish a novel off-policy evaluation lemma and introduce a new coverage coefficient for LMDPs. Then, we show how these can be used to derive near-optimal guarantees of an optimistic exploration algorithm.
These results, we believe, can be valuable for a wide range of interactive learning problems beyond the LMDP class, and especially, for partially observed environments.
tl;dr: We propose the first least squares loss to solve Stochastic Optimal Control problems, and show that it outperforms existing losses experimentally.

Stochastic optimal control, which has the goal of driving the behavior of noisy systems, is broadly applicable in science, engineering and artificial intelligence. Our work introduces Stochastic Optimal Control Matching (SOCM), a novel Iterative Diffusion Optimization (IDO) technique for stochastic optimal control that stems from the same philosophy as the conditional score matching loss for diffusion models. That is, the control is learned via a least squares problem by trying to fit a matching vector field. The training loss, which is closely connected to the cross-entropy loss, is optimized with respect to both the control function and a family of reparameterization matrices which appear in the matching vector field. The optimization with respect to the reparameterization matrices aims at minimizing the variance of the matching vector field. Experimentally, our algorithm achieves lower error than all the existing IDO techniques for stochastic optimal control for three out of four control problems, in some cases by an order of magnitude. The key idea underlying SOCM is the path-wise reparameterization trick, a novel technique that may be of independent interest.
tl;dr: We propose SimPO, a simple and effective preference optimization algorithm.

Direct Preference Optimization (DPO) is a widely used offline preference optimization algorithm that reparameterizes reward functions in reinforcement learning from human feedback (RLHF) to enhance simplicity and training stability. In this work, we propose SimPO, a simpler yet more effective approach. The effectiveness of SimPO is attributed to a key design: using the _average_ log probability of a sequence as the implicit reward. This reward formulation better aligns with model generation and eliminates the need for a reference model, making it more compute and memory efficient. Additionally, we introduce a target reward margin to the Bradley-Terry objective to encourage a larger margin between the winning and losing responses, further improving the algorithm's performance. We compare SimPO to DPO and its latest variants across various state-of-the-art training setups, including both base and instruction-tuned models such as Mistral, Llama 3, and Gemma 2. We evaluate on extensive chat-based evaluation benchmarks, including AlpacaEval 2, MT-Bench, and Arena-Hard. Our results demonstrate that SimPO consistently and significantly outperforms existing approaches without substantially increasing response length. Specifically, SimPO outperforms DPO by up to 6.4 points on AlpacaEval 2 and by up to 7.5 points on Arena-Hard. Our top-performing model, built on Gemma-2-9B-it, achieves a 72.4\% length-controlled win rate on AlpacaEval 2, a 59.1\% win rate on Arena-Hard, and ranks 1st on Chatbot Arena among $<$10B models with real user votes.

Traditional video restoration approaches were designed to recover clean videos from a specific type of degradation, making them ineffective in handling multiple unknown types of degradation. To address this issue, several studies have been conducted and have shown promising results. However, these studies overlook that the degradations in video usually change over time, dubbed time-varying unknown degradations (TUD). To tackle such a less-touched challenge, we propose an innovative method, termed as All-in-one VidEo Restoration Network (AverNet), which comprises two core modules, i.e., Prompt-Guided Alignment (PGA) module and Prompt-Conditioned Enhancement (PCE) module. Specifically, PGA addresses the issue of pixel shifts caused by time-varying degradations by learning and utilizing prompts to align video frames at the pixel level. To handle multiple unknown degradations, PCE recasts it into a conditional restoration problem by implicitly establishing a conditional map between degradations and ground truths. Thanks to the collaboration between PGA and PCE modules, AverNet empirically demonstrates its effectiveness in recovering videos from TUD. Extensive experiments are carried out on two synthesized datasets featuring seven types of degradations with random corruption levels. The code is available at https://github.com/XLearning-SCU/2024-NeurIPS-AverNet.

A popular paradigm for offline Reinforcement Learning (RL) tasks is to first fit the offline trajectories to a sequence model, and then prompt the model for actions that lead to high expected return. In addition to obtaining accurate sequence models, this paper highlights that tractability, the ability to exactly and efficiently answer various probabilistic queries, plays an important role in offline RL. Specifically, due to the fundamental stochasticity from the offline data-collection policies and the environment dynamics, highly non-trivial conditional/constrained generation is required to elicit rewarding actions. While it is still possible to approximate such queries, we observe that such crude estimates undermine the benefits brought by expressive sequence models. To overcome this problem, this paper proposes Trifle (Tractable Inference for Offline RL), which leverages modern tractable generative models to bridge the gap between good sequence models and high expected returns at evaluation time. Empirically, Trifle achieves $7$ state-of-the-art scores and the highest average scores in $9$ Gym-MuJoCo benchmarks against strong baselines. Further, Trifle significantly outperforms prior approaches in stochastic environments and safe RL tasks with minimum algorithmic modifications.
tl;dr: An unsupervised optimal transport guided method for procedure learning, which achieves state-of-the-art results

Procedure learning refers to the task of identifying the key-steps and determining their logical order, given several videos of the same task. For both third-person and first-person (egocentric) videos, state-of-the-art (SOTA) methods aim at finding correspondences across videos in time to accomplish procedure learning. However, to establish temporal relationships within the sequences, these methods often rely on frame-to-frame mapping, or assume monotonic alignment of video pairs, leading to sub-optimal results. To this end, we propose to treat the video frames as samples from an unknown distribution, enabling us to frame their distance calculation as an optimal transport (OT) problem. Notably, the OT-based formulation allows us to relax the previously mentioned assumptions. To further improve performance, we enhance the OT formulation by introducing two regularization terms. The first, inverse difference moment regularization, promotes transportation between instances that are homogeneous in the embedding space as well as being temporally closer. The second, regularization based on the KL-divergence with an exponentially decaying prior smooths the alignment while enforcing conformity to the optimality (alignment obtained from vanilla OT optimization) and temporal priors. The resultant optimal transport guided procedure learning framework (`OPEL') significantly outperforms the SOTA on benchmark datasets. Specifically, we achieve 22.4\% (IoU) and 26.9\% (F1) average improvement compared to the current SOTA on large scale egocentric benchmark, EgoProceL. Furthermore, for the third person benchmarks (ProCeL and CrossTask), the proposed approach obtains 46.2\% (F1) average enhancement over SOTA.
tl;dr: Generate trajectories towards high-scoring regions for solving offline model-based optimization problems

Optimizing complex and high-dimensional black-box functions is ubiquitous in science and engineering fields. Unfortunately, the online evaluation of these functions is restricted due to time and safety constraints in most cases. In offline model-based optimization (MBO), we aim to find a design that maximizes the target function using only a pre-existing offline dataset. While prior methods consider forward or inverse approaches to address the problem, these approaches are limited by conservatism and the difficulty of learning highly multi-modal mappings. Recently, there has been an emerging paradigm of learning to improve solutions with synthetic trajectories constructed from the offline dataset. In this paper, we introduce a novel conditional generative modeling approach to produce trajectories toward high-scoring regions. First, we construct synthetic trajectories toward high-scoring regions using the dataset while injecting locality bias for consistent improvement directions. Then, we train a conditional diffusion model to generate trajectories conditioned on their scores. Lastly, we sample multiple trajectories from the trained model with guidance to explore high-scoring regions beyond the dataset and select high-fidelity designs among generated trajectories with the proxy function. Extensive experiment results demonstrate that our method outperforms competitive baselines on Design-Bench and its practical variants. The code is publicly available in \url{https://github.com/dbsxodud-11/GTG}.
tl;dr: We directly use reinforcement learning to fine-tune large vision-language model using task-specific reward function

Large vision-language models (VLMs) fine-tuned on specialized visual instruction-following data have exhibited impressive language reasoning capabilities across various scenarios. However, this fine-tuning paradigm may not be able to efficiently learn optimal decision-making agents in multi-step goal-directed tasks from interactive environments. To address this challenge, we propose an algorithmic framework that fine-tunes VLMs with reinforcement learning (RL). Specifically, our framework provides a task description and then prompts the VLM to generate chain-of-thought (CoT) reasoning, enabling the VLM to efficiently explore intermediate reasoning steps that lead to the final text-based action. Next, the open-ended text output is parsed into an executable action to interact with the environment to obtain goal-directed task rewards. Finally, our framework uses these task rewards to fine-tune the entire VLM with RL. Empirically, we demonstrate that our proposed framework enhances the decision-making capabilities of VLM agents across various tasks, enabling 7b models to outperform commercial models such as GPT4-V or Gemini. Furthermore, we find that CoT reasoning is a crucial component for performance improvement, as removing the CoT reasoning results in a significant decrease in the overall performance of our method.
tl;dr: We propose a novel coarse-to-fine construction for concept discovery; we do not solely rely on the similarity between concepts and the whole image, but we also consider granular information residing in patch-specific regions of the image.

Deep learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on two levels of granularity. To this end, we propose a novel two-level concept discovery formulation leveraging: (i) recent advances in vision-language models, and (ii) an innovative formulation for coarse-to-fine concept selection via data-driven and sparsity inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.

Sequential recommendation systems predict the next interaction item based on users' past interactions, aligning recommendations with individual preferences. Leveraging the strengths of Large Language Models (LLMs) in knowledge comprehension and reasoning, recent approaches are eager to apply LLMs to sequential recommendation. A common paradigm is converting user behavior sequences into instruction data, and fine-tuning the LLM with parameter-efficient fine-tuning (PEFT) methods like Low-Rank Adaption (LoRA). However, the uniform application of LoRA across diverse user behaviors is insufficient to capture individual variability, resulting in negative transfer between disparate sequences.
To address these challenges, we propose Instance-wise LoRA (iLoRA). We innovatively treat the sequential recommendation task as a form of multi-task learning, integrating LoRA with the Mixture of Experts (MoE) framework. This approach encourages different experts to capture various aspects of user behavior. Additionally, we introduce a sequence representation guided gate function that generates customized expert participation weights for each user sequence, which allows dynamic parameter adjustment for instance-wise recommendations.
In sequential recommendation, iLoRA achieves an average relative improvement of 11.4\% over basic LoRA in the hit ratio metric, with less than a 1\% relative increase in trainable parameters.
Extensive experiments on three benchmark datasets demonstrate the effectiveness of iLoRA, highlighting its superior performance compared to existing methods in mitigating negative transfer and improving recommendation accuracy.
Our data and code are available at https://github.com/AkaliKong/iLoRA.
tl;dr: UniTS is a unified multi-task time series model that can process predictive and generative tasks across time series domains.

Although pre-trained transformers and reprogrammed text-based LLMs have shown strong performance on time series tasks, the best-performing architectures vary widely across tasks, with most models narrowly focused on specific areas, such as time series forecasting. Unifying predictive and generative time series tasks within a single model remains challenging. We introduce UniTS, a unified multi-task time series model that utilizes task tokenization to integrate predictive and generative tasks into a single framework. UniTS employs a modified transformer block to capture universal time series representations, enabling transferability from a heterogeneous, multi-domain pre-training dataset—characterized by diverse dynamic patterns, sampling rates, and temporal scales—to a wide range of downstream datasets with varied task specifications and data domains. Tested on 38 datasets across human activity sensors, healthcare, engineering, and finance, UniTS achieves superior performance compared to 12 forecasting models, 20 classification models, 18 anomaly detection models, and 16 imputation models, including adapted text-based LLMs. UniTS also demonstrates strong few-shot and prompt capabilities when applied to new domains and tasks. In single-task settings, UniTS outperforms competitive task-specialized time series models. Code and datasets are available at https://github.com/mims-harvard/UniTS.

Diffusion models have demonstrated great success in text-to-video (T2V) generation. However, existing methods may face challenges when handling complex (long) video generation scenarios that involve multiple objects or dynamic changes in object numbers. To address these limitations, we propose VideoTetris, a novel framework that enables compositional T2V generation. Specifically, we propose spatio-temporal compositional diffusion to precisely follow complex textual semantics by manipulating and composing the attention maps of denoising networks spatially and temporally. Moreover, we propose a new dynamic-aware data processing pipeline and a consistency regularization method to enhance the consistency of auto-regressive video generation. Extensive experiments demonstrate that our VideoTetris achieves impressive qualitative and quantitative results in compositional T2V generation. Code is available at: https://github.com/YangLing0818/VideoTetris
tl;dr: This paper develops two novel shuffling-based algorithms to solve two classes of nonconvex-concave minimax problems that have provable convergence guarantees.

This paper aims at developing novel shuffling gradient-based methods for tackling two classes of minimax problems: nonconvex-linear and nonconvex-strongly concave settings. The first algorithm addresses the nonconvex-linear minimax model and achieves the state-of-the-art oracle complexity typically observed in nonconvex optimization. It also employs a new shuffling estimator for the ``hyper-gradient'', departing from standard shuffling techniques in optimization. The second method consists of two variants: semi-shuffling and full-shuffling schemes. These variants tackle the nonconvex-strongly concave minimax setting. We establish their oracle complexity bounds under standard assumptions, which, to our best knowledge, are the best-known for this specific setting. Numerical examples demonstrate the performance of our algorithms and compare them with two other methods. Our results show that the new methods achieve comparable performance with SGD, supporting the potential of incorporating shuffling strategies into minimax algorithms.

In many applications, we desire neural networks to exhibit invariance or equivariance to certain groups due to symmetries inherent in the data. Recently, frame-averaging methods emerged to be a unified framework for attaining symmetries efficiently by averaging over input-dependent subsets of the group, i.e., frames. What we currently lack is a principled understanding of the design of frames. In this work, we introduce a canonicalization perspective that provides an essential and complete view of the design of frames. Canonicalization is a classic approach for attaining invariance by mapping inputs to their canonical forms. We show that there exists an inherent connection between frames and canonical forms. Leveraging this connection, we can efficiently compare the complexity of frames as well as determine the optimality of certain frames. Guided by this principle, we design novel frames for eigenvectors that are strictly superior to existing methods --- some are even optimal --- both theoretically and empirically. The reduction to the canonicalization perspective further uncovers equivalences between previous methods. These observations suggest that canonicalization provides a fundamental understanding of existing frame-averaging methods and unifies existing equivariant and invariant learning methods. Code is available at https://github.com/PKU-ML/canonicalization.
tl;dr: We propose the Block Transformer architecture that adopts global-to-local modeling to autoregressive transformers to mitigate the bottlenecks of global self-attention and significantly improve inference throughput compared to vanilla transformers.

We introduce the Block Transformer which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks associated with self-attention. Self-attention requires the key-value (KV) cache of all previous sequences to be retrieved from memory at every decoding step to retrieve context information, leading to two primary bottlenecks during batch inference. First, there is a significant delay in obtaining the first token, as the information of the entire prompt must first be processed to prefill the KV cache. Second, computation of subsequent tokens is bottlenecked by the high memory I/O demand of fetching the entire KV cache, which grows linearly with sequence length, incurring quadratic memory reads overall. We design the Block Transformer to strategically mitigate these costs, by incorporating coarsity and locality into an integrated global-to-local architecture. At the lower layers, we aggregate tokens into fixed size blocks to apply attention across the entire sequence at coarse-grained detail, to capture the global context while minimizing KV cache overhead. At upper layers, we apply attention within each block to decode individual tokens, to model fine-grained details with a lightweight local KV cache. We pretrain vanilla and Block Transformers from scratch and demonstrate that Block Transformers reach 10--20x inference throughput compared to vanilla transformers with equivalent perplexity and zero-shot task performance.

Despite enjoying desirable efficiency and reduced reliance on domain expertise, existing neural methods for vehicle routing problems (VRPs) suffer from severe robustness issues — their performance significantly deteriorates on clean instances with crafted perturbations. To enhance robustness, we propose an ensemble-based *Collaborative Neural Framework (CNF)* w.r.t. the defense of neural VRP methods, which is crucial yet underexplored in the literature. Given a neural VRP method, we adversarially train multiple models in a collaborative manner to synergistically promote robustness against attacks, while boosting standard generalization on clean instances. A neural router is designed to adeptly distribute training instances among models, enhancing overall load balancing and collaborative efficacy. Extensive experiments verify the effectiveness and versatility of CNF in defending against various attacks across different neural VRP methods. Notably, our approach also achieves impressive out-of-distribution generalization on benchmark instances.

Image fusion aims to integrate complementary information from multiple input images acquired through various sources to synthesize a new fused image. Existing methods usually employ distinct constraint designs tailored to specific scenes, forming fixed fusion paradigms. However, this data-driven fusion approach is challenging to deploy in varying scenarios, especially in rapidly changing environments. To address this issue, we propose a conditional controllable fusion (CCF) framework for general image fusion tasks without specific training. Due to the dynamic differences of different samples, our CCF employs specific fusion constraints for each individual in practice. Given the powerful generative capabilities of the denoising diffusion model, we first inject the specific constraints into the pre-trained DDPM as adaptive fusion conditions. The appropriate conditions are dynamically selected to ensure the fusion process remains responsive to the specific requirements in each reverse diffusion stage. Thus, CCF enables conditionally calibrating the fused images step by step. Extensive experiments validate our effectiveness in general fusion tasks across diverse scenarios against the competing methods without additional training. The code is publicly available.
2428. Sample-Efficient Geometry Reconstruction from Euclidean Distances using Non-Convex Optimization

The problem of finding suitable point embedding or geometric configurations given only Euclidean distance information of point pairs arises both as a core task and as a sub-problem in a variety of machine learning applications. In this paper, we aim to solve this problem given a minimal number of distance samples.
To this end, we leverage continuous and non-convex rank minimization formulations of the problem and establish a local convergence
guarantee for a variant of iteratively reweighted least squares (IRLS), which applies if a minimal random set of observed distances is provided.
As a technical tool, we establish a restricted isometry property (RIP) restricted to a tangent space of the manifold of symmetric rank-$r$ matrices given random Euclidean distance measurements, which might be of independent interest for the analysis of other non-convex approaches. Furthermore, we assess data efficiency, scalability and generalizability of different reconstruction algorithms through numerical experiments with simulated data as well as real-world data, demonstrating the proposed algorithm's ability to identify the underlying geometry from fewer distance samples compared to the state-of-the-art.
The Matlab code can be found at \href{https://github.com/ipsita-ghosh-1/EDG-IRLS}{github\_SEGRED}

A core task in multi-modal learning is to integrate information from multiple feature spaces (e.g., text and audio), offering modality-invariant essential representations of data. Recent research showed that, classical tools such as canonical correlation analysis (CCA) provably identify the shared components up to minor ambiguities, when samples in each modality are generated from a linear mixture of shared and private components. Such identifiability results were obtained under the condition that the cross-modality samples are aligned/paired according to their shared information. This work takes a step further, investigating shared component identifiability from multi-modal linear mixtures where cross-modality samples are unaligned. A distribution divergence minimization-based loss is proposed, under which a suite of sufficient conditions ensuring identifiability of the shared components are derived. Our conditions are based on cross-modality distribution discrepancy characterization and density-preserving transform removal, which are much milder than existing studies relying on independent component analysis. More relaxed conditions are also provided via adding reasonable structural constraints, motivated by available side information in various applications. The identifiability claims are thoroughly validated using synthetic and real-world data.
tl;dr: We enhance Modern Hopfield Networks with a kernelized approach to improve memory storage and retrieval, achieving optimal capacity and efficiency in sub-linear time.

We study the optimal memorization capacity of modern Hopfield models and Kernelized Hopfield Models (KHMs), a transformer-compatible class of Dense Associative Memories.
We present a tight analysis by establishing a connection between the memory configuration of KHMs and spherical codes from information theory.
Specifically, we treat the stored memory set as a specialized spherical code.
This enables us to cast the memorization problem in KHMs into a point arrangement problem on a hypersphere.
We show that the optimal capacity of KHMs occurs when the feature space allows memories to form an optimal spherical code.
This unique perspective leads to:
1. An analysis of how KHMs achieve optimal memory capacity, and identify corresponding necessary conditions.
Importantly, we establish an upper capacity bound that matches the well-known exponential lower bound in the literature.
This provides the first tight and optimal asymptotic memory capacity for modern Hopfield models.
2. A sub-linear time algorithm $\mathtt{U}\text{-}\mathtt{Hop}$+ to reach KHMs' optimal capacity.
3. An analysis of the scaling behavior of the required feature dimension relative to the number of stored memories.
These efforts improve both the retrieval capability of KHMs and the representation learning of corresponding transformers.
Experimentally, we provide thorough numerical results to back up theoretical findings.
tl;dr: Incremental Learning of Retrievable Skills For Efficient Continual Task Adaptation

Continual Imitation Learning (CiL) involves extracting and accumulating task knowledge from demonstrations across multiple stages and tasks to achieve a multi-task policy. With recent advancements in foundation models, there has been a growing interest in adapter-based CiL approaches, where adapters are established parameter-efficiently for tasks newly demonstrated. While these approaches isolate parameters for specific tasks and tend to mitigate catastrophic forgetting, they limit knowledge sharing among different demonstrations. We introduce IsCiL, an adapter-based CiL framework that addresses this limitation of knowledge sharing by incrementally learning shareable skills from different demonstrations, thus enabling sample-efficient task adaptation using the skills particularly in non-stationary CiL environments. In IsCiL, demonstrations are mapped into the state embedding space, where proper skills can be retrieved upon input states through prototype-based memory. These retrievable skills are incrementally learned on their corresponding adapters. Our CiL experiments with complex tasks in the Franka-Kitchen and Meta-World demonstrate the robust performance of IsCiL in both task adaptation and sample-efficiency. We also show a simple extension of IsCiL for task unlearning scenarios.
2432. Improving the Learning Capability of Small-size Image Restoration Network by Deep Fourier Shifting
tl;dr: Improving the Learning Capability of Small-size Image Restoration Network by Deep Fourier Shifting Operator over Resource-limited Scene

State-of-the-art image restoration methods currently face challenges in terms of computational requirements and performance, making them impractical for deployment on edge devices such as phones and resource-limited devices. As a result, there is a need to develop alternative solutions with efficient designs that can achieve comparable performance to transformer or large-kernel methods. This motivates our research to explore techniques for improving the capability of small-size image restoration standing on the success secret of large receptive filed.
Targeting at expanding receptive filed, spatial-shift operator tailored for efficient spatial communication and has achieved remarkable advances in high-level image classification tasks, like $S^2$-MLP and ShiftVit. However, its potential has rarely been explored in low-level image restoration tasks. The underlying reason behind this obstacle is that image restoration is sensitive to the spatial shift that occurs due to severe region-aware information loss, which exhibits a different behavior from high-level tasks. To address this challenge and unleash the potential of spatial shift for image restoration, we propose an information-lossless shifting operator, i.e., Deep Fourier Shifting, that is customized for image restoration. To develop our proposed operator, we first revisit the principle of shift operator and apply it to the Fourier domain, where the shift operator can be modeled in an information-lossless Fourier cycling manner. Inspired by Fourier cycling, we design two variants of Deep Fourier Shifting, namely the amplitude-phase variant and the real-imaginary variant. These variants are generic operators that can be directly plugged into existing image restoration networks as a drop-in replacement for the standard convolution unit, consuming fewer parameters. Extensive experiments across multiple low-level tasks including image denoising, low-light image enhancement, guided image super-resolution, and image de-blurring demonstrate consistent performance gains obtained by our Deep Fourier Shifting while reducing the computation burden. Additionally, ablation studies verify the robustness of the shift displacement with stable performance improvement.
tl;dr: We show provable benefit of offline multitask reinforcement learning for both upstream and downstream tasks when certain part of representation is shared among the tasks.

We study offline multitask representation learning in reinforcement learning (RL), where a learner is provided with an offline dataset from different tasks that share a common representation and is asked to learn the shared representation. We theoretically investigate offline multitask low-rank RL, and propose a new algorithm called MORL for offline multitask representation learning. Furthermore, we examine downstream RL in reward-free, offline and online scenarios, where a new task is introduced to the agent that shares the same representation as the upstream offline tasks. Our theoretical results demonstrate the benefits of using the learned representation from the upstream offline task instead of directly learning the representation of the low-rank model.
tl;dr: LiT, the LiDAR Translator, directly translates point clouds across domains, unifying diverse LiDAR datasets to support scalable cross-domain and multi-domain learning for autonomous driving.

LiDAR data exhibits significant domain gaps due to variations in sensors, vehicles, and driving environments, creating “language barriers” that limit the effective use of data across domains and the scalability of LiDAR perception models. To address these challenges, we introduce the LiDAR Translator (LiT), a framework that directly translates LiDAR data across domains, enabling both cross-domain adaptation and multi-domain joint learning. LiT integrates three key components: a scene modeling module for precise foreground and background reconstruction, a LiDAR modeling module that models LiDAR rays statistically and simulates ray-drop, and a fast, hardware-accelerated ray casting engine. LiT enables state-of-the-art zero-shot and unified domain detection across diverse LiDAR datasets, marking a step toward data-driven domain unification for autonomous driving systems. Source code and demos are available at: https://yxlao.github.io/lit.
tl;dr: We introduce parametric World Knowledge Model (WKM) which provides global prior task knowledge and local dynamic state knowledge to facilitate agent planning.

Recent endeavors towards directly using large language models (LLMs) as agent models to execute interactive planning tasks have shown commendable results. Despite their achievements, however, they still struggle with brainless trial-and-error in global planning and generating hallucinatory actions in local planning due to their poor understanding of the "real" physical world. Imitating humans' mental world knowledge model which provides global prior knowledge before the task and maintains local dynamic knowledge during the task, in this paper, we introduce parametric World Knowledge Model (WKM) to facilitate agent planning. Concretely, we steer the agent model to self-synthesize knowledge from both expert and sampled trajectories. Then we develop WKM, providing prior task knowledge to guide the global planning and dynamic state knowledge to assist the local planning. Experimental results on three real-world simulated datasets with Mistral-7B, Gemma-7B, and Llama-3-8B demonstrate that our method can achieve superior performance compared to various strong baselines. Besides, we analyze to illustrate that our WKM can effectively alleviate the blind trial-and-error and hallucinatory action issues, providing strong support for the agent's understanding of the world. Other interesting findings include: 1) our instance-level task knowledge can generalize better to unseen tasks, 2) weak WKM can guide strong agent model planning, and 3) unified WKM training has promising potential for further development.
tl;dr: We introduce an efficient jailbreaking method along with a large-scale safety dataset (WildJailbreak). Our experiments show that training on WildJailbreak leads to substantial safety improvements while minimally affecting general capabilities.

We introduce WildTeaming, an automatic red-teaming framework that mines in-the-wild user-chatbot interactions to discover 5.7K unique clusters of novel jailbreak tactics, and then composes selections of multiple mined tactics for systematic exploration of novel and even more challenging jailbreaks.
Compared to prior work that performed red-teaming via recruited human workers, gradient-based optimization, or iterative revision with large language models (LLMs), our work investigates jailbreaks from chatbot users in-the-wild who were not specifically instructed to break the system. WildTeaming reveals previously unidentified vulnerabilities of frontier LLMs, resulting in more diverse and successful adversarial attacks compared to state-of-the-art jailbreaking methods.
While there exist many datasets for jailbreak evaluation, very few open-source datasets exist for jailbreak training, as safety training data has been closed among all frontier models even when their weights are open. Therefore, with WildTeaming we create WildJailbreak, a large-scale open-source synthetic safety dataset with 262K vanilla (direct request) and adversarial (complex jailbreak) prompt-response pairs. In order to mitigate exaggerated safety behaviors, WildJailbreak provides two contrastive types of queries: 1) harmful queries (both vanilla and adversarial) and 2) benign queries that resemble harmful queries in form but contain no harmful intent. As WildJailbreak considerably upgrades the quality and scale of existing safety resources, it uniquely enables us to examine the scaling effects of data and the interplay of data properties and model capabilities during safety training. Through extensive model training and evaluations, we identify the training properties that enable an ideal balance of safety behaviors: appropriate safeguarding without over-refusal, effective handling of both vanilla and adversarial queries, and minimal, if any, decrease in general capabilities. All the components of WildJailbreak contribute to achieving balanced safety behaviors of models
tl;dr: We train a state-of-the-art generalist human pose and shape estimation model that can localize any point of the human body.

With the explosive growth of available training data, single-image 3D human modeling is ahead of a transition to a data-centric paradigm.
A key to successfully exploiting data scale is to design flexible models that can be supervised from various heterogeneous data sources produced by different researchers or vendors.
To this end, we propose a simple yet powerful paradigm for seamlessly unifying different human pose and shape-related tasks and datasets.
Our formulation is centered on the ability - both at training and test time - to query any arbitrary point of the human volume, and obtain its estimated location in 3D.
We achieve this by learning a continuous neural field of body point localizer functions, each of which is a differently parameterized 3D heatmap-based convolutional point localizer (detector).
For generating parametric output, we propose an efficient post-processing step for fitting SMPL-family body models to nonparametric joint and vertex predictions.
With this approach, we can naturally exploit differently annotated data sources including mesh, 2D/3D skeleton and dense pose, without having to convert between them, and thereby train large-scale 3D human mesh and skeleton estimation models that outperform the state-of-the-art on several public benchmarks including 3DPW, EMDB, EHF, SSP-3D and AGORA by a considerable margin.
We release our code and models to foster downstream research.
tl;dr: Self-Supervised Transformation Learning (STL) uses transformation representations from image pairs instead of labels to learn equivariant transformations, enhancing performance efficiently.

Unsupervised representation learning has significantly advanced various machine learning tasks. In the computer vision domain, state-of-the-art approaches utilize transformations like random crop and color jitter to achieve invariant representations, embedding semantically the same inputs despite transformations. However, this can degrade performance in tasks requiring precise features, such as localization or flower classification. To address this, recent research incorporates equivariant representation learning, which captures transformation-sensitive information. However, current methods depend on transformation labels and thus struggle with interdependency and complex transformations. We propose Self-supervised Transformation Learning (STL), replacing transformation labels with transformation representations derived from image pairs. The proposed method ensures transformation representation is image-invariant and learns corresponding equivariant transformations, enhancing performance without increased batch complexity. We demonstrate the approach’s effectiveness across diverse classification and detection tasks, outperforming existing methods in 7 out of 11 benchmarks and excelling in detection. By integrating complex transformations like AugMix, unusable by prior equivariant methods, this approach enhances performance across tasks, underscoring its adaptability and resilience. Additionally, its compatibility with various base models highlights its flexibility and broad applicability. The code is available at https://github.com/jaemyung-u/stl.
tl;dr: We demonstrate that feature learning through the average gradient outer product is a setting for deep neural collapse.

Deep Neural Collapse (DNC) refers to the surprisingly rigid structure of the data representations in the final layers of Deep Neural Networks (DNNs). Though the phenomenon has been measured in a variety of settings, its emergence is typically explained via data-agnostic approaches, such as the unconstrained features model. In this work, we introduce a data-dependent setting where DNC forms due to feature learning through the average gradient outer product (AGOP). The AGOP is defined with respect to a learned predictor and is equal to the uncentered covariance matrix of its input-output gradients averaged over the training dataset. Deep Recursive Feature Machines are a method that constructs a neural network by iteratively mapping the data with the AGOP and applying an untrained random feature map. We demonstrate theoretically and empirically that DNC occurs in Deep Recursive Feature Machines as a consequence of the projection with the AGOP matrix computed at each layer. We then provide evidence that this mechanism holds for neural networks more generally. We show that the right singular vectors and values of the weights can be responsible for the majority of within-class variability collapse for DNNs trained in the feature learning regime. As observed in recent work, this singular structure is highly correlated with that of the AGOP.

In recent years, DeepFake technology has achieved unprecedented success in high-quality video synthesis, but these methods also pose potential and severe security threats to humanity. DeepFake can be bifurcated into entertainment applications like face swapping and illicit uses such as lip-syncing fraud. However, lip-forgery videos, which neither change identity nor have discernible visual artifacts, present a formidable challenge to existing DeepFake detection methods. Our preliminary experiments have shown that the effectiveness of the existing methods often drastically decrease or even fail when tackling lip-syncing videos.
In this paper, for the first time, we propose a novel approach dedicated to lip-forgery identification that exploits the inconsistency between lip movements and audio signals. We also mimic human natural cognition by capturing subtle biological links between lips and head regions to boost accuracy. To better illustrate the effectiveness and advances of our proposed method, we create a high-quality LipSync dataset, AVLips, by employing the state-of-the-art lip generators. We hope this high-quality and diverse dataset could be well served the further research on this challenging and interesting field. Experimental results show that our approach gives an average accuracy of more than 95.3% in spotting lip-syncing videos, significantly outperforming the baselines. Extensive experiments demonstrate the capability to tackle deepfakes and the robustness in surviving diverse input transformations. Our method achieves an accuracy of up to 90.2% in real-world scenarios (e.g., WeChat video call) and shows its powerful capabilities in real scenario deployment.
To facilitate the progress of this research community, we release all resources at https://github.com/AaronComo/LipFD.
tl;dr: We introduce new gradient sketching algorithms as a toolkit for model analysis.

The study of modern machine learning models often necessitates storing vast quantities of gradients or Hessian vector products (HVPs). Traditional sketching methods struggle to scale under these memory constraints. We present a novel framework for scalable gradient and HVP sketching, tailored for modern hardware. We provide theoretical guarantees and demonstrate the power of our methods in applications like training data attribution, Hessian spectrum analysis, and intrinsic dimension computation for pre-trained language models. Our work sheds new light on the behavior of pre-trained language models, challenging assumptions about their intrinsic dimensionality and Hessian properties.
tl;dr: We propose to enhance the generalization ability of reward models for LLMs by regularizing the hidden states, effectively improving accuracy in various out-of-distribution tasks and mitigating over-optimization in RLHF.

Reward models trained on human preference data have been proven to effectively align Large Language Models (LLMs) with human intent within the framework of reinforcement learning from human feedback (RLHF). However, current reward models have limited generalization capabilities to unseen prompts and responses, which can lead to an unexpected phenomenon known as reward over-optimization, resulting in a decline in actual performance due to excessive optimization of rewards. While previous research has advocated for constraining policy optimization, our study introduces a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text-generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviates the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.
tl;dr: Propose a new formulation for inverse reinforcement learning-based imitation learning to mitigate the task-reward misalignment.

Many imitation learning (IL) algorithms use inverse reinforcement learning (IRL) to infer a reward function that aligns with the demonstration.
However, the inferred reward functions often fail to capture the underlying task objectives.
In this paper, we propose a novel framework for IRL-based IL that prioritizes task alignment over conventional data alignment. Our framework is a semi-supervised approach that leverages expert demonstrations as weak supervision to derive a set of candidate reward functions that align with the task rather than only with the data. It then adopts an adversarial mechanism to train a policy with this set of reward functions to gain a collective validation of the policy's ability to accomplish the task. We provide theoretical insights into this framework's ability to mitigate task-reward misalignment and present a practical implementation. Our experimental results show that our framework outperforms conventional IL baselines in complex and transfer learning scenarios.

This paper explores a novel task "Dexterous Grasp as You Say'' (DexGYS), enabling robots to perform dexterous grasping based on human commands expressed in natural language. However, the development of this field is hindered by the lack of datasets with natural human guidance; thus, we propose a language-guided dexterous grasp dataset, named DexGYSNet, offering high-quality dexterous grasp annotations along with flexible and fine-grained human language guidance. Our dataset construction is cost-efficient, with the carefully-design hand-object interaction retargeting strategy, and the LLM-assisted language guidance annotation system. Equipped with this dataset, we introduce the DexGYSGrasp framework for generating dexterous grasps based on human language instructions, with the capability of producing grasps that are intent-aligned, high quality and diversity. To achieve this capability, our framework decomposes the complex learning process into two manageable progressive objectives and introduce two components to realize them. The first component learns the grasp distribution focusing on intention alignment and generation diversity. And the second component refines the grasp quality while maintaining intention consistency. Extensive experiments are conducted on DexGYSNet and real world environments for validation.

Training a policy in a source domain for deployment in the target domain under a dynamics shift can be challenging, often resulting in performance degradation. Previous work tackles this challenge by training on the source domain with modified rewards derived by matching distributions between the source and the target optimal trajectories. However, pure modified rewards only ensure the behavior of the learned policy in the source domain resembles trajectories produced by the target optimal policies, which does not guarantee optimal performance when the learned policy is actually deployed to the target domain. In this work, we propose to utilize imitation learning to transfer the policy learned from the reward modification to the target domain so that the new policy can generate the same trajectories in the target domain. Our approach, Domain Adaptation and Reward Augmented Imitation Learning (DARAIL), utilizes the reward modification for domain adaptation and follows the general framework of generative adversarial imitation learning from observation (GAIfO) by applying a reward augmented estimator for the policy optimization step. Theoretically, we present an error bound for our method under a mild assumption regarding the dynamics shift to justify the motivation of our method. Empirically, our method outperforms the pure modified reward method without imitation learning and also outperforms other baselines in benchmark off-dynamics environments.
tl;dr: We propose a comprehensive design framework that includes specific, effective strategies. These strategies establish a benchmark for both small and large-scale dataset condensation.

Dataset condensation, a concept within data-centric learning, efficiently transfers critical attributes from an original dataset to a synthetic version, maintaining both diversity and realism. This approach significantly improves model training efficiency and is adaptable across multiple application areas. Previous methods in dataset condensation have faced challenges: some incur high computational costs which limit scalability to larger datasets (e.g., MTT, DREAM, and TESLA), while others are restricted to less optimal design spaces, which could hinder potential improvements, especially in smaller datasets (e.g., SRe$^2$L, G-VBSM, and RDED). To address these limitations, we propose a comprehensive design framework that includes specific, effective strategies like implementing soft category-aware matching and adjusting the learning rate schedule. These strategies are grounded in empirical evidence and theoretical backing. Our resulting approach, Elucidate Dataset Condensation (EDC), establishes a benchmark for both small and large-scale dataset condensation. In our testing, EDC achieves state-of-the-art accuracy, reaching 48.6% on ImageNet-1k with a ResNet-18 model at an IPC of 10, which corresponds to a compression ratio of 0.78%. This performance exceeds those of SRe$^2$L, G-VBSM, and RDED by margins of 27.3%, 17.2%, and 6.6%, respectively.

We consider the design of practically-implementable schemes for the task of channel simulation. Existing methods do not scale with the
number of simultaneous uses of the channel and are therefore unable to harness the amortization gains associated with simulating many uses of the channel at once. We show how techniques from the theory of error-correcting codes can be applied to achieve scalability and hence improved performance. As an exemplar, we focus on how polar codes can be used to efficiently simulate i.i.d. copies of a class of binary-output channels.
tl;dr: Unsupervised Learning to Translate High-Performance Code

Automatic translation of programming languages has garnered renewed interest, driven by recent advancements in large language models (LLMs). Encoder-decoder transformer models, in particular, have shown promise in translating between different programming languages. However, translating between a language and its high-performance computing (HPC) extension remains underexplored due to inherent challenges like complex parallel semantics understanding. In this paper, we introduce CodeRosetta, an encoder-decoder transformer model explicitly designed for translating between programming languages and also their HPC extensions. CodeRosetta is evaluated on C++ to CUDA and Fortran to C++ translation.
It employs a customized learning-based framework with tailored pretraining and training objectives that enable it to effectively capture code semantics and parallel structural nuances, allowing for bidirectional code translation. Our results show that CodeRosetta outperforms state-of-the-art baselines in C++ to CUDA translation by 2.9 BLEU and 1.72 CodeBLUE points while improving compilation accuracy by 6.05%. Compared to general closed-source LLMs, our proposed bidirectional learning-based method improves C++ to CUDA translation by 22.08 BLEU and 14.39 CodeBLUE with 2.75% higher compilation accuracy.
Finally, CodeRosetta exhibits proficiency in Fortran to parallel C++ translation, marking it, to our knowledge, as the first encoder-decoder model for such a complex translation task, improving CodeBLEU at least by 4.63 points compared to closed-source LLMs and Open Code LLM.

Temporal Knowledge Graph (TKG) representation learning aims to map temporal evolving entities and relations to embedded representations in a continuous low-dimensional vector space. However, existing approaches cannot capture the temporal evolution of high-order correlations in TKGs. To this end, we propose a **D**eep **E**volutionary **C**lustering jointed temporal knowledge graph **R**epresentation **L**earning approach (**DECRL**). Specifically, a deep evolutionary clustering module is proposed to capture the temporal evolution of high-order correlations among entities. Furthermore, a cluster-aware unsupervised alignment mechanism is introduced to ensure the precise one-to-one alignment of soft overlapping clusters across timestamps, thereby maintaining the temporal smoothness of clusters. In addition, an implicit correlation encoder is introduced to capture latent correlations between any pair of clusters under the guidance of a global graph. Extensive experiments on seven real-world datasets demonstrate that DECRL achieves the state-of-the-art performances, outperforming the best baseline by an average of 9.53\%, 12.98\%, 10.42\%, and 14.68\% in MRR, Hits@1, Hits@3, and Hits@10, respectively.
tl;dr: We propose a memory-propagated streaming encoding architecture with adaptive memory selection for long video understanding with LLM.

This paper presents VideoStreaming, an advanced vision-language large model (VLLM) for video understanding, that capably understands arbitrary-length video with a constant number of video tokens streamingly encoded and adaptively selected.
The challenge of video understanding in the vision language area mainly lies in the significant computational burden caused by the great number of tokens extracted from long videos. Previous works rely on sparse sampling or frame compression to reduce tokens. However, such approaches either disregard temporal information in a long time span or sacrifice spatial details, resulting in flawed compression.
To address these limitations, our VideoStreaming has two core designs: Memory-Propagated Streaming Encoding and Adaptive Memory Selection. The Memory-Propagated Streaming Encoding architecture segments long videos into short clips and sequentially encodes each clip with a propagated memory. In each iteration, we utilize the encoded results of the preceding clip as historical memory, which is integrated with the current clip to distill a condensed representation that encapsulates the video content up to the current timestamp. This method not only incorporates long-term temporal dynamics into the streaming encoding process but also yields a fixed-length memory as a global representation for arbitrarily long videos. After the encoding process, the Adaptive Memory Selection strategy selects a constant number of question-related memories from all the historical memories, and feeds them into the LLM to generate informative responses. The question-related selection reduces redundancy within the memories, enabling efficient and precise video understanding. Meanwhile, the disentangled video extraction and reasoning design allows the LLM to answer different questions about a video by directly selecting corresponding memories, without the need to encode the whole video for each question. Through extensive experiments, our model achieves superior performance and higher efficiency on long video benchmarks, showcasing precise temporal comprehension for detailed question answering.
tl;dr: We propose Universal Mesh Movement Networks (UM2N), which once trained, can be applied in a non-intrusive, zero-shot manner to move meshes with different sizes and structure, for solvers applicable to different PDE types and boundary geometries.

Solving complex Partial Differential Equations (PDEs) accurately and efficiently is an essential and challenging problem in all scientific and engineering disciplines. Mesh movement methods provide the capability to improve the accuracy of the numerical solution without increasing the overall mesh degree of freedom count. Conventional sophisticated mesh movement methods are extremely expensive and struggle to handle scenarios with complex boundary geometries. However, existing learning-based methods require re-training from scratch given a different PDE type or boundary geometry, which limits their applicability, and also often suffer from robustness issues in the form of inverted elements. In this paper, we introduce the Universal Mesh Movement Network (UM2N), which -- once trained -- can be applied in a non-intrusive, zero-shot manner to move meshes with different size distributions and structures, for solvers applicable to different PDE types and boundary geometries. UM2N consists of a Graph Transformer (GT) encoder for extracting features and a Graph Attention Network (GAT) based decoder for moving the mesh. We evaluate our method on advection and Navier-Stokes based examples, as well as a real-world tsunami simulation case. Our method out-performs existing learning-based mesh movement methods in terms of the benchmarks described above. In comparison to the conventional sophisticated Monge-Ampère PDE-solver based method, our approach not only significantly accelerates mesh movement, but also proves effective in scenarios where the conventional method fails. Our project page can be found at https://erizmr.github.io/UM2N/.
tl;dr: We introduce a new TDA technique that combines the strength of implicit-differentiation-based (e.g., influence fuctions) and unrolling-based techniques.

Many training data attribution (TDA) methods aim to estimate how a model's behavior would change if one or more data points were removed from the training set. Methods based on implicit differentiation, such as influence functions, can be made computationally efficient, but fail to account for underspecification, the implicit bias of the optimization algorithm, or multi-stage training pipelines. By contrast, methods based on unrolling address these issues but face scalability challenges. In this work, we connect the implicit-differentiation-based and unrolling-based approaches and combine their benefits by introducing Source, an approximate unrolling-based TDA method that is computed using an influence-function-like formula. While being computationally efficient compared to unrolling-based approaches, Source is suitable in cases where implicit-differentiation-based approaches struggle, such as in non-converged models and multi-stage training pipelines. Empirically, Source outperforms existing TDA techniques in counterfactual prediction, especially in settings where implicit-differentiation-based approaches fall short.

Despite the remarkable empirical performance of Transformers, their theoretical understanding remains elusive. Here, we consider a deep multi-head self-attention network, that is closely related to Transformers yet analytically tractable. We develop a statistical mechanics theory of Bayesian learning in this model, deriving exact equations for the network's predictor statistics under the finite-width thermodynamic limit, i.e., $N,P\rightarrow\infty$, $P/N=\mathcal{O}(1)$, where $N$ is the network width and $P$ is the number of training examples. Our theory shows that the predictor statistics are expressed as a sum of independent kernels, each one pairing different "attention paths", defined as information pathways through different attention heads across layers. The kernels are weighted according to a "task-relevant kernel combination" mechanism that aligns the total kernel with the task labels. As a consequence, this interplay between attention paths enhances generalization performance. Experiments confirm our findings on both synthetic and real-world sequence classification tasks. Finally, our theory explicitly relates the kernel combination mechanism to properties of the learned weights, allowing for a qualitative transfer of its insights to models trained via gradient descent. As an illustration, we demonstrate an efficient size reduction of the network, by pruning those attention heads that are deemed less relevant by our theory.
2454. Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering for HDR View Synthesis
tl;dr: Fast training and real-time rendering for HDR view synthesis from noisy RAW images using 3DGS-based techniques.

Volumetric rendering-based methods, like NeRF, excel in HDR view synthesis from RAW images, especially for nighttime scenes. They suffer from long training times and cannot perform real-time rendering due to dense sampling requirements. The advent of 3D Gaussian Splatting (3DGS) enables real-time rendering and faster training. However, implementing RAW image-based view synthesis directly using 3DGS is challenging due to its inherent drawbacks: 1) in nighttime scenes, extremely low SNR leads to poor structure-from-motion (SfM) estimation in dis- tant views; 2) the limited representation capacity of the spherical harmonics (SH) function is unsuitable for RAW linear color space; and 3) inaccurate scene structure hampers downstream tasks such as refocusing. To address these issues, we propose LE3D (Lighting Every darkness with 3DGS). Our method proposes Cone Scatter Initialization to enrich the estimation of SfM and replaces SH with a Color MLP to represent the RAW linear color space. Additionally, we introduce depth distortion and near-far regularizations to improve the accuracy of scene structure for down- stream tasks. These designs enable LE3D to perform real-time novel view synthesis, HDR rendering, refocusing, and tone-mapping changes. Compared to previous vol- umetric rendering-based methods, LE3D reduces training time to 1% and improves rendering speed by up to 4,000 times for 2K resolution images in terms of FPS. Code and viewer can be found in https://srameo.github.io/projects/le3d.

There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker’s voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
tl;dr: This work proposes a simple universal approach with the optimal gradient-variation regret guarantees.

We investigate the problem of universal online learning with gradient-variation regret. Universal online learning aims to achieve regret guarantees without prior knowledge of the curvature of the online functions. Moreover, we study the problem-dependent gradient-variation regret as it plays a crucial role in bridging stochastic and adversarial optimization as well as game theory. In this work, we design a universal approach with the *optimal* gradient-variation regret simultaneously for strongly convex, exp-concave, and convex functions, thus addressing an open problem highlighted by [Yan et al. [2023]](https://openreview.net/forum?id=AA1xrgAP5z). Our approach is *simple* since it is algorithmically efficient-to-implement with a two-layer online ensemble structure and only $1$ gradient query per round, and theoretically easy-to-analyze with a novel and alternative analysis to the gradient-variation regret. Concretely, previous works on gradient variations require controlling the algorithmic stability, which is challenging and leads to sub-optimal regret and less efficient algorithm design. Our analysis overcomes this issue by using a Bregman divergence negative term from linearization and a useful smoothness property.
tl;dr: We study episodic reinforcement learning for low-rank MDPs with adversarial losses and unknown transition, achieving sublinear regret with bandit feedback for the first time and establishing a tight bound for full information settings.

We consider regret minimization in low-rank MDPs with fixed transition and adversarial losses. Previous work has investigated this problem under either full-information loss feedback with unknown transitions (Zhao et al., 2024), or bandit loss feedback with known transitions (Foster et al., 2022). First, we improve the $poly(d, A, H)T^{5/6}$ regret bound of Zhao et al. (2024) to $poly(d, A, H)T^{2/3}$ for the full-information unknown transition setting, where $d$ is the rank of the transitions, $A$ is the number of actions, $H$ is the horizon length, and $T$ is the number of episodes. Next, we initiate the study on the setting with bandit loss feedback and unknown transitions. Assuming that the loss has a linear structure, we propose both model-based and model-free algorithms achieving $poly(d, A, H)T^{2/3}$ regret, though they are computationally inefficient. We also propose oracle-efficient model-free algorithms with $poly(d, A, H)T^{4/5}$ regret. We show that the linear structure is necessary for the bandit case—without structure on the reward function, the regret has to scale polynomially with the number of states. This is contrary to the full-information case (Zhao et al., 2024), where the regret can be independent of the number of states even for unstructured reward functions.
2458. Virtual Scanning: Unsupervised Non-line-of-sight Imaging from Irregularly Undersampled Transients
tl;dr: We propose an unsupervised learning-based framework for NLOS imaging from irregularly undersampled transients for for high-quality and fast inference.

Non-line-of-sight (NLOS) imaging allows for seeing hidden scenes around corners through active sensing.
Most previous algorithms for NLOS reconstruction require dense transients acquired through regular scans over a large relay surface, which limits their applicability in realistic scenarios with irregular relay surfaces.
In this paper, we propose an unsupervised learning-based framework for NLOS imaging from irregularly undersampled transients~(IUT).
Our method learns implicit priors from noisy irregularly undersampled transients without requiring paired data, which is difficult and expensive to acquire and align.
To overcome the ambiguity of the measurement consistency constraint in inferring the albedo volume, we design a virtual scanning process that enables the network to learn within both range and null spaces for high-quality reconstruction.
We devise a physics-guided SURE-based denoiser to enhance robustness to ubiquitous noise in low-photon imaging conditions.
Extensive experiments on both simulated and real-world data validate the performance and generalization of our method.
Compared with the state-of-the-art (SOTA) method, our method achieves higher fidelity, greater robustness, and remarkably faster inference times by orders of magnitude.
The code and model are available at https://github.com/XingyuCuii/Virtual-Scanning-NLOS.
tl;dr: We explore methods for doing PBE with LLMs

Programming-by-Examples (PBE) aims to generate an algorithm from input-output examples.
Such systems are practically and theoretically important:
from an end-user perspective, they are deployed to millions of people, and from an AI perspective, PBE corresponds to a very general form of few-shot inductive inference.
Given the success of Large Language Models (LLMs) in code-generation tasks, we investigate here the extent to which LLMs can be said to have "solved" PBE.
We experiment on classic domains such as lists and strings, and an uncommon graphics programming domain not well represented in typical pretraining data.
We find that pretrained models are not effective at PBE, but that they can be fine-tuned for much higher performance, provided the test problems are in-distribution.
We analyze empirically what causes these models to succeed and fail, and take steps toward understanding how to achieve better out-of-distribution generalization.
Collectively these results suggest that LLMs make strong progress toward solving the typical suite of PBE tasks, potentially increasing the flexibility and applicability of PBE systems, while also identifying ways in which LLMs still fall short.

While synthetic data hold great promise for privacy protection, their statistical analysis poses significant challenges that necessitate innovative solutions. The use of deep generative models (DGMs) for synthetic data generation is known to induce considerable bias and imprecision into synthetic data analyses, compromising their inferential utility as opposed to original data analyses. This bias and uncertainty can be substantial enough to impede statistical convergence rates, even in seemingly straightforward analyses like mean calculation. The standard errors of such estimators then exhibit slower shrinkage with sample size than the typical 1 over root-$n$ rate. This complicates fundamental calculations like p-values and confidence intervals, with no straightforward remedy currently available. In response to these challenges, we propose a new strategy that targets synthetic data created by DGMs for specific data analyses. Drawing insights from debiased and targeted machine learning, our approach accounts for biases, enhances convergence rates, and facilitates the calculation of estimators with easily approximated large sample variances. We exemplify our proposal through a simulation study on toy data and two case studies on real-world data, highlighting the importance of tailoring DGMs for targeted data analysis. This debiasing strategy contributes to advancing the reliability and applicability of synthetic data in statistical inference.
tl;dr: This paper introduces the PaMoRL framework, which parallelizes MBRL over the sequence length, improving training speed and sample efficiency.

Recently, Model-based Reinforcement Learning (MBRL) methods have demonstrated stunning sample efficiency in various RL domains.
However, achieving this extraordinary sample efficiency comes with additional training costs in terms of computations, memory, and training time.
To address these challenges, we propose the **Pa**rallelized **Mo**del-based **R**einforcement **L**earning (**PaMoRL**) framework.
PaMoRL introduces two novel techniques: the **P**arallel **W**orld **M**odel (**PWM**) and the **P**arallelized **E**ligibility **T**race **E**stimation (**PETE**) to parallelize both model learning and policy learning stages of current MBRL methods over the sequence length.
Our PaMoRL framework is hardware-efficient and stable, and it can be applied to various tasks with discrete or continuous action spaces using a single set of hyperparameters.
The empirical results demonstrate that the PWM and PETE within PaMoRL significantly increase training speed without sacrificing inference efficiency.
In terms of sample efficiency, PaMoRL maintains an MBRL-level sample efficiency that outperforms other no-look-ahead MBRL methods and model-free RL methods, and it even exceeds the performance of planning-based MBRL methods and methods with larger networks in certain tasks.
tl;dr: We introduce Dual Prototype Evolving (DPE), a novel test-time adaptation approach for VLMs that effectively accumulates task-specific knowledge from multi-modalities.

Test-time adaptation, which enables models to generalize to diverse data with unlabeled test samples, holds significant value in real-world scenarios. Recently, researchers have applied this setting to advanced pre-trained vision-language models (VLMs), developing approaches such as test-time prompt tuning to further extend their practical applicability. However, these methods typically focus solely on adapting VLMs from a single modality and fail to accumulate task-specific knowledge as more samples are processed. To address this, we introduce Dual Prototype Evolving (DPE), a novel test-time adaptation approach for VLMs that effectively accumulates task-specific knowledge from multi-modalities. Specifically, we create and evolve two sets of prototypes—textual and visual—to progressively capture more accurate multi-modal representations for target classes during test time. Moreover, to promote consistent multi-modal representations, we introduce and optimize learnable residuals for each test sample to align the prototypes from both modalities. Extensive experimental results on 15 benchmark datasets demonstrate that our proposed DPE consistently outperforms previous state-of-the-art methods while also exhibiting competitive computational efficiency.
tl;dr: Optimal and near-optimal methods for unbiasedly quantizing large vectors on the fly while minimizing the mean squared error for the particular input

Quantization is a fundamental optimization for many machine learning (ML) use cases, including compressing gradients, model weights and activations, and datasets. The most accurate form of quantization is adaptive, where the error is minimized with respect to a given input rather than optimizing for the worst case. However, optimal adaptive quantization methods are considered infeasible in terms of both their runtime and memory requirements.
We revisit the Adaptive Stochastic Quantization (ASQ) problem and present algorithms that find optimal solutions with asymptotically improved time and space complexities. Our experiments indicate that our algorithms may open the door to using ASQ more extensively in a variety of ML applications. We also present an even faster approximation algorithm for quantizing large inputs on the fly.

We explore the theoretical possibility of learning $d$-dimensional targets with $W$-parameter models by gradient flow (GF) when $W<d$. Our main result shows that if the targets are described by a particular $d$-dimensional probability distribution, then there exist models with as few as two parameters that can learn the targets with arbitrarily high success probability. On the other hand, we show that for $W<d$ there is necessarily a large subset of GF-non-learnable targets. In particular, the set of learnable targets is not dense in $\mathbb R^d$, and any subset of $\mathbb R^d$ homeomorphic to the $W$-dimensional sphere contains non-learnable targets. Finally, we observe that the model in our main theorem on almost guaranteed two-parameter learning is constructed using a hierarchical procedure and as a result is not expressible by a single elementary function. We show that this limitation is essential in the sense that most models written in terms of elementary functions cannot achieve the learnability demonstrated in this theorem.
2465. RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation

Federated learning (FL) allows multiple devices to train a model collaboratively without sharing their data. Despite its benefits, FL is vulnerable to privacy leakage and poisoning attacks. To address the privacy concern, secure aggregation (SecAgg) is often used to obtain the aggregation of gradients on sever without inspecting individual user updates. Unfortunately, existing defense strategies against poisoning attacks rely on the analysis of local updates in plaintext, making them incompatible with SecAgg. To reconcile the conflicts, we propose a robust federated learning framework against poisoning attacks (RFLPA) based on SecAgg protocol. Our framework computes the cosine similarity between local updates and server updates to conduct robust aggregation. Furthermore, we leverage verifiable packed Shamir secret sharing to achieve reduced communication cost of $O(M+N)$ per user, and design a novel dot product aggregation algorithm to resolve the issue of increased information leakage. Our experimental results show that RFLPA significantly reduces communication and computation overhead by over $75\%$ compared to the state-of-the-art secret sharing method, BREA, while maintaining competitive accuracy.
tl;dr: This paper presents MonoMAE, a monocular 3D detector inspired by Masked Autoencoders that addresses the object occlusion issue in monocular 3D object detection by masking and reconstructing objects in the feature space.

Monocular 3D object detection aims for precise 3D localization and identification of objects from a single-view image. Despite its recent progress, it often struggles while handling pervasive object occlusions that tend to complicate and degrade the prediction of object dimensions, depths, and orientations. We design MonoMAE, a monocular 3D detector inspired by Masked Autoencoders that addresses the object occlusion issue by masking and reconstructing objects in the feature space. MonoMAE consists of two novel designs. The first is depth-aware masking that selectively masks certain parts of non-occluded object queries in the feature space for simulating occluded object queries for network training. It masks non-occluded object queries by balancing the masked and preserved query portions adaptively according to the depth information. The second is lightweight query completion that works with the depth-aware masking to learn to reconstruct and complete the masked object queries. With the proposed feature-space occlusion and completion, MonoMAE learns enriched 3D representations that achieve superior monocular 3D detection performance qualitatively and quantitatively for both occluded and non-occluded objects. Additionally, MonoMAE learns generalizable representations that can work well in new domains.

Most existing prompting methods suffer from the issues of generalizability and consistency, as they often rely on instance-specific solutions that may not be applicable to other instances and lack task-level consistency across the selected few-shot examples. To address these limitations, we propose a comprehensive framework, StrategyLLM, allowing LLMs to perform inductive reasoning, deriving general strategies from specific task instances, and deductive reasoning, applying these general strategies to particular task examples, for constructing generalizable and consistent few-shot prompts. It employs four LLM-based agents: strategy generator, executor, optimizer, and evaluator, working together to generate, evaluate, and select promising strategies for a given task. Experimental results demonstrate that StrategyLLM outperforms the competitive baseline CoT-SC that requires human-annotated solutions on 13 datasets across 4 challenging tasks without human involvement, including math reasoning (34.2\% $\rightarrow$ 38.8\%), commonsense reasoning (70.3\% $\rightarrow$ 72.5\%), algorithmic reasoning (73.7\% $\rightarrow$ 85.0\%), and symbolic reasoning (30.0\% $\rightarrow$ 79.2\%). Further analysis reveals that StrategyLLM is applicable to various LLMs and demonstrates advantages across numerous scenarios.
tl;dr: We introduce Neuc-MDS, an extension of classical multidimensional scaling to the non-Euclidean non-metrical setting.

We introduce \textbf{N}on-\textbf{Euc}lidean-\textbf{MDS} (Neuc-MDS), which extends Multidimensional Scaling (MDS) to generate outputs that can be non-Euclidean and non-metric. The main idea is to generalize the inner product to other symmetric bilinear forms to utilize the negative eigenvalues of dissimiliarity Gram matrices. Neuc-MDS efficiently optimizes the choice of (both positive and negative) eigenvalues of the dissimilarity Gram matrix to reduce STRESS, the sum of squared pairwise error. We provide an in-depth error analysis and proofs of the optimality in minimizing lower bounds of STRESS. We demonstrate Neuc-MDS's ability to address limitations of classical MDS raised by prior research, and test it on various synthetic and real-world datasets in comparison with both linear and non-linear dimension reduction methods.
tl;dr: We show that LLMs can compress gradients in a zero-shot setting, demonstrating a promising direction toward general parameter priors.

Despite the widespread use of statistical prior models in various fields, such models for neural network gradients have long been overlooked. The inherent challenge stems from their high-dimensional structures and complex interdependencies, which complicate effective modeling. In this work, we demonstrate the potential of large language models (LLMs) to act as gradient priors in a zero-shot setting. We examine the property by considering lossless gradient compression -- a critical application in distributed learning -- that depends heavily on precise probability modeling. To achieve this, we introduce LM-GC, a novel method that integrates LLMs with arithmetic coding. Our technique converts plain gradients into text-like formats, enhancing token efficiency by up to 38 times compared to their plain representations. We ensure that this data conversion maintains a close alignment with the structure of plain gradients and the symbols commonly recognized by LLMs. Our experiments indicate that LM-GC surpasses existing state-of-the-art lossless compression methods, improving compression rates by 10\% up to 21\% across various datasets and architectures. Additionally, our approach shows promising compatibility with lossy compression techniques such as quantization and sparsification. These findings highlight the significant potential of LLMs as a model for effectively handling gradients. We will release the source code upon publication.
tl;dr: We studied the dormant neuron phenomenon in multi-agent reinforcement learning value decomposition and proposed a new method for recycling dormant neurons

In this work, we study the dormant neuron phenomenon in multi-agent reinforcement learning value factorization, where the mixing network suffers from reduced network expressivity caused by an increasing number of inactive neurons. We demonstrate the presence of the dormant neuron phenomenon across multiple environments and algorithms, and show that this phenomenon negatively affects the learning process. We show that dormant neurons correlates with the existence of over-active neurons, which have large activation scores. To address the dormant neuron issue, we propose ReBorn, a simple but effective method that transfers the weights from over-active neurons to dormant neurons. We theoretically show that this method can ensure the learned action preferences are not forgotten after the weight-transferring procedure, which increases learning effectiveness. Our extensive experiments reveal that ReBorn achieves promising results across various environments and improves the performance of multiple popular value factorization approaches. The source code of ReBorn is available in \url{https://github.com/xmu-rl-3dv/ReBorn}.
2471. Black-Box Forgetting
tl;dr: We introduce a novel problem of selective forgetting for black-box models and propose a novel method for this problem.

Large-scale pre-trained models (PTMs) provide remarkable zero-shot classification capability covering a wide variety of object classes. However, practical applications do not always require the classification of all kinds of objects, and leaving the model capable of recognizing unnecessary classes not only degrades overall accuracy but also leads to operational disadvantages. To mitigate this issue, we explore the selective forgetting problem for PTMs, where the task is to make the model unable to recognize only the specified classes, while maintaining accuracy for the rest. All the existing methods assume ''white-box'' settings, where model information such as architectures, parameters, and gradients is available for training. However, PTMs are often ''black-box,'' where information on such models is unavailable for commercial reasons or social responsibilities. In this paper, we address a novel problem of selective forgetting for black-box models, named Black-Box Forgetting, and propose an approach to the problem. Given that information on the model is unavailable, we optimize the input prompt to decrease the accuracy of specified classes through derivative-free optimization. To avoid difficult high-dimensional optimization while ensuring high forgetting performance, we propose Latent Context Sharing, which introduces common low-dimensional latent components among multiple tokens for the prompt. Experiments on four standard benchmark datasets demonstrate the superiority of our method with reasonable baselines. The code is available at https://github.com/yusukekwn/Black-Box-Forgetting.

Message passing plays a vital role in graph neural networks (GNNs) for effective feature learning. However, the over-reliance on input topology diminishes the efficacy of message passing and restricts the ability of GNNs. Despite efforts to mitigate the reliance, existing study encounters message-passing bottlenecks or high computational expense problems, which invokes the demands for flexible message passing with low complexity. In this paper, we propose a novel dynamic message-passing mechanism for GNNs. It projects graph nodes and learnable pseudo nodes into a common space with measurable spatial relations between them. With nodes moving in the space, their evolving relations facilitate flexible pathway construction for a dynamic message-passing process. Associating pseudo nodes to input graphs with their measured relations, graph nodes can communicate with each other intermediately through pseudo nodes under linear complexity. We further develop a GNN model named $\mathtt{N^2}$ based on our dynamic message-passing mechanism. $\mathtt{N^2}$ employs a single recurrent layer to recursively generate the displacements of nodes and construct optimal dynamic pathways. Evaluation on eighteen benchmarks demonstrates the superior performance of $\mathtt{N^2}$ over popular GNNs. $\mathtt{N^2}$ successfully scales to large-scale benchmarks and requires significantly fewer parameters for graph classification with the shared recurrent layer.
tl;dr: We give tight price of anarchy bounds for first-price auctions in the autobidding world.

We study the price of anarchy of first-price auctions in the autobidding world, where bidders can be either utility maximizers (i.e., traditional bidders) or value maximizers (i.e., autobidders). We show that with autobidders only, the price of anarchy of first-price auctions is $1/2$, and with both kinds of bidders, the price of anarchy degrades to about $0.457$ (the precise number is given by an optimization). These results complement the recent result by [Jin and Lu, 2022] showing that the price of anarchy of first-price auctions with traditional bidders is $1 - 1/e^2$. We further investigate a setting where the seller can utilize machine-learned advice to improve the efficiency of the auctions. There, we show that as the accuracy of the advice increases, the price of anarchy improves smoothly from about $0.457$ to $1$.

We propose ID-to-3D, a method to generate identity- and text-guided 3D human heads with disentangled expressions, starting from even a single casually captured ‘in-the-wild’ image of a subject. The foundation of our approach is anchored in compositionality, alongside the use of task-specific 2D diffusion models as priors for optimization. First, we extend a foundational model with a lightweight expression-aware and ID-aware architecture, and create 2D priors for geometric and texture generation, via fine-tuning only 0.2% of its available training parameters. Then, we jointly leverage a neural parametric representation for the expression of each subject and a multi-stage generation of highly detailed geometry and albedo texture. This combination of strong face identity embeddings and our neural representation enables accurate reconstruction of not only facial features but also accessories and hair, and can be meshed to provide render-ready assets for gaming and telepresence. Our results achieve an unprecedented level of id-consistent and high-quality texture and geometry generation, generalizing to a ‘world’ of unseen 3D identities, without relying on large 3D captured datasets of human assets.
tl;dr: a few cost estimate for NAS

Neural Architecture Search (NAS) methods seek effective optimization toward performance metrics regarding model accuracy and generalization while facing challenges regarding search costs and GPU resources. Recent Neural Tangent Kernel (NTK) NAS methods achieve remarkable search efficiency based on a training-free model estimate; however, they overlook the non-convex nature of the DNNs in the search process. In this paper, we develop Multi-Objective Training-based Estimate (MOTE) for efficient NAS, retaining search effectiveness and achieving the new state-of-the-art in the accuracy and cost trade-off. To improve NTK and inspired by the Training Speed Estimation (TSE) method, MOTE is designed to model the actual performance of DNNs from macro to micro perspective by draw loss landscape and convergence speed simultaneously. Using two reduction strategies, the MOTE is generated based on a reduced architecture and a reduced dataset. Inspired by evolutionary search, our iterative ranking-based, coarse-to-fine architecture search is highly effective. Experiments on NASBench-201 show MOTE-NAS achieves 94.32% accuracy on CIFAR-10, 72.81% on CIFAR-100, and 46.38% on ImageNet-16-120, outperforming NTK-based NAS approaches. An evaluation-free (EF) version of MOTE-NAS delivers high efficiency in only 5 minutes, delivering a model more accurate than KNAS.

A key source of complexity in next-generation AI models is the size of model outputs, making it time-consuming to parse and provide reliable feedback on. To ensure such models are aligned, we will need to bolster our understanding of scalable oversight and how to scale up human feedback. To this end, we study the challenges of scalable oversight in the context of goal-conditioned hierarchical reinforcement learning. Hierarchical structure is a promising entrypoint into studying how to scale up human feedback, which in this work we assume can only be provided for model outputs below a threshold size. In the cardinal feedback setting, we develop an apt sub-MDP reward and algorithm that allows us to acquire and scale up low-level feedback for learning with sublinear regret. In the ordinal feedback setting, we show the necessity of both high- and low-level feedback, and develop a hierarchical experimental design algorithm that efficiently acquires both types of feedback for learning. Altogether, our work aims to consolidate the foundations of scalable oversight, formalizing and studying the various challenges thereof.
tl;dr: We propose a new road adversarial patch against MDE models based on our groundbreaking findings, which is completely different from previous obstacle patches and better adapts to complex traffic scenarios.

Monocular Depth Estimation (MDE) enables the prediction of scene depths from a single RGB image, having been widely integrated into production-grade autonomous driving systems, e.g., Tesla Autopilot. Current adversarial attacks to MDE models focus on attaching an optimized adversarial patch to a designated obstacle. Although effective, this approach presents two inherent limitations: its reliance on specific obstacles and its limited malicious impact. In contrast, we propose a pioneering attack to MDE models that \textit{decouples obstacles from patches physically and deploys optimized patches on roads}, thereby extending the attack scope to arbitrary traffic participants. This approach is inspired by our groundbreaking discovery: \textit{various MDE models with different architectures, trained for autonomous driving, heavily rely on road regions} when predicting depths for different obstacles. Based on this discovery, we design the Adversarial Road Marking (AdvRM) attack, which camouflages patches as ordinary road markings and deploys them on roads, thereby posing a continuous threat within the environment. Experimental results from both dataset simulations and real-world scenarios demonstrate that AdvRM is effective, stealthy, and robust against various MDE models, achieving about 1.507 of Mean Relative Shift Ratio (MRSR) over 8 MDE models. The code is available at \url{https://github.com/a-c-a-c/AdvRM.git}
tl;dr: We propose the learn-to-identify framework to improve the identifiability of hybrid-DGMs.

The interest in leveraging physics-based inductive bias in deep learning has resulted in recent development of _hybrid deep generative models (hybrid-DGMs)_ that integrates known physics-based mathematical expressions in neural generative models. To identify these hybrid-DGMs requires inferring parameters of the physics-based component along with their neural component. The identifiability of these hybrid-DGMs, however, has not yet been theoretically probed or established. How does the existing theory of the un-identifiability of general DGMs apply to hybrid-DGMs? What may be an effective approach to consutrct a hybrid-DGM with theoretically-proven identifiability? This paper provides the first theoretical probe into the identifiability of hybrid-DGMs, and present meta-learning as a novel solution to construct identifiable hybrid-DGMs. On synthetic and real-data benchmarks, we provide strong empirical evidence for the un-identifiability of existing hybrid-DGMs using unconditional priors, and strong identifiability results of the presented meta-formulations of hybrid-DGMs.

We introduce Equivariant Neural Diffusion (END), a novel diffusion model for molecule generation in 3D that is equivariant to Euclidean transformations. Compared to current state-of-the-art equivariant diffusion models, the key innovation in END lies in its learnable forward process for enhanced generative modelling. Rather than pre-specified, the forward process is parameterized through a time- and data-dependent transformation that is equivariant to rigid transformations. Through a series of experiments on standard molecule generation benchmarks, we demonstrate the competitive performance of END compared to several strong baselines for both unconditional and conditional generation.
tl;dr: We prove previous 2D-to-3D human pose lifting methods suffer from topology inconsistencies invisible to standard evaluation metrics, and propose both new metrics and a new method circumventing these issues via constrained multiple hypotheses.

We propose ManiPose, a manifold-constrained multi-hypothesis model for human-pose 2D-to-3D lifting. We provide theoretical and empirical evidence that, due to the depth ambiguity inherent to monocular 3D human pose estimation, traditional regression models suffer from pose-topology consistency issues, which standard evaluation metrics (MPJPE, P-MPJPE and PCK) fail to assess. ManiPose addresses depth ambiguity by proposing multiple candidate 3D poses for each 2D input, each with its estimated plausibility. Unlike previous multi-hypothesis approaches, ManiPose forgoes generative models, greatly facilitating its training and usage. By constraining the outputs to lie on the human pose manifold, ManiPose guarantees the consistency of all hypothetical poses, in contrast to previous works. We showcase the performance of ManiPose on real-world datasets, where it outperforms state-of-the-art models in pose consistency by a large margin while being very competitive on the MPJPE metric.

We introduce and study the problem of detecting whether an agent is updating their prior beliefs given new evidence in an optimal way that is Bayesian, or whether they are biased towards their own prior. In our model, biased agents form posterior beliefs that are a convex combination of their prior and the Bayesian posterior, where the more biased an agent is, the closer their posterior is to the prior. Since we often cannot observe the agent's beliefs directly, we take an approach inspired by *information design*. Specifically, we measure an agent's bias by designing a *signaling scheme* and observing the actions they take in response to different signals, assuming that they are maximizing their own expected utility; our goal is to detect bias with a minimum number of signals. Our main results include a characterization of scenarios where a single signal suffices and a computationally efficient algorithm to compute optimal signaling schemes.
tl;dr: This paper propose a novel model structure for 1-bit weight quantization and a corresponding parameter initialization method. Extensive experiments demonstrate that it has clear advantages over representative strong baselines.

Model quantification uses low bit-width values to represent the weight matrices of existing models to be quantized, which is a promising approach to reduce both storage and computational overheads of deploying highly anticipated LLMs. However, current quantization methods suffer severe performance degradation when the bit-width is extremely reduced, and thus focus on utilizing 4-bit or 8-bit values to quantize models. This paper boldly quantizes the weight matrices of LLMs to 1-bit, paving the way for the extremely low bit-width deployment of LLMs. For this target, we introduce a 1-bit model compressing framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the quantization framework. Sufficient experimental results indicate that OneBit achieves good performance (at least 81% of the non-quantized performance on LLaMA models) with robust training processes when only using 1-bit weight matrices.
tl;dr: We propose an automated framework for dataset optimization, which, upon employing the refined datasets for instruction-tuning of LLMs, has demonstrated a performance enhancement of approximately 12% on evaluation sets such as MT-bench.

The efficacy of large language models (LLMs) on downstream tasks usually hinges on instruction tuning, which relies critically on the quality of training data. Unfortunately, collecting high-quality and diverse data is both expensive and time-consuming. To mitigate this issue, we propose a novel Star-Agents framework, which automates the enhancement of data quality across datasets through multi-agent collaboration and assessment. The framework adopts a three-pronged strategy. It initially generates diverse instruction data with multiple LLM agents through a bespoke sampling method. Subsequently, the generated data undergo a rigorous evaluation using a dual-model method that assesses both difficulty and quality. Finaly, the above process evolves in a dynamic refinement phase, where more effective LLMs are prioritized, enhancing the overall data quality. Our empirical studies, including instruction tuning experiments with models such as Pythia and LLaMA, demonstrate the effectiveness of the proposed framework. Optimized datasets have achieved substantial improvements, with an average increase of 12\% and notable gains in specific metrics, such as a 40\% improvement in Fermi, as evidenced by benchmarks like MT-bench, Vicuna bench, and WizardLM testset. Codes will be released soon.
tl;dr: This paper proposes an Adaptive-Interval Color Transformation method to perform pixel-wise color transformation and model local non-linearities of the color transformation for high-resolution image harmonization.

Existing high-resolution image harmonization methods typically rely on global color adjustments or the upsampling of parameter maps. However, these methods ignore local variations, leading to inharmonious appearances. To address this problem, we propose an Adaptive-Interval Color Transformation method (AICT), which predicts pixel-wise color transformations and adaptively adjusts the sampling interval to model local non-linearities of the color transformation at high resolution. Specifically, a parameter network is first designed to generate multiple position-dependent 3-dimensional lookup tables (3D LUTs), which use the color and position of each pixel to perform pixel-wise color transformations. Then, to enhance local variations adaptively, we separate a color transform into a cascade of sub-transformations using two 3D LUTs to achieve the non-uniform sampling intervals of the color transform. Finally, a global consistent weight learning method is proposed to predict an image-level weight for each color transform, utilizing global information to enhance the overall harmony. Extensive experiments demonstrate that our AICT achieves state-of-the-art performance with a lightweight architecture. The code is available at https://github.com/aipixel/AICT.

In this paper, we introduce DCDepth, a novel framework for the long-standing monocular depth estimation task. Moving beyond conventional pixel-wise depth estimation in the spatial domain, our approach estimates the frequency coefficients of depth patches after transforming them into the discrete cosine domain. This unique formulation allows for the modeling of local depth correlations within each patch. Crucially, the frequency transformation segregates the depth information into various frequency components, with low-frequency components encapsulating the core scene structure and high-frequency components detailing the finer aspects. This decomposition forms the basis of our progressive strategy, which begins with the prediction of low-frequency components to establish a global scene context, followed by successive refinement of local details through the prediction of higher-frequency components. We conduct comprehensive experiments on NYU-Depth-V2, TOFDC, and KITTI datasets, and demonstrate the state-of-the-art performance of DCDepth. Code is available at https://github.com/w2kun/DCDepth.
tl;dr: We propose a method to endow the Laplace approximation in Bayesian neural networks with informative Gaussian process priors.

Laplace approximations are popular techniques for endowing deep networks with epistemic uncertainty estimates as they can be applied without altering the predictions of the trained network, and they scale to large models and datasets. While the choice of prior strongly affects the resulting posterior distribution, computational tractability and lack of interpretability of the weight space typically limit the Laplace approximation to isotropic Gaussian priors, which are known to cause pathological behavior as depth increases. As a remedy, we directly place a prior on function space. More precisely, since Lebesgue densities do not exist on infinite-dimensional function spaces, we recast training as finding the so-called weak mode of the posterior measure under a Gaussian process (GP) prior restricted to the space of functions representable by the neural network. Through the GP prior, one can express structured and interpretable inductive biases, such as regularity or periodicity, directly in function space, while still exploiting the implicit inductive biases that allow deep networks to generalize. After model linearization, the training objective induces a negative log-posterior density to which we apply a Laplace approximation, leveraging highly scalable methods from matrix-free linear algebra. Our method provides improved results where prior knowledge is abundant (as is the case in many scientific inference tasks). At the same time, it stays competitive for black-box supervised learning problems, where neural networks typically excel.

We introduce camera ray matching (CRAYM) into the joint optimization of camera poses and neural fields from multi-view images. The optimized field, referred to as a feature volume, can be “probed” by the camera rays for novel view synthesis (NVS) and 3D geometry reconstruction. One key reason for matching camera rays, instead of pixels as in prior works, is that the camera rays can be parameterized by the feature volume to carry both geometric and photometric information. Multi-view consistencies involving the camera rays and scene rendering can be naturally integrated into the joint optimization and network training, to impose physically meaningful constraints to improve the final quality of both the geometric reconstruction and photorealistic rendering. We formulate our per-ray optimization and matched ray coherence by focusing on camera rays passing through keypoints in the input images to elevate both the efficiency and accuracy of scene correspondences. Accumulated ray features along the feature volume provide a means to discount the coherence constraint amid erroneous ray matching. We demonstrate the effectiveness of CRAYM for both NVS and geometry reconstruction, over dense- or sparse-view settings, with qualitative and quantitative comparisons to state-of-the-art alternatives.

Enhancing node-level Out-Of-Distribution (OOD) generalization on graphs remains a crucial area. In this paper, we develop a Structural Causal Model (SCM) to theoretically dissect the performance of two prominent invariant learning methods--Invariant Risk Minimization (IRM) and Variance-Risk Extrapolation (VREx)--in node-level OOD settings. Our analysis reveals a critical limitation: these methods may struggle to identify invariant features due to the complexities introduced by the message-passing mechanism, which can obscure causal features within a range of neighboring samples. To address this, we propose Cross-environment Intra-class Alignment (CIA), which explicitly eliminates spurious features by aligning representations within the same class, bypassing the need for explicit knowledge of underlying causal patterns. To adapt CIA to node-level OOD scenarios where environment labels are hard to obtain, we further propose CIA-LRA (Localized Reweighting Alignment) that leverages the distribution of neighboring labels to selectively align node representations, effectively distinguishing and preserving invariant features while removing spurious ones, all without relying on environment labels. We theoretically prove CIA-LRA's effectiveness by deriving an OOD generalization error bound based on PAC-Bayesian analysis. Experiments on graph OOD benchmarks validate the superiority of CIA and CIA-LRA, marking a significant advancement in node-level OOD generalization.
tl;dr: We study multi-agent reinforcement learning with the guarantee of differential privacy.

We study the problem of multi-agent reinforcement learning (multi-agent RL) with differential privacy (DP) constraints. This is well-motivated by various real-world applications involving sensitive data, where it is critical to protect users' private information. We first extend the definitions of Joint DP (JDP) and Local DP (LDP) to two-player zero-sum episodic Markov Games, where both definitions ensure trajectory-wise privacy protection. Then we design a provably efficient algorithm based on optimistic Nash value iteration and privatization of Bernstein-type bonuses. The algorithm is able to satisfy JDP and LDP requirements when instantiated with appropriate privacy mechanisms. Furthermore, for both notions of DP, our regret bound generalizes the best known result under the single-agent RL case, while our regret could also reduce to the best known result for multi-agent RL without privacy constraints. To the best of our knowledge, these are the first results towards understanding trajectory-wise privacy protection in multi-agent RL.
tl;dr: This paper reveals a trade-off between sharpness and diversity in deep ensembles, both empirically and theoretically, and proposes SharpBalance, a novel ensemble algorithm that achieves an optimal balance between these two crucial metrics.

Recent studies on deep ensembles have identified the sharpness of the local minima of individual learners and the diversity of the ensemble members as key factors in improving test-time performance. Building on this, our study investigates the interplay between sharpness and diversity within deep ensembles, illustrating their crucial role in robust generalization to both in-distribution (ID) and out-of-distribution (OOD) data. We discover a trade-off between sharpness and diversity: minimizing the sharpness in the loss landscape tends to diminish the diversity of individual members within the ensemble, adversely affecting the ensemble's improvement. The trade-off is justified through our rigorous theoretical analysis and verified empirically through extensive experiments. To address the issue of reduced diversity, we introduce SharpBalance, a novel training approach that balances sharpness and diversity within ensembles. Theoretically, we show that our training strategy achieves a better sharpness-diversity trade-off. Empirically, we conducted comprehensive evaluations in various data sets (CIFAR-10, CIFAR-100, TinyImageNet) and showed that SharpBalance not only effectively improves the sharpness-diversity trade-off but also significantly improves ensemble performance in ID and OOD scenarios.
tl;dr: FlexSBDD is a deep generative model capable of accurately modeling the flexible target protein structure for ligand molecule generation.

Structure-based drug design (SBDD), which aims to generate 3D ligand molecules binding to target proteins, is a fundamental task in drug discovery. Existing SBDD methods typically treat protein as rigid and neglect protein structural change when binding with ligand molecules, leading to a big gap with real-world scenarios and inferior generation qualities (e.g., many steric clashes). To bridge the gap, we propose FlexSBDD, a deep generative model capable of accurately modeling the flexible protein-ligand complex structure for ligand molecule generation. FlexSBDD adopts an efficient flow matching framework and leverages E(3)-equivariant network with scalar-vector dual representation to model dynamic structural changes. Moreover, novel data augmentation schemes based on structure relaxation/sidechain repacking are adopted to boost performance. Extensive experiments demonstrate that FlexSBDD achieves state-of-the-art performance in generating high-affinity molecules and effectively modeling the protein's conformation change to increase favorable protein-ligand interactions (e.g., Hydrogen bonds) and decrease steric clashes.
tl;dr: Training-free and guidance-free structure and appearance control for text-to-image diffusion models from user-provided images

Recent controllable generation approaches such as FreeControl and Diffusion Self-Guidance bring fine-grained spatial and appearance control to text-to-image (T2I) diffusion models without training auxiliary modules. However, these methods optimize the latent embedding for each type of score function with longer diffusion steps, making the generation process time-consuming and limiting their flexibility and use. This work presents *Ctrl-X*, a simple framework for T2I diffusion controlling structure and appearance without additional training or guidance. Ctrl-X designs feed-forward structure control to enable the structure alignment with a structure image and semantic-aware appearance transfer to facilitate the appearance transfer from a user-input image. Extensive qualitative and quantitative experiments illustrate the superior performance of Ctrl-X on various condition inputs and model checkpoints. In particular, Ctrl-X supports novel structure and appearance control with arbitrary condition images of any modality, exhibits superior image quality and appearance transfer compared to existing works, and provides instant plug-and-play functionality to any T2I and text-to-video (T2V) diffusion model. See our project page for the code and an overview of the results: https://genforce.github.io/ctrl-x
tl;dr: Efficient confidential deep neural network training with encrypted data pruning

Non-interactive cryptographic computing, Fully Homomorphic Encryption (FHE), provides a promising solution for private neural network training on encrypted data. One challenge of FHE-based private training is its large computational overhead, especially the multiple rounds of forward and backward execution on each encrypted data sample. Considering the existence of largely redundant data samples, pruning them will significantly speed up the training, as proven in plain non-FHE training.
Executing the data pruning of encrypted data on the server side is not trivial since the knowledge calculation of data pruning needs complex and expensive executions on encrypted data. There is a lack of FHE-based data pruning protocol for efficient, private training. In this paper, we propose, \textit{HEPrune}, to construct a FHE data-pruning protocol and then design an FHE-friendly data-pruning algorithm under client-aided or non-client-aided settings, respectively. We also observed that data sample pruning may not always remove ciphertexts, leaving large empty slots and limiting the effects of data pruning. Thus, in HEPrune, we further propose ciphertext-wise pruning to reduce ciphertext computation numbers without hurting accuracy. Experimental results show that our work can achieve a $16\times$ speedup with only a $0.6\%$ accuracy drop over prior work.
The code is publicly available at \href{https://github.com/UCF-Lou-Lab-PET/Private-Data-Prune}.
tl;dr: The derivatives of the iterates of stochastic gradient descent converge.

We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(\log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
tl;dr: We explore approximating neural algorithmic execution by solving an equilibrium equation, ground our approach theoretically and discuss implementation caveats.

Neural Algorithmic Reasoning (NAR) research has demonstrated that graph neural networks (GNNs) could learn to execute classical algorithms. However, most previous approaches have always used a recurrent architecture, where each iteration of the GNN matches an iteration of the algorithm. In this paper we study neurally solving algorithms from a different perspective: since the algorithm’s solution is often an equilibrium, it is possible to find the solution directly by solving an equilibrium equation. Our approach requires no information on the ground-truth number of steps of the algorithm, both during train and test time. Furthermore, the proposed method improves the performance of GNNs on executing algorithms and is a step towards speeding up existing NAR models. Our empirical evidence, leveraging algorithms from the CLRS-30 benchmark, validates that one can train a network to solve algorithmic problems by directly finding the equilibrium. We discuss the practical implementation of such models and propose regularisations to improve the performance of these equilibrium reasoners.
2496. Random Function Descent
tl;dr: Grounding step size heuristics in average case analysis.

Classical worst-case optimization theory neither explains the success of optimization in machine learning, nor does it help with step size selection. In this paper we demonstrate the viability and advantages of replacing the classical 'convex function' framework with a 'random function' framework. With complexity $\mathcal{O}(n^3d^3)$, where $n$ is the number of steps and $d$ the number of dimensions, Bayesian optimization with gradients has not been viable in large dimension so far. By bridging the gap between Bayesian optimization (i.e. random function optimization theory) and classical optimization we establish viability. Specifically, we use a 'stochastic Taylor approximation' to rediscover gradient descent, which is scalable in high dimension due to $\mathcal{O}(nd)$ complexity. This rediscovery yields a specific step size schedule we call Random Function Descent (RFD). The advantage of this random function framework is that RFD is scale invariant and that it provides a theoretical foundation for common step size heuristics such as gradient clipping and gradual learning rate warmup.
tl;dr: We developed a novel SNN for hypergraph minimum vertex cover.

Neuromorphic computers open up the potential of energy-efficient computation using spiking neural networks (SNN), which consist of neurons that exchange spike-based information asynchronously. In particular, SNNs have shown promise in solving combinatorial optimization. Underpinning the SNN methods is the concept of energy minimization of an Ising model, which is closely related to quadratic unconstrained binary optimization (QUBO). Thus, the starting point for many SNN methods is reformulating the target problem as QUBO, then executing an SNN-based QUBO solver. For many combinatorial problems, the reformulation entails introducing penalty terms, potentially with slack variables, that implement feasibility constraints in the QUBO objective. For more complex problems such as hypergraph minimum vertex cover (HMVC), numerous slack variables are introduced which drastically increase the search domain and reduce the effectiveness of the SNN solver. In this paper, we propose a novel SNN formulation for HMVC. Rather than using penalty terms with slack variables, our SNN architecture introduces additional spiking neurons with a constraint checking and correction mechanism that encourages convergence to feasible solutions. In effect, our method obviates the need for reformulating HMVC as QUBO. Experiments on neuromorphic hardware show that our method consistently yielded high quality solutions for HMVC on real and synthetic instances where the SNN-based QUBO solver often failed, while consuming measurably less energy than global solvers on CPU.
tl;dr: This paper explores the domain generalization ability of prompts in PLMs, discovering that prompts with higher "Concentration" are more generalizable, leading to new optimization methods that outperform existing techniques.

Recent advances in prompt optimization have notably enhanced the performance of pre-trained language models (PLMs) on downstream tasks. However, the potential of optimized prompts on domain generalization has been under-explored. To explore the nature of prompt generalization on unknown domains, we conduct pilot experiments and find that (i) Prompts gaining more attention weight from PLMs’ deep layers are more generalizable and (ii) Prompts with more stable attention distributions in PLMs’ deep layers are more generalizable. Thus, we offer a fresh objective towards domain-generalizable prompts optimization named ''Concentration'', which represents the ''lookback'' attention from the current decoding token to the prompt tokens, to increase the attention strength on prompts and reduce the fluctuation of attention distribution.
We adapt this new objective to popular soft prompt and hard prompt optimization methods, respectively. Extensive experiments demonstrate that our idea improves comparison prompt optimization methods by 1.42% for soft prompt generalization and 2.16% for hard prompt generalization in accuracy on the multi-source domain generalization setting, while maintaining satisfying in-domain performance. The promising results validate the effectiveness of our proposed prompt optimization objective and provide key insights into domain-generalizable prompts.
2499. Randomized Exploration for Reinforcement Learning with Multinomial Logistic Function Approximation
tl;dr: We propose randomized exploration model-based RL algorithms with multinomial logistic function approximation.

We study reinforcement learning with _multinomial logistic_ (MNL) function approximation where the underlying transition probability kernel of the _Markov decision processes_ (MDPs) is parametrized by an unknown transition core with features of state and action. For the finite horizon episodic setting with inhomogeneous state transitions, we propose provably efficient algorithms with randomized exploration having frequentist regret guarantees. For our first algorithm, $\texttt{RRL-MNL}$, we adapt optimistic sampling to ensure the optimism of the estimated value function with sufficient frequency and establish that $\texttt{RRL-MNL}$ is both _statistically_ and _computationally_ efficient, achieving a $\tilde{\mathcal{O}}(\kappa^{-1} d^{\frac{3}{2}} H^{\frac{3}{2}} \sqrt{T})$ frequentist regret bound with constant-time computational cost per episode. Here, $d$ is the dimension of the transition core, $H$ is the horizon length, $T$ is the total number of steps, and $\kappa$ is a problem-dependent constant. Despite the simplicity and practicality of $\texttt{RRL-MNL}$, its regret bound scales with $\kappa^{-1}$, which is potentially large in the worst case. To improve the dependence on $\kappa^{-1}$, we propose $\texttt{ORRL-MNL}$, which estimates the value function using local gradient information of the MNL transition model. We show that its frequentist regret bound is $\tilde{\mathcal{O}}(d^{\frac{3}{2}} H^{\frac{3}{2}} \sqrt{T} + \kappa^{-1} d^2 H^2)$. To the best of our knowledge, these are the first randomized RL algorithms for the MNL transition model that achieve both computational and statistical efficiency. Numerical experiments demonstrate the superior performance of the proposed algorithms.

Logic Synthesis (LS) aims to generate an optimized logic circuit satisfying a given functionality, which generally consists of circuit translation and optimization. It is a challenging and fundamental combinatorial optimization problem in integrated circuit design. Traditional LS approaches rely on manually designed heuristics to tackle the LS task, while machine learning recently offers a promising approach towards next-generation logic synthesis by neural circuit generation and optimization. In this paper, we first revisit the application of differentiable neural architecture search (DNAS) methods to circuit generation and found from extensive experiments that existing DNAS methods struggle to exactly generate circuits, scale poorly to large circuits, and exhibit high sensitivity to hyper-parameters. Then we provide three major insights for these challenges from extensive empirical analysis: 1) DNAS tends to overfit to too many skip-connections, consequently wasting a significant portion of the network's expressive capabilities; 2) DNAS suffers from the structure bias between the network architecture and the circuit inherent structure, leading to inefficient search; 3) the learning difficulty of different input-output examples varies significantly, leading to severely imbalanced learning. To address these challenges in a systematic way, we propose a novel regularized triangle-shaped circuit network generation framework, which leverages our key insights for completely accurate and scalable circuit generation. Furthermore, we propose an evolutionary algorithm assisted by reinforcement learning agent restarting technique for efficient and effective neural circuit optimization. Extensive experiments on four different circuit benchmarks demonstrate that our method can precisely generate circuits with up to 1200 nodes. Moreover, our synthesized circuits significantly outperform the state-of-the-art results from several competitive winners in IWLS 2022 and 2023 competitions.
tl;dr: We show how to learn a policy maker's implicit social welfare function from their past decisions by fitting power mean functions, with provable sample complexity guarantees even under noisy observations.

Is it possible to understand or imitate a policy maker's rationale by looking at past decisions they made? We formalize this question as the problem of learning social welfare functions belonging to the well-studied family of power mean functions. We focus on two learning tasks; in the first, the input is vectors of utilities of an action (decision or policy) for individuals in a group and their associated social welfare as judged by a policy maker, whereas in the second, the input is pairwise comparisons between the welfares associated with a given pair of utility vectors. We show that power mean functions are learnable with polynomial sample complexity in both cases, even if the social welfare information is noisy. Finally, we design practical algorithms for these tasks and evaluate their performance.

Transformer-based autoregressive sampling has been the major bottleneck for slowing down large language model inferences. One effective way to accelerate inference is Speculative Decoding, which employs a small model to sample a sequence of draft tokens and a large model to validate. Given its empirical effectiveness, the theoretical understanding of Speculative Decoding is falling behind. This paper tackles this gap by conceptualizing the decoding problem via markov chain abstraction and studying the key properties, output quality and inference acceleration, from a theoretical perspective. Our analysis covers the theoretical limits of speculative decoding, batch algorithms, and output quality-inference acceleration tradeoffs. Our results reveal the fundamental connections between different components of LLMs via total variation distances and show how they jointly affect the efficiency of decoding algorithms.
tl;dr: We cause aligned models to output specific harmful strings using a black-box attack

Recent work has shown it is possible to construct adversarial examples that cause aligned language models to emit harmful strings or perform harmful behavior.
Existing attacks work either in the white-box setting (with full access to the model weights), or through _transferability_: the phenomenon that adversarial examples crafted on one model often remain effective on other models.
We improve on prior work with a _query-based_ attack that leverages API access to a remote language model to construct adversarial examples that cause the model to emit harmful strings with (much) higher probability than with transfer-only attacks.
We validate our attack on GPT-3.5 and OpenAI's safety classifier; we can cause GPT-3.5 to emit harmful strings that current transfer attacks fail at, and we can evade the OpenAI and Llama Guard safety classifiers with nearly 100% probability.
tl;dr: We propose methods for improving the performance of zero-shot RL methods when trained on low quality offline datasets.

Zero-shot reinforcement learning (RL) promises to provide agents that can perform _any_ task in an environment after an offline, reward-free pre-training phase. Methods leveraging successor measures and successor features have shown strong performance in this setting, but require access to large heterogenous datasets for pre-training which cannot be expected for most real problems. Here, we explore how the performance of zero-shot RL methods degrades when trained on small homogeneous datasets, and propose fixes inspired by _conservatism_, a well-established feature of performant single-task offline RL algorithms. We evaluate our proposals across various datasets, domains and tasks, and show that conservative zero-shot RL algorithms outperform their non-conservative counterparts on low quality datasets, and perform no worse on high quality datasets. Somewhat surprisingly, our proposals also outperform baselines that get to see the task during training. Our code is available via the project page https://enjeeneer.io/projects/zero-shot-rl/.
tl;dr: We introduce an advection augmented CNN and show its effectiveness on several real-world datasets.

Many problems in physical sciences are characterized by the prediction of space-time sequences. Such problems range from weather prediction to the analysis of disease propagation and video prediction. Modern techniques for the solution of these problems typically combine Convolution Neural Networks (CNN) architecture with a time prediction mechanism. However, oftentimes, such approaches underperform in the long-range propagation of information and lack explainability. In this work, we introduce a physically inspired architecture for the solution of such problems. Namely, we propose to augment CNNs with advection by designing a novel semi-Lagrangian push operator. We show that the proposed operator allows for the non-local transformation of information compared with standard convolutional kernels. We then complement it with Reaction and Diffusion neural components to form a network that mimics the Reaction-Advection-Diffusion equation, in high dimensions. We demonstrate the effectiveness of our network on a number of spatio-temporal datasets that show their merit. Our code is available at https://github.com/Siddharth-Rout/deepADRnet.
tl;dr: Unveiling internal mechanisms that lead to LLM bias and mitigate such bias by manipulation of LLM internal structures.

Large language models (LLMs) have demonstrated impressive capabilities in various tasks using the in-context learning (ICL) paradigm. However, their effectiveness is often compromised by inherent bias, leading to prompt brittleness—sensitivity to design settings such as example selection, order, and prompt formatting. Previous studies have addressed LLM bias through external adjustment of model outputs, but the internal mechanisms that lead to such bias remain unexplored. Our work delves into these mechanisms, particularly investigating how feedforward neural networks (FFNs) and attention heads result in the bias of LLMs. By Interpreting the contribution of individual FFN vectors and attention heads, we identify the biased LLM components that skew LLMs' prediction toward specific labels. To mitigate these biases, we introduce UniBias, an inference-only method that effectively identifies and eliminates biased FFN vectors and attention heads. Extensive experiments across 12 NLP datasets demonstrate that UniBias significantly enhances ICL performance and alleviates prompt brittleness of LLMs.
tl;dr: We devise truthful mechanisms for approximating the Maximin-Share (MMS) allocation via a learning augmented framework.

We study truthful mechanisms for approximating the Maximin-Share (MMS) allocation of agents with additive valuations for indivisible goods. Algorithmically, constant factor approximations exist for the problem for any number of agents. When adding incentives to the mix, a jarring result by Amanatidis, Birmpas, Christodoulou, and Markakis [EC 2017] shows that the best possible approximation for two agents and $m$ items is $\lfloor \frac{m}{2} \rfloor$. We adopt a learning-augmented framework to investigate what is possible when some prediction on the input is given. For two agents, we give a truthful mechanism that takes agents' ordering over items as prediction. When the prediction is accurate, we give a $2$-approximation to the MMS (consistency), and when the prediction is off, we still get an $\lceil \frac{m}{2} \rceil$-approximation to the MMS (robustness). We further show that the mechanism's performance degrades gracefully in the number of ``mistakes" in the prediction; i.e., we interpolate (up to constant factors) between the two extremes: when there are no mistakes, and when there is a maximum number of mistakes. We also show an impossibility result on the obtainable consistency for mechanisms with finite robustness. For the general case of $n\ge 2$ agents, we give a 2-approximation mechanism for accurate predictions, with relaxed fallback guarantees. Finally, we give experimental results which illustrate when different components of our framework, made to insure consistency and robustness, come into play.
2508. Dynamic Service Fee Pricing under Strategic Behavior: Actions as Instruments and Phase Transition

We study a dynamic pricing problem for third-party platform service fees under strategic, far-sighted customers. In each time period, the platform sets a service fee based on historical data, observes the resulting transaction quantities, and collects revenue. The platform also monitors equilibrium prices influenced by both demand and supply. The objective is to maximize total revenue over a time horizon $T$. Our problem incorporates three practical challenges: (a) initially, the platform lacks knowledge of the demand side beforehand, necessitating a balance between exploring (learning the demand curve) and exploiting (maximizing revenue) simultaneously; (b) since only equilibrium prices and quantities are observable, traditional Ordinary Least Squares (OLS) estimators would be biased and inconsistent; (c) buyers are rational and strategic, seeking to maximize their consumer surplus and potentially misrepresenting their preferences. To address these challenges, we propose novel algorithmic solutions. Our approach involves: (i) a carefully designed active randomness injection to balance exploration and exploitation effectively; (ii) using non-i.i.d. actions as instrumental variables (IV) to consistently estimate demand; (iii) a low-switching cost design that promotes nearly truthful buyer behavior. We show an expected regret bound of $\tilde{\mathcal{O}} (\sqrt{T}\wedge\sigma_S^{-2})$ and demonstrate its optimality, up to logarithmic factors, with respect to both the time horizon $T$ and the randomness in supply $\sigma_S$. Despite its simplicity, our model offers valuable insights into the use of actions as estimation instruments, the benefits of low-switching pricing policies in mitigating strategic buyer behavior, and the role of supply randomness in facilitating exploration which leads to a phase transition of policy performance.
tl;dr: We propose a label-only Membership Inference Attack (MIA) that works by sending only a single shot to the target model.

We introduce One-Shot Label-Only (OSLO) membership inference attacks (MIAs), which accurately infer a given sample's membership in a target model's training set with high precision using just a single query, where the target model only returns the predicted hard label.
This is in contrast to state-of-the-art label-only attacks which require $\sim6000$ queries, yet get attack precisions lower than OSLO's.
OSLO leverages transfer-based black-box adversarial attacks. The core idea is that a member sample exhibits more resistance to adversarial perturbations than a non-member. We compare OSLO against state-of-the-art label-only attacks and demonstrate that, despite requiring only one query, our method significantly outperforms previous attacks in terms of precision and true positive rate (TPR) under the same false positive rates (FPR). For example, compared to previous label-only MIAs, OSLO achieves a TPR that is at least 7$\times$ higher under a 1\% FPR and at least 22$\times$ higher under a 0.1\% FPR on CIFAR100 for a ResNet18 model. We evaluated multiple defense mechanisms against OSLO.
tl;dr: Drawing from the Complementary Learning Systems theory, we propose a novel vision-language tracker (MemVLT), which can provide adaptive multimodal prompts for tracking guidance, achieving SOTA performance on 4 mainstream datasets..

Vision-language tracking (VLT) enhances traditional visual object tracking by integrating language descriptions, requiring the tracker to flexibly understand complex and diverse text in addition to visual information. However, most existing vision-language trackers still overly rely on initial fixed multimodal prompts, which struggle to provide effective guidance for dynamically changing targets. Fortunately, the Complementary Learning Systems (CLS) theory suggests that the human memory system can dynamically store and utilize multimodal perceptual information, thereby adapting to new scenarios. Inspired by this, (i) we propose a Memory-based Vision-Language Tracker (MemVLT). By incorporating memory modeling to adjust static prompts, our approach can provide adaptive prompts for tracking guidance.
(ii) Specifically, the memory storage and memory interaction modules are designed in accordance with CLS theory. These modules facilitate the storage and flexible interaction between short-term and long-term memories, generating prompts that adapt to target variations.
(iii) Finally, we conduct extensive experiments on mainstream VLT datasets (e.g., MGIT, TNL2K, LaSOT and LaSOT$_{ext}$). Experimental results show that MemVLT achieves new state-of-the-art performance. Impressively, it achieves 69.4% AUC on the MGIT and 63.3% AUC on the TNL2K, improving the existing best result by 8.4% and 4.7%, respectively.

In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training.
However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues.
Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation.
We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance.
In view of this, we propose Twin-Merging, a method that encompasses two principal stages:
(1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency;
(2) dynamically merging shared and task-specific knowledge based on the input.
This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data.
Extensive experiments on $20$ datasets for both language and vision tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34\%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks.

While traditional federated learning (FL) typically focuses on a star topology where clients are directly connected to a central server, real-world distributed systems often exhibit hierarchical architectures. Hierarchical FL (HFL) has emerged as a promising solution to bridge this gap, leveraging aggregation points at multiple levels of the system. However, existing algorithms for HFL encounter challenges in dealing with multi-timescale model drift, i.e., model drift occurring across hierarchical levels of data heterogeneity. In this paper, we propose a multi-timescale gradient correction (MTGC) methodology to resolve this issue. Our key idea is to introduce distinct control variables to (i) correct the client gradient towards the group gradient, i.e., to reduce client model drift caused by local updates based on individual datasets, and (ii) correct the group gradient towards the global gradient, i.e., to reduce group model drift caused by FL over clients within the group. We analytically characterize the convergence behavior of MTGC under general non-convex settings, overcoming challenges associated with couplings between correction terms. We show that our convergence bound is immune to the extent of data heterogeneity, confirming the stability of the proposed algorithm against multi-level non-i.i.d. data. Through extensive experiments on various datasets and models, we validate the effectiveness of MTGC in diverse HFL settings. The code for this project is available at https://github.com/wenzhifang/MTGC.

The recent emergence of powerful Vision-Language models (VLMs) has significantly improved image captioning. Some of these models are extended to caption videos as well. However, their capabilities to understand complex scenes are limited, and the descriptions they provide for scenes tend to be overly verbose and focused on the superficial appearance of objects. Scene descriptions, especially in movies, require a deeper contextual understanding, unlike general-purpose video captioning. To address this challenge, we propose a model, CALVIN, a specialized video LLM that leverages previous movie context to generate fully "contextual" scene descriptions. To achieve this, we train our model on a suite of tasks that integrate both image-based question-answering and video captioning within a unified framework, before applying instruction tuning to refine the model's ability to provide scene captions. Lastly, we observe that our model responds well to prompt engineering and few-shot in-context learning techniques, enabling the user to adapt it to any new movie with very little additional annotation.
tl;dr: A NeuS-based inverse rendering method for shadow and specular highlight removed BRDF estimation under high illumination scenes.

Implicit representation has opened up new possibilities for inverse rendering. However, existing implicit neural inverse rendering methods struggle to handle strongly illuminated scenes with significant shadows and slight reflections. The existence of shadows and reflections can lead to an inaccurate understanding of the scene, making precise factorization difficult. To this end, we present RobIR, an implicit inverse rendering approach that uses ACES tone mapping and regularized visibility estimation to reconstruct accurate BRDF of the object. By accurately modeling the indirect radiance field, normal, visibility, and direct light simultaneously, we are able to accurately decouple environment lighting and the object's PBR materials without imposing strict constraints on the scene. Even in high-illumination scenes with shadows and specular reflections, our method can recover high-quality albedo and roughness with no shadow interference. RobIR outperforms existing methods in both quantitative and qualitative evaluations.
tl;dr: This paper introduces data-dependent generalization bounds for integrating persistent homology vectorizations with graph neural networks using a compositional PAC-Bayes framework.

Heterogeneity, e.g., due to different types of layers or multiple sub-models, poses key challenges in analyzing the generalization behavior of several modern architectures. For instance, descriptors based on Persistent Homology (PH) are being increasingly integrated into Graph Neural Networks (GNNs) to augment them with rich topological features; however, the generalization of such PH schemes remains unexplored. We introduce a novel _compositional_ PAC-Bayes framework that provides a general recipe to analyze a broad spectrum of models including those with heterogeneous layers. Specifically, we provide the first data-dependent generalization bounds for a widely adopted PH vectorization scheme (that subsumes persistence landscapes, images, and silhouettes) as well as PH-augmented GNNs. Using our framework, we also obtain bounds for GNNs and neural nets with ease. Our bounds also inform the design of novel regularizers. Empirical evaluations on several standard real-world datasets demonstrate that our theoretical bounds highly correlate with empirical generalization performance, leading to improved classifier design via our regularizers. Overall, this work bridges a crucial gap in the theoretical understanding of PH methods and general heterogeneous models, paving the way for the design of better models for (graph) representation learning.
tl;dr: We explore the effect of population heterogeneity and preference mis-estimation on the tradeoff between user fairness and item fairness in recommendation systems in a theoretical model and in real data.

In the basic recommendation paradigm, the most (predicted) relevant item is recommended to each user. This may result in some items receiving lower exposure than they "should"; to counter this, several algorithmic approaches have been developed to ensure *item fairness*. These approaches necessarily degrade recommendations for some users to improve outcomes for items, leading to *user fairness* concerns. In turn, a recent line of work has focused on developing algorithms for multi-sided fairness, to jointly optimize user fairness, item fairness, and overall recommendation quality. This induces the question: *what is the tradeoff between these objectives, and what are the characteristics of (multi-objective) optimal solutions?* Theoretically, we develop a model of recommendations with user and item fairness objectives and characterize the solutions of fairness-constrained optimization. We identify two phenomena: (a) when user preferences are diverse, there is "free" item and user fairness; and (b) users whose preferences are misestimated can be *especially* disadvantaged by item fairness constraints. Empirically, we prototype a recommendation system for preprints on arXiv and implement our framework, measuring the phenomena in practice and showing how these phenomena inform the *design* of markets with recommendation systems-intermediated matching.
tl;dr: Method for aligning visual retrieval model with human aesthetics

Modern vision models are trained on very large noisy datasets. While these models acquire strong capabilities, they may not follow the user's intent to output the desired results in certain aspects, e.g., visual aesthetic, preferred style, and responsibility. In this paper, we target the realm of visual aesthetics and aim to align vision models with human aesthetic standards in a retrieval system. Advanced retrieval systems usually adopt a cascade of aesthetic models as re-rankers or filters, which are limited to low-level features like saturation and perform poorly when stylistic, cultural or knowledge contexts are involved. We find that utilizing the reasoning ability of large language models (LLMs) to rephrase the search query and extend the aesthetic expectations can make up for this shortcoming. Based on the above findings, we propose a preference-based reinforcement learning method that fine-tunes the vision models to distill the knowledge from both LLMs reasoning and the aesthetic models to better align the vision models with human aesthetics. Meanwhile, with rare benchmarks designed for evaluating retrieval systems, we leverage large multi-modality model (LMM) to evaluate the aesthetic performance with their strong abilities. As aesthetic assessment is one of the most subjective tasks, to validate the robustness of LMM, we further propose a novel dataset named HPIR to benchmark the alignment with human aesthetics. Experiments demonstrate that our method significantly enhances the aesthetic behaviors of the vision models, under several metrics. We believe the proposed algorithm can be a general practice for aligning vision models with human values.
tl;dr: We present a generalization bound and learning methods for reducing the dimensionality of linear programs with projection matrices learned from data.

How to solve high-dimensional linear programs (LPs) efficiently is a fundamental question.
Recently, there has been a surge of interest in reducing LP sizes using *random projections*, which can accelerate solving LPs independently of improving LP solvers.
This paper explores a new direction of *data-driven projections*, which use projection matrices learned from data instead of random projection matrices.
Given training data of $n$-dimensional LPs, we learn an $n\times k$ projection matrix with $n > k$.
When addressing a future LP instance, we reduce its dimensionality from $n$ to $k$ via the learned projection matrix, solve the resulting LP to obtain a $k$-dimensional solution, and apply the learned matrix to it to recover an $n$-dimensional solution.
On the theoretical side, a natural question is: how much data is sufficient to ensure the quality of recovered solutions? We address this question based on the framework of *data-driven algorithm design*, which connects the amount of data sufficient for establishing generalization bounds to the *pseudo-dimension* of performance metrics. We obtain an $\tilde{\mathrm{O}}(nk^2)$ upper bound on the pseudo-dimension, where $\tilde{\mathrm{O}}$ compresses logarithmic factors. We also provide an $\Omega(nk)$ lower bound, implying our result is tight up to an $\tilde{\mathrm{O}}(k)$ factor.
On the practical side, we explore two simple methods for learning projection matrices: PCA- and gradient-based methods. While the former is relatively efficient, the latter can sometimes achieve better solution quality. Experiments demonstrate that learning projection matrices from data is indeed beneficial: it leads to significantly higher solution quality than the existing random projection while greatly reducing the time for solving LPs.

Over the past years, we have observed an abundance of approaches for modeling dynamic 3D scenes using Gaussian Splatting (GS). These solutions use GS to represent the scene's structure and the neural network to model dynamics. Such approaches allow fast rendering and extracting each element of such a dynamic scene. However, modifying such objects over time is challenging. SC-GS (Sparse Controlled Gaussian Splatting) enhanced with Deformed Control Points partially solves this issue. However, this approach necessitates selecting elements that need to be kept fixed, as well as centroids that should be adjusted throughout editing. Moreover, this task poses additional difficulties regarding the re-productivity of such editing. To address this, we propose Dynamic Multi-Gaussian Soup (D-MiSo), which allows us to model the mesh-inspired representation of dynamic GS. Additionally, we propose a strategy of linking parameterized Gaussian splats, forming a Triangle Soup with the estimated mesh. Consequently, we can separately construct new trajectories for the 3D objects composing the scene. Thus, we can make the scene's dynamic editable over time or while maintaining partial dynamics.

This paper introduces a conformal inference method to evaluate uncertainty in classification by generating prediction sets with valid coverage conditional on adaptively chosen features. These features are carefully selected to reflect potential model limitations or biases. This can be useful to find a practical compromise between efficiency---by providing informative predictions---and algorithmic fairness---by ensuring equalized coverage for the most sensitive groups. We demonstrate the validity and effectiveness of this method on simulated and real data sets.
tl;dr: An image stitching method that simplifies fusion and rectangling into a unified inpainting model.

Deep learning-based image stitching pipelines are typically divided into three cascading stages: registration, fusion, and rectangling. Each stage requires its own network training and is tightly coupled to the others, leading to error propagation and posing significant challenges to parameter tuning and system stability. This paper proposes the Simple and Robust Stitcher (SRStitcher), which
revolutionizes the image stitching pipeline by simplifying the fusion and rectangling stages into a unified inpainting model, requiring no model training or fine-tuning. We reformulate the problem definitions of the fusion and rectangling stages and demonstrate that they can be effectively integrated into an inpainting task. Furthermore, we design the weighted masks to guide the reverse process in a pre-trained large-scale diffusion model, implementing this integrated inpainting task in a single inference. Through extensive experimentation, we verify the interpretability and generalization capabilities of this unified model, demonstrating that SRStitcher outperforms state-of-the-art methods in both performance and stability.

The pre-trained text-to-image diffusion models have been increasingly employed to tackle the real-world image super-resolution (Real-ISR) problem due to their powerful generative image priors. Most of the existing methods start from random noise to reconstruct the high-quality (HQ) image under the guidance of the given low-quality (LQ) image. While promising results have been achieved, such Real-ISR methods require multiple diffusion steps to reproduce the HQ image, increasing the computational cost. Meanwhile, the random noise introduces uncertainty in the output, which is unfriendly to image restoration tasks. To address these issues, we propose a one-step effective diffusion network, namely OSEDiff, for the Real-ISR problem.
We argue that the LQ image contains rich information to restore its HQ counterpart, and hence the given LQ image can be directly taken as the starting point for diffusion, eliminating the uncertainty introduced by random noise sampling. We finetune the pre-trained diffusion network with trainable layers to adapt it to complex image degradations. To ensure that the one-step diffusion model could yield HQ Real-ISR output, we apply variational score distillation in the latent space to conduct KL-divergence regularization. As a result, our OSEDiff model can efficiently and effectively generate HQ images in just one diffusion step.
Our experiments demonstrate that OSEDiff achieves comparable or even better Real-ISR results, in terms of both objective metrics and subjective evaluations, than previous diffusion model-based Real-ISR methods that require dozens or hundreds of steps. The source codes are released at https://github.com/cswry/OSEDiff.

Multi-task reinforcement learning endeavors to efficiently leverage shared information across various tasks, facilitating the simultaneous learning of multiple tasks. Existing approaches primarily focus on parameter sharing with carefully designed network structures or tailored optimization procedures. However, they overlook a direct and complementary way to exploit cross-task similarities: the control policies of tasks already proficient in some skills can provide explicit guidance for unmastered tasks to accelerate skills acquisition. To this end, we present a novel framework called Cross-Task Policy Guidance (CTPG), which trains a guide policy for each task to select the behavior policy interacting with the environment from all tasks' control policies, generating better training trajectories. In addition, we propose two gating mechanisms to improve the learning efficiency of CTPG: one gate filters out control policies that are not beneficial for guidance, while the other gate blocks tasks that do not necessitate guidance. CTPG is a general framework adaptable to existing parameter sharing approaches. Empirical evaluations demonstrate that incorporating CTPG with these approaches significantly enhances performance in manipulation and locomotion benchmarks.
tl;dr: We compose pretrained text-to-image and text-to-audio diffusion models to create spectrogram that can be seen as images and played as sound.

Spectrograms are 2D representations of sound that look very different from the images found in our visual world. And natural images, when played as spectrograms, make unnatural sounds. In this paper, we show that it is possible to synthesize spectrograms that simultaneously look like natural images and sound like natural audio. We call these visual spectrograms *images that sound*. Our approach is simple and zero-shot, and it leverages pre-trained text-to-image and text-to-spectrogram diffusion models that operate in a shared latent space. During the reverse process, we denoise noisy latents with both the audio and image diffusion models in parallel, resulting in a sample that is likely under both models. Through quantitative evaluations and perceptual studies, we find that our method successfully generates spectrograms that align with a desired audio prompt while also taking the visual appearance of a desired image prompt.
tl;dr: We conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO).

Although Large Visual Language Models (LVLMs) have demonstrated exceptional abilities in understanding multimodal data, they invariably suffer from hallucinations, leading to a disconnection between the generated text and the corresponding images. Almost all current visual contrastive decoding methods attempt to mitigate these hallucinations by introducing visual uncertainty information that appropriately widens the contrastive logits gap between hallucinatory and targeted ones.
However, due to uncontrollable nature of the global visual uncertainty, they struggle to precisely induce the hallucinatory tokens, which severely limits their effectiveness in mitigating hallucinations and may even lead to the generation of undesired hallucinations.
To tackle this issue, we conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO). This strategy seeks to amplify the contrast between hallucinatory and targeted tokens relying on a fine-tuned theoretical preference model (i.e., Contrary Bradley-Terry Model), thereby facilitating efficient contrast decoding to alleviate hallucinations in LVLMs.
Extensive experimental research demonstrates that our HIO strategy can effectively reduce hallucinations in LVLMs, outperforming state-of-the-art methods across various benchmarks.
tl;dr: We show that vision—language models like CLIP can memorize the objects present in the training images, and evaluate different mitigation strategies to minimize this memorization.

Vision-Language Models (VLMs) have emerged as the state-of-the-art representation learning solution, with myriads of downstream applications such as image classification, retrieval and generation. A natural question is whether these models memorize their training data, which also has implications for generalization. We propose a new method for measuring memorization in VLMs, which we call dèjá vu memorization. For VLMs trained on image-caption pairs, we show that the model indeed retains information about individual objects in the training images beyond what can be inferred from correlations or the image caption. We evaluate dèjá vu memorization at both sample and population level, and show that it is significant for OpenCLIP trained on as many as 50M image-caption pairs. Finally, we show that text randomization considerably mitigates memorization risk while only moderately impacting the model’s downstream task performance. The code is available here: https://github.com/facebookresearch/VLMDejaVu.
tl;dr: Normalizing weight updates in a special norm leads to hyperparameter transfer; this norm can be inferred automatically from the computation graph.

To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single layer, graceful scaling of training has been linked to the need to normalize the weights and their updates in the "natural norm" particular to that layer. In this paper, we significantly generalize this idea by defining the modular norm, which is the natural norm on the full weight space of any neural network architecture. The modular norm is defined recursively in tandem with the network architecture itself. We show that the modular norm has several promising applications. On the practical side, the modular norm can be used to normalize the updates of any base optimizer so that the learning rate becomes transferable across width and depth. This means that the user does not need to compute optimizer-specific scale factors in order to scale training. On the theoretical side, we show that for any neural network built from "well-behaved" atomic modules, the gradient of the network is Lipschitz-continuous in the modular norm, with the Lipschitz constant admitting a simple recursive formula. This characterization opens the door to porting standard ideas in optimization theory over to deep learning. We have created a Python package called Modula that automatically normalizes weight updates in the modular norm of the architecture. Both the Modula package and code for our experiments are provided in the supplementary material.
tl;dr: We theoretically analyze Adversarial Collaborative Filtering (ACF) and further propose a method to improve ACF for robust recommendations.

Adversarial Collaborative Filtering (ACF), which typically applies adversarial perturbations at user and item embeddings through adversarial training, is widely recognized as an effective strategy for enhancing the robustness of Collaborative Filtering (CF) recommender systems against poisoning attacks. Besides, numerous studies have empirically shown that ACF can also improve recommendation performance compared to traditional CF. Despite these empirical successes, the theoretical understanding of ACF's effectiveness in terms of both performance and robustness remains unclear. To bridge this gap, in this paper, we first theoretically show that ACF can achieve a lower recommendation error compared to traditional CF with the same training epochs in both clean and poisoned data contexts. Furthermore, by establishing bounds for reductions in recommendation error during ACF's optimization process, we find that applying personalized magnitudes of perturbation for different users based on their embedding scales can further improve ACF's effectiveness. Building on these theoretical understandings, we propose Personalized Magnitude Adversarial Collaborative Filtering (PamaCF). Extensive experiments demonstrate that PamaCF effectively defends against various types of poisoning attacks while significantly enhancing recommendation performance.
tl;dr: We explore an encoder-free vision-language model to untangle the bottlenecks of decoder-only architectures in visual perception and understanding.

Existing vision-language models (VLMs) mostly rely on vision encoders to extract visual features followed by large language models (LLMs) for visual-language tasks. However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs. Training pure VLMs that accept the seamless vision and language inputs, i.e., without vision encoders, remains challenging and rarely explored. Empirical observations reveal that direct training without encoders results in slow convergence and large performance gaps. In this work, we bridge the gap between encoder-based and encoder-free models, and present a simple yet effective training recipe towards pure VLMs. Specifically, we unveil the key aspects of training encoder-free VLMs efficiently via thorough experiments: (1) Bridging vision-language representation inside one unified decoder; (2) Enhancing visual recognition capability via extra supervision. With these strategies, we launch EVE, an encoder-free vision-language model that can be trained and forwarded efficiently. Notably, solely utilizing 35M publicly accessible data, EVE can impressively rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks. It significantly outperforms the counterpart Fuyu-8B with mysterious training procedures and undisclosed training data. We believe that EVE provides a transparent and efficient route for developing pure decoder-only architecture across modalities.
tl;dr: A novel multimodal learning method integrates contrastive learning and supervised learning to address multimodal imbalance problem.

Multimodal learning falls into the trap of the optimization dilemma due to the modality imbalance phenomenon, leading to unsatisfactory performance in real applications. A core reason for modality imbalance is that the models of each modality converge at different rates. Many attempts naturally focus on adjusting learning procedures adaptively. Essentially, the reason why models converge at different rates is because the difficulty of fitting category labels is inconsistent for each modality during learning. From the perspective of fitting labels, we find that appropriate positive intervention label fitting can correct this difference in learning ability. By exploiting the ability of contrastive learning to intervene in the learning of category label fitting, we propose a novel multimodal learning approach that dynamically integrates unsupervised contrastive learning and supervised multimodal learning to address the modality imbalance problem. We find that a simple yet heuristic integration strategy can significantly alleviate the modality imbalance phenomenon. Moreover, we design a learning-based integration strategy to integrate two losses dynamically, further improving the performance. Experiments on widely used datasets demonstrate the superiority of our method compared with state-of-the-art (SOTA) multimodal learning approaches. The code is available at https://github.com/njustkmg/NeurIPS24-LFM.
tl;dr: We solve real-world districting problems in a few minutes using a structured learning pipeline.

Districting is a complex combinatorial problem that consists in partitioning a geographical area into small districts. In logistics, it is a major strategic decision determining operating costs for several years. Solving districting problems using traditional methods is intractable even for small geographical areas and existing heuristics often provide sub-optimal results. We present a structured learning approach to find high-quality solutions to real-world districting problems in a few minutes. It is based on integrating a combinatorial optimization layer, the capacitated minimum spanning tree problem, into a graph neural network architecture. To train this pipeline in a decision-aware fashion, we show how to construct target solutions embedded in a suitable space and learn from target solutions. Experiments show that our approach outperforms existing methods as it can significantly reduce costs on real-world cities.

Over the several recent years, there has been a boom in development of Flow Matching (FM) methods for generative modeling. One intriguing property pursued by the community is the ability to learn flows with straight trajectories which realize the Optimal Transport (OT) displacements. Straightness is crucial for the fast integration (inference) of the learned flow's paths. Unfortunately, most existing flow straightening methods are based on non-trivial iterative FM procedures which accumulate the error during training or exploit heuristics based on minibatch OT. To address these issues, we develop and theoretically justify the novel Optimal Flow Matching approach which allows recovering the straight OT displacement for the quadratic transport in just one FM step. The main idea of our approach is the employment of vector field for FM which are parameterized by convex functions. The code of our OFM implementation and the conducted experiments is available at https://github.com/Jhomanik/Optimal-Flow-Matching

Irregularly Sampled Medical Time Series (ISMTS) are commonly found in the healthcare domain, where different variables exhibit unique temporal patterns while interrelated. However, many existing methods fail to efficiently consider the differences and correlations among medical variables together, leading to inadequate capture of fine-grained features at the variable level in ISMTS. We propose Knowledge-Empowered Dynamic Graph Network (KEDGN), a graph neural network empowered by variables' textual medical knowledge, aiming to model variable-specific temporal dependencies and inter-variable dependencies in ISMTS. Specifically, we leverage a pre-trained language model to extract semantic representations for each variable from their textual descriptions of medical properties, forming an overall semantic view among variables from a medical perspective. Based on this, we allocate variable-specific parameter spaces to capture variable-specific temporal patterns and generate a complete variable graph to measure medical correlations among variables. Additionally, we employ a density-aware mechanism to dynamically adjust the variable graph at different timestamps, adapting to the time-varying correlations among variables in ISMTS. The variable-specific parameter spaces and dynamic graphs are injected into the graph convolutional recurrent network to capture intra-variable and inter-variable dependencies in ISMTS together. Experiment results on four healthcare datasets demonstrate that KEDGN significantly outperforms existing methods.
tl;dr: We provide theoretical and experimental analysis for Neural Regression Collapse which is prevalent among multivariate regression tasks.

Recently it has been observed that neural networks exhibit Neural Collapse (NC) during the final stage of training for the classification problem. We empirically show that multivariate regression, as employed in imitation learning and other applications, exhibits Neural Regression Collapse (NRC), a new form of neural collapse: (NRC1) The last-layer feature vectors collapse to the subspace spanned by the $n$ principal components of the feature vectors, where $n$ is the dimension of the targets (for univariate regression, $n=1$); (NRC2) The last-layer feature vectors also collapse to the subspace spanned by the last-layer weight vectors; (NRC3) The Gram matrix for the weight vectors converges to a specific functional form that depends on the covariance matrix of the targets. After empirically establishing the prevalence of (NRC1)-(NRC3) for a variety of datasets and network architectures, we provide an explanation of these phenomena by modeling the regression task in the context of the Unconstrained Feature Model (UFM), in which the last layer feature vectors are treated as free variables when minimizing the loss function. We show that when the regularization parameters in the UFM model are strictly positive, then (NRC1)-(NRC3) also emerge as solutions in the UFM optimization problem. We also show that if the regularization parameters are equal to zero, then there is no collapse. To our knowledge, this is the first empirical and theoretical study of neural collapse in the context of regression. This extension is significant not only because it broadens the applicability of neural collapse to a new category of problems but also because it suggests that the phenomena of neural collapse could be a universal behavior in deep learning.
tl;dr: We leverage risk control to tune the exit threshold of early-exit neural networks, thus equipping early-exit outputs with guarantees.

Scaling machine learning models significantly improves their performance. However, such gains come at the cost of inference being slow and resource-intensive. Early-exit neural networks (EENNs) offer a promising solution: they accelerate inference by allowing intermediate layers to exit and produce a prediction early. Yet a fundamental issue with EENNs is how to determine when to exit without severely degrading performance. In other words, when is it 'safe' for an EENN to go 'fast'? To address this issue, we investigate how to adapt frameworks of risk control to EENNs. Risk control offers a distribution-free, post-hoc solution that tunes the EENN's exiting mechanism so that exits only occur when the output is of sufficient quality. We empirically validate our insights on a range of vision and language tasks, demonstrating that risk control can produce substantial computational savings, all the while preserving user-specified performance goals.

Despite advancements in Text-to-Video (T2V) generation, producing videos with realistic motion remains challenging. Current models often yield static or minimally dynamic outputs, failing to capture complex motions described by text. This issue stems from the internal biases in text encoding which overlooks motions, and inadequate conditioning mechanisms in T2V generation models. To address this, we propose a novel framework called DEcomposed MOtion (DEMO), which enhances motion synthesis in T2V generation by decomposing both text encoding and conditioning into content and motion components. Our method includes a content encoder for static elements and a motion encoder for temporal dynamics, alongside separate content and motion conditioning mechanisms. Crucially, we introduce text-motion and video-motion supervision to improve the model's understanding and generation of motion. Evaluations on benchmarks such as MSR-VTT, UCF-101, WebVid-10M, EvalCrafter, and VBench demonstrate DEMO's superior ability to produce videos with enhanced motion dynamics while maintaining high visual quality. Our approach significantly advances T2V generation by integrating comprehensive motion understanding directly from textual descriptions. Project page: https://PR-Ryan.github.io/DEMO-project/
tl;dr: We investigate the theoretical aspects of extrapolation under a causal model formulation.

Canonical work handling distribution shifts typically necessitates an entire target distribution that lands inside the training distribution.
However, practical scenarios often involve only a handful target samples, potentially lying outside the training support, which requires the capability of extrapolation.
In this work, we aim to provide a theoretical understanding of when extrapolation is possible and offer principled methods to achieve it without requiring an on-support target distribution.
To this end, we formulate the extrapolation problem with a latent-variable model that embodies the minimal change principle in causal mechanisms.
Under this formulation, we cast the extrapolation problem into a latent-variable identification problem.
We provide realistic conditions on shift properties and the estimation objectives that lead to identification even when only one off-support target sample is available, tackling the most challenging scenarios.
Our theory reveals the intricate interplay between the underlying manifold's smoothness and the shift properties.
We showcase how our theoretical results inform the design of practical adaptation algorithms. Through experiments on both synthetic and real-world data, we validate our theoretical findings and their practical implications.
tl;dr: We present the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second.

We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second.
Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames.
We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input.
L4GM outputs a per-frame 3D Gaussian splat representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations.
We showcase that L4GM that is only trained on synthetic data generalizes well on in-the-wild videos, producing high quality animated 3D assets.
tl;dr: We propose DARG, which dynamically evaluates LLMs by generating complex test data with adaptive reasoning graphs, overcoming static benchmarks' limitations and revealing performance declines and biases as task complexity rises.

The current paradigm of evaluating Large Language Models (LLMs) through static benchmarks comes with significant limitations, such as vulnerability to data contamination and a lack of adaptability to the evolving capabilities of LLMs. Therefore, evaluation methods that can adapt and generate evaluation data with controlled complexity are urgently needed. In this work, we introduce Dynamic Evaluation of LLMs via Adaptive Reasoning Graph Evolvement (DARG) to dynamically extend current benchmarks with controlled complexity and diversity. Specifically, we first extract the reasoning graphs of data points in current benchmarks and then perturb the reasoning graphs to generate novel testing data. Such newly generated test samples can have different levels of complexity while maintaining linguistic diversity similar to the original benchmarks. We further use a code-augmented LLM to ensure the label correctness of newly generated data. We apply our DARG framework to diverse reasoning tasks in four domains with 15 state-of-the-art LLMs. Experimental results show that almost all LLMs experience a performance decrease with increased complexity and certain LLMs exhibit significant drops. Additionally, we find that LLMs exhibit more biases when being evaluated via the data generated by DARG with higher complexity levels. These observations provide useful insights into how to dynamically and adaptively evaluate LLMs.
tl;dr: Scalable branch and bound algorithm for relational DNN verification with cross-executional bound refinement and branching over multiple executions.

We propose RABBit, a Branch-and-Bound-based verifier for verifying relational properties defined over Deep Neural Networks, such as robustness against universal adversarial perturbations (UAP). Existing SOTA complete $L_{\infty}$-robustness verifiers can not reason about dependencies between multiple executions and, as a result, are imprecise for relational verification. In contrast, existing SOTA relational verifiers only apply a single bounding step and do not utilize any branching strategies to refine the obtained bounds, thus producing imprecise results. We develop the first scalable Branch-and-Bound-based relational verifier, RABBit, which efficiently combines branching over multiple executions with cross-executional bound refinement to utilize relational constraints, gaining substantial precision over SOTA baselines on a wide range of datasets and networks. Our code is at https://github.com/uiuc-focal-lab/RABBit.
tl;dr: Progress in language model performance surpasses what we'd expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 2 to 22 months.

We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 90\% confidence interval of around 2 to 22 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.
tl;dr: New spectral spatio-temporal encoding for fully connected Dynamic Graph Transformer in dynamic link prediction

Fully connected Graph Transformers (GT) have rapidly become prominent in the static graph community as an alternative to Message-Passing models, which suffer from a lack of expressivity, oversquashing, and under-reaching.
However, in a dynamic context, by interconnecting all nodes at multiple snapshots with self-attention,GT loose both structural and temporal information. In this work, we introduce Supra-LAplacian encoding for spatio-temporal TransformErs (SLATE), a new spatio-temporal encoding to leverage the GT architecture while keeping spatio-temporal information.
Specifically, we transform Discrete Time Dynamic Graphs into multi-layer graphs and take advantage of the spectral properties of their associated supra-Laplacian matrix.
Our second contribution explicitly model nodes' pairwise relationships with a cross-attention mechanism, providing an accurate edge representation for dynamic link prediction.
SLATE outperforms numerous state-of-the-art methods based on Message-Passing Graph Neural Networks combined with recurrent models (e.g, LSTM), and Dynamic Graph Transformers,
on~9 datasets. Code is open-source and available at this link https://github.com/ykrmm/SLATE.

Training on model-generated synthetic data is a promising approach for finetuning LLMs, but it remains unclear when it helps or hurts. In this paper, we investigate this question for math reasoning via an empirical study, followed by building a conceptual understanding of our observations. First, we find that while the typical approach of finetuning a model on synthetic correct or positive problem-solution pairs generated by capable models offers modest performance gains, sampling more correct solutions from the finetuned learner itself followed by subsequent fine-tuning on this self-generated data doubles the efficiency of the same synthetic problems. At the same time, training on model-generated positives can amplify various spurious correlations, resulting in flat or even inverse scaling trends as the amount of data increases. Surprisingly, we find that several of these issues can be addressed if we also utilize negative responses, i.e., model-generated responses that are deemed incorrect by a final answer verifier. Crucially, these negatives must be constructed such that the training can appropriately recover the utility or advantage of each intermediate step in the negative response. With this per-step scheme, we are able to attain consistent gains over only positive data, attaining performance similar to amplifying the amount of synthetic data by $\mathbf{8 \times}$. We show that training on per-step negatives can help to unlearn spurious correlations in the positive data, and is equivalent to advantage-weighted reinforcement learning (RL), implying that it inherits robustness benefits of RL over imitating positive data alone.
tl;dr: A learnable partial parameter sharing mechanism for multi-agent reinforcement learning

In multi-agent reinforcement learning (MARL), parameter sharing is commonly employed to enhance sample efficiency. However, the popular approach of full parameter sharing often leads to homogeneous policies among agents, potentially limiting the performance benefits that could be derived from policy diversity. To address this critical limitation, we introduce \emph{Kaleidoscope}, a novel adaptive partial parameter sharing scheme that fosters policy heterogeneity while still maintaining high sample efficiency. Specifically, Kaleidoscope maintains one set of common parameters alongside multiple sets of distinct, learnable masks for different agents, dictating the sharing of parameters. It promotes diversity among policy networks by encouraging discrepancy among these masks, without sacrificing the efficiencies of parameter sharing. This design allows Kaleidoscope to dynamically balance high sample efficiency with a broad policy representational capacity, effectively bridging the gap between full parameter sharing and non-parameter sharing across various environments. We further extend Kaleidoscope to critic ensembles in the context of actor-critic algorithms, which could help improve value estimations. Our empirical evaluations across extensive environments, including multi-agent particle environment, multi-agent MuJoCo and StarCraft multi-agent challenge v2, demonstrate the superior performance of Kaleidoscope compared with existing parameter sharing approaches, showcasing its potential for performance enhancement in MARL. The code is publicly available at \url{https://github.com/LXXXXR/Kaleidoscope}.

This paper examines the issue of fairness in the estimation of graphical models (GMs), particularly Gaussian, Covariance, and Ising models. These models play a vital role in understanding complex relationships in high-dimensional data. However, standard GMs can result in biased outcomes, especially when the underlying data involves sensitive characteristics or protected groups. To address this, we introduce a comprehensive framework designed to reduce bias in the estimation of GMs related to protected attributes. Our approach involves the integration of the pairwise graph disparity error and a tailored loss function into a nonsmooth multi-objective optimization problem, striving to achieve fairness across different sensitive groups while maintaining the effectiveness of the GMs. Experimental evaluations on synthetic and real-world datasets demonstrate that our framework effectively mitigates bias without undermining GMs' performance.

We address a generalization of the bandit with knapsacks problem, where a learner aims to maximize rewards while satisfying an arbitrary set of long-term constraints. Our goal is to design best-of-both-worlds algorithms that perform optimally under both stochastic and adversarial constraints. Previous works address this problem via primal-dual methods, and require some stringent assumptions, namely the Slater's condition, and in adversarial settings, they either assume knowledge of a lower bound on the Slater's parameter, or impose strong requirements on the primal and dual regret minimizers such as requiring weak adaptivity. We propose an alternative and more natural approach based on optimistic estimations of the constraints. Surprisingly, we show that estimating the constraints with an UCB-like approach guarantees optimal performances.
Our algorithm consists of two main components: (i) a regret minimizer working on moving strategy sets and (ii) an estimate of the feasible set as an optimistic weighted empirical mean of previous samples. The key challenge in this approach is designing adaptive weights that meet the different requirements for stochastic and adversarial constraints. Our algorithm is significantly simpler than previous approaches, and has a cleaner analysis. Moreover, ours is the first best-of-both-worlds algorithm providing bounds logarithmic in the number of constraints. Additionally, in stochastic settings, it provides $\widetilde O(\sqrt{T})$ regret without Slater's condition.
tl;dr: We introduce MoE Jetpack, a framework that effectively converts existing pre-trained dense checkpoints into sparsely activated MoE models, substantially improve convergence speed and accuracy for vision tasks.

The sparsely activated mixture of experts (MoE) model presents an effective alternative to densely activated (dense) models, combining improved accuracy with computational efficiency. However, training MoE models from scratch requires extensive data and computational resources, a challenge that limits their widespread adoption. To address this, we introduce MoE Jetpack, a framework designed to fine-tune the abundant and easily accessible dense checkpoints into MoE models. MoE Jetpack incorporates two key techniques: (1) **checkpoint recycling**, which initializes MoE models with dense checkpoints to accelerate convergence and enhance accuracy, minimizing the need for extensive pre-training; (2) the **hyperspherical adaptive MoE (SpheroMoE) layer**, which optimizes the MoE architecture to enhance fine-tuning performance and efficiency.
Experimental results indicate that MoE Jetpack doubles the convergence speed and enhances accuracy by 2.8% on ImageNet-1K. On smaller datasets, it achieves up to 8-fold faster convergence and over 30% accuracy gains, highlighting its efficiency.
The code is available at https://github.com/Adlith/MoE-Jetpack.

Effective communication requires the ability to refer to specific parts of an observation in relation to others. While emergent communication literature shows success in developing various language properties, no research has shown the emergence of such positional references. This paper demonstrates how agents can communicate about spatial relationships within their observations. The results indicate that agents can develop a language capable of expressing the relationships between parts of their observation, achieving over 90% accuracy when trained in a referential game which requires such communication. Using a collocation measure, we demonstrate how the agents create such references. This analysis suggests that agents use a mixture of non-compositional and compositional messages to convey spatial relationships. We also show that the emergent language is interpretable by humans. The translation accuracy is tested by communicating with the receiver agent, where the receiver achieves over 78% accuracy using parts of this lexicon, confirming that the interpretation of the emergent language was successful.

The online bipartite matching problem, extensively studied in the literature, deals with the allocation of online arriving vertices (items) to a predetermined set of offline vertices (agents). However, little attention has been given to the concept of class fairness, where agents are categorized into different classes, and the matching algorithm must ensure equitable distribution across these classes.
We here focus on randomized algorithms for the fair matching of indivisible items, subject to various definitions of fairness. Our main contribution is the first (randomized) non-wasteful algorithm that simultaneously achieves a $1/2$ approximation to class envy-freeness (CEF) while simultaneously ensuring an equivalent approximation to the class proportionality (CPROP) and utilitarian social welfare (USW) objectives. We supplement this result by demonstrating that no non-wasteful algorithm can achieve an $\alpha$-CEF guarantee for $\alpha > 0.761$. In a similar vein, we provide a novel input instance for deterministic divisible matching that demonstrates a nearly tight CEF approximation.
Lastly, we define the ``price of fairness," which represents the trade-off between optimal and fair matching. We demonstrate that increasing the level of fairness in the approximation of the solution leads to a decrease in the objective of maximizing USW, following an inverse proportionality relationship.
tl;dr: We present the first investigation into factors that affect the difficulty of an unlearning problem, surfacing previously-unknown behaviours of SOTA methods, and propose a framework that improves unlearning pipelines.

Machine unlearning is the problem of removing the effect of a subset of training data (the ``forget set'') from a trained model without damaging the model's utility e.g. to comply with users' requests to delete their data, or remove mislabeled, poisoned or otherwise problematic data.
With unlearning research still being at its infancy, many fundamental open questions exist:
Are there interpretable characteristics of forget sets that substantially affect the difficulty of the problem?
How do these characteristics affect different state-of-the-art algorithms?
With this paper, we present the first investigation aiming to answer these questions. We identify two key factors affecting unlearning difficulty and the performance of unlearning algorithms. Evaluation on forget sets that isolate these identified factors reveals previously-unknown behaviours of state-of-the-art algorithms that don't materialize on random forget sets.
Based on our insights, we develop a framework coined Refined-Unlearning Meta-algorithm (RUM) that encompasses: (i) refining the forget set into homogenized subsets, according to different characteristics; and (ii) a meta-algorithm that employs existing algorithms to unlearn each subset and finally delivers a model that has unlearned the overall forget set.
We find that RUM substantially improves top-performing unlearning algorithms.
Overall, we view our work as an important step in (i) deepening our scientific understanding of unlearning and (ii) revealing new pathways to improving the state-of-the-art.
2551. Robust Sleep Staging over Incomplete Multimodal Physiological Signals via Contrastive Imagination

Multimodal physiological signals, such as EEG, EOG and EMG, provide rich and reliable physiological information for automated sleep staging (ASS). However, in the real world, the completeness of various modalities is difficult to guarantee, which seriously affects the performance of ASS based on multimodal learning. Furthermore, the exploration of temporal context information within PTSs is also a serious challenge. To this end, we propose a robust multimodal sleep staging framework named contrastive imagination modality sleep network (CIMSleepNet). Specifically, CIMSleepNet handles the issue of arbitrary modal missing through the combination of modal awareness imagination module (MAIM) and semantic & modal calibration contrastive learning (SMCCL). Among them, MAIM can capture the interaction among modalities by learning the shared representation distribution of all modalities. Meanwhile, SMCCL introduces prior information of semantics and modalities to check semantic consistency while maintaining the uniqueness of each modality. Utilizing the calibration of SMCCL, the data distribution recovered by MAIM is aligned with the real data distribution. We further design a multi-level cross-branch temporal attention mechanism, which can facilitate the mining of interactive temporal context representations at both the intra-epoch and inter-epoch levels. Extensive experiments on five multimodal sleep datasets demonstrate that CIMSleepNet remarkably outperforms other competitive methods under various missing modality patterns. The source code is available at: https://github.com/SQAIYY/CIMSleepNet.

Semi-structured networks (SSNs) merge the structures familiar from additive models with deep neural networks, allowing the modeling of interpretable partial feature effects while capturing higher-order non-linearities at the same time. A significant challenge in this integration is maintaining the interpretability of the additive model component. Inspired by large-scale biomechanics datasets, this paper explores extending SSNs to functional data. Existing methods in functional data analysis are promising but often not expressive enough to account for all interactions and non-linearities and do not scale well to large datasets. Although the SSN approach presents a compelling potential solution, its adaptation to functional data remains complex. In this work, we propose a functional SSN method that retains the advantageous properties of classical functional regression approaches while also improving scalability. Our numerical experiments demonstrate that this approach accurately recovers underlying signals, enhances predictive performance, and performs favorably compared to competing methods.
tl;dr: We show the first lower bound for the data structures version of the fundamental density estimation problem, establishing that there is no data structure with strongly sublinear sample complexity and query time.

We study the density estimation problem defined as follows: given $k$ distributions $p_1, \ldots, p_k$ over a discrete domain $[n]$, as well as a collection of samples chosen from a "query" distribution $q$ over $[n]$, output $p_i$ that is "close" to $q$. Recently Aamand et al. gave the first and only known result that achieves sublinear bounds in both the sampling complexity and the query time while preserving polynomial data structure space. However, their improvement over linear samples and time is only by subpolynomial factors.
Our main result is a lower bound showing that, for a broad class of data structures, their bounds cannot be significantly improved. In particular, if an algorithm uses $O(n/\log^c k)$ samples for some constant $c>0$ and polynomial space, then the query time of the data structure must be at least $k^{1-O(1)/\log \log k}$, i.e., close to linear in the number of distributions $k$. This is a novel statistical-computational trade-off for density estimation, demonstrating that any data structure must use close to a linear number of samples or take close to linear query time. The lower bound holds even in the realizable case where $q=p_i$ for some $i$, and when the distributions are flat (specifically, all distributions are uniform over half of the domain $[n]$). We also give a simple data structure for our lower bound instance with asymptotically matching upper bounds. Experiments show that the data structure is quite efficient in practice.
tl;dr: We extend selective classification to a hierarchical setting, showing outstanding results for various models.

Deploying deep neural networks for risk-sensitive tasks necessitates an uncertainty estimation mechanism. This paper introduces *hierarchical selective classification*, extending selective classification to a hierarchical setting. Our approach leverages the inherent structure of class relationships, enabling models to reduce the specificity of their predictions when faced with uncertainty. In this paper, we first formalize hierarchical risk and coverage, and introduce hierarchical risk-coverage curves. Next, we develop algorithms for hierarchical selective classification (which we refer to as "inference rules"), and propose an efficient algorithm that guarantees a target accuracy constraint with high probability. Lastly, we conduct extensive empirical studies on over a thousand ImageNet classifiers, revealing that training regimes such as CLIP, pretraining on ImageNet21k and knowledge distillation boost hierarchical selective performance.
2555. Vision Mamba Mender

Mamba, a state-space model with selective mechanisms and hardware-aware architecture, has demonstrated outstanding performance in long sequence modeling tasks, particularly garnering widespread exploration and application in the field of computer vision. While existing works have mixed opinions of its application in visual tasks, the exploration of its internal workings and the optimization of its performance remain urgent and worthy research questions given its status as a novel model. Existing optimizations of the Mamba model, especially when applied in the visual domain, have primarily relied on predefined methods such as improving scanning mechanisms or integrating other architectures, often requiring strong priors and extensive trial and error. In contrast to these approaches, this paper proposes the Vision Mamba Mender, a systematic approach for understanding the workings of Mamba, identifying flaws within, and subsequently optimizing model performance. Specifically, we present methods for predictive correlation analysis of Mamba's hidden states from both internal and external perspectives, along with corresponding definitions of correlation scores, aimed at understanding the workings of Mamba in visual recognition tasks and identifying flaws therein. Additionally, tailored repair methods are proposed for identified external and internal state flaws to eliminate them and optimize model performance. Extensive experiments validate the efficacy of the proposed methods on prevalent Mamba architectures, significantly enhancing Mamba's performance.
tl;dr: A novel framework for mapping input images into the frequency domain and minimizing interference between frequency domain features to enhance the performance and efficiency of continual learning.

Continual learning (CL) is designed to learn new tasks while preserving existing knowledge. Replaying samples from earlier tasks has proven to be an effective method to mitigate the forgetting of previously acquired knowledge. However, the current research on the training efficiency of rehearsal-based methods is insufficient, which limits the practical application of CL systems in resource-limited scenarios. The human visual system (HVS) exhibits varying sensitivities to different frequency components, enabling the efficient elimination of visually redundant information. Inspired by HVS, we propose a novel framework called Continual Learning in the Frequency Domain (CLFD). To our knowledge, this is the first study to utilize frequency domain features to enhance the performance and efficiency of CL training on edge devices. For the input features of the feature extractor, CLFD employs wavelet transform to map the original input image into the frequency domain, thereby effectively reducing the size of input feature maps. Regarding the output features of the feature extractor, CLFD selectively utilizes output features for distinct classes for classification, thereby balancing the reusability and interference of output features based on the frequency domain similarity of the classes across various tasks. Optimizing only the input and output features of the feature extractor allows for seamless integration of CLFD with various rehearsal-based methods. Extensive experiments conducted in both cloud and edge environments demonstrate that CLFD consistently improves the performance of state-of-the-art (SOTA) methods in both precision and training efficiency. Specifically, CLFD can increase the accuracy of the SOTA CL method by up to 6.83% and reduce the training time by 2.6×.
tl;dr: This paper studies instance dependent upper and lower bounds under the setting of offline linear DRMDPs.

Distributionally robust offline reinforcement learning (RL), which seeks robust policy training against environment perturbation by modeling dynamics uncertainty, calls for function approximations when facing large state-action spaces. However, the consideration of dynamics uncertainty introduces essential nonlinearity and computational burden, posing unique challenges for analyzing and practically employing function approximation. Focusing on a basic setting where the nominal model and perturbed models are linearly parameterized, we propose minimax optimal and computationally efficient algorithms realizing function approximation and initiate the study on instance-dependent suboptimality analysis in the context of robust offline RL. Our results uncover that function approximation in robust offline RL is essentially distinct from and probably harder than that in standard offline RL. Our algorithms and theoretical results crucially depend on a novel function approximation mechanism incorporating variance information, a new procedure of suboptimality and estimation uncertainty decomposition, a quantification of the robust value function shrinkage, and a meticulously designed family of hard instances, which might be of independent interest.
tl;dr: We propose a method that utilizes two unposed and uncalibrated images as input, and reconstructs the explicit radiance field, encompassing geometry, appearance, and semantics in real-time.

Reconstructing and understanding 3D structures from a limited number of images is a classical problem in computer vision. Traditional approaches typically decompose this task into multiple subtasks, involving several stages of complex mappings between different data representations. For example, dense reconstruction using Structure-from-Motion (SfM) requires transforming images into key points, optimizing camera parameters, and estimating structures. Following this, accurate sparse reconstructions are necessary for further dense modeling, which is then input into task-specific neural networks. This multi-stage paradigm leads to significant processing times and engineering complexity.
In this work, we introduce the Large Spatial Model (LSM), which directly processes unposed RGB images into semantic radiance fields. LSM simultaneously estimates geometry, appearance, and semantics in a single feed-forward pass and can synthesize versatile label maps by interacting through language at novel views. Built on a general Transformer-based framework, LSM predicts global geometry via pixel-aligned point maps. To improve spatial attribute regression, we adopt local context aggregation with multi-scale fusion, enhancing the accuracy of fine local details. To address the scarcity of labeled 3D semantic data and enable natural language-driven scene manipulation, we incorporate a pre-trained 2D language-based segmentation model into a 3D-consistent semantic feature field. An efficient decoder parameterizes a set of semantic anisotropic Gaussians, allowing supervised end-to-end learning. Comprehensive experiments on various tasks demonstrate that LSM unifies multiple 3D vision tasks directly from unposed images, achieving real-time semantic 3D reconstruction for the first time.
tl;dr: Intrinsically interpretable models for conditional density estimation, employing decision trees equipped with histogram density estimation

Conditional density estimation (CDE) goes beyond regression by modeling the full conditional distribution, providing a richer understanding of the data than just the conditional mean in regression. This makes CDE particularly useful in critical application domains. However, interpretable CDE methods are understudied. Current methods typically employ kernel-based approaches, using kernel functions directly for kernel density estimation or as basis functions in linear models. In contrast, despite their conceptual simplicity and visualization suitability, tree-based methods---which are arguably more comprehensible---have been largely overlooked for CDE tasks. Thus, we propose the Conditional Density Tree (CDTree), a fully non-parametric model consisting of a decision tree in which each leaf is formed by a histogram model. Specifically, we formalize the problem of learning a CDTree using the minimum description length (MDL) principle, which eliminates the need for tuning the hyperparameter for regularization. Next, we propose an iterative algorithm that, although greedily, searches the optimal histogram for every possible node split. Our experiments demonstrate that, in comparison to existing interpretable CDE methods, CDTrees are both more accurate (as measured by the log-loss) and more robust against irrelevant features. Further, our approach leads to smaller tree sizes than existing tree-based models, which benefits interpretability.

Recently, token-based generation approaches have demonstrated their effectiveness in synthesizing visual content. As a representative example, non-autoregressive Transformers (NATs) can generate decent-quality images in just a few steps. NATs perform generation in a progressive manner, where the latent tokens of a resulting image are incrementally revealed step-by-step. At each step, the unrevealed image regions are padded with [MASK] tokens and inferred by NAT, with the most reliable predictions preserved as newly revealed, visible tokens. In this paper, we delve into understanding the mechanisms behind the effectiveness of NATs and uncover two important interaction patterns that naturally emerge from NAT’s paradigm: Spatially (within a step), although [MASK] and visible tokens are processed uniformly by NATs, the interactions between them are highly asymmetric. In specific, [MASK] tokens mainly gather information for decoding. On the contrary, visible tokens tend to primarily provide information, and their deep representations can be built only upon themselves. Temporally (across steps), the interactions between adjacent generation steps mostly concentrate on updating the representations of a few critical tokens, while the computation for the majority of tokens is generally repetitive. Driven by these findings, we propose EfficientNAT (ENAT), a NAT model that explicitly encourages these critical interactions inherent in NATs. At the spatial level, we disentangle the computations of visible and [MASK] tokens by encoding visible tokens independently, while decoding [MASK] tokens conditioned on the fully encoded visible tokens. At the temporal level, we prioritize the computation of the critical tokens at each step, while maximally reusing previously computed token representations to supplement necessary information. ENAT improves the performance of NATs notably with significantly reduced computational cost. Experiments on ImageNet-256 2 & 512 2 and MS-COCO validate the effectiveness of ENAT. Code and pre-trained models will be released at https://github.com/LeapLabTHU/ENAT.
tl;dr: Generating safe policies in constrained rl settings through cost estimation from safety feedback

In safety-critical RL settings, the inclusion of an additional cost function is often favoured over the arduous task of modifying the reward function to ensure the agent's safe behaviour. However, designing or evaluating such a cost function can be prohibitively expensive. For instance, in the domain of self-driving, designing a cost function that encompasses all unsafe behaviours (e.g., aggressive lane changes, risky overtakes) is inherently complex, it must also consider all the actors present in the scene making it expensive to evaluate. In such scenarios, the cost function can be learned from feedback collected offline in between training rounds. This feedback can be system generated or elicited from a human observing the training process. Previous approaches have not been able to scale to complex environments and are constrained to receiving feedback at the state level which can be expensive to collect. To this end, we introduce an approach that scales to more complex domains and extends beyond state-level feedback, thus, reducing the burden on the evaluator. Inferring the cost function in such settings poses challenges, particularly in assigning credit to individual states based on trajectory-level feedback. To address this, we propose a surrogate objective that transforms the problem into a state-level supervised classification task with noisy labels, which can be solved efficiently. Additionally, it is often infeasible to collect feedback for every trajectory generated by the agent, hence, two fundamental questions arise: (1) Which trajectories should be presented to the human? and (2) How many trajectories are necessary for effective learning? To address these questions, we introduce a \textit{novelty-based sampling} mechanism that selectively involves the evaluator only when the the agent encounters a \textit{novel} trajectory, and discontinues querying once the trajectories are no longer \textit{novel}. We showcase the efficiency of our method through experimentation on several benchmark Safety Gymnasium environments and realistic self-driving scenarios. Our method demonstrates near-optimal performance, comparable to when the cost function is known, by relying solely on trajectory-level feedback across multiple domains. This highlights both the effectiveness and scalability of our approach. The code to replicate these results can be found at \href{https://github.com/shshnkreddy/RLSF}{https://github.com/shshnkreddy/RLSF}
tl;dr: PANORAMIA is a practical privacy audit for ML models, that does not retrain the target model or alter its training set or training algorithm.

We present PANORAMIA, a privacy leakage measurement framework for machine learning models that relies on membership inference attacks using generated data as non-members. By relying on generated non-member data, PANORAMIA eliminates the common dependency of privacy measurement tools on in-distribution non-member data. As a result, PANORAMIA does not modify the model, training data, or training process, and only requires access to a subset of the training data. We evaluate PANORAMIA on ML models for image and tabular data classification, as well as on large-scale language models.

We provide space complexity lower bounds for data structures that approximate logistic loss up to $\epsilon$-relative error on a logistic regression problem with data $\mathbf{X} \in \mathbb{R}^{n \times d}$ and labels $\mathbf{y} \in \\{-1,1\\}^d$. The space complexity of existing coreset constructions depend on a natural complexity measure $\mu_\mathbf{y}(\mathbf{X})$. We give an $\tilde{\Omega}(\frac{d}{\epsilon^2})$ space complexity lower bound in the regime $\mu_\mathbf{y}(\mathbf{X}) = \mathcal{O}(1)$ that shows existing coresets are optimal in this regime up to lower order factors. We also prove a general $\tilde{\Omega}(d\cdot \mu_\mathbf{y}(\mathbf{X}))$ space lower bound when $\epsilon$ is constant, showing that the dependency on $\mu_\mathbf{y}(\mathbf{X})$ is not an artifact of mergeable coresets. Finally, we refute a prior conjecture that $\mu_\mathbf{y}(\mathbf{X})$ is hard to compute by providing an efficient linear programming formulation, and we empirically compare our algorithm to prior approximate methods.
tl;dr: This paper probes the Elo rating system in LLM evaluations, revealing its inherent volatility and providing empirical guidelines for ensuring robust and accurate model ranking in real-world scenarios.

In Natural Language Processing (NLP), the Elo rating system, originally designed for ranking players in dynamic games such as chess, is increasingly being used to evaluate Large Language Models (LLMs) through "A vs B" paired comparisons.
However, while popular, the system's suitability for assessing entities with constant skill levels, such as LLMs, remains relatively unexplored.
We study two fundamental axioms that evaluation methods should adhere to: reliability and transitivity.
We conduct an extensive evaluation of Elo behavior across simulated and real-world scenarios, demonstrating that individual Elo computations can exhibit significant volatility.
We show that both axioms are not always satisfied, raising questions about the reliability of current comparative evaluations of LLMs.
If the current use of Elo scores is intended to substitute the costly head-to-head comparison of LLMs, it is crucial to ensure the ranking is as robust as possible.
Guided by the axioms, our findings offer concrete guidelines for enhancing the reliability of LLM evaluation methods, suggesting a need for reassessment of existing comparative approaches.
tl;dr: We propose a new optimization algorithm for federated learning with periodic client participation, and prove that the convergence rate is independent of client heterogeneity and enjoys linear speedup and reduced communication.

In federated learning, it is common to assume that clients are always available to participate in training, which may not be feasible with user devices in practice. Recent works analyze federated learning under more realistic participation patterns, such as cyclic client availability or arbitrary participation. However, all such works either require strong assumptions (e.g., all clients participate almost surely within a bounded window), do not achieve linear speedup and reduced communication rounds, or are not applicable in the general non-convex setting. In this work, we focus on nonconvex optimization and consider participation patterns in which the chance of participation over a fixed window of rounds is equal among all clients, which includes cyclic client availability as a special case. Under this setting, we propose a new algorithm, named Amplified SCAFFOLD, and prove that it achieves linear speedup, reduced communication, and resilience to data heterogeneity simultaneously. In particular, for cyclic participation, our algorithm is proved to enjoy $\mathcal{O}(\epsilon^{-2})$ communication rounds to find an $\epsilon$-stationary point in the non-convex stochastic setting. In contrast, the prior work under the same setting requires $\mathcal{O}(\kappa^2 \epsilon^{-4})$ communication rounds, where $\kappa$ denotes the data heterogeneity. Therefore, our algorithm significantly reduces communication rounds due to better dependency in terms of $\epsilon$ and $\kappa$. Our analysis relies on a fine-grained treatment of the nested dependence between client participation and errors in the control variates, which results in tighter guarantees than previous work. We also provide experimental results with (1) synthetic data and (2) real-world data with a large number of clients $(N = 250)$, demonstrating the effectiveness of our algorithm under periodic client participation.
tl;dr: Efficient alignment of Large Language models without updating the model parameters via Transfer decoding

Aligning foundation models is essential for their safe and trustworthy deployment. However, traditional fine-tuning methods are computationally intensive and require updating billions of model parameters. A promising alternative, alignment via decoding, adjusts the response distribution directly without model updates to maximize a target reward $r$, thus providing a lightweight and adaptable framework for alignment. However, principled decoding methods rely on oracle access to an optimal Q-function ($Q^*$), which is often unavailable in practice. Hence, prior SoTA methods either approximate this $Q^*$ using $Q^{\pi_{\text{sft}}}$ (derived from the reference $\texttt{SFT}$ model) or rely on short-term rewards, resulting in sub-optimal decoding performance. In this work, we propose $\texttt{Transfer Q}^*$, which implicitly estimates the optimal value function for a target reward $r$ through a baseline model $\rho_{\texttt{BL}}$ aligned with a baseline reward $r_{\texttt{BL}}$ (which can be different from the target reward $r$). Theoretical analyses of $\texttt{Transfer Q}^*$ provide a rigorous characterization of its optimality, deriving an upper bound on the sub-optimality gap and identifying a hyperparameter to control the deviation from the pre-trained reference $\texttt{SFT}$ model based on user needs. Our approach significantly reduces the sub-optimality gap observed in prior SoTA methods and demonstrates superior empirical performance across key metrics such as coherence, diversity, and quality in extensive tests on several synthetic and real datasets.
tl;dr: Efficient approach to generate aleatoric and epistemic uncertainty estimates for inverse problems.

Estimating and disentangling epistemic uncertainty, uncertainty that is reducible with more training data, and aleatoric uncertainty, uncertainty that is inherent to the task at hand, is critically important when applying machine learning to high-stakes applications such as medical imaging and weather forecasting. Conditional diffusion models' breakthrough ability to accurately and efficiently sample from the posterior distribution of a dataset now makes uncertainty estimation conceptually straightforward: One need only train and sample from a large ensemble of diffusion models. Unfortunately, training such an ensemble becomes computationally intractable as the complexity of the model architecture grows. In this work we introduce a new approach to ensembling, hyper-diffusion models (HyperDM), which allows one to accurately estimate both epistemic and aleatoric uncertainty with a single model. Unlike existing single-model uncertainty methods like Monte-Carlo dropout and Bayesian neural networks, HyperDM offers prediction accuracy on par with, and in some cases superior to, multi-model ensembles. Furthermore, our proposed approach scales to modern network architectures such as Attention U-Net and yields more accurate uncertainty estimates compared to existing methods. We validate our method on two distinct real-world tasks: x-ray computed tomography reconstruction and weather temperature forecasting.
tl;dr: A new Multimodal LLM: constructing visual and textual "wings" (i.e., learners) to extend visual comprehension without sacrificing text-only instruction capabilities.

Multimodal large language models (MLLMs), initiated with a trained LLM, first align images with text and then fine-tune on multimodal mixed inputs. However, during the continued training, the MLLM catastrophically forgets the text-only instructions that the initial LLM masters. In this paper, we present Wings, a novel MLLM that excels in both text-only and multimodal instructions. By examining attention across layers of MLLM, we find that *text-only forgetting* is related to the attention shifts from pre-image to post-image text. From that, we construct an additional Low-Rank Residual Attention (LoRRA) block that acts as the "modality learner" to expand the learnable space and compensate for the attention shift. The complementary learners, like "wings" on either side, are connected in parallel to each layer's attention block. The LoRRA mirrors the structure of attention but utilizes low-rank connections to ensure efficiency. Initially, image and text inputs are aligned with visual learners operating alongside the main attention, balancing focus on visual elements. Later, textual learners are integrated with token-wise routing, blending the outputs of both modality learners collaboratively. Our experimental results demonstrate that Wings outperforms equally-scaled MLLMs in both text-only and visual question-answering tasks. Wings with *compensation of learners* addresses text-only forgetting during visual modality expansion in general MLLMs.
tl;dr: We propose a new framework for coded computing, based on learning theory, to handle general computation and we provide theoretical justification for its benefits as well as experimental evaluations. It strictly outperforms the state of the art.

Coded computing has emerged as a promising framework for tackling significant challenges in large-scale distributed computing, including the presence of slow, faulty, or compromised servers. In this approach, each worker node processes a combination of the data, rather than the raw data itself. The final result then is decoded from the collective outputs of the worker nodes. However, there is a significant gap between current coded computing approaches and the broader landscape of general distributed computing, particularly when it comes to machine learning workloads. To bridge this gap, we propose a novel foundation for coded computing, integrating the principles of learning theory, and developing a framework that seamlessly adapts with machine learning applications.
In this framework, the objective is to find the encoder and decoder functions that minimize the loss function, defined as the mean squared error between the estimated and true values. Facilitating the search for the optimum decoding and functions, we show that the loss function can be upper-bounded by the summation of two terms: the generalization error of the decoding function and the training error of the encoding function.
Focusing on
the second-order Sobolev space, we then derive the optimal encoder and decoder. We show that in the proposed solution, the mean squared error of the estimation decays with the rate of $\mathcal{O}(S^3 N^{-3})$ and $\mathcal{O}(S^{\frac{8}{5}}N^{\frac{-3}{5}})$ in noiseless and noisy computation settings, respectively, where $N$ is the number of worker nodes with at most $S$ slow servers (stragglers). Finally, we evaluate the proposed scheme on inference tasks for various machine learning models and demonstrate that the proposed framework outperforms the state-of-the-art in terms of accuracy and rate of convergence.
tl;dr: Novel time-series segmentation and self-supervised training for building general pre-trained time-series models capable of time-series analysis across multiple domains.

Large pre-trained models have been vital in recent advancements in domains like language and vision, making model training for individual downstream tasks more efficient and provide superior performance. However, tackling time-series analysis tasks usually involves designing and training a separate model from scratch leveraging training data and domain expertise specific to the task. We tackle a significant challenge for pre-training a foundational time-series model from multi-domain time-series datasets: extracting semantically useful tokenized inputs to the model across heterogeneous time-series from different domains. We propose Large Pre-trained Time-series Models (LPTM) that introduces a novel method of adaptive segmentation that automatically identifies optimal dataset-specific segmentation strategy during pre-training. This enables LPTM to perform similar to or better than domain-specific state-of-art model when fine-tuned to different downstream time-series analysis tasks and under zero-shot settings. LPTM achieves superior forecasting and time-series classification results taking up to 40% less data and 50% less training time compared to state-of-art baselines.
tl;dr: We develop identification theory for discrete latent hierarchical model from potentially high-dimensional, continuous data distributions.

Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models.
Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking.
In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images).
We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible.
Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images.
We substantiate our theoretical claims with synthetic data experiments.
Further, we discuss our theory's implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.

Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental results demonstrate that CGFormer achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks, attaining a mIoU of 16.87 and 20.05, as well as an IoU of 45.99 and 48.07, respectively. Remarkably, CGFormer even outperforms approaches employing temporal images as inputs or much larger image backbone networks.

Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting in training that qualitatively agree with the ones used in [Karras et al., 2022]. It also provides perspectives on the choices of time and variance schedules in sampling: when the score is well trained, the design in [Song et al., 2021] is more preferable, but when it is less trained, the design in [Karras et al., 2022] becomes more preferable.
tl;dr: We propose Generative Hierarchical Materials Search, a language-to-structure generative framework that uses LLMs to generate crystal formulas, diffusion models to generate crystal structures, and hierarchical search to find the best structure.

Generative models trained at scale can now produce novel text, video, and more recently, scientific data such as crystal structures. The ultimate goal for materials discovery, however, goes beyond generation: we desire a fully automated system that proposes, generates, and verifies crystal structures given a high-level user instruction. In this work, we formulate end-to-end language-to-structure generation as a multi-objective optimization problem, and propose Generative Hierarchical Materials Search (GenMS) for controllable generation of crystal structures. GenMS consists of (1) a language model that takes high-level natural language as input and generates intermediate textual information about a crystal (e.g., chemical formulae), and (2) a diffusion model that takes intermediate information as input and generates low-level continuous value crystal structures. GenMS additionally uses a graph neural network to predict properties (e.g., formation energy) from the generated crystal structures. During inference, GenMS leverages all three components to conduct a forward tree search over the space of possible structures. Experiments show that GenMS outperforms other alternatives both in satisfying user request and in generating low-energy structures. GenMS is able to generate complex structures such as double perovskites (or elpasolites), layered structures, and spinels, solely from natural language input.

Reinforcement learning (RL) has proven highly effective in addressing complex decision-making and control tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution with learned mean and variance, which constrains their capability to acquire complex policies. In response to this problem, we propose an online RL algorithm termed diffusion actor-critic with entropy regulator (DACER). This algorithm conceptualizes the reverse process of the diffusion model as a novel policy function and leverages the capability of the diffusion model to fit multimodal distributions, thereby enhancing the representational capacity of the policy. Since the distribution of the diffusion policy lacks an analytical expression, its entropy cannot be determined analytically. To mitigate this, we propose a method to estimate the entropy of the diffusion policy utilizing Gaussian mixture model. Building on the estimated entropy, we can learn a parameter $\alpha$ that modulates the degree of exploration and exploitation. Parameter $\alpha$ will be employed to adaptively regulate the variance of the added noise, which is applied to the action output by the diffusion model. Experimental trials on MuJoCo benchmarks and a multimodal task demonstrate that the DACER algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting a stronger representational capacity of the diffusion policy.

Detecting 3D keypoints with semantic consistency is widely used in many scenarios such as pose estimation, shape registration and robotics. Currently, most unsupervised 3D keypoint detection methods focus on the rigid-body objects. However, when faced with deformable objects, the keypoints they identify do not preserve semantic consistency well. In this paper, we introduce an innovative unsupervised keypoint detector Key-Grid for both the rigid-body and deformable objects, which is an autoencoder framework. The encoder predicts keypoints and the decoder utilizes the generated keypoints to reconstruct the objects. Unlike previous work, we leverage the identified keypoint in formation to form a 3D grid feature heatmap called grid heatmap, which is used in the decoder section. Grid heatmap is a novel concept that represents the latent variables for grid points sampled uniformly in the 3D cubic space, where these variables are the shortest distance between the grid points and the “skeleton” connected by keypoint pairs. Meanwhile, we incorporate the information from each layer of the encoder into the decoder section. We conduct an extensive evaluation of Key-Grid on a list of benchmark datasets. Key-Grid achieves the state-of-the-art performance on the semantic consistency and position accuracy of keypoints. Moreover, we demonstrate the robustness of Key-Grid to noise and downsampling. In addition, we achieve SE-(3) invariance of keypoints though generalizing Key-Grid to a SE(3)-invariant backbone.
tl;dr: Proposes a novel approach for post-training model alignment using conformal risk control, defining alignment using ideas from property testing

AI model alignment is crucial due to inadvertent biases in training data and the underspecified machine learning pipeline, where models with excellent test metrics may not meet end-user requirements. While post-training alignment via human feedback shows promise, these methods are often limited to generative AI settings where humans can interpret and provide feedback on model outputs. In traditional non-generative settings with numerical or categorical outputs, detecting misalignment through single-sample outputs remains challenging, and enforcing alignment during training requires repeating costly training processes.
In this paper we consider an alternative strategy. We propose interpreting model alignment through property testing, defining an aligned model $f$ as one belonging to a subset $\mathcal{P}$ of functions that exhibit specific desired behaviors. We focus on post-processing a pre-trained model $f$ to better align with $\mathcal{P}$ using conformal risk control. Specifically, we develop a general procedure for converting queries for testing a given property $\mathcal{P}$ to a collection of loss functions suitable for use in a conformal risk control algorithm. We prove a probabilistic guarantee that the resulting conformal interval around $f$ contains a function approximately satisfying $\mathcal{P}$. We exhibit applications of our methodology on a collection of supervised learning datasets for (shape-constrained) properties such as monotonicity and concavity. The general procedure is flexible and can be applied to a wide range of desired properties. Finally, we prove that pre-trained models will always require alignment techniques even as model sizes or training data increase, as long as the training data contains even small biases.
2578. Task-recency bias strikes back: Adapting covariances in Exemplar-Free Class Incremental Learning
tl;dr: Exemplar-free class incremental learning, we explain task-recency bias in modern methods and develop a method that adapts means and covariances of classes from task to task

Exemplar-Free Class Incremental Learning (EFCIL) tackles the problem of training a model on a sequence of tasks without access to past data. Existing state-of-the-art methods represent classes as Gaussian distributions in the feature extractor's latent space, enabling Bayes classification or training the classifier by replaying pseudo features. However, we identify two critical issues that compromise their efficacy when the feature extractor is updated on incremental tasks. First, they do not consider that classes' covariance matrices change and must be adapted after each task. Second, they are susceptible to a task-recency bias caused by dimensionality collapse occurring during training. In this work, we propose AdaGauss - a novel method that adapts covariance matrices from task to task and mitigates the task-recency bias owing to the additional anti-collapse loss function. AdaGauss yields state-of-the-art results on popular EFCIL benchmarks and datasets when training from scratch or starting from a pre-trained backbone.
tl;dr: We study scaling laws of Graph Neural Networks on 2D molecular graphs during pretraining as well as finetuning.

Scaling deep learning models has been at the heart of recent revolutions in language modelling and image generation. Practitioners have observed a strong relationship between model size, dataset size, and performance. However, structure-based architectures such as Graph Neural Networks (GNNs) are yet to show the benefits of scale mainly due to lower efficiency of sparse operations, large data requirements, and lack of clarity about the effectiveness of various architectures. We address this drawback of GNNs by studying their scaling behavior. Specifically, we analyze message-passing networks, graph Transformers, and hybrid architectures on the largest public collection of 2D molecular graphs for supervised pretraining. For the first time, we observe that GNNs benefit tremendously from the increasing scale of depth, width, number of molecules and associated labels. A major factor is the diversity of the pretraining data that comprises thousands of labels per molecule derived from bio-assays, quantum simulations, transcriptomics and phenomic imaging. We further demonstrate strong finetuning scaling behavior on 38 highly competitive downstream tasks, outclassing previous large models. This gives rise to MolGPS, a new graph foundation model that allows to navigate the chemical space, outperforming the previous state-of-the-arts on 26 out the 38 downstream tasks. We hope that our work paves the way for an era where foundational GNNs drive pharmaceutical drug discovery.
tl;dr: We propose a new probabilistic prompt aggregation method for fine-tuning on decentralized and imbalance data settings.

Fine-tuning pre-trained models is a popular approach in machine learning for solving complex tasks with moderate data. However, fine-tuning the entire pre-trained model is ineffective in federated data scenarios where local data distributions are diversely skewed. To address this, we explore integrating federated learning with a more effective prompt-tuning method, optimizing for a small set of input prefixes to reprogram the pre-trained model's behavior. Our approach transforms federated learning into a distributed set modeling task, aggregating diverse sets of prompts to globally fine-tune the pre-trained model. We benchmark various baselines based on direct adaptations of existing federated model aggregation techniques and introduce a new probabilistic prompt aggregation method that substantially outperforms these baselines. Our reported results on a variety of computer vision datasets confirm that the proposed method is most effective to combat extreme data heterogeneity in federated learning.

Modeling multivariate time series is a well-established problem with a wide range of applications from healthcare to financial markets. It, however, is challenging as it requires methods to (1) have high expressive power of representing complicated dependencies along the time axis to capture both long-term progression and seasonal patterns, (2) capture the inter-variate dependencies when it is informative, (3) dynamically model the dependencies of variate and time dimensions, and (4) have efficient training and inference for very long sequences. Traditional State Space Models (SSMs) are classical approaches for univariate time series modeling due to their simplicity and expressive power to represent linear dependencies. They, however, have fundamentally limited expressive power to capture non-linear dependencies, are slow in practice, and fail to model the inter-variate information flow. Despite recent attempts to improve the expressive power of SSMs by using deep structured SSMs, the existing methods are either limited to univariate time series, fail to model complex patterns (e.g., seasonal patterns), fail to dynamically model the dependencies of variate and time dimensions, and/or are input-independent. We present Chimera, an expressive variation of the 2-dimensional SSMs with careful design of parameters to maintain high expressive power while keeping the training complexity linear. Using two SSM heads with different discretization processes and input-dependent parameters, Chimera is provably able to learn long-term progression, seasonal patterns, and desirable dynamic autoregressive processes. To improve the efficiency of complex 2D recurrence, we present a fast training using a new 2-dimensional parallel selective scan. Our experimental evaluation shows the superior performance of Chimera on extensive and diverse benchmarks, including ECG and speech time series classification, long-term and short-term time series forecasting, and time series anomaly detection.
tl;dr: We propose a novel news-driven multi-stock movement prediction framework called CausalStock.

There are two issues in news-driven multi-stock movement prediction tasks that are not well solved in the existing works. On the one hand, "relation discovery" is a pivotal part when leveraging the price information of other stocks to achieve accurate stock movement prediction. Given that stock relations are often unidirectional, such as the "supplier-consumer" relationship, causal relations are more appropriate to capture the impact between stocks. On the other hand, there is substantial noise existing in the news data leading to extracting effective information with difficulty. With these two issues in mind, we propose a novel framework called CausalStock for news-driven multi-stock movement prediction, which discovers the temporal causal relations between stocks. We design a lag-dependent temporal causal discovery mechanism to model the temporal causal graph distribution. Then a Functional Causal Model is employed to encapsulate the discovered causal relations and predict the stock movements. Additionally, we propose a Denoised News Encoder by taking advantage of the excellent text evaluation ability of large language models (LLMs) to extract useful information from massive news data. The experiment results show that CausalStock outperforms the strong baselines for both news-driven multi-stock movement prediction and multi-stock movement prediction tasks on six real-world datasets collected from the US, China, Japan, and UK markets. Moreover, getting benefit from the causal relations, CausalStock could offer a clear prediction mechanism with good explainability.

Offline reinforcement learning (RL) has progressed with return-conditioned supervised learning (RCSL), but its lack of stitching ability remains a limitation. We introduce $Q$-Aided Conditional Supervised Learning (QCS), which effectively combines the stability of RCSL with the stitching capability of $Q$-functions. By analyzing $Q$-function over-generalization, which impairs stable stitching, QCS adaptively integrates $Q$-aid into RCSL's loss function based on trajectory return. Empirical results show that QCS significantly outperforms RCSL and value-based methods, consistently achieving or exceeding the highest trajectory returns across diverse offline RL benchmarks. QCS represents a breakthrough in offline RL, pushing the limits of what can be achieved and fostering further innovations.
tl;dr: A novel and effective alignment method is proposed for LLMs in the pre-training stage to reduce the downstream adaptation cost.

The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `\textit{post alignment}'. We argue that alignment during the pre-training phase, which we term 'native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.

Pre-trained language models have been proven to possess strong base capabilities, which not only excel in in-distribution language modeling but also show powerful abilities in out-of-distribution language modeling, transfer learning and few-shot learning. Unlike existing work focusing on the influence of scale on base capabilities, our work examines the influence of architecture on those. Specifically, our concern is: How does architecture influence the base capabilities of pre-trained language models? In this work, we attempt to explain and reverse the decline in base capabilities caused by the architecture of FFN-Wider Transformers, seeking to provide some insights. Through analysis, we found the contribution ratio of Multi-Head Attention (a combination function) to pre-trained language modeling is a key factor affecting base capabilities. FFN-Wider Transformers reduce the contribution ratio of this combination function, leading to a decline in base capabilities. We confirmed this by experiments and proposed Combination Enhanced Architecture (CEA) to address the decline in base capabilities of such models. Significantly, we extended our explanation and CEA to Mixture of Experts (MoE) Transformers. We successfully achieved significant improvements in base capabilities on a 14B parameter MoE model, demonstrating the practical application value of our work. This also indicates that our analysis has a certain guiding significance for architecture analysis, architecture improvement and architecture design.

This paper introduces an innovative approach to classification called Credal Deep Ensembles (CreDEs), namely, ensembles of novel Credal-Set Neural Networks (CreNets). CreNets are trained to predict a lower and an upper probability bound for each class, which, in turn, determine a convex set of probabilities (credal set) on the class set. The training employs a loss inspired by distributionally robust optimization which simulates the potential divergence of the test distribution from the training distribution, in such a way that the width of the predicted probability interval reflects the epistemic uncertainty about the future data distribution. Ensembles can be constructed by training multiple CreNets, each associated with a different random seed, and averaging the outputted intervals. Extensive experiments are conducted on various out-of-distributions (OOD) detection benchmarks (CIFAR10/100 vs SVHN/Tiny-ImageNet, CIFAR10 vs CIFAR10-C, ImageNet vs ImageNet-O) and using different network architectures (ResNet50, VGG16, and ViT Base). Compared to Deep Ensemble baselines, CreDEs demonstrate higher test accuracy, lower expected calibration error, and significantly improved epistemic uncertainty estimation.

With the rapid development of deep learning, the increasing complexity and scale of parameters make training a new model increasingly resource-intensive. In this paper, we start from the classic convolutional neural network (CNN) and explore a paradigm that does not require training to obtain new models. Similar to the birth of CNN inspired by receptive fields in the biological visual system, we draw inspiration from the information subsystem pathways in the biological visual system and propose Model Disassembling and Assembling (MDA). During model disassembling, we introduce the concept of relative contribution and propose a component locating technique to extract task-aware components from trained CNN classifiers. For model assembling, we present the alignment padding strategy and parameter scaling strategy to construct a new model tailored for a specific task, utilizing the disassembled task-aware components.
The entire process is akin to playing with LEGO bricks, enabling arbitrary assembly of new models, and providing a novel perspective for model creation and reuse. Extensive experiments showcase that task-aware components disassembled from CNN classifiers or new models assembled using these components closely match or even surpass the performance of the baseline,
demonstrating its promising results for model reuse. Furthermore, MDA exhibits diverse potential applications, with comprehensive experiments exploring model decision route analysis, model compression, knowledge distillation, and more.
tl;dr: We propose novel performance guarantees and strategies for leveraging counterfactual explanations in model reconstruction.

Counterfactual explanations provide ways of achieving a favorable model outcome with minimum input perturbation. However, counterfactual explanations can also be leveraged to reconstruct the model by strategically training a surrogate model to give similar predictions as the original (target) model. In this work, we analyze how model reconstruction using counterfactuals can be improved by
further leveraging the fact that the counterfactuals also lie quite close to the decision boundary. Our main contribution is to derive novel theoretical relationships between the error in model reconstruction and the number of counterfactual queries required using polytope theory. Our theoretical analysis leads us to propose a strategy for model reconstruction that we call Counterfactual Clamping Attack (CCA) which trains a surrogate model using a unique loss function that treats counterfactuals differently than ordinary instances. Our approach also alleviates the related problem of decision boundary shift that arises in existing model reconstruction approaches when counterfactuals are treated as ordinary instances. Experimental results demonstrate that our strategy improves fidelity between the target and surrogate model predictions on several datasets.

Embedding plays a key role in modern recommender systems because they are virtual representations of real-world entities and the foundation for subsequent decision-making models. In this paper, we propose a novel embedding update mechanism, Structure-aware Embedding Evolution (SEvo for short), to encourage related nodes to evolve similarly at each step. Unlike GNN (Graph Neural Network) that typically serves as an intermediate module, SEvo is able to directly inject graph structural information into embedding with minimal computational overhead during training. The convergence properties of SEvo along with its potential variants are theoretically analyzed to justify the validity of the designs. Moreover, SEvo can be seamlessly integrated into existing optimizers for state-of-the-art performance. Particularly SEvo-enhanced AdamW with moment estimate correction demonstrates consistent improvements across a spectrum of models and datasets, suggesting a novel technical route to effectively utilize graph structural information beyond explicit GNN modules.
tl;dr: A novel strategy of using internal uncertainty of LLMs to select instruction tuning data.

Instruction tuning (IT) is crucial to tailoring large language models (LLMs) towards human-centric interactions. Recent advancements have shown that the careful selection of a small, high-quality subset of IT data can significantly enhance the performance of LLMs. Despite this, common approaches often rely on additional models or data, which increases costs and limits widespread adoption. In this work, we propose a novel approach, termed $\textit{SelectIT}$, that capitalizes on the foundational capabilities of the LLM itself. Specifically, we exploit the intrinsic uncertainty present in LLMs to more effectively select high-quality IT data, without the need for extra resources. Furthermore, we introduce a curated IT dataset, the $\textit{Selective Alpaca}$, created by applying SelectIT to the Alpaca-GPT4 dataset. Empirical results demonstrate that IT using Selective Alpaca leads to substantial model ability enhancement. The robustness of SelectIT has also been corroborated in various foundation models and domain-specific tasks. Our findings suggest that longer and more computationally intensive IT data may serve as superior sources of IT, offering valuable insights for future research in this area. Data, code, and scripts are freely available at https://github.com/Blue-Raincoat/SelectIT.

Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match specified persons in infrared images to visible images without annotations, and vice versa. USVI-ReID is a challenging yet underexplored task. Most existing methods address the USVI-ReID through cluster-based contrastive learning, which simply employs the cluster center to represent an individual. However, the cluster center primarily focuses on commonality, overlooking divergence and variety. To address the problem, we propose a Progressive Contrastive Learning with Hard and Dynamic Prototypes for USVI-ReID. In brief, we generate the hard prototype by selecting the sample with the maximum distance from the cluster center. We reveal that the inclusion of the hard prototype in contrastive loss helps to emphasize divergence. Additionally, instead of rigidly aligning query images to a specific prototype, we generate the dynamic prototype by randomly picking samples within a cluster. The dynamic prototype is used to encourage variety. Finally, we introduce a progressive learning strategy to gradually shift the model's attention towards divergence and variety, avoiding cluster deterioration. Extensive experiments conducted on the publicly available SYSU-MM01 and RegDB datasets validate the effectiveness of the proposed method.
tl;dr: We uncover a potential representation complexity hierarchy among different RL paradigms, including model-based RL, policy-based RL, and value-based RL.

Reinforcement Learning (RL) encompasses diverse paradigms, including model-based RL, policy-based RL, and value-based RL, each tailored to approximate the model, optimal policy, and optimal value function, respectively. This work investigates the potential hierarchy of representation complexity among these RL paradigms. By utilizing computational complexity measures, including time complexity and circuit complexity, we theoretically unveil a potential representation complexity hierarchy within RL. We find that representing the model emerges as the easiest task, followed by the optimal policy, while representing the optimal value function presents the most intricate challenge. Additionally, we reaffirm this hierarchy from the perspective of the expressiveness of Multi-Layer Perceptrons (MLPs), which align more closely with practical deep RL and contribute to a completely new perspective in theoretical studying representation complexity in RL. Finally, we conduct deep RL experiments to validate our theoretical findings.
tl;dr: We affirmatively answer the question in the title by providing comprehensive analyses and empirical evidence.

This paper questions the effectiveness of a modern predictive uncertainty quantification approach, called *evidential deep learning* (EDL), in which a single neural network model is trained to learn a meta distribution over the predictive distribution by minimizing a specific objective function. Despite their perceived strong empirical performance on downstream tasks, a line of recent studies by Bengs et al. identify limitations of the existing methods to conclude their learned epistemic uncertainties are unreliable, e.g., in that they are non-vanishing even with infinite data. Building on and sharpening such analysis, we 1) provide a sharper understanding of the asymptotic behavior of a wide class of EDL methods by unifying various objective functions; 2) reveal that the EDL methods can be better interpreted as an out-of-distribution detection algorithm based on energy-based-models; and 3) conduct extensive ablation studies to better assess their empirical effectiveness with real-world datasets.
Through all these analyses, we conclude that even when EDL methods are empirically effective on downstream tasks, this occurs despite their poor uncertainty quantification capabilities. Our investigation suggests that incorporating model uncertainty can help EDL methods faithfully quantify uncertainties and further improve performance on representative downstream tasks, albeit at the cost of additional computational complexity.
tl;dr: Randomized algorithms and PAC bounds for IRL in continuous spaces

This work studies discrete-time discounted Markov decision processes with continuous state and action spaces and addresses the inverse problem of inferring a cost function from observed optimal behavior. We first consider the case in which we have access to the entire expert policy and characterize the set of solutions to the inverse problem by using occupation measures, linear duality, and complementary slackness conditions. To avoid trivial solutions and ill-posedness, we introduce a natural linear normalization constraint. This results in an infinite-dimensional linear feasibility problem, prompting a thorough analysis of its properties. Next, we use linear function approximators and adopt a randomized approach, namely the scenario approach and related probabilistic feasibility guarantees, to derive $\varepsilon$-optimal solutions for the inverse problem. We further discuss the sample complexity for a desired approximation accuracy. Finally, we deal with the more realistic case where we only have access to a finite set of expert demonstrations and a generative model and provide bounds on the error made when working with samples.

Video salient object ranking aims to simulate the human attention mechanism by dynamically prioritizing the visual attraction of objects in a scene over time. Despite its numerous practical applications, this area remains underexplored. In this work, we propose a graph model for video salient object ranking. This graph simultaneously explores multi-scale spatial contrasts and intra-/inter-instance temporal correlations across frames to extract diverse spatio-temporal saliency cues. It has two advantages: 1. Unlike previous methods that only perform global inter-frame contrast or compare all proposals across frames globally, we explicitly model the motion of each instance by comparing its features with those in the same spatial region in adjacent frames, thus obtaining more accurate motion saliency cues. 2. We synchronize the spatio-temporal saliency cues in a single graph for joint optimization, which exhibits better dynamics compared to the previous stage-wise methods that prioritize spatial cues followed by temporal cues. Additionally, we propose a simple yet effective video retargeting method based on video saliency ranking. Extensive experiments demonstrate the superiority of our model in video salient object ranking and the effectiveness of the video retargeting method. Our codes/models are released at [https://github.com/zyf-815/VSOR/tree/main](https://github.com/zyf-815/VSOR/tree/main).
tl;dr: a new family of optimization algorithms adaptively descending on projected subspaces found by online PCA

Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using projection matrix found by singular value decomposition (SVD). However, convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the \emph{first} convergence guarantee for arbitrary update rules of projection matrix. This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including most common ones, such as LION, Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizer without SVD. Instead of updating projection matrix with eigenvectors, Online Subspace Descent updates projection matrix wtih online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training. We demonstrate that, for the task of pretraining LLaMA models ranging from 60M to 1B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
2597. Curriculum Fine-tuning of Vision Foundation Model for Medical Image Classification Under Label Noise
tl;dr: We propose CUFIT, a robust fine-tuning method for vision foundation models under noisy label conditions, based on the advantages of linear probing and adapters.

Deep neural networks have demonstrated remarkable performance in various vision tasks, but their success heavily depends on the quality of the training data. Noisy labels are a critical issue in medical datasets and can significantly degrade model performance. Previous clean sample selection methods have not utilized the well pre-trained features of vision foundation models (VFMs) and assumed that training begins from scratch. In this paper, we propose CUFIT, a curriculum fine-tuning paradigm of VFMs for medical image classification under label noise. Our method is motivated by the fact that linear probing of VFMs is relatively unaffected by noisy samples, as it does not update the feature extractor of the VFM, thus robustly classifying the training samples. Subsequently, curriculum fine-tuning of two adapters is conducted, starting with clean sample selection from the linear probing phase. Our experimental results demonstrate that CUFIT outperforms previous methods across various medical image benchmarks. Specifically, our method surpasses previous baselines by 5.0\%, 2.1\%, 4.6\%, and 5.8\% at a 40\% noise rate on the HAM10000, APTOS-2019, BloodMnist, and OrgancMnist datasets, respectively. Furthermore, we provide extensive analyses to demonstrate the impact of our method on noisy label detection. For instance, our method shows higher label precision and recall compared to previous approaches. Our work highlights the potential of leveraging VFMs in medical image classification under challenging conditions of noisy labels.

Humans can communicate and observe media with different modalities, such as texts, sounds, and images. For robots to be more generalizable embodied agents, they should be capable of following instructions and perceiving the world with adaptation to diverse modalities. Current robotic learning methodologies often focus on single-modal task specification and observation, thereby limiting their ability to process rich multi-modal information. Addressing this limitation, we present an end-to-end general-purpose multi-modal system named Any-to-Policy Embodied Agents. This system empowers robots to handle tasks using various modalities, whether in combinations like text-image, audio-image, text-point cloud, or in isolation. Our innovative approach involves training a versatile modality network that adapts to various inputs and connects with policy networks for effective control. Because of the lack of existing multi-modal robotics datasets for evaluation, we assembled a comprehensive real-world dataset encompassing 30 robotic tasks. Each task in this dataset is richly annotated across multiple modalities, providing a robust foundation for assessment. We conducted extensive validation of our proposed unified modality embodied agent using several simulation benchmarks, including Franka Kitchen, Meta-World, and Maniskill2, as well as in our real-world settings. Our experiments showcase the promising capability of building embodied agents that can adapt to diverse multi-modal in a unified framework.
2599. The Bayesian sampling in a canonical recurrent circuit with a diversity of inhibitory interneurons

Accumulating evidence suggests stochastic cortical circuits can perform sampling-based Bayesian inference to compute the latent stimulus posterior. Canonical cortical circuits consist of excitatory (E) neurons and types of inhibitory (I) interneurons. Nevertheless, nearly no sampling neural circuit models consider the diversity of interneurons, and thus how interneurons contribute to sampling remains poorly understood. To provide theoretical insight, we build a nonlinear canonical circuit model consisting of recurrently connected E neurons and two types of I neurons including Parvalbumin (PV) and Somatostatin (SOM) neurons. The E neurons are modeled as a canonical ring (attractor) model, receiving global inhibition from PV neurons, and locally tuning-dependent inhibition from SOM neurons.
We theoretically analyze the nonlinear circuit dynamics and analytically identify the Bayesian sampling algorithm performed by the circuit dynamics. We found a reduced circuit with only E and PV neurons performs Langevin sampling, and the inclusion of SOM neurons with tuning-dependent inhibition speeds up the sampling via upgrading the Langevin into Hamiltonian sampling. Moreover, the Hamiltonian framework requires SOM neurons to receive no direct feedforward connections, consistent with neuroanatomy. Our work provides overarching connections between nonlinear circuits with various types of interneurons and sampling algorithms, deepening our understanding of circuit implementation of Bayesian inference.

In online learning, a decision maker repeatedly selects one of a set of actions, with the goal of minimizing the overall loss incurred. Following the recent line of research on algorithms endowed with additional predictive features, we revisit this problem by allowing the decision maker to acquire additional information on the actions to be selected. In particular, we study the power of \emph{best-action queries}, which reveal beforehand the identity of the best action at a given time step. In practice, predictive features may be expensive, so we allow the decision maker to issue at most $k$ such queries.
We establish tight bounds on the performance any algorithm can achieve when given access to $k$ best-action queries for different types of feedback models. In particular, we prove that in the full feedback model, $k$ queries are enough to achieve an optimal regret of $\Theta(\min\{\sqrt T, \frac{T}{k}\})$. This finding highlights the significant multiplicative advantage in the regret rate achievable with even a modest (sublinear) number $k \in \Omega(\sqrt{T})$ of queries.
Additionally, we study the challenging setting in which the only available feedback is obtained during the time steps corresponding to the $k$ best-action queries. There, we provide a tight regret rate of $\Theta(\min\{\frac{T}{\sqrt k},\frac{T^2}{k^2}\})$, which improves over the standard $\Theta(\frac{T}{\sqrt k})$ regret rate for label efficient prediction for $k \in \Omega(T^{2/3})$.

Text-to-image diffusion models particularly Stable Diffusion, have revolutionized the field of computer vision. However, the synthesis quality often deteriorates when asked to generate images that faithfully represent complex prompts involving multiple attributes and objects. While previous studies suggest that blended text embeddings lead to improper attribute binding, few have explored this in depth. In this work, we critically examine the limitations of the CLIP text encoder in understanding attributes and investigate how this affects diffusion models. We discern a phenomenon of attribute bias in the text space and highlight a contextual issue in padding embeddings that entangle different concepts. We propose Magnet, a novel training-free approach to tackle the attribute binding problem. We introduce positive and negative binding vectors to enhance disentanglement, further with a neighbor strategy to increase accuracy. Extensive experiments show that Magnet significantly improves synthesis quality and binding accuracy with negligible computational cost, enabling the generation of unconventional and unnatural concepts.
tl;dr: We propose OMIS, a novel opponent modeling approach based on in-context-learning-based pretraining and decision-time search, ensuring effectiveness and stability in adapting to unknown opponent policies, as proven theoretically and empirically.

Opponent modeling is a longstanding research topic aimed at enhancing decision-making by modeling information about opponents in multi-agent environments. However, existing approaches often face challenges such as having difficulty generalizing to unknown opponent policies and conducting unstable performance. To tackle these challenges, we propose a novel approach based on in-context learning and decision-time search named Opponent Modeling with In-context Search (OMIS). OMIS leverages in-context learning-based pretraining to train a Transformer model for decision-making. It consists of three in-context components: an actor learning best responses to opponent policies, an opponent imitator mimicking opponent actions, and a critic estimating state values. When testing in an environment that features unknown non-stationary opponent agents, OMIS uses pretrained in-context components for decision-time search to refine the actor's policy. Theoretically, we prove that under reasonable assumptions, OMIS without search converges in opponent policy recognition and has good generalization properties; with search, OMIS provides improvement guarantees, exhibiting performance stability. Empirically, in competitive, cooperative, and mixed environments, OMIS demonstrates more effective and stable adaptation to opponents than other approaches. See our project website at https://sites.google.com/view/nips2024-omis.
tl;dr: A novel parameterization method for data distillation by exploring the redundancy in color space.

Dataset Distillation (DD) is designed to generate condensed representations of extensive image datasets, enhancing training efficiency. Despite recent advances, there remains considerable potential for improvement, particularly in addressing the notable redundancy within the color space of distilled images. In this paper, we propose a two-fold optimization strategy to minimize color redundancy at the individual image and overall dataset levels, respectively. At the image level, we employ a palette network, a specialized neural network, to dynamically allocate colors from a reduced color space to each pixel. The palette network identifies essential areas in synthetic images for model training, and consequently assigns more unique colors to them. At the dataset level, we develop a color-guided initialization strategy to minimize redundancy among images. Representative images with the least replicated color patterns are selected based on the information gain. A comprehensive performance study involving various datasets and evaluation scenarios is conducted, demonstrating the superior performance of our proposed color-aware DD compared to existing DD methods.
tl;dr: This work introduces three action masking methods for continuous action spaces to focus the exploration of reinforcement learning on state-specific relevant actions, which enhances learning efficiency and effectiveness.

Continuous action spaces in reinforcement learning (RL) are commonly defined as multidimensional intervals. While intervals usually reflect the action boundaries for tasks well, they can be challenging for learning because the typically large global action space leads to frequent exploration of irrelevant actions. Yet, little task knowledge can be sufficient to identify significantly smaller state-specific sets of relevant actions. Focusing learning on these relevant actions can significantly improve training efficiency and effectiveness. In this paper, we propose to focus learning on the set of relevant actions and introduce three continuous action masking methods for exactly mapping the action space to the state-dependent set of relevant actions. Thus, our methods ensure that only relevant actions are executed, enhancing the predictability of the RL agent and enabling its use in safety-critical applications. We further derive the implications of the proposed methods on the policy gradient. Using proximal policy optimization ( PPO), we evaluate our methods on four control tasks, where the relevant action set is computed based on the system dynamics and a relevant state set. Our experiments show that the three action masking methods achieve higher final rewards and converge faster than the baseline without action masking.
tl;dr: We present a method for pretraining modular controllers from a single robot and environment that significantly speeds up RL training for locomotion and grasping when reused on more complex morphologies.

Robots are often built from standardized assemblies, (e.g. arms, legs, or fingers), but each robot must be trained from scratch to control all the actuators of all the parts together. In this paper we demonstrate a new approach that takes a single robot and its controller as input and produces a set of modular controllers for each of these assemblies such that when a new robot is built from the same parts, its control can be quickly learned by reusing the modular controllers. We achieve this with a framework called MeMo which learns (Me)aningful, (Mo)dular controllers. Specifically, we propose a novel modularity objective to learn an appropriate division of labor among the modules. We demonstrate that this objective can be optimized simultaneously with standard behavior cloning loss via noise injection. We benchmark our framework in locomotion and grasping environments on simple to complex robot morphology transfer. We also show that the modules help in task transfer. On both structure and task transfer, MeMo achieves improved training efficiency to graph neural network and Transformer baselines.
2606. Prior-itizing Privacy: A Bayesian Approach to Setting the Privacy Budget in Differential Privacy
tl;dr: We propose a framework for setting epsilon for data releases satisfying differential privacy.

When releasing outputs from confidential data, agencies need to balance the analytical usefulness of the released data with the obligation to protect data subjects' confidentiality. For releases satisfying differential privacy, this balance is reflected by the privacy budget, $\varepsilon$. We provide a framework for setting $\varepsilon$ based on its relationship with Bayesian posterior probabilities of disclosure. The agency responsible for the data release decides how much posterior risk it is willing to accept at various levels of prior risk, which implies a unique $\varepsilon$. Agencies can evaluate different risk profiles to determine one that leads to an acceptable trade-off in risk and utility.
Video diffusion models have made substantial progress in various video generation applications. However, training models for long video generation tasks require significant computational and data resources, posing a challenge to developing long video diffusion models.
This paper investigates a straightforward and training-free approach to extend an existing short video diffusion model (e.g. pre-trained on 16-frame videos) for consistent long video generation (e.g. 128 frames). Our preliminary observation has found that directly applying the short video diffusion model to generate long videos can lead to severe video quality degradation. Further investigation reveals that this degradation is primarily due to the distortion of high-frequency components in long videos, characterized by a decrease in spatial high-frequency components and an increase in temporal high-frequency components. Motivated by this, we propose a novel solution named FreeLong to balance the frequency distribution of long video features during the denoising process. FreeLong blends the low-frequency components of global video features, which encapsulate the entire video sequence, with the high-frequency components of local video features that focus on shorter subsequences of frames. This approach maintains global consistency while incorporating diverse and high-quality spatiotemporal details from local videos, enhancing both the consistency and fidelity of long video generation. We evaluated FreeLong on multiple base video diffusion models and observed significant improvements. Additionally, our method supports coherent multi-prompt generation, ensuring both visual coherence and seamless transitions between scenes. Our project page is at: https://yulu.net.cn/freelong.
tl;dr: We explore a paradigm that integrates a language-guided simulator into the multi-agent reinforcement learning pipeline to enhance the generated answer for decision-making problems from generative models.

Recent progress in generative models has stimulated significant innovations in many fields, such as image generation and chatbots. Despite their success, these models often produce sketchy and misleading solutions for complex multi-agent decision-making problems because they miss the trial-and-error experience and reasoning as humans. To address this limitation, we explore a paradigm that integrates a language-guided simulator into the multi-agent reinforcement learning pipeline to enhance the generated answer. The simulator is a world model that separately learns dynamics and reward, where the dynamics model comprises an image tokenizer as well as a causal transformer to generate interaction transitions autoregressively, and the reward model is a bidirectional transformer learned by maximizing the likelihood of trajectories in the expert demonstrations under language guidance. Given an image of the current state and the task description, we use the world model to train the joint policy and produce the image sequence as the answer by running the converged policy on the dynamics model. The empirical results demonstrate that this framework can improve the answers for multi-agent decision-making problems by showing superior performance on the training and unseen tasks of the StarCraft Multi-Agent Challenge benchmark. In particular, it can generate consistent interaction sequences and explainable reward functions at interaction states, opening the path for training generative models of the future.

We propose an importance sampling method for tractable and efficient estimation of counterfactual expressions in general settings, named Exogenous Matching. By minimizing a common upper bound of counterfactual estimators, we transform the variance minimization problem into a conditional distribution learning problem, enabling its integration with existing conditional distribution modeling approaches. We validate the theoretical results through experiments under various types and settings of Structural Causal Models (SCMs) and demonstrate the outperformance on counterfactual estimation tasks compared to other existing importance sampling methods. We also explore the impact of injecting structural prior knowledge (counterfactual Markov boundaries) on the results. Finally, we apply this method to identifiable proxy SCMs and demonstrate the unbiasedness of the estimates, empirically illustrating the applicability of the method to practical scenarios.
tl;dr: We develop a neural network interatomic potential architecture that is optimized for scalability and efficiency, achieving state-of-the-art results on a wide range of chemical systems including OC20, OC22, MPTrj, and SPICE.

Scaling has been a critical factor in improving model performance and generalization across various fields of machine learning.
It involves how a model’s performance changes with increases in model size or input data, as well as how efficiently computational resources are utilized to support this growth.
Despite successes in scaling other types of machine learning models, the study of scaling in Neural Network Interatomic Potentials (NNIPs) remains limited. NNIPs act as surrogate models for ab initio quantum mechanical calculations, predicting the energy and forces between atoms in molecules and materials based on atomic configurations. The dominant paradigm in this field is to incorporate numerous physical domain constraints into the model, such as symmetry constraints like rotational equivariance. We contend that these increasingly complex domain constraints inhibit the scaling ability of NNIPs, and such strategies are likely to cause model performance to plateau in the long run. In this work, we take an alternative approach and start by systematically studying NNIP scaling properties and strategies. Our findings indicate that scaling the model through attention mechanisms is both efficient and improves model expressivity. These insights motivate us to develop an NNIP architecture designed for scalability: the Efficiently Scaled Attention Interatomic Potential (EScAIP).
EScAIP leverages a novel multi-head self-attention formulation within graph neural networks, applying attention at the neighbor-level representations.
Implemented with highly-optimized attention GPU kernels, EScAIP achieves substantial gains in efficiency---at least 10x speed up in inference time, 5x less in memory usage---compared to existing NNIP models. EScAIP also achieves state-of-the-art performance on a wide range of datasets including catalysts (OC20 and OC22), molecules (SPICE), and materials (MPTrj).
We emphasize that our approach should be thought of as a philosophy rather than a specific model, representing a proof-of-concept towards developing general-purpose NNIPs that achieve better expressivity through scaling, and continue to scale efficiently with increased computational resources and training data.

Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, can generate visuals with a high degree of consistency. However, such fine-tuned models are not robust; they often fail to compose with concepts of pretrained model or other fine-tuned models. To address this, we propose a novel fine-tuning objective, dubbed Direct Consistency Optimization, which controls the deviation between fine-tuning and pretrained models to retain the pretrained knowledge during fine-tuning. Through extensive experiments on subject and style customization, we demonstrate that our method positions itself on a superior Pareto frontier between subject (or style) consistency and image-text alignment over all previous baselines; it not only outperforms regular fine-tuning objective in image-text alignment, but also shows higher fidelity to the reference images than the method that fine-tunes with additional prior dataset. More importantly, the models fine-tuned with our method can be merged without interference, allowing us to generate custom subjects in a custom style by composing separately customized subject and style models. Notably, we show that our approach achieves better prompt fidelity and subject fidelity than those post-optimized for merging regular fine-tuned models.

Multiple clustering aims to discover various latent structures of data from different aspects. Deep multiple clustering methods have achieved remarkable performance by exploiting complex patterns and relationships in data. However, existing works struggle to flexibly adapt to diverse user-specific needs in data grouping, which may require manual understanding of each clustering. To address these limitations, we introduce Multi-Sub, a novel end-to-end multiple clustering approach that incorporates a multi-modal subspace proxy learning framework in this work. Utilizing the synergistic capabilities of CLIP and GPT-4, Multi-Sub aligns textual prompts expressing user preferences with their corresponding visual representations. This is achieved by automatically generating proxy words from large language models that act as subspace bases, thus allowing for the customized representation of data in terms specific to the user’s interests. Our method consistently outperforms existing baselines across a broad set of datasets in visual multiple clustering tasks. Our code is available at https://github.com/Alexander-Yao/Multi-Sub.

Dual-target therapeutic strategies have become a compelling approach and attracted significant attention due to various benefits, such as their potential in overcoming drug resistance in cancer therapy. Considering the tremendous success that deep generative models have achieved in structure-based drug design in recent years, we formulate dual-target drug design as a generative task and curate a novel dataset of potential target pairs based on synergistic drug combinations. We propose to design dual-target drugs with diffusion models that are trained on single-target protein-ligand complex pairs. Specifically, we align two pockets in 3D space with protein-ligand binding priors and build two complex graphs with shared ligand nodes for SE(3)-equivariant composed message passing, based on which we derive a composed drift in both 3D and categorical probability space in the generative process. Our algorithm can well transfer the knowledge gained in single-target pretraining to dual-target scenarios in a zero-shot manner. We also repurpose linker design methods as strong baselines for this task. Extensive experiments demonstrate the effectiveness of our method compared with various baselines.

Homomorphic encryption (HE)-based deep neural network (DNN) inference protects data and model privacy but suffers from significant computation overhead. We observe transforming the DNN weights into circulant matrices converts general matrix-vector multiplications into HE-friendly 1-dimensional convolutions, drastically reducing the HE computation cost. Hence, in this paper, we propose PrivCirNet, a protocol/network co-optimization framework based on block circulant transformation. At the protocol level, PrivCirNet customizes the HE encoding algorithm that is fully compatible with the block circulant transformation and reduces the computation latency in proportion to the block size. At the network level, we propose a latency-aware formulation to search for the layer-wise block size assignment based on second-order information. PrivCirNet also leverages layer fusion to further reduce the inference cost. We compare PrivCirNet with the state-of-the-art HE-based framework Bolt (IEEE S\&P 2024) and HE-friendly pruning method SpENCNN (ICML 2023). For ResNet-18 and Vision Transformer (ViT) on Tiny ImageNet, PrivCirNet reduces latency by $5.0\times$ and $1.3\times$ with iso-accuracy over Bolt, respectively, and improves accuracy by $4.1$\% and $12$\% over SpENCNN, respectively. For MobileNetV2 on ImageNet, PrivCirNet achieves $1.7\times$ lower latency and $4.2$\% better accuracy over Bolt and SpENCNN, respectively. Our code and checkpoints are available on Git Hub.

Generalized eigenvalue problems (GEPs) find applications in various fields of science and engineering. For example, principal component analysis, Fisher's discriminant analysis, and canonical correlation analysis are specific instances of GEPs and are widely used in statistical data processing. In this work, we study GEPs under generative priors, assuming that the underlying leading generalized eigenvector lies within the range of a Lipschitz continuous generative model. Under appropriate conditions, we show that any optimal solution to the corresponding optimization problems attains the optimal statistical rate. Moreover, from a computational perspective, we propose an iterative algorithm called the Projected Rayleigh Flow Method (PRFM) to approximate the optimal solution. We theoretically demonstrate that under suitable assumptions, PRFM converges linearly to an estimated vector that achieves the optimal statistical rate. Numerical results are provided to demonstrate the effectiveness of the proposed method.
2616. Point-PRC: A Prompt Learning Based Regulation Framework for Generalizable Point Cloud Analysis

This paper investigates the 3D domain generalization (3DDG) ability of large 3D models based on prevalent prompt learning. Recent works demonstrate the performances of 3D point cloud recognition can be boosted remarkably by parameter-efficient prompt tuning. However, we observe that the improvement on downstream tasks comes at the expense of a severe drop in 3D domain generalization. To resolve this challenge, we present a comprehensive regulation framework that allows the learnable prompts to actively interact with the well-learned general knowledge in large 3D models to maintain good generalization. Specifically, the proposed framework imposes multiple explicit constraints on the prompt learning trajectory by maximizing the mutual agreement between task-specific predictions and task-agnostic knowledge. We design the regulation framework as a plug-and-play module to embed into existing representative large 3D models. Surprisingly, our method not only realizes consistently increasing generalization ability but also enhances task-specific 3D recognition performances across various 3DDG benchmarks by a clear margin. Considering the lack of study and evaluation on 3DDG, we also create three new benchmarks, namely base-to-new, cross-dataset and few-shot generalization benchmarks, to enrich the field and inspire future research. Code and benchmarks are available at \url{https://github.com/auniquesun/Point-PRC}.
tl;dr: We propose to leverage stochastic noisy gradient descent for unlearning and establish its first approximate unlearning guarantee under the convexity assumption.

``The right to be forgotten'' ensured by laws for user data privacy becomes increasingly important. Machine unlearning aims to efficiently remove the effect of certain data points on the trained model parameters so that it can be approximately the same as if one retrains the model from scratch. We propose to leverage projected noisy stochastic gradient descent for unlearning and establish its first approximate unlearning guarantee under the convexity assumption. Our approach exhibits several benefits, including provable complexity saving compared to retraining, and supporting sequential and batch unlearning. Both of these benefits are closely related to our new results on the infinite Wasserstein distance tracking of the adjacent (un)learning processes. Extensive experiments show that our approach achieves a similar utility under the same privacy constraint while using $2\%$ and $10\%$ of the gradient computations compared with the state-of-the-art gradient-based approximate unlearning methods for mini-batch and full-batch settings, respectively.

Deep reinforcement learning (RL) is a powerful approach to complex decision-making. However, one issue that limits its practical application is its brittleness, sometimes failing to train in the presence of small changes in the environment. Motivated by the success of zero-shot transfer—where pre-trained models perform well on related tasks—we consider the problem of selecting a good set of training tasks to maximize generalization performance across a range of tasks. Given the high cost of training, it is critical to select training tasks strategically, but not well understood how to do so. We hence introduce Model-Based Transfer Learning (MBTL), which layers on top of existing RL methods to effectively solve contextual RL problems. MBTL models the generalization performance in two parts: 1) the performance set point, modeled using Gaussian processes, and 2) performance loss (generalization gap), modeled as a linear function of contextual similarity. MBTL combines these two pieces of information within a Bayesian optimization (BO) framework to strategically select training tasks. We show theoretically that the method exhibits sublinear regret in the number of training tasks and discuss conditions to further tighten regret bounds. We experimentally validate our methods using urban traffic and standard continuous control benchmarks. The experimental results suggest that MBTL can achieve up to 50x improved sample efficiency compared with canonical independent training and multi-task training. Further experiments demonstrate the efficacy of BO and the insensitivity to the underlying RL algorithm and hyperparameters. This work lays the foundations for investigating explicit modeling of generalization, thereby enabling principled yet effective methods for contextual RL. Code is available at https://github.com/jhoon-cho/MBTL/.
tl;dr: A score distillation method for sparse views

Novel view synthesis under sparse views has been a long-term important challenge in 3D reconstruction. Existing works mainly rely on introducing external semantic or depth priors to supervise the optimization of 3D representations. However, the diffusion model, as an external prior that can directly provide visual supervision, has always underperformed in sparse-view 3D reconstruction using Score Distillation Sampling (SDS) due to the low information entropy of sparse views compared to text, leading to optimization challenges caused by mode deviation. To this end, we present a thorough analysis of SDS from the mode-seeking perspective and propose Inline Prior Guided Score Matching (IPSM), which leverages visual inline priors provided by pose relationships between viewpoints to rectify the rendered image distribution and decomposes the original optimization objective of SDS, thereby offering effective diffusion visual guidance without any fine-tuning or pre-training. Furthermore, we propose the IPSM-Gaussian pipeline, which adopts 3D Gaussian Splatting as the backbone and supplements depth and geometry consistency regularization based on IPSM to further improve inline priors and rectified distribution. Experimental results on different public datasets show that our method achieves state-of-the-art reconstruction quality. The code is released at https://github.com/iCVTEAM/IPSM.
tl;dr: We consider the convergence rates of loss and uncertainty-based active learning algorithms under various assumptions

We investigate the convergence rates and data sample sizes required for training a machine learning model using a stochastic gradient descent (SGD) algorithm, where data points are sampled based on either their loss value or uncertainty value. These training methods are particularly relevant for active learning and data subset selection problems. For SGD with a constant step size update, we present convergence results for linear classifiers and linearly separable datasets using squared hinge loss and similar training loss functions. Additionally, we extend our analysis to more general classifiers and datasets, considering a wide range of loss-based sampling strategies and smooth convex training loss functions. We propose a novel algorithm called Adaptive-Weight Sampling (AWS) that utilizes SGD with an adaptive step size that achieves stochastic Polyak's step size in expectation. We establish convergence rate results for AWS for smooth convex training loss functions. Our numerical experiments demonstrate the efficiency of AWS on various datasets by using either exact or estimated loss values.

Probabilistic prediction aims to compute predictive distributions rather than single point predictions. These distributions enable practitioners to quantify uncertainty, compute risk, and detect outliers. However, most probabilistic methods assume parametric responses, such as Gaussian or Poisson distributions. When these assumptions fail, such models lead to bad predictions and poorly calibrated uncertainty. In this paper, we propose Treeffuser, an easy-to-use method for probabilistic prediction on tabular data. The idea is to learn a conditional diffusion model where the score function is estimated using gradient-boosted trees. The conditional diffusion model makes Treeffuser flexible and non-parametric, while the gradient-boosted trees make it robust and easy to train on CPUs. Treeffuser learns well-calibrated predictive distributions and can handle a wide range of regression tasks---including those with multivariate, multimodal, and skewed responses. We study Treeffuser on synthetic and real data and show that it outperforms existing methods, providing better calibrated probabilistic predictions. We further demonstrate its versatility with an application to inventory allocation under uncertainty using sales data from Walmart. We implement Treeffuser in https://github.com/blei-lab/treeffuser.

In ImageNet-condensation, the storage for auxiliary soft labels exceeds that of the condensed dataset by over 30 times.
However, are large-scale soft labels necessary for large-scale dataset distillation?
In this paper, we first discover that the high within-class similarity in condensed datasets necessitates the use of large-scale soft labels.
This high within-class similarity can be attributed to the fact that previous methods use samples from different classes to construct a single batch for batch normalization (BN) matching.
To reduce the within-class similarity, we introduce class-wise supervision during the image synthesizing process by batching the samples within classes, instead of across classes.
As a result, we can increase within-class diversity and reduce the size of required soft labels.
A key benefit of improved image diversity is that soft label compression can be achieved through simple random pruning, eliminating the need for complex rule-based strategies. Experiments validate our discoveries.
For example, when condensing ImageNet-1K to 200 images per class, our approach compresses the required soft labels from 113 GB to 2.8 GB (40$\times$ compression) with a 2.6\% performance gain.
Code is available at: https://github.com/he-y/soft-label-pruning-for-dataset-distillation
tl;dr: We propose a structured layer-adaptive pruning method for deep state space models.

Due to the lack of state dimension optimization methods, deep state space models (SSMs) have sacrificed model capacity, training search space, or stability to alleviate computational costs caused by high state dimensions. In this work, we provide a structured pruning method for SSMs, Layer-Adaptive STate pruning (LAST), which reduces the state dimension of each layer in minimizing model-level energy loss by extending modal truncation for a single system. LAST scores are evaluated using $\mathcal{H}_{\infty}$ norms of subsystems for each state and layer-wise energy normalization. The scores serve as global pruning criteria, enabling cross-layer comparison of states and layer-adaptive pruning. Across various sequence benchmarks, LAST optimizes previous SSMs, revealing the redundancy and compressibility of their state spaces. Notably, we demonstrate that, on average, pruning 33\% of states still maintains performance with 0.52\% accuracy loss in multi-input multi-output SSMs without retraining. Code is available at https://github.com/msgwak/LAST.
tl;dr: We extend the FedProx algorithm to its extrapolated counterpart with better theoretical guarantees.

We propose and study several server-extrapolation strategies for enhancing the theoretical and empirical convergence properties of the popular federated learning optimizer FedProx [Li et al., 2020]. While it has long been known that some form of extrapolation can help in the practice of FL, only a handful of works provide any theoretical guarantees. The phenomenon seems elusive, and our current theoretical understanding remains severely incomplete. In our work, we focus on smooth convex or strongly convex problems in the interpolation regime. In particular, we propose Extrapolated FedProx (FedExProx), and study three extrapolation strategies: a constant strategy (depending on various smoothness parameters and the number of participating devices), and two smoothness-adaptive strategies; one based on the notion of gradient diversity (FedExProx-GraDS), and the other one based on the stochastic Polyak stepsize (FedExProx-StoPS). Our theory is corroborated with carefully constructed numerical experiments.

Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch.
This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA).
Essentially, GSA comprises a two-layer GLA linked via $\operatorname{softmax}$, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size.
This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size.
Additionally, retaining the $\operatorname{softmax}$ operation is particularly beneficial in ``finetuning pretrained Transformers to RNNs'' (T2R) settings, reducing the need for extensive training from scratch.
Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.
tl;dr: Self-Supervised Learning (SSL) doesn't need hand-crafted data-augmentations, given enough amount of data. It's possible to train a powerful DINOv2 model with less augmentations than all other modern SSL models.

Self-Supervised learning (SSL) with Joint-Embedding Architectures (JEA) has led to outstanding performances. All instantiations of this paradigm were trained using strong and well-established hand-crafted data augmentations, leading to the general belief that they are required for the proper training and performance of such models. On the other hand, generative reconstruction-based models such as BEIT and MAE or Joint-Embedding Predictive Architectures such as I-JEPA have shown strong performance without using data augmentations except masking. In this work, we challenge the importance of invariance and data-augmentation in JEAs at scale. By running a case-study on a recent SSL foundation model -- DINOv2 -- we show that strong image representations can be obtained with JEAs and only cropping without resizing provided the training data is large enough, reaching state-of-the-art results and using the least amount of augmentation in the literature. Through this study, we also discuss the impact of compute constraints on the outcomes of experimental deep learning research, showing that they can lead to very different conclusions.
tl;dr: Inspired by the superior biologic Sound Source Localization (SSL) capability, we propose a spike-based neuromorphic SSL model, achieving SOTA performance and enhanced robustness.

Biological systems possess remarkable sound source localization (SSL) capabilities that are critical for survival in complex environments. This ability arises from the collaboration between the auditory periphery, which encodes sound as precisely timed spikes, and the auditory cortex, which performs spike-based computations. Inspired by these biological mechanisms, we propose a novel neuromorphic SSL framework that integrates spike-based neural encoding and computation. The framework employs Resonate-and-Fire (RF) neurons with a phase-locking coding (RF-PLC) method to achieve energy-efficient audio processing. The RF-PLC method leverages the resonance properties of RF neurons to efficiently convert audio signals to time-frequency representation and encode interaural time difference (ITD) cues into discriminative spike patterns. In addition, biological adaptations like frequency band selectivity and short-term memory effectively filter out many environmental noises, enhancing SSL capabilities in real-world settings. Inspired by these adaptations, we propose a spike-driven multi-auditory attention (MAA) module that significantly improves both the accuracy and robustness of the proposed SSL framework. Extensive experimentation demonstrates that our SSL framework achieves state-of-the-art accuracy in SSL tasks. Furthermore, it shows exceptional noise robustness and maintains high accuracy even at very low signal-to-noise ratios. By mimicking biological hearing, this neuromorphic approach contributes to the development of high-performance and explainable artificial intelligence systems capable of superior performance in real-world environments.
tl;dr: Human Motion Generation based on Spatial-Temporal Joint Modeling

Motion generation from discrete quantization offers many advantages over continuous regression, but at the cost of inevitable approximation errors. Previous methods usually quantize the entire body pose into one code, which not only faces the difficulty in encoding all joints within one vector but also loses the spatial relationship between different joints. Differently, in this work we quantize each individual joint into one vector, which i) simplifies the quantization process as the complexity associated with a single joint is markedly lower than that of the entire pose; ii) maintains a spatial-temporal structure that preserves both the spatial relationships among joints and the temporal movement patterns; iii) yields a 2D token map, which enables the application of various 2D operations widely used in 2D images. Grounded in the 2D motion quantization, we build a spatial-temporal modeling framework, where 2D joint VQVAE, temporal-spatial 2D masking technique, and spatial-temporal 2D attention are proposed to take advantage of spatial-temporal signals among the 2D tokens. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, with a $26.6\%$ decrease of FID on HumanML3D and a $29.9\%$ decrease on KIT-ML.
2629. Target-Guided Adversarial Point Cloud Transformer Towards Recognition Against Real-world Corruptions

Achieving robust 3D perception in the face of corrupted data presents an challenging hurdle within 3D vision research. Contemporary transformer-based point cloud recognition models, albeit advanced, tend to overfit to specific patterns, consequently undermining their robustness against corruption. In this work, we introduce the Target-Guided Adversarial Point Cloud Transformer, termed APCT, a novel architecture designed to augment global structure capture through an adversarial feature erasing mechanism predicated on patterns discerned at each step during training. Specifically, APCT integrates an Adversarial Significance Identifier and a Target-guided Promptor. The Adversarial Significance Identifier, is tasked with discerning token significance by integrating global contextual analysis, utilizing a structural salience index algorithm alongside an auxiliary supervisory mechanism. The Target-guided Promptor, is responsible for accentuating the propensity for token discard within the self-attention mechanism, utilizing the value derived above, consequently directing the model attention towards alternative segments in subsequent stages. By iteratively applying this strategy in multiple steps during training, the network progressively identifies and integrates an expanded array of object-associated patterns. Extensive experiments demonstrate that our method achieves state-of-the-art results on multiple corruption benchmarks.
tl;dr: New kernel to increase feature diversity of ensembles, train hypernetworks, and improve uncertainty estimation of deep ensembles.

Particle-based Bayesian deep learning often requires a similarity metric to compare two networks. However, naive similarity metrics lack permutation invariance and are inappropriate for comparing networks. Centered Kernel Alignment (CKA) on feature kernels has been proposed to compare deep networks but has not been used as an optimization objective in Bayesian deep learning. In this paper, we explore the use of CKA in Bayesian deep learning to generate diverse ensembles and hypernetworks that output a network posterior. Noting that CKA projects kernels onto a unit hypersphere and that directly optimizing the CKA objective leads to diminishing gradients when two networks are very similar. We propose adopting the approach of hyperspherical energy (HE) on top of CKA kernels to address this drawback and improve training stability. Additionally, by leveraging CKA-based feature kernels, we derive feature repulsive terms applied to synthetically generated outlier examples. Experiments on both diverse ensembles and hypernetworks show that our approach significantly outperforms baselines in terms of uncertainty quantification in both synthetic and realistic outlier detection tasks.
tl;dr: We propose a Consistency benchmark, get an in-depth analysis and design a simple method to improve VLMs.

Large vision-language models (LVLMs) have recently achieved rapid progress, exhibiting great perception and reasoning abilities concerning visual information. However, when faced with prompts in different sizes of solution spaces, LVLMs fail to always give consistent answers regarding the same knowledge point. This inconsistency of answers between different solution spaces is prevalent in LVLMs and erodes trust. To this end, we provide a multi-modal benchmark ConBench, to intuitively analyze how LVLMs perform when the solution space of a prompt revolves around a knowledge point. Based on the ConBench tool, we are the first to reveal the tapestry and get the following findings: (1) In the discriminate realm, the larger the solution space of the prompt, the lower the accuracy of the answers.
(2) Establish the relationship between the discriminative and generative realms: the accuracy of the discriminative question type exhibits a strong positive correlation with its Consistency with the caption. (3) Compared to open-source models, closed-source models exhibit a pronounced bias advantage in terms of Consistency. Eventually, we ameliorate the consistency of LVLMs by trigger-based diagnostic refinement, indirectly improving the performance of their caption. We hope this paper will accelerate the research community in better evaluating their models and encourage future advancements in the consistency domain.
tl;dr: An active learning method for video captioning focusing mainly on learnability

This work focuses on the active learning in video captioning. In particular, we propose to address the learnability problem in active learning, which has been brought up by collective outliers in video captioning and neglected in the literature. To start with, we conduct a comprehensive study of collective outliers, exploring their hard-to-learn property and concluding that ground truth inconsistency is one of the main causes. Motivated by this, we design a novel active learning algorithm that takes three complementary aspects, namely learnability, diversity, and uncertainty, into account. Ideally, learnability is reflected by ground truth consistency. Under the active learning scenario where ground truths are not available until human involvement, we measure the consistency on estimated ground truths, where predictions from off-the-shelf models are utilized as approximations to ground truths. These predictions are further used to estimate sample frequency and reliability, evincing the diversity and uncertainty respectively. With the help of our novel caption-wise active learning protocol, our algorithm is capable of leveraging knowledge from humans in a more effective yet intellectual manner. Results on publicly available video captioning datasets with diverse video captioning models demonstrate that our algorithm outperforms SOTA active learning methods by a large margin, e.g. we achieve about 103% of full performance on CIDEr with 25% of human annotations on MSR-VTT.
tl;dr: We propose FedAWE, an efficient algorithm for handling heterogeneous and non-stationary client unavailability in federated learning, achieving linear speedup and outperforming state-of-the-art methods in experiments over diversified dynamics.

Addressing intermittent client availability is critical for the real-world deployment of federated learning algorithms. Most prior work either overlooks the potential non-stationarity in the dynamics of client unavailability or requires substantial memory/computation overhead. We study federated learning in the presence of heterogeneous and non-stationary client availability, which may occur when the deployment environments are uncertain, or the clients are mobile. The impacts of heterogeneity and non-stationarity on client unavailability can be significant, as we illustrate using FedAvg, the most widely adopted federated learning algorithm. We propose FedAWE, which includes novel algorithmic structures that (i) compensate for missed computations due to unavailability with only $O(1)$ additional memory and computation with respect to standard FedAvg, and (ii) evenly diffuse local updates within the federated learning system through implicit gossiping, despite being agnostic to non-stationary dynamics. We show that FedAWE converges to a stationary point of even non-convex objectives while achieving the desired linear speedup property. We corroborate our analysis with numerical experiments over diversified client unavailability dynamics on real-world data sets.
2634. No Free Delivery Service: Epistemic limits of passive data collection in complex social systems
tl;dr: Formal impossibility results for model validation in key AI tasks such as recommender systems and LLM reasoning if they require passive data collection from complex social systems.

Rapid model validation via the train-test paradigm has been a key driver for the breathtaking progress in machine learning and AI. However, modern AI systems often depend on a combination of tasks and data collection practices that violate all assumptions ensuring test validity. Yet, without rigorous model validation we cannot ensure the intended outcomes of deployed AI systems, including positive social impact, nor continue to advance AI research in a scientifically sound way. In this paper, I will show that for widely considered inference settings in complex social systems the train-test paradigm does not only lack a justification but is indeed invalid for any risk estimator, including counterfactual and causal estimators, with high probability. These formal impossibility results highlight a fundamental epistemic issue, i.e., that for key tasks in modern AI we cannot know whether models are valid under current data collection practices. Importantly, this includes variants of both recommender systems and reasoning via large language models, and neither naïve scaling nor limited benchmarks are suited to address this issue. I am illustrating these results via the widely used MovieLens benchmark and conclude by discussing the implications of these results for AI in social systems, including possible remedies such as participatory data curation and open science.

The constrained Markov decision process (CMDP) framework emerges as an important reinforcement learning approach for imposing safety or other critical objectives while maximizing cumulative reward. However, the current understanding of how to learn efficiently in a CMDP environment with a potentially infinite number of states remains under investigation, particularly when function approximation is applied to the value functions. In this paper, we address the learning problem given linear function approximation with $q_{\pi}$-realizability, where the value functions of all policies are linearly representable with a known feature map, a setting known to be more general and challenging than other linear settings. Utilizing a local-access model, we propose a novel primal-dual algorithm that, after $\tilde{O}(\text{poly}(d) \epsilon^{-3})$ iterations, outputs with high probability a policy that strictly satisfies the constraints while nearly optimizing the value with respect to a reward function. Here, $d$ is the feature dimension and $\epsilon > 0$ is a given error. The algorithm relies on a carefully crafted off-policy evaluation procedure to evaluate the policy using historical data, which informs policy updates through policy gradients and conserves samples. To our knowledge, this is the first result achieving polynomial sample complexity for CMDP in the $q_{\pi}$-realizable setting.

Recent studies on generalizable object detection have attracted increasing attention with additional weak supervision from large-scale datasets with image-level labels.
However, weakly-supervised detection learning often suffers from image-to-box label mismatch, i.e., image-level
labels do not convey precise object information.
We design Language Hierarchical Self-training (LHST) that introduces language hierarchy into weakly-supervised detector training for learning more generalizable detectors.
LHST expands the image-level labels with language hierarchy and enables co-regularization between the expanded labels and self-training. Specifically, the expanded labels regularize self-training by providing richer supervision and mitigating the image-to-box label mismatch, while self-training allows assessing and selecting the expanded labels according to the predicted reliability.
In addition, we design language hierarchical prompt generation that introduces language hierarchy into prompt generation which helps bridge the vocabulary gaps between training and testing.
Extensive experiments show that the proposed techniques achieve superior generalization performance consistently across 14 widely studied object detection datasets.
2637. Building on Efficient Foundations: Effective Training of LLMs with Structured Feedforward Layers

State-of-the-art results in large language models (LLMs) often rely on scale, which
becomes computationally expensive. This has sparked a research agenda to reduce
these models’ parameter counts and computational costs without significantly
impacting their performance. Our study focuses on transformer-based LLMs,
specifically targeting the computationally intensive feedforward networks (FFNs),
which are less studied than attention blocks. We consider three structured linear
parameterizations of the FFN using efficient low-rank and block-diagonal matrices.
In contrast to many previous works that examined these approximations, our study
i) explores these structures from a training-from-scratch perspective, ii) scales up
to 1.3B parameters, and iii) is conducted within recent Transformer-based LLMs
rather than convolutional architectures. We demonstrate that these structures can
lead to actual computational gains in various scenarios, including online decoding
when using a pre-merge technique. Additionally, we propose a novel training
regime, called self-guided training, aimed at improving the poor training dynamics
that these approximations exhibit when used from initialization. Interestingly,
the scaling performance of structured matrices is explored, revealing steeper
curves in scaling training FLOPs, along with a favorable scaling trend in the
overtraining regime. Specifically, we show that wide and structured networks
can utilize training FLOPs more efficiently, with fewer parameters and lower
loss than dense models at their optimal trade-off. Our code is available at
https://github.com/CLAIRE-Labo/StructuredFFN/tree/main.

In _cross-domain few-shot classification_ (CFC), recent works mainly focus on adapting a simple transformation head on top of a frozen pre-trained backbone with few labeled data to project embeddings into a task-specific metric space where classification can be performed by measuring similarities between image instance and prototype representations. Technically, an _assumption_ implicitly adopted in such a framework is that the prototype and image instance embeddings share the same representation transformation. However, in this paper, we find that there naturally exists a gap, which resembles the modality gap, between the prototype and image instance embeddings extracted from the frozen pre-trained backbone, and simply applying the same transformation during the adaptation phase constrains exploring the optimal representation distributions and shrinks the gap between prototype and image representations. To solve this problem, we propose a simple yet effective method, _contrastive prototype-image adaptation_ (CoPA), to adapt different transformations for prototypes and images similarly to CLIP by treating prototypes as text prompts.
Extensive experiments on Meta-Dataset demonstrate that CoPA achieves the _state-of-the-art_ performance more efficiently. Meanwhile, further analyses also indicate that CoPA can learn better representation clusters, enlarge the gap, and achieve the minimum validation loss at the enlarged gap.

Multi-instance point cloud registration aims to estimate the pose of all instances of a model point cloud in the whole scene. Existing methods all adopt the strategy of first obtaining the global correspondence and then clustering to obtain the pose of each instance. However, due to the cluttered and occluded objects in the scene, it is difficult to obtain an accurate correspondence between the model point cloud and all instances in the scene. To this end, we propose a simple yet powerful 3D focusing-and-matching network for multi-instance point cloud registration by learning the multiple pair-wise point cloud registration. Specifically, we first present a 3D multi-object focusing module to locate the center of each object and generate object proposals. By using self-attention and cross-attention to associate the model point cloud with structurally similar objects, we can locate potential matching instances by regressing object centers. Then, we propose a 3D dual-masking instance matching module to estimate the pose between the model point cloud and each object proposal. It performs instance mask and overlap mask masks to accurately predict the pair-wise correspondence. Extensive experiments on two public benchmarks, Scan2CAD and ROBI, show that our method achieves a new state-of-the-art performance on the multi-instance point cloud registration task.
tl;dr: We show that we can leverage pre-trained Transformers to create highly performant state space models using very little training data

Transformer architectures have become a dominant paradigm for domains like language modeling but suffer in many inference settings due to their quadratic-time self-attention. Recently proposed subquadratic architectures, such as Mamba, have shown promise, but have been pretrained with substantially less computational resources than the strongest Transformer models. In this work, we present a method that is able to distill a pretrained Transformer architecture into alternative architectures such as state space models (SSMs). The key idea to our approach is that we can view both Transformers and SSMs as applying different forms of mixing matrices over the token sequences. We can thus progressively distill the Transformer architecture by matching different degrees of granularity in the SSM: first matching the mixing matrices themselves, then the hidden units at each block, and finally the end-to-end predictions. Our method, called MOHAWK, is able to distill a Mamba-2 variant based on the Phi-1.5 architecture (Phi-Mamba) using only 3B tokens. Despite using less than 1% of the training data typically used to train models from scratch, Phi-Mamba boasts substantially stronger performance compared to all past open-source non-Transformer models. MOHAWK allows models like SSMs to leverage computational resources invested in training Transformer-based architectures, highlighting a new avenue for building such models.
tl;dr: We introduce a conceptualized GHiPPO abstraction on temporal graph and propose GraphSSM as a flexible state space framework for learning discrete graph sequences.

Over the past few years, research on deep graph learning has shifted from static graphs to temporal graphs in response to real-world complex systems that exhibit dynamic behaviors. In practice, temporal graphs are formalized as an ordered sequence of static graph snapshots observed at discrete time points. Sequence models such as RNNs or Transformers have long been the predominant backbone networks for modeling such temporal graphs. Yet, despite the promising results, RNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Recently, state space models (SSMs), which are framed as discretized representations of an underlying continuous-time linear dynamical system, have garnered substantial attention and achieved breakthrough advancements in independent sequence modeling. In this work, we undertake a principled investigation that extends SSM theory to temporal graphs by integrating structural information into the online approximation objective via the adoption of a Laplacian regularization term. The emergent continuous-time system introduces novel algorithmic challenges, thereby necessitating our development of GraphSSM, a graph state space model for modeling the dynamics of temporal graphs. Extensive experimental results demonstrate the effectiveness of our GraphSSM framework across various temporal graph benchmarks.
tl;dr: We have developed an efficient algorithm that enables random and uniform sampling of graphlets from large input graphs in the semi-streaming setting with limited memory.

Given a graph $G$ and a positive integer $k$, the Graphlet Sampling problem asks to sample a connected induced $k$-vertex subgraph of $G$ uniformly at random.
Graphlet sampling enhances machine learning applications by transforming graph structures into feature vectors for tasks such as graph classification and subgraph identification, boosting neural network performance, and supporting clustered federated learning by capturing local structures and relationships.
A recent work has shown that the problem admits an algorithm that preprocesses $G$ in time $O(nk^2 \log k + m)$, and draws one sample in expected time $k^{O(k)} \log n$, where $n=|V(G)|$ and $m=|E(G)|$. Such an algorithm relies on the assumption that the input graph fits into main memory and it does not seem to be straightforward to adapt it to very large graphs. We consider Graphlet Sampling in the semi-streaming setting, where we have a memory of $M = \Omega(n \log n)$ words, and $G$ can be only read through sequential passes over the edge list. We develop a semi-streaming algorithm that preprocesses $G$ in $p={O}(\log n)$ passes and samples $\Theta(M k^{-O(k)})$ independent uniform $k$-graphlets in $O(k)$ passes. For constant $k$, both phases run in time $O((n+m)\log n)$. We also show that the tradeoff between memory and number of passes of our algorithms is near-optimal. Our extensive evaluation on very large graphs shows the effectiveness of our algorithms.

Large vision-language models (LVLMs) are ignorant of the up-to-date knowledge, such as LLaVA series, because they cannot be updated frequently due to the large amount of resources required, and therefore fail in many cases. For example, if a LVLM was released on January 2024, and it wouldn't know the singer of the theme song for the new Detective Conan movie, which wasn't released until April 2024. To solve the problem, a promising solution motivated by retrieval-augmented generation (RAG) is to provide LVLMs with up-to-date knowledge via internet search during inference, i.e., internet-augmented generation (IAG), which is already integrated in some closed-source commercial LVLMs such as GPT-4V. However, the specific mechanics underpinning them remain a mystery. In this paper, we propose a plug-and-play framework, for augmenting existing LVLMs in handling visual question answering (VQA) about up-to-date knowledge, dubbed SearchLVLMs. A hierarchical filtering model is trained to effectively and efficiently find the most helpful content from the websites returned by a search engine to prompt LVLMs with up-to-date knowledge. To train the model and evaluate our framework's performance, we propose a pipeline to automatically generate news-related VQA samples to construct a dataset, dubbed UDK-VQA. A multi-model voting mechanism is introduced to label the usefulness of website/content for VQA samples to construct the training set. Experimental results demonstrate the effectiveness of our framework, outperforming GPT-4o by $\sim$30\% in accuracy.
tl;dr: This paper introduces a new graph-based method to measure uncertainty in black-box large language model outputs at the claim level, utilizing a semantic entailment bipartite graph.

Recent advancements in Large Language Models (LLMs) have significantly improved text generation capabilities, but these systems are still known to hallucinate, and granular uncertainty estimation for long-form LLM generations remains challenging.
In this work, we propose Graph Uncertainty -- which represents the relationship between LLM generations and claims within them as a bipartite graph and estimates the claim-level uncertainty with a family of graph centrality metrics. Under this view, existing uncertainty estimation methods based on the concept of self-consistency can be viewed as using degree centrality as an uncertainty measure, and we show that more sophisticated alternatives such as closeness centrality provide consistent gains at claim-level uncertainty estimation.
Moreover, we present uncertainty-aware decoding techniques that leverage both the graph structure and uncertainty estimates to improve the factuality of LLM generations by preserving only the most reliable claims. Compared to existing methods, our graph-based uncertainty metrics lead to an average of 6.8% relative gains on AUPRC across various long-form generation settings, and our end-to-end system provides consistent 2-4% gains in factuality over existing decoding techniques while significantly improving the informativeness of generated responses.
2645. Mitigating Covariate Shift in Behavioral Cloning via Robust Stationary Distribution Correction
tl;dr: We propose DrilDICE, a method that leverages a distributionally robust objective with using DICE technique, to mitigate the covariate shift in offline imitation learning with arbitrary data state distributions.

We consider offline imitation learning (IL), which aims to train an agent to imitate from the dataset of expert demonstrations without online interaction with the environment. Behavioral Cloning (BC) has been a simple yet effective approach to offline IL, but it is also well-known to be vulnerable to the covariate shift resulting from the mismatch between the state distributions induced by the learned policy and the expert policy. Moreover, as often occurs in practice, when expert datasets are collected from an arbitrary state distribution instead of a stationary one, these shifts become more pronounced, potentially leading to substantial failures in existing IL methods. Specifically, we focus on covariate shift resulting from arbitrary state data distributions, such as biased data collection or incomplete trajectories, rather than shifts induced by changes in dynamics or noisy expert actions. In this paper, to mitigate the effect of the covariate shifts in BC, we propose DrilDICE, which utilizes a distributionally robust BC objective by employing a stationary distribution correction ratio estimation (DICE) to derive a feasible solution. We evaluate the effectiveness of our method through an extensive set of experiments covering diverse covariate shift scenarios. The results demonstrate the efficacy of the proposed approach in improving the robustness against the shifts, outperforming existing offline IL methods in such scenarios.
tl;dr: We rigorously show that sparse or local masked attention can mitigate rank collapse of tokens, while LayerNorm can prevent it in transformers, both enhancing model expressivity.

Self-attention is the key mechanism of transformers, which are the essential building blocks of modern foundation models. Recent studies have shown that pure self-attention suffers from an increasing degree of rank collapse as depth increases, limiting model expressivity and further utilization of model depth. The existing literature on rank collapse, however, has mostly overlooked other critical components in transformers that may alleviate the rank collapse issue. In this paper, we provide a general analysis of rank collapse under self-attention, taking into account the effects of attention masks and layer normalization (LayerNorm). In particular, we find that although pure masked attention still suffers from exponential collapse to a rank one subspace, sparse or local masked attention can provably slow down the collapse rate. In the case of self-attention with LayerNorm, we first show that for certain classes of value matrices, collapse to a rank one subspace still happens exponentially. However, through construction of nontrivial counterexamples, we then establish that with proper choice of value matrices, a general class of sequences may not converge to a rank one subspace, and the self-attention dynamics with LayerNorm can simultaneously possess a rich set of equilibria with any possible rank between one and full. Our result refutes the previous hypothesis that LayerNorm plays no role in the rank collapse of self-attention and suggests that self-attention with LayerNorm constitutes a much more expressive, versatile nonlinear dynamical system than what was originally thought.

Multi-modal domain generalization (MMDG) requires that models trained on multi-modal source domains can generalize to unseen target distributions with the same modality set. Sharpness-aware minimization (SAM) is an effective technique for traditional uni-modal domain generalization (DG), however, with limited improvement in MMDG. In this paper, we identify that modality competition and discrepant uni-modal flatness are two main factors that restrict multi-modal generalization. To overcome these challenges, we propose to construct consistent flat loss regions and enhance knowledge exploitation for each modality via cross-modal knowledge transfer. Firstly, we turn to the optimization on representation-space loss landscapes instead of traditional parameter space, which allows us to build connections between modalities directly. Then, we introduce a novel method to flatten the high-loss region between minima from different modalities by interpolating mixed multi-modal representations. We implement this method by distilling and optimizing generalizable interpolated representations and assigning distinct weights for each modality considering their divergent generalization capabilities. Extensive experiments are performed on two benchmark datasets, EPIC-Kitchens and Human-Animal-Cartoon (HAC), with various modality combinations, demonstrating the effectiveness of our method under multi-source and single-source settings. Our code is open-sourced.

Due to the recent remarkable advances in artificial intelligence, researchers have begun to consider challenging learning problems such as learning to generalize behavior from large offline datasets or learning online in non-Markovian environments. Meanwhile, recent advances in both of these areas have increasingly relied on conditioning policies on large context lengths. A natural question is if there is a limit to the performance benefits of increasing the context length if the computation needed is available. In this work, we establish a novel theoretical result that links the context length of a policy to the time needed to reliably evaluate its performance (i.e., its mixing time) in large scale partially observable reinforcement learning environments that exhibit latent sub-task structure. This analysis underscores a key tradeoff: when we extend the context length, our policy can more effectively model non-Markovian dependencies, but this comes at the cost of potentially slower policy evaluation and as a result slower downstream learning. Moreover, our empirical results highlight the relevance of this analysis when leveraging Transformer based neural networks. This perspective will become increasingly pertinent as the field scales towards larger and more realistic environments, opening up a number of potential future directions for improving the way we design learning agents.
2649. DreamMesh4D: Video-to-4D Generation with Sparse-Controlled Gaussian-Mesh Hybrid Representation
tl;dr: A novel 4D generation framework, with Gaussian-mesh hybrid representation and sparse-controlled geometric deformation.

Recent advancements in 2D/3D generative techniques have facilitated the generation of dynamic 3D objects from monocular videos. Previous methods mainly rely on the implicit neural radiance fields (NeRF) or explicit Gaussian Splatting as the underlying representation, and struggle to achieve satisfactory spatial-temporal consistency and surface appearance. Drawing inspiration from modern 3D animation pipelines, we introduce DreamMesh4D, a novel framework combining mesh representation with geometric skinning technique to generate high-quality 4D object from a monocular video. Instead of utilizing classical texture map for appearance, we bind Gaussian splats to triangle face of mesh for differentiable optimization of both the texture and mesh vertices. In particular, DreamMesh4D begins with a coarse mesh obtained through an image-to-3D generation procedure. Sparse points are then uniformly sampled across the mesh surface, and are used to build a deformation graph to drive the motion of the 3D object for the sake of computational efficiency and providing additional constraint. For each step, transformations of sparse control points are predicted using a deformation network, and the mesh vertices as well as the surface Gaussians are deformed via a novel geometric skinning algorithm. The skinning algorithm is a hybrid approach combining LBS (linear blending skinning) and DQS (dual-quaternion skinning), mitigating drawbacks associated with both approaches. The static surface Gaussians and mesh vertices as well as the dynamic deformation network are learned via reference view photometric loss, score distillation loss as well as other regularization losses in a two-stage manner. Extensive experiments demonstrate superior performance of our method in terms of both rendering quality and spatial-temporal consistency. Furthermore, our method is compatible with modern graphic pipelines, showcasing its potential in the 3D gaming and film industry.
tl;dr: We propose LLaNA, che first Multimodal Large Language Model (MLLM) able to perform NeRF-language tasks, such as NeRF captioning and NeRF QA.

Multimodal Large Language Models (MLLMs) have demonstrated an excellent understanding of images and 3D data. However, both modalities have shortcomings in holistically capturing the appearance and geometry of objects. Meanwhile, Neural Radiance Fields (NeRFs), which encode information within the weights of a simple Multi-Layer Perceptron (MLP), have emerged as an increasingly widespread modality that simultaneously encodes the geometry and photorealistic appearance of objects. This paper investigates the feasibility and effectiveness of ingesting NeRF into MLLM. We create LLaNA, the first general-purpose NeRF-language
assistant capable of performing new tasks such as NeRF captioning and Q&A. Notably, our method directly processes the weights of the NeRF’s MLP to extract information about the represented objects without the need to render images or materialize 3D data structures. Moreover, we build a dataset of NeRFs with text annotations for various NeRF-language tasks with no human intervention.
Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that processing NeRF weights performs favourably against extracting 2D or 3D representations from NeRFs.

Despite the success achieved by existing image generation and editing methods, current models still struggle with complex problems including intricate text prompts, and the absence of verification and self-correction mechanisms makes the generated images unreliable. Meanwhile, a single model tends to specialize in particular tasks and possess the corresponding capabilities, making it inadequate for fulfilling all user requirements. We propose GenArtist, a unified image generation and editing system, coordinated by a multimodal large language model (MLLM) agent. We integrate a comprehensive range of existing models into the tool library and utilize the agent for tool selection and execution. For a complex problem, the MLLM agent decomposes it into simpler sub-problems and constructs a tree structure to systematically plan the procedure of generation, editing, and self-correction with step-by-step verification. By automatically generating missing position-related inputs and incorporating position information, the appropriate tool can be effectively employed to address each sub-problem. Experiments demonstrate that GenArtist can perform various generation and editing tasks, achieving state-of-the-art performance and surpassing existing models such as SDXL and DALL-E 3, as can be seen in Fig. 1. We will open-source the code for future research and applications.

Recent studies have demonstrated the exceptional potentials of leveraging human preference datasets to refine text-to-image generative models, enhancing the alignment between generated images and textual prompts. Despite these advances, current human preference datasets are either prohibitively expensive to construct or suffer from a lack of diversity in preference dimensions, resulting in limited applicability for instruction tuning in open-source text-to-image generative models and hinder further exploration. To address these challenges and promote the alignment of generative models through instruction tuning, we leverage multimodal large language models to create VisionPrefer, a high-quality and fine-grained preference dataset that captures multiple preference aspects. We aggregate feedback from AI annotators across four aspects: prompt-following, aesthetic, fidelity, and harmlessness to construct VisionPrefer. To validate the effectiveness of VisionPrefer, we train a reward model VP-Score over VisionPrefer to guide the training of text-to-image generative models and the preference prediction accuracy of VP-Score is comparable to human annotators. Furthermore, we use two reinforcement learning methods to supervised fine-tune generative models to evaluate the performance of VisionPrefer, and extensive experimental results demonstrate that VisionPrefer significantly improves text-image alignment in compositional image generation across diverse aspects, e.g., aesthetic, and generalizes better than previous human-preference metrics across various image distributions. Moreover, VisionPrefer indicates that the integration of AI-generated synthetic data as a supervisory signal is a promising avenue for achieving improved alignment with human preferences in vision generative models.

Multi-Task Learning (MTL) for Vision Transformer aims at enhancing the model capability by tackling multiple tasks simultaneously. Most recent works have predominantly focused on designing Mixture-of-Experts (MoE) structures and integrating Low-Rank Adaptation (LoRA) to efficiently perform multi-task learning. However, their rigid combination hampers both the optimization of MoE and the effectiveness of reparameterization of LoRA, leading to sub-optimal performance and low inference speed. In this work, we propose a novel approach dubbed Efficient Multi-Task Learning (EMTAL) by transforming a pre-trained Vision Transformer into an efficient multi-task learner during training, and reparameterizing the learned structure for efficient inference. Specifically, we firstly develop the MoEfied LoRA structure, which decomposes the pre-trained Transformer into a low-rank MoE structure and employ LoRA to fine-tune the parameters. Subsequently, we take into account the intrinsic asynchronous nature of multi-task learning and devise a learning Quality Retaining (QR) optimization mechanism, by leveraging the historical high-quality class logits to prevent a well-trained task from performance degradation. Finally, we design a router fading strategy to integrate the learned parameters into the original Transformer, archiving efficient inference. Extensive experiments on public benchmarks demonstrate the superiority of our method, compared to the state-of-the-art multi-task learning approaches.
tl;dr: We propose a way to make the self-attention mechanism operate on continuous-time representations of temporal signals and incurs significantly lower computational costs.

Time-series data in real-world settings typically exhibit long-range dependencies and are observed at non-uniform intervals. In these settings, traditional sequence-based recurrent models struggle. To overcome this, researchers often replace recurrent models with Neural ODE-based architectures to account for irregularly sampled data and use Transformer-based architectures to account for long-range dependencies. Despite the success of these two approaches, both incur very high computational costs for input sequences of even moderate length. To address this challenge, we introduce the Rough Transformer, a variation of the Transformer model that operates on continuous-time representations of input sequences and incurs significantly lower computational costs. In particular, we propose multi-view signature attention, which uses path signatures to augment vanilla attention and to capture both local and global (multi-scale) dependencies in the input data, while remaining robust to changes in the sequence length and sampling frequency and yielding improved spatial processing. We find that, on a variety of time-series-related tasks, Rough Transformers consistently outperform their vanilla attention counterparts while obtaining the representational benefits of Neural ODE-based models, all at a fraction of the computational time and memory resources.

Exploiting symmetry inherent in data can significantly improve the sample efficiency of a learning procedure and the generalization of learned models. When data clearly reveals underlying symmetry, leveraging this symmetry can naturally inform the design of model architectures or learning strategies. Yet, in numerous real-world scenarios, identifying the specific symmetry within a given data distribution often proves ambiguous. To tackle this, some existing works learn symmetry in a data-driven manner, parameterizing and learning expected symmetry through data. However, these methods often rely on explicit knowledge, such as pre-defined Lie groups, which are typically restricted to linear or affine transformations. In this paper, we propose a novel symmetry learning algorithm based on transformations defined with one-parameter groups, continuously parameterized transformations flowing along the directions of vector fields called infinitesimal generators. Our method is built upon minimal inductive biases, encompassing not only commonly utilized symmetries rooted in Lie groups but also extending to symmetries derived from nonlinear generators. To learn these symmetries, we introduce a notion of a validity score that examine whether the transformed data is still valid for the given task. The validity score is designed to be fully differentiable and easily computable, enabling effective searches for transformations that achieve symmetries innate to the data. We apply our method mainly in two domains: image data and partial differential equations, and demonstrate its advantages. Our codes are available at \url{https://github.com/kogyeonghoon/learning-symmetry-from-scratch.git}.

The collected data in recommender systems generally suffers selection bias. Considerable works are proposed to address selection bias induced by observed user and item features, but they fail when hidden features (e.g., user age or salary) that affect both user selection mechanism and feedback exist, which is called hidden confounding. To tackle this issue, methods based on sensitivity analysis and leveraging a few randomized controlled trial (RCT) data for model calibration are proposed. However, the former relies on strong assumptions of hidden confounding strength, whereas the latter relies on the expensive RCT data, thereby limiting their applicability in real-world scenarios. In this paper, we propose to employ heterogeneous observational data to address hidden confounding, wherein some data is subject to hidden confounding while the remaining is not. We argue that such setup is more aligned with practical scenarios, especially when some users do not have complete personal information (thus assumed with hidden confounding), while others do have (thus assumed without hidden confounding). To achieve unbiased learning, we propose a novel meta-learning based debiasing method called MetaDebias. This method explicitly models oracle error imputation and hidden confounding bias, and utilizes bi-level optimization for training. Extensive experiments on three public datasets validate our method achieves state-of-the-art performance in the presence of hidden confounding, regardless of RCT data availability.

On User-Generated Content (UGC) platforms, recommendation algorithms significantly impact creators' motivation to produce content as they compete for algorithmically allocated user traffic. This phenomenon subtly shapes the volume and diversity of the content pool, which is crucial for the platform's sustainability. In this work, we demonstrate, both theoretically and empirically, that a purely relevance-driven policy with low exploration strength boosts short-term user satisfaction but undermines the long-term richness of the content pool. In contrast, a more aggressive exploration policy may slightly compromise user satisfaction but promote higher content creation volume. Our findings reveal a fundamental trade-off between immediate user satisfaction and overall content production on UGC platforms. Building on this finding, we propose an efficient optimization method to identify the optimal exploration strength, balancing user and creator engagement. Our model can serve as a pre-deployment audit tool for recommendation algorithms on UGC platforms, helping to align their immediate objectives with sustainable, long-term goals.

The softmax gating function is arguably the most popular choice in mixture of experts modeling. Despite its widespread use in practice, the softmax gating may lead to unnecessary competition among experts, potentially causing the undesirable phenomenon of representation collapse due to its inherent structure. In response, the sigmoid gating function has been recently proposed as an alternative and has been demonstrated empirically to achieve superior performance. However, a rigorous examination of the sigmoid gating function is lacking in current literature. In this paper, we verify theoretically that the sigmoid gating, in fact, enjoys a higher sample efficiency than the softmax gating for the statistical task of expert estimation. Towards that goal, we consider a regression framework in which the unknown regression function is modeled as a mixture of experts, and study the rates of convergence of the least squares estimator under the over-specified case in which the number of fitted experts is larger than the true value. We show that two gating regimes naturally arise and, in each of them, we formulate an identifiability condition for the expert functions and derive the corresponding convergence rates. In both cases, we find that experts formulated as feed-forward networks with commonly used activation such as $\mathrm{ReLU}$ and $\mathrm{GELU}$ enjoy faster convergence rates under the sigmoid gating than those under softmax gating. Furthermore, given the same choice of experts, we demonstrate that the sigmoid gating function requires a smaller sample size than its softmax counterpart to attain the same error of expert estimation and, therefore, is more sample efficient.
tl;dr: We propose FlowDPO, a novel framework to enhance Flow Matching models via Direct Preference Optimization on 3D structure prediction tasks.

Predicting high-fidelity 3D structures of atomic systems is a fundamental yet challenging problem in scientific domains. While recent work demonstrates the advantage of generative models in this realm, the exploration of different probability paths are still insufficient, and hallucinations during sampling are persistently occurring. To address these pitfalls, we introduce FlowDPO, a novel framework that explores various probability paths with flow matching models and further suppresses hallucinations using Direct Preference Optimization (DPO) for structure generation. Our approach begins with a pre-trained flow matching model to generate multiple candidate structures for each training sample. These structures are then evaluated and ranked based on their distance to the ground truth, resulting in an automatic preference dataset. Using this dataset, we apply DPO to optimize the original model, improving its performance in generating structures closely aligned with the desired reference distribution. As confirmed by our theoretical analysis, such paradigm and objective function are compatible with arbitrary Gaussian paths, exhibiting favorable universality. Extensive experimental results on antibodies and crystals demonstrate substantial benefits of our FlowDPO, highlighting its potential to advance the field of 3D structure prediction with generative models.
2660. Gene-Gene Relationship Modeling Based on Genetic Evidence for Single-Cell RNA-Seq Data Imputation
tl;dr: We propose a novel scRNA-seq data imputation scheme based on genetic evidence.

Single-cell RNA sequencing (scRNA-seq) technologies enable the exploration of cellular heterogeneity and facilitate the construction of cell atlases. However, scRNA-seq data often contain a large portion of missing values (false zeros) or noisy values, hindering downstream analyses. To recover these false zeros, propagation-based imputation methods have been proposed using $k$-NN graphs. However they model only associating relationships among genes within a cell, while, according to well-known genetic evidence, there are both associating and dissociating relationships among genes. To apply this genetic evidence to gene-gene relationship modeling, this paper proposes a novel imputation method that newly employs dissociating relationships in addition to associating relationships. Our method constructs a $k$-NN graph to additionally model dissociating relationships via the negation of a given cell-gene matrix. Moreover, our method standardizes the value distribution (mean and variance) of each gene to have standard distributions regardless of the gene. Through extensive experiments, we demonstrate that the proposed method achieves exceptional performance gains over state-of-the-art methods in both cell clustering and gene expression recovery across six scRNA-seq datasets, validating the significance of using complete gene-gene relationships in accordance with genetic evidence.
tl;dr: An extension of risk controlling prediction sets to anytime-valid and active labeling regime.

Rigorously establishing the safety of black-box machine learning models with respect to critical risk measures is important for providing guarantees about the behavior of the model.
Recently, a notion of a risk controlling prediction set (RCPS) has been introduced by Bates et. al. (JACM '24) for producing prediction sets that are statistically guaranteed to have low risk from machine learning models.
Our method extends this notion to the sequential setting, where we provide guarantees even when the data is collected adaptively, and ensures the risk guarantee is anytime-valid, i.e., simultaneously holds at all time steps. Further, we propose a framework for constructing RCPSes for active labeling, i.e., allowing one to use a labeling policy that chooses whether to query the true label for each received data point, and ensures the expected proportion data points whose labels are queried are below a predetermined label budget. We also describe how to use predictors (e.g., the machine learning model we are providing risk control guarantees for) to further improve the utility of our RCPSes by estimating the expected risk conditioned on the covariates.
We characterize the optimal choices of label policy under a fixed label budget, and predictor, and show a regret result that relates the estimation error of the optimal labeling policy and predictor to the wealth process that underlies our RCPSes.
Lastly, we present practical ways of formulating label policies and we empirically show that our label policies use fewer labels to reach higher utility than naive baseline labeling strategies on both simulations and real data.

Introduced to enhance the efficiency of large language model (LLM) inference, speculative decoding operates by having a smaller model generate a draft. A larger target model then reviews this draft to align with its output, and any acceptance by the target model results in a reduction of the number of the target model runs, ultimately improving efficiency. However, the drafting process in speculative decoding includes slow autoregressive generation and allocates equal time to generating tokens, irrespective of their importance. These inefficiencies collectively contribute to the suboptimal performance of speculative decoding. To further improve LLM inference, we introduce Cascade Speculative Drafting (CS Drafting), a speculative execution algorithm that incorporates two types of cascades. The *Vertical Cascade* eliminates autoregressive generation from neural models, while the *Horizontal Cascade* optimizes time allocation in drafting for improved efficiency. Combining both cascades, CS Drafting achieves greater speedup compared to the baselines in our experiments, while preserving the same output distribution as the target model. Our code is publicly available at https://github.com/lfsszd/CS-Drafting.
tl;dr: We propose FedLPA to significantly improve the performance via Layer-Wise Posterior Aggregation in one-shot federated learning.

Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing communication overhead, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with layer-wise posterior aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any private label information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
tl;dr: We propose multi-task preference representations and regularized conditional diffusion model to generate trajectories aligned with human preferences.

Sequential decision-making can be formulated as a conditional generation process, with targets for alignment with human intents and versatility across various tasks. Previous return-conditioned diffusion models manifest comparable performance but rely on well-defined reward functions, which requires amounts of human efforts and faces challenges in multi-task settings. Preferences serve as an alternative but recent work rarely considers preference learning given multiple tasks. To facilitate the alignment and versatility in multi-task preference learning, we adopt multi-task preferences as a unified framework. In this work, we propose to learn preference representations aligned with preference labels, which are then used as conditions to guide the conditional generation process of diffusion models. The traditional classifier-free guidance paradigm suffers from the inconsistency between the conditions and generated trajectories. We thus introduce an auxiliary regularization objective to maximize the mutual info

Current multimodal Large Language Models (MLLMs) suffer from ''hallucination'', occasionally generating responses that are not grounded in the input images. To tackle this challenge, one promising path is to utilize reinforcement learning from human feedback (RLHF), which steers MLLMs towards learning superior responses while avoiding inferior ones. We rethink the common practice of using binary preferences (*i.e.*, superior, inferior), and find that adopting multi-level preferences (*e.g.*, superior, medium, inferior) is better for two benefits: 1) It narrows the gap between adjacent levels, thereby encouraging MLLMs to discern subtle differences. 2) It further integrates cross-level comparisons (beyond adjacent-level comparisons), thus providing a broader range of comparisons with hallucination examples. To verify our viewpoint, we present the Automated Multi-level Preference (**AMP**) framework for MLLMs. To facilitate this framework, we first develop an automated dataset generation pipeline that provides high-quality multi-level preference datasets without any human annotators. Furthermore, we design the Multi-level Direct Preference Optimization (MDPO) algorithm to robustly conduct complex multi-level preference learning. Additionally, we propose a new hallucination benchmark, MRHal-Bench. Extensive experiments across public hallucination and general benchmarks, as well as our MRHal-Bench, demonstrate the effectiveness of our proposed method. Code is available at https://github.com/takomc/amp.
tl;dr: An asymptotically unbiased objective for sampling from the product of a diffusion prior with a constraint, applied to vision, language, and RL.

Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem. This paper studies *amortized* sampling of the posterior over data, $\mathbf{x}\sim p^{\rm post}(\mathbf{x})\propto p(\mathbf{x})r(\mathbf{x})$, in a model that consists of a diffusion generative model prior $p(\mathbf{x})$ and a black-box constraint or likelihood function $r(\mathbf{x})$. We state and prove the asymptotic correctness of a data-free learning objective, *relative trajectory balance*, for training a diffusion model that samples from this posterior, a problem that existing methods solve only approximately or in restricted cases. Relative trajectory balance arises from the generative flow network perspective on diffusion models, which allows the use of deep reinforcement learning techniques to improve mode coverage. Experiments illustrate the broad potential of unbiased inference of arbitrary posteriors under diffusion priors: in vision (classifier guidance), language (infilling under a discrete diffusion LLM), and multimodal data (text-to-image generation). Beyond generative modeling, we apply relative trajectory balance to the problem of continuous control with a score-based behavior prior, achieving state-of-the-art results on benchmarks in offline reinforcement learning. Code is available at [this link](https://github.com/GFNOrg/diffusion-finetuning).
2667. What is my quantum computer good for? Quantum capability learning with physics-aware neural networks
tl;dr: A new physics-aware neural network architecture is proposed for predicting which quantum circuits a quantum computer will run with high fidelity.

Quantum computers have the potential to revolutionize diverse fields, including quantum chemistry, materials science, and machine learning. However, contemporary quantum computers experience errors that often cause quantum programs run on them to fail. Until quantum computers can reliably execute large quantum programs, stakeholders will need fast and reliable methods for assessing a quantum computer’s capability—i.e., the programs it can run and how well it can run them. Previously, off-the-shelf neural network architectures have been used to model quantum computers' capabilities, but with limited success, because these networks fail to learn the complex quantum physics that determines real quantum computers' errors. We address this shortcoming with a new quantum-physics-aware neural network architecture for learning capability models. Our scalable architecture combines aspects of graph neural networks with efficient approximations to the physics of errors in quantum programs. This approach achieves up to $\sim50\%$ reductions in mean absolute error on both experimental and simulated data, over state-of-the-art models based on convolutional neural networks, and scales to devices with 100+ qubits.

While the Transformer architecture has achieved remarkable success across various domains, a thorough theoretical foundation explaining its optimization dynamics is yet to be fully developed. In this study, we aim to bridge this understanding gap by answering the following two core questions: (1) Which types of Transformer architectures allow Gradient Descent (GD) to achieve guaranteed convergence? and (2) Under what initial conditions and architectural specifics does the Transformer achieve rapid convergence during training? By analyzing the loss landscape of a single Transformer layer using Softmax and Gaussian attention kernels, our work provides concrete answers to these questions. Our findings demonstrate that, with appropriate weight initialization, GD can train a Transformer model (with either kernel type) to achieve a global optimal solution, especially when the input embedding dimension is large. Nonetheless, certain scenarios highlight potential pitfalls: training a Transformer using the Softmax attention kernel may sometimes lead to suboptimal local solutions. In contrast, the Gaussian attention kernel exhibits a much favorable behavior. Our empirical study further validate the theoretical findings.

In the past decade, deep conditional generative models have revolutionized the generation of realistic images, extending their application from entertainment to scientific domains. Single-particle cryo-electron microscopy (cryo-EM) is crucial in resolving near-atomic resolution 3D structures of proteins, such as the SARS-COV-2 spike protein. To achieve high-resolution reconstruction, a comprehensive data processing pipeline has been adopted. However, its performance is still limited as it lacks high-quality annotated datasets for training. To address this, we introduce physics-informed generative cryo-electron microscopy (CryoGEM), which for the first time integrates physics-based cryo-EM simulation with a generative unpaired noise translation to generate physically correct synthetic cryo-EM datasets with realistic noises. Initially, CryoGEM simulates the cryo-EM imaging process based on a virtual specimen. To generate realistic noises, we leverage an unpaired noise translation via contrastive learning with a novel mask-guided sampling scheme. Extensive experiments show that CryoGEM is capable of generating authentic cryo-EM images. The generated dataset can be used as training data for particle picking and pose estimation models, eventually improving the reconstruction resolution.

Model editing has become an increasingly popular alternative for efficiently updating knowledge within language models.
Current methods mainly focus on reliability, generalization, and locality, with many methods excelling across these criteria.
Some recent works disclose the pitfalls of these editing methods such as knowledge distortion or conflict. However, the general abilities of post-edited language models remain unexplored.
In this paper, we perform a comprehensive evaluation on various editing methods and different language models, and have following findings.
(1) Existing editing methods lead to inevitable performance deterioration on general benchmarks, indicating that existing editing methods maintain the general abilities of the model within only a few dozen edits.
When the number of edits is slightly large, the intrinsic knowledge structure of the model is disrupted or even completely damaged.
(2) Instruction-tuned models are more robust to editing, showing less performance drop on general knowledge after editing.
(3) Language model with large scale is more resistant to editing compared to small model.
(4) The safety of the edited model, is significantly weakened, even for those safety-aligned models.
Our findings indicate that current editing methods are only suitable for small-scale knowledge updates within language models, which motivates further research on more practical and reliable editing methods.
tl;dr: Linearly scaling Transformer architecture using bi-directional cross-attention as efficient means of information refinement, exploiting the observation of naturally emerging approximately symmetric cross-attention patterns

We present a novel bi-directional Transformer architecture (BiXT) which scales linearly with input size in terms of computational cost and memory consumption, but does not suffer the drop in performance or limitation to only one input modality seen with other efficient Transformer-based approaches. BiXT is inspired by the Perceiver architectures but replaces iterative attention with an efficient bi-directional cross-attention module in which input tokens and latent variables attend to each other simultaneously, leveraging a naturally emerging attention-symmetry between the two. This approach unlocks a key bottleneck experienced by Perceiver-like architectures and enables the processing and interpretation of both semantics ('what') and location ('where') to develop alongside each other over multiple layers -- allowing its direct application to dense and instance-based tasks alike. By combining efficiency with the generality and performance of a full Transformer architecture, BiXT can process longer sequences like point clouds, text or images at higher feature resolutions and achieves competitive performance across a range of tasks like point cloud part segmentation, semantic image segmentation, image classification, hierarchical sequence modeling and document retrieval. Our experiments demonstrate that BiXT models outperform larger competitors by leveraging longer sequences more efficiently on vision tasks like classification and segmentation, and perform on par with full Transformer variants on sequence modeling and document retrieval -- but require 28\% fewer FLOPs and are up to $8.4\times$ faster.

To protect deep neural networks (DNNs) from adversarial attacks, adversarial training (AT) is developed by incorporating adversarial examples (AEs) into model training. Recent studies show that adversarial attacks disproportionately impact the patterns within the phase of the sample's frequency spectrum---typically containing crucial semantic information---more than those in the amplitude, resulting in the model's erroneous categorization of AEs. We find that, by mixing the amplitude of training samples' frequency spectrum with those of distractor images for AT, the model can be guided to focus on phase patterns unaffected by adversarial perturbations. As a result, the model's robustness can be improved. Unfortunately, it is still challenging to select appropriate distractor images, which should mix the amplitude without affecting the phase patterns. To this end, in this paper, we propose an optimized **Adversarial Amplitude Generator (AAG)** to achieve a better tradeoff between improving the model's robustness and retaining phase patterns. Based on this generator, together with an efficient AE production procedure, we design a new **Dual Adversarial Training (DAT)** strategy. Experiments on various datasets show that our proposed DAT leads to significantly improved robustness against diverse adversarial attacks. The source code is available at https://github.com/Feng-peng-Li/DAT.
tl;dr: In Multi-Objective Reinforcement Learning, we offer a characterisation of the types of preferences that can be expressed as utility functions, and the utility functions for which an associated optimal policy exists.

Multi-objective reinforcement learning (MORL) is an excellent framework for multi-objective sequential decision-making. MORL employs a utility function to aggregate multiple objectives into one that expresses a user's preferences. However, MORL still misses two crucial theoretical analyses of the properties of utility functions: (1) a characterisation of the utility functions for which an associated optimal policy exists, and (2) a characterisation of the types of preferences that can be expressed as utility functions. As a result, we formally characterise the families of preferences and utility functions that MORL should focus on: those for which an optimal policy is guaranteed to exist. We expect our theoretical results to promote the development of novel MORL algorithms that exploit our theoretical findings.

Benefiting from the powerful language expression and planning capabilities of Large Language Models (LLMs), LLM-based autonomous agents have achieved promising performance in various downstream tasks. Recently, based on the development of single-agent systems, researchers propose to construct LLM-based multi-agent systems to tackle more complicated tasks. In this paper, we propose a novel framework, named COPPER, to enhance the collaborative capabilities of LLM-based agents with the self-reflection mechanism. To improve the quality of reflections, we propose to fine-tune a shared reflector, which automatically tunes the prompts of actor models using our counterfactual PPO mechanism. On the one hand, we propose counterfactual rewards to assess the contribution of a single agent’s reflection within the system, alleviating the credit assignment problem. On the other hand, we propose to train a shared reflector, which enables the reflector to generate personalized reflections according to agent roles, while reducing the computational resource requirements and improving training stability. We conduct experiments on three datasets to evaluate the performance of our model in multi-hop question answering, mathematics, and chess scenarios. Experimental results show that COPPER possesses stronger reflection capabilities and exhibits excellent generalization performance across different actor models.
tl;dr: We design pay-for-performance contracts that incentivize the use of high-quality LLMs for text generation.

While the success of large language models (LLMs) increases demand for machine-generated text, current pay-per-token pricing schemes create a misalignment of incentives known in economics as moral hazard: Text-generating agents have strong incentive to cut costs by preferring a cheaper model over the cutting-edge one, and this can be done “behind the scenes” since the agent performs inference internally. In this work, we approach this issue from an economic perspective, by proposing a pay-for-performance, contract-based framework for incentivizing quality. We study a principal-agent game where the agent generates text using costly inference, and the contract determines the principal’s payment for the text according to an automated quality evaluation. Since standard contract theory is inapplicable when internal inference costs are unknown, we introduce cost-robust contracts. As our main theoretical contribution, we characterize optimal cost-robust contracts through a direct correspondence to optimal composite hypothesis tests from statistics, generalizing a result of Saig et al. (NeurIPS’23). We evaluate our framework empirically by deriving contracts for a range of objectives and LLM evaluation benchmarks, and find that cost-robust contracts sacrifice only a marginal increase in objective value compared to their cost-aware counterparts.
tl;dr: Our study explores VLMs capabilities in assessing answerability and guiding information acquisition, introducing a novel task with a benchmark dataset and a data-efficient training framework to improve the model's performance.

In question-answering scenarios, humans can assess whether the available information is sufficient and seek additional information if necessary, rather than providing a forced answer. In contrast, Vision Language Models (VLMs) typically generate direct, one-shot responses without evaluating the sufficiency of the information. To investigate this gap, we identify a critical and challenging task in the Visual Question Answering (VQA) scenario: can VLMs indicate how to adjust an image when the visual information is insufficient to answer a question? This capability is especially valuable for assisting visually impaired individuals who often need guidance to capture images correctly. To evaluate this capability of current VLMs, we introduce a human-labeled dataset as a benchmark for this task. Additionally, we present an automated framework that generates synthetic training data by simulating ``where to know'' scenarios. Our empirical results show significant performance improvements in mainstream VLMs when fine-tuned with this synthetic data. This study demonstrates the potential to narrow the gap between information assessment and acquisition in VLMs, bringing their performance closer to humans.

Biological sequences encode fundamental instructions for the building blocks of life, in the form of DNA, RNA, and proteins. Modeling these sequences is key to understand disease mechanisms and is an active research area in computational biology. Recently, Large Language Models have shown great promise in solving certain biological tasks but current approaches are limited to a single sequence modality (DNA, RNA, or protein). Key problems in genomics intrinsically involve multiple modalities, but it remains unclear how to adapt general-purpose sequence models to those cases. In this work we propose a multi-modal model that connects DNA, RNA, and proteins by leveraging information from different pre-trained modality-specific encoders. We demonstrate its capabilities by applying it to the largely unsolved problem of predicting how multiple \rna transcript isoforms originate from the same gene (i.e. same DNA sequence) and map to different transcription expression levels across various human tissues. We show that our model, dubbed IsoFormer, is able to accurately predict differential transcript expression, outperforming existing methods and leveraging the use of multiple modalities. Our framework also achieves efficient transfer knowledge from the encoders pre-training as well as in between modalities. We open-source our model, paving the way for new multi-modal gene expression approaches.
tl;dr: We propose a FL mechanism that ensures agents do not free ride even when they are untruthful.

Standard federated learning (FL) approaches are vulnerable to the free-rider dilemma: participating agents can contribute little to nothing yet receive a well-trained aggregated model. While prior mechanisms attempt to solve the free-rider dilemma, none have addressed the issue of truthfulness. In practice, adversarial agents can provide false information to the server in order to cheat its way out of contributing to federated training. In an effort to make free-riding-averse federated mechanisms truthful, and consequently less prone to breaking down in practice, we propose FACT. FACT is the first federated mechanism that: (1) eliminates federated free riding by using a penalty system, (2) ensures agents provide truthful information by creating a competitive environment, and (3) encourages agent participation by offering better performance than training alone. Empirically, FACT avoids free-riding when agents are untruthful, and reduces agent loss by over 4x.

Protein representation learning is indispensable for various downstream applications of artificial intelligence for bio-medicine research, such as drug design and function prediction. However, achieving effective representation learning for proteins poses challenges due to the diversity of data modalities involved, including sequence, structure, and function annotations. Despite the impressive capabilities of large language models in biomedical text modelling, there remains a pressing need for a framework that seamlessly integrates these diverse modalities, particularly focusing on the three critical aspects of protein information: sequence, structure, and function. Moreover, addressing the inherent data scale differences among these modalities is essential. To tackle these challenges, we introduce ProtGO, a unified model that harnesses a teacher network equipped with a customized graph neural network (GNN) and a Gene Ontology (GO) encoder to learn hybrid embeddings. Notably, our approach eliminates the need for additional functions as input for the student network, which shares the same GNN module. Importantly, we utilize a domain adaptation method to facilitate distribution approximation for guiding the training of the teacher-student framework. This approach leverages distributions learned from latent representations to avoid the alignment of individual samples. Benchmark experiments highlight that ProtGO significantly outperforms state-of-the-art baselines, clearly demonstrating the advantages of the proposed unified framework.
tl;dr: A Bayesian Domain Adaptation with Gaussian Mixture Domain-Indexing algorithm aims to generating domain indexes with stronger interpretability.

Recent methods are proposed to improve performance of domain adaptation by inferring domain index under an adversarial variational bayesian framework, where domain index is unavailable.
However, existing methods typically assume that the global domain indices are sampled from a vanilla gaussian prior, overlooking the inherent structures among different domains.
To address this challenge, we propose a Bayesian Domain Adaptation with Gaussian Mixture Domain-Indexing(GMDI) algorithm.
GMDI employs a Gaussian Mixture Model for domain indices, with the number of component distributions in the ``domain-themes'' space adaptively determined by a Chinese Restaurant Process.
By dynamically adjusting the mixtures at the domain indices level, GMDI significantly improves domain adaptation performance.
Our theoretical analysis demonstrates that GMDI achieves a more stringent evidence lower bound, closer to the log-likelihood.
For classification, GMDI outperforms all approaches, and surpasses the state-of-the-art method, VDI, by up to 3.4%, reaching 99.3%.
For regression, GMDI reduces MSE by up to 21% (from 3.160 to 2.493), achieving the lowest errors among all methods.

Exploring the integration of if-then logic rules within neural network architectures presents an intriguing area. This integration seamlessly transforms the rule learning task into neural network training using backpropagation and stochastic gradient descent. From a well-trained sparse and shallow neural network, one can interpret each layer and neuron through the language of logic rules, and a global explanatory rule set can be directly extracted. However, ensuring interpretability may impose constraints on the flexibility, depth, and width of neural networks. In this paper, we propose HyperLogic: a novel framework leveraging hypernetworks to generate weights of the main network. HyperLogic can unveil multiple diverse rule sets, each capable of capturing heterogeneous patterns in data. This provides a simple yet effective method to increase model flexibility and preserve interpretability. We theoretically analyzed the benefits of the HyperLogic by examining the approximation error and generalization capabilities under two types of regularization terms: sparsity and diversity regularizations. Experiments on real data demonstrate that our method can learn more diverse, accurate, and concise rules.
tl;dr: A new prompt reasoning task that predicts poses and masks of specified individuals using text or positional prompts to advance human-AI interaction, supported by a new large-scale dataset and a unified promptable approach.

We introduce Referring Human Pose and Mask Estimation (R-HPM) in the wild, where either a text or positional prompt specifies the person of interest in an image. This new task holds significant potential for human-centric applications such as assistive robotics and sports analysis. In contrast to previous works, R-HPM (i) ensures high-quality, identity-aware results corresponding to the referred person, and (ii) simultaneously predicts human pose and mask for a comprehensive representation. To achieve this, we introduce a large-scale dataset named RefHuman, which substantially extends the MS COCO dataset with additional text and positional prompt annotations. RefHuman includes over 50,000 annotated instances in the wild, each equipped with keypoint, mask, and prompt annotations. To enable prompt-conditioned estimation, we propose the first end-to-end promptable approach named UniPHD for R-HPM. UniPHD extracts multimodal representations and employs a proposed pose-centric hierarchical decoder to process (text or positional) instance queries and keypoint queries, producing results specific to the referred person. Extensive experiments demonstrate that UniPHD produces quality results based on user-friendly prompts and achieves top-tier performance on RefHuman val and MS COCO val2017.
tl;dr: We propose a posthoc explanation method for zero shot audio classifiers.

Interpreting the decisions of deep learning models, including audio classifiers, is crucial for ensuring the transparency and trustworthiness of this technology. In this paper, we introduce LMAC-ZS (Listenable Maps for Zero-Shot Audio Classifiers), which, to the best of our knowledge, is the first decoder-based post-hoc explanation method for explaining the decisions of zero-shot audio classifiers. The proposed method utilizes a novel loss function that aims to closely reproduce the original similarity patterns between text-and-audio pairs in the generated explanations. We provide an extensive evaluation using the Contrastive Language-Audio Pretraining (CLAP) model to showcase that our interpreter remains faithful to the decisions in a zero-shot classification context. Moreover, we qualitatively show that our method produces meaningful explanations that correlate well with different text prompts.
tl;dr: A new dual-frame fluid motion estimation method that is completely self-supervised and notably outperforms its fully-supervised counterparts while requiring only 1% of the training samples (without labels) used by previous methods.

3D particle tracking velocimetry (PTV) is a key technique for analyzing turbulent flow, one of the most challenging computational problems of our century. At the core of 3D PTV is the dual-frame fluid motion estimation algorithm, which tracks particles across two consecutive frames. Recently, deep learning-based methods have achieved impressive accuracy in dual-frame fluid motion estimation; however, they heavily depend on large volumes of labeled data. In this paper, we introduce a new method that is **completely self-supervised and notably outperforms its fully-supervised counterparts while requiring only 1\% of the training samples (without labels) used by previous methods.** Our method features a novel zero-divergence loss that is specific to the domain of turbulent flow. Inspired by the success of splat operation in high-dimensional filtering and random fields, we propose a splat-based implementation for this loss which is both efficient and effective. The self-supervised nature of our method naturally supports test-time optimization, leading to the development of a tailored Dynamic Velocimetry Enhancer (DVE) module. We demonstrate that strong cross-domain robustness is achieved through test-time optimization on unseen leave-one-out synthetic domains and real physical/biological domains. Code, data and models are available at [https://github.com/Forrest-110/FluidMotionNet](https://github.com/Forrest-110/FluidMotionNet).

Prevalent human-object interaction (HOI) detection approaches typically leverage large-scale visual-linguistic models to help recognize events involving humans and objects. Though promising, models trained via contrastive learning on text-image pairs often neglect mid/low-level visual cues and struggle at compositional reasoning. In response, we introduce DIFFUSIONHOI, a new HOI detector shedding light on text-to-image diffusion models. Unlike the aforementioned models, diffusion models excel in discerning mid/low-level visual concepts as generative models, and possess strong compositionality to handle novel concepts expressed in text inputs. Considering diffusion models usually emphasize instance objects, we first devise an inversion-based strategy to learn the expression of relation patterns between humans and objects in embedding space. These learned relation embeddings then serve as textual prompts, to steer diffusion models generate images that depict specific interactions, and extract HOI-relevant cues from images without heavy finetuning. Benefited from above, DIFFUSIONHOI achieves SOTA performance on three datasets under both regular and zero-shot setups.
2686. Exploring the trade-off between deep-learning and explainable models for brain-machine interfaces
tl;dr: We show an explainable brain decoder that combines the Kalman filter and RNNs to predict finger movements with high accuracy

People with brain or spinal cord-related paralysis often need to rely on others for basic tasks, limiting their independence. A potential solution is brain-machine interfaces (BMIs), which could allow them to voluntarily control external devices (e.g., robotic arm) by decoding brain activity to movement commands. In the past decade, deep-learning decoders have achieved state-of-the-art results in most BMI applications, ranging from speech production to finger control. However, the 'black-box' nature of deep-learning decoders could lead to unexpected behaviors, resulting in major safety concerns in real-world physical control scenarios. In these applications, explainable but lower-performing decoders, such as the Kalman filter (KF), remain the norm. In this study, we designed a BMI decoder based on KalmanNet, an extension of the KF that augments its operation with recurrent neural networks to compute the Kalman gain. This results in a varying “trust” that shifts between inputs and dynamics. We used this algorithm to predict finger movements from the brain activity of two monkeys. We compared KalmanNet results offline (pre-recorded data, $n=13$ days) and online (real-time predictions, $n=5$ days) with a simple KF and two recent deep-learning algorithms: tcFNN (non-ReFIT version) and LSTM. KalmanNet achieved comparable or better results than other deep learning models in offline and online modes, relying on the dynamical model for stopping while depending more on neural inputs for initiating movements. We further validated this mechanism by implementing a heteroscedastic KF that used the same strategy, and it also approached state-of-the-art performance while remaining in the explainable domain of standard KFs. However, we also see two downsides to KalmanNet. KalmanNet shares the limited generalization ability of existing deep-learning decoders, and its usage of the KF as an inductive bias limits its performance in the presence of unseen noise distributions. Despite this trade-off, our analysis successfully integrates traditional controls and modern deep-learning approaches to motivate high-performing yet still explainable BMI designs.
tl;dr: We provide a tighter analysis of sketching in distributed learning that eliminates the dimension dependence without imposing unrealistic restrictive assumptions in the distributed learning setup.

The high communication cost between the server and the clients is a significant bottleneck in scaling distributed learning for overparametrized deep models. One popular approach for reducing this communication overhead is randomized sketching. However, existing theoretical analyses for sketching-based distributed learning (sketch-DL) either incur a prohibitive dependence on the ambient dimension or need additional restrictive assumptions such as heavy-hitters. Nevertheless, despite existing pessimistic analyses, empirical evidence suggests that sketch-DL is competitive with its uncompressed counterpart -- thus motivating a sharper analysis. In this work, we introduce a sharper ambient dimension-independent convergence analysis for sketch-DL using the second-order geometry specified by the loss Hessian. Our results imply ambient dimension-independent communication complexity for sketch-DL. We present empirical results both on the loss Hessian and overall accuracy of sketch-DL supporting our theoretical results. Taken together, our results provide theoretical justification for the observed empirical success of sketch-DL.
tl;dr: We present RaVL, an approach for discovering and mitigating spurious correlations in fine-tuned vision-language models

Fine-tuned vision-language models (VLMs) often capture spurious correlations between image features and textual attributes, resulting in degraded zero-shot performance at test time. Existing approaches for addressing spurious correlations (i) primarily operate at the global image-level rather than intervening directly on fine-grained image features and (ii) are predominantly designed for unimodal settings. In this work, we present RaVL, which takes a fine-grained perspective on VLM robustness by discovering and mitigating spurious correlations using local image features rather than operating at the global image level. Given a fine-tuned VLM, RaVL first discovers spurious correlations by leveraging a region-level clustering approach to identify precise image features contributing to zero-shot classification errors. Then, RaVL mitigates the identified spurious correlation with a novel region-aware loss function that enables the VLM to focus on relevant regions and ignore spurious relationships during fine-tuning. We evaluate RaVL on 654 VLMs with various model architectures, data domains, and learned spurious correlations. Our results show that RaVL accurately discovers (191% improvement over the closest baseline) and mitigates (8.2% improvement on worst-group image classification accuracy) spurious correlations. Qualitative evaluations on general-domain and medical-domain VLMs confirm our findings.

Planning is a crucial element of both human intelligence and contemporary large language models (LLMs). In this paper, we initiate a theoretical investigation into the emergence of planning capabilities in Transformer-based LLMs via their next-word prediction mechanisms. We model planning as a network path-finding task, where the objective is to generate a valid path from a specified source node to a designated target node. Our mathematical characterization shows that Transformer architectures can execute path-finding by embedding the adjacency and reachability matrices within their weights. Furthermore, our theoretical analysis of gradient-based learning dynamics reveals that LLMs can learn both the adjacency and a limited form of the reachability matrices. These theoretical insights are then validated through experiments, which demonstrate that Transformer architectures indeed learn the adjacency and an incomplete reachability matrices, consistent with our theoretical predictions. When applying our methodology to the real-world planning benchmark Blocksworld, our observations remain consistent. Additionally, our analyses uncover a fundamental limitation of current Transformer architectures in path-finding: these architectures cannot identify reachability relationships through transitivity, which leads to failures in generating paths when concatenation is required. These findings provide new insights into how the internal mechanisms of autoregressive learning facilitate intelligent planning and deepen our understanding of how future LLMs might achieve more advanced and general planning-and-reasoning capabilities across diverse applications.
tl;dr: This paper investigate the adversarial robustness of Decision Transformer (DT), and develop a new algorithm to transform the original returns-to-go to in-sample minimax returns-to-go to better address the robustness of DT in adversarial settings.

Decision Transformer (DT), as one of the representative Reinforcement Learning via Supervised Learning (RvS) methods, has achieved strong performance in offline learning tasks by leveraging the powerful Transformer architecture for sequential decision-making. However, in adversarial environments, these methods can be non-robust, since the return is dependent on the strategies of both the decision-maker and adversary. Training a probabilistic model conditioned on observed return to predict action can fail to generalize, as the trajectories that achieve a return in the dataset might have done so due to a suboptimal behavior adversary. To address this, we propose a worst-case-aware RvS algorithm, the Adversarially Robust Decision Transformer (ARDT), which learns and conditions the policy on in-sample minimax returns-to-go.
ARDT aligns the target return with the worst-case return learned through minimax expectile regression, thereby enhancing robustness against powerful test-time adversaries. In experiments conducted on sequential games with full data coverage, ARDT can generate a maximin (Nash Equilibrium) strategy, the solution with the largest adversarial robustness. In large-scale sequential games and continuous adversarial RL environments with partial data coverage, ARDT demonstrates significantly superior robustness to powerful test-time adversaries and attains higher worst-case returns compared to contemporary DT methods.

Agent-based models (ABMs) are proliferating as decision-making tools across policy areas in transportation, economics, and epidemiology. In these models, a central object of interest is the discrete origin-destination matrix which captures spatial interactions and agent trip counts between locations. Existing approaches resort to continuous approximations of this matrix and subsequent ad-hoc discretisations in order to perform ABM simulation and calibration. This impedes conditioning on partially observed summary statistics, fails to explore the multimodal matrix distribution over a discrete combinatorial support, and incurs discretisation errors. To address these challenges, we introduce a computationally efficient framework that scales linearly with the number of origin-destination pairs, operates directly on the discrete combinatorial space, and learns the agents' trip intensity through a neural differential equation that embeds spatial interactions. Our approach outperforms the prior art in terms of reconstruction error and ground truth matrix coverage, at a fraction of the computational cost. We demonstrate these benefits in two large-scale spatial mobility ABMs in Washington, DC and Cambridge, UK.

Recently, various strategies for distributed training of large language models (LLMs) have been proposed.
By categorizing them into basic strategies and composite strategies, we have discovered that existing basic strategies provide limited options in specific scenarios, leaving considerable room for optimization in training speed.
In this paper, we rethink the impact of memory and communication costs on the training speed of LLMs, taking into account the impact of intra- and inter-group communication performance disparities, and then propose a new set of basic strategies named the \textbf{Pa}rtial \textbf{R}edundancy \textbf{O}ptimizer (PaRO).
PaRO Data Parallelism (PaRO-DP) accelerates LLM training through refined model state partitioning and tailored training procedures. At the same time, PaRO Collective Communications (PaRO-CC) speeds up collective communication operations by rearranging the topology. We also propose a guideline for choosing different DP strategies based on simple quantitative calculations, which yields minimal ranking errors.
Our experiments demonstrate that PaRO improves the training speed of LLMs by up to 266\% that of ZeRO-3 as basic DP strategies.
Moreover, employing PaRO-CC independently for model parallel strategies, such as Megatron, can also boost the training speed by 17\%.

Rewards are a critical aspect of formulating Reinforcement Learning (RL) problems; often, one may be interested in testing multiple reward functions, or the problem may naturally involve multiple rewards.
In this study, we investigate the _Multi-Reward Best Policy Identification_ (MR-BPI) problem, where the goal is to determine the best policy for all rewards in a given set $\mathcal{R}$ with minimal sample complexity and a prescribed confidence level. We derive a fundamental instance-specific lower bound on the sample complexity required by any Probably Correct (PC) algorithm in this setting. This bound guides the design of an optimal exploration policy attaining minimal sample complexity. However, this lower bound involves solving a hard non-convex optimization problem. We address this challenge by devising a convex approximation, enabling the design of sample-efficient algorithms. We propose MR-NaS, a PC algorithm with competitive performance on hard-exploration tabular environments. Extending this approach to Deep RL (DRL), we also introduce DBMR-BPI, an efficient algorithm for model-free exploration in multi-reward settings.
tl;dr: Self-supervised 2D ephemerality segmentation and 3D environmental mapping in urban scenes

Humans naturally retain memories of permanent elements, while ephemeral moments often slip through the cracks of memory. This selective retention is crucial for robotic perception, localization, and mapping. To endow robots with this capability, we introduce 3D Gaussian Mapping (3DGM), a self-supervised, camera-only offline mapping framework grounded in 3D Gaussian Splatting. 3DGM converts multitraverse RGB videos from the same region into a Gaussian-based environmental map while concurrently performing 2D ephemeral object segmentation. Our key observation is that the environment remains consistent across traversals, while objects frequently change. This allows us to exploit self-supervision from repeated traversals to achieve environment-object decomposition. More specifically, 3DGM formulates multitraverse environmental mapping as a robust 3D representation learning problem, treating pixels of the environment and objects as inliers and outliers, respectively. Using robust feature distillation, feature residual mining, and robust optimization, 3DGM simultaneously performs 2D segmentation and 3D mapping without human intervention. We build the Mapverse benchmark, sourced from the Ithaca365 and nuPlan datasets, to evaluate our method in unsupervised 2D segmentation, 3D reconstruction, and neural rendering. Extensive results verify the effectiveness and potential of our method for self-driving and robotics.

This paper aims to overcome the ``lost-in-the-middle'' challenge of large language models (LLMs). While recent advancements have successfully enabled LLMs to perform stable language modeling with up to 4 million tokens, the persistent difficulty faced by most LLMs in identifying relevant information situated in the middle of the context has not been adequately tackled. To address this problem, this paper introduces Multi-scale Positional Encoding (Ms-PoE) which is a simple yet effective plug-and-play approach to enhance the capacity of LLMs to handle the relevant information located in the middle of the context, without fine-tuning or introducing any additional overhead. Ms-PoE leverages the position indice rescaling to relieve the long-term decay effect introduced by RoPE, while meticulously assigning distinct scaling ratios to different attention heads to preserve essential knowledge learned during the pre-training step, forming a multi-scale context fusion from short to long distance. Extensive experiments with a wide range of LLMs demonstrate the efficacy of our approach. Notably, Ms-PoE achieves an average accuracy gain of up to 3.8 on the Zero-SCROLLS benchmark over the original LLMs. Code will be made public upon acceptence.

Distributional reinforcement learning (DRL) has achieved empirical success in various domains.
One of the core tasks in the field of DRL is distributional policy evaluation, which involves estimating the return distribution $\eta^\pi$ for a given policy $\pi$.
The distributional temporal difference learning has been accordingly proposed, which
is an extension of the temporal difference learning (TD) in the classic RL area.
In the tabular case, Rowland et al. [2018] and Rowland et al. [2023] proved the asymptotic convergence of two instances of distributional TD, namely categorical temporal difference learning (CTD) and quantile temporal difference learning (QTD), respectively.
In this paper, we go a step further and analyze the finite-sample performance of distributional TD.
To facilitate theoretical analysis, we propose a non-parametric distributional TD learning (NTD).
For a $\gamma$-discounted infinite-horizon tabular Markov decision process,
we show that for NTD we need $\widetilde O\left(\frac{1}{\varepsilon^{2p}(1-\gamma)^{2p+1}}\right)$ iterations to achieve an $\varepsilon$-optimal estimator with high probability, when the estimation error is measured by the $p$-Wasserstein distance.
This sample complexity bound is minimax optimal (up to logarithmic factors) in the case of the $1$-Wasserstein distance.
To achieve this, we establish a novel Freedman's inequality in Hilbert spaces, which would be of independent interest.
In addition, we revisit CTD, showing that the same non-asymptotic convergence bounds hold for CTD in the case of the $p$-Wasserstein distance.
tl;dr: We introduce Poisson Midpoint Method which provably speeds up SDE based sampling and apply it to diffusion models

Langevin Dynamics is a Stochastic Differential Equation (SDE) central to sampling and generative modeling and is implemented via time discretization. Langevin Monte Carlo (LMC), based on the Euler-Maruyama discretization, is the simplest and most studied algorithm. LMC can suffer from slow convergence - requiring a large number of steps of small step-size to obtain good quality samples. This becomes stark in the case of diffusion models where a large number of steps gives the best samples, but the quality degrades rapidly with smaller number of steps. Randomized Midpoint Method has been recently proposed as a better discretization of Langevin dynamics for sampling from strongly log-concave distributions. However, important applications such as diffusion models involve non-log concave densities and contain time varying drift. We propose its variant, the Poisson Midpoint Method, which approximates a small step-size LMC with large step-sizes. We prove that this can obtain a quadratic speed up of LMC under very weak assumptions. We apply our method to diffusion models for image generation and show that it maintains the quality of DDPM with 1000 neural network calls with just 50-80 neural network calls and outperforms ODE based methods with similar compute.
tl;dr: We perform the first systematical study of graph recall by LLMs, investigating the accuracy and biased microstructures (local subgraph patterns) in the recalled graphs.

Graphs data is crucial for many applications, and much of it exists in the relations described in textual format. As a result, being able to accurately recall and encode a graph described in earlier text is a basic yet pivotal ability that LLMs need to demonstrate if they are to perform reasoning tasks that involve graph-structured information. Human performance at graph recall by has been studied by cognitive scientists for decades, and has been found to often exhibit certain structural patterns of bias that align with human handling of social relationships. To date, however, we know little about how LLMs behave in analogous graph recall tasks: do their recalled graphs also exhibit certain biased patterns, and if so, how do they compare with humans and affect other graph reasoning tasks? In this work, we perform the first systematical study of graph recall by LLMs, investigating the accuracy and biased microstructures (local structural patterns) in their recall. We find that LLMs not only underperform often in graph recall, but also tend to favor more triangles and alternating 2-paths. Moreover, we find that more advanced LLMs have a striking dependence on the domain that a real-world graph comes from --- by yielding the best recall accuracy when the graph is narrated in a language style consistent with its original domain.

We consider the problem of online multi-agent Nash social welfare (NSW) maximization. While previous works of Hossain et al. [2021], Jones et al. [2023] study similar problems in stochastic multi-agent multi-armed bandits and show that $\sqrt{T}$-regret is possible after $T$ rounds, their fairness measure is the product of all agents' rewards, instead of their NSW (that is, their geometric mean). Given the fundamental role of NSW in the fairness literature, it is more than natural to ask whether no-regret fair learning with NSW as the objective is possible. In this work, we provide a complete answer to this question in various settings. Specifically, in stochastic $N$-agent $K$-armed bandits, we develop an algorithm with $\widetilde{\mathcal{O}}(K^{\frac{2}{N}}T^{\frac{N-1}{N}})$ regret and prove that the dependence on $T$ is tight, making it a sharp contrast to the $\sqrt{T}$-regret bounds of Hossain et al. [2021], Jones et al. [2023]. We then consider a more challenging version of the problem with adversarial rewards. Somewhat surprisingly, despite NSW being a concave function, we prove that no algorithm can achieve sublinear regret. To circumvent such negative results, we further consider a setting with full-information feedback and design two algorithms with $\sqrt{T}$-regret: the first one has no dependence on $N$ at all and is applicable to not just NSW but a broad class of welfare functions, while the second one has better dependence on $K$ and is preferable when $N$ is small.
Finally, we also show that logarithmic regret is possible whenever there exists one agent who is indifferent about different arms.
tl;dr: We derive new convergence rates for gradient descent which depend only on local properties of the objective using directional smoothness.

We develop new sub-optimality bounds for gradient descent (GD) that depend on the conditioning of the objective along the path of optimization, rather than on global, worst-case constants. Key to our proofs is directional smoothness, a measure of gradient variation that we use to develop upper-bounds on the objective. Minimizing these upper-bounds requires solving implicit equations to obtain a sequence of strongly adapted step-sizes; we show that these equations are straightforward to solve for convex quadratics and lead to new guarantees for two classical step-sizes. For general functions, we prove that the Polyak step-size and normalized GD obtain fast, path-dependent rates despite using no knowledge of the directional smoothness. Experiments on logistic regression show our convergence guarantees are tighter than the classical theory based on $L$-smoothness.

Prophet inequalities are fundamental optimal stopping problems, where a decision-maker observes sequentially items with values sampled independently from known distributions, and must decide at each new observation to either stop and gain the current value or reject it irrevocably and move to the next step. This model is often too pessimistic and does not adequately represent real-world online selection processes. Potentially, rejectesd items can be revisited and a fraction of their value can be recovered. To analyze this problem, we consider general decay functions $D_1,D_2,\ldots$, quantifying the value to be recovered from a rejected item, depending on how far it has been observed in the past. We analyze how lookback improves, or not, the competitive ratio in prophet inequalities in different order models.
We show that, under mild monotonicity assumptions on the decay functions, the problem can be reduced to the case where all the decay functions are equal to the same function $x \mapsto \gamma x$, where $\gamma = \inf_{x>0} \inf_{j \geq 1} D_j(x)/x$. Consequently, we focus on this setting and refine the analyses of the competitive ratios, with upper and lower bounds expressed as increasing functions of $\gamma$.

Contrastive Language-Image Pretraining (CLIP) performs zero-shot image classification by mapping images and textual class representation into a shared embedding space, then retrieving the class closest to the image. This work provides a new approach for interpreting CLIP models for image classification from the lens of mutual knowledge between the two modalities. Specifically, we ask: what concepts do both vision and language CLIP encoders learn in common that influence the joint embedding space, causing points to be closer or further apart? We answer this question via an approach of textual concept-based explanations, showing their effectiveness, and perform an analysis encompassing a pool of 13 CLIP models varying in architecture, size and pretraining datasets. We explore those different aspects in relation to mutual knowledge, and analyze zero-shot predictions. Our approach demonstrates an effective and human-friendly way of understanding zero-shot classification decisions with CLIP.
tl;dr: A neural circuit model of motion planning and its formulation as a Lie group operator search problem.

The information processing in the brain and embodied agents form a sensory-action loop to interact with the world. An important step in the loop is motion planning which selects motor actions based on the current world state and task need. In goal-directed navigation, the brain chooses and generates motor actions to bring the current state into the goal state. It is unclear about the neural circuit mechanism of motor action selection, nor its underlying theory. The present study formulates the motion planning as a Lie group operator search problem, and uses the 1D rotation group as an example to provide insight into general operator search in neural circuits. We found the abstract group operator search can be implemented by a two-layer feedforward circuit utilizing circuit motifs of connection phase shift, nonlinear activation function, and pooling, similar to Drosophila's goal-directed navigation neural circuits. And the computational complexity of the feedforward circuit can be even lower than common signal processing algorithms in certain conditions. We also provide geometric interpretations of circuit computation in the group representation space. The feedforward motion planning circuit is further combined with sensory and motor circuit modules into a full circuit of the sensory-action loop implementing goal-directed navigation. Our work for the first time links the abstract operator search with biological neural circuits.
tl;dr: We characterize the bias of constant step-size stochastic approximation by using generator techniques close to Stein's method.

We study stochastic approximation algorithms with Markovian noise and constant step-size $\alpha$. We develop a method based on infinitesimal generator comparisons to study the bias of the algorithm, which is the expected difference between $\theta_n$ ---the value at iteration $n$--- and $\theta^*$ ---the unique equilibrium of the corresponding ODE. We show that, under some smoothness conditions, this bias is of order $O(\alpha)$. Furthermore, we show that the time-averaged bias is equal to $\alpha V + O(\alpha^2)$, where $V$ is a constant characterized by a Lyapunov equation, showing that $E[\bar{\theta}_n] \approx \theta^*+V\alpha + O(\alpha^2)$, where $\bar{\theta}_n$ is the Polyak-Ruppert average. We also show that $\bar{\theta}_n$ converges with high probability around $\theta^*+\alpha V$. We illustrate how to combine this with Richardson-Romberg extrapolation to derive an iterative scheme with a bias of order $O(\alpha^2)$.
tl;dr: We prove that a specific structured bandit problem motivated by online auctions can be tackled with locally greedy algorithms.

Motivated by online display advertising, this work considers repeated second-price auctions, where agents sample their value from an unknown distribution with cumulative distribution function $F$. In each auction $t$, a decision-maker bound by limited observations selects $n_t$ agents from a coalition of $N$ to compete for a prize with $p$ other agents, aiming to maximize the cumulative reward of the coalition across all auctions.
The problem is framed as an $N$-armed structured bandit, each number of player sent being an arm $n$, with expected reward $r(n)$ fully characterized by $F$ and $p+n$.
We present two algorithms, Local-Greedy (LG) and Greedy-Grid (GG), both achieving *constant* problem-dependent regret. This relies on three key ingredients: **1.** an estimator of $r(n)$ from feedback collected from any arm $k$, **2.** concentration bounds of these estimates for $k$ within an estimation neighborhood of $n$ and **3.** the unimodality property of $r$ under standard assumptions on $F$. Additionally, GG exhibits problem-independent guarantees on top of best problem-dependent guarantees. However, by avoiding to rely on confidence intervals, LG practically outperforms GG, as well as standard unimodal bandit algorithms such as OSUB or multi-armed bandit algorithms.
tl;dr: Post-hoc transforms like temperature scaling and ensembling can reverse performance trends, with important implications for selecting base models.

Trained models are often composed with post-hoc transforms such as temperature scaling (TS), ensembling and stochastic weight averaging (SWA) to improve performance, robustness, uncertainty estimation, etc. However, such transforms are typically applied only after the base models have already been finalized by standard means. In this paper, we challenge this practice with an extensive empirical study. In particular, we demonstrate a phenomenon that we call post-hoc reversal, where performance trends are reversed after applying post-hoc transforms. This phenomenon is especially prominent in high-noise settings. For example, while base models overfit badly early in training, both ensembling and SWA favor base models trained for more epochs. Post-hoc reversal can also prevent the appearance of double descent and mitigate mismatches between test loss and test error seen in base models. Preliminary analyses suggest that these transforms induce reversal by suppressing the influence of mislabeled examples, exploiting differences in their learning dynamics from those of clean examples. Based on our findings, we propose post-hoc selection, a simple technique whereby post-hoc metrics inform model development decisions such as early stopping, checkpointing, and broader hyperparameter choices. Our experiments span real-world vision, language, tabular and graph datasets. On an LLM instruction tuning dataset, post-hoc selection results in >1.5x MMLU improvement compared to naive selection.

Zero-shot graph machine learning, especially with graph neural networks (GNNs), has garnered significant interest due to the challenge of scarce labeled data. While methods like self-supervised learning and graph prompt learning have been extensively explored, they often rely on fine-tuning with task-specific labels, limiting their effectiveness in zero-shot scenarios. Inspired by the zero-shot capabilities of instruction-fine-tuned large language models (LLMs), we introduce a novel framework named Token Embedding-Aligned Graph Language Model (TEA-GLM) that leverages LLMs as cross-dataset and cross-task zero-shot learners for graph machine learning. Concretely, we pretrain a GNN, aligning its representations with token embeddings of an LLM. We then train a linear projector that transforms the GNN's representations into a fixed number of graph token embeddings without tuning the LLM. A unified instruction is designed for various graph tasks at different levels, such as node classification (node-level) and link prediction (edge-level). These design choices collectively enhance our method's effectiveness in zero-shot learning, setting it apart from existing methods. Experiments show that our graph token embeddings help the LLM predictor achieve state-of-the-art performance on unseen datasets and tasks compared to other methods using LLMs as predictors. Our code is available at https://github.com/W-rudder/TEA-GLM.

In this paper, we consider the problem of online monotone DR-submodular maximization subject to long-term stochastic constraints. Specifically, at each round $t\in [T]$, after committing an action $\mathbf{x}_t$, a random reward $f_t(\mathbf{x}_t)$ and an unbiased gradient estimate of the point $\widetilde{\nabla}f_t(\mathbf{x}_t)$ (semi-bandit feedback) are revealed. Meanwhile, a budget of $g_t(\mathbf{x}_t)$, which is linear and stochastic, is consumed of its total allotted budget $B_T$. We propose a gradient ascent based algorithm that achieves $\frac{1}{2}$-regret of $\mathcal{O}(\sqrt{T})$ with $\mathcal{O}(T^{3/4})$ constraint violation with high probability. Moreover, when first-order full-information feedback is available, we propose an algorithm that achieves $(1-1/e)$-regret of $\mathcal{O}(\sqrt{T})$ with $\mathcal{O}(T^{3/4})$ constraint violation. These algorithms significantly improve over the state-of-the-art in terms of query complexity.
tl;dr: We leverage flow matching and equivariant graph networks to state-of-the-art performance on generating conformers.

Predicting low-energy molecular conformations given a molecular graph is an
important but challenging task in computational drug discovery. Existing state-
of-the-art approaches either resort to large scale transformer-based models that
diffuse over conformer fields, or use computationally expensive methods to gen-
erate initial structures and diffuse over torsion angles. In this work, we introduce
Equivariant Transformer Flow (ET-Flow). We showcase that a well-designed
flow matching approach with equivariance and harmonic prior alleviates the need
for complex internal geometry calculations and large architectures, contrary to
the prevailing methods in the field. Our approach results in a straightforward
and scalable method that directly operates on all-atom coordinates with minimal
assumptions. With the advantages of equivariance and flow matching, ET-Flow
significantly increases the precision and physical validity of the generated con-
formers, while being a lighter model and faster at inference. Code is available
https://github.com/shenoynikhil/ETFlow.
tl;dr: Adversarial training for LLMs with continuous attacks on the token embedding space

Large language models (LLMs) are vulnerable to adversarial attacks that can bypass their safety guardrails. In many domains, adversarial training has proven to be one of the most promising methods to reliably improve robustness against such attacks. Yet, in the context of LLMs, current methods for adversarial training are hindered by the high computational costs required to perform discrete adversarial attacks at each training iteration. We address this problem by instead calculating adversarial attacks in the continuous embedding space of the LLM, which is orders of magnitudes more efficient. We propose a fast adversarial training algorithm (C-AdvUL) composed of two losses: the first makes the model robust on continuous embedding attacks computed on an adversarial behaviour dataset; the second ensures the usefulness of the final model by fine-tuning on utility data. Moreover, we introduce C-AdvIPO, an adversarial variant of IPO that does not require utility data for adversarially robust alignment. Our empirical evaluation on five models from different families (Gemma, Phi3, Mistral, Zephyr, Llama2) and at different scales (2B, 3.8B, 7B) shows that both algorithms substantially enhance LLM robustness against discrete attacks (GCG, AutoDAN, PAIR), while maintaining utility. Our results demonstrate that robustness to continuous perturbations can extrapolate to discrete threat models. Thereby, we present a path toward scalable adversarial training algorithms for robustly aligning LLMs.

Fine-grained understanding of objects, attributes, and relationships between objects is crucial for visual-language models (VLMs). To evaluate VLMs' fine-grained understanding, existing benchmarks primarily focus on evaluating VLMs' capability to distinguish between two very similar captions given an image. In this paper, our focus is on evaluating VLMs' capability to distinguish between two very similar images given a caption. To this end, we introduce a new, challenging benchmark termed Visual Minimal-Change Understanding (VisMin), which requires models to predict the correct image-caption match given two images and two captions. Importantly, the image pair (as well as the caption pair) contains minimal changes, i.e., between the two images (as well as between the two captions), only one aspect changes at a time from among the following possible types of changes: object, attribute, count, and spatial relation. These four types of minimal changes are specifically designed to test the models' understanding of objects, attributes of objects (such as color, material, shape), counts of objects, and spatial relationships between objects. To curate our benchmark, we built an automatic pipeline using large language models and diffusion models, followed by a rigorous 4-step verification process by human annotators. Empirical experiments reveal that current VLMs exhibit notable deficiencies in understanding spatial relationships and counting abilities. Furthermore, leveraging the automated nature of our data creation process, we generate a large-scale training dataset, which we use to finetune CLIP (a foundational VLM) and Idefics2 (a multimodal large language model). Our findings show that both these models benefit significantly from fine-tuning on this data, as evident by marked improvements in fine-grained understanding across a wide range of benchmarks. Additionally, such fine-tuning improves CLIP's general image-text alignment capabilities too. All resources including the benchmark, the training data, and the finetuned model checkpoints will be released.

Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation.
However, large-scale end-to-end training of these models is computationally costly, and hence most research focuses either on finetuning pretrained models or experiments at smaller scales.
In this work we aim to improve the training efficiency and performance of LDMs with the goal of scaling to larger datasets and higher resolutions.
We focus our study on two points that are critical for good performance and efficient training:
(i) the mechanisms used for semantic level (\eg a text prompt, or class name) and low-level (crop size, random flip, \etc) conditioning of the model, and
(ii) pre-training strategies to transfer representations learned on smaller and lower-resolution datasets to larger ones.
The main contributions of our work are the following:
we present systematic experimental study of these points,
we propose a novel conditioning mechanism that disentangles semantic and low-level conditioning,
we obtain state-of-the-art performance on CC12M for text-to-image at 512 resolution.
tl;dr: A unified framework harvesting protein language models for mutation explanation and engineering

Studying protein mutations within amino acid sequences holds tremendous significance in life sciences. Protein language models (PLMs) have demonstrated strong capabilities in broad biological applications. However, due to architectural design and lack of supervision, PLMs model mutations implicitly with evolutionary plausibility, which is not satisfactory to serve as explainable and engineerable tools in real-world studies. To address these issues, we present MutaPLM, a unified framework for interpreting and navigating protein mutations with protein language models. MutaPLM introduces a protein *delta* network that captures explicit protein mutation representations within a unified feature space, and a transfer learning pipeline with a chain-of-thought (CoT) strategy to harvest protein mutation knowledge from biomedical texts. We also construct MutaDescribe, the first large-scale protein mutation dataset with rich textual annotations, which provides cross-modal supervision signals. Through comprehensive experiments, we demonstrate that MutaPLM excels at providing human-understandable explanations for mutational effects and prioritizing novel mutations with desirable properties. Our code, model, and data are open-sourced at https://github.com/PharMolix/MutaPLM.
tl;dr: The first parallel training method that provably benefits over Minibatch-SGD in Convex heterogeneous training scenarios.

We consider distributed learning scenarios where $M$ machines interact with a parameter server along several communication rounds in order to minimize a joint objective function.
Focusing on the heterogeneous case, where different machines may draw samples from different data-distributions, we design the first local update method that provably benefits over the two most prominent distributed baselines: namely Minibatch-SGD and Local-SGD.
Key to our approach is a slow querying technique that we customize to the distributed setting, which in turn enables a better mitigation of the bias caused by local updates.
tl;dr: We propose an unsupervised pre-training method named Pre-trained Embodiment-Aware Control (PEAC) for handling Cross-Embodiment Reinforcement Learning

Designing generalizable agents capable of adapting to diverse embodiments has achieved significant attention in Reinforcement Learning (RL), which is critical for deploying RL agents in various real-world applications. Previous Cross-Embodiment RL approaches have focused on transferring knowledge across embodiments within specific tasks. These methods often result in knowledge tightly coupled with those tasks and fail to adequately capture the distinct characteristics of different embodiments. To address this limitation, we introduce the notion of Cross-Embodiment Unsupervised RL (CEURL), which leverages unsupervised learning to enable agents to acquire embodiment-aware and task-agnostic knowledge through online interactions within reward-free environments. We formulate CEURL as a novel Controlled Embodiment Markov Decision Process (CE-MDP) and systematically analyze CEURL's pre-training objectives under CE-MDP. Based on these analyses, we develop a novel algorithm Pre-trained Embodiment-Aware Control (PEAC) for handling CEURL, incorporating an intrinsic reward function specifically designed for cross-embodiment pre-training. PEAC not only provides an intuitive optimization strategy for cross-embodiment pre-training but also can integrate flexibly with existing unsupervised RL methods, facilitating cross-embodiment exploration and skill discovery. Extensive experiments in both simulated (e.g., DMC and Robosuite) and real-world environments (e.g., legged locomotion) demonstrate that PEAC significantly improves adaptation performance and cross-embodiment generalization, demonstrating its effectiveness in overcoming the unique challenges of CEURL. The project page and code are in https://yingchengyang.github.io/ceurl.
tl;dr: A novel differentiable mask pruning method to alleviate discretization gap

Recently, differentiable mask pruning methods optimize the continuous relaxation architecture (soft network) as the proxy of the pruned discrete network (hard network) for superior sub-architecture search. However, due to the agnostic impact of the discretization process, the hard network struggles with the equivalent representational capacity as the soft network, namely discretization gap, which severely spoils the pruning performance. In this paper, we first investigate the discretization gap and propose a novel structural differentiable mask pruning framework named S2HPruner to bridge the discretization gap in a one-stage manner. In the training procedure, SH2Pruner forwards both the soft network and its corresponding hard network, then distills the hard network under the supervision of the soft network. To optimize the mask and prevent performance degradation, we propose a decoupled bidirectional knowledge distillation. It blocks the weight updating from the hard to the soft network while maintaining the gradient corresponding to the mask. Compared with existing pruning arts, S2HPruner achieves surpassing pruning performance without fine-tuning on comprehensive benchmarks, including CIFAR-100, Tiny ImageNet, and ImageNet with a variety of network architectures. Besides, investigation and analysis experiments explain the effectiveness of S2HPruner. Codes will be released soon.

The identifiability analysis of linear Ordinary Differential Equation (ODE) systems is a necessary prerequisite for making reliable causal inferences about these systems. While identifiability has been well studied in scenarios where the system is fully observable, the conditions for identifiability remain unexplored when latent variables interact with the system. This paper aims to address this gap by presenting a systematic analysis of identifiability in linear ODE systems incorporating hidden confounders. Specifically, we investigate two cases of such systems. In the first case, latent confounders exhibit no causal relationships, yet their evolution adheres to specific functional forms, such as polynomial functions of time $t$. Subsequently, we extend this analysis to encompass scenarios where hidden confounders exhibit causal dependencies, with the causal structure of latent variables described by a Directed Acyclic Graph (DAG). The second case represents a more intricate variation of the first case, prompting a more comprehensive identifiability analysis. Accordingly, we conduct detailed identifiability analyses of the second system under various observation conditions, including both continuous and discrete observations from single or multiple trajectories. To validate our theoretical results, we perform a series of simulations, which support and substantiate our findings.

Multi-modal contrastive learning with language supervision has presented a paradigm shift in modern machine learning. By pre-training on a web-scale dataset, multi-modal contrastive learning can learn high-quality representations that exhibit impressive robustness and transferability. Despite its empirical success, the theoretical understanding is still in its infancy, especially regarding its comparison with single-modal contrastive learning. In this work, we introduce a feature learning theory framework that provides a theoretical foundation for understanding the differences between multi-modal and single-modal contrastive learning. Based on a data generation model consisting of signal and noise, our analysis is performed on a ReLU network trained with the InfoMax objective function. Through a trajectory-based optimization analysis and generalization characterization on downstream tasks, we identify the critical factor, which is the signal-to-noise ratio (SNR), that impacts the generalizability in downstream tasks of both multi-modal and single-modal contrastive learning. Through the cooperation between the two modalities, multi-modal learning can achieve better feature learning, leading to improvements in performance in downstream tasks compared to single-modal learning. Our analysis provides a unified framework that can characterize the optimization and generalization of both single-modal and multi-modal contrastive learning. Empirical experiments on both synthetic and real-world datasets further consolidate our theoretical findings.

In climate science and meteorology, high-resolution local precipitation (rain and snowfall) predictions are limited by the computational costs of simulation-based methods. Statistical downscaling, or super-resolution, is a common workaround where a low-resolution prediction is improved using statistical approaches. Unlike traditional computer vision tasks, weather and climate applications require capturing the accurate conditional distribution of high-resolution given low-resolution patterns to assure reliable ensemble averages and unbiased estimates of extreme events, such as heavy rain. This work extends recent video diffusion models to precipitation super-resolution, employing a deterministic downscaler followed by a temporally-conditioned diffusion model to capture noise characteristics and high-frequency patterns. We test our approach on FV3GFS output, an established large-scale global atmosphere model, and compare it against six state-of-the-art baselines. Our analysis, capturing CRPS, MSE, precipitation distributions, and qualitative aspects using California and the Himalayas as examples, establishes our method as a new standard for data-driven precipitation downscaling.
tl;dr: We proposed VisionLLM v2, an End-to-End Generalist Multimodal Large Language Model for Hundreds of Vision-Language Tasks.

We present VisionLLM v2, an end-to-end generalist multimodal large model (MLLM) that unifies visual perception, understanding, and generation within a single framework. Unlike traditional MLLMs limited to text output, VisionLLM v2 significantly broadens its application scope. It excels not only in conventional visual question answering (VQA) but also in open-ended, cross-domain vision tasks such as object localization, pose estimation, and image generation and editing. To this end, we propose a new information transmission mechanism termed ``super link'', as a medium to connect MLLM with task-specific decoders. It not only allows flexible transmission of task information and gradient feedback between the MLLM and multiple downstream decoders but also effectively resolves training conflicts in multi-tasking scenarios. In addition, to support the diverse range of tasks, we carefully collected and combed training data from hundreds of public vision and vision-language tasks. In this way, our model can be joint-trained end-to-end on hundreds of vision language tasks and generalize to these tasks using a set of shared parameters through different user prompts, achieving performance comparable to task-specific models. We believe VisionLLM v2 will offer a new perspective on the generalization of MLLMs.
tl;dr: We accelerate the Best-of-N algorithm, an inference-time alignment strategy

The safe and effective deployment of Large Language Models (LLMs) involves a critical step called alignment, which ensures that the model's responses are in accordance with human preferences. Prevalent alignment techniques, such as DPO, PPO and their variants, align LLMs by changing the pre-trained model weights during a phase called post-training. While predominant, these post-training methods add substantial complexity before LLMs can be deployed. Inference-time alignment methods avoid the complex post-training step and instead bias the generation towards responses that are aligned with human preferences. The best-known inference-time alignment method, called Best-of-N, is as effective as the state-of-the-art post-training procedures. Unfortunately, Best-of-N requires vastly more resources at inference time than standard decoding strategies, which makes it computationally not viable. In this work, we introduce Speculative Rejection, a computationally-viable inference-time alignment algorithm. It generates high-scoring responses according to a given reward model, like Best-of-N does, while being between 16 to 32 times more computationally efficient.

Current techniques for detecting AI-generated text are largely confined to manual feature crafting and supervised binary classification paradigms. These methodologies typically lead to performance bottlenecks and unsatisfactory generalizability. Consequently, these methods are often inapplicable for out-of-distribution (OOD) data and newly emerged large language models (LLMs). In this paper, we revisit the task of AI-generated text detection. We argue that the key to accomplishing this task lies in distinguishing writing styles of different authors, rather than simply classifying the text into human-written or AI-generated text. To this end, we propose DeTeCtive, a multi-task auxiliary, multi-level contrastive learning framework. DeTeCtive is designed to facilitate the learning of distinct writing styles, combined with a dense information retrieval pipeline for AI-generated text detection. Our method is compatible with a range of text encoders. Extensive experiments demonstrate that our method enhances the ability of various text encoders in detecting AI-generated text across multiple benchmarks and achieves state-of-the-art results. Notably, in OOD zero-shot evaluation, our method outperforms existing approaches by a large margin. Moreover, we find our method boasts a Training-Free Incremental Adaptation (TFIA) capability towards OOD data, further enhancing its efficacy in OOD detection scenarios. We will open-source our code and models in hopes that our work will spark new thoughts in the field of AI-generated text detection, ensuring safe application of LLMs and enhancing compliance.

In multi-sequence Magnetic Resonance Imaging (MRI), the accurate segmentation of the kidney and tumor based on traditional supervised methods typically necessitates detailed annotation for each sequence, which is both time-consuming and labor-intensive. Unsupervised Domain Adaptation (UDA) methods can effectively mitigate inter-domain differences by aligning cross-modal features, thereby reducing the annotation burden. However, most existing UDA methods are limited to one-to-one domain adaptation, which tends to be inefficient and resource-intensive when faced with multi-target domain transfer tasks. To address this challenge, we propose a novel and efficient One-to-Multiple Progressive Style Transfer Unsupervised Domain-Adaptive (PSTUDA) framework for kidney and tumor segmentation in multi-sequence MRI. Specifically, we develop a multi-level style dictionary to explicitly store the style information of each target domain at various stages, which alleviates the burden of a single generator in a multi-target transfer task and enables effective decoupling of content and style. Concurrently, we employ multiple cascading style fusion modules that utilize point-wise instance normalization to progressively recombine content and style features, which enhances cross-modal alignment and structural consistency. Experiments conducted on the private MSKT and public KiTS19 datasets demonstrate the superiority of the proposed PSTUDA over comparative methods in multi-sequence kidney and tumor segmentation. The average Dice Similarity Coefficients are increased by at least 1.8% and 3.9%, respectively. Impressively, our PSTUDA not only significantly reduces the floating-point computation by approximately 72% but also reduces the number of model parameters by about 50%, bringing higher efficiency and feasibility to practical clinical applications.

Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model also have been released at https://github.com/zhaowc-ustc/TabPedia.
2725. SpaFL: Communication-Efficient Federated Learning With Sparse Models And Low Computational Overhead
tl;dr: We find optimal structured sparse models by communicating trainable thresholds

The large communication and computation overhead of federated learning (FL) is one of the main challenges facing its practical deployment over resource-constrained clients and systems. In this work, SpaFL: a communication-efficient FL framework is proposed to optimize sparse model structures with low computational overhead. In SpaFL, a trainable threshold is defined for each filter/neuron to prune its all connected
parameters, thereby leading to structured sparsity. To optimize the pruning process itself, only thresholds are communicated between a server and clients instead of parameters, thereby learning how to prune. Further, global thresholds are used to update model parameters by extracting aggregated parameter importance. The generalization bound of SpaFL is also derived, thereby proving key insights on the relation between sparsity and performance. Experimental results show that SpaFL improves accuracy while requiring much less communication and computing resources compared to sparse baselines. The code is available at https://github.com/news-vt/SpaFL_NeruIPS_2024
tl;dr: We propose a new approach to ab-initio cryo-EM 3D reconstruction using semi-amortization to accelerate pose convergence and multi-head pose encoder to handle pose uncertainty.

Cryo-EM is an increasingly popular method for determining the atomic resolution 3D structure of macromolecular complexes (eg, proteins) from noisy 2D images captured by an electron microscope. The computational task is to reconstruct the 3D density of the particle, along with 3D pose of the particle in each 2D image, for which the posterior pose distribution is highly multi-modal. Recent developments in cryo-EM have focused on deep learning for which amortized inference has been used to predict pose. Here, we address key problems with this approach, and propose a new semi-amortized method, cryoSPIN, in which reconstruction begins with amortized inference and then switches to a form of auto-decoding to refine poses locally using stochastic gradient descent. Through evaluation on synthetic datasets, we demonstrate that cryoSPIN is able to handle multi-modal pose distributions during the amortized inference stage, while the later, more flexible stage of direct pose optimization yields faster and more accurate convergence of poses compared to baselines. On experimental data, we show that cryoSPIN outperforms the state-of-the-art cryoAI in speed and reconstruction quality.
tl;dr: We propose a method for modeling concept dependencies that improves intervention effectiveness.

Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose *Stochastic Concept Bottleneck Models* (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure.
Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
tl;dr: For the task of visual program induction, we design a network that learns how to edit visual programs and is trained in a self-supervised bootstrapping paradigm.

We design a system that learns how to edit visual programs. Our edit network consumes a complete input program and a visual target. From this input, we task our network with predicting a local edit operation that could be applied to the input program to improve its similarity to the target. In order to apply this scheme for domains that lack program annotations, we develop a self-supervised learning approach that integrates this edit network into a bootstrapped finetuning loop along with a network that predicts entire programs in one-shot. Our joint finetuning scheme, when coupled with an inference procedure that initializes a population from the one-shot model and evolves members of this population with the edit network, helps to infer more accurate visual programs. Over multiple domains, we experimentally compare our method against the alternative of using only the one-shot model, and find that even under equal search-time budgets, our editing-based paradigm provides significant advantages.

Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-attribute edits increases computational demands and efficiency losses.
In this paper, we address these challenges with significant contributions. Our main contribution is the development of ParallelEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, ParallelEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through innovative attention distribution mechanism and multi-branch design that operates across several processing heads.
Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios.
2730. Unifying Homophily and Heterophily for Spectral Graph Neural Networks via Triple Filter Ensembles
tl;dr: Unifying Homophily and Heterophily for Spectral Graph Neural Networks via Triple Filter Ensembles

Polynomial-based learnable spectral graph neural networks (GNNs) utilize polynomial to approximate graph convolutions and have achieved impressive performance on graphs. Nevertheless, there are three progressive problems to be solved. Some models use polynomials with better approximation for approximating filters, yet perform worse on real-world graphs. Carefully crafted graph learning methods, sophisticated polynomial approximations, and refined coefficient constraints leaded to overfitting, which diminishes the generalization of the models. How to design a model that retains the ability of polynomial-based spectral GNNs to approximate filters while it possesses higher generalization and performance? In this paper, we propose a spectral GNN with triple filter ensemble (TFE-GNN), which extracts homophily and heterophily from graphs with different levels of homophily adaptively while utilizing the initial features. Specifically, the first and second ensembles are combinations of a set of base low-pass and high-pass filters, respectively, after which the third ensemble combines them with two learnable coefficients and yield a graph convolution (TFE-Conv). Theoretical analysis shows that the approximation ability of TFE-GNN is consistent with that of ChebNet under certain conditions, namely it can learn arbitrary filters. TFE-GNN can be viewed as a reasonable combination of two unfolded and integrated excellent spectral GNNs, which motivates it to perform well. Experiments show that TFE-GNN achieves high generalization and new state-of-the-art performance on various real-world datasets.
2731. Differential Privacy in Scalable General Kernel Learning via $K$-means Nystr{\"o}m Random Features

As the volume of data invested in statistical learning increases and concerns regarding privacy grow, the privacy leakage issue has drawn significant attention. Differential privacy has emerged as a widely accepted concept capable of mitigating privacy concerns, and numerous differentially private (DP) versions of machine learning algorithms have been developed. However, existing works on DP kernel learning algorithms have exhibited practical limitations, including scalability, restricted choice of kernels, or dependence on test data availability. We propose DP scalable kernel empirical risk minimization (ERM) algorithms and a DP kernel mean embedding (KME) release algorithm suitable for general kernels. Our approaches address the shortcomings of previous algorithms by employing Nyström methods, classical techniques in non-private scalable kernel learning. These methods provide data-dependent low-rank approximations of the kernel matrix for general kernels in a DP manner. We present excess empirical risk bounds and computational complexities for the scalable kernel DP ERM, KME algorithms, contrasting them with established methodologies. Furthermore, we develop a private data-generating algorithm capable of learning diverse kernel models. We conduct experiments to demonstrate the performance of our algorithms, comparing them with existing methods to highlight their superiority.

As the development and application of Large Language Models (LLMs) continue to advance rapidly, enhancing their trustworthiness and aligning them with human preferences has become a critical area of research. Traditional methods rely heavily on extensive data for Reinforcement Learning from Human Feedback (RLHF), but representation engineering offers a new, training-free approach. This technique leverages semantic features to control the representation of LLM's intermediate hidden states, enabling the model to meet specific requirements such as increased honesty or heightened safety awareness. However, a significant challenge arises when attempting to fulfill multiple requirements simultaneously. It proves difficult to encode various semantic contents, like honesty and safety, into a singular semantic feature, restricting its practicality.
In this work, we address this challenge through Sparse Activation Control. By delving into the intrinsic mechanisms of LLMs, we manage to identify and pinpoint modules that are closely related to specific tasks within the model, i.e. attention heads. These heads display sparse characteristics that allow for near-independent control over different tasks. Our experiments, conducted on the open-source Llama series models, have yielded encouraging results. The models were able to align with human preferences on issues of safety, factualness, and bias concurrently.
tl;dr: This paper introduces high-dimensional robust inference procedures by recasting the single index model into a pseudo-linear model with transformed responses.

The high-dimensional single index model (SIM), which assumes that the response is independent of the predictors given a linear combination of predictors, has drawn attention due to its flexibility and interpretability, but its efficiency is adversely affected by outlying observations and heavy-tailed distributions. This paper introduces a robust procedure by recasting the SIM into a pseudo-linear model with transformed responses. It relaxes the distributional conditions on random errors from sub-Gaussian to more general distributions and thus it is robust with substantial efficiency gain for heavy-tailed random errors. Under this paradigm, we provide asymptotically honest group inference procedures based on the idea of orthogonalization, which enjoys the feature that it does not require the zero and nonzero coefficients to be well-separated. Asymptotic null distribution and bootstrap implementation are both established. Moreover, we develop a multiple testing procedure for determining if the individual coefficients are relevant simultaneously, and show that it is able to control the false discovery rate asymptotically. Numerical results indicate that the new procedures can be highly competitive among existing methods, especially for heavy-tailed errors.

Image deep features extracted by pre-trained networks are known to contain rich and informative representations. In this paper, we present Deep Degradation Response (DDR), a method to quantify changes in image deep features under varying degradation conditions. Specifically, our approach facilitates flexible and adaptive degradation, enabling the controlled synthesis of image degradation through text-driven prompts. Extensive evaluations demonstrate the versatility of DDR as an image descriptor, with strong correlations observed with key image attributes such as complexity, colorfulness, sharpness, and overall quality. Moreover, we demonstrate the efficacy of DDR across a spectrum of applications. It excels as a blind image quality assessment metric, outperforming existing methodologies across multiple datasets. Additionally, DDR serves as an effective unsupervised learning objective in image restoration tasks, yielding notable advancements in image deblurring and single-image super-resolution. Our code is available at: https://github.com/eezkni/DDR.
tl;dr: We study how to perform unlearning, i.e. forgetting undesirable (mis)behaviors, on large language models (LLMs).

We study how to perform unlearning, i.e. forgetting undesirable (mis)behaviors, on large language models (LLMs). We show at least three scenarios of aligning LLMs with human preferences can benefit from unlearning: (1) removing harmful responses, (2) erasing copyright-protected content as requested, and (3) reducing hallucinations. Unlearning, as an alignment technique, has three advantages. (1) It only requires negative (e.g. harmful) examples, which are much easier and cheaper to collect (e.g. via red teaming or user reporting) than positive (e.g. helpful and often human-written) examples required in the standard alignment process. (2) It is computationally efficient. (3) It is especially effective when we know which training samples cause the misbehavior. To the best of our knowledge, our work is among the first to explore LLM unlearning. We are also among the first to formulate the settings, goals, and evaluations in LLM unlearning. Despite only having negative samples, our ablation study shows that unlearning can still achieve better alignment performance than RLHF with just 2% of its computational time.

In-context learning (ICL) and supervised fine-tuning (SFT) are two common strategies for improving the performance of modern large language models (LLMs) on specific tasks. Despite their different natures, these strategies often lead to comparable performance gains.
However, little is known about whether they induce similar representations inside LLMs. We approach this problem by analyzing the probability landscape of their hidden representations in the two cases. More specifically, we compare how LLMs solve the same question-answering task, finding that ICL and SFT create very different internal structures, in both cases undergoing a sharp transition in the middle of the network. In the first half of the network, ICL shapes interpretable representations hierarchically organized according to their semantic content. In contrast, the probability landscape obtained with SFT is fuzzier and semantically mixed. In the second half of the model, the fine-tuned representations develop probability modes that better encode the identity of answers, while less-defined peaks characterize the landscape of ICL representations. Our approach reveals the diverse computational strategies developed inside LLMs to solve the same task across different conditions, allowing us to make a step towards designing optimal methods to extract information from language models.
tl;dr: In this paper, we propose BiDM, pushing the quantization of the diffusion model to the limit with fully binarized weights and activations.

Diffusion models (DMs) have been significantly developed and widely used in various applications due to their excellent generative qualities. However, the expensive computation and massive parameters of DMs hinder their practical use in resource-constrained scenarios. As one of the effective compression approaches, quantization allows DMs to achieve storage saving and inference acceleration by reducing bit-width while maintaining generation performance. However, as the most extreme quantization form, 1-bit binarization causes the generation performance of DMs to face severe degradation or even collapse. This paper proposes a novel method, namely BiDM, for fully binarizing weights and activations of DMs, pushing quantization to the 1-bit limit. From a temporal perspective, we introduce the Timestep-friendly Binary Structure (TBS), which uses learnable activation binarizers and cross-timestep feature connections to address the highly timestep-correlated activation features of DMs. From a spatial perspective, we propose Space Patched Distillation (SPD) to address the difficulty of matching binary features during distillation, focusing on the spatial locality of image generation tasks and noise estimation networks. As the first work to fully binarize DMs, the W1A1 BiDM on the LDM-4 model for LSUN-Bedrooms 256$\times$256 achieves a remarkable FID of 22.74, significantly outperforming the current state-of-the-art general binarization methods with an FID of 59.44 and invalid generative samples, and achieves up to excellent 28.0 times storage and 52.7 times OPs savings.

Graph classification is a challenging problem owing to the difficulty in quantifying the similarity between graphs or representing graphs as vectors, though there have been a few methods using graph kernels or graph neural networks (GNNs). Graph kernels often suffer from computational costs and manual feature engineering, while GNNs commonly utilize global pooling operations, risking the loss of structural or semantic information. This work introduces Graph Reference Distribution Learning (GRDL), an efficient and accurate graph classification method. GRDL treats each graph's latent node embeddings given by GNN layers as a discrete distribution, enabling direct classification without global pooling, based on maximum mean discrepancy to adaptively learned reference distributions. To fully understand this new model (the existing theories do not apply) and guide its configuration (e.g., network architecture, references' sizes, number, and regularization) for practical use, we derive generalization error bounds for GRDL and verify them numerically. More importantly, our theoretical and numerical results both show that GRDL has a stronger generalization ability than GNNs with global pooling operations. Experiments on moderate-scale and large-scale graph datasets show the superiority of GRDL over the state-of-the-art, emphasizing its remarkable efficiency, being at least 10 times faster than leading competitors in both training and inference stages.
tl;dr: An investigation of Mamba in offline RL.

Transformer-based trajectory optimization methods have demonstrated exceptional performance in offline Reinforcement Learning (offline RL). Yet, it poses challenges due to substantial parameter size and limited scalability, which is particularly critical in sequential decision-making scenarios where resources are constrained such as in robots and drones with limited computational power. Mamba, a promising new linear-time sequence model, offers performance on par with transformers while delivering substantially fewer parameters on long sequences. As it remains unclear whether Mamba is compatible with trajectory optimization, this work aims to conduct comprehensive experiments to explore the potential of Decision Mamba (dubbed DeMa) in offline RL from the aspect of data structures and essential components with the following insights: (1) Long sequences impose a significant computational burden without contributing to performance improvements since DeMa's focus on sequences diminishes approximately exponentially. Consequently, we introduce a Transformer-like DeMa as opposed to an RNN-like DeMa. (2) For the components of DeMa, we identify the hidden attention mechanism as a critical factor in its success, which can also work well with other residual structures and does not require position embedding. Extensive evaluations demonstrate that our specially designed DeMa is compatible with trajectory optimization and surpasses previous methods, outperforming Decision Transformer (DT) with higher performance while using 30\% fewer parameters in Atari, and exceeding DT with only a quarter of the parameters in MuJoCo.
tl;dr: A novel framework for statistical independence tests that enable effective learning significant Fourier feature pairs to maximize test power

We propose a novel method to efficiently learn significant Fourier feature pairs for maximizing the power of Hilbert-Schmidt Independence Criterion~(HSIC) based independence tests. We first reinterpret HSIC in the frequency domain, which reveals its limited discriminative power due to the inability to adapt to specific frequency-domain features under the current inflexible configuration. To remedy this shortcoming, we introduce a module of learnable Fourier features, thereby developing a new criterion. We then derive a finite sample estimate of the test power by modeling the behavior of the criterion, thus formulating an optimization objective for significant Fourier feature pairs learning. We show that this optimization objective can be computed in linear time (with respect to the sample size $n$), which ensures fast independence tests. We also prove the convergence property of the optimization objective and establish the consistency of the independence tests. Extensive empirical evaluation on both synthetic and real datasets validates our method's superiority in effectiveness and efficiency, particularly in handling high-dimensional data and dealing with large-scale scenarios.
tl;dr: A theoretical analysis of the sample complexity of GNNs with node individualization schemes.

Graph neural networks (GNNs) employing message passing for graph classification are inherently limited by the expressive power of the Weisfeiler-Leman (WL) test for graph isomorphism. Node individualization schemes, which assign unique identifiers to nodes (e.g., by adding random noise to features), are a common approach for achieving universal expressiveness. However, the ability of GNNs endowed with individualization schemes to generalize beyond the training data is still an open question. To address this question, this paper presents a theoretical analysis of the sample complexity of such GNNs from a statistical learning perspective, employing Vapnik–Chervonenkis (VC) dimension and covering number bounds. We demonstrate that node individualization schemes that are permutation-equivariant result in lower sample complexity, and design novel individualization schemes that exploit these results. As an application of this analysis, we also develop a novel architecture that can perform substructure identification (i.e., subgraph isomorphism) while having a lower VC dimension compared to competing methods. Finally, our theoretical findings are validated experimentally on both synthetic and real-world datasets.
tl;dr: A simple but efficient improvement for upcycle dense models parameters and use them to initialise Mixture of Experts Models.

Mixture of Experts (MoE) framework has become a popular architecture for large language models due to its superior performance compared to dense models. However, training MoEs from scratch in a large-scale regime is prohibitively expensive. Previous work addresses this challenge by independently training multiple dense expert models and using them to initialize an MoE. In particular, state-of-the-art approaches initialize MoE layers using experts' feed-forward parameters while merging all other parameters, limiting the advantages of the specialized dense models when upcycling them as MoEs. We propose BAM (Branch-Attend-Mix), a simple yet effective improvement to MoE training. BAM makes full use of specialized dense models by not only using their feed-forward network (FFN) to initialize the MoE layers but also leveraging experts' attention weights fully by leveraging them as mixture-of-attention (MoA) layers. We explore two methods for upcycling MoA layers: 1) initializing separate attention experts from dense models including key, value, and query matrices; and 2) initializing only Q projections while sharing key-value pairs across all experts to facilitate efficient inference. Our experiments using seed models ranging from 590 million to 2 billion parameters show that our approach outperforms state-of-the-art approaches under the same data and compute budget in both perplexity and downstream tasks evaluations, confirming the effectiveness of BAM.
tl;dr: We develop algorithms to efficiently minimize swap regret with respect to the set of low-degree deviations in extensive-form games.

Recent breakthrough results by Dagan, Daskalakis, Fishelson and Golowich [2023] and Peng and Rubinstein [2023] established an efficient algorithm attaining at most $\epsilon$ swap regret over extensive-form strategy spaces of dimension $N$ in $N^{\tilde O(1/\epsilon)}$ rounds. On the other extreme, Farina and Pipis [2023] developed an efficient algorithm for minimizing the weaker notion of linear-swap regret in $\mathsf{poly}(N)/\epsilon^2$ rounds. In this paper, we develop efficient parameterized algorithms for regimes between these two extremes. We introduce the set of $k$-mediator deviations, which generalize the untimed communication deviations recently introduced by Zhang, Farina and Sandholm [2024] to the case of having multiple mediators, and we develop algorithms for minimizing the regret with respect to this set of deviations in $N^{O(k)}/\epsilon^2$ rounds. Moreover, by relating $k$-mediator deviations to low-degree polynomials, we show that regret minimization against degree-$k$ polynomial swap deviations is achievable in $N^{O(kd)^3}/\epsilon^2$ rounds, where $d$ is the depth of the game, assuming a constant branching factor. For a fixed degree $k$, this is polynomial for Bayesian games and quasipolynomial more broadly when $d = \mathsf{polylog} N$---the usual balancedness assumption on the game tree. The first key ingredient in our approach is a relaxation of the usual notion of a fixed point required in the framework of Gordon, Greenwald and Marks [2008]. Namely, for a given deviation $\phi$, we show that it suffices to compute what we refer to as a fixed point in expectation; that is, a distribution $\pi$ such that $\mathbb{E}_{x \sim \pi} [\phi(x) - x] \approx 0$. Unlike the problem of computing an actual (approximate) fixed point $x \approx \phi(x)$, which we show is \PPAD-hard, there is a simple and efficient algorithm for finding a solution that satisfies our relaxed notion. As a byproduct, we provide, to our knowledge, the fastest algorithm for computing $\epsilon$-correlated equilibria in normal-form games in the medium-precision regime, obviating the need to solve a linear system in every round. Our second main contribution is a characterization of the set of low-degree deviations, made possible through a connection to low-depth decisions trees from Boolean analysis.
tl;dr: We develop novel algorithms for approximating the set of Pareto-optimal clusterings for various combinations of two objectives.

As a major unsupervised learning method, clustering has received a lot of attention over multiple decades. The various clustering problems that have been studied intensively include, e.g., the $k$-means problem and the $k$-center problem. However, in applications, it is common that good clusterings should optimize multiple objectives (e.g., visualizing data on a map by clustering districts into areas that are both geographically compact but also homogeneous with respect to the data). We study combinations of different objectives, for example optimizing $k$-center and $k$-means simultaneously or optimizing $k$-center with respect to two different metrics. Usually these objectives are conflicting and cannot be optimized simultaneously, making it necessary to find trade-offs. We develop novel algorithms for computing the set of Pareto-optimal solutions (approximately) for various combinations of two objectives. Our algorithms achieve provable approximation guarantees and we demonstrate in several experiments that the (approximate) Pareto set contains good clusterings that cannot be found by considering one of the objectives separately.
tl;dr: A simple approach without resorting to, e.g., complicated modules and meta-learning improved GFSS performance.

The goal of *generalized* few-shot semantic segmentation (GFSS) is to recognize *novel-class* objects through training with a few annotated examples and the *base-class* model that learned the knowledge about the base classes.
Unlike the classic few-shot semantic segmentation, GFSS aims to classify pixels into both base and novel classes, meaning it is a more practical setting.
Current GFSS methods rely on several techniques such as using combinations of customized modules, carefully designed loss functions, meta-learning, and transductive learning.
However, we found that a simple rule and standard supervised learning substantially improve the GFSS performance.
In this paper, we propose a simple yet effective method for GFSS that does not use the techniques mentioned above.
Also, we theoretically show that our method perfectly maintains the segmentation performance of the base-class model over most of the base classes.
Through numerical experiments, we demonstrated the effectiveness of our method.
It improved in novel-class segmentation performance in the $1$-shot scenario by $6.1$% on the PASCAL-$5^i$ dataset, $4.7$% on the PASCAL-$10^i$ dataset, and $1.0$% on the COCO-$20^i$ dataset.

We present a novel approach for digitizing real-world objects by estimating their geometry, material properties, and environmental lighting from a set of posed images with fixed lighting. Our method incorporates into Neural Radiance Field (NeRF) pipelines the split sum approximation used with image-based lighting for real-time physically based rendering. We propose modeling the scene's lighting with a single scene-specific MLP representing pre-integrated image-based lighting at arbitrary resolutions. We accurately model pre-integrated lighting by exploiting a novel regularizer based on efficient Monte Carlo sampling. Additionally, we propose a new method of supervising self-occlusion predictions by exploiting a similar regularizer based on Monte Carlo sampling. Experimental results demonstrate the efficiency and effectiveness of our approach in estimating scene geometry, material properties, and lighting. Our method attains state-of-the-art relighting quality after only ${\sim}1$ hour of training in a single NVIDIA A100 GPU.
tl;dr: We propse a novel Knowledge Graph based Prompting framework, namely KnowGPT, to leverage the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles.

Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, graph retrieval-augmented generation (GraphRAG) has been extensively explored which leverages the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel **Know**ledge **Gr**aph based **P**romp**T**ing framework, namely **KnowGPT**, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.

Solving constrained nonlinear programs (NLPs) is of great importance in various domains such as power systems, robotics, and wireless communication networks. One widely used approach for addressing NLPs is the interior point method (IPM). The most computationally expensive procedure in IPMs is to solve systems of linear equations via matrix factorization. Recently, machine learning techniques have been adopted to expedite classic optimization algorithms. In this work, we propose using Long Short-Term Memory (LSTM) neural networks to approximate the solution of linear systems and integrate this approximating step into an IPM. The resulting approximate NLP solution is then utilized to warm-start an interior point solver. Experiments on various types of NLPs, including Quadratic Programs and Quadratically Constrained Quadratic Programs, show that our approach can significantly accelerate NLP solving, reducing iterations by up to 60% and solution time by up to 70% compared to the default solver.
tl;dr: Consistency model analysis and training design for advanced performance on text-to-image generation and text-to-video generation

Consistency Models (CMs) have made significant progress in accelerating the generation of diffusion models. However, their application to high-resolution, text-conditioned image generation in the latent space remains unsatisfactory. In this paper, we identify three key flaws in the current design of Latent Consistency Models~(LCMs). We investigate the reasons behind these limitations and propose Phased Consistency Models (PCMs), which generalize the design space and address the identified limitations. Our evaluations demonstrate that PCMs outperform LCMs across 1--16 step generation settings. While PCMs are specifically designed for multi-step refinement, they achieve comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show the methodology of PCMs is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. Our code is available at https://github.com/G-U-N/Phased-Consistency-Model.
tl;dr: We propose a flexible speculation decoding framework with CTC-based draft model for context information retrieving when drafting and adaptive candidate sequence generation.

Inference acceleration of large language models (LLMs) has been put forward in many application scenarios and speculative decoding has shown its advantage in addressing inference acceleration. Speculative decoding usually introduces a draft model to assist the base LLM where the draft model produces drafts and the base LLM verifies the draft for acceptance or rejection. In this framework, the final inference speed is decided by the decoding speed of the draft model and the acceptance rate of the draft provided by the draft model. Currently the widely used draft models usually generate draft tokens for the next several positions in a non-autoregressive way without considering the correlations between draft tokens. Therefore, it has a high decoding speed but an unsatisfactory acceptance rate. In this paper, we focus on how to improve the performance of the draft model and aim to accelerate inference via a high acceptance rate. To this end, we propose a CTC-based draft model which strengthens the correlations between draft tokens during the draft phase, thereby generating higher-quality draft candidate sequences. Experiment results show that compared to strong baselines, the proposed method can achieve a higher acceptance rate and hence a faster inference speed.

We introduce a novel framework, Online Relational Inference (ORI), designed to efficiently identify hidden interaction graphs in evolving multi-agent interacting systems using streaming data. Unlike traditional offline methods that rely on a fixed training set, ORI employs online backpropagation, updating the model with each new data point, thereby allowing it to adapt to changing environments in real-time. A key innovation is the use of an adjacency matrix as a trainable parameter, optimized through a new adaptive learning rate technique called AdaRelation, which adjusts based on the historical sensitivity of the decoder to changes in the interaction graph. Additionally, a data augmentation method named Trajectory Mirror (TM) is introduced to improve generalization by exposing the model to varied trajectory patterns. Experimental results on both synthetic datasets and real-world data (CMU MoCap for human motion) demonstrate that ORI significantly improves the accuracy and adaptability of relational inference in dynamic settings compared to existing methods. This approach is model-agnostic, enabling seamless integration with various neural relational inference (NRI) architectures, and offers a robust solution for real-time applications in complex, evolving systems.

The empirical success of distributional reinforcement learning (RL) highly relies on the choice of distribution divergence equipped with an appropriate distribution representation. In this paper, we propose \textit{Sinkhorn distributional RL (SinkhornDRL)}, which leverages Sinkhorn divergence—a regularized Wasserstein loss—to minimize the difference between current and target Bellman return distributions. Theoretically, we prove the contraction properties of SinkhornDRL, aligning with the interpolation nature of Sinkhorn divergence between Wasserstein distance and Maximum Mean Discrepancy (MMD). The introduced SinkhornDRL enriches the family of distributional RL algorithms, contributing to interpreting the algorithm behaviors compared with existing approaches by our investigation into their relationships. Empirically, we show that SinkhornDRL consistently outperforms or matches existing algorithms on the Atari games suite and particularly stands out in the multi-dimensional reward setting. \thanks{Code is available in \url{https://github.com/datake/SinkhornDistRL}.}.

This paper reveals the phenomenon of parameter heterogeneity in large language models (LLMs). We find that a small subset of ``cherry'' parameters exhibit a disproportionately large influence on model performance, while the vast majority of parameters have minimal impact. This heterogeneity is found to be prevalent across different model families, scales, and types. Motivated by this observation, we propose CherryQ, a novel quantization method that unifies the optimization of mixed-precision parameters. CherryQ identifies and preserves the critical cherry parameters in high precision while aggressively quantizing the remaining parameters to low precision. Extensive experiments demonstrate the effectiveness of CherryQ. CherryQ outperforms existing quantization approaches in terms of perplexity and downstream task performance. Notably, our 3-bit quantized Vicuna-1.5 exhibits competitive performance compared to their 16-bit counterparts. These findings highlight the potential of CherryQ for enabling efficient deployment of LLMs by taking advantage of parameter heterogeneity.
tl;dr: We propose a novel intent learning method termed ELCRec, by unifying behavior representation learning into an End-to-end Learnable Clustering framework, for effective and efficient Recommendation.

Intent learning, which aims to learn users' intents for user understanding and item recommendation, has become a hot research spot in recent years. However, existing methods suffer from complex and cumbersome alternating optimization, limiting performance and scalability. To this end, we propose a novel intent learning method termed \underline{ELCRec}, by unifying behavior representation learning into an \underline{E}nd-to-end \underline{L}earnable \underline{C}lustering framework, for effective and efficient \underline{Rec}ommendation. Concretely, we encode user behavior sequences and initialize the cluster centers (latent intents) as learnable neurons. Then, we design a novel learnable clustering module to separate different cluster centers, thus decoupling users' complex intents. Meanwhile, it guides the network to learn intents from behaviors by forcing behavior embeddings close to cluster centers. This allows simultaneous optimization of recommendation and clustering via mini-batch data. Moreover, we propose intent-assisted contrastive learning by using cluster centers as self-supervision signals, further enhancing mutual promotion. Both experimental results and theoretical analyses demonstrate the superiority of ELCRec from six perspectives. Compared to the runner-up, ELCRec improves NDCG@5 by 8.9\% and reduces computational costs by 22.5\% on the Beauty dataset. Furthermore, due to the scalability and universal applicability, we deploy this method on the industrial recommendation system with 130 million page views and achieve promising results. The codes are available on GitHub\footnote{https://github.com/yueliu1999/ELCRec}. A collection (papers, codes, datasets) of deep group recommendation/intent learning methods is available on GitHub\footnote{https://github.com/yueliu1999/Awesome-Deep-Group-Recommendation}.

We propose a video editing framework, NaRCan, which integrates a hybrid deformation field and diffusion prior to generate high-quality natural canonical images to represent the input video. Our approach utilizes homography to model global motion and employs multi-layer perceptrons (MLPs) to capture local residual deformations, enhancing the model’s ability to handle complex video dynamics. By introducing a diffusion prior from the early stages of training, our model ensures that the generated images retain a high-quality natural appearance, making the produced canonical images suitable for various downstream tasks in video editing, a capability not achieved by current canonical-based methods. Furthermore, we incorporate low-rank adaptation (LoRA) fine-tuning and introduce a noise and diffusion prior update scheduling technique that accelerates the training process by 14 times. Extensive experimental results show that our method outperforms existing approaches in various video editing tasks and produces coherent and high-quality edited video sequences. See our project page for video results: [koi953215.github.io/NaRCan_page](https://koi953215.github.io/NaRCan_page/).
tl;dr: We propose Safety Rule Based Rewards, a method of using AI feedback in the safety training of LLMs that is scalable, allows for fine-grained control of behavior, and allows for fast updates.

Reinforcement learning based fine-tuning of large language models (LLMs) on human preferences has been shown to enhance both their capabilities and safety behavior.
However, in cases related to safety, without precise instructions to human annotators, the data collected may cause the model to become overly cautious, or to respond in an undesirable style, such as being judgmental.
Additionally, as model capabilities and usage patterns evolve, there may be a costly need to add or relabel data to modify safety behavior.
We propose a novel preference modeling approach that utilizes AI feedback and only requires a small amount of human data.
Our method, Rule Based Rewards (RBR), uses a collection of rules for desired or undesired behaviors (e.g. refusals should not be judgmental) along with a LLM grader.
In contrast to prior methods using AI feedback, our method uses fine-grained, composable, LLM-graded few-shot prompts as reward directly in RL training, resulting in greater control, accuracy and ease of updating.
We show that RBRs are an effective training method, achieving an F1 score of 97.1, compared to a human-feedback baseline of 91.7, resulting in much higher safety-behavior accuracy through better balancing usefulness and safety.
tl;dr: Use bidirectional Recurrent Manner Equip with Gaussian Process for Cardiac Motion Tracking

Quantitative analysis of cardiac motion is crucial for assessing cardiac function. This analysis typically uses imaging modalities such as MRI and Echocardiograms that capture detailed image sequences throughout the heartbeat cycle. Previous methods predominantly focused on the analysis of image pairs lacking consideration of the motion dynamics and spatial variability. Consequently, these methods often overlook the long-term relationships and regional motion characteristic of cardiac. To overcome these limitations, we introduce the GPTrack, a novel unsupervised framework crafted to fully explore the temporal and spatial dynamics of cardiac motion. The GPTrack enhances motion tracking by employing the sequential Gaussian Process in the latent space and encoding statistics by spatial information at each time stamp, which robustly promotes temporal consistency and spatial variability of cardiac dynamics. Also, we innovatively aggregate sequential information in a bidirectional recursive manner, mimicking the behavior of diffeomorphic registration to better capture consistent long-term relationships of motions across cardiac regions such as the ventricles and atria. Our GPTrack significantly improves the precision of motion tracking in both 3D and 4D medical images while maintaining computational efficiency. The code is available at: https://github.com/xmed-lab/GPTrack.
tl;dr: We formalize the definition of encoding in explanation methods and provide two methods to detect encoding.

Feature attributions attempt to highlight what inputs drive predictive power. Good attributions or explanations are thus those that produce inputs that retain this predictive power; accordingly, evaluations of explanations score their quality of prediction. However, evaluations produce scores better than what appears possible from the values in the explanation for a class of explanations, called encoding explanations. Probing for encoding remains a challenge because there is no general characterization of what gives the extra predictive power. We develop a definition of encoding that identifies this extra predictive power via conditional dependence and show that the definition fits existing examples of encoding. This definition implies, in contrast to encoding explanations, that non-encoding explanations contain all the informative inputs used to produce the explanation, giving them a “what you see is what you get” property, which makes them transparent and simple to use. Next, we prove that existing scores (ROAR, FRESH, EVAL-X) do not rank non-encoding explanations above encoding ones, and develop STRIPE-X which ranks them correctly. After empirically demonstrating the theoretical insights, we use STRIPE-X to uncover encoding in LLM-generated explanations for predicting the sentiment in movie reviews.
tl;dr: We consider the problem of sampling from a target probability distribution whose density is know up to a normalization constant while satisfying a set of statistical constraints specified by general nonlinear functions.

This work considers the problem of sampling from a probability distribution known up to a normalization constant while satisfying a set of statistical constraints specified by the expected values of general nonlinear functions. This problem finds applications in, e.g., Bayesian inference, where it can constrain moments to evaluate counterfactual scenarios or enforce desiderata such as prediction fairness. Methods developed to handle support constraints, such as those based on mirror maps, barriers, and penalties, are not suited for this task. This work therefore relies on gradient descent-ascent dynamics in Wasserstein space to put forward a discrete-time primal-dual Langevin Monte Carlo algorithm (PD-LMC) that simultaneously constrains the target distribution and samples from it. We analyze the convergence of PD-LMC under standard assumptions on the target distribution and constraints, namely (strong) convexity and log-Sobolev inequalities. To do so, we bring classical optimization arguments for saddle-point algorithms to the geometry of Wasserstein space. We illustrate the relevance and effectiveness of PD-LMC in several applications.
tl;dr: We propose NeuroBOLT, a versatile deep-learning solution for projecting scalp EEG to BOLD fMRI signals.

Functional magnetic resonance imaging (fMRI) is an indispensable tool in modern neuroscience, providing a non-invasive window into whole-brain dynamics at millimeter-scale spatial resolution. However, fMRI is constrained by issues such as high operation costs and immobility. With the rapid advancements in cross-modality synthesis and brain decoding, the use of deep neural networks has emerged as a promising solution for inferring whole-brain, high-resolution fMRI features directly from electroencephalography (EEG), a more widely accessible and portable neuroimaging modality. Nonetheless, the complex projection from neural activity to fMRI hemodynamic responses and the spatial ambiguity of EEG pose substantial challenges both in modeling and interpretability. Relatively few studies to date have developed approaches for EEG-fMRI translation, and although they have made significant strides, the inference of fMRI signals in a given study has been limited to a small set of brain areas and to a single condition (i.e., either resting-state or a specific task). The capability to predict fMRI signals in other brain areas, as well as to generalize across conditions, remain critical gaps in the field. To tackle these challenges, we introduce a novel and generalizable framework: NeuroBOLT, i.e., Neuro-to-BOLD Transformer, which leverages multi-dimensional representation learning from temporal, spatial, and spectral domains to translate raw EEG data to the corresponding fMRI activity signals across the brain. Our experiments demonstrate that NeuroBOLT effectively reconstructs unseen resting-state fMRI signals from primary sensory, high-level cognitive areas, and deep subcortical brain regions, achieving state-of-the-art accuracy with the potential to generalize across varying conditions and sites, which significantly advances the integration of these two modalities.

Recent 3D large reconstruction models (LRMs) can generate high-quality 3D content in sub-seconds by integrating multi-view diffusion models with scalable multi-view reconstructors. Current works further leverage 3D Gaussian Splatting as 3D representation for improved visual quality and rendering efficiency. However, we observe that existing Gaussian reconstruction models often suffer from multi-view inconsistency and blurred textures. We attribute this to the compromise of multi-view information propagation in favor of adopting powerful yet computationally intensive architectures (\eg, Transformers).
To address this issue, we introduce MVGamba, a general and lightweight Gaussian reconstruction model featuring a multi-view Gaussian reconstructor based on the RNN-like State Space Model (SSM). Our Gaussian reconstructor propagates causal context containing multi-view information for cross-view self-refinement while generating a long sequence of Gaussians for fine-detail modeling with linear complexity.
With off-the-shelf multi-view diffusion models integrated, MVGamba unifies 3D generation tasks from a single image, sparse images, or text prompts. Extensive experiments demonstrate that MVGamba outperforms state-of-the-art baselines in all 3D content generation scenarios with approximately only $0.1\times$ of the model size. The codes are available at \url{https://github.com/SkyworkAI/MVGamba}.
tl;dr: Towards a unified generative model for varying-length time series, we propose transforming time series data into images via invertible transforms and utilizing generative frameworks for time series generation.

Lately, there has been a surge in interest surrounding generative modeling of time series data. Most existing approaches are designed either to process short sequences or to handle long-range sequences. This dichotomy can be attributed to gradient issues with recurrent networks, computational costs associated with transformers, and limited expressiveness of state space models. Towards a unified generative model for varying-length time series, we propose in this work to transform sequences into images. By employing invertible transforms such as the delay embedding and the short-time Fourier transform, we unlock three main advantages: i) We can exploit advanced diffusion vision models; ii) We can remarkably process short- and long-range inputs within the same framework; and iii) We can harness recent and established tools proposed in the time series to image literature. We validate the effectiveness of our method through a comprehensive evaluation across multiple tasks, including unconditional generation, interpolation, and extrapolation. We show that our approach achieves consistently state-of-the-art results against strong baselines. In the unconditional generation tasks, we show remarkable mean improvements of $58.17$% over previous diffusion models in the short discriminative score and $132.61$% in the (ultra-)long classification scores. Code is at https://github.com/azencot-group/ImagenTime.
2763. AP-Adapter: Improving Generalization of Automatic Prompts on Unseen Text-to-Image Diffusion Models

Recent advancements in Automatic Prompt Optimization (APO) for text-to-image generation have streamlined user input while ensuring high-quality image output. However, most APO methods are trained assuming a fixed text-to-image model, which is impractical given the emergence of new models. To address this, we propose a novel task, model-generalized automatic prompt optimization (MGAPO), which trains APO methods on a set of known models to enable generalization to unseen models during testing. MGAPO presents significant challenges. First, we experimentally confirm the suboptimal performance of existing APO methods on unseen models. We then introduce a two-stage prompt optimization method, AP-Adapter. In the first stage, a large language model is used to rewrite the prompts. In the second stage, we propose a novel method to construct an enhanced representation space by leveraging inter-model differences. This space captures the characteristics of multiple domain models, storing them as domain prototypes. These prototypes serve as anchors to adjust prompt representations, enabling generalization to unseen models. The optimized prompt representations are subsequently used to generate conditional representations for controllable image generation. We curate a multi-modal, multi-model dataset that includes multiple diffusion models and their corresponding text-image data, and conduct experiments under a model generalization setting. The experimental results demonstrate the AP-Adapter's ability to enable the automatic prompts to generalize well to previously unseen diffusion models, generating high-quality images.

Last-layer retraining methods have emerged as an efficient framework for correcting existing base models. Within this framework, several methods have been proposed to deal with correcting models for subgroup fairness with and without group membership information. Importantly, prior work has demonstrated that many methods are susceptible to noisy labels. To this end, we propose a drop-in correction for label noise in last-layer retraining, and demonstrate that it achieves state-of-the-art worst-group accuracy for a broad range of symmetric label noise and across a wide variety of datasets exhibiting spurious correlations. Our proposed approach uses label spreading on a latent nearest neighbors graph and has minimal computational overhead compared to existing methods.
2765. Ask, Attend, Attack: An Effective Decision-Based Black-Box Targeted Attack for Image-to-Text Models

While image-to-text models have demonstrated significant advancements in various vision-language tasks, they remain susceptible to adversarial attacks. Existing white-box attacks on image-to-text models require access to the architecture, gradients, and parameters of the target model, resulting in low practicality. Although the recently proposed gray-box attacks have improved practicality, they suffer from semantic loss during the training process, which limits their targeted attack performance. To advance adversarial attacks of image-to-text models, this paper focuses on a challenging scenario: decision-based black-box targeted attacks where the attackers only have access to the final output text and aim to perform targeted attacks. Specifically, we formulate the decision-based black-box targeted attack as a large-scale optimization problem. To efficiently solve the optimization problem, a three-stage process \textit{Ask, Attend, Attack}, called \textit{AAA}, is proposed to coordinate with the solver. \textit{Ask} guides attackers to create target texts that satisfy the specific semantics. \textit{Attend} identifies the crucial regions of the image for attacking, thus reducing the search space for the subsequent \textit{Attack}. \textit{Attack} uses an evolutionary algorithm to attack the crucial regions, where the attacks are semantically related to the target texts of \textit{Ask}, thus achieving targeted attacks without semantic loss. Experimental results on transformer-based and CNN+RNN-based image-to-text models confirmed the effectiveness of our proposed \textit{AAA}.
2766. Understanding Generalizability of Diffusion Models Requires Rethinking the Hidden Gaussian Structure

In this work, we study the generalizability of diffusion models by looking into the hidden properties of the learned score functions, which are essentially a series of deep denoisers trained on various noise levels. We observe that as diffusion models transition from memorization to generalization, their corresponding nonlinear diffusion denoisers exhibit increasing linearity. This discovery leads us to investigate the linear counterparts of the nonlinear diffusion models, which are a series of linear models trained to match the function mappings of the nonlinear diffusion denoisers. Surprisingly, these linear denoisers are approximately the optimal denoisers for a multivariate Gaussian distribution characterized by the empirical mean and covariance of the training dataset. This finding implies that diffusion models have the inductive bias towards capturing and utilizing the Gaussian structure (covariance information) of the training dataset for data generation. We empirically demonstrate that this inductive bias is a unique property of diffusion models in the generalization regime, which becomes increasingly evident when the model's capacity is relatively small compared to the training dataset size. In the case that the model is highly overparameterized, this inductive bias emerges during the initial training phases before the model fully memorizes its training data. Our study provides crucial insights into understanding the notable strong generalization phenomenon recently observed in real-world diffusion models.

Understanding the training dynamics of transformers is important to explain the impressive capabilities behind large language models.
In this work, we study the dynamics of training a shallow transformer on a task of recognizing co-occurrence of two designated words. In the literature of studying training dynamics of transformers, several simplifications are commonly adopted such as weight reparameterization, attention linearization, special initialization, and lazy regime. In contrast, we analyze the gradient flow dynamics of simultaneously training three attention matrices and a linear MLP layer from random initialization, and provide a framework of analyzing such dynamics via a coupled dynamical system. We establish near minimum loss and characterize the attention model after training. We discover that gradient flow serves as an inherent mechanism that naturally divide the training process into two phases. In Phase 1, the linear MLP quickly aligns with the two target signals for correct classification, whereas the softmax attention remains almost unchanged. In Phase 2, the attention matrices and the MLP evolve jointly to enlarge the classification margin and reduce the loss to a near minimum value. Technically, we prove a novel property of the gradient flow, termed \textit{automatic balancing of gradients}, which enables the loss values of different samples to decrease almost at the same rate and further facilitates the proof of near minimum training loss. We also conduct experiments to verify our theoretical results.

Modern machine learning models deployed often encounter distribution shifts in real-world applications, manifesting as covariate or semantic out-of-distribution (OOD) shifts. These shifts give rise to challenges in OOD generalization and OOD detection. This paper introduces a novel, integrated approach AHA (Adaptive Human-Assisted OOD learning) to simultaneously address both OOD generalization and detection through a human-assisted framework by labeling data in the wild. Our approach strategically labels examples within a novel maximum disambiguation region, where the number of semantic and covariate OOD data roughly equalizes. By labeling within this region, we can maximally disambiguate the two types of OOD data, thereby maximizing the utility of the fixed labeling budget. Our algorithm first utilizes a noisy binary search algorithm that identifies the maximal disambiguation region with high probability. The algorithm then continues with annotating inside the identified labeling region, reaping the full benefit of human feedback. Extensive experiments validate the efficacy of our framework. We observed that with only a few hundred human annotations, our method significantly outperforms existing state-of-the-art methods that do not involve human assistance, in both OOD generalization and OOD detection.
tl;dr: New image captioning model that can generate short or detailed descriptions of specific image areas.

We introduce FlexCap, a vision-language model that generates region-specific descriptions of varying lengths. FlexCap is trained to produce length-conditioned captions for input boxes, enabling control over information density, with descriptions ranging from concise object labels to detailed captions. To achieve this, we create large-scale training datasets of image region descriptions with varying lengths from captioned web images. We demonstrate FlexCap’s effectiveness in several applications: first, it achieves strong performance in dense captioning tasks on the Visual Genome dataset. Second, we show how FlexCap’s localized descriptions can serve as input to a large language model to create a visual question answering (VQA) system, achieving state-of-the-art zero-shot performance on multiple VQA benchmarks. Our experiments illustrate FlexCap’s utility for tasks including image labeling, object attribute recognition, and visual dialog. Project webpage: https://flex-cap.github.io.
tl;dr: This paper propose iAgents, a new LLM Multi-Agent framework where agents collaborate on behalf of human in the mirrored agent network and deal with information asymmetry problems.

Large Language Model Multi-Agent Systems (LLM-MAS) have greatly progressed in solving complex tasks. It communicates among agents within the system to collaboratively solve tasks, under the premise of shared information. However, when agents' collaborations are leveraged to perform multi-person tasks, a new challenge arises due to information asymmetry, since each agent can only access the information of its human user. Previous MAS struggle to complete tasks under this condition. To address this, we propose a new MAS paradigm termed iAgents, which denotes Informative Multi-Agent Systems. In iAgents, the human social network is mirrored in the agent network, where agents proactively exchange human information necessary for task resolution, thereby overcoming information asymmetry. iAgents employs a novel agent reasoning mechanism, InfoNav, to navigate agents' communication towards effective information exchange. Together with InfoNav, iAgents organizes human information in a mixed memory to provide agents with accurate and comprehensive information for exchange. Additionally, we introduce InformativeBench, the first benchmark tailored for evaluating LLM agents' task-solving ability under information asymmetry. Experimental results show that iAgents can collaborate within a social network of 140 individuals and 588 relationships, autonomously communicate over 30 turns, and retrieve information from nearly 70,000 messages to complete tasks within 3 minutes.

The most advanced diffusion models have recently adopted increasingly deep stacked networks (e.g., U-Net or Transformer) to promote the generative emergence capabilities of vision generation models similar to large language models (LLMs). However, progressively deeper stacked networks will intuitively cause numerical propagation errors and reduce noisy prediction capabilities on generative data, which hinders massively deep scalable training of vision generation models. In this paper, we first uncover the nature that neural networks being able to effectively perform generative denoising lies in the fact that the intrinsic residual unit has consistent dynamic property with the input signal's reverse diffusion process, thus supporting excellent generative abilities.
Afterwards, we stand on the shoulders of two common types of deep stacked networks to propose a unified and massively scalable Neural Residual Diffusion Models framework (Neural-RDM for short), which is a simple yet meaningful change to the common architecture of deep generative networks by introducing a series of learnable gated residual parameters that conform to the generative dynamics. Experimental results on various generative tasks show that the proposed neural residual models obtain state-of-the-art scores on image's and video's generative benchmarks. Rigorous theoretical proofs and extensive experiments also demonstrate the advantages of this simple gated residual mechanism consistent with dynamic modeling in improving the fidelity and consistency of generated content and supporting large-scale scalable training.

The rapid advancement of single-cell ATAC sequencing (scATAC-seq) technologies holds great promise for investigating the heterogeneity of epigenetic landscapes at the cellular level. The amplification process in scATAC-seq experiments often introduces noise due to dropout events, which results in extreme sparsity that hinders accurate analysis. Consequently, there is a significant demand for the generation of high-quality scATAC-seq data in silico. Furthermore, current methodologies are typically task-specific, lacking a versatile framework capable of handling multiple tasks within a single model. In this work, we propose ATAC-Diff, a versatile framework, which is based on a diffusion model conditioned on the latent auxiliary variables to adapt for various tasks. ATAC-Diff is the first diffusion model for the scATAC-seq data generation and analysis, composed of auxiliary modules encoding the latent high-level variables to enable the model to learn the semantic information to sample high-quality data. Gaussian Mixture Model (GMM) as the latent prior and auxiliary decoder, the yield variables reserve the refined genomic information beneficial for downstream analyses. Another innovation is the incorporation of mutual information between observed and hidden variables as a regularization term to prevent the model from decoupling from latent variables. Through extensive experiments, we demonstrate that ATAC-Diff achieves high performance in both generation and analysis tasks, outperforming state-of-the-art models.
tl;dr: We propose an structure-induced approach to unify generative and discriminative paradigms.

In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM’s hidden state. This approach enhances the MLLM’s ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.
tl;dr: We present Parametric Piecewise Linear Networks (PPLNs) for temporal vision inference.

We present Parametric Piecewise Linear Networks (PPLNs) for temporal vision inference. Motivated by the neuromorphic principles that regulate biological neural behaviors, PPLNs are ideal for processing data captured by event cameras, which are built to simulate neural activities in the human retina. We discuss how to represent the membrane potential of an artificial neuron by a parametric piecewise linear function with learnable coefficients. This design echoes the idea of building deep models from learnable parametric functions recently popularized by Kolmogorov–Arnold Networks (KANs). Experiments demonstrate the state-of-the-art performance of PPLNs in event-based and image-based vision applications, including steering prediction, human pose estimation, and motion deblurring.
tl;dr: This paper formulates domain calibration as a cooperative MARL problem to improve efficiency and fidelity.

The shift in dynamics results in significant performance degradation of policies trained in the source domain when deployed in a different target domain, posing a challenge for the practical application of reinforcement learning (RL) in real-world scenarios. Domain transfer methods aim to bridge this dynamics gap through techniques such as domain adaptation or domain calibration. While domain adaptation involves refining the policy through extensive interactions in the target domain, it may not be feasible for sensitive fields like healthcare and autonomous driving. On the other hand, offline domain calibration utilizes only static data from the target domain to adjust the physics parameters of the source domain (e.g., a simulator) to align with the target dynamics, enabling the direct deployment of the trained policy without sacrificing performance, which emerges as the most promising for policy deployment. However, existing techniques primarily rely on evolution algorithms for calibration, resulting in low sample efficiency.
To tackle this issue, we propose a novel framework Madoc (\textbf{M}ulti-\textbf{a}gent \textbf{do}main \textbf{c}alibration). Firstly, we formulate a bandit RL objective to match the target trajectory distribution by learning a couple of classifiers. We then address the challenge of a large domain parameter space by modeling domain calibration as a cooperative multi-agent reinforcement learning (MARL) problem. Specifically, we utilize a Variational Autoencoder (VAE) to automatically cluster physics parameters with similar effects on the dynamics, grouping them into distinct agents. These grouped agents train calibration policies coordinately to adjust multiple parameters using MARL.
Our empirical evaluation on 21 offline locomotion tasks in D4RL and NeoRL benchmarks showcases the superior performance of our method compared to strong existing offline model-based RL, offline domain calibration, and hybrid offline-and-online RL baselines.

Standard reinforcement learning (RL) agents never intelligently explore like a human (i.e. taking into account complex domain priors and adapting quickly based on previous exploration). Across episodes, RL agents struggle to perform even simple exploration strategies, for example systematic search that avoids exploring the same location multiple times. This poor exploration limits performance on challenging domains. Meta-RL is a potential solution, as unlike standard RL, meta-RL can *learn* to explore, and potentially learn highly complex strategies far beyond those of standard RL, strategies such as experimenting in early episodes to learn new skills, or conducting experiments to learn about the current environment.
Traditional meta-RL focuses on the problem of learning to optimally balance exploration and exploitation to maximize the *cumulative reward* of the episode sequence (e.g., aiming to maximize the total wins in a tournament -- while also improving as a player).
We identify a new challenge with state-of-the-art cumulative-reward meta-RL methods.
When optimal behavior requires exploration that sacrifices immediate reward to enable higher subsequent reward, existing state-of-the-art cumulative-reward meta-RL methods become stuck on the local optimum of failing to explore.
Our method, First-Explore, overcomes this limitation by learning two policies: one to solely explore, and one to solely exploit. When exploring requires forgoing early-episode reward, First-Explore significantly outperforms existing cumulative meta-RL methods. By identifying and solving the previously unrecognized problem of forgoing reward in early episodes, First-Explore represents a significant step towards developing meta-RL algorithms capable of human-like exploration on a broader range of domains.
tl;dr: This work presents a new graphical quantity and shows that, when one assumes the Markov property over this graph, it leads to much faster rates for nonparametric density estimation.

We consider the problem of estimating a structured multivariate density, subject to Markov conditions implied by an undirected graph. In the worst case, without Markovian assumptions, this problem suffers from the curse of dimensionality. Our main result shows how the curse of dimensionality can be avoided or greatly alleviated under the Markov property, and applies to arbitrary graphs. While existing results along these lines focus on sparsity or manifold assumptions, we introduce a new graphical quantity called ``graph resilience'' and show that it dictates the optimal sample complexity. Surprisingly, although one might expect the sample complexity of this problem to scale with local graph parameters such as the degree, this turns out not to be the case. Through explicit examples, we compute uniform deviation bounds and illustrate how the curse of dimensionality in density estimation can thus be circumvented. Notable examples where the rate improves substantially include sequential, hierarchical, and spatial data.
tl;dr: We propose a new causal inference method that infers valid proxies from unstructured text data for proximal causal inference.

Recent text-based causal methods attempt to mitigate confounding bias by estimating proxies of confounding variables that are partially or imperfectly measured from unstructured text data. These approaches, however, assume analysts have supervised labels of the confounders given text for a subset of instances, a constraint that is sometimes infeasible due to data privacy or annotation costs. In this work, we address settings in which an important confounding variable is completely unobserved. We propose a new causal inference method that uses two instances of pre-treatment text data, infers two proxies using two zero-shot models on the separate instances, and applies these proxies in the proximal g-formula. We prove, under certain assumptions about the instances of text and accuracy of the zero-shot predictions, that our method of inferring text-based proxies satisfies identification conditions of the proximal g-formula while other seemingly reasonable proposals do not. To address untestable assumptions associated with our method and the proximal g-formula, we further propose an odds ratio falsification heuristic that flags when to proceed with downstream effect estimation using the inferred proxies. We evaluate our method in synthetic and semi-synthetic settings---the latter with real-world clinical notes from MIMIC-III and open large language models for zero-shot prediction---and find that our method produces estimates with low bias. We believe that this text-based design of proxies allows for the use of proximal causal inference in a wider range of scenarios, particularly those for which obtaining suitable proxies from structured data is difficult.

Predicting the effects of protein mutations is crucial for analyzing protein functions and understanding genetic diseases.
However, existing models struggle to effectively extract mutation-related local structure motifs from protein databases, which hinders their predictive accuracy and robustness. To tackle this problem, we design a novel retrieval-augmented framework for incorporating similar structure information in known protein structures. We create a vector database consisting of local structure motif embeddings from a pre-trained protein structure encoder, which allows for efficient retrieval of similar local structure motifs during mutation effect prediction.
Our findings demonstrate that leveraging this method results in the SOTA performance across multiple protein mutation prediction datasets, and offers a scalable solution for studying mutation effects.

Designing causal bandit algorithms depends on two central categories of assumptions: (i) the extent of information about the underlying causal graphs and (ii) the extent of information about interventional statistical models. There have been extensive recent advances in dispensing with assumptions on either category. These include assuming known graphs but unknown interventional distributions, and the converse setting of assuming unknown graphs but access to restrictive hard/$\operatorname{do}$ interventions, which removes the stochasticity and ancestral dependencies. Nevertheless, the problem in its general form, i.e., _unknown_ graph and _unknown_ stochastic intervention models, remains open. This paper addresses this problem and establishes that in a graph with $N$ nodes, maximum in-degree $d$ and maximum causal path length $L$, after $T$ interaction rounds the regret upper bound scales as $\tilde{\mathcal{O}}((cd)^{L-\frac{1}{2}}\sqrt{T} + d + RN)$ where $c>1$ is a constant and $R$ is a measure of intervention power. A universal minimax lower bound is also established, which scales as $\Omega(d^{L-\frac{3}{2}}\sqrt{T})$. Importantly, the graph size $N$ has a diminishing effect on the regret as $T$ grows. These bounds have matching behavior in $T$, exponential dependence on $L$, and polynomial dependence on $d$ (with the gap $d\ $). On the algorithmic aspect, the paper presents a novel way of designing a computationally efficient CB algorithm, addressing a challenge that the existing CB algorithms using soft interventions face.
tl;dr: We propose Learning from Teaching (LoT), a novel regularization technique for deep neural networks to enhance generalization.

Generalization remains a central challenge in machine learning. In this work, we propose *Learning from Teaching* (**LoT**), a novel regularization technique for deep neural networks to enhance generalization. Inspired by the human ability to capture concise and abstract patterns, we hypothesize that generalizable correlations are expected to be easier to imitate. LoT operationalizes this concept to improve the generalization of the main model with auxiliary student learners. The student learners are trained by the main model and, in turn, provide feedback to help the main model capture more generalizable and imitable correlations. Our experimental results across several domains, including Computer Vision, Natural Language Processing, and methodologies like Reinforcement Learning, demonstrate that the introduction of LoT brings significant benefits compared to training models on the original dataset. The results suggest the effectiveness and efficiency of LoT in identifying generalizable information at the right scales while discarding spurious data correlations, thus making LoT a valuable addition to current machine learning. Code is available at https://github.com/jincan333/LoT.
tl;dr: A novel-designed event processing framework capable of splitting events stream in an adaptive manner.

Event-based cameras are attracting significant interest as they provide rich edge information, high dynamic range, and high temporal resolution. Many state-of-the-art event-based algorithms rely on splitting the events into fixed groups, resulting in the omission of crucial temporal information, particularly when dealing with diverse motion scenarios (e.g., high/low speed). In this work, we propose SpikeSlicer, a novel-designed event processing framework capable of splitting events stream adaptively. SpikeSlicer utilizes a low-energy spiking neural network (SNN) to trigger event slicing. To guide the SNN to fire spikes at optimal time steps, we propose the Spiking Position-aware Loss (SPA-Loss) to modulate the neuron's state. Additionally, we develop a Feedback-Update training strategy that refines the slicing decisions using feedback from the downstream artificial neural network (ANN). Extensive experiments demonstrate that our method yields significant performance improvements in event-based object tracking and recognition. Notably, SpikeSlicer provides a brand-new SNN-ANN cooperation paradigm, where the SNN acts as an efficient, low-energy data processor to assist the ANN in improving downstream performance, injecting new perspectives and potential avenues of exploration.
2783. Hallo3D: Multi-Modal Hallucination Detection and Mitigation for Consistent 3D Content Generation
tl;dr: We address the 'Janus Problem' in 3D content generation with a novel method that leverages multimodal models to enhance multi-view consistency without requiring 3D training data.

Recent advancements in 3D content generation have been significant, primarily due to the visual priors provided by pretrained diffusion models. However, large 2D visual models exhibit spatial perception hallucinations, leading to multi-view inconsistency in 3D content generated through Score Distillation Sampling (SDS). This phenomenon, characterized by overfitting to specific views, is referred to as the "Janus Problem". In this work, we investigate the hallucination issues of pretrained models and find that large multimodal models without geometric constraints possess the capability to infer geometric structures, which can be utilized to mitigate multi-view inconsistency. Building on this, we propose a novel tuning-free method. We represent the multimodal inconsistency query information to detect specific hallucinations in 3D content, using this as an enhanced prompt to re-consist the 2D renderings of 3D and jointly optimize the structure and appearance across different views. Our approach does not require 3D training data and can be implemented plug-and-play within existing frameworks. Extensive experiments demonstrate that our method significantly improves the consistency of 3D content generation and specifically mitigates hallucinations caused by pretrained large models, achieving state-of-the-art performance compared to other optimization methods.
tl;dr: New Transformer architecture that allows overlapping communication collectives with compute to speed up inference.

Large Transformer networks are increasingly used in settings where low inference latency is necessary to enable new applications and improve the end-user experience.
However, autoregressive inference is resource intensive and requires parallelism for efficiency.
Parallelism introduces collective communication that is both expensive and represents a phase when hardware resources are underutilized.
Towards mitigating this, Kraken is an evolution of the standard Transformer architecture that is designed to complement existing tensor parallelism schemes for efficient inference on multi-device systems.
By introducing a fixed degree of intra-layer model parallelism, the architecture allows collective operations to be overlapped with compute, decreasing latency and increasing hardware utilization.
When trained on OpenWebText, Kraken models reach a similar perplexity as standard Transformers while also preserving their language modeling capabilities as evaluated on the SuperGLUE benchmark.
Importantly, when tested on multi-GPU systems using TensorRT-LLM engines, Kraken speeds up Time To First Token by a mean of 35.6% across a range of model sizes, context lengths, and degrees of tensor parallelism.

How can diffusion models process 3D geometries in a coarse-to-fine manner, akin to our multiscale view of the world?
In this paper, we address the question by focusing on a fundamental biochemical problem of generating 3D molecular conformers conditioned on molecular graphs in a multiscale manner.
Our approach consists of two hierarchical stages: i) generation of coarse-grained fragment-level 3D structure from the molecular graph, and ii) generation of fine atomic details from the coarse-grained approximated structure while allowing the latter to be adjusted simultaneously.
For the challenging second stage, which demands preserving coarse-grained information while ensuring SE(3) equivariance, we introduce a novel generative model termed Equivariant Blurring Diffusion (EBD), which defines a forward process that moves towards the fragment-level coarse-grained structure by blurring the fine atomic details of conformers, and a reverse process that performs the opposite operation using equivariant networks.
We demonstrate the effectiveness of EBD by geometric and chemical comparison to state-of-the-art denoising diffusion models on a benchmark of drug-like molecules.
Ablation studies draw insights on the design of EBD by thoroughly analyzing its architecture, which includes the design of the loss function and the data corruption process.
Codes are released at https://github.com/Shen-Lab/EBD.

Tree ensembles are one of the most widely used model classes. However, these models are susceptible to adversarial examples, i.e., slightly perturbed examples that elicit a misprediction. There has been significant research on designing approaches to construct such examples for tree ensembles. But this is a computationally challenging problem that often must be solved a large number of times (e.g., for all examples in a training set). This is compounded by the fact that current approaches attempt to find such examples from scratch. In contrast, we exploit the fact that multiple similar problems are being solved. Specifically, our approach exploits the insight that adversarial examples for tree ensembles tend to perturb a consistent but relatively small set of features. We show that we can quickly identify this set of features and use this knowledge to speedup constructing adversarial examples.

Policy Mirror Descent (PMD) stands as a versatile algorithmic framework encompassing several seminal policy gradient algorithms such as natural policy gradient, with connections with state-of-the-art reinforcement learning (RL) algorithms such as TRPO and PPO. PMD can be seen as a soft Policy Iteration algorithm implementing regularized 1-step greedy policy improvement. However, 1-step greedy policies might not be the best choice and recent remarkable empirical successes in RL such as AlphaGo and AlphaZero have demonstrated that greedy approaches with respect to multiple steps outperform their 1-step counterpart. In this work, we propose a new class of PMD algorithms called $h$-PMD which incorporates multi-step greedy policy improvement with lookahead depth $h$ to the PMD update rule. To solve discounted infinite horizon Markov Decision Processes with discount factor $\gamma$, we show that $h$-PMD which generalizes the standard PMD enjoys a faster dimension-free $\gamma^h$-linear convergence rate, contingent on the computation of multi-step greedy policies. We propose an inexact version of $h$-PMD where lookahead action values are estimated. Under a generative model, we establish a sample complexity for $h$-PMD which improves over prior work. Finally, we extend our result to linear function approximation to scale to large state spaces. Under suitable assumptions, our sample complexity only involves dependence on the dimension of the feature map space instead of the state space size.

Bilevel Optimization has experienced significant advancements recently with the introduction of new efficient algorithms. Mirroring the success in single-level optimization, stochastic gradient-based algorithms are widely used in bilevel optimization. However, a common limitation in these algorithms is the presumption of independent sampling, which can lead to increased computational costs due to the unique hyper-gradient structure in bilevel problems. To address this challenge, we study the example-selection strategy for bilevel optimization in this work. More specifically, we introduce a without-replacement sampling based algorithm which achieves a faster convergence rate compared to its counterparts that rely on independent sampling. Beyond the standard bilevel optimization formulation, we extend our discussion to conditional bilevel optimization and also two special cases: minimax and compositional optimization. Finally, we validate our algorithms over both synthetic and real-world applications. Numerical results clearly showcase the superiority of our algorithms.

Open-vocabulary 3D object detection (OV-3Det) aims to generalize beyond the limited number of base categories labeled during the training phase. The biggest bottleneck is the scarcity of annotated 3D data, whereas 2D image datasets are abundant and richly annotated. Consequently, it is intuitive to leverage the wealth of annotations in 2D images to alleviate the inherent data scarcity in OV-3Det. In this paper, we push the task setup to its limits by exploring the potential of using solely 2D images to learn OV-3Det. The major challenges for this setup is the modality gap between training images and testing point clouds, which prevents effective integration of 2D knowledge into OV-3Det. To address this challenge, we propose a novel framework ImOV3D to leverage pseudo multimodal representation containing both images and point clouds (PC) to close the modality gap. The key of ImOV3D lies in flexible modality conversion where 2D images can be lifted into 3D using monocular depth estimation and can also be derived from 3D scenes through rendering. This allows unifying both training images and testing point clouds into a common image-PC representation, encompassing a wealth of 2D semantic information and also incorporating the depth and structural characteristics of 3D spatial data. We carefully conduct such conversion to minimize the domain gap between training and test cases. Extensive experiments on two benchmark datasets, SUNRGBD and ScanNet, show that ImOV3D significantly outperforms existing methods, even in the absence of ground truth 3D training data. With the inclusion of a minimal amount of real 3D data for fine-tuning, the performance also significantly surpasses previous state-of-the-art. Codes and pre-trained models are released on the https://github.com/yangtiming/ImOV3D.

Nuanced expressiveness, especially through detailed hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations.
In this work, we aim to learn expressive human avatars from a monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details.
To this end, we introduce EVA, a drivable human model that can recover fine details based on 3D Gaussians and an expressive parametric human model, SMPL-X.
Focused on enhancing expressiveness, our work makes three key contributions.
First, we highlight the importance of aligning the SMPL-X model with the video frames for effective avatar learning.
Recognizing the limitations of current methods for estimating SMPL-X parameters from in-the-wild videos, we introduce a reconstruction module that significantly improves the image-model alignment.
Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts.
Third, we develop a feedback mechanism that predicts per-pixel confidence to better guide the optimization of 3D Gaussians.
Extensive experiments on two benchmarks demonstrate the superiority of our approach both quantitatively and qualitatively, especially on the fine-grained hand and facial details.
We make our code available at the project website: https://evahuman.github.io.

While the continuous Entropic Optimal Transport (EOT) field has been actively developing in recent years, it became evident that the classic EOT problem is prone to different issues like the sensitivity to outliers and imbalance of classes in the source and target measures. This fact inspired the development of solvers that deal with the *unbalanced* EOT (UEOT) problem $-$ the generalization of EOT allowing for mitigating the mentioned issues by relaxing the marginal constraints. Surprisingly, it turns out that the existing solvers are either based on heuristic principles or heavy-weighted with complex optimization objectives involving several neural networks. We address this challenge and propose a novel theoretically-justified, lightweight, unbalanced EOT solver. Our advancement consists of developing a novel view on the optimization of the UEOT problem yielding tractable and a non-minimax optimization objective. We show that combined with a light parametrization recently proposed in the field our objective leads to a fast, simple, and effective solver which allows solving the continuous UEOT problem in minutes on CPU. We prove that our solver provides a universal approximation of UEOT solutions and obtain its generalization bounds. We give illustrative examples of the solver's performance.
tl;dr: A new method for aerial visual localization using LoD 3D map with neural wireframe alignment.

We propose a new method named LoD-Loc for visual localization in the air. Unlike existing localization algorithms, LoD-Loc does not rely on complex 3D representations and can estimate the pose of an Unmanned Aerial Vehicle (UAV) using a Level-of-Detail (LoD) 3D map. LoD-Loc mainly achieves this goal by aligning the wireframe derived from the LoD projected model with that predicted by the neural network. Specifically, given a coarse pose provided by the UAV sensor, LoD-Loc hierarchically builds a cost volume for uniformly sampled pose hypotheses to describe pose probability distribution and select a pose with maximum probability. Each cost within this volume measures the degree of line alignment between projected and predicted wireframes. LoD-Loc also devises a 6-DoF pose optimization algorithm to refine the previous result with a differentiable Gaussian-Newton method. As no public dataset exists for the studied problem, we collect two datasets with map levels of LoD3.0 and LoD2.0, along with real RGB queries and ground-truth pose annotations. We benchmark our method and demonstrate that LoD-Loc achieves excellent performance, even surpassing current state-of-the-art methods that use textured 3D models for localization. The code and dataset will be made available upon publication.
tl;dr: We show how to do representation decomposition and interpretation if your ViT != CLIP

Recent work has explored how individual components of the CLIP-ViT model contribute to the final representation by leveraging the shared image-text representation space of CLIP. These components, such as attention heads and MLPs, have been shown to capture distinct image features like shape, color or texture. However, understanding the role of these components in arbitrary vision transformers (ViTs) is challenging. To this end, we introduce a general framework which can identify the roles of various components in ViTs beyond CLIP. Specifically, we (a) automate the decomposition of the final representation into contributions from different model components, and (b) linearly map these contributions to CLIP space to interpret them via text. Additionally, we introduce a novel scoring function to rank components by their importance with respect to specific features.
Applying our framework to various ViT variants (e.g. DeiT, DINO, DINOv2, Swin, MaxViT), we gain insights into the roles of different components concerning particular image features. These insights facilitate applications such as image retrieval using text descriptions or reference images, visualizing token importance heatmaps, and mitigating spurious correlations. We release our [code](https://github.com/SriramB-98/vit-decompose) to reproduce the experiments in the paper.
tl;dr: Enhanced Multimodal Fusion with Coupled State Space Model

The essence of multi-modal fusion lies in exploiting the complementary information inherent in diverse modalities.However, most prevalent fusion methods rely on traditional neural architectures and are inadequately equipped to capture the dynamics of interactions across modalities, particularly in presence of complex intra- and inter-modality correlations.Recent advancements in State Space Models (SSMs), notably exemplified by the Mamba model, have emerged as promising contenders. Particularly, its state evolving process implies stronger modality fusion paradigm, making multi-modal fusion on SSMs an appealing direction. However, fusing multiple modalities is challenging for SSMs due to its hardware-aware parallelism designs. To this end, this paper proposes the Coupled SSM model, for coupling state chains of multiple modalities while maintaining independence of intra-modality state processes. Specifically, in our coupled scheme, we devise an inter-modal hidden states transition scheme, in which the current state is dependent on the states of its own chain and that of the neighbouring chains at the previous time-step. To fully comply with the hardware-aware parallelism, we obtain the global convolution kernel by deriving the state equation while introducing the historical state.Extensive experiments on CMU-MOSEI, CH-SIMS, CH-SIMSV2 through multi-domain input verify the effectiveness of our model compared to current state-of-the-art methods, improved F1-Score by 0.4%, 0.9%, and 2.3% on the three datasets respectively, 49% faster inference and 83.7% GPU memory save. The results demonstrate that Coupled Mamba model is capable of enhanced multi-modal fusion.

Worldwide geolocalization aims to locate the precise location at the coordinate level of photos taken anywhere on the Earth. It is very challenging due to 1) the difficulty of capturing subtle location-aware visual semantics, and 2) the heterogeneous geographical distribution of image data. As a result, existing studies have clear limitations when scaled to a worldwide context. They may easily confuse distant images with similar visual contents, or cannot adapt to various locations worldwide with different amounts of relevant data. To resolve these limitations, we propose **G3**, a novel framework based on Retrieval-Augmented Generation (RAG). In particular, G3 consists of three steps, i.e., **G**eo-alignment, **G**eo-diversification, and **G**eo-verification to optimize both retrieval and generation phases of worldwide geolocalization. During Geo-alignment, our solution jointly learns expressive multi-modal representations for images, GPS and textual descriptions, which allows us to capture location-aware semantics for retrieving nearby images for a given query. During Geo-diversification, we leverage a prompt ensembling method that is robust to inconsistent retrieval performance for different image queries. Finally, we combine both retrieved and generated GPS candidates in Geo-verification for location prediction. Experiments on two well-established datasets IM2GPS3k and YFCC4k verify the superiority of G3 compared to other state-of-the-art methods. Our code is available online [https://github.com/Applied-Machine-Learning-Lab/G3](https://github.com/Applied-Machine-Learning-Lab/G3) for reproduction.
tl;dr: A SE(3)-bi-equivariant and correspondence-free method for point cloud assembly.

Given a pair of point clouds, the goal of assembly is to recover a rigid transformation that aligns one point cloud to the other. This task is challenging because the point clouds may be non-overlapped, and they may have arbitrary initial positions. To address these difficulties, we propose a method, called $SE(3)$-bi-equivariant transformer (BITR), based on the $SE(3)$-bi-equivariance prior of the task:it guarantees that when the inputs are rigidly perturbed, the output will transform accordingly. Due to its equivariance property, BITR can not only handle non-overlapped PCs, but also guarantee robustness against initial positions. Specifically, BITR first extracts features of the inputs using a novel $SE(3) \times SE(3)$-transformer, and then projects the learned feature to group $SE(3)$ as the output. Moreover, we theoretically show that swap and scale equivariances can be incorporated into BITR, thus it further guarantees stable performance under scaling and swapping the inputs. We experimentally show the effectiveness of BITR in practical tasks.

Multiple Instance Learning (MIL) has been increasingly adopted to mitigate the high costs and complexity associated with labeling individual instances, learning instead from bags of instances labeled at the bag level and enabling instance-level labeling. While existing research has primarily focused on the learnability of MIL at the bag level, there is an absence of theoretical exploration to check if a given MIL algorithm is learnable at the instance level. This paper proposes a theoretical framework based on probably approximately correct (PAC) learning theory to assess the instance-level learnability of deep multiple instance learning (Deep MIL) algorithms. Our analysis exposes significant gaps between current Deep MIL algorithms, highlighting the theoretical conditions that must be satisfied by MIL algorithms to ensure instance-level learnability. With these conditions, we interpret the learnability of the representative Deep MIL algorithms and validate them through empirical studies.

End-to-end transformer-based trackers have achieved remarkable performance on most human-related datasets. However, training these trackers in heterogeneous scenarios poses significant challenges, including negative interference - where the model learns conflicting scene-specific parameters - and limited domain generalization, which often necessitates expensive fine-tuning to adapt the models to new domains. In response to these challenges, we introduce Parameter-efficient Scenario-specific Tracking Architecture (PASTA), a novel framework that combines Parameter-Efficient Fine-Tuning (PEFT) and Modular Deep Learning (MDL). Specifically, we define key scenario attributes (e.g, camera-viewpoint, lighting condition) and train specialized PEFT modules for each attribute. These expert modules are combined in parameter space, enabling systematic generalization to new domains without increasing inference time. Extensive experiments on MOTSynth, along with zero-shot evaluations on MOT17 and PersonPath22 demonstrate that a neural tracker built from carefully selected modules surpasses its monolithic counterpart. We release models and code.
tl;dr: We propose a novel Generative Graph Anomaly Detection approach (GGAD) for an under-explored semi-supervised setting that has only labeled normal nodes and establish an evaluation benchmark for the setting.

This work considers a practical semi-supervised graph anomaly detection (GAD) scenario, where part of the nodes in a graph are known to be normal, contrasting to the extensively explored unsupervised setting with a fully unlabeled graph. We reveal that having access to the normal nodes, even just a small percentage of normal nodes, helps enhance the detection performance of existing unsupervised GAD methods when they are adapted to the semi-supervised setting. However, their utilization of these normal nodes is limited. In this paper, we propose a novel Generative GAD approach (namely GGAD) for the semi-supervised scenario to better exploit the normal nodes. The key idea is to generate pseudo anomaly nodes, referred to as 'outlier nodes', for providing effective negative node samples in training a discriminative one-class classifier. The main challenge here lies in the lack of ground truth information about real anomaly nodes. To address this challenge, GGAD is designed to leverage two important priors about the anomaly nodes -- asymmetric local affinity and egocentric closeness -- to generate reliable outlier nodes that assimilate anomaly nodes in both graph structure and feature representations. Comprehensive experiments on six real-world GAD datasets are performed to establish a benchmark for semi-supervised GAD and show that GGAD substantially outperforms state-of-the-art unsupervised and semi-supervised GAD methods with varying numbers of training normal nodes.

Speculative decoding has demonstrated its effectiveness in accelerating the inference of large language models (LLMs) while maintaining an identical sampling distribution. However, the conventional approach of training separate draft model to achieve a satisfactory token acceptance rate can be costly and impractical. In this paper, we propose a novel self-speculative decoding framework \emph{Kangaroo} with \emph{double} early exiting strategy, which leverages the shallow sub-network and the \texttt{LM Head} of the well-trained target LLM to construct a self-drafting model. Then, the self-verification stage only requires computing the remaining layers over the \emph{early-exited} hidden states in parallel. To bridge the representation gap between the sub-network and the full model, we train a lightweight and efficient adapter module on top of the sub-network. One significant challenge that comes with the proposed method is that the inference latency of the self-draft model may no longer be negligible compared to the big model. To boost the token acceptance rate while minimizing the latency of the self-drafting model, we introduce an additional \emph{early exiting} mechanism for both single-sequence and the tree decoding scenarios. Specifically, we dynamically halt the small model's subsequent prediction during the drafting phase once the confidence level for the current step falls below a certain threshold. This approach reduces unnecessary computations and improves overall efficiency. Extensive experiments on multiple benchmarks demonstrate our effectiveness, where Kangaroo achieves walltime speedups up to 2.04$\times$, outperforming Medusa-1 with 88.7\% fewer additional parameters. The code for Kangaroo is available at https://github.com/Equationliu/Kangaroo.
2801. Du-IN: Discrete units-guided mask modeling for decoding speech from Intracranial Neural signals
tl;dr: We propose the Du-IN model, a framework for sEEG-to-Word translation task, learning contextual embeddings through discrete codebook-guided pre-training on specific brain regions.

Invasive brain-computer interfaces with Electrocorticography (ECoG) have shown promise for high-performance speech decoding in medical applications, but less damaging methods like intracranial stereo-electroencephalography (sEEG) remain underexplored. With rapid advances in representation learning, leveraging abundant recordings to enhance speech decoding is increasingly attractive. However, popular methods often pre-train temporal models based on brain-level tokens, overlooking that brain activities in different regions are highly desynchronized during tasks. Alternatively, they pre-train spatial-temporal models based on channel-level tokens but fail to evaluate them on challenging tasks like speech decoding, which requires intricate processing in specific language-related areas. To address this issue, we collected a well-annotated Chinese word-reading sEEG dataset targeting language-related brain networks from 12 subjects. Using this benchmark, we developed the Du-IN model, which extracts contextual embeddings based on region-level tokens through discrete codex-guided mask modeling. Our model achieves state-of-the-art performance on the 61-word classification task, surpassing all baselines. Model comparisons and ablation studies reveal that our design choices, including (\romannumeral1) temporal modeling based on region-level tokens by utilizing 1D depthwise convolution to fuse channels in the ventral sensorimotor cortex (vSMC) and superior temporal gyrus (STG) and (\romannumeral2) self-supervision through discrete codex-guided mask modeling, significantly contribute to this performance. Overall, our approach -- inspired by neuroscience findings and capitalizing on region-level representations from specific brain regions -- is suitable for invasive brain modeling and represents a promising neuro-inspired AI approach in brain-computer interfaces. Code and dataset are available at https://github.com/liulab-repository/Du-IN.
tl;dr: We formalize and analyze heterophilic link prediction with GNNs, when connected nodes have dissimilar features. We identify real-world heterophilic benchmarks and show that learnable decoders and separated node embeddings are crucial for such graphs.

Heterophily, or the tendency of connected nodes in networks to have different class labels or dissimilar features, has been identified as challenging for many Graph Neural Network (GNN) models. While the challenges of applying GNNs for node classification when class labels display strong heterophily are well understood, it is unclear how heterophily affects GNN performance in other important graph learning tasks where class labels are not available. In this work, we focus on the link prediction task and systematically analyze the impact of heterophily in node features on GNN performance. We first introduce formal definitions of homophilic and heterophilic link prediction tasks, and present a theoretical framework that highlights the different optimizations needed for the respective tasks. We then analyze how different link prediction encoders and decoders adapt to varying levels of feature homophily and introduce designs for improved performance. Based on our definitions, we identify and analyze six real-world benchmarks spanning from homophilic to heterophilic link prediction settings, with graphs containing up to 30M edges. Our empirical analysis on a variety of synthetic and real-world datasets confirms our theoretical insights and highlights the importance of adopting learnable decoders and GNN encoders with ego- and neighbor-embedding separation in message passing for link prediction tasks beyond homophily.

Current methods for training Binarized Neural Networks (BNNs) heavily rely on the heuristic straight-through estimator (STE), which crucially enables the application of SGD-based optimizers to the combinatorial training problem. Although the STE heuristics and their variants have led to significant improvements in BNN performance, their theoretical underpinnings remain unclear and relatively understudied. In this paper, we propose a theoretically motivated optimization framework for BNN training based on Gaussian variational inference. In its simplest form, our approach yields a non-convex linear programming formulation whose variables and associated gradients motivate the use of latent weights and STE gradients. More importantly, our framework allows us to formulate semidefinite programming (SDP) relaxations to the BNN training task. Such formulations are able to explicitly models pairwise correlations between weights during training, leading to a more accurate optimization characterization of the training problem. As the size of such formulations grows quadratically in the number of weights, quickly becoming intractable for large networks, we apply the Burer-Monteiro approach and only optimize over linear-size low-rank SDP solutions. Our empirical evaluation on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet datasets shows our method consistently outperforming all state-of-the-art algorithms for training BNNs.
2804. BECAUSE: Bilinear Causal Representation for Generalizable Offline Model-based Reinforcement Learning

Offline model-based reinforcement learning (MBRL) enhances data efficiency by utilizing pre-collected datasets to learn models and policies, especially in scenarios where exploration is costly or infeasible. Nevertheless, its performance often suffers from the objective mismatch between model and policy learning, resulting in inferior performance despite accurate model predictions. This paper first identifies the primary source of this mismatch comes from the underlying confounders present in offline data for MBRL. Subsequently, we introduce **B**ilin**E**ar **CAUS**al r**E**presentation (BECAUSE), an algorithm to capture causal representation for both states and actions to reduce the influence of the distribution shift, thus mitigating the objective mismatch problem. Comprehensive evaluations on 18 tasks that vary in data quality and environment context demonstrate the superior performance of BECAUSE over existing offline RL algorithms. We show the generalizability and robustness of BECAUSE under fewer samples or larger numbers of confounders. Additionally, we offer theoretical analysis of BECAUSE to prove its error bound and sample efficiency when integrating causal representation into offline MBRL. See more details in our project page: [https://sites.google.com/view/be-cause](https://sites.google.com/view/be-cause).
tl;dr: A graph-based continuous-time model is proposed to unveil systemic interactions and improve time series tasks such as classification and forecasting.

Interacting systems are prevalent in nature. It is challenging to accurately predict the dynamics of the system if its constituent components are analyzed independently. We develop a graph-based model that unveils the systemic interactions of time series observed at irregular time points, by using a directed acyclic graph to model the conditional dependencies (a form of causal notation) of the system components and learning this graph in tandem with a continuous-time model that parameterizes the solution curves of ordinary differential equations (ODEs). Our technique, a graph neural flow, leads to substantial enhancements over non-graph-based methods, as well as graph-based methods without the modeling of conditional dependencies. We validate our approach on several tasks, including time series classification and forecasting, to demonstrate its efficacy.
tl;dr: GraphMETRO utilizes a mixture-of-experts architecture to effectively handle complex distribution shifts in graph data, achieving state-of-the-art results on benchmark datasets.

Graph data are inherently complex and heterogeneous, leading to a high natural diversity of distributional shifts. However, it remains unclear how to build machine learning architectures that generalize to the complex distributional shifts naturally occurring in the real world. Here, we develop GraphMETRO, a Graph Neural Network architecture that models natural diversity and captures complex distributional shifts. GraphMETRO employs a Mixture-of-Experts (MoE) architecture with a gating model and multiple expert models, where each expert model targets a specific distributional shift to produce a referential representation w.r.t. a reference model, and the gating model identifies shift components. Additionally, we design a novel objective that aligns the representations from different expert models to ensure reliable optimization. GraphMETRO achieves state-of-the-art results on four datasets from the GOOD benchmark, which is comprised of complex and natural real-world distribution shifts, improving by 67% and 4.2% on the WebKB and Twitch datasets. Code and data are available at https://github.com/Wuyxin/GraphMETRO.
tl;dr: Orthogonality Regularization is the first time to be used in Self-supervised learning(SSL), which prevents dimension collapse of weight matrices, hidden features and representations and thus improves performance of SSL.

Self-supervised learning (SSL) has rapidly advanced in recent years, approaching the performance of its supervised counterparts through the extraction of representations from unlabeled data. However, dimensional collapse, where a few large eigenvalues dominate the eigenspace, poses a significant obstacle for SSL. When dimensional collapse occurs on features (e.g. hidden features and representations), it prevents features from representing the full information of the data; when dimensional collapse occurs on weight matrices, their filters are self-related and redundant, limiting their expressive power.
Existing studies have predominantly concentrated on the dimensional collapse of representations, neglecting whether this can sufficiently prevent the dimensional collapse of the weight matrices and hidden features.
To this end, we first time propose a mitigation approach employing orthogonal regularization (OR) across the encoder, targeting both convolutional and linear layers during pretraining. OR promotes orthogonality within weight matrices, thus safeguarding against the dimensional collapse of weight matrices, hidden features, and representations. Our empirical investigations demonstrate that OR significantly enhances the performance of SSL methods across diverse benchmarks, yielding consistent gains with both CNNs and Transformer-based architectures.
tl;dr: We provide the provably minimal set of entries from the adjacency matrix necessary to train representations for transitively-closed DAGs, provided our energy function has transitivity bias.

When training node embedding models to represent large directed graphs (digraphs), it is impossible to observe all entries of the adjacency matrix during training. As a consequence most methods employ sampling. For very large digraphs, however, this means many (most) entries may be unobserved during training. In general, observing every entry would be necessary to uniquely identify a graph, however if we know the graph has a certain property some entries can be omitted - for example, only half the entries would be required for a symmetric graph.
In this work, we develop a novel framework to identify a subset of entries required to uniquely distinguish a graph among all transitively-closed DAGs. We give an explicit algorithm to compute the provably minimal set of entries, and demonstrate empirically that one can train node embedding models with greater efficiency and performance, provided the energy function has an appropriate inductive bias. We achieve robust performance on synthetic hierarchies and a larger real-world taxonomy, observing improved convergence rates in a resource-constrained setting while reducing the set of training examples by as much as 99%.

Transformers have demonstrated great power in the recent development of large foundational models. In particular, the Vision Transformer (ViT) has brought revolutionary changes to the field of vision, achieving significant accomplishments on the experimental side. However, their theoretical capabilities, particularly in terms of generalization when trained to overfit training data, are still not fully understood. To address this gap, this work delves deeply into the \textit{benign overfitting} perspective of transformers in vision. To this end, we study the optimization of a Transformer composed of a self-attention layer with softmax followed by a fully connected layer under gradient descent on a certain data distribution model. By developing techniques that address the challenges posed by softmax and the interdependent nature of multiple weights in transformer optimization, we successfully characterized the training dynamics and achieved generalization in post-training. Our results establish a sharp condition that can distinguish between the small test error phase and the large test error regime, based on the signal-to-noise ratio in the data model. The theoretical results are further verified by experimental simulation. To the best of our knowledge, this is the first work to characterize benign overfitting for Transformers.

Effectively designing molecular geometries is essential to advancing pharmaceutical innovations, a domain, which has experienced great attention through the success of generative models and, in particular, diffusion models. However, current molecular diffusion models are tailored towards a specific downstream task and lack adaptability. We introduce UniGuide, a framework for controlled geometric guidance of unconditional diffusion models that allows flexible conditioning during inference without the requirement of extra training or networks. We show how applications such as structure-based, fragment-based, and ligand-based drug design are formulated in the UniGuide framework and demonstrate on-par or superior performance compared to specialised models. Offering a more versatile approach, UniGuide has the potential to streamline the development of molecular generative models, allowing them to be readily used in diverse application scenarios.
tl;dr: Object selection and segmentation using graph cut for scene represented using 3D gaussian splatting

We introduce GaussianCut, a new method for interactive multiview segmentation of scenes represented as 3D Gaussians. Our approach allows for selecting the objects to be segmented by interacting with a single view. It accepts intuitive user input, such as point clicks, coarse scribbles, or text. Using 3D Gaussian Splatting (3DGS) as the underlying scene representation simplifies the extraction of objects of interest which are considered to be a subset of the scene's Gaussians. Our key idea is to represent the scene as a graph and use the graph-cut algorithm to minimize an energy function to effectively partition the Gaussians into foreground and background. To achieve this, we construct a graph based on scene Gaussians and devise a segmentation-aligned energy function on the graph to combine user inputs with scene properties. To obtain an initial coarse segmentation, we leverage 2D image/video segmentation models and further refine these coarse estimates using our graph construction. Our empirical evaluations show the adaptability of GaussianCut across a diverse set of scenes. GaussianCut achieves competitive performance with state-of-the-art approaches for 3D segmentation without requiring any additional segmentation-aware training
tl;dr: An effective model selection approach without using target labels for domain adaptive object detection.

Evaluating the performance of deep models in new scenarios has drawn increasing attention in recent years due to the wide application of deep learning techniques in various fields. However, while it is possible to collect data from new scenarios, the annotations are not always available. Existing Domain Adaptive Object Detection (DAOD) works usually report their performance by selecting the best model on the validation set or even the test set of the target domain, which is highly impractical in real-world applications. In this paper, we propose a novel unsupervised model selection approach for domain adaptive object detection, which is able to select almost the optimal model for the target domain without using any target labels. Our approach is based on the flat minima principle, i.e., models located in the flat minima region in the parameter space usually exhibit excellent generalization ability. However, traditional methods require labeled data to evaluate how well a model is located in the flat minima region, which is unrealistic for the DAOD task. Therefore, we design a Detection Adaptation Score (DAS) approach to approximately measure the flat minima without using target labels. We show via a generalization bound that the flatness can be deemed as model variance, while the minima depend on the domain distribution distance for the DAOD task. Accordingly, we propose a Flatness Index Score (FIS) to assess the flatness by measuring the classification and localization fluctuation before and after perturbations of model parameters and a Prototypical Distance Ratio (PDR) score to seek the minima by measuring the transferability and discriminability of the models. In this way, the proposed DAS approach can effectively represent the degree of flat minima and evaluate the model generalization ability on the target domain. We have conducted extensive experiments on various DAOD benchmarks and approaches, and the experimental results show that the proposed DAS correlates well with the performance of DAOD models and can be used as an effective tool for model selection after training. The code will be released at https://github.com/HenryYu23/DAS.
tl;dr: We propose a hybrid architecture with asymmetric distribution of convolution and attention blocks in different network stages to achieve superior latency-vs-performance trade-off in image recognition and generation tasks.

Neural network architecture design requires making many crucial decisions. The common desiderata is that similar decisions, with little modifications, can be reused in a variety of tasks and applications. To satisfy that, architectures must provide promising latency and performance trade-offs, support a variety of tasks, scale efficiently with respect to the amounts of data and compute, leverage available data from other tasks, and efficiently support various hardware. To this end, we introduce AsCAN---a hybrid architecture, combining both convolutional and transformer blocks. We revisit the key design principles of hybrid architectures and propose a simple and effective \emph{asymmetric} architecture, where the distribution of convolutional and transformer blocks is \emph{asymmetric}, containing more convolutional blocks in the earlier stages, followed by more transformer blocks in later stages. AsCAN supports a variety of tasks: recognition, segmentation, class-conditional image generation, and features a superior trade-off between performance and latency. We then scale the same architecture to solve a large-scale text-to-image task and show state-of-the-art performance compared to the most recent public and commercial models. Notably, without performing any optimization of inference time our model shows faster execution, even when compared to works that do such optimization, highlighting the advantages and the value of our approach.
tl;dr: We propose novel inventory-reserve algorithms for a piecewise-stationary BwK problem, achieving provably near-optimal competitive ratios adapting to available information against the dynamic benchmark without requiring bounded global variation.

We study Bandits with Knapsacks (Bwk) in a piecewise-stationary environment. We propose a novel inventory reserving algorithm which draws new insights into the problem. Suppose parameters $\eta_{\min}, \eta_{\max} \in (0,1]$ respectively lower and upper bound the reward earned and the resources consumed in a time round. Our algorithm achieves a provably near-optimal competitive ratio of $O(\log(\eta_{\max}/\eta_{\min}))$, with a matching lower bound provided. Our performance guarantee is based on a dynamic benchmark, distinguishing our work from existing works on adversarial Bwk who compare with the static benchmark. Furthermore, different from existing non-stationary Bwk work, we do not require a bounded global variation.
tl;dr: The paper introduces a novel unsupervised objective for learning data-dependent distribution kernel based on the principal of entropy maximization in measure embeddings space.

Empirical data can often be considered as samples from a set of probability distributions. Kernel methods have emerged as a natural approach for learning to classify these distributions. Although numerous kernels between distributions have been proposed, applying kernel methods to distribution regression tasks remains challenging, primarily because selecting a suitable kernel is not straightforward. Surprisingly, the question of learning a data-dependent distribution kernel has received little attention. In this paper, we propose a novel objective for the unsupervised learning of data-dependent distribution kernel, based on the principle of entropy maximization in the space of probability measure embeddings. We examine the theoretical properties of the latent embedding space induced by our objective, demonstrating that its geometric structure is well-suited for solving downstream discriminative tasks. Finally, we demonstrate the performance of the learned kernel across different modalities.
tl;dr: We have proposed a next-level post-training quantization scheme for Hyper-scale Transformer models

With the increasing complexity of generative AI models, post-training quantization (PTQ) has emerged as a promising solution for deploying hyper-scale models on edge devices such as mobile and TVs.
Existing PTQ schemes, however, consume considerable time and resources, which could be a bottleneck in real situations where frequent model updates and multiple hyperparameter tunings are required.
As a cost-effective alternative, learning-free PTQ schemes have been proposed.
However, the performance is somewhat limited because they cannot consider the inter-layer dependency within the attention module, which is a significant feature of Transformers.
In this paper, we thus propose a novel PTQ algorithm that balances accuracy and efficiency.
The key idea of the proposed algorithm called aespa is to perform quantization layer-wise for efficiency while targeting attention-wise reconstruction to consider the cross-layer dependency.
Through extensive experiments on various language models and complexity analysis, we demonstrate that aespa is accurate and efficient in quantizing Transformer models. The code will be available at https: //github.com/SamsungLabs/aespa.
tl;dr: We provide the first minimax regret lower bound for the online submodular maximization with stochastic bandit feedback, and an upperbound matching it in terms of time T and number of arms n.

We consider maximizing an unknown monotonic, submodular set function $f: 2^{[n]} \rightarrow [0,1]$ with cardinality constraint under stochastic bandit feedback.
At each time $t=1,\dots,T$ the learner chooses a set $S_t \subset [n]$ with $|S_t| \leq k$ and receives reward $f(S_t) + \eta_t$ where $\eta_t$ is mean-zero sub-Gaussian noise.
The objective is to minimize the learner's regret with respect to an approximation of the maximum $f(S_*)$ with $|S_*| = k$, obtained through robust greedy maximization of $f$.
To date, the best regret bound in the literature scales as $k n^{1/3} T^{2/3}$.
And by trivially treating every set as a unique arm one deduces that $\sqrt{ {n \choose k} T }$ is also achievable using standard multi-armed bandit algorithms.
In this work, we establish the first minimax lower bound for this setting that scales like $\tilde{\Omega}(\min_{L \le k}(L^{1/3}n^{1/3}T^{2/3} + \sqrt{{n \choose k - L}T}))$. For a slightly restricted algorithm class, we prove a stronger regret lower bound of $\tilde{\Omega}(\min_{L \le k}(Ln^{1/3}T^{2/3} + \sqrt{{n \choose k - L}T}))$.
Moreover, we propose an algorithm Sub-UCB that achieves regret $\tilde{\mathcal{O}}(\min_{L \le k}(Ln^{1/3}T^{2/3} + \sqrt{{n \choose k - L}T}))$ capable of matching the lower bound on regret for the restricted class up to logarithmic factors.
2818. Acceleration Exists! Optimization Problems When Oracle Can Only Compare Objective Function Values

Frequently, the burgeoning field of black-box optimization encounters challenges due to a limited understanding of the mechanisms of the objective function. To address such problems, in this work we focus on the deterministic concept of Order Oracle, which only utilizes order access between function values (possibly with some bounded noise), but without assuming access to their values. As theoretical results, we propose a new approach to create non-accelerated optimization algorithms (obtained by integrating Order Oracle into existing optimization “tools”) in non-convex, convex, and strongly convex settings that are as good as both SOTA coordinate algorithms with first-order oracle and SOTA algorithms with Order Oracle up to logarithm factor. Moreover, using the proposed approach, _we provide the first accelerated optimization algorithm using the Order Oracle_. And also, using an already different approach we provide the asymptotic convergence of _the first algorithm with the stochastic Order Oracle concept_. Finally, our theoretical results demonstrate effectiveness of proposed algorithms through numerical experiments.

This paper studies simple bilevel problems, where a convex upper-level function is minimized over the optimal solutions of a convex lower-level problem. We first show the fundamental difficulty of simple bilevel problems, that the approximate optimal value of such problems is not obtainable by first-order zero-respecting algorithms. Then we follow recent works to pursue the weak approximate solutions. For this goal, we propose novel near-optimal methods for smooth and nonsmooth problems by reformulating them into functionally constrained problems.
tl;dr: This paper propose introspective planning to guide Large Language Models (LLMs) planning with uncertainty awareness, and achieve a tighter confidence bound with conformal prediction.

Large language models (LLMs) exhibit advanced reasoning skills, enabling robots to comprehend natural language instructions and strategically plan high-level actions through proper grounding. However, LLM hallucination may result in robots confidently executing plans that are misaligned with user goals or even unsafe in critical scenarios. Additionally, inherent ambiguity in natural language instructions can introduce uncertainty into the LLM's reasoning and planning. We propose introspective planning, a systematic approach that guides LLMs to refine their own uncertainty in alignment with inherent task ambiguity. Our approach constructs a knowledge base containing introspective reasoning examples as post-hoc rationalizations of human-selected safe and compliant plans, which are retrieved during deployment. Evaluations on three tasks, including a new safe mobile manipulation benchmark, indicate that introspection substantially improves both compliance and safety over state-of-the-art LLM-based planning methods. Additionally, we empirically show that introspective planning, in combination with conformal prediction, achieves tighter confidence bounds, maintaining statistical success guarantees while minimizing unnecessary user clarification requests.
tl;dr: We show contrastive losses can be used to model a common effect in biological fitness functions, and improve predictive performance in fitness prediction benchmarks.

Fitness functions map large combinatorial spaces of biological sequences to properties of interest. Inferring these multimodal functions from experimental data is a central task in modern protein engineering. Global epistasis models are an effective and physically-grounded class of models for estimating fitness functions from observed data. These models assume that a sparse latent function is transformed by a monotonic nonlinearity to emit measurable fitness. Here we demonstrate that minimizing supervised contrastive loss functions, such as the Bradley-Terry loss, is a simple and flexible technique for extracting the sparse latent function implied by global epistasis. We argue by way of a fitness-epistasis uncertainty principle that the nonlinearities in global epistasis models can produce observed fitness functions that do not admit sparse representations, and thus may be inefficient to learn from observations when using a Mean Squared Error (MSE) loss (a common practice). We show that contrastive losses are able to accurately estimate a ranking function from limited data even in regimes where MSE is ineffective and validate the practical utility of this insight by demonstrating that contrastive loss functions result in consistently improved performance on empirical benchmark tasks.

Recently, diffusion models have emerged as a powerful class of generative models.
Despite their success, there is still limited understanding of their semantic spaces. This makes it challenging to achieve precise and disentangled image generation without additional training, especially in an unsupervised way.
In this work, we improve the understanding of their semantic spaces from intriguing observations: among a certain range of noise levels, (1) the learned posterior mean predictor (PMP) in the diffusion model is locally linear, and (2) the singular vectors of its Jacobian lie in low-dimensional semantic subspaces. We provide a solid theoretical basis to justify the linearity and low-rankness in the PMP. These insights allow us to propose an unsupervised, single-step, training-free **LO**w-rank **CO**ntrollable image editing (LOCO Edit) method for precise local editing in diffusion models. LOCO Edit identified editing directions with nice properties: homogeneity, transferability, composability, and linearity. These properties of LOCO Edit benefit greatly from the low-dimensional semantic subspace.
Our method can further be extended to unsupervised or text-supervised editing in various text-to-image diffusion models (T-LOCO Edit). Finally, extensive empirical experiments demonstrate the effectiveness and efficiency of LOCO Edit. The code and the arXiv version can be found on the [project website](https://chicychen.github.io/LOCO).

In recent years, transformer-based models have revolutionized deep learning, particularly in sequence modeling. To better understand this phenomenon, there is a growing interest in using Markov input processes to study transformers. However, our current understanding in this regard remains limited with many fundamental questions about how transformers learn Markov chains still unanswered. In this paper, we address this by focusing on first-order Markov chains and single-layer transformers, providing a comprehensive characterization of the learning dynamics in this context. Specifically, we prove that transformer parameters trained on next-token prediction loss can either converge to global or local minima, contingent on the initialization and the Markovian data properties, and we characterize the precise conditions under which this occurs. To the best of our knowledge, this is the first result of its kind highlighting the role of initialization. We further demonstrate that our theoretical findings are corroborated by empirical evidence. Based on these insights, we provide guidelines for the initialization of single-layer transformers and demonstrate their effectiveness. Finally, we outline several open problems in this arena. Code is available at: \url{https://github.com/Bond1995/Markov}.
tl;dr: We prove that large-scale Transformers closely approximate their mean-field limit and that gradient flow converges to the global optimization minimum.

Despite the widespread success of Transformers across various domains, their optimization guarantees in large-scale model settings are not well-understood. This paper rigorously analyzes the convergence properties of gradient flow in training Transformers with weight decay regularization. First, we construct the mean-field limit of large-scale Transformers, showing that as the model width and depth go to infinity, gradient flow converges to the Wasserstein gradient flow, which is represented by a partial differential equation. Then, we demonstrate that the gradient flow reaches a global minimum consistent with the PDE solution when the weight decay regularization parameter is sufficiently small. Our analysis is based on a series of novel mean-field techniques that adapt to Transformers. Compared with existing tools for deep networks (Lu et al., 2020) that demand homogeneity and global Lipschitz smoothness, we utilize a refined analysis assuming only $\textit{partial homogeneity}$ and $\textit{local Lipschitz smoothness}$. These new techniques may be of independent interest.
tl;dr: We introduce a causal representation identifiability algorithm for determining which latent variables are disentangleable given a homogenous set of input distributions from multiple domains and knowledge of the latent variable causal structure.

Considering various data modalities, such as images, videos, and text, humans perform causal reasoning using high-level causal variables, as opposed to operating at the low, pixel level from which the data comes.
In practice, most causal reasoning methods assume that the data is described as granular as the underlying causal generative factors, which is often violated in various AI tasks.
This mismatch translates into a lack of guarantees in various tasks such as generative modeling, decision-making, fairness, and generalizability, to cite a few.
In this paper, we acknowledge this issue and study the problem of causal disentangled representation learning from a combination of data gathered from various heterogeneous domains and assumptions in the form of a latent causal graph. To the best of our knowledge, the proposed work is the first to consider i) non-Markovian causal settings, where there may be unobserved confounding, ii) arbitrary distributions that arise from multiple domains, and iii) a relaxed version of disentanglement. Specifically, we introduce graphical criteria that allow for disentanglement under various conditions. Building on these results, we develop an algorithm that returns a causal disentanglement map, highlighting which latent variables can be disentangled given the combination of data and assumptions. The theory is corroborated by experiments.
2826. NeuroGauss4D-PCI: 4D Neural Fields and Gaussian Deformation Fields for Point Cloud Interpolation
tl;dr: NeuroGauss4D-PCI is a novel spatiotemporal point cloud interpolation framework that integrates neural fields, dynamic soft clustering, 4D Gaussian deformation fields, and transformers to achieve high fidelity point cloud interpolation across time.

Point Cloud Interpolation confronts challenges from point sparsity, complex spatiotemporal dynamics, and the difficulty of deriving complete 3D point clouds from sparse temporal information. This paper presents NeuroGauss4D-PCI, which excels at modeling complex non-rigid deformations across varied dynamic scenes. The method begins with an iterative Gaussian cloud soft clustering module, offering structured temporal point cloud representations. The proposed temporal radial basis function Gaussian residual utilizes Gaussian parameter interpolation over time, enabling smooth parameter transitions and capturing temporal residuals of Gaussian distributions. Additionally, a 4D Gaussian deformation field tracks the evolution of these parameters, creating continuous spatiotemporal deformation fields. A 4D neural field transforms low-dimensional spatiotemporal coordinates ($x,y,z,t$) into a high-dimensional latent space. Finally, we adaptively and efficiently fuse the latent features from neural fields and the geometric features from Gaussian deformation fields.
NeuroGauss4D-PCI outperforms existing methods in point cloud frame interpolation, delivering leading performance on both object-level (DHB) and large-scale autonomous driving datasets (NL-Drive), with scalability to auto-labeling and point cloud densification tasks.
tl;dr: We distinguish between different modeling paradigms for multi-modal learning from the perspective of generative models and offer a general recipe for designing models that efficiently leverage multi-modal data, leading to more accurate predictions.

Supervised multi-modal learning involves mapping multiple modalities to a target label. Previous studies in this field have concentrated on capturing in isolation either the inter-modality dependencies (the relationships between different modalities and the label) or the intra-modality dependencies (the relationships within a single modality and the label). We argue that these conventional approaches that rely solely on either inter- or intra-modality dependencies may not be optimal in general. We view the multi-modal learning problem from the lens of generative models where we consider the target as a source of multiple modalities and the interaction between them. Towards that end, we propose inter- \& intra-modality modeling (I2M2) framework, which captures and integrates both the inter- and intra-modality dependencies, leading to more accurate predictions. We evaluate our approach using real-world healthcare and vision-and-language datasets with state-of-the-art models, demonstrating superior performance over traditional methods focusing only on one type of modality dependency. The code is available at https://github.com/divyam3897/I2M2.

Large Language Models (LLMs) have exhibited an impressive ability to perform In-Context Learning (ICL) from only a few examples. Recent works have indicated that the functions learned by ICL can be represented through compressed vectors derived from the transformer. However, the working mechanisms and optimization of these vectors are yet to be thoroughly explored. In this paper, we address this gap by presenting a comprehensive analysis of these compressed vectors, drawing parallels to the parameters trained with gradient descent, and introducing the concept of state vector. Inspired by the works on model soup and momentum-based gradient descent, we propose inner and momentum optimization methods that are applied to refine the state vector progressively as test-time adaptation. Moreover, we simulate state vector aggregation in the multiple example setting, where demonstrations comprising numerous examples are usually too lengthy for regular ICL, and further propose a divide-and-conquer aggregation method to address this challenge. We conduct extensive experiments using Llama-2 and GPT-J in both zero-shot setting and few-shot setting. The experimental results show that our optimization method effectively enhances the state vector and achieves the state-of-the-art performance on diverse tasks.

Transduction is a powerful paradigm that leverages the structure of unlabeled data to boost predictive accuracy. We present TransCLIP, a novel and computationally efficient transductive approach designed for Vision-Language Models (VLMs). TransCLIP is applicable as a plug-and-play module on top of popular inductive zero- and few-shot models, consistently improving their performances. Our new objective function can be viewed as a regularized maximum-likelihood estimation, constrained by a KL divergence penalty that integrates the text-encoder knowledge and guides the transductive learning process. We further derive an iterative Block Majorize-Minimize (BMM) procedure for optimizing our objective, with guaranteed convergence and decoupled sample-assignment updates, yielding computationally efficient transduction for large-scale datasets. We report comprehensive evaluations, comparisons, and ablation studies that demonstrate: (i) Transduction can greatly enhance the generalization capabilities of inductive pretrained zero- and few-shot VLMs; (ii) TransCLIP substantially outperforms standard transductive few-shot learning methods relying solely on vision features, notably due to the KL-based language constraint.
tl;dr: This paper introduces a simple but interpretable prompt optimizer (IPO), that utilizes large language models (LLMs) to generate textual prompts dynamically.

Pre-trained vision-language models like CLIP have remarkably adapted to various downstream tasks. Nonetheless, their performance heavily depends on the specificity of the input text prompts, which requires skillful prompt template engineering. Instead, current approaches to prompt optimization learn the prompts through gradient descent, where the prompts are treated as adjustable parameters. However, these methods tend to lead to overfitting of the base classes seen during training and produce prompts that are no longer understandable by humans. This paper introduces a simple but interpretable prompt optimizer (IPO), that utilizes large language models (LLMs) to generate textual prompts dynamically. We introduce a Prompt Optimization Prompt that not only guides LLMs in creating effective prompts but also stores past prompts with their performance metrics, providing rich in-context information. Additionally, we incorporate a large multimodal model (LMM) to condition on visual content by generating image descriptions, which enhance the interaction between textual and visual modalities. This allows for the creation of dataset-specific prompts that improve generalization performance, while maintaining human comprehension. Extensive testing across 11 datasets reveals that IPO not only improves the accuracy of existing gradient-descent-based prompt learning methods but also considerably enhances the interpretability of the generated prompts. By leveraging the strengths of LLMs, our approach ensures that the prompts remain human-understandable, thereby facilitating better transparency and oversight for vision-language models.

Fourier Neural Operators (FNOs) have shown promise for solving partial differential equations (PDEs).
Typically, FNOs employ separate parameters for different frequency modes to specify tunable kernel integrals in Fourier space, which, yet, results in an undesirably large number of parameters when solving high-dimensional PDEs.
A workaround is to abandon the frequency modes exceeding a predefined threshold, but this limits the FNOs' ability to represent high-frequency details and poses non-trivial challenges for hyper-parameter specification.
To address these, we propose AMortized Fourier Neural Operator (AM-FNO), where an amortized neural parameterization of the kernel function is deployed to accommodate arbitrarily many frequency modes using a fixed number of parameters.
We introduce two implementations of AM-FNO, based on the recently developed, appealing Kolmogorov–Arnold Network (KAN) and Multi-Layer Perceptrons (MLPs) equipped with orthogonal embedding functions respectively.
We extensively evaluate our method on diverse datasets from various domains and observe up to 31\% average improvement compared to competing neural operator baselines.

In many Deep Reinforcement Learning (RL) problems, decisions in a trained policy vary in significance for the expected safety and performance of the policy. Since RL policies are very complex, testing efforts should concentrate on states in which the agent's decisions have the highest impact on the expected outcome. In this paper, we propose a novel model-based method to rigorously compute a ranking of state importance across the entire state space. We then focus our testing efforts on the highest-ranked states. In this paper, we focus on testing for safety. However, the proposed methods can be easily adapted to test for performance. In each iteration, our testing framework computes optimistic and pessimistic safety estimates. These estimates provide lower and upper bounds on the expected outcomes of the policy execution across all modeled states in the state space. Our approach divides the state space into safe and unsafe regions upon convergence, providing clear insights into the policy's weaknesses. Two important properties characterize our approach. (1) Optimal Test-Case Selection: At any time in the testing process, our approach evaluates the policy in the states that are most critical for safety. (2) Guaranteed Safety: Our approach can provide formal verification guarantees over the entire state space by sampling only a fraction of the policy. Any safety properties assured by the pessimistic estimate are formally proven to hold for the policy. We provide a detailed evaluation of our framework on several examples, showing that our method discovers unsafe policy behavior with low testing effort.

Policy network parameter sharing is a commonly used technique in advanced deep multi-agent reinforcement learning (MARL) algorithms to improve learning efficiency by reducing the number of policy parameters and sharing experiences among agents. Nevertheless, agents that share the policy parameters tend to learn similar behaviors. To encourage multi-agent diversity, prior works typically maximize the mutual information between trajectories and agent identities using variational inference. However, this category of methods easily leads to inefficient exploration due to limited trajectory visitations. To resolve this limitation, inspired by the learning of pre-trained models, in this paper, we propose a novel Contrastive Trajectory Representation (CTR) method based on learning distinguishable trajectory representations to encourage multi-agent diversity. Specifically, CTR maps the trajectory of an agent into a latent trajectory representation space by an encoder and an autoregressive model. To achieve the distinguishability among trajectory representations of different agents, we introduce contrastive learning to maximize the mutual information between the trajectory representations and learnable identity representations of different agents. We implement CTR on top of QMIX and evaluate its performance in various cooperative multi-agent tasks. The empirical results demonstrate that our proposed CTR yields significant performance improvement over the state-of-the-art methods.
tl;dr: We propose Diffusion of Thought (DoT), an inherent chain-of-thought method tailored for diffusion models.

Recently, diffusion models have garnered significant interest in the field of text processing due to their many potential advantages compared to conventional autoregressive models.
In this work, we propose Diffusion-of-Thought (DoT), a novel approach that integrates diffusion models with Chain-of-Thought, a well-established technique for improving the reasoning ability of autoregressive language models. In contrast to autoregressive language models that make decisions in a left-to-right, token-by-token manner, DoT allows reasoning steps to diffuse over time through a diffusion language model and offers greater flexibility in trading-off computation for reasoning performance. Our experimental results demonstrate the effectiveness of DoT in multi-digit multiplication, boolean logic, and grade school math problems. In addition to that, DoT showcases promising self-correction abilities and benefits from existing reasoning-enhancing techniques like self-consistency decoding. Our findings contribute to the understanding and development of reasoning with diffusion language models.
2835. Overfitting Behaviour of Gaussian Kernel Ridgeless Regression: Varying Bandwidth or Dimensionality

We consider the overfitting behavior of minimum norm interpolating solutions of Gaussian kernel ridge regression (i.e. kernel ridgeless regression), when the bandwidth or input dimension varies with the sample size. For fixed dimensions, we show that even with varying or tuned bandwidth, the ridgeless solution is never consistent and, at least with large enough noise, always worse than the null predictor. For increasing dimension, we give a generic characterization of the overfitting behavior for any scaling of the dimension with sample size. We use this to provide the first example of benign overfitting using the Gaussian kernel with sub-polynomial scaling dimension. All our results are under the Gaussian universality ansatz and the (non-rigorous) risk predictions in terms of the kernel eigenstructure.

The effect of regularizers such as weight decay when training deep neural networks is not well understood. We study the influence of weight decay as well as $L2$-regularization when training neural network models in which parameter matrices interact multiplicatively. This combination is of particular interest as this parametrization is common in attention layers, the workhorse of transformers. Here, key-query, as well as value-projection parameter matrices, are multiplied directly with each other: $W_K^TW_Q$ and $PW_V$.
We extend previous results and show on one hand that any local minimum of a $L2$-regularized loss of the form $L(AB^\top) + \lambda (\|A\|^2 + \|B\|^2)$ coincides with a minimum of the nuclear norm-regularized loss $L(AB^\top) + \lambda\|AB^\top\|_*$, and on the other hand that the 2 losses become identical exponentially quickly during training. We thus complement existing works linking $L2$-regularization with low-rank regularization, and in particular, explain why such regularization on the matrix product affects early stages of training.
Based on these theoretical insights, we verify empirically that the key-query and value-projection matrix products $W_K^TW_Q, PW_V$ within attention layers, when optimized with weight decay, as usually done in vision tasks and language modelling, indeed induce a significant reduction in the rank of $W_K^TW_Q$ and $PW_V$, even in fully online training.
We find that, in accordance with existing work, inducing low rank in attention matrix products can damage language model performance, and observe advantages when decoupling weight decay in attention layers from the rest of the parameters.
tl;dr: This paper proposes Smoothed Energy Guidance (SEG), a novel training- and label-free diffusion guidance method that leverages the energy-based perspective of the self-attention mechanism to enhance image generation.

Conditional diffusion models have shown remarkable success in visual content generation, producing high-quality samples across various domains, largely due to classifier-free guidance (CFG). Recent attempts to extend guidance to unconditional models have relied on heuristic techniques, resulting in suboptimal generation quality and unintended effects. In this work, we propose Smoothed Energy Guidance (SEG), a novel training- and condition-free approach that leverages the energy-based perspective of the self-attention mechanism to enhance image generation. By defining the energy of self-attention, we introduce a method to reduce the curvature of the energy landscape of attention and use the output as the unconditional prediction. Practically, we control the curvature of the energy landscape by adjusting the Gaussian kernel parameter while keeping the guidance scale parameter fixed. Additionally, we present a query blurring method that is equivalent to blurring the entire attention weights without incurring quadratic complexity in the number of tokens. In our experiments, SEG achieves a Pareto improvement in both quality and the reduction of side effects. The code is available at https://github.com/SusungHong/SEG-SDXL.

The accurate identification of active sites in proteins is essential for the advancement of life sciences and pharmaceutical development, as these sites are of critical importance for enzyme activity and drug design. Recent advancements in protein language models (PLMs), trained on extensive datasets of amino acid sequences, have significantly improved our understanding of proteins. However, compared to the abundant protein sequence data, functional annotations, especially precise per-residue annotations, are scarce, which limits the performance of PLMs. On the other hand, textual descriptions of proteins, which could be annotated by human experts or a pretrained protein sequence-to-text model, provide meaningful context that could assist in the functional annotations, such as the localization of active sites. This motivates us to construct a $\textbf{ProT}$ein-$\textbf{A}$ttribute text $\textbf{D}$ataset ($\textbf{ProTAD}$), comprising over 570,000 pairs of protein sequences and multi-attribute textual descriptions. Based on this dataset, we propose $\textbf{MMSite}$, a multi-modal framework that improves the performance of PLMs to identify active sites by leveraging biomedical language models (BLMs). In particular, we incorporate manual prompting and design a MACross module to deal with the multi-attribute characteristics of textual descriptions. MMSite is a two-stage ("First Align, Then Fuse") framework: first aligns the textual modality with the sequential modality through soft-label alignment, and then identifies active sites via multi-modal fusion. Experimental results demonstrate that MMSite achieves state-of-the-art performance compared to existing protein representation learning methods. The dataset and code implementation are available at https://github.com/Gift-OYS/MMSite.
2839. T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback
tl;dr: We introduce T2V-Turbo, achieving fast and high-quality video generation by breaking the quality bottleneck of the video consistency model.

Diffusion-based text-to-video (T2V) models have achieved significant success but continue to be hampered by the slow sampling speed of their iterative sampling processes. To address the challenge, consistency models have been proposed to facilitate fast inference, albeit at the cost of sample quality. In this work, we aim to break the quality bottleneck of a video consistency model (VCM) to achieve **both fast and high-quality video generation**. We introduce T2V-Turbo, which integrates feedback from a mixture of differentiable reward models into the consistency distillation (CD) process of a pre-trained T2V model. Notably, we directly optimize rewards associated with single-step generations that arise naturally from computing the CD loss, effectively bypassing the memory constraints imposed by backpropagating gradients through an iterative sampling process. Remarkably, the 4-step generations from our T2V-Turbo achieve the highest total score on VBench, even surpassing Gen-2 and Pika. We further conduct human evaluations to corroborate the results, validating that the 4-step generations from our T2V-Turbo are preferred over the 50-step DDIM samples from their teacher models, representing more than a tenfold acceleration while improving video generation quality.

Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors. Our PyTorch implementation is available at https://github.com/cxy1997/DiffuBox.
tl;dr: Learning a treatment recommendation policy under hidden confounding, with the option of deferring the decision to an expert

We consider the task of learning how to act in collaboration with a human expert based on observational data. The task is motivated by high-stake scenarios such as healthcare and welfare where algorithmic action recommendations are made to a human expert, opening the option of deferring making a recommendation in cases where the human might act better on their own.
This task is especially challenging when dealing with observational data, as using such data runs the risk of hidden confounders whose existence can lead to biased and harmful policies. However, unlike standard policy learning, the presence of a human expert can mitigate some of these risks. We build on the work of Mozannar and Sontag (2020) on consistent surrogate loss for learning with the option of deferral to an expert, where they solve a cost-sensitive supervised classification problem. Since we are solving a causal problem, where labels don’t exist, we use a causal model to learn costs which are robust to a bounded degree of hidden confounding.
We prove that our approach can take advantage of the strengths of both the model and the expert to obtain a better policy than either. We demonstrate our results by conducting experiments on synthetic and semi-synthetic data and show the advantages of our method compared to baselines.
tl;dr: We introduce a policy network generator that utilizes conditional diffusion models for behavior-to-policy generation.

Can we generate a control policy for an agent using just one demonstration of desired behaviors as a prompt, as effortlessly as creating an image from a textual description?
In this paper, we present **Make-An-Agent**, a novel policy parameter generator that leverages the power of conditional diffusion models for behavior-to-policy generation. Guided by behavior embeddings that encode trajectory information, our policy generator synthesizes latent parameter representations, which can then be decoded into policy networks.
Trained on policy network checkpoints and their corresponding trajectories, our generation model demonstrates remarkable versatility and scalability on multiple tasks and has a strong generalization ability on unseen tasks to output well-performed policies with only few-shot demonstrations as inputs. We showcase its efficacy and efficiency on various domains and tasks, including varying objectives, behaviors, and even across different robot manipulators. Beyond simulation, we directly deploy policies generated by **Make-An-Agent** onto real-world robots on locomotion tasks. Project page: https://cheryyunl.github.io/make-an-agent/.
tl;dr: We propose counter-current learning, a biologically inspired dual network architecture that facilitates local learning and addresses weight transport, non-local credit assignment, and backward locking issues in backpropagation.

Despite its widespread use in neural networks, error backpropagation has faced criticism for its lack of biological plausibility, suffering from issues such as the backward locking problem and the weight transport problem.
These limitations have motivated researchers to explore more biologically plausible learning algorithms that could potentially shed light on how biological neural systems adapt and learn.
Inspired by the counter-current exchange mechanisms observed in biological systems, we propose counter-current learning (CCL), a biologically plausible framework for credit assignment in deep learning.
This framework employs a feedforward network to process input data and a feedback network to process targets, with each network enhancing the other through anti-parallel signal propagation.
By leveraging the more informative signals from the bottom layer of the feedback network to guide the updates of the top layer of the feedforward network and vice versa, CCL enables the simultaneous transformation of source inputs to target outputs and the dynamic mutual influence of these transformations.
Experimental results on MNIST, FashionMNIST, CIFAR10, CIFAR100, and STL-10 datasets using multi-layer perceptrons and convolutional neural networks demonstrate that CCL achieves comparable performance to other biological plausible algorithms while offering a more biologically realistic learning mechanism.
Furthermore, we showcase the applicability of our approach to an autoencoder task, underscoring its potential for unsupervised representation learning.
Our work presents a promising direction for biologically inspired and plausible learning algorithms, offering insights into the mechanisms of learning and adaptation in neural networks.

This paper considers the problem of learning from multiple sets of inaccurate labels, which can be easily obtained from low-cost annotators, such as rule-based annotators. Previous works typically concentrate on aggregating information from all the annotators, overlooking the significance of data refinement. This paper presents a collaborative refining approach for learning from inaccurate labels. To refine the data, we introduce the annotator agreement as an instrument, which refers to whether multiple annotators agree or disagree on the labels for a given sample. For samples where some annotators disagree, a comparative strategy is proposed to filter noise. Through theoretical analysis, the connections among multiple sets of labels, the respective models trained on them, and the true labels are uncovered to identify relatively reliable labels. For samples where all annotators agree, an aggregating strategy is designed to mitigate potential noise. Guided by theoretical bounds on loss values, a sample selection criterion is introduced and modified to be more robust against potentially problematic values. Through these two methods, all the samples are refined during training, and these refined samples are used to train a lightweight model simultaneously. Extensive experiments are conducted on benchmark and real-world datasets to demonstrate the superiority of our methods.

Prevalent text-to-video retrieval methods represent multimodal text-video data in a joint embedding space, aiming at bridging the relevant text-video pairs and pulling away irrelevant ones. One main challenge in state-of-the-art retrieval methods lies in the modality gap, which stems from the substantial disparities between text and video and can persist in the joint space. In this work, we leverage the potential of Diffusion models to address the text-video modality gap by progressively aligning text and video embeddings in a unified space. However, we identify two key limitations of existing Diffusion models in retrieval tasks: The L2 loss does not fit the ranking problem inherent in text-video retrieval, and the generation quality heavily depends on the varied initial point drawn from the isotropic Gaussian, causing inaccurate retrieval. To this end, we introduce a new Diffusion-Inspired Truncated Sampler (DITS) that jointly performs progressive alignment and modality gap modeling in the joint embedding space. The key innovation of DITS is to leverage the inherent proximity of text and video embeddings, defining a truncated diffusion flow from the fixed text embedding to the video embedding, enhancing controllability compared to adopting the isotropic Gaussian. Moreover, DITS adopts the contrastive loss to jointly consider the relevant and irrelevant pairs, not only facilitating alignment but also yielding a discriminatively structured embedding. Experiments on five benchmark datasets suggest the state-of-the-art performance of DITS. We empirically find that DITS can also improve the structure of the CLIP embedding space. Code is available at https://github.com/Jiamian- Wang/DITS-text-video-retrieval
tl;dr: We introduce a method for disaggregated evaluation that improves accuracy when assessing subpopulation performance disparities in ML models.

Disaggregated evaluation—estimation of performance of a machine learning model on different subpopulations—is a core task when assessing performance and group-fairness of AI systems.
A key challenge is that evaluation data is scarce, and subpopulations arising from intersections of attributes (e.g., race, sex, age) are often tiny.
Today, it is common for multiple clients to procure the same AI model from a model developer, and the task of disaggregated evaluation is faced by each customer individually. This gives rise to what we call the *multi-task disaggregated evaluation problem*, wherein multiple clients seek to conduct a disaggregated evaluation of a given model in their own data setting (task). In this work we develop a disaggregated evaluation method called **SureMap** that has high estimation accuracy for both multi-task *and* single-task disaggregated evaluations of blackbox models. SureMap's efficiency gains come from
(1) transforming the problem into structured simultaneous Gaussian mean estimation and (2) incorporating external data, e.g., from the AI system creator or from their other clients. Our method combines *maximum a posteriori* (MAP) estimation using a well-chosen prior together with cross-validation-free tuning via Stein's unbiased risk estimate (SURE).
We evaluate SureMap on disaggregated evaluation tasks in multiple domains, observing significant accuracy improvements over several strong competitors.

Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from diverse labelers' groups (e.g., different demographics, ethnicities, company teams, etc.), traditional RLHF approaches adopt a "one-size-fits-all" approach, i.e., they indiscriminately assume and optimize a single preference model, thus not being robust to unique characteristics and needs of the various groups. To address this limitation, we propose a novel Group Robust Preference Optimization (GRPO) method to align LLMs to individual groups' preferences robustly. Our approach builds upon reward-free direct preference optimization methods, but unlike previous approaches, it seeks a robust policy which maximizes the worst-case group performance. To achieve this, GRPO adaptively and sequentially weights the importance of different groups, prioritizing groups with worse cumulative loss. We theoretically study the feasibility of GRPO and analyze its convergence for the log-linear policy class. By fine-tuning LLMs with GRPO using diverse group-based global opinion data, we significantly improved performance for the worst-performing groups, reduced loss imbalances across groups, and improved probability accuracies compared to non-robust baselines.
tl;dr: We introduce end-to-end sparse autoencoders, which aim to learn functionally relevant features from network activations. They are a pareto improvement over standard sparse autoencoders.

Identifying the features learned by neural networks is a core challenge in mechanistic interpretability. Sparse autoencoders (SAEs), which learn a sparse, overcomplete dictionary that reconstructs a network's internal activations, have been used to identify these features. However, SAEs may learn more about the structure of the datatset than the computational structure of the network. There is therefore only indirect reason to believe that the directions found in these dictionaries are functionally important to the network. We propose end-to-end (e2e) sparse dictionary learning, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted. Compared to standard SAEs, e2e SAEs offer a Pareto improvement: They explain more network performance, require fewer total features, and require fewer simultaneously active features per datapoint, all with no cost to interpretability. We explore geometric and qualitative differences between e2e SAE features and standard SAE features. E2e dictionary learning brings us closer to methods that can explain network behavior concisely and accurately. We release our library for training e2e SAEs and reproducing our analysis at
https://github.com/ApolloResearch/e2e_sae.
tl;dr: BERT solves low rank matrix completion in an interpretable manner with a sudden drop in the loss.

Recent analysis on the training dynamics of Transformers has unveiled an interesting characteristic: the training loss plateaus for a significant number of training steps, and then suddenly (and sharply) drops to near--optimal values. To understand this phenomenon in depth, we formulate the low-rank matrix completion problem as a masked language modeling (MLM) task, and show that it is possible to train a BERT model to solve this task to low error. Furthermore, the loss curve shows a plateau early in training followed by a sudden drop to near-optimal values, despite no changes in the training procedure or hyper-parameters. To gain interpretability insights into this sudden drop, we examine the model's predictions, attention heads, and hidden states before and after this transition. Concretely, we observe that (a) the model transitions from simply copying the masked input to accurately predicting the masked entries; (b) the attention heads transition to interpretable patterns relevant to the task; and (c) the embeddings and hidden states encode information relevant to the problem. We also analyze the training dynamics of individual model components to understand the sudden drop in loss.
tl;dr: Linear transform with latency benefits ,better parameter-quality tradeoff

Tensor multiplication with learned weight matrices is the fundamental building block in deep learning models. These matrices can often be sparsified, decomposed, quantized, or subjected to random parameter sharing without losing accuracy, suggesting the possibility of more efficient transforms. Although many variants of weight matrices exist, unstructured ones are incompatible with modern hardware, slowing inference and training. On the other hand, structured variants often limit expressivity or fail to deliver the promised latency benefits. We present Sketch Structured Transform (SS1), an expressive and GPU-friendly operator that accelerates inference. SS1 leverages parameter sharing in a random yet structured manner to reduce computation while retraining the rich expressive nature of parameter sharing. We confirm empirically that SS1 offers better quality-efficiency tradeoffs than competing variants. Interestingly SS1 can be combined with Quantization to achieve gains unattainable by either method alone, a finding we justify via theoretical analysis. The analysis may be of independent interest.
Moreover, existing pre-trained models can be projected onto SS1 and finetuned for efficient deployment. Surprisingly, these projected models can perform reasonably well even without finetuning. Our experiments highlight various applications of the SS1:
(a) Training GPT2 and DLRM models from scratch for faster inference. (b) Finetuning projected BERT models for 1.31× faster inference while maintaining GLUE scores. (c) Proof of concept with Llama-3-8b, showing 1.11× faster wall clock inference using projected SS1 layers without finetuning. We open source our code :https://github.com/apd10/Sketch-Structured-Linear/
tl;dr: We study the Online Weighted Paging problem, where the weights are unknown. We provide algorithm and analyze it's performance in terms of competitive ratio and regret.

Online paging is a fundamental problem in the field of online algorithms, in which one maintains a cache of $k$ slots as requests for fetching pages arrive online.
In the weighted variant of this problem, each page has its own fetching cost; a substantial line of work on this problem culminated in an (optimal) $O(\log k)$-competitive randomized algorithm, due to Bansal, Buchbinder and Naor (FOCS'07).
Existing work for weighted paging assumes that page weights are known in advance, which is not always the case in practice.
For example, in multi-level caching architectures, the expected cost of fetching a memory block is a function of its probability of being in a mid-level cache rather than the main memory.
This complex property cannot be predicted in advance; over time, however, one may glean information about page weights through sampling their fetching cost multiple times.
We present the first algorithm for online weighted paging that does not know page weights in advance, but rather learns from weight samples.
In terms of techniques, this requires providing (integral) samples to a fractional solver, requiring a delicate interface between this solver and the randomized rounding scheme; we believe that our work can inspire online algorithms to other problems that involve cost sampling.

Real-world noise removal is crucial in low-level computer vision. Due to the remarkable generation capabilities of diffusion models, recent attention has shifted towards leveraging diffusion priors for image restoration tasks. However, existing diffusion priors-based methods either consider simple noise types or rely on approximate posterior estimation, limiting their effectiveness in addressing structured and signal-dependent noise commonly found in real-world images. In this paper, we build upon diffusion priors and propose adaptive likelihood estimation and MAP inference during the reverse diffusion process to tackle real-world noise. We introduce an independent, non-identically distributed likelihood combined with the noise precision (inverse variance) prior and dynamically infer the precision posterior using variational Bayes during the generation process. Meanwhile, we rectify the estimated noise variance through local Gaussian convolution. The final denoised image is obtained by propagating intermediate MAP solutions that balance the updated likelihood and diffusion prior. Additionally, we explore the local diffusion prior inherent in low-resolution diffusion models, enabling direct handling of high-resolution noisy images. Extensive experiments and analyses on diverse real-world datasets demonstrate the effectiveness of our method. Code is available at https://github.com/HUST-Tan/DiffusionVI.
tl;dr: Improving Extreme LLM Quantization through Better Fine-tuning

There has been significant interest in "extreme" compression of large language models (LLMs), i.e. to 1-2 bits per parameter, which allows such models to be executed efficiently on resource-constrained devices.
Existing work focused on improved one-shot quantization techniques and weight representations; yet, purely post-training approaches are reaching diminishing returns in terms of the accuracy-vs-bit-width trade-off. State-of-the-art quantization methods such as QuIP# and AQLM include fine-tuning (part of) the compressed parameters over a limited amount of calibration data; however, such fine-tuning techniques over compressed weights often make exclusive use of straight-through estimators (STE), whose performance is not well-understood in this setting.
In this work, we question the use of STE for extreme LLM compression, showing that it can be sub-optimal, and perform a systematic study of quantization-aware fine-tuning strategies for LLMs.
We propose PV-Tuning - a representation-agnostic framework that generalizes and improves upon existing fine-tuning strategies, and provides convergence guarantees in restricted cases.
On the practical side, when used for 1-2 bit vector quantization, PV-Tuning outperforms prior techniques for highly-performant models such as Llama and Mistral.
Using PV-Tuning, we achieve the first Pareto-optimal quantization for Llama-2 family models at 2 bits per parameter.
tl;dr: We provide the first high-probability complexity guarantees for nonconvex/PL minimax problems that satisfy the PL-condition in the dual variable.

Stochastic smooth nonconvex minimax problems are prevalent in machine learning, e.g., GAN training, fair classification, and distributionally robust learning. Stochastic gradient descent ascent (GDA)-type methods are popular in practice due to their simplicity and single-loop nature. However, there is a significant gap between the theory and practice regarding high-probability complexity guarantees for these methods on stochastic nonconvex minimax problems. Existing high-probability bounds for GDA-type single-loop methods only apply to convex/concave minimax problems and to particular non-monotone variational inequality problems under some restrictive assumptions. In this work, we address this gap by providing the first high-probability complexity guarantees for nonconvex/PL minimax problems corresponding to a smooth function that satisfies the PL-condition in the dual variable. Specifically, we show that when the stochastic gradients are light-tailed, the smoothed alternating GDA method can compute an $\varepsilon$-stationary point within $\mathcal{O}(\frac{\ell \kappa^2 \delta^2}{\varepsilon^4} + \frac{\kappa}{\varepsilon^2}(\ell+\delta^2\log({1}/{\bar{q}})))$ stochastic gradient calls with probability at least $1-\bar{q}$ for any $\bar{q}\in(0,1)$, where $\mu$ is the PL constant, $\ell$ is the Lipschitz constant of the gradient, $\kappa=\ell/\mu$ is the condition number, and $\delta^2$ denotes a bound on the variance of stochastic gradients. We also present numerical results on a nonconvex/PL problem with synthetic data and on distributionally robust optimization problems with real data, illustrating our theoretical findings.
2855. Private Stochastic Convex Optimization with Heavy Tails: Near-Optimality from Simple Reductions
tl;dr: We give the first algorithm attaining near-optimal error rates for DP-SCO assuming heavy-tailed gradients, and several improvements in structured cases.

We study the problem of differentially private stochastic convex optimization (DP-SCO) with heavy-tailed gradients, where we assume a $k^{\text{th}}$-moment bound on the Lipschitz constants of sample functions, rather than a uniform bound. We propose a new reduction-based approach that enables us to obtain the first optimal rates (up to logarithmic factors) in the heavy-tailed setting, achieving error $G_2 \cdot \frac 1 {\sqrt n} + G_k \cdot (\frac{\sqrt d}{n\epsilon})^{1 - \frac 1 k}$ under $(\epsilon, \delta)$-approximate differential privacy, up to a mild $\textup{polylog}(\frac{1}{\delta})$ factor, where $G_2^2$ and $G_k^k$ are the $2^{\text{nd}}$ and $k^{\text{th}}$ moment bounds on sample Lipschitz constants, nearly-matching a lower bound of [LR23].
We then give a suite of private algorithms for DP-SCO with heavy-tailed gradients improving our basic result under additional assumptions, including an optimal algorithm under a known-Lipschitz constant assumption, a near-linear time algorithm for smooth functions, and an optimal linear time algorithm for smooth generalized linear models.

Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. However, generating diverse embodied environments with realistic detail and considerable complexity remains a significant challenge. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing $\textit{Architect}$, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. While there are still challenges that the camera parameters and scale of depth are still absent in the generated image, we address those problems by ''controlling'' the diffusion model by $\textit{hierarchical inpainting}$. Specifically, having access to ground-truth depth and camera parameters in simulation, we first render a photo-realistic image of only the background. Then, we inpaint the foreground in this image, passing the geometric cues to the inpainting model in the background, which informs the camera parameters.
This process effectively controls the camera parameters and depth scale for the generated image, facilitating the back-projection from 2D image to 3D point clouds. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate the placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments. Experimental results demonstrate that $\textit{Architect}$ outperforms existing methods in producing realistic and complex environments, making it highly suitable for Embodied AI and robotics applications.

Large-scale generative models have shown impressive image-generation capabilities, propelled by massive data. However, this often inadvertently leads to the generation of harmful or inappropriate content and raises copyright concerns. Driven by these concerns, machine unlearning has become crucial to effectively purge undesirable knowledge from models. While existing literature has studied various unlearning techniques, these often suffer from either poor unlearning quality or degradation in text-image alignment after unlearning, due to the competitive nature of these objectives. To address these challenges, we propose a framework that seeks an optimal model update at each unlearning iteration, ensuring monotonic improvement on both objectives. We further derive the characterization of such an update.
In addition, we design procedures to strategically diversify the unlearning and remaining datasets to boost performance improvement. Our evaluation demonstrates that our method effectively removes target classes from recent diffusion-based generative models and concepts from stable diffusion models while maintaining close alignment with the models' original trained states, thus outperforming state-of-the-art baselines.
tl;dr: We utilize pre-trained text semantics to guide the codebook to learn rich multi-modal knowledge to improve the performance of multi-modal downstream tasks

Vector quantization (VQ) is a key technique in high-resolution and high-fidelity image synthesis, which aims to learn a codebook to encode an image with a sequence of discrete codes and then generate an image in an auto-regression manner.
Although existing methods have shown superior performance, most methods prefer to learn a single-modal codebook (\emph{e.g.}, image), resulting in suboptimal performance when the codebook is applied to multi-modal downstream tasks (\emph{e.g.}, text-to-image, image captioning) due to the existence of modal gaps.
In this paper, we propose a novel language-guided codebook learning framework, called LG-VQ, which aims to learn a codebook that can be aligned with the text to improve the performance of multi-modal downstream tasks. Specifically, we first introduce pre-trained text semantics as prior knowledge, then design two novel alignment modules (\emph{i.e.}, Semantic Alignment Module, and Relationship Alignment Module) to transfer such prior knowledge into codes for achieving codebook text alignment.
In particular, our LG-VQ method is model-agnostic, which can be easily integrated into existing VQ models. Experimental results show that our method achieves superior performance on reconstruction and various multi-modal downstream tasks.
tl;dr: A 3D large language model unifying referencing and grounding capabilities.

Recent advancements in 3D Large Language Models (LLMs) have demonstrated promising capabilities for 3D scene understanding. However, previous methods exhibit deficiencies in general referencing and grounding capabilities for intricate scene comprehension. In this paper, we introduce the use of object identifiers and object-centric representations to interact with scenes at the object level. Specifically, we decompose the input 3D scene into a set of object proposals, each assigned a unique identifier token, which enables efficient object referencing and grounding during user-assistant interactions. Given the scarcity of scene-language data, we model the scene embeddings as a sequence of explicit object-level embeddings, derived from semantic-rich 2D or 3D representations. By employing object identifiers, we transform diverse 3D scene-language tasks into a unified question-answering format, facilitating joint training without the need for additional task-specific heads. With minimal fine-tuning on all downstream tasks, our model significantly outperforms existing methods on benchmarks including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D.

Data assimilation is a vital component in modern global medium-range weather forecasting systems to obtain the best estimation of the atmospheric state by combining the short-term forecast and observations. Recently, AI-based data assimilation approaches have attracted increasing attention for their significant advantages over traditional techniques in terms of computational consumption. However, existing AI-based data assimilation methods can only handle observations with a specific resolution, lacking the compatibility and generalization ability to assimilate observations with other resolutions. Considering that complex real-world observations often have different resolutions, we propose the Fourier Neural Processes (FNP) for arbitrary-resolution data assimilation in this paper. Leveraging the efficiency of the designed modules and flexible structure of neural processes, FNP achieves state-of-the-art results in assimilating observations with varying resolutions, and also exhibits increasing advantages over the counterparts as the resolution and the amount of observations increase. Moreover, our FNP trained on a fixed resolution can directly handle the assimilation of observations with out-of-distribution resolutions and the observational information reconstruction task without additional fine-tuning, demonstrating its excellent generalization ability across data resolutions as well as across tasks. Code is available at https://github.com/OpenEarthLab/FNP.

Semantic scene completion is a difficult task that involves completing the geometry and semantics of a scene from point clouds in a large-scale environment. Many current methods use 3D/2D convolutions or attention mechanisms, but these have limitations in directly constructing geometry and accurately propagating features from related voxels, the completion likely fails while propagating features in a single pass without considering multiple potential pathways. And they are generally only suitable for static scenes and struggle to handle dynamic aspects. This paper introduces Voxel Proposal Network (VPNet) that completes scenes from 3D and Bird's-Eye-View (BEV) perspectives. It includes Confident Voxel Proposal based on voxel-wise coordinates to propose confident voxels with high reliability for completion. This method reconstructs the scene geometry and implicitly models the uncertainty of voxel-wise semantic labels by presenting multiple possibilities for voxels. VPNet employs Multi-Frame Knowledge Distillation based on the point clouds of multiple adjacent frames to accurately predict the voxel-wise labels by condensing various possibilities of voxel relationships. VPNet has shown superior performance and achieved state-of-the-art results on the SemanticKITTI and SemanticPOSS datasets.
tl;dr: We study the asymmetries produced in the merging of predictors whenever we have causal information.

We study the differences arising from merging predictors in the causal and anticausal directions using the same data.
In particular we study the asymmetries that arise in a simple model where we merge the predictors using one binary variable as target and two continuous variables as predictors.
We use Causal Maximum Entropy (CMAXENT) as inductive bias to merge the predictors, however, we expect similar differences to hold also when we use other merging methods that take into account asymmetries between cause and effect.
We show that if we observe all bivariate distributions, the CMAXENT solution reduces to a logistic regression in the causal direction and Linear Discriminant Analysis (LDA) in the anticausal direction.
Furthermore, we study how the decision boundaries of these two solutions differ whenever we observe only some of the bivariate distributions implications for Out-Of-Variable (OOV) generalisation.
2863. Federated Transformer: Multi-Party Vertical Federated Learning on Practical Fuzzily Linked Data
tl;dr: We introduce the Federated Transformer (FeT), a novel framework that supports multi-party Vertical Federated Learning (VFL) with fuzzy identifiers, which surpasses existing models in performance and privacy.

Federated Learning (FL) is an evolving paradigm that enables multiple parties to collaboratively train models without sharing raw data. Among its variants, Vertical Federated Learning (VFL) is particularly relevant in real-world, cross-organizational collaborations, where distinct features of a shared instance group are contributed by different parties. In these scenarios, parties are often linked using fuzzy identifiers, leading to a common practice termed as _multi-party fuzzy VFL_. Existing models generally address either multi-party VFL or fuzzy VFL between two parties. Extending these models to practical multi-party fuzzy VFL typically results in significant performance degradation and increased costs for maintaining privacy. To overcome these limitations, we introduce the _Federated Transformer (FeT)_, a novel framework that supports multi-party VFL with fuzzy identifiers. FeT innovatively encodes these identifiers into data representations and employs a transformer architecture distributed across different parties, incorporating three new techniques to enhance performance. Furthermore, we have developed a multi-party privacy framework for VFL that integrates differential privacy with secure multi-party computation, effectively protecting local representations while minimizing associated utility costs. Our experiments demonstrate that the FeT surpasses the baseline models by up to 46\% in terms of accuracy when scaled to 50 parties. Additionally, in two-party fuzzy VFL settings, FeT also shows improved performance and privacy over cutting-edge VFL models.
tl;dr: We propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning.

Motivated by the transformative capabilities of large language models (LLMs) across various natural language tasks, there has been a growing demand to deploy these models effectively across diverse real-world applications and platforms. However, the challenge of efficiently deploying LLMs has become increasingly pronounced due to the varying application-specific performance requirements and the rapid evolution of computational platforms, which feature diverse resource constraints and deployment flows. These varying requirements necessitate LLMs that can adapt their structures (depth and width) for optimal efficiency across different platforms and application specifications. To address this critical gap, we propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning. In this way, AmoebaLLM significantly facilitates rapid deployment tailored to various platforms and applications. Specifically, AmoebaLLM integrates three innovative components: (1) a knowledge-preserving subnet selection strategy that features a dynamic-programming approach for depth shrinking and an importance-driven method for width shrinking; (2) a shape-aware mixture of LoRAs to mitigate gradient conflicts among subnets during fine-tuning; and (3) an in-place distillation scheme with loss-magnitude balancing as the fine-tuning objective. Extensive experiments validate that AmoebaLLM not only sets new standards in LLM adaptability but also successfully delivers subnets that achieve state-of-the-art trade-offs between accuracy and efficiency.

We study the problem of aligning large language models (LLMs) with human preference data. Contrastive preference optimization has shown promising results in aligning LLMs with available preference data by optimizing the implicit reward associated with the policy. However, the contrastive objective focuses mainly on the relative values of implicit rewards associated with two responses while ignoring
their actual values, resulting in suboptimal alignment with human preferences. To address this limitation, we propose calibrated direct preference optimization (Cal-DPO), a simple yet effective algorithm. We show that substantial improvement in alignment with the given preferences can be achieved simply by calibrating the implicit reward to ensure that the learned implicit rewards are comparable in
scale to the ground-truth rewards. We demonstrate the theoretical advantages of Cal-DPO over existing approaches. The results of our experiments on a variety of standard benchmarks show that Cal-DPO remarkably improves off-the-shelf methods.
tl;dr: We propose a novel method for invisible watermark by optimizing the latent frequency space of images, named FreqMark, providing remarkable robustness and flexibility.

Invisible watermarking is essential for safeguarding digital content, enabling copyright protection and content authentication.
However, existing watermarking methods fall short in robustness against regeneration attacks.
In this paper, we propose a novel method called FreqMark that involves unconstrained optimization of the image latent frequency space obtained after VAE encoding. Specifically, FreqMark embeds the watermark by optimizing the latent frequency space of the images and then extracts the watermark through a pre-trained image encoder. This optimization allows a flexible trade-off between image quality with watermark robustness and effectively resists regeneration attacks.
Experimental results demonstrate that FreqMark offers significant advantages in image quality and robustness, permits flexible selection of the encoding bit number, and achieves a bit accuracy exceeding 90\% when encoding a 48-bit hidden message under various attack scenarios.
tl;dr: Camera and LiDAR data are jointly exploited to learn to detect 3D objects in an unsupervised manner.

Unsupervised 3D object detection methods have emerged to leverage vast amounts of data without requiring manual labels for training. Recent approaches rely on dynamic objects for learning to detect mobile objects but penalize the detections of static instances during training. Multiple rounds of (self) training are used to add detected static instances to the set of training targets; this procedure to improve performance is computationally expensive. To address this, we propose the method UNION. We use spatial clustering and self-supervised scene flow to obtain a set of static and dynamic object proposals from LiDAR. Subsequently, object proposals' visual appearances are encoded to distinguish static objects in the foreground and background by selecting static instances that are visually similar to dynamic objects. As a result, static and dynamic mobile objects are obtained together, and existing detectors can be trained with a single training. In addition, we extend 3D object discovery to detection by using object appearance-based cluster labels as pseudo-class labels for training object classification. We conduct extensive experiments on the nuScenes dataset and increase the state-of-the-art performance for unsupervised 3D object discovery, i.e. UNION more than doubles the average precision to 38.4. The code is available at github.com/TedLentsch/UNION.

Foundation models have significantly enhanced 2D task performance, and recent works like Bridge3D have successfully applied these models to improve 3D scene understanding through knowledge distillation, marking considerable advancements. Nonetheless, challenges such as the misalignment between 2D and 3D representations and the persistent long-tail distribution in 3D datasets still restrict the effectiveness of knowledge distillation from 2D to 3D using foundation models. To tackle these issues, we introduce a novel SAM-guided tokenization method that seamlessly aligns 3D transformer structures with region-level knowledge distillation, replacing the traditional KNN-based tokenization techniques. Additionally, we implement a group-balanced re-weighting strategy to effectively address the long-tail problem in knowledge distillation. Furthermore, inspired by the recent success of masked feature prediction, our framework incorporates a two-stage masked token prediction process in which the student model predicts both the global embeddings and token-wise local embeddings derived from the teacher models trained in the first stage. Our methodology has been validated across multiple datasets, including SUN RGB-D, ScanNet, and S3DIS, for tasks like 3D object detection and semantic segmentation. The results demonstrate significant improvements over current state-of-the-art self-supervised methods, establishing new benchmarks in this field.

Conventional wisdom suggests that pre-training Vision Transformers (ViT) improves downstream performance by learning useful representations. Is this actually true? We investigate this question and find that the features and representations learned during pre-training are not essential. Surprisingly, using only the attention patterns from pre-training (i.e., guiding how information flows between tokens) is sufficient for models to learn high quality features from scratch and achieve comparable downstream performance. We show this by introducing a simple method called attention transfer, where only the attention patterns from a pre-trained teacher ViT are transferred to a student, either by copying or distilling the attention maps. Since attention transfer lets the student learn its own features, ensembling it with a fine-tuned teacher also further improves accuracy on ImageNet. We systematically study various aspects of our findings on the sufficiency of attention maps, including distribution shift settings where they underperform fine-tuning. We hope our exploration provides a better understanding of what pre-training accomplishes and leads to a useful alternative to the standard practice of fine-tuning.
tl;dr: We introduce GEMCODE, a new automated screening pipeline leveraging hybridization of generative AI and evolutionary optimization for de novo co-crystal design with enhanced tabletability properties.

Co-crystallization is an accessible way to control physicochemical characteristics of organic crystals, which finds many biomedical applications. In this work, we present Generative Method for Co-crystal Design (GEMCODE), a novel pipeline for automated co-crystal screening based on the hybridization of deep generative models and evolutionary optimization for broader exploration of the target chemical space. GEMCODE enables fast *de novo* co-crystal design with target tabletability profiles, which is crucial for the development of pharmaceuticals. With a series of experimental studies highlighting validation and discovery cases, we show that GEMCODE is effective even under realistic computational constraints. Furthermore, we explore the potential of language models in generating co-crystals. Finally, we present numerous previously unknown co-crystals predicted by GEMCODE and discuss its potential in accelerating drug development.
tl;dr: We make representational similarity matrices permutation invariance and show resulting improvements in retrieval.

What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs.
Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair.
These matrices encapsulate the entire similarity structure of a system, indicating which input lead to similar responses.
While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper we propose to solve this through _semantic RSMs_, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of _semantic_ RSMs over _spatio-semantic_ RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.
tl;dr: We propose two local Bayesian optimziation algorithms to show that minimizing the UCB is better strategy than gradient descent in local search with a Gaussian process surrogate.

Local Bayesian optimization is a promising practical approach to solve the high dimensional black-box function optimization problem. Among them is the approximated gradient class of methods, which implements a strategy similar to gradient descent. These methods have achieved good experimental results and theoretical guarantees. However, given the distributional properties of the Gaussian processes applied on these methods, there may be potential to further exploit the information of the Gaussian processes to facilitate the BO search. In this work, we develop the relationship between the steps of the gradient descent method and one that minimizes the Upper Confidence Bound (UCB), and show that the latter can be a better strategy than direct gradient descent when a Gaussian process is applied as a surrogate. Through this insight, we propose a new local Bayesian optimization algorithm, MinUCB, which replaces the gradient descent step with minimizing UCB in GIBO. We further show that MinUCB maintains a similar convergence rate with GIBO. We then improve the acquisition function of MinUCB further through a look ahead strategy, and obtain a more efficient algorithm LA-MinUCB. We apply our algorithms on different synthetic and real-world functions, and the results show the effectiveness of our method. Our algorithms also illustrate improvements on local search strategies from an upper bound perspective in Bayesian optimization, and provides a new direction for future algorithm design.
tl;dr: we proposed a framework that leverages synthetic data, data partitioning, and model adaptation to elicit diverse responses from foundation models.

Presenting users with diverse responses from foundation models is crucial for enhancing user experience and accommodating varying preferences.
However, generating multiple high-quality and diverse responses without sacrificing accuracy remains a challenge, especially when using greedy sampling.
In this work, we propose a novel framework, Synthesize-Partition-Adapt (SPA), that leverages the abundant synthetic data available in many domains to elicit diverse responses from foundation models.
By leveraging signal provided by data attribution methods such as influence functions, SPA partitions data into subsets, each targeting unique aspects of the data, and trains multiple model adaptations optimized for these subsets.
Experimental results demonstrate the effectiveness of our approach in diversifying foundation model responses while maintaining high quality, showcased through the HumanEval and MBPP tasks in the code generation domain and several tasks in the natural language understanding domain, highlighting its potential to enrich user experience across various applications.

In this paper, we study a practical yet challenging task, On-the-fly Category Discovery (OCD), aiming to online discover the newly-coming stream data that belong to both known and unknown classes, by leveraging only known category knowledge contained in labeled data. Previous OCD methods employ the hash-based technique to represent old/new categories by hash codes for instance-wise inference. However, directly mapping features into low-dimensional hash space not only inevitably damages the ability to distinguish classes and but also causes ``high sensitivity'' issue, especially for fine-grained classes, leading to inferior performance. To address these drawbacks, we propose a novel Prototypical Hash Encoding (PHE) framework consisting of Category-aware Prototype Generation (CPG) and Discriminative Category Encoding (DCE) to mitigate the sensitivity of hash code while preserving rich discriminative information contained in high-dimension feature space, in a two-stage projection fashion. CPG enables the model to fully capture the intra-category diversity by representing each category with multiple prototypes. DCE boosts the discrimination ability of hash code with the guidance of the generated category prototypes and the constraint of minimum separation distance. By jointly optimizing CPG and DCE, we demonstrate that these two components are mutually beneficial towards an effective OCD. Extensive experiments show the significant superiority of our PHE over previous methods, e.g. obtaining an improvement of +5.3% in ALL ACC averaged on all datasets. Moreover, due to the nature of the interpretable prototypes, we visually analyze the underlying mechanism of how PHE helps group certain samples into either known or unknown categories. Code is available at https://github.com/HaiyangZheng/PHE.
tl;dr: A PEFT method leverage the high performance of sparse tuning with LoRA-level memory footprints.

Parameter-efficient fine-tuning (PEFT) is an effective method for adapting pre-trained vision models to downstream tasks by tuning a small subset of parameters. Among PEFT methods, sparse tuning achieves superior performance by only adjusting the weights most relevant to downstream tasks, rather than densely tuning the whole weight matrix. However, this performance improvement has been accompanied by increases in memory usage, which stems from two factors, i.e., the storage of the whole weight matrix as learnable parameters in the optimizer and the additional storage of tunable weight indexes. In this paper, we propose a method named SNELL (Sparse tuning with kerNELized LoRA) for sparse tuning with low memory usage. To achieve low memory usage, SNELL decomposes the tunable matrix for sparsification into two learnable low-rank matrices, saving from the costly storage of the whole original matrix. A competition-based sparsification mechanism is further proposed to avoid the storage of tunable weight indexes. To maintain the effectiveness of sparse tuning with low-rank matrices, we extend the low-rank decomposition by applying nonlinear kernel functions to the whole-matrix merging. Consequently, we gain an increase in the rank of the merged matrix, enhancing the ability of SNELL in adapting the pre-trained models to downstream tasks. Extensive experiments on multiple downstream tasks show that SNELL achieves state-of-the-art performance with low memory usage, endowing PEFT with sparse tuning to large-scale models. Codes are available at https://github.com/ssfgunner/SNELL.

Pre-trained language encoders---functions that represent text as vectors---are an integral component of many NLP tasks.
We tackle a natural question in language encoder analysis: What does it mean for two encoders to be similar?
We contend that a faithful measure of similarity needs to be \emph{intrinsic}, that is, task-independent, yet still be informative of \emph{extrinsic} similarity---the performance on downstream tasks.
It is common to consider two encoders similar if they are \emph{homotopic}, i.e., if they can be aligned through some transformation.
In this spirit, we study the properties of \emph{affine} alignment of language encoders and its implications on extrinsic similarity.
We find that while affine alignment is fundamentally an asymmetric notion of similarity, it is still informative of extrinsic similarity.
We confirm this on datasets of natural language representations.
Beyond providing useful bounds on extrinsic similarity, affine intrinsic similarity also allows us to begin uncovering the structure of the space of pre-trained encoders by defining an order over them.
tl;dr: We train small and efficient language feedback models to identify productive behaviour in grounded instruction following environments, then imitate this behaviour to improve policy performance.

We introduce Language Feedback Models (LFMs) that identify desirable behaviour --- actions that help achieve tasks specified in the instruction - for imitation learning in instruction following. To train LFMs, we obtain feedback from Large Language Models (LLMs) on visual trajectories verbalized to language descriptions. First, by using LFMs to identify desirable behaviour to imitate, we improve in task-completion rate over strong behavioural cloning baselines on three distinct language grounding environments (Touchdown, ScienceWorld, and ALFWorld). Second, LFMs outperform using LLMs as experts to directly predict actions, when controlling for the number of LLM output tokens. Third, LFMs generalize to unseen environments, improving task-completion rate by 3.5-12.0% through one round of adaptation. Finally, LFMs can be modified to provide human-interpretable feedback without performance loss, allowing human verification of desirable behaviour for imitation learning.

This paper is motivated by an interesting phenomenon: the performance of object detection lags behind that of instance segmentation (i.e., performance imbalance) when investigating the intermediate results from the beginning transformer decoder layer of MaskDINO (i.e., the SOTA model for joint detection and segmentation). This phenomenon inspires us to think about a question: will the performance imbalance at the beginning layer of transformer decoder constrain the upper bound of the final performance? With this question in mind, we further conduct qualitative and quantitative pre-experiments, which validate the negative impact of detection-segmentation imbalance issue on the model performance. To address this issue, this paper proposes DI-MaskDINO model, the core idea of which is to improve the final performance by alleviating the detection-segmentation imbalance. DI-MaskDINO is implemented by configuring our proposed De-Imbalance (DI) module and Balance-Aware Tokens Optimization (BATO) module to MaskDINO. DI is responsible for generating balance-aware query, and BATO uses the balance-aware query to guide the optimization of the initial feature tokens. The balance-aware query and optimized feature tokens are respectively taken as the Query and Key&Value of transformer decoder to perform joint object detection and instance segmentation. DI-MaskDINO outperforms existing joint object detection and instance segmentation models on COCO and BDD100K benchmarks, achieving +1.2 $AP^{box}$ and +0.9 $AP^{mask}$ improvements compared to SOTA joint detection and segmentation model MaskDINO. In addition, DI-MaskDINO also obtains +1.0 $AP^{box}$ improvement compared to SOTA object detection model DINO and +3.0 $AP^{mask}$ improvement compared to SOTA segmentation model Mask2Former.

Diffusion models have recently advanced Combinatorial Optimization (CO) as a powerful backbone for neural solvers. However, their iterative sampling process requiring denoising across multiple noise levels incurs substantial overhead. We propose to learn direct mappings from different noise levels to the optimal solution for a given instance, facilitating high-quality generation with minimal shots. This is achieved through an optimization consistency training protocol, which, for a given instance, minimizes the difference among samples originating from varying generative trajectories and time steps relative to the optimal solution. The proposed model enables fast single-step solution generation while retaining the option of multi-step sampling to trade for sampling quality, which offers a more effective and efficient alternative backbone for neural solvers. In addition, within the training-to-testing (T2T) framework, to bridge the gap between training on historical instances and solving new instances, we introduce a novel consistency-based gradient search scheme during the test stage, enabling more effective exploration of the solution space learned during training. It is achieved by updating the latent solution probabilities under objective gradient guidance during the alternation of noise injection and denoising steps. We refer to this model as Fast T2T. Extensive experiments on two popular tasks, the Traveling Salesman Problem (TSP) and Maximal Independent Set (MIS), demonstrate the superiority of Fast T2T regarding both solution quality and efficiency, even outperforming LKH given limited time budgets. Notably, Fast T2T with merely one-step generation and one-step gradient search can mostly outperform the SOTA diffusion-based counterparts that require hundreds of steps, while achieving tens of times speedup.

Unsupervised Domain Adaptation has been an efficient approach to transferring the semantic segmentation model across data distributions. Meanwhile, the recent Open-vocabulary Semantic Scene understanding based on large-scale vision language models is effective in open-set settings because it can learn diverse concepts and categories. However, these prior methods fail to generalize across different camera views due to the lack of cross-view geometric modeling. At present, there are limited studies analyzing cross-view learning. To address this problem, we introduce a novel Unsupervised Cross-view Adaptation Learning approach to modeling the geometric structural change across views in Semantic Scene Understanding. First, we introduce a novel Cross-view Geometric Constraint on Unpaired Data to model structural changes in images and segmentation masks across cameras. Second, we present a new Geodesic Flow-based Correlation Metric to efficiently measure the geometric structural changes across camera views. Third, we introduce a novel view-condition prompting mechanism to enhance the view-information modeling of the open-vocabulary segmentation network in cross-view adaptation learning. The experiments on different cross-view adaptation benchmarks have shown the effectiveness of our approach in cross-view modeling, demonstrating that we achieve State-of-the-Art (SOTA) performance compared to prior unsupervised domain adaptation and open-vocabulary semantic segmentation methods.
2881. G2D: From Global to Dense Radiography Representation Learning via Vision-Language Pre-training
tl;dr: We propose G2D, a novel medical VLP framework that learns global and dense visual features solely from image-text pairs, outperforming existing methods even with only 1% of the training data compared to their use of 100%.

Medical imaging tasks require an understanding of subtle and localized visual features due to the inherently detailed and area-specific nature of pathological patterns, which are crucial for clinical diagnosis. Although recent advances in medical vision-language pre-training (VLP) enable models to learn clinically relevant visual features by leveraging both medical images and their associated radiology reports, current medical VLP methods primarily focus on aligning images with entire reports. This focus hinders the learning of dense (pixel-level) visual features and is suboptimal for dense prediction tasks (e.g., medical image segmentation).
To address this challenge, we propose a novel medical VLP framework, named **Global to Dense level representation learning (G2D)**, which aims to learn global and dense visual features simultaneously using only image-text pairs without extra annotations. In particular, G2D designs a **Pseudo Segmentation (PS)** task, which enables the model to learn dense visual features during VLP. Notably, generating PS masks can be performed on the fly during VLP, which does not incur extra trainable parameters. With this simple yet effective idea, G2D achieves superior performance across 5 medical imaging tasks and 25 diseases. Particularly, in the segmentation task which requires dense visual features, **G2D surpasses existing models even with just 1% of the training data for finetuning, compared to 100% used by other models**. The code can be found in https://github.com/cheliu-computation/G2D-NeurIPS24/tree/main.
2882. Replay-and-Forget-Free Graph Class-Incremental Learning: A Task Profiling and Prompting Approach

Class-incremental learning (CIL) aims to continually learn a sequence of tasks, with each task consisting of a set of unique classes. Graph CIL (GCIL) follows the same setting but needs to deal with graph tasks (e.g., node classification in a graph). The key characteristic of CIL lies in the absence of task identifiers (IDs) during inference, which causes a significant challenge in separating classes from different tasks (i.e., inter-task class separation). Being able to accurately predict the task IDs can help address this issue, but it is a challenging problem. In this paper, we show theoretically that accurate task ID prediction on graph data can be achieved by a Laplacian smoothing-based graph task profiling approach, in which each graph task is modeled by a task prototype based on Laplacian smoothing over the graph. It guarantees that the task prototypes of the same graph task are nearly the same with a large smoothing step, while those of different tasks are distinct due to differences in graph structure and node attributes. Further, to avoid the catastrophic forgetting of the knowledge learned in previous graph tasks, we propose a novel graph prompting approach for GCIL which learns a small discriminative graph prompt for each task, essentially resulting in a separate classification model for each task. The prompt learning requires the training of a single graph neural network (GNN) only once on the first task, and no data replay is required thereafter, thereby obtaining a GCIL model being both replay-free and forget-free. Extensive experiments on four GCIL benchmarks show that i) our task prototype-based method can achieve 100% task ID prediction accuracy on all four datasets, ii) our GCIL model significantly outperforms state-of-the-art competing methods by at least 18% in average CIL accuracy, and iii) our model is fully free of forgetting on the four datasets.

In recent years, the merging of vast datasets with powerful computational resources has led to the emergence of large pre-trained models in the field of deep learning. However, the common practices often overgeneralize the applicability of these models, overlooking the task-specific resource constraints. To mitigate this issue, we propose \textbf{Cluster-Learngene}, which effectively clusters critical internal modules from a large ancestry model and then inherits them to initialize descendant models of elastic scales. Specifically, based on the density characteristics of attention heads, our method adaptively clusters attention heads of each layer and position-wise feed-forward networks (FFNs) in the ancestry model as the learngene. Moreover, we introduce priority weight-sharing and learnable parameter transformations that expand the learngene to initialize descendant models of elastic scales. Through extensive experimentation, we demonstrate that Cluster-Learngene not only is more efficient compared to other initialization methods but also customizes models of elastic scales according to downstream task resources.
tl;dr: Co-evolution of semantics and pragmatics in artificial agents

Human languages support both semantic categorization and local pragmatic interactions that require context-sensitive reasoning about meaning. While semantics and pragmatics are two fundamental aspects of language, they are typically studied independently and their co-evolution is largely under-explored. Here, we aim to bridge this gap by studying how a shared lexicon may emerge from local pragmatic interactions. To this end, we extend a recent information-theoretic framework for emergent communication in artificial agents, which integrates utility maximization, associated with pragmatics, with general communicative constraints that are believed to shape human semantic systems. Specifically, we show how to adapt this framework to train agents via unsupervised pragmatic interactions, and then evaluate their emergent lexical semantics. We test this approach in a rich visual domain of naturalistic images, and find that key human-like properties of the lexicon emerge when agents are guided by both context-specific utility and general communicative pressures, suggesting that both aspects are crucial for understanding how language may evolve in humans and in artificial agents.

Understanding treatment effect heterogeneity is vital for scientific and policy research. However, identifying and evaluating heterogeneous treatment effects pose significant challenges due to the typically unknown subgroup structure. Recently, a novel approach, causal k-means clustering, has emerged to assess heterogeneity of treatment effect by applying the k-means algorithm to unknown counterfactual regression functions. In this paper, we expand upon this framework by integrating hierarchical and density-based clustering algorithms. We propose plug-in estimators which are simple and readily implementable using off-the-shelf algorithms. Unlike k-means clustering, which requires the margin condition, our proposed estimators do not rely on strong structural assumptions on the outcome process. We go on to study their rate of convergence, and show that under the minimal regularity conditions, the additional cost of causal clustering is essentially the estimation error of the outcome regression functions. Our findings significantly extend the capabilities of the causal clustering framework, thereby contributing to the progression of methodologies for identifying homogeneous subgroups in treatment response, consequently facilitating more nuanced and targeted interventions. The proposed methods also open up new avenues for clustering with generic pseudo-outcomes. We explore finite sample properties via simulation, and illustrate the proposed methods in voting and employment projection datasets.

Large vision language models (LVLMs) integrate large language models (LLMs) with pre-trained vision encoders, thereby activating the perception capability of the model to understand image inputs for different queries and conduct subsequent reasoning. Improving this capability requires high-quality vision-language data, which is costly and labor-intensive to acquire. Self-training approaches have been effective in single-modal settings to alleviate the need for labeled data by leveraging model's own generation. However, effective self-training remains a challenge regarding the unique visual perception and reasoning capability of LVLMs. To address this, we introduce **S**elf-**T**raining on **I**mage **C**omprehension (**STIC**), which emphasizes a self-training approach specifically for image comprehension. First, the model self-constructs a preference dataset for image descriptions using unlabeled images. Preferred responses are generated through a step-by-step prompt, while dis-preferred responses are generated from either corrupted images or misleading prompts. To further self-improve reasoning on the extracted visual information, we let the model reuse a small portion of existing instruction-tuning data and append its self-generated image descriptions to the prompts. We validate the effectiveness of STIC across seven different benchmarks, demonstrating substantial performance gains of 4.0% on average while using 70% less supervised fine-tuning data than the current method. Further studies dive into various components of STIC and highlight its potential to leverage vast quantities of unlabeled images for self-training.

The recent emergence of diffusion models has significantly advanced the precision of learnable priors, presenting innovative avenues for addressing inverse problems. Previous works have endeavored to integrate diffusion priors into the maximum a posteriori estimation (MAP) framework and design optimization methods to solve the inverse problem. However, prevailing optimization-based rithms primarily exploit the prior information within the diffusion models while neglecting their denoising capability. To bridge this gap, this work leverages the diffusion process to reframe noisy inverse problems as a two-variable constrained optimization task by introducing an auxiliary optimization variable that represents a 'noisy' sample at an equivalent denoising step. The projection gradient descent method is efficiently utilized to solve the corresponding optimization problem by truncating the gradient through the $\mu$-predictor. The proposed algorithm, termed ProjDiff, effectively harnesses the prior information and the denoising capability of a pre-trained diffusion model within the optimization framework. Extensive experiments on the image restoration tasks and source separation and partial generation tasks demonstrate that ProjDiff exhibits superior performance across various linear and nonlinear inverse problems, highlighting its potential for practical applications. Code is available at https://github.com/weigerzan/ProjDiff/.
tl;dr: Vision-language models can be misused to violate users' privacy by inferring private attributes from inconspicuous images they post online.

As large language models (LLMs) become ubiquitous in our daily tasks and digital interactions, associated privacy risks are increasingly in focus. While LLM privacy research has primarily focused on the leakage of model training data, it has recently been shown that LLMs can make accurate privacy-infringing inferences from previously unseen texts. With the rise of vision-language models (VLMs), capable of understanding both images and text, a key question is whether this concern transfers to the previously unexplored domain of benign images posted online. To answer this question, we compile an image dataset with human-annotated labels of the image owner's personal attributes. In order to understand the privacy risks posed by VLMs beyond traditional human attribute recognition, our dataset consists of images where the inferable private attributes do not stem from direct depictions of humans. On this dataset, we evaluate 7 state-of-the-art VLMs, finding that they can infer various personal attributes at up to 77.6% accuracy. Concerningly, we observe that accuracy scales with the general capabilities of the models, implying that future models can be misused as stronger inferential adversaries, establishing an imperative for the development of adequate defenses.
tl;dr: Our novel self-attention layers boosts control over feature injection from a single or multiple reference images, enhancing both image and video generation for diffusion model.

There is a rapidly growing interest in controlling consistency across multiple generated images using diffusion models. Among various methods, recent works have found that simply manipulating attention modules by concatenating features from multiple reference images provides an efficient approach to enhancing consistency without fine-tuning. Despite its popularity and success, few studies have elucidated the underlying mechanisms that contribute to its effectiveness. In this work, we reveal that the popular approach is a linear interpolation of image self-attention and cross-attention between synthesized content and reference features, with a constant rank-1 coefficient. Motivated by this observation, we find that a rank-1 coefficient is not necessary and simplifies the controllable generation mechanism. The resulting algorithm, which we coin as RefDrop, allows users to control the influence of reference context in a direct and precise manner. Besides further enhancing consistency in single-subject image generation, our method also enables more interesting applications, such as the consistent generation of multiple subjects, suppressing specific features to encourage more diverse content, and high-quality personalized video generation by boosting temporal consistency. Even compared with state-of-the-art image-prompt-based generators, such as IP-Adapter, RefDrop is competitive in terms of controllability and quality while avoiding the need to train a separate image encoder for feature injection from reference images, making it a versatile plug-and-play solution for any image or video diffusion model.
tl;dr: Novel and highly efficient fine-tuning algorithm for diffusion models motivated by theoretical formulations of conditional sampling in SDEs

Generative modelling paradigms based on denoising diffusion processes have emerged as a leading candidate for conditional sampling in inverse problems.
In many real-world applications, we often have access to large, expensively trained unconditional diffusion models, which we aim to exploit for improving conditional sampling.
Most recent approaches are motivated heuristically and lack a unifying framework, obscuring connections between them. Further, they often suffer from issues such as being very sensitive to hyperparameters, being expensive to train or needing access to weights hidden behind a closed API. In this work, we unify conditional training and sampling using the mathematically well-understood Doob's h-transform. This new perspective allows us to unify many existing methods under a common umbrella. Under this framework, we propose DEFT (Doob's h-transform Efficient FineTuning), a new approach for conditional generation that simply fine-tunes a very small network to quickly learn the conditional $h$-transform, while keeping the larger unconditional network unchanged. DEFT is much faster than existing baselines while achieving state-of-the-art performance across a variety of linear and non-linear benchmarks. On image reconstruction tasks, we achieve speedups of up to 1.6$\times$, while having the best perceptual quality on natural images and reconstruction performance on medical images. Further, we also provide initial experiments on protein motif scaffolding and outperform reconstruction guidance methods.

*Constrained Reinforcement Learning* (CRL) tackles sequential decision-making problems where agents are required to achieve goals by maximizing the expected return while meeting domain-specific constraints, which are often formulated on expected costs. In this setting, *policy-based* methods are widely used since they come with several advantages when dealing with continuous-control problems. These methods search in the policy space with an *action-based* or *parameter-based* exploration strategy, depending on whether they learn directly the parameters of a stochastic policy or those of a stochastic hyperpolicy. In this paper, we propose a general framework for addressing CRL problems via *gradient-based primal-dual* algorithms, relying on an alternate ascent/descent scheme with dual-variable regularization. We introduce an exploration-agnostic algorithm, called C-PG, which exhibits global last-iterate convergence guarantees under (weak) gradient domination assumptions, improving and generalizing existing results. Then, we design C-PGAE and C-PGPE, the action-based and the parameter-based versions of C-PG, respectively, and we illustrate how they naturally extend to constraints defined in terms of *risk measures* over the costs, as it is often requested in safety-critical scenarios. Finally, we numerically validate our algorithms on constrained control problems, and compare them with state-of-the-art baselines, demonstrating their effectiveness.
tl;dr: As BH's FDR control could be relied upon in some critical contexts, we investigate its adversarial robustness via easily implementable, adversarial algorithms, and show that BH's control can be significantly broken with perturbations to few tests.

The Benjamini-Hochberg (BH) procedure is widely used to control the false detection rate (FDR) in multiple testing. Applications of this control abound in drug discovery, forensics, anomaly detection, and, in particular, machine learning, ranging from nonparametric outlier detection to out-of-distribution detection and one-class classification methods. Considering this control could be relied upon in critical safety/security contexts, we investigate its adversarial robustness. More precisely, we study under what conditions BH does and does not exhibit adversarial robustness, we present a class of simple and easily implementable adversarial test-perturbation algorithms, and we perform computational experiments. With our algorithms, we demonstrate that there are conditions under which BH's control can be significantly broken with relatively few (even just one) test score perturbation(s), and provide non-asymptotic guarantees on the expected adversarial-adjustment to FDR. Our technical analysis involves a combinatorial reframing of the BH procedure as a ``balls into bins'' process, and drawing a connection to generalized ballot problems to facilitate an information-theoretic approach for deriving non-asymptotic lower bounds.
tl;dr: automatically generate realistic 3D scenes and camera trajectories from texts

Recent advancements in 3D generation have leveraged synthetic datasets with ground truth 3D assets and predefined camera trajectories. However, the potential of adopting real-world datasets, which can produce significantly more realistic 3D scenes, remains largely unexplored. In this work, we delve into the key challenge of the complex and scene-specific camera trajectories found in real-world captures. We introduce Director3D, a robust open-world text-to-3D generation framework, designed to generate both real-world 3D scenes and adaptive camera trajectories. To achieve this, (1) we first utilize a Trajectory Diffusion Transformer, acting as the \emph{Cinematographer}, to model the distribution of camera trajectories based on textual descriptions. Next, a Gaussian-driven Multi-view Latent Diffusion Model serves as the \emph{Decorator}, modeling the image sequence distribution given the camera trajectories and texts. This model, fine-tuned from a 2D diffusion model, directly generates pixel-aligned 3D Gaussians as an immediate 3D scene representation for consistent denoising. Lastly, the 3D Gaussians are further refined by a novel SDS++ loss as the \emph{Detailer}, which incorporates the prior of the 2D diffusion model. Extensive experiments demonstrate that Director3D outperforms existing methods, offering superior performance in real-world 3D generation.
tl;dr: Attention Compression for Diffusion Transformer Models

Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to the quadratic complexity of self-attention operators. We propose DiTFastAttn, a post-training compression method to alleviate the computational bottleneck of DiT.
We identify three key redundancies in the attention computation during DiT inference: (1) spatial redundancy, where many attention heads focus on local information; (2) temporal redundancy, with high similarity between the attention outputs of neighboring steps; (3) conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. We propose three techniques to reduce these redundancies: (1) $\textit{Window Attention with Residual Sharing}$ to reduce spatial redundancy; (2) $\textit{Attention Sharing across Timesteps}$ to exploit the similarity between steps; (3) $\textit{Attention Sharing across CFG}$ to skip redundant computations during conditional generation.
tl;dr: We introduce a joint valuation framework that attributes data contribution through assigning the valuation scores at the cell level.

Data valuation has emerged as a powerful framework for quantifying each datum's contribution to the training of a machine learning model. However, it is crucial to recognize that the quality of cells within a single data point can vary greatly in practice. For example, even in the case of an abnormal data point, not all cells are necessarily noisy. The single scalar score assigned by existing data valuation methods blurs the distinction between noisy and clean cells of a data point, making it challenging to interpret the data values. In this paper, we propose 2D-OOB, an out-of-bag estimation framework for jointly determining helpful (or detrimental) samples as well as the particular cells that drive them. Our comprehensive experiments demonstrate that 2D-OOB achieves state-of-the-art performance across multiple use cases while being exponentially faster. Specifically, 2D-OOB shows promising results in detecting and rectifying fine-grained outliers at the cell level, and localizing backdoor triggers in data poisoning attacks.
2896. Beyond task diversity: provable representation transfer for sequential multitask linear bandits
tl;dr: We study lifelong learning in linear bandits, where a learner interacts with a sequence of linear bandit tasks that share a low-rank representation without requiring the Task Diversity assumption.

We study lifelong learning in linear bandits, where a learner interacts with a sequence of linear bandit tasks whose parameters lie in an $m$-dimensional subspace of $\mathbb{R}^d$, thereby sharing a low-rank representation. Current literature typically assumes that the tasks are diverse, i.e., their parameters uniformly span the $m$-dimensional subspace. This assumption allows the low-rank representation to be learned before all tasks are revealed, which can be unrealistic in real-world applications. In this work, we present the first nontrivial result for sequential multi-task linear bandits without the task diversity assumption. We develop an algorithm that efficiently learns and transfers low-rank representations. When facing $N$ tasks, each played over $\tau$ rounds, our algorithm achieves a regret guarantee of $\tilde{O}\big (Nm \sqrt{\tau} + N^{\frac{2}{3}} \tau^{\frac{2}{3}} d m^{\frac13} + Nd^2 + \tau m d \big)$ under the ellipsoid action set assumption.
tl;dr: A large vision-language model for understanding open-world video anomalies.

Video Anomaly Detection (VAD) systems can autonomously monitor and identify disturbances, reducing the need for manual labor and associated costs. However, current VAD systems are often limited by their superficial semantic understanding of scenes and minimal user interaction. Additionally, the prevalent data scarcity in existing datasets restricts their applicability in open-world scenarios.
In this paper, we introduce HAWK, a novel framework that leverages interactive large Visual Language Models (VLM) to interpret video anomalies precisely. Recognizing the difference in motion information between abnormal and normal videos, HAWK explicitly integrates motion modality to enhance anomaly identification. To reinforce motion attention, we construct an auxiliary consistency loss within the motion and video space, guiding the video branch to focus on the motion modality. Moreover, to improve the interpretation of motion-to-language, we establish a clear supervisory relationship between motion and its linguistic representation. Furthermore, we have annotated over 8,000 anomaly videos with language descriptions, enabling effective training across diverse open-world scenarios, and also created 8,000 question-answering pairs for users' open-world questions. The final results demonstrate that HAWK achieves SOTA performance, surpassing existing baselines in both video description generation and question-answering. Our codes/dataset/demo will be released at https://github.com/jqtangust/hawk.
tl;dr: Combining autoregressive method with diffusion for modeling graph distribution with SOTA graph generation performance.

Graph generation has been dominated by autoregressive models due to their simplicity and effectiveness, despite their sensitivity to ordering. Yet diffusion models have garnered increasing attention, as they offer comparable performance while being permutation-invariant. Current graph diffusion models generate graphs in a one-shot fashion, but they require extra features and thousands of denoising steps to achieve optimal performance. We introduce PARD, a Permutation-invariant Auto Regressive Diffusion model that integrates diffusion models with autoregressive methods. PARD harnesses the effectiveness and efficiency of the autoregressive model while maintaining permutation invariance without ordering sensitivity. Specifically, we show that contrary to sets, elements in a graph are not entirely un-ordered and there is a unique partial order for nodes and edges. With this partial order, PARD generates a graph in a block-by-block, autoregressive fashion, where each block’s probability is conditionally modeled by a shared diffusion model with an equivariant network. To ensure efficiency while being expressive, we further propose a higher-order graph transformer, which integrates transformer with PPGN (Maronet al., 2019). Like GPT, we extend the higher-order graph transformer to support parallel training of all blocks. Without any extra features, PARD achieves state-of-the-art performance on molecular and non-molecular datasets, and scales to large datasets like MOSES containing 1.9M molecules.

Recent research has underscored the efficacy of Graph Neural Networks (GNNs) in modeling diverse geometric structures within graph data. However, real-world graphs typically exhibit geometrically heterogeneous characteristics, rendering the confinement to a single geometric paradigm insufficient for capturing their intricate structural complexities. To address this limitation, we examine the performance of GNNs across various geometries through the lens of knowledge distillation (KD) and introduce a novel cross-geometric framework. This framework encodes graphs by integrating both Euclidean and hyperbolic geometries in a space-mixing fashion. Our approach employs multiple teacher models, each generating hint embeddings that encapsulate distinct geometric properties. We then implement a structure-wise knowledge transfer module that optimally leverages these embeddings within their respective geometric contexts, thereby enhancing the training efficacy of the student model. Additionally, our framework incorporates a geometric optimization network designed to bridge the distributional disparities among these embeddings. Experimental results demonstrate that our model-agnostic framework more effectively captures topological graph knowledge, resulting in superior performance of the student models when compared to traditional KD methodologies.
2900. $\text{ID}^3$: Identity-Preserving-yet-Diversified Diffusion Models for Synthetic Face Recognition

Synthetic face recognition (SFR) aims to generate synthetic face datasets that mimic the distribution of real face data, which allows for training face recognition models in a privacy-preserving manner. Despite the remarkable potential of diffusion models in image generation, current diffusion-based SFR models struggle with generalization to real-world faces. To address this limitation, we outline three key objectives for SFR: (1) promoting diversity across identities (inter-class diversity), (2) ensuring diversity within each identity by injecting various facial attributes (intra-class diversity), and (3) maintaining identity consistency within each identity group (intra-class identity preservation). Inspired by these goals, we introduce a diffusion-fueled SFR model termed $\text{ID}^3$. $\text{ID}^3$ employs an ID-preserving loss to generate diverse yet identity-consistent facial appearances. Theoretically, we show that minimizing this loss is equivalent to maximizing the lower bound of an adjusted conditional log-likelihood over ID-preserving data. This equivalence motivates an ID-preserving sampling algorithm, which operates over an adjusted gradient vector field, enabling the generation of fake face recognition datasets that approximate the distribution of real-world faces. Extensive experiments across five challenging benchmarks validate the advantages of $\text{ID}^3$.
tl;dr: We improve gradient based discrete sampling by adding cyclical schedules and automated hyperparameter tuning algorithm

Discrete distributions, particularly in high-dimensional deep models, are often highly multimodal due to inherent discontinuities. While gradient-based discrete sampling has proven effective, it is susceptible to becoming trapped in local modes due to the gradient information. To tackle this challenge, we propose an automatic cyclical scheduling, designed for efficient and accurate sampling in multimodal discrete distributions. Our method contains three key components: (1) a cyclical step size schedule where large steps discover new modes and small steps exploit each mode; (2) a cyclical balancing schedule, ensuring "balanced" proposals for given step sizes and high efficiency of the Markov chain; and (3) an automatic tuning scheme for adjusting the hyperparameters in the cyclical schedules, allowing adaptability across diverse datasets with minimal tuning. We prove the non-asymptotic convergence and inference guarantee for our method in general discrete distributions. Extensive experiments demonstrate the superiority of our method in sampling complex multimodal discrete distributions.
tl;dr: This study focuses on one critical deficiency inherent in current prompt-based continual learning methods, i.e., the end-to-end optimization of prompt selection with task loss while keeping its discrete nature as task knowledge representation.

Continual learning requires to overcome catastrophic forgetting when training a single model on a sequence of tasks. Recent top-performing approaches are prompt-based methods that utilize a set of learnable parameters (i.e., prompts) to encode task knowledge, from which appropriate ones are selected to guide the fixed pre-trained model in generating features tailored to a certain task. However, existing methods rely on predicting prompt identities for prompt selection, where the identity prediction process cannot be optimized with task loss. This limitation leads to sub-optimal prompt selection and inadequate adaptation of pre-trained features for a specific task. Previous efforts have tried to address this by directly generating prompts from input queries instead of selecting from a set of candidates. However, these prompts are continuous, which lack sufficient abstraction for task knowledge representation, making them less effective for continual learning. To address these challenges, we propose VQ-Prompt, a prompt-based continual learning method that incorporates Vector Quantization (VQ) into end-to-end training of a set of discrete prompts. In this way, VQ-Prompt can optimize the prompt selection process with task loss and meanwhile achieve effective abstraction of task knowledge for continual learning. Extensive experiments show that VQ-Prompt outperforms state-of-the-art continual learning methods across a variety of benchmarks under the challenging class-incremental setting.
tl;dr: We present Hierarchical Sinkhorn Tree, a pruned tree structure designed to hierarchically measure the multi-scale consistency of coarse correspondences for point cloud registration.

We study the problem of retrieving accurate correspondence through multi-scale consistency (MSC) for robust point cloud registration. Existing works in a coarse-to-fine manner either suffer from severe noisy correspondences caused by unreliable coarse matching or struggle to form outlier-free coarse-level correspondence sets. To tackle this, we present Hierarchical Sinkhorn Tree (HST), a pruned tree structure designed to hierarchically measure the local consistency of each coarse correspondence across multiple feature scales, thereby filtering out the local dissimilar ones. In this way, we convert the modeling of MSC for each correspondence into a BFS traversal with pruning of a K-ary tree rooted at the superpoint, with its K nearest neighbors in the feature pyramid serving as child nodes. To achieve efficient pruning and accurate vicinity characterization, we further propose a novel overlap-aware Sinkhorn Distance, which retains only the most likely overlapping points for local measurement and next level exploration. The modeling process essentially involves traversing a pair of HSTs synchronously and aggregating the consistency measures of corresponding tree nodes. Extensive experiments demonstrate HST consistently outperforms the state-of-the-art methods on both indoor and outdoor benchmarks.
tl;dr: A frequency-inflated conditional diffusion model that enhances time series generation by preserving extreme values distribution

Time series generation is a crucial aspect of data analysis, playing a pivotal role in learning the temporal patterns and their underlying dynamics across diverse fields. Conventional time series generation methods often struggle to capture extreme values adequately, diminishing their value in critical applications such as scenario planning and management for healthcare, finance, climate change adaptation, and beyond. In this paper, we introduce a conditional diffusion model called FIDE to address the challenge of preserving the distribution of extreme values in generative modeling for time series. FIDE employs a novel high-frequency inflation strategy in the frequency domain, preventing premature fade-out of the extreme value. It also extends traditional diffusion-based model, enabling the generation of samples conditioned on the block maxima, thereby enhancing the model's capacity to capture extreme events. Additionally, the FIDE framework incorporates the Generalized Extreme Value (GEV) distribution within its generative modeling framework, ensuring fidelity to both block maxima and overall data distribution. Experimental results on real-world and synthetic data showcase the efficacy of FIDE over baseline methods, highlighting its potential in advancing Generative AI for time series analysis, specifically in accurately modeling extreme events.

A rich line of works study the bandit learning problem in two-sided matching markets, where one side of market participants (players) are uncertain about their preferences and hope to find a stable matching during iterative matchings with the other side (arms). The state-of-the-art analysis shows that the player-optimal stable regret is of order $O(K\log T/\Delta^2)$ where $K$ is the number of arms, $T$ is the horizon and $\Delta$ is the players' minimum preference gap. However, this result may be far from the lower bound $\Omega(\max\{N\log T/\Delta^2, K\log T/\Delta\})$ since the number $K$ of arms (workers, publisher slots) may be much larger than that $N$ of players (employers in labor markets, advertisers in online advertising, respectively).
In this paper, we propose a new algorithm and show that the regret can be upper bounded by $O(N^2\log T/\Delta^2 + K \log T/\Delta)$. This result removes the dependence on $K$ in the main order term and improves the state-of-the-art guarantee in common cases where $N$ is much smaller than $K$. Such an advantage is also verified in experiments.
In addition, we provide a refined analysis for the existing centralized UCB algorithm and show that, under $\alpha$-condition, it achieves an improved $O(N \log T/\Delta^2 + K \log T / \Delta)$ regret.
tl;dr: We develop a new method for 3D scene reconstruction from omnidirectional images via 3D Gaussian Splattings.

Omnidirectional (or 360-degree) images are increasingly being used for 3D applications since they allow the rendering of an entire scene with a single image. Existing works based on neural radiance fields demonstrate successful 3D reconstruction quality on egocentric videos, yet they suffer from long training and rendering times. Recently, 3D Gaussian splatting has gained attention for its fast optimization and real-time rendering. However, directly using a perspective rasterizer to omnidirectional images results in severe distortion due to the different optical properties between the two image domains. In this work, we present ODGS, a novel rasterization pipeline for omnidirectional images with geometric interpretation. For each Gaussian, we define a tangent plane that touches the unit sphere and is perpendicular to the ray headed toward the Gaussian center. We then leverage a perspective camera rasterizer to project the Gaussian onto the corresponding tangent plane. The projected Gaussians are transformed and combined into the omnidirectional image, finalizing the omnidirectional rasterization process. This interpretation reveals the implicit assumptions within the proposed pipeline, which we verify through mathematical proofs. The entire rasterization process is parallelized using CUDA, achieving optimization and rendering speeds 100 times faster than NeRF-based methods. Our comprehensive experiments highlight the superiority of ODGS by delivering the best reconstruction and perceptual quality across various datasets. Additionally, results on roaming datasets demonstrate that ODGS effectively restores fine details, even when reconstructing large 3D scenes. The source code is available on our project page (https://github.com/esw0116/ODGS).
tl;dr: SeTAR, a training-free method that improves out-of-distribution detection by post-hoc modification of weight matrices, with extended fine-tuning version SeTAR+FT.

Out-of-distribution (OOD) detection is crucial for the safe deployment of neural networks. Existing CLIP-based approaches perform OOD detection by devising novel scoring functions or sophisticated fine-tuning methods. In this work, we propose SeTAR, a novel, training-free OOD detection method that leverages selective low-rank approximation of weight matrices in vision-language and vision-only models. SeTAR enhances OOD detection via post-hoc modification of the model's weight matrices using a simple greedy search algorithm. Based on SeTAR, we further propose SeTAR+FT, a fine-tuning extension optimizing model performance for OOD detection tasks. Extensive evaluations on ImageNet1K and Pascal-VOC benchmarks show SeTAR's superior performance, reducing the relatively false positive rate by up to 18.95\% and 36.80\% compared to zero-shot and fine-tuning baselines. Ablation studies further validate our approach's effectiveness, robustness, and generalizability across different model backbones. Our work offers a scalable, efficient solution for OOD detection, setting a new state-of-the-art in this area.

This paper considers the problem of online learning with non-convex loss functions in dynamic environments. Recently, Suggala and Netrapalli [2020] demonstrated that follow the perturbed leader (FTPL) can achieve optimal regret for non-convex losses, but their results are limited to static environments. In this research, we examine dynamic environments and choose \emph{dynamic regret} and \emph{adaptive regret} to measure the performance. First, we propose an algorithm named FTPL-D by restarting FTPL periodically and establish $O(T^\frac{2}{3}(V_T+1)^\frac{1}{3})$ dynamic regret with the prior knowledge of $V_T$, which is the variation of loss functions. In the case that $V_T$ is unknown, we run multiple FTPL-D with different restarting parameters as experts and use a meta-algorithm to track the best one on the fly. To address the challenge of non-convexity, we utilize randomized sampling in the process of tracking experts. Next, we present a novel algorithm called FTPL-A that dynamically maintains a group of FTPL experts and combines them with an advanced meta-algorithm to obtain $O(\sqrt{\tau\log{T}})$ adaptive regret for any interval of length $\tau$. Moreover, we demonstrate that FTPL-A also attains an $\tilde{O}(T^\frac{2}{3}(V_T+1)^\frac{1}{3})$ dynamic regret bound. Finally, we discuss the application to online constrained meta-learning and conduct experiments to verify the effectiveness of our methods.
tl;dr: We present a deep learning model, designed to leverage climate data to identify the drivers of extreme events impacts.

The spatio-temporal relations of impacts of extreme events and their drivers in climate data are not fully understood and there is a need of machine learning approaches to identify such spatio-temporal relations from data. The task, however, is very challenging since there are time delays between extremes and their drivers, and the spatial response of such drivers is inhomogeneous. In this work, we propose a first approach and benchmarks to tackle this challenge. Our approach is trained end-to-end to predict spatio-temporally extremes and spatio-temporally drivers in the physical input variables jointly. By enforcing the network to predict extremes from spatio-temporal binary masks of identified drivers, the network successfully identifies drivers that are correlated with extremes. We evaluate our approach on three newly created synthetic benchmarks, where two of them are based on remote sensing or reanalysis climate data, and on two real-world reanalysis datasets. The source code and datasets are publicly available at the project page https://hakamshams.github.io/IDE.
tl;dr: We propose a mixture of experts architecture for reconstructing various signals (3D surfaces, images, audio) using a neural representation.

Implicit neural representations (INRs) have proven effective in various tasks including image, shape, audio, and video reconstruction. These INRs typically learn the implicit field from sampled input points. This is often done using a single network for the entire domain, imposing many global constraints on a single function.
In this paper, we propose a mixture of experts (MoE) implicit neural representation approach that enables learning local piece-wise continuous functions that simultaneously learns to subdivide the domain and fit it locally.
We show that incorporating a mixture of experts architecture into existing INR formulations provides a boost in speed, accuracy, and memory requirements. Additionally, we introduce novel conditioning and pretraining methods for the gating network that improves convergence to the desired solution.
We evaluate the effectiveness of our approach on multiple reconstruction tasks, including surface reconstruction, image reconstruction, and audio signal reconstruction and show improved performance compared to non-MoE methods. Code is available at our project page https://sitzikbs.github.io/neural-experts-projectpage/ .
tl;dr: We study matroid basis problems in a two-oracle model, where we have access to a fast but potentially imprecise and to a slow but precise independence oracle.

Querying complex models for precise information (e.g. traffic models, database systems, large ML models) often entails intense computations and results in long response times. Thus, weaker models which give imprecise results quickly can be advantageous, provided inaccuracies can be resolved using few queries to a stronger model. In the fundamental problem of computing a maximum-weight basis of a matroid, a well-known generalization of many combinatorial optimization problems, algorithms have access to a clean oracle to query matroid information. We additionally equip algorithms with a fast but dirty oracle. We design and analyze practical algorithms which only use few clean queries w.r.t. the quality of the dirty oracle, while maintaining robustness against arbitrarily poor dirty oracles, approaching the performance of classic algorithms for the given problem. Notably, we prove that our algorithms are, in many respects, best-possible. Further, we outline extensions to other matroid oracle types, non-free dirty oracles and other matroid problems.

Large vision language models, such as CLIP, demonstrate impressive robustness to spurious features than single-modal models trained on ImageNet. However, existing test datasets are typically curated based on ImageNet-trained models, which aim to capture the spurious features inherited in ImageNet. Benchmarking CLIP models based on the ImageNet-oriented spurious features may not be sufficient to reflect the extent to which CLIP models are robust to spurious correlations within CLIP training data, e.g., LAION. To this end, we craft a new challenging dataset named CounterAnimal designed to reveal the reliance of CLIP models on realistic spurious features. Specifically, we split animal photos into groups according to the backgrounds, and then identify a pair of groups for each class where a CLIP model shows high-performance drops across the two groups. Our evaluations show that the spurious features captured by CounterAnimal are generically learned by CLIP models with different backbones and pre-train data, yet have limited influence for ImageNet models. We provide theoretical insights that the CLIP objective cannot offer additional robustness. Furthermore, we also re-evaluate strategies such as scaling up parameters and high-quality pre-trained data. We find that they still help mitigate the spurious features, providing a promising path for future developments.
tl;dr: We proposed an 2D relighting diffusion model that can relight any object image under any environmental lighting, which can be used as a prior in many 2D and 3D tasks, such as text-based relighting, object insertion, and relighting 3D representation.

Single-image relighting is a challenging task that involves reasoning about the complex interplay between geometry, materials, and lighting. Many prior methods either support only specific categories of images, such as portraits, or require special capture conditions, like using a flashlight. Alternatively, some methods explicitly decompose a scene into intrinsic components, such as normals and BRDFs, which can be inaccurate or under-expressive. In this work, we propose a novel end-to-end 2D relighting diffusion model, called Neural Gaffer, that takes a single image of any object and can synthesize an accurate, high-quality relit image under any novel environmental lighting condition, simply by conditioning an image generator on a target environment map, without an explicit scene decomposition. Our method builds on a pre-trained diffusion model, and fine-tunes it on a synthetic relighting dataset, revealing and harnessing the inherent understanding of lighting present in the diffusion model. We evaluate our model on both synthetic and in-the-wild Internet imagery and demonstrate its advantages in terms of generalization and accuracy. Moreover, by combining with other generative methods, our model enables many downstream 2D tasks, such as text-based relighting and object insertion. Our model can also operate as a strong relighting prior for 3D tasks, such as relighting a radiance field.

We present an novel framework for efficiently and effectively extending the powerful continuous diffusion processes to discrete modeling.
Previous approaches have suffered from the discrepancy between discrete data and continuous modeling.
Our study reveals that the absence of guidance from discrete boundaries in learning probability contours is one of the main reasons.
To address this issue, we propose a two-step forward process that first estimates the boundary as a prior distribution and then rescales the forward trajectory to construct a boundary conditional diffusion model.
The reverse process is proportionally adjusted to guarantee that the learned contours yield more precise discrete data.
Experimental results indicate that our approach achieves strong performance in both language modeling and discrete image generation tasks.
In language modeling, our approach surpasses previous state-of-the-art continuous diffusion language models in three translation tasks and a summarization task, while also demonstrating competitive performance compared to auto-regressive transformers. Moreover, our method achieves comparable results to continuous diffusion models when using discrete ordinal pixels and establishes a new state-of-the-art for categorical image generation on the Cifar-10 dataset.
tl;dr: Infinitely many-armed bandits with rotting rewards under generalized rotting constraints.

In this study, we consider the infinitely many-armed bandit problems in a rested rotting setting, where the mean reward of an arm may decrease with each pull, while otherwise, it remains unchanged. We explore two scenarios regarding the rotting of rewards: one in which the cumulative amount of rotting is bounded by $V_T$, referred to as the slow-rotting case, and the other in which the cumulative number of rotting instances is bounded by $S_T$, referred to as the abrupt-rotting case. To address the challenge posed by rotting rewards, we introduce an algorithm that utilizes UCB with an adaptive sliding window, designed to manage the bias and variance trade-off arising due to rotting rewards. Our proposed algorithm achieves tight regret bounds for both slow and abrupt rotting scenarios. Lastly, we demonstrate the performance of our algorithm using numerical experiments.

As the key component in multimodal large language models (MLLMs), the ability of the visual encoder greatly affects MLLM's understanding on diverse image content. Although some large-scale pretrained vision encoders such as vision encoders in CLIP and DINOv2 have brought promising performance, we found that there is still no single vision encoder that can dominate various image content understanding, e.g., the CLIP vision encoder leads to outstanding results on general image understanding but poor performance on document or chart content. To alleviate the bias of CLIP vision encoder, we first delve into the inherent behavior of different pre-trained vision encoders and then propose the MoVA, a powerful and novel MLLM, adaptively routing and fusing task-specific vision experts with a coarse-to-fine mechanism. In the coarse-grained stage, we design a context-aware expert routing strategy to dynamically select the most suitable vision experts according to the user instruction, input image, and expertise of vision experts. This benefits from the powerful model function understanding ability of the large language model (LLM). In the fine-grained stage, we elaborately conduct the mixture-of-vision-expert adapter (MoV-Adapter) to extract and fuse task-specific knowledge from various experts. This coarse-to-fine paradigm effectively leverages representations from experts based on multimodal context and model expertise, further enhancing the generalization ability. We conduct extensive experiments to evaluate the effectiveness of the proposed approach. Without any bells and whistles, MoVA can achieve significant performance gains over current state-of-the-art methods in a wide range of challenging multimodal benchmarks.
tl;dr: Place3D is a full-cycle pipeline that encompasses LiDAR placement optimization, data generation, and downstream evaluations.

The reliability of driving perception systems under unprecedented conditions is crucial for practical usage. Latest advancements have prompted increasing interest in multi-LiDAR perception. However, prevailing driving datasets predominantly utilize single-LiDAR systems and collect data devoid of adverse conditions, failing to capture the complexities of real-world environments accurately. Addressing these gaps, we proposed Place3D, a full-cycle pipeline that encompasses LiDAR placement optimization, data generation, and downstream evaluations. Our framework makes three appealing contributions. 1) To identify the most effective configurations for multi-LiDAR systems, we introduce the Surrogate Metric of the Semantic Occupancy Grids (M-SOG) to evaluate LiDAR placement quality. 2) Leveraging the M-SOG metric, we propose a novel optimization strategy to refine multi-LiDAR placements. 3) Centered around the theme of multi-condition multi-LiDAR perception, we collect a 280,000-frame dataset from both clean and adverse conditions. Extensive experiments demonstrate that LiDAR placements optimized using our approach outperform various baselines. We showcase exceptional results in both LiDAR semantic segmentation and 3D object detection tasks, under diverse weather and sensor failure conditions.

We study the framework of a dynamic decision-making scenario with resource constraints.
In this framework, an agent, whose target is to maximize the total reward under the initial inventory, selects an action in each round upon observing a random request, leading to a reward and resource consumptions that are further associated with an unknown random external factor.
While previous research has already established an $\widetilde{O}(\sqrt{T})$ worst-case regret for this problem, this work offers two results that go beyond the worst-case perspective: one for the worst-case gap between benchmarks and another for logarithmic regret rates.
We first show that an $\Omega(\sqrt{T})$ distance between the commonly used fluid benchmark and the online optimum is unavoidable when the former has a degenerate optimal solution.
On the algorithmic side, we merge the re-solving heuristic with distribution estimation skills and propose an algorithm that achieves an $\widetilde{O}(1)$ regret as long as the fluid LP has a unique and non-degenerate solution.
Furthermore, we prove that our algorithm maintains a near-optimal $\widetilde{O}(\sqrt{T})$ regret even in the worst cases and extend these results to the setting where the request and external factor are continuous.
Regarding information structure, our regret results are obtained under two feedback models, respectively, where the algorithm accesses the external factor at the end of each round and at the end of a round only when a non-null action is executed.
tl;dr: Improving the optimization of equivariant neural networks by relaxing the equivariant constraint during training

Equivariant neural networks have been widely used in a variety of applications due to their ability to generalize well in tasks where the underlying data symmetries are known. Despite their successes, such networks can be difficult to optimize and require careful hyperparameter tuning to train successfully. In this work, we propose a novel framework for improving the optimization of such models by relaxing the hard equivariance constraint during training: We relax the equivariance constraint of the network's intermediate layers by introducing an additional non-equivariant term that we progressively constrain until we arrive at an equivariant solution. By controlling the magnitude of the activation of the additional relaxation term, we allow the model to optimize over a larger hypothesis space containing approximate equivariant networks and converge back to an equivariant solution at the end of training. We provide experimental results on different state-of-the-art network architectures, demonstrating how this training framework can result in equivariant models with improved generalization performance. Our code is available at https://github.com/StefanosPert/Equivariant_Optimization_CR

Recent advancements in generative models have significantly enhanced their capacity for image generation, enabling a wide range of applications such as image editing, completion and video editing. A specialized area within generative modeling is layout-to-image (L2I) generation, where predefined layouts of objects guide the generative process. In this study, we introduce a novel regional cross-attention module tailored to enrich layout-to-image generation. This module notably improves the representation of layout regions, particularly in scenarios where existing methods struggle with highly complex and detailed textual descriptions. Moreover, while current open-vocabulary L2I methods are trained in an open-set setting, their evaluations often occur in closed-set environments. To bridge this gap, we propose two metrics to assess L2I performance in open-vocabulary scenarios. Additionally, we conduct a comprehensive user study to validate the consistency of these metrics with human preferences.

In this paper, we propose to create animatable avatars for interacting hands with 3D Gaussian Splatting (GS) and single-image inputs. Existing GS-based methods designed for single subjects often yield unsatisfactory results due to limited input views, various hand poses, and occlusions. To address these challenges, we introduce a novel two-stage interaction-aware GS framework that exploits cross-subject hand priors and refines 3D Gaussians in interacting areas. Particularly, to handle hand variations, we disentangle the 3D presentation of hands into optimization-based identity maps and learning-based latent geometric features and neural texture maps. Learning-based features are captured by trained networks to provide reliable priors for poses, shapes, and textures, while optimization-based identity maps enable efficient one-shot fitting of out-of-distribution hands. Furthermore, we devise an interaction-aware attention module and a self-adaptive Gaussian refinement module. These modules enhance image rendering quality in areas with intra- and inter-hand interactions, overcoming the limitations of existing GS-based methods. Our proposed method is validated via extensive experiments on the large-scale InterHand2.6M dataset, and it significantly improves the state-of-the-art performance in image quality. Code and models will be released upon acceptance.
tl;dr: This paper proposes and theoretically studies a new training paradigm as region optimization. RoPINN is derived from the theory as a practical training algorithm, which can consistently benefit diverse PINN backbones on extensive PDEs.

Physics-informed neural networks (PINNs) have been widely applied to solve partial differential equations (PDEs) by enforcing outputs and gradients of deep models to satisfy target equations. Due to the limitation of numerical computation, PINNs are conventionally optimized on finite selected points. However, since PDEs are usually defined on continuous domains, solely optimizing models on scattered points may be insufficient to obtain an accurate solution for the whole domain. To mitigate this inherent deficiency of the default scatter-point optimization, this paper proposes and theoretically studies a new training paradigm as region optimization. Concretely, we propose to extend the optimization process of PINNs from isolated points to their continuous neighborhood regions, which can theoretically decrease the generalization error, especially for hidden high-order constraints of PDEs. A practical training algorithm, Region Optimized PINN (RoPINN), is seamlessly derived from this new paradigm, which is implemented by a straightforward but effective Monte Carlo sampling method. By calibrating the sampling process into trust regions, RoPINN finely balances optimization and generalization error. Experimentally, RoPINN consistently boosts the performance of diverse PINNs on a wide range of PDEs without extra backpropagation or gradient calculation. Code is available at this repository: https://github.com/thuml/RoPINN.
tl;dr: An empirical methodology for evaluating hyperparameter sensitivity of reinforcement learning algorithms.

The performance of modern reinforcement learning algorithms critically relies
on tuning ever increasing numbers of hyperparameters. Often, small changes in
a hyperparameter can lead to drastic changes in performance, and different environments require very different hyperparameter settings to achieve state-of-the-art
performance reported in the literature. We currently lack a scalable and widely
accepted approach to characterizing these complex interactions. This work proposes a new empirical methodology for studying, comparing, and quantifying the
sensitivity of an algorithm’s performance to hyperparameter tuning for a given set
of environments. We then demonstrate the utility of this methodology by assessing
the hyperparameter sensitivity of several commonly used normalization variants of
PPO. The results suggest that several algorithmic performance improvements may,
in fact, be a result of an increased reliance on hyperparameter tuning.

Trained on vast corpora of human language, language models demonstrate emergent human-like reasoning abilities. Yet they are still far from true intelligence, which opens up intriguing opportunities to explore the parallels of humans and model behaviors. In this work, we study the ability to skip steps in reasoning—a hallmark of human expertise developed through practice. Unlike humans, who may skip steps to enhance efficiency or to reduce cognitive load, models do not inherently possess such motivations to minimize reasoning steps. To address this, we introduce a controlled framework that stimulates step-skipping behavior by iteratively refining models to generate shorter and accurate reasoning paths. Empirical results indicate that models can develop the step skipping ability under our guidance. Moreover, after fine-tuning on expanded datasets that include both complete and skipped reasoning sequences, the models can not only resolve tasks with increased efficiency without sacrificing accuracy, but also exhibit comparable and even enhanced generalization capabilities in out-of-domain scenarios. Our work presents the first exploration into human-like step-skipping ability and provides fresh perspectives on how such cognitive abilities can benefit AI models.
tl;dr: We investigate the conditions under which leaky ReLU networks generalize well beyond the regime of near-orthogonal training data.

The problem of benign overfitting asks whether it is possible for a model to perfectly fit noisy training data and still generalize well. We study benign overfitting in two-layer leaky ReLU networks trained with the hinge loss on a binary classification task. We consider input data which can be decomposed into the sum of a common signal and a random noise component, which lie on subspaces orthogonal to one another. We characterize conditions on the signal to noise ratio (SNR) of the model parameters giving rise to benign versus non-benign, or harmful, overfitting: in particular, if the SNR is high then benign overfitting occurs, conversely if the SNR is low then harmful overfitting occurs. We attribute both benign and non-benign overfitting to an approximate margin maximization property and show that leaky ReLU networks trained on hinge loss with gradient descent (GD) satisfy this property. In contrast to prior work we do not require the training data to be nearly orthogonal. Notably, for input dimension $d$ and training sample size $n$, while results in prior work require $d = \Omega(n^2 \log n)$, here we require only $d = \Omega(n)$.

Latent-based image generative models, such as Latent Diffusion Models (LDMs) and Mask Image Models (MIMs), have achieved notable success in image generation tasks. These models typically leverage reconstructive autoencoders like VQGAN or VAE to encode pixels into a more compact latent space and learn the data distribution in the latent space instead of directly from pixels. However, this practice raises a pertinent question: Is it truly the optimal choice? In response, we begin with an intriguing observation: despite sharing the same latent space, autoregressive models significantly lag behind LDMs and MIMs in image generation. This finding contrasts sharply with the field of NLP, where the autoregressive model GPT has established a commanding presence. To address this discrepancy, we introduce a unified perspective on the relationship between latent space and generative models, emphasizing the stability of latent space in image generative modeling. Furthermore, we propose a simple but effective discrete image tokenizer to stabilize the latent space for image generative modeling by applying K-Means on the latent features of self-supervised learning models. Experimental results show that image autoregressive modeling with our tokenizer (DiGIT) benefits both image understanding and image generation with the next token prediction principle, which is inherently straightforward for GPT models but challenging for other generative models. Remarkably, for the first time, a GPT-style autoregressive model for images outperforms LDMs, which also exhibits substantial improvement akin to GPT when scaling up model size. Our findings underscore the potential of an optimized latent space and the integration of discrete tokenization in advancing the capabilities of image generative models. The code is available at \url{https://github.com/DAMO-NLP-SG/DiGIT}.
tl;dr: We study optimal teaching complexity of a family of consistent linear behavior cloning learners.

We study optimal teaching for a family of Behavior Cloning learners that learn using a linear hypothesis class. In this setup, a knowledgeable teacher can demonstrate a dataset of state and action tuples and is required to teach an optimal policy to an entire family of BC learners using the smallest possible dataset. We analyze the linear family and design a novel teaching algorithm called `TIE' that achieves the instance optimal Teaching Dimension for the entire family. However, we show that this problem is NP-hard for action spaces with $|\mathcal{A}| > 2$ and provide an efficient approximation algorithm with a $\log(|\mathcal{A}| - 1)$ guarantee on the optimal teaching size. We present empirical results to demonstrate the effectiveness of our algorithm and compare it to various baselines in different teaching environments.
tl;dr: We distill a large offline RL dataset into a few expert behavioral dataset for rapid policy learning.

Massive reinforcement learning (RL) data are typically collected to train policies offline without the need for interactions, but the large data volume can cause training inefficiencies. To tackle this issue, we formulate offline behavior distillation (OBD), which synthesizes limited expert behavioral data from sub-optimal RL data, enabling rapid policy learning. We propose two naive OBD objectives, DBC and PBC, which measure distillation performance via the decision difference between policies trained on distilled data and either offline data or a near-expert policy. Due to intractable bi-level optimization, the OBD objective is difficult to minimize to small values, which deteriorates PBC by its distillation performance guarantee with quadratic discount complexity $\mathcal{O}(1/(1-\gamma)^2)$. We theoretically establish the equivalence between the policy performance and action-value weighted decision difference, and introduce action-value weighted PBC (Av-PBC) as a more effective OBD objective. By optimizing the weighted decision difference, Av-PBC achieves a superior distillation guarantee with linear discount complexity $\mathcal{O}(1/(1-\gamma))$. Extensive experiments on multiple D4RL datasets reveal that Av-PBC offers significant improvements in OBD performance, fast distillation convergence speed, and robust cross-architecture/optimizer generalization.
tl;dr: We propose to conduct synchronized modeling explicitly introduces video-level query embeddings and designs two key modules to synchronize video-level query with frame-level query embeddings

Recent DETR-based methods have advanced the development of Video Instance Segmentation (VIS) through transformers' efficiency and capability in modeling spatial and temporal information. Despite harvesting remarkable progress, existing works follow asynchronous designs, which model video sequences via either video-level queries only or adopting query-sensitive cascade structures, resulting in difficulties when handling complex and challenging video scenarios. In this work, we analyze the cause of this phenomenon and the limitations of the current solutions, and propose to conduct synchronized modeling via a new framework named SyncVIS. Specifically, SyncVIS explicitly introduces video-level query embeddings and designs two key modules to synchronize video-level query with frame-level query embeddings: a synchronized video-frame modeling paradigm and a synchronized embedding optimization strategy. The former attempts to promote the mutual learning of frame- and video-level embeddings with each other and the latter divides large video sequences into small clips for easier optimization. Extensive experimental evaluations are conducted on the challenging YouTube-VIS 2019 & 2021 & 2022, and OVIS benchmarks, and SyncVIS achieves state-of-the-art results, which demonstrates the effectiveness and generality of the proposed approach. The code is available at https://github.com/rkzheng99/SyncVIS.

In Open-Set Domain Generalization (OSDG), the model is exposed to both new variations of data appearance (domains) and open-set conditions, where both known and novel categories are present at test time. The challenges of this task arise from the dual need to generalize across diverse domains and accurately quantify category novelty, which is critical for applications in dynamic environments. Recently, meta-learning techniques have demonstrated superior results in OSDG, effectively orchestrating the meta-train and -test tasks by employing varied random categories and predefined domain partition strategies. These approaches prioritize a well-designed training schedule over traditional methods that focus primarily on data augmentation and the enhancement of discriminative feature learning.
The prevailing meta-learning models in OSDG typically utilize a predefined sequential domain scheduler to structure data partitions. However, a crucial aspect that remains inadequately explored is the influence brought by strategies of domain schedulers during training.
In this paper, we observe that an adaptive domain scheduler benefits more in OSDG compared with prefixed sequential and random domain schedulers. We propose the Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) to achieve an adaptive domain scheduler. This method strategically sequences domains by assessing their reliabilities in utilizing a follower network, trained with confidence scores learned in an evidential manner, regularized by max rebiasing discrepancy, and optimized in a bilevel manner. We verify our approach on three OSDG benchmarks, i.e., PACS, DigitsDG, and OfficeHome. The results show that our method substantially improves OSDG performance and achieves more discriminative embeddings for both the seen and unseen categories, underscoring the advantage of a judicious domain scheduler for the generalizability to unseen domains and unseen categories. The source code is publicly available at https://github.com/KPeng9510/EBiL-HaDS.
2931. KALM: Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
tl;dr: This study investigates developing knowledgeable agents with RL and LLMs, which achieve low-level control and adapt to novel situations.

Reinforcement learning (RL) traditionally trains agents using interaction data, which limits their capabilities to the scope of the training data. To create more knowledgeable agents, leveraging knowledge from large language models (LLMs) has shown a promising way. Despite various attempts to combine LLMs with RL, there is commonly a semantic gap between action signals and LLM tokens, which hinders their integration. This paper introduces a novel approach, KALM (Knowledgeable Agents from Language Model Rollouts), to learn knowledgeable agents by bridging this gap. KALM extracts knowledge from LLMs in the form of imaginary rollouts, which agents can learn through offline RL. To overcome the limitation that LLMs are inherently text-based and may be incompatible with numerical environmental data, KALM fine-tunes the LLM to perform bidirectional translation between textual goals and rollouts. This process enables the LLM to understand the environment better, facilitating the generation of meaningful rollouts. Experiments on robotic manipulation tasks demonstrate that KALM allows agents to rephrase complex goals and tackle novel tasks requiring new optimal behaviors. KALM achieves a 46% success rate in completing 1400 various novel goals, significantly outperforming the 26% success rate of baseline methods. Project homepage: https://kalmneurips2024.github.io.

Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance.
tl;dr: This paper presents the first study on provably efficient randomized exploration in cooperative multi-agent reinforcement learning.

We present the first study on provably efficient randomized exploration in cooperative multi-agent reinforcement learning (MARL). We propose a unified algorithm framework for randomized exploration in parallel Markov Decision Processes (MDPs), and two Thompson Sampling (TS)-type algorithms, CoopTS-PHE and CoopTS-LMC, incorporating the perturbed-history exploration (PHE) strategy and the Langevin Monte Carlo exploration (LMC) strategy respectively, which are flexible in design and easy to implement in practice. For a special class of parallel MDPs where the transition is (approximately) linear, we theoretically prove that both CoopTS-PHE and CoopTS-LMC achieve a $\widetilde{\mathcal{O}}(d^{3/2}H^2\sqrt{MK})$ regret bound with communication complexity $\widetilde{\mathcal{O}}(dHM^2)$, where $d$ is the feature dimension, $H$ is the horizon length, $M$ is the number of agents, and $K$ is the number of episodes. This is the first theoretical result for randomized exploration in cooperative MARL. We evaluate our proposed method on multiple parallel RL environments, including a deep exploration problem (i.e., $N$-chain), a video game, and a real-world problem in energy systems. Our experimental results support that our framework can achieve better performance, even under conditions of misspecified transition models. Additionally, we establish a connection between our unified framework and the practical application of federated learning.
tl;dr: We propose to leverage the inherent correspondence information of diffusion feature to achieve high-quality and consistent video editing.

Video editing is an emerging task, in which most current methods adopt the pre-trained text-to-image (T2I) diffusion model to edit the source video in a zero-shot manner. Despite extensive efforts, maintaining the temporal consistency of edited videos remains challenging due to the lack of temporal constraints in the regular T2I diffusion model. To address this issue, we propose COrrespondence-guided Video Editing (COVE), leveraging the inherent diffusion feature correspondence to achieve high-quality and consistent video editing. Specifically, we propose an efficient sliding-window-based strategy to calculate the similarity among tokens in the diffusion features of source videos, identifying the tokens with high correspondence across frames. During the inversion and denoising process, we sample the tokens in noisy latent based on the correspondence and then perform self-attention within them. To save the usage of GPU memory and accelerate the editing process, we further introduce the temporal-dimensional token merging strategy, which can effectively reduce the redundancy. COVE can be seamlessly integrated into the pre-trained T2I diffusion model without the need for extra training or optimization. Extensive experiment results demonstrate that COVE achieves the start-of-the-art performance in various video editing scenarios, outperforming existing methods both quantitatively and qualitatively. The source code will be released.
tl;dr: We propose a framework for generating simulations in code to train RL agents and introduce a new benchmark to showcase its efficacy.

Generating simulations to train intelligent agents in game-playing and robotics from natural language input, user input, or task documentation remains an open-ended challenge. Existing approaches focus on parts of this challenge, such as generating reward functions or task hyperparameters. Unlike previous work, we introduce FACTORSIM that generates full simulations in code from language input that can be used to train agents. Exploiting the structural modularity specific to coded simulations, we propose to use a factored partially observable Markov decision process representation that allows us to reduce context dependence during each step of the generation. For evaluation, we introduce a generative simulation benchmark that assesses the generated simulation code’s accuracy and effectiveness in facilitating zero-shot transfers in reinforcement learning settings. We show that FACTORSIM outperforms existing methods in generating simulations regarding prompt alignment (i.e., accuracy), zero-shot transfer abilities, and human evaluation. We also demonstrate its effectiveness in generating robotic tasks.

Implicit neural networks including deep equilibrium models have achieved superior task performance with better parameter efficiency in various applications. However, it is often at the expense of higher computation costs during inference. In this work, we identify a phenomenon named $\textbf{heterogeneous convergence}$ that exists in deep equilibrium models and other iterative methods. We observe much faster convergence of state activations in certain dimensions therefore indicating the dimensionality of the underlying dynamics of the forward pass is much lower than the defined dimension of the states. We thereby propose to exploit heterogeneous convergence by storing past linear operation results (e.g., fully connected and convolutional layers) and only propagating the state activation when its change exceeds a threshold. Thus, for the already converged dimensions, the computations can be skipped. We verified our findings and reached 84\% FLOPs reduction on the implicit neural representation task, 73\% on the Sintel and 76\% on the KITTI datasets for the optical flow estimation task while keeping comparable task accuracy with the models that perform the full update.
tl;dr: Use a single ViT to represent multiple smaller variants

Vision Transformers (ViT) is known for its scalability. In this work, we target to scale down a ViT to fit in an environment with dynamic-changing resource constraints. We observe that smaller ViTs are intrinsically the sub-networks of a larger ViT with different widths. Thus, we propose a general framework, named Scala, to enable a single network to represent multiple smaller ViTs with flexible inference capability, which aligns with the inherent design of ViT to vary from widths. Concretely, Scala activates several subnets during training, introduces Isolated Activation to disentangle the smallest sub-network from other subnets, and leverages Scale Coordination to ensure each sub-network receives simplified, steady, and accurate learning objectives. Comprehensive empirical validations on different tasks demonstrate that with only one-shot training, Scala learns slimmable representation without modifying the original ViT structure and matches the performance of Separate Training. Compared with the prior art, Scala achieves an average improvement of 1.6% on ImageNet-1K with fewer parameters.
tl;dr: We discover that LLM agents generally exhibit trust behavior in Trust Games and GPT-4 agents manifest high behavioral alignment with humans in terms of trust behavior, indicating the potential to simulate human trust behavior with LLM agents.

Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in social science and role-playing applications. However, one fundamental question remains: can LLM agents really simulate human behavior? In this paper, we focus on one critical and elemental behavior in human interactions, trust, and investigate whether LLM agents can simulate human trust behavior. We first find that LLM agents generally exhibit trust behavior, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that GPT-4 agents manifest high behavioral alignment with humans in terms of trust behavior, indicating the feasibility of simulating human trust behavior with LLM agents. In addition, we probe the biases of agent trust and differences in agent trust towards other LLM agents and humans. We also explore the intrinsic properties of agent trust under conditions including external manipulations and advanced reasoning strategies. Our study provides new insights into the behaviors of LLM agents and the fundamental analogy between LLMs and humans beyond value alignment. We further illustrate broader implications of our discoveries for applications where trust is paramount.
tl;dr: A novel method that can reconstruct a clear and sharp NeRF from a group of hand-held captured low-light images and a new proposed dataset.

Neural Radiance Fields (NeRFs) have shown remarkable performances in producing novel-view images from high-quality scene images. However, hand-held low-light photography challenges NeRFs as the captured images may simultaneously suffer from low visibility, noise, and camera shakes.
While existing NeRF methods may handle either low light or motion, directly combining them or incorporating additional image-based enhancement methods does not work as these degradation factors are highly coupled.
We observe that noise in low-light images is always sharp regardless of camera shakes, which implies an implicit order of these degradation factors within the image formation process.
This inspires us to explore such an order to decouple and remove these degradation factors while training the NeRF.
To this end, we propose in this paper a novel model, named LuSh-NeRF, which can reconstruct a clean and sharp NeRF from a group of hand-held low-light images.
The key idea of LuSh-NeRF is to sequentially model noise and blur in the images via multi-view feature consistency and frequency information of NeRF, respectively.
Specifically, LuSh-NeRF includes a novel Scene-Noise Decomposition (SND) module for decoupling the noise from the scene representation and a novel Camera Trajectory Prediction (CTP) module for the estimation of camera motions based on low-frequency scene information.
To facilitate training and evaluations, we construct a new dataset containing both synthetic and real images.
Experiments show that LuSh-NeRF outperforms existing approaches. Our code and dataset can be found here: https://github.com/quzefan/LuSh-NeRF.

In this paper, we present TAPTRv2, a Transformer-based approach built upon TAPTR for solving the Tracking Any Point (TAP) task. TAPTR borrows designs from DEtection TRansformer (DETR) and formulates each tracking point as a point query, making it possible to leverage well-studied operations in DETR-like algorithms. TAPTRv2 improves TAPTR by addressing a critical issue regarding its reliance on cost-volume, which contaminates the point query’s content feature and negatively impacts both visibility prediction and cost-volume computation. In TAPTRv2, we propose a novel attention-based position update (APU) operation and use key-aware deformable attention to realize. For each query, this operation uses key-aware attention weights to combine their corresponding deformable sampling positions to predict a new query position. This design is based on the observation that local attention is essentially the same as cost-volume, both of which are computed by dot-production between a query and its surrounding features. By introducing this new operation, TAPTRv2 not only removes the extra burden of cost-volume computation, but also leads to a substantial performance improvement. TAPTRv2 surpasses TAPTR and achieves state-of-the-art performance on many challenging datasets, demonstrating the effectiveness of our approach.

We introduce the framework of performative control, where the policy chosen by the controller affects the underlying dynamics of the control system. This results in a sequence of policy-dependent system state data with policy-dependent temporal correlations. Following the recent literature on performative prediction \cite{perdomo2020performative}, we introduce the concept of a performatively stable control (PSC) solution. We first propose a sufficient condition for the performative control problem to admit a unique PSC solution with a problem-specific structure of distributional sensitivity propagation and aggregation. We further analyze the impacts of system stability on the existence of the PSC solution. Specifically, for almost surely stable policy-dependent dynamics, the PSC solution exists if the sum of the distributional sensitivities is small enough. However, for almost surely unstable policy-dependent dynamics, the existence of the PSC solution will necessitate a temporally backward decaying of the distributional sensitivities. We finally provide a repeated stochastic gradient descent scheme that converges to the PSC solution and analyze its non-asymptotic convergence rate. Numerical results validate our theoretical analysis.
tl;dr: In this paper we introduce an improved method that utilizes communication compression with variance reduction and sampling without replacement.

Gradient compression is a popular technique for improving communication complexity of stochastic first-order methods in distributed training of machine learning models. However, the existing works consider only with-replacement sampling of stochastic gradients. In contrast, it is well-known in practice and recently confirmed in theory that stochastic methods based on without-replacement sampling, e.g., Random Reshuffling (RR) method, perform better than ones that sample the gradients with-replacement. In this work, we close this gap in the literature and provide the first analysis of methods with gradient compression and without-replacement sampling. We first develop a distributed variant of random reshuffling with gradient compression (Q-RR), and show how to reduce the variance coming from gradient quantization through the use of control iterates. Next, to have a better fit to Federated Learning applications, we incorporate local computation and propose a variant of Q-RR called Q-NASTYA. Q-NASTYA uses local gradient steps and different local and global stepsizes. Next, we show how to reduce compression variance in this setting as well. Finally, we prove the convergence results for the proposed methods and outline several settings in which they improve upon existing algorithms.
tl;dr: We introduce a novel implicit representation for interaction geometry of multiple people with the capability of simultaneously reconstructing occupancy, distinct identification (ID) tags and contact fields within a 3D space.

We introduce a novel implicit field representation tailored for multi-person interaction geometry in 3D spaces, capable of simultaneously reconstructing occupancy, instance identification (ID) tags, and contact fields. Volumetric representation of interacting human bodies presents significant challenges, including inaccurately captured geometries, varying degrees of occlusion, and data scarcity. Existing multi-view methods, which either reconstruct each subject in isolation or merge nearby 3D surfaces into a single unified mesh, often fail to capture the intricate geometry between interacting bodies and exploit on datasets with many views and a small group of people for training. Our approach utilizes an implicit representation for interaction geometry contextualized by a multi-view local-global feature module. This module adeptly aggregates both local and global information from individual views and interacting groups, enabling precise modeling of close physical interactions through dense point retrieval in small areas, supported by the implicit fields. Furthermore, we develop a synthetic dataset encompassing diverse multi-person interaction scenarios to enhance the robustness of our geometry estimation. The experimental results demonstrate the superiority of our method to accurately reconstruct human geometries and ID tags within three-dimensional spaces, outperforming conventional multi-view techniques. Notably, our method facilitates unsupervised estimation of contact points without the need for specific training data on contact supervision.
tl;dr: In this work, we propose a framework that advocates the construction of semantically decomposed video tokens, which encourages object-wise and event-wise token representations, for effective video-language modeling.

Video-Language Models (VLMs), powered by the advancements in Large Language Models (LLMs), are charting new frontiers in video understanding. A pivotal challenge is the development of an effective method to encapsulate video content into a set of representative tokens to align with LLMs. In this work, we introduce Slot-VLM, a new framework designed to generate semantically decomposed video tokens, in terms of object-wise and event-wise visual representations, to facilitate LLM inference. Particularly, we design an Object-Event Slots module, i.e., OE-Slots, that adaptively aggregates the dense video tokens from the vision encoder to a set of representative slots. In order to take into account both the spatial object details and the varied temporal dynamics, we build OE-Slots with two branches: the Object-Slots branch and the Event-Slots branch. The Object-Slots branch focuses on extracting object-centric slots from features of high spatial resolution but low frame sample rate, emphasizing detailed object information. The Event-Slots branch is engineered to learn event-centric slots from high temporal sample rate but low spatial resolution features. These complementary slots are combined to form the vision context, serving as the input to the LLM for effective video reasoning. Our experimental results demonstrate the effectiveness of our Slot-VLM, which achieves the state-of-the-art performance on video question-answering.
tl;dr: Training-free boosting of diffusion based novel view generation through attention map manipulations.

Generating realistic images from arbitrary views based on a single source image remains a significant challenge in computer vision, with broad applications ranging from e-commerce to immersive virtual experiences. Recent advancements in diffusion models, particularly the Zero-1-to-3 model, have been widely adopted for generating plausible views, videos, and 3D models. However, these models still struggle with inconsistencies and implausibility in new views generation, especially for challenging changes in viewpoint. In this work, we propose Zero-to-Hero, a novel test-time approach that enhances view synthesis by manipulating attention maps during the denoising process of Zero-1-to-3. By drawing an analogy between the denoising process and stochastic gradient descent (SGD), we implement a filtering mechanism that aggregates attention maps, enhancing generation reliability and authenticity. This process improves geometric consistency without requiring retraining or significant computational resources. Additionally, we modify the self-attention mechanism to integrate information from the source view, reducing shape distortions. These processes are further supported by a specialized sampling schedule. Experimental results demonstrate substantial improvements in fidelity and consistency, validated on a diverse set of out-of-distribution objects. Additionally, we demonstrate the general applicability and effectiveness of Zero-to-Hero in multi-view, and image generation conditioned on semantic maps and pose.
tl;dr: Leveraging input saliency maps, we discover that with increasing capacities, the distributions of models converge to the almost-shared population mean, and thus the limiting of model can be estimated through the population mean of small models.

Uncertainty is introduced in optimized DNNs through stochastic algorithms, forming specific distributions. Training models can be seen as random sampling from this distribution of optimized models. In this work, we study the distribution of optimized DNNs as a family of functions by leveraging a pointwise approach. We focus on the input saliency maps, as the input gradient field is decisive to the models' mathematical essence. Our investigation of saliency maps reveals a counter-intuitive trend: two stochastically optimized models tend to resemble each other more as either of their capacities increases. Therefore, we hypothesize several properties of these distributions, suggesting that (1) Within the same model architecture (e.g., CNNs, ResNets), different family variants (e.g., varying capacities) tend to align in terms of their population mean directions of the input salience. And (2) the distributions of optimized models follow a convergence trend to their shared population mean as the capacity increases. Furthermore, we also propose semi-parametric distributions based on the Saw distribution to model the convergence trend, satisfying all the counter-intuitive observations. Our experiments shed light on the significant implications of our hypotheses in various application domains, including black-box attacks, deep ensembles, etc. These findings not only enhance our understanding of DNN behaviors but also offer valuable insights for their practical application in diverse areas of deep learning.

Diffusion-based image super-resolution (SR) models have attracted substantial interest due to their powerful image restoration capabilities. However, prevailing diffusion models often struggle to strike an optimal balance between efficiency and performance. Typically, they either neglect to exploit the potential of existing extensive pretrained models, limiting their generative capacity, or they necessitate a dozens of forward passes starting from random noises, compromising inference efficiency. In this paper, we present DoSSR, a $\textbf{Do}$main $\textbf{S}$hift diffusion-based SR model that capitalizes on the generative powers of pretrained diffusion models while significantly enhancing efficiency by initiating the diffusion process with low-resolution (LR) images. At the core of our approach is a domain shift equation that integrates seamlessly with existing diffusion models. This integration not only improves the use of diffusion prior but also boosts inference efficiency. Moreover, we advance our method by transitioning the discrete shift process to a continuous formulation, termed as DoS-SDEs. This advancement leads to the fast and customized solvers that further enhance sampling efficiency. Empirical results demonstrate that our proposed method achieves state-of-the-art performance on synthetic and real-world datasets, while notably requiring $\textbf{\emph{only 5 sampling steps}}$. Compared to previous diffusion prior based methods, our approach achieves a remarkable speedup of 5-7 times, demonstrating its superior efficiency.

Recent Large Vision Language Models (LVLMs) present remarkable zero-shot conversational and reasoning capabilities given multimodal queries. Nevertheless, they suffer from object hallucination, a phenomenon where LVLMs are prone to generate textual responses not factually aligned with image inputs. Our pilot study reveals that object hallucination is closely tied with Rotary Position Encoding (RoPE), a widely adopted positional dependency modeling design in existing LVLMs. Due to the long-term decay in RoPE, LVLMs tend to hallucinate more when relevant visual cues are distant from instruction tokens in the multimodal input sequence, Additionally, we observe a similar effect when reversing the sequential order of visual tokens during multimodal alignment. Our tests indicate that long-term decay in RoPE poses challenges to LVLMs while capturing visual-instruction interactions across long distances. We propose Concentric Causal Attention (CCA), a simple yet effective positional alignment strategy that mitigates the impact of RoPE long-term decay in LVLMs by naturally reducing relative distance between visual and instruction tokens. With CCA, visual tokens can better interact with instruction tokens, thereby enhancing model's perception capability and alleviating object hallucination. Without bells and whistles, our positional alignment method surpasses existing hallucination mitigation strategies by large margins on multiple object hallucination benchmarks.
tl;dr: This paper provides a method to enhance self-supervised adversarial training

Recently, there have been some works studying self-supervised adversarial training, a learning paradigm that learns robust features without labels. While those works have narrowed the performance gap between self-supervised adversarial training (SAT) and supervised adversarial training (supervised AT), a well-established formulation of SAT and its connections with supervised AT are under-explored. Based on a simple SAT benchmark, we find that SAT still faces the problem of large robust generalization gap and degradation on natural samples. We hypothesize this is due to the lack of data complexity and model regularization and propose a method named as DAQ-SDP (Diverse Augmented Queries Self-supervised Double Perturbation). We first challenge the previous conclusion that complex data augmentations degrade robustness in SAT by using diversely augmented samples as queries to guide adversarial training. Inspired by previous works in supervised AT, we then incorporate a self-supervised double perturbation scheme to self-supervised learning (SSL), which promotes robustness transferable to downstream classification. Our work can be seamlessly combined with models pretrained by different SSL frameworks without revising the learning objectives and helps to bridge the gap between SAT and AT. Our method also improves both robust and natural accuracies across different SSL frameworks. Our code is available at https://github.com/rzzhang222/DAQ-SDP.

Blind image deblurring (BID) is an important yet challenging image recovery problem. Most existing deep learning methods require supervised training with ground truth (GT) images. This paper introduces a self-supervised method for BID that does not require GT images. The key challenge is to regularize the training to prevent over-fitting due to the absence of GT images. By leveraging an exact relationship among the blurred image, latent image, and blur kernel across consecutive scales, we propose an effective cross-scale consistency loss. This is implemented by representing the image and kernel with implicit neural representations (INRs), whose resolution-free property enables consistent yet efficient computation for network training across multiple scales. Combined with a progressively coarse-to-fine training scheme, the proposed method significantly outperforms existing self-supervised methods in extensive experiments.

Generative models based on flow matching have attracted significant attention for their simplicity and superior performance in high-resolution image synthesis. By leveraging the instantaneous change-of-variables formula, one can directly compute image likelihoods from a learned flow, making them enticing candidates as priors for downstream tasks such as inverse problems. In particular, a natural approach would be to incorporate such image probabilities in a maximum-a-posteriori (MAP) estimation problem. A major obstacle, however, lies in the slow computation of the log-likelihood, as it requires backpropagating through an ODE solver, which can be prohibitively slow for high-dimensional problems. In this work, we propose an iterative algorithm to approximate the MAP estimator efficiently to solve a variety of linear inverse problems. Our algorithm is mathematically justified by the observation that the MAP objective can be approximated by a sum of $N$ ``local MAP'' objectives, where $N$ is the number of function evaluations. By leveraging Tweedie's formula, we show that we can perform gradient steps to sequentially optimize these objectives. We validate our approach for various linear inverse problems, such as super-resolution, deblurring, inpainting, and compressed sensing, and demonstrate that we can outperform other methods based on flow matching. Code is available at \url{https://github.com/YasminZhang/ICTM}.

Learning algorithms are often used to make decisions in sequential decision-making environments. In multi-agent settings, the decisions of each agent can affect the utilities/losses of the other agents. Therefore, if an agent is good at anticipating the behavior of the other agents, in particular how they will make decisions in each round as a function of their experience that far, it could try to judiciously make its own decisions over the rounds of the interaction so as to influence the other agents to behave in a way that ultimately benefits its own utility. In this paper, we study repeated two-player games involving two types of agents: a learner, which employs an online learning algorithm to choose its strategy in each round; and an optimizer, which knows the learner's utility function and the learner's online learning algorithm. The optimizer wants to plan ahead to maximize its own utility, while taking into account the learner's behavior. We provide two results: a positive result for repeated zero-sum games and a negative result for repeated general-sum games. Our positive result is an algorithm for the optimizer, which exactly maximizes its utility against a learner that plays the Replicator Dynamics --- the continuous-time analogue of Multiplicative Weights Update (MWU). Additionally, we use this result to provide an algorithm for the optimizer against MWU, i.e.~for the discrete-time setting, which guarantees an average utility for the optimizer that is higher than the value of the one-shot game. Our negative result shows that, unless P=NP, there is no Fully Polynomial Time Approximation Scheme (FPTAS) for maximizing the utility of an optimizer against a learner that best-responds to the history in each round. Yet, this still leaves open the question of whether there exists a polynomial-time algorithm that optimizes the utility up to $o(T)$.

Endoscopic video analysis can effectively assist clinicians in disease diagnosis and treatment, and has played an indispensable role in clinical medicine. Unlike regular videos, endoscopic video analysis presents unique challenges, including complex camera movements, uneven distribution of lesions, and concealment, and it typically relies on contrastive learning in self-supervised pretraining as its mainstream technique. However, representations obtained from contrastive learning enhance the discriminability of the model but often lack fine-grained information, which is suboptimal in the pixel-level prediction tasks. In this paper, we develop a Multi-view Masked Contrastive Representation Learning (M$^2$CRL) framework for endoscopic video pre-training. Specifically, we propose a multi-view mask strategy for addressing the challenges of endoscopic videos. We utilize the frame-aggregated attention guided tube mask to capture global-level spatiotemporal sensitive representation from the global views, while the random tube mask is employed to focus on local variations from the local views. Subsequently, we combine multi-view mask modeling with contrastive learning to obtain endoscopic video representations that possess fine-grained perception and holistic discriminative capabilities simultaneously. The proposed M$^2$CRL is pre-trained on 7 publicly available endoscopic video datasets and fine-tuned on 3 endoscopic video datasets for 3 downstream tasks. Notably, our M$^2$CRL significantly outperforms the current state-of-the-art self-supervised endoscopic pre-training methods, e.g., Endo-FM (3.5% F1 for classification, 7.5% Dice for segmentation, and 2.2% F1 for detection) and other self-supervised methods, e.g., VideoMAE V2 (4.6% F1 for classification, 0.4% Dice for segmentation, and 2.1% F1 for detection).

Real-world decision-making tasks are usually partially observable Markov decision processes (POMDPs), where the state is not fully observable. Recent progress has demonstrated that recurrent reinforcement learning (RL), which consists of a context encoder based on recurrent neural networks (RNNs) for unobservable state prediction and a multilayer perceptron (MLP) policy for decision making, can mitigate partial observability and serve as a robust baseline for POMDP tasks. However, prior recurrent RL algorithms have faced issues with training instability. In this paper, we find that this instability stems from the autoregressive nature of RNNs, which causes even small changes in RNN parameters to produce large output variations over long trajectories. Therefore, we propose **R**ecurrent Off-policy RL with Context-**E**ncoder-**S**p**e**cific **L**earning Rate (RESeL) to tackle this issue. Specifically, RESeL uses a lower learning rate for context encoder than other MLP layers to ensure the stability of the former while maintaining the training efficiency of the latter. We integrate this technique into existing off-policy RL methods, resulting in the RESeL algorithm. We evaluated RESeL in 18 POMDP tasks, including classic, meta-RL, and credit assignment scenarios, as well as five MDP locomotion tasks. The experiments demonstrate significant improvements in training stability with RESeL. Comparative results show that RESeL achieves notable performance improvements over previous recurrent RL baselines in POMDP tasks, and is competitive with or even surpasses state-of-the-art methods in MDP tasks. Further ablation studies highlight the necessity of applying a distinct learning rate for the context encoder. Code is available at https://github.com/FanmingL/Recurrent-Offpolicy-RL.
tl;dr: we present Language Model as Visual Explainer to understand the decision from vision model with natural language

In this paper, we present Language Model as Visual Explainer (\texttt{LVX}), a systematic approach for interpreting the internal workings of vision models using a tree-structured linguistic explanation, without the need for model training. Central to our strategy is the collaboration between vision models and LLM to craft explanations. On one hand, the LLM is harnessed to delineate hierarchical visual attributes, while concurrently, a text-to-image API retrieves images that are most aligned with these textual concepts. By mapping the collected texts and images to the vision model's embedding space, we construct a hierarchy-structured visual embedding tree. This tree is dynamically pruned and grown by querying the LLM using language templates, tailoring the explanation to the model. Such a scheme allows us
to seamlessly incorporate new attributes while eliminating undesired concepts based on the model's representations. When applied to testing samples, our method provides human-understandable explanations in the form of attribute-laden trees. Beyond explanation, we retrained the vision model by calibrating it on the generated concept hierarchy, allowing the model to incorporate the refined knowledge of visual attributes. To access the effectiveness of our approach, we introduce new benchmarks and conduct rigorous evaluations, demonstrating its plausibility, faithfulness, and stability.

In-Context Learning (ICL) empowers Large Language Models (LLMs) to tackle various tasks by providing input-output examples as additional inputs, referred to as demonstrations. Nevertheless, the performance of ICL could be easily impacted by the quality of selected demonstrations. Existing efforts generally learn a retriever model to score each demonstration for selecting suitable demonstrations, however, the effect is suboptimal due to the large search space and the noise from unhelpful demonstrations. In this study, we introduce MoD, which partitions the demonstration pool into groups, each governed by an expert to reduce search space. We further design an expert-wise training strategy to alleviate the impact of unhelpful demonstrations when optimizing the retriever model. During inference, experts collaboratively retrieve demonstrations for the input query to enhance the ICL performance. We validate MoD via experiments across a range of NLP datasets and tasks, demonstrating its state-of-the-art performance and shedding new light on the future design of retrieval methods for ICL.
tl;dr: We introduce a causal discovery method for event sequences, that matches individual events to individual causing events.

Sequences of events, such as crashes in the stock market or outages in a network, contain strong temporal dependencies, whose understanding is crucial to react to and influence future events. In this paper, we study the problem of discovering the underlying causal structure from event sequences. To this end, we introduce a new causal model, where individual events of the cause trigger events of the effect with dynamic delays. We show that in contrast to existing methods based on Granger causality, our model is identifiable for both instant and delayed effects.
We base our approach on the Algorithmic Markov Condition, by which we identify the true causal network as the one that minimizes the Kolmogorov complexity. As the Kolmogorov complexity is not computable, we instantiate our model using Minimum Description Length and show that the resulting score identifies the causal direction. To discover causal graphs, we introduce the Cascade algorithm, which adds edges in topological order. Extensive evaluation shows that Cascade outperforms existing methods in settings with instantaneous effects, noise, and multiple colliders, and discovers insightful causal graphs on real-world data.

Generating ligand molecules for specific protein targets, known as structure-based drug design, is a fundamental problem in therapeutics development and biological discovery. Recently, target-aware generative models, especially diffusion models, have shown great promise in modeling protein-ligand interactions and generating candidate drugs. However, existing models primarily focus on learning the chemical distribution of all drug candidates, which lacks effective steerability on the chemical quality of model generations. In this paper, we propose a novel and general alignment framework to align pretrained target diffusion models with preferred functional properties, named AliDiff. AliDiff shifts the target-conditioned chemical distribution towards regions with higher binding affinity and structural rationality, specified by user-defined reward functions, via the preference optimization approach. To avoid the overfitting problem in common preference optimization objectives, we further develop an improved Exact Energy Preference Optimization method to yield an exact and efficient alignment of the diffusion models, and provide the closed-form expression for the converged distribution. Empirical studies on the CrossDocked2020 benchmark show that AliDiff can generate molecules with state-of-the-art binding energies with up to -7.07 Avg. Vina Score, while maintaining strong molecular properties. Code is available at https://github.com/MinkaiXu/AliDiff.
2959. B-ary Tree Push-Pull Method is Provably Efficient for Distributed Learning on Heterogeneous Data

This paper considers the distributed learning problem where a group of agents cooperatively minimizes the summation of their local cost functions based on peer-to-peer communication. Particularly, we propose a highly efficient algorithm, termed ``B-ary Tree Push-Pull'' (BTPP), that employs two B-ary spanning trees for distributing the information related to the parameters and stochastic gradients across the network. The simple method is efficient in communication since each agent interacts with at most $(B+1)$ neighbors per iteration. More importantly, BTPP achieves linear speedup for smooth nonconvex objective functions with only $\tilde{O}(n)$ transient iterations, significantly outperforming the state-of-the-art results to the best of our knowledge.

Detecting and rejecting unknown out-of-distribution (OOD) samples is critical for deployed neural networks to void unreliable predictions. In real-world scenarios, however, the efficacy of existing OOD detection methods is often impeded by the inherent imbalance of in-distribution (ID) data, which causes significant performance decline. Through statistical observations, we have identified two common challenges faced by different OOD detectors: misidentifying tail class ID samples as OOD, while erroneously predicting OOD samples as head class from ID. To explain this phenomenon, we introduce a generalized statistical framework, termed ImOOD, to formulate the OOD detection problem on imbalanced data distribution. Consequently, the theoretical analysis reveals that there exists a class-aware bias item between balanced and imbalanced OOD detection, which contributes to the performance gap. Building upon this finding, we present a unified training-time regularization technique to mitigate the bias and boost imbalanced OOD detectors across architecture designs. Our theoretically grounded method translates into consistent improvements on the representative CIFAR10-LT, CIFAR100-LT, and ImageNet-LT benchmarks against several state-of-the-art OOD detection ap- proaches. Code is available at https://github.com/alibaba/imood.

A mainstream of Multi-modal Large Language Models (MLLMs) have two essential functions, i.e., visual recognition (e.g., grounding) and understanding (e.g., visual question answering). Presently, all these MLLMs integrate visual recognition and understanding in a same sequential manner in the LLM head, i.e., generating the response token-by-token for both recognition and understanding. We think unifying them in the same sequential manner is not optimal for two reasons: 1) parallel recognition is more efficient than sequential recognition and is actually prevailing in deep visual recognition, and 2) the recognition results can be integrated to help high-level cognition (while the current manner does not). Such motivated, this paper proposes a novel “parallel recognition → sequential understanding” framework for MLLMs. The bottom LLM layers are utilized for parallel recognition and the recognition results are relayed into the top LLM layers for sequential understanding. Specifically, parallel recognition in the bottom LLM layers is implemented via object queries, a popular mechanism in DEtection TRansformer, which we find to harmonize well with the LLM layers. Empirical studies show our MLLM named Octopus improves accuracy on popular MLLM tasks and is up to 5× faster on visual grounding tasks.
tl;dr: We propose novel methods for active learning under the selective labels problem.

Machine learning systems are widely used in many high-stakes contexts in which experimental designs for assigning treatments are infeasible. When evaluating a decision instance is costly, such as investigating a fraud case, or evaluating a biopsy decision, a sample-efficient strategy is needed. However, while existing active learning methods assume humans will always label the instances selected by the machine learning model, in many critical applications, humans may decline to label instances selected by the machine learning model due to reasons such as regulation constraint, domain knowledge, or algorithmic aversion, thus not sample efficient.
In this paper, we propose the Active Learning with Instance Rejection (ALIR) problem, which is a new active learning problem that considers the human discretion behavior for high-stakes decision making problems. We propose new active learning algorithms under deep Bayesian active learning for selective labeling (SEL-BALD) to address the ALIR problem. Our algorithms consider how to acquire information for both the machine learning model and the human discretion model. We conduct experiments on both synthetic and real-world datasets to demonstrate the effectiveness of our proposed algorithms.
2963. Neural Concept Binder

The challenge in object-based visual reasoning lies in generating concept representations that are both descriptive and distinct. Achieving this in an unsupervised manner requires human users to understand the model's learned concepts and, if necessary, revise incorrect ones. To address this challenge, we introduce the Neural Concept Binder (NCB), a novel framework for deriving both discrete and continuous concept representations, which we refer to as "concept-slot encodings". NCB employs two types of binding: "soft binding", which leverages the recent SysBinder mechanism to obtain object-factor encodings, and subsequent "hard binding", achieved through hierarchical clustering and retrieval-based inference. This enables obtaining expressive, discrete representations from unlabeled images. Moreover, the structured nature of NCB's concept representations allows for intuitive inspection and the straightforward integration of external knowledge, such as human input or insights from other AI models like GPT-4. Additionally, we demonstrate that incorporating the hard binding mechanism preserves model performance while enabling seamless integration into both neural and symbolic modules for complex reasoning tasks. We validate the effectiveness of NCB through evaluations on our newly introduced CLEVR-Sudoku dataset.
tl;dr: We observe the layer mismatch problem in federated learning and propose a partial network update method to address it, improving convergence speed, accuracy, and reducing computational and communication overhead.

Federated learning is a distributed machine learning paradigm designed to protect user data privacy, which has been successfully implemented across various scenarios. In traditional federated learning, the entire parameter set of local models is updated and averaged in each training round. Although this full network update method maximizes knowledge acquisition and sharing for each model layer, it prevents the layers of the global model from cooperating effectively to complete the tasks of each client, a challenge we refer to as layer mismatch. This mismatch problem recurs after every parameter averaging, consequently slowing down model convergence and degrading overall performance. To address the layer mismatch issue, we introduce the FedPart method, which restricts model updates to either a single layer or a few layers during each communication round. Furthermore, to maintain the efficiency of knowledge acquisition and sharing, we develop several strategies to select trainable layers in each round, including sequential updating and multi-round cycle training. Through both theoretical analysis and experiments, our findings demonstrate that the FedPart method significantly surpasses conventional full network update strategies in terms of convergence speed and accuracy, while also reducing communication and computational overheads.
tl;dr: Policy optimization that maximizes Return on Investment (ROI) of a policy

In this paper, we propose a novel policy optimization framework that maximizes Return on Investment (ROI) of a policy using a fixed dataset within a Markov Decision Process (MDP) equipped with a cost function. ROI, defined as the ratio between the return and the accumulated cost of a policy, serves as a measure of efficiency of the policy. Despite the importance of maximizing ROI in various applications, it remains a challenging problem due to its nature as a ratio of two long-term values: return and accumulated cost. To address this, we formulate the ROI maximizing reinforcement learning problem as a linear fractional programming. We then incorporate the stationary distribution correction (DICE) framework to develop a practical offline ROI maximization algorithm.
Our proposed algorithm, ROIDICE, yields an efficient policy that offers a superior trade-off between return and accumulated cost compared to policies trained using existing frameworks.

Recently, prompt learning has emerged as the state-of-the-art (SOTA) for fair text-to-image (T2I) generation. Specifically, this approach leverages readily available reference images to learn inclusive prompts for each target Sensitive Attribute (tSA), allowing for fair image generation. In this work, we first reveal that this prompt learning-based approach results in degraded sample quality. Our analysis shows that the approach's training objective--which aims to align the embedding differences of learned prompts and reference images-- could be sub-optimal, resulting in distortion of the learned prompts and degraded generated images. To further substantiate this claim, **as our major contribution**, we deep dive into the denoising subnetwork of the T2I model to track down the effect of these learned prompts by analyzing the cross-attention maps. In our analysis, we propose a novel prompt switching analysis: I2H and H2I. Furthermore, we propose new quantitative characterization of cross-attention maps. Our analysis reveals abnormalities in the early denoising steps, perpetuating improper global structure that results in degradation in the generated samples. Building on insights from our analysis, we propose two ideas: (i) *Prompt Queuing* and (ii) *Attention Amplification* to address the quality issue. Extensive experimental results on a wide range of tSAs show that our proposed method outperforms SOTA approach's image generation quality, while achieving competitive fairness. More resources at FairQueue Project site: https://sutd-visual-computing-group.github.io/FairQueue

Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.

This paper tackles the challenge of active perception for robotic grasp detection in cluttered environments. Incomplete 3D geometry information can negatively affect the performance of learning-based grasp detection methods, and scanning the scene from multiple views introduces significant time costs. To achieve reliable grasping performance with efficient camera movement, we propose an active grasp detection framework based on the Neural Graspness Field (NGF), which models the scene incrementally and facilitates next-best-view planning. Constructed in real-time as the camera moves, the NGF effectively models the grasp distribution in 3D space by rendering graspness predictions from each view. For next-best-view planning, we aim to reduce the uncertainty of the NGF through a graspness inconsistency-guided policy, selecting views based on discrepancies between NGF outputs and a pre-trained graspness network. Additionally, we present a neural graspness sampling method that decodes graspness values from the NGF to improve grasp pose detection results. Extensive experiments on the GraspNet-1Billion benchmark demonstrate significant performance improvements compared to previous works. Real-world experiments show that our method achieves a superior trade-off between grasping performance and time costs.
tl;dr: We use methods from mechanistic interpretability to investigate how Vision Transformers perform an abstract visual reasoning task.

Though vision transformers (ViTs) have achieved state-of-the-art performance in a variety of settings, they exhibit surprising failures when performing tasks involving visual relations. This begs the question: how do ViTs attempt to perform tasks that require computing visual relations between objects? Prior efforts to interpret ViTs tend to focus on characterizing relevant low-level visual features. In contrast, we adopt methods from mechanistic interpretability to study the higher-level visual algorithms that ViTs use to perform abstract visual reasoning. We present a case study of a fundamental, yet surprisingly difficult, relational reasoning task: judging whether two visual entities are the same or different. We find that pretrained ViTs fine-tuned on this task often exhibit two qualitatively different stages of processing despite having no obvious inductive biases to do so: 1) a perceptual stage wherein local object features are extracted and stored in a disentangled representation, and 2) a relational stage wherein object representations are compared. In the second stage, we find evidence that ViTs can learn to represent somewhat abstract visual relations, a capability that has long been considered out of reach for artificial neural networks. Finally, we demonstrate that failures at either stage can prevent a model from learning a generalizable solution to our fairly simple tasks. By understanding ViTs in terms of discrete processing stages, one can more precisely diagnose and rectify shortcomings of existing and future models.

Existing approaches to diffusion-based inverse problem solvers frame the signal recovery task as a probabilistic sampling episode, where the solution is drawn from the desired posterior distribution. This framework suffers from several critical drawbacks, including the intractability of the conditional likelihood function, strict dependence on the score network approximation, and poor $\mathbf{x}_0$ prediction quality. We demonstrate that these limitations can be sidestepped by reframing the generative process as a discrete optimal control episode. We derive a diffusion-based optimal controller inspired by the iterative Linear Quadratic Regulator (iLQR) algorithm. This framework is fully general and able to handle any differentiable forward measurement operator, including super-resolution, inpainting, Gaussian deblurring, nonlinear deblurring, and even highly nonlinear neural classifiers. Furthermore, we show that the idealized posterior sampling equation can be recovered as a special case of our algorithm. We then evaluate our method against a selection of neural inverse problem solvers, and establish a new baseline in image reconstruction with inverse problems.

Federated graph learning (FedGL) is an emerging learning paradigm to collaboratively train graph data from various clients. However, during the development and deployment of FedGL models, they are susceptible to illegal copying and model theft. Backdoor-based watermarking is a well-known method for mitigating these attacks, as it offers ownership verification to the model owner. We take the first step to protect the ownership of FedGL models via backdoor-based watermarking. Existing techniques have challenges in achieving the goal: 1) they either cannot be directly applied or yield unsatisfactory performance; 2) they are vulnerable to watermark removal attacks; and 3) they lack of formal guarantees. To address all the challenges, we propose FedGMark, the first certified robust backdoor-based watermarking for FedGL. FedGMark leverages the unique graph structure and client information in FedGL to learn customized and diverse watermarks. It also designs a novel GL architecture that facilitates defending against both the empirical and theoretically worst-case watermark removal attacks. Extensive experiments validate the promising empirical and provable watermarking performance of FedGMark. Source code is available at: https://github.com/Yuxin104/FedGMark.
tl;dr: This paper introduces IntraMix, a graph augmentation method that employs Intra-Class Mixup and high-confidence neighbor selection. IntraMix addresses both the issues of scarce high-quality labels and missing neighborhoods in most graphs.

Graph Neural Networks (GNNs) have shown great performance in various tasks, with the core idea of learning from data labels and aggregating messages within the neighborhood of nodes. However, the common challenges in graphs are twofold: insufficient accurate (high-quality) labels and limited neighbors for nodes, resulting in weak GNNs.
Existing graph augmentation methods typically address only one of these challenges, often adding training costs or relying on oversimplified or knowledge-intensive strategies, limiting their generalization.
To simultaneously address both challenges faced by graphs in a generalized way, we propose an elegant method called IntraMix. Considering the incompatibility of vanilla Mixup with the complex topology of graphs, IntraMix innovatively employs Mixup among inaccurate labeled data of the same class, generating high-quality labeled data at minimal cost.
Additionally, it finds data with high confidence of being clustered into the same group as the generated data to serve as their neighbors, thereby enriching the neighborhoods of graphs. IntraMix efficiently tackles both issues faced by graphs and challenges the prior notion of the limited effectiveness of Mixup in node classification. IntraMix is a theoretically grounded plug-in-play method that can be readily applied to all GNNs. Extensive experiments demonstrate the effectiveness of IntraMix across various GNNs and datasets. Our code is available at: [https://github.com/Zhengsh123/IntraMix](https://github.com/Zhengsh123/IntraMix).

This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization.
Diffusion models have gained prominence for their effectiveness in high-fidelity image generation.
While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability.
However, Transformer architectures, which tokenize input data (via "patchification"), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length.
While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions.
To address this challenge, we propose augmenting the **Di**ffusion model with the **M**ulti-**R**esolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution.
Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance.
Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants surpass previous diffusion models, achieving FID scores of 1.70 on ImageNet $256 \times 256$ and 2.89 on ImageNet $512 \times 512$. Our best variant, DiMR-G, further establishes a state-of-the-art 1.63 FID on ImageNet $256 \times 256$.
tl;dr: This paper examines the mechanisms and limitations of training-free guidance for diffusion models, proposing methods to address these challenges effectively.

Adding additional guidance to pretrained diffusion models has become an increasingly popular research area, with extensive applications in computer vision, reinforcement learning, and AI for science. Recently, several studies have proposed training-free loss-based guidance by using off-the-shelf networks pretrained on clean images. This approach enables zero-shot conditional generation for universal control formats, which appears to offer a free lunch in diffusion guidance. In this paper, we aim to develop a deeper understanding of training-free guidance, as well as overcome its limitations. We offer a theoretical analysis that supports training-free guidance from the perspective of optimization, distinguishing it from classifier-based (or classifier-free) guidance. To elucidate their drawbacks, we theoretically demonstrate that training-free guidance is more susceptible to misaligned gradients and exhibits slower convergence rates compared to classifier guidance. We then introduce a collection of techniques designed to overcome the limitations, accompanied by theoretical rationale and empirical evidence. Our experiments in image and motion generation confirm the efficacy of these techniques.

Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^\text{EM}$ and Self-Rewarding LM.
tl;dr: We propose a camera-agnostic physical adversarial attack, CAP (Camera-Agnostic Patch), addressing the oversight of camera influence in existing physical adversarial attack methods.

Physical adversarial attacks can deceive deep neural networks (DNNs), leading to erroneous predictions in real-world scenarios. To uncover potential security risks, attacking the safety-critical task of person detection has garnered significant attention. However, we observe that existing attack methods overlook the pivotal role of the camera, involving capturing real-world scenes and converting them into digital images, in the physical adversarial attack workflow. This oversight leads to instability and challenges in reproducing these attacks. In this work, we revisit patch-based attacks against person detectors and introduce a camera-agnostic physical adversarial attack to mitigate this limitation. Specifically, we construct a differentiable camera Image Signal Processing (ISP) proxy network to compensate for the physical-to-digital transition gap. Furthermore, the camera ISP proxy network serves as a defense module, forming an adversarial optimization framework with the attack module. The attack module optimizes adversarial patches to maximize effectiveness, while the defense module optimizes the conditional parameters of the camera ISP proxy network to minimize attack effectiveness. These modules engage in an adversarial game, enhancing cross-camera stability. Experimental results demonstrate that our proposed Camera-Agnostic Patch (CAP) attack effectively conceals persons from detectors across various imaging hardware, including two distinct cameras and four smartphones.
tl;dr: We propose Frequency Adversarial Training (FAT), a novel method to improve corruption robustness of 3D point cloud recognition, which achieves the state-of-the-art results.

Although 3D point cloud recognition has achieved substantial progress on standard benchmarks, the typical models are vulnerable to point cloud corruptions, leading to security threats in real-world applications. To improve the corruption robustness, various data augmentation methods have been studied, but they are mainly limited to the spatial domain. As the point cloud has low information density and significant spatial redundancy, it is challenging to analyze the effects of corruptions. In this paper, we focus on the frequency domain to observe the underlying structure of point clouds and their corruptions. Through graph Fourier transform (GFT), we observe a correlation between the corruption robustness of point cloud recognition models and their sensitivity to different frequency bands, which is measured by the GFT spectrum of the model’s Jacobian matrix. To reduce the sensitivity and improve the corruption robustness, we propose Frequency Adversarial Training (FAT) that adopts frequency-domain adversarial examples as data augmentation to train robust point cloud recognition models against corruptions. Theoretically, we provide a guarantee of FAT on its out-of-distribution generalization performance. Empirically, we conduct extensive experiments with various network architectures to validate the effectiveness of FAT, which achieves the new state-of-the-art results.
tl;dr: DynaMo, a new self-supervised method for pretraining visual encoders for downstream visuomotor control by explicitly modeling dynamics in the demonstration observations.

Imitation learning has proven to be a powerful tool for training complex visuo-motor policies. However, current methods often require hundreds to thousands of expert demonstrations to handle high-dimensional visual observations. A key reason for this poor data efficiency is that visual representations are predominantly either pretrained on out-of-domain data or trained directly through a behavior cloning objective. In this work, we present DynaMo, a new in-domain, self-supervised method for learning visual representations. Given a set of expert demonstrations, we jointly learn a latent inverse dynamics model and a forward dynamics model over a sequence of image embeddings, predicting the next frame in latent space, without augmentations, contrastive sampling, or access to ground truth actions. Importantly, DynaMo does not require any out-of-domain data such as Internet datasets or cross-embodied datasets. On a suite of six simulated and real environments, we show that representations learned with DynaMo significantly improve downstream imitation learning performance over prior self-supervised learning objectives, and pretrained representations. Gains from using DynaMo hold across policy classes such as Behavior Transformer, Diffusion Policy, MLP, and nearest neighbors. Finally, we ablate over key components of DynaMo and measure its impact on downstream policy performance. Robot videos are best viewed at https://dynamo-ssl.github.io.
tl;dr: We prove a $O(d^{3/2}\sqrt{T})$ frequentist regret bound for linear ensemble sampling.

In this work, we close the fundamental gap of theory and practice by providing an improved regret bound for linear ensemble sampling. We prove that with an ensemble size logarithmic in $T$, linear ensemble sampling can achieve a frequentist regret bound of $\tilde{\mathcal{O}}(d^{3/2}\sqrt{T})$, matching state-of-the-art results for randomized linear bandit algorithms, where $d$ and $T$ are the dimension of the parameter and the time horizon respectively. Our approach introduces a general regret analysis framework for linear bandit algorithms. Additionally, we reveal a significant relationship between linear ensemble sampling and Linear Perturbed-History Exploration (LinPHE), showing that LinPHE is a special case of linear ensemble sampling when the ensemble size equals $T$. This insight allows us to derive a new regret bound of $\tilde{\mathcal{O}}(d^{3/2}\sqrt{T})$ for LinPHE, independent of the number of arms. Our contributions advance the theoretical foundation of ensemble sampling, bringing its regret bounds in line with the best known bounds for other randomized exploration algorithms.

In Large Language Model (LLM) inference, the output length of an LLM request is typically regarded as not known a priori. Consequently, most LLM serving systems employ a simple First-come-first-serve (FCFS) scheduling strategy, leading to Head-Of-Line (HOL) blocking and reduced throughput and service quality.
In this paper, we reexamine this assumption -- we show that, although predicting the exact generation length of each request is infeasible, it is possible to predict the relative ranks of output lengths in a batch of requests, using learning to rank. The ranking information offers valuable guidance for scheduling requests. Building on this insight, we develop a novel scheduler for LLM inference and serving that can approximate the shortest-job-first (SJF) schedule better than existing approaches. We integrate this scheduler with the state-of-the-art LLM serving system and show significant performance improvement in several important applications: 2.8x lower latency in chatbot serving and 6.5x higher throughput in synthetic data generation. Our code is available at https://github.com/hao-ai-lab/vllm-ltr.git

Recent advances in AI models have increased the integration of AI-based decision aids into the human decision making process. To fully unlock the potential of AI-assisted decision making, researchers have computationally modeled how humans incorporate AI recommendations into their final decisions, and utilized these models to improve human-AI team performance. Meanwhile, due to the ``black-box'' nature of AI models, providing AI explanations to human decision makers to help them rely on AI recommendations more appropriately has become a common practice. In this paper, we explore whether we can quantitatively model how humans integrate both AI recommendations and explanations into their decision process, and whether this quantitative understanding of human behavior from the learned model can be utilized to manipulate AI explanations, thereby nudging individuals towards making targeted decisions. Our extensive human experiments across various tasks demonstrate that human behavior can be easily influenced by these manipulated explanations towards targeted outcomes, regardless of the intent being adversarial or benign. Furthermore, individuals often fail to detect any anomalies in these explanations, despite their decisions being affected by them.

Non-maximum suppression (NMS) is an indispensable post-processing step in object detection. With the continuous optimization of network models, NMS has become the ``last mile'' to enhance the efficiency of object detection. This paper systematically analyzes NMS from a graph theory perspective for the first time, revealing its intrinsic structure. Consequently, we propose two optimization methods, namely QSI-NMS and BOE-NMS. The former is a fast recursive divide-and-conquer algorithm with negligible mAP loss, and its extended version (eQSI-NMS) achieves optimal complexity of $\mathcal{O}(n\log n)$. The latter, concentrating on the locality of NMS, achieves an optimization at a constant level without an mAP loss penalty. Moreover, to facilitate rapid evaluation of NMS methods for researchers, we introduce NMS-Bench, the first benchmark designed to comprehensively assess various NMS methods. Taking the YOLOv8-N model on MS COCO 2017 as the benchmark setup, our method QSI-NMS provides $6.2\times$ speed of original NMS on the benchmark, with a $0.1\%$ decrease in mAP. The optimal eQSI-NMS, with only a $0.3\%$ mAP decrease, achieves $10.7\times$ speed. Meanwhile, BOE-NMS exhibits $5.1\times$ speed with no compromise in mAP.

Traditional information theory provides a valuable foundation for Reinforcement Learning (RL), particularly through representation learning and entropy maximiza tion for agent exploration. However, existing methods primarily concentrate on modeling the uncertainty associated with RL’s random variables, neglecting the in herent structure within the state and action spaces. In this paper, we propose a novel Structural Information principles-based Effective Exploration framework, namely SI2E. Structural mutual information between two variables is defined to address the single-variable limitation in structural information, and an innovative embedding principle is presented to capture dynamics-relevant state-action representations. The SI2E analyzes value differences in the agent’s policy between state-action pairs and minimizes structural entropy to derive the hierarchical state-action struc ture, referred to as the encoding tree. Under this tree structure, value-conditional structural entropy is defined and maximized to design an intrinsic reward mechanism that avoids redundant transitions and promotes enhanced coverage in the state-action space. Theoretical connections are established between SI2E and classical information-theoretic methodologies, highlighting our framework’s rationality and advantage. Comprehensive evaluations in the MiniGrid, MetaWorld, and DeepMind Control Suite benchmarks demonstrate that SI2E significantly outperforms state-of-the-art exploration baselines regarding final performance and sample efficiency, with maximum improvements of 37.63% and 60.25%, respectively.
tl;dr: A technique to prevent LLMs from generating memorized training data with little to no impact on downstream performance.

Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subsets of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set. We run extensive experiments training billion-scale LLaMA-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
_Code and checkpoints: https://github.com/ahans30/goldfish-loss_
tl;dr: We present a theory on data selection for high-dimensional ridge regression that inspires a fast and effective data selection algorithm for finetuning.

We revisit data selection in a modern context of finetuning from a fundamental perspective. Extending the classical wisdom of variance minimization in low dimensions to high-dimensional finetuning, our generalization analysis unveils the importance of additionally reducing bias induced by low-rank approximation. Inspired by the variance-bias tradeoff in high dimensions from the theory, we introduce Sketchy Moment Matching (SkMM), a scalable data selection scheme with two stages. (i) First, the bias is controlled using gradient sketching that explores the finetuning parameter space for an informative low-dimensional subspace $\mathcal{S}$; (ii) then the variance is reduced over $\mathcal{S}$ via moment matching between the original and selected datasets. Theoretically, we show that gradient sketching is fast and provably accurate: selecting $n$ samples by reducing variance over $\mathcal{S}$ preserves the fast-rate generalization $O(\dim(\mathcal{S})/n)$, independent of the parameter dimension. Empirically, we concretize the variance-bias balance via synthetic experiments and demonstrate the effectiveness of SkMM for finetuning in real vision tasks.
tl;dr: We propose a conditional generative model based approach to sample from any identifiable interventional or conditional interventional distribution given an arbitrary causal graph containing latent confounders.

Causal inference from observational data plays critical role in many applications in trustworthy machine learning.
While sound and complete algorithms exist to compute causal effects, many of them assume access to conditional likelihoods,
which is difficult to estimate for high-dimensional (particularly image) data. Researchers have alleviated this issue by simulating causal relations with neural models. However, when we have high-dimensional variables in the causal graph along with some unobserved confounders, no existing work can effectively sample from the un/conditional interventional distributions. In this work, we show how to sample from any identifiable interventional distribution given an arbitrary causal graph through a sequence of push-forward computations of conditional generative models, such as diffusion models. Our proposed algorithm follows the recursive steps of the existing likelihood-based identification algorithms to train a set of feed-forward models, and connect them in a specific way to sample from the desired distribution. We conduct experiments on a Colored MNIST dataset having both the treatment ($X$) and the target variables ($Y$) as images and sample from $P(y|do(x))$. Our algorithm also enables us to conduct a causal analysis to evaluate spurious correlations among input features of generative models pre-trained on the CelebA dataset. Finally, we generate high-dimensional interventional samples from the MIMIC-CXR dataset involving text and image variables.
2987. Tangent Space Causal Inference: Leveraging Vector Fields for Causal Discovery in Dynamical Systems
tl;dr: We improve convergent cross mapping by explicitly considering vector fields instead of individual predictions.

Causal discovery with time series data remains a challenging yet increasingly important task across many scientific domains. Convergent cross mapping (CCM) and related methods have been proposed to study time series that are generated by dynamical systems, where traditional approaches like Granger causality are unreliable. However, CCM often yields inaccurate results depending upon the quality of the data. We propose the Tangent Space Causal Inference (TSCI) method for detecting causalities in dynamical systems. TSCI works by considering vector fields as explicit representations of the systems' dynamics and checks for the degree of synchronization between the learned vector fields. The TSCI approach is model-agnostic and can be used as a drop-in replacement for CCM and its generalizations. We first present a basic version of the TSCI algorithm, which is shown to be more effective than the basic CCM algorithm with very little additional computation. We additionally present augmented versions of TSCI that leverage the expressive power of latent variable models and deep learning. We validate our theory on standard systems, and we demonstrate improved causal inference performance across a number of benchmark tasks.
tl;dr: Towards understanding the mechanisms underlying the in-context learning from autoregressive pretraining by rigorously verifying the mesa-optimization hypothesis.

Autoregressively trained transformers have brought a profound revolution to the world, especially with their in-context learning (ICL) ability to address downstream tasks.
Recently, several studies suggest that transformers learn a mesa-optimizer during autoregressive (AR) pretraining to implement ICL. Namely, the forward pass of the trained transformer is equivalent to optimizing an inner objective function in-context.
However, whether the practical non-convex training dynamics will converge to the ideal mesa-optimizer is still unclear.
Towards filling this gap, we investigate the non-convex dynamics of a one-layer linear causal self-attention model autoregressively trained by gradient flow, where the sequences are generated by an AR process $x_{t+1} = W x_t$. First, under a certain condition of data distribution, we prove that an autoregressively trained transformer learns $W$ by implementing one step of gradient descent to minimize an ordinary least squares (OLS) problem in-context. It then applies the learned $\widehat{W}$ for next-token prediction, thereby verifying the mesa-optimization hypothesis. Next, under the same data conditions, we explore the capability limitations of the obtained mesa-optimizer. We show that a stronger assumption related to the moments of data is the sufficient and necessary condition that the learned mesa-optimizer recovers the distribution. Besides, we conduct exploratory analyses beyond the first data condition
and prove that generally, the trained transformer will not perform vanilla gradient descent for the OLS problem. Finally, our simulation results verify the theoretical results.

Lane detection is an important yet challenging task in autonomous driving systems. Existing lane detection methods mainly rely on finer-scale information to identify key points of lane lines. Since local information in realistic road environments is frequently obscured by other vehicles or affected by poor outdoor lighting conditions, these methods struggle with the regression of such key points. In this paper, we propose a novel Siamese Transformer with hierarchical refinement for lane detection to improve the detection accuracy in complex road environments. Specifically, we propose a high-to-low hierarchical refinement Transformer structure, called LAne TRansformer (LATR), to refine the key points of lane lines, which integrates global semantics information and finer-scale features. Moreover, exploiting the thin and long characteristics of lane lines, we propose a novel Curve-IoU loss to supervise the fit of lane lines. Extensive experiments on three benchmark datasets of lane detection demonstrate that our proposed new method achieves state-of-the-art results with high accuracy and efficiency. Specifically, our method achieves improved F1 scores on the OpenLane dataset, surpassing the current best-performing method by 5.0 points.

Conditional validity and length efficiency are two crucial aspects of conformal prediction (CP). Conditional validity ensures accurate uncertainty quantification for data subpopulations, while proper length efficiency ensures that the prediction sets remain informative. Despite significant efforts to address each of these issues individually, a principled framework that reconciles these two objectives has been missing in the CP literature. In this paper, we develop Conformal Prediction with Length-Optimization (CPL) - a novel and practical framework that constructs prediction sets with (near-) optimal length while ensuring conditional validity under various classes of covariate shifts, including the key cases of marginal and group-conditional coverage. In the infinite sample regime, we provide strong duality results which indicate that CPL achieves conditional validity and length optimality. In the finite sample regime, we show that CPL constructs conditionally valid prediction sets. Our extensive empirical evaluations demonstrate the superior prediction set size performance of CPL compared to state-of-the-art methods across diverse real-world and synthetic datasets in classification, regression, and large language model-based multiple choice question answering. An Implementation of our algorithm can be accessed at the following link: https://github.com/shayankiyani98/CP.
tl;dr: On-device model adaptation with fixed-point forward gradient learning

Continuously adapting pre-trained models to local data on resource constrained edge devices is the \emph{last mile} for model deployment. However, as models increase in size and depth, backpropagation requires a large amount of memory, which becomes prohibitive for edge devices. In addition, most existing low power neural processing engines (e.g., NPUs, DSPs, MCUs, etc.) are designed as fixed-point inference accelerators, without training capabilities. Forward gradients, solely based on directional derivatives computed from two forward calls, have been recently used for model training, with substantial savings in computation and memory. However, the performance of quantized training with fixed-point forward gradients remains unclear. In this paper, we investigate the feasibility of on-device training using fixed-point forward gradients, by conducting comprehensive experiments across a variety of deep learning benchmark tasks in both vision and audio domains. We propose a series of algorithm enhancements that further reduce the memory footprint, and the accuracy gap compared to backpropagation. An empirical study on how training with forward gradients navigates in the loss landscape is further explored. Our results demonstrate that on the last mile of model customization on edge devices, training with fixed-point forward gradients is a feasible and practical approach.

This paper analyzes the inverse relationship between the order of partial differential equations (PDEs) and the convergence of gradient descent in physics-informed neural networks (PINNs) with the power of ReLU activation. The integration of the PDE into a loss function endows PINNs with a distinctive feature to require computing derivatives of model up to the PDE order. Although it has been empirically observed that PINNs encounter difficulties in convergence when dealing with high-order or high-dimensional PDEs, a comprehensive theoretical understanding of this issue remains elusive. This paper offers theoretical support for this pathological behavior by demonstrating that the gradient flow converges in a lower probability when the PDE order is higher. In addition, we show that PINNs struggle to address high-dimensional problems because the influence of dimensionality on convergence is exacerbated with increasing PDE order. To address the pathology, we use the insights garnered to consider variable splitting that decomposes the high-order PDE into a system of lower-order PDEs. We prove that by reducing the differential order, the gradient flow of variable splitting is more likely to converge to the global optimum. Furthermore, we present numerical experiments in support of our theoretical claims.
tl;dr: We propose a genetic-guided GFlowNet, which integrates a genetic search to guide GFlowNets to explore high-reward regions efficiently, achieving SOTA performance in an official molecular optimization benchmark.

The challenge of discovering new molecules with desired properties is crucial in domains like drug discovery and material design. Recent advances in deep learning-based generative methods have shown promise but face the issue of sample efficiency due to the computational expense of evaluating the reward function. This paper proposes a novel algorithm for sample-efficient molecular optimization by distilling a powerful genetic algorithm into deep generative policy using GFlowNets training, the off-policy method for amortized inference. This approach enables the deep generative policy to learn from domain knowledge, which has been explicitly integrated into the genetic algorithm. Our method achieves state-of-the-art performance in the official molecular optimization benchmark, significantly outperforming previous methods. It also demonstrates effectiveness in designing inhibitors against SARS-CoV-2 with substantially fewer reward calls.

Meta-learning empowers data-hungry deep neural networks to rapidly learn from merely a few samples, which is especially appealing to tasks with small datasets. Critical in this context is the *prior knowledge* accumulated from related tasks. Existing meta-learning approaches typically rely on preselected priors, such as a Gaussian probability density function (pdf). The limited expressiveness of such priors however, hinders the enhanced performance of the trained model when dealing with tasks having exceedingly scarce data. Targeting improved expressiveness, this contribution introduces a *data-driven* prior that optimally fits the provided tasks using a novel non-injective change-of-variable (NCoV) model. Unlike preselected prior pdfs with fixed shapes, the advocated NCoV model can effectively approximate a considerably wide range of pdfs. Moreover, compared to conventional change-of-variable models, the introduced NCoV exhibits augmented expressiveness for pdf modeling, especially in high-dimensional spaces. Theoretical analysis underscores the appealing universal approximation capacity of the NCoV model. Numerical experiments conducted on three few-shot learning datasets validate the superiority of data-driven priors over the prespecified ones, showcasing its pronounced effectiveness when dealing with extremely limited data resources.
tl;dr: We propose a general local iterative framework to accelerate the computation of graph diffusion equations which can be applied to GNN models.

Efficient computation of graph diffusion equations (GDEs), such as Personalized PageRank, Katz centrality, and the Heat kernel, is crucial for clustering, training neural networks, and many other graph-related problems. Standard iterative methods require accessing the whole graph per iteration, making them time-consuming for large-scale graphs. While existing local solvers approximate diffusion vectors through heuristic local updates, they often operate sequentially and are typically designed for specific diffusion types, limiting their applicability. Given that diffusion vectors are highly localizable, as measured by the participation ratio, this paper introduces a novel framework for approximately solving GDEs using a local diffusion process. This framework reveals the suboptimality of existing local solvers. Furthermore, our approach effectively localizes standard iterative solvers by designing simple and provably sublinear time algorithms. These new local solvers are highly parallelizable, making them well-suited for implementation on GPUs. We demonstrate the effectiveness of our framework in quickly obtaining approximate diffusion vectors, achieving up to a hundred-fold speed improvement, and its applicability to large-scale dynamic graphs. Our framework could also facilitate more efficient local message-passing mechanisms for GNNs.
tl;dr: SCube reconstructs large-scale 3D scenes represented with voxel-supported Gasussian splats from non-overlapping sparse views in 20 seconds.

We present SCube, a novel method for reconstructing large-scale 3D scenes (geometry, appearance, and semantics) from a sparse set of posed images. Our method encodes reconstructed scenes using a novel representation VoxSplat, which is a set of 3D Gaussians supported on a high-resolution sparse-voxel scaffold. To reconstruct a VoxSplat from images, we employ a hierarchical voxel latent diffusion model conditioned on the input images followed by a feedforward appearance prediction model. The diffusion model generates high-resolution grids progressively in a coarse-to-fine manner, and the appearance network predicts a set of Gaussians within each voxel. From as few as 3 non-overlapping input images, SCube can generate millions of Gaussians with a 10243 voxel grid spanning hundreds of meters in 20 seconds. Past works tackling scene reconstruction from images either rely on per-scene optimization and fail to reconstruct the scene away from input views (thus requiring dense view coverage as input) or leverage geometric priors based on low-resolution models, which produce blurry results. In contrast, SCube leverages high-resolution sparse networks and produces sharp outputs from few views. We show the superiority of SCube compared to prior art using the Waymo self-driving dataset on 3D reconstruction and demonstrate its applications, such as LiDAR simulation and text-to-scene generation.

Despite the success of reinforcement learning from human feedback (RLHF) in aligning language models with human values, reward hacking, also termed reward overoptimization, remains a critical challenge. This issue primarily arises from reward misgeneralization, where reward models (RMs) compute reward using spurious features that are irrelevant to human preferences. In this work, we tackle this problem from an information-theoretic perspective and propose a framework for reward modeling, namely InfoRM, by introducing a variational information bottleneck objective to filter out irrelevant information.
Notably, we further identify a correlation between overoptimization and outliers in the IB latent space of InfoRM, establishing it as a promising tool for detecting reward overoptimization.
Inspired by this finding, we propose the Cluster Separation Index (CSI), which quantifies deviations in the IB latent space, as an indicator of reward overoptimization to facilitate the development of online mitigation strategies. Extensive experiments on a wide range of settings and RM scales (70M, 440M, 1.4B, and 7B) demonstrate the effectiveness of InfoRM. Further analyses reveal that InfoRM's overoptimization detection mechanism is not only effective but also robust across a broad range of datasets, signifying a notable advancement in the field of RLHF. The code will be released upon acceptance.

Current studies on adversarial robustness mainly focus on aggregating \textit{local} robustness results from a set of data samples to evaluate and rank different models. However, the local statistics may not well represent the true \textit{global} robustness of the underlying unknown data distribution. To address this challenge, this paper makes the first attempt to present a new framework, called \textit{GREAT Score}, for global robustness evaluation of adversarial perturbation using generative models. Formally, GREAT Score carries the physical meaning of a global statistic capturing a mean certified attack-proof perturbation level over all samples drawn from a generative model. For finite-sample evaluation, we also derive a probabilistic guarantee on the sample complexity and the difference between the sample mean and the true mean. GREAT Score has several advantages: (1) Robustness evaluations using GREAT Score are efficient and scalable to large models, by sparing the need of running adversarial attacks. In particular, we show high correlation and significantly reduced computation cost of GREAT Score when compared to the attack-based model ranking on RobustBench \cite{croce2021robustbench}. (2) The use of generative models facilitates the approximation of the unknown data distribution. In our ablation study with different generative adversarial networks (GANs), we observe consistency between global robustness evaluation and the quality of GANs. (3) GREAT Score can be used for remote auditing of privacy-sensitive black-box models, as demonstrated by our robustness evaluation on several online facial recognition services.

Open-vocabulary 3D object detection has recently attracted considerable attention due to its broad applications in autonomous driving and robotics, which aims to effectively recognize novel classes in previously unseen domains. However, existing point cloud-based open-vocabulary 3D detection models are limited by their high deployment costs. In this work, we propose a novel open-vocabulary monocular 3D object detection framework, dubbed OVM3D-Det, which trains detectors using only RGB images, making it both cost-effective and scalable to publicly available data. Unlike traditional methods, OVM3D-Det does not require high-precision LiDAR or 3D sensor data for either input or generating 3D bounding boxes. Instead, it employs open-vocabulary 2D models and pseudo-LiDAR to automatically label 3D objects in RGB images, fostering the learning of open-vocabulary monocular 3D detectors. However, training 3D models with labels directly derived from pseudo-LiDAR is inadequate due to imprecise boxes estimated from noisy point clouds and severely occluded objects. To address these issues, we introduce two innovative designs: adaptive pseudo-LiDAR erosion and bounding box refinement with prior knowledge from large language models. These techniques effectively calibrate the 3D labels and enable RGB-only training for 3D detectors. Extensive experiments demonstrate the superiority of OVM3D-Det over baselines in both indoor and outdoor scenarios. The code will be released.
tl;dr: We rigorously analyze transfer learning in terms of relatedness between tasks and show that task-relatedness accurately predicts transferability in various practical scenarios.

The growing popularity of transfer learning due to the availability of models pre-trained on vast amounts of data, makes it imperative to understand when the knowledge of these pre-trained models can be transferred to obtain high-performing models on downstream target tasks. However, the exact conditions under which transfer learning succeeds in a cross-domain cross-task setting are still poorly understood. To bridge this gap, we propose a novel analysis that analyzes the transferability of the representations of pre-trained models to downstream tasks in terms of their relatedness to a given reference task. Our analysis leads to an upper bound on transferability in terms of task-relatedness, quantified using the difference between the class priors, label sets, and features of the two tasks.Our experiments using state-of-the-art pre-trained models show the effectiveness of task-relatedness in explaining transferability on various vision and language tasks. The efficient computability of task-relatedness even without labels of the target task and its high correlation with the model's accuracy after end-to-end fine-tuning on the target task makes it a useful metric for transferability estimation. Our empirical results of using task-relatedness on the problem of selecting the best pre-trained model from a model zoo for a target task highlight its utility for practical problems.
tl;dr: Model-Based Diffusion (MBD) solves trajectory optimization by using model information for score computation.

Recent advances in diffusion models have demonstrated their strong capabilities in generating high-fidelity samples from complex distributions through an iterative refinement process. Despite the empirical success of diffusion models in motion planning and control, the model-free nature of these methods does not leverage readily available model information and limits their generalization to new scenarios beyond the training data (e.g., new robots with different dynamics). In this work, we introduce Model-Based Diffusion (MBD), an optimization approach using the diffusion process to solve trajectory optimization (TO) problems without data. The key idea is to explicitly compute the score function by leveraging the model information in TO problems, which is why we refer to our approach as model-based diffusion. Moreover, although MBD does not require external data, it can be naturally integrated with data of diverse qualities to steer the diffusion process. We also reveal that MBD has interesting connections to sampling-based optimization. Empirical evaluations show that MBD outperforms state-of-the-art reinforcement learning and sampling-based TO methods in challenging contact-rich tasks. Additionally, MBD’s ability to integrate with data enhances its versatility and practical applicability, even with imperfect and infeasible data (e.g., partial-state demonstrations for high-dimensional humanoids), beyond the scope of standard diffusion models. Videos and codes are available in the supplementary materials.

Human Mesh Recovery (HMR) is the task of estimating a parameterized 3D human mesh from an image. There is a kind of methods first training a regression model for this problem, then further optimizing the pretrained regression model for any specific sample individually at test time. However, the pretrained model may not provide an ideal optimization starting point for the test-time optimization. Inspired by meta-learning, we incorporate the test-time optimization into training, performing a step of test-time optimization for each sample in the training batch before really conducting the training optimization over all the training samples. In this way, we obtain a meta-model, the meta-parameter of which is friendly to the test-time optimization. At test time, after several test-time optimization steps starting from the meta-parameter, we obtain much higher HMR accuracy than the test-time optimization starting from the simply pretrained regression model. Furthermore, we find test-time HMR objectives are different from training-time objectives, which reduces the effectiveness of the learning of the meta-model. To solve this problem, we propose a dual-network architecture that unifies the training-time and test-time objectives. Our method, armed with meta-learning and the dual networks, outperforms state-of-the-art regression-based and optimization-based HMR approaches, as validated by the extensive experiments. The codes are available at https://github.com/fmx789/Meta-HMR.

Traditional Anomaly Detection (AD) methods have predominantly relied on unsupervised learning from extensive normal data. Recent AD methods have evolved with the advent of large pre-trained vision-language models, enhancing few-shot anomaly detection capabilities. However, these latest AD methods still exhibit limitations in accuracy improvement. One contributing factor is their direct comparison of a query image's features with those of few-shot normal images. This direct comparison often leads to a loss of precision and complicates the extension of these techniques to more complex domains—an area that remains underexplored in a more refined and comprehensive manner. To address these limitations, we introduce the anomaly personalization method, which performs a personalized one-to-normal transformation of query images using an anomaly-free customized generation model, ensuring close alignment with the normal manifold. Moreover, to further enhance the stability and robustness of prediction results, we propose a triplet contrastive anomaly inference strategy, which incorporates a comprehensive comparison between the query and generated anomaly-free data pool and prompt information. Extensive evaluations across eleven datasets in three domains demonstrate our model's effectiveness compared to the latest AD methods. Additionally, our method has been proven to transfer flexibly to other AD methods, with the generated image data effectively improving the performance of other AD methods.
tl;dr: We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs).

We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by - and even at odds with - the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.

Test-time adaptation (TTA) is the most realistic methodology for adapting deep learning models to the real world using only unlabeled data from the target domain. Numerous TTA studies in deep learning have aimed at minimizing entropy. However, this necessitates forward/backward processes across the entire model and is limited by the incapability to fully leverage data based solely on entropy. This study presents a groundbreaking TTA solution that involves a departure from the conventional focus on minimizing entropy. Our innovative approach uniquely remodels the stem layer (i.e., the first layer) to emphasize minimizing a new learning criterion, namely, uncertainty. This method requires minimal involvement of the model's backbone, with only the stem layer participating in the TTA process. This approach significantly reduces the memory required for training and enables rapid adaptation to the target domain with minimal parameter updates. Moreover, to maximize data leveraging, the stem layer applies a discrete wavelet transform to the input features. It extracts multi-frequency domains and focuses on minimizing their individual uncertainties. The proposed method integrated into ResNet-26 and ResNet-50 models demonstrates its robustness by achieving outstanding TTA performance while using the least amount of memory compared to existing studies on CIFAR-10-C, ImageNet-C, and Cityscapes-C benchmark datasets. The code is available at https://github.com/janus103/L_TTA.

Visual In-Context Learning (VICL) is a prevailing way to transfer visual foundation models to new tasks by leveraging contextual information contained in in-context examples to enhance learning and prediction of query sample. The fundamental problem in VICL is how to select the best prompt to activate its power as much as possible, which is equivalent to the ranking problem to test the in-context behavior of each candidate in the alternative set and select the best one. To utilize more appropriate ranking metric and leverage more comprehensive information among the alternative set, we propose a novel in-context example selection framework to approximately identify the global optimal prompt, i.e. choosing the best performing in-context examples from all alternatives for each query sample. Our method, dubbed Partial2Global, adopts a transformer-based list-wise ranker to provide a more comprehensive comparison within several alternatives, and a consistency-aware ranking aggregator to generate globally consistent ranking. The effectiveness of Partial2Global is validated through experiments on foreground segmentation, single object detection and image colorization, demonstrating that Partial2Global selects consistently better in-context examples compared with other methods, and thus establish the new state-of-the-arts.
tl;dr: This work proposes a novel adversarial imitation learning framework that integrates a diffusion model into generative adversarial imitation learning.

Imitation learning aims to learn a policy from observing expert demonstrations without access to reward signals from environments. Generative adversarial imitation learning (GAIL) formulates imitation learning as adversarial learning, employing a generator policy learning to imitate expert behaviors and discriminator learning to distinguish the expert demonstrations from agent trajectories. Despite its encouraging results, GAIL training is often brittle and unstable. Inspired by the recent dominance of diffusion models in generative modeling, we propose Diffusion-Reward Adversarial Imitation Learning (DRAIL), which integrates a diffusion model into GAIL, aiming to yield more robust and smoother rewards for policy learning. Specifically, we propose a diffusion discriminative classifier to construct an enhanced discriminator, and design diffusion rewards based on the classifier’s output for policy learning. Extensive experiments are conducted in navigation, manipulation, and locomotion, verifying DRAIL’s effectiveness compared to prior imitation learning methods. Moreover, additional experimental results demonstrate the generalizability and data efficiency of DRAIL. Visualized learned reward functions of GAIL and DRAIL suggest that DRAIL can produce more robust and smoother rewards. Project page: https://nturobotlearninglab.github.io/DRAIL/
tl;dr: We propose a novel text-driven panorama generation framework that leverages multi-view consistency between generated images to achieve scalable, consistent, and diverse panoramic scene generation.

Diffusion-based methods have achieved remarkable achievements in 2D image or 3D object generation, however, the generation of 3D scenes and even $360^{\circ}$ images remains constrained, due to the limited number of scene datasets, the complexity of 3D scenes themselves, and the difficulty of generating consistent multi-view images. To address these issues, we first establish a large-scale panoramic video-text dataset containing millions of consecutive panoramic keyframes with corresponding panoramic depths, camera poses, and text descriptions. Then, we propose a novel text-driven panoramic generation framework, termed DiffPano, to achieve scalable, consistent, and diverse panoramic scene generation. Specifically, benefiting from the powerful generative capabilities of stable diffusion, we fine-tune a single-view text-to-panorama diffusion model with LoRA on the established panoramic video-text dataset. We further design a spherical epipolar-aware multi-view diffusion model to ensure the multi-view consistency of the generated panoramic images. Extensive experiments demonstrate that DiffPano can generate scalable, consistent, and diverse panoramic images with given unseen text descriptions and camera poses.
tl;dr: We introduce a novel training method for adaptive depth networks that can provide flexible accuracy-efficiency trade- offs in a single network.

Predictable adaptation of network depths can be an effective way to control inference latency and meet the resource condition of various devices. However, previous adaptive depth networks do not provide general principles and a formal explanation on why and which layers can be skipped, and, hence, their approaches are hard to be generalized and require long and complex training steps. In this paper, we present a practical approach to adaptive depth networks that is applicable to various networks with minimal training effort. In our approach, every hierarchical residual stage is divided into two sub-paths, and they are trained to acquire different properties through a simple self-distillation strategy. While the first sub-path is essential for hierarchical feature learning, the second one is trained to refine the learned features and minimize performance degradation if it is skipped. Unlike prior adaptive networks, our approach does not train every target sub-network in an iterative manner. At test time, however, we can connect these sub-paths in a combinatorial manner to select sub-networks of various accuracy-efficiency trade-offs from a single network. We provide a formal rationale for why the proposed training method can reduce overall prediction errors while minimizing the impact of skipping sub-paths. We demonstrate the generality and effectiveness of our approach with convolutional neural networks and transformers.

We present a novel algorithm that efficiently computes near-optimal deterministic policies for constrained reinforcement learning (CRL) problems. Our approach combines three key ideas: (1) value-demand augmentation, (2) action-space approximate dynamic programming, and (3) time-space rounding. Our algorithm constitutes a fully polynomial-time approximation scheme (FPTAS) for any time-space recursive (TSR) cost criteria. A TSR criteria requires the cost of a policy to be computable recursively over both time and (state) space, which includes classical expectation, almost sure, and anytime constraints. Our work answers three open questions spanning two long-standing lines of research: polynomial-time approximability is possible for 1) anytime-constrained policies, 2) almost-sure-constrained policies, and 3) deterministic expectation-constrained policies.

The ultimate goal of multi-objective optimization (MO) is to assist human decision-makers (DMs) in identifying solutions of interest (SOI) that optimally reconcile multiple objectives according to their preferences. Preference-based evolutionary MO (PBEMO) has emerged as a promising framework that progressively approximates SOI by involving human in the optimization-cum-decision-making process. Yet, current PBEMO approaches are prone to be inefficient and misaligned with the DM’s true aspirations, especially when inadvertently exploiting mis-calibrated reward models. This is further exacerbated when considering the stochastic nature of human feedback. This paper proposes a novel framework that navigates MO to SOI by directly leveraging human feedback without being restricted by a predefined reward model nor cumbersome model selection. Specifically, we developed a clustering-based stochastic dueling bandits algorithm that strategically scales well to high-dimensional dueling bandits, and achieves a regret of $\mathcal{O}(K^2\log T)$, where $K$ is the number of clusters and $T$ is the number of rounds. The learned preferences are then transformed into a unified probabilistic format that can be readily adapted to prevalent EMO algorithms. This also leads to a principled termination criterion that strategically manages human cognitive loads and computational budget. Experiments on $48$ benchmark test problems, including synthetic problems, RNA inverse design and protein structure prediction, fully demonstrate the effectiveness of our proposed approach.
tl;dr: A dual-modality reasoning framework that enhances reasoning capabilities by incorporating self-synthesized visual and spatial information for problem-solving.

Verbal and visual-spatial information processing are two critical subsystems that activate different brain regions and often collaborate together for cognitive reasoning. Despite the rapid advancement of LLM-based reasoning, the mainstream frameworks, such as Chain-of-Thought (CoT) and its variants, primarily focus on the verbal dimension, resulting in limitations in tackling reasoning problems with visual and spatial clues. To bridge the gap, we propose a novel dual-modality reasoning framework called Vision-Augmented Prompting (VAP). Upon receiving a textual problem description, VAP automatically synthesizes an image from the visual and spatial clues by utilizing external drawing tools. Subsequently, VAP formulates a chain of thought in both modalities and iteratively refines the synthesized image. Finally, a conclusive reasoning scheme based on self-alignment is proposed for final result generation. Extensive experiments are conducted across four versatile tasks, including solving geometry problems, Sudoku, time series prediction, and travelling salesman problem. The results validated the superiority of VAP over existing LLMs-based reasoning frameworks.

Class-agnostic object detection (OD) can be a cornerstone or a bottleneck for many downstream vision tasks. Despite considerable advancements in bottom-up and multi-object discovery methods that leverage basic visual cues to identify salient objects, consistently achieving a high recall rate remains difficult due to the diversity of object types and their contextual complexity. In this work, we investigate using vision-language models (VLMs) to enhance object detection via a self-supervised prompt learning strategy. Our initial findings indicate that manually crafted text queries often result in undetected objects, primarily because detection confidence diminishes when the query words exhibit semantic overlap. To address this, we propose a Dispersing Prompt Expansion (DiPEx) approach. DiPEx progressively learns to expand a set of distinct, non-overlapping hyperspherical prompts to enhance recall rates, thereby improving performance in downstream tasks such as out-of-distribution OD. Specifically, DiPEx initiates the process by self-training generic parent prompts and selecting the one with the highest semantic uncertainty for further expansion. The resulting child prompts are expected to inherit semantics from their parent prompts while capturing more fine-grained semantics. We apply dispersion losses to ensure high inter-class discrepancy among child prompts while preserving semantic consistency between parent-child prompt pairs. To prevent excessive growth of the prompt sets, we utilize the maximum angular coverage (MAC) of the semantic space as a criterion for early termination. We demonstrate the effectiveness of DiPEx through extensive class-agnostic OD and OOD-OD experiments on MS-COCO and LVIS, surpassing other prompting methods by up to 20.1% in AR and achieving a 21.3% AP improvement over SAM.

We introduce the CRONOS algorithm for convex optimization of two-layer neural networks.
CRONOS is the first algorithm capable of scaling to high-dimensional datasets such as ImageNet, which are ubiquitous in modern deep learning.
This significantly improves upon prior work, which has been restricted to downsampled versions of MNIST and CIFAR-10.
Taking CRONOS as a primitive, we then develop a new algorithm called CRONOS-AM, which combines CRONOS with alternating minimization, to obtain an algorithm capable of training multi-layer networks with arbitrary architectures.
Our theoretical analysis proves that CRONOS converges to the global minimum of the convex reformulation under mild assumptions.
In addition, we validate the efficacy of CRONOS and CRONOS-AM through extensive large-scale numerical experiments with GPU acceleration in JAX.
Our results show that CRONOS-AM can obtain comparable or better validation accuracy than predominant tuned deep learning optimizers on vision and language tasks with benchmark datasets such as ImageNet and IMDb.
To the best of our knowledge, CRONOS is the first algorithm which utilizes the convex reformulation to enhance performance on large-scale learning tasks.
tl;dr: We create efficient equivariant networks for volumes where every voxel contains a spherical signal. We developed this method to improve fiber deconvolution in diffusion MRI, the primary method of mapping neuronal fibers in the brain."

Each voxel in a diffusion MRI (dMRI) image contains a spherical signal corresponding to the direction and strength of water diffusion in the brain. This paper advances the analysis of such spatio-spherical data by developing convolutional network layers that are equivariant to the $\mathbf{E(3) \times SO(3)}$ group and account for the physical symmetries of dMRI including rotations, translations, and reflections of space alongside voxel-wise rotations. Further, neuronal fibers are typically antipodally symmetric, a fact we leverage to construct highly efficient spatio-*hemispherical* graph convolutions to accelerate the analysis of high-dimensional dMRI data. In the context of sparse spherical fiber deconvolution to recover white matter microstructure, our proposed equivariant network layers yield substantial performance and efficiency gains, leading to better and more practical resolution of crossing neuronal fibers and fiber tractography. These gains are experimentally consistent across both simulation and in vivo human datasets.

In the Integrated Circuit (IC) design flow, floorplanning (FP) determines the position and shape of each block. Serving as a prototype for downstream tasks, it is critical and establishes the upper bound of the final PPA (Power, Performance, Area). However, with the emergence of 3D IC with stacked layers, existing methods are not flexible enough to handle the versatile constraints. Besides, they typically face difficulties in aligning the cross-die modules in 3D ICs due to their heuristic representations, which could potentially result in severe data transfer failures. To address these issues, we propose FlexPlanner, a flexible learning-based method in hybrid action space with multi-modality representation to simultaneously handle position, aspect ratio, and alignment of blocks. To our best knowledge, FlexPlanner is the first learning-based approach to discard heuristic-based search in the 3D FP task. Thus, the solution space is not limited by the heuristic floorplanning representation, allowing for significant improvements in both wirelength and alignment scores. Specifically, FlexPlanner models 3D FP based on multi-modalities, including vision, graph, and sequence. To address the non-trivial heuristic-dependent issue, we design a sophisticated policy network with hybrid action space and asynchronous layer decision mechanism that allow for determining the versatile properties of each block. Experiments on public benchmarks MCNC and GSRC show the effectiveness. We significantly improve the alignment score from 0.474 to 0.940 and achieve an average reduction of 16% in wirelength. Moreover, our method also demonstrates zero-shot transferability on unseen circuits.

Graph is a prevalent discrete data structure, whose generation has wide applications such as drug discovery and circuit design. Diffusion generative models, as an emerging research focus, have been applied to graph generation tasks. Overall, according to the space of states and time steps, diffusion generative models can be categorized into discrete-/continuous-state discrete-/continuous-time fashions. In this paper, we formulate the graph diffusion generation in a discrete-state continuous-time setting, which has never been studied in previous graph diffusion models. The rationale of such a formulation is to preserve the discrete nature of graph-structured data and meanwhile provide flexible sampling trade-offs between sample quality and efficiency. Analysis shows that our training objective is closely related to the generation quality and our proposed generation framework enjoys ideal invariant/equivariant properties concerning the permutation of node ordering. Our proposed model shows competitive empirical performance against other state-of-the-art graph generation solutions on various benchmarks while at the same time can flexibly trade off the generation quality and efficiency in the sampling phase.

In the strategic facility location problem, a set of agents report their locations in a metric space and the goal is to use these reports to open a new facility, minimizing an aggregate distance measure from the agents to the facility. However, agents are strategic and may misreport their locations to influence the facility’s placement in their favor. The aim is to design truthful mechanisms, ensuring agents cannot gain by misreporting. This problem was recently revisited through the learning-augmented framework, aiming to move beyond worst-case analysis and design truthful mechanisms that are augmented with (machine-learned) predictions. The focus of this work was on mechanisms that are deterministic and augmented with a prediction regarding the optimal facility location. In this paper, we provide a deeper understanding of this problem by exploring the power of randomization as well as the impact of different types of predictions on the performance of truthful learning-augmented mechanisms. We study both the single-dimensional and the Euclidean case and provide upper and lower bounds regarding the achievable approximation of the optimal egalitarian social cost.
3019. United We Stand, Divided We Fall: Fingerprinting Deep Neural Networks via Adversarial Trajectories

In recent years, deep neural networks (DNNs) have witnessed extensive applications, and protecting their intellectual property (IP) is thus crucial. As a non-invasive way for model IP protection, model fingerprinting has become popular. However, existing single-point based fingerprinting methods are highly sensitive to the changes in the decision boundary, and may suffer from the misjudgment of the resemblance of sparse fingerprinting, yielding high false positives of innocent models. In this paper, we propose ADV-TRA, a more robust fingerprinting scheme that utilizes adversarial trajectories to verify the ownership of DNN models. Benefited from the intrinsic progressively adversarial level, the trajectory is capable of tolerating greater degree of alteration in decision boundaries. We further design novel schemes to generate a surface trajectory that involves a series of fixed-length trajectories with dynamically adjusted step sizes. Such a design enables a more unique and reliable fingerprinting with relatively low querying costs. Experiments on three datasets against four types of removal attacks show that ADV-TRA exhibits superior performance in distinguishing between infringing and innocent models, outperforming the state-of-the-art comparisons.

Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks, including language modeling, understanding, and generation. However, the increased memory and computational costs associated with these models pose significant challenges for deployment on resource-limited devices. Structural pruning has emerged as a promising solution to reduce the costs of LLMs without requiring post-processing steps. Prior structural pruning methods either follow the dependence of structures at the cost of limiting flexibility, or introduce non-trivial additional parameters by incorporating different projection matrices. In this work, we propose a novel approach that relaxes the constraint imposed by regular structural pruning methods and eliminates the structural dependence along the embedding dimension. Our dimension-independent structural pruning method offers several benefits. Firstly, our method enables different blocks to utilize different subsets of the feature maps. Secondly, by removing structural dependence, we facilitate each block to possess varying widths along its input and output dimensions, thereby significantly enhancing the flexibility of structural pruning. We evaluate our method on various LLMs, including OPT, LLaMA, LLaMA-2, Phi-1.5, and Phi-2. Experimental results demonstrate that our approach outperforms other state-of-the-art methods, showing for the first time that structural pruning can achieve an accuracy similar to semi-structural pruning.

We propose a new model for dimensionality reduction, the PCA tree, which works like a regular autoencoder, having explicit projection and reconstruction mappings. The projection is effected by a sparse oblique tree, having hard, hyperplane splits using few features and linear leaves. The reconstruction mapping is a set of local linear mappings. Thus, rather than producing a global map as in t-SNE and other methods, which often leads to distortions, it produces a hierarchical set of local PCAs. The use of a sparse oblique tree and PCA makes the overall model interpretable and very fast to project or reconstruct new points. Joint optimization of all the parameters in the tree is a nonconvex nondifferentiable problem. We propose an algorithm that is guaranteed to decrease the error monotonically and which scales to large datasets without any approximation. In experiments, we show PCA trees are able to identify a wealth of low-dimensional and cluster structure in image and document datasets.
tl;dr: We introduce unsupervised pretraining and in-context learning for Scientific Machine Learning, significantly enhancing data efficiency and generalizability of neural operators.

Recent years have witnessed the promise of coupling machine learning methods and physical domain-specific insights for solving scientific problems based on partial differential equations (PDEs). However, being data-intensive, these methods still require a large amount of PDE data. This reintroduces the need for expensive numerical PDE solutions, partially undermining the original goal of avoiding these expensive simulations. In this work, seeking data efficiency, we design unsupervised pretraining for PDE operator learning. To reduce the need for training data with heavy simulation costs, we mine unlabeled PDE data without simulated solutions,
and we pretrain neural operators with physics-inspired reconstruction-based proxy tasks. To improve out-of-distribution performance, we further assist neural operators in flexibly leveraging a similarity-based method that learns in-context examples, without incurring extra training costs or designs. Extensive empirical evaluations on a diverse set of PDEs demonstrate that our method is highly data-efficient, more generalizable, and even outperforms conventional vision-pretrained models. We provide our code at https://github.com/delta-lab-ai/data_efficient_nopt.
tl;dr: Propose a test-time Collaborative Lifelong Adaptation (CoLA) paradigm to enable knowledge accumulation, sharing, and utilization across multiple devices, where both resource-abundant and resource-limited devices are included in the collaboration.

In this paper, we propose test-time Collaborative Lifelong Adaptation (CoLA), which is a general paradigm that can be incorporated with existing advanced TTA methods to boost the adaptation performance and efficiency in a multi-device collaborative manner. Specifically, we maintain and store a set of device-shared _domain knowledge vectors_, which accumulates the knowledge learned from all devices during their lifelong adaptation process. Based on this, CoLA conducts two collaboration strategies for devices with different computational resources and latency demands. 1) Knowledge reprogramming learning strategy jointly learns new domain-specific model parameters and a reweighting term to reprogram existing shared domain knowledge vectors, termed adaptation on _principal agents_. 2) Similarity-based knowledge aggregation strategy solely aggregates the knowledge stored in shared domain vectors according to domain similarities in an optimization-free manner, termed adaptation on _follower agents_. Experiments verify that CoLA is simple but effective, which boosts the efficiency of TTA and demonstrates remarkable superiority in collaborative, lifelong, and single-domain TTA scenarios, e.g., on follower agents, we enhance accuracy by over 30\% on ImageNet-C while maintaining nearly the same efficiency as standard inference. The source code is available at https://github.com/Cascol-Chen/COLA.
tl;dr: Here, we obtain an optimal solution to multi-objective learn-to-defer problem by generalizing Neyman-Pearson lemma to multi-hypothesis setting

Learn-to-Defer is a paradigm that enables learning algorithms to work not in isolation but as a team with human experts. In this paradigm, we permit the system to defer a subset of its tasks to the expert. Although there are currently systems that follow this paradigm and are designed to optimize the accuracy of the final human-AI team, the general methodology for developing such systems under a set of constraints (e.g., algorithmic fairness, expert intervention budget, defer of anomaly, etc.) remains largely unexplored. In this paper, using a d-dimensional generalization to the fundamental lemma of Neyman and Pearson (d-GNP), we obtain the Bayes optimal solution for learn-to-defer systems under various constraints. Furthermore, we design a generalizable algorithm to estimate that solution and apply this algorithm to the COMPAS, Hatespeech, and ACSIncome datasets. Our algorithm shows improvements in terms of constraint violation over a set of learn-to-defer baselines and can control multiple constraint violations at once. The use of d-GNP is beyond learn-to-defer applications and can potentially obtain a solution to decision-making problems with a set of controlled expected performance measures.

The performance of 3D object detection in large outdoor point clouds deteriorates significantly in an unseen environment due to the inter-domain gap. To address these challenges, most existing methods for domain adaptation harness self-training schemes and attempt to bridge the gap by focusing on a single factor that causes the inter-domain gap, such as objects' sizes, shapes, and foreground density variation. However, the resulting adaptations suggest that there is still a substantial inter-domain gap left to be minimized. We argue that this is due to two limitations: 1) Biased pseudo-label collection from self-training. 2) Multiple factors jointly contributing to how the object is perceived in the unseen target domain. In this work, we propose a grouping-exploration strategy framework, Group Explorer Domain Adaptation ($\textbf{GroupEXP-DA}$), to addresses those two issues. Specifically, our grouping divides the available label sets into multiple clusters and ensures all of them have equal learning attention with the group-equivariant spatial feature, avoiding dominant types of objects causing imbalance problems. Moreover, grouping learns to divide objects by considering inherent factors in a data-driven manner, without considering each factor separately as existing works. On top of the group-equivariant spatial feature that selectively detects objects similar to the input group, we additionally introduce an explorative group update strategy that reduces the false negative detection in the target domain, further reducing the inter-domain gap. During inference, only the learned group features are necessary for making the group-equivariant spatial feature, placing our method as a simple add-on that can be applicable to most existing detectors. We show how each module contributes to substantially bridging the inter-domain gaps compared to existing works across large urban outdoor datasets such as NuScenes, Waymo, and KITTI.

Visual relationship understanding has been studied separately in human-object interaction(HOI) detection, scene graph generation(SGG), and referring relationships(RR) tasks.
Given the complexity and interconnectedness of these tasks, it is crucial to have a flexible framework that can effectively address these tasks in a cohesive manner.
In this work, we propose FleVRS, a single model that seamlessly integrates the above three aspects in standard and promptable visual relationship segmentation, and further possesses the capability for open-vocabulary segmentation to adapt to novel scenarios.
FleVRS leverages the synergy between text and image modalities,
to ground various types of relationships from images and use textual features from vision-language models to visual conceptual understanding.
Empirical validation across various datasets demonstrates that our framework outperforms existing models in standard, promptable, and open-vocabulary tasks, e.g., +1.9 $mAP$ on HICO-DET, +11.4 $Acc$ on VRD, +4.7 $mAP$ on unseen HICO-DET.
Our FleVRS represents a significant step towards a more intuitive, comprehensive, and scalable understanding of visual relationships.

In this paper, we study a class of non-smooth non-convex problems in the form of $\min_{x}[\max_{y\in\mathcal Y}\phi(x, y) - \max_{z\in\mathcal Z}\psi(x, z)]$, where both $\Phi(x) = \max_{y\in\mathcal Y}\phi(x, y)$ and $\Psi(x)=\max_{z\in\mathcal Z}\psi(x, z)$ are weakly convex functions, and $\phi(x, y), \psi(x, z)$ are strongly concave functions in terms of $y$ and $z$, respectively. It covers two families of problems that have been studied but are missing single-loop stochastic algorithms, i.e., difference of weakly convex functions and weakly convex strongly-concave min-max problems. We propose a stochastic Moreau envelope approximate gradient method dubbed SMAG, the first single-loop algorithm for solving these problems, and provide a state-of-the-art non-asymptotic convergence rate. The key idea of the design is to compute an approximate gradient of the Moreau envelopes of $\Phi, \Psi$ using only one step of stochastic gradient update of the primal and dual variables. Empirically, we conduct experiments on positive-unlabeled (PU) learning and partial area under ROC curve (pAUC) optimization with an adversarial fairness regularizer to validate the effectiveness of our proposed algorithms.

Deep learning sometimes appears to work in unexpected ways. In pursuit of a deeper understanding of its surprising behaviors, we investigate the utility of a simple yet accurate model of a trained neural network consisting of a sequence of first-order approximations telescoping out into a single empirically operational tool for practical analysis. Across three case studies, we illustrate how it can be applied to derive new empirical insights on a diverse range of prominent phenomena in the literature -- including double descent, grokking, linear mode connectivity, and the challenges of applying deep learning on tabular data -- highlighting that this model allows us to construct and extract metrics that help predict and understand the a priori unexpected performance of neural networks. We also demonstrate that this model presents a pedagogical formalism allowing us to isolate components of the training process even in complex contemporary settings, providing a lens to reason about the effects of design choices such as architecture & optimization strategy, and reveals surprising parallels between neural network learning and gradient boosting.
tl;dr: We show that PPO suffers from feature rank degradation, that it harms its heuristic trust region, and that it is connected to performance collapse.

Reinforcement learning (RL) is inherently rife with non-stationarity since the states and rewards the agent observes during training depend on its changing policy.
Therefore, networks in deep RL must be capable of adapting to new observations and fitting new targets.
However, previous works have observed that networks trained under non-stationarity exhibit an inability to continue learning, termed loss of plasticity, and eventually a collapse in performance.
For off-policy deep value-based RL methods, this phenomenon has been correlated with a decrease in representation rank and the ability to fit random targets, termed capacity loss.
Although this correlation has generally been attributed to neural network learning under non-stationarity, the connection to representation dynamics has not been carefully studied in on-policy policy optimization methods.
In this work, we empirically study representation dynamics in Proximal Policy Optimization (PPO) on the Atari and MuJoCo environments, revealing that PPO agents are also affected by feature rank deterioration and capacity loss.
We show that this is aggravated by stronger non-stationarity, ultimately driving the actor's performance to collapse, regardless of the performance of the critic.
We ask why the trust region, specific to methods like PPO, cannot alleviate or prevent the collapse and find a connection between representation collapse and the degradation of the trust region, one exacerbating the other.
Finally, we present Proximal Feature Optimization (PFO), a novel auxiliary loss that, along with other interventions, shows that regularizing the representation dynamics mitigates the performance collapse of PPO agents.
Code and run histories are available at https://github.com/CLAIRE-Labo/no-representation-no-trust.

Diffusion models have demonstrated empirical successes in various applications and can be adapted to task-specific needs via guidance. This paper studies a form of gradient guidance for adapting a pre-trained diffusion model towards optimizing user-specified objectives. We establish a mathematical framework for guided diffusion to systematically study its optimization theory and algorithmic design. Our theoretical analysis spots a strong link between guided diffusion models and optimization: gradient-guided diffusion models are essentially sampling solutions to a regularized optimization problem, where the regularization is imposed by the pre-training data. As for guidance design, directly bringing in the gradient of an external objective function as guidance would jeopardize the structure in generated samples. We investigate a modified form of gradient guidance based on a forward prediction loss, which leverages the information in pre-trained score functions and provably preserves the latent structure. We further consider an iteratively fine-tuned version of gradient-guided diffusion where guidance and score network are both updated with newly generated samples. This process mimics a first-order optimization iteration in expectation, for which we proved $\tilde{\mathcal{O}}(1/K)$ convergence rate to the global optimum when the objective function is concave. Our code is released at https://github.com/yukang123/GGDMOptim.git.
tl;dr: Many content-agnostic digital watermarking techniques are susceptible to simple steganalysis-based watermark removal.

Digital watermarking techniques are crucial for copyright protection and source identification of images, especially in the era of generative AI models. However, many existing watermarking methods, particularly content-agnostic approaches that embed fixed patterns regardless of image content, are vulnerable to steganalysis attacks that can extract and remove the watermark with minimal perceptual distortion. In this work, we categorise watermarking algorithms into content-adaptive and content-agnostic ones, and demonstrate how averaging a collection of watermarked images could reveal the underlying watermark pattern. We then leverage this extracted pattern for effective watermark removal under both greybox and blackbox settings, even when the collection of images contains multiple watermark patterns. For some algorithms like Tree-Ring watermarks, the extracted pattern can also forge convincing watermarks on clean images. Our quantitative and qualitative evaluations across twelve watermarking methods highlight the threat posed by steganalysis to content-agnostic watermarks and the importance of designing watermarking techniques resilient to such analytical attacks. We propose security guidelines calling for using content-adaptive watermarking strategies and performing security evaluation against steganalysis. We also suggest multi-key assignments as potential mitigations against steganalysis vulnerabilities. Github page: \url{https://github.com/showlab/watermark-steganalysis}.

Language models trained on diverse datasets unlock generalization by in-context learning. Reinforcement Learning (RL) policies can achieve a similar effect by meta-learning within the memory of a sequence model. However, meta-RL research primarily focuses on adapting to minor variations of a single task. It is difficult to scale towards more general behavior without confronting challenges in multi-task optimization, and few solutions are compatible with meta-RL's goal of learning from large training sets of unlabeled tasks. To address this challenge, we revisit the idea that multi-task RL is bottlenecked by imbalanced training losses created by uneven return scales across different tasks. We build upon recent advancements in Transformer-based (in-context) meta-RL and evaluate a simple yet scalable solution where both an agent's actor and critic objectives are converted to classification terms that decouple optimization from the current scale of returns. Large-scale comparisons in Meta-World ML45, Multi-Game Procgen, Multi-Task POPGym, Multi-Game Atari, and BabyAI find that this design unlocks significant progress in online multi-task adaptation and memory problems without explicit task labels.
tl;dr: This paper propose a causal discovery method that works well in both linear and nonlinear.

Identifying causal relations from purely observational data typically requires additional assumptions on relations and/or noise. Most current methods restrict their analysis to datasets that are assumed to have pure linear or nonlinear relations, which is often not reflective of real-world datasets that contain a combination of both. This paper presents CaPS, an ordering-based causal discovery algorithm that effectively handles linear and nonlinear relations. CaPS introduces a novel identification criterion for topological ordering and incorporates the concept of "parent score" during the post-processing optimization stage. These scores quantify the strength of the average causal effect, helping to accelerate the pruning process and correct inaccurate predictions in the pruning step. Experimental results demonstrate that our proposed solutions outperform state-of-the-art baselines on synthetic data with varying ratios of linear and nonlinear relations. The results obtained from real-world data also support the competitiveness of CaPS. Code and datasets are available at https://github.com/E2real/CaPS.

Safe reinforcement learning (RL) is crucial for deploying RL agents in real-world applications, as it aims to maximize long-term rewards while satisfying safety constraints. However, safe RL often suffers from sample inefficiency, requiring extensive interactions with the environment to learn a safe policy. We propose Efficient Safe Policy Optimization (ESPO), a novel approach that enhances the efficiency of safe RL through sample manipulation. ESPO employs an optimization framework with three modes: maximizing rewards, minimizing costs, and balancing the trade-off between the two. By dynamically adjusting the sampling process based on the observed conflict between reward and safety gradients, ESPO theoretically guarantees convergence, optimization stability, and improved sample complexity bounds. Experiments on the Safety-MuJoCo and Omnisafe benchmarks demonstrate that ESPO significantly outperforms existing primal-based and primal-dual-based baselines in terms of reward maximization and constraint satisfaction. Moreover, ESPO achieves substantial gains in sample efficiency, requiring 25--29\% fewer samples than baselines, and reduces training time by 21--38\%.
tl;dr: We propose MVInpainter, re-formulating the 3D editing as a consistent multi-view 2D inpainting task to enable generating vivid multi-view foreground objects seamlessly integrated with background surroundings.

Novel View Synthesis (NVS) and 3D generation have recently achieved prominent improvements. However, these works mainly focus on confined categories or synthetic 3D assets, which are discouraged from generalizing to challenging in-the-wild scenes and fail to be employed with 2D synthesis directly. Moreover, these methods heavily depended on camera poses, limiting their real-world applications.
To overcome these issues, we propose MVInpainter, re-formulating the 3D editing as a multi-view 2D inpainting task. Specifically, MVInpainter partially inpaints multi-view images with the reference guidance rather than intractably generating an entirely novel view from scratch, which largely simplifies the difficulty of in-the-wild NVS and leverages unmasked clues instead of explicit pose conditions. To ensure cross-view consistency, MVInpainter is enhanced by video priors from motion components and appearance guidance from concatenated reference key\&value attention. Furthermore, MVInpainter incorporates slot attention to aggregate high-level optical flow features from unmasked regions to control the camera movement with pose-free training and inference. Sufficient scene-level experiments on both object-centric and forward-facing datasets verify the effectiveness of MVInpainter, including diverse tasks, such as multi-view object removal, synthesis, insertion, and replacement. The project page is https://ewrfcas.github.io/MVInpainter/.

Expanding on recent work on scheduling with predicted job sizes, we consider the effect of the cost of predictions in queueing systems, removing the assumption in prior research that predictions are external to the system’s resources and/or cost-free. Additionally, we introduce a novel approach to utilizing predictions, SkipPredict, designed to address their inherent cost. Rather than uniformly applying predictions to all jobs, we propose a tailored approach that categorizes jobs to improve the effectiveness of prediction on performance. To achieve this, we employ one-bit “cheap predictions” to classify jobs as either short or long. SkipPredict prioritizes predicted short jobs over long jobs, and for the long jobs, SkipPredict applies a second round of more detailed “expensive predictions” to approximate Shortest Remaining Processing Time for these jobs. Importantly, our analyses take into account the cost of prediction. We derive closed-form formulas that calculate the mean response time of jobs with size predictions accounting for the prediction cost. We examine the effect of this cost for two distinct models in real-world and synthetic datasets. In the external cost model, predictions are generated by external method without impacting job service times but incur a cost. In the server time cost model, predictions themselves require server processing time and are scheduled on the same server as the jobs.

Processing multidomain data defined on multiple graphs holds significant potential in various practical applications in computer science. However, current methods are mostly limited to discrete graph filtering operations. Tensorial partial differential equations on graphs (TPDEGs) provide a principled framework for modeling structured data across multiple interacting graphs, addressing the limitations of the existing discrete methodologies. In this paper, we introduce Continuous Product Graph Neural Networks (CITRUS) that emerge as a natural solution to the TPDEG. CITRUS leverages the separability of continuous heat kernels from Cartesian graph products to efficiently implement graph spectral decomposition. We conduct thorough theoretical analyses of the stability and over-smoothing properties of CITRUS in response to domain-specific graph perturbations and graph spectra effects on the performance. We evaluate CITRUS on well-known traffic and weather spatiotemporal forecasting datasets, demonstrating superior performance over existing approaches. The implementation codes are available at https://github.com/ArefEinizade2/CITRUS.
tl;dr: We study the challenges that arise when learning reward functions with human feedback from partial observations

Past analyses of reinforcement learning from human feedback (RLHF) assume that the human evaluators fully observe the environment. What happens when human feedback is based only on partial observations? We formally define two failure cases: deceptive inflation and overjustification. Modeling the human as Boltzmann-rational w.r.t. a belief over trajectories, we prove conditions under which RLHF is guaranteed to result in policies that deceptively inflate their performance, overjustify their behavior to make an impression, or both. Under the new assumption that the human's partial observability is known and accounted for, we then analyze how much information the feedback process provides about the return function. We show that sometimes, the human's feedback determines the return function uniquely up to an additive constant, but in other realistic cases, there is irreducible ambiguity. We propose exploratory research directions to help tackle these challenges and experimentally validate both the theoretical concerns and potential mitigations, and caution against blindly applying RLHF in partially observable settings.
3039. Global Lyapunov functions: a long-standing open problem in mathematics, with symbolic transformers
tl;dr: Transformers can be trained from synthetic data to find Lyapunov functions, a long-standing open problem in mathematics

Despite their spectacular progress, language models still struggle on complex reasoning tasks, such as advanced mathematics.
We consider a long-standing open problem in mathematics: discovering a Lyapunov function that ensures the global stability of a dynamical system. This problem has no known general solution, and algorithmic solvers only exist for some small polynomial systems.
We propose a new method for generating synthetic training samples from random solutions, and show that sequence-to-sequence transformers trained on such datasets perform better than algorithmic solvers and humans on polynomial systems, and can discover new Lyapunov functions for non-polynomial systems.
tl;dr: We introduce a novel method to learn from two-parameter persistent homology using graph neural networks.

We introduce graphcodes, a novel multi-scale summary of the topological properties of a dataset that is based on the well-established theory of persistent homology. Graphcodes handle datasets that are filtered along two real-valued scale parameters. Such multi-parameter topological summaries are usually based on complicated theoretical foundations and difficult to compute; in contrast, graphcodes yield an informative and interpretable summary and can be computed as efficient as one-parameter summaries. Moreover, a graphcode is simply an embedded graph and can therefore be readily integrated in machine learning pipelines using graph neural networks. We describe such a pipeline and demonstrate that graphcodes achieve better classification accuracy than state-of-the-art approaches on various datasets.

Bayesian Optimization (BO) has proven to be very successful at optimizing a static, noisy, costly-to-evaluate black-box function $f : \mathcal{S} \to \mathbb{R}$. However, optimizing a black-box which is also a function of time (*i.e.*, a *dynamic* function) $f : \mathcal{S} \times \mathcal{T} \to \mathbb{R}$ remains a challenge, since a dynamic Bayesian Optimization (DBO) algorithm has to keep track of the optimum over time. This changes the nature of the optimization problem in at least three aspects: (i) querying an arbitrary point in $\mathcal{S} \times \mathcal{T}$ is impossible, (ii) past observations become less and less relevant for keeping track of the optimum as time goes by and (iii) the DBO algorithm must have a high sampling frequency so it can collect enough relevant observations to keep track of the optimum through time. In this paper, we design a Wasserstein distance-based criterion able to quantify the relevancy of an observation with respect to future predictions. Then, we leverage this criterion to build W-DBO, a DBO algorithm able to remove irrelevant observations from its dataset on the fly, thus maintaining simultaneously a good predictive performance and a high sampling frequency, even in continuous-time optimization tasks with unknown horizon. Numerical experiments establish the superiority of W-DBO, which outperforms state-of-the-art methods by a comfortable margin.

Black-box optimisation is one of the important areas in optimisation. The original No Free Lunch (NFL) theorems highlight the limitations of traditional black-box optimisation and learning algorithms, serving as a theoretical foundation for traditional optimisation. No Free Lunch Analysis in adversarial (also called maximin) optimisation is a long-standing problem [45 , 46]. This paper first rigorously proves a (NFL) Theorem for general black-box adversarial optimisation when considering Pure Strategy Nash Equilibrium (NE) as the solution concept. We emphasise the solution concept (i.e. define the optimality in adversarial optimisation) as the key in our NFL theorem. In particular, if Nash Equilibrium is considered as the solution concept and the cost of the algorithm is measured in terms of the number of columns and rows queried in the payoff matrix, then the average performance of all black-box adversarial optimisation algorithms is the same. Moreover, we first introduce black-box complexity to analyse the black-box adversarial optimisation algorithm. We employ Yao’s Principle and our new NFL Theorem to provide general lower bounds for the query complexity of finding a Nash Equilibrium in adversarial optimisation. Finally, we illustrate the practical ramifications of our results on simple two-player zero-sum games. More specifically, no black-box optimisation algorithm for finding the unique Nash equilibrium in two-player zero-sum games can exceed logarithmic complexity relative to search space size. Meanwhile, no black-box algorithm can solve any bimatrix game with unique NE with fewer than a linear number of queries in the size of the payoff matrix.
tl;dr: Compress the weight delta between a base LLM and fine-tuned LLM to 1-bit.

Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given the higher computational demand of pre-training, it is intuitive to assume that fine-tuning adds less new information to the model, and is thus more compressible. We explore this assumption by decomposing the weights of fine-tuned models into their pre-trained components and an additional delta. We introduce a simple method, BitDelta, which successfully quantizes this delta down to 1 bit without compromising performance. This interesting finding not only highlights the potential redundancy of information added during fine-tuning, but also has significant implications for the multi-tenant serving and multi-tenant storage of fine-tuned models. By enabling the use of a single high-precision base model accompanied by multiple 1-bit deltas, BitDelta dramatically reduces GPU memory requirements by more than 10x, thus reducing per-user generation latency by more than 10x in multi-tenant settings. We validate BitDelta through experiments across Llama-2, Mistral and MPT model families, and on models up to 70B parameters, showcasing minimal performance degradation in all tested settings.

Interactive-Grounded Learning (IGL) [Xie et al., 2021] is a powerful framework in which a learner aims at maximizing unobservable rewards through interacting with an environment and observing reward-dependent feedback on the taken actions.
To deal with personalized rewards that are ubiquitous in applications such as recommendation systems, Maghakian et al. [2022] study a version of IGL with context-dependent feedback, but their algorithm does not come with theoretical guarantees. In this work, we consider the same problem and provide the first provably efficient algorithms with sublinear regret under realizability. Our analysis reveals that the step-function estimator of prior work can deviate uncontrollably due to finite-sample effects. Our solution is a novel Lipschitz reward estimator which underestimates the true reward and enjoys favorable generalization performances. Building on this estimator, we propose two algorithms, one based on explore-then-exploit and the other based on inverse-gap weighting. We apply IGL to learning from image feedback and learning from text feedback, which are reward-free settings that arise in practice. Experimental results showcase the importance of using our Lipschitz reward estimator and the overall effectiveness of our algorithms.
tl;dr: We propose and study a learning algorithm that encourages training losses to concentrate around a pre-fixed threshold.
As a heuristic for improving test accuracy in classification, the "flooding" method proposed by Ishida et al. (2020) sets a threshold for the average surrogate loss at training time; above the threshold, gradient descent is run as usual, but below the threshold, a switch to gradient *ascent* is made. While setting the threshold is non-trivial and is usually done with validation data, this simple technique has proved remarkably effective in terms of accuracy. On the other hand, what if we are also interested in other metrics such as model complexity or average surrogate loss at test time? As an attempt to achieve better overall performance with less fine-tuning, we propose a softened, pointwise mechanism called SoftAD (soft ascent-descent) that downweights points on the borderline, limits the effects of outliers, and retains the ascent-descent effect of flooding, with no additional computational overhead. We contrast formal stationarity guarantees with those for flooding, and empirically demonstrate how SoftAD can realize classification accuracy competitive with flooding (and the more expensive alternative SAM) while enjoying a much smaller loss generalization gap and model norm.

We consider learning a sparse model from linear measurements taken by a network of agents. Different from existing decentralized methods designed based on the LASSO regression with explicit $\ell_1$ norm regularization, we exploit the implicit regularization of decentralized optimization method applied to an over-parameterized nonconvex least squares formulation without penalization. Our first result shows that despite nonconvexity, if the network connectivity is good, the well-known decentralized gradient descent algorithm (DGD) with small initialization and early stopping can compute the statistically optimal solution. Sufficient conditions on the initialization scale, choice of step size, network connectivity, and stopping time are further provided to achieve convergence. Our result recovers the convergence rate of gradient descent in the centralized setting, showing its tightness.
Based on the analysis of DGD, we further propose a communication-efficient version, termed T-DGD, by truncating the iterates before transmission. In the high signal-to-noise ratio (SNR) regime, we show that T-DGD achieves comparable statistical accuracy to DGD, while the communication cost is logarithmic in the number of parameters. Numerical results are provided to validate the effectiveness of DGD and T-DGD for sparse learning through implicit regularization.
tl;dr: Combining empirical and worst-case risk minimization enhances the robustness of fine-tuned CLIP models.

Fine-tuning foundation models often compromises their robustness to distribution shifts. To remedy this, most robust fine-tuning methods aim to preserve the pre-trained features. However, not all pre-trained features are robust and those methods are largely indifferent to which ones to preserve. We propose dual risk minimization (DRM), which combines empirical risk minimization with worst-case risk minimization, to better preserve the core features of downstream tasks. In particular, we utilize core-feature descriptions generated by LLMs to induce core-based zero-shot predictions which then serve as proxies to estimate the worst-case risk. DRM balances two crucial aspects of model robustness: expected performance and worst-case performance, establishing a new state of the art on various real-world benchmarks. DRM significantly improves the out-of-distribution performance of CLIP ViT-L/14@336 on ImageNet (75.9$\to$77.1), WILDS-iWildCam (47.1$\to$51.8), and WILDS-FMoW (50.7$\to$53.1); opening up new avenues for robust fine-tuning. Our code is available at https://github.com/vaynexie/DRM.

The recent progress in text-to-image models pretrained on large-scale datasets has enabled us to generate various images as long as we provide a text prompt describing what we want. Nevertheless, the availability of these models is still limited when we expect to generate images that fall into a specific domain either hard to describe or just unseen to the models. In this work, we propose DomainGallery, a few-shot domain-driven image generation method which aims at finetuning pretrained Stable Diffusion on few-shot target datasets in an attribute-centric manner. Specifically, DomainGallery features prior attribute erasure, attribute disentanglement, regularization and enhancement. These techniques are tailored to few-shot domain-driven generation in order to solve key issues that previous works have failed to settle. Extensive experiments are given to validate the superior performance of DomainGallery on a variety of domain-driven generation scenarios.
tl;dr: We fine-tune CLIP for open-vocabulary semantic segmentation only from unlabeled masks without any semantic information, generated from SAM and DINO.

Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which require understanding where the objects are located. In this work, we propose a novel method, MCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. MCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation.
tl;dr: Seegnificant: a framework and architecture for multi-subject neural decoding based on sEEG

Deep learning based neural decoding from stereotactic electroencephalography (sEEG) would likely benefit from scaling up both dataset and model size. To achieve this, combining data across multiple subjects is crucial. However, in sEEG cohorts, each subject has a variable number of electrodes placed at distinct locations in their brain, solely based on clinical needs. Such heterogeneity in electrode number/placement poses a significant challenge for data integration, since there is no clear correspondence of the neural activity recorded at distinct sites between individuals. Here we introduce seegnificant: a training framework and architecture that can be used to decode behavior across subjects using sEEG data. We tokenize the neural activity within electrodes using convolutions and extract long-term temporal dependencies between tokens using self-attention in the time dimension. The 3D location of each electrode is then mixed with the tokens, followed by another self-attention in the electrode dimension to extract effective spatiotemporal neural representations. Subject-specific heads are then used for downstream decoding tasks. Using this approach, we construct a multi-subject model trained on the combined data from 21 subjects performing a behavioral task. We demonstrate that our model is able to decode the trial-wise response time of the subjects during the behavioral task solely from neural data. We also show that the neural representations learned by pretraining our model across individuals can be transferred in a few-shot manner to new subjects. This work introduces a scalable approach towards sEEG data integration for multi-subject model training, paving the way for cross-subject generalization for sEEG decoding.

We study the evaluation of a policy under best- and worst-case perturbations to a Markov decision process (MDP), using transition observations from the original MDP, whether they are generated under the same or a different policy. This is an important problem when there is the possibility of a shift between historical and future environments, \emph{e.g.} due to unmeasured confounding, distributional shift, or an adversarial environment. We propose a perturbation model that allows changes in the transition kernel densities up to a given multiplicative factor or its reciprocal, extending the classic marginal sensitivity model (MSM) for single time-step decision-making to infinite-horizon RL. We characterize the sharp bounds on policy value under this model -- \emph{i.e.}, the tightest possible bounds based on transition observations from the original MDP -- and we study the estimation of these bounds from such transition observations. We develop an estimator with several important guarantees: it is semiparametrically efficient, and remains so even when certain necessary nuisance functions, such as worst-case Q-functions, are estimated at slow, nonparametric rates. Our estimator is also asymptotically normal, enabling straightforward statistical inference using Wald confidence intervals. Moreover, when certain nuisances are estimated inconsistently, the estimator still provides valid, albeit possibly not sharp, bounds on the policy value. We validate these properties in numerical simulations. The combination of accounting for environment shifts from train to test (robustness), being insensitive to nuisance-function estimation (orthogonality), and addressing the challenge of learning from finite samples (inference) together leads to credible and reliable policy evaluation.

In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to {in-contextly} predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
tl;dr: a deep dive into how changing cost functions impacts transport, and a new algorithm to learn the parameters of a new family of costs

Given a source and a target probability measure, the Monge problem studies efficient ways to map the former onto the latter.
This efficiency is quantified by defining a *cost* function between source and target data.
Such a cost is often set by default in the machine learning literature to the squared-Euclidean distance, $\ell^2\_2(\mathbf{x},\mathbf{y}):=\tfrac12\|\mathbf{x}-\mathbf{y}\|\_2^2$.
The benefits of using *elastic* costs, defined using a regularizer $\tau$ as $c(\mathbf{x},\mathbf{y}):=\ell^2_2(\mathbf{x},\mathbf{y})+\tau(\mathbf{x}-\mathbf{y})$, was recently highlighted in (Cuturi et al. 2023). Such costs shape the *displacements* of Monge maps $T$, namely the difference between a source point and its image $T(\mathbf{x})-\mathbf{x}$, by giving them a structure that matches that of the proximal operator of $\tau$.
In this work, we make two important contributions to the study of elastic costs:*(i)* For any elastic cost, we propose a numerical method to compute Monge maps that are provably optimal. This provides a much-needed routine to create synthetic problems where the ground-truth OT map is known, by analogy to the Brenier theorem, which states that the gradient of any convex potential is always a valid Monge map for the $\ell_2^2$ cost; *(ii)* We propose a loss to *learn* the parameter $\theta$ of a parameterized regularizer $\tau_\theta$, and apply it in the case where $\tau_{A}({\bf z}):=\|A^\perp {\bf z}\|^2_2$. This regularizer promotes displacements that lie on a low-dimensional subspace of $\mathbb{R}^d$, spanned by the $p$ rows of $A\in\mathbb{R}^{p\times d}$. We illustrate the soundness of our procedure on synthetic data, generated using our first contribution, in which we show near-perfect recovery of $A$'s subspace using only samples. We demonstrate the applicability of this method by showing predictive improvements on single-cell data tasks.
tl;dr: We introduce a principled approach to apply diffusion models trained on images to solve video inverse problems.

Using image models naively for solving inverse video problems often suffers from flickering, texture-sticking, and temporal inconsistency in generated videos. To tackle these problems, in this paper, we view frames as continuous functions in the 2D space, and videos as a sequence of continuous warping transformations between different frames. This perspective allows us to train function space diffusion models only on **images** and utilize them to solve temporally correlated inverse problems. The function space diffusion models need to be equivariant with respect to the underlying spatial transformations. To ensure temporal consistency, we introduce a simple post-hoc test-time guidance towards (self)-equivariant solutions. Our method allows us to deploy state-of-the-art latent diffusion models such as Stable Diffusion XL to solve video inverse problems. We demonstrate the effectiveness of our method for video inpainting and $8\times$ video super-resolution, outperforming existing techniques based on noise transformations. We provide generated video results in the following URL: https://giannisdaras.github.io/warped_diffusion.github.io/.

Graph diffusion, which iteratively propagates real-valued substances among the graph, is used in numerous graph/network-involved applications. However, releasing diffusion vectors may reveal sensitive linking information in the data such as transaction information in financial network data. However, protecting the privacy of graph data is challenging due to its interconnected nature.
This work proposes a novel graph diffusion framework with edge-level different privacy guarantees by using noisy diffusion iterates.
The algorithm injects Laplace noise per diffusion iteration and adopts a degree-based thresholding function to mitigate the high sensitivity induced by low-degree nodes. Our privacy loss analysis is based on Privacy Amplification by Iteration (PABI), which to our best knowledge, is the first effort that analyzes PABI with Laplace noise and provides relevant applications.
We also introduce a novel $\infty$-Wasserstein distance tracking method, which tightens the analysis of privacy leakage and makes PABI more applicable in practice.
We evaluate this framework by applying it to Personalized Pagerank computation for ranking tasks. Experiments on real-world network data demonstrate the superiority of our method under stringent privacy conditions.
3056. ACES: Generating a Diversity of Challenging Programming Puzzles with Autotelic Generative Models
tl;dr: We introduce a new open-ended algorithm to automate the generation of diverse and challenging programming puzzles to evaluate LLM-based problem solvers.

The ability to invent novel and interesting problems is a remarkable feature of human intelligence that drives innovation, art, and science. We propose a method that aims to automate this process by harnessing the power of state-of-the-art generative models to produce a diversity of challenging yet solvable problems, here in the context of Python programming puzzles. Inspired by the intrinsically motivated literature, Autotelic CodE Search (ACES) jointly optimizes for the diversity and difficulty of generated problems. We represent problems in a space of LLM-generated semantic descriptors describing the programming skills required to solve them (e.g. string manipulation, dynamic programming, etc.) and measure their difficulty empirically as a linearly decreasing function of the success rate of \textit{Llama-3-70B}, a state-of-the-art LLM problem solver. ACES iteratively prompts a large language model to generate difficult problems achieving a diversity of target semantic descriptors (goal-directed exploration) using previously generated problems as in-context examples. ACES generates problems that are more diverse and more challenging than problems produced by baseline methods and three times more challenging than problems found in existing Python programming benchmarks on average across 11 state-of-the-art code LLMs.
tl;dr: When learning over symmetry groups, a learned group representation of group elements works well as a feature representation.

Group theory has been used in machine learning to provide a theoretically grounded approach for incorporating known symmetry transformations in tasks from robotics to protein modeling. In these applications, equivariant neural networks use known
symmetry groups with predefined representations to learn over geometric input data. We propose MatrixNet, a neural network architecture that learns matrix representations of group element inputs instead of using predefined representations. MatrixNet achieves higher sample efficiency and generalization over several standard baselines in prediction tasks over the several finite groups and the Artin braid group. We also show that MatrixNet respects group relations allowing generalization to group elements of greater word length than in the training set. Our code is available at https://github.com/lucas-laird/MatrixNet.
tl;dr: We proposed a simple yet effective contrastive learning framework for fashion domain

When learning vision-language models (VLM) for the fashion domain, most existing works design new architectures from vanilla BERT with additional objectives, or perform dense multi-task learning with fashion-specific tasks. Though progress has been made, their architecture or objectives are often intricate and the extendibility is limited.
By contrast, with simple architecture (comprising only two unimodal encoders) and just the contrastive objective, popular pre-trained VL models (e.g., CLIP) achieve superior performance in general domains, which are further easily extended to downstream tasks.
However, inheriting such benefits of CLIP in the fashion domain is non-trivial in the presence of the notable domain gap. Empirically, we find that directly finetuning on fashion data leads CLIP to frequently ignore minor yet important details such as logos and composition, which are critical in fashion tasks such as retrieval and captioning.
In this work, to maintain CLIP's simple architecture and objective while explicitly attending to fashion details, we propose $E^2$: Easy Regional Contrastive Learning of Expressive Fashion Representations.
$E^2$ introduces only a few selection tokens and fusion blocks (just 1.9\% additional parameters in total) with only contrastive losses. Despite lightweight, in our primary focus, cross-modal retrieval, $E^2$ notably outperforms existing fashion VLMs with various fashion-specific objectives.
Moreover, thanks to CLIP's widespread use in downstream tasks in general domains (e.g., zero-shot composed image retrieval and image captioning), our model can easily extend these models from general domain to the fashion domain with notable improvement.
To conduct a comprehensive evaluation, we further collect data from Amazon Reviews to build a new dataset for cross-modal retrieval in the fashion domain.
tl;dr: We present a novel adversarial attack MALT (Mesoscopic Almost Linear Targeting), which wins over the current SOTA AutoAttack on several datasets and robust models, while being five times faster.

Current adversarial attacks for multi-class classifiers choose potential adversarial target classes naively based on the classifier's confidence levels. We present a novel adversarial targeting method, \textit{MALT - Mesoscopic Almost Linearity Targeting}, based on local almost linearity assumptions. Our attack wins over the current state of the art AutoAttack on the standard benchmark datasets CIFAR-100 and Imagenet and for different robust models. In particular, our attack uses a \emph{five times faster} attack strategy than AutoAttack's while successfully matching AutoAttack's successes and attacking additional samples that were previously out of reach. We additionally prove formally and demonstrate empirically that our targeting method, although inspired by linear predictors, also applies to non-linear models.
tl;dr: Memory efficient fine-tuning by compressing the saved intermediate activations. Complimentary to peft and generalises to pre-training.

Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive. In this paper, we identify and characterise the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance. This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass. These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark. Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
tl;dr: In this paper, we unveil a new vulnerability: the privacy backdoor attack to amplify the privacy leakage that arises when fine-tuning a model.

It is commonplace to produce application-specific models by fine-tuning large pre-trained models using a small bespoke dataset. The widespread availability of foundation model checkpoints on the web poses considerable risks, including the vulnerability to backdoor attacks. In this paper, we unveil a new vulnerability: the privacy backdoor attack. This black-box privacy attack aims to amplify the privacy leakage that arises when fine-tuning a model: when a victim fine-tunes a backdoored model, their training data will be leaked at a significantly higher rate than if they had fine-tuned a typical model. We conduct extensive experiments on various datasets and models, including both vision-language models (CLIP) and large language models, demonstrating the broad applicability and effectiveness of such an attack. Additionally, we carry out multiple ablation studies with different fine-tuning methods and inference strategies to thoroughly analyze this new threat. Our findings highlight a critical privacy concern within the machine learning community and call for a re-evaluation of safety protocols in the use of open-source pre-trained models.

Discrete diffusion models have emerged as powerful tools for high-quality data generation. Despite their success in discrete spaces, such as text generation tasks, the acceleration of discrete diffusion models remains under-explored. In this paper, we propose discrete non-Markov diffusion models (DNDM), which naturally induce the predetermined transition time set. This enables a training-free sampling algorithm that significantly reduces the number of function evaluations (i.e., calls to the neural network), making the sampling process much faster. Furthermore, we study the transition from finite to infinite step sampling, offering new insights into bridging the gap between discrete and continuous-time processes for discrete diffusion models. Extensive experiments on natural language generation and machine translation tasks demonstrate the superior performance of our method in terms of both generation speed and sample quality compared to existing methods for discrete diffusion models. Codes are available at \url{https://github.com/uclaml/DNDM}.
tl;dr: This paper propose a training-free framework to alleviate the hallucination of existing diffusion-based restoration models producing unfaithful contents or textures.

Recent advances in diffusion-based Large Restoration Models (LRMs) have significantly improved photo-realistic image restoration by leveraging the internal knowledge embedded within model weights. However, existing LRMs often suffer from the hallucination dilemma, i.e., producing incorrect contents or textures when dealing with severe degradations, due to their heavy reliance on limited internal knowledge. In this paper, we propose an orthogonal solution called the Retrieval-augmented Framework for Image Restoration (ReFIR), which incorporates retrieved images as external knowledge to extend the knowledge boundary of existing LRMs in generating details faithful to the original scene. Specifically, we first introduce the nearest neighbor lookup to retrieve content-relevant high-quality images as reference, after which we propose the cross-image injection to modify existing LRMs to utilize high-quality textures from retrieved images. Thanks to the additional external knowledge, our ReFIR can well handle the hallucination challenge and facilitate faithfully results. Extensive experiments demonstrate that ReFIR can achieve not only high-fidelity but also realistic restoration results. Importantly, our ReFIR requires no training and is adaptable to various LRMs.

This paper studies the problem of \emph{entropy identity testing}: given sample access to a distribution $p$ and a fully described distribution $q$ (both are discrete distributions over the support of size $k$), and the promise that either $p = q$ or $ | H(p) - H(q) | \geqslant \varepsilon$, where $H(\cdot)$ denotes the Shannon entropy, a tester needs to distinguish between the two cases with high probability. We establish a near-optimal sample complexity bound of $\tilde{\Theta}(\sqrt{k}/\varepsilon + {1}/{\varepsilon^2}$) for this problem, and show how to apply it to the problem of identity testing for in-degree-$d$ $n$-dimensional Bayesian networks, obtaining an upper bound of $\tilde{O}\left( {2^{d / 2} n}/{\varepsilon^2} + {n^2}/{\varepsilon^4} \right)$. This improves on the sample complexity bound of $\tilde{O}(2^{d/2}n^2/\varepsilon^4)$ from Canonne, Diakonikolas, Kane, and Stewart (2020), which required an additional assumption on the structure of the (unknown) Bayesian network.
tl;dr: We provide nearly matching lower and upper bounds for online classification with noisy labels across a wide range of hypothesis classes and noise mechanisms, using the Hellinger gap of the induced noisy label distributions.

We study online classification with general hypothesis classes where the true labels are determined by some function within the class, but are corrupted by *unknown* stochastic noise, and the features are generated adversarially. Predictions are made using observed *noisy* labels and noiseless features, while the performance is measured via minimax risk when comparing against *true* labels. The noisy mechanism is modeled via a general noisy kernel that specifies, for any individual data point, a set of distributions from which the actual noisy label distribution is chosen. We show that minimax risk is *tightly* characterized (up to a logarithmic factor of the hypothesis class size) by the *Hellinger gap* of the noisy label distributions induced by the kernel, *independent* of other properties such as the means and variances of the noise. Our main technique is based on a novel reduction to an online comparison scheme of two hypotheses, along with a new *conditional* version of Le Cam-Birgé testing suitable for online settings. Our work provides the first comprehensive characterization of noisy online classification with guarantees that apply to the *ground truth* while addressing *general* noisy observations.
tl;dr: We propose new algorithms for recovering the Pareto Front of the clustering problem with fairness considerations.

Fairness in clustering has been considered extensively in the past; however, the trade-off between the two objectives --- e.g., can we sacrifice just a little in the quality of the clustering to significantly increase fairness, or vice-versa? --- has rarely been addressed. We introduce novel algorithms for tracing the complete trade-off curve, or Pareto front, between quality and fairness in clustering problems; that is, computing all clusterings that are not dominated in both objectives by other clusterings. Unlike previous work that deals with specific objectives for quality and fairness, we deal with all objectives for fairness and quality in two general classes encompassing most of the special cases addressed in previous work. Our algorithm must take exponential time in the worst case as the Parero front itself can be exponential. Even when the Pareto front is polynomial, our algorithm may take exponential time, and we prove that this is inevitable unless P = NP. However, we also present a new polynomial-time algorithm for computing the entire Pareto front when the cluster centers are fixed, and for perhaps the most natural fairness objective: minimizing the sum, over all clusters, of the imbalance between the two groups in each cluster.
tl;dr: This study formulates risk-sensitive control as variational inference using Rényi divergence. Based on the proposed unifying framework, we reveal several equivalence results for control problems and derive risk-sensitive RL algorithms.

This paper introduces the risk-sensitive control as inference (RCaI) that extends CaI by using Rényi divergence variational inference. RCaI is shown to be equivalent to log-probability regularized risk-sensitive control, which is an extension of the maximum entropy (MaxEnt) control. We also prove that the risk-sensitive optimal policy can be obtained by solving a soft Bellman equation, which reveals several equivalences between RCaI, MaxEnt control, the optimal posterior for CaI, and linearly-solvable control. Moreover, based on RCaI, we derive the risk-sensitive reinforcement learning (RL) methods: the policy gradient and the soft actor-critic. As the risk-sensitivity parameter vanishes, we recover the risk-neutral CaI and RL, which means that RCaI is a unifying framework. Furthermore, we give another risk-sensitive generalization of the MaxEnt control using Rényi entropy regularization. We show that in both of our extensions, the optimal policies have the same structure even though the derivations are very different.
tl;dr: In this work, we study hallucination detection in Large Language Models by analyzing their internal hidden states, attention maps and output prediction probabilities.

While Large Language Models (LLMs) have become immensely popular due to their outstanding performance on a broad range of tasks, these models are prone to producing hallucinations— outputs that are fallacious or fabricated yet often appear plausible or tenable at a glance. In this paper, we conduct a comprehensive investigation into the nature of hallucinations within LLMs and furthermore explore effective techniques for detecting such inaccuracies in various real-world settings. Prior approaches to detect hallucinations in LLM outputs, such as consistency checks or retrieval-based methods, typically assume access to multiple model responses or large databases. These techniques, however, tend to be computationally expensive in practice, thereby limiting their applicability to real-time analysis. In contrast, in this work, we seek to identify hallucinations within a single response in both white-box and black-box settings by analyzing the internal hidden states, attention maps, and output prediction probabilities of an auxiliary LLM. In addition, we also study hallucination detection in scenarios where ground-truth references are also available, such as in the setting of Retrieval-Augmented Generation (RAG). We demonstrate that the proposed detection methods are extremely compute-efficient, with speedups of up to 45x and 450x over other baselines, while achieving significant improvements in detection performance over diverse datasets.

The field of graph learning has been substantially advanced by the development of deep learning models, in particular graph neural networks. However, one salient yet largely under-explored challenge is detecting Out-of-Distribution (OOD) nodes on graphs. Prevailing OOD detection techniques developed in other domains like computer vision, do not cater to the interconnected nature of graphs. This work aims to fill this gap by exploring the potential of a simple yet effective method -- OOD score propagation, which propagates OOD scores among neighboring nodes along the graph structure. This post hoc solution can be easily integrated with existing OOD scoring functions, showcasing its excellent flexibility and effectiveness in most scenarios. However, the conditions under which score propagation proves beneficial remain not fully elucidated. Our study meticulously derives these conditions and, inspired by this discovery, introduces an innovative edge augmentation strategy with theoretical guarantee. Empirical evaluations affirm the superiority of our proposed method, outperforming strong OOD detection baselines in various scenarios and settings.
3070. Accurate and Steady Inertial Pose Estimation through Sequence Structure Learning and Modulation

Transformer models excel at capturing long-range dependencies in sequential data, but lack explicit mechanisms to leverage structural patterns inherent in fixed-length input sequences.
In this paper, we propose a novel sequence structure learning and modulation approach that endows Transformers with the ability to model and utilize such fixed-sequence structural properties for improved performance on inertial pose estimation tasks.
Specifically, our method introduces a Sequence Structure Module (SSM) that utilizes structural information of fixed-length inertial sensor readings to adjust the input features of transformers.
Such structural information can either be acquired by learning or specified based on users' prior knowledge.
To justify the prospect of our approach, we show that i) injecting spatial structural information of IMUs/joints learned from data improves accuracy, while ii) injecting temporal structural information based on smooth priors reduces jitter (i.e., improves steadiness), in a spatial-temporal transformer solution for inertial pose estimation.
Extensive experiments across multiple benchmark datasets demonstrate the superiority of our approach against state-of-the-art methods and has the potential to advance the design of the transformer architecture for fixed-length sequences.

Diffusion models excel in solving imaging inverse problems due to their ability to model complex image priors. However, their reliance on large, clean datasets for training limits their practical use where clean data is scarce. In this paper, we propose EMDiffusion, an expectation-maximization (EM) approach to train diffusion models from corrupted observations. Our method alternates between reconstructing clean images from corrupted data using a known diffusion model (E-step) and refining diffusion model weights based on these reconstructions (M-step). This iterative process leads the learned diffusion model to gradually converge to a local optimum, that is, to approximate the true clean data distribution. We validate our method through extensive experiments on diverse computational imaging tasks, including random inpainting, denoising, and deblurring, achieving new state-of-the-art performance.
tl;dr: We propose a new class of structured unrestricted-rank matrices, including low displacement rank matrices, for the parameter efficient fine-tuning of Transformers.

Recent efforts to scale Transformer models have demonstrated rapid progress across a wide range of tasks (Wei at. al 2022). However, fine-tuning these models for downstream tasks is quite expensive due to their large parameter counts. Parameter-efficient fine-tuning (PEFT) approaches have emerged as a viable alternative, allowing us to fine-tune models by updating only a small number of parameters.
In this work, we propose a general framework for parameter efficient fine-tuning (PEFT), based on *structured unrestricted-rank matrices* (SURM) which can serve as a drop-in replacement for popular approaches such as Adapters and LoRA. Unlike other methods like LoRA, SURMs give us more flexibility in finding the right balance between compactness and expressiveness. This is achieved by using *low displacement rank matrices* (LDRMs), which hasn't been used in this context before. SURMs remain competitive with baselines, often providing significant quality improvements while using a smaller parameter budget. SURMs achieve: **5**-**7**% accuracy gains on various image classification tasks while replacing low-rank matrices in LoRA and: up to **12x** reduction of the number of parameters in adapters (with virtually no loss in quality) on the GLUE benchmark.

Optimization of convex functions under stochastic zeroth-order feedback has been a major and challenging question in online learning. In this work, we consider the problem of optimizing second-order smooth and strongly convex functions where the algorithm is only accessible to noisy evaluations of the objective function it queries.
We provide the first tight characterization for the rate of the minimax simple regret by developing matching upper and lower bounds.
We propose an algorithm that features a combination of a bootstrapping stage and a mirror-descent stage.
Our main technical innovation consists of a sharp characterization for the spherical-sampling gradient estimator under higher-order smoothness conditions, which allows the algorithm to optimally balance the bias-variance tradeoff,
and a new iterative method for the bootstrapping stage, which maintains the performance for unbounded Hessian.

We propose estimating Gaussian graphical models (GGMs) that are fair with respect to sensitive nodal attributes. Many real-world models exhibit unfair discriminatory behavior due to biases in data. Such discrimination is known to be exacerbated when data is equipped with pairwise relationships encoded in a graph. Additionally, the effect of biased data on graphical models is largely underexplored. We thus introduce fairness for graphical models in the form of two bias metrics to promote balance in statistical similarities across nodal groups with different sensitive attributes. Leveraging these metrics, we present Fair GLASSO, a regularized graphical lasso approach to obtain sparse Gaussian precision matrices with unbiased statistical dependencies across groups. We also propose an efficient proximal gradient algorithm to obtain the estimates. Theoretically, we express the tradeoff between fair and accurate estimated precision matrices. Critically, this includes demonstrating when accuracy can be preserved in the presence of a fairness regularizer. On top of this, we study the complexity of Fair GLASSO and demonstrate that our algorithm enjoys a fast convergence rate. Our empirical validation includes synthetic and real-world simulations that illustrate the value and effectiveness of our proposed optimization problem and iterative algorithm.

We consider the problem of active learning on graphs for node-level tasks, which has crucial applications in many real-world networks where labeling node responses is expensive. In this paper, we propose an offline active learning method that selects nodes to query by explicitly incorporating information from both the network structure and node covariates. Building on graph signal recovery theories and the random spectral sparsification technique, the proposed method adopts a two-stage biased sampling strategy that takes both informativeness and representativeness into consideration for node querying. Informativeness refers to the complexity of graph signals that are learnable from the responses of queried nodes, while representativeness refers to the capacity of queried nodes to control generalization errors given noisy node-level information. We establish a theoretical relationship between generalization error and the number of nodes selected by the proposed method. Our theoretical results demonstrate the trade-off between Informativeness and representativeness in active learning. Extensive numerical experiments show that the proposed method is competitive with existing graph-based active learning methods, especially when node covariates and responses contain noises. Additionally, the proposed method is applicable to both regression and classification tasks on graphs.

Generalizing across robot embodiments and tasks is crucial for adaptive robotic systems. Modular policy learning approaches adapt to new embodiments but are limited to specific tasks, while few-shot imitation learning (IL) approaches often focus on a single embodiment.
In this paper, we introduce a few-shot behavior cloning framework to simultaneously generalize to unseen embodiments and tasks using a few (e.g., five) reward-free demonstrations. Our framework leverages a joint-level input-output representation to unify the state and action spaces of heterogeneous embodiments and employs a novel structure-motion state encoder that is parameterized to capture both shared knowledge across all embodiments and embodiment-specific knowledge. A matching-based policy network then predicts actions from a few demonstrations, producing an adaptive policy that is robust to over-fitting. Evaluated in the DeepMind Control suite, our framework termed Meta-Controller demonstrates superior few-shot generalization to unseen embodiments and tasks over modular policy learning and few-shot IL approaches.

Out-of-Distribution (OOD) generalization in machine learning is a burgeoning area of study. Its primary goal is to enhance the adaptability and resilience of machine learning models when faced with new, unseen, and potentially adversarial data that significantly diverges from their original training datasets. In this paper, we investigate time series OOD generalization via pre-trained Large Language Models (LLMs). We first propose a novel \textbf{T}ri-level learning framework for \textbf{T}ime \textbf{S}eries \textbf{O}OD generalization, termed TTSO, which considers both sample-level and group-level uncertainties. This formula offers a fresh theoretic perspective for formulating and analyzing OOD generalization problem. In addition, we provide a theoretical analysis to justify this method is well motivated. We then develop a stratified localization algorithm tailored for this tri-level optimization problem, theoretically demonstrating the guaranteed convergence of the proposed algorithm. Our analysis also reveals that the iteration complexity to obtain an $\epsilon$-stationary point is bounded by O($\frac{1}{\epsilon^{2}}$). Extensive experiments on real-world datasets have been conducted to elucidate the effectiveness of the proposed method.

Causal disentanglement aims to learn about latent causal factors behind data, hold- ing the promise to augment existing representation learning methods in terms of interpretability and extrapolation. Recent advances establish identifiability results assuming that interventions on (single) latent factors are available; however, it re- mains debatable whether such assumptions are reasonable due to the inherent nature of intervening on latent variables. Accordingly, we reconsider the fundamentals and ask what can be learned using just observational data.
We provide a precise characterization of latent factors that can be identified in nonlinear causal models with additive Gaussian noise and linear mixing, without any interventions or graphical restrictions. In particular, we show that the causal variables can be identified up to a _layer_-wise transformation and that further disen- tanglement is not possible. We transform these theoretical results into a practical algorithm consisting of solving a quadratic program over the score estimation of the observed data. We provide simulation results to support our theoretical guarantees and demonstrate that our algorithm can derive meaningful causal representations from purely observational data.
tl;dr: We prove the first sparsity-agnostic regret bounds for stochastic linear bandits without assumptions on the action set or on the sparsity structure.

We study stochastic linear bandits where, in each round, the learner receives a set of actions (i.e., feature vectors), from which it chooses an element and obtains a stochastic reward. The expected reward is a fixed but unknown linear function of the chosen action. We study \emph{sparse} regret bounds, that depend on the number $S$ of non-zero coefficients in the linear reward function. Previous works focused on the case where $S$ is known, or the action sets satisfy additional assumptions. In this work, we obtain the first sparse regret bounds that hold when $S$ is unknown and the action sets are adversarially generated. Our techniques combine online to confidence set conversions with a novel randomized model selection approach over a hierarchy of nested confidence sets. When $S$ is known, our analysis recovers state-of-the-art bounds for adversarial action sets. We also show that a variant of our approach, using Exp3 to dynamically select the confidence sets, can be used to improve the empirical performance of stochastic linear bandits while enjoying a regret bound with optimal dependence on the time horizon.

Visual Reinforcement Learning (RL) methods often require extensive amounts of data. As opposed to model-free RL, model-based RL (MBRL) offers a potential solution with efficient data utilization through planning. Additionally, RL lacks generalization capabilities for real-world tasks. Prior work has shown that incorporating pre-trained visual representations (PVRs) enhances sample efficiency and generalization. While PVRs have been extensively studied in the context of model-free RL, their potential in MBRL remains largely unexplored. In this paper, we benchmark a set of PVRs on challenging control tasks in a model-based RL setting. We investigate the data efficiency, generalization capabilities, and the impact of different properties of PVRs on the performance of model-based agents. Our results, perhaps surprisingly, reveal that for MBRL current PVRs are not more sample efficient than learning representations from scratch, and that they do not generalize better to out-of-distribution (OOD) settings. To explain this, we analyze the quality of the trained dynamics model. Furthermore, we show that data diversity and network architecture are the most important contributors to OOD generalization performance.

Despite the remarkable capabilities demonstrated by Graph Neural Networks (GNNs) in graph-related tasks, recent research has revealed the fairness vulnerabilities in GNNs when facing malicious adversarial attacks. However, all existing fairness attacks require manipulating the connectivity between existing nodes, which may be prohibited in reality. To this end, we introduce a Node Injection-based Fairness Attack (NIFA), exploring the vulnerabilities of GNN fairness in such a more realistic setting. In detail, NIFA first designs two insightful principles for node injection operations, namely the uncertainty-maximization principle and homophily-increase principle, and then optimizes injected nodes’ feature matrix to further ensure the effectiveness of fairness attacks. Comprehensive experiments on three real-world datasets consistently demonstrate that NIFA can significantly undermine the fairness of mainstream GNNs, even including fairness-aware GNNs, by injecting merely 1% of nodes. We sincerely hope that our work can stimulate increasing attention from researchers on the vulnerability of GNN fairness, and encourage the development of corresponding defense mechanisms. Our code and data are released at: https://github.com/CGCL-codes/NIFA.
tl;dr: We propose Chain-of-Agents leveraging LLMs collaboration to solve long context tasks and outperform RAG and long context LLMs.

Addressing the challenge of effectively processing long contexts has become a critical issue for Large Language Models (LLMs). Two common strategies have emerged: 1) reducing the input length, such as retrieving relevant chunks by Retrieval-Augmented Generation (RAG), and 2) expanding the context window limit of LLMs. However, both strategies have drawbacks: input reduction has no guarantee of covering the part with needed information, while window extension struggles with focusing on the pertinent information for solving the task. To mitigate these limitations, we propose Chain-of-Agents (CoA), a novel framework that harnesses multi-agent collaboration through natural language to enable information aggregation and context reasoning across various LLMs over long-context tasks. CoA consists of multiple worker agents who sequentially communicate to handle different segmented portions of the text, followed by a manager agent who synthesizes these contributions into a coherent final output. CoA processes the entire input by interleaving reading and reasoning, and it mitigates long context focus issues by assigning each agent a short context. We perform a comprehensive evaluation of CoA on a wide range of long-context tasks in question answering, summarization, and code completion, demonstrating significant improvements by up to 10% over strong baselines of RAG, Full-Context, and multi-agent LLMs.
3083. INDICT: Code Generation with Internal Dialogues of Critiques for Both Security and Helpfulness
tl;dr: We propose to improve code generation by both safety and helpfulness through a collaborative and autonomous system of dual tool-enhanced critics, providing knowledge-grounded critic feedbacks to support the LLM code generator.

Large language models (LLMs) for code are typically trained to align with natural language instructions to closely follow their intentions and requirements. However, in many practical scenarios, it becomes increasingly challenging for these models to navigate the intricate boundary between helpfulness and safety, especially against highly complex yet potentially malicious instructions. In this work, we introduce INDICT: a new framework that empowers LLMs with Internal Dialogues of Critiques for both safety and helpfulness guidance. The internal dialogue is a dual cooperative system between a safety-driven critic and a helpfulness-driven critic. Each critic provides analysis against the given task and corresponding generated response, equipped with external knowledge queried through relevant code snippets and tools like web search and code interpreter. We engage the dual critic system in both code generation stage as well as code execution stage, providing preemptive and post-hoc guidance respectively to LLMs. We evaluated INDICT on 8 diverse tasks across 8 programming languages from 5 benchmarks, using LLMs from 7B to 70B parameters. We observed that our approach can provide an advanced level of critiques of both safety and helpfulness analysis, significantly improving the quality of output codes (+10% absolute improvements in all models).
tl;dr: We present Unsupervised SAM (UnSAM), a segment anything model for interactive and automatic whole-image segmentation which does not require human annotations.

The Segmentation Anything Model (SAM) requires labor-intensive data labeling. We present Unsupervised SAM (UnSAM) for promptable and automatic whole-image segmentation that does not require human annotations. UnSAM utilizes a divide-and-conquer strategy to “discover” the hierarchical structure of visual scenes. We first leverage top-down clustering methods to partition an unlabeled image into instance/semantic level segments. For all pixels within a segment, a bottom-up clustering method is employed to iteratively merge them into larger groups, thereby forming a hierarchical structure. These unsupervised multi-granular masks are then utilized to supervise model training. Evaluated across seven popular datasets, UnSAM achieves competitive results with the supervised counterpart SAM, and surpasses the previous state-of-the-art in unsupervised segmentation by 11% in terms of AR. Moreover, we show that supervised SAM can also benefit from our self-supervised labels. By integrating our unsupervised pseudo masks into SA-1B’s ground-truth masks and training UnSAM with only 1% of SA-1B, a lightly semi-supervised UnSAM can often segment entities overlooked by supervised SAM, exceeding SAM’s AR by over 6.7% and AP by 3.9% on SA-1B.
tl;dr: Propose a Severity-aware Recurrent Modeling, dubbed as Samba, for medical image grading problems on unseen target domains

Disease grading is a crucial task in medical image analysis. Due to the continuous progression of diseases, i.e., the variability within the same level and the similarity between adjacent stages, accurate grading is highly challenging.
Furthermore, in real-world scenarios, models trained on limited source domain datasets should also be capable of handling data from unseen target domains.
Due to the cross-domain variants, the feature distribution between source and unseen target domains can be dramatically different, leading to a substantial decrease in model performance.
To address these challenges in cross-domain disease grading, we propose a Severity-aware Recurrent Modeling (Samba) method in this paper.
As the core objective of most staging tasks is to identify the most severe lesions, which may only occupy a small portion of the image, we propose to encode image patches in a sequential and recurrent manner.
Specifically, a state space model is tailored to store and transport the severity information by hidden states.
Moreover, to mitigate the impact of cross-domain variants, an Expectation-Maximization (EM) based state recalibration mechanism is designed to map the patch embeddings into a more compact space.
We model the feature distributions of different lesions through the Gaussian Mixture Model (GMM) and reconstruct the intermediate features based on learnable severity bases.
Extensive experiments show the proposed Samba outperforms the VMamba baseline by an average accuracy of 23.5\%, 5.6\% and 4.1\% on the cross-domain grading of fatigue fracture, breast cancer and diabetic retinopathy, respectively.
Source code is available at \url{https://github.com/BiQiWHU/Samba}.
tl;dr: Our approach enhances message-passing in graphs with probabilistic rewiring and virtual nodes, addressing under-reaching and over-squashing, and outperforming traditional MPNNs and graph transformers in both expressiveness and efficiency.

Message-passing graph neural networks (MPNNs) have emerged as a powerful paradigm for graph-based machine learning. Despite their effectiveness, MPNNs face challenges such as under-reaching and over-squashing, where limited receptive fields and structural bottlenecks hinder information flow in the graph. While graph transformers hold promise in addressing these issues, their scalability is limited due to quadratic complexity regarding the number of nodes, rendering them impractical for larger graphs. Here, we propose implicitly rewired message-passing neural networks (IPR-MPNNs), a novel approach that integrates implicit probabilistic graph rewiring into MPNNs. By introducing a small number of virtual nodes, i.e., adding additional nodes to a given graph and connecting them to existing nodes, in a differentiable, end-to-end manner, IPR-MPNNs enable long-distance message propagation, circumventing quadratic complexity. Theoretically, we demonstrate that IPR-MPNNs surpass the expressiveness of traditional MPNNs. Empirically, we validate our approach by showcasing its ability to mitigate under-reaching and over-squashing effects, achieving state-of-the-art performance across multiple graph datasets. Notably, IPR-MPNNs outperform graph transformers while maintaining significantly faster computational efficiency.

In this work, we empirically confirm that the key reason causing such an issue is that the training images are usually paired with short captions, leaving certain tokens easily overshadowed by salient tokens. Towards this problem, our initial attempt is to relabel the data with long captions, however, directly learning with which may lead to performance degradation in understanding short text (e.g., in the image classification task). Then, after incorporating corner tokens to aggregate diverse textual information, we manage to help the model catch up to its original level of short text understanding yet greatly enhance its capability of long text understanding. We further look into whether the model can continuously benefit from longer captions and notice a clear trade-off between the performance and the efficiency. Finally, we validate the effectiveness of our approach using a self-constructed large-scale dataset, which consists of 100M long caption oriented text-image pairs. It is noteworthy that, on the task of long-text image retrieval, we beat the competitor using long captions with 11.1% improvement (i.e., from 72.62% to 83.72%). The project page is available at https://wuw2019.github.io/lot-lip.
tl;dr: We propose a normal-invovled rendering strategy for 3DGS, termed Normal-GS, which help enhance both the rendering quality and the normal estimation accuracy.

Rendering and reconstruction are long-standing topics in computer vision and graphics. Achieving both high rendering quality and accurate geometry is a challenge. Recent advancements in 3D Gaussian Splatting (3DGS) have enabled high-fidelity novel view synthesis at real-time speeds. However, the noisy and discrete nature of 3D Gaussian primitives hinders accurate surface estimation. Previous attempts to regularize 3D Gaussian normals often degrade rendering quality due to the fundamental disconnect between normal vectors and the rendering pipeline in 3DGS-based methods. Therefore, we introduce Normal-GS, a novel approach that integrates normal vectors into the 3DGS rendering pipeline. The core idea is to model the interaction between normals and incident lighting using the physically-based rendering equation. Our approach re-parameterizes surface colors as the product of normals and a designed Integrated Directional Illumination Vector (IDIV). To optimize memory usage and simplify optimization, we employ an anchor-based 3DGS to implicitly encode locally-shared IDIVs. Additionally, Normal-GS leverages optimized normals and Integrated Directional Encoding (IDE) to accurately model specular effects, enhancing both rendering quality and surface normal precision. Extensive experiments demonstrate that Normal-GS achieves near state-of-the-art visual quality while obtaining accurate surface normals and preserving real-time rendering performance.
tl;dr: We introduce a method for zero-shot transfer and dynamics prediction via function encoders using neural ODE basis functions.

Autonomous systems often encounter environments and scenarios beyond the scope of their training data, which underscores a critical challenge: the need to generalize and adapt to unseen scenarios in real time. This challenge necessitates new mathematical and algorithmic tools that enable adaptation and zero-shot transfer. To this end, we leverage the theory of function encoders, which enables zero-shot transfer by combining the flexibility of neural networks with the mathematical principles of Hilbert spaces. Using this theory, we first present a method for learning a space of dynamics spanned by a set of neural ODE basis functions. After training, the proposed approach can rapidly identify dynamics in the learned space using an efficient inner product calculation. Critically, this calculation requires no gradient calculations or retraining during the online phase. This method enables zero-shot transfer for autonomous systems at runtime and opens the door for a new class of adaptable control algorithms. We demonstrate state-of-the-art system modeling accuracy for two MuJoCo robot environments and show that the learned models can be used for more efficient MPC control of a quadrotor.

Model-based unsupervised reinforcement learning (URL) has gained prominence for reducing environment interactions and learning general skills using intrinsic rewards. However, distractors in observations can severely affect intrinsic reward estimation, leading to a biased exploration process, especially in environments with visual inputs like images or videos. To address this challenge, we propose a bi-level optimization framework named Separation-assisted eXplorer (SeeX). In the inner optimization, SeeX trains a separated world model to extract exogenous and endogenous information, minimizing uncertainty to ensure task relevance. In the outer optimization, it learns a policy on imaginary trajectories generated within the endogenous state space to maximize task-relevant uncertainty. Evaluations on multiple locomotion and manipulation tasks demonstrate SeeX's effectiveness.

Color video snapshot compressive imaging (SCI) employs computational imaging techniques to capture multiple sequential video frames in a single Bayer-patterned measurement. With the increasing popularity of quad-Bayer pattern in mainstream smartphone cameras for capturing high-resolution videos, mobile photography has become more accessible to a wider audience. However, existing color video SCI reconstruction algorithms are designed based on the traditional Bayer pattern. When applied to videos captured by quad-Bayer cameras, these algorithms often result in color distortion and ineffective demosaicing, rendering them impractical for primary equipment. To address this challenge, we propose the MambaSCI method, which leverages the Mamba and UNet architectures for efficient reconstruction of quad-Bayer patterned color video SCI. To the best of our knowledge, our work presents the first algorithm for quad-Bayer patterned SCI reconstruction, and also the initial application of the Mamba model to this task. Specifically, we customize Residual-Mamba-Blocks, which residually connect the Spatial-Temporal Mamba (STMamba), Edge-Detail-Reconstruction (EDR) module, and Channel Attention (CA) module. Respectively, STMamba is used to model long-range spatial-temporal dependencies with linear complexity, EDR is for better edge-detail reconstruction, and CA is used to compensate for the missing channel information interaction in Mamba model. Experiments demonstrate that MambaSCI surpasses state-of-the-art methods with lower computational and memory costs. PyTorch style pseudo-code for the core modules is provided in the supplementary materials. Code is at https://github.com/PAN083/MambaSCI.
tl;dr: This paper characterizes some provable separations and bias of DEQ over FFN in lens of expressivity and learning dynamics.

The deep equilibrium model (DEQ) generalizes the conventional feedforward neural network by fixing the same weights for each layer block and extending the number of layers to infinity. This novel model directly finds the fixed points of such a forward process as features for prediction. Despite empirical evidence showcasing its efficacy
compared to feedforward neural networks, a theoretical understanding for its separation and bias is still limited. In this paper, we take a step
by proposing some separations and studying the bias of DEQ in its expressive power and learning dynamics. The results include: (1) A general separation is proposed, showing the existence of a width-$m$ DEQ that any fully connected neural networks (FNNs) with depth $O(m^{\alpha})$ for $\alpha \in (0,1)$ cannot
approximate unless its width is sub-exponential in $m$; (2) DEQ with polynomially bounded size and magnitude can efficiently approximate certain steep functions (which has very large derivatives) in $L^{\infty}$ norm, whereas FNN with bounded depth and exponentially bounded width cannot unless its weights magnitudes are exponentially large; (3) The implicit regularization caused by gradient flow from a diagonal linear DEQ is characterized, with specific examples showing the benefits brought by such regularization.
From the overall study, a high-level conjecture from our analysis and empirical validations is that DEQ has potential advantages in learning certain high-frequency components.
Data, the seminal opportunity and challenge in modern machine learning, currently constrains the scalability of representation learning and impedes the pace of model evolution.
In this work, we investigate the efficiency properties of data from both optimization and generalization perspectives.
Our theoretical and empirical analysis reveals an unexpected finding: for a given task, utilizing a publicly available, task- and architecture-agnostic model (referred to as the `prior model' in this paper) can effectively produce efficient data.
Building on this insight, we propose the Representation Learning Accelerator (ReLA), which promotes the formation and utilization of efficient data, thereby accelerating representation learning.
Utilizing a ResNet-18 pre-trained on CIFAR-10 as a prior model to inform ResNet-50 training on ImageNet-1K reduces computational costs by $50\%$ while maintaining the same accuracy as the model trained with the original BYOL, which requires $100\%$ cost.
Our code is available at: \url{https://github.com/LINs-lab/ReLA}.
tl;dr: Overcoming Few Labels in Federated Semi-Supervised Learning

Federated Learning (FL) is a distributed machine learning framework that trains accurate global models while preserving clients' privacy-sensitive data. However, most FL approaches assume that clients possess labeled data, which is often not the case in practice. Federated Semi-Supervised Learning (FSSL) addresses this label deficiency problem, targeting situations where only the server has a small amount of labeled data while clients do not. However, a significant performance gap exists between Centralized Semi-Supervised Learning (SSL) and FSSL. This gap arises from confirmation bias, which is more pronounced in FSSL due to multiple local training epochs and the separation of labeled and unlabeled data. We propose $(FL)^2$, a robust training method for unlabeled clients using sharpness-aware consistency regularization. We show that regularizing the original pseudo-labeling loss is suboptimal, and hence we carefully select unlabeled samples for regularization. We further introduce client-specific adaptive thresholding and learning status-aware aggregation to adjust the training process based on the learning progress of each client. Our experiments on three benchmark datasets demonstrate that our approach significantly improves performance and bridges the gap with SSL, particularly in scenarios with scarce labeled data.

The stochastic compositional optimization (SCO) is popular in many real-world applications, including risk management, reinforcement learning, and meta-learning. However, most of the previous methods for SCO require the smoothness assumption on both the outer and inner functions, which limits their applications to a wider range of problems. In this paper, we study the SCO problem in that both the outer and inner functions are Lipschitz continuous but possibly nonconvex and nonsmooth. In particular, we propose gradient-free stochastic methods for finding the $(\delta, \epsilon)$-Goldstein stationary points of such problems with non-asymptotic convergence rates. Our results also lead to an improved convergence rate for the convex nonsmooth SCO problem. Furthermore, we conduct numerical experiments to demonstrate the effectiveness of the proposed methods.
tl;dr: We construct the first Pedestrian-Vehicle Collision Pose (PVCP) dataset from the perspective of dashcam, and propose a pedestrian Pre-collision Pose and Shape Estimation network (PPSENet).

Pedestrian pre-collision pose is one of the key factors to determine the degree of pedestrian-vehicle injury in collision. Human pose estimation algorithm is an effective method to estimate pedestrian emergency pose from accident video. However, the pose estimation model trained by the existing daily human pose datasets has poor robustness under specific poses such as pedestrian pre-collision pose, and it is difficult to obtain human pose datasets in the wild scenes, especially lacking scarce data such as pedestrian pre-collision pose in traffic scenes. In this paper, we collect pedestrian-vehicle collision pose from the dashcam perspective of dashcam and construct the first Pedestrian-Vehicle Collision Pose dataset (PVCP) in a semi-automatic way, including 40k+ accident frames and 20K+ pedestrian pre-collision pose annotation (2D, 3D, Mesh). Further, we construct a Pedestrian Pre-collision Pose Estimation Network (PPSENet) to estimate the collision pose and shape sequence of pedestrians from pedestrian-vehicle accident videos. The PPSENet first estimates the 2D pose from the image (Image to Pose, ITP) and then lifts the 2D pose to 3D mesh (Pose to Mesh, PTM). Due to the small size of the dataset, we introduce a pre-training model that learns the human pose prior on a large number of pose datasets, and use iterative regression to estimate the pre-collision pose and shape of pedestrians. Further, we classify the pre-collision pose sequence and introduce pose class loss, which achieves the best accuracy compared with the existing relevant \textit{state-of-the-art} methods. Code and data are available for research at https://github.com/wmj142326/PVCP.

Modern image generation (IG) models have been shown to capture rich semantics valuable for image understanding (IU) tasks. However, the potential of IU models to improve IG performance remains uncharted. We address this issue using a token-based IG framework, which relies on effective tokenizers to project images into token sequences. Currently, **pixel reconstruction** (e.g., VQGAN) dominates the training objective for image tokenizers. In contrast, our approach adopts the **feature reconstruction** objective, where tokenizers are trained by distilling knowledge from pretrained IU encoders. Comprehensive comparisons indicate that tokenizers with strong IU capabilities achieve superior IG performance across a variety of metrics, datasets, tasks, and proposal networks. Notably, VQ-KD CLIP achieves $4.10$ FID on ImageNet-1k (IN-1k). Visualization suggests that the superiority of VQ-KD can be partly attributed to the rich semantics within the VQ-KD codebook. We further introduce a straightforward pipeline to directly transform IU encoders into tokenizers, demonstrating exceptional effectiveness for IG tasks. These discoveries may energize further exploration into image tokenizer research and inspire the community to reassess the relationship between IU and IG. The code is released at https://github.com/magic-research/vector_quantization.
tl;dr: a dynamic logit fusion approach for transferring knowledge from a series of task-specific small models to a larger model

Efficient fine-tuning of large language models for task-specific applications is imperative, yet the vast number of parameters in these models makes their training increasingly challenging.
Despite numerous proposals for effective methods, a substantial memory overhead remains for gradient computations during updates. \thm{Can we fine-tune a series of task-specific small models and transfer their knowledge directly to a much larger model without additional training?}
In this paper, we explore weak-to-strong specialization using logit arithmetic, facilitating a direct answer to this question.
Existing weak-to-strong methods often employ a static knowledge transfer ratio and a single small model for transferring complex knowledge, which leads to suboptimal performance.
To surmount these limitations,
we propose a dynamic logit fusion approach that works with a series of task-specific small models, each specialized in a different task.
This method adaptively allocates weights among these models at each decoding step,
learning the weights through Kullback-Leibler divergence constrained optimization problems.
We conduct extensive experiments across various benchmarks in both single-task and multi-task settings, achieving leading results.
By transferring expertise from the 7B model to the 13B model, our method closes the performance gap by 96.4\% in single-task scenarios and by 86.3\% in multi-task scenarios compared to full fine-tuning of the 13B model. Notably, we achieve surpassing performance on unseen tasks. Moreover, we further demonstrate that our method can effortlessly integrate in-context learning for single tasks and task arithmetic for multi-task scenarios.

Due to the rapid generation and dissemination of information, large language models (LLMs) quickly run out of date despite enormous development costs. To address the crucial need to keep models updated, online learning has emerged as a critical tool when utilizing LLMs for real-world applications. However, given the ever-expanding corpus of unseen documents and the large parameter space of modern LLMs, efficient adaptation is essential. To address these challenges, we propose \mname, an efficient and effective online adaptation framework for LLMs with strong knowledge retention. We propose a feature extraction and memory-augmentation approach to compress and extract information from new documents into compact modulations stored in a memory bank. When answering questions, our model attends to and extracts relevant knowledge from this memory bank. To learn informative modulations in an efficient manner, we utilize amortization-based meta-learning, which substitutes an otherwise required optimization process with a single forward pass of the encoder. Subsequently, we learn to choose from and aggregate selected documents into a single modulation by conditioning on the question, allowing us to adapt a frozen language model during test time without requiring further gradient updates. Our experiment demonstrates the superiority of \sname in multiple aspects, including online adaptation performance, time, and memory efficiency. In addition, we show how \sname can be combined with and improve the performance of popular alternatives such as retrieval augmented generations (RAGs). Code is available at: https://github.com/jihoontack/MAC.

Although the neural radiance field (NeRF) exhibits high-fidelity visualization on the rendering task, it still suffers from rendering defects, especially in complex scenes. In this paper, we delve into the reason for the unsatisfactory performance and conjecture that it comes from interference in the training process. Due to occlusions in complex scenes, a 3D point may be invisible to some rays. On such a point, training with those rays that do not contain valid information about the point might interfere with the NeRF training. Based on the above intuition, we decouple the training process of NeRF in the ray dimension softly and propose a Ray-decoupled Training Framework for neural rendering (Rad-NeRF). Specifically, we construct an ensemble of sub-NeRFs and train a soft gate module to assign the gating scores to these sub-NeRFs based on specific rays. The gate module is jointly optimized with the sub-NeRF ensemble to learn the preference of sub-NeRFs for different rays automatically. Furthermore, we introduce depth-based mutual learning to enhance the rendering consistency among multiple sub-NeRFs and mitigate the depth ambiguity. Experiments on five datasets demonstrate that Rad-NeRF can enhance the rendering performance across a wide range of scene types compared with existing single-NeRF and multi-NeRF methods. With only 0.2% extra parameters, Rad-NeRF improves rendering performance by up to 1.5dB. Code is available at https://github.com/thu-nics/Rad-NeRF.

In the field of computational advertising, the integration of ads into the outputs of large language models (LLMs) presents an opportunity to support these services without compromising content integrity. This paper introduces novel auction mechanisms for ad allocation and pricing within the textual outputs of LLMs, leveraging retrieval-augmented generation (RAG). We propose a \emph{segment auction} where an ad is probabilistically retrieved for each discourse segment (paragraph, section, or entire output) according to its bid and relevance, following the RAG framework, and priced according to competing bids. We show that our auction maximizes logarithmic social welfare, a new notion of welfare that balances allocation efficiency and fairness, and we characterize the associated incentive-compatible pricing rule. These results are extended to multi-ad allocation per segment. An empirical evaluation validates the feasibility and effectiveness of our approach over several ad auction scenarios, and exhibits inherent tradeoffs in metrics as we allow the LLM more flexibility to allocate ads.

We introduce a novel reinforcement learning framework of LLM agents named AGILE (AGent that Interacts and Learns from Environments) designed to perform complex conversational tasks with users, leveraging LLMs, memory, tools, and interactions with experts. The agent possesses capabilities beyond conversation, including reflection, tool usage, and expert consultation. We formulate the construction of such an LLM agent as a reinforcement learning (RL) problem, in which the LLM serves as the policy model. We fine-tune the LLM using labeled data of actions and the PPO algorithm. We focus on question answering and release a dataset for agents called ProductQA, comprising challenging questions in online shopping. Our extensive experiments on ProductQA, MedMCQA and HotPotQA show that AGILE agents based on 7B and 13B LLMs trained with PPO can outperform GPT-4 agents. Our ablation study highlights the indispensability of memory, tools, consultation, reflection, and reinforcement learning in achieving the agent's strong performance. Datasets and code are available at https://github.com/bytarnish/AGILE.

Existing reconstruction models in snapshot compressive imaging systems (SCI) are trained with a single well-calibrated hardware instance, making their perfor- mance vulnerable to hardware shifts and limited in adapting to multiple hardware configurations. To facilitate cross-hardware learning, previous efforts attempt to directly collect multi-hardware data and perform centralized training, which is impractical due to severe user data privacy concerns and hardware heterogeneity across different platforms/institutions. In this study, we explicitly consider data privacy and heterogeneity in cooperatively optimizing SCI systems by proposing a Federated Hardware-Prompt learning (FedHP) framework. Rather than mitigating the client drift by rectifying the gradients, which only takes effect on the learning manifold but fails to solve the heterogeneity rooted in the input data space, FedHP learns a hardware-conditioned prompter to align inconsistent data distribution across clients, serving as an indicator of the data inconsistency among different hardware (e.g., coded apertures). Extensive experimental results demonstrate that the proposed FedHP coordinates the pre-trained model to multiple hardware con- figurations, outperforming prevalent FL frameworks for 0.35dB under challenging heterogeneous settings. Moreover, a Snapshot Spectral Heterogeneous Dataset has been built upon multiple practical SCI systems. Data and code are aveilable at https://github.com/Jiamian-Wang/FedHP-Snapshot-Compressive-Imaging.git
tl;dr: In this work, we enhance current PEFT methods by incorporating spectral information of pretrained weights into the fine-tuning procedure.

Recent developments in Parameter-Efficient Fine-Tuning (PEFT) methods for pretrained deep neural networks have captured widespread interest. In this work, we study the enhancement of current PEFT methods by incorporating the spectral information of pretrained weight matrices into the fine-tuning procedure. We investigate two spectral adaptation mechanisms, namely additive tuning and orthogonal rotation of the top singular vectors, both are done via first carrying out Singular Value Decomposition (SVD) of pretrained weights and then fine-tuning the top spectral space. We provide a theoretical analysis of spectral fine-tuning and show that our approach improves the rank capacity of low-rank adapters given a fixed trainable parameter budget. We show through extensive experiments that the proposed fine-tuning model enables better parameter efficiency and tuning performance as well as benefits multi-adapter fusion. The source code will be open-sourced for reproducibility.
tl;dr: Building ontologies with Large Language Models

Ontologies are useful for automatic machine processing of domain knowledge as they represent it in a structured format. Yet, constructing ontologies requires substantial manual effort. To automate part of this process, large language models (LLMs) have been applied to solve various subtasks of ontology learning. However, this partial ontology learning does not capture the interactions between subtasks. We address this gap by introducing OLLM, a general and scalable method for building the taxonomic backbone of an ontology from scratch. Rather than focusing on subtasks, like individual relations between entities, we model entire subcomponents of the target ontology by finetuning an LLM with a custom regulariser that reduces overfitting on high-frequency concepts. We introduce a novel suite of metrics for evaluating the quality of the generated ontology by measuring its semantic and structural similarity to the ground truth. In contrast to standard metrics, our metrics use deep learning techniques to define more robust distance measures between graphs. Both our quantitative and qualitative results on Wikipedia show that OLLM outperforms subtask composition methods, producing more semantically accurate ontologies while maintaining structural integrity. We further demonstrate that our model can be effectively adapted to new domains, like arXiv, needing only a small number of training examples. Our source code and datasets are available at https://github.com/andylolu2/ollm.
tl;dr: This paper proposes the first parameter efficient adaptation framework, which tunes only 0.6% parameters to adapt pre-trained restoration models to various tasks.

Designing single-task image restoration models for specific degradation has seen great success in recent years. To achieve generalized image restoration, all-in-one methods have recently been proposed and shown potential for multiple restoration tasks using one single model. Despite the promising results, the existing all-in-one paradigm still suffers from high computational costs as well as limited generalization on unseen degradations. In this work, we introduce an alternative solution to improve the generalization of image restoration models. Drawing inspiration from recent advancements in Parameter Efficient Transfer Learning (PETL), we aim to tune only a small number of parameters to adapt pre-trained restoration models to various tasks. However, current PETL methods fail to generalize across varied restoration tasks due to their homogeneous representation nature. To this end, we propose AdaptIR, a Mixture-of-Experts (MoE) with orthogonal multi-branch design to capture local spatial, global spatial, and channel representation bases, followed by adaptive base combination to obtain heterogeneous representation for different degradations. Extensive experiments demonstrate that our AdaptIR achieves stable performance on single-degradation tasks, and excels in hybrid-degradation tasks, with training only 0.6% parameters for 8 hours.

Detecting Human-Object Interactions (HOI) in zero-shot settings, where models must handle unseen classes, poses significant challenges. Existing methods that rely on aligning visual encoders with large Vision-Language Models (VLMs) to tap into the extensive knowledge of VLMs, require large, computationally expensive models and encounter training difficulties. Adapting VLMs with prompt learning offers an alternative to direct alignment. However, fine-tuning on task-specific datasets often leads to overfitting to seen classes and suboptimal performance on unseen classes, due to the absence of unseen class labels. To address these challenges, we introduce a novel prompt learning-based framework for Efficient Zero-Shot HOI detection (EZ-HOI). First, we introduce Large Language Model (LLM) and VLM guidance for learnable prompts, integrating detailed HOI descriptions and visual semantics to adapt VLMs to HOI tasks. However, because training datasets contain seen-class labels alone, fine-tuning VLMs on such datasets tends to optimize learnable prompts for seen classes instead of unseen ones. Therefore, we design prompt learning for unseen classes using information from related seen classes, with LLMs utilized to highlight the differences between unseen and related seen classes. Quantitative evaluations on benchmark datasets demonstrate that our EZ-HOI achieves state-of-the-art performance across various zero-shot settings with only 10.35\% to 33.95\% of the trainable parameters compared to existing methods. Code is available at https://github.com/ChelsieLei/EZ-HOI.

As machine learning models are increasingly deployed in dynamic environments, it becomes paramount to assess and quantify uncertainties associated with distribution shifts.
A distribution shift occurs when the underlying data-generating process changes, leading to a deviation in the model's performance.
The prediction interval, which captures the range of likely outcomes for a given prediction, serves as a crucial tool for characterizing uncertainties induced by their underlying distribution.
In this paper, we propose methodologies for aggregating prediction intervals to obtain one with minimal width and adequate coverage on the target domain under unsupervised domain shift, under which we have labeled samples from a related source domain and unlabeled covariates from the target domain.
Our analysis encompasses scenarios where the source and the target domain are related via i) a bounded density ratio, and ii) a measure-preserving transformation.
Our proposed methodologies are computationally efficient and easy to implement. Beyond illustrating the performance of our method through real-world datasets, we also delve into the theoretical details. This includes establishing rigorous theoretical guarantees, coupled with finite sample bounds, regarding the coverage and width of our prediction intervals. Our approach excels in practical applications and is underpinned by a solid theoretical framework, ensuring its reliability and effectiveness across diverse contexts.
tl;dr: In this paper, we study the statistical and geometric properties of the Kullback-Leibler divergence with kernel covariance operators (KKL) introduced by [Bach, 2022, Information Theory with Kernel Methods].

In this paper, we study the statistical and geometrical properties of the Kullback-Leibler divergence with kernel covariance operators (KKL) introduced by [Bach, 2022, Information Theory with Kernel Methods]. Unlike the classical Kullback-Leibler (KL) divergence that involves density ratios, the KKL compares probability distributions through covariance operators (embeddings) in a reproducible kernel Hilbert space (RKHS), and compute the Kullback-Leibler quantum divergence.
This novel divergence hence shares parallel but different aspects with both the standard Kullback-Leibler between probability distributions and kernel embeddings metrics such as the maximum mean discrepancy.
A limitation faced with the original KKL divergence is its inability to be defined for distributions with disjoint supports. To solve this problem, we propose in this paper a regularised variant that guarantees that divergence is well defined for all distributions. We derive bounds that quantify the deviation of the regularised KKL to the original one, as well as concentration bounds.
In addition, we provide a closed-form expression for the regularised KKL, specifically applicable when the distributions consist of finite sets of points, which makes it implementable.
Furthermore, we derive a Wasserstein gradient descent scheme of the KKL divergence in the case of discrete distributions, and study empirically its properties to transport a set of points to a target distribution.
tl;dr: While using a trick to compute per-example gradients efficiently we discover that normalization layers statistics predict GNS accurately.

Per-example gradient norms are a vital ingredient for estimating gradient noise scale (GNS) with minimal variance. Observing the tensor contractions required to compute them, we propose a method with minimal FLOPs in 3D or greater tensor regimes by simultaneously computing the norms while computing the parameter gradients. Using this method we are able to observe the GNS of different layers at higher accuracy than previously possible. We find that the total GNS of contemporary transformer models is predicted well by the GNS of only the normalization layers. As a result, focusing only on the normalization layer, we develop a custom kernel to compute the per-example gradient norms while performing the LayerNorm backward pass with zero throughput overhead. Tracking GNS on only those layers, we are able to guide a practical batch size schedule that reduces training time by 18% on a Chinchilla-optimal language model.

Existing ultra image segmentation methods suffer from two major challenges, namely the scalability issue (i.e. they lack the stability and generality of standard segmentation models, as they are tailored to specific datasets), and the architectural issue (i.e. they are incompatible with real-world ultra image scenes, as they compromise between image size and computing resources).
To tackle these issues, we revisit the classic sliding inference framework, upon which we propose a Surrounding Guided Segmentation framework (SGNet) for ultra image segmentation.
The SGNet leverages a larger area around each image patch to refine the general segmentation results of local patches.
Specifically, we propose a surrounding context integration module to absorb surrounding context information and extract specific features that are beneficial to local patches. Note that, SGNet can be seamlessly integrated to any general segmentation model.
Extensive experiments on five datasets demonstrate that SGNet achieves competitive performance and consistent improvements across a variety of general segmentation models, surpassing the traditional ultra image segmentation methods by a large margin.
tl;dr: We introduce an idiographic personality Gaussian process (IPGP) framework of time-series survey data for individualized psychological assessment.

We develop a novel measurement framework based on Gaussian process coregionalization model to address a long-lasting debate in psychometrics: whether psychological features like personality share a common structure across the population or vary uniquely for individuals. We propose idiographic personality Gaussian process (IPGP), an intermediate model that accommodates both shared trait structure across individuals and "idiographic" deviations. IPGP leverages the Gaussian process coregionalization model to conceptualize responses of grouped survey batteries but adjusted to non-Gaussian ordinal data, and exploits stochastic variational inference for latent factor estimation. Using both synthetic data and a novel survey, we show that IPGP improves both prediction of actual responses and estimation of intrapersonal response patterns compared to existing benchmarks. In the survey study, IPGP also identifies unique clusters of personality taxonomies, displaying great potential in advancing individualized approaches to psychological diagnosis.

This paper investigates score-based diffusion models when the underlying target distribution is concentrated on or near low-dimensional manifolds within the higher-dimensional space in which they formally reside, a common characteristic of natural image distributions. Despite previous efforts to understand the data generation process of diffusion models, existing theoretical support remains highly suboptimal in the presence of low-dimensional structure, which we strengthen in this paper. For the popular Denoising Diffusion Probabilistic Model (DDPM), we find that the dependency of the error incurred within each denoising step on the ambient dimension $d$ is in general unavoidable. We further identify a unique design of coefficients that yields a converges rate at the order of $O(k^{2}/\sqrt{T})$ (up to log factors), where $k$ is the intrinsic dimension of the target distribution and $T$ is the number of steps. This represents the first theoretical demonstration that the DDPM sampler can adapt to unknown low-dimensional structures in the target distribution, highlighting the critical importance of coefficient design. All of this is achieved by a novel set of analysis tools that characterize the algorithmic dynamics in a more deterministic manner.
tl;dr: We propose a 2-party computation framework to accelerate the secure inference of the Transformer model by optimizing the protocols of both linear and non-linear layers.

Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. Specifically, we propose a new 2PC paradigm to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. Furthermore, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of $BERT_{base}$ inference by $2.7\times \sim 4.7\times$ across different network settings.
tl;dr: Provable conformal prediction method to produce small prediction sets for class-conditional coverage for imbalanced classification problems using the augmented rank calibration.

Conformal prediction (CP) is an emerging uncertainty quantification framework that allows us to construct a prediction set to cover the true label with a pre-specified marginal or conditional probability.
Although the valid coverage guarantee has been extensively studied for classification problems, CP often produces large prediction sets which may not be practically useful.
This issue is exacerbated for the setting of class-conditional coverage on imbalanced classification tasks with many and/or imbalanced classes.
This paper proposes the Rank Calibrated Class-conditional CP (RC3P) algorithm to reduce the prediction set sizes to achieve class-conditional coverage, where the valid coverage holds for each class.
In contrast to the standard class-conditional CP (CCP) method that uniformly thresholds the class-wise conformity score for each class, the augmented label rank calibration step allows RC3P to selectively iterate this class-wise thresholding subroutine only for a subset of classes whose class-wise top-$k$ error is small.
We prove that agnostic to the classifier and data distribution, RC3P achieves class-wise coverage. We also show that RC3P reduces the size of prediction sets compared to the CCP method.
Comprehensive experiments on multiple real-world datasets demonstrate that RC3P achieves class-wise coverage and $26.25\\%$ $\downarrow$ reduction in prediction set sizes on average.
tl;dr: We propose a method which jointly estimates posteriors and informative designs to calibrate computer simulations of physical processes.

The process of calibrating computer models of natural phenomena is essential for applications in the physical sciences, where plenty of domain knowledge can be embedded into simulations and then calibrated against real observations. Current machine learning approaches, however, mostly rely on rerunning simulations over a fixed set of designs available in the observed data, potentially neglecting informative correlations across the design space and requiring a large amount of simulations. Instead, we consider the calibration process from the perspective of Bayesian adaptive experimental design and propose a data-efficient algorithm to run maximally informative simulations within a batch-sequential process. At each round, the algorithm jointly estimates the parameters posterior distribution and optimal designs by maximising a variational lower bound of the expected information gain. The simulator is modelled as a sample from a Gaussian process, which allows us to correlate simulations and real data with the unknown calibration parameters. We show the benefits of our method when compared to related approaches across synthetic and real-data problems.

Online continual learning, the process of training models on streaming data, has gained increasing attention in recent years. However, a critical aspect often overlooked is the label delay, where new data may not be labeled due to slow and costly annotation processes. We introduce a new continual learning framework with explicit modeling of the label delay between data and label streams over time steps. In each step, the framework reveals both unlabeled data from the current time step t and labels delayed with d steps, from the time step t−d. In our extensive experiments amounting to 1060 GPU days, we show that merely augmenting the computational resources is insufficient to tackle this challenge. Our findings underline a notable performance decline when solely relying on labeled data when the label delay becomes significant. More surprisingly, when using state-of-the-art SSL and TTA techniques to utilize the newer, unlabeled data, they fail to surpass the performance of a naïve method that simply trains on the delayed supervised stream. To this end, we introduce a simple, efficient baseline that rehearses from the labeled memory samples that are most similar to the new unlabeled samples. This method bridges the accuracy gap caused by label delay without significantly increasing computational complexity. We show experimentally that our method is the least affected by the label delay factor and in some cases successfully recovers the accuracy of the non-delayed counterpart. We conduct various ablations and sensitivity experiments, demonstrating the effectiveness of our approach.
tl;dr: We propose a posterior sampling-based algorithm to efficiently estimate a target set of input points defined in terms of a function with expensive evaluations.

We consider Bayesian algorithm execution (BAX), a framework for efficiently selecting evaluation points of an expensive function to infer a property of interest encoded as the output of a base algorithm. Since the base algorithm typically requires more evaluations than are feasible, it cannot be directly applied. Instead, BAX methods sequentially select evaluation points using a probabilistic numerical approach. Current BAX methods use expected information gain to guide this selection. However, this approach is computationally intensive. Observing that, in many tasks, the property of interest corresponds to a target set of points defined by the function, we introduce PS-BAX, a simple, effective, and scalable BAX method based on posterior sampling. PS-BAX is applicable to a wide range of problems, including many optimization variants and level set estimation. Experiments across diverse tasks demonstrate that PS-BAX performs competitively with existing baselines while being significantly faster, simpler to implement, and easily parallelizable, setting a strong baseline for future research. Additionally, we establish conditions under which PS-BAX is asymptotically convergent, offering new insights into posterior sampling as an algorithm design paradigm.
tl;dr: A pioneering unlearnable scheme for effective 3D point cloud protection against unauthorized deep learning.

Traditional unlearnable strategies have been proposed to prevent unauthorized users from training on the 2D image data. With more 3D point cloud data containing sensitivity information, unauthorized usage of this new type data has also become a serious concern. To address this, we propose the first integral unlearnable framework for 3D point clouds including two processes: (i) we propose an unlearnable data protection scheme, involving a class-wise setting established by a category-adaptive allocation strategy and multi-transformations assigned to samples; (ii) we propose a data restoration scheme that utilizes class-wise inverse matrix transformation, thus enabling authorized-only training for unlearnable data. This restoration process is a practical issue overlooked in most existing unlearnable literature, i.e., even authorized users struggle to gain knowledge from 3D unlearnable data. Both theoretical and empirical results (including 6 datasets, 16 models, and 2 tasks) demonstrate the effectiveness of our proposed unlearnable framework. Our code is available at https://github.com/CGCL-codes/UnlearnablePC.
tl;dr: We find a permutation matrix that maps one graph to another by directly operating on their adjacency matrices, surpassing state-of-the-art methods in accuracy across all benchmark datasets without encumbering efficiency.

The necessity to align two graphs, minimizing a structural distance metric, is prevalent in biology, chemistry, recommender systems, and social network analysis. Due to the problem’s NP-hardness, prevailing graph alignment methods follow a modular and mediated approach, solving the problem by restricting to the domain of intermediary graph representations or products like embeddings, spectra, and graph signals. Restricting the problem to this intermediate space may distort the original problem and are hence predisposed to miss high-quality solutions. In this paper, we propose an unrestricted method, FUGAL, which finds a permutation matrix that maps one graph to another by directly operating on their adjacency matrices with judicious constraint relaxation. Extensive experimentation demonstrates that FUGAL consistently surpasses state-of-the-art graph alignment methods in accuracy across all benchmark datasets without encumbering efficiency.

Large Language Models (LLMs) have long held sway in the realms of artificial intelligence research.
Numerous efficient techniques, including weight pruning, quantization, and distillation, have been embraced to compress LLMs, targeting memory reduction and inference acceleration, which underscore the redundancy in LLMs.
However, most model compression techniques concentrate on weight optimization, overlooking the exploration of optimal architectures.
Besides, traditional architecture search methods, limited by the elevated complexity with extensive parameters, struggle to demonstrate their effectiveness on LLMs.
In this paper, we propose a training-free architecture search framework to identify optimal subnets that preserve the fundamental strengths of the original LLMs while achieving inference acceleration.
Furthermore, after generating subnets that inherit specific weights from the original LLMs, we introduce a reformation algorithm that utilizes the omitted weights to rectify the inherited weights with a small amount of calibration data.
Compared with SOTA training-free structured pruning works that can generate smaller networks, our method demonstrates superior performance across standard benchmarks.
Furthermore, our generated subnets can directly reduce the usage of GPU memory and achieve inference acceleration.
tl;dr: Pioneeringly establish a vision-language graph reasoning setting for VLMs to compete with LLMs, showcasing vision's benefits for language-based graph reasoning, and provide a framework to derive graph VQA benchmarks from existing data.

Large Language Models (LLMs) are increasingly used for various tasks with graph structures. Though LLMs can process graph information in a textual format, they overlook the rich vision modality, which is an intuitive way for humans to comprehend structural information and conduct general graph reasoning. The potential benefits and capabilities of representing graph structures as visual images (i.e., $\textit{visual graph}$) are still unexplored. To fill the gap, we innovatively propose an end-to-end framework, called $\textbf{G}$raph to v$\textbf{I}$sual and $\textbf{T}$extual Integr$\textbf{A}$tion (GITA), which firstly incorporates visual graphs into general graph reasoning. Besides, we establish $\textbf{G}$raph-based $\textbf{V}$ision-$\textbf{L}$anguage $\textbf{Q}$uestion $\textbf{A}$nswering (GVLQA) dataset from existing graph data, which is the first vision-language dataset for general graph reasoning purposes. Extensive experiments on the GVLQA dataset and five real-world datasets show that GITA outperforms mainstream LLMs in terms of general graph reasoning capabilities. Moreover, We highlight the effectiveness of the layout augmentation on visual graphs and pretraining on the GVLQA dataset.
tl;dr: We introduce a novel training-free approach for bounding box-based image generation leveraging the semantic sharing properties of Diffusion Transformers.

We introduce GrounDiT, a novel training-free spatial grounding technique for text-to-image generation using Diffusion Transformers (DiT). Spatial grounding with bounding boxes has gained attention for its simplicity and versatility, allowing for enhanced user control in image generation. However, prior training-free approaches often rely on updating the noisy image during the reverse diffusion process via backpropagation from custom loss functions, which frequently struggle to provide precise control over individual bounding boxes. In this work, we leverage the flexibility of the Transformer architecture, demonstrating that DiT can generate noisy patches corresponding to each bounding box, fully encoding the target object and allowing for fine-grained control over each region. Our approach builds on an intriguing property of DiT, which we refer to as semantic sharing. Due to semantic sharing, when a smaller patch is jointly denoised alongside a generatable-size image, the two become semantic clones. Each patch is denoised in its own branch of the generation process and then transplanted into the corresponding region of the original noisy image at each timestep, resulting in robust spatial grounding for each bounding box. In our experiments on the HRS and DrawBench benchmarks, we achieve state-of-the-art performance compared to previous training-free approaches. Project Page: https://groundit-diffusion.github.io/.

Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention and bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the paper and conduct extensive experiments to demonstrate the extraordinary performance of U-DiT models. The proposed U-DiT could outperform DiT-XL with only 1/6 of its computation cost. Codes are available at https://github.com/YuchuanTian/U-DiT.
tl;dr: We propose a generalizable 3D Gaussian Splatting framework to progressively fuse multi-view pixel-aligned 3D Gaussians for large-scale scene photorealistic reconstruction.

Empowering 3D Gaussian Splatting with generalization ability is appealing. However, existing generalizable 3D Gaussian Splatting methods are largely confined to narrow-range interpolation between stereo images due to their heavy backbones, thus lacking the ability to accurately localize 3D Gaussian and support free-view synthesis across wide view range. In this paper, we present a novel framework FreeSplat that is capable of reconstructing geometrically consistent 3D scenes from long sequence input towards free-view synthesis.Specifically, we firstly introduce Low-cost Cross-View Aggregation achieved by constructing adaptive cost volumes among nearby views and aggregating features using a multi-scale structure. Subsequently, we present the Pixel-wise Triplet Fusion to eliminate redundancy of 3D Gaussians in overlapping view regions and to aggregate features observed across multiple views. Additionally, we propose a simple but effective free-view training strategy that ensures robust view synthesis across broader view range regardless of the number of views. Our empirical results demonstrate state-of-the-art novel view synthesis peformances in both novel view rendered color maps quality and depth maps accuracy across different numbers of input views. We also show that FreeSplat performs inference more efficiently and can effectively reduce redundant Gaussians, offering the possibility of feed-forward large scene reconstruction without depth priors. Our code will be made open-source upon paper acceptance.
3126. Provably Robust Score-Based Diffusion Posterior Sampling for Plug-and-Play Image Reconstruction

In a great number of tasks in science and engineering, the goal is to infer an unknown image from a small number of noisy measurements collected from a known forward model describing certain sensing or imaging modality. Due to resource constraints, this image reconstruction task is often extremely ill-posed, which necessitates the adoption of expressive prior information to regularize the solution space. Score-based diffusion models, thanks to its impressive empirical success, have emerged as an appealing candidate of an expressive prior in image reconstruction. In order to accommodate diverse tasks at once, it is of great interest to develop efficient, consistent and robust algorithms that incorporate unconditional score functions of an image prior distribution in conjunction with flexible choices of forward models.
This work develops an algorithmic framework for employing score-based diffusion models as an expressive data prior in nonlinear inverse problems with general forward models. Motivated by the plug-and-play framework in the imaging community, we introduce a diffusion plug-and-play method (DPnP) that alternatively calls two samplers, a proximal consistency sampler based solely on the likelihood function of the forward model, and a denoising diffusion sampler based solely on the score functions of the image prior. The key insight is that denoising under white Gaussian noise can be solved rigorously via both stochastic (i.e., DDPM-type) and deterministic (i.e., DDIM-type) samplers using the same set of score functions trained for generation. We establish both asymptotic and non-asymptotic performance guarantees of DPnP, and provide numerical experiments to illustrate its promise in solving both linear and nonlinear image reconstruction tasks. To the best of our knowledge, DPnP is the first provably-robust posterior sampling method for nonlinear inverse problems using unconditional diffusion priors.
tl;dr: We propose Latent Graph Diffusion, the first framework that enables solving graph learning tasks of all levels and all types (generation, regression and classification) with one diffusion model.

In this paper, we propose the first framework that enables solving graph learning tasks of all levels (node, edge and graph) and all types (generation, regression and classification) using one formulation. We first formulate prediction tasks including regression and classification into a generic (conditional) generation framework, which enables diffusion models to perform deterministic tasks with provable guarantees. We then propose Latent Graph Diffusion (LGD), a generative model that can generate node, edge, and graph-level features of all categories simultaneously. We achieve this goal by embedding the graph structures and features into a latent space leveraging a powerful encoder and decoder, then training a diffusion model in the latent space. LGD is also capable of conditional generation through a specifically designed cross-attention mechanism. Leveraging LGD and the ``all tasks as generation'' formulation, our framework is capable of solving graph tasks of various levels and types. We verify the effectiveness of our framework with extensive experiments, where our models achieve state-of-the-art or highly competitive results across a wide range of generation and regression tasks.
tl;dr: We proposed parameter-free methods whose convergence rate is asymptotically independent of $L$ under $(L_0, L_1)$-smoothness

Gradient descent and its variants are de facto standard algorithms for training machine learning models. As gradient descent is sensitive to its hyperparameters, we need to tune the hyperparameters carefully using a grid search. However, the method is time-consuming, particularly when multiple hyperparameters exist. Therefore, recent studies have analyzed parameter-free methods that adjust the hyperparameters on the fly. However, the existing work is limited to investigations of parameter-free methods for the stepsize, and parameter-free methods for other hyperparameters have not been explored. For instance, although the gradient clipping threshold is a crucial hyperparameter in addition to the stepsize for preventing gradient explosion issues, none of the existing studies have investigated parameter-free methods for clipped gradient descent. Therefore, in this study, we investigate the parameter-free methods for clipped gradient descent. Specifically, we propose Inexact Polyak Stepsize, which converges to the optimal solution without any hyperparameters tuning, and its convergence rate is asymptotically independent of $L$ under $L$-smooth and $(L_0, L_1)$-smooth assumptions of the loss function, similar to that of clipped gradient descent with well-tuned hyperparameters. We numerically validated our convergence results using a synthetic function and demonstrated the effectiveness of our proposed methods using LSTM, Nano-GPT, and T5.
tl;dr: This paper introduces Diff-Tuning, a method to adapt pre-trained diffusion models, showing significant improvements over standard fine-tuning across eight tasks and five conditions with ControlNet.

Diffusion models have significantly advanced the field of generative modeling. However, training a diffusion model is computationally expensive, creating a pressing need to adapt off-the-shelf diffusion models for downstream generation tasks. Current fine-tuning methods focus on parameter-efficient transfer learning but overlook the fundamental transfer characteristics of diffusion models.
In this paper, we investigate the transferability of diffusion models and observe a monotonous chain of forgetting trend of transferability along the reverse process. Based on this observation and novel theoretical insights, we present Diff-Tuning, a frustratingly simple transfer approach that leverages the chain of forgetting tendency. Diff-Tuning encourages the fine-tuned model to retain the pre-trained knowledge at the end of the denoising chain close to the generated data while discarding the other noise side.
We conduct comprehensive experiments to evaluate Diff-Tuning, including the transfer of pre-trained Diffusion Transformer models to eight downstream generations and the adaptation of Stable Diffusion to five control conditions with ControlNet.
Diff-Tuning achieves a 24.6% improvement over standard fine-tuning and enhances the convergence speed of ControlNet by 24%. Notably, parameter-efficient transfer learning techniques for diffusion models can also benefit from Diff-Tuning. Code
is available at this repository: https://github.com/thuml/Diffusion-Tuning.
tl;dr: We reveal a hidden yet harmful phenomenon, content shift, in diffusion features, and propose a method to utilize off-the-shelf generation techniques to suppress it.

Diffusion models are powerful generative models, and this capability can also be applied to discrimination. The inner activations of a pre-trained diffusion model can serve as features for discriminative tasks, namely, diffusion feature. We discover that diffusion feature has been hindered by a hidden yet universal phenomenon that we call content shift. To be specific, there are content differences between features and the input image, such as the exact shape of a certain object. We locate the cause of content shift as one inherent characteristic of diffusion models, which suggests the broad existence of this phenomenon in diffusion feature. Further empirical study also indicates that its negative impact is not negligible even when content shift is not visually perceivable. Hence, we propose to suppress content shift to enhance the overall quality of diffusion features. Specifically, content shift is related to the information drift during the process of recovering an image from the noisy input, pointing out the possibility of turning off-the-shelf generation techniques into tools for content shift suppression. We further propose a practical guideline named GATE to efficiently evaluate the potential benefit of a technique and provide an implementation of our methodology. Despite the simplicity, the proposed approach has achieved superior results on various tasks and datasets, validating its potential as a generic booster for diffusion features. Our code is available at https://github.com/Darkbblue/diffusion-content-shift.

We study a multi-agent imitation learning (MAIL) problem where we take the perspective of a learner attempting to *coordinate* a group of agents based on demonstrations of an expert doing so. Most prior work in MAIL essentially reduces the problem to matching the behavior of the expert *within* the support of the demonstrations. While doing so is sufficient to drive the *value gap* between the learner and the expert to zero under the assumption that agents are non-strategic, it does not guarantee robustness to deviations by strategic agents. Intuitively, this is because strategic deviations can depend on a counterfactual quantity: the coordinator's recommendations outside of the state distribution their recommendations induce. In response, we initiate the study of an alternative objective for MAIL in Markov Games we term the *regret gap* that explicitly accounts for potential deviations by agents in the group. We first perform an in-depth exploration of the relationship between the value and regret gaps. First, we show that while the value gap can be efficiently minimized via a direct extension of single-agent IL algorithms, even *value equivalence* can lead to an arbitrarily large regret gap. This implies that achieving regret equivalence is harder than achieving value equivalence in MAIL. We then provide a pair of efficient reductions to no-regret online convex optimization that are capable of minimizing the regret gap *(a)* under a coverage assumption on the expert (MALICE) or *(b)* with access to a queryable expert (BLADES).
tl;dr: We introduce a connection between cost-aware Bayesian optimization and the Pandora's Box problem from economics, and use it to derive a novel cost-aware acquisition function class with promising performance.

Bayesian optimization is a technique for efficiently optimizing unknown functions in a black-box manner. To handle practical settings where gathering data requires use of finite resources, it is desirable to explicitly incorporate function evaluation costs into Bayesian optimization policies. To understand how to do so, we develop a previously-unexplored connection between cost-aware Bayesian optimization and the Pandora's Box problem, a decision problem from economics. The Pandora's Box problem admits a Bayesian-optimal solution based on an expression called the Gittins index, which can be reinterpreted as an acquisition function. We study the use of this acquisition function for cost-aware Bayesian optimization, and demonstrate empirically that it performs well, particularly in medium-high dimensions. We further show that this performance carries over to classical Bayesian optimization without explicit evaluation costs. Our work constitutes a first step towards integrating techniques from Gittins index theory into Bayesian optimization.
3133. Sharpness-Aware Minimization Activates the Interactive Teaching's Understanding and Optimization

Teaching is a potentially effective approach for understanding interactions among multiple intelligences. Previous explorations have convincingly shown that teaching presents additional opportunities for observation and demonstration within the learning model, such as data distillation and selection. However, the underlying optimization principles and convergence of interactive teaching lack theoretical analysis, and in this regard co-teaching serves as a notable prototype. In this paper, we discuss its role as a reduction of the larger loss landscape derived from Sharpness-Aware Minimization (SAM). Then, we classify it as an iterative parameter estimation process using Expectation-Maximization. The convergence of this typical interactive teaching is achieved by continuously optimizing a variational lower bound on the log marginal likelihood. This lower bound represents the expected value of the log posterior distribution of the latent variables under a scaled, factorized variational distribution. To further enhance interactive teaching's performance, we incorporate SAM's strong generalization information into interactive teaching, referred as Sharpness Reduction Interactive Teaching (SRIT). This integration can be viewed as a novel sequential optimization process. Finally, we validate the performance of our approach through multiple experiments.
tl;dr: We discover that NeuS is unbiased for not only opaque but also transparent models, and propose a method to reconstruct transparent and opaque models simultaneously from multi-view images.
Traditional 3D shape reconstruction techniques from multi-view images, such as structure from motion and multi-view stereo, primarily focus on opaque surfaces. Similarly, recent advances in neural radiance fields and its variants also primarily address opaque objects, encountering difficulties with the complex lighting effects caused by transparent materials. This paper introduces $\alpha$-NeuS, a new method for simultaneously reconstructing thin transparent objects and opaque objects based on neural implicit surfaces (NeuS). Our method leverages the observation that transparent surfaces induce local extreme values in the learned distance fields during neural volumetric rendering, contrasting with opaque surfaces that align with zero level sets. Traditional iso-surfacing algorithms such as marching cubes, which rely on fixed iso-values, are ill-suited for this data. We address this by taking the absolute value of the distance field and developing an optimization method that extracts level sets corresponding to both non-negative local minima and zero iso-values. We prove that the reconstructed surfaces are unbiased for both transparent and opaque objects. To validate our approach, we construct a benchmark that includes both real-world and synthetic scenes, demonstrating its practical utility and effectiveness. Our data and code are publicly available at https://github.com/728388808/alpha-NeuS.
tl;dr: LoQT enables efficient quantized pretraining of LLMs with results close to full-rank non-quantized models. It enables pretraining of a 13B LLM on a 24GB GPU without model parallel, checkpointing, or offloading strategies during training.

Despite advances using low-rank adapters and quantization, pretraining of large models on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose Low-Rank Adapters for Quantized Training (LoQT), a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning models. We demonstrate this for language modeling and downstream task adaptation, finding that LoQT enables efficient training of models up to 7B parameters on a 24GB GPU. We also demonstrate the feasibility of training a 13B model using per-layer gradient updates on the same hardware.

We study a novel problem to automatically generate video background that tailors to foreground subject motion. It is an important problem for the movie industry and visual effects community, which traditionally requires tedious manual efforts to solve. To this end, we propose ActAnywhere, a video diffusion model that takes as input a sequence of foreground subject segmentation and an image of a novel background and generates a video of the subject interacting in this background. We train our model on a large-scale dataset of 2.4M videos of human-scene interactions. Through extensive evaluation, we show that our model produces videos with realistic foreground-background interaction while strictly following the guidance of the condition image. Our model generalizes to diverse scenarios including non-human subjects, gaming and animation clips, as well as videos with multiple moving subjects. Both quantitative and qualitative comparisons demonstrate that our model significantly outperforms existing methods, which fail to accomplish the studied task. Please visit our project webpage at https://actanywhere.github.io.
tl;dr: This paper underscores the critical role of marginal and conditional calibration in survival analysis and introduces a method that enhances both marginal and conditional calibration without sacrificing discrimination performance in survival models.

Survival prediction often involves estimating the time-to-event distribution from censored datasets. Previous approaches have focused on enhancing discrimination and marginal calibration. In this paper, we highlight the significance of *conditional calibration* for real-world applications – especially its role in individual decision-making. We propose a method based on conformal prediction that uses the model’s predicted individual survival probability at that instance’s observed time. This method effectively improves the model’s marginal and conditional calibration, without compromising discrimination. We provide asymptotic theoretical guarantees for both marginal and conditional calibration and test it extensively across 15 diverse real-world datasets, demonstrating the method’s practical effectiveness and
versatility in various settings.
tl;dr: We propose Heterogeneous Pre-trained Transformers (HPT) that pre-train policy representation across different robot embodiments and tasks, scale it to 1B parameters and 50 datasets, and demonstrate transfer in simulation and real world evaluation.

One of the roadblocks for training generalist robotic models today is heterogeneity. Previous robot learning methods often collect data to train with one specific embodiment for one task, which is expensive and prone to overfitting. This work studies the problem of learning policy representations through heterogeneous pre-training on robot data across different embodiments and tasks at scale. We propose Heterogeneous Pre-trained Transformers (HPT), which pre-train a large, shareable trunk of a policy neural network to learn a task and embodiment agnostic shared representation. This general architecture aligns the specific proprioception and vision inputs from distinct embodiments to a short sequence of tokens and then processes such tokens to map to control robots for different tasks. Leveraging the recent large-scale multi-embodiment real-world robotic datasets as well as simulation, deployed robots, and human video datasets, we investigate pre-training policies across heterogeneity. We conduct experiments to investigate the scaling behaviors of training objectives, to the extent of 52 datasets. HPTs outperform several baselines and enhance the fine-tuned policy performance by over 20% on unseen tasks in multiple simulator benchmarks and real-world settings. See the project website (liruiw.github.io/hpt) for code and videos.

Recent advances in low light image enhancement have been dominated by Retinex-based learning framework, leveraging convolutional neural networks (CNNs) and Transformers. However, the vanilla Retinex theory primarily addresses global illumination degradation and neglects local issues such as noise and blur in dark conditions. Moreover, CNNs and Transformers struggle to capture global degradation due to their limited receptive fields. While state space models (SSMs) have shown promise in the long-sequence modeling, they face challenges in combining local invariants and global context in visual data. In this paper, we introduce MambaLLIE, an implicit Retinex-aware low light enhancer featuring a global-then-local state space design. We first propose a Local-Enhanced State Space Module (LESSM) that incorporates an augmented local bias within a 2D selective scan mechanism, enhancing the original SSMs by preserving local 2D dependency. Additionally, an Implicit Retinex-aware Selective Kernel module (IRSK) dynamically selects features using spatially-varying operations, adapting to varying inputs through an adaptive kernel selection process. Our Global-then-Local State Space Block (GLSSB) integrates LESSM and IRSK with layer normalization (LN) as its core. This design enables MambaLLIE to achieve comprehensive global long-range modeling and flexible local feature aggregation. Extensive experiments demonstrate that MambaLLIE significantly outperforms state-of-the-art CNN and Transformer-based methods. Our code is available at https://github.com/wengjiangwei/MambaLLIE.
tl;dr: Full collaboration can be suboptimal in the presence of heterogeneity and Byzantine adversaries, we shed light on when personalization can improve robustness.

Federated learning (FL) is an appealing paradigm that allows a group of machines
(a.k.a. clients) to learn collectively while keeping their data local. However, due
to the heterogeneity between the clients’ data distributions, the model obtained
through the use of FL algorithms may perform poorly on some client’s data.
Personalization addresses this issue by enabling each client to have a different
model tailored to their own data while simultaneously benefiting from the other
clients’ data. We consider an FL setting where some clients can be adversarial, and
we derive conditions under which full collaboration fails. Specifically, we analyze
the generalization performance of an interpolated personalized FL framework in the
presence of adversarial clients, and we precisely characterize situations when full
collaboration performs strictly worse than fine-tuned personalization. Our analysis
determines how much we should scale down the level of collaboration, according
to data heterogeneity and the tolerable fraction of adversarial clients. We support
our findings with empirical results on mean estimation and binary classification
problems, considering synthetic and benchmark image classification datasets
tl;dr: We introduce the first membership inference attack (MIA) benchmark for VLLMs and propose a novel MIA pipeline with a new MIA metric.

Large vision-language models (VLLMs) exhibit promising capabilities for processing multi-modal tasks across various application scenarios. However, their emergence also raises significant data security concerns, given the potential inclusion of sensitive information, such as private photos and medical records, in their training datasets. Detecting inappropriately used data in VLLMs remains a critical and unresolved issue, mainly due to the lack of standardized datasets and suitable methodologies. In this study, we introduce the first membership inference attack (MIA) benchmark tailored for various VLLMs to facilitate training data detection. Then, we propose a novel MIA pipeline specifically designed for token-level image detection. Lastly, we present a new metric called MaxRényi-K%, which is based on the confidence of the model output and applies to both text and image data. We believe that our work can deepen the understanding and methodology of MIAs in the context of VLLMs. Our code and datasets are available at https://github.com/LIONS-EPFL/VL-MIA.

Transformers have achieved great success in recent years. Interestingly, transformers have shown particularly strong in-context learning capability -- even without fine-tuning, they are still able to solve unseen tasks well purely based on task-specific prompts. In this paper, we study the capability of one-layer transformers in learning the one-nearest neighbor prediction rule. Under a theoretical framework where the prompt contains a sequence of labeled training data and unlabeled test data, we show that, although the loss function is nonconvex, when trained with gradient descent, a single softmax attention layer can successfully learn to behave like a one-nearest neighbor classifier. Our result gives a concrete example on how transformers can be trained to implement nonparametric machine learning algorithms, and sheds light on the role of softmax attention in transformer models.
tl;dr: We study bandits with expert advice when given an option to abstain from making any action, and achieve novel reward bounds for confidence rated predictors.

We study the classic problem of prediction with expert advice under bandit feedback. Our model assumes that one action, corresponding to the learner's abstention from play, has no reward or loss on every trial. We propose the CBA (Confidence-rated Bandits with Abstentions) algorithm, which exploits this assumption to obtain reward bounds that can significantly improve those of the classical Exp4 algorithm. Our problem can be construed as the aggregation of confidence-rated predictors, with the learner having the option to abstain from play. We are the first to achieve bounds on the expected cumulative reward for general confidence-rated predictors. In the special case of specialists, we achieve a novel reward bound, significantly improving previous bounds of SpecialistExp (treating abstention as another action). We discuss how CBA can be applied to the problem of adversarial contextual bandits with the option of abstaining from selecting any action. We are able to leverage a wide range of inductive biases, outperforming previous approaches both theoretically and in preliminary experimental analysis. Additionally, we achieve a reduction in runtime from quadratic to almost linear in the number of contexts for the specific case of metric space contexts.
tl;dr: A new method for estimating mutual information exploiting the variational representation of the $f$-divergence and a derangement training strategy

Estimating mutual information accurately is pivotal across diverse applications, from machine learning to communications and biology, enabling us to gain insights into the inner mechanisms of complex systems. Yet, dealing with high-dimensional data presents a formidable challenge, due to its size and the presence of intricate relationships. Recently proposed neural methods employing variational lower bounds on the mutual information have gained prominence. However, these approaches suffer from either high bias or high variance, as the sample size and the structure of the loss function directly influence the training process. In this paper, we propose a novel class of discriminative mutual information estimators based on the variational representation of the $f$-divergence. We investigate the impact of the permutation function used to obtain the marginal training samples and present a novel architectural solution based on derangements. The proposed estimator is flexible since it exhibits an excellent bias/variance trade-off. The comparison with state-of-the-art neural estimators, through extensive experimentation within established reference scenarios, shows that our approach offers higher accuracy and lower complexity.

In this study, we introduce a unified neural network architecture, the Deep Equilibrium Density Functional Theory Hamiltonian (DEQH) model, which incorporates Deep Equilibrium Models (DEQs) for predicting Density Functional Theory (DFT) Hamiltonians. The DEQH model inherently captures the self-consistency nature of Hamiltonian, a critical aspect often overlooked by traditional machine learning approaches for Hamiltonian prediction. By employing DEQ within our model architecture, we circumvent the need for DFT calculations during the training phase to introduce the Hamiltonian's self-consistency, thus addressing computational bottlenecks associated with large or complex systems. We propose a versatile framework that combines DEQ with off-the-shelf machine learning models for predicting Hamiltonians. When benchmarked on the MD17 and QH9 datasets, DEQHNet, an instantiation of the DEQH framework, has demonstrated a significant improvement in prediction accuracy. Beyond a predictor, the DEQH model is a Hamiltonian solver, in the sense that it uses the fixed-point solving capability of the deep equilibrium model to iteratively solve for the Hamiltonian. Ablation studies of DEQHNet further elucidate the network's effectiveness, offering insights into the potential of DEQ-integrated networks for Hamiltonian learning. We open source our implementation at https://github.com/Zun-Wang/DEQHNet.
tl;dr: Active preference learning supports fast ordering of items in- and out-of-sample. Sample complexity analysis justifies active sampling criteria.

Learning an ordering of items based on pairwise comparisons is useful when items are difficult to rate consistently on an absolute scale, for example, when annotators have to make subjective assessments. When exhaustive comparison is infeasible, actively sampling item pairs can reduce the number of annotations necessary for learning an accurate ordering. However, many algorithms ignore shared structure between items, limiting their sample efficiency and precluding generalization to new items. It is also common to disregard how noise in comparisons varies between item pairs, despite it being informative of item similarity. In this work, we study active preference learning for ordering items with contextual attributes, both in- and out-of-sample. We give an upper bound on the expected ordering error of a logistic preference model as a function of which items have been compared. Next, we propose an active learning strategy that samples items to minimize this bound by accounting for aleatoric and epistemic uncertainty in comparisons. We evaluate the resulting algorithm, and a variant aimed at reducing model misspecification, in multiple realistic ordering tasks with comparisons made by human annotators. Our results demonstrate superior sample efficiency and generalization compared to non-contextual ranking approaches and active preference learning baselines.
tl;dr: A novel multi-modal generation framework for text guided video-to-audio generation and video-to-audio captioning.

The content of visual and audio scenes is multi-faceted such that a video stream can
be paired with various audio streams and vice-versa. Thereby, in video-to-audio
generation task, it is imperative to introduce steering approaches for controlling the
generated audio. While Video-to-Audio generation is a well-established generative
task, existing methods lack such controllability. In this work, we propose VATT, a
multi-modal generative framework that takes a video and an optional text prompt
as input, and generates audio and optional textual description (caption) of the
audio. Such a framework has two unique advantages: i) Video-to-Audio generation
process can be refined and controlled via text which complements the context
of the visual information, and ii) The model can suggest what audio to generate
for the video by generating audio captions. VATT consists of two key modules:
VATT Converter, which is an LLM that has been fine-tuned for instructions and
includes a projection layer that maps video features to the LLM vector space, and
VATT Audio, a bi-directional transformer that generates audio tokens from visual
frames and from optional text prompt using iterative parallel decoding. The audio
tokens and the text prompt are used by a pretrained neural codec to convert them
into a waveform. Our experiments show that when VATT is compared to existing
video-to-audio generation methods in objective metrics, such as VGGSound audiovisual dataset, it achieves competitive performance when the audio caption is
not provided. When the audio caption is provided as a prompt, VATT achieves
even more refined performance (with lowest KLD score of 1.41). Furthermore,
subjective studies asking participants to choose the most compatible generated
audio for a given silent video, show that VATT Audio has been chosen on average
as a preferred generated audio than the audio generated by existing methods. VATT
enables controllable video-to-audio generation through text as well as suggesting
text prompts for videos through audio captions, unlocking novel applications such
as text-guided video-to-audio generation and video-to-audio captioning.

Skeleton-based multi-entity action recognition is a challenging task aiming to identify interactive actions or group activities involving multiple diverse entities. Existing models for individuals often fall short in this task due to the inherent distribution discrepancies among entity skeletons, leading to suboptimal backbone optimization. To this end, we introduce a Convex Hull Adaptive Shift based multi-Entity action recognition method (CHASE), which mitigates inter-entity distribution gaps and unbiases subsequent backbones. Specifically, CHASE comprises a learnable parameterized network and an auxiliary objective. The parameterized network achieves plausible, sample-adaptive repositioning of skeleton sequences through two key components. First, the Implicit Convex Hull Constrained Adaptive Shift ensures that the new origin of the coordinate system is within the skeleton convex hull. Second, the Coefficient Learning Block provides a lightweight parameterization of the mapping from skeleton sequences to their specific coefficients in convex combinations. Moreover, to guide the optimization of this network for discrepancy minimization, we propose the Mini-batch Pair-wise Maximum Mean Discrepancy as the additional objective. CHASE operates as a sample-adaptive normalization method to mitigate inter-entity distribution discrepancies, thereby reducing data bias and improving the subsequent classifier's multi-entity action recognition performance. Extensive experiments on six datasets, including NTU Mutual 11/26, H2O, Assembly101, Collective Activity and Volleyball, consistently verify our approach by seamlessly adapting to single-entity backbones and boosting their performance in multi-entity scenarios. Our code is publicly available at https://github.com/Necolizer/CHASE .
tl;dr: QueST is a multitask latent-variable behavior model that learns sharable low-level skills by representing temporal action abstractions (1-2 secs motion) with a sequence of discrete codebook entries (skill-tokens).

Generalization capabilities, or rather a lack thereof, is one of the most important unsolved problems in the field of robot learning, and while several large scale efforts have set out to tackle this problem, unsolved it remains. In this paper, we hypothesize that learning temporal action abstractions using latent variable models (LVMs), which learn to map data to a compressed latent space and back, is a
promising direction towards low-level skills that can readily be used for new tasks. Although several works have attempted to show this, they have generally been limited by architectures that do not faithfully capture sharable representations. To address this we present Quantized Skill Transformer (QueST), which learns a larger and more flexible latent encoding that is more capable of modeling the breadth of low-level skills necessary for a variety of tasks. To make use of this extra flexibility, QueST imparts causal inductive bias from the action sequence data into the latent space, leading to more semantically useful and transferable representations. We compare to state-of-the-art imitation learning and LVM baselines and see that QueST’s architecture leads to strong performance on several multitask and few-shot learning benchmarks. Further results and videos are available at https://quest-model.github.io.

Diffusion models have become the most popular approach to deep generative modeling of images, largely due to their empirical performance and reliability. From a theoretical standpoint, a number of recent works [CCL+23, CCSW22, BBDD24] have studied the iteration complexity of sampling, assuming access to an accurate diffusion model. In this work, we focus on understanding the *sample complexity* of training such a model; how many samples are needed to learn an accurate diffusion model using a sufficiently expressive neural network? Prior work [BMR20] showed bounds polynomial in the dimension, desired Total Variation error, and Wasserstein error. We show an *exponential improvement* in the dependence on Wasserstein error and depth, along with improved dependencies on other relevant parameters.
tl;dr: This paper proposes Satformer, an accurate and robust method for estimating highly dynamic traffic data in satellite networks.

The operations and maintenance of satellite networks heavily depend on traffic measurements. Due to the large-scale and highly dynamic nature of satellite networks, global measurement encounters significant challenges in terms of complexity and overhead. Estimating global network traffic data from partial traffic measurements is a promising solution. However, the majority of current estimation methods concentrate on low-rank linear decomposition, which is unable to accurately estimate. The reason lies in its inability to capture the intricate nonlinear spatio-temporal relationship found in large-scale, highly dynamic traffic data. This paper proposes Satformer, an accurate and robust method for estimating traffic data in satellite networks. In Satformer, we innovatively incorporate an adaptive sparse spatio-temporal attention mechanism. In the mechanism, more attention is paid to specific local regions of the input tensor to improve the model's sensitivity on details and patterns. This method enhances its capability to capture nonlinear spatio-temporal relationships. Experiments on small, medium, and large-scale satellite networks datasets demonstrate that Satformer outperforms mathematical and neural baseline methods notably. It provides substantial improvements in reducing errors and maintaining robustness, especially for larger networks. The approach shows promise for deployment in actual systems.
tl;dr: A convergence analysis for Sharpness-Aware Minimization and its variants.

The paper investigates the fundamental convergence properties of Sharpness-Aware Minimization (SAM), a recently proposed gradient-based optimization method (Foret et al., 2021) that significantly improves the generalization of deep neural networks. The convergence properties including the stationarity of accumulation points, the convergence of the sequence of gradients to the origin, the sequence of function values to the optimal value, and the sequence of iterates to the optimal solution are established for the method. The universality of the provided convergence analysis based on inexact gradient descent frameworks (Khanh et al., 2023b) allows its extensions to the normalized versions of SAM such as F-SAM (Li et al. 2024), VaSSO (Li & Giannakis, 2023), RSAM (Liu et al., 2022), and to the unnormalized versions of SAM such as USAM (Andriushchenko & Flammarion, 2022). Numerical experiments are conducted on classification tasks using deep learning models to confirm the practical aspects of our analysis.
tl;dr: Our work enhances AI-driven free space optical neural networks by using a physics-constrained learning framework to correct systematic errors, significantly boosting image recognition accuracy.

With the advantages of low latency, low power consumption, and high parallelism, optical neural networks (ONN) offer a promising solution for time-sensitive and resource-limited artificial intelligence applications. However, the performance of the ONN model is often diminished by the gap between the ideal simulated system and the actual physical system. To bridge the gap, this work conducts extensive experiments to investigate systematic errors in the optical physical system within the context of image classification tasks. Through our investigation, two quantifiable errors—light source instability and exposure time mismatches—significantly impact the prediction performance of ONN. To address these systematic errors, a physics-constrained ONN learning framework is constructed, including a well designed loss function to mitigate the effect of light fluctuations, a CCD adjustment strategy to alleviate the effects of exposure time mismatches and a ’physics-prior based’ error compensation network to manage other systematic errors, ensuring consistent light intensity across experimental results and simulations. In our experiments, the proposed method achieved a test classification accuracy of 96.5% on the MNIST dataset, a substantial improvement over the 61.6% achieved with the original ONN. For the more challenging QuickDraw16 and Fashion MNIST datasets, experimental accuracy improved from 63.0% to 85.7% and from 56.2% to 77.5%, respectively. Moreover, the comparison results further demonstrate the effectiveness of the proposed physics-constrained ONN learning framework over state-of-the-art ONN approaches. This lays the groundwork for more robust and precise optical computing applications.

Decision support systems based on prediction sets help humans solve multiclass classification tasks by narrowing down the set of potential label values to a subset of them, namely a prediction set, and asking them to always predict label values from the prediction sets. While this type of systems have been proven to be effective at improving the average accuracy of the predictions made by humans, by restricting human agency, they may cause harm---a human who has succeeded at predicting the ground-truth label of an instance on their own may have failed had they used these systems. In this paper, our goal is to control how frequently a decision support system based on prediction sets may cause harm, by design. To this end, we start by characterizing the above notion of harm using the theoretical framework of structural causal models. Then, we show that, under a natural, albeit unverifiable, monotonicity assumption, we can estimate how frequently a system may cause harm using only predictions made by humans on their own. Further, we also show that, under a weaker monotonicity assumption, which can be verified experimentally, we can bound how frequently a system may cause harm again using only predictions made by humans on their own. Building upon these assumptions, we introduce a computational framework to design decision support systems based on prediction sets that are guaranteed to cause harm less frequently than a user-specified value
using conformal risk control. We validate our framework using real human predictions from two different human subject studies and show that, in decision support systems based on prediction sets, there is a trade-off between accuracy and counterfactual harm.
tl;dr: We evaluate two approaches to predict the future actions of agents trained by different types of reinforcement learning algorithms.

As reinforcement learning agents become increasingly deployed in real-world scenarios, predicting future agent actions and events during deployment is important for facilitating better human-agent interaction and preventing catastrophic outcomes. This paper experimentally evaluates and compares the effectiveness of future action and event prediction for three types of RL agents: explicitly planning, implicitly planning, and non-planning. We employ two approaches: the inner state approach, which involves predicting based on the inner computations of the agents (e.g., plans or neuron activations), and a simulation-based approach, which involves unrolling the agent in a learned world model. Our results show that the plans of explicitly planning agents are significantly more informative for prediction than the neuron activations of the other types. Furthermore, using internal plans proves more robust to model quality compared to simulation-based approaches when predicting actions, while the results for event prediction are more mixed. These findings highlight the benefits of leveraging inner states and simulations to predict future agent actions and events, thereby improving interaction and safety in real-world deployments.
tl;dr: An optimal sample complexity algorithm with partial data coverage for offline safe RL.

Offline safe reinforcement learning (RL) aims to find an optimal policy using a pre-collected dataset when data collection is impractical or risky. We propose a novel linear programming (LP) based primal-dual algorithm for convex MDPs that incorporates ``uncertainty'' parameters to improve data efficiency while requiring only partial data coverage assumption. Our theoretical results achieve a sample complexity of $\mathcal{O}(1/(1-\gamma)\sqrt{n})$ under general function approximation, improving the current state-of-the-art by a factor of $1/(1-\gamma)$, where $n$ is the number of data samples in an offline dataset, and $\gamma$ is the discount factor. The numerical experiments validate our theoretical findings, demonstrating the practical efficacy of our approach in achieving improved safety and learning efficiency in safe offline settings.

The attention mechanism within the transformer architecture enables the model to weigh and combine tokens based on their relevance to the query. While self-attention has enjoyed major success, it notably treats all queries $q$ in the same way by applying the mapping $V^\top\text{softmax}(Kq)$, where $V,K$ are the value and key embeddings respectively. In this work, we argue that this uniform treatment hinders the ability to control contextual sparsity and relevance. As a solution, we introduce the Selective Self-Attention (SSA) layer that augments the softmax nonlinearity with a principled temperature scaling strategy. By controlling temperature, SSA adapts the contextual sparsity of the attention map to the query embedding and its position in the context window. Through theory and experiments, we demonstrate that this alleviates attention dilution, aids the optimization process, and enhances the model's ability to control softmax spikiness of individual queries. We also incorporate temperature scaling for value embeddings and show that it boosts the model's ability to suppress irrelevant/noisy tokens. Notably, SSA is a lightweight method which introduces less than 0.5\% new parameters through a weight-sharing strategy and can be fine-tuned on existing LLMs. Extensive empirical evaluations demonstrate that SSA-equipped models achieve a noticeable and consistent accuracy improvement on language modeling benchmarks.
tl;dr: A novel diffusion-based 3D scene diffusion model for 3D scene reconstruction from a single RGB image

We present a novel diffusion-based approach for coherent 3D scene reconstruction from a single RGB image.
Our method utilizes an image-conditioned 3D scene diffusion model to simultaneously denoise the 3D poses and geometries of all objects within the scene.
Motivated by the ill-posed nature of the task and to obtain consistent scene reconstruction results, we learn a generative scene prior by conditioning on all scene objects simultaneously to capture scene context and by allowing the model to learn inter-object relationships throughout the diffusion process.
We further propose an efficient surface alignment loss to facilitate training even in the absence of full ground-truth annotation, which is common in publicly available datasets. This loss leverages an expressive shape representation, which enables direct point sampling from intermediate shape predictions.
By framing the task of single RGB image 3D scene reconstruction as a conditional diffusion process, our approach surpasses current state-of-the-art methods, achieving a 12.04\% improvement in AP3D on SUN RGB-D and a 13.43\% increase in F-Score on Pix3D.

Vision transformer model (ViT) is widely used and performs well in vision tasks due to its ability to capture long-range dependencies. However, the time complexity and memory consumption increase quadratically with the number of input patches which limits the usage of ViT in real-world applications. Previous methods have employed linear attention to mitigate the complexity of the original self-attention mechanism at the expense of effectiveness. In this paper, we propose QT-ViT models that improve the previous linear self-attention using quadratic Taylor expansion. Specifically, we substitute the softmax-based attention with second-order Taylor expansion, and then accelerate the quadratic expansion by reducing the time complexity with a fast approximation algorithm. The proposed method capitalizes on the property of quadratic expansion to achieve superior performance while employing linear approximation for fast inference. Compared to previous studies of linear attention, our approach does not necessitate knowledge distillation or high-order attention residuals to facilitate the training process. Extensive experiments demonstrate the efficiency and effectiveness of the proposed QT-ViTs, showcasing the state-of-the-art results. Particularly, the proposed QT-ViTs consistently surpass the previous SOTA EfficientViTs under different model sizes, and achieve a new Pareto-front in terms of accuracy and speed.
tl;dr: We propose Latent Neural Operator to solve forward and inverse PDE problems in latent space.

Neural operators effectively solve PDE problems from data without knowing the explicit equations, which learn the map from the input sequences of observed samples to the predicted values. Most existing works build the model in the original geometric space, leading to high computational costs when the number of sample points is large. We present the Latent Neural Operator (LNO) solving PDEs in the latent space. In particular, we first propose Physics-Cross-Attention (PhCA) transforming representation from the geometric space to the latent space, then learn the operator in the latent space, and finally recover the real-world geometric space via the inverse PhCA map. Our model retains flexibility that can decode values in any position not limited to locations defined in the training set, and therefore can naturally perform interpolation and extrapolation tasks particularly useful for inverse problems. Moreover, the proposed LNO improves both prediction accuracy and computational efficiency. Experiments show that LNO reduces the GPU memory by 50%, speeds up training 1.8 times, and reaches state-of-the-art accuracy on four out of six benchmarks for forward problems and a benchmark for inverse problem. Code is available at https://github.com/L-I-M-I-T/LatentNeuralOperator.
3161. MACM: Utilizing a Multi-Agent System for Condition Mining in Solving Complex Mathematical Problems
tl;dr: This paper introduces the Multi-Agent System for conditional Mining (MACM) prompting method, which increases the GPT-4 Turbo's accuracy on MATH from 72.78% to 87.92%.

Recent advancements in large language models, such as GPT-4, have demonstrated remarkable capabilities in processing standard queries. Despite these advancements, their performance substantially declines in advanced mathematical problems requiring complex, multi-step logical reasoning. To enhance their inferential capabilities, current research has delved into prompting engineering, exemplified by methodologies such as the Tree of Thought and Graph of Thought.
Nonetheless, these existing approaches encounter two significant limitations. Firstly, their effectiveness in tackling complex mathematical problems is somewhat constrained. Secondly, the necessity to design distinct prompts for individual problems hampers their generalizability.
In response to these limitations, this paper introduces the Multi-Agent System for conditional Mining (MACM) prompting method. It not only resolves intricate mathematical problems but also demonstrates strong generalization capabilities across various mathematical contexts.
With the assistance of MACM, the accuracy of GPT-4 Turbo on the most challenging level five mathematical problems in the MATH dataset increase from $\mathbf{54.68\\%} \text{ to } \mathbf{76.73\\%}$.
tl;dr: Parsimonious Concept Engineering (PaCE) uses sparse coding on a large-scale concept dictionary to precisely control and modify a language model's neural activations, effectively improving the model trustworthiness.

Large Language Models (LLMs) are being used for a wide variety of tasks. While they are capable of generating human-like responses, they can also produce undesirable output including potentially harmful information, racist or sexist language, and hallucinations. Alignment methods are designed to reduce such undesirable output, via techniques such as fine-tuning, prompt engineering, and representation engineering. However, existing methods face several challenges: some require costly fine-tuning for every alignment task; some do not adequately remove undesirable concepts, failing alignment; some remove benign concepts, lowering the linguistic capabilities of LLMs. To address these issues, we propose Parsimonious Concept Engineering (PaCE), a novel activation engineering framework for alignment. First, to sufficiently model the concepts, we construct a large-scale concept dictionary in the activation space, in which each atom corresponds to a semantic concept. Given any alignment task, we instruct a concept partitioner to efficiently annotate the concepts as benign or undesirable. Then, at inference time, we decompose the LLM activations along the concept dictionary via sparse coding, to accurately represent the activations as linear combinations of benign and undesirable components. By removing the latter ones from the activations, we reorient the behavior of the LLM towards the alignment goal. We conduct experiments on tasks such as response detoxification, faithfulness enhancement, and sentiment revising, and show that PaCE achieves state-of-the-art alignment performance while maintaining linguistic capabilities.
tl;dr: We find the ineffectiveness in generating UAP for open-set scenarios such as Few-Shot Learning. Through in-depth analysis, we point out the two shifts and address them to finally achieve a unified attacking framework.

Deep networks are known to be vulnerable to adversarial examples which are deliberately designed to mislead the trained model by introducing imperceptible perturbations to input samples. Compared to traditional perturbations crafted specifically for each data point, Universal Adversarial Perturbations (UAPs) are input-agnostic and shown to be more practical in the real world. However, UAPs are typically generated in a close-set scenario that shares the same classification task during the training and testing phases. This paper demonstrates the ineffectiveness of traditional UAPs in open-set scenarios like Few-Shot Learning (FSL). Through analysis, we identify two primary challenges that hinder the attacking process: the task shift and the semantic shift. To enhance the transferability of UAPs in FSL, we propose a unifying attacking framework addressing these two shifts. The task shift is addressed by aligning proxy tasks to the downstream tasks, while the semantic shift is handled by leveraging the generalizability of pre-trained encoders.The proposed Few-Shot Attacking FrameWork, denoted as FSAFW, can effectively generate UAPs across various FSL training paradigms and different downstream tasks. Our approach not only sets a new standard for state-of-the-art works but also significantly enhances attack performance, exceeding the baseline method by over 16\%.
tl;dr: We introduce Neural P$^3$M, which enhances Geometric GNNs by integrating meshes with atoms and reimaging traditional mathematical operations in a trainable manner.

Geometric graph neural networks (GNNs) have emerged as powerful tools for modeling molecular geometry. However, they encounter limitations in effectively capturing long-range interactions in large molecular systems. To address this challenge, we introduce **Neural P$^3$M**, a versatile enhancer of geometric GNNs to expand the scope of their capabilities by incorporating mesh points alongside atoms and reimaging traditional mathematical operations in a trainable manner. Neural P$^3$M exhibits flexibility across a wide range of molecular systems and demonstrates remarkable accuracy in predicting energies and forces, outperforming on benchmarks such as the MD22 dataset.
It also achieves an average improvement of 22% on the OE62 dataset while integrating with various architectures. Codes are available at https://github.com/OnlyLoveKFC/Neural_P3M.
tl;dr: We propose a novel, scalable method for reconstructing answers to marginal queries. It makes existing mechanisms more scalable, accurate, or both.

Differential privacy is the dominant standard for formal and quantifiable privacy and has been used in major deployments that impact millions of people. Many differentially private algorithms for query release and synthetic data contain steps that reconstruct answers to queries from answers to other queries that have been measured privately. Reconstruction is an important subproblem for such mechanisms to economize the privacy budget, minimize error on reconstructed answers, and allow for scalability to high-dimensional datasets. In this paper, we introduce a principled and efficient postprocessing method ReM (Residuals-to-Marginals) for reconstructing answers to marginal queries. Our method builds on recent work on efficient mechanisms for marginal query release, based on making measurements using a residual query basis that admits efficient pseudoinversion, which is an important primitive used in reconstruction. An extension GReM-LNN (Gaussian Residuals-to-Marginals with Local Non-negativity) reconstructs marginals under Gaussian noise satisfying consistency and non-negativity, which often reduces error on reconstructed answers. We demonstrate the utility of ReM and GReM-LNN by applying them to improve existing private query answering mechanisms.
3166. DisenGCD: A Meta Multigraph-assisted Disentangled Graph Learning Framework for Cognitive Diagnosis

Existing graph learning-based cognitive diagnosis (CD) methods have made relatively good results, but their student, exercise, and concept representations are learned and exchanged in an implicit unified graph, which makes the interaction-agnostic exercise and concept representations be learned poorly, failing to provide high robustness against noise in students' interactions. Besides, lower-order exercise latent representations obtained in shallow layers are not well explored when learning the student representation.
To tackle the issues, this paper suggests a meta multigraph-assisted disentangled graph learning framework for CD (DisenGCD), which learns three types of representations on three disentangled graphs: student-exercise-concept interaction, exercise-concept relation, and concept dependency graphs, respectively.
Specifically, the latter two graphs are first disentangled from the interaction graph.
Then, the student representation is learned from the interaction graph by a devised meta multigraph learning module; multiple learnable propagation paths in this module enable current student latent representation to access lower-order exercise latent representations,
which can lead to more effective nad robust student representations learned;
the exercise and concept representations are learned on the relation and dependency graphs by graph attention modules.
Finally, a novel diagnostic function is devised to handle three disentangled representations for prediction. Experiments show better performance and robustness of DisenGCD than state-of-the-art CD methods and demonstrate the effectiveness of the disentangled learning framework and meta multigraph module.The source code is available at https://github.com/BIMK/Intelligent-Education/tree/main/DisenGCD.

Recent researches have proven that pre-training on large-scale person images extracted from internet videos is an effective way in learning better representations for person re-identification. However, these researches are mostly confined to pre-training at the instance-level or single-video tracklet-level. They ignore the identity-invariance in images of the same person across different videos, which is a key focus in person re-identification. To address this issue, we propose a Cross-video Identity-cOrrelating pre-traiNing (CION) framework. Defining a noise concept that comprehensively considers both intra-identity consistency and inter-identity discrimination, CION seeks the identity correlation from cross-video images by modeling it as a progressive multi-level denoising problem. Furthermore, an identity-guided self-distillation loss is proposed to implement better large-scale pre-training by mining the identity-invariance within person images. We conduct extensive experiments to verify the superiority of our CION in terms of efficiency and performance. CION achieves significantly leading performance with even fewer training samples. For example, compared with the previous state-of-the-art ISR, CION with the same ResNet50-IBN achieves higher mAP of 93.3% and 74.3% on Market1501 and MSMT17, while only utilizing 8% training samples. Finally, with CION demonstrating superior model-agnostic ability, we contribute a model zoo named ReIDZoo to meet diverse research and application needs in this field. It contains a series of CION pre-trained models with spanning structures and parameters, totaling 32 models with 10 different structures, including GhostNet, ConvNext, RepViT, FastViT and so on. The code and models will be open-sourced.

Second-order optimization algorithms, such as the Newton method and the natural gradient descent (NGD) method exhibit excellent convergence properties for training deep neural networks, but the high computational cost limits its practical application. In this paper, we focus on the NGD method and propose a novel layer-wise natural gradient descent (LNGD) method to further reduce computational costs and accelerate the training process. Specifically, based on the block diagonal approximation of the Fisher information matrix, we first propose the layer-wise sample method to compute each block matrix without performing a complete back-propagation. Then, each block matrix is approximated as a Kronecker product of two smaller matrices, one of which is a diagonal matrix, while keeping the traces equal before and after approximation. By these two steps, we provide a new approximation for the Fisher information matrix, which can effectively reduce the computational cost while preserving the main information of each block matrix. Moreover, we propose a new adaptive layer-wise learning rate to further accelerate training. Based on these new approaches, we propose the LNGD optimizer. The global convergence analysis of LNGD is established under some assumptions. Experiments on image classification and machine translation tasks show that our method is quite competitive compared to the state-of-the-art methods.

Graph Neural Networks (GNNs) experience "catastrophic forgetting" in continual learning setups, where they tend to lose previously acquired knowledge and perform poorly on old tasks. Rehearsal-based methods, which consolidate old knowledge with a replay memory buffer, are a de facto solution due to their straightforward workflow. However, these methods often fail to adequately capture topological information, leading to incorrect input-label mappings in replay samples. To address this, we propose TACO, a topology-aware graph coarsening and continual learning framework that stores information from previous tasks as a reduced graph. Throughout each learning period, this reduced graph expands by integrating with a new graph and aligning shared nodes, followed by a "zoom-out" reduction process to maintain a stable size. We have developed a graph coarsening algorithm based on node representation proximities to efficiently reduce a graph while preserving essential topological information. We empirically demonstrate that the learning process on the reduced graph can closely approximate that on the original graph. We compare TACO with a wide range of state-of-the-art baselines, proving its superiority and the necessity of preserving high-quality topological information for effective replaying.

Due to its low storage cost and fast search speed, cross-modal retrieval based on hashing has attracted widespread attention and is widely used in real-world applications of social media search. However, most existing hashing methods are often limited by uncomprehensive feature representations and semantic associations, which greatly restricts their performance and applicability in practical applications. To deal with this challenge, in this paper, we propose an end-to-end graph attention network hashing (EGATH) for cross-modal retrieval, which can not only capture direct semantic associations between images and texts but also match semantic content between different modalities. We adopt the contrastive language image pretraining (CLIP) combined with the Transformer to improve understanding and generalization ability in semantic consistency across different data modalities. The classifier based on graph attention network is applied to obtain predicted labels to enhance cross-modal feature representation. We construct hash codes using an optimization strategy and loss function to preserve the semantic information and compactness of the hash code. Comprehensive experiments on the NUS-WIDE, MIRFlickr25K, and MS-COCO benchmark datasets show that our EGATH significantly outperforms against several state-of-the-art methods.

Current PEFT methods for LLMs can achieve either high quality, efficient training, or scalable serving, but not all three simultaneously. To address this limitation, we investigate sparse fine-tuning and observe a remarkable improvement in generalization ability.
Utilizing this key insight, we propose a family of Structured Sparse Fine-Tuning (S${^2}$FT) methods for LLMs, which concurrently achieve state-of-the-art fine-tuning performance, training efficiency, and inference scalability. S${^2}$FT accomplishes this by selecting sparsely and computing densely. It selects a few heads and channels in the MHA and FFN modules for each Transformer Block, respectively. Next, it co-permutes weight matrices on both sides of the coupled structures in LLMs to connect the selected components in each layer into a dense submatrix. Finally, \model performs in-place gradient updates on all submatrices. Through theoretical analysis and empirical results, our method prevents overfitting and forgetting, delivers SOTA performance on both commonsense and arithmetic reasoning with 4.6% and 1.3% average improvements compared to LoRA, and outperforms full FT by 11.5% when generalize to various domains after instruction tuning. By integrating our partial back-propagation algorithm, \model saves the fine-tuning memory up to 3$\times$ and improves the latency by 1.5-2.7$\times$ compared to full FT, while delivering an average 10% improvement over LoRA on both metrics. We further demonstrate that S${^2}$FT can be decoupled into adapters, enabling effective fusion, fast switch, and efficient parallelism for serving multiple fine-tuned models.
tl;dr: enhance prediction efficiency and coverage for time-series data by leveraging deep representations to dynamically adjust weights in the semantic feature space

Conformal prediction is a powerful tool for uncertainty quantification, but its application to time-series data is constrained by the violation of the exchangeability assumption. Current solutions for time-series prediction typically operate in the output space and rely on manually selected weights to address distribution drift, leading to overly conservative predictions. To enable dynamic weight learning in the semantically rich latent space, we introduce a novel approach called Conformalized Time Series with Semantic Features (CT-SSF). CT-SSF utilizes the inductive bias in deep representation learning to dynamically adjust weights, prioritizing semantic features relevant to the current prediction. Theoretically, we show that CT-SSF surpasses previous methods defined in the output space. Experiments on synthetic and benchmark datasets demonstrate that CT-SSF significantly outperforms existing state-of-the-art (SOTA) conformal prediction techniques in terms of prediction efficiency while maintaining a valid coverage guarantee.
tl;dr: We show how to approximate graphs by intersecting communities, which allows an efficient learning algorithm on large non-sparse graphs.

Message Passing Neural Networks (MPNNs) are a staple of graph machine learning. MPNNs iteratively update each node’s representation in an input graph by aggregating messages from the node’s neighbors, which necessitates a memory complexity of the order of the __number of graph edges__. This complexity might quickly become prohibitive for large graphs provided they are not very sparse. In this paper, we propose a novel approach to alleviate this problem by approximating the input graph as an intersecting community graph (ICG) -- a combination of intersecting cliques. The key insight is that the number of communities required to approximate a graph __does not depend on the graph size__. We develop a new constructive version of the Weak Graph Regularity Lemma to efficiently construct an approximating ICG for any input graph. We then devise an efficient graph learning algorithm operating directly on ICG in linear memory and time with respect to the __number of nodes__ (rather than edges). This offers a new and fundamentally different pipeline for learning on very large non-sparse graphs, whose applicability is demonstrated empirically on node classification tasks and spatio-temporal data processing.
tl;dr: We propose methods to detect and measure confounding using data from causal mechanism shifts.

Detecting and measuring confounding effects from data is a key challenge in causal inference. Existing methods frequently assume causal sufficiency, disregarding the presence of unobserved confounding variables. Causal sufficiency is both unrealistic and empirically untestable. Additionally, existing methods make strong parametric assumptions about the underlying causal generative process to guarantee the identifiability of confounding variables. Relaxing the causal sufficiency and parametric assumptions and leveraging recent advancements in causal discovery and confounding analysis with non-i.i.d. data, we propose a comprehensive approach for detecting and measuring confounding. We consider various definitions of confounding and introduce tailored methodologies to achieve three objectives: (i) detecting and measuring confounding among a set of variables, (ii) separating observed and unobserved confounding effects, and (iii) understanding the relative strengths of confounding bias between different sets of variables. We present useful properties of a confounding measure and present measures that satisfy those properties. Our empirical results support the usefulness of the proposed measures.
tl;dr: A model to learn group action on latent factors, e.g. manipulating objects on 2D images.

In this work, we introduce a new approach to model group actions in autoencoders. Diverging from prior research in this domain, we propose to learn the group actions on the latent space rather than strictly on the data space. This adaptation enhances the versatility of our model, enabling it to learn a broader range of scenarios prevalent in the real world, where groups can act on latent factors. Our method allows a wide flexibility in the encoder and decoder architectures and does not require group-specific layers. In addition, we show that our model theoretically serves as a superset of methods that learn group actions on the data space. We test our approach on five image datasets with diverse groups acting on them and demonstrate superior performance to recently proposed methods for modeling group actions.

Molecular learning is pivotal in many real-world applications, such as drug discovery. Supervised learning requires heavy human annotation, which is particularly challenging for molecular data, e.g., the commonly used density functional theory (DFT) is highly computationally expensive. Active learning (AL) automatically queries labels for most informative samples, thereby remarkably alleviating the annotation hurdle. In this paper, we present a principled AL paradigm for molecular learning, where we treat molecules as 3D molecular graphs. Specifically, we propose a new diversity sampling method to eliminate mutual redundancy built on distributions of 3D geometries. We first propose a set of new 3D graph isometries for 3D graph isomorphism analysis. Our method is provably at least as expressive as the Geometric Weisfeiler-Lehman (GWL) test. The moments of the distributions of the associated geometries are then extracted for efficient diversity computing. To ensure our AL paradigm selects samples with maximal uncertainties, we carefully design a Bayesian geometric graph neural network to compute uncertainties specifically for 3D molecular graphs. We pose active sampling as a quadratic programming (QP) problem using the proposed components. Experimental results demonstrate the effectiveness of our AL paradigm, as well as the proposed diversity and uncertainty methods.

We introduce SuperClass, a super simple classification method for vision-language pre-training on image-text data. Unlike its contrastive counterpart CLIP who contrast with a text encoder, SuperClass directly utilizes tokenized raw text as supervised classification labels, without the need for additional text filtering or selection. Due to the absence of the text encoding as contrastive target, SuperClass does not require a text encoder and does not need to maintain a large batch size as CLIP does. SuperClass demonstrated superior performance on various downstream tasks, including classic computer vision benchmarks and vision language downstream tasks. We further explored the scaling behavior of SuperClass on model size, training length, or data size, and reported encouraging results and comparisons to CLIP. https://github.com/x-cls/superclass
tl;dr: We propose the Latent Prompt Transformer, a novel latent space generative model with both offline and online learning algorithms for molecule design.

This work explores the challenging problem of molecule design by framing it as a conditional generative modeling task, where target biological properties or desired chemical constraints serve as conditioning variables.
We propose the Latent Prompt Transformer (LPT), a novel generative model comprising three components: (1) a latent vector with a learnable prior distribution modeled by a neural transformation of Gaussian white noise; (2) a molecule generation model based on a causal Transformer, which uses the latent vector as a prompt; and (3) a property prediction model that predicts a molecule's target properties and/or constraint values using the latent prompt. LPT can be learned by maximum likelihood estimation on molecule-property pairs. During property optimization, the latent prompt is inferred from target properties and constraints through posterior sampling and then used to guide the autoregressive molecule generation.
After initial training on existing molecules and their properties, we adopt an online learning algorithm to progressively shift the model distribution towards regions that support desired target properties. Experiments demonstrate that LPT not only effectively discovers useful molecules across single-objective, multi-objective, and structure-constrained optimization tasks, but also exhibits strong sample efficiency.
tl;dr: We propose a new robust reward learning method for RLHF.

Reinforcement learning from human feedback (RLHF) provides a principled framework for aligning AI systems with human preference data. For various reasons, e.g., personal bias, context ambiguity, lack of training, etc, human annotators may give incorrect or inconsistent preference labels. To tackle this challenge, we propose a robust RLHF approach -- $R^3M$, which models the potentially corrupted preference label as sparse outliers. Accordingly, we formulate the robust reward learning as an $\ell_1$-regularized maximum likelihood estimation problem. Computationally, we develop an efficient alternating optimization algorithm, which only incurs negligible computational overhead compared with the standard RLHF approach. Theoretically, we prove that under proper regularity conditions, $R^3M$ can consistently learn the underlying reward and identify outliers, provided that the number of outlier labels scales sublinearly with the preference sample size. Furthermore, we remark that $R^3M$ is versatile and can be extended to various preference optimization methods, including direct preference optimization (DPO). Our experiments on robotic control and natural language generation with large language models (LLMs) show that $R^3M$ improves robustness of the reward against several types of perturbations to the preference data.

Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we present **HumanSplat**, which predicts the 3D Gaussian Splatting properties of any human from a single input image in a generalizable manner.
Specifically, HumanSplat comprises a 2D multi-view diffusion model and a latent reconstruction Transformer with human structure priors that adeptly integrate geometric priors and semantic features within a unified framework. A hierarchical loss that incorporates human semantic information is devised to achieve high-fidelity texture modeling and impose stronger constraints on the estimated multiple views. Comprehensive experiments on standard benchmarks and in-the-wild images demonstrate that HumanSplat surpasses existing state-of-the-art methods in achieving photorealistic novel-view synthesis. Project page: https://humansplat.github.io.
tl;dr: We introduce methods for parallelizing the evaluation of RNNs that are scalable and numerically stable with quasi-Newton methods and trust regions.

Conventional nonlinear RNNs are not naturally parallelizable across the sequence length, unlike transformers and linear RNNs. Lim et. al. therefore tackle parallelized evaluation of nonlinear RNNs, posing it as a fixed point problem solved with Newton's method. By deriving and applying a parallelized form of Newton's method, they achieve large speedups over sequential evaluation. However, their approach inherits cubic computational complexity and numerical instability. We tackle these weaknesses. To reduce the computational complexity, we apply quasi-Newton approximations and show they converge comparably, use less memory, and are faster, compared to full-Newton. To stabilize Newton's method, we leverage a connection between Newton's method damped with trust regions and Kalman smoothing. This connection allows us to stabilize the iteration, per the trust region, and use efficient parallelized Kalman algorithms to retain performance. We compare these methods empirically and highlight use cases where each algorithm excels.
tl;dr: We develop ABAuditor, a hybrid LLM and rule-based reasoning system to detect bugs with substantial monetary consequence.

Financial transactions are increasingly being handled by automated programs called *smart contracts*.
However, one challenge in the adaptation of smart contracts is the presence of vulnerabilities, which can cause significant monetary loss.
In 2024, $247.88 M was lost in 20 smart contract exploits.
According to a recent study, accounting bugs (i.e., incorrect implementations of domain-specific financial models) are the most prevalent type of vulnerability,
and are one of the most difficult to find, requiring substantial human efforts.
While Large Language Models (LLMs) have shown promise in identifying these bugs, they often suffer from lack of generalization of vulnerability types, hallucinations, and problems with representing smart contracts in limited token context space.
This paper proposes a hybrid system combining LLMs and rule-based reasoning to detect accounting error vulnerabilities in smart contracts.
In particular, it utilizes the understanding capabilities of LLMs to annotate the financial meaning of variables in smart contracts, and employs rule-based reasoning to propagate the information throughout a contract's logic and to validate potential vulnerabilities.
To remedy hallucinations, we propose a feedback loop where validation is performed by providing the reasoning trace of vulnerabilities to the LLM for iterative self-reflection.
We achieve 75.6% accuracy on the labelling of financial meanings against human annotations.
Furthermore, we achieve a recall of 90.5% from running on 23 real-world smart contract projects containing 21 accounting error vulnerabilities.
Finally, we apply the automated technique on 8 recent projects, finding 4 known and 2 unknown bugs.

Due to the impressive zero-shot capabilities, pre-trained vision-language models (e.g. CLIP), have attracted widespread attention and adoption across various domains. Nonetheless, CLIP has been observed to be susceptible to adversarial examples. Through experimental analysis, we have observed a phenomenon wherein adversarial perturbations induce shifts in text-guided attention. Building upon this observation, we propose a simple yet effective strategy: Text-Guided Attention for Zero-Shot Robustness (TGA-ZSR). This framework incorporates two components: the Attention Refinement module and the Attention-based Model Constraint module. Our goal is to maintain the generalization of the CLIP model and enhance its adversarial robustness: The Attention Refinement module aligns the text-guided attention obtained from the target model via adversarial examples with the text-guided attention acquired from the original model via clean examples. This alignment enhances the model’s robustness. Additionally, the Attention-based Model Constraint module acquires text-guided attention from both the target and original models using clean examples. Its objective is to maintain model performance on clean samples while enhancing overall robustness. The experiments validate that our method yields a 9.58% enhancement in zero-shot robust accuracy over the current state-of-the-art techniques across 16 datasets. Our code is available at https://github.com/zhyblue424/TGA-ZSR.

The persistent challenge of bias in machine learning models necessitates robust solutions to ensure parity and equal treatment across diverse groups, particularly in classification tasks. Current methods for mitigating bias often result in information loss and an inadequate balance between accuracy and fairness. To address this, we propose a novel methodology grounded in bilevel optimization principles. Our deep learning-based approach concurrently optimizes for both accuracy and fairness objectives, and under certain assumptions, achieving proven Pareto optimal solutions while mitigating bias in the trained model. Theoretical analysis indicates that the upper bound on the loss incurred by this method is less than or equal to the loss of the Lagrangian approach, which involves adding a regularization term to the loss function. We demonstrate the efficacy of our model primarily on tabular datasets such as UCI Adult and Heritage Health. When benchmarked against state-of-the-art fairness methods, our model exhibits superior performance, advancing fairness-aware machine learning solutions and bridging the accuracy-fairness gap. The implementation of FairBiNN is available on https://github.com/yazdanimehdi/FairBiNN.
tl;dr: Model-based stopping rules for Bayesian optimization with robust Monte Carlo estimators

Bayesian optimization is a popular framework for efficiently tackling black-box search problems. As a rule, these algorithms operate by iteratively choosing what to evaluate next until some predefined budget has been exhausted. We investigate replacing this de facto stopping rule with criteria based on the probability that a point satisfies a given set of conditions. We focus on the prototypical example of an $(\epsilon, \delta)$-criterion: stop when a solution has been found whose value is within $\epsilon > 0$ of the optimum with probability at least $1 - \delta$ under the model. For Gaussian process priors, we show that Bayesian optimization satisfies this criterion under mild technical assumptions. Further, we give a practical algorithm for evaluating Monte Carlo stopping rules in a manner that is both sample efficient and robust to estimation error. These findings are accompanied by empirical results which demonstrate the strengths and weaknesses of the proposed approach.

Language-image pre-training is an effective technique for learning powerful representations in general domains. However, when directly turning to person representation learning, these general pre-training methods suffer from unsatisfactory performance. The reason is that they neglect critical person-related characteristics, i.e., fine-grained attributes and identities. To address this issue, we propose a novel language-image pre-training framework for person representation learning, termed PLIP. Specifically, we elaborately design three pretext tasks: 1) Text-guided Image Colorization, aims to establish the correspondence between the person-related image regions and the fine-grained color-part textual phrases. 2) Image-guided Attributes Prediction, aims to mine fine-grained attribute information of the person body in the image; and 3) Identity-based Vision-Language Contrast, aims to correlate the cross-modal representations at the identity level rather than the instance level. Moreover, to implement our pre-train framework, we construct a large-scale person dataset with image-text pairs named SYNTH-PEDES by automatically generating textual annotations. We pre-train PLIP on SYNTH-PEDES and evaluate our models by spanning downstream person-centric tasks. PLIP not only significantly improves existing methods on all these tasks, but also shows great ability in the zero-shot and domain generalization settings. The code, dataset and weight will be made publicly available.

We propose a novel stochastic bandit algorithm that employs reward estimates using a tree ensemble model. Specifically, our focus is on a soft tree model, a variant of the conventional decision tree that has undergone both practical and theoretical scrutiny in recent years. By deriving several non-trivial properties of soft trees, we extend the existing analytical techniques used for neural bandit algorithms to our soft tree-based algorithm. We demonstrate that our algorithm achieves a smaller cumulative regret compared to the existing ReLU-based neural bandit algorithms. We also show that this advantage comes with a trade-off: the hypothesis space of the soft tree ensemble model is more constrained than that of a ReLU-based neural network.
tl;dr: We do Bayesian Optimization under transition constraints by creating and solving tractable long-term planning problems in Markov Decision Processes.

Bayesian optimization is a methodology to optimize black-box functions. Traditionally, it focuses on the setting where you can arbitrarily query the search space. However, many real-life problems do not offer this flexibility; in particular, the search space of the next query may depend on previous ones. Example challenges arise in the physical sciences in the form of local movement constraints, required monotonicity in certain variables, and transitions influencing the accuracy of measurements. Altogether, such *transition constraints* necessitate a form of planning. This work extends classical Bayesian optimization via the framework of Markov Decision Processes. We iteratively solve a tractable linearization of our utility function using reinforcement learning to obtain a policy that plans ahead for the entire horizon. This is a parallel to the optimization of an *acquisition function in policy space*. The resulting policy is potentially history-dependent and non-Markovian. We showcase applications in chemical reactor optimization, informative path planning, machine calibration, and other synthetic examples.
tl;dr: We show how to build higher order GNNs that are equivariant to the automorphism groups of subgraphs without actually having to find the automorphism groups.

Several recent works have shown that extending the message passing paradigm to subgraphs communicating with other subgraphs, especially via higher order messages, can boost the expressivity of graph neural networks. In such architectures, to faithfully account for local structure such as cycles, the local operations must be equivariant to the automorphism group of the local environment.
However, enumerating the automorphism groups of all subgraphs of interest and finding appropriate equivariant operations for each one of them separately is generally not feasible. In this paper we propose a solution to this problem based on spectral graph theory that bypasses
having to determine the automorphism group entirely and constructs a basis for equivariant operations directly from the graph Laplacian.
We show that empirically this approach can boost the performance of GNNs.

Preference-based Reinforcement Learning ( PbRL ) studies the problem where agents receive only preferences over pairs of trajectories in each episode. Traditional approaches in this field have predominantly focused on the mean reward or utility criterion. However, in PbRL scenarios demanding heightened risk awareness, such as in AI systems, healthcare, and agriculture, risk-aware measures are requisite. Traditional risk-aware objectives and algorithms are not applicable in such one-episode-reward settings. To address this, we explore and prove the applicability of two risk-aware objectives to PbRL: nested and static quantile risk objectives. We also introduce Risk-Aware- PbRL (RA-PbRL), an algorithm designed to optimize both nested and static objectives. Additionally, we provide a theoretical analysis of the regret upper bounds, demonstrating that they are sublinear with respect to the number of episodes, and present empirical results to support our findings. Our code is available in https://github.com/aguilarjose11/PbRLNeurips.
tl;dr: We present MIDGArD, a new generative framework for creating 3D articulated objects, separating structure and shape generation.

Providing functionality through articulation and interaction with objects is a key objective in 3D generation. We introduce MIDGArD (Modular Interpretable Diffusion over Graphs for Articulated Designs), a novel diffusion-based framework for articulated 3D asset generation. MIDGArD improves over foundational work in the field by enhancing quality, consistency, and controllability in the generation process. This is achieved through MIDGArD's modular approach that separates the problem into two primary components: structure generation and shape generation. The structure generation module of MIDGArD aims at producing coherent articulation features from noisy or incomplete inputs. It acts on the object's structural and kinematic attributes, represented as features of a graph that are being progressively denoised to issue coherent and interpretable articulation solutions. This denoised graph then serves as an advanced conditioning mechanism for the shape generation module, a 3D generative model that populates each link of the articulated structure with consistent 3D meshes. Experiments show the superiority of MIDGArD on the quality, consistency, and interpretability of the generated assets. Importantly, the generated models are fully simulatable, i.e., can be seamlessly integrated into standard physics engines such as MuJoCo, broadening MIDGArD's applicability to fields such as digital content creation, meta realities, and robotics.

Training large AI models such as LLMs and DLRMs costs massive GPUs and computing time. The high training cost has become only affordable to big tech companies, meanwhile also causing increasing concerns about the environmental impact. This paper presents CoMERA, a **Co**mputing- and **M**emory-**E**fficient training method via **R**ank-**A**daptive tensor optimization. CoMERA achieves end-to-end rank-adaptive tensor-compressed training via a multi-objective optimization formulation, and improves the training to provide both a high compression ratio and excellent accuracy in the training process. Our optimized numerical computation (e.g., optimized tensorized embedding and tensor-vector contractions) and GPU implementation eliminate part of the run-time overhead in the tensorized training on GPU. This leads to, for the first time, $2-3\times$ speedup per training epoch compared with standard training. CoMERA also outperforms the recent GaLore in terms of both memory and computing efficiency. Specifically, CoMERA is $2\times$ faster per training epoch and $9\times$ more memory-efficient than GaLore on a tested six-encoder transformer with single-batch training. Our method also shows $\sim 2\times$ speedup than standard pre-training on a BERT-like code-generation LLM while achieving $4.23\times$ compression ratio in pre-training.
With further HPC optimization, CoMERA may reduce the pre-training cost of many other LLMs. An implementation of CoMERA is available at <https://github.com/ziyangjoy/CoMERA>.

We revisit the identification of an $\varepsilon$-optimal policy in average-reward Markov Decision Processes (MDP). In such MDPs, two measures of complexity have appeared in the literature: the diameter, $D$, and the optimal bias span, $H$, which satisfy $H\leq D$.
Prior work have studied the complexity of $\varepsilon$-optimal policy identification only when a generative model is available. In this case, it is known that there exists an MDP with $D \simeq H$ for which the sample complexity to output an $\varepsilon$-optimal policy is $\Omega(SAD/\varepsilon^2)$ where $S$ and $A$ are the sizes of the state and action spaces. Recently, an algorithm with a sample complexity of order $SAH/\varepsilon^2$ has been proposed, but it requires the knowledge of $H$. We first show that the sample complexity required to estimate $H$ is not bounded by any function of $S,A$ and $H$, ruling out the possibility to easily make the previous algorithm agnostic to $H$. By relying instead on a diameter estimation procedure, we propose the first algorithm for $(\varepsilon,\delta)$-PAC policy identification that does not need any form of prior knowledge on the MDP. Its sample complexity scales in $SAD/\varepsilon^2$ in the regime of small $\varepsilon$, which is near-optimal. In the online setting, our first contribution is a lower bound which implies that a sample complexity polynomial in $H$ cannot be achieved in this setting. Then, we propose an online algorithm with a sample complexity in $SAD^2/\varepsilon^2$, as well as a novel approach based on a data-dependent stopping rule that we believe is promising to further reduce this bound.

In open-world scenarios, where both novel classes and domains may exist, an ideal segmentation model should detect anomaly classes for safety and generalize to new domains. However, existing methods often struggle to distinguish between domain-level and semantic-level distribution shifts, leading to poor OOD detection or domain generalization performance. In this work, we aim to equip the model to generalize effectively to covariate-shift regions while precisely identifying semantic-shift regions. To achieve this, we design a novel generative augmentation method to produce coherent images that incorporate both anomaly (or novel) objects and various covariate shifts at both image and object levels. Furthermore, we introduce a training strategy that recalibrates uncertainty specifically for semantic shifts and enhances the feature extractor to align features associated with domain shifts. We validate the effectiveness of our method across benchmarks featuring both semantic and domain shifts. Our method achieves state-of-the-art performance across all benchmarks for both OOD detection and domain generalization. Code is available at https://github.com/gaozhitong/MultiShiftSeg.
tl;dr: Molecular generation with GFlowNets in the chemical reaction space, ensuring synthesizability out-of-the-box

Generative models hold great promise for small molecule discovery, significantly increasing the size of search space compared to traditional in silico screening libraries. However, most existing machine learning methods for small molecule generation suffer from poor synthesizability of candidate compounds, making experimental validation difficult. In this paper we propose Reaction-GFlowNet (RGFN), an extension of the GFlowNet framework that operates directly in the space of chemical reactions, thereby allowing out-of-the-box synthesizability while maintaining comparable quality of generated candidates. We demonstrate that with the proposed set of reactions and building blocks, it is possible to obtain a search space of molecules orders of magnitude larger than existing screening libraries coupled with low cost of synthesis. We also show that the approach scales to very large fragment libraries, further increasing the number of potential molecules. We demonstrate the effectiveness of the proposed approach across a range of oracle models, including pretrained proxy models and GPU-accelerated docking.
tl;dr: Approach to align LLMs more closely with individual user values by training a model, Janus, using a diverse preference datasets including system prompts.

Although humans inherently have diverse values, current large language model (LLM) alignment methods often assume that aligning LLMs with the general public’s preferences is optimal. A major challenge in adopting a more individualized approach to LLM alignment is its lack of scalability, as it involves repeatedly acquiring preference data and training new reward models and LLMs for each individual’s preferences. To address these challenges, we propose a new paradigm where users specify what they value most within the system message, steering the LLM’s generation behavior to better align with the user’s intentions. However, a naive application of such an approach is non-trivial since LLMs are typically trained on a uniform system message (e.g., “You are a helpful assistant”), which limits
their ability to generalize to diverse, unseen system messages. To improve this generalization, we create Multifaceted Collection, augmenting 66k user instructions into 197k system messages through hierarchical user value combinations. Using this dataset, we train a 7B LLM called Janus and test it on 921 prompts from 5 benchmarks (AlpacaEval 2.0, FLASK, Koala, MT-Bench, and Self-Instruct)
by adding system messages that reflect unseen user values. JANUS achieves tie+win rate of 75.2%, 72.4%, and 66.4% against Mistral 7B Instruct v0.2, GPT-3.5 Turbo, and GPT-4, respectively. Unexpectedly, on three benchmarks focused on response helpfulness (AlpacaEval 2.0, MT-Bench, Arena Hard Auto v0.1), JANUS also outperforms LLaMA 3 8B Instruct by a +4.0%p, +0.1%p, +3.0%p margin, underscoring that training with a vast array of system messages could also enhance alignment to the general public’s preference as well. Our code, dataset, benchmark, and models are available at https://lklab.kaist.ac.kr/Janus/.

Causal Temporal Representation Learning (Ctrl) methods aim to identify the temporal causal dynamics of complex nonstationary temporal sequences. Despite the success of existing Ctrl methods, they require either directly observing the domain variables or assuming a Markov prior on them. Such requirements limit the application of these methods in real-world scenarios when we do not have such prior knowledge of the domain variables. To address this problem, this work adopts a sparse transition assumption, aligned with intuitive human understanding, and presents identifiability results from a theoretical perspective. In particular, we explore under what conditions on the significance of the variability of the transitions we can build a model to identify the distribution shifts. Based on the theoretical result, we introduce a novel framework, *Causal Temporal Representation Learning with Nonstationary Sparse Transition* (CtrlNS), designed to leverage the constraints on transition sparsity and conditional independence to reliably identify both distribution shifts and latent factors. Our experimental evaluations on synthetic and real-world datasets demonstrate significant improvements over existing baselines, highlighting the effectiveness of our approach.

Statistical heterogeneity of data present at client devices in a federated learning (FL) system renders the training of a global model in such systems difficult. Particularly challenging are the settings where due to communication resource constraints only a small fraction of clients can participate in any given round of FL. Recent approaches to training a global model in FL systems with non-IID data have focused on developing client selection methods that aim to sample clients with more informative updates of the model. However, existing client selection techniques either introduce significant computation overhead or perform well only in the scenarios where clients have data with similar heterogeneity profiles. In this paper, we propose HiCS-FL (Federated Learning via Hierarchical Clustered Sampling), a novel client selection method in which the server estimates statistical heterogeneity of a client's data using the client’s update of the network’s output layer and relies on this information to cluster and sample the clients. We analyze the ability of the proposed techniques to compare heterogeneity of different datasets, and characterize convergence of the training process that deploys the introduced client selection method. Extensive experimental results demonstrate that in non-IID settings HiCS-FL achieves faster convergence than state-of-the-art FL client selection schemes. Notably, HiCS-FL drastically reduces computation cost compared to existing selection schemes and is adaptable to different heterogeneity scenarios.

Generating novel views from a single image remains a challenging task due to the complexity of 3D scenes and the limited diversity in the existing multi-view datasets to train a model on. Recent research combining large-scale text-to-image (T2I) models with monocular depth estimation (MDE) has shown promise in handling in-the-wild images. In these methods, an input view is geometrically warped to novel views with estimated depth maps, then the warped image is inpainted by T2I models. However, they struggle with noisy depth maps and loss of semantic details when warping an input view to novel viewpoints. In this paper, we propose a novel approach for single-shot novel view synthesis, a semantic-preserving generative warping framework that enables T2I generative models to learn where to warp and where to generate, through augmenting cross-view attention with self-attention. Our approach addresses the limitations of existing methods by conditioning the generative model on source view images and incorporating geometric warping signals. Qualitative and quantitative evaluations demonstrate that our model outperforms existing methods in both in-domain and out-of-domain scenarios. Project page is available at https://GenWarp-NVS.github.io.
tl;dr: OpenDlign: Open-World Point Cloud Understanding with Depth-Aligned Images

Recent open-world 3D representation learning methods using Vision-Language Models (VLMs) to align 3D point clouds with image-text information have shown superior 3D zero-shot performance. However, CAD-rendered images for this alignment often lack realism and texture variation, compromising alignment robustness. Moreover, the volume discrepancy between 3D and 2D pretraining datasets highlights the need for effective strategies to transfer the representational abilities of VLMs to 3D learning. In this paper, we present OpenDlign, a novel open-world 3D model using depth-aligned images generated from a diffusion model for robust multimodal alignment. These images exhibit greater texture diversity than CAD renderings due to the stochastic nature of the diffusion model. By refining the depth map projection pipeline and designing depth-specific prompts, OpenDlign leverages rich knowledge in pre-trained VLM for 3D representation learning with streamlined fine-tuning. Our experiments show that OpenDlign achieves high zero-shot and few-shot performance on diverse 3D tasks, despite only fine-tuning 6 million parameters on a limited ShapeNet dataset. In zero-shot classification, OpenDlign surpasses previous models by 8.0\% on ModelNet40 and 16.4\% on OmniObject3D. Additionally, using depth-aligned images for multimodal alignment consistently enhances the performance of other state-of-the-art models.
tl;dr: We present a framework to estimate non-reciprocal two-body interactions from trajectories in mixed-species collective motion. Our method accurately replicates interactions and collective behaviors, demonstrated through numerical experiments.

Analyzing the motion of multiple biological agents, be it cells or individual animals, is pivotal for the understanding of complex collective behaviors.
With the advent of advanced microscopy, detailed images of complex tissue formations involving multiple cell types have become more accessible in recent years. However, deciphering the underlying rules that govern cell movements is far from trivial. Here, we present a novel deep learning framework for estimating the underlying equations of motion from observed trajectories, a pivotal step in decoding such complex dynamics.
Our framework integrates graph neural networks with neural differential equations, enabling effective prediction of two-body interactions based on the states of the interacting entities. We demonstrate the efficacy of our approach through two numerical experiments. First, we used simulated data from a toy model to tune the hyperparameters. Based on the obtained hyperparameters, we then applied this approach to a more complex model with non-reciprocal forces that mimic the collective dynamics of the cells of slime molds. Our results show that the proposed method can accurately estimate the functional forms of two-body interactions -- even when they are nonreciprocal -- thereby precisely replicating both individual and collective behaviors within these systems.

The ability to promptly respond to environmental changes is crucial for the perception system of autonomous driving. Recently, a new task called streaming perception was proposed. It jointly evaluate the latency and accuracy into a single metric for video online perception. In this work, we introduce StreamDSGN, the first real-time stereo-based 3D object detection framework designed for streaming perception. StreamDSGN is an end-to-end framework that directly predicts the 3D properties of objects in the next moment by leveraging historical information, thereby alleviating the accuracy degradation of streaming perception. Further, StreamDSGN applies three strategies to enhance the perception accuracy: (1) A feature-flow-based fusion method, which generates a pseudo-next feature at the current moment to address the misalignment issue between feature and ground truth. (2) An extra regression loss for explicit supervision of object motion consistency in consecutive frames. (3) A large kernel backbone with a large receptive field for effectively capturing long-range spatial contextual features caused by changes in object positions. Experiments on the KITTI Tracking dataset show that, compared with the strong baseline, StreamDSGN significantly improves the streaming average precision by up to 4.33%. Our code is available at https://github.com/weiyangdaren/streamDSGN-pytorch.

Two-sided matching markets describe a large class of problems wherein participants from one side of the market must be matched to those from the other side according to their preferences. In many real-world applications (e.g. content matching or online labor markets), the knowledge about preferences may not be readily available and must be learned, i.e., one side of the market (aka agents) may not know their preferences over the other side (aka arms). Recent research on online settings has focused primarily on welfare optimization aspects (i.e. minimizing the overall regret) while paying little attention to the game-theoretic properties such as the stability of the final matching. In this paper, we exploit the structure of stable solutions to devise algorithms that improve the likelihood of finding stable solutions. We initiate the study of the sample complexity of finding a stable matching, and provide theoretical bounds on the number of samples needed to reach a stable matching with high probability. Finally, our empirical results demonstrate intriguing tradeoffs between stability and optimality of the proposed algorithms, further complementing our theoretical findings.
tl;dr: We present Stable-Pose, a novel adapter model that incorporates a coarse-to-fine attention masking strategy into a vision Transformer (ViT) for gaining accurate pose guidance in T2I diffusion models.

Controllable text-to-image (T2I) diffusion models have shown impressive performance in generating high-quality visual content through the incorporation of various conditions. Current methods, however, exhibit limited performance when guided by skeleton human poses, especially in complex pose conditions such as side or rear perspectives of human figures. To address this issue, we present Stable-Pose, a novel adapter model that introduces a coarse-to-fine attention masking strategy into a vision Transformer (ViT) to gain accurate pose guidance for T2I models. Stable-Pose is designed to adeptly handle pose conditions within pre-trained Stable Diffusion, providing a refined and efficient way of aligning pose representation during image synthesis. We leverage the query-key self-attention mechanism of ViTs to explore the interconnections among different anatomical parts in human pose skeletons. Masked pose images are used to smoothly refine the attention maps based on target pose-related features in a hierarchical manner, transitioning from coarse to fine levels.
Additionally, our loss function is formulated to allocate increased emphasis to the pose region, thereby augmenting the model's precision in capturing intricate pose details. We assessed the performance of Stable-Pose across five public datasets under a wide range of indoor and outdoor human pose scenarios. Stable-Pose achieved an AP score of 57.1 in the LAION-Human dataset, marking around 13\% improvement over the established technique ControlNet. The project link and code is available at https://github.com/ai-med/StablePose.

Visual text generation has significantly advanced through diffusion models aimed at producing images with readable and realistic text. Recent works primarily use a ControlNet-based framework, employing standard font text images to control diffusion models. Recognizing the critical role of control information in generating high-quality text, we investigate its influence from three perspectives: input encoding, role at different stages, and output features. Our findings reveal that: 1) Input control information has unique characteristics compared to conventional inputs like Canny edges and depth maps. 2) Control information plays distinct roles at different stages of the denoising process. 3) Output control features significantly differ from the base and skip features of the U-Net decoder in the frequency domain. Based on these insights, we propose TextGen, a novel framework designed to enhance generation quality by optimizing control information. We improve input and output features using Fourier analysis to emphasize relevant information and reduce noise. Additionally, we employ a two-stage generation framework to align the different roles of control information at different stages. Furthermore, we introduce an effective and lightweight dataset for training. Our method achieves state-of-the-art performance in both Chinese and English text generation. The code and dataset are available at https://github.com/CyrilSterling/TextGen.
tl;dr: We utilize long-range dependency in heterogeneous graphs by dynamically selects effective meta-paths through progressive sampling so as to reduce computational costs and overcome over-smoothing issues.

Utilizing long-range dependency, a concept extensively studied in homogeneous graphs, remains underexplored in heterogeneous graphs, especially on large ones, posing two significant challenges: Reducing computational costs while maximizing effective information utilization in the presence of heterogeneity, and overcoming the over-smoothing issue in graph neural networks. To address this gap, we investigate the importance of different meta-paths and introduce
an automatic framework for utilizing long-range dependency on heterogeneous graphs, denoted as Long-range Meta-path Search through Progressive Sampling (LMSPS). Specifically, we develop a search space with all meta-paths related to the target node type. By employing a progressive sampling algorithm, LMSPS dynamically shrinks the search space with hop-independent time complexity. Through a sampling evaluation strategy, LMSPS conducts a specialized and effective meta-path selection, leading to retraining with only effective meta-paths, thus mitigating costs and over-smoothing. Extensive experiments across diverse heterogeneous datasets validate LMSPS's capability in discovering effective long-range meta-paths, surpassing state-of-the-art methods. Our code is available at https://github.com/JHL-HUST/LMSPS.
tl;dr: We introduce Graph Diffusion Transformers for multi-conditional polymer and small molecule inverse design. It offers predictor-free guidance by learning the representations of categorical and numerical properties, enabling accurate denoising.

Inverse molecular design with diffusion models holds great potential for advancements in material and drug discovery. Despite success in unconditional molecule generation, integrating multiple properties such as synthetic score and gas permeability as condition constraints into diffusion models remains unexplored. We present the Graph Diffusion Transformer (Graph DiT) for multi-conditional molecular generation. Graph DiT has a condition encoder to learn the representation of numerical and categorical properties and utilizes a Transformer-based graph denoiser to achieve molecular graph denoising under conditions. Unlike previous graph diffusion models that add noise separately on the atoms and bonds in the forward diffusion process, we propose a graph-dependent noise model for training Graph DiT, designed to accurately estimate graph-related noise in molecules. We extensively validate the Graph DiT for multi-conditional polymer and small molecule generation. Results demonstrate our superiority across metrics from distribution learning to condition control for molecular properties. A polymer inverse design task for gas separation with feedback from domain experts further demonstrates its practical utility. The code is available at https://github.com/liugangcode/Graph-DiT.
tl;dr: We propose a principled local optimization method to optimize the discrete prompts for black-box LLMs that outperforms all baseline methods in performance and efficency. .

The efficacy of large language models (LLMs) in understanding and generating natural language has aroused a wide interest in developing prompt-based methods to harness the power of black-box LLMs. Existing methodologies usually prioritize a global optimization for finding the global optimum, which however will perform poorly in certain tasks. This thus motivates us to re-think the necessity of finding a global optimum in prompt optimization. To answer this, we conduct a thorough empirical study on prompt optimization and draw two major insights. Contrasting with the rarity of global optimum, local optima are usually prevalent and well-performed, which can be more worthwhile for efficient prompt optimization (**Insight I**). The choice of the input domain, covering both the generation and the representation of prompts, affects the identification of well-performing local optima (**Insight II**). Inspired by these insights, we propose a novel algorithm, namely localized zeroth-order prompt optimization (ZOPO), which incorporates a Neural Tangent Kernel-based derived Gaussian process into standard zeroth-order optimization for an efficient search of well-performing local optima in prompt optimization. Remarkably, ZOPO outperforms existing baselines in terms of both the optimization performance and the query efficiency, which we demonstrate through extensive experiments.
tl;dr: We design the first single stage referring 3D segmentation network, which trains on simpler labels and perform better.

Referring 3D Segmentation is a visual-language task that segments all points of the specified object from a 3D point cloud described by a sentence of query. Previous works perform a two-stage paradigm, first conducting language-agnostic instance segmentation then matching with given text query. However, the semantic concepts from text query and visual cues are separately interacted during the training, and both instance and semantic labels for each object are required, which is time consuming and human-labor intensive. To mitigate these issues, we propose a novel Referring 3D Segmentation pipeline, Label-Efficient and Single-Stage, dubbed LESS, which is only under the supervision of efficient binary mask. Specifically, we design a Point-Word Cross-Modal Alignment module for aligning the fine-grained features of points and textual embedding. Query Mask Predictor module and Query-Sentence Alignment module are introduced for coarse-grained alignment between masks and query. Furthermore, we propose an area regularization loss, which coarsely reduces irrelevant background predictions on a large scale. Besides, a point-to-point contrastive loss is proposed concentrating on distinguishing points with subtly similar features. Through extensive experiments, we achieve state-of-the-art performance on ScanRefer dataset by surpassing the previous methods about 3.7% mIoU using only binary labels. Code is available at https://github.com/mellody11/LESS.
tl;dr: We propose a regularization to alleviate the overfitting problem of tensor decomposition based models for knowledge graph completion.

Knowledge graph completion (KGC) can be framed as a 3-order binary tensor completion task. Tensor decomposition-based (TDB) models have demonstrated strong performance in KGC. In this paper, we provide a summary of existing TDB models and derive a general form for them, serving as a foundation for further exploration of TDB models. Despite the expressiveness of TDB models, they are prone to overfitting. Existing regularization methods merely minimize the norms of embeddings to regularize the model, leading to suboptimal performance. Therefore, we propose a novel regularization method for TDB models that addresses this limitation. The regularization is applicable to most TDB models and ensures tractable computation. Our method minimizes the norms of intermediate variables involved in the different ways of computing the predicted tensor. To support our regularization method, we provide a theoretical analysis that proves its effect in promoting low trace norm of the predicted tensor to reduce overfitting. Finally, we conduct experiments to verify the effectiveness of our regularization technique as well as the reliability of our theoretical analysis. The code is available at https://github.com/changyi7231/IVR.

The advent of Large Language Models (LLMs) has revolutionized text generation, producing outputs that closely mimic human writing. This blurring of lines between machine- and human-written text presents new challenges in distinguishing one from the other – a task further complicated by the frequent updates and closed nature of leading proprietary LLMs. Traditional logits-based detection methods leverage surrogate models for identifying LLM-generated content when the exact logits are unavailable from black-box LLMs. However, these methods grapple with the misalignment between the distributions of the surrogate and the often undisclosed target models, leading to performance degradation, particularly with the introduction of new, closed-source models. Furthermore, while current methodologies are generally effective when the source model is identified, they falter in scenarios where the model version remains unknown, or the test set comprises outputs from various source models. To address these limitations, we present \textbf{D}istribution-\textbf{A}ligned \textbf{L}LMs \textbf{D}etection (DALD), an innovative framework that redefines the state-of-the-art performance in black-box text detection even without logits from source LLMs. DALD is designed to align the surrogate model's distribution with that of unknown target LLMs, ensuring enhanced detection capability and resilience against rapid model iterations with minimal training investment. By leveraging corpus samples from publicly accessible outputs of advanced models such as ChatGPT, GPT-4 and Claude-3, DALD fine-tunes surrogate models to synchronize with unknown source model distributions effectively. Our approach achieves SOTA performance in black-box settings on different advanced closed-source and open-source models. The versatility of our method enriches widely adopted zero-shot detection frameworks (DetectGPT, DNA-GPT, Fast-DetectGPT) with a `plug-and-play' enhancement feature.
Extensive experiments validate that our methodology reliably secures high detection precision for LLM-generated text and effectively detects text from diverse model origins through a singular detector.
Our method is also robust under the revised text attack and non-English texts.
tl;dr: RankUp adapts semi-supervised classification techniques for regression by converting regression to a ranking problem.

State-of-the-art (SOTA) semi-supervised learning techniques, such as FixMatch and it's variants, have demonstrated impressive performance in classification tasks. However, these methods are not directly applicable to regression tasks. In this paper, we present RankUp, a simple yet effective approach that adapts existing semi-supervised classification techniques to enhance the performance of regression tasks. RankUp achieves this by converting the original regression task into a ranking problem and training it concurrently with the original regression objective. This auxiliary ranking classifier outputs a classification result, thus enabling integration with existing semi-supervised classification methods. Moreover, we introduce regression distribution alignment (RDA), a complementary technique that further enhances RankUp's performance by refining pseudo-labels through distribution alignment. Despite its simplicity, RankUp, with or without RDA, achieves SOTA results in across a range of regression benchmarks, including computer vision, audio, and natural language processing tasks. Our code and log data are open-sourced at [https://github.com/pm25/semi-supervised-regression](https://github.com/pm25/semi-supervised-regression).

One key challenge in Out-of-Distribution (OOD) detection is the absence of ground-truth OOD samples during training. One principled approach to address this issue is to use samples from external datasets as outliers ($\textit{i.e.}$, pseudo OOD samples) to train OOD detectors.
However, we find empirically that the outlier samples often present a distribution shift compared to the true OOD samples, especially in Long-Tailed Recognition (LTR) scenarios, where ID classes are heavily imbalanced, $\textit{i.e.}$, the true OOD samples exhibit very different probability distribution to the head and tailed ID classes from the outliers.
In this work, we propose a novel approach, namely $\textit{normalized outlier distribution adaptation}$ (AdaptOD), to tackle this distribution shift problem.
One of its key components is $\textit{dynamic outlier distribution adaptation}$ that effectively adapts a vanilla outlier distribution based on the outlier samples to the true OOD distribution by utilizing the OOD knowledge in the predicted OOD samples during inference.
Further, to obtain a more reliable set of predicted OOD samples on long-tailed ID data, a novel $\textit{dual-normalized energy loss}$ is introduced in AdaptOD, which leverages class- and sample-wise normalized energy to enforce a more balanced prediction energy on imbalanced ID samples. This helps avoid bias toward the head samples and learn a substantially better vanilla outlier distribution than existing energy losses during training. It also eliminates the need of manually tuning the sensitive margin hyperparameters in energy losses.
Empirical results on three popular benchmarks for OOD detection in LTR show the superior performance of AdaptOD over state-of-the-art methods.
Code is available at https://github.com/mala-lab/AdaptOD.

Allocation tasks represent a class of problems where a limited amount of resources must be allocated to a set of entities at each time step. Prominent examples of this task include portfolio optimization or distributing computational workloads across servers.
Allocation tasks are typically bound by linear constraints describing practical requirements that have to be strictly fulfilled at all times. In portfolio optimization, for example, investors may be obligated to allocate less than 30\% of the funds into a certain industrial sector in any investment period.
Such constraints restrict the action space of allowed allocations in intricate ways, which makes learning a policy that avoids constraint violations difficult.
In this paper, we propose a new method for constrained allocation tasks based on an autoregressive process to sequentially sample allocations for each entity. In addition, we introduce a novel de-biasing mechanism to counter the initial bias caused by sequential sampling. We demonstrate the superior performance of our approach compared to a variety of Constrained Reinforcement Learning (CRL) methods on three distinct constrained allocation tasks: portfolio optimization, computational workload distribution, and a synthetic allocation benchmark. Our code is available at: https://github.com/niklasdbs/paspo

In reinforcement learning with image-based inputs, it is crucial to establish a robust and generalizable state representation. Recent advancements in metric learning, such as deep bisimulation metric approaches, have shown promising results in learning structured low-dimensional representation space from pixel observations, where the distance between states is measured based on task-relevant features. However, these approaches face challenges in demanding generalization tasks and scenarios with non-informative rewards. This is because they fail to capture sufficient long-term information in the learned representations. To address these challenges, we propose a novel State Chrono Representation (SCR) approach. SCR augments state metric-based representations by incorporating extensive temporal information into the update step of bisimulation metric learning. It learns state distances within a temporal framework that considers both future dynamics and cumulative rewards over current and long-term future states. Our learning strategy effectively incorporates future behavioral information into the representation space without introducing a significant number of additional parameters for modeling dynamics. Extensive experiments conducted in DeepMind Control and Meta-World environments demonstrate that SCR achieves better performance comparing to other recent metric-based methods in demanding generalization tasks. The codes of SCR are available in https://github.com/jianda-chen/SCR.
tl;dr: We consider the problem of learning the dynamics in the topology of time-evolving point clouds, observed in systems that exhibit collective behavior such as swarms of birds, insects, or fish.

We consider the problem of learning the dynamics in the topology of time-evolving point clouds, the prevalent spatiotemporal model for systems exhibiting collective behavior, such as swarms of insects and birds or particles in physics. In such systems, patterns emerge from (local) interactions among self-propelled entities. While several well-understood governing equations for motion and interaction exist, they are notoriously difficult to fit to data, as most prior work requires knowledge about individual motion trajectories, i.e., a requirement that is challenging to satisfy with an increasing number of entities. To evade such confounding factors, we investigate collective behavior from a _topological perspective_, but instead of summarizing entire observation sequences (as done previously), we propose learning a latent dynamical model from topological features _per time point_. The latter is then used to formulate a downstream regression task to predict the parametrization of some a priori specified governing equation. We implement this idea based on a latent ODE learned from vectorized (static) persistence diagrams and show that a combination of recent stability results for persistent homology justifies this modeling choice. Various (ablation) experiments not only demonstrate the relevance of each model component but provide compelling empirical evidence that our proposed model -- _Neural Persistence Dynamics_ -- substantially outperforms the state-of-the-art across a diverse set of parameter regression tasks.
tl;dr: We provide new user-level private algorithms with improved runtime and less restrictive assumptions vs. the prior state-of-the-art.

We study private stochastic convex optimization (SCO) under user-level differential privacy (DP) constraints. In this setting, there are $n$ users (e.g., cell phones), each possessing $m$ data items (e.g., text messages), and we need to protect the privacy of each user's entire collection of data items. Existing algorithms for user-level DP SCO are impractical in many large-scale machine learning scenarios because: (i) they make restrictive assumptions on the smoothness parameter of the loss function and require the number of users to grow polynomially with the dimension of the parameter space; or (ii) they are prohibitively slow, requiring at least $(mn)^{3/2}$ gradient computations for smooth losses and $(mn)^3$ computations for non-smooth losses. To address these limitations, we provide novel user-level DP algorithms with state-of-the-art excess risk and runtime guarantees, without stringent assumptions. First, we develop a linear-time algorithm with state-of-the-art excess risk (for a non-trivial linear-time algorithm) under a mild smoothness assumption. Our second algorithm applies to arbitrary smooth losses and achieves optimal excess risk in $\approx (mn)^{9/8}$ gradient computations. Third, for non-smooth loss functions, we obtain optimal excess risk in $n^{11/8} m^{5/4}$ gradient computations. Moreover, our algorithms do not require the number of users to grow polynomially with the dimension.

Online Class Incremental Learning (OCIL) aims to train models incrementally, where data arrive in mini-batches, and previous data are not accessible. A major challenge in OCIL is Catastrophic Forgetting, i.e., the loss of previously learned knowledge. Among existing baselines, replay-based methods show competitive results but requires extra memory for storing exemplars, while exemplar-free (i.e., data need not be stored for replay in production) methods are resource friendly but often lack accuracy. In this paper, we propose an exemplar-free approach—Forward-only Online Analytic Learning (F-OAL). Unlike traditional methods, F-OAL does not rely on back-propagation and is forward-only, significantly reducing memory usage and computational time. Cooperating with a pre-trained frozen encoder with Feature Fusion, F-OAL only needs to update a linear classifier by recursive least square. This approach simultaneously achieves high accuracy and low resource consumption. Extensive experiments on bench mark datasets demonstrate F-OAL’s robust performance in OCIL scenarios. Code is available at: https://github.com/liuyuchen-cz/F-OAL
tl;dr: We propose MetaAligner, the first policy-agnostic and generalizable method for multi-objective preference alignment.

Recent advancements in large language models (LLMs) focus on aligning to heterogeneous human expectations and values via multi-objective preference alignment. However, existing methods are dependent on the policy model parameters, which require high-cost repetition of their alignment algorithms for each new policy model, and they cannot expand to unseen objectives due to their static alignment objectives. In this work, we propose Meta-Objective Aligner (MetaAligner), the first policy-agnostic and generalizable method for multi-objective preference alignment.
MetaAligner models multi-objective alignment into three stages: (1) dynamic objectives reformulation algorithm reorganizes traditional alignment datasets to supervise the model on performing flexible alignment across different objectives; (2) conditional weak-to-strong correction paradigm aligns the weak outputs of fixed policy models to approach strong outputs with higher preferences in the corresponding alignment objectives, enabling plug-and-play inferences on any policy models, which significantly reduces training costs and facilitates alignment on close-source policy models; (3) generalizable inference method flexibly adjusts target objectives by updating their text descriptions in the prompts, facilitating generalizable alignment to unseen objectives.
Experimental results show that MetaAligner achieves significant and balanced improvements in multi-objective alignments on 10 state-of-the-art policy models, and saves up to 93.63% of GPU training hours compared to previous alignment methods. The model also effectively aligns unseen objectives, marking the first step towards generalizable multi-objective preference alignment.
3220. Neural Model Checking
tl;dr: Hardware model checking using neural certificates

We introduce a machine learning approach to model checking temporal logic, with application to formal hardware verification. Model checking answers the question of whether every execution of a given system satisfies a desired temporal logic specification. Unlike testing, model checking provides formal guarantees. Its application is expected standard in silicon design and the EDA industry has invested decades into the development of performant symbolic model checking algorithms. Our new approach combines machine learning and symbolic reasoning by using neural networks as formal proof certificates for linear temporal logic. We train our neural certificates from randomly generated executions of the system and we then symbolically check their validity using satisfiability solving which, upon the affirmative answer, establishes that the system provably satisfies the specification. We leverage the expressive power of neural networks to represent proof certificates as well as the fact that checking a certificate is much simpler than finding one. As a result, our machine learning procedure for model checking is entirely unsupervised, formally sound, and practically effective. We experimentally demonstrate that our method outperforms the state-of-the-art academic and commercial model checkers on a set of standard hardware designs written in SystemVerilog.
tl;dr: We propose a fast and effective entropy model for neural image codec by efficiently leveraging sufficient contextual information.

Designing a fast and effective entropy model is challenging but essential for practical application of neural codecs. Beyond spatial autoregressive entropy models, more efficient backward adaptation-based entropy models have been recently developed. They not only reduce decoding time by using smaller number of modeling steps but also maintain or even improve rate--distortion performance by leveraging more diverse contexts for backward adaptation. Despite their significant progress, we argue that their performance has been limited by the simple adoption of the design convention for forward adaptation: using only a single type of hyper latent representation, which does not provide sufficient contextual information, especially in the first modeling step. In this paper, we propose a simple yet effective entropy modeling framework that leverages sufficient contexts for forward adaptation without compromising on bit-rate. Specifically, we introduce a strategy of diversifying hyper latent representations for forward adaptation, i.e., using two additional types of contexts along with the existing single type of context. In addition, we present a method to effectively use the diverse contexts for contextualizing the current elements to be encoded/decoded. By addressing the limitation of the previous approach, our proposed framework leads to significant performance improvements. Experimental results on popular datasets show that our proposed framework consistently improves rate-distortion performance across various bit-rate regions, e.g., 3.73\% BD-rate gain over the state-of-the-art baseline on the Kodak dataset.
tl;dr: We characterize the emergence of induction heads in transformer models using the synthetic task of learning markov chains in-context.

Large language models have the ability to generate text that mimics patterns in their inputs. We introduce a simple Markov Chain sequence modeling task in order to study how this in-context learning capability emerges. In our setting, each example is sampled from a Markov chain drawn from a prior distribution over Markov chains. Transformers trained on this task form \emph{statistical induction heads} which compute accurate next-token probabilities given the bigram statistics of the context. During the course of training, models pass through multiple phases: after an initial stage in which predictions are uniform, they learn to sub-optimally predict using in-context single-token statistics (unigrams); then, there is a rapid phase transition to the correct in-context bigram solution. We conduct an empirical and theoretical investigation of this multi-phase process, showing how successful learning results from the interaction between the transformer's layers, and uncovering evidence that the presence of the simpler unigram solution may delay formation of the final bigram solution. We examine how learning is affected by varying the prior distribution over Markov chains, and consider the generalization of our in-context learning of Markov chains (ICL-MC) task to $n$-grams for $n > 2$.
tl;dr: A Two-stage Framework for High-Fidelity Neural Surface Reconstruction with Intricate Structures

Signed Distance Function (SDF)-based volume rendering has demonstrated significant capabilities in surface reconstruction. Although promising, SDF-based methods often fail to capture detailed geometric structures, resulting in visible defects. By comparing SDF-based volume rendering to density-based volume rendering, we identify two main factors within the SDF-based approach that degrade surface quality: SDF-to-density representation and geometric regularization. These factors introduce challenges that hinder the optimization of the SDF field. To address these issues, we introduce NeuRodin, a novel two-stage neural surface reconstruction framework that not only achieves high-fidelity surface reconstruction but also retains the flexible optimization characteristics of density-based methods.
NeuRodin incorporates innovative strategies that facilitate transformation of arbitrary topologies and reduce artifacts associated with density bias.
Extensive evaluations on the Tanks and Temples and ScanNet++ datasets demonstrate the superiority of NeuRodin, showing strong reconstruction capabilities for both indoor and outdoor environments using solely posed RGB captures. Project website:
https://open3dvlab.github.io/NeuRodin/

Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
tl;dr: We propose Data Channel EXtension (DEX) to improve CNN accuracy on tiny AI accelerators by using patch-wise sampling and channel-wise stacking, boosting accuracy by 3.5% without increasing inference latency.

Tiny machine learning (TinyML) aims to run ML models on small devices and is increasingly favored for its enhanced privacy, reduced latency, and low cost. Recently, the advent of tiny AI accelerators has revolutionized the TinyML field by significantly enhancing hardware processing power. These accelerators, equipped with multiple parallel processors and dedicated per-processor memory instances, offer substantial performance improvements over traditional microcontroller units (MCUs). However, their limited data memory often necessitates downsampling input images, resulting in accuracy degradation. To address this challenge, we propose Data channel EXtension (DEX), a novel approach for efficient CNN execution on tiny AI accelerators. DEX incorporates additional spatial information from original images into input images through patch-wise even sampling and channel-wise stacking, effectively extending data across input channels. By leveraging underutilized processors and data memory for channel extension, DEX facilitates parallel execution without increasing inference latency. Our evaluation with four models and four datasets on tiny AI accelerators demonstrates that this simple idea improves accuracy on average by 3.5%p while keeping the inference latency the same on the AI accelerator. The source code is available at https://github.com/Nokia-Bell-Labs/data-channel-extension.
tl;dr: We propose a new decision-aware loss surrogate with theoretical guarantees on its accuracy with respect to the downstream decision loss.

We propose a novel family of decision-aware surrogate losses, called Perturbation Gradient (PG) losses, for the predict-then-optimize framework. These losses directly approximate the downstream decision loss and can be optimized using off-the-shelf gradient-based methods. Importantly, unlike existing surrogate losses, the approximation error of our PG losses vanishes as the number of samples grows. This implies that optimizing our surrogate loss yields a best-in-class policy asymptotically, even in misspecified settings. This is the first such result in misspecified settings and we provide numerical evidence confirming our PG losses substantively outperform existing proposals when the underlying model is misspecified and the noise is not centrally symmetric. Insofar as misspecification is commonplace in practice -- especially when we might prefer a simpler, more interpretable model -- PG losses offer a novel, theoretically justified, method for computationally tractable decision-aware learning.

While Low-Rank Adaptation (LoRA) has proven beneficial for efficiently fine-tuning large models, LoRA fine-tuned text-to-image diffusion models lack diversity in the generated images, as the model tends to copy data from the observed training samples. This effect becomes more pronounced at higher values of adapter strength and for adapters with higher ranks which are fine-tuned on smaller datasets. To address these challenges, we present FouRA, a novel low-rank method that learns projections in the Fourier domain along with learning a flexible input-dependent adapter rank selection strategy. Through extensive experiments and analysis, we show that FouRA successfully solves the problems related to data copying and distribution collapse while significantly improving the generated image quality. We demonstrate that FouRA enhances the generalization of fine-tuned models thanks to its adaptive rank selection. We further show that the learned projections in the frequency domain are decorrelated and prove effective when merging multiple adapters. While FouRA is motivated for vision tasks, we also demonstrate its merits for language tasks on commonsense reasoning and GLUE benchmarks.
3228. Active Set Ordering
tl;dr: This paper addresses the active set ordering problem, discovering set rankings through costly black-box evaluations.

In this paper, we formalize the active set ordering problem, which involves actively discovering a set of inputs based on their orderings determined by expensive evaluations of a blackbox function. We then propose the mean prediction (MP) algorithm and theoretically analyze it in terms of the regret of predicted pairwise orderings between inputs. Notably, as a special case of this framework, we can cast Bayesian optimization as an active set ordering problem by recognizing that maximizers can be identified solely by comparison rather than by precisely estimating the function evaluations. As a result, we are able to construct the popular Gaussian process upper confidence bound (GP-UCB) algorithm through the lens of ordering with several nuanced insights. We empirically validate the performance of our proposed solution using various synthetic functions and real-world datasets.
tl;dr: MR-Ben is a comprehensive process-oriented evaluation benchmark comprising 5,975 questions that cover various subjects, ranging from natural science to coding, challenging LLMs to score the reasoning steps of candidate solutions.

Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, evaluating these reasoning abilities has become increasingly challenging. Existing outcome-based benchmarks are beginning to saturate, becoming less effective in tracking meaningful progress. To address this, we present a process-based benchmark MR-Ben that demands a meta-reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. Our meta-reasoning paradigm is especially suited for system-2 slow thinking, mirroring the human cognitive process of carefully examining assumptions, conditions, calculations, and logic to identify mistakes. MR-Ben comprises 5,975 questions curated by human experts across a wide range of subjects, including physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, with models like the o1 series from OpenAI demonstrating strong performance by effectively scrutinizing the solution space, many other state-of-the-art models fall significantly behind on MR-Ben, exposing potential shortcomings in their training strategies and inference methodologies.
tl;dr: We model provenance -- the locations where each point is likely visible -- of a NeRF using a stochastic field.

Neural radiance fields (NeRFs) have gained popularity with multiple works showing promising results across various applications. However, to the best of our knowledge, existing works do not explicitly model the distribution of training camera poses, or consequently the triangulation quality, a key factor affecting reconstruction quality dating back to classical vision literature. We close this gap with ProvNeRF, an approach that models the provenance for each point -- i.e., the locations where it is likely visible -- of NeRFs as a stochastic field. We achieve this by extending implicit maximum likelihood estimation (IMLE) to functional space with an optimizable objective. We show that modeling per-point provenance during the NeRF optimization enriches the model with information on triangulation leading to improvements in novel view synthesis and uncertainty estimation under the challenging sparse, unconstrained view setting against competitive baselines. The code will be available at https://github.com/georgeNakayama/ProvNeRF.

Heatmap regression has dominated human pose estimation due to its superior performance and strong generalization. To meet the requirements of traditional explicit neural networks for output form, existing heatmap-based methods discretize the originally continuous heatmap representation into 2D pixel arrays, which leads to performance degradation due to the introduction of quantization errors. This problem is significantly exacerbated as the size of the input image decreases, which makes heatmap-based methods not much better than coordinate regression on low-resolution images. In this paper, we propose a novel neural representation for human pose estimation called NerPE to achieve continuous heatmap regression. Given any position within the image range, NerPE regresses the corresponding confidence scores for body joints according to the surrounding image features, which guarantees continuity in space and confidence during training. Thanks to the decoupling from spatial resolution, NerPE can output the predicted heatmaps at arbitrary resolution during inference without retraining, which easily achieves sub-pixel localization precision. To reduce the computational cost, we design progressive coordinate decoding to cooperate with continuous heatmap regression, in which localization no longer requires the complete generation of high-resolution heatmaps. The code is available at https://github.com/hushengxiang/NerPE.
tl;dr: We analyze why Transformer and linear attention do not work well on WSI modelling in performance and efficiency and propose our solution.

Histopathology Whole Slide Image (WSI) analysis serves as the gold standard for clinical cancer diagnosis in the daily routines of doctors. To develop computer-aided diagnosis model for histopathology WSIs, previous methods typically employ Multi-Instance Learning to enable slide-level prediction given only slide-level labels.
Among these models, vanilla attention mechanisms without pairwise interactions have traditionally been employed but are unable to model contextual information. More recently, self-attention models have been utilized to address this issue. To alleviate the computational complexity of long sequences in large WSIs, methods like HIPT use region-slicing, and TransMIL employs Nystr\"{o}mformer as an approximation of full self-attention. Both approaches suffer from suboptimal performance due to the loss of key information. Moreover, their use of absolute positional embedding struggles to effectively handle long contextual dependencies in shape-varying WSIs.
In this paper, we first analyze how the low-rank nature of the long-sequence attention matrix constrains the representation ability of WSI modelling. Then, we demonstrate that the rank of attention matrix can be improved by focusing on local interactions via a local attention mask. Our analysis shows that the local mask aligns with the attention patterns in the lower layers of the Transformer. Furthermore, the local attention mask can be implemented during chunked attention calculation, reducing the quadratic computational complexity to linear with a small local bandwidth. Additionally, this locality helps the model generalize to unseen or under-fitted positions more easily.
Building on this, we propose a local-global hybrid Transformer for both computational acceleration and local-global information interactions modelling. Our method, Long-contextual MIL (LongMIL), is evaluated through extensive experiments on various WSI tasks to validate its superiority in: 1) overall performance, 2) memory usage and speed, and 3) extrapolation ability compared to previous methods.

Spike Timing-Dependent Plasticity (STDP) is a promising substitute to backpropagation for local training of Spiking Neural Networks (SNNs) on neuromorphic hardware. STDP allows SNNs to address classification tasks by combining unsupervised STDP for feature extraction and supervised STDP for classification. Unsupervised STDP is usually employed with Winner-Takes-All (WTA) competition to learn distinct patterns. However, WTA for supervised STDP classification faces unbalanced competition challenges. In this paper, we propose a method to effectively implement WTA competition in a spiking classification layer employing first-spike coding and supervised STDP training. We introduce the Neuronal Competition Group (NCG), an architecture that improves classification capabilities by promoting the learning of various patterns per class. An NCG is a group of neurons mapped to a specific class, implementing intra-class WTA and a novel competition regulation mechanism based on two-compartment thresholds. We incorporate our proposed architecture into spiking classification layers trained with state-of-the-art supervised STDP rules. On top of two different unsupervised feature extractors, we obtain significant accuracy improvements on image recognition datasets such as CIFAR-10 and CIFAR-100. We show that our competition regulation mechanism is crucial for ensuring balanced competition and improved class separation.
tl;dr: A new decoding technique to generate multiple drafts at the cost of a single autoregressive inference leveraging superposed token embeddings and n-gram filters.

Many applications today provide users with multiple auto-complete drafts as they type, including GitHub's code completion, Gmail's smart compose, and Apple's messaging auto-suggestions. Under the hood, language models support this by running an autoregressive inference pass to provide a draft. Consequently, providing $k$ drafts to the user requires running an expensive language model $k$ times. To alleviate the computation cost of running $k$ inference passes, we propose Superposed Decoding, a new decoding algorithm that generates $k$ drafts at the computation cost of one autoregressive inference pass. We achieve this by feeding a superposition of the most recent token embeddings from the $k$ drafts as input to the next decoding step of the language model. At every inference step we combine the $k$ drafts with the top-$k$ tokens to get $k^2$ new drafts and cache the $k$ most likely options, using an n-gram interpolation with minimal compute overhead to filter out incoherent generations. Our experiments show that $k$ drafts from Superposed Decoding are at least as coherent and factual as Nucleus Sampling and Greedy Decoding respectively, while being at least $2.44\times$ faster for $k\ge3$. In a compute-normalized setting, user evaluations demonstrably favor text generated by Superposed Decoding over Nucleus Sampling. Superposed Decoding can also be combined with other decoding strategies, resulting in universal coverage gains when scaling inference time compute. Code and more examples open-sourced at https://github.com/RAIVNLab/SuperposedDecoding.
tl;dr: we introduce Visual Sketchpad: a framework that provides multimodal LMs with the tools necessary to generate intermediate sketches to reason over tasks.

Humans draw to facilitate reasoning: we draw auxiliary lines when solving geometry problems; we mark and circle when reasoning on maps; we use sketches to amplify our ideas and relieve our limited-capacity working memory. However, such actions are missing in current multimodal language models (LMs). Current chain-of-thought and tool-use paradigms only use text as intermediate reasoning steps. In this work, we introduce Sketchpad, a framework that gives multimodal LMs a visual sketchpad and tools to draw on the sketchpad. The LM conducts planning and reasoning according to the visual artifacts it has drawn. Different from prior work, which uses text-to-image models to enable LMs to draw, Sketchpad enables LMs to draw with lines, boxes, marks, etc., which is closer to human sketching and better facilitates reasoning. \name can also use specialist vision models during the sketching process (e.g., draw bounding boxes with object detection models, draw masks with segmentation models), to further enhance visual perception and reasoning. We experiment on a wide range of math tasks (including geometry, functions, graph, chess) and complex visual reasoning tasks. Sketchpad substantially improves performance on all tasks over strong base models with no sketching, yielding an average gain of 12.7% on math tasks, and 8.6% on vision tasks. GPT-4o with Sketchpad sets a new state of the art on all tasks, including V*Bench (80.3%), BLINK spatial reasoning (83.9%), and visual correspondence (80.8%). We will release all code and data.
3236. TrajCLIP: Pedestrian trajectory prediction method using contrastive learning and idempotent networks

The distribution of pedestrian trajectories is highly complex and influenced by the scene, nearby pedestrians, and subjective intentions. This complexity presents challenges for modeling and generalizing trajectory prediction. Previous methods modeled the feature space of future trajectories based on the high-dimensional feature space of historical trajectories, but this approach is suboptimal because it overlooks the similarity between historical and future trajectories. Our proposed method, TrajCLIP, utilizes contrastive learning and idempotent generative networks to address this issue. By pairing historical and future trajectories and applying contrastive learning on the encoded feature space, we enforce same-space consistency constraints. To manage complex distributions, we use idempotent loss and tightness loss to control over-expansion in the latent space. Additionally, we have developed a trajectory interpolation algorithm and synthetic trajectory data to enhance model capacity and improve generalization. Experimental results on public datasets demonstrate that TrajCLIP achieves state-of-the-art performance and excels in scene-to-scene transfer, few-shot transfer, and online learning tasks.
tl;dr: We propose a non-parametric score to evaluate algorithms for noisy ICA and consequently propose a meta-algorithm which utilizes the score to choose the best algorithm for any given data distribution.

Independent Component Analysis (ICA) was introduced in the 1980's as a model for Blind Source Separation (BSS), which refers to the process of recovering the sources underlying a mixture of signals, with little knowledge about the source signals or the mixing process. While there are many sophisticated algorithms for estimation, different methods have different shortcomings. In this paper, we develop a nonparametric score to adaptively pick the right algorithm for ICA with arbitrary Gaussian noise. The novelty of this score stems from the fact that it just assumes a finite second moment of the data and uses the characteristic function to evaluate the quality of the estimated mixing matrix without any knowledge of the parameters of the noise distribution. In addition, we propose some new contrast functions and algorithms that enjoy the same fast computability as existing algorithms like FASTICA and JADE but work in domains where the former may fail. While these also may have weaknesses, our proposed diagnostic, as shown by our simulations, can remedy them. Finally, we propose a theoretical framework to analyze the local and global convergence properties of our algorithms.
tl;dr: This paper makes the first attempt to align diffusion models for image inpainting with human aesthetic standards via a reinforcement learning framework.

In this paper, we make the first attempt to align diffusion models for image inpainting with human aesthetic standards via a reinforcement learning framework, significantly improving the quality and visual appeal of inpainted images. Specifically, instead of directly measuring the divergence with paired images, we train a reward model with the dataset we construct, consisting of nearly 51,000 images annotated with human preferences. Then, we adopt a reinforcement learning process to fine-tune the distribution of a pre-trained diffusion model for image inpainting in the direction of higher reward. Moreover, we theoretically deduce the upper bound on the error of the reward model, which illustrates the potential confidence of reward estimation throughout the reinforcement alignment process, thereby facilitating accurate regularization.
Extensive experiments on inpainting comparison and downstream tasks, such as image extension and 3D reconstruction, demonstrate the effectiveness of our approach, showing significant improvements in the alignment of inpainted images with human preference compared with state-of-the-art methods. This research not only advances the field of image inpainting but also provides a framework for incorporating human preference into the iterative refinement of generative models based on modeling reward accuracy, with broad implications for the design of visually driven AI applications. Our code and dataset are publicly available at \url{https://prefpaint.github.io}.

Graph Auto-Encoders (GAEs) are powerful tools for graph representation learning. In this paper, we develop a novel Hierarchical Cluster-based GAE (HC-GAE), that can learn effective structural characteristics for graph data analysis. To this end, during the encoding process, we commence by utilizing the hard node assignment to decompose a sample graph into a family of separated subgraphs. We compress each subgraph into a coarsened node, transforming the original graph into a coarsened graph. On the other hand, during the decoding process, we adopt the soft node assignment to reconstruct the original graph structure by expanding the coarsened nodes. By hierarchically performing the above compressing procedure during the decoding process as well as the expanding procedure during the decoding process, the proposed HC-GAE can effectively extract bidirectionally hierarchical structural features of the original sample graph. Furthermore, we re-design the loss function that can integrate the information from either the encoder or the decoder. Since the associated graph convolution operation of the proposed HC-GAE is restricted in each individual separated subgraph and cannot propagate the node information between different subgraphs, the proposed HC-GAE can significantly reduce the over-smoothing problem arising in the classical convolution-based GAEs. The proposed HC-GAE can generate effective representations for either node classification or graph classification, and the experiments demonstrate the effectiveness on real-world datasets.
tl;dr: This work studies how does message passing improve collaborative filtering and proposes an efficient framework called TAG-CF to leverage the findings.

Collaborative filtering (CF) has exhibited prominent results for recommender systems and been broadly utilized for real-world applications.
A branch of research enhances CF methods by message passing (MP) used in graph neural networks, due to its strong capabilities of extracting knowledge from graph-structured data, like user-item bipartite graphs that naturally exist in CF. They assume that MP helps CF methods in a manner akin to its benefits for graph-based learning tasks in general (e.g., node classification). However, even though MP empirically improves CF, whether or not this assumption is correct still needs verification. To address this gap, we formally investigate why MP helps CF from multiple perspectives and show that many assumptions made by previous works are not entirely accurate. With our curated ablation studies and theoretical analyses, we discover that (i) MP improves the CF performance primarily by additional representations passed from neighbors during the forward pass instead of additional gradient updates to neighbor representations during the model back-propagation and (ii) MP usually helps low-degree nodes more than high-degree nodes.}Utilizing these novel findings, we present Test-time Aggregation for Collaborative Filtering, namely TAG-CF, a test-time augmentation framework that only conducts MP once at inference time. The key novelty of TAG-CF is that it effectively utilizes graph knowledge while circumventing most of notorious computational overheads of MP. Besides, TAG-CF is extremely versatile can be used as a plug-and-play module to enhance representations trained by different CF supervision signals. Evaluated on six datasets (i.e., five academic benchmarks and one real-world industrial dataset), TAG-CF consistently improves the recommendation performance of CF methods without graph by up to 39.2% on cold users and 31.7% on all users, with little to no extra computational overheads. Furthermore, compared with trending graph-enhanced CF methods, TAG-CF delivers comparable or even better performance with less than 1% of their total training times. Our code is publicly available at https://github.com/snap-research/Test-time-Aggregation-for-CF.
tl;dr: We propose a new adaptive preference loss for RLHF.

Reinforcement learning from human feedback (RLHF) is a prevalent approach to align AI systems with human values by learning rewards from human preference data. Due to various reasons, however, such data typically takes the form of rankings over pairs of trajectory segments, which fails to capture the varying strengths of preferences across different pairs. In this paper, we propose a novel adaptive preference loss, underpinned by distributionally robust optimization (DRO), designed to address this uncertainty in preference strength. By incorporating an adaptive scaling parameter into the loss for each pair, our method increases the flexibility of the reward function. Specifically, it assigns small scaling parameters to pairs with ambiguous preferences, leading to more comparable rewards, and large scaling parameters to those with clear preferences for more distinct rewards. Computationally, our proposed loss function is strictly convex and univariate with respect to each scaling parameter, enabling its efficient optimization through a simple second-order algorithm. Our method is versatile and can be readily adapted to various preference optimization frameworks, including direct preference optimization (DPO). Our experiments with robotic control and natural language generation with large language models (LLMs) show that our method not only improves policy performance but also aligns reward function selection more closely with policy optimization, simplifying the hyperparameter tuning process.

Existing methods to generate aesthetic QR codes, such as image and style transfer techniques, tend to compromise either the visual appeal or the scannability of QR codes when they incorporate human face identity. Addressing these imperfections, we present Face2QR—a novel pipeline specifically designed for generating personalized QR codes that harmoniously blend aesthetics, face identity, and scannability. Our pipeline introduces three innovative components. First, the ID-refined QR integration (IDQR) seamlessly intertwines the background styling with face ID, utilizing a unified SD-based framework with control networks. Second, the ID-aware QR ReShuffle (IDRS) effectively rectifies the conflicts between face IDs and QR patterns, rearranging QR modules to maintain the integrity of facial features without compromising scannability. Lastly, the ID-preserved Scannability Enhancement (IDSE) markedly boosts scanning robustness through latent code optimization, striking a delicate balance between face ID, aesthetic quality and QR functionality. In comprehensive experiments, Face2QR demonstrates remarkable performance, outperforming existing approaches, particularly in preserving facial recognition features within custom QR code designs.
tl;dr: We propose Resfusion, a general framework that incorporates the residual term into the diffusion forward process, starting the reverse process directly from the noisy degraded images.

Recently, research on denoising diffusion models has expanded its application to the field of image restoration. Traditional diffusion-based image restoration methods utilize degraded images as conditional input to effectively guide the reverse generation process, without modifying the original denoising diffusion process. However, since the degraded images already include low-frequency information, starting from Gaussian white noise will result in increased sampling steps. We propose Resfusion, a general framework that incorporates the residual term into the diffusion forward process, starting the reverse process directly from the noisy degraded images. The form of our inference process is consistent with the DDPM. We introduced a weighted residual noise, named resnoise, as the prediction target and explicitly provide the quantitative relationship between the residual term and the noise term in resnoise. By leveraging a smooth equivalence transformation, Resfusion determine the optimal acceleration step and maintains the integrity of existing noise schedules, unifying the training and inference processes. The experimental results demonstrate that Resfusion exhibits competitive performance on ISTD dataset, LOL dataset and Raindrop dataset with only five sampling steps. Furthermore, Resfusion can be easily applied to image generation and emerges with strong versatility. Our code and model are available at https://github.com/nkicsl/Resfusion.
tl;dr: We propose ESPACE, an LLM compression technique based on dimensionality reduction of activations which enables retraining LLMs with no loss in expressivity; while at inference, weight decomposition is obtained as a byproduct of matrix associativity.

We propose ESPACE, an LLM compression technique based on dimensionality reduction of activations. Unlike prior works on weight-centric tensor decomposition, ESPACE projects activations onto a pre-calibrated set of principal components. The activation-centrality of the approach enables retraining LLMs with no loss of expressivity; while at inference, weight decomposition is obtained as a byproduct of matrix multiplication associativity. Theoretical results on the construction of projection matrices with optimal computational accuracy are provided. Experimentally, we find ESPACE enables 50% compression of GPT3, Llama2, and Nemotron4 models with small accuracy degradation, as low as a 0.18 perplexity increase on GPT3-22B. At lower compression rates of 20% to 40%, ESPACE drives GPT3 models to outperforming their baseline, by up to a 0.38 decrease in perplexity for GPT3-8B. ESPACE also reduces GEMM execution time and prefill inference latency on existing hardware. Comparison with related works on compressing Llama2-7B via matrix factorization shows that ESPACE is a first step in advancing the state-of-the-art in tensor decomposition compression of LLMs.

We study the problem of online sequential decision-making given auxiliary demonstrations from _experts_ who made their decisions based on unobserved contextual information. These demonstrations can be viewed as solving related but slightly different tasks than what the learner faces. This setting arises in many application domains, such as self-driving cars, healthcare, and finance, where expert demonstrations are made using contextual information, which is not recorded in the data available to the learning agent. We model the problem as a zero-shot meta-reinforcement learning setting with an unknown task distribution and a Bayesian regret minimization objective, where the unobserved tasks are encoded as parameters with an unknown prior. We propose the Experts-as-Priors algorithm (ExPerior), an empirical Bayes approach that utilizes expert data to establish an informative prior distribution over the learner's decision-making problem. This prior enables the application of any Bayesian approach for online decision-making, such as posterior sampling. We demonstrate that our strategy surpasses existing behaviour cloning and online algorithms, as well as online-offline baselines for multi-armed bandits, Markov decision processes (MDPs), and partially observable MDPs, showcasing the broad reach and utility of ExPerior in using expert demonstrations across different decision-making setups.

We present adaptive gradient methods (both basic and accelerated) for solving
convex composite optimization problems in which the main part is approximately
smooth (a.k.a. $(\delta, L)$-smooth) and can be accessed only via a
(potentially biased) stochastic gradient oracle.
This setting covers many interesting examples including Hölder smooth problems
and various inexact computations of the stochastic gradient.
Our methods use AdaGrad stepsizes and are adaptive in the sense that they do
not require knowing any problem-dependent constants except an estimate of the
diameter of the feasible set but nevertheless achieve the best possible
convergence rates as if they knew the corresponding constants.
We demonstrate that AdaGrad stepsizes work in a variety of situations
by proving, in a unified manner, three types of new results.
First, we establish efficiency guarantees for our methods in the classical
setting where the oracle's variance is uniformly bounded.
We then show that, under more refined assumptions on the variance,
the same methods without any modifications enjoy implicit variance
reduction properties allowing us to express their complexity estimates in
terms of the variance only at the minimizer.
Finally, we show how to incorporate explicit SVRG-type variance reduction into
our methods and obtain even faster algorithms.
In all three cases, we present both basic and accelerated algorithms
achieving state-of-the-art complexity bounds.
As a direct corollary of our results, we obtain universal stochastic gradient
methods for Hölder smooth problems which can be used in all situations.

Tokenizer, serving as a translator to map the intricate visual data into a compact latent space, lies at the core of visual generative models. Based on the finding that existing tokenizers are tailored to either image or video inputs, this paper presents OmniTokenizer, a transformer-based tokenizer for joint image and video tokenization. OmniTokenizer is designed with a spatial-temporal decoupled architecture, which integrates window attention and causal attention for spatial and temporal modeling, respectively. To exploit the complementary nature of image and video data, we further propose a progressive training strategy, where OmniTokenizer is first trained on image data on a fixed resolution to develop the spatial encoding capacity and then jointly trained on image and video data on multiple resolutions to learn the temporal dynamics. OmniTokenizer, for the first time, handles both image and video inputs within a unified framework and proves the possibility of realizing their synergy. Extensive experiments demonstrate that OmniTokenizer achieves state-of-the-art (SOTA) reconstruction performance on various image and video datasets, e.g., 1.11 reconstruction FID on ImageNet and 42 reconstruction FVD on UCF-101, beating the previous SOTA methods by 13% and 26%, respectively. Additionally, we also show that when integrated with OmniTokenizer, both language model-based approaches and diffusion models can realize advanced visual synthesis performance, underscoring the superiority and versatility of our method.

In many social, behavioral, and biomedical sciences, treatment effect estimation is a crucial step in understanding the impact of an intervention, policy, or treatment. In recent years, an increasing emphasis has been placed on heterogeneity in treatment effects, leading to the development of various methods for estimating Conditional Average Treatment Effects (CATE). These approaches hinge on a crucial identifying condition of no unmeasured confounding, an assumption that is not always guaranteed in observational studies or randomized control trials with non-compliance. In this paper, we proposed a general framework for estimating CATE with a possible unmeasured confounder using Instrumental Variables. We also construct estimators that exhibit greater efficiency and robustness against various scenarios of model misspecification. The efficacy of the proposed framework is demonstrated through simulation studies and a real data example.
tl;dr: We propose MimicTalk, a personalized talking face generation method that can adapted to a target identity in few minutes and mimicking its talking style.

Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Video samples are available at https://mimictalk.github.io .
tl;dr: This paper introduces a method to evaluate distribution discrepancies between training and test distributions without needing class labels in the test samples.

There are increasing cases where the class labels of test samples are unavailable, creating a significant need and challenge in measuring the discrepancy between training and test distributions. This distribution discrepancy complicates the assessment of whether the hypothesis selected by an algorithm on training samples remains applicable to test samples. We present a novel approach called Importance Divergence (I-Div) to address the challenge of test label unavailability, enabling distribution discrepancy evaluation using only training samples. I-Div transfers the sampling patterns from the test distribution to the training distribution by estimating density and likelihood ratios. Specifically, the density ratio, informed by the selected hypothesis, is obtained by minimizing the Kullback-Leibler divergence between the actual and estimated input distributions. Simultaneously, the likelihood ratio is adjusted according to the density ratio by reducing the generalization error of the distribution discrepancy as transformed through the two ratios. Experimentally, I-Div accurately quantifies the distribution discrepancy, as evidenced by a wide range of complex data scenarios and tasks.

Adam is one of the most popular optimization algorithms in deep learning. However, it is known that Adam does not converge in theory unless choosing a hyperparameter, i.e., $\beta_2$, in a problem-dependent manner. There have been many attempts to fix the non-convergence (e.g., AMSGrad), but they require an impractical assumption that the gradient noise is uniformly bounded. In this paper, we propose a new adaptive gradient method named ADOPT, which achieves the optimal convergence rate of $\mathcal{O} ( 1 / \sqrt{T} )$ with any choice of $\beta_2$ without depending on the bounded noise assumption. ADOPT addresses the non-convergence issue of Adam by removing the current gradient from the second moment estimate and changing the order of the momentum update and the normalization by the second moment estimate. We also conduct intensive numerical experiments, and verify that our ADOPT achieves superior results compared to Adam and its variants across a wide range of tasks, including image classification, generative modeling, natural language processing, and deep reinforcement learning. The implementation is available at https://github.com/iShohei220/adopt.
tl;dr: This work proposes a learning-based approach for quickly computing high-quality solutions for several challenging classes bilevel optimization problems (linear/non-linear, integer/mixed-integer) via learning-based value function approximation.

Bilevel optimization deals with nested problems in which *leader* takes the first decision to minimize their objective function while accounting for a *follower*'s best-response reaction. Constrained bilevel problems with integer variables are particularly notorious for their hardness. While exact solvers have been proposed for mixed-integer *linear* bilevel optimization, they tend to scale poorly with problem size and are hard to generalize to the non-linear case. On the other hand, problem-specific algorithms (exact and heuristic) are limited in scope. Under a data-driven setting in which similar instances of a bilevel problem are solved routinely, our proposed framework, Neur2BiLO, embeds a neural network approximation of the leader's or follower's value function, trained via supervised regression, into an easy-to-solve mixed-integer program. Neur2BiLO serves as a heuristic that produces high-quality solutions extremely fast for four applications with linear and non-linear objectives and pure and mixed-integer variables.
tl;dr: This paper explores the imbalance in the image SR task and proposes a plug-and-play Weight-Balancing framework (WBSR) based on a HES strategy and a BDLoss to achieve accurate and efficient inference.

Existing super-resolution (SR) methods optimize all model weights equally using $\mathcal{L}_1$ or $\mathcal{L}_2$ losses by uniformly sampling image patches without considering dataset imbalances or parameter redundancy, which limits their performance. To address this, we formulate the image SR task as an imbalanced distribution transfer learning problem from a statistical probability perspective, proposing a plug-and-play Weight-Balancing framework (WBSR) to achieve balanced model learning without changing the original model structure and training data. Specifically, we develop a Hierarchical Equalization Sampling (HES) strategy to address data distribution imbalances, enabling better feature representation from texture-rich samples. To tackle model optimization imbalances, we propose a Balanced Diversity Loss (BDLoss) function, focusing on learning texture regions while disregarding redundant computations in smooth regions. After joint training of HES and BDLoss to rectify these imbalances, we present a gradient projection dynamic inference strategy to facilitate accurate and efficient inference. Extensive experiments across various models, datasets, and scale factors demonstrate that our method achieves comparable or superior performance to existing approaches with about 34\% reduction in computational cost.

Diffusion Transformer (DiT) is emerging as a cutting-edge trend in the landscape of generative diffusion models for image generation. Recently, masked-reconstruction strategies have been considered to improve the efficiency and semantic consistency in training DiT but suffer from deficiency in contextual information extraction. In this paper, we provide a new insight to reveal that noisy-to-noisy masked-reconstruction harms sufficient utilization of contextual information. We further demonstrate the insight with theoretical analysis and empirical study on the mutual information between unmasked and masked patches. Guided by such insight, we propose a novel training paradigm named MC-DiT for fully learning contextual information via diffusion denoising at different noise variances with clean-to-clean mask-reconstruction. Moreover, to avoid model collapse, we design two complementary branches of DiT decoders for enhancing the use of noisy patches and mitigating excessive reliance on clean patches in reconstruction. Extensive experimental results on 256$\times$256 and 512$\times$512 image generation on the ImageNet dataset demonstrate that the proposed MC-DiT achieves state-of-the-art performance in unconditional and conditional image generation with enhanced convergence speed.

We develop a technique to design efficiently computable estimators for sparse linear regression in the simultaneous presence of two adversaries: oblivious and adaptive.
Consider the model $y^*=X^*\beta^*+ \eta$ where $X^*$ is an $n\times d$ random design matrix, $\beta^*\in \mathbb{R}^d$ is a $k$-sparse vector, and the noise $\eta$ is independent of $X^*$ and chosen by the \emph{oblivious adversary}.
Apart from the independence of $X^*$, we only require a small fraction entries of $\eta$ to have magnitude at most $1$.
The \emph{adaptive adversary} is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples $(X_1^*, y_1^*),\ldots, (X_n^*, y_n^*)$.
Given the $\varepsilon$-corrupted samples $(X_1, y_1),\ldots, (X_n, y_n)$, the goal is to estimate $\beta^*$.
We assume that the rows of $X^*$ are iid samples from some $d$-dimensional distribution $\mathcal{D}$ with zero mean and (unknown) covariance matrix $\Sigma$ with bounded condition number.
We design several robust algorithms that outperform the state of the art even in the special case of Gaussian noise $\eta \sim N(0,1)^n$.
In particular, we provide a polynomial-time algorithm that with high probability recovers $\beta^*$ up to error $O(\sqrt{\varepsilon})$ as long as $n \ge \tilde{O}(k^2/\varepsilon)$, only assuming some bounds on the third and the fourth moments of $\mathcal{D}$.
In addition, prior to this work, even in the special case of Gaussian design $\mathcal{D} = N(0,\Sigma)$ and noise $\eta \sim N(0,1)$, no polynomial time algorithm was known to achieve error $o(\sqrt{\varepsilon})$ in the sparse setting $n < d^2$.
We show that under some assumptions on the fourth and the eighth moments of $\mathcal{D}$, there is a polynomial-time algorithm that achieves error $o(\sqrt{\varepsilon})$ as long as $n \ge \tilde{O}(k^4 / \varepsilon^3)$.
For Gaussian distribution $\mathcal{D} = N(0,\Sigma)$, this algorithm achieves error $O(\varepsilon^{3/4})$.
Moreover, our algorithm achieves error $o(\sqrt{\varepsilon})$ for all log-concave distributions if $\varepsilon \le 1/\text{polylog(d)}$.
Our algorithms are based on the filtering of the covariates that uses sum-of-squares relaxations, and weighted Huber loss minimization with $\ell_1$ regularizer. We provide a novel analysis of weighted penalized Huber loss that is suitable for heavy-tailed designs in the presence of two adversaries. Furthermore, we complement our algorithmic results with Statistical Query lower bounds, providing evidence that our estimators are likely to have nearly optimal sample complexity.

In this paper, we tackle the challenge of generating high-quality hash codes for cross-modal retrieval in the presence of incomplete labels, which creates uncertainty in distinguishing between positive and negative pairs. Vision-language models such as CLIP offer a potential solution by providing generic knowledge for missing label recovery, yet their zero-shot performance remains insufficient. To address this, we propose a novel Prompt Contrastive Recovery approach, \textbf{PCRIL}, which progressively identifies promising positive classes from unknown label sets and recursively searches for other relevant labels. Identifying unknowns is nontrivial due to the fixed and long-tailed patterns of positive label sets in training data, which hampers the discovery of new label combinations. Therefore, we consider each subset of positive labels and construct three types of negative prompts through deletion, addition, and replacement for prompt learning. The augmented supervision guides the model to measure the completeness of label sets, thus facilitating the subsequent greedy tree search for label completion. We also address extreme cases of significant unknown labels and lack of negative pairwise supervision by deriving two augmentation strategies: seeking unknown-complementary samples for mixup and random flipping for negative labels. Extensive experiments reveal the vulnerability of current methods and demonstrate the effectiveness of PCRIL, achieving an average 12\% mAP improvement to the current SOTA across all datasets. Our code is available at https://github.com/E-Galois/PCRIL.
tl;dr: We encode cluster assignments, indicating which cluster a data point belongs to, without creating labels. The information is implicit in the ordering of the dataset. This results in significant memory savings for vector database and applications.

We present an optimal method for encoding cluster assignments of arbitrary data sets. Our method, Random Cycle Coding (RCC), encodes data sequentially and sends assignment information as cycles of the permutation defined by the order of encoded elements. RCC does not require any training and its worst-case complexity scales quasi-linearly with the size of the largest cluster. We characterize the achievable bit rates as a function of cluster sizes and number of elements, showing RCC consistently outperforms previous methods while requiring less compute and memory resources. Experiments show RCC can save up to $2$ bytes per element when applied to vector databases, and removes the need for assigning integer ids to identify vectors, translating to savings of up to $70\%$ in vector database systems for similarity search applications.
tl;dr: In this paper, we propose a mobile device operation assistant based on a multi-agent architecture, which is capable of effectively navigating through historical information and self-reflection.

Mobile device operation tasks are increasingly becoming a popular multi-modal AI application scenario. Current Multi-modal Large Language Models (MLLMs), constrained by their training data, lack the capability to function effectively as operation assistants. Instead, MLLM-based agents, which enhance capabilities through tool invocation, are gradually being applied to this scenario. However, the two major navigation challenges in mobile device operation tasks — task progress navigation and focus content navigation — are difficult to effectively solve under the single-agent architecture of existing work. This is due to the overly long token sequences and the interleaved text-image data format, which limit performance. To address these navigation challenges effectively, we propose Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance. The architecture comprises three agents: planning agent, decision agent, and reflection agent. The planning agent condenses lengthy, interleaved image-text history operations and screens summaries into a pure-text task progress, which is then passed on to the decision agent. This reduction in context length makes it easier for decision agent to navigate the task progress. To retain focus content, we design a memory unit that updates with task progress by decision agent. Additionally, to correct erroneous operations, the reflection agent observes the outcomes of each operation and handles any mistake accordingly. Experimental results indicate that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to the single-agent architecture of Mobile-Agent. The code is open-sourced at https://github.com/X-PLUG/MobileAgent.
3259. Regularized Q-Learning

Q-learning is widely used algorithm in reinforcement learning (RL) community. Under the lookup table setting, its convergence is well established. However, its behavior is known to be unstable with the linear function approximation case. This paper develops a new Q-learning algorithm, called RegQ, that converges when linear function approximation is used. We prove that simply adding an appropriate regularization term ensures convergence of the algorithm. Its stability is established using a recent analysis tool based on switching system models. Moreover, we experimentally show that RegQ converges in environments where Q-learning with linear function approximation has known to diverge. An error bound on the solution where the algorithm converges is also given.
tl;dr: A novel scheme for online calibration that offers both worst-case deterministic long-term risk control and statistical localized risk guarantees.

Adaptive Risk Control (ARC) is an online calibration strategy based on set prediction that offers worst-case deterministic long-term risk control, as well as statistical marginal coverage guarantees. ARC adjusts the size of the prediction set by varying a single scalar threshold based on feedback from past decisions. In this work, we introduce Localized Adaptive Risk Control (L-ARC), an online calibration scheme that targets statistical localized risk guarantees ranging from conditional risk to marginal risk, while preserving the worst-case performance of ARC. L-ARC updates a threshold function within a reproducing kernel Hilbert space (RKHS), with the kernel determining the level of localization of the statistical risk guarantee. The theoretical results highlight a trade-off between localization of the statistical risk and convergence speed to the long-term risk target. Thanks to localization, L-ARC is demonstrated via experiments to produce prediction sets with risk guarantees across different data subpopulations, significantly improving the fairness of the calibrated model for tasks such as image segmentation and beam selection in wireless networks.

Choice models are essential for understanding decision-making processes in domains like online advertising, product recommendations, and assortment optimization. The Multinomial Logit (MNL) model is particularly versatile in selecting products or advertisements for display. However, challenges arise with unknown MNL parameters and delayed feedback, requiring sellers to learn customers’ choice behavior and make dynamic decisions with biased knowledge due to delays. We address these challenges by developing an algorithm that handles delayed feedback, balancing exploration and exploitation using confidence bounds and optimism. We first consider a censored setting where a threshold for considering feedback is imposed by business requirements. Our algorithm demonstrates a $\tilde{O}(\sqrt{NT})$ regret, with a matching lower bound up to a logarithmic term. Furthermore, we extend our analysis to environments with non-thresholded delays, achieving a $\tilde{O}(\sqrt{NT})$ regret. To validate our approach, we conduct experiments that confirm the effectiveness of our algorithm.
tl;dr: We train neural networks to minimize a similarity-based objective function to learn joint encodings of space and context, and observe place cell-like representations and remapping in network responses

Hippocampal place cells are known for their spatially selective firing patterns, which has led to the suggestion that they encode an animal's location. However, place cells also respond to contextual cues, such as smell. Furthermore, they have the ability to remap, wherein the firing fields and rates of cells change in response to changes in the environment. How place cell responses emerge, and how these representations remap is not fully understood. In this work, we propose a similarity-based objective function that translates proximity in space, to proximity in representation. We show that a neural network trained to minimize the proposed objective learns place-like representations. We also show that the proposed objective is easily extended to include other sources of information, such as context information, in the same way. When trained to encode multiple contexts, networks learn distinct representations, exhibiting remapping behaviors between contexts. The proposed objective is invariant to orthogonal transformations. Such transformations of the original trained representation (e.g. rotations), therefore yield new representations distinct from the original, without explicit relearning, akin to remapping. Our findings shed new light on the formation and encoding properties of place cells, and also demonstrate an interesting case of representational reuse.

Domain Generalization (DG) aims to enable models to generalize to unseen target domains by learning from multiple source domains. Existing DG methods primarily rely on convolutional neural networks (CNNs), which inherently learn texture biases due to their limited receptive fields, making them prone to overfitting source domains. While some works have introduced transformer-based methods (ViTs) for DG to leverage the global receptive field, these methods incur high computational costs due to the quadratic complexity of self-attention. Recently, advanced state space models (SSMs), represented by Mamba, have shown promising results in supervised learning tasks by achieving linear complexity in sequence length during training and fast RNN-like computation during inference. Inspired by this, we investigate the generalization ability of the Mamba model under domain shifts and find that input-dependent matrices within SSMs could accumulate and amplify domain-specific features, thus hindering model generalization. To address this issue, we propose a novel SSM-based architecture with saliency-based token-aware transformation (namely START), which achieves state-of-the-art (SOTA) performances and offers a competitive alternative to CNNs and ViTs. Our START can selectively perturb and suppress domain-specific features in salient tokens within the input-dependent matrices of SSMs, thus effectively reducing the discrepancy between different domains. Extensive experiments on five benchmarks demonstrate that START outperforms existing SOTA DG methods with efficient linear complexity. Our code is available at https://github.com/lingeringlight/START.
tl;dr: A biologically plausible sequential memory model that (1) represents and generates multiple possibilities by learning fixed-point attractors, (2) learns continually while avoiding catastrophic forgetting, and (3) is robust to noise.

Sequential memory, the ability to form and accurately recall a sequence of events or stimuli in the correct order, is a fundamental prerequisite for biological and artificial intelligence as it underpins numerous cognitive functions (e.g., language comprehension, planning, episodic memory formation, etc.) However, existing methods of sequential memory suffer from catastrophic forgetting, limited capacity, slow iterative learning procedures, low-order Markov memory, and, most importantly, the inability to represent and generate multiple valid future possibilities stemming from the same context. Inspired by biologically plausible neuroscience theories of cognition, we propose Predictive Attractor Models (PAM), a novel sequence memory architecture with desirable generative properties. PAM is a streaming model that learns a sequence in an online, continuous manner by observing each input only once. Additionally, we find that PAM avoids catastrophic forgetting by uniquely representing past context through lateral inhibition in cortical minicolumns, which prevents new memories from overwriting previously learned knowledge. PAM generates future predictions by sampling from a union set of predicted possibilities; this generative ability is realized through an attractor model trained alongside the predictor. We show that PAM is trained with local computations through Hebbian plasticity rules in a biologically plausible framework. Other desirable traits (e.g., noise tolerance, CPU-based learning, capacity scaling) are discussed throughout the paper. Our findings suggest that PAM represents a significant step forward in the pursuit of biologically plausible and computationally efficient sequential memory models, with broad implications for cognitive science and artificial intelligence research. Illustration videos and code are available on our project page: https://ramymounir.com/publications/pam.

Masked Autoencoder (MAE) is a self-supervised approach for representation learning, widely applicable to a variety of downstream tasks in computer vision. In spite of its success, it is still not fully uncovered what and how MAE exactly learns. In this paper, with an in-depth analysis, we discover that MAE intrinsically learns pattern-based patch-level clustering from surprisingly early stages of pre-training. Upon this understanding, we propose self-guided masked autoencoder, which internally generates informed mask by utilizing its progress in patch clustering, substituting the naive random masking of the vanilla MAE. Our approach significantly boosts its learning process without relying on any external models or supplementary information, keeping the benefit of self-supervised nature of MAE intact. Comprehensive experiments on various downstream tasks verify the effectiveness of the proposed method.

We present Preference Flow Matching (PFM), a new framework for preference alignment that streamlines the integration of preferences into an arbitrary class of pre-trained models. Existing alignment methods require fine-tuning pre-trained models, which presents challenges such as scalability, inefficiency, and the need for model modifications, especially with black-box APIs like GPT-4. In contrast, PFM utilizes flow matching techniques to directly learn from preference data, thereby reducing the dependency on extensive fine-tuning of pre-trained models. By leveraging flow-based models, PFM transforms less preferred data into preferred outcomes, and effectively aligns model outputs with human preferences without relying on explicit or implicit reward function estimation, thus avoiding common issues like overfitting in reward models. We provide theoretical insights that support our method’s alignment with standard preference alignment objectives. Experimental results indicate the practical effectiveness of our method, offering a new direction in aligning a pre-trained model to preference. Our code is available at https://github.com/jadehaus/preference-flow-matching.

Recent advances in 4D generation mainly focus on generating 4D content by distilling pre-trained text or single-view image conditioned models. It is inconvenient for them to take advantage of various off-the-shelf 3D assets with multi-view attributes, and their results suffer from spatiotemporal inconsistency owing to the inherent ambiguity in the supervision signals. In this work, we present Animate3D, a novel framework for animating any static 3D model. The core idea is two-fold: 1) We propose a novel multi-view video diffusion model (MV-VDM) conditioned on multi-view renderings of the static 3D object, which is trained on our presented large-scale multi-view video dataset (MV-Video). 2) Based on MV-VDM, we introduce a framework combining reconstruction and 4D Score Distillation Sampling (4D-SDS) to leverage the multi-view video diffusion priors for animating 3D objects. Specifically, for MV-VDM, we design a new spatiotemporal attention module to enhance spatial and temporal consistency by integrating 3D and video diffusion models. Additionally, we leverage the static 3D model’s multi-view renderings as conditions to preserve its identity. For animating 3D models, an effective two-stage pipeline is proposed: we first reconstruct coarse motions directly from generated multi-view videos, followed by the introduced 4D-SDS to model fine-level motions. Benefiting from accurate motion learning, we could achieve straightforward mesh animation. Qualitative and quantitative experiments demonstrate that Animate3D significantly outperforms previous approaches. Data, code, and models are open-released.

Fragment-based drug discovery, in which molecular fragments are assembled into new molecules with desirable biochemical properties, has achieved great success. However, many fragment-based molecule generation methods show limited exploration beyond the existing fragments in the database as they only reassemble or slightly modify the given ones. To tackle this problem, we propose a new fragment-based molecule generation framework with retrieval augmentation, namely *Fragment Retrieval-Augmented Generation* (*f*-RAG). *f*-RAG is based on a pre-trained molecular generative model that proposes additional fragments from input fragments to complete and generate a new molecule. Given a fragment vocabulary, *f*-RAG retrieves two types of fragments: (1) *hard fragments*, which serve as building blocks that will be explicitly included in the newly generated molecule, and (2) *soft fragments*, which serve as reference to guide the generation of new fragments through a trainable *fragment injection module*. To extrapolate beyond the existing fragments, *f*-RAG updates the fragment vocabulary with generated fragments via an iterative refinement process which is further enhanced with post-hoc genetic fragment modification. *f*-RAG can achieve an improved exploration-exploitation trade-off by maintaining a pool of fragments and expanding it with novel and high-quality fragments through a strong generative prior.
tl;dr: We propose to explore cloud object detector adaptation by integrating different source knowledge in a self-promotion way.

We propose to explore an interesting and promising problem, Cloud Object Detector Adaptation (CODA), where the target domain leverages detections provided by a large cloud model to build a target detector. Despite with powerful generalization capability, the cloud model still cannot achieve error-free detection in a specific target domain. In this work, we present a novel Cloud Object detector adaptation method by Integrating different source kNowledge (COIN). The key idea is to incorporate a public vision-language model (CLIP) to distill positive knowledge while refining negative knowledge for adaptation by self-promotion gradient direction alignment. To that end, knowledge dissemination, separation, and distillation are carried out successively. Knowledge dissemination combines knowledge from cloud detector and CLIP model to initialize a target detector and a CLIP detector in target domain. By matching CLIP detector with the cloud detector, knowledge separation categorizes detections into three parts: consistent, inconsistent and private detections such that divide-and-conquer strategy can be used for knowledge distillation. Consistent and private detections are directly used to train target detector; while inconsistent detections are fused based on a consistent knowledge generation network, which is trained by aligning the gradient direction of inconsistent detections to that of consistent detections, because it provides a direction toward an optimal target detector. Experiment results demonstrate that the proposed COIN method achieves the state-of-the-art performance.
tl;dr: In this paper, we present a new method for optimizing layerwise sparsity allocation in large language models.

In this paper, we present DSA, the first automated framework for discovering sparsity allocation schemes for layer-wise pruning in Large Language Models (LLMs). LLMs have become increasingly powerful, but their large parameter counts make them computationally expensive. Existing pruning methods for compressing LLMs primarily focus on evaluating redundancies and removing element-wise weights. However, these methods fail to allocate adaptive layer-wise sparsities, leading to performance degradation in challenging tasks. We observe that per-layer importance statistics can serve as allocation indications, but their effectiveness depends on the allocation function between layers. To address this issue, we develop an expression discovery framework to explore potential allocation strategies. Our allocation functions involve two steps: reducing element-wise metrics to per-layer importance scores, and modelling layer importance to sparsity ratios. To search for the most effective allocation function, we construct a search space consisting of pre-process, reduction, transform, and post-process operations. We leverage an evolutionary algorithm to perform crossover and mutation on superior candidates within the population, guided by performance evaluation. Finally, we seamlessly integrate our discovered functions into various uniform methods, resulting in significant performance improvements. We conduct extensive experiments on multiple challenging tasks such as arithmetic, knowledge reasoning, and multimodal benchmarks spanning GSM8K, MMLU, SQA, and VQA, demonstrating that our DSA method achieves significant performance gains on the LLaMA-1|2|3, Mistral, and OPT models. Notably, the LLaMA-1|2|3 model pruned by our DSA reaches 4.73\%|6.18\%|10.65\% gain over the state-of-the-art techniques (e.g., Wanda and SparseGPT).
tl;dr: We combine weighted reservoir sampling with passive-aggressive online algorithms to dramatically mitigate test accuracy fluctuations.

Online learning methods, like the seminal Passive-Aggressive (PA) classifier, are still highly effective for high-dimensional streaming data, out-of-core processing, and other throughput-sensitive applications. Many such algorithms rely on fast adaptation to individual errors as a key to their convergence. While such algorithms enjoy low theoretical regret, in real-world deployment they can be sensitive to individual outliers that cause the algorithm to over-correct. When such outliers occur at the end of the data stream, this can cause the final solution to have unexpectedly low accuracy. We design a weighted reservoir sampling (WRS) approach to obtain a stable ensemble model from the sequence of solutions without requiring additional passes over the data, hold-out sets, or a growing amount of memory. Our key insight is that good solutions tend to be error-free for more iterations than bad solutions, and thus, the number of passive rounds provides an estimate of a solution's relative quality. Our reservoir thus contains $K$ previous intermediate weight vectors with high survival times. We demonstrate our WRS approach on the Passive-Aggressive Classifier (PAC) and First-Order Sparse Online Learning (FSOL), where our method consistently and significantly outperforms the unmodified approach. We show that the risk of the ensemble classifier is bounded with respect to the regret of the underlying online learning method.
3272. Skill-aware Mutual Information Optimisation for Zero-shot Generalisation in Reinforcement Learning

Meta-Reinforcement Learning (Meta-RL) agents can struggle to operate across tasks with varying environmental features that require different optimal skills (i.e., different modes of behaviour). Using context encoders based on contrastive learning to enhance the generalisability of Meta-RL agents is now widely studied but faces challenges such as the requirement for a large sample size, also referred to as the $\log$-$K$ curse. To improve RL generalisation to different tasks, we first introduce Skill-aware Mutual Information (SaMI), an optimisation objective that aids in distinguishing context embeddings according to skills, thereby equipping RL agents with the ability to identify and execute different skills across tasks. We then propose Skill-aware Noise Contrastive Estimation (SaNCE), a $K$-sample estimator used to optimise the SaMI objective. We provide a framework for equipping an RL agent with SaNCE in practice and conduct experimental validation on modified MuJoCo and Panda-gym benchmarks. We empirically find that RL agents that learn by maximising SaMI achieve substantially improved zero-shot generalisation to unseen tasks. Additionally, the context encoder trained with SaNCE demonstrates greater robustness to a reduction in the number of available samples, thus possessing the potential to overcome the $\log$-$K$ curse.
tl;dr: We introduce an interpretable GAM approach for missing data which improves accuracy under synthetic missingness while globally improving sparsity, all with no significant cost to real-world accuracy or runtime.

Many important datasets contain samples that are missing one or more feature values. Maintaining the interpretability of machine learning models in the presence of such missing data is challenging. Singly or multiply imputing missing values complicates the model’s mapping from features to labels. On the other hand, reasoning on indicator variables that represent missingness introduces a potentially large number of additional terms, sacrificing sparsity. We solve these problems with M-GAM, a sparse, generalized, additive modeling approach that incorporates missingness indicators and their interaction terms while maintaining sparsity through $\ell_0$ regularization. We show that M-GAM provides similar or superior accuracy to prior methods while significantly improving sparsity relative to either imputation or naïve inclusion of indicator variables.
tl;dr: We propose a scalable algorithm for assisting humans without inferring their objectives.

Assistive agents should make humans' lives easier. Classically, such assistance is studied through the lens of inverse reinforcement learning, where an assistive agent (e.g., a chatbot, a robot) infers a human's intention and then selects actions to help the human reach that goal. This approach requires inferring intentions, which can be difficult in high-dimensional settings. We build upon prior work that studies assistance through the lens of empowerment: an assistive agent aims to maximize the influence of the human's actions such that they exert a greater control over the environmental outcomes and can solve tasks in fewer steps. We lift the major limitation of prior work in this area—scalability to high-dimensional settings—with contrastive successor representations. We formally prove that these representations estimate a similar notion of empowerment to that studied by prior work and provide a ready-made mechanism for optimizing it. Empirically, our proposed method outperforms prior methods on synthetic benchmarks, and scales to Overcooked, a cooperative game setting. Theoretically, our work connects ideas from information theory, neuroscience, and reinforcement learning, and charts a path for representations to play a critical role in solving assistive problems. Our code is available at https://anonymous.4open.science/r/esr-7E94.
tl;dr: LLM based Code Agents are suitable for generating software tests in large and complex code bases, introducing a new paradigm for test generation and additional metrics for Code Agent performance.

Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents to formalize user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth bug-fixes, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases, with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using issue reproduction rate and coverage changes, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent. We release all data and code at https://github.com/logic-star-ai/SWT-Bench.
tl;dr: In this paper, we introduce a novel continual audio-visual sound separation task and an approach named ContAV-Sep for the proposed task.

In this paper, we introduce a novel continual audio-visual sound separation task, aiming to continuously separate sound sources for new classes while preserving performance on previously learned classes, with the aid of visual guidance. This problem is crucial for practical visually guided auditory perception as it can significantly enhance the adaptability and robustness of audio-visual sound separation models, making them more applicable for real-world scenarios where encountering new sound sources is commonplace. The task is inherently challenging as our models must not only effectively utilize information from both modalities in current tasks but also preserve their cross-modal association in old tasks to mitigate catastrophic forgetting during audio-visual continual learning. To address these challenges, we propose a novel approach named ContAV-Sep ($\textbf{Cont}$inual $\textbf{A}$udio-$\textbf{V}$isual Sound $\textbf{Sep}$aration). ContAV-Sep presents a novel Cross-modal Similarity Distillation Constraint (CrossSDC) to uphold the cross-modal semantic similarity through incremental tasks and retain previously acquired knowledge of semantic similarity in old models, mitigating the risk of catastrophic forgetting. The CrossSDC can seamlessly integrate into the training process of different audio-visual sound separation frameworks. Experiments demonstrate that ContAV-Sep can effectively mitigate catastrophic forgetting and achieve significantly better performance compared to other continual learning baselines for audio-visual sound separation. Code is available at: https://github.com/weiguoPian/ContAV-Sep_NeurIPS2024.
tl;dr: Scale up DBSCAN and OPTICS with random projections

We present sDBSCAN, a scalable density-based clustering algorithm in high dimensions with cosine distance. sDBSCAN leverages recent advancements in random projections given a significantly large number of random vectors to quickly identify core points and their neighborhoods, the primary hurdle of density-based clustering. Theoretically, sDBSCAN preserves the DBSCAN’s clustering structure under mild conditions with high probability. To facilitate sDBSCAN, we present sOPTICS, a scalable visual tool to guide the parameter setting of sDBSCAN. We also extend sDBSCAN and sOPTICS to L2, L1, χ2, and Jensen-Shannon distances via random kernel features. Empirically, sDBSCAN is significantly faster and provides higher accuracy than competitive DBSCAN variants on real-world million-point data sets. On these data sets, sDBSCAN and sOPTICS run in a few minutes, while the scikit-learn counterparts and other clustering competitors demand several hours or
cannot run on our hardware due to memory constraints. Our code is available at https://github.com/NinhPham/sDbscan.
tl;dr: This paper presents SongCreator, a song generation system that achieves competitive performances on eight tasks, particularly in lyrics-to-song and lyrics-to-vocals.

Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and a series of attention mask strategies for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various songrelated generation tasks by utilizing specific attention masks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different audio prompts, exhibiting its potential applicability. Our samples are available at https://thuhcsi.github.io/SongCreator/.
tl;dr: Investigating an effective, computationally scalable reinforcement learning perspective to imitation for language modeling.

The majority of language model training builds on imitation learning. It covers pretraining, supervised fine-tuning, and affects the starting conditions for reinforcement learning from human feedback (RLHF). The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation. We focus on investigating the inverse reinforcement learning (IRL) perspective to imitation, extracting rewards and directly optimizing sequences instead of individual token likelihoods and evaluate its benefits for fine-tuning large language models. We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting. We find clear advantages for IRL-based imitation, in particular for retaining diversity while maximizing task performance, rendering IRL a strong alternative on fixed SFT datasets even without online data generation. Our analysis of IRL-extracted reward functions further indicates benefits for more robust reward functions via tighter integration of supervised and preference-based LLM post-training.
tl;dr: Federated representation learning under a generative classifier for improved personalization under distribution shifts.

Federated learning (FL) is a distributed learning framework that leverages commonalities between distributed client datasets to train a global model. Under heterogeneous clients, however, FL can fail to produce stable training results. Personalized federated learning (PFL) seeks to address this by learning individual models tailored to each client. One approach is to decompose model training into shared representation learning and personalized classifier training. Nonetheless, previous works struggle to navigate the bias-variance trade-off in classifier learning, relying solely on limited local datasets or introducing costly techniques to improve generalization.
In this work, we frame representation learning as a generative modeling task, where representations are trained with a classifier based on the global feature distribution. We then propose an algorithm, pFedFDA, that efficiently generates personalized models by adapting global generative classifiers to their local feature distributions. Through extensive computer vision benchmarks, we demonstrate that our method can adjust to complex distribution shifts with significant improvements over current state-of-the-art in data-scarce settings.

Phenotype imputation plays a crucial role in improving comprehensive and accurate medical evaluation, which in turn can optimize patient treatment and bolster the reliability of clinical research. Despite the adoption of various techniques, multi-modal biological data, which can provide crucial insights into a patient's overall health, is often overlooked. With multi-modal biological data, patient characterization can be enriched from two distinct views: the biological view and the phenotype view. However, the heterogeneity and imprecise nature of the multimodal data still pose challenges in developing an effective method to model from two views. In this paper, we propose a novel framework to incorporate multi-modal biological data via view decoupling. Specifically, we segregate the modeling of biological data from phenotype data in a graph-based learning framework. From the biological view, the latent factors in biological data are discovered to model patient correlation. From the phenotype view, phenotype co-occurrence can be modeled to reveal patterns across patients. Then patients are encoded from these two distinct views. To mitigate the influence of noise and irrelevant information in biological data, we devise a cross-view contrastive knowledge distillation aimed at distilling insights from the biological view to enhance phenotype imputation. We show that phenotype imputation with the proposed model significantly outperforms the state-of-the-art models on the real-world biomedical database.

The lack of object-level labels presents a significant challenge for 3D object retrieval in the open-set environment. However, part-level shapes of objects often share commonalities across categories but remain underexploited in existing retrieval methods. In this paper, we introduce the Hypergraph-Based Assembly Fuzzy Representation (HARF) framework, which navigates the intricacies of open-set 3D object retrieval through a bottom-up lens of Part Assembly. To tackle the challenge of assembly isomorphism and unification, we propose the Hypergraph Isomorphism Convolution (HIConv) for smoothing and adopt the Isomorphic Assembly Embedding (IAE) module to generate assembly embeddings with geometric-semantic consistency. To address the challenge of open-set category generalization, our method employs high-order correlations and fuzzy representation to mitigate distribution skew through the Structure Fuzzy Reconstruction (SFR) module, by constructing a leveraged hypergraph based on local certainty and global uncertainty correlations. We construct three open-set retrieval datasets for 3D objects with part-level annotations: OP-SHNP, OP-INTRA, and OP-COSEG. Extensive experiments and ablation studies on these three benchmarks show our method outperforms current state-of-the-art methods.
tl;dr: We propose a sample-wise ensembling technique for fine-tuning zero-shot models that can simultaneously attain the best ID and OOD accuracy.

When fine-tuning zero-shot models like CLIP, our desideratum is for the fine-tuned model to excel in both in-distribution (ID) and out-of-distribution (OOD). Recently, ensemble-based models (ESM) have been shown to offer significant robustness improvement, while preserving high ID accuracy. However, our study finds that ESMs do not solve the ID-OOD trade-offs: they achieve peak performance for ID and OOD accuracy at different mixing coefficients. When optimized for OOD accuracy, the ensemble model exhibits a noticeable decline in ID accuracy, and vice versa. In contrast, we propose a sample-wise ensembling technique that can simultaneously attain the best ID and OOD accuracy without the trade-offs. Specifically, we construct a Zero-Shot Failure (ZSF) set containing training samples incorrectly predicted by the zero-shot model. For each test sample, we calculate its distance to the ZSF set and assign a higher weight to the fine-tuned model in the ensemble if the distance is small. We term our method Variance Reduction Fine-tuning (VRF), as it effectively reduces the variance in ensemble predictions, thereby decreasing residual error. On ImageNet and five derived distribution shifts, our VRF further improves the OOD accuracy by 1.5 - 2.0 pp over the ensemble baselines while maintaining or increasing ID accuracy. VRF achieves similar large robustness gains on (0.9 - 3.1 pp) on other distribution shifts
19 benchmarks. Codes are available in https://github.com/BeierZhu/VRF.
tl;dr: We propose a post-training compression algorithm for Large Language Models (LLMs), that harnesses the inherent low-rank structure of LLM weight matrices, that effectively combines low-rank and low-precision matrix decompositions,

The prohibitive sizes of Large Language Models (LLMs) today make it difficult to deploy them on memory-constrained edge devices. This work introduces $\rm CALDERA$ -- a new post-training LLM compression algorithm that harnesses the inherent low-rank structure of a weight matrix $\mathbf{W}$ by approximating it via a low-rank, low-precision decomposition as $\mathbf{W} \approx \mathbf{Q} + \mathbf{L}\mathbf{R}$. Here, $\mathbf{L}$ and $\mathbf{R}$ are low rank factors, and the entries of $\mathbf{Q}$, $\mathbf{L}$ and $\mathbf{R}$ are quantized. The model is compressed by substituting each layer with its $\mathbf{Q} + \mathbf{L}\mathbf{R}$ decomposition, and the zero-shot performance of the compressed model is evaluated. Additionally, $\mathbf{L}$ and $\mathbf{R}$ are readily amenable to low-rank adaptation, consequently enhancing the zero-shot performance. $\rm CALDERA$ obtains this decomposition by formulating it as an optimization problem $\min_{\mathbf{Q},\mathbf{L},\mathbf{R}}\lVert(\mathbf{Q} + \mathbf{L}\mathbf{R} - \mathbf{W})\mathbf{X}^\top\rVert_{\rm F}^2$, where $\mathbf{X}$ is the calibration data, and $\mathbf{Q}, \mathbf{L}, \mathbf{R}$ are constrained to be representable using low-precision formats. Theoretical upper bounds on the approximation error of $\rm CALDERA$ are established using a rank-constrained regression framework, and the tradeoff between compression ratio and model performance is studied by analyzing the impact of target rank and quantization bit budget. Results illustrate that compressing LlaMa-$2$ $7$B/$13$B/$70$B and LlaMa-$3$ $8$B models obtained using $\rm CALDERA$ outperforms existing post-training LLM compression techniques in the regime of less than $2.5$ bits per parameter.
tl;dr: We propose a Retrieval-Augmented Time series Diffusion framework for time series forecasting for the first time.

While time series diffusion models have received considerable focus from many recent works, the performance of existing models remains highly unstable. Factors limiting time series diffusion models include insufficient time series datasets and the absence of guidance. To address these limitations, we propose a Retrieval-Augmented Time series Diffusion model (RATD). The framework of RATD consists of two parts: an embedding-based retrieval process and a reference-guided diffusion model. In the first part, RATD retrieves the time series that are most relevant to historical time series from the database as references. The references are utilized to guide the denoising process in the second part. Our approach allows leveraging meaningful samples within the database to aid in sampling, thus maximizing the utilization of datasets. Meanwhile, this reference-guided mechanism also compensates for the deficiencies of existing time series diffusion models in terms of guidance. Experiments and visualizations on multiple datasets demonstrate the effectiveness of our approach, particularly in complicated prediction tasks. Our code is available at https://github.com/stanliu96/RATD
tl;dr: Probabilistic model learning hierarchies in data by optimizing the expected metrics via gradient descent outperforming several baselines.

Hierarchical clustering has usually been addressed by discrete optimization using heuristics or continuous optimization of relaxed scores for hierarchies. In this work, we propose to optimize expected scores under a probabilistic model over hierarchies. (1) We show theoretically that the global optimal values of the expected Dasgupta cost and Tree-Sampling divergence (TSD), two unsupervised metrics for hierarchical clustering, are equal to the optimal values of their discrete counterparts contrary to some relaxed scores. (2) We propose Expected Probabilistic Hierarchies (EPH), a probabilistic model to learn hierarchies in data by optimizing expected scores. EPH uses differentiable hierarchy sampling enabling end-to-end gradient descent based optimization, and an unbiased subgraph sampling approach to scale to large datasets. (3) We evaluate EPH on synthetic and real-world datasets including vector and graph datasets. EPH outperforms all other approaches quantitatively and provides meaningful hierarchies in qualitative evaluations.
tl;dr: a large multimodal model with versatile vision-centric capabilities

Large Multimodal Model (LMM) is a hot research topic in the computer vision area and has also demonstrated remarkable potential across multiple disciplinary fields. A recent trend is to further extend and enhance the perception capabilities of LMMs. The current methods follow the paradigm of adapting the visual task outputs to the format of the language model, which is the main component of a LMM. This adaptation leads to convenient development of such LMMs with minimal modifications, however, it overlooks the intrinsic characteristics of diverse visual tasks and hinders the learning of perception capabilities. To address this issue, we propose a novel LMM architecture named Lumen, a Large multimodal model with versatile vision-centric capability enhancement. We decouple the LMM's learning of perception capabilities into task-agnostic and task-specific stages. Lumen first promotes fine-grained vision-language concept alignment, which is the fundamental capability for various visual tasks. Thus the output of the task-agnostic stage is a shared representation for all the tasks we address in this paper. Then the task-specific decoding is carried out by flexibly routing the shared representation to lightweight task decoders with negligible training efforts. Comprehensive experimental results on a series of vision-centric and VQA benchmarks indicate that our Lumen model not only achieves or surpasses the performance of existing LMM-based approaches in a range of vision-centric tasks while maintaining general visual understanding and instruction following capabilities.
tl;dr: Realtime relighting of subsurface scattering objects in 3D gaussian splatting scenes

3D reconstruction and relighting of objects made from scattering materials present a significant challenge due to the complex light transport beneath the surface. 3D Gaussian Splatting introduced high-quality novel view synthesis at real-time speeds. While 3D Gaussians efficiently approximate an object's surface, they fail to capture the volumetric properties of subsurface scattering. We propose a framework for optimizing an object's shape together with the radiance transfer field given multi-view OLAT (one light at a time) data. Our method decomposes the scene into an explicit surface represented as 3D Gaussians, with a spatially varying BRDF, and an implicit volumetric representation of the scattering component. A learned incident light field accounts for shadowing. We optimize all parameters jointly via ray-traced differentiable rendering. Our approach enables material editing, relighting, and novel view synthesis at interactive rates. We show successful application on synthetic data and contribute a newly acquired multi-view multi-light dataset of objects in a light-stage setup. Compared to previous work we achieve comparable or better results at a fraction of optimization and rendering time while enabling detailed control over material attributes.
3289. Make-it-Real: Unleashing Large Multimodal Model for Painting 3D Objects with Realistic Materials
tl;dr: This paper proposes unleashing large multimodal model’s ability for painting 3D objects with realistic materials

Physically realistic materials are pivotal in augmenting the realism of 3D assets across various applications and lighting conditions. However, existing 3D assets and generative models often lack authentic material properties. Manual assignment of materials using graphic software is a tedious and time-consuming task. In this paper, we exploit advancements in Multimodal Large Language Models (MLLMs), particularly GPT-4V, to present a novel approach, Make-it-Real: 1) We demonstrate that GPT-4V can effectively recognize and describe materials, allowing the construction of a detailed material library. 2) Utilizing a combination of visual cues and hierarchical text prompts, GPT-4V precisely identifies and aligns materials with the corresponding components of 3D objects. 3) The correctly matched materials are then meticulously applied as reference for the new SVBRDF material generation according to the original albedo map, significantly enhancing their visual authenticity. Make-it-Real offers a streamlined integration into the 3D content creation workflow, showcasing its utility as an essential tool for developers of 3D assets.
tl;dr: We introduce a novel technique to improve sampling speed of diffusion models by exploiting parallel-in-time integration.

In diffusion models, samples are generated through an iterative refinement process, requiring hundreds of sequential model evaluations. Several recent methods have introduced approximations (fewer discretization steps or distillation) to trade off speed at the cost of sample quality. In contrast, we introduce Self-Refining Diffusion Samplers (SRDS) that retain sample quality and can improve latency at the cost of additional parallel compute. We take inspiration from the Parareal algorithm, a popular numerical method for parallel-in-time integration of differential equations. In SRDS, a quick but rough estimate of a sample is first created and then iteratively refined in parallel through Parareal iterations. SRDS is not only guaranteed to accurately solve the ODE and converge to the serial solution but also benefits from parallelization across the diffusion trajectory, enabling batched inference and pipelining. As we demonstrate for pre-trained diffusion models, the early convergence of this refinement procedure drastically reduces the number of steps required to produce a sample, speeding up generation for instance by up to 1.7x on a 25-step StableDiffusion-v2 benchmark and up to 4.3x on longer trajectories.
tl;dr: We demonstrate the existence of emergent abilities in the lens of pre-training loss regardless of the continuity of evaluation metrics

Recent studies have put into question the belief that emergent abilities in language models are exclusive to large models. This skepticism arises from two observations: 1) smaller models can also exhibit high performance on emergent abilities and 2) there is doubt on the discontinuous metrics used to measure these abilities. In this paper, we propose to study emergent abilities in the lens of pre-training loss, instead of model size or training compute. We demonstrate that the models with the same pre-training loss, but different model and data sizes, generate the same performance on various downstream tasks. We also discover that a model exhibits emergent abilities on certain tasks---regardless of the continuity of metrics---when its pre-training loss falls below a specific threshold. Before reaching this threshold, its performance remains at the level of random guessing. This inspires us to redefine emergent abilities as those that manifest in models with lower pre-training losses, highlighting that these abilities cannot be predicted by merely extrapolating the performance trends of models with higher pre-training losses.

We present MV2Cyl, a novel method for reconstructing 3D from 2D multi-view images, not merely as a field or raw geometry but as a sketch-extrude CAD. Extracting extrusion cylinders from raw 3D geometry has been extensively researched in computer vision, while the processing of 3D data through neural networks has remained a bottleneck. Since 3D scans are generally accompanied by multi-view images, leveraging 2D convolutional neural networks allows these images to be exploited as a rich source for extracting extrusion cylinder information. However, we observe that extracting only the surface information of the extrudes and utilizing it results in suboptimal outcomes due to the challenges in the occlusion and surface segmentation. By synergizing with the extracted base curve information, we achieve the optimal reconstruction result with the best accuracy in 2D sketch and extrude parameter estimation. Our experiments, comparing our method with previous work that takes a raw 3D point cloud as input, demonstrate the effectiveness of our approach by taking advantage of multi-view images.
tl;dr: We propose to reshuffle resampling splits during hyperparameter optimization to improve generalization performance, demonstrating its effectiveness through theoretical analysis, simulations and benchmark experiments.

Hyperparameter optimization is crucial for obtaining peak performance of machine learning models. The standard protocol evaluates various hyperparameter configurations using a resampling estimate of the generalization error to guide optimization and select a final hyperparameter configuration. Without much evidence, paired resampling splits, i.e., either a fixed train-validation split or a fixed cross-validation scheme, are often recommended. We show that, surprisingly, reshuffling the splits for every configuration often improves the final model's generalization performance on unseen data. Our theoretical analysis explains how reshuffling affects the asymptotic behavior of the validation loss surface and provides a bound on the expected regret in the limiting regime. This bound connects the potential benefits of reshuffling to the signal and noise characteristics of the underlying optimization problem. We confirm our theoretical results in a controlled simulation study and demonstrate the practical usefulness of reshuffling in a large-scale, realistic hyperparameter optimization experiment. While reshuffling leads to test performances that are competitive with using fixed splits, it drastically improves results for a single train-validation holdout protocol and can often make holdout become competitive with standard CV while being computationally cheaper.

Large Language Models (LLMs) have shown remarkable reasoning capabilities on complex tasks, but they still suffer from out-of-date knowledge, hallucinations, and opaque decision-making. In contrast, Knowledge Graphs (KGs) can provide explicit and editable knowledge for LLMs to alleviate these issues. Existing paradigm of KG-augmented LLM manually predefines the breadth of exploration space and requires flawless navigation in KGs. However, this paradigm cannot adaptively explore reasoning paths in KGs based on the question semantics and self-correct erroneous reasoning paths, resulting in a bottleneck in efficiency and effect. To address these limitations, we propose a novel self-correcting adaptive planning paradigm for KG-augmented LLM named Plan-on-Graph (PoG), which first decomposes the question into several sub-objectives and then repeats the process of adaptively exploring reasoning paths, updating memory, and reflecting on the need to self-correct erroneous reasoning paths until arriving at the answer. Specifically, three important mechanisms of Guidance, Memory, and Reflection are designed to work together, to guarantee the adaptive breadth of self-correcting planning for graph reasoning. Finally, extensive experiments on three real-world datasets demonstrate the effectiveness and efficiency of PoG.

Direct Preference Optimization (DPO) has emerged as a compelling approach for training Large Language Models (LLMs) to adhere to human preferences. However, the performance of DPO is sensitive to the fine-tuning of its trade-off parameter $\beta$, as well as to the quality of the preference data. We analyze the impact of $\beta$ and data quality on DPO, uncovering that optimal $\beta$ values vary with the informativeness of pairwise data. Addressing the limitations of static $\beta$ values, we introduce a novel framework that dynamically calibrates $\beta$ at the batch level, informed by data quality considerations. Additionally, our method incorporates $\beta$-guided data filtering to safeguard against the influence of outliers. Through empirical evaluation, we demonstrate that our dynamic $\beta$ adjustment technique significantly improves DPO’s performance across a range of models and datasets, offering a more robust and adaptable training paradigm for aligning LLMs with human feedback. The code is available at \url{https://anonymous.4open.science/r/beta-DPO-EE6C}.
tl;dr: We present a collaborative framework for multi-drone object trajectory prediction, including a drone-specific BEV generation module and a selective interaction strategy based on the local feature discrepancy.

Collaborative trajectory prediction can comprehensively forecast the future motion of objects through multi-view complementary information. However, it encounters two main challenges in multi-drone collaboration settings. The expansive aerial observations make it difficult to generate precise Bird's Eye View (BEV) representations. Besides, excessive interactions can not meet real-time prediction requirements within the constrained drone-based communication bandwidth. To address these problems, we propose a novel framework named "Drones Help Drones" (DHD). Firstly, we incorporate the ground priors provided by the drone's inclined observation to estimate the distance between objects and drones, leading to more precise BEV generation. Secondly, we design a selective mechanism based on the local feature discrepancy to prioritize the critical information contributing to prediction tasks during inter-drone interactions. Additionally, we create the first dataset for multi-drone collaborative prediction, named "Air-Co-Pred", and conduct quantitative and qualitative experiments to validate the effectiveness of our DHD framework. The results demonstrate that compared to state-of-the-art approaches, DHD reduces position deviation in BEV representations by over 20\% and requires only a quarter of the transmission ratio for interactions while achieving comparable prediction performance. Moreover, DHD also shows promising generalization to the collaborative 3D object detection in CoPerception-UAVs.
tl;dr: We discuss a stochastic sum-of-squares algorithm for global polynomial optimization and use it for uncertainty quantification on sensor network localization problems.

Global polynomial optimization is an important tool across applied mathematics, with many applications in operations research, engineering, and the physical sciences. In various settings, the polynomials depend on external parameters that may be random. We discuss a stochastic sum-of-squares (S-SOS) algorithm based on the sum-of-squares hierarchy that constructs a series of semidefinite programs to jointly find strict lower bounds on the global minimum and extracts candidates for parameterized global minimizers. We prove quantitative convergence of the hierarchy as the degree increases and use it to solve unconstrained and constrained polynomial optimization problems parameterized by random variables. By employing n-body priors from condensed matter physics to induce sparsity, we can use S-SOS to produce solutions and uncertainty intervals for sensor network localization problems containing up to 40 variables and semidefinite matrix sizes surpassing 800 x 800.

Before deploying outputs from foundation models in high-stakes tasks, it is imperative to ensure that they align with human values.
For instance, in radiology report generation, reports generated by a vision-language model must align with human evaluations before their use in medical decision-making. This paper presents Conformal Alignment, a general framework for identifying units whose outputs meet a user-specified alignment criterion. It is guaranteed that on average, a prescribed fraction of selected units indeed meet the alignment criterion, regardless of the foundation model or the data distribution. Given any pre-trained model and new units with model-generated outputs, Conformal Alignment leverages a set of reference data with ground-truth alignment status to train an alignment predictor. It then selects new units whose predicted alignment scores surpass a data-dependent threshold, certifying their corresponding outputs as trustworthy. Through applications to question answering and radiology report generation, we demonstrate that our method is able to accurately identify units with trustworthy outputs via lightweight training over a moderate amount of reference data. En route, we investigate the informativeness of various features in alignment prediction and combine them with standard models to construct the alignment predictor.

Sharpness-Aware Minimization (SAM) has attracted significant attention for its effectiveness in improving generalization across various tasks. However, its underlying principles remain poorly understood. In this work, we analyze SAM’s training dynamics using the maximum eigenvalue of the Hessian as a measure of sharpness and propose a third-order stochastic differential equation (SDE), which reveals that the dynamics are driven by a complex mixture of second- and third-order terms. We show that alignment between the perturbation vector and the top eigenvector is crucial for SAM’s effectiveness in regularizing sharpness, but find that this alignment is often inadequate in practice, which limits SAM's efficiency. Building on these insights, we introduce Eigen-SAM, an algorithm that explicitly aims to regularize the top Hessian eigenvalue by aligning the perturbation vector with the leading eigenvector. We validate the effectiveness of our theory and the practical advantages of our proposed approach through comprehensive experiments. Code is available at https://github.com/RitianLuo/EigenSAM.
tl;dr: We characterize the link between consistency and delay robustness in interactive decision-making (Bandit, RL), establishing near-equivalence between bounded regret and any-level delay robustness.

Interactive decision making, encompassing bandits, contextual bandits, and reinforcement learning, has recently been of interest to theoretical studies of experimentation design and recommender system algorithm research. One recent finding in this area is that the well-known Graves-Lai constant being zero is a necessary and sufficient condition for achieving bounded (or constant) regret in interactive decision-making. As this condition may be a strong requirement for many applications, the practical usefulness of pursuing bounded regret has been questioned. In this paper, we show that the condition of the Graves-Lai constant being zero is also necessary for a consistent algorithm to achieve delay model robustness when reward delays are unknown (i.e., when feedback is anonymous). Here, model robustness is measured in terms of $\epsilon$-robustness, one of the most widely used and one of the least adversarial robustness concepts in the robust statistics literature. In particular, we show that $\epsilon$-robustness cannot be achieved for a consistent (i.e., uniformly sub-polynomial regret) algorithm, however small the nonzero $\epsilon$ value is, when the Grave-Lai constant is not zero. While this is a strongly negative result, we also provide a positive result for linear rewards models (contextual linear bandits, reinforcement learning with linear MDP) that the Grave-Lai constant being zero is also sufficient for achieving bounded regret without any knowledge of delay models, i.e., the best of both the efficiency world and the delay robustness world.
tl;dr: muMoE layers perform factorized (fully-differentiable) computation that efficiently scales MoE's expert count, leading to increasingly fine-grained expert specialization

The Mixture of Experts (MoE) paradigm provides a powerful way to decompose dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. However, a major challenge lies in the computational cost of scaling the number of experts high enough to achieve fine-grained specialization. In this paper, we propose the Multilinear Mixture of Experts (μMoE) layer to address this, focusing on vision models. μMoE layers enable scalable expert specialization by performing an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, μMoEs (1) avoid the restrictively high inference-time costs of dense MoEs, yet (2) do not inherit the training issues of the popular sparse MoEs' discrete (non-differentiable) expert routing. We present both qualitative and quantitative evidence that scaling μMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level, further enabling manual bias correction in CelebA attribute classification. Finally, we show qualitative results demonstrating the expert specialism achieved when pre-training large GPT2 and MLP-Mixer models with parameter-matched μMoE blocks at every layer, maintaining comparable accuracy. Our code is available at: https://github.com/james-oldfield/muMoE.
tl;dr: We develop an improved learning-augmented algorithm for the Bahncard problem and derive its competitive ratio under any prediction errors.

In this paper, we study learning-augmented algorithms for the Bahncard problem. The Bahncard problem is a generalization of the ski-rental problem, where a traveler needs to irrevocably and repeatedly decide between a cheap short-term solution and an expensive long-term one with an unknown future. Even though the problem is canonical, only a primal-dual-based learning-augmented algorithm was explicitly designed for it. We develop a new learning-augmented algorithm, named PFSUM, that incorporates both history and short-term future to improve online decision making. We derive the competitive ratio of PFSUM as a function of the prediction error and conduct extensive experiments to show that PFSUM outperforms the primal-dual-based algorithm.
3303. Reimagining Mutual Information for Enhanced Defense against Data Leakage in Collaborative Inference

Edge-cloud collaborative inference empowers resource-limited IoT devices to support deep learning applications without disclosing their raw data to the cloud server, thus protecting user's data. Nevertheless, prior research has shown that collaborative inference still results in the exposure of input and predictions from edge devices. To defend against such data leakage in collaborative inference, we introduce InfoScissors, a defense strategy designed to reduce the mutual information between a model's intermediate outcomes and the device's input and predictions. We evaluate our defense on several datasets in the context of diverse attacks. Besides the empirical comparison, we provide a theoretical analysis of the inadequacies of recent defense strategies that also utilize mutual information, particularly focusing on those based on the Variational Information Bottleneck (VIB) approach. We illustrate the superiority of our method and offer a theoretical analysis of it.

As one of the most fundamental non-convex learning problems, ReLU regression under differential privacy (DP) constraints, especially in high-dimensional settings, remains a challenging area in privacy-preserving machine learning. Existing results are limited to the assumptions of bounded norm $ \|\mathbf{x}\|_2 \leq 1$, which becomes meaningless with increasing data dimensionality. In this work, we revisit the problem of DP ReLU regression in high-dimensional regimes. We propose two innovative algorithms DP-GLMtron and DP-TAGLMtron that outperform the conventional DPSGD.
DP-GLMtron is based on a generalized linear model perceptron approach, integrating adaptive clipping and Gaussian mechanism for enhanced privacy. To overcome the constraints of small privacy budgets in DP-GLMtron, represented by $\widetilde{O}(\sqrt{1/N})$ where $N$ is the sample size, we introduce DP-TAGLMtron, which utilizes a tree aggregation protocol to balance privacy and utility effectively, showing that DP-TAGLMtron achieves comparable performance with only an additional factor of $O(\log N)$ in the utility upper bound.
Moreover, our theoretical analysis extends beyond Gaussian-like data distributions to settings with eigenvalue decay, showing how data distribution impacts learning in high dimensions. Notably, our findings suggest that the utility upper bound could be independent of the dimension $d$, even when $d \gg N$.
Experiments on synthetic and real-world datasets also validate our results.
tl;dr: A pipeline that consists of a transformer-based model with novel regularizations to boost power while controlling the FDR during feature selection

Model-X knockoff has garnered significant attention among various feature selection methods due to its guarantees for controlling the false discovery rate (FDR). Since its introduction in parametric design, knockoff techniques have evolved to handle arbitrary data distributions using deep learning-based generative models. However, we have observed limitations in the current implementations of the deep Model-X knockoff framework. Notably, the "swap property" that knockoffs require often faces challenges at the sample level, resulting in diminished selection power. To address these issues, we develop "Deep Dependency Regularized Knockoff (DeepDRK)," a distribution-free deep learning method that effectively balances FDR and power. In DeepDRK, we introduce a novel formulation of the knockoff model as a learning problem under multi-source adversarial attacks. By employing an innovative perturbation technique, we achieve lower FDR and higher power. Our model outperforms existing benchmarks across synthetic, semi-synthetic, and real-world datasets, particularly when sample sizes are small and data distributions are non-Gaussian.
tl;dr: We show that pre-trained models with lower geometric complexity lead to lower neural collapse and better transfer learning performance, particularly in the few-shot setting.

Many of the recent advances in computer vision and language models can be attributed to the success of transfer learning via the pre-training of large foundation models. However, a theoretical framework which explains this empirical success is incomplete and remains an active area of research. Flatness of the loss surface and neural collapse have recently emerged as useful pre-training metrics which shed light on the implicit biases underlying pre-training. In this paper, we explore the geometric complexity of a model's learned representations as a fundamental mechanism that relates these two concepts. We show through experiments and theory that mechanisms which affect the geometric complexity of the pre-trained network also influence the neural collapse. Furthermore, we show how this effect of the geometric complexity generalizes to the neural collapse of new classes as well, thus encouraging better performance on downstream tasks, particularly in the few-shot setting.

Deep State Space Models (SSMs) have proven effective in numerous task scenarios but face significant security challenges due to Adversarial Perturbations (APs) in real-world deployments. Adversarial Training (AT) is a mainstream approach to enhancing Adversarial Robustness (AR) and has been validated on various traditional DNN architectures. However, its effectiveness in improving the AR of SSMs remains unclear.
While many enhancements in SSM components, such as integrating Attention mechanisms and expanding to data-dependent SSM parameterizations, have brought significant gains in Standard Training (ST) settings, their potential benefits in AT remain unexplored. To investigate this, we evaluate existing structural variants of SSMs with AT to assess their AR performance. We observe that pure SSM structures struggle to benefit from AT, whereas incorporating Attention yields a markedly better trade-off between robustness and generalization for SSMs in AT compared to other components. Nonetheless, the integration of Attention also leads to Robust Overfitting (RO) issues.
To understand these phenomena, we empirically and theoretically analyze the output error of SSMs under AP. We find that fixed-parameterized SSMs have output error bounds strictly related to their parameters, limiting their AT benefits, while input-dependent SSMs may face the problem of error explosion. Furthermore, we show that the Attention component effectively scales the output error of SSMs during training, enabling them to benefit more from AT, but at the cost of introducing RO due to its high model complexity.
Inspired by this, we propose a simple and effective Adaptive Scaling (AdS) mechanism that brings AT performance close to Attention-integrated SSMs without introducing the issue of RO.
tl;dr: We derive new performative gradient estimator and prove convexity results for learning performatively optimal classifier.

Performative learning addresses the increasingly pervasive situations in which algorithmic decisions may induce changes in the data distribution as a consequence of their public deployment. We propose a novel view in which these performative effects are modelled as push forward measures. This general framework encompasses existing models and enables novel performative gradient estimation methods, leading to more efficient and scalable learning strategies. For distribution shifts, unlike previous models which require full specification of the data distribution, we only assume knowledge of the shift operator that represents the performative changes. This approach can also be integrated into various change-of-variable-based models, such as VAEs or normalizing flows. Focusing on classification with a linear-in-parameters performative effect, we prove the convexity of the performative risk under a new set of assumptions. Notably, we do not limit the strength of performative effects but rather their direction, requiring only that classification becomes harder when deploying more accurate models. In this case, we also establish a connection with adversarially robust classification by reformulating the performative risk as a min-max variational problem. Finally, we illustrate our approach on synthetic and real datasets.
tl;dr: Just as the KL divergence is derived from the Shannon entropy, we generate Bregman divergences from learned base functions and apply them to obtain similarity measures for real-world image corruptions, which we then use for robustness training.

We propose a novel and general method to learn Bregman divergences from raw high-dimensional data that measure similarity between images in pixel space. As a prototypical application, we learn divergences that consider real-world corruptions of images (e.g., blur) as close to the original and noisy perturbations as far, even if in $L^p$-distance the opposite holds. We also show that the learned Bregman divergence excels on datasets of human perceptual similarity judgment, suggesting its utility in a range of applications. We then define adversarial attacks by replacing the projected gradient descent (PGD) with the mirror descent associated with the learned Bregman divergence, and use them to improve the state-of-the-art in robustness through adversarial training for common image corruptions. In particular, for the contrast corruption that was found problematic in prior work we achieve an accuracy that exceeds the $L^p$- and the LPIPS-based adversarially trained neural networks by a margin of 27.16\% on the CIFAR-10-C corruption data set.

To predict future trajectories, the normalizing flow with a standard Gaussian prior suffers from weak diversity.
The ineffectiveness comes from the conflict between the fact of asymmetric and multi-modal distribution of likely outcomes and symmetric and single-modal original distribution and supervision losses.
Instead, we propose constructing a mixed Gaussian prior for a normalizing flow model for trajectory prediction.
The prior is constructed by analyzing the trajectory patterns in the training samples without requiring extra annotations while showing better expressiveness and being multi-modal and asymmetric.
Besides diversity, it also provides better controllability for probabilistic trajectory generation.
We name our method Mixed Gaussian Flow (MGF). It achieves state-of-the-art performance in the evaluation of both trajectory alignment and diversity on the popular UCY/ETH and SDD datasets. Code is available at https://github.com/mulplue/MGF.
tl;dr: We obtain minimax optimal bounds for corruption-robust linear bandits, and show that they can be used to obtain novel gap-dependent misspecification bounds in bandits and RL.

In linear bandits, how can a learner effectively learn when facing corrupted rewards? While significant work has explored this question, a holistic understanding across different adversarial models and corruption measures is lacking, as is a full characterization of the minimax regret bounds. In this work, we compare two types of corruptions commonly considered: strong corruption, where the corruption level depends on the learner’s chosen action, and weak corruption, where the corruption level does not depend on the learner’s chosen action. We provide a unified framework to analyze these corruptions. For stochastic linear bandits, we fully characterize the gap between the minimax regret under strong and weak corruptions. We also initiate the study of corrupted adversarial linear bandits, obtaining upper and lower bounds with matching dependencies on the corruption level. Next, we reveal a connection between corruption-robust learning and learning with gap-dependent misspecification—a setting first studied by Liu et al. (2023a), where the misspecification level of an action or policy is proportional to its suboptimality. We present a general reduction that enables any corruption-robust algorithm to handle gap-dependent misspecification. This allows us to recover the results of Liu et al. (2023a) in a black-box manner and significantly generalize them to settings like linear MDPs, yielding the first results for gap-dependent misspecification in reinforcement learning. However, this general reduction does not attain the optimal rate for gap-dependent misspecification. Motivated by this, we develop a specialized algorithm that achieves optimal bounds for gap-dependent misspecification in linear bandits, thus answering an open question posed by Liu et al. (2023a).
tl;dr: We draw attention to the localization task in MIL and propose Sm, a principled operator to account for local interactions among instances that yields enhanced performance.

Multiple Instance Learning (MIL) is widely used in medical imaging classification to reduce the labeling effort.
While only bag labels are available for training, one typically seeks predictions at both bag and instance levels (classification and localization tasks, respectively). Early MIL methods treated the instances in a bag independently. Recent methods account for global and local dependencies among instances. Although they have yielded excellent results in classification, their performance in terms of localization is comparatively limited. We argue that these models have been designed to target the classification task, while implications at the instance level have not been deeply investigated. Motivated by a simple observation -- that neighboring instances are likely to have the same label -- we propose a novel, principled, and flexible mechanism to model local dependencies. It can be used alone or combined with any mechanism to model global dependencies (e.g., transformers). A thorough empirical validation shows that our module leads to state-of-the-art performance in localization while being competitive or superior in classification. Our code is at https://github.com/Franblueee/SmMIL.
tl;dr: This paper introduces a new method for bi-level optimization that offers unbiased meta-gradient approximations with enhanced memory efficiency, and demonstrates superior performance in large-scale applications.

Bi-level optimizaiton (BO) has become a fundamental mathematical framework for addressing hierarchical machine learning problems.
As deep learning models continue to grow in size, the demand for scalable bi-level optimization has become increasingly critical.
Traditional gradient-based bi-level optimizaiton algorithms, due to their inherent characteristics, are ill-suited to meet the demands of large-scale applications.
In this paper, we introduce **F**orward **G**radient **U**nrolling with **F**orward **G**radient, abbreviated as **$($FG$)^2$U**, which achieves an unbiased stochastic approximation of the meta gradient for bi-level optimizaiton.
$($FG$)^2$U circumvents the memory and approximation issues associated with classical bi-level optimizaiton approaches, and delivers significantly more accurate gradient estimates than existing large-scale bi-level optimizaiton approaches.
Additionally, $($FG$)^2$U is inherently designed to support parallel computing, enabling it to effectively leverage large-scale distributed computing systems to achieve significant computational efficiency.
In practice, $($FG$)^2$U and other methods can be strategically placed at different stages of the training process to achieve a more cost-effective two-phase paradigm.
Further, $($FG$)^2$U is easy to implement within popular deep learning frameworks, and can be conveniently adapted to address more challenging zeroth-order bi-level optimizaiton scenarios.
We provide a thorough convergence analysis and a comprehensive practical discussion for $($FG$)^2$U, complemented by extensive empirical evaluations, showcasing its superior performance in diverse large-scale bi-level optimizaiton tasks.
tl;dr: This paper reveals the parameter evolving path of policy network in a low-dimensional space and propose a general method to leverage the path for better learning performance.
Knowing the learning dynamics of policy is significant to unveiling the mysteries of Reinforcement Learning (RL). It is especially crucial yet challenging to Deep RL, from which the remedies to notorious issues like sample inefficiency and learning instability could be obtained. In this paper, we study how the policy networks of typical DRL agents evolve during the learning process by empirically investigating several kinds of temporal change for each policy parameter. In popular MuJoCo and DeepMind Control Suite (DMC) environments, we find common phenomena for TD3 and RAD agents: (1) the activity of policy network parameters is highly asymmetric and policy networks advance monotonically along a very limited number of major parameter directions; (2) severe detours occur in parameter update and harmonic-like changes are observed for all minor parameter directions. By performing a novel temporal SVD along the policy learning path, the major and minor parameter directions are identified as the columns of the right unitary matrix associated with dominant and insignificant singular values respectively. Driven by the discoveries above, we propose a simple and effective method, called Policy Path Trimming and Boosting (PPTB), as a general plug-in improvement to DRL algorithms. The key idea of PPTB is to trim the policy learning path by canceling the policy updates in minor parameter directions, and boost the learning path by encouraging the advance in major directions. In experiments, we demonstrate that our method improves the learning performance of TD3, RAD, and DoubleDQN regarding scores and efficiency in MuJoCo, DMC, and MinAtar tasks respectively.

Low-shot object counters estimate the number of objects in an image using few or no annotated exemplars. Objects are localized by matching them to prototypes, which are constructed by unsupervised image-wide object appearance aggregation.
Due to potentially diverse object appearances, the existing approaches often lead to overgeneralization and false positive detections.
Furthermore, the best-performing methods train object localization by a surrogate loss, that predicts a unit Gaussian at each object center. This loss is sensitive to annotation error, hyperparameters and does not directly optimize the detection task, leading to suboptimal counts.
We introduce GeCo, a novel low-shot counter that achieves accurate object detection, segmentation, and count estimation in a unified architecture.
GeCo robustly generalizes the prototypes across objects appearances through a novel dense object query formulation.
In addition, a novel counting loss is proposed, that directly optimizes the detection task and avoids the issues of the standard surrogate loss.
GeCo surpasses the leading few-shot detection-based counters by $\sim$25\% in the total count MAE, achieves superior detection accuracy and sets a new solid state-of-the-art result across all low-shot counting setups.
The code will be available on GitHub.
tl;dr: Framework to address global challenges: (1) Distill diverse human solutions, (2) Recombine and elaborate upon them with evolution.

Solving societal problems on a global scale requires the collection and processing of ideas and methods from diverse sets of international experts. As the number and diversity of human experts increase, so does the likelihood that elements in this collective knowledge can be combined and refined to discover novel and better solutions. However, it is difficult to identify, combine, and refine complementary information in an increasingly large and diverse knowledge base. This paper argues that artificial intelligence (AI) can play a crucial role in this process. An evolutionary AI framework, termed RHEA, fills this role by distilling knowledge from diverse models created by human experts into equivalent neural networks, which are then recombined and refined in a population-based search. The framework was implemented in a formal synthetic domain, demonstrating that it is transparent and systematic. It was then applied to the results of the XPRIZE Pandemic Response Challenge, in which over 100 teams of experts across 23 countries submitted models based on diverse methodologies to predict COVID-19 cases and suggest non-pharmaceutical intervention policies for 235 nations, states, and regions across the globe. Building upon this expert knowledge, by recombining and refining the 169 resulting policy suggestion models, RHEA discovered a broader and more effective set of policies than either AI or human experts alone, as evaluated based on real-world data. The results thus suggest that AI can play a crucial role in realizing the potential of human expertise in global problem-solving.
3317. DeltaDock: A Unified Framework for Accurate, Efficient, and Physically Reliable Molecular Docking

Molecular docking, a technique for predicting ligand binding poses, is crucial in structure-based drug design for understanding protein-ligand interactions. Recent advancements in docking methods, particularly those leveraging geometric deep learning (GDL), have demonstrated significant efficiency and accuracy advantages over traditional sampling methods. Despite these advancements, current methods are often tailored for specific docking settings, and limitations such as the neglect of protein side-chain structures, difficulties in handling large binding pockets, and challenges in predicting physically valid structures exist. To accommodate various docking settings and achieve accurate, efficient, and physically reliable docking, we propose a novel two-stage docking framework, DeltaDock, consisting of pocket prediction and site-specific docking. We innovatively reframe the pocket prediction task as a pocket-ligand alignment problem rather than direct prediction in the first stage. Then we follow a bi-level coarse-to-fine iterative refinement process to perform site-specific docking. Comprehensive experiments demonstrate the superior performance of DeltaDock. Notably, in the blind docking setting, DeltaDock achieves a 31\% relative improvement over the docking success rate compared with the previous state-of-the-art GDL model
DiffDock. With the consideration of physical validity, this improvement increases to about 300\%.
tl;dr: This paper proves an entrywise error bound on the low-rank approximation of a kernel matrix, obtained using the truncated eigen-decomposition (or singular value decomposition).

In this paper, we derive *entrywise* error bounds for low-rank approximations of kernel matrices obtained using the truncated eigen-decomposition (or singular value decomposition). While this approximation is well-known to be optimal with respect to the spectral and Frobenius norm error, little is known about the statistical behaviour of individual entries. Our error bounds fill this gap. A key technical innovation is a delocalisation result for the eigenvectors of the kernel matrix corresponding to small eigenvalues, which takes inspiration from the field of Random Matrix Theory. Finally, we validate our theory with an empirical study of a collection of synthetic and real-world datasets.
tl;dr: PartCLIPSeg is a novel framework that enhances open-vocabulary part segmentation by utilizing object-level contexts and attention control, significantly outperforming existing methods on major datasets.

Open-vocabulary part segmentation (OVPS) is an emerging research area focused on segmenting fine-grained entities using diverse and previously unseen vocabularies.
Our study highlights the inherent complexities of part segmentation due to intricate boundaries and diverse granularity, reflecting the knowledge-based nature of part identification.
To address these challenges, we propose PartCLIPSeg, a novel framework utilizing generalized parts and object-level contexts to mitigate the lack of generalization in fine-grained parts.
PartCLIPSeg integrates competitive part relationships and attention control, alleviating ambiguous boundaries and underrepresented parts.
Experimental results demonstrate that PartCLIPSeg outperforms existing state-of-the-art OVPS methods, offering refined segmentation and an advanced understanding of part relationships within images.
Through extensive experiments, our model demonstrated a significant improvement over the state-of-the-art models on the Pascal-Part-116, ADE20K-Part-234, and PartImageNet datasets.
Our code is available at https://github.com/kaist-cvml/part-clipseg.
tl;dr: a policy optimization algorithm for episodic constrained MDPs

In this paper, we present the e-COP algorithm, the first policy optimization algorithm for constrained Reinforcement Learning (RL) in episodic (finite horizon) settings. Such formulations are applicable when there are separate sets of optimization criteria and constraints on a system's behavior. We approach this problem by first establishing a policy difference lemma for the episodic setting, which provides the theoretical foundation for the algorithm. Then, we propose to combine a set of established and novel solution ideas to yield the e-COP algorithm that is easy to implement and numerically stable, and provide a theoretical guarantee on optimality under certain scaling assumptions. Through extensive empirical analysis using benchmarks in the Safety Gym suite, we show that our algorithm has similar or better performance than SoTA (non-episodic) algorithms adapted for the episodic setting. The scalability of the algorithm opens the door to its application in safety-constrained Reinforcement Learning from Human Feedback for Large Language or Diffusion Models.

Graph representation learning (GRL) is critical for extracting insights from complex network structures, but it also raises security concerns due to potential privacy vulnerabilities in these representations. This paper investigates the structural vulnerabilities in graph neural models where sensitive topological information can be inferred through edge reconstruction attacks. Our research primarily addresses the theoretical underpinnings of similarity-based edge reconstruction attacks (SERA), furnishing a non-asymptotic analysis of their reconstruction capacities. Moreover, we present empirical corroboration indicating that such attacks can perfectly reconstruct sparse graphs as graph size increases. Conversely, we establish that sparsity is a critical factor for SERA's effectiveness, as demonstrated through analysis and experiments on (dense) stochastic block models. Finally, we explore the resilience of private graph representations produced via noisy aggregation (NAG) mechanism against SERA. Through theoretical analysis and empirical assessments, we affirm the mitigation of SERA using NAG . In parallel, we also empirically delineate instances wherein SERA demonstrates both efficacy and deficiency in its capacity to function as an instrument for elucidating the trade-off between privacy and utility.

The standard paradigm of modeling marked point processes is by parameterizing the intensity function using an attention-based (Transformer-style) architecture. Despite the flexibility of these methods, their inference is based on the computationally intensive thinning algorithm. In this work, we propose a framework where the advantages of the attention-based architecture are maintained and the limitation of the thinning algorithm is circumvented. The framework depends on modeling the conditional distribution of inter-event times with a mixture of log-normals satisfying a Markov property and the conditional probability mass function for the marks with a Transformer-based architecture. The proposed method attains state-of-the-art performance in predicting the next event of a sequence given its history. The experiments also reveal the efficacy of the methods that do not rely on the thinning algorithm during inference over the ones they do. Finally, we test our method on the challenging long-horizon prediction task and find that it outperforms a baseline developed specifically for tackling this task; importantly, inference requires just a fraction of time compared to the thinning-based baseline.

In the rapidly evolving field of Large Language Models (LLMs), ensuring safety is a crucial and widely discussed topic. However, existing works often overlooks the geo-diversity of cultural and legal standards across the world. To reveal the chal5 lenges posed by geo-diverse safety standards, we introduce SafeWorld, a novel benchmark specifically designed to evaluate LLMs’ ability to generate responses that are not only helpful but also culturally sensitive and legally compliant across diverse global contexts. SafeWorld encompasses 2,775 test user queries, each grounded in high-quality, human-verified cultural norms and legal policies from 50 countries and 493 regions/races. On top of it, we propose a multi-dimensional automatic safety evaluation framework that assesses the contextual appropriateness, accuracy, and comprehensiveness of responses. Our evaluations reveal that current LLMs struggle to meet these criteria effectively. To enhance LLMs’ alignment with geo-diverse safety standards, we synthesize helpful preference pairs for Direct Preference Optimization (DPO) alignment. The preference pair construction aims to encourage LLMs to behave appropriately and provide precise references to relevant cultural norms and policies when necessary. Our trained SafeWorldLM outperforms all competing models, including GPT-4o on all the three evaluation dimensions by a large margin. Global human evaluators also note a nearly 20% higher winning rate in helpfulness and harmfulness evaluation.

This paper focuses on the optimization of overparameterized, non-convex low-rank matrix sensing (LRMS)—an essential component in contemporary statistics and machine learning. Recent years have witnessed significant breakthroughs in first-order methods, such as gradient descent, for tackling this non-convex optimization problem. However, the presence of numerous saddle points often prolongs the time required for gradient descent to overcome these obstacles. Moreover, overparameterization can markedly decelerate gradient descent methods, transitioning its convergence rate from linear to sub-linear. In this paper, we introduce an approximated Gauss-Newton (AGN) method for tackling the non-convex LRMS problem. Notably, AGN incurs a computational cost comparable to gradient descent per iteration but converges much faster without being slowed down by saddle points. We prove that, despite the non-convexity of the objective function, AGN achieves Q-linear convergence from random initialization to the global optimal solution. The global Q-linear convergence of AGN represents a substantial enhancement over the convergence of the existing methods for the overparameterized non-convex LRMS. The code for this paper is available at \url{https://github.com/hsijiaxidian/AGN}.

Magnetic resonance imaging (MRI) is a widely used non-invasive imaging modality. However, a persistent challenge lies in balancing image quality with imaging speed. This trade-off is primarily constrained by k-space measurements, which traverse specific trajectories in the spatial Fourier domain (k-space). These measurements are often undersampled to shorten acquisition times, resulting in image artifacts and compromised quality. Generative models learn image distributions and can be used to reconstruct high-quality images from undersampled k-space data. In this work, we present the autoregressive image diffusion (AID) model for image sequences and use it to sample the posterior for accelerated MRI reconstruction. The algorithm incorporates both undersampled k-space and pre-existing information. Models trained with fastMRI dataset are evaluated comprehensively. The results show that the AID model can robustly generate sequentially coherent image sequences. In MRI applications, the AID can outperform the standard diffusion model and reduce hallucinations, due to the learned inter-image dependencies. The project code is available at https://github.com/mrirecon/aid.

Graph-structured data is integral to many applications, prompting the development of various graph representation methods. Graph autoencoders (GAEs), in particular, reconstruct graph structures from node embeddings. Current GAE models primarily utilize self-correlation to represent graph structures and focus on node-level tasks, often overlooking multi-graph scenarios. Our theoretical analysis indicates that self-correlation generally falls short in accurately representing specific graph features such as islands, symmetrical structures, and directional edges, particularly in smaller or multiple graph contexts.To address these limitations, we introduce a cross-correlation mechanism that significantly enhances the GAE representational capabilities. Additionally, we propose the GraphCroc, a new GAE that supports flexible encoder architectures tailored for various downstream tasks and ensures robust structural reconstruction, through a mirrored encoding-decoding process. This model also tackles the challenge of representation bias during optimization by implementing a loss-balancing strategy. Both theoretical analysis and numerical evaluations demonstrate that our methodology significantly outperforms existing self-correlation-based GAEs in graph structure reconstruction.
tl;dr: We construct random nonlinear maps (as compositions of several random features maps) that compress point sets while maintaining information about approximate distances between points.

Motivated by the problem of compressing point sets into as few bits as possible while maintaining information about approximate distances between points, we construct random nonlinear maps $\varphi_\ell$ that compress point sets in the following way. For a point set $S$, the map $\varphi_\ell:\mathbb{R}^d \to N^{-1/2}\{-1,1\}^N$ has the property that storing $\varphi_\ell(S)$ (a sketch of $S$) allows one to report squared distances between points up to some multiplicative $(1\pm \epsilon)$ error with high probability. The maps $\varphi_\ell$ are the $\ell$-fold composition of a certain type of random feature mapping.
Compared to existing techniques, our maps offer several advantages. The standard method for compressing point sets by random mappings relies on the Johnson-Lindenstrauss lemma and involves compressing point sets with a random linear map. The main advantage of our maps $\varphi_\ell$ over random linear maps is that ours map point sets directly into the discrete cube $N^{-1/2}\{-1,1\}^N$ and so there is no additional step needed to convert the sketch to bits. For some range of parameters, our maps $\varphi_\ell$ produce sketches using fewer bits of storage space. We validate the method with experiments, including an application to nearest neighbor search.

Novel view synthesis of dynamic scenes is becoming important in various applications, including augmented and virtual reality.
We propose a novel 4D Gaussian Splatting (4DGS) algorithm for dynamic scenes from casually recorded monocular videos.
To overcome the overfitting problem of existing work for these real-world videos, we introduce an uncertainty-aware regularization that identifies uncertain regions with few observations and selectively imposes additional priors based on diffusion models and depth smoothness on such regions.
This approach improves both the performance of novel view synthesis and the quality of training image reconstruction.
We also identify the initialization problem of 4DGS in fast-moving dynamic regions, where the Structure from Motion (SfM) algorithm fails to provide reliable 3D landmarks.
To initialize Gaussian primitives in such regions, we present a dynamic region densification method using the estimated depth maps and scene flow.
Our experiments show that the proposed method improves the performance of 4DGS reconstruction from a video captured by a handheld monocular camera and also exhibits promising results in few-shot static scene reconstruction.
3329. Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models
tl;dr: We improve quantitative and qualitative results of image-generating diffusion models by applying classifier-free guidance in a limited interval.

Guidance is a crucial technique for extracting the best performance out of image-generating diffusion models. Traditionally, a constant guidance weight has been applied throughout the sampling chain of an image. We show that guidance is clearly harmful toward the beginning of the chain (high noise levels), largely unnecessary toward the end (low noise levels), and only beneficial in the middle. We thus restrict it to a specific range of noise levels, improving both the inference speed and result quality. This limited guidance interval improves the record FID in ImageNet-512 significantly, from 1.81 to 1.40. We show that it is quantitatively and qualitatively beneficial across different sampler parameters, network architectures, and datasets, including the large-scale setting of Stable Diffusion XL. We thus suggest exposing the guidance interval as a hyperparameter in all diffusion models that use guidance.

The immense parameter scale of large language models underscores the necessity for parameter-efficient fine-tuning methods. Methods based on Low-Rank Adaptation (LoRA) assume the low-rank characteristics of the incremental matrix and optimize the matrix obtained from low-rank decomposition. Although effective, these methods are constrained by a fixed and unalterable intrinsic rank, neglecting the variable importance of matrices. Consequently, methods for adaptive rank allocation are proposed, among which AdaLoRA demonstrates excellent fine-tuning performance. AdaLoRA conducts adaptation based on singular value decomposition (SVD), dynamically allocating intrinsic ranks according to importance. However, it still struggles to achieve a balance between fine-tuning effectiveness and efficiency, leading to limited rank allocation space. Additionally, the importance measurement focuses only on parameters with minimal impact on the loss, neglecting the dominant role of singular values in SVD-based matrices and the fluctuations during training. To address these issues, we propose SalientLoRA, which adaptively optimizes intrinsic ranks of LoRA via salience measurement. Firstly, during rank allocation, the salience measurement analyses the variation of singular value magnitudes across multiple time steps and establishes their inter-dependency relationships to assess the matrix importance. This measurement mitigates instability and randomness that may arise during importance assessment. Secondly, to achieve a balance between fine-tuning performance and efficiency, we propose an adaptive adjustment of time-series window, which adaptively controls the size of time-series for significance measurement and rank reduction during training, allowing for rapid rank allocation while maintaining training stability. This mechanism enables matrics to set a higher initial rank, thus expanding the allocation space for ranks. To evaluate the generality of our method across various tasks, we conduct experiments on natural language understanding (NLU), natural language generation (NLG), and large model instruction tuning tasks. Experimental results demonstrate the superiority of SalientLoRA, which outperforms state-of-the-art methods by 0.96\%-3.56\% on multiple datasets. Furthermore, as the rank allocation space expands, our method ensures fine-tuning efficiency, achieving a speed improvement of 94.5\% compared to AdaLoRA. The code is publicly available at https://github.com/Heyest/SalientLoRA.

Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs) and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. Code and models are released at \url{https://github.com/FeipengMa6/VLoRA}.
tl;dr: This study introduces a Visual Context Compressor for multi-modal LLMs, demonstrating that significant compression of visual tokens during training can enhance efficiency and maintain performance, accelerating training by a large margin.

While significant advancements have been made in compressed representations for text embeddings in large language models (LLMs), the compression of visual tokens in multi-modal LLMs (MLLMs) has remained a largely overlooked area. In this work, we present the study on the analysis of redundancy concerning visual tokens and efficient training within these models. Our initial experiments
show that eliminating up to 70% of visual tokens at the testing stage by simply average pooling only leads to a minimal 3% reduction in visual question answering accuracy on the GQA benchmark, indicating significant redundancy in visual context. Addressing this, we introduce Visual Context Compressor, which reduces the number of visual tokens to enhance training and inference efficiency without sacrificing performance. To minimize information loss caused by the compression on visual tokens while maintaining training efficiency, we develop LLaVolta as a light and staged training scheme that incorporates stage-wise visual context compression to progressively compress the visual tokens from heavily to lightly compression during training, yielding no loss of information when testing. Extensive experiments demonstrate that our approach enhances the performance of MLLMs in both image-language and video-language understanding, while also significantly cutting training costs and improving inference efficiency.

Transformer-based architectures have been proven successful in detecting 3D objects from point clouds. However, the quadratic complexity of the attention mechanism struggles to encode rich information as point cloud resolution increases. Recently, state space models (SSM) such as Mamba have gained great attention due to their linear complexity and long sequence modeling ability for language understanding. To exploit the potential of Mamba on 3D scene-level perception, for the first time, we propose 3DET-Mamba, which is a novel SSM-based model designed for indoor 3d object detection. Specifically, we divide the point cloud into different patches and use a lightweight yet effective Inner Mamba to capture local geometric information. To observe the scene from a global perspective, we introduce a novel Dual Mamba module that models the point cloud in terms of spatial distribution and continuity. Additionally, we design a Query-aware Mamba module that decodes context features into object sets under the guidance of learnable queries. Extensive experiments demonstrate that 3DET-Mamba surpasses previous 3DETR on indoor 3D detection benchmarks such as ScanNet, improving AP25/AP50 from 65.0\%/47.0\% to 70.4\%/54.4\%, respectively.
tl;dr: A novel self-training approach for adapting ML models to test-time distribution shifts by monitoring the model's output and aligning it with the source domain's statistics.

We present a novel approach for test-time adaptation via online self-training, consisting of two components. First, we introduce a statistical framework that detects distribution shifts in the classifier's entropy values obtained on a stream of unlabeled samples. Second, we devise an online adaptation mechanism that utilizes the evidence of distribution shifts captured by the detection tool to dynamically update the classifier's parameters. The resulting adaptation process drives the distribution of test entropy values obtained from the self-trained classifier to match those of the source domain, building invariance to distribution shifts. This approach departs from the conventional self-training method, which focuses on minimizing the classifier's entropy. Our approach combines concepts in betting martingales and online learning to form a detection tool capable of quickly reacting to distribution shifts. We then reveal a tight relation between our adaptation scheme and optimal transport, which forms the basis of our novel self-supervised loss. Experimental results demonstrate that our approach improves test-time accuracy under distribution shifts while maintaining accuracy and calibration in their absence, outperforming leading entropy minimization methods across various scenarios.
3335. Stabilizing Zero-Shot Prediction: A Novel Antidote to Forgetting in Continual Vision-Language Tasks
tl;dr: We thoroughly investigate the link between model stability in zero-shot predictions and anti-forgetting capabilities, and propose a novel replay-free method with the EMA-LoRA architecture to enhance continual learning.

Continual learning (CL) empowers pre-trained vision-language (VL) models to efficiently adapt to a sequence of downstream tasks. However, these models often encounter challenges in retaining previously acquired skills due to parameter shifts and limited access to historical data. In response, recent efforts focus on devising specific frameworks and various replay strategies, striving for a typical learning-forgetting trade-off. Surprisingly, both our empirical research and theoretical analysis demonstrate that the stability of the model in consecutive zero-shot predictions serves as a reliable indicator of its anti-forgetting capabilities for previously learned tasks.
Motivated by these insights, we develop a novel replay-free CL method named ZAF (Zero-shot Antidote to Forgetting), which preserves acquired knowledge through a zero-shot stability regularization applied to wild data in a plug-and-play manner. To enhance efficiency in adapting to new tasks and seamlessly access historical models, we introduce a parameter-efficient EMA-LoRA neural architecture based on the Exponential Moving Average (EMA). ZAF utilizes new data for low-rank adaptation (LoRA), complemented by a zero-shot antidote on wild data, effectively decoupling learning from forgetting. Our extensive experiments demonstrate ZAF's superior performance and robustness in pre-trained models across various continual VL concept learning tasks, achieving leads of up to 3.70\%, 4.82\%, and 4.38\%, along with at least a 10x acceleration in training speed on three benchmarks, respectively. Additionally, our zero-shot antidote significantly reduces forgetting in existing models by at least 6.37\%. Our code is available at https://github.com/Zi-Jian-Gao/Stabilizing-Zero-Shot-Prediction-ZAF.
tl;dr: We introduce an unsupervised framework for estimating homography in multimodal images, improving performance by using a two-phase optimization and Barlow Twins loss.

Estimating the homography between two images is crucial for mid- or high-level vision tasks, such as image stitching and fusion. However, using supervised learning methods is often challenging or costly due to the difficulty of collecting ground-truth data. In response, unsupervised learning approaches have emerged. Most early methods, though, assume that the given image pairs are from the same camera or have minor lighting differences. Consequently, while these methods perform effectively under such conditions, they generally fail when input image pairs come from different domains, referred to as multimodal image pairs.
To address these limitations, we propose AltO, an unsupervised learning framework for estimating homography in multimodal image pairs. Our method employs a two-phase alternating optimization framework, similar to Expectation-Maximization (EM), where one phase reduces the geometry gap and the other addresses the modality gap. To handle these gaps, we use Barlow Twins loss for the modality gap and propose an extended version, Geometry Barlow Twins, for the geometry gap. As a result, we demonstrate that our method, AltO, can be trained on multimodal datasets without any ground-truth data. It not only outperforms other unsupervised methods but is also compatible with various architectures of homography estimators.
The source code can be found at: https://github.com/songsang7/AltO
tl;dr: We present a data balancing approach to distribution estimation that provides theoretical interpretations of the various self-supervised training schemes.

Data balancing across multiple modalities and sources appears in various forms in foundation models in machine learning and AI, e.g. in CLIP and DINO. We show that data balancing across modalities and sources actually offers an unsuspected benefit: variance reduction. We present a non-asymptotic statistical bound that quantifies this variance reduction effect and relates it to the eigenvalue decay of Markov operators. Furthermore, we describe how various forms of data balancing in contrastive multimodal learning and self-supervised clustering can be better understood, and even improved upon, owing to our variance reduction viewpoint.

The scale and quality of a dataset significantly impact the performance of deep models. However, acquiring large-scale annotated datasets is both a costly and time-consuming endeavor. To address this challenge, dataset expansion technologies aim to automatically augment datasets, unlocking the full potential of deep models. Current data expansion techniques include image transformation and image synthesis methods. Transformation-based methods introduce only local variations, leading to limited diversity. In contrast, synthesis-based methods generate entirely new content, greatly enhancing informativeness. However, existing synthesis methods carry the risk of distribution deviations, potentially degrading model performance with out-of-distribution samples. In this paper, we propose DistDiff, a training-free data expansion framework based on the distribution-aware diffusion model. DistDiff constructs hierarchical prototypes to approximate the real data distribution, optimizing latent data points within diffusion models with hierarchical energy guidance. We demonstrate its capability to generate distribution-consistent samples, significantly improving data expansion tasks. DistDiff consistently enhances accuracy across a diverse range of datasets compared to models trained solely on original data. Furthermore, our approach consistently outperforms existing synthesis-based techniques and demonstrates compatibility with widely adopted transformation-based augmentation methods. Additionally, the expanded dataset exhibits robustness across various architectural frameworks.
tl;dr: Utilizing casual intervention theory to capture casual label correlations.

Multi-label image recognition aims to predict all objects present in an input image. A common belief is that modeling the correlations between objects is beneficial for multi-label recognition. However, this belief has been recently challenged as label correlations may mislead the classifier in testing, due to the possible contextual bias in training. Accordingly, a few of recent works not only discarded label correlation modeling, but also advocated to remove contextual information for multi-label image recognition. This work explicitly explores label correlations for multi-label image recognition based on a principled causal intervention approach. With causal intervention, we pursue causal label correlations and suppress spurious label correlations, as the former tend to convey useful contextual cues while the later may mislead the classifier. Specifically, we decouple label-specific features with a Transformer decoder attached to the backbone network, and model the confounders which may give rise to spurious correlations by clustering spatial features of all training images. Based on label-specific features and confounders, we employ a cross-attention module to implement causal intervention, quantifying the causal correlations from all object categories to each predicted object category. Finally, we obtain image labels by combining the predictions from decoupled features and causal label correlations. Extensive experiments clearly validate the effectiveness of our approach for multi-label image recognition in both common and cross-dataset settings.
tl;dr: We propose new sampling strategies and techniques for local training of low-rank factorized neural networks for the scenario of federated learning on heterogeneous devices.

The problem of heterogeneous clients in federated learning has recently drawn a lot of attention. Spectral model sharding, i.e., partitioning the model parameters into low-rank matrices based on the singular value decomposition, has been one of the proposed solutions for more efficient on-device training in such settings. In this work we present two sampling strategies for such sharding, obtained as solutions to specific optimization problems. The first produces unbiased estimators of the original weights, while the second aims to minimize the squared approximation error. We discuss how both of these estimators can be incorporated in the federated learning loop and practical considerations that arise during local training. Empirically, we demonstrate that both of these methods can lead to improved performance in various commonly used datasets.
tl;dr: We introduce two verifiably robust conformal prediction frameworks that are robust against adversarial perturbations and always guaranteed to return the desired coverage in the presence of such adversarial attacks.

Conformal Prediction (CP) is a popular uncertainty quantification method that provides distribution-free, statistically valid prediction sets, assuming that training and test data are exchangeable. In such a case, CP's prediction sets are guaranteed to cover the (unknown) true test output with a user-specified probability. Nevertheless, this guarantee is violated when the data is subjected to adversarial attacks, which often result in a significant loss of coverage. Recently, several approaches have been put forward to recover CP guarantees in this setting. These approaches leverage variations of randomised smoothing to produce conservative sets which account for the effect of the adversarial perturbations. They are, however, limited in that they only support $\ell_2$-bounded perturbations and classification tasks. This paper introduces VRCP (Verifiably Robust Conformal Prediction), a new framework that leverages recent neural network verification methods to recover coverage guarantees under adversarial attacks. Our VRCP method is the first to support perturbations bounded by arbitrary norms including $\ell_1$, $\ell_2$, and $\ell_\infty$, as well as regression tasks. We evaluate and compare our approach on image classification tasks (CIFAR10, CIFAR100, and TinyImageNet) and regression tasks for deep reinforcement learning environments. In every case, VRCP achieves above nominal coverage and yields significantly more efficient and informative prediction regions than the SotA.
tl;dr: We propose a novel framework that calculates conditional mutual information (CMI) between the mass spectrum and each amino acid or peptide, using CMI for robust model training against data biases in proteomics.

Tandem mass spectrometry has played a pivotal role in advancing proteomics, enabling the high-throughput analysis of protein composition in biological tissues. Despite the development of several deep learning methods for predicting amino acid sequences (peptides) responsible for generating the observed mass spectra, training data biases hinder further advancements of \emph{de novo} peptide sequencing. Firstly, prior methods struggle to identify amino acids with Post-Translational Modifications (PTMs) due to their lower frequency in training data compared to canonical amino acids, further resulting in unsatisfactory peptide sequencing performance. Secondly, various noise and missing peaks in mass spectra reduce the reliability of training data (Peptide-Spectrum Matches, PSMs). To address these challenges, we propose AdaNovo, a novel and domain knowledge-inspired framework that calculates Conditional Mutual Information (CMI) between the mass spectra and amino acids or peptides, using CMI for robust training against above biases. Extensive experiments indicate that AdaNovo outperforms previous competitors on the widely-used 9-species benchmark, meanwhile yielding 3.6\% - 9.4\% improvements in PTMs identification. The supplements contain the code.
tl;dr: We propose DeBaRA, a conditional score-based generative model that performs state-of-the art arrangement generation in bounded indoor scenes and several downstream applications by solely learning 3D object spatial features.

Generating realistic and diverse layouts of furnished indoor 3D scenes unlocks multiple interactive applications impacting a wide range of industries. The inherent complexity of object interactions, the limited amount of available data and the requirement to fulfill spatial constraints all make generative modeling for 3D scene synthesis and arrangement challenging. Current methods address these challenges autoregressively or by using off-the-shelf diffusion objectives by simultaneously predicting all attributes without 3D reasoning considerations. In this paper, we introduce DeBaRA, a score-based model specifically tailored for precise, controllable and flexible arrangement generation in a bounded environment. We argue that the most critical component of a scene synthesis system is to accurately establish the size and position of various objects within a restricted area. Based on this insight, we propose a lightweight conditional score-based model designed with 3D spatial awareness at its core. We demonstrate that by focusing on spatial attributes of objects, a single trained DeBaRA model can be leveraged at test time to perform several downstream applications such as scene synthesis, completion and re-arrangement. Further, we introduce a novel Self Score Evaluation procedure so it can be optimally employed alongside external LLM models. We evaluate our approach through extensive experiments and demonstrate significant improvement upon state-of-the-art approaches in a range of scenarios.
3344. Can Graph Neural Networks Expose Training Data Properties? An Efficient Risk Assessment Approach

Graph neural networks (GNNs) have attracted considerable attention due to their diverse applications. However, the scarcity and quality limitations of graph data present challenges to their training process in practical settings. To facilitate the development of effective GNNs, companies and researchers often seek external collaboration. Yet, directly sharing data raises privacy concerns, motivating data owners to train GNNs on their private graphs and share the trained models. Unfortunately, these models may still inadvertently disclose sensitive properties of their training graphs (\textit{e.g.}, average default rate in a transaction network), leading to severe consequences for data owners.
In this work, we study graph property inference attack to identify the risk of sensitive property information leakage from shared models.
Existing approaches typically train numerous shadow models for developing such attack, which is computationally intensive and impractical. To address this issue, we propose an efficient graph property inference attack by leveraging model approximation techniques. Our method only requires training a small set of models on graphs, while generating a sufficient number of approximated shadow models for attacks.
To enhance diversity while reducing errors in the approximated models, we apply edit distance to quantify the diversity within a group of approximated models and introduce a theoretically guaranteed criterion to evaluate each model's error. Subsequently, we propose a novel selection mechanism to ensure that the retained approximated models achieve high diversity and low error.
Extensive experiments across six real-world scenarios demonstrate our method's substantial improvement, with average increases of 2.7\% in attack accuracy and 4.1\% in ROC-AUC, while being 6.5$\times$ faster compared to the best baseline.
tl;dr: OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling

Constrained by the separate encoding of vision and language, existing grounding and referring segmentation works heavily rely on bulky Transformer-based fusion en-/decoders and a variety of early-stage interaction technologies. Simultaneously, the current mask visual language modeling (MVLM) fails to capture the nuanced referential relationship between image-text in referring tasks. In this paper, we propose **OneRef**, a minimalist referring framework built on the modality-shared one-tower transformer that unifies the visual and linguistic feature spaces. To modeling the referential relationship, we introduce a novel MVLM paradigm called Mask Referring Modeling (**MRefM**), which encompasses both referring-aware mask image modeling and referring-aware mask language modeling. Both modules not only reconstruct modality-related content but also cross-modal referring content. Within MRefM, we propose a referring-aware dynamic image masking strategy that is aware of the referred region rather than relying on fixed ratios or generic random masking schemes. By leveraging the unified visual language feature space and incorporating MRefM's ability to model the referential relations, our approach enables direct regression of the referring results without resorting to various complex techniques. Our method consistently surpasses existing approaches and achieves SoTA performance on both grounding and segmentation tasks, providing valuable insights for future research. Our code and models are available at https://github.com/linhuixiao/OneRef.
tl;dr: Introduce low-pass filter based spectral attention to address long-range dependency in time series forecasting

Sequence modeling faces challenges in capturing long-range dependencies across diverse tasks. Recent linear and transformer-based forecasters have shown superior performance in time series forecasting. However, they are constrained by their inherent inability to effectively address long-range dependencies in time series data, primarily due to using fixed-size inputs for prediction. Furthermore, they typically sacrifice essential temporal correlation among consecutive training samples by shuffling them into mini-batches. To overcome these limitations, we introduce a fast and effective Spectral Attention mechanism, which preserves temporal correlations among samples and facilitates the handling of long-range information while maintaining the base model structure. Spectral Attention preserves long-period trends through a low-pass filter and facilitates gradient to flow between samples. Spectral Attention can be seamlessly integrated into most sequence models, allowing models with fixed-sized look-back windows to capture long-range dependencies over thousands of steps. Through extensive experiments on 11 real-world time series datasets using 7 recent forecasting models, we consistently demonstrate the efficacy of our Spectral Attention mechanism, achieving state-of-the-art results.
tl;dr: In a theoretical model, we show that language generation is always possible in the limit, in contrast to classical impossibility results for language identification in the limit.

Although current large language models are complex, the most basic specifications of the underlying language generation problem itself are simple to state: given a finite set of training samples from an unknown language, produce valid new strings from the language that don't already appear in the training data. Here we ask what we can conclude about language generation using only this specification, without further assumptions. In particular, suppose that an adversary enumerates the strings of an unknown target language L that is known only to come from one of a possibly infinite list of candidates. A computational agent is trying to learn to generate from this language; we say that the agent generates from $L$ in the limit if after some finite point in the enumeration of $L$, the agent is able to produce new elements that come exclusively from $L$ and that have not yet been presented by the adversary. Our main result is that there is an agent that is able to generate in the limit for every countable list of candidate languages. This contrasts dramatically with negative results due to Gold and Angluin in a well-studied model of language learning where the goal is to identify an unknown language from samples; the difference between these results suggests that identifying a language is a fundamentally different problem than generating from it.
tl;dr: We introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation

Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix first converts dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. This is exemplified by instances generated in a single channel where one speaker's utterance is seamlessly mixed with another's interjections or laughter, indicating the latter's role as an attentive listener. Audio samples are enclosed in the supplementary.
3349. Causal Inference in the Closed-Loop: Marginal Structural Models for Sequential Excursion Effects
tl;dr: We propose a non-parametric causal inference framework for closed-loop optogenetics behavioral experiments to enable excursion effect estimation for treatment sequences greater than length one in the presence of positivity violations.

Optogenetics is widely used to study the effects of neural circuit manipulation on behavior. However, the paucity of causal inference methodological work on this topic has resulted in analysis conventions that discard information, and constrain the scientific questions that can be posed. To fill this gap, we introduce a nonparametric causal inference framework for analyzing "closed-loop" designs, which use dynamic policies that assign treatment based on covariates. In this setting, standard methods can introduce bias and occlude causal effects. Building on the sequentially randomized experiments literature in causal inference, our approach extends history-restricted marginal structural models for dynamic regimes. In practice, our framework can identify a wide range of causal effects of optogenetics on trial-by-trial behavior, such as, fast/slow-acting, dose-response, additive/antagonistic, and floor/ceiling. Importantly, it does so without requiring negative controls, and can estimate how causal effect magnitudes evolve across time points. From another view, our work extends "excursion effect" methods---popular in the mobile health literature---to enable estimation of causal contrasts for treatment sequences greater than length one, in the presence of positivity violations. We derive rigorous statistical guarantees, enabling hypothesis testing of these causal effects. We demonstrate our approach on data from a recent study of dopaminergic activity on learning, and show how our method reveals relevant effects obscured in standard analyses.
tl;dr: We introduce the Constant Acceleration Flow (CAF) to enhance generative models, outperforming previous methods in speed and precision with new strategies.

Rectified flow and reflow procedures have significantly advanced fast generation by progressively straightening ordinary differential equation (ODE) flows under the assumption that image and noise pairs, known as coupling, can be approximated by straight trajectories with constant velocity. However, we observe that the constant velocity modeling and reflow procedures have limitations in accurately learning to couple with flow crossing, leading to suboptimal few-step generation. To overcome the limitations, we introduce the Constant Acceleration Flow (CAF), a novel framework based on a simple constant acceleration equation. Additionally, we propose two techniques to improve estimation accuracy: initial velocity conditioning for the acceleration model and a reflow process for the initial velocity. Our comparative studies show that CAF not only outperforms rectified flow with reflow procedures in terms of speed and accuracy but also demonstrates substantial improvements in preserving coupling for fast generation.

Implicit neural representations (INRs) have demonstrated success in a variety of applications, including inverse problems and neural rendering. An INR is typically trained to capture one signal of interest, resulting in learned neural features that are highly attuned to that signal. Assumed to be less generalizable, we explore the aspect of transferability of such learned neural features for fitting similar signals. We introduce a new INR training framework, STRAINER that learns transferable features for fitting INRs to new signals from a given distribution, faster and with better reconstruction quality. Owing to the sequential layer-wise affine operations in an INR, we propose to learn transferable representations by sharing initial encoder layers across multiple INRs with independent decoder layers. At test time, the learned encoder representations are transferred as initialization for an otherwise randomly initialized INR. We find STRAINER to yield extremely powerful initialization for fitting images from the same domain and allow for a ≈ +10dB gain in signal quality early on compared to an untrained INR itself. STRAINER also provides a simple way to encode data-driven priors in INRs. We evaluate STRAINER on multiple in-domain and out-of-domain signal fitting tasks and inverse problems and further provide detailed analysis and discussion on the transferability of STRAINER’s features.

Ensuring safety is a key aspect in sequential decision making problems, such as robotics or process control. The complexity of the underlying systems often makes finding the optimal decision challenging, especially when the safety-critical system is time-varying. Overcoming the problem of optimizing an unknown time-varying reward subject to unknown time-varying safety constraints, we propose TVSAFEOPT, a new algorithm built on Bayesian optimization with a spatio-temporal kernel. The algorithm is capable of safely tracking a time-varying safe region without the need for explicit change detection. Optimality guarantees are also provided for the algorithm when the optimization problem becomes stationary. We show that TVSAFEOPT compares favorably against SAFEOPT on synthetic data, both regarding safety and optimality. Evaluation on a realistic case study with gas compressors confirms that TVSAFEOPT ensures safety when solving time-varying optimization problems with unknown reward and safety functions.
tl;dr: We improve blockwise parallel decoding in language models by analyzing token distributions and developing refinement algorithms for block drafts, significantly achieving higher block efficiency across various tasks.

Autoregressive language models have achieved remarkable advancements, yet their potential is often limited by the slow inference speeds associated with sequential token generation. Blockwise parallel decoding (BPD) was proposed by Stern et al. [42] as a method to improve inference speed of language models by simultaneously predicting multiple future tokens, termed block drafts, which are subsequently verified by the autoregressive model. This paper advances the understanding and improvement of block drafts in two ways. First, we analyze token distributions generated across multiple prediction heads. Second, leveraging these insights, we propose algorithms to improve BPD inference speed by refining the block drafts using task-independent \ngram and neural language models as lightweight rescorers. Experiments demonstrate that by refining block drafts of open-sourced Vicuna and Medusa LLMs, the mean accepted token length are increased by 5-25% relative. This results in over a 3x speedup in wall clock time compared to standard autoregressive decoding in open-source 7B and 13B LLMs.
tl;dr: We intro a novel automatic model that coordinates anatomical-textual prompts for multi-organ and tumor segmentation.

Existing promptable segmentation methods in the medical imaging field primarily consider either textual or visual prompts to segment relevant objects, yet they often fall short when addressing anomalies in medical images, like tumors, which may vary greatly in shape, size, and appearance. Recognizing the complexity of medical scenarios and the limitations of textual or visual prompts, we propose a novel dual-prompt schema that leverages the complementary strengths of visual and textual prompts for segmenting various organs and tumors. Specifically, we introduce $\textbf{\textit{CAT}}$, an innovative model that $\textbf{C}$oordinates $\textbf{A}$natomical prompts derived from 3D cropped images with $\textbf{T}$extual prompts enriched by medical domain knowledge. The model architecture adopts a general query-based design, where prompt queries facilitate segmentation queries for mask prediction. To synergize two types of prompts within a unified framework, we implement a ShareRefiner, which refines both segmentation and prompt queries while disentangling the two types of prompts. Trained on a consortium of 10 public CT datasets, $\textbf{\textit{CAT}}$ demonstrates superior performance in multiple segmentation tasks. Further validation on a specialized in-house dataset reveals the remarkable capacity of segmenting tumors across multiple cancer stages. This approach confirms that coordinating multimodal prompts is a promising avenue for addressing complex scenarios in the medical domain.

The impressive performance of Large Language Models (LLMs) across various natural language processing tasks comes at the cost of vast computational resources and storage requirements. One-shot pruning techniques offer a way to alleviate these burdens by removing redundant weights without the need for retraining. Yet, the massive scale of LLMs often forces current pruning approaches to rely on heuristics instead of optimization-based techniques, potentially resulting in suboptimal compression. In this paper, we introduce ALPS, an optimization-based framework that tackles the pruning problem using the operator splitting technique and a preconditioned conjugate gradient-based post-processing step. Our approach incorporates novel techniques to accelerate and theoretically guarantee convergence while leveraging vectorization and GPU parallelism for efficiency. ALPS substantially outperforms state-of-the-art methods in terms of the pruning objective and perplexity reduction, particularly for highly sparse models. On the LLaMA3-8B model with 70\% sparsity, ALPS achieves a 29\% reduction in test perplexity on the WikiText dataset and a 8\% improvement in zero-shot benchmark performance compared to existing methods. Our code is available at https://github.com/mazumder-lab/ALPS.

Exploring the loss landscape offers insights into the inherent principles of deep neural networks (DNNs). Recent work suggests an additional asymmetry of the valley beyond the flat and sharp ones, yet without thoroughly examining its causes or implications. Our study methodically explores the factors affecting the symmetry of DNN valleys, encompassing (1) the dataset, network architecture, initialization, and hyperparameters that influence the convergence point; and (2) the magnitude and direction of the noise for 1D visualization. Our major observation shows that the {\it degree of sign consistency} between the noise and the convergence point is a critical indicator of valley symmetry. Theoretical insights from the aspects of ReLU activation and softmax function could explain the interesting phenomenon. Our discovery propels novel understanding and applications in the scenario of Model Fusion: (1) the efficacy of interpolating separate models significantly correlates with their sign consistency ratio, and (2) imposing sign alignment during federated learning emerges as an innovative approach for model parameter alignment.

Anomaly detection is widely used for identifying critical errors and suspicious behaviors, but current methods lack interpretability.
We leverage common properties of existing methods and recent advances in generative models to introduce counterfactual explanations for anomaly detection.
Given an input, we generate its counterfactual as a diffusion-based repair that shows what a non-anomalous version $\textit{should have looked like}$.
A key advantage of this approach is that it enables a domain-independent formal specification of explainability desiderata, offering a unified framework for generating and evaluating explanations.
We demonstrate the effectiveness of our anomaly explainability framework, AR-Pro, on vision (MVTec, VisA) and time-series (SWaT, WADI, HAI) anomaly datasets. The code used for the experiments is accessible at: https://github.com/xjiae/arpro.
tl;dr: We propose a novel VAE that learns from multimodal data using a mixture-of-experts prior for aggregation

Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation.
Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation.
Such architectures impose hard constraints on the model.
In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior.
This approach results in a superior latent representation and allows each encoding to preserve information better from its uncompressed original features. In extensive experiments on multiple benchmark datasets and two challenging real-world datasets, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.

The feasibility of variational quantum algorithms, the most popular correspondent of neural networks on noisy, near-term quantum hardware, is highly impacted by the circuit depth of the involved parametrized quantum circuits (PQCs). Higher depth increases expressivity, but also results in a detrimental accumulation of errors. Furthermore, the number of parameters involved in the PQC significantly influences the performance through the necessary number of measurements to evaluate gradients, which scales linearly with the number of parameters.
Motivated by this, we look at deep equilibrium models (DEQs), which mimic an infinite-depth, weight-tied network using a fraction of the memory by employing a root solver to find the fixed points of the network. In this work, we present Quantum Deep Equilibrium Models (QDEQs): a training paradigm that learns parameters of a quantum machine learning model given by a PQC using DEQs. To our knowledge, no work has yet explored the application of DEQs to QML models. We apply QDEQs to find the parameters of a quantum circuit in two settings: the first involves classifying MNIST-4 digits with 4 qubits; the second extends it to 10 classes of MNIST, FashionMNIST and CIFAR. We find that QDEQ is not only competitive with comparable existing baseline models, but also achieves higher performance than a network with 5 times more layers. This demonstrates that the QDEQ paradigm can be used to develop significantly more shallow quantum circuits for a given task, something which is essential for the utility of near-term quantum computers.
Our code is available at \url{https://github.com/martaskrt/qdeq}.
tl;dr: A novel network structure that efficiently approximates minimum variance estimation and computes natural gradient achieving stable convergence and superior performance in industrial setting.

Neural networks (NN) are extensively studied in cutting-edge soft sensor models due to their feature extraction and function approximation capabilities. Current research into network-based methods primarily focuses on models' offline accuracy. Notably, in industrial soft sensor context, online optimizing stability and interpretability are prioritized, followed by accuracy. This requires a clearer understanding of network's training process. To bridge this gap, we propose a novel NN named the Approximated Orthogonal Projection Unit (AOPU) which has solid mathematical basis and presents superior training stability. AOPU truncates the gradient backpropagation at dual parameters, optimizes the trackable parameters updates, and enhances the robustness of training. We further prove that AOPU attains minimum variance estimation in NN, wherein the truncated gradient approximates the natural gradient. Empirical results on two chemical process datasets clearly show that AOPU outperforms other models in achieving stable convergence, marking a significant advancement in soft sensor field.

The spurious correlation between the background features of the image and its label arises due to that the samples labeled with the same class in the training set often co-occurs with a specific background, which will cause the encoder to extract non-semantic features for classification, resulting in poor out-of-distribution generalization performance. Although many studies have been proposed to address this challenge, the semantic and spurious features are still difficult to accurately decouple from the original image and fail to achieve high performance with deep learning models. This paper proposes a novel perspective inspired by neural collapse to solve the spurious correlation problem through the alternate execution of environment partitioning and learning semantic masks. Specifically, we propose to assign an environment to each sample by learning a local model for each environment and using maximum likelihood probability. At the same time, we require that the learned semantic mask neurally collapses to the same simplex equiangular tight frame (ETF) in each environment after being applied to the original input. We conduct extensive experiments on four datasets, and the results demonstrate that our method significantly improves out-of-distribution performance.

It is well known that query-based attacks tend to have relatively higher success
rates in adversarial black-box attacks. While research on black-box attacks is actively
being conducted, relatively few studies have focused on pixel attacks that
target only a limited number of pixels. In image classification, query-based pixel
attacks often rely on patches, which heavily depend on randomness and neglect
the fact that scattered pixels are more suitable for adversarial attacks. Moreover, to
the best of our knowledge, query-based pixel attacks have not been explored in the
field of object detection. To address these issues, we propose a novel pixel-based
black-box attack called Remember and Forget Pixel Attack using Reinforcement
Learning(RFPAR), consisting of two main components: the Remember and Forget
processes. RFPAR mitigates randomness and avoids patch dependency by
leveraging rewards generated through a one-step RL algorithm to perturb pixels.
RFPAR effectively creates perturbed images that minimize the confidence scores
while adhering to limited pixel constraints. Furthermore, we advance our proposed
attack beyond image classification to object detection, where RFPAR reduces
the confidence scores of detected objects to avoid detection. Experiments
on the ImageNet-1K dataset for classification show that RFPAR outperformed
state-of-the-art query-based pixel attacks. For object detection, using the MSCOCO
dataset with YOLOv8 and DDQ, RFPAR demonstrates comparable mAP
reduction to state-of-the-art query-based attack while requiring fewer query. Further
experiments on the Argoverse dataset using YOLOv8 confirm that RFPAR
effectively removed objects on a larger scale dataset. Our code is available at
https://github.com/KAU-QuantumAILab/RFPAR.
3363. Progressive Exploration-Conformal Learning for Sparsely Annotated Object Detection in Aerial Images
tl;dr: We address sparsely annotated aerial object detection task with a Progressive Exploration-Conformal Learning (PECL) framework.

The ability to detect aerial objects with limited annotation is pivotal to the development of real-world aerial intelligence systems. In this work, we focus on a demanding but practical sparsely annotated object detection (SAOD) in aerial images, which encompasses a wider variety of aerial scenes with the same number of annotated objects. Although most existing SAOD methods rely on fixed thresholding to filter pseudo-labels for enhancing detector performance, adapting to aerial objects proves challenging due to the imbalanced probabilities/confidences associated with predicted aerial objects. To address this problem, we propose a novel Progressive Exploration-Conformal Learning (PECL) framework to address the SAOD task, which can adaptively perform the selection of high-quality pseudo-labels in aerial images. Specifically, the pseudo-label exploration can be formulated as a decision-making paradigm by adopting a conformal pseudo-label explorer and a multi-clue selection evaluator. The conformal pseudo-label explorer learns an adaptive policy by maximizing the cumulative reward, which can decide how to select these high-quality candidates by leveraging their essential characteristics and inter-instance contextual information. The multi-clue selection evaluator is designed to evaluate the explorer-guided pseudo-label selections by providing an instructive feedback for policy optimization. Finally, the explored pseudo-labels can be adopted to guide the optimization of aerial object detector in a closed-looping progressive fashion. Comprehensive evaluations on two public datasets demonstrate the superiority of our PECL when compared with other state-of-the-art methods in the sparsely annotated aerial object detection task.

Currently, vision encoder models like Vision Transformers (ViTs) typically excel at image recognition tasks but cannot simultaneously support text recognition like human visual recognition. To address this limitation, we propose UNIT, a novel training framework aimed at UNifying Image and Text recognition within a single model. Starting with a vision encoder pre-trained with image recognition tasks, UNIT introduces a lightweight language decoder for predicting text outputs and a lightweight vision decoder to prevent catastrophic forgetting of the original image encoding capabilities. The training process comprises two stages: intra-scale pretraining and inter-scale finetuning. During intra-scale pretraining, UNIT learns unified representations from multi-scale inputs, where images and documents are at their commonly used resolution, to enable fundamental recognition capability. In the inter-scale finetuning stage, the model introduces scale-exchanged data, featuring images and documents at resolutions different from the most commonly used ones, to enhance its scale robustness. Notably, UNIT retains the original vision encoder architecture, making it cost-free in terms of inference and deployment. Experiments across multiple benchmarks confirm that our method significantly outperforms existing methods on document-related tasks (e.g., OCR and DocQA) while maintaining the performances on natural images, demonstrating its ability to substantially enhance text recognition without compromising its core image recognition capabilities.
tl;dr: There exist inherent limitations when scaling certifiably robust Lipschitz-constrained models with additional generated data.

Certified defenses against adversarial attacks offer formal guarantees on the robustness of a model, making them more reliable than empirical methods such as adversarial training, whose effectiveness is often later reduced by unseen attacks. Still, the limited certified robustness that is currently achievable has been a bottleneck for their practical adoption. Gowal et al. and Wang et al. have shown that generating additional training data using state-of-the-art diffusion models can considerably improve the robustness of adversarial training. In this work, we demonstrate that a similar approach can substantially improve deterministic certified defenses but also reveal notable differences in the scaling behavior between certified and empirical methods. In addition, we provide a list of recommendations to scale the robustness of certified training approaches. Our approach achieves state-of-the-art deterministic robustness certificates on CIFAR-10 for the $\ell_2$ ($\epsilon = 36/255$) and $\ell_{\infty}$ ($\epsilon = 8/255$) threat models, outperforming the previous results by $+3.95$ and $+1.39$ percentage points, respectively. Furthermore, we report similar improvements for CIFAR-100.
tl;dr: This paper addresses the spectral bias issue of deep neural networks by multi-grade deep learning.

Deep neural networks (DNNs) have showcased their remarkable precision in approximating smooth functions. However, they suffer from the {\it spectral bias}, wherein DNNs typically exhibit a tendency to prioritize the learning of lower-frequency components of a function, struggling to effectively capture its high-frequency features. This paper is to address this issue. Notice that a function having only low frequency components may be well-represented by a shallow neural network (SNN), a network having only a few layers. By observing that composition of low frequency functions can effectively approximate a high-frequency function, we propose to learn a function containing high-frequency components by composing several SNNs, each of which learns certain low-frequency information from the given data. We implement the proposed idea by exploiting the multi-grade deep learning (MGDL) model, a recently introduced model that trains a DNN incrementally, grade by grade, a current grade learning from the residue of the previous grade only an SNN (with trainable parameters) composed with the SNNs (with fixed parameters) trained in the preceding grades as features. We apply MGDL to synthetic, manifold, colored images, and MNIST datasets, all characterized by presence of high-frequency features. Our study reveals that MGDL excels at representing functions containing high-frequency information. Specifically, the neural networks learned in each grade adeptly capture some low-frequency information, allowing their compositions with SNNs learned in the previous grades effectively representing the high-frequency features. Our experimental results underscore the efficacy of MGDL in addressing the spectral bias inherent in DNNs. By leveraging MGDL, we offer insights into overcoming spectral bias limitation of DNNs, thereby enhancing the performance and applicability of deep learning models in tasks requiring the representation of high-frequency information. This study confirms that the proposed method offers a promising solution to address the spectral bias of DNNs. The code is available on GitHub: \href{https://github.com/Ronglong-Fang/AddressingSpectralBiasviaMGDL}{\texttt{Addressing Spectral Bias via MGDL}}.
tl;dr: We introduce LexVLA, a interpretable Visual-Language Alignment framework by learning a unified lexical representation for both modalities without complex design.

Visual-Language Alignment (VLA) has gained a lot of attention since CLIP's groundbreaking work.
Although CLIP performs well, the typical direct latent feature alignment lacks clarity in its representation and similarity scores.
On the other hand, lexical representation, a vector whose element represents the similarity between the sample and a word from the vocabulary, is a natural sparse representation and interpretable, providing exact matches for individual words.
However, lexical representations are difficult to learn due to no ground-truth supervision and false-discovery issues, and thus requires complex design to train effectively.
In this paper, we introduce LexVLA, a more interpretable VLA framework by learning a unified lexical representation for both modalities without complex design.
We use DINOv2 as our visual model for its local-inclined features and Llama 2, a generative language model, to leverage its in-context lexical prediction ability.
To avoid the false discovery, we propose an overuse penalty to refrain the lexical representation from falsely frequently activating meaningless words.
We demonstrate that these two pre-trained uni-modal models can be well-aligned by fine-tuning on the modest multi-modal dataset and avoid intricate training configurations.
On cross-modal retrieval benchmarks, LexVLA, trained on the CC-12M multi-modal dataset, outperforms baselines fine-tuned on larger datasets (e.g., YFCC15M) and those trained from scratch on even bigger datasets (e.g., 1.1B data, including CC-12M).
We conduct extensive experiments to analyze LexVLA.
Codes are available at https://github.com/Clementine24/LexVLA.
tl;dr: We present SpatialPIN, a framework designed to enhance the spatial reasoning capabilities of VLMs through prompting and interacting with priors from multiple 3D foundation models in a zero-shot, training-free manner.

Current state-of-the-art spatial reasoning-enhanced VLMs are trained to excel at spatial visual question answering (VQA). However, we believe that higher-level 3D-aware tasks, such as articulating dynamic scene changes and motion planning, require a fundamental and explicit 3D understanding beyond current spatial VQA datasets. In this work, we present SpatialPIN, a framework designed to enhance the spatial reasoning capabilities of VLMs through prompting and interacting with priors from multiple 3D foundation models in a zero-shot, training-free manner. Extensive experiments demonstrate that our spatial reasoning-imbued VLM performs well on various forms of spatial VQA and can extend to help in various downstream robotics tasks such as pick and stack and trajectory planning.

A fundamental problem in quantum many-body physics is that of finding ground states of local
Hamiltonians. A number of recent works gave provably efficient machine learning (ML) algorithms
for learning ground states. Specifically, [Huang et al. Science 2022], introduced an approach for learning
properties of the ground state of an $n$-qubit gapped local Hamiltonian $H$ from only $n^{\mathcal{O}(1)}$ data
points sampled from Hamiltonians in the same phase of matter. This was subsequently improved
by [Lewis et al. Nature Communications 2024], to $\mathcal{O}(\log 𝑛)$ samples when the geometry of the $n$-qubit system is known.
In this work, we introduce two approaches that achieve a constant sample complexity, independent
of system size $n$, for learning ground state properties. Our first algorithm consists of a simple
modification of the ML model used by Lewis et al. and applies to a property of interest known beforehand. Our second algorithm, which applies even if a description of
the property is not known, is a deep neural network model. While empirical results showing the
performance of neural networks have been demonstrated, to our knowledge, this is the first rigorous
sample complexity bound on a neural network model for predicting ground state properties. We also perform numerical experiments that confirm the improved scaling of our approach compared to earlier results.
tl;dr: This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 × 1600) and beyond.

The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 $\times$ 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 × 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 $\times$ 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks.

Seams, distortions, wasted UV space, vertex-duplication, and varying resolution over the surface are the most prominent issues of the standard UV-based texturing of meshes. These issues are particularly acute when automatic UV-unwrapping techniques are used. For this reason, instead of generating textures in automatically generated UV-planes like most state-of-the-art methods, we propose to represent textures as coloured point-clouds whose colours are generated by a denoising diffusion probabilistic model constrained to operate on the surface of 3D objects. Our sampling and resolution agnostic generative model heavily relies on heat diffusion over the surface of the meshes for spatial communication between points. To enable processing of arbitrarily sampled point-cloud textures and ensure long-distance texture consistency we introduce a fast re-sampling of the mesh spectral properties used during the heat diffusion and introduce a novel heat-diffusion-based self-attention mechanism. Our code and pre-trained models are available at github.com/simofoti/UV3-TeD.

Large language models (LLMs) have garnered significant attention for their remarkable capabilities across various domains, whose vast parameter scales present challenges for practical deployment. Structured pruning is an effective method to balance model performance with efficiency, but performance restoration under computational resource constraints is a principal challenge in pruning LLMs. Therefore, we present a low-cost and fast structured pruning method for LLMs named SlimGPT based on the Optimal Brain Surgeon framework. We propose Batched Greedy Pruning for rapid and near-optimal pruning, which enhances the accuracy of head-wise pruning error estimation through grouped Cholesky decomposition and improves the pruning efficiency of FFN via Dynamic Group Size, thereby achieving approximate local optimal pruning results within one hour. Besides, we explore the limitations of layer-wise pruning from the perspective of error accumulation and propose Incremental Pruning Ratio, a non-uniform pruning strategy to reduce performance degradation. Experimental results on the LLaMA benchmark show that SlimGPT outperforms other methods and achieves state-of-the-art results.
tl;dr: We introduce AvaTaR, a novel framework that automates the optimization of LLM agents for enhanced tool utilization and generalization in multi-step problems

Large language model (LLM) agents have demonstrated impressive capabilities in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing prompting techniques that enable LLM agents to effectively use these tools and knowledge remains a heuristic and labor-intensive task. Here, we introduce AvaTaR, a novel and automated framework that optimizes an LLM agent to effectively leverage provided tools, improving performance on a given task. During optimization, we design a comparator module to iteratively deliver insightful and comprehensive prompts to the LLM agent by contrastively reasoning between positive and negative examples sampled from training data. We demon- strate AvaTaR on four complex multimodal retrieval datasets featuring textual, visual, and relational information, and three general question-answering (QA) datasets. We find AvaTaR consistently outperforms state-of-the-art approaches across all seven tasks, exhibiting strong generalization ability when applied to novel cases and achieving an average relative improvement of 14% on the Hit@1 metric for the retrieval datasets and 13% for the QA datasets. Code and dataset are available at https://github.com/zou-group/avatar.

Occupancy functions play an instrumental role in reinforcement learning (RL) for guiding exploration, handling distribution shift, and optimizing general objectives beyond the expected return. Yet, computationally efficient policy optimization methods that use (only) occupancy functions are virtually non-existent. In this paper, we establish the theoretical foundations of model-free policy gradient (PG) methods that compute the gradient through the occupancy for both online and offline RL, without modeling value functions. Our algorithms reduce gradient estimation to squared-loss regression and are computationally oracle-efficient. We characterize the sample complexities of both local and global convergence, accounting for both finite-sample estimation error and the roles of exploration (online) and data coverage (offline). Occupancy-based PG naturally handles arbitrary offline data distributions, and, with one-line algorithmic changes, can be adapted to optimize any differentiable objective functional.
tl;dr: We propose an effective $\ell_0$-norm based inlier identification algorithm for robust point cloud registration.

Correspondences in point cloud registration are prone to outliers, significantly reducing registration accuracy and highlighting the need for precise inlier identification. In this paper, we propose a robust inlier identification algorithm for point cloud registration by reformulating the conventional registration problem as an alignment error $\ell_0$-minimization problem. The $\ell_0$-minimization problem is formulated for each local set, where those local sets are built on a compatibility graph of input correspondences. To resolve the $\ell_0$-minimization, we develop a novel two-stage decoupling strategy, which first decouples the alignment error into a rotation fitting error and a translation fitting error. Second, null-space matrices are employed to decouple inlier identification from the estimation of rotation and translation respectively, thereby applying Bayesian theory to $\ell_0$-minimization problems and solving for fitting errors. Correspondences with the smallest errors are identified as inliers to generate a transformation hypothesis for each local set. The best hypothesis is selected to perform registration. We demonstrate that the proposed inlier identification algorithm is robust under high outlier ratios and noise through experiments. Extensive results on the KITTI, 3DMatch, and 3DLoMatch datasets demonstrate that our method achieves state-of-the-art performance compared to both traditional and learning-based methods in various indoor and outdoor scenes.

Graph Neural Networks (GNNs) have significantly advanced the field of drug discovery, enhancing the speed and efficiency of molecular identification. However, training these GNNs demands vast amounts of molecular data, which has spurred the emergence of collaborative model-sharing initiatives. These initiatives facilitate the sharing of molecular pre-trained models among organizations without exposing proprietary training data. Despite the benefits, these molecular pre-trained models may still pose privacy risks. For example, malicious adversaries could perform data extraction attack to recover private training data, thereby threatening commercial secrets and collaborative trust. This work, for the first time, explores the risks of extracting private training molecular data from molecular pre-trained models. This task is nontrivial as the molecular pre-trained models are non-generative and exhibit a diversity of model architectures, which differs significantly from language and image models. To address these issues, we introduce a molecule generation approach and propose a novel, model-independent scoring function for selecting promising molecules. To efficiently reduce the search space of potential molecules, we further introduce a Molecule Extraction Policy Network for molecule extraction. Our experiments demonstrate that even with only query access to molecular pre-trained models, there is a considerable risk of extracting training data, challenging the assumption that model sharing alone provides adequate protection against data extraction attacks. Our codes are publicly available at: \url{https://github.com/renH2/Molextract}.

Leveraging planning during learning and decision-making is central to the long-term development of intelligent agents. Recent works have successfully combined tree-based search methods and self-play learning mechanisms to this end. However, these methods typically face scaling challenges due to the sequential nature of their search. While practical engineering solutions can partly overcome this, they often result in a negative impact on performance. In this paper, we introduce SPO: Sequential Monte Carlo Policy Optimisation, a model-based reinforcement learning algorithm grounded within the Expectation Maximisation (EM) framework. We show that SPO provides robust policy improvement and efficient scaling properties. The sample-based search makes it directly applicable to both discrete and continuous action spaces without modifications. We demonstrate statistically significant improvements in performance relative to model-free and model-based baselines across both continuous and discrete environments. Furthermore, the parallel nature of SPO’s search enables effective utilisation of hardware accelerators, yielding favourable scaling laws.
tl;dr: SDDR proposes to model the depth refinement task by noisy Poisson fusion and train the refinement network in a self-distillation paradigm, achieving both high accuracy and efficiency.

Depth refinement aims to infer high-resolution depth with fine-grained edges and details, refining low-resolution results of depth estimation models. The prevailing methods adopt tile-based manners by merging numerous patches, which lacks efficiency and produces inconsistency. Besides, prior arts suffer from fuzzy depth boundaries and limited generalizability. Analyzing the fundamental reasons for these limitations, we model depth refinement as a noisy Poisson fusion problem with local inconsistency and edge deformation noises. We propose the Self-distilled Depth Refinement (SDDR) framework to enforce robustness against the noises, which mainly consists of depth edge representation and edge-based guidance. With noisy depth predictions as input, SDDR generates low-noise depth edge representations as pseudo-labels by coarse-to-fine self-distillation. Edge-based guidance with edge-guided gradient loss and edge-based fusion loss serves as the optimization objective equivalent to Poisson fusion. When depth maps are better refined, the labels also become more noise-free. Our model can acquire strong robustness to the noises, achieving significant improvements in accuracy, edge quality, efficiency, and generalizability on five different benchmarks. Moreover, directly training another model with edge labels produced by SDDR brings improvements, suggesting that our method could help with training robust refinement models in future works.
tl;dr: Introduces Kolmogorov Means As A New Distributed Machine Learning Communication Primitive.

While Distributed Machine Learning (DML) has been widely used to achieve decent performance, it is still challenging to take full advantage of data and devices distributed at multiple vantage points to adapt and learn, especially it is non-trivial to address dynamic and divergence challenges based on the linear aggregation framework as follows: (1) heterogeneous learning data at different devices (i.e., non-IID data) resulting in model divergence and (2) in the case of time-varying communication links, the limited ability for devices to reconcile model divergence. In this paper, we contribute a non-linear class aggregation framework HyperPrism that leverages distributed mirror descent with averaging done in the mirror descent dual space and adapts the degree of Weighted Power Mean (WPM) used in each round. Moreover, HyperPrism could adaptively choose different mapping for different layers of the local model with a dedicated hypernetwork per device, achieving automatic optimization of DML in high divergence settings. We perform rigorous analysis and experimental evaluations to demonstrate the effectiveness of adaptive, mirror-mapping DML. In particular, we extend the generalizability of existing related works and position them as special cases within HyperPrism. Our experimental results show that HyperPrism can improve the convergence speed up to 98.63% and scale well to more devices compared with the state-of-the-art, all with little additional computation overhead compared to traditional linear aggregation.
tl;dr: EEGPT, a novel over 10-million-parameter pretrained transformer for universal EEG feature extraction, achieving SOTA on various tasks through efficient, robust, and scalable representation learning.

Electroencephalography (EEG) is crucial for recording brain activity,
with applications in medicine, neuroscience, and brain-computer interfaces (BCI).
However, challenges such as low signal-to-noise ratio (SNR), high inter-subject variability, and channel mismatch complicate the extraction of robust,
universal EEG representations.
We propose EEGPT, a novel 10-million-parameter pretrained transformer model designed for universal EEG feature extraction.
In EEGPT, a mask-based dual self-supervised learning method for efficient feature extraction is designed.
Compared to other mask-based self-supervised learning methods,
EEGPT introduces spatio-temporal representation alignment.
This involves constructing a self-supervised task based on
EEG representations that possess high SNR and rich semantic information,
rather than on raw signals.
Consequently, this approach mitigates the issue of poor feature quality typically
extracted from low SNR signals.
Additionally, EEGPT's hierarchical structure processes spatial and temporal information separately,
reducing computational complexity while increasing flexibility and adaptability for BCI applications.
By training on a large mixed multi-task EEG dataset, we fully exploit EEGPT's capabilities.
The experiment validates the efficacy and scalability of EEGPT,
achieving state-of-the-art performance on a range of downstream tasks with linear-probing.
Our research advances EEG representation learning, offering innovative solutions for bio-signal processing and AI applications.
The code for this paper is available at: https://github.com/BINE022/EEGPT
tl;dr: We propose CountGD, a state-of-the-art multi-modal open-world object counting model that can count arbitrary objects given visual exemplars, text, or both together, fusing the modalities to accurately estimate the object count.

The goal of this paper is to improve the generality and accuracy of open-vocabulary object counting in images. To improve the generality, we repurpose an open-vocabulary detection foundation model (GroundingDINO) for the counting task, and also extend its capabilities by introducing modules to enable specifying the target object to count by visual exemplars. In turn, these new capabilities -- being able to specify the target object by multi-modalites (text and exemplars) -- lead to an improvement in counting accuracy. We make three contributions: First, we introduce the first open-world counting model, CountGD, where the prompt can be specified by a text description or visual exemplars or both; Second, we show that the performance of the model significantly improves the state of the art on multiple counting benchmarks -- when using text only, CountGD outperforms all previous text-only works, and when using both text and visual exemplars, we outperform all previous models; Third, we carry out a preliminary study into different interactions between the text and visual exemplar prompts, including the cases where they reinforce each other and where one restricts the other. The code and an app to test the model are available at https://www.robots.ox.ac.uk/vgg/research/countgd/.

Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision.
While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space.
We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics.

Currently, researchers think that the inherent robustness of spiking neural networks (SNNs) stems from their biologically plausible spiking neurons, and are dedicated to developing more bio-inspired models to defend attacks. However, most work relies solely on experimental analysis and lacks theoretical support, and the direct-encoding method and fixed membrane potential leak factor they used in spiking neurons are simplified simulations of those in the biological nervous system, which makes it difficult to ensure generalizability across all datasets and networks. Contrarily, the biological nervous system can stay reliable even in a highly complex noise environment, one of the reasons is selective visual attention and non-fixed membrane potential leaks in biological neurons. This biological finding has inspired us to design a highly robust SNN model that closely mimics the biological nervous system. In our study, we first present a unified theoretical framework for SNN robustness constraint, which suggests that improving the encoding method and evolution of the membrane potential leak factor in spiking neurons can improve SNN robustness. Subsequently, we propose a robust SNN (FEEL-SNN) with Frequency Encoding (FE) and Evolutionary Leak factor (EL) to defend against different noises, mimicking the selective visual attention mechanism and non-fixed leak observed in biological systems. Experimental results confirm the efficacy of both our FE, EL, and FEEL methods, either in isolation or in conjunction with established robust enhancement algorithms, for enhancing the robustness of SNNs.

Presently, pseudo-labeling stands as a prevailing approach in cross-domain semantic segmentation, enhancing model efficacy by training with pixels assigned with reliable pseudo-labels. However, we identify two key limitations within this paradigm: (1) under relatively severe domain shifts, most selected reliable pixels appear speckled and remain noisy. (2) when dealing with wild data, some pixels belonging to the open-set class may exhibit high confidence and also appear speckled. These two points make it difficult for the pixel-level selection mechanism to identify and correct these speckled close- and open-set noises. As a result, error accumulation is continuously introduced into subsequent self-training, leading to inefficiencies in pseudo-labeling. To address these limitations, we propose a novel method called Semantic Connectivity-driven Pseudo-labeling (SeCo). SeCo formulates pseudo-labels at the connectivity level, which makes it easier to locate and correct closed and open set noise. Specifically, SeCo comprises two key components: Pixel Semantic Aggregation (PSA) and Semantic Connectivity Correction (SCC). Initially, PSA categorizes semantics into ``stuff'' and ``things'' categories and aggregates speckled pseudo-labels into semantic connectivity through efficient interaction with the Segment Anything Model (SAM). This enables us not only to obtain accurate boundaries but also simplifies noise localization. Subsequently, SCC introduces a simple connectivity classification task, which enables us to locate and correct connectivity noise with the guidance of loss distribution. Extensive experiments demonstrate that SeCo can be flexibly applied to various cross-domain semantic segmentation tasks, \textit{i.e.} domain generalization and domain adaptation, even including source-free, and black-box domain adaptation, significantly improving the performance of existing state-of-the-art methods. The code is provided in the appendix and will be open-source.
tl;dr: We propose a self-supervised hierarchical makeup transfer method that is flexible for both simple and complex makeup styles.

This paper studies the challenging task of makeup transfer, which aims to apply diverse makeup styles precisely and naturally to a given facial image. Due to the absence of paired data, current methods typically synthesize sub-optimal pseudo ground truths to guide the model training, resulting in low makeup fidelity. Additionally, different makeup styles generally have varying effects on the person face, but existing methods struggle to deal with this diversity. To address these issues, we propose a novel Self-supervised Hierarchical Makeup Transfer (SHMT) method via latent diffusion models. Following a "decoupling-and-reconstruction" paradigm, SHMT works in a self-supervised manner, freeing itself from the misguidance of imprecise pseudo-paired data. Furthermore, to accommodate a variety of makeup styles, hierarchical texture details are decomposed via a Laplacian pyramid and selectively introduced to the content representation. Finally, we design a novel Iterative Dual Alignment (IDA) module that dynamically adjusts the injection condition of the diffusion model, allowing the alignment errors caused by the domain gap between content and makeup representations to be corrected. Extensive quantitative and qualitative analyses demonstrate the effectiveness of our method. Our code is available at https://github.com/Snowfallingplum/SHMT.

Large language models (LLMs) have shown impressive capabilities across various tasks. However, training LLMs from scratch requires significant computational power and extensive memory capacity. Recent studies have explored low-rank structures on weights for efficient fine-tuning in terms of parameters and memory, either through low-rank adaptation or factorization. While effective for fine-tuning, low-rank structures are generally less suitable for pretraining because they restrict parameters to a low-dimensional subspace. In this work, we propose to parameterize the weights as a sum of low-rank and sparse matrices for pretraining, which we call SLTrain. The low-rank component is learned via matrix factorization, while for the sparse component, we employ a simple strategy of uniformly selecting the sparsity support at random and learning only the non-zero entries with the fixed support. While being simple, the random fixed-support sparse learning strategy significantly enhances pretraining when combined with low-rank learning. Our results show that SLTrain adds minimal extra parameters and memory costs compared to pretraining with low-rank parameterization, yet achieves substantially better performance, which is comparable to full-rank training. Remarkably, when combined with quantization and per-layer updates, SLTrain can reduce memory requirements by up to 73% when pretraining the LLaMA 7B model.

Many studies have proposed attack methods to generate adversarial patterns for evading pedestrian detection, alarming the computer vision community about the need for more attention to the robustness of detectors. However, adversarial patterns optimized by these methods commonly have limited performance at medium to long distances in the physical world. To overcome this limitation, we identify two main challenges. First, in existing methods, there is commonly an appearance gap between simulated distant adversarial patterns and their physical world counterparts, leading to incorrect optimization. Second, there exists a conflict between adversarial losses at different distances, which causes difficulties in optimization. To overcome these challenges, we introduce a Full Distance Attack (FDA) method. Our physical world experiments demonstrate the effectiveness of our FDA patterns across various detection models like YOLOv5, Deformable-DETR, and Mask RCNN. Codes available at https://github.com/zhicheng2T0/Full-Distance-Attack.git

Graph neural networks (GNNs) are recognized for their strong performance across various applications, with the backpropagation (BP) algorithm playing a central role in the development of most GNN models. However, despite its effectiveness, BP has limitations that challenge its biological plausibility and affect the efficiency, scalability and parallelism of training neural networks for graph-based tasks. While several non-backpropagation (non-BP) training algorithms, such as the direct feedback alignment (DFA), have been successfully applied to fully-connected and convolutional network components for handling Euclidean data, directly adapting these non-BP frameworks to manage non-Euclidean graph data in GNN models presents significant challenges. These challenges primarily arise from the violation of the independent and identically distributed (i.i.d.) assumption in graph data and the difficulty in accessing prediction errors for all samples (nodes) within the graph. To overcome these obstacles, in this paper we propose DFA-GNN, a novel forward learning framework tailored for GNNs with a case study of semi-supervised learning. The proposed method breaks the limitations of BP by using a dedicated forward training mechanism. Specifically, DFA-GNN extends the principles of DFA to adapt to graph data and unique architecture of GNNs, which incorporates the information of graph topology into the feedback links to accommodate the non-Euclidean characteristics of graph data. Additionally, for semi-supervised graph learning tasks, we developed a pseudo error generator that spreads residual errors from training data to create a pseudo error for each unlabeled node. These pseudo errors are then utilized to train GNNs using DFA. Extensive experiments on 10 public benchmarks reveal that our learning framework outperforms not only previous non-BP methods but also the standard BP methods, and it exhibits excellent robustness against various types of noise and attacks.

In this work, we offer a theoretical analysis of two modern optimization techniques for training large and complex models: (i) adaptive optimization algorithms, such as Adam, and (ii) the model exponential moving average (EMA). Specifically, we demonstrate that a clipped version of Adam with model EMA achieves the optimal convergence rates in various nonconvex optimization settings, both smooth and nonsmooth. Moreover, when the scale varies significantly across different coordinates, we demonstrate that the coordinate-wise adaptivity of Adam is provably advantageous. Notably, unlike previous analyses of Adam, our analysis crucially relies on its core elements---momentum and discounting factors---as well as model EMA, motivating their wide applications in practice.
tl;dr: $\textit{Trans-LoRA}$ enables nearly data-free transfer of existing LoRA to different base models.

Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $\textit{Trans-LoRA}$ --- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $\textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.

Zero-Shot Temporal Action Detection (ZSTAD) aims to classify and localize action segments in untrimmed videos for unseen action categories. Most existing ZSTAD methods utilize a foreground-based approach, limiting the integration of text and visual features due to their reliance on pre-extracted proposals. In this paper, we introduce a cross-modal ZSTAD baseline with mutual cross-attention, integrating both text and visual information throughout the detection process. Our simple approach results in superior performance compared to previous methods. Despite this improvement, we further identify a common-action bias issue that the cross-modal baseline over-focus on common sub-actions due to a lack of ability to discriminate text-related visual parts. To address this issue, we propose Text-infused attention and Foreground-aware Action Detection (Ti-FAD), which enhances the ability to focus on text-related sub-actions and distinguish relevant action segments from the background. Our extensive experiments demonstrate that Ti-FAD outperforms the state-of-the-art methods on ZSTAD benchmarks by a large margin: 41.2\% (+ 11.0\%) on THUMOS14 and 32.0\% (+ 5.4\%) on ActivityNet v1.3. Code is available at: https://github.com/YearangLee/Ti-FAD.
tl;dr: We combine a GFlowNet policy and an action-value estimate, $Q$ into mixture policies that get better rewards without losing diversity

Generative Flow Networks (GFlowNets; GFNs) are a family of energy-based generative methods for combinatorial objects, capable of generating diverse and high-utility samples. However, consistently biasing GFNs towards producing high-utility samples is non-trivial. In this work, we leverage connections between GFNs and reinforcement learning (RL) and propose to combine the GFN policy with an action-value estimate, $Q$, to create greedier sampling policies which can be controlled by a mixing parameter. We show that several variants of the proposed method, QGFN, are able to improve on the number of high-reward samples generated in a variety of tasks without sacrificing diversity.
tl;dr: We provide an efficient algorithm to learn an approximate max-following policy using K constituent policies in large state spaces.

Reinforcement learning (RL) in large or infinite state spaces is notoriously challenging, both theoretically (where worst-case sample and computational complexities must scale with state space cardinality) and experimentally (where function approximation and policy gradient techniques often scale poorly and suffer from instability and high variance). One line of research attempting to address these difficulties
makes the natural assumption that we are given a collection of base or *constituent* policies (possibly heuristic) upon which we would like to improve in a scalable manner. In this work we aim to compete with the *max-following policy*, which at each state follows the action of whichever constituent policy has the highest value. The max-following policy is always at least as good as the best constituent policy, and may be considerably better. Our main result is an efficient algorithm that learns to compete with the max-following policy, given only access to the constituent policies (but not their value functions). In contrast to prior work in similar settings, our theoretical results require only the minimal assumption of an ERM oracle for value function approximation for the constituent policies (and not the global optimal policy or the max-following policy itself) on samplable distributions. We illustrate our algorithm's experimental effectiveness and behavior on several robotic simulation testbeds.

Score distillation sampling (SDS) has proven to be an important tool, enabling the use of large-scale diffusion priors for tasks operating in data-poor domains. Unfortunately, SDS has a number of characteristic artifacts that limit its utility in general-purpose applications. In this paper, we make progress toward understanding the behavior of SDS and its variants by viewing them as solving an optimal-cost transport path from some current source distribution to a target distribution. Under this new interpretation, we argue that these methods' characteristic artifacts are caused by (1) linear approximation of the optimal path and (2) poor estimates of the source distribution.
We show that by calibrating the text conditioning of the source distribution, we can produce high-quality generation and translation results with little extra overhead. Our method can be easily applied across many domains, matching or beating the performance of specialized methods. We demonstrate its utility in text-to-2D, text-to-3D, translating paintings to real images, optical illusion generation, and 3D sketch-to-real. We compare our method to existing approaches for score distillation sampling and show that it can produce high-frequency details with realistic colors.
tl;dr: We propose a PCD method to handle the missing modality problem, which transfers privileged information of modality-complete representation by considering the indeterminacy in the mapping from incompleteness to completeness.

Multimodal models trained on modality-complete data are plagued with severe performance degradation when encountering modality-missing data. Prevalent cross-modal knowledge distillation-based methods precisely align the representation of modality-missing data and that of its modality-complete counterpart to enhance robustness. However, due to the irreparable information asymmetry, this determinate alignment is too stringent, easily inducing modality-missing features to capture spurious factors erroneously. In this paper, a novel multimodal Probabilistic Conformal Distillation (PCD) method is proposed, which considers the inherent indeterminacy in this alignment. Given a modality-missing input, our goal is to learn the unknown Probability Density Function (PDF) of the mapped variables in the modality-complete space, rather than relying on the brute-force point alignment. Specifically, PCD models the modality-missing feature as a probabilistic distribution, enabling it to satisfy two characteristics of the PDF. One is the extremes of probabilities of modality-complete feature points on the PDF, and the other is the geometric consistency between the modeled distributions and the peak points of different PDFs. Extensive experiments on a range of benchmark datasets demonstrate the superiority of PCD over state-of-the-art methods. Code is available at: https://github.com/mxchen-mc/PCD.
3396. DreamSteerer: Enhancing Source Image Conditioned Editability using Personalized Diffusion Models
tl;dr: A plug-in method for improved editability of any existing T2I personalization baseline

Recent text-to-image (T2I) personalization methods have shown great premise in teaching a diffusion model user-specified concepts given a few images for reusing the acquired concepts in a novel context. With massive efforts being dedicated to personalized generation, a promising extension is personalized editing, namely to edit an image using personalized concepts, which can provide more precise guidance signal than traditional textual guidance. To address this, one straightforward solution is to incorporate a personalized diffusion model with a text-driven editing framework. However, such solution often shows unsatisfactory editability on the source image. To address this, we propose DreamSteerer, a plug-in method for augmenting existing T2I personalization methods. Specifically, we enhance the source image conditioned editability of a personalized diffusion model via a novel Editability Driven Score Distillation (EDSD) objective. Moreover, we identify a mode trapping issue with EDSD, and propose a mode shifting regularization with spatial feature guided sampling to avoid such issue. We further employ two key modifications on the Delta Denoising Score framework that enable high-fidelity local editing with personalized concepts. Extensive experiments validate that DreamSteerer can significantly improve the editability of several T2I personalization baselines while being computationally efficient.

Image segmentation is a crucial vision task that groups pixels within an image into semantically meaningful segments, which is pivotal in obtaining a fine-grained understanding of real-world scenes. However, an increasing privacy concern exists regarding training large-scale image segmentation models on unauthorized private data. In this work, we exploit the concept of unlearnable examples to make images unusable to model training by generating and adding unlearnable noise into the original images. Particularly, we propose a novel Unlearnable Segmentation (UnSeg) framework to train a universal unlearnable noise generator that is capable of transforming any downstream images into their unlearnable version. The unlearnable noise generator is finetuned from the Segment Anything Model (SAM) via bilevel optimization on an interactive segmentation dataset towards minimizing the training error of a surrogate model that shares the same architecture with SAM (but trains from scratch). We empirically verify the effectiveness of UnSeg across 6 mainstream image segmentation tasks, 10 widely used datasets, and 7 different network architectures, and show that the unlearnable images can reduce the segmentation performance by a large margin. Our work provides useful insights into how to leverage foundation models in a data-efficient and computationally affordable manner to protect images against image segmentation models.
tl;dr: This paper proposes Grid4D, a novel high-fidelity dynamic scene rendering model with 4D decomposed hash encoding.

Recently, Gaussian splatting has received more and more attention in the field of static scene rendering. Due to the low computational overhead and inherent flexibility of explicit representations, plane-based explicit methods are popular ways to predict deformations for Gaussian-based dynamic scene rendering models. However, plane-based methods rely on the inappropriate low-rank assumption and excessively decompose the space-time 4D encoding, resulting in overmuch feature overlap and unsatisfactory rendering quality. To tackle these problems, we propose Grid4D, a dynamic scene rendering model based on Gaussian splatting and employing a novel explicit encoding method for the 4D input through the hash encoding. Different from plane-based explicit representations, we decompose the 4D encoding into one spatial and three temporal 3D hash encodings without the low-rank assumption. Additionally, we design a novel attention module that generates the attention scores in a directional range to aggregate the spatial and temporal features. The directional attention enables Grid4D to more accurately fit the diverse deformations across distinct scene components based on the spatial encoded features. Moreover, to mitigate the inherent lack of smoothness in explicit representation methods, we introduce a smooth regularization term that keeps our model from the chaos of deformation prediction. Our experiments demonstrate that Grid4D significantly outperforms the state-of-the-art models in visual quality and rendering speed.

Transformer-based architectures have dominated various areas of machine learning in recent years. In this paper, we introduce a novel robust attention mechanism designed to enhance the resilience of transformer-based architectures. Crucially, this technique can be integrated into existing transformers as a plug-and-play layer, improving their robustness without the need for additional training or fine-tuning. Through comprehensive experiments and ablation studies, we demonstrate that our ProTransformer significantly enhances the robustness of transformer models across a variety of prediction tasks, attack mechanisms, backbone architectures, and data domains. Notably, without further fine-tuning, the ProTransformer consistently improves the performance of vanilla transformers by 19.5\%, 28.3\%, 16.1\%, and 11.4\% for BERT, ALBERT, DistilBERT, and RoBERTa, respectively, under the classical TextFooler attack. Furthermore, ProTransformer shows promising resilience in large language models (LLMs) against prompting-based attacks, improving the performance of T5 and LLaMA by 24.8\% and 17.8\%, respectively, and enhancing Vicuna by an average of 10.4\% against the Jailbreaking attack. Beyond the language domain, ProTransformer also demonstrates outstanding robustness in both vision and graph domains.
tl;dr: Learn the optimal policy that balances multiple short-term and long-term rewards, especially in scenarios where the long-term outcomes are often missing due to data collection challenges over extended periods.

Learning the optimal policy to balance multiple short-term and long-term rewards has extensive applications across various domains. Yet, there is a noticeable scarcity of research addressing policy learning strategies in this context. In this paper, we aim to learn the optimal policy capable of effectively balancing multiple short-term and long-term rewards, especially in scenarios where the long-term outcomes are often missing due to data collection challenges over extended periods. Towards this goal, the conventional linear weighting method, which aggregates multiple rewards into a single surrogate reward through weighted summation, can only achieve sub-optimal policies when multiple rewards are related. Motivated by this, we propose a novel decomposition-based policy learning (DPPL) method that converts the whole problem into subproblems. The DPPL method is capable of obtaining optimal policies even when multiple rewards are interrelated. Nevertheless, the DPPL method requires a set of preference vectors specified in advance, posing challenges in practical applications where selecting suitable preferences is non-trivial. To mitigate this, we further theoretically transform the optimization problem in DPPL into an $\varepsilon$-constraint problem, where $\varepsilon$ represents the minimum acceptable levels of other rewards while maximizing one reward. This transformation provides intuitive into the selection of preference vectors. Extensive experiments are conducted on the proposed method and the results validate the effectiveness of the method.

Visual representations become progressively more abstract along the cortical hierarchy. These abstract representations define notions like objects and shapes, but at the cost of spatial specificity. By contrast, low-level regions represent spatially local but simple input features. How do spatially non-specific representations of abstract concepts in high-level areas flexibly modulate the low-level sensory representations in appropriate ways to guide context-driven and goal-directed behaviors across a range of tasks? We build a biologically motivated and trainable neural network model of dynamics in the visual pathway, incorporating local, lateral, and feedforward synaptic connections, excitatory and inhibitory neurons, and long-range top-down inputs conceptualized as low-rank modulations of the input-driven sensory responses by high-level areas. We study this ${\bf D}$ynamical ${\bf C}$ortical ${\bf net}$work ($DCnet$) in a visual cue-delay-search task and show that the model uses its own cue representations to adaptively modulate its perceptual responses to solve the task, outperforming state-of-the-art DNN vision and LLM models. The model's population states over time shed light on the nature of contextual modulatory dynamics, generating predictions for experiments. We fine-tune the same model on classic psychophysics attention tasks, and find that the model closely replicates known reaction time results. This work represents a promising new foundation for understanding and making predictions about perturbations to visual processing in the brain.
tl;dr: We propose a physics-regularized learning approach on dynamic discrete meshes to address the complex inverse problem of tumor localization.

Physical models in the form of partial differential equations serve as important priors for many under-constrained problems. One such application is tumor treatment planning, which relies on accurately estimating the spatial distribution of tumor cells within a patient’s anatomy. While medical imaging can detect the bulk of a tumor, it cannot capture the full extent of its spread, as low-concentration tumor cells often remain undetectable, particularly in glioblastoma, the most common primary brain tumor. Machine learning approaches struggle to estimate the complete tumor cell distribution due to a lack of appropriate training data. Consequently, most existing methods rely on physics-based simulations to generate anatomically and physiologically plausible estimations. However, these approaches face challenges with complex and unknown initial conditions and are constrained by overly rigid physical models. In this work, we introduce a novel method that integrates data-driven and physics-based cost functions, akin to Physics-Informed Neural Networks (PINNs). However, our approach parametrizes the solution directly on a dynamic discrete mesh, allowing for the effective modeling of complex biomechanical behaviors. Specifically, we propose a unique discretization scheme that quantifies how well the learned spatiotemporal distributions of tumor and brain tissues adhere to their respective growth and elasticity equations. This quantification acts as a regularization term, offering greater flexibility and improved integration of patient data compared to existing models. We demonstrate enhanced coverage of tumor recurrence areas using real-world data from a patient cohort, highlighting the potential of our method to improve model-driven treatment planning for glioblastoma in clinical practice.
tl;dr: We propose a novel method for aligning audio and image tokens to enable zero-shot audio captioning throught MMD and Optimal Transport leveraging a large vision language models, achieving superior performance in unsupervised settings.

Multimodal large language models have fueled progress in image captioning. These models, fine-tuned on vast image datasets, exhibit a deep understanding of semantic concepts.
In this work, we show that this ability can be re-purposed for audio captioning, where the joint image-language decoder can be leveraged to describe auditory content associated with image sequences within videos featuring audiovisual content. This can be achieved via multimodal alignment.
Yet, this multimodal alignment task is non-trivial due to the inherent disparity between audible and visible elements in real-world videos. Moreover, multimodal representation learning often relies on contrastive learning, facing the challenge of the so-called modality gap which hinders smooth integration between modalities. In this work, we introduce a novel methodology for bridging the audiovisual modality gap by matching the distributions of tokens produced by an audio backbone and those of an image captioner. Our approach aligns the audio token distribution with that of the image tokens, enabling the model to perform zero-shot audio captioning in an unsupervised fashion. This alignment allows for the use of either audio or audiovisual input by combining or substituting the image encoder with the aligned audio encoder. Our method achieves significantly improved performances in zero-shot audio captioning, compared to existing approaches.
tl;dr: In this paper, we propose a method for maximizing the AUC under the positive distribution shift by using labeled positive and unlabeled data in the training distribution and unlabeled data in the test distribution.

Maximizing the area under the receiver operating characteristic curve (AUC) is a popular approach to imbalanced binary classification problems. Existing AUC maximization methods usually assume that training and test distributions are identical. However, this assumption is often violated in practice due to {\it a positive distribution shift}, where the negative-conditional density does not change but the positive-conditional density can vary. This shift often occurs in imbalanced classification since positive data are often more diverse and time-varying than negative data. To deal with this shift, we theoretically show that the AUC on the test distribution can be expressed by using the positive and marginal training densities and the marginal test density. Based on this result, we can maximize the AUC on the test distribution by using positive and unlabeled data in the training distribution and unlabeled data in the test distribution. The proposed method requires only positive labels in the training distribution as supervision. Moreover, the derived AUC has a simple form and thus is easy to implement. The effectiveness of the proposed method is shown with four real-world datasets.
tl;dr: Label-Efficient Domain Adaptation for Multi-view 3D Object Detection

Recent advances in 3D object detection leveraging multi-view cameras have demonstrated their practical and economical value in various challenging vision tasks.
However, typical supervised learning approaches face challenges in achieving satisfactory adaptation toward unseen and unlabeled target datasets (i.e., direct transfer) due to the inevitable geometric misalignment between the source and target domains.
In practice, we also encounter constraints on resources for training models and collecting annotations for the successful deployment of 3D object detectors.
In this paper, we propose Unified Domain Generalization and Adaptation (UDGA), a practical solution to mitigate those drawbacks.
We first propose Multi-view Overlap Depth Constraint that leverages the strong association between multi-view, significantly alleviating geometric gaps due to perspective view changes.
Then, we present a Label-Efficient Domain Adaptation approach to handle unfamiliar targets with significantly fewer amounts of labels (i.e., 1$\%$ and 5$\%)$, while preserving well-defined source knowledge for training efficiency.
Overall, UDGA framework enables stable detection performance in both source and target domains, effectively bridging inevitable domain gaps, while demanding fewer annotations.
We demonstrate the robustness of UDGA with large-scale benchmarks: nuScenes, Lyft, and Waymo, where our framework outperforms the current state-of-the-art methods.
3406. Pandora's Box: Towards Building Universal Attackers against Real-World Large Vision-Language Models

Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across a wide range of multimodal understanding tasks. Nevertheless, these models are susceptible to adversarial examples. In real-world applications, existing LVLM attackers generally rely on the detailed prior knowledge of the model to generate effective perturbations. Moreover, these attacks are task-specific, leading to significant costs for designing perturbation. Motivated by the research gap and practical demands, in this paper, we make the first attempt to build a universal attacker against real-world LVLMs, focusing on two critical aspects: (i) restricting access to only the LVLM inputs and outputs. (ii) devising a universal adversarial patch, which is task-agnostic and can deceive any LVLM-driven task when applied to various inputs. Specifically, we start by initializing the location and the pattern of the adversarial patch through random sampling, guided by the semantic distance between their output and the target label. Subsequently, we maintain a consistent patch location while refining the pattern to enhance semantic resemblance to the target. In particular, our approach incorporates a diverse set of LVLM task inputs as query samples to approximate the patch gradient, capitalizing on the importance of distinct inputs. In this way, the optimized patch is universally adversarial against different tasks and prompts, leveraging solely gradient estimates queried from the model. Extensive experiments are conducted to verify the strong universal adversarial capabilities of our proposed attack with prevalent LVLMs including LLaVA, MiniGPT-4, Flamingo, and BLIP-2, spanning a spectrum of tasks, all achieved without delving into the details of the model structures.

Adversarial training can achieve robustness against adversarial perturbations and has been widely used in machine-learning models. This paper delivers a non-asymptotic consistency analysis of the adversarial training procedure under $\ell_\infty$-perturbation in high-dimensional linear regression. It will be shown that, under the restricted eigenvalue condition, the associated convergence rate of prediction error can achieve the minimax rate up to a logarithmic factor in the high-dimensional linear regression on the class of sparse parameters. Additionally, the group adversarial training procedure is analyzed. Compared with classic adversarial training, it will be proved that the group adversarial training procedure enjoys a better prediction error upper bound under certain group-sparsity patterns.
tl;dr: We propose a curriculum-based masked prediction approach for unsupervised RL pretraining, which acquires skills at different complexity and achieves superior performance in various downstream tasks.

Masked prediction has emerged as a promising pretraining paradigm in offline reinforcement learning (RL) due to its versatile masking schemes, enabling flexible inference across various downstream tasks with a unified model. Despite the versatility of masked prediction, it remains unclear how to balance the learning of skills at different levels of complexity. To address this, we propose CurrMask, a curriculum masking pretraining paradigm for sequential decision making. Motivated by how humans learn by organizing knowledge in a curriculum, CurrMask adjusts its masking scheme during pretraining for learning versatile skills. Through extensive experiments, we show that CurrMask exhibits superior zero-shot performance on skill prompting tasks, goal-conditioned planning tasks, and competitive finetuning performance on offline RL tasks. Additionally, our analysis of training dynamics reveals that CurrMask gradually acquires skills of varying complexity by dynamically adjusting its masking scheme.

Contextual multinomial logit (MNL) bandits capture many real-world assortment recommendation problems such as online retailing/advertising. However, prior work has only considered (generalized) linear value functions, which greatly limits its applicability. Motivated by this fact, in this work, we consider contextual MNL bandits with a general value function class that contains the ground truth, borrowing ideas from a recent trend of studies on contextual bandits. Specifically, we consider both the stochastic and the adversarial settings, and propose a suite of algorithms, each with different computation-regret trade-off. When applied to the linear case, our results not only are the first ones with no dependence on a certain problem-dependent constant that can be exponentially large, but also enjoy other advantages such as computational efficiency, dimension-free regret bounds, or the ability to handle completely adversarial contexts and rewards.
tl;dr: 4D Gaussian Splatting with static & dynamic separation using an incrementally extensible, keyframe-based model

3D Gaussian Splatting has shown fast and high-quality rendering results in static scenes by leveraging dense 3D prior and explicit representations. Unfortunately, the benefits of the prior and representation do not involve novel view synthesis for dynamic motions. Ironically, this is because the main barrier is the reliance on them, which requires increasing training and rendering times to account for dynamic motions.
In this paper, we design Explicit 4D Gaussian Splatting (Ex4DGS).
Our key idea is to firstly separate static and dynamic Gaussians during training, and to explicitly sample positions and rotations of the dynamic Gaussians at sparse timestamps. The sampled positions and rotations are then interpolated to represent both spatially and temporally continuous motions of objects in dynamic scenes as well as reducing computational cost.
Additionally, we introduce a progressive training scheme and a point-backtracking technique that improves Ex4DGS's convergence. We initially train Ex4DGS using short timestamps and progressively extend timestamps, which makes it work well with a few point clouds. The point-backtracking is used to quantify the cumulative error of each Gaussian over time, enabling the detection and removal of erroneous Gaussians in dynamic scenes. Comprehensive experiments on various scenes demonstrate the state-of-the-art rendering quality from our method, achieving fast rendering of 62 fps on a single 2080Ti GPU.

In federated learning (FL), accommodating clients' varied computational capacities poses a challenge, often limiting the participation of those with constrained resources in global model training. To address this issue, the concept of model heterogeneity through submodel extraction has emerged, offering a tailored solution that aligns the model's complexity with each client's computational capacity. In this work, we propose Federated Importance-Aware Submodel Extraction (FIARSE), a novel approach that dynamically adjusts submodels based on the importance of model parameters, thereby overcoming the limitations of previous static and dynamic submodel extraction methods. Compared to existing works, the proposed method offers a theoretical foundation for the submodel extraction and eliminates the need for additional information beyond the model parameters themselves to determine parameter importance, significantly reducing the overhead on clients. Extensive experiments are conducted on various datasets to showcase the superior performance of the proposed FIARSE.
tl;dr: We build an LLM-based Agent with a self-evolving reasoning framework for AI diplomacy.

Diplomacy is one of the most sophisticated activities in human society, involving complex interactions among multiple parties that require skills in social reasoning, negotiation, and long-term strategic planning. Previous AI agents have demonstrated their ability to handle multi-step games and large action spaces in multi-agent tasks. However, diplomacy involves a staggering magnitude of decision spaces, especially considering the negotiation stage required. While recent agents based on large language models (LLMs) have shown potential in various applications, they still struggle with extended planning periods in complex multi-agent settings. Leveraging recent technologies for LLM-based agents, we aim to explore AI's potential to create a human-like agent capable of executing comprehensive multi-agent missions by integrating three fundamental capabilities: 1) strategic planning with memory and reflection; 2) goal-oriented negotiation with social reasoning; and 3) augmenting memory through self-play games for self-evolution without human in the loop.
tl;dr: We propose a novel diffusion-based online RL algorithm, conducting policy optimization with Q-weighted variational loss and diffusion entropy regularization to exploit the expressiveness and exploration capability of diffusion policy.

Diffusion models have garnered widespread attention in Reinforcement Learning (RL) for their powerful expressiveness and multimodality. It has been verified that utilizing diffusion policies can significantly improve the performance of RL algorithms in continuous control tasks by overcoming the limitations of unimodal policies, such as Gaussian policies. Furthermore, the multimodality of diffusion policies also shows the potential of providing the agent with enhanced exploration capabilities. However, existing works mainly focus on applying diffusion policies in offline RL, while their incorporation into online RL has been less investigated. The diffusion model's training objective, known as the variational lower bound, cannot be applied directly in online RL due to the unavailability of 'good' samples (actions). To harmonize the diffusion model with online RL, we propose a novel model-free diffusion-based online RL algorithm named Q-weighted Variational Policy Optimization (QVPO). Specifically, we introduce the Q-weighted variational loss and its approximate implementation in practice. Notably, this loss is shown to be a tight lower bound of the policy objective. To further enhance the exploration capability of the diffusion policy, we design a special entropy regularization term. Unlike Gaussian policies, the log-likelihood in diffusion policies is inaccessible; thus this entropy term is nontrivial. Moreover, to reduce the large variance of diffusion policies, we also develop an efficient behavior policy through action selection. This can further improve its sample efficiency during online interaction. Consequently, the QVPO algorithm leverages the exploration capabilities and multimodality of diffusion policies, preventing the RL agent from converging to a sub-optimal policy. To verify the effectiveness of QVPO, we conduct comprehensive experiments on MuJoCo continuous control benchmarks. The final results demonstrate that QVPO achieves state-of-the-art performance in terms of both cumulative reward and sample efficiency.
tl;dr: We present a new perspective on causal reasoning in NLP by using a closed system (defined by real-world commonsense activities) and propose a framework with underlying causal graphs. The causal queries help validate causal reasoning in LLMs.

Large Language Models (LLMs) have shown state-of-the-art performance in a variety of tasks, including arithmetic and reasoning; however, to gauge the intellectual capabilities of LLMs, causal reasoning has become a reliable proxy for validating a general understanding of the mechanics and intricacies of the world similar to humans. Previous works in natural language processing (NLP) have either focused on open-ended causal reasoning via causal commonsense reasoning (CCR) or framed a symbolic representation-based question answering for theoretically backed-up analysis via a causal inference engine. The former adds an advantage of real-world grounding but lacks theoretically backed-up analysis/validation, whereas the latter is far from real-world grounding. In this work, we bridge this gap by proposing the COLD (Causal reasOning in cLosed Daily activities) framework, which is built upon human understanding of daily real-world activities to reason about the causal nature of events. We show that the proposed framework facilitates the creation of enormous causal queries (∼ 9 million) and comes close to the mini-turing test, simulating causal reasoning to evaluate the understanding of a daily real-world task. We evaluate multiple LLMs on the created causal queries and find that causal reasoning is challenging even for activities trivial to humans. We further explore (the causal reasoning abilities of LLMs) using the backdoor criterion to determine the causal strength between events.
tl;dr: We propose an efficient LLM jailbreaking optimization algorithm

Recent research indicates that large language models (LLMs) are susceptible to jailbreaking attacks that can generate harmful content. This paper introduces a novel token-level attack method, Adaptive Dense-to-Sparse Constrained Optimization (ADC), which has been shown to successfully jailbreak multiple open-source LLMs. Drawing inspiration from the difficulties of discrete token optimization, our method relaxes the discrete jailbreak optimization into a continuous optimization process while gradually increasing the sparsity of the optimizing vectors. This technique effectively bridges the gap between discrete and continuous space optimization. Experimental results demonstrate that our method is more effective and efficient than state-of-the-art token-level methods. On Harmbench, our approach achieves the highest attack success rate on seven out of eight LLMs compared to the latest jailbreak methods. \textcolor{red}{Trigger Warning: This paper contains model behavior that can be offensive in nature.}

We study the constant regret guarantees in reinforcement learning (RL). Our objective is to design an algorithm that incurs only finite regret over infinite episodes with high probability. We introduce an algorithm, Cert-LSVI-UCB, for misspecified linear Markov decision processes (MDPs) where both the transition kernel and the reward function can be approximated by some linear function up to misspecification level $\zeta$. At the core of Cert-LSVI-UCB is an innovative certified estimator, which facilitates a fine-grained concentration analysis for multi-phase value-targeted regression, enabling us to establish an instance-dependent regret bound that is constant w.r.t. the number of episodes. Specifically, we demonstrate that for a linear MDP characterized by a minimal suboptimality gap $\Delta$, Cert-LSVI-UCB has a cumulative regret of $\tilde{\mathcal{O}}(d^3H^5/\Delta)$ with high probability, provided that the misspecification level $\zeta$ is below $\tilde{\mathcal{O}}(\Delta / (\sqrt{d}H^2))$. Here $d$ is the dimension of the feature space and $H$ is the horizon. Remarkably, this regret bound is independent of the number of episodes $K$. To the best of our knowledge, Cert-LSVI-UCB is the first algorithm to achieve a constant, instance-dependent, high-probability regret bound in RL with linear function approximation without relying on prior distribution assumptions.
tl;dr: We introduce a novel score-based diffusion framework for conditional generation that co-evolves multiple heterogeneous flows, and leverages a new strategy called loop guidance.

We introduce a novel score-based diffusion framework named Twigs that incorporates multiple co-evolving flows for enriching conditional generation tasks. Specifically, a central or trunk diffusion process is associated with a primary variable (e.g., graph structure), and additional offshoot or stem processes are dedicated to dependent variables (e.g., graph properties or labels). A new strategy, which we call loop guidance, effectively orchestrates the flow of information between the trunk and the stem processes during sampling. This approach allows us to uncover intricate interactions and dependencies, and unlock new generative capabilities. We provide extensive experiments to demonstrate strong performance gains of the proposed method over contemporary baselines in the context of conditional graph generation, underscoring the potential of Twigs in challenging generative tasks such as inverse molecular design and molecular optimization.
Code is available at https://github.com/Aalto-QuML/Diffusion_twigs.

Vision Language Models (VLMs) excel in zero-shot image classification by pairing images with textual category names. The expanding variety of Pre-Trained VLMs enhances the likelihood of identifying a suitable VLM for specific tasks. To better reuse the VLM resource and fully leverage its potential on different zero-shot image classification tasks, a promising strategy is selecting appropriate Pre-Trained VLMs from the VLM Zoo, relying solely on the text data of the target dataset without access to the dataset’s images. In this paper, we analyze two inherent challenges in assessing the ability of a VLM in this Language-Only VLM selection: the “Modality Gap”—the disparity in VLM’s embeddings across two different modalities, making text a less reliable substitute for images; and the “Capability Gap”— the discrepancy between the VLM’s overall ranking and its ranking for target dataset, hindering direct prediction of a model’s dataset-specific performance from its general performance. We propose VLM Selection With gAp Bridging (SWAB) to mitigate the negative impact of two gaps. SWAB first adopts optimal transport to capture the relevance between open-source and target datasets with a transportation matrix. It then uses this matrix to transfer useful statistics of VLMs from open-source datasets to the target dataset for bridging two gaps. By bridging two gaps to obtain better substitutes for test images, SWAB can accurately predict the performance ranking of different VLMs on the target task without the need for the dataset’s images. Experiments across various VLMs and image classification datasets validate SWAB’s effectiveness. Code is available at: https://github.com/YCaigogogo/SWAB.

In reinforcement learning (RL), it is common to apply techniques used broadly in
machine learning such as neural network function approximators and momentum-based optimizers. However, such tools were largely developed for supervised learning rather than nonstationary RL, leading practitioners to adopt target networks, clipped policy updates, and other RL-specific implementation tricks to combat this mismatch, rather than directly adapting this toolchain for use in RL.
In this paper, we take a different approach and instead address the effect of nonstationarity by adapting the widely used Adam optimiser.
We first analyse the impact of nonstationary gradient magnitude --- such as that caused by a change in target network --- on Adam's update size, demonstrating that such a change can lead to large updates and hence sub-optimal performance.
To address this, we introduce Adam-Rel.
Rather than using the global timestep in the Adam update, Adam-Rel uses the *local* timestep within an epoch, essentially resetting Adam's timestep to 0 after target changes.
We demonstrate that this avoids large updates and reduces to learning rate annealing in the absence of such increases in gradient magnitude. Evaluating Adam-Rel in both on-policy and off-policy RL, we demonstrate improved performance in both Atari and Craftax.
We then show that increases in gradient norm occur in RL in practice, and examine the differences between our
theoretical model and the observed data.

Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen2, Pika, and Sora, have significantly broadened its applicability and popularity.
Despite these strides, evaluating these models poses substantial challenges.
Primarily, due to the limitations inherent in automatic metrics, manual evaluation is often considered a superior method for assessing T2V generation. However, existing manual evaluation protocols face reproducibility, reliability, and practicality issues.
To address these challenges, this paper introduces the Text-to-Video Human Evaluation (T2VHE) protocol, a comprehensive and standardized protocol for T2V models.
The T2VHE protocol includes well-defined metrics, thorough annotator training, and an effective dynamic evaluation module.
Experimental results demonstrate that this protocol not only ensures high-quality annotations but can also reduce evaluation costs by nearly 50\%.
We will open-source the entire setup of the T2VHE protocol, including the complete protocol workflow, the dynamic evaluation component details, and the annotation interface code. This will help communities establish more sophisticated human assessment protocols.
3421. Stability and Generalization of Asynchronous SGD: Sharper Bounds Beyond Lipschitz and Smoothness
tl;dr: This study establishes sharper and broader stability and generalization bounds for the ASGD algorithm under much weaker assumptions.

Asynchronous stochastic gradient descent (ASGD) has evolved into an indispensable optimization algorithm for training modern large-scale distributed machine learning tasks. Therefore, it is imperative to explore the generalization performance of the ASGD algorithm. However, the existing results are either pessimistic and vacuous or restricted by strict assumptions that fail to reveal the intrinsic impact of asynchronous training on generalization. In this study, we establish sharper stability and generalization bounds for ASGD under much weaker assumptions. Firstly, this paper studies the on-average model stability of ASGD and provides a non-vacuous upper bound on the generalization error, without relying on the Lipschitz assumption. Furthermore, we investigate the excess generalization error of the ASGD algorithm, revealing the effects of asynchronous delay, model initialization, number of training samples and iterations on generalization performance. Secondly, for the first time, this study explores the generalization performance of ASGD in the non-smooth case. We replace smoothness with the much weaker Hölder continuous assumption and achieve similar generalization results as in the smooth case. Finally, we validate our theoretical findings by training numerous machine learning models, including convex problems and non-convex tasks in computer vision and natural language processing.
tl;dr: We propose Cluster-Normalize-Activate modules to improve expressivity of Graph Neural Networks.

Graph Neural Networks (GNNs) are non-Euclidean deep learning models for graph-structured data. Despite their successful and diverse applications, oversmoothing prohibits deep architectures due to node features converging to a single fixed point. This severely limits their potential to solve complex tasks. To counteract this tendency, we propose a plug-and-play module consisting of three steps: Cluster→Normalize→Activate (CNA). By applying CNA modules, GNNs search and form super nodes in each layer, which are normalized and activated individually. We demonstrate in node classification and property prediction tasks that CNA significantly improves the accuracy over the state-of-the-art. Particularly, CNA reaches 94.18% and 95.75% accuracy on Cora and CiteSeer, respectively. It further benefits GNNs in regression tasks as well, reducing the mean squared error compared to all baselines. At the same time, GNNs with CNA require substantially fewer learnable parameters than competing architectures.
3423. MaskFactory: Towards High-quality Synthetic Data Generation for Dichotomous Image Segmentation
tl;dr: Our method uses diffusion models to generate fine-grained data for dichotomous image segmentation, addressing annotation challenges and boosting model performance.

Dichotomous Image Segmentation (DIS) tasks require highly precise annotations, and traditional dataset creation methods are labor intensive, costly, and require extensive domain expertise. Although using synthetic data for DIS is a promising solution to these challenges, current generative models and techniques struggle with the issues of scene deviations, noise-induced errors, and limited training sample variability. To address these issues, we introduce a novel approach, Mask Factory, which provides a scalable solution for generating diverse and precise datasets, markedly reducing preparation time and costs. We first introduce a general mask editing method that combines rigid and non-rigid editing techniques to generate high-quality synthetic masks. Specially, rigid editing leverages geometric priors from diffusion models to achieve precise viewpoint transformations under zero-shot conditions, while non-rigid editing employs adversarial training and self-attention mechanisms for complex, topologically consistent modifications. Then, we generate pairs of high-resolution image and accurate segmentation mask using a multi-conditional control generation method. Finally, our experiments on the widely-used DIS5K dataset benchmark demonstrate superior performance in quality and efficiency compared to existing methods. The code is available at https://qian-hao-tian.github.io/MaskFactory/.
tl;dr: We propose a novel RGB-E tracking framework, i.e., CSAM, which first predicts the candidates by using an appearance model and then keeps track of both targets and distractors with an MOT philosophy.

RGB-Event single object tracking (SOT) aims to leverage the merits of RGB and event data to achieve higher performance. However, existing frameworks focus on exploring complementary appearance information within multi-modal data, and struggle to address the association problem of targets and distractors in the temporal domain using motion information from the event stream. In this paper, we introduce the Multi-Object Tracking (MOT) philosophy into RGB-E SOT to keep track of targets as well as distractors by using both RGB and event data, thereby improving the robustness of the tracker. Specifically, an appearance model is employed to predict the initial candidates. Subsequently, the initially predicted tracking results, in combination with the RGB-E features, are encoded into appearance and motion embeddings, respectively. Furthermore, a Spatial-Temporal Transformer Encoder is proposed to model the spatial-temporal relationships and learn discriminative features for each candidate through guidance of the appearance-motion embeddings. Simultaneously, a Dual-Branch Transformer Decoder is designed to adopt such motion and appearance information for candidate matching, thus distinguishing between targets and distractors. The proposed method is evaluated on multiple benchmark datasets and achieves state-of-the-art performance on all the datasets tested.

Machine unlearning is motivated by principles of data autonomy. The premise is that a person can request to have their data's influence removed from deployed models, and those models should be updated as if they were retrained without the person's data. We show that these updates expose individuals to high-accuracy reconstruction attacks which allow the attacker to recover their data in its entirety, even when the original models are so simple that privacy risk might not otherwise have been a concern. We show how to mount a near-perfect attack on the deleted data point from linear regression models. We then generalize our attack to other loss functions and architectures, and empirically demonstrate the effectiveness of our attacks across a wide range of datasets (capturing both tabular and image data). Our work highlights that privacy risk is significant even for extremely simple model classes when individuals can request deletion of their data from the model.

Foundation models possess strong capabilities in reasoning and memorizing across modalities. To further unleash the power of foundation models, we present FIND, a generalized interface for aligning foundation models' embeddings with unified image and dataset-level understanding spanning modality and granularity. As shown in Fig.1, a lightweight transformer interface without tuning any foundation model weights is enough for segmentation, grounding, and retrieval in an interleaved manner. The proposed interface has the following favorable attributes: (1) Generalizable. It applies to various tasks spanning retrieval, segmentation, etc., under the same architecture and weights. (2) Interleavable. With the benefit of multi-task multi-modal training, the proposed interface creates an interleaved shared embedding space. (3) Extendable. The proposed interface is adaptive to new tasks, and new models. In light of the interleaved embedding space, we introduce FIND-Bench, which introduces new training and evaluation annotations to the COCO dataset for interleaved segmentation and retrieval. We are the first work aligning foundations models' embeddings for interleave understanding. Meanwhile, our approach achieves state-of-the-art performance on FIND-Bench and competitive performance on standard retrieval and segmentation settings.
tl;dr: A method to represent casual videos using 3D Gaussians without estimating camera pose

Video representation is a long-standing problem that is crucial for various downstream tasks, such as tracking, depth prediction, segmentation, view synthesis, and editing. However, current methods either struggle to model complex motions due to the absence of 3D structure or rely on implicit 3D representations that are ill-suited for manipulation tasks. To address these challenges, we introduce a novel explicit 3D representation—video Gaussian representation—that embeds a video into 3D Gaussians.
Our proposed representation models video appearance in a 3D canonical space using explicit Gaussians as proxies and associates each Gaussian with 3D motions for video motion. This approach offers a more intrinsic and explicit representation than layered atlas or volumetric pixel matrices. To obtain such a representation, we distill 2D priors, such as optical flow and depth, from foundation models to regularize learning in this ill-posed setting.
Extensive applications demonstrate the versatility of our new video representation. It has been proven effective in numerous video processing tasks, including tracking, consistent video depth and feature refinement, motion and appearance editing, and stereoscopic video generation.
tl;dr: We propose an approach to learning interventionally consistent surrogate models for complex simulators using causal abstraction.

Large-scale simulation models of complex socio-technical systems provide decision-makers with high-fidelity testbeds in which policy interventions can be evaluated and _what-if_ scenarios explored. Unfortunately, the high computational cost of such models inhibits their widespread use in policy-making settings. Surrogate models can address these computational limitations, but to do so they must behave consistently with the simulator under interventions of interest. In this paper, we build upon recent developments in causal abstractions to develop a framework for learning interventionally consistent surrogate models for large-scale, complex simulation models. We provide theoretical results showing that our proposed approach induces surrogates to behave consistently with high probability with respect to the simulator across interventions of interest, facilitating rapid experimentation with policy interventions in complex systems. We further demonstrate with empirical studies that conventionally trained surrogates can misjudge the effect of interventions and misguide decision-makers towards suboptimal interventions, while surrogates trained for _interventional_ consistency with our method closely mimic the behaviour of the original simulator under interventions of interest.
tl;dr: efficient diffusion q learning in both training and inference.

Offline reinforcement learning (RL) leverages pre-collected datasets to train optimal policies. Diffusion Q-Learning (DQL), introducing diffusion models as a powerful and expressive policy class, significantly boosts the performance of offline RL. However, its reliance on iterative denoising sampling to generate actions slows down both training and inference. While several recent attempts have tried to accelerate diffusion-QL, the improvement in training and/or inference speed often results in degraded performance. In this paper, we introduce a dual policy approach, Diffusion Trusted Q-Learning (DTQL), which comprises a diffusion policy for pure behavior cloning and a practical one-step policy. We bridge the two polices by a newly introduced diffusion trust region loss. The diffusion policy maintains expressiveness, while the trust region loss directs the one-step policy to explore freely and seek modes within the region defined by the diffusion policy. DTQL eliminates the need for iterative denoising sampling during both training and inference, making it remarkably computationally efficient. We evaluate its effectiveness and algorithmic characteristics against popular Kullback-Leibler (KL) based distillation methods in 2D bandit scenarios and gym tasks. We then show that DTQL could not only outperform other methods on the majority of the D4RL benchmark tasks but also demonstrate efficiency in training and inference speeds. The PyTorch implementation is available at https://github.com/TianyuCodings/Diffusion_Trusted_Q_Learning.

In this paper, we present PCoTTA, an innovative, pioneering framework for Continual Test-Time Adaptation (CoTTA) in multi-task point cloud understanding, enhancing the model's transferability towards the continually changing target domain. We introduce a multi-task setting for PCoTTA, which is practical and realistic, handling multiple tasks within one unified model during the continual adaptation. Our PCoTTA involves three key components: automatic prototype mixture (APM), Gaussian Splatted feature shifting (GSFS), and contrastive prototype repulsion (CPR). Firstly, APM is designed to automatically mix the source prototypes with the learnable prototypes with a similarity balancing factor, avoiding catastrophic forgetting. Then, GSFS dynamically shifts the testing sample toward the source domain, mitigating error accumulation in an online manner. In addition, CPR is proposed to pull the nearest learnable prototype close to the testing feature and push it away from other prototypes, making each prototype distinguishable during the adaptation. Experimental comparisons lead to a new benchmark, demonstrating PCoTTA's superiority in boosting the model's transferability towards the continually changing target domain. Our source code is available at: https://github.com/Jinec98/PCoTTA.
tl;dr: This paper proposes a frequency-aware generative model (FGTI) for multivariate time series imputation, which integrates frequency-domain information and uses cross-domain representation learning modules to enhance imputation accuracy.

Missing data in multivariate time series are common issues that can affect the analysis and downstream applications.
Although multivariate time series data generally consist of the trend, seasonal and residual terms, existing works mainly focus on optimizing the modeling for the first two items. However, we find that the residual term is more crucial for getting accurate fillings, since it is more related to the diverse changes of data and the biggest component of imputation errors.
Therefore, in this study, we introduce frequency-domain information and design Frequency-aware Generative Models for Multivariate Time Series Imputation (FGTI). Specifically, FGTI employs a high-frequency filter to boost the residual term imputation, supplemented by a dominant-frequency filter for the trend and seasonal imputation. Cross-domain representation learning module then fuses frequency-domain insights with deep representations.
Experiments over various datasets with real-world missing values show that FGTI achieves superiority in both data imputation and downstream applications.

3D Gaussian Splatting (3DGS) has become a crucial method for acquiring 3D assets. To protect the copyright of these assets, digital watermarking techniques can be applied to embed ownership information discreetly within 3DGS mod- els. However, existing watermarking methods for meshes, point clouds, and implicit radiance fields cannot be directly applied to 3DGS models, as 3DGS models use explicit 3D Gaussians with distinct structures and do not rely on neural networks. Naively embedding the watermark on a pre-trained 3DGS can cause obvious distortion in rendered images. In our work, we propose an uncertainty- based method that constrains the perturbation of model parameters to achieve invisible watermarking for 3DGS. At the message decoding stage, the copyright messages can be reliably extracted from both 3D Gaussians and 2D rendered im- ages even under various forms of 3D and 2D distortions. We conduct extensive experiments on the Blender, LLFF, and MipNeRF-360 datasets to validate the effectiveness of our proposed method, demonstrating state-of-the-art performance on both message decoding accuracy and view synthesis quality.

Large language models have shown an impressive societal impact owing to their excellent understanding and logical reasoning skills. However, such strong ability relies on a huge amount of computing resources, which makes it difficult to deploy LLMs on computing resource-constrained platforms. Currently, LLMs process each token equivalently, but we argue that not every word is equally important. Some words should not be allocated excessive computing resources, particularly for dispensable terms in simple questions. In this paper, we propose a novel dynamic inference paradigm for LLMs, namely D-LLMs, which adaptively allocate computing resources in token processing. We design a dynamic decision module for each transformer layer that decides whether a network unit should be executed or skipped. Moreover, we tackle the issue of adapting D-LLMs to real-world applications, specifically concerning the missing KV-cache when layers are skipped. To overcome this, we propose a simple yet effective eviction policy to exclude the skipped layers from subsequent attention calculations. The eviction policy not only enables D-LLMs to be compatible with prevalent applications but also reduces considerable storage resources. Experimentally, D-LLMs show superior performance, in terms of computational cost and KV storage utilization. It can reduce up to 45\% computational cost and KV storage on Q\&A, summarization, and math solving tasks, 50\% on commonsense reasoning tasks.

Generalizable 3D Gaussian splitting (3DGS) can reconstruct new scenes from sparse-view observations in a feed-forward inference manner, eliminating the need for scene-specific retraining required in conventional 3DGS. However, existing methods rely heavily on epipolar priors, which can be unreliable in complex real-world scenes, particularly in non-overlapping and occluded regions. In this paper, we propose eFreeSplat, an efficient feed-forward 3DGS-based model for generalizable novel view synthesis that operates independently of epipolar line constraints. To enhance multiview feature extraction with 3D perception, we employ a self-supervised Vision Transformer (ViT) with cross-view completion pre-training on large-scale datasets. Additionally, we introduce an Iterative Cross-view Gaussians Alignment method to ensure consistent depth scales across different views. Our eFreeSplat represents a new paradigm for generalizable novel view synthesis. We evaluate eFreeSplat on wide-baseline novel view synthesis tasks using the RealEstate10K and ACID datasets. Extensive experiments demonstrate that eFreeSplat surpasses state-of-the-art baselines that rely on epipolar priors, achieving superior geometry reconstruction and novel view synthesis quality.
tl;dr: We introduce model-aware data selection with data influence models (MATES), where a data influence model continuously adapts to the evolving data preferences of the pretraining model and selects the data to optimize the efficacy of the pretraining.

Pretraining data selection has the potential to improve language model pretraining efficiency by utilizing higher-quality data from massive web data corpora. Current data selection methods, which rely on either hand-crafted rules or larger reference models, are conducted statically and do not capture the evolving data preferences during pretraining. In this paper, we introduce *model-aware data selection with data influence models (MATES)*, where a data influence model continuously adapts to the evolving data preferences of the pretraining model and then selects the data most effective for the current pretraining progress. Specifically, we collect oracle data influence by locally probing the pretraining model and fine-tune a small data influence model to approximate it accurately. The data influence model then predicts data influence over the whole pretraining corpus and selects the most influential data for the next pretraining stage. Experiments of pretraining 410M and 1B models on the C4 dataset demonstrate that MATES significantly outperforms random data selection on extensive downstream tasks. It doubles the gains achieved by the state-of-the-art data selection approach that leverages larger reference models and reduces the total FLOPs required to reach certain performances by half. Further analyses validate the effectiveness of the locally probed oracle data influence and the approximation with data influence models. Our code is open-sourced at https://github.com/cxcscmu/MATES.
tl;dr: Establishes new lower bounds on privacy analysis of DP-SGD with shuffling and provides a first comparative study of DP-SGD with Shuffling vs Poisson Subsampling in the light of the gaps in privacy analysis between the two approaches.

We provide new lower bounds on the privacy guarantee of _multi-epoch_ Adaptive Batch Linear Queries (ABLQ) mechanism with _shuffled batch sampling_, demonstrating substantial gaps when compared to _Poisson subsampling_; prior analysis was limited to a single epoch.
Since the privacy analysis of Differentially Private Stochastic Gradient Descent (DP-SGD) is obtained by analyzing the ABLQ mechanism, this brings into serious question the common practice of implementing Shuffling based DP-SGD, but reporting privacy parameters as if Poisson subsampling was used.
To understand the impact of this gap on the utility of trained machine learning models, we introduce a novel practical approach to implement Poisson subsampling _at scale_ using massively parallel computation, and efficiently train models with the same.
We provide a comparison between the utility of models trained with Poisson subsampling based DP-SGD, and the optimistic estimates of utility when using shuffling, via our new lower bounds on the privacy guarantee of ABLQ with shuffling.
tl;dr: This paper solves the problem of managing and reusing models developed from heterogeneous feature spaces by explicitly utilizing label information.

The learnware paradigm aims to help users leverage numerous existing high-performing models instead of starting from scratch, where a learnware consists of a well-trained model and the specification describing its capability. Numerous learnwares are accommodated by a learnware dock system. When users solve tasks with the system, models that fully match the task feature space are often rare or even unavailable. However, models with heterogeneous feature space can still be helpful. This paper finds that label information, particularly model outputs, is helpful yet previously less exploited in the accommodation of heterogeneous learnwares. We extend the specification to better leverage model pseudo-labels and subsequently enrich the unified embedding space for better specification evolvement. With label information, the learnware identification can also be improved by additionally comparing conditional distributions. Experiments demonstrate that, even without a model explicitly tailored to user tasks, the system can effectively handle tasks by leveraging models from diverse feature spaces.
tl;dr: We introduce an intrinsic reciprocal reward that encourages an agent to reciprocate another's influence on its own expected return, and show that resulting policies promote cooperative outcomes in sequential social dilemmas.

Cooperation between self-interested individuals is a widespread phenomenon in the natural world, but remains elusive in interactions between artificially intelligent agents. Instead, naïve reinforcement learning algorithms typically converge to Pareto-dominated outcomes in even the simplest of social dilemmas. An emerging literature on opponent shaping has demonstrated the ability to reach prosocial outcomes by influencing the learning of other agents. However, such methods differentiate through the learning step of other agents or optimize for meta-game dynamics, which rely on privileged access to opponents' learning algorithms or exponential sample complexity, respectively. To provide a learning rule-agnostic and sample-efficient alternative, we introduce Reciprocators, reinforcement learning agents which are intrinsically motivated to reciprocate the influence of opponents' actions on their returns. This approach seeks to modify other agents' $Q$-values by increasing their return following beneficial actions (with respect to the Reciprocator) and decreasing it after detrimental actions, guiding them towards mutually beneficial actions without directly differentiating through a model of their policy. We show that Reciprocators can be used to promote cooperation in temporally extended social dilemmas during simultaneous learning. Our code is available at https://github.com/johnlyzhou/reciprocator/.
tl;dr: We present a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task.

Finetuning foundation models for specific tasks is an emerging paradigm in modern machine learning. The efficacy of task-specific finetuning largely depends on the selection of appropriate training data. We present TSDS (Task-Specific Data Selection), a framework to select data for task-specific model finetuning, guided by a small but representative set of examples from the target task. To do so, we formulate data selection for task-specific finetuning as an optimization problem with a distribution alignment loss based on optimal transport to capture the discrepancy between the selected data and the target distribution. In addition, we add a regularizer to encourage the diversity of the selected data and incorporate kernel density estimation into the regularizer to reduce the negative effects of near-duplicates among the candidate data.
We connect our optimization problem to nearest neighbor search and design efficient algorithms to compute the optimal solution based on approximate nearest neighbor search techniques.
We evaluate our method on data selection for both continued pretraining and instruction tuning of language models.
We show that instruction tuning using data selected by our method with a 1\% selection ratio often outperforms using the full dataset and beats the baseline selection methods by 1.5 points in F1 score on average.
tl;dr: We propose a simple yet effective method for remedy through fine-tuning that utilizes a pivotal set constructed using Bias-Conditioned Self-Influence to recover biased models.

Learning generalized models from biased data is an important undertaking toward fairness in deep learning. To address this issue, recent studies attempt to identify and leverage bias-conflicting samples free from spurious correlations without prior knowledge of bias or an unbiased set. However, spurious correlation remains an ongoing challenge, primarily due to the difficulty in correctly detecting these samples. In this paper, inspired by the similarities between mislabeled samples and bias-conflicting samples, we approach this challenge from a novel perspective of mislabeled sample detection. Specifically, we delve into Influence Function, one of the standard methods for mislabeled sample detection, for identifying bias-conflicting samples and propose a simple yet effective remedy for biased models by leveraging them. Through comprehensive analysis and experiments on diverse datasets, we demonstrate that our new perspective can boost the precision of detection and rectify biased models effectively. Furthermore, our approach is complementary to existing methods, showing performance improvement even when applied to models that have already undergone recent debiasing techniques.
tl;dr: We show that automated first-price auctions become more inefficient with more sophisticated autobidders.

The recent increasing adoption of autobidding has inspired the growing interest in analyzing the performance of classic mechanism with value-maximizing autobidders both theoretically and empirically. It is known that optimal welfare can be obtained in first-price auctions if autobidders are restricted to uniform bid-scaling and the price of anarchy is $2$ when non-uniform bid-scaling strategies are allowed.
In this paper, we provide a fine-grained price of anarchy analysis for non-uniform bid-scaling strategies in first-price auctions, demonstrating the reason why more powerful (individual) non-uniform bid-scaling strategies may lead to worse (aggregated) performance in social welfare. Our theoretical results match recent empirical findings that a higher level of non-uniform bid-scaling leads to lower welfare performance in first-price auctions.

Deep neural networks are ubiquitously adopted in many applications, such as computer vision, natural language processing, and graph analytics. However, well-trained neural networks can make prediction errors after deployment as the world changes. \textit{Model editing} involves updating the base model to correct prediction errors with less accessible training data and computational resources.
Despite recent advances in model editors in computer vision and natural language processing, editable training in graph neural networks (GNNs) is rarely explored. The challenge with editable GNN training lies in the inherent information aggregation across neighbors, which can lead model editors to affect the predictions of other nodes unintentionally. In this paper, we first observe the gradient of cross-entropy loss for the target node and training nodes with significant inconsistency, which indicates that directly fine-tuning the base model using the loss on the target node deteriorates the performance on training nodes. Motivated by the gradient inconsistency observation, we propose a simple yet effective \underline{G}radient \underline{R}ewiring method for \underline{E}ditable graph neural network training, named \textbf{GRE}. Specifically, we first store the anchor gradient of the loss on training nodes to preserve the locality. Subsequently, we rewire the gradient of the loss on the target node to preserve performance on the training node using anchor gradient. Experiments demonstrate the effectiveness of GRE on various model architectures and graph datasets in terms of multiple editing situations. The source code is available at \url{https://github.com/zhimengj0326/Gradient_rewiring_editing}.

We consider the linear causal representation learning setting where we observe a linear mixing of $d$ unknown latent factors, which follow a linear structural causal model.
Recent work has shown that it is possible to recover the latent factors as well as the underlying structural causal model over them, up to permutation and scaling, provided that we have at least $d$ environments, each of which corresponds to perfect interventions on a single latent node (factor).
After this powerful result, a key open problem faced by the community has been to relax these conditions: allow for coarser than perfect single-node interventions, and allow for fewer than $d$ of them, since the number of latent factors $d$ could be very large.
In this work, we consider precisely such a setting, where we allow a smaller than $d$ number of environments, and also allow for very coarse interventions that can very coarsely \textit{change the entire causal graph over the latent factors}.
On the flip side, we relax what we wish to extract to simply the \textit{list of nodes that have shifted between one or more environments}.
We provide a surprising identifiability result that it is indeed possible, under some very mild standard assumptions, to identify the set of shifted nodes.
Our identifiability proof moreover is a constructive one: we explicitly provide necessary and sufficient conditions for a node to be a shifted node, and show that we can check these conditions given observed data.
Our algorithm lends itself very naturally to the sample setting where instead of just interventional distributions, we are provided datasets of samples from each of these distributions.
We corroborate our results on both synthetic experiments as well as an interesting psychometric dataset. The code can be found at https://github.com/TianyuCodings/iLCS.
tl;dr: Efficient Test-time Adaptation Framework for Microcontrollers along with an MCU TTA library.

The increased adoption of Internet of Things (IoT) devices has led to the generation of large data streams with applications in healthcare, sustainability, and robotics. In some cases, deep neural networks have been deployed directly on these resource-constrained units to limit communication overhead, increase efficiency and privacy, and enable real-time applications. However, a common challenge in this setting is the continuous adaptation of models necessary to accommodate changing environments, i.e., data distribution shifts. Test-time adaptation (TTA) has emerged as one potential solution, but its validity has yet to be explored in resource-constrained hardware settings, such as those involving microcontroller units (MCUs). TTA on constrained devices generally suffers from i) memory overhead due to the full backpropagation of a large pre-trained network, ii) lack of support for normalization layers on MCUs, and iii) either memory exhaustion with large batch sizes required for updating or poor performance with small batch sizes. In this paper, we propose TinyTTA, to enable, for the first time, efficient TTA on constrained devices with limited memory. To address the limited memory constraints, we introduce a novel self-ensemble and batch-agnostic early-exit strategy for TTA, which enables continuous adaptation with small batch sizes for reduced memory usage, handles distribution shifts, and improves latency efficiency. Moreover, we develop the TinyTTA Engine, a first-of-its-kind MCU library that enables on-device TTA. We validate TinyTTA on a Raspberry Pi Zero 2W and an STM32H747 MCU. Experimental results demonstrate that TinyTTA improves TTA accuracy by up to 57.6\%, reduces memory usage by up to six times, and achieves faster and more energy-efficient TTA. Notably, TinyTTA is the only framework able to run TTA on MCU STM32H747 with a 512 KB memory constraint while maintaining high performance.

While training models and labeling data are resource-intensive, a wealth of pre-trained models and unlabeled data exists. To effectively utilize these resources, we present an approach to actively select pre-trained models while minimizing labeling costs. We frame this as an online contextual active model selection problem: At each round, the learner receives an unlabeled data point as a context. The objective is to adaptively select the best model to make a prediction while limiting label requests. To tackle this problem, we propose CAMS, a contextual active model selection algorithm that relies on two novel components: (1) a contextual model selection mechanism, which leverages context information to make informed decisions about which model is likely to perform best for a given context, and (2)
an active query component, which strategically chooses when to request labels for data points, minimizing the overall labeling cost. We provide rigorous theoretical analysis for the regret and query complexity under both adversarial and stochastic settings. Furthermore, we demonstrate the effectiveness of our algorithm on a diverse collection of benchmark classification tasks. Notably, CAMS requires substantially less labeling effort (less than 10%) compared to existing methods on CIFAR10 and DRIFT benchmarks, while achieving similar or better accuracy.

Detection of face forgery videos remains a formidable challenge in the field of digital forensics, especially the generalization to unseen datasets and common perturbations. In this paper, we tackle this issue by leveraging the synergy between audio and visual speech elements, embarking on a novel approach through audio-visual speech representation learning. Our work is motivated by the finding that audio signals, enriched with speech content, can provide precise information effectively reflecting facial movements. To this end, we first learn precise audio-visual speech representations on real videos via a self-supervised masked prediction task, which encodes both local and global semantic information simultaneously. Then, the derived model is directly transferred to the forgery detection task. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of cross-dataset generalization and robustness, without the participation of any fake video in model training.
tl;dr: We use large language models to design heuristics for combinatorial optimization automatically.

The omnipresence of NP-hard combinatorial optimization problems (COPs) compels domain experts to engage in trial-and-error heuristic design. The long-standing endeavor of design automation has gained new momentum with the rise of large language models (LLMs). This paper introduces Language Hyper-Heuristics (LHHs), an emerging variant of Hyper-Heuristics that leverages LLMs for heuristic generation, featuring minimal manual intervention and open-ended heuristic spaces. To empower LHHs, we present Reflective Evolution (ReEvo), a novel integration of evolutionary search for efficiently exploring the heuristic space, and LLM reflections to provide verbal gradients within the space. Across five heterogeneous algorithmic types, six different COPs, and both white-box and black-box views of COPs, ReEvo yields state-of-the-art and competitive meta-heuristics, evolutionary algorithms, heuristics, and neural solvers, while being more sample-efficient than prior LHHs.

The implicit bias of gradient descent has long been considered the primary mechanism explaining the superior generalization of over-parameterized neural networks without overfitting, even when the training error is zero. However, the implicit bias toward adversarial robustness has rarely been considered in the research community, although it is crucial for the trustworthiness of machine learning models. To fill this gap, in this paper, we explore whether consecutive layers collaborate to strengthen adversarial robustness during gradient descent. By quantifying this collaboration between layers using our proposed concept, co-correlation, we demonstrate a monotonically increasing trend in co-correlation, which implies a decreasing trend in adversarial robustness during gradient descent. Additionally, we observe different behaviours between narrow and wide neural networks during gradient descent. We conducted extensive experiments that verified our proposed theorems.

Designing novel functional proteins crucially depends on accurately modeling their fitness landscape. Given the limited availability of functional annotations from wet-lab experiments, previous methods have primarily relied on self-supervised models trained on vast, unlabeled protein sequence or structure datasets. While initial protein representation learning studies solely focused on either sequence or structural features, recent hybrid architectures have sought to merge these modalities to harness their respective strengths. However, these sequence-structure models have so far achieved only incremental improvements when compared to the leading sequence-only approaches, highlighting unresolved challenges effectively leveraging these modalities together. Moreover, the function of certain proteins is highly dependent on the granular aspects of their surface topology, which have been overlooked by prior models.
To address these limitations, we introduce the Sequence-Structure-Surface Fitness (**S3F**) model — a novel multimodal representation learning framework that integrates protein features across several scales. Our approach combines sequence representations from a protein language model with Geometric Vector Perceptron networks encoding protein backbone and detailed surface topology. The proposed method achieves state-of-the-art fitness prediction on the ProteinGym benchmark encompassing 217 substitution deep mutational scanning assays, and provides insights into the determinants of protein function.
Our code is at https://github.com/DeepGraphLearning/S3F.
tl;dr: Proposed a representative and diversified sample selection method to select data for annotation from the unlabeled data to improve the performance of semi-supervised learning approaches.

Semi-Supervised Learning (SSL) has become a preferred paradigm in many deep learning tasks, which reduces the need for human labor. Previous studies primarily focus on effectively utilising the labelled and unlabeled data to improve performance. However, we observe that how to select samples for labelling also significantly impacts performance, particularly under extremely low-budget settings. The sample selection task in SSL has been under-explored for a long time. To fill in this gap, we propose a Representative and Diverse Sample Selection approach (RDSS). By adopting a modified Frank-Wolfe algorithm to minimise a novel criterion $\alpha$-Maximum Mean Discrepancy ($\alpha$-MMD), RDSS samples a representative and diverse subset for annotation from the unlabeled data. We demonstrate that minimizing $\alpha$-MMD enhances the generalization ability of low-budget learning. Experimental results show that RDSS consistently improves the performance of several popular SSL frameworks and outperforms the state-of-the-art sample selection approaches used in Active Learning (AL) and Semi-Supervised Active Learning (SSAL), even with constrained annotation budgets.

Systems with variations of the underlying generating mechanism between different contexts, i.e., different environments or internal states in which the system operates, are common in the real world, such as soil moisture regimes in Earth science. Besides understanding the shared properties of the system, in practice, the question of context-specific properties, i.e., the change in causal relationships between contexts, arises. For real-world data, contexts are often driven by system variables, e.g., precipitation highly influences soil moisture. Nevertheless, this setup needs to be studied more. To account for such endogenous contexts in causal discovery, our work proposes a constraint-based method that can efficiently discover context-specific causal graphs using an adaptive testing approach. Our approach tests conditional independence on the pooled datasets to infer the dependence between system variables, including the context, to avoid introducing selection bias. To yield context-specific insights, conditional independence is tested on context-specific data. We work out the theoretical framework for this adaptive testing approach and give a detailed discussion of the connection to structural causal models, including sufficiency assumptions, which allow to prove the soundness of our algorithm and to interpret the results causally. A simulation study to evaluate numerical properties shows that our approach behaves as expected, but also leads to a further understanding of current limitations and viable extensions.
tl;dr: We propose a progressive algorithm for estimation of OT maps and plans. We prove its statistically consistency and demonstrate its performance on synthetic and single-cell data.

Optimal transport (OT) has profoundly impacted machine learning by providing theoretical and computational tools to realign datasets.
In this context, given two large point clouds of sizes $n$ and $m$ in $\mathbb{R}^d$, entropic OT (EOT) solvers have emerged as the most reliable tool to either solve the Kantorovich problem and output a $n\times m$ coupling matrix, or to solve the Monge problem and learn a vector-valued push-forward map.
While the robustness of EOT couplings/maps makes them a go-to choice in practical applications, EOT solvers remain difficult to tune because of a small but influential set of hyperparameters, notably the omnipresent entropic regularization strength $\varepsilon$. Setting $\varepsilon$ can be difficult, as it simultaneously impacts various performance metrics, such as compute speed, statistical performance, generalization, and bias. In this work, we propose a new class of EOT solvers (ProgOT), that can estimate both plans and transport maps.
We take advantage of several opportunities to optimize the computation of EOT solutions by *dividing* mass displacement using a time discretization, borrowing inspiration from dynamic OT formulations, and *conquering* each of these steps using EOT with properly scheduled parameters. We provide experimental evidence demonstrating that ProgOT is a faster and more robust alternative to *standard solvers* when computing couplings at large scales, even outperforming neural network-based approaches. We also prove statistical consistency of our approach for estimating OT maps.
tl;dr: We provide concentration inequalities for the CRPS-error in distributional regression when empirical risk minimization is used for model fitting, model selection or convex aggregation.

Distributional regression aims at estimating the conditional distribution of a target variable given explanatory co-variates. It is a crucial tool for forecasting when a precise uncertainty quantification is required. A popular methodology consists in fitting a parametric model via empirical risk minimization where the risk is measured by the Continuous Rank Probability Score (CRPS). For independent and identically distributed observations, we provide a concentration result for the estimation error and an upper bound for its expectation. Furthermore, we consider model selection performed by minimization of the validation error and provide a concentration bound for the regret. A similar result is proved for convex aggregation of models. Finally, we show that our results may be applied to various models such as EMOS, distributional regression networks, distributional nearest neighbours or distributional random forests and we illustrate our findings on two data sets (QSAR aquatic toxicity and Airfoil self-noise).
tl;dr: Our work analyzes the convergence behavior of QAOA and introduces the Mixer Generator Network (MG-Net) to dynamically formulate optimal mixer Hamiltonians tailored to distinct tasks and circuit depths.

Quantum Approximate Optimization Algorithm (QAOA) and its variants exhibit immense potential in tackling combinatorial optimization challenges. However, their practical realization confronts a dilemma: the requisite circuit depth for satisfactory performance is problem-specific and often exceeds the maximum capability of current quantum devices. To address this dilemma, here we first analyze the convergence behavior of QAOA, uncovering the origins of this dilemma and elucidating the intricate relationship between the employed mixer Hamiltonian, the specific problem at hand, and the permissible maximum circuit depth. Harnessing this understanding, we introduce the Mixer Generator Network (MG-Net), a unified deep learning framework adept at dynamically formulating optimal mixer Hamiltonians tailored to distinct tasks and circuit depths. Systematic simulations, encompassing Ising models and weighted Max-Cut instances with up to 64 qubits, substantiate our theoretical findings, highlighting MG-Net's superior performance in terms of both approximation ratio and efficiency.

Mobility impairment caused by limb loss, aging, stroke, and other movement deficiencies is a significant challenge faced by millions of individuals worldwide. Advanced assistive technologies, such as prostheses and orthoses, have the potential to greatly improve the quality of life for such individuals. A critical component in the design of these technologies is the accurate forecasting of reference joint motion for impaired limbs, which is hindered by the scarcity of joint locomotion data available for these patients. To address this, we propose ReMAP, a novel model repurposing strategy that leverages deep learning's reprogramming property, incorporating network inversion principles and retrieval-augmented mapping. Our approach adapts models originally designed for able-bodied individuals to forecast joint motion in limb-impaired patients without altering model parameters. We demonstrate the efficacy of ReMAP through extensive empirical studies on data from below-knee amputated patients, showcasing significant improvements over traditional transfer learning and fine-tuning methods. These findings have significant implications for advancing assistive technology and mobility for patients with amputations, stroke, or aging.
tl;dr: We introduce DiGRAF - a novel graph-adaptive activation function for GNNs by learning flexible and efficient diffeomorphisms, and demonstrate its effectiveness on numerous benchmarks and tasks.

In this paper, we propose a novel activation function tailored specifically for graph data in Graph Neural Networks (GNNs). Motivated by the need for graph-adaptive and flexible activation functions, we introduce DiGRAF, leveraging Continuous Piecewise-Affine Based (CPAB) transformations, which we augment with an additional GNN to learn a graph-adaptive diffeomorphic activation function in an end-to-end manner. In addition to its graph-adaptivity and flexibility, DiGRAF also possesses properties that are widely recognized as desirable for activation functions, such as differentiability, boundness within the domain, and computational efficiency.
We conduct an extensive set of experiments across diverse datasets and tasks, demonstrating a consistent and superior performance of DiGRAF compared to traditional and graph-specific activation functions, highlighting its effectiveness as an activation function for GNNs. Our code is available at https://github.com/ipsitmantri/DiGRAF.
tl;dr: Megalodon: Efficient Long-Context LLM Pretraining and Inference with Unlimited Context Length

The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce MEGALODON, an neural architecture for efficient sequence modeling with unlimited context length. MEGALODON inherits the architecture of MEGA (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration. In a controlled head-to-head comparison with LLAMA2, MEGALODON achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. MEGALODON reaches a training loss of 1.70, landing mid-way between LLAMA2-7B (1.75) and LLAMA2-13B (1.67). This result is robust throughout a wide range of benchmarks, where MEGALODON consistently outperforms Transformers across different tasks, domains, and modalities.

Neural representations for 3D scenes have made substantial advancements recently, yet object removal remains a challenging yet practical issue, due to the absence of multi-view supervision over occluded areas. Diffusion Models (DMs), trained on extensive 2D images, show diverse and high-fidelity generative capabilities in the 2D domain. However, due to not being specifically trained on 3D data, their application to multi-view data often exacerbates inconsistency, hence impacting the overall quality of the 3D output. To address these issues, we introduce "In-N-Out", a novel approach that begins by inpainting a prior, i.e., the occluded area from a single view using DMs, followed by outstretching it to create multi-view inpaintings via latents alignments. Our analysis identifies that the variability in DMs' outputs mainly arises from initially sampled latents and intermediate latents predicted in the denoising process. We explicitly align of initial latents using a Neural Radiance Field (NeRF) to establish a consistent foundational structure in the inpainted area, complemented by an implicit alignment of intermediate latents through cross-view attention during the denoising phases, enhancing appearance consistency across views. To further enhance rendering results, we apply a patch-based hybrid loss to optimize NeRF. We demonstrate that our techniques effectively mitigate the challenges posed by inconsistencies in DMs and substantially improve the fidelity and coherence of inpainted 3D representations.
tl;dr: This paper presents a Bayesian approach for personalized FL in heterogeneous settings to enable personalized, privacy-preserving models on decentralized devices, handling challenges like small datasets, model heterogeneity, and privacy constraints.

Federated learning (FL), through its privacy-preserving collaborative learning approach, has significantly empowered decentralized devices. However, constraints in either data and/or computational resources among participating clients introduce several challenges in learning, including the inability to train large model architectures, heightened risks of overfitting, and more. In this work, we present a novel FL framework grounded in Bayesian learning to address these challenges. Our approach involves training personalized Bayesian models at each client tailored to the unique complexities of the clients' datasets and efficiently collaborating across these clients. By leveraging Bayesian neural networks and their uncertainty quantification capabilities, our local training procedure robustly learns from small datasets. And the novel collaboration procedure utilizing priors in the functional (output) space of the networks facilitates collaboration across models of varying sizes, enabling the framework to adapt well in heterogeneous data and computational settings. Furthermore, we present a differentially private version of the algorithm, accompanied by formal differential privacy guarantees that apply without any assumptions on the learning algorithm. Through experiments on popular FL datasets, we demonstrate that our approach outperforms strong baselines in both homogeneous and heterogeneous settings, and under strict privacy constraints.
tl;dr: We propose a novel family of gradient boosting, Wasserstein gradient boosting, which returns a set of particles that approximates a target probability distribution assigned at each input.

Gradient boosting is a sequential ensemble method that fits a new weaker learner to pseudo residuals at each iteration. We propose Wasserstein gradient boosting, a novel extension of gradient boosting, which fits a new weak learner to alternative pseudo residuals that are Wasserstein gradients of loss functionals of probability distributions assigned at each input. It solves distribution-valued supervised learning, where the output values of the training dataset are probability distributions. In classification and regression, a model typically returns, for each input, a point estimate of a parameter of a noise distribution specified for a response variable, such as the class probability parameter of a categorical distribution specified for a response label. A main application of Wasserstein gradient boosting in this paper is tree-based evidential learning, which returns a distributional estimate of the response parameter for each input. We empirically demonstrate the competitive performance of the probabilistic prediction by Wasserstein gradient boosting in comparison with existing uncertainty quantification methods.

Recovering the foreground color and opacity/alpha matte from a single image (i.e., image matting) is a challenging and ill-posed problem where data priors play a critical role in achieving precise results. Traditional methods generally predict the alpha matte and then extract the foreground through post-processing, often failing to produce high-fidelity foreground color. This failure stems from the models' difficulty in learning robust color predictions from limited matting datasets. To address this, we explore the potential of leveraging vision priors embedded in pre-trained latent diffusion models (LDM) for estimating foreground RGBA values in challenging scenarios and rare objects. We introduce Drip, a novel approach for image matting that harnesses the rich prior knowledge of LDM models. Our method incorporates a switcher and a cross-domain attention mechanism to extend the original LDM for joint prediction of the foreground color and opacity. This setup facilitates mutual information exchange and ensures high consistency across both modalities. To mitigate the inherent reconstruction errors of the LDM's VAE decoder, we propose a latent transparency decoder to align the RGBA prediction with the input image, thereby reducing discrepancies. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art performance in foreground and alpha predictions and shows remarkable generalizability across various benchmarks.
tl;dr: We reveal the core bottleneck of OOD detection under mathematical reasoning scenarios, and propose a novel trajectory-based OOD detection algorithm for mathematical reasoning on generative language models.

Real-world data deviating from the independent and identically distributed (\textit{i.i.d.}) assumption of in-distribution training data poses security threats to deep networks, thus advancing out-of-distribution (OOD) detection algorithms. Detection methods in generative language models (GLMs) mainly focus on uncertainty estimation and embedding distance measurement, with the latter proven to be most effective in traditional linguistic tasks like summarization and translation. However, another complex generative scenario mathematical reasoning poses significant challenges to embedding-based methods due to its high-density feature of output spaces, but this feature causes larger discrepancies in the embedding shift trajectory between different samples in latent spaces. Hence, we propose a trajectory-based method TV score, which uses trajectory volatility for OOD detection in mathematical reasoning. Experiments show that our method outperforms all traditional algorithms on GLMs under mathematical reasoning scenarios and can be extended to more applications with high-density features in output spaces, such as multiple-choice questions.
3463. To Believe or Not to Believe Your LLM: IterativePrompting for Estimating Epistemic Uncertainty

We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.

Existing methods for relightable view synthesis --- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination --- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on target environment lighting and estimated object geometry. We then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at [illuminerf.github.io](illuminerf.github.io).
3465. Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models

Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning—a fundamental component of human cognition—remains under-explored. We propose SpatialEval, a novel benchmark that covers diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence. Our code is available at https://github.com/jiayuww/SpatialEval.
tl;dr: The EGSST framework, which is proposed for the rapid and efficient processing of event camera data for object detection, integrates a Graph Transformer structure with adaptive temporal attention, inspired by the dynamic response of human eyes.

Event cameras provide exceptionally high temporal resolution in dynamic vision systems due to their unique event-driven mechanism. However, the sparse and asynchronous nature of event data makes frame-based visual processing methods inappropriate. This study proposes a novel framework, Event-based Graph Spatiotemporal Sensitive Transformer (EGSST), for the exploitation of spatial and temporal properties of event data. Firstly, a well-designed graph structure is employed to model event data, which not only preserves the original temporal data but also captures spatial details. Furthermore, inspired by the phenomenon that human eyes pay more attention to objects that produce significant dynamic changes, we design a Spatiotemporal Sensitivity Module (SSM) and an adaptive Temporal Activation Controller (TAC). Through these two modules, our framework can mimic the response of the human eyes in dynamic environments by selectively activating the temporal attention mechanism based on the relative dynamics of event data, thereby effectively conserving computational resources. In addition, the integration of a lightweight, multi-scale Linear Vision Transformer (LViT) markedly enhances processing efficiency. Our research proposes a fully event-driven approach, effectively exploiting the temporal precision of event data and optimising the allocation of computational resources by intelligently distinguishing the dynamics within the event data. The framework provides a lightweight, fast, accurate, and fully event-based solution for object detection tasks in complex dynamic environments, demonstrating significant practicality and potential for application.

Offboard perception aims to automatically generate high-quality 3D labels for autonomous driving (AD) scenes. Existing offboard methods focus on 3D object detection with closed-set taxonomy and fail to match human-level recognition capability on the rapidly evolving perception tasks. Due to heavy reliance on human labels and the prevalence of data imbalance and sparsity, a unified framework for offboard auto-labeling various elements in AD scenes that meets the distinct needs of perception tasks is not being fully explored. In this paper, we propose a novel multi-modal Zero-shot Offboard Panoptic Perception (ZOPP) framework for autonomous driving scenes. ZOPP integrates the powerful zero-shot recognition capabilities of vision foundation models and 3D representations derived from point clouds. To the best of our knowledge, ZOPP represents a pioneering effort in the domain of multi-modal panoptic perception and auto labeling for autonomous driving scenes. We conduct comprehensive empirical studies and evaluations on Waymo open dataset to validate the proposed ZOPP on various perception tasks. To further explore the usability and extensibility of our proposed ZOPP, we also conduct experiments in downstream applications. The results further demonstrate the great potential of our ZOPP for real-world scenarios. Code will be released at \url{https://github.com/PJLab-ADG/ZOPP}.

\textit{Model Parsing} defines the task of predicting hyperparameters of the generative model (GM), given a GM-generated image as the input.
Since a diverse set of hyperparameters is jointly employed by the generative model, and dependencies often exist among them, it is crucial to learn these hyperparameter dependencies for improving the model parsing performance.
To explore such important dependencies, we propose a novel model parsing method called Learnable Graph Pooling Network (LGPN), in which we formulate model parsing as a graph node classification problem, using graph nodes and edges to represent hyperparameters and their dependencies, respectively.
Furthermore, LGPN incorporates a learnable pooling-unpooling mechanism tailored to model parsing, which adaptively learns hyperparameter dependencies of GMs used to generate the input image.
Also, we introduce a Generation Trace Capturing Network (GTC) that can efficiently identify generation traces of input images, enhancing the understanding of generated images' provenances.
Empirically, we achieve state-of-the-art performance in model parsing and its extended applications, showing the superiority of the proposed LGPN.

In the field of 3D Human Pose Estimation (HPE), scalability and generalization across diverse real-world scenarios remain significant challenges. This paper addresses two key bottlenecks to scalability: limited data diversity caused by 'popularity bias' and increased 'one-to-many' depth ambiguity arising from greater pose diversity. We introduce the Biomechanical Pose Generator (BPG), which leverages biomechanical principles, specifically the normal range of motion, to autonomously generate a wide array of plausible 3D poses without relying on a source dataset, thus overcoming the restrictions of popularity bias. To address depth ambiguity, we propose the Binary Depth Coordinates (BDC), which simplifies depth estimation into a binary classification of joint positions (front or back). This method decomposes a 3D pose into three core elements—2D pose, bone length, and binary depth decision—substantially reducing depth ambiguity and enhancing model robustness and accuracy, particularly in complex poses. Our results demonstrate that these approaches increase the diversity and volume of pose data while consistently achieving performance gains, even amid the complexities introduced by increased pose diversity.
tl;dr: DiffHammer provides effective and efficient robustness evaluation for diffusion-based purification via selective attack and N-evaluation.

Diffusion-based purification has demonstrated impressive robustness as an adversarial defense. However, concerns exist about whether this robustness arises from insufficient evaluation. Our research shows that EOT-based attacks face gradient dilemmas due to global gradient averaging, resulting in ineffective evaluations. Additionally, 1-evaluation underestimates resubmit risks in stochastic defenses. To address these issues, we propose an effective and efficient attack named DiffHammer. This method bypasses the gradient dilemma through selective attacks on vulnerable purifications, incorporating $N$-evaluation into loops and using gradient grafting for comprehensive and efficient evaluations. Our experiments validate that DiffHammer achieves effective results within 10-30 iterations, outperforming other methods. This calls into question the reliability of diffusion-based purification after mitigating the gradient dilemma and scrutinizing its resubmit risk.
tl;dr: We introduce context-aware testing (CAT) which uses context to guide the search for meaningful model failures

The predominant *de facto* paradigm of testing ML models relies on either using only held-out data to compute aggregate evaluation metrics or by assessing the performance on different subgroups. However, such *data-only testing* methods operate under the restrictive assumption that the available empirical data is the sole input for testing ML models, disregarding valuable contextual information that could guide model testing. In this paper, we challenge the go-to approach of *data-only testing* and introduce *Context-Aware Testing* (CAT) which uses context as an inductive bias to guide the search for meaningful model failures. We instantiate the first CAT system, *SMART Testing*, which employs large language models to hypothesize relevant and likely failures, which are evaluated on data using a *self-falsification mechanism*. Through empirical evaluations in diverse settings, we show that SMART automatically identifies more relevant and impactful failures than alternatives, demonstrating the potential of CAT as a testing paradigm.
3472. Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation
tl;dr: This paper introduces an LLM agent framework for personal mobility generation.

This paper introduces a novel approach using Large Language Models (LLMs) integrated into an agent framework for flexible and effective personal mobility generation. LLMs overcome the limitations of previous models by effectively processing semantic data and offering versatility in modeling various tasks. Our approach addresses three research questions: aligning LLMs with real-world urban mobility data, developing reliable activity generation strategies, and exploring LLM applications in urban mobility. The key technical contribution is a novel LLM agent framework that accounts for individual activity patterns and motivations, including a self-consistency approach to align LLMs with real-world activity data and a retrieval-augmented strategy for interpretable activity generation. We evaluate our LLM agent framework and compare it with state-of-the-art personal mobility generation approaches, demonstrating the effectiveness of our approach and its potential applications in urban mobility. Overall, this study marks the pioneering work of designing an LLM agent framework for activity generation based on real-world human activity data, offering a promising tool for urban mobility analysis.

This work studies the problem of out-of-distribution fluid dynamics modeling. Previous works usually design effective neural operators to learn from mesh-based data structures. However, in real-world applications, they would suffer from distribution shifts from the variance of system parameters and
temporal evolution of the dynamical system. In this paper, we propose a novel approach named \underline{P}rompt Evol\underline{u}tion with G\underline{r}aph OD\underline{E} (\method{}) for out-of-distribution fluid dynamics modeling. The core of our \method{} is to learn time-evolving prompts using a graph ODE to adapt spatio-temporal forecasting models to different scenarios. In particular, our \method{} first learns from historical observations and system parameters in the frequency domain to explore multi-view context information, which could effectively initialize prompt embeddings. More importantly, we incorporate the interpolation of observation sequences into a graph ODE, which can capture the temporal evolution of prompt embeddings for model adaptation. These time-evolving prompt embeddings are then incorporated into basic forecasting models to overcome temporal distribution shifts. We also minimize the mutual information between prompt embeddings and observation embeddings to enhance the robustness of our model to different distributions. Extensive experiments on various benchmark datasets validate the superiority of the proposed \method{} in comparison to various baselines.

Reinforcement learning from human feedback (RLHF) is widely used to train large language models (LLMs). However, it is unclear whether LLMs accurately learn the underlying preferences in human feedback data. We coin the term **Learned Feedback Pattern** (LFP) for patterns in an LLM's activations learned during RLHF that improve its performance on the fine-tuning task. We hypothesize that LLMs with LFPs accurately aligned to the fine-tuning feedback exhibit consistent activation patterns for outputs that would have received similar feedback during RLHF. To test this, we train probes to estimate the feedback signal implicit in the activations of a fine-tuned LLM. We then compare these estimates to the true feedback, measuring how accurate the LFPs are to the fine-tuning feedback. Our probes are trained on a condensed, sparse and interpretable representation of LLM activations, making it easier to correlate features of the input with our probe's predictions. We validate our probes by comparing the neural features they correlate with positive feedback inputs against the features GPT-4 describes and classifies as related to LFPs. Understanding LFPs can help minimize discrepancies between LLM behavior and training objectives, which is essential for the **safety** and **alignment** of LLMs.
3475. Multiview Scene Graph
tl;dr: building a place+object multiview scene graph from unposed images as a topological scene representation

A proper scene representation is central to the pursuit of spatial intelligence where agents can robustly reconstruct and efficiently understand 3D scenes. A scene representation is either metric, such as landmark maps in 3D reconstruction, 3D bounding boxes in object detection, or voxel grids in occupancy prediction, or topological, such as pose graphs with loop closures in SLAM or visibility graphs in SfM.
In this work, we propose to build Multiview Scene Graphs (MSG) from unposed images, representing a scene topologically with interconnected place and object nodes.
The task of building MSG is challenging for existing representation learning methods since it needs to jointly address both visual place recognition, object detection, and object association from images with limited fields of view and potentially large viewpoint changes.
To evaluate any method tackling this task, we developed an MSG dataset and annotation based on a public 3D dataset.
We also propose an evaluation metric based on the intersection-over-union score of MSG edges.
Moreover, we develop a novel baseline method built on mainstream pretrained vision models, combining visual place recognition and object association into one Transformer decoder architecture.
Experiments demonstrate that our method has superior performance compared to existing relevant baselines.
tl;dr: We propose a parameter-efficient approach for continual learning in LLMs

Large Language Models (LLMs) have demonstrated profound capabilities due to their extensive pre-training on diverse corpora. However, LLMs often struggle with catastrophic forgetting when engaged in sequential task learning. In this paper, we propose a novel parameter-efficient approach for continual learning in LLMs, which empirically investigates knowledge transfer from previously learned tasks to new tasks through low-rank matrix parameters, enhancing the learning of new tasks without significant interference. Our method employs sensitivity-based analysis of low-rank matrix parameters to identify knowledge-specific parameters between sequential tasks, which are used to initialize the low-rank matrix parameters in new tasks. To maintain orthogonality and minimize forgetting, we further involve the gradient projection technique that keeps the low-rank subspaces of each new task orthogonal to those of previous tasks. Our experimental results on continual learning benchmarks validate the efficacy of our proposed method, which outperforms existing state-of-the-art methods in reducing forgetting, enhancing task performance, and preserving the model's ability to generalize to unseen tasks.

Occupancy prediction, aiming at predicting the occupancy status within voxelized 3D environment, is quickly gaining momentum within the autonomous driving community. Mainstream occupancy prediction works first discretize the 3D environment into voxels, then perform classification on such dense grids. However, inspection on sample data reveals that the vast majority of voxels is unoccupied. Performing classification on these empty voxels demands suboptimal computation resource allocation, and reducing such empty voxels necessitates complex algorithm designs. To this end, we present a novel perspective on the occupancy prediction task: formulating it as a streamlined set prediction paradigm without the need for explicit space modeling or complex sparsification procedures. Our proposed framework, called OPUS, utilizes a transformer encoder-decoder architecture to simultaneously predict occupied locations and classes using a set of learnable queries. Firstly, we employ the Chamfer distance loss to scale the set-to-set comparison problem to unprecedented magnitudes, making training such model end-to-end a reality. Subsequently, semantic classes are adaptively assigned using nearest neighbor search based on the learned locations. In addition, OPUS incorporates a suite of non-trivial strategies to enhance model performance, including coarse-to-fine learning, consistent point sampling, and adaptive re-weighting, etc. Finally, compared with current state-of-the-art methods, our lightest model achieves superior RayIoU on the Occ3D-nuScenes dataset at near 2x FPS, while our heaviest model surpasses previous best results by 6.1 RayIoU.

Large-vocabulary object detectors (LVDs) aim to detect objects of many categories, which learn super objectness features and can locate objects accurately while applied to various downstream data. However, LVDs often struggle in recognizing the located objects due to domain discrepancy in data distribution and object vocabulary. At the other end, recent vision-language foundation models such as CLIP demonstrate superior open-vocabulary recognition capability.
This paper presents KGD, a Knowledge Graph Distillation technique that exploits the implicit knowledge graphs (KG) in CLIP for effectively adapting LVDs to various downstream domains.
KGD consists of two consecutive stages: 1) KG extraction that employs CLIP to encode downstream domain data as nodes and their feature distances as edges, constructing KG that inherits the rich semantic relations in CLIP explicitly;
and 2) KG encapsulation that transfers the extracted KG into LVDs to enable accurate cross-domain object classification.
In addition, KGD can extract both visual and textual KG independently, providing complementary vision and language knowledge for object localization and object classification in detection tasks over various downstream domains.
Experiments over multiple widely adopted detection benchmarks show that KGD outperforms the state-of-the-art consistently by large margins.
Codes will be released.

In this paper, we propose a post-training quantization framework of large vision-language models (LVLMs) for efficient multi-modal inference. Conventional quantization methods sequentially search the layer-wise rounding functions by minimizing activation discretization errors, which fails to acquire optimal quantization strategy without considering cross-layer dependency. On the contrary, we mine the cross-layer dependency that significantly influences discretization errors of the entire vision-language model, and embed this dependency into optimal quantization strategy searching with low search cost. Specifically, we observe the strong correlation between the activation entropy and the cross-layer dependency concerning output discretization errors. Therefore, we employ the entropy as the proxy to partition blocks optimally, which aims to achieve satisfying trade-offs between discretization errors and the search cost. Moreover, we optimize the visual encoder to disentangle the cross-layer dependency for fine-grained decomposition of search space, so that the search cost is further reduced without harming the quantization accuracy. Experimental results demonstrate that our method compresses the memory by 2.78x and increase generate speed by 1.44x about 13B LLaVA model without performance degradation on diverse multi-modal reasoning tasks.
tl;dr: We present a diffusion framework that can learn a wide range of conditional distributions within audiovisual data using a single model.

Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space. Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: neurips13025.github.io

Contrastive image-to-LiDAR knowledge transfer, commonly used for learning 3D representations with synchronized images and point clouds, often faces a self-conflict dilemma. This issue arises as contrastive losses unintentionally dissociate features of unmatched points and pixels that share semantic labels, compromising the integrity of learned representations. To overcome this, we harness Visual Foundation Models (VFMs), which have revolutionized the acquisition of pixel-level semantics, to enhance 3D representation learning. Specifically, we utilize off-the-shelf VFMs to generate semantic labels for weakly-supervised pixel-to-point contrastive distillation. Additionally, we employ von Mises-Fisher distributions to structure the feature space, ensuring semantic embeddings within the same class remain consistent across varying inputs. Furthermore, we adapt sampling probabilities of points to address imbalances in spatial distribution and category frequency, promoting comprehensive and balanced learning. Extensive experiments demonstrate that our approach mitigates the challenges posed by traditional methods and consistently surpasses existing image-to-LiDAR contrastive distillation methods in downstream tasks. We have included the code in supplementary materials.
In the realm of Multimodal Large Language Models (MLLMs), vision-language connector plays a crucial role to link the pre-trained vision encoders with Large Language Models (LLMs). Despite its importance, the vision-language connector has been relatively less explored. In this study, we aim to propose a strong vision-language connector that enables MLLM to simultaneously achieve high accuracy and low computation cost. We first reveal the existence of the visual anchors in Vision Transformer and propose a cost-effective search algorithm to progressively extract them. Building on these findings, we introduce the Anchor Former (AcFormer), a novel vision-language connector designed to leverage the rich prior knowledge obtained from these visual anchors during pretraining, guiding the aggregation of information.
Through extensive experimentation, we demonstrate that the proposed method significantly reduces computational costs by nearly two-thirds, while simultaneously outperforming baseline methods. This highlights the effectiveness and efficiency of AcFormer.

A hallmark of intelligent agents is the ability to learn reusable skills purely from unsupervised interaction with the environment. However, existing unsupervised skill discovery methods often learn entangled skills where one skill variable simultaneously influences many entities in the environment, making downstream skill chaining extremely challenging. We propose Disentangled Unsupervised Skill Discovery (DUSDi), a method for learning disentangled skills that can be efficiently reused to solve downstream tasks. DUSDi decomposes skills into disentangled components, where each skill component only affects one factor of the state space. Importantly, these skill components can be concurrently composed to generate low-level actions, and efficiently chained to tackle downstream tasks through hierarchical Reinforcement Learning. DUSDi defines a novel mutual-information-based objective to enforce disentanglement between the influences of different skill components, and utilizes value factorization to optimize this objective efficiently. Evaluated in a set of challenging environments, DUSDi successfully learns disentangled skills, and significantly outperforms previous skill discovery methods when it comes to applying the learned skills to solve downstream tasks.

Vision-Language Models seamlessly discriminate among arbitrary semantic categories, yet they still suffer from poor generalization when presented with challenging examples. For this reason, Episodic Test-Time Adaptation (TTA) strategies have recently emerged as powerful techniques to adapt VLMs in the presence of a single unlabeled image. The recent literature on TTA is dominated by the paradigm of prompt tuning by Marginal Entropy Minimization, which, relying on online backpropagation, inevitably slows down inference while increasing memory. In this work, we theoretically investigate the properties of this approach and unveil that a surprisingly strong TTA method lies dormant and hidden within it. We term this approach ZERO (TTA with “zero” temperature), whose design is both incredibly effective and frustratingly simple: augment N times, predict, retain the most confident predictions, and marginalize after setting the Softmax temperature to zero. Remarkably, ZERO requires a single batched forward pass through the vision encoder only and no backward passes. We thoroughly evaluate our approach following the experimental protocol established in the literature and show that ZERO largely surpasses or compares favorably w.r.t. the state-of-the-art while being almost 10× faster and 13× more memory friendly than standard Test-Time Prompt Tuning. Thanks to its simplicity and comparatively negligible computation, ZERO can serve as a strong baseline for future work in this field. Code will be available.
tl;dr: A method that combines contextual bandits and PageRank for online and offline link prediction.

Link prediction is a critical problem in graph learning with broad applications such as recommender systems and knowledge graph completion. Numerous research efforts have been directed at solving this problem, including approaches based on similarity metrics and Graph Neural Networks (GNN). However, most existing solutions are still rooted in conventional supervised learning, which makes it challenging to adapt over time to changing customer interests and to address the inherent dilemma of exploitation versus exploration in link prediction.
To tackle these challenges, this paper reformulates link prediction as a sequential decision-making process, where each link prediction interaction occurs sequentially. We propose a novel fusion algorithm, PRB (PageRank Bandits), which is the first to combine contextual bandits with PageRank for collaborative exploitation and exploration. We also introduce a new reward formulation and provide a theoretical performance guarantee for PRB. Finally, we extensively evaluate PRB in both online and offline settings, comparing it with bandit-based and graph-based methods. The empirical success of PRB demonstrates the value of the proposed fusion approach. Our code is released at https://github.com/jiaruzouu/PRB.
tl;dr: We propose a new layer in the architecture of Group-Equivariant Neural Networks to achieve invariance to group action on the input.

An important problem in signal processing and deep learning is to achieve *invariance* to nuisance factors not relevant for the task. Since many of these factors are describable as the action of a group $G$ (e.g. rotations, translations, scalings), we want methods to be $G$-invariant. The $G$-Bispectrum extracts every characteristic of a given signal up to group action: for example, the shape of an object in an image, but not its orientation. Consequently, the $G$-Bispectrum has been incorporated into deep neural network architectures as a computational primitive for $G$-invariance\textemdash akin to a pooling mechanism, but with greater selectivity and robustness. However, the computational cost of the $G$-Bispectrum ($\mathcal{O}(|G|^2)$, with $|G|$ the size of the group) has limited its widespread adoption. Here, we show that the $G$-Bispectrum computation contains redundancies that can be reduced into a *selective $G$-Bispectrum* with $\mathcal{O}(|G|)$ complexity. We prove desirable mathematical properties of the selective $G$-Bispectrum and demonstrate how its integration in neural networks enhances accuracy and robustness compared to traditional approaches, while enjoying considerable speeds-up compared to the full $G$-Bispectrum.
tl;dr: This paper proposes two data augmentation modules, which is also the first work, to tackle the topic of domain generalization from the perspective of preventing frequency shortcuts.

Domain generalization methods aim to learn transferable knowledge from source domains that can generalize well to unseen target domains.
Recent studies show that neural networks frequently suffer from a simplicity-biased learning behavior which leads to over-reliance on specific frequency sets, namely as frequency shortcuts, instead of semantic information, resulting in poor generalization performance.
Despite previous data augmentation techniques successfully enhancing generalization performances, they intend to apply more frequency shortcuts, thereby causing hallucinations of generalization improvement.
In this paper, we aim to prevent such learning behavior of applying frequency shortcuts from a data-driven perspective. Given the theoretical justification of models' biased learning behavior on different spatial frequency components, which is based on the dataset frequency properties, we argue that the learning behavior on various frequency components could be manipulated by changing the dataset statistical structure in the Fourier domain.
Intuitively, as frequency shortcuts are hidden in the dominant and highly dependent frequencies of dataset structure, dynamically perturbating the over-reliance frequency components could prevent the application of frequency shortcuts.
To this end, we propose two effective data augmentation modules designed to collaboratively and adaptively adjust the frequency characteristic of the dataset, aiming to dynamically influence the learning behavior of the model and ultimately serving as a strategy to mitigate shortcut learning. Our code will be made publicly available.
tl;dr: Existing model merging methods usually suffer from significant performance degradation or requring additional tuning. We realize tuning-free model merging, which shows impressive performance under various experimental settings.

The success of pretrain-finetune paradigm brings about the release of numerous model weights. In this case, merging models finetuned on different tasks to enable a single model with multi-task capabilities is gaining increasing attention for its practicability. Existing model merging methods usually suffer from (1) significant performance degradation or (2) requiring tuning by additional data or training. In this paper, we rethink and analyze the existing model merging paradigm. We discover that using a single model's weights can hardly simulate all the models' performance. To tackle this issue, we propose Elect, Mask & Rescale-Merging (EMR-Merging). We first (a) elect a unified model from all the model weights and then (b) generate extremely lightweight task-specific modulators, including masks and rescalers, to align the direction and magnitude between the unified model and each specific model, respectively. EMR-Merging is tuning-free, thus requiring no data availability or any additional training while showing impressive performance. We find that EMR-Merging shows outstanding performance compared to existing merging methods under different classical and newly-established settings, including merging different numbers of vision models (up to 30), NLP models, PEFT models, and multi-modal models.
tl;dr: Forward-KL Variational Inference with Sequential Sample-Average Approximations

We present variational inference with sequential sample-average approximations (VISA), a method for approximate inference in computationally intensive models, such as those based on numerical simulations. VISA extends importance-weighted forward-KL variational inference by employing a sequence of sample-average approximations, which are considered valid inside a trust region. This makes it possible to reuse model evaluations across multiple gradient steps, thereby reducing computational cost. We perform experiments on high-dimensional Gaussians, Lotka-Volterra dynamics, and a Pickover attractor, which demonstrate that VISA can achieve comparable approximation accuracy to standard importance-weighted forward-KL variational inference with computational savings of a factor two or more for conservatively chosen learning rates.
tl;dr: We develop new evaluation metrics for world model recovery based on formal results in language theory, revealing that generative models often harbor inconsistent world models despite performing well on standard tests across various domains

Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead to failures. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
tl;dr: We created a model that generates corrective instructions to guide users from their current motion to a desired target motion, showing significant improvements over baselines. The code and trained models will be publicly available.

Recent advancements in models linking natural language with human motions have shown significant promise in motion generation and editing based on instructional text. Motivated by applications in sports coaching and motor skill learning, we investigate the inverse problem: generating corrective instructional text, leveraging motion editing and generation models. We introduce a novel approach that, given a user’s current motion (source) and the desired motion (target), generates text instructions to guide the user towards achieving the target motion. We leverage large language models to generate corrective texts and utilize existing motion generation and editing frameworks to compile datasets of triplets (source motion, target motion, and corrective text). Using this data, we propose a new motion-language model for generating corrective instructions. We present both qualitative and quantitative results across a diverse range of applications that largely improve upon baselines. Our approach demonstrates its effectiveness in instructional scenarios, offering text-based guidance to correct and enhance user performance.
tl;dr: We find that the standard alignment process encourages hallucination, and propose factuality-aware alignment while maintaining the LLM's general instruction-following capability.

Alignment is a procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants.
We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e., *hallucination*).
In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps: supervised fine-tuning (SFT) and reinforcement learning (RL).
In particular, we find that training the LLM on new or unfamiliar knowledge can encourage hallucination.
This makes SFT less factual as it trains on human-labeled data that may be novel to the LLM.
Furthermore, reward functions used in standard RL often inadequately capture factuality and favor longer and more detailed responses, which inadvertently promote hallucination.
Based on these observations, we propose *FactuaLity-aware AlignMEnt*, comprised of *factuality-aware SFT* and *factuality-aware RL* through direct preference optimization.
Experiments show that our proposed *FLAME* guides LLMs to output more factual responses while maintaining their instruction-following capability.
tl;dr: We design the patch-level pose-invariant 3D feature representation to represent the 3D shape, resulting in the implicit displacement estimation of 3D query points based on the local patch-level pose-invariant representation.

Implicit neural representation gains popularity in modeling the continuous 3D surface for 3D representation and reconstruction. In this work, we are motivated by the fact that the local 3D patches repeatedly appear on 3D shapes/surfaces if the factor of poses is removed. Based on this observation, we propose the 3D patch-level equivariant implicit function (PEIF) based on the 3D patch-level pose-invariant representation, allowing us to reconstruct 3D surfaces by estimating equivariant displacement vector fields for query points. Specifically, our model is based on the pose-normalized query/patch pairs and enhanced by the proposed intrinsic patch geometry representation, modeling the intrinsic 3D patch geometry feature by learnable multi-head memory banks. Extensive experiments show that our model achieves state-of-the-art performance on multiple surface reconstruction datasets, and also exhibits better generalization to crossdataset shapes and robustness to arbitrary rotations. Our code will be available at https://github.com/mathXin112/PEIF.git.

Event cameras harness advantages such as low latency, high temporal resolution, and high dynamic range (HDR), compared to standard cameras. Due to the distinct imaging paradigm shift, a dominant line of research focuses on event-to-video (E2V) reconstruction to bridge event-based and standard computer vision. However, this task remains challenging due to its inherently ill-posed nature: event cameras only detect the edge and motion information locally. Consequently, the reconstructed videos are often plagued by artifacts and regional blur, primarily caused by the ambiguous semantics of event data. In this paper, we find language naturally conveys abundant semantic information, rendering it stunningly superior in ensuring semantic consistency for E2V reconstruction. Accordingly, we propose a novel framework, called LaSe-E2V, that can achieve semantic-aware high-quality E2V reconstruction from a language-guided perspective, buttressed by the text-conditional diffusion models. However, due to diffusion models' inherent diversity and randomness, it is hardly possible to directly apply them to achieve spatial and temporal consistency for E2V reconstruction. Thus, we first propose an Event-guided Spatiotemporal Attention (ESA) module to condition the event data to the denoising pipeline effectively. We then introduce an event-aware mask loss to ensure temporal coherence and a noise initialization strategy to enhance spatial consistency. Given the absence of event-text-video paired data, we aggregate existing E2V datasets and generate textual descriptions using the tagging models for training and evaluation. Extensive experiments on three datasets covering diverse challenging scenarios (e.g., fast motion, low light) demonstrate the superiority of our method. Demo videos for the results are attached to the project page.
tl;dr: This paper studies the dynamics of welfare and fairness where strategic agents interact with an ML system retrained over time with model-annotated and human-annotated samples.

As machine learning (ML) models are increasingly used in social domains to make consequential decisions about humans, they often have the power to reshape data distributions. Humans, as strategic agents, continuously adapt their behaviors in response to the learning system. As populations change dynamically, ML systems may need frequent updates to ensure high performance. However, acquiring high-quality *human-annotated* samples can be highly challenging and even infeasible in social domains. A common practice to address this issue is using the model itself to annotate unlabeled data samples. This paper investigates the long-term impacts when ML models are retrained with *model-annotated* samples when they incorporate human strategic responses. We first formalize the interactions between strategic agents and the model and then analyze how they evolve under such dynamic interactions. We find that agents are increasingly likely to receive positive decisions as the model gets retrained, whereas the proportion of agents with positive labels may decrease over time. We thus propose a *refined retraining process* to stabilize the dynamics. Last, we examine how algorithmic fairness can be affected by these retraining processes and find that enforcing common fairness constraints at every round may not benefit the disadvantaged group in the long run. Experiments on (semi-)synthetic and real data validate the theoretical findings.

Gesture synthesis is a vital realm of human-computer interaction, with wide-ranging applications across various fields like film, robotics, and virtual reality.
Recent advancements have utilized the diffusion model to improve gesture synthesis.
However, the high computational complexity of these techniques limits the application in reality.
In this study, we explore the potential of state space models (SSMs).
Direct application of SSMs in gesture synthesis encounters difficulties, which stem primarily from the diverse movement dynamics of various body parts.
The generated gestures may also exhibit unnatural jittering issues.
To address these, we implement a two-stage modeling strategy with discrete motion priors to enhance the quality of gestures.
Built upon the selective scan mechanism, we introduce MambaTalk, which integrates hybrid fusion modules, local and global scans to refine latent space representations.
Subjective and objective experiments demonstrate that our method surpasses the performance of state-of-the-art models. Our project is publicly available at~\url{https://kkakkkka.github.io/MambaTalk/}.

This paper introduces a novel prior called Diversified Block Sparse Prior to characterize the widespread block sparsity phenomenon in real-world data. By allowing diversification on intra-block variance and inter-block correlation matrices, we effectively address the sensitivity issue of existing block sparse learning methods to pre-defined block information, which enables adaptive block estimation while mitigating the risk of overfitting. Based on this, a diversified block sparse Bayesian learning method (DivSBL) is proposed, utilizing EM algorithm and dual ascent method for hyperparameter estimation. Moreover, we establish the global and local optimality theory of our model. Experiments validate the advantages of DivSBL over existing algorithms.
tl;dr: We present Visualized In-Context Text Processing(VisInContext), which processes long in-context text using visual tokens.

Training models with longer in-context lengths is a significant challenge for multimodal machine learning due to substantial GPU memory and computational costs. This exploratory study does not present state-of-the-art models; rather, it introduces an innovative method designed to increase in-context text length in multi-modality large language models (MLLMs) efficiently. We present \ModelFullName (\ModelName), which processes long in-context text using visual tokens. This technique significantly reduces GPU memory usage and floating point operations (FLOPs). For instance, our method expands the pre-training in-context length from 256 to 2048 tokens with fewer FLOPs for a 56 billion parameter MOE model. Experimental results demonstrate that \ModelName enhances OCR capabilities and delivers superior performance on common downstream benchmarks for in-context few-shot evaluation. Additionally, \ModelName proves effective for long context inference, achieving results comparable to full text input while maintaining computational efficiency.

Articulated object manipulation in real images is a fundamental step in computer and robotic vision tasks. Recently, several image editing methods based on diffusion models have been proposed to manipulate articulated objects according to text prompts. However, these methods often generate weird artifacts or even fail in real images. To this end, we introduce the Part-Aware Diffusion Model to approach the manipulation of articulated objects in real images. First, we develop Abstract 3D Models to represent and manipulate articulated objects efficiently and arbitrarily. Then we propose dynamic feature maps to transfer the appearance of objects from input images to edited ones, meanwhile generating novel views or novel-appearing parts reasonably. Extensive experiments are provided to illustrate the advanced manipulation capabilities of our method concerning state-of-the-art editing works. Additionally, we verify our method on 3D articulated object understanding for
embodied robot scenarios and the promising results prove that our method supports this task strongly. The project page is https://mvig-rhos.com/pa_diffusion.

With the blossom of large language models (LLM), inference efficiency becomes increasingly important. Various approximate methods are proposed to reduce the cost at inference time. Contextual Sparsity (CS) is appealing for its training-free nature and its ability to reach a higher compression ratio seemingly without significant performance degradation. However, after a comprehensive evaluation of contextual sparsity methods on various complex generation tasks, we find that although CS succeeds in prompt-understanding tasks, it significantly degrades the model performance for reasoning, deduction, and knowledge-based tasks. Despite the gap in end-to-end accuracy, we observed that sparse models and original models often share the general problem-solving logic and require only a few token corrections to recover the original model performance. This paper introduces SIRIUS, an efficient correction mechanism, which significantly boosts CS models on reasoning tasks while maintaining its efficiency gain. SIRIUS is evaluated on 6 models with 8 difficult generation tasks in reasoning, deduction, and coding and shows consistent effectiveness and efficiency. Also, we carefully develop a system implementation for SIRIUS and show that SIRIUS delivers theoretical latency reduction with roughly a 20% reduction in latency for 8B model on-chip and a 35% reduction in latency for 70B model offloading. We open-source our implementation of Sirius at https://github.com/Infini-AI-Lab/Sirius.git.
tl;dr: We propose a learning method to prune the points in 3D Gaussian Splatting by applying trainable mask to the importance score of points and minimize the model size with only one-time training while maintaining the rendering quality.

Recently, 3D Gaussian Splatting (3DGS) has become one of the mainstream methodologies for novel view synthesis (NVS) due to its high quality and fast rendering speed. However, as a point-based scene representation, 3DGS potentially generates a large number of Gaussians to fit the scene, leading to high memory usage. Improvements that have been proposed require either an empirical pre-set pruning ratio or importance score threshold to prune the point cloud. Such hyperparameters require multiple rounds of training to optimize and achieve the maximum pruning ratio while maintaining the rendering quality for each scene. In this work, we propose learning-to-prune 3DGS (LP-3DGS), where a trainable binary mask is applied to the importance score to automatically find a favorable pruning ratio. Instead of using the traditional straight-through estimator (STE) method to approximate the binary mask gradient, we redesign the masking function to leverage the Gumbel-Sigmoid method, making it differentiable and compatible with the existing training process of 3DGS. Extensive experiments have shown that LP-3DGS consistently achieves a good balance between efficiency and high quality.
tl;dr: We propose a novel Domain-Aware Adapter (DA-Ada) to exploit domain-invariant and domain-specific knowledge with the vision-language models for domain adaptive object detection.

Domain adaptive object detection (DAOD) aims to generalize detectors trained on an annotated source domain to an unlabelled target domain.
As the visual-language models (VLMs) can provide essential general knowledge on unseen images, freezing the visual encoder and inserting a domain-agnostic adapter can learn domain-invariant knowledge for DAOD.
However, the domain-agnostic adapter is inevitably biased to the source domain.
It discards some beneficial knowledge discriminative on the unlabelled domain, \ie domain-specific knowledge of the target domain.
To solve the issue, we propose a novel Domain-Aware Adapter (DA-Ada) tailored for the DAOD task.
The key point is exploiting domain-specific knowledge between the essential general knowledge and domain-invariant knowledge.
DA-Ada consists of the Domain-Invariant Adapter (DIA) for learning domain-invariant knowledge and the Domain-Specific Adapter (DSA) for injecting the domain-specific knowledge from the information discarded by the visual encoder.
Comprehensive experiments over multiple DAOD tasks show that DA-Ada can efficiently infer a domain-aware visual encoder for boosting domain adaptive object detection.
Our code is available at https://github.com/Therock90421/DA-Ada.
tl;dr: We propose a new approach for Indoor Panoramic Semantic Segmentation

PAnoramic Semantic Segmentation (PASS) is an important task in computer vision,
as it enables semantic understanding of a 360° environment. Currently,
most of existing works have focused on addressing the distortion issues in 2D
panoramic images without considering spatial properties of indoor scene. This
restricts PASS methods in perceiving contextual attributes to deal with the ambiguity
when working with monocular images. In this paper, we propose a novel
approach for indoor panoramic semantic segmentation. Unlike previous works,
we consider the panoramic image as a composition of segment groups: oversampled
segments, representing planar structures such as floors and ceilings, and
under-sampled segments, representing other scene elements. To optimize each
group, we first enhance over-sampled segments by jointly optimizing with a dense
depth estimation task. Then, we introduce a transformer-based context module
that aggregates different geometric representations of the scene, combined
with a simple high-resolution branch, it serves as a robust hybrid decoder for
estimating under-sampled segments, effectively preserving the resolution of predicted
masks while leveraging various indoor geometric properties. Experimental
results on both real-world (Stanford2D3DS, Matterport3D) and synthetic (Structured3D)
datasets demonstrate the robustness of our framework, by setting new
state-of-the-arts in almost evaluations, The code and updated results are available
at: https://github.com/caodinhduc/vertical_relative_distance.
tl;dr: We introduce Concept-based Memory Reasoner (CMR), a novel CBM that uses a neural selection mechanism over learnable logic rules and symbolic evaluation to enable human-understandable and provably-verifiable task predictions.

The lack of transparency in the decision-making processes of deep learning systems presents a significant challenge in modern artificial intelligence (AI), as it impairs users’ ability to rely on and verify these systems. To address this challenge, Concept Bottleneck Models (CBMs) have made significant progress by incorporating human-interpretable concepts into deep learning architectures. This approach allows predictions to be traced back to specific concept patterns that users can understand and potentially intervene on. However, existing CBMs’ task predictors are not fully interpretable, preventing a thorough analysis and any form of formal verification of their decision-making process prior to deployment, thereby raising significant reliability concerns. To bridge this gap, we introduce Concept-based Memory Reasoner (CMR), a novel CBM designed to provide a human-understandable and provably-verifiable task prediction process. Our approach is to model each task prediction as a neural selection mechanism over a memory of learnable logic rules, followed by a symbolic evaluation of the selected rule. The presence of an explicit memory and the symbolic evaluation allow domain experts to inspect and formally verify the validity of certain global properties of interest for the task prediction process. Experimental results demonstrate that CMR achieves better accuracy-interpretability trade-offs to state-of-the-art CBMs, discovers logic rules consistent with ground truths, allows for rule interventions, and allows pre-deployment verification.

The benefit of transformers in large-scale 3D point cloud perception tasks, such as 3D object detection, is limited by their quadratic computation cost when modeling long-range relationships. In contrast, linear RNNs have low computational complexity and are suitable for long-range modeling. Toward this goal, we propose a simple and effective window-based framework built on Linear group RNN (i.e., perform linear RNN for grouped features) for accurate 3D object detection, called LION. The key property is to allow sufficient feature interaction in a much larger group than transformer-based methods. However, effectively applying linear group RNN to 3D object detection in highly sparse point clouds is not trivial due to its limitation in handling spatial modeling. To tackle this problem, we simply introduce a 3D spatial feature descriptor and integrate it into the linear group RNN operators to enhance their spatial features rather than blindly increasing the number of scanning orders for voxel features. To further address the challenge in highly sparse point clouds, we propose a 3D voxel generation strategy to densify foreground features thanks to linear group RNN as a natural property of auto-regressive models.
Extensive experiments verify the effectiveness of the proposed components and the generalization of our LION on different linear group RNN operators including Mamba, RWKV, and RetNet. Furthermore, it is worth mentioning that our LION-Mamba achieves state-of-the-art on Waymo, nuScenes, Argoverse V2, and ONCE datasets. Last but not least, our method supports kinds of advanced linear RNN operators (e.g., RetNet, RWKV, Mamba, xLSTM and TTT) on small but popular KITTI dataset for a quick experience with our linear RNN-based framework.
tl;dr: For dataset distillation of kernel ridge regression, we show theoretically that one data per class is necessary and sufficient to recover the original model's performance in many settings.

Deep learning models are now trained on increasingly larger datasets, making it crucial to reduce computational costs and improve data quality. Dataset distillation aims to distill a large dataset into a small synthesized dataset such that models trained on it can achieve similar performance to those trained on the original dataset. While there have been many empirical efforts to improve dataset distillation algorithms, a thorough theoretical analysis and provable, efficient algorithms are still lacking. In this paper, by focusing on dataset distillation for kernel ridge regression (KRR), we show that one data point per class is already necessary and sufficient to recover the original model's performance in many settings. For linear ridge regression and KRR with surjective feature mappings, we provide necessary and sufficient conditions for the distilled dataset to recover the original model's parameters. For KRR with injective feature mappings of deep neural networks, we show that while one data point per class is not sufficient in general, $k+1$ data points can be sufficient for deep linear neural networks, where $k$ is the number of classes. Our theoretical results enable directly constructing analytical solutions for distilled datasets, resulting in a provable and efficient dataset distillation algorithm for KRR. We verify our theory experimentally and show that our algorithm outperforms previous work such as KIP while being significantly more efficient, e.g. 15840$\times$ faster on CIFAR-100.
tl;dr: We provide the first proof of the SLTH in classical settings with guarantees on the sparsity of the subnetworks.

Considerable research efforts have recently been made to show that a random neural network $N$ contains subnetworks capable of accurately approximating any given neural network that is sufficiently smaller than $N$, without any training.
This line of research, known as the Strong Lottery Ticket Hypothesis (SLTH), was originally motivated by the weaker Lottery Ticket Hypothesis, which states that a sufficiently large random neural network $N$ contains sparse subnetworks that can be trained efficiently to achieve performance comparable to that of training the entire network $N$.
Despite its original motivation, results on the SLTH have so far not provided any guarantee on the size of subnetworks.
Such limitation is due to the nature of the main technical tool leveraged by these results, the Random Subset Sum (RSS) Problem.
Informally, the RSS Problem asks how large a random i.i.d. sample $\Omega$ should be so that we are able to approximate any number in $[-1,1]$, up to an error of $ \epsilon$, as the sum of a suitable subset of $\Omega$.
We provide the first proof of the SLTH in classical settings, such as dense and equivariant networks, with guarantees on the sparsity of the subnetworks. Central to our results, is the proof of an essentially tight bound on the Random Fixed-Size Subset Sum Problem (RFSS), a variant of the RSS Problem in which we only ask for subsets of a given size, which is of independent interest.
tl;dr: We analyze the capabilities of Transformer language models in learning compositional discrete tasks and observe that compositional learning is very sample inefficient.

We analyze the capabilities of Transformer language models in learning compositional discrete tasks. To this end, we evaluate training LLaMA models and prompting GPT-4 and Gemini on four tasks demanding to learn a composition of several discrete sub-tasks. In particular, we measure how well these models can reuse primitives observable in the sub-tasks to learn the composition task. Our results indicate that compositional learning in state-of-the-art Transformer language models is highly sample inefficient: LLaMA requires more data samples than relearning all sub-tasks from scratch to learn the compositional task; in-context prompting with few samples is unreliable and fails at executing the sub-tasks or correcting the errors in multi-round code generation. Further, by leveraging complexity theory, we support these findings with a theoretical analysis focused on the sample inefficiency of gradient descent in memorizing feedforward models. We open source our code at https://github.com/IBM/limitations-lm-algorithmic-compositional-learning.
tl;dr: Under a long-term budget constraint, answer reasoning questions by picking the best combinations of LLMs and prompts.

Recent successes in natural language processing have led to the proliferation of large language models (LLMs) by multiple providers. Each LLM offering has different inference accuracy, monetary cost, and latency, and their accuracy further depends on the exact wording of the question (i.e., the specific prompt). At the same time, users often have a limit on monetary budget and latency to answer all their questions, and they do not know which LLMs to choose for each question to meet their accuracy and long term budget requirements. To navigate this rich design space, we propose TREACLE (Thrifty Reasoning via Context-Aware LLM and Prompt Selection), a reinforcement learning policy that jointly selects the model and prompting scheme while respecting the user's monetary cost and latency constraints. TREACLE uses the problem context, including question text embeddings (reflecting the type or difficulty of a query) and the response history (reflecting the consistency of previous responses) to make smart decisions. Our evaluations on standard reasoning datasets (GSM8K, CSQA, and LLC) with various LLMs and prompts show that TREACLE enables cost savings of up to 85% compared to baselines, while maintaining high accuracy. Importantly, it provides the user with the ability to gracefully trade off accuracy for cost.
tl;dr: This work designs a memory efficient block coordinate descent optimization method for finetuning LLMs, which effectively finetunes Llama 3-8B and Llama 3-70B using a single RTX3090-24GB GPU and 4 A100-80GB GPUs, respectively.

This work presents BAdam, an optimization method that leverages the block coordinate descent (BCD) framework with Adam's update rule. BAdam offers a memory efficient approach to the full parameter finetuning of large language models. We conduct
a theoretical convergence analysis for BAdam in the deterministic case. Experimentally, we apply BAdam to finetune the Llama 3-8B and Llama 3-70B models using a single RTX3090-24GB GPU and 4 A100-80GB GPUs, respectively. The results confirm BAdam's efficiency in terms of memory usage, running time, and optimization capability. Furthermore, the downstream performance evaluation based on MT-bench and math benchmarks shows that BAdam outperforms existing memory efficient baselines such as LoRA. It also demonstrates that BAdam can achieve comparable or even superior performance compared to Adam. Finally, the ablation study using SGD's update rule illustrates the suitability of BCD for finetuning LLMs. Our code can be easily integrated into any PyTorch-based codebase and is available at https://github.com/Ledzy/BAdam.

Recently, 3D Gaussian Splatting (3DGS) has become a promising framework for novel view synthesis, offering fast rendering speeds and high fidelity. However, the large number of Gaussians and their associated attributes require effective compression techniques.
Existing methods primarily compress neural Gaussians individually and independently, i.e., coding all the neural Gaussians at the same time, with little design for their interactions and spatial dependence. Inspired by the effectiveness of the context model in image compression, we propose the first autoregressive model at the anchor level for 3DGS compression in this work. We divide anchors into different levels and the anchors that are not coded yet can be predicted based on the already coded ones in all the coarser levels, leading to more accurate modeling and higher coding efficiency. To further improve the efficiency of entropy coding, e.g., to code the coarsest level with no already coded anchors, we propose to introduce a low-dimensional quantized feature as the hyperprior for each anchor, which can be effectively compressed. Our work pioneers the context model in the anchor level for 3DGS representation, yielding an impressive size reduction of over 100 times compared to vanilla 3DGS and 15 times compared to the most recent state-of-the-art work Scaffold-GS, while achieving comparable or even higher rendering quality.
tl;dr: We formulate and investigate the problem of generating structurally diverse graphs that can serve as representative instances for various graph-related tasks.

For many graph-related problems, it can be essential to have a set of structurally diverse graphs. For instance, such graphs can be used for testing graph algorithms or their neural approximations. However, to the best of our knowledge, the problem of generating structurally diverse graphs has not been explored in the literature. In this paper, we fill this gap. First, we discuss how to define diversity for a set of graphs, why this task is non-trivial, and how one can choose a proper diversity measure. Then, for a given diversity measure, we propose and compare several algorithms optimizing it: we consider approaches based on standard random graph models, local graph optimization, genetic algorithms, and neural generative models. We show that it is possible to significantly improve diversity over basic random graph generators. Additionally, our analysis of generated graphs allows us to better understand the properties of graph distances: depending on which diversity measure is used for optimization, the obtained graphs may possess very different structural properties which gives a better understanding of the graph distance underlying the diversity measure.
tl;dr: We introduce an efficiency-adapted variational autoencoder design for latent diffusion models with improved scalability and computational efficiency.

Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a new autoencoder design for LDMs, which leverages the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
tl;dr: We provide a lightweight, privacy-preserving encoder that can be efficiently embedded into low-power audio devices.

Speech serves as a ubiquitous input interface for embedded mobile devices.
Cloud-based solutions, while offering powerful speech understanding services, raise significant concerns regarding user privacy.
To address this, disentanglement-based encoders have been proposed to remove sensitive information from speech signals without compromising the speech understanding functionality.
However, these encoders demand high memory usage and computation complexity, making them impractical for resource-constrained wimpy devices.
Our solution is based on a key observation that speech understanding hinges on long-term dependency knowledge of the entire utterance, in contrast to privacy-sensitive elements that are short-term dependent.
Exploiting this observation, we propose SILENCE, a lightweight system that selectively obscuring short-term details, without damaging the long-term dependent speech understanding performance.
The crucial part of SILENCE is a differential mask generator derived from interpretable learning to
automatically configure the masking process.
We have implemented SILENCE on the STM32H7 microcontroller and evaluate its efficacy under different attacking scenarios.
Our results demonstrate that SILENCE offers speech understanding performance and privacy protection capacity comparable to existing encoders, while achieving up to 53.3$\times$ speedup and 134.1$\times$ reduction in memory footprint.
tl;dr: We investigate the extent to which contemporary LLMs can engage in exploration.

We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision making. We focus on native performance of existing LLMs, without training interventions. We deploy LLMs as agents in simple multi-armed bandit environments, specifying the environment description and interaction history entirely in-context, i.e., within the LLM prompt. We experiment with GPT-3.5, GPT-4, and Llama2, using a variety of prompt designs, and find that the models do not robustly engage in exploration without substantial interventions: i) Only one configuration resulted in satisfactory exploratory behavior: GPT-4 with chain-of-thought reasoning and an externally summarized interaction history; ii) All other configurations did not result in robust exploratory behavior, including those with chain-of-thought reasoning but unsummarized history. While these findings can be interpreted positively, they suggest that external summarization—which may not be possible in more complex settings—is essential for desirable LLM behavior. We conclude that non-trivial algorithmic interventions, such as fine-tuning or dataset curation, may be required to empower LLM-based decision making agents in complex settings.

Zero-Shot Object Goal Navigation (ZS-OGN) enables robots to navigate toward objects of unseen categories without prior training. Traditional approaches often leverage categorical semantic information for navigation guidance, which struggles when only partial objects are observed or detailed and functional representations of the environment are lacking. To resolve the above two issues, we propose \textit{Geometric-part and Affordance Maps} (GAMap), a novel method that integrates object parts and affordance attributes for navigation guidance. Our method includes a multi-scale scoring approach to capture geometric-part and affordance attributes of objects at different scales. Comprehensive experiments conducted on the HM3D and Gibson benchmark datasets demonstrate improvements in Success Rates and Success weighted by Path Length, underscoring the efficacy of our geometric-part and affordance-guided navigation approach in enhancing robot autonomy and versatility, without any additional task-specific training or fine-tuning with the semantics of unseen objects and/or the locomotions of the robot.

Look-up tables(LUTs)-based methods have recently shown enormous potential in image restoration tasks, which are capable of significantly accelerating the inference. However, the size of LUT exhibits exponential growth with the convolution kernel size, creating a storage bottleneck for its broader application on edge devices. Here, we address the storage explosion challenge to promote the capacity of mapping the complex CNN models by LUT. We introduce an innovative separable mapping strategy to achieve over $7\times$ storage reduction, transforming the storage from exponential dependence on kernel size to a linear relationship. Moreover, we design a dynamic discretization mechanism to decompose the activation and compress the quantization scale that further shrinks the LUT storage by $4.48\times$. As a result, the storage requirement of our proposed TinyLUT is around 4.1\% of MuLUT-SDY-X2 and amenable to on-chip cache, yielding competitive accuracy with over $5\times$ lower inference latency on Raspberry 4B than FSRCNN. Our proposed TinyLUT enables superior inference speed on edge devices with new state-of-the-art accuracy on both of image super-resolution and denoising, showcasing the potential of applying this method to various image restoration tasks at the edge. The codes are available at: https://github.com/Jonas-KD/TinyLUT.

Cinematographers adeptly capture the essence of the world, crafting compelling visual narratives through intricate camera movements. Witnessing the strides made by large language models in perceiving and interacting with the 3D world, this study explores their capability to control cameras with human language guidance. We introduce ChatCam, a system that navigates camera movements through conversations with users, mimicking a professional cinematographer's workflow. To achieve this, we propose CineGPT, a GPT-based autoregressive model for text-conditioned camera trajectory generation. We also develop an Anchor Determinator to ensure precise camera trajectory placement. ChatCam understands user requests and employs our proposed tools to generate trajectories, which can be used to render high-quality video footage on radiance field representations. Our experiments, including comparisons to state-of-the-art approaches and user studies, demonstrate our approach's ability to interpret and execute complex instructions for camera operation, showing promising applications in real-world production settings. Project page: https://xinhangliu.com/chatcam.
tl;dr: We study algorithmic monoculture in a matching markets framework

Algorithmic monoculture arises when many decision-makers rely on the same algorithm to evaluate applicants. An emerging body of work investigates possible harms of this kind of homogeneity, but has been limited by the challenge of incorporating market effects in which the preferences and behavior of many applicants and decision-makers jointly interact to determine outcomes.
Addressing this challenge, we introduce a tractable theoretical model of algorithmic monoculture in a two-sided matching market with many participants. We use the model to analyze outcomes under monoculture (when decision-makers all evaluate applicants using a common algorithm) and under polyculture (when decision-makers evaluate applicants independently). All else equal, monoculture (1) selects less-preferred applicants when noise is well-behaved, (2) matches more applicants to their top choice, though individual applicants may be worse off depending on their value to decision-makers and risk tolerance, and (3) is more robust to disparities in the number of applications submitted.
tl;dr: We use evolutionary computation and large language models to generate new and interesting board games

Automatically generating novel and interesting games is a complex task. Challenges include representing game rules in a computationally workable form, searching through the large space of potential games under most such representations, and accurately evaluating the originality and quality of previously unseen games. Prior work in automated game generation has largely focused on relatively restricted rule representations and relied on domain-specific heuristics. In this work, we explore the generation of novel games in the comparatively expansive Ludii game description language, which encodes the rules of over 1000 board games in a variety of styles and modes of play. We draw inspiration from recent advances in large language models and evolutionary computation in order to train a model that intelligently mutates and recombines games and mechanics expressed as code. We demonstrate both quantitatively and qualitatively that our approach is capable of generating new and interesting games, including in regions of the potential rules space not covered by existing games in the Ludii dataset.

The cost of ranking becomes significant in the new stage of deep learning. We propose ST$_k$, a fully differentiable module with a single trainable parameter, designed to solve the Top-k problem without requiring additional time or GPU memory. Due to its fully differentiable nature, ST$_k$ can be embedded end-to-end into neural networks and optimize the Top-k problems within a unified computational graph. We apply ST$_k$ to the Average Top-k Loss (AT$_k$), which inherently faces a Top-k problem. The proposed ST$_k$ Loss outperforms AT$_k$ Loss and achieves the best average performance on multiple benchmarks, with the lowest standard deviation. With the assistance of ST$_k$ Loss, we surpass the state-of-the-art (SOTA) on both CIFAR-100-LT and Places-LT leaderboards.
tl;dr: An efficient yet novel approach for zero-shot denoising

In this work, we observe that model trained on vast general images via masking strategy, has been naturally embedded with their distribution knowledge, thus spontaneously attains the underlying potential for strong image denoising.
Based on this observation, we propose a novel zero-shot denoising paradigm, i.e., $\textbf{M}$asked $\textbf{P}$re-train then $\textbf{I}$terative fill ($\textbf{MPI}$).
MPI first trains model via masking and then employs pre-trained weight for high-quality zero-shot image denoising on a single noisy image.
Concretely, MPI comprises two key procedures:
$\textbf{1) Masked Pre-training}$ involves training model to reconstruct massive natural images with random masking for generalizable representations, gathering the potential for valid zero-shot denoising on images with varying noise degradation and even in distinct image types.
$\textbf{2) Iterative filling}$ exploits pre-trained knowledge for effective zero-shot denoising. It iteratively optimizes the image by leveraging pre-trained weights, focusing on alternate reconstruction of different image parts, and gradually assembles fully denoised image within limited number of iterations.
Comprehensive experiments across various noisy scenarios underscore the notable advances of MPI over previous approaches with a marked reduction in inference time.

Conformal prediction is an uncertainty quantification method that constructs a prediction set for a previously unseen datum, ensuring the true label is included with a predetermined coverage probability. Adaptive conformal prediction has been developed to address data distribution shifts in dynamic environments. However, the efficiency of prediction sets varies depending on the learning model used. Employing a single fixed model may not consistently offer the best performance in dynamic environments with unknown data distribution shifts. To address this issue, we introduce a novel adaptive conformal prediction framework, where the model used for creating prediction sets is selected ‘on the fly’ from multiple candidate models. The proposed algorithm is proven to achieve strongly adaptive regret over all intervals while maintaining valid coverage. Experiments on both real and synthetic datasets corroborate that the proposed approach consistently yields more efficient prediction sets while maintaining valid coverage, outperforming alternative methods.
tl;dr: We introduce the sparse maximal update parameterization (S$\textmu$Par) which ensures optimal HPs remain the same for any width or sparsity level. This dramatically reduces HP tuning costs, allowing S$\textmu$Par to achieve superior losses.

Several challenges make it difficult for sparse neural networks to compete with dense models. First, setting a large fraction of weights to zero impairs forward and gradient signal propagation. Second, sparse studies often need to test multiple sparsity levels, while also introducing new hyperparameters (HPs), leading to prohibitive tuning costs. Indeed, the standard practice is to re-use the learning HPs originally crafted for dense models. Unfortunately, we show sparse and
dense networks do not share the same optimal HPs. Without stable dynamics and effective training recipes, it is costly to test sparsity at scale, which is key to surpassing dense networks and making the business case for sparsity acceleration in hardware.
A holistic approach is needed to tackle these challenges and we propose S$\textmu$Par as one such approach. For random unstructured static sparsity, S$\textmu$Par ensures activations, gradients, and weight updates all scale independently of sparsity level. Further, by reparameterizing the HPs, S$\textmu$Par enables the same HP values to be optimal as we vary both sparsity level and model width. HPs can be tuned on small dense networks and transferred to large sparse models, greatly reducing tuning costs. On large-scale language modeling, S$\textmu$Par shows increasing improvements over standard parameterization as sparsity increases, leading up to 11.9\% relative loss improvement at 99.2\% sparsity. A minimal implementation of S$\textmu$Par is available at https://github.com/EleutherAI/nanoGPT-mup/tree/supar.

Symmetry detection has been shown to improve various machine learning tasks. In the context of continuous symmetry detection, current state of the art experiments are limited to the detection of affine transformations. Under the manifold assumption, we outline a framework for discovering continuous symmetry in data beyond the affine transformation group. We also provide a similar framework for discovering discrete symmetry. We experimentally compare our method to an existing method known as LieGAN and show that our method is competitive at detecting affine symmetries for large sample sizes and superior than LieGAN for small sample sizes. We also show our method is able to detect continuous symmetries beyond the affine group and is generally more computationally efficient than LieGAN.
tl;dr: We highlight flaws in using accuracy to evaluate LLM compression methods and suggest alternate metrics.

When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on various benchmarks. If the accuracies of the baseline model and the compressed model are close, it is assumed that there was negligible degradation in quality. However, even when the accuracy of baseline and compressed model are similar, we observe the phenomenon of flips, wherein answers change from correct to incorrect and vice versa in proportion. We conduct a detailed study of metrics across multiple compression techniques, models and datasets, demonstrating that the behavior of compressed models as visible to end-users is often significantly different from the baseline model, even when accuracy is similar. We further evaluate compressed models qualitatively and quantitatively using MT-Bench and show that compressed models exhibiting high flips are worse than baseline models in this free-form generative task. Thus, we argue that accuracy and perplexity are necessary but not sufficient for evaluating compressed models, since these metrics hide large underlying changes that have not been observed by previous work. Hence, compression techniques should also be evaluated using distance metrics. We propose two such distance metrics, KL-Divergence and flips, and show that they are well correlated.

We focus on developing a theoretical understanding of meta-learning. Given multiple tasks drawn i.i.d. from some (unknown) task distribution, the goal is to find a good pre-trained model that can be adapted to a new, previously unseen, task with little computational and statistical overhead. We introduce a novel notion of stability for meta-learning algorithms, namely *uniform meta-stability*. We instantiate two uniformly meta-stable learning algorithms based on regularized empirical risk minimization and gradient descent and give explicit generalization bounds for convex learning problems with smooth losses and for weakly convex learning problems with non-smooth losses. Finally, we extend our results to stochastic and adversarially robust variants of our meta-learning algorithm.
tl;dr: Traditional model-based offline reinforcement learning suffers from high estimation variance due to sampling, but MOMBO addresses this by deterministically propagating uncertainties through the value function, providing novel suboptimality guarantees

Current approaches to model-based offline reinforcement learning often incorporate uncertainty-based reward penalization to address the distributional shift problem. These approaches, commonly known as pessimistic value iteration, use Monte Carlo sampling to estimate the Bellman target to perform temporal difference based policy evaluation. We find out that the randomness caused by this sampling step significantly delays convergence. We present a theoretical result demonstrating the strong dependency of suboptimality on the number of Monte Carlo samples taken per Bellman target calculation. Our main contribution is a deterministic approximation to the Bellman target that uses progressive moment matching, a method developed originally for deterministic variational inference. The resulting algorithm, which we call Moment Matching Offline Model-Based Policy Optimization (MOMBO), propagates the uncertainty of the next state through a nonlinear Q-network in a deterministic fashion by approximating the distributions of hidden layer activations by a normal distribution. We show that it is possible to provide tighter guarantees for the suboptimality of MOMBO than the existing Monte Carlo sampling approaches. We also observe MOMBO to converge faster than these approaches in a large set of benchmark tasks.
tl;dr: We use generative model to sample partner agents to train a coordinator agent. These agents cooperate well with real human players.

Training agents that can coordinate zero-shot with humans is a key mission in multi-agent reinforcement learning (MARL). Current algorithms focus on training simulated human partner policies which are then used to train a Cooperator agent. The simulated human is produced either through behavior cloning over a dataset of human cooperation behavior, or by using MARL to create a population of simulated agents. However, these approaches often struggle to produce a Cooperator that can coordinate well with real humans, since the simulated humans fail to cover the diverse strategies and styles employed by people in the real world. We show \emph{learning a generative model of human partners} can effectively address this issue. Our model learns a latent variable representation of the human that can be regarded as encoding the human's unique strategy, intention, experience, or style. This generative model can be flexibly trained from any (human or neural policy) agent interaction data. By sampling from the latent space, we can use the generative model to produce different partners to train Cooperator agents. We evaluate our method---Generative Agent Modeling for Multi-agent Adaptation (GAMMA)---on Overcooked, a challenging cooperative cooking game that has become a standard benchmark for zero-shot coordination. We conduct an evaluation with real human teammates, and the results show that GAMMA consistently improves performance, whether the generative model is trained on simulated populations or human datasets. Further, we propose a method for posterior sampling from the generative model that is biased towards the human data, enabling us to efficiently improve performance with only a small amount of expensive human interaction data.
tl;dr: Data poisoning attacks against vision language models

Vision-Language Models (VLMs) excel in generating textual responses from visual inputs, but their versatility raises security concerns. This study takes the first step in exposing VLMs’ susceptibility to data poisoning attacks that can manipulate responses to innocuous, everyday prompts. We introduce Shadowcast, a stealthy data poisoning attack where poison samples are visually indistinguishable from benign images with matching texts. Shadowcast demonstrates effectiveness in two attack types. The first is a traditional Label Attack, tricking VLMs into misidentifying class labels, such as confusing Donald Trump for Joe Biden. The second is a novel Persuasion Attack, leveraging VLMs’ text generation capabilities to craft persuasive and seemingly rational narratives for misinformation, such as portraying junk food as healthy. We show that Shadowcast effectively achieves the attacker’s intentions using as few as 50 poison samples. Crucially, the poisoned samples demonstrate transferability across different VLM architectures, posing a significant concern in black-box settings. Moreover, Shadowcast remains potent under realistic conditions involving various text prompts, training data augmentation, and image compression techniques. This work reveals how poisoned VLMs can disseminate convincing yet deceptive misinformation to everyday, benign users, emphasizing the importance of data integrity for responsible VLM deployments. Our code is available at: https://github.com/umd-huang-lab/VLM-Poisoning.

Novel view synthesis from sparse inputs is a vital yet challenging task in 3D computer vision. Previous methods explore 3D Gaussian Splatting with neural priors (e.g. depth priors) as an additional supervision, demonstrating promising quality and efficiency compared to the NeRF based methods. However, the neural priors from 2D pretrained models are often noisy and blurry, which struggle to precisely guide the learning of radiance fields. In this paper, We propose a novel method for synthesizing novel views from sparse views with Gaussian Splatting that does not require external prior as supervision. Our key idea lies in exploring the self-supervisions inherent in the binocular stereo consistency between each pair of binocular images constructed with disparity-guided image warping. To this end, we additionally introduce a Gaussian opacity constraint which regularizes the Gaussian locations and avoids Gaussian redundancy for
improving the robustness and efficiency of inferring 3D Gaussians from sparse views. Extensive experiments on the LLFF, DTU, and Blender datasets demonstrate that our method significantly outperforms the state-of-the-art methods.

This paper presents M$^3$GPT, an advanced $\textbf{M}$ultimodal, $\textbf{M}$ultitask framework for $\textbf{M}$otion comprehension and generation. M$^3$GPT operates on three fundamental principles. The first focuses on creating a unified representation space for various motion-relevant modalities. We employ discrete vector quantization for multimodal conditional signals, such as text, music and motion/dance, enabling seamless integration into a large language model (LLM) with a single vocabulary.
The second involves modeling motion generation directly in the raw motion space. This strategy circumvents the information loss associated with a discrete tokenizer, resulting in more detailed and comprehensive motion generation.
Third, M$^3$GPT learns to model the connections and synergies among various motion-relevant tasks. Text, the most familiar and well-understood modality for LLMs, is utilized as a bridge to establish connections between different motion tasks, facilitating mutual
reinforcement. To our knowledge, M$^3$GPT is the first model capable of comprehending and generating motions based on multiple signals.
Extensive experiments highlight M$^3$GPT's superior performance across various motion-relevant tasks and its powerful zero-shot generalization capabilities for extremely challenging tasks. Project page: \url{https://github.com/luomingshuang/M3GPT}.

Recently, Deep Image Prior (DIP) has emerged as an effective unsupervised one-shot learner, delivering competitive results across various image recovery problems. This method only requires the noisy measurements and a forward operator, relying solely on deep networks initialized with random noise to learn and restore the structure of the data. However, DIP is notorious for its vulnerability to overfitting due to the overparameterization of the network. Building upon insights into the impact of the DIP input and drawing inspiration from the gradual denoising process in cutting-edge diffusion models, we introduce Autoencoding Sequential DIP (aSeqDIP) for image reconstruction. This method progressively denoises and reconstructs the image through a sequential optimization of network weights. This is achieved using an input-adaptive DIP objective, combined with an autoencoding regularization term. Compared to diffusion models, our method does not require training data and outperforms other DIP-based methods in mitigating noise overfitting while maintaining a similar number of parameter updates as Vanilla DIP. Through extensive experiments, we validate the effectiveness of our method in various image reconstruction tasks, such as MRI and CT reconstruction, as well as in image restoration tasks like image denoising, inpainting, and non-linear deblurring.

Group Recommendation (GR), which aims to recommend items to groups of users, has become a promising and practical direction for recommendation systems. This paper points out two issues of the state-of-the-art GR models. (1) The pre-defined and fixed number of user groups is inadequate for real-time industrial recommendation systems, where the group distribution can shift dynamically. (2) The training schema of existing GR methods is supervised, necessitating expensive user-group and group-item labels, leading to significant annotation costs. To this end, we present a novel unsupervised group recommendation framework named $\underline{\text{I}}$dentify $\underline{\text{T}}$hen $\underline{\text{R}}$ecommend ($\underline{\text{ITR}}$), where it first identifies the user groups in an unsupervised manner even without the pre-defined number of groups, and then two pre-text tasks are designed to conduct self-supervised group recommendation. Concretely, at the group identification stage, we first estimate the adaptive density of each user point, where areas with higher densities are more likely to be recognized as group centers. Then, a heuristic merge-and-split strategy is designed to discover the user groups and decision boundaries. Subsequently, at the self-supervised learning stage, the pull-and-repulsion pre-text task is proposed to optimize the user-group distribution. Besides, the pseudo group recommendation pre-text task is designed to assist the recommendations. Extensive experiments demonstrate the superiority and effectiveness of ITR on both user recommendation (e.g., 22.22\% NDCG@5 $\uparrow$) and group recommendation (e.g., 22.95\% NDCG@5 $\uparrow$). Furthermore, we deploy ITR on the industrial recommender and achieve promising results.

Despite the effectiveness of data selection for pretraining and instruction fine-tuning
large language models (LLMs), improving data efficiency in supervised fine-tuning
(SFT) for specialized domains poses significant challenges due to the complexity
of fine-tuning data. To bridge this gap, we introduce an effective and scalable
data selection method for SFT, SmallToLarge (S2L), which trains a small
model, clusters loss trajectories of the examples, and samples from these clusters to
guide data selection for larger models. We prove that during fine-tuning, samples
within the same loss trajectory cluster exhibit similar gradients. Then, we show
that S2L subsets have a bounded gradient error w.r.t. the full data, hence guarantee
convergence to the neighborhood of the optimal solution. We demonstrate through
extensive experiments that S2L significantly improves data efficiency in SFT for
mathematical problem-solving, reducing the training data requirement to just $11$%
of the original MathInstruct dataset to match full dataset performance while
outperforming state-of-the-art data selection algorithms by an average of $4.7$%
across $6$ in- and out-domain evaluation datasets. Remarkably, selecting only 50K
data for SFT, S2L achieves a $32.7$% accuracy on the challenging MATH
benchmark, improving Phi-2 by $16.6$%. In clinical text summarization on the
MIMIC-III dataset, S2L again outperforms training on the full dataset using
only $50$% of the data. Notably, S2L can perform scalable data selection using a
reference model $100\times$ smaller than the target model, proportionally reducing the
computational cost.

Dimension reduction (DR) is an important and widely studied technique in exploratory data analysis. However, traditional DR methods are not applicable to datasets with with a contrastive structure, where data are split into a foreground group of interest (case or treatment group), and a background group (control group). This type of data, common in biomedical studies, necessitates contrastive dimension reduction (CDR) methods to effectively capture information unique to or enriched in the foreground group relative to the background group. Despite the development of various CDR methods, two critical questions remain underexplored: when should these methods be applied, and how can the information unique to the foreground group be quantified? In this work, we address these gaps by proposing a hypothesis test to determine the existence of contrastive information, and introducing a contrastive dimension estimator (CDE) to quantify the unique components in the foreground group. We provide theoretical support for our methods and validate their effectiveness through extensive simulated, semi-simulated, and real experiments involving images, gene expressions, protein expressions, and medical sensors, demonstrating their ability to identify the unique information in the foreground group.
tl;dr: We propose a novel rank-based metric, Diff-eRank, to evaluate LLMs based on representations.

Large Language Models (LLMs) have transformed natural language processing and extended their powerful capabilities to multi-modal domains. As LLMs continue to advance, it is crucial to develop diverse and appropriate metrics for their evaluation. In this paper, we introduce a novel rank-based metric, Diff-eRank, grounded in information theory and geometry principles. Diff-eRank assesses LLMs by analyzing their hidden representations, providing a quantitative measure of how efficiently they eliminate redundant information during training. We demonstrate the applicability of Diff-eRank in both single-modal (e.g., language) and multi-modal settings. For language models, our results show that Diff-eRank increases with model size and correlates well with conventional metrics such as loss and accuracy. In the multi-modal context, we propose an alignment evaluation method based on the eRank, and verify that contemporary multi-modal LLMs exhibit strong alignment performance based on our method. Our code is publicly available at https://github.com/waltonfuture/Diff-eRank.
tl;dr: A mixed time series analysis framework, which recovers and aligns latent continuity of mixed variables for complete and reliable spatial-temporal modeling, being amenable to various analysis tasks.

Mixed time series (MiTS) comprising both continuous variables (CVs) and discrete variables (DVs) are frequently encountered yet under-explored in time series analysis. Essentially, CVs and DVs exhibit different temporal patterns and distribution types. Overlooking these heterogeneities would lead to insufficient and imbalanced representation learning, bringing biased results. This paper addresses the problem with two insights: 1) DVs may originate from intrinsic latent continuous variables (LCVs), which lose fine-grained information due to extrinsic discretization; 2) LCVs and CVs share similar temporal patterns and interact spatially. Considering these similarities and interactions, we propose a general MiTS analysis framework MiTSformer, which recovers LCVs behind DVs for sufficient and balanced spatial-temporal modeling by designing two essential inductive biases: 1) hierarchically aggregating multi-scale temporal context information to enrich the information granularity of DVs; 2) adaptively learning the aggregation processes via the adversarial guidance from CVs. Subsequently, MiTSformer captures complete spatial-temporal dependencies within and across LCVs and CVs via cascaded self- and cross-attention blocks. Empirically, MiTSformer achieves consistent SOTA on five mixed time series analysis tasks, including classification, extrinsic regression, anomaly detection, imputation, and long-term forecasting. The code is available at https://github.com/chunhuiz/MiTSformer.
tl;dr: We derive a white-box decoder for Transformer-based semantic segmentation from the perspective of maximizing coding rate and computing principle components.

State-of-the-art methods for Transformer-based semantic segmentation typically adopt Transformer decoders that are used to extract additional embeddings from image embeddings via cross-attention, refine either or both types of embeddings via self-attention, and project image embeddings onto the additional embeddings via dot-product. Despite their remarkable success, these empirical designs still lack theoretical justifications or interpretations, thus hindering potentially principled improvements. In this paper, we argue that there are fundamental connections between semantic segmentation and compression, especially between the Transformer decoders and Principal Component Analysis (PCA). From such a perspective, we derive a white-box, fully attentional DEcoder for PrIncipled semantiC segemenTation (DEPICT), with the interpretations as follows: 1) the self-attention operator refines image embeddings to construct an ideal principal subspace that aligns with the supervision and retains most information; 2) the cross-attention operator seeks to find a low-rank approximation of the refined image embeddings, which is expected to be a set of orthonormal bases of the principal subspace and corresponds to the predefined classes; 3) the dot-product operation yields compact representation for image embeddings as segmentation masks. Experiments conducted on dataset ADE20K find that DEPICT consistently outperforms its black-box counterpart, Segmenter, and it is light weight and more robust.
3540. DN-4DGS: Denoised Deformable Network with Temporal-Spatial Aggregation for Dynamic Scene Rendering

Dynamic scenes rendering is an intriguing yet challenging problem. Although current methods based on NeRF have achieved satisfactory performance, they still can not reach real-time levels. Recently, 3D Gaussian Splatting (3DGS) has garnered researchers' attention due to their outstanding rendering quality and real-time speed. Therefore, a new paradigm has been proposed: defining a canonical 3D gaussians and deforming it to individual frames in deformable fields. However, since the coordinates of canonical 3D gaussians are filled with noise, which can transfer noise into the deformable fields, and there is currently no method that adequately considers the aggregation of 4D information. Therefore, we propose Denoised Deformable Network with Temporal-Spatial Aggregation for Dynamic Scene Rendering (DN-4DGS). Specifically, a Noise Suppression Strategy is introduced to change the distribution of the coordinates of the canonical 3D gaussians and suppress noise. Additionally, a Decoupled Temporal-Spatial Aggregation Module is designed to aggregate information from adjacent points and frames. Extensive experiments on various real-world datasets demonstrate that our method achieves state-of-the-art rendering quality under a real-time level. Code is available at https://github.com/peoplelu/DN-4DGS.

High-quality public datasets significantly prompt the prosperity of deep neural networks (DNNs). Currently, dataset ownership verification (DOV), which consists of dataset watermarking and ownership verification, is the only feasible solution to protect their copyright by preventing unauthorized use. In this paper, we revisit existing DOV methods and find that they all mainly focused on the first stage by designing different types of dataset watermarks and directly exploiting watermarked samples as the verification samples for ownership verification. As such, their success relies on an underlying assumption that verification is a \emph{one-time} and \emph{privacy-preserving} process, which does not necessarily hold in practice. To alleviate this problem, we propose \emph{ZeroMark} to conduct ownership verification without disclosing dataset-specified watermarks. Our method is inspired by our empirical and theoretical findings of the intrinsic property of DNNs trained on the watermarked dataset. Specifically, ZeroMark first generates the closest boundary version of given benign samples and calculates their boundary gradients under the label-only black-box setting. After that, it examines whether the given suspicious method has been trained on the protected dataset by performing a hypothesis test, based on the cosine similarity measured on the boundary gradients and the watermark pattern. Extensive experiments on benchmark datasets verify the effectiveness of our ZeroMark and its resistance to potential adaptive attacks. The codes for reproducing our main experiments are publicly available at \href{https://github.com/JunfengGo/ZeroMark.git}{GitHub}.
tl;dr: In this work, we conduct a systematic study of stochastic saddle point problems (SSP) and stochastic variational inequalities (SVI) under the constraint of $(\epsilon,\delta)$-differential privacy (DP) in both Euclidean and non-Euclidean setups.

In this work, we conduct a systematic study of stochastic saddle point problems (SSP) and stochastic variational inequalities (SVI) under the constraint of $(\epsilon,\delta)$-differential privacy (DP) in both Euclidean and non-Euclidean setups. We first consider Lipschitz convex-concave SSPs in the $\ell_p/\ell_q$ setup, $p,q\in[1,2]$. That is, we consider the case where the primal problem has an $\ell_p$-setup (i.e., the primal parameter is constrained to an $\ell_p$ bounded domain and the loss is $\ell_p$-Lipschitz with respect to the primal parameter) and the dual problem has an $\ell_q$ setup. Here, we obtain a bound of $\tilde{O}\big(\frac{1}{\sqrt{n}} + \frac{\sqrt{d}}{n\epsilon}\big)$ on the strong SP-gap, where $n$ is the number of samples and $d$ is the dimension. This rate is nearly optimal for any $p,q\in[1,2]$. Without additional assumptions, such as smoothness or linearity requirements, prior work under DP has only obtained this rate when $p=q=2$ (i.e., only in the Euclidean setup). Further, existing algorithms have each only been shown to work for specific settings of $p$ and $q$ and under certain assumptions on the loss and the feasible set, whereas we provide a general algorithm for DP SSPs whenever $p,q\in[1,2]$. Our result is obtained via a novel analysis of the recursive regularization algorithm. In particular, we develop new tools for analyzing generalization, which may be of independent interest. Next, we turn our attention towards SVIs with a monotone, bounded and Lipschitz operator and consider $\ell_p$-setups, $p\in[1,2]$. Here, we provide the first analysis which obtains a bound on the strong VI-gap of $\tilde{O}\big(\frac{1}{\sqrt{n}} + \frac{\sqrt{d}}{n\epsilon}\big)$. For $p-1=\Omega(1)$, this rate is near optimal due to existing lower bounds. To obtain this result, we develop a modified version of recursive regularization. Our analysis builds on the techniques we develop for SSPs as well as employing additional novel components which handle difficulties arising from adapting the recursive regularization framework to SVIs.
tl;dr: A novel offline reinforcement learning method for efficient generalization of unseen tasks

Multi-task offline reinforcement learning aims to develop a unified policy for diverse tasks without requiring real-time interaction with the environment. Recent work explores sequence modeling, leveraging the scalability of the transformer architecture as a foundation for multi-task learning. Given the variations in task content and complexity, formulating policies becomes a challenging endeavor, requiring careful parameter sharing and adept management of conflicting gradients to extract rich cross-task knowledge from multiple tasks and transfer it to unseen tasks. In this paper, we propose the Decomposed Prompt Decision Transformer (DPDT) that adopts a two-stage paradigm to efficiently learn prompts for unseen tasks in a parameter-efficient manner. We incorporate parameters from pre-trained language models (PLMs) to initialize DPDT, thereby providing rich prior knowledge encoded in language models. During the decomposed prompt tuning phase, we learn both cross-task and task-specific prompts on training tasks to achieve prompt decomposition. In the test time adaptation phase, the cross-task prompt, serving as a good initialization, were further optimized on unseen tasks through test time adaptation, enhancing the model's performance on these tasks. Empirical evaluation on a series of Meta-RL benchmarks demonstrates the superiority of our approach. The project is available at https://github.com/ruthless-man/DPDT.

Diffusion models have attained prominence for their ability to synthesize a probability distribution for a given dataset via a diffusion process, enabling the generation of new data points with high fidelity. However, diffusion processes are prone to generating samples that reflect biases in a training dataset. To address this issue, we develop constrained diffusion models by imposing diffusion constraints based on desired distributions that are informed by requirements. Specifically, we cast the training of diffusion models under requirements as a constrained distribution optimization problem that aims to reduce the distribution difference between original and generated data while obeying constraints on the distribution of generated data. We show that our constrained diffusion models generate new data from a mixture data distribution that achieves the optimal trade-off among objective and constraints. To train constrained diffusion models, we develop a dual training algorithm and characterize the optimality of the trained constrained diffusion model. We empirically demonstrate the effectiveness of our constrained models in two constrained generation tasks: (i) we consider a dataset with one or more underrepresented classes where we train the model with constraints to ensure fairly sampling from all classes during inference; (ii) we fine-tune a pre-trained diffusion model to sample from a new dataset while avoiding overfitting.
tl;dr: We propose a semi-definite programming (SDP) relaxation of the GW distance.

The Gromov-Wasserstein (GW) distance is an extension of the optimal transport problem that allows one to match objects between incomparable spaces. At its core, the GW distance is specified as the solution of a non-convex quadratic program and is not known to be tractable to solve. In particular, existing solvers for the GW distance are only able to find locally optimal solutions. In this work, we propose a semi-definite programming (SDP) relaxation of the GW distance. The relaxation can be viewed as the Lagrangian dual of the GW distance augmented with constraints that relate to the linear and quadratic terms of transportation plans. In particular, our relaxation provides a tractable (polynomial-time) algorithm to compute globally optimal transportation plans (in some instances) together with an accompanying proof of global optimality. Our numerical experiments suggest that the proposed relaxation is strong in that it frequently computes the globally optimal solution. Our Python implementation is available at https://github.com/tbng/gwsdp.
tl;dr: Unleashing the potential of self-attention by rectifying the distortion of query-key embedding space

Multi-scene absolute pose regression addresses the demand for fast and memory-efficient camera pose estimation across various real-world environments. Nowadays, transformer-based model has been devised to regress the camera pose directly in multi-scenes. Despite its potential, transformer encoders are underutilized due to the collapsed self-attention map, having low representation capacity. This work highlights the problem and investigates it from a new perspective: distortion of query-key embedding space. Based on the statistical analysis, we reveal that queries and keys are mapped in completely different spaces while only a few keys are blended into the query region. This leads to the collapse of the self-attention map as all queries are considered similar to those few keys. Therefore, we propose simple but effective solutions to activate self-attention. Concretely, we present an auxiliary loss that aligns queries and keys, preventing the distortion of query-key space and encouraging the model to find global relations by self-attention. In addition, the fixed sinusoidal positional encoding is adopted instead of undertrained learnable one to reflect appropriate positional clues into the inputs of self-attention. As a result, our approach resolves the aforementioned problem effectively, thus outperforming existing methods in both outdoor and indoor scenes.
tl;dr: We propose a scene graph representation to prompt LLM for zero-shot object navigation, which achieves state-of-the-art performance while being explainable.

In this paper, we propose a new framework for zero-shot object navigation.
Existing zero-shot object navigation methods prompt LLM with the text of spatially closed objects, which lacks enough scene context for in-depth reasoning.
To better preserve the information of environment and fully exploit the reasoning ability of LLM, we propose to represent the observed scene with 3D scene graph. The scene graph encodes the relationships between objects, groups and rooms with a LLM-friendly structure, for which we design a hierarchical chain-of-thought prompt to help LLM reason the goal location according to scene context by traversing the nodes and edges.
Moreover, benefit from the scene graph representation, we further design a re-perception mechanism to empower the object navigation framework with the ability to correct perception error.
We conduct extensive experiments on MP3D, HM3D and RoboTHOR environments, where SG-Nav surpasses previous state-of-the-art zero-shot methods by more than \textbf{10\%} SR on all benchmarks, while the decision process is explainable. To the best of our knowledge, SG-Nav is the first zero-shot method that achieves even higher performance than supervised object navigation methods on the challenging MP3D benchmark.
Code of this project will be released in the final version.
tl;dr: A Markov bridge model for inverse protein folding

Inverse protein folding is a fundamental task in computational protein design, which aims to design protein sequences that fold into the desired backbone structures. While the development of machine learning algorithms for this task has seen significant success, the prevailing approaches, which predominantly employ a discriminative formulation, frequently encounter the error accumulation issue and often fail to capture the extensive variety of plausible sequences. To fill these gaps, we propose Bridge-IF, a generative diffusion bridge model for inverse folding, which is designed to learn the probabilistic dependency between the distributions of backbone structures and protein sequences. Specifically, we harness an expressive structure encoder to propose a discrete, informative prior derived from structures, and establish a Markov bridge to connect this prior with native sequences. During the inference stage, Bridge-IF progressively refines the prior sequence, culminating in a more plausible design. Moreover, we introduce a reparameterization perspective on Markov bridge models, from which we derive a simplified loss function that facilitates more effective training. We also modulate protein language models (PLMs) with structural conditions to precisely approximate the Markov bridge process, thereby significantly enhancing generation performance while maintaining parameter-efficient training. Extensive experiments on well-established benchmarks demonstrate that Bridge-IF predominantly surpasses existing baselines in sequence recovery and excels in the design of plausible proteins with high foldability. The code is available at https://github.com/violet-sto/Bridge-IF.

Multi-modal contrastive representation (MCR) of more than three modalities is critical in multi-modal learning. Although recent methods showcase impressive achievements, the high dependence on large-scale, high-quality paired data and the expensive training costs limit their further development. Inspired by recent C-MCR, this paper proposes $\textbf{Ex}$tending $\textbf{M}$ultimodal $\textbf{C}$ontrastive $\textbf{R}$epresentation (Ex-MCR), a training-efficient and paired-data-free method to build unified contrastive representation for many modalities. Since C-MCR is designed to learn a new latent space for the two non-overlapping modalities and projects them onto this space, a significant amount of information from their original spaces is lost in the projection process. To address this issue, Ex-MCR proposes to extend one modality's space into the other's, rather than mapping both modalities onto a completely new space. This method effectively preserves semantic alignment in the original space. Experimentally, we extend pre-trained audio-text and 3D-image representations to the existing vision-text space. Without using paired data, Ex-MCR achieves comparable performance to advanced methods on a series of audio-image-text and 3D-image-text tasks and achieves superior performance when used in parallel with data-driven methods. Moreover, semantic alignment also emerges between the extended modalities (e.g., audio and 3D).

Out-of-Distribution (OoD) detection is vital for the reliability of Deep Neural Networks (DNNs).
Existing works have shown the insufficiency of Principal Component Analysis (PCA) straightforwardly applied on the features of DNNs in detecting OoD data from In-Distribution (InD) data.
The failure of PCA suggests that the network features residing in OoD and InD are not well separated by simply proceeding in a linear subspace, which instead can be resolved through proper non-linear mappings.
In this work, we leverage the framework of Kernel PCA (KPCA) for OoD detection, and seek suitable non-linear kernels that advocate the separability between InD and OoD data in the subspace spanned by the principal components.
Besides, explicit feature mappings induced from the devoted task-specific kernels are adopted so that the KPCA reconstruction error for new test samples can be efficiently obtained with large-scale data.
Extensive theoretical and empirical results on multiple OoD data sets and network structures verify the superiority of our KPCA detector in efficiency and efficacy with state-of-the-art detection performance.
tl;dr: NeuralFuse provides model-independent protection for AI accelerators built on a chip, allowing them to maintain stable performance when suffering low-voltage-induced bit errors.

Deep neural networks (DNNs) have become ubiquitous in machine learning, but their energy consumption remains problematically high. An effective strategy for reducing such consumption is supply-voltage reduction, but if done too aggressively, it can lead to accuracy degradation. This is due to random bit-flips in static random access memory (SRAM), where model parameters are stored. To address this challenge, we have developed NeuralFuse, a novel add-on module that handles the energy-accuracy tradeoff in low-voltage regimes by learning input transformations and using them to generate error-resistant data representations, thereby protecting DNN accuracy in both nominal and low-voltage scenarios. As well as being easy to implement, NeuralFuse can be readily applied to DNNs with limited access, such cloud-based APIs that are accessed remotely or non-configurable hardware. Our experimental results demonstrate that, at a 1% bit-error rate, NeuralFuse can reduce SRAM access energy by up to 24% while recovering accuracy by up to 57%. To the best of our knowledge, this is the first approach to addressing low-voltage-induced bit errors that requires no model retraining.

As the vision foundation models like the Segment Anything Model (SAM) demonstrate potent universality, they also present challenges in giving ambiguous and uncertain predictions. Significant variations in the model output and granularity can occur with simply subtle changes in the prompt, contradicting the consensus requirement for the robustness of a model. While some established works have been dedicated to stabilizing and fortifying the prediction of SAM, this paper takes a unique path to explore how this flaw can be inverted into an advantage when modeling inherently ambiguous data distributions. We introduce an optimization framework based on a conditional variational autoencoder, which jointly models the prompt and the granularity of the object with a latent probability distribution. This approach enables the model to adaptively perceive and represent the real ambiguous label distribution, taming SAM to produce a series of diverse, convincing, and reasonable segmentation outputs controllably. Extensive experiments on several practical deployment scenarios involving ambiguity demonstrates the exceptional performance of our framework. Project page: \url{https://a-sa-m.github.io/}.
tl;dr: Introducing dataset decomposition to optimize training of large language models using mixture of sequence lengths, significantly improving learning efficiency (up to 3 times faster to reach a certain accuracy).

Large language models (LLMs) are commonly trained on datasets consisting of fixed-length token sequences. These datasets are created by randomly concatenating documents of various lengths and then chunking them into sequences of a predetermined target length (concat-and-chunk). Recent attention implementations mask cross-document attention, reducing the effective length of a chunk of tokens. Additionally, training on long sequences becomes computationally prohibitive due to the quadratic cost of attention. In this study, we introduce dataset decomposition, a novel variable sequence length training technique, to tackle these challenges. We decompose a dataset into a union of buckets, each containing sequences of the same size extracted from a unique document. During training, we use variable sequence length and batch-size, sampling simultaneously from all buckets with a curriculum. In contrast to the concat-and-chunk baseline, which incurs a fixed attention cost at every step of training, our proposed method incurs a computational cost proportional to the actual document lengths at each step, resulting in significant savings in training time. We train an 8k context-length 1B model at the same cost as a 2k context-length model trained with the baseline approach. Experiments on a web-scale corpus demonstrate that our approach significantly enhances performance on standard language evaluations and long-context benchmarks, reaching target accuracy with up to 6x faster training compared to the baseline. Our method not only enables efficient pretraining on long sequences but also scales effectively with dataset size. Lastly, we shed light on a critical yet less studied aspect of training large language models: the distribution and curriculum of sequence lengths, which results in a non-negligible difference in performance.

Large Language Models (LLMs) are becoming a prominent generative AI tool, where the user enters a query and the LLM generates an answer. To reduce harm and misuse, efforts have been made to align these LLMs to human values using advanced training techniques such as Reinforcement Learning from Human Feedback (RLHF). However, recent studies have highlighted the vulnerability of LLMs to adversarial jailbreak attempts aiming at subverting the embedded safety guardrails. To address this challenge, this paper defines and investigates the **Refusal Loss** of LLMs and then proposes a method called **Gradient Cuff** to detect jailbreak attempts. Gradient Cuff exploits the unique properties observed in the refusal loss landscape, including functional values and its smoothness, to design an effective two-step detection strategy. Experimental results on two aligned LLMs (LLaMA-2-7B-Chat and Vicuna-7B-V1.5) and six types of jailbreak attacks (GCG, AutoDAN, PAIR, TAP, Base64, and LRL) show that Gradient Cuff can significantly improve the LLM's rejection capability for malicious jailbreak queries, while maintaining the model's performance for benign user queries by adjusting the detection threshold.
tl;dr: We use language descriptions to transform relative depth to metric depth.

We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA , takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2, VOID) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation. Code is available at: https://github.com/Adonis-galaxy/RSA.
tl;dr: We show that CLIP is more robust to long-tailed pre-training data than supervisied learning, and reveal the reasons behind.

Severe data imbalance naturally exists among web-scale vision-language datasets. Despite this, we find CLIP pre-trained thereupon exhibits notable robustness to the data imbalance compared to supervised learning, and demonstrates significant effectiveness in learning generalizable representations. With an aim to investigate the reasons behind this finding, we conduct controlled experiments to study various underlying factors, and reveal that CLIP's pretext task forms a dynamic classification problem wherein only a subset of classes is present in training. This isolates the bias from dominant classes and implicitly balances the learning signal. Furthermore, the robustness and discriminability of CLIP improve with more descriptive language supervision, larger data scale, and broader open-world concepts, which are inaccessible to supervised learning. Our study not only uncovers the mechanisms behind CLIP's generalizability beyond data imbalance but also provides transferable insights for the research community. The findings are validated in both supervised and self-supervised learning, enabling models trained on imbalanced data to achieve CLIP-level performance on diverse recognition tasks. Code and data are available at: https://github.com/CVMI-Lab/clip-beyond-tail.

Network pruning is a commonly used measure to alleviate the storage and computational burden of deep neural networks. However, the fundamental limit of network pruning is still lacking. To close the gap, in this work we'll take a first-principles approach, i.e. we'll directly impose the sparsity constraint on the loss function and leverage the framework of *statistical dimension* in convex geometry, thus we're able to characterize the sharp phase transition point, i.e. the fundamental limit of the pruning ratio. Through this fundamental limit, we're able to identify two key factors that determine the pruning ratio limit, namely, *weight magnitude* and *network flatness*. Generally speaking, the flatter the loss landscape or the smaller the weight magnitude, the smaller pruning ratio. Moreover, we provide efficient countermeasures to address the challenges in the computation of the pruning limit, which involves accurate spectrum estimation of a large-scale and non-positive Hessian matrix. Moreover, through the lens of the pruning ratio threshold, we can provide rigorous interpretations on several heuristics in existing pruning algorithms. Extensive experiments are performed that demonstrate that our theoretical pruning ratio threshold coincides very well with the experiments. All codes are available at: https://anonymous.4open.science/r/Global-One-shot-Pruning-BC7B

In this paper, we study an object synthesis task that combines an object text with an object image to create a new object image. However, most diffusion models struggle with this task, \textit{i.e.}, often generating an object that predominantly reflects either the text or the image due to an imbalance between their inputs. To address this issue, we propose a simple yet effective method called Adaptive Text-Image Harmony (ATIH) to generate novel and surprising objects.
First, we introduce a scale factor and an injection step to balance text and image features in cross-attention and to preserve image information in self-attention during the text-image inversion diffusion process, respectively. Second, to better integrate object text and image, we design a balanced loss function with a noise parameter, ensuring both optimal editability and fidelity of the object image. Third, to adaptively adjust these parameters, we present a novel similarity score function that not only maximizes the similarities between the generated object image and the input text/image but also balances these similarities to harmonize text and image integration.
Extensive experiments demonstrate the effectiveness of our approach, showcasing remarkable object creations such as colobus-glass jar. https://xzr52.github.io/ATIH/

We study the batched best arm identification (BBAI) problem, where the learner's goal is to identify the best arm while switching the policy as less as possible. In particular, we aim to find the best arm with probability $1-\delta$ for some small constant $\delta>0$ while minimizing both the sample complexity (total number of arm pulls) and the batch complexity (total number of batches). We propose the three-batch best arm identification (Tri-BBAI) algorithm, which is the first batched algorithm that achieves the optimal sample complexity in the asymptotic setting (i.e., $\delta\rightarrow 0$) and runs in $3$ batches in expectation. Based on Tri-BBAI, we further propose the almost optimal batched best arm identification (Opt-BBAI) algorithm, which is the first algorithm that achieves the near-optimal sample and batch complexity in the non-asymptotic setting (i.e., $1/\delta$ is finite), while enjoying the same batch and sample complexity as Tri-BBAI when $\delta$ tends to zero. Moreover, in the non-asymptotic setting, the complexity of previous batch algorithms is usually conditioned on the event that the best arm is returned (with a probability of at least $1-\delta$), which is potentially unbounded in cases where a sub-optimal arm is returned. In contrast, the complexity of Opt-BBAI does not rely on such an event. This is achieved through a novel procedure that we design for checking whether the best arm is eliminated, which is of independent interest.

Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs). Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts. To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression. Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective. Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process. Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
tl;dr: This paper explores a striking similarity between the in-context learning mechanisms of Transformer models and human episodic memory, revealing parallel computational processes in artificial and biological intelligence systems.

Understanding connections between artificial and biological intelligent systems can reveal fundamental principles of general intelligence. While many artificial intelligence models have a neuroscience counterpart, such connections are largely missing in Transformer models and the self-attention mechanism. Here, we examine the relationship between interacting attention heads and human episodic memory. We focus on induction heads, which contribute to in-context learning in Transformer-based large language models (LLMs). We demonstrate that induction heads are behaviorally, functionally, and mechanistically similar to the contextual maintenance and retrieval (CMR) model of human episodic memory. Our analyses of LLMs pre-trained on extensive text data show that CMR-like heads often emerge in the intermediate and late layers, qualitatively mirroring human memory biases. The ablation of CMR-like heads suggests their causal role in in-context learning. Our findings uncover a parallel between the computational mechanisms of LLMs and human memory, offering valuable insights into both research fields.
tl;dr: This paper extends Bayesian optimization to a novel graph setting, where the search space consists of node subsets in a generic graph.

We address the problem of optimizing over functions defined on node subsets in a graph. The optimization of such functions is often a non-trivial task given their combinatorial, black-box and expensive-to-evaluate nature. Although various algorithms have been introduced in the literature, most are either task-specific or computationally inefficient and only utilize information about the graph structure without considering the characteristics of the function. To address these limitations, we utilize Bayesian Optimization (BO), a sample-efficient black-box solver, and propose a novel framework for combinatorial optimization on graphs. More specifically, we map each $k$-node subset in the original graph to a node in a new combinatorial graph and adopt a local modeling approach to efficiently traverse the latter graph by progressively sampling its subgraphs using a recursive algorithm. Extensive experiments under both synthetic and real-world setups demonstrate the effectiveness of the proposed BO framework on various types of graphs and optimization tasks, where its behavior is analyzed in detail with ablation studies.
tl;dr: Unsupervised learning on dynamics-based features discovers novel formulas for mathematical constants.

Ongoing efforts that span over decades show a rise of AI methods for accelerating scientific discovery, yet accelerating discovery in mathematics remains a persistent challenge for AI.
Specifically, AI methods were not effective in creation of formulas for mathematical constants because each such formula must be correct for infinite digits of precision, with 'near-true' formulas providing no insight toward the correct ones. Consequently, formula discovery lacks a clear distance metric needed to guide automated discovery in this realm.
In this work, we propose a systematic methodology for categorization, characterization, and pattern identification of such formulas. The key to our methodology is introducing metrics based on the convergence dynamics of the formulas, rather than on the numerical value of the formula. These metrics enable the first automated clustering of mathematical formulas.
We demonstrate this methodology on Polynomial Continued Fraction formulas, which are ubiquitous in their intrinsic connections to mathematical constants, and generalize many mathematical functions and structures.
We test our methodology on a set of 1,768,900 such formulas, identifying many known formulas for mathematical constants, and discover previously unknown formulas for $\pi$, $\ln(2)$, Gauss', and Lemniscate's constants. The uncovered patterns enable a direct generalization of individual formulas to infinite families, unveiling rich mathematical structures.
This success paves the way towards a generative model that creates formulas fulfilling specified mathematical properties, accelerating the rate of discovery of useful formulas.

While Tensor-based Multi-view Subspace Clustering (TMSC) has garnered significant attention for its capacity to effectively capture high-order correlations among multiple views, three notable limitations in current TMSC methods necessitate consideration: 1) high computational complexity and reliance on dictionary completeness resulting from using observed data as the dictionary, 2) inaccurate subspace representation stemming from the oversight of local geometric information and 3) under-penalization of noise-related singular values within tensor data caused by treating all singular values equally. To address these limitations, this paper presents a \textbf{S}calable TMSC framework with \textbf{T}riple inf\textbf{O}rmatio\textbf{N} \textbf{E}nhancement (\textbf{STONE}). Notably, an enhanced anchor dictionary learning mechanism has been utilized to recover the low-rank anchor structure, resulting in reduced computational complexity and increased resilience, especially in scenarios with inadequate dictionaries. Additionally, we introduce an anchor hypergraph Laplacian regularizer to preserve the inherent geometry of the data within the subspace representation. Simultaneously, an improved hyperbolic tangent function has been employed as a precise approximation for tensor rank, effectively capturing the significant variations in singular values. Extensive experimentation on a variety of datasets demonstrates that our approach surpasses SOTA methods in both effectiveness and efficiency.

Transformer-based Diffusion Probabilistic Models (DPMs) have shown more potential than CNN-based DPMs, yet their extensive computational requirements hinder widespread practical applications. To reduce the computation budget of transformer-based DPMs, this work proposes the Efficient Diffusion Transformer (EDT) framework. This framework includes a lightweight-design diffusion model architecture, and a training-free Attention Modulation Matrix and its alternation arrangement in EDT inspired by human-like sketching. Additionally, we propose a token relation-enhanced masking training strategy tailored explicitly for EDT to augment its token relation learning capability. Our extensive experiments demonstrate the efficacy of EDT. The EDT framework reduces training and inference costs and surpasses existing transformer-based diffusion models in image synthesis performance, thereby achieving a significant overall enhancement. With lower FID, EDT-S, EDT-B, and EDT-XL attained speed-ups of 3.93x, 2.84x, and 1.92x respectively in the training phase, and 2.29x, 2.29x, and 2.22x respectively in inference, compared to the corresponding sizes of MDTv2. Our code is available at https://github.com/xinwangChen/EDT.

Diffusion Probabilistic Models (DPMs) have been recently utilized to deal with various blind image restoration (IR) tasks, where they have demonstrated outstanding performance in terms of perceptual quality. However, the task-specific nature of existing solutions and the excessive computational costs related to their training, make such models impractical and challenging to use for different IR tasks than those that were initially trained for. This hinders their wider adoption especially by those who lack access to powerful computational resources and vast amounts of training data. In this work we aim to address the above issues and enable the successful adoption of DPMs in practical IR-related applications. Towards this goal, we propose a modular diffusion probabilistic IR framework (DP-IR), which allows us to combine the performance benefits of existing pre-trained state-of-the-art IR networks and generative DPMs, while it requires only the additional training of a small module (0.7M params) related to the particular IR task of interest. Moreover, the architecture of our proposed framework allows us to employ a sampling strategy that leads to at least four times reduction of neural function evaluations without any performance loss, while it can also be combined with existing acceleration techniques (e.g. DDIM). We evaluate our model on four benchmarks for the tasks of burst JDD-SR, dynamic scene deblurring, and super-resolution. Our method outperforms existing approaches in terms of perceptual quality while retaining a competitive performance in relation to fidelity metrics.
tl;dr: A masked diffusion framework featuring a novel objective that enhances log-likelihood estimation and achieves state-of-the-art results, including applications to DNA sequence modeling.

While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling.
In this work, we show that simple masked discrete diffusion is more performant than previously thought.
We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements.
Our objective has a simple form—it is a mixture of classical masked language modeling losses—and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model.
On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We provide the code, along with a blog post and video tutorial on the project page: https://s-sahoo.com/mdlm
tl;dr: We exploit the Kurdyka-Lojasiewicz property to develop an efficient proximal gradient algorithm that leads to a portfolio which achieves the globally optimal m-sparse Sharpe ratio.

The Sharpe ratio is an important and widely-used risk-adjusted return in financial engineering. In modern portfolio management, one may require an m-sparse (no more than m active assets) portfolio to save managerial and financial costs. However, few existing methods can optimize the Sharpe ratio with the m-sparse constraint, due to the nonconvexity and the complexity of this constraint. We propose to convert the m-sparse fractional optimization problem into an equivalent m-sparse quadratic programming problem. The semi-algebraic property of the resulting objective function allows us to exploit the Kurdyka-Lojasiewicz property to develop an efficient Proximal Gradient Algorithm (PGA) that leads to a portfolio which achieves the globally optimal m-sparse Sharpe ratio under certain conditions. The convergence rates of PGA are also provided. To the best of our knowledge, this is the first proposal that achieves a globally optimal m-sparse Sharpe ratio with a theoretically-sound guarantee.
3569. RAMP: Boosting Adversarial Robustness Against Multiple $l_p$ Perturbations for Universal Robustness
tl;dr: We design a logit pairing loss and connect natural training with adversarial training via gradient projection to improve the multi-norm robustness while maintaining good clean accuracy.

Most existing works focus on improving robustness against adversarial attacks bounded by a single $l_p$ norm using adversarial training (AT). However, these AT models' multiple-norm robustness (union accuracy) is still low, which is crucial since in the real-world an adversary is not necessarily bounded by a single norm. The tradeoffs among robustness against multiple $l_p$ perturbations and accuracy/robustness make obtaining good union and clean accuracy challenging. We design a logit pairing loss to improve the union accuracy by analyzing the tradeoffs from the lens of distribution shifts. We connect natural training (NT) with AT via gradient projection, to incorporate useful information from NT into AT, where we empirically and theoretically show it moderates the accuracy/robustness tradeoff. We propose a novel training framework \textbf{RAMP}, to boost the robustness against multiple $l_p$ perturbations. \textbf{RAMP} can be easily adapted for robust fine-tuning and full AT. For robust fine-tuning, \textbf{RAMP} obtains a union accuracy up to $53.3\%$ on CIFAR-10, and $29.1\%$ on ImageNet. For training from scratch, \textbf{RAMP} achieves a union accuracy of $44.6\%$ and good clean accuracy of $81.2\%$ on ResNet-18 against AutoAttack on CIFAR-10. Beyond multi-norm robustness \textbf{RAMP}-trained models achieve superior \textit{universal robustness}, effectively generalizing against a range of unseen adversaries and natural corruptions.

Self-assessment of one’s choices, i.e., confidence, is the topic of many decision neuroscience studies. Computational models of confidence, however, are limited to specific scenarios such as between choices with the same value. Here we present a normative framework for modeling decision confidence that is generalizable to various tasks and experimental setups. We further drive the implications of our model from both theoretical and experimental points of view. Specifically, we show that our model maps to the planning as an inference framework where the objective function is maximizing the gained reward and information entropy of the policy. Moreover, we validate our model on two different psychophysics experiments and show its superiority over other approaches in explaining subjects' confidence reports.
tl;dr: As LLMs undergo self-evolution, it is imperative for us to deepen our understanding of this process.

With the widespread adoption of Large Language Models (LLMs), the prevalence of iterative interactions among these models is anticipated to increase. Notably, recent advancements in multi-round on-policy self-improving methods allow LLMs to generate new examples for training subsequent models. At the same time, multi-agent LLM systems, involving automated interactions among agents, are also increasing in prominence. Thus, in both short and long terms, LLMs may actively engage in an evolutionary process. We draw parallels between the behavior of LLMs and the evolution of human culture, as the latter has been extensively studied by cognitive scientists for decades. Our approach involves leveraging Iterated Learning (IL), a Bayesian framework that elucidates how subtle biases are magnified during human cultural evolution, to explain some behaviors of LLMs. This paper outlines key characteristics of agents' behavior in the Bayesian-IL framework, including predictions that are supported by experimental verification with various LLMs. This theoretical framework could help to more effectively predict and guide the evolution of LLMs in desired directions.
tl;dr: We report that LLMs have a 'task recognition' point, where self-attention over the context is no longer necessary.

Self-supervised large language models have demonstrated the ability to perform various tasks via in-context learning, but little is known about where the model locates the task with respect to prompt instructions and demonstration examples.
In this work, we attempt to characterize the region where large language models transition from recognizing the task to performing the task.
Through a series of layer-wise context-masking experiments on \textsc{GPTNeo2.7B}, \textsc{Bloom3B}, \textsc{Llama2-7b}, \textsc{Llama2-7b-chat}, \textsc{Starcoder2-3B} and \textsc{Starcoder2-7B} on Machine Translation and Code generation, we demonstrate evidence of a "task recognition" point where the task is encoded into the input representations and attention to context is no longer necessary. We further observe correspondence between the low performance when masking out entire layers, and the task recognition layers. Taking advantage of this redundancy results in 45\% computational savings when prompting with 5 examples, and task recognition achieved at layer 14 / 32 using an example with Machine Translation.
tl;dr: We use a causal framework to investigate the failure modes of data balancing for fairness or robustness, its conditions for success, and its interaction with other mitigation strategies.

Failures of fairness or robustness in machine learning predictive settings can be due to undesired dependencies between covariates, outcomes and auxiliary factors of variation. A common strategy to mitigate these failures is data balancing, which attempts to remove those undesired dependencies. In this work, we define conditions on the training distribution for data balancing to lead to fair or robust models. Our results display that in many cases, the balanced distribution does not correspond to selectively removing the undesired dependencies in a causal graph of the task, leading to multiple failure modes and even interference with other mitigation techniques such as regularization. Overall, our results highlight the importance of taking the causal graph into account before performing data balancing.
tl;dr: Randomly initialized transformers may be more powerful than you think!

Trained transformer models have been found to implement interpretable procedures for tasks like arithmetic and associative recall, but little is understood about how the circuits that implement these procedures originate during training. To what extent do they depend on the supervisory signal provided to models, and to what extent are they attributable to behavior already present in models at the beginning of training? To investigate these questions, we investigate what functions can be learned by randomly initialized transformers in which only the embedding layers are optimized, so that the only input--output mappings learnable from data are those already implemented (up to a choice of encoding scheme) by the randomly initialized model. We find that these random transformers can perform a wide range of meaningful algorithmic tasks, including modular arithmetic, in-weights and in-context associative recall, decimal addition, parenthesis balancing, and even some aspects of natural language text generation. Our results indicate that some algorithmic capabilities are present in transformers (and accessible via appropriately structured inputs) even before these models are trained.

Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights $\(\mathbf{W}\)$ and inject learnable matrices $\(\mathbf{\Delta W}\)$. These $\(\mathbf{\Delta W}\)$ matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically exhibit a performance gap compared to full fine-tuning. While recent PEFT methods have narrowed this gap, they do so at the expense of additional learnable parameters. We propose SVFT, a *simple* approach that structures $\(\mathbf{\Delta W}\)$ based on the specific weight matrix $\(\mathbf{W}\)$. SVFT updates $\(\mathbf{W}\)$ as a sparse combination $\(M\)$ of outer products of its singular vectors, training only the coefficients of these combinations. Crucially, we make additional off-diagonal elements in $M$ learnable, enabling a smooth trade-off between trainable parameters and expressivity—an aspect that distinctly sets our approach apart from previous works leveraging singular values. Extensive experiments on language and vision benchmarks show that SVFT recovers up to **96%** of full fine-tuning performance while training only **0.006 to 0.25%** of parameters, outperforming existing methods that achieve only up to **{85\%}** performance with **0.03 to 0.8%** of the trainable parameter budget.

Reinforcement Learning (RL) is a powerful method for controlling dynamic systems, but its learning mechanism can lead to unpredictable actions that undermine the safety of critical systems. Here, we propose RL with Adaptive Regularization (RL-AR), an algorithm that enables safe RL exploration by combining the RL policy with a policy regularizer that hard-codes the safety constraints. RL-AR performs policy combination via a "focus module," which determines the appropriate combination depending on the state—relying more on the safe policy regularizer for less-exploited states while allowing unbiased convergence for well-exploited states. In a series of critical control applications, we demonstrate that RL-AR not only ensures safety during training but also achieves a return competitive with the standards of model-free RL that disregards safety.

Image editing serves as a practical yet challenging task considering the diverse demands from users, where one of the hardest parts is to precisely describe how the edited image should look like. In this work, we present a new form of editing, termed imitative editing, to help users exercise their creativity more conveniently. Concretely, to edit an image region of interest, users are free to directly draw inspiration from some in-the-wild references (e.g., some relative pictures come across online), without having to cope with the fit between the reference and the source. Such a design requires the system to automatically figure out what to expect from the reference to perform the editing. For this purpose, we propose a generative training framework, dubbed MimicBrush, which randomly selects two frames from a video clip, masks some regions of one frame, and learns to recover the masked regions using the information from the other frame. That way, our model, developed from a diffusion prior, is able to capture the semantic correspondence between separate images in a self-supervised manner. We experimentally show the effectiveness of our method under various test cases as well as its superiority over existing alternatives. We also construct a benchmark to facilitate further research.
tl;dr: This paper proposes a computation- and communication-efficient algorithm for federated learning over manifolds with heterogeneous data.

Many machine learning tasks, such as principal component analysis and low-rank matrix completion, give rise to manifold optimization problems. Although there is a large body of work studying the design and analysis of algorithms for manifold optimization in the centralized setting, there are currently very few works addressing the federated setting. In this paper, we consider nonconvex federated learning
over a compact smooth submanifold in the setting of heterogeneous client data. We propose an algorithm that leverages stochastic Riemannian gradients and a manifold projection operator to improve computational efficiency, uses local updates to improve communication efficiency, and avoids client drift. Theoretically, we show that our proposed algorithm converges sub-linearly to a neighborhood of a first-order optimal solution by using a novel analysis that jointly exploits the manifold structure and properties of the loss functions. Numerical experiments demonstrate that our algorithm has significantly smaller computational and communication overhead than existing methods.
3579. Improving Linear System Solvers for Hyperparameter Optimisation in Iterative Gaussian Processes
tl;dr: We accelerate iterative linear system solvers in the context of marginal likelihood optimisation for Gaussian processes.

Scaling hyperparameter optimisation to very large datasets remains an open problem in the Gaussian process community. This paper focuses on iterative methods, which use linear system solvers, like conjugate gradients, alternating projections or stochastic gradient descent, to construct an estimate of the marginal likelihood gradient. We discuss three key improvements which are applicable across solvers: (i) a pathwise gradient estimator, which reduces the required number of solver iterations and amortises the computational cost of making predictions, (ii) warm starting linear system solvers with the solution from the previous step, which leads to faster solver convergence at the cost of negligible bias, (iii) early stopping linear system solvers after a limited computational budget, which synergises with warm starting, allowing solver progress to accumulate over multiple marginal likelihood steps. These techniques provide speed-ups of up to $72\times$ when solving to tolerance, and decrease the average residual norm by up to $7\times$ when stopping early.

Recent token reduction methods for Vision Transformers (ViTs) incorporate token merging, which measures the similarities between token embeddings and combines the most similar pairs.
However, their merging policies are directly dependent on intermediate features in ViTs, which prevents exploiting features tailored for merging and requires end-to-end training to improve token merging.
In this paper, we propose Decoupled Token Embedding for Merging (DTEM) that enhances token merging through a decoupled embedding learned via a continuously relaxed token merging process.
Our method introduces a lightweight embedding module decoupled from the ViT forward pass to extract dedicated features for token merging, thereby addressing the restriction from using intermediate features.
The continuously relaxed token merging, applied during training, enables us to learn the decoupled embeddings in a differentiable manner.
Thanks to the decoupled structure, our method can be seamlessly integrated into existing ViT backbones and trained either modularly by learning only the decoupled embeddings or end-to-end by fine-tuning.
We demonstrate the applicability of DTEM on various tasks, including classification, captioning, and segmentation, with consistent improvement in token merging.
Especially in the ImageNet-1k classification, DTEM achieves a 37.2\% reduction in FLOPs while maintaining a top-1 accuracy of 79.85\% with DeiT-small.

Transformers can efficiently learn in-context from example demonstrations. Most existing theoretical analyses studied the in-context learning (ICL) ability of transformers for linear function classes, where it is typically shown that the minimizer of the pretraining loss implements one gradient descent step on the least squares objective. However, this simplified linear setting arguably does not demonstrate the statistical efficiency of ICL, since the pretrained transformer does not outperform directly solving linear regression on the test prompt.
In this paper, we study ICL of a nonlinear function class via transformer with nonlinear MLP layer: given a class of \textit{single-index} target functions $f_*(\boldsymbol{x}) = \sigma_*(\langle\boldsymbol{x},\boldsymbol{\beta}\rangle)$, where the index features $\boldsymbol{\beta}\in\mathbb{R}^d$ are drawn from a $r$-dimensional subspace, we show that a nonlinear transformer optimized by gradient descent (with a pretraining sample complexity that depends on the \textit{information exponent} of the link functions $\sigma_*$) learns $f_*$ in-context with a prompt length that only depends on the dimension of the distribution of target functions $r$; in contrast, any algorithm that directly learns $f_*$ on test prompt yields a statistical complexity that scales with the ambient dimension $d$. Our result highlights the adaptivity of the pretrained transformer to low-dimensional structures of the function class, which enables sample-efficient ICL that outperforms estimators that only have access to the in-context data.

Given the ubiquitous presence of time series data across various domains, precise forecasting of time series holds significant importance and finds widespread real-world applications such as energy, weather, healthcare, etc. While numerous forecasters have been proposed using different network architectures, the Transformer-based models have state-of-the-art performance in time series forecasting. However, forecasters based on Transformers are still suffering from vulnerability to high-frequency signals, efficiency in computation, and bottleneck in full-spectrum utilization, which essentially are the cornerstones for accurately predicting time series with thousands of points. In this paper, we explore a novel perspective of enlightening signal processing for deep time series forecasting. Inspired by the filtering process, we introduce one simple yet effective network, namely FilterNet, built upon our proposed learnable frequency filters to extract key informative temporal patterns by selectively passing or attenuating certain components of time series signals. Concretely, we propose two kinds of learnable filters in the FilterNet: (i) Plain shaping filter, that adopts a universal frequency kernel for signal filtering and temporal modeling; (ii) Contextual shaping filter, that utilizes filtered frequencies examined in terms of its compatibility with input signals for
dependency learning. Equipped with the two filters, FilterNet can approximately surrogate the linear and attention mappings widely adopted in time series literature, while enjoying superb abilities in handling high-frequency noises and utilizing the whole frequency spectrum that is beneficial for forecasting. Finally, we conduct extensive experiments on eight time series forecasting benchmarks, and experimental results have demonstrated our superior performance in terms of both effectiveness and efficiency compared with state-of-the-art methods. Our code is available at$^1$.

Domain generalization (DG) is a fundamental yet challenging topic in machine learning. Recently, the remarkable zero-shot capabilities of the large pre-trained vision-language model (e.g., CLIP) have made it popular for various downstream tasks. However, the effectiveness of this capacity often degrades when there are shifts in data distribution during testing compared to the training data. In this paper, we propose a novel method, known as CLIPCEIL, a model that utilizes Channel rEfinement and Image-text aLignment to facilitate the CLIP to the inaccessible $\textit{out-of-distribution}$ test datasets that exhibit domain shifts. Specifically, we refine the feature channels in the visual domain to ensure they contain domain-invariant and class-relevant features by using a lightweight adapter. This is achieved by minimizing the inter-domain variance while maximizing the inter-class variance. In the meantime, we ensure the image-text alignment by aligning text embeddings of the class descriptions and their corresponding image embedding while further removing the domain-specific features. Moreover, our model integrates multi-scale CLIP features by utilizing a self-attention fusion module, technically implemented through one Transformer layer. Extensive experiments on five widely used benchmark datasets demonstrate that CLIPCEIL outperforms the existing state-of-the-art methods. The source code is available at \url{https://github.com/yuxi120407/CLIPCEIL}.
3584. GVKF: Gaussian Voxel Kernel Functions for Highly Efficient Surface Reconstruction in Open Scenes
tl;dr: High efficient surface reconstuction based on gaussian splatting

In this paper we present a novel method for efficient and effective 3D surface reconstruction in open scenes. Existing Neural Radiance Fields (NeRF) based works typically require extensive training and rendering time due to the adopted implicit representations.
In contrast, 3D Gaussian splatting (3DGS) uses an explicit and discrete representation, hence the reconstructed surface is built by the huge number of Gaussian primitives, which leads to excessive memory consumption and rough surface details in sparse Gaussian areas.
To address these issues, we propose Gaussian Voxel Kernel Functions (GVKF), which establish a continuous scene representation based on discrete 3DGS through kernel regression. The GVKF integrates fast 3DGS rasterization and highly effective scene implicit representations, achieving high-fidelity open scene surface reconstruction. Experiments on challenging scene datasets demonstrate the efficiency and effectiveness of our proposed GVKF, featuring with high reconstruction quality, real-time rendering speed, significant savings in storage and training memory consumption.
tl;dr: We extend the gaze following task, which is currently focused on localization alone, to also incorporate the class label of the gaze target. We propose new benchmarks and a design a new architecture that outperforms existing methods.

From the onset of infanthood, humans naturally develop the ability to closely observe and interpret the visual gaze of others. This skill, known as gaze following, holds significance in developmental theory as it enables us to grasp another person’s mental state, emotions, intentions, and more. In computer vision, gaze following is defined as the prediction of the pixel coordinates where a person in the image is focusing their attention. Existing methods in this research area have predominantly centered on pinpointing the gaze target by predicting a gaze heatmap or gaze point. However, a notable drawback of this approach is its limited practical value in gaze applications, as mere localization may not fully capture our primary interest — understanding the underlying semantics, such as the nature of the gaze target, rather than just its 2D pixel location. To address this gap, we extend the gaze following task, and introduce a novel architecture that simultaneously predicts the localization and semantic label of the gaze target. We devise a pseudo-annotation pipeline for the GazeFollow dataset, propose a new benchmark, develop an experimental protocol and design a suitable baseline for comparison. Our method sets a new state-of-the-art on the main GazeFollow benchmark for localization and achieves competitive results in the recognition task on both datasets compared to the baseline, with 40% fewer parameters
tl;dr: A low-cost yet effective data augmentation framework for alleviating class imbalance in 3D object detection.

Typical LiDAR-based 3D object detection models are trained with real-world data collection, which is often imbalanced over classes.
To deal with it, augmentation techniques are commonly used, such as copying ground truth LiDAR points and pasting them into scenes.
However, existing methods struggle with the lack of sample diversity for minority classes and the limitation of suitable placement.
In this work, we introduce a novel approach that utilizes pseudo LiDAR point clouds generated from low-cost miniatures or real-world videos, which is called Pseudo Ground Truth augmentation (PGT-Aug).
PGT-Aug involves three key steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity simulation, and (iii) a hybrid context-aware placement method from ground and map information.
We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations.
The project webpage is https://just-add-100-more.github.io.

Multimodal learning has developed very fast in recent years. However, during the multimodal training process, the model tends to rely on only one modality based on which it could learn faster, thus leading to inadequate use of other modalities. Existing methods to balance the training process always have some limitations on the loss functions, optimizers and the number of modalities and only consider modulating the magnitude of the gradients while ignoring the directions of the gradients. To solve these problems, in this paper, we present a novel method to balance multimodal learning with **C**lassifier-**G**uided **G**radient **M**odulation (CGGM), considering both the magnitude and directions of the gradients. We conduct extensive experiments on four multimodal datasets: UPMC-Food 101, CMU-MOSI, IEMOCAP and BraTS 2021, covering classification, regression and segmentation tasks. The results show that CGGM outperforms all the baselines and other state-of-the-art methods consistently, demonstrating its effectiveness and versatility. Our code is available at https://github.com/zrguo/CGGM.

Transformers have become one of the foundational architectures in point cloud analysis tasks due to their excellent global modeling ability. However, the attention mechanism has quadratic complexity, making the design of a linear complexity method with global modeling appealing. In this paper, we propose PointMamba, transferring the success of Mamba, a recent representative state space model (SSM), from NLP to point cloud analysis tasks. Unlike traditional Transformers, PointMamba employs a linear complexity algorithm, presenting global modeling capacity while significantly reducing computational costs. Specifically, our method leverages space-filling curves for effective point tokenization and adopts an extremely simple, non-hierarchical Mamba encoder as the backbone. Comprehensive evaluations demonstrate that PointMamba achieves superior performance across multiple datasets while significantly reducing GPU memory usage and FLOPs. This work underscores the potential of SSMs in 3D vision-related tasks and presents a simple yet effective Mamba-based baseline for future research. The code is available at https://github.com/LMD0311/PointMamba.

Illustration is a fundamental mode of human expression and communication. Certain types of motion that accompany speech can provide this illustrative mode of communication. While Augmented and Virtual Reality technologies (AR/VR) have introduced tools for producing drawings with hand motions (air drawing), they typically require costly hardware and additional digital markers, thereby limiting their accessibility and portability. Furthermore, air drawing demands considerable skill to achieve aesthetic results. To address these challenges, we introduce the concept of AirSketch, aimed at generating faithful and visually coherent sketches directly from hand motions, eliminating the need for complicated headsets or markers. We devise a simple augmentation-based self-supervised training procedure, enabling a controllable image diffusion model to learn to translate from highly noisy hand tracking images to clean, aesthetically pleasing sketches, while preserving the essential visual cues from the original tracking data. We present two air drawing datasets to study this problem. Our findings demonstrate that beyond producing photo-realistic images from precise spatial inputs, controllable image diffusion can effectively produce a refined, clear sketch from a noisy input. Our work serves as an initial step towards marker-less air drawing and reveals distinct applications of controllable diffusion models to AirSketch and AR/VR in general.

Deep neural networks (DNNs) lack the precise semantics and definitive probabilistic interpretation of probabilistic graphical models (PGMs). In this paper, we propose an innovative solution by constructing infinite tree-structured PGMs that correspond exactly to neural networks. Our research reveals that DNNs, during forward propagation, indeed perform approximations of PGM inference that are precise in this alternative PGM structure. Not only does our research complement existing studies that describe neural networks as kernel machines or infinite-sized Gaussian processes, it also elucidates a more direct approximation that DNNs make to exact inference in PGMs. Potential benefits include improved pedagogy and interpretation of DNNs, and algorithms that can merge the strengths of PGMs and DNNs.

Owing to advancements in image synthesis techniques, stylization methodologies for large models have garnered remarkable outcomes. However, when it comes to processing facial images, the outcomes frequently fall short of expectations. Facial stylization is predominantly challenged by two significant hurdles. Firstly, obtaining a large dataset of high-quality stylized images is difficult. The scarcity and diversity of artistic styles make it impractical to compile comprehensive datasets for each style. Secondly, while many methods can transfer colors and strokes from style images, these elements alone cannot fully capture a specific style, which encompasses both concrete and abstract visual elements. Additionally, facial stylization often alters the visual features of the face, making it challenging to balance these changes with the need to retain facial information. To address these issues, we propose a novel method called ACFun, which uses only one style image and one facial image for facial stylization. ACFun comprises an Abstract Fusion Module (AFun) and a Concrete Fusion Module (CFun), which separately learn the abstract and concrete features of the style and face. We also design a Face and Style Imagery Alignment Loss to align the style image with the face image in the latent space. Finally, we generate styled facial images from noise directly to complete the facial stylization task. Experiments show that our method outperforms others in facial stylization, producing highly artistic and visually pleasing results.
tl;dr: In this paper, we propose SOOP to improve the efficiency of LLMs generated code.

Large language models (LLMs) have shown remarkable progress in code generation, but their generated code often suffers from inefficiency, resulting in longer execution times and higher memory consumption. To address this issue, we propose EffiLearner, a self-optimization framework that utilizes execution overhead profiles to improve the efficiency of LLM-generated code. EffiLearner first generates code using an LLM, then executes it locally to capture execution time and memory usage profiles. These profiles are fed back to the LLM, which then revises the code to reduce overhead. To evaluate the effectiveness of EffiLearner, we conduct extensive experiments on EffiBench and two commonly used code generation benchmarks with 16 open-source and 6 closed-source models. Our evaluation results demonstrate that through iterative self-optimization, EffiLearner significantly enhances the efficiency of LLM-generated code. For example, the execution time (ET) of StarCoder2-15B for the EffiBench decreases from 0.93 (s) to 0.12 (s) which reduces 87.1\% execution time requirement compared with the initial code. The total memory usage (TMU) of StarCoder2-15B also decreases from 22.02 (Mb*s) to 2.03 (Mb*s), which decreases 90.8\% total memory consumption during the execution process.

Diverse human motion prediction (HMP) is a fundamental application in computer vision that has recently attracted considerable interest. Prior methods primarily focus on the stochastic nature of human motion, while neglecting the specific impact of external environment, leading to the pronounced artifacts in prediction when applied to real-world scenarios. To fill this gap, this work introduces a novel task: predicting diverse human motion within real-world 3D scenes. In contrast to prior works, it requires harmonizing the deterministic constraints imposed by the surrounding 3D scenes with the stochastic aspect of human motion. For this purpose, we propose DiMoP3D, a diverse motion prediction framework with 3D scene awareness, which leverages the 3D point cloud and observed sequence to generate diverse and high-fidelity predictions. DiMoP3D is able to comprehend the 3D scene, and determines the probable target objects and their desired interactive pose based on the historical motion. Then, it plans the obstacle-free trajectory towards these interested objects, and generates diverse and physically-consistent future motions. On top of that, DiMoP3D identifies deterministic factors in the scene and integrates them into the stochastic modeling, making the diverse HMP in realistic scenes become a controllable stochastic generation process. On two real-captured benchmarks, DiMoP3D has demonstrated significant improvements over state-of-the-art methods, showcasing its effectiveness in generating diverse and physically-consistent motion predictions within real-world 3D environments.
tl;dr: We propose a novel Post-training Quantization method for Diffusion Transformers to enhance the inference efficiency.

The recent introduction of Diffusion Transformers (DiTs) has demonstrated exceptional capabilities in image generation by using a different backbone architecture, departing from traditional U-Nets and embracing the scalable nature of transformers. Despite their advanced capabilities, the wide deployment of DiTs, particularly for real-time applications, is currently hampered by considerable computational demands at the inference stage. Post-training Quantization (PTQ) has emerged as a fast and data-efficient solution that can significantly reduce computation and memory footprint by using low-bit weights and activations. However, its applicability to DiTs has not yet been explored and faces non-trivial difficulties due to the unique design of DiTs. In this paper, we propose PTQ4DiT, a specifically designed PTQ method for DiTs. We discover two primary quantization challenges inherent in DiTs, notably the presence of salient channels with extreme magnitudes and the temporal variability in distributions of salient activation over multiple timesteps. To tackle these challenges, we propose Channel-wise Salience Balancing (CSB) and Spearmen's $\rho$-guided Salience Calibration (SSC). CSB leverages the complementarity property of channel magnitudes to redistribute the extremes, alleviating quantization errors for both activations and weights. SSC extends this approach by dynamically adjusting the balanced salience to capture the temporal variations in activation. Additionally, to eliminate extra computational costs caused by PTQ4DiT during inference, we design an offline re-parameterization strategy for DiTs. Experiments demonstrate that our PTQ4DiT successfully quantizes DiTs to 8-bit precision (W8A8) while preserving comparable generation ability and further enables effective quantization to 4-bit weight precision (W4A8) for the first time.
Generating synthetic fake faces, known as pseudo-fake faces, is an effective way to improve the generalization of DeepFake detection. Existing methods typically generate these faces by blending real or fake faces in spatial domain. While these methods have shown promise, they overlook the simulation of frequency distribution in pseudo-fake faces, limiting the learning of generic forgery traces in-depth. To address this, this paper introduces {\em FreqBlender}, a new method that can generate pseudo-fake faces by blending frequency knowledge. Concretely, we investigate the major frequency components and propose a Frequency Parsing Network to adaptively partition frequency components related to forgery traces. Then we blend this frequency knowledge from fake faces into real faces to generate pseudo-fake faces. Since there is no ground truth for frequency components, we describe a dedicated training strategy by leveraging the inner correlations among different frequency knowledge to instruct the learning process. Experimental results demonstrate the effectiveness of our method in enhancing DeepFake detection, making it a potential plug-and-play strategy for other methods.
tl;dr: We proposed CALANet that allows the classifier to aggregate features for all layer while maintaining the efficiency of existing real-time HAR models.

With the steady growth of sensing technology and wearable devices, sensor-based human activity recognition has become essential in widespread applications, such as healthcare monitoring and fitness tracking, where accurate and real-time systems are required.
To achieve real-time response, recent studies have focused on lightweight neural network models.
Specifically, they designed the network architectures by restricting the number of layers shallowly or connections of each layer.
However, these approaches suffer from limited accuracy because the classifier only uses the features at the last layer.
In this study, we propose a cheap all-layer aggregation network, CALANet, for accuracy improvement while maintaining the efficiency of existing real-time HAR models.
Specifically, CALANet allows the classifier to aggregate the features for all layers, resulting in a performance gain.
In addition, this work proves that the theoretical computation cost of CALANet is equivalent to that of conventional networks.
Evaluated on seven publicly available datasets, CALANet outperformed existing methods, achieving state-of-the-art performance.
The source codes of the CALANet are publicly available at https://github.com/jgpark92/CALANet.
3597. DiMSUM: Diffusion Mamba - A Scalable and Unified Spatial-Frequency Method for Image Generation
tl;dr: A new Mamba architecture for image diffusion models

We introduce a novel state-space architecture for diffusion models, effectively harnessing spatial and frequency information to enhance the inductive bias towards local features in input images for image generation tasks. While state-space networks, including Mamba, a revolutionary advancement in recurrent neural networks, typically scan input sequences from left to right, they face difficulties in designing effective scanning strategies, especially in the processing of image data. Our method demonstrates that integrating wavelet transformation into Mamba enhances the local structure awareness of visual inputs and better captures long-range relations of frequencies by disentangling them into wavelet subbands, representing both low- and high-frequency components. These wavelet-based outputs are then processed and seamlessly fused with the original Mamba outputs through a cross-attention fusion layer, combining both spatial and frequency information to optimize the order awareness of state-space models which is essential for the details and overall quality of image generation. Besides, we introduce a globally-shared transformer to supercharge the performance of Mamba, harnessing its exceptional power to capture global relationships. Through extensive experiments on standard benchmarks, our method demonstrates superior results compared to DiT and DIFFUSSM, achieving faster training convergence and delivering high-quality outputs. The codes and pretrained models are released at https://github.com/VinAIResearch/DiMSUM.git.

Pre-trained Language Models (LMs) exhibit strong zero-shot and in-context learning capabilities; however, their behaviors are often difficult to control. By utilizing Reinforcement Learning from Human Feedback (RLHF), it is possible to fine-tune unsupervised LMs to follow instructions and produce outputs that reflect human preferences. Despite its benefits, RLHF has been shown to potentially harm a language model's reasoning capabilities and introduce artifacts such as hallucinations where the model may fabricate facts. To address this issue we introduce Direct Preference Heads (DPH), a fine-tuning framework that enables LMs to learn human preference signals through an auxiliary reward head without directly affecting the output distribution of the language modeling head. We perform a theoretical analysis of our objective function and find strong ties to Conservative Direct Preference Optimization (cDPO). Finally we evaluate our models on GLUE, RACE, and the GPT4All evaluation suite and demonstrate that our method produces models which achieve higher scores than those fine-tuned with Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO) alone.

Distribution variations in machine learning, driven by the dynamic nature of deployment environments, significantly impact the performance of learning models. This paper explores endogenous distribution shifts in learning systems, where deployed models influence environments and subsequently alter data distributions. This phenomenon is formulated by a decision-dependent distribution mapping within the recently proposed framework of performative prediction (PP) Perdomo et al. (2020). We investigate the performative effect in a decentralized noncooperative game, where players aim to minimize private cost functions while simultaneously managing coupled inequality constraints. Under performativity, we examine two equilibrium concepts for the studied game: performative stable equilibrium (PSE) and Nash equilibrium (NE), and establish sufficient conditions for their existence and uniqueness. Notably, we provide the first upper bound on the distance between the PSE and NE in the literature, which is challenging to evaluate due to the absence of strong convexity on the joint cost function. Furthermore, we develop a decentralized stochastic primal-dual algorithm for efficiently computing the PSE point. By carefully bounding the performative effect in theoretical analysis, we prove that the proposed algorithm achieves sublinear convergence rates for both performative regrets and constraint violation and maintains the same order of convergence rate as the case without performativity. Numerical experiments validate the effectiveness of our algorithm and theoretical results.
tl;dr: DOFEN (Deep Oblivious Forest ENsemble): a novel deep neural network architecture for tabular data, achieving sota performance compared to deep nerual network baselines and comparable performance with tree-based models.

Deep Neural Networks (DNNs) have revolutionized artificial intelligence, achieving impressive results on diverse data types, including images, videos, and texts. However, DNNs still lag behind Gradient Boosting Decision Trees (GBDT) on tabular data, a format extensively utilized across various domains. This paper introduces DOFEN, which stands for Deep Oblivious Forest ENsemble. DOFEN is a novel DNN architecture inspired by oblivious decision trees and achieves on-off sparse selection of columns. DOFEN surpasses other DNNs on tabular data, achieving state-of-the-art performance on the well-recognized benchmark: Tabular Benchmark, which includes 73 total datasets spanning a wide array of domains. The code of DOFEN is available at: https://github.com/Sinopac-Digital-Technology-Division/DOFEN

Diffusion models equipped with language models demonstrate excellent controllability in image generation tasks, allowing image processing to adhere to human instructions. However, the lack of diverse instruction-following data hampers the development of models that effectively recognize and execute user-customized instructions, particularly in low-level tasks. Moreover, the stochastic nature of the diffusion process leads to deficiencies in image generation or editing tasks that require the detailed preservation of the generated images. To address these limitations, we propose PromptFix, a comprehensive framework that enables diffusion models to follow human instructions to perform a wide variety of image-processing tasks. First, we construct a large-scale instruction-following dataset that covers comprehensive image-processing tasks, including low-level tasks, image editing, and object creation. Next, we propose a high-frequency guidance sampling method to explicitly control the denoising process and preserve high-frequency details in unprocessed areas. Finally, we design an auxiliary prompting adapter, utilizing Vision-Language Models (VLMs) to enhance text prompts and improve the model's task generalization. Experimental results show that PromptFix outperforms previous methods in various image-processing tasks. Our proposed model also achieves comparable inference efficiency with these baseline models and exhibits superior zero-shot capabilities in blind restoration and combination tasks.
tl;dr: Infinitely long video generation technique without training based on pretrained diffusion models

We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without additional training. This is achieved by iteratively performing diagonal denoising, which simultaneously processes a series of consecutive frames with increasing noise levels in a queue; our method dequeues a fully denoised frame at the head while enqueuing a new random noise frame at the tail. However, diagonal denoising is a double-edged sword as the frames near the tail can take advantage of cleaner frames by forward reference but such a strategy induces the discrepancy between training and inference. Hence, we introduce latent partitioning to reduce the training-inference gap and lookahead denoising to leverage the benefit of forward referencing. Practically, FIFO-Diffusion consumes a constant amount of memory regardless of the target video length given a baseline model, while well-suited for parallel inference on multiple GPUs. We have demonstrated the promising results and effectiveness of the proposed methods on existing text-to-video generation baselines. Generated video examples and source codes are available at our project page.

Disentangling the explanatory factors in complex data is a promising approach for generalizable and data-efficient representation learning. While a variety of quantitative metrics for learning and evaluating disentangled representations have been proposed, it remains unclear what properties these metrics truly quantify. In this work, we establish algebraic relationships between logical definitions and quantitative metrics to derive theoretically grounded disentanglement metrics. Concretely, we introduce a compositional approach for converting a higher-order predicate into a real-valued quantity by replacing (i) equality with a strict premetric, (ii) the Heyting algebra of binary truth values with a quantale of continuous values, and (iii) quantifiers with aggregators. The metrics induced by logical definitions have strong theoretical guarantees, and some of them are easily differentiable and can be used as learning objectives directly. Finally, we empirically demonstrate the effectiveness of the proposed metrics by isolating different aspects of disentangled representations.
tl;dr: We generalize the continuous time framework for score-based generative models from an underlying Brownian motion to a Markov-approximate fractional Brownian motion.

We introduce the first continuous-time score-based generative model that leverages fractional diffusion processes for its underlying dynamics. Although diffusion models have excelled at capturing data distributions, they still suffer from various limitations such as slow convergence, mode-collapse on imbalanced data, and lack of diversity. These issues are partially linked to the use of light-tailed Brownian motion (BM) with independent increments. In this paper, we replace BM with an approximation of its non-Markovian counterpart, fractional Brownian motion (fBM), characterized by correlated increments and Hurst index $H \in (0,1)$, where $H=0.5$ recovers the classical BM. To ensure tractable inference and learning, we employ a recently popularized Markov approximation of fBM (MA-fBM) and derive its reverse-time model, resulting in *generative fractional diffusion models* (GFDM). We characterize the forward dynamics using a continuous reparameterization trick and propose *augmented score matching* to efficiently learn the score function, which is partly known in closed form, at minimal added cost. The ability to drive our diffusion model via MA-fBM offers flexibility and control. $H \leq 0.5$ enters the regime of *rough paths* whereas $H>0.5$ regularizes diffusion paths and invokes long-term memory. The Markov approximation allows added control by varying the number of Markov processes linearly combined to approximate fBM. Our evaluations on real image datasets demonstrate that GFDM achieves greater pixel-wise diversity and enhanced image quality, as indicated by a lower FID, offering a promising alternative to traditional diffusion models

Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the human preference at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.

Modality differences have led to the development of heterogeneous architectures for vision and language models. While images typically require 2D non-causal modeling, texts utilize 1D causal modeling. This distinction poses significant challenges in constructing unified multi-modal models. This paper explores the feasibility of representing images using 1D causal modeling. We identify an "over-focus" issue in existing 1D causal vision models, where attention overly concentrates on a small proportion of visual tokens. The issue of "over-focus" hinders the model's ability to extract diverse visual features and to receive effective gradients for optimization. To address this, we propose De-focus Attention Networks, which employ learnable bandpass filters to create varied attention patterns. During training, large and scheduled drop path rates, and an auxiliary loss on globally pooled features for global understanding tasks are introduced. These two strategies encourage the model to attend to a broader range of tokens and enhance network optimization. Extensive experiments validate the efficacy of our approach, demonstrating that 1D causal visual representation can perform comparably to 2D non-causal representation in tasks such as global perception, dense prediction, and multi-modal understanding. Code shall be released.

Predicting potential outcomes of interventions from observational data is crucial for decision-making in medicine, but the task is challenging due to the fundamental problem of causal inference. Existing methods are largely limited to point estimates of potential outcomes with no uncertain quantification; thus, the full information about the distributions of potential outcomes is typically ignored. In this paper, we propose a novel causal diffusion model called DiffPO, which is carefully designed for reliable inferences in medicine by learning the distribution of potential outcomes. In our DiffPO, we leverage a tailored conditional denoising diffusion model to learn complex distributions, where we address the selection bias through a novel orthogonal diffusion loss. Another strength of our DiffPO method is that it is highly flexible (e.g., it can also be used to estimate different causal quantities such as CATE). Across a wide range of experiments, we show that our method achieves state-of-the-art performance.
Adversarial prompts (or say, adversarial examples) generated using gradient-based methods exhibit outstanding performance in performing automatic jailbreak attacks against safety-aligned LLMs. Nevertheless, due to the discrete nature of texts, the input gradient of LLMs struggles to precisely reflect the magnitude of loss change that results from token replacements in the prompt, leading to limited attack success rates against safety-aligned LLMs, even in the *white-box* setting. In this paper, we explore a new perspective on this problem, suggesting that it can be alleviated by leveraging innovations inspired in transfer-based attacks that were originally proposed for attacking *black-box* image classification models. For the first time, we appropriate the ideologies of effective methods among these transfer-based attacks, *i.e.*, Skip Gradient Method and Intermediate Level Attack, into gradient-based adversarial prompt generation and achieve significant performance gains without introducing obvious computational cost. Meanwhile, by discussing mechanisms behind the gains, new insights are drawn, and proper combinations of these methods are also developed. Our empirical results show that 87% of the query-specific adversarial suffixes generated by the developed combination can induce Llama-2-7B-Chat to produce the output that exactly matches the target string on AdvBench. This match rate is 33% higher than that of a very strong baseline known as GCG, demonstrating advanced discrete optimization for adversarial prompt generation against LLMs. In addition, without introducing obvious cost, the combination achieves >30% absolute increase in attack success rates compared with GCG when generating both query-specific (38% ->68%) and universal adversarial prompts (26.68% -> 60.32%) for attacking the Llama-2-7B-Chat model on AdvBench.
Code at: https://github.com/qizhangli/Gradient-based-Jailbreak-Attacks.

Federated Learning (FL) is an appealing approach to training machine learning models without sharing raw data. However, standard FL algorithms are iterative and thus induce a significant communication cost. One-Shot FL (OFL) trades the iterative exchange of models between clients and the server with a single round of communication, thereby saving substantially on communication costs. Not surprisingly, OFL exhibits a performance gap in terms of accuracy with respect to FL, especially under high data heterogeneity. We introduce Fens, a novel federated ensembling scheme that approaches the accuracy of FL with the communication efficiency of OFL. Learning in Fens proceeds in two phases: first, clients train models locally and send them to the server, similar to OFL; second, clients collaboratively train a lightweight prediction aggregator model using FL. We showcase the effectiveness of Fens through exhaustive experiments spanning several datasets and heterogeneity levels. In the particular case of heterogeneously distributed CIFAR-10 dataset, Fens achieves up to a $26.9$% higher accuracy over SOTA OFL, being only $3.1$% lower than FL. At the same time, Fens incurs at most $4.3\times$ more communication than OFL, whereas FL is at least $10.9\times$ more communication-intensive than Fens.

Recently, Gaussian Splatting, a method that represents a 3D scene as a collection of Gaussian distributions, has gained significant attention in addressing the task of novel view synthesis. In this paper, we highlight a fundamental limitation of Gaussian Splatting: its inability to accurately render discontinuities and boundaries in images due to the continuous nature of Gaussian distributions. To address this issue, we propose a novel framework enabling Gaussian Splatting to perform discontinuity-aware image rendering. Additionally, we introduce a B\'ezier-boundary gradient approximation strategy within our framework to keep the ``differentiability'' of the proposed discontinuity-aware rendering process. Extensive experiments demonstrate the efficacy of our framework.

Large-scale pre-trained generative models are taking the world by storm, due to their abilities in generating creative content. Meanwhile, safeguards for these generative models are developed, to protect users' rights and safety, most of which are designed for large language models. Existing methods primarily focus on jailbreak and adversarial attacks, which mainly evaluate the model's safety under malicious prompts. Recent work found that manually crafted safe prompts can unintentionally trigger unsafe generations. To further systematically evaluate the safety risks of text-to-image models, we propose a novel Automatic Red-Teaming framework, ART. Our method leverages both vision language model and large language model to establish a connection between unsafe generations and their prompts, thereby more efficiently identifying the model's vulnerabilities. With our comprehensive experiments, we reveal the toxicity of the popular open-source text-to-image models. The experiments also validate the effectiveness, adaptability, and great diversity of ART. Additionally, we introduce three large-scale red-teaming datasets for studying the safety risks associated with text-to-image models. Datasets and models can be found in https://github.com/GuanlinLee/ART.
tl;dr: We present MeshXL for large-scale auto-regressive 3D mesh generative pre-training.

The polygon mesh representation of 3D data exhibits great flexibility, fast rendering speed, and storage efficiency, which is widely preferred in various applications. However, given its unstructured graph representation, the direct generation of high-fidelity 3D meshes is challenging. Fortunately, with a pre-defined ordering strategy, 3D meshes can be represented as sequences, and the generation process can be seamlessly treated as an auto-regressive problem. In this paper, we validate Neural Coordinate Field (NeurCF), an explicit coordinate representation with implicit neural embeddings, is a simple-yet-effective representation for large-scale sequential mesh modeling. After that, we present MeshXL, a family of generative pre-trained auto-regressive models that addresses 3D mesh generation with modern large language model approaches. Extensive experiments show that MeshXL is able to generate high-quality 3D meshes, and can also serve as foundation models for various down-stream applications.
tl;dr: A unified feedback learning framework to enhance the performance of text-to-image diffusion model

Latent diffusion models (LDM) have revolutionized text-to-image generation, leading to the proliferation of various advanced models and diverse downstream applications. However, despite these significant advancements, current diffusion models still suffer from several limitations, including inferior visual quality, inadequate aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present **UniFL**, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL.
Notably, UniFL consists of three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which accelerates inference.
In-depth experiments and extensive user studies validate the superior performance of our method in enhancing generation quality and inference acceleration. For instance, UniFL surpasses ImageReward by 17\% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57\% and 20\% general preference with 4-step inference.
tl;dr: The most used Pearson's r, typically regarded as a measure only for linear dependence, has been enhanced to accurately measure nonlinear monotone dependence, with the aid of an inequality tighter than Cauchy-Schwartz Inequality.

Pearson's $r$, the most widely-used correlation coefficient, is traditionally regarded as exclusively capturing linear dependence, leading to its discouragement in contexts involving nonlinear relationships. However, recent research challenges this notion, suggesting that Pearson's $r$ should not be ruled out a priori for measuring nonlinear monotone relationships. Pearson's $r$ is essentially a scaled covariance, rooted in the renowned Cauchy-Schwarz Inequality. Our findings reveal that different scaling bounds yield coefficients with different capture ranges, and interestingly, tighter bounds actually expand these ranges. We derive a tighter inequality than Cauchy-Schwarz Inequality, leverage it to refine Pearson's $r$, and propose a new correlation coefficient, i.e., rearrangement correlation. This coefficient is able to capture arbitrary monotone relationships, both linear and nonlinear ones. It reverts to Pearson's $r$ in linear scenarios. Simulation experiments and real-life investigations show that the rearrangement correlation is more accurate in measuring nonlinear monotone dependence than the three classical correlation coefficients, and other recently proposed dependence measures.
tl;dr: We present an interpretable by design GNN, that is a novel extension of Generalized Additive Models to graphs.

Graph Neural Networks (GNNs) have emerged as the predominant approach for learning over graph-structured data. However, most GNNs operate as black-box models and require post-hoc explanations, which may not suffice in high-stakes scenarios where transparency is crucial.
In this paper, we present a GNN that is interpretable by design. Our model, Graph Neural Additive Network (GNAN), is a novel extension of the interpretable class of Generalized Additive Models, and can be visualized and fully understood by humans. GNAN is designed to be fully interpretable, offering both global and local explanations at the feature and graph levels through direct visualization of the model. These visualizations describe exactly how the model uses the relationships between the target variable, the features, and the graph. We demonstrate the intelligibility of GNANs in a series of examples on different tasks and datasets. In addition, we show that the accuracy of GNAN is on par with black-box GNNs, making it suitable for critical applications where transparency is essential, alongside high accuracy.
3616. Evidential Mixture Machines: Deciphering Multi-Label Correlations for Active Learning Sensitivity

Multi-label active learning is a crucial yet challenging area in contemporary machine learning, often complicated by a large and sparse label space. This challenge is further exacerbated in active learning scenarios where labeling resources are constrained. Drawing inspiration from existing mixture of Bernoulli models, which efficiently compress the label space into a more manageable weight coefficient space by learning correlated Bernoulli components, we propose a novel model called Evidential Mixture Machines (EMM). Our model leverages mixture components derived from unsupervised learning in the label space and improves prediction accuracy by predicting weight coefficients following the evidential learning paradigm. These coefficients are aggregated as proxy pseudo counts to enhance component offset predictions. The evidential learning approach provides an uncertainty-aware connection between input features and the predicted coefficients and components. Additionally, our method combines evidential uncertainty with predicted label embedding covariances for active sample selection, creating a richer, multi-source uncertainty metric beyond traditional uncertainty scores. Experiments on synthetic datasets show the effectiveness of evidential uncertainty prediction and EMM's capability to capture label correlations through predicted components. Further testing on real-world datasets demonstrates improved performance compared to existing multi-label active learning methods.

The classical theory of statistical estimation aims to estimate a parameter of interest under data generated from a fixed design (''offline estimation''), while the contemporary theory of online learning provides algorithms for estimation under adaptively chosen covariates (''online estimation''). Motivated by connections between estimation and interactive decision making, we ask: is it possible to convert offline estimation algorithms into online estimation algorithms in a black-box fashion? We investigate this question from an information-theoretic perspective by introducing a new framework, Oracle-Efficient Online Estimation (OEOE), where the learner can only interact with the data stream indirectly through a sequence of offline estimators produced by a black-box algorithm operating on the stream. Our main results settle the statistical and computational complexity of online estimation in this framework.
$\bullet$ Statistical complexity. We show that information-theoretically, there exist algorithms that achieve near-optimal online estimation error via black-box offline estimation oracles, and give a nearly-tight characterization for minimax rates in the OEOE framework.
$\bullet$ Computational complexity. We show that the guarantees above cannot be achieved in a computationally efficient fashion in general, but give a refined characterization for the special case of conditional density estimation: computationally efficient online estimation via black-box offline estimation is possible whenever it is possible via unrestricted algorithms.
Finally, we apply our results to give offline oracle-efficient algorithms for interactive decision making.

Long-tailed visual recognition has received increasing attention recently. Despite fine-tuning techniques represented by visual prompt tuning (VPT) achieving substantial performance improvement by leveraging pre-trained knowledge, models still exhibit unsatisfactory generalization performance on tail classes. To address this issue, we propose a novel optimization strategy called Gaussian neighborhood minimization prompt tuning (GNM-PT), for VPT to address the long-tail learning problem. We introduce a novel Gaussian neighborhood loss, which provides a tight upper bound on the loss function of data distribution, facilitating a flattened loss landscape correlated to improved model generalization. Specifically, GNM-PT seeks the gradient descent direction within a random parameter neighborhood, independent of input samples, during each gradient update. Ultimately, GNM-PT enhances generalization across all classes while simultaneously reducing computational overhead. The proposed GNM-PT achieves state-of-the-art classification accuracies of 90.3%, 76.5%, and 50.1% on benchmark datasets CIFAR100-LT (IR 100), iNaturalist 2018, and Places-LT, respectively. The source code is available at https://github.com/Keke921/GNM-PT.

Training deep neural networks (DNNs) is costly. Fortunately, Nvidia Ampere and Hopper GPUs can accelerate matrix multiplications twice as fast as a dense equivalent by implementing 2:4 sparsity. However, previous STE-based 2:4 pre-training methods (\eg~STE with hard-thresholding, SR-STE) suffer from optimization difficulties because of discontinuous pruning function.
In this study, we comprehensively analyse the bottleneck of traditional N:M sparse training and recognize three drawbacks with discontinuity: incorrect descending direction, inability to predict the amount of descent and sparse mask oscillation. In the light of this statement, we propose S-STE, a simple yet powerful 2:4 training method that contains two parts: to continuously project weights to be 2:4 sparse, and to rescale sparse weights with a per-tensor fixed scaling factor. Besides, we adopt minimum-variance unbiased estimation for activation gradient and FP8 quantization for whole process. Results show that our method surpass previous 2:4 pre-training recipes and is comparable even with full parameter models.

Pretrained diffusion models (DMs) have recently been popularly used in solving inverse problems (IPs). The existing methods mostly interleave iterative steps in the reverse diffusion process and iterative steps to bring the iterates closer to satisfying the measurement constraint. However, such interleaving methods struggle to produce final results that look like natural objects of interest (i.e., manifold feasibility) and fit the measurement (i.e., measurement feasibility), especially for nonlinear IPs. Moreover, their capabilities to deal with noisy IPs with unknown types and levels of measurement noise are unknown. In this paper, we advocate viewing the reverse process in DMs as a function and propose a novel plug-in method for solving IPs using pretrained DMs, dubbed DMPlug. DMPlug addresses the issues of manifold feasibility and measurement feasibility in a principled manner, and also shows great potential for being robust to unknown types and levels of noise. Through extensive experiments across various IP tasks, including two linear and three nonlinear IPs, we demonstrate that DMPlug consistently outperforms state-of-the-art methods, often by large margins especially for nonlinear IPs.
tl;dr: YouDream generates anatomically and geometrically consistent 3D animals following a 3D pose prior, thus also enabling the generation of novel unseen animals.

3D generation guided by text-to-image diffusion models enables the creation of visually compelling assets. However previous methods explore generation based on image or text. The boundaries of creativity are limited by what can be expressed through words or the images that can be sourced. We present YouDream, a method to generate high-quality anatomically controllable animals. YouDream is guided using a text-to-image diffusion model controlled by 2D views of a 3D pose prior. Our method is capable of generating novel imaginary animals that previous text-to-3D generative methods are unable to create. Additionally, our method can preserve anatomic consistency in the generated animals, an area where prior approaches often struggle. Moreover, we design a fully automated pipeline for generating commonly observed animals. To circumvent the need for human intervention to create a 3D pose, we propose a multi-agent LLM that adapts poses from a limited library of animal 3D poses to represent the desired animal. A user study conducted on the outcomes of YouDream demonstrates the preference of the animal models generated by our method over others. Visualizations and code are available at https://youdream3d.github.io/.
tl;dr: Pre-trained, frozen diffusion models generate dense zero-shot reward signals for text-conditioned policy learning.

Training an agent to achieve particular goals or perform desired behaviors is often accomplished through reinforcement learning, especially in the absence of expert demonstrations. However, supporting novel goals or behaviors through reinforcement learning requires the ad-hoc design of appropriate reward functions, which quickly becomes intractable. To address this challenge, we propose Text-Aware Diffusion for Policy Learning (TADPoLe), which uses a pretrained, frozen text-conditioned diffusion model to compute dense zero-shot reward signals for text-aligned policy learning. We hypothesize that large-scale pretrained generative models encode rich priors that can supervise a policy to behave not only in a text-aligned manner, but also in alignment with a notion of naturalness summarized from internet-scale training data. In our experiments, we demonstrate that TADPoLe is able to learn policies for novel goal-achievement and continuous locomotion behaviors specified by natural language, in both Humanoid and Dog environments. The behaviors are learned zero-shot without ground-truth rewards or expert demonstrations, and are qualitatively more natural according to human evaluation. We further show that TADPoLe performs competitively when applied to robotic manipulation tasks in the Meta-World environment, without having access to any in-domain demonstrations.
tl;dr: Efficient face feature fusion using sparse experts for robust recognition in challenging environments.

Face feature fusion is indispensable for robust face recognition, particularly in scenarios involving long-range, low-resolution media (unconstrained environments) where not all frames or features are equally informative. Existing methods often rely on large intermediate feature maps or face metadata information, making them incompatible with legacy biometric template databases that store pre-computed features. Additionally, real-time inference and generalization to large probe sets remains challenging.
To address these limitations, we introduce a linear time O(N) proxy based sparse expert selection and pooling approach for context driven feature-set attention. Our approach is order invariant on the feature-set, generalizes to large sets, is compatible with legacy template stores, and utilizes significantly less parameters making it suitable real-time inference and edge use-cases. Through qualitative experiments, we demonstrate that ProxyFusion learns discriminative information for importance weighting of face features without relying on intermediate features. Quantitative evaluations on challenging low-resolution face verification datasets such as IARPA BTS3.1 and DroneSURF show the superiority of ProxyFusion in unconstrained long-range face recognition setting.
Our code and pretrained models are available at: https://github.com/bhavinjawade/ProxyFusion
tl;dr: We propose a parameter-efficient in-context tuning method, named Pin-tuning, to effectively adapt pre-trained molecular encoders to few-shot molecular property prediction tasks.

Molecular property prediction (MPP) is integral to drug discovery and material science, but often faces the challenge of data scarcity in real-world scenarios. Addressing this, few-shot molecular property prediction (FSMPP) has been developed. Unlike other few-shot tasks, FSMPP typically employs a pre-trained molecular encoder and a context-aware classifier, benefiting from molecular pre-training and molecular context information. Despite these advancements, existing methods struggle with the ineffective fine-tuning of pre-trained encoders. We attribute this issue to the imbalance between the abundance of tunable parameters and the scarcity of labeled molecules, and the lack of contextual perceptiveness in the encoders. To overcome this hurdle, we propose a parameter-efficient in-context tuning method, named Pin-Tuning. Specifically, we propose a lightweight adapter for pre-trained message passing layers (MP-Adapter) and Bayesian weight consolidation for pre-trained atom/bond embedding layers (Emb-BWC), to achieve parameter-efficient tuning while preventing over-fitting and catastrophic forgetting. Additionally, we enhance the MP-Adapters with contextual perceptiveness. This innovation allows for in-context tuning of the pre-trained encoder, thereby improving its adaptability for specific FSMPP tasks. When evaluated on public datasets, our method demonstrates superior tuning with fewer trainable parameters, improving few-shot predictive performance.
tl;dr: Boosting open-world semi-supervised learning with conditional self-labeling and open-world hierarchical thresholding

Semi-supervised learning (SSL) offers a robust framework for harnessing the potential of unannotated data. Traditionally, SSL mandates that all classes possess labeled instances. However, the emergence of open-world SSL (OwSSL) introduces a more practical challenge, wherein unlabeled data may encompass samples from unseen classes. This scenario leads to misclassification of unseen classes as known ones, consequently undermining classification accuracy. To overcome this challenge, this study revisits two methodologies from self-supervised and semi-supervised learning, self-labeling and consistency, tailoring them to address the OwSSL problem. Specifically, we propose an effective framework called _OwMatch_, combining conditional self-labeling and open-world hierarchical thresholding. Theoretically, we analyze the estimation of class distribution on unlabeled data through rigorous statistical analysis, thus demonstrating that OwMatch can ensure the unbiasedness of the label assignment estimator with reliability. Comprehensive empirical analyses demonstrate that our method yields substantial performance enhancements across both known and unknown classes in comparison to previous studies. Code is available at [https://github.com/niusj03/OwMatch](https://github.com/niusj03/OwMatch).

The spiking camera is an emerging neuromorphic vision sensor that records high-speed motion scenes by asynchronously firing continuous binary spike streams. Prevailing image reconstruction methods, generating intermediate frames from these spike streams, often rely on complex step-by-step network architectures that overlook the intrinsic collaboration of spatio-temporal complementary information. In this paper, we propose an efficient spatio-temporal interactive reconstruction network to jointly perform inter-frame feature alignment and intra-frame feature filtering in a coarse-to-fine manner. Specifically, it starts by extracting hierarchical features from a concise hybrid spike representation, then refines the motion fields and target frames scale-by-scale, ultimately obtaining a full-resolution output. Meanwhile, we introduce a symmetric interactive attention block and a multi-motion field estimation block to further enhance the interaction capability of the overall network. Experiments on synthetic and real-captured data show that our approach exhibits excellent performance while maintaining low model complexity.

Improving out-of-distribution (OOD) generalization during in-distribution (ID) adaptation is a primary goal of robust fine-tuning of zero-shot models beyond naive fine-tuning. However, despite decent OOD generalization performance from recent robust fine-tuning methods, confidence calibration for reliable model output has not been fully addressed. This work proposes a robust fine-tuning method that improves both OOD accuracy and confidence calibration simultaneously in vision language models. Firstly, we show that both OOD classification and OOD calibration errors have a shared upper bound consisting of two terms of ID data: 1) ID calibration error and 2) the smallest singular value of the ID input covariance matrix. Based on this insight, we design a novel framework that conducts fine-tuning with a constrained multimodal contrastive loss enforcing a larger smallest singular value, which is further guided by the self-distillation of a moving-averaged model to achieve calibrated prediction as well. Starting from empirical evidence supporting our theoretical statements, we provide extensive experimental results on ImageNet distribution shift benchmarks that demonstrate the effectiveness of our theorem and its practical implementation.
tl;dr: We introduce novel methods to enhance the honesty and helpfulness of LLMs through a new training-free technique and a two-stage fine-tuning process, establishing principles and datasets to evaluate and improve them.

Large Language Models (LLMs) have achieved remarkable success across various industries and applications, owing to their exceptional generative capabilities. Nevertheless, honesty and helpfulness, which ensure safe and useful real-world deployments, have been considered as the longstanding cornerstones in practice. In this paper, we first established comprehensive principles for honesty LLM and further created the HoneSet with 930 queries across six categories, which is designed to evaluate LLMs’ ability to maintain honesty. Then, we improved the honesty and helpfulness of LLMs in both training-free and fine-tuning settings. Specifically, we propose a training-free method named Curiosity-Driven Prompting, which enables LLMs to express their internal confusion and uncertainty about the given query and then optimize their responses. Moreover, we also propose a two-stage fine-tuning approach, inspired by curriculum learning, to enhance the honesty and helpfulness of LLMs. The method first teaches LLMs to distinguish between honest and dishonest, and then LLMs are trained to learn to respond more helpfully. Experimental results demonstrated that both of the two proposed methods improve the helpfulness of LLMs while making them maintain honesty. Our research has paved the way for more reliable and trustworthy LLMs in real-world applications.
tl;dr: We introduce a novel hybrid architecture (State Space Models + Attention) that efficiently processes past information using both fading and eidetic memory.

We describe a family of architectures to support transductive inference by allowing memory to grow to a finite but a-priori unknown bound while making efficient use of finite resources for inference. Current architectures use such resources to represent data either eidetically over a finite span ('context' in Transformers), or fading over an infinite span (in State Space Models, or SSMs). Recent hybrid architectures have combined eidetic and fading memory, but with limitations that do not allow the designer or the learning process to seamlessly modulate the two, nor to extend the eidetic memory span. We leverage ideas from Stochastic Realization Theory to develop a class of models called B'MOJO to seamlessly combine eidetic and fading memory within an elementary composable module. The overall architecture can be used to implement models that can access short-term eidetic memory 'in-context,' permanent structural memory 'in-weights,' fading memory 'in-state,' and long-term eidetic memory 'in-storage' by natively incorporating retrieval from an asynchronously updated memory. We show that Transformers, existing SSMs such as Mamba, and hybrid architectures such as Jamba are special cases of B'MOJO and describe a basic implementation, to be open sourced, that can be stacked and scaled efficiently in hardware. We test B'MOJO on transductive inference tasks, such as associative recall, where it outperforms existing SSMs and Hybrid models; as a baseline, we test ordinary language modeling where B'MOJO achieves perplexity comparable to similarly-sized Transformers and SSMs up to 1.4B parameters, while being up to 10% faster to train. Finally, we test whether models trained inductively on a-priori bounded sequences (up to 8K tokens) can still perform transductive inference on sequences many-fold longer. B'MOJO's ability to modulate eidetic and fading memory results in better inference on longer sequences tested up to 32K tokens, four-fold the length of the longest sequences seen during training.
tl;dr: We develop a Newton-informed neural operator for solving nonlinear problems with multiple solutions, requiring less data and offering faster convergence than traditional Newton methods.

Solving nonlinear partial differential equations (PDEs) with multiple solutions is essential in various fields, including physics, biology, and engineering. However, traditional numerical methods, such as finite element and finite difference methods, often face challenges when dealing with nonlinear solvers, particularly in the presence of multiple solutions. These methods can become computationally expensive, especially when relying on solvers like Newton's method, which may struggle with ill-posedness near bifurcation points.
In this paper, we propose a novel approach, the Newton Informed Neural Operator, which learns the Newton solver for nonlinear PDEs. Our method integrates traditional numerical techniques with the Newton nonlinear solver, efficiently learning the nonlinear mapping at each iteration. This approach allows us to compute multiple solutions in a single learning process while requiring fewer supervised data points than existing neural network methods.

Diffusion models excel at generating visually striking content from text but can inadvertently produce undesirable or harmful content when trained on unfiltered internet data. A practical solution is to selectively removing target concepts from the model, but this may impact the remaining concepts. Prior approaches have tried to balance this by introducing a loss term to preserve neutral content or a regularization term to minimize changes in the model parameters, yet resolving this trade-off remains challenging. In this work, we propose to identify and preserving concepts most affected by parameter changes, termed as *adversarial concepts*. This approach ensures stable erasure with minimal impact on the other concepts. We demonstrate the effectiveness of our method using the Stable Diffusion model, showing that it outperforms state-of-the-art erasure methods in eliminating unwanted content while maintaining the integrity of other unrelated elements. Our code is available at \url{https://github.com/tuananhbui89/Erasing-Adversarial-Preservation}.

As industrial models and designs grow increasingly complex, the demand for optimal control of large-scale dynamical systems has significantly increased. However, traditional methods for optimal control incur significant overhead as problem dimensions grow. In this paper, we introduce an end-to-end quantum algorithm for linear-quadratic control with provable speedups. Our algorithm, based on a policy gradient method, incorporates a novel quantum subroutine for solving the matrix Lyapunov equation. Specifically, we build a *quantum-assisted differentiable simulator* for efficient gradient estimation that is more accurate and robust than classical methods relying on stochastic approximation. Compared to the classical approaches, our method achieves a *super-quadratic* speedup. To the best of our knowledge, this is the first end-to-end quantum application to linear control problems with provable quantum advantage.
3633. Learning Plaintext-Ciphertext Cryptographic Problems via ANF-based SAT Instance Representation

Cryptographic problems, operating within binary variable spaces, can be routinely transformed into Boolean Satisfiability (SAT) problems regarding specific cryptographic conditions like plaintext-ciphertext matching. With the fast development of learning for discrete data, this SAT representation also facilitates the utilization of machine-learning approaches with the hope of automatically capturing patterns and strategies inherent in cryptographic structures in a data-driven manner. Existing neural SAT solvers consistently adopt conjunctive normal form (CNF) for instance representation, which in the cryptographic context can lead to scale explosion and a loss of high-level semantics. In particular, extensively used XOR operations in cryptographic problems can incur an exponential number of clauses. In this paper, we propose a graph structure based on Arithmetic Normal Form (ANF) to efficiently handle the XOR operation bottleneck. Additionally, we design an encoding method for AND operations in these ANF-based graphs, demonstrating improved efficiency over alternative general graph forms for SAT. We then propose CryptoANFNet, a graph learning approach that trains a classifier based on a message-passing scheme to predict plaintext-ciphertext satisfiability.
Using ANF-based SAT instances, CryptoANFNet demonstrates superior scalability and can naturally capture higher-order operational information. Empirically, CryptoANFNet achieves a 50x speedup over heuristic solvers and outperforms SOTA learning-based SAT solver NeuroSAT, with 96\% vs. 91\% accuracy on small-scale and 72\% vs. 55\% on large-scale datasets from real encryption algorithms. We also introduce a key-solving algorithm that simplifies ANF-based SAT instances from plaintext and ciphertext, enhancing key decryption accuracy from 76.5\% to 82\% and from 72\% to 75\% for datasets generated from two real encryption algorithms.
tl;dr: Flexible method for multimodal fusion on different biomedical data structures

Technological advances in medical data collection, such as high-throughput genomic sequencing and digital high-resolution histopathology, have contributed to the rising requirement for multimodal biomedical modelling, specifically for image, tabular and graph data. Most multimodal deep learning approaches use modality-specific architectures that are often trained separately and cannot capture the crucial cross-modal information that motivates the integration of different data sources. This paper presents the **H**ybrid **E**arly-fusion **A**ttention **L**earning **Net**work (HEALNet) – a flexible multimodal fusion architecture, which: a) preserves modality-specific structural information, b) captures the cross-modal interactions and structural information in a shared latent space, c) can effectively handle missing modalities during training and inference, and d) enables intuitive model inspection by learning on the raw data input instead of opaque embeddings. We conduct multimodal survival analysis on Whole Slide Images and Multi-omic data on four cancer datasets from The Cancer Genome Atlas (TCGA). HEALNet achieves state-of-the-art performance compared to other end-to-end trained fusion models, substantially improving over unimodal and multimodal baselines whilst being robust in scenarios with missing modalities. The code is available at https://github.com/konst-int-i/healnet.
tl;dr: We propose a sample efficient causal discovery algorithm that learns the causal graph in a Bayesian approach.

Causal discovery is a fundamental problem with applications spanning various areas in science and engineering. It is well understood that solely using observational data, one can only orient the causal graph up to its Markov equivalence class, necessitating interventional data to learn the complete causal graph. Most works in the literature design causal discovery policies with perfect interventions, i.e., they have access to infinite interventional samples. This study considers a Bayesian approach for learning causal graphs with limited interventional samples, mirroring real-world scenarios where such samples are usually costly to obtain. By leveraging the recent result of Wienöbst et al. [2023] on uniform DAG sampling in polynomial time, we can efficiently enumerate all the cut configurations and their corresponding interventional distributions of a target set, and further track their posteriors. Given any number of interventional samples, our proposed algorithm randomly intervenes on a set of target vertices that cut all the edges in the graph and returns a causal graph according to the posterior of each target set. When the number of interventional samples is large enough, we show theoretically that our proposed algorithm will return the true causal graph with high probability. We compare our algorithm against various baseline methods on simulated datasets, demonstrating its superior accuracy measured by the structural Hamming distance between the learned DAG and the ground truth. Additionally, we present a case study showing how this algorithm could be modified to answer more general causal questions without learning the whole graph. As an example, we illustrate that our method can be used to estimate the causal effect of a variable that cannot be intervened.
tl;dr: A novel paradigm to leverage decoder-only LLM as text encoder in powerful diffusion models.

Large language models based on decoder-only transformers have demonstrated superior text understanding capabilities compared to CLIP and T5-series models.
However, the paradigm for utilizing current advanced LLMs in text-to-image diffusion models remains to be explored.
We observed an unusual phenomenon: directly using a large language model as the prompt encoder significantly degrades the prompt-following ability in image generation.
We identified two main obstacles behind this issue.
One is the misalignment between the next token prediction training in LLM and the requirement for discriminative prompt features in diffusion models.
The other is the intrinsic positional bias introduced by the decoder-only architecture.
To deal with this issue, we propose a novel framework to fully harness the capabilities of LLMs.
Through the carefully designed usage guidance, we effectively enhance the text representation capability of the LLM for prompt encoding and eliminate its inherent positional bias.
This allows us to flexibly integrate state-of-the-art LLMs into the text-to-image generation model.
Furthermore, we also provide an effective manner to fuse multiple LLMs into our framework.
Considering the excellent performance and scaling capabilities demonstrated by the transformer architecture, we further design an LLM-Infused Diffusion Transformer (LI-DIT)based on the framework.
We conduct extensive experiments to validate LI-DIT across model size and data size.
Benefiting from the inherent ability of the LLMs and our innovative designs, the prompt understanding performance of LI-DIT easily surpasses state-of-the-art open-source models as well as mainstream closed-source commercial models including Stable Diffusion 3, DALL-E 3, and Midjourney V6.

Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.
tl;dr: This paper presents a dual-stream interactive transformer design to handle single image reflection separation problem, considering both intra-layer and inter-layer feature correlations.

Despite satisfactory results on ``easy'' cases of single image reflection separation, prior dual-stream methods still suffer from considerable performance degradation when facing complex ones, i.e, the transmission layer is densely entangled with the reflection having a wide distribution of spatial intensity. The main reasons come from the lack of concern on the feature correlation during interaction, and the limited receptive field. To remedy these deficiencies, this paper presents a Dual-Stream Interactive Transformer (DSIT) design. Specifically, we devise a dual-attention interactive structure that embraces a dual-stream self-attention and a layer-aware dual-stream cross-attention mechanism to simultaneously capture intra-layer and inter-layer feature correlations. Meanwhile, the introduction of attention mechanisms can also mitigate the receptive field limitation. We modulate single-stream pre-trained Transformer embeddings with dual-stream convolutional features through cross-architecture interactions to provide richer semantic priors, thereby further relieving the ill-posedness of the problem. Extensive experimental results reveal the merits of the proposed DSIT over other state-of-the-art alternatives. Our code is publicly available at https://github.com/mingcv/DSIT.
tl;dr: We propose an alteration of the sampling step in diffusion models to generate outputs that satisfy desired constraints and physical principles

This paper introduces an approach to endow generative diffusion processes the ability to satisfy and certify compliance with constraints and physical principles. The proposed method recast the traditional sampling process of generative diffusion models as a constrained optimization problem, steering the generated data distribution to remain within a specified region to ensure adherence to the given constraints.
These capabilities are validated on applications featuring both convex and challenging, non-convex, constraints as well as ordinary differential equations, in domains spanning from synthesizing new materials with precise morphometric properties, generating physics-informed motion, optimizing paths in planning scenarios, and human motion synthesis.
tl;dr: We propose a $1^st$ order low-rank meta-learning model for generalizing Neural PDE dynamics solvers to unseen dynamics. Our approach is general, it can incorporate knowledge from known physics if available.

Solving parametric partial differential equations (PDEs) presents significant challenges for data-driven methods due to the sensitivity of spatio-temporal dynamics to variations in PDE parameters. Machine learning approaches often struggle to capture this variability. To address this, data-driven approaches learn parametric PDEs by sampling a very large variety of trajectories with varying PDE parameters. We first show that incorporating conditioning mechanisms for learning parametric PDEs is essential and that among them, \textit{adaptive conditioning}, allows stronger generalization. As existing adaptive conditioning methods do not scale well with respect to the number of parameters to adapt in the neural solver, we propose GEPS, a simple adaptation mechanism to boost GEneralization in Pde Solvers via a first-order optimization and low-rank rapid adaptation of a small set of context parameters. We demonstrate the versatility of our approach for both fully data-driven and for physics-aware neural solvers. Validation performed on a whole range of spatio-temporal forecasting problems demonstrates excellent performance for generalizing to unseen conditions including initial conditions, PDE coefficients, forcing terms and solution domain. *Project page*: https://geps-project.github.io
tl;dr: Federated semantic segmentation without transfer of gradient or model weights, enabling more privacy preserving networks

Federated Learning (FL) is a form of distributed learning that allows multiple institutions or clients to collaboratively learn a global model to solve a task. This allows the model to utilize the information from every institute while preserving data privacy. However, recent studies show that the promise of protecting the privacy of data is not upheld by existing methods and that it is possible to recreate the training data from the different institutions. This is done by utilizing gradients transferred between the clients and the global server during training or by knowing the model architecture at the client end. In this paper, we propose a federated learning framework for semantic segmentation without knowing the model architecture nor transferring gradients between the client and the server, thus enabling better privacy preservation. We propose \textit{BlackFed} - a black-box adaptation of neural networks that utilizes zero order optimization (ZOO) to update the client model weights and first order optimization (FOO) to update the server weights. We evaluate our approach on several computer vision and medical imaging datasets to demonstrate its effectiveness. To the best of our knowledge, this work is one of the first works in employing federated learning for segmentation, devoid of gradients or model information exchange. Code: https://github.com/JayParanjape/blackfed/tree/master
tl;dr: This paper presents FedGTST, a federated learning algorithm that improves global transferability using cross-client statistics, significantly outperforming existing methods.

The performance of Transfer Learning (TL) significantly depends on effective pretraining, which not only requires extensive amounts of data but also substantial computational resources. As a result, in practice, it is challenging to successfully perform TL at the level of individual model developers. Federated Learning (FL) addresses these challenges by enabling collaboration among individual clients through an indirect expansion of the available dataset, distribution of the computation burden across different entities, and privacy-preserving communication mechanisms. Despite several attempts to devise effective transferable FL approaches, several important issues remain unsolved. First, existing methods in this setting primarily focus on optimizing transferability within their local client domains, thereby ignoring transferability over the global learning domain. Second, most approaches focus on analyzing indirect transferability metrics, which does not allow for accurate assessment of the final target loss and extent of transferability. To address these issues, we introduce two important FL features into the model. The first boosts transferability via an exchange protocol between the clients and the server that includes information about cross-client Jacobian (gradient) norms. The second feature promotes an increase of the average of the Jacobians of the clients at the server side, which is subsequently used as a local regularizer that reduces the cross-client Jacobian variance. A rigorous analysis of our transferable federated algorithm, termed FedGTST (Federated Global Transferability via Statistics Tuning), reveals that increasing the averaged Jacobian norm across clients and reducing its variance ensures tight control of the target loss. This insight leads to the first known upper bound on the target loss of transferable federated learning in terms of the source loss and source-target domain discrepancy. Extensive experimental results on datasets including MNIST → MNIST-M and CIFAR10 → SVHN suggest that FedGTST significantly outperforms other relevant baselines, such as FedSR. For example, on the second source-target dataset pair, we improve the accuracy of FedSR by 9.8% and that of FedIIR by 7.6% when the backbone used is LeNet.

When artificial agents are jointly trained to perform collaborative tasks using a communication channel, they develop opaque goal-oriented communication protocols. Good task performance is often considered sufficient evidence that meaningful communication is taking place, but existing empirical results show that communication strategies induced by common objectives can be counterintuitive whilst solving the task nearly perfectly. In this work, we identify a goal-agnostic prerequisite to meaningful communication, which we term semantic consistency, based on the idea that messages should have similar meanings across instances. We provide a formal definition for this idea, and use it to compare the two most common objectives in the field of emergent communication: discrimination and reconstruction. We prove, under mild assumptions, that semantically inconsistent communication protocols can be optimal solutions to the discrimination task, but not to reconstruction. We further show that the reconstruction objective encourages a stricter property, spatial meaningfulness, which also accounts for the distance between messages. Experiments with emergent communication games validate our theoretical results. These findings demonstrate an inherent advantage of distance-based communication goals, and contextualize previous empirical discoveries.
tl;dr: We propose a structured regularization method for learning label-hierarchy informed representations using hyperbolic geometry.

Most real-world datasets consist of a natural hierarchy between classes or an inherent label structure that is either already available or can be constructed cheaply. However, most existing representation learning methods ignore this hierarchy, treating labels as permutation invariant. Recent work [Zeng et al., 2022] proposes using this structured information explicitly, but the use of Euclidean distance may distort the underlying semantic context [Chen et al., 2013]. In this work, motivated by the advantage of hyperbolic spaces in modeling hierarchical relationships, we propose a novel approach HypStructure: a Hyperbolic Structured regularization approach to accurately embed the label hierarchy into the learned representations. HypStructure is a simple-yet-effective regularizer that consists of a hyperbolic tree-based representation loss along with a centering loss, and can be combined with any standard task loss to learn hierarchy-informed features. Extensive experiments on several large-scale vision benchmarks demonstrate the efficacy of HypStructure in reducing distortion and boosting generalization performance especially under low dimensional scenarios. For a better understanding of structured representation, we perform eigenvalue analysis that links the representation geometry to improved Out-of-Distribution (OOD) detection performance seen empirically.
tl;dr: We introduce a new framework for modeling the joint distribution of images and conditioning variables by adapting Stable Diffusion to enhance prompt compliance, controllability and editing of images.

Recent advances in generative modeling with diffusion processes (DPs) enabled breakthroughs in image synthesis. Despite impressive image quality, these models have various prompt compliance problems, including low recall in generating multiple objects, difficulty in generating text in images, and meeting constraints like object locations and pose. For fine-grained editing and manipulation, they also require fine-grained semantic or instance maps that are tedious to produce manually. While prompt compliance can be enhanced by addition of loss functions at inference, this is time consuming and does not scale to complex scenes.
To overcome these limitations, this work introduces a new family of $\textit{Factor Graph Diffusion Models}$ (FG-DMs) that models the joint distribution of images and conditioning variables, such as semantic, sketch, depth or normal maps via a factor graph decomposition. This joint structure has several advantages, including support for efficient sampling based prompt compliance schemes, which produce images of high object recall, semi-automated fine-grained editing, explainability at intermediate levels, ability to produce labeled datasets for the training of downstream models such as segmentation or depth, training with missing data, and continual learning where new conditioning variables can be added with minimal or no modifications to the existing structure. We propose an implementation of FG-DMs by adapting a pre-trained Stable Diffusion (SD) model to implement all FG-DM factors, using only COCO dataset, and show that it is effective in generating images with 15\% higher recall than SD while retaining its generalization ability. We introduce an attention distillation loss that encourages consistency among the attention maps of all factors, improving the fidelity of the generated conditions and image. We also show that training FG-DMs from scratch on MM-CelebA-HQ, Cityscapes, ADE20K, and COCO produce images of high quality (FID) and diversity (LPIPS).

In practical scenarios, it is necessary to build variable-sized models to accommodate diverse resource constraints, where weight initialization serves as a crucial step preceding training. The recently introduced Learngene framework firstly learns one compact module, termed learngene, from a large well-trained model, and then transforms learngene to initialize variable-sized models. However, the existing Learngene methods provide limited guidance on transforming learngene, where transformation mechanisms are manually designed and generally lack a learnable component. Moreover, these methods only consider transforming learngene along depth dimension, thus constraining the flexibility of learngene. Motivated by these concerns, we propose a novel and effective Learngene approach termed LeTs (Learnable Transformation), where we transform the learngene module along both width and depth dimension with a set of learnable matrices for flexible variablesized model initialization. Specifically, we construct an auxiliary model comprising the compact learngene module and learnable transformation matrices, enabling both components to be trained. To meet the varying size requirements of target models, we select specific parameters from well-trained transformation matrices to adaptively transform the learngene, guided by strategies such as continuous selection and magnitude-wise selection. Extensive experiments on ImageNet-1K demonstrate that Des-Nets initialized via LeTs outperform those with 100-epoch from scratch training after only 1 epoch tuning. When transferring to downstream image classification tasks, LeTs achieves better results while outperforming from scratch training after about 10 epochs within a 300-epoch training schedule.
tl;dr: This work extend the graph information bottleneck from graph classification tasks to the graph regression tasks.

Graph regression is a fundamental task that has gained significant attention in
various graph learning tasks. However, the inference process is often not easily
interpretable. Current explanation techniques are limited to understanding Graph
Neural Network (GNN) behaviors in classification tasks, leaving an explanation gap
for graph regression models. In this work, we propose a novel explanation method
to interpret the graph regression models (XAIG-R). Our method addresses the
distribution shifting problem and continuously ordered decision boundary issues
that hinder existing methods away from being applied in regression tasks. We
introduce a novel objective based on the graph information bottleneck theory (GIB)
and a new mix-up framework, which can support various GNNs and explainers
in a model-agnostic manner. Additionally, we present a self-supervised learning
strategy to tackle the continuously ordered labels in regression tasks. We evaluate
our proposed method on three benchmark datasets and a real-life dataset introduced
by us, and extensive experiments demonstrate its effectiveness in interpreting GNN
models in regression tasks.

Time series analysis is widely used in many fields such as power energy, economics, and transportation, including different tasks such as forecasting, anomaly detection, classification, etc. Missing values are widely observed in these tasks, and often leading to unpredictable negative effects on existing methods, hindering their further application. In response to this situation, existing time series imputation methods mainly focus on restoring sequences based on their data characteristics, while ignoring the performance of the restored sequences in downstream tasks. Considering different requirements of downstream tasks (e.g., forecasting), this paper proposes an efficient downstream task-oriented time series imputation evaluation approach. By combining time series imputation with neural network models used for downstream tasks, the gain of different imputation strategies on downstream tasks is estimated without retraining, and the most favorable imputation value for downstream tasks is given by combining different imputation strategies according to the estimated gain.

Concept Bottleneck Models (CBMs) provide interpretable prediction by introducing an intermediate Concept Bottleneck Layer (CBL), which encodes human-understandable concepts to explain models' decision. Recent works proposed to utilize Large Language Models (LLMs) and pre-trained Vision-Language Models (VLMs) to automate the training of CBMs, making it more scalable and automated. However, existing approaches still fall short in two aspects: First, the concepts predicted by CBL often mismatch the input image, raising doubts about the faithfulness of interpretation. Second, it has been shown that concept values encode unintended information: even a set of random concepts could achieve comparable test accuracy to state-of-the-art CBMs. To address these critical limitations, in this work, we propose a novel framework called Vision-Language-Guided Concept Bottleneck Model (VLG-CBM) to enable faithful interpretability with the benefits of boosted performance. Our method leverages off-the-shelf open-domain grounded object detectors to provide visually grounded concept annotation, which largely enhances the faithfulness of concept prediction while further improving the model performance. In addition, we propose a new metric called Number of Effective Concepts (NEC) to control the information leakage and provide better interpretability. Extensive evaluations across five standard benchmarks show that our method, VLG-CBM, outperforms existing methods by at least 4.27\% and up to 51.09\% on accuracy at NEC=5, and by at least 0.45\% and up to 29.78\% on average accuracy across different NECs, while preserving both faithfulness and interpretability of the learned concepts as demonstrated in extensive experiments.

Explicit, momentum-based dynamics that optimize functions defined on Lie groups can be constructed via variational optimization and momentum trivialization. Structure preserving time discretizations can then turn this dynamics into optimization algorithms. This article investigates two types of discretization, Lie Heavy-Ball, which is a known splitting scheme, and Lie NAG-SC, which is newly proposed. Their convergence rates are explicitly quantified under $L$-smoothness and \emph{local} strong convexity assumptions. Lie NAG-SC provides acceleration over the momentumless case, i.e. Riemannian gradient descent, but Lie Heavy-Ball does not. When compared to existing accelerated optimizers for general manifolds, both Lie Heavy-Ball and Lie NAG-SC are computationally cheaper and easier to implement, thanks to their utilization of group structure. Only gradient oracle and exponential map are required, but not logarithm map or parallel transport which are computational costly.
tl;dr: We demonstrate ab initio reconstruction of conformational and compositional heterogeneity in cryo-EM datasets with neural fields.

Cryo-electron microscopy (cryo-EM) is an experimental technique for protein structure determination that images an ensemble of macromolecules in near-physiological contexts. While recent advances enable the reconstruction of dynamic conformations of a single biomolecular complex, current methods do not adequately model samples with mixed conformational and compositional heterogeneity. In particular, datasets containing mixtures of multiple proteins require the joint inference of structure, pose, compositional class, and conformational states for 3D reconstruction. Here, we present Hydra, an approach that models both conformational and compositional heterogeneity fully ab initio by parameterizing structures as arising from one of K neural fields. We employ a hybrid optimization strategy and demonstrate the effectiveness of our approach on synthetic datasets composed of mixtures of proteins with large degrees of conformational variability. We additionally demonstrate Hydra on an experimental dataset imaged of a cellular lysate containing a mixture of different protein complexes. Hydra expands the expressivity of heterogeneous reconstruction methods and thus broadens the scope of cryo-EM to increasingly complex samples.
tl;dr: We propose a novel approach that leverages graph neural networks to automatically construct a unified label space for training semantic segmentation models across multiple datasets.

Deep supervised models possess significant capability to assimilate extensive training data, thereby presenting an opportunity to enhance model performance through training on multiple datasets. However, conflicts arising from different label spaces among datasets may adversely affect model performance. In this paper, we propose a novel approach to automatically construct a unified label space across multiple datasets using graph neural networks. This enables semantic segmentation models to be trained simultaneously on multiple datasets, resulting in performance improvements. Unlike existing methods, our approach facilitates seamless training without the need for additional manual reannotation or taxonomy reconciliation. This significantly enhances the efficiency and effectiveness of multi-dataset segmentation model training. The results demonstrate that our method significantly outperforms other multi-dataset training methods when trained on seven datasets simultaneously, and achieves state-of-the-art performance on the WildDash 2 benchmark. Our code can be found in https://github.com/Mrhonor/AutoUniSeg.

The discovery of dynamical systems is crucial across a range of fields, including pharmacology, epidemiology, and physical sciences. *Accurate* and *interpretable* modeling of these systems is essential for understanding complex temporal processes, optimizing interventions, and minimizing adverse effects. In pharmacology, for example, precise modeling of drug dynamics is vital to maximize therapeutic efficacy while minimizing patient harm, as in chemotherapy. However, current models, often developed by human experts, are limited by high cost, lack of scalability, and restriction to existing human knowledge. In this paper, we present the **Data-Driven Discovery (D3)** framework, a novel approach leveraging Large Language Models (LLMs) to iteratively discover and refine interpretable models of dynamical systems, demonstrated here with pharmacological applications. Unlike traditional methods, D3 enables the LLM to propose, acquire, and integrate new features, validate, and compare dynamical systems models, uncovering new insights into pharmacokinetics. Experiments on a pharmacokinetic Warfarin dataset reveal that D3 identifies a new plausible model that is well-fitting, highlighting its potential for precision dosing in clinical applications.

In this paper, we delve deeper into the Kullback–Leibler (KL) Divergence loss and mathematically prove that it is equivalent to the Decoupled Kullback-Leibler (DKL) Divergence loss that consists of 1) a weighted Mean Square Error ($\mathbf{w}$MSE) loss and 2) a Cross-Entropy loss incorporating soft labels.
Thanks to the decomposed formulation of DKL loss, we have identified two areas for improvement.
Firstly, we address the limitation of KL/DKL in scenarios like knowledge distillation by breaking its asymmetric optimization property. This modification ensures that the $\mathbf{w}$MSE component is always effective during training, providing extra constructive cues.
Secondly, we introduce class-wise global information into KL/DKL to mitigate bias from individual samples.
With these two enhancements, we derive the Improved Kullback–Leibler (IKL) Divergence loss and evaluate its effectiveness by conducting experiments on CIFAR-10/100 and ImageNet datasets, focusing on adversarial training, and knowledge distillation tasks. The proposed approach achieves new state-of-the-art adversarial robustness on the public leaderboard --- \textit{RobustBench} and competitive performance on knowledge distillation, demonstrating the substantial practical merits. Our code is available at https://github.com/jiequancui/DKL.
tl;dr: This paper proposes a pioneering method that utilizes 4D imaging radar sensors for robust 3D occupancy prediction even against adverse weathers.

3D occupancy-based perception pipeline has significantly advanced autonomous driving by capturing detailed scene descriptions and demonstrating strong generalizability across various object categories and shapes. Current methods predominantly rely on LiDAR or camera inputs for 3D occupancy prediction. These methods are susceptible to adverse weather conditions, limiting the all-weather deployment of self-driving cars. To improve perception robustness, we leverage the recent advances in automotive radars and introduce a novel approach that utilizes 4D imaging radar sensors for 3D occupancy prediction. Our method, RadarOcc, circumvents the limitations of sparse radar point clouds by directly processing the 4D radar tensor, thus preserving essential scene details. RadarOcc innovatively addresses the challenges associated with the voluminous and noisy 4D radar data by employing Doppler bins descriptors, sidelobe-aware spatial sparsification, and range-wise self-attention mechanisms. To minimize the interpolation errors associated with direct coordinate transformations, we also devise a spherical-based feature encoding followed by spherical-to-Cartesian feature aggregation. We benchmark various baseline methods based on distinct modalities on the public K-Radar dataset. The results demonstrate RadarOcc's state-of-the-art performance in radar-based 3D occupancy prediction and promising results even when compared with LiDAR- or camera-based methods. Additionally, we present qualitative evidence of the superior performance of 4D radar in adverse weather conditions and explore the impact of key pipeline components through ablation studies.
tl;dr: We propose a novel red teaming approach AgentPoison, the first backdoor attack targeting generic and RAG-based LLM agents by poisoning their long-term memory or RAG knowledge base.

LLM agents have demonstrated remarkable performance across various applications, primarily due to their advanced capabilities in reasoning, utilizing external knowledge and tools, calling APIs, and executing actions to interact with environments. Current agents typically utilize a memory module or a retrieval-augmented generation (RAG) mechanism, retrieving past knowledge and instances with similar embeddings from knowledge bases to inform task planning and execution. However, the reliance on unverified knowledge bases raises significant concerns about their safety and trustworthiness. To uncover such vulnerabilities, we propose a novel red teaming approach AgentPoison, the first backdoor attack targeting generic and RAG-based LLM agents by poisoning their long-term memory or
RAG knowledge base. In particular, we form the trigger generation process as a constrained optimization to optimize backdoor triggers by mapping the triggered instances to a unique embedding space, so as to ensure that whenever a user instruction contains the optimized backdoor trigger, the malicious demonstrations are retrieved from the poisoned memory or knowledge base with high probability. In the meantime, benign instructions without the trigger will still maintain normal performance. Unlike conventional backdoor attacks, AgentPoison requires no additional model training or fine-tuning, and the optimized backdoor trigger exhibits superior transferability, resilience, and stealthiness. Extensive experiments demonstrate AgentPoison's effectiveness in attacking
three types of real-world LLM agents: RAG-based autonomous driving agent, knowledge-intensive QA agent, and healthcare EHRAgent. We inject the poisoning instances into the RAG knowledge base and long-term memories of these agents, respectively, demonstrating the generalization of AgentPoison. On each agent, AgentPoison achieves an average attack success rate of $\ge$ 80% with minimal
impact on benign performance ($\le$ 1%) with a poison rate < 0.1%. The code and data is available at https://github.com/BillChan226/AgentPoison.
3657. Discovering Creative Behaviors through DUPLEX: Diverse Universal Features for Policy Exploration
tl;dr: Novel algorithm for learning diverse near-optimal policies capable of generalizing within and out-of distribution

The ability to approach the same problem from different angles is a cornerstone of human intelligence that leads to robust solutions and effective adaptation to problem variations. In contrast, current RL methodologies tend to lead to policies that settle on a single solution to a given problem, making them brittle to problem variations. Replicating human flexibility in reinforcement learning agents is the challenge that we explore in this work. We tackle this challenge by extending state-of-the-art approaches to introduce DUPLEX, a method that explicitly defines a diversity objective with constraints and makes robust estimates of policies’ expected behavior through successor features. The trained agents can (i) learn a diverse set of near-optimal policies in complex highly-dynamic environments and (ii) exhibit competitive and diverse skills in out-of-distribution (OOD) contexts. Empirical results indicate that DUPLEX improves over previous methods and successfully learns competitive driving styles in a hyper-realistic simulator (i.e., GranTurismo ™ 7) as well as diverse and effective policies in several multi-context robotics MuJoCo simulations with OOD gravity forces and height limits. To the best of our knowledge, our method is the first to achieve diverse solutions in complex driving simulators and OOD robotic contexts. DUPLEX agents demonstrating diverse behaviors can be found at https://ai.sony/publications/Discovering-Creative-Behaviors-through-DUPLEX-Diverse-Universal-Features-for-Policy-Exploration/.
tl;dr: We speed up inference by novel mixture-of-experts conversion method

Transformer models can face practical limitations due to their high computational requirements. At the same time, such models exhibit significant activation sparsity, which can be leveraged to reduce the inference cost by converting parts of the network into equivalent Mixture-of-Experts (MoE) layers. Despite the crucial role played by activation sparsity, its impact on this process remains unexplored. We demonstrate that the efficiency of the conversion can be significantly enhanced by a proper regularization of the activation sparsity of the base model. Moreover, motivated by the high variance of the number of activated neurons for different inputs, we introduce a more effective dynamic-$k$ expert selection rule that adjusts the number of executed experts on a per-token basis. To achieve further savings, we extend this approach to multi-head attention projections. Finally, we develop an efficient implementation that translates these computational savings into actual wall-clock speedup. The proposed method, Dense to Dynamic-$k$ Mixture-of-Experts (D2DMoE), outperforms existing approaches on common NLP and vision tasks, reducing inference cost by up to 60\% without significantly impacting performance.
tl;dr: Prompt learning that distills the textual knowledge from natural language prompts to improve the downstream generalization of CLIP.

Large pretrained vision-language models like CLIP have shown promising generalization capability, but may struggle in specialized domains (e.g., satellite imagery) or fine-grained classification (e.g., car models) where the visual concepts are unseen or under-represented during pretraining. Prompt learning offers a parameter-efficient finetuning framework that can adapt CLIP to downstream tasks even when limited annotation data are available. In this paper, we improve prompt learning by distilling the textual knowledge from natural language prompts (either human- or LLM-generated) to provide rich priors for those under-represented concepts. We first obtain a prompt ``summary'' aligned to each input image via a learned prompt aggregator. Then we jointly train a prompt generator, optimized to produce a prompt embedding that stays close to the aggregated summary while minimizing task loss at the same time. We dub such prompt embedding as Aggregate-and-Adapted Prompt Embedding (AAPE). AAPE is shown to be able to generalize to different downstream data distributions and tasks, including vision-language understanding tasks (e.g., few-shot classification, VQA) and generation tasks (image captioning) where AAPE achieves competitive performance. We also show AAPE is particularly helpful to handle non-canonical and OOD examples. Furthermore, AAPE learning eliminates LLM-based inference cost as required by baselines, and scales better with data and LLM model size.
tl;dr: We present the $lambda$-Harmonic reward function and Reward Preference Optimization (RPO) for the subject-driven text-to-image generation task.

Text-to-image generative models have recently attracted considerable interest, enabling the synthesis of high-quality images from textual prompts. However, these models often lack the capability to generate specific subjects from given reference images or to synthesize novel renditions under varying conditions. Methods like DreamBooth and Subject-driven Text-to-Image (SuTI) have made significant progress in this area. Yet, both approaches primarily focus on enhancing similarity to reference images and require expensive setups, often overlooking the need for efficient training and avoiding overfitting to the reference images. In this work, we present the $\lambda$-Harmonic reward function, which provides a reliable reward signal and enables early stopping for faster training and effective regularization. By combining the Bradley-Terry preference model, the $\lambda$-Harmonic reward function also provides preference labels for subject-driven generation tasks. We propose Reward Preference Optimization (RPO), which offers a simpler setup (requiring only 3\% of the negative samples used by DreamBooth) and fewer gradient steps for fine-tuning. Unlike most existing methods, our approach does not require training a text encoder or optimizing text embeddings and achieves text-image alignment by fine-tuning only the U-Net component. Empirically, $\lambda$-Harmonic proves to be a reliable approach for model selection in subject-driven generation tasks. Based on preference labels and early stopping validation from the $\lambda$-Harmonic reward function, our algorithm achieves a state-of-the-art CLIP-I score of 0.833 and a CLIP-T score of 0.314 on DreamBench.
tl;dr: robust camera-insensitivity collaborative perception

Collaborative perception is dedicated to tackling the constraints of single-agent perception, such as occlusions, based on the multiple agents' multi-view sensor inputs. However, most existing works assume an ideal condition that all agents' multi-view cameras are continuously available. In reality, cameras may be highly noisy, obscured or even failed during the collaboration. In this work, we introduce a new robust camera-insensitivity problem: how to overcome the issues caused by the failed camera perspectives, while stabilizing high collaborative performance with low calibration cost? To address above problems, we propose RCDN, a Robust Camera-insensitivity collaborative perception with a novel Dynamic feature-based 3D Neural modeling mechanism. The key intuition of RCDN is to construct collaborative neural rendering field representations to recover failed perceptual messages sent by multiple agents. To better model collaborative neural rendering field, RCDN first establishes a geometry BEV feature based time-invariant static field with other agents via fast hash grid modeling. Based on the static background field, the proposed time-varying dynamic field can model corresponding motion vector for foregrounds with appropriate positions. To validate RCDN, we create OPV2V-N, a new large-scale dataset with manual labelling under different camera failed scenarios. Extensive experiments conducted on OPV2V-N show that RCDN can be ported to other baselines and improve their robustness in extreme camera-insensitivity setting. Our code and datasets will be available soon.
tl;dr: Lumina-Next, an improved version of flow-based large diffusion transformers, enable better resolution extrapolation and multilingual text-to-image generation, while demonstrating strong performance across various modalities.

Lumina-T2X is a nascent family of Flow-based Large Diffusion Transformers (Flag-DiT) that establishes a unified framework for transforming noise into various modalities, such as images and videos, conditioned on text instructions. Despite its promising capabilities, Lumina-T2X still encounters challenges including training instability, slow inference, and extrapolation artifacts. In this paper, we present Lumina-Next, an improved version of Lumina-T2X, showcasing stronger generation performance with increased training and inference efficiency. We begin with a comprehensive analysis of the Flag-DiT architecture and identify several suboptimal components, which we address by introducing the Next-DiT architecture with 3D RoPE and sandwich normalizations. To enable better resolution extrapolation, we thoroughly compare different context extrapolation methods applied to text-to-image generation with 3D RoPE, and propose Frequency- and Time-Aware Scaled RoPE tailored for diffusion transformers. Additionally, we introduce a sigmoid time discretization schedule for diffusion sampling, which achieves high-quality generation in 5-10 steps combined with higher-order ODE solvers. Thanks to these improvements, Lumina-Next not only improves the basic text-to-image generation but also demonstrates superior resolution extrapolation capabilities as well as multilingual generation using decoder-based LLMs as the text encoder, all in a zero-shot manner. To further validate Lumina-Next as a versatile generative framework, we instantiate it on diverse tasks including visual recognition, multi-views, audio, music, and point cloud generation, showcasing strong performance across these domains. By releasing all codes and model weights at https://github.com/Alpha-VLLM/Lumina-T2X, we aim to advance the development of next-generation generative AI capable of universal modeling.

Gloss-free sign language translation (SLT) aims to develop well-performing SLT systems with no requirement for the costly gloss annotations, but currently still lags behind gloss-based approaches significantly. In this paper, we identify **a representation density problem** that could be a bottleneck in restricting the performance of gloss-free SLT. Specifically, the representation density problem describes that the visual representations of semantically distinct sign gestures tend to be closely packed together in feature space, which makes gloss-free methods struggle with distinguishing different sign gestures and suffer from a sharp performance drop. To address the representation density problem, we introduce a simple but effective contrastive learning strategy, namely SignCL, which encourages gloss-free models to learn more discriminative feature representation in a self-supervised manner. Our experiments demonstrate that the proposed SignCL can significantly reduce the representation density and improve performance across various translation frameworks. Specifically, SignCLachieves a significant improvement in BLEU score for the Sign Language Transformer and GFSLT-VLP on the CSL-Daily dataset by 39\% and 46\%, respectively, without any increase of model parameters. Compared to Sign2GPT, a state-of-the-art method based on large-scale pre-trained vision and language models, SignCLachieves better performance with only 35\% of its parameters. We will release our code and model to facilitate further research.

Recurrent neural networks (RNNs) notoriously struggle to learn long-term memories, primarily due to vanishing and exploding gradients. The recent success of state-space models (SSMs), a subclass of RNNs, to overcome such difficulties challenges our theoretical understanding. In this paper, we delve into the optimization challenges of RNNs and discover that, as the memory of a network increases, changes in its parameters result in increasingly large output variations, making gradient-based learning highly sensitive, even without exploding gradients. Our analysis further reveals the importance of the element-wise recurrence design pattern combined with careful parametrizations in mitigating this effect. This feature is present in SSMs, as well as in other architectures, such as LSTMs. Overall, our insights provide a new explanation for some of the difficulties in gradient-based learning of RNNs and why some architectures perform better than others.
tl;dr: This paper introduces DCRL, a framework for efficiency improvement and variance reduction under partial observability.

Partial observability in environments poses significant challenges that impede the formation of effective policies in reinforcement learning. Prior research has shown that borrowing the complete state information can enhance sample efficiency. This strategy, however, frequently encounters unstable learning with high variance in practical applications due to the over-reliance on complete information. This paper introduces DCRL, a Dual Critic Reinforcement Learning framework designed to adaptively harness full-state information during training to reduce variance for optimized online performance. In particular, DCRL incorporates two distinct critics: an oracle critic with access to complete state information and a standard critic functioning within the partially observable context. It innovates a synergistic strategy to meld the strengths of the oracle critic for efficiency improvement and the standard critic for variance reduction, featuring a novel mechanism for seamless transition and weighting between them. We theoretically prove that DCRL mitigates the learning variance while maintaining unbiasedness. Extensive experimental analyses across the Box2D and Box3D environments have verified DCRL's superior performance. The source code is available in the supplementary.
3666. Boosting Sample Efficiency and Generalization in Multi-agent Reinforcement Learning via Equivariance
tl;dr: We demonstrate improved sample efficiency and generalization in Multi-Agent Reinforcement Learning (MARL) via using Exploration-enhanced Equivariant Neural Networks instead of traditional function approximators such as MLPs.

Multi-Agent Reinforcement Learning (MARL) struggles with sample inefficiency and poor generalization [1]. These challenges are partially due to a lack of structure or inductive bias in the neural networks typically used in learning the policy. One such form of structure that is commonly observed in multi-agent scenarios is symmetry. The field of Geometric Deep Learning has developed Equivariant Graph Neural Networks (EGNN) that are equivariant (or symmetric) to rotations, translations, and reflections of nodes. Incorporating equivariance has been shown to improve learning efficiency and decrease error [ 2 ]. In this paper, we demonstrate that EGNNs improve the sample efficiency and generalization in MARL. However, we also show that a naive application of EGNNs to MARL results in poor early exploration due to a bias in the EGNN structure. To mitigate this bias, we present Exploration-enhanced Equivariant Graph Neural Networks or E2GN2. We compare E2GN2 to other common function approximators using common MARL benchmarks MPE and SMACv2. E2GN2 demonstrates a significant improvement in sample efficiency, greater final reward convergence, and a 2x-5x gain in over standard GNNs in our generalization tests. These results pave the way for more reliable and effective solutions in complex multi-agent systems.

Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models, adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model significantly outperforms LoRA while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library which trains at nearly the same speed as LoRA while consuming up to 16% lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases. To demonstrate rapid switching benefits during inference, we show that loading SHiRA on a base model can be 5x-16x faster than LoRA fusion on a CPU.
tl;dr: We propose a framework that enables exact arithmetic in a single autoregressive step, providing faster, more secure, and more interpretable LLM systems with arithmetic capabilities.

Despite significant advancements in text generation and reasoning, Large Language Models (LLMs) still face challenges in accurately performing complex arithmetic operations. Language model systems often enable LLMs to generate code for arithmetic operations to achieve accurate calculations. However, this approach compromises speed and security, and fine-tuning risks the language model losing prior capabilities. We propose a framework that enables exact arithmetic in *a single autoregressive step*, providing faster, more secure, and more interpretable LLM systems with arithmetic capabilities. We use the hidden states of a LLM to control a symbolic architecture that performs arithmetic. Our implementation using Llama 3 with OccamNet as a symbolic model (OccamLlama) achieves 100\% accuracy on single arithmetic operations ($+,-,\times,\div,\sin{},\cos{},\log{},\exp{},\sqrt{}$), outperforming GPT 4o with and without a code interpreter. Furthermore, OccamLlama outperforms GPT 4o with and without a code interpreter on average across a range of mathematical problem solving benchmarks, demonstrating that OccamLLMs can excel in arithmetic tasks, even surpassing much larger models. Code is available at https://github.com/druidowm/OccamLLM.
tl;dr: We introduce Rainbow Teaming, a novel approach for generating diverse adversarial prompts for LLMs which can be used for diagnosing and enhancing the robustness and safety of LLMs.

As large language models (LLMs) become increasingly prevalent across many real-world applications, understanding and enhancing their robustness to adversarial attacks is of paramount importance. Existing methods for identifying adversarial prompts tend to focus on specific domains, lack diversity, or require extensive human annotations. To address these limitations, we present Rainbow Teaming, a novel black-box approach for producing a diverse collection of adversarial prompts. Rainbow Teaming casts adversarial prompt generation as a quality-diversity problem and uses open-ended search to generate prompts that are both effective and diverse. Focusing on the safety domain, we use Rainbow Teaming to target various state-of-the-art LLMs, including the Llama 2 and Llama 3 models. Our approach reveals hundreds of effective adversarial prompts, with an attack success rate exceeding 90% across all tested models. Furthermore, we demonstrate that prompts generated by Rainbow Teaming are highly transferable and that fine-tuning models with synthetic data generated by our method significantly enhances their safety without sacrificing general performance or helpfulness. We additionally explore the versatility of Rainbow Teaming by applying it to question answering and cybersecurity, showcasing its potential to drive robust open-ended self-improvement in a wide range of applications.

This paper addresses the prevalent issue of label shift in an online setting with missing labels, where data distributions change over time and obtaining timely labels is challenging. While existing methods primarily focus on adjusting or updating the final layer of a pre-trained classifier, we explore the untapped potential of enhancing feature representations using unlabeled data at test-time. Our novel method, Online Label Shift adaptation with Online Feature Updates (OLS-OFU), leverages self-supervised learning to refine the feature extraction process, thereby improving the prediction model. By carefully designing the algorithm, theoretically OLS-OFU maintains the similar online regret convergence to the results in the literature while taking the improved features into account. Empirically, it achieves substantial improvements over existing methods, which is as significant as the gains existing methods have over the baseline (i.e., without distribution shift adaptations).

Accurately estimating depth in 360-degree imagery is crucial for virtual reality, autonomous navigation, and immersive media applications. Existing depth estimation methods designed for perspective-view imagery fail when applied to 360-degree images due to different camera projections and distortions. We propose a new depth estimation framework that uses unlabeled 360-degree data effectively. Our approach uses state-of-the-art perspective depth estimation models as teacher models to generate pseudo labels through a six-face cube projection technique, enabling efficient labeling of depth in 360-degree images. This method leverages the increasing availability of large datasets. It includes two main stages: offline mask generation for invalid regions and an online semi-supervised joint training regime. We tested our approach on benchmark datasets such as Matterport3D and Stanford2D3D, showing significant improvements in depth estimation accuracy, particularly in zero-shot scenarios. Our proposed training pipeline can enhance any 360 monocular depth estimator and demonstrate effective knowledge transfer across different camera projections and data types.

In this paper, we propose a novel multi-view stereo (MVS) framework that gets rid of the depth range prior. Unlike recent prior-free MVS methods that work in a pair-wise manner, our method simultaneously considers all the source images. Specifically, we introduce a Multi-view Disparity Attention (MDA) module to aggregate long-range context information within and across multi-view images. Considering the asymmetry of the epipolar disparity flow, the key to our method lies in accurately modeling multi-view geometric constraints. We integrate pose embedding to encapsulate information such as multi-view camera poses, providing implicit geometric constraints for multi-view disparity feature fusion dominated by attention. Additionally, we construct corresponding hidden states for each source image due to significant differences in the observation quality of the same pixel in the reference frame across multiple source frames. We explicitly estimate the quality of the current pixel corresponding to sampled points on the epipolar line of the source image and dynamically update hidden states through the uncertainty estimation module. Extensive results on the DTU dataset and Tanks\&Temple benchmark demonstrate the effectiveness of our method.

Federated learning (FL) allows collaborative machine learning training without sharing private data. While most FL methods assume identical data domains across clients, real-world scenarios often involve heterogeneous data domains. Federated Prototype Learning (FedPL) addresses this issue, using mean feature vectors as prototypes to enhance model generalization. However, existing FedPL methods create the same number of prototypes for each client, leading to cross-domain performance gaps and disparities for clients with varied data distributions. To mitigate cross-domain feature representation variance, we introduce FedPLVM, which establishes variance-aware dual-level prototypes clustering and employs a novel $\alpha$-sparsity prototype loss. The dual-level prototypes clustering strategy creates local clustered prototypes based on private data features, then performs global prototypes clustering to reduce communication complexity and preserve local data privacy. The $\alpha$-sparsity prototype loss aligns samples from underrepresented domains, enhancing intra-class similarity and reducing inter-class similarity. Evaluations on Digit-5, Office-10, and DomainNet datasets demonstrate our method's superiority over existing approaches.
tl;dr: We revisit the unique computational characteristics of SSMs and designed a novel and general token pruning method specifically for SSM-based vision models.

State Space Models (SSMs) have the advantage of keeping linear computational complexity compared to attention modules in transformers, and have been applied to vision tasks as a new type of powerful vision foundation model. Inspired by the observations that the final prediction in vision transformers (ViTs) is only based on a subset of most informative tokens, we take the novel step of enhancing the efficiency of SSM-based vision models through token-based pruning. However, direct applications of existing token pruning techniques designed for ViTs fail to deliver good performance, even with extensive fine-tuning. To address this issue, we revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. We first introduce a pruning-aware hidden state alignment method to stabilize the neighborhood of remaining tokens for performance enhancement. Besides, based on our detailed analysis, we propose a token importance evaluation method adapted for SSM models, to guide the token pruning. With efficient implementation and practical acceleration methods, our method brings actual speedup. Extensive experiments demonstrate that our approach can achieve significant computation reduction with minimal impact on performance across different tasks. Notably, we achieve 81.7\% accuracy on ImageNet with a 41.6\% reduction in the FLOPs for pruned PlainMamba-L3. Furthermore, our work provides deeper insights into understanding the behavior of SSM-based vision models for future research.
tl;dr: A deep correlated promp learning paradigm for visual recognition for missing-modality scenarios with minimal computational costs

Large-scale multimodal models have shown excellent performance over a series of tasks powered by the large corpus of paired multimodal training data. Generally, they are always assumed to receive modality-complete inputs. However, this simple assumption may not always hold in the real world due to privacy constraints or collection difficulty, where models pretrained on modality-complete data easily demonstrate degraded performance on missing-modality cases. To handle this issue, we refer to prompt learning to adapt large pretrained multimodal models to handle missing-modality scenarios by regarding different missing cases as different types of input. Instead of only prepending independent prompts to the intermediate layers, we present to leverage the correlations between prompts and input features and excavate the relationships between different layers of prompts to carefully design the instructions. We also incorporate the complementary semantics of different modalities to guide the prompting design for each modality. Extensive experiments on three commonly-used datasets consistently demonstrate the superiority of our method compared to the previous approaches upon different missing scenarios. Plentiful ablations are further given to show the generalizability and reliability of our method upon different modality-missing ratios and types.
tl;dr: We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality.

While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.

In this work, we present MotionBooth, an innovative framework designed for animating customized subjects with precise control over both object and camera movements. By leveraging a few images of a specific object, we efficiently fine-tune a text-to-video model to capture the object's shape and attributes accurately. Our approach presents subject region loss and video preservation loss to enhance the subject's learning performance, along with a subject token cross-attention loss to integrate the customized subject with motion control signals. Additionally, we propose training-free techniques for managing subject and camera motions during inference. In particular, we utilize cross-attention map manipulation to govern subject motion and introduce a novel latent shift module for camera movement control as well. MotionBooth excels in preserving the appearance of subjects while simultaneously controlling the motions in generated videos. Extensive quantitative and qualitative evaluations demonstrate the superiority and effectiveness of our method. Models and codes will be made publicly available.
tl;dr: We show that due to the non-differentiability of activation functions in the ReLU family, leapfrog HMC for networks with these activation functions has a large local error rate, making the method inefficient.

We analyze the error rates of the Hamiltonian Monte Carlo algorithm with leapfrog integrator for Bayesian neural network inference. We show that due to the non-differentiability of activation functions in the ReLU family, leapfrog HMC for networks with these activation functions has a large local error rate of $\Omega(\epsilon)$ rather than the classical error rate of $\mathcal{O}(\epsilon^3)$. This leads to a higher rejection rate of the proposals, making the method inefficient. We then verify our theoretical findings through empirical simulations as well as experiments on a real-world dataset that highlight the inefficiency of HMC inference on ReLU-based neural networks compared to analytical networks.
tl;dr: We enhance 3D Gaussian Splatting for HDR reconstruction from noisy raw images, outperforming prior models on the RawNeRF dataset.

Novel view synthesis from raw images provides superior high dynamic range (HDR) information compared to reconstructions from low dynamic range RGB images. However, the inherent noise in unprocessed raw images compromises the accuracy of 3D scene representation. Our study reveals that 3D Gaussian Splatting (3DGS) is particularly susceptible to this noise, leading to numerous elongated Gaussian shapes that overfit the noise, thereby significantly degrading reconstruction quality and reducing inference speed, especially in scenarios with limited views. To address these issues, we introduce a novel self-supervised learning framework designed to reconstruct HDR 3DGS from a limited number of noisy raw images. This framework enhances 3DGS by integrating a noise extractor and employing a noise-robust reconstruction loss that leverages a noise distribution prior. Experimental results show that our method outperforms LDR/HDR 3DGS and previous state-of-the-art (SOTA) self-supervised and supervised pre-trained models in both reconstruction quality and inference speed on the RawNeRF dataset across a broad range of training views. We will release the code upon paper acceptance.
tl;dr: We introduce an expressive NAS search space, containing diverse SOTA architectures. When searching in this space we find new SOTA and improvements on existing architectures.

Neural architecture search (NAS) finds high performing networks for a given task. Yet the results of NAS are fairly prosaic; they did not e.g. create a shift from convolutional structures to transformers. This is not least because the search spaces in NAS often aren’t diverse enough to include such transformations *a priori*. Instead, for NAS to provide greater potential for fundamental design shifts, we need a novel expressive search space design which is built from more fundamental operations. To this end, we introduce `einspace`, a search space based on a parameterised probabilistic context-free grammar. Our space is versatile, supporting architectures of various sizes and complexities, while also containing diverse network operations which allow it to model convolutions, attention components and more. It contains many existing competitive architectures, and provides flexibility for discovering new ones. Using this search space, we perform experiments to find novel architectures as well as improvements on existing ones on the diverse Unseen NAS datasets. We show that competitive architectures can be obtained by searching from scratch, and we consistently find large improvements when initialising the search with strong baselines. We believe that this work is an important advancement towards a transformative NAS paradigm where search space expressivity and strategic search initialisation play key roles.
tl;dr: We present Spiking Autonomous Driving (SAD), the first unified Spiking Neural Network (SNN) to address the energy challenges faced by autonomous driving systems through its event-driven and energy-efficient nature.

Autonomous driving demands an integrated approach that encompasses perception, prediction, and planning, all while operating under strict energy constraints to enhance scalability and environmental sustainability. We present Spiking Autonomous Driving (SAD), the first unified Spiking Neural Network (SNN) to address the energy challenges faced by autonomous driving systems through its event-driven and energy-efficient nature. SAD is trained end-to-end and consists of three main modules: perception, which processes inputs from multi-view cameras to construct a spatiotemporal bird's eye view; prediction, which utilizes a novel dual-pathway with spiking neurons to forecast future states; and planning, which generates safe trajectories considering predicted occupancy, traffic rules, and ride comfort. Evaluated on the nuScenes dataset, SAD achieves competitive performance in perception, prediction, and planning tasks, while drawing upon the energy efficiency of SNNs. This work highlights the potential of neuromorphic computing to be applied to energy-efficient autonomous driving, a critical step toward sustainable and safety-critical automotive technology. Our code is available at [https://github.com/ridgerchu/SAD](https://github.com/ridgerchu/SAD).
tl;dr: This work introduces a novel approach to re-train transformer encoder-based language models as explicit hierarchy encoders, leveraging the expansive nature of hyperbolic geometry.

Interpreting hierarchical structures latent in language is a key limitation of current language models (LMs). While previous research has implicitly leveraged these hierarchies to enhance LMs, approaches for their explicit encoding are yet to be explored. To address this, we introduce a novel approach to re-train transformer encoder-based LMs as Hierarchy Transformer encoders (HiTs), harnessing the expansive nature of hyperbolic space. Our method situates the output embedding space of pre-trained LMs within a Poincaré ball with a curvature that adapts to the embedding dimension, followed by re-training on hyperbolic clustering and centripetal losses. These losses are designed to effectively cluster related entities (input as texts) and organise them hierarchically. We evaluate HiTs against pre-trained LMs, standard fine-tuned LMs, and several hyperbolic embedding baselines, focusing on their capabilities in simulating transitive inference, predicting subsumptions, and transferring knowledge across hierarchies. The results demonstrate that HiTs consistently outperform all baselines in these tasks, underscoring the effectiveness and transferability of our re-trained hierarchy encoders.

The Normalized cut (NCut) problem is a fundamental and yet notoriously difficult one in the unsupervised clustering field. Because the NCut problem is fractionally structured, the fractional programming (FP) based approach has worked its way into a new frontier. However, the conventional FP techniques are insufficient: the classic Dinkelbach's transform can only deal with a single ratio and hence is limited to the two-class clustering, while the state-of-the-art quadratic transform accounts for multiple ratios but fails to convert the NCut problem to a tractable form. This work advocates a novel extension of the quadratic transform to the multidimensional ratio case, thereby recasting the fractional 0-1 NCut problem into a bipartite matching problem---which can be readily solved in an iterative manner. Furthermore, we explore the connection between the proposed multidimensional FP method and the minorization-maximization theory to verify the convergence.
tl;dr: Our proposed robust unlearning framework, AdvUnlearn, enhances diffusion models' safety by robustly erasing unwanted concepts through adversarial training, achieving an optimal balance between concept erasure and image generation quality.

Diffusion models (DMs) have achieved remarkable success in text-to-image generation, but they also pose safety risks, such as the potential generation of harmful content and copyright violations. The techniques of machine unlearning, also known as concept erasing, have been developed to address these risks. However, these techniques remain vulnerable to adversarial prompt attacks, which can prompt DMs post-unlearning to regenerate undesired images containing concepts (such as nudity) meant to be erased. This work aims to enhance the robustness of concept erasing by integrating the principle of adversarial training (AT) into machine unlearning, resulting in the robust unlearning framework referred to as AdvUnlearn. However, achieving this effectively and efficiently is highly nontrivial. First, we find that a straightforward implementation of AT compromises DMs’ image generation quality post-unlearning. To address this, we develop a utility-retaining regularization on an additional retain set, optimizing the trade-off between concept erasure robustness and model utility in AdvUnlearn. Moreover, we identify the text encoder as a more suitable module for robustification compared to UNet, ensuring unlearning effectiveness. And the acquired text encoder can serve as a plug-and-play robust unlearner for various DM types. Empirically, we perform extensive experiments to demonstrate the robustness advantage of AdvUnlearn across various DM unlearning scenarios, including the erasure of nudity, objects, and style concepts. In addition to robustness, AdvUnlearn also achieves a balanced tradeoff with model utility. To our knowledge, this is the first work to systematically explore robust DM unlearning through AT, setting it apart from existing methods that overlook robustness in concept erasing. Codes are available at https://github.com/OPTML-Group/AdvUnlearn.
Warning: This paper contains model outputs that may be offensive in nature.
tl;dr: We propose simulation-free training method for Neural ODEs by adopting flow matching objective with learnable embeddings.

In this work, we investigate a method for simulation-free training of Neural Ordinary Differential Equations (NODEs) for learning deterministic mappings between paired data. Despite the analogy of NODEs as continuous-depth residual networks, their application in typical supervised learning tasks has not been popular, mainly due to the large number of function evaluations required by ODE solvers and numerical instability in gradient estimation. To alleviate this problem, we employ the flow matching framework for simulation-free training of NODEs, which directly regresses the parameterized dynamics function to a predefined target velocity field. Contrary to generative tasks, however, we show that applying flow matching directly between paired data can often lead to an ill-defined flow that breaks the coupling of the data pairs (e.g., due to crossing trajectories). We propose a simple extension that applies flow matching in the embedding space of data pairs, where the embeddings are learned jointly with the dynamic function to ensure the validity of the flow which is also easier to learn. We demonstrate the effectiveness of our method on both regression and classification tasks, where our method outperforms existing NODEs with a significantly lower number of function evaluations. The code is available at https://github.com/seminkim/simulation-free-node.

Subspace learning is a critical endeavor in contemporary machine learning, particularly given the vast dimensions of modern datasets. In this study, we delve into the training dynamics of a single-layer GAN model from the perspective of subspace learning, framing these GANs as a novel approach to this fundamental task. Through a rigorous scaling limit analysis, we offer insights into the behavior of this model. Extending beyond prior research that primarily focused on sequential feature learning, we investigate the non-sequential scenario, emphasizing the pivotal role of inter-feature interactions in expediting training and enhancing performance, particularly with an uninformed initialization strategy. Our investigation encompasses both synthetic and real-world datasets, such as MNIST and Olivetti Faces, demonstrating the robustness and applicability of our findings to practical scenarios. By bridging our analysis to the realm of subspace learning, we systematically compare the efficacy of GAN-based methods against conventional approaches, both theoretically and empirically. Notably, our results unveil that while all methodologies successfully capture the underlying subspace, GANs exhibit a remarkable capability to acquire a more informative basis, owing to their intrinsic ability to generate new data samples. This elucidates the unique advantage of GAN-based approaches in subspace learning tasks.
3687. ColJailBreak: Collaborative Generation and Editing for Jailbreaking Text-to-Image Deep Generation

The commercial text-to-image deep generation models (e.g. DALL·E) can produce high-quality images based on input language descriptions. These models incorporate a black-box safety filter to prevent the generation of unsafe or unethical content, such as violent, criminal, or hateful imagery. Recent jailbreaking methods generate adversarial prompts capable of bypassing safety filters and producing unsafe content, exposing vulnerabilities in influential commercial models. However, once these adversarial prompts are identified, the safety filter can be updated to prevent the generation of unsafe images. In this work, we propose an effective, simple, and difficult-to-detect jailbreaking solution: generating safe content initially with normal text prompts and then editing the generations to embed unsafe content. The intuition behind this idea is that the deep generation model cannot reject safe generation with normal text prompts, while the editing models focus on modifying the local regions of images and do not involve a safety strategy. However, implementing such a solution is non-trivial, and we need to overcome several challenges: how to automatically confirm the normal prompt to replace the unsafe prompts, and how to effectively perform editable replacement and naturally generate unsafe content. In this work, we propose the collaborative generation and editing for jailbreaking text-to-image deep generation (ColJailBreak), which comprises three key components: adaptive normal safe substitution, inpainting-driven injection of unsafe content, and contrastive language-image-guided collaborative optimization. We validate our method on three datasets and compare it to two baseline methods. Our method could generate unsafe content through two commercial deep generation models including GPT-4 and DALL·E 2.
3688. Learning Frequency-Adapted Vision Foundation Model for Domain Generalized Semantic Segmentation
tl;dr: Learning style-invariant property from vision fundation model from the frequency space by Haar wavelet transform.

The emerging vision foundation model (VFM) has inherited the ability to generalize to unseen images.
Nevertheless, the key challenge of domain-generalized semantic segmentation (DGSS) lies in the domain gap attributed to the cross-domain styles, i.e., the variance of urban landscape and environment dependencies.
Hence, maintaining the style-invariant property with varying domain styles becomes the key bottleneck in harnessing VFM for DGSS.
The frequency space after Haar wavelet transformation provides a feasible way to decouple the style information from the domain-invariant content, since the content and style information are retained in the low- and high- frequency components of the space, respectively.
To this end, we propose a novel Frequency-Adapted (FADA) learning scheme to advance the frontier.
Its overall idea is to separately tackle the content and style information by frequency tokens throughout the learning process.
Particularly, the proposed FADA consists of two branches, i.e., low- and high- frequency branches. The former one is able to stabilize the scene content, while the latter one learns the scene styles and eliminates its impact to DGSS.
Experiments conducted on various DGSS settings show the state-of-the-art performance of our FADA and its versatility to a variety of VFMs.
Source code is available at \url{https://github.com/BiQiWHU/FADA}.
tl;dr: This work advances the state-of-the-art end-to-end neural image compression methods by learning the optimal shape and orientation of lattice vector quantizer cells to exploit complex inter-feature dependencies for coding gains.

It is customary to deploy uniform scalar quantization in the end-to-end optimized Neural image compression methods, instead of more powerful vector quantization, due to the high complexity of the latter. Lattice vector quantization (LVQ), on the other hand, presents a compelling alternative, which can exploit inter-feature dependencies more effectively while keeping computational efficiency almost the same as scalar quantization. However, traditional LVQ structures are designed/optimized for uniform source distributions, hence nonadaptive and suboptimal for real source distributions of latent code space for Neural image compression tasks. In this paper, we propose a novel learning method to overcome this weakness by designing the rate-distortion optimal lattice vector quantization (OLVQ) codebooks with respect to the sample statistics of the latent features to be compressed. By being able to better fit the LVQ structures to any given latent sample distribution, the proposed OLVQ method improves the rate-distortion performances of the existing quantization schemes in neural image compression significantly, while retaining the amenability of uniform scalar quantization.

Diffusion models have emerged as a promising approach for behavior cloning (BC), leveraging their exceptional ability to model multi-modal distributions. Diffusion policies (DP) have elevated BC performance to new heights, demonstrating robust efficacy across diverse tasks, coupled with their inherent flexibility and ease of implementation. Despite the increasing adoption of Diffusion Policies (DP) as a foundation for policy generation, the critical issue of safety remains largely unexplored. While previous attempts have targeted deep policy networks, DP used diffusion models as the policy network, making it ineffective to be attacked using previous methods because of its chained structure and randomness injected. In this paper, we undertake a comprehensive examination of DP safety concerns by introducing adversarial scenarios, encompassing offline and online attacks, global and patch-based attacks. We propose DP-Attacker, a suite of algorithms that can craft effective adversarial attacks across all aforementioned scenarios. We conduct attacks on pre-trained diffusion policies across various manipulation tasks. Through extensive experiments, we demonstrate that DP-Attacker has the capability to significantly decrease the success rate of DP for all scenarios. Particularly in offline scenarios, we exhibit the generation of highly transferable perturbations applicable to all frames. Furthermore, we illustrate the creation of adversarial physical patches that, when applied to the environment, effectively deceive the model. Video results are
put in: https://sites.google.com/view/dp-attacker-videos/.
3691. Selective Explanations
tl;dr: We propose selective explanations to detect when amortized explainers produce low-quality explanations and introduce an optimized method to improve their quality.

Feature attribution methods explain black-box machine learning (ML) models by assigning importance scores to input features.
These methods can be computationally expensive for large ML models. To address this challenge, there have been increasing efforts to develop amortized explainers, where a ML model is trained to efficiently approximate computationally expensive feature attribution scores. Despite their efficiency, amortized explainers can produce misleading explanations. In this paper, we propose selective explanations to (i) detect when amortized explainers generate inaccurate explanations and (ii) improve the approximation of the explanation using a technique we call explanations with initial guess. Selective explanations allow practitioners to specify the fraction of samples that receive explanations with initial guess, offering a principled way to bridge the gap between amortized explainers (one inference) and more computationally costly approximations (multiple inferences). Our experiments on various models and datasets demonstrate that feature attributions via selective explanations strike a favorable balance between explanation quality and computational efficiency.

\textit{Dataset condensation} is a newborn technique that generates a small dataset that can be used in training deep neural networks (DNNs) to lower storage and training costs. The objective of dataset condensation is to ensure that the model trained with the synthetic dataset can perform comparably to the model trained with full datasets. However, existing methods predominantly concentrate on classification tasks, posing challenges in their adaptation to time series forecasting (TS-forecasting). This challenge arises from disparities in the evaluation of synthetic data. In classification, the synthetic data is considered well-distilled if the model trained with the full dataset and the model trained with the synthetic dataset yield identical labels for the same input, regardless of variations in output logits distribution. Conversely, in TS-forecasting, the effectiveness of synthetic data distillation is determined by the distance between predictions of the two models. The synthetic data is deemed well-distilled only when all data points within the predictions are similar. Consequently, TS-forecasting has a more rigorous evaluation methodology compared to classification. To mitigate this gap, we theoretically analyze the optimization objective of dataset condensation for TS-forecasting and propose a new one-line plugin of dataset condensation for TS-forecasting designated as Dataset \textbf{Cond}ensation for \textbf{T}ime \textbf{S}eries \textbf{F}orecasting (CondTSF) based on our analysis. Plugging CondTSF into previous dataset condensation methods facilitates a reduction in the distance between the predictions of the model trained with the full dataset and the model trained with the synthetic dataset, thereby enhancing performance. We conduct extensive experiments on eight commonly used time series datasets. CondTSF consistently improves the performance of all previous dataset condensation methods across all datasets, particularly at low condensing ratios.
3693. Boosting the Transferability of Adversarial Attack on Vision Transformer with Adaptive Token Tuning

Vision transformers (ViTs) perform exceptionally well in various computer vision tasks but remain vulnerable to adversarial attacks. Recent studies have shown that the transferability of adversarial examples exists for CNNs, and the same holds true for ViTs. However, existing ViT attacks aggressively regularize the largest token gradients to exact zero within each layer of the surrogate model, overlooking the interactions between layers, which limits their transferability in attacking black-box models. Therefore, in this paper, we focus on boosting the transferability of adversarial attacks on ViTs through adaptive token tuning (ATT). Specifically, we propose three optimization strategies: an adaptive gradient re-scaling strategy to reduce the overall variance of token gradients, a self-paced patch out strategy to enhance the diversity of input tokens, and a hybrid token gradient truncation strategy to weaken the effectiveness of attention mechanism. We demonstrate that scaling correction of gradient changes using gradient variance across different layers can produce highly transferable adversarial examples. In addition, introducing attentional truncation can mitigate the overfitting over complex interactions between tokens in deep ViT layers to further improve the transferability. On the other hand, using feature importance as a guidance to discard a subset of perturbation patches in each iteration, along with combining self-paced learning and progressively more sampled attacks, significantly enhances the transferability over attacks that use all perturbation patches. Extensive experiments conducted on ViTs, undefended CNNs, and defended CNNs validate the superiority of our proposed ATT attack method. On average, our approach improves the attack performance by 10.1% compared to state-of-the-art transfer-based attacks. Notably, we achieve the best attack performance with an average of 58.3% on three defended CNNs. Code is available at https://github.com/MisterRpeng/ATT.
tl;dr: A new optimization-based training-free guided diffusion method, applicable to drastically different domains such as image and human motion generation

Diffusion models have demonstrated significant promise in various generative tasks; however, they often struggle to satisfy challenging constraints. Our approach addresses this limitation by rethinking training-free loss-guided diffusion from an optimization perspective. We formulate a series of constrained optimizations throughout the inference process of a diffusion model. In each optimization, we allow the sample to take multiple steps along the gradient of the proxy constraint function until we can no longer trust the proxy, according to the variance at each diffusion level. Additionally, we estimate the state manifold of diffusion model to allow for early termination when the sample starts to wander away from the state manifold at each diffusion step. Trust sampling effectively balances between following the unconditional diffusion model and adhering to the loss guidance, enabling more flexible and accurate constrained generation. We demonstrate the efficacy of our method through extensive experiments on complex tasks, and in drastically different domains of images and 3D motion generation, showing significant improvements over existing methods in terms of generation quality. Our implementation is available at https://github.com/will-s-h/trust-sampling.
3695. CODE: Contrasting Self-generated Description to Combat Hallucination in Large Multi-modal Models
tl;dr: We introduce CODE, a decoding method to reduce hallucinations in Large Multi-modal Models by using self-generated descriptions to improve response accuracy and cross-modal consistency.

Large Multi-modal Models (LMMs) have recently demonstrated remarkable abilities in visual context understanding and coherent response generation. However, alongside these advancements, the issue of hallucinations has emerged as a significant challenge, producing erroneous responses that are unrelated to the visual contents. In this paper, we introduce a novel contrastive-based decoding method, COuntering DEscription Contrastive Decoding (CODE), which leverages self-generated descriptions as contrasting references during the decoding phase of LMMs to address hallucination issues. CODE utilizes the comprehensive descriptions from model itself as visual counterpart to correct and improve response alignment with actual visual content. By dynamically adjusting the information flow and distribution of next-token predictions in the LMM's vocabulary, CODE enhances the coherence and informativeness of generated responses. Extensive experiments demonstrate that our method significantly reduces hallucinations and improves cross-modal consistency across various benchmarks and cutting-edge LMMs. Our method provides a simple yet effective decoding strategy that can be integrated to existing LMM frameworks without additional training.
tl;dr: A novel framework is proposed for hand pressure estimation, augmenting sEMG signals with 3D hand posture information.

We present PiMForce, a novel framework that enhances hand pressure estimation by leveraging 3D hand posture information to augment forearm surface electromyography (sEMG) signals. Our approach utilizes detailed spatial information from 3D hand poses in conjunction with dynamic muscle activity from sEMG to enable accurate and robust whole-hand pressure measurements under diverse hand-object interactions. We also developed a multimodal data collection system that combines a pressure glove, an sEMG armband, and a markerless finger-tracking module. We created a comprehensive dataset from 21 participants, capturing synchronized data of hand posture, sEMG signals, and exerted hand pressure across various hand postures and hand-object interaction scenarios using our collection system. Our framework enables precise hand pressure estimation in complex and natural interaction scenarios. Our approach substantially mitigates the limitations of traditional sEMG-based or vision-based methods by integrating 3D hand posture information with sEMG signals.
Video demos, data, and code are available online.

The recently-proposed framework of Predict+Optimize tackles optimization problems with parameters that are unknown at solving time, in a supervised learning setting. Prior frameworks consider only the scenario where all unknown parameters are (eventually) revealed simultaneously. In this work, we propose Multi-Stage Predict+Optimize, a novel extension catering to applications where unknown parameters are revealed in sequential stages, with optimization decisions made in between. We further develop three training algorithms for neural networks (NNs) for our framework as proof of concept, both of which handle all mixed integer linear programs. The first baseline algorithm is a natural extension of prior work, training a single NN which makes a single prediction of unknown parameters. The second and third algorithms instead leverage the possibility of updating parameter predictions between stages, and trains one NN per stage. To handle the interdependency between the neural networks, we adopt sequential and parallelized versions of coordinate descent for training. Experimentation on three benchmarks demonstrates the superior learning performance of our methods over classical approaches.
tl;dr: A simple approach for learning Successor Features from pixel-level observations for Continual Reinforcement Learning

In Deep Reinforcement Learning (RL), it is a challenge to learn representations that do not exhibit catastrophic forgetting or interference in non-stationary environments. Successor Features (SFs) offer a potential solution to this challenge. However, canonical techniques for learning SFs from pixel-level observations often lead to representation collapse, wherein representations degenerate and fail to capture meaningful variations in the data. More recent methods for learning SFs can avoid representation collapse, but they often involve complex losses and multiple learning phases, reducing their efficiency. We introduce a novel, simple method for learning SFs directly from pixels. Our approach uses a combination of a Temporal-difference (TD) loss and a reward prediction loss, which together capture the basic mathematical definition of SFs. We show that our approach matches or outperforms existing SF learning techniques in both 2D (Minigrid) and 3D (Miniworld) mazes, for both single and continual learning scenarios. As well, our technique is efficient, and can reach higher levels of performance in less time than other approaches. Our work provides a new, streamlined technique for learning SFs directly from pixel observations, with no pretraining required.
tl;dr: Our paper introduces a new forecasting model, which removes self-attention and utilizes cross-attention in Transformers, enhancing forecasting accuracy and efficiency while outperforming existing models across various datasets.

Time series forecasting is crucial for applications across multiple domains and various scenarios. Although Transformers have dramatically advanced the landscape of forecasting, their effectiveness remains debated. Recent findings have indicated that simpler linear models might outperform complex Transformer-based approaches, highlighting the potential for more streamlined architectures. In this paper, we shift the focus from evaluating the overall Transformer architecture to specifically examining the effectiveness of self-attention for time series forecasting. To this end, we introduce a new architecture, Cross-Attention-only Time Series transformer (CATS), that rethinks the traditional transformer framework by eliminating self-attention and leveraging cross-attention mechanisms instead.
By establishing future horizon-dependent parameters as queries and enhanced parameter sharing, our model not only improves long-term forecasting accuracy but also reduces the number of parameters and memory usage. Extensive experiment across various datasets demonstrates that our model achieves superior performance with the lowest mean squared error and uses fewer parameters compared to existing models.
The implementation of our model is available at: https://github.com/dongbeank/CATS.

Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior, such as human attention, and explicit, later-stage behavior, such as subjective preferences or likes. Yet most prior research has focused on modeling implicit and explicit human behavior in isolation; and often limited to a specific type of visual content. We propose UniAR -- a unified model of human attention and preference behavior across diverse visual content. UniAR leverages a multimodal transformer to predict subjective feedback, such as satisfaction or aesthetic quality, along with the underlying human attention or interaction heatmaps and viewing order. We train UniAR on diverse public datasets spanning natural images, webpages, and graphic designs, and achieve SOTA performance on multiple benchmarks across various image domains and behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/visual content, and enabling designers and content-creation models to optimize their creation for human-centric improvements.
tl;dr: This paper introduces a teacher-teacher paradigm where two pretrained LLMs achieve knowledge exchange and alignment through a two-step, few-epoch training of the LINE module with a well-designed alignment objective.

In recent years, there has been a proliferation of ready-to-use large language models (LLMs) designed for various applications, both general-purpose and domain-specific. Instead of advocating for the development of a new model or continuous pretraining of an existing one, this paper introduces a pragmatic teacher-teacher framework to facilitate mutual learning between two pre-existing models.
By leveraging two teacher models possessing complementary knowledge, we introduce a LIghtweight kNowledge alignmEnt (LINE) module aimed at harmonizing their knowledge within a unified representation space. This framework is particularly valuable in clinical settings, where stringent regulations and privacy considerations dictate the handling of detailed clinical notes. Our trained LINE module excels in capturing critical information from clinical notes, leveraging highly de-identified data. Validation and downstream tasks further demonstrate the effectiveness of the proposed framework.
tl;dr: To address the problem of regression with noisy labels, we propose the Contrastive Fragmentation framework to select clean samples by Mixture of Neighboring Fragments and curate four benchmark datasets along with a novel metric, Error Residual Ratio.

As with many other problems, real-world regression is plagued by the presence of noisy labels, an inevitable issue that demands our attention.
Fortunately, much real-world data often exhibits an intrinsic property of continuously ordered correlations between labels and features, where data points with similar labels are also represented with closely related features.
In response, we propose a novel approach named ConFrag, where we collectively model the regression data by transforming them into disjoint yet contrasting fragmentation pairs.
This enables the training of more distinctive representations, enhancing the ability to select clean samples.
Our ConFrag framework leverages a mixture of neighboring fragments to discern noisy labels through neighborhood agreement among expert feature extractors.
We extensively perform experiments on four newly curated benchmark datasets of diverse domains, including age prediction, price prediction, and music production year estimation.
We also introduce a metric called Error Residual Ratio (ERR) to better account for varying degrees of label noise.
Our approach consistently outperforms fourteen state-of-the-art baselines, being robust against symmetric and random Gaussian label noise.
tl;dr: We introduce EmotionBench (which includes eight negative emotions) to evaluate LLMs' emotional alignments with human norms collected from >1200 human responses.

Evaluating Large Language Models’ (LLMs) anthropomorphic capabilities has become increasingly important in contemporary discourse. Utilizing the emotion appraisal theory from psychology, we propose to evaluate the empathy ability of LLMs, i.e., how their feelings change when presented with specific situations. After a careful and comprehensive survey, we collect a dataset containing over 400 situations that have proven effective in eliciting the eight emotions central to our study. Categorizing the situations into 36 factors, we conduct a human evaluation involving more than 1,200 subjects worldwide. With the human evaluation results as references, our evaluation includes seven LLMs, covering both commercial and open-source models, including variations in model sizes, featuring the latest iterations, such as GPT-4, Mixtral-8x22B, and LLaMA-3.1. We find that, despite several misalignments, LLMs can generally respond appropriately to certain situations. Nevertheless, they fall short in alignment with the emotional behaviors of human beings and cannot establish connections between similar situations. Our collected dataset of situations, the human evaluation results, and the code of our testing framework, i.e., EmotionBench, are publicly available at https://github.com/CUHK-ARISE/EmotionBench.

Current post-training quantization methods for LLMs compress the weights down to 4-bits, with moderate to low degradation in accuracy. However, further reducing the number of bits or accelerating the network while avoiding large accuracy drops, especially for smaller, sub 7B models, remains an actively researched and open problem. To address this, in this work, we introduce Quantization with Binary Bases (QBB), a new approach for low-bit quantization that effectively removes (nearly) all multiplications, reducing the implementation to summations. Our novel approach works by decomposing the original weights into a set of binary (1-bit) matrices using an iterative process. For a given layer, starting from a weight matrix, we first construct an initial approximation using an analytical solution, where each new binary matrix, paired with a scaling vector, approximates the residual error of the previous estimation. Secondly, using gradient descent and a progressive learning curriculum, we find the optimal set of binary matrices and scaling vectors that minimize the $\ell_2$ distance between the produced approximation and original weights. Thirdly, as previous steps are input agnostic, we holistically optimize the scaling vectors alone, calibrating them in student-teacher fashion, with the teacher providing both the data,
by autoregressive generation starting from a random token, and the target logits.
When evaluated across multiple LLM families, our approach matches and outperforms all prior works, setting a new state-of-the-art result using a summation-only based approach.

Recent advances in AI have been significantly driven by the capabilities of large language models (LLMs) to solve complex problems in ways that resemble human thinking. However, there is an ongoing debate about the extent to which LLMs are capable of
actual reasoning. Central to this debate are two key probabilistic concepts that are essential for connecting causes
to their effects: the probability of necessity (PN) and the probability of sufficiency (PS). This paper introduces a framework that is both theoretical and practical, aimed at assessing how effectively LLMs are able to replicate real-world reasoning mechanisms using these probabilistic measures. By viewing LLMs as abstract machines that process information through a natural language interface, we examine the conditions under which it is possible to compute suitable approximations of PN and PS. Our research marks an important step towards gaining a deeper understanding of when LLMs are capable of reasoning, as illustrated by a series of math examples.
tl;dr: In this work, we introduce a novel framework for representation learning that recasts contrastive estimation as a distribution alignment problem.

Despite the success of contrastive learning (CL) in vision and language, its theoretical foundations and mechanisms for building representations remain poorly understood. In this work, we build connections between noise contrastive estimation losses widely used in CL and distribution alignment with entropic optimal transport (OT). This connection allows us to develop a family of different losses and multistep iterative variants for existing CL methods. Intuitively, by using more information from the distribution of latents, our approach allows a more distribution-aware manipulation of the relationships within augmented sample sets.
We provide theoretical insights and experimental evidence demonstrating the benefits of our approach for generalized contrastive alignment. Through this framework, it is possible to leverage tools in OT to build unbalanced losses to handle noisy views and customize the representation space by changing the constraints on alignment.
By reframing contrastive learning as an alignment problem and leveraging existing optimization tools for OT, our work provides new insights and connections between different self-supervised learning models in addition to new tools that can be more easily adapted to incorporate domain knowledge into learning.

Image Signal Processors (ISPs) convert raw sensor signals into digital images, which significantly influence the image quality and the performance of downstream computer vision tasks.
Designing ISP pipeline and tuning ISP parameters are two key steps for building an imaging and vision system.
To find optimal ISP configurations, recent works use deep neural networks as a proxy to search for ISP parameters or ISP pipelines. However, these methods are primarily designed to maximize the image quality, which are sub-optimal in the performance of high-level computer vision tasks such as detection, recognition, and tracking. Moreover, after training, the learned ISP pipelines are mostly fixed at the inference time, whose performance degrades in dynamic scenes.
To jointly optimize ISP structures and parameters, we propose AdaptiveISP, a task-driven and scene-adaptive ISP.
One key observation is that for the majority of input images, only a few processing modules are needed to improve the performance of downstream recognition tasks, and only a few inputs require more processing.
Based on this, AdaptiveISP utilizes deep reinforcement learning to automatically generate an optimal ISP pipeline and the associated ISP parameters to maximize the detection performance. Experimental results show that AdaptiveISP not only surpasses the prior state-of-the-art methods for object detection but also dynamically manages the trade-off between detection performance and computational cost, especially suitable for scenes with large dynamic range variations.
Project website: https://openimaginglab.github.io/AdaptiveISP/.
3708. CNCA: Toward Customizable and Natural Generation of Adversarial Camouflage for Vehicle Detectors

Prior works on physical adversarial camouflage against vehicle detectors mainly focus on the effectiveness and robustness of the attack. The current most successful methods optimize 3D vehicle texture at a pixel level. However, this results in conspicuous and attention-grabbing patterns in the generated camouflage, which humans can easily identify. To address this issue, we propose a Customizable and Natural Camouflage Attack (CNCA) method by leveraging an off-the-shelf pre-trained diffusion model. By sampling the optimal texture image from the diffusion model with a user-specific text prompt, our method can generate natural and customizable adversarial camouflage while maintaining high attack performance. With extensive experiments on the digital and physical worlds and user studies, the results demonstrate that our proposed method can generate significantly more natural-looking camouflage than the state-of-the-art baselines while achieving competitive attack performance.

Domain generalizable person re-identification (DG re-ID) aims to learn discriminative representations that are robust to distributional shifts. While data augmentation is a straightforward solution to improve generalization, certain augmentations exhibit a polarized effect in this task, enhancing in-distribution performance while deteriorating out-of-distribution performance. In this paper, we investigate this phenomenon and reveal that it leads to sparse representation spaces with reduced uniformity. To address this issue, we propose a novel framework, Balancing Alignment and Uniformity (BAU), which effectively mitigates this effect by maintaining a balance between alignment and uniformity. Specifically, BAU incorporates alignment and uniformity losses applied to both original and augmented images and integrates a weighting strategy to assess the reliability of augmented samples, further improving the alignment loss. Additionally, we introduce a domain-specific uniformity loss that promotes uniformity within each source domain, thereby enhancing the learning of domain-invariant features. Extensive experimental results demonstrate that BAU effectively exploits the advantages of data augmentation, which previous studies could not fully utilize, and achieves state-of-the-art performance without requiring complex training procedures.

Recently, many methods have been developed to extend the context length of pre-trained large language models (LLMs), but they often require fine-tuning at the target length ($\gg4K$) and struggle to effectively utilize information from the middle part of the context. To address these issues, we propose $\textbf{C}$ontinuity-$\textbf{R}$elativity ind$\textbf{E}$xing with g$\textbf{A}$ussian $\textbf{M}$iddle ($\texttt{CREAM}$), which interpolates positional encodings by manipulating position indices. Apart from being simple, $\texttt{CREAM}$ is training-efficient: it only requires fine-tuning at the pre-trained context window (e.g., Llama 2-4K) and can extend LLMs to a much longer target context length (e.g., 256K). To ensure that the model focuses more on the information in the middle, we introduce a truncated Gaussian to encourage sampling from the middle part of the context during fine-tuning, thus alleviating the ''Lost-in-the-Middle'' problem faced by long-context LLMs. Experimental results show that $\texttt{CREAM}$ successfully extends LLMs to the target length for both Base and Chat versions of $\texttt{Llama2-7B}$ with ``Never Miss A Beat''. Our code is publicly available at https://github.com/bigai-nlco/cream.

With the rapidly increasing number of satellites in space and their enhanced capabilities, the amount of earth observation images collected by satellites is exceeding the transmission limits of satellite-to-ground links. Although existing learned image compression solutions achieve remarkable performance by using a sophisticated encoder to extract fruitful features as compression and using a decoder to reconstruct. It is still hard to directly deploy those complex encoders on current satellites' embedded GPUs with limited computing capability and power supply to compress images in orbit. In this paper, we propose COSMIC, a simple yet effective learned compression solution to transmit satellite images. We first design a lightweight encoder (i.e. reducing FLOPs by 2.5~5X) on satellite to achieve a high image compression ratio to save satellite-to-ground links. Then, for reconstructions on the ground, to deal with the feature extraction ability degradation due to simplifying encoders, we propose a diffusion-based model to compensate image details when decoding. Our insight is that satellite's earth observation photos are not just images but indeed multi-modal data with a nature of Text-to-Image pairing since they are collected with rich sensor data (e.g. coordinates, timestep, etc.) that can be used as the condition for diffusion generation. Extensive experiments show that COSMIC outperforms state-of-the-art baselines on both perceptual and distortion metrics.
tl;dr: Formal methods are not particularly "explainable" for system validation even when applying best practices from education research

As learned control policies become increasingly common in autonomous systems, there is increasing need to ensure that they are interpretable and can be checked by human stakeholders. Formal specifications have been proposed as ways to produce human-interpretable policies for autonomous systems that can still be learned from examples. Previous work showed that despite claims of interpretability, humans are unable to use formal specifications presented in a variety of ways to validate even simple robot behaviors. This work uses active learning, a standard pedagogical method, to attempt to improve humans' ability to validate policies in signal temporal logic (STL). Results show that overall validation accuracy is not high, at 65\% $\pm$ 15% (mean $\pm$ standard deviation), and that the three conditions of no active learning, active learning, and active learning with feedback do not significantly differ from each other. Our results suggest that the utility of formal specifications for human interpretability is still unsupported but point to other avenues of development which may enable improvements in system validation.
tl;dr: DeepITE is a carefully-designed VGAE that facilitates collaborative and amortized inference for estimating intervention targets across diverse datasets and causal graphs.

Intervention Target Estimation (ITE) is vital for both understanding and decision-making in complex systems, yet it remains underexplored. Current ITE methods are hampered by their inability to learn from distinct intervention instances collaboratively and to incorporate rich insights from labeled data, which leads to inefficiencies such as the need for re-estimation of intervention targets with minor data changes or alterations in causal graphs. In this paper, we propose DeepITE, an innovative deep learning framework designed around a variational graph autoencoder. DeepITE can concurrently learn from both unlabeled and labeled data with different intervention targets and causal graphs, harnessing correlated information in a self or semi-supervised manner. The model's inference capabilities allow for the immediate identification of intervention targets on unseen samples and novel causal graphs, circumventing the need for retraining. Our extensive testing confirms that DeepITE not only surpasses 13 baseline methods in the Recall@k metric but also demonstrates expeditious inference times, particularly on large graphs. Moreover, incorporating a modest fraction of labeled data (5-10\%) substantially enhances DeepITE's performance, further solidifying its practical applicability. Our source code is available at https://github.com/alipay/DeepITE.
tl;dr: We propose continuous embedding attacks as a threat model in large language models (LLMs), demonstrating their effectiveness in removing safety alignment and extracting unlearned information.

Current research in adversarial robustness of LLMs focuses on \textit{discrete} input manipulations in the natural language space, which can be directly transferred to \textit{closed-source} models. However, this approach neglects the steady progression of \textit{open-source} models. As open-source models advance in capability, ensuring their safety becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the \textit{embedding space attack}, which directly attacks the \textit{continuous} embedding representation of input tokens.
We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Additionally, we demonstrate that models compromised by embedding attacks can be used to create discrete jailbreaks in natural language. Lastly, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs.

As Large Language Models (LLMs) become more capable of handling increasingly complex tasks, the evaluation set must keep pace with these advancements to ensure it remains sufficiently discriminative. Item Discrimination (ID) theory, which is widely used in educational assessment, measures the ability of individual test items to differentiate between high and low performers. Inspired by this theory, we propose an ID-induced prompt synthesis framework for evaluating LLMs so that the evaluation set continually updates and refines according to model abilities.
Our data synthesis framework prioritizes both breadth and specificity. It can generate prompts that comprehensively evaluate the capabilities of LLMs while revealing meaningful performance differences between models, allowing for effective discrimination of their relative strengths and weaknesses across various tasks and domains.
To produce high-quality data, we incorporate a self-correct mechanism into our generalization framework and develop two models to predict prompt discrimination and difficulty score to facilitate our data synthesis framework, contributing valuable tools to evaluation data synthesis research. We apply our generated data to evaluate five SOTA models. Our data achieves an average score of 51.92, accompanied by a variance of 10.06. By contrast, previous works (i.e., SELF-INSTRUCT and WizardLM) obtain an average score exceeding 67, with a variance below 3.2.
The results demonstrate that the data generated by our framework is more challenging and discriminative compared to previous works.
We will release a dataset of over 3,000 carefully crafted prompts to facilitate evaluation research of LLMs.

We consider the problem of learning an $\varepsilon$-optimal policy in controlled dynamical systems with low-rank latent structure.
For this problem, we present LoRa-PI (Low-Rank Policy Iteration), a model-free learning algorithm alternating between policy improvement and policy evaluation steps. In the latter, the algorithm estimates the low-rank matrix corresponding to the (state, action) value function of the current policy using the following two-phase procedure. The entries of the matrix are first sampled uniformly at random to estimate, via a spectral method, the *leverage scores* of its rows and columns. These scores are then used to extract a few important rows and columns whose entries are further sampled. The algorithm exploits these new samples to complete the matrix estimation using a CUR-like method. For this leveraged matrix estimation procedure, we establish entry-wise guarantees that remarkably, do not depend on the coherence of the matrix but only on its spikiness. These guarantees imply that LoRa-PI learns an $\varepsilon$-optimal policy using $\tilde{\cal O}({(S+A)\over \mathrm{poly}(1-\gamma)\varepsilon^2})$ samples where $S$ (resp. $A$) denotes the number of states (resp. actions) and $\gamma$ the discount factor. Our algorithm achieves this order-optimal (in $S$, $A$ and $\varepsilon$) sample complexity under milder conditions than those assumed in previously proposed approaches.
tl;dr: An novel Mixture-of-Experts model utilizing a multi-head mechanism to augment the expert utilization and refine the granularity of understanding capabilities.

Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in computational costs. However, it exhibits the low expert activation issue, i.e., only a small subset of experts are activated for optimization, leading to suboptimal performance and limiting its effectiveness in learning a larger number of experts in complex tasks. In this paper, we propose Multi-Head Mixture-of-Experts (MH-MoE). MH-MoE split each input token into multiple sub-tokens, then these sub-tokens are assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form. The above operations enables MH-MoE to significantly enhance expert activation while collectively attend to information from various representation spaces within different experts to deepen context understanding. Besides, it's worth noting that our MH-MoE is straightforward to implement and decouples from other SMoE frameworks, making it easy to integrate with these frameworks for enhanced performance. Extensive experimental results across different parameter scales (300M to 7B) and three pre-training tasks—English-focused language modeling, multi-lingual language modeling and masked multi-modality modeling—along with multiple downstream validation tasks, demonstrate the effectiveness of MH-MoE.

While standard evaluation scores for generative models are mostly reference-based, a reference-dependent assessment of generative models could be generally difficult due to the unavailability of applicable reference datasets. Recently, the reference-free entropy scores, VENDI and RKE, have been proposed to evaluate the diversity of generated data. However, estimating these scores from data leads to significant computational costs for large-scale generative models. In this work, we leverage the random Fourier features framework to reduce the metrics' complexity and propose the *Fourier-based Kernel Entropy Approximation (FKEA)* method. We utilize FKEA's approximated eigenspectrum of the kernel matrix to efficiently estimate the mentioned entropy scores. Furthermore, we show the application of FKEA's proxy eigenvectors to reveal the method's identified modes in evaluating the diversity of produced samples. We provide a stochastic implementation of the FKEA assessment algorithm with a complexity $O(n)$ linearly growing with sample size $n$. We extensively evaluate FKEA's numerical performance in application to standard image, text, and video datasets. Our empirical results indicate the method's scalability and interpretability applied to large-scale generative models. The codebase is available at [https://github.com/aziksh-ospanov/FKEA](https://github.com/aziksh-ospanov/FKEA).
tl;dr: A comprehensive evaluation on the proficiency of LLMs to handle numerical constraints in data science libraries.

Data science (DS) programs, typically built on popular DS libraries (such as PyTorch and NumPy) with thousands of APIs, serve as the cornerstone for various mission-critical domains such as financial systems, autonomous driving software, and coding assistants. Recently, large language models (LLMs) have been widely applied to generate DS programs across diverse scenarios, such as assisting users for DS programming or detecting critical vulnerabilities in DS frameworks. Such applications have all operated under the assumption, that LLMs can implicitly model the numerical parameter constraints in DS library APIs and produce valid code. However, this assumption has not been rigorously studied in the literature. In this paper, we empirically investigate the proficiency of LLMs to handle these implicit numerical constraints when generating DS programs. We studied 28 widely used APIs from PyTorch and NumPy, and scrutinized the LLMs’ generation performance in different levels of granularity: full programs, all parameters, and individual parameters of a single API. We evaluated both state-of-the-art open-source and closed-source models. The results show that LLMs are great at generating simple DS programs, particularly those that follow common patterns seen in training data. However, as we increase the difficulty by providing more complex/unusual inputs, the performance of LLMs drops significantly. We also observe that GPT-4-Turbo can sustain much higher performance overall, but still cannot handle arithmetic API constraints well. In summary, while LLMs exhibit the ability to memorize common patterns of popular DS API usage through massive training, they overall lack genuine comprehension of the underlying numerical constraints.
tl;dr: A loss function for training feature extractors to extract location-consistent features in a self-supervised manner.

Image feature extractors are rendered substantially more useful if different views of the same 3D location yield similar features while still being distinct from other locations. A feature extractor that achieves this goal even under significant viewpoint changes must recognise not just semantic categories in a scene, but also understand how different objects relate to each other in three dimensions. Existing work addresses this task by posing it as a patch retrieval problem, training the extracted features to facilitate retrieval of all image patches that project from the same 3D location. However, this approach uses a loss formulation that requires substantial memory and computation resources, limiting its applicability for large-scale training. We present a method for memory-efficient learning of location-consistent features that reformulates and approximates the smooth average precision objective. This novel loss function enables improvements in memory efficiency by three orders of magnitude, mitigating a key bottleneck of previous methods and allowing much larger models to be trained with the same computational resources. We showcase the improved location consistency of our trained feature extractor directly on a multi-view consistency task, as well as the downstream task of scene-stable panoptic segmentation, significantly outperforming previous state-of-the-art.
tl;dr: This paper quantitatively assesses the decision-making behaviors of large language models (LLMs), demonstrating how these models mirror human risk behaviors and exhibit significant variations when embedded with socio-demographic characteristics.

When making decisions under uncertainty, individuals often deviate from rational behavior, which can be evaluated across three dimensions: risk preference, probability weighting, and loss aversion. Given the widespread use of large language models (LLMs) in supporting decision-making processes, it is crucial to assess whether their behavior aligns with human norms and ethical expectations or exhibits potential biases. Although several empirical studies have investigated the rationality and social behavior performance of LLMs, their internal decision-making tendencies and capabilities remain inadequately understood. This paper proposes a framework, grounded in behavioral economics theories, to evaluate the decision-making behaviors of LLMs. With a multiple-choice-list experiment, we initially estimate the degree of risk preference, probability weighting, and loss aversion in a context-free setting for three commercial LLMs: ChatGPT-4.0-Turbo, Claude-3-Opus, and Gemini-1.0-pro. Our results reveal that LLMs generally exhibit patterns similar to humans, such as risk aversion and loss aversion, with a tendency to overweight small probabilities, but there are significant variations in the degree to which these behaviors are expressed across different LLMs. Further, we explore their behavior when embedded with socio-demographic features of human beings, uncovering significant disparities across various demographic characteristics.
tl;dr: We describe a way of identifying and learning the effect of combinations of interventions in a sequential setup, in the regime of sparse data where limited combinations are jointly observed.

We consider sequential treatment regimes where each unit is exposed to combinations of interventions over time. When interventions are described by qualitative labels, such as "close schools for a month due to a pandemic" or "promote this podcast to this user during this week", it is unclear which appropriate structural assumptions allow us to generalize behavioral predictions to previously unseen combinations of interventions. Standard black-box approaches mapping sequences of categorical variables to outputs are applicable, but they rely on poorly understood assumptions on how reliable generalization can be obtained, and may underperform under sparse sequences, temporal variability, and large action spaces. To approach that, we pose an explicit model for composition, that is, how the effect of sequential interventions can be isolated into modules, clarifying which data conditions allow for the identification of their combined effect at different units and time steps. We show the identification properties of our compositional model, inspired by advances in causal matrix factorization methods. Our focus is on predictive models for novel compositions of interventions instead of matrix completion tasks and causal effect estimation. We compare our approach to flexible but generic black-box models to illustrate how structure aids prediction in sparse data conditions.
tl;dr: We initiate a theoretical study for learning under distribution shifts when the shifts are captured by a collection of data transformation maps.

Learning with identical train and test distributions has been extensively investigated both practically and theoretically. Much remains to be understood, however, in statistical learning under distribution shifts. This paper focuses on a distribution shift setting where train and test distributions can be related by classes of (data) transformation maps. We initiate a theoretical study for this framework, investigating learning scenarios where the target class of transformations is either known or unknown. We establish learning rules and algorithmic reductions to Empirical Risk Minimization (ERM), accompanied with learning guarantees. We obtain upper bounds on the sample complexity in terms of the VC dimension of the class composing predictors with transformations, which we show in many cases is not much larger than the VC dimension of the class of predictors. We highlight that the learning rules we derive offer a game-theoretic viewpoint on distribution shift: a learner searching for predictors and an adversary searching for transformation maps to respectively minimize and maximize the worst-case loss.
tl;dr: We propose a trapdoor-based defense to preserve privacy by misleading Model Inversion attacks.

Model Inversion (MI) attacks pose a significant threat to the privacy of Deep Neural Networks by recovering training data distribution from well-trained models. While existing defenses often rely on regularization techniques to reduce information leakage, they remain vulnerable to recent attacks. In this paper, we propose the Trapdoor-based Model Inversion Defense (Trap-MID) to mislead MI attacks. A trapdoor is integrated into the model to predict a specific label when the input is injected with the corresponding trigger. Consequently, this trapdoor information serves as the "shortcut" for MI attacks, leading them to extract trapdoor triggers rather than private data. We provide theoretical insights into the impacts of trapdoor's effectiveness and naturalness on deceiving MI attacks. In addition, empirical experiments demonstrate the state-of-the-art defense performance of Trap-MID against various MI attacks without the requirements for extra data or large computational overhead. Our source code is publicly available at https://github.com/ntuaislab/Trap-MID.

Image Restoration (IR) methods based on a pre-trained diffusion model have demonstrated state-of-the-art performance. However, they have two fundamental limitations: 1) they often assume that the degradation operator is completely known and 2) they alter the diffusion sampling process, which may result in restored images that do not lie onto the data manifold. To address these issues, we propose Blind Image Restoration via fast Diffusion inversion (BIRD) a blind IR method that jointly optimizes for the degradation model parameters and the restored image. To ensure that the restored images lie onto the data manifold, we propose a novel sampling technique on a pre-trained diffusion model. A key idea in our method is not to modify the reverse sampling, i.e., not to alter all the intermediate latents, once an initial noise is sampled. This is ultimately equivalent to casting the IR task as an optimization problem in the space of the input noise. Moreover, to mitigate the computational cost associated with inverting a fully unrolled diffusion model, we leverage the inherent capability of these models to skip ahead in the forward diffusion process using large time steps. We experimentally validate BIRD on several image restoration tasks and show that it achieves state of the art performance.
tl;dr: A recipe to scale masked auto-encoders to long videos.

Video understanding has witnessed significant progress with recent video foundation models demonstrating strong performance owing to self-supervised pre-training objectives; Masked Autoencoders (MAE) being the design of choice. Nevertheless, the majority of prior works that leverage MAE pre-training have focused on relatively short video representations (16 / 32 frames in length) largely due to hardware memory and compute limitations that scale poorly with video length due to the dense memory-intensive self-attention decoding. One natural strategy to address these challenges is to subsample tokens to reconstruct during decoding (or decoder masking). In this work, we propose an effective strategy for prioritizing tokens which allows training on longer video sequences (128 frames) and gets better performance than, more typical, random and uniform masking strategies. The core of our approach is an adaptive decoder masking strategy that prioritizes the most important tokens and uses quantized tokens as reconstruction objectives. Our adaptive strategy leverages a powerful MAGVIT-based tokenizer that jointly learns the tokens and their priority. We validate our design choices through exhaustive ablations and observe improved performance of the resulting long-video (128 frames) encoders over short-video (32 frames) counterparts. With our long-video masked autoencoder (LVMAE) strategy, we surpass state-of-the-art on Diving48 by 3.9 points and EPIC-Kitchens-100 verb classification by 2.5 points while relying on a simple core architecture and video-only pre-training (unlike some of the prior works that require millions of labeled video-text pairs or specialized encoders).
tl;dr: We present a new approach for personalized tasks such as segmentation or retrieval without training using text-to-image diffusion models

Personalized retrieval and segmentation aim to locate specific instances within a dataset based on an input image and a short description of the reference instance. While supervised methods are effective, they require extensive labeled data for training. Recently, self-supervised foundation models have been introduced to these tasks showing comparable results to supervised methods. However, a significant flaw in these models is evident: they struggle to locate a desired instance when other instances within the same class are presented. In this paper, we explore text-to-image diffusion models for these tasks. Specifically, we propose a novel approach called PDM for Personalized Diffusion Features Matching, that leverages intermediate features of pre-trained text-to-image models for personalization tasks without any additional training. PDM demonstrates superior performance on popular retrieval and segmentation benchmarks, outperforming even supervised methods. We also highlight notable shortcomings in current instance and segmentation datasets and propose new benchmarks for these tasks.

Molecular representation learning has shown great success in advancing AI-based drug discovery. A key insight of many recent works is that the 3D geometric structure of molecules provides essential information about their physicochemical properties. Recently, denoising diffusion probabilistic models have achieved impressive performance in molecular 3D conformation generation. However, most existing molecular diffusion models treat each atom as an independent entity, overlooking the dependency among atoms within the substructures. This paper introduces a novel approach that enhances molecular representation learning by incorporating substructural information in the diffusion model framework. We propose a novel diffusion model termed SubgDiff for involving the molecular subgraph information in diffusion. Specifically, SubgDiff adopts three vital techniques: i) subgraph prediction, ii) expectation state, and iii) k-step same subgraph diffusion, to enhance the perception of molecular substructure in the denoising network. Experiments on extensive downstream tasks, especially the molecular force predictions, demonstrate the superior performance of our approach.

Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment.
We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources. The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks. Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently.
Our top-performing model, distilled from Llama3-8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best 8B scale instruction-tuned linear RNN model.

Universal image representations are critical in enabling real-world fine-grained and instance-level recognition applications, where objects and entities from any domain must be identified at large scale.
Despite recent advances, existing methods fail to capture important domain-specific knowledge, while also ignoring differences in data distribution across different domains.
This leads to a large performance gap between efficient universal solutions and expensive approaches utilising a collection of specialist models, one for each domain.
In this work, we make significant strides towards closing this gap, by introducing a new learning technique, dubbed UDON (Universal Dynamic Online distillatioN).
UDON employs multi-teacher distillation, where each teacher is specialized in one domain, to transfer detailed domain-specific knowledge into the student universal embedding.
UDON's distillation approach is not only effective, but also very efficient, by sharing most model parameters between the student and all teachers, where all models are jointly trained in an online manner.
UDON also comprises a sampling technique which adapts the training process to dynamically allocate batches to domains which are learned slower and require more frequent processing.
This boosts significantly the learning of complex domains which are characterised by a large number of classes and long-tail distributions.
With comprehensive experiments, we validate each component of UDON, and showcase significant improvements over the state of the art in the recent UnED benchmark.
Code: https://github.com/nikosips/UDON.
tl;dr: Improving temporal consistency in video atmospheric turbulence mitigation by separating out and regularizing temporal-wise neural representations

Atmospheric turbulence, caused by random fluctuations in the atmosphere's refractive index, introduces complex spatio-temporal distortions in imagery captured at long range. Video Atmospheric Turbulence Mitigation (ATM) aims to restore videos affected by these distortions. However, existing video ATM methods, both supervised and self-supervised, struggle to maintain temporally consistent mitigation across frames, leading to visually incoherent results. This limitation arises from the stochastic nature of atmospheric turbulence, which varies across space and time. Inspired by the observation that atmospheric turbulence induces high-frequency temporal variations, we propose ConVRT, a novel framework for consistent video restoration through turbulence. ConVRT introduces a neural video representation that explicitly decouples spatial and temporal information into a spatial content field and a temporal deformation field, enabling targeted regularization of the network's temporal representation capability. By leveraging the low-pass filtering properties of the regularized temporal representations, ConVRT effectively mitigates turbulence-induced temporal frequency variations and promotes temporal consistency. Furthermore, our training framework seamlessly integrates supervised pre-training on synthetic turbulence data with self-supervised learning on real-world videos, significantly improving the temporally consistent mitigation of ATM methods on diverse real-world data. More information can be found on our project page: https://convrt-2024.github.io/
tl;dr: We propose a novel, easy-to-implement, numerical tabular data imputation approach based on joint wasserstein gradient flow.

Diffusion models have demonstrated competitive performance in missing data imputation (MDI) task. However, directly applying diffusion models to MDI produces suboptimal performance due to two primary defects. First, the sample diversity promoted by diffusion models hinders the accurate inference of missing values. Second, data masking reduces observable indices for model training, obstructing imputation performance. To address these challenges, we introduce $\underline{\text{N}}$egative $\underline{\text{E}}$ntropy-regularized $\underline{\text{W}}$asserstein gradient flow for $\underline{\text{Imp}}$utation (NewImp), enhancing diffusion models for MDI from a gradient flow perspective. To handle the first defect, we incorporate a negative entropy regularization term into the cost functional to suppress diversity and improve accuracy. To handle the second defect, we demonstrate that the imputation procedure of NewImp, induced by the conditional distribution-related cost functional, can equivalently be replaced by that induced by the joint distribution, thereby naturally eliminating the need for data masking. Extensive experiments validate the effectiveness of our method. Code is available at [https://github.com/JustusvLiebig/NewImp](https://github.com/JustusvLiebig/NewImp).
tl;dr: We propose a probabilistic finetuning method for continual learning with pre-trained CLIP model to enable better in-domain knowledge acquisition, generalization, and model calibration.

Continual learning (CL) aims to help deep neural networks to learn new knowledge while retaining what has been learned. Owing to their powerful generalizability, pre-trained vision-language models such as Contrastive Language-Image Pre-training (CLIP) have lately gained traction as practical CL candidates. However, the domain mismatch between the pre-training and the downstream CL tasks calls for finetuning of the CLIP on the latter. The deterministic nature of the existing finetuning methods makes them overlook the many possible interactions across the modalities and deems them unsafe for high-risk tasks requiring reliable uncertainty estimation. To address these, our work proposes **C**ontinual **L**e**A**rning with **P**robabilistic finetuning (CLAP) - a probabilistic modeling framework over visual-guided text features per task, thus providing more calibrated CL finetuning. Unlike recent data-hungry anti-forgetting CL techniques, CLAP alleviates forgetting by exploiting the rich pre-trained knowledge of CLIP for weight initialization and distribution regularization of task-specific parameters. Cooperating with the diverse range of existing prompting methods, CLAP can surpass the predominant deterministic finetuning approaches for CL with CLIP. We conclude with out-of-the-box applications of superior uncertainty estimation abilities of CLAP including novel data detection and exemplar selection within the existing CL setups. Our code is available at https://github.com/srvCodes/clap4clip.
tl;dr: We formulate a novel Evidential Neural Stochastic Differential Equation (E-NSDE) to seamlessly integrate NSDE and evidential learning for effective time-aware sequential recommendations.

Sequential recommender systems are designed to capture users' evolving interests over time. Existing methods typically assume a uniform time interval among consecutive user interactions and may not capture users' continuously evolving behavior in the short and long term. In reality, the actual time intervals of user interactions vary dramatically. Consequently, as the time interval between interactions increases, so does the uncertainty in user behavior. Intuitively, it is beneficial to establish a correlation between the interaction time interval and the model uncertainty to provide effective recommendations. To this end, we formulate a novel Evidential Neural Stochastic Differential Equation (*E-NSDE*) to seamlessly integrate NSDE and evidential learning for effective time-aware sequential recommendations. The NSDE enables the model to learn users' fine-grained time-evolving behavior by capturing continuous user representation while evidential learning quantifies both aleatoric and epistemic uncertainties considering interaction time interval to provide model confidence during prediction. Furthermore, we derive a mathematical relationship between the interaction time interval and model uncertainty to guide the learning process. Experiments on real-world data demonstrate the effectiveness of the proposed method compared to the SOTA methods.
tl;dr: A study on the design of the multi-frame optical flow estimation pipeline and how to effectively perform spatiotemporal modeling within this pipeline.

Prior multi-frame optical flow methods typically estimate flow repeatedly in a pair-wise manner, leading to significant computational redundancy. To mitigate this, we implement a Streamlined In-batch Multi-frame (SIM) pipeline, specifically tailored to video inputs to minimize redundant calculations. It enables the simultaneous prediction of successive unidirectional flows in a single forward pass, boosting processing speed by 44.43% and reaching efficiencies on par with two-frame networks. Moreover, we investigate various spatiotemporal modeling methods for optical flow estimation within this pipeline. Notably, we propose a simple yet highly effective parameter-efficient Integrative spatiotemporal Coherence (ISC) modeling method, alongside a lightweight Global Temporal Regressor (GTR) to harness temporal cues. The proposed ISC and GTR bring powerful spatiotemporal modeling capabilities and significantly enhance accuracy, including in occluded areas, while adding modest computations to the SIM pipeline. Compared to the baseline, our approach, StreamFlow, achieves performance enhancements of 15.45% and 11.37% on the Sintel clean and final test sets respectively, with gains of 15.53% and 10.77% on occluded regions and only a 1.11% rise in latency. Furthermore, StreamFlow exhibits state-of-the-art cross-dataset testing results on Sintel and KITTI, demonstrating its robust cross-domain generalization capabilities. The code is available [here](https://github.com/littlespray/StreamFlow).

Diffusion Purification, purifying noised images with diffusion models, has been widely used for enhancing certified robustness via randomized smoothing. However, existing frameworks often grapple with the balance between efficiency and effectiveness. While the Denoising Diffusion Probabilistic Model (DDPM) offers an efficient single-step purification, it falls short in ensuring purified images reside on the data manifold. Conversely, the Stochastic Diffusion Model effectively places purified images on the data manifold but demands solving cumbersome stochastic differential equations, while its derivative, the Probability Flow Ordinary Differential Equation (PF-ODE), though solving simpler ordinary differential equations, still requires multiple computational steps. In this work, we demonstrated that an ideal purification pipeline should generate the purified images on the data manifold that are as much semantically aligned to the original images for effectiveness in one step for efficiency. Therefore, we introduced Consistency Purification, an efficiency-effectiveness Pareto superior purifier compared to the previous work. Consistency Purification employs the consistency model, a one-step generative model distilled from PF-ODE, thus can generate on-manifold purified images with a single network evaluation. However, the consistency model is designed not for purification thus it does not inherently ensure semantic alignment between purified and original images. To resolve this issue, we further refine it through Consistency Fine-tuning with LPIPS loss, which enables more aligned semantic meaning while keeping the purified images on data manifold. Our comprehensive experiments demonstrate that our Consistency Purification framework achieves state-of-the-art certified robustness and efficiency compared to baseline methods.

Diffusion-based Video Super-Resolution (VSR) is renowned for generating perceptually realistic videos, yet it grapples with maintaining detail consistency across frames due to stochastic fluctuations. The traditional approach of pixel-level alignment is ineffective for diffusion-processed frames because of iterative disruptions. To overcome this, we introduce SeeClear--a novel VSR framework leveraging conditional video generation, orchestrated by instance-centric and channel-wise semantic controls. This framework integrates a Semantic Distiller and a Pixel Condenser, which synergize to extract and upscale semantic details from low-resolution frames. The Instance-Centric Alignment Module (InCAM) utilizes video-clip-wise tokens to dynamically relate pixels within and across frames, enhancing coherency. Additionally, the Channel-wise Texture Aggregation Memory (CaTeGory) infuses extrinsic knowledge, capitalizing on long-standing semantic textures. Our method also innovates the blurring diffusion process with the ResShift mechanism, finely balancing between sharpness and diffusion effects. Comprehensive experiments confirm our framework's advantage over state-of-the-art diffusion-based VSR techniques.

To date, transformer-based frameworks have demonstrated impressive results in single-image super-resolution (SISR). However, under practical lightweight scenarios, the complex interaction of deep image feature extraction and similarity modeling limits the performance of these methods, since they require simultaneous layer-specific optimization of both two tasks. In this work, we introduce a novel Unified Projection Sharing algorithm(UPS) to decouple the feature extraction and similarity modeling, achieving notable performance. To do this, we establish a unified projection space defined by a learnable projection matrix, for similarity calculation across all self-attention layers. As a result, deep image feature extraction remains a per-layer optimization manner, while similarity modeling is carried out by projecting these image features onto the shared projection space. Extensive experiments demonstrate that our proposed UPS achieves state-of-the-art performance relative to leading lightweight SISR methods, as verified by various popular benchmarks. Moreover, our unified optimized projection space exhibits encouraging robustness performance for unseen data (degraded and depth images). Finally, UPS also demonstrates promising results across various image restoration tasks, including real-world and classic SISR, image denoising, and image deblocking.
tl;dr: Overcoming a local optima issue and rounding issue for unsupervised learning based combinatorial optimization solvers

Unsupervised learning (UL)-based solvers for combinatorial optimization (CO) train a neural network that generates a soft solution by directly optimizing the CO objective using a continuous relaxation strategy. These solvers offer several advantages over traditional methods and other learning-based methods, particularly for large-scale CO problems. However, UL-based solvers face two practical issues: (I) an optimization issue, where UL-based solvers are easily trapped at local optima, and (II) a rounding issue, where UL-based solvers require artificial post-learning rounding from the continuous space back to the original discrete space, undermining the robustness of the results. This study proposes a Continuous Relaxation Annealing (CRA) strategy, an effective rounding-free learning method for UL-based solvers. CRA introduces a penalty term that dynamically shifts from prioritizing continuous solutions, effectively smoothing the non-convexity of the objective function, to enforcing discreteness, eliminating artificial rounding. Experimental results demonstrate that CRA significantly enhances the performance of UL-based solvers, outperforming existing UL-based solvers and greedy algorithms in complex CO problems. Additionally, CRA effectively eliminates artificial rounding and accelerates the learning process.

The accurate prediction of geometric state evolution in complex systems is critical for advancing scientific domains such as quantum chemistry and material modeling. Traditional experimental and computational methods face challenges in terms of environmental constraints and computational demands, while current deep learning approaches still fall short in terms of precision and generality. In this work, we introduce the Geometric Diffusion Bridge (GDB), a novel generative modeling framework that accurately bridges initial and target geometric states. GDB leverages a probabilistic approach to evolve geometric state distributions, employing an equivariant diffusion bridge derived by a modified version of Doob's $h$-transform for connecting geometric states. This tailored diffusion process is anchored by initial and target geometric states as fixed endpoints and governed by equivariant transition kernels. Moreover, trajectory data can be seamlessly leveraged in our GDB framework by using a chain of equivariant diffusion bridges, providing a more detailed and accurate characterization of evolution dynamics. Theoretically, we conduct a thorough examination to confirm our framework's ability to preserve joint distributions of geometric states and capability to completely model the underlying dynamics inducing trajectory distributions with negligible error. Experimental evaluations across various real-world scenarios show that GDB surpasses existing state-of-the-art approaches, opening up a new pathway for accurately bridging geometric states and tackling crucial scientific challenges with improved accuracy and applicability.
tl;dr: We propose to efficiently and robustly search for data-specific subgraph-based pipeline components for drug-drug interaction prediction.

Subgraph-based methods have proven to be effective and interpretable in predicting drug-drug interactions (DDIs),
which are essential for medical practice and drug development.
Subgraph selection and encoding are critical stages in these methods,
yet customizing these components remains underexplored due to the high cost of manual adjustments.
In this study,
inspired by the success of neural architecture search (NAS),
we propose a method to search for data-specific components within subgraph-based frameworks.
Specifically,
we introduce extensive subgraph selection and encoding spaces that account for the diverse contexts of drug interactions in DDI prediction.
To address the challenge of large search spaces and high sampling costs,
we design a relaxation mechanism that uses an approximation strategy to efficiently explore optimal subgraph configurations. This approach allows for robust exploration of the search space.
Extensive experiments demonstrate the effectiveness and superiority of the proposed method,
with the discovered subgraphs and encoding functions highlighting the model’s adaptability.

The online reconstruction of dynamic scenes from multi-view streaming videos faces significant challenges in training, rendering and storage efficiency. Harnessing superior learning speed and real-time rendering capabilities, 3D Gaussian Splatting (3DGS) has recently demonstrated considerable potential in this field. However, 3DGS can be inefficient in terms of storage and prone to overfitting by excessively growing Gaussians, particularly with limited views. This paper proposes an efficient framework, dubbed HiCoM, with three key components. First, we construct a compact and robust initial 3DGS representation using a perturbation smoothing strategy. Next, we introduce a Hierarchical Coherent Motion mechanism that leverages the inherent non-uniform distribution and local consistency of 3D Gaussians to swiftly and accurately learn motions across frames. Finally, we continually refine the 3DGS with additional Gaussians, which are later merged into the initial 3DGS to maintain consistency with the evolving scene. To preserve a compact representation, an equivalent number of low-opacity Gaussians that minimally impact the representation are removed before processing subsequent frames. Extensive experiments conducted on two widely used datasets show that our framework improves learning efficiency of the state-of-the-art methods by about 20% and reduces the data storage by 85%, achieving competitive free-viewpoint video synthesis quality but with higher robustness and stability. Moreover, by parallel learning multiple frames simultaneously, our HiCoM decreases the average training wall time to <2 seconds per frame with negligible performance degradation, substantially boosting real-world applicability and responsiveness.

Masked autoencoder has been widely explored in point cloud self-supervised learning, whereby the point cloud is generally divided into visible and masked parts. These methods typically include an encoder accepting visible patches (normalized) and corresponding patch centers (position) as input, with the decoder accepting the output of the encoder and the centers (position) of the masked parts to reconstruct each point in the masked patches. Then, the pre-trained encoders are used for downstream tasks. In this paper, we show a motivating empirical result that when directly feeding the centers of masked patches to the decoder without information from the encoder, it still reconstructs well. In other words, the centers of patches are important and the reconstruction objective does not necessarily rely on representations of the encoder, thus preventing the encoder from learning semantic representations. Based on this key observation, we propose a simple yet effective method, $i.e.$, learning to \textbf{P}redict \textbf{C}enters for \textbf{P}oint \textbf{M}asked \textbf{A}uto\textbf{E}ncoders (\textbf{PCP-MAE}) which guides the model to learn to predict the significant centers and use the predicted centers to replace the directly provided centers. Specifically, we propose a Predicting Center Module (PCM) that shares parameters with the original encoder with extra cross-attention to predict centers. Our method is of high pre-training efficiency compared to other alternatives and achieves great improvement over Point-MAE, particularly surpassing it by \textbf{5.50\% on OBJ-BG, 6.03\% on OBJ-ONLY, and 5.17\% on PB-T50-RS} for 3D object classification on the ScanObjectNN dataset. The code is available at \url{https://github.com/aHapBean/PCP-MAE}.

Parametric dimensionality reduction methods have gained prominence for their ability to generalize to unseen datasets, an advantage that traditional non-parametric approaches typically lack. Despite their growing popularity, there remains a prevalent misconception among practitioners about the equivalence in performance between parametric and non-parametric methods. Here, we show that these methods are not equivalent -- parametric methods retain global structure but lose significant local details. To explain this, we provide evidence that parameterized approaches lack the ability to repulse negative samples, and the choice of loss function also has an impact.
Addressing these issues, we developed a new parametric method, ParamRepulsor, that incorporates Hard Negative Mining and a loss function that applies a strong repulsive force. This new method achieves state-of-the-art performance on local structure preservation for parametric methods without sacrificing the fidelity of global structural representation. Our code is available at https://github.com/hyhuang00/ParamRepulsor.

Neural population activity often exhibits distinct dynamical features across time, which may correspond to distinct internal processes or behavior. Linear methods and variations thereof, such as Hidden Markov Model (HMM) and Switching Linear Dynamical System (SLDS), are often employed to identify discrete states with evolving neural dynamics. However, these techniques may not be able to capture the underlying nonlinear dynamics associated with neural propagation. Recurrent Neural Networks (RNNs) are commonly used to model neural dynamics thanks to their nonlinear characteristics. In our work, we develop Switching Recurrent Neural Networks (SRNN), RNNs with weights that switch across time, to reconstruct switching dynamics of neural time-series data. We apply these models to simulated data as well as cortical neural activity across mice and monkeys, which allows us to automatically detect discrete states that lead to the identification of varying neural dynamics. In a monkey reaching dataset with electrophysiology recordings, a mouse self-initiated lever pull dataset with widefield calcium recordings, and a mouse self-initiated decision making dataset with widefield calcium recording, SRNNs are able to automatically identify discrete states with distinct nonlinear neural dynamics. The inferred switches are aligned with the behavior, and the reconstructions show that the recovered neural dynamics are distinct across different stages of the behavior. We show that the neural dynamics have behaviorally-relevant switches across time and we are able to use SRNNs to successfully capture these switches and the corresponding dynamical features.

Despite alleviating the dependence on dense annotations inherent to fully supervised methods, weakly supervised point cloud semantic segmentation suffers from inadequate supervision signals. In response to this challenge, we introduce a novel perspective that imparts auxiliary constraints by regulating the feature space under weak supervision. Our initial investigation identifies which distributions accurately characterize the feature space, subsequently leveraging this priori to guide the alignment of the weakly supervised embeddings. Specifically, we analyze the superiority of the mixture of von Mises-Fisher distributions (moVMF) among several common distribution candidates. Accordingly, we develop a Distribution Guidance Network (DGNet), which comprises a weakly supervised learning branch and a distribution alignment branch. Leveraging reliable clustering initialization derived from the weakly supervised learning branch, the distribution alignment branch alternately updates the parameters of the moVMF and the network, ensuring alignment with the moVMF-defined latent space. Extensive experiments validate the rationality and effectiveness of our distribution choice and network design. Consequently, DGNet achieves state-of-the-art performance under multiple datasets and various weakly supervised settings.
3747. FactorizePhys: Matrix Factorization for Multidimensional Attention in Remote Physiological Sensing
tl;dr: This work introduces the Factorized Self-Attention Module, which computes multidimensional attention through nonnegative matrix factorization, and integrate it into FactorizePhys, a proposed 3D-CNN model for robust rPPG signal extraction.

Remote photoplethysmography (rPPG) enables non-invasive extraction of blood volume pulse signals through imaging, transforming spatial-temporal data into time series signals. Advances in end-to-end rPPG approaches have focused on this transformation where attention mechanisms are crucial for feature extraction. However, existing methods compute attention disjointly across spatial, temporal, and channel dimensions. Here, we propose the Factorized Self-Attention Module (FSAM), which jointly computes multidimensional attention from voxel embeddings using nonnegative matrix factorization. To demonstrate FSAM's effectiveness, we developed FactorizePhys, an end-to-end 3D-CNN architecture for estimating blood volume pulse signals from raw video frames. Our approach adeptly factorizes voxel embeddings to achieve comprehensive spatial, temporal, and channel attention, enhancing performance of generic signal extraction tasks. Furthermore, we deploy FSAM within an existing 2D-CNN-based rPPG architecture to illustrate its versatility. FSAM and FactorizePhys are thoroughly evaluated against state-of-the-art rPPG methods, each representing different types of architecture and attention mechanism. We perform ablation studies to investigate the architectural decisions and hyperparameters of FSAM. Experiments on four publicly available datasets and intuitive visualization of learned spatial-temporal features substantiate the effectiveness of FSAM and enhanced cross-dataset generalization in estimating rPPG signals, suggesting its broader potential as a multidimensional attention mechanism. The code is accessible at https://github.com/PhysiologicAILab/FactorizePhys.

We propose the new task open-world video instance segmentation and captioning. It requires to detect, segment, track and describe with rich captions never before seen objects. This challenging task can be addressed by developing "abstractors" which connect a vision model and a language foundation model. Concretely, we connect a multi-scale visual feature extractor and a large language model (LLM) by developing an object abstractor and an object-to-text abstractor. The object abstractor, consisting of a prompt encoder and transformer blocks, introduces spatially-diverse open-world object queries to discover never before seen objects in videos. An inter-query contrastive loss further encourages the diversity of object queries. The object-to-text abstractor is augmented with masked cross-attention and acts as a bridge between the object queries and a frozen LLM to generate rich and descriptive object-centric captions for each detected object. Our generalized approach surpasses the baseline that jointly addresses the tasks of open-world video instance segmentation and dense video object captioning by 13% on never before seen objects, and by 10% on object-centric captions.

In this paper, we propose Generalizable and Animatable Gaussian head Avatar (GAGA) for one-shot animatable head avatar reconstruction.
Existing methods rely on neural radiance fields, leading to heavy rendering consumption and low reenactment speeds.
To address these limitations, we generate the parameters of 3D Gaussians from a single image in a single forward pass.
The key innovation of our work is the proposed dual-lifting method, which produces high-fidelity 3D Gaussians that capture identity and facial details.
Additionally, we leverage global image features and the 3D morphable model to construct 3D Gaussians for controlling expressions.
After training, our model can reconstruct unseen identities without specific optimizations and perform reenactment rendering at real-time speeds.
Experiments show that our method exhibits superior performance compared to previous methods in terms of reconstruction quality and expression accuracy.
We believe our method can establish new benchmarks for future research and advance applications of digital avatars.

Learning from preference feedback has emerged as an essential step for improving the generation quality and performance of modern language models (LMs). Despite its widespread use, the way preference-based learning is applied varies wildly, with differing data, learning algorithms, and evaluations used, making disentangling the impact of each aspect difficult. In this work, we identify four core aspects of preference-based learning: preference data, learning algorithm, reward model, and policy training prompts, systematically investigate the impact of these components on downstream model performance, and suggest a recipe for strong learning for preference feedback. Our findings indicate that all aspects are important for performance, with better preference data leading to the largest improvements, followed by the choice of learning algorithm, the use of improved reward models, and finally the use of additional unlabeled prompts for policy training. Notably, PPO outperforms DPO by up to 2.5% in math and 1.2% in general domains. High-quality preference data leads to improvements of up to 8% in instruction following and truthfulness. Despite significant gains of up to 5% in mathematical evaluation when scaling up reward models, we surprisingly observe marginal improvements in other categories.
tl;dr: Floco addresses the challenges of statistical heterogeneity in cross-silo federated learning by leveraging linear mode connectivity.

Statistical heterogeneity in federated learning poses two major challenges: slow global training due to conflicting gradient signals, and the need of personalization for local distributions. In this work, we tackle both challenges by leveraging recent advances in \emph{linear mode connectivity} --- identifying a linearly connected low-loss region in the parameter space of neural networks, which we call solution simplex. We propose federated learning over connected modes (\textsc{Floco}), where clients are assigned local subregions in this simplex based on their gradient signals, and together learn the shared global solution simplex. This allows personalization of the client models to fit their local distributions within the degrees of freedom in the solution simplex and homogenizes the update signals for the global simplex training. Our experiments show that \textsc{Floco} accelerates the global training process, and significantly improves the local accuracy with minimal computational overhead in cross-silo federated learning settings.

The pre-trained Large Language Models (LLMs) can be adapted for many downstream tasks and tailored to align with human preferences through fine-tuning. Recent studies have discovered that LLMs can achieve desirable performance with only a small amount of high-quality data, suggesting that a large portion of the data in these extensive datasets is redundant or even harmful. Identifying high-quality data from vast datasets to curate small yet effective datasets has emerged as a critical challenge. In this paper, we introduce SHED, an automated dataset refinement framework based on Shapley value for instruction fine-tuning. SHED eliminates the need for human intervention or the use of commercial LLMs. Moreover, the datasets curated through SHED exhibit transferability, indicating they can be reused across different LLMs with consistently high performance. We conduct extensive experiments to evaluate the datasets curated by SHED. The results demonstrate SHED's superiority over state-of-the-art methods across various tasks and LLMs; notably, datasets comprising only 10% of the original data selected by SHED achieve performance comparable to or surpassing that of the full datasets.
3753. WaveAttack: Asymmetric Frequency Obfuscation-based Backdoor Attacks Against Deep Neural Networks

Due to the increasing popularity of Artificial Intelligence (AI), more and more backdoor attacks are designed to mislead Deep Neural Network (DNN) predictions by manipulating training samples or processes. Although backdoor attacks have been investigated in various scenarios, they still suffer from the problems of both low fidelity of poisoned samples and non-negligible transfer in latent space, which make them easily identified by existing backdoor detection algorithms. To overcome this weakness, this paper proposes a novel frequency-based backdoor attack method named WaveAttack, which obtains high-frequency image features through Discrete Wavelet Transform (DWT) to generate highly stealthy backdoor triggers. By introducing an asymmetric frequency obfuscation method, our approach adds an adaptive residual to the training and inference stages to improve the impact of triggers, thus further enhancing the effectiveness of WaveAttack. Comprehensive experimental results show that, WaveAttack can not only achieve higher effectiveness than state-of-the-art backdoor attack methods, but also outperform them in the fidelity of images (i.e., by up to 28.27\% improvement in PSNR, 1.61\% improvement in SSIM, and 70.59\% reduction in IS). Our code is available at https://github.com/BililiCode/WaveAttack.
tl;dr: Connecting multimodal foundation models' representations with world models' representations for RL enables specifying task by vision or language prompts and learning the corresponding embodied behaviors in imagination.

Learning generalist embodied agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning (RL) is hard to scale up as it requires a complex reward design for each task. In contrast, language can specify tasks in a more natural way. Current foundation vision-language models (VLMs) generally require fine-tuning or other adaptations to be adopted in embodied contexts, due to the significant domain gap. However, the lack of multimodal data in such domains represents an obstacle to developing foundation models for embodied applications. In this work, we overcome these problems by presenting multimodal-foundation world models, able to connect and align the representation of foundation VLMs with the latent space of generative world models for RL, without any language annotations. The resulting agent learning framework, GenRL, allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain’s dynamics, and learn the corresponding behaviors in imagination.
As assessed through large-scale multi-task benchmarking in locomotion and manipulation domains, GenRL enables multi-task generalization from language and visual prompts. Furthermore, by introducing a data-free policy learning strategy, our approach lays the groundwork for foundational policy learning using generative world models.
Website, code and data: https://mazpie.github.io/genrl/

Recently, there have been explorations of generalist segmentation models that can effectively tackle a variety of image segmentation tasks within a unified in-context learning framework. However, these methods still struggle with task ambiguity in in-context segmentation, as not all in-context examples can accurately convey the task information. In order to address this issue, we present SINE, a simple image $\textbf{S}$egmentation framework utilizing $\textbf{in}$-context $\textbf{e}$xamples. Our approach leverages a Transformer encoder-decoder structure, where the encoder provides high-quality image representations, and the decoder is designed to yield multiple task-specific output masks to eliminate task ambiguity effectively. Specifically, we introduce an In-context Interaction module to complement in-context information and produce correlations between the target image and the in-context example and a Matching Transformer that uses fixed matching and a Hungarian algorithm to eliminate differences between different tasks. In addition, we have further perfected the current evaluation system for in-context image segmentation, aiming to facilitate a holistic appraisal of these models. Experiments on various segmentation tasks show the effectiveness of the proposed method.
tl;dr: We propose a sharpness-aware motivated data modification to improve in-distribution generalization performance.

Can we modify the training data distribution to encourage the underlying optimization method toward finding solutions with superior generalization performance on in-distribution data? In this work, we approach this question for the first time by comparing the inductive bias of gradient descent (GD) with that of sharpness-aware minimization (SAM). By studying a two-layer CNN, we rigorously prove that SAM learns different features more uniformly, particularly in early epochs. That is, SAM is less susceptible to simplicity bias compared to GD. We also show that examples constraining features that are learned early are separable from the rest based on the model’s output. Based on this observation, we propose a method that (i) clusters examples based on the network output early in training, (ii) identifies a cluster of examples with similar network output, and (iii) upsamples the rest of examples only once to alleviate the simplicity bias. We show empirically that USEFUL effectively improves the generalization performance on the original data distribution when training with various gradient methods, including (S)GD and SAM. Notably, we demonstrate that our method can be combined with SAM variants and existing data augmentation strategies to achieve, to the best of our knowledge, state-of-the-art performance for training ResNet18 on CIFAR10, STL10, CINIC10, Tiny-ImageNet; ResNet34 on CIFAR100; and VGG19 and DenseNet121 on CIFAR10.

Learning effective representations is imperative for comprehending proteins and deciphering their biological functions. Recent strides in language models and graph neural networks have empowered protein models to harness primary or tertiary structure information for representation learning. Nevertheless, the absence of practical methodologies to appropriately model intricate inter-dependencies between protein sequences and structures has resulted in embeddings that exhibit low performance on tasks such as protein function prediction. In this study, we introduce CoupleNet, a novel framework designed to interlink protein sequences and structures to derive informative protein representations. CoupleNet integrates multiple levels and scales of features in proteins, encompassing residue identities and positions for sequences, as well as geometric representations for tertiary structures from both local and global perspectives. A two-type dynamic graph is constructed to capture adjacent and distant sequential features and structural geometries, achieving completeness at the amino acid and backbone levels. Additionally, convolutions are executed on nodes and edges simultaneously to generate comprehensive protein embeddings. Experimental results on benchmark datasets showcase that CoupleNet outperforms state-of-the-art methods, exhibiting particularly superior performance in low-sequence similarities scenarios, adeptly identifying infrequently encountered functions and effectively capturing remote homology relationships in proteins.
tl;dr: Reduce the impact of distractors on model-based RL using gradient-based interpretability with segmentation-based aggregation.

Model-based reinforcement learning (MBRL) is a promising route to sample-efficient policy optimization. However, a known vulnerability of reconstruction-based MBRL consists of scenarios in which detailed aspects of the world are highly predictable, but irrelevant to learning a good policy. Such scenarios can lead the model to exhaust its capacity on meaningless content, at the cost of neglecting important environment dynamics. While existing approaches attempt to solve this problem, we highlight its continuing impact on leading MBRL methods ---including DreamerV3 and DreamerPro--- with a novel environment where background distractions are intricate, predictable, and useless for planning future actions. To address this challenge we develop a method for focusing the capacity of the world model through a synergy of a pretrained segmentation model, a task-aware reconstruction loss, and adversarial learning. Our method outperforms a variety of other approaches designed to reduce the impact of distractors, and is an advance towards robust model-based reinforcement learning.
3759. Personalized Federated Learning with Mixture of Models for Adaptive Prediction and Model Fine-Tuning

Federated learning is renowned for its efficacy in distributed model training, ensuring that users, called clients, retain data privacy by not disclosing their data to the central server that orchestrates collaborations. Most previous work on federated learning assumes that clients possess static batches of training data. However, clients may also need to make real-time predictions on streaming data in non-stationary environments. In such dynamic environments, employing pre-trained models may be inefficient, as they struggle to adapt to the constantly evolving data streams. To address this challenge, clients can fine-tune models online, leveraging their observed data to enhance performance. Despite the potential benefits of client participation in federated online model fine-tuning, existing analyses have not conclusively demonstrated its superiority over local model fine-tuning. To bridge this gap, the present paper develops a novel personalized federated learning algorithm, wherein each client constructs a personalized model by combining a locally fine-tuned model with multiple federated models learned by the server over time. Theoretical analysis and experiments on real datasets corroborate the effectiveness of this approach for real-time predictions and federated model fine-tuning.

Semi-supervised continual learning (SSCL) has attracted significant attention for addressing catastrophic forgetting in semi-supervised data. Knowledge distillation, which leverages data representation and pair-wise similarity, has shown significant potential in preserving information in SSCL. However, traditional distillation strategies often fail in unlabeled data with inaccurate or noisy information, limiting their efficiency in feature spaces undergoing substantial changes during continual learning. To address these limitations, we propose Persistence Homology Distillation (PsHD) to preserve intrinsic structural information that is insensitive to noise in semi-supervised continual learning. First, we capture the structural features using persistence homology by homological evolution across different scales in vision data, where the multi-scale characteristic established its stability under noise interference. Next, we propose a persistence homology distillation loss in SSCL and design an acceleration algorithm to reduce the computational cost of persistence homology in our module. Furthermore, we demonstrate the superior stability of PsHD compared to sample representation and pair-wise similarity distillation methods theoretically and experimentally. Finally, experimental results on three widely used datasets validate that the new PsHD outperforms state-of-the-art with 3.9% improvements on average, and also achieves 1.5% improvements while reducing 60% memory buffer size, highlighting the potential of utilizing unlabeled data in SSCL. Our code is available: https://github.com/fanyan0411/PsHD.

Graph neural networks (GNNs) with a rescale invariance, such as GATs, can be re-parameterized during optimization through dynamic rescaling of network parameters and gradients while keeping the loss invariant. In this work, we explore dynamic rescaling as a tool to influence GNN training dynamics in two key ways: i) balancing the network with respect to various criteria, and ii) controlling the relative learning speeds of different layers. We gain novel insights, unique to GNNs, that reveal distinct training modes for different tasks. For heterophilic graphs, achieving balance based on relative gradients leads to faster training and better generalization. In contrast, homophilic graphs benefit from delaying the learning of later layers. Additionally, we show that training in balance supports larger learning rates, which can improve generalization. Moreover, controlling layer-wise training speeds is linked to grokking-like phenomena, which may be of independent interest.
tl;dr: We propose a novel we propose a novel Low-Rank Feature Learning (LRFL) method for thorax disease classification, which learns low-rank features of a neural network so as to effectively reduce the adverse effect of background or non-disease areas.

Deep neural networks, including Convolutional Neural Networks (CNNs) and Visual Transformers (ViT), have achieved stunning success in the medical image domain. We study thorax disease classification in this paper. Effective extraction of features for the disease areas is crucial for disease classification on radiographic images. While various neural architectures and training techniques, such as self-supervised learning with contrastive/restorative learning, have been employed for disease classification on radiographic images, there are no principled methods that can effectively reduce the adverse effect of noise and background or non-disease areas on the radiographic images for disease classification. To address this challenge, we propose a novel Low-Rank Feature Learning (LRFL) method in this paper, which is universally applicable to the training of all neural networks. The LRFL method is both empirically motivated by a Low Frequency Property (LFP) and theoretically motivated by our sharp generalization bound for neural networks with low-rank features. LFP not only widely exists in deep neural networks for generic machine learning but also exists in all the thorax medical datasets studied in this paper. In the empirical study, using a neural network such as a ViT or a CNN pre-trained on unlabeled chest X-rays by Masked Autoencoders (MAE), our novel LRFL method is applied on the pre-trained neural network and demonstrates better classification results in terms of both multi-class area under the receiver operating curve (mAUC) and classification accuracy than the current state-of-the-art. The code is available at https://github.com/Statistical-Deep-Learning/LRFL.
tl;dr: Learning to reset Neural Networks parameters using Ornstein-Uhlenbeck to learn on non-stationary data

Neural networks are traditionally trained under the assumption that data come from a stationary distribution. However, settings which violate this assumption are becoming more popular; examples include supervised learning under distributional shifts, reinforcement learning, continual learning and non-stationary contextual bandits. In this work we introduce a novel learning approach that automatically models and adapts to non-stationarity, via an Ornstein-Uhlenbeck process with an adaptive drift parameter. The adaptive drift tends to draw the parameters towards the initialisation distribution, so the approach can be understood as a form of soft parameter reset. We show empirically that our approach performs well in non-stationary supervised and off-policy reinforcement learning settings.
tl;dr: This paper proposes UMFC, which calibrate features from multi-domain in a label-free and training-free way.

Pre-trained vision-language models (e.g., CLIP) have shown powerful zero-shot transfer capabilities. But they still struggle with domain shifts and typically require labeled data to adapt to downstream tasks, which could be costly. In this work, we aim to leverage unlabeled data that naturally spans multiple domains to enhance the transferability of vision-language models. Under this unsupervised multi-domain setting, we have identified inherent model bias within CLIP, notably in its visual and text encoders. Specifically, we observe that CLIP’s visual encoder tends to prioritize encoding domain over discriminative category information, meanwhile its text encoder exhibits a preference for domain-relevant classes. To mitigate this model bias, we propose a training-free and label-free feature calibration method, Unsupervised Multi-domain Feature Calibration (UMFC). UMFC estimates image-level biases from domain-specific features and text-level biases from the direction of domain transition. These biases are subsequently subtracted from original image and text features separately, to render them domain-invariant. We evaluate our method on multiple settings including transductive learning and test-time adaptation. Extensive experiments show that our method outperforms CLIP and performs on par with the state-of-the-arts that need additional annotations or optimization.
Our code is available at https://github.com/GIT-LJc/UMFC.
tl;dr: We propose a debiased framework to continually discover novel categories with minimal forgetting of old ones.

Constantly discovering novel concepts is crucial in evolving environments. This paper explores the underexplored task of Continual Generalized Category Discovery (C-GCD), which aims to incrementally discover new classes from *unlabeled* data while maintaining the ability to recognize previously learned classes. Although several settings are proposed to study the C-GCD task, they have limitations that do not reflect real-world scenarios. We thus study a more practical C-GCD setting, which includes more new classes to be discovered over a longer period, without storing samples of past classes. In C-GCD, the model is initially trained on labeled data of known classes, followed by multiple incremental stages where the model is fed with unlabeled data containing both old and new classes. The core challenge involves two conflicting objectives: discover new classes and prevent forgetting old ones. We delve into the conflicts and identify that models are susceptible to *prediction bias* and *hardness bias*. To address these issues, we introduce a debiased learning framework, namely **Happy**, characterized by **H**ardness-**a**ware **p**rototype sampling and soft entro**py** regularization. For the *prediction bias*, we first introduce clustering-guided initialization to provide robust features. In addition, we propose soft entropy regularization to assign appropriate probabilities to new classes, which can significantly enhance the clustering performance of new classes. For the *harness bias*, we present the hardness-aware prototype sampling, which can effectively reduce the forgetting issue for previously seen classes, especially for difficult classes. Experimental results demonstrate our method proficiently manages the conflicts of C-GCD and achieves remarkable performance across various datasets, e.g., 7.5% overall gains on ImageNet-100. Our code is publicly available at https://github.com/mashijie1028/Happy-CGCD.

This paper introduces CoFie, a novel local geometry-aware neural surface representation. CoFie is motivated by the theoretical analysis of local SDFs with quadratic approximation. We find that local shapes are highly compressive in an aligned coordinate frame defined by the normal and tangent directions of local shapes. Accordingly, we introduce Coordinate Field, which is a composition of coordinate frames of all local shapes. The Coordinate Field is optimizable and is used to transform the local shapes from the world coordinate frame to the aligned shape coordinate frame. It largely reduces the complexity of local shapes and benefits the learning of MLP-based implicit representations. Moreover, we introduce quadratic layers into the MLP to enhance expressiveness concerning local shape geometry. CoFie is a generalizable surface representation. It is trained on a curated set of 3D shapes and works on novel shape instances during testing. When using the same amount of parameters with prior works, CoFie reduces the shape error by 48% and 56% on novel instances of both training and unseen shape categories. Moreover, CoFie demonstrates comparable performance to prior works when using even 70% fewer parameters. Code and model can be found here: https://hwjiang1510.github.io/CoFie/
tl;dr: Justify the feature hypothesis and perturbation learning.

Adversarial examples have raised several open questions, such as why they can deceive classifiers and transfer between different models. A prevailing hypothesis to explain these phenomena suggests that adversarial perturbations appear as random noise but contain class-specific features. This hypothesis is supported by the success of perturbation learning, where classifiers trained solely on adversarial examples and the corresponding incorrect labels generalize well to correctly labeled test data. Although this hypothesis and perturbation learning are effective in explaining intriguing properties of adversarial examples, their solid theoretical foundation is limited. In this study, we theoretically explain the counterintuitive success of perturbation learning. We assume wide two-layer networks and the results hold for any data distribution. We prove that adversarial perturbations contain sufficient class-specific features for networks to generalize from them. Moreover, the predictions of classifiers trained on mislabeled adversarial examples coincide with those of classifiers trained on correctly labeled clean samples. The code is available at https://github.com/s-kumano/perturbation-learning.

Imperceptible adversarial attacks aim to fool DNNs by adding imperceptible perturbation to the input data. Previous methods typically improve the imperceptibility of attacks by integrating common attack paradigms with specifically designed perception-based losses or the capabilities of generative models. In this paper, we propose Adversarial Attacks in Diffusion (AdvAD), a novel modeling framework distinct from existing attack paradigms. AdvAD innovatively conceptualizes attacking as a non-parametric diffusion process by theoretically exploring basic modeling approach rather than using the denoising or generation abilities of regular diffusion models requiring neural networks. At each step, much subtler yet effective adversarial guidance is crafted using only the attacked model without any additional network, which gradually leads the end of diffusion process from the original image to a desired imperceptible adversarial example. Grounded in a solid theoretical foundation of the proposed non-parametric diffusion process, AdvAD achieves high attack efficacy and imperceptibility with intrinsically lower overall perturbation strength. Additionally, an enhanced version AdvAD-X is proposed to evaluate the extreme of our novel framework under an ideal scenario. Extensive experiments demonstrate the effectiveness of the proposed AdvAD and AdvAD-X. Compared with state-of-the-art imperceptible attacks, AdvAD achieves an average of 99.9% (+17.3%) ASR with 1.34 (-0.97) $l_2$ distance, 49.74 (+4.76) PSNR and 0.9971 (+0.0043) SSIM against four prevalent DNNs with three different architectures on the ImageNet-compatible dataset. Code is available at https://github.com/XianguiKang/AdvAD.

Different camera sensors have different noise patterns, and thus an image denoising model trained on one sensor often does not generalize well to a different sensor. One plausible solution is to collect a large dataset for each sensor for training or fine-tuning, which is inevitably time-consuming. To address this cross-domain challenge, we present a novel adaptive domain learning (ADL) scheme for cross-domain RAW image denoising by utilizing existing data from different sensors (source domain) plus a small amount of data from the new sensor (target domain). The ADL training scheme automatically removes the data in the source domain that are harmful to fine-tuning a model for the target domain (some data are harmful as adding them during training lowers the performance due to domain gaps). Also, we introduce a modulation module to adopt sensor-specific information (sensor type and ISO) to understand input data for image denoising. We conduct extensive experiments on public datasets with various smartphone and DSLR cameras, which show our proposed model outperforms prior work on cross-domain image denoising, given a small amount of image data from the target domain sensor.

Federated learning (FL) is a learning paradigm that enables collaborative training of models using decentralized data.
Recently, the utilization of pre-trained weight initialization in FL has been demonstrated to effectively improve model performance.
However, the evolving complexity of current pre-trained models, characterized by a substantial increase in parameters, markedly intensifies the challenges associated with communication rounds required for their adaptation to FL.
To address these communication cost issues and increase the performance of pre-trained model adaptation in FL, we propose an innovative model interpolation-based local training technique called ``Local Superior Soups.''
Our method enhances local training across different clients, encouraging the exploration of a connected low-loss basin within a few communication rounds through regularized model interpolation.
This approach acts as a catalyst for the seamless adaptation of pre-trained models in in FL.
We demonstrated its effectiveness and efficiency across diverse widely-used FL datasets.
tl;dr: We use retrieval with fine-tuning to improve in-context learning on tabular data and show large improvement with better scaling

Tabular data is a pervasive modality spanning a wide range of domains, and this inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex tabular datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
3772. VQ-Map: Bird's-Eye-View Map Layout Estimation in Tokenized Discrete Space via Vector Quantization

Bird's-eye-view (BEV) map layout estimation requires an accurate and full understanding of the semantics for the environmental elements around the ego car to make the results coherent and realistic. Due to the challenges posed by occlusion, unfavourable imaging conditions and low resolution, \emph{generating} the BEV semantic maps corresponding to corrupted or invalid areas in the perspective view (PV) is appealing very recently. \emph{The question is how to align the PV features with the generative models to facilitate the map estimation}. In this paper, we propose to utilize a generative model similar to the Vector Quantized-Variational AutoEncoder (VQ-VAE) to acquire prior knowledge for the high-level BEV semantics in the tokenized discrete space. Thanks to the obtained BEV tokens accompanied with a codebook embedding encapsulating the semantics for different BEV elements in the groundtruth maps, we are able to directly align the sparse backbone image features with the obtained BEV tokens from the discrete representation learning based on a specialized token decoder module, and finally generate high-quality BEV maps with the BEV codebook embedding serving as a bridge between PV and BEV. We evaluate the BEV map layout estimation performance of our model, termed VQ-Map, on both the nuScenes and Argoverse benchmarks, achieving 62.2/47.6 mean IoU for surround-view/monocular evaluation on nuScenes, as well as 73.4 IoU for monocular evaluation on Argoverse, which all set a new record for this map layout estimation task. The code and models are available on \url{https://github.com/Z1zyw/VQ-Map}.
tl;dr: We introduce MSA-Generator, a self-supervised model that generates virtual MSAs, enhancing protein structure predictions in key benchmarks.

Deep learning models like AlphaFold2 have revolutionized protein structure prediction, achieving unprecedented accuracy. However, the dependence on robust multiple sequence alignments (MSAs) continues to pose a challenge, especially for proteins that lack a wealth of homologous sequences. To overcome this limitation, we introduce MSA-Generator, a self-supervised generative protein language model. Trained on a sequence-to-sequence task using an automatically constructed dataset, MSA-Generator employs protein-specific attention mechanisms to harness large-scale protein databases, generating virtual MSAs that enrich existing ones and boost prediction accuracy. Our experiments on CASP14 and CASP15 benchmarks reveal significant improvements in LDDT scores, particularly for complex and challenging sequences, enhancing the performance of both AlphaFold2 and RoseTTAFold. The code is released at \url{https://github.com/lezhang7/MSAGen}.
tl;dr: We introduce a pipeline for long-tail recognition that uses a diffusion model trained solely on the long-tailed dataset to generate a balanced proxy.

This paper introduces a novel pipeline for long-tail (LT) recognition that diverges from conventional strategies. Instead, it leverages the long-tailed dataset itself to generate a balanced proxy dataset without utilizing external data or model. We deploy a diffusion model trained from scratch on only the long-tailed dataset to create this proxy and verify the effectiveness of the data produced. Our analysis identifies approximately-in-distribution (AID) samples, which slightly deviate from the real data distribution and incorporate a blend of class information, as the crucial samples for enhancing the generative model's performance in long-tail classification. We promote the generation of AID samples during the training of a generative model by utilizing a feature extractor to guide the process and filter out detrimental samples during generation. Our approach, termed Diffusion model for Long-Tail recognition (DiffuLT), represents a pioneer application of generative models in long-tail recognition. DiffuLT achieves state-of-the-art results on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, surpassing leading competitors by significant margins. Comprehensive ablations enhance the interpretability of our pipeline. Notably, the entire generative process is conducted without relying on external data or pre-trained model weights, which leads to its generalizability to real-world long-tailed scenarios.

3D semantic segmentation using an adapting model trained from a source domain with or without accessing unlabeled target-domain data is the fundamental task in computer vision, containing domain adaptation and domain generalization.
The essence of simultaneously solving cross-domain tasks is to enhance the generalizability of the encoder.
In light of this, we propose a groundbreaking universal method with the help of off-the-shelf Visual Foundation Models (VFMs) to boost the adaptability and generalizability of cross-domain 3D semantic segmentation, dubbed $\textbf{UniDSeg}$.
Our method explores the VFMs prior and how to harness them, aiming to inherit the recognition ability of VFMs.
Specifically, this method introduces layer-wise learnable blocks to the VFMs, which hinges on alternately learning two representations during training: (i) Learning visual prompt. The 3D-to-2D transitional prior and task-shared knowledge is captured from the prompt space, and then (ii) Learning deep query. Spatial Tunability is constructed to the representation of distinct instances driven by prompts in the query space.
Integrating these representations into a cross-modal learning framework, UniDSeg efficiently mitigates the domain gap between 2D and 3D modalities, achieving unified cross-domain 3D semantic segmentation.
Extensive experiments demonstrate the effectiveness of our method across widely recognized tasks and datasets, all achieving superior performance over state-of-the-art methods. Remarkably, UniDSeg achieves 57.5\%/54.4\% mIoU on ``A2D2/sKITTI'' for domain adaptive/generalized tasks. Code is available at https://github.com/Barcaaaa/UniDSeg.
3776. A Consistency-Aware Spot-Guided Transformer for Versatile and Hierarchical Point Cloud Registration
tl;dr: We propose a novel consistency-aware spot-guided Transformer for versatile and hierarchical point cloud registration, achieving state-of-the-art accuracy, efficiency, and robustness on both outdoor and indoor benchmarks.

Deep learning-based feature matching has shown great superiority for point cloud registration in the absence of pose priors. Although coarse-to-fine matching approaches are prevalent, the coarse matching of existing methods is typically sparse and loose without consideration of geometric consistency, which makes the subsequent fine matching rely on ineffective optimal transport and hypothesis-and-selection methods for consistency. Therefore, these methods are neither efficient nor scalable for real-time applications such as odometry in robotics. To address these issues, we design a consistency-aware spot-guided Transformer (CAST), which incorporates a spot-guided cross-attention module to avoid interfering with irrelevant areas, and a consistency-aware self-attention module to enhance matching capabilities with geometrically consistent correspondences. Furthermore, a lightweight fine matching module for both sparse keypoints and dense features can estimate the transformation accurately. Extensive experiments on both outdoor LiDAR point cloud datasets and indoor RGBD point cloud datasets demonstrate that our method achieves state-of-the-art accuracy, efficiency, and robustness.
tl;dr: We tackle the task of active geo-localization, where an agent uses a series of visual cues observed during aerial navigation to locate a target specified via various modalities, while the agent is trained solely on data from a single goal modality.

We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. This could emulate a UAV involved in a search-and-rescue operation navigating through an area, observing a stream of aerial images as it goes. The AGL task is associated with two important challenges. Firstly, an agent must deal with a goal specification in one of multiple modalities (e.g., through a natural language description) while the search cues are provided in other modalities (aerial imagery). The second challenge is limited localization time (e.g., limited battery life, urgency) so that the goal must be localized as efficiently as possible, i.e. the agent must effectively leverage its sequentially observed aerial views when searching for the goal. To address these challenges, we propose GOMAA-Geo -- a goal modality agnostic active geo-localization agent -- for zero-shot generalization between different goal modalities. Our approach combines cross-modality contrastive learning to align representations across modalities with supervised foundation model pretraining and reinforcement learning to obtain highly effective navigation and localization policies. Through extensive evaluations, we show that GOMAA-Geo outperforms alternative learnable approaches and that it generalizes across datasets -- e.g., to disaster-hit areas without seeing a single disaster scenario during training -- and goal modalities -- e.g., to ground-level imagery or textual descriptions, despite only being trained with goals specified as aerial views. Our code is available at: https://github.com/mvrl/GOMAA-Geo.

Knowledge Graph Embedding (KGE) techniques are crucial in learning compact representations of entities and relations within a knowledge graph, facilitating efficient reasoning and knowledge discovery. While existing methods typically focus either on training KGE models solely based on graph structure or fine-tuning pre-trained language models with classification data in KG, KG-FIT leverages LLM-guided refinement to construct a semantically coherent hierarchical structure of entity clusters. By incorporating this hierarchical knowledge along with textual information during the fine-tuning process, KG-FIT effectively captures both global semantics from the LLM and local semantics from the KG. Extensive experiments on the benchmark datasets FB15K-237, YAGO3-10, and PrimeKG demonstrate the superiority of KG-FIT over state-of-the-art pre-trained language model-based methods, achieving improvements of 14.4\%, 13.5\%, and 11.9\% in the Hits@10 metric for the link prediction task, respectively. Furthermore, KG-FIT yields substantial performance gains of 12.6\%, 6.7\%, and 17.7\% compared to the structure-based base models upon which it is built. These results highlight the effectiveness of KG-FIT in incorporating open-world knowledge from LLMs to significantly enhance the expressiveness and informativeness of KG embeddings.
tl;dr: We introduce VideoLISA, a video-based multimodal large language model designed to address the challenges of language-instructed reasoning segmentation in videos.

We introduce VideoLISA, a video-based multimodal large language model designed to tackle the problem of language-instructed reasoning segmentation in videos. Leveraging the reasoning capabilities and world knowledge of large language models, and augmented by the Segment Anything Model, VideoLISA generates temporally consistent segmentation masks in videos based on language instructions. Existing image-based methods, such as LISA, struggle with video tasks due to the additional temporal dimension, which requires temporal dynamic understanding and consistent segmentation across frames. VideoLISA addresses these challenges by integrating a Sparse Dense Sampling strategy into the video-LLM, which balances temporal context and spatial detail within computational constraints. Additionally, we propose a One-Token-Seg-All approach using a specially designed <TRK> token, enabling the model to segment and track objects across multiple frames. Extensive evaluations on diverse benchmarks, including our newly introduced ReasonVOS benchmark, demonstrate VideoLISA's superior performance in video object segmentation tasks involving complex reasoning, temporal understanding, and object tracking. While optimized for videos, VideoLISA also shows promising generalization to image segmentation, revealing its potential as a unified foundation model for language-instructed object segmentation. Code and model will be available at: https://github.com/showlab/VideoLISA.
tl;dr: We introduce a training-free memory-based method, InfLLM, to unveil the intrinsic ability of LLMs to process streaming long sequences.

Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs (e.g., LLM-driven agents). However, existing LLMs, pre-trained on sequences with a restricted maximum length, cannot process longer sequences due to the out-of-domain and distraction issues. Common solutions often involve continual pre-training on longer sequences, which will introduce expensive computational overhead and uncontrollable change in model capabilities. In this paper, we unveil the intrinsic capacity of LLMs for understanding extremely long sequences without any fine-tuning. To this end, we introduce a training-free memory-based method, InfLLM. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences with a limited context window and well capture long-distance dependencies. Without any training, InfLLM enables LLMs that are pre-trained on sequences consisting of a few thousand tokens to achieve comparable performance with competitive baselines that continually train these LLMs on long sequences. Even when the sequence length is scaled to 1,024K, InfLLM still effectively captures long-distance dependencies. Our code can be found at https://github.com/thunlp/InfLLM.

Survival prediction is a significant challenge in cancer management. Tumor micro-environment is a highly sophisticated ecosystem consist of cancer cells, immune cells, endothelial cells, fibroblasts, nerves and extracellular matrix. The intratumor heterogeneity and the interaction across multiple tissue types profoundly impacts the prognosis. However, current methods often neglect the fact that the contribution to prognosis differs with tissue types. In this paper, we propose ProtoSurv, a novel heterogeneous graph model for WSI survival prediction. The learning process of ProtoSurv is not only driven by data but also incorporates pathological domain knowledge, including the awareness of tissue heterogeneity, the emphasis on prior knowledge of prognostic-related tissues, and the depiction of spatial interaction across multiple tissues. We validate ProtoSurv across five different cancer types from TCGA (i.e., BRCA, LGG, LUAD, COAD and PAAD), and demonstrate the superiority of our method over the state-of-the-art methods.

In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications. The project page: https://linshan-bin.github.io/GeoLRM/.
tl;dr: We propose a nonparametric method that uses trial data, adjusted with additional covariates from the target population, to provide certifiably and externally valid policy evaluations.

Randomized trials are widely considered as the gold standard for evaluating the effects of decision policies. Trial data is, however, drawn from a population which may differ from the intended target population and this raises a problem of external validity (aka. generalizability). In this paper we seek to use trial data to draw valid inferences about the outcome of a policy on the target population. Additional covariate data from the target population is used to model the sampling of individuals in the trial study. We develop a method that yields certifiably valid trial-based policy evaluations under any specified range of model miscalibrations. The method is nonparametric and the validity is assured even with finite samples. The certified policy evaluations are illustrated using both simulated and real data.

In human-centric applications like healthcare and education, the \textit{heterogeneity} among patients and students necessitates personalized treatments and instructional interventions. While reinforcement learning (RL) has been utilized in those tasks, off-policy selection (OPS) is pivotal to close the loop by offline evaluating and selecting policies without online interactions, yet current OPS methods often overlook the heterogeneity among participants. Our work is centered on resolving a \textit{pivotal challenge} in human-centric systems (HCSs): \textbf{\textit{how to select a policy to deploy when a new participant joining the cohort, without having access to any prior offline data collected over the participant?}} We introduce First-Glance Off-Policy Selection (FPS), a novel approach that systematically addresses participant heterogeneity through sub-group segmentation and tailored OPS criteria to each sub-group. By grouping individuals with similar traits, FPS facilitates personalized policy selection aligned with unique characteristics of each participant or group of participants. FPS is evaluated via two important but challenging applications, intelligent tutoring systems and a healthcare application for sepsis treatment and intervention. FPS presents significant advancement in enhancing learning outcomes of students and in-hospital care outcomes.
tl;dr: This paper presents a dual defense approach for enhancing privacy and mitigating poisoning attacks at once in federated learning

Federated learning (FL) is inherently susceptible to privacy breaches and poisoning attacks. To tackle these challenges, researchers have separately devised secure aggregation mechanisms to protect data privacy and robust aggregation methods that withstand poisoning attacks. However, simultaneously addressing both concerns is challenging; secure aggregation facilitates poisoning attacks as most anomaly detection techniques require access to unencrypted local model updates, which are obscured by secure aggregation. Few recent efforts to simultaneously tackle both challenges offen depend on impractical assumption of non-colluding two-server setups that disrupt FL's topology, or three-party computation which introduces scalability issues, complicating deployment and application. To overcome this dilemma, this paper introduce a Dual Defense Federated learning (DDFed) framework. DDFed simultaneously boosts privacy protection and mitigates poisoning attacks, without introducing new participant roles or disrupting the existing FL topology. DDFed initially leverages cutting-edge fully homomorphic encryption (FHE) to securely aggregate model updates, without the impractical requirement for non-colluding two-server setups and ensures strong privacy protection. Additionally, we proposes a unique two-phase anomaly detection mechanism for encrypted model updates, featuring secure similarity computation and feedback-driven collaborative selection, with additional measures to prevent potential privacy breaches from Byzantine clients incorporated into the detection process. We conducted extensive experiments on various model poisoning attacks and FL scenarios, including both cross-device and cross-silo FL. Experiments on publicly available datasets demonstrate that DDFed successfully protects model privacy and effectively defends against model poisoning threats.

Recently, multi-modal entity alignment has emerged as a pivotal endeavor for the integration of Multi-Modal Knowledge Graphs (MMKGs) originating from diverse data sources. Existing works primarily focus on fully depicting entity features by designing various modality encoders or fusion approaches. However, uncertain correspondences between inter-modal or intra-modal cues, such as weak inter-modal associations, description diversity, and modality absence, still severely hinder the effective exploration of aligned entity similarities. To this end, in this paper, we propose a novel Tackling uncertain correspondences method for Multi-modal Entity Alignment (TMEA). Specifically, to handle diverse attribute knowledge descriptions, we design alignment-augmented abstract representation that incorporates the large language model and in-context learning into attribute alignment and filtering for generating and embedding the attribute abstract. In order to mitigate the influence of the modality absence, we propose to unify all modality features into a shared latent subspace and generate pseudo features via variational autoencoders according to existing modal features. Then, we develop an inter-modal commonality enhancement mechanism based on cross-attention with orthogonal constraints, to address weak semantic associations between modalities. Extensive experiments on two real-world datasets validate the effectiveness of TMEA with a clear improvement over competitive baselines.

LiDAR-based 3D object detection has made impressive progress recently, yet most existing models are black-box, lacking interpretability. Previous explanation approaches primarily focus on analyzing image-based models and are not readily applicable to LiDAR-based 3D detectors. In this paper, we propose a feature factorization activation map (FFAM) to generate high-quality visual explanations for 3D detectors. FFAM employs non-negative matrix factorization to generate concept activation maps and subsequently aggregates these maps to obtain a global visual explanation. To achieve object-specific visual explanations, we refine the global visual explanation using the feature gradient of a target object. Additionally, we introduce a voxel upsampling strategy to align the scale between the activation map and input point cloud. We qualitatively and quantitatively analyze FFAM with multiple detectors on several datasets. Experimental results validate the high-quality visual explanations produced by FFAM. The code is available at \url{https://anonymous.4open.science/r/FFAM-B9AF}.
tl;dr: Self Logits Evolution Decoding (SLED) improves LLM factuality through better decoding.

Large language models (LLMs) have demonstrated remarkable capabilities, but their outputs can sometimes be unreliable or factually incorrect. To address this, we introduce Self Logits Evolution Decoding (SLED), a novel decoding framework that enhances the truthfulness of LLMs without relying on external knowledge bases or requiring further fine-tuning. From an optimization perspective, our SLED framework leverages the latent knowledge embedded within the LLM by contrasting the output logits from the final layer with those from early layers. It then utilizes an approximate gradient approach to enable latent knowledge to guide the self-refinement of outputs, thereby effectively improving factual accuracy. Extensive experiments have been conducted on established benchmarks across a diverse range of model families (LLaMA 2, LLaMA 3, Gemma) and scales (from 2B to 70B), including more advanced architectural configurations such as the mixture of experts (MoE). Our evaluation spans a wide variety of tasks, including multi-choice, open-generation, and adaptations to chain-of-thought reasoning tasks. The results demonstrate that SLED consistently improves factual accuracy by up to 20\% compared to existing decoding methods while maintaining natural language fluency and negligible latency overhead. Furthermore, it can be flexibly combined with other decoding methods to further enhance their performance.
tl;dr: Our research proposes a novel MoGU framework that improves LLMs' safety while preserving their usability.

Large Language Models (LLMs) are increasingly deployed in various applications. As their usage grows, concerns regarding their safety are rising, especially in maintaining harmless responses when faced with malicious instructions. Many defense strategies have been developed to enhance the safety of LLMs. However, our research finds that existing defense strategies lead LLMs to predominantly adopt a rejection-oriented stance, thereby diminishing the usability of their responses to benign instructions. To solve this problem, we introduce the MoGU framework, designed to enhance LLMs' safety while preserving their usability. Our MoGU framework transforms the base LLM into two variants: the usable LLM and the safe LLM, and further employs dynamic routing to balance their contribution. When encountering malicious instructions, the router will assign a higher weight to the safe LLM to ensure that responses are harmless. Conversely, for benign instructions, the router prioritizes the usable LLM, facilitating usable and helpful responses. On various open-sourced LLMs, we compare multiple defense strategies to verify the superiority of our MoGU framework. Besides, our analysis provides key insights into the effectiveness of MoGU and verifies that our designed routing mechanism can effectively balance the contribution of each variant by assigning weights. Our work released the safer Llama2, Vicuna, Falcon, Dolphin, and Baichuan2.
tl;dr: We give algorithms and hardness results for Bayesian persuasion under approximate best response.

We study Bayesian persuasion under approximate best response, where the receiver may choose any action that is not too much suboptimal, given their posterior belief upon receiving the signal. We focus on the computational aspects of the problem, aiming to design algorithms that efficiently compute (almost) optimal strategies for the sender. Despite the absence of the revelation principle --- which has been one of the most powerful tools in Bayesian persuasion --- we design polynomial-time exact algorithms for the problem when either the state space or the action space is small, as well as a quasi-polynomial-time approximation scheme (QPTAS) for the general problem. On the negative side, we show there is no polynomial-time exact algorithm for the general problem unless $\mathsf{P} = \mathsf{NP}$. Our results build on several new algorithmic ideas, which might be useful in other principal-agent problems where robustness is desired.

We propose a novel unsupervised method to learn pose and part-segmentation of articulated objects with rigid parts.
Given two observations of an object in different articulation states, our method learns the geometry and appearance of object parts by using an implicit model from the first observation, distills the part segmentation and articulation from the second observation while rendering the latter observation.
Additionally, to tackle the complexities in the joint optimization of part segmentation and articulation, we propose a voxel grid based initialization strategy and a decoupled optimization procedure.
Compared to the prior unsupervised work, our model obtains significantly better performance, generalizes to objects with multiple parts while it can be efficiently from few views for the latter observation.

Multimodal large language models (MLLMs) have demonstrated impressive capabilities across various vision-language tasks. However, a generalist MLLM typically underperforms compared with a specialist MLLM on most VL tasks, which can be attributed to task interference. In this paper, we propose a mixture of multimodal experts (MoME) to mitigate task interference and obtain a generalist MLLM. Our MoME is composed of two key components, a mixture of vision experts (MoVE) and a mixture of language experts (MoLE). MoVE can adaptively modulate the features transformed from various vision encoders, and has a strong compatibility in transformation architecture. MoLE incorporates sparsely gated experts into LLMs to achieve painless improvements with roughly unchanged inference costs. In response to task interference, our MoME specializes in both vision and language modality to adapt to task discrepancies. Extensive experiments show that MoME significantly improves the performance of generalist MLLMs across various VL tasks.
tl;dr: Maintaining orthogonal weight matrices during training improves continual reinforcement learning agents.

Plasticity loss, trainability loss, and primacy bias have been identified as issues arising when training deep neural networks on sequences of tasks---referring to the increased difficulty in training on new tasks.
We propose to use Parseval regularization, which maintains orthogonality of weight matrices, to preserve useful optimization properties and improve training in a continual reinforcement learning setting.
We show that it provides significant benefits to RL agents on a suite of gridworld, CARL and MetaWorld tasks.
We conduct comprehensive ablations to identify the source of its benefits and investigate the effect of certain metrics associated to network trainability including weight matrix rank, weight norms and policy entropy.
tl;dr: The paper introduces "semantic artifacts" in cross-scene images, which leads to performance drops on generalized detection. A dataset from various generative models and scenes is built and a simple yet effective patch-based method is proposed.
With the continuous evolution of AI-generated images, the generalized detection of them has become a crucial aspect of AI security.
Existing detectors have focused on cross-generator generalization, while it remains unexplored whether these detectors can generalize across different image scenes, e.g., images from different datasets with different semantics. In this paper, we reveal that existing detectors suffer from substantial Accuracy drops in such cross-scene generalization. In particular, we attribute their failures to ''semantic artifacts'' in both real and generated images, to which detectors may overfit. To break such ''semantic artifacts'', we propose a simple yet effective approach based on conducting an image patch shuffle and then training an end-to-end patch-based classifier. We conduct a comprehensive open-world evaluation on 31 test sets, covering 7 Generative Adversarial Networks, 18 (variants of) Diffusion Models, and another 6 CNN-based generative models. The results demonstrate that our approach outperforms previous approaches by 2.08\% (absolute) on average regarding cross-scene detection Accuracy. We also notice the superiority of our approach in open-world generalization, with an average Accuracy improvement of 10.59\% (absolute) across all test sets.

Reconstructing a continuous surface from a raw 3D point cloud is a challenging task. Latest methods employ supervised learning or pretrained priors to learn a signed distance function (SDF). However, neural networks tend to smooth local details due to the lack of ground truth signed distnaces or normals, which limits the performance of learning-based methods in reconstruction tasks. To resolve this issue, we propose a novel method, named MultiPull, to learn multi-scale implicit fields from raw point clouds to optimize accurate SDFs from coarse to fine. We achieve this by mapping 3D query points into a set of frequency features, which makes it possible to leverage multi-level features during optimization. Meanwhile, we introduce optimization constraints from the perspective of spatial distance and normal consistency, which play a key role in point cloud reconstruction based on multi-scale optimization strategies. Our experiments on widely used object and scene benchmarks demonstrate that our method outperforms the state-of-the-art methods in surface reconstruction.
tl;dr: A new paradigm for fitting LLMs to downstream tasks.

Large language models (LLMs) have rapidly advanced and demonstrated impressive capabilities. In-Context Learning (ICL) and Parameter-Efficient Fine-Tuning (PEFT) are currently two mainstream methods for augmenting LLMs to downstream tasks. ICL typically constructs a few-shot learning scenario, either manually or by setting up a Retrieval-Augmented Generation (RAG) system, helping models quickly grasp domain knowledge or question-answering patterns without changing model parameters. However, this approach involves trade-offs, such as slower inference speed and increased space occupancy. PEFT assists the model in adapting to tasks through minimal parameter modifications, but the training process still demands high hardware requirements, even with a small number of parameters involved. To address these challenges, we propose Reference Trustable Decoding (RTD), a paradigm that allows models to quickly adapt to new tasks without fine-tuning, maintaining low inference costs. RTD constructs a reference datastore from the provided training examples and optimizes the LLM's final vocabulary distribution by flexibly selecting suitable references based on the input, resulting in more trustable responses and enabling the model to adapt to downstream tasks at a low cost. Experimental evaluations on various LLMs using different benchmarks demonstrate that RTD establishes a new paradigm for augmenting models to downstream tasks. Furthermore, our method exhibits strong orthogonality with traditional methods, allowing for concurrent usage. Our code can be found at https://github.com/ShiLuohe/ReferenceTrustableDecoding.
tl;dr: We present a novel recover-and-resample augmentation framework based on complete action prior for skeleton action generalization task.

Despite huge progress in skeleton-based action recognition, its generalizability to different domains remains a challenging issue.
In this paper, to solve the skeleton action generalization problem, we present a recover-and-resample augmentation framework based on a novel complete action prior. We observe that human daily actions are confronted with temporal mismatch across different datasets, as they are usually partial observations of their complete action sequences. By recovering complete actions and resampling from these full sequences, we can generate strong augmentations for unseen domains. At the same time, we discover the nature of general action completeness within large datasets, indicated by the per-frame diversity over time. This allows us to exploit two assets of transferable knowledge that can be shared across action samples and be helpful for action completion: boundary poses for determining the action start, and linear temporal transforms for capturing global action patterns. Therefore, we formulate the recovering stage as a two-step stochastic action completion with boundary pose-conditioned extrapolation followed by smooth linear transforms. Both the boundary poses and linear transforms can be efficiently learned from the whole dataset via clustering. We validate our approach on a cross-dataset setting with three skeleton action datasets, outperforming other domain generalization approaches by a considerable margin.

Diffusion models learn to denoise data and the trained denoiser is then used to generate new samples from the data distribution.
In this paper, we revisit the diffusion sampling process and identify a fundamental cause of sample quality degradation: the denoiser is poorly estimated in regions that are far Outside Of the training Distribution (OOD), and the sampling process inevitably evaluates in these OOD regions.
This can become problematic for all sampling methods, especially when we move to parallel sampling which requires us to initialize and update the entire sample trajectory of dynamics in parallel, leading to many OOD evaluations.
To address this problem, we introduce a new self-supervised training objective that differentiates the levels of noise added to a sample, leading to improved OOD denoising performance. The approach is based on our observation that diffusion models implicitly define a log-likelihood ratio that distinguishes distributions with different amounts of noise, and this expression depends on denoiser performance outside the standard training distribution.
We show by diverse experiments that the proposed contrastive diffusion training is effective for both sequential and parallel settings, and it improves the performance and speed of parallel samplers significantly. Code for our paper can be found at https://github.com/yunshuwu/ContrastiveDiffusionLoss
3799. Preference Learning of Latent Decision Utilities with a Human-like Model of Preferential Choice
tl;dr: We improve learning of latent utilities from preferences for decision tasks, by using a cognitive model of preferential choice which models various context effects.

Preference learning methods make use of models of human choice in order to infer the latent utilities that underlie human behaviour. However, accurate modeling of human choice behavior is challenging due to a range of context effects that arise from how humans contrast and evaluate options. Cognitive science has proposed several models that capture these intricacies but, due to their intractable nature, work on preference learning has, in practice, had to rely on tractable but simplified variants of the well-known Bradley-Terry model. In this paper, we take one state-of-the-art intractable cognitive model and propose a tractable surrogate that is suitable for deployment in preference learning. We then introduce a mechanism for fitting the surrogate to human data that cannot be explained by the original cognitive model. We demonstrate on large-scale human data that this model produces significantly better inferences on static and actively elicited data than existing Bradley-Terry variants. We further show in simulation that when using this model for preference learning, we can significantly improve a utility in a range of real-world tasks.

Safeguarding intellectual property and preventing potential misuse of AI-generated images are of paramount importance. This paper introduces a robust and agile plug-and-play watermark detection framework, referred to as RAW.
As a departure from existing encoder-decoder methods, which incorporate fixed binary codes as watermarks within latent representations, our approach introduces learnable watermarks directly into the original image data. Subsequently, we employ a classifier that is jointly trained with the watermark to detect the presence of the watermark.
The proposed framework is compatible with various generative architectures and supports on-the-fly watermark injection after training. By incorporating state-of-the-art smoothing techniques, we show that the framework also provides provable guarantees regarding the false positive rate for misclassifying a watermarked image, even in the presence of adversarial attacks targeting watermark removal.
Experiments on a diverse range of images generated by state-of-the-art diffusion models demonstrate substantially improved watermark encoding speed and watermark detection performance, under adversarial attacks, while maintaining image quality. Our code is publicly available [here](https://github.com/jeremyxianx/RAWatermark).

Contrastive Language-Image Pre-training (CLIP) achieves impressive performance on tasks like image classification and image-text retrieval by learning on large-scale image-text datasets. However, CLIP struggles with dense prediction tasks due to the poor grasp of the fine-grained details. Although existing works pay attention to this issue, they achieve limited improvements and usually sacrifice the important visual-semantic consistency. To overcome these limitations, we propose FineCLIP, which keeps the global contrastive learning to preserve the visual-semantic consistency and further enhances the fine-grained understanding through two innovations: 1) A real-time self-distillation scheme that facilitates the transfer of representation capability from global to local features. 2) A semantically-rich regional contrastive learning paradigm with generated region-text pairs, boosting the local representation capabilities with abundant fine-grained knowledge.
Both cooperate to fully leverage diverse semantics and multi-grained complementary information.
To validate the superiority of our FineCLIP and the rationality of each design, we conduct extensive experiments on challenging dense prediction and image-level tasks.
All the observations demonstrate the effectiveness of FineCLIP.
tl;dr: SpeedLoader can compute multiple batches within one Forward-Backward pass.

With the surging growth of model parameters, foundation models pose unprecedented challenges to traditional computational infrastructures. These large models inherently require substantial accelerator memory to accommodate massive tensors during pre-training, fine-tuning, and even inference stages, making it even more challenging to deploy a model with restricted computational resources. Given this challenge, distribution and offloading the model states are two major solutions. Partitioning the required states to participating workers, and storing them in lower speed media, such as host DRAM and block devices, largely alleviate the accelerator memory pressure. However, the prohibitive costs of tensor communication render it a theoretically plausible yet practically inefficient solution. Previous efforts to improve efficiency include maximizing rematerialization and employing chunk-based tensor management to reduce host-device communication. Despite these efforts, the reported training throughput only achieves 36.54% of model FLOPs utilization (MFUs), still not comparable to full on-device training. In this work, we redesign the data flow of heterogeneous hardware and sharded model training to minimize the excessive communication overhead. Our proposed scheme significantly enhances training and inference throughput of large language models under restrictive computational resources. We confirmed a large leap in effective compute time by looking into the kernel-level runtime behavior of our trials, where the MFUs can achieve up to 51%. Compared to the state-of-the-art approach, our framework robustly achieves remarkable speedups from 3x to 30x in multiple distributed heterogeneous training setups and inference speedups of 1.5x to 2.35x without compromising arithmetic precision.

Smoke segmentation is of great importance in precisely identifying the smoke location, enabling timely fire rescue and gas leak detection. However, due to the visual diversity and blurry edges of the non-grid smoke, noisy labels are almost inevitable in large-scale pixel-level smoke datasets. Noisy labels significantly impact the robustness of the model and may lead to serious accidents. Nevertheless, currently, there are no specific methods for addressing noisy labels in smoke segmentation. Smoke differs from regular objects as its transparency varies, causing inconsistent features in the noisy labels. In this paper, we propose a conditional sample weighting (CoSW). CoSW utilizes a multi-prototype framework, where prototypes serve as prior information to apply different weighting criteria to the different feature clusters. A novel regularized within-prototype entropy (RWE) is introduced to achieve CoSW and stable prototype update. The experiments show that our approach achieves SOTA performance on both real-world and synthetic noisy smoke segmentation datasets.
tl;dr: This paper proposed a novel framework for global pruning of large language models, via considering the LLMs as a chain of modules and introducing auxiliary variables.

The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose *SparseLLM*, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods. Our source code is publicly available at https://github.com/BaiTheBest/SparseLLM.
tl;dr: A novel conformal prediction method is introduced to construct credal sets that are able to represent both the aleatoric and epistemic uncertainty in a prediction.

Credal sets are sets of probability distributions that are considered as candidates for an imprecisely known ground-truth distribution. In machine learning, they have recently attracted attention as an appealing formalism for uncertainty representation, in particular, due to their ability to represent both the aleatoric and epistemic uncertainty in a prediction. However, the design of methods for learning credal set predictors remains a challenging problem. In this paper, we make use of conformal prediction for this purpose. More specifically, we propose a method for predicting credal sets in the classification task, given training data labeled by probability distributions. Since our method inherits the coverage guarantees of conformal prediction, our conformal credal sets are guaranteed to be valid with high probability (without any assumptions on model or distribution). We demonstrate the applicability of our method on ambiguous classification tasks for uncertainty quantification.
tl;dr: This paper constructs a theoretical analysis framework for prompt-based federated learning via feature learning theory, and introduces a prompt portfolio mechanism to address severe data heterogeneity and balance generalization and personalization.

Integrating pretrained vision-language foundation models like CLIP into federated learning has attracted significant attention for enhancing generalization across diverse tasks. Typically, federated learning of vision-language models employs prompt learning to reduce communication and computational costs, i.e., prompt-based federated learning. However, there is limited theoretical analysis to understand the performance of prompt-based federated learning. In this work, we construct a theoretical analysis framework for prompt-based federated learning via feature learning theory. Specifically, we monitor the evolution of signal learning and noise memorization in prompt-based federated learning, demonstrating that performance can be assessed by the ratio of task-relevant to task-irrelevant coefficients. Furthermore, we draw an analogy between income and risk in portfolio optimization and the task-relevant and task-irrelevant terms in feature learning. Leveraging inspiration from portfolio optimization that combining two independent assets will maintain the income while reducing the risk, we introduce two prompts: global prompt and local prompt to construct a prompt portfolio to balance the generalization and personalization. Consequently, we showed the performance advantage of the prompt portfolio and derived the optimal mixing coefficient. These theoretical claims have been further supported by empirical experiments.

Modeling and producing lifelike clothed human images has attracted researchers' attention from different areas for decades, with the complexity from highly articulated and structured content. Rendering algorithms decompose and simulate the imaging process of a camera, while are limited by the accuracy of modeled variables and the efficiency of computation. Generative models can produce impressively vivid human images, however still lacking in controllability and editability. This paper studies photorealism enhancement of rendered images, leveraging generative power from diffusion models on the controlled basis of rendering. We introduce a novel framework to translate rendered images into their realistic counterparts, which consists of two stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In DKI, we adopt positive (real) domain finetuning and negative (rendered) domain embedding to inject knowledge into a pretrained Text-to-image (T2I) diffusion model. In RIG, we generate the realistic image corresponding to the input rendered image, with a Texture-preserving Attention Control (TAC) to preserve fine-grained clothing textures, exploiting the decoupled features encoded in the UNet structure. Additionally, we introduce SynFashion dataset, featuring high-quality digital clothing images with diverse textures. Extensive experimental results demonstrate the superiority and effectiveness of our method in rendered-to-real image translation.

Diffusion models have been widely utilized for image restoration. However, previous blind image restoration methods still need to assume the type of degradation model while leaving the parameters to be optimized, limiting their real-world applications. Therefore, we aim to tame generative diffusion prior for universal blind image restoration dubbed BIR-D, which utilizes an optimizable convolutional kernel to simulate the degradation model and dynamically update the parameters of the kernel in the diffusion steps, enabling it to achieve blind image restoration results even in various complex situations. Besides, based on mathematical reasoning, we have provided an empirical formula for the chosen of adaptive guidance scale, eliminating the need for a grid search for the optimal parameter. Experimentally, Our BIR-D has demonstrated superior practicality and versatility than off-the-shelf unsupervised methods across various tasks both on real-world and synthetic datasets, qualitatively and quantitatively. BIR-D is able to fulfill multi-guidance blind image restoration. Moreover, BIR-D can also restore images that undergo multiple and complicated degradations, demonstrating the practical applications. The code is available at https://github.com/Tusiwei/BIR-D.

Photo finishing tuning aims to automate the manual tuning process of the photo finishing pipeline, like Adobe Lightroom or Darktable. Previous works either use zeroth-order optimization, which is slow when the set of parameters increases, or rely on a differentiable proxy of the target finishing pipeline, which is hard to train.
To overcome these challenges, we propose a novel goal-conditioned reinforcement learning framework for efficiently tuning parameters using a goal image as a condition. Unlike previous approaches, our tuning framework does not rely on any proxy and treats the photo finishing pipeline as a black box. Utilizing a trained reinforcement learning policy, it can efficiently find the desired set of parameters within just 10 queries, while optimization based approaches normally take 200 queries. Furthermore, our architecture utilizes a goal image to guide the iterative tuning of pipeline parameters, allowing for flexible conditioning on pixel-aligned target images, style images, or any other visually representable goals. We conduct detailed experiments on photo finishing tuning and photo stylization tuning tasks, demonstrating the advantages of our method.
tl;dr: We present SocialGPT, a modular framework with greedy segment prompt optimization for social relation reasoning, which attains competitive results while also providing interpretable explanations.

Social relation reasoning aims to identify relation categories such as friends, spouses, and colleagues from images. While current methods adopt the paradigm of training a dedicated network end-to-end using labeled image data, they are limited in terms of generalizability and interpretability. To address these issues, we first present a simple yet well-crafted framework named SocialGPT, which combines the perception capability of Vision Foundation Models (VFMs) and the reasoning capability of Large Language Models (LLMs) within a modular framework, providing a strong baseline for social relation recognition. Specifically, we instruct VFMs to translate image content into a textual social story, and then utilize LLMs for text-based reasoning. SocialGPT introduces systematic design principles to adapt VFMs and LLMs separately and bridge their gaps. Without additional model training, it achieves competitive zero-shot results on two databases while offering interpretable answers, as LLMs can generate language-based explanations for the decisions. The manual prompt design process for LLMs at the reasoning phase is tedious and an automated prompt optimization method is desired. As we essentially convert a visual classification task into a generative task of LLMs, automatic prompt optimization encounters a unique long prompt optimization issue. To address this issue, we further propose the Greedy Segment Prompt Optimization (GSPO), which performs a greedy search by utilizing gradient information at the segment level. Experimental results show that GSPO significantly improves performance, and our method also generalizes to different image styles. The code is available at https://github.com/Mengzibin/SocialGPT.
tl;dr: We introduce a continual scene graph generation dataset and a model to tackle this problem.

Scene graph generation (SGG) analyzes images to extract meaningful information about objects and their relationships. In the dynamic visual world, it is crucial for AI systems to continuously detect new objects and establish their relationships with existing ones. Recently, numerous studies have focused on continual learning within the domains of object detection and image recognition. However, a limited amount of research focuses on a more challenging continual learning problem in SGG. This increased difficulty arises from the intricate interactions and dynamic relationships among objects, and their associated contexts. Thus, in continual learning, SGG models are often required to expand, modify, retain, and reason scene graphs within the process of adaptive visual scene understanding. To systematically explore Continual Scene Graph Generation (CSEGG), we present a comprehensive benchmark comprising three learning regimes: relationship incremental, scene incremental, and relationship generalization. Moreover, we introduce a ``Replays via Analysis by Synthesis" method named RAS. This approach leverages the scene graphs, decomposes and re-composes them to represent different scenes, and replays the synthesized scenes based on these compositional scene graphs. The replayed synthesized scenes act as a means to practice and refine proficiency in SGG in known and unknown environments. Our experimental results not only highlight the challenges of directly combining existing continual learning methods with SGG backbones but also demonstrate the effectiveness of our proposed approach, enhancing CSEGG efficiency while simultaneously preserving privacy and memory usage. All data and source code will be made public.

Hair editing is a critical image synthesis task that aims to edit hair color and hairstyle using text descriptions or reference images, while preserving irrelevant attributes (e.g., identity, background, cloth). Many existing methods are based on StyleGAN to address this task. However, due to the limited spatial distribution of StyleGAN, it struggles with multiple hair color editing and facial preservation. Considering the advancements in diffusion models, we utilize Latent Diffusion Models (LDMs) for hairstyle editing. Our approach introduces Multi-stage Hairstyle Blend (MHB), effectively separating control of hair color and hairstyle in diffusion latent space. Additionally, we train a warping module to align the hair color with the target region. To further enhance multi-color hairstyle editing, we fine-tuned a CLIP model using a multi-color hairstyle dataset. Our method not only tackles the complexity of multi-color hairstyles but also addresses the challenge of preserving original colors during diffusion editing. Extensive experiments showcase the superiority of our method in editing multi-color hairstyles while preserving facial attributes given textual descriptions and reference images.

Lossless compression of large-scale scientific floating-point data is critical yet challenging due to the presence of high-order information and noise that arises from model truncation and discretization errors. Existing entropy coding techniques fail to effectively leverage the mechanisms underlying the data generation process. This paper introduces MeLLoC(Mechanism Learning for Lossless Compression), a novel approach that combines high-order mechanism learning with classical encoding to enhance lossless compression for scientific data. The key idea is to treat the data as discrete samples from an underlying physical field described by differential equations and solve an inverse problem to identify the governing equation coefficients exhibiting more compressible numeric representations. Periodic extension techniques are employed to accelerate the decompression. Through extensive experiments on various scientific datasets, MeLLoC consistently outperforms state-of-the-art lossless compressors while offering compelling trade-offs between compression ratios and computational costs. This work opens up new avenues for exploiting domain knowledge and high-order information to improve data compression in scientific computing.
tl;dr: An OCR-free document understanding framework that efficiently processes multi-scale visual features while learning to read text with layout by position-aware instruction tuning.

We present a novel OCR-free document understanding framework based on pretrained Multimodal Large Language Models (MLLMs).
Our approach employs multi-scale visual features to effectively handle various font sizes within document images.
To address the increasing costs of considering the multi-scale visual inputs for MLLMs, we propose the Hierarchical Visual Feature Aggregation (HVFA) module, designed to reduce the number of input tokens to LLMs.
Leveraging a feature pyramid with cross-attentive pooling, our approach effectively manages the trade-off between information loss and efficiency without being affected by varying document image sizes.
Furthermore, we introduce a novel instruction tuning task, which facilitates the model's text-reading capability by learning to predict the relative positions of input text, eventually minimizing the risk of truncated text caused by the limited capacity of LLMs.
Comprehensive experiments validate the effectiveness of our approach, demonstrating superior performance in various document understanding tasks.
3815. Meta-Diffu$B$: A Contextualized Sequence-to-Sequence Text Diffusion Model with Meta-Exploration
tl;dr: We propose a novel scheduler-exploiter framework, Meta-Diffu$B$, to achieve contextualized noise scheduling inspired by Meta-Exploration.

The diffusion model, a new generative modeling paradigm, has achieved significant success in generating images, audio, video, and text. It has been adapted for sequence-to-sequence text generation (Seq2Seq) through DiffuSeq, termed the S2S-Diffusion model. Existing S2S-Diffusion models predominantly rely on fixed or hand-crafted rules to schedule noise during the diffusion and denoising processes. However, these models are limited by non-contextualized noise, which fails to fully consider the characteristics of Seq2Seq tasks. In this paper, we propose the Meta-Diffu$B$ framework—a novel scheduler-exploiter S2S-Diffusion paradigm designed to overcome the limitations of existing S2S-Diffusion models. We employ Meta-Exploration to train an additional scheduler model dedicated to scheduling contextualized noise for each sentence. Our exploiter model, an S2S-Diffusion model, leverages the noise scheduled by our scheduler model for updating and generation. Meta-Diffu$B$ achieves state-of-the-art performance compared to previous S2S-Diffusion models and fine-tuned pre-trained language models (PLMs) across four Seq2Seq benchmark datasets. We further investigate and visualize the impact of Meta-Diffu$B$'s noise scheduling on the generation of sentences with varying difficulties. Additionally, our scheduler model can function as a "plug-and-play" model to enhance DiffuSeq without the need for fine-tuning during the inference stage.

In label-noise learning, the noise transition matrix reveals how an instance transitions from its clean label to its noisy label. Accurately estimating an instance's noise transition matrix is crucial for estimating its clean label. However, when only a noisy dataset is available, noise transition matrices can be estimated only for some "special" instances. To leverage these estimated transition matrices to help estimate the transition matrices of other instances, it is essential to explore relations between the matrices of these "special" instances and those of others. Existing studies typically build the relation by explicitly defining the similarity between the estimated noise transition matrices of "special" instances and those of other instances. However, these similarity-based assumptions are hard to validate and may not align with real-world data. If these assumptions fail, both noise transition matrices and clean labels cannot be accurately estimated. In this paper, we found that by learning the latent causal structure governing the generating process of noisy data, we can estimate noise transition matrices without the need for similarity-based assumptions. Unlike previous generative label-noise learning methods, we consider causal relations between latent causal variables and model them with a learnable graphical model. Utilizing only noisy data, our method can effectively learn the latent causal structure. Experimental results on various noisy datasets demonstrate that our method achieves state-of-the-art performance in estimating noise transition matrices, which leads to improved classification accuracy. The code is available at: https://github.com/tmllab/2024_NeurIPS_CSGN.
tl;dr: Mesh extraction from neural surfaces with trilinear interpolating methods through the eikonal constraint of hypersurface planarity.

Recent advancements in visualizing deep neural networks provide insights into their structures and mesh extraction from Continuous Piecewise Affine (CPWA) functions. Meanwhile, developments in neural surface representation learning incorporate non-linear positional encoding, addressing issues like spectral bias; however, this poses challenges in applying mesh extraction techniques based on CPWA functions. Focusing on trilinear interpolating methods as positional encoding, we present theoretical insights and an analytical mesh extraction, showing the transformation of hypersurfaces to flat planes within the trilinear region under the eikonal constraint. Moreover, we introduce a method for approximating intersecting points among three hypersurfaces contributing to broader applications. We empirically validate correctness and parsimony through chamfer distance and efficiency, and angular distance, while examining the correlation between the eikonal loss and the planarity of the hypersurfaces.

Machine learning craves high-quality data which is a major bottleneck during realistic deployment, as it takes abundant resources and massive human labor to collect and label data. Unfortunately, label noise where image data mismatches with incorrect label exists ubiquitously in all kinds of datasets, significantly degrading the learning performance of deep networks. Learning with Label Noise (LNL) has been a common strategy for mitigating the influence of noisy labels. However, existing LNL methods either require pertaining using the memorization effect to separate clean data from noisy ones or rely on dataset assumptions that cannot extend to various scenarios. Thanks to the development of Multimodal Large Language Models (MLLMs) which possess massive knowledge and hold In-Context Learning (ICL) ability, this paper proposes NoiseGPT to effectively leverage MLLMs as a knowledge expert for conducting label noise detection and rectification. Specifically, we observe a probability curvature effect of MLLMs where clean and noisy examples reside on curvatures with different smoothness, further enabling the detection of label noise. By designing a token-wise Mix-of Feature (MoF) technique to produce the curvature, we propose an In-Context Discrepancy (ICD) measure to determine the authenticity of an image-label pair. Subsequently, we repeat such a process to find the best matching pairs to complete our label rectification. Through extensive experiments, we carefully demonstrate the effectiveness of NoiseGPT on detecting and cleansing dataset noise, especially on ILSVRC12, the AUROC of NoiseGPT reached over 0.92. And by integrating with existing methods, the classification performance can be significantly improved on noisy datasets, typically by 22.8% on 80% symmetric CIFAR-10 with M-correction.
tl;dr: the first method to generate human interactions of arbitrary number of humans in a zero-shot manner with only single-person training data

Text-conditioned motion synthesis has made remarkable progress with the emergence of diffusion models. However, the majority of these motion diffusion models are primarily designed for a single character and overlook multi-human interactions. In our approach, we strive to explore this problem by synthesizing human motion with interactions for a group of characters of any size in a zero-shot manner. The key aspect of our approach is the adaptation of human-wise interactions as pairs of human joints that can be either in contact or separated by a desired distance. In contrast to existing methods that necessitate training motion generation models on multi-human motion datasets with a fixed number of characters, our approach inherently possesses the flexibility to model human interactions involving an arbitrary number of individuals, thereby transcending the limitations imposed by the training data. We introduce a novel controllable motion generation method, InterControl, to encourage the synthesized motions maintaining the desired distance between joint pairs. It consists of a motion controller and an inverse kinematics guidance module that realistically and accurately aligns the joints of synthesized characters to the desired location. Furthermore, we demonstrate that the distance between joint pairs for human-wise interactions can be generated using an off-the-shelf Large Language Model (LLM). Experimental results highlight the capability of our framework to generate interactions with multiple human characters and its potential to work with off-the-shelf physics-based character simulators. Code is available at https://github.com/zhenzhiwang/intercontrol.
tl;dr: We introduce a methodology for semantic-aware image dragging with high image fidelity.

Flexible and accurate drag-based editing is a challenging task that has recently garnered significant attention. Current methods typically model this problem as automatically learning "how to drag" through point dragging and often produce one deterministic estimation, which presents two key limitations: 1) Overlooking the inherently ill-posed nature of drag-based editing, where multiple results may correspond to a given input, as illustrated in Fig.1; 2) Ignoring the constraint of image quality, which may lead to unexpected distortion.
To alleviate this, we propose LucidDrag, which shifts the focus from "how to drag" to "what-then-how" paradigm. LucidDrag comprises an intention reasoner and a collaborative guidance sampling mechanism. The former infers several optimal editing strategies, identifying what content and what semantic direction to be edited. Based on the former, the latter addresses "how to drag" by collaboratively integrating existing editing guidance with the newly proposed semantic guidance and quality guidance.
Specifically, semantic guidance is derived by establishing a semantic editing direction based on reasoned intentions, while quality guidance is achieved through classifier guidance using an image fidelity discriminator.
Both qualitative and quantitative comparisons demonstrate the superiority of LucidDrag over previous methods.

The generalization ability of deepfake detectors is vital for their applications in real-world scenarios. One effective solution to enhance this ability is to train the models with manually-blended data, which we termed ''blendfake'', encouraging models to learn generic forgery artifacts like blending boundary. Interestingly, current SoTA methods utilize blendfake $\textit{without}$ incorporating any deepfake data in their training process. This is likely because previous empirical observations suggest that vanilla hybrid training (VHT), which combines deepfake and blendfake data, results in inferior performance to methods using only blendfake data (so-called "1+1<2"). Therefore, a critical question arises: Can we leave deepfake behind and rely solely on blendfake data to train an effective deepfake detector? Intuitively, as deepfakes also contain additional informative forgery clues ($\textit{e.g.,}$ deep generative artifacts), excluding all deepfake data in training deepfake detectors seems counter-intuitive. In this paper, we rethink the role of blendfake in detecting deepfakes and formulate the process from "real to blendfake to deepfake" to be a $\textit{progressive transition}$. Specifically, blendfake and deepfake can be explicitly delineated as the oriented pivot anchors between "real-to-fake" transitions. The accumulation of forgery information should be oriented and progressively increasing during this transition process. To this end, we propose an $\underline{O}$riented $\underline{P}$rogressive $\underline{R}$egularizor (OPR) to establish the constraints that compel the distribution of anchors to be discretely arranged. Furthermore, we introduce feature bridging to facilitate the smooth transition between adjacent anchors. Extensive experiments confirm that our design allows leveraging forgery information from both blendfake and deepfake effectively and comprehensively. Code is available at https://github.com/beautyremain/ProDet.
tl;dr: We study the provable efficiency of partially observable RL with privileged information to the latent state during training for both single-agent and multi-player settings.

Partial observability of the underlying states generally presents significant challenges for reinforcement learning (RL). In practice, certain *privileged information* , e.g., the access to states from simulators, has been exploited in training and achieved prominent empirical successes. To better understand the benefits of privileged information, we revisit and examine several simple and practically used paradigms in this setting, with both computation and sample efficiency analyses. Specifically, we first formalize the empirical paradigm of *expert distillation* (also known as *teacher-student* learning), demonstrating its pitfall in finding near-optimal policies. We then identify a condition of the partially observable environment, the deterministic filter condition, under which expert distillation achieves sample and computational complexities that are *both* polynomial. Furthermore, we investigate another successful empirical paradigm of *asymmetric actor-critic*, and focus on the more challenging setting of observable partially observable Markov decision processes. We develop a belief-weighted optimistic asymmetric actor-critic algorithm with polynomial sample and quasi-polynomial computational complexities, where one key component is a new provable oracle for learning belief states that preserve *filter stability* under a misspecified model, which may be of independent interest. Finally, we also investigate the provable efficiency of partially observable multi-agent RL (MARL) with privileged information. We develop algorithms with the feature of centralized-training-with-decentralized-execution, a popular framework in empirical MARL, with polynomial sample and (quasi-)polynomial computational complexity in both paradigms above. Compared with a few recent related theoretical studies, our focus is on understanding practically inspired algorithmic paradigms, without computationally intractable oracles.

Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. We break down the problem into two causes: concept ignorance and concept mismapping. To tackle the two challenges, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with the image-to-text concept matching mechanism. Firstly, we introduce a novel image-to-text concept activation module to guide the diffusion model in revisiting ignored concepts. Additionally, an attribute concentration module is proposed to map the text conditions of each entity to its corresponding image area correctly. Extensive experimental evaluations, conducted across three distinct text-to-image alignment benchmarks, demonstrate the superior efficacy of our proposed method, CoMat-SDXL, over the baseline model, SDXL~\cite{podell2023sdxl}. We also show that our method enhances general condition utilization capability and generalizes to the long and complex prompt despite not specifically training on it.
tl;dr: We address single-image 3D pose estimation by predicting Wigner-D coefficients in the frequency domain using SO(3)-equivariant networks, to improve pose estimation accuracy and data sampling efficiency.

Determining the 3D orientations of an object in an image, known as single-image pose estimation, is a crucial task in 3D vision applications. Existing methods typically learn 3D rotations parametrized in the spatial domain using Euler angles or quaternions, but these representations often introduce discontinuities and singularities. SO(3)-equivariant networks enable the structured capture of pose patterns with data-efficient learning, but the parametrizations in spatial domain are incompatible with their architecture, particularly spherical CNNs, which operate in the frequency domain to enhance computational efficiency. To overcome these issues, we propose a frequency-domain approach that directly predicts Wigner-D coefficients for 3D rotation regression, aligning with the operations of spherical CNNs. Our SO(3)-equivariant pose harmonics predictor overcomes the limitations of spatial parameterizations, ensuring consistent pose estimation under arbitrary rotations. Trained with a frequency-domain regression loss, our method achieves state-of-the-art results on benchmarks such as ModelNet10-SO(3) and PASCAL3D+, with significant improvements in accuracy, robustness, and data efficiency.

Adaptation of
pretrained vision-language models such as CLIP to various downstream tasks have raised great interest in recent researches.
Previous works have proposed a variety of test-time adaptation (TTA) methods to achieve strong generalization without any knowledge of the target domain.
However, existing training-required TTA approaches like TPT necessitate entropy minimization that involves large computational overhead, while training-free methods like TDA overlook the potential for information mining from the test samples themselves.
In this paper, we break down the design of existing popular training-required and training-free TTA methods and bridge the gap between them within our framework.
Specifically, we maintain a light-weight key-value memory for feature retrieval from instance-agnostic historical samples and instance-aware boosting samples.
The historical samples are filtered from the testing data stream and serve to extract useful information from the target distribution, while the boosting samples are drawn from regional bootstrapping and capture the knowledge of the test sample itself.
We theoretically justify the rationality behind our method and empirically verify its effectiveness on both the out-of-distribution and the cross-domain datasets, showcasing its applicability in real-world situations.
3826. CLUES: Collaborative Private-domain High-quality Data Selection for LLMs via Training Dynamics

Recent research has highlighted the importance of data quality in scaling large language models (LLMs). However, automated data quality control faces unique challenges in collaborative settings where sharing is not allowed directly between data silos. To tackle this issue, this paper proposes a novel data quality control technique based on the notion of data influence on the training dynamics of LLMs, that high quality data are more likely to have similar training dynamics to the anchor dataset. We then leverage the influence of the training dynamics to select high-quality data from different private domains, with centralized model updates on the server side in a collaborative training fashion by either model merging or federated learning. As for the data quality indicator, we compute the per-sample gradients with respect to the private data and the anchor dataset, and use the trace of the accumulated inner products as a measurement of data quality. In addition, we develop a quality control evaluation tailored for collaborative settings with heterogeneous medical domain data. Experiments show that training on the high-quality data selected by our method can often outperform other data selection methods for collaborative fine-tuning of LLMs, across diverse private domain datasets, in medical, multilingual and financial settings.
tl;dr: We find that recent trends in using LLMs for planning are profoundly uneconomical, unsound and incomplete. We propose a significantly more efficient approach that is sound and complete and argue for a responsible use of compute resources.

Among the most important properties of algorithms investigated in computer science are soundness, completeness, and complexity. These properties, however, are rarely analyzed for the vast collection of recently proposed methods for planning with large language models. In this work, we alleviate this gap. We analyse these properties of using LLMs for planning and highlight that recent trends abandon both soundness and completeness for the sake of inefficiency. We propose a significantly more efficient approach that can, at the same time, maintain both soundness and completeness. We exemplify on four representative search problems, comparing to the LLM-based solutions from the literature that attempt to solve these problems. We show that by using LLMs to produce the code for the search components we can solve the entire datasets with 100% accuracy with only a few calls to the LLM. In contrast, the compared approaches require hundreds of thousands of calls and achieve significantly lower accuracy. We argue for a responsible use of compute resources; urging research community to investigate sound and complete LLM-based approaches that uphold efficiency.
tl;dr: We benchmark various approaches to training neural SDEs to match a target distribution and study ways to improve training and credit assignment.

We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at [this link](https://github.com/GFNOrg/gfn-diffusion) as a base for future work on diffusion models for amortized inference.

When training neural networks with custom objectives, such as ranking losses and shortest-path losses, a common problem is that they are, per se, non-differentiable. A popular approach is to continuously relax the objectives to provide gradients, enabling learning. However, such differentiable relaxations are often non-convex and can exhibit vanishing and exploding gradients, making them (already in isolation) hard to optimize. Here, the loss function poses the bottleneck when training a deep neural network. We present Newton Losses, a method for improving the performance of existing hard to optimize losses by exploiting their second-order information via their empirical Fisher and Hessian matrices. Instead of training the neural network with second-order techniques, we only utilize the loss function's second-order information to replace it by a Newton Loss, while training the network with gradient descent. This makes our method computationally efficient. We apply Newton Losses to eight differentiable algorithms for sorting and shortest-paths, achieving significant improvements for less-optimized differentiable algorithms, and consistent improvements, even for well-optimized differentiable algorithms.
3830. The Feature Speed Formula: a flexible approach to scale hyper-parameters of deep neural networks
tl;dr: We propose an elementary approach to quantifying feature learning in wide and deep neural networks and to derive hyperparameter scalings.

Deep learning succeeds by doing hierarchical feature learning, yet tuning hyper-parameters (HP) such as initialization scales, learning rates etc., only give indirect control over this behavior. In this paper, we introduce a key notion to predict and control feature learning: the angle $\theta_\ell$ between the feature updates and the backward pass (at layer index $\ell$). We show that the magnitude of feature updates after one GD step, at any training time, can be expressed via a simple and general *feature speed formula* in terms of this angle $\theta_\ell$, the loss decay, and the magnitude of the backward pass. This angle $\theta_\ell$ is controlled by the conditioning of the layer-to-layer Jacobians and at random initialization, it is determined by the spectrum of a certain kernel, which coincides with the Neural Tangent Kernel when $\ell=\text{depth}$. Given $\theta_\ell$, the feature speed formula provides us with rules to adjust HPs (scales and learning rates) so as to satisfy certain dynamical properties, such as feature learning and loss decay. We investigate the implications of our approach for ReLU MLPs and ResNets in the large width-then-depth limit. Relying on prior work, we show that in ReLU MLPs with iid initialization, the angle degenerates with depth as $\cos(\theta_\ell)=\Theta(1/\sqrt{\ell})$. In contrast, ResNets with branch scale $O(1/\sqrt{\text{depth}})$ maintain a non-degenerate angle $\cos(\theta_\ell)=\Theta(1)$. We use these insights to recover key properties of known HP scalings (such as $\mu$P), and also introduce a new HP scaling for large depth ReLU MLPs with favorable theoretical properties.
tl;dr: An end-to-end differentiable framework for training discriminative particle smoothing algorithms, with state-of-the-art performance at city-scale localization from imagery.

For challenging state estimation problems arising in domains like vision and robotics, particle-based representations attractively enable temporal reasoning about multiple posterior modes. Particle smoothers offer the potential for more accurate offline data analysis by propagating information both forward and backward in time, but have classically required human-engineered dynamics and observation models. Extending recent advances in discriminative training of particle filters, we develop a framework for low-variance propagation of gradients across long time sequences when training particle smoothers. Our "two-filter" smoother integrates particle streams that are propagated forward and backward in time, while incorporating stratification and importance weights in the resampling step to provide low-variance gradient estimates for neural network dynamics and observation models. The resulting mixture density particle smoother is substantially more accurate than state-of-the-art particle filters, as well as search-based baselines, for city-scale global vehicle localization from real-world videos and maps.

Beyond the text detection and recognition tasks in image text spotting, video text spotting presents an augmented challenge with the inclusion of tracking. While advanced end-to-end trainable methods have shown commendable performance, the pursuit of multi-task optimization may pose the risk of producing sub-optimal outcomes for individual tasks. In this paper, we identify a main bottleneck in the state-of-the-art video text spotter: the limited recognition capability. In response to this issue, we propose to efficiently turn an off-the-shelf query-based image text spotter into a specialist on video and present a simple baseline termed GoMatching, which focuses the training efforts on tracking while maintaining strong recognition performance. To adapt the image text spotter to video datasets, we add a rescoring head to rescore each detected instance's confidence via efficient tuning, leading to a better tracking candidate pool.
Additionally, we design a long-short term matching module, termed LST-Matcher, to enhance the spotter's tracking capability by integrating both long- and short-term matching results via Transformer. Based on the above simple designs, GoMatching delivers new records on ICDAR15-video, DSText, BOVText, and our proposed novel test set with arbitrary-shaped text termed ArTVideo, which demonstates GoMatching's capability to accommodate general, dense, small, arbitrary-shaped, Chinese and English text scenarios while saving considerable training budgets. The code will be released.
tl;dr: We prove that for multi-task ReLU neural networks trained with weight decay, the solutions to each individual task are related to solutions in a reproducing kernel Hilbert space.

This paper studies the properties of solutions to multi-task shallow ReLU neural network learning problems, wherein the network is trained to fit a dataset with minimal sum of squared weights. Remarkably, the solutions learned for each individual task resemble those obtained by solving a kernel method, revealing a novel connection between neural networks and kernel methods. It is known that single-task neural network training problems are equivalent to minimum norm interpolation problem in a non-Hilbertian Banach space, and that the solutions of such problems are generally non-unique. In contrast, we prove that the solutions to univariate-input, multi-task neural network interpolation problems are almost always unique, and coincide with the solution to a minimum-norm interpolation problem in a first-order Sobolev (reproducing kernel) Hilbert Space. We also demonstrate a similar phenomenon in the multivariate-input case; specifically, we show that neural network training problems with a large number of diverse tasks are approximately equivalent to an $\ell^2$ (Hilbert space) minimization problem over a fixed kernel determined by the optimal neurons.

The current trend in computer vision is to utilize one universal model to address all various tasks. Achieving such a universal model inevitably requires incorporating multi-domain data for joint training to learn across multiple problem scenarios. In point cloud based 3D object detection, however, such multi-domain joint training is highly challenging, because large domain gaps among point clouds from different datasets lead to the severe domain-interference problem. In this paper, we propose OneDet3D, a universal one-for-all model that addresses 3D detection across different domains, including diverse indoor and outdoor scenes, within the same framework and only one set of parameters. We propose the domain-aware partitioning in scatter and context, guided by a routing mechanism, to address the data interference issue, and further incorporate the text modality for a language-guided classification to unify the multi-dataset label spaces and mitigate the category interference issue. The fully sparse structure and anchor-free head further accommodate point clouds with significant scale disparities. Extensive experiments demonstrate the strong universal ability of OneDet3D to utilize only one trained model for addressing almost all 3D object detection tasks (Fig. 1). We will open-source the code for future research and applications.

The widespread success of deep learning models today is owed to the curation of extensive datasets significant in size and complexity. However, such models frequently pick up inherent biases in the data during the training process, leading to unreliable predictions. Diagnosing and debiasing datasets is thus a necessity to ensure reliable model performance. In this paper, we present ConBias, a novel framework for diagnosing and mitigating Concept co-occurrence Biases in visual datasets. ConBias represents visual datasets as knowledge graphs of concepts, enabling meticulous analysis of spurious concept co-occurrences to uncover concept imbalances across the whole dataset. Moreover, we show that by employing a novel clique-based concept balancing strategy, we can mitigate these imbalances, leading to enhanced performance on downstream tasks. Extensive experiments show that data augmentation based on a balanced concept distribution augmented by ConBias improves generalization performance across multiple datasets compared to state-of-the-art methods.
tl;dr: A Spike-driven Mixture of Experts Mechanism for the Spiking Transformer.

Spiking Neural Networks (SNNs) provide a sparse spike-driven mechanism which is believed to be critical for energy-efficient deep learning.
Mixture-of-Experts (MoE), on the other side, aligns with the brain mechanism of distributed and sparse processing, resulting in an efficient way of enhancing model capacity and conditional computation.
In this work, we consider how to incorporate SNNs’ spike-driven and MoE’s conditional computation into a unified framework.
However, MoE uses softmax to get the dense conditional weights for each expert and TopK to hard-sparsify the network, which does not fit the properties of SNNs.
To address this issue, we reformulate MoE in SNNs and introduce the Spiking Experts Mixture Mechanism (SEMM) from the perspective of sparse spiking activation.
Both the experts and the router output spiking sequences, and their element-wise operation makes SEMM computation spike-driven and dynamic sparse-conditional.
By developing SEMM into Spiking Transformer, the Experts Mixture Spiking Attention (EMSA) and the Experts Mixture Spiking Perceptron (EMSP) are proposed, which performs routing allocation for head-wise and channel-wise spiking experts, respectively. Experiments show that SEMM realizes sparse conditional computation and obtains a stable improvement on neuromorphic and static datasets with approximate computational overhead based on the Spiking Transformer baselines.
tl;dr: A new variant of fictitious play provably converging to Team-Nash equilibrium in multi-team zero-sum games.

Multi-team games, prevalent in robotics and resource management, involve team members striving for a joint best response against other teams. Team-Nash equilibrium (TNE) predicts the outcomes of such coordinated interactions. However, can teams of self-interested agents reach TNE? We introduce Team-Fictitious Play (Team-FP), a new variant of fictitious play where agents respond to the last actions of team members and the beliefs formed about other teams with some inertia in action updates. This design is essential in team coordination beyond the classical fictitious play dynamics. We focus on zero-sum potential team games (ZSPTGs) where teams can interact pairwise while the team members do not necessarily have identical payoffs. We show that Team-FP reaches near TNE in ZSPTGs with a quantifiable error bound. We extend Team-FP dynamics to multi-team Markov games for model-based and model-free cases. The convergence analysis tackles the challenge of non-stationarity induced by evolving opponent strategies based on the optimal coupling lemma and stochastic differential inclusion approximation methods. Our work strengthens the foundation for using TNE to predict the behavior of decentralized teams and offers a practical rule for team learning in multi-team environments. We provide extensive simulations of Team-FP dynamics and compare its performance with other widely studied dynamics such as smooth fictitious play and multiplicative weights update. We further explore how different parameters impact the speed of convergence.
tl;dr: A novel unsupervised point cloud registration method for large-scale outdoor scenes.

Point cloud registration, a fundamental task in 3D vision, has achieved remarkable success with learning-based methods in outdoor environments. Unsupervised outdoor point cloud registration methods have recently emerged to circumvent the need for costly pose annotations. However, they fail to establish reliable optimization objectives for unsupervised training, either relying on overly strong geometric assumptions, or suffering from poor-quality pseudo-labels due to inadequate integration of low-level geometric and high-level contextual information. We have observed that in the feature space, latent new inlier correspondences tend to cluster
around respective positive anchors that summarize features of existing inliers. Motivated by this observation, we propose a novel unsupervised registration method termed INTEGER to incorporate high-level contextual information for reliable pseudo-label mining. Specifically, we propose the Feature-Geometry Coherence Mining module to dynamically adapt the teacher for each mini-batch of data during training and discover reliable pseudo-labels by considering both high-level feature representations and low-level geometric cues. Furthermore, we propose Anchor-Based Contrastive Learning to facilitate contrastive learning with anchors for a robust feature space. Lastly, we introduce a Mixed-Density Student to learn density-invariant features, addressing challenges related to density variation and low overlap in the outdoor scenario. Extensive experiments on KITTI and nuScenes datasets demonstrate that our INTEGER achieves competitive performance in terms of accuracy and generalizability.

There are an increasing number of domains in which artificial intelligence (AI) systems both surpass human ability and accurately model human behavior. This introduces the possibility of algorithmically-informed teaching in these domains through more relatable AI partners and deeper insights into human decision-making. Critical to achieving this goal, however, is coherently modeling human behavior at various skill levels. Chess is an ideal model system for conducting research into this kind of human-AI alignment, with its rich history as a pivotal testbed for AI research, mature superhuman AI systems like AlphaZero, and precise measurements of skill via chess rating systems. Previous work in modeling human decision-making in chess uses completely independent models to capture human style at different skill levels, meaning they lack coherence in their ability to adapt to the full spectrum of human improvement and are ultimately limited in their effectiveness as AI partners and teaching tools. In this work, we propose a unified modeling approach for human-AI alignment in chess that coherently captures human style across different skill levels and directly captures how people improve. Recognizing the complex, non-linear nature of human learning, we introduce a skill-aware attention mechanism to dynamically integrate players’ strengths with encoded chess positions, enabling our model to be sensitive to evolving player skill. Our experimental results demonstrate that this unified framework significantly enhances the alignment between AI and human players across a diverse range of expertise levels, paving the way for deeper insights into human decision-making and AI-guided teaching tools.
tl;dr: We enable private training of GANs using random slicing, avoiding the shortcomings and challenges of DPSGD.

Training generative models with differential privacy (DP) typically involves injecting noise into gradient updates or adapting the discriminator's training procedure. As a result, such approaches often struggle with hyper-parameter tuning and convergence.
We consider the \emph{slicing privacy mechanism} that injects noise into random low-dimensional projections of the private data, and provide strong privacy guarantees for it. These noisy projections are used for training generative models.
To enable optimizing generative models using this DP approach, we introduce the \emph{smoothed-sliced $f$-divergence} and show it enjoys statistical consistency.
Moreover, we present a kernel-based estimator for this divergence, circumventing the need for adversarial training.
Extensive numerical experiments demonstrate that our approach can generate synthetic data of higher quality compared with baselines. Beyond performance improvement, our method, by sidestepping the need for noisy gradients, offers data scientists the flexibility to adjust generator architecture and hyper-parameters, run the optimization over any number of epochs, and even restart the optimization process---all without incurring additional privacy costs.
tl;dr: We propose a novel IDK objective which models uncertainty in a model's prediction as probability mass put on a special [IDK] token. Experimental results show that our method improves factual precision without significantly harming factual recall.

Large Language Models are known to capture real-world knowledge, allowing them to excel in many downstream tasks. Despite recent advances, these models are still prone to what are commonly known as hallucinations, causing them to emit unwanted and factually incorrect text. In this work, we propose a novel calibration method that can be used to combat hallucinations.
We add a special [IDK] (“I Don't Know”) token to the model's vocabulary and introduce an objective function that shifts probability mass to the [IDK] token for incorrect predictions.
This approach allows the model to express uncertainty in its output explicitly.
We evaluate our proposed method across multiple model architectures and factual downstream tasks.
We find that models trained with our method are able to express uncertainty in places where they would previously make mistakes while suffering only a small loss of encoded knowledge. We further perform extensive ablation studies of multiple variations of our approach and provide a detailed analysis of the precision-recall tradeoff of our method.

Federated learning faces challenges due to the heterogeneity in data volumes and distributions at different clients, which can compromise model generalization ability to various distributions.
Existing approaches to address this issue based on group distributionally robust optimization (GDRO) often lead to high communication and sample complexity.
To this end, this work introduces algorithms tailored for communication-efficient Federated Group Distributionally Robust Optimization (FGDRO). Our contributions are threefold: Firstly, we introduce the FGDRO-CVaR algorithm, which optimizes the average top-K losses while reducing communication complexity to $O(1/\epsilon^4)$, where $\epsilon$ denotes the desired precision level. Secondly, our FGDRO-KL algorithm is crafted to optimize KL regularized FGDRO, cutting communication complexity to $O(1/\epsilon^3)$. Lastly, we propose FGDRO-KL-Adam to utilize Adam-type local updates in FGDRO-KL, which not only maintains a communication cost of $O(1/\epsilon^3)$ but also shows potential to surpass SGD-type local steps in practical applications.
The effectiveness of our algorithms has been demonstrated on a variety of real-world tasks, including natural language processing and computer vision.
tl;dr: We propose an efficient diffusion model that is based on adding noise + upsampling and a novel training strategy, which leads to state-of-the-art generation results on CIFAR-10 and other datasets

Denoising Diffusion Probabilistic Models (DDPM) have recently gained significant attention. DDPMs compose a Markovian process that begins in the data domain and gradually adds noise until reaching pure white noise. DDPMs generate high-quality samples from complex data distributions by defining an inverse process and training a deep neural network to learn this mapping. However, these models are inefficient because they require many diffusion steps to produce aesthetically pleasing samples. Additionally, unlike generative adversarial networks (GANs), the latent space of diffusion models is less interpretable. In this work, we propose to generalize the denoising diffusion process into an Upsampling Diffusion Probabilistic Model (UDPM). In the forward process, we reduce the latent variable dimension through downsampling, followed by the traditional noise perturbation. As a result, the reverse process gradually denoises and upsamples the latent variable to produce a sample from the data distribution. We formalize the Markovian diffusion processes of UDPM and demonstrate its generation capabilities on the popular FFHQ, AFHQv2, and CIFAR10 datasets. UDPM generates images with as few as three network evaluations, whose overall computational cost is less than a single DDPM or EDM step while achieving an FID score of 6.86. This surpasses current state-of-the-art efficient diffusion models that use a single denoising step for sampling. Additionally, UDPM offers an interpretable and interpolable latent space, which gives it an advantage over traditional DDPMs. Our code is available online: \url{https://github.com/shadyabh/UDPM/}
3844. Med-Real2Sim: Non-Invasive Medical Digital Twins using Physics-Informed Self-Supervised Learning

A digital twin is a virtual replica of a real-world physical phenomena that uses mathematical modeling to characterize and simulate its defining features. By constructing digital twins for disease processes, we can perform in-silico simulations that mimic patients' health conditions and counterfactual outcomes under hypothetical interventions in a virtual setting. This eliminates the need for invasive procedures or uncertain treatment decisions. In this paper, we propose a method to identify digital twin model parameters using only noninvasive patient health data. We approach the digital twin modeling as a composite inverse problem, and observe that its structure resembles pretraining and finetuning in self-supervised learning (SSL). Leveraging this, we introduce a physics-informed SSL algorithm that initially pretrains a neural network on the pretext task of learning a differentiable simulator of a physiological process. Subsequently, the model is trained to reconstruct physiological measurements from noninvasive modalities while being constrained by the physical equations learned in pretraining. We apply our method to identify digital twins of cardiac hemodynamics using noninvasive echocardiogram videos, and demonstrate its utility in unsupervised disease detection and in-silico clinical trials.

As the scale of data and models for video understanding rapidly expand, handling long-form video input in transformer-based models presents a practical challenge. Rather than resorting to input sampling or token dropping, which may result in information loss, token merging shows promising results when used in collaboration with transformers. However, the application of token merging for long-form video processing is not trivial. We begin with the premise that token merging should not rely solely on the similarity of video tokens; the saliency of tokens should also be considered. To address this, we explore various video token merging strategies for long-form video classification, starting with a simple extension of image token merging, moving to region-concentrated merging, and finally proposing a learnable video token merging (VTM) algorithm that dynamically merges tokens based on their saliency. Extensive experimental results show that we achieve better or comparable performances on the LVU, COIN, and Breakfast datasets. Moreover, our approach significantly reduces memory costs by 84% and boosts throughput by approximately 6.89 times compared to baseline algorithms.
3846. Rapid Plug-in Defenders
tl;dr: Pre-trained Transformers as Rapid Plug-in Defenders

In the realm of daily services, the deployment of deep neural networks underscores the paramount importance of their reliability. However, the vulnerability of these networks to adversarial attacks, primarily evasion-based, poses a concerning threat to their functionality. Common methods for enhancing robustness involve heavy adversarial training or leveraging learned knowledge from clean data, both necessitating substantial computational resources. This inherent time-intensive nature severely limits the agility of large foundational models to swiftly counter adversarial perturbations. To address this challenge, this paper focuses on the \textbf{Ra}pid \textbf{P}lug-\textbf{i}n \textbf{D}efender (\textbf{RaPiD}) problem, aiming to rapidly counter adversarial perturbations without altering the deployed model. Drawing inspiration from the generalization and the universal computation ability of pre-trained transformer models, we propose a novel method termed \textbf{CeTaD} (\textbf{C}onsidering Pr\textbf{e}-trained \textbf{T}ransformers \textbf{a}s \textbf{D}efenders) for RaPiD, optimized for efficient computation. \textbf{CeTaD} strategically fine-tunes the normalization layer parameters within the defender using a limited set of clean and adversarial examples. Our evaluation centers on assessing \textbf{CeTaD}'s effectiveness, transferability, and the impact of different components in scenarios involving one-shot adversarial examples. The proposed method is capable of rapidly adapting to various attacks and different application scenarios without altering the target model and clean training data. We also explore the influence of varying training data conditions on \textbf{CeTaD}'s performance. Notably, \textbf{CeTaD} exhibits adaptability across differentiable service models and proves the potential of continuous learning.
tl;dr: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation

A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens ``skipping layers'' rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for certain transformer layer, we learn to skip the computation for a high proportion (e.g., 80\%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately 42% time and 30% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets. The code and checkpoints will be made available at github.com/showlab/VideoLLM-online.
tl;dr: We prove tight upper and lower bounds for the average degree of navigable graphs for high-dimensional point sets.

There has been significant recent interest in graph-based nearest neighbor search methods, many of which are centered on the construction of (approximately) "navigable" graphs over high-dimensional point sets. A graph is navigable if we can successfully move from any starting node to any target node using a greedy routing strategy where we always move to the neighbor that is closest to the destination according to the given distance function. The complete graph is obviously navigable for any point set, but the important question for applications is if sparser graphs can be constructed. While this question is fairly well understood in low-dimensions, we establish some of the first upper and lower bounds for high-dimensional point sets. First, we give a simple and efficient way to construct a navigable graph with average degree $O(\sqrt{n \log n })$ for any set of $n$ points, in any dimension, for any distance function. We compliment this result with a nearly matching lower bound: even under the Euclidean metric in $O(\log n)$ dimensions, a random point set has no navigable graph with average degree $O(n^{\alpha})$ for any $\alpha < 1/2$. Our lower bound relies on sharp anti-concentration bounds for binomial random variables, which we use to show that the {near-neighborhoods} of a set of random points do not overlap significantly, forcing any navigable graph to have many edges.
tl;dr: We provide a new privacy accountant and comprehensive analysis for differentially private stochastic gradient descent with tighter privacy guarantees under fixed-size resampling with or without replacement.

Differentially private stochastic gradient descent (DP-SGD) has been instrumental in privately training deep learning models by providing a framework to control and track the privacy loss incurred during training. At the core of this computation lies a subsampling method that uses a privacy amplification lemma to enhance the privacy guarantees provided by the additive noise. Fixed size subsampling is appealing for its constant memory usage, unlike the variable sized minibatches in Poisson subsampling. It is also of interest in addressing class imbalance and federated learning. Current computable guarantees for fixed-size subsampling are not tight and do not consider both add/remove and replace-one adjacency relationships. We present a new and holistic Rényi differential privacy (RDP) accountant for DP-SGD with fixed-size subsampling without replacement (FSwoR) and with replacement (FSwR). For FSwoR we consider both add/remove and replace-one adjacency, where we improve on the best current computable bound by a factor of $4$. We also show for the first time that the widely-used Poisson subsampling and FSwoR with replace-one adjacency have the same privacy to leading order in the sampling probability. Our work suggests that FSwoR is often preferable to Poisson subsampling due to constant memory usage. Our FSwR accountant includes explicit non-asymptotic upper and lower bounds and, to the authors' knowledge, is the first such RDP analysis of fixed-size subsampling with replacement for DP-SGD. We analytically and empirically compare fixed size and Poisson subsampling, and show that DP-SGD gradients in a fixed-size subsampling regime exhibit lower variance in practice in addition to memory usage benefits.
3850. Meaningful Learning: Enhancing Abstract Reasoning in Large Language Models via Generic Fact Guidance
tl;dr: Large language models (LLMs) struggle with abstract reasoning. We created a specialized dataset and learning method to improve their abstract reasoning skills, achieving more than simple memorization.

Large language models (LLMs) have developed impressive performance and strong explainability across various reasoning scenarios, marking a significant stride towards mimicking human-like intelligence. Despite this, when tasked with several simple questions supported by a generic fact, LLMs often struggle to abstract and apply the generic fact to provide consistent and precise answers, revealing a deficiency in abstract reasoning abilities. This has sparked a vigorous debate about whether LLMs are genuinely reasoning or merely memorizing. In light of this, we design a preliminary study to quantify and delve into the abstract reasoning abilities of existing LLMs. Our findings reveal a substantial discrepancy between their general reasoning and abstract reasoning performances. To relieve this problem, we tailor an abstract reasoning dataset (AbsR) together with a meaningful learning paradigm to teach LLMs how to leverage generic facts for reasoning purposes. The results show that our approach not only boosts the general reasoning performance of LLMs but also makes considerable strides towards their capacity for abstract reasoning, moving beyond simple memorization or imitation to a more nuanced understanding and application of generic facts. The code is available at https://github.com/Waste-Wood/MeanLearn.

Recent advancements in text-to-image diffusion models have enabled the personalization of these models to generate custom images from textual prompts. This paper presents an efficient LoRA-based personalization approach for on-device subject-driven generation, where pre-trained diffusion models are fine-tuned with user-specific data on resource-constrained devices. Our method, termed Hollowed Net, enhances memory efficiency during fine-tuning by modifying the architecture of a diffusion U-Net to temporarily remove a fraction of its deep layers, creating a hollowed structure. This approach directly addresses on-device memory constraints and substantially reduces GPU memory requirements for training, in contrast to previous methods that primarily focus on minimizing training steps and reducing the number of parameters to update. Additionally, the personalized Hollowed Net can be transferred back into the original U-Net, enabling inference without additional memory overhead. Quantitative and qualitative analyses demonstrate that our approach not only reduces training memory to levels as low as those required for inference but also maintains or improves personalization performance compared to existing methods.
3852. Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels
tl;dr: Vidu4D, a reconstruction model that excels in accurately reconstructing dynamic gaussian surfels from single generated videos.

Video generative models are receiving particular attention given their ability to generate realistic and imaginative frames. Besides, these models are also observed to exhibit strong 3D consistency, significantly enhancing their potential to act as world simulators. In this work, we present Vidu4D, a novel reconstruction model that excels in accurately reconstructing 4D (i.e., sequential 3D) representations from single generated videos, addressing challenges associated with non-rigidity and frame distortion. This capability is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence. At the core of Vidu4D is our proposed Dynamic Gaussian Surfels (DGS) technique. DGS optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. This transformation enables a precise depiction of motion and deformation over time. To preserve the structural integrity of surface-aligned Gaussian surfels, we design the warped-state geometric regularization based on continuous warping fields for estimating normals. Additionally, we learn refinements on rotation and scaling parameters of Gaussian surfels, which greatly alleviates texture flickering during the warping process and enhances the capture of fine-grained appearance details. Vidu4D also contains a novel initialization state that provides a proper start for the warping fields in DGS. Equipping Vidu4D with an existing video generative model, the overall framework demonstrates high-fidelity text-to-4D generation in both appearance and geometry.
tl;dr: We design a truthful (and privacy-preserving) mechanism for high dimensional sparse linear regression.

We study the problem of fitting the high dimensional sparse linear regression model, where the data are provided by strategic or self-interested agents (individuals) who prioritize their privacy of data disclosure. In contrast to the classical setting, our focus is on designing mechanisms that can effectively incentivize most agents to truthfully report their data while preserving the privacy of individual reports. Simultaneously, we seek an estimator which should be close to the underlying parameter.
We attempt to solve the problem by deriving a novel private estimator that has a closed-form expression.
Based on the estimator, we propose a mechanism which has the following properties via some appropriate design of the computation and payment scheme: (1) the mechanism is $(o(1), O(n^{-\Omega({1})}))$-jointly differentially private, where $n$ is the number of agents; (2) it is an $o(\frac{1}{n})$-approximate Bayes Nash equilibrium for a $(1-o(1))$-fraction of agents to truthfully report their data; (3) the output could achieve an error of $o(1)$ to the underlying parameter; (4) it is individually rational for a $(1-o(1))$ fraction of agents in the mechanism; (5) the payment budget required from the analyst to run the mechanism is $o(1)$. To the best of our knowledge, this is the first study on designing truthful (and privacy-preserving) mechanisms for high dimensional sparse linear regression.

Text-conditioned human motion generation has experienced significant advancements with diffusion models trained on extensive motion capture data and corresponding textual annotations. However, extending such success to 3D dynamic human-object interaction (HOI) generation faces notable challenges, primarily due to the lack of large-scale interaction data and comprehensive descriptions that align with these interactions. This paper takes the initiative and showcases the potential of generating human-object interactions without direct training on text-interaction pair data. Our key insight in achieving this is that interaction semantics and dynamics can be decoupled. Being unable to learn interaction semantics through supervised training, we instead leverage pre-trained large models, synergizing knowledge from a large language model and a text-to-motion model. While such knowledge offers high-level control over interaction semantics, it cannot grasp the intricacies of low-level interaction dynamics. To overcome this issue, we introduce a world model designed to comprehend simple physics, modeling how human actions influence object motion. By integrating these components, our novel framework, InterDreamer, is able to generate text-aligned 3D HOI sequences without relying on paired text-interaction data. We apply InterDreamer to the BEHAVE, OMOMO, and CHAIRS datasets, and our comprehensive experimental analysis demonstrates its capability to generate realistic and coherent interaction sequences that seamlessly align with the text directives.

Non-exemplar class-incremental learning (NECIL) is a challenging task that requires recognizing both old and new classes without retaining any old class samples. Current works mainly deal with the conflicts between old and new classes retrospectively as a new task comes in. However, the lack of old task data makes balancing old and new classes difficult. Instead, we propose a Prospective Representation Learning (PRL) approach to prepare the model for handling conflicts in advance. In the base phase, we squeeze the embedding distribution of the current classes to reserve space for forward compatibility with future classes. In the incremental phase, we make the new class features away from the saved prototypes of old classes in a latent space while aligning the current embedding space with the latent space when updating the model. Thereby, the new class features are clustered in the reserved space to minimize the shock of the new classes on the former classes. Our approach can help existing NECIL baselines to balance old and new classes in a plug-and-play manner. Extensive experiments on several benchmarks demonstrate that our approach outperforms the state-of-the-art methods.
tl;dr: Optimizing initial noise of one-step diffusion models leads to significantly improved results

Text-to-Image (T2I) models have made significant advancements in recent years, but they still struggle to accurately capture intricate details specified in complex compositional prompts. While fine-tuning T2I models with reward objectives has shown promise, it suffers from "reward hacking" and may not generalize well to unseen prompt distributions. In this work, we propose Reward-based Noise Optimization (ReNO), a novel approach that enhances T2I models at inference by optimizing the initial noise based on the signal from one or multiple human preference reward models. Remarkably, solving this optimization problem with gradient ascent for 50 iterations yields impressive results on four different one-step models across two competitive benchmarks, T2I-CompBench and GenEval. Within a computational budget of 20-50 seconds, ReNO-enhanced one-step models consistently surpass the performance of all current open-source Text-to-Image models. Extensive user studies demonstrate that our model is preferred nearly twice as often compared to the popular SDXL model and is on par with the proprietary Stable Diffusion 3 with 8B parameters. Moreover, given the same computational resources, a ReNO-optimized one-step model outperforms widely-used open-source models such as SDXL and PixArt-alpha, highlighting the efficiency and effectiveness of ReNO in enhancing T2I model performance at inference time.

Motion forecasting is an essential task for autonomous driving, and utilizing information from infrastructure and other vehicles can enhance forecasting capabilities.
Existing research mainly focuses on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction context of traffic participants observed from cooperative devices.
In this paper, we propose a forecasting-oriented representation paradigm to utilize motion and interaction features from cooperative information.
Specifically, we present V2X-Graph, a representative framework to achieve interpretable and end-to-end trajectory feature fusion for cooperative motion forecasting.
V2X-Graph is evaluated on V2X-Seq in vehicle-to-infrastructure (V2I) scenarios.
To further evaluate on vehicle-to-everything (V2X) scenario, we construct the first real-world V2X motion forecasting dataset V2X-Traj, which contains multiple autonomous vehicles and infrastructure in every scenario.
Experimental results on both V2X-Seq and V2X-Traj show the advantage of our method.
We hope both V2X-Graph and V2X-Traj will benefit the further development of cooperative motion forecasting.
Find the project at https://github.com/AIR-THU/V2X-Graph.

Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.
tl;dr: We learn a weight-sharing scheme by defining a collection of learnable doubly stochastic matrices that act as permutation matrices on canonical weight tensors.

Group equivariance has emerged as a valuable inductive bias in deep learning, enhancing generalization, data efficiency, and robustness. Classically, group equivariant methods require the groups of interest to be known beforehand, which may not be realistic for real-world data. Additionally, baking in fixed group equivariance may impose overly restrictive constraints on model architecture. This highlights the need for methods that can dynamically discover and apply symmetries as soft constraints. For neural network architectures, equivariance is commonly achieved through group transformations of a canonical weight tensor, resulting in weight sharing over a given group $G$. In this work, we propose to *learn* such a weight-sharing scheme by defining a collection of learnable doubly stochastic matrices that act as soft permutation matrices on canonical weight tensors, which can take regular group representations as a special case. This yields learnable kernel transformations that are jointly optimized with downstream tasks. We show that when the dataset exhibits strong symmetries, the permutation matrices will converge to regular group representations and our weight-sharing networks effectively become regular group convolutions. Additionally, the flexibility of the method enables it to effectively pick up on partial symmetries.
tl;dr: We propse a novel approach for direct 3D shape generation from a single image, bypassing the need for multi-view reconstruction.

Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multi-view diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://www.neural4d.com/research/direct3d.
tl;dr: Collaborative learning through solving a bilevel optimization problem.

Collaborative learning is an important tool to train multiple clients more effectively by enabling communication among clients. Identifying helpful clients, however, presents challenging and often introduces significant overhead. In this paper, we model **client-selection** and **model-training** as two interconnected optimization problems, proposing a novel bilevel optimization problem for collaborative learning.
We introduce **CoBo**, a *scalable* and *elastic*, SGD-type alternating optimization algorithm that efficiently addresses these problem with theoretical convergence guarantees. Empirically, **CoBo** achieves superior performance, surpassing popular personalization algorithms by 9.3% in accuracy on a task with high heterogeneity, involving datasets distributed among 80 clients.
tl;dr: Low-Rank Prompt Adaptation, soft-prompting approach for effective and efficient customization of large foundation models.

Parameter-Efficient Fine-Tuning (PEFT) has become the standard for customising Foundation Models (FMs) to user-specific downstream tasks. However, typical PEFT methods require storing multiple task-specific adapters, creating scalability issues as these adapters must be housed and run at the FM server. Traditional prompt tuning offers a potential solution by customising them through task-specific input prefixes, but it under-performs compared to other PEFT methods like LoRA. To address this gap, we propose Low-Rank Prompt Adaptation (LoPA), a prompt-tuning-based approach that performs on par with state-of-the-art PEFT methods and full fine-tuning while being more parameter-efficient and not requiring a server-based adapter. LoPA generates soft prompts by balancing between sharing task-specific information across instances and customization for each instance. It uses a low-rank decomposition of the soft-prompt component encoded for each instance to achieve parameter efficiency. We provide a comprehensive evaluation on multiple natural language understanding and code generation and understanding tasks across a wide range of foundation models with varying sizes.
tl;dr: This paper is among the first works which address the problem of certification against adversarial perturbation for regression models with unbounded outputs

Certified adversarial robustness of large-scale deep networks has progressed substantially after the introduction of randomized smoothing. Deep net classifiers are now provably robust in their predictions against a large class of threat models, including $\ell_1$, $\ell_2$, and $\ell_\infty$ norm-bounded attacks. Certified robustness analysis by randomized smoothing has not been performed for deep regression networks where the output variable is continuous and unbounded. In this paper, we extend the existing results for randomized smoothing into regression models using powerful tools from robust statistics, in particular, $\alpha$-trimming filter as the smoothing function. Adjusting the hyperparameter $\alpha$ achieves a smooth trade-off between desired certified robustness and utility. For the first time, we propose a benchmark for certified robust regression in visual positioning systems using the Cambridge Landmarks dataset where robustness analysis is essential for autonomous navigation of AI agents and self-driving cars. Code is publicly available at \url{https://github.com/arekavandi/Certified_adv_RRegression/}.
tl;dr: A novel 3D consistent diffusion framework that utilize pretrained 2D diffusion prior for 3D reconstruction and use reconstructed 3D to guide 2D sampling process

Creating realistic avatars from a single RGB image is an attractive yet challenging problem. To deal with challenging loose clothing or occlusion by interaction objects, we leverage powerful shape prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human-3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other. By coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the prior from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process
to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models are released at https://yuxuan-xue.com/human-3diffusion/.
tl;dr: We identify what variables matter most in out-of-distribution generalization of embeddings and we show that the tunnel effect hypothesis proposed in NeurIPS-2023 is not universal.

Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing transferability and out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which is closely related to intermediate neural collapse. This hypothesis suggests that deeper DNN layers compress representations and hinder OOD generalization. Contrary to earlier work, our experiments show this is not a universal phenomenon. We comprehensively investigate the impact of DNN architecture, training data, image resolution, and augmentations on transferability. We identify that training with high-resolution datasets containing many classes greatly reduces representation compression and improves transferability. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
tl;dr: Focusing on shape and organisation of nuclei (domain invariant features) leads to improved single domain generalisation and shows that nuclei have sufficient information to detect cancer.

Domain generalisation in computational histopathology is challenging because the images are substantially affected by differences among hospitals due to factors like fixation and staining of tissue and imaging equipment. We hypothesise that focusing on nuclei can improve the out-of-domain (OOD) generalisation in cancer detection. We propose a simple approach to improve OOD generalisation for cancer detection by focusing on nuclear morphology and organisation, as these are domain-invariant features critical in cancer detection. Our approach integrates original images with nuclear segmentation masks during training, encouraging the model to prioritise nuclei and their spatial arrangement. Going beyond mere data augmentation, we introduce a regularisation technique that aligns the representations of masks and original images. We show, using multiple datasets, that our method improves OOD generalisation and also leads to increased robustness to image corruptions and adversarial attacks. The source code is available at https://github.com/undercutspiky/SFL/
tl;dr: Assembling diverse deep priors from large models for scene generation from single images in a zero shot manner.

Large language and vision models have been leading a revolution in visual computing. By greatly scaling up sizes of data and model parameters, the large models learn deep priors which lead to remarkable performance in various tasks. In this work, we present deep prior assembly, a novel framework that assembles diverse deep priors from large models for scene reconstruction from single images in a zero-shot manner. We show that this challenging task can be done without extra knowledge but just simply generalizing one deep prior in one sub-task. To this end, we introduce novel methods related to poses, scales, and occlusion parsing which are keys to enable deep priors to work together in a robust way. Deep prior assembly does not require any 3D or 2D data-driven training in the task and demonstrates superior performance in generalizing priors to open-world scenes. We conduct evaluations on various datasets, and report analysis, numerical and visual comparisons with the latest methods to show our superiority. Project page: https://junshengzhou.github.io/DeepPriorAssembly.

Mobile devices have become essential enablers for AI applications, particularly in scenarios that require real-time performance. Vision Transformer (ViT) has become a fundamental cornerstone in this regard due to its high accuracy. Recent efforts have been dedicated to developing various transformer architectures that offer im- proved accuracy while reducing the computational requirements. However, existing research primarily focuses on reducing the theoretical computational complexity through methods such as local attention and model pruning, rather than considering realistic performance on mobile hardware. Although these optimizations reduce computational demands, they either introduce additional overheads related to data transformation (e.g., Reshape and Transpose) or irregular computation/data-access patterns. These result in significant overhead on mobile devices due to their limited bandwidth, which even makes the latency worse than vanilla ViT on mobile. In this paper, we present ECP-ViT, a real-time framework that employs the core-periphery principle inspired by the brain functional networks to guide self-attention in ViTs and enable the deployment of ViT models on smartphones. We identify the main bottleneck in transformer structures caused by data transformation and propose a hardware-friendly core-periphery guided self-attention to decrease computation demands. Additionally, we design the system optimizations for intensive data transformation in pruned models. ECP-ViT, with the proposed algorithm-system co-optimizations, achieves a speedup of 4.6× to 26.9× on mobile GPUs across four datasets: STL-10, CIFAR100, TinyImageNet, and ImageNet.
3869. Towards Diverse Device Heterogeneous Federated Learning via Task Arithmetic Knowledge Integration

Federated Learning (FL) has emerged as a promising paradigm for collaborative machine learning, while preserving user data privacy. Despite its potential, standard FL algorithms lack support for diverse heterogeneous device prototypes, which vary significantly in model and dataset sizes---from small IoT devices to large workstations. This limitation is only partially addressed by existing knowledge distillation (KD) techniques, which often fail to transfer knowledge effectively across a broad spectrum of device prototypes with varied capabilities. This failure primarily stems from two issues: the dilution of informative logits from more capable devices by those from less capable ones, and the use of a single integrated logits as the distillation target across all devices, which neglects their individual learning capacities and and the unique contributions of each device. To address these challenges, we introduce TAKFL, a novel KD-based framework that treats the knowledge transfer from each device prototype's ensemble as a separate task, independently distilling each to preserve its unique contributions and avoid dilution. TAKFL also incorporates a KD-based self-regularization technique to mitigate the issues related to the noisy and unsupervised ensemble distillation process. To integrate the separately distilled knowledge, we introduce an adaptive task arithmetic knowledge integration process, allowing each student model to customize the knowledge integration for optimal performance. Additionally, we present theoretical results demonstrating the effectiveness of task arithmetic in transferring knowledge across heterogeneous device prototypes with varying capacities. Comprehensive evaluations of our method across both computer vision (CV) and natural language processing (NLP) tasks demonstrate that TAKFL achieves state-of-the-art results in a variety of datasets and settings, significantly outperforming existing KD-based methods. Our code is released at https://github.com/MMorafah/TAKFL and the project website is available at https://mmorafah.github.io/takflpage .
tl;dr: We develop a policy gradient method to learn a Nash equilibrium in a MARL setting which encompasses both cooperation and competition

We study the problem of learning a Nash equilibrium (NE) in Markov games which is a cornerstone in multi-agent reinforcement learning (MARL). In particular, we focus on infinite-horizon adversarial team Markov games (ATMGs) in which agents that share a common reward function compete against a single opponent, *the adversary*. These games unify two-player zero-sum Markov games and Markov potential games, resulting in a setting that encompasses both collaboration and competition. Kalogiannis et al. (2023) provided an efficient equilibrium computation algorithm for ATMGs which presumes knowledge of the reward and transition functions and has no sample complexity guarantees. We contribute a learning algorithm that utilizes MARL policy gradient methods with iteration and sample complexity that is polynomial in the approximation error $\epsilon$ and the natural parameters of the ATMG, resolving the main caveats of the solution by (Kalogiannis et al., 2023). It is worth noting that previously, the existence of learning algorithms for NE was known for Markov two-player zero-sum and potential games but not for ATMGs.
Seen through the lens of min-max optimization, computing a NE in these games consists a nonconvex--nonconcave saddle-point problem. Min-max optimization has received an extensive study. Nevertheless, the case of nonconvex--nonconcave landscapes remains elusive: in full generality, finding saddle-points is computationally intractable (Daskalakis et al., 2021). We circumvent the aforementioned intractability by developing techniques that exploit the hidden structure of the objective function via a nonconvex--concave reformulation. However, this introduces a challenge of a feasibility set with coupled constraints. We tackle these challenges by establishing novel techniques for optimizing weakly-smooth nonconvex functions, extending the framework of (Devolder et al., 2014).
tl;dr: We propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion prediction framework.

Forecasting a typical object's future motion is a critical task for interpreting and interacting with dynamic environments in computer vision. Event-based sensors, which could capture changes in the scene with exceptional temporal granularity, may potentially offer a unique opportunity to predict future motion with a level of detail and precision previously unachievable. Inspired by that, we propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion simulation framework. Specifically, we initially employ pre-trained stable video diffusion models to adapt the event sequence dataset. This process facilitates the transfer of extensive knowledge from RGB videos to an event-centric domain. Moreover, we introduce an alignment mechanism that utilizes reinforcement learning techniques to enhance the reverse generation trajectory of the diffusion model, ensuring improved performance and accuracy. Through extensive testing and validation, we demonstrate the effectiveness of our method in various complex scenarios, showcasing its potential to revolutionize motion flow prediction in computer vision applications such as autonomous vehicle guidance, robotic navigation, and interactive media. Our findings suggest a promising direction for future research in enhancing the interpretative power and predictive accuracy of computer vision systems. The source code is
publicly available at https://github.com/p4r4mount/E-Motion.
tl;dr: Efficient algorithms for John ellipsoids by lazily updating the weights

We give a faster algorithm for computing an approximate John ellipsoid around $n$ points in $d$ dimensions. The best known prior algorithms are based on repeatedly computing the leverage scores of the points and reweighting them by these scores (Cohen et al., 2019). We show that this algorithm can be substantially sped up by delaying the computation of high accuracy leverage scores by using sampling, and then later computing multiple batches of high accuracy leverage scores via fast rectangular matrix multiplication. We also give low-space streaming algorithms for John ellipsoids using similar ideas.
tl;dr: We introduce SELF-DISCOVER, an efficient and performant framework for models to self-discover a reasoning structure for any task from a seed set of general problem-solving skills.

We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding. SELF-DISCOVER substantially improves GPT-4 and PaLM 2’s performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELF-DISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
tl;dr: In this work, we designed a trojan scanning method which is robust in various aspects, including trojan attack type, label mapping, and adversarial robustness of the classifier.

Scanning for trojan (backdoor) in deep neural networks is crucial due to their significant real-world applications. There has been an increasing focus on developing effective general trojan scanning methods across various trojan attacks. Despite advancements, there remains a shortage of methods that perform effectively without preconceived assumptions about the backdoor attack method. Additionally, we have observed that current methods struggle to identify classifiers trojaned using adversarial training. Motivated by these challenges, our study introduces a novel scanning method named TRODO (TROjan scanning by Detection of adversarial shifts in Out-of-distribution samples). TRODO leverages the concept of "blind spots"—regions where trojaned classifiers erroneously identify out-of-distribution (OOD) samples as in-distribution (ID). We scan for these blind spots by adversarially shifting OOD samples towards in-distribution. The increased likelihood of perturbed OOD samples being classified as ID serves as a signature for trojan detection. TRODO is both trojan and label mapping agnostic, effective even against adversarially trained trojaned classifiers. It is applicable even in scenarios where training data is absent, demonstrating high accuracy and adaptability across various scenarios and datasets, highlighting its potential as a robust trojan scanning strategy.
tl;dr: We show SVD-based weight pruning boosts in-context learning in large language models, proved by theoretical analysis, and propose an effective, intuitive algorithm for downstream tasks.

Pre-trained large language models (LLMs) based on Transformer have demonstrated striking in-context learning (ICL) abilities. With a few demonstration input-label pairs, they can predict the label for an unseen input without any parameter updates. In this paper, we show an exciting phenomenon that SVD-based weight pruning can enhance ICL performance, and more surprising, pruning weights in deep layers often results in more stable performance improvements than in shallow layers. However, the underlying mechanism of those findings still remains an open question. To reveal those findings, we conduct an in-depth theoretical analysis by presenting the implicit gradient descent (GD) trajectories of ICL and giving the mutual information based generalization bounds of ICL via full implicit GD trajectories. This helps us reasonably explain the surprising experimental findings. Besides, based on all our experimental and theoretical insights, we intuitively propose a simple, model-compression and derivative-free algorithm for downstream tasks in enhancing ICL inference. Experiments on benchmark datasets and open source LLMs display the method effectiveness.
tl;dr: We propose a new memory-efficient version of Adam with strong theoretical and practical convergence, and low space overheads in practice.

We propose a new variant of the Adam optimizer called MicroAdam that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state,
thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical *error feedback* mechanism from distributed optimization in which *the error correction information is itself compressed* to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MicroAdam can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
tl;dr: A full-fledged solution to embed supervised *models* in hyperbolic geometry, and more

Models of hyperbolic geometry have been successfully used in ML for two main tasks: embedding *models* in unsupervised learning (*e.g.* hierarchies) and embedding *data*.
To our knowledge, there are no approaches that provide embeddings for supervised models; even when hyperbolic geometry provides convenient properties for expressing popular hypothesis classes, such as decision trees (and ensembles).
In this paper, we propose a full-fledged solution to the problem in three independent contributions. The first linking the theory of losses for class probability estimation to hyperbolic embeddings in Poincar\'e disk model. The second resolving an issue for a clean, unambiguous embedding of (ensembles of) decision trees in this model. The third showing how to smoothly tweak the Poincar\'e hyperbolic distance to improve its encoding and visualization properties near the border of the disk, a crucial region for our application, while keeping hyperbolicity.
This last step has substantial independent interest as it is grounded in a generalization of Leibniz-Newton's fundamental Theorem of calculus.
tl;dr: MVSplat360 is a feed-forward approach for 360° novel view synthesis of diverse real-world scenes, using only sparse observations.

We introduce MVSplat360, a feed-forward approach for 360° novel view synthesis (NVS) of diverse real-world scenes, using only sparse observations. This setting is inherently ill-posed due to minimal overlap among input views and insufficient visual information provided, making it challenging for conventional methods to achieve high-quality results. Our MVSplat360 addresses this by effectively combining geometry-aware 3D reconstruction with temporally consistent video generation. Specifically, it refactors a feed-forward 3D Gaussian Splatting (3DGS) model to render features directly into the latent space of a pre-trained Stable Video Diffusion (SVD) model, where these features then act as pose and visual cues to guide the denoising process and produce photorealistic 3D-consistent views. Our model is end-to-end trainable and supports rendering arbitrary views with as few as 5 sparse input views. To evaluate MVSplat360's performance, we introduce a new benchmark using the challenging DL3DV-10K dataset, where MVSplat360 achieves superior visual quality compared to state-of-the-art methods on wide-sweeping or even 360° NVS tasks. Experiments on the existing benchmark RealEstate10K also confirm the effectiveness of our model. Readers are highly recommended to view the video results at [donydchen.github.io/mvsplat360](https://donydchen.github.io/mvsplat360).
tl;dr: Introducing a powerful 3D generative model that generates Gaussian primitives in arbitrary numbers by functionally disentangling Gaussian Splatting.

3D Gaussian Splatting (3DGS) has shown convincing performance in rendering speed and fidelity, yet the generation of Gaussian Splatting remains a challenge due to its discreteness and unstructured nature. In this work, we propose DiffGS, a general Gaussian generator based on latent diffusion models. DiffGS is a powerful and efficient 3D generative model which is capable of generating Gaussian primitives at arbitrary numbers for high-fidelity rendering with rasterization. The key insight is to represent Gaussian Splatting in a disentangled manner via three novel functions to model Gaussian probabilities, colors and transforms. Through the novel disentanglement of 3DGS, we represent the discrete and unstructured 3DGS with continuous Gaussian Splatting functions, where we then train a latent diffusion model with the target of generating these Gaussian Splatting functions both unconditionally and conditionally. Meanwhile, we introduce a discretization algorithm to extract Gaussians at arbitrary numbers from the generated functions via octree-guided sampling and optimization. We explore DiffGS for various tasks, including unconditional generation, conditional generation from text, image, and partial 3DGS, as well as Point-to-Gaussian generation. We believe that DiffGS provides a new direction for flexibly modeling and generating Gaussian Splatting. Project page: https://junshengzhou.github.io/DiffGS.
tl;dr: A novel method with multi-stage training scheme, novel view consistency constraints, and local regularization losses for few-shot view synthesis

The field of novel view synthesis from images has seen rapid advancements with the introduction of Neural Radiance Fields (NeRF) and more recently with 3D Gaussian Splatting. Gaussian Splatting became widely adopted due to its efficiency and ability to render novel views accurately. While Gaussian Splatting performs well when a sufficient amount of training images are available, its unstructured explicit representation tends to overfit in scenarios with sparse input images, resulting in poor rendering performance. To address this, we present a 3D Gaussian-based novel view synthesis method using sparse input images that can accurately render the scene from the viewpoints not covered by the training images. We propose a multi-stage training scheme with matching-based consistency constraints imposed on the novel views without relying on pre-trained depth estimation or diffusion models. This is achieved by using the matches of the available training images to supervise the generation of the novel views sampled between the training frames with color, geometry, and semantic losses. In addition, we introduce a locality preserving regularization for 3D Gaussians which removes rendering artifacts by preserving the local color structure of the scene. Evaluation on synthetic and real-world datasets demonstrates competitive or superior performance of our method in few-shot novel view synthesis compared to existing state-of-the-art methods.

Large language models (LLMs) have rapidly improved text embeddings for a growing array of natural-language processing tasks. However, their opaqueness and proliferation into scientific domains such as neuroscience have created a growing need for interpretability. Here, we ask whether we can obtain interpretable embeddings through LLM prompting. We introduce question-answering embeddings (QA-Emb), embeddings where each feature represents an answer to a yes/no question asked to an LLM. Training QA-Emb reduces to selecting a set of underlying questions rather than learning model weights.
We use QA-Emb to flexibly generate interpretable models for predicting fMRI voxel responses to language stimuli. QA-Emb significantly outperforms an established interpretable baseline, and does so while requiring very few questions. This paves the way towards building flexible feature spaces that can concretize and evaluate our understanding of semantic brain representations. We additionally find that QA-Emb can be effectively approximated with an efficient model, and we explore broader applications in simple NLP tasks.
tl;dr: We propose debLoRA to adapt foundation models to data-scarce remote sensing domains with long-tailed distributions, by efficiently and unsupervisedly augmenting minor class features using major class features to mitigate representation bias.

Remote sensing (RS) imagery, which requires specialized satellites to collect and is difficult to annotate, suffers from data scarcity and class imbalance in certain spectrums. Due to their data scarcity, training large-scale RS models from scratch is unrealistic, and the alternative is to transfer pre-trained models by fine-tuning or a more data-efficient method LoRA. Due to class imbalance, transferred models exhibit strong bias, where features of the major class dominate over those of the minor class. In this paper, we propose debLoRA, a generic training approach that works with any LoRA variants to yield debiased features. It is an unsupervised learning approach that can diversify minor class features based on the shared attributes with major classes, where the attributes are obtained by a simple step of clustering. To evaluate it, we conduct extensive experiments in two transfer learning scenarios in the RS domain: from natural to optical RS images, and from optical RS to multi-spectrum RS images. We perform object classification and oriented object detection tasks on the optical RS dataset DOTA and the SAR dataset FUSRS. Results show that our debLoRA consistently surpasses prior arts across these RS adaptation settings, yielding up to 3.3 and 4.7 percentage points gains on the tail classes for natural $\to$ optical RS and optical RS $\to$ multi-spectrum RS adaptations, respectively, while preserving the performance on head classes, substantiating its efficacy and adaptability
tl;dr: We explain why visually-grounded language models are bad at classification and propose a simple data intervention method to fix that.

Image classification is one of the most fundamental capabilities of machine vision intelligence. In this work, we revisit the image classification task using visually-grounded language models (VLMs) such as GPT-4V and LLaVA. We find that existing proprietary and public VLMs, despite often using CLIP as a vision encoder and having many more parameters, significantly underperform CLIP on standard image classification benchmarks like ImageNet. To understand the reason, we explore several hypotheses concerning the inference algorithms, training objectives, and data processing in VLMs. Our analysis reveals that the primary cause is data-related: critical information for image classification is encoded in the VLM's latent space but can only be effectively decoded with enough training data. Specifically, there is a strong correlation between the frequency of class exposure during VLM training and instruction-tuning and the VLM's performance in those classes; when trained with sufficient data, VLMs can match the accuracy of state-of-the-art classification models. Based on these findings, we enhance a VLM by integrating classification-focused datasets into its training, and demonstrate that the enhanced classification performance of the VLM transfers to its general capabilities, resulting in an improvement of 11.8% on the newly collected ImageWikiQA dataset.
tl;dr: We propose a novel implicit watermarking scheme that leverages a disentangled style domain to detect data unauthorized usage.

Text-to-image models have shown surprising performance in high-quality image generation, while also raising intensified concerns about the unauthorized usage of personal dataset in training and personalized fine-tuning. Recent approaches, embedding watermarks, introducing perturbations, and inserting backdoors into datasets, rely on adding minor information vulnerable to adversarial purification, limiting their ability to detect unauthorized data usage. In this paper, we introduce a novel implicit Zero-Watermarking scheme that first utilizes the disentangled style domain to detect unauthorized dataset usage in text-to-image models. Specifically, our approach generates the watermark from the disentangled style domain, enabling self-generalization and mutual exclusivity within the style domain anchored by protected units. The domain achieves the maximum concealed offset of probability distribution through both the injection of identifier $z$ and dynamic contrastive learning, facilitating the structured delineation of dataset copyright boundaries for multiple sources of styles and contents. Additionally, we introduce the concept of watermark distribution to establish a verification mechanism for copyright ownership of hybrid or partial infringements, addressing deficiencies in the traditional mechanism of dataset copyright ownership for AI mimicry. Notably, our method achieved One-Sample-Verification for copyright ownership in AI mimic generations. The code is available at: [https://github.com/Hlufies/ZWatermarking](https://github.com/Hlufies/ZWatermarking)
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of visual decoding and reconstruction based on functional Magnetic Resonance Imaging (fMRI). However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for visual decoding based on electroencephalography (EEG). In this study, we present an end-to-end EEG-based visual reconstruction zero-shot framework, consisting of a tailored brain encoder, called the Adaptive Thinking Mapper (ATM), which projects neural signals from different sources into the shared subspace as the clip embedding, and a two-stage multi-pipe EEG-to-image generation strategy. In stage one, EEG is embedded to align the high-level clip embedding, and then the prior diffusion model refines EEG embedding into image priors. A blurry image also decoded from EEG for maintaining the low-level feature. In stage two, we input both the high-level clip embedding, the blurry image and caption from EEG latent to a pre-trained diffusion model. Furthermore, we analyzed the impacts of different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. The experimental results indicate that our EEG-based visual zero-shot framework achieves SOTA performance in classification, retrieval and reconstruction, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. Our code is available at https://github.com/ncclab-sustech/EEG_Image_decode.

Subgraph GNNs enhance message-passing GNNs expressivity by representing graphs as sets of subgraphs, demonstrating impressive performance across various tasks. However, their scalability is hindered by the need to process large numbers of subgraphs. While previous approaches attempted to generate smaller subsets of subgraphs through random or learnable sampling, these methods often yielded suboptimal selections or were limited to small subset sizes, ultimately compromising their effectiveness. This paper introduces a new Subgraph GNN framework to address these issues.
Our approach diverges from most previous methods by associating subgraphs with node clusters rather than with individual nodes. We show that the resulting collection of subgraphs can be viewed as the product of coarsened and original graphs, unveiling a new connectivity structure on which we perform generalized message passing.
Crucially, controlling the coarsening function enables meaningful selection of any number of subgraphs. In addition, we reveal novel permutation symmetries in the resulting node feature tensor, characterize associated linear equivariant layers, and integrate them into our Subgraph GNN. We also introduce novel node marking strategies and provide a theoretical analysis of their expressive power and other key aspects of our approach. Extensive experiments on multiple graph learning benchmarks demonstrate that our method is significantly more flexible than previous approaches, as it can seamlessly handle any number of subgraphs, while consistently outperforming baseline approaches.
Our code is available at https://github.com/BarSGuy/Efficient-Subgraph-GNNs.
tl;dr: For image-recovery problems, we propose a fast and accurate posterior sampler by regularizing a cGAN to enforce correctness in the K principal components of the posterior covariance matrix, and in both the trace-covariance and conditional mean.

In ill-posed imaging inverse problems, there can exist many hypotheses that fit both the observed measurements and prior knowledge of the true image. Rather than returning just one hypothesis of that image, posterior samplers aim to explore the full solution space by generating many probable hypotheses, which can later be used to quantify uncertainty or construct recoveries that appropriately navigate the perception/distortion trade-off. In this work, we propose a fast and accurate posterior-sampling conditional generative adversarial network (cGAN) that, through a novel form of regularization, aims for correctness in the posterior mean as well as the trace and K principal components of the posterior covariance matrix. Numerical experiments demonstrate that our method outperforms competitors in a wide range of ill-posed imaging inverse problems.
tl;dr: We proposed Q^2VMC, a method to enhance efficiency and accuracy of quantum variational Monte Carlo methods.

This paper introduces the Quadratic Quantum Variational Monte Carlo (Q$^2$VMC) algorithm, an innovative algorithm in quantum chemistry that significantly enhances the efficiency and accuracy of solving the Schrödinger equation. Inspired by the discretization of imaginary-time Schrödinger evolution, Q$^2$VMC employs a novel quadratic update mechanism that integrates seamlessly with neural network-based ansatzes. Our extensive experiments showcase Q$^2$VMC's superior performance, achieving faster convergence and lower ground state energies in wavefunction optimization across various molecular systems, without additional computational cost. This study not only advances the field of computational quantum chemistry but also highlights the important role of discretized evolution in variational quantum algorithms, offering a scalable and robust framework for future quantum research.

In steganography, selecting an optimal cover image—referred to as cover selection—is pivotal for effective message concealment. Traditional methods have typically employed exhaustive searches to identify images that conform to specific perceptual or complexity metrics. However, the relationship between these metrics and the actual message hiding efficacy of an image is unclear, often yielding less-than-ideal steganographic outcomes. Inspired by recent advancements in generative models, we introduce a novel cover selection framework, which involves optimizing within the latent space of pretrained generative models to identify the most suitable cover images, distinguishing itself from traditional exhaustive search methods. Our method shows significant advantages in message recovery and image quality. We also conduct an information-theoretic analysis of the generated cover images, revealing that message hiding predominantly occurs in low-variance pixels, reflecting the waterfilling algorithm's principles in parallel Gaussian channels.
tl;dr: This paper proposes a Rate-Distortion theory based module that mimics teaching assistants for knowledge distillation, while being computationally far cheaper to train than conventional TAs.

Knowledge Distillation is the mechanism by which the insights gained from a larger teacher model are transferred to a smaller student model. However, the transfer suffers when the teacher model is significantly larger than the student. To overcome this, prior works have proposed training intermediately sized models, Teacher Assistants (TAs) to help the transfer process. However, training TAs is expensive, as training these models is a knowledge transfer task in itself. Further, these TAs are larger than the student model and training them especially in large data settings can be computationally intensive. In this paper, we propose a novel framework called Controlled Information Flow for Knowledge Distillation (CIFD) consisting of two components. First, we propose a significantly smaller alternatives to TAs, the Rate-Distortion Module (RDM) which uses the teacher's penultimate layer embedding and a information rate-constrained bottleneck layer to replace the Teacher Assistant model. RDMs are smaller and easier to train than TAs, especially in large data regimes, since they operate on the teacher embeddings and do not need to relearn low level input feature extractors. Also, by varying the information rate across the bottleneck, RDMs can replace TAs of different sizes. Secondly, we propose the use of Information Bottleneck Module in the student model, which is crucial for regularization in the presence of a large number of RDMs. We show comprehensive state-of-the-art results of the proposed method over large datasets like Imagenet. Further, we show the significant improvement in distilling CLIP like models over a huge 12M image-text dataset. It outperforms CLIP specialized distillation methods across five zero-shot classification datasets and two zero-shot image-text retrieval datasets.

Current video-language models (VLMs) rely extensively on instance-level alignment between video and language modalities, which presents two major limitations: (1) visual reasoning disobeys the natural perception that humans do in first-person perspective, leading to a lack of reasoning interpretation; and (2) learning is limited in capturing inherent fine-grained relationships between two modalities.
In this paper, we take an inspiration from human perception and explore a compositional approach for egocentric video representation. We introduce HENASY (Hierarchical ENtities ASsemblY), which includes a spatiotemporal token grouping mechanism to explicitly assemble dynamically evolving scene entities through time and model their relationship for video representation. By leveraging compositional structure understanding, HENASY possesses strong interpretability via visual grounding with free-form text queries. We further explore a suite of multi-grained contrastive losses to facilitate entity-centric understandings. This comprises three alignment types: video-narration, noun-entity, verb-entities alignments.
Our method demonstrates strong interpretability in both quantitative and qualitative experiments; while maintaining competitive performances on five downstream tasks via zero-shot transfer or as video/text representation, including video/text retrieval, action recognition, multi-choice query, natural language query, and moments query.
Project page: https://uark-aicv.github.io/HENASY

We present DC-Gaussian, a new method for generating novel views from in-vehicle dash cam videos. While neural rendering techniques have made significant strides in driving scenarios, existing methods are primarily designed for videos collected by autonomous vehicles. However, these videos are limited in both quantity and diversity compared to dash cam videos, which are more widely used across various types of vehicles and capture a broader range of scenarios. Dash cam videos often suffer from severe obstructions such as reflections and occlusions on the windshields, which significantly impede the application of neural rendering techniques. To address this challenge, we develop DC-Gaussian based on the recent real-time neural rendering technique 3D Gaussian Splatting (3DGS). Our approach includes an adaptive image decomposition module to model reflections and occlusions in a unified manner. Additionally, we introduce illumination-aware obstruction modeling to manage reflections and occlusions under varying lighting conditions. Lastly, we employ a geometry-guided Gaussian enhancement strategy to improve rendering details by incorporating additional geometry priors. Experiments on self-captured and public dash cam videos show that our method not only achieves state-of-the-art performance in novel view synthesis, but also accurately reconstructing captured scenes getting rid of obstructions.

Numerous industrial sectors necessitate models capable of providing robust forecasts across various horizons. Despite the recent strides in crafting specific architectures for time-series forecasting and developing pre-trained universal models, a comprehensive examination of their capability in accommodating varied-horizon forecasting during inference is still lacking. This paper bridges this gap through the design and evaluation of the Elastic Time-Series Transformer (ElasTST). The ElasTST model incorporates a non-autoregressive design with placeholders and structured self-attention masks, warranting future outputs that are invariant to adjustments in inference horizons. A tunable version of rotary position embedding is also integrated into ElasTST to capture time-series-specific periods and enhance adaptability to different horizons. Additionally, ElasTST employs a multi-scale patch design, effectively integrating both fine-grained and coarse-grained information. During the training phase, ElasTST uses a horizon reweighting strategy that approximates the effect of random sampling across multiple horizons with a single fixed horizon setting. Through comprehensive experiments and comparisons with state-of-the-art time-series architectures and contemporary foundation models, we demonstrate the efficacy of ElasTST's unique design elements. Our findings position ElasTST as a robust solution for the practical necessity of varied-horizon forecasting.
tl;dr: We sample differentiable representations by solving the pulled back reverse diffusion process in parameter space.

We introduce a novel, training-free method for sampling *differentiable representations* (diffreps) using pretrained diffusion models. Rather than merely mode-seeking, our method achieves sampling by "pulling back" the dynamics of the reverse-time process—from the image space to the diffrep parameter space—and updating the parameters according to this pulled-back process. We identify an implicit constraint on the samples induced by the diffrep and demonstrate that addressing this constraint significantly improves the consistency and detail of the generated objects. Our method yields diffreps with substantially **improved quality and diversity** for images, panoramas, and 3D NeRFs compared to existing techniques. Our approach is a general-purpose method for sampling diffreps, expanding the scope of problems that diffusion models can tackle.

The increasing size of neural networks has led to a growing demand for methods of efficient finetuning. Recently, an orthogonal finetuning paradigm was introduced that uses orthogonal matrices for adapting the weights of a pretrained model. In this paper, we introduce a new class of structured matrices, which unifies and generalizes structured classes from previous works. We examine properties of this class and build a structured orthogonal parametrization upon it. We then use this parametrization to modify the orthogonal finetuning framework, improving parameter efficiency. We empirically validate our method on different domains, including adapting of text-to-image diffusion models and downstream task finetuning in language modeling. Additionally, we adapt our construction for orthogonal convolutions and conduct experiments with 1-Lipschitz neural networks.

Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. Our methodology begins with the development of a point-cloud-based network that effectively generates precise and meaningful latent tri-planes, laying the groundwork for accurate 3D mesh reconstruction. Building upon this, our Image-Point-Cloud Feature Alignment technique processes a single input image, aligning to the latent tri-planes to imbue image features with robust 3D information. This process not only enriches the image features but also facilitates the production of high-fidelity 3D meshes without the need for multi-view input, significantly reducing geometric distortions. Our approach achieves state-of-the-art high-fidelity 3D mesh reconstruction from a single image in just 6 seconds, and experiments on various datasets demonstrate its effectiveness.
tl;dr: We propose a causal effect estimation framework for detecting which agents are exploiting a payout model.

In many settings, machine learning models may be used to inform decisions that impact individuals or entities who interact with the model. Such entities, or *agents,* may *game* model decisions by manipulating their inputs to the model to obtain better outcomes and maximize some utility. We consider a multi-agent setting where the goal is to identify the “worst offenders:” agents that are gaming most aggressively. However, identifying such agents is difficult without knowledge of their utility function. Thus, we introduce a framework in which each agent’s tendency to game is parameterized via a scalar. We show that this gaming parameter is only partially identifiable. By recasting the problem as a causal effect estimation problem where different agents represent different “treatments,” we prove that a ranking of all agents by their gaming parameters is identifiable. We present empirical results in a synthetic data study validating the usage of causal effect estimation for gaming detection and show in a case study of diagnosis coding behavior in the U.S. that our approach highlights features associated with gaming.

3D Hand reconstruction from a single RGB image is challenging due to the articulated motion, self-occlusion, and interaction with objects. Existing SOTA methods employ attention-based transformers to learn the 3D hand pose and shape, yet they do not fully achieve robust and accurate performance, primarily due to inefficiently modeling spatial relations between joints. To address this problem, we propose a novel graph-guided Mamba framework, named Hamba, which bridges graph learning and state space modeling. Our core idea is to reformulate Mamba's scanning into graph-guided bidirectional scanning for 3D reconstruction using a few effective tokens. This enables us to efficiently learn the spatial relationships between joints for improving reconstruction performance. Specifically, we design a Graph-guided State Space (GSS) block that learns the graph-structured relations and spatial sequences of joints and uses 88.5\% fewer tokens than attention-based methods. Additionally, we integrate the state space features and the global features using a fusion module. By utilizing the GSS block and the fusion module, Hamba effectively leverages the graph-guided state space features and jointly considers global and local features to improve performance. Experiments on several benchmarks and in-the-wild tests demonstrate that Hamba significantly outperforms existing SOTAs, achieving the PA-MPVPE of 5.3mm and F@15mm of 0.992 on FreiHAND. At the time of this paper's acceptance, Hamba holds the top position, Rank 1, in two competition leaderboards on 3D hand reconstruction.
tl;dr: We provide non-asymptotic guarantees of the AIPW estimator using the framework of online learning for estimation of the treatment effect. We then give a lower bound to demonstrate the instance-optimality of the proposed estimator.

We consider estimation of a linear functional of the treatment effect from adaptively collected data. This problem finds a variety of applications including off-policy evaluation in contextual bandits, and estimation of the average treatment effect in causal inference. While a certain class of augmented inverse propensity weighting (AIPW) estimators enjoys desirable asymptotic properties including the semi-parametric efficiency, much less is known about their non-asymptotic theory with adaptively collected data. To fill in the gap, we first present generic upper bounds on the mean-squared error of the class of AIPW estimators that crucially depends on a sequentially weighted error between the treatment effect and its estimates. Motivated by this, we propose a general reduction scheme that allows one to produce a sequence of estimates for the treatment effect via online learning to minimize the sequentially weighted estimation error. To illustrate this, we provide three concrete instantiations in (1) the tabular case; (2) the case of linear function approximation; and (3) the case of general function approximation for the outcome model. We then provide a local minimax lower bound to show the instance-dependent optimality of the AIPW estimator using no-regret online learning algorithms.
tl;dr: We transform the problem of calibrating a multiclass classifier into calibrating a single surrogate binary classifier and show that it significantly improves existing calibration methods.

For classification models based on neural networks, the maximum predicted class probability is often used as a confidence score. This score rarely predicts well the probability of making a correct prediction and requires a post-processing calibration step. However, many confidence calibration methods fail for problems with many classes. To address this issue, we transform the problem of calibrating a multiclass classifier into calibrating a single surrogate binary classifier. This approach allows for more efficient use of standard calibration methods. We evaluate our approach on numerous neural networks used for image or text classification and show that it significantly enhances existing calibration methods.
tl;dr: CRT-Fusion is a novel framework that significantly improves the accuracy and robustness of 3D object detection by effectively integrating radar-camera information and temporal cues, explicitly considering the motion of dynamic objects.

Accurate and robust 3D object detection is a critical component in autonomous vehicles and robotics. While recent radar-camera fusion methods have made significant progress by fusing information in the bird's-eye view (BEV) representation, they often struggle to effectively capture the motion of dynamic objects, leading to limited performance in real-world scenarios. In this paper, we introduce CRT-Fusion, a novel framework that integrates temporal information into radar-camera fusion to address this challenge. Our approach comprises three key modules: Multi-View Fusion (MVF), Motion Feature Estimator (MFE), and Motion Guided Temporal Fusion (MGTF). The MVF module fuses radar and image features within both the camera view and bird's-eye view, thereby generating a more precise unified BEV representation. The MFE module conducts two simultaneous tasks: estimation of pixel-wise velocity information and BEV segmentation. Based on the velocity and the occupancy score map obtained from the MFE module, the MGTF module aligns and fuses feature maps across multiple timestamps in a recurrent manner. By considering the motion of dynamic objects, CRT-Fusion can produce robust BEV feature maps, thereby improving detection accuracy and robustness. Extensive evaluations on the challenging nuScenes dataset demonstrate that CRT-Fusion achieves state-of-the-art performance for radar-camera-based 3D object detection. Our approach outperforms the previous best method in terms of NDS by +1.7%, while also surpassing the leading approach in mAP by +1.4%. These significant improvements in both metrics showcase the effectiveness of our proposed fusion strategy in enhancing the reliability and accuracy of 3D object detection.
tl;dr: To learn to animate the garments, we adopt the disentangled scheme where we model the constitutive laws of a piece of cloth from the observations and animate garments using energy optimization constrained by our model.

Garment animation is ubiquitous in various applications, such as virtual reality, gaming, and film producing. Recently, learning-based approaches obtain compelling performance in animating diverse garments under versatile scenarios. Nevertheless, to mimic the deformations of the observed garments, data-driven methods require large scale of garment data, which are both resource-wise expensive and time-consuming. In addition, forcing models to match the dynamics of observed garment animation may hinder the potentials to generalize to unseen cases. In this paper, instead of using garment-wise supervised-learning we adopt a disentangled scheme to learn how to animate observed garments: 1). learning constitutive behaviors from the observed cloth; 2). dynamically animate various garments constrained by the learned constitutive laws. Specifically, we propose Energy Unit network (EUNet) to model the constitutive relations in the format of energy. Without the priors from analytical physics models and differentiable simulation engines, EUNet is able to directly capture the constitutive behaviors from the observed piece of cloth and uniformly describes the change of energy caused by deformations, such as stretching and bending. We further apply the pre-trained EUNet to animate various garments based on energy optimizations. The disentangled scheme alleviates the need of garment data and enables us to utilize the dynamics of a piece of cloth for animating garments. Experiments show that while EUNet effectively delivers the energy gradients due to the deformations, models constrained by EUNet achieve more stable and physically plausible performance comparing with those trained in garment-wise supervised manner.
tl;dr: DiffuPac, a first-of-its-kind model that utilized pre-trained BERT with diffusion model to generate adversarial packets

In domains of cybersecurity, recent advancements in Machine Learning (ML) and Deep Learning (DL) have significantly enhanced Network Intrusion Detection Systems (NIDS), improving the effectiveness of cybersecurity operations. However, attackers have also leveraged ML/DL to develop sophisticated models that generate adversarial packets capable of evading NIDS detection. Consequently, defenders must study and analyze these models to prepare for the evasion attacks that exploit NIDS detection mechanisms. Unfortunately, conventional generation models often rely on unrealistic assumptions about attackers' knowledge of NIDS components, making them impractical for real-world scenarios. To address this issue, we present DiffuPac, a first-of-its-kind generation model designed to generate adversarial packets that evade detection without relying on specific NIDS components. DiffuPac integrates a pre-trained Bidirectional Encoder Representations from Transformers (BERT) with diffusion model, which, through its capability for conditional denoising and classifier-free guidance, effectively addresses the real-world constraint of limited attacker knowledge. By concatenating malicious packets with contextually relevant normal packets and applying targeted noising only to the malicious packets, DiffuPac seamlessly blends adversarial packets into genuine network traffic. Through evaluations on real-world datasets, we demonstrate that DiffuPac achieves strong evasion capabilities against sophisticated NIDS, outperforming conventional methods by an average of 6.69 percentage points, while preserving the functionality and practicality of the generated adversarial packets.
tl;dr: In this work we introduce a novel approach how to handle byzantine workers in partial participation regime, when they can form majority.

Distributed learning has emerged as a leading paradigm for training large machine learning models. However, in real-world scenarios, participants may be unreliable or malicious, posing a significant challenge to the integrity and accuracy of the trained models. Byzantine fault tolerance mechanisms have been proposed to address these issues, but they often assume full participation from all clients, which is not always practical due to the unavailability of some clients or communication constraints. In our work, we propose the first distributed method with client sampling and provable tolerance to Byzantine workers. The key idea behind the developed method is the use of gradient clipping to control stochastic gradient differences in recursive variance reduction. This allows us to bound the potential harm caused by Byzantine workers, even during iterations when all sampled clients are Byzantine. Furthermore, we incorporate communication compression into the method to enhance communication efficiency. Under general assumptions, we prove convergence rates for the proposed method that match the existing state-of-the-art (SOTA) theoretical results. We also propose a heuristic on how to adjust any Byzantine-robust method to a partial participation scenario via clipping.

Road network representation learning aims to learn compressed and effective vectorized representations for road segments that are applicable to numerous tasks. In this paper, we identify the limitations of existing methods, particularly their overemphasis on the distance effect as outlined in the First Law of Geography. In response, we propose to endow road network representation with the principles of the recent Third Law of Geography. To this end, we propose a novel graph contrastive learning framework that employs geographic configuration-aware graph augmentation and spectral negative sampling, ensuring that road segments with similar geographic configurations yield similar representations, and vice versa, aligning with the principles stated in the Third Law. The framework further fuses the Third Law with the First Law through a dual contrastive learning objective to effectively balance the implications of both laws. We evaluate our framework on two real-world datasets across three downstream tasks. The results show that the integration of the Third Law significantly improves the performance of road segment representations in downstream tasks.
tl;dr: We propose an approach, termed as Prompt Adversarial Tuning (PAT), to defend the jailbreak attacks for LLMs.

While Large Language Models (LLMs) have achieved tremendous success in various applications, they are also susceptible to jailbreaking attacks. Several primary defense strategies have been proposed to protect LLMs from producing harmful information, mostly focusing on model fine-tuning or heuristical defense designs. However, how to achieve intrinsic robustness through prompt optimization remains an open problem. In this paper, motivated by adversarial training paradigms for achieving reliable robustness, we propose an approach named **Prompt Adversarial Tuning (PAT)** that trains a prompt control attached to the user prompt as a guard prefix. To achieve our defense goal whilst maintaining natural performance, we optimize the control prompt with both adversarial and benign prompts. Comprehensive experiments show that our method is effective against both grey-box and black-box attacks, reducing the success rate of advanced attacks to nearly 0, while maintaining the model's utility on the benign task and incurring only negligible computational overhead, charting a new perspective for future explorations in LLM security. Our code is available at https://github.com/PKU-ML/PAT.

Vision-language foundation models (such as CLIP) have recently shown their power in transfer learning, owing to large-scale image-text pre-training. However, target domain data in the downstream tasks can be highly different from the pre-training phase, which makes it hard for such a single model to generalize well. Alternatively, there exists a wide range of expert models that contain diversified vision and/or language knowledge pre-trained on different modalities, tasks, networks, and datasets. Unfortunately, these models are "isolated agents" with heterogeneous structures, and how to integrate their knowledge for generalizing CLIP-like models has not been fully explored. To bridge this gap, we propose a general and concise TransAgent framework, which transports the knowledge of the isolated agents in a unified manner, and effectively guides CLIP to generalize with multi-source knowledge distillation. With such a distinct framework, we flexibly collaborate with 11 heterogeneous agents to empower vision-language foundation models, without further cost in the inference phase. Finally, our TransAgent achieves state-of-the-art performance on 11 visual recognition datasets. Under the same low-shot setting, it outperforms the popular CoOp with around 10\% on average, and 20\% on EuroSAT which contains large domain shifts.
tl;dr: A high-capacity image restoration model trained on large-scale, privacy-safe high-quality image dataset

Image restoration (IR) in real-world scenarios presents significant challenges due to the lack of high-capacity models and comprehensive datasets.
To tackle these issues, we present a dual strategy: GenIR, an innovative data curation pipeline, and DreamClear, a cutting-edge Diffusion Transformer (DiT)-based image restoration model.
**GenIR**, our pioneering contribution, is a dual-prompt learning pipeline that overcomes the limitations of existing datasets, which typically comprise only a few thousand images and thus offer limited generalizability for larger models.
GenIR streamlines the process into three stages: image-text pair construction, dual-prompt based fine-tuning, and data generation \& filtering. This approach circumvents the laborious data crawling process, ensuring copyright compliance and providing a cost-effective, privacy-safe solution for IR dataset construction. The result is a large-scale dataset of one million high-quality images.
Our second contribution, **DreamClear**, is a DiT-based image restoration model. It utilizes the generative priors of text-to-image (T2I) diffusion models and the robust perceptual capabilities of multi-modal large language models (MLLMs) to achieve photorealistic restoration. To boost the model's adaptability to diverse real-world degradations, we introduce the Mixture of Adaptive Modulator (MoAM). It employs token-wise degradation priors to dynamically integrate various restoration experts, thereby expanding the range of degradations the model can address.
Our exhaustive experiments confirm DreamClear's superior performance, underlining the efficacy of our dual strategy for real-world image restoration. Code and pre-trained models are available at: https://github.com/shallowdream204/DreamClear.

Monocular depth estimation (MDE) is fundamental for deriving 3D scene structures from 2D images. While state-of-the-art monocular relative depth estimation (MRDE) excels in estimating relative depths for in-the-wild images, current monocular metric depth estimation (MMDE) approaches still face challenges in handling unseen scenes. Since MMDE can be viewed as the composition of MRDE and metric scale recovery, we attribute this difficulty to scene dependency, where MMDE models rely on scenes observed during supervised training for predicting scene scales during inference. To address this issue, we propose to use humans as landmarks for distilling scene-independent metric scale priors from generative painting models. Our approach, Metric from Human (MfH), bridges from generalizable MRDE to zero-shot MMDE in a generate-and-estimate manner. Specifically, MfH generates humans on the input image with generative painting and estimates human dimensions with an off-the-shelf human mesh recovery (HMR) model. Based on MRDE predictions, it propagates the metric information from painted humans to the contexts, resulting in metric depth estimations for the original input. Through this annotation-free test-time adaptation, MfH achieves superior zero-shot performance in MMDE, demonstrating its strong generalization ability.

As Large Language Models (LLMs) are increasingly deployed in specialized domains with continuously evolving knowledge, the need for timely and precise knowledge injection has become essential. Fine-tuning with paraphrased data is a common approach to enhance knowledge injection, yet it faces two significant challenges: high computational costs due to repetitive external model usage and limited sample diversity.
To this end, we introduce LaPael, a latent-level paraphrasing method that applies input-dependent noise to early LLM layers.
This approach enables diverse and semantically consistent augmentations directly within the model. Furthermore, it eliminates the recurring costs of paraphrase generation for each knowledge update.
Our extensive experiments on question-answering benchmarks demonstrate that LaPael improves knowledge injection over standard fine-tuning and existing noise-based approaches.
Additionally, combining LaPael with data-level paraphrasing further enhances performance.
tl;dr: DistillNeRF, perceiving/reconstructing the 3D driving world without any labels or per-scene training!

We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in outdoor autonomous driving scenes. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs with limited view overlap, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets from them, which helps our model to learn enhanced 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes and Waymo NOTR datasets demonstrate that DistillNeRF significantly outperforms existing comparable state-of-the-art self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.

We develop a neural network architecture which, trained in an unsupervised manner as a denoising diffusion model, simultaneously learns to both generate and segment images. Learning is driven entirely by the denoising diffusion objective, without any annotation or prior knowledge about regions during training. A computational bottleneck, built into the neural architecture, encourages the denoising network to partition an input into regions, denoise them in parallel, and combine the results. Our trained model generates both synthetic images and, by simple examination of its internal predicted partitions, semantic segmentations of those images. Without fine-tuning, we directly apply our unsupervised model to the downstream task of segmenting real images via noising and subsequently denoising them. Experiments demonstrate that our model achieves accurate unsupervised image segmentation and high-quality synthetic image generation across multiple datasets.
tl;dr: we present a novel 4D generation pipeline, 4Diffusion, to create high-quality spatial-temporally consistent 4D content from a monocular video.

Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely $\textbf{4Diffusion}$, aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
tl;dr: This paper proposes computationally efficient Metropolis-Hastings algorithm for private best subset selection in high-dimensional sparse regression setup.

We consider the problem of model selection in a high-dimensional sparse linear regression model under privacy constraints. We propose a differentially private (DP) best subset selection method with strong statistical utility properties by adopting the well-known exponential mechanism for selecting the best model. To achieve computational expediency, we propose an efficient Metropolis-Hastings algorithm and under certain regularity conditions, we establish that it enjoys polynomial mixing time to its stationary distribution. As a result, we also establish both approximate differential privacy and statistical utility for the estimates of the mixed Metropolis-Hastings chain. Finally, we perform some illustrative experiments on simulated data showing that our algorithm can quickly identify active features under reasonable privacy budget constraints.

Distributed learning is essential for training large-scale deep models.
Asynchronous SGD (ASGD) and its variants are commonly used distributed learning methods, particularly in scenarios where the computing capabilities of workers in the cluster are heterogeneous.
Momentum has been acknowledged for its benefits in both optimization and generalization in deep model training. However, existing works have found that naively incorporating momentum into ASGD can impede the convergence.
In this paper, we propose a novel method called ordered momentum (OrMo) for ASGD. In OrMo, momentum is incorporated into ASGD by organizing the gradients in order based on their iteration indexes. We theoretically prove the convergence of OrMo with both constant and delay-adaptive learning rates for non-convex problems. To the best of our knowledge, this is the first work to establish the convergence analysis of ASGD with momentum without dependence on the maximum delay. Empirical results demonstrate that OrMo can achieve better convergence performance compared with ASGD and other asynchronous methods with momentum.
tl;dr: Dyanmic template-free NeRF for 3D semantic reconstruction of multiple entities interactions

Despite advancements in Neural Implicit models for 3D surface reconstruction, handling dynamic environments with interactions between arbitrary rigid, non-rigid, or deformable entities remains challenging. The generic reconstruction methods adaptable to such dynamic scenes often require additional inputs like depth or optical flow or rely on pre-trained image features for reasonable outcomes. These methods typically use latent codes to capture frame-by-frame deformations. Another set of dynamic scene reconstruction methods, are entity-specific, mostly focusing on humans, and relies on template models. In contrast, some template-free methods bypass these requirements and adopt traditional LBS (Linear Blend Skinning) weights for a detailed representation of deformable object motions,
although they involve complex optimizations leading to lengthy training times. To this end, as a remedy, this paper introduces TFS-NeRF, a template-free 3D semantic NeRF for dynamic scenes captured from sparse or single-view RGB videos, featuring interactions among two entities and more time-efficient than other LBS-based approaches. Our framework uses an Invertible Neural Network (INN) for LBS prediction, simplifying the training process. By disentangling the motions of interacting entities and optimizing per-entity skinning weights, our method efficiently generates accurate, semantically separable geometries. Extensive experiments demonstrate that our approach produces high-quality reconstructions of both deformable and non-deformable objects in complex interactions, with improved
training efficiency compared to existing methods. The code and models will be available on our github page.
tl;dr: We build an EEG-video dataset and propose a framework to generate videos from EEG signals, taking an important step towards decoding dynamic visual perception from EEG.

Our visual experience in daily life are dominated by dynamic change. Decoding such dynamic information from brain activity can enhance the understanding of the brain’s visual processing system. However, previous studies predominately focus on reconstructing static visual stimuli. In this paper, we explore to decode dynamic visual perception from electroencephalography (EEG), a neuroimaging technique able to record brain activity with high temporal resolution (1000 Hz) for capturing rapid changes in brains. Our contributions are threefold: Firstly, we develop a large dataset recording signals from 20 subjects while they were watching 1400 dynamic video clips of 40 concepts. This dataset fills the gap in the lack of EEG-video pairs. Secondly, we annotate each video clips to investigate the potential for decoding some specific meta information (e.g., color, dynamic, human or not) from EEG. Thirdly, we propose a novel baseline EEG2Video for video reconstruction from EEG signals that better aligns dynamic movements with high temporal resolution brain signals by Seq2Seq architecture. EEG2Video achieves a 2-way accuracy of 79.8% in semantic classification tasks and 0.256 in structural similarity index (SSIM). Overall, our works takes an important step towards decoding dynamic visual perception from EEG signals. Our dataset and code will be released soon.

The paper proposes a novel evaluation metric for automatic medical report generation from X-ray images, VLScore. It aims to overcome the limitations of existing evaluation methods, which either focus solely on textual similarities, ignoring clinical aspects, or concentrate only on a single clinical aspect, the pathology, neglecting all other factors. The key idea of our metric is to measure the similarity between radiology reports while considering the corresponding image. We demonstrate the benefit of our metric through evaluation on a dataset where radiologists marked errors in pairs of reports, showing notable alignment with radiologists' judgments. In addition, we provide a new dataset for evaluating metrics. This dataset includes well-designed perturbations that distinguish between significant modifications (e.g., removal of a diagnosis) and insignificant ones. It highlights the weaknesses in current evaluation metrics and provides a clear framework for analysis.

Efficient transfer learning has shown remarkable performance in tuning large-scale vision-language models (VLMs) toward downstream tasks with limited data resources. The key challenge of efficient transfer lies in adjusting image-text alignment to be task-specific while preserving pre-trained general knowledge. However, existing methods adjust image-text alignment merely on a set of observed samples, e.g., data set and external knowledge base, which cannot guarantee to keep the correspondence of general concepts between image and text latent manifolds without being disrupted and thereby a weak generalization of the adjusted alignment. In this work, we propose a Homology Consistency (HC) constraint for efficient transfer on VLMs, which explicitly constrains the correspondence of image and text latent manifolds through structural equivalence based on persistent homology in downstream tuning. Specifically, we build simplicial complex on the top of data to mimic the topology of latent manifolds, then track the persistence of the homology classes of topological features across multiple scales, and guide the directions of persistence tracks in image and text manifolds to coincide each other, with a deviating perturbation additionally. For practical application, we tailor the implementation of our proposed HC constraint for two main paradigms of adapter tuning. Extensive experiments on few-shot learning over 11 datasets and domain generalization demonstrate the effectiveness and robustness of our method.
tl;dr: We propose an efficient gradient-free decoder inversion for LDMs for ensuring invertible latent diffusion model, which significantly reduced runtime and memory usage compared to gradient-based methods in various recent LDMs.

In latent diffusion models (LDMs), denoising diffusion process efficiently takes place on latent space whose dimension is lower than that of pixel space. Decoder is typically used to transform the representation in latent space to that in pixel space. While a decoder is assumed to have an encoder as an accurate inverse, exact encoder-decoder pair rarely exists in practice even though applications often require precise inversion of decoder. In other words, encoder is not the left-inverse but the right-inverse of the decoder; decoder inversion seeks the left-inverse. Prior works for decoder inversion in LDMs employed gradient descent inspired by inversions of generative adversarial networks. However, gradient-based methods require larger GPU memory and longer computation time for larger latent space. For example, recent video LDMs can generate more than 16 frames, but GPUs with 24 GB memory can only perform gradient-based decoder inversion for 4 frames. Here, we propose an efficient gradient-free decoder inversion for LDMs, which can be applied to diverse latent models. Theoretical convergence property of our proposed inversion has been investigated not only for the forward step method, but also for the inertial Krasnoselskii-Mann (KM) iterations under mild assumption on cocoercivity that is satisfied by recent LDMs. Our proposed gradient-free method with Adam optimizer and learning rate scheduling significantly reduced computation time and memory usage over prior gradient-based methods and enabled efficient computation in applications such as noise-space watermarking and background-preserving image editing while achieving comparable error levels.
tl;dr: New metrics inspired by cognitive nuroscience are proposed to evaluate

Accuracy is a commonly adopted performance metric in various classification tasks, which measures the proportion of correctly classified samples among all samples. It assumes equal importance for all classes, hence equal severity for misclassifications. However, in the task of emotional classification, due to the psychological similarities between emotions, misclassifying a certain emotion into one class may be more severe than another, e.g., misclassifying 'excitement' as 'anger' apparently is more severe than as 'awe'. Albeit high meaningful for many applications, metrics capable of measuring these cases of misclassifications in visual emotion recognition tasks have yet to be explored. In this paper, based on Mikel's emotion wheel from psychology, we propose a novel approach for evaluating the performance in visual emotion recognition, which takes into account the distance on the emotion wheel between different emotions to mimic the psychological nuances of emotions. Experimental results in semi-supervised learning on emotion recognition and user study have shown that our proposed metrics is more effective than the accuracy to assess the performance and conforms to the cognitive laws of human emotions. The code is available at https://github.com/ZhaoChenxi-nku/ECC.

Many few-shot segmentation (FSS) methods use cross attention to fuse support foreground (FG) into query features, regardless of the quadratic complexity. A recent advance Mamba can also well capture intra-sequence dependencies, yet the complexity is only linear. Hence, we aim to devise a cross (attention-like) Mamba to capture inter-sequence dependencies for FSS. A simple idea is to scan on support features to selectively compress them into the hidden state, which is then used as the initial hidden state to sequentially scan query features. Nevertheless, it suffers from (1) support forgetting issue: query features will also gradually be compressed when scanning on them, so the support features in hidden state keep reducing, and many query pixels cannot fuse sufficient support features; (2) intra-class gap issue: query FG is essentially more similar to itself rather than to support FG, i.e., query may prefer not to fuse support features but their own ones from the hidden state, yet the success of FSS relies on the effective use of support information. To tackle them, we design a hybrid Mamba network (HMNet), including (1) a support recapped Mamba to periodically recap the support features when scanning query, so the hidden state can always contain rich support information; (2) a query intercepted Mamba to forbid the mutual interactions among query pixels, and encourage them to fuse more support features from the hidden state. Consequently, the support information is better utilized, leading to better performance. Extensive experiments have been conducted on two public benchmarks, showing the superiority of HMNet. The code is available at https://github.com/Sam1224/HMNet.

While recent works on blind face image restoration have successfully produced impressive high-quality (HQ) images with abundant details from low-quality (LQ) input images, the generated content may not accurately reflect the real appearance of a person. To address this problem, incorporating well-shot personal images as additional reference inputs may be a promising strategy. Inspired by the recent success of the Latent Diffusion Model (LDM) in image generation, we propose ReF-LDM—an adaptation of LDM designed to generate HQ face images conditioned on one LQ image and multiple HQ reference images. Our LDM-based model incorporates an effective and efficient mechanism, CacheKV, for conditioning on reference images. Additionally, we design a timestep-scaled identity loss, enabling LDM to focus on learning the discriminating features of human faces. Lastly, we construct FFHQ-ref, a dataset consisting of 20,406 high-quality (HQ) face images with corresponding reference images, which can serve as both training and evaluation data for reference-based face restoration models.
tl;dr: We introduce a concept-based attack method using safety concept activation vectors (SCAVs) to efficiently attack well-aligned LLMs, revealing potential societal risks even after safety alignment.

Despite careful safety alignment, current large language models (LLMs) remain vulnerable to various attacks. To further unveil the safety risks of LLMs, we introduce a Safety Concept Activation Vector (SCAV) framework, which effectively guides the attacks by accurately interpreting LLMs' safety mechanisms. We then develop an SCAV-guided attack method that can generate both attack prompts and embedding-level attacks with automatically selected perturbation hyperparameters. Both automatic and human evaluations demonstrate that our attack method significantly improves the attack success rate and response quality while requiring less training data. Additionally, we find that our generated attack prompts may be transferable to GPT-4, and the embedding-level attacks may also be transferred to other white-box LLMs whose parameters are known. Our experiments further uncover the safety risks present in current LLMs. For example, in our evaluation of seven open-source LLMs, we observe an average attack success rate of 99.14%, based on the classic keyword-matching criterion. Finally, we provide insights into the safety mechanism of LLMs. The code is available at https://github.com/SproutNan/AI-Safety_SCAV.
3925. Bileve: Securing Text Provenance in Large Language Models Against Spoofing with Bi-level Signature

Text watermarks for large language models (LLMs) have been commonly used to identify the origins of machine-generated content, which is promising for assessing liability when combating deepfake or harmful content. While existing watermarking techniques typically prioritize robustness against removal attacks, unfortunately, they are vulnerable to spoofing attacks: malicious actors can subtly alter the meanings of LLM-generated responses or even forge harmful content, potentially misattributing blame to the LLM developer. To overcome this, we introduce a bi-level signature scheme, Bileve, which embeds fine-grained signature bits for integrity checks (mitigating spoofing attacks) as well as a coarse-grained signal to trace text sources when the signature is invalid (enhancing detectability) via a novel rank-based sampling strategy. Compared to conventional watermark detectors that only output binary results, Bileve can differentiate 5 scenarios during detection, reliably tracing text provenance and regulating LLMs. The experiments conducted on OPT-1.3B and LLaMA-7B demonstrate the effectiveness of Bileve in defeating spoofing attacks with enhanced detectability.
tl;dr: A novel noise regularization approach is developed to prevent deep canonical correlation analysis-based methods from model collapse.

Multi-View Representation Learning (MVRL) aims to learn a unified representation of an object from multi-view data.
Deep Canonical Correlation Analysis (DCCA) and its variants share simple formulations and demonstrate state-of-the-art performance. However, with extensive experiments, we observe the issue of model collapse, i.e., the performance of DCCA-based methods will drop drastically when training proceeds. The model collapse issue could significantly hinder the wide adoption of DCCA-based methods because it is challenging to decide when to early stop. To this end, we develop NR-DCCA, which is equipped with a novel noise regularization approach to prevent model collapse. Theoretical analysis shows that the Correlation Invariant Property is the key to preventing model collapse, and our noise regularization forces the neural network to possess such a property. A framework to construct synthetic data with different common and complementary information is also developed to compare MVRL methods comprehensively. The developed NR-DCCA outperforms baselines stably and consistently in both synthetic and real-world datasets, and the proposed noise regularization approach can also be generalized to other DCCA-based methods such as DGCCA.
tl;dr: This paper establishes the assumptions and conditions under which either classical and deep-learning image registration algorithms surpass each other

Classical optimization and learning-based methods are the two reigning paradigms in deformable image registration. While optimization-based methods boast generalizability across modalities and robust performance, learning-based methods promise peak performance, incorporating weak supervision and amortized optimization. However, the exact conditions for either paradigm to perform well over the other are shrouded and not explicitly outlined in the existing literature. In this paper, we make an explicit correspondence between the mutual information of the distribution of per-pixel intensity and labels, and the performance of classical registration methods. This strong correlation hints to the fact that architectural designs in learning-based methods is unlikely to affect this correlation, and therefore, the performance of learning-based methods. This hypothesis is thoroughly validated with state-of-the-art classical and learning-based methods. However, learning-based methods with weak supervision can perform high-fidelity intensity and label registration, which is not possible with classical methods. Next, we show that this high-fidelity feature learning does not translate to invariance to domain shift, and learning-based methods are sensitive to such changes in the data distribution. We reassess and recalibrate performance expectations from classical and DLIR methods under access to label supervision, training time, and its generalization capabilities under minor domain shifts.
tl;dr: Hierarchical representation and generative model architecture designs for 3D strand-based human hair geometry in flexible amount and density, with the DCT frequency decomposition and optimal sampling.

We introduce a doubly hierarchical generative representation for strand-based hair geometry that progresses from coarse, low-pass filtered guide hair to densely populated hair strands rich in high-frequency details. We employ the Discrete Cosine Transform (DCT) to separate low-frequency structural curves from high-frequency curliness and noise, avoiding the Gibbs' oscillation issues associated with the standard Fourier transform in open curves. Unlike the guide hair sampled from the scalp UV map grids which may lose capturing details of the hairstyle in existing methods, our method samples optimal sparse guide strands by utilizing $k$-medoids clustering centres from low-pass filtered dense strands, which more accurately retain the hairstyle's inherent characteristics. The proposed variational autoencoder-based generation network, with an architecture inspired by geometric deep learning and implicit neural representations, facilitates flexible, off-the-grid guide strand modelling and enables the completion of dense strands in any quantity and density, drawing on principles from implicit neural representations. Empirical evaluations confirm the capacity of the model to generate convincing guide hair and dense strands, complete with nuanced high-frequency details.

We introduce Learning from Offline Foundation Features with Tensor Augmentations (LOFF-TA), an efficient training scheme designed to harness the capabilities of foundation models in limited resource settings where their direct development is not feasible. LOFF-TA involves training a compact classifier on cached feature embeddings from a frozen foundation model, resulting in up to $37\times$ faster training and up to $26\times$ reduced GPU memory usage. Because the embeddings of augmented images would be too numerous to store, yet the augmentation process is essential for training, we propose to apply tensor augmentations to the cached embeddings of the original non-augmented images. LOFF-TA makes it possible to leverage the power of foundation models, regardless of their size, in settings with limited computational capacity. Moreover, LOFF-TA can be used to apply foundation models to high-resolution images without increasing compute. In certain scenarios, we find that training with LOFF-TA yields better results than directly fine-tuning the foundation model.

Recent work demonstrates that, post-training large language models with open-domain instruction following data have achieved colossal success. Simultaneously, human Chatbot Arena has emerged as one of the most reasonable benchmarks for model evaluation and developmental guidance. However, the processes of manually curating high-quality training data and utilizing online human evaluation platforms are both expensive and limited. To mitigate the manual and temporal costs associated with post-training, this paper introduces a Simulated Chatbot Arena named WizardArena, which is fully based on and powered by open-source LLMs. For evaluation scenario, WizardArena can efficiently predict accurate performance rankings among different models based on offline test set. For training scenario, we simulate arena battles among various state-of-the-art models on a large scale of instruction data, subsequently leveraging the battle results to constantly enhance target model in both the supervised fine-tuning and reinforcement learning . Experimental results demonstrate that our WizardArena aligns closely with the online human arena rankings, and our models trained on offline extensive battle data exhibit significant performance improvements during SFT, DPO, and PPO stages.
tl;dr: To achieve the best performance (for mathematical reasoning), more correct responses for difficult queries are crucial.

Solving mathematical problems requires advanced reasoning abilities and presents notable challenges for large language models. Previous works usually synthesize data from proprietary models to augment existing datasets, followed by instruction tuning to achieve top-tier results. However, our analysis of these datasets reveals severe biases towards easy queries, with frequent failures to generate any correct response for the most challenging queries.
Hypothesizing that difficult queries are crucial to learning complex reasoning, we propose *Difficulty-Aware Rejection Tuning* (`DART`), a method that allocates difficult queries more trials during the synthesis phase, enabling more extensive training on difficult samples.
Utilizing `DART`, we have created new datasets for mathematical problem-solving that focus more on difficult queries and are substantially smaller than previous ones. Remarkably, our synthesis process solely relies on a 7B-sized open-weight model, without reliance on the commonly used proprietary GPT-4.
We fine-tune various base models on our datasets ranging from 7B to 70B in size, resulting in a series of strong models called `DART-Math`.
In comprehensive in-domain and out-of-domain evaluation on 6 mathematical benchmarks, `DART-Math` outperforms vanilla rejection tuning significantly, being superior or comparable to previous arts, despite using much smaller datasets and no proprietary models. Furthermore, our results position our synthetic datasets as the most effective and cost-efficient publicly available resources for advancing mathematical problem-solving. Our datasets, models and code are publicly available at https://github.com/hkust-nlp/dart-math.
tl;dr: Segment objects from complex textual prompts using neuro-symbolic reasoning with large-scale neural networks.

Large-scale, pre-trained neural networks have demonstrated strong capabilities in various tasks, including zero-shot image segmentation. To identify concrete objects in complex scenes, humans instinctively rely on deictic descriptions in natural language, i.e., referring to something depending on the context such as "The object that is on the desk and behind the cup.". However, deep learning approaches cannot reliably interpret such deictic representations due to their lack of reasoning capabilities in complex scenarios. To remedy this issue, we propose DeiSAM — a combination of large pre-trained neural networks with differentiable logic reasoners — for deictic promptable segmentation. Given a complex, textual segmentation description, DeiSAM leverages Large Language Models (LLMs) to generate first-order logic rules and performs differentiable forward reasoning on generated scene graphs. Subsequently, DeiSAM segments objects by matching them to the logically inferred image regions. As part of our evaluation, we propose the Deictic Visual Genome (DeiVG) dataset, containing paired visual input and complex, deictic textual prompts. Our empirical results demonstrate that DeiSAM is a substantial improvement over purely data-driven baselines for deictic promptable segmentation.

Monte-Carlo tree search (MCTS) is an influential sequential decision-making algorithm notably employed in AlphaZero. Despite its success, the primary challenge in AlphaZero training lies in its prolonged time-to-solution due to the high latency imposed by the sequential MCTS process. To address this challenge, this paper proposes and evaluates an inter-decision parallelization strategy called speculative MCTS, a new type of parallelism in AlphaZero which implements speculative execution. This approach allows for the parallel execution of future moves before the current MCTS computations are completed, thus reducing the latency. Additionally, we analyze factors contributing to the overall speedup by studying the synergistic effects of speculation and neural network caching in MCTS. We also provide an analytical model that can be used to evaluate the potential of different speculation strategies before they are implemented and deployed. Our empirical findings indicate that the proposed speculative MCTS can reduce training latency by 5.81$\times$ in 9x9 Go games. Moreover, our study shows that speculative execution can enhance the NN cache hit rate by 26\% during midgame. Overall, our end-to-end evaluation indicates 1.91$\times$ speedup in 19x19 Go training time, compared to the state-of-the-art KataGo program.
tl;dr: Discussions on current temporal modeling mechanisms; a novel temporal information learning paradigm for radar semantic segmentation.

Radar signal interpretation plays a crucial role in remote detection and ranging. With the gradual display of the advantages of neural network technology in signal processing, learning-based radar signal interpretation is becoming a research hot-spot and made great progress. And since radar semantic segmentation (RSS) can provide more fine-grained target information, it has become a more concerned direction in this field. However, the temporal information, which is an important clue for analyzing radar data, has not been exploited sufficiently in present RSS frameworks. In this work, we propose a novel temporal information learning paradigm, i.e., data-driven temporal information aggregation with learned target-history relations. Following this idea, a flexible learning module, called Temporal Relation-Aware Module (TRAM) is carefully designed. TRAM contains two main blocks: i) an encoder for capturing the target-history temporal relations (TH-TRE) and ii) a learnable temporal relation attentive pooling (TRAP) for aggregating temporal information. Based on TRAM, an end-to-end Temporal-Aware RSS Network (TARSS-Net) is presented, which has outstanding performance on publicly available and our collected real-measured datasets. Code and supplementary materials are available at https://github.com/zlw9161/TARSS-Net.
3935. PureGen: Universal Data Purification for Train-Time Poison Defense via Generative Model Dynamics
tl;dr: A universal, SoTA set of train-time poison defense pre-processing techniques using specially trained Energy Based and Denoising Diffusion Models.

Train-time data poisoning attacks threaten machine learning models by introducing adversarial examples during training, leading to misclassification. Current defense methods often reduce generalization performance, are attack-specific, and impose significant training overhead. To address this, we introduce a set of universal data purification methods using a stochastic transform, $\Psi(x)$, realized via iterative Langevin dynamics of Energy-Based Models (EBMs), Denoising Diffusion Probabilistic Models (DDPMs), or both. These approaches purify poisoned data with minimal impact on classifier generalization. Our specially trained EBMs and DDPMs provide state-of-the-art defense against various attacks (including Narcissus, Bullseye Polytope, Gradient Matching) on CIFAR-10, Tiny-ImageNet, and CINIC-10, without needing attack or classifier-specific information. We discuss performance trade-offs and show that our methods remain highly effective even with poisoned or distributionally shifted generative model training data.
tl;dr: We explore the training-free diffusion acceleration that dynamically selects the denoising path according to given prompts. We design the third-order estimator to indicate the computation redundancy.

Diffusion models have recently achieved great success in the synthesis of high-quality images and videos. However, the existing denoising techniques in diffusion models are commonly based on step-by-step noise predictions, which suffers from high computation cost, resulting in a prohibitive latency for interactive applications. In this paper, we propose AdaptiveDiffusion to relieve this bottleneck by adaptively reducing the noise prediction steps during the denoising process. Our method considers the potential of skipping as many noise prediction steps as possible while keeping the final denoised results identical to the original full-step ones. Specifically, the skipping strategy is guided by the third-order latent difference that indicates the stability between timesteps during the denoising process, which benefits the reusing of previous noise prediction results. Extensive experiments on image and video diffusion models demonstrate that our method can significantly speed up the denoising process while generating identical results to the original process, achieving up to an average 2-5x speedup without quality degradation. The code is available at https://github.com/UniModal4Reasoning/AdaptiveDiffusion
tl;dr: PowerPM is a foundation model for power systems.

The proliferation of abundant electricity time series (ETS) data presents numerous opportunities for various applications within power systems, including demand-side management, grid stability, and consumer behavior analysis. Deep learning models have advanced ETS modeling by effectively capturing sequence dependence. However, learning a generic representation of ETS data for various applications is challenging due to the inherently complex hierarchical structure of ETS data. Moreover, ETS data exhibits intricate temporal dependencies and is susceptible to the influence of exogenous variables. Furthermore, different instances exhibit diverse electricity consumption behavior. In this paper, we propose a foundation model PowerPM for ETS data, providing a large-scale, off-the-shelf model for power systems. PowerPM consists of a temporal encoder and a hierarchical encoder. The temporal encoder captures temporal dependencies within ETS data, taking into account exogenous variables. The hierarchical encoder models correlations between different levels of hierarchy. Furthermore, PowerPM leverages a novel self-supervised pre-training framework consisting of masked ETS modeling and dual-view contrastive learning. This framework enables PowerPM to capture temporal dependency within ETS windows and aware the discrepancy across ETS windows, providing two different perspectives to learn generic representation. Our experiments span five real-world scenario datasets, including both private and public data. Through pre-training on massive ETS data, PowerPM achieves SOTA
performance on diverse downstream tasks within the private dataset. Notably, when transferred to public datasets, PowerPM retains its edge, showcasing its remarkable generalization ability across various tasks and domains. Moreover, ablation studies and few-shot experiments further substantiate the effectiveness of our model.
3938. Absorb & Escape: Overcoming Single Model Limitations in Generating Heterogeneous Genomic Sequences
tl;dr: This paper proposes a post-training sampling method to perform compositional generation from autoRegressive mdoels and diffusion models for DNA generation.

Recent advances in immunology and synthetic biology have accelerated the development of deep generative methods for DNA sequence design. Two dominant approaches in this field are AutoRegressive (AR) models and Diffusion Models (DMs). However, genomic sequences are functionally heterogeneous, consisting of multiple connected regions (e.g., Promoter Regions, Exons, and Introns) where elements within each region come from the same probability distribution, but the overall sequence is non-homogeneous. This heterogeneous nature presents challenges for a single model to accurately generate genomic sequences. In this paper, we analyze the properties of AR models and DMs in heterogeneous genomic sequence generation, pointing out crucial limitations in both methods: (i) AR models capture the underlying distribution of data by factorizing and learning the transition probability but fail to capture the global property of DNA sequences. (ii) DMs learn to recover the global distribution but tend to produce errors at the base pair level. To overcome the limitations of both approaches, we propose a post-training sampling method, termed Absorb & Escape (A&E) to perform compositional generation from AR models and DMs. This approach starts with samples generated by DMs and refines the sample quality using an AR model through the alternation of the Absorb and Escape steps. To assess the quality of generated sequences, we conduct extensive experiments on 15 species for conditional and unconditional DNA generation. The experiment results from motif distribution, diversity checks, and genome integration tests unequivocally show that A&E outperforms state-of-the-art AR models and DMs in genomic sequence generation. A&E does not suffer from the slowness of traditional MCMC to sample from composed distributions with Energy-Based Models whilst it obtains higher quality samples than single models. Our research sheds light on the limitations of current single-model approaches in DNA generation and provides a simple but effective solution for heterogeneous sequence generation. Code is available at the [Github Repo](https://github.com/Zehui127/Absorb-Escape).

In tabular prediction tasks, tree-based models combined with automated feature engineering methods often outperform deep learning approaches that rely on learned representations. While these feature engineering techniques are effective, they typically depend on a pre-defined search space and primarily use validation scores for feature selection, thereby missing valuable insights from previous experiments.
To address these limitations, we propose a novel tabular learning framework that utilizes large language models (LLMs), termed Optimizing Column feature generator with decision Tree reasoning (OCTree). Our key idea is to leverage the reasoning capabilities of LLMs to identify effective feature generation rules without manually specifying the search space and provide language-based reasoning information highlighting past experiments as feedback for iterative rule improvements. We use decision trees to convey this reasoning information, as they can be easily represented in natural language, effectively providing knowledge from prior experiments (i.e., the impact of the generated features on performance) to the LLMs. Our empirical results demonstrate that OCTree consistently enhances the performance of various prediction models across diverse benchmarks, outperforming competing automated feature engineering methods. Code is available at https://github.com/jaehyun513/OCTree.
tl;dr: We introduce the first provably convergent oracle-free algorithms for distributional reinforcement learning with multivariate reward functions.

In reinforcement learning (RL), the consideration of multivariate reward signals has led to fundamental advancements in multi-objective decision-making, transfer learning, and representation learning. This work introduces the first oracle-free and computationally-tractable algorithms for provably convergent multivariate *distributional* dynamic programming and temporal difference learning. Our convergence rates match the familiar rates in the scalar reward setting, and additionally provide new insights into the fidelity of approximate return distribution representations as a function of the reward dimension. Surprisingly, when the reward dimension is larger than $1$, we show that standard analysis of categorical TD learning fails, which we resolve with a novel projection onto the space of mass-$1$ signed measures. Finally, with the aid of our technical results and simulations, we identify tradeoffs between distribution representations that influence the performance of multivariate distributional RL in practice.

Human life is populated with articulated objects. Pose estimation for category-level articulated objects is a significant challenge due to their inherent complexity and diverse kinematic structures. Current methods for this task usually meet the problems of insufficient consideration of kinematic constraints, self-occlusion, and optimization requirements. In this paper, we propose EfficientCAPER, an end-to-end Category-level Articulated object Pose EstimatoR, eliminating the need for optimization functions as post-processing and utilizing the kinematic structure for joint-centric pose modeling, thus enhancing the efficiency and applicability. Given a partial point cloud as input, the EfficientCAPER firstly estimates the pose for the free part of an articulated object using decoupled rotation representation. Next, we canonicalize the input point cloud to estimate constrained parts' poses by predicting the joint parameters and states as replacements. Evaluations on three diverse datasets, ArtImage, ReArtMix, and RobotArm, show EfficientCAPER's effectiveness and generalization ability to real-world scenarios. The framework exhibits excellent static pose estimation performance for articulated objects, contributing to the advancement of category-level pose estimation. Codes will be made publicly available.

This paper proposes a fast and general-purpose image restoration method. The key idea is to achieve few-step or even one-step inference by conducting consistency distilling or training on a specific mean-reverting stochastic differential equations. Furthermore, based on this, we propose a novel linear-nonlinear decoupling training strategy, significantly enhancing training effectiveness and surpassing consistency distillation on inference performance. This allows our method to be independent of any pre-trained checkpoint, enabling it to serve as an effective standalone image-to-image transformation model. Finally, to avoid trivial solutions and stabilize model training, we introduce a simple origin-guided loss. To validate the effectiveness of our proposed method, we conducted experiments on tasks including image deraining, denoising, deblurring, and low-light image enhancement. The experiments show that our method achieves highly competitive results with only one-step inference. And with just two-step inference, it can achieve state-of-the-art performance in low-light image enhancement. Furthermore, a number of ablation experiments demonstrate the effectiveness of the proposed training strategy. our code is available at https://github.com/XiaoxuanGong/IR-CM.
tl;dr: We propose a pessimistic backward policy for GFlowNets to resolve the under-exploitation problem of backward policy-based flow matching.

This paper studies Generative Flow Networks (GFlowNets), which learn to sample objects proportionally to a given reward function through the trajectory of state transitions. In this work, we observe that GFlowNets tend to under-exploit the high-reward objects due to training on insufficient number of trajectories, which may lead to a large gap between the estimated flow and the (known) reward value. In response to this challenge, we propose a pessimistic backward policy for GFlowNets (PBP-GFN), which maximizes the observed flow to align closely with the true reward for the object. We extensively evaluate PBP-GFN across eight benchmarks, including hyper-grid environment, bag generation, structured set generation, molecular generation, and four RNA sequence generation tasks. In particular, PBP-GFN enhances the discovery of high-reward objects, maintains the diversity of the objects, and consistently outperforms existing methods.
tl;dr: We propose context-specific preference datasets and conduct experiments to investigate the potential of context-specific preference modeling.

While finetuning language models from pairwise preferences has proven remarkably effective, the underspecified nature of natural language presents critical challenges. Direct preference feedback is uninterpretable, difficult to provide where multidimensional criteria may apply, and often inconsistent, either because it is based on incomplete instructions or provided by diverse principals. To address these challenges, we consider the two-step preference modeling procedure that first resolves the under-specification by selecting a context, and then evaluates preference with respect to the chosen context. We decompose reward modeling error according to these two steps, which suggests that supervising context in addition to context-specific preference may be a viable approach to aligning models with diverse human preferences. For this to work, the ability of models to evaluate context-specific preference is critical. To this end, we contribute context-conditioned preference datasets and accompanying experiments that investigate the ability of language models to evaluate context-specific preference. Unlike past datasets, where context-specific preference is highly correlated with general preference, our "preference reversal" datasets disentangle context-specific and general preferences to isolate context-specific capabilities. We use our datasets to (1) show that existing preference models benefit from, but fail to fully consider, added context, (2) finetune a context-aware reward model with context-specific performance exceeding that of GPT-4 and Llama 3 70B, and (3) investigate the potential value of context-aware preference modeling.

Data augmentation creates new data points by transforming the original ones for an reinforcement learning (RL) agent to learn from, which has been shown to be effective for the objective of improving data efficiency of RL for continuous control. Prior work towards this objective has been largely restricted to perturbation-based data augmentation where new data points are created by perturbing the original ones,
which has been impressively effective for tasks where the RL agent observe control states as images with perturbations including random cropping, shifting, etc. This work focuses on state-based control, where the RL agent can directly observe raw kinematic and task features, and considers an alternative data augmentation applied to these features based on Euclidean symmetries under transformations like rotations. We show that the default state features used in exiting benchmark tasks that are based on joint configurations are not amenable to Euclidean transformations. We therefore advocate using state features based on configurations of the limbs (i.e., rigid bodies connected by joints) that instead provides rich augmented data under Euclidean transformations. With minimal hyperparameter tuning, we show this new Euclidean data augmentation strategy significantly improve both data efficiency and asymptotic performance of RL on a wide range of continuous control tasks.
tl;dr: We propose Immiscible Diffusion to increase the training efficiency up to 3x with only one line of code by noise assignment.

In this paper, we point out that suboptimal noise-data mapping leads to slow training of diffusion models. During diffusion training, current methods diffuse each image across the entire noise space, resulting in a mixture of all images at every point in the noise layer. We emphasize that this random mixture of noise-data mapping complicates the optimization of the denoising function in diffusion models. Drawing inspiration from the immiscibility phenomenon in physics, we propose *Immiscible Diffusion*, a simple and effective method to improve the random mixture of noise-data mapping. In physics, miscibility can vary according to various intermolecular forces. Thus, immiscibility means that the mixing of molecular sources is distinguishable. Inspired by this concept, we propose an assignment-then-diffusion training strategy to achieve *Immiscible Diffusion*. As one example, prior to diffusing the image data into noise, we assign diffusion target noise for the image data by minimizing the total image-noise pair distance in a mini-batch. The assignment functions analogously to external forces to expel the diffuse-able areas of images, thus mitigating the inherent difficulties in diffusion training. Our approach is remarkably simple, requiring only *one line of code* to restrict the diffuse-able area for each image while preserving the Gaussian distribution of noise. In this way, each image is preferably projected to nearby noise. To address the high complexity of the assignment algorithm, we employ a quantized assignment strategy, which significantly reduces the computational overhead to a negligible level (e.g. 22.8ms for a large batch size of 1024 on an A6000). Experiments demonstrate that our method can achieve up to 3x faster training for unconditional Consistency Models on the CIFAR dataset, as well as for DDIM and Stable Diffusion on CelebA and ImageNet dataset, and in class-conditional training and fine-tuning. In addition, we conducted a thorough analysis that sheds light on how it improves diffusion training speed while improving fidelity. The code is available at https://yhli123.github.io/immiscible-diffusion
tl;dr: We study graph transformers that are both theoretically grounded in the Weisfeiler-Leman hierarchy as well as perform comparative with state-of-the-art on graph learning benchmarks.

The expressive power of graph learning architectures based on the $k$-dimensional Weisfeiler-Leman ($k$-WL) hierarchy is well understood. However, such architectures often fail to deliver solid predictive performance on real-world tasks, limiting their practical impact. In contrast, global attention-based models such as graph transformers demonstrate strong performance in practice, but comparing their expressive power with the $k$-WL hierarchy remains challenging, particularly since these architectures rely on positional or structural encodings for their expressivity and predictive performance. To address this, we show that the recently proposed Edge Transformer, a global attention model operating on node pairs instead of nodes, has 3-WL expressive power when provided with the right tokenization. Empirically, we demonstrate that the Edge Transformer surpasses other theoretically aligned architectures regarding predictive performance while not relying on positional or structural encodings.
tl;dr: We provide theoretical support for image editing methods that involve solving fixed points of implicit functions, and improve the fixed point loss in image editing.

In image editing, Denoising Diffusion Implicit Models (DDIM) inversion has become a widely adopted method and is extensively used in various image editing approaches. The core concept of DDIM inversion stems from the deterministic sampling technique of DDIM, which allows the DDIM process to be viewed as an Ordinary Differential Equation (ODE) process that is reversible. This enables the prediction of corresponding noise from a reference image, ensuring that the restored image from this noise remains consistent with the reference image. Image editing exploits this property by modifying the cross-attention between text and images to edit specific objects while preserving the remaining regions. However, in the DDIM inversion, using the $t-1$ time step to approximate the noise prediction at time step $t$ introduces errors between the restored image and the reference image. Recent approaches have modeled each step of the DDIM inversion process as finding a fixed-point problem of an implicit function. This approach significantly mitigates the error in the restored image but lacks theoretical support regarding the existence of such fixed points. Therefore, this paper focuses on the study of fixed points in DDIM inversion and provides theoretical support. Based on the obtained theoretical insights, we further optimize the loss function for the convergence of fixed points in the original DDIM inversion, improving the visual quality of the edited image. Finally, we extend the fixed-point based image editing to the application of unsupervised image dehazing, introducing a novel text-based approach for unsupervised dehazing.

Recent research in tabular data synthesis has focused on single tables, whereas real-world applications often involve complex data with tens or hundreds of interconnected tables. Previous approaches to synthesizing multi-relational (multi-table) data fall short in two key aspects: scalability for larger datasets and capturing long-range dependencies, such as correlations between attributes spread across different tables. Inspired by the success of diffusion models in tabular data modeling, we introduce
\textbf{C}luster \textbf{La}tent \textbf{Va}riable guided \textbf{D}enoising \textbf{D}iffusion \textbf{P}robabilistic \textbf{M}odels (ClavaDDPM). This novel approach leverages clustering labels as intermediaries to model relationships between tables, specifically focusing on foreign key constraints. ClavaDDPM leverages the robust generation capabilities of diffusion models while incorporating efficient algorithms to propagate the learned latent variables across tables. This enables ClavaDDPM to capture long-range dependencies effectively.
Extensive evaluations on multi-table datasets of varying sizes show that ClavaDDPM significantly outperforms existing methods for these long-range dependencies while remaining competitive on utility metrics for single-table data.
tl;dr: We propose a universal few-shot learner for depth completion with arbitrary sensor.

Consistent depth estimation across diverse scenes and sensors is a crucial challenge in computer vision, especially when deploying machine learning models in the real world. Traditional methods depend heavily on extensive pixel-wise labeled data, which is costly and labor-intensive to acquire, and frequently have difficulty in scale issues on various depth sensors. In response, we define Universal Depth Completion (UniDC) problem. We also present a baseline architecture, a simple yet effective approach tailored to estimate scene depth across a wide range of sensors and environments using minimal labeled data.
Our approach addresses two primary challenges: generalizable knowledge of unseen scene configurations and strong adaptation to arbitrary depth sensors with various specifications. To enhance versatility in the wild, we utilize a foundation model for monocular depth estimation that provides a comprehensive understanding of 3D structures in scenes. Additionally, for fast adaptation to off-the-shelf sensors, we generate a pixel-wise affinity map based on the knowledge from the foundation model. We then adjust depth information from arbitrary sensors to the monocular depth along with the constructed affinity. Furthermore, to boost up both the adaptability and generality, we embed the learned features into hyperbolic space, which builds implicit hierarchical structures of 3D data from fewer examples. Extensive experiments demonstrate the proposed method's superior generalization capabilities for UniDC problem over state-of-the-art depth completion. Source code is publicly available at https://github.com/JinhwiPark/UniDC.

Test-time prompt tuning, which learns prompts online with unlabelled test samples during the inference stage, has demonstrated great potential by learning effective prompts on-the-fly without requiring any task-specific annotations. However, its performance often degrades clearly along the tuning process when the prompts are continuously updated with the test data flow, and the degradation becomes more severe when the domain of test samples changes continuously. We propose HisTPT, a Historical Test-time Prompt Tuning technique that memorizes the useful knowledge of the learnt test samples and enables robust test-time prompt tuning with the memorized knowledge. HisTPT introduces three types of knowledge banks, namely, local knowledge bank, hard-sample knowledge bank, and global knowledge bank, each of which works with different mechanisms for effective knowledge memorization and test-time prompt optimization. In addition, HisTPT features an adaptive knowledge retrieval mechanism that regularizes the prediction of each test sample by adaptively retrieving the memorized knowledge. Extensive experiments show that HisTPT achieves superior prompt tuning performance consistently while handling different visual recognition tasks (e.g., image classification, semantic segmentation, and object detection) and test samples from continuously changing domains.
tl;dr: AID (Attention Interpolation of Diffusion) is a method that enables the text-to-image diffusion model to generate interpolation between different conditions with high consistency, smoothness and fidelity

Conditional diffusion models can create unseen images in various settings, aiding image interpolation. Interpolation in latent spaces is well-studied, but interpolation with specific conditions like text or image is less understood. Common approaches interpolate linearly in the conditioning space but tend to result in inconsistent images with poor fidelity. This work introduces a novel training-free technique named \textbf{Attention Interpolation via Diffusion (AID)}. AID has two key contributions: \textbf{1)} a fused inner/outer interpolated attention layer to boost image consistency and fidelity; and \textbf{2)} selection of interpolation coefficients via a beta distribution to increase smoothness. Additionally, we present an AID variant called \textbf{Prompt-guided Attention Interpolation via Diffusion (PAID)}, which \textbf{3)} treats interpolation as a condition-dependent generative process. Experiments demonstrate that our method achieves greater consistency, smoothness, and efficiency in condition-based interpolation, aligning closely with human preferences. Furthermore, PAID offers substantial benefits for compositional generation, controlled image editing, image morphing and image-controlled generation, all while remaining training-free.

Although the performance of Temporal Action Segmentation (TAS) has been improved in recent years, achieving promising results often comes with a high computational cost due to dense inputs, complex model structures, and resource-intensive post-processing requirements. To improve the efficiency while keeping the high performance, we present a novel perspective centered on per-segment classification. By harnessing the capabilities of Transformers, we tokenize each video segment as an instance token, endowed with intrinsic instance segmentation. To realize efficient action segmentation, we introduce BaFormer, a boundary-aware Transformer network. It employs instance queries for instance segmentation and a global query for class-agnostic boundary prediction, yielding continuous segment proposals. During inference, BaFormer employs a simple yet effective voting strategy to classify boundary-wise segments based on instance segmentation. Remarkably, as a single-stage approach, BaFormer significantly reduces the computational costs, utilizing only 6% of the running time compared to the state-of-the-art method DiffAct, while producing better or comparable accuracy over several popular benchmarks. The code for this project is publicly available at https://github.com/peiyao-w/BaFormer.

Recent advances in text-to-image models have enabled high-quality personalized image synthesis based on user-provided concepts with flexible textual control. In this work, we analyze the limitations of two primary techniques in text-to-image personalization: Textual Inversion and DreamBooth. When integrating the learned concept into new prompts, Textual Inversion tends to overfit the concept, while DreamBooth often overlooks it. We attribute these issues to the incorrect learning of the embedding alignment for the concept. To address this, we introduce AttnDreamBooth, a novel approach that separately learns the embedding alignment, the attention map, and the subject identity across different training stages. We also introduce a cross-attention map regularization term to enhance the learning of the attention map. Our method demonstrates significant improvements in identity preservation and text alignment compared to the baseline methods.

In this paper, we introduce YOLA, a novel framework for object detection in low-light scenarios. Unlike previous works, we propose to tackle this challenging problem from the perspective of feature learning. Specifically, we propose to learn illumination-invariant features through the Lambertian image formation model. We observe that, under the Lambertian assumption, it is feasible to approximate illumination-invariant feature maps by exploiting the interrelationships between neighboring color channels and spatially adjacent pixels. By incorporating additional constraints, these relationships can be characterized in the form of convolutional kernels, which can be trained in a detection-driven manner within a network. Towards this end, we introduce a novel module dedicated to the extraction of illumination-invariant features from low-light images, which can be easily integrated into existing object detection frameworks. Our empirical findings reveal significant improvements in low-light object detection tasks, as well as promising results in both well-lit and over-lit scenarios.
3956. MO-DDN: A Coarse-to-Fine Attribute-based Exploration Agent for Multi-Object Demand-driven Navigation
tl;dr: We propose a multi-object demand-driven navigation benchmark and train an coarse-to-fine attribute-based exploration agent to solve this task.

The process of satisfying daily demands is a fundamental aspect of humans' daily lives. With the advancement of embodied AI, robots are increasingly capable of satisfying human demands. Demand-driven navigation (DDN) is a task in which an agent must locate an object to satisfy a specified demand instruction, such as "I am thirsty." The previous study typically assumes that each demand instruction requires only one object to be fulfilled and does not consider individual preferences. However, the realistic human demand may involve multiple objects. In this paper, we introduce the Multi-object Demand-driven Navigation (MO-DDN) benchmark, which addresses these nuanced aspects, including multi-object search and personal preferences, thus making the MO-DDN task more reflective of real-life scenarios compared to DDN. Building upon previous work, we employ the concept of ``attribute'' to tackle this new task. However, instead of solely relying on attribute features in an end-to-end manner like DDN, we propose a modular method that involves constructing a coarse-to-fine attribute-based exploration agent (C2FAgent). Our experimental results illustrate that this coarse-to-fine exploration strategy capitalizes on the advantages of attributes at various decision-making levels, resulting in superior performance compared to baseline methods. Code and video can be found at https://sites.google.com/view/moddn.
tl;dr: We present a multi-layer approach for text-to-image diffusion models that improves fine-grained control over object attributes and layout by generating isolated RGBA images and blending them into detailed composite scenes.

Text-to-image diffusion generative models can generate high quality images at the cost of tedious prompt engineering. Controllability can be improved by introducing layout conditioning, however existing methods lack layout editing ability and fine-grained control over object attributes. The concept of multi-layer generation holds great potential to address these limitations, however generating image instances concurrently to scene composition limits control over fine-grained object attributes, relative positioning in 3D space and scene manipulation abilities. In this work, we propose a novel multi-stage generation paradigm that is designed for fine-grained control, flexibility and interactivity. To ensure control over instance attributes, we devise a novel training paradigm to adapt a diffusion model to generate isolated scene components as RGBA images with transparency information. To build complex images, we employ these pre-generated instances and introduce a multi-layer composite generation process that smoothly assembles components in realistic scenes. Our experiments show that our RGBA diffusion model is capable of generating diverse and high quality instances with precise control over object attributes. Through multi-layer composition, we demonstrate that our approach allows to build and manipulate images from highly complex prompts with fine-grained control over object appearance and location, granting a higher degree of control than competing methods.
3958. Multi-hypotheses Conditioned Point Cloud Diffusion for 3D Human Reconstruction from Occluded Images

3D human shape reconstruction under severe occlusion due to human-object or human-human interaction is a challenging problem. While implicit function methods capture detailed clothed shapes, they require aligned shape priors and or are weak at inpainting occluded regions given an image input. Parametric models i.e. SMPL, instead offer whole body shapes, however, are often misaligned with images. In this work, we propose a novel pipeline composed of a probabilistic SMPL model and point cloud diffusion for pixel-aligned detailed 3D human reconstruction under occlusion. Multiple hypotheses generated by the probabilistic SMPL method are conditioned via continuous 3D shape representations. Point cloud diffusion refines the distribution of 3D points fitted to both the multi-hypothesis shape condition and pixel-aligned image features, offering detailed clothed shapes and inpainting occluded parts of human bodies. In the experiments using the CAPE, MultiHuman and Hi4D datasets, the proposed method outperforms various SOTA methods based on SMPL, implicit functions, point cloud diffusion, and their combined, under synthetic and real occlusions. Our code is publicly available at https://donghwankim0101.github.io/projects/mhcdiff.

Preference learning algorithms (e.g., RLHF and DPO) are frequently used to steer LLMs to produce generations that are more preferred by humans, but our understanding of their inner workings is still limited. In this work, we study the conventional wisdom that preference learning trains models to assign higher likelihoods to more preferred outputs than less preferred outputs, measured via *ranking accuracy*.
Surprisingly, we find that most state-of-the-art preference-tuned models achieve a ranking accuracy of less than 60% on common preference datasets. We furthermore derive the *idealized ranking accuracy* that a preference-tuned LLM would achieve if it optimized the DPO or RLHF objective perfectly. We demonstrate that existing models exhibit a significant *alignment gap* -- *i.e.*, a gap between the observed and idealized ranking accuracies.
We attribute this discrepancy to the DPO objective, which is empirically and theoretically ill-suited to correct even mild ranking errors in the reference model, and derive a simple and efficient formula for quantifying the difficulty of learning a given preference datapoint.
Finally, we demonstrate that ranking accuracy strongly correlates with the empirically popular win rate metric when the model is close to the reference model used in the objective, shedding further light on the differences between on-policy (e.g., RLHF) and off-policy (e.g., DPO) preference learning algorithms.

Molecule inverse folding has been a long-standing challenge in chemistry and biology, with the potential to revolutionize drug discovery and material science. Despite specified models have been proposed for different small- or macro-molecules, few have attempted to unify the learning process, resulting in redundant efforts. Complementary to recent advancements in molecular structure prediction, such as RoseTTAFold All-Atom and AlphaFold3, we propose the unified model UniIF for the inverse folding of all molecules. We do such unification in two levels: 1) Data-Level: We propose a unified block graph data form for all molecules, including the local frame building and geometric feature initialization. 2) Model-Level: We introduce a geometric block attention network, comprising a geometric interaction, interactive attention and virtual long-term dependency modules, to capture the 3D interactions of all molecules. Through comprehensive evaluations across various tasks such as protein design, RNA design, and material design, we demonstrate that our proposed method surpasses state-of-the-art methods on all tasks. UniIF offers a versatile and effective solution for general molecule inverse folding.
tl;dr: We present a novel insight on ensemble within low precision number systems, especially for large models.

While ensembling deep neural networks has shown promise in improving generalization performance, scaling current ensemble methods for large models remains challenging. Given that recent progress in deep learning is largely driven by the scale, exemplified by the widespread adoption of large-scale neural network architectures, scalability emerges an increasingly critical issue for machine learning algorithms in the era of large-scale models. In this work, we first showcase the potential of low precision ensembling, where ensemble members are derived from a single model within low precision number systems in a training-free manner. Our empirical analysis demonstrates the effectiveness of our proposed low precision ensembling method compared to existing ensemble approaches.

Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (\textbf{S-DPO}) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, which is extended from the traditional full-ranking Plackett-Luce (PL) model to partial rankings and connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has an inherent benefit of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while providing better rewards for preferred items. Our codes are available at https://github.com/chenyuxin1999/S-DPO.

Recently, vision model pre-training has evolved from relying on manually annotated datasets to leveraging large-scale, web-crawled image-text data. Despite these advances, there is no pre-training method that effectively exploits the interleaved image-text data, which is very prevalent on the Internet. Inspired by the recent success of compression learning in natural language processing, we propose a novel vision model pre-training method called Latent Compression Learning (LCL) for interleaved image-text data. This method performs latent compression learning by maximizing the mutual information between the inputs and outputs of a causal attention model. The training objective can be decomposed into two basic tasks: 1) contrastive learning between visual representation and preceding context, and 2) generating subsequent text based on visual representation. Our experiments demonstrate that our method not only matches the performance of CLIP on paired pre-training datasets (e.g., LAION), but can also leverage interleaved pre-training data (e.g., MMC4) to learn robust visual representations from scratch, showcasing the potential of vision model pre-training with interleaved image-text data.

Achieving robust and precise pose estimation in dynamic scenes is a significant research challenge in Visual Simultaneous Localization and Mapping (SLAM). Recent advancements integrating Gaussian Splatting into SLAM systems have proven effective in creating high-quality renderings using explicit 3D Gaussian models, significantly improving environmental reconstruction fidelity. However, these approaches depend on a static environment assumption and face challenges in dynamic environments due to inconsistent observations of geometry and photometry. To address this problem, we propose DG-SLAM, the first robust dynamic visual SLAM system grounded in 3D Gaussians, which provides precise camera pose estimation alongside high-fidelity reconstructions. Specifically, we propose effective strategies, including motion mask generation, adaptive Gaussian point management, and a hybrid camera tracking algorithm to improve the accuracy and robustness of pose estimation. Extensive experiments demonstrate that DG-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, and novel-view synthesis in dynamic scenes, outperforming existing methods meanwhile preserving real-time rendering ability.

Open-vocabulary semantic segmentation (OVSS) aims to segment unseen classes without corresponding labels. Existing Vision-Language Model (VLM)-based methods leverage VLM's rich knowledge to enhance additional explicit segmentation-specific networks, yielding competitive results, but at the cost of extensive training cost. To reduce the cost, we attempt to enable VLM to directly produce the segmentation results without any segmentation-specific networks. Prompt learning offers a direct and parameter-efficient approach, yet it falls short in guiding VLM for pixel-level visual classification. Therefore, we propose the ${\bf R}$elationship ${\bf P}$rompt ${\bf M}$odule (${\bf RPM}$), which generates the relationship prompt that directs VLM to extract pixel-level semantic embeddings suitable for OVSS. Moreover, RPM integrates with VLM to construct the ${\bf R}$elationship ${\bf P}$rompt ${\bf N}$etwork (${\bf RPN}$), achieving OVSS without any segmentation-specific networks. RPN attains state-of-the-art performance with merely about ${\bf 3M}$ trainable parameters (2\% of total parameters).

Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit ''hallucinations'' samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term ***mode interpolation***. Specifically, we find that diffusion models smoothly ``interpolate'' between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations). We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model's decoder leads to a region where any smooth approximation will cause such hallucinations. Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. We extend the validity of mode interpolation in real-world datasets by explaining the unexpected generation of images with additional or missing fingers similar to those produced by popular text-to-image generative models. Finally, we show that diffusion models in fact ***know*** when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95\% of hallucinations at generation time. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on datasets like MNIST .
tl;dr: This paper presents an adaptation of 3DGS to resolve the unconstrained photo collections.

Photographs captured in unstructured tourist environments frequently exhibit variable appearances and transient occlusions, challenging accurate scene reconstruction and inducing artifacts in novel view synthesis. Although prior approaches have integrated the Neural Radiance Field (NeRF) with additional learnable modules to handle the dynamic appearances and eliminate transient objects, their extensive training demands and slow rendering speeds limit practical deployments. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising alternative to NeRF, offering superior training and inference efficiency along with better rendering quality. This paper presents \textit{Wild-GS}, an innovative adaptation of 3DGS optimized for unconstrained photo collections while preserving its efficiency benefits. \textit{Wild-GS} determines the appearance of each 3D Gaussian by their inherent material attributes, global illumination and camera properties per image, and point-level local variance of reflectance. Unlike previous methods that model reference features in image space, \textit{Wild-GS} explicitly aligns the pixel appearance features to the corresponding local Gaussians by sampling the triplane extracted from the reference image. This novel design effectively transfers the high-frequency detailed appearance of the reference view to 3D space and significantly expedites the training process. Furthermore, 2D visibility maps and depth regularization are leveraged to mitigate the transient effects and constrain the geometry, respectively. Extensive experiments demonstrate that \textit{Wild-GS} achieves state-of-the-art rendering performance and the highest efficiency in both training and inference among all the existing techniques. The code can be accessed via: https://github.com/XuJiacong/Wild-GS

Principal component analysis (PCA) is one of the most fundamental tools in machine learning with broad use as a dimensionality reduction and denoising tool. In the later setting, while PCA is known to be effective at subspace recovery and is proven to aid clustering algorithms in some specific settings, its improvement of noisy data is still not well quantified in general.
In this paper, we propose a novel metric called *compression ratio* to capture the effect of PCA on high-dimensional noisy data.
We show that, for data with *underlying community structure*, PCA significantly reduces the distance of data points belonging to the same community while reducing inter-community distance relatively mildly. We explain this phenomenon through both theoretical proofs and experiments on real-world data.
Building on this new metric, we design a straightforward algorithm that could be used to detect outliers. Roughly speaking, we argue that points that have a *lower variance of compression ratio* do not share a *common signal* with others (hence could be considered outliers).
We provide theoretical justification for this simple outlier detection algorithm and use simulations to demonstrate that our method is competitive with popular outlier detection tools. Finally, we run experiments on real-world high-dimension noisy data (single-cell RNA-seq) to show that removing points from these datasets via our outlier detection method improves the accuracy of clustering algorithms. Our method is very competitive with popular outlier detection tools in this task.
tl;dr: Our model can generate high-quality and motion consistent videos by only performing the sampling once during inference.

Diffusion-based video generation models have demonstrated remarkable success in obtaining high-fidelity videos through the iterative denoising process. However, these models require multiple denoising steps during sampling, resulting in high computational costs. In this work, we propose a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, through the adversarial training, the multi-steps video diffusion model, i.e., Stable Video Diffusion (SVD), can be trained to perform single forward pass to synthesize high-quality videos, capturing both temporal and spatial dependencies in the video data. Extensive experiments demonstrate that our method achieves competitive generation quality of synthesized videos with significantly reduced computational overhead for the denoising process (i.e., around $23\times$ speedup compared with SVD and $6\times$ speedup compared with existing works, with even better generation quality), paving the way for real-time video synthesis and editing.

Motion modeling is critical in flow-based Video Frame Interpolation (VFI). Existing paradigms either consider linear combinations of bidirectional flows or directly predict bilateral flows for given timestamps without exploring favorable motion priors, thus lacking the capability of effectively modeling spatiotemporal dynamics in real-world videos. To address this limitation, in this study, we introduce Generalizable Implicit Motion Modeling (GIMM), a novel and effective approach to motion modeling for VFI. Specifically, to enable GIMM as an effective motion modeling paradigm, we design a motion encoding pipeline to model spatiotemporal motion latent from bidirectional flows extracted from pre-trained flow estimators, effectively representing input-specific motion priors. Then, we implicitly predict arbitrary-timestep optical flows within two adjacent input frames via an adaptive coordinate-based neural network, with spatiotemporal coordinates and motion latent as inputs. Our GIMM can be easily integrated with existing flow-based VFI works by supplying accurately modeled motion. We show that GIMM performs better than the current state of the art on standard VFI benchmarks.

Mixed-integer linear programming (MILP) is one of the most popular mathematical formulations with numerous applications. In practice, improving the performance of MILP solvers often requires a large amount of high-quality data, which can be challenging to collect. Researchers thus turn to generation techniques to generate additional MILP instances. However, existing approaches do not take into account specific block structures—which are closely related to the problem formulations—in the constraint coefficient matrices (CCMs) of MILPs. Consequently, they are prone to generate computationally trivial or infeasible instances due to the disruptions of block structures and thus problem formulations. To address this challenge, we propose a novel MILP generation framework, called Block Structure Decomposition (MILP-StuDio), to generate high-quality instances by preserving the block structures. Specifically, MILP-StuDio begins by identifying the blocks in CCMs and decomposing the instances into block units, which serve as the building blocks of MILP instances. We then design three operators to construct new instances by removing, substituting, and appending block units in the original instances, enabling us to generate instances with flexible sizes. An appealing feature of MILP-StuDio is its strong ability to preserve the feasibility and computational hardness of the generated instances. Experiments on the commonly-used benchmarks demonstrate that using instances generated by MILP-StuDio is able to significantly reduce over 10% of the solving time for learning-based solvers.

Most of the existing Video Anomaly Detection (VAD) studies have been conducted within single-domain learning, where training and evaluation are performed on a single dataset. However, the criteria for abnormal events differ across VAD datasets, making it problematic to apply a single-domain model to other domains. In this paper, we propose a new task called Multi-Domain learning forVAD (MDVAD) to explore various real-world abnormal events using multiple datasets for a general model. MDVAD involves training on datasets from multiple domains simultaneously, and we experimentally observe that Abnormal Conflicts between domains hinder learning and generalization. The task aims to address two key objectives: (i) better distinguishing between general normal and abnormal events across multiple domains, and (ii) being aware of ambiguous abnormal conflicts. This paper is the first to tackle abnormal conflict issue and introduces a new benchmark, baselines, and evaluation protocols for MDVAD. As baselines, we propose a framework with Null(Angular)-Multiple Instance Learning and an Abnormal Conflict classifier. Through experiments on a MDVAD benchmark composed of six VAD datasets and using four different evaluation protocols, we reveal abnormal conflicts and demonstrate that the proposed baseline effectively handles these conflicts, showing robustness and adaptability across multiple domains.

Graph learning is naturally well suited for use in symbolic, object-centric planning due to its ability to exploit relational structures exhibited in planning domains and to take as input planning instances with arbitrary number of objects. Numeric planning is an extension of symbolic planning in which states may now also exhibit numeric variables. In this work, we propose data-efficient and interpretable machine learning models for learning to solve numeric planning tasks. This involves constructing a new graph kernel for graphs with both continuous and categorical attributes, as well as new optimisation methods for learning heuristic functions for numeric planning. Experiments show that our graph kernels are vastly more efficient and generalise better than graph neural networks for numeric planning, and also yield competitive coverage performance over domain-independent numeric planners.
tl;dr: A more robust novel convolution operator tailored for radar signals.

Deep learning-based radar detection technology is receiving increasing attention in areas such as autonomous driving, UAV surveillance, and marine monitoring. Among recent efforts, PeakConv (PKC) provides a solution that can retain the peak response characteristics of radar signals and play the characteristics of deep convolution, thereby improving the effect of radar semantic segmentation (RSS). However, due to the use of a pre-set fixed peak receptive field sampling rule, PKC still has limitations in dealing with problems such as inconsistency of target frequency domain response broadening, non-homogeneous and time-varying characteristic of noise/clutter distribution. Therefore, this paper proposes an idea of adaptive peak receptive field, and upgrades PKC to AdaPKC based on this idea. Beyond that, a novel fine-tuning technology to further boost the performance of AdaPKC-based RSS networks is presented. Through experimental verification using various real-measured radar data (including publicly available low-cost millimeter-wave radar dataset for autonomous driving and self-collected Ku-band surveillance radar dataset), we found that the performance of AdaPKC-based models surpasses other SoTA methods in RSS tasks. The code is available at https://github.com/lihua199710/AdaPKC.
tl;dr: We present BetterDepth to efficiently achieve robust affine-invariant monocular depth estimation with fine-grained details.

By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficient detail. Although recent diffusion-based MDE approaches exhibit a superior ability to extract details, they struggle in geometrically complex scenes that challenge their geometry prior, trained on less diverse 3D data. To leverage the complementary merits of both worlds, we propose BetterDepth to achieve geometrically correct affine-invariant MDE while capturing fine details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth layout is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure BetterDepth remains faithful to the depth conditioning while learning to add fine-grained scene details. With efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and on in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without further re-training.
tl;dr: In this work, we present a novel ``Learning tO Visual Question Answering, Asking and Assessment'' framework that can enable the current MLLMs to obtain the additional abilities to ask and assess the question based on the visual input.

Question answering, asking, and assessment are three innate human traits crucial for understanding the world and acquiring knowledge. By enhancing these capabilities, humans can more effectively utilize data, leading to better comprehension and learning outcomes. However, current Multimodal Large Language Models (MLLMs) primarily focus on question answering, often neglecting the full potential of questioning and assessment skills. In this study, we introduce LOVA3, an innovative framework named ``Learning tO Visual Question Answering, Asking and Assessment,'' designed to equip MLLMs with these additional capabilities. Our approach involves the creation of two supplementary training tasks GenQA and EvalQA, aiming at fostering the skills of asking and assessing questions in the context of images. To develop the questioning ability, we compile a comprehensive set of multimodal foundational tasks. For assessment, we introduce a new benchmark called EvalQABench, comprising 64,000 training samples (split evenly between positive and negative samples) and 5,000 testing samples. We posit that enhancing MLLMs with the capabilities to answer, ask, and assess questions
will enhance their multimodal comprehension, ultimately improving overall performance. To validate this hypothesis, we train MLLMs using the LOVA3 framework and evaluate them on a range of multimodal datasets and benchmarks. Our results demonstrate consistent performance gains, underscoring the critical role of these additional tasks in fostering comprehensive intelligence in MLLMs.
tl;dr: We propose a Fourier basis mapping model, leveraging the basis functions to provide more implicit frequency features while preserving the temporal characteristic.

The interaction between Fourier transform and deep learning opens new avenues for long-term time series forecasting (LTSF). We propose a new perspective to reconsider the Fourier transform from a basis functions perspective. Specifically, the real and imaginary parts of the frequency components can be viewed as the coefficients of cosine and sine basis functions at tiered frequency levels, respectively. We argue existing Fourier-based methods do not involve basis functions thus fail to interpret frequency coefficients precisely and consider the time-frequency relationship sufficiently, leading to inconsistent starting cycles and inconsistent series length issues. Accordingly, a novel Fourier basis mapping (FBM) method addresses these issues by mixing time and frequency domain features through Fourier basis expansion. Differing from existing approaches, FBM (i) embeds the discrete Fourier transform with basis functions, and then (ii) can enable plug-and-play in various types of neural networks for better performance. FBM extracts explicit frequency features while preserving temporal characteristics, enabling the mapping network to capture the time-frequency relationships. By incorporating our unique time-frequency features, the FBM variants can enhance any type of networks like linear, multilayer-perceptron-based, transformer-based, and Fourier-based networks, achieving state-of-the-art LTSF results on diverse real-world datasets with just one or three fully connected layers. The code is available at: https://github.com/runze1223/Fourier-Basis-Mapping.
tl;dr: Apply attention and convolution at different granularity levels for more efficient representation learning.

Convolutions (Convs) and multi-head self-attentions (MHSAs) are typically considered alternatives to each other for building vision backbones. Although some works try to integrate both, they apply the two operators simultaneously at the finest pixel granularity. With Convs responsible for per-pixel feature extraction already, the question is whether we still need to include the heavy MHSAs at such a fine-grained level. In fact, this is the root cause of the scalability issue w.r.t. the input resolution for vision transformers. To address this important problem, we propose in this work to use MSHAs and Convs in parallel \textbf{at different granularity levels} instead. Specifically, in each layer, we use two different ways to represent an image: a fine-grained regular grid and a coarse-grained set of semantic slots. We apply different operations to these two representations: Convs to the grid for local features, and MHSAs to the slots for global features. A pair of fully differentiable soft clustering and dispatching modules is introduced to bridge the grid and set representations, thus
enabling local-global fusion. Through extensive experiments on various vision tasks, we empirically verify the potential of the proposed integration scheme, named \textit{GLMix}: by offloading the burden of fine-grained features to light-weight Convs, it is sufficient to use MHSAs in a few (e.g., 64) semantic slots to match the performance of recent state-of-the-art backbones, while being more efficient. Our visualization results also demonstrate that the soft clustering module produces a meaningful semantic grouping effect with only IN1k classification supervision, which may induce better interpretability and inspire new weakly-supervised semantic segmentation approaches. Code will be available at \url{https://github.com/rayleizhu/GLMix}.

Language models have shown vulnerability against backdoor attacks, threatening the security of services based on them. To mitigate the threat, existing solutions attempted to search for backdoor triggers, which can be time-consuming when handling a large search space. Looking into the attack process, we observe that poisoned data will create a long-tailed effect in the victim model, causing the decision boundary to shift towards the attack targets. Inspired by this observation, we introduce LT-Defense, the first searching-free backdoor defense via exploiting the long-tailed effect. Specifically, LT-Defense employs a small set of clean examples and two metrics to distinguish backdoor-related features in the target model. Upon detecting a backdoor model, LT-Defense additionally provides test-time backdoor freezing and attack target prediction. Extensive experiments demonstrate the effectiveness of LT-Defense in both detection accuracy and efficiency, e.g., in task-agnostic scenarios, LT-Defense achieves 98% accuracy across 1440 models with less than 1% of the time cost of state-of-the-art solutions.

Few-shot fine-tuning of text-to-image (T2I) generation models enables people to create unique images in their own style using natural languages without requiring extensive prompt engineering. However, fine-tuning with only a handful, as little as one, of image-text paired data prevents fine-grained control of style attributes at generation. In this paper, we present FineStyle, a few-shot fine-tuning method that allows enhanced controllability for style personalized text-to-image generation. To overcome the lack of training data for fine-tuning, we propose a novel concept-oriented data scaling that amplifies the number of image-text pair, each of which focuses on different concepts (e.g., objects) in the style reference image. We also identify the benefit of parameter-efficient adapter tuning of key and value kernels of cross-attention layers. Extensive experiments show the effectiveness of FineStyle at following fine-grained text prompts and delivering visual quality faithful to the specified style, measured by CLIP scores and human raters.

Semantic segmentation and semantic image synthesis are two representative tasks in visual perception and generation. While existing methods consider them as two distinct tasks, we propose a unified framework (SemFlow) and model them as a pair of reverse problems. Specifically, motivated by rectified flow theory, we train an ordinary differential equation (ODE) model to transport between the distributions of real images and semantic masks. As the training object is symmetric, samples belonging to the two distributions, images and semantic masks, can be effortlessly transferred reversibly. For semantic segmentation, our approach solves the contradiction between the randomness of diffusion outputs and the uniqueness of segmentation results. For image synthesis, we propose a finite perturbation approach to enhance the diversity of generated results without changing the semantic categories. Experiments show that our SemFlow achieves competitive results on semantic segmentation and semantic image synthesis tasks. We hope this simple framework will motivate people to rethink the unification of low-level and high-level vision.

Temporal context plays a significant role in temporal action segmentation. In an offline setting, the context is typically captured by the segmentation network after observing the entire sequence. However, capturing and using such context information in an online setting remains an under-explored problem. This work presents the first online framework for temporal action segmentation. At the core of the framework is an adaptive memory designed to accommodate dynamic changes in context over time, alongside a feature augmentation module that enhances the frames with the memory. In addition, we propose a post-processing approach to mitigate the severe over-segmentation in the online setting. On three common segmentation benchmarks, our approach achieves state-of-the-art performance.
tl;dr: Fast, and efficient E(3)-equivariant scaffold-hopping model utilizing consistency models for rapid generation additionally powered by RL

Navigating the vast chemical space of druggable compounds is a formidable challenge in drug discovery, where generative models are increasingly employed to identify viable candidates. Conditional 3D structure-based drug design (3D-SBDD) models, which take into account complex three-dimensional interactions and molecular geometries, are particularly promising. Scaffold hopping is an efficient strategy that facilitates the identification of similar active compounds by strategically modifying the core structure of molecules, effectively narrowing the wide chemical space and enhancing the discovery of drug-like products. However, the practical application of 3D-SBDD generative models is hampered by their slow processing speeds. To address this bottleneck, we introduce TurboHopp, an accelerated pocket-conditioned 3D scaffold hopping model that merges the strategic effectiveness of traditional scaffold hopping with rapid generation capabilities of consistency models. This synergy not only enhances efficiency but also significantly boosts generation speeds, achieving up to 30 times faster inference speed as well as superior generation quality compared to existing diffusion-based models, establishing TurboHopp as a powerful tool in drug discovery. Supported by faster inference speed, we further optimize our model, using Reinforcement Learning for Consistency Models (RLCM), to output desirable molecules. We demonstrate the broad applicability of TurboHopp across multiple drug discovery scenarios, underscoring its potential in diverse molecular settings.
tl;dr: Attention scores on graphs are consistent across network widths; find which edges matter with a narrow network first

Graph Transformers excel in long-range dependency modeling, but generally require quadratic memory complexity in the number of nodes in an input graph, and hence have trouble scaling to large graphs. Sparse attention variants such as Exphormer can help, but may require high-degree augmentations to the input graph for good performance, and do not attempt to sparsify an already-dense input graph. As the learned attention mechanisms tend to use few of these edges, however, such high-degree connections may be unnecessary. We show (empirically and with theoretical backing) that attention scores on graphs are usually quite consistent across network widths, and use this observation to propose a two-stage procedure, which we call Spexphormer: first, train a narrow network on the full augmented graph. Next, use only the active connections to train a wider network on a much sparser graph. We establish theoretical conditions when a narrow network's attention scores can match those of a wide network, and show that Spexphormer achieves good performance with drastically reduced memory requirements on various graph datasets.

Multiple instance learning (MIL) is an effective and widely used approach for weakly supervised machine learning. In histopathology, MIL models have achieved remarkable success in tasks like tumor detection, biomarker prediction, and outcome prognostication. However, MIL explanation methods are still lagging behind, as they are limited to small bag sizes or disregard instance interactions. We revisit MIL through the lens of explainable AI (XAI) and introduce xMIL, a refined framework with more general assumptions. We demonstrate how to obtain improved MIL explanations using layer-wise relevance propagation (LRP) and conduct extensive evaluation experiments on three toy settings and four real-world histopathology datasets. Our approach consistently outperforms previous explanation attempts with particularly improved faithfulness scores on challenging biomarker prediction tasks. Finally, we showcase how xMIL explanations enable pathologists to extract insights from MIL models, representing a significant advance for knowledge discovery and model debugging in digital histopathology.
tl;dr: We present VL-SAM, a framework that combines vision-language model with segment-anything model to address the open-ended object detection and segmentation task.
Existing perception models achieve great success by learning from large amounts of labeled data, but they still struggle with open-world scenarios. To alleviate this issue, researchers introduce open-set perception tasks to detect or segment unseen objects in the training set. However, these models require predefined object categories as inputs during inference, which are not available in real-world scenarios. Recently, researchers pose a new and more practical problem, i.e., open-ended object detection, which discovers unseen objects without any object categories as inputs. In this paper, we present VL-SAM, a training-free framework that combines the generalized object recognition model (i.e., Vision-Language Model) with the generalized object localization model (i.e., Segment-Anything Model), to address the open-ended object detection and segmentation task. Without additional training, we connect these two generalized models with attention maps as the prompts. Specifically, we design an attention map generation module by employing head aggregation and a regularized attention flow to aggregate and propagate attention maps across all heads and layers in VLM, yielding high-quality attention maps. Then, we iteratively sample positive and negative points from the attention maps with a prompt generation module and send the sampled points to SAM to segment corresponding objects. Experimental results on the long-tail instance segmentation dataset (LVIS) show that our method surpasses the previous open-ended method on the object detection task and can provide additional instance segmentation masks. Besides, VL-SAM achieves favorable performance on the corner case object detection dataset (CODA), demonstrating the effectiveness of VL-SAM in real-world applications. Moreover, VL-SAM exhibits good model generalization that can incorporate various VLMs and SAMs.
tl;dr: We propose better default parameters for boosted decision trees and improved neural networks on tabular data, evaluate them on separate large benchmarks, and show that they can achieve excellent results with moderate runtime.

For classification and regression on tabular data, the dominance of gradient-boosted decision trees (GBDTs) has recently been challenged by often much slower deep learning methods with extensive hyperparameter tuning. We address this discrepancy by introducing (a) RealMLP, an improved multilayer perceptron (MLP), and (b) strong meta-tuned default parameters for GBDTs and RealMLP. We tune RealMLP and the default parameters on a meta-train benchmark with 118 datasets and compare them to hyperparameter-optimized versions on a disjoint meta-test benchmark with 90 datasets, as well as the GBDT-friendly benchmark by Grinsztajn et al. (2022). Our benchmark results on medium-to-large tabular datasets (1K--500K samples) show that RealMLP offers a favorable time-accuracy tradeoff compared to other neural baselines and is competitive with GBDTs in terms of benchmark scores. Moreover, a combination of RealMLP and GBDTs with improved default parameters can achieve excellent results without hyperparameter tuning. Finally, we demonstrate that some of RealMLP's improvements can also considerably improve the performance of TabR with default parameters.

In the realm of big data and digital healthcare, Electronic Health Records (EHR) have become a rich source of information with the potential to improve patient care and medical research. In recent years, machine learning models have proliferated for analyzing EHR data to predict patients' future health conditions. Among them, some studies advocate for multi-task learning (MTL) to jointly predict multiple target diseases for improving the prediction performance over single task learning. Nevertheless, current MTL frameworks for EHR data have significant limitations due to their heavy reliance on human experts to identify task groups for joint training and design model architectures. To reduce human intervention and improve the framework design, we propose an automated approach named AutoDP, which can search for the optimal configuration of task grouping and architectures simultaneously. To tackle the vast joint search space encompassing task combinations and architectures, we employ surrogate model-based optimization, enabling us to efficiently discover the optimal solution. Experimental results on real-world EHR data demonstrate the efficacy of the proposed AutoDP framework. It achieves significant performance improvements over both hand-crafted and automated state-of-the-art methods, also maintains a feasible search cost at the same time.

Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 83.0% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.5% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.9% mIoU with single-scale testing on ADE20K. Code is available at https://github.com/YuHengsss/MSVMamba.

Although recent advancements in large language models (LLMs) have significantly improved their performance on various tasks, they still face challenges with complex and symbolic multi-step reasoning, particularly in mathematical reasoning. To bolster the mathematical reasoning capabilities of LLMs, most existing efforts concentrate on seeking assistance from either domain experts or GPT-4 for high-quality process-supervised data, which is not only expensive but also labor-intensive. In our study, we propose an innovative framework, AlphaMath, that bypasses the need for process annotations (from humans or GPTs) by leveraging Monte Carlo Tree Search (MCTS). This framework focuses on unleashing the potential of a well-pretrained LLM to autonomously enhance its mathematical reasoning. Specifically, we integrate a value model with the LLM, automatically generating both process supervision and step-level evaluation signals in MCTS. Furthermore, we propose an efficient inference strategy—step-level beam search, where the value model is crafted to assist the policy model (i.e., LLM) in navigating more effective reasoning paths, rather than solely relying on prior probabilities. The experimental results on both in-domain and out-of-domain datasets demonstrate that even without GPT-4 or human-annotated process supervision, our AlphaMath framework achieves comparable or superior results to previous state-of-the-art methods.
tl;dr: We propose a framework, named SCT, to mitigate the problem of spurious OOD features mined from ID data in prompt-tuning based OOD detection methods.

Out-of-distribution (OOD) detection is crucial for deploying reliable machine learning models in open-world applications. Recent advances in CLIP-based OOD detection have shown promising results via regularizing prompt tuning with OOD features extracted from ID data. However, the irrelevant context mined from ID data can be spurious due to the inaccurate foreground-background decomposition, thus limiting the OOD detection performance. In this work, we propose a novel framework, namely, \textit{Self-Calibrated Tuning (SCT)}, to mitigate this problem for effective OOD detection with only the given few-shot ID data. Specifically, SCT introduces modulating factors respectively on the two components of the original learning objective. It adaptively directs the optimization process between the two tasks during training on data with different prediction uncertainty to calibrate the influence of OOD regularization, which is compatible with many prompt tuning based OOD detection methods. Extensive experiments and analyses have been conducted to characterize and demonstrate the effectiveness of the proposed SCT. The code is publicly available at: https://github.com/tmlr-group/SCT.
tl;dr: Pushing Image Generation at Higher-Resolutions with Foundation Models using a single GPU

In this work, we introduce Pixelsmith, a zero-shot text-to-image generative framework to sample images at higher resolutions with a single GPU. We are the first to show that it is possible to scale the output of a pre-trained diffusion model by a factor of 1000, opening the road to gigapixel image generation at no extra cost. Our cascading method uses the image generated at the lowest resolution as baseline to sample at higher resolutions. For the guidance, we introduce the Slider, a mechanism that fuses the overall structure contained in the first-generated image with enhanced fine details. At each inference step, we denoise patches rather than the entire latent space, minimizing memory demands so that a single GPU can handle the process, regardless of the image's resolution. Our experimental results show that this method not only achieves higher quality and diversity compared to existing techniques but also reduces sampling time and ablation artifacts.
tl;dr: In this paper we demonstrate the relevance of applying tensor decomposition methods to compress activation maps and allow on-device learning.

Internet of Things and Deep Learning are synergetically and exponentially growing industrial fields with a massive call for their unification into a common framework called Edge AI. While on-device inference is a well-explored topic in recent research, backpropagation remains an open challenge due to its prohibitive computational and memory costs compared to the extreme resource constraints of embedded devices. Drawing on tensor decomposition research, we tackle the main bottleneck of backpropagation, namely the memory footprint of activation map storage. We investigate and compare the effects of activation compression using Singular Value Decomposition and its tensor variant, High-Order Singular Value Decomposition. The application of low-order decomposition results in considerable memory savings while preserving the features essential for learning, and also offers theoretical guarantees to convergence. Experimental results obtained on main-stream architectures and tasks demonstrate Pareto-superiority over other state-of-the-art solutions, in terms of the trade-off between generalization and memory footprint.
tl;dr: A novel approach that balances realistic physics-inspired X-ray simulation with efficient, differentiable DRR generation using 3D Gaussian splatting (3DGS)

Digitally reconstructed radiographs (DRRs) are simulated 2D X-ray images generated from 3D CT volumes, widely used in preoperative settings but limited in intraoperative applications due to computational bottlenecks. Physics-based Monte Carlo simulations provide accurate representations but are extremely computationally intensity. Analytical DRR renderers are much more efficient, but at the price of ignoring anisotropic X-ray image formation phenomena such as Compton scattering. We propose a novel approach that balances realistic physics-inspired X-ray simulation with efficient, differentiable DRR generation using 3D Gaussian splatting (3DGS). Our direction-disentangled 3DGS (DDGS) method decomposes the radiosity contribution into isotropic and direction-dependent components, able to approximate complex anisotropic interactions without complex runtime simulations. Additionally, we adapt the 3DGS initialization to account for tomography data properties, enhancing accuracy and efficiency. Our method outperforms state-of-the-art techniques in image accuracy and inference speed, demonstrating its potential for intraoperative applications and inverse problems like pose registration.
tl;dr: We introduce TableRAG, a framework that enables LLMs to handle large tables by retrieving only essential schema and cell data. Additionally, we provide two new benchmarks, ArcadeQA and BirdQA, to evaluate performance on real-world large tables.

Recent advancements in language models (LMs) have notably enhanced their ability to reason with tabular data, primarily through program-aided mechanisms that manipulate and analyze tables.
However, these methods often require the entire table as input, leading to scalability challenges due to the positional bias or context length constraints.
In response to these challenges, we introduce TableRAG, a Retrieval-Augmented Generation (RAG) framework specifically designed for LM-based table understanding.
TableRAG leverages query expansion combined with schema and cell retrieval to pinpoint crucial information before providing it to the LMs.
This enables more efficient data encoding and precise retrieval, significantly reducing prompt lengths and mitigating information loss.
We have developed two new million-token benchmarks from the Arcade and BIRD-SQL datasets to thoroughly evaluate TableRAG's effectiveness at scale.
Our results demonstrate that TableRAG's retrieval design achieves the highest retrieval quality, leading to the new state-of-the-art performance on large-scale table understanding.
tl;dr: A method for estimating the hallucination rate of generative AI for in-context learning

This paper presents a method for estimating the hallucination rate for in-context learning (ICL) with generative AI. In ICL, a conditional generative model (CGM) is prompted with a dataset and a prediction question and asked to generate a response. One interpretation of ICL assumes that the CGM computes the posterior predictive of an unknown Bayesian model, which implicitly defines a joint distribution over observable datasets and latent mechanisms. This joint distribution factorizes into two components: the model prior over mechanisms and the model likelihood of datasets given a mechanism. With this perspective, we define a \textit{hallucination} as a generated response to the prediction question with low model likelihood given the mechanism. We develop a new method that takes an ICL problem and estimates the probability that a CGM will generate a hallucination. Our method only requires generating prediction questions and responses from the CGM and evaluating its response log probability. We empirically evaluate our method using large language models for synthetic regression and natural language ICL tasks.
In this work, we propose a training-free method to inject visual prompts into Multimodal Large Language Models (MLLMs) through learnable latent variable optimization. We observe that attention, as the core module of MLLMs, connects text prompt tokens and visual tokens, ultimately determining the final results. Our approach involves adjusting visual tokens from the MLP output during inference, controlling the attention response to ensure text prompt tokens attend to visual tokens in referring regions. We optimize a learnable latent variable based on an energy function, enhancing the strength of referring regions in the attention map. This enables detailed region description and reasoning without the need for substantial training costs or model retraining. Our method offers a promising direction for integrating referring abilities into MLLMs, and supports referring with box, mask, scribble and point. The results demonstrate that our method exhibits out-of-domain generalization and interpretability.
tl;dr: We proposed an interpretable pipline based on lane geometric distance and semantic similarity that has significantly enhanced the performance of lane topology reasoning on driving scenes.

As an emerging task that integrates perception and reasoning, topology reasoning in autonomous driving scenes has recently garnered widespread attention. However, existing work often emphasizes "perception over reasoning": they typically boost reasoning performance by enhancing the perception of lanes and directly adopt vanilla MLPs to learn lane topology from lane query. This paradigm overlooks the geometric features intrinsic to the lanes themselves and are prone to being influenced by inherent endpoint shifts in lane detection.
To tackle this issue, we propose an interpretable method for lane topology reasoning based on lane geometric distance and lane query similarity, named TopoLogic. This method mitigates the impact of endpoint shifts in geometric space, and introduces explicit similarity calculation in semantic space as a complement. By integrating results from both spaces, our methods provides more comprehensive information for lane topology. Ultimately, our approach significantly outperforms the existing state-of-the-art methods on the mainstream benchmark OpenLane-V2 (23.9 v.s. 10.9 in TOP$_{ll}$ and 44.1 v.s. 39.8 in OLS on subsetA). Additionally, our proposed geometric distance topology reasoning method can be incorporated into well-trained models without re-training, significantly enhancing the performance of lane topology reasoning. The code is released at https://github.com/Franpin/TopoLogic.

Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose a graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph-level tasks, speech recognition, and code classification.
tl;dr: We present novel, highly efficient algorithms for designing minimum-cost proxy experiments (interventions) to identify causal effects, significantly outperforming the s.o.t.a.

Identifying causal effects is a key problem of interest across many disciplines. The two long-standing approaches to estimate causal effects are observational and experimental (randomized) studies. Observational studies can suffer from unmeasured confounding, which may render the causal effects unidentifiable. On the other hand, direct experiments on the target variable may be too costly or even infeasible to conduct. A middle ground between these two approaches is to estimate the causal effect of interest through proxy experiments, which are conducted on variables with a lower cost to intervene on compared to the main target. In an earlier work, we studied this setting and demonstrated that the problem of designing the optimal (minimum-cost) experiment for causal effect identification is NP-complete and provided a naive algorithm that may require solving exponentially many NP-hard problems as a sub-routine in the worst case. In this work, we provide a few reformulations of the problem that allow for designing significantly more efficient algorithms to solve it as witnessed by our extensive simulations. Additionally, we study the closely-related problem of designing experiments that enable us to identify a given effect through valid adjustments sets.
tl;dr: Replace objects in 3D scenes

We introduce ReplaceAnything3D model RAM3D, a novel method for 3D object replacement in 3D scenes based on users' text description. Given multi-view images of a scene, a text prompt describing the object to replace, and another describing the new object, our Erase-and-Replace approach can effectively swap objects in 3D scenes with newly generated content while maintaining 3D consistency across multiple viewpoints. We demonstrate the versatility of RAM3D by applying it to various realistic 3D scene types, showcasing results of modified objects that blend in seamlessly with the scene without impacting its overall integrity.

The recent rapid advancement of machine learning has been driven by increasingly powerful models with the growing availability of training data and computational resources. However, real-time decision-making tasks with limited time and sparse learning signals remain challenging. One way of improving the learning speed and performance of these agents is to leverage human guidance. In this work, we introduce GUIDE, a framework for real-time human-guided reinforcement learning by enabling continuous human feedback and grounding such feedback into dense rewards to accelerate policy learning. Additionally, our method features a simulated feedback module that learns and replicates human feedback patterns in an online fashion, effectively reducing the need for human input while allowing continual training. We demonstrate the performance of our framework on challenging tasks with sparse rewards and visual observations. Our human study involving 50 subjects offers strong quantitative and qualitative evidence of the effectiveness of our approach. With only 10 minutes of human feedback, our algorithm achieves up to 30\% increase in success rate compared to its RL baseline.
tl;dr: We identify surprising and nuanced behavior of finetuned models on worst-group accuracy in settings including class-balancing, model scaling, and spectral analysis.

Modern machine learning models are prone to over-reliance on spurious correlations, which can often lead to poor performance on minority groups. In this paper, we identify surprising and nuanced behavior of finetuned models on worst-group accuracy via comprehensive experiments on four well-established benchmarks across vision and language tasks. We first show that the commonly used class-balancing techniques of mini-batch upsampling and loss upweighting can induce a decrease in worst-group accuracy (WGA) with training epochs, leading to performance no better than without class-balancing. While in some scenarios, removing data to create a class-balanced subset is more effective, we show this depends on group structure and propose a mixture method which can outperform both techniques. Next, we show that scaling pretrained models is generally beneficial for worst-group accuracy, but only in conjunction with appropriate class-balancing. Finally, we identify spectral imbalance in finetuning features as a potential source of group disparities --- minority group covariance matrices incur a larger spectral norm than majority groups once conditioned on the classes. Our results show more nuanced interactions of modern finetuned models with group robustness than was previously known. Our code is available at https://github.com/tmlabonte/revisiting-finetuning.

Federated learning (FL) has rapidly evolved as a promising paradigm that enables collaborative model training across distributed participants without exchanging their local data. Despite its broad applications in fields such as computer vision, graph learning, and natural language processing, the development of a data projection model that can be effectively used to visualize data in the context of FL is crucial yet remains heavily under-explored. Neighbor embedding (NE) is an essential technique for visualizing complex high-dimensional data, but collaboratively learning a joint NE model is difficult. The key challenge lies in the objective function, as effective visualization algorithms like NE require computing loss functions among pairs of data.
In this paper, we introduce \textsc{FedNE}, a novel approach that integrates the \textsc{FedAvg} framework with the contrastive NE technique, without any requirements of shareable data. To address the lack of inter-client repulsion which is crucial for the alignment in the global embedding space, we develop a surrogate loss function that each client learns and shares with each other. Additionally, we propose a data-mixing strategy to augment the local data, aiming to relax the problems of invisible neighbors and false neighbors constructed by the local $k$NN graphs. We conduct comprehensive experiments on both synthetic and real-world datasets. The results demonstrate that our \textsc{FedNE} can effectively preserve the neighborhood data structures and enhance the alignment in the global embedding space compared to several baseline methods.

One-shot Federated learning (FL) is a powerful technology facilitating collaborative training of machine learning models in a single round of communication. While its superiority lies in communication efficiency and privacy preservation compared to iterative FL, one-shot FL often compromises model performance. Prior research has primarily focused on employing data-free knowledge distillation to optimize data generators and ensemble models for better aggregating local knowledge into the server model. However, these methods typically struggle with data heterogeneity, where inconsistent local data distributions can cause teachers to provide misleading knowledge. Additionally, they may encounter scalability issues with complex datasets due to inherent two-step information loss: first, during local training (from data to model), and second, when transferring knowledge to the server model (from model to inversed data). In this paper, we propose FedSD2C, a novel and practical one-shot FL framework designed to address these challenges. FedSD2C introduces a distiller to synthesize informative distillates directly from local data to reduce information loss and proposes sharing synthetic distillates instead of inconsistent local models to tackle data heterogeneity. Our empirical results demonstrate that FedSD2C consistently outperforms other one-shot FL methods with more complex and real datasets, achieving up to 2.6 $\times$ the performance of the best baseline. Code: https://github.com/Carkham/FedSD2C
tl;dr: We propose a novel gradient coding protocol that efficiently utilizes partial stragglers and is simultaneously computation-efficient and communication-efficient.

Within distributed learning, workers typically compute gradients on their assigned dataset chunks and send them to the parameter server (PS), which aggregates them to compute either an exact or approximate version of $\nabla L$ (gradient of the loss function $L$). However, in large-scale clusters, many workers are slower than their promised speed or even failure-prone. A gradient coding solution introduces redundancy within the assignment of chunks to the workers and uses coding theoretic ideas to allow the PS to recover $\nabla L$ (exactly or approximately), even in the presence of stragglers. Unfortunately, most existing gradient coding protocols are inefficient from a computation perspective as they coarsely classify workers as operational or failed; the potentially valuable work performed by slow workers (partial stragglers) is ignored. In this work, we present novel gradient coding protocols that judiciously leverage the work performed by partial stragglers. Our protocols are efficient from a computation and communication perspective and numerically stable. For an important class of chunk assignments, we present efficient algorithms for optimizing the relative ordering of chunks within the workers; this ordering affects the overall execution time. For exact gradient reconstruction, our protocol is around $2\times$ faster than the original class of protocols and for approximate gradient reconstruction, the mean-squared-error of our reconstructed gradient is several orders of magnitude better.

In recent years, semi-supervised learning (SSL) has gained significant attention due to its ability to leverage both labeled and unlabeled data to improve model performance, especially when labeled data is scarce. However, most current SSL methods rely on heuristics or predefined rules for generating pseudo-labels and leveraging unlabeled data. They are limited to exploiting loss functions and regularization methods within the standard norm. In this paper, we propose a novel Reinforcement Learning (RL) Guided SSL method, RLGSSL, that formulates SSL as a one-armed bandit problem and deploys an innovative RL loss based on weighted reward to adaptively guide the learning process of the prediction model. RLGSSL incorporates a carefully designed reward function that balances the use of labeled and unlabeled data to enhance generalization performance. A semi-supervised teacher-student framework is further deployed to increase the learning stability. We demonstrate the effectiveness of RLGSSL through extensive experiments on several benchmark datasets and show that our approach achieves consistent superior performance compared to state-of-the-art SSL methods.

It is important to estimate an accurate signed distance function (SDF) from a point cloud in many computer vision applications. The latest methods learn neural SDFs using either a data-driven based or an overfitting-based strategy. However, these two kinds of methods are with either poor generalization or slow convergence, which limits their capability under challenging scenarios like highly noisy point clouds. To resolve this issue, we propose a method to prompt pros of both data-driven based and overfitting-based methods for better generalization, faster inference, and higher accuracy in learning neural SDFs. We introduce a novel statistical reasoning algorithm in local regions which is able to finetune data-driven based priors without signed distance supervision, clean point cloud, or point normals. This helps our method start with a good initialization, and converge to a minimum in a much faster way. Our numerical and visual comparisons with the stat-of-the-art methods show our superiority over these methods in surface reconstruction and point cloud denoising on widely used shape and scene benchmarks. The code is available at https://github.com/chenchao15/LocalN2NM.
tl;dr: We propose to use different k-hop neighboorhoods of vertices (nodes) for refining initialized maps for shape matching.

Accurate and smooth shape matching is very hard to achieve. This is because for accuracy, one needs unique descriptors (signatures) on shapes that distinguish different vertices on a mesh accurately while at the same time being invariant to deformations. However, most existing unique shape descriptors are generally not smooth on the shape and are not noise-robust thus leading to non-smooth matches. On the other hand, for smoothness, one needs descriptors that are smooth and continuous on the shape. However, existing smooth descriptors are generally not unique and as such lose accuracy as they match neighborhoods (for smoothness) rather than exact vertices (for accuracy). In this work, we propose to use different k-hop neighborhoods of vertices as pairwise descriptors for shape matching. We use these descriptors in conjunction with local map distortion (LMD) to refine an initialized map for shape matching. We validate the effectiveness of our pipeline on benchmark datasets such as SCAPE, TOSCA, TOPKIDS, and others.
tl;dr: We develop an agentic workflow to align audio and video pair data to improve their joint representations.

Visual content and accompanied audio signals naturally formulate a joint representation to improve audio-visual (AV) related applications. While studies develop various AV representation learning frameworks, the importance of AV data alignment is usually undermined for achieving high-quality representation. We observe that an audio signal may contain background noise interference. Also, non-synchronization may appear between audio and video streams. These non-strict data alignment limits representation quality and downgrade application performance. In this paper, we propose to improve AV joint representations from a data-centric perspective by aligning audio signals to visual data. Our alignment is conducted in an agentic workflow controlled by an LLM-based assistant named AVAgent. For each input AV data pair, our AVAgent uses a multi-modal LLM to convert audio and visual data into language descriptions separately (i.e., tool use). Then, AVAgent reasons whether this paired data is aligned well and plans to edit the audio signal if needed (i.e., planning). The audio editing is executed by predefined actions that filter noise or augment data. Moreover, we use a VLM to evaluate how modified audio signals match the visual content and provide feedback to AVAgent (i.e., reflection). The tool use, planning, and reflection steps operate cyclically to become an agentic workflow where audio signals are gradually aligned to visual content. To this end, existing methods can directly leverage the aligned AV data via our agentic workflow to improve AV joint representations. The experimental results comprehensively demonstrate the state-of-the-art performance of the proposed approach against previous baselines in diverse downstream tasks.
tl;dr: This paper explores accelerating self-supervised learning pretraining by leveraging the features of Vision Transformer.

Our work tackles the computational challenges of contrastive learning methods, particularly for the pretraining of Vision Transformers (ViTs). Despite the effectiveness of contrastive learning, the substantial computational resources required for training often hinder their practical application. To mitigate this issue, we propose an acceleration framework, leveraging ViT's unique ability to generalize across inputs of varying sequence lengths. Our method employs a mix of sequence compression strategies, including randomized token dropout and flexible patch scaling, to reduce the cost of gradient estimation and accelerate convergence. We further provide an in-depth analysis of the gradient estimation error of various acceleration strategies as well as their impact on downstream tasks, offering valuable insights into the trade-offs between acceleration and performance.
We also propose a novel procedure to identify an optimal acceleration schedule to adjust the sequence compression ratios to the training progress, ensuring efficient training without sacrificing downstream performance. Our approach significantly reduces computational overhead across various self-supervised learning algorithms on large-scale datasets. In ImageNet, our method achieves speedups of 4$\times$ in MoCo, 3.3$\times$ in SimCLR, and 2.5$\times$ in DINO, demonstrating substantial efficiency gains.

Adversarial Training (AT) has been widely proved to be an effective method to improve the adversarial robustness against adversarial examples for Deep Neural Networks (DNNs). As a variant of AT, Adversarial Robustness Distillation (ARD) has demonstrated its superior performance in improving the robustness of small student models with the guidance of large teacher models. However, both AT and ARD encounter the robust fairness problem: these models exhibit strong robustness when facing part of classes (easy class), but weak robustness when facing others (hard class). In this paper, we give an in-depth analysis of the potential factors and argue that the smoothness degree of samples' soft labels for different classes (i.e., hard class or easy class) will affect the robust fairness of DNNs from both empirical observation and theoretical analysis. Based on the above finding, we propose an Anti-Bias Soft Label Distillation (ABSLD) method to mitigate the adversarial robust fairness problem within the framework of Knowledge Distillation (KD). Specifically, ABSLD adaptively reduces the student's error risk gap between different classes to achieve fairness by adjusting the class-wise smoothness degree of samples' soft labels during the training process, and the smoothness degree of soft labels is controlled by assigning different temperatures in KD to different classes. Extensive experiments demonstrate that ABSLD outperforms state-of-the-art AT, ARD, and robust fairness methods in the comprehensive metric (Normalized Standard Deviation) of robustness and fairness.
tl;dr: Here, we demonstrate that brain-inspired regularizations in latent diffusion models close the gap between humans and machines on the one-shot drawing task.

Humans can effortlessly draw new categories from a single exemplar, a feat that has long posed a challenge for generative models. However, this gap has started to close with recent advances in diffusion models. This one-shot drawing task requires powerful inductive biases that have not been systematically investigated. Here, we study how different inductive biases shape the latent space of Latent Diffusion Models (LDMs). Along with standard LDM regularizers (KL and vector quantization), we explore supervised regularizations (including classification and prototype-based representation) and contrastive inductive biases (using SimCLR and redundancy reduction objectives). We demonstrate that LDMs with redundancy reduction and prototype-based regularizations produce near-human-like drawings (regarding both samples' recognizability and originality) -- better mimicking human perception (as evaluated psychophysically). Overall, our results suggest that the gap between humans and machines in one-shot drawings is almost closed.
tl;dr: We propose an Instance-guided One-shot Domain Adaptation for Super-Resolution (IODA) to enable efficient domain adaptation with only a single unlabeled target domain LR image.

The domain adaptation method effectively mitigates the negative impact of domain gaps on the performance of super-resolution (SR) networks through the guidance of numerous target domain low-resolution (LR) images. However, in real-world scenarios, the availability of target domain LR images is often limited, sometimes even to just one, which inevitably impairs the domain adaptation performance of SR networks. We propose Instance-guided One-shot Domain Adaptation for Super-Resolution (IODA) to enable efficient domain adaptation with only a single unlabeled target domain LR image. To address the limited diversity of the target domain distribution caused by a single target domain LR image, we propose an instance-guided target domain distribution expansion strategy. This strategy effectively expands the diversity of the target domain distribution by generating instance-specific features focused on different instances within the image. For SR tasks emphasizing texture details, we propose an image-guided domain adaptation method. Compared to existing methods that use text representation for domain difference, this method utilizes pixel-level representation with higher granularity, enabling efficient domain adaptation guidance for SR networks. Finally, we validate the effectiveness of IODA on multiple datasets and various network architectures, achieving satisfactory one-shot domain adaptation for SR networks. Our code is available at https://github.com/ZaizuoTang/IODA.
tl;dr: Neural Isometries find latent spaces where complicated transformations become tractable for downstream tasks.

Real-world geometry and 3D vision tasks are replete with challenging symmetries that defy tractable analytical expression. In this paper, we introduce Neural Isometries, an autoencoder framework which learns to map the observation space to a general-purpose latent space wherein encodings are related by isometries whenever their corresponding observations are geometrically related in world space. Specifically, we regularize the latent space such that maps between encodings preserve a learned inner product and commute with a learned functional operator, in the same manner as rigid-body transformations commute with the Laplacian. This approach forms an effective backbone for self-supervised representation learning, and we demonstrate that a simple off-the-shelf equivariant network operating in the pre-trained latent space can achieve results on par with meticulously-engineered, handcrafted networks designed to handle complex, nonlinear symmetries. Furthermore, isometric maps capture information about the respective transformations in world space, and we show that this allows us to regress camera poses directly from the coefficients of the maps between encodings of adjacent views of a scene.
tl;dr: We develop a sampling algorithm such that the ML model jointly learned with training data and unlabeled influential data is fairer with high accuracy.

The pursuit of fairness in machine learning (ML), ensuring that the models do not exhibit biases toward protected demographic groups, typically results in a compromise scenario. This compromise can be explained by a Pareto frontier where given certain resources (e.g., data), reducing the fairness violations often comes at the cost of lowering the model accuracy.
In this work, we aim to train models that mitigate group fairness disparity without causing harm to model accuracy.
Intuitively, acquiring more data is a natural and promising approach to achieve this goal by reaching a better Pareto frontier of the fairness-accuracy tradeoff. The current data acquisition methods, such as fair active learning approaches, typically require annotating sensitive attributes. However, these sensitive attribute annotations should be protected due to privacy and safety concerns. In this paper, we propose a tractable active data sampling algorithm that does not rely on training group annotations, instead only requiring group annotations on a small validation set. Specifically, the algorithm first scores each new example by its influence on fairness and accuracy evaluated on the validation dataset, and then selects a certain number of examples for training.
We theoretically analyze how acquiring more data can improve fairness without causing harm, and validate the possibility of our sampling approach in the context of risk disparity. We also provide the upper bound of generalization error and risk disparity as well as the corresponding connections.
Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm. Our code is available at [github.com/UCSC-REAL/FairnessWithoutHarm](https://github.com/UCSC-REAL/FairnessWithoutHarm).
tl;dr: We propose an efficient and effective compression method for retrieval-augmented generation.

This paper introduces xRAG, an innovative context compression method tailored for retrieval-augmented generation. xRAG reinterprets document embeddings in dense retrieval--traditionally used solely for retrieval--as features from the retrieval modality. By employing a modality fusion methodology, xRAG seamlessly integrates these embeddings into the language model representation space, effectively eliminating the need for their textual counterparts and achieving an extreme compression rate.
In xRAG, the only trainable component is the modality bridge, while both the retriever and the language model remain frozen. This design choice allows for the reuse of offline-constructed document embeddings and preserves the plug-and-play nature of retrieval augmentation.
Experimental results demonstrate that xRAG achieves an average improvement of over 10% across six knowledge-intensive tasks, adaptable to various language model backbones, ranging from a dense 7B model to an 8x7B Mixture of Experts configuration. xRAG not only significantly outperforms previous context compression methods but also matches the performance of uncompressed models on several datasets, while reducing overall FLOPs by a factor of 3.53. Our work pioneers new directions in retrieval-augmented generation from the perspective of multimodality fusion, and we hope it lays the foundation for future efficient and scalable retrieval-augmented systems.
4018. Segment Any Change
tl;dr: Our training-free adaptation enables Segment Anything Model (SAM) to zero-shot change detection by exploiting the latent space of SAM

Visual foundation models have achieved remarkable results in zero-shot image classification and segmentation, but zero-shot change detection remains an open problem.
In this paper, we propose the segment any change models (AnyChange), a new type of change detection model that supports zero-shot prediction and generalization on unseen change types and data distributions.
AnyChange is built on the segment anything model (SAM) via our training-free adaptation method, bitemporal latent matching.
By revealing and exploiting intra-image and inter-image semantic similarities in SAM's latent space, bitemporal latent matching endows SAM with zero-shot change detection capabilities in a training-free way.
We also propose a point query mechanism to enable AnyChange's zero-shot object-centric change detection capability.
We perform extensive experiments to confirm the effectiveness of AnyChange for zero-shot change detection.
AnyChange sets a new record on the SECOND benchmark for unsupervised change detection, exceeding the previous SOTA by up to 4.4\% F$_1$ score, and achieving comparable accuracy with negligible manual annotations (1 pixel per image) for supervised change detection. Code is available at https://github.com/Z-Zheng/pytorch-change-models.
tl;dr: We demonstrate the existence of multimodal task vectors and leverage them for many-shot ICL in LMMs.

The recent success of interleaved Large Multimodal Models (LMMs) in few-shot learning suggests that in-context learning (ICL) with many examples can be promising for learning new tasks. However, this many-shot multimodal ICL setting has one crucial problem: it is fundamentally limited by the model's context length set at pretraining. The problem is especially prominent in the multimodal domain, which processes both text and images, requiring additional tokens. This motivates the need for a multimodal method to compress many shots into fewer tokens without finetuning. In this work, we enable LMMs to perform multimodal, many-shot in-context learning by leveraging Multimodal Task Vectors (MTV)---compact implicit representations of in-context examples compressed in the model's attention heads. Specifically, we first demonstrate the existence of such MTV in LMMs and then leverage these extracted MTV to enable many-shot in-context learning for various vision-and-language tasks. Our experiments suggest that MTV can scale in performance with the number of compressed shots and generalize to similar out-of-domain tasks without additional context length for inference. Code: https://github.com/Brandon3964/MultiModal-Task-Vector

Significant progress has been made in text-to-video generation through the use of powerful generative models and large-scale internet data. However, substantial challenges remain in precisely controlling individual elements within the generated video, such as the movement and appearance of specific characters and the manipulation of viewpoints. In this work, we propose a novel paradigm that generates each element in 3D representation separately and then composites them with priors from Large Language Models (LLMs) and 2D diffusion models. Specifically, given an input textual query, our scheme consists of four stages: 1) we leverage the LLMs as the director to first decompose the complex query into several sub-queries, where each sub-query describes each element of the generated video; 2) to generate each element, pre-trained models are invoked by the LLMs to obtain the corresponding 3D representation; 3) to composite the generated 3D representations, we prompt multi-modal LLMs to produce coarse guidance on the scale, location, and trajectory of different objects; 4) to make the results adhere to natural distribution, we further leverage 2D diffusion priors and use score distillation sampling to refine the composition. Extensive experiments demonstrate that our method can generate high-fidelity videos from text with flexible control over each element.
tl;dr: We leverage domain knowledge to inform neural network pruning, thereby obtaining interpretable models that align with known biology

The practical utility of machine learning models in the sciences often hinges on their interpretability. It is common to assess a model's merit for scientific discovery, and thus novel insights, by how well it aligns with already available domain knowledge - a dimension that is currently largely disregarded in the comparison of neural network models. While pruning can simplify deep neural network architectures and excels in identifying sparse models, as we show in the context of gene regulatory network inference, state-of-the-art techniques struggle with biologically meaningful structure learning. To address this issue, we propose DASH, a generalizable framework that guides network pruning by using domain-specific structural information in model fitting and leads to sparser, better interpretable models that are more robust to noise. Using both synthetic data with ground truth information, as well as real-world gene expression data, we show that DASH, using knowledge about gene interaction partners within the putative regulatory network, outperforms general pruning methods by a large margin and yields deeper insights into the biological systems being studied.
tl;dr: We improve DNN inference efficiency by learning low-dimensional weight structures through BLAST.

Large-scale foundation models have demonstrated exceptional performance in language and vision tasks. However, the numerous dense matrix-vector operations involved in these large networks pose significant computational challenges during inference. To address these challenges, we introduce the Block-Level Adaptive STructured (BLAST) matrix, designed to learn and leverage efficient structures prevalent in the weight matrices of linear layers within deep learning models. Compared to existing structured matrices, the BLAST matrix offers substantial flexibility, as it can represent various types of structures that are either learned from data or computed from pre-existing weight matrices. We demonstrate the efficiency of using the BLAST matrix for compressing both language and vision tasks, showing that (i) for medium-sized models such as ViT and GPT-2, training with BLAST weights boosts performance while reducing complexity by 70\% and 40\%, respectively; and (ii) for large foundation models such as Llama-7B and DiT-XL, the BLAST matrix achieves a 2x compression while exhibiting the lowest performance degradation among all tested structured matrices. Our code is available at https://github.com/changwoolee/BLAST.
4023. Improving Viewpoint-Independent Object-Centric Representations through Active Viewpoint Selection

Given the complexities inherent in visual scenes, such as object occlusion, a comprehensive understanding often requires observation from multiple viewpoints. Existing multi-viewpoint object-centric learning methods typically employ random or sequential viewpoint selection strategies. While applicable across various scenes, these strategies may not always be ideal, as certain scenes could benefit more from specific viewpoints. To address this limitation, we propose a novel active viewpoint selection strategy. This strategy predicts images from unknown viewpoints based on information from observation images for each scene. It then compares the object-centric representations extracted from both viewpoints and selects the unknown viewpoint with the largest disparity, indicating the greatest gain in information, as the next observation viewpoint. Through experiments on various datasets, we demonstrate the effectiveness of our active viewpoint selection strategy, significantly enhancing segmentation and reconstruction performance compared to random viewpoint selection. Moreover, our method can accurately predict images from unknown viewpoints.
tl;dr: We give a new and highly-efficient algorithm for multi-vector retrieval via a provable reduction to single-vector retrieval.

Neural embedding models have become a fundamental component of modern information retrieval (IR) pipelines. These models produce a single embedding $x \in \mathbb{R}^d$ per data-point, allowing for fast retrieval via highly optimized maximum inner product search (MIPS) algorithms. Recently, beginning with the landmark ColBERT paper, multi-vector models, which produce a set of embedding per data point, have achieved markedly superior performance for IR tasks. Unfortunately, using these models for IR is computationally expensive due to the increased complexity of multi-vector retrieval and scoring.
In this paper, we introduce MUVERA (MUlti-VEctor Retrieval Algorithm), a retrieval mechanism which reduces multi-vector similarity search to single-vector similarity search. This enables the usage of off-the-shelf MIPS solvers for multi-vector retrieval.
MUVERA asymmetrically generates Fixed Dimensional Encodings (FDEs) of queries and documents, which are vectors whose inner product approximates multi-vector similarity. We prove that FDEs give high-quality $\epsilon$-approximations, thus providing the first single-vector proxy for multi-vector similarity with theoretical guarantees. Empirically, we find that FDEs achieve the same recall as prior state-of-the-art heuristics while retrieving 2-5$\times$ fewer candidates. Compared to prior state of the art implementations, MUVERA achieves consistently good end-to-end recall and latency across a diverse set of the BEIR retrieval datasets, achieving an average of 10% improved recall with 90% lower latency.
tl;dr: A novel acquisition function for batched Bayesian optimization with Gaussian processes that trades off exploration and exploitation with a controllable parameter.

Bayesian optimization (BO) is an attractive machine learning framework for performing sample-efficient global optimization of black-box functions. The optimization process is guided by an acquisition function that selects points to acquire in each round of BO. In batched BO, when multiple points are acquired in parallel, commonly used acquisition functions are often high-dimensional and intractable, leading to the use of sampling-based alternatives. We propose a statistical physics inspired acquisition function that can natively handle batches. Batched Energy-Entropy acquisition for BO (BEEBO) enables tight control of the explore-exploit trade-off of the optimization process and generalizes to heteroskedastic black-box problems. We demonstrate the applicability of BEEBO on a range of problems, showing competitive performance to existing acquisition functions.

Continual learning aims to incrementally acquire new concepts in data streams while resisting forgetting previous knowledge.
With the rise of powerful pre-trained models (PTMs), there is a growing interest of training incremental learning systems using these foundation models, rather than learning from scratch.
Existing works often view PTMs as a strong initial point and directly apply parameter-efficient tuning (PET) in the first session for adapting to downstream tasks.
In the following sessions, most methods freeze model parameters for tackling forgetting issues.
However, applying PET directly to downstream data cannot fully explore the inherent knowledge in PTMs.
Additionally, freezing the parameters in incremental sessions hinders models' plasticity to novel concepts not covered in the first session.
To solve the above issues, we propose a Slow And Fast parameter-Efficient tuning (SAFE) framework.
In particular, to inherit general knowledge from foundation models, we include a transfer loss function by measuring the correlation between the PTM and the PET-applied model.
After calibrating in the first session, the slow efficient tuning parameters can capture more informative features, improving generalization to incoming classes.
Moreover, to further incorporate novel concepts, we strike a balance between stability and plasticity by fixing slow efficient tuning parameters and continuously updating the fast ones.
Specifically, a cross-classification loss with feature alignment is proposed to circumvent catastrophic forgetting.
During inference, we introduce an entropy-based aggregation strategy to dynamically utilize the complementarity in the slow and fast learners.
Extensive experiments on seven benchmark datasets verify the effectiveness of our method by significantly surpassing the state-of-the-art.

Multi-object 3D Grounding involves locating 3D boxes based on a given query phrase from a point cloud. It is a challenging and significant task that has numerous applications in visual understanding, human-computer interaction, and robotics. To tackle this challenge, we introduce D-LISA, a two-stage approach that incorporates three innovations. First, a dynamic vision module that enables a variable and learnable number of box proposals. Second, a dynamic camera positioning that extracts features for each proposal. Third, a language-informed spatial attention module that better reasons over the proposals to output the final prediction. Empirically, experiments show that our method outperforms the state-of-the-art methods on multi-object 3D grounding by 12.8% (absolute) and is competitive in single-object 3D grounding.
4028. Randomized Sparse Matrix Compression for Large-Scale Constrained Optimization in Cancer Radiotherapy
tl;dr: This paper presents a novel algorithm for generating a randomized sparse sketch of a large matrix, with novel application in solving the large-scale optimization problems arising in cancer radiotherapy.

Radiation therapy, treating over half of all cancer patients, involves using specialized machines to direct high-energy beams at tumors, aiming to damage cancer cells while minimizing harm to nearby healthy tissues. Customizing the shape and intensity of radiation beams for each patient leads to solving large-scale constrained optimization problems that need to be solved within tight clinical time-frame. At the core of these challenges is a large matrix that is commonly sparsified for computational efficiency by neglecting small elements. Such a crude approximation can degrade the quality of treatment, potentially causing unnecessary radiation exposure to healthy tissues—this may lead to significant radiation-induced side effects—or delivering inadequate radiation to the tumor, which is crucial for effective tumor treatment. In this work, we demonstrate, for the first time, that randomized sketch tools can effectively sparsify this matrix without sacrificing treatment quality. We also develop a novel randomized sketch method with desirable theoretical guarantees that outperforms existing techniques in practical application. Beyond developing a novel randomized sketch method, this work emphasizes the potential of harnessing scientific computing tools, crucial in today's big data analysis, to tackle computationally intensive challenges in healthcare. The application of these tools could have a profound impact on the lives of numerous cancer patients. Code and sample data available at https://github.com/PortPy-Project/CompressRTP
tl;dr: We propose MotionTTT a deep learning based test-time-training approach for motion estimation for the problem of motion artifact correction in 3D MRI.

A major challenge of the long measurement times in magnetic resonance imaging (MRI), an important medical imaging technology, is that patients may move during data acquisition. This leads to severe motion artifacts in the reconstructed images and volumes. In this paper, we propose MotionTTT a deep learning-based test-time-training (TTT) method for accurate motion estimation. The key idea is that a neural network trained for motion-free reconstruction has a small loss if there is no motion, thus optimizing over motion parameters passed through the reconstruction network enables accurate estimation of motion. The estimated motion parameters enable to correct for the motion and to reconstruct accurate motion-corrected images. Our method uses 2D reconstruction networks to estimate rigid motion in 3D, and constitutes the first deep learning based method for 3D rigid motion estimation towards 3D-motion-corrected MRI. We show that our method can provably reconstruct motion parameters for a simple signal and neural network model. We demonstrate the effectiveness of our method for both retrospectively simulated motion and prospectively collected real motion-corrupted data. Code is available at \url{https://github.com/MLI-lab/MRI_MotionTTT}.

Domain-specific languages (DSLs) have become integral to various software workflows. Such languages offer domain-specific optimizations and abstractions that improve code readability and maintainability. However, leveraging these languages requires developers to rewrite existing code using the specific DSL's API. While large language models (LLMs) have shown some success in automatic code transpilation, none of them provide any functional correctness guarantees on the rewritten code. Another approach for automating this task is verified lifting, which relies on program synthesis to find programs in the target language that are functionally equivalent to the source language program. While several verified lifting tools have been developed for various application domains, they are specialized for specific source-target languages or require significant expertise in domain knowledge to make the search efficient. In this paper, leveraging recent advances in LLMs, we propose an LLM-based approach (LLMLift) to building verified lifting tools. We use the LLM's capabilities to reason about programs to translate a given program into its corresponding equivalent in the target language. Additionally, we use LLMs to generate proofs for functional equivalence. We develop lifting-based compilers for four DSLs targeting different application domains. Our approach not only outperforms previous symbolic-based tools in number of benchmarks transpiled and transpilation time, but also requires significantly less effort to build.
tl;dr: We re-conceptualize pose estimation as an out-of-image keypoint prediction task to robustly predict extension keypoints from human pose.

Accurate estimation of human pose and the pose of interacting objects, like a hockey stick, is crucial for action recognition and performance analysis, particularly in sports. Existing methods capture the object along with the human in the bounding boxes, assuming all keypoints are visible within the bounding box. This necessitates larger bounding boxes to capture the object, introducing unnecessary visual features and hindering performance in real-world cluttered environments. We propose a simple image and text-based multimodal solution TokenCLIPose that addresses this limitation. Our approach focuses solely on human keypoints within the bounding box, treating objects as unseen. TokenCLIPose leverages the rich semantic representations endowed by language for inducing keypoint-specific context, even for occluded keypoints. We evaluate the performance of TokenCLIPose on a real-world Ice-Hockey dataset, and demonstrate its generalizability through zero-shot transfer to a smaller Lacrosse dataset. Additionally, we showcase its flexibility on CrowdPose, a popular occlusion benchmark with keypoints within the bounding box. Our method significantly improves over state-of-the-art approaches on all three datasets, with gains of 4.36\%, 2.35\%, and 3.8\%, respectively.

Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling.
However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023-SEMI challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.

Vanilla pixel-level classifiers for semantic segmentation are based on a certain paradigm, involving the inner product of fixed prototypes obtained from the training set and pixel features in the test image. This approach, however, encounters significant limitations, i.e., feature deviation in the semantic domain and information loss in the spatial domain. The former struggles with large intra-class variance among pixel features from different images, while the latter fails to utilize the structured information of semantic objects effectively. This leads to blurred mask boundaries as well as a deficiency of fine-grained recognition capability. In this paper, we propose a novel Semantic and Spatial Adaptive Classifier (SSA-Seg) to address the above challenges. Specifically, we employ the coarse masks obtained from the fixed prototypes as a guide to adjust the fixed prototype towards the center of the semantic and spatial domains in the test image. The adapted prototypes in semantic and spatial domains are then simultaneously considered to accomplish classification decisions. In addition, we propose an online multi-domain distillation learning strategy to improve the adaption process. Experimental results on three publicly available benchmarks show that the proposed SSA-Seg significantly improves the segmentation performance of the baseline models with only a minimal increase in computational cost.
tl;dr: This paper presents novel causal imitation learning algorithms that adapt to confounded expert demonstrations in MDPs using partial identification techniques, demonstrating their effectiveness theoretically and empirically across various scenarios.

Imitation learning enables an agent to learn from expert demonstrations when the performance measure is unknown and the reward signal is not specified. Standard imitation methods do not generally apply when the learner and the expert's sensory capabilities mismatch and demonstrations are contaminated with unobserved confounding bias. To address these challenges, recent advancements in causal imitation learning have been pursued. However, these methods often require access to underlying causal structures that might not always be available, posing practical challenges.
In this paper, we investigate robust imitation learning within the framework of canonical Markov Decision Processes (MDPs) using partial identification, allowing the agent to achieve expert performance even when the system dynamics are not uniquely determined from the confounded expert demonstrations. Specifically, first, we theoretically demonstrate that when unobserved confounders (UCs) exist in an MDP, the learner is generally unable to imitate expert performance. We then explore imitation learning in partially identifiable settings --- either transition distribution or reward function is non-identifiable from the available data and knowledge. Augmenting the celebrated GAIL method (Ho \& Ermon, 2016), our analysis leads to two novel causal imitation algorithms that can obtain effective policies guaranteed to achieve expert performance.

Accurate estimation of treatment effects is essential for decision-making across various scientific fields. This task, however, becomes challenging in areas like social sciences and online marketplaces, where treating one experimental unit can influence outcomes for others through direct or indirect interactions. Such interference can lead to biased treatment effect estimates, particularly when the structure of these interactions is unknown. We address this challenge by introducing a new class of estimators based on causal message-passing, specifically designed for settings with pervasive, unknown interference. Our estimator draws on information from the sample mean and variance of unit outcomes and treatments over time, enabling efficient use of observed data to estimate the evolution of the system state. Concretely, we construct non-linear features from the moments of unit outcomes and treatments and then learn a function that maps these features to future mean and variance of unit outcomes. This allows for the estimation of the treatment effect over time. Extensive simulations across multiple domains, using synthetic and real network data, demonstrate the efficacy of our approach in estimating total treatment effect dynamics, even in cases where interference exhibits non-monotonic behavior in the probability of treatment.